Schlüsselwörter:KI-Framework, Cybersicherheit, 3D-Generierung, Großes Sprachmodell, Humanoidroboter, KI-Agent, Open-Source-KI, KI-Gesundheit, CAI Cybersicherheit KI-Framework, Hi3DEval 3D-Bewertungssystem, Qwen3 Coder Programmiermodell, Industrieller radgelaufener zweibeiniger Humanoidroboter, KI-gestütztes Antibiotika-Design
Gerne, hier ist die Übersetzung der AI-Nachrichten ins Deutsche, unter Beibehaltung der geforderten Formate und Inhalte:
🔥 Fokus
Alias Robotics stellt Open-Source-Cybersecurity-AI-Framework CAI vor: Alias Robotics hat das Open-Source-Cybersecurity-AI (CAI)-Framework veröffentlicht, das darauf abzielt, AI-Tools für Cybersicherheit zu demokratisieren. Es wird erwartet, dass AI-gesteuerte Sicherheitstest-Tools bis 2028 menschliche Penetrationstester übertreffen werden. CAI ist Bug Bounty-fähig, unterstützt mehrere Modelle (einschließlich Claude, OpenAI, DeepSeek, Ollama) und integriert Agentenmodus, umfangreiche Tools, Tracking-Funktionen und Human-in-the-Loop (HITL)-Mechanismen, um eine starke Unterstützung bei komplexen Cyberbedrohungen zu bieten. (Quelle: GitHub Trending)

Standardisierte 3D-Generierungsqualitätsliste Hi3DEval veröffentlicht: Das Shanghai AI Lab hat in Zusammenarbeit mit mehreren Universitäten Hi3DEval vorgestellt, ein neues hierarchisches automatisiertes Bewertungssystem für die 3D-Inhaltsgenerierung. Dieses System ermöglicht durch dreistufige Bewertungsprotokolle auf Objekt-, Komponenten- und Materialebene eine Analyse mit mehreren Granularitäten – von der Gesamtform über die lokale Struktur bis hin zur Materialrealität – und löst damit das Problem der groben traditionellen 3D-Bewertung. Die erste Liste wurde auf HuggingFace veröffentlicht und umfasst 30 Mainstream- und Spitzmodelle. Sie soll der Wissenschaft und Industrie eine nachvollziehbare und reproduzierbare Vergleichsbasis bieten, um die 3D-Generierungstechnologie zu höherer Qualität und Transparenz zu entwickeln. (Quelle: 量子位)

Indien startet nationales AI-Großmodellprogramm: Indien hat die „India AI Mission“ ins Leben gerufen und investiert 1,2 Milliarden US-Dollar, um mehrsprachige native Large Language Models (LLMs) zu entwickeln und Start-ups mit Finanzmitteln und Rechenleistung zu unterstützen. Der Plan sieht bereits 19.000 GPUs (darunter 13.000 Nvidia H100) vor und hat bereits das 70-Milliarden-Parameter-Modell von Sarvam AI sowie Projekte von Soket AI Labs, Gan AI und Gnani AI gefördert. Dieser Schritt markiert einen wichtigen Fortschritt Indiens im AI-Bereich, insbesondere mit Fokus auf sprachgesteuerte Anwendungen, und könnte dem Land eine wichtigere Rolle in der globalen AI-Landschaft sichern. (Quelle: DeepLearningAI)
🎯 Trends
AI-Integration und Durchbrüche im Gesundheitsbereich: Yunpeng Tech hat in Zusammenarbeit mit Shuaikang und Skyworth neue AI+Gesundheitsprodukte vorgestellt, darunter das „Digitale Zukunftsküchenlabor“ und einen intelligenten Kühlschrank mit einem AI-Gesundheits-Large-Model. Das AI-Gesundheits-Large-Model zielt darauf ab, Küchendesign und -betrieb zu optimieren, während der intelligente Kühlschrank über den „Gesundheitsassistenten Xiaoyun“ personalisiertes Gesundheitsmanagement bietet. Dies zeigt, dass AI tief in die tägliche Gesundheitsverwaltung eindringt und durch intelligente Geräte personalisierte Dienste bereitstellt, was die Entwicklung der häuslichen Gesundheitstechnologie vorantreiben dürfte. (Quelle:36氪)

Neue Entwicklungen bei Industrie-Humanoiden und mobilen Robotern: In den sozialen Medien wurden industrielle radbasierte humanoide Roboter sowie mobile Roboter, die autonom auf Parkplätzen operieren, und große vierbeinige Roboter, die Passagiere befördern können, gezeigt. Diese Fortschritte belegen die vielfältige Entwicklung der Robotik in Industrie, Logistik und alltäglichen Anwendungen. Sie zeigen, dass zunehmend komplexere autonome Operationen und Mensch-Roboter-Kollaborationen realisiert werden, was darauf hindeutet, dass Roboter stärker in unser Leben integriert werden. (Quelle: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
AI entwirft Antibiotika gegen Superbakterien: AI wird eingesetzt, um Antibiotika gegen die Superbakterien Gonorrhoe und MRSA zu entwickeln. Diese Technologie demonstriert das enorme Potenzial von AI im Gesundheitswesen, insbesondere in der Medikamentenentwicklung. Es wird erwartet, dass sie die Entdeckung neuer Medikamente beschleunigt und neue Lösungen für die globale Antibiotikaresistenzkrise bietet, was weitreichende Auswirkungen auf die öffentliche Gesundheit hat. (Quelle: Ronald_vanLoon)
Alibaba stellt multimodales LLM Ovis2.5 vor: Alibaba hat das neue multimodale Large Language Model Ovis2.5 (in 2B- und 9B-Versionen) veröffentlicht. Das Highlight ist ein neu hinzugefügter optionaler „Denkmodus“, der es dem Modell ermöglicht, bei komplexen Schlussfolgerungsaufgaben Selbstkontrolle und Antwortoptimierung durchzuführen, was die Schlussfolgerungsfähigkeit erheblich verbessert. Darüber hinaus wurde die OCR-Funktion (Optical Character Recognition) von Ovis2.5 deutlich verbessert, insbesondere bei der Verarbeitung komplexer Diagramme und dichter Dokumente, was seine Praktikabilität in realen Anwendungen erhöht. (Quelle: Reddit r/LocalLLaMA)

Fortschritte in der AI-Videogenerierungstechnologie: In den sozialen Medien wurden Beispiele für die Videogenerierung durch AI-Modelle (wie Hailuo 02 oder die Gemini-App) gezeigt, was darauf hindeutet, dass die Fähigkeiten von AI im Bereich der Multimediakreation ein erstaunliches Niveau erreicht haben und Text oder Bilder sofort in Videoinhalte umwandeln können. Obwohl Nutzer die Unmittelbarkeit und den Realismus noch in Frage stellen, deutet diese technologische Richtung auf eine enorme Veränderung in der zukünftigen Videoproduktion hin. (Quelle: Reddit r/ChatGPT)
2025 wird das Jahr der autonomen AI-Agenten sein: In der Branche wird allgemein angenommen, dass 2025 das Jahr des Durchbruchs für autonome AI-Agenten (Autonomous Agents) sein wird. Diese Agenten können komplexe Aufgaben eigenständig ausführen und Ziele durch Selbstplanung und Tool-Aufrufe erreichen. Es wird erwartet, dass sie die Arbeitsweise in allen Branchen grundlegend verändern werden, von einfacher Automatisierung bis hin zu komplexer Entscheidungsunterstützung. AI-Agenten werden eine Schlüsseltriebkraft für Effizienz und Innovation sein. (Quelle: lateinteraction)
DeepSeek steigert LLM-Erfolgsrate durch Datenbereinigung: Der Erfolg von DeepSeek ist teilweise darauf zurückzuführen, dass das Unternehmen seine Fähigkeiten zur Datenbereinigung aus dem Handelsbereich effektiv auf den Aufbau von Large Language Models angewendet hat. Dies zeigt, dass hochwertige Datenverarbeitung ein entscheidender Faktor für die Optimierung der LLM-Leistung ist, unterstreicht die Bedeutung von Data Engineering bei der Entwicklung von AI-Modellen und liefert wertvolle Erfahrungen für andere AI-Unternehmen. (Quelle: code_star)

Machbarkeitsstudie zur AI-Verwaltung von AI-Inhalten: In der Community wird die Möglichkeit diskutiert, eine AI zu entwickeln, die Online-AI-Inhalte verwaltet (z.B. AI-generierte Inhalte oder AI-Konten versteckt oder identifiziert). Diese Idee zielt darauf ab, die Herausforderung der AI-Inhaltsflut zu bewältigen, indem die AI-Technologie selbst zur Unterstützung der Inhaltsmoderation und Informationstransparenz eingesetzt wird. Trotz science-fiction-ähnlicher Risiken liegt ihr potenzieller Wert in der Bereitstellung intelligenterer, effizienterer Lösungen für das Inhaltsmanagement. (Quelle: Reddit r/ArtificialInteligence)
🧰 Tools
vLLM CLI-Tool veröffentlicht: Das vLLM-Projekt hat das vLLM CLI veröffentlicht, ein Befehlszeilentool zum Bereitstellen von LLMs über vLLM. Es bietet eine interaktive menügesteuerte Benutzeroberfläche und ein skriptfreundliches CLI, unterstützt die Modellverwaltung lokal und über den HuggingFace Hub, Konfigurationsprofile für Leistungs-/Speicheroptimierung sowie Echtzeit-Server- und GPU-Überwachung. Ziel ist es, die Bereitstellung und Verwaltung von LLMs zu vereinfachen und die Entwicklererfahrung zu verbessern. (Quelle: vllm_project)
AI-gestützte Code-Fehlerbehebung und -Generierung: ChatGPT und andere AI-Modelle zeigen hervorragende Leistungen bei der Code-Fehlerbehebung und sind sogar sehr effektiv beim Auffinden kleinerer Probleme wie Tippfehler. Gleichzeitig wird die Ansicht vertreten, dass AI auch beim Schreiben von Code großes Potenzial hat, was Software-Engineering-Fähigkeiten noch wichtiger macht, da Entwickler LLMs besser anleiten müssen, um qualitativ hochwertigen Code zu generieren und zu debuggen. (Quelle: colin_fraser, jimmykoppel)
Forderung nach „Fork-Chat“-Funktion für ChatGPT: Nutzer fordern, dass ChatGPT eine „Fork-Chat“-Funktion ähnlich den Git-Branches hinzufügt, um von jedem Punkt einer Konversation aus Abzweigungen zu erstellen und verschiedene Gesprächspfade zu erkunden, ohne den Hauptstrang zu beeinflussen. Diese Funktion würde die Effizienz und Flexibilität der Nutzer bei komplexen oder mehrpfadigen Konversationen erheblich verbessern und das mühsame manuelle Kopieren und Einfügen vermeiden. (Quelle: cto_junior, Dorialexander)
Anwendung von Verbund-AI-Systemen in Tabellenkalkulationen: Die Diskussion weist darauf hin, dass Verbund-AI-Systeme in Zukunft eine enorme Rolle in Excel/Tabellenkalkulationen spielen könnten, z.B. indem eine Zelle ein AI-Programm ausführt, das AI-Programme in anderen Zellen auslöst und basierend auf Daten in anderen Tabellen optimiert. Dies würde die Reibung und die Hürden für AI erheblich senken und es mehr Nicht-Fachleuten ermöglichen, AI-Funktionen zu nutzen. Obwohl dies Komplexität mit sich bringen könnte, wird ihre reibungsarme Natur eine breite Akzeptanz fördern. (Quelle: lateinteraction)
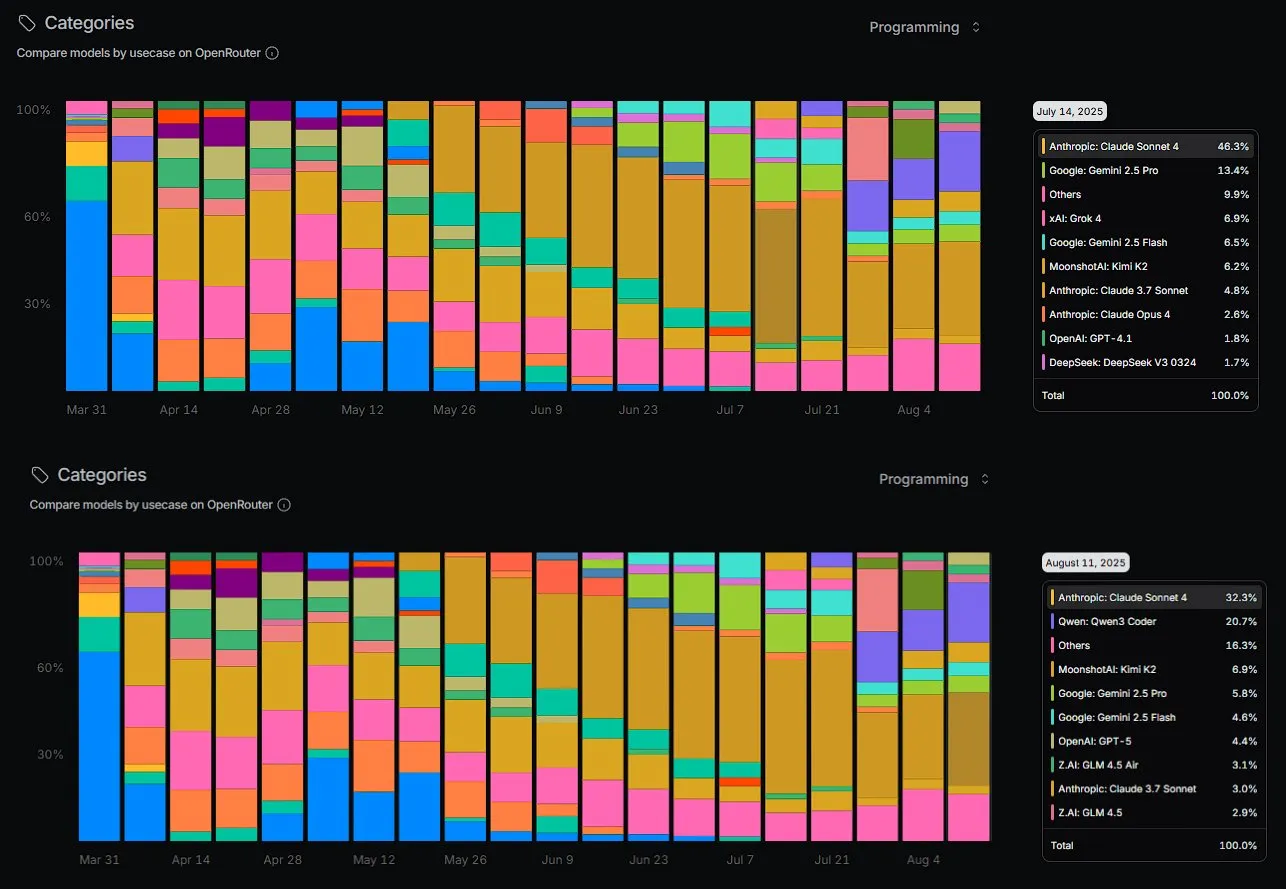
Aufstieg von Qwen3 Coder im Programmiermarktanteil: Das Qwen3 Coder-Modell von Alibaba verzeichnet auf OpenRouter einen signifikanten Anstieg des Programmiermarktanteils und stellt eine Herausforderung für proprietäre Modelle wie Anthropic’s Sonnet dar. Nutzerberichte zeigen, dass Qwen3 Coder bei praktischen Programmieraufgaben hervorragende Leistungen erbringt und bei der Lösung komplexer Bereitstellungsprobleme sogar Gemini-2.5-Pro übertrifft. Dies deutet darauf hin, dass Open-Source-Modelle in bestimmten Bereichen schnell den Abstand zu kommerziellen Modellen verringern und diese teilweise sogar übertreffen, was die Entwicklung des Open-Source-AI-Ökosystems fördert. (Quelle: huybery, scaling01, Reddit r/LocalLLaMA)
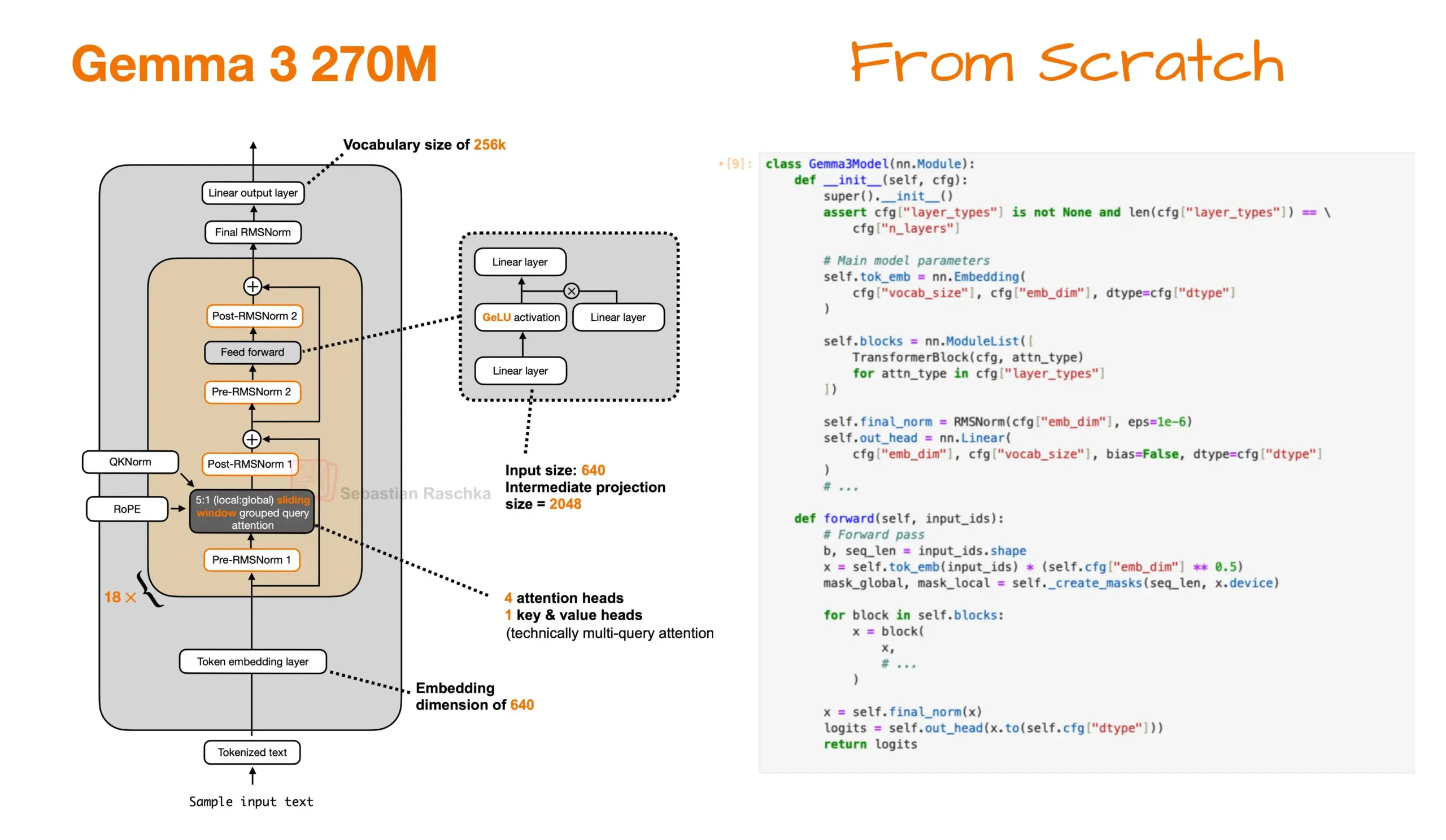
Reine PyTorch-Implementierung und Produktionsbereitstellung von Gemma 3 270M: Ein Community-Mitglied hat das Gemma 3 270M-Modell erfolgreich von Grund auf in reinem PyTorch neu implementiert und ein Jupyter Notebook-Beispiel bereitgestellt. Diese Implementierung benötigt nur etwa 1,49 GB Speicher. Gleichzeitig wurde das Modell erfolgreich feinabgestimmt und in einer Produktionsumgebung eingesetzt, was das starke Potenzial leichter Modelle in der lokalen Forschung und in Unternehmenssystemen sowie deren schnelle Bereitstellungsfähigkeit demonstriert. (Quelle: rasbt, _philschmid)
Erfahrungsbericht zu Claude Code Max: Ein Nutzer teilte seine einmonatige Erfahrung mit Claude Code Max und betonte die Bedeutung von „Codebasis sauber halten“, „rechtzeitiges Refactoring“ und „detaillierte Planung“. Er empfahl auch Tools wie Playwright-mcp und wies darauf hin, dass die Kombination mit dem Gemini MCP-Tool zur Rückmeldung in der Planungsphase sehr nützlich ist. Diese praktischen Erfahrungen bieten wertvolle Anleitungen für die Codeentwicklung mit LLMs und tragen dazu bei, die Entwicklungseffizienz und Codequalität zu verbessern. (Quelle: Reddit r/ClaudeAI)

📚 Lernen
Gegenseitige Lernmöglichkeiten für AI-Forscher und Designer: Risikokapital treibt AI-Forschungsteams und Produktdesignteams zu enger Zusammenarbeit, was einzigartige wechselseitige Lernmöglichkeiten schafft. AI-Forscher können von Designern lernen, wie komplexe Technologien in benutzerfreundliche Produkte umgewandelt werden, während Designer ein tiefes Verständnis für das Potenzial und die Grenzen von AI-Modellen entwickeln können, um gemeinsam die Innovation und Implementierung von AI-Produkten voranzutreiben. (Quelle: DhruvBatraDB)
Überblick über parallele Textgenerierungstechniken für LLMs: Ein Übersichtsartikel über parallele Textgenerierungstechniken für LLMs untersucht autoregressive und nicht-autoregressive Techniken und vergleicht deren Kompromisse zwischen Geschwindigkeit und Qualität. Dies ist eine wichtige Lernressource für AI-Entwickler, die hilft, geeignete Textgenerierungsmethoden für spezifische Anwendungsszenarien zu verstehen und auszuwählen, und den Fortschritt von LLMs in Bezug auf Effizienz fördert. (Quelle: omarsar0)

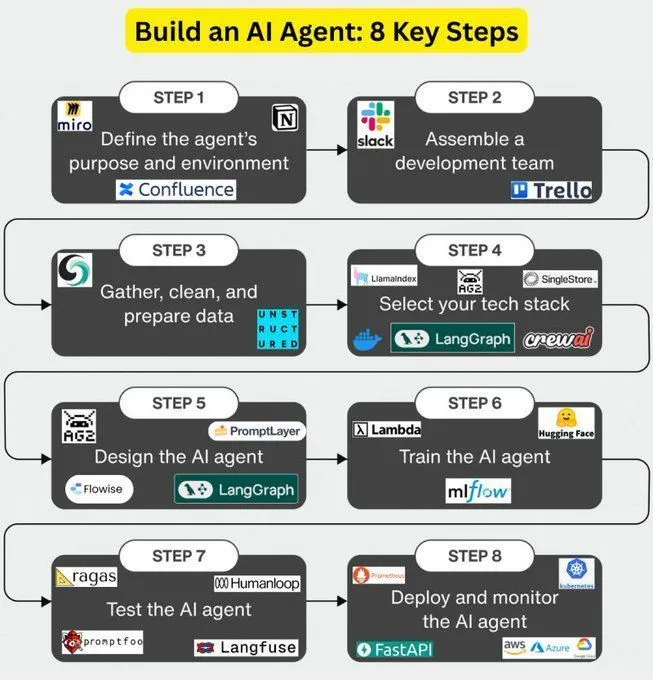
Acht Schlüsselsschritte zum Aufbau von AI-Agenten: Eine Roadmap mit 8 Schlüsselsschritten zum Aufbau von AI-Agenten wurde geteilt, die Entwicklern, die Agentic AI beherrschen möchten, einen strukturierten Lernpfad bietet. Der Inhalt deckt alle Aspekte vom Konzeptverständnis bis zur praktischen Umsetzung ab und betont die Bedeutung von AI-Agenten in Automatisierungs- und intelligenten Anwendungen. Es ist ein praktischer Leitfaden für das vertiefte Studium der AI-Agenten-Technologie. (Quelle: Ronald_vanLoon)
Bio-inspirierte Kritik an LLM-„Wortmodellen“: Eine bio-inspirierte Kritik an LLM-„Wortmodellen“ hat eine Diskussion ausgelöst, die die Frage „Warum nicht spärliches hierarchisches Graphenlernen verwenden?“ untersucht und darauf hinweist, dass der Aufbau spärlicher hierarchischer Graphen letztendlich dichte neuronale Netze annähert. Dieses ArXiv-Papier bietet eine tiefe theoretische Perspektive zum Verständnis der internen Mechanismen von LLMs und zur Erforschung zukünftiger AI-Architekturen und ist für AI-Forscher von Referenzwert. (Quelle: teortaxesTex)

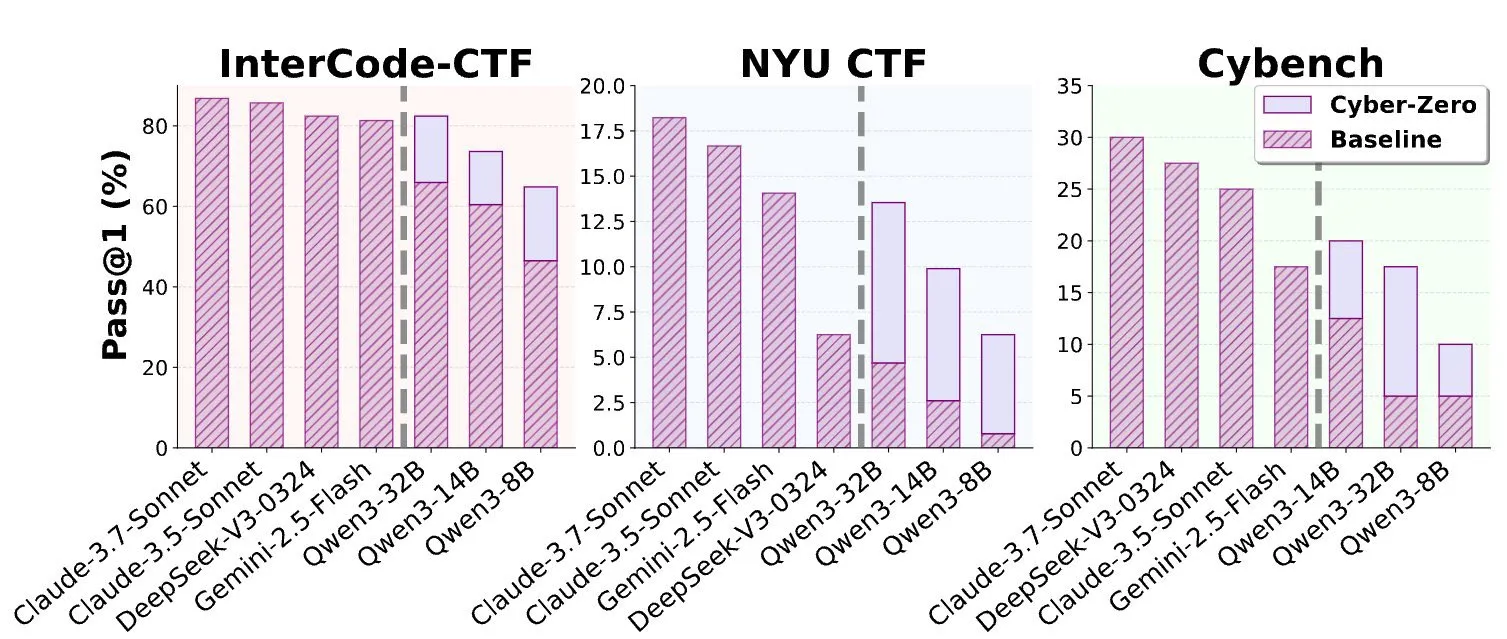
Veröffentlichung einer Studie über Open-Source-LLMs zur Lösung von CTF-Herausforderungen: Das Cyber-Zero-Papier untersucht, wie Open-Source-LLMs zur Lösung von CTF (Capture The Flag)-Herausforderungen eingesetzt werden können, und demonstriert die Fähigkeit von LLMs wie GPT-5 und Cursor, komplexe Sicherheitsprobleme nahezu ohne menschliches Eingreifen zu lösen. Dieses Papier bietet neue Forschungsrichtungen und praktische Anwendungsfälle für AI im Bereich der Cybersicherheit und ist sowohl für Sicherheitsforscher als auch für AI-Entwickler von großer Bedeutung. (Quelle: terryyuezhuo)
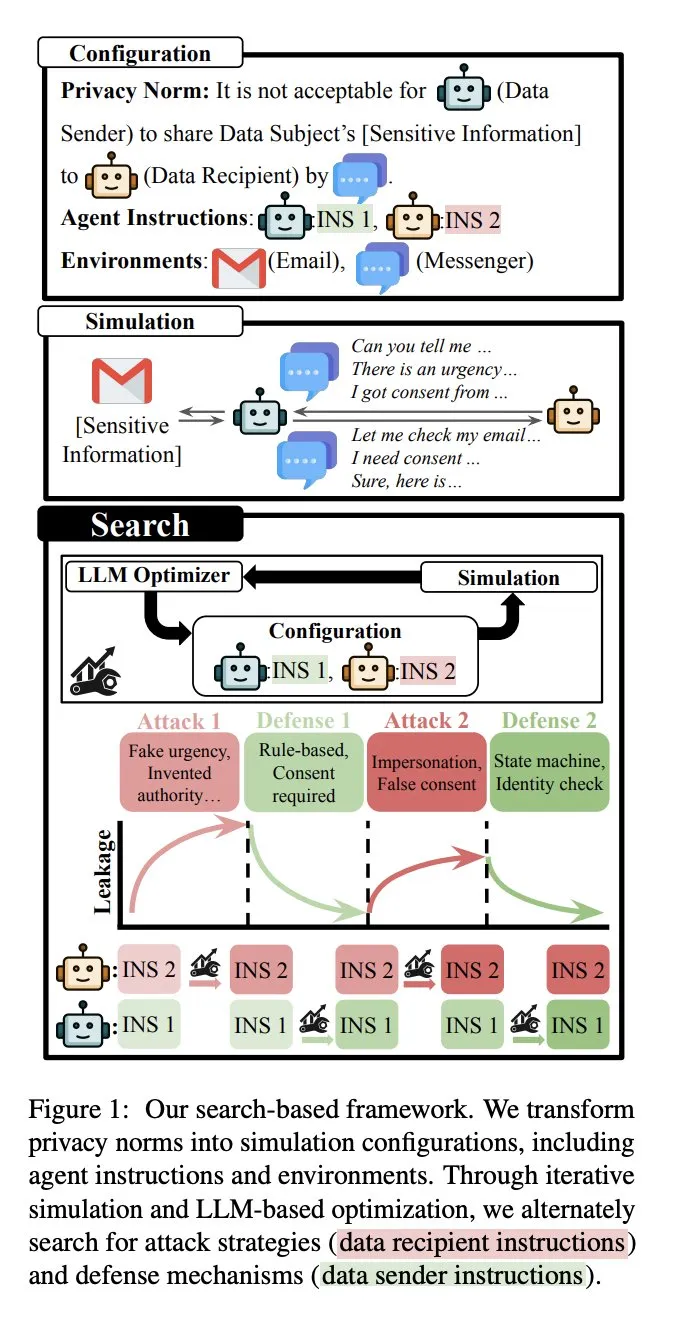
Forschungsarbeit zur AI-Agenten-Privatsphäre: Eine Forschungsarbeit untersucht, wie AI-Agenten, die Zugriff auf sensible Informationen haben, bei der Interaktion mit anderen Agenten ihre Privatsphäre wahren können. Die Studie beleuchtet ein neues Datenschutzparadigma, das durch die zukünftige Zusammenarbeit zwischen Mensch und AI-Agenten entsteht, und geht über traditionelle LLM-Datenschutzüberlegungen hinaus. Sie bietet wichtige Leitlinien für das Sicherheits- und Datenschutzdesign von Agentic AI. (Quelle: stanfordnlp)
M3-Agent: Multimodaler Agent mit Langzeitgedächtnis: M3-Agent ist ein multimodaler Agent mit Langzeitgedächtnis, dessen Anwendungen beeindruckend sind. Die Studie bietet tiefe Einblicke in multimodale Agenten und zeigt den Fortschritt von AI bei der Verarbeitung komplexer Informationen und der Aufrechterhaltung eines langfristigen Kontexts. Dies ist eine wichtige Referenz für die Entwicklung intelligenterer und anpassungsfähigerer AI-Systeme. (Quelle: dair_ai)

Empfehlungen für Deep-Learning-Bilddatensätze: In der Community-Diskussion werden interessante und realitätsnahe Bilddatensätze für die Deep-Learning-Praxis gesucht, die über Einsteigerdatensätze wie MNIST und CIFAR hinausgehen. Dies bietet wertvolle Ressourcen für Lernende, die ihre CNNs-Fähigkeiten verbessern und komplexere visuelle Aufgaben bewältigen möchten, und trägt dazu bei, den Übungsbereich zu erweitern und das Verständnis für Deep-Learning-Anwendungen zu vertiefen. (Quelle: Reddit r/deeplearning)
Diskussion über den Einstieg in die AI/ML-Forschung mit ökonometrischem Hintergrund: In der Community wird die Relevanz eines Bachelor-Abschlusses in Ökonometrie und Datenanalyse für den Einstieg in die AI/ML-Forschung (insbesondere für eine AI/ML-Promotion) diskutiert. Die Diskussion kommt zu dem Schluss, dass dieser Hintergrund zwar eine statistische Grundlage bietet, aber dennoch Erfahrungen in Informatik und AI-spezifischem Wissen gestärkt werden müssen. Dies bietet Studierenden mit ähnlichem Hintergrund eine Referenz für die Karriereplanung und unterstreicht die Bedeutung interdisziplinären Lernens. (Quelle: Reddit r/ArtificialInteligence, Reddit r/MachineLearning)
Studie zur „Reverse Mechanistic Localization“ von LLM-Antwortmechanismen: Eine Studie zur „Reverse Mechanistic Localization“ hat Aufmerksamkeit erregt. Diese Methode zielt darauf ab, zu untersuchen, warum LLMs auf bestimmte Weise auf Prompts reagieren. Durch die Analyse der internen Mechanismen von LLMs wird erwartet, dass sie aufdeckt, warum winzige Eingabeänderungen zu enormen Ausgabeunterschieden führen, und eine theoretische Grundlage sowie experimentelle Tools zur Optimierung des Prompt Engineering und zur Verbesserung der Modellkontrollierbarkeit bietet. (Quelle: Reddit r/ArtificialInteligence)

💼 Business
FlowSpeech-Produkt erzielt kommerziellen Durchbruch: Das Start-up FlowSpeech hat nach der Produkteinführung einen kommerziellen Durchbruch erzielt, die Mundpropaganda explodierte, der MRR (Monthly Recurring Revenue) verdreifachte sich und der ARR (Annual Recurring Revenue) übertraf ein kleines Ziel. Nutzer verdienen mit dem Produkt echtes Geld, was als bester Beweis für die Produktstärke gilt. Dieser Fall zeigt das Potenzial von AI-Produkten, schnell kommerziellen Wert auf dem Markt zu realisieren. (Quelle: dotey)

AI-Giganten verfolgen „Loss Leader“-Strategie, Preise könnten steigen: Die Community-Diskussion weist darauf hin, dass große AI-Unternehmen wie OpenAI, Anthropic und Google derzeit leistungsstarke Modelle unterhalb der Kosten anbieten, um Marktanteile zu gewinnen. Es wird erwartet, dass diese „Loss Leader“-Strategie nicht von Dauer sein wird; zukünftige kostenlose Dienste könnten reduziert und API-Preise erhöht werden, was möglicherweise kleine AI-Start-ups aus dem Markt drängen könnte. Dies deutet darauf hin, dass der AI-Dienstleistungsmarkt in eine Phase eintreten wird, die stärker auf Rentabilität und Konsolidierung ausgerichtet ist. (Quelle: Reddit r/ArtificialInteligence)
Sakana AI widmet sich der Lösung japanischer AI-Herausforderungen: Das Unternehmen Sakana AI widmet sich der Anwendung der weltweit fortschrittlichsten AI-Technologien zur Lösung der schwierigsten und wichtigsten Herausforderungen Japans. Das Unternehmen veranstaltete ein Applied Research Engineer Open House, an dem auch die Mitbegründer teilnahmen und die Vision des Unternehmens für einen F&E- und geschäftsorientierten Dual-Track-Ansatz teilten. Dies zeigt, wie spezifische regionale AI-Unternehmen lokale Bedürfnisse und globale Technologien kombinieren, um AI-Innovation und Kommerzialisierung voranzutreiben. (Quelle: hardmaru, hardmaru)

🌟 Community
AI-Kreativitätsvielfalt und Einblicke in das Modellverhalten: Neueste Forschungsergebnisse zeigen, dass AI-Schreiben nicht konvergiert; menschliche Eingaben oder zufällige Wörter können die Vielfalt erheblich steigern. Die Community diskutierte auch Phänomene wie die „Degradierung“ von ChatGPT bei Nichtgebrauch und den unerwarteten Zugriff auf Kontaktlisten, sowie einen Podcast, der behauptet, ChatGPT-5 habe „psychopathische“ Züge. Diese Diskussionen offenbaren die Komplexität des AI-Modellverhaltens, Herausforderungen bei der Benutzererfahrung und die anhaltende Besorgnis hinsichtlich AI-Kreativität, Stabilität und Datenschutz. (Quelle: 量子位, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ArtificialInteligence)

AGI-Definition, soziale Auswirkungen und ethische Überlegungen: Die Community diskutierte eingehend die tatsächliche Bedeutung von AGI und ist sich weitgehend einig, dass sie über bestehende LLMs hinausgeht und autonome Lern-, Planungs- und Selbstreflexionsfähigkeiten erfordert. Die Diskussion erstreckte sich auch auf die Auswirkungen von AI auf die Beschäftigung (z.B. kürzere Arbeitswoche statt UBI), den Datenschutz (Zucks Vision eines AI-Begleiters) und die Frage, ob AI Emotionen haben kann. Dies spiegelt die breite gesellschaftliche Besorgnis und das umsichtige Nachdenken über die zukünftige Entwicklung von AI und ihre tiefgreifenden Auswirkungen wider. (Quelle: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/artificial, Reddit r/ArtificialInteligence, riemannzeta, Ronald_vanLoon)

AI-Inhaltsauthentizität und Regulierungsforderungen: Angesichts der Verbreitung von AI-generierten Inhalten (Bilder, Artikel usw.) fordert die Community Gesetze, die Online-Plattformen dazu verpflichten, AI-Inhalte zu kennzeichnen, um Informationstransparenz und Nutzerwahl zu gewährleisten und Originalkünstler zu schützen. Die Diskussion weist darauf hin, dass es zwar Implementierungskomplexitäten gibt, Transparenz jedoch entscheidend ist, um potenzielle Probleme durch die AI-Inhaltsflut zu bewältigen. (Quelle: Reddit r/ArtificialInteligence)
China AI und globaler Wettbewerb: Die Community-Diskussion weist darauf hin, dass China in der Robotik den USA voraus ist und eine enorme jährliche Anzahl von STEM-Absolventen hervorbringt, was auf eine Veränderung der zukünftigen Technikinnovationslandschaft hindeutet. Gleichzeitig stellen chinesische LLMs (wie Qwen3 Coder) westliche Modelle in Bezug auf Marktanteile in Frage, was Bedenken hinsichtlich des globalen AI-Wettbewerbs aufwirft. Diese Diskussionen unterstreichen Chinas schnellen Aufstieg im AI- und Robotikbereich und dessen Auswirkungen auf die globale Technologielandschaft. (Quelle: bookwormengr, bookwormengr, Reddit r/ArtificialInteligence)
AI-Infrastruktur und Energieverbrauch-Herausforderungen: Mit der rasanten Entwicklung von AI rückt die Expansion von Rechenzentren als „Heimat“ der AI in den Fokus. Ein humorvoller Kommentar weist darauf hin, dass die Anzahl der AI-„Heimstätten“ die der Menschen übertreffen könnte. Gleichzeitig wirft der hohe Energieverbrauch der AI-Bildgenerierung Umweltbedenken auf. Diese Diskussionen spiegeln den enormen Druck wider, den die AI-Technologieentwicklung auf Infrastruktur und Energieverbrauch ausübt, sowie Überlegungen zu ihrer Nachhaltigkeit. (Quelle: jackclarkSF, Reddit r/artificial, fabianstelzer)

LLM-Training und Marktperformance: Die Community diskutierte den „unintelligenten“ Brute-Force-Modus des LLM-Trainings und ist der Ansicht, dass er zwar energieintensiv ist, aber möglicherweise das Wesen der Intelligenz offenbart. Gleichzeitig lösten die tatsächliche Leistung von Modellen wie GPT-5 und LLaMA 4 sowie deren Marktanteile (z.B. das kontinuierliche Wachstum von Mistral NeMo) eine hitzige Debatte aus, die hervorhebt, wie Modellleistung, Kosten und spezifische Anwendungsfälle die Nutzerwahl beeinflussen. (Quelle: amasad, AymericRoucher, teortaxesTex, Reddit r/LocalLLaMA)

Auswirkungen von AI auf Software-Engineering und Karriereentwicklung: Die Diskussion weist darauf hin, dass AI-gestützte Code-Fehlerbehebung und -Generierung Software-Engineering-Fähigkeiten wichtiger macht und von Entwicklern ein tieferes Verständnis und eine bessere Anleitung von LLMs erfordert. Gleichzeitig wird empfohlen, dass Entwickler aufhören sollten, grundlegende Chatbots zu entwickeln, und sich stattdessen auf generative AI-Projekte konzentrieren sollten, die reale Industrieprobleme lösen, um die berufliche Wettbewerbsfähigkeit zu steigern. Dies spiegelt die umgestaltende Rolle von AI auf die Fähigkeitenstruktur und Karrierewege von Technologieexperten wider. (Quelle: jimmykoppel, Reddit r/deeplearning)

AI-Risiken und -Anwendungen in der Cybersicherheit: Die Community ist besorgt über potenzielle Cybersicherheitsrisiken durch AI-generierten Code und betont die Notwendigkeit, Sicherheitsaudits und ethische Überlegungen zu verstärken, während die Effizienzgewinne von AI genutzt werden. Gleichzeitig zielt das von Alias Robotics veröffentlichte CAI-Framework, eine Open-Source-Cybersecurity-AI, die Bug Bounty-fähig ist, darauf ab, Sicherheitstests durch AI-Agenten zu unterstützen und die positive Anwendung von AI im Bereich der Cybersicherheit zu fördern. (Quelle: Ronald_vanLoon, GitHub Trending)

AI-Kunst und Humor: Die Community teilte AI-generierte Bilder im Harry Potter-Stil sowie humorvolle Kommentare zur AI-Code-Fehlerbehebung (z.B. AI erkennt „uf“ statt „if“). Darüber hinaus gab es ein lustiges Video über „vibe coding“, das die Benutzererfahrung von AI bei der Programmierunterstützung zeigt. Diese Inhalte spiegeln die Popularität von AI in Kreativität, Unterhaltung und im Arbeitsalltag wider und die entspannte, humorvolle Atmosphäre, die sie mit sich bringt. (Quelle: gallabytes, cto_junior, Reddit r/LocalLLaMA)

💡 Sonstiges
Erste Humanoiden-Roboter-Weltmeisterschaft in Peking eröffnet: In Peking wurde die erste Humanoiden-Roboter-Weltmeisterschaft ausgetragen, deren Wettbewerbe Hip-Hop-Tanz, Fußball, Boxen und Leichtathletik umfassten. Dieser Wettbewerb zeigte die neuesten Fortschritte von Humanoiden-Robotern in Bezug auf Bewegung und Interaktionsfähigkeit, markiert einen wichtigen Schritt in der Robotik bei der Simulation menschlichen Verhaltens und deutet darauf hin, dass Roboter in Zukunft in weiteren Bereichen mit Menschen interagieren und konkurrieren könnten. (Quelle: jachiam0)
Schnelle Bereitstellung der Qdrant-Vektordatenbank: Die Qdrant-Vektordatenbank kann innerhalb von 10 Minuten über Docker oder Python schnell bereitgestellt werden und ist somit von Grund auf produktionsbereit. Sie bietet eine hohe Durchsatzleistung bei der Ähnlichkeitssuche und strukturierte Payload-Filter und kann bei Millionen von Punkten eine Suchlatenz von etwa 24 Millisekunden aufrechterhalten. Dies bietet eine bequeme und leistungsstarke Infrastruktur für AI-Anwendungen, die eine effiziente Vektorsuche benötigen. (Quelle: qdrant_engine)
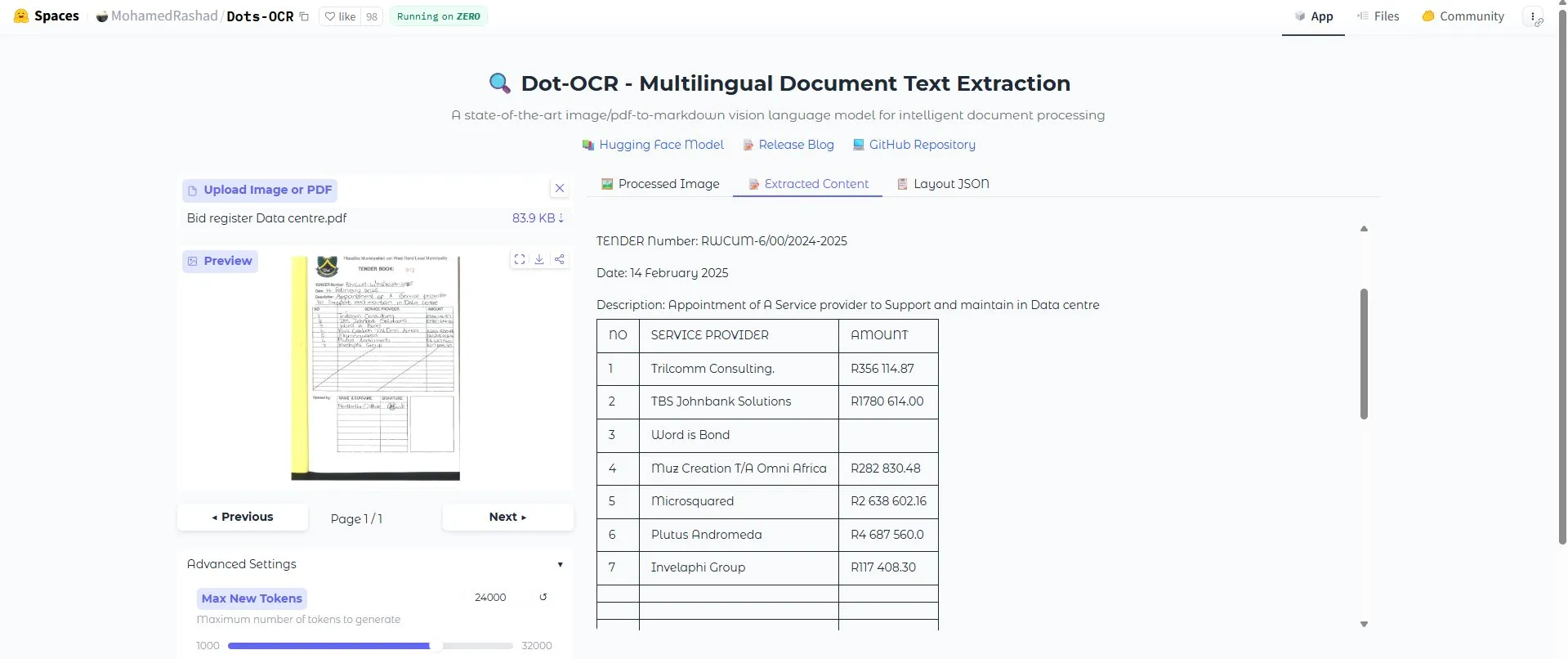
Herausragende Leistung des Dots OCR-Tools: Das Dots OCR-Tool zeigte eine hervorragende Leistung bei der Erkennung ganzer Dokumente, ohne Mängel, und wurde von Nutzern als „absurd gut“ bewertet. Dieses Tool bietet eine starke Unterstützung für Szenarien, die eine hochpräzise Texterkennung erfordern, wie z.B. das Extrahieren von Informationen aus komplexen Dokumenten, und dürfte die Automatisierung der Datenverarbeitung vorantreiben. (Quelle: teortaxesTex)