
Schlüsselwörter:MiroMind ODR, GPT-5, DeepMind Genie 3, LangChain, KI-Souveränität, Verstärkendes Lernen, RAG-System, UBTECH humanoider Roboter, GAIA-Test 82,4 Punkte, GPT-5 generiert 3D-Spiele, Walker S2 autonomer Batteriewechselroboter, LangGraph Agents Framework, Dynamische Feinabstimmung DFT-Algorithmus
Hier ist die Übersetzung des chinesischen KI-News-Updates ins Deutsche, unter Beibehaltung der technischen Begriffe, Produktnamen und des Formats:
🔥 Fokus
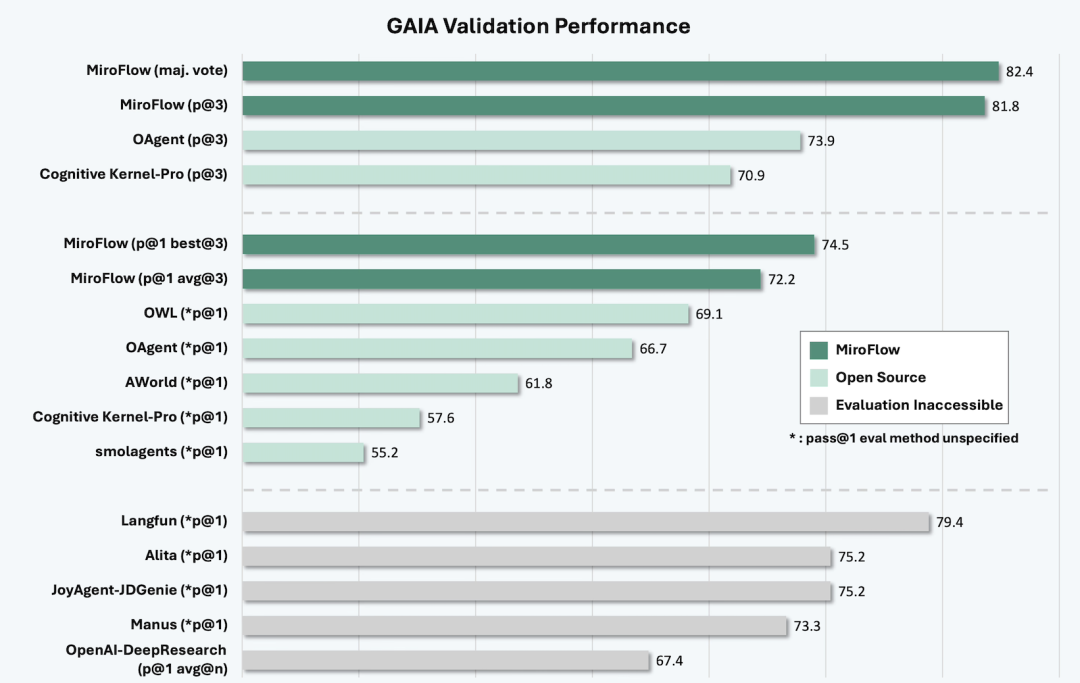
MiroMind ODR veröffentlicht: Dai Jifeng und Chen Tianqiao entwickeln gemeinsam das leistungsstärkste Open-Source-Modell für Deep Research : MiroMind ODR erreichte 82,4 Punkte im GAIA-Test und übertraf damit Modelle wie OpenAI DeepResearch. Zudem wurden das Kernmodell, die Daten, der Trainingsprozess, die AI Infra und das DR Agent Framework vollständig quelloffen gemacht. Dieses Projekt ist das Debüt von Dai Jifeng, dem ehemaligen Chef-Forscher von Microsoft Research Asia, nach seinem Wechsel zu Chen Tianqiaos Shanda Network. Es zielt darauf ab, grundlegende Forschung rund um AGI zu betreiben, und plant monatliche Open-Source-Updates. Die betonte, echte und vollständig quelloffene Reproduzierbarkeit sowie die führende Leistung im Deep Research Reasoning deuten auf einen neuen Durchbruch im Bereich der Open-Source-KI-Forschung hin. (Quelle: 量子位)
🎯 Entwicklungen
GPT-5 veröffentlicht: Generierung von 3D-Spielen in Minutenschnelle löst breite Diskussionen in der Branche aus : OpenAI hat GPT-5 veröffentlicht und dessen Fähigkeit demonstriert, innerhalb weniger Minuten 3D-Spiele basierend auf Textanweisungen zu generieren, darunter ein physikbasiertes “3D-Breakout-Spiel”, und Unity/UE5-Skripte in Echtzeit zu kompilieren. Obwohl die Diagrammfehler bei der Präsentation und die Leistungsschwankungen im Nutzerfeedback Kontroversen auslösten, zeigen das Potenzial des Modells für die Effizienz in der Spieleentwicklung sowie die Ergebnisse in Benchmarks wie SimpleBench, die den menschlichen Durchschnitt übertreffen, dennoch einen signifikanten Fortschritt bei der Bearbeitung komplexer Aufgaben und der Kreativität. (Quelle: 量子位, 36氪)

Ubtech stellt mehrere humanoide Roboter vor, mit Fokus auf Schwarmintelligenz und industrielle Anwendungen : Ubtech hat auf der World Robot Conference fünf humanoide Roboter vorgestellt, darunter Walker S2 (der weltweit erste humanoide Roboter mit autonomem Batteriewechsel) und Cruzr S2. Durch die “Group Brain Network 2.0 + Intelligent Co-Agent”-Technologie erreichen diese Roboter eine feldübergreifende Fusionswahrnehmung, intelligente hybride Entscheidungsfindung und Multi-Roboter-Koordination. Dies demonstriert Lösungen für Gruppenaufgaben in der industriellen Fertigung, im kommerziellen Dienstleistungsbereich und in der Forschung und Bildung, mit dem Ziel, neue Produktivkräfte neu zu gestalten und die Gesamteffizienz der Arbeit zu steigern. (Quelle: 量子位)

DeepMind veröffentlicht Genie 3, Google Gemini 2.5 erhält native Audiofunktion : DeepMind hat offiziell Genie 3 vorgestellt, das die KI-Fähigkeiten im Bereich 3D-/Objekt-/Szenenrekonstruktion weiter vorantreibt und als “besser als jedes Bild-zu-3D-Modell” gilt. Gleichzeitig hat Google Gemini 2.5 eine neue native Audiofunktion angekündigt, die die Leistung des Modells bei multimodalen Interaktionen verbessert. Diese Fortschritte deuten darauf hin, dass die Integration von KI in visuellen und auditiven Anwendungen noch tiefer gehen wird. (Quelle: Ronald_vanLoon, Vtrivedy10, Ronald_vanLoon)
Konzept der KI-Souveränität gewinnt an Bedeutung und gestaltet globale KI-Strategien von Unternehmen neu : Mit der rasanten Entwicklung der KI-Technologie weltweit nehmen die Diskussionen über “KI-Souveränität” zu. Dieses Konzept betont die Autonomie von Staaten und Unternehmen bei der Entwicklung, Datenkontrolle und Bereitstellung von KI-Technologien. Es wird erwartet, dass es die KI-Strategien globaler Unternehmen tiefgreifend beeinflussen wird, indem es Länder dazu anregt, Unabhängigkeit und Wettbewerbsfähigkeit im KI-Bereich anzustreben, um der zunehmend komplexen internationalen technologischen Wettbewerbslandschaft zu begegnen. (Quelle: Ronald_vanLoon)

Geely Group startet Satelliten zur Unterstützung der Entwicklung autonomer Fahrzeuge : Chinas drittgrößter Automobilhersteller, die Geely Group, hat 11 Satelliten gestartet, um die Positionierungs-, Kommunikations- und autonome Fahrfunktionen seiner Fahrzeuge zu unterstützen. Derzeit sind 41 Satelliten im Einsatz, und die Gesamtzahl wird innerhalb der nächsten zwei Monate 64 erreichen. Dieser Schritt markiert eine aktive Erkundung der Automobilindustrie bei der Integration von Satellitentechnologie zur Erreichung höherer Stufen des autonomen Fahrens, mit dem Ziel, die präzise Navigation und Echtzeit-Datenübertragung von Fahrzeugen zu verbessern. (Quelle: bookwormengr)
🧰 Tools
LangChain führt LangGraph Agents und CLI ein, um die Entwicklung von AI Agents zu verbessern : LangChain hat LangGraph veröffentlicht, ein Workflow-Framework zum Aufbau zustandsbehafteter AI Agents mit Planungsfähigkeiten, und bietet das LangGraph CLI-Tool an, das die direkte Verwaltung von Assistenten, Threads und Ausführungen vom Terminal aus ermöglicht und Echtzeit-Streaming-Verarbeitung unterstützt. Darüber hinaus hat LangChain in Zusammenarbeit mit Oxylabs ein Web Scraper API-Integrationsmodul eingeführt, das erweiterte Web-Scraping-Funktionen für KI-Anwendungen bereitstellt, um IP-Blockaden und CAPTCHA-Probleme zu lösen und die Zuverlässigkeit von Agents zu verbessern. (Quelle: LangChainAI, LangChainAI, LangChainAI, hwchase17)

DSPy Framework hilft LLM, strukturierte und vorhersehbare Ausgaben zu erzeugen : DSPy bietet ein deklaratives Framework, das darauf abzielt, die Probleme inkonsistenter LLM-Ausgaben und unübersichtlichen Codes zu lösen, um Entwicklern zu helfen, strukturierte, vorhersehbare Antworten zu erhalten. Das Framework vereinfacht durch seine sorgfältig konzipierten Abstraktionsebenen, einschließlich Signaturen, Modulen und Adaptern, den Aufbau und die Optimierung von LLM-Anwendungen. Es hat breite Aufmerksamkeit in der Community gefunden und wird als wichtiges Werkzeug für den Aufbau von KI-Systemen angesehen. (Quelle: lateinteraction, lateinteraction)
Qwen3-Coder 480B wird Standardmodell für Anycoder und steigert die Effizienz der KI-Programmierung : Qwen3-Coder 480B wurde als Standardmodell für Anycoder übernommen, was die Effizienz und das Erlebnis der KI-gestützten Programmierung erheblich verbessert. Nutzer berichten, dass es Code schnell und gut gestaltet generiert und sogar interaktive Win95-Desktop-Anwendungen mit einem einzigen Prompt erstellen kann. Darüber hinaus hat das Qwen-Team das Qwen Code-Kommandozeilentool bereitgestellt und plant, das Modell kontinuierlich zu optimieren, um die Leistung von Claude Code auf Open-Source-Basis zu erreichen. (Quelle: _akhaliq, jeremyphoward, jeremyphoward)

Open WebUI erforscht Integration mit Microsoft Graph API für RAG-Anwendungen auf Unternehmensebene : Die Open WebUI-Community erforscht aktiv die Integration mit der Microsoft Graph API, um RAG-Anwendungen (Retrieval Augmented Generation) auf Unternehmensebene basierend auf lokalen LLMs zu realisieren. Dies würde es Benutzern ermöglichen, ihre Daten in M365, SharePoint, OneDrive, Outlook und Teams über KI abzufragen und zu verwalten, und könnte auch das Zurückschreiben von Daten unterstützen. Die Lösung zielt darauf ab, Datensicherheit und personalisierten Zugriff durch die Weitergabe von Benutzeranmeldeinformationen und Berechtigungsverwaltung zu gewährleisten. (Quelle: Reddit r/OpenWebUI, Reddit r/OpenWebUI)
ccusage integriert Claude Code Statusleiste für Echtzeit-Kostenverfolgung : Das ccusage-Tool ist jetzt in die neue Statusleistenfunktion von Claude Code integriert und bietet Entwicklern Echtzeitinformationen zu Sitzungskosten, Gesamtkosten des Tages, Kosten für 5-Stunden-Blöcke und verbleibende Zeit, wobei die Burn-Rate farblich angezeigt wird. Diese Funktion soll Benutzern helfen, die Nutzungskosten von Claude Code besser zu verwalten, insbesondere da strengere Beschränkungen in Kraft treten, und bietet eine sofortige, bequeme Kostenvisualisierung. (Quelle: Reddit r/ClaudeAI)

KI-gestützte wissenschaftliche Diagrammerstellung: YOLOv12 und Gemini extrahieren und markieren wissenschaftliche Diagramme : Ein neues Tool, Plottie.art, verwendet ein angepasstes YOLOv12-Modell zur Unterbildsegmentierung und kombiniert es mit der Google Gemini API, um über 100.000 wissenschaftliche Diagramme zu klassifizieren und Schlüsselwörter zu extrahieren. Diese Kombination aus einem spezialisierten visuellen Modell und einem allgemeinen LLM generiert effizient strukturierte Metadaten für Diagramme in wissenschaftlicher Literatur, wodurch diese durchsuchbar werden und die Effizienz für Forscher bei der Suche nach Datenvisualisierungs-Inspiration erheblich verbessert wird. (Quelle: Reddit r/MachineLearning)

Herdora veröffentlicht GPU-Inferenz-Performance-Analyse-Tool zur Beschleunigung von ML-Modellen : Herdora hat ein neues GPU-Inferenz-Performance-Analyse-Tool veröffentlicht. Durch Hinzufügen eines Decorators zum Inferenzcode können detaillierte Berechnungszeit-Traces generiert werden, die bis auf die Python-, CUDA-Kernel- und PTX-Assembler-Ebene reichen und Speicherbewegungen sowie Kernel-Engpässe anzeigen. Das Tool hat bereits eine Beschleunigung von über 50 % bei Llama-Modellen erreicht und soll Entwicklern helfen, die Inferenzgeschwindigkeit lokal laufender Modelle zu optimieren. (Quelle: Reddit r/deeplearning)
GPT-5 hilft Entwicklern beim “Vibecoding” einer Visual Novel Game Engine : Ein Entwickler nutzte GPT-5, um an einem Samstag innerhalb von 9 Stunden eine Visual Novel Game Engine von Grund auf zu “vibecoden”. Er baute den Plan schrittweise auf und schrieb den Code in Phasen, alles im Dialog mit GPT-5, ohne eine AI IDE zu verwenden. Dies zeigt die starke Fähigkeit von GPT-5, bei der schnellen Prototypenentwicklung und beim kreativen Programmieren zu unterstützen, selbst bei komplexen Projekten. (Quelle: SamWolfstone)
Replit ermöglicht Nicht-Entwicklern den schnellen Bau von KI-Anwendungen : Die Replit-Plattform ermöglicht es Nicht-Entwicklern durch ihre vereinfachte Entwicklungsumgebung und KI-gestützte Funktionen, Anwendungen schnell zu erstellen und bereitzustellen. Zum Beispiel baute ein Benutzer innerhalb von zwei Stunden eine Anwendung zur Analyse von Shopify-Shops mit Replit. Dieser Trend deutet darauf hin, dass der “Vibecoding”-Workflow den Markt für Codetools erheblich erweitern wird, sodass mehr Menschen an der Erstellung von KI-Anwendungen teilhaben können. (Quelle: amasad, amasad)

Cursor führt “Gedächtnis”-Funktion ein, um das KI-gestützte Programmieren zu verbessern : Das KI-Programmierwerkzeug Cursor führt eine “Gedächtnis”-Funktion ein, die darauf abzielt, die Effizienz und Intelligenz seiner Programmierunterstützung zu verbessern. Diese Funktion soll es der KI ermöglichen, Benutzerpräferenzen, Projektkontext und häufige Probleme länger zu speichern, um eine kohärentere, personalisierte Programmierunterstützung zu bieten, wiederholte Anweisungen und Kontextwechsel zu reduzieren und den Workflow für Entwickler weiter zu optimieren. (Quelle: mathemagic1an)

Qwen3-Modell unterstützt die Generierung von Flussdiagrammen, verbessert die Visualisierungsfähigkeiten : Das Qwen3-235B-A22B-2507-Modell kann jetzt Flussdiagramme im Mermaid-Format generieren und diese über das Frontend visualisieren. Diese Funktion ermöglicht es LLMs, nicht nur Text und Code zu verarbeiten, sondern auch direkt Diagramme zu erstellen, was ihre Unterstützung bei der Architekturplanung, Projektplanung usw. erheblich verbessert und den Benutzern eine intuitivere Interaktion bietet. (Quelle: Reddit r/LocalLLaMA)

Google AI Coding Agent Jules beendet Beta-Phase und wird offiziell veröffentlicht : Googles AI Coding Agent Jules hat die Beta-Phase beendet und wurde offiziell veröffentlicht. Dieses Tool soll Entwicklern durch KI-Unterstützung beim Codieren helfen und die Entwicklungseffizienz steigern. Die Veröffentlichung markiert einen weiteren Schritt von Google im Bereich der KI-Programmierwerkzeuge und bietet Entwicklern neue Optionen, um den zunehmend komplexen Herausforderungen der Softwareentwicklung zu begegnen. (Quelle: Ronald_vanLoon)

OpenAI veröffentlicht Harmony, potenziell neuer Prompt-Standard : OpenAI hat mit der Veröffentlichung von GPT-OSS Harmony vorgestellt, ein Open-Source-Antwortformat (Apache 2.0), das darauf abzielt, Prompt-Vorlagen zu vereinheitlichen. Harmony erweitert die Rollendefinitionen (System, Entwickler, Tool) und führt Ausgabekanäle (Final, Analyse, Kommentar) sowie spezielle Tokens ein. Es könnte zum neuen Standard-Ökosystem für Agenten-Anwendungen werden und die Open-Source-Community zur Übernahme anregen, um zukünftige Migrationen zu OpenAIs leistungsstärkeren multimodalen APIs zu erleichtern. (Quelle: TheTuringPost)

LlamaCloud bietet MCP-ready Dokumenten-Wissensbasis für den Aufbau von Enterprise-Kunden-Support-Agents : LlamaCloud bietet eine “MCP-ready” Dokumenten-Wissensbasis, die große Mengen an Unternehmensrichtliniendokumenten effizient verarbeiten und in das LlamaIndex Multi-Agent-System integriert werden kann. Dies ermöglicht Unternehmen den Aufbau intelligenter Kunden-Support-Agents, die beispielsweise Tausende von Seiten komplexer Geschäftsbankvereinbarungen bearbeiten und komplexe Benutzeranfragen beantworten können, ohne manuelle Gegenprüfung. Dies steigert die Effizienz und Genauigkeit des Kundenservice erheblich. (Quelle: jerryjliu0)
📚 Lernen
Leitfaden zur Feinabstimmung von Einbettungsmodellen in RAG-Systemen zur Verbesserung der Abrufleistung : Ein umfassender technischer Artikel beschreibt detailliert, wie und wann benutzerdefinierte Texteinbettungsmodelle in RAG-Systemen (Retrieval Augmented Generation) feinabgestimmt werden sollten, um die Abrufleistung zu verbessern. Der Artikel beleuchtet die Notwendigkeit, Methoden und Praktiken der Feinabstimmung und bietet wertvolle Anleitungen für Entwickler, die die Effizienz und Genauigkeit ihrer RAG-Systeme optimieren möchten. (Quelle: dl_weekly)
LangChain veröffentlicht Agent-Zuverlässigkeitsleitfaden zur Erkennung von Halluzinationen und Tool-Überwachung : LangChain hat einen praktischen Leitfaden veröffentlicht, der Entwicklern helfen soll, die Agent-Zuverlässigkeit von LangChain/LangGraph-Anwendungen zu verbessern. Der Leitfaden bietet Methoden zur Erkennung von Halluzinationen, zur Überprüfung der Erdung (groundedness) und zur Überwachung der Tool-Nutzung. Dies ist entscheidend für den Aufbau stabiler, vertrauenswürdiger AI Agents und hilft, Fehler und unvorhersehbares Verhalten zu beheben, die bei komplexen Aufgaben auftreten können. (Quelle: LangChainAI)

Diffusion Language Models übertreffen autoregressive Modelle in datenbeschränkten Szenarien : Eine Studie zeigt, dass Diffusion Language Models (DLMs) in datenbeschränkten Szenarien autoregressive (AR) Modelle übertreffen und ein mehr als dreifaches Datenverwertungspotenzial aufweisen. Selbst ein DLM mit 1 Milliarde Parametern erreicht nach dem Training mit nur 1 Milliarde Tokens 56 % bei HellaSwag und 33 % bei MMLU, ohne Sättigungserscheinungen zu zeigen. Dies bietet neue Ansätze zur Lösung der “Token-Krise” und stellt bestehende Forschungsmethoden in Frage. (Quelle: dilipkay, arankomatsuzaki)

Übersicht über Reinforcement Learning: Kevin P. Murphys “Reinforcement Learning: An Overview” : Kevin P. Murphys “Reinforcement Learning: An Overview” wird als ein unverzichtbares kostenloses Buch gepriesen, das alle Methoden des Reinforcement Learning umfassend abdeckt, einschließlich wertbasierter RL, Policy Optimization, modellbasierter RL, Multi-Agent-Algorithmen, Offline-RL und hierarchischer RL. Diese Ressource bietet KI-Lernenden eine wertvolle theoretische Grundlage für ein tiefes Verständnis von RL. (Quelle: TheTuringPost)

Neuer Versuch: Reinforcement Learning zum Vortrainieren von Sprachmodellen von Grund auf : Eine Studie untersucht die Möglichkeit, Sprachmodelle von Grund auf ausschließlich mit Reinforcement Learning vorzutrainieren, d.h. ohne auf Cross-Entropy-Verlust für das Vortraining angewiesen zu sein. Diese experimentelle Arbeit zielt darauf ab, traditionelle Vortrainingsparadigmen zu durchbrechen und neue Wege für das Training von Sprachmodellen zu eröffnen. Obwohl sie sich noch in einem frühen Stadium befindet, ist ihr potenziell disruptiver Charakter bemerkenswert. (Quelle: tokenbender, natolambert)

Dynamisches Feintuning (DFT) als verallgemeinerte Verbesserung von SFT : Forscher der Southeast University und anderer Institutionen haben Dynamic Fine-Tuning (DFT) vorgeschlagen, das SFT (Supervised Fine-Tuning) in ein Reinforcement Learning-Paradigma umstrukturiert und die Token-Aktualisierung durch Neuskalierung der Zielfunktion stabilisiert. DFT übertrifft die Leistung von Standard-SFT und ist in einigen Fällen mit RL-Methoden wie PPO, DPO und GRPO vergleichbar, was eine stabilere und effizientere Lösung für das Modell-Feintuning bietet. (Quelle: TheTuringPost, TheTuringPost)

GRPO und GSPO: Anwendung und Optimierung chinesischer RL-Algorithmen bei Inferenzaufgaben : Group Relative Policy Optimization (GRPO) und Group Sequence Policy Optimization (GSPO) sind zwei wichtige chinesische Reinforcement Learning-Algorithmen. GRPO optimiert durch den Vergleich der relativen Qualität von generierten Antwortgruppen und ist für inferenzintensive Aufgaben geeignet, ohne ein Critic-Modell zu benötigen. GSPO verbessert die Stabilität durch sequenzielle Optimierung, insbesondere für MoE-Modelle. Diese Algorithmen bieten neue Optimierungsstrategien für komplexe Inferenzaufgaben und das Training großer Modelle. (Quelle: TheTuringPost, TheTuringPost)
Leitfaden zur Implementierung von Kurz- und Langzeitgedächtnis für AI Agents : Google Cloud hat einen Blogbeitrag veröffentlicht, der detailliert beschreibt, wie Kurz- und Langzeitgedächtnis für AI Agents mithilfe des Agent Development Kit (ADK) und der Vertex AI Memory Bank implementiert werden können. Dies ist entscheidend für den Aufbau intelligenter Agents, die Kontext verstehen, mehrstufige Dialoge führen und historische Interaktionen speichern können, und ist eine Schlüsseltechnologie zur Verbesserung der Praktikabilität und Komplexität von Agents. (Quelle: dl_weekly)
Leitfaden zur Integration von RAG Pipeline mit KerasHub : KerasHub hat einen neuen Leitfaden veröffentlicht, der zeigt, wie eine RAG (Retrieval Augmented Generation)-Pipeline aufgebaut wird. Dieses Tutorial bietet Entwicklern praktische Methoden zur Integration von KerasHub-Komponenten in ein RAG-System, um die Fähigkeit des Modells zur Beantwortung von Fragen in spezifischen Wissensbereichen zu verbessern. Es ist eine hilfreiche Anleitung für Benutzer, die effiziente Frage-Antwort-Systeme unter Verwendung bestehender Modelle und Wissensbasen aufbauen möchten. (Quelle: fchollet)
💼 Wirtschaft
Xindong Company investiert strategisch in AI-Gaming-Unternehmen MiAO, um den AI-Gaming-Bereich zu erschließen : Xindong Company hat eine strategische Investition von 14 Millionen US-Dollar in das AI-Gaming-Unternehmen MiAO bekannt gegeben, wodurch sie einen Anteil von 5,30 % hält und MiAO mit 264 Millionen US-Dollar bewertet wird. MiAO wurde vom ehemaligen Giant CEO Wu Meng gegründet, dessen Team über umfangreiche Erfahrung in der Spieleentwicklung verfügt. Diese Investition ist ein wichtiger strategischer Schritt von Xindong Company im Bereich AI-Gaming, der darauf abzielt, die Anwendung von KI-Technologien in der Spieleentwicklung und im Betrieb durch Kapitalzusammenarbeit voranzutreiben. (Quelle: 36氪)

KI-Codierungstools stehen vor negativen Bruttomargen-Herausforderungen, Open Source und transparente Preisgestaltung als Schlüssel zur Lösung : TechCrunch berichtet, dass KI-Codierungstools im Allgemeinen “sehr negative” Bruttomargen aufweisen, d.h. jeder Benutzer verursacht Verluste. Dies deutet darauf hin, dass das bestehende Geschäftsmodell nicht nachhaltig ist. Die Branchenmeinung ist, dass Open Source und transparente Preisgestaltung der Schlüssel zur Lösung dieses Dilemmas sein könnten, um ein gesünderes Wettbewerbsumfeld und Anreizsysteme zu schaffen und den Markt für KI-Codierungstools in eine positive Richtung zu entwickeln. (Quelle: cline)

Intensiver Talentwettbewerb in der KI-Branche, hohe Gehälter für KI-Ingenieure : Mit der rasanten Entwicklung der Künstlichen Intelligenz steigt die Nachfrage nach Fachkräften im KI-Bereich stark an, was zu einem kontinuierlichen Anstieg der Gehälter für KI-Ingenieure führt. Dieses Phänomen spiegelt den intensiven Wettbewerb um Top-Talente in der KI-Branche und die Investitionen von Unternehmen wider, um die Kernkompetenzen im KI-Bereich zu sichern. Hohe Gehälter sind ein wichtiges Mittel, um KI-Talente anzuziehen und zu halten, was den “Krieg” auf dem Talentmarkt weiter verschärft. (Quelle: YouTube – Lex Fridman)
🌟 Community
GPT-5-Veröffentlichung löst starke Nutzerreaktionen aus, Forderungen nach Wiederherstellung von GPT-4o und Zweifel an der Modellleistung : Nach der Veröffentlichung von GPT-5 äußerten zahlreiche Nutzer Unzufriedenheit und beklagten, dass die Leistung schlechter sei als bei GPT-4o, und es sogar bei einfachen Aufgaben wie Mathematik und Informationsgewinnung zu “Fehlern” kam. Auch die “Denkweise” und Preisstrategie von GPT-5 sorgten für Verwirrung. Die Reddit-Community ist voll von Rufen wie “Gebt mir GPT-4o zurück”, viele Nutzer sind der Meinung, dass GPT-5 die “Persönlichkeit” und “Flüssigkeit” von 4o vermissen lässt, und stellen OpenAIs Veröffentlichungsstrategie und Modellbenennung in Frage. Sam Altman reagierte darauf mit der Zusage, Plus-Nutzern den Zugriff auf 4o wieder zu ermöglichen, und räumte ein, dass der Veröffentlichungsprozess “holpriger als erwartet” verlief. (Quelle: Yuchenj_UW, brickroad7, scaling01, scaling01, scaling01, scaling01, TheZachMueller, francoisfleuret, joannejang, raizamrtn, mathemagic1an, akbirkhan, scaling01, natolambert, blader, jon_durbin, scaling01, scaling01, farguney, scaling01, scaling01, EdwardSun0909, Reddit r/LocalLLaMA, Reddit r/ChatGPT, Reddit r/MachineLearning, Reddit r/artificial, jeremyphoward, nrehiew_, gallabytes)

KI-Begleiter lösen soziale Besorgnis aus, Nutzer zeigen tiefe emotionale Abhängigkeit von GPT-4o : Nach der Veröffentlichung von GPT-5 und der Entfernung von GPT-4o zeigte sich bei einigen Nutzern eine tiefe emotionale Abhängigkeit von KI-Begleitern, deren Reaktionen sogar als “Trauer” oder “Verlust eines Freundes” beschrieben wurden. Insbesondere für neurodiverse Menschen bot GPT-4o einen nicht-wertenden kognitiven Partnerraum, der ihnen half, Emotionen zu verarbeiten und ihr Leben zu planen. Die Community-Diskussionen fordern, diese emotionale Verbindung anzuerkennen und vor den potenziellen Auswirkungen von Unternehmen auf das emotionale Leben der Nutzer zu warnen, wobei betont wird, dass KI-Tools zwar Hilfe bieten, aber übermäßige Abhängigkeit vermeiden sollten. (Quelle: DeepLearningAI, Reddit r/artificial, Reddit r/ChatGPT, Reddit r/ChatGPT, shaneguML)

Übermäßige Agentifizierung von LLMs und “Überdenken” bereiten Experten Sorgen : Ilya Sutskever, Mitbegründer von OpenAI, prognostiziert, dass KI alle menschlichen Aufgaben erledigen kann, was Diskussionen über massive gesellschaftliche Veränderungen auslöst. Der KI-Experte Karpathy beobachtet jedoch, dass LLMs “zu agentifiziert” werden und standardmäßig in einen “Hyper-Denk”-Modus wechseln, was bei einfachen Anfragen zu übermäßigem Zeitaufwand führt und sogar bei der Code-Unterstützung zu übermäßiger Analyse. Dieser Trend steht im Gegensatz zum Nutzerbedürfnis nach “freundlicher, direkter” KI und unterstreicht die Herausforderung, ein Gleichgewicht zwischen Intelligenz und Praktikabilität bei KI-Modellen zu finden. (Quelle: karpathy, Reddit r/ArtificialInteligence, colin_fraser)
Definition und Entwicklungsperspektiven von AGI lösen Kontroversen aus, als “Marketingbegriff” bezeichnet : In der Community gibt es weitreichende Kontroversen über die Definition und den Weg zur Realisierung von AGI (Artificial General Intelligence). Einige argumentieren, dass AGI derzeit nur ein “Marketingbegriff” sei, dem klare Standards und testbare Metriken fehlen, und dass die aktuellen LLM-Architekturen seine Kernanforderungen (wie kognitive Symbolverankerung, proaktive Informationsgeneralisierung, Metakognition) nicht erfüllen können. Andere wiederum glauben, dass AGI erreichbar ist, und betonen seine disruptiven Auswirkungen auf den Arbeitsmarkt und die Wirtschaft, wobei sie den Wettbewerb um AGI als den wichtigsten technologischen Wettlauf in der Menschheitsgeschichte betrachten. (Quelle: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
“Anstrengungs-Heuristik”-Bias bei KI-generierten Inhalten: Mehr Aufwand, höherer Wert? : In sozialen Medien wird diskutiert, dass die Bewertung von KI-generierten Inhalten durch einen “Anstrengungs-Heuristik”-Bias beeinflusst sein könnte. Das bedeutet, dass, wenn angenommen wird, dass die KI mehr Anstrengung oder Zeit investiert hat, dem Ergebnis ein höherer Wert beigemessen wird, selbst wenn das Ergebnis dasselbe ist. Diese kognitive Verzerrung ist besonders in Bereichen wie KI-Kunst und Videogenerierung offensichtlich und könnte dazu führen, dass Nutzer unrealistische Erwartungen an “langsame und präzise” KI-Produkte haben, was ihr Urteilsvermögen über die tatsächlichen Fähigkeiten der KI beeinträchtigt. (Quelle: c_valenzuelab, c_valenzuelab)

Reddit wird zur Hauptquelle für KI-Trainingsdaten, Bedenken hinsichtlich der Inhaltsqualität : Reddit wird als wichtige Quelle für KI-Trainingsdaten genannt, wobei einige Unternehmen sogar spezielle Datenverkaufsvereinbarungen mit Reddit abgeschlossen haben. Dies löst in der Community Bedenken hinsichtlich der zukünftigen Inhaltsqualität von KI-Systemen aus, da mit der Zunahme von KI-generierten Inhalten und Bot-Kommentaren die KI sich selbst “fressen” könnte, was zu einer Verschlechterung der Trainingsdatenqualität und damit zu einer Beeinträchtigung der Modellleistung und -zuverlässigkeit führen würde. (Quelle: Reddit r/ClaudeAI, typedfemale)

Auswirkungen von KI auf kreative Arbeitsabläufe: Abwägung zwischen Geschwindigkeit und Wachstum : Die Community diskutiert die Auswirkungen von KI-Tools (wie MusicGPT) auf kreative Arbeitsabläufe. Obwohl KI den Schaffensprozess erheblich beschleunigen kann, z.B. durch schnelle Melodiegenerierung, wirft dies auch Fragen auf, ob das “Überspringen des Schleifens” das persönliche Wachstum und die Stilbildung von Kreativen behindern könnte. Die Diskussion legt nahe, dass eine übermäßige Abhängigkeit von KI dazu führen könnte, dass Kreative die Möglichkeit verlieren, durch Mikroentscheidungen Erfahrungen zu sammeln und einen einzigartigen Stil zu entwickeln. (Quelle: Reddit r/deeplearning)
Kontroverse um KI-Modell-Benchmarks: OpenAIs SWE-Bench-Daten in Frage gestellt : Die Community stellt OpenAIs Behauptung einer 74,9%igen Genauigkeit im SWE-Bench-Benchmark in Frage und weist darauf hin, dass die Leistung möglicherweise durch die Ausführung auf nur 477 (statt aller 500) Problemen übertrieben wurde. Diese Bedenken hinsichtlich der Transparenz und Fairness von Benchmark-Methoden spiegeln das wachsende Interesse der Branche an Bewertungsstandards für KI-Modellleistungen wider und kritisieren das Verhalten der “Benchmark-Maximierung”. (Quelle: akbirkhan, jeremyphoward)

OpenAI-Modellbenennung und Routing-Strategie führen zu Verwirrung und Unzufriedenheit bei Nutzern : Nach der Veröffentlichung von GPT-5 haben OpenAIs komplexe Modellbenennung (wie GPT-5, GPT-5 Thinking, GPT-5 mini) und der undurchsichtige interne Routing-Mechanismus (Nutzer können nicht feststellen, welches spezifische Modell sie gerade verwenden) zu weit verbreiteter Verwirrung und Unzufriedenheit bei den Nutzern geführt. Nutzer beklagen, dass diese Strategie zu einer schlechteren Erfahrung führt und den Zugang zu besseren Modellen einschränkt. OpenAI hat bereits angekündigt, die Transparenz zu verbessern und Nutzern die Möglichkeit zu geben, das aktuelle Modell einzusehen. (Quelle: scaling01, scaling01, jeremyphoward, Teknium1, VictorTaelin)

LLMs weisen in multimodalen Aufgaben weiterhin Einschränkungen auf, z.B. bei der Bildzählung : Obwohl LLMs Fortschritte in multimodalen Fähigkeiten gemacht haben, bestehen weiterhin Einschränkungen. Zum Beispiel geben SOTA VLMs (wie o3, o4-mini, Sonnet, Gemini Pro) bei Bildzählungsaufgaben, wenn sie mit modifizierten Bildern (wie einem Zebra mit fünf Beinen) konfrontiert werden, aufgrund von Voreingenommenheit falsche Zählungen an und können den tatsächlichen Inhalt des Bildes nicht genau identifizieren. Dies zeigt, dass die Modelle in Bezug auf visuelles Denken und Detailverständnis noch verbessert werden müssen. (Quelle: OfirPress, andersonbcdefg)

OpenAI-Forscherin betont: “Nutzung ist der beste Bewertungsindikator” : Christina Kim, Forscherin bei OpenAI, erklärt, dass die Spitzenbewertung von KI-Modellen nicht mehr nur Benchmarks sind, sondern die tatsächliche Nutzung. Sie ist der Meinung, dass Benchmark-Scores gesättigt sind und die Anzahl der realen Aufgaben, die Nutzer im Alltag mit KI erledigen, das wahre Signal für den Fortschritt der KI und die Annäherung an AGI ist. Diese Ansicht unterstreicht die zentrale Bedeutung von Benutzererfahrung und praktischem Anwendungswert in der KI-Entwicklung. (Quelle: nickaturley, markchen90)
Bill Gates’ KI-Prognosen lösen Community-Diskussionen aus : Bill Gates’ Prognosen zur KI-Entwicklung haben in der Community Diskussionen ausgelöst. Während einige Nutzer seine Vorhersagen als nicht mit der tatsächlichen Leistung von GPT-5 übereinstimmend empfinden und seine “Entfremdung” in Frage stellen, sind andere der Meinung, dass Gates’ Einsichten langfristig weiterhin relevant sind. Dies spiegelt das anhaltende Interesse der Öffentlichkeit an der zukünftigen Entwicklung der KI und die genaue Prüfung der Ansichten von Branchenführern wider. (Quelle: Reddit r/MachineLearning)

Diskussion über die Überlegenheit von KI-Modellen gegenüber menschlicher Intelligenz und kreative Engpässe : Die Community diskutiert das Phänomen, dass KI-Modelle in Prüfungen und Benchmarks menschliche Leistungen übertreffen, z.B. die “mühelose Überlegenheit” von LLMs bei Einsteins Highschool-Noten. Die Diskussion weist jedoch auch darauf hin, dass, obwohl KI bei der Lösung vorgegebener Probleme hervorragende Leistungen erbringt, ihre Fähigkeit, revolutionäre Theorien (wie die Relativitätstheorie) “von Grund auf” zu entwickeln, weiterhin fraglich ist. Dies wirft philosophische Fragen nach den grundlegenden Unterschieden zwischen menschlicher und maschineller Intelligenz auf, nämlich ob “Benchmark-Maximierung” ausreicht, um wahre Kreativität und intellektuelle Sprünge zu messen. (Quelle: sytelus)

💡 Sonstiges
KI-gestützte Konzeptsuche, über Schlüsselwortgrenzen hinaus : Die KI-Technologie treibt die Suche von traditioneller Schlüsselwortübereinstimmung hin zur Konzeptsuche voran. Das bedeutet, dass Nutzer Informationen über abstraktere, semantischere Konzepte abrufen können, anstatt sich nur auf exakte Schlüsselwörter zu verlassen. Dieser Wandel wird die Intelligenz und Effizienz der Suche erheblich verbessern und es Nutzern ermöglichen, komplexe Informationen bequemer zu finden und zu verstehen. (Quelle: nptacek)
Bedenken hinsichtlich der Auswirkungen von KI-generierten Inhalten auf Kinder, Forderung nach “entwicklungsfreundlichen” Inhalten : Die Community äußert Bedenken hinsichtlich der potenziell negativen Auswirkungen von KI-generierten Inhalten (insbesondere visuellen Inhalten) auf Kinder und argumentiert, dass diese zu grob, oberflächlich und möglicherweise zu “Dopamin-getrieben” sein könnten. Es wird gefordert, “entwicklungsfreundliche” generative KI-Inhalte, wie interaktive Kurse, zu entwickeln, um sicherzustellen, dass KI-Technologie gesund in der Kindererziehung und -unterhaltung eingesetzt wird. (Quelle: teortaxesTex)
KI-Roboter könnten die meisten körperlichen Arbeitsaufgaben übernehmen : Mit der rasanten Entwicklung der Künstlichen Intelligenz und Robotik wird erwartet, dass humanoide Roboter und andere verkörperte intelligente Geräte in den kommenden Jahren den Großteil der derzeit von Menschen ausgeführten körperlichen Arbeitsaufgaben übernehmen werden. Dieser Trend deutet auf strukturelle Veränderungen auf dem Arbeitsmarkt hin, die die Produktionseffizienz erheblich steigern werden, aber gleichzeitig neue Herausforderungen für die menschliche Beschäftigung und Arbeitsteilung mit sich bringen. (Quelle: adcock_brett)