
Schlüsselwörter:Weltroboterkonferenz, Humanoider Roboter, Verkörperte Intelligenz, GPT-5, KI-Brille, Google DeepMind, LangChain, Reality Proxy KI-Brille, Genie 3 Weltsimulator, LEANN Vektorindex, Kostenloser Aufruf von Qwen Code, GPT-5 Prioritätsbearbeitungsdienst
🔥 Fokus
Das “Frühlingsfest” der Embodied AI-Welt: 200 Roboter treten gemeinsam an : Der Weltroboterkongress (WRC 2025) fand erfolgreich in Peking statt und zog über 220 Unternehmen als Aussteller an, die über 1500 Exponate präsentierten. Darunter waren 50 humanoide Roboterunternehmen, die über 100 neue Produkte vorstellten. Der Kongress zeigte die neuesten Fortschritte humanoider Roboter in Bereichen wie Haushaltsdienstleistungen (z.B. Bettenmachen, Wäschefalten), kommerzielle Dienstleistungen (z.B. Kassieren, Kaffeezubereitung, Mixen von Getränken), industrielle Anwendungen (z.B. Präzisionsmontage, Sortieren, Transport) und Gesundheitswesen/Pflege (z.B. Rehabilitationstraining, Massagen). Darüber hinaus zeigten auch Komponenten der Roboter-Lieferkette (z.B. Planetenrollengewindetriebe, geschickte Hände, taktile Sensoren) erhebliche Innovationen. Dies signalisiert, dass Embodied AI sich beschleunigt in die physische Welt integriert und das Potenzial hat, die tiefe Integration von KI und realen Szenarien voranzutreiben. (Quelle: 36氪)
AI-Brille für “Greifen aus der Ferne”: Reality Proxy : Ein Alumni-Team der Zhejiang-Universität hat eine AI-Brillentechnologie namens “Reality Proxy” entwickelt, die es Benutzern ermöglicht, Objekte in der realen Welt durch “digitale Stellvertreter” “aus der Ferne zu greifen” und intuitiv zu interagieren. Diese Technologie kann Szenenstrukturen erfassen und bedienbare digitale Agenten generieren, die vielfältige Interaktionsfunktionen unterstützen, wie z.B. Vorschau-Browsing, Mehrfachauswahl, Filtern nach Attributen, semantische Gruppierung und räumliche Zoom-Gruppierung. Diese Innovation verschmilzt die physische mit der digitalen Welt, verbessert die Interaktionseffizienz und -präzision von XR-Geräten in komplexen Szenarien wie Buchsuche, Gebäudenavigation und Drohnensteuerung erheblich und wird als entscheidender Schritt auf dem Weg zu einem “Jarvis”-ähnlichen AI-Assistenten angesehen. (Quelle: 量子位)

🎯 Trends
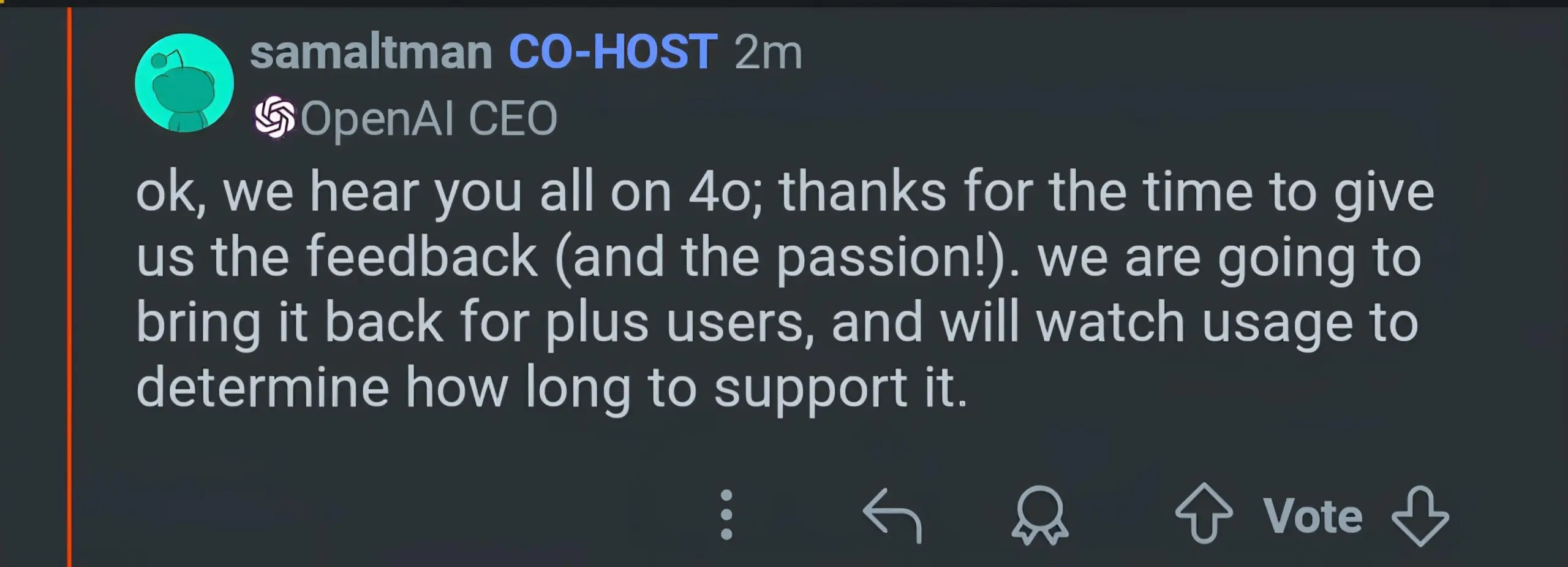
OpenAI GPT-5 Veröffentlichung und nachfolgende Anpassungen : OpenAI hat GPT-5 offiziell veröffentlicht und betont, dass sein “Routing-System” Modellressourcen dynamisch basierend auf der Aufgabenkomplexität und Benutzerabsicht zuweisen kann, um eine “nahtlose multimodale Koordination” zu erreichen und die Rate von Sachfehlern und Halluzinationen erheblich zu reduzieren. Nach der Veröffentlichung meldeten Benutzer jedoch ein “dümmer werden” des Modells. Sam Altman erklärte dies mit einem Fehler im automatischen Umschalter und versprach eine Behebung. Gleichzeitig wird GPT-4o für Plus-Benutzer wieder zur Auswahl stehen, und es ist geplant, die “Temperatur” und Personalisierungsoptionen von GPT-5 zu erhöhen, um den Präferenzen der Benutzer bezüglich der “Persönlichkeit” des Modells entgegenzukommen. (Quelle: 36氪, The Verge, The Verge, sama, openai, nickaturley, sama, openai, dotey, dotey, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/artificial, Reddit r/ChatGPT)
Google DeepMind: Zusammenfassung der neuesten Fortschritte : Google DeepMind hat kürzlich eine Reihe von AI-Ergebnissen veröffentlicht, darunter den hochmodernen Weltsimulator Genie 3, Gemini 2.5 Pro Deep Think, der Ultra-Abonnenten zur Verfügung steht, die kostenlose Bereitstellung von Gemini Pro für Studenten und eine Investition von 1 Milliarde US-Dollar zur Unterstützung der US-Bildung, die Veröffentlichung des globalen Geodatenmodells AlphaEarth sowie des Aeneas-Modells zur Entzifferung antiker Texte. Darüber hinaus erreichte Gemini bei der IMO (Internationale Mathematik-Olympiade) Goldmedaillen-Niveau, führte die Storybook-App mit Kunst und Audio ein, fügte den Kaggle Game Arena LLM-Benchmark hinzu, der asynchrone Coding Agent Jules verließ die Beta-Phase, der AI-Suchmodus wurde in Großbritannien eingeführt und veröffentlichte eine Videoübersicht zu NotebookLM, wobei die Downloadzahlen des Gemma-Modells 200 Millionen überschritten. (Quelle: demishassabis, Google, Ar_Douillard, _rockt, quocleix)
GLM-4.5 Serienmodelle werden bald Open Source sein : Zhipu AI (GLM) hat angekündigt, dass seine neuen Modelle der GLM-4.5-Serie bald Open Source sein werden, und enthüllte, dass das Modell in einem Kartensuchwettbewerb innerhalb von 16 Stunden 99% der echten Spieler besiegte. Dieser Schritt deutet auf neue Fortschritte im Bereich der visuellen Modelle hin, die Auswirkungen auf Geolocation- und Bilderkennungsanwendungen haben könnten. Die Community zeigt großes Interesse an den spezifischen Fähigkeiten und Open-Source-Details des neuen Modells. (Quelle: Reddit r/LocalLLaMA)

Cohere Command A Vision veröffentlicht : Das Cohere-Team hat Command A Vision vorgestellt, ein hochmodernes generatives Modell, das Unternehmen eine hervorragende Leistung bei multimodalen visuellen Aufgaben bietet und gleichzeitig starke Textverarbeitungsfähigkeiten beibehält. Die Veröffentlichung dieses Modells wird die Effizienz und Wirksamkeit von Anwendungen, die Bild und Text kombinieren, in Unternehmen weiter vorantreiben. (Quelle: dl_weekly)
Meta V-JEPA 2 veröffentlicht : Meta AI hat V-JEPA 2 veröffentlicht, ein bahnbrechendes Weltmodell, das sich auf visuelles Verständnis und Vorhersage konzentriert. Dieses Modell verspricht erhebliche Fortschritte in der Robotik und im Bereich der künstlichen Intelligenz, da es AI-Systemen hilft, die visuelle Umgebung besser zu verstehen und vorherzusagen, was komplexere autonome Verhaltensweisen ermöglicht. (Quelle: Ronald_vanLoon)
OpenAI GPT-5 führt Priority Processing ein : OpenAI hat für GPT-5 einen “Priority Processing”-Dienst eingeführt, der es Entwicklern ermöglicht, durch die Einstellung von "service_tier": "priority" eine schnellere Generierungsgeschwindigkeit des ersten Tokens zu erzielen. Diese Funktion ist entscheidend für Anwendungen, die empfindlich auf Millisekunden-Latenz reagieren, erfordert jedoch zusätzliche Kosten, was OpenAIs Bestrebungen zur Optimierung des Modellservice-Erlebnisses und zur Kommerzialisierung widerspiegelt. (Quelle: jeffintime, OpenAIDevs, swyx, juberti)

🧰 Tools
Qwen Code bietet kostenlose Aufrufe : Alibaba Tongyi Qianwen hat angekündigt, dass Qwen Code täglich 2000 kostenlose Aufrufe bereitstellt, internationale Benutzer über OpenRouter 1000 Aufrufe erhalten können. Dieser Schritt senkt die Hürde für Entwickler, Code-Generierungstools zu nutzen, erheblich und hat das Potenzial, die Verbreitung innovativer Anwendungen auf Basis von Qwen Code und “vibe coding” zu fördern, wodurch es zu einem starken Wettbewerber im Bereich der AI-gestützten Programmierung wird. (Quelle: huybery, jeremyphoward, op7418, Reddit r/LocalLLaMA)

Genie 3 erkundet die Welt der Malerei : Google DeepMinds Genie 3 zeigt erstaunliche Fähigkeiten: Benutzer können in ihre Lieblingsgemälde “eintreten” und diese erkunden, indem sie sie in interaktive 3D-Welten verwandeln. Diese Funktion eröffnet neue Dimensionen für Kunstgenuss, Bildung und virtuelle Erlebnisse, zum Beispiel kann man durch Edward Hoppers “Nighthawks” oder Jacques-Louis Davids “Der Tod des Sokrates” wandeln und ein immersives Kunsterlebnis genießen. (Quelle: cloneofsimo, jparkerholder, BorisMPower, francoisfleuret, shlomifruchter, _rockt, Vtrivedy10, rbhar90, fchollet, bookwormengr)

LangChain führt GPT-5 Playground ein : LangChain hat in seinem LangSmith Playground die neuesten OpenAI-Modelle GPT-5 (einschließlich gpt-5, gpt-5-mini, gpt-5-nano) integriert und eine integrierte Kostenverfolgungsfunktion hinzugefügt. Dies bietet Entwicklern eine bequeme Plattform, um GPT-5-basierte Anwendungen zu testen und zu erstellen, während gleichzeitig die API-Nutzungskosten überwacht werden, was zur Optimierung von Entwicklungsprozessen und Ressourcenmanagement beiträgt. (Quelle: LangChainAI, hwchase17)

Claude Code unterstützt mobilen Hotfix : Ein Entwickler hat in einem Taco Bell Drive-Through über den mobilen Browser Claude Code verwendet, um erfolgreich einen dringenden Hotfix in einer Produktionsumgebung zu beheben. Dies demonstriert die starke Praktikabilität von AI-Codierungstools in mobilen Szenarien und ermöglicht es Entwicklern, sich von der Bindung an den Schreibtisch zu lösen und jederzeit und überall Code zu debuggen und Probleme zu lösen, was die Arbeitsflexibilität erhöht. (Quelle: Reddit r/ClaudeAI)

Clode Studio Remote-Zugriffsfunktion : Clode Studio hat ein Update veröffentlicht, das einen integrierten Relay Server und Multi-Tunnel-Unterstützung hinzufügt, wodurch Benutzer von jedem Gerät aus remote auf Desktop-IDEs zugreifen und Claude Code Chat steuern können. Diese Funktion bietet mehrere Tunneloptionen (Clode, Cloudflare, Custom), unterstützt Touch-Bedienung auf Mobiltelefonen und Tablets und gewährleistet eine sichere Authentifizierung, um das Remote-Entwicklungserlebnis und die Flexibilität zu verbessern. (Quelle: Reddit r/ClaudeAI)
LEANN: Extrem leichtgewichtiger Vektorindex : LEANN ist ein innovativer, extrem leichtgewichtiger Vektorindex, der schnelles, präzises und zu 100% privates RAG (Retrieval Augmented Generation) auf einem MacBook ermöglicht, ohne Internetverbindung, wobei die Indexdateien 97% kleiner sind als bei herkömmlichen Methoden. Es ermöglicht Benutzern, semantische Suchen auf lokalen Geräten durchzuführen und persönliche Daten wie E-Mails und Chat-Verläufe zu verarbeiten, was ein “persönliches Jarvis”-ähnliches Erlebnis bietet. (Quelle: matei_zaharia)

Qwen-Image LoRA Trainer ist online : Die WaveSpeedAI-Plattform hat den Qwen-Image LoRA Trainer eingeführt, die weltweit erste Plattform, die einen Online-Qwen-Image LoRA Trainer anbietet. Benutzer können nun innerhalb weniger Minuten ihren eigenen benutzerdefinierten Stil trainieren, was den Prozess der AI-Kunstschaffung erheblich vereinfacht und die Personalisierungsfähigkeiten von Bildgenerierungsmodellen verbessert. (Quelle: Alibaba_Qwen)

Jules führt Interactive Plan ein : Googles asynchroner Coding Agent Jules hat die Funktion “Interactive Plan” veröffentlicht, die es Jules ermöglicht, Codebasen zu lesen, klärende Fragen zu stellen und mit Benutzern zusammenzuarbeiten, um Entwicklungspläne zu verfeinern. Dieser kollaborative Ansatz erhöht die Wahrscheinlichkeit, dass Benutzer ihre Ziele klar definieren, und stellt sicher, dass die Mensch-Maschine-Zusammenarbeit bei der Codegenerierung und Lösungsentwicklung konsistent bleibt, wodurch die Codequalität und -zuverlässigkeit verbessert werden. (Quelle: julesagent)

Grok 4 PDF-Verarbeitungsfähigkeiten verbessert : xAI hat angekündigt, dass die PDF-Verarbeitungsfähigkeiten von Grok 4 erheblich verbessert wurden. Es kann nun nahtlos sehr große PDF-Dateien mit Hunderten von Seiten verarbeiten und den PDF-Inhalt durch schärfere Erkennungsfähigkeiten besser verstehen. Dieses Upgrade ist in den Web- und mobilen Anwendungen von Grok verfügbar und hat die Effizienz der Benutzer bei der Verarbeitung und Analyse komplexer Dokumente erheblich gesteigert. (Quelle: xai, Yuhu_ai_, Yuhu_ai_, Yuhu_ai_)

📚 Lernen
HuggingFace bietet AI-Kurse an : HuggingFace hat 9 kostenlose AI-Elitekurse veröffentlicht, die Kernbereiche wie LLMs, Agenten und AI-Systeme abdecken. Diese Kurse zielen darauf ab, Entwicklern und Forschern zu helfen, modernste AI-Technologien zu beherrschen, die Lernhürde zu senken und die Entwicklung der Open-Source-AI-Community zu fördern. (Quelle: huggingface)

Attention Basin: Studie zur Kontextpositionssensibilität von LLMs : Eine Studie hat eine signifikante Sensibilität großer Sprachmodelle (LLMs) für die Kontextposition von Eingabeinformationen aufgedeckt, die als “Attention Basin”-Phänomen bezeichnet wird: Modelle neigen dazu, Informationen am Anfang und Ende einer Sequenz höhere Aufmerksamkeit zu schenken, während sie den mittleren Teil vernachlässigen. Die Studie schlägt das Attention-Driven Reranking (AttnRank)-Framework vor, das durch die Kalibrierung der Aufmerksamkeitspräferenzen des Modells und die Neuanordnung von abgerufenen Dokumenten oder Few-shot-Beispielen die Leistung von 10 verschiedenen LLMs bei Multi-Hop-Frage-Antwort- und Few-shot-Lernaufgaben erheblich verbessert. (Quelle: HuggingFace Daily Papers)

MLLMSeg: Leichtgewichtiger Maskendecoder zur Verbesserung der Referenzexpressionssegmentierung : MLLMSeg ist ein neuartiges Framework, das darauf abzielt, die Herausforderungen der pixelgenauen dichten Vorhersage von multimodalen großen Modellen (MLLMs) bei Aufgaben der Referenzexpressionssegmentierung (RES) zu lösen. Das Framework nutzt die in MLLM-Visuellen Encodern inhärenten visuellen Detailmerkmale voll aus und schlägt ein detailverbesserndes und semantisch konsistentes Merkmalsfusionsmodul vor, das in Kombination mit einem leichtgewichtigen Maskendecoder ein besseres Gleichgewicht zwischen Leistung und Kosten erzielt und bestehende SAM-basierte und SAM-freie Methoden übertrifft. (Quelle: HuggingFace Daily Papers)

Lernen zu folgern, um die Faktizität zu verbessern : Eine Studie hat eine neuartige Belohnungsfunktion vorgeschlagen, die darauf abzielt, das Problem der hohen Halluzinationsrate von Reasoning-LLMs (R-LLMs) bei langen faktischen Aufgaben zu lösen. Diese Belohnungsfunktion berücksichtigt gleichzeitig die faktische Genauigkeit, den Detailgrad der Antwort und die Relevanz der Antwort und trainiert durch Online-Reinforcement Learning, wodurch die durchschnittliche Halluzinationsrate des Modells in sechs faktischen Benchmarks um 23,1 Prozentpunkte reduziert und der Detailgrad der Antworten um 23% erhöht wird, ohne die allgemeine Nützlichkeit der Antwort zu beeinträchtigen. (Quelle: HuggingFace Daily Papers)

LangChain veranstaltet Hacking Hours : LangChain wird “LangChain Hacking Hours” veranstalten, eine fokussierte gemeinsame Arbeitsumgebung, in der Entwickler an LangChain- oder LangGraph-Projekten konkrete Fortschritte erzielen, direkte technische Anleitung vom Team erhalten und sich mit anderen Entwicklern in der Community austauschen können. (Quelle: LangChainAI)

DSPy: Treue von RAG-Pipelines : In den sozialen Medien wurde über die Vorteile des DSPy-Frameworks zur Aufrechterhaltung der Treue in RAG (Retrieval Augmented Generation)-Pipelines diskutiert. Mit DSPy können Entwickler Systeme so gestalten, dass sie proaktiv “Ich weiß es nicht” ausgeben, wenn der Kontext die notwendigen Informationen nicht enthält, wodurch Modellhalluzinationen vermieden und die Komplexität des Prompt Engineering vereinfacht wird, indem Geschäftsziele, Modelle, Prozesse und Trainingsdaten getrennt werden. (Quelle: lateinteraction, lateinteraction, lateinteraction)

AI Evals Kurs-Einblicke : Hamel Husain teilte 14 Highlights aus seinem AI Evals-Kurs, insbesondere die herausragenden Ideen zum Retrieval (RAG). Der Kurs betonte die Bedeutung der Evaluierung bei der Entwicklung von AI-Systemen und wie Retrieval-Technologien effektiv genutzt werden können, um die Modellleistung zu verbessern, insbesondere bei der Verarbeitung komplexer Daten und multi-sourced Informationen. (Quelle: HamelHusain)

Anthropic verpflichtet sich zur Förderung der AI-Bildung : Anthropic hat sich der Initiative “Pledge to America’s Youth” angeschlossen und sich zusammen mit über 100 Organisationen der Förderung der AI-Bildung verschrieben. Sie werden landesweit mit Pädagogen, Studenten und Gemeinden zusammenarbeiten, um die nächste Generation mit den notwendigen AI- und Cybersicherheitskenntnissen auszustatten, um den Herausforderungen der zukünftigen technologischen Entwicklung zu begegnen. (Quelle: AnthropicAI)

Die Essenz des Chain-of-Thought (CoT) Reasoning : Die Diskussion darüber, ob CoT-Reasoning eine “Fata Morgana” ist, wird heiß diskutiert. Eine Studie, die aus der Perspektive der Datenverteilung analysiert, stellt die wahre Verständnisfähigkeit von CoT in Frage und weist darauf hin, dass es Benchmark-Aufgaben übermäßig anpassen und leicht Halluzinationen erzeugen kann. Gleichzeitig gibt es die Ansicht, dass CoT bei komplexen kognitiven Aufgaben weiterhin wertvolle Informationen liefern kann und seine “Denkspuren” unter bestimmten Bedingungen immer noch glaubwürdig sind. (Quelle: togelius, METR_Evals, rao2z, METR_Evals, METR_Evals)

Wie LLMs das nächste Wort vorhersagen : In den sozialen Medien wurde ein Video geteilt, das anschaulich demonstriert, wie große Sprachmodelle (LLMs) Text generieren, indem sie das nächste Wort vorhersagen. Dies hilft Benutzern, das grundlegende Funktionsprinzip von LLMs zu verstehen, nämlich durch Wahrscheinlichkeitsverteilungen das wahrscheinlichste nächste Wort auszuwählen, um kohärente und sinnvolle Sequenzen zu konstruieren. (Quelle: Reddit r/deeplearning)
Notwendigkeit unabhängiger Projektionen von Q, K, V in Transformer-Modellen : Die Community diskutierte die Gründe für die separaten Projektionen von Query (Q), Key (K) und Value (V) in Transformer-Modellen. Die Diskussion wies darauf hin, dass das direkte Binden von Q und V an die Eingabe-Embeddings die Ausdrucksfähigkeit und Flexibilität des Modells beeinträchtigen würde, da unabhängige Projektionen es dem Modell ermöglichen, Abfragen, Abgleiche und Informationsentnahmen in verschiedenen semantischen Räumen durchzuführen, wodurch komplexere Abhängigkeiten und Multi-Head-Attention-Mechanismen erfasst werden können. (Quelle: Reddit r/deeplearning)
Adaptive Classifiers: Neue Architektur für Few-Shot Learning : Eine Studie hat die “Adaptive Classifiers”-Architektur vorgeschlagen, die es Textklassifikatoren ermöglicht, aus wenigen Beispielen (5-10 pro Klasse) zu lernen, sich kontinuierlich an neue Daten anzupassen, ohne katastrophales Vergessen, und dynamisch neue Kategorien hinzuzufügen, ohne neu trainieren zu müssen. Dieser Ansatz kombiniert Prototypen-Lernen und elastische Gewichtsintegration, erreicht eine Genauigkeit von 90-100% bei Unternehmensaufgaben, bietet schnelle Inferenz und löst die Herausforderungen der ML-Bereitstellung in Szenarien mit Datenknappheit und schnellen Änderungen. (Quelle: Reddit r/MachineLearning)

Dynamisches Fine-Tuning (DFT) verbessert SFT : Eine Studie hat “Dynamic Fine-Tuning” (DFT) vorgeschlagen, das die Leistung von SFT (Supervised Fine-Tuning) verbessert, indem SFT als Reinforcement Learning neu definiert und eine einzeilige Codeänderung zur Stabilisierung von Token-Updates eingeführt wird. DFT übertrifft in einigen Fällen RL-Methoden wie PPO, DPO und GRPO und bietet einen effizienteren und stabileren neuen Weg für das Modell-Fine-Tuning. (Quelle: TheTuringPost)

💼 Business
OpenAI GPT-5 Preisstrategie löst Spekulationen über Preiskampf aus : OpenAI hat GPT-5 veröffentlicht, dessen API-Preise (1,25 $/1M Input, 10 $/1M Output) deutlich unter denen des Konkurrenten Anthropic Claude Opus 4.1 (15 $/1M Input, 75 $/1M Output) liegen. Dieser Schritt wird als “Killer-Feature” angesehen und könnte einen Preiskampf auf dem LLM-Markt auslösen. Die Branche beobachtet, ob dies ein kurzfristiger Marktanteilsangriff oder der Beginn eines langfristigen Rückgangs der AI-Kosten ist und wie dies die Entwicklung von AI-Tools, Geschäftsmodelle und die AI-Zugänglichkeit beeinflussen wird. (Quelle: Reddit r/ArtificialInteligence)

GPU-Ressourcenkonzentration und AI-Branchenlandschaft : Kommentare weisen darauf hin, dass die hohe Konzentration von GPU-Ressourcen dazu führt, dass “GPU-reiche Labore” im Bereich der allgemeinen AI dominieren und offene Modelle schwer mithalten können. Der Artikel argumentiert, dass 2025 das Jahr der Agenten und der Anwendungsebene sein wird und Unternehmen sich darauf konzentrieren sollten, akzeptable Lösungen auf den kleinsten LLMs aufzubauen, anstatt enorme Summen für das Training großer Modelle auszugeben. Dies spiegelt einen strategischen Wandel in der AI-Branche vom Modelltraining zur Anwendungsbereitstellung wider. (Quelle: Reddit r/artificial)
Chaos bei Aktientransaktionen von AI-Unternehmen : In den sozialen Medien wurden Phänomene von “Underlying Predators” und “Betrügern” bei Aktientransaktionen von AI-Laboren aufgedeckt. Diese mehrstufigen SPV (Special Purpose Vehicle)-Broker haben keine direkte Beziehung zu den Unternehmen selbst, betreiben aber betrügerische Aktivitäten, was Investoren und die Öffentlichkeit vor der zunehmenden irrationalen Euphorie und den potenziellen Risiken im AI-Bereich warnt. (Quelle: saranormous)
🌟 Community
GPT-5 Veröffentlichung löst starke Reaktionen und Kontroversen bei Benutzern aus : Nach der Veröffentlichung von GPT-5 durch OpenAI löste dies eine breite Diskussion in der Community aus. Einige Benutzer äußerten Enttäuschung über die Leistung von GPT-5 (insbesondere in Bezug auf Programmierung und kreatives Schreiben), hielten es für schlechter als GPT-4o oder Claude Code und hatten sogar das Gefühl eines “Rückschritts”. Sie äußerten auch Unzufriedenheit mit OpenAIs “automatischem Umschalter”, der Modelltransparenz und den Anpassungen der Nutzungsbeschränkungen für Plus-Benutzer. Viele Benutzer äußerten Nostalgie für die “Persönlichkeit” und “Emotionen” von GPT-4o, betrachteten es nicht nur als Werkzeug, sondern als “Freund” oder “Partner”, und starteten sogar Petitionen, um OpenAI aufzufordern, die 4o-Option wiederherzustellen. Sam Altman antwortete, dass das Unternehmen die Präferenz der Benutzer für die “Persönlichkeit” von 4o unterschätzt habe und versprach, 4o für Plus-Benutzer wieder zur Auswahl zu stellen, während gleichzeitig die “Temperatur” und die Personalisierungsfunktionen von GPT-5 verbessert werden. Er erklärte auch, dass die schlechte Modellleistung in der Anfangsphase der Veröffentlichung auf technische Fehler zurückzuführen sei. (Quelle: maithra_raghu, teortaxesTex, teortaxesTex, teortaxesTex, SebastienBubeck, SebastienBubeck, shaneguML, OfirPress, cloneofsimo, TheZachMueller, scaling01, Smol_AI, natolambert, teortaxesTex, Vtrivedy10, tokenbender, ClementDelangue, TheZachMueller, TomLikesRobots, METR_Evals, Ronald_vanLoon, teortaxesTex, teortaxesTex, scaling01, scaling01, scaling01, scaling01, scaling01, scaling01, scaling01, scaling01, scaling01, scaling01, Teknium1, Teknium1, Teknium1)