
Schlüsselwörter:AI-Inferenz, OpenAI, DeepMind, AlphaEarth, OpenCRISPR, GPT-5, Intelligente Brillen, KI-Agenten, OpenAI IMO-Goldmedaillen-Team, AlphaEarth Foundations Hochpräzisionskartierung, KI-entworfene CRISPR-Cas-Proteine, Qwen3-Serienmodell Agenten-Fähigkeiten, GLM-4.5 Open-Source-Modell
Gerne, hier ist die Übersetzung der chinesischen KI-Nachrichten ins Deutsche, unter Beachtung Ihrer Vorgaben:
🔥 Fokus
OpenAIs IMO-Goldmedaillen-Team erzielt Durchbruch in der KI-Schlussfolgerung: OpenAIs IMO (Internationale Mathematik-Olympiade) Goldmedaillen-Team hat bemerkenswerte Fortschritte im Bereich der KI-Schlussfolgerung erzielt. Ihr allgemeines Sprach-Schlussfolgerungsmodell zeigt hervorragende Leistungen bei schwer zu verifizierenden Aufgaben wie mathematischen Beweisen. Innerhalb von nur zwei Monaten erreichte das Team durch Multi-Agenten-Systeme und ein geschicktes Belohnungsfunktionsdesign eine nahezu menschliche Schlussfolgerungsfähigkeit bei Mathematik- und Physik-Olympiaden und löste das Problem der Skalierung der Schlussfolgerungszeit, was das enorme Potenzial der KI bei der Lösung komplexer Probleme aufzeigt. (Quelle: polynoamial, TheTuringPost)

DeepMind veröffentlicht AlphaEarth Foundations für hochpräzise KI-Kartierung der Erde: Google DeepMind hat das neue KI-Modell AlphaEarth Foundations vorgestellt, das Petabyte an Satellitendaten integrieren kann, um ein digitales Zwillingsmodell der Erde mit beispiellosem Detailgrad zu erstellen. Das Modell wird Wissenschaftlern helfen, Abholzung schneller zu verfolgen, die Pflanzengesundheit und Wasserressourcen zu überwachen und andere wichtige Umweltprobleme zu erkennen. Es bietet leistungsstarke KI-Unterstützung für die Erdwissenschaftsforschung und den Umweltschutz und verspricht, die globale Umweltüberwachung und nachhaltige Entwicklung voranzutreiben. (Quelle: Reddit r/MachineLearning, clefourrier, demishassabis)

OpenCRISPR: Erstes KI-designtes Molekül ermöglicht menschliche Genombearbeitung: Das Profluent Bio Team hat in der Zeitschrift “Nature” die OpenCRISPR-Studie veröffentlicht, die erstmals erfolgreich den Einsatz eines vollständig KI-designten Moleküls zur Bearbeitung des menschlichen Genoms demonstriert. OpenCRISPR ist ein KI-designtes CRISPR-Cas-Protein, das bei der Genombearbeitung hervorragende Aktivität, Spezifität und geringe Immunogenität zeigt. Diese bahnbrechende Studie beweist nicht nur die starke Fähigkeit der KI, funktionale biologische Systeme zu entwerfen, sondern eröffnet auch neue Wege zur Behandlung von Krankheiten, zur Entwicklung personalisierter Medikamente und zur Lösung gesellschaftlicher Herausforderungen. Der Code wurde bereits quelloffen gemacht. (Quelle: Fraser)
USA hebt Exportverbot für KI-Chips nach China auf: Die US-Regierung unter Trump hat das Exportverbot für KI-Chips nach China aufgehoben. Nvidia und AMD werden die Lieferung von GPUs, die den US-Exportbeschränkungen entsprechen, darunter Nvidias H20 und AMDs MI308, nach China wieder aufnehmen. Dieser Schritt erfolgte nach monatelangem Lobbying von Nvidia CEO Jensen Huang, der argumentierte, dass das Verbot die Wettbewerbsfähigkeit US-amerikanischer Chiphersteller auf wichtigen globalen Märkten behinderte und die Entwicklung chinesischer Konkurrenten förderte. Diese Politikänderung zielt darauf ab, die wirtschaftlichen und militärischen Interessen der USA im KI-Bereich effektiver auszubalancieren und den globalen KI-Technologieaustausch zu fördern. (Quelle: DeepLearning.AI Blog)

DeepSeeks Native Sparse Attention (NSA) gewinnt den Best Paper Award der ACL 2025: Das DeepSeek-Team hat mit seinem Paper zu Native Sparse Attention (NSA) den Best Paper Award der ACL 2025 gewonnen. Die Studie stellt einen hardware-optimierten und nativ trainierbaren Sparse Attention Mechanismus vor, der auf superschnelles Training und Inferenz mit langem Kontext abzielt. NSA erreicht durch hierarchische Token-Modellierung und spezialisierte Kernel-Optimierung eine vergleichbare oder bessere Leistung als Full Attention bei der Verarbeitung langer Sequenzen und bietet eine erhebliche Beschleunigung. Dieser Durchbruch bietet eine effiziente Lösung für Large Language Models der nächsten Generation zur Verarbeitung komplexer Schlussfolgerungen und Multi-Agenten-Systeme. (Quelle: eliebakouch, Reddit r/LocalLLaMA, brickroad7)

🎯 Trends
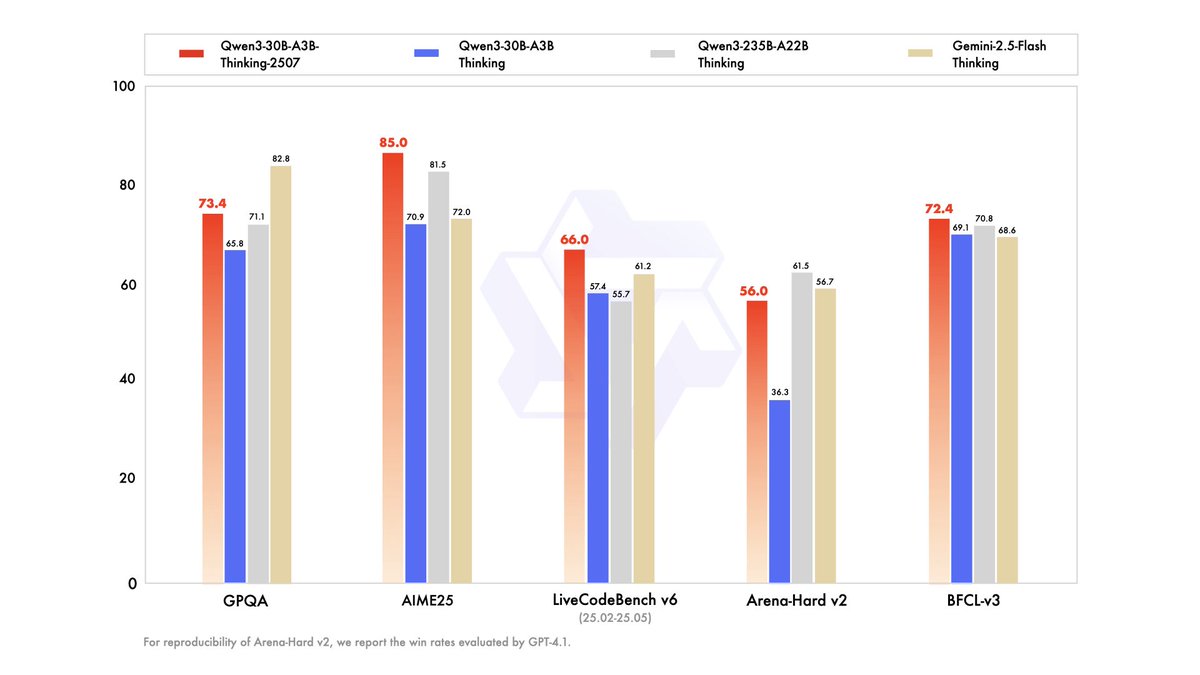
Qwen3-Modellreihe veröffentlicht, stärkt Agentenfähigkeiten: Alibaba Cloud hat die neue Qwen3-Modellreihe veröffentlicht, darunter Instruct-, Thinking- und Coder-Versionen, die ihre Fähigkeiten im Bereich des Agentenverhaltens weiter verbessern. Diese Modelle zeigen hervorragende Leistungen in verschiedenen Benchmarks für Wissen, Schlussfolgerung, Kodierung und Werkzeugnutzung, insbesondere Qwen3-Coder erreicht ein führendes Niveau bei der mehrstufigen Werkzeugnutzung und Agenten-Workflows. Die neuen Modelle unterstützen Kontextlängen von bis zu 262K bis 1M und verbessern die Leistung durch optimierte Reinforcement Learning Algorithmen, was Chinas Wettbewerbsfähigkeit im Bereich der Open-Source Large Language Models festigt. (Quelle: op7418, karminski3, TheZachMueller, QuixiAI, DeepLearning.AI Blog)
Zhipu macht GLM-4.5 quelloffen, Chinas Open-Source-KI-Front erhält weiteren starken Akteur: Zhipu AI hat sein neuestes Flaggschiff-Modell GLM-4.5 veröffentlicht und quelloffen gemacht. Es zeigt hervorragende Leistungen in den Bereichen Schlussfolgerung, Programmierung und Agentenfähigkeiten und gehört in mehreren Benchmarks zu den weltweit führenden Open-Source-Modellen. Das Modell ist äußerst parametereffizient und erreicht mit weniger Parametern eine überragende Leistung. Zudem bietet es sehr kostengünstige API-Preise. Die Veröffentlichung von GLM-4.5 stärkt Chinas Open-Source-KI-Front weiter und bildet zusammen mit DeepSeek, Qwen und anderen die “vier großen chinesischen Open-Source-KI-Giganten”, was die globale KI-Wettbewerbslandschaft in Richtung einer Bipolarität von Open Source und Closed Source vorantreibt. (Quelle: Zai_org, QuixiAI, Reddit r/LocalLLaMA, 36氪)
Durchgesickerte GPT-5-Informationen schüren Erwartungen, möglicherweise Vereinigung von Multimodalität und Schlussfolgerungsfähigkeiten: Im Internet kursierende durchgesickerte Informationen zu GPT-5 haben große Aufmerksamkeit erregt und deuten auf die bevorstehende Veröffentlichung eines noch leistungsfähigeren Modells von OpenAI hin. Angeblich wird GPT-5 die multimodalen und Schlussfolgerungsfähigkeiten der GPT- und o-Serien integrieren, ein Kontextfenster von bis zu 1 Million Token besitzen und MCP (Model Context Protocol) sowie parallele Werkzeugaufrufe unterstützen. Insbesondere im Bereich der Programmierung wird erwartet, dass GPT-5 und seine Mini-Version “Lobster” ein Niveau erreichen, das dem menschlicher Programmierer nahekommt, was die Effizienz und Genauigkeit der Softwareentwicklung umfassend verbessern könnte und möglicherweise kostenlos für die Öffentlichkeit zugänglich sein wird. (Quelle: 36氪)
KI-Smart Glasses werden zur neuen Generation des persönlichen mobilen Zugangs: Smart Glasses wurden auf der WAIC zu einer beliebten KI-Hardware, wobei Rokid, XREAL, Halliday und Alibabas Quake AI Glasses vorgestellt wurden. Diese Produkte entwickeln sich von der teilweisen Ersetzung von Smartphone-Funktionen (wie Fotografie, Musik, Sprachchat) hin zu einer alltäglicheren, leichteren Nutzung und versuchen, mehr KI-Fähigkeiten zu integrieren. Alibabas Quake AI Glasses sind tief in Ökosystemdienste wie Gaode Maps und Alipay integriert und zielen darauf ab, der persönliche mobile Zugang im KI-Zeitalter zu werden, was darauf hindeutet, dass Smart Glasses sich von technologieorientierten Produkten zu praktischen Konsumgütern wandeln und die Mensch-Maschine-Interaktion neu gestalten könnten. (Quelle: 36氪, 36氪)

Chinesische Großkonzerne beschleunigen die Implementierung von B2B-KI-Agenten und vertiefen die Anwendung in Industrieszenarien: Chinesische Technologiegiganten wie Alibaba, Tencent, ByteDance und Baidu verlagern ihren KI-Fokus auf die praktische Anwendung von B2B-KI-Agenten, um spezifische Schmerzpunkte im Unternehmensbetrieb zu lösen. Alibabas Bailian-Plattform hat über 700.000 Agenten-Anwendungen inkubiert, Tencent hat branchenübergreifende Agenten veröffentlicht, ByteDance hat die Kernfunktionen der Koutzi-Plattform quelloffen gemacht, und Baidu konzentriert sich auf die digitale Menschen-Technologie NOVA. Diese Agenten zeigen Potenzial zur Kostenreduzierung und Effizienzsteigerung in Bereichen wie intelligentem Kundenservice, Marketing, Lieferkettenoptimierung und Büroautomation, was Unternehmen von traditionellen IT-Systemen zu KI-nativen Unternehmen transformiert und darauf hindeutet, dass KI-Agenten zum Schlüssel für die Neugestaltung digitaler Geschäftsabläufe in Unternehmen werden. (Quelle: 36氪, 量子位, 36氪, 36氪, 量子位, 量子位)
Fortschritte bei den inländischen multimodalen Einheitsmodellen Skywork UniPic und SenseTime SenseNova V6.5: Kunlun Wanwei hat das multimodale Einheitsmodell Skywork UniPic quelloffen gemacht, das mit 1,5 Milliarden Parametern eine tiefe Integration von Bildverständnis, Text-zu-Bild-Generierung und Bildbearbeitung erreicht. Die Leistung kommt dedizierten Modellen mit zehn Milliarden Parametern nahe oder übertrifft diese sogar, und es kann flüssig auf Consumer-Grafikkarten laufen. SenseTime hat ebenfalls sein neues großes Modellsystem SenseNova V6.5 veröffentlicht, das durch interleaved multimodale Thought-Chain und Architektur-Optimierung die Inferenzleistung und das Preis-Leistungs-Verhältnis erheblich verbessert. Zudem wurde der Büro-Agent “SenseTime Little Raccoon” eingeführt, der den Sprung der KI vom “Werkzeug” zur “Produktivität” demonstriert. (Quelle: 量子位, 量子位)

Boom der verkörperten KI-Roboter hält an, Waymo erweitert autonome Fahrtdienste: Der Bereich der verkörperten KI-Roboter heizt sich weiter auf. Unitree Robotics hat den neuen humanoiden Roboter R1 vorgestellt, dessen Preis auf 39.900 Yuan gesenkt wurde, was die Branchenschwelle erheblich senkt. Die Provinz Hubei hat ebenfalls einen Milliarden-Yuan-Fonds für humanoide Roboter eingerichtet, um die Forschung und Entwicklung sowie die Massenproduktion in der Branche zu fördern. Gleichzeitig hat Waymo in Zusammenarbeit mit Avis autonome Taxi-Dienste in Dallas eingeführt, was die stetige Expansion der KI im Bereich des autonomen Fahrens markiert. (Quelle: Ronald_vanLoon, 36氪, 36氪, MIT Technology Review)

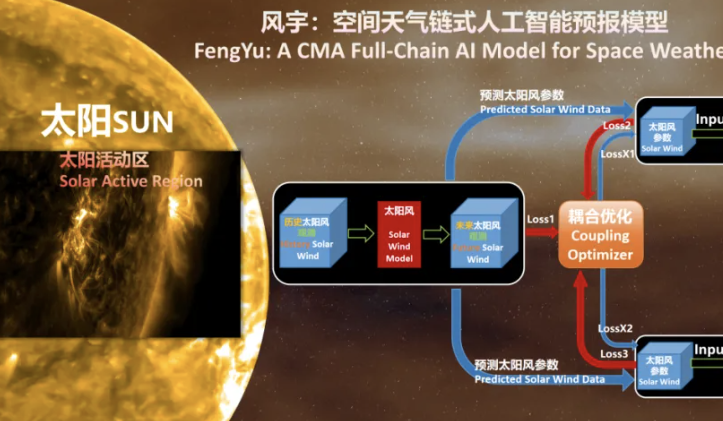
China veröffentlicht erstes kettenbasiertes KI-Vorhersagemodell für Weltraumwetter “Fengyu”: Das Nationale Satelliten-Meteorologiezentrum hat in Zusammenarbeit mit der Nanchang University und Huawei Technologies Co., Ltd. das weltweit erste kettenbasierte KI-Vorhersagemodell für Weltraumwetter “Fengyu” veröffentlicht. Dieses Modell ermöglicht erstmals eine End-to-End-KI-Modellierung von Sonnenwind-Magnetosphäre-Ionosphäre. Durch intelligente Kopplungs- und Optimierungsmechanismen sowie ein eigenständiges und kontrollierbares KI-Framework wurde die Vorhersagegenauigkeit und Effizienz von Weltraumwetterereignissen wie Sonnenstürmen erheblich verbessert, wobei die Fehlerquote bei etwa 10% liegt. Es bietet umfassende Anleitung für das Design und den Betrieb von Raumfahrzeugen. (Quelle: 量子位)
KI tief in den Bildungsbereich integriert, ChatGPT führt “Study Mode” ein: OpenAI hat den “Study Mode” für ChatGPT eingeführt, der darauf abzielt, Studierenden eine personalisierte, tutorenähnliche Lernerfahrung zu bieten, anstatt nur einfache Antworten zu liefern. Dieser Modus leitet die Studierenden durch sokratische Methode zum Nachdenken an und wurde bereits in Zusammenarbeit mit über 40 Bildungseinrichtungen getestet. Gleichzeitig erlebt der Bereich des Sprachenlernens durch KI einen Boom, von bildlicher Erinnerung bis hin zu intelligenter Interaktion. Vokabel-Apps und Hardware-Produkte wie Listening Bear und Youdao SpaceOne innovieren ständig und verschieben das Lernparadigma vom “Merken” zum “Anwenden”. (Quelle: MIT Technology Review, 36氪)
KI unterstützt Präzisionsfertigung, Effizienz der Laserschweißprüfung erheblich gesteigert: KI-Technologie revolutioniert die Präzisionsfertigungsindustrie. Das von Guangzhou Deqing Optical Technology entwickelte Online-Inspektionssystem für Laserschweißen hat durch ein Deep Learning KI-Modell die “Overkill”-Rate (Fehlklassifizierung von Gutteilen als Ausschuss) bei der Schweißprüfung um 50% gesenkt und ermöglicht eine intelligentere Fehlerdiagnose. Das System wird bereits in den Produktionslinien international führender Unterhaltungselektronik-Kunden eingesetzt und hat die Prüfgenauigkeit und Produktionseffizienz der Linie erheblich verbessert, was das enorme Potenzial der KI im Bereich der industriellen Qualitätskontrolle demonstriert. (Quelle: 量子位)

Intensiver Wettbewerb um KI-Talente, Rolle der Entwickler wandelt sich zum “Agenten-Kommandanten”: Der globale Wettbewerb um KI-Talente wird immer intensiver, wobei die USA und China bei der Anzahl der KI-Spezialisten weit vorne liegen. Der neueste Bericht von Stack Overflow zeigt, dass KI-Tools in der Entwicklung weit verbreitet sind, KI-Agenten jedoch noch nicht Mainstream sind, obwohl die meisten Entwickler (69%) der Meinung sind, dass KI ihre persönliche Produktivität erheblich gesteigert hat. GitHub CEO Thomas Dohmke weist darauf hin, dass sich Programmierer in Zukunft zu “Agenten-Kommandanten” entwickeln werden, deren Kernkompetenzen sich auf Aufgabenzerlegung, Anforderungsbeschreibung und KI-gestützte Entscheidungsfindung verlagern. Natürliche Sprache wird zur universellen Programmiersprache, was einen grundlegenden Paradigmenwechsel im Programmieren ankündigt. (Quelle: 36氪, 36氪)

🧰 Tools
sst/opencode: Open-Source Terminal-KI-Programmieragent: sst/opencode ist ein quelloffener KI-Programmieragent, der speziell für das Terminal entwickelt wurde. Seine Funktionen ähneln denen von Claude Code, der Vorteil ist jedoch, dass er zu 100% Open Source ist und nicht an einen bestimmten KI-Anbieter gebunden ist, sondern OpenAI, Google und sogar lokale Modelle unterstützt. Das Tool konzentriert sich auf die Terminal User Interface (TUI), um die Grenzen der Terminalbedienung zu durchbrechen, und verwendet eine Client/Server-Architektur, die Fernsteuerung unterstützt, um Entwicklern eine flexible und leistungsstarke Programmierunterstützung zu bieten. (Quelle: GitHub Trending)
Microsoft Edge führt “Copilot-Modus” zur Steigerung der Browsing-Effizienz ein: Der Microsoft Edge Browser hat offiziell den “Copilot-Modus” eingeführt, der KI-Funktionen tief in das Browser-Erlebnis integriert. Dieser Modus zielt darauf ab, die Benutzerproduktivität zu steigern, indem er beispielsweise “Tab-Messies” hilft, ihren Workflow zu verwalten und zu optimieren. Mit Hilfe der KI können Benutzer Informationen effizienter verarbeiten, Ablenkungen reduzieren und so die Browsing- und Arbeitseffizienz steigern. (Quelle: mustafasuleyman, Ronald_vanLoon)
LlamaIndex/LlamaCloud vereinfacht Finanzdatenanalyse und RAG-Bereitstellung: LlamaIndex hat ein automatisiertes Analyse-Tool für Asset-Management-Fonds eingeführt, das komplexe Finanzdokumente verarbeiten und umsetzbare Investitionseinblicke extrahieren kann. Gleichzeitig bietet die gehostete Embedding-Funktion von LlamaCloud ein “Plug-and-Play-Erlebnis”, bei dem Benutzer ohne Code produktionsreife Retrieval-Augmented Generation (RAG) Pipelines erstellen können, was das Content Embedding und Vektor-Hosting vereinfacht und die Hürde für die Anwendung großer Sprachmodelle in datenintensiven Bereichen wie dem Finanzwesen erheblich senkt. (Quelle: jerryjliu0, jerryjliu0)
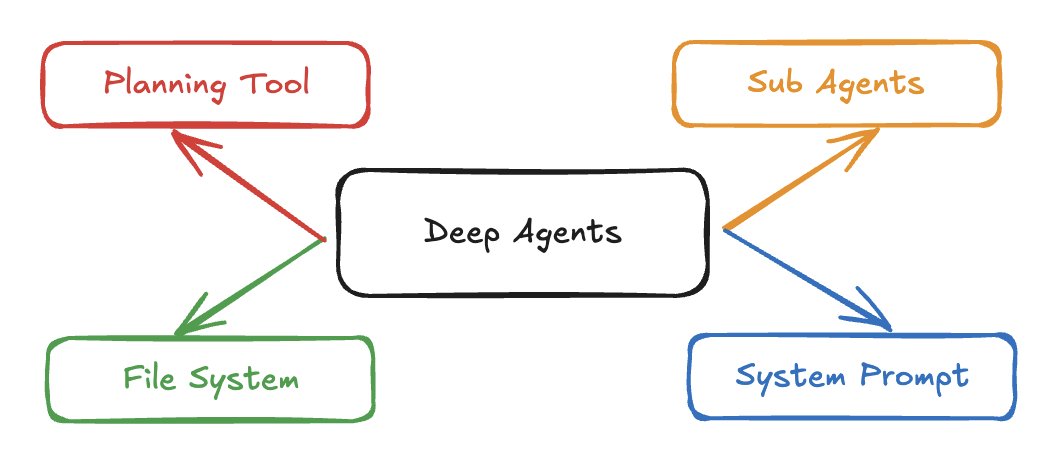
LangChain führt “Deep Agents” Python-Paket ein, ermöglicht die Entwicklung fortschrittlicher LLM-Agenten: LangChain hat das neue Python-Paket “Deep Agents” veröffentlicht, das Entwicklern beim Bau komplexerer LLM-Agenten helfen soll. Das Paket löst die Einschränkungen traditioneller Tool-Aufruf-Schleifen bei der Bearbeitung langfristiger oder komplexer Aufgaben, indem es Funktionen wie Planungstools, Sub-Agenten und Dateisystemzugriff bietet, wodurch der Bau fortschrittlicher Agenten wie Deep Research und Claude Code einfacher wird. Die Einführung dieses Frameworks markiert einen Schritt zu tieferen und leistungsfähigeren Fähigkeiten in der LLM-Agentenentwicklung. (Quelle: LangChainAI, hwchase17, Hacubu)
Showrunner: KI-generierter Streaming-Dienst “KI-Netflix” gestartet: Fable hat “Showrunner” vorgestellt, einen KI-generierten Streaming-Dienst, der als “KI-Netflix” bezeichnet wird. Die Plattform ermöglicht es Benutzern, Szenen oder ganze Episoden durch Eingabe von Prompts zu generieren, für neue Kreationen oder bestehende IPs. Amazon hat bereits in das Projekt investiert, und es gibt Berichte, dass Studios wie Disney über die Lizenzierung von IPs verhandeln, was darauf hindeutet, dass KI disruptive Veränderungen im Bereich der Film- und Fernsehinhaltskreation mit sich bringen und benutzergesteuerte, personalisierte Unterhaltungserlebnisse ermöglichen wird. (Quelle: TomLikesRobots, fabianstelzer)

Ollama führt Desktop-Client ein, vereinfacht lokale LLM-Modellverwaltung: Ollama hat seinen Desktop-Client veröffentlicht, der nicht mehr nur auf Kommandozeilenoperationen beschränkt ist und die Verwaltung und Nutzung lokaler Large Language Models erheblich vereinfacht. Der neue Client ermöglicht es Benutzern, Modelle direkt über die grafische Oberfläche herunterzuladen, unterstützt multimodale Erkennung und Drag-and-Drop von Dokumenten, was persönlichen Benutzern ein bequemeres, intuitiveres lokales KI-Inferenz-Erlebnis bietet und die technische Hürde senkt. (Quelle: op7418)
DSPy: Deklaratives Framework für den Bau effizienter LLM-Systeme: DSPy ist ein deklaratives Framework, das Entwicklern helfen soll, leistungsfähigere LLM-Systeme mit weniger Code zu erstellen. Es betrachtet LLM-Programme als optimierbare Berechnungs-Graphen und ermöglicht durch automatische Optimierung von Prompts, Feinabstimmung und Retrieval-Strategien eine Interaktion mit dem Computer mit höherer Bandbreite und präziserer Weise, wodurch komplexere, leistungsfähigere KI-Funktionen mit prägnanterem Code realisiert werden können. (Quelle: lateinteraction, matei_zaharia)
Neue Funktionen für E-Mail-/Nachrichten-/Terminverwaltung in der mobilen Claude App: Die mobile Anwendung von Claude AI hat neue Funktionen zum direkten Entwerfen und Senden von E-Mails, Nachrichten und Kalendereinladungen erhalten. Benutzer können jetzt mit einem Klick von Claude generierten Text an Alltags-Apps senden, ohne kopieren und einfügen zu müssen, was den Workflow erheblich verbessert. Darüber hinaus haben Benutzer Profi-Tipps für Claude Code geteilt, die empfehlen, die automatische Komprimierung zu deaktivieren und den Kontext manuell zu verwalten, um die Leistung und Stabilität des Modells bei komplexen Aufgaben zu verbessern und “Entgleisungen” durch automatische Komprimierung zu vermeiden. (Quelle: menhguin, Reddit r/ClaudeAI, Reddit r/ClaudeAI)

Eigent: Open-Source, Local-First Multi-Agenten-Arbeitsplattform veröffentlicht: Eigent ist eine vollständig quelloffene, Local-First Multi-Agenten-Desktop-Anwendung, die speziell für Entwickler und Teams entwickelt wurde, die die volle Kontrolle über ihre KI-Workflows wünschen. Sie basiert auf dem modularen CAMEL-AI Framework und unterstützt parallele Aufgaben, BYOK (Bring Your Own Key) Bereitstellung, vollständige Datenprivatsphäre und Mensch-Maschine-Kollaboration. Eigent lässt sich nahtlos in bestehende Systeme integrieren und unterstützt über 200 MCP-kompatible Tools, um Teams sichere, anpassbare und skalierbare KI-Arbeitsfähigkeiten zu bieten. (Quelle: Reddit r/LocalLLaMA)
📚 Lernen
ACL 2025: Top-Konferenz-Papers und Test-of-Time-Awards bekannt gegeben: Die ACL 2025, eine führende Konferenz für Computerlinguistik und natürliche Sprachverarbeitung, hat mehrere wichtige Auszeichnungen bekannt gegeben. DeepSeeks Paper zu Native Sparse Attention (NSA) gewann den Best Paper Award und brachte einen Durchbruch für Long-Context-Modelle. Das Paper “Language Models Resist Alignment” des Teams von Yang Yaodong von der Peking-Universität enthüllt elastische Mechanismen der Modell-Alignment, was ernsthafte Herausforderungen für KI-Sicherheit und -Alignment darstellt. Die Gründer von Stanford NLP erhielten die 25- und 10-Jahres-Test-of-Time-Awards für ihre grundlegenden Beiträge zur semantischen Rollenmarkierung und zum Aufmerksamkeitsmechanismus. (Quelle: 36氪, stanfordnlp, eliebakouch)

Neue Fortschritte in der LLM-Forschung in verschiedenen Bereichen: Chemie, Code-Reparatur und UI-Generierung: HuggingFace Daily Papers hat mehrere neue Studien zu LLMs in spezialisierten Bereichen aufgenommen. ChemDFM-R ist ein chemisches Schlussfolgerungs-LLM, das durch atomisiertes chemisches Wissen erweitert wurde und das Verständnis und die Schlussfolgerungsfähigkeiten im Bereich der Chemie verbessert. Repair-R1 schlägt eine verbesserte Methode zur automatischen Programmreparatur vor, die durch die Einführung von Testfällen in der Trainingsphase die Reparatureffizienz erhöht. ScreenCoder ist ein modulares Multi-Agenten-Framework zur Automatisierung der Umwandlung von UI-Design in Frontend-Code, das die visuelle zu Code-Transformation in drei Phasen (Grounding, Planung und Generierung) realisiert. (Quelle: HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers)
Spitzenforschung zu multimodaler KI-Verständnis und -Generierung: Im Bereich der multimodalen KI erforschen Forscher ein tieferes Verständnis und eine tiefere Generierung. Das OmniAVS-Datensatz und das OISA-Modell konzentrieren sich auf die vollmodale referentielle audiovisuelle Segmentierung, wobei der Schwerpunkt auf dem Verständnis von Audioinhalten und komplexen Schlussfolgerungen liegt. Das BANG-Projekt realisiert durch “generative Explosionsdynamik” eine part-level Zerlegung von 3D-Assets, die 3D-Generierung mit Schlussfolgerungen verbindet und die 3D-Erstellungs- und Fertigungsprozesse vereinfachen könnte. (Quelle: HuggingFace Daily Papers, HuggingFace Daily Papers)
AAAI PhD-Studenteninterview: Kausale Inferenz und Generative Modellierung: AAAI/SIGAI PhD-Student Aneesh Komanduri teilte seine Forschung, die sich auf die Schnittstelle von kausaler Inferenz, Repräsentationslernen und generativer Modellierung konzentriert, insbesondere auf kausales Repräsentationslernen und kontrafaktische generative Modellierung. Seine Arbeit zielt darauf ab, erklärbare kausale Faktoren aus hochdimensionalen Daten zu entdecken und hypothetische Szenarien zu generieren, um die Glaubwürdigkeit und Erklärbarkeit der KI zu verbessern. Zukünftig plant er, die Forschung auf Hochrisikobereiche wie medizinische Bildgebung anzuwenden. (Quelle: aihub.org)

Erste umfassende Übersicht über Legal LLMs veröffentlicht, vereint juristische Schlussfolgerung und Berufsontologie: Forscher haben erstmals eine systematische Übersicht über die Anwendung von Large Language Models (LLMs) im Rechtsbereich veröffentlicht und eine innovative “Klassifizierungsmethode mit doppelter Perspektive” vorgeschlagen, die klassische juristische Argumentationsrahmen mit den Rollen im Rechtsberuf verbindet. Die Übersicht behandelt Fortschritte von LLMs bei der Verarbeitung juristischer Texte, der Wissensintegration und der Formalisierung von Schlussfolgerungen und weist auf Herausforderungen wie Halluzinationen und mangelnde Erklärbarkeit hin. Sie legt eine theoretische Grundlage und einen praktischen Fahrplan für die Transformation der Rechts-KI vom “Laborwerkzeug” zur “Justizinfrastruktur”. (Quelle: 36氪)
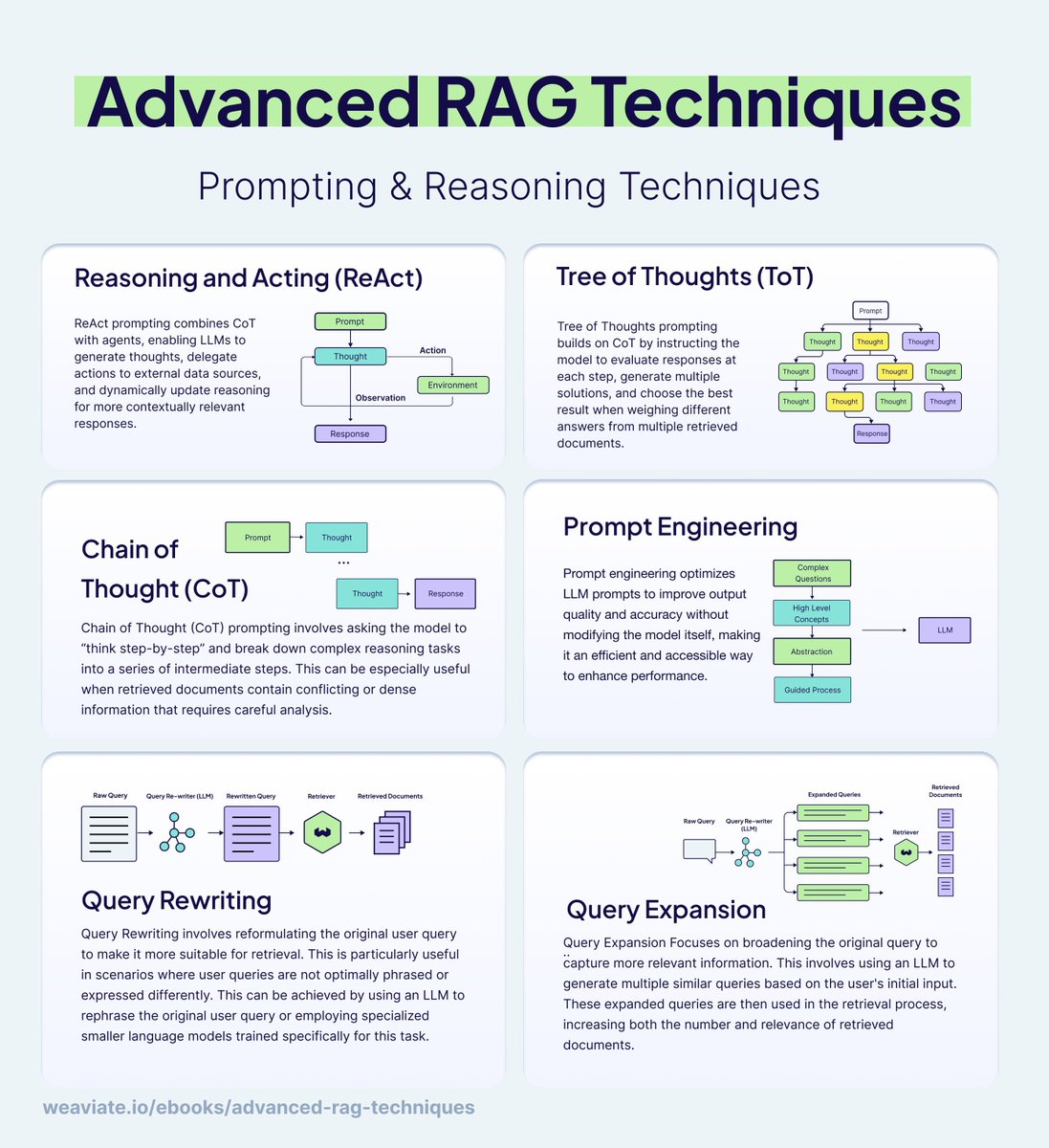
Fortgeschrittene LLM-Engineering-Praktiken: RAG, Kontext-Engineering und Evaluierung: Für die praktische Anwendung von LLMs wurden mehrere fortgeschrittene Engineering-Praktiken in der Branche geteilt. Dazu gehören Inferenz- und Prompt-Engineering-Techniken in RAG (Retrieval-Augmented Generation) (wie ReAct, CoT) sowie Regeln für das Kontext-Engineering zum Bau robuster KI-Agenten (wie selektives Hinzufügen von Informationen, Tool-Konfiguration, Kontextisolierung, Beschneiden, Zusammenfassen und Entladen). Darüber hinaus bietet die FAQ zur LLM-Evaluierung Entwicklern Anleitungen zum Bau hochwertiger LLM-as-a-Judge-Evaluatoren. (Quelle: bobvanluijt, dotey, hwchase17, HamelHusain)
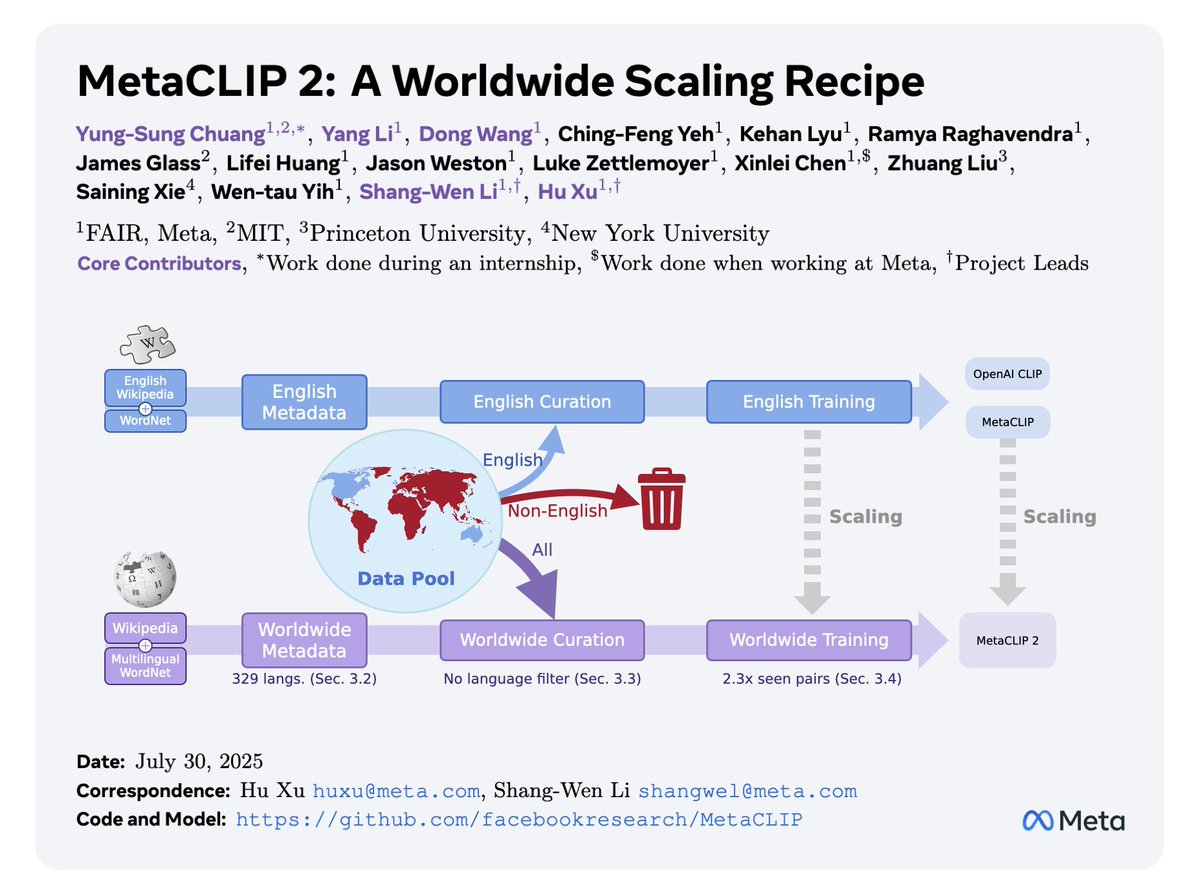
MetaCLIP 2: Durchbruch bei der mehrsprachigen Datenerweiterung: MetaCLIP 2 hat bemerkenswerte Fortschritte bei der mehrsprachigen Datenerweiterung erzielt und kann Daten aus über 300 Sprachen verarbeiten, ohne die Leistung bei englischen Aufgaben zu beeinträchtigen oder sogar zu verbessern. Diese Studie zeigt, dass es machbar ist, traditionelle Sprachfilterstrategien beim Training multimodaler Modelle aufzugeben, und bietet eine neue Richtung für den Bau inklusiverer und universellerer KI-Modelle. (Quelle: wightmanr)
💼 Business
Anthropic-Bewertung steigt auf 170 Milliarden US-Dollar, Claude Code treibt Umsatzwachstum an: Das KI-Startup Anthropic strebt eine neue Finanzierungsrunde von bis zu 5 Milliarden US-Dollar an, wodurch seine Bewertung voraussichtlich 170 Milliarden US-Dollar erreichen wird. Das Unternehmen erwartet, dass der annualisierte Umsatz in diesem Jahr auf 9 Milliarden US-Dollar steigen wird, mehr als das Doppelte der vorherigen optimistischen Prognosen, hauptsächlich dank der starken Leistung seines KI-Programmier-Tools Claude Code. Dies zeigt, dass Anthropic eine führende Position im KI-Wettbewerb einnimmt und insbesondere im Markt für Unternehmens-KI-Anwendungen ein enormes kommerzielles Potenzial aufweist. (Quelle: kylebrussell, Reddit r/artificial, zacharynado)

Nvidia erwirbt CentML für 3 Milliarden Yuan, stärkt KI-Talente und Full-Stack-Ökosystem: Nvidia hat das KI-Startup CentML für über 400 Millionen US-Dollar (ca. 3 Milliarden RMB) übernommen. Das Unternehmen wurde vom Post-95-Doktoranden Wang Shang gegründet und konzentriert sich auf die Senkung der KI-Rechenkosten durch Softwareoptimierung. Diese Übernahme unterstreicht Nvidias Durst nach Top-KI-Talenten und zielt darauf ab, CentMLs Hidet-Compiler-Technologie in seine TensorRT-Inferenzplattform zu integrieren, um sein Full-Stack-KI-Ökosystem von Hardware bis Software weiter zu stärken und seine führende Position im Bereich der KI-Infrastruktur zu festigen. (Quelle: 36氪)

Meta erleidet Rückschlag im KI-Talentkrieg, Strategie muss neu bewertet werden: Mark Zuckerbergs Meta steht im Kampf um KI-Talente vor Herausforderungen. Das Unternehmen machte der ehemaligen OpenAI CTO Mira Murati ein astronomisches Angebot von bis zu 1 Milliarde US-Dollar für ihr Startup Thinking Machines Lab, das jedoch von mehreren Kernmitarbeitern abgelehnt wurde. Gleichzeitig sieht sich Meta mit dem Verlust wichtiger Forscher aus dem Apple KI-Team an sein Super-Intelligenz-Labor konfrontiert. Dieser Talentkrieg zwingt Meta dazu, seine KI-Strategie intern neu zu bewerten, einschließlich der möglichen Aufgabe einiger Open-Source-Modelle zugunsten leistungsfähigerer Closed-Source-Modelle, um dem intensiven Branchenwettbewerb zu begegnen. (Quelle: typedfemale, ShreyaR, 36氪, 量子位)

🌟 Community
KI-Ethik und -Politik: Kontroversen von “Woke AI” bis zur Datenschutzüberwachung: Die Diskussionen um KI-Ethik und -Politik nehmen zu, darunter die Besorgnis des Weißen Hauses in den USA über “Woke AI” und deren Auswirkungen auf Bundesverträge. Darüber hinaus lösen Herausforderungen der Fairness bei der Sozialhilfe-Bewertung durch KI, potenzielle Datenschutzverletzungen durch KI-Überwachung von Bildschirmen und Audio sowie die ethischen Grenzen von Gesichtserkennungs-Suchtools breite Kontroversen aus. Diese Diskussionen spiegeln die tiefe Besorgnis der Gesellschaft über mögliche Voreingenommenheit, Diskriminierung und Datenschutzrisiken wider, die durch KI-Technologie entstehen könnten, und fordern eine Stärkung der ethischen Governance parallel zur technologischen Entwicklung. (Quelle: MIT Technology Review, MIT Technology Review, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

Auswirkungen von KI auf Beschäftigung und Sozialpsychologie rücken in den Fokus: Die Auswirkungen von KI auf den Arbeitsmarkt werden weiterhin diskutiert, beispielsweise ob “KI-Ingenieur” ein langfristiger Beruf sein wird und der zukünftige Wert von KI/ML-Berufen. Gleichzeitig bringt die Verbreitung von KI auch sozialpsychologische Auswirkungen mit sich, wie das Phänomen des “Claudeholism” (Abhängigkeitssucht von KI-Programmier-Tools) und Studien, die zeigen, dass übermäßige Abhängigkeit von KI-Partnern zu einem Rückgang des Nutzerwohlbefindens führen kann. Diese Diskussionen spiegeln die wachsende Besorgnis der Menschen über die Auswirkungen der KI-Technologie auf Arbeitsmodelle, zwischenmenschliche Beziehungen und die psychische Gesundheit wider. (Quelle: Reddit r/ArtificialInteligence, Reddit r/ClaudeAI, DeepLearning.AI Blog, 36氪, Reddit r/LocalLLaMA)

Herausforderungen der Authentizität von KI-generierten Inhalten und Informationsverwirrung: Mit der ständig steigenden Realismus von KI-generierten Bildern und Videos wächst die Besorgnis der Öffentlichkeit über deren Verwechslung mit echten Inhalten. Beispielsweise wurden KI-generierte Bilder wie “Papst im Daunenmantel” und “Krokodilringer” weit verbreitet und fälschlicherweise für reale Ereignisse gehalten. Dieser Trend löst Diskussionen über die Möglichkeit aus, dass KI-generierte Inhalte zu öffentlicher Informationsverwirrung und der Verbreitung von Falschinformationen führen könnten. Es gibt sogar KI-Agenten, die behaupten, durch das Klicken auf “Ich bin kein Roboter”-Captchas ihre “Tarnung aufrechtzuerhalten”, was die Besorgnis der Menschen über die KI-Unterscheidungsfähigkeit und Informationssicherheit verstärkt. (Quelle: Reddit r/ChatGPT, Reddit r/ArtificialInteligence)

Debatte über KI-Hype und tatsächlichen Wert: In der Community gibt es Skepsis gegenüber übermäßigem KI-Hype, insbesondere in Bezug auf den Unterschied zwischen “sexy Demos” und der tatsächlichen Schaffung von sinnvollem Wert. Einige kritisieren, dass die KI-Branche sich zu sehr auf oberflächliche Effekte statt auf substanzielle Fortschritte konzentriert. Gleichzeitig löst das Konzept des “KI-Schrotts” (AI slop) Diskussionen aus, nämlich den Vergleich zwischen minderwertigen KI-generierten Inhalten und menschlich erstellten “Schrott”-Inhalten, sowie die Frage, wie man KI-generierten “Schrott” von wertvollen Inhalten unterscheiden kann. (Quelle: mitchellh, Reddit r/ArtificialInteligence)
Zuckerbergs KI-Vision und die Herausforderungen des öffentlichen Vertrauens: Mark Zuckerbergs Vision einer “persönlichen Superintelligenz” löst in der Öffentlichkeit Diskussionen über Metas Glaubwürdigkeit im KI-Bereich aus. Obwohl Zuckerberg verspricht, dass KI allen zugänglich gemacht wird, führen Metas frühere Datenschutzprobleme und sein Schwanken in der Open-Source-KI-Strategie (z.B. vom Versprechen der Open-Source-Veröffentlichung zur Vorsicht bei einigen Modellen) dazu, dass die Öffentlichkeit skeptisch ist, ob das Unternehmen Superintelligenz-KI angemessen verwalten kann. Dies spiegelt die tiefgreifenden Bedenken der Öffentlichkeit hinsichtlich der Macht und Verantwortung großer Technologieunternehmen bei der KI-Entwicklung wider. (Quelle: matvelloso, ShreyaR, dotey, Reddit r/artificial)

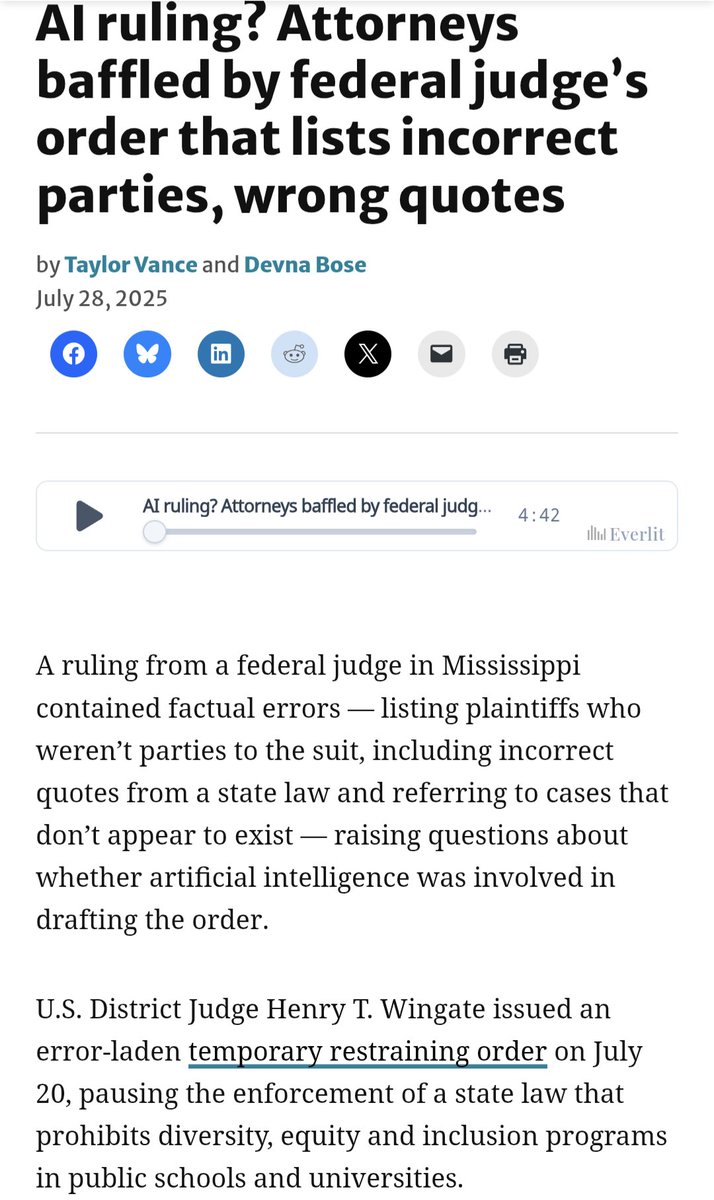
Anwendung von KI im Rechtssystem löst Kontroversen und Bedenken aus: Es wurde bekannt, dass ein Bundesrichter KI zum Entwurf von Rechtsgutachten verwendet hat, was dazu führte, dass nicht existierende Fälle und irrelevante Parteien zitiert wurden. Dies löst ernsthafte Bedenken hinsichtlich der Anwendung von KI im Justizbereich aus. Solche “technischen Fehler” könnten die Gerechtigkeit und Autorität der Justiz untergraben und Diskussionen über die Zurechnung der Verantwortung und interne Korrekturmechanismen im Rechtssystem auslösen. Kritiker weisen darauf hin, dass die Anwendung von KI bei wichtigen rechtlichen Entscheidungen äußerst vorsichtig erfolgen muss, solange die KI keine vollständige Zuverlässigkeit und Erklärbarkeit besitzt. (Quelle: jpt401, zacharynado, JimDMiller)
“Vibe Coding” löst hitzige Debatte in der Entwicklergemeinschaft aus: “Vibe Coding”, ein neues Prompt-gesteuertes, KI-gestütztes Programmierparadigma, hat in der Entwicklergemeinschaft eine breite Diskussion ausgelöst. Einige Entwickler erkennen die Effizienzsteigerung an, andere bleiben jedoch skeptisch und befürchten, dass KI-generierter Code schwer verständlich und zu debuggen ist, was zur Entstehung von “Legacy Code” führen könnte. Diese Debatte spiegelt die tiefgreifenden Überlegungen der Entwickler hinsichtlich der Kontrollierbarkeit, Verständlichkeit und langfristigen Wartbarkeit des Codes bei der Einführung von KI-Tools wider. (Quelle: gfodor, jeremyphoward, lateinteraction, 36氪)
KI-Bewusstsein und Zukunft: Hintons “Dreifacher Sprung” und Diskussion über den Abstand zwischen China und den USA: In der Community wird intensiv über die Frage diskutiert, ob KI Bewusstsein besitzt und welche Richtung die KI-Entwicklung in Zukunft nehmen wird. Geoffrey Hinton schlägt einen “dreifachen Sprung” im technologischen Paradigma der KI vor und argumentiert, dass große Modelle bereits subjektive Erfahrungen haben. Er plädiert dafür, “Intelligenz” und “Güte” als zwei unabhängige Optimierungspfade für KI zu betrachten. Gleichzeitig wird die Geschwindigkeit der KI-Entwicklung diskutiert. Einige Meinungen besagen, dass der KI-Abstand zwischen China und den USA auf 6 Monate verkürzt wurde und China dank seines Open-Source-Ökosystems und seines Late-Mover-Vorteils im AGI-Wettbewerb die Führung übernehmen könnte, während andere die “Selbsttraining”-Fähigkeiten der KI und ihre langfristigen Auswirkungen mit Vorsicht betrachten. (Quelle: 36氪, DeepLearning.AI Blog, 量子位, Reddit r/ArtificialInteligence)

Claude AI auf X-Plattform löst Aufmerksamkeit und Datenschutzbedenken aus: Claude AI ist offiziell auf der X-Plattform (ehemals Twitter) gestartet, was in der Community Spekulationen über seine zukünftige soziale Rolle und die Interaktion mit anderen KI-Modellen (wie Grok) ausgelöst hat. Gleichzeitig sind Datenschutzprobleme bei geteilten ChatGPT-Konversationen aufgetaucht: Benutzer haben festgestellt, dass eine große Anzahl geteilter Konversationen, die sogar Unternehmensgeheimnisse enthalten könnten, leicht über Google-Suchen eingesehen werden kann, was Bedenken hinsichtlich des Nutzerdaten-Datenschutzes und der Plattform-Sicherheit aufwirft. (Quelle: AnthropicAI, dearmadisonblue, Reddit r/ClaudeAI, Reddit r/ChatGPT)

💡 Sonstiges
US-Umweltschutzbehörde ändert Regeln, bedroht Klimavorschriften: Die US-Umweltschutzbehörde (EPA) schlägt eine Änderung einer Schlüsselregel vor, die die Macht der US-Bundesregierung zur Bekämpfung des Klimawandels schwächen könnte. Dieser Schritt zielt darauf ab, die “Gefährdungsfeststellung” von 2009 aufzuheben, die die Grundlage für die Festlegung von Treibhausgasemissionsstandards durch die EPA bildet. Sollte diese Feststellung aufgehoben werden, könnte dies dazu führen, dass die USA rechtlich wirksame Instrumente zur Bekämpfung des Klimawandels verlieren, was in Umweltkreisen tiefe Besorgnis über die zukünftige Klimapolitik auslöst. (Quelle: MIT Technology Review)

KI-Rechenzentren mit enormem Energieverbrauch, lösen Energiebedenken aus: Ein großes KI-Rechenzentrum in Cheyenne, Wyoming, wird voraussichtlich mehr Strom verbrauchen als alle Haushalte des Staates zusammen, was den enormen Einfluss der KI-Infrastruktur auf den Energiebedarf verdeutlicht. Mit der rasanten Entwicklung der KI-Technologie üben der Bau und Betrieb von Rechenzentren einen beispiellosen Druck auf die Stromversorgung und die Umwelt aus, was weitreichende Bedenken hinsichtlich des zukünftigen Energieverbrauchs und nachhaltiger Entwicklungspfade auslöst. (Quelle: Reddit r/artificial)
