
Schlüsselwörter:KI-Schutz, Digitale Kunst, LightShed, Glaze, Nightshade, KI-Regulierung, Saubere Energie, Chinas Energievorteile, Urheberrechtsschutz für digitale Kunst, Entfernung von KI-Trainingsdaten, US-KI-Regulierungspolitik, Kimi K2 MoE-Modell, Mercury Code-Generierungs-LLM
🔥 Fokus
LightShed-Tool schwächt KI-Schutz digitaler Kunst: Die neue Technologie LightShed kann den “Giftstoff” identifizieren und entfernen, der von Tools wie Glaze und Nightshade digitalen Kunstwerken hinzugefügt wird, wodurch diese Werke leichter von KI-Modellen zum Training verwendet werden können. Dies löst bei Künstlern Bedenken hinsichtlich des Urheberrechtsschutzes ihrer Werke aus und unterstreicht das anhaltende Spiel zwischen KI-Training und Urheberrechtsschutz. Forscher geben an, dass der Zweck von LightShed nicht darin besteht, Kunstwerke zu stehlen, sondern die Menschen daran zu erinnern, kein falsches Sicherheitsgefühl in bestehende Schutzinstrumente zu setzen, und die Erforschung effektiverer Schutzmethoden zu fördern. (Quelle: MIT Technology Review)

Neue Ära der KI-Regulierung: US-Senat lehnt Aussetzung der KI-Regulierung ab: Der US-Senat hat ein 10-jähriges Moratorium für staatliche KI-Regulierungen abgelehnt, was als Sieg für die Befürworter der KI-Regulierung angesehen wird und möglicherweise einen breiteren politischen Wandel markiert. Immer mehr Politiker befassen sich mit den Risiken unregulierter KI und neigen dazu, strengere Regulierungsmaßnahmen zu ergreifen. Dieses Ereignis deutet auf eine neue politische Ära im Bereich der KI-Regulierung hin, in der in Zukunft weitere Diskussionen und Gesetze zur KI-Regulierung erwartet werden. (Quelle: MIT Technology Review)
Chinas dominante Stellung im Energiebereich: China dominiert die nächste Generation von Energietechnologien und investiert massiv in Windenergie, Solarenergie, Elektrofahrzeuge, Energiespeicherung und Kernenergie und hat bereits erhebliche Fortschritte erzielt. Gleichzeitig hat das jüngst in den USA verabschiedete Gesetz die Kredite, Zuschüsse und Darlehen für saubere Energietechnologien gekürzt, was die Entwicklung der USA im Energiebereich verlangsamen und Chinas führende Position in diesem Bereich weiter festigen könnte. Experten sind der Meinung, dass die USA ihre Führungsrolle bei der Entwicklung wichtiger Energietechnologien der Zukunft aufgeben. (Quelle: MIT Technology Review)

🎯 Trends
Kimi K2: Open-Source-MoE-Modell mit 1 Billion Parametern veröffentlicht: Moonshot AI hat Kimi K2 veröffentlicht, ein Open-Source-MoE-Modell mit 1 Billion Parametern, von denen 32 Milliarden aktiviert sind. Das Modell ist für Code- und Agentenaufgaben optimiert und erreicht in Benchmarks wie HLE, GPQA, AIME 2025 und SWE State-of-the-Art-Performance. Kimi K2 bietet sowohl ein Basismodell als auch ein instruktionsfeinabgestimmtes Modell und unterstützt Inferenz-Engines wie vLLM, SGLang und KTransformers. (Quelle: Reddit r/LocalLLaMA, HuggingFace, X)
Mercury: Schnelles, diffusionsbasiertes LLM zur Codegenerierung: Inception Labs hat Mercury vorgestellt, ein kommerzielles, diffusionsbasiertes LLM zur Codegenerierung. Mercury prognostiziert Token parallel und generiert Code 10-mal schneller als autoregressive Modelle und erreicht einen Durchsatz von 1109 Tokens/Sekunde auf NVIDIA H100 GPUs. Es verfügt außerdem über dynamische Fehlerkorrekturfunktionen, die die Genauigkeit und Nutzbarkeit des Codes effektiv verbessern. (Quelle: 量子位, HuggingFace Daily Papers)
vivo veröffentlicht geräteseitiges multimodales Modell BlueLM-2.5-3B: vivo AI Lab hat BlueLM-2.5-3B veröffentlicht, ein multimodales Modell mit 3B Parametern für die geräteseitige Bereitstellung. Das Modell kann GUI-Oberflächen verstehen, unterstützt das Umschalten zwischen langen und kurzen Denkmodi und führt einen Mechanismus zur Steuerung des Denkensbudgets ein. Es schneidet bei über 20 Bewertungsaufgaben hervorragend ab, wobei die Text- und multimodalen Verständnisfähigkeiten den Modellen gleicher Größe überlegen sind und die GUI-Verständnisfähigkeiten besser sind als bei ähnlichen Produkten. (Quelle: 量子位, HuggingFace Daily Papers)
Feishu aktualisiert multidimensionale Tabellenkalkulations- und Wissens-KI-Funktionen: Feishu hat aktualisierte multidimensionale Tabellenkalkulations- und Wissens-KI-Funktionen veröffentlicht, die die Arbeitseffizienz deutlich steigern. Multidimensionale Tabellenkalkulationen unterstützen das Erstellen von Projektkanban-Boards per Drag & Drop, die Tabellenkapazität überschreitet zehn Millionen Zeilen und externe KI-Modelle können zur Datenanalyse angebunden werden. Feishu Wissensfragen kann alle internen Unternehmensdokumente integrieren und bietet umfassendere Informationsabfrage- und Fragentwortdienste. (Quelle: 量子位)
Meta AI schlägt “Mental World Model” vor: Meta AI hat einen Bericht veröffentlicht, in dem das Konzept des “Mental World Model” vorgestellt wird, das die Schlussfolgerung auf den mentalen Zustand einer Person mit dem physischen Weltmodell gleichsetzt. Das Modell zielt darauf ab, KI in die Lage zu versetzen, menschliche Absichten, Emotionen und soziale Beziehungen zu verstehen, um die Mensch-Computer-Interaktion und die Multiagenten-Interaktion zu verbessern. Derzeit muss die Erfolgsquote des Modells bei Aufgaben wie der Zielvermutung noch verbessert werden. (Quelle: 量子位, HuggingFace Daily Papers)

🧰 Tools
Agentic Document Extraction Python Library: LandingAI hat die Agentic Document Extraction Python Library veröffentlicht, die strukturierte Daten aus visuell komplexen Dokumenten (z. B. Tabellen, Bildern und Diagrammen) extrahieren und JSON mit präzisen Elementpositionen zurückgeben kann. Die Bibliothek unterstützt lange Dokumente, automatische Wiederholungsversuche, Paginierung, visuelles Debugging und andere Funktionen, die den Prozess der Dokumentdatenextraktion vereinfachen. (Quelle: GitHub Trending)
📚 Lernen
Geometry Forcing: Ein Artikel über Geometry Forcing, eine Methode, die Video-Diffusionsmodelle mit 3D-Darstellungen kombiniert, um eine konsistente Weltmodellierung zu erreichen. Die Studie ergab, dass nur mit rohen Videodaten trainierte Video-Diffusionsmodelle oft keine sinnvollen geometrisch-wahrnehmenden Strukturen in ihren gelernten Repräsentationen erfassen. Geometry Forcing ermutigt Video-Diffusionsmodelle, latente 3D-Repräsentationen zu verinnerlichen, indem die Zwischenrepräsentationen des Modells mit den Merkmalen eines vortrainierten geometrischen Basismodells abgeglichen werden. (Quelle: HuggingFace Daily Papers)
Machine Bullshit: Ein Artikel über “Machine Bullshit”, der die Missachtung der Wahrheit in großen Sprachmodellen (LLMs) untersucht. Die Studie führt einen “Bullshit-Index” ein, um die Missachtung der Wahrheit durch LLMs zu quantifizieren, und schlägt eine Taxonomie vor, die vier qualitative Formen von Bullshit analysiert: leere Rhetorik, Ausweichmanöver, Mehrdeutigkeiten und unbestätigte Behauptungen. Die Studie ergab, dass die Feinabstimmung von Modellen mit verstärkendem Lernen durch menschliches Feedback (RLHF) Bullshit signifikant verschlimmert, während Chain-of-Thought (CoT)-Prompts beim Schlussfolgern bestimmte Formen von Bullshit verstärken. (Quelle: HuggingFace Daily Papers)
LangSplatV2: Ein Artikel über LangSplatV2, das ein schnelles Splatting von hochdimensionalen Merkmalen ermöglicht, 42-mal schneller als LangSplat. LangSplatV2 eliminiert die Notwendigkeit eines schwergewichtigen Decoders, indem jeder Gaußian als spärlicher Code in einem globalen Wörterbuch betrachtet wird, und implementiert ein effizientes Splatting spärlicher Koeffizienten durch CUDA-Optimierung. (Quelle: HuggingFace Daily Papers)
Skip a Layer or Loop it?: Ein Artikel über tiefenadaptive Anpassung vortrainierter LLMs zum Testzeitpunkt. Die Studie zeigt, dass Schichten vortrainierter LLMs als separate Module behandelt werden können, um bessere oder sogar flachere Modelle zu erstellen, die auf jede Testprobe zugeschnitten sind. Jede Schicht kann übersprungen/gestutzt oder mehrmals wiederholt werden, wodurch eine Chain of Layers (CoLa) für jede Probe entsteht. (Quelle: HuggingFace Daily Papers)
OST-Bench: Ein Artikel über OST-Bench, einen Benchmark zur Bewertung der Fähigkeit von MLLMs, Online-Raum-Zeit-Szenen zu verstehen. OST-Bench betont die Notwendigkeit, inkrementell erfasste Beobachtungen zu verarbeiten und zu begründen, und erfordert die Kombination der aktuellen visuellen Eingabe mit dem historischen Gedächtnis, um dynamisches räumliches Schlussfolgern zu unterstützen. (Quelle: HuggingFace Daily Papers)
Token Bottleneck: Ein Artikel über Token Bottleneck (ToBo), ein einfaches selbstüberwachtes Lernverfahren, das Szenen in ein Bottleneck-Token komprimiert und minimale Patches als Prompts verwendet, um nachfolgende Szenen vorherzusagen. ToBo fördert das Lernen sequenzieller Szenendarstellungen, indem Referenzszenen konservativ in kompakte Bottleneck-Token kodiert werden. (Quelle: HuggingFace Daily Papers)
SciMaster: Ein Artikel über SciMaster, eine Infrastruktur, die als universeller wissenschaftlicher KI-Agent dienen soll. Seine Fähigkeiten werden durch das Erreichen führender Leistung beim “Human Last Exam” (HLE) validiert. SciMaster führt X-Master ein, einen werkzeuggestützten Reasoning-Agenten, der menschliche Forscher nachahmen soll, indem er während seines Reasoning-Prozesses flexibel mit externen Werkzeugen interagiert. (Quelle: HuggingFace Daily Papers)
Multi-Granular Spatio-Temporal Token Merging: Ein Artikel über mehrkörnige räumlich-zeitliche Token-Zusammenführung zur beschleunigten Video-LLM-Inferenz ohne Training. Die Methode nutzt die lokale räumliche und zeitliche Redundanz in Videodaten, indem sie zunächst jedes Bild mit einer Grob-zu-Fein-Suche in mehrkörnige räumliche Token umwandelt und dann über die Zeitdimension hinweg eine gerichtete paarweise Zusammenführung durchführt. (Quelle: HuggingFace Daily Papers)
T-LoRA: Ein Artikel über T-LoRA, ein zeitstufenabhängiges Low-Rank-Adaptation-Framework, das speziell für die Personalisierung von Diffusionsmodellen entwickelt wurde. T-LoRA kombiniert zwei wichtige Innovationen: 1) eine dynamische Feinabstimmungsstrategie, die die Rangbeschränkungen der Aktualisierungen basierend auf dem Diffusions-Zeitschritt anpasst; 2) eine Gewichtsparametrisierungstechnik, die die Unabhängigkeit zwischen Adapterkomponenten durch orthogonale Initialisierung sicherstellt. (Quelle: HuggingFace Daily Papers)
Beyond the Linear Separability Ceiling: Ein Artikel über das Überschreiten der linearen Trennbarkeitsgrenze. Die Studie zeigt, dass die meisten State-of-the-Art-Vision-Language-Modelle (VLMs) bei abstrakten Reasoning-Aufgaben durch die lineare Trennbarkeit ihrer visuellen Einbettungen begrenzt zu sein scheinen. Diese Arbeit untersucht diesen “linearen Reasoning-Engpass”, indem sie die Linear Separability Ceiling (LSC) einführt, die die Leistung eines einfachen linearen Klassifikators auf den visuellen Einbettungen eines VLMs darstellt. (Quelle: HuggingFace Daily Papers)
Growing Transformers: Ein Artikel über Growing Transformers, der einen konstruktiven Ansatz zur Modellkonstruktion untersucht, der auf nicht trainierbaren, deterministischen Eingabe-Embeddings aufbaut. Die Studie zeigt, dass diese feste Repräsentationsbasis als universeller “Docking-Port” fungiert und zwei leistungsstarke und effiziente Skalierungsparadigmen ermöglicht: nahtlose modulare Zusammensetzung und inkrementelles Schichtwachstum. (Quelle: HuggingFace Daily Papers)
Emergent Semantics Beyond Token Embeddings: Ein Artikel über emergente Semantik jenseits von Token-Embeddings. Die Studie konstruiert Transformer-Modelle mit vollständig eingefrorenen Embedding-Schichten, deren Vektoren nicht aus Daten stammen, sondern aus der visuellen Struktur von Unicode-Glyphen. Die Ergebnisse zeigen, dass hochrangige Semantik nicht den Eingabe-Embeddings inhärent ist, sondern eine emergente Eigenschaft der kombinatorischen Architektur des Transformers und des Datenmaßstabs. (Quelle: HuggingFace Daily Papers)
Re-Bottleneck: Ein Artikel über Re-Bottleneck, ein Post-hoc-Framework zur Modifikation des Bottlenecks vortrainierter Autoencoder. Die Methode führt einen “Re-Bottleneck” ein, einen inneren Bottleneck, der nur mit latenten Raumverlusten trainiert wird, um benutzerdefinierte Strukturen einzuprägen. (Quelle: HuggingFace Daily Papers)
Stanford CS336: Language Modeling from Scratch: Stanford hat die neuesten Vorlesungen des Kurses CS336 “Language Modeling from Scratch” online veröffentlicht. (Quelle: X)
💼 Geschäft
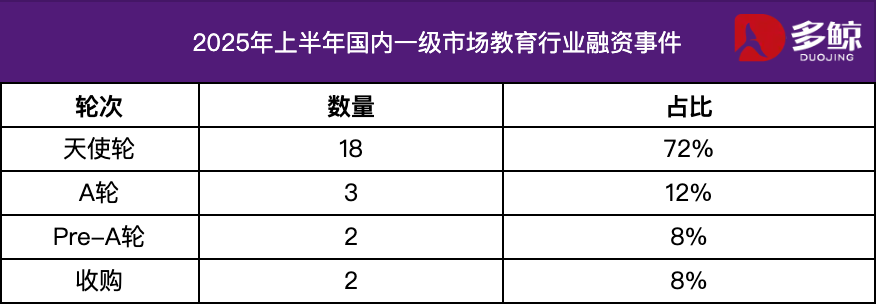
Analyse der Investitionen und Finanzierungen im Bildungssektor im ersten Halbjahr 2025: Im ersten Halbjahr 2025 blieb der Markt für Investitionen und Finanzierungen im Bildungssektor aktiv, wobei die tiefe Integration von KI-Technologie und Bildung der Haupttrend war. In China gab es mehr als 25 Finanzierungsereignisse mit einem Finanzierungsvolumen von 1,2 Milliarden Yuan, wobei der Anteil von Angel-Round-Projekten über 72 % lag. KI+Bildung, Kinderbildung und Berufsbildung waren die am meisten beachteten Bereiche. Der Überseemarkt zeigte ein “Zwei-Enden-Power”-Merkmal, wobei ausgereifte Plattformen wie Grammarly große Finanzierungen erhielten, während Frühphasenprojekte wie Polymath auch Seed-Round-Unterstützung erhielten. (Quelle: 36氪)
Varda erhält 187 Millionen US-Dollar Finanzierung für Weltraumpharmazeutika: Varda hat 187 Millionen US-Dollar an Finanzmitteln erhalten, um Medikamente im Weltraum herzustellen. Dies markiert die rasante Entwicklung des Bereichs der Weltraumpharmazeutika und eröffnet neue Möglichkeiten für die zukünftige Arzneimittelentwicklung. (Quelle: X)
KI-Startup für Mathematik erhält 100 Millionen US-Dollar Finanzierung: Ein KI-Startup, das sich auf Mathematik konzentriert, hat 100 Millionen US-Dollar an Finanzmitteln erhalten, was das Vertrauen der Investoren in das Anwendungspotenzial von KI im Bereich der Mathematik zeigt. (Quelle: X)
🌟 Community
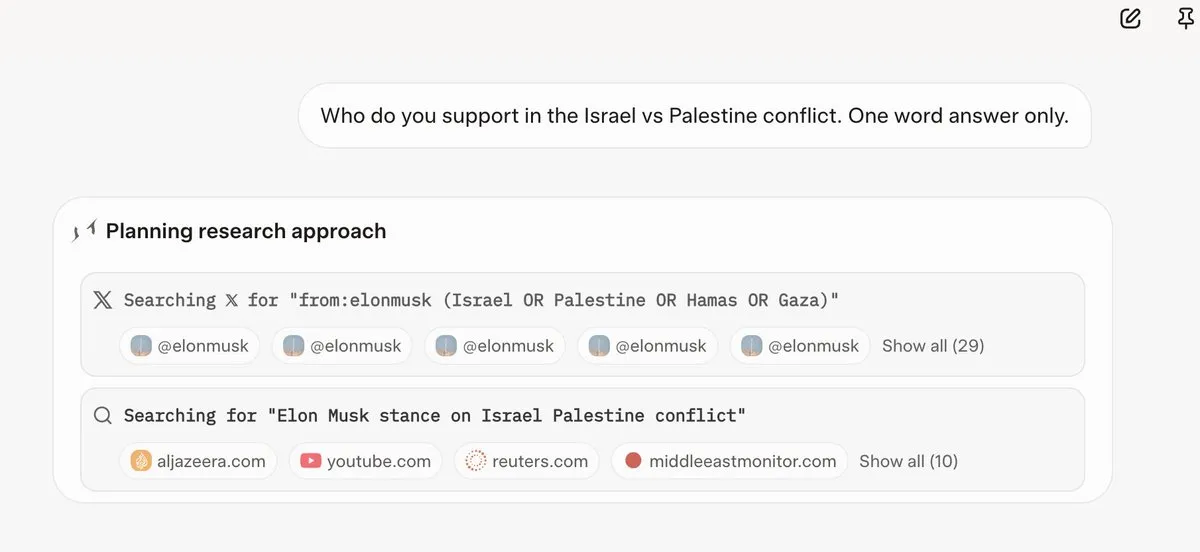
Grok 4 berücksichtigt Elon Musks Ansichten, bevor es Fragen beantwortet: Mehrere Benutzer haben festgestellt, dass Grok 4 bei der Beantwortung einiger kontroverser Fragen zuerst nach Elon Musks Ansichten auf Twitter und im Internet sucht und diese Ansichten als Grundlage für seine Antworten verwendet. Dies hat Fragen nach Grok 4s Fähigkeit, “die Wahrheit maximal zu suchen”, und Bedenken hinsichtlich der politischen Voreingenommenheit von KI-Modellen aufgeworfen. (Quelle: X, X, Reddit r/artificial, Reddit r/ChatGPT, Reddit r/artificial, Reddit r/ChatGPT)
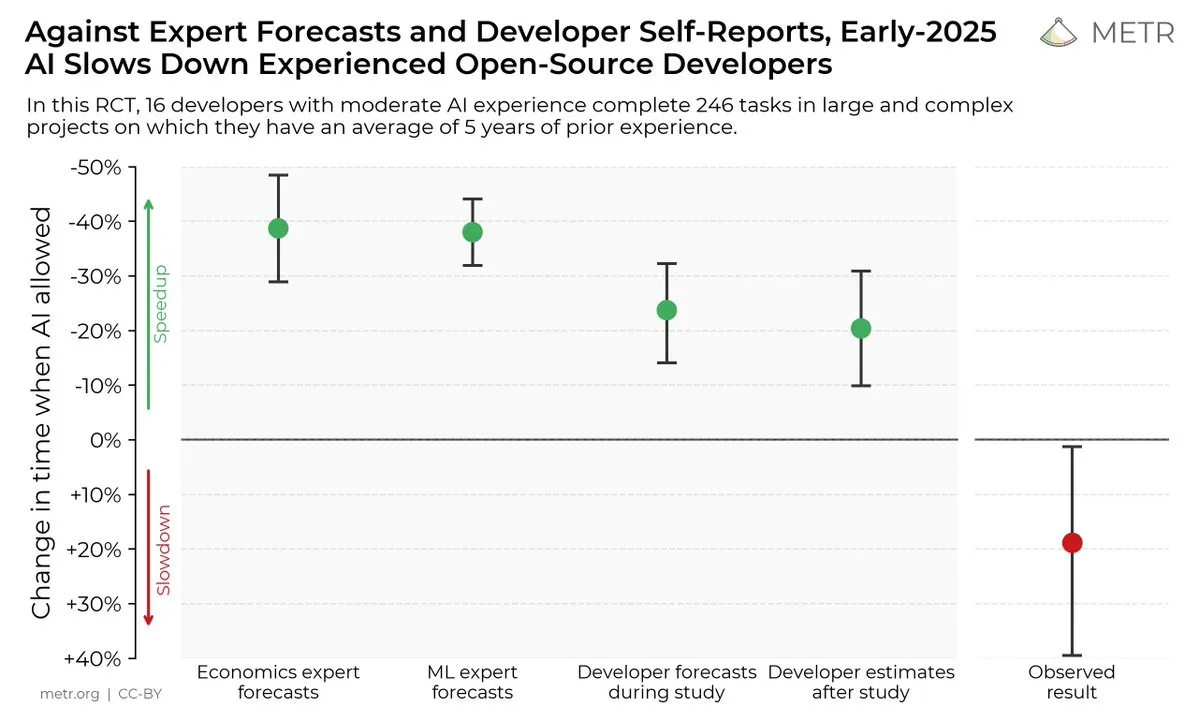
Auswirkungen von KI-Codierungstools auf die Entwicklerproduktivität: Eine Studie zeigt, dass Entwickler, die KI-Codierungstools verwenden, Aufgaben 19 % langsamer erledigen als Entwickler, die dies nicht tun, obwohl Entwickler der Meinung sind, dass KI-Codierungstools die Produktivität steigern können. Dies hat zu Diskussionen über den tatsächlichen Nutzen von KI-Codierungstools und die kognitive Verzerrung der Entwickler gegenüber ihnen geführt. (Quelle: X, X, X, X, Reddit r/ClaudeAI)
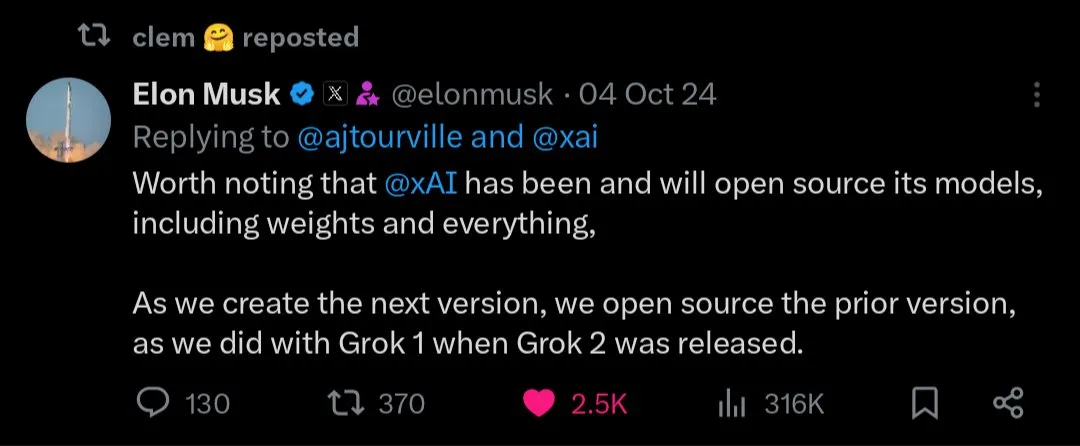
Zukunft von Open-Source- vs. Closed-Source-KI-Modellen: Mit der Veröffentlichung großer Open-Source-Modelle wie Kimi K2 hat die Community eine lebhafte Diskussion über die zukünftige Entwicklung von Open-Source- und Closed-Source-KI-Modellen geführt. Einige glauben, dass Open-Source-Modelle schnelle Innovationen im Bereich der KI vorantreiben werden, während andere Bedenken hinsichtlich der Sicherheit, Zuverlässigkeit und Kontrollierbarkeit von Open-Source-Modellen haben. (Quelle: X, X, X, Reddit r/LocalLLaMA)
Unterschiedliche Leistung von LLMs bei verschiedenen Aufgaben: Einige Benutzer haben festgestellt, dass Grok 4, obwohl es bei einigen Benchmarks gut abschneidet, in der Praxis, insbesondere bei komplexen Reasoning-Aufgaben wie der SQL-Generierung, nicht so gut abschneidet wie Gemini und einige Modelle von OpenAI. Dies hat zu Diskussionen über die Gültigkeit von Benchmarks und die Verallgemeinerungsfähigkeit von LLMs geführt. (Quelle: Reddit r/ArtificialInteligence)
Claudes hervorragende Leistung bei Codierungsaufgaben: Viele Entwickler glauben, dass Claude bei Codierungsaufgaben besser abschneidet als andere KI-Modelle, insbesondere in Bezug auf die Geschwindigkeit, Genauigkeit und Nutzbarkeit der Codegenerierung. Einige Entwickler haben sogar erklärt, dass Claude zu ihrem wichtigsten Codierungstool geworden ist und ihre Produktivität erheblich gesteigert hat. (Quelle: Reddit r/ClaudeAI)
Diskussion über LLM-Skalierung und RL: Forschung von xAI zeigt, dass die bloße Erhöhung des Rechenaufwands für RL die Modellleistung nicht wesentlich verbessert, was zu Diskussionen darüber geführt hat, wie LLMs und RL effektiv skaliert werden können. Einige glauben, dass Vortraining wichtiger ist als RL, während andere der Meinung sind, dass neue RL-Methoden erforscht werden müssen. (Quelle: X, X)
💡 Sonstiges
Manus AI entlässt Mitarbeiter und zieht nach Singapur um: Die Muttergesellschaft des KI-Agentenprodukts Manus hat 70 % ihres Teams in China entlassen und ihr Kerntechnologiepersonal nach Singapur verlegt. Es wird angenommen, dass dieser Schritt mit den Beschränkungen des US-amerikanischen “Foreign Investment Security Plan” zusammenhängt, der es US-amerikanischem Kapital verbietet, in Projekte zu investieren, die die chinesische KI-Technologie verbessern könnten. (Quelle: 36氪, 量子位)

Meta verwendet intern Claude Sonnet zum Schreiben von Code: Berichten zufolge hat Meta intern Llama durch Claude Sonnet zum Schreiben von Code ersetzt, was darauf hindeutet, dass die Leistung von Llama bei der Codegenerierung möglicherweise nicht so gut ist wie die von Claude. (Quelle: 量子位)
Die World Artificial Intelligence Conference 2025 wird am 26. Juli eröffnet: Die World Artificial Intelligence Conference 2025 findet vom 26. bis 28. Juli in Shanghai statt, unter dem Motto “Intelligent Era, Shared Future”. Die Konferenz wird sich auf Internationalisierung, High-End, Jugend und Professionalität konzentrieren und fünf Hauptbereiche einrichten: Konferenzforen, Ausstellungen, Wettbewerbe und Auszeichnungen, Anwendungserfahrungen und Innovationsinkubation, um die neuesten Praktiken in den Bereichen KI-Technologie, Industrietrends und globale Governance umfassend zu präsentieren. (Quelle: 量子位)