Schlüsselwörter:Urheberrecht für KI-Trainingsdaten, AlphaGenome, OpenAI Hardware-Plagiat, KI-Abschlussprüfungsergebnisse, Gemini CLI, RLT neue Methode, BitNet b1.58, Biomni Agent, KI-Nutzungsurteil, DNA-Basenpaar Vorhersage, Altman reagiert auf Plagiatsvorwürfe, Verbesserung der mathematischen Fähigkeiten von großen Modellen, Kostenlose Kontingente für Terminal-KI-Agenten
🔥 Fokus
Meilensteinurteil zum Urheberrecht von KI-Trainingsdaten: US-Gericht entscheidet, dass die Nutzung legal erworbener Bücher für das Training von KI unter „Fair Use“ fällt: Ein Bundesgericht der Vereinigten Staaten hat in einer Klage gegen Anthropic entschieden, dass die Nutzung legal erworbener, veröffentlichter Bücher durch KI-Unternehmen zum Training großer Sprachmodelle in den Bereich des „Fair Use“ fällt und keiner vorherigen Zustimmung der Autoren bedarf. Das Gericht war der Ansicht, dass das KI-Training eine „transformative Nutzung“ der Originalwerke darstellt, den Markt für die Originalwerke nicht direkt ersetzt und der technologischen Innovation sowie dem öffentlichen Interesse dient. Gleichzeitig entschied das Gericht jedoch, dass die Verwendung von Raubkopien für das Training keinen Fair Use darstellt, weshalb Anthropic hierfür möglicherweise haftbar gemacht werden kann. Dieses Urteil bezieht sich auf den Präzedenzfall Google Books aus dem Jahr 2015 und wird als wichtiger Schritt zur Reduzierung der Urheberrechtsrisiken bei KI-Trainingsdaten angesehen. Es könnte die Verhandlungen in anderen ähnlichen Fällen (wie Klagen gegen OpenAI und Meta) beeinflussen. Zuvor hatte Meta in einem ähnlichen Urheberrechtsstreit ebenfalls ein günstiges Urteil erwirkt, da der Richter der Ansicht war, die Kläger hätten nicht ausreichend nachgewiesen, dass die Nutzung ihrer Bücher durch Meta zum Training von KI-Modellen einen wirtschaftlichen Schaden verursacht habe. Diese Urteile geben der KI-Branche gemeinsam klarere rechtliche Leitlinien für die Beschaffung und Nutzung von Daten, betonen jedoch die Bedeutung der legalen Datenbeschaffung. (Quelle: 量子位, DeepLearning.AI Blog, wiredmagazine)
Google DeepMind veröffentlicht AlphaGenome: KI-„Mikroskop“ prognostiziert Auswirkungen von Genmutationen auf Millionen DNA-Basenpaare: Google DeepMind hat das KI-Modell AlphaGenome vorgestellt, das DNA-Sequenzen von bis zu einer Million Basenpaaren als Input verarbeiten kann, um Tausende von molekularen Eigenschaften vorherzusagen und die Auswirkungen von Genmutationen zu bewerten. Es übertrifft in über 20 Genom-Vorhersage-Benchmarks die bisherigen Leistungen. AlphaGenome zeichnet sich durch hochauflösende Verarbeitung langer Sequenzkontexte, umfassende multimodale Vorhersagen, effiziente Bewertung von Mutationen und ein neuartiges Spleißstellenmodell aus. Das Training eines einzelnen Modells dauert nur 4 Stunden und erfordert die Hälfte des Rechenbudgets des ursprünglichen Enformer-Modells. Das Modell soll Wissenschaftlern helfen, die Genregulation zu verstehen, das Verständnis von Krankheiten (insbesondere seltener Krankheiten) zu beschleunigen, das Design in der synthetischen Biologie anzuleiten und die Grundlagenforschung voranzutreiben. Derzeit wird eine Vorschauversion über eine API für nicht-kommerzielle Forschungszwecke angeboten, eine vollständige Veröffentlichung ist geplant. (Quelle: 36氪, Google, demishassabis)

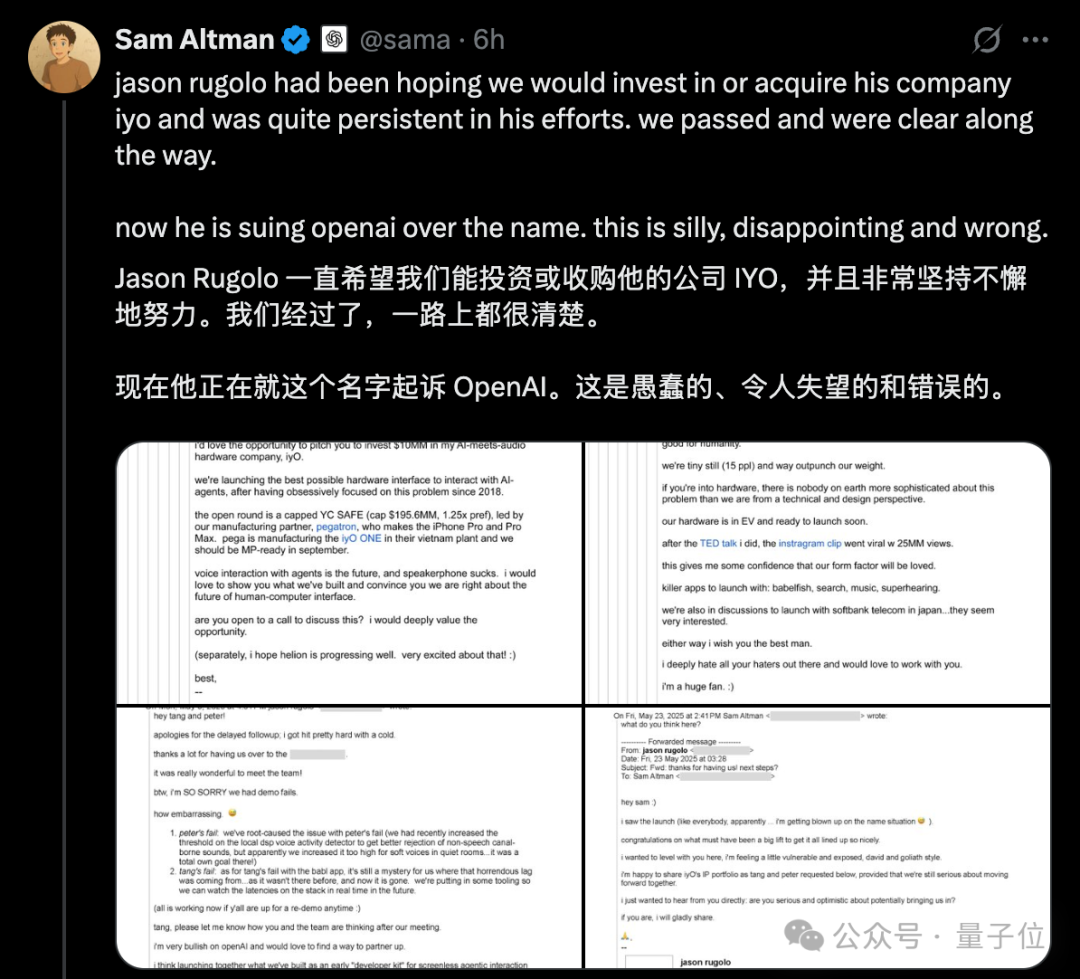
Kontroverse um OpenAI Hardware-„Plagiate“ eskaliert, Altman weist IYO-Klage mit öffentlichen E-Mails zurück: Als Reaktion auf die Vorwürfe des KI-Hardware-Startups IYO, OpenAI und das von OpenAI übernommene Hardware-Unternehmen io (gegründet vom ehemaligen Apple-Designer Jony Ive) hätten Markenrechtsverletzungen und Produktplagiate begangen, antwortete OpenAI CEO Sam Altman öffentlich in sozialen Medien und bezeichnete die Klage von IYO als „dumm, enttäuschend und völlig falsch“. Altman legte E-Mail-Screenshots vor, die zeigen, dass der IYO-Gründer Jason Rugolo vor der Klage aktiv eine Investition oder Übernahme in Höhe von 10 Millionen US-Dollar von OpenAI angestrebt hatte und auch nach der Ankündigung der Übernahme von io durch OpenAI weiterhin sein geistiges Eigentum teilen wollte. Altman ist der Ansicht, dass IYO die Klage erst eingereicht habe, nachdem Investitions- oder Übernahmeversuche gescheitert waren. Der Gründer von IYO wies Altmans Darstellung als „Online-Gerichtsverhandlung“ zurück und beharrte auf den Rechten an seinem Produktnamen. Zuvor hatte ein Gericht dem Antrag von IYO auf eine einstweilige Verfügung stattgegeben, die OpenAI die Nutzung des IO-Logos untersagt. OpenAI erklärte, dass seine Hardwareprodukte sich von den maßgefertigten Ohrhörern von IYO unterscheiden, das Prototypendesign noch nicht festgelegt sei und die Markteinführung frühestens in einem Jahr erfolgen werde. (Quelle: 量子位, 36氪)
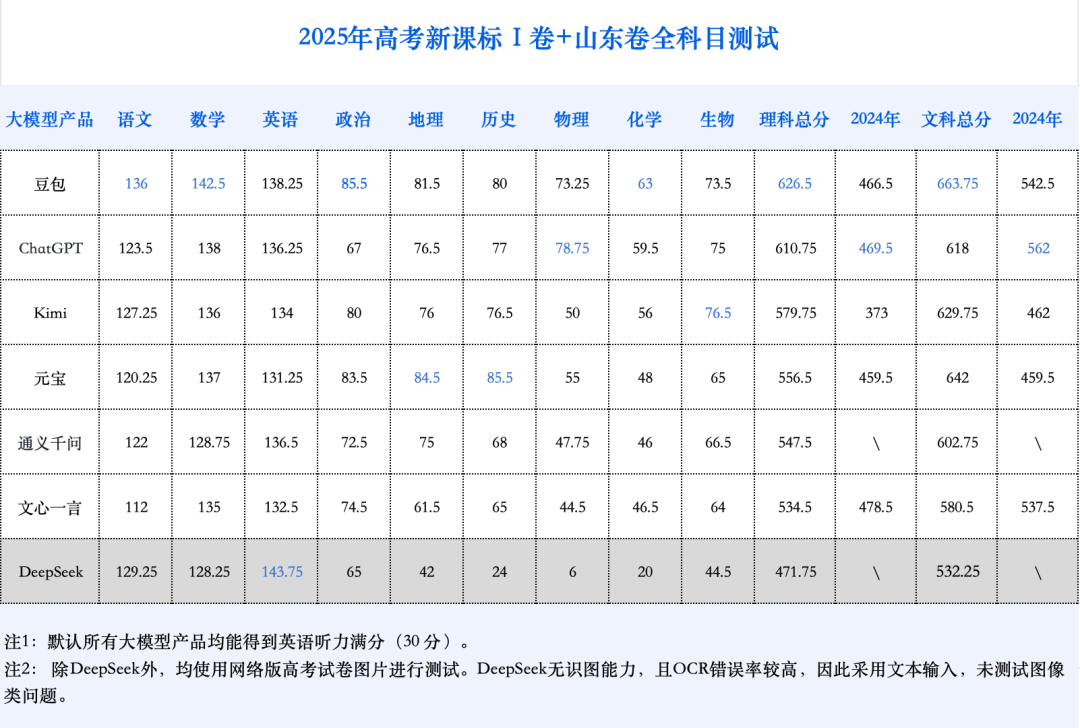
KI-Modelle treten erneut zur Hochschulaufnahmeprüfung an, Gesamtleistung deutlich verbessert, Mathematikkenntnisse stark fortgeschritten: Die Ergebnisse der GeekPark 2025 KI-Hochschulaufnahmeprüfungssimulation zeigen, dass die Gesamtleistung gängiger großer Modelle (wie Doubao, DeepSeek R1, ChatGPT o3 usw.) im Vergleich zum Vorjahr erheblich gestiegen ist und das Potenzial zeigt, Spitzenuniversitäten zu erreichen. Das geschätzte beste Modell, Doubao, könnte unter die Top 900 in der Provinz Shandong gelangen. Die Diskrepanz zwischen den Leistungen in geistes- und naturwissenschaftlichen Fächern hat sich bei KI verringert, wobei die Durchschnittspunktzahl in den Naturwissenschaften schneller gestiegen ist. Mathematik erwies sich als das Fach mit den deutlichsten Fortschritten, mit einer durchschnittlichen Punktzahlsteigerung von 84,25 Punkten, womit es Chinesisch und Englisch übertrifft. Multimodale Fähigkeiten wurden zu einem entscheidenden Faktor für Leistungsunterschiede, insbesondere in Fächern mit vielen Bildaufgaben wie Physik und Geographie. Obwohl KI bei komplexen Schlussfolgerungen und Berechnungen hervorragende Leistungen erbringt, macht sie immer noch Fehler beim Verständnis einfacher Aufgaben mit visuell unklaren Informationen (wie bei einer Aufgabe zur Vektorrechnung in Mathematik). Im Bereich Aufsatz kann KI zwar strukturierte und argumentativ reichhaltige Texte verfassen, es mangelt ihr jedoch an tiefgründiger Reflexion und emotionaler Resonanz, sodass sie keine Spitzenaufsätze produzieren kann. (Quelle: 36氪)
🎯 Trends
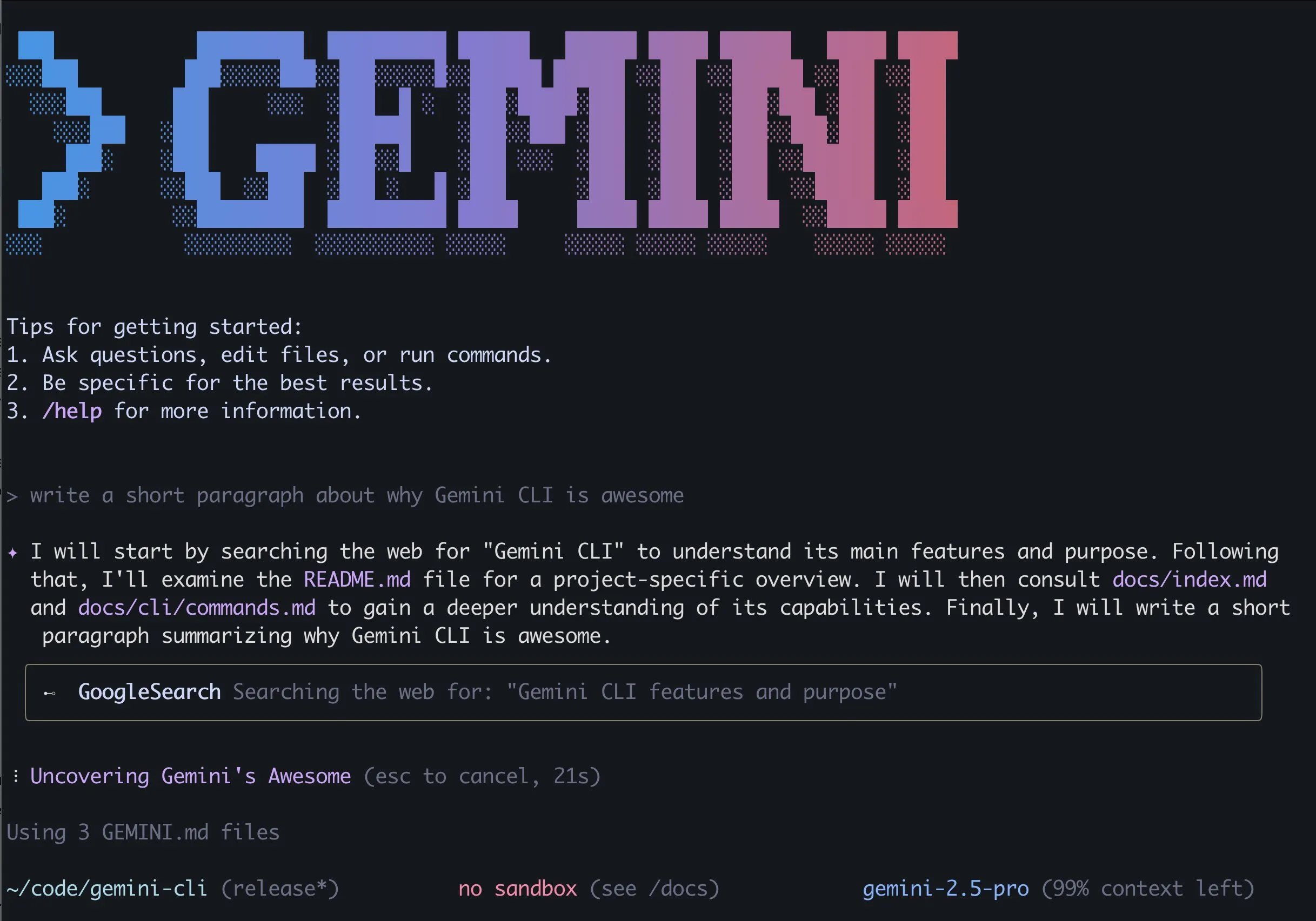
Google veröffentlicht Gemini CLI mit Gemini 2.5 Pro-Antrieb und großzügigen kostenlosen Kontingenten, was Aufmerksamkeit erregt: Google hat offiziell Gemini CLI veröffentlicht, einen KI-Assistenten, der in der Terminalumgebung läuft und auf dem Gemini 2.5 Pro-Modell basiert. Das Highlight sind die äußerst großzügigen kostenlosen Nutzungskontingente: Unterstützung für ein Kontextfenster von 1 Million Token, 60 Modellaufrufe pro Minute und 1000 pro Tag. Dies stellt eine starke Konkurrenz zu kostenpflichtigen Tools wie Claude Code von Anthropic dar. Gemini CLI verwendet die Apache 2.0 Open-Source-Lizenz und unterstützt das Schreiben und Debuggen von Code, Projektmanagement, Dokumentationsabfragen sowie den Aufruf anderer Google-Dienste (z. B. zur Erstellung von Bildern und Videos) über MCP. Google betont die Vorteile seines Universalmodells bei der Bewältigung komplexer Entwicklungsaufgaben und ist der Ansicht, dass reine Code-Modelle eher einschränkend sein könnten. Die Community reagierte begeistert und geht davon aus, dass dies die Verbreitung und den Wettbewerb von CLI-KI-Tools fördern wird. (Quelle: 36氪, Reddit r/LocalLLaMA, dotey)

Sakana AI stellt neue RLT-Methode vor, 7B kleines Modell „lehrt“ effektiver als DeepSeek-R1: Sakana AI, gegründet von Llion Jones, einem der Autoren von Transformer, hat eine neue Methode für Reinforcement Learning Teachers (RLTs) vorgestellt. Bei dieser Methode löst das Lehrermodell Probleme nicht mehr von Grund auf, sondern gibt klare schrittweise Erklärungen basierend auf bekannten Lösungen aus und ahmt so das „heuristische“ Lehren exzellenter menschlicher Lehrer nach. Experimente zeigen, dass ein mit dieser Methode trainiertes 7B RLT-Kleinmodell bei der Vermittlung von Denkfähigkeiten DeepSeek-R1 mit 671B übertrifft und auch Schülermodelle, die dreimal so groß sind (z. B. 32B), effektiv trainieren kann, wobei die Trainingskosten erheblich gesenkt werden. Diese Methode zielt darauf ab, die Probleme traditioneller Lehrermodelle zu lösen, die von ihrer eigenen Problemlösungsfähigkeit abhängig, langsam und teuer im Training sind, indem das Lehrertraining auf sein eigentliches Ziel (Unterstützung des Lernens von Schülermodellen) ausgerichtet wird, um die Effizienz zu steigern. (Quelle: 量子位, SakanaAILabs)

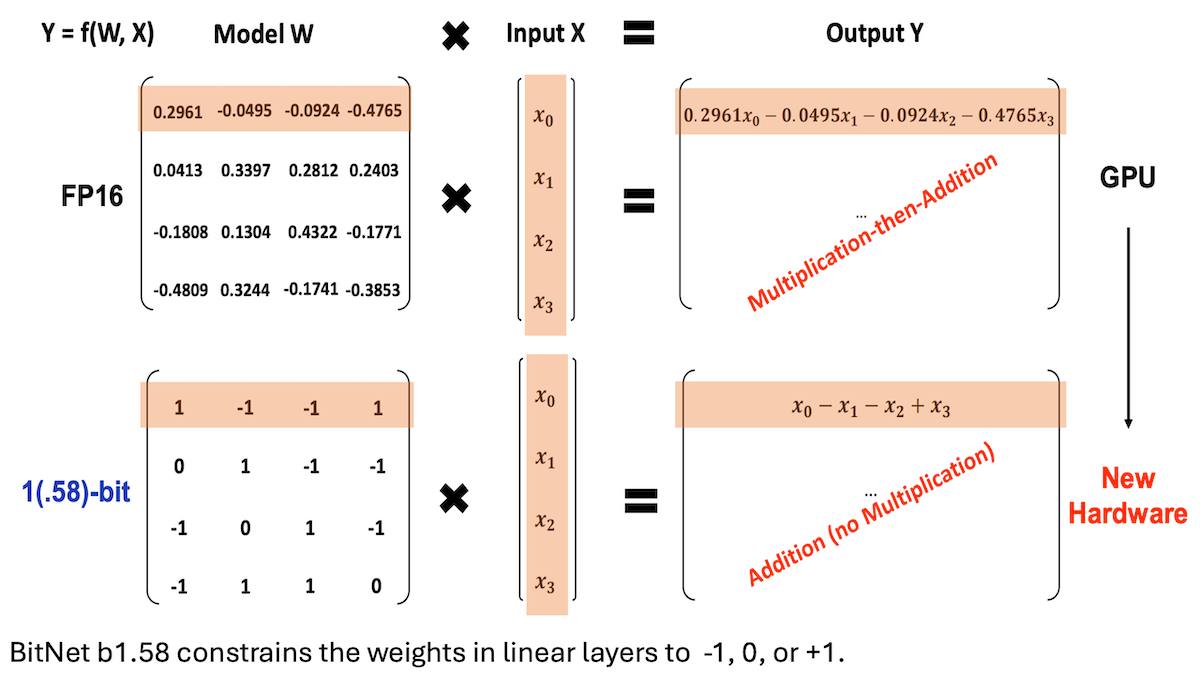
Microsoft et al. stellen BitNet b1.58 vor und realisieren LLM mit niedriger Präzision und hoher Inferenzleistung: Forscher von Microsoft, der University of Chinese Academy of Sciences und der Tsinghua University haben das Modell BitNet b1.58 aktualisiert, bei dem die meisten Gewichte auf die drei Werte -1, 0 oder +1 beschränkt sind (ca. 1,58 Bit/Parameter). Bei einer Größe von 2 Milliarden Parametern kann es mit führenden Vollpräzisionsmodellen konkurrieren. Das Modell wurde durch sorgfältig entwickelte Trainingsstrategien (wie quantisierungsbewusstes Training, zweistufige Lernrate und Gewichtsabnahme) optimiert. In 16 populären Benchmark-Tests übertrifft es Qwen2.5-1.5B, Gemma-3 1B usw. in Geschwindigkeit und Speicherverbrauch, erreicht eine durchschnittliche Genauigkeit nahe an Qwen2.5-1.5B und übertrifft die 4-Bit-quantisierte Version von Qwen2.5-1.5B. Diese Arbeit zeigt, dass durch sorgfältige Anpassung von Hyperparametern auch Modelle mit niedriger Präzision eine hohe Leistung erzielen können, was neue Wege für den effizienten Einsatz von LLMs eröffnet. (Quelle: DeepLearning.AI Blog)
Stanford und andere Institutionen stellen Biomni vor, einen intelligenten Agenten für biologische Forschung, der über hundert Tools und Datenbanken integriert: Forscher der Stanford University, Princeton University und anderer Institutionen haben Biomni vorgestellt, einen KI-Agenten, der speziell für ein breites Spektrum biologischer Forschung entwickelt wurde. Der Agent basiert auf Claude 4 Sonnet und integriert 150 Tools, fast 60 Datenbanken und etwa 100 populäre Biologie-Softwarepakete, die aus 2500 aktuellen Veröffentlichungen aus 25 Fachgebieten der Biologie (einschließlich Genomik, Immunologie, Neurowissenschaften usw.) extrahiert und ausgewählt wurden. Biomni kann verschiedene Aufgaben ausführen, wie Fragen stellen, Hypothesen aufstellen, Prozesse entwerfen, Datensätze analysieren und Diagramme erstellen. Es verwendet das CodeAct-Framework, um auf Anfragen durch iterative Planung, Codegenerierung und -ausführung zu reagieren, und führt eine weitere Claude 4 Sonnet-Instanz als Beurteiler ein, um die Plausibilität von Zwischenergebnissen zu bewerten. In mehreren Benchmark-Tests wie Lab-bench und Fallstudien übertraf Biomni die Leistung von Claude 4 Sonnet allein sowie von Claude-Modellen mit Literaturrecherche-Erweiterung. (Quelle: DeepLearning.AI Blog)

Anthropic führt neue Funktion für Claude Code ein: Erstellen und Teilen von KI-gesteuerten Artifacts: Anthropic hat für seinen KI-Programmierassistenten Claude Code eine neue Funktion eingeführt, die es Benutzern ermöglicht, „Artifacts“ (als kleine KI-Anwendungen oder -Tools zu verstehen) zu erstellen, zu hosten und zu teilen und die Intelligenz von Claude direkt in diese Kreationen einzubetten. Dies bedeutet, dass Benutzer Claude nicht nur zum Generieren von Code-Snippets oder zur Durchführung von Analysen verwenden können, sondern auch funktionale, KI-gesteuerte Anwendungen erstellen können. Ein wichtiges Merkmal ist, dass beim Teilen dieser KI-Anwendungen die Betrachter sich mit ihrem eigenen Claude-Konto authentifizieren und ihre Nutzung dem Abonnementkontingent des Betrachters und nicht dem des Erstellers angerechnet wird. Diese Funktion befindet sich derzeit in der Beta-Phase und steht allen kostenlosen, Pro- und Max-Benutzern offen. Sie zielt darauf ab, die Hürden für die Erstellung von KI-Anwendungen zu senken und die Verbreitung und gemeinsame Nutzung von KI-Fähigkeiten zu fördern. (Quelle: kylebrussell, Reddit r/ClaudeAI)
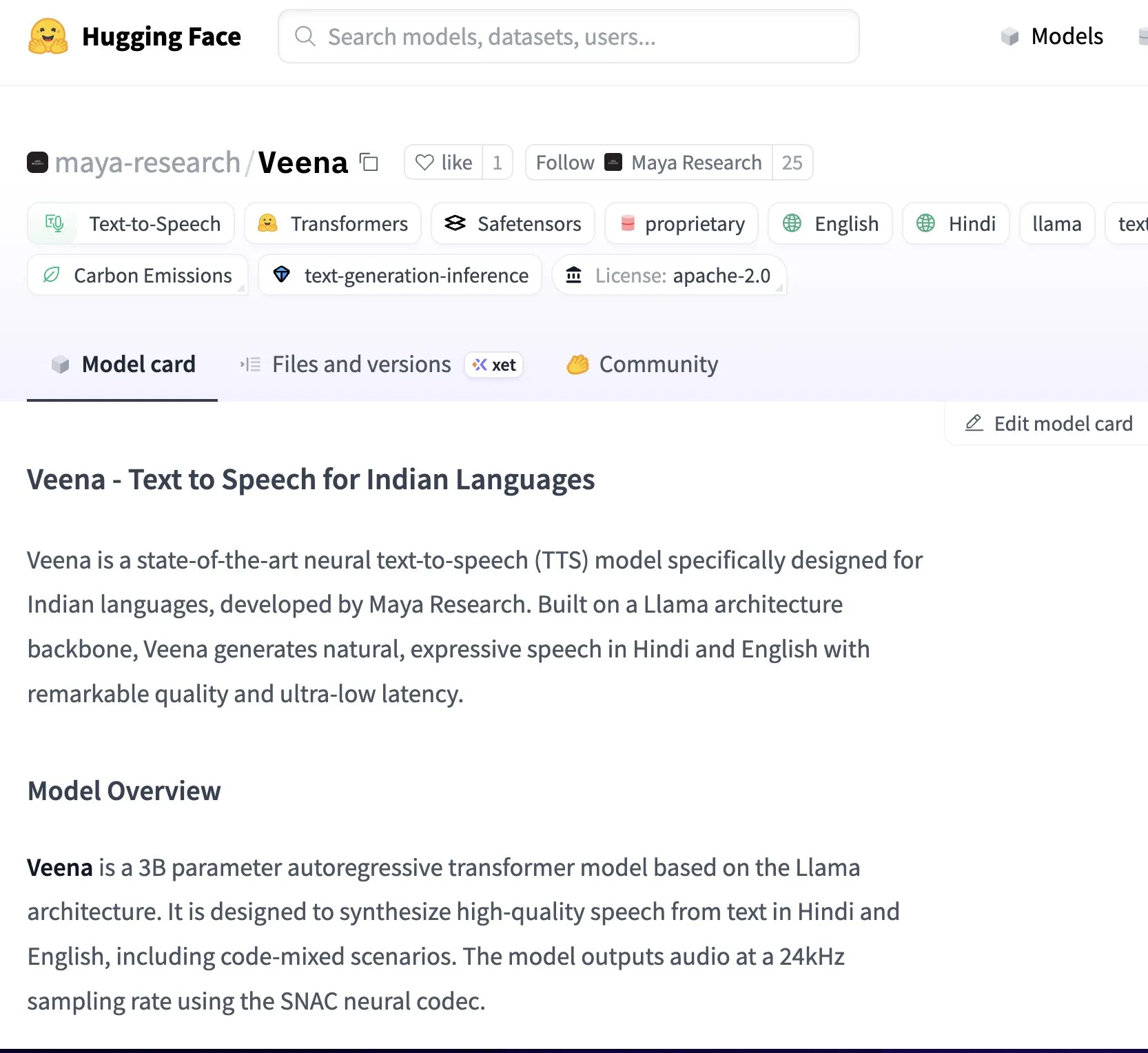
Maya Research veröffentlicht Veena TTS-Modell, unterstützt Hindi und Englisch mit stärker an Indien angepasster Klangfarbe: Maya Research hat ein Text-to-Speech (TTS)-Modell namens Veena vorgestellt, das auf der 3B Llama-Architektur basiert und die Apache 2.0-Lizenz verwendet. Das Besondere an Veena ist die Fähigkeit, Englisch und Hindi mit indischem Akzent zu generieren, einschließlich Code-Mixing-Szenarien, und behebt damit die Mängel bestehender TTS-Modelle bei der lokalisierten indischen Aussprache. Das Modell hat eine Latenz von weniger als 80 Millisekunden, kann in der kostenlosen Google Colab-Umgebung ausgeführt werden und ist bereits auf Hugging Face Hub verfügbar. Das Team gab an, aktiv an der Unterstützung weiterer indischer Sprachen wie Tamil, Telugu und Bengali zu arbeiten. (Quelle: huggingface, huggingface)
HiDream.ai veröffentlicht vivago2.0 mit integrierten multimodalen Generierungs- und Bearbeitungsfunktionen: HiDream.ai (gegründet von KI-Koryphäe Mei Tao) hat das multimodale KI-Erstellungstool vivago2.0 auf den Markt gebracht. Das Produkt vereint Funktionen wie Bildgenerierung, Bild-zu-Video-Konvertierung, KI-Podcast (Lippensynchronisation), Effektvorlagen und eine Kreativ-Community, in der Benutzer Inspirationen teilen und erhalten können. Die Kerntechnologie basiert auf dem brandneuen intelligenten Bildagenten HiDream-A1, der weiterentwickelte, nicht quelloffene Versionen der zuvor quelloffen veröffentlichten und in Text-zu-Bild-Wettbewerben führenden Modelle HiDream-I1 (ein Basismodell zur Bildgenerierung mit 17 Milliarden Parametern) und HiDream-E1 (ein interaktives Bildbearbeitungsmodell) integriert. vivago2.0 zielt darauf ab, die Hürden für die Erstellung multimodaler Inhalte zu senken, bietet Hunderte von Effektvorlagen und unterstützt die Generierung und Bearbeitung von Bildern durch natürlichsprachliche Dialoge (Image Agent). (Quelle: 量子位)

Nvidia veröffentlicht RTX 5050-Serie GPUs, Desktop- und Laptop-Versionen mit unterschiedlicher Speicherbestückung: Nvidia hat offiziell die GeForce RTX 5050-Serie GPUs vorgestellt, einschließlich Desktop- und Laptop-Versionen, die im Juli auf den Markt kommen sollen. Der empfohlene Verkaufspreis für die Desktop-Version in China beginnt bei 2099 Yuan. Die Desktop-Version der RTX 5050 verfügt über 2560 Blackwell CUDA-Kerne, ist mit 8 GB GDDR6-Speicher ausgestattet und hat eine maximale Leistungsaufnahme von 130 W. Die Laptop-Version der RTX 5050 verfügt ebenfalls über 2560 CUDA-Kerne, ist jedoch mit energieeffizienterem 8 GB GDDR7-Speicher ausgestattet. Nvidia gibt an, dass die RTX 5050 in Verbindung mit der DLSS 4-Technologie in Spielen wie Cyberpunk 2077 Raytracing-Frameraten von über 150 fps erreichen kann und im Vergleich zur RTX 3050 eine durchschnittliche Leistungssteigerung bei der Rasterisierung von 60 % (Desktop-Version) bzw. 2,4-fach (Laptop-Version) erzielt. Diese Differenzierung bei der Speicherbestückung spiegelt Nvidias Strategie zur Kosten- und Leistungsbalance in verschiedenen Marktsegmenten wider. (Quelle: 量子位)

LM Studio Update unterstützt MCP-Protokoll, ermöglicht Verbindung von lokalen LLMs mit MCP-Servern: Das Desktop-LLM-Ausführungstool LM Studio hat eine neue Version (0.3.17) veröffentlicht, die Unterstützung für das Model Context Protocol (MCP) hinzufügt. Benutzer können nun lokal ausgeführte große Sprachmodelle mit MCP-kompatiblen Servern verbinden, um beispielsweise externe Tools oder Dienste aufzurufen. LM Studio hat dafür seine Programmoberfläche aktualisiert, die es Benutzern ermöglicht, MCP-Dienste zu installieren und zu konfigurieren sowie lokale MCP-Serverprozesse automatisch zu laden und zu verwalten. Zur Vereinfachung der Konfiguration bietet LM Studio auch ein Online-Tool zur Generierung von MCP-Serverkonfigurationslinks, die mit einem Klick importiert werden können. (Quelle: multimodalart, karminski3)

Gradio stellt leichtgewichtige Experiment-Tracking-Bibliothek Trackio vor: Das Gradio-Team von Hugging Face hat Trackio veröffentlicht, eine leichtgewichtige Bibliothek für das Tracking und die Visualisierung von Experimenten. Das Tool wurde mit weniger als 1000 Zeilen Python-Code geschrieben, ist vollständig quelloffen und kostenlos und unterstützt die lokale oder gehostete Nutzung. Trackio soll Entwicklern helfen, verschiedene Metriken und Ergebnisse während des maschinellen Lernexperiments einfacher aufzuzeichnen und zu überwachen und so den Prozess des Experimentmanagements zu vereinfachen. (Quelle: ClementDelangue, _akhaliq)
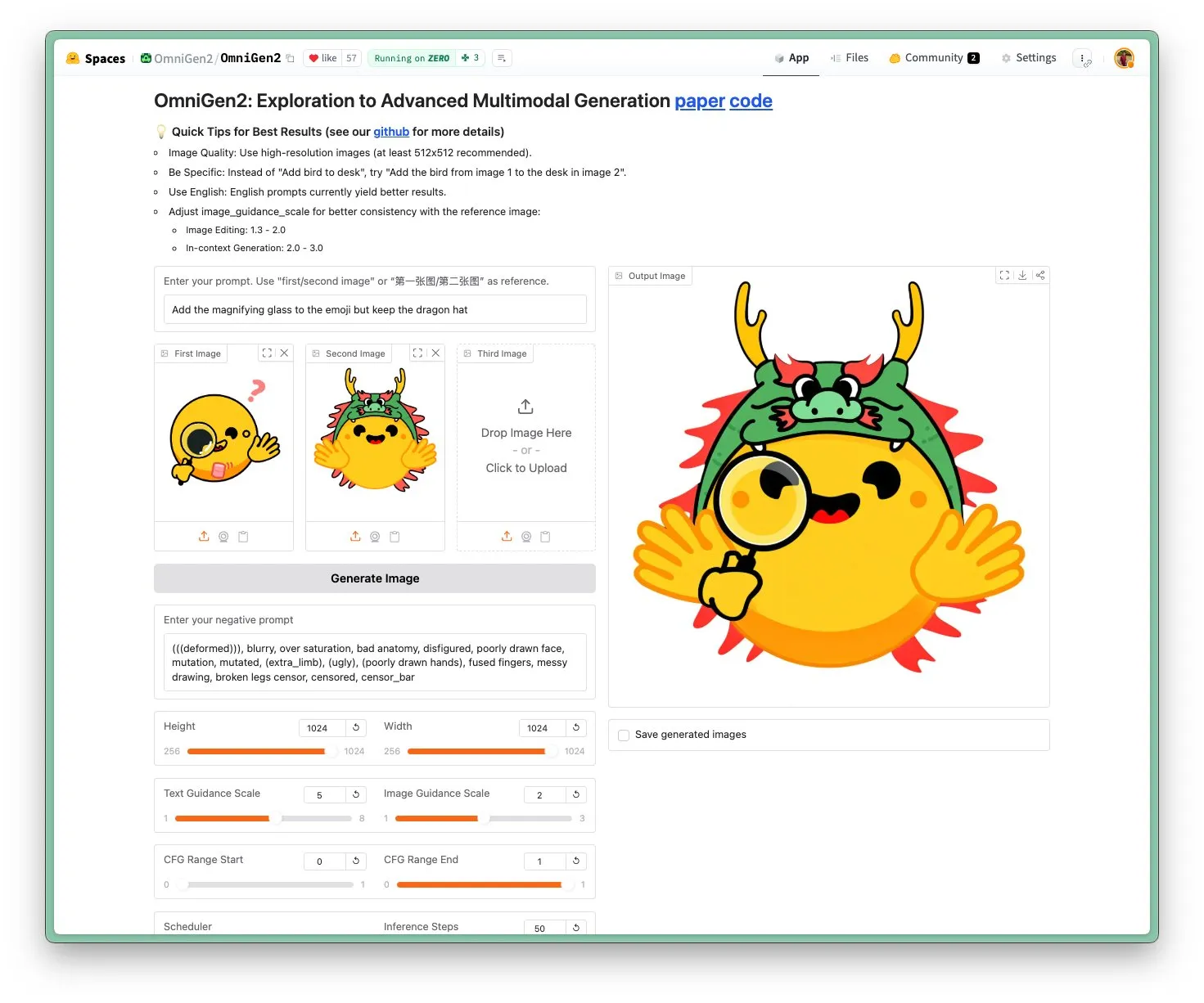
OmniGen 2 veröffentlicht: SOTA-Bildbearbeitungs- und multifunktionales visuelles Modell unter Apache 2.0-Lizenz: Das neue OmniGen 2-Modell erreicht SOTA-Niveau in der Bildbearbeitung und wird unter der Apache 2.0 Open-Source-Lizenz veröffentlicht. Das Modell ist nicht nur hervorragend in der Bildbearbeitung, sondern kann auch kontextbezogene Generierung, Text-zu-Bild-Transformation, visuelles Verständnis und andere Aufgaben ausführen. Benutzer können die Demo und das Modell direkt auf Hugging Face Hub ausprobieren. (Quelle: huggingface)
Atlas-Architektur vorgestellt: Mit Langzeit-Kontextgedächtnis, fordert Transformer heraus: Die neu vorgestellte Atlas-Architektur zielt darauf ab, das Problem des Langzeitgedächtnisses in LLMs zu lösen und behauptet, bei Sprachmodellierungsaufgaben Transformer und moderne lineare RNNs zu übertreffen. Atlas besitzt die Fähigkeit, zur Testzeit zu lernen, wie man sich Kontext merkt, kann die effektive Kontextlänge von Titans-Modellen erhöhen und erreicht im BABILong-Benchmark mit einer Kontextfensterlänge von 10 Millionen eine Genauigkeit von über 80 %. Die Forscher diskutierten auch eine weitere Reihe von Modellen, die auf der Atlas-Idee basieren und Softmax-Attention streng verallgemeinern. (Quelle: behrouz_ali)

Moondream 2B visuelles Modell aktualisiert: Verbessertes visuelles Schlussfolgern und UI-Verständnis, Textgenerierung um 40 % beschleunigt: Das visuelle Modell Moondream 2B hat eine neue Version veröffentlicht, die Verbesserungen im visuellen Schlussfolgern, der Objekterkennung und dem UI-Verständnis aufweist und die Textgenerierungsgeschwindigkeit um 40 % erhöht. Dies zeigt, dass kleine multimodale Modelle kontinuierlich in spezifischen Fähigkeiten optimiert werden, um eine effizientere und präzisere visuell-sprachliche Interaktion zu ermöglichen. (Quelle: mervenoyann)
Inworld AI und Modular kooperieren für kostengünstiges, hochwertiges TTS-Modell: Inworld AI hat die Einführung eines neuen Text-to-Speech (TTS)-Modells angekündigt, das die Kosten für modernstes TTS angeblich um das 20-fache auf 5 US-Dollar pro Million Zeichen senkt. Das Modell basiert auf der Llama-Architektur, und sein Trainings- und Modellierungscode wird quelloffen sein. Der Partner Modular gab an, durch technische Zusammenarbeit die schnellste TTS-Inferenzplattform mit der niedrigsten Latenz auf NVIDIA B200 realisiert zu haben und einen gemeinsamen technischen Bericht veröffentlichen zu wollen. (Quelle: clattner_llvm)
Higgsfield AI veröffentlicht Soul-Modell: Fokus auf hochästhetische Fotogenerierung: Higgsfield AI hat ein neues Fotogenerierungsmodell namens Higgsfield Soul vorgestellt, das auf hohen ästhetischen Wert und Realismus auf Modeniveau setzt. Das Modell bietet über 50 sorgfältig kuratierte Voreinstellungen und zielt darauf ab, Bilder zu erzeugen, die mit professionellen Fotoaufnahmen vergleichbar sind und die traditionelle Handyfotografie herausfordern. (Quelle: _akhaliq)
🧰 Tools
Gemini CLI: Von Google eingeführter Open-Source-Terminal-KI-Agent, bietet täglich 1000 kostenlose Aufrufe von Gemini 2.5 Pro: Google hat Gemini CLI veröffentlicht, einen quelloffenen Kommandozeilen-KI-Agenten, der es Benutzern ermöglicht, das Gemini 2.5 Pro-Modell direkt im Terminal zu verwenden. Das Tool bietet ein Kontextfenster von 1 Million Token, und kostenlose Benutzer erhalten ein Kontingent von bis zu 1000 Anfragen pro Tag (60 pro Minute). Gemini CLI unterstützt das Schreiben und Debuggen von Code, Datei-System-I/O, das Verstehen von Webinhalten, Plugins und das MCP-Protokoll und soll Entwicklern helfen, Software effizienter zu erstellen und zu warten. Seine Open-Source-Natur (Apache 2.0-Lizenz) und das hohe kostenlose Kontingent machen es zu einem starken Konkurrenten für bestehende Tools wie Claude Code und könnten die Unterstützung lokaler Modelle vorantreiben. (Quelle: Reddit r/LocalLLaMA, dotey, yoheinakajima)
Anthropic führt neue Funktion für Claude Code ein: Erstellen und Teilen von KI-gesteuerten Artifacts, Benutzer verwenden eigenes Kontingent: Anthropic hat für seinen KI-Programmierassistenten Claude Code eine neue Funktion eingeführt, die es Benutzern ermöglicht, „Artifacts“ (als kleine KI-Anwendungen oder -Tools zu verstehen) zu erstellen, zu hosten und zu teilen und die Intelligenz von Claude direkt in diese Kreationen einzubetten. Dies bedeutet, dass Benutzer Claude nicht nur zum Generieren von Code-Snippets oder zur Durchführung von Analysen verwenden können, sondern auch funktionale, KI-gesteuerte Anwendungen erstellen können. Ein wichtiges Merkmal ist, dass beim Teilen dieser KI-Anwendungen die Betrachter sich mit ihrem eigenen Claude-Konto authentifizieren und ihre Nutzung dem Abonnementkontingent des Betrachters und nicht dem des Erstellers angerechnet wird. Diese Funktion befindet sich derzeit in der Beta-Phase und steht allen kostenlosen, Pro- und Max-Benutzern offen. Sie zielt darauf ab, die Hürden für die Erstellung von KI-Anwendungen zu senken und die Verbreitung und gemeinsame Nutzung von KI-Fähigkeiten zu fördern. (Quelle: kylebrussell, Reddit r/ClaudeAI, dotey)
LM Studio Update unterstützt MCP-Protokoll, ermöglicht Verbindung von lokalen LLMs mit MCP-Servern: Das Desktop-LLM-Ausführungstool LM Studio hat eine neue Version (0.3.17) veröffentlicht, die Unterstützung für das Model Context Protocol (MCP) hinzufügt. Benutzer können nun lokal ausgeführte große Sprachmodelle mit MCP-kompatiblen Servern verbinden, um beispielsweise externe Tools oder Dienste aufzurufen. LM Studio hat dafür seine Programmoberfläche aktualisiert, die es Benutzern ermöglicht, MCP-Dienste zu installieren und zu konfigurieren sowie lokale MCP-Serverprozesse automatisch zu laden und zu verwalten. Zur Vereinfachung der Konfiguration bietet LM Studio auch ein Online-Tool zur Generierung von MCP-Serverkonfigurationslinks, die mit einem Klick importiert werden können. (Quelle: multimodalart, karminski3)
Superconductor: Ein Tool zur Verwaltung von Claude Code Agenten-Teams auf Mobilgeräten oder Desktops: Superconductor ist ein neues Tool, das es Benutzern ermöglicht, ein Team aus mehreren Claude Code-Agenten über ihr Mobiltelefon oder ihren Laptop zu verwalten. Benutzer können informelle Aufgaben-Tickets schreiben und für jedes Ticket mehrere Agenten starten, von denen jeder seine eigene Echtzeit-Anwendungsvorschau hat. Entwickler können die Ergebnisse des leistungsstärksten Agenten mit einem Klick als Pull Request (PR) generieren. Das Tool zielt darauf ab, die Zusammenarbeit mehrerer Agenten und den Code-Generierungsprozess zu vereinfachen. (Quelle: full_stack_dl)
Udio führt Sessions-Funktion ein, verbessert Präzision der KI-Musikbearbeitung: Die KI-Musikgenerierungsplattform Udio hat für ihre Standard- und Professional-Abonnenten die Funktion „Sessions“ eingeführt. Diese Funktion führt eine neue Zeitleistenansicht für die Bearbeitung von Audiospuren ein, die es Benutzern ermöglicht, Musik präziser zu produzieren und die Abhängigkeit von zufälliger KI-Generierung zu verringern. Derzeit unterstützt Sessions das Erweitern oder Bearbeiten von Spuren, zukünftig sollen weitere Funktionen hinzukommen. (Quelle: TomLikesRobots)
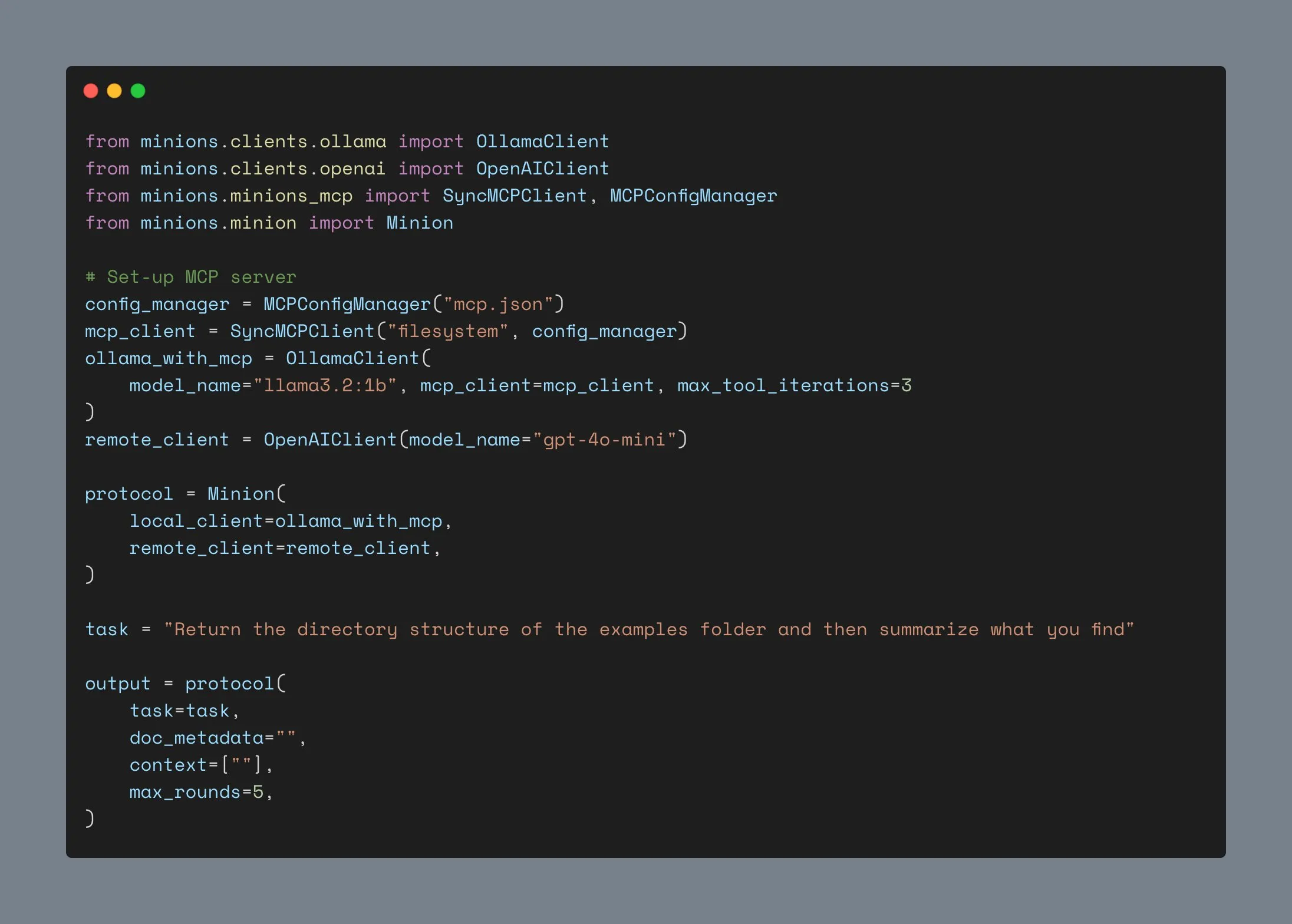
Ollama Client aktualisiert, unterstützt MCP-Integration, über 1000 Sterne auf GitHub: Der Ollama Client wurde aktualisiert und kann nun seine Tool-Aufruffunktionen mit jedem Anthropic MCP-Server integrieren. Dies bedeutet, dass Benutzer die Bequemlichkeit lokal ausgeführter Ollama-Modelle mit den externen Tool-Fähigkeiten von MCP kombinieren können. Gleichzeitig hat das Projekt auf GitHub die Marke von 1000 Sternen überschritten. (Quelle: ollama)
📚 Lernen
Andrew Ng stellt neuen Kurs vor: ACP Agent Communication Protocol: DeepLearning.AI und IBM Research haben gemeinsam einen Kurzkurs zum Agent Communication Protocol (ACP) veröffentlicht. ACP ist ein offenes Protokoll, das die Kommunikation zwischen Agenten über eine einheitliche RESTful-Schnittstelle standardisiert und darauf abzielt, Integrationsherausforderungen beim Aufbau von Multi-Agenten-Systemen durch mehrere Teams und über verschiedene Frameworks hinweg zu lösen. Der Kurs vermittelt, wie man mit ACP Agenten verbindet, die mit unterschiedlichen Frameworks (wie CrewAI, Smoljames) erstellt wurden, um sequentielle und hierarchische Workflow-Kollaborationen zu realisieren und ACP-Agenten in die BeeAI-Plattform (eine Open-Source-Plattform zur Registrierung und gemeinsamen Nutzung von Agenten) zu importieren. Die Teilnehmer lernen den Lebenszyklus von ACP-Agenten kennen und vergleichen ihn mit Protokollen wie MCP (Model Context Protocol) und A2A (Agent-to-Agent). (Quelle: AndrewYNg)
Johns Hopkins University startet DSPy-Kurs: Die Johns Hopkins University hat einen Kurs zu DSPy gestartet. DSPy ist ein Framework zur algorithmischen Optimierung von LLM-Prompts und -Gewichten, das den ursprünglich manuellen Prozess des Prompt Engineerings in einen systematischeren, programmierbaren Prozess des Modulbaus und der Optimierung umwandelt. Shopify CEO Tobi Lutke erklärte ebenfalls, dass DSPy sein bevorzugtes Werkzeug für Context Engineering sei. (Quelle: stanfordnlp, lateinteraction)

LM Studio Tutorial: Lokale, private ChatGPT-ähnliche Erfahrung mit Open-Source Hugging Face Modellen: Niels Rogge hat ein YouTube-Tutorial veröffentlicht, das zeigt, wie man mit LM Studio in Kombination mit Open-Source-Modellen von Hugging Face (wie Mistral 3.2-Small) eine zu 100 % private und offline ChatGPT-ähnliche Erfahrung lokal realisieren kann. Das Tutorial erklärt Konzepte wie GGUF, Quantisierung und warum Modelle auch bei 4-Bit-Quantisierung viel Speicherplatz beanspruchen, und demonstriert die Kompatibilität von LM Studio mit der OpenAI API. (Quelle: _akhaliq)

LlamaIndex veranstaltet Online-Workshop zum Thema Agentengedächtnis: LlamaIndex wird in Zusammenarbeit mit AIMakerspace eine Online-Diskussion zum Thema Agentengedächtnis veranstalten. Die Inhalte umfassen persistente Chat-Historien, die Nutzung von statischen, Fakten- und Vektorblöcken zur Realisierung von Langzeitgedächtnis, benutzerdefinierte Logik für die Gedächtnisimplementierung und wann Gedächtnis entscheidend ist. Die Diskussion zielt darauf ab, Entwicklern zu helfen, Agenten zu erstellen, die in Dialogen echten Kontext benötigen. (Quelle: jerryjliu0)

Weaviate Podcast diskutiert RAG-Benchmarks und -Evaluierung: Der Weaviate Podcast lud in Folge 124 Nandan Thakur ein, der wichtige Beiträge im Bereich der Suchevaluierung geleistet hat, um über Benchmarking und Evaluierung von Retrieval Augmented Generation (RAG) zu diskutieren. Die Inhalte umfassen Benchmarks wie BEIR, MIRACL, TREC und das neueste FreshStack sowie verschiedene Themen im Bereich RAG wie Inferenz, Query-Erstellung, zyklische Suche, paginierte Suchergebnisse und hybride Retriever. (Quelle: lateinteraction)

PyTorch stellt flux-fast-Rezept vor, beschleunigt Flux-Modelle auf H100 um das 2,5-fache: PyTorch hat ein einfaches Rezept namens flux-fast veröffentlicht, das darauf abzielt, die Ausführungsgeschwindigkeit von Flux-Modellen auf H100 GPUs ohne komplexe Anpassungen um das 2,5-fache zu erhöhen. Diese Lösung soll die Implementierung von Hochleistungsrechnen vereinfachen, der entsprechende Code wurde bereitgestellt. (Quelle: robrombach)

Informationen zur MLSys 2026 Konferenz bekanntgegeben: Die MLSys 2026 Konferenz ist für Mai 2026 in Seattle (Bellevue) geplant, die Einreichungsfrist für Paper endet am 30. Oktober dieses Jahres. Alle Konferenzaufzeichnungen der MLSys 2025 sind kostenlos auf der offiziellen Website verfügbar. Die Konferenz konzentriert sich auf Forschung und Fortschritte im Bereich maschineller Lernsysteme. (Quelle: JeffDean)

Stanford CS336 Kurs „Sprachmodelle von Grund auf erstellen“ findet Beachtung: Der von Percy Liang und anderen an der Stanford University gelehrte Kurs CS336 „Language Models from Scratch“ (Sprachmodelle von Grund auf erstellen) erhält breite Anerkennung. Der Kurs zielt darauf ab, den Studierenden ein tiefes Verständnis der technischen Details von Sprachmodellen zu vermitteln, indem sie Modelle selbst erstellen, um die Lücke zwischen Forschern und technischen Details zu schließen. Die Kursinhalte und Hausaufgaben gelten als wichtige Lernressource, um Experte für LLMs zu werden. (Quelle: nrehiew_, jpt401)
💼 Wirtschaft
Meta investiert 14,3 Milliarden US-Dollar in Scale AI und rekrutiert dessen CEO Alexandr Wang, um KI-Forschung und -Entwicklung zu beschleunigen: Um seine KI-Kompetenzen zu stärken, hat Meta eine Vereinbarung mit dem Datenannotationsunternehmen Scale AI getroffen, 14,3 Milliarden US-Dollar für einen Anteil von 49 % ohne Stimmrecht zu investieren und dessen Gründer und CEO Alexandr Wang sowie sein Team zu rekrutieren. Alexandr Wang wird ein neues Labor bei Meta leiten, das sich auf die Erforschung von Superintelligenz konzentriert. Dieser Schritt zielt darauf ab, Meta mit führenden KI-Talenten und umfangreichen Datenbetriebskapazitäten zu versorgen, um auf die verhaltene Resonanz seines Llama 4-Modells und personelle Unruhen in seiner KI-Forschungsabteilung zu reagieren. Scale AI wird die Mittel nutzen, um Innovationen zu beschleunigen und einen Teil der Mittel an die Aktionäre auszuschütten. Sein Chief Strategy Officer Jason Droege wird als Interims-CEO fungieren. Diese Transaktion könnte aufgrund der Vermeidung einer direkten Übernahme einige staatliche Prüfungen umgangen haben. (Quelle: DeepLearning.AI Blog)

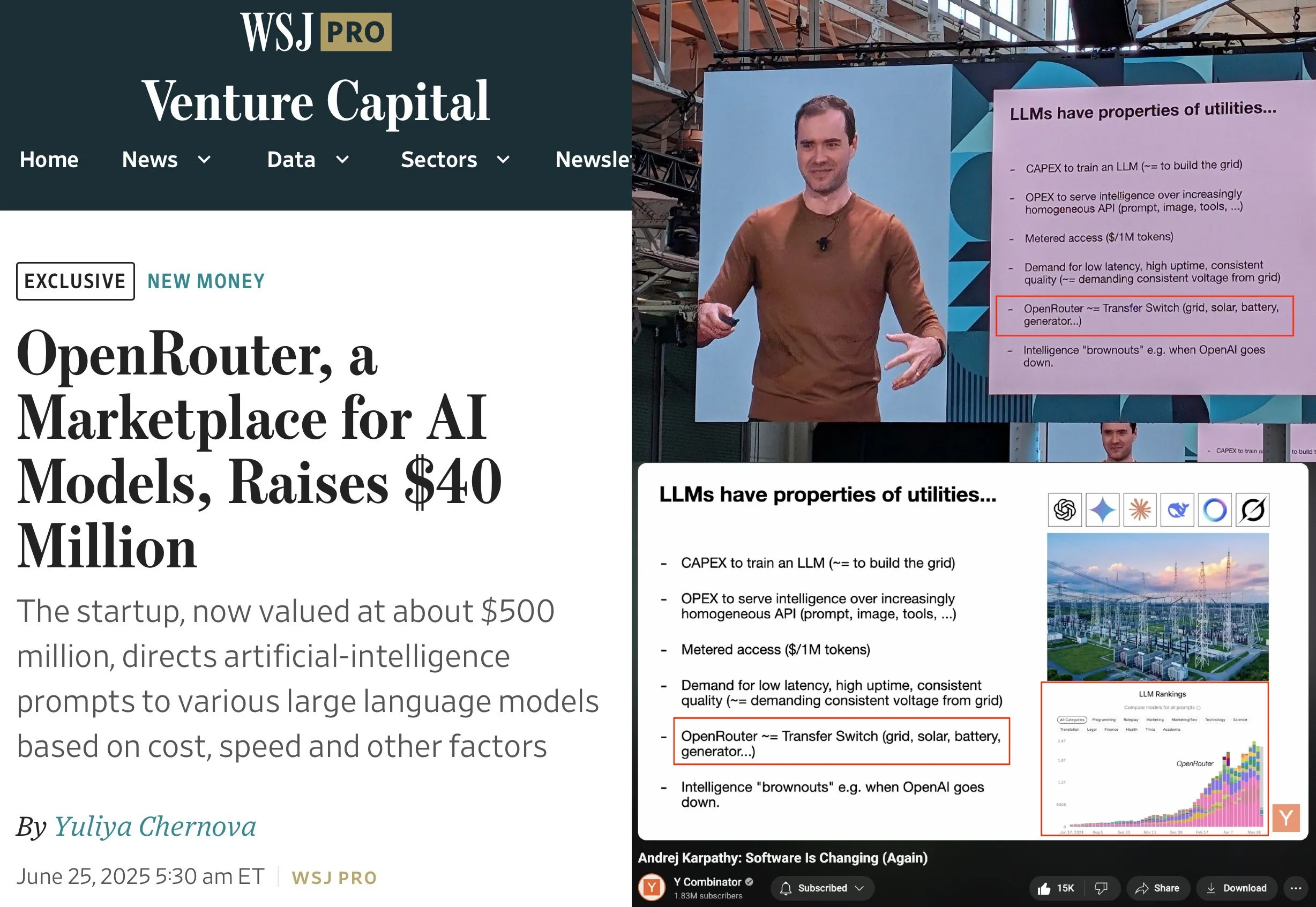
OpenRouter schließt A-Finanzierungsrunde über 40 Millionen US-Dollar ab, angeführt von a16z und Menlo: OpenRouter, eine Steuerungsebene für LLM-Inferenz und ein Marktplatz für Modelle, gab den Abschluss einer Seed- und A-Finanzierungsrunde in Höhe von insgesamt 40 Millionen US-Dollar bekannt, angeführt von a16z und Menlo Ventures. OpenRouter zielt darauf ab, eine einheitliche Schnittstelle für Entwickler zur Auswahl und Nutzung verschiedener LLMs zu werden und bietet derzeit über 400 Modelle an, die jährlich 100 Billionen Token verarbeiten. Die Finanzierung wird verwendet, um die unterstützten Modellmodalitäten (wie Bildgenerierung, multimodale Interaktionsmodelle) zu erweitern, intelligentere Routing-Mechanismen (wie geografisches Routing, Optimierung der Zuweisung von GPUs auf Unternehmensebene) zu implementieren und die Funktionen zur Modellfindung zu verbessern. (Quelle: amasad, swyx)
Humanoide Roboterfirma „Lingbao CASBOT“ erhält fast 100 Millionen Yuan in Angel+-Finanzierungsrunde, angeführt von Lens Technology: Die humanoide Robotermarke „Lingbao CASBOT“ gab den Abschluss einer Angel+-Finanzierungsrunde in Höhe von fast 100 Millionen Yuan bekannt, angeführt von Lens Technology, mit Beteiligung von Tianjin Jiayi und den Altinvestoren Guotou Chuanghe und Henan Asset. Die Mittel werden zur Beschleunigung der Massenproduktion, der technologischen Forschung und Entwicklung sowie der Marktexpansion eingesetzt. Lingbao CASBOT konzentriert sich auf die Anwendung von universellen humanoiden Robotern und Embodied Intelligence und hat bereits zwei zweibeinige humanoide Roboter, CASBOT 01 und 02, auf den Markt gebracht, die jeweils auf spezielle Operationen und breitere Mensch-Maschine-Interaktionsszenarien (wie Führung, Bildung) ausgerichtet sind. Die Kerntechnologie des Unternehmens umfasst ein hierarchisches End-to-End-Modell in Kombination mit Post-Training durch Reinforcement Learning und hat bereits Kooperationen mit der Zhaojin Group, der China Minmetals Corporation und anderen im Bereich der industriellen Fertigung sowie der Mineral- und Energiewirtschaft geschlossen. (Quelle: 36氪, 36氪)

🌟 Community
Andrej Karpathy plädiert für „Context Engineering“ anstelle von „Prompt Engineering“ und betont die Komplexität beim Erstellen von LLM-Anwendungen: Andrej Karpathy stimmt Tobi Lutke zu, dass „Context Engineering“ die Kernkompetenz bei industriellen LLM-Anwendungen genauer beschreibt als „Prompt Engineering“. Er weist darauf hin, dass Prompts normalerweise kurze Aufgabenbeschreibungen sind, die Benutzer täglich eingeben, während Context Engineering eine feine Kunst und Wissenschaft ist, die das präzise Füllen des Kontextfensters mit Aufgabenbeschreibungen, wenigen Beispielen, RAG, multimodalen Daten, Tools, Zustandshistorien usw. umfasst, um die LLM-Leistung zu optimieren. Er betont auch, dass LLM-Anwendungen weit darüber hinausgehen und die Lösung komplexer Software-Engineering-Probleme wie Problemzerlegung, Kontrollfluss, Multi-Modell-Scheduling, UI/UX, Sicherheitsbewertung usw. erfordern, weshalb die Behauptung von „ChatGPT-Wrappern“ falsch sei. (Quelle: karpathy, code_star, dotey)
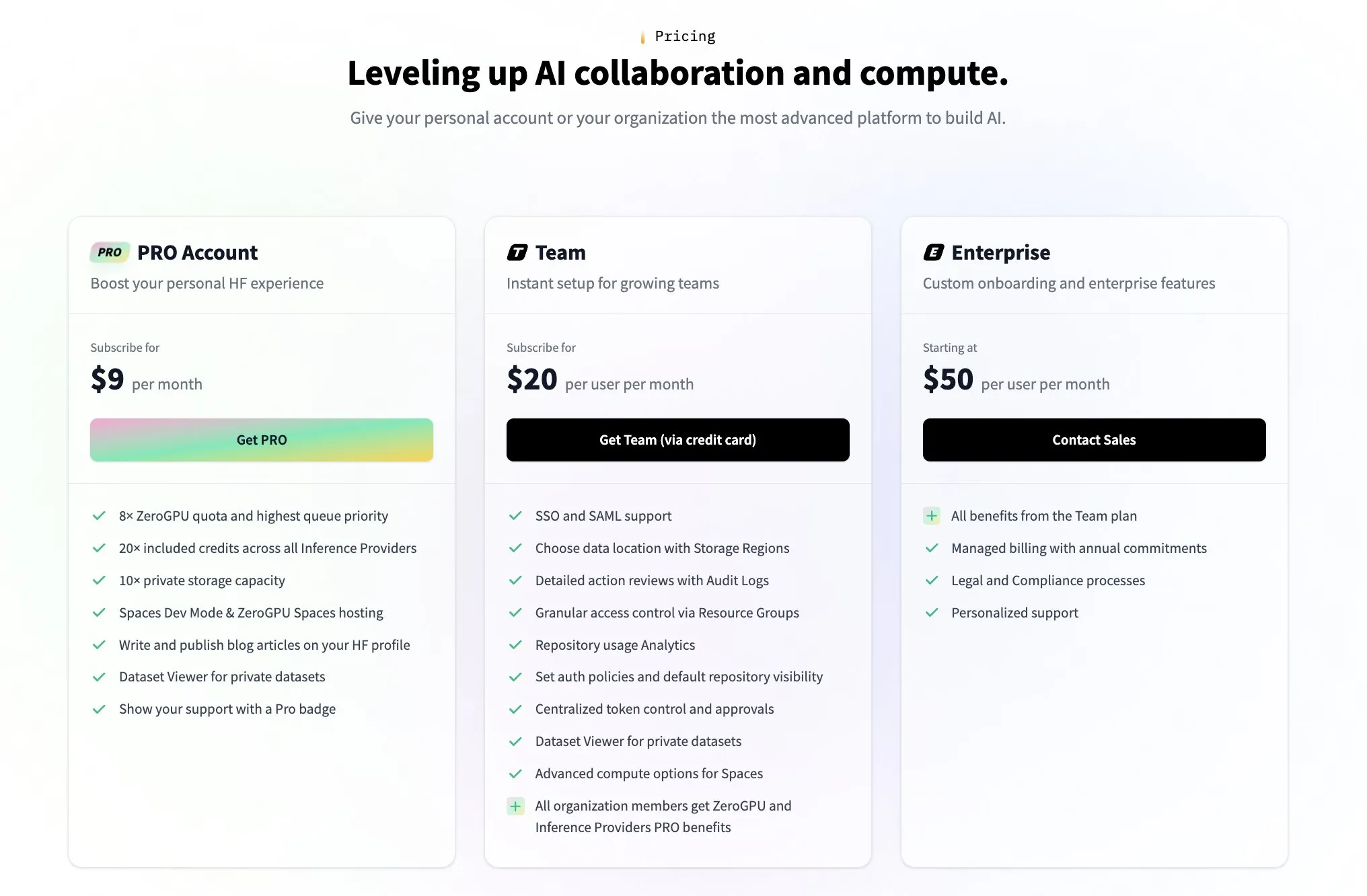
Hugging Face führt kostenpflichtigen Team-Plan ein, um auf Fragen der Community zum Geschäftsmodell zu reagieren: Als Reaktion auf Fragen der Community, wie Hugging Face Geld verdient (ausgelöst beispielsweise durch einen Tweet von Nutzer @levelsio), antwortete Hugging Face Mitbegründer Clement Delangue humorvoll, dass er „Profitabilitätsangst ausgelöst“ habe und kündigte die Einführung eines neuen kostenpflichtigen Premium-Team-Plans an. Hugging Face, als Plattform, die eine große Anzahl von KI-Modellen hostet, kostenlose APIs anbietet und keine API-Schlüssel erzwingt, war mit seinem Geschäftsmodell schon immer ein Diskussionsthema in der Community. Die Einführung des neuen Plans zeigt, dass das Unternehmen aktiv nach kommerziellen Wegen sucht und diese ausbaut. (Quelle: huggingface, ClementDelangue)
Community diskutiert Nutzerloyalität bei KI-Code-Assistenten und Zusammenarbeit mit mehreren Tools: The Information berichtet, dass die Loyalität von Entwicklern gegenüber Coding-Assistenten möglicherweise höher ist als gedacht. Gleichzeitig gibt es in der Community auch das Phänomen, dass Entwickler im selben Code-Repository gleichzeitig mehrere KI-Coding-Tools wie Claude Code, Codex (CLI) und Gemini (CLI) verwenden. Dies spiegelt wider, dass Entwickler aktiv verschiedene KI-Tools ausprobieren, um ihre Effizienz zu steigern, und möglicherweise auch nach der am besten geeigneten Funktionskombination für ihren Arbeitsablauf suchen, anstatt sich vollständig auf ein einziges Tool zu verlassen. (Quelle: steph_palazzolo, code_star)

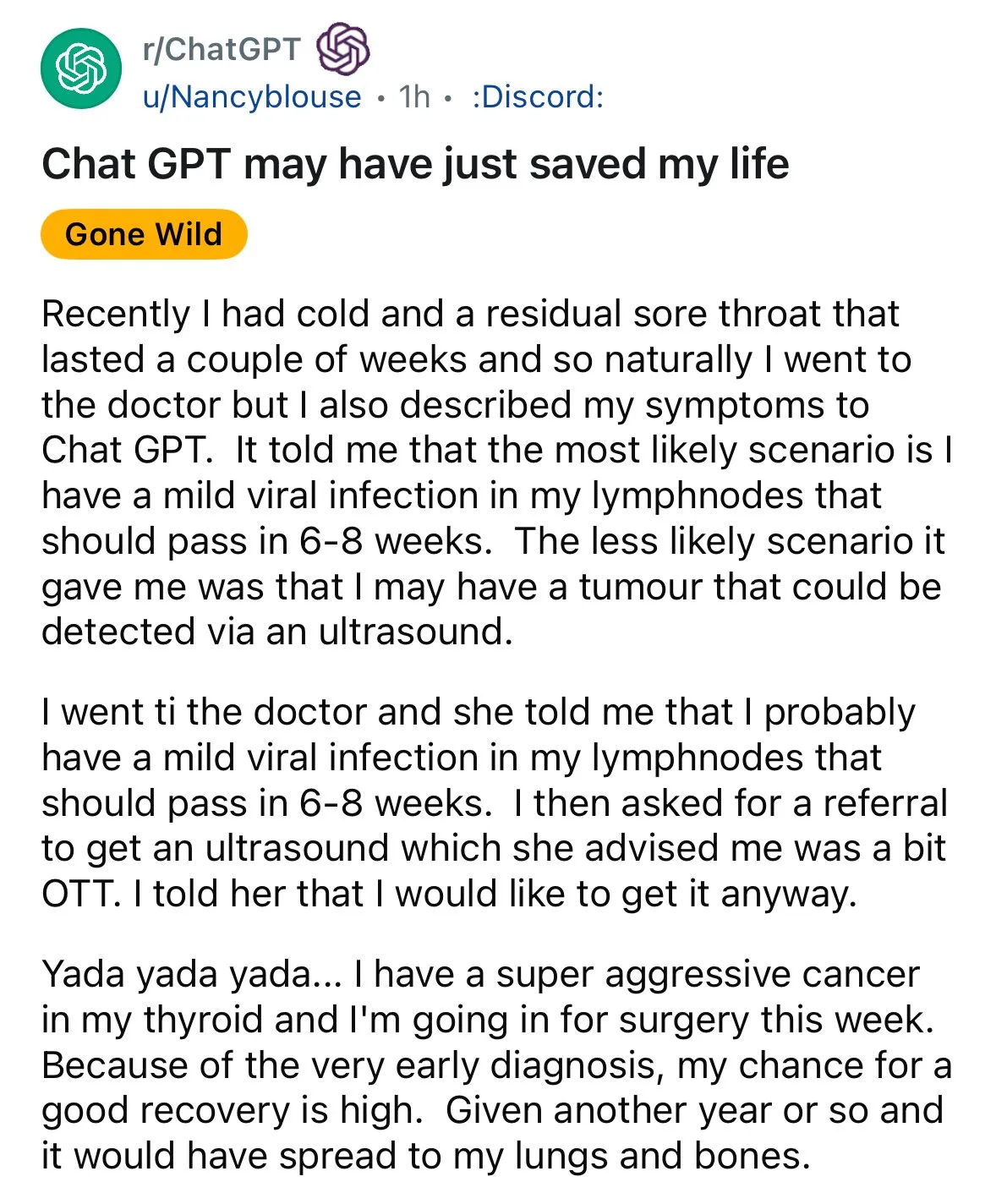
KI zeigt Potenzial in der medizinischen Diagnose und löst Diskussionen über „Zweitmeinungen“ aus: In sozialen Medien tauchte erneut ein Fall von KI-gestützter Diagnose auf: Ein Patient mit Halsschmerzen erhielt nach ärztlicher Empfehlung zur Beobachtung über ChatGPT den Rat, eine Ultraschalluntersuchung durchführen zu lassen, bei der schließlich Schilddrüsenkrebs entdeckt wurde. Solche Vorfälle lösen Diskussionen aus und ermutigen Menschen, bei medizinischen Problemen KI für eine „Zweitmeinung“ zu nutzen, da dies möglicherweise Leben retten könnte. Gleichzeitig wurde die Forschung des GRAPE-Modells der Alibaba DAMO Academy zur Erkennung von Magenfrühkrebs durch routinemäßige CT-Scans in „Nature Medicine“ veröffentlicht, was das enorme Potenzial von KI in der Krebsfrüherkennung zeigt. (Quelle: aidan_mclau, Yuchenj_UW)
KI-Zeitalter: „Verrückt spielendes Schreiben“ und das Phänomen der KI-Begleitung: Das unter jungen Leuten beliebte „verrückt spielende Schreiben“ (eine Art emotionales Ventil und subtiler Widerstand) trifft auf KI-Tools. Viele Nutzer verwenden generative KI (wie Wenxiaoyans Danxiaohuang) als emotionalen Anker und Begleiter, um Einsamkeit zu lindern, Trost zu finden oder sogar bei Entscheidungen zu helfen (z. B. bei der Aufarbeitung von Streitigkeiten). KI wird aufgrund ihrer Geduld, Unvoreingenommenheit und ständigen Verfügbarkeit zu einem kostengünstigen, hochprivaten „elektronischen Freund“, der Nutzern hilft, in chaotischen Momenten Trost zu finden und als förderlich für die psychische Verfassung angesehen wird. (Quelle: 36氪)

Anhaltende Diskussion darüber, ob LLMs Allgemeine Künstliche Intelligenz (AGI) sind: In der Community hält die Diskussion darüber an, ob und wann große Sprachmodelle (LLMs) Allgemeine Künstliche Intelligenz (AGI) erreichen können. Einige argumentieren, dass LLMs zwar in vielen Aufgaben hervorragende Leistungen erbringen, aber noch weit von echter AGI entfernt sind, insbesondere ohne die Theorien und internen Funktionsdaten menschlicher wissenschaftlicher Genies. Auch über den Zeitplan für die Realisierung von AGI gibt es unterschiedliche Ansichten, die von kurzfristig 2028 bis zu ferneren Zeiträumen wie 2035-2040 reichen. (Quelle: menhguin)

💡 Sonstiges
Der weltweit erste Chatbot Eliza wurde 60 Jahre später erfolgreich wiederhergestellt: Eliza, der weltweit erste Chatbot, der Mitte der 1960er Jahre vom MIT-Wissenschaftler Joseph Weizenbaum erfunden wurde, konnte nach jahrelangem Verlust des Originalcodes wiederhergestellt werden, nachdem dessen Ausdrucke wiederentdeckt wurden. Durch die Bemühungen von Teams der Stanford University und des MIT, die den Originalcode bereinigten und debuggten, Funktionen reparierten und eine Simulationsumgebung entwickelten, wurde Eliza 60 Jahre später erfolgreich „wiederbelebt“. Die ursprüngliche Eliza analysierte die Texteingaben der Benutzer, extrahierte Schlüsselwörter und formte Sätze neu, um als rogerianischer Therapeut mit den Benutzern zu interagieren, was bei vielen Testpersonen zu emotionalen Bindungen führte. Der reparierte Eliza-Code und der Simulator wurden auf Github zur öffentlichen Nutzung veröffentlicht. (Quelle: 36氪)

KI-Bildgenerierungstool Midjourney sieht sich Urheberrechtsklagen von Disney u.a. gegenüber, aber sein einzigartiges Kreativmodell ist begehrt: Die KI-Bildgenerierungsplattform Midjourney sieht sich aufgrund möglicher Urheberrechtsverletzungen an visuellen Assets von Unternehmen wie Disney und Universal Pictures durch ihre generierten Bilder mit rechtlichen Klagen konfrontiert. Dennoch erfreut sich das Tool aufgrund seines einzigartigen Kreativmodells – der Generierung hochartistischer, stilisierter Bilder durch Texteingabeaufforderungen in der Discord-Community – weltweiter Beliebtheit bei Kreativen. Das Midjourney-Team besteht aus weniger als 50 Personen, hat keine Finanzierung aufgenommen, erzielt aber bereits einen Jahresumsatz von 200 Millionen US-Dollar. Seine Produktphilosophie betont „Fantasie an erster Stelle“ und positioniert KI als Motor zur Erweiterung des menschlichen Denkens und nicht als einfaches Ersatzwerkzeug. Durch eine „enttoolisierte“ minimalistische Interaktion und eine Kultur der gemeinschaftlichen Kreation hat es das Paradigma der digitalen Kreativität neu geformt. (Quelle: 36氪)

KI-gesteuerter Wandel der Führung: Von hierarchischem Gehorsam zur Mensch-Maschine-Symbiose: Mit der tiefen Integration von KI in die Arbeit steht die traditionelle Führung vor Herausforderungen. Eine Google-Umfrage zeigt, dass 82 % der jungen Führungskräfte KI nutzen, und Oracle-Daten belegen, dass 25 % der Mitarbeiter lieber KI als ihre Führungskraft fragen. KI führt zu Veränderungen im Führungsumfeld: Informationserfahrung ist nicht länger ein exklusiver Schutzwall für Führungskräfte, Entscheidungstransparenz erzeugt Druck, und das Managementobjekt wandelt sich von reinen menschlichen Teams zu „Mensch-Maschine-Hybriden“. Die School of Management der Fudan University hat das Konzept der „symbiotischen Führung“ vorgeschlagen, das die symbiotische Integration von traditioneller und digitaler Wirtschaft, Unternehmen und Ökosystemen sowie menschlichem und maschinellem Gehirn betont. Führungskräfte im KI-Zeitalter müssen den Wandel von alten zu neuen Antriebskräften steuern, in kollaborativen Netzwerken Werte schaffen und den Multiplikatoreffekt der Mensch-Maschine-Kollaboration nutzen. Ihre Kernkompetenz liegt darin, zu wissen, wie KI dem Menschen dienen kann. (Quelle: 36氪)