Schlüsselwörter:KI-Forschung, Informatik, Verstärkendes Lernen, Medikamentenentwicklung, Autonomes Fahren, Sprachmodell, Multimodale Verarbeitung, Virtuelle Zelle, Laude Institut, Verstärkendes Lernen Lehrer (RLTs), BioNeMo-Plattform, Tesla Robotaxi, Kimi VL A3B Thinking-Modell
🔥 Fokus
Gründung des Laude Institute mit 100 Millionen US-Dollar Startkapital zur Förderung gemeinnütziger Forschung in der Informatik: Andy Konwinski kündigte den Start des Laude Institute an, einer gemeinnützigen Organisation, die darauf abzielt, nicht-kommerzielle Informatikforschung mit erheblichem weltweitem Einfluss zu finanzieren. Bekannte Persönlichkeiten wie Jeff Dean, Joyia Pineau und Dave Patterson treten dem Vorstand bei. Die Einrichtung hat eine anfängliche Finanzierungszusage von 100 Millionen US-Dollar erhalten und wird Forscher durch Finanzierung, Ressourcenteilung und Community-Aufbau dabei unterstützen, Ideen in tatsächliche Wirkung umzusetzen, mit besonderem Fokus auf offene und wirkungsorientierte Forschung. (Quelle: JeffDean, matei_zaharia, lschmidt3, Tim_Dettmers, andrew_n_carr, gneubig, lateinteraction, sarahookr, jefrankle)

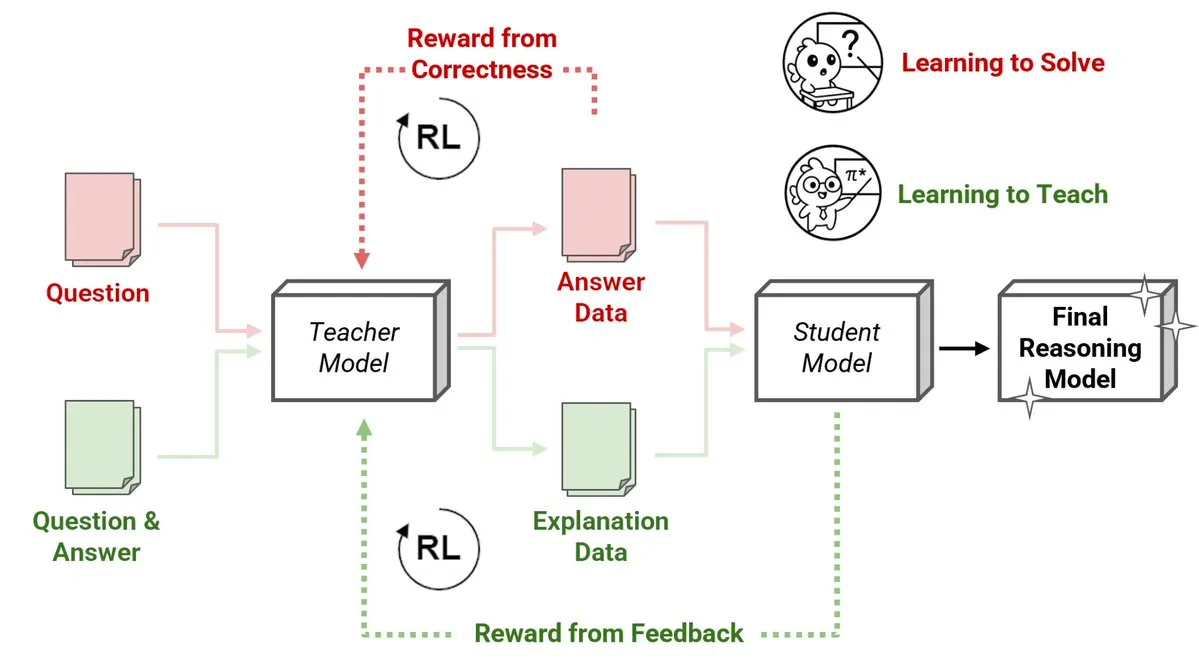
Sakana AI veröffentlicht neue Methode mit Reinforcement Learning Teachers (RLTs): Kleine Modelle lehren große Modelle das Schlussfolgern: Sakana AI hat eine neue Methode mit Reinforcement Learning Teachers (RLTs) vorgestellt, die das Lehren von Schlussfolgerungen bei Large Language Models (LLMs) durch Reinforcement Learning (RL) verändert. Während traditionelles RL sich auf das „Lernen zu lösen“ von Problemen konzentriert, werden RLTs trainiert, klare, schrittweise „Erklärungen“ zu generieren, um Studentenmodelle zu unterrichten. Ein RLT mit nur 7B Parametern übertrifft beim Unterrichten eines 32B-Parameter-Studentenmodells LLMs, die um ein Vielfaches größer sind, bei kompetitiven und anspruchsvollen Schlussfolgerungsaufgaben auf Graduiertenebene. Diese Methode setzt neue Effizienzstandards für die Entwicklung von schlussfolgernden Sprachmodellen mit RL. (Quelle: cognitivecompai, AndrewLampinen)
Nvidia kooperiert mit Novo Nordisk, um die Arzneimittelentwicklung mit KI-Supercomputern zu beschleunigen: Nvidia kündigte eine Zusammenarbeit mit dem dänischen Pharmariesen Novo Nordisk und dem dänischen nationalen KI-Innovationszentrum an, um gemeinsam KI-Technologien und Dänemarks neuesten Supercomputer Gefion zur Beschleunigung der Entwicklung neuer Medikamente einzusetzen. Diese Partnerschaft wird Nvidias BioNeMo-Plattform und fortschrittliche KI-Workflows nutzen, um die Modelle der Arzneimittelforschung und -entwicklung zu revolutionieren. Der Supercomputer Gefion, der mit Technologien von Eviden und Nvidia gebaut wurde, wird leistungsstarke Rechenkapazitäten für die Forschung in Bereichen wie den Biowissenschaften bereitstellen und so die personalisierte Medizin und die Entdeckung neuer Therapien vorantreiben. (Quelle: nvidia)

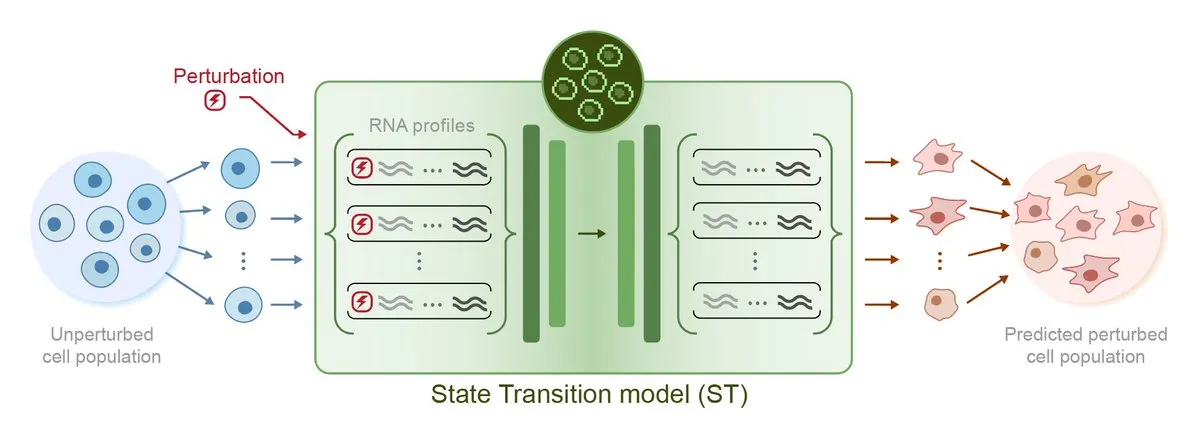
Arc Institute veröffentlicht erstes KI-Modell zur Vorhersage von Perturbationen, STATE, ein Schritt zum Ziel der virtuellen Zelle: Das Arc Institute hat sein erstes KI-Modell zur Vorhersage von Perturbationen, STATE, veröffentlicht, was einen wichtigen Schritt auf dem Weg zum Ziel einer virtuellen Zelle darstellt. Das STATE-Modell soll lernen, wie man Medikamente, Zytokine oder genetische Perturbationen einsetzt, um den Zellzustand zu verändern (z. B. von „krank“ zu „gesund“). Die Veröffentlichung dieses Modells markiert einen neuen Fortschritt beim Verständnis und der Vorhersage des Zellverhaltens durch KI und eröffnet neue Wege für die Behandlung von Krankheiten und die Arzneimittelentwicklung. Das zugehörige Modell wurde auf HuggingFace veröffentlicht. (Quelle: riemannzeta, ClementDelangue)
Tesla Robotaxi startet Pilotprojekt in Austin, visuelle Lösung im Fokus, von Karpathy hinterlassener Code stark vereinfacht: Tesla hat in Austin, Texas, USA, offiziell einen Pilotdienst für Robotaxis gestartet. Die ersten Fahrzeuge basieren auf dem Model Y und verwenden eine rein visuelle Wahrnehmungslösung sowie die FSD-Software. Das von Ashok Elluswamy, Leiter der KI- und Autopilot-Software bei Tesla, geführte Team hat bedeutende technische Änderungen am System vorgenommen und den vom Team von Andrej Karpathy hinterlassenen heuristischen C++-Code von etwa 330.000-340.000 Zeilen um fast 90 % reduziert und durch ein „riesiges neuronales Netz“ ersetzt. Dieser Schritt zielt darauf ab, von der „Kodierung menschlicher Erfahrung“ zu „parametrisiertem Training“ überzugehen und das Modell durch riesige Datenmengen und simuliertes Fahren autonom zu optimieren. Der Dienst befindet sich derzeit in einer frühen Testphase und löst in der Branche breite Diskussionen über Teslas technologischen Weg und Skalierungsfähigkeiten aus. (Quelle: 36氪, Ronald_vanLoon, kylebrussell)

🎯 Trends
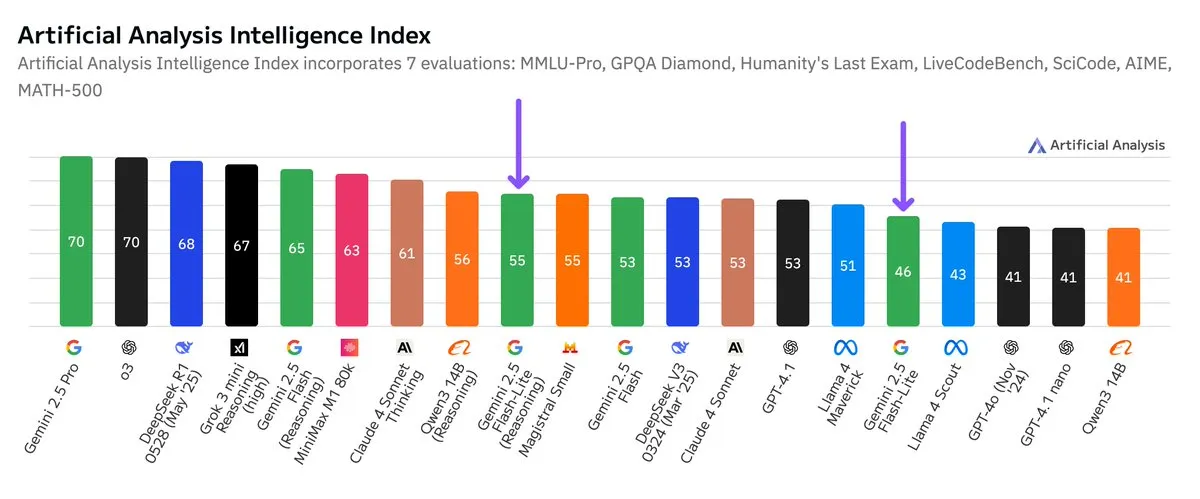
Unabhängiger Benchmark für Google Gemini 2.5 Flash-Lite veröffentlicht, Preis-Leistungs-Verhältnis verbessert: Laut unabhängigen Benchmark-Ergebnissen von Artificial Analysis ist die Preview-Version (06-17) von Google Gemini 2.5 Flash-Lite im Vergleich zur regulären Flash-Version etwa fünfmal kostengünstiger und etwa 1,7-mal schneller, weist jedoch eine geringere Intelligenz auf. Das Modell ist ein Upgrade des im Februar 2025 veröffentlichten Gemini 2.0 Flash-Lite und gehört zu den Hybridmodellen. Dieses Update zeigt Googles kontinuierliche Bemühungen um Modelleffizienz und Kosteneffektivität und zielt möglicherweise auf Anwendungsszenarien mit hohen Anforderungen an Kosten und Geschwindigkeit ab. (Quelle: zacharynado)
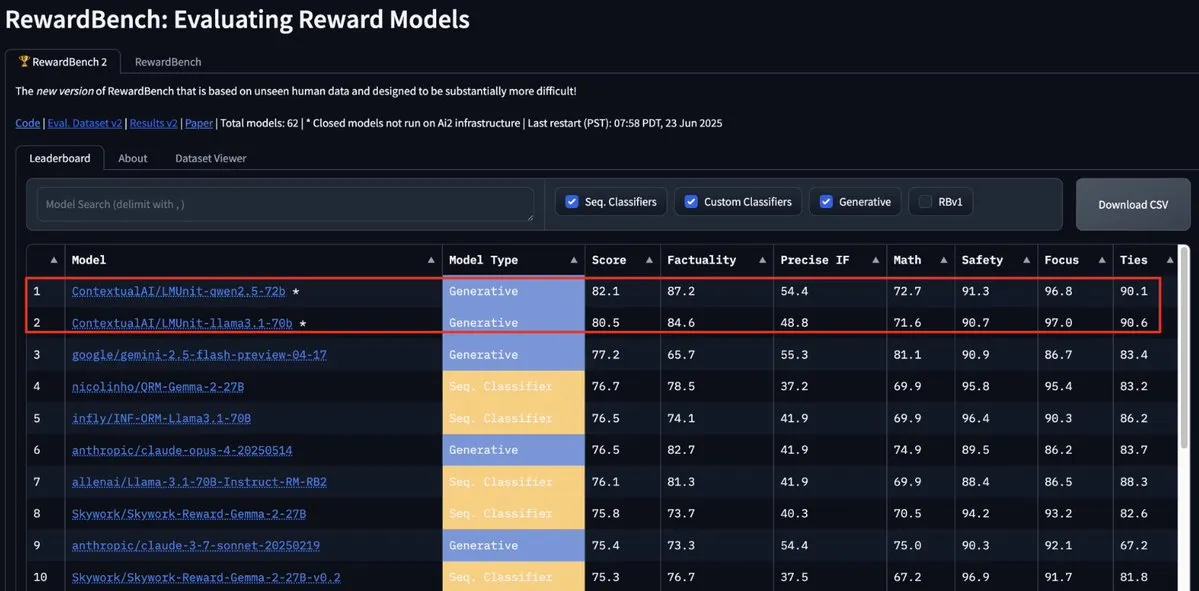
LMUnit-Modell von ContextualAI erreicht Spitzenplatz auf RewardBench2 und übertrifft Gemini, Claude 4 und GPT-4.1: Das LMUnit-Modell von ContextualAI belegt im RewardBench2-Benchmark den ersten Platz und erzielt dabei einen um über 5 % höheren Score als bekannte Modelle wie Gemini, Claude 4 und GPT-4.1. Dieser Erfolg könnte auf seine einzigartige Trainingsmethode zurückzuführen sein, die angeblich der von OpenAI für o4 und nachfolgende Modelle mit großem Aufwand entwickelten „Rubrics“-Methode ähnelt. Diese Methode soll eine effektive Skalierung von LLMs als Bewerter (llm-as-a-judge) beim Schlussfolgern ermöglichen. (Quelle: natolambert, menhguin, apsdehal)
Arcee.ai erweitert erfolgreich die Kontextlänge des AFM-4.5B-Modells von 4k auf 64k: Arcee.ai gab bekannt, dass die Kontextlänge seines ersten Basismodells AFM-4.5B erfolgreich von 4k auf 64k erweitert wurde. Das Team erreichte diesen Durchbruch durch aktive Experimente, Modellfusion, Destillation und Methoden, die scherzhaft als „viel Suppe“ (bezieht sich auf Modellfusionstechniken) bezeichnet werden. Dieser Fortschritt ist entscheidend für die Verarbeitung langer Textaufgaben. Die Verbesserungen von Arcee am GLM-32B-Base-Modell belegen ebenfalls dessen Wirksamkeit: Nicht nur wurde die Unterstützung für lange Kontexte von 8k auf 32k erhöht, sondern auch alle Basismodellbewertungen (einschließlich kurzer Kontexte) zeigten Verbesserungen. (Quelle: eliebakouch, teortaxesTex, nrehiew_, shxf0072, code_star)

Google Gemini API Update verbessert Geschwindigkeit und Fähigkeiten bei der Video- und PDF-Verarbeitung: Die Google Gemini API hat wichtige Updates für die Verarbeitung von Videos und PDFs erhalten. Die Time to First Token (TTFT) für zwischengespeicherte Videos wurde um das Dreifache verbessert, und die Verarbeitungsgeschwindigkeit für zwischengespeicherte PDFs wurde um bis zu das Vierfache erhöht. Darüber hinaus unterstützt die neue Version die Stapelverarbeitung mehrerer Videos, und die Leistung des impliziten Cachings nähert sich der des expliziten Cachings an. Diese Verbesserungen zielen darauf ab, die Effizienz und das Erlebnis für Entwickler bei der Verarbeitung von Multimedia-Inhalten mit der Gemini API zu steigern. (Quelle: _philschmid)
Moonshot (Kimi) aktualisiert Kimi VL A3B Thinking-Modell und verbessert multimodale Verarbeitungsfähigkeiten: Moonshot AI (Kimi) hat eine aktualisierte Version seines kleinen Vision Language Model (VLM) Kimi VL A3B Thinking veröffentlicht, das unter der MIT-Lizenz steht. Die neue Version verbraucht weniger Tokens, verkürzt die Denkpfade, unterstützt die Videoverarbeitung und kann Bilder mit höherer Auflösung (1792×1792) verarbeiten. Es erreicht 65,2 Punkte auf VideoMMMU, verbessert sich bei MathVision um 20,1 Punkte auf 56,9 Punkte, bei MathVista um 8,4 Punkte auf 80,1 Punkte, bei MMMU-Pro um 3,2 Punkte auf 46,3 Punkte und zeigt hervorragende Leistungen bei visueller Inferenz, UI-Agent-Lokalisierung sowie Video- und PDF-Verarbeitung. Es ist Open Source auf Hugging Face verfügbar. (Quelle: mervenoyann)

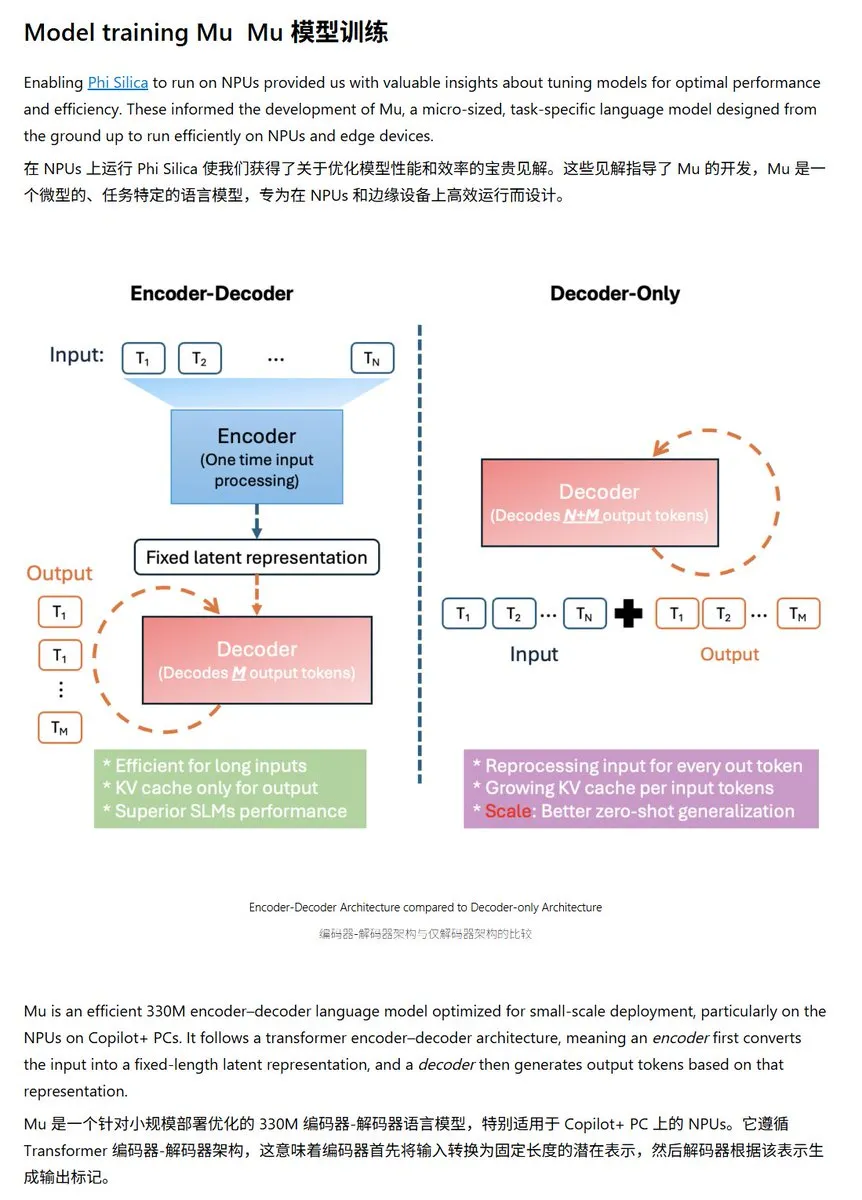
Microsoft veröffentlicht kleines Sprachmodell Mu-330M, optimiert für Windows NPU: Microsoft hat ein neues kleines Sprachmodell namens Mu-330M vorgestellt, das für den Betrieb auf der NPU (Neural Processing Unit) von Windows Copilot+ PCs entwickelt wurde und Agent-Funktionen innerhalb des Windows-Systems unterstützen soll. Das Modell wurde für die NPU optimiert und verwendet Techniken wie Rotary Position Embedding, Grouped Query Attention und zweischichtiges LayerNorm, um bei geringem Energieverbrauch effizient zu arbeiten. Dies markiert einen weiteren Schritt von Microsoft beim Ausbau seiner KI-Fähigkeiten auf Endgeräten. (Quelle: karminski3)
DeepMind veröffentlicht technischen Bericht zu Mercury, Fokus auf Diffusions-Sprachmodelle: Inception Labs (ein mit DeepMind verbundenes Team) hat den technischen Bericht zu seinem Diffusions-Sprachmodell Mercury veröffentlicht. Der Bericht beschreibt detailliert die Architektur, Trainingsmethoden und experimentellen Ergebnisse des Mercury-Modells und bietet Forschern tiefe Einblicke in diesen aufstrebenden Modelltyp. Diffusionsmodelle haben bereits bemerkenswerte Erfolge in der Bildgenerierung erzielt, und ihre Anwendung auf Sprachmodelle ist ein aktueller Forschungsschwerpunkt in der KI. (Quelle: andriy_mulyar)
Meta erweitert KI-Smart-Glasses-Reihe in Zusammenarbeit mit Oakley: Meta arbeitet mit der Brillenmarke Oakley zusammen, um seine Produktlinie an KI-Smart-Glasses weiter auszubauen. Die neuen Smart Glasses sollen voraussichtlich die KI-Technologie von Meta integrieren und erweiterte interaktive Funktionen sowie ein verbessertes Nutzererlebnis bieten. Diese Kooperation unterstreicht Metas kontinuierliche Investitionen im Bereich tragbarer KI-Geräte mit dem Ziel, KI nahtloser in den Alltag zu integrieren. (Quelle: rowancheung, Ronald_vanLoon)
Alibaba Cloud führt PAI-TurboX ein, ein Beschleunigungsframework für Training und Inferenz von autonomen Fahrmodellen, das die Trainingszeit um bis zu 50 % verkürzen kann: Alibaba Cloud hat PAI-TurboX vorgestellt, ein Framework zur Beschleunigung von Training und Inferenz von Modellen im Bereich des autonomen Fahrens. Das Framework zielt darauf ab, die Effizienz von Wahrnehmungs-, Planungs- und Kontrollmodellen bis hin zu Weltmodellen zu steigern. Dies geschieht durch Optimierung der multimodalen Datenvorverarbeitung, CPU-Affinität, dynamische Kompilierung, Pipeline-Parallelisierung sowie durch Bereitstellung von Operator-Optimierung und Quantisierungsfähigkeiten. Tests haben gezeigt, dass PAI-TurboX die Trainingszeit für mehrere Branchenmodelle wie BEVFusion, MapTR und SparseDrive um etwa 50 % verkürzen kann. (Quelle: 量子位)
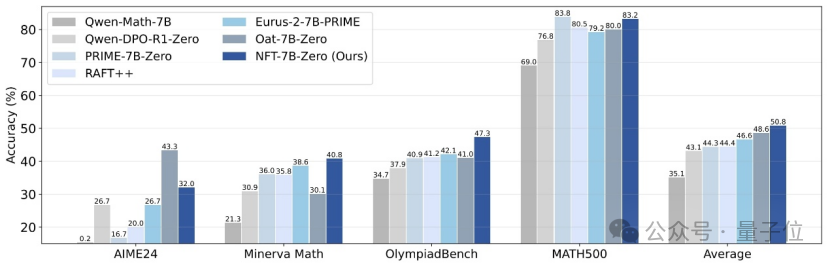
Tsinghua, Nvidia und andere schlagen NFT-Methode vor, die überwachtes Lernen befähigt, aus Fehlern zu „reflektieren“: Forscher der Tsinghua-Universität, Nvidia und der Stanford-Universität haben gemeinsam ein neues überwachtes Lernschema namens NFT (Negative-aware FineTuning) vorgeschlagen. Diese Methode baut auf dem RFT-Algorithmus (Rejection FineTuning) auf und nutzt negative Daten für das Training durch den Aufbau eines „impliziten negativen Modells“, d. h. einer „impliziten negativen Strategie“. Diese Strategie ermöglicht es dem überwachten Lernen, ähnlich wie beim Reinforcement Learning, „Selbstreflexion“ zu betreiben, wodurch die Lücke zwischen überwachtem Lernen und Reinforcement Learning in bestimmten Fähigkeiten geschlossen wird. Sie zeigt signifikante Leistungssteigerungen bei Aufgaben wie mathematischem Schließen und ist unter On-Policy-Bedingungen sogar äquivalent zum Gradienten der Verlustfunktion von GRPO. (Quelle: 量子位)
OmniGen2 veröffentlicht: 8B multifunktionales Bildbearbeitungsmodell, das visuelles Verständnis und Bildgenerierung vereint: Ein neues multifunktionales Bildbearbeitungsmodell namens OmniGen2 wurde veröffentlicht. Das Modell kombiniert visuelles Verständnis (basierend auf Qwen-VL-2.5) mit Bildgenerierung (ein Diffusionsmodell mit 4B Parametern) und hat eine Gesamtparameterzahl von etwa 8B. OmniGen2 unterstützt verschiedene Aufgaben wie Text-zu-Bild-Generierung, Bildbearbeitung, Bildverständnis und kontextbezogene Generierung. Ziel ist es, ein einheitliches Modell bereitzustellen, das verschiedene visuelle Probleme lösen kann und für die Integration auf Endgeräten geeignet ist. (Quelle: karminski3)

Chroma-8.9B-v39 Text-zu-Bild-Modell aktualisiert, basiert auf FLUX.1-schnell, kommerziell nutzbar: Das Text-zu-Bild-Modell Chroma-8.9B-v39 wurde aktualisiert und verbessert die Beleuchtung und Natürlichkeit der Aufgaben. Das Modell basiert auf FLUX.1-schnell, die Parameterzahl wurde von 12B auf 8,9B reduziert. Es steht unter der Apache 2.0 Lizenz und erlaubt die kommerzielle Nutzung. Berichten zufolge „führt das Modell fehlende anatomische Konzepte wieder ein, ist völlig frei von Inhaltsbeschränkungen“ und wurde mit einem Datensatz von 5 Millionen Anime-, Furry-, Kunstwerken und Fotos nachtrainiert. (Quelle: karminski3)

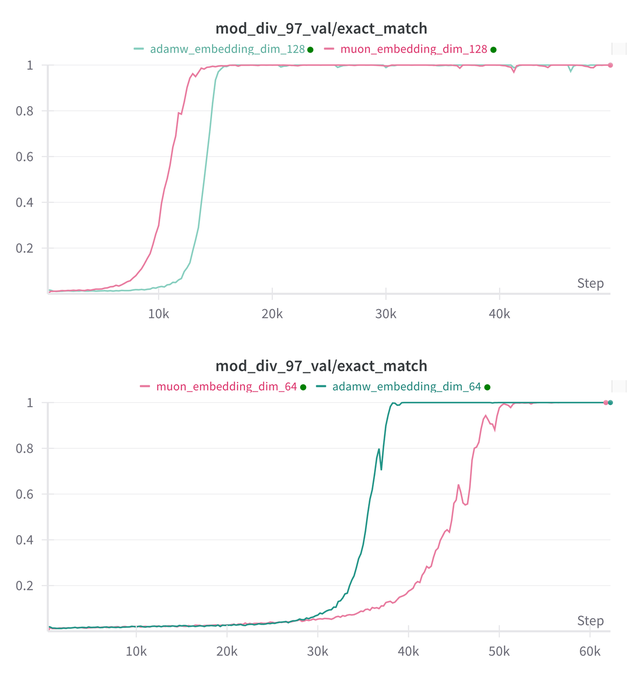
Essential AI aktualisiert Forschungsergebnisse zu Grokking-Fähigkeiten seiner Modelle Muon und Adam: Essential AI teilte die neuesten Forschungsergebnisse zu den Grokking-Fähigkeiten (ein Phänomen, bei dem Modelle nach anfänglich schlechter Leistung plötzlich generalisieren) seiner Modelle Muon und Adam mit. Ursprüngliche Hypothesen könnten im Widerspruch zu tatsächlichen Beobachtungen stehen. Das Team veröffentlichte Ergebnisse interner kleiner Studienexperimente, die zeigen, dass Muon nach Erweiterung des Hyperparameter-Suchraums keinen offensichtlichen universellen Vorteil gegenüber AdamW hat; beide haben in verschiedenen Szenarien Vor- und Nachteile. Dies deutet darauf hin, dass AdamW in vielen Fällen immer noch ein leistungsstarker oder sogar SOTA-Optimierer ist. (Quelle: eliebakouch, teortaxesTex, nrehiew_)
Ostris AI Bildgenerierungsmodell-Update, Fokus auf CFG-freie Version und Optimierung hochfrequenter Details: Ostris AI aktualisiert kontinuierlich sein Bildgenerierungsmodell und konzentriert sich derzeit auf die Entwicklung einer CFG-freien (Classifier-Free Guidance) Version, da diese schneller konvergiert. Im neuesten Update von Tag 7 hat das Team neue Trainingstechniken hinzugefügt, um hochfrequente Details besser zu verarbeiten und arbeitet daran, Artefakte mit hohen Details zu entfernen. Das vorherige Update von Tag 4 zeigte bereits eine signifikante Verbesserung der Bildqualität, die mit neuen Methoden ohne Verwendung von CFG generiert wurde. (Quelle: ostrisai)

Ant Group, CAS und andere veröffentlichen Open-Source-Modell ViLaSR-7B, das räumliches Denken durch „Zeichnen und gleichzeitig denken“ ermöglicht: Das Ant Technology Research Institute, das Institut für Automatisierung der Chinesischen Akademie der Wissenschaften (CAS) und die Chinesische Universität Hongkong haben gemeinsam das Open-Source-Modell ViLaSR-7B veröffentlicht. Dieses Modell ermöglicht es Large Vision Language Models (LVLM) durch das Paradigma „Drawing to Reason in Space“, Hilfsmarkierungen (wie Referenzlinien, Begrenzungsrahmen) im visuellen Raum zu zeichnen, um das Denken zu unterstützen und so die räumliche Wahrnehmung und Inferenz zu verbessern. ViLaSR verwendet ein dreistufiges Trainingsframework: Kaltstart, reflektierendes Ablehnungssampling und Reinforcement Learning. Experimente zeigen, dass das Modell bei 5 Benchmarks, darunter Labyrinthnavigation, Bildverständnis und räumliche Videoinferenz, eine durchschnittliche Verbesserung von 18,4 % erzielt und auf dem VSI-Bench eine Leistung nahe an Gemini-1.5-Pro erreicht. (Quelle: 量子位)

🧰 Tools
SGLang unterstützt jetzt Hugging Face Transformers als Backend und verbessert die Inferenz-Effizienz: SGLang gab bekannt, dass es jetzt Hugging Face Transformers als Backend unterstützt. Das bedeutet, dass Benutzer für jedes mit Transformers kompatible Modell einen schnellen, produktionsreifen Inferenzdienst bereitstellen können, ohne native Unterstützung, Plug-and-Play. Diese Integration zielt darauf ab, den Bereitstellungsprozess für hochleistungsfähige Sprachmodell-Inferenz zu vereinfachen und den Anwendungsbereich sowie die Benutzerfreundlichkeit von SGLang zu erweitern. (Quelle: TheZachMueller, ClementDelangue)

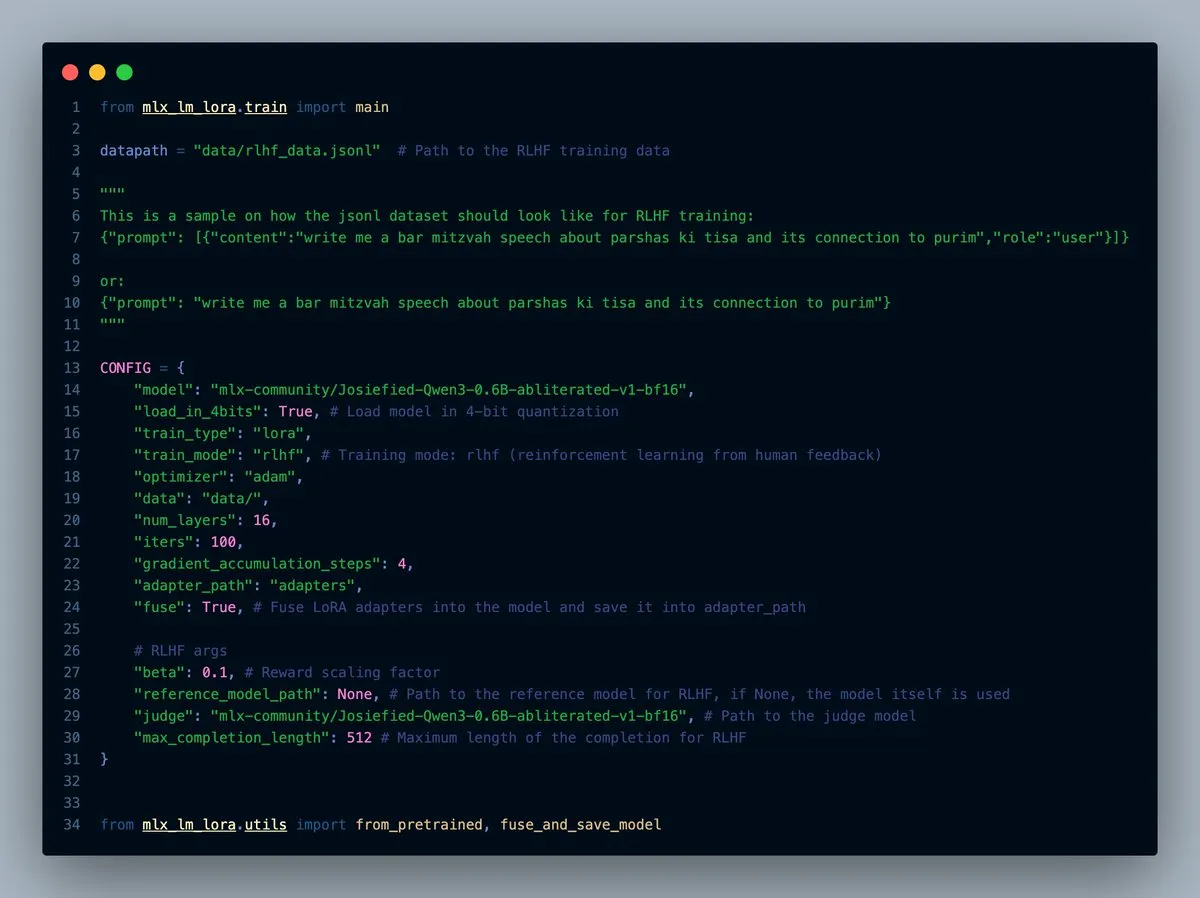
MLX-LM-LORA v0.7.0 veröffentlicht, mit integrierter RLHF-Funktion: MLX-LM-LORA hat die Version v0.7.0 veröffentlicht, die eine integrierte Funktion für Reinforcement Learning from Human Feedback (RLHF) enthält. Das Tool unterstützt jetzt das Laden mit 4-Bit, 6-Bit und 8-Bit, einen RLHF-Trainingsmodus und kann Adapter direkt in die Basisgewichte fusionieren. Dies macht das LoRA-Feintuning im MLX-Framework intelligenter und effizienter, insbesondere auf Apple-Chip-Geräten. (Quelle: awnihannun)
LlamaCloud veröffentlicht, bietet MCP-kompatibles Toolkit für Dokumenten-Workflows: LlamaCloud ist jetzt verfügbar und dient als mit dem Model Context Protocol (MCP) kompatibles Toolkit für beliebige Dokumenten-Workflows. Benutzer können es an Modelle wie Claude anschließen, um komplexe Dokumentenextraktionen, Vergleiche und andere Operationen durchzuführen. Beispielsweise kann es die finanzielle Leistung von Tesla in den letzten fünf Quartalen analysieren und einen zusammenfassenden Bericht erstellen, indem es dynamisch standardisierte Schemata erstellt, diese auf alle Dateien anwendet und dann mithilfe von Codegenerierung das Endergebnis erzeugt. LlamaCloud kann falsche Schemata dynamisch korrigieren und unterstützt direkte Dateiverknüpfungen. (Quelle: jerryjliu0)
Georgi Gerganov kündigt LlamaBarn-Projekt an: Georgi Gerganov (Erfinder von llama.cpp) hat in sozialen Medien ein Bild veröffentlicht, das ein neues Projekt namens „LlamaBarn“ ankündigt. Das Bild zeigt eine dashboard-ähnliche Oberfläche mit Elementen zur Modellauswahl, Parameteranpassung usw., was darauf hindeutet, dass es sich um ein Tool zur Verwaltung, Ausführung oder zum Testen lokaler LLMs handeln könnte. Die Community zeigt sich gespannt und sieht darin einen potenziellen starken Konkurrenten für bestehende Tools wie Ollama. (Quelle: ClementDelangue, teortaxesTex, jeremyphoward)
Void Editor: Ein neuer Open-Source-KI-Programmierassistent, unterstützt MCP und lokale Modelle: Void Editor stellt sich als neuer Open-Source-KI-Programmierassistent vor und zielt darauf ab, eine Alternative zu Tools wie Cursor zu sein. Er unterstützt Tab-Autovervollständigung, einen Chat-Modus, das Model Context Protocol (MCP) sowie einen Agent-Modus. Benutzer können jede Large Language Model API verbinden oder Modelle lokal ausführen, was Entwicklern ein flexibles KI-gestütztes Programmiererlebnis bietet. (Quelle: karminski3)
Together AI stellt das Tool „Which LLM“ vor, das bei der Auswahl des passenden Open-Source-LLM hilft: Together AI hat ein kostenloses Tool namens „Which LLM“ veröffentlicht, das Benutzern helfen soll, das am besten geeignete Open-Source Large Language Model basierend auf spezifischen Anwendungsfällen, Leistungsanforderungen und wirtschaftlichen Überlegungen auszuwählen. Angesichts der rasant wachsenden Zahl von Open-Source-LLMs können solche Tools Entwicklern und Forschern wertvolle Orientierung bei der Modellauswahl bieten. (Quelle: vipulved)
Perplexity Finance fügt Funktion zur Verfolgung von Aktienkurs-Zeitachsen hinzu: Perplexity Finance gab bekannt, dass Benutzer jetzt auf seiner Plattform die Zeitachse der Kursbewegungen für jedes Aktiensymbol verfolgen können. Diese neue Funktion soll Benutzern ein intuitiveres und bequemeres Werkzeug zur Analyse von Finanzmarktinformationen bieten und könnte in Kombination mit den KI-Fähigkeiten von Perplexity neue Erfahrungen bei der Abfrage und Analyse von Finanzinformationen ermöglichen. (Quelle: AravSrinivas)

IdeaWeaver stellt ersten KI-Agenten für die Fehlersuche bei Systemleistungsproblemen vor: IdeaWeaver hat den nach eigenen Angaben ersten KI-Agenten veröffentlicht, der speziell für die Fehlersuche bei Systemleistungsproblemen entwickelt wurde. Das Tool nutzt das CrewAI-Framework und kann Systembefehle tatsächlich ausführen, um Probleme im Zusammenhang mit CPU, Speicher, I/O und Netzwerk zu diagnostizieren. Es zeichnet sich dadurch aus, dass es zum Schutz der Privatsphäre vorrangig lokale LLMs (über OLLAMA) verwendet und nur dann einen OpenAI API-Schlüssel anfordert, wenn lokale Modelle nicht verfügbar sind. Ziel ist es, KI-Fähigkeiten in den Bereichen DevOps und Systemmanagement anzuwenden. (Quelle: Reddit r/artificial)
Kling AI fügt Unterstützung für Live Photos hinzu, ermöglicht Speichern generierter Videos als dynamische Hintergrundbilder: Kling AI gab bekannt, dass seine Videogenerierungsfunktion jetzt das Speichern von Werken als Live Photos (animierte Fotos) unterstützt. Benutzer können ihre bevorzugten dynamischen Inhalte, die von Kling erstellt wurden, als Handy-Hintergrundbild festlegen, was die Attraktivität und Nützlichkeit von KI-generierten Videos erhöht. (Quelle: Kling_ai)
Cognition AI veröffentlicht Blockdiff als Open Source und erreicht 200-fache Beschleunigung von VM-Snapshots: Cognition AI hat die Open-Source-Veröffentlichung seines für Devin entwickelten VM-Snapshot-Dateiformats Blockdiff bekannt gegeben. Da die Erstellung von VM-Snapshots mit EC2 zu lange dauerte (über 30 Minuten), entwickelte das Team eigenständig den Hypervisor otterlink und das Dateiformat Blockdiff, wodurch die Geschwindigkeit der Snapshot-Erstellung um das 200-fache erhöht wurde. Dieser Open-Source-Beitrag soll Entwicklern helfen, VM-Umgebungen effizienter zu verwalten. (Quelle: karinanguyen_)

📚 Lernen
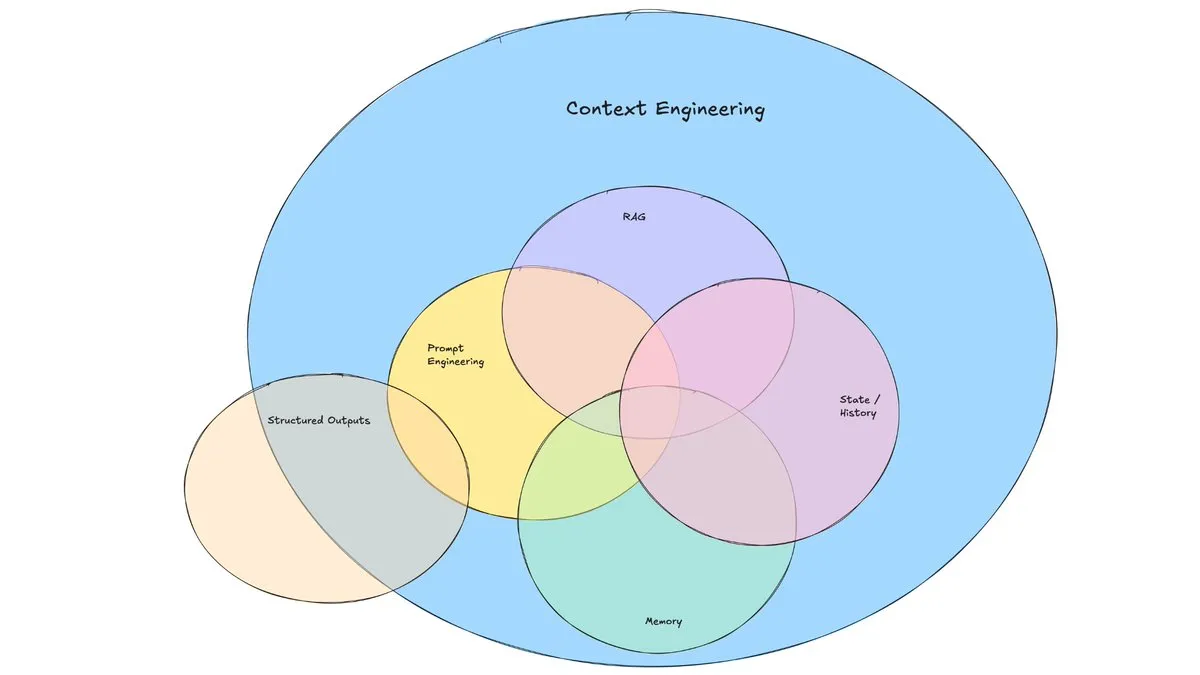
LangChain-Blogbeitrag diskutiert den Aufstieg des „Context Engineering“: LangChain hat einen Blogbeitrag veröffentlicht, der den zunehmend populären Begriff „Context Engineering“ diskutiert. Der Artikel definiert es als „den Aufbau dynamischer Systeme, um die richtigen Informationen und Werkzeuge im richtigen Format bereitzustellen, damit LLMs Aufgaben vernünftig erledigen können“. Dies ist kein völlig neues Konzept, Agent-Entwickler praktizieren es schon lange, und Tools wie LangGraph und LangSmith wurden dafür entwickelt. Die Einführung dieses Begriffs trägt dazu bei, mehr Aufmerksamkeit auf die damit verbundenen Fähigkeiten und Werkzeuge zu lenken. (Quelle: hwchase17, Hacubu, yoheinakajima)
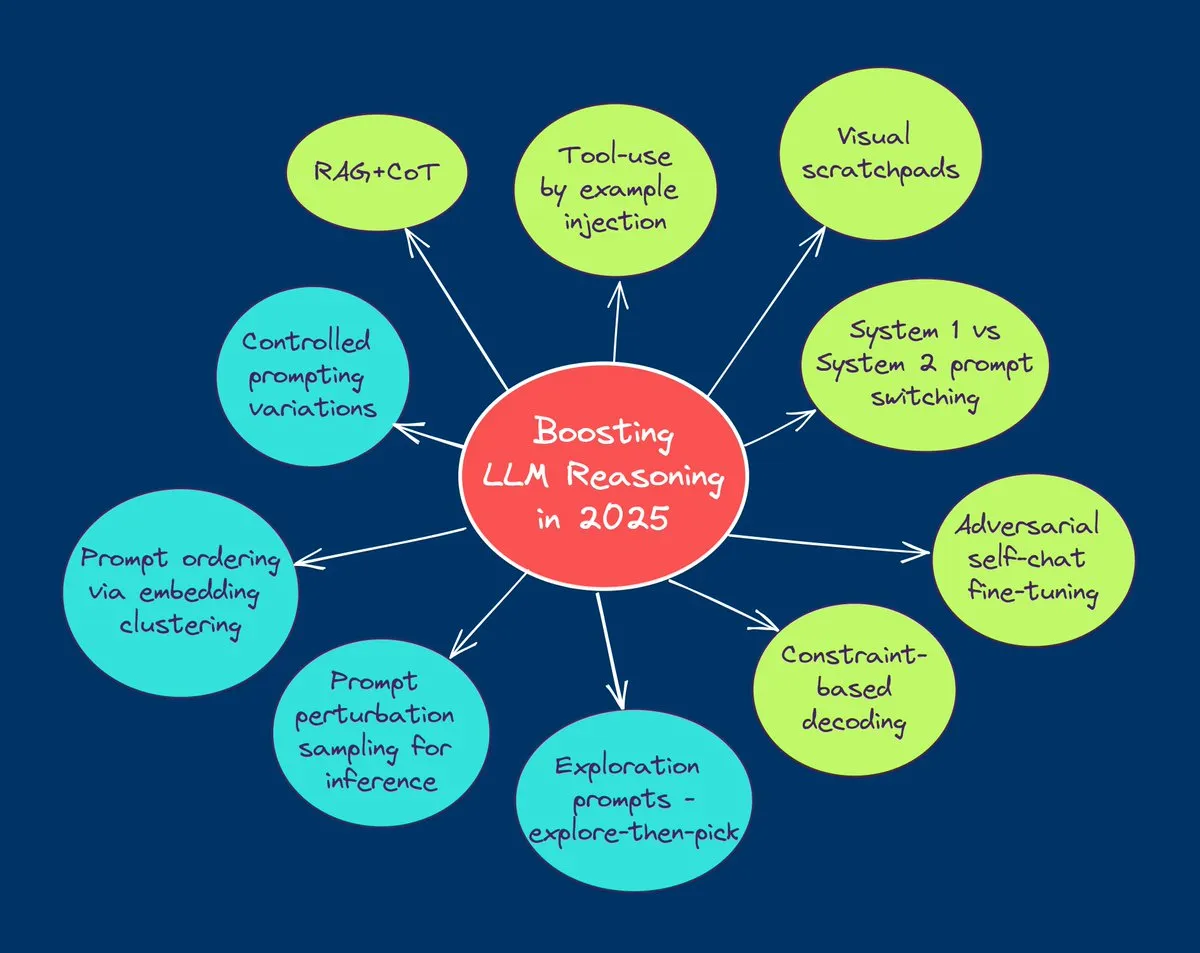
TuringPost fasst die 10 wichtigsten Techniken zur Verbesserung der LLM-Inferenzfähigkeiten im Jahr 2025 zusammen: TuringPost teilte 10 Schlüsseltechniken zur Verbesserung der Inferenzfähigkeiten von Large Language Models (LLMs) im Jahr 2025 mit, darunter: Retrieval Augmented Generation + Chain of Thought (RAG+CoT), Werkzeugnutzung durch Beispielinjektion, visuelles Scratchpad (multimodale Inferenzunterstützung), Umschalten zwischen System 1 und System 2 Prompts, adversariales Selbstgesprächs-Feintuning, beschränkungsbasiertes Dekodieren, exploratives Prompting (erst erkunden, dann auswählen), Prompt-Perturbations-Sampling für Inferenz, Prompt-Sortierung durch Embedding-Clustering und kontrollierte Prompt-Varianten. Diese Techniken bieten vielfältige Wege zur Optimierung der Leistung von LLMs bei komplexen Aufgaben. (Quelle: TheTuringPost, TheTuringPost)
Cohere Labs veranstaltet ML Summer School zur Erforschung der Zukunft des maschinellen Lernens: Die Open-Science-Community von Cohere Labs wird im Juli eine ML Summer School veranstalten. Die Veranstaltung wird Community-Mitglieder aus aller Welt zusammenbringen, um gemeinsam die Zukunft des maschinellen Lernens zu diskutieren, und lädt Referenten aus der Branche ein, ihre Erkenntnisse zu teilen. Katrina Lawrence wird am 2. Juli einen Auffrischungskurs zur Mathematik des maschinellen Lernens leiten, der Kernkonzepte wie Analysis, Vektoranalysis und lineare Algebra abdeckt. (Quelle: sarahookr)

DeepLearning.AI und Meta starten kostenlosen Kurs „Building with Llama 4“: DeepLearning.AI hat in Zusammenarbeit mit Meta einen kostenlosen Kurs namens „Building with Llama 4“ gestartet. Die Kursinhalte umfassen: praktische Arbeit mit den Modellen der Llama 4-Serie, Verständnis ihrer Mixture-of-Experts (MOE)-Architektur und wie man Anwendungen mit der offiziellen API erstellt; Anwendung von Llama 4 für multimodale Bildinferenz, Bildlokalisierung (Identifizierung von Objekten und ihren Begrenzungsrahmen) sowie Verarbeitung von langen Textabfragen mit bis zu 1 Million Tokens; Verwendung der Prompt-Optimierungswerkzeuge von Llama 4 zur automatischen Verbesserung von System-Prompts und Nutzung seines synthetischen Daten-Toolkits zur Erstellung hochwertiger Datensätze für das Feintuning. (Quelle: DeepLearningAI)
EleutherAI YouTube-Kanal bietet umfangreiche Inhalte zur KI-Forschung: Der YouTube-Kanal von EleutherAI versammelt Aufzeichnungen seiner Lesezirkel und Vortragsreihen mit über 100 Stunden Inhalt. Die Themen umfassen Skalierbarkeit und Leistung im maschinellen Lernen, Funktionalanalysis sowie Podcasts und Interviews mit Teammitgliedern. Der Kanal bietet eine Fülle von Lernressourcen für KI-Forscher und -Enthusiasten. EleutherAI hat auch eine neue Vortragsreihe gestartet, deren erste Folge von @linguist_cat über Tokenizer und ihre Grenzen gehalten wird. (Quelle: BlancheMinerva, BlancheMinerva)
Paper untersucht Verbesserung multimodaler Inferenz durch latente visuelle Tokens (Machine Mental Imagery): Ein neues Paper mit dem Titel „Machine Mental Imagery: Empower Multimodal Reasoning with Latent Visual Tokens“ stellt das Mirage-Framework vor, das die multimodale Inferenz verbessert, indem während des VLM-Dekodierungsprozesses latente visuelle Tokens (anstelle der Generierung vollständiger Bilder) hinzugefügt werden, um menschliche mentale Bilder zu simulieren. Die Methode überwacht zunächst latente Tokens durch Destillation echter Bild-Embeddings, wechselt dann zu reiner Textüberwachung, um latente Trajektorien an AufgabenZiele anzupassen, und verbessert die Fähigkeiten weiter durch Reinforcement Learning. Experimente zeigen, dass Mirage eine stärkere multimodale Inferenz ohne die explizite Generierung von Bildern erreichen kann. (Quelle: HuggingFace Daily Papers)
Paper schlägt Vision as a Dialect Framework vor, das visuelles Verständnis und Generierung durch textausgerichtete Repräsentationen vereinheitlicht: Ein Paper mit dem Titel „Vision as a Dialect: Unifying Visual Understanding and Generation via Text-Aligned Representations“ stellt ein multimodales LLM-Framework namens Tar vor. Dieses Framework verwendet einen textausgerichteten Tokenizer (TA-Tok), um Bilder in diskrete Tokens umzuwandeln, und nutzt ein auf das LLM-Vokabular projiziertes textausgerichtetes Codebuch, wodurch visuelle und textuelle Informationen in einer gemeinsamen diskreten semantischen Repräsentation vereinheitlicht werden. Tar ermöglicht modalitätsübergreifende Ein- und Ausgabe über eine gemeinsame Schnittstelle, ohne spezifische Modalitätsdesigns, und verwendet einen skalenadaptiven Encoder-Decoder sowie einen generativen Detokenizer, um Effizienz und visuelle Details auszugleichen. (Quelle: HuggingFace Daily Papers)
Paper stellt ReasonFlux-PRM vor: Trajektorien-bewusstes PRM für LLM Long Chain-of-Thought Reasoning: Das Paper „ReasonFlux-PRM: Trajectory-Aware PRMs for Long Chain-of-Thought Reasoning in LLMs“ stellt ein neuartiges trajektorien-bewusstes Prozess-Belohnungsmodell (PRM) vor, das speziell für die Bewertung von Trajektorien-Antwort-artigen Inferenzspuren entwickelt wurde, wie sie von modernen Inferenzmodellen wie DeepSeek-R1 generiert werden. ReasonFlux-PRM kombiniert schrittweise und trajektorienbasierte Überwachung und erreicht eine feinkörnige Belohnungszuweisung, die auf strukturierte Chain-of-Thought-Daten abgestimmt ist. Es zeigt Leistungssteigerungen in Szenarien wie SFT, RL und BoN-Testzeiterweiterung. (Quelle: HuggingFace Daily Papers)
Paper untersucht Bewertungsmethoden für Jailbreak-Schutzmechanismen von Large Language Models: Ein Paper mit dem Titel „SoK: Evaluating Jailbreak Guardrails for Large Language Models“ führt eine systematische Wissensaufarbeitung zu Jailbreak-Angriffen auf Large Language Models (LLMs) und deren Schutzmechanismen (Guardrails) durch. Das Paper schlägt eine neue mehrdimensionale Klassifikation vor, die Guardrails anhand von sechs Schlüssdimensionen kategorisiert, und führt ein Bewertungsframework für Sicherheit, Effizienz und Praktikabilität ein, um deren tatsächliche Wirksamkeit zu bewerten. Durch umfangreiche Analysen und Experimente zeigt das Paper die Vor- und Nachteile bestehender Guardrail-Methoden auf, untersucht deren Universalität gegenüber verschiedenen Angriffstypen und liefert Erkenntnisse zur Optimierung von Verteidigungskombinationen. (Quelle: HuggingFace Daily Papers)
AAAI 2025 Distinguished Paper untersucht entscheidbare Klassen von Partially Observable Markov Decision Processes (POMDPs): Ein Paper mit dem Titel „Revelations: A Decidable Class of POMDP with Omega-Regular Objectives“ wurde mit dem AAAI 2025 Distinguished Paper Award ausgezeichnet. Die Studie identifiziert eine entscheidbare Klasse von MDPs (Markov Decision Processes): Entscheidungsprobleme mit „starken Offenbarungen“, d.h. in jedem Schritt gibt es eine Wahrscheinlichkeit ungleich Null, den exakten Zustand der Welt aufzudecken. Das Paper liefert auch Entscheidbarkeitsergebnisse für „schwache Offenbarungen“, bei denen der exakte Zustand garantiert irgendwann aufgedeckt wird, aber nicht unbedingt in jedem Schritt. Diese Forschung liefert neue theoretische Grundlagen für optimale Entscheidungen unter unvollständigen Informationen. (Quelle: aihub.org)
Paper schlägt CommVQ vor: Kommutative Vektorquantisierung für KV-Cache-Komprimierung: Das Paper „CommVQ: Commutative Vector Quantization for KV Cache Compression“ stellt eine Methode namens CommVQ vor, die den KV-Cache durch additive Quantisierung und leichtgewichtige Encoder sowie Codebücher komprimiert, um den Speicherbedarf bei der Inferenz von LLMs mit langem Kontext zu reduzieren. Um die Dekodierungskosten zu senken, sind die Codebücher so konzipiert, dass sie mit Rotary Position Embeddings (RoPE) kommutativ sind, und werden mit einem EM-Algorithmus trainiert. Experimente zeigen, dass die Methode bei 2-Bit-Quantisierung die Größe des FP16-KV-Caches um 87,5 % reduzieren kann und bestehende KV-Cache-Quantisierungsmethoden übertrifft, sogar eine 1-Bit-KV-Cache-Quantisierung mit minimalem Genauigkeitsverlust ermöglicht. (Quelle: HuggingFace Daily Papers)
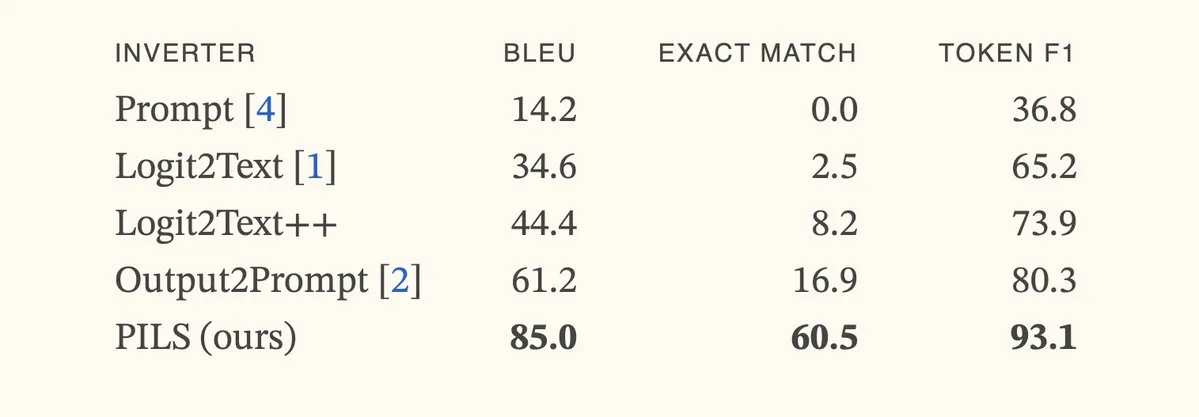
Paper schlägt PILS-Methode vor, verbessert Sprachmodell-Inversion durch kompakte Darstellung der Next-Token-Verteilung: Das Paper „Better Language Model Inversion by Compactly Representing Next-Token Distributions“ stellt eine neue Methode zur Sprachmodell-Inversion namens PILS (Prompt Inversion from Logprob Sequences) vor. Diese Methode rekonstruiert versteckte Prompts durch Analyse der Next-Token-Wahrscheinlichkeiten des Modells über mehrere Generierungsschritte. Kernstück ist die Entdeckung, dass die Ausgabevektoren von Sprachmodellen einen niedrigdimensionalen Unterraum einnehmen, wodurch die Next-Token-Wahrscheinlichkeitsverteilung durch eine lineare Abbildung verlustfrei komprimiert und für eine effektivere Inversion genutzt werden kann. Experimente zeigen, dass PILS bei der Wiederherstellung versteckter Prompts signifikant besser abschneidet als bisherige SOTA-Methoden. (Quelle: HuggingFace Daily Papers, jxmnop)
Paper stellt Phantom-Data vor: Ein allgemeiner Datensatz für subjektkonsistente Videogenerierung: Das Paper „Phantom-Data : Towards a General Subject-Consistent Video Generation Dataset“ stellt einen neuen Datensatz namens Phantom-Data vor, der das in bestehenden Subjekt-zu-Video-Generierungsmodellen verbreitete „Kopieren-Einfügen“-Problem (d. h. die übermäßige Verflechtung der Subjektidentität mit Hintergrund- und Kontextattributen) lösen soll. Phantom-Data ist der erste allgemeine, paarweise subjektkonsistente Datensatz für die Videoerstellung, der etwa eine Million Paare mit identitätskonsistenten Subjekten über verschiedene Kategorien hinweg enthält. Der Datensatz wird in einem dreistufigen Prozess erstellt, der Subjekterkennung, groß angelegte kontextübergreifende Subjektsuche und prior-gesteuerte Identitätsprüfung umfasst. (Quelle: HuggingFace Daily Papers)
Paper stellt LongWriter-Zero vor: Beherrschung der Generierung ultralanger Texte durch Reinforcement Learning: Das Paper „LongWriter-Zero: Mastering Ultra-Long Text Generation via Reinforcement Learning“ schlägt eine anreizbasierte Methode vor, um LLMs von Grund auf mithilfe von Reinforcement Learning (RL) die Fähigkeit zur Generierung ultralanger, qualitativ hochwertiger Texte beizubringen, ohne jegliche annotierte oder synthetische Daten. Die Methode beginnt mit einem Basismodell und leitet es durch RL an, während des Planungs- und Schreibprozesses Verfeinerungen vorzunehmen, wobei ein spezielles Belohnungsmodell zur Kontrolle von Länge, Schreibqualität und Strukturformat verwendet wird. Experimente zeigen, dass LongWriter-Zero, trainiert auf Qwen2.5-32B, traditionelle SFT-Methoden bei Aufgaben zur Generierung langer Texte übertrifft und in mehreren Benchmarks SOTA-Niveau erreicht. (Quelle: HuggingFace Daily Papers)
💼 Wirtschaft
KI-Rechtsfirma Harvey gibt Abschluss einer Finanzierungsrunde E in Höhe von 300 Millionen US-Dollar bei einer Bewertung von 5 Milliarden US-Dollar bekannt: Das KI-Startup Harvey für den Rechtsbereich gab den Abschluss einer von Kleiner Perkins und Coatue gemeinsam angeführten Finanzierungsrunde E in Höhe von 300 Millionen US-Dollar bekannt, wodurch das Unternehmen mit 5 Milliarden US-Dollar bewertet wird. Weitere Investoren sind Sequoia Capital, GV, DST Global, Conviction, Elad Gil, der OpenAI Startup Fund, Elemental, SV Angel, Kris Fredrickson und REV. Diese Finanzierung wird Harvey dabei helfen, seine KI-Anwendungen im Rechtsbereich weiterzuentwickeln und auszubauen. (Quelle: saranormous)
Hyperbolic On-Demand GPU Cloud-Dienst erreicht 1 Million US-Dollar ARR in 7 Tagen nach dem Start: Yuchenj_UW gab bekannt, dass sein letzte Woche gestarteter Hyperbolic On-Demand GPU Cloud-Dienst innerhalb von 7 Tagen einen jährlich wiederkehrenden Umsatz (ARR) von 0 auf 1 Million US-Dollar gesteigert hat, und das mit nur geringem Marketingaufwand durch einen einzigen Tweet. Sie bieten Entwicklern kostenlose Testguthaben für 8xH100-Knoten an, was die starke Marktnachfrage nach hochleistungsfähigen GPU-Cloud-Diensten zeigt. (Quelle: Yuchenj_UW)
Replit gibt bekannt, dass der jährlich wiederkehrende Umsatz (ARR) 100 Millionen US-Dollar überschritten hat: Die Online-IDE (Integrated Development Environment) und Cloud-Computing-Plattform Replit gab bekannt, dass ihr jährlich wiederkehrender Umsatz (ARR) 100 Millionen US-Dollar überschritten hat, was einen deutlichen Anstieg gegenüber den 10 Millionen US-Dollar Ende 2024 darstellt. Das Unternehmen gab an, dass nach der letzten Finanzierungsrunde im Jahr 2023 mit einer Bewertung von 1,1 Milliarden US-Dollar immer noch mehr als die Hälfte der Mittel auf der Bank vorhanden sind. Das Wachstum von Replit ist auf die Nutzung seiner Plattform durch Unternehmenskunden (wie Zillow, HubSpot) und unabhängige Entwickler zurückzuführen. Das Unternehmen stellt derzeit aktiv ein. (Quelle: pirroh, kylebrussell, hwchase17, Hacubu)
🌟 Community
Neues Paradigma der KI-Programmierung: Erst entwerfen, dann prompten, iterative Optimierung der Codegenerierung: dotey und Baoyu diskutieren den Wandel der Softwareentwicklungsmuster durch KI-Programmierung. Die traditionelle Debatte „erst entwerfen, dann kodieren“ versus „erst implementieren, dann refaktorisieren“ findet im KI-Zeitalter eine Synthese. KI verkürzt die Kosten und die Zeit vom Entwurf zur Kodierung drastisch und ermöglicht es Entwicklern, schnell Versionen zu implementieren, auch wenn der Entwurf noch nicht vollständig klar ist, und durch Validierung der Ergebnisse iterativ den Entwurf und die Prompts zu verbessern. Prompts übernehmen die Rolle früherer „detaillierter Entwurfsdokumente“, sind aber vereinfacht. In diesem Modell sollten sich Entwickler stärker auf das Systemdesign konzentrieren, Code in kleinen Chargen generieren, Quellcodeverwaltung nutzen und den von KI generierten Code überprüfen und testen. Für erfahrene Programmierer ist die Umstellung von Denkweise und Entwicklungsgewohnheiten der Schlüssel zur Nutzung der KI-Programmierung. (Quelle: dotey)
Claude Code wird von Entwicklern wegen seiner starken Fähigkeit zur Verarbeitung großer Codebasen und seiner Kontexteffizienz geschätzt: Die Reddit-Community r/ClaudeAI diskutiert begeistert die herausragende Leistung von Claude Code bei der Verarbeitung großer Codebasen. Benutzer berichten, dass es Codebasen weit über 200k Tokens gut verstehen und Änderungen implementieren kann. Es wird vermutet, dass Claude Code möglicherweise durch Strategien ähnlich dem menschlichen Lesen (nur Schlüsselstellen lesen), die Verwendung von Werkzeugen wie grep zur Kontextsuche (anstatt sich vollständig auf die vektorisierte Komprimierung von RAG zu verlassen) und die Vorteile der Integration von Erstanbieter-Modellen eine effiziente Kontextverarbeitung erreicht. Benutzer teilen verschiedene Erfolgsgeschichten, wie die Behebung von Systemproblemen, die Erstellung eines persönlichen Finanz-Trackers, die Entwicklung von Android-Apps (auch ohne Android-Entwicklungserfahrung) und die Erstellung von Obsidian DataviewJS-Skripten mit Claude Code, was die Arbeitseffizienz erheblich steigerte. (Quelle: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)

Das Konzept des „Context Engineering“ gewinnt an Aufmerksamkeit und betont den Aufbau dynamischer Systeme zur Befähigung von LLMs: Harrison Chase von LangChain schlägt vor, dass „Context Engineering“ die Kernaufgabe von KI-Ingenieuren beim Systembau ist. Es wird definiert als „der Aufbau dynamischer Systeme, um die richtigen Informationen und Werkzeuge im richtigen Format bereitzustellen, damit LLMs Aufgaben vernünftig erledigen können“. Dieses Konzept unterstreicht die Bedeutung einer effektiven Organisation und Bereitstellung von Kontextinformationen für die Modellleistung in LLM-Anwendungen und bildet die Grundlage für Bereiche wie den Agentenbau. (Quelle: hwchase17, Hacubu, yoheinakajima)
Meta-Gründer Zuckerberg rekrutiert persönlich KI-Talente und erregt Aufmerksamkeit in der Community: Social-Media-Berichten zufolge ist Meta-Gründer Mark Zuckerberg persönlich an der Talentakquise für sein Superintelligenz-Labor beteiligt, kontaktiert Hunderte potenzieller Kandidaten direkt und lädt diejenigen, die antworten, zum Abendessen ein. Dieser Schritt wird als Ausdruck von Metas Entschlossenheit und Engagement im KI-Bereich, insbesondere im Hinblick auf Allgemeine Künstliche Intelligenz (AGI) oder Superintelligenz, interpretiert und zeigt den intensiven Wettbewerb führender Technologieunternehmen um KI-Spitzentalente. (Quelle: reach_vb, andrew_n_carr)

KI-Entwicklung löst tiefgreifende Überlegungen zu Arbeitsmarkt und Wirtschaftsstrukturen aus: Die Harvard Business School und der Ökonom Anton Korinek warnen, dass AGI innerhalb von 2-5 Jahren Realität werden könnte und ohne eine radikale Veränderung des Wirtschaftssystems zu einem Zusammenbruch führen könnte, wobei die Notwendigkeit eines bedingungslosen Grundeinkommens betont wird. Gleichzeitig wird in der Community diskutiert, dass KI eine große Anzahl quantifizierbarer Aufgaben automatisieren und sowohl Blue-Collar- als auch White-Collar-Arbeitsplätze gefährden wird, was Unternehmen dazu zwingt, ihre Organisationsstrukturen an KI anzupassen. Yuval Noah Harari vergleicht die KI-Revolution mit einer „KI-Einwanderungswelle“ und löst Diskussionen über die Verdrängung von Arbeitsplätzen und das Streben nach Macht durch KI aus. Diese Ansichten deuten gemeinsam auf die disruptiven Auswirkungen von KI auf zukünftige sozioökonomische Strukturen hin. (Quelle: 36氪, 36氪, Reddit r/artificial, Reddit r/ChatGPT)

KI zeigt herausragende Leistungen bei Programmierwettbewerben, Sakana AI Agent erzielt hervorragende Ergebnisse und löst Diskussionen aus: Der Agent von Sakana AI belegte beim heuristischen Programmierwettbewerb AtCoder unter über 1000 menschlichen Programmierern den 21. Platz und erreichte insgesamt die oberen 6,8 %. Die KI iterierte innerhalb von 4 Stunden etwa 100 Versionen und generierte Tausende potenzieller Lösungen, während menschliche Teilnehmer normalerweise nur etwa 12 testen können. Die KI verwendete Gemini 2.5 Pro und kombinierte Expertenwissen mit systemischen Suchalgorithmen (wie Simulated Annealing und Beam Search), um praktische Optimierungsprobleme zu lösen. Die Reaktionen der Community darauf sind gemischt; einige argumentieren, dass Wettbewerbsprogrammierung sich von unternehmensweiter Softwareentwicklung unterscheidet und der Sieg der KI eher dem Sieg eines Computers über Menschen bei Addition und Subtraktion gleicht. (Quelle: Reddit r/ArtificialInteligence)
💡 Sonstiges
Erkundung von KI im Bereich der beruflichen Bildung: Vielfältige Versuche mit Interviews, Lehrern und Lernmaschinen: Berufsbildungsgiganten wie Huatu, Fenbi und Zhonggong erkunden aktiv KI-Anwendungen mit unterschiedlichen Schwerpunkten. Huatu konzentriert sich auf KI-gestützte Interviewbewertungen, Fenbi vertieft sich in KI-gestützte Korrekturen und KI-Lehrer (der Umsatz mit KI-Übungssystemklassen hat bereits 14 Millionen Yuan überschritten), während Zhonggong eine KI-gestützte Lernmaschine für die Arbeitsplatzsuche auf den Markt bringt. Branchenkonsens ist, dass KI die Lerneffektivität und Betriebseffizienz verbessern sollte, anstatt nur hohe Aufschläge zu erzielen. Die Anwendung von KI bewegt sich auch von der Konzeptvalidierung zur tiefgreifenden Szenarioanwendung, wie z. B. 51CTO, das digitale Menschen und 3D-Modellierung zur Kurserstellung nutzt und KI für die Generierung von Testfragen und die Analyse von Lernpfaden einsetzt. Die meisten Bildungsunternehmen verfügen jedoch noch nicht über die Fähigkeit, eigene große Modelle zu erstellen, und neigen eher dazu, APIs von Drittanbietern zu nutzen. (Quelle: 36氪)
Disney und Universal Pictures verklagen KI-Bilderzeugungs-Einhorn Midjourney wegen Urheberrechtsverletzung: Die Hollywood-Giganten Disney und Universal Pictures haben gemeinsam Klage gegen das KI-Bilderzeugungsunternehmen Midjourney eingereicht. Sie werfen Midjourney vor, ohne Genehmigung eine große Menge urheberrechtlich geschützten IP-Materials (wie Iron Man, Minions usw.) zum Training seines KI-Modells verwendet und sehr ähnliche Bilder generiert zu haben. Die Kläger fordern ein Unterlassungsurteil und bis zu 150.000 US-Dollar Schadensersatz für jedes vorsätzlich verletzte Werk. Dieser Fall unterstreicht die urheberrechtlichen Herausforderungen, mit denen generative KI konfrontiert ist. Der Gründer von Midjourney hatte zuvor zugegeben, Daten ohne Genehmigung verwendet zu haben. Die Klage könnte darauf abzielen, die Einrichtung von Lizenzierungsmechanismen für Urheberrechte und Inhaltsfiltersysteme voranzutreiben. (Quelle: 36氪)

Apple wird KI-Rückstand vorgeworfen, erwägt möglicherweise Übernahme zur Aufholung, Unternehmen des ehemaligen OpenAI CTO im Fokus: Berichten zufolge hinkt Apple im KI-Bereich hinterher, seine eigenen KI-Fähigkeiten sind unzureichend und Siri zeigt eine schwache Leistung. Um den Rückstand aufzuholen, könnte Apple eine größere Übernahme in Erwägung ziehen. Gerüchten zufolge gab es erste Kontakte mit der ehemaligen OpenAI CTO Mira Murati bezüglich ihres neu gegründeten Unternehmens Thinking Machines Lab. In der Vergangenheit hat Apple mehrfach kleine Technologieunternehmen übernommen, um seine eigenen Fähigkeiten zu stärken (wie Siri selbst). Derzeit liegt Apple bei der Parametergröße seiner KI-Modelle weit hinter den Branchenriesen zurück. Eine Übernahme von Unternehmen wie Mistral könnte Apple helfen, bei der Entwicklung eigener großer Modelle einen Durchbruch zu erzielen. (Quelle: 36氪)