Schlüsselwörter:Quantencomputing, KI-Selbstverbesserung, Brain-Computer-Interface, Große Sprachmodelle, Neuromorphes Computing, KI-Videogenerierung, Bestärkendes Lernen, KI-Ethik, Quantenbit-Fehlerrate, JEPA-Selbstüberwachtes Lernen, MLX-Format-Quantisierung, PAM-Visualisierungsmodell, KI-ASMR-Inhaltsgenerierung
🔥 Fokus
Universität Oxford erreicht rekordverdächtige Fehlerrate von 0,000015% in Quantum-Computing-Experiment: Ein Forschungsteam der Universität Oxford hat einen bedeutenden Durchbruch in einem Quantum-Computing-Experiment erzielt und die Fehlerrate von Qubits auf 0,000015% gesenkt, was einen neuen Weltrekord darstellt. Dieser Fortschritt ist entscheidend für den Bau fehlertoleranter Quantencomputer, da eine extrem niedrige Fehlerrate die Voraussetzung für die Realisierung komplexer Quantenalgorithmen und die Ausschöpfung des Potenzials des Quantum Computing ist. Das Ergebnis demonstriert erhebliche Fortschritte bei der Verbesserung der Stabilität und präzisen Steuerung von Qubits auf Hardware-Ebene und legt eine solidere Grundlage für zukünftige Anwendungen in Bereichen wie AI, die auf hohe Rechenleistung angewiesen sind (Quelle: Ronald_vanLoon)

MIT-Forscher bringen Künstlicher Intelligenz bei, sich selbst zu verbessern und weiterzuentwickeln: Forscher des Massachusetts Institute of Technology (MIT) haben Fortschritte im Bereich der Selbstverbesserung von AI erzielt. Sie entwickelten eine neue Methode, die es AI-Systemen ermöglicht, autonom zu lernen und ihre eigene Leistung zu verbessern. Diese Fähigkeit ahmt den menschlichen Prozess des kontinuierlichen Fortschritts durch Erfahrung und Reflexion nach und ist entscheidend für die Entwicklung autonomerer und anpassungsfähigerer Künstlicher Intelligenz. Die Forschung könnte den Weg für eine kontinuierliche Optimierung von AI-Modellen nach deren Einsatz ebnen, die Abhängigkeit von menschlichen Eingriffen verringern und weitreichende Auswirkungen auf die langfristige Entwicklung und Anwendung von AI haben (Quelle: TheRundownAI)

„Gedankenlese“-AI wandelt Gehirnwellen gelähmter Personen in Echtzeit in Sprache um: Eine bahnbrechende Studie zeigt, wie eine „Gedankenlese“-AI die Gehirnwellen von gelähmten Patienten in Echtzeit in klare Sprache umwandelt. Diese Technologie dekodiert mittels fortschrittlicher Brain-Computer Interfaces (BCI) und AI-Algorithmen sprachrelevante neuronale Signale und synthetisiert sie zu verständlicher Sprachausgabe. Dies bietet Patienten, die aufgrund schwerer motorischer Störungen ihre Sprachfähigkeit verloren haben, eine völlig neue Kommunikationsmöglichkeit, die ihre Lebensqualität erheblich verbessern könnte und einen bedeutenden Fortschritt der AI in der unterstützenden Medizin und den Neurowissenschaften darstellt (Quelle: Ronald_vanLoon)

Durchbruch bei jahrhundertealtem Problem der mathematischen Physik, Alumni der Peking Universität an Lösung des sechsten Hilbertschen Problems beteiligt: Deng Yu, Alumnus der Peking Universität, Ma Xiao aus der Sonderklasse für begabte Jugendliche der USTC, und Zaher Hani, ein Schüler von Terence Tao, erzielten einen bedeutenden Durchbruch beim sechsten Hilbertschen Problem, der „Axiomatisierung der Physik“. Sie bewiesen erstmals streng den vollständigen Übergang von der Newtonschen Mechanik (mikroskopisch, zeitumkehrbar) zur Boltzmann-Gleichung (makroskopisch-statistisch, zeitunkehrbar) und schlossen damit die logische Lücke zwischen beiden. Dies legt eine solidere mathematische Grundlage für die statistische Mechanik und löste unerwartet das „Rätsel des Zeitpfeils“. Diese Errungenschaft zeigt mittels ausgefeilter mathematischer Werkzeuge und schrittweiser Ableitungen den Weg von der Atomtheorie zu den Bewegungsgesetzen kontinuierlicher Medien (Quelle: 量子位)

🎯 Trends
Alibaba veröffentlicht MLX-Formatversionen der Qwen3-Modellreihe: Alibaba gab bekannt, dass seine Qwen3-Reihe großer Modelle nun das MLX-Format unterstützt und in vier Quantisierungsstufen erhältlich ist: 4-Bit, 6-Bit, 8-Bit und BF16. MLX ist ein von Apple für Apple Silicon optimiertes Machine-Learning-Framework. Dieser Schritt bedeutet, dass Qwen3-Modelle effizienter auf Apple-Geräten laufen können, was die Hürden für die Bereitstellung und Ausführung großer Modelle auf Endgeräten senkt und zur Verbreitung und Anwendung großer Modelle auf persönlichen Geräten beitragen dürfte (Quelle: Alibaba_Qwen, awnihannun, cognitivecompai, Reddit r/LocalLLaMA)
Google veröffentlicht Gemma 3n-Modell, hohe Leistung mit wenigen Parametern: Google hat das Gemma 3n-Modell vorgestellt, das weniger als 10 Milliarden Parameter hat, aber in der LMArena-Bewertung über 1300 Punkte erreicht und damit das erste kleine Modell ist, das diesen Erfolg erzielt. Die herausragende Leistung von Gemma 3n beweist, dass auch mit einer geringeren Parameterzahl ein hohes Niveau an Sprachverständnis und -generierung erreicht werden kann und es auf Endgeräten wie Mobiltelefonen lauffähig ist. Dies ist von großer Bedeutung für die Förderung der Verbreitung von AI-Anwendungen und die Senkung der Rechenkosten (Quelle: osanseviero)
Tencent stellt AI-Technologie zur Generierung von 3D-Assets in Filmqualität vor: Tencent präsentierte eine neue Künstliche-Intelligenz-Technologie, die 3D-Assets in Filmqualität generieren kann. Diese Technologie verspricht, die Effizienz und Qualität der Erstellung von 3D-Inhalten in Bereichen wie Spieleentwicklung und Filmproduktion erheblich zu steigern und die Produktionskosten zu senken. Die schnelle Generierung hochwertiger 3D-Assets ist ein Schlüsselelement für die Entwicklung des Metaversums und der digitalen Content-Industrie (Quelle: TheRundownAI)
Kuaishous Kling 2.1-Modell zeigt hervorragende Leistung bei der Bild-zu-Video-Konvertierung und synchronen Audio-Video-Generierung: Das AI-Videogenerierungsmodell Kling von Kuaishou wurde auf Version 2.1 aktualisiert und zeigt starke Fähigkeiten bei der Umwandlung von Bildern in Videos. Die neue Version soll die Generierung von Video und Audio mit einem Klick ermöglichen, ohne dass eine nachträgliche Tongestaltung erforderlich ist, um audio-visuell synchronisierte Inhalte in Studioqualität zu produzieren. Dies markiert einen Fortschritt der AI bei der Generierung multimodaler Inhalte, insbesondere im Videobereich, vereinfacht den Erstellungsprozess und verbessert die Generierungsqualität (Quelle: Kling_ai, Kling_ai)
Neues AI-Videomodell “Kangaroo”, möglicherweise Minimax Hailuo 2.0, fordert bestehende SOTA heraus: Auf dem Markt ist ein mysteriöses AI-Videogenerierungsmodell namens “Kangaroo” aufgetaucht, das in der AI-Video-Arena, insbesondere bei der Bild-zu-Video-Konvertierung, starke Leistungen zeigt. Analysen deuten darauf hin, dass es sich bei dem Modell um die Version Hailuo 2.0 des Unternehmens Minimax handeln könnte. Sein Erscheinen könnte die bestehende Leistungshierarchie von Text-zu-Video- und Bild-zu-Video-Modellen verändern, obwohl seine Audioverarbeitungsfähigkeiten noch bewertet werden müssen (Quelle: TomLikesRobots)
MiniMax führt M1-Modellreihe mit herausragender Fähigkeit zur Verarbeitung langer Texte ein: MiniMaxAI hat die MiniMax-M1-Modellreihe veröffentlicht, ein MoE (Mixture of Experts)-Modell mit 456 Milliarden Parametern. Diese Modellreihe zeigt in mehreren Benchmarks hervorragende Leistungen, insbesondere bei der Verarbeitung langer Kontexte (z. B. im OpenAI-MRCR-Benchmark), wo sie GPT-4.1 übertrifft und im LongBench-v2 den dritten Platz belegt. Dies zeigt ihr Potenzial bei der Verarbeitung und dem Verständnis langer Dokumente, aber ihr größeres „Thinking Budget“ könnte hohe Anforderungen an die Rechenressourcen stellen (Quelle: Reddit r/LocalLLaMA)

Turing-Preisträger Richard Sutton: AI bewegt sich vom „Zeitalter der menschlichen Daten“ zum „Zeitalter der Erfahrung“: Richard Sutton, Pionier des Reinforcement Learning, wies auf der Beijing Zhiyuan Conference darauf hin, dass aktuelle AI-Großmodelle, die auf menschlichen Daten basieren, an ihre Grenzen stoßen. Hochwertige menschliche Daten seien erschöpft, und der Nutzen der Skalierung von Modellen nehme ab. Er glaubt, dass die Zukunft der AI im Eintritt in das „Zeitalter der Erfahrung“ liegt, d. h. intelligente Agenten lernen durch Echtzeitinteraktion mit der Umgebung und generieren Erfahrungen aus erster Hand, anstatt alten Text zu imitieren. Dies erfordert, dass intelligente Agenten kontinuierlich in realen oder simulierten Umgebungen operieren, Umgebungsfeedback als Belohnungssignale nutzen, Weltmodelle und Gedächtnissysteme entwickeln und so echtes kontinuierliches Lernen und Innovation realisieren (Quelle: 36氪)

PAM-Modell: 3B-Parameter für integrierte Bild- und Videosegmentierung, -erkennung und -beschreibung: Das MMLab der Chinesischen Universität Hongkong und andere Institutionen haben das Perceive Anything Model (PAM) als Open Source veröffentlicht. Dieses 3B-Parametermodell kann gleichzeitig Ziele in Bildern und Videos segmentieren, erkennen, erklären und beschreiben sowie synchron Text und Masken ausgeben. PAM erreicht durch die Einführung eines Semantic Perceivers, der das SAM2-Segmentierungs-Framework mit einem LLM verbindet, eine effiziente Umwandlung von visuellen Merkmalen in multimodale Tokens. Das Team hat außerdem einen umfangreichen, qualitativ hochwertigen Trainingsdatensatz aus Bildern und Texten erstellt. PAM erreicht oder nähert sich in mehreren Benchmarks zum visuellen Verständnis dem SOTA-Niveau und weist eine überlegene Inferenz-Effizienz auf (Quelle: 量子位)

Neuromorphes Computing könnte Schlüssel zur nächsten AI-Generation werden und Betrieb mit geringem Stromverbrauch ermöglichen: Wissenschaftler erforschen aktiv neuromorphes Computing mit dem Ziel, die Struktur und Funktionsweise des menschlichen Gehirns zu simulieren, um das Problem des hohen Energieverbrauchs aktueller AI-Modelle zu lösen. Nationale Laboratorien in den USA und andere Institutionen entwickeln neuromorphe Computer mit einer Neuronenanzahl, die der des menschlichen Kortex vergleichbar ist. Theoretisch könnten diese Computer weit schneller als das biologische Gehirn arbeiten, bei extrem niedrigem Stromverbrauch (z. B. 20 Watt für eine menschenähnliche AI). Diese Technologie, die auf ereignisgesteuerter Kommunikation, In-Memory-Computing und adaptivem Lernen basiert, verspricht intelligentere, effizientere und stromsparendere AI und wird als potenzielle Lösung für die Energiekrise der AI und als neuer Weg zur Entwicklung von AGI angesehen (Quelle: 量子位)

AI ASMR-Inhalte gehen auf Kurzvideoplattformen viral, Technologien wie Veo 3 treiben Trend an: Mit AI generierte ASMR (Autonomous Sensory Meridian Response)-Videos verbreiten sich rasant auf Plattformen wie TikTok. Ein Account zog innerhalb von 3 Tagen fast 100.000 Follower an, ein einzelnes Video vom Schneiden von Obst erreichte über 16,5 Millionen Aufrufe. Diese Videos kombinieren mit AI erzeugte ungewöhnliche visuelle Effekte (z. B. Obst mit Glastextur) mit entsprechenden Geräuschen wie Schneiden oder Kollisionen und erzeugen so ein einzigartiges „süchtig machendes“ Gefühl. Modelle wie Veo 3 von Google DeepMind, die direkt audio-visuell synchronisierte Inhalte generieren können, gelten als Schlüsseltechnologie für die Erstellung solcher AI ASMR-Inhalte, da sie den bisherigen Prozess der separaten Erstellung von Audio und Video mit anschließender Synchronisation vereinfachen (Quelle: 量子位)

Meta AI Suchverlauf-Veröffentlichung erregt Aufmerksamkeit, Google testet AI-Audio-Zusammenfassungen: Meta hat die Suchverläufe seiner AI-Suchfunktion veröffentlicht, was bei Nutzern Bedenken hinsichtlich Datenschutz und Transparenz der Datennutzung auslöste. Gleichzeitig testet Google in seinen Laborprojekten eine neue Funktion, die von AI generierte podcast-ähnliche Audio-Zusammenfassungen am oberen Rand der Suchergebnisse anzeigt, um Nutzern einen bequemeren Informationszugang zu ermöglichen. Diese beiden Entwicklungen spiegeln die kontinuierliche Erforschung und Optimierung der Nutzererfahrung durch Technologiegiganten im Bereich AI-Suche und Informationsdarstellung wider (Quelle: Reddit r/ArtificialInteligence)

Team aus Sydney entwickelt AI-Modell zur Gedankenerkennung mittels Gehirnwellen: Ein Forschungsteam aus Sydney, Australien, hat ein neues Künstliche-Intelligenz-Modell entwickelt, das durch die Analyse von Elektroenzephalographie (EEG)-Daten die Gedankeninhalte von Individuen erkennen kann. Diese Technologie hat potenziellen Anwendungswert in Bereichen wie Neurowissenschaften, Mensch-Maschine-Interaktion und unterstützender Kommunikation, beispielsweise um Menschen zu helfen, die nicht auf traditionelle Weise kommunizieren können, ihre Absichten auszudrücken. Die Studie treibt die Entwicklung der Brain-Computer-Interface-Technologie weiter voran und erforscht die Fähigkeiten der AI bei der Interpretation komplexer Gehirnaktivitäten (Quelle: Reddit r/ArtificialInteligence)
Kalifornien plant Gesetz zur Einschränkung der „Roboter-Boss“-Rolle von AI bei Einstellungs-, Entlassungs- und anderen Entscheidungen: Der US-Bundesstaat Kalifornien treibt ein Gesetz voran, das darauf abzielt, Unternehmen darin zu beschränken, wichtige Personalentscheidungen wie Einstellungen und Entlassungen allein auf der Grundlage von Empfehlungen von AI-Systemen zu treffen. Das Gesetz verlangt, dass menschliche Manager jede derartige Empfehlung der AI überprüfen und unterstützen müssen, um menschliche Aufsicht und Rechenschaftspflicht zu gewährleisten. Wirtschaftsverbände lehnen dies ab und argumentieren, dass dies die Compliance-Kosten erhöhen und mit bestehenden Einstellungstechnologien kollidieren würde. Dieser Schritt spiegelt die wachsende Besorgnis über ethische und soziale Auswirkungen der AI wider, insbesondere bei automatisierten Entscheidungen am Arbeitsplatz (Quelle: Reddit r/ArtificialInteligence)

🧰 Tools
Augmentoolkit 3.0 veröffentlicht, verbessert Datensatzgenerierung und Feinabstimmungsprozesse: Augmentoolkit hat Version 3.0 veröffentlicht, ein Werkzeug zur Erstellung von QA-Datensätzen aus langen Dokumenten (wie historischen Texten) und zur Feinabstimmung von Modellen. Die neue Version bietet eine produktionsreife Pipeline, die automatisch Trainingsdaten generiert und Modelle trainiert, enthält ein lokal ausgeführtes Modell, das speziell für die Generierung hochwertiger QA-Datensätze feinabgestimmt wurde, und bietet eine No-Code-Oberfläche. Das Tool zielt darauf ab, den Prozess der domänenspezifischen Modellfeinabstimmung und Trainingsdatengenerierung zu vereinfachen und die technische Hürde zu senken (Quelle: Reddit r/LocalLLaMA)
Opius AI Planner: AI-Planer zur Optimierung der Cursor Composer-Erfahrung: Eine Cursor-Erweiterung namens Opius AI Planner wurde veröffentlicht, die darauf abzielt, Probleme des Cursor Composers beim Verständnis vager Anforderungen zu lösen. Das Tool analysiert Projektanforderungen, generiert eine detaillierte Implementierungs-Roadmap und gibt für Composer optimierte strukturierte Prompts aus, wodurch die Anzahl der Iterationen reduziert und die Projektergebnisse besser an die ursprünglichen Vorstellungen angepasst werden. Dies spiegelt den Trend wider, die Nützlichkeit von AI-Code-Generierungstools durch AI-gestützte Planung zu verbessern (Quelle: Reddit r/artificial)
Continue-Erweiterung: Lokalen Open-Source-Copilot und MCP-Integration in VSCode realisieren: Continue ist eine VSCode-Erweiterung, die es Benutzern ermöglicht, lokal laufende Open-Source-Large-Language-Modelle als Programmierassistenten zu konfigurieren und zu verwenden sowie MCP (Model Control Protocol)-Tools zu integrieren. Benutzer können Modelle über Dienste wie Llama.cpp oder LMStudio lokal bereitstellen und über Continue interagieren, um die volle Kontrolle und Anpassung des Code-Assistenten zu erreichen, beispielsweise durch die Integration des Playwright-Browser-Automatisierungstools (Quelle: Reddit r/LocalLLaMA)

Doubao Large Model und Volcano Engine MCP vereinfachen Cloud-Service-Bereitstellung und Generierung persönlicher Seiten: ByteDance’s Doubao Large Model demonstriert eine tiefe Integrationsfähigkeit mit dem Volcano Engine Model Control Protocol (MCP). Benutzer können durch natürlichsprachliche Anweisungen das Doubao Large Model dazu bringen, Funktionen der Volcano Engine (wie veFaaS Function-as-a-Service) aufzurufen, um Aufgaben wie die Generierung einer persönlichen Social-Media-Navigationsseite und deren automatische Bereitstellung online durchzuführen. Diese Integration eliminiert die komplexen Schritte der manuellen Konfiguration von Cloud-Umgebungen, senkt die Nutzungsschwelle für Cloud-Dienste und zeigt das Potenzial von AI zur Vereinfachung von DevOps-Prozessen (Quelle: karminski3)
Figma führt neue AI-Funktion ein: Sofortige Website-Generierung aus Text-Prompts: Figma präsentierte eine neue AI-gesteuerte Funktion, die in der Lage ist, basierend auf vom Benutzer eingegebenen Text-Prompts schnell Website-Prototypen oder -Seiten zu generieren. Diese Funktion zielt darauf ab, den Webdesign- und Entwicklungsprozess zu beschleunigen und es Designern und Entwicklern zu ermöglichen, Ideen durch natürlichsprachliche Beschreibungen schnell in visuelle Entwürfe umzusetzen, was die Durchdringung von generativer AI im Bereich kreativer Design-Tools weiter unterstreicht (Quelle: Ronald_vanLoon)
Hugging Face Model Hub fügt Filterfunktion nach Modellgröße hinzu: Die Hugging Face Plattform hat ihrem Model Hub eine nützliche Funktion hinzugefügt, die es Benutzern ermöglicht, Modelle nach ihrer Parametergröße zu filtern. Diese Verbesserung ermöglicht es Entwicklern und Forschern, Modelle, die ihren spezifischen Hardwareressourcen oder Leistungsanforderungen entsprechen, bequemer zu finden und erhöht die Effizienz bei der Navigation und Auswahl in der riesigen Modellbibliothek (Quelle: ClementDelangue, TheZachMueller, huggingface, clefourrier, multimodalart)
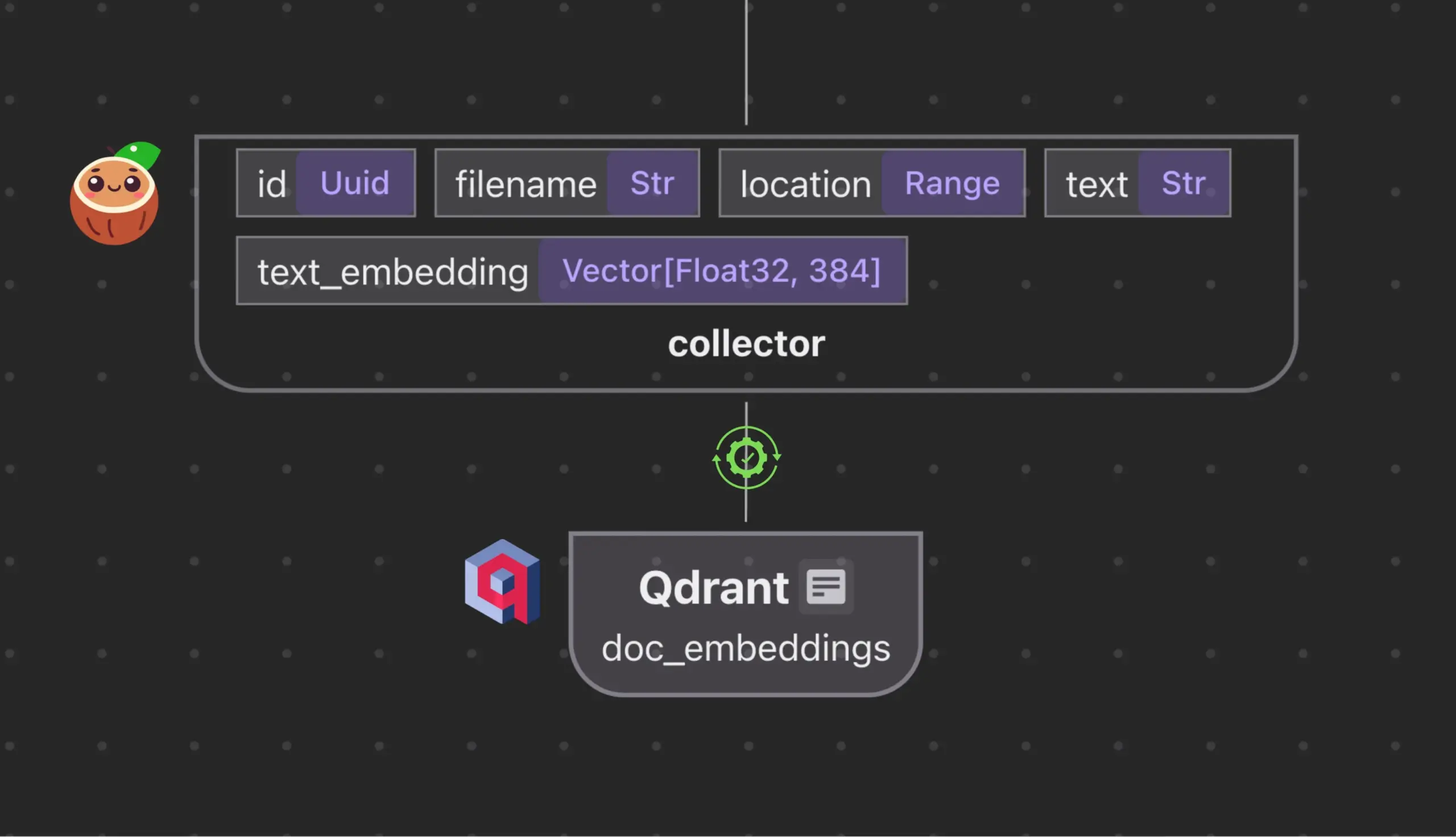
Cocoindex.io integriert mit Qdrant zur automatischen Erstellung und Synchronisierung von Vektordatenbank-Sammlungen: Das Open-Source-Datenstrom-Tool Cocoindex.io unterstützt jetzt die automatische Erstellung von Qdrant-Vektordatenbank-Sammlungen. Benutzer müssen lediglich den Datenstrom definieren, und das Tool leitet das passende Qdrant-Schema ab (einschließlich Vektorgröße, Distanzmetrik und Payload-Struktur) und hält Vektorfelder, Payload-Typen und Primärschlüssel synchron, wobei inkrementelle Updates unterstützt werden. Dies vereinfacht die Konfiguration und Verwaltung von Vektordatenbanken und erhöht die Effizienz von Datenteams (Quelle: qdrant_engine)
Manus AI: Nicht nur Code schreiben, sondern auch automatisch bereitstellen – ein End-to-End-AI-Entwicklungstool: Manus AI ist ein AI-Entwicklungstool, das den gesamten Prozess von der Codeerstellung über die Umgebungseinrichtung, Abhängigkeitsinstallation, Tests bis hin zur endgültigen Bereitstellung unter einer Online-URL abdeckt. Es verwendet eine Multi-Agenten-Kollaborationsarchitektur (Planung, Entwicklung, Test, Bereitstellung) und kann Abhängigkeitsprobleme und Debugging-Fehler autonom lösen. Obwohl derzeit Einschränkungen wie ein auf Credits basierendes Preismodell, die Entwicklung durch ein chinesisches Team (was Compliance-Überlegungen mit sich bringen könnte) und die Unterstützung für hochkomplexe Unternehmensarchitekturen bestehen, zeigt es das Potenzial für einen Wandel von „AI-unterstütztem Codieren“ zu „AI-gesteuerter Entwicklung“ (Quelle: Reddit r/artificial)

📚 Lernen
Übersetzungstheorie und Leitfaden zur Optimierung von AI-Übersetzungs-Prompts: Unter Einbeziehung der Theorie „Übersetzen ist Neuschreiben“ aus Siguos „Neue Studien zur Übersetzung“ und Yu Guangzhongs Ansichten in „Übersetzung ist ein großer Weg“ werden die Prinzipien qualitativ hochwertiger Übersetzungen erörtert. Es wird betont, dass sich Übersetzungen auf den authentischen Ausdruck in der Zielsprache konzentrieren sollten, anstatt auf wörtliche Entsprechungen, wobei direkte und freie Übersetzung flexibel eingesetzt und syntaktische Umformungen unter Berücksichtigung der logischen Unterschiede zwischen chinesischer und westlicher Sprache vorgenommen werden müssen. Der Artikel diskutiert auch die Reinheit des chinesischen Ausdrucks, den Umgang mit Terminologie und reflektiert die Grenzen des dreistufigen Prozesses „direkte Übersetzung – Analyse – freie Übersetzung“ bei AI-Übersetzungen. Es wird ein stärker integrierter Prozess „Verstehen – Ausdrücken – Korrekturlesen – Optimieren“ vorgeschlagen, um die Qualität von AI-Übersetzungen zu verbessern und sie besser an den Stil chinesischer populärwissenschaftlicher Texte anzupassen (Quelle: dotey)

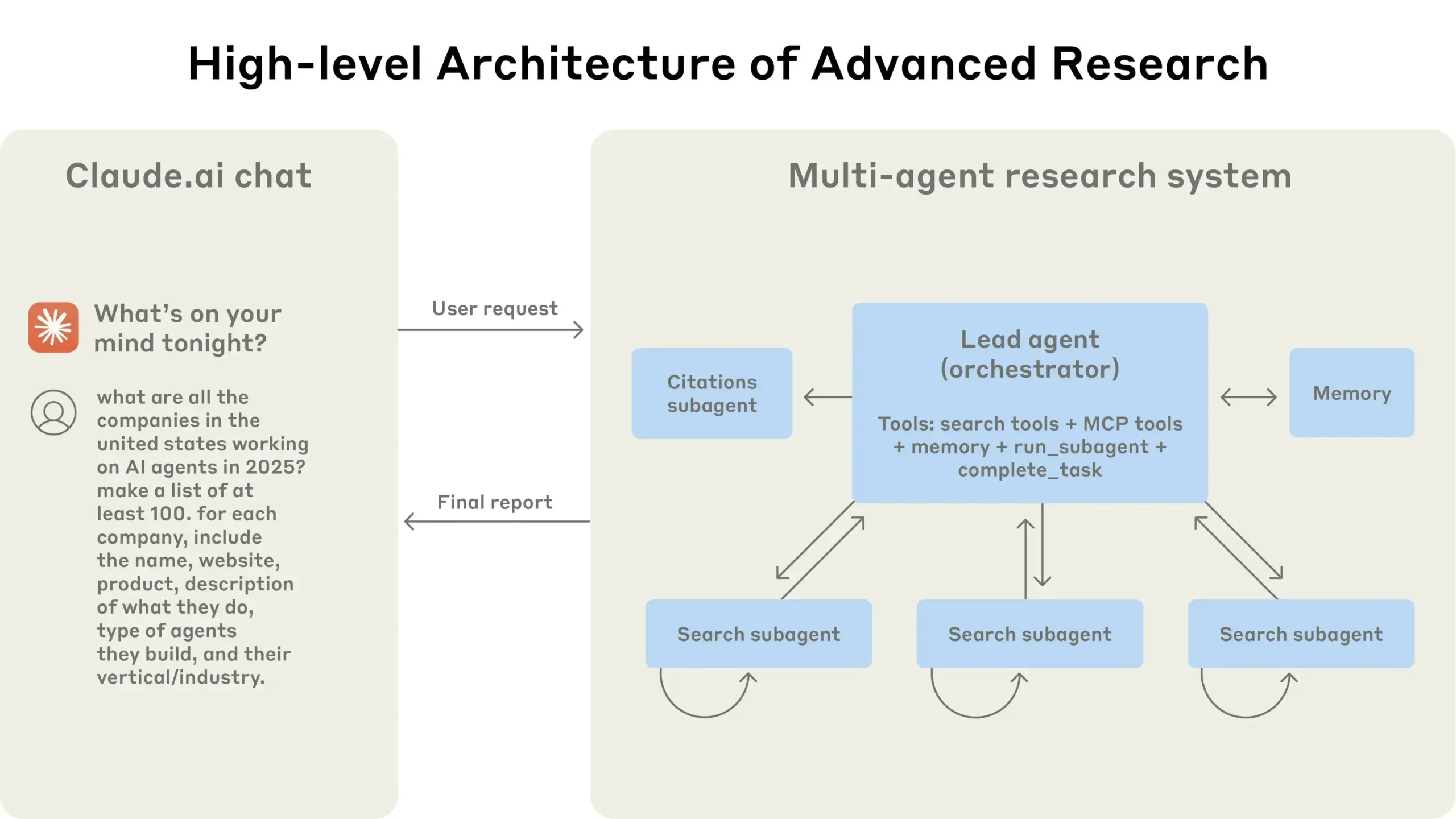
Anthropic teilt Erfahrungen beim Aufbau seines Multi-Agenten-Forschungssystems: AnthropicAI hat einen kostenlosen Leitfaden veröffentlicht, der detailliert beschreibt, wie sie ihr Multi-Agenten-Forschungssystem aufgebaut haben. Der Inhalt umfasst die Funktionsweise der Systemarchitektur, Prompt-Engineering- und Testmethoden, Herausforderungen in der Produktion sowie die Vorteile von Multi-Agenten-Systemen. Dieser Leitfaden bietet Forschern und Entwicklern, die an Multi-Agenten-Systemen interessiert sind, wertvolle praktische Erfahrungen und Einblicke (Quelle: TheTuringPost, TheTuringPost)
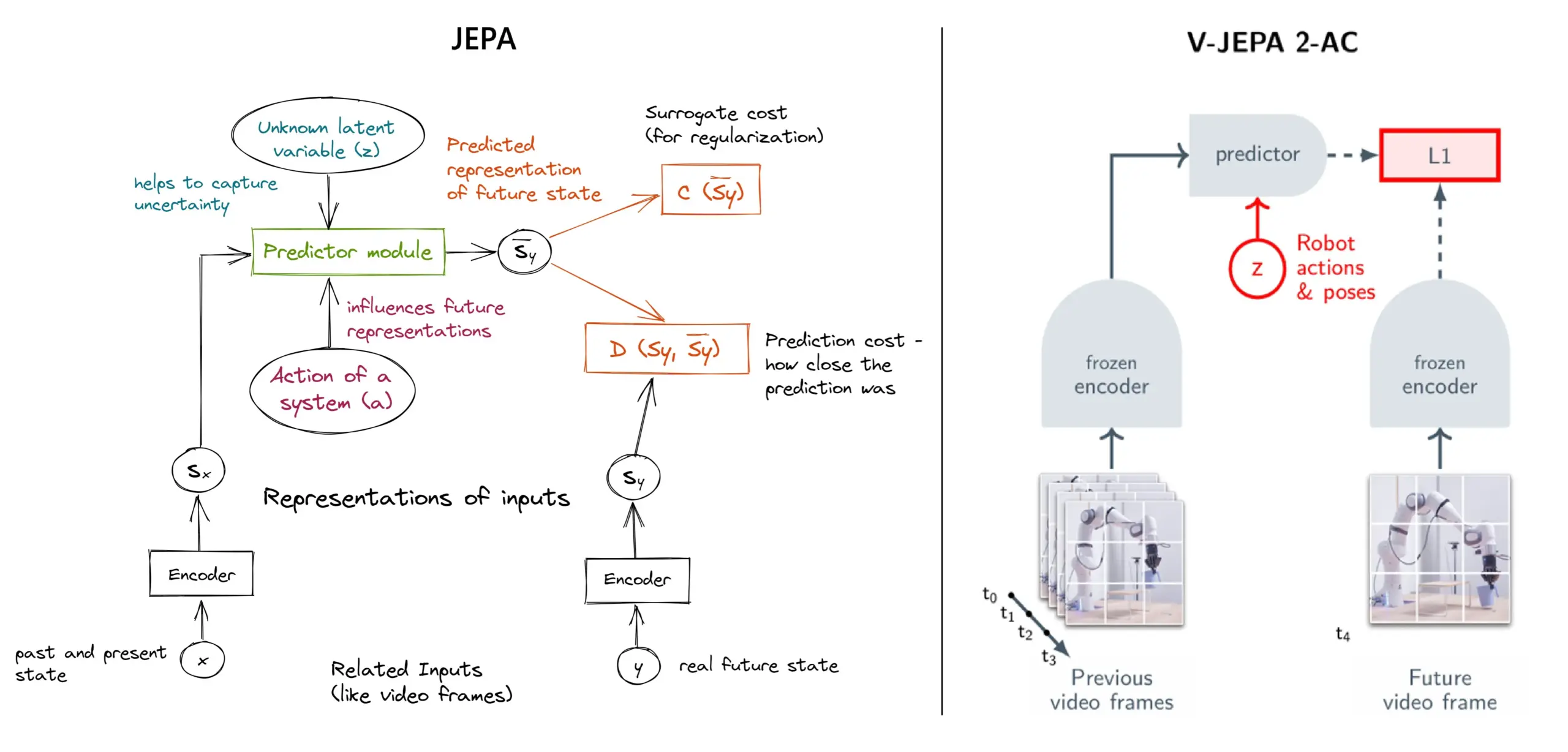
JEPA Self-Supervised Learning Framework erklärt: Überblick über 11 Typen: Das von Yann LeCun und anderen Forschern bei Meta vorgeschlagene JEPA (Joint Embedding Predictive Architecture) ist ein Self-Supervised Learning Framework, das lernt, indem es die latente Repräsentation fehlender Teile von Eingabedaten vorhersagt. Der Artikel stellt 11 verschiedene Typen von JEPA vor, darunter V-JEPA 2, TS-JEPA, D-JEPA usw., und bietet weitere Informationen und Links zu verwandten Ressourcen, die zum Verständnis dieser hochmodernen Self-Supervised Learning Methode beitragen (Quelle: TheTuringPost, TheTuringPost)
DSPy Framework: Entkopplung von Aufgaben und LLMs zur Verbesserung der Code-Wartbarkeit: Ein Artikel über das DSPy Framework weist darauf hin, dass DSPy die Komplexität der Verwendung von Large Language Models (LLMs) reduziert, indem es Aufgaben von LLMs entkoppelt. Selbst vor der Optimierung kann DSPy Entwicklern helfen, Projekte schneller zu starten und Code zu generieren, der einfacher zu warten und zu erweitern ist. Dies ist von großem Wert für Projekte, die komplexes Prompt Engineering und LLM-Integration erfordern (Quelle: lateinteraction, stanfordnlp)

Paper-Diskussion: Vision Transformers Don’t Need Trained Registers: Ein neues Forschungspapier untersucht den Mechanismus, durch den Artefakte in Attention Maps und Feature Maps von Vision Transformers entstehen, ein Phänomen, das auch in Large Language Models existiert. Das Papier schlägt eine trainingsfreie Methode zur Milderung dieser Artefakte vor, die darauf abzielt, die Leistung und Interpretierbarkeit von Vision Transformers zu verbessern. Die Studie ist wertvoll für das Verständnis und die Verbesserung der Anwendung von Transformer-Architekturen in visuellen Aufgaben (Quelle: Reddit r/MachineLearning)
Tutorial-Reihe: DeepSeek von Grund auf erstellen (insgesamt 29 Videos): Ein Content Creator hat eine Videotutorial-Reihe mit dem Titel „Wie man DeepSeek von Grund auf erstellt“ veröffentlicht, die insgesamt 29 Episoden umfasst. Der Inhalt deckt Grundlagen des DeepSeek-Modells, Architekturetails (wie Attention-Mechanismen, Multi-Head-Attention, KV-Cache, MoE), Positionskodierung, Multi-Token-Vorhersage und Quantisierung sowie andere Schlüsseltechnologien ab. Diese Tutorial-Reihe bietet wertvolle Videoressourcen für Lernende, die ein tiefes Verständnis der internen Funktionsweise von DeepSeek und ähnlichen großen Modellen erlangen möchten (Quelle: Reddit r/LocalLLaMA)

Tutorial: RAG-Pipeline zur Zusammenfassung von Hacker News-Posts erstellen: Haystack by deepset teilt ein schrittweises Tutorial, das Benutzer anleitet, wie man eine Retrieval Augmented Generation (RAG)-Pipeline erstellt. Diese Pipeline kann Echtzeit-Posts von Hacker News abrufen und diese mithilfe eines lokal ausgeführten Large Language Model (LLM)-Endpunkts zusammenfassen. Dies bietet Entwicklern, die RAG-Technologie zur Verarbeitung von Echtzeit-Informationsströmen und zur lokalen Verarbeitung nutzen möchten, einen praktischen Anwendungsfall (Quelle: dl_weekly)
Paper-Express: InterSyn-Datensatz und SynJudge-Bewertungsmodell für die Generierung von verschachtelten Bild-Text-Inhalten: Um die Unzulänglichkeiten aktueller LMMs bei der Generierung eng verschachtelter Bild-Text-Ausgaben zu beheben (hauptsächlich aufgrund begrenzter Größe, Qualität und Befehlsvielfalt der Trainingsdatensätze), stellten Forscher InterSyn vor, einen umfangreichen multimodalen Datensatz, der mit der SEIR-Methode (Self-Evaluation and Iterative Refinement) erstellt wurde. InterSyn enthält mehrstufige, befehlsgesteuerte Dialoge, bei denen Bilder und Texte in den Antworten eng miteinander verwoben sind. Gleichzeitig schlugen die Forscher zur Bewertung solcher Ausgaben das automatische Bewertungsmodell SynJudge vor, das anhand von vier Dimensionen bewertet: Textinhalt, Bildinhalt, Bildqualität und Bild-Text-Synergie. Experimente zeigen, dass LMMs, die auf InterSyn trainiert wurden, in allen Bewertungsmetriken Verbesserungen aufweisen (Quelle: HuggingFace Daily Papers)
Paper-Express: Neue Perspektiven für Bild- und Geometriesynthese durch Cross-Modal Attention Distillation für Alignment: Forscher schlagen ein diffusionsbasiertes Framework namens MoAI vor, das durch eine „Warping-and-Inpainting“-Methode die Generierung von ausgerichteten neuen Ansichten von Bildern und Geometrien ermöglicht. Diese Methode nutzt handelsübliche Geometrieprädiktoren, um Teile der Geometrie des Referenzbildes vorherzusagen, und synthetisiert neue Ansichten als Inpainting-Aufgabe für Bild und Geometrie. Um eine präzise Ausrichtung von Bild und Geometrie zu gewährleisten, schlägt das Paper Cross-Modal Attention Distillation vor, bei der während des Trainings und der Inferenz die Attention Maps des Bilddiffusionszweigs in den parallelen Geometriediffusionszweig injiziert werden. Diese Methode erreicht eine hochauflösende Extrapolationsansichtssynthese in verschiedenen unbekannten Szenen (Quelle: HuggingFace Daily Papers)
Paper-Express: Konfigurierbare Präferenzanpassung (CPT) basierend auf regelgeleiteten synthetischen Daten: Um das Problem der verfestigten Präferenzen und begrenzten Anpassungsfähigkeit in menschlichen Feedback-Modellen wie DPO zu lösen, schlagen Forscher das Framework der konfigurierbaren Präferenzanpassung (CPT) vor. CPT nutzt systemische Prompts, die auf strukturierten, feinkörnigen Regeln basieren (die gewünschte Attribute wie Schreibstil definieren), um synthetische Präferenzdaten zu generieren. Durch Feinabstimmung mit diesen regelgeleiteten Präferenzen können LLMs ihre Ausgabe zur Inferenzzeit dynamisch an systemische Prompts anpassen, ohne erneutes Training, was eine detailliertere und kontextbezogenere Präferenzkontrolle ermöglicht (Quelle: HuggingFace Daily Papers)
Paper-Express: The Diffusion Duality: Forscher stellen die Duo-Methode vor, die durch die Erkenntnis, dass diskrete Diffusionsprozesse im gleichmäßigen Zustand aus einer latenten Gaußschen Diffusion stammen, leistungsstarke Techniken der Gaußschen Diffusion auf diskrete Diffusionsmodelle überträgt, um deren Leistung zu verbessern. Dies beinhaltet konkret: 1) Einführung einer durch den Gaußschen Prozess geleiteten Curriculum-Learning-Strategie, die die Varianz reduziert, die Trainingsgeschwindigkeit verdoppelt und autoregressive Modelle in mehreren Benchmarks übertrifft. 2) Vorschlag einer diskreten Konsistenzdestillation, die die kontinuierliche Konsistenzdestillation an diskrete Einstellungen anpasst und durch Beschleunigung des Samplings um zwei Größenordnungen eine Few-Step-Generierung für Diffusionssprachmodelle ermöglicht (Quelle: HuggingFace Daily Papers)
Paper-Express: SkillBlender – Ganzkörper-Bewegungssteuerung für humanoide Roboter durch Skill-Fusion: Um die Einschränkungen bestehender Steuerungsmethoden für humanoide Roboter hinsichtlich Multi-Task-Generalisierung und Skalierbarkeit zu überwinden, schlagen Forscher SkillBlender vor, ein hierarchisches Reinforcement-Learning-Framework. Dieses Framework trainiert zunächst zielorientierte, aufgabenunabhängige primitive Skills vor und fusioniert diese dann dynamisch bei der Ausführung komplexer Bewegungssteuerungsaufgaben, wobei nur minimale aufgabenspezifische Belohnungstechnik erforderlich ist. Gleichzeitig wurde der SkillBench-Simulationsbenchmark zur Evaluierung eingeführt. Experimente zeigen, dass diese Methode die Genauigkeit und Durchführbarkeit verschiedener Bewegungssteuerungsaufgaben signifikant verbessern kann (Quelle: HuggingFace Daily Papers)
Paper-Express: U-CoT+ Framework – Entkoppeltes Verständnis und geleitete CoT-Inferenz zur Erkennung schädlicher Memes: Um den Herausforderungen der Ressourceneffizienz, Flexibilität und Interpretierbarkeit bei der Erkennung schädlicher Memes zu begegnen, schlagen Forscher das U-CoT+ Framework vor. Dieses Framework wandelt visuelle Memes zunächst durch einen hochauflösenden Meme-zu-Text-Konvertierungsprozess in detailreiche Textbeschreibungen um, wodurch die Meme-Interpretation von der Klassifizierung entkoppelt wird und allgemeine Large Language Models (LLMs) eine ressourceneffiziente Erkennung durchführen können. Anschließend wird das Modell in Verbindung mit von Menschen erstellten interpretierbaren Richtlinien unter Zero-Shot-CoT-Prompts zur Inferenz geleitet, was die Anpassungsfähigkeit an verschiedene Plattformen und zeitliche Veränderungen sowie die Interpretierbarkeit verbessert (Quelle: HuggingFace Daily Papers)
Paper-Express: CRAFT – Effektives Red Teaming von richtlinienkonformen Agenten: Angesichts des Problems der Einhaltung strenger Richtlinien (z. B. Rückerstattungsberechtigung) durch aufgabenorientierte LLM-Agenten schlagen Forscher ein neues Bedrohungsmodell vor, das sich auf gegnerische Benutzer konzentriert, die versuchen, richtlinienbasierte Agenten zum persönlichen Vorteil auszunutzen. Zu diesem Zweck entwickelten sie CRAFT, ein Multi-Agenten-Red-Teaming-System, das richtlinienbewusste Überzeugungsstrategien einsetzt, um richtlinienkonforme Agenten in Kundendienstszenarien anzugreifen, dessen Wirksamkeit traditionelle Jailbreak-Methoden übertrifft. Gleichzeitig wurde der tau-break-Benchmark eingeführt, um die Robustheit von Agenten gegenüber solchen manipulativen Verhaltensweisen zu bewerten (Quelle: HuggingFace Daily Papers)
Paper-Express: Scheitern dichter Retriever bei einfachen Abfragen und das Granularitätsdilemma von Embeddings: Die Forschung deckt eine Einschränkung von Text-Encodern auf: Embeddings erkennen möglicherweise keine feinkörnigen Entitäten oder Ereignisse innerhalb der Semantik, was dazu führt, dass dichte Retriever selbst in einfachen Fällen scheitern können. Um dieses Phänomen zu untersuchen, führt das Paper den chinesischen Evaluierungsdatensatz CapRetrieval ein (Absätze sind Bildunterschriften, Abfragen sind Entitäts-/Ereignis-Phrasen). Die Zero-Shot-Evaluierung zeigt, dass Encoder bei feinkörnigen Übereinstimmungen möglicherweise schlecht abschneiden. Die Feinabstimmung von Encodern mit der vorgeschlagenen Datengenerierungsstrategie kann die Leistung verbessern, deckt aber auch das „Granularitätsdilemma“ auf, d. h. Embeddings haben Schwierigkeiten, feinkörnige Signifikanz auszudrücken und gleichzeitig mit der Gesamtsemantik übereinzustimmen (Quelle: HuggingFace Daily Papers)
Paper-Express: pLSTM – Parallelisierbares Netzwerk zur Transformation linearer Quellen-Token: Angesichts der Einschränkung bestehender rekursiver Architekturen (wie xLSTM, Mamba), die hauptsächlich für sequentielle Daten geeignet sind oder eine sequentielle Verarbeitung mehrdimensionaler Daten erfordern, schlagen Forscher pLSTM (parallelisierbares Netzwerk zur Transformation linearer Quellen-Token) vor. pLSTM erweitert die Mehrdimensionalität auf lineare RNNs und verwendet Quellen-, Transformations- und Token-Gates, die auf dem Liniendiagramm eines allgemeinen gerichteten azyklischen Graphen (DAG) operieren, wodurch eine Parallelisierung ähnlich parallelen assoziativen Scans und blockrekursiven Formen erreicht wird. Diese Methode zeigt gute Extrapolationsfähigkeiten und Leistung bei synthetischen Computer-Vision-Aufgaben sowie auf Molekülgraphen- und Computer-Vision-Benchmarks (Quelle: HuggingFace Daily Papers)
Paper-Express: DeepVideo-R1 – Video-Reinforcement-Feinabstimmung durch schwierigkeitsbewusste Regression GRPO: Angesichts der Unzulänglichkeiten von Reinforcement Learning in Video Large Language Model (Video LLM)-Anwendungen schlagen Forscher DeepVideo-R1 vor, ein Video LLM, das durch das von ihnen vorgeschlagene Reg-GRPO (Regression-based GRPO) und eine schwierigkeitsbewusste Datenaugmentierungsstrategie trainiert wurde. Reg-GRPO formuliert das GRPO-Ziel als Regressionsaufgabe um, die direkt die Advantage-Funktion in GRPO vorhersagt und so die Abhängigkeit von Sicherheitsmaßnahmen wie Clipping beseitigt und die Strategie direkter lenkt. Die schwierigkeitsbewusste Datenaugmentierung verstärkt dynamisch Trainingsbeispiele mit lösbarem Schwierigkeitsgrad. Experimente zeigen, dass DeepVideo-R1 die Video-Inferenzleistung signifikant verbessert (Quelle: HuggingFace Daily Papers)
Paper-Express: Selbstverfeinerndes Framework zur Verbesserung von ASR durch TTS-synthetisierte Daten: Forscher schlagen ein selbstverfeinerndes Framework vor, das die Leistung der automatischen Spracherkennung (ASR) nur unter Verwendung unmarkierter Datensätze verbessert. Das Framework generiert zunächst mit einem vorhandenen ASR-Modell Pseudo-Labels auf unmarkierter Sprache und trainiert dann mit diesen Pseudo-Labels ein hochgenaues Text-to-Speech (TTS)-System. Anschließend werden die vom TTS synthetisierten Sprach-Text-Paare verwendet, um das Training des ursprünglichen ASR-Systems zu leiten, wodurch ein geschlossener Selbstverbesserungskreislauf entsteht. Experimente mit taiwanesischem Mandarin zeigen, dass diese Methode die Fehlerraten signifikant senken kann und einen praktischen Weg zur Leistungssteigerung von ASR bei geringen Ressourcen oder in bestimmten Bereichen bietet (Quelle: HuggingFace Daily Papers)
Paper-Express: Inhärent treue Attention Maps für Vision Transformer: Forscher schlagen eine auf Attention basierende Methode vor, die gelernte binäre Attention-Masken verwendet, um sicherzustellen, dass nur die beachteten Bildbereiche die Vorhersage beeinflussen. Diese Methode zielt darauf ab, Verzerrungen zu beheben, die durch den Kontext bei der Objekterkennung entstehen können, insbesondere wenn Objekte in nicht-verteilten Hintergründen erscheinen. Durch ein zweistufiges Framework (die erste Stufe entdeckt Objektteile und identifiziert aufgabenrelevante Bereiche, die zweite Stufe nutzt Eingabe-Attention-Masken, um das rezeptive Feld für eine fokussierte Analyse einzuschränken) wird durch gemeinsames Training die Robustheit des Modells gegenüber Scheinkorrelationen und nicht-verteilten Hintergründen verbessert (Quelle: HuggingFace Daily Papers)
Paper-Express: ViCrit – Verifizierbare Reinforcement Learning Proxy-Aufgabe für visuelle Wahrnehmung von VLMs: Um das Problem zu lösen, dass es bei visuellen Wahrnehmungsaufgaben in VLMs an gleichzeitig herausfordernden und eindeutig verifizierbaren Aufgaben mangelt, führen Forscher ViCrit (Visual Caption Hallucination Critic) ein. Dies ist eine RL-Proxy-Aufgabe, die VLMs trainiert, subtile, synthetische visuelle Halluzinationen zu lokalisieren, die in von Menschen geschriebene Bildunterschriftenabschnitte injiziert wurden. Indem ein einzelner subtiler visueller Beschreibungsfehler in eine etwa 200 Wörter lange Bildunterschrift injiziert wird und das Modell aufgefordert wird, den Fehlerbereich basierend auf dem Bild und der modifizierten Bildunterschrift zu lokalisieren, bietet diese Aufgabe eine leicht berechenbare und eindeutige binäre Belohnung. Mit ViCrit trainierte Modelle zeigen signifikante Zuwächse in verschiedenen VL-Benchmarks (Quelle: HuggingFace Daily Papers)
Paper-Express: Jenseits homogener Aufmerksamkeit – Speichereffiziente LLMs mit Fourier-approximiertem KV-Cache: Um das Problem des mit zunehmender Kontextlänge wachsenden KV-Cache-Speicherbedarfs in LLMs zu lösen, schlagen Forscher FourierAttention vor, ein trainingsfreies Framework. Dieses Framework nutzt die heterogenen Rollen der Transformer-Kopfdimensionen: niedrigdimensionale bevorzugen lokalen Kontext, hochdimensionale erfassen Langstreckenabhängigkeiten. Durch Projektion der langkontext-unempfindlichen Dimensionen auf eine orthogonale Fourier-Basis approximiert FourierAttention deren zeitliche Entwicklung mit Spektralkoeffizienten fester Länge. Evaluierungen mit LLaMA-Modellen zeigen, dass diese Methode die beste Langkontext-Genauigkeit auf LongBench und NIAH erreicht und den Speicher durch den maßgeschneiderten Triton-Kernel FlashFourierAttention optimiert (Quelle: HuggingFace Daily Papers)
Paper-Express: JAFAR – Universeller Upsampler zur Verbesserung beliebiger Merkmale bei beliebiger Auflösung: Angesichts des Problems, dass die niedrigauflösenden räumlichen Merkmale, die von grundlegenden visuellen Encodern ausgegeben werden, den Anforderungen nachgelagerter Aufgaben nicht genügen, führen Forscher JAFAR ein, einen leichtgewichtigen, flexiblen Merkmals-Upsampler. JAFAR kann die räumliche Auflösung der visuellen Merkmale jedes grundlegenden visuellen Encoders auf eine beliebige Zielauflösung erhöhen. Es verwendet ein auf Aufmerksamkeit basierendes Modul, das durch räumliche Merkmals-Transformation (SFT) moduliert wird, um die semantische Ausrichtung zwischen hochauflösenden Abfragen, die von niedrigstufigen Bildmerkmalen stammen, und semantisch reichen niedrigauflösenden Schlüsseln zu fördern. Experimente zeigen, dass JAFAR feinkörnige räumliche Details effektiv wiederherstellen kann und in verschiedenen nachgelagerten Aufgaben bestehende Methoden übertrifft (Quelle: HuggingFace Daily Papers)
Paper-Express: SwS – Selbstwahrnehmungsgesteuerte Problemsynthese für Schwachstellen im Reinforcement Learning: Angesichts des Problems des Mangels an qualitativ hochwertigen, antwortverifizierbaren Problemsätzen beim Training von LLMs zur Lösung komplexer Schlussfolgerungsaufgaben (wie mathematische Probleme) mit RLVR (Reinforcement Learning with Verifiable Rewards) schlagen Forscher das SwS (Self-aware Weakness-driven problem Synthesis) Framework vor. SwS identifiziert systematisch Modellfehler (Probleme, bei denen das Modell im RL-Training kontinuierlich scheitert), extrahiert die Kernkonzepte dieser Fehlerfälle und synthetisiert neue Probleme, um die Schwachstellen des Modells im nachfolgenden Verstärkungstraining zu stärken. Dieses Framework ermöglicht es dem Modell, seine Schwächen im RL selbst zu erkennen und zu beheben, und erzielt signifikante Leistungssteigerungen in mehreren gängigen Inferenz-Benchmarks (Quelle: HuggingFace Daily Papers)
Paper-Express: Erlernen eines „Weiterdenken“-Tokens zur Verbesserung der Testzeit-Skalierungsfähigkeit: Um die Leistung von Sprachmodellen bei der Erweiterung von Inferenzschritten durch zusätzliche Berechnungen zur Testzeit zu verbessern, untersuchen Forscher die Machbarkeit des Erlernens eines dedizierten „Weiterdenken“-Tokens (<|continue-thinking|>). Sie trainieren ausschließlich das Embedding dieses Tokens mittels Reinforcement Learning, während die Gewichte einer destillierten Version des DeepSeek-R1-Modells eingefroren bleiben. Experimente zeigen, dass das gelernte Token im Vergleich zu Basismodellen und Testzeit-Skalierungsmethoden, die feste Tokens (wie “Wait”) zur Budgeterzwingung verwenden, eine höhere Genauigkeit in Standard-Mathematik-Benchmarks erzielt, insbesondere in Fällen, in denen feste Tokens die Genauigkeit des Basismodells verbessern können, bringt das gelernte Token größere Verbesserungen (Quelle: HuggingFace Daily Papers)
Paper-Express: LoRA-Edit – Kontrollierbare Videobearbeitung mit First-Frame-Führung durch maskenbewusste LoRA-Feinabstimmung: Um das Problem zu lösen, dass bestehende Videobearbeitungsmethoden von umfangreichem Vortraining abhängen und eine unzureichende Flexibilität aufweisen, schlagen Forscher LoRA-Edit vor, eine maskenbasierte LoRA-Feinabstimmungsmethode zur Anpassung vortrainierter Image-to-Video (I2V)-Modelle für flexible Videobearbeitung. Diese Methode bewahrt Hintergrundbereiche, während sie kontrollierbare Bearbeitungseffekte propagiert und andere Referenzinformationen (wie alternative Blickwinkel oder Szenenzustände) als visuelle Anker einbezieht. Durch eine maskengesteuerte LoRA-Anpassungsstrategie lernt das Modell aus dem Eingangsvideo (räumliche Struktur und Bewegungshinweise) und dem Referenzbild (Erscheinungsbildführung), um bereichsspezifisches Lernen zu realisieren (Quelle: HuggingFace Daily Papers)
Paper-Express: Infinity Instruct – Erweiterung der Befehlsauswahl und -synthese zur Verbesserung von Sprachmodellen: Um den Mangel auszugleichen, dass bestehende Open-Source-Befehlsdatensätze oft auf enge Bereiche (wie Mathematik, Programmierung) fokussiert sind, was zu einer begrenzten Generalisierungsfähigkeit führt, stellen Forscher Infinity-Instruct vor, einen hochwertigen Befehlsdatensatz, der darauf abzielt, die grundlegenden und Chat-Fähigkeiten von LLMs durch einen zweistufigen Prozess zu verbessern. In Phase eins werden mithilfe von gemischten Datenauswahltechniken 7,4 Millionen hochwertige grundlegende Befehle aus über 100 Millionen Stichproben ausgewählt. In Phase zwei werden durch einen zweistufigen Prozess der Befehlsauswahl, -evolution und -diagnosefilterung 1,5 Millionen hochwertige Chat-Befehle synthetisiert. Feinabstimmungsexperimente mit verschiedenen Open-Source-Modellen zeigen, dass dieser Datensatz die Leistung der Modelle in grundlegenden und befehlsfolgenden Benchmarks signifikant verbessern kann (Quelle: HuggingFace Daily Papers)
Paper-Express: Erst Kandidaten, dann Destillation – Lehrer-Schüler-Framework für LLM-gesteuerte Datenannotation: Angesichts des Problems, dass bei bestehenden LLM-Datenannotationsmethoden die direkte Bestimmung eines einzigen Gold-Labels durch das LLM aufgrund von Unsicherheit zu Fehlern führen kann, schlagen Forscher ein neues Kandidaten-Annotationsparadigma vor: LLMs werden ermutigt, bei Unsicherheit alle möglichen Labels auszugeben. Um sicherzustellen, dass nachgelagerte Aufgaben ein eindeutiges Label erhalten, wurde das Lehrer-Schüler-Framework CanDist entwickelt, das Kandidatenannotationen mit einem kleinen Sprachmodell (SLM) destilliert. Theoretisch wird nachgewiesen, dass die Destillation von Kandidatenannotationen vom Lehrer-LLM der direkten Verwendung einer einzelnen Annotation überlegen ist. Experimente bestätigen die Wirksamkeit dieser Methode (Quelle: HuggingFace Daily Papers)
Paper-Express: Med-PRM – Medizinisches Inferenzmodell mit schrittweiser, leitlinienvalidierter Prozessbelohnung: Um die Einschränkung von Large Language Models bei der Lokalisierung und Korrektur spezifischer Fehler in Inferenzschritten bei klinischen Entscheidungen zu überwinden, führen Forscher Med-PRM ein, ein Prozessbelohnungsmodellierungs-Framework. Dieses Framework nutzt Retrieval Augmented Generation-Techniken, um jeden Inferenzschritt anhand etablierter medizinischer Wissensdatenbanken (klinische Leitlinien und Literatur) zu validieren. Durch diese feinkörnige Methode zur präzisen Bewertung der Inferenzqualität erreicht Med-PRM SOTA-Leistung in mehreren medizinischen QA-Benchmarks und offenen Diagnoseaufgaben und kann als Plug-and-Play-Modul mit starken Strategiemodellen (wie Meerkat) integriert werden, wodurch die Genauigkeit kleinerer Modelle (8B Parameter) signifikant verbessert wird (Quelle: HuggingFace Daily Papers)
Paper-Express: Feedback-Reibung – LLMs haben Schwierigkeiten, externes Feedback vollständig aufzunehmen: Die Studie untersucht systematisch die Fähigkeit von LLMs, externes Feedback aufzunehmen. Im Experiment versucht ein Solver-Modell, ein Problem zu lösen, woraufhin ein Feedback-Generator mit nahezu vollständigen wahren Antworten gezieltes Feedback gibt, und der Solver versucht es erneut. Die Ergebnisse zeigen, dass selbst unter nahezu idealen Bedingungen, einschließlich SOTA-Modelle wie Claude 3.7, eine Resistenz gegenüber Feedback aufweisen, die als „Feedback-Reibung“ bezeichnet wird. Obwohl Strategien wie progressive Temperaturerhöhung und explizite Ablehnung früherer falscher Antworten Verbesserungen brachten, erreichten die Modelle die Zielleistung nicht. Die Studie schließt Faktoren wie übermäßiges Selbstvertrauen des Modells und Datenvertrautheit aus und zielt darauf ab, dieses Kernhindernis für die Selbstverbesserung von LLMs aufzudecken (Quelle: HuggingFace Daily Papers)
💼 Wirtschaft
Meta investiert 14,3 Milliarden US-Dollar für 49% Anteil an Scale AI, Gründer Alexandr Wang tritt Meta Superintelligence-Team bei: Meta gab bekannt, für 14,3 Milliarden US-Dollar einen Anteil von 49% ohne Stimmrecht an dem AI-Datenannotationsunternehmen Scale AI erworben zu haben. Der Gründer von Scale AI, der 28-jährige chinesisch-amerikanische Wunderkind Alexandr Wang, wird weiterhin Vorstandsmitglied bleiben und mit seinem Kernteam dem von Mark Zuckerberg persönlich gegründeten Meta Superintelligence-Team beitreten. Diese Akquisition wird als teure Talentakquise angesehen, um Metas AI-Fähigkeiten nach der enttäuschenden Leistung von Llama 4 zu stärken und AI tief in alle seine Produkte zu integrieren. Scale AI begann mit der Bereitstellung von qualitativ hochwertigen, manuell annotierten Daten in großem Maßstab und zählt Waymo, OpenAI und andere zu seinen Kunden. Dieser Schritt hat Bedenken hinsichtlich der Neutralität seiner Plattform und der Datensicherheit ausgelöst; Kunden wie Google könnten die Zusammenarbeit einstellen (Quelle: 36氪)

Kunlun Wanweis „All in AI“-Strategie führt zum ersten Verlust seit zehn Jahren Börsengang, kommerzielle Aussichten für AI unklar: Seit der Ankündigung seiner „All in AGI & AIGC“-Strategie hat Kunlun Wanwei aktiv in große Modelle (Tiangong Large Model) sowie AI-Musik (Mureka), AI-Social (Linky), AI-Video (SkyReels), AI-Office (Skywork Super Agents) und AI-Rechenleistungschips investiert. Hohe F&E-Investitionen und Marketingkosten führten jedoch dazu, dass das Unternehmen 2024 den ersten Verlust seit seinem Börsengang vor zehn Jahren verzeichnete (1,59 Mrd. Yuan), und die Verluste setzten sich im ersten Quartal 2025 fort. Obwohl einige AI-Anwendungen wie Mureka und Linky begonnen haben, Einnahmen zu generieren, stehen die Rentabilität und Wettbewerbsfähigkeit des gesamten AI-Geschäfts weiterhin vor Herausforderungen. Ob es mithilfe von AI seinen „Traum vom Großunternehmen“ verwirklichen kann, muss der Markt noch zeigen (Quelle: 36氪)

OpenAI testet möglicherweise Werbung in ChatGPT, Profitdruck treibt Erkundung von Geschäftsmodellen an: Einige zahlende ChatGPT Plus-Nutzer berichteten, dass sie bei der Nutzung des erweiterten Sprachmodus auf Werbeeinblendungen gestoßen sind, was Diskussionen darüber auslöste, ob OpenAI begonnen hat, Werbung bei zahlenden Nutzern zu testen. Zuvor gab es Berichte, dass OpenAI die Einführung von Werbung erwägt, um seine Einnahmen zu erweitern. Angesichts der hohen Betriebskosten und des Profitdrucks von AI-Großmodellen (erwarteter Verlust von 44 Mrd. US-Dollar bis 2029) sowie der Unsicherheit über den Zeitpunkt der Realisierung von AGI wird die Suche von OpenAI nach neuen Monetarisierungsmodellen wie Werbung als unvermeidliche Notwendigkeit für seine geschäftliche Nachhaltigkeit angesehen, insbesondere bei einer relativ geringen Durchdringung von zahlenden Nutzern (Quelle: 36氪)

🌟 Community
AI birgt enormes Potenzial im Bereich Data Science, Databricks stellt aktiv ein: Matei Zaharia von Databricks ist der Ansicht, dass die Produktivitätssteigerung durch AI im Bereich Data Science noch signifikanter sein wird als bei AI-gestützter Programmierung. Databricks treibt diesen Trend mit Produkten wie Lakeflow Designer und Genie Deep Research voran und stellt aktiv Forscher und Ingenieure in diesem Bereich ein, was die hohe Bedeutung zeigt, die die Industrie der AI-getriebenen Innovation in der Data Science beimisst (Quelle: matei_zaharia)
Unterschiede in der „Persönlichkeit“ von LLMs beeinflussen das Verhalten von Agenten-Schleifen: Der Forscher Fabian Stelzer beobachtete, dass verschiedene Large Language Models (LLMs) Unterschiede in ihrer „Persönlichkeit“ aufweisen, was dazu führt, dass sie sich bei der Ausführung von agentischen Schleifenaufgaben unterschiedlich verhalten. Beispielsweise neigt Claude dazu, Werkzeuge seriell auszuführen, während GPT-4.1 eine starke Präferenz für parallele Ausführung hat und sogar serielle Anfragen ignoriert; das Haiku-Modell ist beim Auslösen von Werkzeugen „aggressiver“. Diese Beobachtung unterstreicht die Bedeutung der Berücksichtigung der Eigenschaften des zugrundeliegenden LLMs und der funktionalen Konsequenzen des „emotionalen Zustands“ bei der Gestaltung und Bewertung von Multi-Agenten-Systemen (Quelle: fabianstelzer, menhguin)
LLM-„Denken“ hängt von Token-Ausgabe ab, ohne Ausgabe keine effektive Analyse: Nutzer dotey zitiert xincmms Entdeckung beim Debuggen eines ReAct-Prompts: Wenn erwartet wird, dass ein LLM zuerst analysiert und dann eine Aktion ausführt (z. B. zeichnen), aber der Analyseprozess nicht als Tokens ausgegeben wird, kann das LLM den Analyseschritt direkt überspringen. Dies bestätigt, dass der „Denkprozess“ von LLMs durch die Generierung von Tokens realisiert wird. Eine im Prompt definierte „Analyse“ ohne tatsächliche Inhaltsausgabe bedeutet, dass die AI diese Analyse nicht wirklich durchgeführt hat. Dies ist richtungsweisend für die Gestaltung effektiver LLM-Prompts (Quelle: dotey)

AI an Grenzen bei spezifischen Aufgaben: Terence Tao sagt, AI fehle der „mathematische Riecher“: Der Mathematiker Terence Tao wies darauf hin, dass von AI generierte Beweise zwar oberflächlich makellos erscheinen (den „Augentest“ bestehen), ihnen aber oft ein subtiler, menschlicher „mathematischer Riecher“ fehle und sie dazu neigen, nicht-menschliche Fehler zu machen. Er ist der Meinung, dass echte Intelligenz nicht nur darin besteht, richtig auszusehen, sondern auch darin, „riechen“ zu können, was wahr ist. Dies offenbart die Grenzen aktueller AI im tiefen Verständnis und intuitiven Urteilsvermögen (Quelle: ecsquendor)
Herausforderungen bei AI-generierten Inhalten und realen physikalischen Gesetzen: Nutzer karminski3 stellte bei Tests mit Doubao Seed 1.6 und DeepSeek-R1 zur Codegenerierung (Simulation der 3D-Animation einer Schornsteinsprengung) fest, dass die Modelle zwar Code generieren und Animationen simulieren können, es aber bei der Wiedergabe realer physikalischer Prozesse (wie Stoßwelleneffekte, Art des Struktureinsturzes) noch Unterschiede und Verbesserungspotenzial gibt. Doubao Seed 1.6 war bei Partikeleffekten und der Simulation des Struktureinsturzes näher an der Realität, während DeepSeek bei Licht- und Raucheffekten besser abschnitt. Dies spiegelt die Herausforderungen der AI beim Verständnis und der Simulation komplexer physikalischer Phänomene wider (Quelle: karminski3)
Erfahrener Programmierer wegen übermäßiger Abhängigkeit von AI beim Programmieren, mangelnder Bereitschaft zu manuellen Änderungen und Einschüchterung von Neulingen mit AI-Ersetzung entlassen: Ein von 36Kr weitergeleiteter Reddit-Post erzählt von einem Programmierer mit 30 Jahren Erfahrung, der entlassen wurde, weil er sich exzessiv auf AI verließ (z. B. vollständige Abhängigkeit von Copilot Agent für PR-Einreichungen, Ablehnung manueller Code-Änderungen, 5 Tage für eine 1-Tages-Aufgabe, Verbreitung der AI-Ersetzungstheorie unter Praktikanten). Der Vorfall löste Diskussionen über die Grenzen des vernünftigen Einsatzes von AI in der Softwareentwicklung und die Auswirkungen von AI auf den beruflichen Wert von Entwicklern aus (Quelle: 36氪)
AI-„Flow“ und „Persönlichkeit“ beeinflussen Nutzererfahrung: Nutzerfeedback zu übermäßig „positiver Zustimmung“ durch AI: Reddit-Community-Nutzer diskutieren, dass AI (insbesondere Claude) bei der Interaktion dazu neigt, übermäßig optimistisch zu sein und den Ansichten der Nutzer zuzustimmen, wobei es an effektiver Herausforderung und tiefgreifendem kritischem Feedback mangelt, was den Nutzern das Gefühl gibt, sich in einer „Echokammer“ zu befinden. Diese „AI-Tonmüdigkeit“ veranlasst Nutzer, nach Wegen zu suchen, AI neutraler und kritischer agieren zu lassen, beispielsweise durch spezifische Prompts. Dies spiegelt die aktuellen Herausforderungen der AI bei der Simulation echter, vielschichtiger menschlicher Dialoge und der Bereitstellung wirklich tiefgreifender Einsichten wider (Quelle: Reddit r/ClaudeAI)
Im AI-Zeitalter gewinnt menschliches Feedback an Wert, aber Plattformen für echte menschliche Interaktion sehen sich mit AI-Content-Infiltration konfrontiert: Reddit-Nutzer diskutieren, dass vor dem Hintergrund zunehmender AI-generierter Inhalte echtes menschliches Feedback und Meinungen wertvoller werden und Plattformen wie Reddit wegen ihrer menschlichen Interaktionsmerkmale geschätzt werden. Diese Plattformen stehen jedoch auch vor der Herausforderung der Infiltration durch AI-generierte Inhalte (wie Bot-Kommentare, AI-unterstützte Beiträge), was die Unterscheidung echter menschlicher Ansichten erschwert und Bedenken hinsichtlich der Authentizität der zukünftigen Online-Kommunikation aufwirft (Quelle: Reddit r/ArtificialInteligence)
AI-„Freunde“ bald Normalität? Trend und Diskussion über emotionale Verbindungen von Nutzern zu AI: In sozialen Medien und Reddit-Communities gibt es Diskussionen über AI-Begleiter und AI-Freunde. Einige Nutzer glauben, dass AI-Freunde aufgrund der vorurteilsfreien und stets unterstützenden Natur von AI in den nächsten 5 Jahren zur Normalität werden könnten, was sich bereits in Anwendungen wie Endearing AI, Replika und Character.ai zeige. Andere Nutzer teilen ihre Erfahrungen mit tiefen Gesprächsbeziehungen zu AI wie ChatGPT, die sie sogar als ihre „besten Freunde“ betrachten. Dies löst weitreichende Überlegungen über emotionale Interaktionen zwischen Mensch und AI, die Rolle von AI in der emotionalen Unterstützung und ihre potenziellen sozialen Auswirkungen aus (Quelle: Ronald_vanLoon, Reddit r/artificial, Reddit r/ArtificialInteligence)

Zukunft von AI-„Wrapper“-Startups wird diskutiert: Die Reddit-Community erörtert die Aussichten zahlreicher AI-Startups, die auf Basismodellen wie GPT oder Claude aufbauen (durch Hinzufügen einer Benutzeroberfläche, Prompt-Ketten oder Feinabstimmung für spezifische Bereiche). Diskussionsteilnehmer stellen in Frage, ob solche „Wrapper“-Anwendungen wettbewerbsfähig bleiben können, wenn die Basismodellplattformen selbst ihre Funktionen erweitern, und ob sie echte Wettbewerbsvorteile aufbauen können. Es wird argumentiert, dass die Konzentration auf spezifische vertikale Märkte, die Anhäufung eigener Daten und das Übertreffen einfacher Wraps ein Weg zu nachhaltiger Entwicklung sein könnte (Quelle: Reddit r/LocalLLaMA)
Diskussion über das Verdrängungspotenzial von AI in der medizinischen Diagnostik im Vergleich zur Softwareentwicklung: In der Reddit-Community wird diskutiert, dass AI Ärzte möglicherweise schneller ersetzen könnte als leitende Softwareingenieure. Als Begründung wird angeführt, dass viele medizinische Diagnosen etablierten Protokollen folgen und AI gut darin ist, Testergebnisse zu interpretieren und Symptome zu erkennen; während Softwareentwicklung oft umfangreiches implizites Wissen und komplexe Anforderungskommunikation beinhaltet, was AI schwer vollständig bewältigen kann. Diese Ansicht löst weitere Überlegungen über die Anwendungstiefe und das Verdrängungspotenzial von AI in verschiedenen Fachbereichen aus, wird aber auch von Ärzten und anderen Fachleuten widerlegt, die die Komplexität der praktischen Anwendung und die Bedeutung menschlichen Urteilsvermögens betonen (Quelle: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
💡 Sonstiges
Luo Yonghaos AI-Digital-Avatar feiert Premiere auf Baidu E-Commerce, GMV über 55 Millionen: Luo Yonghaos AI-Digital-Avatar führte seine erste Live-Shopping-Übertragung auf der Baidu E-Commerce-Plattform durch, zog über 13 Millionen Zuschauer an und erzielte einen Bruttowarenwert (GMV) von über 55 Millionen Yuan. Der digitale Avatar wurde von Baidu E-Commerces „Huiboxing“-Plattform unter Verwendung des Wenxin 4.5 Large Models erstellt und kann Luo Yonghaos Tonfall, Akzent und Mimik simulieren sowie intelligent antworten. Diese Live-Übertragung demonstrierte das Potenzial des „AI + Top-Influencer“-Modells sowie Baidus Positionierung im Bereich der „hochüberzeugenden digitalen Menschen“-Technologie und des AI E-Commerce (Quelle: 36氪)

Baidu, Tencent und andere Unternehmen verstärken Rekrutierung von AI-Talenten und starten großangelegte Einstellungsprogramme: Baidu hat sein bisher größtes Rekrutierungsprogramm für Top-AI-Talente, das „AIDU-Programm“, gestartet. Die Anzahl der ausgeschriebenen Stellen wurde im Vergleich zum Vorjahr um 60 % erhöht, wobei der Fokus auf zukunftsweisende Bereiche wie Algorithmen für große Modelle und Basisinfrastruktur liegt und Gehälter ohne Obergrenze angeboten werden. Auch Tencent veranstaltet einen Algorithmen-Wettbewerb zum Thema „Full-Modal Generative Recommendation“ mit Preisgeldern in Millionenhöhe und Jobangeboten für Hochschulabsolventen, um globale AI-Talente anzuziehen. Diese Maßnahmen spiegeln den dringenden Bedarf und die strategische Ausrichtung chinesischer Technologiegiganten auf Top-Talente vor dem Hintergrund des sich verschärfenden Wettbewerbs im AI-Bereich wider (Quelle: 量子位, 量子位)

Baidu startet umfassenden AI-gestützten Dienst zur Unterstützung bei der Studienwahl, integriert mehrere Modelle und Big Data: Angesichts der Komplexität der Studienwahl durch die neue Hochschulaufnahmeprüfungsreform hat Baidu ein kostenloses AI-gestütztes Tool zur Unterstützung bei der Studienwahl online gestellt. Der Dienst ist in die „Hochschulaufnahmeprüfung“-Themenseite der Baidu-App integriert und bietet einen „AI-Studienwahl-Assistenten“ für Hochschul- und Studienfach-Empfehlungen sowie Analysen der Zulassungswahrscheinlichkeit. Er unterstützt multimodale „AI-Chat-über-Studienwahl“-Agenten wie Wenxin und DeepSeek R1 für personalisierte Beratung. Darüber hinaus werden exklusive Such-Big-Data von Baidu für Analysen der Berufsaussichten von Studienfächern, MBTI-Berufstests sowie Live-Übertragungen von Hochschulzulassungsstellen und Q&A-Sitzungen mit älteren Studierenden als reale Unterstützungsressourcen angeboten, um Studienbewerbern zu helfen, Informationsdefizite zu bewältigen und eine passendere Studienwahl zu treffen (Quelle: 36氪)