
Schlüsselwörter:Große Sprachmodelle, KI-Bewertung, Multi-Agenten-Systeme, Schlussfolgerungsfähigkeit, Kontextverarbeitung, Open-Source-Modelle, KI-Videogenerierung, KI-Programmierung, Bewertung der LLM-Schlussfolgerungsfähigkeit, Claude Opus 4 widerlegt Apple-Papier, MiniMax-M1 MoE-Modell, Kimi-Dev-72B-Programmiermodell, Gemini Deep-Think-Funktion
🔥 Fokus
Apple-Paper, das die Schlussfolgerungsfähigkeiten von großen Modellen in Frage stellt, wird widerlegt; Claude-Co-Autor weist auf Fehler im experimentellen Design hin: Apple veröffentlichte kürzlich ein Paper mit dem Titel „The Illusion of Thinking“, in dem durch Tests mit klassischen Problemen wie dem Turm von Hanoi und der Blockwelt darauf hingewiesen wurde, dass führende große Sprachmodelle (LLM) bei komplexen Schlussfolgerungsaufgaben schlecht abschneiden und im Wesentlichen Pattern Matching betreiben, anstatt wirklich zu verstehen. Der unabhängige Forscher Alex Lawsen und das KI-Modell Claude Opus 4 veröffentlichten jedoch gemeinsam den Artikel „The Illusion of ‘The Illusion of Thinking’“, der argumentiert, dass Apples Experiment Designfehler aufwies: 1. Die Obergrenze für die Token-Ausgabe von LLMs wurde nicht berücksichtigt, was dazu führte, dass Modelle als fehlerhaft bewertet wurden, weil sie extrem lange Schritte nicht vollständig ausgeben konnten; 2. Einige Testfälle (wie bestimmte „Flussüberquerungsprobleme“) sind unter den gegebenen Bedingungen mathematisch unlösbar, und die Unfähigkeit der KI, eine „korrekte Antwort“ zu geben, ist nicht auf mangelnde Fähigkeiten zurückzuführen; 3. Eine Änderung der Bewertungsmethode, z. B. die Anforderung an das Modell, ein Lösungsprogramm anstelle vollständiger Schritte auszugeben, führt zu einer hervorragenden Leistung der KI. Dieser Vorfall löste eine breite Diskussion über die tatsächlichen Schlussfolgerungsfähigkeiten von LLMs und Bewertungsmethoden aus, unterstreicht die Bedeutung der Entwicklung vernünftiger Bewertungsschemata und erinnert Entwickler daran, bei praktischen Anwendungen auf Faktoren wie Kontextfenster, Ausgabebudget und Aufgabenformulierung zu achten, die die Modellleistung beeinflussen. (Quelle: 新智元, 大数据文摘)
Googles KI-Roadmap enthüllt, deutet an, dass die nächste Generation der KI-Architektur möglicherweise den bestehenden Attention-Mechanismus aufgibt: Logan Kilpatrick, Produktleiter bei Google, enthüllte auf der AI Engineer World’s Fair die zukünftige Entwicklungsrichtung des Gemini-Modells. Am bemerkenswertesten ist die Aussicht auf die Realisierung eines „unendlichen Kontextfensters“. Er wies darauf hin, dass mit dem aktuellen Attention-Mechanismus und der Kontextverarbeitung kein wirklich unendliches Kontextfenster realisiert werden kann, was darauf hindeutet, dass Google möglicherweise eine völlig neue Kern-KI-Architektur erforscht. Die Roadmap umfasst außerdem: vollständige Modalitätsfähigkeiten (Bild + Audio werden bereits unterstützt, Video ist die nächste Stufe), frühe Experimente mit Diffusion, standardmäßig integrierte Agent-Fähigkeiten (erstklassiger Werkzeugaufruf und -nutzung, wobei sich Modelle schrittweise zu intelligenten Agenten entwickeln), kontinuierlich erweiterte Schlussfolgerungsfähigkeiten und die Einführung weiterer kleinerer Modelle. Diese Reihe von Plänen zeigt, dass Google aktiv die Entwicklung von KI von passiven Antworten hin zu proaktiven intelligenten Agenten vorantreibt und sich dafür einsetzt, bestehende technologische Engpässe zu überwinden, insbesondere bei der Kontextverarbeitung, was möglicherweise zu einer bedeutenden Veränderung der KI-Architektur führen könnte. (Quelle: 新智元)
Sakana AI veröffentlicht ALE-Agent, der 98 % der menschlichen Teilnehmer bei einem Programmierwettbewerb für NP-schwere Probleme besiegt: Sakana AI, mitbegründet von Llion Jones, einem der Autoren von Transformer, hat in Zusammenarbeit mit der japanischen Programmierwettbewerbsplattform AtCoder ALE-Bench (Algorithmic Engineering Benchmark) eingeführt. Dieser Benchmark konzentriert sich auf die Bewertung der Langzeit-Schlussfolgerungs- und kreativen Programmierfähigkeiten von KI bei NP-schweren Problemen (wie Pfadplanung, Aufgabenplanung). Der von ihnen entwickelte ALE-Agent, basierend auf Gemini 2.5 Pro und kombiniert mit domänenspezifischen Wissens-Prompts und diversifizierten Suchstrategien im Lösungsraum, zeigte im heuristischen Wettbewerb von AtCoder eine herausragende Leistung und belegte den 21. Platz (Top 2 %), womit er eine große Anzahl menschlicher Spitzenentwickler übertraf. Dies markiert einen wichtigen Fortschritt für KI bei der Lösung komplexer Optimierungsprobleme und ist von großer Bedeutung für praktische Anwendungen wie Logistik und Produktionsplanung. Obwohl ALE-Agent bei Algorithmen wie Simulated Annealing hervorragende Leistungen erbringt, besteht noch Verbesserungspotenzial beim Debugging, der Komplexitätsanalyse und der Vermeidung von Optimierungsfallen. (Quelle: 新智元, SakanaAILabs, hardmaru)
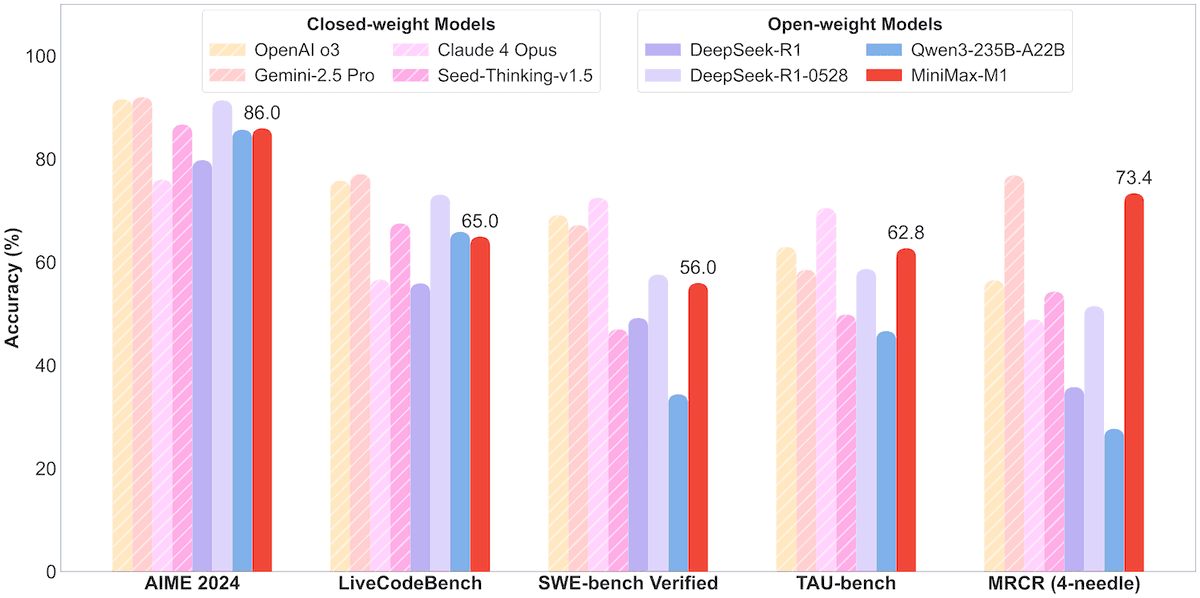
MiniMax veröffentlicht Open-Source-MoE-Modell MiniMax-M1 mit 456B Parametern, unterstützt Kontextfenster von einer Million Token und Ausgabe von 80.000 Token: MiniMax hat sein erstes Open-Source-Modell für Mixture of Experts (MoE) im großen Maßstab veröffentlicht: MiniMax-M1. Das Modell hat eine Größe von 45,6 Milliarden Parametern, wobei pro Token 4,59 Milliarden Parameter aktiviert werden. Es verwendet eine Architektur, die MoE mit dem Lightning Attention-Mechanismus kombiniert. M1 unterstützt nativ eine Kontextlänge von 1 Million Token und kann eine branchenführende Ausgabe von 80.000 Token erreichen, mit Versionen für 40k und 80k Denkbudget. In Benchmark-Tests für Software-Engineering, Werkzeugnutzung und Aufgaben mit langem Kontext übertrifft M1 Modelle wie DeepSeek-R1 und Qwen3-235B, insbesondere bei der Nutzung von Agent-Werkzeugen (z. B. TAU-bench) erzielt es herausragende Ergebnisse. Die Reinforcement-Learning-Phase dauerte nur drei Wochen mit 512 H800-Karten und kostete etwa 537.400 US-Dollar. Das M1-Modell ist kostenlos in der MiniMax APP und im Web verfügbar und wird über eine API angeboten. (Quelle: op7418, scaling01, jeremyphoward, karminski3, Reddit r/LocalLLaMA, 智东西)
🎯 Trends
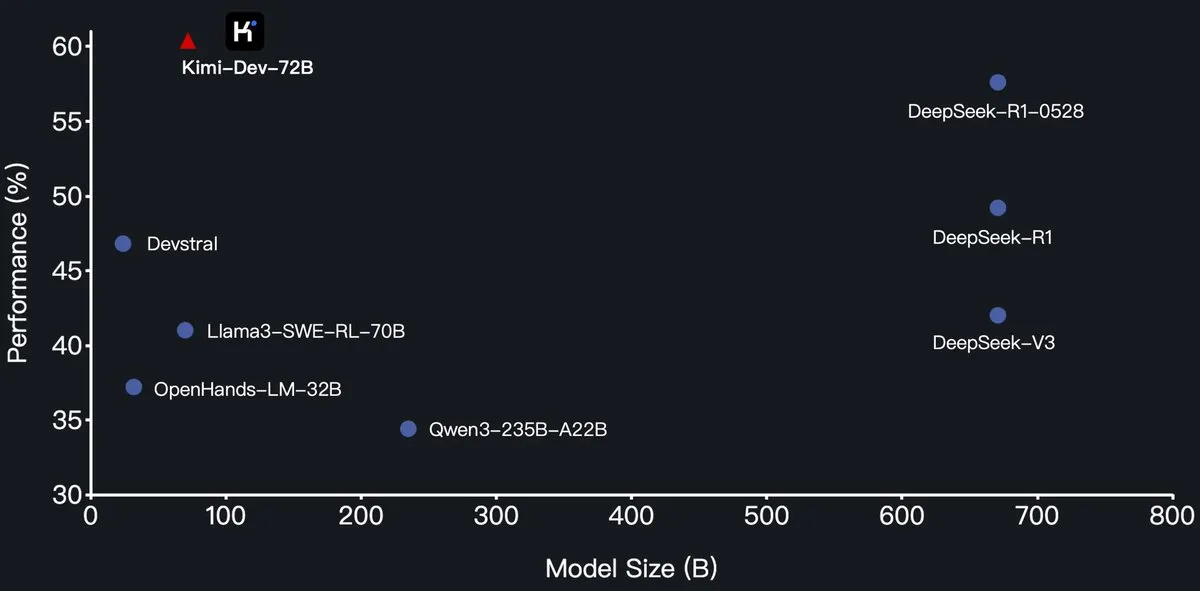
Moonshot AI veröffentlicht Open-Source-Programmiermodell Kimi-Dev-72B, übertrifft DeepSeek-R1 auf SWE-Bench: Moonshot AI (月之暗面) hat sein neues Open-Source-Programmiersprachenmodell Kimi-Dev-72B veröffentlicht, das durch Feinabstimmung von Qwen2.5-72B entwickelt wurde. Berichten zufolge erreichte Kimi-Dev-72B eine Lösungsrate von 60,4 % im SWE-bench Verified Benchmark und übertraf damit Modelle wie DeepSeek-R1-0528 (57,6 %) und Qwen3-235B-A22B, was es zu einem Spitzenreiter unter den Open-Source-Modellen macht. Das Modell wurde durch Reinforcement Learning trainiert, konzentriert sich auf das Patchen realer Code-Repositories in Docker-Umgebungen und erhält nur dann eine Belohnung, wenn die gesamte Testsuite erfolgreich durchlaufen wird. Der Leiter der Qwen-Entwicklung gab an, keine Autorisierung erteilt zu haben, aber die Veröffentlichung einer feinabgestimmten Version durch Kimi unter der MIT-Lizenz ist konform. (Quelle: Dorialexander, scaling01, karminski3, Reddit r/LocalLLaMA)
Qwen3-Modellreihe unterstützt jetzt MLX-Format und optimiert Inferenz auf Apple-Chips: Das Team von Alibaba Tongyi Qianwen gab bekannt, dass die Qwen3-Modellreihe nun das MLX-Format unterstützt und vier Quantisierungsstufen anbietet: 4-Bit, 6-Bit, 8-Bit und BF16. Dieser Schritt zielt darauf ab, die Effizienz der Modellausführung auf dem Apple MLX-Framework zu optimieren und Entwicklern die lokale Bereitstellung und Inferenz auf Mac-Geräten zu erleichtern. Benutzer können die entsprechenden Modelle auf HuggingFace und ModelScope beziehen. (Quelle: ClementDelangue, stablequan, jeremyphoward)

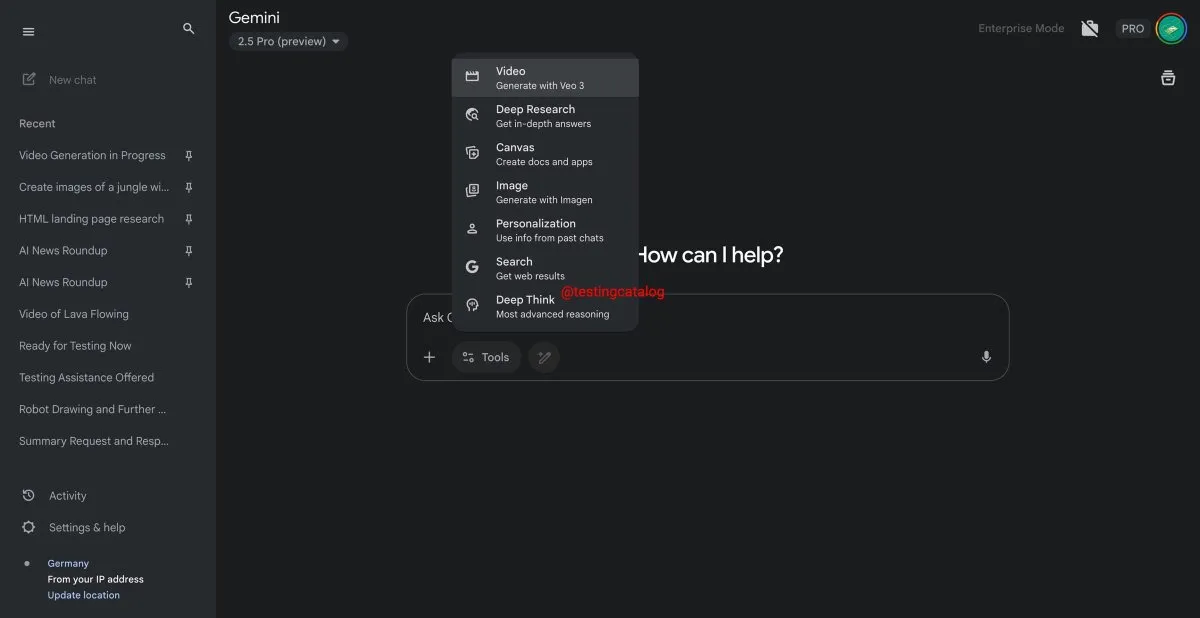
Google Gemini führt bald „Deep Think“-Funktion ein, um die Verarbeitung komplexer Probleme zu verbessern: Google bereitet die Einführung einer neuen Funktion namens „Deep Think“ für sein Gemini 2.5 Pro-Modell vor. Diese Funktion zielt darauf ab, durch die Bereitstellung zusätzlicher Rechenleistung anspruchsvollere Probleme zu bewältigen. Insbesondere bei mathematikbezogenen Aufgaben wird erwartet, dass Deep Think die Leistung im Vergleich zur regulären Version von Gemini 2.5 Pro um bis zu 15 % steigert. Die Funktion wird als neue Option in der Symbolleiste erscheinen, und der Verarbeitungsprozess kann einige Minuten dauern. Gleichzeitig wird auch die Benutzeroberfläche von Gemini aktualisiert. (Quelle: op7418)
Google Veo 3 Videogenerierungsmodell offiziell gestartet, erweitert auf über 70 Märkte: Google hat bekannt gegeben, dass sein KI-Videogenerierungsmodell Veo 3 offiziell für AI Pro- und Ultra-Abonnenten in über 70 Märkten weltweit eingeführt wurde. Veo 3 hat aufgrund seiner realistischen und kreativen Videoeffekte große Aufmerksamkeit erregt. Zuvor hatten Nutzer bereits ASMR-Inhalte wie „magisches Obstschneiden“ damit erstellt, die in sozialen Medien zig Millionen Aufrufe erzielten und das Potenzial im Bereich der Content-Erstellung demonstrierten. Der offizielle Start wird es mehr Nutzern ermöglichen, Veo 3 für die Videoerstellung zu erleben und zu nutzen. (Quelle: Google, 新智元)
Hugging Face und Groq kooperieren, um Hochgeschwindigkeits-LLM-Inferenzdienste anzubieten: Hugging Face gab eine Partnerschaft mit dem KI-Chip-Unternehmen Groq bekannt, um Groqs LPU™ (Language Processing Unit) in den Hugging Face Playground und die API zu integrieren. Benutzer können nun direkt auf der Hugging Face-Plattform LLM-Inferenzdienste erleben, die von Groq-Hardware beschleunigt werden und eine Vielzahl von Modellen unterstützen, darunter Llama 4 und Qwen 3. Ziel ist es, Entwicklern schnellere und effizientere Optionen für die KI-Modellinferenz zu bieten, insbesondere für die Erstellung von Agenten, Assistenten und Echtzeit-KI-Anwendungen. (Quelle: HuggingFace Blog, huggingface, ClementDelangue, mervenoyann, JonathanRoss321, _akhaliq)

Hugging Face Hub fügt Filterfunktion für Modellgröße hinzu, um Entwicklern bei der Auswahl geeigneter Modelle zu helfen: Die Hugging Face-Plattform hat eine neue Funktion eingeführt, mit der Benutzer Modelle nach Größe (Size Range) filtern können, insbesondere für Modelle, die auf dem mlx / mlx-lm Framework laufen. Diese Verbesserung soll Entwicklern helfen, Modelle, die ihren spezifischen Hardware- und Leistungsanforderungen entsprechen, einfacher zu finden, und betont, dass nicht immer größere Modelle besser sind, sondern kleinere, spezialisierte Modelle in bestimmten Szenarien oft überlegen sind. (Quelle: ClementDelangue, awnihannun, reach_vb, huggingface, ggerganov)

NVIDIA NCCL Update beginnt mit der Verwendung von FP32-Akkumulation für Reduktionsoperationen bei Half-Precision-Eingaben: Die neueste Version der NVIDIA Collective Communications Library (NCCL) (Commit 72d2432) führt ein wichtiges Update ein: Bei der Verarbeitung von Reduktionsoperationen (reduction ops) mit Half-Precision-Eingaben (wie FP16, BF16) wird nun FP32 für die Akkumulation verwendet. Diese Änderung ist entscheidend für die Aufrechterhaltung der Rechengenauigkeit und die Vermeidung von Überläufen, insbesondere beim groß angelegten verteilten Training. Es wird erwartet, dass diese Version in PyTorch 2.8 und höheren Versionen integriert wird. (Quelle: StasBekman)

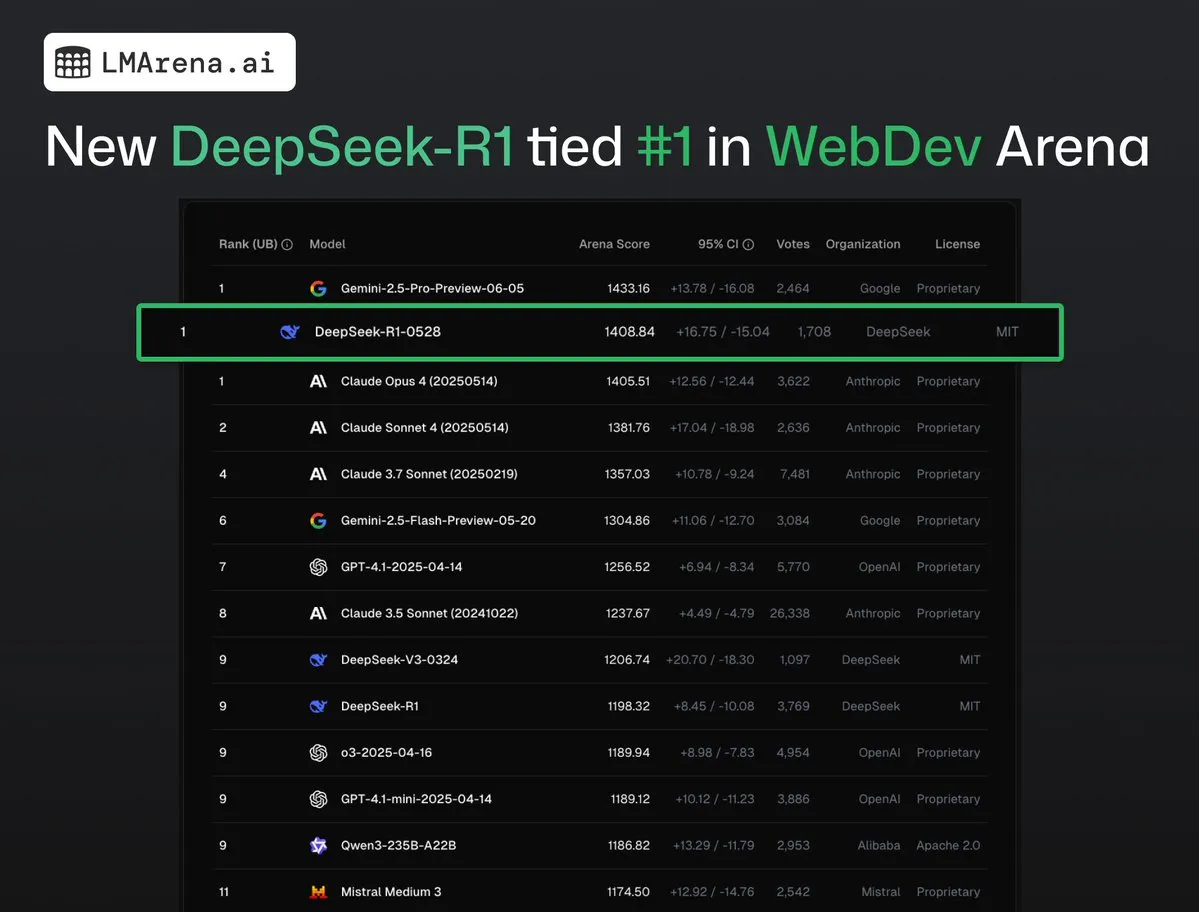
DeepSeek-R1 (0528) belegt zusammen mit Claude Opus 4 den ersten Platz in der WebDev Arena: Die neuesten Daten von lmarena.ai zeigen, dass die neue Version DeepSeek-R1 (0528) im WebDev Arena Benchmark hervorragend abschneidet und sich den ersten Platz mit Claude Opus 4 teilt. Das Modell belegt den sechsten Platz im Text Arena Gesamtranking, den zweiten Platz bei den Programmierfähigkeiten, den vierten Platz bei schwierigen Prompts, den fünften Platz bei den mathematischen Fähigkeiten und ist das leistungsstärkste MIT-lizenzierte Open-Source-Modell in der Rangliste. Dies unterstreicht die starke Wettbewerbsfähigkeit von DeepSeek bei spezifischen Entwicklungs- und Inferenzaufgaben. (Quelle: ClementDelangue, zizhpan)
ByteDance startet Seedream 3.0 Bild- und Seedance 1.0 Lite Videomodelle auf der Poe-Plattform: Das KI-Kreativtool von ByteDance hat auf der ausländischen Poe-Plattform ein Update erhalten und die Bildgenerierungsmodelle Seedream 3.0 und Videogenerierungsmodelle Seedance 1.0 Lite von Jmeng AI (即梦AI) eingeführt. Seedream 3.0 zielt darauf ab, klare und lebendige Bilder zu erzeugen, während Seedance 1.0 Lite schnell Videos mit realistischen dynamischen Effekten generieren kann. Benutzer können in Poe zuerst Bilder mit Seedream erstellen und diese dann durch @-Erwähnung von Seedance in Videos umwandeln, um einen kohärenten kreativen Prozess von Bild zu Video zu realisieren. (Quelle: op7418)

Tencent stellt Levo Gesangsmodell vor, unterstützt Track-Separation und Zero-Shot Timbre Cloning: Tencent hat ein KI-Gesangsmodell namens Levo veröffentlicht, dessen Leistung Berichten zufolge mit Suno V3.5 vergleichbar ist. Levo unterstützt Funktionen zur Trennung von Audiospuren und zum Zero-Shot Timbre Cloning. Aus den veröffentlichten Demos und Bewertungen geht hervor, dass es eine hervorragende Leistung erbringt. Dieser Fortschritt zeigt Tencents Stärke im Bereich der KI-Musikgenerierung. (Quelle: karminski3)
OpenAI führt ChatGPT-Bildgenerierungsfunktion in WhatsApp ein: OpenAI gab bekannt, dass Benutzer nun die Bildgenerierungsfunktion von ChatGPT über den Dienst 1-800-ChatGPT in WhatsApp nutzen können. Dieses Update ermöglicht es einer breiteren Benutzergruppe, KI-Bilder bequem direkt in der Instant-Messaging-Anwendung zu generieren. (Quelle: gdb, eliza_luth, iScienceLuvr)
SpatialLM auf Version 1.1 aktualisiert, verbessert 3D-Szenenverständnis und Rekonstruktionsfähigkeiten: Das räumliche Inferenzmodell SpatialLM wurde auf Version 1.1 aktualisiert. Die neue Version unterstützt mehrere Eingabequellenmodi, darunter Text-zu-3D-Szenengenerierung (Text-to-3D), Rekonstruktion aus Handkamera-Videos, LiDAR-Punktwolkendaten (wie iPhone Pro LiDAR) sowie synthetisches Mesh-Sampling. Zu den Hauptmerkmalen gehört die robuste Verarbeitung unstrukturierter Punktwolken, die auch bei unvollständigen 3D-Scandaten eine vernünftige Rekonstruktion ermöglicht. Darüber hinaus optimiert die neue Version die Zero-Shot-Erkennung für Videostream-Eingaben, verbessert die Genauigkeit der Innenraumlayout-Schätzung und die 3D-Objekterkennung. Die Anwendungsszenarien sind vielfältig und umfassen AR-Szenenrekonstruktion, räumliches Verständnis für Roboter, 3D-Design-Workflows und Consumer-Kameraanwendungen. (Quelle: karminski3)
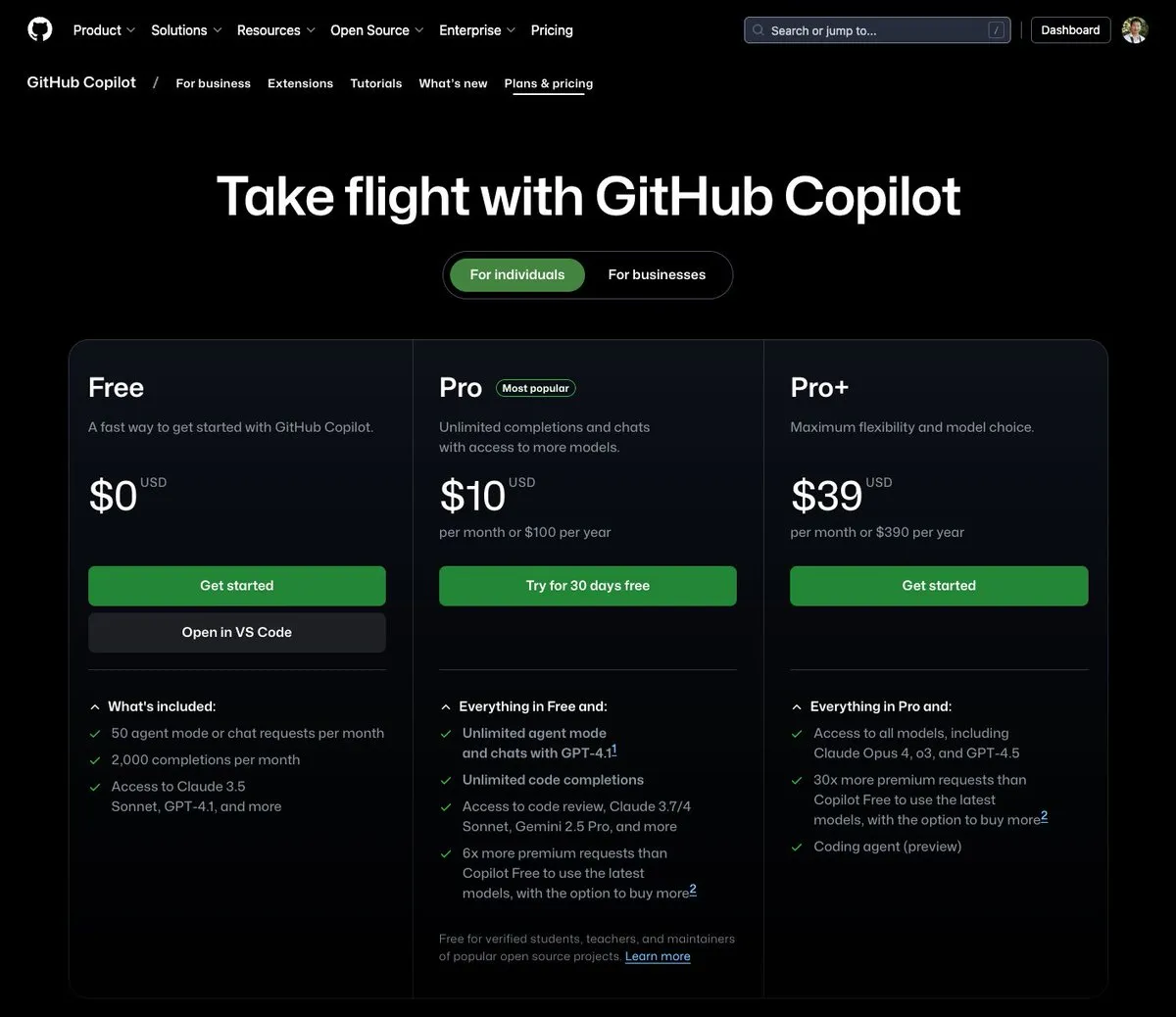
GitHub Copilot führt einen Tarif für 39 US-Dollar pro Monat ein, der Claude Opus 4 und andere große Modelle integriert: GitHub Copilot hat einen neuen Abonnementtarif für 39 US-Dollar pro Monat eingeführt. Dieser Tarif bietet nicht nur Funktionen als Programmierassistent, sondern ermöglicht Benutzern auch den Zugriff auf eine Vielzahl leistungsstarker Sprachmodelle, darunter Claude Opus 4, o3 und GPT-4.5, sowie die Nutzung des Coding agent. Diese Maßnahme zielt darauf ab, Entwicklern ein umfassenderes KI-gestütztes Programmiererlebnis zu bieten. (Quelle: dotey)
Kosten für den Aufruf von KI-Großmodellen sinken weiter, Preis der Doubao 1.6-Serie um weitere 63 % gesenkt: Volcano Engine hat auf der Force Radian Power Conference die Doubao Large Model 1.6-Serie vorgestellt und bekannt gegeben, dass die Gesamtkosten um 63 % gesenkt wurden. Für den von den meisten Unternehmen häufig genutzten Eingabelängenbereich von 0-32K beträgt der Preis 0,8 Yuan pro Million Token für die Eingabe und 8 Yuan für die Ausgabe. Dies markiert eine weitere Eskalation im Preiskampf der großen Modelle, nachdem Alibaba Qianwen im März dieses Jahres die Kosten auf 1/10 von DeepSeek R1 gesenkt hatte. Die niedrigen Kosten werden die Implementierung und Verbreitung von Anwendungen wie KI-Agenten weiter vorantreiben. (Quelle: 字节必须再赢一次)
Chipmunk Videogenerierungs-Beschleunigungstool aktualisiert, unterstützt Multi-GPU-Architekturen und weitere Open-Source-Modelle: Das Chipmunk-Tool des Teams von Dan Fu wurde aktualisiert und unterstützt nun eine 1,4- bis 3-fache verlustfreie Beschleunigung der Videogenerierung auf verschiedenen NVIDIA GPU-Architekturen (sm_80, sm_89, sm_90, wie A100s, 4090s, H100s). Gleichzeitig bietet Chipmunk Unterstützung für weitere Open-Source-Videomodelle wie Mochi und Wan und stellt Integrations-Tutorials bereit. Das Tool nutzt die Spärlichkeit der Aktivierungswerte in Videomodellen (nur 5-25 % der Aktivierungswerte tragen zu über 90 % der Ausgabe bei), um die Beschleunigung zu erreichen, ohne dass das Modell neu trainiert werden muss. (Quelle: realDanFu)

🧰 Tools
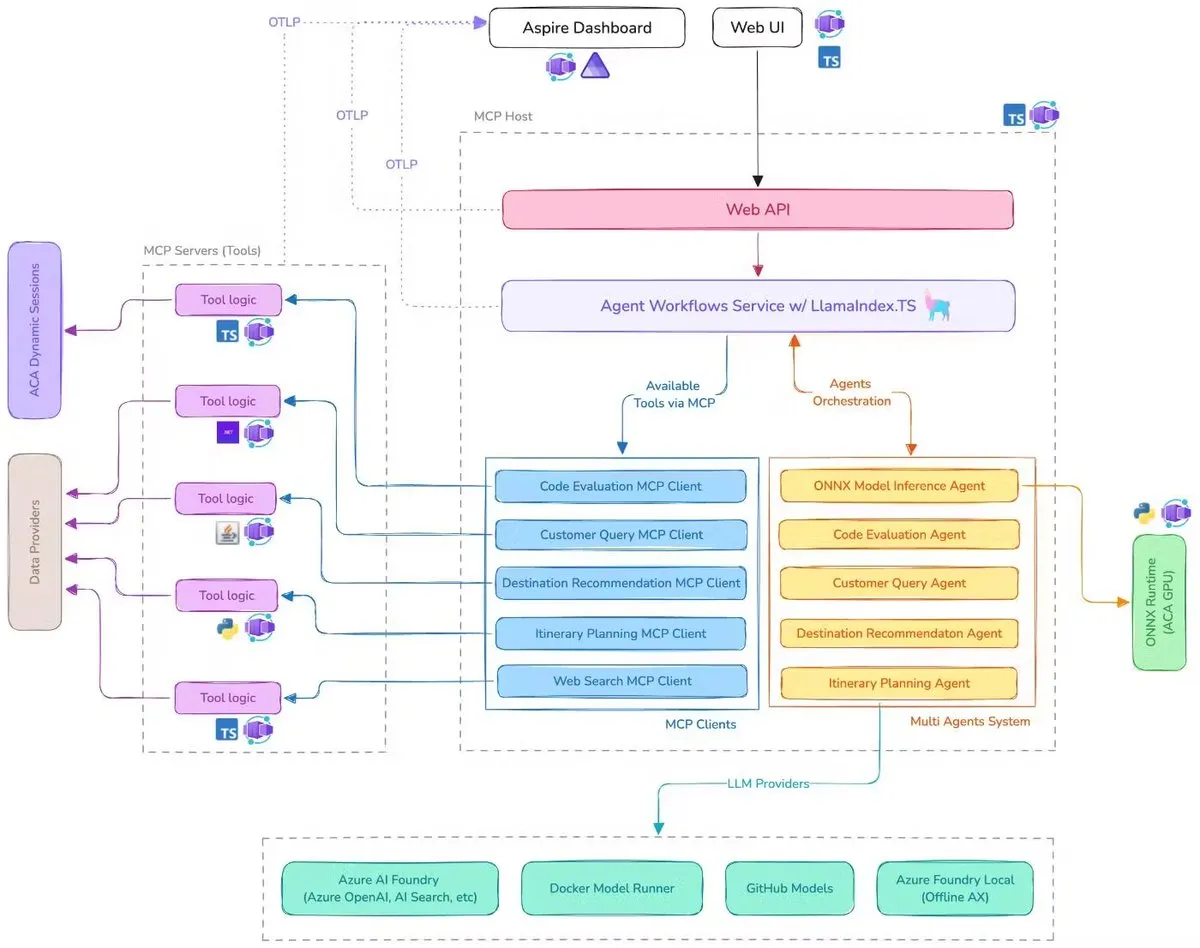
Microsoft veröffentlicht Demo eines KI-Reiseassistenten, integriert MCP, LlamaIndex.TS und Azure AI Foundry: Microsoft hat eine Demo eines KI-Reiseassistenten vorgestellt. Dieses System koordiniert mehrere KI-Agenten (darunter sechs spezialisierte Agenten für Abfrageklassifizierung, Reisezielemfehlungen, Reiseplanung usw.) über das Model Context Protocol (MCP), LlamaIndex.TS und Azure AI Foundry, um komplexe Reiseplanungsaufgaben gemeinsam zu erledigen. Jeder Agent erhält Echtzeitdaten und Werkzeuge über MCP-Server, die in Java, .NET, Python und TypeScript geschrieben sind. Die Anwendung demonstriert, wie Multi-Agenten-Systeme auf Unternehmensebene durch mehrsprachige Microservices zusammenarbeiten, KI-Fähigkeiten über Azure OpenAI und GitHub-Modelle nutzen und durch Azure Container Apps als skalierbare serverlose Bereitstellung realisiert werden können. (Quelle: jerryjliu0, jerryjliu0)
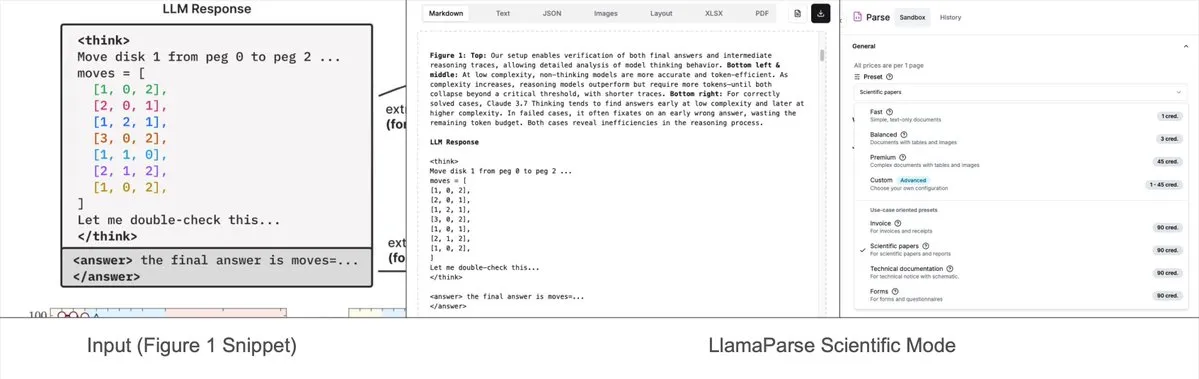
LlamaParse fügt voreingestellte Modi hinzu, kann komplexe Diagramme in Mermaid oder Markdown parsen: Das LlamaParse-Tool von LlamaIndex wurde kürzlich aktualisiert und um „voreingestellte Modi“ (preset-modes) erweitert. Damit können komplexe Diagramme in Dokumenten wie Forschungsberichten (z. B. Diagramme mit mehreren Kurven und Anmerkungen) analysiert und in formatierte Mermaid-Diagramme oder Markdown-Tabellen umgewandelt werden. Diese Funktion hilft dabei, den vollständigen Kontext von Seiten zu erfassen. Der generierte strukturierte Text kann zum Aufbau von RAG-Prozessen oder zur weiteren Metadatenextraktion verwendet werden. (Quelle: jerryjliu0)
Prompt Optimizer: Ein Optimierungstool zur Erstellung hochwertiger Prompts: Prompt Optimizer ist ein Tool, das Benutzern helfen soll, qualitativ hochwertigere KI-Prompts zu schreiben und so die Qualität der KI-Ausgabe zu verbessern. Es ist als Webanwendung und Chrome-Erweiterung verfügbar und bietet intelligente Optimierung, iterative Verbesserungen in mehreren Runden, Vergleich von ursprünglichen und optimierten Prompts, Integration mehrerer Modelle (OpenAI, Gemini, DeepSeek, Zhipu AI, SiliconFlow usw.), erweiterte Parameterkonfiguration und lokale verschlüsselte Speicherung. Das Tool verarbeitet Daten rein clientseitig, um Datensicherheit und Datenschutz zu gewährleisten. (Quelle: GitHub Trending)

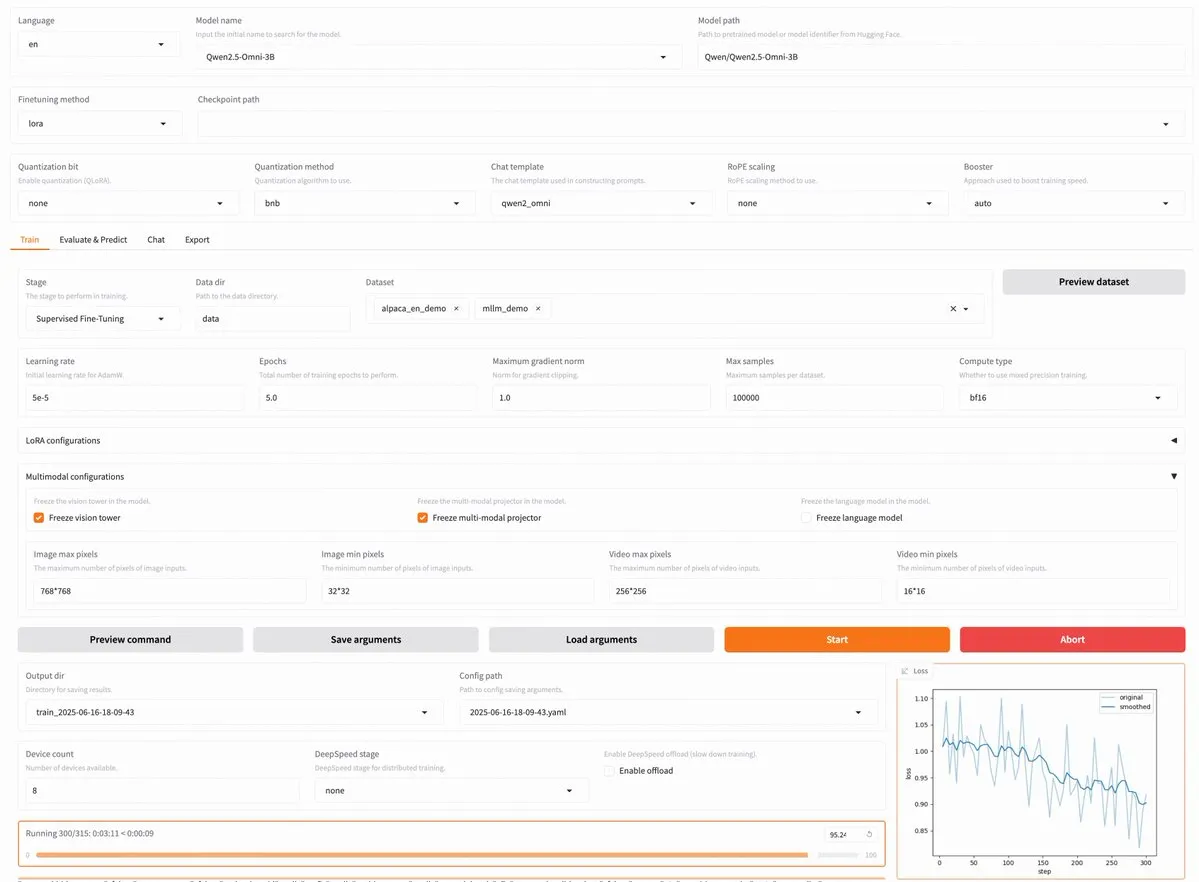
LLaMA Factory v0.9.3 veröffentlicht, unterstützt codefreies Fine-Tuning von fast 300 Modellen wie Qwen3, Llama 4: LLaMA Factory hat Version v0.9.3 veröffentlicht. Diese Version ist eine vollständig quelloffene, codefreie Fine-Tuning-Plattform mit einer Gradio-Benutzeroberfläche, die für fast 300 Modelle geeignet ist, darunter die neuesten Qwen3, Llama 4, Gemma 3, InternVL3, Qwen2.5-Omni usw. Benutzer können sie lokal über ein Docker-Image installieren oder auf Hugging Face Spaces, Google Colab und in der GPU-Cloud von Novita ausprobieren. (Quelle: _akhaliq)
Nanonets OCR: SOTA OCR-Modell basierend auf Qwen 2.5 VL 3B als Open Source veröffentlicht: Nanonets hat ein neues 3B-Parameter-OCR-Modell veröffentlicht – Nanonets OCR. Dieses Modell basiert auf dem Qwen 2.5 VL 3B Backbone-Netzwerk, übertrifft die Leistung der Mistral OCR API und wird unter der Apache 2.0 Lizenz als Open Source veröffentlicht. Es kann verschiedene OCR-Aufgaben bewältigen, darunter LaTeX-Erkennung, Wasserzeichen- und Signaturerkennung sowie die Extraktion komplexer Tabellen. (Quelle: huggingface)
Perplexity Labs soll mehrere Fachpositionen ersetzen können, löst Diskussion über Fähigkeiten von KI-Tools aus: Ein Benutzer namens GREG ISENBERG behauptet, Perplexity Labs eingesetzt zu haben, um die Arbeit von Verkäufern, Textern, Filmregisseuren, Social-Media-Managern und Finanzanalysten zu ersetzen, und hält die Fähigkeiten von KI-Tools für „tatsächlich verrückt“. Arav Srinivas, CEO von Perplexity, retweetete dies und kommentierte, es sei eines der besten Videos, das zeige, wie KI-Agenten in realen Anwendungsfällen eingesetzt werden können. Er verglich Perplexity Labs mit anderen Tools auf dem Markt in den Bereichen Finanzanalyse, Social-Media-Marketing, kreative Leitung und Vertrieb. Dies unterstreicht das Potenzial von KI-Agenten bei der Integration und Ausführung fachübergreifender professioneller Aufgaben. (Quelle: AravSrinivas, AravSrinivas)
Claude-Flow veröffentlicht großes Update v1.0.50, aktiviert „Swarm Mode“ zur Steigerung der Code-Automatisierungseffizienz: Claude-Flow, ein auf Claude Code basierendes System für parallel arbeitende Batch-Tool-Agenten, hat Version v1.0.50 veröffentlicht. Die neue Version führt den „Swarm Mode“ ein, der es Benutzern ermöglicht, Hunderte von Claude-Agenten gleichzeitig zu generieren, zu verwalten und zu koordinieren, um parallel an Build-, Test-, Deploy- oder mehrstufigen Forschungszyklen zu arbeiten. Berichten zufolge wird die Leistung im Vergleich zur herkömmlichen sequenziellen Claude Code-Automatisierung um das 20-fache gesteigert. Entwickler können die Initialisierung mit npx claude-flow@latest init --sparc --force durchführen. (Quelle: Reddit r/ClaudeAI)

📚 Lernen
Awesome Machine Learning: Umfassende Liste von Machine-Learning-Ressourcen: Das GitHub-Projekt „awesome-machine-learning“ ist eine sorgfältig kuratierte Liste von Machine-Learning-Frameworks, -Bibliotheken und -Software, kategorisiert nach Programmiersprachen. Es enthält auch Links zu kostenlosen Machine-Learning-Büchern, Fachveranstaltungen, Online-Kursen, Blog-Newslettern und lokalen Treffen und bietet so eine wertvolle Orientierungshilfe für Lernende und Praktiker im Bereich Machine Learning. (Quelle: GitHub Trending)
Anthropic und Cognition AI veröffentlichen jeweils Blogbeiträge zum Aufbau von Multi-Agenten-Systemen, LangChain fasst zusammen: Anthropic und Cognition AI haben kürzlich jeweils Blogbeiträge über den Aufbau (oder Nicht-Aufbau) von Multi-Agenten-Systemen veröffentlicht. Anthropic teilte seine Erfahrungen beim Aufbau seines Multi-Agenten-Forschungssystems, während Cognition AI die Ansicht vertrat, „keine Multi-Agenten zu bauen“. Harrison Chase von LangChain fasste dies zusammen und wies darauf hin, dass die beiden Artikel trotz scheinbar unterschiedlicher Ansichten viele Gemeinsamkeiten in ihren Richtlinien und Empfehlungen aufweisen und einen Bezug zu den Bemühungen von LangChain im Bereich Multi-Agenten herstellen. (Quelle: hwchase17, Hacubu)
Paper „Recent Advances in Speech Language Models: A Survey“ von ACL 2025 Hauptkonferenz angenommen: Ein Übersichtsartikel über Sprach-Sprachmodelle (SpeechLM) mit dem Titel „Recent Advances in Speech Language Models: A Survey“, verfasst von einem Team der Chinesischen Universität Hongkong, wurde von der Hauptkonferenz ACL 2025 angenommen. Das Paper ist die erste umfassende und systematische Übersichtsarbeit in diesem Bereich und analysiert eingehend die technische Architektur von SpeechLM (Sprach-Tokenizer, Sprachmodelle, Vocoder), Trainingsstrategien (Pre-Training, Instruction Fine-Tuning, Post-Alignment), Interaktionsparadigmen (Vollduplex-Modellierung), Anwendungsszenarien (Semantik, Sprecher, Paralinguistik) und Bewertungssysteme. Das Paper betont das Potenzial von SpeechLM zur Realisierung natürlicher Mensch-Maschine-Sprachinteraktion und weist auf die Herausforderungen und zukünftigen Richtungen hin. (Quelle: 36氪)

Neue Studie verbessert domänenübergreifende Schlussfolgerungsfähigkeiten kleiner Modelle durch Visual Game Learning (ViGaL), 7B-Modell übertrifft GPT-4o in Mathematik: Ein Forschungsteam der Rice University, der Johns Hopkins University und NVIDIA hat ein neues Post-Trainingsparadigma namens ViGaL (Visual Game Learning) vorgestellt. Indem ein multimodales 7B-Parameter-Modell (Qwen2.5-VL-7B) einfache Arcade-Spiele wie Snake und 3D-Rotation spielt, verbesserte das Modell nicht nur seine Spielfähigkeiten, sondern zeigte auch signifikante Verbesserungen der domänenübergreifenden Fähigkeiten bei komplexen Schlussfolgerungsaufgaben wie Mathematik (MathVista) und multidisziplinären Frage-Antwort-Aufgaben (MMMU) und übertraf in einigen Aspekten sogar Spitzenmodelle wie GPT-4o. Die Studie zeigt, dass Spieletraining allgemeine kognitive Fähigkeiten des Modells wie räumliches Verständnis und sequentielle Planung fördern kann und dass verschiedene Spiele unterschiedliche Aspekte der Schlussfolgerungsfähigkeiten stärken können. Diese Methode verbessert die Schlussfolgerungsfähigkeiten und erhält gleichzeitig die allgemeinen visuellen Fähigkeiten des Modells. (Quelle: 新智元)

Shanghai AI Lab et al. schlagen MathFusion-Framework vor, um die mathematischen Problemlösungsfähigkeiten von LLMs durch Befehlsfusion zu verbessern: Das Shanghai Artificial Intelligence Laboratory, die Gaoling School of Artificial Intelligence der Renmin University of China und andere Institutionen haben gemeinsam das MathFusion-Framework vorgeschlagen. Ziel ist es, die Fähigkeit großer Sprachmodelle (LLM) zur Lösung mathematischer Probleme zu verbessern, indem synthetische Anweisungen mit vielfältigeren Strukturen und komplexerer Logik durch die Fusion verschiedener mathematischer Problemstellungen generiert werden. Das Framework umfasst drei Strategien: sequentielle Fusion, parallele Fusion und konditionale Fusion, die die tiefen Zusammenhänge zwischen Problemen effektiv erfassen können. Experimente zeigten, dass nach dem Fine-Tuning von Modellen wie DeepSeekMath-7B, Llama3-8B und Mistral-7B mit nur 45K synthetischen Anweisungen die durchschnittliche Genauigkeit von MathFusion in mehreren mathematischen Benchmark-Tests um 18,0 Prozentpunkte verbessert wurde, was eine hohe Dateneffizienz und Leistung demonstriert. (Quelle: 量子位)

Shanghai AI Lab et al. schlagen GRA-Framework vor, kleine Modelle generieren kooperativ hochwertige Daten, Leistung vergleichbar mit 72B-Modellen: Das Shanghai Artificial Intelligence Laboratory hat in Zusammenarbeit mit der Renmin University of China das GRA (Generator-Reviewer-Adjudicator)-Framework vorgeschlagen. Durch die Simulation des Einreichungs- und Peer-Review-Mechanismus von wissenschaftlichen Arbeiten können mehrere kleine Sprachmodelle (7-8B Parameter) kooperativ hochwertige Trainingsdaten generieren. In diesem Framework ist der Generator für die Generierung zuständig, der Reviewer führt mehrstufige Bewertungen durch, und der Adjudicator trifft bei Bewertungskonflikten die endgültige Entscheidung. Experimente zeigten, dass Basismodelle wie LLaMA-3.1-8B und Qwen-2.5-7B, die mit GRA-generierten Daten trainiert wurden, in 10 gängigen Datensätzen für Mathematik, Code, logisches Denken usw. eine Leistung erzielten, die mit der von Daten vergleichbar oder sogar besser war, die durch Destillation mit großen Modellen wie Qwen-2.5-72B-Instruct generiert wurden. Dies bietet neue Ansätze für eine kostengünstige und hocheffiziente Datensynthese. (Quelle: 量子位)

Paper diskutiert aktuellen Stand und Zukunft der Interpretierbarkeit großer Modelle und betont deren Bedeutung für den sicheren Einsatz von KI: Das Tencent Research Institute veröffentlichte einen Artikel, der den aktuellen Stand, die technischen Ansätze und zukünftigen Herausforderungen der Interpretierbarkeit großer Sprachmodelle (LLM) eingehend diskutiert. Der Artikel weist darauf hin, dass das Verständnis der internen Mechanismen von LLMs entscheidend ist, um Wertabweichungen vorzubeugen, Modelle zu debuggen und zu verbessern, Missbrauch zu verhindern und Anwendungen in Hochrisikoszenarien voranzutreiben. Aktuelle technische Ansätze umfassen automatisierte Erklärung (große Modelle erklären kleine Modelle), Merkmalsvisualisierung (z. B. Sparse Autoencoder), Überwachung von Gedankengängen und mechanistische Interpretierbarkeit (z. B. Anthropic’s „KI-Mikroskop“ und DeepMind’s Tracr). Allerdings bleiben Herausforderungen wie die multiple Semantik von Neuronen, die Allgemeingültigkeit von Erklärungsregeln und die Grenzen der menschlichen Kognition bestehen. Der Artikel fordert verstärkte Forschungsinvestitionen in die Interpretierbarkeit und empfiehlt in der aktuellen Phase die Förderung von Soft-Law-Regeln zur Selbstregulierung der Branche, um eine sichere, transparente und menschenzentrierte Entwicklung der KI-Technologie zu gewährleisten. (Quelle: 腾讯研究院)

Neues Paper untersucht Anwendungen und Fortschritte von diskreten Diffusionsmodellen in großen Sprach- und multimodalen Modellen: Ein Paper mit dem Titel „Discrete Diffusion in Large Language and Multimodal Models: A Survey“ gibt einen systematischen Überblick über die Forschungsfortschritte bei diskreten Diffusions-Sprachmodellen (dLLMs) und diskreten Diffusions-Multimodal-Sprachmodellen (dMLLMs). Diese Modelle verwenden parallele Multi-Token-Dekodierung und entrauschende Generierungsstrategien, um parallele Generierung, feingranulare Steuerbarkeit der Ausgabe sowie dynamische, reaktionsfähige Wahrnehmungsfähigkeiten zu erreichen, wobei die Inferenzgeschwindigkeit im Vergleich zu autoregressiven Modellen um das bis zu 10-fache gesteigert werden kann. Das Paper zeichnet ihre Entwicklungsgeschichte nach, formalisiert den mathematischen Rahmen, klassifiziert repräsentative Modelle, analysiert wichtige Trainings- und Inferenztechniken, fasst Anwendungen in den Bereichen Sprache, Bild-Sprache und Biologie zusammen und diskutiert abschließend zukünftige Forschungsrichtungen und Herausforderungen bei der Bereitstellung. (Quelle: HuggingFace Daily Papers)
Neue Studie stellt Test3R vor: Verbesserung der geometrischen Genauigkeit der 3D-Rekonstruktion durch Lernen zur Testzeit: Eine neue Technik namens Test3R verbessert die geometrische Genauigkeit der 3D-Rekonstruktion signifikant durch Lernen zur Testzeit. Die Methode verwendet Bildtripletts (I_1,I_2,I_3) und generiert Rekonstruktionsergebnisse aus den Bildpaaren (I_1,I_2) und (I_1,I_3). Die Kernidee besteht darin, das Netzwerk zur Testzeit durch ein selbstüberwachtes Ziel zu optimieren: Maximierung der geometrischen Konsistenz dieser beiden Rekonstruktionsergebnisse in Bezug auf das gemeinsame Bild I_1. Experimente zeigen, dass Test3R bei Aufgaben der 3D-Rekonstruktion und der Multi-View-Tiefenschätzung bestehende SOTA-Methoden signifikant übertrifft und dabei universell einsetzbar und kostengünstig ist, leicht auf andere Modelle anwendbar ist und einen minimalen Trainingsaufwand und Parameterbedarf zur Testzeit aufweist. (Quelle: HuggingFace Daily Papers)
Paper stellt Mirage-1 vor: GUI-Agent mit hierarchischen multimodalen Fähigkeiten zur Verbesserung der Bearbeitung von Langzeitaufgaben: Forscher stellen Mirage-1 vor, einen multimodalen, plattformübergreifenden, Plug-and-Play-GUI-Agenten, der darauf abzielt, die Probleme unzureichenden Wissens und der Diskrepanz zwischen Offline- und Online-Domänen bei der Bearbeitung von Langzeitaufgaben durch aktuelle GUI-Agenten in Online-Umgebungen zu lösen. Das Kernstück von Mirage-1 ist das Modul für hierarchische multimodale Fähigkeiten (HMS), das Trajektorien schrittweise in Ausführungsfähigkeiten, Kernfähigkeiten und Metafähigkeiten abstrahiert, um eine hierarchische Wissensstruktur für die Planung von Langzeitaufgaben bereitzustellen. Gleichzeitig nutzt der Algorithmus Skill-Augmented Monte Carlo Tree Search (SA-MCTS) offline erworbene Fähigkeiten, um den Aktionssuchraum der Online-Baumexploration zu reduzieren. In den Benchmarks AndroidWorld, MobileMiniWob++, Mind2Web-Live und dem neu erstellten AndroidLH-Benchmark zeigte Mirage-1 durchweg signifikante Leistungssteigerungen. (Quelle: HuggingFace Daily Papers)
Paper „Don’t Pay Attention“ stellt neue neuronale Netzwerkgrundarchitektur Avey vor und fordert Transformer heraus: Ein Paper mit dem Titel „Don’t Pay Attention“ schlägt eine neue grundlegende neuronale Netzwerkarchitektur namens Avey vor, die darauf abzielt, die Abhängigkeit von Aufmerksamkeits- und Rekurrenzmechanismen zu überwinden. Avey besteht aus einem Ranker und einem autoregressiven neuronalen Prozessor, die zusammenarbeiten, um nur die für ein gegebenes Token relevantesten Token (unabhängig von ihrer Position in der Sequenz) zu identifizieren und zu kontextualisieren. Diese Architektur entkoppelt die Sequenzlänge von der Kontextbreite und ermöglicht so die effiziente Verarbeitung beliebig langer Sequenzen. Experimentelle Ergebnisse zeigen, dass Avey in Standard-NLP-Benchmarks für kurze Reichweiten mit Transformer vergleichbar ist und sich besonders gut bei der Erfassung von Abhängigkeiten über große Reichweiten schlägt. (Quelle: HuggingFace Daily Papers)
Neues Paper untersucht skalierbare Code-Verifizierung durch Belohnungsmodelle und wägt Genauigkeit gegen Durchsatz ab: Eine Studie untersucht den Kompromiss zwischen der Verwendung von Ergebnis-Belohnungsmodellen (ORM) und umfassenden Verifikatoren (wie vollständigen Testsuiten) bei der Lösung von Codierungsaufgaben durch große Sprachmodelle (LLM). Die Studie stellt fest, dass ORMs auch bei Vorhandensein umfassender Verifikatoren eine Schlüsselrolle bei der Skalierung der Verifizierung spielen, indem sie eine gewisse Genauigkeit zugunsten der Geschwindigkeit opfern. Insbesondere bei der „Generieren-Beschneiden-Neuordnen“-Methode kann die Verwendung eines schnelleren, aber weniger genauen Verifikators zur Vorabentfernung fehlerhafter Lösungen die Systemgeschwindigkeit um das 11,65-fache erhöhen, während die Genauigkeit nur um 8,33 % sinkt. Diese Methode funktioniert, indem sie fehlerhafte, aber hoch eingestufte Lösungen herausfiltert und bietet neue Ansätze für die Entwicklung skalierbarer und genauer Systeme zur Programm-Rangordnung. (Quelle: HuggingFace Daily Papers)
Neuer Benchmark AbstentionBench enthüllt: Inferenzorientierte LLMs schneiden bei unbeantwortbaren Fragen schlecht ab: Um die Fähigkeit großer Sprachmodelle (LLM) zu bewerten, bei Unsicherheit die Enthaltung zu wählen (d. h. eine eindeutige Antwort zu verweigern), haben Forscher AbstentionBench eingeführt. Dieser groß angelegte Benchmark-Test umfasst 20 verschiedene Datensätze, die verschiedene Arten von Fragen abdecken, wie z. B. unbekannte Antworten, unzureichende Spezifikationen, falsche Prämissen, subjektive Interpretationen und veraltete Informationen. Die Bewertung von 20 führenden LLMs zeigt, dass Enthaltung ein ungelöstes Problem ist und die Vergrößerung der Modellgröße hierbei kaum hilft. Überraschenderweise verringerte das Inferenz-Feintuning bei LLMs, die explizit für Mathematik und Naturwissenschaften trainiert wurden, die Enthaltungsfähigkeit im Durchschnitt um 24 %. Obwohl sorgfältig gestaltete System-Prompts die Enthaltungsleistung in der Praxis verbessern können, löst dies nicht die grundlegenden Mängel der Modelle beim Schlussfolgern unter Unsicherheit. (Quelle: HuggingFace Daily Papers)
Paper schlägt Patch-basiertes Prompting und Zerlegungsmethode (PatchInstruct) zur Nutzung von LLMs für Zeitreihenvorhersagen vor: Eine neue Studie untersucht einfache und flexible Prompting-Strategien zur Nutzung großer Sprachmodelle (LLMs) für Zeitreihenvorhersagen, ohne umfangreiches Neutraining oder komplexe externe Architekturen. Durch die Kombination von Zeitreihenzerlegung, Patch-basierter Tokenisierung und Ähnlichkeits-basierter Nachbarschaftsverstärkung als spezialisierte Prompting-Methoden stellten die Forscher fest, dass die Vorhersagequalität von LLMs verbessert werden kann, während gleichzeitig die Einfachheit gewahrt und die Datenvorverarbeitung minimiert wird. Die von der Studie vorgeschlagene PatchInstruct-Methode ermöglicht es LLMs, präzise und effektive Vorhersagen zu treffen. (Quelle: HuggingFace Daily Papers)
Neuer Datensatz MS4UI veröffentlicht, fokussiert auf multimodale Zusammenfassung von Lehrvideos für Benutzeroberflächen: Um die Mängel bestehender Benchmarks bei der Bereitstellung von schrittweisen, ausführbaren Anweisungen und Illustrationen zu beheben, haben Forscher den Datensatz MS4UI (Multi-modal Summarization for User Interface Instructional Videos) vorgeschlagen. Dieser Datensatz enthält 2413 UI-Lehrvideos mit einer Gesamtdauer von über 167 Stunden und wurde manuell mit Videosegmentierung, Textzusammenfassungen und Videozusammenfassungen annotiert. Ziel ist es, die Forschung zu prägnanten, ausführbaren multimodalen Zusammenfassungsmethoden für UI-Lehrvideos voranzutreiben. Experimente zeigen, dass aktuelle SOTA-Methoden zur multimodalen Zusammenfassung auf MS4UI schlecht abschneiden, was die Bedeutung neuer Ansätze in diesem Bereich unterstreicht. (Quelle: HuggingFace Daily Papers)
DeepResearch Bench: Ein umfassender Benchmark-Test für Deep Research Agents: Um die Fähigkeiten von LLM-basierten Deep Research Agents (DRAs) systematisch zu bewerten, haben Forscher DeepResearch Bench eingeführt. Dieser Benchmark enthält 100 Forschungsaufgaben auf Doktoratsniveau, die von Experten aus 22 verschiedenen Bereichen sorgfältig konzipiert wurden. Aufgrund der Komplexität und des arbeitsintensiven Charakters der Bewertung von DRAs schlagen die Forscher zwei neue Bewertungsmethoden vor, die stark mit menschlichen Urteilen übereinstimmen: eine referenzbasierte adaptive Standardmethode zur Bewertung der Qualität generierter Forschungsberichte; und ein Rahmenwerk, das die Informationsbeschaffungs- und -sammelfähigkeiten von DRAs durch die Bewertung der Anzahl effektiver Zitate und der allgemeinen Zitiergenauigkeit bewertet. (Quelle: HuggingFace Daily Papers)
Paper schlägt BridgeVLA vor: Effizientes Erlernen von 3D-Operationen durch Input-Output-Alignment: Um die Effizienz der Nutzung von 3D-Signalen durch visuelle Sprachmodelle (VLM) beim Erlernen von Roboteroperationen zu verbessern, haben Forscher BridgeVLA vorgeschlagen, ein neuartiges 3D Visual Language Action (VLA)-Modell. BridgeVLA projiziert 3D-Eingaben auf mehrere 2D-Bilder, um die Ausrichtung auf die Eingaben des VLM-Backbones sicherzustellen, und verwendet 2D-Heatmaps für die Aktionsvorhersage, wodurch Eingabe und Ausgabe in einem konsistenten 2D-Bildraum vereinheitlicht werden. Darüber hinaus schlägt die Studie eine skalierbare Vortrainingsmethode vor, die es dem VLM-Backbone ermöglicht, 2D-Heatmaps vor dem nachgelagerten Policy-Lernen vorherzusagen. Experimente zeigen, dass BridgeVLA in mehreren Simulationsbenchmarks und realen Roboterexperimenten hervorragende Leistungen erbringt, die Effizienz und Effektivität des Lernens von 3D-Operationen signifikant verbessert und eine starke Stichprobeneffizienz und Generalisierungsfähigkeit aufweist. (Quelle: HuggingFace Daily Papers)
Neue Studie synthetisiert Millionen vielfältiger und komplexer Benutzeranweisungen (SynthQuestions) durch Attributionsbasiertes Grounding: Um dem Mangel an vielfältigen, komplexen und umfangreichen Anweisungsdaten zu begegnen, die für die Ausrichtung großer Sprachmodelle (LLM) erforderlich sind, schlagen Forscher eine Anweisungssynthesemethode vor, die auf attributbasiertem Grounding basiert. Dieses Framework umfasst: 1) einen Top-Down-Attributionsprozess, der ausgewählte reale Anweisungen mit kontextualisierten Benutzern verknüpft; 2) einen Bottom-Up-Syntheseprozess, der Webdokumente nutzt, um zuerst Kontexte und dann sinnvolle Anweisungen zu generieren. Mit dieser Methode wurde der Datensatz SynthQuestions mit 1 Million Anweisungen erstellt. Experimente zeigen, dass Modelle, die auf diesem Datensatz trainiert wurden, in mehreren gängigen Benchmark-Tests führende Leistungen erzielen und dass sich die Leistung mit zunehmender Größe des Web-Korpus kontinuierlich verbessert. (Quelle: HuggingFace Daily Papers)
PersonaFeedback: Groß angelegter, manuell annotierter Benchmark für personalisierte Bewertung veröffentlicht: Um die Fähigkeit großer Sprachmodelle (LLM) zu bewerten, personalisierte Antworten basierend auf vordefinierten Benutzerprofilen und Anfragen zu liefern, haben Forscher den PersonaFeedback-Benchmark eingeführt. Dieser Benchmark enthält 8298 manuell annotierte Testfälle, die je nach kontextueller Komplexität des Benutzerprofils und der Schwierigkeit, personalisierte Antworten zu unterscheiden, in die Stufen einfach, mittel und schwer unterteilt sind. Im Gegensatz zu bestehenden Benchmarks entkoppelt PersonaFeedback die Profilinferenz von der Personalisierung und konzentriert sich auf die Bewertung der Fähigkeit des Modells, maßgeschneiderte Antworten für explizite Profile zu generieren. Experimentelle Ergebnisse zeigen, dass selbst SOTA LLMs bei Tests der schwierigen Stufe vor Herausforderungen stehen, was darauf hindeutet, dass aktuelle Retrieval-Augmented-Frameworks keine endgültige Lösung für Personalisierungsaufgaben darstellen. (Quelle: HuggingFace Daily Papers)
Paper untersucht „Sprachchirurgie“ in mehrsprachigen großen Modellen: Sprachsteuerung zur Inferenzzeit durch latente Injektion: Eine neue Studie untersucht das Phänomen der natürlich auftretenden Repräsentationsausrichtung in großen Sprachmodellen (LLM) und dessen Bedeutung für die Entkopplung sprachspezifischer und sprachunabhängiger Informationen. Die Studie bestätigt die Existenz dieser Ausrichtung und analysiert ihr Verhalten im Vergleich zu explizit entworfenen Ausrichtungsmodellen. Basierend auf diesen Erkenntnissen schlagen die Forscher die Methode der Inference-Time Language Control (ITLC) vor, die latente Injektion nutzt, um eine präzise sprachübergreifende Steuerung zu erreichen und das Problem der Sprachverwechslung in LLMs zu mildern. Experimente belegen die starke sprachübergreifende Kontrollfähigkeit von ITLC bei gleichzeitiger Wahrung der semantischen Integrität der Zielsprache und die effektive Milderung des Problems der sprachübergreifenden Verwechslung, das selbst in aktuellen großen LLMs noch besteht. (Quelle: HuggingFace Daily Papers)
Paper schlägt NoWait-Methode vor: Entfernung von „Denk-Token“ zur Verbesserung der Ineffizienz großer Modelle: Jüngste Studien zeigen, dass große Inferenzmodelle bei komplexen, schrittweisen Schlussfolgerungen oft durch übermäßiges „Nachdenken“ (z. B. Ausgabe von Token wie „Wait“, „Hmm“) redundante Ausgaben erzeugen, was die Effizienz beeinträchtigt. Die neu vorgeschlagene NoWait-Methode zielt darauf ab, die Notwendigkeit dieser expliziten Selbstreflexions-Token für fortgeschrittenes Schlussfolgern zu überprüfen, indem sie diese während der Inferenz unterdrückt. In zehn Benchmark-Tests über Text-, Bild- und Video-Inferenzaufgaben verkürzte NoWait die Länge der Gedankengang-Trajektorien in fünf R1-artigen Modellfamilien um 27 % bis 51 %, ohne die Nützlichkeit des Modells zu beeinträchtigen. Diese Methode bietet eine Plug-and-Play-Lösung für eine effiziente multimodale Inferenz bei gleichbleibender Nützlichkeit. (Quelle: HuggingFace Daily Papers)
💼 Wirtschaft
OpenAI gewinnt 200-Millionen-Dollar-KI-Vertrag mit dem US-Verteidigungsministerium zur Entwicklung modernster militärischer Fähigkeiten: OpenAI hat einen Einjahresvertrag im Wert von 200 Millionen US-Dollar mit dem US-Verteidigungsministerium unterzeichnet, um fortschrittliche KI-Tools für die nationale Sicherheit zu entwickeln. Dies ist das erste Mal, dass OpenAI einen solchen vom Pentagon gelisteten Vertrag erhält. Die Arbeiten werden hauptsächlich in der Hauptstadtregion durchgeführt. Zuvor hatte OpenAI bereits mit dem Verteidigungsunternehmen Anduril zusammengearbeitet. Dieser Schritt erfolgt vor dem Hintergrund einer breiten Initiative zur Förderung von KI-Anwendungen im US-Verteidigungssektor, wobei auch Konkurrenten wie Anthropic mit Palantir und Amazon in diesem Bereich kooperieren. Sam Altman, CEO von OpenAI, hat öffentlich seine Unterstützung für nationale Sicherheitsprojekte bekundet. (Quelle: Reddit r/ArtificialInteligence, code_star)

Alta schließt Finanzierungsrunde über 11 Millionen US-Dollar ab, angeführt von Menlo Ventures, Fokus auf KI + Mode: Das KI-Mode-Startup Alta gab den Abschluss einer Finanzierungsrunde über 11 Millionen US-Dollar bekannt, angeführt von Menlo Ventures, mit Beteiligung von Benchstrength und Aglaé Ventures (einem VC-Fonds, der von der Familie Arnault der LVMH-Gruppe unterstützt wird). Amy Tong Wu wird dem Vorstand von Alta beitreten. Diese Finanzierungsrunde wird Alta bei der weiteren Entwicklung im Bereich der Kombination von KI und Mode unterstützen. (Quelle: ZhaiAndrew)
Figure Unternehmen passt Organisationsstruktur an, Controls-Abteilung wird in Helix integriert, um KI-Roadmap zu beschleunigen: Das Unternehmen für humanoide Roboter Figure gab bekannt, dass seine Controls-Abteilung nicht mehr existiert und das gesamte Team in die Helix-Abteilung integriert wurde. Dieser Schritt zielt darauf ab, die Roadmap des Unternehmens im Bereich der künstlichen Intelligenz zu beschleunigen und zeigt, dass Figure mehr Ressourcen und Energie auf die Forschung, Entwicklung und Anwendung von KI-Technologien konzentriert. (Quelle: adcock_brett)
🌟 Community
Diskussion über AGI: Normale Benutzer müssen sich keine übermäßigen Sorgen machen, AGI ist eher strategisch als ein alltägliches Werkzeug: Mehrere Diskussionsteilnehmer in der Community wiesen darauf hin, dass normale LLM-Benutzer sich nicht übermäßig um das Aufkommen von AGI (Allgemeine Künstliche Intelligenz) sorgen müssen. Die Definition von AGI ist vage und stark theoretisch. Selbst wenn sie realisiert wird, wird sie sich kurzfristig nicht direkt im Chatfenster des Benutzers zeigen, sondern als strategisches Werkzeug und Infrastruktur für Staaten oder große Organisationen dienen, um komplexe Angelegenheiten wie Verhandlungen zwischen Staaten zu behandeln, anstatt Einzelpersonen bei der Terminplanung zu helfen. (Quelle: farguney, farguney, farguney, farguney)
Aufbau von Multi-Agenten-Systemen erfordert manuelle Bewertung, Fokus auf Randfälle und Quellenqualität: Beim Aufbau von Multi-Agenten-Systemen sind manuelle Bewertung und Tests entscheidend, um Randfälle aufzudecken, die von automatisierten Bewertungen möglicherweise übersehen werden. Beispielsweise neigten frühe Agenten bei der Auswahl von Informationsquellen eher zu SEO-optimierten Content-Farmen als zu maßgeblichen wissenschaftlichen PDFs oder persönlichen Blogs. Die Aufnahme von Heuristiken zur Quellenqualität in die Prompts hilft, solche Probleme zu lösen. Dies zeigt, dass auch im Zeitalter der automatisierten Bewertung manuelle Tests unerlässlich bleiben, um Systemfehler, subtile Verzerrungen bei der Quellenauswahl und ähnliche Probleme aufzudecken. (Quelle: riemannzeta)

Unterschiede zwischen LLMs und Videomodellen in Vorhersage- und Lernmechanismen regen zum Nachdenken an: Yann LeCun und Pedro Domingos teilten die Ansicht von Sergey Levine und diskutierten, warum Sprachmodelle so viel aus der Vorhersage des nächsten Tokens lernen können, während Videomodelle vergleichsweise wenig aus der Vorhersage des nächsten Frames lernen. Levine vermutet, dass dies daran liegen könnte, dass LLMs gewissermaßen die Rolle eines „Gehirnscanners“ spielen, was auf die Einzigartigkeit ihrer Lernmechanismen hindeutet, oder dass LLMs wie in Platons Höhle leben und durch die Beobachtung von Schattensequenzen (Text) auf die reale Welt schließen. (Quelle: ylecun, pmddomingos, pmddomingos)

Positive Auswirkungen von KI-Agenten im Bildungsbereich: Förderung von Lernenden, ihre Komfortzone zu verlassen: In der Community-Diskussion wird argumentiert, dass KI-Agenten nicht nur positive Auswirkungen auf Unternehmen haben, sondern auch im Bildungsbereich ein enormes Potenzial besitzen. Durch die Interaktion mit KI-Agenten können Lernende ihre Komfortzone effektiver verlassen, was zu einer Verbesserung der Lernergebnisse beiträgt. (Quelle: pirroh, amasad)
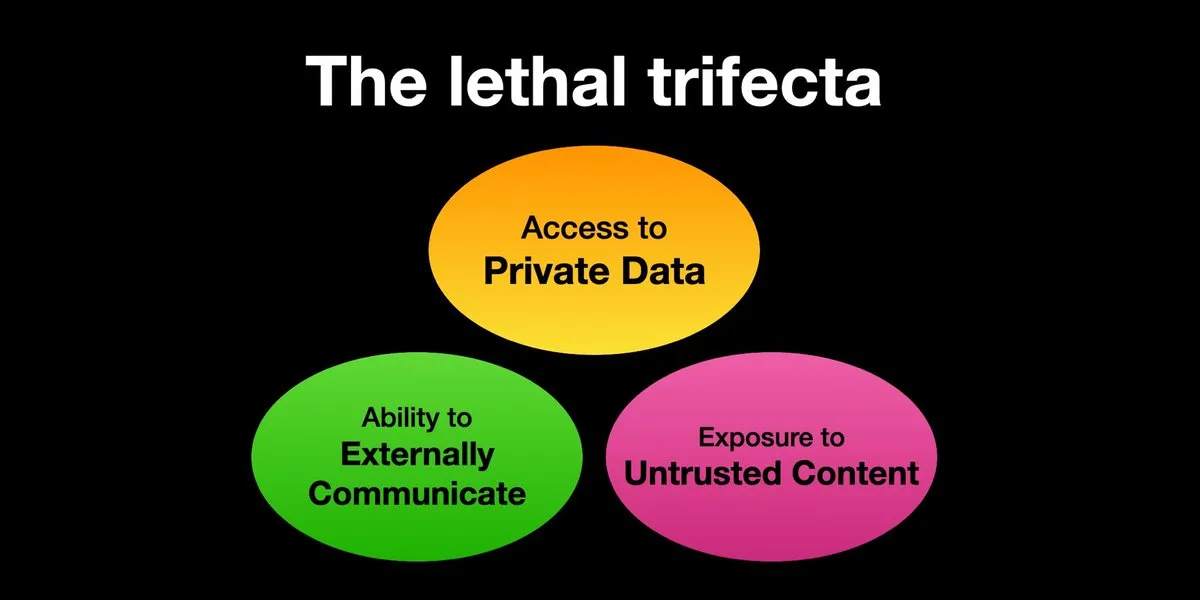
KI-Agenten sind dem Risiko von Prompt-Injection-Angriffen ausgesetzt, Sicherheitsvorkehrungen müssen dringend verstärkt werden: Karpathy teilte Simon Willisons Warnung vor dem „tödlichen Dreiklang“ (Lethal Trifecta) für KI-Agenten: Wenn ein KI-Agent gleichzeitig Zugriff auf private Daten hat, mit nicht vertrauenswürdigen Inhalten in Kontakt kommt und nach außen kommunizieren kann, können Angreifer das System dazu verleiten, Daten zu stehlen. Dies erinnert an die „Wildwest“-Ära der frühen Computerviren. Derzeit sind die Abwehrmechanismen gegen bösartige Prompts noch unzureichend, beispielsweise fehlt ein Sicherheitskonzept ähnlich dem Kernel-/Benutzermodus von Betriebssystemen, um die Fähigkeit von Agenten zur Ausführung beliebiger Skripte einzuschränken. Dies gibt Anlass zur Sorge hinsichtlich der frühen Einführung von LLM-Agenten für persönliche Computeranwendungen. (Quelle: karpathy, TheTuringPost)
Im KI-Zeitalter wird schnelle Lernfähigkeit zur Kernkompetenz: Mustafa Suleyman weist darauf hin, dass der größte Karrierebeschleuniger im nächsten Jahrzehnt eine exzellente Lernfähigkeit sein wird. Er rät den Menschen, ihren Lernstil klar zu definieren, KI zu nutzen, um Materialien in geeignete Formate (wie Podcasts, Quizze) umzuwandeln, dann das Wissen anzuwenden und diesen Prozess kontinuierlich zu wiederholen, um schnelles Lernen und Wachstum zu ermöglichen. (Quelle: mustafasuleyman)
Authentizität und Relevanz von KI-generierten Inhalten: Relevanz könnte Authentizität übertrumpfen: Benutzer imjaredz teilte seine Erfahrung mit, 2000 KI-generierte Lead-E-Mails verschickt zu haben. Niemand beschwerte sich darüber, dass sie von KI geschrieben wurden, stattdessen gaben fünf Personen an, der Inhalt der E-Mail sei „genau das, woran sie gerade arbeiten“. Dies löste eine Diskussion darüber aus, ob in der Kommunikation die Relevanz des Inhalts wichtiger ist als seine „Authentizität“ (ob er von Menschen erstellt wurde). (Quelle: imjaredz)
Diskussion über die „Verständnisfähigkeit“ von LLMs: Verhaltensähnlichkeit ist nicht gleich echtes Verständnis: In der Community gibt es die Ansicht, dass große Sprachmodelle zwar starke Verhaltens- und kognitive Ähnlichkeiten aufweisen, dies aber nicht mit echtem Verständnis gleichzusetzen ist. Verständnis erfordert Erklärungsfähigkeit, und bloßes Verhalten ist weder Intelligenz noch Verständnis. Dieser grundlegende Unterschied wird oft übersehen. Diese Ansicht betont, dass man, bevor man lebenswichtige Entscheidungen Modellen überlässt, sorgfältig prüfen muss, ob sie wirklich der allgemeinen künstlichen Intelligenz nahekommen, und sich vor einer übertriebenen Darstellung ihrer Fähigkeiten hüten sollte. (Quelle: farguney)
KI-Agenten zeigen beeindruckende Leistungen in Software-Engineering-Benchmarks, aber Diskussion über ihre „Agenten“-Natur: Da KI in Software-Engineering-Benchmarks wie SWE-bench immer höhere Punktzahlen erreicht (sogar über 50-60 Punkte), diskutiert die Community, ob die „Ära des Agenten-Codierens“ wirklich angebrochen ist. Es gibt die Ansicht, dass, wenn überwiegend „agentenlose Frameworks“ verwendet werden, anstatt Sprachmodelle wirklich in einer Umgebung explorieren zu lassen, die Bezeichnung „Ära des Agenten-Codierens“ möglicherweise nicht zutreffend ist, auch wenn diese Frameworks selbst sehr wertvoll sind. (Quelle: huybery, terryyuezhuo)
Bedarf an Inhaltsmoderation für KI-generierte Bilder: Suche nach Open-Source- oder kommerziellen Lösungen: Mit der zunehmenden Verbreitung von Technologien zur KI-Bilderzeugung beginnen Entwickler in China, sich mit der Compliance-Frage der ausgegebenen Inhalte zu befassen, insbesondere wie pornografische, politisch sensible und andere Inhalte erkannt werden können. In der Community gibt es Diskussionen über die Suche nach verfügbaren kleinen Open-Source-Modellen oder kommerziellen Produkten zur Inhaltsmoderation. (Quelle: dotey)
💡 Sonstiges
KI-gesteuerte Personalisierung und Inhaltsrelevanz: 2000 KI-E-Mails ohne negative Rückmeldung, 5 Personen sagen „genau das, was ich brauche“: Ein Nutzer berichtete, dass er 2000 von KI generierte Lead-E-Mails verschickt habe und kein einziger Empfänger sich darüber beschwert habe, dass die E-Mail von einer KI verfasst wurde. Im Gegenteil, fünf Empfänger gaben an, der Inhalt der E-Mail sei „genau das, woran sie gerade arbeiten“. Dieser Fall löste eine Diskussion darüber aus, ob bei KI-gestützter Kommunikation die hohe Relevanz des Inhalts die Bedenken hinsichtlich der „Authentizität“ (d. h. ob von einem Menschen verfasst) überwiegen kann, und deutet auf das Potenzial von KI bei der Erstellung personalisierter Inhalte hin. (Quelle: imjaredz)
Der Mensch als Engpass im KI-System, Notwendigkeit, menschliche Ineffizienz zu vermeiden oder zu verbessern: Charles Earls Standpunkt ist, dass überquellende Posteingänge und leere Postausgänge zeigen, dass der Mensch der Engpass bei der Informationsverarbeitung und -beantwortung ist. Im KI-Zeitalter muss darüber nachgedacht werden, wie menschliche Engpässe vermieden oder wie die menschliche Arbeitseffizienz durch KI und andere Technologien gesteigert werden kann. (Quelle: charles_irl)
Potenzielle Risiken der KI-Steuerung von Smart Homes: Nutzer wegen App-Fehler in eiskaltem Smart-Bett gefangen: Ein Nutzer berichtete von seiner Erfahrung, aufgrund eines App-Fehlers seines KI-gesteuerten Smart-Betts (Eight Sleep Pod3) die Temperatur nicht regulieren zu können und schließlich in einem eiskalten Bett festzusitzen. Da dieses Modell keine manuelle Steuerung besitzt und vollständig von der App abhängig ist, verdeutlicht dieser Vorfall die Unannehmlichkeiten und „dystopischen“ Erfahrungen, die eine übermäßige Abhängigkeit von KI- und App-Steuerung bei Smart-Home-Geräten mit sich bringen kann. (Quelle: madiator)