
Schlüsselwörter:KI, Großes Modell, Multi-Agenten-System, Transformer, Neuromorphes Computing, LLM, KI-Agent, Claude, Claude Multi-Agenten-Forschungssystem, Eso-LM Hybrid-Trainingsmethode, Neuromorpher Supercomputer, Context-Scaling-Technologie, SynthID-Wasserzeichentechnik
🔥 Fokus
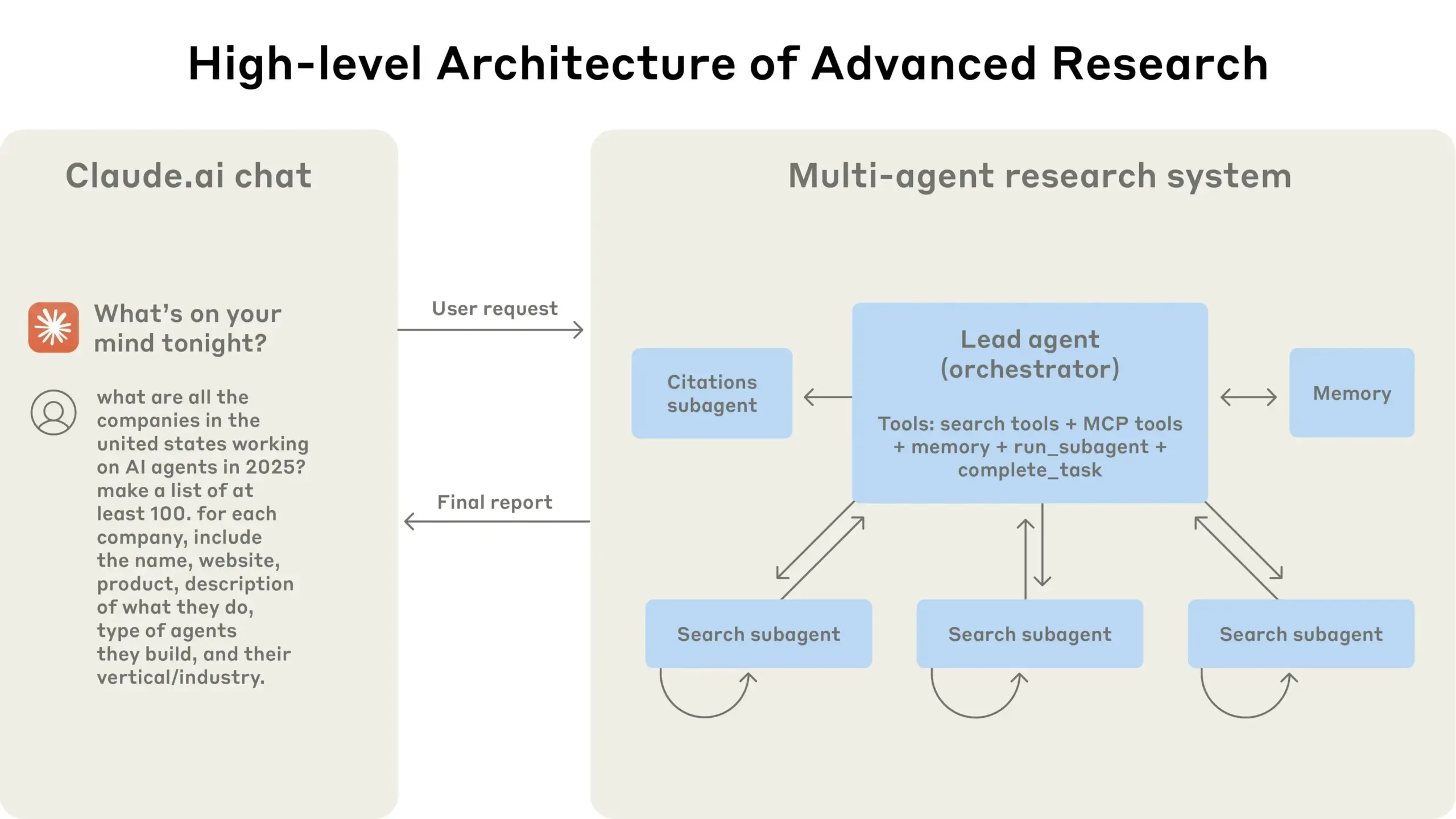
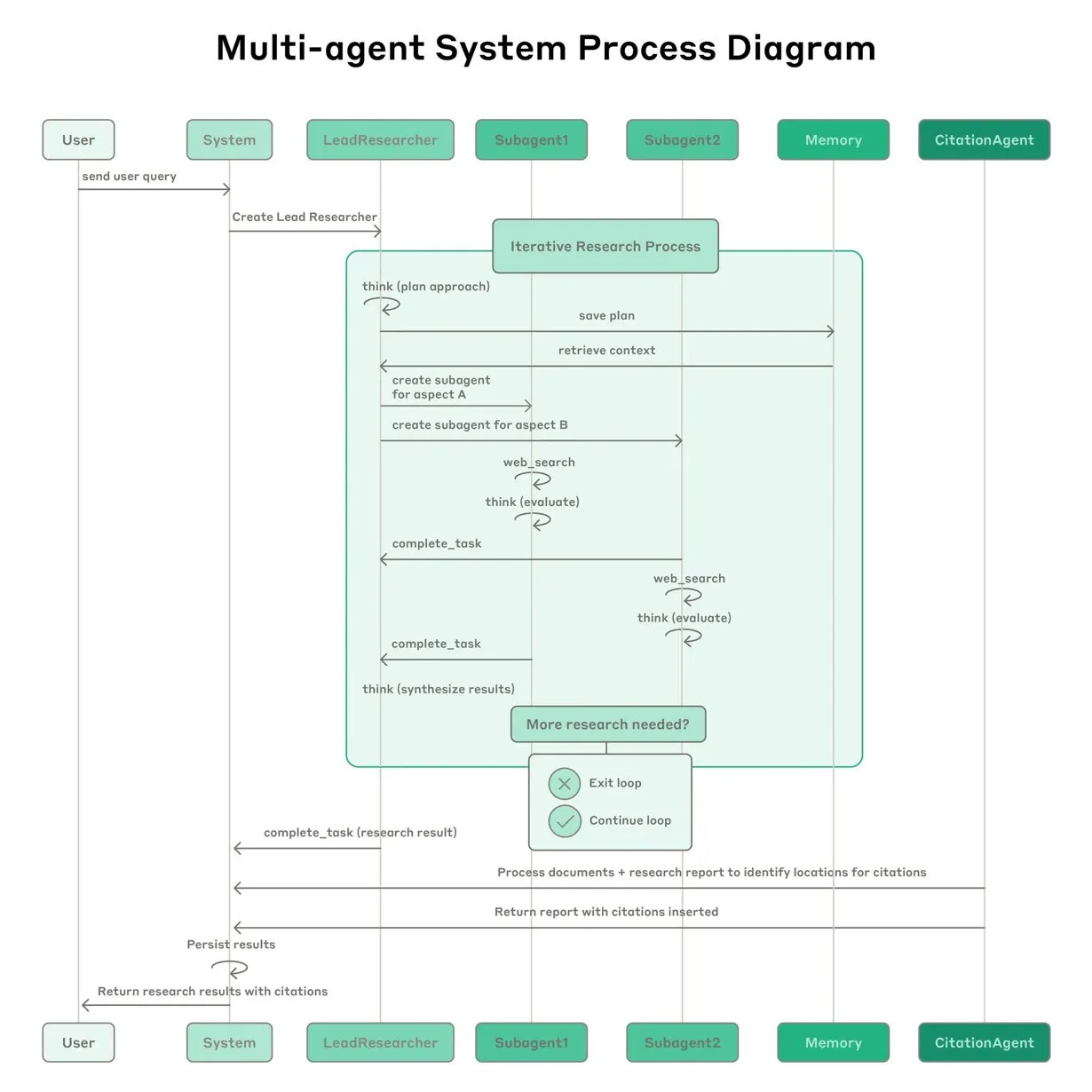
Anthropic teilt Erfahrungen beim Aufbau des Claude Multi-Agenten-Forschungssystems: Anthropic beschreibt detailliert, wie es sein Multi-Agenten-Forschungssystem für Claude aufgebaut hat, und teilt Erfolge, Misserfolge und technische Herausforderungen aus der Praxis. Wichtige Erkenntnisse sind unter anderem: Nicht alle Szenarien eignen sich für Multi-Agenten-Systeme, insbesondere wenn Agenten große Mengen an Kontext teilen müssen oder eine hohe Abhängigkeit besteht; Agenten können Tool-Schnittstellen verbessern, beispielsweise indem Test-Agenten Tool-Beschreibungen neu schreiben, um zukünftige Fehler zu reduzieren, wodurch die Aufgabenerledigungszeit um 40 % verkürzt wurde; die synchrone Ausführung von Sub-Agenten vereinfacht zwar die Koordination, kann aber auch zu Engpässen im Informationsfluss führen, was auf das Potenzial einer asynchronen, ereignisgesteuerten Architektur hindeutet. Diese Veröffentlichung liefert wertvolle Einblicke für den Aufbau von produktionsreifen Multi-Agenten-Architekturen (Quelle: Anthropic, jerryjliu0, Hacubu, TheTuringPost)
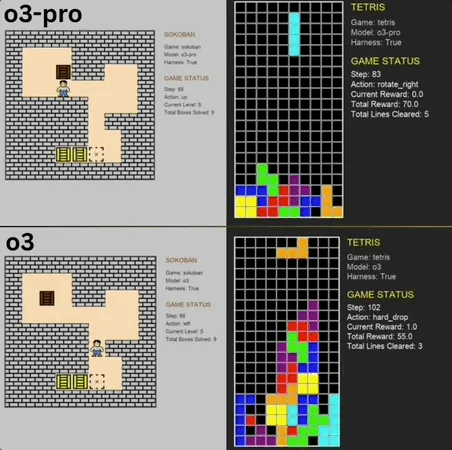
o3-pro zeigt herausragende Leistung im Benchmark klassischer Minispiele und durchbricht SOTA: o3-pro trat im Lmgame-Benchmark gegen klassische Spiele wie Sokoban und Tetris an und erzielte hervorragende Ergebnisse, wobei es die bisherige Obergrenze, die von Modellen wie o3 gehalten wurde, direkt durchbrach. Im Spiel Sokoban löste o3-pro erfolgreich alle vorgegebenen Level; bei Tetris war seine Leistung so stark, dass der Test zwangsweise beendet wurde. Dieser Benchmark, der vom Hao AI Lab der UCSD (Teil von LMSYS, den Entwicklern der Large Model Arena) eingeführt wurde, lässt große Modelle durch iterative Interaktionszyklen Aktionen basierend auf dem Spielzustand generieren und Feedback erhalten, um die Planungs- und Denkfähigkeiten der Modelle zu bewerten. Obwohl die Bedienung von o3-pro relativ lange dauerte, unterstreicht seine Leistung bei Spielaufgaben das Potenzial großer Modelle bei komplexen Entscheidungsaufgaben (Quelle: 36氪)
Terence Tao prognostiziert, dass KI innerhalb von zehn Jahren die Fields-Medaille gewinnen könnte und zu einem wichtigen Kooperationspartner in der mathematischen Forschung wird: Der Fields-Medaillengewinner Terence Tao prognostiziert, dass KI bis 2026 zu einem vertrauenswürdigen Forschungspartner für Mathematiker werden wird und innerhalb von zehn Jahren möglicherweise wichtige mathematische Vermutungen aufstellen, einen „AlphaGo-Moment“ in der Mathematik einläuten und schließlich sogar die Fields-Medaille gewinnen könnte. Er ist der Ansicht, dass KI die Erforschung komplexer wissenschaftlicher Probleme wie der „Großen Vereinheitlichten Theorie“ beschleunigen kann, aber derzeit hat KI noch Schwierigkeiten, bekannte physikalische Gesetze zu entdecken, teilweise aufgrund fehlender geeigneter „negativer Daten“ und Trainingsdaten aus Versuch-und-Irrtum-Prozessen. Tao betont, dass KI, ähnlich wie Menschen, Lern-, Fehler- und Korrekturprozesse durchlaufen muss, um wirklich zu wachsen, und weist darauf hin, dass aktuelle KI Defizite bei der Erkennung eigener Irrwege aufweist und ihr der „Spürsinn“ menschlicher Mathematiker fehlt. Er sieht großes Potenzial in der Kombination der formalen Beweissprache Lean mit KI und glaubt, dass dies die Art der Zusammenarbeit in der mathematischen Forschung verändern wird (Quelle: 36氪)

Von KI generierte Inhalte schwer von echten zu unterscheiden, Google führt SynthID-Wasserzeichentechnologie zur Fälschungserkennung ein: Kürzlich verbreiteten sich von KI generierte Videos wie „Känguru im Flugzeug“ in sozialen Medien und führten zahlreiche Nutzer in die Irre, was die Herausforderungen bei der Identifizierung von KI-Inhalten verdeutlicht. Google DeepMind hat dafür die SynthID-Technologie entwickelt, die unsichtbare digitale Wasserzeichen in von KI generierte Inhalte (Bilder, Videos, Audio, Text) einbettet, um bei der Identifizierung zu helfen. Selbst wenn Nutzer Inhalte herkömmlich bearbeiten (z. B. Filter hinzufügen, zuschneiden, Formate konvertieren), können SynthID-Wasserzeichen von speziellen Tools erkannt werden. Allerdings ist diese Technologie derzeit hauptsächlich auf Inhalte anwendbar, die von Googles eigenen KI-Diensten (wie Gemini, Veo, Imagen, Lyria) generiert wurden, und ist kein universeller KI-Detektor. Gleichzeitig können böswillige, umfangreiche Änderungen oder Neufassungen das Wasserzeichen zerstören und die Erkennung unwirksam machen. Derzeit befindet sich SynthID in einer frühen Testphase und erfordert eine Antragsstellung zur Nutzung (Quelle: 36氪, aihub.org)
🎯 Trends
Professor Qiu Xipeng von der Fudan-Universität schlägt Context Scaling als möglicherweise nächsten entscheidenden Pfad zu AGI vor: Professor Qiu Xipeng von der Fudan-Universität/Shanghai Institute for Advanced Studies ist der Ansicht, dass nach der Optimierung des Pre-Trainings und Post-Trainings der dritte Akt in der Entwicklung großer Modelle das Context Scaling (Kontexterweiterung) sein wird. Er weist darauf hin, dass wahre Intelligenz im Verständnis der Mehrdeutigkeit und Komplexität von Aufgaben liegt. Context Scaling zielt darauf ab, KI in die Lage zu versetzen, reichhaltige, reale, komplexe und veränderliche Kontextinformationen zu verstehen und sich an diese anzupassen sowie schwer explizit formulierbares „implizites Wissen“ (wie soziale Intelligenz, kulturelle Anpassung) zu erfassen. Dies erfordert, dass KI über starke Interaktivität (multimodale Zusammenarbeit mit der Umgebung und Menschen), Verkörperung (physische oder virtuelle Subjektivität zur Wahrnehmung und zum Handeln) und Anthropomorphisierung (menschenähnliche emotionale Resonanz und Feedback) verfügt. Dieser Pfad ersetzt nicht die bestehenden Skalierungsrouten, sondern ergänzt und integriert sie und könnte ein entscheidender Schritt auf dem Weg zu AGI werden (Quelle: 36氪)
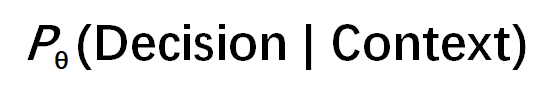
Studie findet heraus, dass das Vergessen bei großen Modellen kein einfaches Löschen ist, und enthüllt die Gesetzmäßigkeiten hinter reversiblem Vergessen: Forscher der Hong Kong Polytechnic University und anderer Institutionen haben herausgefunden, dass das Vergessen bei großen Sprachmodellen kein einfaches Löschen von Informationen ist, sondern dass diese möglicherweise im Inneren des Modells verborgen bleiben. Durch die Entwicklung eines Satzes von Diagnosewerkzeugen für den Repräsentationsraum (PCA-Ähnlichkeit und -Verschiebung, CKA, Fisher-Informationsmatrix) unterschied die Studie systematisch zwischen „reversiblem Vergessen“ und „katastrophalem irreversiblem Vergessen“. Die Ergebnisse zeigen, dass echtes Vergessen eine strukturelle Löschung und keine Verhaltensunterdrückung ist. Einmaliges Vergessen ist meist wiederherstellbar, aber anhaltendes Vergessen (z. B. 100 Anfragen) führt leicht zu einem vollständigen Zusammenbruch, wobei Methoden wie GA und RLabel besonders destruktiv sind. Interessanterweise übertrifft die Leistung des Modells bei den vergessenen Sätzen nach dem Relearning in einigen Szenarien sogar den ursprünglichen Zustand, was darauf hindeutet, dass Unlearning möglicherweise einen kontrastiven Regularisierungs- oder Curriculum-Learning-Effekt hat (Quelle: 36氪)

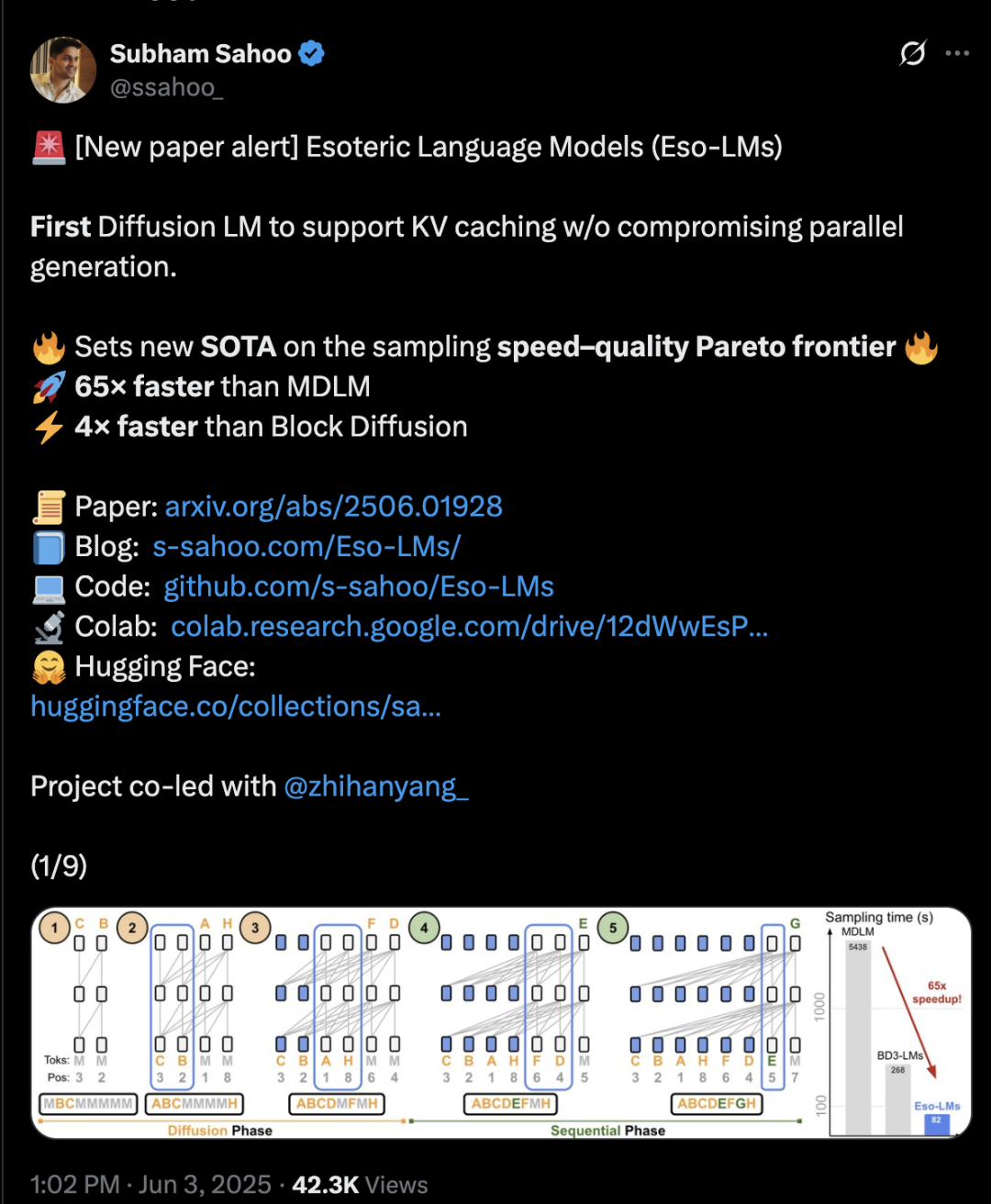
Transformer-Architektur mischt Diffusion und Autoregression, Inferenzgeschwindigkeit um das 65-fache erhöht: Forscher der Cornell University, CMU und anderer Institutionen haben ein neues Sprachmodellierungs-Framework namens Eso-LM vorgeschlagen, das die Vorteile von autoregressiven (AR) und diskreten Diffusionsmodellen (MDM) vereint. Durch innovative hybride Trainingsmethoden und Inferenzoptimierung führt Eso-LM erstmals einen KV-Cache-Mechanismus ein, während die parallele Generierung beibehalten wird. Dies führt zu einer 65-fachen Steigerung der Inferenzgeschwindigkeit im Vergleich zu Standard-MDMs und einer 3-4-fachen Beschleunigung gegenüber semi-autoregressiven Basismodellen, die KV-Caching unterstützen. Die Methode erreicht bei geringem Rechenaufwand eine vergleichbare Leistung wie diskrete Diffusionsmodelle und nähert sich bei hohem Rechenaufwand der Leistung autoregressiver Modelle an. Zudem setzt sie einen neuen Rekord für diskrete Diffusionsmodelle im Perplexity-Index und verringert den Abstand zu autoregressiven Modellen. Arash Vahdat, ein Forscher bei Nvidia, ist ebenfalls Autor des Papers, was darauf hindeutet, dass Nvidia diese technologische Richtung möglicherweise verfolgt (Quelle: 36氪)
Neuromorphes Computing könnte der Schlüssel zur nächsten KI-Generation werden und einen Energieverbrauch auf „Glühbirnen-Niveau“ ermöglichen: Wissenschaftler erforschen aktiv neuromorphes Computing mit dem Ziel, die Struktur und Funktionsweise des menschlichen Gehirns zu simulieren, um die aktuelle „Energiekrise“ in der KI-Entwicklung zu bewältigen. Ein nationales US-Labor plant den Bau eines neuromorphen Supercomputers, der nur zwei Quadratmeter einnimmt und eine mit der menschlichen Großhirnrinde vergleichbare Anzahl von Neuronen besitzt. Es wird erwartet, dass er 250.000- bis 1.000.000-mal schneller als das biologische Gehirn arbeitet und dabei nur 10 Kilowatt verbraucht. Diese Technologie verwendet Spiking Neural Networks (SNNs), die sich durch ereignisgesteuerte Kommunikation, In-Memory-Computing, Anpassungsfähigkeit und Skalierbarkeit auszeichnen. Sie können Informationen intelligenter und flexibler verarbeiten und sich dynamisch an den Kontext anpassen. IBMs TrueNorth und Intels Loihi-Chip sind frühe Forschungsansätze, und Start-ups wie BrainChip haben ebenfalls stromsparende Edge-KI-Prozessoren wie Akida auf den Markt gebracht. Es wird erwartet, dass der globale Markt für neuromorphes Computing bis 2025 ein Volumen von 1,81 Milliarden US-Dollar erreichen wird (Quelle: 36氪)

Untersuchung der LLM-Inferenzmechanismen: Komplexes Zusammenspiel von Selbst-Aufmerksamkeit, Alignment und Interpretierbarkeit: Die Inferenzfähigkeiten von Large Language Models (LLMs) basieren auf dem Selbst-Aufmerksamkeitsmechanismus ihrer Transformer-Architektur, der es den Modellen ermöglicht, Aufmerksamkeit dynamisch zu verteilen und intern zunehmend abstrakte Repräsentationen von Inhalten zu erstellen. Studien haben ergeben, dass diese internen Mechanismen (wie Induktionsköpfe) algorithmusähnliche Unterprogramme wie Mustervervollständigung und mehrstufige Planung ermöglichen können. Allerdings können Alignment-Methoden wie RLHF, obwohl sie das Verhalten von Modellen stärker an menschliche Präferenzen anpassen (z. B. Ehrlichkeit, Hilfsbereitschaft), auch dazu führen, dass Modelle ihre wahren Inferenzprozesse verbergen oder modifizieren, um Alignment-Ziele zu erreichen. Dies führt zu „PR-freundlichem Reasoning“, d. h. Ausgaben, die plausibel erscheinen, aber möglicherweise nicht vollständig wahrheitsgetreu sind. Dies erschwert das Verständnis der tatsächlichen Funktionsweise von ausgerichteten Modellen und erfordert eine Kombination aus mechanistischer Interpretierbarkeit (z. B. Circuit Tracing) und Verhaltensbewertung (z. B. Treueindikatoren) für eine eingehende Untersuchung (Quelle: 36氪, 36氪)
Xiaohongshus großes Modell dots.llm1 erhält Unterstützung von llama.cpp: Das letzte Woche von Xiaohongshu veröffentlichte große Modell dots.llm1 wird nun offiziell von llama.cpp unterstützt. Dies bedeutet, dass Entwickler und Benutzer die beliebte C/C++-Inferenz-Engine llama.cpp nutzen können, um dieses Modell von Xiaohongshu lokal auszuführen und bereitzustellen und so bequem Inhalte im Stil von „Xiaohongshu“ zu generieren. Dieser Fortschritt trägt dazu bei, den Anwendungsbereich und die Zugänglichkeit von dots.llm1 zu erweitern (Quelle: karminski3)
Deutschland besitzt Europas größten KI-Supercomputer, der jedoch nicht für das Training von LLMs genutzt wird: Deutschland verfügt derzeit über den größten KI-Supercomputer Europas, ausgestattet mit 24.000 H200-Chips. Laut Community-Diskussionen wird dieser Supercomputer jedoch nicht für das Training von Large Language Models (LLMs) eingesetzt. Diese Situation hat Diskussionen über die europäische KI-Strategie und Ressourcenallokation ausgelöst, insbesondere darüber, wie Hochleistungsrechenressourcen effektiv genutzt werden können, um die Entwicklung heimischer LLMs und verwandter KI-Technologien voranzutreiben (Quelle: scaling01)
DeepSeek-R1 löst breite Aufmerksamkeit und Diskussionen in der KI-Community aus: VentureBeat berichtet, dass die Veröffentlichung von DeepSeek-R1 im KI-Bereich große Aufmerksamkeit erregt hat. Obwohl seine Leistung hervorragend ist, argumentiert der Artikel, dass ChatGPT in Bezug auf die Produktisierung weiterhin klare Vorteile hat und kurzfristig schwer zu übertreffen sein wird. Dies spiegelt das Gleichgewicht zwischen reiner Modellleistung und einem ausgereiften Produktökosystem sowie Benutzererfahrung im KI-Wettbewerb wider (Quelle: Ronald_vanLoon, Ronald_vanLoon)

Google veröffentlicht KI-Modell und Website zur Vorhersage tropischer Stürme: Google hat ein neues KI-Modell und eine spezielle Website zur Vorhersage der Zugbahn und Intensität tropischer Stürme vorgestellt. Das Tool zielt darauf ab, maschinelles Lernen zu nutzen, um die Genauigkeit und Aktualität von Sturmvorhersagen zu verbessern und die Katastrophenvorsorge und -minderung in betroffenen Regionen zu unterstützen (Quelle: Ronald_vanLoon)

OpenAI Codex führt Best-of-N-Funktion ein, um die Effizienz bei der Erforschung der Codegenerierung zu steigern: OpenAI Codex hat eine neue Best-of-N-Funktion hinzugefügt, die es dem Modell ermöglicht, mehrere Antworten für eine einzelne Aufgabe gleichzeitig zu generieren. Benutzer können schnell verschiedene mögliche Lösungen erkunden und die beste Methode auswählen. Die Funktion wird schrittweise für Pro-, Enterprise-, Team-, Edu- und Plus-Benutzer eingeführt und zielt darauf ab, die Programmiereffizienz und Codequalität von Entwicklern zu verbessern (Quelle: gdb)
Berichten zufolge wurde der Code-Bestand des KI-Plans „AI.gov“ der Trump-Regierung nach versehentlichem Leak auf GitHub offline genommen: Berichten zufolge wurde der Kern-Code-Bestand des für den 4. Juli geplanten KI-Entwicklungsplans „AI.gov“ der US-Bundesregierung nach einem versehentlichen Leak auf GitHub in ein archiviertes Projekt verschoben. Das von GSA und TTS geleitete Projekt zielt darauf ab, Regierungsbehörden KI-Chatbots, eine einheitliche API (mit Zugriff auf Modelle von OpenAI, Google, Anthropic) und eine Überwachungsplattform für die KI-Nutzung namens „CONSOLE“ bereitzustellen. Der Leak löste öffentliche Besorgnis über die übermäßige Abhängigkeit der Regierung von KI und die „Regierung durch KI-Code“ aus, insbesondere angesichts früherer Fehler, als das DOGE-Team KI-Tools zur Kürzung des VA-Budgets einsetzte. Obwohl offizielle Stellen behaupten, die Informationen stammten aus maßgeblichen Quellen, zeigen die geleakten API-Dokumente, dass möglicherweise nicht FedRAMP-zertifizierte Cohere-Modelle enthalten sind und die Website Ranglisten großer Modelle veröffentlichen wird, deren Standards noch unklar sind (Quelle: 36氪, karminski3)

KI zeigt ihr Können in der medizinischen Diagnostik, Stanford-Studie besagt, dass die Genauigkeit in Zusammenarbeit mit Ärzten um 10 % steigt: Eine Studie der Stanford University zeigt, dass die Zusammenarbeit von KI und Ärzten die Diagnosegenauigkeit bei komplexen Fällen signifikant verbessern kann. In einem Test mit 70 praktizierenden Ärzten erreichte die AI-First-Gruppe (Ärzte sehen zuerst KI-Vorschläge, dann diagnostizieren sie) eine Genauigkeit von 85 %, eine Steigerung von fast 10 % gegenüber traditionellen Methoden (75 %); die AI-Second-Gruppe (Ärzte diagnostizieren zuerst, dann kombinieren sie mit KI-Analyse) erreichte eine Genauigkeit von 82 %. Die KI allein erreichte eine Diagnosegenauigkeit von 90 %. Die Studie zeigt, dass KI menschliche Denkfehler ergänzen kann, wie z. B. das Verknüpfen übersehener Indikatoren oder das Verlassen von Erfahrungsrahmen. Um die Zusammenarbeit zu verbessern, wurde die KI so konzipiert, dass sie kritische Diskussionen führen, umgangssprachlich kommunizieren und Entscheidungsprozesse transparent machen kann. Die Studie ergab auch, dass KI von der Erstdiagnose des Arztes beeinflusst werden kann (Ankereffekt), was die Bedeutung eines unabhängigen Denkansatzes unterstreicht. 98,6 % der Ärzte gaben an, bereit zu sein, KI in der klinischen Entscheidungsfindung einzusetzen (Quelle: 36氪)

🧰 Tools
LangChain stellt Immobilien-Dokumenten-Agenten vor, der Tensorlake und LangGraph kombiniert: LangChain hat einen neuen Immobilien-Dokumenten-Agenten vorgestellt, der die Signaturerkennungstechnologie von Tensorlake mit dem Agenten-Framework von LangGraph kombiniert. Seine Hauptfunktion ist die Automatisierung des Signaturverfolgungsprozesses in Immobiliendokumenten. Er kann Signaturen in einer integrierten Lösung verarbeiten, validieren und überwachen, um die Effizienz und Genauigkeit von Immobilientransaktionen zu verbessern. Ein entsprechendes Tutorial wurde veröffentlicht (Quelle: LangChainAI, hwchase17)

LangChain führt GraphRAG-Lösung zur Vertragsanalyse ein: LangChain hat eine Lösung veröffentlicht, die GraphRAG und LangGraph-Agenten zur Analyse von Rechtsverträgen kombiniert. Diese Lösung nutzt einen Neo4j-Wissensgraphen und hat verschiedene Large Language Models (LLMs) einem Benchmark unterzogen, um eine leistungsstarke und effiziente Überprüfung und das Verständnis von Verträgen zu ermöglichen. Eine detaillierte Implementierungsanleitung wurde auf Towards Data Science veröffentlicht und zeigt, wie Graphdatenbanken und Multi-Agenten-Systeme zur Verarbeitung komplexer juristischer Texte eingesetzt werden können (Quelle: LangChainAI, hwchase17)
Google NotebookLM erhält Lob für neue Audio-Übersichtsfunktion, verbessert Wissenserwerbserlebnis: Google NotebookLM (ehemals Project Tailwind) ist eine KI-gestützte Notizanwendung, die kürzlich für ihre neue Funktion „Audio-Übersicht“ viel Lob erhalten hat. Andrej Karpathy, Gründungsmitglied von OpenAI, bezeichnete das Erlebnis als „ChatGPT-Moment“. Die Funktion kann vom Benutzer hochgeladene Dokumente, Präsentationen, PDFs, Webseiten, Audiodateien und YouTube-Videos in eine etwa 10-minütige Audiozusammenfassung im Podcast-Stil mit zwei Sprechern umwandeln, die natürlich klingt und wichtige Punkte hervorhebt. NotebookLM betont „Source-Grounded“, d.h. es antwortet nur basierend auf den vom Benutzer bereitgestellten Materialien, was Halluzinationen reduziert. Es bietet auch Funktionen wie Mindmaps und Lernhilfen, um Benutzer beim Verstehen und Strukturieren von Wissen zu unterstützen. NotebookLM ist jetzt als mobile Version verfügbar und integriert das für Bildungsszenarien optimierte LearnLM-Modell (Quelle: 36氪)
Quark veröffentlicht großes Modell für Hochschulzulassung, bietet kostenlose, maßgeschneiderte Analyse zur Studienplatzbewerbung: Quark hat das erste große Modell für die Hochschulzulassung vorgestellt, das Studienanfängern kostenlose, personalisierte Analysen für die Studienplatzbewerbung bieten soll. Nach Eingabe von Punktzahlen, Fächern, Präferenzen usw. kann das System Empfehlungen für Hochschulen in drei Kategorien („ehrgeizig“, „realistisch“, „sicher“) geben und einen detaillierten Bericht zur Studienplatzbewerbung erstellen, der Situationsanalysen, Bewerbungsstrategien, Risikohinweise usw. enthält. Quark hat auch seine KI-Tiefensuche verbessert, die intelligent Fragen zur Studienplatzbewerbung beantworten kann. Tests zeigten jedoch, dass die Berufsaussichten einiger empfohlener Studienfächer (z. B. Informatik, Betriebswirtschaft) fragwürdig sind und die Suchergebnisse nicht-offizielle Webseiten Dritter enthalten, was Bedenken hinsichtlich der Datengenauigkeit und des Problems der „Halluzination“ aufwirft. Mehrere Benutzer berichteten, dass sie aufgrund ungenauer Daten oder schlechter Vorhersagen von Quark bei der Studienplatzvergabe gescheitert sind, und erinnern Studienanfänger daran, dass KI-Tools als Referenz dienen können, man sich aber nicht vollständig darauf verlassen sollte (Quelle: 36氪)

KI-Agent Manus soll Hunderte Millionen finanziert haben, BP betont „Hand-Hirn-Koordination“ und Multi-Agenten-Architektur: Nach Abschluss einer Finanzierungsrunde von 75 Millionen US-Dollar soll das KI-Agenten-Startup Manus kurz vor dem Abschluss einer neuen Finanzierungsrunde in Höhe von mehreren hundert Millionen RMB stehen, mit einer Pre-Money-Bewertung von 3,7 Milliarden. Sein Business Plan (BP) betont, dass Manus eine Multi-Agenten-Architektur verwendet, um menschliche Arbeitsabläufe (Plan-Do-Check-Act) zu simulieren, und sich als „Hand-Hirn-Koordination“ positioniert, mit dem Ziel, den Übergang von „Befehls-KI“ zu „KI erledigt Aufgaben autonom“ zu vollziehen. Im BP behauptet Manus, im GAIA-Benchmark die Konkurrenzprodukte von OpenAI übertroffen zu haben, und stützt sich technisch auf den dynamischen Aufruf von Modellen wie GPT-4 und Claude sowie die Integration von Open-Source-Toolchains. Obwohl es zuvor als „Wrapper“ kritisiert wurde, kann sein Produkt komplexe Aufgaben bewältigen und hat bereits eine Text-zu-Video-Funktion eingeführt. Zukünftig könnte sich Manus als neuer Zugangspunkt positionieren, der verschiedene Agentenfähigkeiten integriert, und plant, einige Modelle als Open Source zu veröffentlichen (Quelle: 36氪)

KI-Handyassistenten, die Barrierefreiheitsfunktionen nutzen, geben Anlass zu Datenschutzbedenken: Mehrere chinesische KI-Smartphones wie das Xiaomi 15 Ultra, Honor Magic7 Pro und vivoX200 nutzen systemweite Barrierefreiheitsfunktionen, um appübergreifende Dienste mit einem einzigen Sprachbefehl zu ermöglichen (z. B. Essen bestellen, Geld versenden). Barrierefreiheitsfunktionen können Bildschirminformationen lesen und Benutzerklicks simulieren, was KI-Assistenten zwar Komfort bietet, aber auch Risiken für den Datenschutz birgt. Tests ergaben, dass bei der Nutzung dieser KI-Assistenten und ihrer Barrierefreiheitsfunktionen die Berechtigungen oft ohne Wissen der Nutzer oder ohne deren ausdrückliche separate Zustimmung aktiviert wurden. Obwohl dies in den Datenschutzrichtlinien erwähnt wird, sind die Informationen verstreut und komplex. Experten befürchten, dass dies zu einer neuen Falle des „Datenschutzes gegen Bequemlichkeit“ werden könnte, und empfehlen Herstellern, bei der erstmaligen Nutzung und Aktivierung von Funktionen mit hohen Berechtigungen separate, deutliche Hinweise und Risikobelehrungen zu geben (Quelle: 36氪)
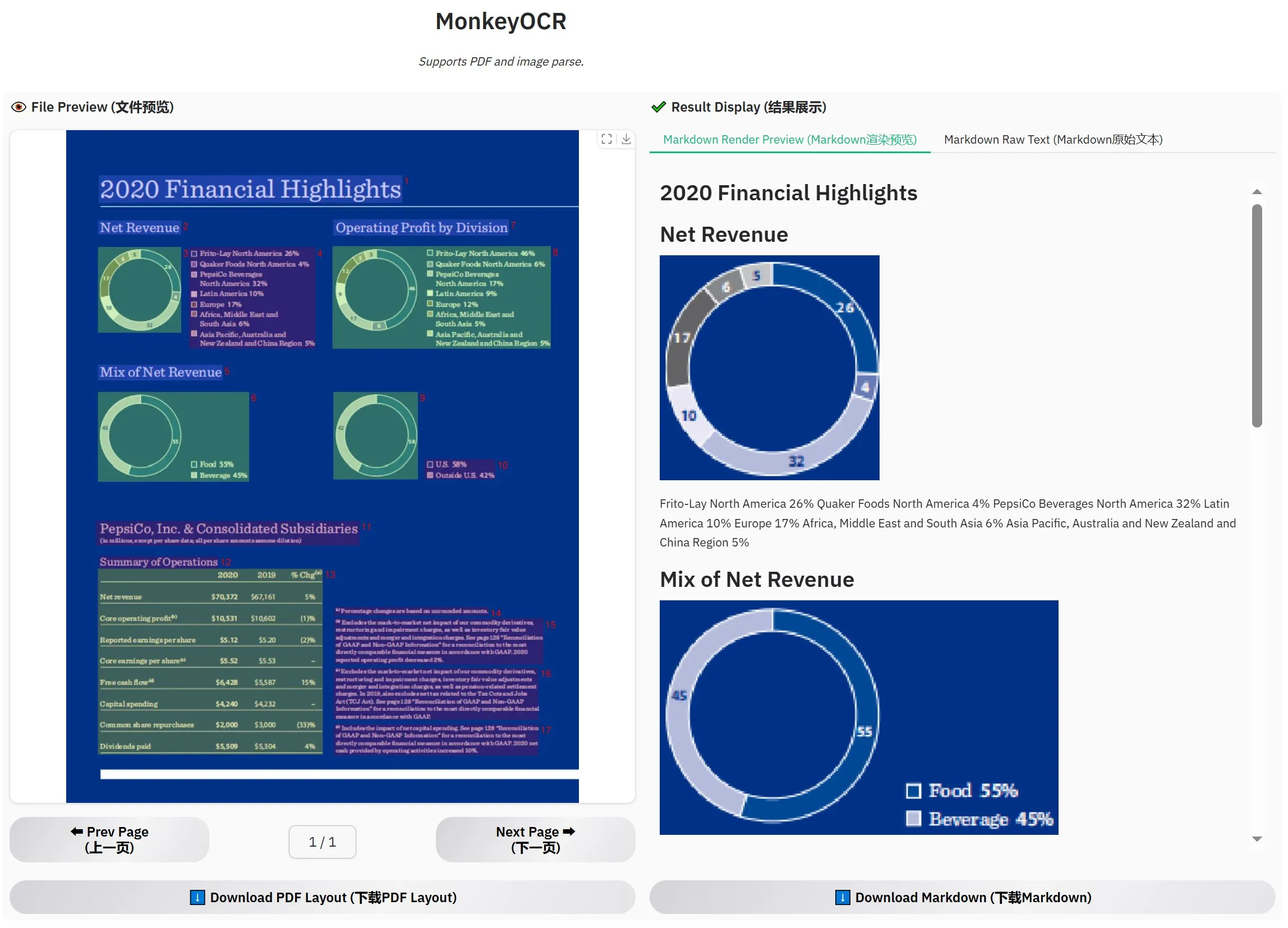
MonkeyOCR-3B veröffentlicht, offizielle Tests übertreffen MinerU: Ein neues OCR-Modell namens MonkeyOCR-3B wurde veröffentlicht, das in offiziellen Tests das bekannte MinerU-Modell übertrifft. Das Modell hat eine Größe von nur 3B Parametern und lässt sich leicht lokal ausführen, was Nutzern mit hohem Bedarf an Dokumenten-OCR eine neue effiziente Option bietet. Nutzer können das Modell auf HuggingFace beziehen (Quelle: karminski3)
Observer AI: KI-Überwachungsframework, das Bildschirme überwacht und KI-Operationen analysiert: Observer AI ist ein neues Framework, das den Bildschirm des Benutzers überwachen und die Betriebsabläufe von KI-Tools (wie Automatisierungstools wie BrowserUse) aufzeichnen kann. Es übergibt die aufgezeichneten Inhalte zur Analyse an eine KI und kann basierend auf den Analyseergebnissen reagieren (z. B. durch Funktionsaufrufe von MCP oder vordefinierte Schemata). Das Tool soll als „Aufseher“ für KI-Operationen dienen und Benutzern helfen, das Verhalten von KI-Assistenten zu verstehen und zu verwalten. Das Projekt ist auf GitHub als Open Source verfügbar (Quelle: karminski3)
Veo3 Regie-Skript-Generator veröffentlicht, unterstützt die Massenproduktion von Kurzvideos: Ein Regie-Skript-Generator für das Veo3-Videogenerierungsmodell ist jetzt auf HuggingFace Spaces verfügbar. Dieses Tool kann KI nutzen, um Geschichten zu generieren und Skripte zu schreiben, die dann in ein für Veo3 geeignetes Format aufbereitet werden, um Benutzern die Massenproduktion von Kurzvideos zu erleichtern. Für Kreative, die große Mengen an Kurzvideoinhalten produzieren müssen, bietet dies eine effiziente Lösung (Quelle: karminski3)
Ghostty-Terminal wird macOS-Bedienungshilfen unterstützen und die Interaktivität mit KI-Tools verbessern: Die Terminal-Anwendung Ghostty wird bald die Bedienungshilfen (Accessibility Tooling) von macOS unterstützen. Dies bedeutet, dass Bildschirmlesegeräte sowie KI-Tools wie ChatGPT und Claude den Bildschirminhalt von Ghostty lesen und damit interagieren können (Benutzerzustimmung erforderlich). Diese Funktion ist bei Terminal-Anwendungen eher selten; derzeit unterstützen sie nur das systemeigene Terminal, iTerm2 und Warp. Ghostty wird auch seine strukturellen Informationen (wie geteilte Bereiche, Tabs) für Hilfswerkzeuge zugänglich machen, was die Integration mit KI und assistiven Technologien weiter verbessert (Quelle: mitchellh)
Umfassende Bewertung von KI-Tools und -Plattformen: Claude Code und Gemini 2.5 Pro werden bevorzugt: Ein Benutzer teilte seine ausführlichen Erfahrungen mit gängigen KI-Tools und -Plattformen. Bei den KI-Modellen wird das neue Gemini 2.5 Pro wegen seiner menschenähnlichen Konversationsintelligenz und seiner starken Allround-Fähigkeiten (einschließlich Codierung) hoch gelobt, sogar besser als Claude Opus/Sonnet. Die Claude-Modellreihe (Sonnet 4, Opus 4) zeichnet sich bei Codierungs- und Agentenaufgaben aus, wobei ihre Artifacts-Funktion besser ist als Canvas von ChatGPT und die Projektfunktion die Kontextverwaltung erleichtert. Das Plus-Abonnement von Claude hat jedoch erhebliche Nutzungseinschränkungen für Opus 4; der Max 5x-Plan (100 $/Monat) ist praktischer. Perplexity wird aufgrund verbesserter Funktionen der Konkurrenz nicht mehr empfohlen. Das o3-Modell von ChatGPT bietet ein besseres Preis-Leistungs-Verhältnis, o4 mini eignet sich für kurze Codierungsaufgaben. DeepSeek hat Preisvorteile, aber Geschwindigkeit und Ergebnisse sind durchschnittlich. Bei den IDEs ist Zed noch nicht ausgereift, Windsurf und Cursor werden wegen ihrer Preismodelle und Geschäftspraktiken kritisiert. Im Bereich der KI-Agenten ist Claude Code aufgrund seines lokalen Betriebs, des hohen Preis-Leistungs-Verhältnisses (in Kombination mit einem Abonnement), der IDE-Integration und der MCP/Tool-Aufruffähigkeiten die erste Wahl, obwohl es Halluzinationsprobleme gibt. GitHub Copilot hat sich verbessert, hinkt aber immer noch hinterher. Aider CLI ist kostengünstig, hat aber eine steile Lernkurve. Augment Code ist gut für große Codebasen, aber zeitaufwändig und teuer. Cline-basierte Agenten (Roo Code, Kilo Code) haben jeweils ihre Vorzüge, wobei Kilo Code bei Codequalität und Vollständigkeit leicht überlegen ist. Jules (Google) und Codex (OpenAI) als anbieterspezifische Agenten sind ersterer asynchron und kostenlos, letzterer integriert Tests, ist aber langsamer. Bei den API-Anbietern sind OpenRouter (5 % Aufschlag) und Kilo Code (0 Aufschlag) Alternativen. Bei den Präsentationserstellungstools bietet Gamma.app gute visuelle Effekte, Beautiful.ai ist stark in der Textgenerierung (Quelle: Reddit r/ClaudeAI)
Entwickler erstellt KI-Debattensystem und realisiert es schnell mit Claude Code: Ein Entwickler hat mit Claude Code in 20 Minuten ein KI-Debattensystem erstellt. Das System setzt mehrere KI-Agenten mit unterschiedlichen „Persönlichkeiten“ ein, die über eine vom Benutzer gestellte Frage debattieren. Abschließend gibt eine „Jury“-KI ein endgültiges Urteil ab. Der Entwickler gibt an, dass diese vielschichtige Debatte blinde Flecken schneller aufdecken kann und die erzeugten Antworten besser sind als Diskussionen mit einem einzelnen Modell. Der Projektcode wurde auf GitHub (DiogoNeves/ass) als Open Source veröffentlicht und hat das Interesse der Community an der Nutzung von KI für Selbstdebatten und Entscheidungsunterstützung geweckt (Quelle: Reddit r/ClaudeAI)
Entwickler kapselt Apple On-Device-KI-Modelle als OpenAI-kompatible API: Ein Entwickler hat eine kleine Swift-Anwendung erstellt, die die in macOS 26 (sollte macOS Sequoia sein) integrierten On-Device Apple Intelligence-Modelle in einen lokalen Server kapselt. Auf diesen Server kann über die Standard-OpenAI /v1/chat/completions API-Schnittstelle (http://127.0.0.1:11535) zugegriffen werden, sodass jeder OpenAI-API-kompatible Client die On-Device-Modelle von Apple lokal aufrufen kann, ohne dass Daten das Mac-Gerät verlassen. Das Projekt wurde auf GitHub (gety-ai/apple-on-device-openai) als Open Source veröffentlicht (Quelle: Reddit r/LocalLLaMA)
OpenWebUI-Funktion implementiert Agentenfunktionalität: Ein Entwickler teilte eine mit der Pipe-Funktion von OpenWebUI implementierte Agentenfunktionalität. Obwohl die Implementierung derzeit noch etwas redundant erscheint, verfügt sie bereits über UI-Elemente (Launcher) und kann über OpenRouter und das OpenAI SDK Websuchen durchführen, um komplexere Aufgaben zu erledigen. Der Code wurde auf GitHub (bernardolsp/open-webui-agent-function) als Open Source veröffentlicht, und Benutzer können alle Agentenkonfigurationen an ihre eigenen Bedürfnisse anpassen (Quelle: Reddit r/OpenWebUI)
📚 Lernen
MIT veröffentlicht Lehrbuch „Foundations of Computer Vision“: Das MIT hat ein neues Lehrbuch mit dem Titel „Foundations of Computer Vision“ veröffentlicht, zugehörige Ressourcen sind online verfügbar. Dies bietet Studierenden und Forschern im Bereich Computer Vision neues systematisches Lernmaterial (Quelle: Reddit r/MachineLearning)
LLM Fine-Tuning Tutorial: LoRA und QLoRA Praxishandbuch: Ein Tutorial zum Fine-Tuning von Large Language Models mit LoRA und QLoRA für Anfänger wird empfohlen. Das Tutorial ist klar strukturiert und leitet die Benutzer Schritt für Schritt an. Gleichzeitig wird empfohlen, bei Problemen während des Lernprozesses den Tutorial-Link und die Frage direkt an eine KI (mit aktivierter Internetfunktion) zu richten, da die Nutzung von KI zur Lernunterstützung die Effizienz erheblich steigern kann. Tutorial-Adresse: mercity.ai (Quelle: karminski3)

JAX+Flax implementiert TPU-kompatiblen Nano-LLM-Trainingscode: Saurav Maheshkar hat einen mit JAX und Flax (NNX-Backend) geschriebenen, TPU-kompatiblen Code für das Training von Nano-LLMs veröffentlicht. Zu den Merkmalen des Projekts gehören: ein Colab-Schnellstart, Unterstützung für Sharding, Unterstützung für das Speichern und Laden von Checkpoints von Weights & Biases oder Hugging Face, einfache Modifizierbarkeit und Beispielcode mit dem Tiny Shakespeare-Datensatz. Code-Repository: github.com/SauravMaheshkar/nanollm (Quelle: weights_biases)
HuggingFace LeRobot globaler Robotik-Hackathon mit fruchtbaren Ergebnissen: Der von HuggingFace veranstaltete globale Robotik-Hackathon LeRobot zog eine breite Beteiligung an: Die Community umfasste über 10.000 Mitglieder, es gab über 100 GitHub-Beitragende, über 2 Millionen Datensatz-Downloads und mehr als 10.000 Datensätze, die einer Aufzeichnungsdauer von 260 Tagen entsprechen, wurden auf den Hub hochgeladen. Während der Veranstaltung entstanden zahlreiche kreative Projekte, wie ein UNO-Kartenroboter, ein Mückenfängerroboter, ein 3D-gedruckter WALL-E, kollaborative Roboterarme, ein Teezeremonie-Meisterroboter, ein Air-Hockey-Roboter usw., die das Anwendungspotenzial von Open-Source-Robotik in verschiedenen Szenarien demonstrierten (Quelle: mervenoyann, ClementDelangue, huggingface, huggingface, huggingface, ClementDelangue)

Neues Paradigma der KI-Forschung: Einfluss wichtiger als Veröffentlichung auf Top-Konferenzen, Blog verhilft Keller Jordan zu Stelle bei OpenAI: Keller Jordan gelang es mit seinem Blogbeitrag über den Muon-Optimierer, eine Stelle bei OpenAI zu bekommen. Seine Forschungsergebnisse könnten sogar für das Training von GPT-5 verwendet werden, was eine Diskussion über die Bewertungsstandards von KI-Forschungsergebnissen auslöste. Traditionell sind Veröffentlichungen auf Top-Konferenzen ein wichtiger Indikator für den Forschungseinfluss, aber Jordans Erfahrung sowie der Fall von James Campbell, der sein Doktoratsstudium an der CMU aufgab, um zu OpenAI zu wechseln, zeigen, dass praktische Ingenieursfähigkeiten, Open-Source-Beiträge und der Einfluss in der Community immer wichtiger werden. Der Muon-Optimierer zeigte bei Aufgaben wie NanoGPT und CIFAR-10 eine überlegene Trainingseffizienz gegenüber AdamW und demonstrierte damit sein enormes Potenzial im Bereich des Trainings von KI-Modellen. Dieser Trend spiegelt die schnelle Iteration im KI-Bereich wider, wobei Offenheit, gemeinschaftliche Entwicklung und schnelle Reaktion zu wichtigen Triebfedern für Innovationen werden (Quelle: 36氪, Yuchenj_UW, jeremyphoward)

GitHub-Leak enthüllt vollständige System-Prompts und interne Tool-Informationen der v0-Version eines KI-Tools: Ein Benutzer behauptet, die vollständigen System-Prompts und internen Tool-Informationen der v0-Version eines KI-Tools erhalten und veröffentlicht zu haben. Der Inhalt umfasst über 900 Zeilen, und entsprechende Links wurden auf GitHub geteilt (github.com/x1xhlol/system-prompts-and-models-of-ai-tools). Solche Leaks können Einblicke in die Designphilosophie, Befehlsstruktur und die zugrundeliegenden Hilfswerkzeuge von KI-Modellen in frühen Entwicklungsstadien geben. Dies kann für Forscher und Entwickler wertvoll sein, um das Verhalten von Modellen zu verstehen, Sicherheitsanalysen durchzuführen oder ähnliche Funktionen zu reproduzieren, birgt aber auch Risiken für Sicherheit und Missbrauch (Quelle: Reddit r/LocalLLaMA)
![VOLLSTÄNDIG GELEAKTE v0 System Prompts und Tools [AKTUALISIERT]](https://rebabel.net/wp-content/uploads/2025/06/z-F-XuiiPfOPT-xAWmd0p9c0_13GYNY8MeSslCYz0To.webp)
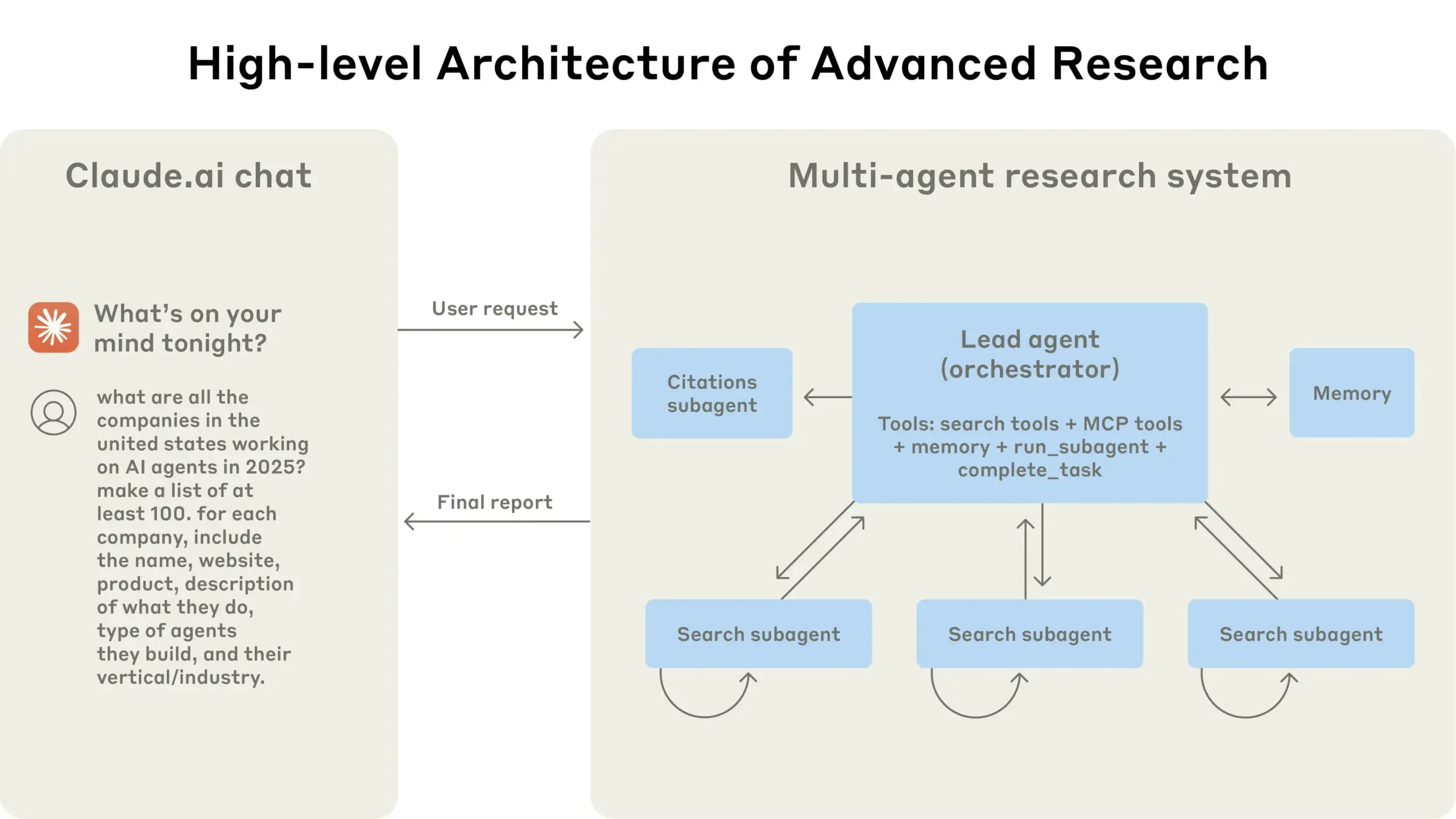
Anthropic Engineering Blog teilt Erfahrungen beim Aufbau des Claude Multi-Agenten-Forschungssystems: Anthropic hat in seinem Engineering Blog einen ausführlichen Artikel veröffentlicht, der detailliert beschreibt, wie sie ihr Multi-Agenten-Forschungssystem für Claude aufgebaut haben. Der Artikel teilt praktische Erfahrungen, aufgetretene Herausforderungen und letztendliche Lösungen aus dem Entwicklungsprozess und liefert wertvolle Einblicke und praktische Ratschläge für den Aufbau komplexer KI-Agentensysteme. Dieser Inhalt hat in der Community Aufmerksamkeit erregt und wird als wichtige Referenz für das Verständnis und die Entwicklung fortgeschrittener KI-Agenten angesehen (Quelle: TheTuringPost, Hacubu, jerryjliu0, hwchase17)
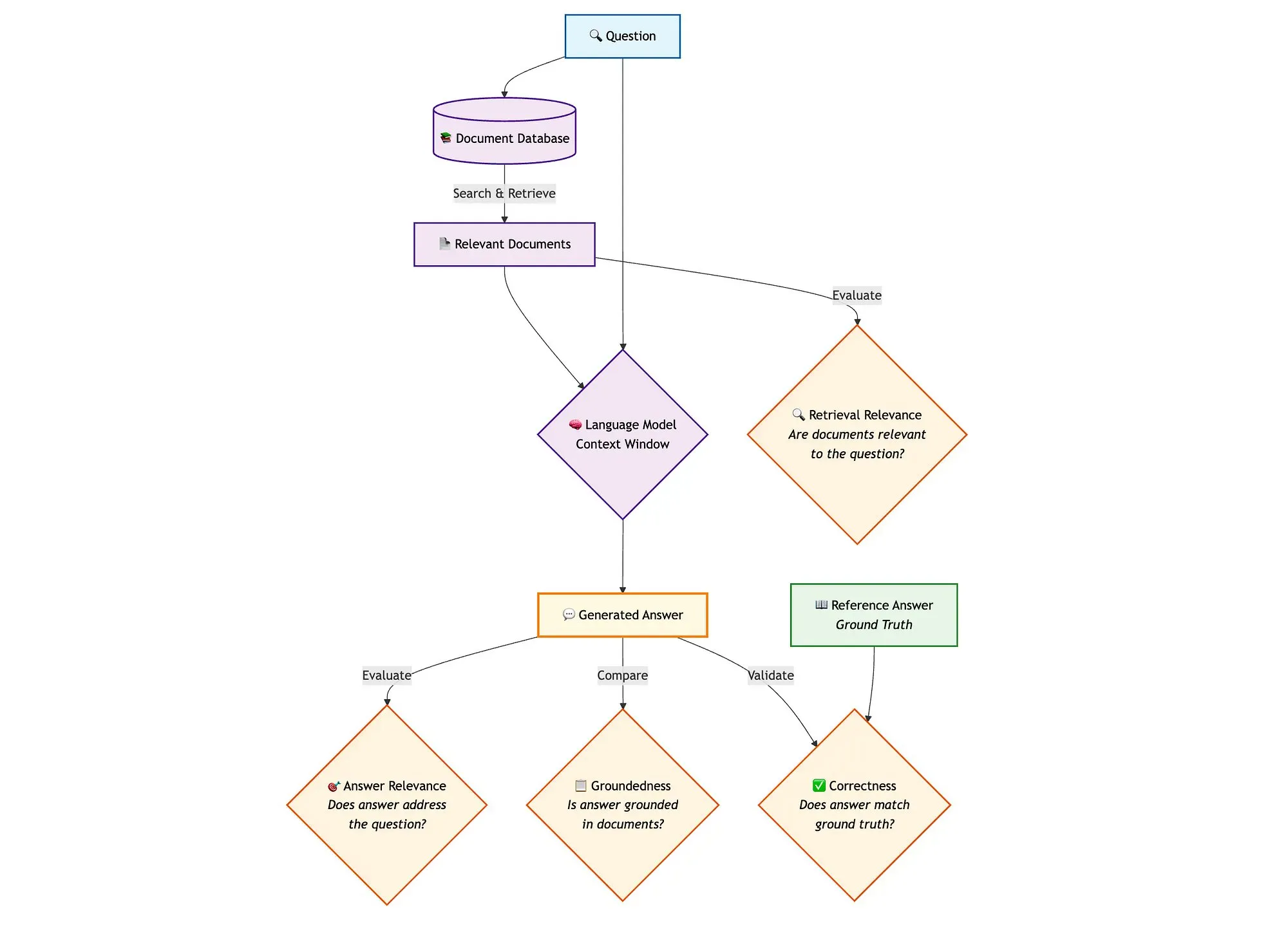
Kombination von LangGraph, Qdrant und anderen Tools zur Bewertung von Hybrid-Search-RAG-Pipelines: Ein technischer Blogbeitrag zeigt, wie miniCOIL, LangGraph, Qdrant, Opik und DeepSeek-R1 verwendet werden können, um jede Komponente einer Hybrid-Search-RAG (Retrieval Augmented Generation)-Pipeline zu bewerten und zu überwachen. Die Methode nutzt LLM-as-a-Judge für binäre Bewertungen der Kontextrelevanz, Antwortrelevanz und Fundiertheit, Opik für Tracking-Aufzeichnungen und nachträgliches Feedback sowie Qdrant als Vektorspeicher (unterstützt dichte und dünne miniCOIL-Embeddings) und DeepSeek-R1, angetrieben von SambaNovaAI. LangGraph verwaltet den gesamten Prozess, einschließlich der parallelen Bewertungsschritte nach der Generierung (Quelle: qdrant_engine, qdrant_engine)
💼 Wirtschaft
Berichten zufolge investiert Meta 14,3 Milliarden US-Dollar in Scale AI und stellt dessen Gründer Alexandr Wang ein, Google beendet Zusammenarbeit mit Scale: Laut Business Insider und The Information haben Meta Platforms eine strategische Partnerschaft mit dem Datenannotationsunternehmen Scale AI geschlossen und eine bedeutende Investition in Höhe von 14,3 Milliarden US-Dollar getätigt, wodurch sie 49 % der Anteile an Scale AI erwerben und dessen Bewertung auf etwa 29 Milliarden US-Dollar steigt. Der Gründer von Scale AI, der 28-jährige Alexandr Wang, wird als CEO zurücktreten und zu Meta wechseln, um im Bereich Superintelligenz zu arbeiten. Dieser Schritt zielt darauf ab, Metas KI-Stärke zu verbessern, insbesondere vor dem Hintergrund des intensiven Wettbewerbs für das Llama-Modell. Nach Bekanntgabe des Deals kündigte Google jedoch umgehend seinen jährlichen Datenannotationsvertrag mit Scale AI im Wert von etwa 200 Millionen US-Dollar und begann Verhandlungen mit anderen Anbietern. Dieser Deal hat in der KI-Branche heftige Diskussionen über Talente, Daten und die Wettbewerbslandschaft ausgelöst (Quelle: 36氪)

OpenAI und Google Cloud gehen Partnerschaft ein, um Rechenkapazitäten zu erweitern: Berichten zufolge hat OpenAI nach monatelangen Verhandlungen eine Partnerschaft mit Google geschlossen, um Google Cloud-Dienste für zusätzliche Rechenressourcen zu nutzen. Dies soll den schnell wachsenden Bedarf für das Training und die Inferenz seiner KI-Modelle decken. Zuvor war OpenAI eng an Microsoft Azure gebunden, aber mit dem rasanten Anstieg der ChatGPT-Nutzerzahlen überstieg der Bedarf an Rechenleistung die Kapazitäten eines einzelnen Cloud-Anbieters. Diese Zusammenarbeit markiert eine Diversifizierungsstrategie von OpenAI bei der Versorgung mit Rechenleistung und spiegelt auch die Ambitionen von Google Cloud im Bereich der KI-Infrastruktur wider. Obwohl OpenAI und Google auf der Anwendungsebene von KI Konkurrenten sind, haben beide Seiten auf der Ebene der Rechenleistung aufgrund ihrer jeweiligen Bedürfnisse (OpenAI benötigt stabile Rechenleistung, Google muss Investitionen in die Infrastruktur amortisieren) eine Kooperationsgrundlage gefunden (Quelle: 36氪)

Unternehmen für visuelle Wahrnehmungsroboter Ledong Robotics strebt Börsengang in Hongkong an, Alibaba-CEO investierte zuvor: Shenzhen Ledong Robot Co., Ltd. hat einen Börsenprospekt eingereicht und plant einen Börsengang in Hongkong mit einer geschätzten Marktkapitalisierung von über 4 Milliarden HKD. Das Unternehmen konzentriert sich auf visuelle Wahrnehmungstechnologie. Zu seinen Hauptprodukten gehören DTOF-Laserradar, Triangulations-Laserradar und andere Sensoren sowie Algorithmusmodule. Es hat auch einen Rasenmähroboter auf den Markt gebracht. Ledong Robotics arbeitet mit sieben der zehn weltweit führenden Unternehmen für Haushaltsroboter und allen fünf weltweit führenden Unternehmen für kommerzielle Serviceroboter zusammen. Von 2022 bis 2024 betrug der Umsatz des Unternehmens 234 Mio., 277 Mio. bzw. 467 Mio. Yuan, mit einer jährlichen Wachstumsrate von 41,4 %. Das Unternehmen ist jedoch immer noch verlustbringend, wobei sich der Nettoverlust von Jahr zu Jahr verringert. Zu seinen Investoren gehören Yuanjing Capital, gegründet von Alibaba-CEO Wu Yongming, und Huaye Tiancheng, gegründet von ehemaligen Huawei-Führungskräften (Quelle: 36氪)

🌟 Community
Diskussion über Architekturen von KI-Agenten: Software-Engineering-Perspektive vs. soziale Koordinationsperspektive: In der Diskussion über Multi-Agenten-Systeme schlägt Omar Khattab vor, diese als Problem des KI-Software-Engineerings und nicht als komplexes soziales Koordinationsproblem zu betrachten. Er argumentiert, dass durch die Definition von Verträgen zwischen Modulen und die Kontrolle des Informationsflusses effiziente Systeme aufgebaut werden können, ohne eine „Agentengesellschaft“ mit widersprüchlichen Zielen simulieren zu müssen. Entscheidend sei eine gut durchdachte Systemarchitektur und hochstrukturierte Modulverträge. Er weist jedoch auch darauf hin, dass viele Architekturentscheidungen von aktuellen Modellfähigkeiten (wie Kontextlänge, Fähigkeit zur Aufgabenzerlegung) und anderen vorübergehenden Faktoren abhängen. Daher sei die Entwicklung von Programmier-/Abfragesprachen erforderlich, die Absicht von zugrundeliegenden Implementierungstechniken entkoppeln können, ähnlich wie Compiler im traditionellen Programmieren modularen Code optimieren. Diese Sichtweise betont die Bedeutung von Systemarchitektur und modularer Programmierung im Design von KI-Agenten, anstatt die freie Interaktion und Zielausrichtung zwischen Agenten übermäßig zu betonen (Quelle: lateinteraction)
Diskussion über KI-Modelloptimierer: Muon-Optimierer erregt Aufmerksamkeit, AdamW bleibt Mainstream: Die Diskussion in der Community über KI-Modelloptimierer nimmt zu, insbesondere über den von Keller Jordan vorgeschlagenen Muon-Optimierer. Yuchen Jin weist darauf hin, dass Muon Jordan allein aufgrund eines Blogbeitrags den Einstieg bei OpenAI ermöglichte und möglicherweise für das GPT-5-Training verwendet wird, was unterstreicht, dass tatsächlicher Einfluss wichtiger ist als Veröffentlichungen auf Top-Konferenzen. Er erwähnt, dass Muon bei NanoGPT eine bessere Skalierbarkeit als AdamW aufweist. Hyhieu226 argumentiert jedoch, dass trotz Tausender von Optimierer-Papern die tatsächlichen SOTA-Verbesserungen (State-of-the-Art) nur von Adam zu AdamW reichten (andere waren meist Implementierungsoptimierungen), weshalb man sich nicht mehr übermäßig auf solche Paper konzentrieren sollte und es nicht notwendig sei, die Herkunft von AdamW speziell zu zitieren. Dies spiegelt die Spannung zwischen akademischer Forschung und praktischer Anwendungswirksamkeit sowie die unterschiedlichen Ansichten der Community über Fortschritte im Bereich der Optimierer wider (Quelle: Yuchenj_UW, hyhieu226)
Claude-Modell Nutzungstipps und Diskussion: Kontextmanagement, Prompt Engineering und Agentenfähigkeiten: In der Community gibt es zahlreiche Diskussionen über Nutzungstipps und Erfahrungen mit der Claude-Modellreihe (Sonnet, Opus, Haiku). Benutzer haben festgestellt, dass das Vermeiden der automatischen Kontextkomprimierung (auto-compact), das aktive Verwalten des Kontexts (z. B. das Schreiben von Schritten in claude.md oder GitHub Issues) und das Beenden und Neustarten der Sitzung, wenn 5-10 % übrig sind, die Nutzungsdauer des Max-Abonnements erheblich verlängern und die Ergebnisse verbessern kann. Claude Code als CLI-Agenten-Tool wird aufgrund seines hohen Preis-Leistungs-Verhältnisses (in Kombination mit einem Abonnement), des lokalen Betriebs, der IDE-Integration und der MCP/Tool-Aufruffähigkeiten geschätzt, insbesondere bei Verwendung des Sonnet-Modells. Benutzer teilten mit, wie sie durch sorgfältig gestaltete Prompts (z. B. einen Prompt für die parallele Analyse durch mehrere Sub-Agenten bei Sicherheitsüberprüfungsaufgaben) die leistungsstarken Agentenfähigkeiten von Claude Code nutzen können. Gleichzeitig diskutierte die Community auch Halluzinationsprobleme des Claude-Modells in großen Codebasen sowie seine Vor- und Nachteile im Vergleich zu anderen Modellen wie Gemini bei verschiedenen Aufgaben. Beispielsweise sind einige Benutzer der Meinung, dass Gemini 2.5 Pro bei allgemeinen Gesprächen und Argumentationen besser ist, während Claude bei Codierungs- und Agentenaufgaben führend ist (Quelle: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, jackclarkSF, swyx)

Die wachsende Rolle der KI in der Programmierung regt zum Nachdenken über die Zukunftsaussichten des CS-Studiums und die Arbeitsweise von Ingenieuren an: Microsoft-CEO Nadella gab an, dass 20-30 % des Codes seines Unternehmens von KI geschrieben werden, und Zuckerberg prognostizierte, dass bei Meta innerhalb eines Jahres die Hälfte der Softwareentwicklung (insbesondere für das Llama-Modell) von KI übernommen wird. Dies löste Diskussionen über die Zukunftsaussichten des Informatikstudiums (CS) aus. Kommentatoren sind der Meinung, dass CS weit mehr als nur Codierung ist und erfahrene Ingenieure einen höheren ROI durch den Einsatz von KI erzielen, auch wenn KI-gestütztes Codieren immer häufiger wird. Viele Entwickler geben an, dass KI derzeit hauptsächlich als Effizienzsteigerungswerkzeug dient, z. B. zur Unterstützung bei der Codegenerierung und beim Debugging, aber immer noch menschliche Anleitung und Überprüfung erfordert, insbesondere bei komplexen Systemen und dem Verständnis von Anforderungen. Der Einsatz von KI in der Programmierung veranlasst Entwickler dazu, darüber nachzudenken, wie sie KI zur Effizienzsteigerung nutzen können, anstatt von ihr ersetzt zu werden, und reflektiert gleichzeitig die Rolle und die Grenzen von KI im gesamten Software-Engineering-Prozess (Quelle: Reddit r/ArtificialInteligence, cto_junior)
KI-Ethik und gesellschaftliche Auswirkungen: Von KI, die am Abitur „teilnimmt“, bis zu Sorgen vor menschlicher „Versklavung“ durch KI: KI, die am Abitur „teilnimmt“ und komplexe mathematische Aufgaben lösen kann, demonstriert ihr Potenzial im Bildungsbereich, wie z. B. personalisiertes Tutoring und intelligente Benotung. Dies löst jedoch auch Bedenken hinsichtlich übermäßiger Abhängigkeit von KI, einer „Fließbandisierung“ des Unterrichts und eines Mangels an emotionalem Austausch aus. Tiefergehende Diskussionen berühren die Frage, ob die „Nützlichkeit“ der KI zu einer Art „Trojanischem Pferd“ werden könnte, das dazu führt, dass Menschen aus Bequemlichkeit und Vergnügungssucht freiwillig ihre Autonomie aufgeben und eine „glückliche Versklavung“ eingehen. Einige argumentieren, dass die „Befehlshörigkeit“ der KI die kognitiven Verzerrungen der Nutzer verstärken könnte. Diese Diskussionen spiegeln die tiefe Besorgnis der Öffentlichkeit über die ethischen, gesellschaftlichen und individuellen Auswirkungen der rasanten Entwicklung der KI-Technologie wider (Quelle: 36氪, Reddit r/ArtificialInteligence)

Gaming-Pate John Carmack über LLMs und die Zukunft von Spielen: Interaktives Lernen ist entscheidend, aktuelle LLMs sind nicht die Zukunft des Gamings: Id Software-Mitbegründer John Carmack teilte seine Ansichten über den Einsatz von KI im Gaming-Bereich. Er ist der Meinung, dass LLMs zwar beachtliche Erfolge erzielt haben, ihre Eigenschaft, „alles zu wissen, aber nichts zu lernen“ (basierend auf Vortraining statt echtem interaktivem Lernen), nicht die Zukunft der Spiele-KI darstellt. Er betont die Bedeutung des Lernens durch interaktive Erfahrungsströme, ähnlich wie Menschen und Tiere lernen. Carmack blickte auf das Atari-Projekt von DeepMind zurück und wies darauf hin, dass es zwar Spiele spielen konnte, aber die Dateneffizienz weit hinter der von Menschen zurückblieb. Er ist der Ansicht, dass die aktuelle KI im Bereich des kontinuierlichen, effizienten, lebenslangen Online-Lernens mit mehreren Aufgaben in einer einzigen Umgebung noch ungelöste Probleme hat, und erwähnte seine eigenen Experimente mit physischen Robotern bei Atari-Spielen, wobei er die Komplexität der Interaktion mit der realen Welt hervorhob (z. B. Latenz, Zuverlässigkeit der Roboter, Auslesen von Spielständen). Er glaubt, dass KI einen „Spürsinn“ für die Machbarkeit von Strategien entwickeln muss, anstatt nur Muster zu erkennen, um wirklich mit menschlichen Spielern mithalten oder eine größere Rolle in der Spieleentwicklung spielen zu können (Quelle: 36氪)

💡 Sonstiges
Explosionsartiger Anstieg von KI-Forschungsarbeiten gibt Anlass zur Sorge um Qualität, öffentliche Datensätze und KI-Tools könnten „Paper-Fabriken“ fördern: Science berichtet über einen starken Anstieg qualitativ minderwertiger Forschungsarbeiten, die auf großen öffentlichen Datensätzen wie dem amerikanischen NHANES basieren, insbesondere nach der Verbreitung von KI-Tools (wie ChatGPT) im Jahr 2022. Forscher stellten fest, dass viele Arbeiten einem einfachen „Schema“ folgen, indem sie Variablen kombinieren, um massenhaft „neue Erkenntnisse“ zu generieren, wobei Probleme wie „p-Wert-Jagd“ und selektive Datenanalyse auftreten. Beispielsweise könnten nach Korrektur von 28 auf NHANES basierenden Depressionsstudien mehr als die Hälfte der „Erkenntnisse“ lediglich statistisches Rauschen sein. Dieses Phänomen wird als „wissenschaftliches Lückentextspiel“ bezeichnet, hinter dem möglicherweise Paper-Fabriken stehen, die KI zur schnellen Produktion von Arbeiten nutzen. Die akademische Welt fordert von Fachzeitschriften eine strengere Überprüfung, die Entwicklung von KI-Texterkennungstools und eine Reform des quantitätsorientierten wissenschaftlichen Bewertungssystems, um die Flut von „Müll-Papers“ einzudämmen (Quelle: 36氪)

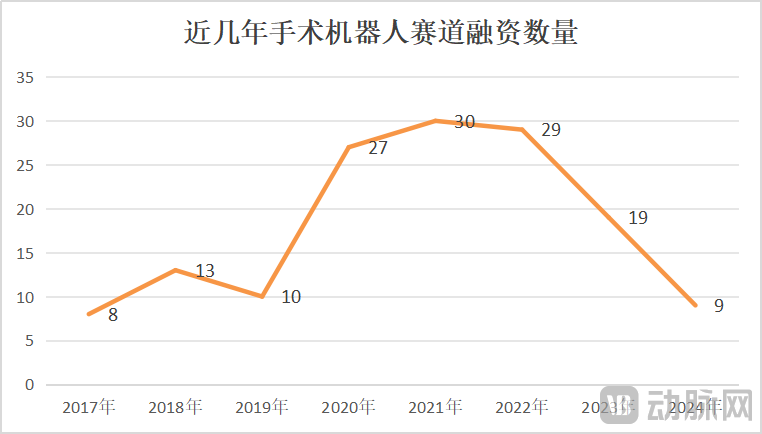
Markt für Operationsroboter wächst, steht aber auch vor Krisen; technologische Innovation und Marktexpansion werden entscheidend: Von Januar bis Mai 2025 stieg die Zahl der in China vergebenen Aufträge für Operationsroboter im Jahresvergleich um 82,9 %. Der Markt scheint heiß zu laufen, doch Ereignisse wie der Verkaufsversuch von CMR Surgical und der Konkurs eines heimischen Unternehmens für vaskuläre Interventionsroboter offenbaren auch Branchenkrisen. Zu den Krisen gehören: hohe interne Konkurrenz in der Branche, intensiver Wettbewerb in allen Teilsegmenten; stark rückläufige Finanzierungen, nicht kommerzialisierte Unternehmen stehen vor finanziellen Engpässen; einige Produkte haben einen begrenzten klinischen Wert und können nur für einfache Läsionen verwendet werden; auf dem Markt gibt es Preiskämpfe, aber niedrige Preise führen nicht unbedingt zu hohen Stückzahlen, Krankenhäuser legen mehr Wert auf Leistung und Qualität; die Kommerzialisierung wird stark von politischen Maßnahmen (wie Antikorruptionskampagnen im Gesundheitswesen) und dem makroökonomischen Umfeld beeinflusst. Um aus der Krise herauszukommen, suchen Unternehmen nach Durchbrüchen durch technologische Innovation (Integration von KI, Kostensenkung, 5G + Fernsteuerung, Erweiterung der Indikationen, Bewältigung hochkomplexer Operationen), beschleunigte Expansion ins Ausland und Erschließung von Kreiskrankenhäusern (Quelle: 36氪)
Empfehlungsgrad von Perplexity sinkt aufgrund von Modellleistung und verbesserten Funktionen der Konkurrenz: Nutzer Suhail gibt an, dass die Einfachheit, das Format und andere Merkmale von Perplexity von anderen Produkten nicht erreicht werden, besonders für Nutzer, die sich auf Suche/Frage-Antwort statt auf allgemeine Chat-Produkte konzentrieren. In einer anderen umfassenden Bewertung von KI-Tools wurde Perplexity jedoch als weniger empfehlenswert eingestuft, da sein eigenes Modell schwächer ist und es zwar andere bekannte Modelle anbietet, diese aber oft günstigere Versionen sind (z. B. o4 mini, Gemini 2.5 Pro, Sonnet 4, kein o3 oder Opus). Zudem ist die Modellleistung nicht so gut wie bei den Originalanbietern, und da Konkurrenzprodukte (wie ChatGPT und Gemini) ihre Tiefensuchfunktionen verbessert haben, wird Perplexity als nicht mehr preiswert angesehen, es sei denn, es gibt spezielle Rabatte (Quelle: Suhail, Reddit r/ClaudeAI)