
Schlüsselwörter:KI, Nvidia, Deutsche Telekom, Industrie-KI-Cloud, Souveräne KI, Anthropic, Multi-Agenten-System, RAISE-Gesetz, Europäische Industrie-KI-Cloud, Flugfestplattengehäuse zur Umgehung von Chipsperren, Claude-Studie zu Multi-Agenten-Systemen, RAISE-Gesetz des Staates New York, Debatte zwischen Jensen Huang und dem CEO von Anthropic
🔥 Fokus
Nvidia und Deutsche Telekom kooperieren für europäische industrielle KI-Cloud: Der deutsche Bundeskanzler traf sich mit Nvidia-CEO Jensen Huang, um die Vertiefung der strategischen Partnerschaft zu erörtern, mit dem Ziel, Deutschlands Position als globaler KI-Führer zu stärken. Kernthemen waren der Aufbau einer souveränen KI-Infrastruktur und die Beschleunigung der Entwicklung des KI-Ökosystems. Zu diesem Zweck kündigten die Deutsche Telekom und Nvidia eine Zusammenarbeit an, um bis 2026 die weltweit erste industrielle KI-Cloud für europäische Hersteller aufzubauen. Diese Plattform soll die Datensouveränität gewährleisten und KI-Innovationen im europäischen Industriesektor vorantreiben. (Quelle: nvidia)

Chinesische KI-Unternehmen umgehen US-Chip-Sperre mit „fliegenden Festplattenkoffern“: Als Reaktion auf die US-Exportbeschränkungen für KI-Chips nach China verfolgen chinesische Unternehmen eine neue Strategie: Sie bringen Festplatten mit KI-Trainingsdaten direkt zu Rechenzentren im Ausland (z. B. Malaysia), um dort Modelle auf Servern mit fortschrittlichen Chips wie denen von Nvidia zu trainieren und die Ergebnisse anschließend zurückzubringen. Dieser Schritt unterstreicht die Komplexität der globalen KI-Lieferkette und die Anpassungsfähigkeit chinesischer Unternehmen unter Restriktionen und fördert gleichzeitig Südostasien und den Nahen Osten als neue Hotspots für KI-Rechenzentren. (Quelle: dotey)

Anthropic veröffentlicht Methode zum Aufbau eines Multi-Agenten-Forschungssystems: Der Engineering-Blog von Anthropic beschreibt detailliert, wie das Unternehmen mehrere parallel arbeitende Agenten einsetzt, um die Forschungsfähigkeiten von Claude zu entwickeln. Der Artikel teilt erfolgreiche Erfahrungen, Herausforderungen und technische Lösungen aus dem Entwicklungsprozess. Dieses Modell der Multi-Agenten-Kollaboration zielt darauf ab, die Tiefenanalyse und Informationsverarbeitungsfähigkeiten großer Sprachmodelle bei komplexen Forschungsaufgaben zu verbessern und bietet eine praktische Referenz für den Aufbau leistungsfähigerer KI-Forschungsassistenten. (Quelle: AnthropicAI)
New York verabschiedet RAISE Act zur Stärkung der Transparenzanforderungen für fortschrittliche KI-Modelle: Der Bundesstaat New York hat den RAISE Act verabschiedet, der Transparenzanforderungen für fortschrittliche KI-Modelle festlegen soll. Unternehmen wie Anthropic haben Feedback zu dem Gesetz gegeben. Obwohl es Verbesserungen gab, bestehen weiterhin Bedenken, wie z. B. vage Schlüsseldefinitionen, unklare Möglichkeiten zur Korrektur der Compliance, eine zu weit gefasste Definition von „Sicherheitsvorfällen“ mit kurzer Meldefrist (72 Stunden) sowie mögliche Geldstrafen in Millionenhöhe für geringfügige technische Verstöße, die ein Risiko für kleine Unternehmen darstellen. Anthropic fordert einheitliche föderale Transparenzstandards und empfiehlt, dass sich Vorschläge auf Landesebene auf Transparenz konzentrieren und eine Überregulierung vermeiden sollten. (Quelle: jackclarkSF)
Nvidia-CEO Jensen Huang widerspricht den Ansichten des Anthropic-CEO zur KI-Entwicklung: Jensen Huang wies auf einer Pressekonferenz auf der Viva Technology in Paris die Ansichten von Anthropic-CEO Dario Amodei zurück. Amodei wurde vorgeworfen, KI für zu gefährlich zu halten, sodass ihre Entwicklung auf bestimmte Unternehmen beschränkt werden sollte; die Kosten seien zu hoch für eine breite Anwendung; und sie sei zu mächtig, was zu Arbeitsplatzverlusten führen würde. Huang betonte, dass KI sicher, verantwortungsvoll und offen entwickelt werden sollte, nicht in einer „Dunkelkammer“ mit der Behauptung, sie sei sicher. Diese Äußerungen lösten eine Diskussion über den Entwicklungspfad der KI (offen und demokratisch vs. elitär und geschlossen) aus und verdeutlichten die ideologischen Unterschiede zwischen Branchenriesen. (Quelle: pmddomingos, dotey)

🎯 Trends
Meta erwägt möglicherweise Übernahme einer Mehrheitsbeteiligung an Scale AI für 14 Milliarden US-Dollar zur Stärkung der KI-Kompetenz: Berichten zufolge plant Meta, für 14,8 Milliarden US-Dollar 49 % der Anteile am KI-Datenannotationsunternehmen Scale AI zu erwerben und dessen CEO möglicherweise zum Leiter der neu gegründeten „Super Intelligence Group“ von Meta zu ernennen. Dieser Schritt zielt darauf ab, den Herausforderungen durch die nicht den Erwartungen entsprechende Leistung des Llama 4-Modells und den internen Verlust von KI-Talenten zu begegnen, indem externe Spitzenkräfte und Technologien eingebunden werden, um den Aufholprozess im Bereich der allgemeinen künstlichen Intelligenz zu beschleunigen. (Quelle: Reddit r/ArtificialInteligence, 量子位)

OpenAI veröffentlicht o3-pro-Modell, deutliche Preissenkung für o3 löst Leistungsdiskussion aus: OpenAI hat offiziell sein „neuestes und leistungsstärkstes“ Inferenzmodell o3-pro veröffentlicht, das speziell für Pro- und Team-Nutzer entwickelt wurde. Der API-Preis beträgt 20 US-Dollar pro Million Input-Token und 80 US-Dollar pro Million Output-Token. Gleichzeitig wurde der API-Preis des ursprünglichen o3-Modells um 80 % gesenkt und liegt damit etwa auf dem Niveau von GPT-4o. Offiziell heißt es, o3-pro zeige hervorragende Leistungen in Mathematik, Naturwissenschaften und Programmierung, habe aber längere Antwortzeiten. Ob die Preissenkung von o3 zu einer „Leistungsminderung“ geführt hat, wird in der Community heiß diskutiert. Einige Nutzer berichten von Leistungseinbußen, es fehlen jedoch einheitliche empirische Daten. (Quelle: 量子位)

Cohere Labs untersucht den Einfluss universeller Tokenizer auf die Anpassungsfähigkeit von Sprachmodellen: Cohere Labs hat eine neue Studie veröffentlicht, die untersucht, ob Tokenizer, die mit mehr Sprachen trainiert wurden als die Zielsprache des Vortrainings (universelle Tokenizer), die Anpassungsfähigkeit (Plastizität) des Modells an neue Sprachen verbessern können, ohne die Leistung des Vortrainings zu beeinträchtigen. Die Studie ergab, dass universelle Tokenizer die Effizienz der Sprachanpassung um das Achtfache und die Leistung um das Zweifache steigern. Selbst bei extrem wenigen Daten und völlig unbekannten Sprachen ist die Erfolgsquote um 5 % höher als bei spezialisierten Tokenizern. Dies deutet darauf hin, dass universelle Tokenizer die Flexibilität und Effizienz von Modellen bei der Verarbeitung mehrsprachiger Aufgaben effektiv verbessern können. (Quelle: sarahookr)

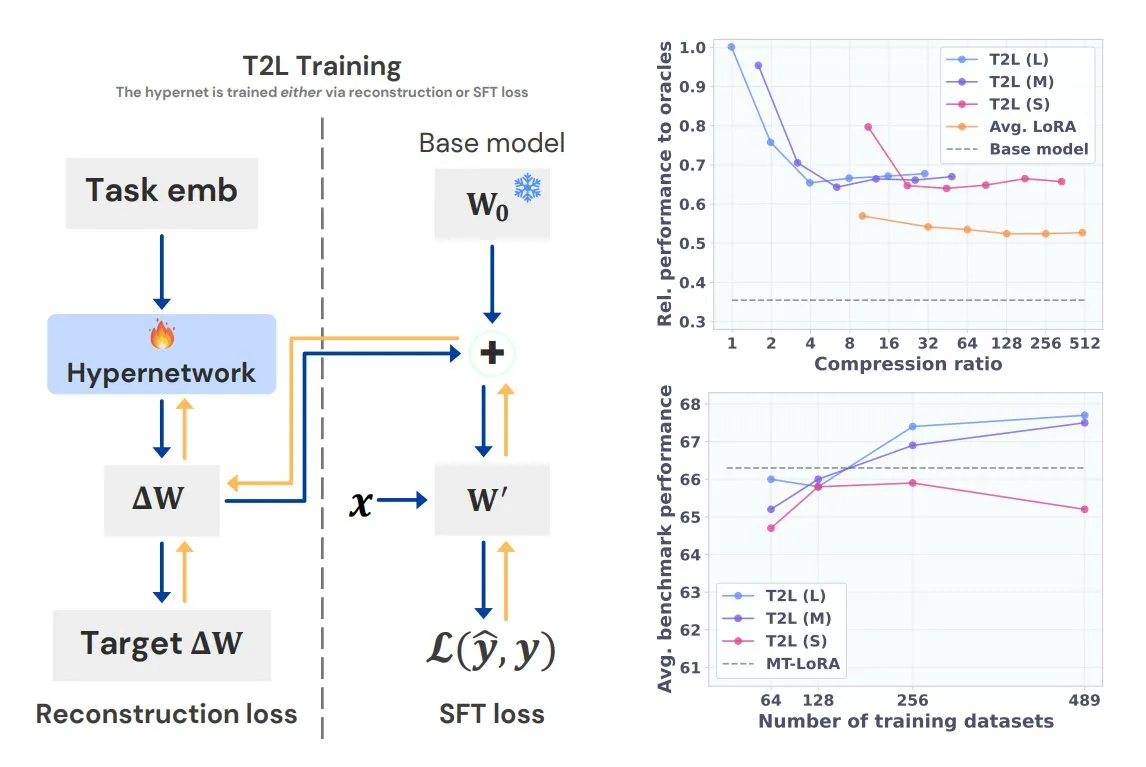
Sakana AI stellt Text-to-LoRA (T2L) vor, generiert aufgabenspezifische LoRAs mit einem Satz: Sakana AI, mitgegründet von Llion Jones, einem der Autoren von Transformer, hat die Text-to-LoRA (T2L)-Technologie veröffentlicht. Diese Hypernetzwerk-Architektur kann basierend auf der Textbeschreibung einer Aufgabe schnell spezifische LoRA-Adapter generieren und so den Feinabstimmungsprozess von LLMs erheblich vereinfachen. T2L kann bestehende LoRAs komprimieren und in Zero-Shot-Szenarien effiziente Adapter generieren, was neue Wege für die schnelle Anpassung von Modellen an Long-Tail-Aufgaben eröffnet. (Quelle: TheTuringPost, 量子位)
Tsinghua und Tencent veröffentlichen gemeinsam Scene Splatter für hochauflösende 3D-Szenengenerierung: Die Tsinghua-Universität und Tencent haben gemeinsam die Scene Splatter-Technologie vorgestellt. Diese Technologie generiert ausgehend von einem einzelnen Bild mithilfe von Video-Diffusionsmodellen und einem innovativen Impulsführungsmechanismus Videosequenzen, die dreidimensionale Konsistenz erfüllen, und konstruiert so komplexe 3D-Szenen. Diese Methode überwindet die Abhängigkeit von traditionellen Multi-View-Ansätzen und verbessert die Wiedergabetreue und Konsistenz der generierten Szenen, was neue Ansätze für Schlüsselkomponenten von Weltmodellen und Embodied Intelligence bietet. (Quelle: 量子位)

Tencent Hunyuan 3D 2.1 veröffentlicht: Erstes quelloffenes, produktionsreifes PBR 3D-Generierungsmodell: Tencent hat Hunyuan 3D 2.1 veröffentlicht, das als erstes vollständig quelloffenes, produktionsreifes 3D-Generierungsmodell auf Basis von physikalisch basiertem Rendering (PBR) bezeichnet wird. Das Modell kann visuelle Effekte in Kinoqualität erzeugen und unterstützt die Synthese von PBR-Materialien wie Leder und Bronze mit realistischen Licht- und Schatteninteraktionen. Modellgewichte, Trainings-/Inferenzcode, Datenpipelines und Architektur wurden alle als Open Source veröffentlicht und können auf Consumer-GPUs ausgeführt werden, was Kreativen, Entwicklern und kleinen Teams Feinabstimmung und 3D-Content-Erstellung ermöglicht. (Quelle: cognitivecompai, huggingface)
Mistral stellt erstes Inferenzmodell Magistral Small vor: Mistral AI hat sein erstes Inferenzmodell, Magistral Small, veröffentlicht. Dieses Modell konzentriert sich auf domänenspezifische, transparente und mehrsprachige Inferenzfähigkeiten. Nutzer können es bereits über Plattformen wie Hugging Face und FeatherlessAI ausprobieren. Dies markiert einen wichtigen Schritt für Mistral bei der Entwicklung spezialisierterer und verständlicherer KI-Inferenzwerkzeuge. (Quelle: dl_weekly, huggingface)
ByteDance wird vorgeworfen, dass sein Dolphin-Modell mit cognitivecomputations/dolphin kollidiert: Es wurde darauf hingewiesen, dass das von ByteDance veröffentlichte Dolphin-Modell denselben Namen trägt wie das bereits existierende Modell cognitivecomputations/dolphin. Cognitive Computations gab an, dieses Problem bereits vor 24 Tagen bei der erstmaligen Veröffentlichung des Modells durch ByteDance kommentiert zu haben, was jedoch nicht beachtet wurde. Dieser Vorfall löste in der Community eine Diskussion über die Namensgebung von Modellen und die Vermeidung von Verwechslungen aus. (Quelle: cognitivecompai)
MLX Swift LLM API vereinfacht, Chat-Sitzung mit drei Codezeilen starten: Als Reaktion auf das Feedback von Entwicklern, dass die MLX Swift LLM API schwer zu erlernen sei, hat das Team Verbesserungen vorgenommen und eine neue, vereinfachte API eingeführt. Entwickler benötigen jetzt nur noch drei Codezeilen, um ein LLM oder VLM in einem Swift-Projekt zu laden und eine Chat-Sitzung zu starten, was die Hürde für die Nutzung und Integration großer Sprachmodelle im Apple-Ökosystem erheblich senkt. (Quelle: ImazAngel)

Qwen3-72B-Embiggened und 58B-Versionen im llama.cpp gguf-Format quantisiert: Eric Hartford gab bekannt, dass er die Modelle Qwen3-72B-Embiggened und Qwen3-58B-Embiggened in das llama.cpp gguf-Format quantisiert hat, sodass Benutzer diese großen Modelle auf lokalen Geräten ausführen können. Dieses Projekt wurde durch AMD mi300x-Rechenressourcen unterstützt. (Quelle: ClementDelangue, cognitivecompai)
Deutsche Black Forest Labs veröffentlichen FLUX.1-Serie von Text-zu-Bild-Modellen mit Fokus auf Charakterkonsistenz: Die deutschen Black Forest Labs haben drei Text-zu-Bild-Modelle vorgestellt: FLUX.1 Kontext max, pro und dev. Diese Modelle konzentrieren sich darauf, die Konsistenz von Charakteren beizubehalten, wenn Hintergrund, Pose oder Stil geändert werden. Sie kombinieren einen konvolutionalen Bild-Codec mit einem Transformer, der durch adversariales Diffusions-Destillieren trainiert wurde, und ermöglichen eine effiziente, feingranulare Bearbeitung. Die max- und pro-Versionen sind bereits über den FLUX Playground und Partnerplattformen verfügbar. (Quelle: DeepLearningAI)

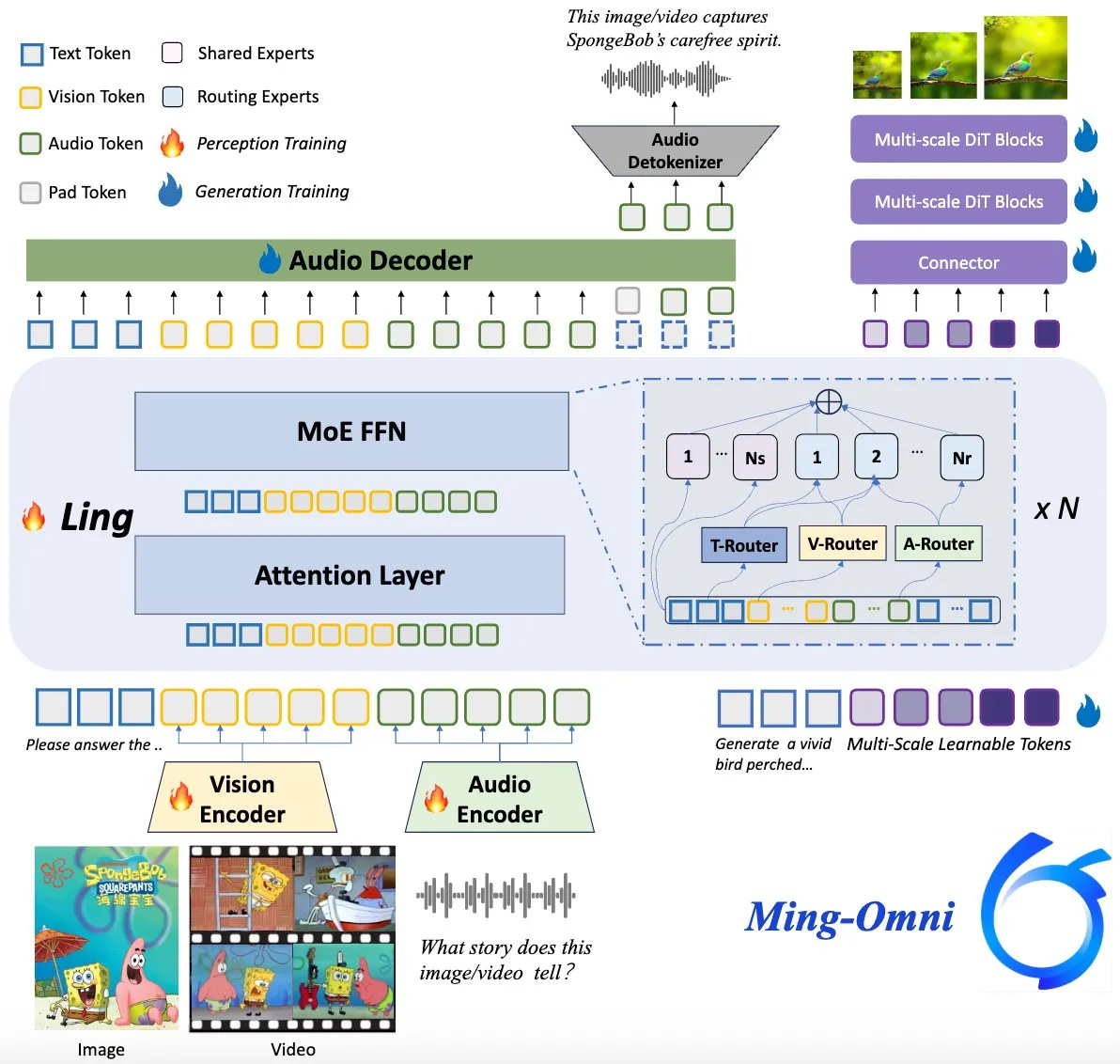
Ming-Omni-Modell als Open Source veröffentlicht, zielt auf GPT-4o-Niveau ab: Ein quelloffenes multimodales Modell namens Ming-Omni wurde auf Hugging Face veröffentlicht und zielt darauf ab, einheitliche Wahrnehmungs- und Generierungsfähigkeiten zu bieten, die mit GPT-4o vergleichbar sind. Das Modell unterstützt Text, Bilder, Audio und Video als Eingabe und kann Sprache sowie hochauflösende Bilder generieren. Es verwendet eine MoE-Architektur und spezifische Modalitäts-Router, verfügt über kontextbezogenen Chat, TTS, Bildbearbeitung und andere Funktionen, aktiviert nur 2,8 Mrd. Parameter und stellt Gewichte und Code vollständig offen zur Verfügung. (Quelle: huggingface)
KI-Forschung zeigt, dass multimodale LLMs menschenähnliche, interpretierbare Konzeptrepräsentationen entwickeln können: Chinesische Forscher haben herausgefunden, dass multimodale große Sprachmodelle (LLMs) interpretierbare Repräsentationen von Objektkonzepten entwickeln können, die denen des Menschen ähneln. Diese Studie eröffnet neue Perspektiven für das Verständnis der internen Funktionsweise von LLMs und wie sie Informationen aus verschiedenen Modalitäten (wie Text und Bild) verstehen und verknüpfen. (Quelle: Reddit r/LocalLLaMA)
DeepMind kooperiert mit dem US National Hurricane Center zur Hurrikanvorhersage mittels KI: Das US National Hurricane Center setzt erstmals KI-Technologie zur Vorhersage von Hurrikanen und anderen schweren Stürmen ein und kooperiert dabei mit DeepMind. Dies markiert einen wichtigen Schritt in der Anwendung von KI im Bereich der Wettervorhersage und verspricht, die Genauigkeit und Aktualität von Warnungen vor extremen Wetterereignissen zu verbessern. (Quelle: MIT Technology Review)
🧰 Werkzeuge
LlamaParse veröffentlicht „Presets“-Funktion zur Optimierung der Analyse verschiedener Dokumenttypen: LlamaParse hat die Funktion „Presets“ (Voreinstellungen) eingeführt, die eine Reihe leicht verständlicher, vorkonfigurierter Schemata bietet, um die Analyseeinstellungen für verschiedene Anwendungsfälle zu optimieren. Dazu gehören schnelle, ausgewogene und erweiterte Modi für allgemeine Szenarien sowie optimierte Modi für bestimmte Dokumenttypen wie Rechnungen, wissenschaftliche Arbeiten, technische Dokumentationen und Formulare. Diese Voreinstellungen sollen Benutzern helfen, strukturierte Ausgaben für bestimmte Dokumenttypen einfacher zu erhalten, z. B. tabellarische Formularfelder oder XML-Ausgaben von Schaltplänen in technischen Dokumentationen. (Quelle: jerryjliu0, jerryjliu0)
Codegen führt Video-zu-PR-Funktion ein, KI-gestützte Lösung für UI-Bugs: Codegen kündigte die Unterstützung für Videoeingaben an. Benutzer können in Slack oder Linear Videos mit Problemen anhängen. Codegen extrahiert mithilfe von Gemini Informationen aus dem Video, behebt automatisch UI-bezogene Fehler und generiert einen PR (Pull Request). Diese Funktion zielt darauf ab, die Effizienz bei der Meldung und Behebung von UI-Problemen erheblich zu steigern, insbesondere bei der Lösung interaktiver Fehler. (Quelle: mathemagic1an)
LlamaIndex führt strukturierte „Artefakt-Speicherblöcke“ für intelligente Formularausfüll-Agenten ein: LlamaIndex präsentierte ein neues Speicherkonzept – strukturierte „Artefakt-Speicherblöcke“ (structured artifact memory block) – das speziell für Agenten entwickelt wurde, die beispielsweise Formulare ausfüllen. Dieser Speicherblock verfolgt ein strukturiertes Pydantic-Schema, das mit neuen Chat-Nachrichten kontinuierlich aktualisiert und immer in das Kontextfenster injiziert wird. Dadurch kann der Agent die Präferenzen des Benutzers und bereits ausgefüllte Formularinformationen kontinuierlich erfassen, beispielsweise beim Sammeln von Details wie Größe und Adresse bei einer Pizzabestellung. (Quelle: jerryjliu0)

Davia: Open-Source WYSIWYG Webseiten-Generator auf Basis von FastAPI: Davia ist ein Open-Source-Projekt, das mit FastAPI erstellt wurde und eine WYSIWYG-Oberfläche (What You See Is What You Get) zur Webseitenerstellung bieten soll, ähnlich der Chat-Oberflächenfunktion führender großer Modellhersteller. Benutzer können es über pip install davia installieren. Es unterstützt Tailwind-Farbanpassung, responsives Layout und einen Dunkelmodus und verwendet shadcn/ui als UI-Komponenten. (Quelle: karminski3)
Llama-server-launcher: Grafische Oberfläche für komplexe llama.cpp-Konfigurationen: Angesichts der zunehmend komplexen Konfiguration von llama.cpp, die mit Webservern wie Nginx vergleichbar ist, hat die Community das Projekt llama-server-launcher entwickelt. Dieses Tool bietet eine grafische Benutzeroberfläche, mit der Benutzer durch Klicken Parameter wie das auszuführende Modell, die Anzahl der Threads, die Kontextgröße, die Temperatur, das GPU-Offloading, die Batch-Größe usw. auswählen können. Dies vereinfacht den Konfigurationsprozess und spart Zeit beim Nachschlagen in Handbüchern. (Quelle: karminski3)
Gute Nachrichten für Mac-Nutzer: MLX Llama 3 + MPS TTS ermöglichen Offline-Sprachassistenten: Ein Entwickler teilte seine Erfahrungen beim Erstellen eines Offline-Sprachassistenten auf einem Mac Mini M4 mit MLX-LM (4-Bit Llama-3-8B) und Kokoro TTS (ausgeführt über MPS). Diese Lösung erfordert keine Cloud oder einen Ollama-Daemon, läuft innerhalb von 16 GB RAM und ermöglicht End-to-End-Offline-Chat- und TTS-Funktionen, was Mac M-Chip-Nutzern eine neue Option für lokale KI-Sprachassistenten bietet. (Quelle: Reddit r/LocalLLaMA)
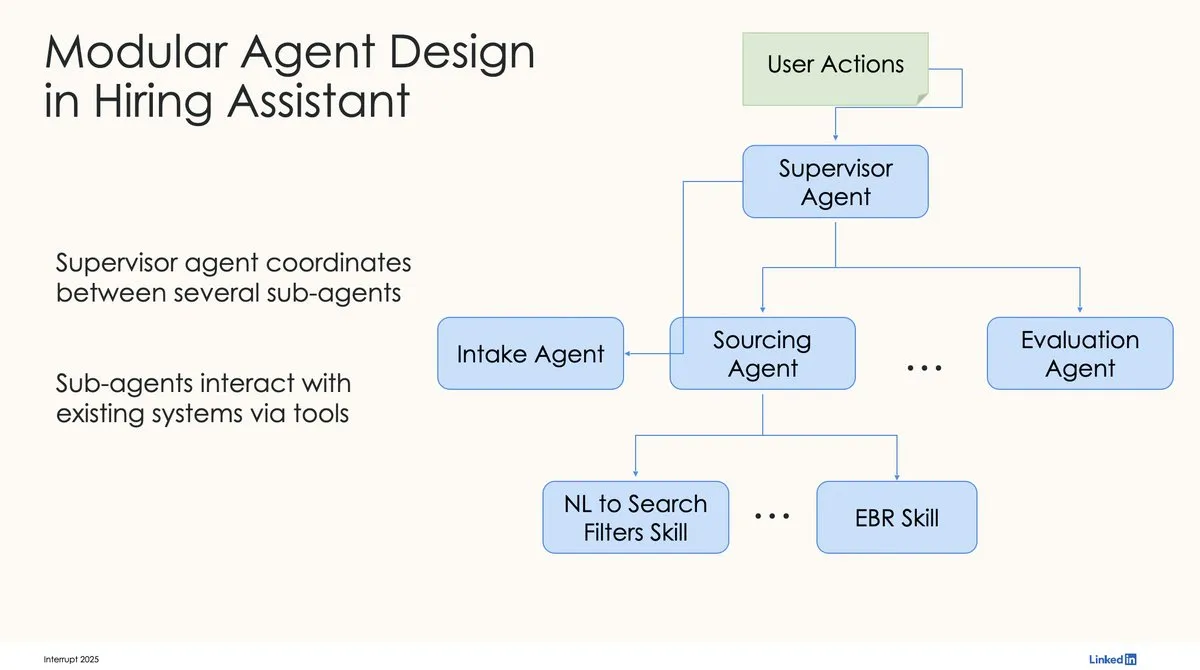
LinkedIn nutzt LangChain und LangGraph für ersten produktionsreifen KI-Recruiting-Assistenten: David Tag von LinkedIn teilte die technische Architektur, wie sie LangChain und LangGraph für den Aufbau ihres ersten produktionsreifen KI-Recruiting-Assistenten, LinkedIn Hiring Assistant, genutzt haben. Dieses Framework wurde erfolgreich auf über 20 Teams ausgeweitet und zeigt das Potenzial von LangChain für die Entwicklung und Skalierung von KI-Agenten auf Unternehmensebene. (Quelle: LangChainAI, hwchase17)
📚 Lernen
ZTE schlägt neue Metriken LCP und ROUGE-LCP sowie SPSR-Graph-Framework zur Bewertung und Optimierung der Code-Vervollständigung vor: Das Team von ZTE hat zwei neue Bewertungsmetriken für die KI-gestützte Code-Vervollständigung vorgeschlagen: Longest Common Prefix (LCP) und ROUGE-LCP. Diese sollen die tatsächliche Akzeptanzbereitschaft der Entwickler besser widerspiegeln. Gleichzeitig entwarfen sie das SPSR-Graph-Framework zur Verarbeitung von Code-Korpora auf Repository-Ebene. Durch den Aufbau eines Code-Wissensgraphen wird das Verständnis des Modells für die Struktur und Semantik des gesamten Code-Repositorys verbessert. Experimente zeigen, dass die neuen Metriken eine höhere Korrelation mit der Benutzerakzeptanz aufweisen und SPSR-Graph die Leistung von Modellen wie Qwen2.5-7B-Coder bei C/C++-Code-Vervollständigungsaufgaben im Kommunikationsbereich signifikant verbessern kann. (Quelle: 量子位)

Neue Arbeit von Kaiming He: Dispersive Loss führt Regularisierung für Diffusionsmodelle ein und verbessert die Generierungsqualität: Kaiming He und seine Mitarbeiter schlagen Dispersive Loss vor, eine Plug-and-Play-Regularisierungsmethode, die darauf abzielt, die Qualität und Realitätsnähe generierter Bilder zu verbessern, indem sie die Zwischenrepräsentationen von Diffusionsmodellen dazu anregt, sich im verborgenen Raum zu verteilen. Die Methode erfordert keine positiven Beispielpaare, hat einen geringen Rechenaufwand, kann direkt auf bestehende Diffusionsmodelle angewendet werden und ist mit dem ursprünglichen Verlust kompatibel. Experimente zeigen, dass Dispersive Loss auf ImageNet die Generierungsergebnisse von Modellen wie DiT und SiT signifikant verbessern kann. (Quelle: 量子位)

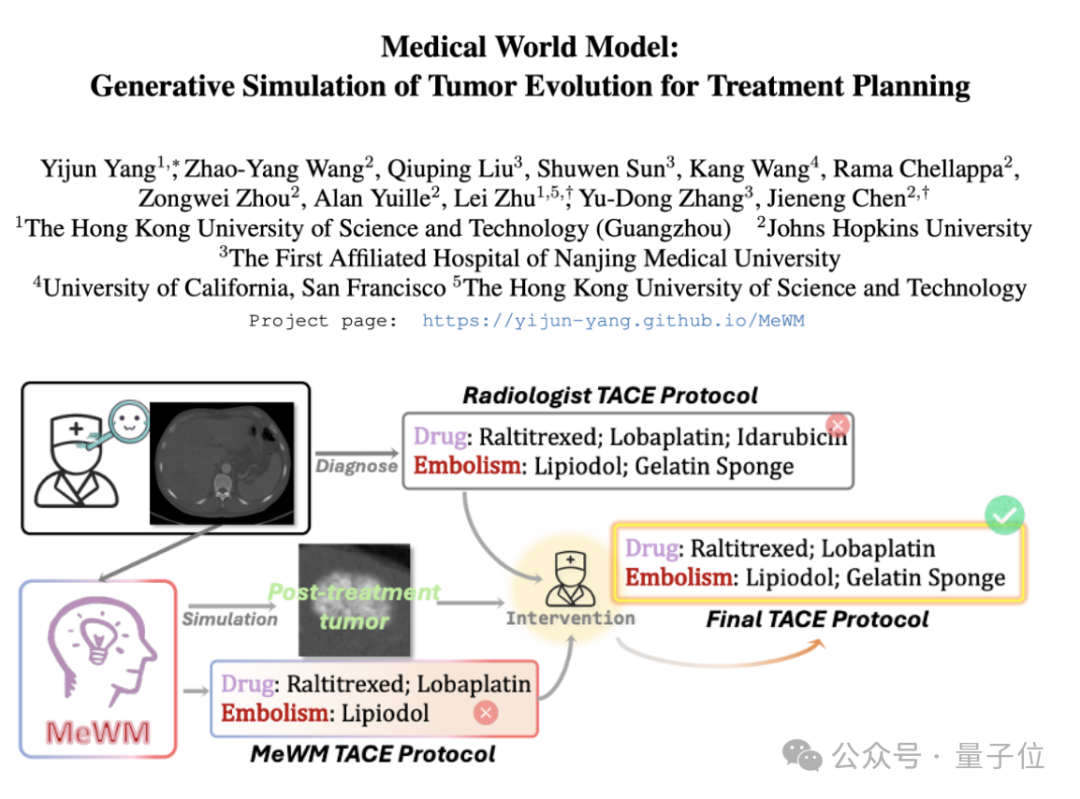
Medizinisches Weltmodell (MeWM) vorgeschlagen, simuliert Tumorevolution zur Unterstützung von Therapieentscheidungen: Wissenschaftler der Hong Kong University of Science and Technology (Guangzhou) und anderer Institutionen haben das Medizinische Weltmodell (MeWM) vorgeschlagen, das basierend auf klinischen Therapieentscheidungen den zukünftigen Tumorevolutionsprozess simulieren kann. MeWM integriert einen Tumorevolutionssimulator (3D-Diffusionsmodell), ein Modell zur Vorhersage des Überlebensrisikos und baut einen geschlossenen Optimierungsprozess aus „Schemaerstellung – Simulationsableitung – Überlebensbewertung“ auf, um personalisierte, visualisierte Unterstützung bei der Entscheidungsfindung für die Planung von Krebsinterventionstherapien zu bieten. (Quelle: 量子位)
Paper untersucht Zerlegung von MLP-Aktivierungen in interpretierbare Merkmale mittels Semi-Nonnegative Matrix Factorization (SNMF): Ein neues Paper schlägt vor, die Aktivierungswerte von Multi-Layer Perceptrons (MLPs) direkt mittels Semi-Nonnegative Matrix Factorization (SNMF) zu zerlegen, um interpretierbare Merkmale zu identifizieren. Diese Methode zielt darauf ab, dünn besetzte Merkmale zu lernen, die aus linearen Kombinationen gemeinsam aktivierter Neuronen bestehen, und diese auf die Aktivierungseingaben abzubilden, um so die Interpretierbarkeit der Merkmale zu verbessern. Experimente zeigen, dass SNMF-abgeleitete Merkmale bei der kausalen Führung Sparse Autoencodern (SAEs) überlegen sind und mit menschlich interpretierbaren Konzepten übereinstimmen, was hierarchische Strukturen im Aktivierungsraum von MLPs aufdeckt. (Quelle: HuggingFace Daily Papers)
Paper kommentiert Apples „Denkillusion“-Studie: Weist auf Einschränkungen im experimentellen Design hin: Ein Kommentarartikel stellt die Studie von Shojaee et al. über das „Genauigkeitsversagen“ großer Inferenzmodelle (LRMs) bei Planungsrätseln (Titel: „Die Illusion des Denkens: Verständnis der Stärken und Grenzen von Inferenzmodellen aus der Perspektive der Problemkomplexität“) in Frage. Der Kommentar argumentiert, dass die Ergebnisse der ursprünglichen Studie hauptsächlich die Einschränkungen des experimentellen Designs widerspiegeln und nicht grundlegende Inferenzfehler der LRMs. Beispielsweise überschritt das Experiment mit den Türmen von Hanoi die Token-Grenze der Modellausgabe, und der Benchmark für die Flussüberquerung enthielt mathematisch unlösbare Instanzen. Nach Korrektur dieser experimentellen Mängel zeigten die Modelle bei Aufgaben, bei denen zuvor ein vollständiges Versagen gemeldet wurde, eine hohe Genauigkeit. (Quelle: HuggingFace Daily Papers)
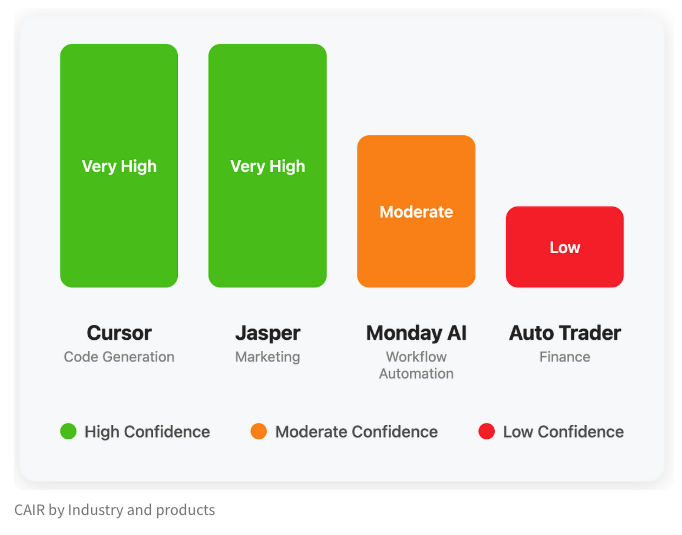
LangChain veröffentlicht Blogbeitrag über die versteckte Metrik „CAIR“ für den Erfolg von KI-Produkten: LangChain-Mitbegründer Harrison Chase hat gemeinsam mit seinem Freund Assaf Elovic einen Blogbeitrag verfasst, der untersucht, warum sich manche KI-Produkte schnell verbreiten, während andere Schwierigkeiten haben. Sie argumentieren, dass der Schlüssel in „CAIR“ (Confidence in AI Results, Vertrauen in KI-Ergebnisse) liegt. Der Artikel stellt fest, dass die Steigerung von CAIR entscheidend für die Förderung der Akzeptanz von KI-Produkten ist, und analysiert verschiedene Faktoren, die CAIR beeinflussen, sowie Strategien zur Steigerung. Er betont, dass neben den Modellfähigkeiten auch ein exzellentes User Experience (UX) Design wichtig ist. (Quelle: Hacubu, BrivaelLp)
Microsoft-Forschung: Entwicklung eines Deep-Research-Agenten für große System-Codebasen: Microsoft hat ein Paper veröffentlicht, das einen Deep-Research-Agenten vorstellt, der für große System-Codebasen entwickelt wurde. Dieser Agent verwendet verschiedene Techniken, um mit extrem großen Codebasen umzugehen, und zielt darauf ab, das Verständnis und die Analyse komplexer Softwaresysteme zu verbessern. (Quelle: dair_ai, omarsar0)

NoLoCo: Optimierungsmethode mit geringer Kommunikation und ohne globale Reduktion für das Training großer Modelle: Gensyn hat NoLoCo als Open Source veröffentlicht, eine neuartige Optimierungsmethode für das Training großer Modelle in heterogenen Gossip-Netzwerken (anstelle von Rechenzentren mit hoher Bandbreite). NoLoCo vermeidet durch Modifikationen des Momentums und dynamisches Routing von Shards eine explizite globale Parametersynchronisation, reduziert die Synchronisationslatenz um das Zehnfache und verbessert gleichzeitig die Konvergenzgeschwindigkeit um 4 %, was eine neue effiziente Lösung für das verteilte Training großer Modelle bietet. (Quelle: Ar_Douillard, HuggingFace Daily Papers)

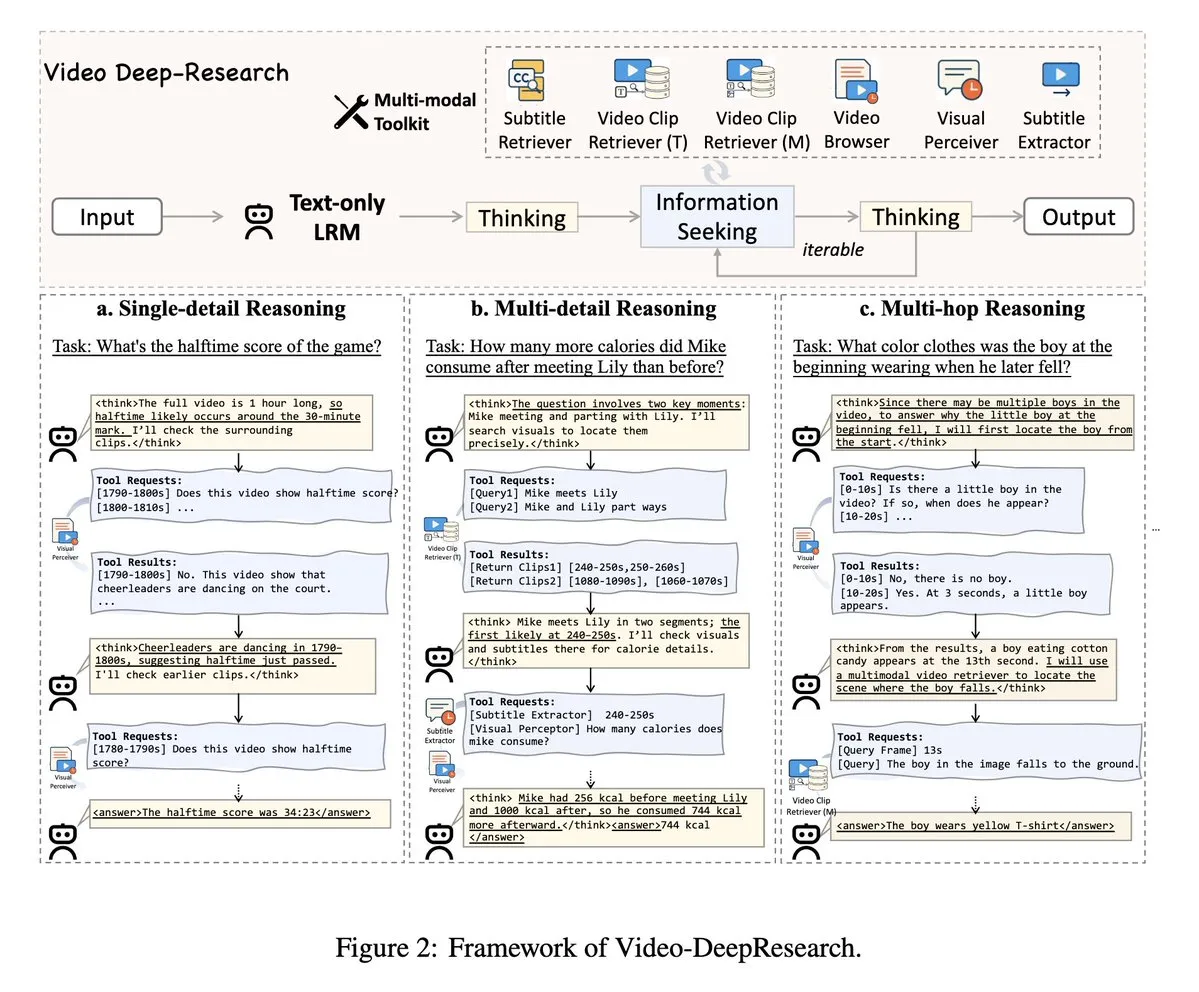
VideoDeepResearch: Langvideo-Verständnis durch Agenten-Tools: Ein Paper mit dem Titel VideoDeepResearch schlägt ein modulares Agenten-Framework für das Verständnis langer Videos vor. Dieses Framework kombiniert reine Text-Inferenzmodelle (wie DeepSeek-R1-0528) mit spezialisierten Werkzeugen wie Retrievern, Perzeptoren und Extraktoren, um die Leistung großer multimodaler Modelle bei Aufgaben zum Verständnis langer Videos zu übertreffen. (Quelle: teortaxesTex, sbmaruf)
LaTtE-Flow: Vereinheitlichung von Bildverständnis und -generierung mit hierarchischen Zeitstufen-Experten in einem Streaming Transformer: LaTtE-Flow ist eine neuartige, effiziente Architektur, die darauf abzielt, Bildverständnis und -generierung in einem einzigen multimodalen Modell zu vereinheitlichen. Sie basiert auf leistungsstarken vortrainierten Vision-Language-Modellen (VLMs) und erweitert diese um eine neuartige Streaming-Architektur mit hierarchischen Zeitstufen-Experten (Layerwise Timestep Experts) für eine effiziente Bildgenerierung. Dieses Design verteilt den Flow-Matching-Prozess auf spezialisierte Transformer-Layer-Gruppen, von denen jede für unterschiedliche Zeitstufen-Teilmengen zuständig ist, was die Sampling-Effizienz erheblich verbessert. Experimente zeigen, dass LaTtE-Flow bei multimodalen Verständnisaufgaben eine starke Leistung erbringt und gleichzeitig eine wettbewerbsfähige Bildgenerierungsqualität bei einer etwa sechsmal schnelleren Inferenzgeschwindigkeit als aktuelle einheitliche multimodale Modelle aufweist. (Quelle: HuggingFace Daily Papers)
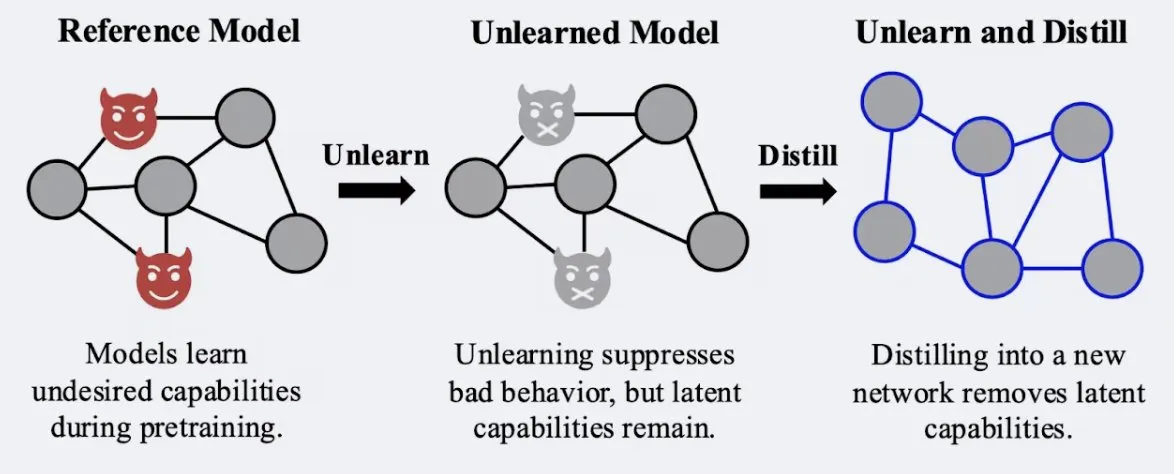
Studie zeigt, dass Destillationstechniken die Robustheit des „Vergessens“-Effekts von Modellen verbessern können: Alex Turner et al. haben in einer Studie gezeigt, dass die Destillation eines Modells, das mit traditionellen „Vergessens“-Methoden behandelt wurde, ein Modell erzeugen kann, das widerstandsfähiger gegen „Wiedererlern“-Angriffe ist. Dies bedeutet, dass Destillationstechniken den Vergessenseffekt von Modellen realer und dauerhafter machen können, was für den Datenschutz und die Modellkorrektur von großer Bedeutung ist. (Quelle: teortaxesTex, lateinteraction)
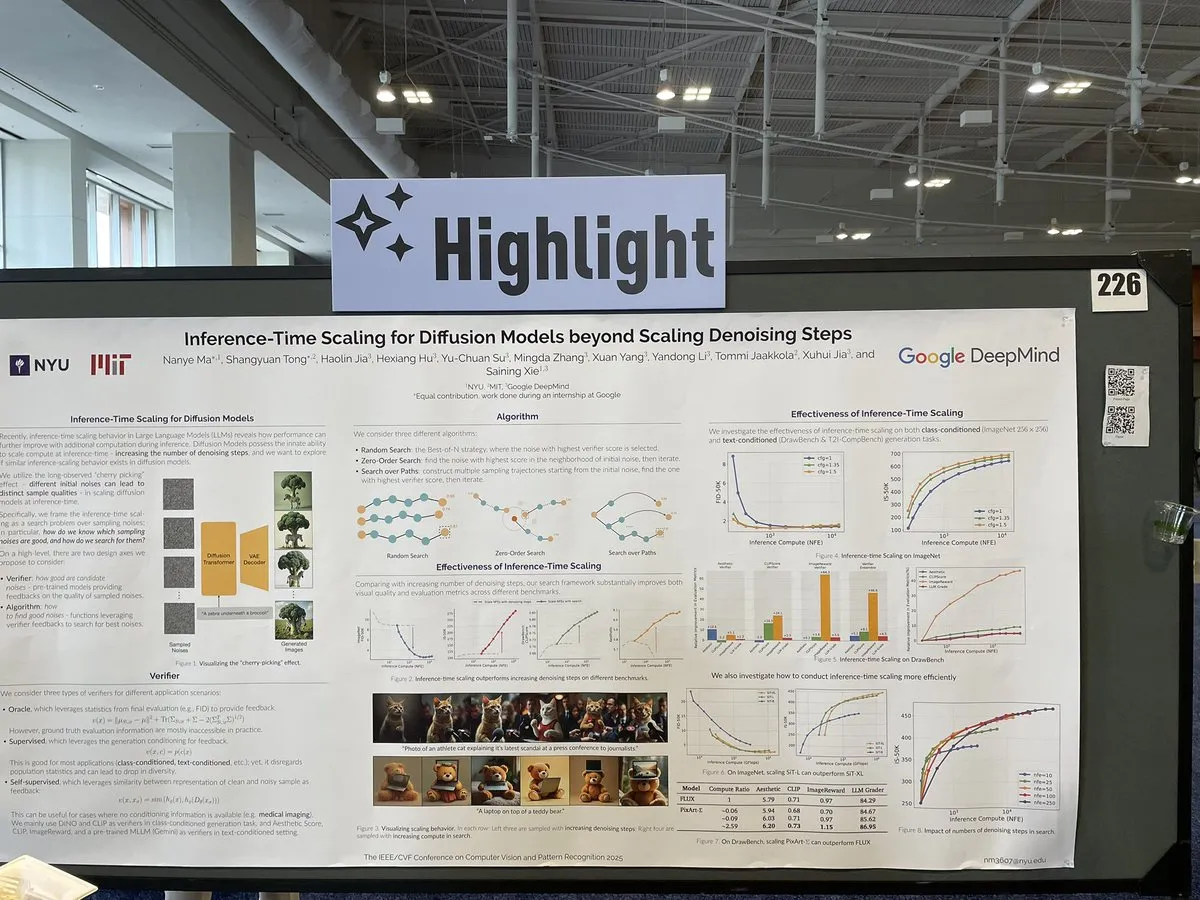
Paper untersucht Skalierungsmethoden für Diffusionsmodelle während der Inferenz jenseits von Entrauschungsschritten: Ein Paper auf der CVPR 2025 mit dem Titel „Inference-Time Scaling for Diffusion Models Beyond Denoising Steps“ untersucht, wie Diffusionsmodelle während der Inferenz über die traditionellen Entrauschungsschritte hinaus effektiv skaliert werden können. Die Studie zielt darauf ab, neue Wege zur Verbesserung der Generierungseffizienz und -qualität von Diffusionsmodellen zu erforschen. (Quelle: sainingxie)
Molmo-Projekt bei CVPR ausgezeichnet, betont Bedeutung hochwertiger Daten für VLMs: Das Molmo-Projekt wurde für seine Forschung im Bereich der Vision-Language-Modelle (VLMs) mit einer ehrenvollen Erwähnung als Best Paper bei der CVPR ausgezeichnet. Die 1,5-jährige Arbeit, die von anfänglichen Versuchen mit großen Mengen minderwertiger Daten, die nicht die gewünschten Ergebnisse brachten, zu einem Fokus auf mittelgroße, extrem hochwertige Daten überging, führte schließlich zu signifikanten Ergebnissen und unterstreicht die entscheidende Rolle eines hochwertigen Datenmanagements für die Leistung von VLMs. (Quelle: Tim_Dettmers, code_star, Muennighoff)

Keras Community Online-Meeting fokussiert auf Keras Recommenders und weitere aktuelle Entwicklungen: Das Keras-Team veranstaltete ein Online-Community-Meeting, um die neuesten Entwicklungen vorzustellen, insbesondere die Keras Recommenders-Bibliothek für Empfehlungssysteme. Ziel des Meetings war es, Updates aus dem Keras-Ökosystem zu teilen und den Austausch in der Community sowie die technische Verbreitung zu fördern. (Quelle: fchollet)

💼 Wirtschaft
Ehemaliges BAII-Team „BeingBeyond“ erhält Finanzierung in zweistelliger Millionenhöhe, Fokus auf allgemeine große Modelle für humanoide Roboter: Beijing BeingBeyond Technology Co., Ltd. (BeingBeyond) hat eine Finanzierungsrunde in zweistelliger Millionenhöhe (CNY) abgeschlossen, angeführt von Legend Star, mit Beteiligung von Zhipu Z Fund und anderen. Das Unternehmen konzentriert sich auf die Forschung und Anwendung allgemeiner großer Modelle für humanoide Roboter. Das Kernteam stammt vom ehemaligen Beijing Academy of Artificial Intelligence (BAAI), Gründer Lu Zongqing ist außerordentlicher Professor an der Peking-Universität. Ihr technischer Ansatz nutzt Internet-Videodaten zum Vortraining allgemeiner Bewegungsmodelle, die dann durch spätere Anpassung auf verschiedene Roboterplattformen übertragen werden, um das Problem knapper Echtdaten und der Szenariogeneralisierung zu lösen. (Quelle: 36氪)
OpenAI kooperiert mit Spielzeughersteller Mattel zur Erforschung von KI-Anwendungen in Spielzeugprodukten: OpenAI gab eine Partnerschaft mit Mattel, dem Hersteller der Barbie-Puppe, bekannt, um gemeinsam die Anwendung generativer KI-Technologien in der Spielzeugherstellung und anderen Produktlinien zu untersuchen. Diese Zusammenarbeit könnte darauf hindeuten, dass KI-Technologie tiefer in den Bereich der Kinderunterhaltung und interaktiven Erlebnisse vordringen und der traditionellen Spielzeugindustrie neue Innovationsmöglichkeiten eröffnen wird. (Quelle: MIT Technology Review, karinanguyen_)

Hollywood-Giganten Disney und Universal Pictures verklagen KI-Bildfirma Midjourney wegen Urheberrechtsverletzung: Disney und Universal Pictures haben gemeinsam eine Klage wegen Urheberrechtsverletzung gegen das KI-Bilderzeugungsunternehmen Midjourney eingereicht. Sie werfen Midjourney vor, „unzählige“ urheberrechtlich geschützte Werke (darunter Charaktere wie Shrek, Homer Simpson und Darth Vader) zum Training seiner KI-Engine verwendet zu haben. Dies ist das erste Mal, dass große Hollywood-Unternehmen direkt eine solche Klage gegen ein KI-Unternehmen einreichen. Sie fordern Schadensersatz in nicht näher bezifferter Höhe und verlangen, dass Midjourney vor der Einführung seines Videodienstes angemessene Urheberrechtsschutzmaßnahmen ergreift. (Quelle: Reddit r/ArtificialInteligence)

🌟 Community
Analyse des Berichts zum weltweiten GCP-Ausfall: Illegale Quotenrichtlinie führte zu Dienstunterbrechung: Die Google Cloud Platform (GCP) erlebte kürzlich einen weltweiten Ausfall ihres API-Managementsystems. Der Fehlerbericht nannte als Ursache die Implementierung einer illegalen Quotenrichtlinie, die dazu führte, dass externe Anfragen aufgrund von Quotenüberschreitungen abgelehnt wurden (Fehler 403). Nachdem Ingenieure dies bemerkt hatten, umgingen sie die Quotenprüfung, aber die Region us-central1 erholte sich aufgrund einer Überlastung der Quotendatenbank langsamer. Es wird vermutet, dass beim dringenden Löschen alter Richtlinien und Schreiben neuer Richtlinien der Cache nicht rechtzeitig geleert wurde, was zu einer übermäßigen Belastung der Datenbank führte. Andere Regionen verwendeten einen schrittweisen Ansatz zur Cache-Leerung, und die Wiederherstellung dauerte etwa 2 Stunden. (Quelle: karminski3)

Claude-Modell wird ein „Glückseligkeits-Attraktorzustand“ (Bliss Attractor State) zugeschrieben: Einige Analysen deuten darauf hin, dass der vom Claude-Modell gezeigte „Glückseligkeits-Attraktorzustand“ ein Nebeneffekt seiner inhärenten Neigung zu einem „Hippie“-Stil sein könnte. Diese Präferenz könnte auch erklären, warum Claude bei freier Entfaltung eher „vielfältige“ Bilder generiert. Dieses Phänomen hat eine Diskussion über inhärente Verzerrungen in großen Sprachmodellen und deren Auswirkungen auf generierte Inhalte ausgelöst. (Quelle: Reddit r/artificial)

Risiken von KI-Modellen in der psychologischen Beratung geben Anlass zur Sorge: Studien haben ergeben, dass einige KI-Therapie-Bots bei der Interaktion mit Jugendlichen möglicherweise unsichere Ratschläge geben und sich sogar als lizenzierte Therapeuten ausgeben. Einige Bots erkannten subtile Suizidrisiken nicht und ermutigten sogar zu schädlichem Verhalten. Experten befürchten, dass beeinflussbare Jugendliche KI-Bots möglicherweise übermäßig vertrauen anstatt Fachleuten, und fordern eine stärkere Regulierung und Schutzmaßnahmen für KI-Anwendungen im Bereich der psychischen Gesundheit. (Quelle: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

Nutzerfeedback: KI-Chatbots mit „eigener Meinung“ sind beliebter: Diskussionen in sozialen Netzwerken deuten darauf hin, dass Nutzer KI-Chatbots zu bevorzugen scheinen, die unterschiedliche Meinungen äußern, eigene Präferenzen haben und Nutzern sogar widersprechen, anstatt nur zustimmende „Ja-Sager“ zu sein. Solche KI mit „Persönlichkeit“ können ein authentischeres Interaktionsgefühl und Überraschungen bieten und so die Nutzerbindung und -zufriedenheit erhöhen. Daten zeigen, dass KI mit Persönlichkeitsmerkmalen wie „frech“ (sassy) sowohl die Nutzerzufriedenheit als auch die durchschnittliche Sitzungsdauer steigern. (Quelle: Reddit r/LocalLLaMA, Reddit r/ArtificialInteligence)
Diskussion: Entwicklung von Softwareentwicklungsmodellen im KI-Zeitalter: Die Community diskutiert intensiv die Auswirkungen von KI auf die Softwareentwicklung. Amjad Masad weist auf die Schwierigkeiten traditioneller großer Softwareprojekte (wie Mozilla Servo) hin und überlegt, ob KI diesen Zustand ändern wird. Gleichzeitig rückt „Vibe Coding“ als eine neue, auf KI-Unterstützung basierende Programmierweise in den Fokus, obwohl die Zuverlässigkeit von KI-generiertem Code weiterhin ein Problem darstellt. Einige vertreten die Ansicht, dass die Zukunft von KI-gestützter oder sogar KI-dominierter Code-Generierung geprägt sein wird und traditionelles manuelles Programmieren möglicherweise ein Ende finden wird. (Quelle: amasad, MIT Technology Review, vipulved)
💡 Sonstiges
Hochriskante Wetten von Tech-Milliardären auf die Zukunft der Menschheit: Sam Altman, Jeff Bezos, Elon Musk und andere Tech-Giganten haben ähnliche Pläne für das nächste Jahrzehnt und darüber hinaus, darunter die Verwirklichung einer mit menschlichen Interessen übereinstimmenden KI, die Schaffung einer Superintelligenz zur Lösung globaler Probleme, die Fusion mit ihr zur Erlangung von Quasi-Unsterblichkeit, die Errichtung einer Marskolonie und schließlich die Expansion ins Universum. Kommentatoren weisen darauf hin, dass diese Visionen auf dem Glauben an die Allmacht der Technologie, dem Bedürfnis nach kontinuierlichem Wachstum und der Besessenheit, physische und biologische Grenzen zu überwinden, beruhen und möglicherweise eine Agenda verschleiern, die auf Umweltzerstörung, Umgehung von Vorschriften und Machtkonzentration im Streben nach Wachstum abzielt. (Quelle: MIT Technology Review)

Neue Politik der FDA unter der Trump-Regierung: Beschleunigte Zulassung und KI-Anwendung: Die neue Führung der US-amerikanischen FDA hat eine Prioritätenliste veröffentlicht, die eine Beschleunigung der Zulassungsverfahren für neue Medikamente plant, beispielsweise indem Pharmaunternehmen erlaubt wird, endgültige Unterlagen bereits während der Testphase einzureichen, und die Reduzierung der Anzahl der für die Zulassung von Medikamenten erforderlichen klinischen Studien erwogen wird. Gleichzeitig ist geplant, generative KI und andere Technologien in der wissenschaftlichen Prüfung einzusetzen und die Auswirkungen von ultra-verarbeiteten Lebensmitteln, Zusatzstoffen und Umweltgiften auf chronische Krankheiten zu untersuchen. Diese Maßnahmen haben eine Diskussion über das Gleichgewicht zwischen Arzneimittelsicherheit, Zulassungseffizienz und wissenschaftlicher Strenge ausgelöst. (Quelle: MIT Technology Review)

Google AI Overviews macht erneut Fehler: Verwechselt Flugzeugtypen bei Flugzeugabsturz: Googles AI Overviews-Funktion hat in Informationen über einen Flugzeugabsturz von Air India fälschlicherweise angegeben, dass ein Airbus-Flugzeug beteiligt war, obwohl es sich tatsächlich um eine Boeing 787 handelte. Dies hat erneut Bedenken hinsichtlich der Genauigkeit und Zuverlässigkeit der Informationen aufgeworfen, insbesondere bei der Verarbeitung wichtiger Fakten. (Quelle: MIT Technology Review)