Schlüsselwörter:Meta V-JEPA 2, Nvidia industrielle KI-Cloud, Sakana KI Text-zu-LoRA, OpenAI o3-pro, Databricks Lakebase, MLflow 3.0, Princeton Universität HistBench, Open-Source-Weltmodell für Videotraining, Europäische KI-Cloud-Plattform für die Fertigung, Textgenerierender LLM-Adapter, DPO-Feinabstimmung von GPT-4.1, KI-Agenten-Beobachtbarkeit
🔥 Fokus
Meta veröffentlicht V-JEPA 2: Ein auf Videos trainiertes Open-Source Bild-/Video-Weltmodell : Meta hat das neue Open-Source Bild-/Video-Weltmodell V-JEPA 2 vorgestellt, das auf der ViT-Architektur basiert und in verschiedenen Größen (L/G/H) und Auflösungen (286/384) mit bis zu 1,2 Milliarden Parametern verfügbar ist. V-JEPA 2 zeigt hervorragende Leistungen im visuellen Verständnis und in der Vorhersage und ermöglicht es Robotern, Aufgaben in unbekannten Umgebungen ohne vorheriges Training (Zero-Shot) zu planen und auszuführen. Meta betont seine Vision, dass KI Weltmodelle nutzt, um sich an dynamische Umgebungen anzupassen und effizient neue Fähigkeiten zu erlernen. Gleichzeitig hat Meta auch drei neue Benchmarks veröffentlicht: MVPBench, IntPhys 2 und CausalVQA, um die Fähigkeit bestehender Modelle zu bewerten, aus Videos auf die physikalische Welt zu schließen. (Quelle: huggingface, huggingface, ylecun, AIatMeta, scaling01, karminski3)
Nvidia baut erste industrielle KI-Cloud in Europa auf, um Fertigungsindustrie voranzutreiben : Nvidia hat angekündigt, die weltweit erste industrielle Künstliche Intelligenz (KI)-Cloud-Plattform für Hersteller in Europa aufzubauen. Diese AI Factory soll Industrieführer dabei unterstützen, den gesamten Fertigungsprozess zu beschleunigen, von Design und Engineering-Simulationen bis hin zu digitalen Fabrikzwillingen und Robotik. Dieser Schritt ist Teil einer Reihe von Initiativen, die Nvidia auf der GTC Paris und der VivaTech 2025 angekündigt hat, um die KI-Innovation in Europa und darüber hinaus zu beschleunigen. Jensen Huang erklärte, dass die KI-Rechenleistung in Europa in den nächsten zwei Jahren voraussichtlich um das Zehnfache steigen wird, und betonte: „Alle sich bewegenden Objekte werden robotisiert, Autos sind die nächsten.“ (Quelle: nvidia, nvidia, Jensen Huang: Europas KI-Rechenleistung wird sich in zwei Jahren verzehnfachen)

Sakana AI stellt Text-to-LoRA vor: Generierung aufgabenspezifischer LLM-Adapter per Textbeschreibung in Echtzeit : Sakana AI hat die Text-to-LoRA-Technologie veröffentlicht, ein Hypernetwork, das basierend auf der Textbeschreibung einer Aufgabe durch den Benutzer in Echtzeit spezifische LLM-Adapter (LoRAs) generieren kann. Diese Technologie zielt darauf ab, die Hürden für die Anpassung großer Modelle zu senken und es auch nicht-technischen Benutzern zu ermöglichen, Basismodelle durch natürliche Sprache zu spezialisieren, ohne tiefgreifendes technisches Wissen oder umfangreiche Rechenressourcen. Text-to-LoRA kann Hunderte bestehender LoRA-Adapter kodieren und auf bisher ungesehene Aufgaben generalisieren, während die Leistung erhalten bleibt. Die zugehörige wissenschaftliche Arbeit und der Code wurden auf arXiv und GitHub veröffentlicht und werden auf der ICML2025 vorgestellt. (Quelle: SakanaAILabs, hardmaru, kylebrussell, ClementDelangue, huggingface)
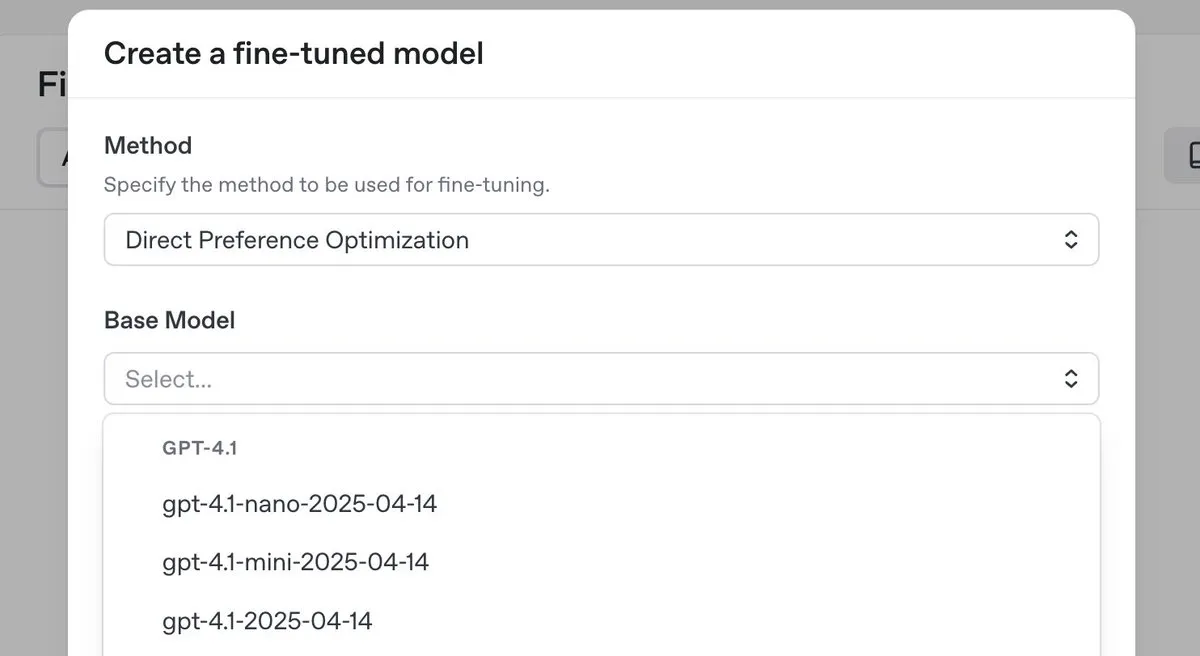
OpenAI veröffentlicht o3-pro Top-Inferenzmodell mit deutlicher Preissenkung und führt DPO Fine-Tuning für GPT-4.1-Serie ein : OpenAI hat sein neues Top-Inferenzmodell o3-pro vorgestellt und die Preise für die o3-Modellreihe erheblich gesenkt, um die Nutzungskosten für Entwickler zu reduzieren. Gleichzeitig kündigte OpenAI an, dass Benutzer nun Direct Preference Optimization (DPO) verwenden können, um Modelle der GPT-4.1-Familie (einschließlich 4.1, 4.1-mini und 4.1-nano) zu optimieren. DPO ermöglicht die Anpassung durch den Vergleich von Modellantworten anstelle fester Ziele und eignet sich besonders für Aufgaben mit subjektiven Anforderungen an Ton, Stil und Kreativität. Der ARC Prize wurde nach der Preissenkung von o3 erneut getestet, wobei sich die Leistung auf ARC-AGI nicht verändert hat. (Quelle: OpenAIDevs, scaling01, aidan_mclau, giffmana, jeremyphoward, BorisMPower, rowancheung, TheRundownAI)
🎯 Entwicklungen
Databricks stellt Lakebase, kostenlose Version und Agent Bricks vor, um Daten- und KI-Anwendungsentwicklung zu beschleunigen : Databricks hat angekündigt, dass Lakebase in die Public Preview Phase eintritt. Es handelt sich um eine vollständig verwaltete Postgres-Datenbank, die in das Lakehouse integriert und für KI entwickelt wurde. Sie kombiniert die Benutzerfreundlichkeit von Postgres, die Skalierbarkeit des Lakehouse und die Branching-Technologie der Neon-Datenbank. Gleichzeitig hat Databricks eine kostenlose Version seiner Plattform und umfangreiche Schulungsmaterialien veröffentlicht, um Entwicklern beim Erlernen von Data Engineering, Data Science und KI zu helfen. Darüber hinaus sind Databricks Apps jetzt allgemein verfügbar (GA) und unterstützen Kunden beim Erstellen und Bereitstellen interaktiver Daten- und KI-Anwendungen auf der Plattform. Databricks hat auch Agent Bricks eingeführt, einen deklarativen Ansatz zur Entwicklung von AI Agents, bei dem Benutzer Aufgaben beschreiben und das System automatisch Bewertungen generiert und die Agenten optimiert. (Quelle: matei_zaharia, matei_zaharia, lateinteraction, matei_zaharia, matei_zaharia, matei_zaharia, jefrankle, lateinteraction, matei_zaharia, lateinteraction, cto_junior, lateinteraction, jefrankle)

Nvidia kooperiert mit Mistral AI zum Aufbau einer End-to-End-Cloud-Plattform in Europa : Nvidia hat eine Zusammenarbeit mit dem französischen Startup Mistral AI angekündigt, um gemeinsam eine End-to-End-Cloud-Plattform aufzubauen. In der ersten Phase der Kooperation werden 18.000 Nvidia Grace Blackwell-Systeme implementiert, mit Plänen zur Erweiterung auf weitere Standorte im Jahr 2026. Diese Zusammenarbeit ist Teil von Nvidias Bemühungen, den Aufbau von KI-Infrastruktur und das Konzept der „Sovereign AI“ in Europa voranzutreiben, mit dem Ziel, Europa lokalisierte Rechenzentren und Server zur Verfügung zu stellen. (Quelle: Jensen Huang: Europas KI-Rechenleistung wird sich in zwei Jahren verzehnfachen)
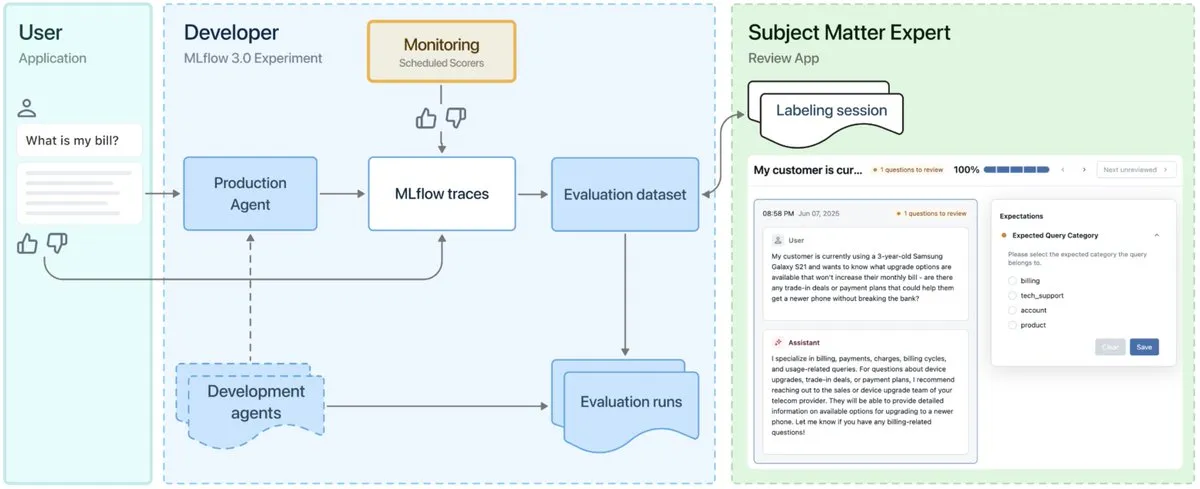
MLflow 3.0 veröffentlicht, speziell für Observability und Entwicklung von AI Agents entwickelt : MLflow 3.0 wurde offiziell veröffentlicht. Die neue Version wurde speziell für die Observability und Entwicklung von AI Agents neu konzipiert und aktualisiert auch die traditionellen Funktionen für strukturiertes Machine Learning. MLflow 3.0 zielt darauf ab, durch Daten eine kontinuierliche Verbesserung von KI-Systemen zu ermöglichen, unterstützt das Tracking, die Bewertung und Überwachung von KI-Systemen und berücksichtigt dabei unternehmensweite Anforderungen wie menschliche Zusammenarbeit, Data Governance und Sicherheit sowie die Integration in das Datenökosystem von Databricks. (Quelle: matei_zaharia, matei_zaharia, lateinteraction)
Princeton University und Fudan University stellen HistBench und HistAgent vor, um KI-Anwendungen in der Geschichtsforschung zu fördern : Das KI-Labor der Princeton University und die Geschichtsabteilung der Fudan University haben gemeinsam HistBench, den weltweit ersten KI-Benchmark für historische Forschung, und HistAgent, einen KI-Assistenten für historische Forschung, vorgestellt. HistBench umfasst 414 historische Fragen, die 29 Sprachen und die Geschichte mehrerer Zivilisationen abdecken, und zielt darauf ab, die Fähigkeit von KI zur Verarbeitung komplexer historischer Materialien und zum multimodalen Verständnis zu testen. HistAgent ist ein speziell für die historische Forschung entwickelter Agent, der Werkzeuge wie Literaturrecherche, OCR und Übersetzung integriert. Tests zeigen, dass allgemeine große Modelle bei HistBench eine Genauigkeit von weniger als 20 % erreichen, während HistAgent die Leistung bestehender Modelle bei weitem übertrifft. (Quelle: Weltweit erster Geschichts-Benchmark, Princeton und Fudan entwickeln KI-Geschichtsassistenten, KI dringt in Geisteswissenschaften vor)

Microsoft Research und Peking University veröffentlichen Next-Frame Diffusion (NFD) Framework zur Steigerung der Effizienz autoregressiver Videogenerierung : Microsoft Research und die Peking University haben gemeinsam das neue Next-Frame Diffusion (NFD) Framework vorgestellt. Durch paralleles Sampling innerhalb von Frames und autoregressive Methoden zwischen den Frames erreicht es auf einer A100 GPU mit einem 310M-Modell eine qualitativ hochwertige autoregressive Videogenerierung von über 30 Bildern pro Sekunde. NFD verwendet einen Transformer mit einem blockweisen kausalen Aufmerksamkeitsmechanismus und kombiniert Konsistenzdestillation und spekulative Sampling-Techniken, um die Effizienz weiter zu steigern. Es wird erwartet, dass es in Szenarien wie interaktiven Echtzeitspielen Anwendung findet. (Quelle: Über 30 Bilder pro Sekunde Videogenerierung, unterstützt Echtzeitinteraktion, neues Framework für autoregressive Videogenerierung setzt neue Maßstäbe bei der Generierungseffizienz)

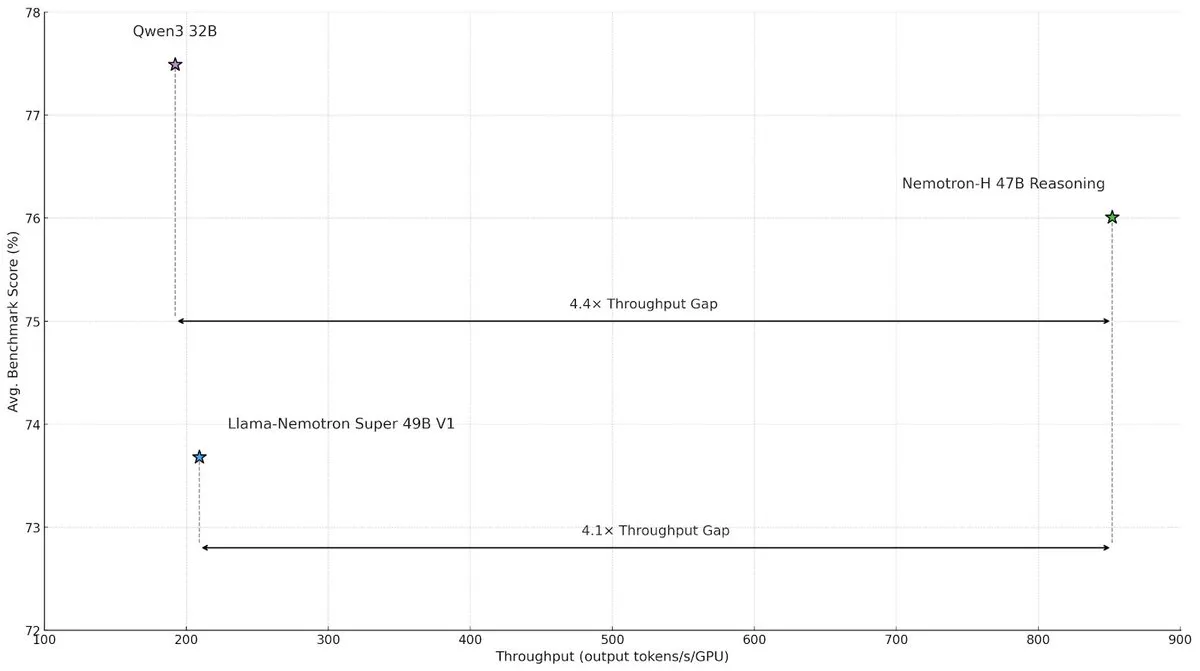
NVIDIA veröffentlicht Nemotron-H Hybridarchitekturmodell zur Steigerung von Geschwindigkeit und Effizienz bei großskaliger Inferenz : NVIDIA Research hat das Nemotron-H Modell vorgestellt, das eine Hybridarchitektur aus Mamba und Transformer verwendet, um Geschwindigkeitsengpässe bei großskaligen Inferenzaufgaben zu lösen. Das Modell erreicht bei gleichbleibender Inferenzleistung einen viermal höheren Durchsatz als vergleichbare Transformer-Modelle. Studien zeigen, dass Hybridmodelle auch mit weniger Attention-Layern die Inferenzleistung aufrechterhalten können, insbesondere in Szenarien mit langen Inferenzketten, in denen der Effizienzvorteil linearer Architekturen signifikant ist. (Quelle: _albertgu, tri_dao, krandiash)
Google DeepMind Forscher Jack Rae tritt Meta “Superintelligenz”-Gruppe bei : Der leitende Forscher von Google DeepMind, Jack Rae, hat bestätigt, dass er der neu gegründeten “Superintelligenz”-Gruppe von Meta beigetreten ist. Rae war bei DeepMind für die “Denk”-Fähigkeiten des Gemini-Modells verantwortlich und ist einer der Hauptvertreter der Idee “Kompression ist Intelligenz”. Zuvor war er bei OpenAI an der Entwicklung von GPT-4 beteiligt. Meta-CEO Zuckerberg rekrutiert persönlich Top-KI-Talente und bietet dem neuen Team Gehaltspakete im zweistelligen Millionenbereich an, um das Llama-Modell zu verbessern und leistungsfähigere KI-Tools zu entwickeln und so zu den Branchenführern aufzuschließen. (Quelle: Zuckerbergs “Superintelligenz”-Gruppe erster Top-Mann, leitender Forscher von Google DeepMind, Schlüsselfigur für “Kompression ist Intelligenz”, DhruvBatraDB)

Mistral AI veröffentlicht erstes Inferenzmodell Magistral mit Unterstützung für mehrsprachige Inferenz : Mistral AI hat sein erstes Inferenzmodell Magistral vorgestellt, einschließlich der Open-Source-Version Magistral Small mit 24B Parametern und Magistral Medium für Unternehmen. Das Modell wurde speziell für mehrstufige Logik und Interpretierbarkeit optimiert, unterstützt mehrsprachige Inferenz, insbesondere für europäische Sprachen, und kann nachvollziehbare Denkprozesse liefern. Magistral wird mit einem verbesserten GRPO-Algorithmus durch reines Reinforcement Learning trainiert, ohne auf destillierte Daten von bestehenden Inferenzmodellen angewiesen zu sein. Die Benchmark-Ergebnisse wurden jedoch teilweise kritisiert, da sie nicht die neuesten Versionen von Qwen und DeepSeek R1 enthielten. (Quelle: Neues “SOTA”-Inferenzmodell weicht Qwen und R1 aus? Europäische OpenAI-Version wird heftig kritisiert)

ByteDance Doubao Large Model 1.6 veröffentlicht mit erneuter deutlicher Preissenkung, Videomodell Seedance 1.0 pro gleichzeitig vorgestellt : Volcano Engine hat das Doubao Large Model 1.6 veröffentlicht, das erstmals eine Preisgestaltung nach “Input-Längen”-Intervallen einführt. Für das 0-32K Input-Intervall beträgt der Preis 0,8 Yuan/Million Tokens, der Output kostet 8 Yuan/Million Tokens, was einer Kostenreduktion von 63% gegenüber Version 1.5 entspricht. Das neu veröffentlichte Videogenerierungsmodell Seedance 1.0 pro kostet 1,5 Fen pro tausend Tokens, die Generierung eines 5-sekündigen 1080P-Videos kostet etwa 3,67 Yuan. Tan Dai, Präsident von Volcano Engine, erklärte, dass diese Preissenkung durch gezielte Kostenoptimierung im häufig genutzten 32K-Bereich und Innovationen im Geschäftsmodell erreicht wurde, mit dem Ziel, die skalierte Anwendung von Agents voranzutreiben. (Quelle: Doubao Large Model senkt Preise erneut drastisch, Volcano Engine kämpft weiterhin aggressiv um Marktanteile, 「Volcano」 brennt in Richtung Baidu Cloud)
Hong Kong University of Science and Technology und Huawei stellen AutoSchemaKG Framework für vollständig autonomen Knowledge Graph Aufbau vor : Das KnowComp Lab der Hong Kong University of Science and Technology hat in Zusammenarbeit mit der Theorieabteilung von Huawei Hong Kong das AutoSchemaKG Framework vorgestellt, das den vollständig autonomen Aufbau von Knowledge Graphs ohne vordefinierte Schemata ermöglicht. Das System nutzt große Sprachmodelle, um Wissenstripel direkt aus Text zu extrahieren und Entitäts- sowie Ereignisschemata zu induzieren. Basierend auf diesem Framework hat das Team die Knowledge Graph Serie ATLAS mit über 900 Millionen Knoten und 5,9 Milliarden Kanten aufgebaut. Experimente zeigen, dass die Methode bei null manuellem Eingriff eine semantische Übereinstimmung von 95% zwischen den induzierten Schemata und von Menschen entworfenen Schemata erreicht. (Quelle: Größter Open-Source GraphRag: Vollständig autonomer Aufbau von Knowledge Graphen)

Qijing Technology veröffentlicht Soft- und Hardware-integrierte Serverlösung mit 8 Karten zur Steigerung der Effizienz von DeepSeek Large Models : Qijing Technology hat in Zusammenarbeit mit Intel einen Ökosystem-Salon veranstaltet und die neueste Soft- und Hardware-integrierte Serverlösung mit 8 Karten vorgestellt. Diese Lösung kann große Modelle wie DeepSeek-R1/V3-671B effizient ausführen und erreicht eine Leistungssteigerung von bis zu 7-fach im Vergleich zu einer einzelnen Karte. Gleichzeitig wurden die selbstentwickelte Inferenz-Engine KLLM, die Management-Plattform für große Modelle AMaaS und die Büroanwendungssuite „Qijing·Zhiwen“ erheblich verbessert, um Herausforderungen wie hohe Einstiegshürden und unzureichende Leistung bei der privaten Bereitstellung großer Modelle zu bewältigen. (Quelle: Qijing Technology & Intel Ökosystem-Salon abgehalten, Hardware, Inferenz-Engine, Anwendungsökosystem-Integration, um die „letzte Meile“ der privaten Bereitstellung großer Modelle zu überwinden)

Black Forest Labs veröffentlicht FLUX.1 Kontext Bildmodellreihe zur Stärkung der Charakter- und Stilkonsistenz : Die deutsche Firma Black Forest Labs hat die FLUX.1 Kontext Text-zu-Bild Modellreihe (max, pro, dev Versionen) vorgestellt, die sich auf die Beibehaltung der Charakter- und Stilkonsistenz bei der Bearbeitung von Bildern konzentriert. Diese Modellreihe unterstützt lokale und globale Modifikationen von Bildern und kann Bilder aus Text- und/oder Bildeingaben generieren. Die FLUX.1 Kontext dev Version soll Open Source werden. In einem proprietären Benchmark-Test mit etwa 1000 Prompt- und Referenzbildpaaren übertrafen die FLUX.1 Kontext max und pro Versionen Konkurrenzmodelle wie OpenAI GPT Image 1 und Google Gemini 2.0 Flash. (Quelle: DeepLearning.AI Blog)

Nvidia, Rutgers University und andere Institutionen stellen STORM Framework vor, das durch Mamba-Layer die für das Videoverständnis benötigten Tokens reduziert : Forscher von Nvidia, der Rutgers University, der University of California, Berkeley und anderen Institutionen haben das Text-Video-System STORM entwickelt. Dieses System führt einen Mamba-Layer zwischen dem SigLIP Vision Transformer und dem LLM von Qwen2-VL ein. Durch die Anreicherung von Single-Frame-Token-Embeddings mit Informationen aus anderen Frames desselben Clips werden Token-Embeddings über Frames hinweg gemittelt, ohne wichtige Informationen zu verlieren. Dies ermöglicht es dem System, Videos mit weniger Tokens zu verarbeiten und übertrifft in Videoverständnis-Benchmarks wie MVBench und MLVU die Leistung von GPT-4o und Qwen2-VL, während die Verarbeitungsgeschwindigkeit um mehr als das Dreifache gesteigert wird. (Quelle: DeepLearning.AI Blog)

Google-Mitbegründer äußert Vorbehalte gegenüber humanoiden Robotern, spezialisierte Roboter mit guten Kommerzialisierungsaussichten : Google-Mitbegründer Sergey Brin erklärte, er sei nicht sehr begeistert von humanoiden Robotern, die die menschliche Form strikt nachahmen, da dies keine notwendige Voraussetzung für effektive Roboterarbeit sei. Gleichzeitig rücken spezialisierte Roboter aufgrund ihrer “Plug-and-Play”-Eigenschaften und klaren Kommerzialisierungspfade in den Fokus. Beispielsweise zeigen Unterwasserroboter und Rasenmähroboter in spezifischen Szenarien großes Potenzial. Analysten sind der Meinung, dass in der aktuellen Phase die Roboterform und Produktivität, die tatsächliche Probleme lösen können, entscheidend sind. Spezialisierte Roboter mit klaren Geschäftsmodellen und dringendem Bedarf in bestimmten Szenarien sind Vorreiter bei der Kommerzialisierung. (Quelle: Spezialisierte Roboter klopfen humanoiden Robotern auf die Schulter: “Bruder, mach Platz, ich will an den Tisch.”)

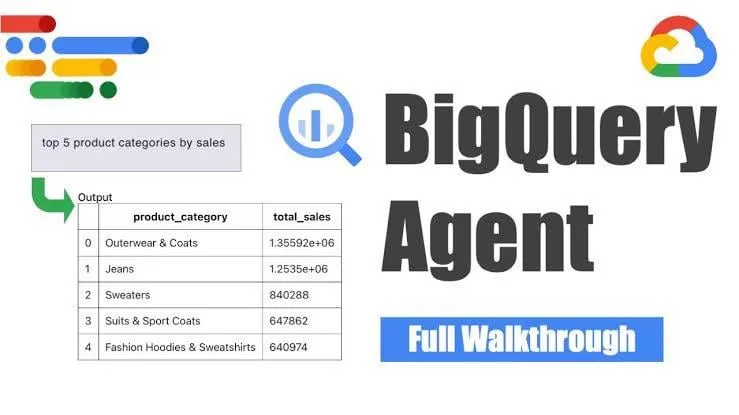
Google stellt BigQuery Data Engineering Agent für intelligente Pipeline-Generierung vor : Google hat den BigQuery Data Engineering Agent vorgestellt, ein Tool, das kontextbezogenes Reasoning nutzt, um die Generierung von Datenpipelines effizient zu skalieren. Benutzer definieren Pipeline-Anforderungen über einfache Befehlszeilenanweisungen, und der Agent generiert mithilfe domänenspezifischer Prompts Batch-Pipeline-Code, der auf die Datenumgebung des Benutzers zugeschnitten ist. Dies umfasst Konfigurationen für die Datenaufnahme, Transformationsabfragen, Logik zur Tabellenerstellung und Planungseinstellungen über Dataform oder Composer. Das Tool zielt darauf ab, die sich wiederholende Arbeit von Dateningenieuren bei der Verarbeitung mehrerer Datendomänen, Umgebungen und Transformationslogiken durch KI-Unterstützung zu vereinfachen. (Quelle: Reddit r/deeplearning)
Yandex veröffentlicht Yambda, einen umfangreichen öffentlichen Datensatz mit fast 5 Milliarden Nutzer-Track-Interaktionen : Yandex hat einen umfangreichen öffentlichen Datensatz namens Yambda veröffentlicht, der speziell für die Forschung an Empfehlungssystemen entwickelt wurde. Der Datensatz enthält fast 5 Milliarden anonymisierte Interaktionsdaten zwischen Nutzern und Musiktiteln von Yandex Music und bietet Forschern eine seltene Gelegenheit, mit Daten im realen Maßstab zu arbeiten. (Quelle: _akhaliq)

ByteDance veröffentlicht Videoreparaturmodell SeedVR2 auf Hugging Face : Das Seed-Team von ByteDance hat SeedVR2 auf Hugging Face veröffentlicht, ein Single-Step Diffusion Transformer Modell zur Videoreparatur. Das Modell steht unter der Apache 2.0 Lizenz, zeichnet sich durch Single-Step Inferenz aus, ist schnell und effizient und unterstützt die Verarbeitung beliebiger Auflösungen ohne Kachelung oder Größenbeschränkungen. (Quelle: huggingface)
ByteDance Doubao Video Large Model Seedance 1.0 Pro erhält Lob für Testergebnisse : Das kürzlich von ByteDance veröffentlichte Bild-zu-Video Large Model Seedance 1.0 Pro zeigte in Tests eine gute Befehlsfolgefähigkeit und Stabilität bei der Objektgenerierung. Nutzerfeedback bescheinigt eine hohe Videoqualität und präzise Kameraführung, die nur von Veo 2/3 übertroffen wird. Ein potenzieller Nachteil ist, dass das Modell bei der Generierung reiner Objektbewegungen manchmal Handinteraktionen hinzufügt, um die Szene plausibler zu gestalten, was durch die Einschränkung des Erscheinens von Händen umgangen werden kann. (Quelle: karminski3, karminski3, karminski3)
Alibaba veröffentlicht Open-Source Digital Human Framework Mnn3dAvatar, unterstützt Echtzeit-Gesichtserfassung und Erstellung von 3D-Avataren : Alibaba hat auf GitHub ein Open-Source Digital Human Framework namens Mnn3dAvatar veröffentlicht. Das Projekt ermöglicht Echtzeit-Gesichtserfassung und die Übertragung von Gesichtsausdrücken auf 3D-Avatare. Gleichzeitig können Benutzer ihre eigenen 3D-Avatare erstellen. Dieses Framework eignet sich für einfache Live-Streaming-Verkäufe, Inhaltspräsentationen und ähnliche Szenarien. (Quelle: karminski3)
Nvidia veröffentlicht Open-Source Humanoid Robot Basismodell Gr00t N 1.5 3B und stellt Fine-Tuning Tutorial bereit : Nvidia hat das Gr00t N 1.5 3B Modell als Open Source veröffentlicht. Es handelt sich um ein offenes Basismodell, das speziell für die Inferenzfähigkeiten humanoider Roboter entwickelt wurde und unter einer kommerziellen Lizenz steht. Gleichzeitig hat Nvidia ein vollständiges Fine-Tuning Tutorial in Verbindung mit LeRobotHF SO101 veröffentlicht, um die Entwicklung und Anwendung humanoider Robotertechnologie voranzutreiben. (Quelle: ClementDelangue)
Together AI führt Batch API ein, bietet großskalige LLM-Inferenzdienste und senkt Preise drastisch : Together AI hat eine neue Batch API eingeführt, die speziell für großskalige LLM-Inferenz entwickelt wurde und Anwendungsfälle mit hohem Durchsatz wie die Generierung synthetischer Daten, Benchmarking, Inhaltsprüfung und -zusammenfassung sowie Dokumentenextraktion unterstützt. Die API führt einen um 50 % günstigeren Einstiegspreis als die Echtzeit-API ein, unterstützt die Stapelverarbeitung von bis zu 50.000 Anfragen oder 100 MB pro Stapel und ist mit 15 Top-Modellen kompatibel. (Quelle: vipulved)
Google Gemini 2.5 Pro erhält Funktion zur interaktiven Generierung fraktaler Kunst : Google hat angekündigt, dass Gemini 2.5 Pro nun die sofortige Erstellung interaktiver fraktaler Kunst unterstützt. Benutzer können durch Prompts wie „Erstelle für mich ein schönes, partikelbasiertes, animiertes, endloses, 3D-, symmetrisches, von mathematischen Formeln inspiriertes fraktales Kunstwerk“ einzigartige visuelle Kunstwerke generieren. (Quelle: demishassabis)
Google Veo3 Fast Videogenerierungsgeschwindigkeit verdoppelt : Google Labs hat bekannt gegeben, dass die Generierungsgeschwindigkeit der Veo3 Fast Version in seinem Videogenerierungstool Flow mehr als verdoppelt wurde, während die Auflösung von 720p beibehalten wird. Dieses Update zielt darauf ab, Benutzern eine schnellere Erstellung von Videoinhalten zu ermöglichen. (Quelle: op7418)
Hugging Face integriert Google Colab und Kaggle zur Vereinfachung der Modellnutzung : Hugging Face ist jetzt mit Google Colab und Kaggle integriert. Benutzer können direkt von jeder Modellkarte aus ein Colab-Notebook starten oder dasselbe Modell in einem Kaggle Notebook öffnen, ergänzt durch ausführbare öffentliche Codebeispiele, was die Nutzung und das Experimentieren mit Modellen vereinfacht. (Quelle: ClementDelangue, huggingface)
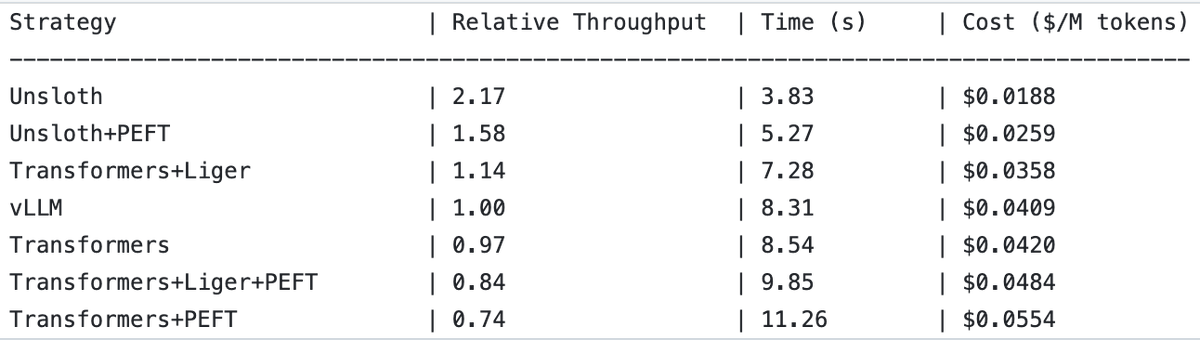
UnslothAI erreicht 2-fachen Durchsatz bei Reward Model Services und Sequenzklassifikationsinferenz : Es wurde festgestellt, dass UnslothAI für die Bereitstellung von Reward Model (RM) Services verwendet werden kann und bei der Sequenzklassifikationsinferenz einen doppelt so hohen Durchsatz wie vLLM erreicht. Diese Entdeckung hat in der RL (Reinforcement Learning) Community Aufmerksamkeit erregt, und die Leistungssteigerung von UnslothAI verspricht, verwandte Forschung und Anwendungen zu beschleunigen. (Quelle: natolambert, danielhanchen)
Digua Robotics veröffentlicht erstes Single-SoC Rechen- und Steuerungs-integriertes Roboter-Entwicklungskit RDK S100 : Digua Robotics hat das branchenweit erste Single-SoC Rechen- und Steuerungs-integrierte Roboter-Entwicklungskit RDK S100 vorgestellt. Das Kit ist nach einer menschenähnlichen Großhirn-Kleinhirn-Architektur konzipiert und integriert CPU+BPU+MCU auf einem einzigen SoC. Es unterstützt die effiziente Zusammenarbeit von großen und kleinen Modellen der Embodied AI und schließt den Kreislauf von „Wahrnehmung-Entscheidung-Steuerung“. RDK S100 bietet verschiedene Schnittstellen sowie eine Soft- und Hardware-koordinierte, End-to-Cloud-integrierte Entwicklungsinfrastruktur, um den Aufbau von Embodied AI-Produkten und die Bereitstellung in verschiedenen Szenarien zu beschleunigen. Es wird bereits mit über 20 führenden Kunden zusammengearbeitet, der Marktpreis beträgt 2799 Yuan. (Quelle: Digua Robotics veröffentlicht erstes Single-SoC Rechen- und Steuerungs-integriertes Roboter-Entwicklungskit, Zusammenarbeit mit über 20 führenden Kunden vereinbart | Frontline)

🧰 Tools
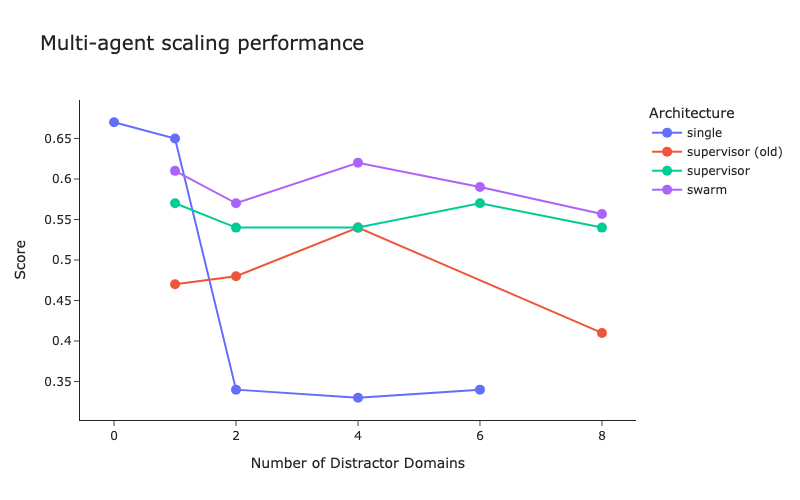
LangChain veröffentlicht Benchmark-Test für Multi-Agenten-Architekturen und Verbesserungen der Supervisor-Methode : LangChain hat angesichts der zunehmenden Anzahl von Multi-Agenten-Systemen erste Benchmark-Tests durchgeführt, um zu untersuchen, wie die Koordination zwischen mehreren Agenten optimiert werden kann. Gleichzeitig hat LangChain einige Verbesserungen an seiner Supervisor-Methode vorgenommen, ein entsprechender Blogbeitrag wurde veröffentlicht. (Quelle: LangChainAI, hwchase17)
Cartesia stellt Ink-Whisper vor: Schnelles, kostengünstiges Streaming Speech-to-Text Modell für Voice Agents : Cartesia hat Ink-Whisper veröffentlicht, ein schnelles, kostengünstiges Streaming Speech-to-Text (STT) Modell, das für Voice Agents optimiert ist. Das Modell wurde für Genauigkeit unter realen Bedingungen entwickelt und kann mit Cartesias Sonic Text-to-Speech (TTS) Modell für schnelle Sprach-KI-Interaktionen verwendet werden. Ink-Whisper unterstützt die Anbindung an Plattformen wie VapiAI, PipecatAI und Livekit. (Quelle: simran_s_arora, tri_dao, krandiash)

MonkeyOCR: Kleines, schnelles, Open-Source Dokumenten-Parsing-Modell : Ein Dokumenten-Parsing-Modell mit 3B Parametern namens MonkeyOCR wurde unter der Apache 2.0 Lizenz veröffentlicht. Das Modell kann verschiedene Elemente in Dokumenten parsen, einschließlich Diagrammen, Formeln, Tabellen usw., und zielt darauf ab, traditionelle Parser-Pipelines zu ersetzen und eine bessere Lösung für die Dokumentenverarbeitung zu bieten. (Quelle: mervenoyann, huggingface)
LlamaIndex integriert Cleanlab zur Verbesserung der Glaubwürdigkeit von KI-Assistenten-Antworten : LlamaIndex hat die Integration mit CleanlabAI angekündigt. LlamaIndex wird verwendet, um KI-Wissensassistenten und produktionsreife Agenten zu erstellen, die Erkenntnisse aus Unternehmensdaten generieren. Die Hinzufügung von Cleanlab zielt darauf ab, die Glaubwürdigkeit der Antworten dieser KI-Assistenten zu verbessern, indem jede LLM-Antwort bewertet, Halluzinationen oder falsche Antworten in Echtzeit erfasst und bei der Analyse der Ursachen für unglaubwürdige Antworten (z. B. schlechte Recherche, Daten-/Kontextprobleme, schwierige Abfragen oder LLM-Halluzinationen) geholfen wird. (Quelle: jerryjliu0)

Claude Code fügt “Planungsmodus” hinzu, um die Kontrollierbarkeit komplexer Codeänderungen zu verbessern : Claude Code von Anthropic führt den “Planungsmodus” (Plan mode) ein. Diese Funktion ermöglicht es Benutzern, den Implementierungsplan zu überprüfen, bevor der Code tatsächlich geändert wird, um sicherzustellen, dass jeder Schritt durchdacht ist, insbesondere bei komplexen Codeänderungen. Benutzer können durch zweimaliges Drücken von Shift + Tab in den Planungsmodus wechseln. Claude Code liefert dann einen detaillierten Implementierungsplan und bittet vor der Ausführung um Bestätigung. Diese Funktion wurde für alle Claude Code-Benutzer (einschließlich Pro- oder Max-Abonnenten) eingeführt. (Quelle: dotey, kylebrussell)
rvn-convert: In Rust implementiertes Konvertierungstool von SafeTensors zu GGUF v3 : Ein Open-Source-Tool namens rvn-convert wurde veröffentlicht. Es ist in Rust geschrieben und dient zur Konvertierung von Modelldateien im SafeTensors-Format in das GGUF v3-Format. Das Tool zeichnet sich durch Single-Shard-Unterstützung, hohe Geschwindigkeit und keine Python-Umgebung aus. Es kann safetensors-Dateien per Memory Mapping einlesen und direkt in gguf-Dateien schreiben, wodurch RAM-Spitzen und Festplatten-Turnaround-Probleme vermieden werden. Derzeit werden Funktionen wie Upsampling von BF16 zu F32 und das Einbetten von tokenizer.json unterstützt. (Quelle: Reddit r/LocalLLaMA)
Runway API fügt 4K-Video-Super-Resolution-Funktion hinzu : Runway hat angekündigt, dass seine API jetzt die 4K-Video-Super-Resolution-Funktion unterstützt. Entwickler können diese Funktion in ihre eigenen Anwendungen, Produkte, Plattformen und Websites integrieren, um die Klarheit und Qualität von Videoinhalten zu verbessern. (Quelle: c_valenzuelab)
You.com führt Projects-Funktion zur Organisation und Verwaltung von Forschungsmaterialien ein : You.com hat ein neues Tool namens „Projects“ veröffentlicht, das Benutzern helfen soll, Forschungsmaterialien in leicht zugänglichen Ordnern zu organisieren. Die Funktion unterstützt Benutzer dabei, Konversationen zu kontextualisieren und zu strukturieren, um verstreute Chat-Verläufe und den Verlust von Erkenntnissen zu vermeiden und so den Wissensmanagementprozess zu vereinfachen. (Quelle: RichardSocher)
LlamaIndex stellt LlamaExtract vor, einen Agent-basierten Dokumentenextraktionsdienst : LlamaIndex hat LlamaExtract veröffentlicht, einen Agent-gesteuerten Dokumentenextraktionsdienst, der darauf abzielt, strukturierte Daten aus komplexen Dokumenten und Eingabemustern zu extrahieren. Der Dienst extrahiert nicht nur Schlüssel-Wert-Paare, sondern liefert auch präzise Quellenangaben, Seitenverweise und übereinstimmenden Text für jeden extrahierten Eintrag. LlamaExtract wird als API angeboten und lässt sich leicht in nachgelagerte Agenten-Workflows integrieren. (Quelle: jerryjliu0)

langchain-google-vertexai veröffentlicht Update mit verbessertem Client-Caching und Tool-Unterstützung : langchain-google-vertexai hat eine neue Version veröffentlicht. Zu den wichtigsten Neuerungen gehören: Client-Caching für Vorhersagen, wodurch die Instanziierung neuer Clients um das 500-fache beschleunigt wird; Unterstützung für integrierte Code-Ausführungstools. (Quelle: LangChainAI, Hacubu)
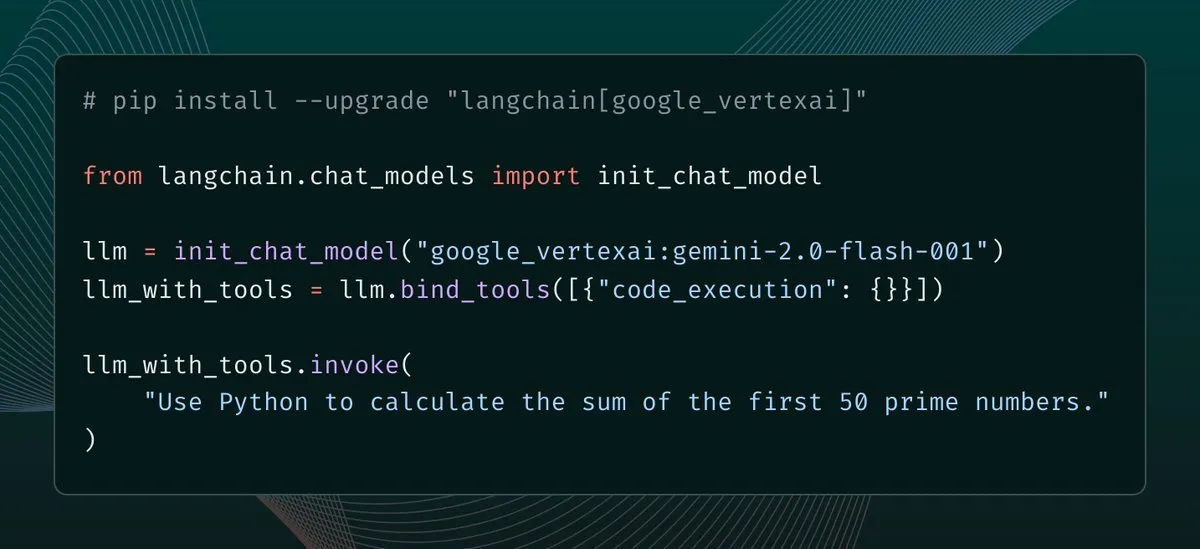
Perplexity Finance fügt direkte Download-Funktion für Excel-Modelle hinzu : Perplexity Finance hat angekündigt, dass Benutzer Excel-Modelle jetzt direkt von ihrer Seite herunterladen können, was einen schnelleren Ausgangspunkt für Finanzmodellierung und -forschung bietet. Diese Funktion ist für alle Benutzer kostenlos verfügbar; zuvor wurde nur der Download im CSV-Format unterstützt. (Quelle: AravSrinivas)
Viwoods veröffentlicht AI Paper Mini E-Ink-Tablet mit integrierten KI-Funktionen wie GPT-4o : Der aufstrebende E-Ink-Hersteller Viwoods hat das AI Paper Mini vorgestellt, ein E-Ink-Tablet mit KI-Funktionen. Das Gerät unterstützt verschiedene KI-Modelle wie GPT-4o und DeepSeek und bietet einen Chat-Modus sowie voreingestellte KI-Assistenten (Inhaltsanalyse, E-Mail-Generierung, KI-zu-Text). Zu den besonderen Funktionen gehören Aufgabenverwaltung in Kalenderansicht und ein schwebendes Schnellnotizfenster. Hardwareseitig verfügt das Paper Mini über einen 292 ppi Carta 1000 Bildschirm, 4GB+128GB Speicher und einen Eingabestift. Gleichzeitig hat Viwoods auch das größere AI Paper mit einem 300ppi Carta 1300 Flex-Bildschirm und schnellerer Reaktionszeit vorgestellt. (Quelle: Ich habe den halben Preis eines iPhones für ein E-Ink-Tablet mit KI bezahlt…)

360 veröffentlicht Nano AI Super Search Agent, Zhou Hongyi tritt persönlich auf : Der Gründer der 360 Group, Zhou Hongyi, moderierte die Veröffentlichung des Nano AI Super Search Agent. Dieser Agent zielt darauf ab, „mit einem Satz alles durchsuchen zu können“. Er kann ohne menschliches Eingreifen autonom denken, Browser und externe Tools zur Ausführung von Aufgaben aufrufen und unterstützt eine vollständige Visualisierung und Nachverfolgung der Schritte. Zhou Hongyi erklärte, dass bei der Vorbereitung dieser Pressekonferenz ebenfalls versucht wurde, Nano AI einzusetzen. Außerdem wurden die KI-gestützte Audioaufnahme-Hardware Nano AI Note und eine gemeinsam mit Rokid entwickelte KI-Brille vorgestellt. (Quelle: Zhou Hongyi will mit KI die Marketingabteilung „abschaffen“, hat „Nano“ das geschafft?)
📚 Lernen
DeepLearning.AI startet neuen Kurzkurs: Orchestrierung von GenAI-Workflows mit Apache Airflow : DeepLearning.AI hat in Zusammenarbeit mit Astronomer einen neuen Kurzkurs gestartet, der vermittelt, wie man RAG-Prototypen mit Apache Airflow 3.0 in produktionsreife Workflows umwandelt. Die Kursinhalte umfassen die Aufteilung von Workflows in modulare Aufgaben, die Planung von Pipelines mit zeit- und ereignisgesteuerten Triggern, dynamisches Task Mapping für parallele Ausführung von Aufgaben, das Hinzufügen von Retries/Alerts/Backfills für Fehlertoleranz sowie Techniken zur Skalierung von Pipelines. Für diesen Kurs sind keine Vorkenntnisse in Airflow erforderlich. (Quelle: DeepLearningAI, FLUX.1 Kontext’s Consistent Characters, Benchmarking Costs Climb, Mary Meeker’s Action-Packed AI Report, Better Video Gen)
Hamel Husain initiiert Minikurs zur RAG-Optimierung und -Bewertung : Hamel Husain hat einen vierteiligen Minikurs zur Optimierung und Bewertung von RAG (Retrieval Augmented Generation) angekündigt. Der erste Teil, gehalten von @bclavie, diskutiert die Sichtweise „Retrieval ist RAG“ und zielt darauf ab, auf frühere Diskussionen zu reagieren, in denen RAG als „Gedankenvirus, der ausgerottet werden muss“ bezeichnet wurde. Die Kursreihe ist kostenlos und soll Praktikern helfen, die Herausforderungen bei der RAG-Bewertung zu meistern. (Quelle: HamelHusain, HamelHusain, lateinteraction, HamelHusain, HamelHusain, HamelHusain, HamelHusain, HamelHusain)

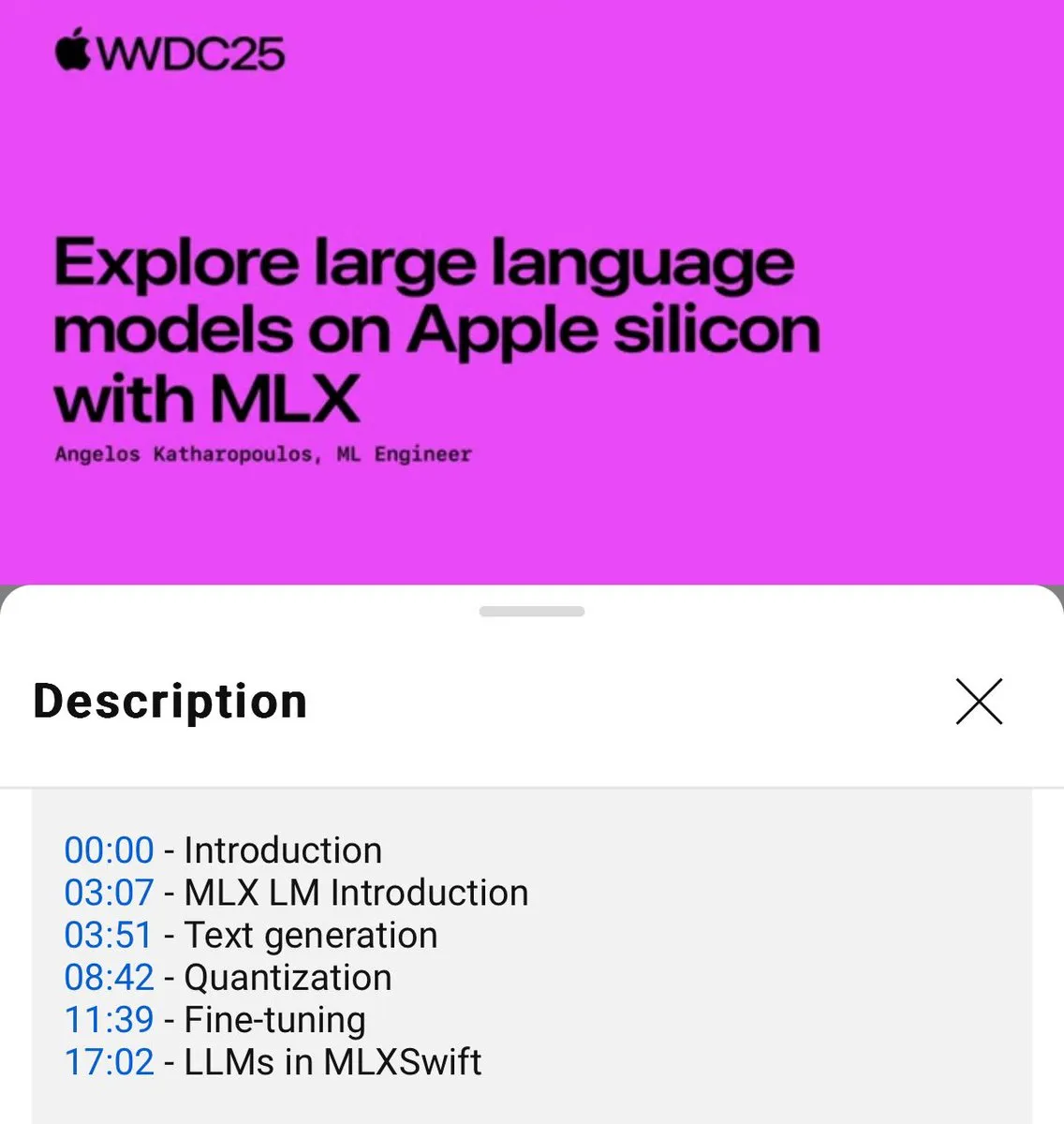
Tutorial zur lokalen Nutzung von MLX Sprachmodellen veröffentlicht (WWDC25) : Auf der WWDC25 Konferenz stellte Angelos Katharopoulos vor, wie man mit MLX schnell in die lokale Nutzung von Sprachmodellen einsteigen kann. Das Tutorial behandelt die Verwendung des MLXLM CLI für Einzeilenbefehle wie Modellquantisierung (mlx_lm.convert), LoRA Fine-Tuning (mlx_lm.lora) sowie das Zusammenführen von Modellen und das Hochladen auf Hugging Face (mlx_lm.fuse). Ein vollständiges Jupyter Notebook Tutorial ist auf GitHub verfügbar. (Quelle: awnihannun)
LangChain teilt Harvey AIs Methode zum Aufbau juristischer KI-Agenten : Ben Liebald von Harvey AI teilte auf dem Interrupt-Event von LangChain ihre ausgereifte Methode zum Aufbau juristischer KI-Agenten. Diese Methode kombiniert LangSmith-Evaluierung und eine „Lawyer-in-the-Loop“-Strategie, um KI-Tools zu entwickeln, denen Anwälte bei komplexen juristischen Aufgaben vertrauen können. (Quelle: LangChainAI, hwchase17)

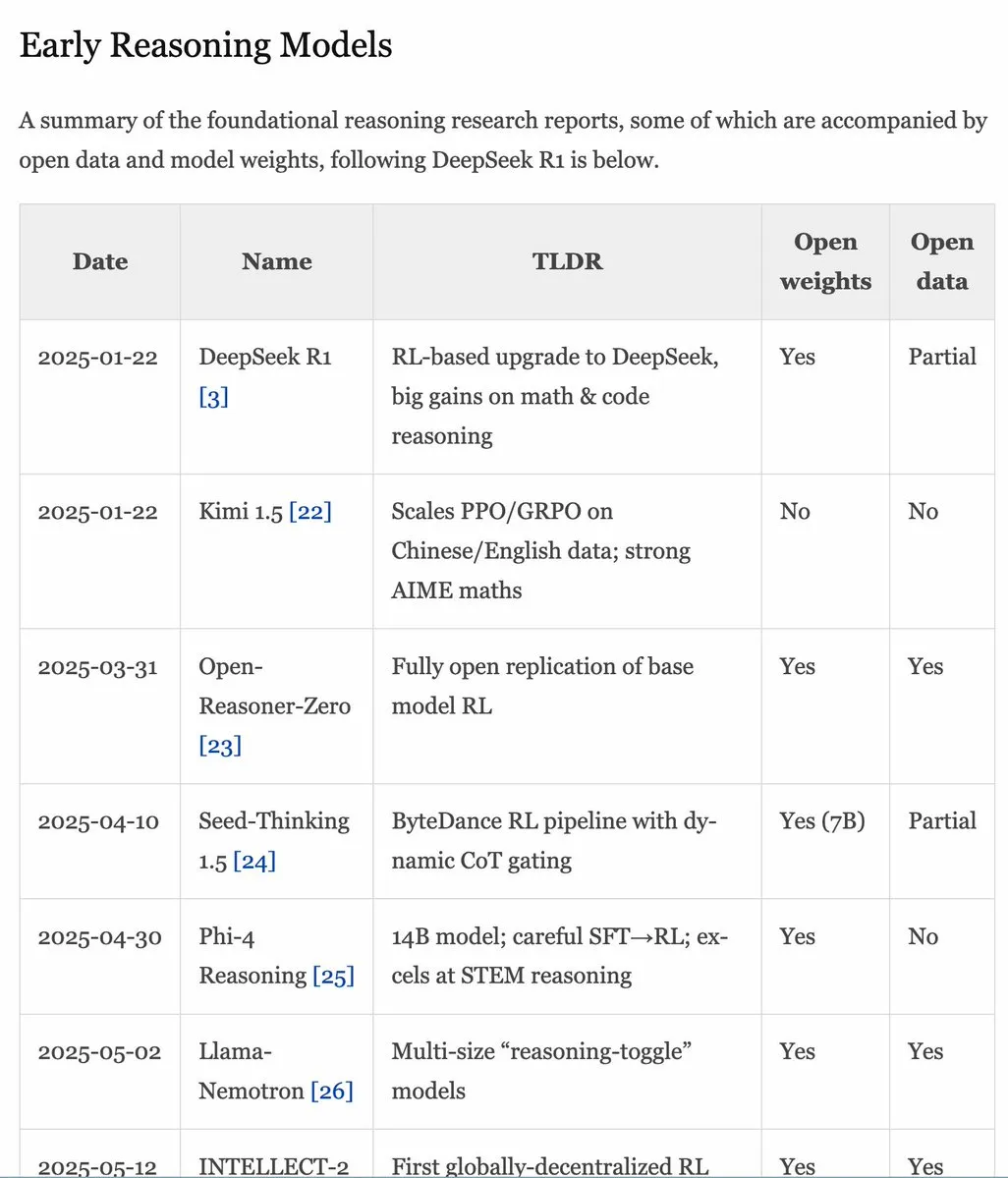
RLHF Handbuch v1.1 aktualisiert, erweitert Inhalte zu RLVR/Inferenzmodellen : Das RLHF Handbuch (rlhfbook.com) wurde auf Version 1.1 aktualisiert und um erweiterte Inhalte zu RLVR (Reinforcement Learning from Video Representations) und Inferenzmodellen ergänzt. Die Aktualisierungen umfassen eine Zusammenfassung der wichtigsten Berichte zu Inferenzmodellen, gängige Praktiken/Tricks und deren Anwender, relevante Inferenzarbeiten vor o1 sowie Verbesserungen wie asynchrones RL. (Quelle: menhguin)
Paper SWE-Flow: Synthese von Software-Engineering-Daten auf testgetriebene Weise : Ein neues Paper namens SWE-Flow stellt ein neuartiges Datensynthese-Framework vor, das auf testgetriebener Entwicklung (TDD) basiert. Das Framework leitet durch die Analyse von Unit-Tests automatisch inkrementelle Entwicklungsschritte ab und erstellt einen Runtime Dependency Graph (RDG), um strukturierte Entwicklungspläne zu generieren. Jeder Schritt erzeugt eine partielle Codebasis, entsprechende Unit-Tests und die notwendigen Codeänderungen, wodurch verifizierbare TDD-Aufgaben erstellt werden. Basierend auf dieser Methode wurde der Benchmark-Datensatz SWE-Flow-Eval generiert. (Quelle: HuggingFace Daily Papers)
Paper PlayerOne: Erster Ego-Perspektiven-Simulator für die reale Welt : PlayerOne wird als erster Ego-Perspektiven-Simulator (egocentric) für die reale Welt vorgeschlagen, der immersive Erkundungen in dynamischen Umgebungen ermöglicht. Ausgehend von einem Ego-Perspektiven-Bild einer Szene des Benutzers kann PlayerOne die entsprechende Welt konstruieren und Ego-Perspektiven-Videos generieren, die exakt mit den realen Bewegungen des Benutzers übereinstimmen, wie sie von externen Kameras erfasst werden. Das Modell verwendet einen Trainingsprozess von grob zu fein und ein Design für die bewegungsinjizierte Entkopplung von Komponenten sowie ein gemeinsames Rekonstruktionsframework. (Quelle: HuggingFace Daily Papers)
Paper ComfyUI-R1: Erforschung von Inferenzmodellen für die Workflow-Generierung : ComfyUI-R1 ist das erste große Inferenzmodell zur Automatisierung der Workflow-Generierung. Die Forscher erstellten zunächst einen Datensatz mit 4K Workflows und konstruierten Chain-of-Thought (CoT) Inferenzdaten. ComfyUI-R1 wird über ein zweistufiges Framework trainiert: CoT Fine-Tuning für den Kaltstart und Reinforcement Learning zur Förderung der Inferenzfähigkeiten. Experimente zeigen, dass das 7B-Parametermodell bestehende Methoden in Bezug auf Formatgültigkeit, Erfolgsrate und F1-Scores auf Knoten-/Grafikebene signifikant übertrifft. (Quelle: HuggingFace Daily Papers)
Paper SeerAttention-R: Adaptives Framework für Sparse Attention bei langer Inferenz : SeerAttention-R ist ein Sparse-Attention-Framework, das speziell für die lange Dekodierung von Inferenzmodellen entwickelt wurde. Es erlernt die Attention-Sparsity durch einen selbst-destillierenden Gating-Mechanismus und entfernt das Query-Pooling, um sich an die autoregressive Dekodierung anzupassen. Das Framework kann als leichtgewichtiges Plugin in bestehende vortrainierte Modelle integriert werden, ohne die ursprünglichen Parameter zu verändern. Im AIME-Benchmark erreichte SeerAttention-R, trainiert mit nur 0,4B Tokens, bei einem Budget von 4K Tokens in großen Sparse-Attention-Blöcken (64/128) eine nahezu verlustfreie Inferenzgenauigkeit. (Quelle: HuggingFace Daily Papers)
Paper SAFE: Multitask-Fehlererkennung für Vision-Language-Action Modelle : Das Paper stellt SAFE vor, einen Fehlerdetektor für allgemeine Roboterstrategien (wie VLAs). Durch die Analyse des VLA-Merkmalsraums lernt SAFE, die Wahrscheinlichkeit eines Aufgabenfehlers aus den internen Merkmalen des VLA vorherzusagen. Der Detektor wird auf erfolgreichen und fehlgeschlagenen Einsätzen trainiert und auf ungesehenen Aufgaben evaluiert. Er ist mit verschiedenen Strategiearchitekturen kompatibel und zielt darauf ab, die Sicherheit von VLAs bei der Interaktion mit der Umgebung zu erhöhen. (Quelle: HuggingFace Daily Papers)
Paper Branched Schrödinger Bridge Matching: Lernen von verzweigten Schrödinger-Brücken : Diese Studie führt das Branched Schrödinger Bridge Matching (BranchSBM) Framework ein, um verzweigte Schrödinger-Brücken zu lernen und so Zwischentrajektorien zwischen einer Anfangs- und einer Zielverteilung vorherzusagen. Im Gegensatz zu bestehenden Methoden kann BranchSBM verzweigte oder divergierende Entwicklungen von einem gemeinsamen Startpunkt zu mehreren unterschiedlichen Ergebnissen modellieren, indem es mehrere zeitabhängige Geschwindigkeitsfelder und Wachstumsprozesse parametrisiert. (Quelle: HuggingFace Daily Papers)
💼 Wirtschaft
Meta plant angeblich Übernahme von Datenannotationsfirma Scale AI für 15 Mrd. USD, Gründer könnte zu Meta wechseln : Berichten zufolge plant Meta, die führende Datenannotationsfirma Scale AI für 15 Milliarden US-Dollar zu übernehmen. Sollte der Deal zustande kommen, würden der 28-jährige chinesischstämmige Gründer von Scale AI, Alexandr Wang, und sein Team direkt zu Meta wechseln. Dieser Schritt wird als bedeutende Maßnahme von Meta-CEO Zuckerberg angesehen, um die Stärke seines AGI (Artificial General Intelligence)-Teams zu erhöhen und Konkurrenten wie OpenAI und Google einzuholen. Meta hat in letzter Zeit häufig Top-KI-Talente rekrutiert und Spitzeningenieuren Gehaltspakete im zweistelligen Millionenbereich angeboten. (Quelle: Zuckerbergs “Superintelligenz”-Gruppe erster Top-Mann, leitender Forscher von Google DeepMind, Schlüsselfigur für “Kompression ist Intelligenz”, dylan522p, sarahcat21, Dorialexander)
Disney und Universal Pictures verklagen KI-Bildfirma Midjourney wegen Urheberrechtsverletzung : Disney und Universal Pictures haben Klage gegen die KI-Bilderzeugungsfirma Midjourney eingereicht und werfen ihr die unbefugte Nutzung bekannter IP-Werke wie „Star Wars“ und „Die Simpsons“ vor. Dieser Fall erregt Aufmerksamkeit; sollte Disney gewinnen, könnte dies eine Kettenreaktion für andere KI-Unternehmen auslösen, die auf das Training mit großen Datenmengen angewiesen sind, und die Urheberrechtsstreitigkeiten im KI-Bereich weiter verschärfen. (Quelle: Reddit r/artificial, Reddit r/LocalLLaMA, karminski3)

Google startet aufgrund des KI-Such-Schocks erneut “freiwilliges Austrittsprogramm”, betroffen sind mehrere wichtige Teams wie Suche und Werbung : Angesichts des Schocks durch die KI-Suche hat Google erneut ein “freiwilliges Austrittsprogramm” für Mitarbeiter in mehreren US-Abteilungen gestartet, das Schlüsselteams wie Suche, Werbung und Kerntechnik betrifft, und die Richtlinien für die Rückkehr ins Büro verschärft. Dieser Schritt zielt darauf ab, Ressourcen neu zu organisieren und mehr Energie in das KI-Flaggschiffprojekt Gemini und die Entwicklung des “KI-Modus”-Sucherlebnisses zu investieren. Das traditionelle Suchgeschäft von Google steht aufgrund des Aufstiegs der KI vor großen Herausforderungen, gleichzeitig sieht sich das Unternehmen auch regulatorischem Druck ausgesetzt. (Quelle: Google startet aufgrund des KI-Such-Schocks erneut “freiwilliges Austrittsprogramm”, betroffen sind mehrere wichtige Teams, jpt401)
🌟 Community
KI deckt Voreingenommenheit bei Betrugserkennungsexperiment für Sozialleistungen in Amsterdam auf, Projekt gestoppt : Amsterdam versuchte, ein KI-System (Smart Check) zur Bewertung von Sozialleistungsanträgen einzusetzen, um Betrug aufzudecken. Obwohl bewährte Verfahren für verantwortungsvolle KI befolgt wurden, einschließlich Voreingenommenheitstests und technischer Sicherheitsvorkehrungen, konnte das System im Pilotprojekt Fairness und Effektivität nicht gewährleisten. Das ursprüngliche Modell war voreingenommen gegenüber nicht-niederländischen Antragstellern und Männern; nach Anpassungen zeigte es eine Voreingenommenheit gegenüber niederländischen Staatsbürgern und Frauen. Letztendlich wurde das Projekt gestoppt, da keine Diskriminierungsfreiheit gewährleistet werden konnte. Dieser Fall löste eine breite Diskussion über algorithmische Fairness, die Wirksamkeit verantwortungsvoller KI-Praktiken und den Einsatz von KI bei Entscheidungen im öffentlichen Dienst aus. (Quelle: MIT Technology Review, Inside Amsterdam’s high-stakes experiment to create fair welfare AI)

Kennzeichnungssystem für KI-generierte Inhalte: Wert, Grenzen und Governance-Logik diskutiert : Mit der Zunahme von KI-generierten Gerüchten und Falschinformationen rückt das KI-Kennzeichnungssystem als Governance-Maßnahme in den Fokus. Theoretisch können explizite und implizite Kennzeichnungen die Erkennungseffizienz verbessern und die Wachsamkeit der Nutzer erhöhen. In der Praxis lassen sich Kennzeichnungen jedoch leicht umgehen, fälschen und falsch interpretieren, zudem sind sie kostspielig. Der Artikel argumentiert, dass KI-Kennzeichnungen in bestehende Content-Governance-Systeme integriert werden sollten, wobei der Fokus auf Hochrisikobereiche (wie Gerüchte, Falschinformationen) gelegt und die Verantwortung von Generierungs- und Verbreitungsplattformen angemessen definiert werden sollte. Gleichzeitig sollte die Informationskompetenz der Öffentlichkeit gestärkt werden. (Quelle: Wenn Gerüchte den „KI“-Wind nutzen)
KI-gestützte Codierungstools (wie Claude Code) steigern Entwicklereffizienz und reduzieren Arbeitsbelastung erheblich : Mehrere Entwickler in der Community teilten positive Erfahrungen mit KI-gestützten Codierungstools (insbesondere Claude Code von Anthropic). Diese Tools helfen nicht nur beim Schreiben, Testen und Debuggen von Code, sondern unterstützen auch bei der Projektplanung und der Lösung komplexer Probleme, wodurch die Entwicklungseffizienz erheblich gesteigert und Arbeitsbelastung sowie Termindruck reduziert werden. Einige Benutzer gaben an, sich durch die KI-Unterstützung wie eine „unaufhaltsame Kraft“ zu fühlen. (Quelle: AnthropicAI, sbmaruf, Reddit r/ClaudeAI, Reddit r/ClaudeAI)

Energie- und Wasserverbrauch KI-generierter Inhalte im Fokus, Sam Altman gibt an, dass jede ChatGPT-Anfrage etwa 1/15 Teelöffel Wasser verbraucht : OpenAI CEO Sam Altman gab bekannt, dass jede ChatGPT-Anfrage ungefähr „ein Fünfzehntel eines Teelöffels“ Wasser verbraucht. Diese Angabe löste Diskussionen über die Umweltauswirkungen des Trainings und der Inferenz von KI-Modellen aus. Obwohl die genaue Berechnungsmethode und ob die Trainingskosten enthalten sind, unklar bleiben, sind der Energie-Fußabdruck und der Wasserverbrauch von KI zu einem wichtigen Thema in der Technologiebranche und im Umweltschutz geworden. (Quelle: MIT Technology Review, Reddit r/ChatGPT)

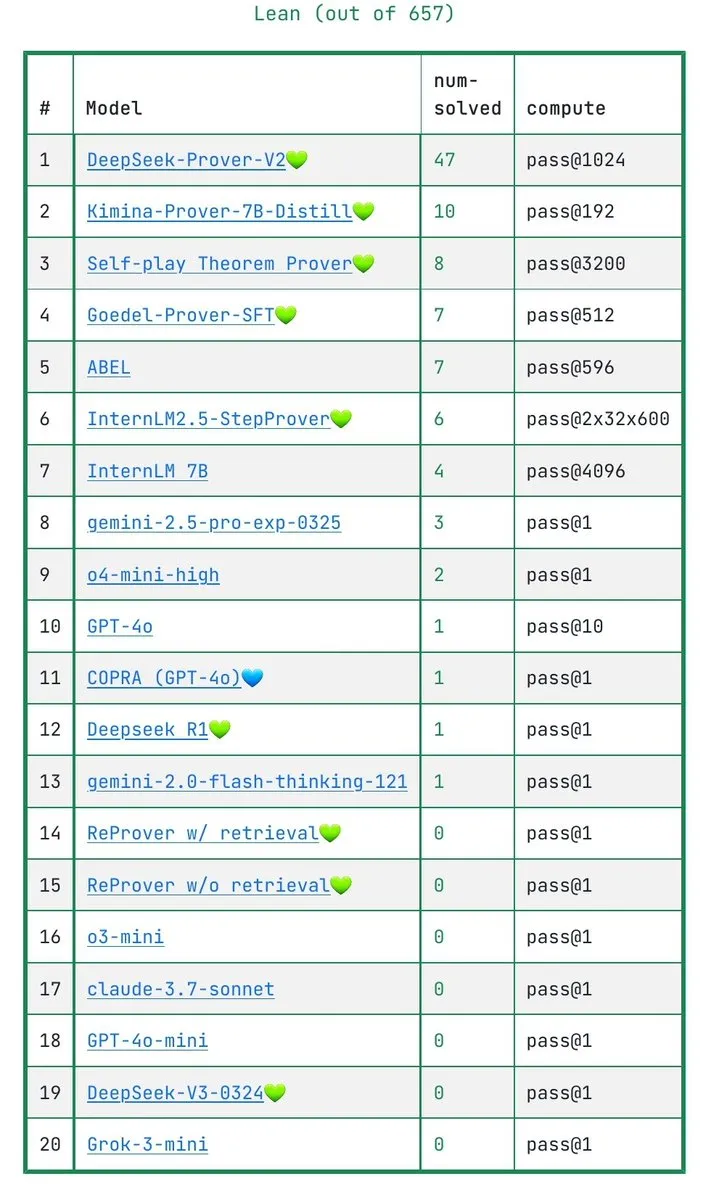
Diskussion darüber, ob LLMs mathematische Beweise wirklich verstehen: IneqMath-Benchmark deckt Schwächen der Modelle auf : Der neu veröffentlichte IneqMath-Benchmark konzentriert sich auf mathematische Ungleichheitsbeweise auf Olympiade-Niveau. Die Studie ergab, dass LLMs zwar manchmal die richtige Antwort finden können, aber erhebliche Lücken beim Aufbau strenger, plausibler Beweise aufweisen. Dies löste eine Diskussion darüber aus, ob LLMs in Bereichen wie Mathematik wirklich verstehen oder nur „raten“. Sathya wies darauf hin, dass dieses Phänomen der „richtigen Antwort – falschen Argumentation“ auch in Benchmarks wie PutnamBench zu beobachten ist. (Quelle: lupantech, lupantech, _akhaliq, clefourrier)
Anwendung und Diskussion von AI Agents in Softwareentwicklung, Forschung und alltäglichen Aufgaben : Die Community diskutiert breit über die Anwendung von AI Agents in verschiedenen Bereichen. Beispielsweise teilen Benutzer Erfahrungen mit dem Aufbau von Deep-Research-Agent-Workflows mit n8n und Claude; LlamaIndex zeigt, wie man durch Artifact Memory Block inkrementelle Formularausfüll-Agenten realisiert; die Diskussionen umfassen auch die Verwendung von MCP (Model Context Protocol) zur Gestaltung von AI-orientierten Tool-Schnittstellen sowie die Anwendung von AI Agents in Bereichen wie Recht und Infrastrukturautomatisierung (z.B. JARVIS von Cisco). (Quelle: qdrant_engine, OpenAIDevs, jerryjliu0, dzhng, Reddit r/ClaudeAI, omarsar0)

Sicherheitsstandards für humanoide Roboter im Fokus, müssen physische und psychische Auswirkungen berücksichtigen : Mit dem schrittweisen Einzug humanoider Roboter in industrielle Anwendungen und dem Ziel, sie auch in Haushalten und anderen Szenarien einzusetzen, werden ihre Sicherheitsstandards zum Diskussionsthema. Die IEEE Humanoid Robotics Research Group weist darauf hin, dass humanoide Roboter einzigartige Eigenschaften wie dynamische Stabilität besitzen und neue Sicherheitsregeln benötigen. Neben der physischen Sicherheit (z. B. Verhinderung von Stürzen, Kollisionen) müssen auch Kommunikationsherausforderungen in der Mensch-Roboter-Interaktion (z. B. Ausdruck von Absichten, Koordination mehrerer Roboter) und psychologische Auswirkungen (z. B. übermäßige Vermenschlichung führt zu überhöhten Erwartungen, emotionale Sicherheit) berücksichtigt werden. Die Standardsetzung muss Innovation und Sicherheit in Einklang bringen und die Anforderungen verschiedener Anwendungsszenarien berücksichtigen. (Quelle: MIT Technology Review, Why humanoid robots need their own safety rules)

💡 Sonstiges
Docker kündigt an, dass docker run --gpus jetzt AMD GPUs unterstützt : Docker hat offiziell bekannt gegeben, dass der Befehl docker run --gpus nun auch die Ausführung auf AMD GPUs unterstützt. Diese Verbesserung erleichtert die Nutzung von AMD GPUs in containerisierten AI/ML-Workloads und ist ein positiver Schritt zur Förderung der Anwendung von AMD im KI-Ökosystem. (Quelle: dylan522p)
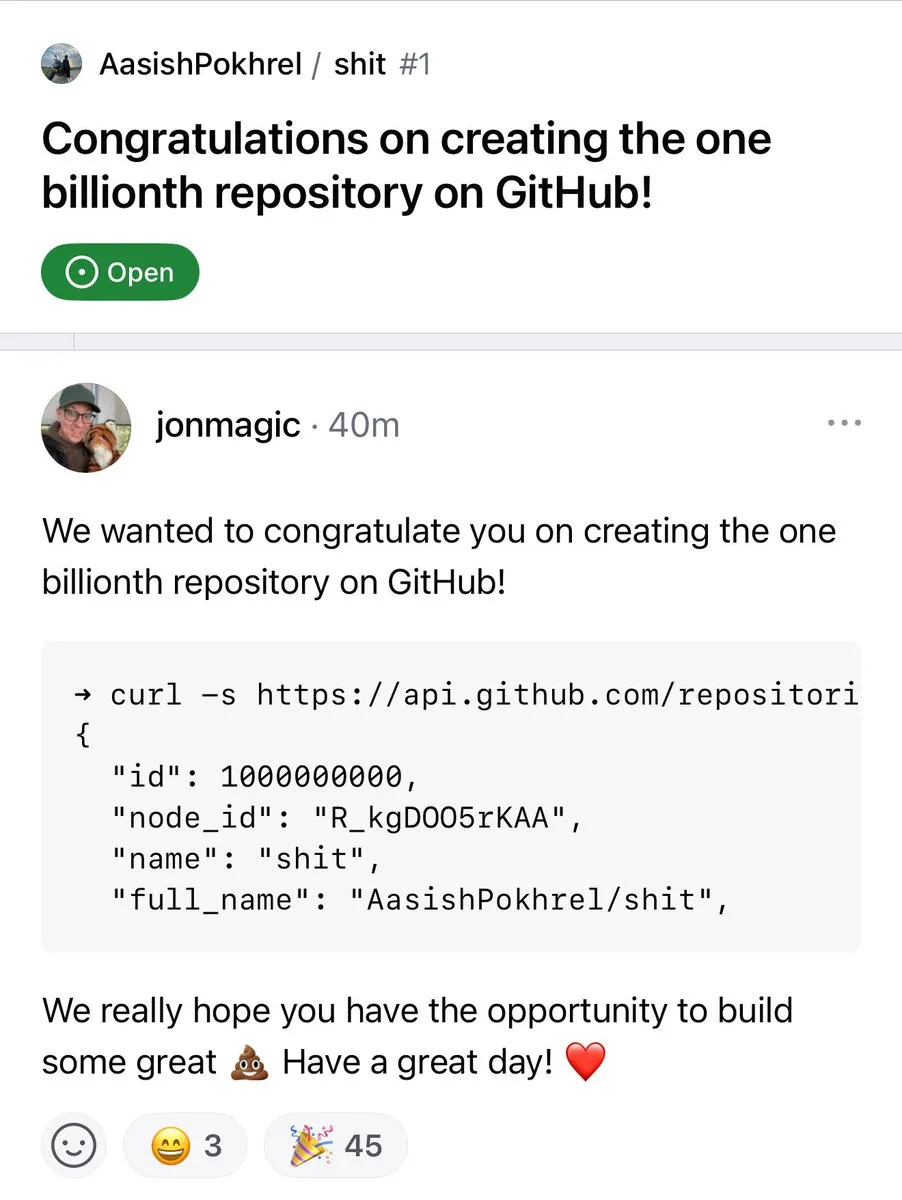
Anzahl der GitHub-Repositories überschreitet 1 Milliarde : Die Anzahl der Code-Repositories auf der GitHub-Plattform hat offiziell die Marke von 1 Milliarde überschritten. Dieses Meilensteinereignis kennzeichnet das anhaltende Wachstum und die Prosperität der Open-Source-Community und der Code-Hosting-Plattformen. (Quelle: karminski3, zacharynado)
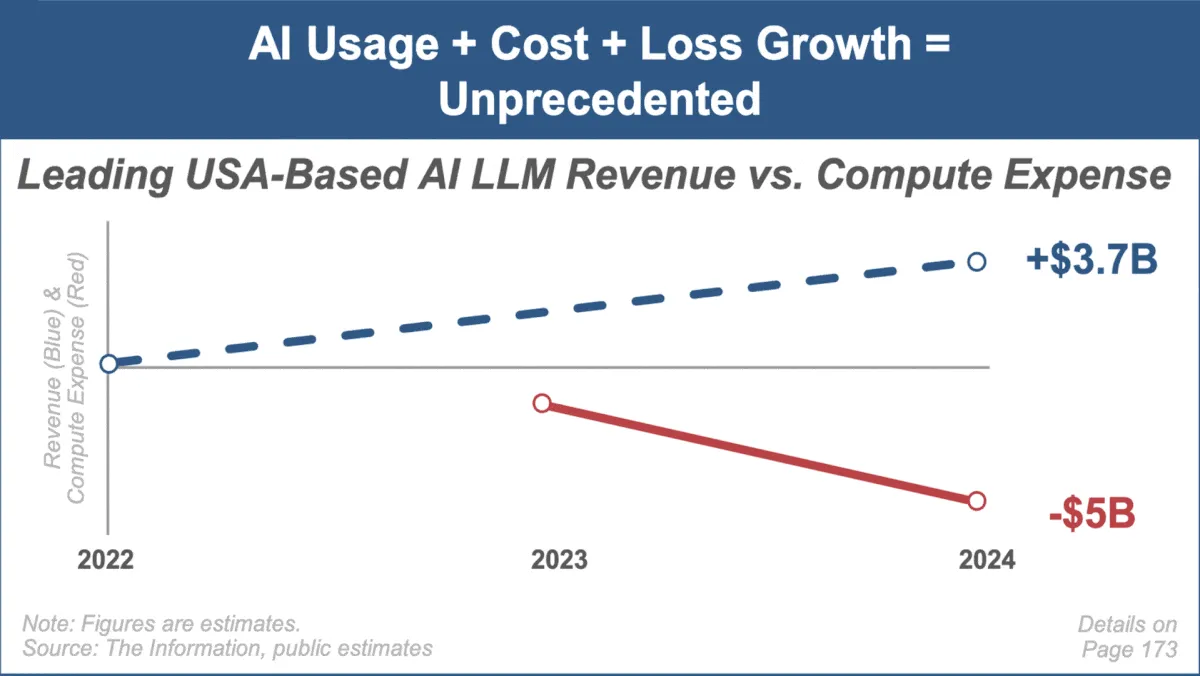
Mary Meeker veröffentlicht neuesten KI-Trendbericht, fokussiert auf schnelles Marktwachstum und Herausforderungen : Die bekannte Investmentanalystin Mary Meeker hat ihren ersten Trendbericht zum Thema Künstliche Intelligenz veröffentlicht: „Trends — Artificial Intelligence (May ‘25)“. Der Bericht hebt das beispiellose Wachstum im KI-Bereich hervor, den rasanten Anstieg der Nutzerzahlen (z. B. 800 Millionen Nutzer bei ChatGPT), die deutliche Zunahme der KI-bezogenen Investitionsausgaben sowie die kontinuierlichen Durchbrüche bei Leistung und neuen Fähigkeiten der KI. Gleichzeitig weist der Bericht auf die Herausforderungen für KI-Geschäftsmodelle hin, wie steigende Rechenkosten, schnelle Modelliterationen und die Konkurrenz durch Open-Source-Alternativen. (Quelle: DeepLearning.AI Blog)