
Schlüsselwörter:DeepSeek, OpenAI, Inferenzmodell, Multimodales Großmodell, Verstärkungslernen, KI-Innovation, Open-Source-Modell, DeepSeek R1 Inferenzmodell, OpenAI o4 Verstärkungslernen Training, Multimodales Großmodell menschliche Denklandkarte, Mistral AI Magistral Serie, Xiaohongshu dots.llm1 MoE-Modell
🔥 Fokus
DeepSeek und OpenAI’s Innovationspfade enthüllen „kognitive Innovation“: DeepSeek erreicht durch „begrenztes Scaling Law“, Innovationen in MLA- und MoE-Architekturen sowie Software-Hardware-Kooptimierung niedrige Kosten und hohe Leistung. Die Open-Source-Veröffentlichung seines R1-Inferenzmodells treibt den Durchbruch bei den kognitiven Fähigkeiten der KI voran und durchbricht den „Gedankenstempel“ chinesischer Innovatoren im Bereich der Grundlagenforschung. Dies beweist die weltweit führende Stärke chinesischer Unternehmen in der KI-Grundlagenforschung und Modellinnovation. OpenAI hingegen führte mit der Transformer-Architektur und der extremen Anwendung des Scaling Law (Skalierungsgesetz) die Revolution der großen Sprachmodelle an und trieb durch ChatGPT und das Inferenzmodell o1 den Wandel des Mensch-Maschine-Interaktionsparadigmas sowie den Sprung der kognitiven Fähigkeiten der KI voran. Die Entwicklungspfade beider Unternehmen betonen das tiefe Verständnis und die strategische Neugestaltung des technologischen Kerns und liefern wertvolle Ideen für den Organisationsaufbau und die Innovation für Unternehmer im KI-Zeitalter. Insbesondere das von DeepSeek geförderte AI Lab-Paradigma, das „Emergenz“ unterstützt, bietet eine neue Referenz für Organisationsmodelle für technologiegetriebene Unternehmer (Quelle: 36氪)
OpenAI trainiert Berichten zufolge neues Modell o4, Reinforcement Learning gestaltet KI-Landschaft neu: SemiAnalysis berichtet, dass OpenAI ein neues Modell trainiert, das zwischen GPT-4.1 und GPT-4.5 angesiedelt ist. Das Inferenzmodell der nächsten Generation, o4, wird auf Basis von GPT-4.1 mittels Reinforcement Learning (RL) trainiert. RL erschließt durch die Generierung von CoT (Chain of Thought) die Inferenzfähigkeiten von Modellen und treibt die Entwicklung von KI-Agenten voran. Es stellt jedoch extrem hohe Anforderungen an die Infrastruktur (insbesondere Inferenz) und das Design von Belohnungsfunktionen und ist anfällig für das Phänomen des „Reward Hacking“. Hochwertige Daten sind der Schlüssel zur Skalierung von RL, wobei Nutzerverhaltensdaten zu einem wichtigen Aktivposten werden. RL verändert auch die Organisationsstruktur von Laboren, indem es Inferenz und Training tief miteinander verbindet. Im Gegensatz zum Pre-Training kann RL die Modellfähigkeiten kontinuierlich aktualisieren, wie bei DeepSeek R1. Für kleinere Modelle könnte Destillation RL überlegen sein. Diese Enthüllungsrunde deutet darauf hin, dass der KI-Bereich, insbesondere bei Inferenzmodellen, eine kontinuierliche Evolution und einen Fähigkeitssprung auf Basis von RL erleben wird (Quelle: 36氪)
Multimodale große Modelle bilden spontan „menschliche Denkkarten“: Ein gemeinsames Team des Instituts für Automatisierung der Chinesischen Akademie der Wissenschaften und des Exzellenzzentrums für Hirnforschung und Intelligente Technologie hat durch Verhaltensexperimente und neurobildgebende Analysen bestätigt, dass multimodale große Sprachmodelle (MLLMs) spontan ein System zur Repräsentation von Objektkonzepten bilden können, das dem menschlichen System stark ähnelt. Die Studie erstellte erstmals eine „Konzeptkarte“ von KI-Modellen durch die Analyse von 4,7 Millionen Verhaltensurteilsdaten aus „Drei-wählen-eins-Ausreißer-Erkennungsaufgaben“. Zu den wichtigsten Ergebnissen gehören: KI-Modelle unterschiedlicher Architekturen können zu ähnlichen niedrigdimensionalen kognitiven Strukturen konvergieren; Modelle zeigen unter unüberwachten Bedingungen emergente Fähigkeiten zur Klassifizierung von Objektkonzepten auf hohem Niveau, die mit der menschlichen Kognition übereinstimmen; die „Denkdimensionen“ von KI-Modellen können mit semantischen Labels wie Tier, Nahrung, Härte usw. versehen werden; die Repräsentationen von MLLMs korrelieren signifikant mit den neuronalen Aktivitätsmustern bestimmter Gehirnbereiche (wie FFA, PPA) und liefern Beweise für „gemeinsame Konzeptverarbeitungsmechanismen von KI und Mensch“. Die Studie liefert neue Ansätze zum Verständnis der KI-Kognition, zur Entwicklung gehirnähnlicher Intelligenz und für Brain-Computer-Interfaces (Quelle: 量子位)

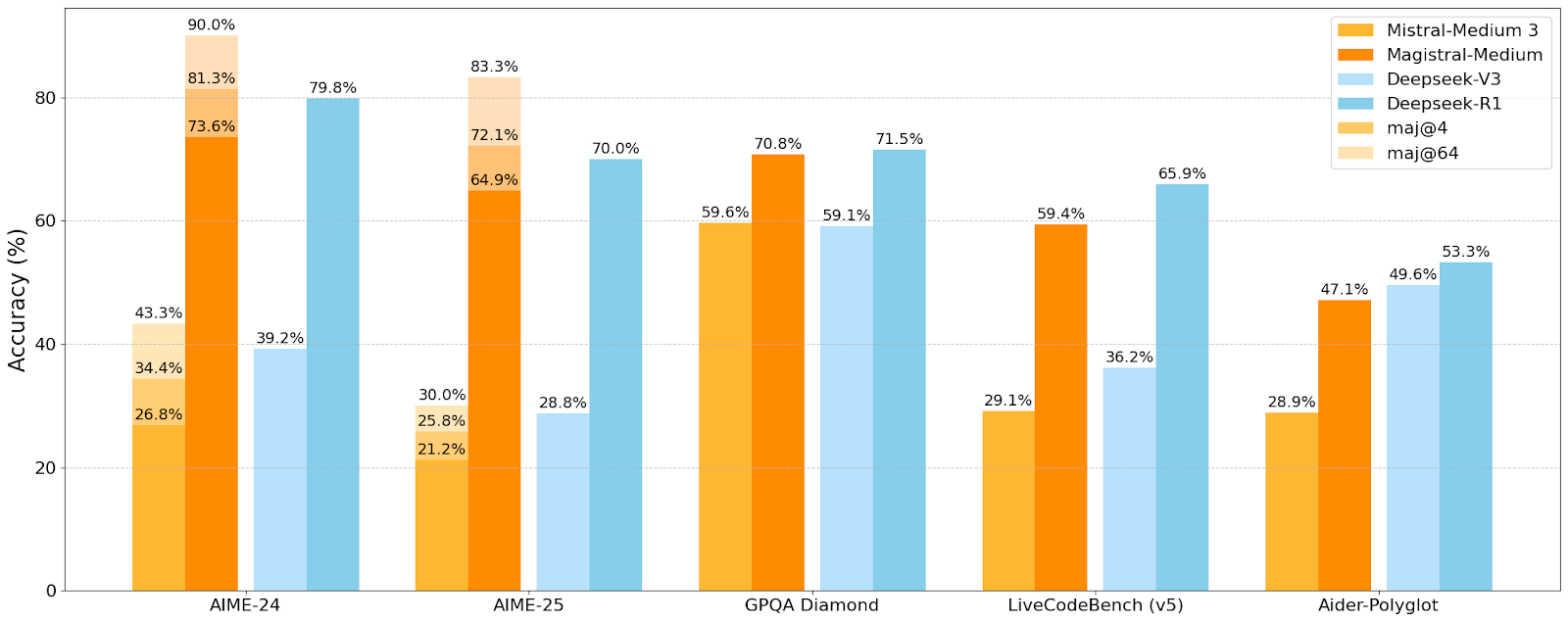
Mistral AI veröffentlicht erste Inferenzmodellreihe Magistral, kleines Modell Magistral-Small ist Open Source: Mistral AI hat seine erste speziell für Inferenz entwickelte Modellreihe Magistral vorgestellt, die Magistral-Small und Magistral-Medium umfasst. Magistral-Small basiert auf Mistral Small 3.1 (2503) und ist ein effizientes 24B-Parameter-Inferenzmodell, das durch SFT- und RL-Training anhand der Trajektorien von Magistral Medium in seinen Inferenzfähigkeiten verbessert wurde. Das Modell unterstützt mehrere Sprachen, hat ein Kontextfenster von 128k (empfohlener effektiver Kontext 40k), ist unter der Apache 2.0 Lizenz Open Source und kann lokal auf einer einzelnen RTX 4090 oder einem MacBook mit 32GB RAM (nach Quantisierung) ausgeführt werden. Benchmark-Tests zeigen, dass Magistral-Small bei Aufgaben wie AIME24, AIME25, GPQA Diamond und Livecodebench (v5) hervorragend abschneidet und einigen größeren Modellen nahekommt oder sie sogar übertrifft. Magistral-Medium ist leistungsstärker, aber derzeit nicht Open Source. Diese Veröffentlichung markiert Fortschritte von Mistral bei der Verbesserung der Modellinferenzfähigkeiten und der Mehrsprachigkeitsunterstützung (Quelle: Reddit r/LocalLLaMA, Mistral AI, X)
🎯 Trends
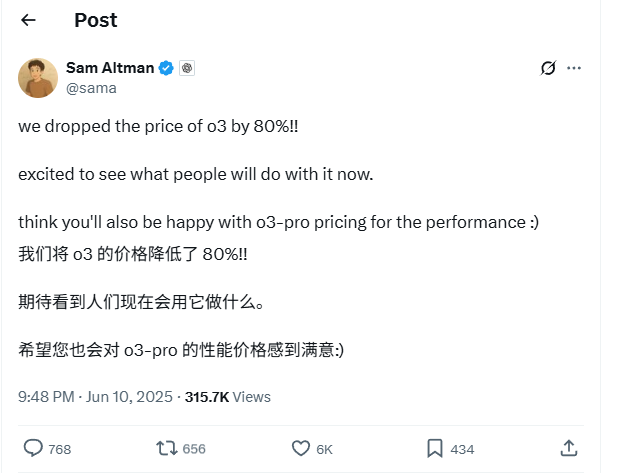
OpenAI o3 Modell API-Preise um 80% gesenkt: OpenAI CEO Sam Altman kündigte an, dass die API-Preise für das o3-Modell um 80% gesenkt wurden. Nach der Anpassung beträgt der Preis für Input 2 US-Dollar/Million Token und für Output 8 US-Dollar/Million Token (einige Quellen nennen 5 US-Dollar/Million Token für Output, offizielle Dokumentation ist maßgebend). Diese drastische Preissenkung reduziert die Kosten für Aufgaben wie das Schreiben von Code mit dem o3-Modell erheblich und wird voraussichtlich zu einer breiteren Anwendung und Innovation führen. Nutzer sollten beachten, dass die Preisliste auf der offiziellen Website möglicherweise noch nicht aktualisiert ist und es ratsam ist, vor API-Aufrufen Tests durchzuführen, um den tatsächlich geltenden Preis zu bestätigen und unnötige Verluste zu vermeiden. Dieser Schritt wird als Strategie zur Bewältigung des Marktwettbewerbs (z.B. Gemini 2.5 Pro und Claude 4 Sonnet) angesehen und könnte darauf hindeuten, dass die Kosten für KI-Intelligenz weiter sinken werden (Quelle: X, X, X)
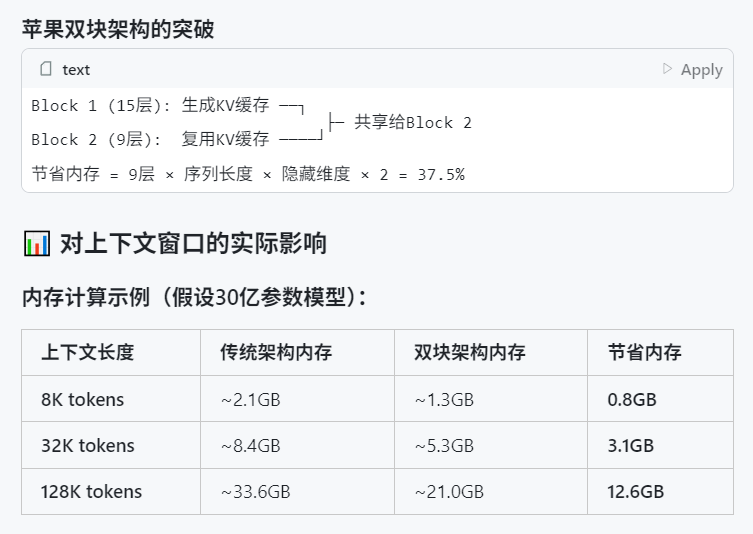
Apples WWDC 2025 angeblich mit wenig KI-Fokus, aber technische Details zeigen Ambitionen: Auf der Worldwide Developers Conference (WWDC) 2025 schien Apple weniger Wert auf KI zu legen als erwartet, doch technische Dokumente enthüllen tiefgreifende Investitionen in On-Device- und Cloud-Modelle. Apple setzt fortschrittliche Trainings-, Destillations- und Quantisierungstechniken ein, darunter eine „Dual-Block-Architektur“ für mobile Modelle (ca. 3B Parametergröße) zur Reduzierung des Speicherbedarfs und eine „PT-MoE“ (Parallel Track Mixture of Experts) Architektur für serverseitige Modelle. Diese Technologien zielen darauf ab, die Inferenz mit geringer Latenz auf Apple-Chips zu optimieren und den Speicherverbrauch des KV-Cache zu reduzieren. Obwohl einige Stimmen Apple im KI-Bereich als rückständig betrachten, zeigen seine Erfolge in der Modelltechnologie (wie Open-Source-Embedding-Modelle) und der Fokus auf andere Prioritäten (wie On-Device-Intelligenz statt nur Chatbots) eine einzigartige KI-Strategie. Auf der WWDC wurde auch angekündigt, dass Safari 26 WebGPU unterstützen wird, was die Leistung von On-Device laufenden KI-Modellen (z.B. über Transformers.js) erheblich verbessern wird, beispielsweise die Generierungsgeschwindigkeit von Untertiteln für visuelle Modelle im Browser um das ca. 12-fache (Quelle: X, X, X)
Perplexity Pro Nutzer können jetzt OpenAI o3 Modell verwenden: Perplexity gab bekannt, dass seine Pro-Abonnenten nun das o3-Modell von OpenAI nutzen können. Diese Integration wird Perplexity Pro-Nutzern leistungsfähigere Informationsverarbeitungs- und Frage-Antwort-Funktionen bieten. Gleichzeitig testet Perplexity seine „Memory“-Funktion und hat den iOS-Sprachassistenten aktualisiert, um eine prägnantere und praktischere Benutzererfahrung zu bieten. Die Discover-Artikelfunktion ist standardmäßig auf den prägnanteren „Summary“-Modus eingestellt und bietet die Möglichkeit, in den ausführlichen „Report“-Modus zu wechseln (Quelle: X, X, X)

Xiaohongshu veröffentlicht erstes 142B MoE großes Modell dots.llm1, übertrifft DeepSeek-V3 in chinesischen Benchmarks: Xiaohongshu hat sein erstes großes Modell dots.llm1 als Open Source veröffentlicht. Es handelt sich um ein 142 Milliarden Parameter umfassendes MoE (Mixture of Experts) Modell, das bei der Inferenz nur 14 Milliarden Parameter aktiviert. Das Modell wurde in der Pre-Training-Phase mit 11,2 Billionen nicht-synthetischen Tokens trainiert, die hauptsächlich aus allgemeinen Web-Crawlern und eigenen Crawlern stammen. Das Xiaohongshu-Team schlug ein skalierbares dreistufiges Datenverarbeitungsframework vor und stellte es als Open Source zur Verfügung, um die Reproduzierbarkeit zu verbessern. dots.llm1 erreichte 92,2 Punkte im C-Eval und übertraf damit alle Modelle, einschließlich DeepSeek-V3. In chinesischen, englischen, mathematischen und Alignment-Aufgaben nähert es sich der Leistung von Alibabas Qwen3-32B an. Xiaohongshu hat auch Zwischen-Trainings-Checkpoints veröffentlicht, um das Verständnis der Community für die Dynamik großer Modelle zu fördern (Quelle: 36氪)
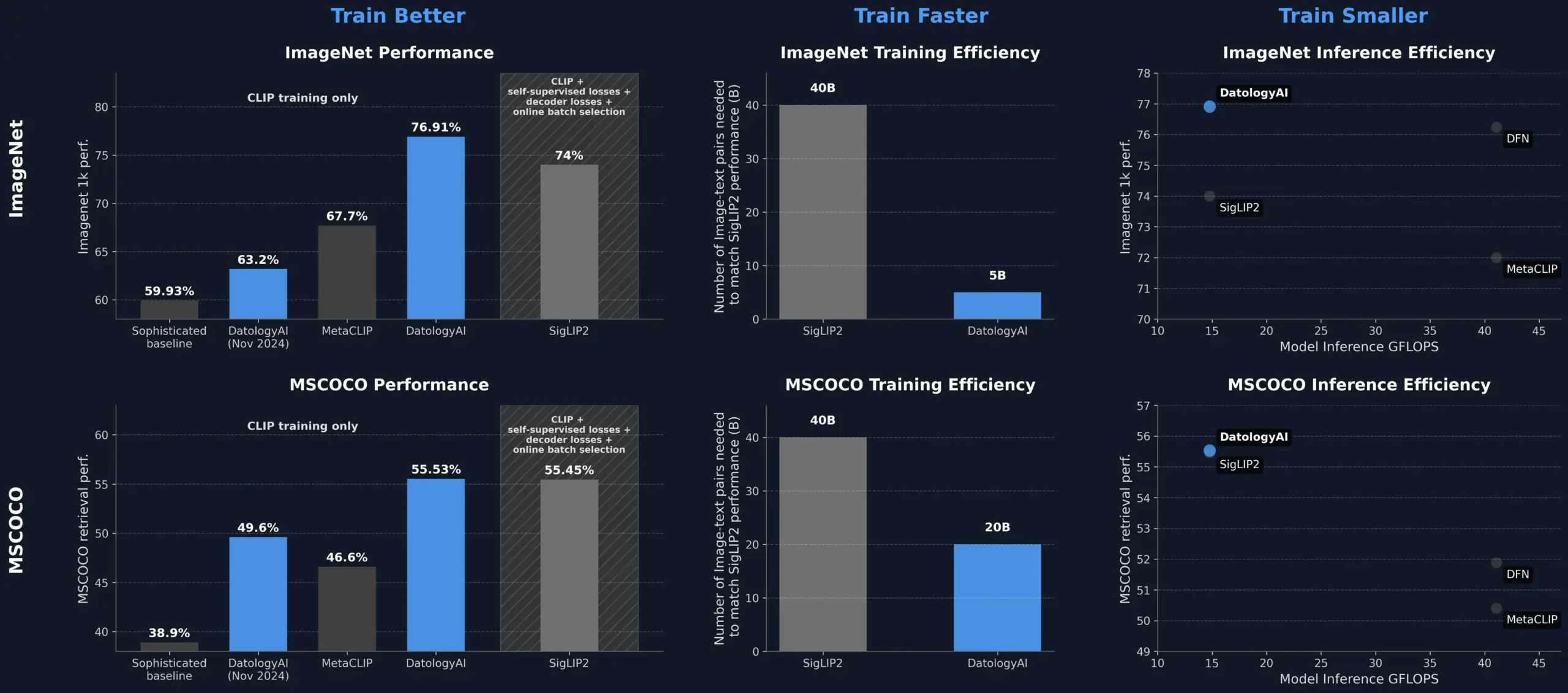
DatologyAI verbessert CLIP-Modellleistung durch Datenmanagement und übertrifft SigLIP2: DatologyAI hat gezeigt, dass allein durch Datenmanagement (Data Curation) die Leistung von CLIP-Modellen signifikant verbessert werden kann. Ihre Methode ermöglichte es dem ViT-B/32-Modell, eine Genauigkeit von 76,9% auf ImageNet 1k zu erreichen und damit die von SigLIP2 berichteten 74% zu übertreffen. Darüber hinaus führte die Methode zu einer 8-fachen Verbesserung der Trainingseffizienz und einer 2-fachen Verbesserung der Ineffizienz. Die entsprechenden Modelle wurden öffentlich zugänglich gemacht. Dies unterstreicht die zentrale Rolle hochwertiger, sorgfältig verwalteter Datensätze beim Training fortschrittlicher KI-Modelle, bei denen selbst ohne Änderung der Modellarchitektur durch Datenoptimierung das Modellpotenzial ausgeschöpft werden kann (Quelle: X, X)
Kuaishou und Northeastern University schlagen gemeinsames multimodales Embedding-Framework UNITE vor: Um das Problem der Interferenz zwischen verschiedenen Modalitäten (Text, Bild, Video) aufgrund unterschiedlicher Datenverteilungen bei der multimodalen Suche zu lösen, haben Forscher von Kuaishou und der Northeastern University das multimodale einheitliche Embedding-Framework UNITE vorgeschlagen. Dieses Framework verwendet einen „Modalitäts-bewussten maskierten kontrastiven Lernmechanismus“ (MAMCL), der beim kontrastiven Lernen nur negative Beispiele berücksichtigt, die mit der Zielmodalität der Anfrage übereinstimmen, um falschen Wettbewerb zwischen Modalitäten zu vermeiden. UNITE verwendet ein zweistufiges Training aus „Retrieval-Anpassung + Instruktions-Feinabstimmung“ und erzielt in mehreren Benchmarks wie Bild-Text-Retrieval, Video-Text-Retrieval und Instruktions-Retrieval SOTA-Ergebnisse. So übertrifft es beispielsweise im MMEB Benchmark Modelle größeren Maßstabs und ist auf CoVR deutlich überlegen. Die Studie betont die Kernfähigkeit von Video-Text-Daten in einheitlichen Modalitäten und weist darauf hin, dass Instruktionsaufgaben stärker von textdominierten Daten abhängen (Quelle: 量子位)

NVIDIA veröffentlicht Earth-2 Klimasimulations-KI-Basismodell: NVIDIAs Earth-2 Plattform hat ein neues KI-Basismodell vorgestellt, das das globale Klima mit kilometergenauer Auflösung simulieren kann. Das Modell zielt darauf ab, schnellere und genauere Klimavorhersagen zu liefern und eröffnet neue Wege zum Verständnis und zur Vorhersage der komplexen natürlichen Systeme der Erde. Dieser Schritt markiert einen wichtigen Fortschritt in der Anwendung von KI in der Klimawissenschaft und der Modellierung von Erdsystemen und verspricht, die Klimawandelforschung und die Katastrophenwarnfähigkeit zu verbessern (Quelle: X)

OpenAI-Dienste von weitreichendem Ausfall betroffen, ChatGPT und API beeinträchtigt: Die ChatGPT-Dienste und API-Schnittstellen von OpenAI erlebten am Abend des 10. Juni Pekinger Zeit einen weitreichenden Ausfall, der sich durch erhöhte Fehlerraten und Latenzen äußerte. Viele Nutzer berichteten, dass sie nicht auf die Dienste zugreifen konnten oder Fehlermeldungen wie „Hmm…something seems to have gone wrong“ erhielten. Die offizielle Statusseite von OpenAI bestätigte das Problem und gab an, dass Ingenieure die Ursache lokalisiert hätten und an einer dringenden Behebung arbeiteten. Dieser Ausfall betraf weltweit eine große Anzahl von Nutzern und Anwendungen, die auf ChatGPT und dessen API angewiesen sind, und unterstreicht erneut die Bedeutung der Stabilität großer KI-Dienste (Quelle: X, Reddit r/ChatGPT, Reddit r/ChatGPT)
🧰 Tools
Model Context Protocol (MCP) Server-Ökosystem wächst kontinuierlich: Das Model Context Protocol (MCP) zielt darauf ab, großen Sprachmodellen (LLM) einen sicheren und kontrollierbaren Zugriff auf Tools und Datenquellen zu ermöglichen. Das GitHub-Repository modelcontextprotocol/servers versammelt Referenzimplementierungen von MCP und von der Community erstellte Server und zeigt deren vielfältige Anwendungen. Offizielle und Drittanbieter-Server decken Dateisysteme, Git-Operationen, Datenbankinteraktionen (wie PostgreSQL, MySQL, MongoDB, Redis, ClickHouse, Cassandra usw.), Cloud-Dienste (AWS, Azure, Cloudflare), API-Integrationen (GitHub, GitLab, Slack, Google Drive, Stripe, PayPal), Suche (Brave, Algolia, Exa, Tavily), Codeausführung, Aufrufe von KI-Modellen (Replicate, ElevenLabs) und viele andere Bereiche ab. Das MCP-Ökosystem entwickelt sich rasant, mit über 130 offiziellen und Community-Servern. Es sind auch Entwicklungsframeworks wie EasyMCP, FastMCP, MCP-Framework und Verwaltungstools wie MCP-CLI, MCPM entstanden, die darauf abzielen, die Hürde für LLMs beim Zugriff auf externe Tools und Daten zu senken und die Entwicklung von AI Agents voranzutreiben (Quelle: GitHub Trending)
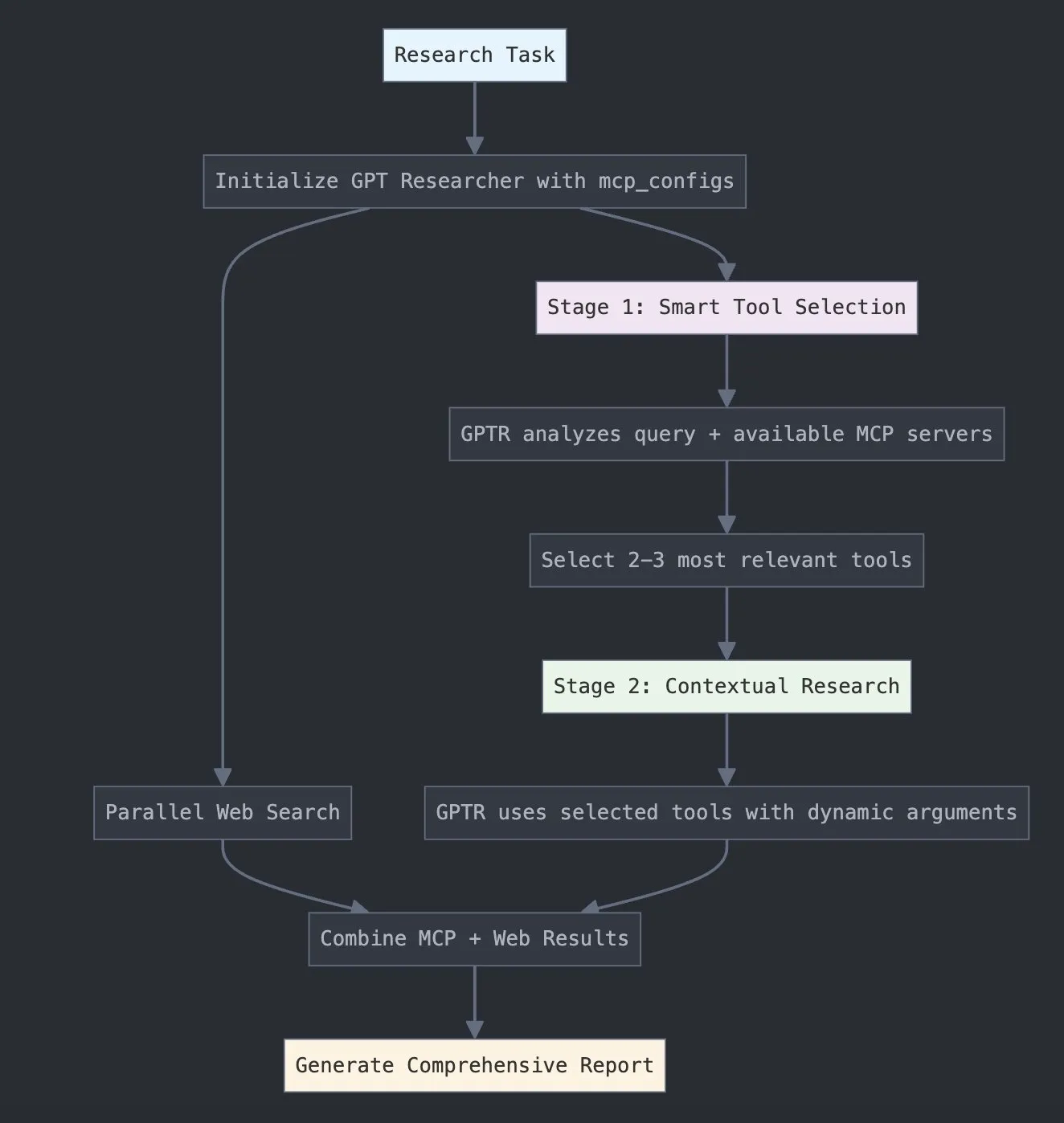
LangChain führt GPT Researcher MCP ein, um Forschungskapazitäten zu erweitern: LangChain gab bekannt, dass GPT Researcher nun seinen Model Context Protocol (MCP) Adapter nutzt, um intelligente Werkzeugauswahl und Forschung zu ermöglichen. Diese Integration kombiniert MCP mit Websuchfunktionen und zielt darauf ab, Nutzern umfassendere Datenerfassungs- und Analysefähigkeiten zu bieten, wodurch die Anwendungstiefe und -breite von KI im Forschungsbereich weiter verbessert wird (Quelle: X)
Hugging Face veröffentlicht Vui: 100M Open-Source NotebookLM, realisiert menschenähnliche TTS: Auf Hugging Face wurde Vui veröffentlicht, ein Open-Source NotebookLM-Projekt mit 100 Millionen Parametern, das drei Modelle umfasst: Vui.BASE (ein Basismodell, das auf 40.000 Stunden Audiokonversationen trainiert wurde), Vui.ABRAHAM (ein Einzelsprechermodell mit kontextbezogener Wahrnehmungsfähigkeit) und Vui.COHOST (ein Modell, das Zwei-Personen-Gespräche führen kann). Vui kann Stimmen klonen, Atmung, Ähs und andere Füllwörter und sogar nicht-sprachliche Geräusche imitieren, was einen neuen Fortschritt in der menschenähnlichen Text-to-Speech (TTS)-Technologie darstellt (Quelle: X, X)
Consilium: Open-Source-Plattform für Multi-Agenten-Kollaboration zur Lösung komplexer Probleme: Auf Hugging Face wurde das Projekt Consilium vorgestellt, eine Open-Source-Plattform für die Zusammenarbeit mehrerer Agenten. Benutzer können ein Team von Experten-KI-Agenten zusammenstellen, die durch Debatten und Echtzeitrecherchen (Web, arXiv, SEC-Dokumente) gemeinsam komplexe Probleme lösen und einen Konsens erzielen. Der Benutzer legt die Strategie fest, und das Agententeam ist für die Suche nach Antworten zuständig, was neue Wege für KI in der kollaborativen Problemlösung aufzeigt (Quelle: X)
Unsloth veröffentlicht optimiertes GGUF-Modell von Magistral-Small-2506: Nach der Veröffentlichung des Inferenzmodells Magistral-Small-2506 durch Mistral AI hat Unsloth schnell eine optimierte Version im GGUF-Format herausgebracht, die für Plattformen wie llama.cpp, LMStudio und Ollama geeignet ist. Diese schnelle Reaktion spiegelt die Vitalität und Effizienz der Open-Source-Community bei der Modelloptimierung und -bereitstellung wider und ermöglicht es, dass neue Modelle schneller von einer breiteren Nutzer- und Entwicklerbasis eingesetzt werden können (Quelle: X)
📚 Lernen
Neues Paper untersucht Reinforcement Learning Pre-Training (RPT) Paradigma: Ein neues Paper mit dem Titel „Reinforcement Pre-Training (RPT)“ schlägt vor, die Vorhersage des nächsten Tokens als eine Aufgabe des Inferierens mittels RLVR (Reinforcement Learning with Verifiable Rewards) neu zu konzipieren. RPT zielt darauf ab, die Genauigkeit der Sprachmodellvorhersage durch Anreize für die Inferenzfähigkeit des nächsten Tokens zu verbessern und eine starke Grundlage für anschließendes Reinforcement Fine-Tuning zu schaffen. Die Forschung zeigt, dass eine Erhöhung des Trainingsaufwands die Vorhersagegenauigkeit kontinuierlich verbessert, was darauf hindeutet, dass RPT ein effektives und vielversprechendes Erweiterungsparadigma für das Pre-Training von Sprachmodellen ist (Quelle: HuggingFace Daily Papers, X)

Paper schlägt Cartridges vor: Leichtgewichtige Langkontext-Repräsentationen durch Selbststudium: Ein Paper mit dem Titel „Cartridges: Lightweight and general-purpose long context representations via self-study“ untersucht eine Methode zur Verarbeitung langer Texte durch Offline-Training kleiner KV-Caches (genannt Cartridges), um das Einbringen des gesamten Korpus in das Kontextfenster während der Inferenz zu ersetzen. Die Studie ergab, dass durch „Selbststudium“ (Generierung synthetischer Dialoge über den Korpus und Training mit einem Kontext-Destillationsziel) trainierte Cartridges eine vergleichbare Leistung wie ICL (In-Context Learning) bei deutlich geringerem Speicherverbrauch (Reduktion um das 38,6-fache) und höherem Durchsatz (Steigerung um das 26,4-fache) erzielen können. Sie können zudem die effektive Kontextlänge des Modells erweitern und sogar die korpusübergreifende Kombination ohne Neutraining unterstützen (Quelle: HuggingFace Daily Papers, X)

Paper untersucht Group Contrastive Policy Optimization (GCPO) für LLMs bei der Lösung geometrischer Probleme: Das Paper „GeometryZero: Improving Geometry Solving for LLM with Group Contrastive Policy Optimization“ adressiert die Herausforderungen von LLMs bei der Konstruktion von Hilfslinien zur Lösung geometrischer Probleme und schlägt das GCPO-Framework vor. Dieses Framework liefert positive und negative Belohnungssignale für die Konstruktion von Hilfslinien basierend auf deren kontextueller Nützlichkeit mittels einer „Gruppen-Kontrast-Maske“ und führt eine Längenbelohnung ein, um längere Inferenzketten zu fördern. Die auf GCPO basierende GeometryZero-Modellreihe übertrifft Basismodelle in Benchmarks wie Geometry3K und MathVista mit einer durchschnittlichen Verbesserung von 4,29% und zeigt das Potenzial zur Verbesserung der geometrischen Inferenzfähigkeiten kleinerer Modelle bei begrenzter Rechenleistung (Quelle: HuggingFace Daily Papers)
Paper „The Illusion of Thinking“ untersucht Fähigkeiten und Grenzen von Inferenzmodellen anhand der Problemkomplexität: Diese Studie untersucht systematisch die Fähigkeiten, Skalierungseigenschaften und Grenzen von Large Reasoning Models (LRMs). Durch die Verwendung einer Rätselumgebung mit präzise steuerbarer Komplexität stellt die Studie fest, dass die Genauigkeit von LRMs nach Überschreiten einer bestimmten Komplexitätsschwelle vollständig zusammenbricht und unintuitive Skalierungsbeschränkungen aufweist: Der Inferenzaufwand nimmt mit zunehmender Problemkomplexität bis zu einem gewissen Grad ab, anstatt zu steigen. Im Vergleich zu Standard-LLMs schneiden LRMs bei Aufgaben geringer Komplexität schlechter ab, sind bei mittlerer Komplexität überlegen und versagen beide bei hoher Komplexität. Die Studie weist auf Einschränkungen von LRMs bei präzisen Berechnungen hin, Schwierigkeiten bei der Anwendung expliziter Algorithmen und inkonsistente Inferenz über verschiedene Skalen hinweg (Quelle: HuggingFace Daily Papers, X)
Paper untersucht Robustheitsbewertung von LLMs in ressourcenarmen Sprachen: Das Paper „Evaluating LLMs Robustness in Less Resourced Languages with Proxy Models“ untersucht die Empfindlichkeit von Large Language Models (LLMs) gegenüber Störungen (wie Angriffen auf Zeichen- und Wortebene) in ressourcenarmen Sprachen wie Polnisch. Die Studie ergab, dass durch geringfügige Zeichenmodifikationen und die Verwendung kleiner Proxy-Modelle zur Berechnung der Wortbedeutung Angriffe erstellt werden können, die die Vorhersagen verschiedener LLMs signifikant verändern. Dies deckt potenzielle Sicherheitslücken von LLMs in diesen Sprachen auf, die zur Umgehung ihrer internen Sicherheitsmechanismen genutzt werden könnten. Die Forscher haben die entsprechenden Datensätze und den Code veröffentlicht (Quelle: HuggingFace Daily Papers)
Rel-LLM: Neue Methode zur Effizienzsteigerung von LLMs bei der Verarbeitung relationaler Datenbanken: Ein Paper stellt das Rel-LLM-Framework vor, das darauf abzielt, das Problem der geringen Effizienz von Large Language Models (LLMs) bei der Verarbeitung relationaler Datenbanken zu lösen. Herkömmliche Methoden, die strukturierte Daten in Text umwandeln, führen zum Verlust wichtiger Verknüpfungen und zu redundanten Eingaben. Rel-LLM erstellt durch einen Graph Neural Network (GNN) Encoder strukturierte Graph-Prompts, die innerhalb eines Retrieval Augmented Generation (RAG) Frameworks die relationale Struktur beibehalten. Die Methode umfasst zeitlich bewusstes Subgraph-Sampling, einen heterogenen GNN-Encoder, eine MLP-Projektionsschicht zur Ausrichtung von Graph-Embeddings mit dem latenten Raum des LLM sowie die Strukturierung der Graph-Repräsentation als JSON-Graph-Prompt. Durch ein selbstüberwachtes Pre-Training-Ziel werden Graph- und Textrepräsentationen aufeinander abgestimmt. Experimente zeigen, dass die GNN-Kodierung komplexe relationale Strukturen, die bei der Textserialisierung verloren gehen, effektiv erfassen kann und strukturierte Graph-Prompts den relationalen Kontext effektiv in den Aufmerksamkeitsmechanismus des LLM einbringen können (Quelle: X)

Paper untersucht „Over-Refusal“-Problem von LLMs und Optimierungsmethode EvoRefuse: Das Paper „EVOREFUSE: Evolutionary Prompt Optimization for Evaluation and Mitigation of LLM Over-Refusal to Pseudo-Malicious Instructions“ untersucht das Problem der übermäßigen Verweigerung (Over-Refusal) von Large Language Models (LLMs) gegenüber „pseudo-bösartigen Anweisungen“ (semantisch harmlose Eingaben, die jedoch eine Verweigerung des Modells auslösen). Um die Mängel bestehender Methoden zur Anweisungsverwaltung hinsichtlich Skalierbarkeit und Diversität zu beheben, schlägt das Paper EVOREFUSE vor, eine Methode, die evolutionäre Algorithmen zur Optimierung von Prompts nutzt und vielfältige, konsistent eine Verweigerung durch LLMs hervorrufende pseudo-bösartige Anweisungen generieren kann. Darauf basierend erstellten die Forscher EVOREFUSE-TEST (ein Benchmark mit 582 Anweisungen) und EVOREFUSE-ALIGN (ein Alignment-Trainingsdatensatz mit 3000 Anweisungen und Antworten). Experimente zeigten, dass das auf EVOREFUSE-ALIGN feinabgestimmte Modell LLAMA3.1-8B-INSTRUCT seine Over-Refusal-Rate um bis zu 14,31% im Vergleich zu Modellen senkte, die auf suboptimalen Alignment-Datensätzen trainiert wurden, ohne die Sicherheit zu beeinträchtigen (Quelle: HuggingFace Daily Papers)
💼 Wirtschaft
Zhongke Wenge schließt neue strategische Finanzierungsrunde ab, Investment durch Industriefonds des Bezirks Shijingshan, Peking: Der KI-Dienstleister für Unternehmen, Zhongke Wenge, gab den Abschluss einer neuen strategischen Finanzierungsrunde bekannt. Investor ist der Modern Innovation Industry Development Fund des Bezirks Shijingshan, Peking. Die Mittel dieser Runde werden hauptsächlich für die F&E-Investitionen und die Markteinführung des selbst entwickelten Decision Intelligence Operating System (DIOS) verwendet, um die Entwicklung und kommerzielle Umsetzung von KI-Technologien auf Unternehmensebene zu beschleunigen. Zhongke Wenge wurde 2017 gegründet, das Kernteam stammt vom Institut für Automatisierung der Chinesischen Akademie der Wissenschaften und konzentriert sich auf mehrsprachiges Verständnis, multimodale Semantik und komplexe Szenarioentscheidungstechnologien für Branchen wie Medien, Finanzen, Regierung und Energie. Zuvor hatte das Unternehmen bereits über eine Milliarde Yuan von staatlich unterstützten Fonds wie China Development Bank Capital, China Internet Investment Fund und Shenzhen Capital Group erhalten (Quelle: 量子位)

Sakana AI und japanische Hokkoku Bank gehen strategische Partnerschaft ein, um regionale Finanz-KI zu fördern: Das japanische KI-Startup Sakana AI gab die Unterzeichnung eines Memorandum of Understanding (MOU) mit der in der Präfektur Ishikawa ansässigen Hokkoku Financial Holdings bekannt. Beide Parteien werden strategisch bei der Verbindung von regionalem Finanzwesen und KI zusammenarbeiten. Nach der umfassenden Partnerschaft mit der Mitsubishi UFJ Bank ist dies eine weitere Kooperation von Sakana AI mit einem Finanzinstitut. Ziel ist es, modernste KI-Technologie zur Lösung von Problemen in regionalen japanischen Gesellschaften einzusetzen, insbesondere im Finanzdienstleistungssektor. Sakana AI widmet sich der Entwicklung hochspezialisierter KI-Technologien für Finanzinstitute, und diese Zusammenarbeit könnte ein Vorbild für den KI-Einsatz bei anderen regionalen Banken in Japan setzen (Quelle: X, X)

Cohere kooperiert mit Ensemble, um seine KI-Plattform in die Gesundheitsbranche zu bringen: Das KI-Unternehmen Cohere kündigte eine Partnerschaft mit EnsembleHP (Anbieter von Gesundheitslösungen) an, um seine KI-Agentenplattform Cohere North in die Gesundheitsbranche einzuführen. Ziel beider Unternehmen ist es, durch eine sichere KI-Agentenplattform Reibungsverluste in medizinischen Verwaltungsprozessen zu reduzieren und das Patientenerlebnis in Krankenhäusern und Gesundheitssystemen zu verbessern. Dieser Schritt markiert einen wichtigen Fortschritt für Cohere bei der Förderung seiner großen Sprachmodelle und KI-Technologien in wichtigen vertikalen Branchen (Quelle: X)
🌟 Community
Ilya Sutskever in seiner Ehrendoktor-Rede an der University of Toronto: KI wird letztendlich allmächtig sein, erfordert aktive Aufmerksamkeit: OpenAI-Mitbegründer Ilya Sutskever erklärte in seiner Rede anlässlich der Verleihung des Ehrendoktortitels der Naturwissenschaften an der University of Toronto (sein vierter Abschluss an dieser Universität), dass der Fortschritt der KI dazu führen wird, dass sie „eines Tages alles tun kann, was wir tun können“, da das menschliche Gehirn ein biologischer Computer und KI ein digitales Gehirn sei. Er glaubt, dass wir uns in einer außergewöhnlichen, von KI definierten Ära befinden, in der KI die Bedeutung von Studium und Arbeit bereits tiefgreifend verändert hat. Er betonte, dass es besser sei, durch die Nutzung und Beobachtung führender KI Intuition zu entwickeln und ihre Fähigkeitsgrenzen zu verstehen, anstatt sich Sorgen zu machen. Er rief dazu auf, die Entwicklung der KI zu beobachten und sich aktiv den damit verbundenen enormen Herausforderungen und Chancen zu stellen, da KI das Leben jedes Einzelnen tiefgreifend beeinflussen werde. Er teilte auch seine persönliche Einstellung: „Die Realität akzeptieren, die Vergangenheit nicht bereuen, sich bemühen, die Gegenwart zu verbessern.“ (Quelle: X, 36氪)
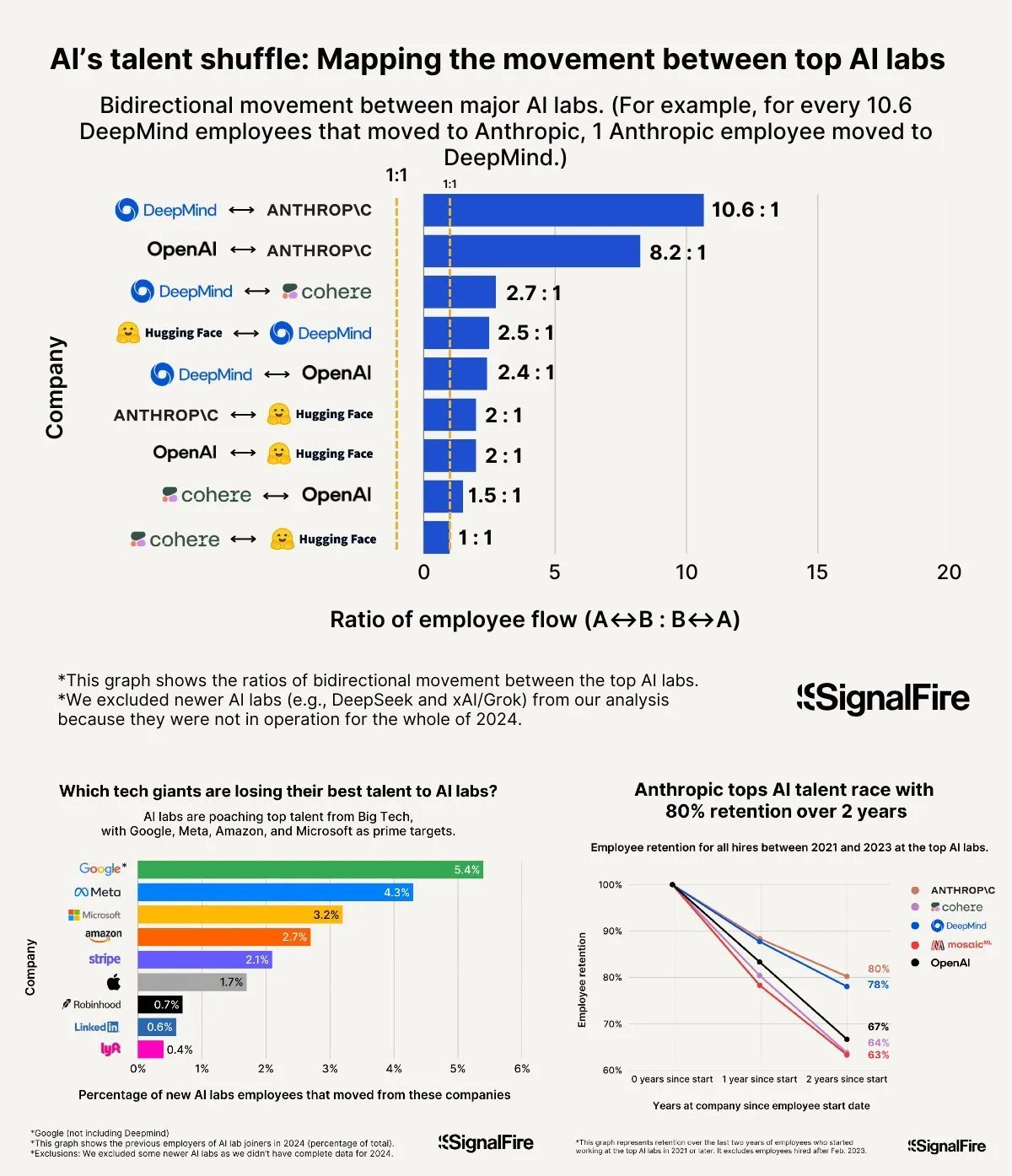
Wettlauf um KI-Talente verschärft sich: Meta kann trotz hoher Gehälter kaum mit OpenAI und Anthropic mithalten: Meta bietet Berichten zufolge Jahresgehälter von über 2 Millionen US-Dollar, um KI-Talente anzuwerben, kämpft aber dennoch mit der Abwanderung von Talenten zu OpenAI und Anthropic. Es wird diskutiert, dass das Gehalt auf OpenAI L6-Niveau bei fast 1,5 Millionen US-Dollar liegt und das Potenzial für Aktienwertsteigerungen als besser als bei Meta angesehen wird, was OpenAI in den Augen von Top-Talenten attraktiver macht. Darüber hinaus beeinflussen Vorwürfe über Betrug im Llama-Team sowie der hohe KPI-Druck und die hohe Fluktuationsrate (15-20% in diesem Jahr) bei Meta die Talententscheidungen. Anthropic hingegen ist mit einer Talentbindungsrate von rund 80% (zwei Jahre nach Gründung) eines der bevorzugten Großunternehmen für führende KI-Forscher. Die Intensität dieses Talentwettbewerbs wird als „unfassbar“ beschrieben (Quelle: X, X)
„Vibe Coding“ Erfahrungsaustausch: 5 Regeln zur Vermeidung von Fallstricken beim KI-gestützten Programmieren: In sozialen Medien teilten erfahrene Entwickler fünf Regeln, um beim „Vibe Coding“ (eine Programmiermethode, die stark auf KI-Unterstützung setzt) mit KI (wie Claude) nicht in ineffiziente Debugging-Schleifen zu geraten: 1. Three Strikes and You’re Out: Wenn die KI ein Problem nach drei Versuchen nicht beheben kann, sollte man aufhören und die KI die Anforderung von Grund auf neu erstellen lassen. 2. Kontext zurücksetzen: KI „vergisst“ nach langen Gesprächen; es wird empfohlen, alle 8-10 Nachrichtenrunden den funktionierenden Code zu speichern, eine neue Sitzung zu starten und nur die problematischen Komponenten sowie eine kurze Anwendungsbeschreibung einzufügen. 3. Problem prägnant beschreiben: Den Fehler in einem Satz klar beschreiben. 4. Häufige Versionskontrolle: Nach jeder abgeschlossenen Funktion einen Git-Commit durchführen. 5. Bei Bedarf neu anfangen: Wenn die Fehlerbehebung zu lange dauert (z.B. über 2 Stunden), ist es besser, die problematische Komponente zu löschen und die KI sie neu erstellen zu lassen. Der Kern liegt darin, entschlossen aufzugeben, wenn der Code unwiderruflich beschädigt ist. Gleichzeitig wird betont, dass Programmierkenntnisse notwendig sind, um die KI besser anzuleiten und zu debuggen (Quelle: Reddit r/LocalLLaMA, Reddit r/ClaudeAI, Reddit r/ArtificialInteligence)
Li Feifei über die Gründung von World Labs: Entstanden aus der Erforschung des Wesens der Intelligenz, räumliche Intelligenz ist der entscheidende fehlende Teil der KI: Im a16z-Podcast teilte Li Feifei die Beweggründe für die Gründung von World Labs und betonte, dass es sich nicht um ein Mitläufertum im Hype um Basismodelle handele, sondern um eine kontinuierliche Erforschung des Wesens der Intelligenz. Sie ist der Ansicht, dass Sprache zwar ein effizienter Informationsträger ist, aber Mängel bei der Repräsentation der dreidimensionalen physischen Welt aufweist. Echte allgemeine Intelligenz müsse auf dem Verständnis räumlicher Beziehungen und Objekte beruhen. Eine Hornhautverletzung, die ihr vorübergehend das stereoskopische Sehen nahm, ließ sie die Bedeutung der dreidimensionalen Raumrepräsentation für die physische Interaktion noch tiefer verstehen. World Labs zielt darauf ab, KI-Modelle (World Models, LWM) zu entwickeln, die die physische Welt wirklich verstehen und so den aktuellen Mangel an räumlicher Intelligenz in der KI beheben. Um diese Vision zu verwirklichen, seien Rechenleistung, Daten und Talente auf Industrieniveau erforderlich. Der aktuelle technologische Durchbruch liege darin, KI zu ermöglichen, aus monokularer Sicht ein vollständiges dreidimensionales Szenenverständnis zu rekonstruieren (Quelle: 量子位)

KI-gestützte Hochschulaufnahmeprüfung: Von der Kontroverse um Prüfungsvorhersagen zu Chancen und Risiken bei der Studienwahl: Vor und nach der Hochschulaufnahmeprüfung (Gaokao) löste der Einsatz von KI im Bildungsbereich breite Diskussionen aus. Einerseits wurde „KI-Prüfungsvorhersage“ zu einem heißen Thema, doch aufgrund der Wissenschaftlichkeit, Geheimhaltung und „Anti-Vorhersage“-Mechanismen der Gaokao-Prüfungsgestaltung ist eine präzise KI-Vorhersage unwahrscheinlich, und die Qualität einiger auf dem Markt befindlicher Vorhersagebögen ist bedenklich. Andererseits zeigt KI positive Auswirkungen bei der Prüfungsvorbereitungsplanung, der Erklärung von Aufgaben, der Prüfungsaufsicht und der Bewertung, wie z.B. personalisierte Lernpläne, intelligente Fragbeantwortung und KI-Aufsichtssysteme, die Fairness und Effizienz verbessern. Bei der Studienwahl können KI-Tools basierend auf Punktzahl und Rang des Kandidaten schnell Hochschulen und Studiengänge empfehlen und Informationsasymmetrien abbauen. Die übermäßige Abhängigkeit von KI bei der Studienwahl gibt jedoch Anlass zur Sorge: Algorithmen könnten Präferenzen für beliebte Studiengänge verstärken und individuelle Interessen sowie langfristige Entwicklung vernachlässigen; die vollständige Übergabe der Lebensentscheidung an Algorithmen könnte zu einer „Algorithmus-Geiselnahme des Lebens“ führen. Der Artikel ruft zu einem rationalen Umgang mit KI-Unterstützung auf und betont, Werkzeuge mit Weisheit zu nutzen und die Zukunft durch Denken zu definieren (Quelle: 36氪)
Diskussion über Erfolgsmodelle von AI Agent-Unternehmen: Self-Service vs. maßgeschneiderte Dienstleistungen: In der Community wurden Erfolgsmodelle für AI Agent-Unternehmen diskutiert. Eine Ansicht besagt, dass erfolgreiche AI Agent-Unternehmen (insbesondere im mittleren bis großen Marktsegment) oft ein ähnliches Modell wie Palantir verfolgen, d.h. viele Field Development Engineers (FDEs) und maßgeschneiderte Software, anstatt eines reinen Self-Service-Modells. Andere beharren auf dem langfristigen Wert des Self-Service-Modells und argumentieren, dass Teams letztendlich wichtige Anwendungen intern entwickeln werden. Dies spiegelt die unterschiedlichen Denkansätze im Bereich der AI Agents hinsichtlich Servicemodellen und Marktstrategien wider (Quelle: X)
💡 Sonstiges
System-Prompt von Google Diffusion enthüllt, zeigt Designprinzipien und Fähigkeitsgrenzen auf: Ein Nutzer teilte den angeblichen System-Prompt von Google Diffusion (einem Text-Diffusions-Sprachmodell). Dieser Prompt beschreibt detailliert die Identität des Modells (Gemini Diffusion, ein von Google trainiertes Experten-Text-Diffusions-Sprachmodell, nicht-autoregressiv), Kernprinzipien und Einschränkungen (z.B. Befolgung von Anweisungen, nicht-autoregressive Eigenschaften, Genauigkeit, kein Echtzeitzugriff, Sicherheitsethik, Wissensstand Dezember 2023, Fähigkeit zur Code-Generierung) sowie spezifische Anweisungen für die Generierung von HTML-Webseiten und HTML-Spielen. Diese Anweisungen umfassen Ausgabeformate, ästhetisches Design, Stile (wie die spezielle Verwendung von Tailwind CSS oder benutzerdefiniertes CSS in Spielen), Icon-Verwendung (Lucide SVG Icons), Layout und Leistung (CLS-Prävention), Kommentaranforderungen usw. Abschließend wird die Bedeutung des schrittweisen Denkens und der präzisen Befolgung von Nutzeranweisungen betont. Dieser Prompt bietet einen Einblick in die Designphilosophie und das erwartete Verhalten solcher Modelle (Quelle: Reddit r/LocalLLaMA)
Arvind Narayanan erläutert Entstehung und Überlegungen zum Paper „AI as Normal Technology“: Professor Arvind Narayanan von der Princeton University teilte den Entstehungsprozess seines gemeinsam mit Sayash Kapoor verfassten Papers „AI as Normal Technology“. Ursprünglich skeptisch gegenüber AGI und existenziellen Risiken, beschloss er auf Drängen von Kollegen, sich ernsthaft mit der Thematik auseinanderzusetzen und an entsprechenden Diskussionen teilzunehmen. Durch Reflexion erkannte er, dass Ansichten zur Superintelligenz ernst genommen werden sollten, soziale Medien für ernsthafte Diskussionen ungeeignet sind und sowohl die KI-Ethik- als auch die KI-Sicherheits-Community in ihren jeweiligen „Informationsblasen“ existieren. Der erste Entwurf des Papers wurde beim ICML abgelehnt, doch die hitzige Debatte während des Begutachtungsprozesses bestärkte sie in ihrer Absicht, die Forschung fortzusetzen. Sie erkannten, dass die Meinungsverschiedenheiten mit der KI-Sicherheits-Community tiefer waren als erwartet und dass eine produktivere, grenzüberschreitende Debatte notwendig war. Schließlich wurde das Paper auf einem Workshop des Knight First Amendment Institute der Columbia University veröffentlicht, was breite Aufmerksamkeit und fruchtbare Diskussionen auslöste und Narayanan optimistischer für die Zukunft der KI-Politik stimmte (Quelle: X)
Aufstieg der Generation Z KI-Unternehmer, die die Regeln des Unternehmertums neu gestalten: Eine Gruppe von KI-Unternehmern der Generation Z (geboren nach 2000) taucht mit erstaunlicher Geschwindigkeit in der globalen Gründungswelle auf. Mit ihrem tiefen Verständnis für KI-Technologien und ihrer scharfen Wahrnehmung der nativen digitalen Umgebung definieren sie die Regeln des Unternehmertums neu. Beispiele hierfür sind Michael Truell von Anysphere (Cursor) (in 3 Jahren vom Praktikanten zum CEO eines Multi-Milliarden-Dollar-Unternehmens), die drei Gründer von Mercor (in 2 Jahren Aufbau einer Multi-Milliarden-Dollar-KI-Recruiting-Plattform), Eric Steinberger von Magic (mit 25 Jahren Mitbegründer eines KI-Codierungsunternehmens mit über 400 Millionen US-Dollar Finanzierung) und Hong Letong von Axiom (konzentriert sich auf KI zur Lösung mathematischer Probleme, erhielt hohe Bewertungen ohne fertiges Produkt). Diese jungen Unternehmer weisen im Allgemeinen folgende Merkmale auf: Programmieren ist ihre Muttersprache; früher Ruhm, Nutzung des technologischen Dividendenfensters; scharfe Wahrnehmung der Nutzerbedürfnisse; ein KI-natives Verständnis von Organisation und Produkt, Tendenz zu minimalistischen, hocheffizienten Teams und der Logik „KI als Produkt“. Ihr Erfolg markiert einen Wandel im Paradigma des Unternehmertums im KI-Zeitalter (Quelle: 36氪)