
Schlüsselwörter:OpenAI, Meta, IBM, Mistral AI, Superintelligenz-Labor, Quantencomputer, o3-pro, Magistral, o3-pro Preisgestaltung, Scale AI Investition, Magistral-Small-2506, Starling Quantencomputer, Militärische Anwendungstests von KI
🔥 Fokus
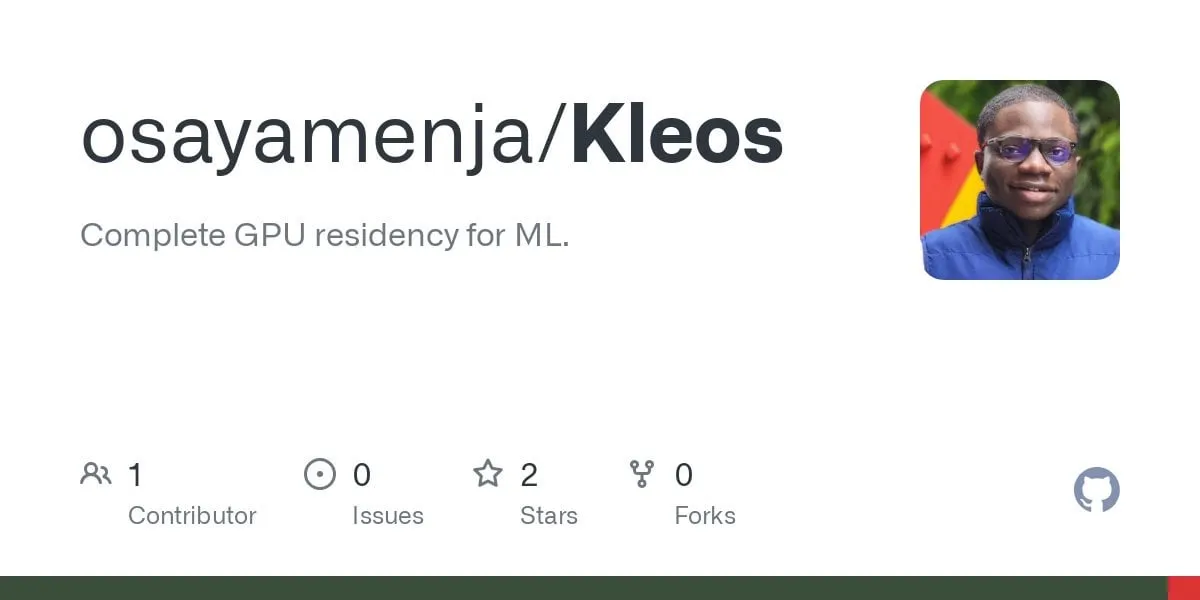
OpenAI veröffentlicht o3-pro, das als das bisher stärkste Modell bezeichnet wird, und senkt den Preis für o3 erheblich: OpenAI hat offiziell sein bisher leistungsstärkstes Inferenzmodell o3-pro vorgestellt, das bereits für ChatGPT Pro- und Team-Nutzer verfügbar ist; die API wurde ebenfalls gleichzeitig veröffentlicht. o3-pro übertrifft frühere Generationen in Bereichen wie Wissenschaft, Bildung, Programmierung, Wirtschaft und Schreibassistenz und unterstützt verschiedene Tools wie Websuche, Dateianalyse, visuelle Eingabe und Python-Programmierung. Der Preis beträgt 20 US-Dollar pro Million Tokens für die Eingabe und 80 US-Dollar für die Ausgabe. Gleichzeitig wurde der Preis des ursprünglichen o3-Modells um 80 % gesenkt, nach der Anpassung beträgt der Preis 2 US-Dollar pro Million Tokens für die Eingabe und 8 US-Dollar für die Ausgabe, was dem Niveau von GPT-4o entspricht. Dieser Schritt könnte einen Preiskampf bei KI-Modellen auslösen und die tiefgreifende Anwendung von KI in professionellen Bereichen fördern. o3-pro weist jedoch auch Einschränkungen auf, wie längere Antwortzeiten und die vorübergehende Nichtunterstützung von temporären Konversationen. (Quelle: OpenAI, sama, OpenAIDevs, scaling01, dotey)
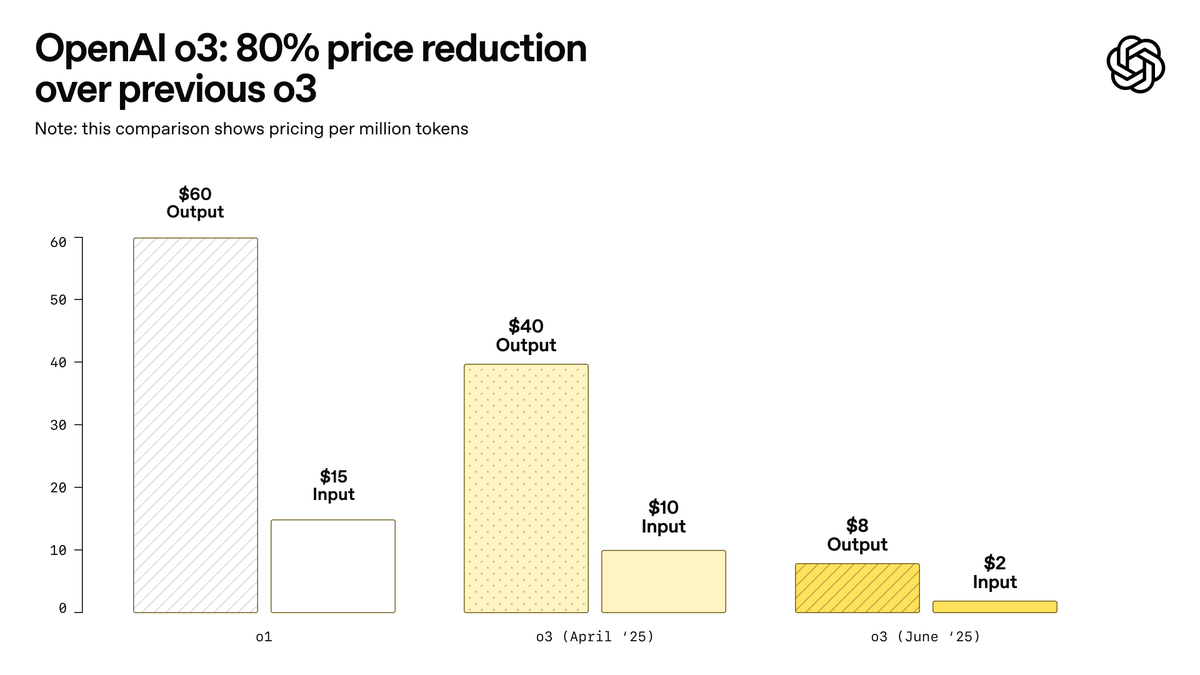
Meta gründet „Superintelligence Lab“ und investiert massiv in Scale AI, um die KI-Wettbewerbsfähigkeit wiederzubeleben: Laut Berichten der New York Times und anderer Quellen restrukturiert Meta Platforms seine KI-Abteilung, gründet ein neues „Superintelligence Lab“ und plant, über 14 Milliarden US-Dollar zu investieren, um 49 % der Anteile am Datenannotationsunternehmen Scale AI zu erwerben. Alexandr Wang, Mitbegründer und CEO von Scale AI, wird zu Meta wechseln und das neue Labor leiten. Dieser Schritt zielt darauf ab, die Forschung und Entwicklung im Bereich der allgemeinen künstlichen Intelligenz (AGI) zu beschleunigen und die allgemeine Wettbewerbsfähigkeit von Meta im KI-Bereich zu verbessern, insbesondere bei der Verarbeitung hochwertiger Daten und der Rekrutierung von Spitzenkräften. Dies markiert eine bedeutende Anpassung der KI-Strategie von Meta und könnte tiefgreifende Auswirkungen auf die Wettbewerbslandschaft der Branche haben. (Quelle: natolambert, kylebrussell, Yuchenj_UW, steph_palazzolo)

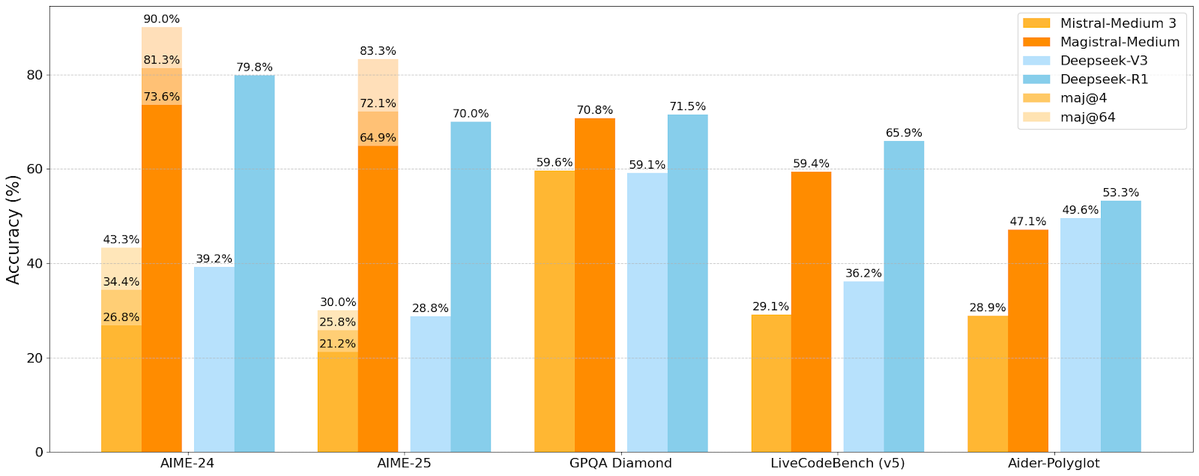
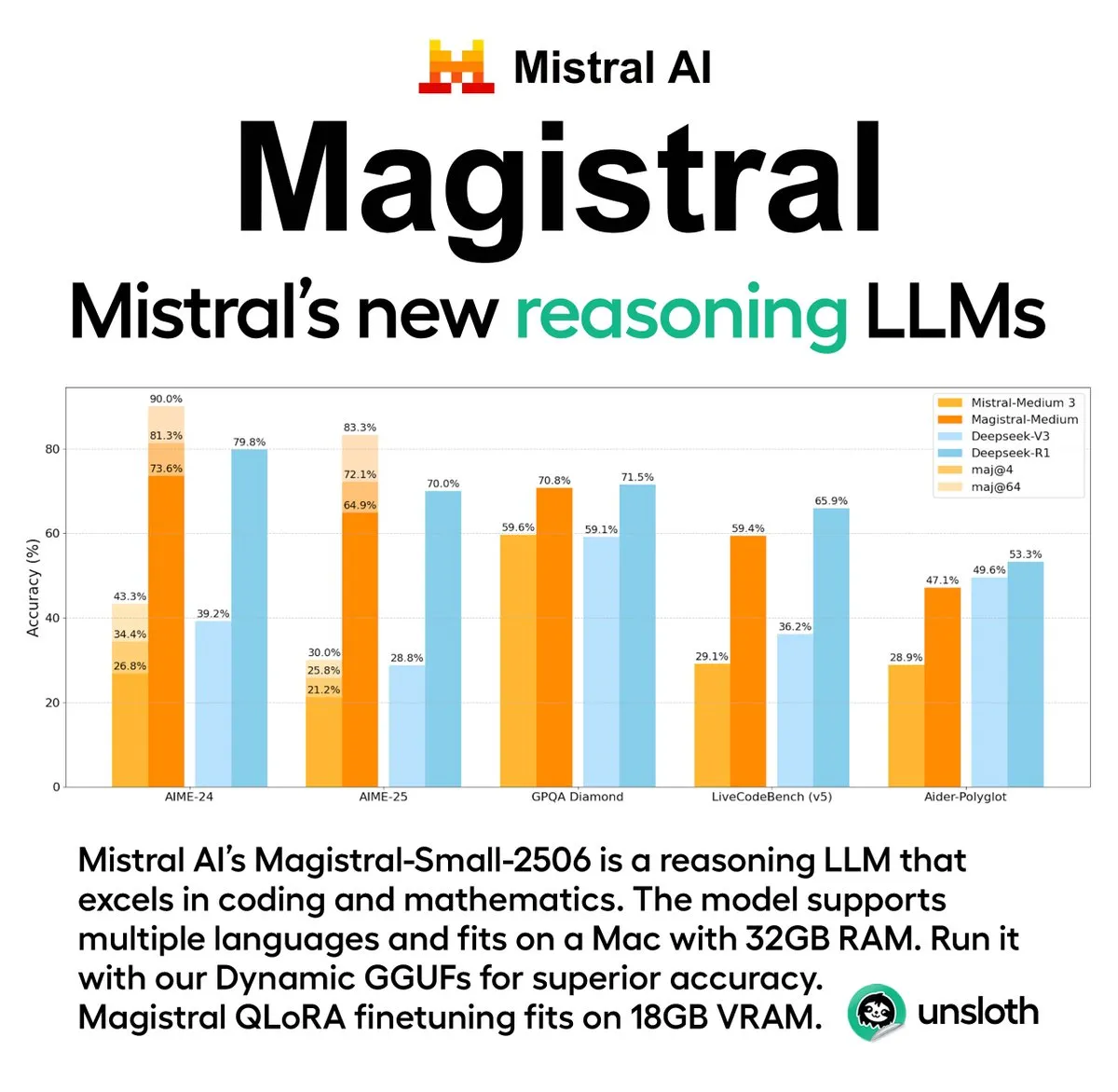
Mistral AI veröffentlicht erste Inferenzmodellreihe Magistral, einschließlich Open-Source-Version: Das französische KI-Startup Mistral AI hat seine erste speziell für Inferenz entwickelte Modellreihe Magistral vorgestellt. Die Reihe umfasst ein leistungsstärkeres, Closed-Source-Modell für Unternehmen, Magistral Medium, und ein Open-Source-Modell mit 24 Milliarden Parametern, Magistral Small (Magistral-Small-2506), das unter der Apache 2.0-Lizenz veröffentlicht wurde. Diese Modelle zeichnen sich durch hervorragende Leistungen in Mathematik, Codierung und mehrsprachiger Inferenz aus und zielen darauf ab, transparentere und domänenspezifische Inferenzfähigkeiten bereitzustellen. Magistral Medium soll auf der Le Chat-Plattform eine zehnmal schnellere Inferenzgeschwindigkeit als Wettbewerber erreichen, während Magistral Small der Community leistungsstarke Optionen für den lokalen Betrieb bietet. (Quelle: Mistral AI, jxmnop, karminski3)
IBM plant Bau eines großen fehlertoleranten Quantencomputers Starling bis 2028: IBM hat seine Roadmap für die Quantencomputerentwicklung bekannt gegeben und plant, bis 2028 einen großen fehlertoleranten Quantencomputer namens Starling zu bauen, der ab 2029 über Cloud-Dienste für Nutzer zugänglich sein soll. Das Starling-System wird voraussichtlich etwa 100 Module und 200 logische Qubits umfassen. Hauptziel ist die Realisierung einer effektiven Fehlerkorrektur, eine der größten technologischen Herausforderungen im aktuellen Quantencomputing. Die Maschine wird IBMs Low-Density Parity-Check Codes (LDPC) zur Fehlerkorrektur verwenden und eine Echtzeit-Fehlerdiagnose anstreben. Bei Erfolg wäre dies ein bedeutender Durchbruch im Quantencomputing, der dessen Anwendung bei komplexen Problemen wie Materialwissenschaft und Medikamentenentwicklung beschleunigen könnte. (Quelle: MIT Technology Review)

🎯 Trends
KI-Fortschritte auf Apples WWDC 2025 enttäuschen Entwickler nicht: Apple hat auf der WWDC 2025 mehrere Updates veröffentlicht, darunter eine brandneue Designsprache namens „Liquid Glass“ und die Integration von ChatGPT in Xcode 26. Die Entwicklergemeinschaft äußerte sich jedoch allgemein „unter den Erwartungen“ über die Fortschritte im Bereich der künstlichen Intelligenz. Obwohl Apple erstmals sein On-Device KI-Modell für Entwickler öffnete und das Foundation Models Framework zur Vereinfachung der KI-Funktionsintegration einführte, könnte das mit Spannung erwartete Update für Siri auf nächstes Jahr verschoben werden. Der Analyst Ming-Chi Kuo wies darauf hin, dass Apples KI-Strategie im Mittelpunkt stehe, es aber keine größeren technologischen Durchbrüche gegeben habe und das Erwartungsmanagement entscheidend sei. Apple scheint sich eher auf die Verbesserung der Benutzeroberfläche und der Betriebssystemfunktionen zu konzentrieren als auf disruptive Innovationen bei den KI-Modellen selbst. (Quelle: MIT Technology Review, jonst0kes, rowancheung)
Pentagon reduziert Größe des Büros für Tests und Bewertungen von KI-Waffensystemen: US-Verteidigungsminister Pete Hegseth kündigte an, die Größe des Director, Operational Test and Evaluation (DOT&E) Büros des Verteidigungsministeriums um die Hälfte zu reduzieren, von 94 auf etwa 45 Mitarbeiter. Dieses Büro ist für die Prüfung und Bewertung der Sicherheit und Wirksamkeit von Waffen und KI-Systemen zuständig. Die Anpassung zielt darauf ab, „aufgeblähte Bürokratie und verschwenderische Ausgaben zu reduzieren und die Letalität zu erhöhen“. Dieser Schritt hat Bedenken ausgelöst, dass Tests zur Sicherheit und Wirksamkeit militärischer KI-Anwendungen beeinträchtigt werden könnten, insbesondere vor dem Hintergrund, dass das Pentagon aktiv KI-Technologien (einschließlich großer Sprachmodelle) in verschiedene Militärsysteme integriert. (Quelle: MIT Technology Review)

OpenBMB veröffentlicht MiniCPM-4-Serie hocheffizienter On-Device Large Language Models: OpenBMB (Zhipu AI) hat die MiniCPM-4-Modellreihe vorgestellt, die speziell für Edge-Geräte entwickelt wurde und einen extrem effizienten Betrieb ermöglichen soll. Die Reihe umfasst MiniCPM4-0.5B, MiniCPM4-8B (Flaggschiffmodell), BitCPM4 (1-Bit-quantisiertes Modell), das speziell für die Berichterstellung entwickelte MiniCPM4-Survey sowie das MCP-spezifische Modell MiniCPM4-MCP. Der technische Bericht beschreibt detailliert die effiziente Modellarchitektur (wie den trainierbaren Sparse-Attention-Mechanismus InfLLM v2), effiziente Lernalgorithmen (wie Model Wind Tunnel 2.0) sowie Methoden zur Verarbeitung hochwertiger Trainingsdaten. Diese Modelle stehen ab sofort auf Hugging Face zum Download bereit. (Quelle: _akhaliq, arankomatsuzaki, karminski3)
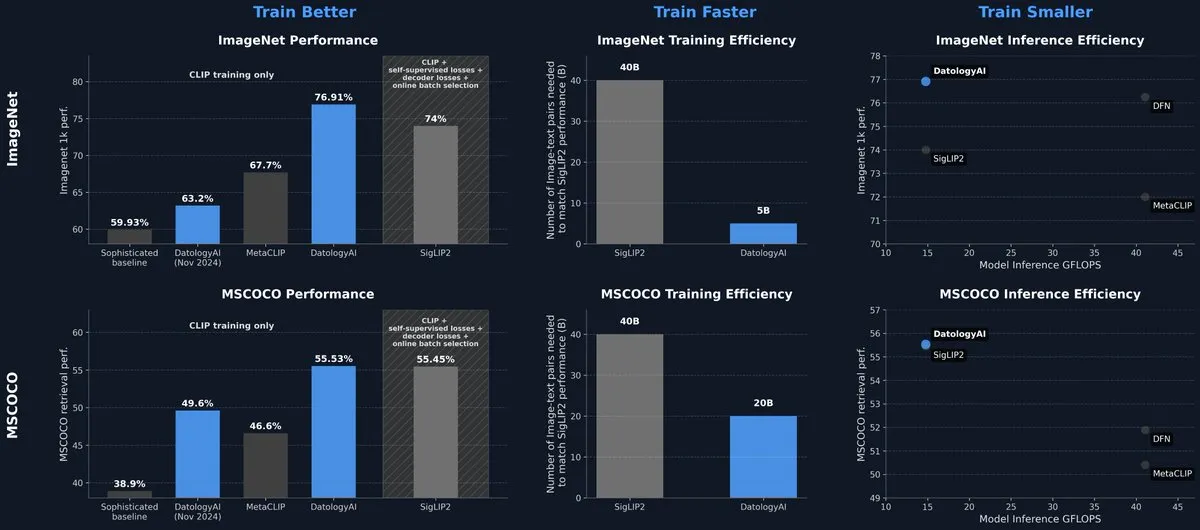
DatologyAI veröffentlicht CLIP-Modell, das SOTA-Niveau allein durch Datenmanagement erreicht: DatologyAI präsentierte seine neuesten Forschungsergebnisse im multimodalen Bereich. Durch sorgfältiges Datenmanagement (Data Curation) anstelle von Algorithmus- oder Architekturinnovationen erreichte sein CLIP ViT-B/32-Modell eine Genauigkeit von 76,9 % auf ImageNet 1k und übertraf damit die von SigLIP2 gemeldeten 74 %. Diese Methode führte gleichzeitig zu einer achtfachen Steigerung der Trainingseffizienz und einer zweifachen Steigerung der Ineffizienzen. Das Modell wurde öffentlich zugänglich gemacht und unterstreicht das enorme Potenzial hochwertiger Daten zur Verbesserung der Modellleistung. (Quelle: code_star, andersonbcdefg)
Krea AI veröffentlicht erstes eigenes Bildmodell Krea 1: Krea AI hat sein erstes Bildmodell Krea 1 vorgestellt, das sich durch hervorragende ästhetische Kontrolle und Bildqualität auszeichnet, über ein breites künstlerisches Wissensrepertoire verfügt und Stilreferenzen sowie benutzerdefiniertes Training unterstützt. Krea 1 zielt darauf ab, den Realismus, die feinen Texturen und die reiche Stilvielfalt von Bildern zu verbessern. Krea 1 ist derzeit als kostenlose Beta-Version verfügbar, sodass Benutzer seine leistungsstarken Bilderzeugungsfähigkeiten testen können. (Quelle: _akhaliq, op7418)
NVIDIA veröffentlicht anpassbares Open-Source-Modell für humanoide Roboter GR00T N1: NVIDIA hat GR00T N1 vorgestellt, ein anpassbares Open-Source-Modell für humanoide Roboter. Dieser Schritt zielt darauf ab, Forschung und Entwicklung im Bereich humanoider Roboter voranzutreiben und Entwicklern eine flexible Plattform zum Erstellen und Experimentieren mit verschiedenen Roboteranwendungen zu bieten. Es wird erwartet, dass die Open-Source-Natur von GR00T N1 eine breitere Community-Beteiligung anzieht und den Fortschritt der Technologie für humanoide Roboter beschleunigt. (Quelle: Ronald_vanLoon)
RoboBrain 2.0 veröffentlicht multimodale Robotermodelle mit 7B und 32B Parametern: RoboBrain 2.0 hat seine multimodalen Robotermodelle mit 7B und 32B Parametern veröffentlicht, die darauf abzielen, die Fähigkeiten von Robotern in den Bereichen Wahrnehmung, Denken und Aufgabenausführung zu verbessern. Die neuen Modelle unterstützen interaktive Inferenz, langfristige Planung, Closed-Loop-Feedback, präzise räumliche Wahrnehmung (Punkt- und Bounding-Box-Vorhersage), zeitliche Wahrnehmung (Vorhersage zukünftiger Trajektorien) sowie Szeneninferenz durch den Aufbau und die Aktualisierung eines echtzeitstrukturierten Gedächtnisses. Diese verbesserten Fähigkeiten sollen die autonome Bedienung und Entscheidungsfindung von Robotern in komplexen Umgebungen vorantreiben. (Quelle: Reddit r/LocalLLaMA)
Kling AI wird auf der CVPR 2025 neueste Forschung zu Videogenerierungsmodellen vorstellen: Pengfei Wan, Leiter des Kling AI Videogenerierungsmodells, wird auf der führenden Konferenz für Computer Vision, CVPR 2025, einen Vortrag mit dem Titel „Einführung in Kling und unsere Forschung zu leistungsstärkeren Videogenerierungsmodellen“ halten. Gemeinsam mit Experten von Institutionen wie Google DeepMind wird er die neuesten Durchbrüche und Fortschritte in der Videogenerierungstechnologie diskutieren. Diese Präsentation wird die Errungenschaften von Kling bei der Förderung der Videogenerierungstechnologie detailliert vorstellen. (Quelle: Kling_ai)

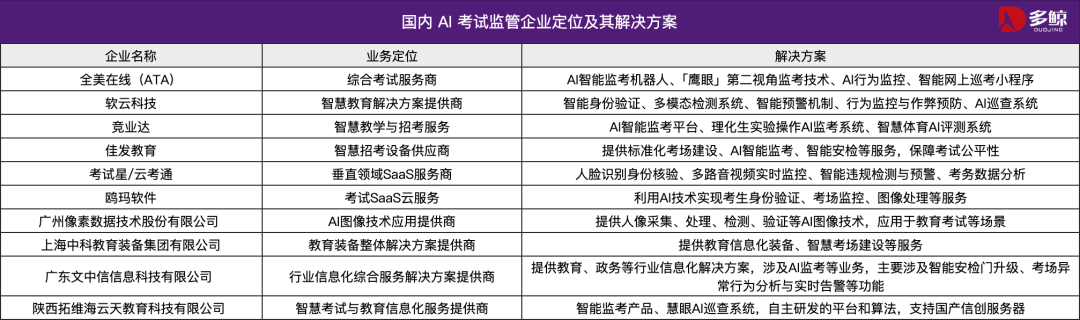
KI-Technologie unterstützt Chinas Gaokao 2025, mehrere Regionen führen intelligente Überwachungssysteme ein: Bei Chinas nationaler Hochschulaufnahmeprüfung (Gaokao) 2025 werden in großem Umfang intelligente KI-Überwachungssysteme eingesetzt. In Städten wie Tianjin, Jiangxi, Hubei und Yangjiang (Guangdong) wird eine vollständige KI-Überwachung der Prüfungsräume realisiert. Diese Systeme nutzen 4K-Kameras, Skelett-Tracking, Gesichtserkennung, Audioüberwachung und andere Technologien, um in Echtzeit Verstöße von Prüfungsteilnehmern wie vorzeitiges Beginnen, Weitergabe von Gegenständen, unerlaubte Kommunikation und ungewöhnliche Blickabweichungen zu erkennen und Warnungen auszugeben. Ziel ist es, die Fairness der Prüfungen zu erhöhen und die Disziplin in den Prüfungsräumen sicherzustellen. Der Einsatz von KI-Überwachungssystemen markiert den Eintritt des Prüfungsmanagements in eine intelligente Ära und revolutioniert traditionelle Überwachungsmethoden. (Quelle: 36氪)
Gemma 3n Desktop-Modell veröffentlicht, unterstützt plattformübergreifende und IoT-Geräte: Google hat das Gemma 3n Desktop-Modell in Versionen mit 2 Milliarden und 4 Milliarden Parametern veröffentlicht, das speziell für Desktop- (Mac/Windows/Linux) und Internet-of-Things (IoT)-Geräte optimiert ist. Das Modell wird von der neuen LiteRT-LM-Bibliothek angetrieben und zielt darauf ab, effiziente lokale Ausführungsfähigkeiten bereitzustellen. Entwickler können über Hugging Face eine Vorschau erhalten und über GitHub auf verwandte Ressourcen zugreifen, um die Anwendung von leichtgewichtigen KI-Modellen auf Edge-Geräten weiter voranzutreiben. (Quelle: ClementDelangue, demishassabis)
🧰 Tools
Yutori AI stellt Scouts vor: KI-Agenten für Echtzeit-Webüberwachung: Yutori AI, gegründet von ehemaligen Meta AI-Forschern, hat ein KI-Agentenprodukt namens Scouts veröffentlicht. Scouts können das Internet basierend auf vom Benutzer festgelegten Themen oder Schlüsselwörtern in Echtzeit überwachen und Benutzer benachrichtigen, wenn relevante Inhalte erscheinen. Das Tool soll Benutzern helfen, wertvolle Informationen aus der riesigen Menge an Online-Informationen herauszufiltern, z. B. das Verfolgen von Nachrichten in bestimmten Bereichen, Markttrends, Produktangeboten oder sogar knappen Reservierungen. Die Einführung von Scouts markiert eine Weiterentwicklung personalisierter Informationsbeschaffungstools und macht KI zu digitalen „Scouts“ für Benutzer. (Quelle: DhruvBatraDB, krandiash, saranormous, JeffDean)
Replit führt neue Funktion ein: Designentwürfe von Figma etc. mit einem Klick in funktionale Anwendungen umwandeln: Replit hat die Funktion Replit Import veröffentlicht, mit der Benutzer Designentwürfe von Plattformen wie Figma, Lovable, Bolt direkt importieren und in lauffähige Anwendungen umwandeln können. Die Funktion zielt darauf ab, die Entwicklungsschwelle zu senken und es auch Nicht-Programmierern zu ermöglichen, Designideen schnell in die Realität umzusetzen. Replit Import unterstützt die Beibehaltung der Designgenauigkeit und verfügt über integrierte Sicherheitsscans und Schlüsselverwaltung. In Kombination mit Replit Agent, Datenbanken, Authentifizierung und Hosting-Diensten können Full-Stack-Anwendungen erstellt werden. (Quelle: amasad, pirroh)
Hugging Face veröffentlicht AISheets: Tabellenkalkulationen mit Tausenden von KI-Modellen kombinieren: Thomas Wolf, Mitbegründer von Hugging Face, kündigte das experimentelle Produkt AISheets an. Dieses Tool kombiniert die Benutzerfreundlichkeit von Tabellenkalkulationen mit der Leistungsfähigkeit von Tausenden von Open-Source-KI-Modellen (insbesondere LLMs). Benutzer können Datenverarbeitungsaufgaben in einer vertrauten Tabellenkalkulationsoberfläche erstellen, analysieren und automatisieren, KI-Modelle für Dateneinblicke und Aufgabenautomatisierung nutzen und so eine schnelle, einfache und leistungsstarke neue Methode der Datenanalyse bereitstellen. (Quelle: _akhaliq, clefourrier, ClementDelangue, huggingface)
LlamaIndex unterstützt die Umwandlung von Agents in MCP-Server zur Interaktion mit Claude und anderen Modellen: LlamaIndex gab bekannt, dass es nun die Umwandlung jedes seiner Agents in einen Model Context Protocol (MCP)-Server unterstützt. Anhand von Beispielcode und Videos wird gezeigt, wie ein benutzerdefinierter FidelityFundExtraction-Workflow (zur Extraktion strukturierter Daten aus komplexen PDFs) als MCP-Server bereitgestellt und von einem Claude-Modell aufgerufen werden kann. Diese Funktion zielt darauf ab, die Agentenfähigkeiten von Tools zu verbessern, die Integration mit MCP-Clients wie Claude Desktop und Cursor zu erleichtern und den Prozess der Anbindung bestehender Workflows an ein breiteres KI-Ökosystem zu vereinfachen. (Quelle: jerryjliu0)
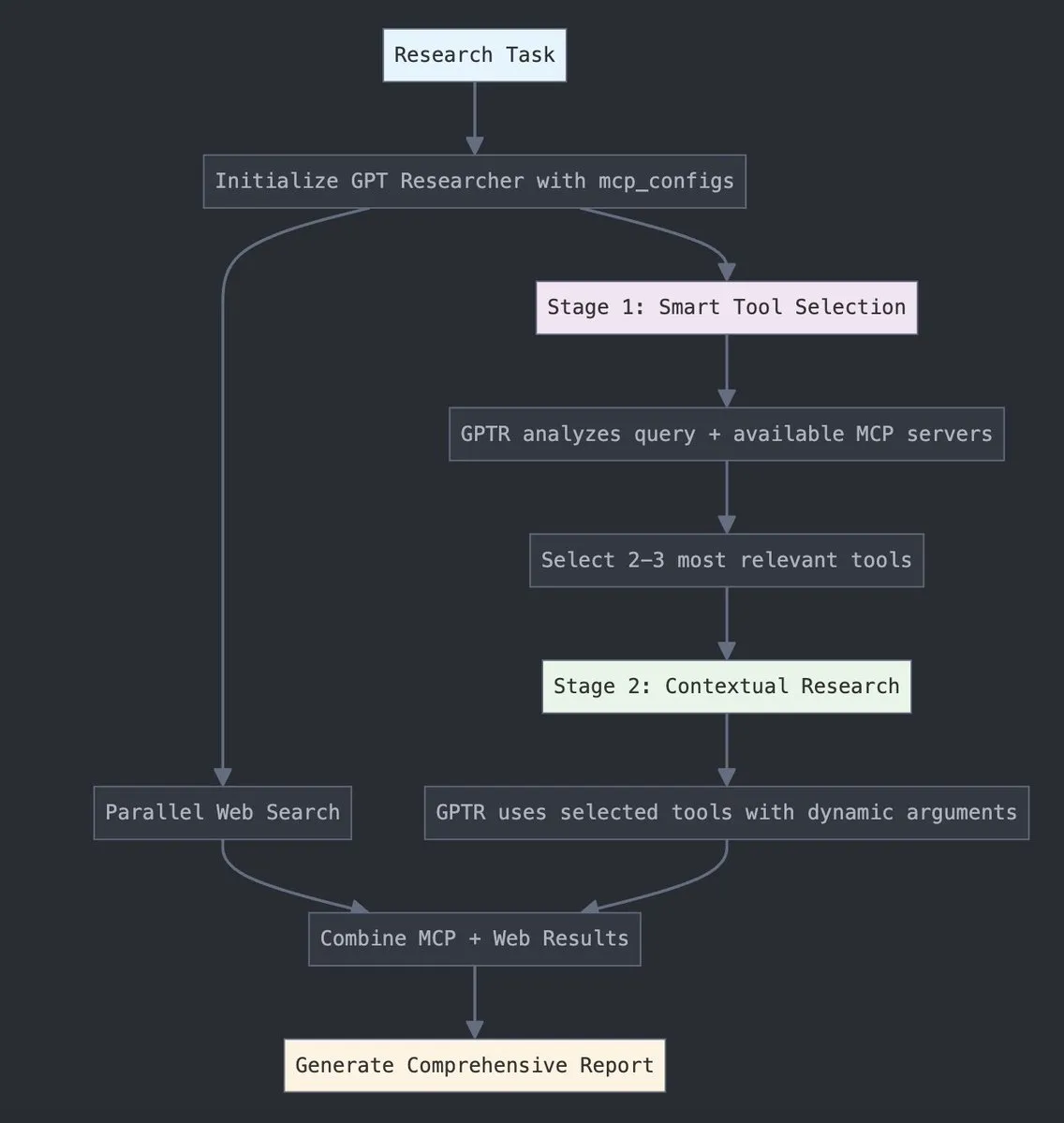
GPT Researcher integriert LangChain Model Context Protocol (MCP): GPT Researcher nutzt jetzt den Model Context Protocol (MCP)-Adapter von LangChain für intelligente Werkzeugauswahl und Recherche. Diese Integration verbindet MCP nahtlos mit Websuchfunktionen, um eine umfassende Datenerfassung zu ermöglichen. Benutzer können die entsprechende Integrationsdokumentation konsultieren, um zu erfahren, wie diese neue Funktion konfiguriert und verwendet wird, um die Forschungseffizienz und -tiefe zu verbessern. (Quelle: hwchase17)
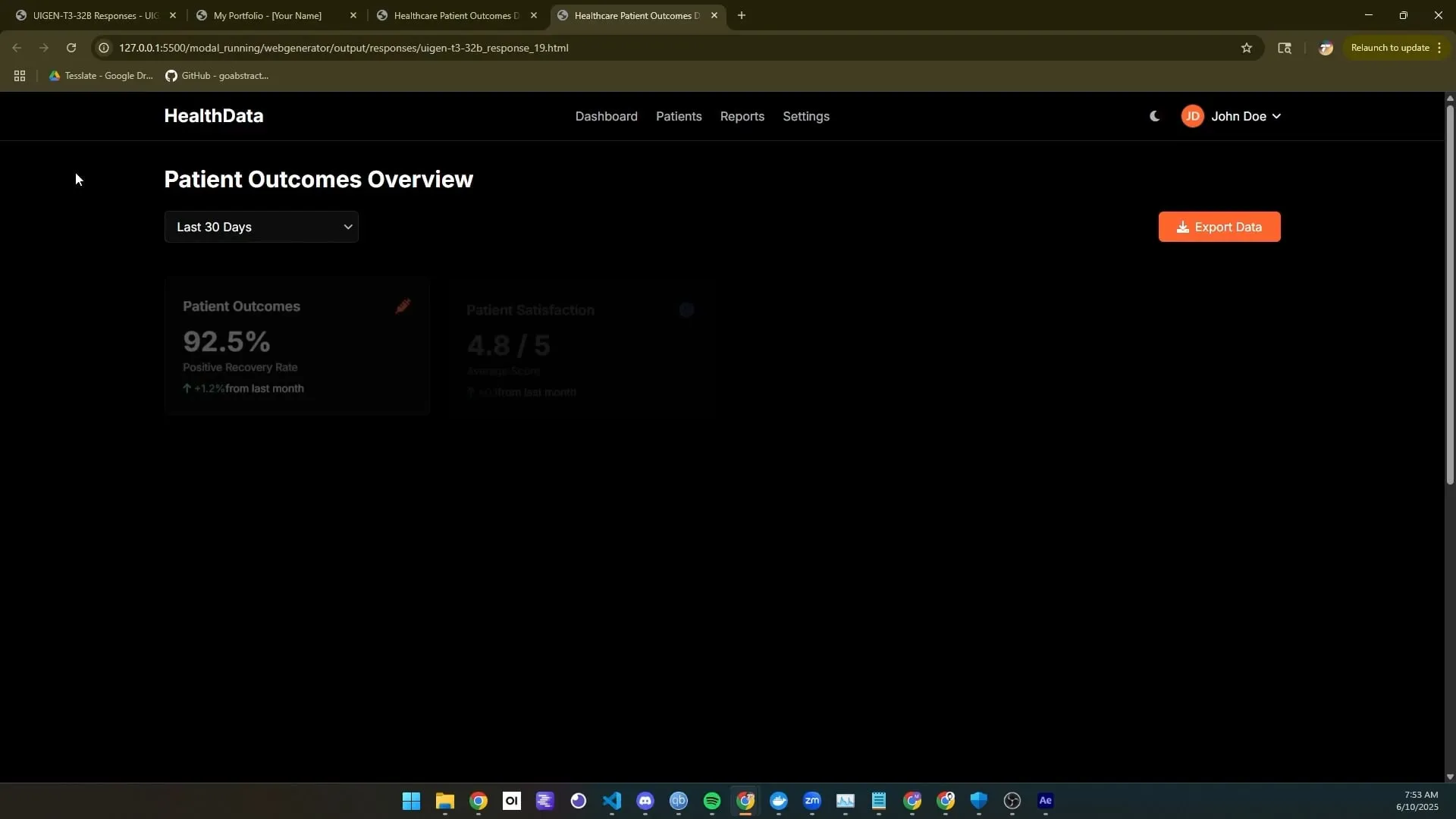
Tesslate veröffentlicht UIGEN-T3-Serie von UI-Generierungsmodellen, unterstützt verschiedene Größen: Das Tesslate-Team hat die UIGEN-T3-Serie von UI-Generierungsmodellen vorgestellt, die verschiedene Parametergrößen wie 32B, 14B, 8B und 4B umfasst. Diese Modelle sind speziell für die Generierung von UI-Komponenten (wie Breadcrumbs, Buttons, Karten) und vollständigem Frontend-Code (wie Anmeldeseiten, Dashboards, Chat-Schnittstellen) konzipiert und unterstützen Tailwind CSS. Die Modelle sind auf Hugging Face verfügbar und sollen Entwicklern helfen, schnell Benutzeroberflächen zu erstellen. Entwickler berichten, dass eine Standardquantisierung die Modellqualität erheblich reduziert und empfehlen, die Modelle in BF16 oder FP8 für optimale Ergebnisse auszuführen. (Quelle: Reddit r/LocalLLaMA)
Doubao Podcast-Modell veröffentlicht, generiert mit einem Klick menschenähnliche KI-Podcasts: Volcano Engine hat das Doubao Podcast-Modell veröffentlicht, das basierend auf vom Benutzer eingegebenem Text (wie Artikellinks oder Prompts) schnell Podcasts mit einem stark menschenähnlichen Dialogstil generieren kann. Die vom Modell erzeugten Audiodaten ähneln in Tonfall, Pausen und umgangssprachlichen Ausdrücken echten Menschen und können sogar basierend auf dem Inhalt pointierte Diskussionen führen. Diese Technologie basiert auf dem End-to-End-Echtzeit-Sprachmodell des Sprachtechnologie-Teams von ByteDance und ermöglicht direktes Verstehen und Inferieren auf der Sprachebene. Derzeit ist diese Funktion in der Doubao PC-Version und im Kouzi Space verfügbar und zielt darauf ab, die Hürde für die Erstellung von Audioinhalten zu senken und eine effiziente, personalisierte Informationsbeschaffung zu ermöglichen. (Quelle: 量子位)

Unsloth AI bietet GGUF-quantisierte Version von Magistral-Small-2506 an: Für das neu von Mistral AI veröffentlichte Inferenzmodell Magistral-Small-2506 bietet Unsloth AI eine GGUF-quantisierte Version an. Dies ermöglicht es Benutzern, dieses 24-Milliarden-Parameter-Modell lokal auszuführen, beispielsweise auf Geräten mit nur 32 GB RAM. Dieser Schritt senkt die Hardwareanforderungen für Hochleistungs-Inferenzmodelle und erleichtert es einer breiteren Gruppe von Entwicklern und Forschern, das Magistral-Modell in lokalen Umgebungen zu erleben und zu nutzen. (Quelle: ImazAngel)
📚 Lernen
Technische Tiefenanalyse zum Aufbau des LLaVA-1.5 Vision Assistant: LearnOpenCV hat einen Artikel veröffentlicht, der eine technische Tiefenanalyse der LLaVA-1.5-Architektur bietet. Der Artikel beschreibt detailliert, wie LLaVA-1.5 modernste KI-Vision-Assistenten erstellt, einschließlich seiner bahnbrechenden Visual Instruction Tuning-Technologie und der Open-Source-Datensätze, die den Bereich der multimodalen KI verändert haben. Dieser Leitfaden ist eine wichtige Referenz für KI/ML-Ingenieure und Forscher, um die Funktionsweise und Trainingsmethoden multimodaler großer Sprachmodelle zu verstehen. (Quelle: LearnOpenCV)
Einführungsleitfaden für maschinelles Lernen bei Proteinen veröffentlicht: DL Weekly hat einen umfassenden Leitfaden für maschinelles Lernen bei Proteinen für Anfänger geteilt. Der Leitfaden behandelt grundlegende Datentypen im Zusammenhang mit Proteinen, Deep-Learning-Modelle, Berechnungsmethoden sowie grundlegende biologische Konzepte und soll Forschern und Entwicklern, die an diesem interdisziplinären Bereich interessiert sind, einen schnellen Einstieg ermöglichen. (Quelle: dl_weekly)
Qdrant und DataTalksClub bieten kostenlosen Kurs zu RAG und Vektorsuche an: Qdrant kündigte eine Zusammenarbeit mit DataTalksClub an, um einen 10-wöchigen kostenlosen Online-Kurs anzubieten. Die Kursinhalte umfassen Retrieval Augmented Generation (RAG), Vektorsuche, hybride Suche, Bewertungsmethoden und ein End-to-End-Projektpraktikum. Die Qdrant-Experten Kacper Łukawski und Daniel Wanderung werden den Kurs persönlich leiten, um den Lernenden praktische Fähigkeiten zum Aufbau fortschrittlicher KI-Anwendungen zu vermitteln. (Quelle: qdrant_engine)
Weaviate-Podcast diskutiert strukturierte Ausgabe von LLMs und Constrained Decoding: Die neueste Folge des Weaviate-Podcasts lud Will Kurt und Cameron Pfiffer von dottxt.ai ein, um mit Moderator Connor Shorten über das Problem der strukturierten Ausgabe von Large Language Models (LLMs) zu diskutieren. Die Sendung erörterte eingehend, wie durch Constrained Decoding-Techniken sichergestellt werden kann, dass LLMs zuverlässige, vorhersagbare Ergebnisse (wie gültiges JSON, E-Mails, Tweets usw.) generieren, anstatt nur eine einfache JSON-Formatvalidierung durchzuführen. Sie stellten auch das Open-Source-Tool Outlines und seine Anwendung in realen KI-Anwendungsfällen vor und blickten auf die Auswirkungen dieser Technologie auf zukünftige KI-Systeme. (Quelle: bobvanluijt)
ACL2025 NLP-Paper SynthesizeMe!: Personalisierte Prompts aus Benutzerinteraktionen generieren: Ein Paper mit dem Titel “SynthesizeMe!” für die ACL 2025 NLP-Konferenz schlägt eine neue Methode vor, um durch die Analyse von Benutzerinteraktionen mit KI (einschließlich implizitem und explizitem Feedback) personalisierte Benutzermodelle in natürlicher Sprache zu erstellen. Die Methode generiert und validiert zunächst Inferenzprozesse, die Benutzerpräferenzen erklären, leitet daraus synthetische Benutzerprofile ab, filtert informationsreiche frühere Benutzerinteraktionen und erstellt schließlich personalisierte Prompts für bestimmte Benutzer, um das personalisierte Belohnungsmodellierungs- und Antwortverhalten von LLMs zu verbessern. DSPy hat dies ebenfalls weitergeleitet und als eine hervorragende Anwendung von dspy.MIPROv2 erwähnt. (Quelle: lateinteraction, stanfordnlp)
Neues Paper untersucht Überwachung und Übertaktung von Test-Time Scaling bei LLMs: Ein neues Paper befasst sich mit der Test-Time Scaling-Technologie, die von Modellen wie o3 und DeepSeek-R1 verwendet wird. Diese Technologie ermöglicht es LLMs, vor der Antwort mehr Inferenz durchzuführen, aber Benutzer können oft den internen Fortschritt nicht nachvollziehen oder kontrollieren. Forscher schlagen vor, die interne „Uhr“ von LLMs offenzulegen und zeigen, wie ihr Inferenzprozess überwacht und „übertaktet“ werden kann, um ihn zu beschleunigen. Dies bietet neue Ansätze zum Verständnis und zur Optimierung der Effizienz großer Inferenzmodelle. (Quelle: arankomatsuzaki)

Paper schlägt CARTRIDGES vor: Komprimierung des KV-Cache von LLMs mit langem Kontext durch Offline-Selbstlernen: Forscher von HazyResearch an der Stanford University haben eine neue Methode namens CARTRIDGES vorgeschlagen, die darauf abzielt, das Problem des hohen Speicherbedarfs des KV-Cache in LLMs mit langem Kontext zu lösen. Die Methode trainiert offline einen kleineren KV-Cache (genannt Cartridge) durch einen „selbstlernenden“ Testzeit-Trainingsmechanismus, um Dokumentinformationen zu speichern. Dadurch wird der Cache-Speicher im Durchschnitt um das 39-fache reduziert und der Spitzendurchsatz um das 26-fache erhöht, während die Aufgabenleistung erhalten bleibt. Eine einmal trainierte Cartridge kann von verschiedenen Benutzeranfragen wiederverwendet werden und bietet einen neuen Optimierungsansatz für die Verarbeitung langer Kontexte. (Quelle: gallabytes, simran_s_arora, stanfordnlp)

Neues Paper Grafting: Kostengünstige Bearbeitung der Architektur vortrainierter Diffusion Transformer: Forscher der Stanford University haben eine neue Methode namens Grafting zur Bearbeitung der Architektur vortrainierter Diffusion Transformer-Modelle vorgeschlagen. Diese Technik ermöglicht es, Aufmerksamkeitsmechanismen und andere Komponenten im Modell durch neue Rechenprimitive zu ersetzen, und das mit nur 2 % der Rechenkosten des Vortrainings. Dies ermöglicht die Anpassung von Modellarchitekturen mit geringem Rechenbudget und ist wichtig für die Erforschung neuer Modellarchitekturen und die Effizienzsteigerung bestehender Modelle. (Quelle: realDanFu, togethercompute)
Neues ICML-Paper: Methode der durchschnittlichen Checkpoints beschleunigt Modelltraining auf AlgoPerf-Benchmark: Ein neues ICML-Paper untersucht die Anwendung der klassischen Methode der durchschnittlichen Checkpoints (Averaging Checkpoints) zur Verbesserung der Trainingsgeschwindigkeit und Leistung von Machine-Learning-Modellen. Die Forscher testeten diese Methode auf AlgoPerf, einem strukturierten und vielfältigen Benchmark für Optimierungsalgorithmen, und untersuchten ihren praktischen Nutzen bei verschiedenen Aufgaben, um praktische Referenzen für die Beschleunigung des Modelltrainings zu liefern. (Quelle: aaron_defazio)
Open-Source-Tool zur Visualisierung und Erklärung von Transformern: DL Weekly stellt ein interaktives Visualisierungstool vor, das Benutzern helfen soll, die Funktionsweise von Modellen zu verstehen, die auf der Transformer-Architektur basieren (wie GPT). Das Tool zerlegt die internen Mechanismen des Modells visuell, um komplexe Konzepte leichter verständlich zu machen, und eignet sich für Lernende und Forscher, die sich für Transformer-Modelle interessieren. Das Projekt ist auf GitHub als Open Source verfügbar. (Quelle: dl_weekly)
Zhejiang Universität schlägt InftyThink vor: Unendliche Tiefeninferenz durch Segmentierung und Zusammenfassung: Ein Forschungsteam der Zhejiang Universität in Zusammenarbeit mit der Peking Universität hat ein neues Paradigma für die Inferenz großer Modelle namens InftyThink vorgeschlagen. Diese Methode zerlegt lange Inferenzen in mehrere kurze Segmente und führt Zusammenfassungen zwischen den Segmenten ein, um den Kontext zu verknüpfen. Dadurch wird theoretisch eine unendliche Tiefeninferenz bei gleichzeitig hohem Generierungsdurchsatz ermöglicht. Diese Methode erfordert keine Anpassung der Modellstruktur und ist durch die Umstrukturierung der Trainingsdaten in ein mehrstufiges Inferenzformat mit bestehenden Vortrainings- und Feinabstimmungsprozessen kompatibel. Experimente zeigen, dass InftyThink die Leistung von Modellen auf Benchmarks wie AIME24 signifikant verbessern und den Generierungsdurchsatz erhöhen kann. (Quelle: 量子位)

Paper untersucht Pixel-Space Reasoning: VLMs sollen wie Menschen „Augen und Gehirn gleichzeitig nutzen“: Ein Forschungsteam der University of Waterloo, der Hong Kong University of Science and Technology und der University of Science and Technology of China schlägt das Paradigma des „Pixel-Space Reasoning“ vor. Es ermöglicht visuellen Sprachmodellen (VLMs), direkt auf Pixelebene zu operieren und zu schlussfolgern, z. B. durch visuellen Zoom oder raumzeitliche Markierungen, anstatt sich auf Text-Token als Vermittler zu verlassen. Durch ein Verstärkungslernschema mit intrinsischer Neugier-Motivation und extrinsischer Korrektheitsmotivation wird die „kognitive Trägheit“ der Modelle überwunden. Der auf Qwen2.5-VL-7B basierende Pixel-Reasoner zeigt auf mehreren Benchmarks wie V*Bench hervorragende Leistungen, wobei das 7B-Modell GPT-4o übertrifft. (Quelle: 量子位)
DeepLearning.AI startet fünften Kurs des Datenanalyse-Zertifikats: Data Storytelling: DeepLearning.AI hat den fünften Kurs seines Datenanalyse-Zertifikatsprogramms zum Thema „Data Storytelling“ veröffentlicht. Der Kurs lehrt, wie man das geeignete Medium (Dashboard, Memo, Präsentation) zur Darstellung von Erkenntnissen auswählt, interaktive Dashboards mit Tableau entwirft, Ergebnisse mit Geschäftszielen in Einklang bringt und effektiv kommuniziert, sowie Ratschläge zur Stellensuche. Er betont die Bedeutung von Data Storytelling für die Verbesserung der Geschäftsleistung und die effektive Vermittlung von Erkenntnissen. (Quelle: DeepLearningAI)

Paper untersucht den Einfluss von Wissenskonflikten auf große Sprachmodelle: Ein neues Paper bewertet systematisch das Verhalten von Large Language Models (LLMs), wenn kontextuelle Eingaben mit parametrisiertem Wissen (d.h. dem internen „Gedächtnis“ des Modells) kollidieren. Die Studie ergab, dass Wissenskonflikte Aufgaben, die nicht auf Wissensnutzung angewiesen sind, kaum beeinflussen; wenn Kontext und parametrisches Wissen übereinstimmen, ist die Leistung des Modells besser; selbst wenn dazu aufgefordert, können Modelle ihr internes Wissen nicht vollständig unterdrücken; die Bereitstellung von Erklärungen für Konflikte erhöht die Abhängigkeit des Modells vom Kontext. Diese Ergebnisse stellen die Validität modellbasierter Bewertungen in Frage und betonen die Notwendigkeit, Wissenskonflikte beim Einsatz von LLMs zu berücksichtigen. (Quelle: HuggingFace Daily Papers)
Paper CyberV: Ein kybernetisches Framework für Test-Time Scaling im Videoverständnis: Um die Probleme der Rechenanforderungen, Robustheit und Genauigkeit von multimodalen großen Sprachmodellen (MLLMs) bei der Verarbeitung langer oder komplexer Videos anzugehen, schlagen Forscher das CyberV-Framework vor. Inspiriert von kybernetischen Prinzipien, gestaltet dieses Framework Video-MLLMs als adaptive Systeme neu, die ein MLLM-Inferenzsystem, Sensoren und einen Controller umfassen. Die Sensoren überwachen den Vorwärtsdurchlauf des Modells und sammeln intermediäre Interpretationen (wie Aufmerksamkeitsdrift), während der Controller entscheidet, wann und wie Selbstkorrekturen ausgelöst und Feedback generiert werden. Dieses adaptive Test-Time Scaling Framework verbessert bestehende MLLMs ohne Neutraining. Experimente zeigen, dass es die Leistung von Modellen wie Qwen2.5-VL-7B auf Benchmarks wie VideoMMMU signifikant steigert. (Quelle: HuggingFace Daily Papers)
Paper schlägt LoRMA vor: Low-Rank Multiplicative Adaptation für parametereffizientes Fine-Tuning von LLMs: Um die Probleme des Repräsentationskollaps und der unausgewogenen Expertenlast bei bestehenden parametereffizienten Feinabstimmungsmethoden (PEFT) auf Basis von LoRA und MoE zu lösen, schlagen Forscher Low-Rank Multiplicative Adaptation (LoRMA) vor. Diese Methode wandelt die Aktualisierungsweise von PEFT-Adapter-Experten von additiv zu reichhaltigeren Matrixmultiplikationstransformationen um. Durch effektive Umordnungsoperationen und die Einführung einer Rangexpansionsstrategie werden Rechenkomplexität und Rangengpässe angegangen. Experimente zeigen, dass die heterogene MoA (Mixture of Adapters)-Methode sowohl in Bezug auf Leistung als auch Parametereffizienz der homogenen MoE-LoRA-Methode überlegen ist. (Quelle: Reddit r/MachineLearning)
Paper schlägt FlashDMoE vor: Schnelle verteilte MoE-Implementierung auf einem einzelnen Kern: Forscher stellen FlashDMoE vor, das erste System, das den verteilten Mixture-of-Experts (MoE) Forward-Pass vollständig in einem einzigen CUDA-Kern zusammenführt. Durch das Schreiben der fusionierten Schicht von Grund auf in reinem CUDA erreicht FlashDMoE eine bis zu 9-fache Steigerung der GPU-Auslastung, eine 6-fache Latenzreduktion und eine 4-fache Verbesserung der schwachen Skalierungseffizienz. Diese Arbeit bietet neue Ansätze und Implementierungen zur Optimierung der Ineffizienz von groß angelegten MoE-Modellen. (Quelle: Reddit r/MachineLearning)
💼 Wirtschaft
xAI und Polymarket kooperieren, um Marktprognosen mit Grok-Analysen zu verbinden: xAI, das von Elon Musk gegründete Unternehmen für künstliche Intelligenz, hat eine Partnerschaft mit der dezentralen Prognosemarktplattform Polymarket bekannt gegeben. Ziel der Zusammenarbeit ist es, die Marktprognosedaten von Polymarket mit Daten von X (ehemals Twitter) und den Analysefähigkeiten von Grok AI zu kombinieren, um eine „Hardcore Truth Engine“ zu schaffen, die die Faktoren aufdeckt, die die Welt prägen. xAI erklärte, dies sei erst der Anfang der Zusammenarbeit, weitere Kooperationen würden folgen. (Quelle: xai)
KI-Inferenzchip-Unternehmen Groq erhält Investitionszusage von 1,5 Milliarden US-Dollar aus Saudi-Arabien, konzentriert sich auf vertikale Integrationsstrategie: Das KI-Inferenzchip-Unternehmen Groq gab eine Investitionszusage von 1,5 Milliarden US-Dollar aus Saudi-Arabien bekannt, um den Ausbau seiner auf LPU (Language Processing Unit) basierenden KI-Inferenzinfrastruktur vor Ort zu finanzieren. Groq wurde von Jonathan Ross, einem der Erfinder des TPU, gegründet und konzentriert sich auf KI-Inferenzberechnungen. Seine LPU-Chips verwenden eine programmierbare Pipeline-Architektur, bei der Speicher und Recheneinheiten auf demselben Chip integriert sind, was die Datenzugriffsgeschwindigkeit und Energieeffizienz erheblich verbessert. Groq verkauft nicht nur Chips, sondern bietet auch GroqRack-Cluster (Private Cloud/KI-Rechenzentren) und die GroqCloud-Plattform (Tokens-as-a-Service) an und unterstützt gängige Open-Source-Modelle wie Llama, DeepSeek und Qwen. Das Unternehmen hat auch das Compound AI-System entwickelt, um den Wert der KI-Inferenz-Cloud zu steigern. (Quelle: 36氪)

Shenzhener Unternehmen für interaktive humanoide Roboter „Digital Huaxia“ schließt Angel+-Finanzierungsrunde in Höhe von mehreren zehn Millionen Yuan ab: Digital Huaxia (Shenzhen) Technology Co., Ltd. hat kürzlich eine Angel+-Finanzierungsrunde in Höhe von mehreren zehn Millionen Yuan abgeschlossen, die exklusiv von Co-Stone Capital investiert wurde. Das Unternehmen konzentriert sich auf die kommerzielle Skalierung von AGI-Robotern. Zu den Kernprodukten gehören der humanoide Roboter „Xia Lan“, der universelle humanoide Roboter „Xia Qi“ und der IP-Serienroboter „Xing Xing Xia“. Der „Xia Lan“-Roboter basiert auf präziser bionischer Technologie, kann die meisten menschlichen Gesichtsausdrücke nachahmen und verfügt über multimodale Interaktionsfähigkeiten. Das Unternehmen hat bereits Aufträge im Wert von mehreren hundert Millionen Yuan erhalten, zu den Kunden zählen führende ICT-Hersteller und lokale Stromnetzbetreiber. (Quelle: 36氪)

🌟 Community
Sam Altman veröffentlicht Blogbeitrag „Sanfte Singularität“, diskutiert die graduelle Revolution der KI und die Zukunft: OpenAI CEO Sam Altman veröffentlichte einen Blogbeitrag, in dem er argumentiert, dass die technologische Singularität auf eine sanftere, „behutsamere“ Weise geschieht als erwartet, als ein kontinuierlicher, exponentiell beschleunigender gradueller Prozess. Er prognostiziert, dass KI-Agenten, die 2025 komplexe intellektuelle Aufgaben (wie Programmierung) selbstständig erledigen können, die Softwarebranche umgestalten werden, 2026 Systeme entstehen könnten, die völlig neue wissenschaftliche Erkenntnisse entdecken, und 2027 Roboter erscheinen könnten, die Aufgaben in der realen Welt erledigen. Altman betont, dass die Lösung des KI-Alignment-Problems und die Gewährleistung des allgemeinen Zugangs zur Technologie Schlüssel zu einer prosperierenden Zukunft sind. Er verriet auch, dass das erste Open-Source-Gewichtsmodell von OpenAI auf den Spätsommer verschoben wird, da das Forschungsteam „unerwartet erstaunliche Ergebnisse“ erzielt habe. (Quelle: dotey, scaling01, sama)
Community diskutiert OpenAI o3-pro: Leistungsstark, aber teuer; o3-Preissenkung löst Kettenreaktion aus: Die Veröffentlichung von OpenAI o3-pro und sein hoher Preis (Ausgabe $80/M Tokens) sind zum Mittelpunkt der Community-Diskussionen geworden. Benutzer erkennen allgemein seine starke Leistungsfähigkeit bei komplexen Schlussfolgerungen, Programmierung usw. an, äußern aber auch Bedenken hinsichtlich seiner Reaktionsgeschwindigkeit und Kosten. Ein Benutzer scherzte, dass eine einfache Begrüßung mit „Hi“ 80 US-Dollar kosten könnte. Gleichzeitig wird die drastische Preissenkung des o3-Modells um 80 % als möglicher Auslöser eines Preiskampfes bei KI-Modellen angesehen, der sich an GPT-4o und andere Konkurrenzprodukte richtet. In der Community gibt es eine Debatte darüber, ob die Leistung von o3 nach der Preissenkung „dümmer“ geworden ist. OpenAI kündigte daraufhin an, das o3-Nutzungskontingent für ChatGPT Plus-Benutzer zu verdoppeln, um auf die Benutzernachfrage zu reagieren. (Quelle: Yuchenj_UW, scaling01, imjaredz, kevinweil, dotey)
Metas hohe Gehälter zur Talentgewinnung und Investitionen in KI-Organisationen sorgen für Diskussionen: Metas hohe Gehaltspakete für KI-Forscher (angeblich im neunstelligen US-Dollar-Bereich) haben in der Community Diskussionen ausgelöst. Nat Lambert kommentierte, dass solche Gehälter möglicherweise eine ganze Forschungseinrichtung von der Größe von AI2 finanzieren könnten, was auf die hohen Kosten für Spitzenkräfte hindeutet. In Verbindung mit der Gründung des „Superintelligence Lab“ durch Meta und den massiven Investitionen in Scale AI ist die Community allgemein der Ansicht, dass Meta keine Kosten scheut, um seine KI-Wettbewerbsfähigkeit neu zu gestalten, beobachtet aber auch interne Organisationspolitik und Effizienzprobleme. Von Helen Toner weitergeleitete Inhalte von ChinaTalk deuten darauf hin, dass dieser Schritt von Meta darauf abzielt, interne politische und egoistische Probleme in der Organisation zu durchbrechen. (Quelle: natolambert, natolambert)
Apples neuer UI-Stil „Liquid Glass“ auf der WWDC löst Diskussionen über Design und Benutzerfreundlichkeit aus: Der von Apple auf der WWDC 2025 vorgestellte neue UI-Designstil „Liquid Glass“ hat in der Entwickler- und Design-Community breite Diskussionen ausgelöst. Einige sehen darin einen neuartigen visuellen Effekt, der Apples Vorstoß in Richtung 3D-Interface-Design widerspiegelt. Erfahrene Persönlichkeiten wie ID_AA_Carmack (John Carmack) wiesen jedoch darauf hin, dass semitransparente UIs oft Probleme mit der Benutzerfreundlichkeit haben, leicht visuelle Störungen und geringen Kontrast verursachen, was das Lesen und die Bedienung beeinträchtigt. Sie erwähnten auch, dass Windows und Mac in der Vergangenheit ähnliche Designs ausprobiert, diese aber letztendlich aufgrund von Usability-Problemen angepasst hätten. Die User Experience (UX) sollte Vorrang vor den visuellen Effekten der Benutzeroberfläche (UI) haben, wurde zum Kern der Diskussion. (Quelle: gfodor, ID_AA_Carmack, ReamBraden, dotey)
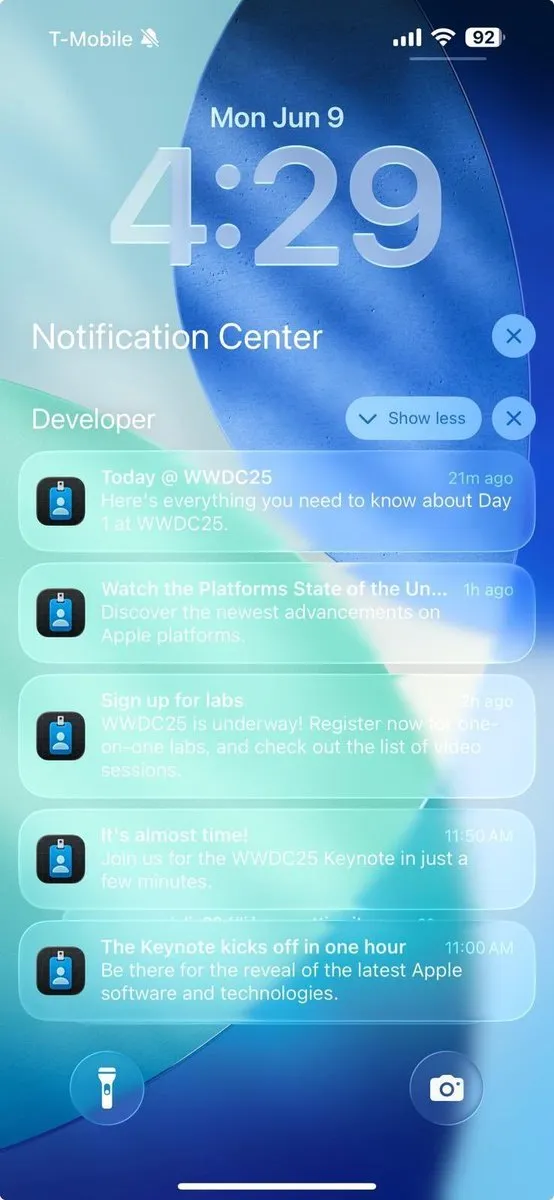
KI-gestützte Programmierpraxis: Agile Iteration besser als einmalige Generierung: In sozialen Medien äußerte dotey seine Meinung zu Best Practices für die Programmierung mit KI (wie Claude Code). Er argumentiert, dass man nicht den Ansatz verfolgen sollte, einmalig vollständige Anforderungen zu liefern und die KI ein riesiges halbfertiges Produkt generieren zu lassen (Wasserfallmodell) oder zuerst ein unvollkommenes Produkt zu generieren und es dann zu optimieren (ähnlich dem dritten Muster in der Abbildung), da dies die Qualitätskontrolle erschwert und die spätere Wartung schwierig macht. Er plädiert für ein agiles Iterationsmodell (ähnlich dem ersten Muster in der Abbildung), bei dem große Projekte (wie ERP-Systeme) in mehrere unabhängig stabil lauffähige kleine Versionen zerlegt und schrittweise iterativ entwickelt werden, um die funktionale Vollständigkeit und Kontrollierbarkeit jeder Version sicherzustellen, was mit den Best Practices der traditionellen Softwareentwicklung übereinstimmt. (Quelle: dotey)
Mustafa Suleyman: KI-Technologie entwickelt sich von fest und einheitlich zu dynamisch und personalisiert: Mustafa Suleyman, Mitbegründer von Inflection AI und ehemals DeepMind, kommentierte, dass traditionelle Technologien typischerweise fest, einheitlich und nach dem „One-Size-Fits-All“-Prinzip funktionieren, während die aktuelle künstliche Intelligenz dynamische, personalisierte und emergente Eigenschaften aufweist. Er ist der Ansicht, dass dies bedeutet, dass sich die Technologie von der Bereitstellung einzelner, sich wiederholender Ergebnisse hin zur Erforschung unendlicher Möglichkeiten wandelt, und betont das enorme Potenzial der KI für personalisierte Dienste und kreative Anwendungen. (Quelle: mustafasuleyman)
Perplexity AI kämpft mit Infrastrukturproblemen, CEO erklärt sich: Arav Srinivas, CEO von Perplexity AI, antwortete in sozialen Medien auf Benutzerfragen zu Dienstinstabilitäten und erklärte, dass aufgrund von Infrastrukturproblemen für einen Teil des Traffics eine verschlechterte Benutzererfahrung (degraded UX) aktiviert werden musste. Er betonte, dass Benutzerdaten (wie Library oder Threads) nicht verloren gegangen seien und alle Funktionen wiederhergestellt würden, sobald das System stabil sei. Dies spiegelt die Herausforderungen wider, denen KI-Dienste bei ihrer schnellen Entwicklung in Bezug auf Stabilität und Skalierbarkeit der Infrastruktur gegenüberstehen. (Quelle: AravSrinivas)
Sergey Levine diskutiert Lernunterschiede zwischen Sprach- und Videomodellen: Professor Sergey Levine von der UC Berkeley stellt in seinem Artikel „Sprachmodelle in Platons Höhle“ eine tiefgreifende Frage: Warum lernen Sprachmodelle so viel aus der Vorhersage des nächsten Wortes, während Videomodelle aus der Vorhersage des nächsten Frames vergleichsweise wenig lernen? Er argumentiert, dass LLMs durch das Erlernen der „Schatten“ menschlichen Wissens (Textdaten) mächtige Inferenzfähigkeiten erworben haben, was eher einem „Reverse Engineering“ menschlicher Kognition als einer wirklich autonomen Erkundung der physischen Welt gleicht. Videomodelle beobachten die physische Welt direkt, sind aber derzeit in komplexen Schlussfolgerungen LLMs unterlegen. Er schlägt vor, dass das langfristige Ziel der KI darin bestehen sollte, die Abhängigkeit von den „Schatten“ menschlichen Wissens zu überwinden und durch Sensoren direkt mit der physischen Welt zu interagieren, um eine autonome Erkundung zu ermöglichen. (Quelle: 36氪)
💡 Sonstiges
Diskussion über KI-Ethik und Bewusstsein: Kann KI echtes Bewusstsein besitzen?: MIT Technology Review befasst sich mit dem komplexen Thema des KI-Bewusstseins. Der Artikel weist darauf hin, dass KI-Bewusstsein nicht nur ein intellektuelles Rätsel ist, sondern auch ein Thema mit moralischem Gewicht. Eine Fehleinschätzung des KI-Bewusstseins könnte dazu führen, dass empfindungsfähige KI unbeabsichtigt versklavt wird oder menschliches Wohlergehen für nicht empfindungsfähige Maschinen geopfert wird. Die Forschungsgemeinschaft hat Fortschritte im Verständnis der Natur des Bewusstseins gemacht, und diese Ergebnisse könnten als Leitfaden für die Erforschung und den Umgang mit künstlichem Bewusstsein dienen. Dies wirft tiefgreifende Fragen zu KI-Rechten, Verantwortung und den Beziehungen zwischen Mensch und Maschine auf. (Quelle: MIT Technology Review)
Turing-Preisträger Joseph Sifakis: Aktuelle KI ist keine echte Intelligenz, Vorsicht vor Verwechslung von Wissen und Information: Turing-Preisträger Joseph Sifakis weist in seinen Schriften und Interviews darauf hin, dass das derzeitige gesellschaftliche Verständnis von KI fehlerhaft ist, indem es die Anhäufung von Informationen mit der Schaffung von Weisheit verwechselt und die „Intelligenz“ von Maschinen überschätzt. Er ist der Ansicht, dass es derzeit keine wirklich intelligenten Systeme gibt und die tatsächlichen Auswirkungen der KI auf die Industrie gering sind. KI fehlt es an gesundem Menschenverstand, ihre „Intelligenz“ ist ein Produkt statistischer Modelle und es ist schwierig, in komplexen sozialen Kontexten Werte und Risiken abzuwägen. Er betont, dass der Kern der Bildung die Förderung kritischen Denkens und Kreativität ist, nicht die Wissensvermittlung, und fordert die Schaffung globaler Standards für KI-Anwendungen, die klare Verantwortungsgrenzen definieren, damit KI zu einem Partner wird, der den Menschen erweitert, anstatt ihn zu ersetzen. (Quelle: 36氪)
Neugestaltung der Werbebranche im KI-Zeitalter: Von der kreativen Generierung bis zur personalisierten Ausspielung: Die Google I/O 2025 Konferenz zeigte, wie KI die Werbebranche tiefgreifend umgestaltet. Zu den Trends gehören: 1) KI-gesteuerte Kreativautomatisierung, von Bildern bis zu Videoskripten kann alles von KI generiert werden, Tools wie Veo 3, Imagen 4 und Flow senken die Hürde für die Erstellung hochwertiger Inhalte. 2) Das Personalisierungsparadigma wandelt sich von „Tausend Gesichter für Tausend Menschen“ zu „Tausend Gesichter für eine Person“, KI-intelligente Agenten können Benutzerbedürfnisse proaktiv verstehen und Transaktionen fördern. 3) Die Grenzen zwischen Werbung und Inhalt verschwimmen, Werbung wird direkt in KI-generierte Suchergebnisse integriert und wird Teil der Information. Markeninhaber müssen eigene intelligente Agenten aufbauen, KI-orientierte Dienste anbieten und an einer langfristigen Strategie der „Marken-Performance-Integration“ festhalten, um sich an den Wandel anzupassen. (Quelle: 36氪)