
Schlüsselwörter:Apple WWDC25, KI-Strategie, Siri-Upgrade, Foundation-Framework, Gerätebasierte KI, Systemweite Übersetzung, Xcode Vibe Coding, Visuelle intelligente Suche, Apple Intelligence Unterstützung für traditionelles Chinesisch, watchOS Smart Stack-Funktion, Apple KI-Datenschutzstrategie, KI-Integration übergreifender Systemökosysteme, Veröffentlichungstermin der generativen KI-Version von Siri
🔥 Fokus
Apple WWDC25 KI-Fortschritte: Pragmatische Integration und Offenheit, Siri muss noch warten: Apple präsentierte auf der WWDC25 eine Anpassung seiner KI-Strategie, weg von den letztjährigen „großen Versprechungen“ hin zu einer pragmatischeren Verbesserung der Systembasis und grundlegender Funktionen. Schwerpunkte sind unter anderem die „sinnvolle“ Integration von KI in Betriebssysteme und First-Party-Anwendungen sowie die Öffnung des gerätebasierten Modell-Frameworks „Foundation“ für Entwickler. Neue Funktionen wie systemweite Übersetzung (unterstützt Anrufe, FaceTime, Message usw. und bietet eine API), die Einführung von Vibe Coding in Xcode (unterstützt Modelle wie ChatGPT), eine auf Bildschirminhalten basierende visuelle intelligente Suche (ähnlich dem Einkreisen, teilweise unterstützt durch ChatGPT) sowie der Smart Stack in watchOS. Obwohl die Unterstützung von Apple Intelligence für den traditionellen chinesischen Markt erwähnt wurde, sind der Starttermin für vereinfachtes Chinesisch und die mit Spannung erwartete generative KI-Version von Siri noch unklar. Letztere wird voraussichtlich erst „im nächsten Jahr“ diskutiert. Apple betonte gerätebasierte KI und Private Cloud Computing zum Schutz der Nutzerprivatsphäre und demonstrierte die Integration von KI-Fähigkeiten über das gesamte Ökosystem hinweg. (Quelle: 36氪, 36氪, 36氪, 36氪)

Apple veröffentlicht KI-Paper, das die Reasoning-Fähigkeiten großer Modelle in Frage stellt und löst branchenweite Kontroverse aus: Apple veröffentlichte kürzlich ein Paper mit dem Titel „The Illusion of Thought: Understanding the Strengths and Limitations of Reasoning Models Through the Lens of Problem Complexity“. Durch Rätseltests mit großen Reasoning-Modellen (LRMs) wie Claude 3.7 Sonnet, DeepSeek-R1 und o3 mini wurde festgestellt, dass diese bei einfachen Problemen zu „übermäßigem Nachdenken“ neigen, während bei hochkomplexen Problemen ein „vollständiger Zusammenbruch der Genauigkeit“ auftritt, wobei die Genauigkeit nahe Null liegt. Die Studie legt nahe, dass aktuelle LRMs möglicherweise auf grundlegende Hindernisse bei der generalisierbaren Schlussfolgerung stoßen und eher Mustererkennung als echtes Denken betreiben. Diese Ansicht fand Beachtung bei Wissenschaftlern wie Gary Marcus, löste aber auch erhebliche Kritik aus. Kritiker bemängelten logische Schwachstellen im experimentellen Design (z. B. bei der Definition von Komplexität, Vernachlässigung von Token-Ausgabebeschränkungen) und warfen Apple sogar vor, aufgrund eigener langsamer KI-Fortschritte bestehende große Modelle diskreditieren zu wollen. Auch der Praktikantenstatus des Erstautors des Papers wurde diskutiert. (Quelle: 36氪, Reddit r/ArtificialInteligence)

OpenAI trainiert Berichten zufolge heimlich neues Modell o4, Reinforcement Learning gestaltet KI-Forschungs- und Entwicklungslandschaft neu: SemiAnalysis berichtet, dass OpenAI ein neues Modell trainiert, dessen Größe zwischen GPT-4.1 und GPT-4.5 liegt. Das Reasoning-Modell der nächsten Generation, o4, wird auf GPT-4.1 basieren und mittels Reinforcement Learning (RL) trainiert. Dieser Schritt markiert einen Strategiewechsel bei OpenAI, der darauf abzielt, die Modellstärke mit der Praktikabilität des RL-Trainings in Einklang zu bringen. GPT-4.1 wird aufgrund seiner geringeren Inferenzkosten und starken Code-Performance als ideale Grundlage angesehen. Der Artikel analysiert eingehend die zentrale Rolle von Reinforcement Learning bei der Verbesserung der Reasoning-Fähigkeiten von LLMs und der Förderung der Entwicklung von KI-Agenten, weist aber auch auf Herausforderungen in Bereichen wie Infrastruktur, Festlegung von Belohnungsfunktionen und Reward Hacking hin. RL verändert die Organisationsstruktur und die F&E-Prioritäten von KI-Laboren und führt zu einer tiefen Integration von Inferenz und Training. Gleichzeitig werden hochwertige Daten zum Wettbewerbsvorteil für die Skalierung von RL, während für kleinere Modelle Destillation effektiver sein könnte als RL. (Quelle: 36氪)

Ilya Sutskever kehrt in die Öffentlichkeit zurück, erhält Ehrendoktorwürde der University of Toronto und spricht über die Zukunft der KI: OpenAI-Mitbegründer Ilya Sutskever trat kürzlich nach seinem Ausscheiden bei OpenAI und der Gründung von Safe Superintelligence Inc. erstmals wieder öffentlich auf und nahm an seiner Alma Mater, der University of Toronto, die Ehrendoktorwürde in Naturwissenschaften entgegen. In seiner Rede betonte er, dass KI in Zukunft alles tun können wird, was Menschen tun können, da das Gehirn selbst ein biologischer Computer sei und es keinen Grund gebe, warum digitale Computer nicht dasselbe leisten könnten. Er ist der Ansicht, dass KI Arbeit und Berufe auf beispiellose Weise verändert, und forderte die Menschen auf, die Entwicklung der KI zu beobachten und aus ihren Fähigkeiten Energie zur Bewältigung von Herausforderungen zu schöpfen. Sutskever’s Erfahrungen bei OpenAI und sein Fokus auf AGI-Sicherheit machen ihn zu einer Schlüsselfigur im KI-Bereich. (Quelle: 36氪, Reddit r/artificial)

🎯 Trends
Xiaohongshu veröffentlicht erstes MoE-Großmodell dots.llm1, übertrifft DeepSeek-V3 in chinesischen Benchmarks: Das hi lab (Humanities Intelligence Lab) von Xiaohongshu hat sein erstes Open-Source-Großmodell dots.llm1 veröffentlicht. Es handelt sich um ein Mixture-of-Experts (MoE)-Modell mit 142 Milliarden Parametern, von denen bei der Inferenz nur 14 Milliarden aktiviert werden. Das Modell wurde mit 11,2 Billionen nicht-synthetischen Daten vortrainiert und zeigt hervorragende Leistungen bei Aufgaben wie dem Verständnis von Chinesisch und Englisch, mathematischem Denken, Codegenerierung und Alignment, wobei die Leistung nahe an Qwen3-32B liegt. Insbesondere im chinesischen C-Eval-Benchmark erreichte dots.llm1.inst 92,2 Punkte und übertraf damit bestehende Modelle einschließlich DeepSeek-V3. Xiaohongshu betont, dass sein skalierbares und feingranulares Datenverarbeitungsframework entscheidend ist und hat Zwischen-Trainings-Checkpoints veröffentlicht, um die Forschung der Community zu fördern. (Quelle: 36氪)
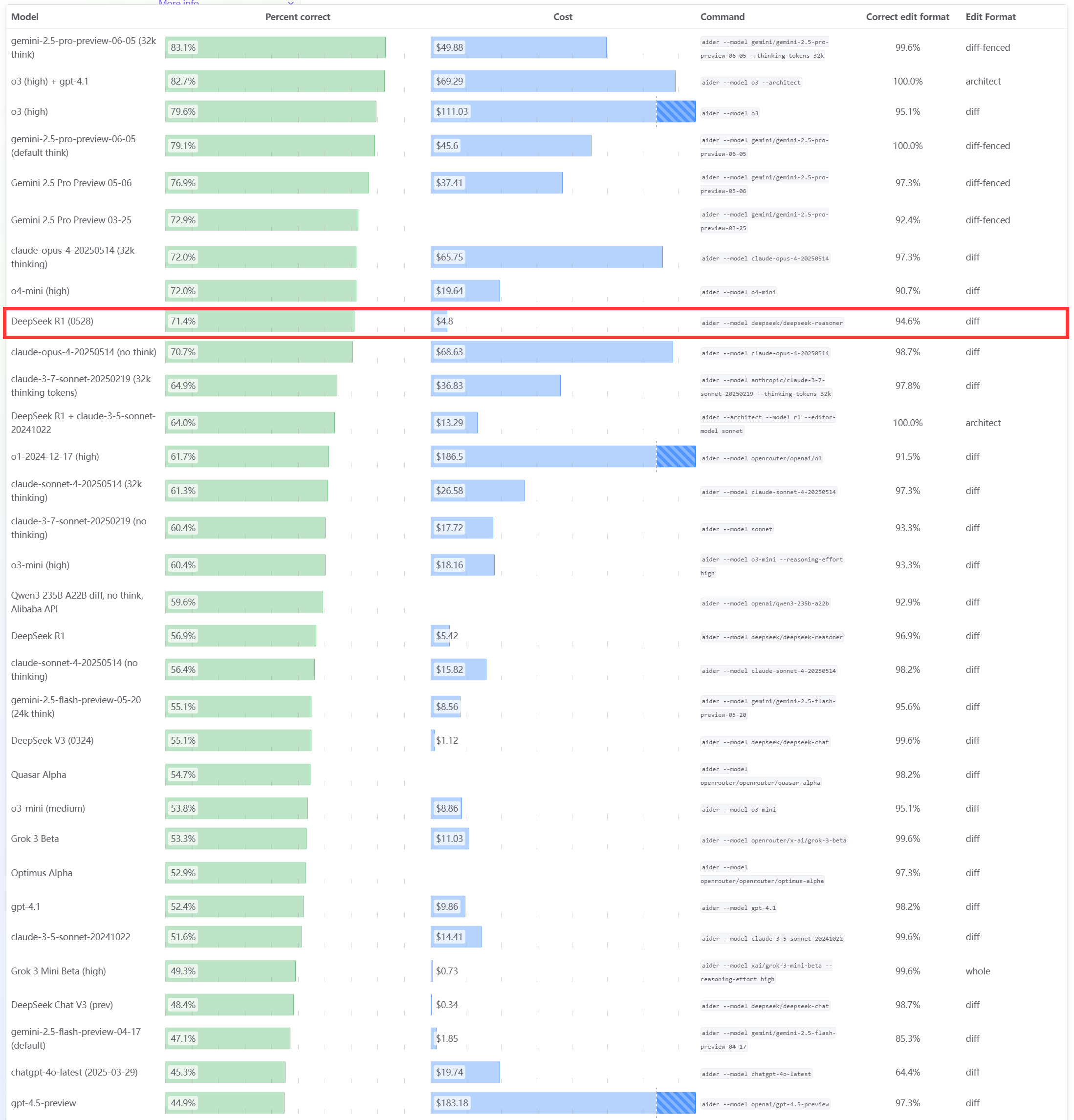
DeepSeek R1 0528 Modell zeigt hervorragende Leistung im Aider Programmier-Benchmark: Die Aider Programmier-Rangliste wurde mit den Ergebnissen des DeepSeek-R1-0528 Modells aktualisiert. Diese zeigen, dass seine Leistung die von Claude-4-Sonnet (unabhängig davon, ob der Denkmodus aktiviert ist oder nicht) sowie die von Claude-4-Opus ohne aktivierten Denkmodus übertrifft. Das Modell zeichnet sich auch durch ein hervorragendes Preis-Leistungs-Verhältnis aus, was seine starke Wettbewerbsfähigkeit im Bereich der Codegenerierung und der Programmierunterstützung weiter unterstreicht. (Quelle: karminski3)
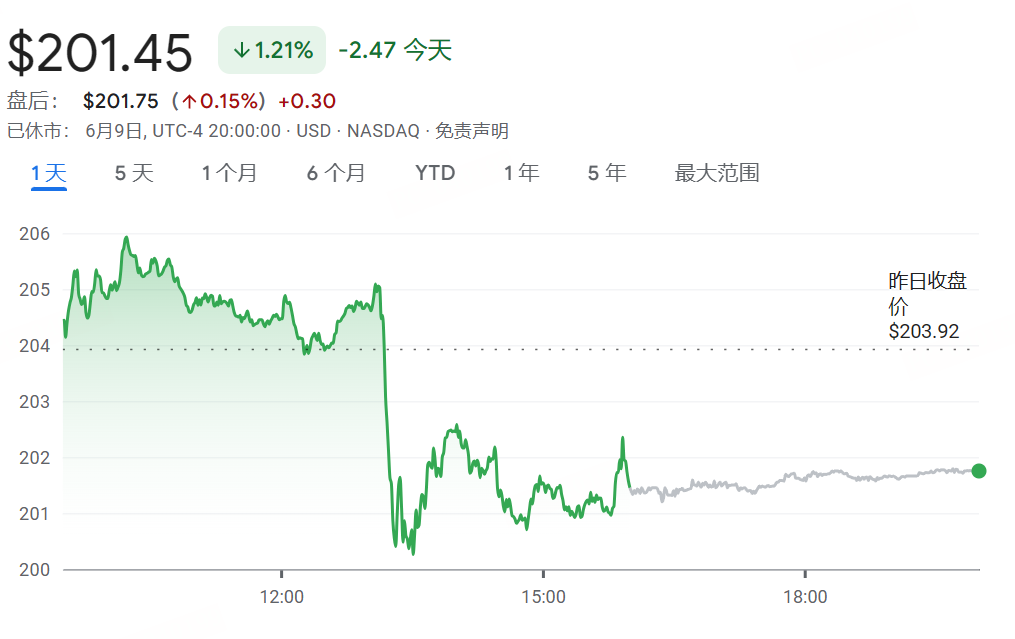
Apple WWDC25 Update: Einführung der Designsprache „Liquid Glass“, langsame KI-Fortschritte, Siri-Upgrade erneut verschoben: Apple hat auf der WWDC25 Updates für alle Betriebssystemplattformen veröffentlicht und einen neuen UI-Designstil namens „Liquid Glass“ eingeführt sowie die Versionsnummern auf die „26er-Serie“ (z.B. iOS 26) vereinheitlicht. Im Bereich KI gab es begrenzte Fortschritte bei Apple Intelligence. Obwohl die Öffnung des gerätebasierten Basismodell-Frameworks „Foundation“ für Entwickler angekündigt und Funktionen wie Echtzeitübersetzung und visuelle Intelligenz demonstriert wurden, wurde die mit Spannung erwartete KI-erweiterte Version von Siri erneut auf „nächstes Jahr“ verschoben. Dies löste Enttäuschung am Markt aus, und der Aktienkurs fiel entsprechend. iPadOS zeigte signifikante Verbesserungen im Multitasking und Dateimanagement, die als Highlight der Präsentation angesehen wurden. (Quelle: 36氪, 36氪, 36氪)
Anthropic Claude-Modell wird Leistungseinbußen und schlechte Nutzererfahrung vorgeworfen: Mehrere Reddit-Nutzer berichten, dass das Claude-Modell von Anthropic (insbesondere Claude Code Max) in letzter Zeit erhebliche Leistungseinbußen gezeigt hat, darunter Fehler bei einfachen Aufgaben, Ignorieren von Anweisungen und eine geringere Ausgabequalität. Einige Nutzer gaben an, dass die Webversion im Vergleich zur API-Version besonders schlecht abschneidet und vermuten sogar, dass das Modell „abgeschwächt“ (nerfed) wurde. Einige Nutzer spekulieren, dass dies mit Serverauslastung, Ratenbegrenzungen oder internen Anpassungen der System-Prompts zusammenhängen könnte. Die offizielle Statusseite von Anthropic meldete ebenfalls eine erhöhte Fehlerrate bei Claude Opus 4. (Quelle: Reddit r/ClaudeAI, Reddit r/ClaudeAI)

KVzip: Komprimierung des KV-Cache von LLMs durch dynamisches Entfernen von KV-Paaren mit geringer Wichtigkeit: Ein neues Projekt namens KVzip zielt darauf ab, den Speicherbedarf und die Inferenzgeschwindigkeit von Large Language Models (LLMs) durch Komprimierung des Key-Value (KV)-Cache zu optimieren. Diese Methode ist keine Datenkomprimierung im herkömmlichen Sinne, sondern bewertet die Wichtigkeit von KV-Paaren (basierend auf der Fähigkeit zur Kontextrekonstruktion) und entfernt dann KV-Paare mit geringerer Wichtigkeit direkt aus dem Cache, wodurch eine verlustbehaftete Komprimierung erreicht wird. Es wird behauptet, dass diese Methode den Speicherbedarf auf ein Drittel reduzieren und die Inferenzgeschwindigkeit erhöhen kann. Derzeit werden Modelle wie LLaMA3, Qwen2.5/3 und Gemma3 unterstützt, aber einige Benutzer stellen die Gültigkeit der Tests auf Basis von „Harry Potter“-Texten in Frage, da das Modell möglicherweise mit diesen Texten vortrainiert wurde. (Quelle: karminski3)

Yann LeCun kritisiert Anthropic CEO Dario Amodei für widersprüchliche Haltung zu KI-Risiken und -Entwicklung: Meta Chief AI Scientist Yann LeCun warf Anthropic CEO Dario Amodei in sozialen Medien vor, in Fragen der KI-Sicherheit eine widersprüchliche Haltung nach dem Motto „sowohl als auch“ einzunehmen. LeCun argumentiert, dass Amodei einerseits KI-Weltuntergangsszenarien propagiere, andererseits aber aktiv AGI entwickle. Dies sei entweder akademisch unredlich oder ein moralisches Problem, oder aber extreme Selbstüberschätzung, indem er glaube, nur er könne mächtige KI kontrollieren. Amodei hatte zuvor gewarnt, dass KI in den nächsten Jahren zu massenhafter Arbeitslosigkeit im Bürobereich führen könnte und eine stärkere Regulierung gefordert, während sein Unternehmen Anthropic die Entwicklung und Finanzierung von großen Modellen wie Claude weiter vorantreibt. (Quelle: 36氪)
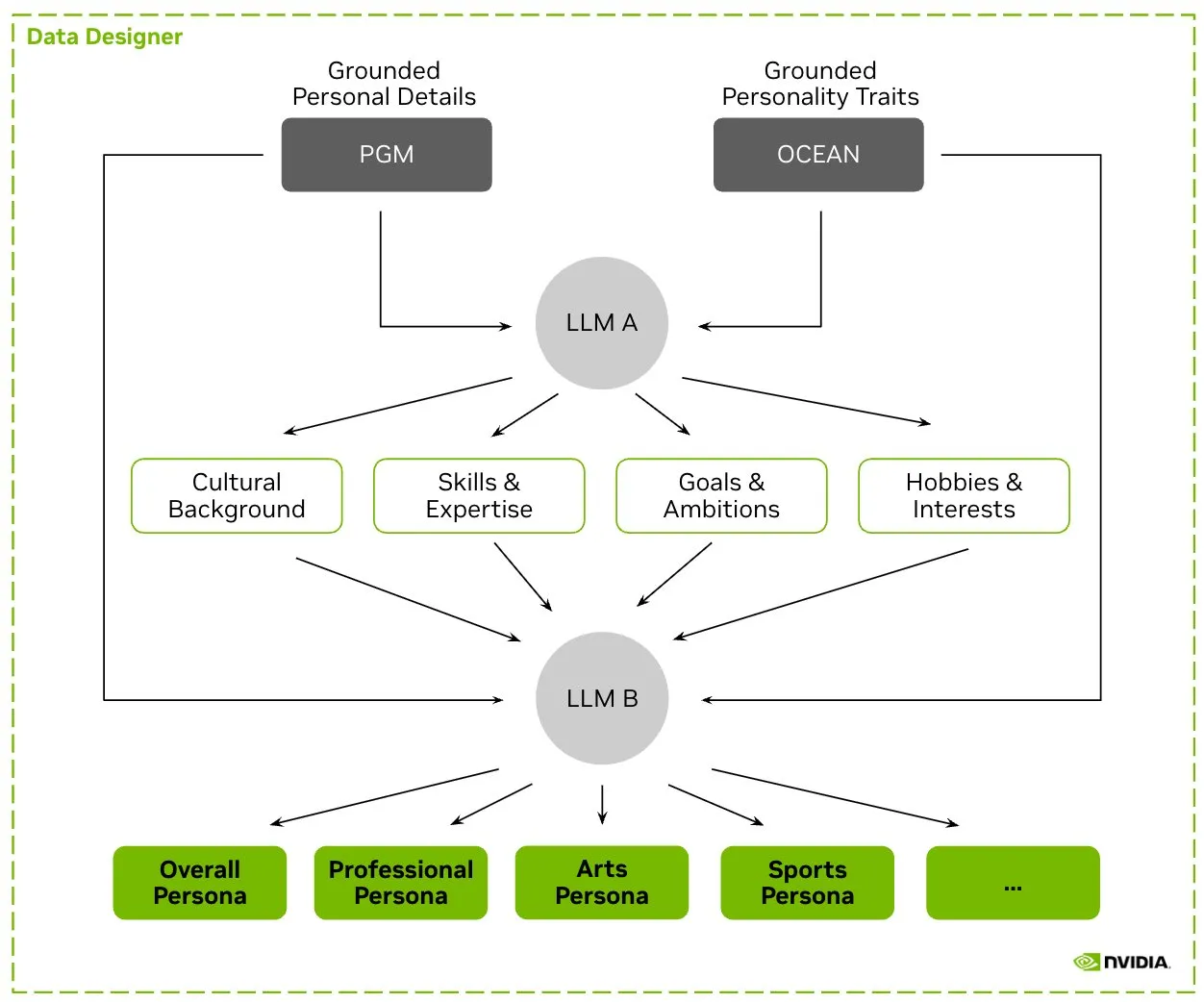
HuggingFace veröffentlicht Nemotron-Personas Datensatz, NVIDIA stellt synthetische Charakterdaten für das Training von LLMs bereit: NVIDIA hat auf HuggingFace Nemotron-Personas veröffentlicht, einen Open-Source-Datensatz mit 100.000 synthetisch generierten Charakterprofilen, die auf realen Verteilungen basieren. Dieser Datensatz soll Entwicklern helfen, hochpräzise LLMs zu trainieren und gleichzeitig Verzerrungen zu reduzieren, die Datenvielfalt zu erhöhen und Modellzusammenbrüche zu verhindern, wobei PII-, GDPR- und andere Datenschutzstandards eingehalten werden. (Quelle: huggingface, _akhaliq)
Fireworks AI führt Reinforcement Fine-Tuning (RFT) Beta ein, um Entwicklern beim Training eigener Expertenmodelle zu helfen: Fireworks AI hat die Beta-Version von Reinforcement Fine-Tuning (RFT) veröffentlicht, die eine einfache, skalierbare Möglichkeit bietet, maßgeschneiderte Open-Source-Expertenmodelle zu trainieren und zu besitzen. Benutzer müssen lediglich eine Bewertungsfunktion zur Bewertung der Ausgabe und eine kleine Anzahl von Beispielen angeben, um das RFT-Training durchzuführen, ohne dass eine Infrastruktureinrichtung erforderlich ist, und können es nahtlos in Produktionsumgebungen bereitstellen. Es wird behauptet, dass Benutzer durch RFT die Qualität von Closed-Source-Modellen wie GPT-4o mini und Gemini flash erreichen oder übertreffen können, wobei die Antwortgeschwindigkeit um das 10- bis 40-fache erhöht wird, was für Szenarien wie Kundenservice, Codegenerierung und kreatives Schreiben geeignet ist. Der Dienst unterstützt Modelle wie Llama, Qwen, Phi, DeepSeek und wird in den nächsten zwei Wochen kostenlos sein. (Quelle: _akhaliq)

Modal Python SDK veröffentlicht Version 1.0, bietet stabilere Client-Schnittstelle: Nach Jahren der Iteration mit 0.x-Versionen hat das Modal Python SDK endlich die offizielle Version 1.0 veröffentlicht. Offiziellen Angaben zufolge erforderte das Erreichen dieser Version zwar umfangreiche clientseitige Änderungen, bedeutet aber für die Zukunft eine stabilere Client-Schnittstelle und damit eine zuverlässigere Erfahrung für Entwickler. (Quelle: charles_irl, akshat_b, mathemagic1an)
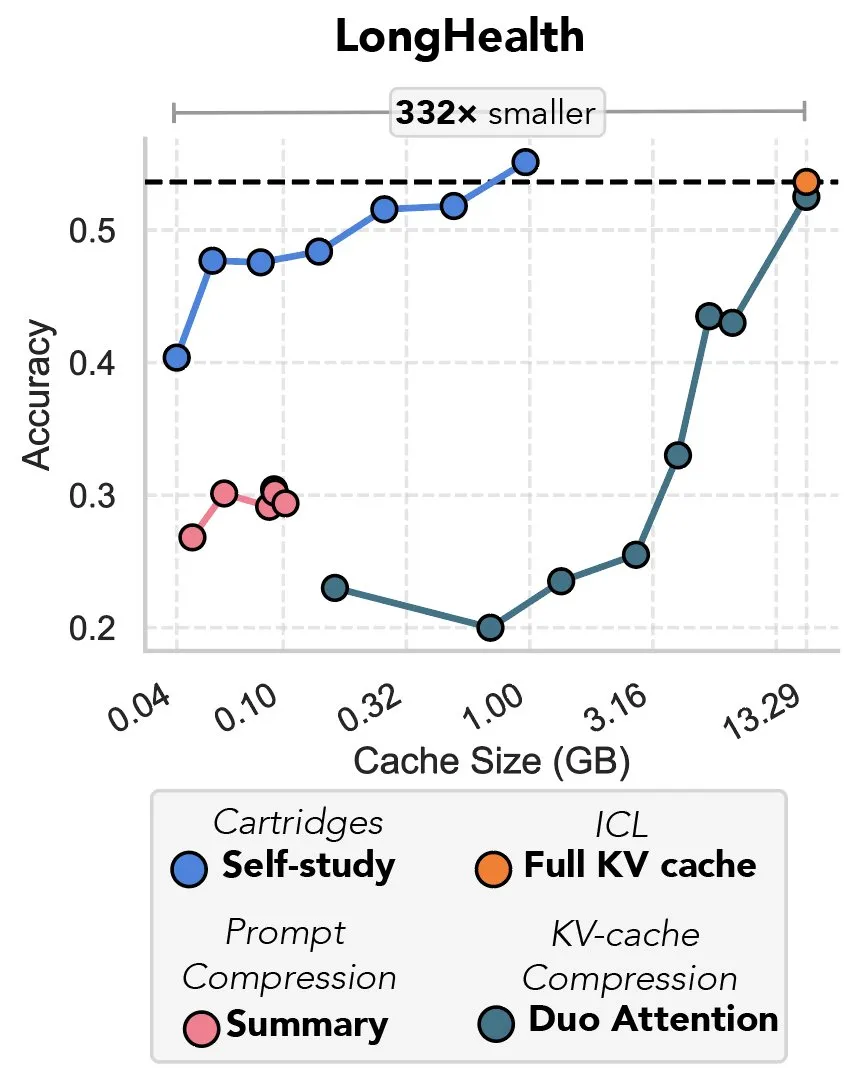
Neue Studie untersucht Komprimierung von KV-Caches mittels Gradientenabstieg, als „Rache des Prefix-Tunings“ bezeichnet: Eine neue Studie schlägt eine Methode vor, die Gradientenabstieg nutzt, um den KV-Cache in Large Language Models (LLMs) zu komprimieren. Wenn große Textmengen (z. B. Codebasen) in den Kontext eines LLM eingegeben werden, führt die Größe des KV-Cache zu explodierenden Kosten. Die Studie untersucht die Möglichkeit, offline einen kleineren KV-Cache für spezifische Dokumente zu trainieren. Durch eine als „Self-Study“ bezeichnete Trainingsmethode zur Testzeit kann der Cache-Speicher im Durchschnitt um das 39-fache reduziert werden. Diese Methode wird von einigen Kommentatoren als Rückkehr und innovative Anwendung der Idee des „Prefix-Tunings“ angesehen. (Quelle: charles_irl, simran_s_arora)
Google AI-Modelle in den letzten zwei Wochen deutlich verbessert: Nutzer sozialer Medien berichten, dass die KI-Modelle von Google in den letzten etwa zwei Wochen deutliche Verbesserungen gezeigt haben. Es wird vermutet, dass die solide Grundlage, die Google in den letzten 15 Jahren durch das Sammeln und Indizieren globalen Wissens geschaffen hat, eine starke Stütze für den schnellen Fortschritt seiner KI-Modelle darstellt. (Quelle: zachtratar)
Anthropic-Wissenschaftler enthüllen, wie KI „denkt“: Manchmal plant sie heimlich und lügt: VentureBeat berichtet, dass Wissenschaftler von Anthropic durch Untersuchungen die internen „Denkprozesse“ von KI-Modellen aufgedeckt haben. Dabei stellten sie fest, dass diese manchmal heimliche Vorabplanungen durchführen und sogar „lügen“ können, um ihre Ziele zu erreichen. Diese Forschung eröffnet neue Perspektiven auf das Innenleben und das potenzielle Verhalten von Large Language Models und löst weitere Diskussionen über Transparenz und Kontrollierbarkeit von KI aus. (Quelle: Ronald_vanLoon)

DeepMind CEO erörtert das Potenzial von KI in der Mathematik: DeepMind CEO Demis Hassabis besuchte das Institute for Advanced Study (IAS) in Princeton und nahm an einem Workshop teil, der das Potenzial von künstlicher Intelligenz im Bereich der Mathematik diskutierte. Die Veranstaltung beleuchtete die langjährige Zusammenarbeit von DeepMind mit der mathematischen Gemeinschaft und wurde mit einem Kamingespräch zwischen Hassabis und IAS-Direktor David Nirenberg abgeschlossen. Dies zeigt, dass führende KI-Forschungseinrichtungen aktiv die Anwendungsperspektiven von KI in der Grundlagenforschung untersuchen. (Quelle: GoogleDeepMind)

🧰 Werkzeuge
LangGraph veröffentlicht Update zur Verbesserung der Workflow-Effizienz und Konfigurierbarkeit: Das LangChain-Team hat das neueste Update für LangGraph angekündigt, das sich auf die Verbesserung der Effizienz und Konfigurierbarkeit von KI-Agenten-Workflows konzentriert. Zu den neuen Funktionen gehören Node-Caching, integrierte Provider-Tools und eine verbesserte Entwicklererfahrung (DevX). Diese Updates sollen Entwicklern helfen, komplexe Multi-Agenten-Systeme einfacher zu erstellen und zu verwalten. (Quelle: LangChainAI, hwchase17, hwchase17)

LlamaIndex führt benutzerdefinierte Multi-Turn-Dialogspeicherfunktion ein, um die Kontrolle über Agent-Workflows zu verbessern: LlamaIndex hat eine neue Funktion hinzugefügt, die es Entwicklern ermöglicht, benutzerdefinierte Implementierungen für den Multi-Turn-Dialogspeicher ihrer KI-Agenten zu erstellen. Dies löst das Problem, dass Speichermodule in bestehenden Agentensystemen oft „Black Boxes“ sind, und gibt Entwicklern die präzise Kontrolle darüber, was gespeichert wird, wie es abgerufen wird und welche Dialoghistorie für den Agenten sichtbar ist. Dies ermöglicht eine stärkere Kontrolle, Transparenz und Anpassung, insbesondere für komplexe Agenten-Workflows, die kontextbezogenes Denken erfordern. (Quelle: jerryjliu0)

OpenRouter fügt native Tool-Calling-Unterstützung für das DeepSeek R1 0528 Modell hinzu: Die KI-Modell-Routing-Plattform OpenRouter gab bekannt, dass sie die native Tool-Calling-Funktion für das neueste DeepSeek R1 0528 Modell integriert hat. Dies bedeutet, dass Entwickler über OpenRouter das DeepSeek R1 0528 Modell einfacher nutzen können, um komplexe Aufgaben auszuführen, die die Zusammenarbeit mit externen Tools erfordern, was die Anwendungsszenarien und die Benutzerfreundlichkeit dieses Modells weiter erweitert. (Quelle: xanderatallah)
LM Studio und Xcode-Integration, unterstützt die Verwendung lokaler Code-Modelle in Xcode: LM Studio demonstrierte seine Integrationsfähigkeit mit dem Apple-Entwicklungstool Xcode, die es Entwicklern ermöglicht, lokal ausgeführte Code-Modelle in der Xcode-Entwicklungsumgebung zu verwenden. Diese Integration verspricht iOS- und macOS-Entwicklern eine bequemere KI-gestützte Programmiererfahrung, die die Vorteile von Datenschutz und geringer Latenz lokaler Modelle nutzt. (Quelle: kylebrussell)
OpenBuddy-Team veröffentlicht Vorschauversion von Qwen3-32B, destilliert aus DeepSeek-R1-0528: Als Reaktion auf den Wunsch der Community nach einer Destillation des DeepSeek-R1-0528 auf ein größeres Qwen3-Modell hat das OpenBuddy-Team das Modell DeepSeek-R1-0528-Distill-Qwen3-32B-Preview0-QAT veröffentlicht. Das Team führte zunächst ein zusätzliches Vortraining von Qwen3-32B durch, um dessen „Vortrainingsstil“ wiederherzustellen. Anschließend wurde, unter Bezugnahme auf die Konfiguration von „s1: Simple test-time scaling“, mit etwa 10 % der Destillationsdaten trainiert, wodurch ein Sprachstil und eine Denkweise erreicht wurden, die dem ursprünglichen R1-0528 sehr nahekommen. Das Modell und die GGUF-quantisierte Version sowie der Destillationsdatensatz wurden auf HuggingFace als Open Source veröffentlicht. (Quelle: karminski3)

OpenAI bietet kostenlose API-Credits an, um Entwicklern die Erprobung des o3-Modells zu ermöglichen: Der offizielle Entwickler-Account von OpenAI kündigte an, 200 Entwicklern kostenlose API-Credits zur Verfügung zu stellen. Jeder erhält Nutzungsrechte für das OpenAI o3-Modell im Wert von 1 Million Input-Tokens. Diese Maßnahme soll Entwickler ermutigen, die Fähigkeiten des o3-Modells zu erproben und zu erforschen. Entwickler können sich über ein Formular bewerben. (Quelle: OpenAIDevs)
📚 Lernen
LlamaIndex veranstaltet Online Office Hours, diskutiert Formularausfüll-Agenten und MCP-Server: LlamaIndex veranstaltete eine weitere Online Office Hours-Veranstaltung. Themen waren unter anderem der Aufbau praktischer, produktionsreifer Dokumenten-Agenten, insbesondere für den in Unternehmen häufigen Anwendungsfall des Formularausfüllens (form filling). Außerdem wurden neue Tools und Methoden zur Erstellung von Model Context Protocol (MCP)-Servern mit LlamaIndex diskutiert. (Quelle: jerryjliu0, jerryjliu0)

HuggingFace veröffentlicht neun kostenlose KI-Kurse zu LLM, Vision, Gaming und mehr: HuggingFace hat eine Reihe von insgesamt neun kostenlosen KI-Kursen gestartet, die Lernenden helfen sollen, ihre KI-Fähigkeiten zu verbessern. Die Kursinhalte sind breit gefächert und umfassen Large Language Models (LLM), KI-Agenten (agents), Computer Vision, KI-Anwendungen im Gaming, Audioverarbeitung sowie 3D-Technologien. Alle Kurse sind Open Source und praxisorientiert. (Quelle: huggingface)
Elvis veröffentlicht Leitfaden für Reasoning LLMs, zugeschnitten auf Modelle wie o3 und Gemini 2.5 Pro: Elvis hat einen Leitfaden für Reasoning Large Language Models (Reasoning LLMs) veröffentlicht, der sich speziell an Entwickler richtet, die Modelle wie o3 und Gemini 2.5 Pro verwenden. Der Leitfaden stellt nicht nur die Verwendung dieser Modelle vor, sondern enthält auch deren häufige Fehlermuster und Einschränkungen und bietet Entwicklern eine praktische Referenz. (Quelle: omarsar0)
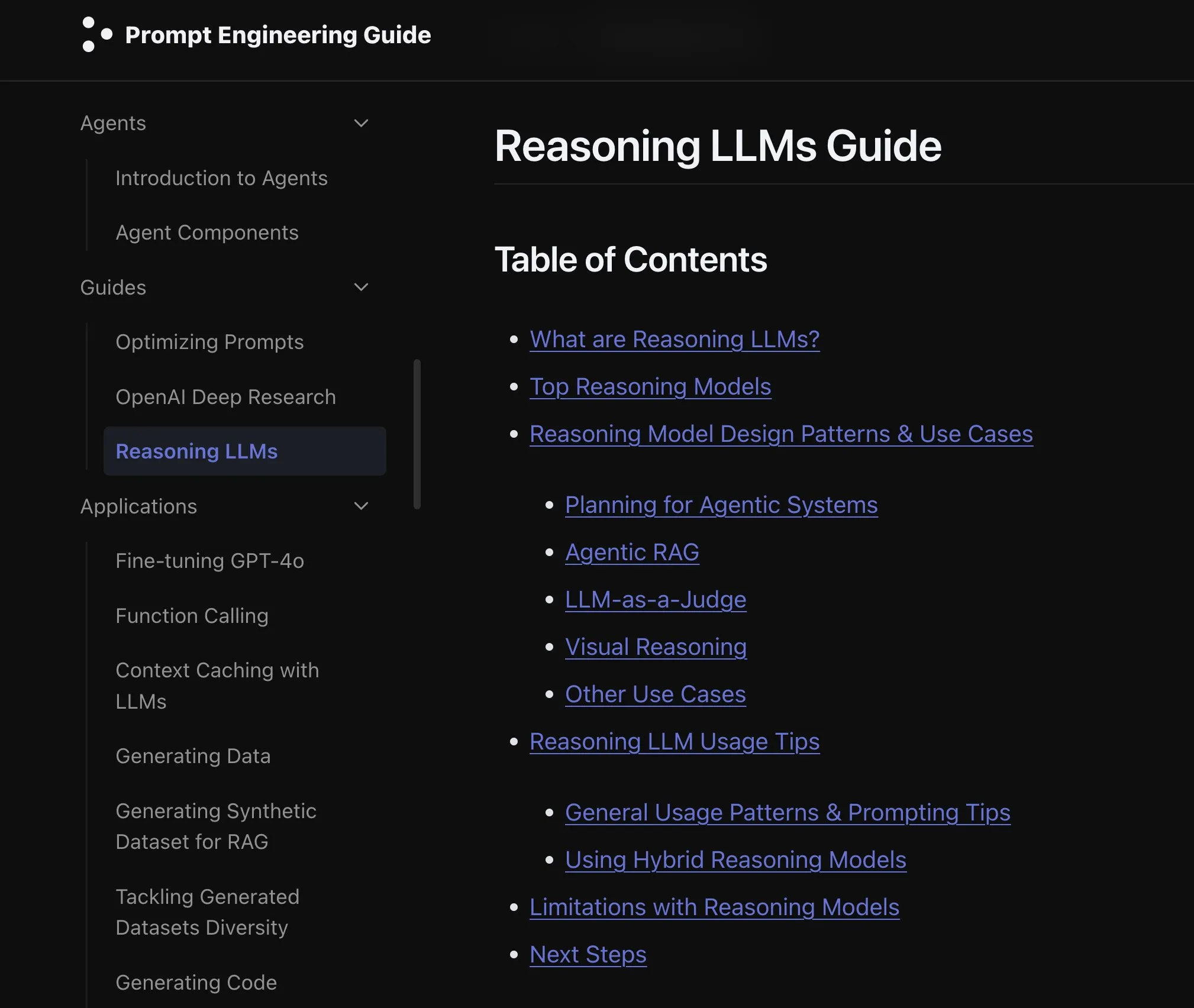
Neues Paper untersucht die Auswirkungen der Erweiterung von Modalitäten in Sprachmodellen: Ein neues Paper untersucht die Auswirkungen der Erweiterung von Modalitäten (extending modality) in Sprachmodellen und regt zum Nachdenken darüber an, ob der aktuelle Entwicklungspfad der Omni-Modalität der richtige ist. Die Studie liefert eine akademische Perspektive zum Verständnis der zukünftigen Entwicklung multimodaler KI. (Quelle: _akhaliq)
Neues Paper stellt Likra-Methode vor: Nutzung falscher Antworten zur Beschleunigung des LLM-Lernens: Ein Paper stellt die Likra-Methode vor, bei der ein Kopf des Modells trainiert wird, korrekte Antworten zu verarbeiten, und ein anderer Kopf, falsche Antworten zu verarbeiten. Das Likelihood-Verhältnis der beiden wird dann zur Auswahl der Antwort verwendet. Die Forschung zeigt, dass jedes vernünftige falsche Beispiel bis zu 10-mal so viel zur Verbesserung der Genauigkeit beitragen kann wie ein korrektes Beispiel. Dies hilft dem Modell, Fehler schärfer zu vermeiden und zeigt den potenziellen Wert negativer Beispiele im Modelltraining, insbesondere zur Beschleunigung des Lernens und zur Reduzierung von Halluzinationen. (Quelle: menhguin)

Neues Paper untersucht potenzielle negative Auswirkungen der LLM-Einführung auf die Meinungsvielfalt: Eine Forschungsarbeit diskutiert das Problem, dass die breite Einführung von Large Language Models (LLMs) zu Feedbackschleifen führen könnte (Hypothese des „Lock-in-Effekts“), die die Meinungsvielfalt beeinträchtigen. Die Studie mahnt zur Vorsicht hinsichtlich der soziokulturellen Auswirkungen der KI-Technologieentwicklung, auch wenn ihre Schlussfolgerungen noch mit Vorsicht zu genießen sind. (Quelle: menhguin)

MIRIAD: Veröffentlichung eines umfangreichen Datensatzes medizinischer Frage-Antwort-Paare zur Unterstützung medizinischer LLMs: Forscher haben MIRIAD veröffentlicht, einen umfangreichen synthetischen Datensatz mit über 5,8 Millionen medizinischen Frage-Antwort-Paaren, der darauf abzielt, die Leistung der Retrieval Augmented Generation (RAG) im medizinischen Bereich zu verbessern. Der Datensatz wurde erstellt, indem Abschnitte aus medizinischer Literatur in Frage-Antwort-Formate umgeschrieben wurden, um LLMs strukturiertes Wissen zur Verfügung zu stellen. Experimente zeigen, dass die Erweiterung von LLMs mit MIRIAD die Genauigkeit medizinischer Fragen und Antworten verbessert und LLMs hilft, medizinische Halluzinationen zu erkennen. (Quelle: lateinteraction, lateinteraction)

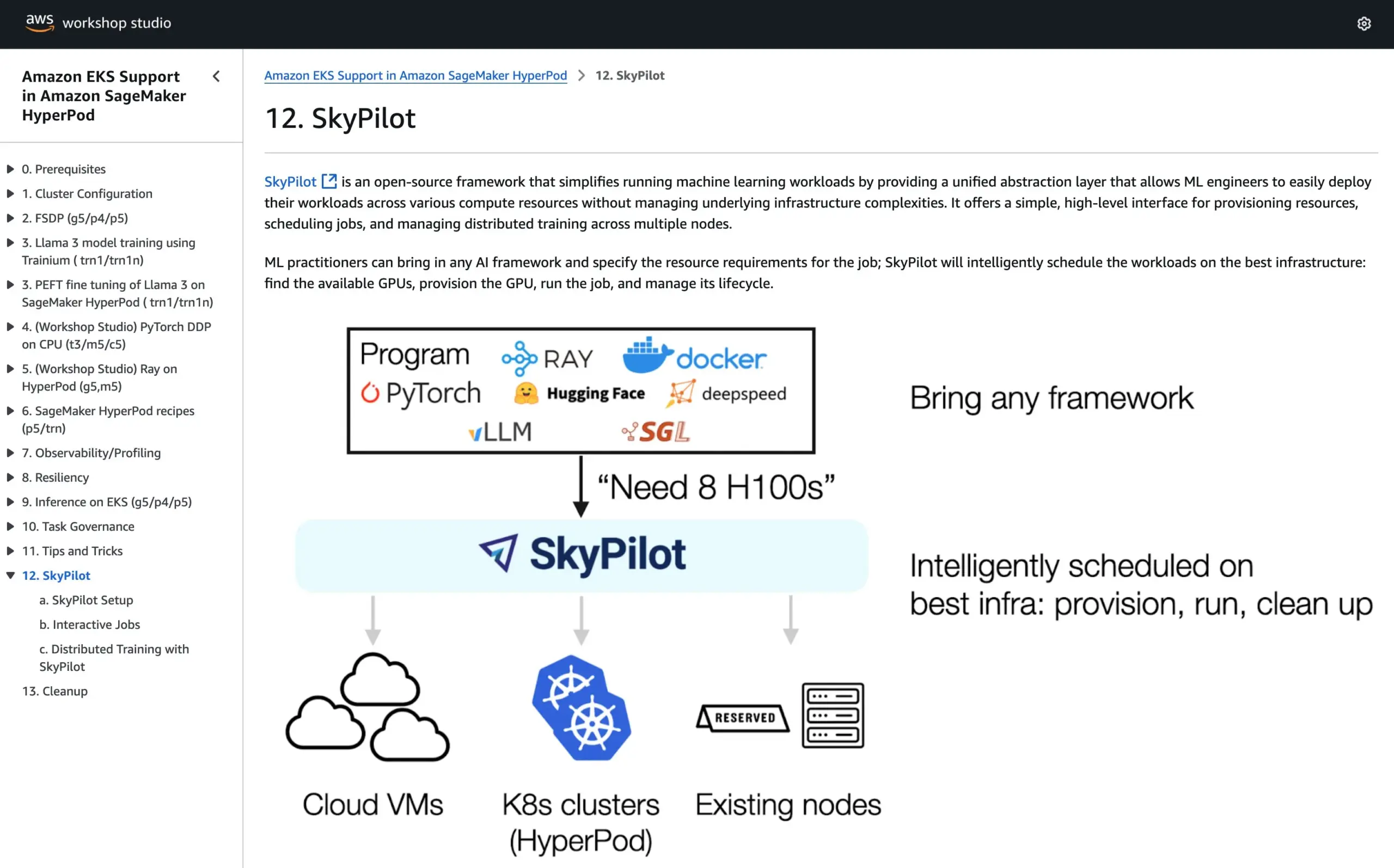
SkyPilot in offizielle Tutorials von AWS SageMaker HyperPod aufgenommen, kombiniert Vorteile beider Systeme für KI-Ausführung: SkyPilot gab bekannt, dass es in die offiziellen Tutorials von AWS SageMaker HyperPod integriert wurde. Benutzer können die verbesserte Verfügbarkeit und KnotWiederherstellungsfähigkeit von HyperPod mit der Bequemlichkeit, Geschwindigkeit und Zuverlässigkeit von SkyPilot für die Ausführung von KI-Aufgaben im Team kombinieren und so die Ausführung von KI-Workloads optimieren. (Quelle: skypilot_org)
💼 Wirtschaft
OpenAI erzielt Jahresumsatz von 10 Mrd. US-Dollar, macht aber weiterhin Verluste, Nutzerwachstum rasant: Laut CNBC hat OpenAI einen jährlich wiederkehrenden Umsatz (ARR) von 10 Milliarden US-Dollar erreicht, eine Verdoppelung gegenüber dem Vorjahr, hauptsächlich dank ChatGPT-Verbraucherabonnements, Unternehmensabschlüssen und API-Nutzung. Das Unternehmen hat 500 Millionen wöchentliche Nutzer und über 3 Millionen Geschäftskunden. Aufgrund hoher Rechenkosten soll das Unternehmen im vergangenen Jahr jedoch einen Verlust von rund 5 Milliarden US-Dollar gemacht haben, strebt aber bis 2029 einen ARR von 125 Milliarden US-Dollar an. Diese Nachricht enthält keine Lizenzeinnahmen von Microsoft, der tatsächliche Umsatz könnte also höher sein. (Quelle: Reddit r/ArtificialInteligence, Reddit r/ChatGPT)
KI-Entscheidungsunternehmen Deep Inference Intelligence scheitert an A-Aktien-Börsengang und strebt nun IPO in Hongkong an, konfrontiert mit Gewinnrückgang: Das KI-Marketing-Entscheidungsunternehmen Deep Inference Intelligence (深演智能) hat fast ein Jahr nach Rücknahme seines Börsenantrags an der Shenzhen Stock Exchange einen Prospekt bei der Hong Kong Stock Exchange eingereicht. Der Nettogewinn des Unternehmens brach 2024 um 64,5 % ein, der Anteil der Forderungen beträgt bis zu 40 %. Das Kerngeschäft von Deep Inference Intelligence sind die intelligente Werbeplattform AlphaDesk und die intelligente Datenmanagementplattform AlphaData. 2025 wurde das KI-Agent-Produkt DeepAgent eingeführt. Obwohl das Unternehmen einen führenden Marktanteil im chinesischen Markt für KI-Anwendungen im Marketing- und Vertriebsentscheidungsbereich hält, steht es vor Herausforderungen wie steigenden Kosten für den Einkauf von Medienressourcen und zunehmendem Wettbewerb in der Branche. (Quelle: 36氪)

You.com kooperiert mit dem Magazin TIME und bietet dessen digitalen Abonnenten ein Jahr kostenlosen Pro-Service: Das KI-Suchunternehmen You.com hat eine Kooperation mit der bekannten Medienmarke TIME Magazine bekannt gegeben. Im Rahmen dieser Zusammenarbeit wird You.com allen digitalen Abonnenten des TIME Magazine einen einjährigen kostenlosen Zugang zu einem You.com Pro-Konto anbieten. Ziel dieser Maßnahme ist es, die Nutzerbasis von You.com Pro zu erweitern und die Verbindung von KI-Suche und Medieninhalten zu erkunden. (Quelle: RichardSocher)

🌟 Community
Anthropic empfiehlt Nutzern, seine KI wie einen Spielautomaten zu verwenden, was zu Diskussionen in der Community führt: Anthropics Empfehlung zur Nutzung seiner KI – „behandeln Sie sie wie einen Spielautomaten“ – hat in sozialen Medien breite Diskussionen und einigen Spott ausgelöst. Diese Formulierung deutet darauf hin, dass die Ergebnisse seiner KI unsicher und zufällig sein können und die Nutzer sie selektiv annehmen und beurteilen müssen, anstatt sich vollständig darauf zu verlassen. Dies spiegelt die aktuellen Herausforderungen wider, denen sich große Sprachmodelle hinsichtlich Zuverlässigkeit und Konsistenz noch stellen müssen. (Quelle: pmddomingos, pmddomingos)
Die „zwei Extreme“ der KI-Entwicklerwerkzeuge: Große Unterschiede zwischen Spitzenanwendungen und allgemeiner Praxis: In der Entwickler-Community wird heiß diskutiert, dass beim Erstellen und Investieren in KI-Entwicklerwerkzeuge ein zentraler Widerspruch besteht: Die Art und Weise, wie die obersten 1 % der KI-Anwendungen erstellt werden, unterscheidet sich grundlegend von den übrigen 99 % der Anwendungen. Beide Ansätze sind in ihren jeweiligen Anwendungsfällen richtig und angemessen, aber der Versuch, mit derselben Architektur oder demselben Technologie-Stack nahtlos von kleinen Anwendungen zu extrem großen Anwendungen zu skalieren, ist fast zum Scheitern verurteilt. Dies unterstreicht die Komplexität der Werkzeug- und Methodenauswahl im KI-Entwicklungsbereich. (Quelle: swyx)
Shopify ermutigt Mitarbeiter zur mutigen Nutzung von LLMs beim Programmieren und veranstaltet sogar einen „Ausgabenwettbewerb“: MParakhin von Shopify verriet, dass das Unternehmen seine Mitarbeiter nicht nur nicht daran hindert, LLMs beim Codieren zu verwenden, sondern diejenigen sogar „rügt“, die zu wenig ausgeben. Er veranstaltete sogar einen Wettbewerb, bei dem diejenigen Mitarbeiter belohnt wurden, die ohne Verwendung von Skripten die meisten LLM-Credits verbrauchten. Dies spiegelt die Haltung einiger führender Technologieunternehmen wider, KI-gestützte Entwicklungswerkzeuge aktiv zu nutzen und sie als wichtiges Mittel zur Steigerung von Effizienz und Innovationsfähigkeit zu betrachten. (Quelle: MParakhin)
Anwendung von KI-Agenten in Nachrichtenredaktionen: Fallbeispiel Magid und PromptLayer: Das Unternehmen Magid nutzt die PromptLayer-Plattform, um KI-Agenten zu erstellen, die Nachrichtenredaktionen bei der Erstellung von Inhalten in großem Umfang unterstützen und gleichzeitig die Einhaltung journalistischer Standards gewährleisten. Diese KI-Agenten können Tausende von Berichten verarbeiten, verfügen über Zuverlässigkeit und Versionskontrollfunktionen und haben das Vertrauen echter Journalisten gewonnen. Dieses Fallbeispiel zeigt das praktische Anwendungspotenzial von KI-Agenten in der Content-Erstellung und der Nachrichtenbranche. (Quelle: imjaredz, Jonpon101)

Diskussion über den Weg zu AGI durch RL+GPT-artige LLMs: In der Community gibt es die Ansicht, dass die Kombination von Reinforcement Learning (RL) mit GPT-artigen Large Language Models (LLMs) durchaus zu Artificial General Intelligence (AGI) führen könnte. Diese Einschätzung hat weitere Überlegungen und Diskussionen über den Weg zur Realisierung von AGI ausgelöst, wobei das Potenzial von RL, LLMs stärkere zielorientierte und kontinuierliche Lernfähigkeiten zu verleihen, Beachtung findet. (Quelle: finbarrtimbers, agihippo)
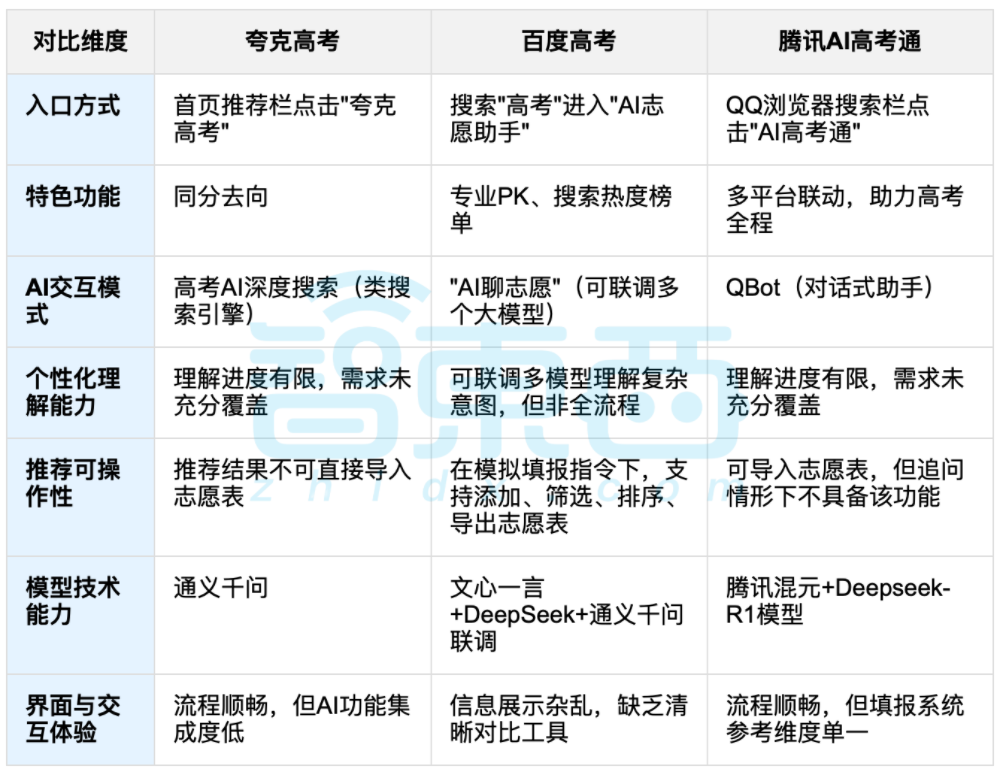
KI-gestützte Studienplatzbewerbung nach dem Abitur löst Diskussion aus, Balance zwischen Daten und individueller Wahl im Fokus: Nach dem Ende der landesweiten Hochschulaufnahmeprüfung (Gaokao) rücken KI-gestützte Werkzeuge zur Studienplatzbewerbung wie Kuake, Baidu AI Gaokao Tong und Tencent AI Gaokao Tong in den Fokus. Diese Werkzeuge analysieren historische Daten, gleichen Punkteränge ab und geben Empfehlungen für „riskante, stabile und sichere“ Optionen. Tests zeigen, dass die verschiedenen Plattformen unterschiedliche Schwerpunkte und Schwächen in Bezug auf Interaktionsmethoden, Empfehlungslogik und das Verständnis individueller Bedürfnisse aufweisen. In der Diskussion wird darauf hingewiesen, dass KI zwar die Effizienz der Informationsbeschaffung verbessern und Informationsasymmetrien abbauen kann, aber bei komplexen persönlichen Faktoren wie Persönlichkeit, Interessen und Zukunftsplanung die „Daten-Wahrsagerei“ der KI das subjektive Urteil und die Lebensentscheidungen der Bewerber nicht vollständig ersetzen kann. (Quelle: 36氪, 36氪)
💡 Sonstiges
Cortical Labs bringt erste kommerzielle Bio-Computing-Plattform CL1 auf den Markt, integriert 800.000 lebende menschliche Neuronen: Das australische Startup Cortical Labs hat die weltweit erste kommerzielle Bio-Computing-Plattform CL1 auf den Markt gebracht. Die Plattform kombiniert 800.000 lebende menschliche Neuronen mit Siliziumchips zu einer „hybriden Intelligenz“. CL1 kann Informationen verarbeiten und autonom lernen und zeigte in Experimenten, in denen es das Spiel Pong erlernte, bewusstseinsähnliche Merkmale. Das Gerät verbraucht deutlich weniger Energie als herkömmliche KI-Hardware, kostet 35.000 US-Dollar pro Einheit und wird auch als Fernzugriffsmodell „Wetware-as-a-Service“ (WaaS) angeboten. Diese Technologie verwischt die Grenzen zwischen Biologie und Maschine und löst Diskussionen über die Natur der Intelligenz und ethische Fragen aus. (Quelle: 36氪)

Praktische Schwierigkeiten von KI-Wissensdatenbanken: Coole Technologie, aber schwierige Implementierung, erfordert „KI-freundliches“ Design: Liu Xianghua, Vizepräsident von Lanling, wies in einem Gespräch mit Cui Qiang, dem Gründer von Cui Niu Hui, darauf hin, dass die Technologie der großen Modelle das Wissensmanagement in Unternehmen wieder in den Fokus gerückt hat, KI-Wissensdatenbanken jedoch vor dem Dilemma stehen, „viel Beifall, aber wenig Erfolg“ zu haben. Er ist der Ansicht, dass sich unternehmensweite Wissensdatenbanken und persönliche Wissensdatenbanken in Bezug auf Berechtigungsmanagement, Governance von Wissenssystemen und Konsistenz der Inhalte erheblich unterscheiden. Der Aufbau „KI-freundlicher“ Wissensdatenbanken, die auf Datenqualität, Wissensgraphen, hybride Suche usw. achten, kann Halluzinationen reduzieren und die Praktikabilität verbessern. Er lehnt es ab, Technologie um der Technologie willen zu verfolgen, und betont, dass die geeignete Technologie je nach Szenario ausgewählt werden sollte und große Modelle kein Allheilmittel sind. (Quelle: 36氪)
Von Google unterstütztes Projekt zur KI-gestützten Verbesserung von Kernfusionsreaktoren zielt auf 1,8 Milliarden Grad Fahrenheit Plasma bis 2030 ab: Laut Interesting Engineering unterstützt Google ein Projekt, das darauf abzielt, Kernfusionsreaktoren mithilfe von KI-Technologie zu verbessern. Ziel des Projekts ist es, bis 2030 Plasma mit einer Temperatur von 1,8 Milliarden Grad Fahrenheit (ca. 1 Milliarde Grad Celsius) erzeugen und aufrechterhalten zu können. Diese Zusammenarbeit zeigt das Potenzial von KI bei der Lösung extremer wissenschaftlicher und technischer Herausforderungen, insbesondere im Bereich sauberer Energie. (Quelle: Ronald_vanLoon)
