
Schlüsselwörter:Große Sprachmodelle (LLM), Schlussfolgerungsfähigkeit, Mustererkennung, Denkillusionen, Apple Forschung, Allgemeine Künstliche Intelligenz (AGI), KI-Detektoren, KI-Regulierung, Log-Linear Attention Mechanismus, Huawei PanGu MoE-Modell, ChatGPT erweiterter Sprachmodus, TensorZero Framework, Anthropic CEO Regulierungsansichten
🔥 Fokus
Apple-Studie enthüllt „Illusion des Denkens“: Aktuelle „Reasoning“-Modelle denken nicht wirklich, sondern stützen sich eher auf Mustererkennung: Apples neueste Forschungsarbeit mit dem Titel „The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models through the Lens of Problem Complexity“ weist darauf hin, dass große Sprachmodelle (wie Claude, DeepSeek-R1, GPT-4o-mini usw.), die angeblich über „Reasoning“-Fähigkeiten verfügen, in ihrer Leistung eher effizienten Mustererkennungsalgorithmen ähneln als echter logischer Schlussfolgerung. Die Studie ergab, dass die Leistung dieser Modelle bei der Verarbeitung von Problemen außerhalb der Trainingsverteilung oder mit höherer Komplexität erheblich abnimmt. Sie machen sogar bei einfachen Problemen Fehler durch „Überdenken“ und können frühe Fehler nur schwer korrigieren. Die Forschung betont, dass der sogenannte „Denkprozess“ der Modelle (wie Chain-of-Thought) bei neuartigen oder komplexen Aufgaben oft versagt, was darauf hindeutet, dass wir von allgemeiner künstlicher Intelligenz (AGI) möglicherweise weiter entfernt sind als erwartet. (Quelle: machinelearning.apple.com, TheTuringPost, mervenoyann, Reddit r/artificial, Reddit r/LocalLLaMA, Reddit r/MachineLearning)

OpenAI führt Update für den Advanced Voice Mode von ChatGPT ein, verbessert Natürlichkeit und Übersetzungsfunktionen: OpenAI hat ein umfangreiches Update für den Advanced Voice Mode für zahlende ChatGPT-Nutzer veröffentlicht. Die neue Version verbessert die Natürlichkeit und Flüssigkeit der Stimme erheblich, sodass sie eher wie ein Mensch als ein KI-Assistent klingt. Darüber hinaus verbessert das Update die Leistung bei Sprachübersetzungen und die Fähigkeit, Anweisungen zu befolgen. Es wurde auch ein Übersetzungsmodus hinzugefügt, mit dem Nutzer ChatGPT während des gesamten Gesprächs die Dialoge beider Seiten kontinuierlich übersetzen lassen können, bis dies widerrufen wird. Dieses Update zielt darauf ab, die Sprachinteraktion einfacher und natürlicher zu gestalten und das Nutzererlebnis zu verbessern. (Quelle: juberti, Plinz, op7418, BorisMPower)
KI-Detektoren als wirkungslos bezeichnet und könnten „Tarnung“ von KI-Inhalten fördern: In sozialen Medien und Technikforen wird breit diskutiert, dass aktuelle Tools zur Erkennung von KI-Inhalten nicht nur schlecht funktionieren, sondern möglicherweise unbeabsichtigt dazu beitragen, dass KI-generierte Inhalte schwerer zu erkennen sind. Viele Nutzer und Experten sind der Meinung, dass diese Detektoren hauptsächlich auf Sprachmustern und spezifischen Vokabeln (wie dem akademischen Begriff „delve“) basieren, anstatt die Herkunft des Inhalts wirklich zu verstehen. Aufgrund des Risikos von Fehlurteilen (was zu Ungerechtigkeiten für Gruppen wie Studenten führen kann) und der Tatsache, dass sich KI-Modelle selbst weiterentwickeln, um die Erkennung zu umgehen, wird die Zuverlässigkeit dieser Tools stark in Frage gestellt. Es gibt die Ansicht, dass die Existenz von KI-Detektoren KI-generierte Inhalte dazu veranlasst, bestimmte leicht markierbare Merkmale zu vermeiden und somit menschlicherem Schreiben ähnlicher zu werden. (Quelle: Reddit r/ArtificialInteligence, sytelus)

CEO von Anthropic fordert stärkere Transparenz und Rechenschaftspflicht für KI-Unternehmen: Der CEO von Anthropic hat in einem Meinungsartikel in der New York Times betont, dass die Regulierung von KI-Unternehmen nicht gelockert werden dürfe, insbesondere müsse deren Transparenz erhöht und ihre Rechenschaftspflicht eingefordert werden. Diese Ansicht ist vor dem Hintergrund der rasanten Entwicklung und der täglich wachsenden Fähigkeiten der KI-Branche besonders wichtig und spiegelt die gesellschaftlichen Bedenken hinsichtlich potenzieller Risiken und ethischer Fragen der KI wider. Der Artikel argumentiert, dass mit dem wachsenden Einfluss der KI-Technologie sichergestellt werden muss, dass ihre Entwicklung dem öffentlichen Interesse dient und Missbrauch vermieden wird, was sowohl Selbstregulierung der Branche als auch externe Aufsicht erfordert. (Quelle: Reddit r/artificial)

🎯 Trends
Jeff Dean blickt in die KI-Zukunft: Spezialisierte Hardware, Modellentwicklung und wissenschaftliche Anwendungen: Googles KI-Chef Jeff Dean teilte auf dem AI Ascent Event von Sequoia Capital seine Ansichten zur zukünftigen Entwicklung der KI. Er betonte die Bedeutung spezialisierter Hardware (wie TPUs) für den KI-Fortschritt und diskutierte die Entwicklungstrends von Modellarchitekturen. Dean blickte auch auf die zukünftige Gestalt der Recheninfrastruktur sowie das enorme Anwendungspotenzial der KI in Bereichen wie der wissenschaftlichen Forschung und ist der Meinung, dass KI ein Schlüsselinstrument zur Förderung wissenschaftlicher Entdeckungen sein wird. (Quelle: TheTuringPost)

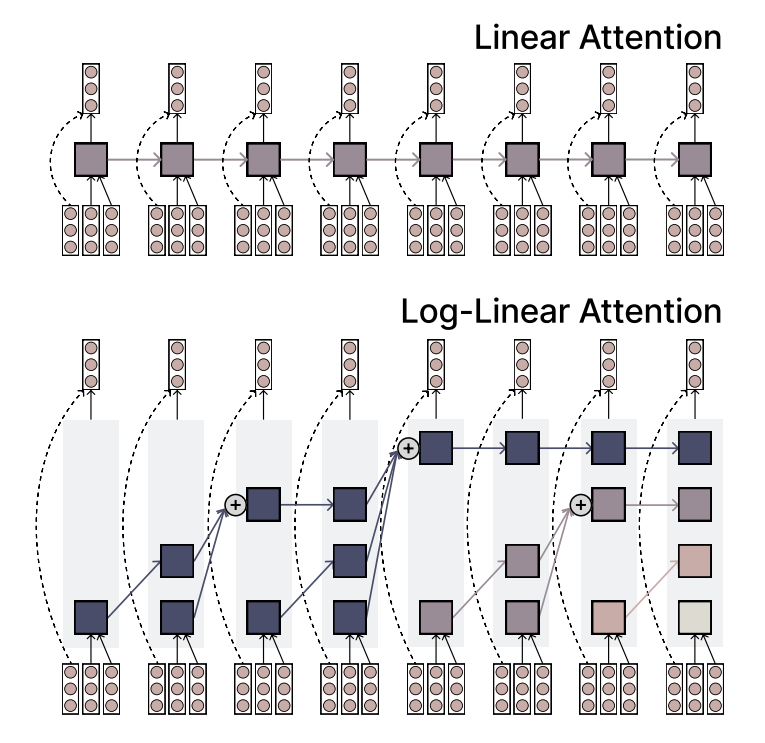
MIT schlägt Log-Linear Attention-Mechanismus vor, der Effizienz und Ausdruckskraft vereint: Forscher des MIT haben einen neuen Attention-Mechanismus namens Log-Linear Attention vorgeschlagen. Dieser Mechanismus zielt darauf ab, die hohe Effizienz von Linear Attention mit der starken Ausdruckskraft von Softmax Attention zu kombinieren. Sein Hauptmerkmal ist die Verwendung einer geringen Anzahl von Memory Slots, die jedoch logarithmisch mit der Sequenzlänge wachsen, wodurch bei der Verarbeitung langer Sequenzen eine geringe Rechenkomplexität beibehalten und gleichzeitig wichtige Informationen erfasst werden können. (Quelle: TheTuringPost)
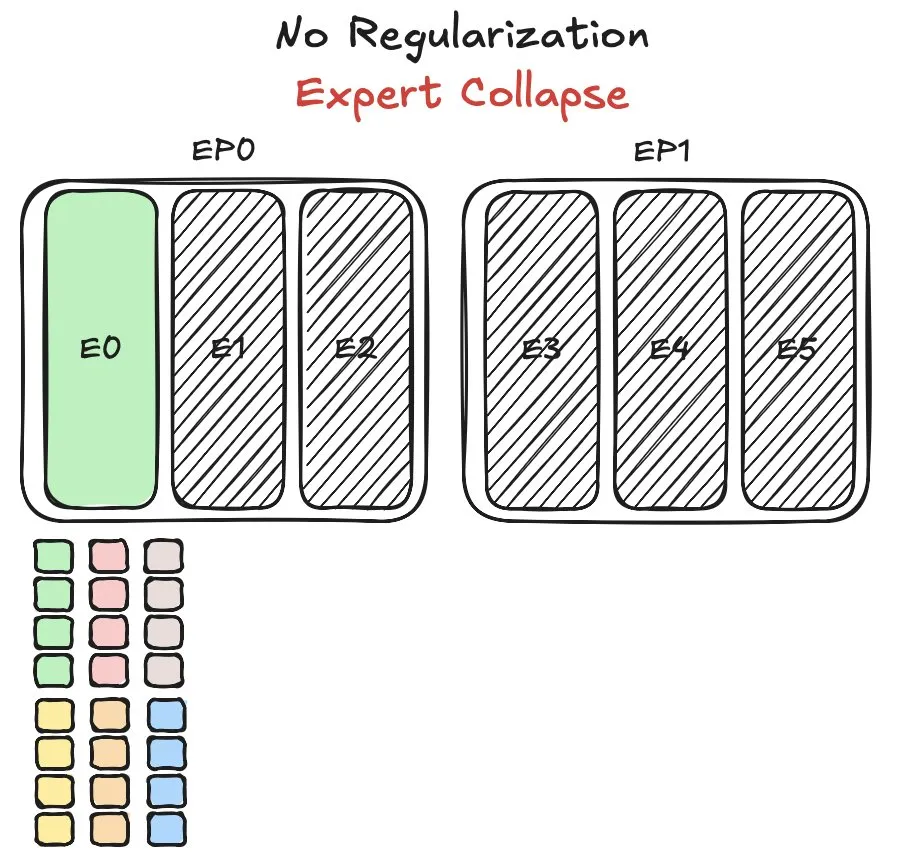
Huawei Pangu MoE-Modell steht vor Herausforderungen beim Experten-Load-Balancing und schlägt neue Methode vor: Huawei stieß beim Training seines Mixture of Experts (MoE)-Modells Pangu Ultra MoE auf das Schlüsselproblem des Experten-Load-Balancings. Das Experten-Load-Balancing erfordert einen Kompromiss zwischen Trainingsdynamik und Systemeffizienz. Huawei hat für dieses Problem eine neue Lösung vorgeschlagen, die darauf abzielt, die Aufgabenverteilung und Rechenlast verschiedener Expertenmodule im MoE-Modell zu optimieren, um die Trainingseffizienz und Modellleistung zu verbessern. Entsprechende Forschungsergebnisse wurden in einem Paper veröffentlicht. (Quelle: finbarrtimbers)
NVIDIA veröffentlicht Cascade Mask R-CNN Mamba Vision-Modell mit Fokus auf Objekterkennung: NVIDIA hat auf Hugging Face ein neues Modell namens cascade_mask_rcnn_mamba_vision_tiny_3x_coco veröffentlicht. Dem Namen nach zu urteilen, ist dieses Modell speziell für Objekterkennungsaufgaben konzipiert und könnte die Cascade R-CNN-Architektur mit der Mamba (ein State Space Model) Vision-Technologie kombinieren, um die Genauigkeit und Effizienz der Objekterkennung zu verbessern. (Quelle: _akhaliq)
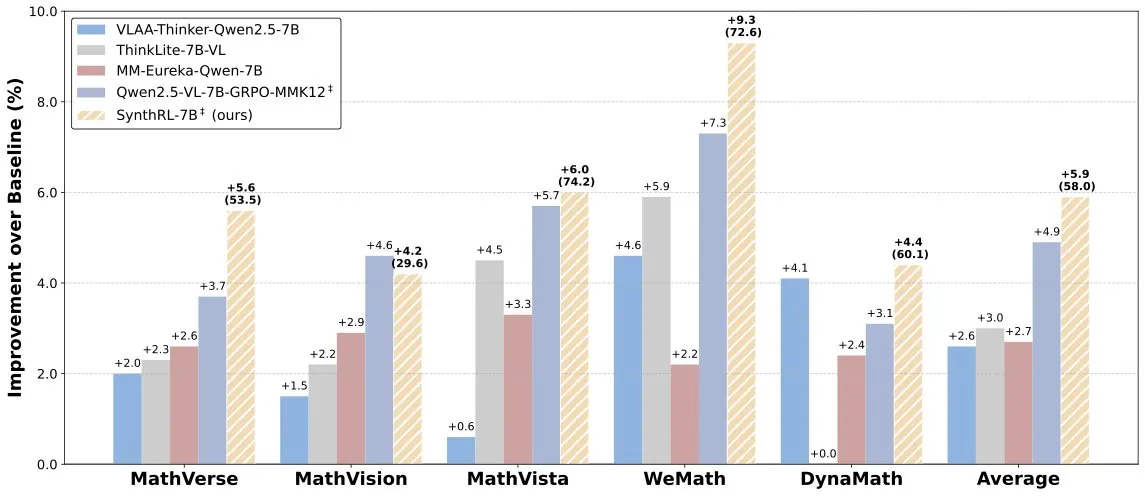
SynthRL-Modell veröffentlicht: Skalierbares visuelles Reasoning durch verifizierbare Datensynthese: Auf Hugging Face wurde das SynthRL-Modell veröffentlicht, das sich auf skalierbare visuelle Reasoning-Fähigkeiten konzentriert. Seine Kerntechnologie liegt in der Generierung anspruchsvollerer Varianten von visuellen Reasoning-Aufgaben durch verifizierbare Datensynthesemethoden, wobei die Korrektheit der ursprünglichen Antworten erhalten bleibt. Dies trägt dazu bei, das Verständnis und die Reasoning-Fähigkeiten des Modells in komplexen visuellen Szenarien zu verbessern. (Quelle: _akhaliq)
DeepSeek-R1 zeigt gute Leistung, aber ChatGPTs Produktvorteil bleibt stabil: VentureBeat kommentiert, dass trotz der hervorragenden Leistung neuer Modelle wie DeepSeek-R1 in einigen Bereichen ChatGPT aufgrund seines First-Mover-Vorteils, seiner breiten Nutzerbasis, seines ausgereiften Produktökosystems und seiner kontinuierlichen Iterationsfähigkeit seine führende Position auf Produktebene kurzfristig kaum zu übertreffen sein wird. Der KI-Wettbewerb ist nicht nur ein Vergleich technischer Parameter, sondern ein umfassender Wettstreit um Produkterfahrung, Ökosystemaufbau und Geschäftsmodelle. (Quelle: Ronald_vanLoon)

Qwen-Team bestätigt, dass Qwen3-coder in Entwicklung ist: Junyang Lin vom Qwen-Team bestätigte, dass sie an Qwen3-coder arbeiten, einer Version der Qwen3-Serie mit verbesserten Coding-Fähigkeiten. Obwohl kein genauer Zeitplan bekannt gegeben wurde, wird erwartet, dass es unter Berücksichtigung des Veröffentlichungszyklus von Qwen2.5 möglicherweise in einigen Wochen erscheint. Die Community erwartet, dass dieses Modell Durchbrüche in der Codegenerierung und der Integration von autonomen/Agenten-Workflows erzielt und eine gute Unterstützung für verschiedene Programmiersprachen beibehält. (Quelle: Reddit r/LocalLLaMA)

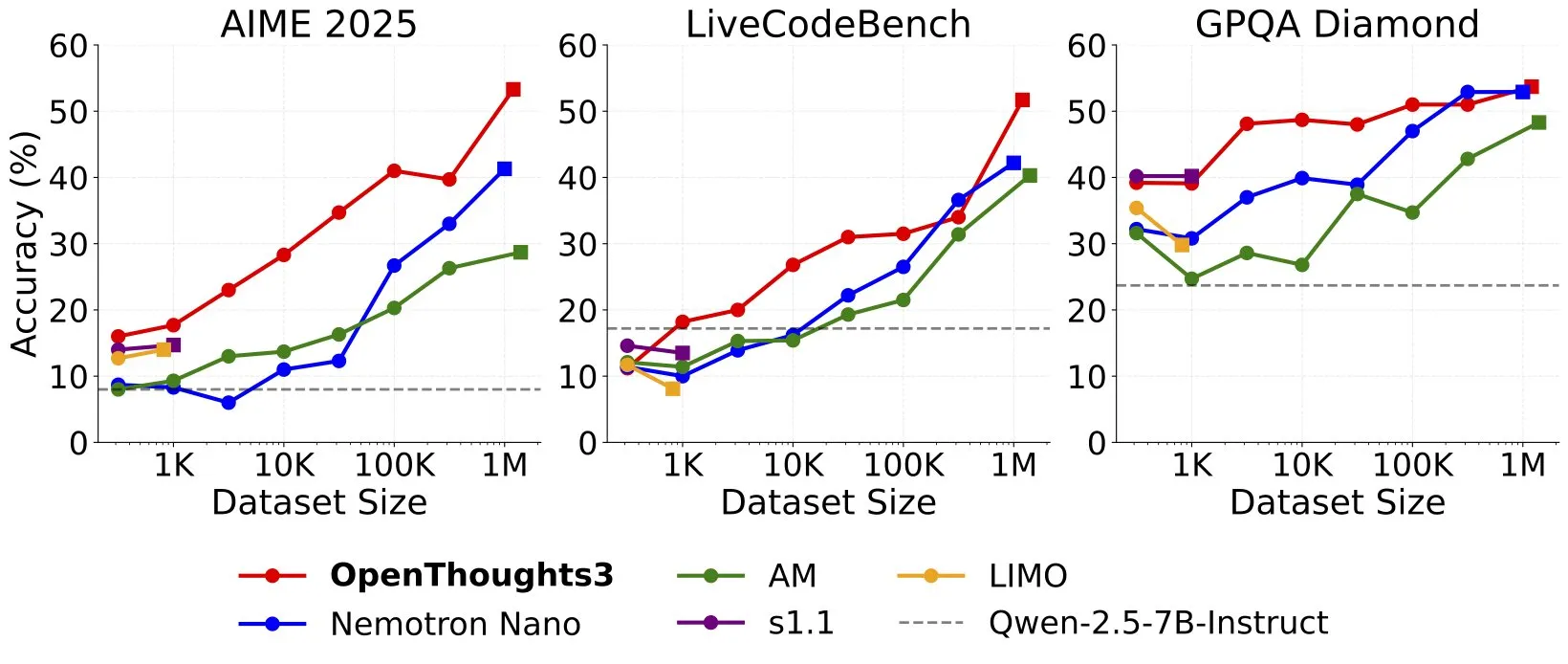
OpenThinker3-7B veröffentlicht, angeblich SOTA Open-Data 7B Reasoning-Modell: Ryan Marten kündigte die Veröffentlichung des OpenThinker3-7B-Modells an und bezeichnete es als das derzeit fortschrittlichste 7B-Parameter-Reasoning-Modell, das auf offenen Daten trainiert wurde. Berichten zufolge übertrifft dieses Modell DeepSeek-R1-Distill-Qwen-7B bei Code-, Wissenschafts- und Mathematikbewertungen im Durchschnitt um 33 %. Gleichzeitig wurde auch der zugehörige Trainingsdatensatz OpenThoughts3-1.2M veröffentlicht. (Quelle: menhguin)
🧰 Tools
TensorZero: Open-Source LLMOps-Framework zur Optimierung der Entwicklung und Bereitstellung von LLM-Anwendungen: TensorZero ist ein Open-Source-Framework zur Optimierung von LLM-Anwendungen, das darauf abzielt, Produktionsdaten durch Feedback-Schleifen in intelligentere, schnellere und kostengünstigere Modelle umzuwandeln. Es integriert LLM-Gateways (unterstützt verschiedene Modellanbieter), Beobachtbarkeit, Optimierung (Prompting, Fine-Tuning, RL), Evaluierung und Experimente (A/B-Tests) und unterstützt niedrige Latenz, hohen Durchsatz und GitOps. Das Tool ist in Rust geschrieben und legt Wert auf Leistung und Anforderungen für den industriellen Einsatz. (Quelle: GitHub Trending)

LangChain stellt leistungsstarkes RAG-System mit SambaNova, Qdrant und LangGraph vor: LangChain präsentierte eine leistungsstarke Implementierungslösung für Retrieval Augmented Generation (RAG). Diese Lösung kombiniert das DeepSeek-R1-Modell von SambaNova, die binäre Quantisierungstechnologie von Qdrant und LangGraph und ermöglicht eine 32-fache Speicherreduktion, wodurch große Dokumentenmengen effizient verarbeitet werden können. Dies eröffnet neue Möglichkeiten für den Aufbau kostengünstigerer und schnellerer RAG-Anwendungen. (Quelle: hwchase17, qdrant_engine)
Googles App Sparkify zur Erstellung von Erklärvideos mit einem Klick zeigt hochwertige Beispiele: Die von Google eingeführte App Sparkify, die mit einem Klick Erklärvideos erstellen kann, zeigt Beispiele von beachtlicher Qualität. Die Videoinhalte weisen eine gute Gesamtkonsistenz auf, die Vertonung ist natürlich, und es können sogar komplexe Effekte wie Split-Screen-Darstellungen realisiert werden, was das Potenzial der KI in der automatisierten Erstellung von Videoinhalten demonstriert. (Quelle: op7418)
Hugging Face stellt ersten MCP-Server vor und erweitert Chatbot-Funktionen: Hugging Face hat seinen ersten MCP (Modular Chat Processor) Server (hf.co/mcp) veröffentlicht, den Nutzer in das Chatfenster einfügen können. Der MCP-Server zielt darauf ab, die Funktionen von Chatbots zu erweitern und durch modulare Verarbeitungseinheiten ein reichhaltigeres interaktives Erlebnis zu bieten. Die Community hat gleichzeitig eine Liste weiterer nützlicher MCP-Server zusammengestellt, wie z.B. Agentset MCP, GitHub MCP usw. (Quelle: TheTuringPost)
Chatterbox TTS-Effekte vergleichbar mit ElevenLabs, bereits in gptme integriert: Das TTS (Text-to-Speech)-Tool Chatterbox hat aufgrund seiner hervorragenden Sprachsyntheseeffekte Aufmerksamkeit erregt. Nutzer berichten, dass seine Effekte mit denen des bekannten ElevenLabs vergleichbar und denen von Kokoro überlegen sind. Chatterbox unterstützt die Anpassung der Stimme anhand von Referenzmustern und wurde nun als TTS-Backend zu gptme hinzugefügt, was den Nutzern hochwertige Sprachausgabeoptionen bietet. (Quelle: teortaxesTex, _akhaliq)
E-Library-Agent: Intelligentes Such- und Q&A-System für lokale Bücher/Literatur: E-Library-Agent ist ein selbst gehosteter KI-Agent, der persönliche Bücher- oder Papiersammlungen extrahieren, indizieren und abfragen kann. Das Projekt basiert auf ingest-anything und wird von LlamaIndex, Qdrant und der Linkup-Plattform unterstützt. Es ermöglicht die lokale Materialextraktion, kontextsensitive Fragenbeantwortung sowie die Netzwerkentdeckung über eine einzige Schnittstelle und erleichtert Nutzern die Verwaltung und Nutzung ihrer persönlichen Wissensdatenbank. (Quelle: qdrant_engine)
Claude Code wird von Entwicklern für seine leistungsstarke Coding-Unterstützung hoch bewertet: Nutzer der Reddit-Community teilten positive Erfahrungen mit der Verwendung von Anthropic’s Claude Code für die Softwareentwicklung, insbesondere in Bereichen wie der Spieleentwicklung (z.B. Godot C#-Projekte). Nutzer lobten seine Fähigkeit, komplexe Probleme zu lösen, die weit über die anderer KI-Coding-Assistenten (wie GitHub Copilot) hinausgeht, Kontext zu verstehen und effektiven Code zu generieren. Selbst die monatlichen Kosten von 100 US-Dollar werden als preiswert angesehen. Entwickler sind der Meinung, dass erfahrene Programmierer in Kombination mit Claude Code äußerst produktiv sein werden. (Quelle: Reddit r/ClaudeAI)
ChatterUI implementiert Unterstützung für lokale Vision-Modelle, aber langsame Verarbeitung auf Android: Eine Vorabversion des LLM-Chat-Clients ChatterUI fügt Unterstützung für Anhänge und lokale Vision-Modelle hinzu (über llama.rn). Benutzer können mmproj-Dateien für lokal kompatible Modelle laden oder sich mit APIs verbinden, die Vision-Funktionen unterstützen (wie Google AI Studio, OpenAI). Aufgrund des Fehlens eines stabilen GPU-Backends für llama.cpp auf Android ist die Bildverarbeitung jedoch extrem langsam (z. B. 5 Minuten für ein 512×512-Bild), während die Leistung auf iOS relativ besser ist. (Quelle: Reddit r/LocalLLaMA)
FLUX kontext zeigt hervorragende Leistung beim Austausch von Hintergründen in Autobildern: Nutzertests haben ergeben, dass das KI-Bildbearbeitungstool FLUX kontext beim Ändern von Hintergründen in Autobildern bemerkenswerte Ergebnisse erzielt. Beispielsweise beim Austausch des Hintergrunds offizieller Bilder des Xiaomi SU7 (z.B. Strand bei Sonnenuntergang, Rennstrecke) kann das Tool nicht nur den Hintergrund natürlich integrieren, sondern auch intelligent Bewegungsunschärfe für fahrende Fahrzeuge hinzufügen, was den Realismus und die visuelle Wirkung der Bilder verbessert. (Quelle: op7418)

📚 Lernen
Neue Funktion flexicache in fastcore: Flexibler Caching-Decorator: Jeremy Howard stellte eine praktische neue Funktion in der fastcore-Bibliothek vor: flexicache. Dies ist ein äußerst flexibler Caching-Decorator mit zwei integrierten Caching-Strategien, ‘mtime’ (basierend auf der Dateiänderungszeit) und ‘time’ (basierend auf Zeitstempeln), und ermöglicht es Benutzern, mit wenig Code neue Caching-Strategien anzupassen. Diese Funktion, die von Daniel Roy Greenfeld ausführlich beschrieben wurde, trägt zur Verbesserung der Codeausführungseffizienz bei. (Quelle: jeremyphoward)
Diskussion über das Potenzial der Kombination von MuP und Muon für das Training von Transformer-Modellen: Jingyuan Liu vertiefte sich in Jeremy Bernsteins Arbeit zur Ableitung von Muon und spektralen Bedingungen und äußerte seine Bewunderung für die Eleganz der Ableitung, insbesondere wie MuP (Maximal Update Parametrization) und Muon (ein Optimierer) zusammenarbeiten. Er ist der Ansicht, dass die Verwendung von Muon als Optimierer für das Training von auf MuP basierenden Modellen aus der Ableitung heraus eine natürliche Wahl ist, und weist darauf hin, dass dies möglicherweise spannender ist als die Übertragung von Hyperparametern von AdamW zu Muon durch Abgleich der Update-RMS in Moonshots Moonlight-Arbeit. Die Community diskutiert, dass die Kombination MuP + Muon bis Ende des Jahres von großen Technologieunternehmen skaliert eingesetzt werden könnte. (Quelle: jeremyphoward)

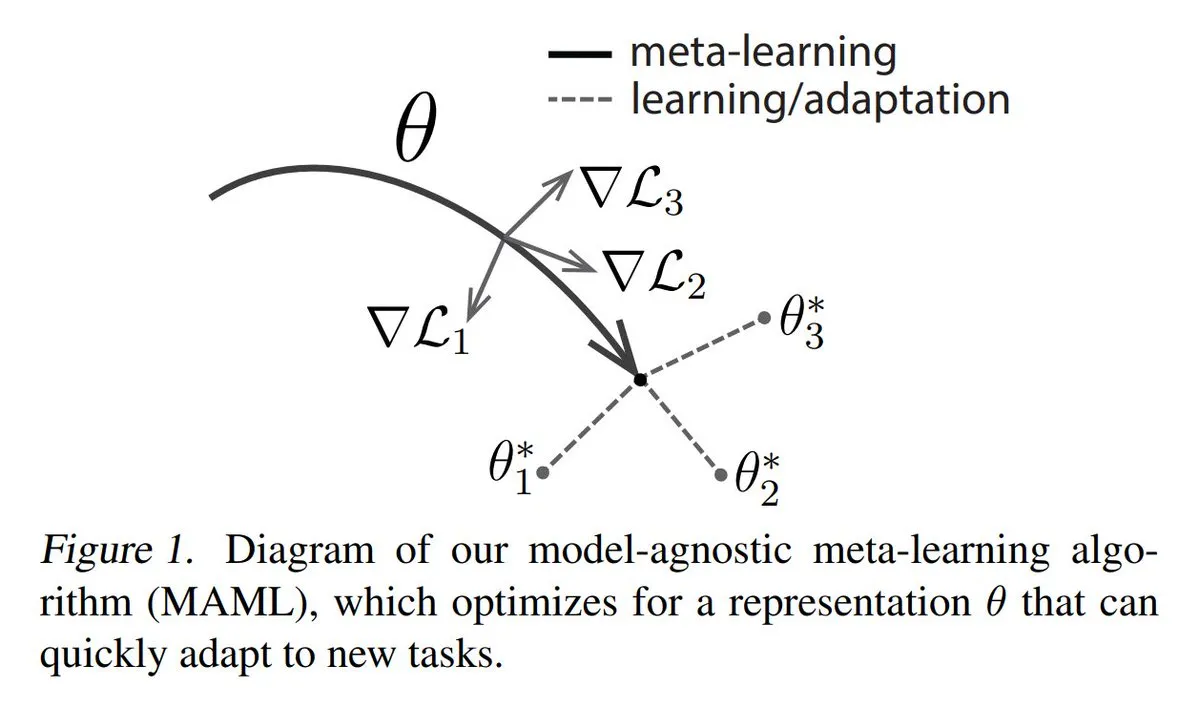
Analyse der drei Hauptansätze des Meta-Learnings: Meta-Learning zielt darauf ab, Modelle so zu trainieren, dass sie schnell neue Aufgaben lernen können, selbst mit nur wenigen Beispielen. Gängige Methoden sind: 1. Optimierungsbasierte/Gradientenbasierte: Suche nach Modellparametern, die durch wenige Gradientenschritte effizient auf einer Aufgabe feinabgestimmt werden können. 2. Metrikbasierte: Helfen dem Modell, bessere Methoden zur Messung der Ähnlichkeit zwischen neuen und alten Beispielen zu finden und verwandte Beispiele effektiv zu gruppieren. 3. Modellbasierte: Das gesamte Modell ist so konzipiert, dass es integrierten Speicher oder dynamische Mechanismen zur schnellen Anpassung nutzen kann. TuringPost bietet eine detaillierte Erläuterung von den Grundlagen bis zu modernen Meta-Learning-Methoden. (Quelle: TheTuringPost)
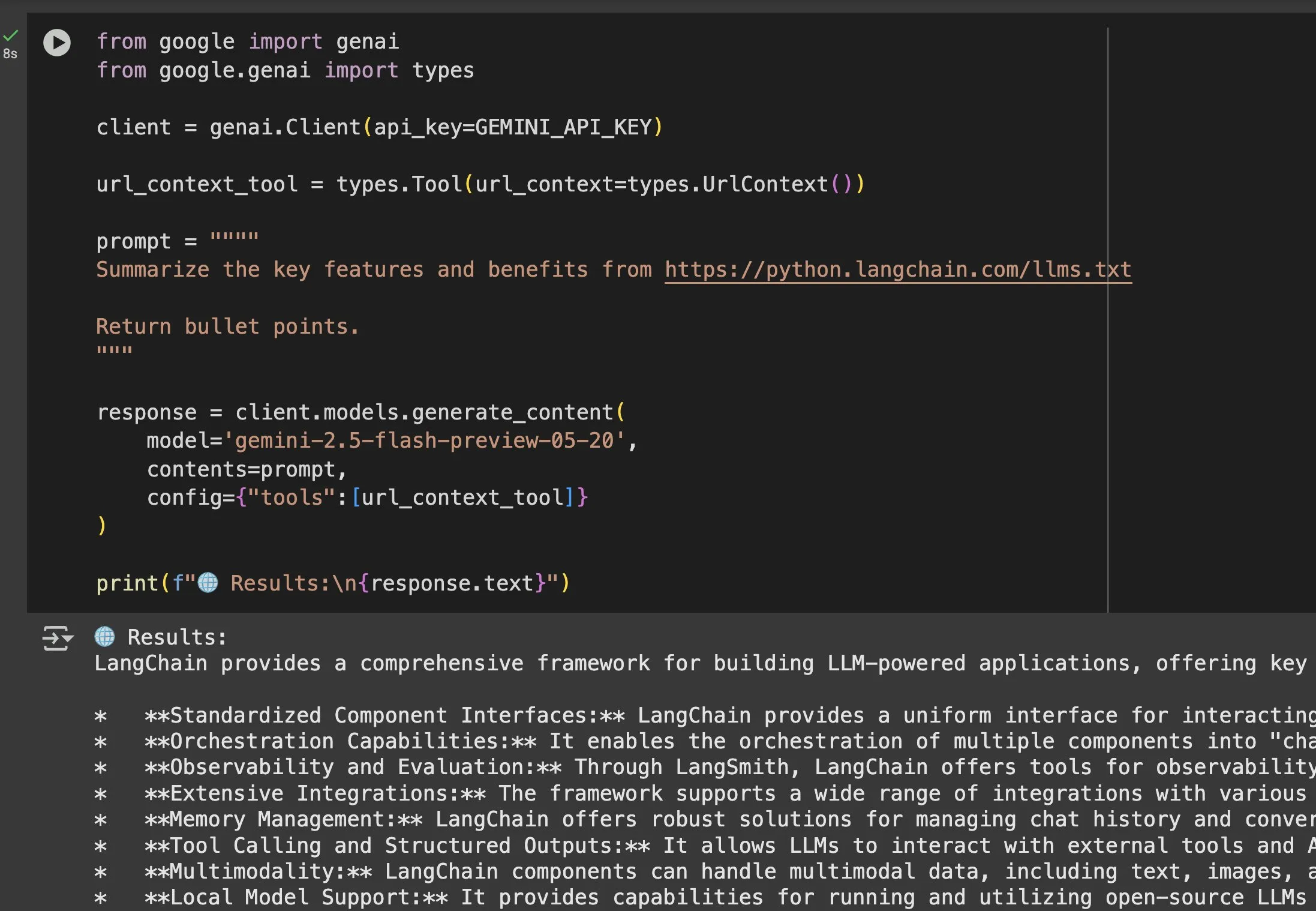
Der Wert von llms.txt-Dateien in Modellen wie Gemini wird deutlich: Jeremy Phoward betonte die Nützlichkeit von llms.txt-Dateien. Beispielsweise kann Gemini jetzt Inhalte von URLs verstehen, indem einfach die URL zum Prompt hinzugefügt und das URL-Kontext-Tool konfiguriert wird. Dies bedeutet, dass Clients (wie Gemini) durch Lesen des llms.txt-Endpunkts genau wissen, wo die benötigten Informationen gespeichert sind, was den programmatischen Zugriff und die Nutzung von Informationen erheblich erleichtert. (Quelle: jeremyphoward)
EleutherAI veröffentlicht 8TB Open-Source-Textdatensatz Common Pile v0.1: EleutherAI kündigte die Veröffentlichung von Common Pile v0.1 an, einem großen Datensatz mit 8 TB an Open-Source- und gemeinfreien Texten. Auf Basis dieses Datensatzes trainierten sie Sprachmodelle mit 7B Parametern (trainiert mit 1T bzw. 2T Token), deren Leistung mit ähnlichen Modellen wie LLaMA 1 und LLaMA 2 vergleichbar ist. Dies liefert wertvolle Ressourcen und empirische Belege für die Erforschung des Trainings leistungsstarker Sprachmodelle unter ausschließlicher Verwendung konformer Daten. (Quelle: clefourrier)

SelfCheckGPT: Eine referenzfreie Methode zur Erkennung von LLM-Halluzinationen: Ein Blogbeitrag untersucht SelfCheckGPT als Alternative zu LLM-as-a-judge (Verwendung von LLMs als Bewerter) zur Erkennung von Halluzinationen in Sprachmodellen. Dies ist eine referenzfreie, ressourcenlose Erkennungsmethode, die neue Ansätze zur Bewertung und Verbesserung der Wahrhaftigkeit von LLM-Ausgaben bietet. (Quelle: dl_weekly)
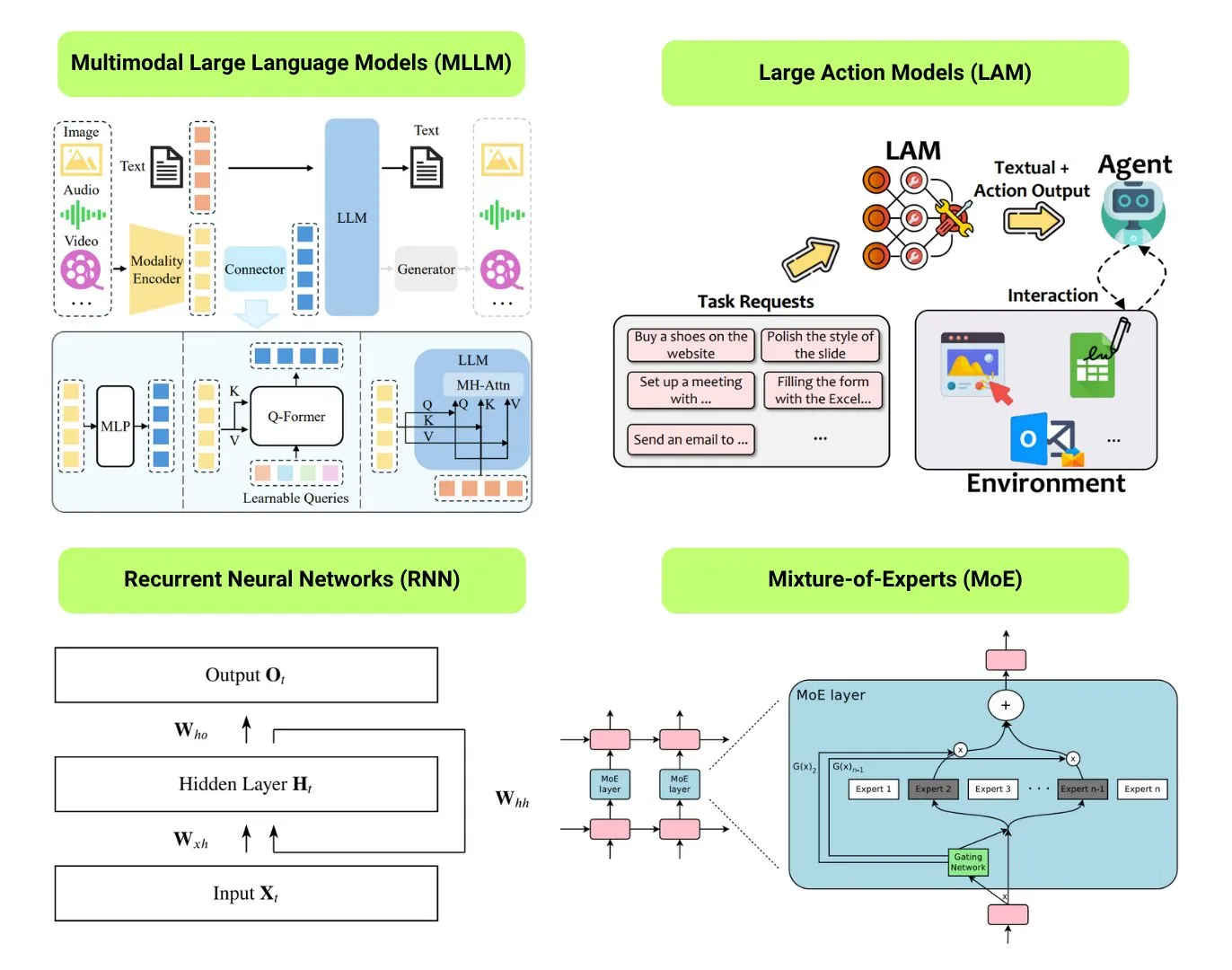
Übersicht über 12 grundlegende KI-Modelltypen: The Turing Post hat 12 grundlegende KI-Modelltypen zusammengestellt, darunter LLM (Large Language Model), SLM (Small Language Model), VLM (Vision Language Model), MLLM (Multimodal Large Language Model), LAM (Large Action Model), LRM (Large Reasoning Model), MoE (Mixture of Experts), SSM (State Space Model), RNN (Recurrent Neural Network), CNN (Convolutional Neural Network), SAM (Segment Anything Model) und LNN (Logic Neural Network). Zugehörige Ressourcen bieten Erklärungen und nützliche Links zu diesen Modelltypen. (Quelle: TheTuringPost)
GitHub-Trend: Kubernetes The Hard Way Tutorial: Kelsey Hightowers Tutorial „Kubernetes The Hard Way“ erfreut sich auf GitHub weiterhin großer Beliebtheit. Das Tutorial zielt darauf ab, Benutzern dabei zu helfen, Kubernetes-Cluster schrittweise manuell aufzubauen, um dessen Kernkomponenten und Funktionsweise tiefgreifend zu verstehen, anstatt sich auf automatisierte Skripte zu verlassen. Das Tutorial richtet sich an Lernende, die sich Grundkenntnisse in Kubernetes aneignen möchten, und deckt den gesamten Prozess von der Umgebungsvorbereitung bis zur Clusterbereinigung ab. (Quelle: GitHub Trending)
GitHub-Trend: Liste kostenloser GPTs und Prompts: Das Repository friuns2/BlackFriday-GPTs-Prompts ist auf GitHub beliebt. Es sammelt und organisiert eine Reihe kostenloser GPT-Modelle und hochwertiger Prompts, die Benutzer ohne Plus-Abonnement verwenden können. Diese Ressourcen decken verschiedene Bereiche wie Programmierung, Marketing, akademische Forschung, Jobsuche, Spiele, Kreativität ab und enthalten einige „Jailbreaks“-Tricks, die GPT-Nutzern eine Fülle von sofort einsatzbereiten Werkzeugen und Inspirationen bieten. (Quelle: GitHub Trending)

Planung und Verfolgung von KI-Codierungsprojekten mit CSV zur Verbesserung von Codequalität und Effizienz: Ein Entwickler teilte seine Erfahrungen bei der Entwicklung eines ERP-Systems mit Claude Code, bei der er durch die Erstellung detaillierter CSV-Dateien zur Planung und Verfolgung des Codierungsfortschritts jeder Datei die Entwicklungseffizienz komplexer Funktionen und die Codequalität erheblich verbesserte. Die CSV-Datei enthält Status, Dateiname, Priorität, Codezeilenanzahl, Komplexität, Abhängigkeiten, Funktionsbeschreibung, verwendete Hooks, Import-/Exportmodule sowie wichtige „Fortschrittsnotizen“. Diese Methode ermöglicht es der KI, sich konzentrierter auf die Codeerstellung zu konzentrieren und dem Entwickler einen klaren Überblick über den tatsächlichen Projektfortschritt im Vergleich zum ursprünglichen Plan zu geben. (Quelle: Reddit r/ClaudeAI)
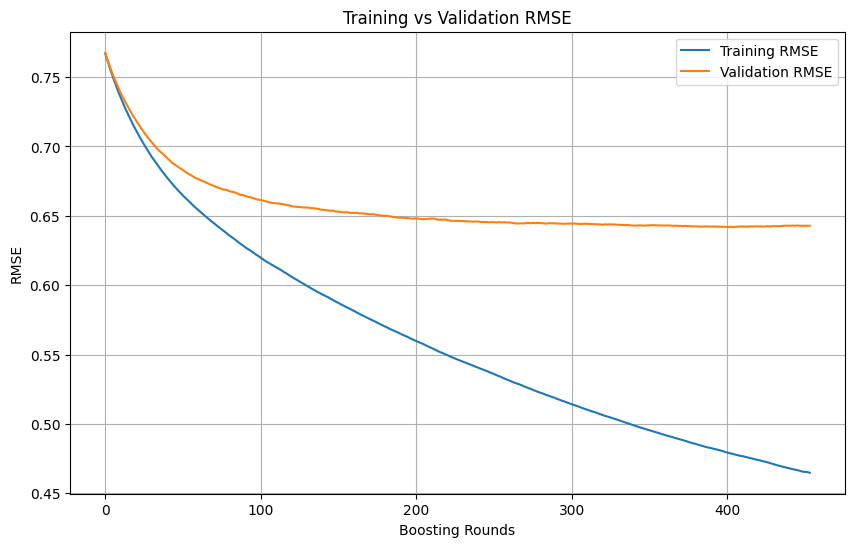
Beurteilung von Overfitting und Zeitpunkt des Stopps beim Training von Machine-Learning-Modellen: Wenn während des Trainings eines Machine-Learning-Modells der Trainingsverlust kontinuierlich schnell abnimmt, während der Validierungsverlust langsam abnimmt oder sogar stagniert oder ansteigt, deutet dies normalerweise darauf hin, dass das Modell möglicherweise überangepasst (Overfitting) ist. Grundsätzlich kann das Training fortgesetzt werden, solange der Validierungsverlust noch abnimmt. Entscheidend ist sicherzustellen, dass das Validierungsset unabhängig vom Trainingsset ist und die reale Datenverteilung der Aufgabe repräsentiert. Wenn der Validierungsverlust nicht mehr abnimmt oder zu steigen beginnt, sollte ein vorzeitiger Stopp des Trainings in Betracht gezogen oder Methoden wie Regularisierung ergriffen werden, um die Generalisierungsfähigkeit des Modells zu verbessern. (Quelle: Reddit r/MachineLearning)
🌟 Community
AI Engineer World’s Fair 2025 fokussiert auf Themen wie RL+Reasoning, Eval etc.: Die AI Engineer World’s Fair 2025 befasst sich mit zukunftsweisenden Themen wie Reinforcement Learning + Reasoning (RL+Reasoning), Evaluierung (Eval), Software Engineering Agents (SWE-Agent), KI-Architekten und Agenten-Infrastruktur. Teilnehmer berichteten, dass die Konferenz voller Dynamik und innovativem Denken war, viele Menschen mutig Neues ausprobierten, sich ständig neu erfanden und sich dem KI-Bereich widmeten. Die Konferenz bot auch KI-Ingenieuren eine Plattform für Austausch und Lernen. (Quelle: swyx, hwchase17, charles_irl, swyx)

Sam Altmans ideale KI: Kleines Modell + überragendes Reasoning + riesiger Kontext + universelle Werkzeuge: Sam Altman beschrieb seine Vorstellung von der idealen KI: ein Modell mit übermenschlichen Reasoning-Fähigkeiten und extrem geringer Größe, das auf Billionen von Kontextinformationen zugreifen und jedes erdenkliche Werkzeug aufrufen kann. Diese Ansicht löste Diskussionen aus, wobei einige argumentierten, dass dies von der aktuellen Situation abweicht, in der große Modelle auf Wissensspeicherung angewiesen sind, und die Machbarkeit bezweifelten, dass kleine Modelle Wissen in riesigen Kontexten analysieren und komplexe Schlussfolgerungen ziehen können, da Wissen und Denkfähigkeit schwer effizient zu trennen seien. (Quelle: teortaxesTex)
Coding-Agenten wecken den Wunsch nach Code-Refactoring, Herausforderungen und Chancen der KI-gestützten Programmierung: Entwickler berichten, dass das Aufkommen von Coding-Agenten die „Versuchung“, den Code anderer umzugestalten, erheblich verstärkt und auch neue Gefahren mit sich bringt. Ein Entwickler teilte seine Erfahrungen bei der Erledigung einer Programmieraufgabe mit KI-Unterstützung, die manuell etwa 10 Minuten gedauert hätte. Obwohl die KI schnell funktionierenden Code generieren konnte, waren immer noch erhebliche manuelle Anleitungen und Umgestaltungen erforderlich, um das Organisations- und Stilniveau eines erfahrenen Programmierers zu erreichen. Dies unterstreicht die Herausforderungen der KI-gestützten Programmierung bei der Verbesserung der Qualität von Anfänger-/Mittelstufencode zu fortgeschrittenem Code. (Quelle: finbarrtimbers, mitchellh)
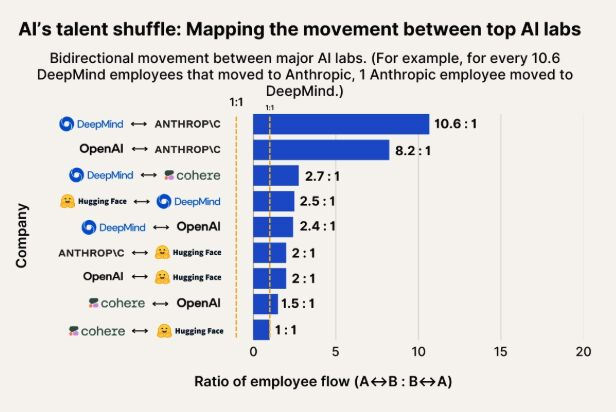
Beobachtung der KI-Talentmobilität: Anthropic wird zu wichtigem Ziel für Talente von Google DeepMind und OpenAI: Eine Grafik, die die Talentmobilität im KI-Bereich darstellt, zeigt, dass Anthropic zu einem wichtigen Unternehmen wird, das Forscher von Google DeepMind und OpenAI anzieht. Die Community stimmt dieser Einschätzung zu, und einige Nutzer vermuten, dass Anthropic möglicherweise über bestimmte „Geheimwaffen“ oder einzigartige Forschungsrichtungen verfügt, die Spitzenkräfte anziehen. (Quelle: bookwormengr, TheZachMueller)
Verbreitung humanoider Roboter steht vor Herausforderungen in Bezug auf Vertrauen und gesellschaftliche Akzeptanz: Der Technologiekommentator Faruk Guney prognostiziert, dass die erste Welle humanoider Roboter aufgrund eines enormen Vertrauensdefizits scheitern könnte. Er ist der Ansicht, dass die Gesellschaft trotz des technologischen Fortschritts noch nicht bereit ist, diese „Blackbox-Intelligenzen“ in ihre Häuser zu lassen, um Aufgaben wie Begleitung, Hausarbeit oder sogar Kinderbetreuung zu übernehmen. Die undurchsichtigen Entscheidungen der Roboter, potenzielle Überwachungsrisiken und ihr von Menschen deutlich abweichendes „niedliches“ Aussehen (weniger wie Wall-E) könnten zu Hindernissen für ihre breite Anwendung werden. Erst nach ausreichender gesellschaftlicher Diskussion, Regulierung, Auditierung und Wiederherstellung des Vertrauens könne die eigentliche Verbreitung humanoider Roboter erfolgen. (Quelle: farguney, farguney)
KI-Persönlichkeitsdesign: „Unvollkommenheit“ schlägt „Perfektion“: Ein Entwickler teilte seine Erfahrungen bei der Erstellung von 50 KI-Persönlichkeiten auf einer KI-Audio-Plattform. Zusammenfassend lässt sich sagen, dass übermäßig gestaltete Hintergrundgeschichten, absolute logische Konsistenz und extrem einseitige Charaktere die KI mechanisch und unrealistisch erscheinen ließen. Erfolgreiche KI-Persönlichkeitsgestaltung liegt in einem „3-Schichten-Persönlichkeits-Stack“ (Kernmerkmale + modifizierende Merkmale + Eigenheiten), angemessenen „Unvollkommenheitsmustern“ (wie gelegentliche Versprecher, Selbstkorrekturen) und genau der richtigen Menge an Hintergrundinformationen (300-500 Wörter, einschließlich positiver und herausfordernder Erfahrungen, spezifischer Leidenschaften und berufsbezogener Schwachstellen). Diese „unvollkommenen“ Details verleihen der KI反而 mehr Menschlichkeit und Verbundenheit. (Quelle: Reddit r/LocalLLaMA, Reddit r/ArtificialInteligence)
Diskussion über „Wahrnehmung“ und „AGI“ von LLMs: Aufregung und Skepsis zugleich: Die Community ist allgemein begeistert vom enormen Potenzial von LLMs und betrachtet sie als vergleichbar mit historisch bedeutsamen Erfindungen, die alles verändern werden. Viele bleiben jedoch skeptisch gegenüber Behauptungen, LLMs hätten bereits „Wahrnehmungsfähigkeiten“, bräuchten „Rechte“ oder würden die „Menschheit auslöschen“ oder „AGI“ herbeiführen. Es wird betont, dass bei der Interpretation der Fähigkeiten und Forschungsergebnisse von LLMs Sorgfalt und Vorsicht geboten sind. (Quelle: fabianstelzer)
💡 Sonstiges
Erforschung der autonomen Geh-Kollaboration mehrerer Roboter: In sozialen Medien tauchen Erkundungen zur Kollaboration mehrerer Roboter im Bereich des autonomen Gehens auf. Dies beinhaltet komplexe Technologien wie Roboter-Pfadplanung, Aufgabenverteilung, Informationsaustausch und Kollisionsvermeidung und ist ein kontinuierlich beachtetes Forschungsfeld in der Robotik, RPA (Robotic Process Automation) und im Machine Learning. (Quelle: Ronald_vanLoon)
Trick zur Optimierung von ULMFiT-Hyperparametern mit Random Forests: Jeremy Howard teilte einen Trick, den er bei der Optimierung von ULMFiT (einer Transfer-Learning-Methode) anwendet: Durch die Durchführung zahlreicher Ablationsexperimente und die Einspeisung aller Hyperparameter und Ergebnisdaten in ein Random-Forest-Modell werden die Hyperparameter identifiziert, die den größten Einfluss auf die Modellleistung haben. Diese Methode wurde von Weights & Biases in ihr Produkt integriert und bietet neue Ansätze für die Hyperparameter-Optimierung. (Quelle: jeremyphoward)

Humanoider Roboter der Firma Figure demonstriert 60-minütige Bearbeitung von Logistikaufgaben: Die Firma Figure veröffentlichte ein 60-minütiges Video, das zeigt, wie ihr humanoider Roboter, angetrieben vom Helix-Neuronalen-Netzwerk, autonom verschiedene Aufgaben in einem Logistikszenario erledigt. Diese Demonstration zielt darauf ab, die Fähigkeit des Roboters zu langem, stabilem Arbeiten und autonomer Entscheidungsfindung in komplexen realen Umgebungen zu beweisen. (Quelle: adcock_brett)