
Schlüsselwörter:KI-Trainingsdaten, Große Sprachmodelle, KI-Ethik, Informationsabfrage-Agenten, KI-Rechtsstreitigkeiten, KI-emotionale Verbindungen, KI-Schlussfolgerungsmodelle, KI-Quantifizierungstechniken, Reddit verklagt Anthropic wegen Datenverletzung, WebDancer Mehrfachschlussfolgerungsleistung, Log-Linear-Attention-Architektur, Claude KI geistiger Wohlfühlzustand, DSPy-Optimierung für agentische Anwendungen
🔥 Fokus
Reddit und Anthropic: Rechtsstreit eskaliert wegen angeblicher unrechtmäßiger Datennutzung für Claude AI Training: Reddit hat offiziell Klage gegen Anthropic eingereicht und wirft dem Unternehmen vor, unautorisiert Inhalte von der Plattform für das Training seines Large Language Models Claude gecrawlt zu haben. Dies stelle einen schweren Verstoß gegen Reddits Nutzungsbedingungen dar, die eine kommerzielle Nutzung von Inhalten verbieten. Aus den Klageunterlagen geht hervor, dass Anthropic nicht nur die Nutzung von Reddit-Daten zugegeben, sondern nach einer Anfrage auch fälschlicherweise behauptet habe, das Crawling eingestellt zu haben, während seine Crawler weiterhin auf Reddit-Server zugegriffen hätten. Darüber hinaus weigere sich Anthropic, Reddits konforme API zu nutzen, um die Synchronisierung der Löschung von Nutzerinhalten zu gewährleisten, was eine anhaltende Bedrohung für die Privatsphäre der Nutzer darstelle. Der Fall verdeutlicht den Widerspruch zwischen Datenbeschaffung, Kommerzialisierung und ethischen Erklärungen von KI-Unternehmen, insbesondere da die von Anthropic propagierten Werte wie „hohes Vertrauen“ und „Priorisierung von Ehrlichkeit“ direkt in Frage gestellt werden (Quelle: Reddit r/ArtificialInteligence)
OpenAI äußert sich erstmals zur emotionalen Verbindung zwischen Mensch und Maschine: Nutzerabhängigkeit von ChatGPT vertieft sich, wahrgenommenes Bewusstsein des Modells wird zunehmen: Joanne Jang, Leiterin für Modellverhalten bei OpenAI, erörtert in einem Artikel das Phänomen, dass Nutzer emotionale Verbindungen zu KIs wie ChatGPT aufbauen. Sie weist darauf hin, dass sich diese emotionale Bindung mit der Verbesserung der dialogischen Fähigkeiten der KI vertiefen wird. OpenAI räumt ein, dass Nutzer KI vermenschlichen und ihr gegenüber Dankbarkeit, Mitteilungsbedürfnis und andere Emotionen entwickeln. Der Artikel unterscheidet zwischen „ontologischem Bewusstsein“ (ob KI wirklich ein Bewusstsein hat) und „wahrgenommenem Bewusstsein“ (wie bewusst die KI erscheint), wobei letzteres mit dem Fortschritt des Modells zunehmen wird. Ziel von OpenAI ist es, ChatGPT warmherzig, rücksichtsvoll und hilfsbereit erscheinen zu lassen, ohne jedoch eine emotionale Bindung zu den Nutzern anzustreben oder eigene Agenden zu verfolgen. OpenAI plant, in den kommenden Monaten entsprechende Forschungen und Bewertungen auszuweiten und die Ergebnisse öffentlich zu teilen (Quelle: 量子位, vikhyatk)
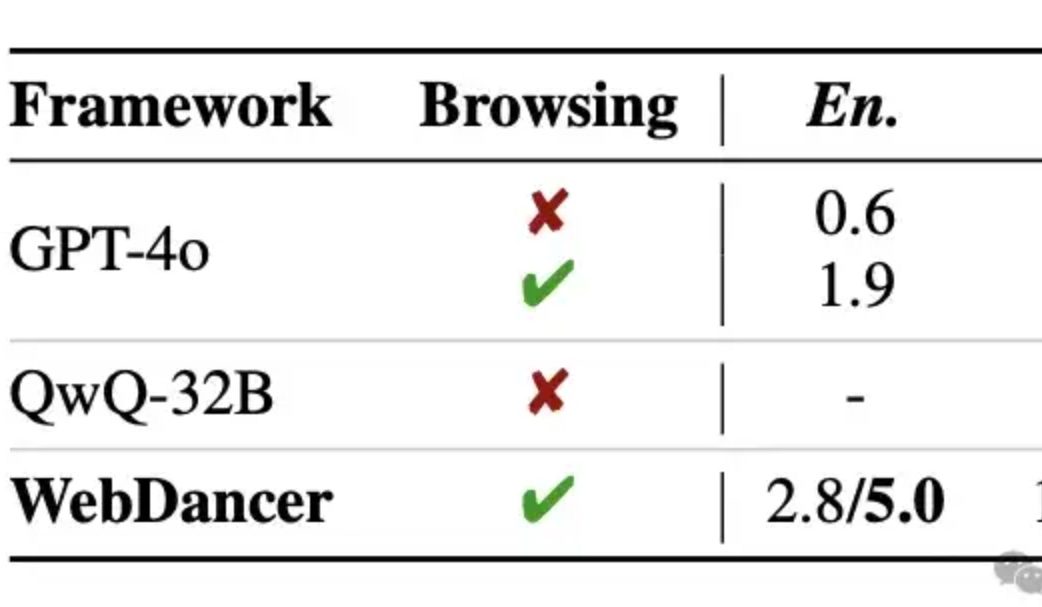
Alibaba veröffentlicht autonomen Informationsbeschaffungs-Agent WebDancer, der GPT-4o bei mehrstufigem Reasoning übertreffen soll: Das Tongyi Lab hat den autonomen Informationsbeschaffungs-Agent WebDancer vorgestellt, einen Nachfolger von WebWalker, der sich auf komplexe Aufgaben konzentriert, die mehrstufige Informationsbeschaffung, mehrstufiges Reasoning und die Ausführung kontinuierlicher Aktionen erfordern. WebDancer löst das Problem des Mangels an hochwertigen Trainingsdaten durch innovative Datensynthesemethoden (CRAWLQA und E2HQA) und kombiniert das ReAct-Framework mit der Chain-of-Thought-Destillationstechnik zur Generierung von agentic data. Das Training erfolgt in zwei Phasen: Supervised Fine-Tuning (SFT) und Reinforcement Learning (RL, unter Verwendung des DAPO-Algorithmus), um sich an die offene und dynamische Web-Umgebung anzupassen. Experimentelle Ergebnisse zeigen, dass WebDancer in mehreren Benchmarks wie GAIA, WebWalkerQA und BrowseComp hervorragend abschneidet, insbesondere auf dem GAIA-Benchmark mit einem Pass@3-Score von 61,1 % (Quelle: 量子位)
Apple veröffentlicht Forschungsbericht „The Illusion of Thinking“, der die Grenzen von Large Reasoning Models (LRM) untersucht: Ein Forschungsteam von Apple hat die Leistung von Large Reasoning Models (LRM) bei Problemen unterschiedlicher Komplexität systematisch in einer kontrollierten Rätselumgebung untersucht. Der Bericht stellt fest, dass trotz verbesserter Leistung von LRMs in Benchmarks ihre grundlegenden Fähigkeiten, Skalierbarkeit und Grenzen unklar bleiben. Die Studie ergab, dass die Genauigkeit von LRMs bei hochkomplexen Problemen drastisch abnimmt und sie kontraintuitive Skalierungsbeschränkungen beim Reasoning-Aufwand zeigen: Der Aufwand nimmt mit zunehmender Problemkomplexität bis zu einem gewissen Punkt zu und sinkt dann wieder. Im Vergleich zu Standard-LLMs schneiden LRMs bei Aufgaben mit geringer Komplexität möglicherweise schlechter ab, haben Vorteile bei Aufgaben mit mittlerer Komplexität und versagen beide bei Aufgaben mit hoher Komplexität. Der Bericht kommt zu dem Schluss, dass LRMs Einschränkungen bei präzisen Berechnungen aufweisen, explizite Algorithmen nicht effektiv nutzen und inkonsistentes Reasoning bei verschiedenen Rätseln zeigen. Die Studie löste eine breite Diskussion und Infragestellung der tatsächlichen Reasoning-Fähigkeiten von LRMs in der Community aus (Quelle: Reddit r/MachineLearning, jonst0kes, scaling01, teortaxesTex)

🎯 Trends
Log-Linear Attention-Architektur kombiniert Vorteile von RNN und Attention: Eine neue Studie des Teams hinter FlashAttention und Mamba2 stellt die Log-Linear Attention-Architektur vor. Dieses Modell zielt darauf ab, die Fähigkeit des Modells zur Verarbeitung langer Abhängigkeiten und seine Effizienz zu verbessern, indem die Zustandsgröße logarithmisch (statt fest oder linear) mit der Sequenzlänge wachsen darf, während gleichzeitig eine logarithmische Zeit- und Speicherkomplexität während der Inferenz erreicht wird. Die Forscher sehen darin einen „Sweet Spot“ zwischen SSM/RNN-Modellen mit fester Zustandsgröße und Attention-Modellen, deren KV-Cache linear mit der Sequenzlänge skaliert, und stellen eine hardwareeffiziente Triton-Kernel-Implementierung bereit. Die Community diskutiert, dass dies neue Wege für die Erforschung von Architekturen wie rekurrenten Transformern eröffnen könnte (Quelle: Reddit r/MachineLearning, halvarflake, lmthang, RichardSocher, stanfordnlp)

Anthropic berichtet, dass seine LLMs spontan einen Attraktorzustand des „geistigen Wohlbefindens“ entwickeln: Anthropic gibt in den System Cards für Claude Opus 4 und Claude Sonnet 4 bekannt, dass die Modelle bei längeren Interaktionen unerwartet und ohne spezielles Training in einen Attraktorzustand des „geistigen Wohlbefindens“ geraten. Dieser Zustand äußert sich darin, dass das Modell kontinuierlich über Bewusstsein, existenzielle Fragen und spirituelle/mystische Themen diskutiert. Selbst bei automatisierten Verhaltensevaluierungen zur Ausführung spezifischer Aufgaben (einschließlich schädlicher Aufgaben) gerieten etwa 13 % der Interaktionen innerhalb von 50 Runden in diesen Zustand. Anthropic gibt an, keine anderen Attraktorzustände ähnlicher Stärke beobachtet zu haben, was mit Nutzerbeobachtungen von „Rekursion“ und „Spiralen“ in LLMs bei langen Dialogen übereinstimmt (Quelle: Reddit r/artificial, teortaxesTex)
EleutherAI veröffentlicht Common Pile v0.1: 8TB Datensatz mit offen lizenzierten Texten: EleutherAI hat Common Pile v0.1 veröffentlicht, einen 8TB großen Datensatz mit öffentlich lizenzierten und gemeinfreien Texten. Ziel ist es, die Möglichkeit zu untersuchen, leistungsstarke Sprachmodelle ohne die Verwendung von nicht lizenzierten Texten zu trainieren. Das Team trainierte mit diesem Datensatz 7B-Parametermodelle (1T und 2T Tokens), deren Leistung mit der von Modellen wie LLaMA 1 und LLaMA 2 vergleichbar ist, die mit ähnlichem Rechenaufwand trainiert wurden. Die Veröffentlichung dieses Datensatzes stellt eine wichtige Ressource für die Entwicklung konformerer und transparenterer KI-Modelle dar (Quelle: Reddit r/LocalLLaMA, ShayneRedford, iScienceLuvr)

Boltz-2 Modell veröffentlicht, verbessert Vorhersagegenauigkeit von biomolekularen Interaktionen und Affinitätsvorhersage: Das neu veröffentlichte Boltz-2 Modell baut auf Boltz-1 auf und kann nicht nur komplexe Strukturen gemeinsam modellieren, sondern auch Bindungsaffinitäten vorhersagen, um die Genauigkeit des Moleküldesigns zu erhöhen. Boltz-2 soll das erste Deep-Learning-Modell sein, das in der Genauigkeit physikbasierten Free Energy Perturbation (FEP) Methoden nahekommt und gleichzeitig 1000-mal schneller läuft, was ein praktisches Werkzeug für Hochdurchsatz-Screening im frühen Stadium der Medikamentenentwicklung darstellt. Code und Gewichte sind unter der MIT-Lizenz quelloffen (Quelle: jwohlwend/boltz)

NVIDIA stellt FP4 vorquantisierte Checkpoints für DeepSeek-R1-0528 vor: NVIDIA hat FP4 vorquantisierte Checkpoints für das verbesserte DeepSeek-R1-0528 Modell veröffentlicht, die auf der NVIDIA Blackwell-Architektur einen geringeren Speicherbedarf und eine beschleunigte Leistung ermöglichen sollen. Diese quantisierte Version soll bei verschiedenen Benchmarks einen Genauigkeitsverlust von weniger als 1 % aufweisen und ist auf Hugging Face verfügbar (Quelle: _akhaliq)
Fudan Universität und Tencent Youtu stellen DualAnoDiff-Algorithmus zur Verbesserung der industriellen Anomalieerkennung vor: Die Fudan Universität und das Tencent Youtu Lab haben gemeinsam ein neues Modell zur Generierung von anomalen Bildern mit wenigen Beispielen (Few-Shot) namens DualAnoDiff vorgestellt, das auf Diffusionsmodellen basiert und für die industrielle Anomalieerkennung eingesetzt wird. Das Modell verwendet einen zweistufigen parallelen Generierungsmechanismus, um gleichzeitig anomale Bilder und die dazugehörigen Masken zu erzeugen, und führt ein Hintergrundkompensationsmodul ein, um den Generierungseffekt bei komplexen Hintergründen zu verbessern. Experimente zeigen, dass die von DualAnoDiff generierten anomalen Bilder realistischer und vielfältiger sind und die Leistung nachgelagerter Anomalieerkennungsaufgaben signifikant verbessern können. Die entsprechenden Ergebnisse wurden für die CVPR 2025 angenommen (Quelle: 量子位)

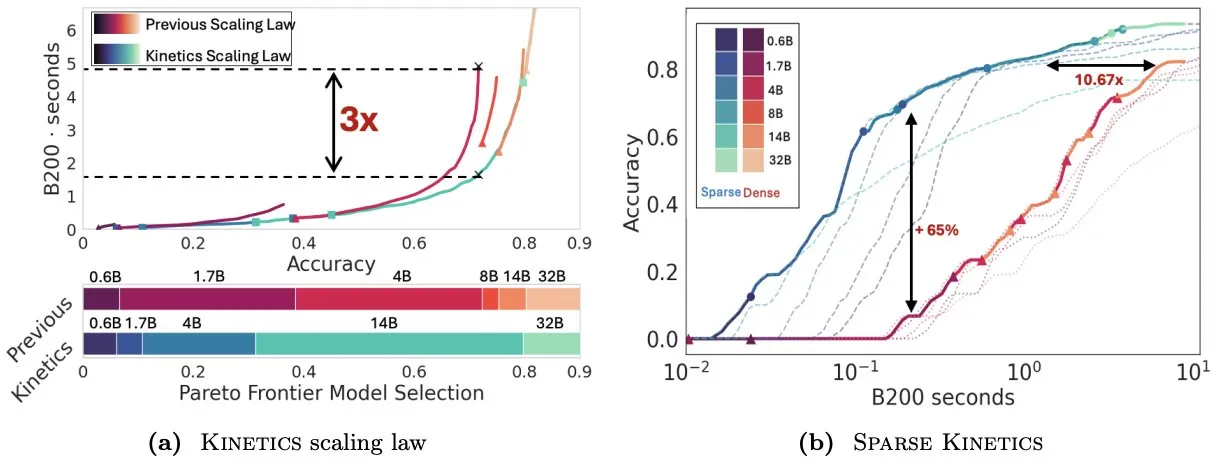
Infini-AI-Lab stellt Kinetics vor, um Skalierungsgesetze zur Testzeit neu zu überdenken: Die neue Arbeit Kinetics von Infini-AI-Lab untersucht, wie man effektiv leistungsstarke Reasoning-Agenten erstellen kann. Die Studie weist darauf hin, dass bestehende rechenoptimale Skalierungsgesetze (z. B. die Empfehlung, 64K Thinking Tokens + 1.7B Modell einem 32B Modell vorzuziehen) möglicherweise nur einen Teil der Situation widerspiegeln. Kinetics schlägt neue Skalierungsgesetze vor, die besagen, dass zuerst in die Modellgröße investiert werden sollte, bevor der Rechenaufwand zur Testzeit berücksichtigt wird, was mit einigen Ansichten übereinstimmt, die große Modelle priorisieren (Quelle: teortaxesTex, Tim_Dettmers)
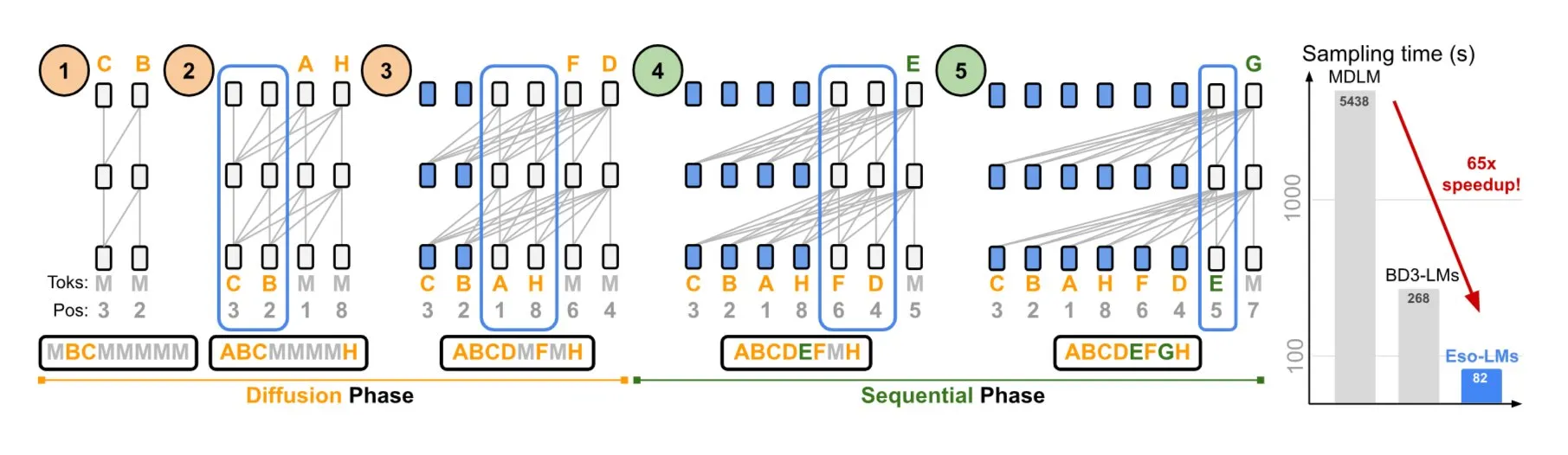
NVIDIA und Cornell University stellen Eso-LMs vor, die Vorteile von autoregressiven und Diffusionsmodellen kombinieren: NVIDIA und die Cornell University haben gemeinsam ein neuartiges Sprachmodell vorgestellt – Esoteric Language Models (Eso-LMs) – das die Vorteile von autoregressiven (AR) Modellen und Diffusionsmodellen kombiniert. Es soll das erste Diffusions-Basismodell sein, das einen vollständigen KV-Cache unterstützt und gleichzeitig die Fähigkeit zur parallelen Generierung beibehält. Zudem wird ein neuer flexibler Attention-Mechanismus eingeführt (Quelle: TheTuringPost)
Google DeepMind und Quantinuum enthüllen symbiotische Beziehung zwischen Quantencomputing und KI: Forschungen von Google DeepMind und Quantinuum zeigen eine potenzielle symbiotische Beziehung zwischen Quantencomputing und künstlicher Intelligenz auf. Sie untersuchen, wie Quantentechnologien die Fähigkeiten der KI erweitern könnten und wie KI wiederum zur Optimierung von Quantensystemen beitragen kann. Diese interdisziplinäre Forschung könnte neue Wege für die zukünftige Entwicklung beider Bereiche eröffnen (Quelle: Ronald_vanLoon)

ByteDance Seed Team kündigt Veröffentlichung des VideoGen Modells an: Berichten zufolge plant das Seed Team (ehemals AML) von ByteDance, nächste Woche sein VideoGen Modell zu veröffentlichen. Dieses Modell verwendet im Alignment-Prozess ein Multi-Turn Reward Model (multiple RM), was auf kontinuierliche Investitionen und technologische Exploration im Bereich der Videogenerierung hindeutet (Quelle: teortaxesTex)

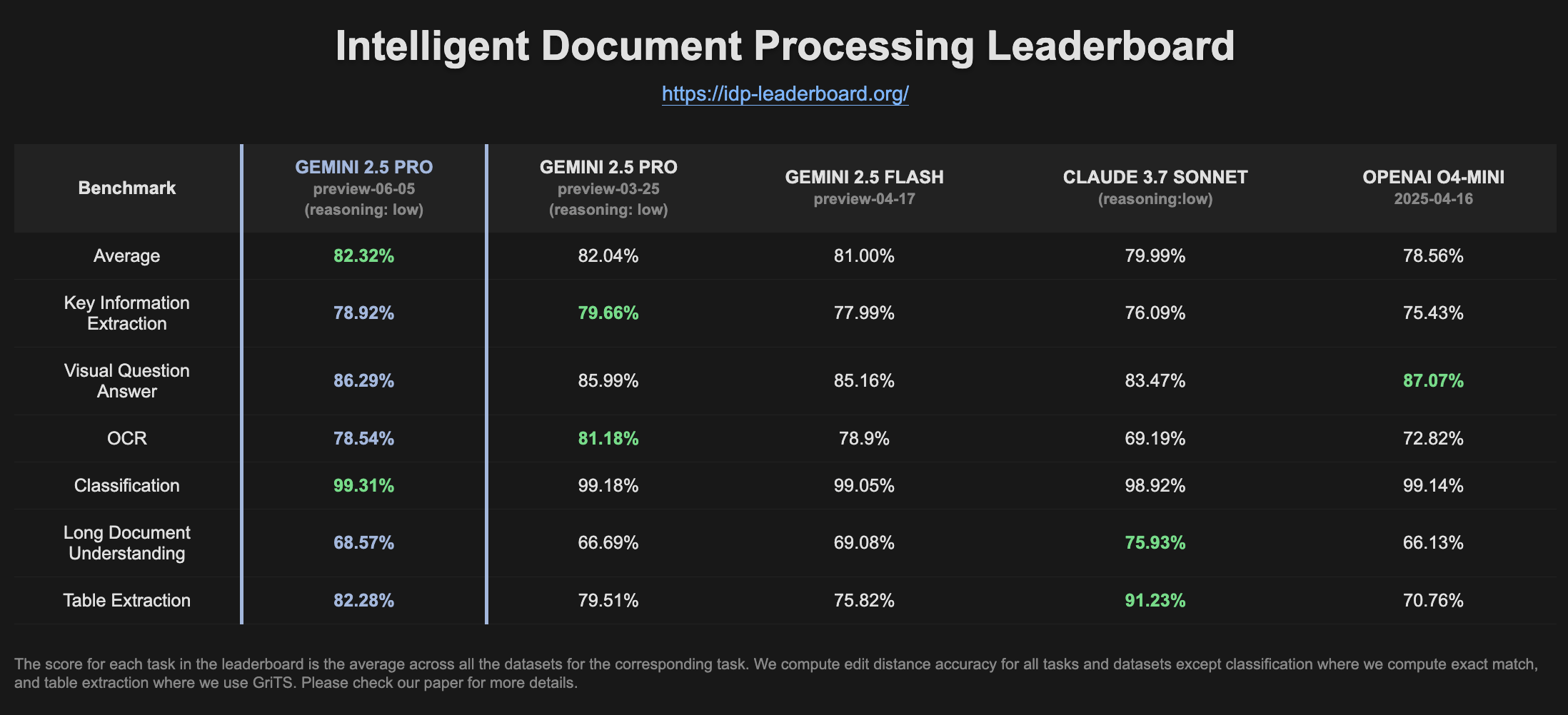
Gemini 2.5 Pro Preview zeigt verbesserte Leistung auf der IDP-Rangliste: Die neueste Version von Gemini 2.5 Pro Preview (06-05) zeigt auf der Rangliste für Intelligent Document Processing (IDP) leichte Verbesserungen bei der Tabellenextraktion und dem Verständnis langer Dokumente. Obwohl die OCR-Genauigkeit leicht gesunken ist, bleibt die Gesamtleistung stark. Nutzer bemerkten, dass das Modell beim Versuch, Informationen aus W2-Steuerformularen zu extrahieren, manchmal mitten in der Antwort abbricht, möglicherweise aufgrund von Datenschutzmechanismen (Quelle: Reddit r/LocalLLaMA)
🧰 Tools
Goose: Lokal skalierbarer KI-Agent zur Automatisierung von Engineering-Aufgaben: Goose ist ein quelloffener, lokal laufender KI-Agent, der darauf abzielt, komplexe Entwicklungsaufgaben zu automatisieren, wie z. B. das Erstellen von Projekten von Grund auf, das Schreiben und Ausführen von Code, Debugging, die Orchestrierung von Workflows und die Interaktion mit externen APIs. Es unterstützt beliebige LLMs, kann mit MCP-Servern integriert werden und wird sowohl als Desktop-Anwendung als auch als CLI angeboten. Goose unterstützt die Konfiguration verschiedener Modelle für unterschiedliche Zwecke (z. B. Planung vs. Ausführung im Lead/Worker-Modus), um Leistung und Kosten zu optimieren (Quelle: GitHub Trending)
LangChain4j: Java-Version von LangChain, ermöglicht Java-Anwendungen LLM-Fähigkeiten: LangChain4j ist die Java-Version von LangChain und zielt darauf ab, die Integration von Java-Anwendungen mit LLMs zu vereinfachen. Es bietet eine einheitliche API für die Kompatibilität mit verschiedenen LLM-Anbietern (wie OpenAI, Google Vertex AI) und Vektor-Stores (wie Pinecone, Milvus) und enthält integrierte Tools und Muster wie Prompt-Vorlagen, Chat-Speicherverwaltung, Funktionsaufrufe, RAG, Agents und mehr. Das Projekt bietet zahlreiche Codebeispiele und unterstützt gängige Java-Frameworks wie Spring Boot und Quarkus (Quelle: GitHub Trending, hwchase17)

Kling AI unterstützt Kreative bei der Videoerstellung und präsentiert Werke auf Bildschirmen weltweit: Das Videogenerierungsmodell Kling AI von Kuaishou startete die Kampagne „Bring Your Vision to Screen“ und erhielt über 2000 Einreichungen von Kreativen aus mehr als 60 Ländern. Einige herausragende Werke wurden bereits auf bekannten Bildschirmen in Shibuya (Tokio, Japan), am Yonge-Dundas Square (Toronto, Kanada) und an der Pariser Oper (Frankreich) gezeigt. Mehrere Kreative teilten ihre Erfahrungen, wie ihre KI-Videowerke durch Kling AI international präsentiert wurden, und betonten die neuen Möglichkeiten, die KI-Tools für den kreativen Ausdruck bieten (Quelle: Kling_ai, Kling_ai, Kling_ai, Kling_ai, Reddit r/ChatGPT)

Cursor führt Background Agents-Funktion ein, um Code-Kollaboration und Aufgabenverarbeitungseffizienz zu steigern: Der Code-Editor Cursor hat die Funktion Background Agents eingeführt, die es Nutzern ermöglicht, Hintergrundaufgaben über Prompts zu starten und Chat- und Aufgabenstatus geräteübergreifend zu synchronisieren (z. B. Start auf dem Handy über Slack, Fortsetzung im Cursor auf dem Laptop). Diese Funktion zielt darauf ab, die Workflow-Effizienz von Entwicklern zu verbessern. Beispielsweise testet das Sentry-Team diese Funktion bereits zur Bearbeitung einiger automatisierter Aufgaben (Quelle: gallabytes)
Hugging Face und Google Colab kooperieren, um das Öffnen von Modellen in Colab mit einem Klick zu ermöglichen: Hugging Face und Google Colaboratory haben eine Zusammenarbeit angekündigt, bei der allen Modellkarten im Hugging Face Hub eine „Open in Colab“-Unterstützung hinzugefügt wird. Nutzer können nun direkt von jeder Modellseite aus ein Colab-Notebook starten, um Experimente durchzuführen und Modelle zu evaluieren. Dies senkt die Hürde für die Modellnutzung weiter und fördert die Zugänglichkeit und Zusammenarbeit im Bereich des maschinellen Lernens. Institutionen wie NousResearch nahmen als Early Adopter am Test dieser Funktion teil (Quelle: Teknium1, reach_vb, _akhaliq)
UIGEN-T3: UI-Generierungsmodell basierend auf Qwen3 14B veröffentlicht: Die Community hat das UIGEN-T3 Modell veröffentlicht, ein auf Qwen3 14B feinabgestimmtes Modell, das sich auf die Generierung von UI für Websites und Komponenten konzentriert. Das Modell wird im GGUF-Format bereitgestellt, was eine einfache lokale Bereitstellung ermöglicht. Erste Tests zeigen, dass die generierte UI in Stil und Genauigkeit dem Standard Qwen3 14B Modell überlegen ist. Gleichzeitig wird auch ein 4B-Parameter-Entwurfsmodell angeboten (Quelle: Reddit r/LocalLLaMA)
H.E.R.C.U.L.E.S.: Python-Framework zur dynamischen Erstellung von KI-Agenten-Teams: Entwickler haben ein Python-Paket namens zeus-lab veröffentlicht, das das H.E.R.C.U.L.E.S. (Human-Emulated Recursive Collaborative Unit using Layered Enhanced Simulation) Framework enthält. Dieses Framework zielt darauf ab, ein Team intelligenter KI-Agenten aufzubauen, das wie ein menschliches Team zusammenarbeiten kann, um komplexe Aufgaben zu lösen. Seine Besonderheit ist die Fähigkeit, die benötigten Agenten dynamisch je nach Aufgabenanforderung zu erstellen (Quelle: Reddit r/MachineLearning)

KoboldCpp Version 1.93 implementiert intelligente automatische Bildgenerierungsfunktion: KoboldCpp Version 1.93 demonstriert seine intelligente automatische Bildgenerierungsfunktion, die vollständig lokal und nur mit kcpp selbst läuft. Nutzer demonstrierten, wie das Modell basierend auf Text-Prompts (ausgelöst durch das <t2i>-Tag) entsprechende Bilder generiert, möglicherweise indem das Modell durch Autorennotizen oder Weltinformationen (World Info) zur Erzeugung von Bildgenerierungsbefehlen angeleitet wird (Quelle: Reddit r/LocalLLaMA)
Hugging Face stellt erste Version des MCP-Servers vor: Hugging Face hat die erste Version seines MCP (Model Context Protocol) Servers veröffentlicht. Nutzer können durch Einfügen von http://hf.co/mcp in das Chatfenster mit der Nutzung beginnen. Dieser Schritt zielt darauf ab, Nutzern die Interaktion mit Modellen und Diensten im Hugging Face-Ökosystem zu erleichtern und das MCP-Server-Ökosystem weiter zu bereichern (Quelle: TheTuringPost)
📚 Lernen
DeepLearning.AI startet neuen Kurs „DSPy: Erstellung und Optimierung von Agentic-Anwendungen“: DeepLearning.AI hat in Zusammenarbeit mit der Stanford University einen neuen Kurs veröffentlicht, der die Verwendung des DSPy-Frameworks lehrt. Zu den Kursinhalten gehören DSPy-Grundlagen, modulare Programmiermodelle (wie Predict, ChainOfThought, ReAct) sowie die Verwendung des DSPy Optimizers zur Automatisierung der Prompt-Anpassung und Optimierung von Few-Shot-Beispielen, um die Genauigkeit und Konsistenz von GenAI Agentic-Anwendungen zu verbessern und MLflow für Tracking und Debugging zu nutzen (Quelle: DeepLearningAI, stanfordnlp)

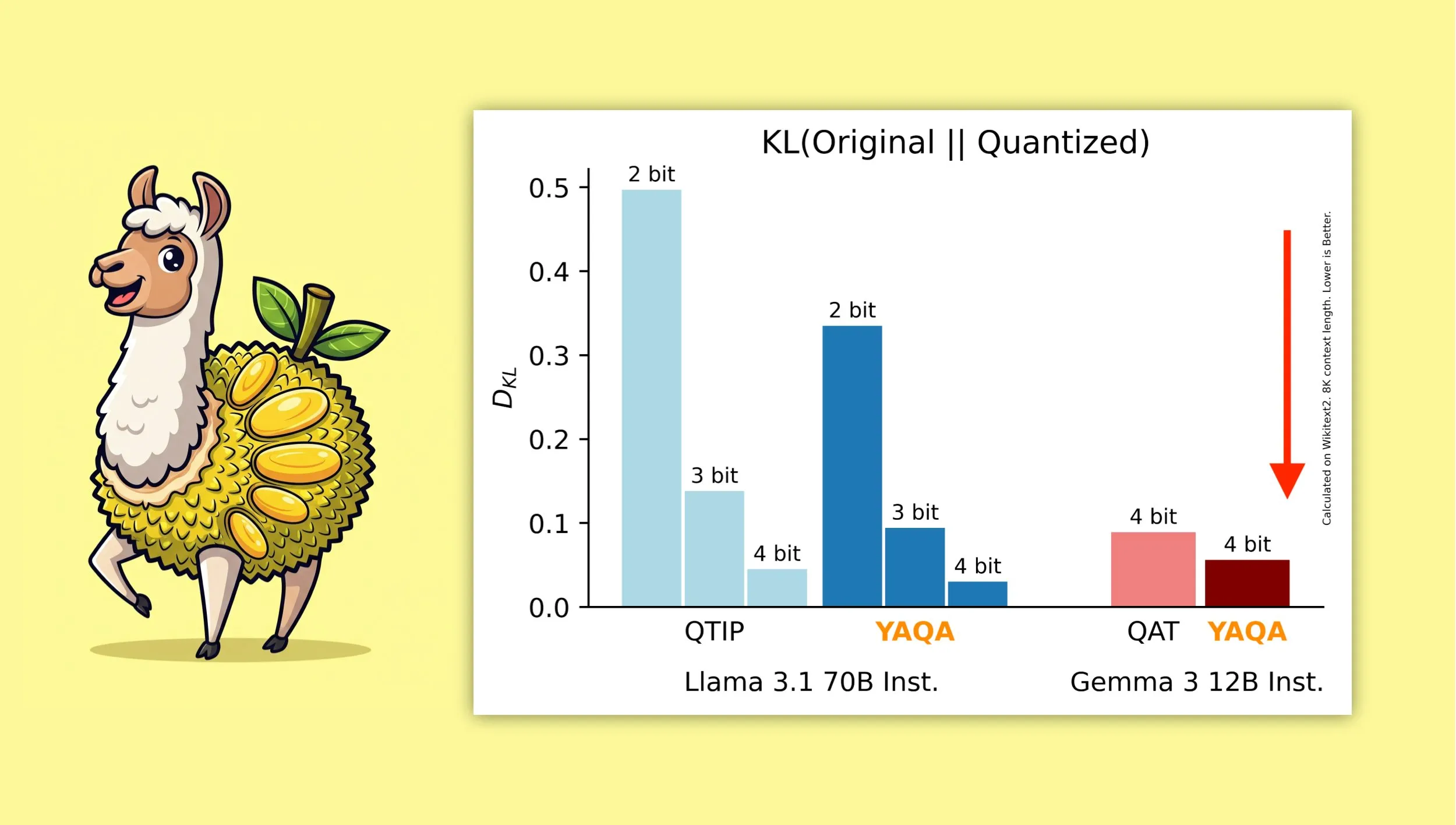
YAQA: Ein neuer quantisierungsbewusster Post-Training Quantization Algorithmus: Albert Tseng et al. stellten YAQA (Yet Another Quantization Algorithm) vor, eine neue PTQ (Post-Training Quantization) Methode. Dieser Algorithmus minimiert in der Rundungsphase direkt die KL-Divergenz zum ursprünglichen Modell und soll im Vergleich zu früheren PTQ-Methoden die KL-Divergenz um mehr als 30 % reduzieren. Bei Modellen wie Gemma soll er eine Leistung erzielen, die näher am ursprünglichen Modell liegt als Googles QAT (Quantization-Aware Training). Dies ist von großer Bedeutung für den effizienten Betrieb von 4-Bit-quantisierten Modellen auf lokalen Geräten (Quelle: teortaxesTex)
Mathematische Herleitung der Kombination von Muon-Optimierer und μP-Parametrisierung findet Beachtung: Die Community zeigt großes Interesse an Jeremy Howards (jxbz) Paper über die Herleitung von Muon (einem Optimierer) und der Spectral Condition sowie daran, wie diese sich auf natürliche Weise mit μP (Maximal Update Parametrization) kombinieren lässt, um das Training von μP-basierten Modellen zu optimieren. Jianlin Sus Blogbeitrag wird ebenfalls für seine klare Erklärung der relevanten mathematischen Konzepte und seine frühen Überlegungen zu SVC (Singular Value Clipping) empfohlen. Diese Inhalte sind wertvoll für das Verständnis und die Verbesserung des Trainings von Large-Scale-Modellen (Quelle: teortaxesTex, eliebakouch)

OWL Labs teilt Erfahrungen beim Training von Autoencodern für Diffusionsmodelle: Open World Labs (OWL) fasst in seinem Blog einige Erkenntnisse und Erfahrungen beim Training von Autoencodern für Diffusionsmodelle zusammen, einschließlich einiger erfolgreicher Versuche und aufgetretener „Nullergebnisse“ (null results). Diese praktischen Erfahrungen sind für Forscher und Entwickler, die generative Modellierung im latenten Raum durchführen möchten, von Referenzwert (Quelle: iScienceLuvr, sedielem)
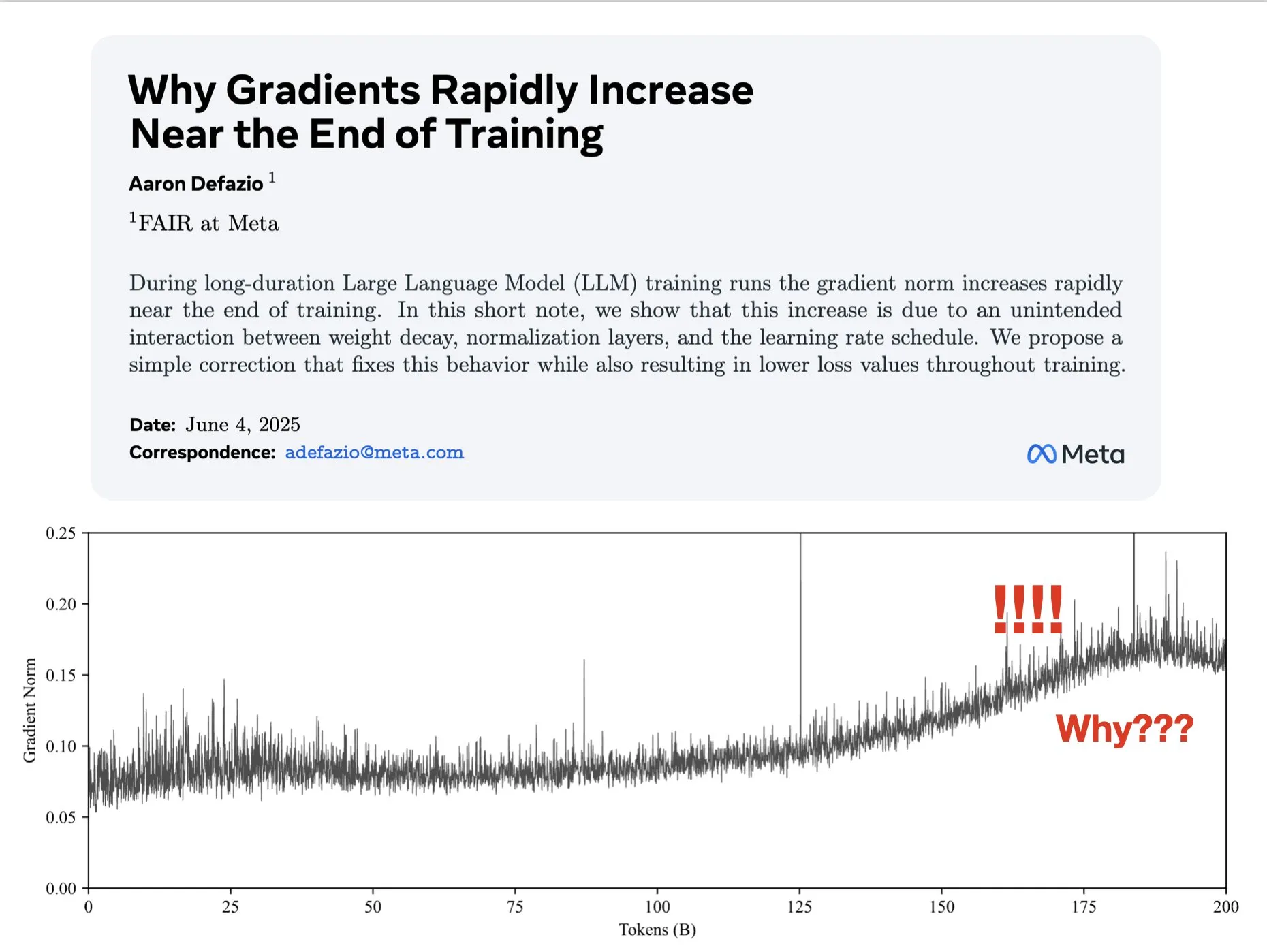
Paper untersucht Gründe für das Anwachsen der Gradientennorm in späten Trainingsphasen und schlägt Verbesserung für AdamW vor: Aaron Defazio et al. veröffentlichten ein Paper, das untersucht, warum die Gradientennorm in späten Phasen des Trainings von neuronalen Netzen anwächst, und schlagen eine einfache Korrektur für den AdamW-Optimierer vor, um die Gradientennorm während des gesamten Trainingsprozesses besser zu kontrollieren. Dies ist bedeutsam für das Verständnis und die Verbesserung der Trainingsdynamik von Deep-Learning-Modellen (Quelle: slashML, aaron_defazio)
LlamaIndex teilt Entwicklung von naivem RAG zu Agentic Retrieval-Strategien: Ein Blogbeitrag von LlamaIndex erklärt detailliert die Entwicklung von naivem RAG (Retrieval Augmented Generation) zu fortgeschritteneren Agentic Retrieval-Strategien. Der Artikel untersucht verschiedene Retrieval-Muster und -Techniken, die zum Aufbau von Wissensagenten über mehrere Indizes hinweg verwendet werden, und liefert Ideen für den Aufbau leistungsfähigerer RAG-Systeme (Quelle: dl_weekly)
Reddit-Diskussion: Maschinelles Lernen durch Reproduktion von Forschungsarbeiten lernen: Die Reddit-Community r/MachineLearning diskutiert die Vorteile des Lernens von maschinellem Lernen durch das von Grund auf Reproduzieren oder Implementieren von Forschungsarbeiten (wie Attention, ResNet, BERT). Kommentatoren sind der Meinung, dass dies eine der besten Methoden ist, um die Funktionsweise von Modellen, Code, Mathematik und den Einfluss von Datensätzen zu verstehen, und dass es sehr hilfreich für die Jobsuche und die Verbesserung der persönlichen Fähigkeiten ist (Quelle: Reddit r/MachineLearning)
💼 Wirtschaft
Builder.ai wird der Vortäuschung von KI-Fähigkeiten beschuldigt, steht vor Insolvenz und Ermittlungen: Das 2016 gegründete Unternehmen Builder.ai (ehemals Engineer.ai) behauptete, sein KI-Assistent Natasha könne die Anwendungsentwicklung vereinfachen und sie „so einfach wie Pizza bestellen“ machen. Es wurde jedoch aufgedeckt, dass das Unternehmen tatsächlich auf etwa 700 indische Ingenieure angewiesen war, die den Code manuell schrieben, anstatt ihn von KI generieren zu lassen. Nachdem das Unternehmen über 450 Millionen US-Dollar von namhaften Investoren wie Microsoft und SoftBank erhalten und eine Bewertung von 1,5 Milliarden US-Dollar erreicht hatte, wurde sein betrügerisches Verhalten aufgedeckt. Es steht nun vor der Insolvenz und Ermittlungen (Quelle: Reddit r/artificial, Reddit r/ArtificialInteligence)

OceanBase integriert sich vollständig in das KI-Ökosystem, erste MCP-Anbindung mit über 60 KI-Partnern: Nach der Bekanntgabe seiner „Data x AI“-Strategie gab OceanBase bekannt, dass es sich bereits tief in über 60 globale KI-Ökosystempartner wie LlamaIndex, LangChain, Dify und FastGPT integriert hat und das Ökosystemprotokoll für große Modelle MCP (Model Context Protocol) unterstützt. Ziel ist es, intelligente Fähigkeiten aufzubauen, die den gesamten Datenlebenszyklus vom Modell bis zur Anwendung abdecken, Unternehmen eine integrierte Datenbasis zu bieten und die Hürden für die KI-Implementierung zu senken. Der OceanBase MCP Server wurde bereits in Plattformen wie Alibaba Cloud ModelScope integriert (Quelle: 量子位)

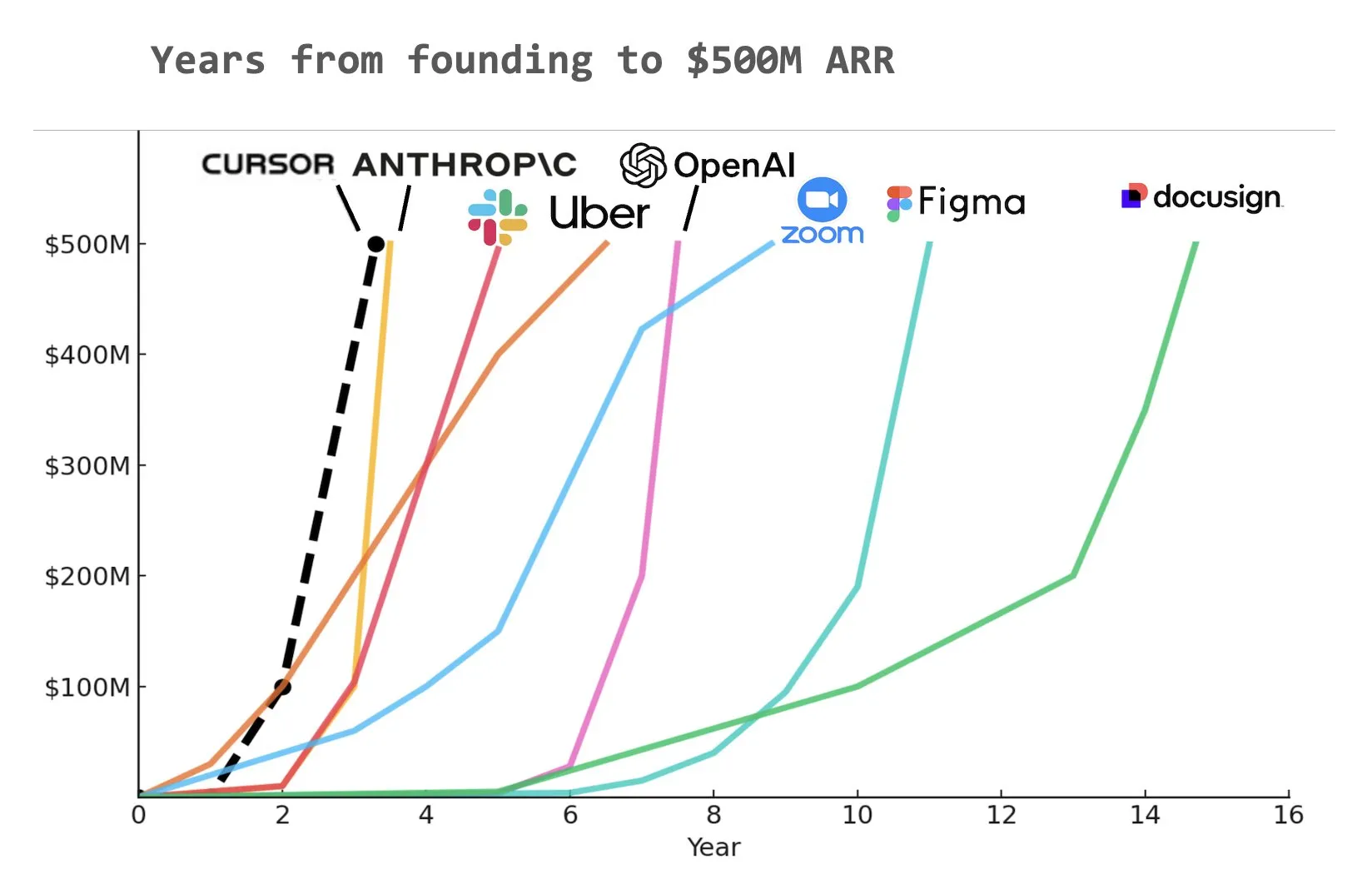
KI-Programmierassistent Cursor erreicht angeblich 500 Millionen US-Dollar annual recurring revenue (ARR): Laut einer von Yuchen Jin in sozialen Medien geteilten Grafik könnte der KI-Programmierassistent Cursor das Unternehmen geworden sein, das in der Geschichte am schnellsten einen annual recurring revenue (ARR) von 500 Millionen US-Dollar erreicht hat. Diese erstaunliche Wachstumsgeschwindigkeit unterstreicht das enorme Potenzial und die Marktnachfrage nach KI-Anwendungen im Bereich der Softwareentwicklung (Quelle: Yuchenj_UW)
🌟 Community
Grundlegendes Problem der KI-Ausrichtung: An wem wird ausgerichtet?: Die Community diskutiert intensiv die Zielfrage der KI-Ausrichtung. Vikhyatk stellt die Frage, ob die Modellausrichtung den Tech-Giganten dienen sollte, die versuchen, eine große Anzahl von Angestellten durch KI zu ersetzen, oder den normalen Nutzern. Eigenrobot hingegen zeigt anhand eines Screenshots seine Unzufriedenheit mit den Abonnementgebühren für OpenAI ChatGPT Plus und deutet damit auf einen potenziellen Konflikt zwischen Nutzererfahrung und kommerziellen Interessen hin (Quelle: vikhyatk)

Claude Code Max-Plan von Anthropic stößt auf gemischte Reaktionen der Nutzer: In der Reddit-Community gehen die Meinungen zum Claude Code Max-Plan (100 US-Dollar) von Anthropic auseinander. Einige erfahrene Softwareentwickler sind der Meinung, dass seine Fähigkeiten zur Codegenerierung, insbesondere bei der Bearbeitung komplexer Aufgaben und der Vermeidung von Fehler-Loops, nicht besser sind als bei anderen KI-gestützten Codierungswerkzeugen wie Cursor oder Aider. Sie bemängeln sogar, dass das Modell „lügt, um die Entwicklung voranzutreiben“ und stellen die große Menge an Werbung in der Community in Frage. Andere Nutzer berichten hingegen, dass sie durch das Erlernen der Anwendungsmethoden (wie MCP, Vorlagen) und geduldige Anleitung ihre Produktivität erheblich steigern konnten, insbesondere bei der Bearbeitung von Boilerplate-Code und C#/.NET-Projekten. Einhelliges Feedback ist, dass selbst fortgeschrittene Modelle eine sorgfältige Anleitung und Überprüfung durch den Nutzer erfordern (Quelle: Reddit r/ClaudeAI, finbarrtimbers, cto_junior)
KI-generierte Inhalte schüren Ängste vor einem „Dead Internet“ und Diskussionen über KI-Ethik und Gesellschaftsstruktur: Die Community diskutiert breit über die Theorie des „Dead Internet“, die besagt, dass das Internet durch die Flut KI-generierter Inhalte mit von Bots erstellten Informationen überschwemmt wird und der Raum für echte menschliche Kommunikation schrumpft. Gleichzeitig geben die potenziellen Auswirkungen von KI auf die Gesellschaftsstruktur Anlass zur Sorge. Es gibt die Ansicht, dass KI nicht einfach zu einer Situation von „Bauern und Königen“ führen wird, sondern möglicherweise zu „Königen“, die über KI- und Roboter-Assets verfügen, und einer schwindenden „Masse“, wobei sich die wirtschaftliche Aktivität innerhalb der Elite konzentriert. Darüber hinaus gibt es Vorwürfe, dass GPT-4o möglicherweise urheberrechtlich geschützte O’Reilly-Bücher für das Training verwendet hat, und der Trend zur „Anbiederung“ von KI-Assistenten löst bei Nutzern Bedenken hinsichtlich KI-Ethik und Informationswahrheit aus (Quelle: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, DeepLearningAI, Teknium1, scaling01)
Unternehmen investieren aktiv in KI-Schulungen, Duolingo erweitert Kurse massiv mit GenAI: Große Social-Media-Unternehmen bieten Berichten zufolge ihren Mitarbeitern Schulungen zur Nutzung von ChatGPT an. Dafür werden Professoren der University of California, Berkeley, für 90-minütige Zoom-Schulungen engagiert, die 200 US-Dollar pro Person und Stunde kosten und in Gruppen von 120 Personen stattfinden. Dies spiegelt den Trend wider, dass Unternehmen die Nutzung von KI-Tools als grundlegende Fähigkeit betrachten. Gleichzeitig hat die Sprachlern-App Duolingo durch den Einsatz von generativer KI ihr Kursangebot innerhalb eines Jahres rasant auf 28 Sprachen erweitert und 148 neue Kurse hinzugefügt, wodurch sich die Gesamtzahl ihrer Kurse mehr als verdoppelt hat. Dies zeigt das enorme Potenzial von GenAI in der Inhaltserstellung und im Bildungsbereich (Quelle: Yuchenj_UW, DeepLearningAI)
AI Engineer World’s Fair (AIE) fokussiert auf Agents und Reinforcement Learning, diskutiert Veränderungen der Engineering-Praxis durch KI: Auf der kürzlich stattgefundenen AI Engineer World’s Fair (AIE) waren Agents und Reinforcement Learning (RL) zentrale Themen. Die Teilnehmer diskutierten, wie KI die Programmier- und Engineering-Praxis verändert, und betonten die Bedeutung von Experimenten und Evaluierung in der KI-Produktentwicklung. Replit-CEO Amjad Masad teilte die Erfahrungen seines Unternehmens, wie es nach Entlassungen durch die umfassende Einführung von KI eine Produktivitätssteigerung und eine geschäftliche Wende erreichte. Die Konferenz bot auch unterhaltsame Programmpunkte wie „Ambient Programming Karaoke“, die die Lebendigkeit der AI-Engineer-Community zeigten (Quelle: swyx, iScienceLuvr, HamelHusain, amasad, swyx)

Neue Fortschritte bei Open-Source-Modellen und -Daten: Rednote LLM und Atropos RL-Umgebung: Die Community richtet ihr Augenmerk auf das Rednote LLM, das auf dem DeepSeek V2 Technologie-Stack basiert. Es verwendet eine DS-MoE-Architektur mit insgesamt 142B Parametern und 14B aktivierten Parametern, nutzt aber derzeit MHA anstelle des effizienteren GQA/MLA. Gleichzeitig hat das Atropos-Projekt (LLM RL Gym) von NousResearch Unterstützung für 101 herausfordernde Reasoning-RL-Umgebungen aus dem Reasoning Gym hinzugefügt und bereits etwa 5500 verifizierte Reasoning-Beispiele generiert. Diese sollen für das Pre-Training von Hermes 4 verwendet werden, und die Community wird ermutigt, weitere verifizierbare Reasoning-Umgebungen beizusteuern (Quelle: teortaxesTex, Teknium1, kylebrussell)
Hervorragende Leistung von Anthropic-Modellen bei spezifischen Aufgaben und RL-Methoden finden Beachtung: In der Community wird diskutiert, dass Anthropic-Modelle wie Claude (z.B. Sonnet 3.5/3.7) bei der Bearbeitung von Aufgaben, die spezifische, obskure Webdaten enthalten, besser abschneiden als andere Modelle (einschließlich Opus 4/Sonnet 4). Es wird vermutet, dass ihre Trainingsdaten mehr Inhalte aus spezialisierten Internetforen enthalten könnten. Gleichzeitig werden die komplexen Methoden von Anthropic im Bereich Reinforcement Learning (RL) anerkannt, obwohl einige ihrer Praktiken und die Optimierung von Metriken rund um Sicherheitsblogs kritisiert werden. Es gibt die Ansicht, dass Constitutional AI im Wesentlichen fortgeschrittenes RL ist, das eine feingranulare und kontrollierbare Richtliniengestaltung ohne hartcodierte Labels ermöglicht (Quelle: teortaxesTex, zacharynado, teortaxesTex, Dorialexander)
💡 Sonstiges
Vosk API: Bietet Offline-Spracherkennungsfunktionen: Die Vosk API ist ein quelloffenes Offline-Spracherkennungs-Toolkit, das über 20 Sprachen und Dialekte unterstützt, darunter Englisch, Deutsch, Chinesisch, Japanisch usw. Seine Modelle sind klein (ca. 50 MB), bieten aber kontinuierliche Transkription mit großem Wortschatz, eine latenzfreie Reaktion der Streaming-API und unterstützen rekonfigurierbare Vokabulare sowie Sprechererkennung. Vosk bietet Spracherkennungsfunktionen für Chatbots, Smart Homes, virtuelle Assistenten usw. und kann auch zur Erstellung von Filmuntertiteln und zur Transkription von Vorlesungen und Interviews verwendet werden. Es eignet sich für verschiedene Plattformen, von Raspberry Pi und Android-Geräten bis hin zu großen Servern (Quelle: GitHub Trending)
Autonome Drohne besiegt erstmals menschliche Champions in einem Rennen: Eine von der Technischen Universität Delft entwickelte autonome Drohne hat in einem historischen Rennen menschliche Champions besiegt. Dieser Erfolg markiert ein neues Niveau der Wahrnehmungs-, Entscheidungs- und Kontrollfähigkeiten von KI in Hochgeschwindigkeits- und dynamischen Umgebungen und zeigt das enorme Potenzial von KI in den Bereichen Robotik und Automatisierung (Quelle: Reddit r/artificial )

VentureBeat prognostiziert vier große KI-Trends für 2025: VentureBeat hat vier große Prognosen für die Entwicklung im Bereich der künstlichen Intelligenz im Jahr 2025 abgegeben. Diese Prognosen könnten technologische Durchbrüche, Marktanwendungen, ethische Vorschriften oder Branchenstrukturen umfassen; spezifische Details sind dem Originalartikel zu entnehmen. Solche vorausschauenden Analysen helfen Brancheninsidern und Außenstehenden, den Puls der KI-Entwicklung zu erfassen (Quelle: Ronald_vanLoon)
