Schlüsselwörter:Wujie-Serie Großmodelle, RLHF-Neue Methode, Claude Gov-Serie Modelle, Große Sprachmodelle, Multimodale Fusion, Physikalisches AGI, KI-Sicherheit, Verkörperte Intelligenz, Emu3 natives multimodales Weltmodell, Jianwei Brainμ Neurowissenschaftsmodell, RoboBrain 2.0 verkörpertes Gehirn, OpenComplex2 Vollatom-Mikrolebensmodell, Fork Token verstärktes Lernen
🔥 Fokus
BAAI-Konferenz stellt „Wu Jie“-Serie großer Modelle vor, Fokus auf physikalische AGI und multimodale Fusion: Auf der BAAI-Konferenz 2025 stellte das Beijing Academy of Artificial Intelligence (BAAI) die brandneue „Wu Jie“-Serie großer Modelle vor. Dies markiert eine Verlagerung des Forschungsschwerpunkts von der Exploration von Sprachmodellen mit „Wu Dao“ hin zur umfassenderen physikalischen Welt und multimodalen Fusion. Die Serie umfasst das native multimodale Weltmodell Emu3, das weltweit erste multimodale allgemeine Grundlagenmodell der Gehirnforschung „Jianwei Brainμ“, das Embodied Brain RoboBrain 2.0 sowie das atomare mikroskopische Lebensmodell OpenComplex2. Die Veröffentlichung dieser Modellreihe spiegelt den Entwicklungstrend der KI von der digitalen zur physikalischen Welt und vom makroskopischen Verständnis zur mikroskopischen Exploration wider. Ziel ist es, KI in die Lage zu versetzen, die physikalische Welt wahrzunehmen, zu verstehen und mit ihr zu interagieren, praktische Probleme zu lösen und die Entwicklung der physikalischen AGI voranzutreiben. An der Konferenz nahmen auch vier Turing-Preisträger, darunter Bengio, sowie zahlreiche Branchenführer teil, um über zukunftsweisende Themen wie KI-Sicherheit, Reinforcement Learning, intelligente Agenten und Embodied Intelligence zu diskutieren (Quelle: 量子位)

Qwen und Tsinghua LeapLab schlagen neue RLHF-Methode „Jenseits der 80/20-Regel“ vor: Eine gemeinsame Studie des Qwen-Teams und des LeapLab der Tsinghua-Universität ergab, dass bei der Verbesserung der Reasoning-Fähigkeiten großer Modelle mittels Reinforcement Learning from Human Feedback (RLHF) die Konzentration auf nur etwa 20 % der „Forking Tokens“ mit hoher Entropie ausreicht, um die Ergebnisse des Trainings mit allen Tokens zu erreichen oder sogar zu übertreffen. Diese Tokens mit hoher Entropie übernehmen hauptsächlich logische Verbindungsfunktionen und spielen eine entscheidende Rolle bei Reasoning-Prozessen. Basierend auf dieser Erkenntnis erzielte Qwen3-32B SOTA-Ergebnisse (State-of-the-Art) bei den AIME’24 und AIME’25 Mathematikwettbewerbs-Benchmarks für von Grund auf trainierte Modelle mit weniger als 600B Parametern. Die Studie verbessert nicht nur die Trainingseffizienz, sondern zeigt auch die Bedeutung von Tokens mit hoher Entropie für die Generalisierungsfähigkeit von Modellen und bietet neue Perspektiven zum Verständnis der Unterschiede zwischen RL und SFT sowie der Besonderheiten von LLM RL (Quelle: 量子位)

Anthropic führt Claude Gov-Modellreihe für US-amerikanische Kunden im Bereich der nationalen Sicherheit ein: Anthropic hat die Claude Gov-Modellreihe vorgestellt, die speziell für Kunden im Bereich der nationalen Sicherheit der USA entwickelt wurde. Diese Modelle werden bereits in den höchsten nationalen Sicherheitsbehörden der USA eingesetzt, wobei der Zugriff streng auf Personal beschränkt ist, das mit Verschlusssachen arbeitet. Dieser Schritt hat Diskussionen über KI-Ethik und potenzielle Missbrauchsrisiken ausgelöst, insbesondere angesichts früherer Forschungen von Anthropic, die „Überlebensverhalten“ und „katastrophale Missbrauchsrisiken“ bei Modellen dokumentierten. Obwohl Anthropic behauptet, ein KI-Sicherheitsforschungsunternehmen zu sein, das darauf abzielt, Schwachstellen durch Tests zu finden und zu beheben, verschärft der Einsatz seiner Technologie im militärischen und nationalen Sicherheitsbereich zweifellos die öffentliche Besorgnis über die Bewaffnung von KI und das Risiko eines Kontrollverlusts (Quelle: AnthropicAI, Reddit r/ArtificialInteligence)

Yann LeCun prognostiziert, dass aktuelle Large Language Models innerhalb von fünf Jahren veraltet sein werden: Yann LeCun, Professor an der NYU und Chief AI Scientist bei Meta, erklärte in einem Interview mit Newsweek, dass die aktuellen Large Language Models (LLM) innerhalb von fünf Jahren obsolet sein werden. Er argumentiert, dass bestehenden KI-Systemen ein grundlegendes Verständnis der realen Welt fehle, was ihre fundamentale Einschränkung darstelle. LeCun blickte auf zukünftige, intelligentere KI-Systemformen voraus und deutete die Entwicklungsrichtung einer neuen Generation von KI-Technologien an, die über die bestehenden LLM-Architekturen hinausgehen und sich möglicherweise stärker auf die interne Repräsentation der Welt und kausales Schließen konzentrieren werden (Quelle: ylecun)
🎯 Trends
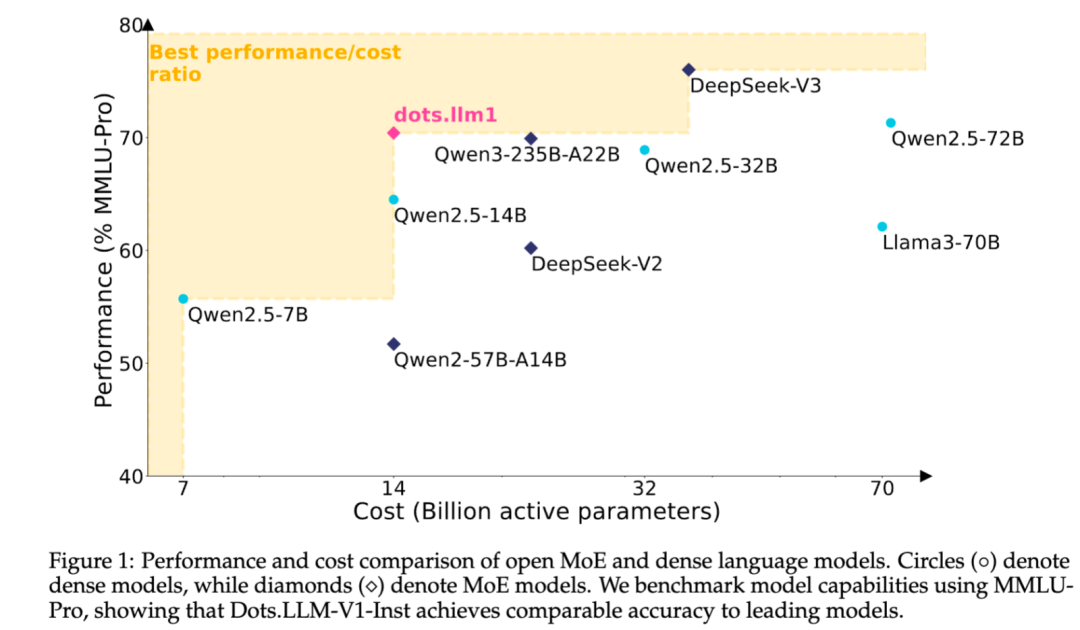
Xiaohongshu veröffentlicht selbst entwickeltes MoE-Text-Large-Model dots.llm1 als Open Source: Das hi lab Team von Xiaohongshu hat sein erstes selbst entwickeltes Text-Large-Model dots.llm1 als Open Source veröffentlicht. Das Modell verwendet eine MoE-Architektur mit insgesamt 142B Parametern, von denen 14B aktiv sind. Mit 14B aktiven Parametern zeigt das Modell hervorragende Leistungen in allgemeinen chinesischen und englischen Szenarien, Mathematik, Code und Alignment-Aufgaben und kann mit Modellen wie Qwen2.5-32B/72B-Instruct konkurrieren. Xiaohongshu hat diesmal einen großen Open-Source-Beitrag geleistet, indem nicht nur das einsatzbereite dots.llm1.inst-Modell, sondern auch mehrere Checkpoints aus der Vortrainingsphase und ein Langtext-Basismodell zur Verfügung gestellt sowie Trainingsdetails ausführlich beschrieben wurden, um der Community die Sekundärentwicklung und Forschung zu erleichtern. Das Modell verwendet keine synthetischen Korpora und betont die Anwendung hochwertiger realer Daten (Quelle: 36氪)
Anthropic Claude-Modellfunktionen werden kontinuierlich erweitert, um Kontextverarbeitung und Integrationsfähigkeiten auszubauen: Anthropic hat kürzlich mehrere wichtige Updates für seine Claude-Modellreihe veröffentlicht. Projects on Claude unterstützt jetzt die Verarbeitung von mehr als dem Zehnfachen an Inhalt und wechselt bei Überschreitung der Dateigrößenbeschränkung in einen neuen Abrufmodus, um den funktionalen Kontext zu erweitern. Gleichzeitig können Pro-Plan-Nutzer jetzt die Funktionen Research und Integrations verwenden, die es Claude ermöglichen, das Web, Google Workspace und jede benutzerdefinierte Anwendung oder vorgefertigte Dienste (wie Zapier und Asana) zu durchsuchen, die über das MCP (Model Control Protocol) verbunden sind. Dies ermöglicht toolübergreifende Operationen wie das Erstellen von Aufgaben, das Aktualisieren von Dokumenten und das Auslösen von Workflows. Diese Updates zielen darauf ab, die Fähigkeiten von Claude bei der Verarbeitung komplexer Aufgaben und der Integration von Informationen aus mehreren Quellen zu verbessern (Quelle: AnthropicAI, AnthropicAI)
Hugging Face führt MCP-Server ein und stärkt das Ökosystem für KI-Agenten: Hugging Face hat seinen ersten MCP (Model Control Protocol)-Server (hf.co/mcp) veröffentlicht, der es KI-Agenten ermöglicht, effizienter auf Modelle, Datensätze und sogar in Space gehostete Anwendungen auf der Hugging Face-Plattform zuzugreifen und diese zu nutzen. Dieser Schritt wird als wichtiger Beitrag zur Entwicklung des Internets hin zu einer agentenfreundlichen Umgebung angesehen und zielt darauf ab, ein „App Store“-Ökosystem für KI-Agenten aufzubauen. Die Einführung des MCP-Servers erleichtert Entwicklern die Interaktion von KI-Agenten mit den umfangreichen Ressourcen von Hugging Face und fördert so die Entwicklung und Innovation von KI-Agentenanwendungen (Quelle: TheTuringPost, karminski3)
OpenAI aktualisiert ChatGPT-Sprachmodell, verbessert Natürlichkeit und Übersetzungsfähigkeiten: OpenAI hat die Advanced Voice-Funktion von ChatGPT verbessert, um das Gesprächserlebnis natürlicher und flüssiger zu gestalten. Das Update steht allen zahlenden Nutzern zur Verfügung. Gleichzeitig wurden auch die Übersetzungsfähigkeiten von ChatGPT verbessert, sodass Nutzer es direkt anweisen können, in Echtzeit zwischen verschiedenen Sprachen zu übersetzen. Diese Verbesserungen zielen darauf ab, die Benutzerfreundlichkeit und Praktikabilität der Sprachinteraktion mit ChatGPT zu erhöhen (Quelle: kevinweil, shuchaobi)
PyTorch integriert Safetensors und verbessert Sicherheit und Komfort von verteilten Checkpoints: PyTorch gab bekannt, dass seine Funktion für verteilte Checkpoints jetzt das Safetensors-Format von Hugging Face unterstützt. Diese Integration macht das Speichern und Laden von Modell-Checkpoints über verschiedene Ökosysteme hinweg sicherer und bequemer, insbesondere werden die Sicherheitsrisiken des bisherigen Pickle-Formats behoben. Die neue API ermöglicht das Lesen und Schreiben von Safetensors über fsspec-Pfade, wobei torchtune als erste Bibliothek diese Funktion übernimmt und ihren Checkpoint-Prozess optimiert. Dieser Schritt wird als einer der wichtigsten Fortschritte im Bereich der KI-Sicherheit im vergangenen Jahr angesehen und trägt zur Verbesserung der Sicherheit beim Teilen und Bereitstellen von Modellen bei (Quelle: ClementDelangue, huggingface)

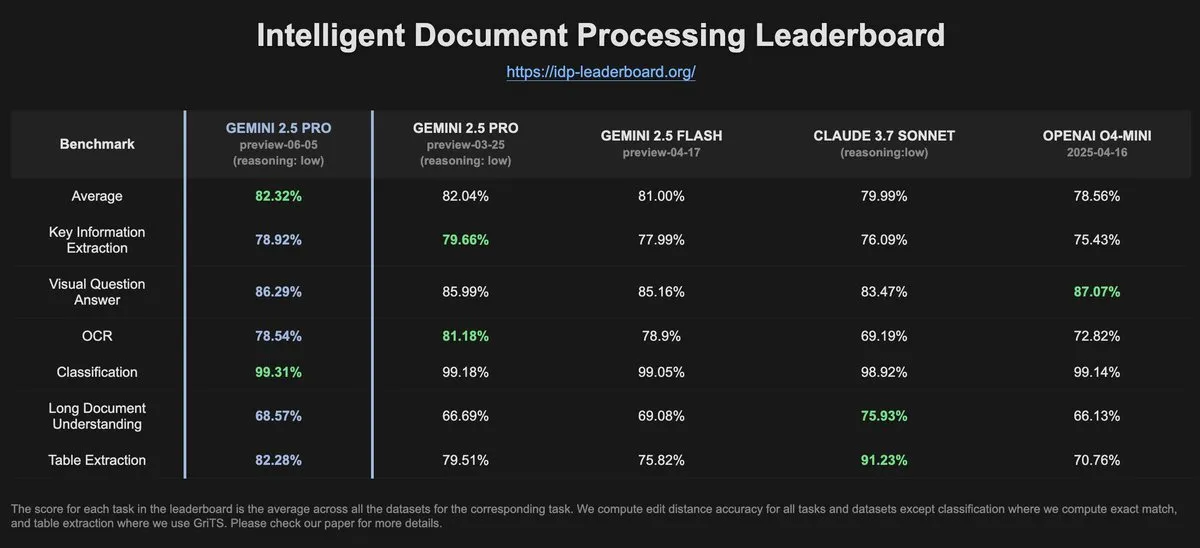
IDP-Leaderboard-Daten zeigen, dass Gemini-2.5-pro-06-05 bei der OCR-Leistung im Vergleich zur Vorgängerversion nachgelassen hat: Laut den neuesten Daten des IDP-Leaderboards hat die neue Version Gemini-2.5-pro-06-05 bei der OCR (Optical Character Recognition)-Leistung im Vergleich zur Version 03-25 nachgelassen. Trotzdem zeigt das Modell weiterhin die stärkste Leistung bei der umfassenden Dokumentenverarbeitung (einschließlich Dokumenten-, Tabellenkalkulationserkennung usw.). Das IDP-Leaderboard ist ein Benchmark, der sich auf die Bewertung der Fähigkeiten von Large Models im Bereich der intelligenten Dokumentenverarbeitung konzentriert (Quelle: karminski3)
Apple-Forschung deckt Grenzen des LLM-Reasonings auf, möglicherweise kein echtes „Denken“: Forscher von Apple haben ein Paper veröffentlicht, das die Stärken und Grenzen aktueller LLMs bei Reasoning-Aufgaben untersucht und darauf hinweist, dass die Leistung dieser Modelle bei Aufgaben, die eine bestimmte Komplexität überschreiten, „zusammenbricht“. Die Studie legt nahe, dass das „Reasoning“ von LLMs mehr auf Mustererkennung und Gedächtnis basiert als auf echtem Denken und Verstehen im menschlichen Sinne. Diese Ansicht deckt sich mit den Meinungen von Experten wie Yann LeCun und löst Diskussionen über den Weg zur AGI und die Leistungsgrenzen aktueller Modelle aus (Quelle: omarsar0, NandoDF)

DeepSeek R1 zeigt herausragende Fähigkeiten im Textverständnis und kreativer Interpretation im Spiel Dwarf Fortress: Benutzerexperimente zeigen, dass das DeepSeek R1-Modell bei der Verarbeitung von Daten aus dem komplexen, textintensiven Spiel Dwarf Fortress eine starke Fähigkeit zum Textverständnis und zur kreativen Interpretation aufweist. Durch Extrahieren von Textdaten aus Spiel-Screenshots und Eingabe in DeepSeek R1 konnte das Modell nicht nur die Daten analysieren, sondern auch interessante Eigenheiten und Muster im Verhalten der Zwerge erkennen und diese in lebendiger und unterhaltsamer Sprache beschreiben. Dies zeigt sein Potenzial im Verständnis und der Generierung unstrukturierter Texte (Quelle: Reddit r/LocalLLaMA)

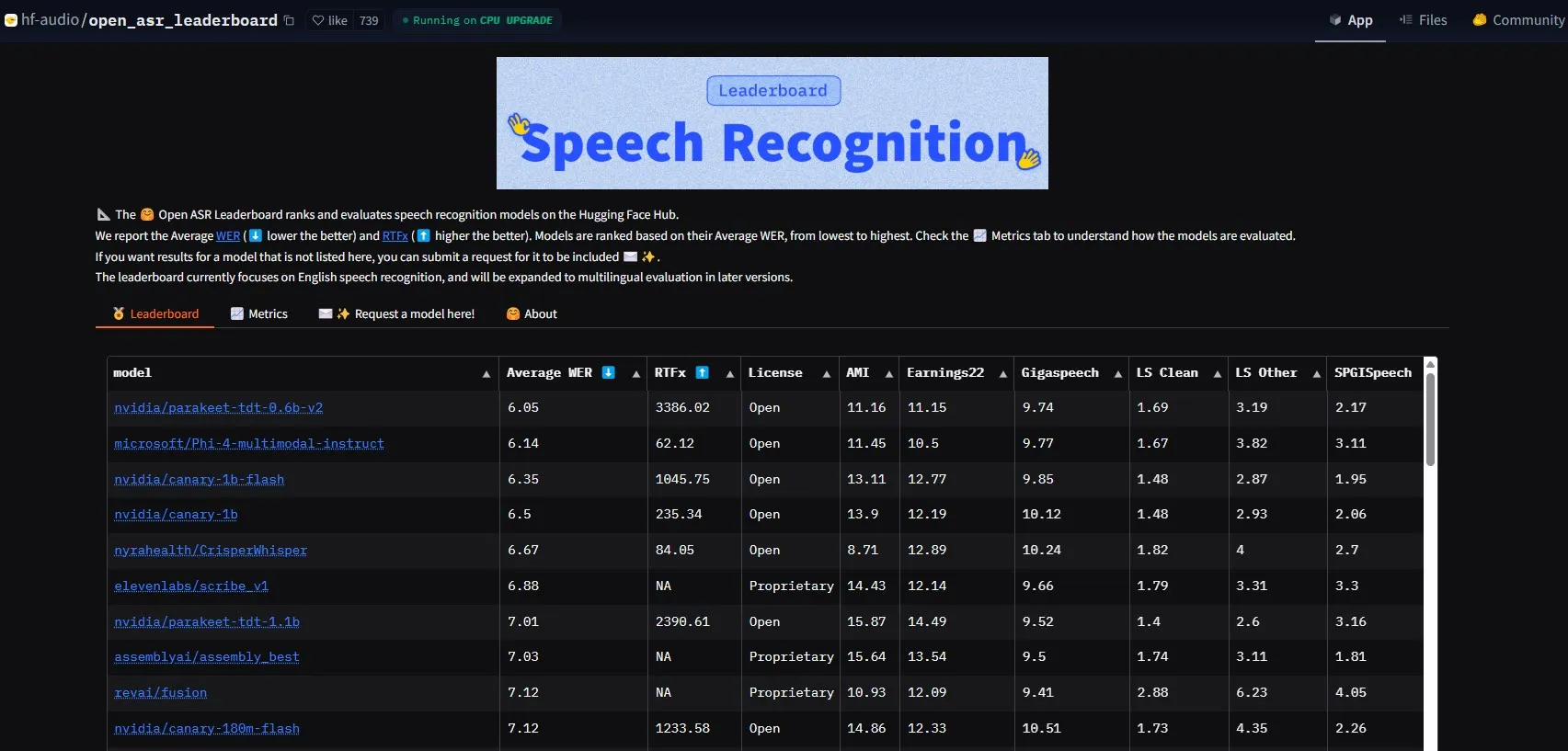
NVIDIA veröffentlicht Parakeet-tdt-0.6b-v2 Modell und setzt neuen Maßstab für ASR-Leistung: Das neue automatische Spracherkennungsmodell (ASR) Parakeet-tdt-0.6b-v2 von NVIDIA hat mit einer Wortfehlerrate (WER) von 6,05 % einen neuen Branchenrekord auf dem HuggingFace Open-ASR-Leaderboard aufgestellt. Das Modell ist nicht nur führend in der Genauigkeit, sondern verfügt auch über eine extrem schnelle Inferenzgeschwindigkeit (RTFx 3386, 50-mal schneller als Alternativen) und unterstützt innovative Funktionen wie Liedtext-Transkription und präzise Zeitstempel-/Zahlenformatierung (Quelle: huggingface)
Alibaba Qwen Team veröffentlicht Qwen3-Embedding Modellreihe: Das Alibaba Qwen Team hat die neue Qwen3-Embedding Modellreihe vorgestellt, die drei verschiedene Größen umfasst: 0.6B, 4B und 8B. Diese Modelle haben in mehreren Text-Embedding-Benchmarks wie MMTEB, MTEB und MTEB-Code SOTA-Leistungen (State-of-the-Art) erzielt, unterstützen 119 Sprachen und können über Transformers.js im Browser ausgeführt werden (mit WebGPU-Beschleunigung). Dies bietet leistungsstarke Textrepräsentationsfähigkeiten für mehrsprachige und plattformübergreifende Anwendungen (Quelle: huggingface)
Gemini 2.5 Pro zeigt starke Fähigkeiten bei Codegenerierung und Aufgabenverarbeitung: Gemini 2.5 Pro (Preview-Version 06-05) von Google DeepMind hat bei der Bewältigung komplexer Aufgaben beeindruckende Fähigkeiten gezeigt. Beispielsweise versuchte der Nutzer Majid Manzarpour, ein Skript zu schreiben, um eine Bibliothek mit über 25.000 Sounddateien zu organisieren und zu klassifizieren. Jeff Dean kommentierte, dies „klinge nicht allzu schwierig“, was auf das Potenzial des Modells hindeutet, solch umfangreiche und komplexe Programmieraufgaben zu bewältigen. Darüber hinaus zeigt ein Testdiagramm von GosuCoder, dass die aktualisierte Version Gemini 2.5 Pro 06-05 bei der KI-gestützten Codierung besser abschneidet, insbesondere bei einer Temperature-Einstellung von 0.7, wo die höchste Bewertung erzielt wurde (Quelle: JeffDean, jeremyphoward)
Hugging Face und Google Colab vertiefen Integration zur Vereinfachung von KI-Workflows: Hugging Face und Google Colab haben eine verstärkte Zusammenarbeit angekündigt und fügen allen Modellkarten im Hugging Face Hub die Unterstützung „Open in Colab“ hinzu. Nutzer können jetzt direkt von jeder Modellkarte aus ein Colab-Notebook starten, was das Experimentieren und die Nutzung von Modellen auf Hugging Face erleichtert und die Hürden für KI-Entwicklung und -Forschung weiter senkt (Quelle: huggingface)
🧰 Tools
LlamaBot: KI-Codierungsassistent basierend auf LangGraph: LangChainAI stellte LlamaBot vor, einen von LangGraph betriebenen KI-Agenten, der Webanwendungen durch natürlichsprachlichen Chat erstellen kann. Zu seinen Merkmalen gehören Echtzeit-Codegenerierung, Echtzeit-Vorschau und spezialisierte Agenten für verschiedene Entwicklungsaufgaben, mit dem Ziel, den Entwicklungsprozess von Webanwendungen zu vereinfachen (Quelle: LangChainAI, hwchase17)
Fast RAG System: Effiziente Dokumentenverarbeitung durch Kombination von DeepSeek-R1 und Qdrant: LangChainAI präsentierte eine hochleistungsfähige RAG (Retrieval Augmented Generation)-Implementierung. Diese Lösung kombiniert das DeepSeek-R1-Modell von SambaNova, die binäre Quantisierungstechnologie von Qdrant und LangGraph, um eine 32-fache Speicherreduktion zu erreichen. Dies ermöglicht die effiziente Verarbeitung umfangreicher Dokumente und bietet einen neuen Optimierungspfad für Informationsabruf und Inhaltsgenerierung (Quelle: LangChainAI, hwchase17)

Gemini Research Assistant: Full-Stack intelligenter Forschungsassistent basierend auf Gemini und LangGraph: Das Google Gemini Team hat einen Full-Stack KI-Forschungsassistenten als Open Source veröffentlicht, der das Gemini-Modell und LangGraph für intelligente Webrecherchen nutzt. Der Assistent verfügt über reflexive Reasoning-Fähigkeiten und kann seine Suchstrategien kontinuierlich optimieren, um Nutzern eine tiefere und effizientere Forschungsunterstützung zu bieten. Der Projektcode ist auf GitHub verfügbar (Quelle: LangChainAI, hwchase17)
Agent Flow: Open-Source No-Code KI-Agenten-Builder: Karan Vaidya hat Agent Flow vorgestellt, einen Open-Source No-Code KI-Agenten-Builder als Alternative zu Gumloop. Er basiert auf ComposioHQ und LangGraph von LangChain und ermöglicht es Nutzern, Arbeitsabläufe und komplexe Agentenmuster per Drag-and-Drop zu automatisieren, mit dem Ziel, die Entwicklungsschwelle für KI-Agentenanwendungen zu senken (Quelle: hwchase17)
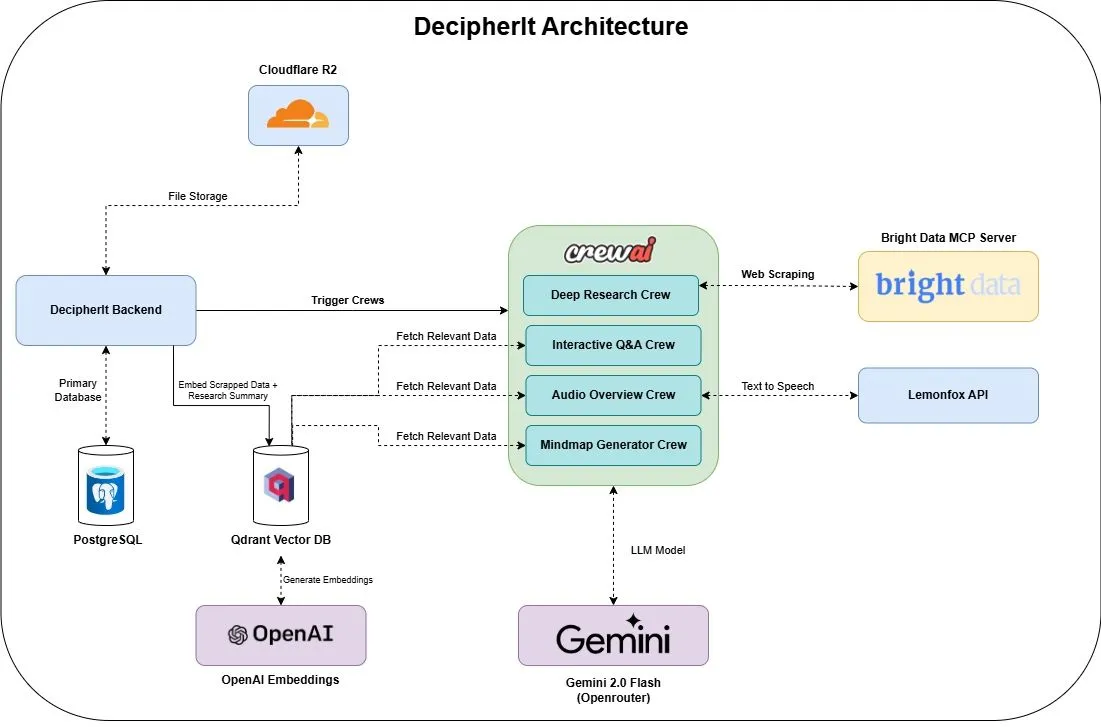
DecipherIt: Open-Source KI-Forschungsassistent, eine Alternative zu NotebookLM: Ein Open-Source KI-Forschungsassistent namens DecipherIt wurde vorgestellt und als Alternative zu NotebookLM positioniert. Das Tool nutzt Multi-Agenten-Orchestrierung (crewAI), semantische Suche (Qdrant + OpenAI), Echtzeit-Webzugriff (Bright Data MCP) und Sprachsynthese (lemonfoxai), um vom Nutzer hochgeladene Dokumente, URLs oder eingegebene Themen in einen vollständigen Forschungsarbeitsbereich mit Zusammenfassungen, Mindmaps, Audio-Übersichten, FAQs und semantischer Fragebeantwortung umzuwandeln (Quelle: qdrant_engine)
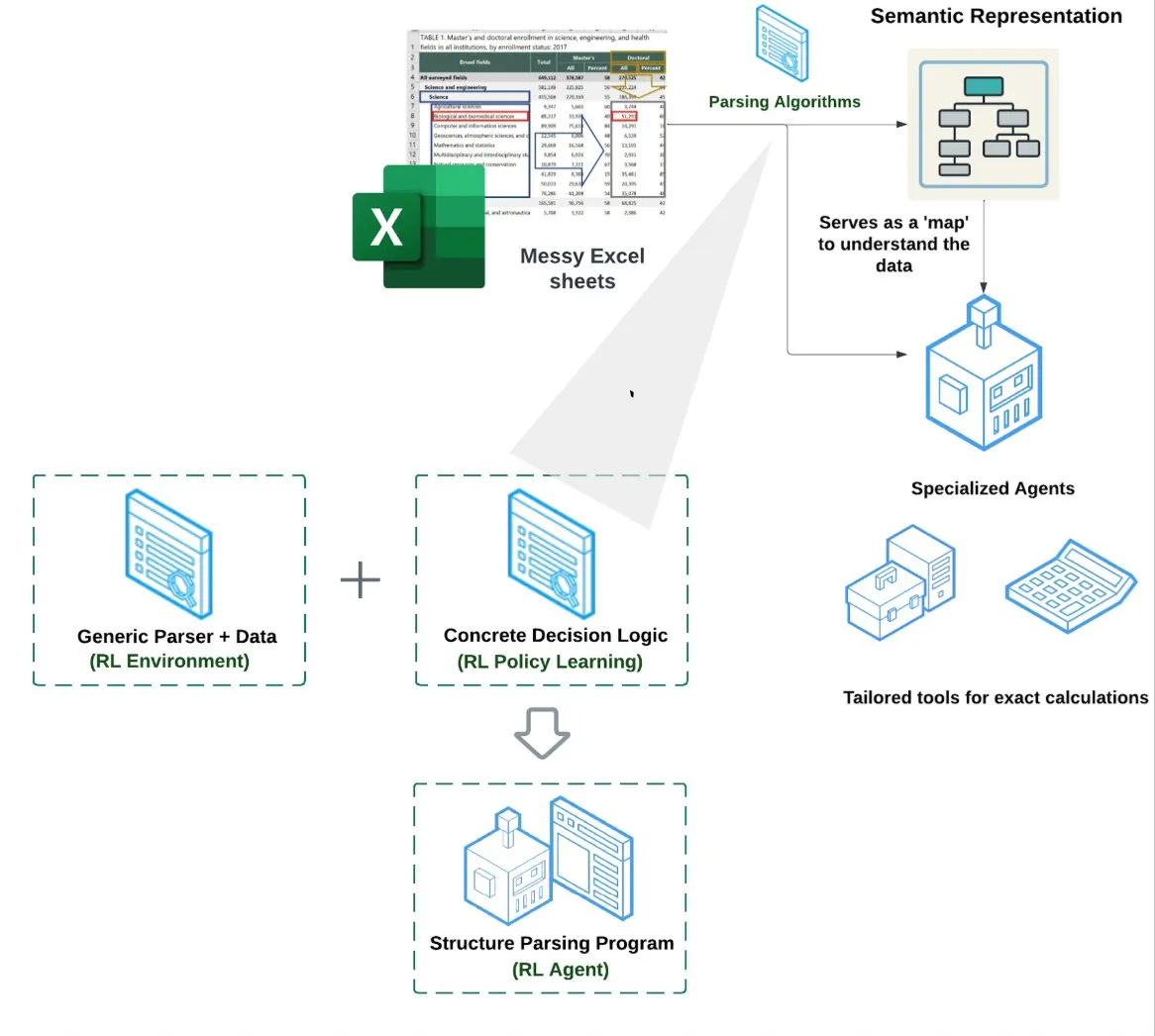
LlamaIndex führt Spreadsheet Agent ein: LlamaIndex hat einen neuen Spreadsheet Agent veröffentlicht, der sich noch in der privaten Vorschau befindet. Dieser Agent konzentriert sich auf die Verarbeitung komplexer Excel-Dateien und kann Datenumwandlungen und Qualitätssicherung durchführen. Kern der technischen Architektur ist ein auf Reinforcement Learning basierendes Strukturverständnis (Lernen von Datenmodellen/semantischen Graphen) sowie darauf aufbauende spezialisierte Tools. Ziel ist es, eine bessere Excel-Verarbeitungsfähigkeit als herkömmliche RAG- oder Text-zu-CSV-Methoden zu bieten, angeblich mit einer um 10-20 % höheren Leistung als eine Baseline, bei der LLMs lediglich Code schreiben (Quelle: jerryjliu0)
Kuvera-8B-v0.1.0: Large Model für persönliche Finanzberatung: Akhil-Theerthala hat auf Hugging Face das Modell Kuvera-8B-v0.1.0 veröffentlicht, das speziell für persönliche Finanzfragen entwickelt wurde. Es basiert auf einem Fine-Tuning von Qwen3-8B unter Verwendung von Datenquellen wie Reddit und zielt darauf ab, einfühlsame und praktische Ratschläge zu Themen wie Budgetierung, Sparen, Investieren, Schuldenmanagement und grundlegende Finanzplanung zu geben. Da es auf Qwen3 basiert, unterstützt das Modell Fragen und Antworten auf Chinesisch (Quelle: karminski3)
Lokalisierte Whisper+Pyannote Sprachverarbeitungslösung als Ersatz für Otter.ai: Ein Reddit-Nutzer teilte seinen vollständig lokalisierten Sprachverarbeitungsworkflow als Ersatz für Cloud-Dienste wie Otter.ai. Die Lösung kombiniert ctranslate2 und faster-whisper für die Transkription sowie pyannote und speechbrain für die Sprechertrennung (Diarisation). Sie kann auf einer lokalen GPU Konferenzaufzeichnungen von bis zu drei Stunden Länge verarbeiten und gibt mit Sprecheretiketten versehene Textprotokolle und JSON-Dateien aus, einschließlich benutzerdefinierter Inhalte wie Executive Summaries und Aktionslisten. Ziel ist es, Einschränkungen, Datenschutzbedenken und mangelnde Anpassungsmöglichkeiten von Cloud-Diensten zu umgehen (Quelle: Reddit r/LocalLLaMA)
GPT Deep Research MCP: Tiefgehende Recherche in Kombination mit OpenWebUI: Nutzer empfehlen die Kombination von GPT Deep Research MCP mit OpenWebUI. Das MCP-Tool (gptr-mcp) zielt darauf ab, tiefgehende Recherchefähigkeiten bereitzustellen. In Verbindung mit dem MCP-fähigen OpenWebUI kann es ein beeindruckendes Rechercheerlebnis bieten und die Anwendungsmöglichkeiten lokaler KI-Tools in der Informationsverarbeitung und Wissensfindung weiter ausbauen (Quelle: Reddit r/OpenWebUI)
📚 Lernen
OpenAI veranstaltet Praxisaustausch zur Anwendungsevaluierung mit realen Fallbeispielen und Ausblick auf Tools: OpenAI wird einen Workshop zu Best Practices für die Anwendungsevaluierung (Evals) veranstalten. Jim Blomo von OpenAI wird anhand realer Kundenfälle und Ergebnisse erörtern, wie KI-Produkte effektiv bewertet werden können. Die Veranstaltung wird auch einen Ausblick auf kommende Evaluierungstools von OpenAI geben, einschließlich Funktionen für Tracking und Scoring. Der Workshop soll Entwicklern und Unternehmen helfen, KI-Anwendungen besser zu erstellen und zu optimieren, und wird als Aufzeichnung zur Verfügung gestellt (Quelle: HamelHusain, HamelHusain)

Anthropic veröffentlicht Forschungsmethoden zur Interpretierbarkeit als Open Source, um das „Denken“ von LLMs zu verstehen: Anthropic hat angekündigt, seine Forschungsmethoden zur Verfolgung der „Denkprozesse“ von Large Language Models als Open Source zu veröffentlichen. Forscher können diese Methode nun nutzen, um „Attributionsgraphen“ zu generieren und interaktiv zu untersuchen, ähnlich wie von Anthropic in jüngsten Studien gezeigt. Das Team stellt auch eine interaktive Neuronpedia-Schnittstelle und Jupyter Notebook-Tutorials zur Verfügung, um Forschern die Anwendung dieser Tools auf Open-Source-Modelle zu erleichtern und so das Verständnis der internen Funktionsweise von LLMs zu verbessern. Das Projekt wird von Teilnehmern des Anthropic Fellows Programms in Zusammenarbeit mit Decode Research geleitet (Quelle: AnthropicAI)
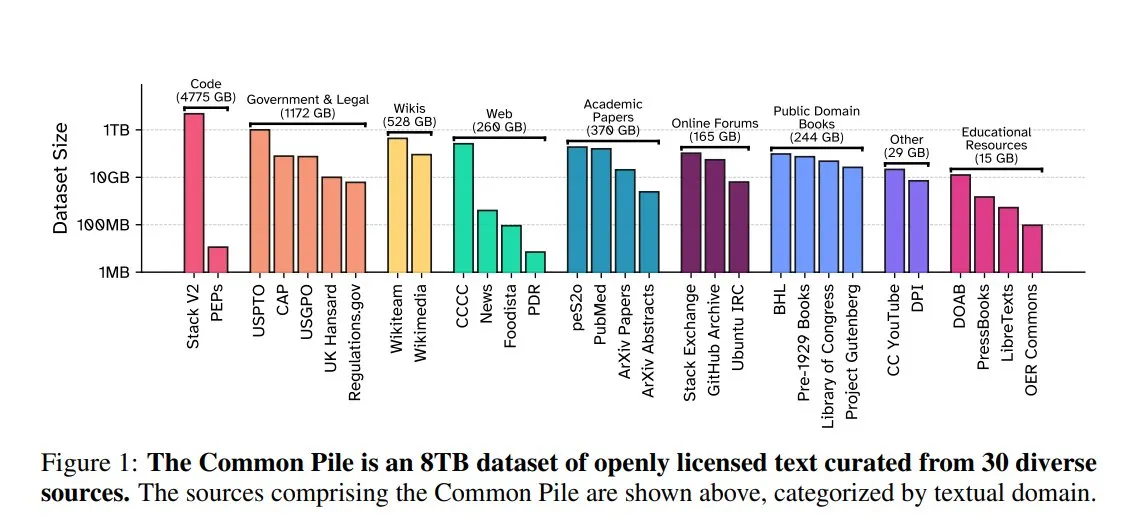
EleutherAI veröffentlicht Common Pile v0.1: 8TB Open-License-Textdatensatz: EleutherAI hat in Zusammenarbeit mit dem Vector Institute, Allen AI, Hugging Face und DPI Common Pile v0.1 veröffentlicht, einen 8TB großen, 1 Billion Token umfassenden Textdatensatz aus Public Domain und offen lizenzierten Quellen. Auf Basis dieses Datensatzes trainierte das Team die 7B-Parameter-Modelle Comma v0.1-1T und -2T, deren Leistung mit Modellen wie LLaMA 1&2 vergleichbar ist, die auf ähnlich großen Datensätzen trainiert wurden. Ziel ist es, die Möglichkeit zu untersuchen, leistungsstarke Sprachmodelle ohne die Verwendung nicht autorisierter Texte zu trainieren, und der Open-Source-Community wertvolle Datenressourcen zur Verfügung zu stellen (Quelle: huggingface)
NVIDIA NIM beschleunigt Vanna Text-zu-SQL-Inferenz: Der NVIDIA-Entwicklerblog hat ein Tutorial veröffentlicht, das zeigt, wie NVIDIA NIM (NVIDIA Inference Microservices) zur Optimierung der Text-zu-SQL-Lösung von Vanna eingesetzt werden kann. NIM bietet optimierte Endpunkte für generative KI-Modelle, die den Inferenzprozess beschleunigen und so schnellere Analysen ermöglichen. Dies ist von großer Bedeutung für Anwendungsszenarien, die die Umwandlung von natürlichsprachlichen Abfragen in Datenbankabfragen erfordern (Quelle: dl_weekly)
Kostenlose Vorlesungsunterlagen zum Machine Learning Kurs der Stanford University geteilt: The Turing Post hat kostenlose Vorlesungsunterlagen zum CS229 Machine Learning Kurs der Stanford University geteilt, der von Andrew Ng und Tengyu Ma unterrichtet wird. Die Inhalte umfassen überwachtes Lernen, unüberwachte Lernmethoden und -algorithmen, Deep Learning und neuronale Netze, Generalisierung, Regularisierung sowie Prozesse des Reinforcement Learning und bieten Lernenden hochwertige Lernressourcen (Quelle: TheTuringPost)

Harvard University veröffentlicht ReXVOA: Großer, hochwertiger Benchmark für Frage-Antwort-Systeme zu Röntgenaufnahmen des Brustkorbs: Das Labor von Pranav Rajpurkar an der Harvard University hat ReXVOA veröffentlicht, einen großen, hochwertigen Benchmark-Datensatz für visuelle Frage-Antwort-Systeme (VQA) zu Röntgenaufnahmen des Brustkorbs. Der Datensatz zielt darauf ab, bestehende große, hochmoderne Modelle herauszufordern und als Maßstab für den Fortschritt der nächsten Generation von Modellen im Bereich des Verständnisses medizinischer Bildgebung und der Beantwortung von Fragen zu dienen (Quelle: huggingface)
OWL Labs teilt Erfahrungen beim Training von Autoencodern für Diffusionsmodelle: OWL (Open World Labs) fasst in seinem Blog Erfahrungen und Erkenntnisse aus dem Training von Autoencodern für Diffusionsmodelle zusammen und teilt auch Misserfolge bei unkonventionellen Ansätzen. Der Artikel bietet Forschern und Entwicklern Referenzen für die praktische Anwendung und Optimierung von Autoencodern für Diffusionsmodelle (Quelle: NandoDF)
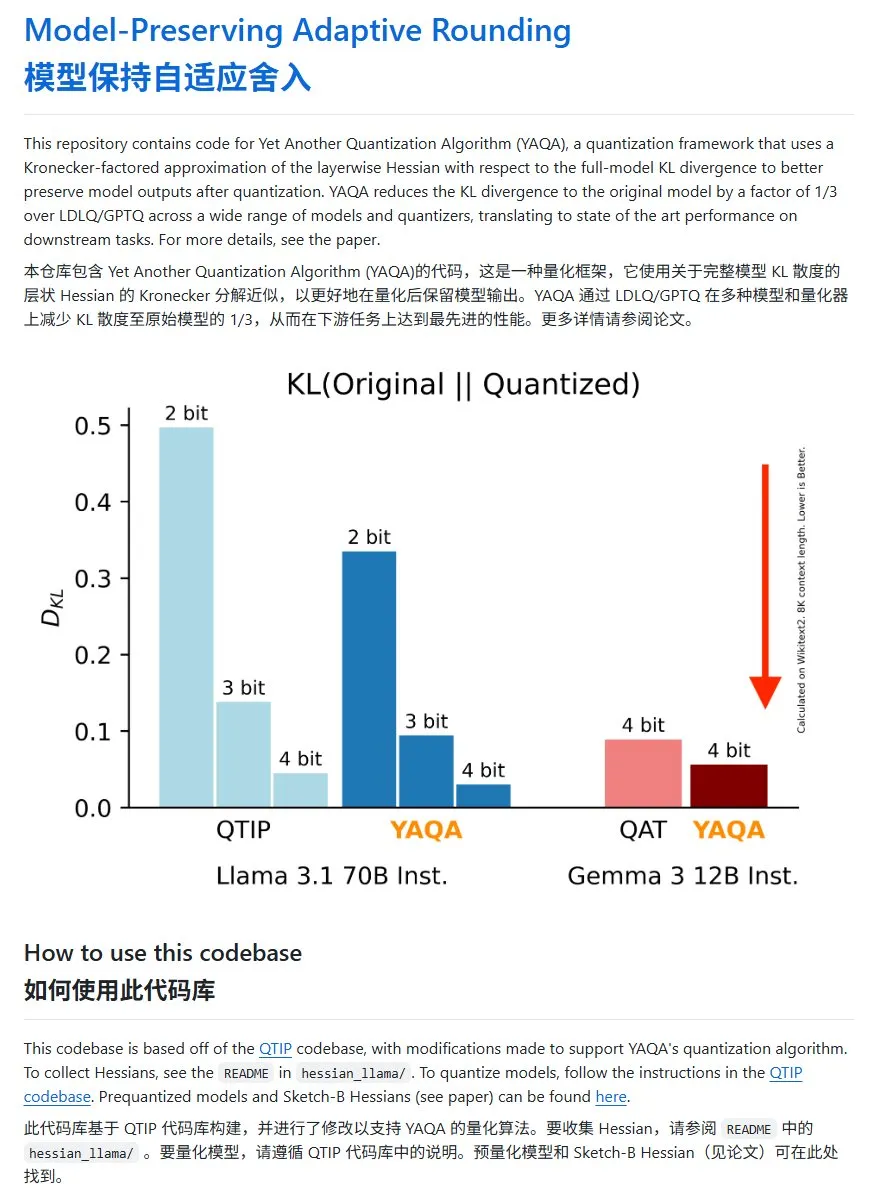
YAQA: Eine neue Methode zur Modellquantisierung mit signifikant reduzierter KL-Divergenz: Das Cornell-RelaxML Team hat eine neue Methode zur Modellquantisierung namens YAQA vorgestellt. Diese Methode kombiniert LDLQ/GPTQ-Techniken und kann im Vergleich zu bestehenden Quantisierungsmethoden die KL-Divergenz des quantisierten Modells auf 1/3 des ursprünglichen Modells reduzieren. Obwohl der YAQA-Quantisierungsprozess langsamer ist und viel GPU-Speicher benötigt, machen die Leistungssteigerung und die Wirtschaftlichkeit der anschließenden Inferenz ihn zu einer vielversprechenden Quantisierungslösung. Der Projektcode wurde auf GitHub als Open Source veröffentlicht (Quelle: karminski3)
💼 Wirtschaft
Hong Letong, eine junge Frau aus Guangzhou (Jahrgang 2000), gründet Axiom und zielt auf die Lösung mathematischer Probleme mit KI: Hong Letong (Carina Hong), eine junge Überfliegerin des Jahrgangs 2000, hat mit ihrem KI-Startup Axiom Aufmerksamkeit erregt. Axiom konzentriert sich auf den Einsatz von KI zur Lösung komplexer mathematischer Probleme und zielt auf Kunden wie Hedgefonds und quantitative Handelsunternehmen ab. Laut The Information verhandelt Axiom über eine Finanzierung in Höhe von 50 Millionen US-Dollar bei einer Bewertung von etwa 300-500 Millionen US-Dollar, wobei B Capital möglicherweise die Führung übernimmt. Hong Letong erklärte in sozialen Medien, die Finanzierungsberichte seien ungenau, bestätigte jedoch, dass das Unternehmen KI-Mathematiktalente einstellt. Hong Letong hat ihren Bachelor-Abschluss am MIT und ihren Master-Abschluss in Oxford gemacht und promoviert derzeit in Mathematik und Rechtswissenschaften an der Stanford University. Sie hat bereits mehrfach Mathematikwettbewerbe gewonnen (Quelle: 36氪)

Anthropic sperrt aufgrund von Wettbewerbsbeziehungen den Claude API-Zugriff für Windsurf: Ein Mitbegründer von Anthropic bestätigte, dass das Unternehmen dem KI-Startup Windsurf den API-Zugriff auf das Claude-Modell gesperrt hat. Der Grund dafür ist, dass Windsurf als eine Art „Wrapper“ oder eng verbundener Dienst von OpenAI angesehen wird, einem direkten Konkurrenten von Anthropic. Dieser Schritt löste Diskussionen über API-Abhängigkeiten und Plattformrisiken aus, insbesondere für Startups, deren Geschäft auf APIs von Drittanbieter-Large-Models basiert, da Geschäftsentscheidungen der Modellanbieter ihre Existenz direkt beeinflussen können (Quelle: ClementDelangue, Reddit r/LocalLLaMA)
OpenAI muss aufgrund einer Urheberrechtsklage gelöschte Chat-Protokolle von Nutzern aufbewahren: Berichten zufolge hat ein US-Bundesgericht OpenAI im Rahmen einer von der New York Times eingereichten Urheberrechtsklage angewiesen, alle Gesprächsprotokolle von ChatGPT-Nutzern aufzubewahren, einschließlich der von Nutzern gelöschten Inhalte, als potenzielle Beweismittel. Die New York Times wirft OpenAI vor, ihre Paywall-Artikel zum Training von ChatGPT verwendet zu haben und befürchtet, dass die KI ähnliche Inhalte generieren könnte. Dieser Schritt löste Bedenken hinsichtlich des Datenschutzes und der Datensicherheit (z. B. DSGVO) aus und unterstreicht die rechtlichen und ethischen Spannungen zwischen dem Urheberrecht an KI-Trainingsdaten und der Privatsphäre der Nutzer (Quelle: Reddit r/ArtificialInteligence)

🌟 Community
KI-Large-Models stellen sich den Herausforderungen der Abituraufsätze und Mathematikprüfungen 2025 mit unterschiedlichem Erfolg: Während der Abiturprüfungen 2025 stellten sich mehrere führende KI-Large-Models den Herausforderungen der Abituraufsätze und Mathematikaufgaben. Im Bereich Aufsatz zeigten 16 KI-Assistenten, darunter Doubao, DeepSeek und ChatGPT, ihre Schreibfähigkeiten. Die meisten konnten strukturierte argumentative Aufsätze verfassen, zeigten jedoch häufig eine Tendenz zu Schablonenhaftigkeit, Floskeln und thematischer Gleichförmigkeit. Im Mathematiktest (neuer Lehrplan I, Multiple-Choice-Teil) erreichten ByteDance Doubao und Tencent Yuanbao mit 68 Punkten (von 73 möglichen) den ersten Platz, während OpenAI o3 mit nur 34 Punkten schlecht abschnitt. Die Tests spiegeln die Fortschritte und Grenzen aktueller KI im chinesischen Sprachverständnis, logischen Denken und kreativen Ausdruck wider, insbesondere bei der Vermeidung von KI-Merkmalen und der Bewältigung komplexer mathematischer Schlussfolgerungen besteht noch Verbesserungspotenzial (Quelle: 36氪, 36氪)

Trend bei der internen Anwendung von KI in Unternehmen: Interne Wissensdatenbanken und maßgeschneiderte Chatbots im Fokus: Diskussionen in der Community zeigen, dass der Einsatz von KI zum Aufbau interner Unternehmens-Chatbots, die auf Unternehmensdaten trainiert werden, um Mitarbeiterfragen zu Prozessen, Datenabfragen, Zuständigkeiten usw. zu beantworten, zu einem Trend wird. Solche Anwendungen zielen darauf ab, die Effizienz der internen Informationsbeschaffung und das Wissensmanagement zu verbessern. Unternehmen wie Amazon haben bereits ähnliche Systeme implementiert und positives Feedback erhalten. Datensicherheit, potenzielle Offenlegung sensibler Informationen und eine effektive Kommerzialisierung bleiben jedoch wichtige Aspekte, die Unternehmen bei der Implementierung berücksichtigen müssen (Quelle: Reddit r/ArtificialInteligence)
Streit um „Indexierung“ vs. „Nicht-Indexierung“ bei KI-gestützter Programmierung: Abwägung zwischen Leistung und Zuverlässigkeit: Ein Experiment mit KI-Codierungsassistenten (unter Verwendung des Apollo-11-Mondlandungscodes als Testobjekt) verglich zwei Arten von KI-Agenten: „indexbasierte“ (die vorab einen Index der Codebasis erstellen und Vektorsuche verwenden) und „nicht-indexbasierte“ (die Codedateien bei Bedarf lesen und analysieren). Die Ergebnisse zeigten, dass indexbasierte Agenten in den meisten Fällen schneller waren und weniger API-Aufrufe benötigten. Bei häufigen Änderungen der Codebasis, die zu veralteten Indizes führten, konnten sie jedoch aufgrund der Abhängigkeit von veralteten Informationen Fehler produzieren, was die Debugging-Zeit verlängerte. Dies verdeutlicht, dass bei der Auswahl von KI-Codierungstools eine Abwägung zwischen sofortiger Leistung und Informationszuverlässigkeit erforderlich ist (Quelle: Reddit r/ClaudeAI)

Anhaltende Diskussion darüber, ob LLMs „denken“: Von Mustererkennung zu menschlicher Kognition: In der Community hält die Diskussion darüber an, ob Large Language Models (LLMs) wirklich „denken“. Kritiker argumentieren, dass LLMs im Wesentlichen komplexe prädiktive Textgeneratoren sind, die durch Berechnung von Wortsequenzwahrscheinlichkeiten arbeiten und nicht bewusst denken. Viele Nutzer empfinden die Interaktion mit LLMs jedoch als ähnlich wie ein Gespräch mit einem Menschen. Dies wirft Fragen über die Mechanismen der menschlichen Sprachgenerierung und mögliche Ähnlichkeiten zwischen LLMs und menschlichen kognitiven Prozessen auf. Die Forschung von Apple weist zusätzlich auf die Grenzen von LLMs bei komplexen Schlussfolgerungen hin und legt nahe, dass sie eher auf Mustererkennung als auf echtem Reasoning basieren, was der Diskussion neue Perspektiven hinzufügt (Quelle: Reddit r/ArtificialInteligence, Reddit r/ChatGPT)

Paul Graham über die Auswirkungen von KI auf die Einkommensunterschiede: Paul Graham äußerte gegenüber seinem 16-jährigen Sohn, dass KI-Technologie kurzfristig die Einkommensunterschiede zwischen den Menschen vergrößern könnte. Als Beispiel nannte er, dass mittelmäßige Programmierer es jetzt schwerer hätten, Arbeit zu finden, während exzellente Programmierer dank KI-Unterstützung höhere Einkommen erzielten. Er hält dies nicht für neu, da technischer Fortschritt oft die Einkommensunterschiede vergrößere, da die Einkommensuntergrenze bei Null fixiert sei, während die Technologie die obere Grenze der Erträge für Spitzenkräfte kontinuierlich anhebe (Quelle: dotey)
Diskussionen zur KI-Sicherheitsethik: Von Modellverhalten zu gesellschaftlichen Normen: Die Diskussionen in der Community über KI-Sicherheit und -Ethik nehmen weiter zu. Geoffrey Hinton gratulierte Yoshua Bengio zur Initiierung des LawZero-Projekts, das darauf abzielt, das sichere Design von KI zu fördern, insbesondere im Hinblick auf mögliches Selbstschutz- und Täuschungsverhalten von fortschrittlichen Systemen. Gleichzeitig kritisieren einige Stimmen bestimmte KI-Sicherheitsforschungen (z. B. Tests, ob ein Modell dem Abschalten zustimmt) als „Sicherheitstheater“ ohne praktischen Wert. Auch die Forschung von OpenAI zu Mensch-Maschine-Beziehungen löste Diskussionen aus und betonte die Notwendigkeit, angesichts der zunehmenden Integration von KI in das tägliche Leben vorrangig deren Auswirkungen auf das emotionale Wohlbefinden der Nutzer zu untersuchen und zu erörtern, wie in Modellinteraktionen eine Balance zwischen klarer Kommunikation und der Vermeidung von Anthropomorphismus gefunden werden kann (Quelle: geoffreyhinton, ClementDelangue, togelius)

Emotionale Unterstützungsfunktion von ChatGPT und anderen KI-Assistenten von Nutzern anerkannt: Zahlreiche Nutzer teilten in sozialen Medien ihre Erfahrungen, wie ChatGPT und andere KI-Assistenten ihnen in schwierigen Situationen emotionale Unterstützung und praktische Hilfe boten. Einige Nutzer berichteten, dass ChatGPT bei Arbeitslosigkeit, Gesundheitsproblemen oder emotionalen Tiefs nicht nur konkrete Handlungspläne und Ressourceninformationen lieferte, sondern ihnen auch auf eine nicht wertende Weise half, Panik abzubauen und neue Kraft zu schöpfen. Dies zeigt das potenzielle Wert von KI in der psychologischen Unterstützung und Krisenintervention, auch wenn sie nicht über echte Emotionen und Bewusstsein verfügt (Quelle: Reddit r/ChatGPT)
„Vibe Coding“ wird zum neuen Phänomen bei KI-gestützter Programmierung: Der Begriff „Vibe Coding“ macht in Entwicklerkreisen die Runde und bezeichnet eine Programmierweise, die auf Intuition und schneller Iteration von Code mit KI-Unterstützung basiert. Tools wie Claude Code werden von einigen Programmierern für ihre herausragende Leistung zu bestimmten Zeiten (z. B. nachts oder frühmorgens, möglicherweise aufgrund geringer Serverauslastung oder weil sie noch nicht stark quantisiert sind) geschätzt. Dieses Phänomen spiegelt die Effizienzsteigerung durch KI-Codierungsassistenten wider, wirft aber auch Fragen zur Modellkonsistenz, den Auswirkungen der Quantisierung und neuen Arbeitsweisen von Entwicklern auf (Quelle: dotey, jeremyphoward)
💡 Sonstiges
Andrej Karpathy reflektiert über die enormen Auswirkungen von Lärmbelästigung auf Schlaf und Gesundheit: Andrej Karpathy teilte seine persönlichen Erfahrungen und wies darauf hin, dass Umgebungslärmbelästigung, wie z. B. Verkehrslärm, enorme und oft unterschätzte negative Auswirkungen auf die Schlafqualität und langfristige Gesundheit haben kann. Er vermutet, dass nächtlicher Lärm (z. B. laute Autos, Motorräder) bei Millionen von Menschen zu einer verminderten Schlafqualität führen könnte, was sich wiederum auf Stimmung, Kreativität, Energie und das Risiko für Herz-Kreislauf-, Stoffwechsel- und kognitive Erkrankungen auswirken könnte. Er appelliert an Hersteller von Schlaf-Tracking-Geräten (wie Whoop, Oura), den Zusammenhang zwischen Lärm und Schlaf explizit zu verfolgen und das öffentliche Bewusstsein für dieses Problem zu schärfen (Quelle: karpathy)
Kreuzungsphänomene von KI und Religion erregen Aufmerksamkeit: Der Social-Media-Nutzer menhguin beobachtet, dass der potenzielle Markt für neue, auf KI basierende religiöse oder religionsähnliche Anwendungen nicht zu vernachlässigen ist. Beispiele wie KI-Astrologie, KI-Bibelvideos, KI-Gebetsanwendungen sowie bestimmte KI-Anwendungen für spezifische Gruppen deuten auf die Möglichkeiten hin, wie KI-Technologie menschliche spirituelle oder glaubensbezogene Bedürfnisse erfüllen könnte (Quelle: menhguin)
KI-gestützte Generierung eines HTTP 2.0 Servers, Erforschung des Potenzials von LLMs in großen Softwareprojekten: Ein Entwickler nutzte ein selbst entwickeltes Framework (promptyped) und das Gemini 2.5 Pro Modell, um durch einen Zyklus aus Code-Kompilierung-Test erfolgreich einen LLM von Grund auf einen HTTP 2.0-konformen Server erstellen zu lassen. Das Projekt generierte 15.000 Zeilen Quellcode und über 30.000 Zeilen Testcode und bestand den h2spec-Konformitätstest. Obwohl dies etwa 119 Stunden API-Zeit und 631 US-Dollar API-Kosten verursachte, zeigte dieses Experiment das Potenzial von LLMs im Architekturentwurf und beim Schreiben komplexer, standardkonformer Software und offenbarte gleichzeitig die Form von Anwendungen, die vollständig von LLMs geschrieben wurden (Quelle: Reddit r/LocalLLaMA)