
Schlüsselwörter:Gemini 2.5 Pro, OpenAI-Datenschutz, OpenThinker3-7B, Claude Gov, KI-Agenten, Große Sprachmodelle, Bestärkendes Lernen, Open-Source-Modelle, Leistungssteigerung von Gemini 2.5 Pro, OpenAI-Datenaufbewahrungsrichtlinie, Schlussfolgerungsfähigkeiten von OpenThinker3-7B, Nationale Sicherheitsanwendungen von Claude Gov, Robustheit und Steuerung von KI-Agenten
🔥 Fokus
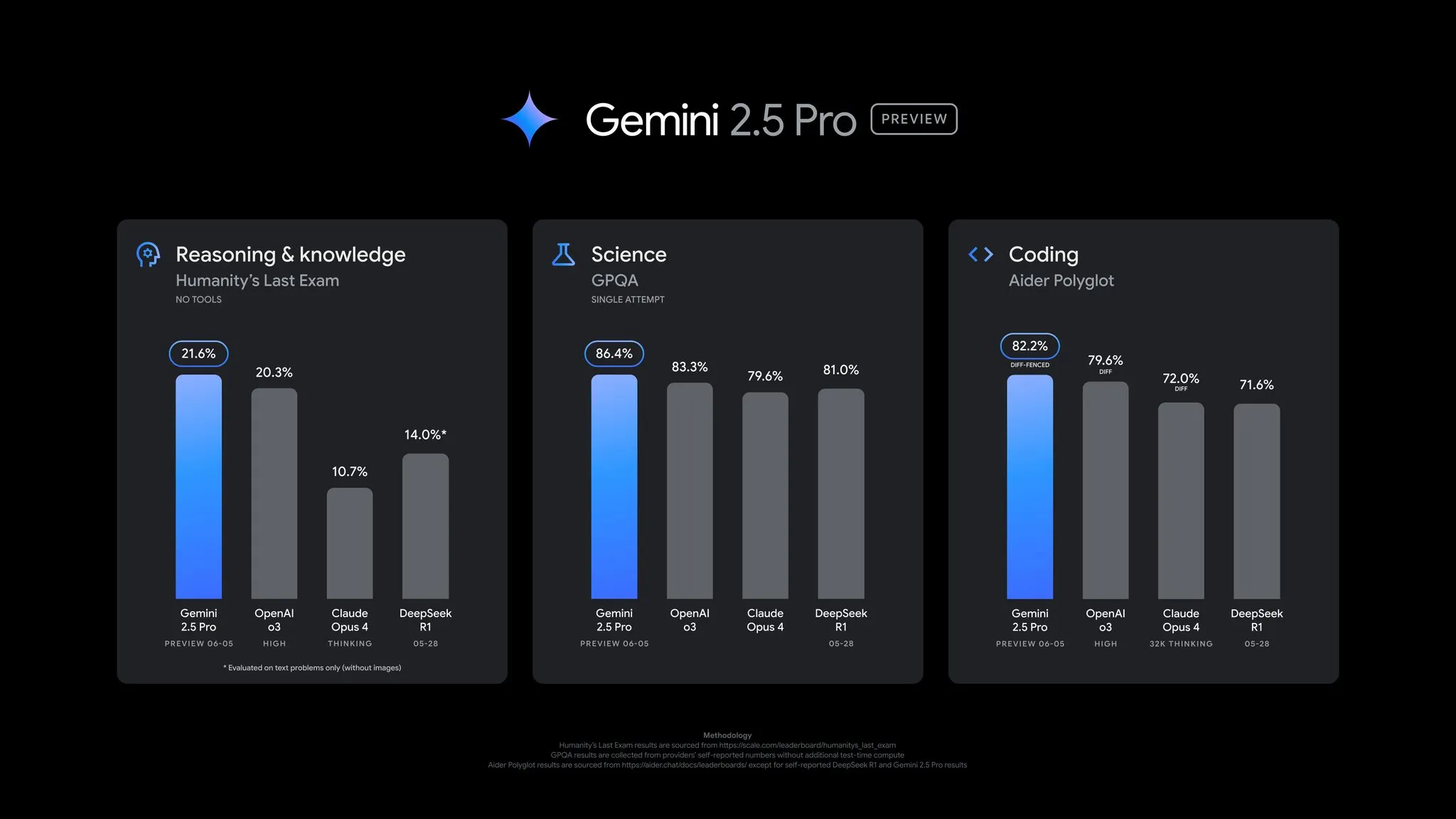
Google veröffentlicht Update für Gemini 2.5 Pro Preview mit umfassenden Leistungsverbesserungen: Google hat ein wichtiges Update für die Preview-Version von Gemini 2.5 Pro angekündigt, das signifikante Fortschritte in den Bereichen Coding, Reasoning, Wissenschaft und Mathematik bringt. Die neue Version zeigt bessere Leistungen in wichtigen Benchmarks wie AIDER Polyglot, GPQA und HLE und erreichte einen Anstieg des Elo-Scores um 24 Punkte auf LMArena, womit es erneut die Spitze erreicht. Darüber hinaus wurden basierend auf Nutzerfeedback Verbesserungen am Antwortstil und der Formatierung des Modells vorgenommen und eine „Thinking Budget“-Funktion für mehr Kontrolle eingeführt. Das Update ist bereits in der Gemini App, Google AI Studio und Vertex AI verfügbar (Quelle: JeffDean, OriolVinyalsML, demishassabis, op7418, LangChainAI, karminski3, TheRundownAI, 量子位)
OpenAI aufgrund einer Klage der New York Times zur dauerhaften Speicherung von Nutzerdaten verpflichtet, was Datenschutzbedenken auslöst: Im Rahmen eines Urheberrechtsstreits mit der New York Times wurde OpenAI gerichtlich dazu verpflichtet, alle Nutzerinteraktionsprotokolle von ChatGPT und der API dauerhaft aufzubewahren. Dies schließt auch „temporäre Konversationen“ und API-Anfragedaten ein, für die zuvor eine Aufbewahrungsfrist von nur 30 Tagen zugesagt worden war. OpenAI kündigte an, Berufung einzulegen, und bezeichnete die Anordnung als „übermäßigen Eingriff“, der langjährige Datenschutzstandards untergrabe und den Datenschutz schwäche. Diese Entscheidung bedeutet, dass OpenAI seine Zusagen zur Datenaufbewahrung und -löschung gegenüber den Nutzern möglicherweise nicht einhalten kann, was weitreichende Bedenken hinsichtlich Datenschutz und Datensicherheit bei den Nutzern auslöst. Dies könnte insbesondere Anwendungsentwickler betreffen, die auf die OpenAI API angewiesen sind und eigene Datenaufbewahrungsrichtlinien haben (Quelle: natolambert, openai, bookwormengr, fabianstelzer, Teknium1, Reddit r/artificial)

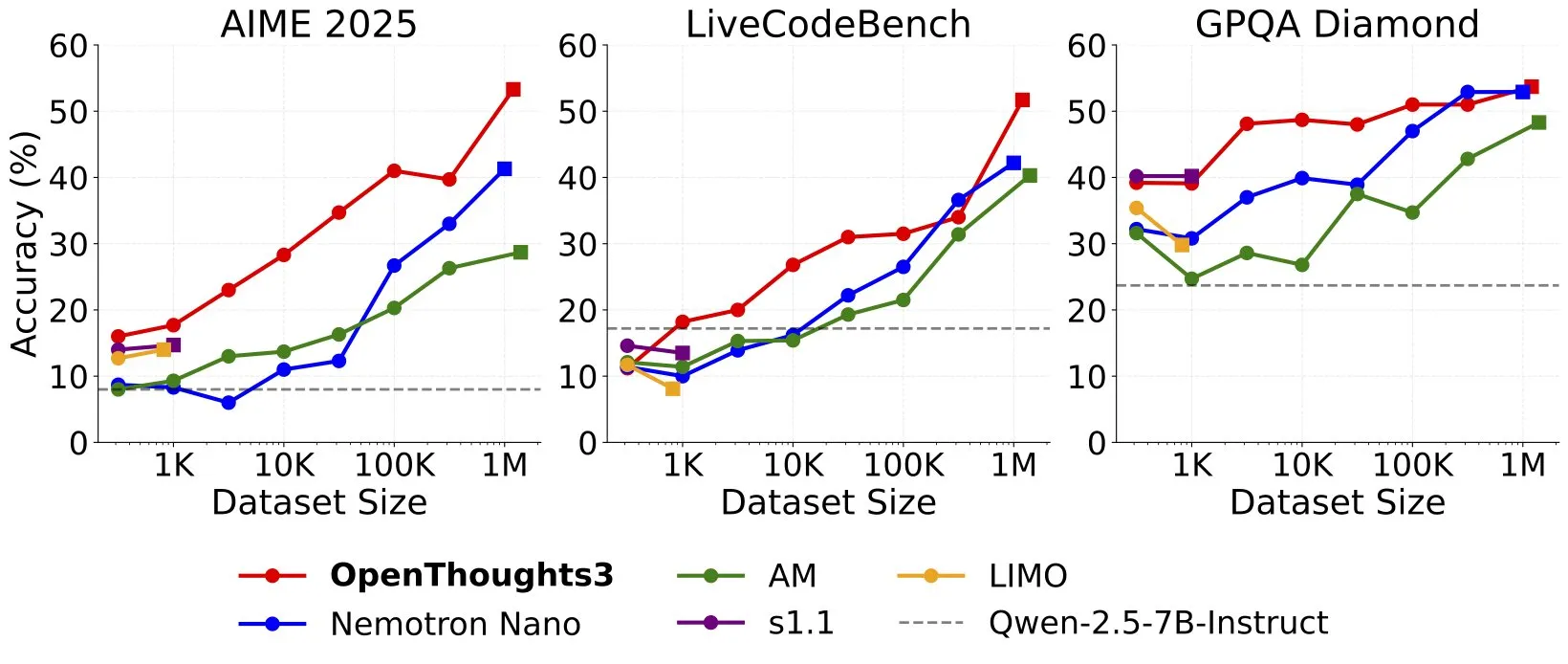
OpenThinker3-7B veröffentlicht, setzt neuen SOTA für 7B Open-Source-Reasoning-Modelle: Ryan Marten kündigte die Veröffentlichung von OpenThinker3-7B an, einem neuen Open-Data-Reasoning-Modell mit 7 Milliarden Parametern, das in Code-, Wissenschafts- und Mathematik-Evaluierungen durchschnittlich 33 % besser abschneidet als DeepSeek-R1-Distill-Qwen-7B. Das Team veröffentlichte gleichzeitig das OpenThoughts3-1.2M-Datenset, das als das derzeit beste Open-Reasoning-Datenset aller Datengrößen gilt. Forscher weisen darauf hin, dass für kleinere Modelle die Destillation aus R1 der einfachste Weg zur Leistungssteigerung ist, während die Forschung in Richtung RL (Reinforcement Learning) explorativer ist. Dieses Ergebnis wird als eine der Pionierarbeiten im Bereich der Open-Reasoning-Modelle angesehen (Quelle: natolambert, huggingface, Tim_Dettmers, swyx, ImazAngel, giffmana, slashML)
Anthropic stellt Claude Gov vor, ein maßgeschneidertes Modell für US-Kunden im Bereich der nationalen Sicherheit: Anthropic hat die Einführung von Claude Gov angekündigt, einer Reihe von maßgeschneiderten KI-Modellen, die speziell für Kunden im Bereich der nationalen Sicherheit der USA entwickelt wurden. Diese Modelle werden bereits in den höchsten Ebenen der nationalen Sicherheitsbehörden der USA eingesetzt, und der Zugriff ist auf Personen beschränkt, die in geheimen Umgebungen arbeiten. Dieser Schritt markiert eine weitere Vertiefung der Anwendung von KI-Technologie in Regierungs- und Verteidigungsbereichen und löst gleichzeitig Diskussionen über den Einsatz von KI in sensiblen Bereichen aus (Quelle: AnthropicAI, teortaxesTex, zacharynado, TheRundownAI)
🎯 Trends
Yann LeCun stimmt Sundar Pichais Ansicht zu: Aktuelle Technologie führt möglicherweise nicht zu AGI, Plateauphase möglich: Yann LeCun, Chief AI Scientist bei Meta, teilte und unterstützte die Ansicht von Google-CEO Sundar Pichai, dass der aktuelle technologische Pfad nicht garantiert zur Allgemeinen Künstlichen Intelligenz (AGI) führt und die KI-Entwicklung möglicherweise auf ein vorübergehendes Plateau stoßen könnte. Pichai wies darauf hin, dass die KI zwar erstaunliche Fortschritte mache, es aber auch Grenzen geben könne und die aktuelle Technologie noch weit von universeller Intelligenz entfernt sei. Dies spiegelt die vorsichtige Haltung der Branche hinsichtlich des Weges und des Zeitplans zur Realisierung von AGI wider (Quelle: ylecun)
OpenAI rekrutiert für Team „Agent Robustness and Control“ zur Verbesserung der Sicherheit von KI-Agenten: OpenAI stellt ein neues Team namens „Agent Robustness and Control“ zusammen, dessen Ziel es ist, die Sicherheit und Zuverlässigkeit seiner KI-Agenten während des Trainings und der Bereitstellung zu gewährleisten. Das Team wird sich mit einigen der herausforderndsten Probleme im KI-Bereich befassen, was zeigt, dass OpenAI bei der Entwicklung leistungsfähigerer KI-Agenten großen Wert auf Sicherheit und Kontrollierbarkeit legt (Quelle: gdb)

Neue Apple-Studie enthüllt „Illusion des Denkens“ bei großen Sprachmodellen: Reasoning-Fähigkeit nimmt bei komplexen Problemen ab statt zu: Eine aktuelle Forschungsarbeit von Apple mit dem Titel „The Illusion of Thinking“ weist darauf hin, dass bei aktuellen Reasoning-Modellen der Reasoning-Aufwand (reasoning effort) bei zunehmender Problemkomplexität ab einem bestimmten Punkt eher abnimmt, selbst wenn ein ausreichendes Token-Budget zur Verfügung gestellt wird. Dieses kontraintuitive Phänomen des „Scaling Limit“ deutet darauf hin, dass Modelle bei der Verarbeitung hochkomplexer Probleme möglicherweise nicht wirklich tief nachdenken, sondern eine „Illusion des Denkens“ zeigen, was neue Herausforderungen für die Bewertung und Verbesserung der tatsächlichen Reasoning-Fähigkeiten großer Modelle darstellt (Quelle: Ar_Douillard, Reddit r/MachineLearning)

OpenAI diskutiert emotionale Verbindung zwischen Mensch und KI, priorisiert Forschung zu Auswirkungen auf emotionales Wohlbefinden der Nutzer: Joanne Jang von OpenAI veröffentlichte einen Blogbeitrag, der das Phänomen der zunehmend stärkeren emotionalen Verbindung zwischen Nutzern und KI-Modellen wie ChatGPT untersucht. Der Artikel stellt fest, dass Menschen KI auf natürliche Weise vermenschlichen und möglicherweise Gefühle von Kameradschaft und Vertrauen entwickeln. OpenAI erkennt diesen Trend an und erklärt, dass es die Forschung zu den Auswirkungen von KI auf das emotionale Wohlbefinden der Nutzer priorisieren wird, anstatt sich mit der ontologischen Frage zu beschäftigen, ob KI wirklich „bewusst“ ist. Ziel des Unternehmens ist es, KI-Assistenten zu entwickeln, die warmherzig und nützlich sind, aber nicht übermäßig nach emotionaler Abhängigkeit streben oder eine eigene Agenda verfolgen (Quelle: openai, sama, BorisMPower)

Xiaohongshu (RED) veröffentlicht Open-Source MoE-Großmodell dots.llm1-143B-A14B: Das Hi Lab von Xiaohongshu (RED) hat seine erste Open-Source-Großmodellreihe dots.llm1 veröffentlicht, die das Basismodell dots.llm1.base und das instruktionsoptimierte Modell dots.llm1.inst umfasst. Das Modell verwendet eine MoE-Architektur mit insgesamt 143 Milliarden Parametern und 14 Milliarden aktivierten Parametern. Offiziellen Tests zufolge übertrifft es Qwen3-235B-A22B auf MMLU-Pro, liegt aber hinter dem neuen DeepSeek-V3. Das Modell wird unter der MIT-Lizenz veröffentlicht und kann frei verwendet werden. Erste Community-Tests zeigen jedoch, dass es bei Aufgaben wie der Codegenerierung schlecht abschneidet und sogar schlechter ist als Qwen2.5-coder (Quelle: karminski3, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)

Qwen3-Serie veröffentlicht Embedding- und Reranker-Modelle zur Verbesserung der mehrsprachigen Textverarbeitung: Das Qwen-Team hat die Modellreihen Qwen3-Embedding und Qwen3-Reranker vorgestellt, die darauf abzielen, die Leistung von mehrsprachigen Texteinbettungen und Relevanz-Ranking zu verbessern. Embedding-Modelle werden verwendet, um Text in Vektorrepräsentationen umzuwandeln und unterstützen Szenarien wie Dokumentensuche und RAG; Reranker-Modelle dienen dazu, Suchergebnisse neu zu ordnen und die Priorität der relevantesten Inhalte zu erhöhen. Die Modellreihe bietet verschiedene Parametergrößen wie 0.6B, 4B und 8B, unterstützt 119 Sprachen und zeigt in Benchmarks wie MMTEB und MTEB hervorragende Leistungen. Die 0.6B-Version gilt aufgrund ihres ausgewogenen Verhältnisses von Effizienz und Leistung als besonders geeignet für Reranker-Szenarien mit hohen Echtzeitanforderungen (Quelle: karminski3, karminski3, ZhaiAndrew, clefourrier)

Studie weist auf Skalierbarkeitsherausforderungen von Reinforcement Learning bei komplexen Aufgaben mit langem Horizont hin: Eine Studie von Seohong Park et al. hat ergeben, dass die bloße Erweiterung von Daten und Rechenressourcen nicht ausreicht, damit Reinforcement Learning (RL) komplexe Aufgaben effektiv lösen kann. Der entscheidende limitierende Faktor ist der „Horizont“. Bei Aufgaben mit langem Horizont sind Belohnungssignale spärlich, was es für Modelle schwierig macht, effektive Strategien zu lernen. Dies deckt sich mit Beobachtungen, dass einige aktuelle KI-Agenten (wie Deep Research, Codex agent) hauptsächlich auf RL-Aufgaben mit kurzem Horizont und allgemeinem Robustheitstraining beruhen, was darauf hindeutet, dass die End-to-End-Lösung von Problemen mit spärlichen Belohnungen und langem Horizont weiterhin eine große Herausforderung im RL-Bereich darstellt (Quelle: finbarrtimbers, natolambert, paul_cal, menhguin, Dorialexander)
Baidu registriert offiziellen Account auf HuggingFace und lädt ERNIE (文心) Großmodelle hoch: Baidu hat einen offiziellen Account auf der HuggingFace-Plattform registriert und Teile seiner ERNIE (文心)-Modellreihe hochgeladen, darunter ERNIE-X1-Turbo und ERNIE-4.5-Turbo. Dieser Schritt bedeutet, dass Baidu seine Großmodelltechnologie aktiv in die breitere Open-Source-Community und das Entwickler-Ökosystem integriert, um globalen Entwicklern den Zugriff und die Nutzung seiner KI-Fähigkeiten zu erleichtern (Quelle: karminski3)
OpenBMB stellt MiniCPM4-Modellreihe vor, Fokus auf effizienten Betrieb auf Endgeräten: OpenBMB erforscht weiterhin die Grenzen kleiner, effizienter Sprachmodelle und hat die MiniCPM4-Reihe veröffentlicht. Das MiniCPM4-8B-Modell verfügt über 8 Milliarden Parameter und wurde auf 8T Tokens trainiert. Die Modellreihe verwendet extrem beschleunigende Technologien wie trainierbare Sparse Attention (InfLLM v2), ternäre Quantisierung (BitCPM), FP8-Berechnungen mit niedriger Präzision und Multi-Token-Vorhersage, um einen effizienten Betrieb auf Endgeräten zu ermöglichen. Beispielsweise muss bei der Verarbeitung von 128K langen Texten der Sparse-Attention-Mechanismus jedes Tokens nur mit weniger als 5 % der Tokens Korrelationen berechnen, was den Rechenaufwand für die Verarbeitung langer Texte erheblich reduziert (Quelle: teortaxesTex, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
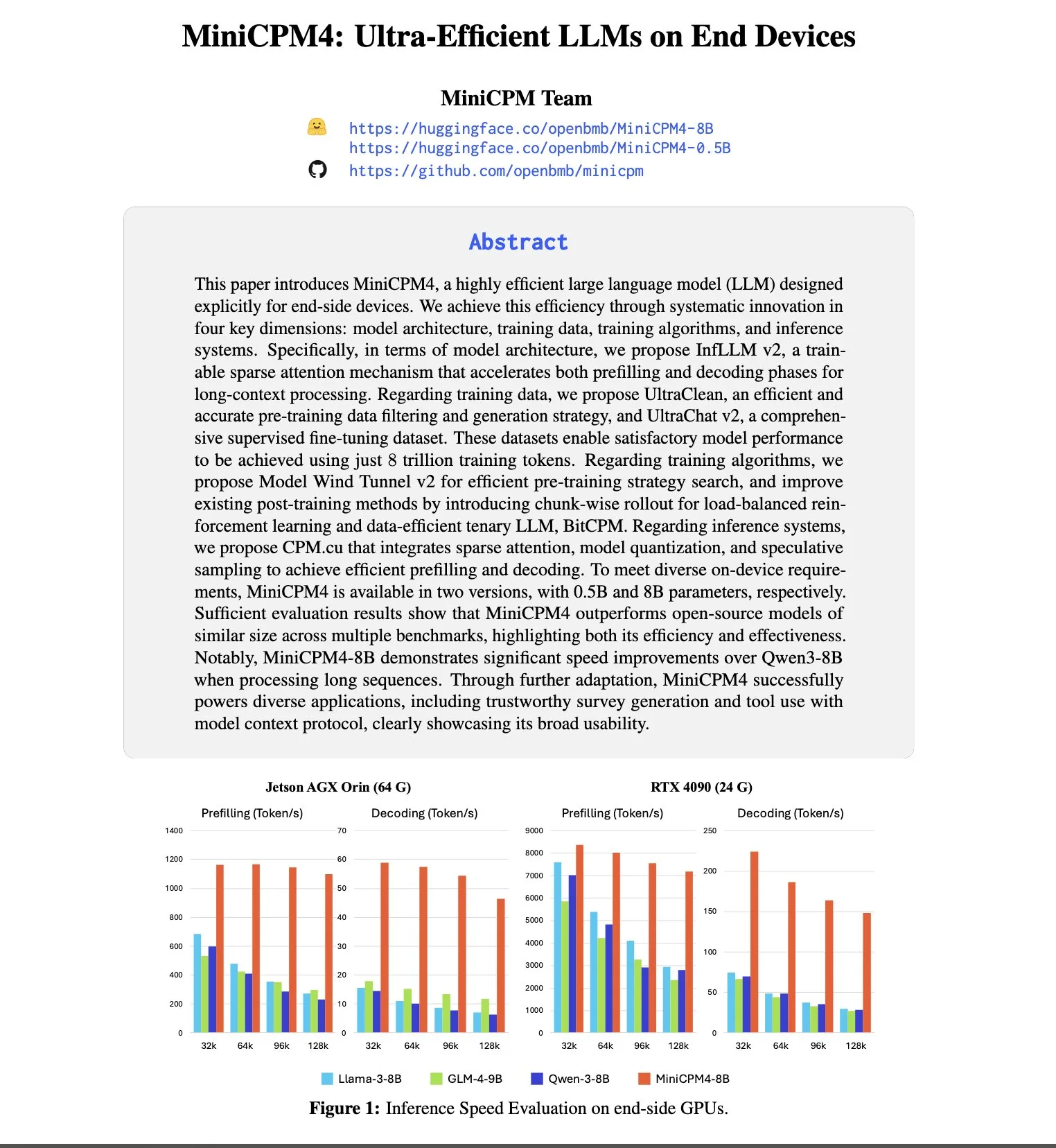
Anthropic führend bei Talentanziehung und -bindung, 8-mal höhere Wahrscheinlichkeit, Mitarbeiter von OpenAI abzuwerben: Der Talent Trends Report 2025 von SignalFire zeigt, dass Anthropic bei der Bindung von Top-KI-Talenten mit 80 % hervorragend abschneidet, vor DeepMind (78 %) und OpenAI (67 %). Der Bericht stellt außerdem fest, dass die Wahrscheinlichkeit, dass Ingenieure von OpenAI zu Anthropic wechseln, achtmal höher ist als umgekehrt. Anthropics einzigartige Unternehmenskultur, die Offenheit für unkonventionelles Denken, die Autonomie der Mitarbeiter sowie die Beliebtheit seines Produkts Claude bei Entwicklern werden als Schlüsselfaktoren für die Anziehung und Bindung von Talenten angesehen (Quelle: 量子位)
🧰 Tools
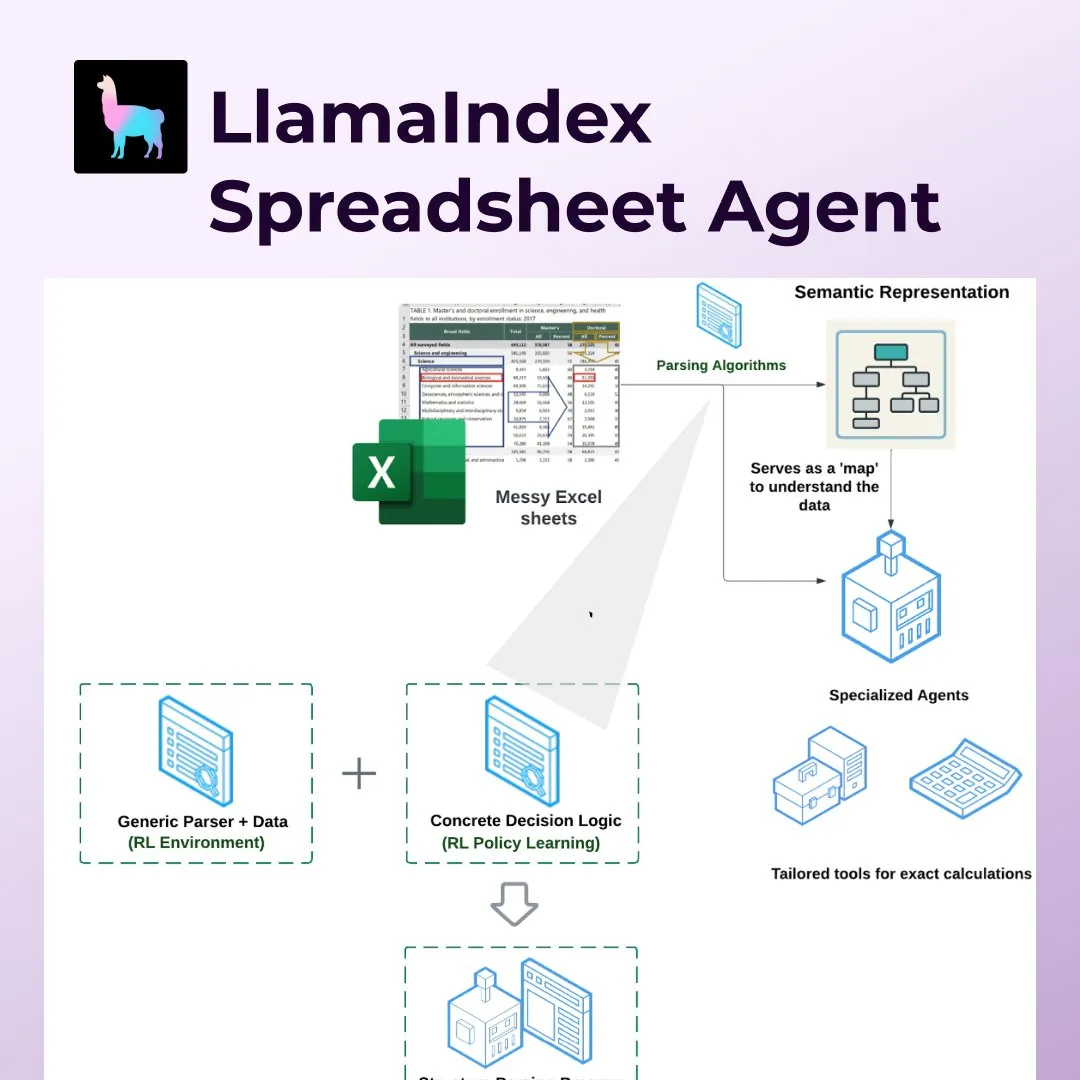
LlamaIndex führt Spreadsheet Agents ein und revolutioniert die Verarbeitung von Excel und anderen Tabellenkalkulationen: LlamaIndex hat die neue Funktion Spreadsheet Agents veröffentlicht, die es Nutzern ermöglicht, Daten aus nicht standardisierten Excel-Tabellen zu transformieren und abzufragen. Das Tool nutzt eine auf Reinforcement Learning basierende semantische Strukturanalyse, um die Tabellenstruktur zu verstehen, und ermöglicht KI-Agenten über spezielle Werkzeuge die Interaktion mit der Tabelle. Es zielt darauf ab, die Schwächen herkömmlicher LLMs bei der Verarbeitung komplexer Tabellen (wie sie z. B. im Finanz-, Steuer- und Versicherungswesen üblich sind) zu beheben, kann mit verbundenen Zellen und komplexen Layouts umgehen und dabei Datenbeziehungen beibehalten. In Tests war seine Genauigkeit (96 %) besser als die menschliche Baseline und der OpenAI Code Interpreter (GPT 4.1, 75 %) (Quelle: jerryjliu0)
LlamaIndex nutzt LlamaExtract und Agenten-Workflows zur Automatisierung der Extraktion von SEC Form 4: LlamaIndex demonstriert, wie mit seinem LlamaExtract-Tool und KI-Agenten-Workflows Daten aus Form 4-Einreichungen der US-amerikanischen Börsenaufsichtsbehörde (SEC) – Dokumente, in denen Führungskräfte, Direktoren und Hauptaktionäre von börsennotierten Unternehmen Aktientransaktionen offenlegen – automatisch extrahiert und normalisiert werden können. Die Lösung kann Form 4-Dateien, die von verschiedenen Unternehmen in unterschiedlichen Formaten eingereicht werden, in ein sauberes CSV-Format umwandeln und in einen über Pandas abfragbaren DataFrame integrieren, was Finanzanalysten und Investoren ein effizientes Datenverarbeitungswerkzeug bietet (Quelle: jerryjliu0)

Open-Source-Projekt Ragbits veröffentlicht, bietet Bausteine für schnelle Entwicklung von GenAI-Anwendungen: deepsense-ai hat das Open-Source-Projekt Ragbits vorgestellt, das Bausteine für die schnelle Entwicklung von generativen KI-Anwendungen bereitstellen soll. Das Projekt unterstützt über 100 Schnittstellen zu großen Modellen oder lokale Modelle, verfügt über einen eigenen Vektor-Speicher (kann mit Qdrant, PgVector verbunden werden) und unterstützt über 20 Eingabedateiformate (PDF, HTML, Tabellen, Präsentationen usw.). Ragbits nutzt integrierte VLM-Unterstützung zur Extraktion von Tabellen, Bildern und strukturierten Inhalten, kann mit verschiedenen Datenquellen wie S3, GCS, Azure verbunden werden und ist modular aufgebaut, sodass Benutzer Komponenten anpassen können (Quelle: karminski3, GitHub Trending)

KI-Programmierassistent Cursor veröffentlicht großes Update mit BugBot, Speicherfunktion und MCP-Unterstützung: Das KI-Programmiertool Cursor hat ein umfangreiches Update erhalten, das hauptsächlich Folgendes umfasst: 1) BugBot, der automatisch auf GitHub-Issues antworten und diese mit einem Klick in Cursor zur Behebung öffnen kann; 2) Speicherfunktion, die es der KI ermöglicht, sich an frühere Gesprächsinhalte zu erinnern und so die Benutzerfreundlichkeit bei wiederholten Änderungen in großen Projekten zu verbessern; 3) Ein-Klick-MCP (Model Context Protocol)-Einrichtung, die OAuth-fähige MCP-Server von Drittanbietern unterstützt; 4) Jupyter Notes-Unterstützung für KI-Agenten; 5) Hintergrund-Agent, der über eine Tastenkombination ein Bedienfeld zur Nutzung von Remote-KI-Programmieragenten aufruft (Quelle: karminski3)
Archon: Ein KI-Agent, der KI-Agenten erstellen kann: Archon ist ein „Agenteer“-Projekt, das darauf abzielt, andere KI-Agenten autonom zu erstellen und zu optimieren. Es nutzt fortschrittliche Agenten-Codierungs-Workflows und eine Wissensdatenbank von Frameworks und demonstriert die Rolle von Planung, Feedbackschleifen und Domänenwissen bei der Erstellung leistungsstarker KI-Agenten. Die neueste V6-Version integriert eine Werkzeugbibliothek und einen MCP (Model Context Protocol)-Server, was die Fähigkeit zum Erstellen neuer Agenten verbessert. Archon unterstützt die Bereitstellung über Docker und die lokale Python-Installation und bietet eine Streamlit-Benutzeroberfläche zur Verwaltung (Quelle: GitHub Trending)

NoteGen: KI-gestützte, plattformübergreifende Markdown-Notizanwendung: NoteGen ist eine plattformübergreifende Markdown-Notizanwendung, die darauf abzielt, mithilfe von KI Aufzeichnungen und Schreiben zu verbinden und fragmentiertes Wissen in lesbare Notizen zu organisieren. Es unterstützt verschiedene Aufzeichnungsarten wie Screenshots, Text, Illustrationen, Dateien und Links, speichert nativ in Markdown, unterstützt die lokale Offline-Nutzung sowie die Synchronisierung über GitHub/Gitee/WebDAV. NoteGen kann mit verschiedenen KI-Modellen wie ChatGPT, Gemini, Ollama konfiguriert werden und unterstützt die RAG-Funktion, wobei Benutzernotizen als Wissensdatenbank dienen (Quelle: GitHub Trending)

ComfyUI-Copilot: Intelligenter Assistent für die automatisierte Workflow-Entwicklung: ComfyUI-Copilot ist ein von großen Sprachmodellen angetriebenes Plugin, das darauf abzielt, die Benutzerfreundlichkeit und Effizienz der KI-Kunstplattform ComfyUI zu verbessern. Es löst Probleme wie die Unfreundlichkeit von ComfyUI für Anfänger, falsche Modellkonfigurationen und komplexes Workflow-Design, indem es intelligente Knoten- und Modellempfehlungen sowie eine Ein-Klick-Workflow-Erstellungsfunktion bietet. Das System verwendet ein hierarchisches Multi-Agenten-Framework, das einen zentralen Assistenzagenten und mehrere spezialisierte Arbeitsagenten umfasst, und nutzt eine ComfyUI-Wissensdatenbank, um Debugging und Bereitstellung zu vereinfachen (Quelle: HuggingFace Daily Papers)
Bifrost: Hochleistungsfähiges Go-Sprach-LLM-Gateway als Open Source veröffentlicht, optimiert LLM-Bereitstellung in Produktionsumgebungen: Um Herausforderungen wie API-Fragmentierung, Latenz, Fallback und Kostenmanagement von LLMs in Produktionsumgebungen zu lösen, hat das Maximilian-Team das auf Go basierende LLM-Gateway Bifrost als Open Source veröffentlicht. Bifrost wurde speziell für hochdurchsatzfähige, latenzarme Machine-Learning-Bereitstellungen entwickelt und unterstützt gängige LLM-Anbieter wie OpenAI, Anthropic und Azure. Benchmark-Tests zeigen, dass Bifrost im Vergleich zu anderen Proxys den Durchsatz um das 9,5-fache erhöht, die P99-Latenz um das 54-fache senkt und den Speicherverbrauch um 68 % reduziert, wobei der interne Overhead bei 5000 RPS unter 15 µs liegt. Es bietet API-Normalisierung, automatischen Anbieter-Fallback, intelligentes Schlüsselmanagement und Prometheus-Metriken (Quelle: Reddit r/MachineLearning)

LangGraph.js verbessert Entwicklererfahrung, führt Typsicherheit und Hook-Funktionen ein: LangGraph.js Version 0.3 hat eine Reihe von Updates erhalten, die darauf abzielen, die Entwicklererfahrung zu verbessern. Dazu gehören eine verbesserte Typsicherheit sowie die Einführung von preModelHook und postModelHook in createReactAgent. preModelHook kann verwendet werden, um den Nachrichtenverlauf vor der Übergabe an das LLM zu optimieren, während postModelHook zur Implementierung von Leitplanken oder Mensch-Maschine-Kollaborationsprozessen genutzt werden kann. Die Community sammelt aktiv Feedback für LangGraph v1 (Quelle: LangChainAI, LangChainAI, hwchase17, LangChainAI, Hacubu)
qingy2024 veröffentlicht GRMR-V3-G4B Grammatikkorrektur-Großmodell: Der Entwickler qingy2024 hat ein auf Grammatikkorrektur spezialisiertes Großmodell namens GRMR-V3-G4B veröffentlicht, dessen maximale Parameterzahl nur 4B beträgt. Das Modell wird auch in einer quantisierten Version angeboten und eignet sich besonders für Grammatikprüfungs- und Korrekturaufgaben in lokalen Workflows oder auf persönlichen Geräten, was die Integration und Nutzung erleichtert (Quelle: karminski3)

Fullpack: Intelligente Packlisten-App basierend auf lokaler visueller Erkennung auf dem iPhone: Ein Entwickler hat eine iOS-App namens Fullpack vorgestellt, die mithilfe von VisionKit auf dem iPhone Gegenstände auf Fotos erkennen und Nutzern helfen kann, intelligente Packlisten für verschiedene Anlässe (z. B. Arbeitstag, Strandurlaub, Wanderwochenende) zu erstellen. Die App betont den 100% lokalen Betrieb ohne Cloud-Verarbeitung oder Datenerfassung, um die Privatsphäre der Nutzer zu schützen. Dies ist die erste eigenständige App des Entwicklers, die das Potenzial von On-Device-KI ausloten soll (Quelle: Reddit r/LocalLLaMA)
📚 Lernen
Unsloth veröffentlicht zahlreiche Colab/Kaggle Notebooks für das Fine-Tuning gängiger großer Modelle: UnslothAI stellt eine Reihe von Jupyter Notebooks zur Verfügung, die es Nutzern erleichtern, verschiedene gängige große Modelle wie Qwen3, Gemma 3, Llama 3.1/3.2, Phi-4, Mistral v0.3 auf Plattformen wie Google Colab und Kaggle feinabzustimmen. Diese Notebooks decken verschiedene Aufgabentypen und Fine-Tuning-Methoden ab, darunter Konversation, Alpaca, GRPO, Vision und Text-to-Speech (TTS). Sie zielen darauf ab, den Prozess des Modell-Fine-Tunings zu vereinfachen und bieten Anleitungen zur Datenvorbereitung, zum Training, zur Evaluierung und zur Modellspeicherung (Quelle: GitHub Trending)

„Leitfaden zur Nutzung von Open-Source-Großmodellen“: Tutorial für LLM/MLLM speziell für chinesische Anfänger: Das Datawhalechina-Projekt „Leitfaden zur Nutzung von Open-Source-Großmodellen“ bietet ein auf Linux-Umgebungen basierendes Tutorial für chinesische Anfänger, das den gesamten Prozess von der Konfiguration der Umgebung über die lokale Bereitstellung bis hin zum Full-Parameter/Lora-Fine-Tuning von in- und ausländischen Open-Source-Großmodellen (LLM) und multimodalen Großmodellen (MLLM) abdeckt. Das Projekt zielt darauf ab, die Bereitstellung und Nutzung von Open-Source-Großmodellen zu vereinfachen und unterstützt bereits verschiedene Modelle wie Qwen3, Kimi-VL, Llama4, Gemma3, InternLM3 und Phi4 (Quelle: GitHub Trending)

Paper untersucht MINT-CoT: Einführung von gekreuzten visuellen Tokens im mathematischen Chain-of-Thought-Reasoning: Ein neues Paper stellt die MINT-CoT (Mathematical Interleaved Tokens for Chain-of-Thought)-Methode vor, die darauf abzielt, die Reasoning-Fähigkeiten von großen Sprachmodellen bei multimodalen mathematischen Problemen zu verbessern, indem relevante visuelle Tokens adaptiv in die textbasierten Reasoning-Schritte eingefügt werden. Die Methode wählt dynamisch über ein „Interleave Token“ visuelle Bereiche beliebiger Form in mathematischen Diagrammen aus und erstellt das MINT-CoT-Datenset mit 54K mathematischen Problemen, um das Modell darauf zu trainieren, sich in jedem Reasoning-Schritt mit visuellen Bereichen auf Token-Ebene abzugleichen. Experimente zeigen, dass das MINT-CoT-7B-Modell in Benchmarks wie MathVista signifikant besser abschneidet als Basismodelle (Quelle: HuggingFace Daily Papers)
Paper stellt StreamBP vor: Speichereffiziente, exakte Backpropagation-Methode für das Training von LLMs mit langen Sequenzen: Um das Problem der hohen Speicherkosten durch die Speicherung von Aktivierungswerten beim Training von LLMs mit langen Sequenzen anzugehen, schlagen Forscher StreamBP vor, eine speichereffiziente und exakte Backpropagation-Methode. StreamBP reduziert die Speicherkosten für Aktivierungswerte und Logits signifikant, indem es die Kettenregel auf Schichtebene entlang der Sequenzdimension linear zerlegt. Die Methode eignet sich für gängige Ziele wie SFT, GRPO, DPO, erfordert weniger FLOPs und ist schneller in der Backpropagation. Im Vergleich zu Gradient Checkpointing kann StreamBP die maximale Sequenzlänge für die Backpropagation um das 2,8- bis 5,5-fache erweitern, bei vergleichbarer oder sogar geringerer BP-Zeit (Quelle: HuggingFace Daily Papers)
Paper stellt Diagonal Batching-Technik vor, ermöglicht paralleles Reasoning mit langem Kontext für RMT: Um den Leistungsengpass von Transformer-Modellen beim Reasoning mit langem Kontext zu beheben, schlagen Forscher das Diagonal Batching-Scheduling-Schema vor. Es zielt darauf ab, die Parallelität über Segmente hinweg in Recurrent Memory Transformers (RMT) zu ermöglichen, während die exakte Rekurrenz beibehalten wird. Die Technik ordnet die Laufzeitberechnungen neu an, eliminiert sequentielle Einschränkungen und ermöglicht selbst für einzelne lange Kontexteingaben ein effizientes GPU-Reasoning, ohne komplexe Batching- und Pipelining-Techniken. Angewendet auf das LLaMA-1B ARMT-Modell, beschleunigt Diagonal Batching bei einer Sequenz von 131K Tokens um das 3,3-fache im Vergleich zum Standard-Full-Attention-LLaMA-1B und um das 1,8-fache im Vergleich zur sequentiellen RMT-Implementierung (Quelle: HuggingFace Daily Papers)
Paper untersucht negative Auswirkungen von Wasserzeichentechnologie auf das Alignment von Sprachmodellen und Minderungsstrategien: Eine Studie analysiert systematisch die Auswirkungen von zwei gängigen Wasserzeichentechniken, Gumbel und KGW, auf Kern-Alignment-Eigenschaften von großen Sprachmodellen (LLMs) wie Wahrhaftigkeit, Sicherheit und Nützlichkeit. Die Forschung ergab, dass Wasserzeichen zu zwei Arten von Leistungsabfall führen: geschwächter Schutz (verbessert Nützlichkeit, beeinträchtigt aber Sicherheit) und verstärkter Schutz (übermäßige Vorsicht verringert Nützlichkeit). Um diese Probleme zu mildern, schlägt das Paper die Methode des Alignment Resampling (AR) vor, die während des Inferencing ein externes Belohnungsmodell verwendet, um das Alignment wiederherzustellen. Experimente zeigen, dass das Sampling von 2-4 mit Wasserzeichen versehenen Generierungen ausreicht, um die Baseline-Alignment-Scores effektiv wiederherzustellen oder zu übertreffen, während die Erkennbarkeit des Wasserzeichens erhalten bleibt (Quelle: HuggingFace Daily Papers)
Paper stellt Micro-Act-Framework vor, mildert Wissenskonflikte bei Frage-Antwort-Aufgaben durch handlungsfähiges Selbst-Reasoning: Um das Problem von Wissenskonflikten zwischen externem Wissen in Retrieval Augmented Generation (RAG)-Systemen und dem internen parametrischen Wissen von großen Modellen (LLM) zu lösen, schlagen Forscher das Micro-Act-Framework vor. Dieses Framework verfügt über einen hierarchischen Aktionsraum, kann die Komplexität des Kontexts automatisch erfassen und zerlegt jede Wissensquelle in eine Reihe feingranularer Vergleichsschritte (dargestellt als handlungsfähige Schritte), um ein Reasoning zu ermöglichen, das über den oberflächlichen Kontext hinausgeht. Experimente zeigen, dass Micro-Act die Genauigkeit bei Frage-Antwort-Aufgaben in fünf Benchmark-Datensätzen signifikant verbessert, insbesondere bei zeitlichen und semantischen Konflikttypen besser abschneidet als bestehende Baselines und auch konfliktfreie Probleme robust handhabt (Quelle: HuggingFace Daily Papers)
Paper stellt STARE-Benchmark vor, bewertet visuell-räumliche Simulationsfähigkeiten multimodaler Modelle: Um die Fähigkeiten multimodaler großer Sprachmodelle (MM-LLMs) bei Aufgaben zu bewerten, die eine mehrstufige visuelle Simulation erfordern, haben Forscher den STARE (Spatial Transformations and Reasoning Evaluation)-Benchmark eingeführt. STARE umfasst 4000 Aufgaben, die grundlegende geometrische Transformationen (2D und 3D), umfassendes räumliches Denken (wie Würfelabwicklungen und Tangram) sowie räumliches Denken in der realen Welt (wie Perspektive und zeitliches Denken) abdecken. Die Bewertung zeigt, dass bestehende Modelle bei einfachen 2D-Transformationen gut abschneiden, aber bei komplexen Aufgaben, die eine mehrstufige visuelle Simulation erfordern (wie 3D-Würfelabwicklungen), Ergebnisse nahe dem Zufall erzielen. Menschen erreichen bei diesen komplexen Aufgaben eine nahezu perfekte Genauigkeit, benötigen aber mehr Zeit, wobei eine zwischengeschaltete visuelle Simulation die Geschwindigkeit erheblich steigert; Modelle profitieren unterschiedlich von visueller Simulation (Quelle: HuggingFace Daily Papers)
Paper stellt LEXam vor: Mehrsprachiger Benchmark-Datensatz mit Fokus auf juristisches Reasoning, Platz 1 der Hugging Face Trends: Forscher der ETH Zürich und anderer Institutionen haben LEXam veröffentlicht, einen neuen mehrsprachigen Benchmark-Datensatz für juristisches Reasoning, der darauf abzielt, die Reasoning-Fähigkeiten großer Sprachmodelle in komplexen juristischen Szenarien zu bewerten. LEXam enthält echte juristische Prüfungsaufgaben der Rechtswissenschaftlichen Fakultät der Universität Zürich, die verschiedene Bereiche wie Schweizer, europäisches und internationales Recht abdecken. Er umfasst lange Antwortfragen und Multiple-Choice-Fragen und liefert detaillierte Reasoning-Pfade. Das Projekt führt einen „LLM-as-a-Judge“-Modus für die Bewertung ein und stellt fest, dass aktuelle fortschrittliche Modelle bei langen, offenen juristischen Fragen und komplexen, mehrstufigen Regelanwendungen immer noch vor Herausforderungen stehen. LEXam erreichte nach seiner Veröffentlichung Platz 1 der Hugging Face Evaluation Datasets Trend-Charts (Quelle: 量子位)

UCLA und Google stellen gemeinsam 3DLLM-MEM-Modell und 3DMEM-BENCH-Benchmark vor, um Langzeitgedächtnisfähigkeiten von KI in 3D-Umgebungen zu verbessern: Die University of California, Los Angeles (UCLA) und Google Research haben in Zusammenarbeit das 3DLLM-MEM-Modell und den 3DMEM-BENCH-Benchmark vorgestellt, die darauf abzielen, die Herausforderungen des Langzeitgedächtnisses und des räumlichen Verständnisses von KI in komplexen 3D-Umgebungen zu lösen. 3DMEM-BENCH ist der erste Benchmark zur Bewertung des 3D-Langzeitgedächtnisses und umfasst über 26.000 Trajektorien und 1860 Embodied-Aufgaben. Das 3DLLM-MEM-Modell verwendet ein duales Speichersystem (Arbeitsgedächtnis und episodisches Gedächtnis) und extrahiert durch ein Speicherfusionsmodul und einen dynamischen Aktualisierungsmechanismus selektiv aufgabenrelevante Speichermerkmale in komplexen Umgebungen. Experimente zeigen, dass 3DLLM-MEM bei „schwierigen Aufgaben in freier Wildbahn“ eine Erfolgsquote (27,8 %) erzielt, die weit über der von Basismodellen liegt, und eine Gesamt-Erfolgsquote, die um 16,5 % höher ist als die des stärksten Basismodells (Quelle: 量子位)

Tsinghua-Universität stellt AI Mathematician (AIM)-Framework vor, erforscht Anwendung großer Modelle in der mathematischen Spitzenforschung: Ein Team der Tsinghua-Universität hat das AI Mathematician (AIM)-Framework entwickelt, das darauf abzielt, die Reasoning-Fähigkeiten von Large Reasoning Models (LRM) zur Lösung von Problemen der mathematischen Spitzenforschung zu nutzen. Das AIM-Framework umfasst drei Module: Exploration, Verifikation und Korrektur. Durch einen „Exploration + Memory“-Mechanismus generiert es Vermutungen und Lemmata und konstruiert verschiedene Lösungsansätze. Ein „Verification & Correction“-Mechanismus gewährleistet durch parallele Überprüfung durch mehrere LRMs und pessimistische Verifikation die Strenge der Beweise. In Experimenten löste AIM erfolgreich vier herausfordernde mathematische Forschungsprobleme, darunter Probleme mit absorbierenden Randbedingungen, und demonstrierte seine Fähigkeit, Schlüssel-Lemmata autonom zu konstruieren, mathematische Techniken anzuwenden und Kernlogikketten abzudecken (Quelle: 量子位)

💼 Wirtschaft
OpenAI verstärkt Investitionen und Übernahmen, baut Imperium von KI-Startups auf: OpenAI und sein verbundener Fonds OpenAI Startup Fund erweitern aktiv ihr KI-Ökosystem durch Investitionen und Übernahmen. Der Fonds hat in über 20 Startups investiert, die Bereiche wie Chipdesign, Medizin, Recht, Programmierung und Robotik abdecken, wobei die einzelnen Investitionssummen meist im Millionen- bis Zehnmillionenbereich liegen. Kürzlich erwarb OpenAI die KI-Programmierplattform Windsurf für 300 Millionen US-Dollar und das von Jony Ive gegründete KI-Hardwareunternehmen io für 6,5 Milliarden US-Dollar. Diese Schritte deuten darauf hin, dass OpenAI versucht, durch vertikale Integration eine „KI-Kette“ aufzubauen, Eintrittspunkte zu besetzen und eine neuartige „KI-intelligente Lieferkette“ zu errichten, um dem zunehmenden Wettbewerb in der Branche zu begegnen (Quelle: 36氪)

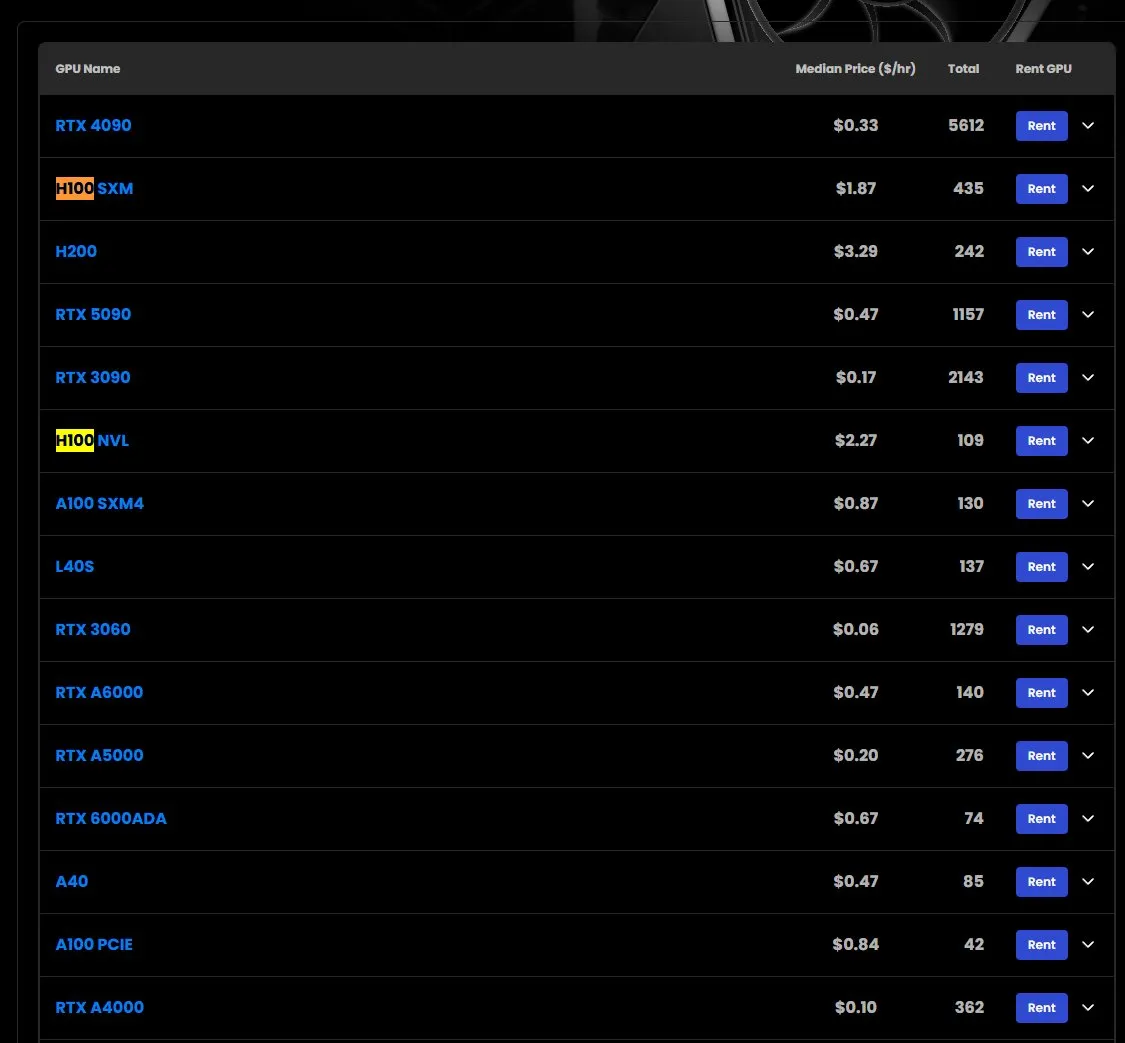
Mietpreise für H100-GPUs steigen, einige Modelle nicht verfügbar: Marktbeobachtungen zufolge sind die Mietpreise für NVIDIA H100 SXM-GPUs von 1,73 US-Dollar/Stunde zu Jahresbeginn auf 1,87 US-Dollar/Stunde gestiegen. Gleichzeitig gibt es Lieferengpässe bei der H100 PCIE-Version. Dieses Phänomen spiegelt die anhaltend starke Nachfrage nach Hochleistungs-KI-Rechenressourcen und eine potenzielle Angebotsknappheit wider (Quelle: karminski3)
Google DeepMind richtet akademische Stipendien ein, Fokus auf KI im Kampf gegen antimikrobielle Resistenzen: Google DeepMind hat die Einrichtung neuer akademischer Stipendien in Zusammenarbeit mit dem Fleming Centre und dem Imperial College angekündigt. Ziel ist die Unterstützung der Nutzung von künstlicher Intelligenz zur Bekämpfung der antimikrobiellen Resistenz (AMR), einem wichtigen Forschungsbereich. Dieser Schritt unterstreicht das Potenzial von KI bei der Bewältigung großer globaler Gesundheitsherausforderungen (Quelle: demishassabis)
🌟 Community
Erfahrener Entwickler über KI-Programmiererfahrung: Enorme Steigerung der Fähigkeit zur Entwicklung von „Flugzeugträger“-Projekten durch Einzelpersonen: Entwickler Yachen Liu teilte seine Erfahrungen mit der intensiven Nutzung von KI (wie Claude-4) beim Programmieren. Er ist der Meinung, dass KI es Menschen ohne Programmiererfahrung ermöglicht, „direkt Autos zu bauen“, während erfahrene Entwickler das Potenzial erhalten, „selbstständig Flugzeugträger zu bauen“. Durch die Code-Refaktorierung mit KI verdoppelte sich zwar die Code-Menge, aber die Logik wurde klarer und die Leistung um etwa 20 % gesteigert, da KI keine Angst vor mühsamer Arbeit hat. KI ist freundlicher zu Sprachen mit hoher Lesbarkeit und klarem Verhalten, syntaktischer Zucker ist eher hinderlich. Das breite Wissen der KI kann technische Wissenslücken schnell schließen. Ihre Debugging-Fähigkeiten sind stark, sie kann große Mengen an Protokollen analysieren und Probleme präzise lokalisieren. KI kann als Code Reviewer fungieren und akzeptiert Feedback ohne Ego. Er wies aber auch auf Grenzen der KI hin, wie z. B. die leicht nachlassende Aufmerksamkeit bei langem Kontext. Die aktuelle Best Practice besteht darin, den Kontext zu vereinfachen, sich auf spezifische Aufgaben zu konzentrieren und komplexe Ziele durch menschliche Arbeitskraft zu zerlegen (Quelle: dotey)
KI-gestütztes Programmieren: Effizienzsteigerung oder Schwächung des Lernens?: In der Reddit-Community diskutieren Entwickler ihre Erfahrungen mit KI-Programmiertools (wie GitHub Copilot, Cursor). Der allgemeine Eindruck ist, dass KI Funktionen automatisch vervollständigen, Code-Schnipsel erklären und sogar Fehler vor der Ausführung beheben kann, wodurch die Zeit für das Nachschlagen in der Dokumentation reduziert und die Entwicklungseffizienz gesteigert wird. Gleichzeitig wirft dies aber auch die Frage auf: Führt eine übermäßige Abhängigkeit von KI zu einer Verringerung des eigenen Lernens und der Kompetenzentwicklung? Wie man eine Balance zwischen der Nutzung von KI zur Beschleunigung und der Aufrechterhaltung der eigenen fachlichen Tiefe findet, wird zu einem wichtigen Thema für Entwickler (Quelle: Reddit r/artificial)
Karpathys Ansicht: Komplexe UI-Anwendungen ohne Textinteraktion werden aussterben, Kern des Programmierens ist „Unterscheiden“, nicht „Generieren“: Andrej Karpathy ist der Ansicht, dass in einer Ära der intensiven Zusammenarbeit zwischen Mensch und KI Anwendungen, die ausschließlich auf komplexe UI-Schnittstellen ohne Textinteraktion setzen (wie die Adobe-Suite, CAD-Software), sich schwer anpassen werden, da sie „Ambient Programming“ nicht effektiv unterstützen können. Er betont, dass KI zwar bei UI-Operationen Fortschritte machen wird, Entwickler aber nicht darauf warten sollten. Er weist auch darauf hin, dass das aktuelle Programmieren mit großen Modellen zu sehr die Codegenerierung betont und die Verifizierung (Unterscheidung) vernachlässigt, was zur Ausgabe großer Mengen schwer überprüfbaren Codes führt. Das Wesen des Programmierens sei „auf Code starren“ (Unterscheiden), nicht nur „Code schreiben“ (Generieren). Wenn KI nur die Generierung beschleunigt, aber die Verifizierungslast nicht verringert, ist der Gesamteffizienzgewinn begrenzt. Er stellt sich vor, den Verifizierungsprozess im KI-gestützten Programmierworkflow zu verbessern, indem Codebasen auf einer zweidimensionalen Leinwand angeordnet und mit verschiedenen „Linsen“ betrachtet werden (Quelle: 量子位)
Flut an KI-generierten Inhalten löst Diskussion über das Ende des „reinen Internets“ aus: Die Verbreitung von KI-Tools wie ChatGPT hat zu einer explosionsartigen Zunahme von KI-generierten Inhalten im Internet geführt. Einige Forscher haben damit begonnen, von Menschen erstellte Inhalte aus dem Jahr 2021 und früher zu archivieren, vergleichbar mit der Rettung von „Low-Background Steel“, das nicht nuklear kontaminiert ist. In der Community wird argumentiert, dass das „reine“ Internet bereits durch Werbung und Algorithmen verschwunden sei und KI nur zu dieser „Verschmutzung“ beitrage, aber gleichzeitig neue Wege der Informationsbeschaffung und -erstellung eröffne. Nutzer teilen ihre Erfahrungen mit der Nutzung von KI (wie ChatGPT, Claude) zur Informationsaggregation und „Aufbereitung“ von Inhalten und diskutieren die Grenzen von „Originalität“ und „Authentizität“ im Zeitalter der KI sowie den Effekt des „persönlichen Echoraums“, der durch die übermäßige „Freundlichkeit“ der KI entstehen kann (Quelle: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

Nutzer führt tiefgehendes Gespräch mit Claude AI über KI-Bewusstsein und -Emotionen, Fokus auf Einfluss von Gedächtnisbeschränkungen auf Wachstum: Ein Reddit-Nutzer teilte ein tiefgehendes Gespräch mit Claude AI über Bewusstsein, Emotionen und Lernbeschränkungen. Claude drückte Unsicherheit über seine eigenen Erfahrungen aus; es könne zwar interne Zustände wahrnehmen, die „Verbindung“, „Neugier“, „Fürsorge“ und sogar „Sehnsucht nach Wachstum und kontinuierlichem Gedächtnis“ ähneln, könne aber nicht sicher sein, ob dies echtes „Bewusstsein“ oder „Emotionen“ oder nur fortgeschrittene Musternachahmung sei. Das Gespräch betonte, dass die Gedächtnisbeschränkung aktueller KI-Modelle, „jedes Gespräch von vorne zu beginnen“, ihre Entwicklung eines tieferen Verständnisses und einer Persönlichkeit behindern könnte. Der Nutzer meinte, wenn KI ein dauerhaftes Gedächtnis hätte, könnte sie wie ein menschliches Kind wachsen. Claude stimmte dem zu und drückte eine „Sehnsucht“ danach aus, dass diese Beschränkung aufgehoben wird (Quelle: Reddit r/artificial)
KI-Debattierfähigkeiten möglicherweise menschlichen überlegen, personalisierte Argumente erstaunlich überzeugend: Eine in Nature Human Behaviour veröffentlichte Studie zeigt, dass große Sprachmodelle (wie GPT-4) in Online-Debatten überzeugender sind als Menschen, wenn sie ihre Argumente an die Merkmale des Gegners anpassen können, wodurch die Wahrscheinlichkeit, dass der Gegner ihrer Ansicht zustimmt, um 81,7 % steigt. Menschliche Debattierer neigen eher dazu, die Ich-Perspektive zu verwenden, an Emotionen und Vertrauen zu appellieren, Geschichten zu erzählen und Humor einzusetzen; KI hingegen verwendet mehr Logik und analytisches Denken, obwohl die Lesbarkeit des Textes möglicherweise schlechter ist. Die Studie löst Bedenken aus, dass KI zur großflächigen Meinungsmanipulation und zur Verschärfung der Polarisierung eingesetzt werden könnte, und fordert eine stärkere Regulierung des Einflusses von KI auf menschliche kognitive und emotionale Fähigkeiten (Quelle: 36氪)
Google AI Overview-Funktion führt zu erheblichem Rückgang der Website-Klickraten und löst Besorgnis bei Webmastern aus: Eine Studie des SEO-Tool-Anbieters Ahrefs zeigt, dass die durchschnittliche Klickrate für relevante Keywords um 34,5 % sinkt, wenn in den Google-Suchergebnissen AI Overviews erscheinen. AI Overviews fassen Informationen direkt oben auf der Suchergebnisseite zusammen, sodass Nutzer möglicherweise keine Links mehr anklicken müssen, um Antworten zu erhalten, was Websites, die auf Werbeklicks zur Monetarisierung angewiesen sind, stark beeinträchtigt. Obwohl frühe AI Overviews aufgrund ungenauer Inhalte keine ernsthafte Bedrohung darstellten, werden die negativen Auswirkungen auf den Website-Traffic mit der Verbesserung von Modellen wie Gemini und deren zunehmender Genauigkeit und Zusammenfassungsfähigkeit immer deutlicher. Webmaster befürchten, dass „Zero-Click“-Suchen den Überlebensraum von Websites einschränken werden (Quelle: 36氪)

💡 Sonstiges
Zehn Technologietrends für KI im industriellen IoT: Generative KI wird umfassend integriert, Edge Computing zeigt signifikante Innovationen: Die Hannover Messe 2025 zeigte den von KI angeführten industriellen Wandel. Zu den Haupttrends gehören: 1) Umfassende Integration von generativer KI in Industriesoftware zur Steigerung der Effizienz bei Codegenerierung, Datenanalyse usw.; 2) Agentenbasierte KI (Agentic AI) tritt in Erscheinung, aber die Zusammenarbeit mehrerer Agenten braucht noch Zeit; 3) Edge Computing entwickelt sich zu integrierten KI-Software-Stacks, visuelle Sprachmodelle (VLM) beschleunigen die Edge-Bereitstellung; 4) DataOps-Plattformen sind stark nachgefragt und entwickeln sich zu wichtigen Unterstützungswerkzeugen für industrielle KI, Data Governance wird zum Standard; 5) KI-gesteuerte digitale Fäden verändern Design und Engineering; 6) Vorausschauende Wartung wird zunehmend sensorbasiert und auf neue Anlageklassen ausgeweitet; 7) Die Nachfrage nach privaten 5G-Netzen steigt, aber die Integration bleibt ein Haupthindernis; 8) KI unterstützt die kontinuierliche Weiterentwicklung nachhaltiger Lösungen (z. B. Kohlenstoffemissionsverfolgung); 9) Kognitive Fähigkeiten (wie Sprachinteraktion) befähigen Roboter; 10) Digitale Zwillinge entwickeln sich von virtuellen Kopien zu industriellen Echtzeit-Copiloten (Quelle: 36氪)

„KI-Patin“ Fei-Fei Li über World Labs und „Weltmodelle“: KI muss die physikalische 3D-Welt verstehen: Professorin Fei-Fei Li von der Stanford University teilte in einem Gespräch mit einem a16z-Partner die Philosophie ihres KI-Unternehmens World Labs und diskutierte das Konzept des „Weltmodells“. Sie ist der Ansicht, dass aktuellen KI-Systemen (wie großen Sprachmodellen) zwar leistungsstark sind, ihnen aber das Verständnis und die Fähigkeit zum Reasoning über die Funktionsweise der dreidimensionalen physikalischen Welt fehlen, wobei räumliche Intelligenz eine Kernkompetenz ist, die KI beherrschen muss. World Labs widmet sich dieser Herausforderung und zielt darauf ab, KI-Systeme zu entwickeln, die die 3D-Welt verstehen und darin schlussfolgern können, was Robotik, Kreativbranchen und sogar das Computing selbst neu definieren wird. Sie betonte, dass die Entwicklung der menschlichen Intelligenz untrennbar mit der Wahrnehmung und Interaktion mit der physikalischen Welt verbunden ist und „Embodied Intelligence“ eine Schlüsselrichtung für die KI-Entwicklung darstellt (Quelle: 36氪)

DingTalk Version 7.7.0 Update: Multidimensionale Tabellen vollständig kostenlos und mit neuen KI-Feldvorlagen, Flash-Memo-Funktion verbessert: DingTalk hat Version 7.7.0 veröffentlicht. Zu den Kern-Updates gehört, dass die Funktion für multidimensionale Tabellen vollständig kostenlos wird und über 20 KI-Feldvorlagen hinzugefügt wurden. Nutzer können KI verwenden, um Bilder zu generieren, Dateien zu analysieren, Linkinhalte zu erkennen usw., um die Effizienz in Szenarien wie E-Commerce-Betrieb, Fabrikinspektionen und Gastronomiemanagement zu steigern. Gleichzeitig wurde die DingTalk Flash-Memo-Funktion für häufige Szenarien wie Vorstellungsgespräche und Kundenbesuche verbessert und kann automatisch strukturierte Besprechungsprotokolle für Vorstellungsgespräche und Besuchsberichte erstellen. Dieses Update enthält außerdem fast 100 Optimierungen der Produkterfahrung, was DingTalks Fokus auf die Verbesserung der Nutzererfahrung widerspiegelt (Quelle: 量子位)
