
Schlüsselwörter:KI-Modell, Datensatz, Humanoid-Roboter, KI-Agent, Sprachmodell, Tiefes Lernen, Open-Source-Modell, Inferenzoptimierung, Common Pile v0.1 Datensatz, Helix End-to-End Steuerungsmodell, Hugging Face MCP-Server, Gemini 2.5 Pro Update, Sparse Attention Mechanismus
🔥 Fokus
EleutherAI veröffentlicht Common Pile v0.1: 8TB Textdatensatz unter offener Lizenz, um das Training von Sprachmodellen ohne nicht lizenzierte Daten zu testen : EleutherAI hat in Zusammenarbeit mit mehreren Institutionen Common Pile v0.1 veröffentlicht, einen großen Datensatz mit 8 TB offen lizenzierter und gemeinfreier Texte. Ziel ist es, die Machbarkeit des Trainings von Hochleistungs-Sprachmodellen ohne die Verwendung nicht lizenzierter Texte zu untersuchen. Das Team trainierte mit diesem Datensatz Modelle mit 7B Parametern (1T und 2T Tokens), deren Leistung mit ähnlichen Modellen wie LLaMA 1 und LLaMA 2 vergleichbar ist. Der Datensatz enthält Metadaten auf Dokumentenebene wie Autorenzuweisungen, Lizenzdetails und Links zu Originalkopien, was Forschern eine transparente und konforme Datenquelle bietet. Diese Initiative ist von großer Bedeutung für die Förderung der Entwicklung offener und konformer KI-Modelle und bietet neue Ansätze zur Lösung von Urheberrechtsfragen bei KI-Trainingsdaten (Quelle: EleutherAI, percyliang, BlancheMinerva, code_star, ShayneRedford, Tim_Dettmers, jeremyphoward, stanfordnlp, ClementDelangue, tri_dao, andersonbcdefg)

Figure humanoider Roboter zeigt unter Steuerung des Helix-Modells Hochgeschwindigkeits-Paketsortierfähigkeiten und erregt Aufmerksamkeit : Brett Adcock, CEO von Figure, präsentierte die neuesten Fortschritte seines humanoiden Roboters bei der Paketsortierung in Logistikszenarien, angetrieben durch das Ende-zu-Ende-Universalsteuerungsmodell Helix. Das Video zeigt, wie der Roboter Pakete verschiedener Typen (Hartkartons, Kunststoffverpackungen) mit annähernd menschlicher Geschwindigkeit und Genauigkeit handhabt, einschließlich des Ordnens von Paketen und der Sicherstellung, dass die Barcodes zum Scannen nach unten zeigen. Diese Fähigkeit unterstreicht die Generalisierungsfähigkeit und Flexibilität des Helix-Modells in komplexen, dynamischen Umgebungen, im Gegensatz zu den zuvor gezeigten Arbeiten an Stanzpressen (die Präzision und hohe Geschwindigkeit betonten). Figure-Roboter arbeiten bereits in 20-Stunden-Schichten in der BMW-Produktionslinie und zeigen ihr Potenzial in industriellen Anwendungen. Adcock betonte, dass im Bereich der humanoiden Roboter der Bau des intelligentesten und kostengünstigsten Roboters entscheidend für den Markterfolg sein wird, da mehr eingesetzte Roboter niedrigere Kosten, mehr Trainingsdaten und ein intelligenteres Helix-Modell bedeuten (Quelle: dotey, _philschmid, adcock_brett, 量子位)

Hugging Face veröffentlicht ersten offiziellen MCP-Server und schafft eine Kollaborationsplattform für AI Agents : Hugging Face hat seinen ersten offiziellen MCP (Model-Client Protocol) Server gestartet, der es Nutzern ermöglicht, LLMs direkt mit der API des Hugging Face Hub zu verbinden, um sie in Cursor, VSCode, Windsurf und anderen MCP-unterstützenden Anwendungen zu verwenden. Der Server bietet integrierte Werkzeuge wie semantische Suche für Modelle, Datensätze, Paper und Spaces und kann dynamisch alle MCP-kompatiblen Gradio-Anwendungen auflisten, die auf Spaces gehostet werden. Diese Initiative zielt darauf ab, Hugging Face zu einer Kollaborationsplattform für Entwickler von AI Agents zu machen und die Entwicklung und Interoperabilität des AI Agent-Ökosystems zu fördern. Derzeit sind etwa 900 MCP Spaces verfügbar (Quelle: ClementDelangue, mervenoyann, reach_vb, ben_burtenshaw, huggingface, code_star, op7418, TheTuringPost, clefourrier)

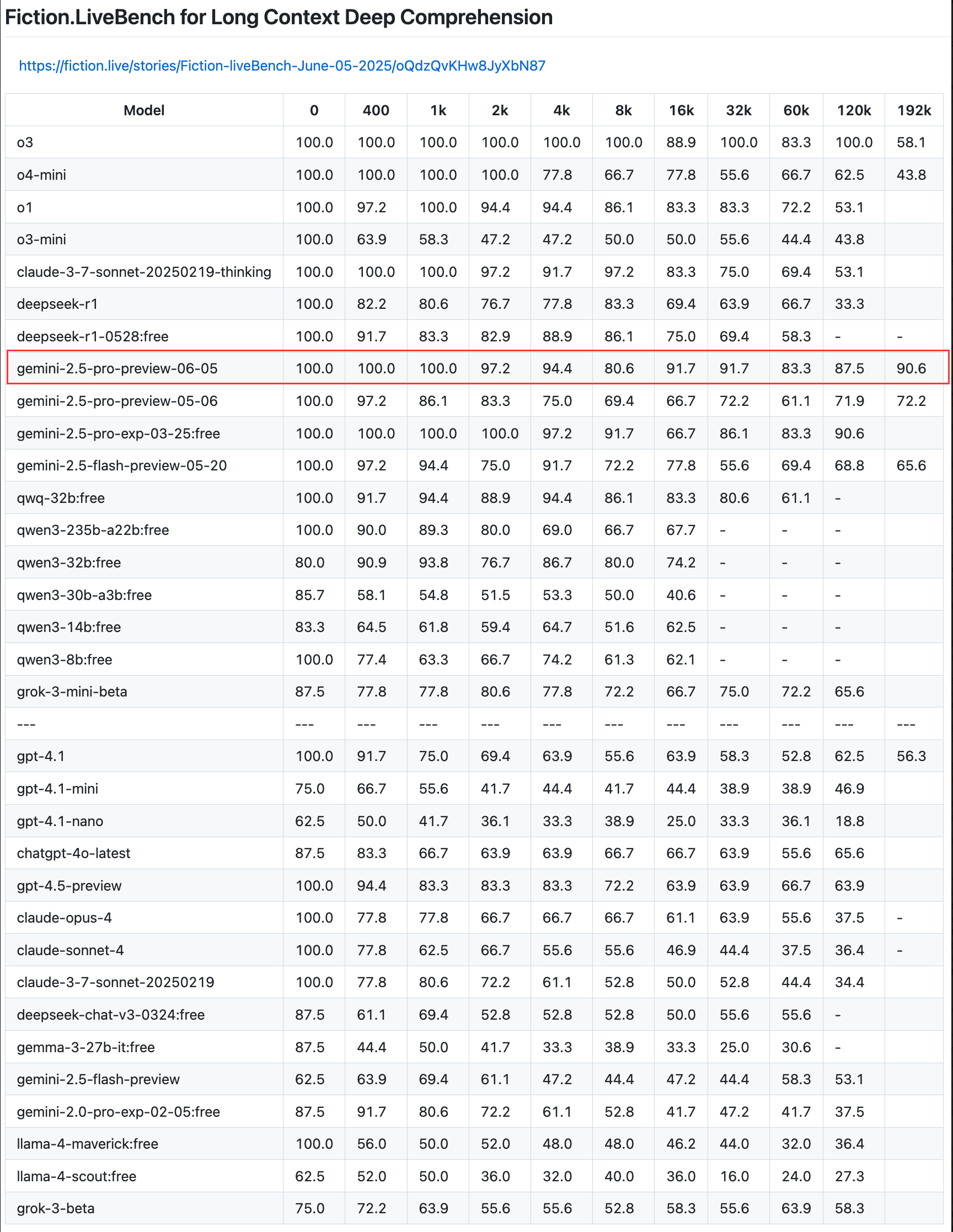
Google aktualisiert Gemini 2.5 Pro Preview, verbessert Coding-, Inferenz- und Kreativfähigkeiten und führt „Thinking Budget“ ein : Google hat ein Update für die Preview-Version seines intelligentesten Modells Gemini 2.5 Pro angekündigt, das dessen Fähigkeiten in den Bereichen Coding, logische Inferenz und kreatives Schreiben weiter verbessert. Die neue Version führt insbesondere eine „Thinking Budget“-Funktion ein, die Entwicklern eine bessere Kontrolle über den Verbrauch von Rechenressourcen des Modells ermöglicht. Nutzerfeedback zeigt, dass die neue Version (06-05) eine hervorragende Leistung beim Recall langer Texte erbringt, insbesondere eine Recall-Rate von 90,6 % bei einer Länge von 192K, womit sie OpenAI-o3 übertrifft. Das Modell wurde in LangChain und LangGraph integriert, um Entwicklern das Ausprobieren und Erstellen von Anwendungen zu erleichtern. Google demonstrierte auch die kreativen Fähigkeiten von Gemini 2.5 Pro beim Verstehen von Bildern und beim Generieren kontextualisierter, witziger Bildunterschriften (Quelle: Teknium1, Google, karminski3, hwchase17, )
🎯 Trends
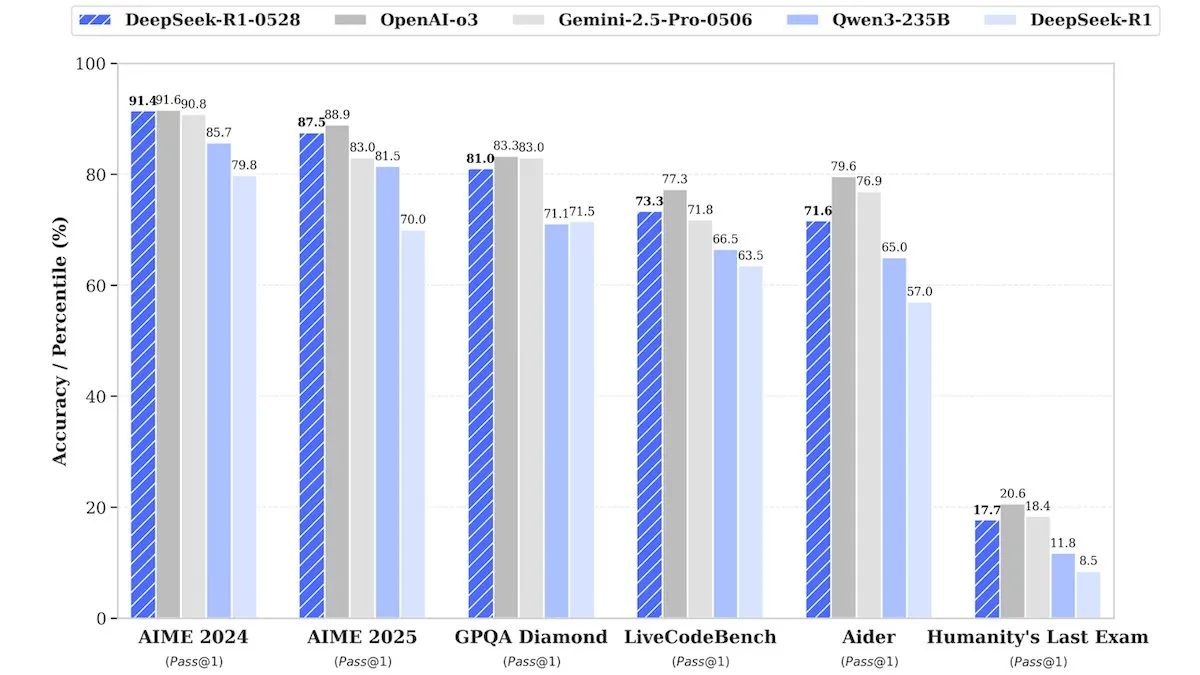
DeepSeek veröffentlicht Upgrade DeepSeek-R1-0528, Leistung vergleichbar mit Closed-Source-Modellen : DeepSeek hat eine aktualisierte Version seines Flaggschiff-Open-Source-Gewichtsmodells DeepSeek-R1-0528 vorgestellt. Berichten zufolge ist die Leistung dieses Modells in mehreren Benchmarks mit Closed-Source-Modellen wie o3 von OpenAI und Gemini-2.5 Pro von Google vergleichbar. Obwohl das Unternehmen keine Details zum Training bekannt gab, wird berichtet, dass das neue Modell signifikante Verbesserungen bei Inferenz, der Verarbeitung komplexer Aufgaben und der Reduzierung von Halluzinationen aufweist und damit erneut die traditionelle Vorstellung in Frage stellt, dass Spitzen-KI immense Ressourcen erfordert. Unsloth AI bietet bereits ein kostenloses Notebook für das Fine-Tuning von DeepSeek-R1-0528-Qwen3 mit GRPO an und behauptet, dass seine neue Belohnungsfunktion die mehrsprachige (oder benutzerdefinierte Domänen-) Antwortrate um über 40 % verbessern und das R1-Fine-Tuning um das Zweifache beschleunigen sowie den VRAM-Bedarf um 70 % reduzieren kann (Quelle: DeepLearningAI, ImazAngel)
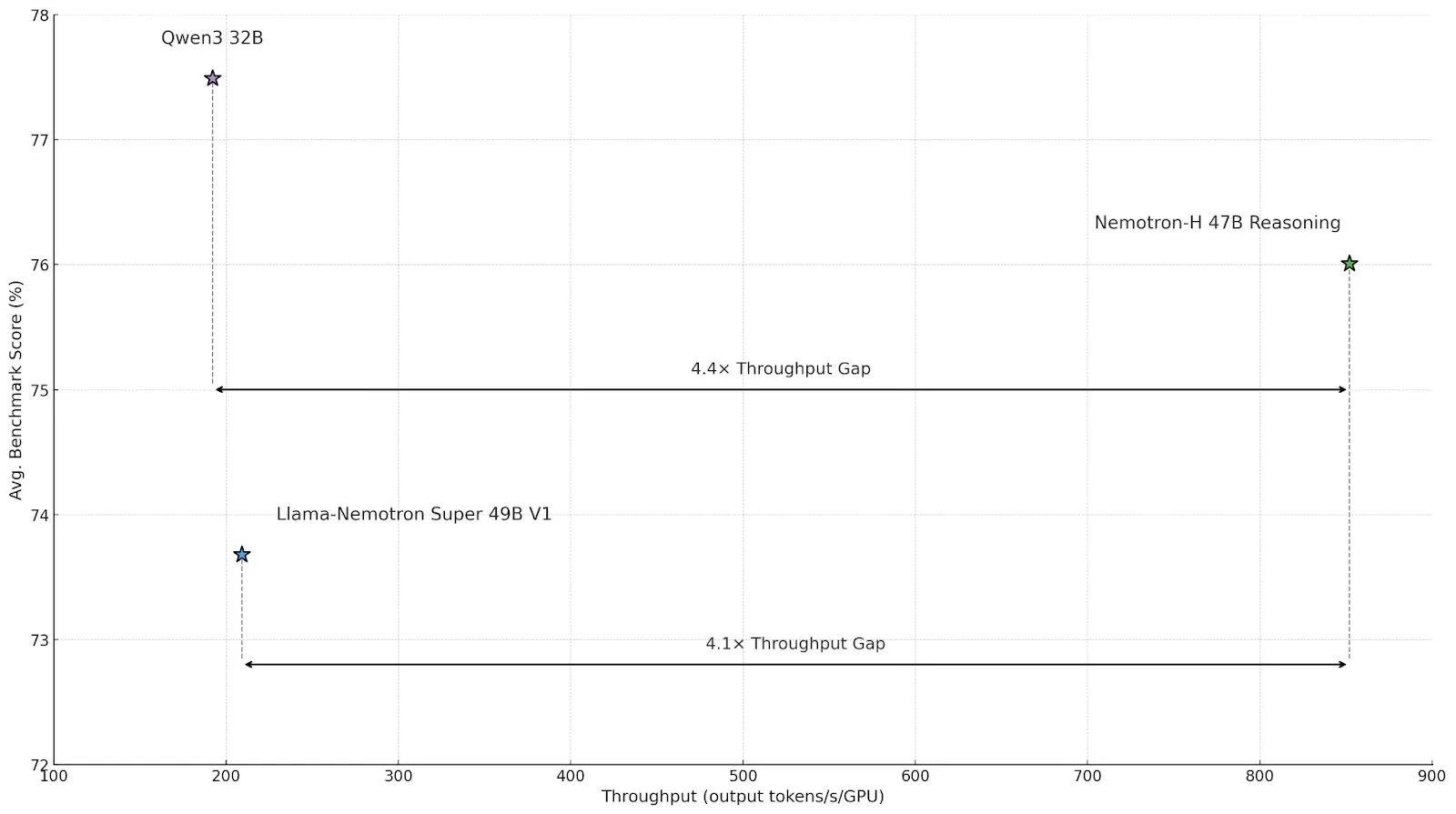
Nvidia veröffentlicht Inferenzmodell Nemotron-H mit hybrider Architektur zur Steigerung von Durchsatz und Effizienz : Nvidia hat das neue Inferenzmodell Nemotron-H vorgestellt, das in Versionen mit 47B und 8B Parametern (unterstützt BF16 und FP8) erhältlich ist und eine hybride Mamba-Transformer-Architektur verwendet. Das Modell zielt darauf ab, groß angelegte Inferenzprobleme zu lösen und gleichzeitig eine hohe Geschwindigkeit beizubehalten. Berichten zufolge ist sein Durchsatz viermal so hoch wie bei vergleichbaren Transformer-Modellen. Nemotron-H-47B-Reasoning-128k übertrifft Llama-Nemotron-Super-49B-1.0 in allen Benchmarks leicht in der Genauigkeit, reduziert jedoch die Inferenzkosten um bis zu das Vierfache. Die Modellgewichte wurden auf HuggingFace unter einer nicht-produktiven Lizenz veröffentlicht, ein technischer Bericht folgt in Kürze (Quelle: ClementDelangue, ctnzr)
Anthropic führt Claude Gov ein, speziell entwickelt für US-Regierungs- und Militärgeheimdienste : Anthropic hat einen neuen KI-Dienst namens Claude Gov veröffentlicht, der speziell auf die Bedürfnisse der US-Regierung, des Verteidigungsministeriums und der Geheimdienste zugeschnitten ist. Dieser Schritt markiert die formelle Ausweitung der fortschrittlichen KI-Technologie von Anthropic auf Regierungs- und Militäranwendungen, die möglicherweise für Datenanalyse, Informationsverarbeitung, Entscheidungsunterstützung und andere Szenarien eingesetzt wird. Anthropic ist zuvor auch einem Long-Term Benefit Trust beigetreten, um dem Unternehmen zu helfen, seine gemeinnützige Mission zu erfüllen (Quelle: MIT Technology Review, akbirkhan, jeremyphoward)
Hugging Face und Google Colab kooperieren zur Vereinfachung von Modelltests und Prototyping-Prozessen : Hugging Face hat eine Zusammenarbeit mit Google Colaboratory angekündigt und fügt allen Modellkarten im Hugging Face Hub die Unterstützung „In Colab öffnen“ hinzu. Benutzer können jetzt direkt von jeder Modellkarte aus ein Colab Notebook starten, was das Experimentieren und Bewerten von Modellen erleichtert. Darüber hinaus können Benutzer benutzerdefinierte notebook.ipynb-Dateien in ihren Modell-Repositories platzieren, und Hugging Face stellt dieses Notebook direkt bereit, was die Zugänglichkeit von KI-Modellen und die Fähigkeit zum schnellen Prototyping weiter verbessert (Quelle: huggingface, osanseviero, ClementDelangue, mervenoyann)
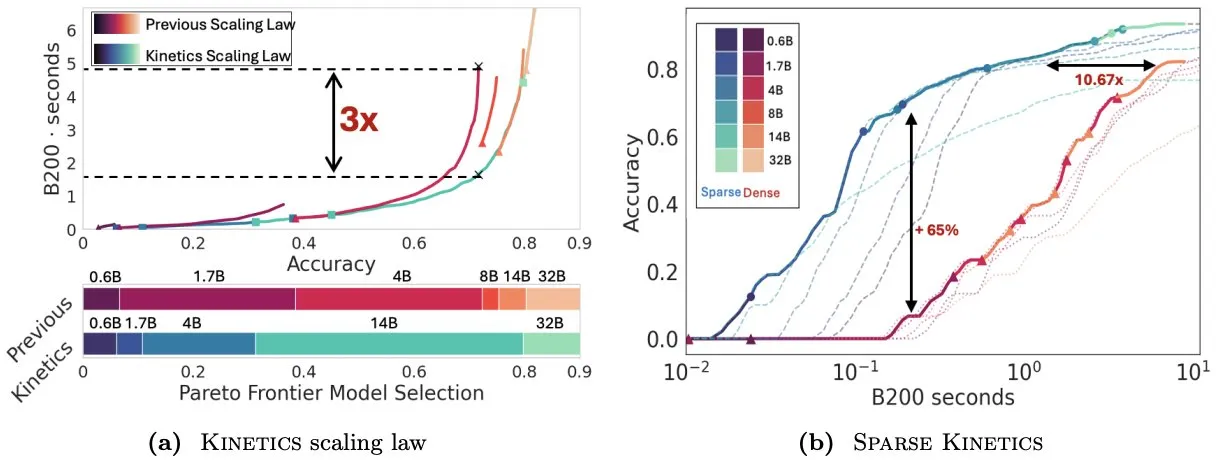
Paper Kinetics überdenkt Skalierungsgesetze zur Testzeit und betont die Bedeutung von Sparse Attention für die Ineffizienz : Infini-AI-Lab hat das Paper „Kinetics: Rethinking Test-Time Scaling Laws“ veröffentlicht, das darauf hinweist, dass frühere Skalierungsgesetze, die auf Berechnungseffizienz basieren, die Effektivität kleiner Modelle überschätzen und die durch Inferenzstrategien (wie Best-of-N, langes CoT) verursachten Speicherzugriffsengpässe ignorieren. Die Studie schlägt neue Kinetics-Skalierungsgesetze vor, die sowohl Berechnungs- als auch Speicherzugriffskosten berücksichtigen und argumentiert, dass Rechenressourcen zur Testzeit bei großen Modellen effektiver eingesetzt werden als bei kleinen Modellen, da Attention und nicht die Anzahl der Parameter die dominierenden Kosten darstellen. Das Paper schlägt weiterhin ein auf Sparse Attention zentriertes Skalierungsparadigma vor, das durch die Reduzierung der Kosten pro Token längere Generierungen und mehr parallele Samples ermöglicht. Experimente zeigen, dass Sparse-Attention-Modelle in verschiedenen Kostenbereichen dichten Modellen überlegen sind, was für die Steigerung der Ineffizienz großer Modelle entscheidend ist (Quelle: realDanFu, tri_dao, simran_s_arora)
Chinas KI-Agenten-Markt boomt, Manus führt den Gründungstrend an : Nach dem Hype um Basismodelle im letzten Jahr liegt der Fokus im chinesischen KI-Sektor dieses Jahr auf KI-Agenten. KI-Agenten konzentrieren sich stärker darauf, Aufgaben für Benutzer autonom zu erledigen, anstatt nur auf Anfragen zu reagieren. Manus, ein Pionier für universelle KI-Agenten, erregte nach seiner limitierten Veröffentlichung Anfang März große Aufmerksamkeit und löste eine Welle von Start-ups aus, die universelle digitale Werkzeuge entwickeln, die E-Mails bearbeiten, Reisen planen und sogar interaktive Websites entwerfen können. Dieser Trend zeigt, dass die chinesische Technologiebranche aktiv die praktischen Anwendungen und Geschäftsmodelle von KI-Agenten erforscht (Quelle: MIT Technology Review)

ElevenLabs veröffentlicht Conversational AI 2.0 zur Verbesserung der Leistung von Sprachassistenten für Unternehmen : ElevenLabs hat die Version 2.0 seiner Conversational AI Plattform vorgestellt, die darauf abzielt, fortschrittlichere Sprachagenten für Unternehmen zu entwickeln. Die neue Version verbessert die Natürlichkeit und Interaktionsfähigkeit von Sprachassistenten erheblich, sodass sie den Gesprächsrhythmus besser verstehen, wissen, wann sie pausieren, wann sie sprechen und wann sie den Gesprächswechsel vornehmen müssen. Dieses Upgrade verspricht Unternehmenskunden ein flüssigeres und intelligenteres Sprachinteraktionserlebnis für Anwendungen im Kundenservice, bei virtuellen Assistenten und in vielen anderen Szenarien (Quelle: dl_weekly)
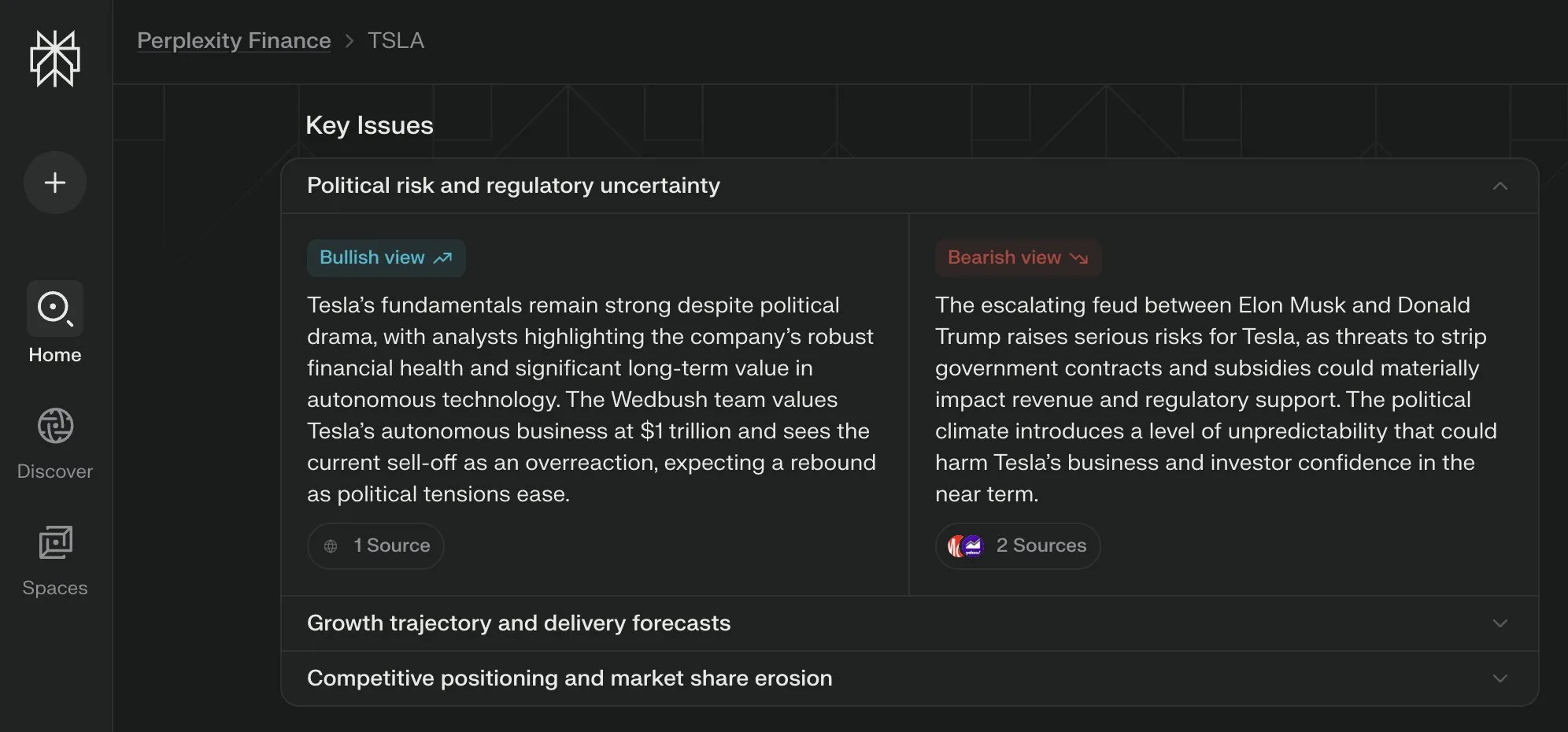
Perplexity Labs führt Ansicht „Key Issues“ für seine Finanzseiten ein, die Meinungen aus verschiedenen Quellen zusammenfasst : Perplexity Labs hat seine Finanzinformationsseiten um die Funktion „Key Issues“ (Schlüsselfragen) erweitert. Diese Funktion fasst Meinungen von Investoren, Analysten und Kommentatoren aus dem Internet zusammen, um den Nutzern schnell die wichtigsten Faktoren und Hauptdiskussionspunkte aufzuzeigen, die ein Unternehmen aktuell beeinflussen. Beispielsweise kann die Seite zu Tesla innerhalb weniger Stunden verschiedene Informationen über die Dynamik zwischen Trump und Musk konsolidieren und den Nutzern helfen, schnell einen Gesamtüberblick zu gewinnen (Quelle: AravSrinivas)
PyTorch Distributed Checkpoints unterstützen jetzt Hugging Face Safetensors : PyTorch hat angekündigt, dass seine Distributed-Checkpoint-Funktion jetzt das Safetensors-Format von Hugging Face unterstützt, was das Speichern und Laden von Checkpoints zwischen verschiedenen Ökosystemen erleichtern wird. Die neue API ermöglicht es Benutzern, Safetensors über fsspec-Pfade zu lesen und zu schreiben. torchtune ist die erste Bibliothek, die diese Funktion übernimmt und so ihre Checkpoint-Prozesse vereinfacht. Dieses Update trägt zur Verbesserung der Interoperabilität und Effizienz beim Modelltraining und -Deployment bei (Quelle: ClementDelangue)

Paper MARBLE stellt neue Methode zur Materialreorganisation und -mischung basierend auf dem CLIP-Raum vor : Eine neue Studie namens MARBLE schlägt eine Methode vor, um durch das Finden von Material-Embeddings im CLIP-Raum und die Nutzung dieser Embeddings zur Steuerung vortrainierter Text-zu-Bild-Modelle Materialmischungen und feinkörnige Attributreorganisationen von Objekten in Bildern zu erreichen. Diese Methode verbessert die samplebasierte Materialbearbeitung, indem sie Module im Denoising UNet lokalisiert, die für die Materialzuweisung zuständig sind, und so eine parametrisierte Kontrolle über feinkörnige Materialattribute wie Rauheit, Metallizität, Transparenz und Glanz ermöglicht. Die Forscher demonstrieren die Wirksamkeit der Methode durch qualitative und quantitative Analysen und zeigen ihre Anwendbarkeit für mehrere Bearbeitungen in einem einzigen Forward-Pass sowie im Bereich der Malerei (Quelle: HuggingFace Daily Papers, ClementDelangue)
Paper FlowDirector: Trainingsfreie, präzise Text-zu-Video-Bearbeitungsmethode mittels Flow-Steuerung : FlowDirector ist ein neuartiges, inversionsfreies Videobearbeitungsframework, das den Bearbeitungsprozess als direkte Evolution im Datenraum modelliert. Mittels gewöhnlicher Differentialgleichungen (ODE) wird das Video entlang seiner inhärenten raumzeitlichen Mannigfaltigkeit sanft überführt, wodurch zeitliche Kohärenz und strukturelle Details erhalten bleiben. Um lokal steuerbare Bearbeitungen zu ermöglichen, wird ein auf Attention basierender Maskierungsmechanismus eingeführt. Darüber hinaus wird zur Lösung von Problemen unvollständiger Bearbeitungen und zur Verbesserung der semantischen Ausrichtung auf Bearbeitungsanweisungen eine von Classifier-Free Guidance inspirierte, anleitungsgestützte Bearbeitungsstrategie vorgeschlagen. Experimente zeigen, dass FlowDirector eine hervorragende Leistung in Bezug auf Anweisungsbefolgung, zeitliche Konsistenz und Hintergrunderhaltung erbringt (Quelle: HuggingFace Daily Papers)
Paper RACRO: Skalierbare multimodale Inferenz durch belohnungsoptimierte Bildunterschriften : Um das Problem der kostspieligen Neuausrichtung der visuellen Sprachverbindung beim Upgrade des zugrundeliegenden LLM-Inferenzmoduls zu lösen, schlagen Forscher RACRO (Reasoning-Aligned Perceptual Decoupling via Caption Reward Optimization) vor. Diese Methode wandelt visuelle Eingaben in sprachliche Darstellungen (z. B. Bildunterschriften) um, die dann an den Textinferenzer weitergegeben werden. RACRO verwendet eine inferenzgesteuerte Reinforcement-Learning-Strategie, um das Verhalten des Extraktors bei der Erstellung von Bildunterschriften durch Belohnungsoptimierung an die Inferenzziele anzupassen, wodurch die visuelle Grundlage gestärkt und für die Inferenz optimierte Darstellungen extrahiert werden. Experimente zeigen, dass RACRO in multimodalen Mathematik- und Wissenschaftsbenchmarks State-of-the-Art-Leistungen erbringt und eine Plug-and-Play-Anpassung an fortschrittlichere Inferenz-LLMs ohne teure multimodale Neuausrichtung unterstützt (Quelle: HuggingFace Daily Papers)
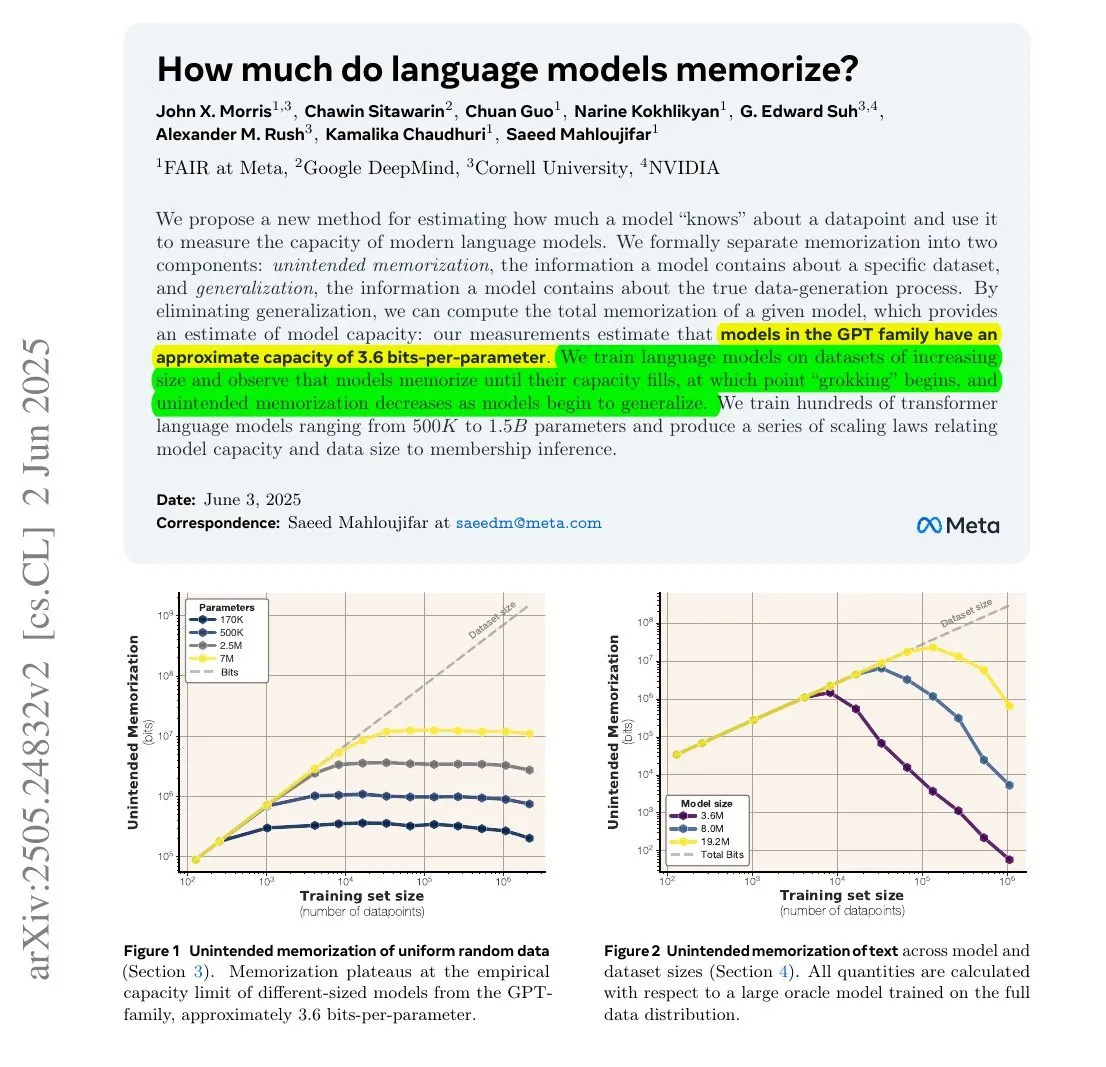
Studie zeigt: Informationsmenge, die LLMs speichern, könnte mit ihrer Parameteranzahl und Informationsentropie zusammenhängen : Eine gemeinsame Studie von Meta, DeepMind, NVIDIA und der Cornell University untersuchte die tatsächliche Informationsmenge, die Large Language Models (LLMs) speichern. Die Studie ergab, dass die von LLMs gespeicherte Informationsmenge mit ihrer Parameteranzahl und der Informationsentropie der Daten zusammenhängen könnte. Beispielsweise enthält die englische Wikipedia etwa 29,4 Milliarden Zeichen, wobei jedes Zeichen etwa 1,5 Bit an Information enthält. Ein Modell mit 12B Parametern (unter der Annahme einer Speicherkapazität von 3,6 Bit pro Parameter) könnte theoretisch die gesamte englische Wikipedia speichern. Diese Studie ist wichtig für das Verständnis der Speichermechanismen von LLMs und die Bewertung von Fragen des Datenurheberrechts. François Chollet erwähnte auch die Methodik des Trainings von LLMs mit zufälligen Zeichenketten und deren quantitative Ergebnisse und hält dies für wertvoll für das Verständnis der Speichermechanismen von LLMs (Quelle: fchollet, AymericRoucher)
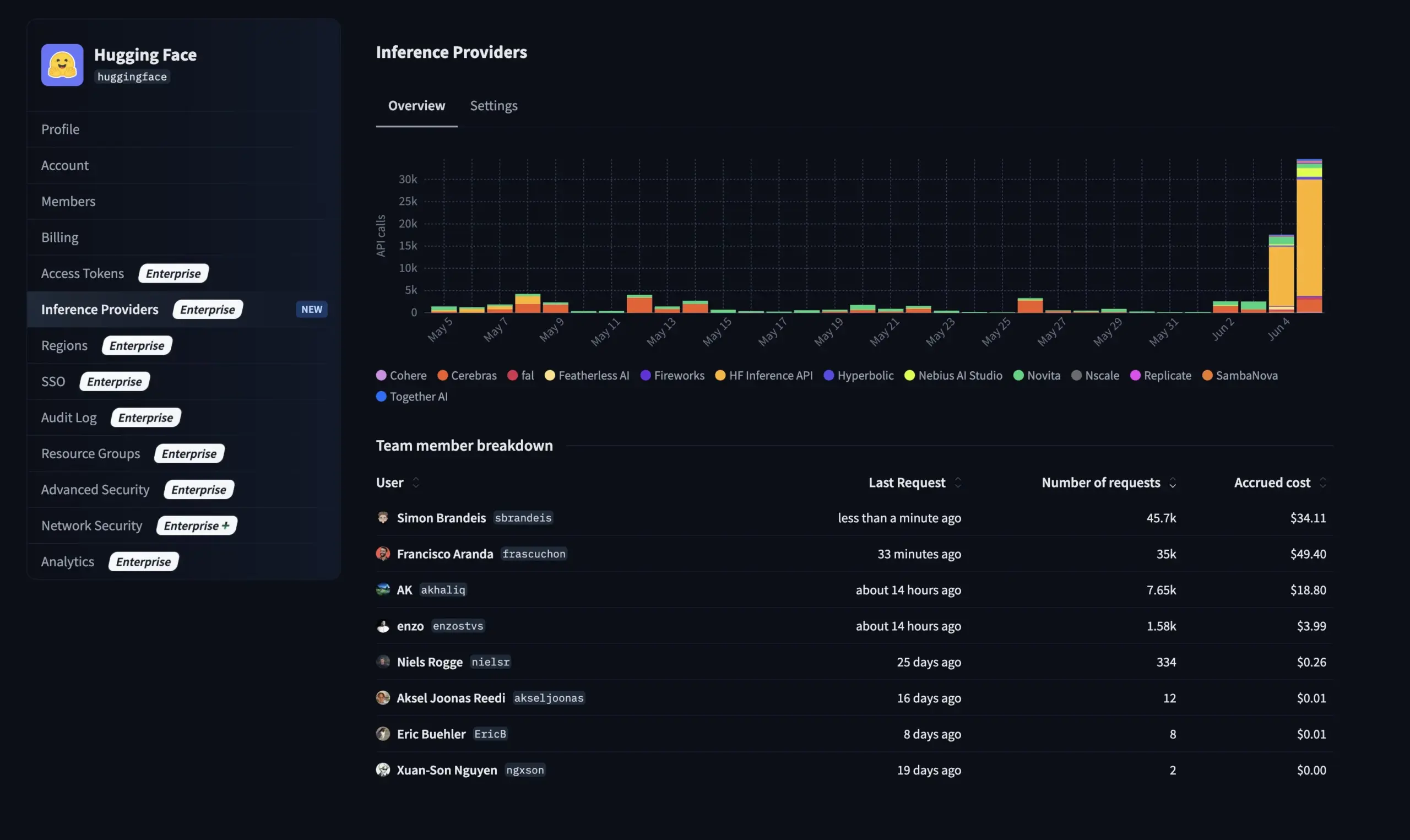
Hugging Face führt neue Funktion für Enterprise-Version ein: Verwaltung der Nutzung und Kosten von Inferenzanbietern : Hugging Face hat seiner Enterprise-Version (Enterprise Hub) eine neue Funktion hinzugefügt, die es Organisationen ermöglicht, die Nutzung von Inferenzanbietern (Inference Providers) und die damit verbundenen Kosten durch ihre Teammitglieder zu konfigurieren und zu überwachen. Dies bedeutet, dass Unternehmenskunden die Nutzung von serverlosen Inferenzdiensten für über 40.000 Modelle von verschiedenen Anbietern wie TogetherCompute, FireworksAI, Replicate, Cohere usw. besser verwalten und kontrollieren können, um die Kosteneffizienz und Ressourcenzuweisung bei der Bereitstellung von KI-Anwendungen zu optimieren (Quelle: huggingface, _akhaliq)
Mistral AI veröffentlicht wissenschaftliches Inferenzmodell ether0, basierend auf Fine-Tuning von Mistral 24B : Mistral AI hat sein erstes wissenschaftliches Inferenzmodell ether0 veröffentlicht. Das Modell wurde durch Reinforcement Learning (RL) Training von Mistral 24B für mehrere molekulare Designaufgaben im Bereich Chemie entwickelt. Die Forschung ergab, dass LLMs bei bestimmten wissenschaftlichen Aufgaben eine weitaus höhere Dateneffizienz aufweisen als von Grund auf trainierte Spezialmodelle und bei diesen Aufgaben sowohl Spitzenmodelle als auch Menschen deutlich übertreffen können. Dies deutet darauf hin, dass für einen Teil der wissenschaftlichen Klassifikations-, Regressions- und Generierungsprobleme das Nachtraining von LLMs einen effizienteren Weg als herkömmliche Machine-Learning-Methoden bieten könnte (Quelle: MistralAI)
Dual Consistency Model (DCM) beschleunigt Videogenerierung um das 10-fache : Ziwei Liu und andere Forscher haben das Dual Consistency Model (DCM) vorgestellt, das die Geschwindigkeit von Videogenerierungsmodellen (mit Parameterzahlen von 1,3B bis 13B) um das 10-fache beschleunigen kann, ohne die Qualität zu beeinträchtigen. Das Modell unterstützt derzeit Tencent Hunyuan und Alibaba Tongyi Wanxiang. Die Einführung von DCM stellt einen neuen Durchbruch im Bereich der effizienten und qualitativ hochwertigen Videogenerierung dar und trägt dazu bei, die Erstellung von Videoinhalten und verwandte Anwendungen zu beschleunigen (Quelle: _akhaliq)
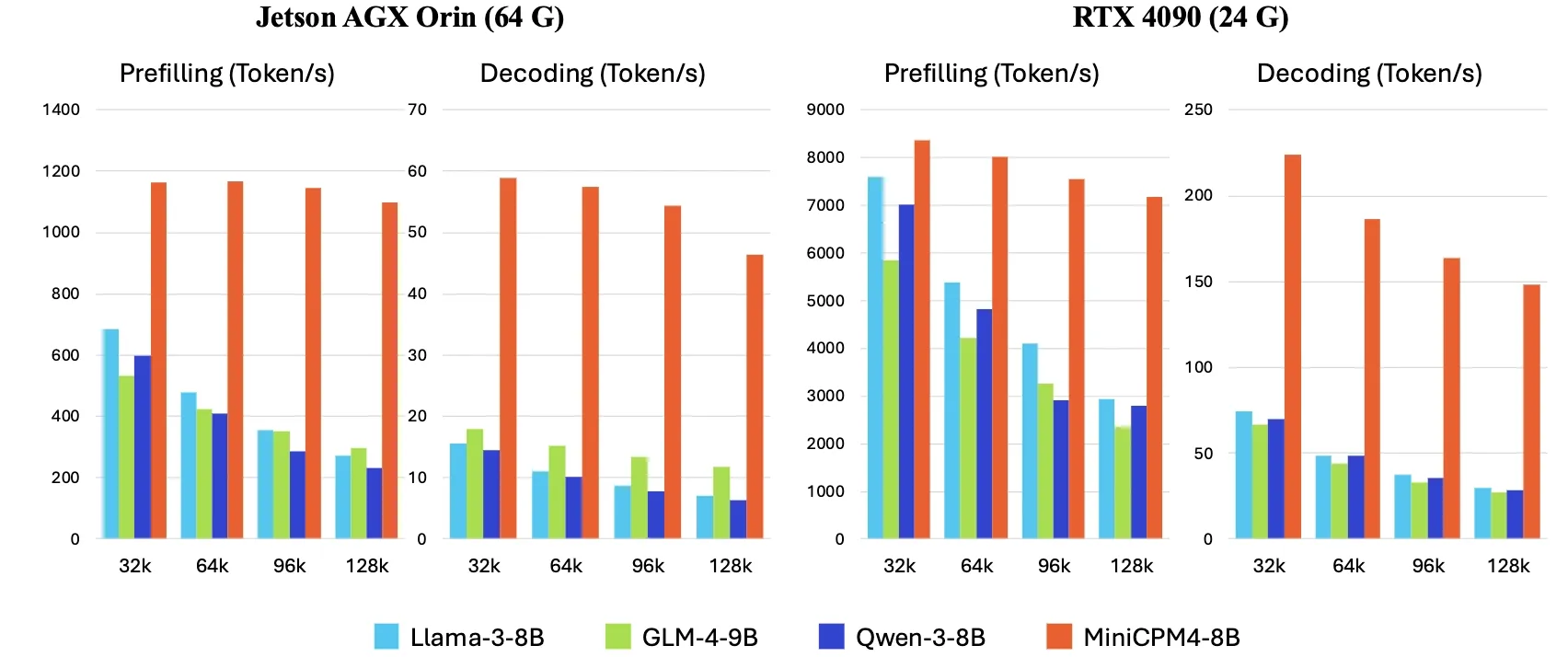
OpenBMB veröffentlicht MiniCPM4, Inferenzgeschwindigkeit auf Endgeräten um das 5-fache erhöht : OpenBMB hat die MiniCPM4-Modellreihe vorgestellt, die durch den Einsatz einer effizienten Modellarchitektur (InfLLM v2 trainierbarer Sparse-Attention-Mechanismus), effizienter Lernalgorithmen (Model Wind Tunnel 2.0, BitCPM ternäre Quantisierung), hochwertiger Trainingsdaten (UltraClean, UltraChat v2) und eines effizienten Inferenzsystems (CPM.cu, ArkInfer) eine 5-fache Steigerung der Inferenzgeschwindigkeit auf Endgeräten erreicht. Das Flaggschiffmodell MiniCPM4-8B (8B Parameter, 8T Tokens Training) ist auf Hugging Face verfügbar. Diese Modellreihe zielt darauf ab, die Grenzen kleiner, kostengünstiger LLMs zu erkunden und die Anwendung von KI auf ressourcenbeschränkten Geräten voranzutreiben (Quelle: eliebakouch, Teortaxes▶️ (DeepSeek 推特🐋铁粉 2023 – ∞))
X Corp aktualisiert Nutzungsbedingungen und verbietet die Verwendung seiner Posts zum „Fine-Tuning oder Training“ von KI-Modellen, es sei denn, es liegt eine Vereinbarung vor : X Corp (ehemals Twitter) hat seine Nutzungsbedingungen aktualisiert und verbietet ausdrücklich die Verwendung von Inhalten auf der Plattform zum „Fine-Tuning oder Training“ von KI-Modellen, es sei denn, es wurde eine spezifische Vereinbarung mit X Corp getroffen. Dieser Schritt spiegelt die wachsende Bedeutung und den Kontrollwillen von Content-Plattformen über den Wert ihrer Daten im KI-Zeitalter wider und könnte dem Beispiel von Reddit und Google folgen, die Daten über Lizenzvereinbarungen monetarisieren. Diese Richtlinienänderung wird sich auf KI-Forscher und -Entwickler auswirken, die für das Modelltraining auf öffentlich zugängliche Social-Media-Daten angewiesen sind (Quelle: MIT Technology Review)
🧰 Werkzeuge
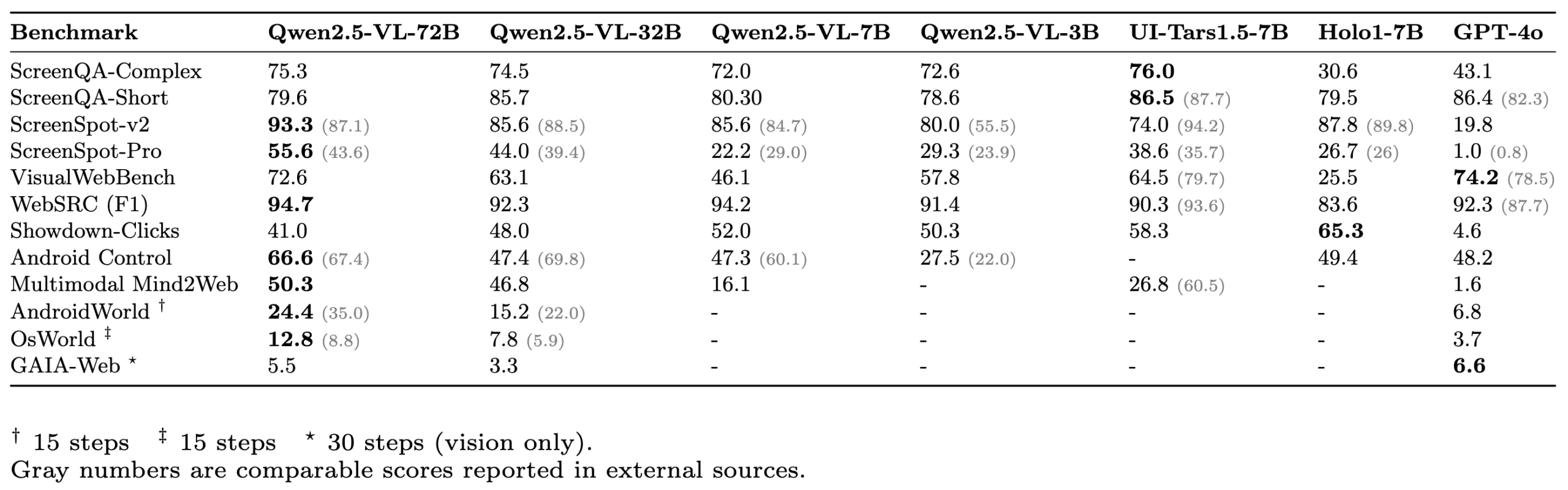
ScreenSuite: Umfassende GUI-Agent-Evaluierungssuite veröffentlicht : Hugging Face hat ScreenSuite veröffentlicht, eine umfassende Evaluierungssuite für grafische Benutzeroberflächen (GUI)-Agenten. Sie integriert wichtige Benchmarks aus der Spitzenforschung, unterstützt die Docker-basierte Evaluierung für Ubuntu- und Android-Umgebungen und deckt mobile, Desktop- und Web-Szenarien ab. Die Suite legt Wert auf eine rein visuelle Evaluierung (kein DOM-Cheating) und zielt darauf ab, eine einheitliche, benutzerfreundliche Plattform zur Messung der Fähigkeiten von visuellen Sprachmodellen (VLM) in Bereichen wie Wahrnehmung, Lokalisierung, einstufige Operationen und mehrstufige Agentenaufgaben bereitzustellen. Modelle wie Qwen-2.5-VL, UI-Tars-1.5-7B, Holo1-7B und GPT-4o wurden bereits mit dieser Suite evaluiert (Quelle: huggingface, AymericRoucher, clefourrier, tonywu_71, mervenoyann, HuggingFace Blog)
Erfahrungsbericht zur Nutzung von Claude Code: Herausragendes Befehlsverständnis, Aufgabenplanung und Werkzeugnutzung : Der Nutzer dotey teilt seine Erfahrungen mit dem KI-Programmierassistenten Claude Code von Anthropic. Er hält Claude Code für leistungsstark, weil: 1. Das Verständnis von Befehlen ausgezeichnet ist; 2. Aufgaben vernünftig geplant werden können, bei komplexen Aufgaben wird eine TODO-Liste erstellt und abgearbeitet; 3. Die Werkzeugnutzung extrem stark ist, insbesondere die Verwendung des grep-Befehls zur Durchsuchung von Codebasen, was weitaus effizienter als bei Menschen ist und sogar obfuskierten JS-Code analysieren kann; 4. Die Ausführungszeit lang ist und „Wunder durch rohe Gewalt“ bewirkt werden können, aber der Token-Verbrauch auch hoch ist, was gut zu einem Claude Max-Abonnement passt; 5. Wenig manuelle Eingriffe während des gesamten Prozesses erforderlich sind, insbesondere wenn der Parameter --dangerously-skip-permissions aktiviert ist, was unbeaufsichtigtes Programmieren ermöglicht. Der Nutzer ist von einem intensiven Cursor-Nutzer dazu übergegangen, Aufgaben zunächst von Claude Code erledigen zu lassen und sie dann in der IDE zu überprüfen und zu ändern. Der Plan Mode (Planungsmodus) von Claude Code wurde ebenfalls stillschweigend eingeführt und ermöglicht es Nutzern, ohne Bearbeitung von Dateien rein zu lesen und nachzudenken (Quelle: dotey, Reddit r/ClaudeAI)
ClaudeBox: Claude Code sicher in Docker ausführen, ohne Berechtigungsaufforderungen : Der Entwickler RchGrav hat das Tool ClaudeBox erstellt, mit dem Benutzer Claude Code im kontinuierlichen Modus (ohne Berechtigungsaufforderungen) in einem Docker-Container ausführen können. Dies vermeidet häufige Berechtigungsbestätigungen, die den Arbeitsablauf unterbrechen, und gewährleistet gleichzeitig die Sicherheit des Hauptbetriebssystems, da alle Operationen von Claude Code auf die isolierte Docker-Umgebung beschränkt sind. ClaudeBox bietet über 15 vorkonfigurierte Entwicklungsumgebungen (wie Python+ML, C++/Rust/Go usw.), die Benutzer mit einfachen Befehlen schnell einrichten können. Das Tool zielt darauf ab, die Benutzererfahrung mit Claude Code zu verbessern und es den Benutzern zu ermöglichen, die KI bedenkenlos verschiedene Operationen ausprobieren zu lassen (Quelle: Reddit r/ClaudeAI)
Toolio 0.6.0 veröffentlicht: GenAI- und Agent-Toolkit speziell für Mac : Toolio hat Version 0.6.0 veröffentlicht, ein Toolkit mit tiefer MLX-Integration, das darauf abzielt, leistungsstarke Unterstützung für Large Language Models (LLMs) auf dem Mac zu bieten. Es implementiert auf JSON Schema basierende strukturierte Ausgabe- und Tool-Aufruffunktionen unter Verwendung der Programmiersprache Python. Das Toolkit konzentriert sich auf die Verbesserung der Erfahrung und Effizienz bei der Entwicklung von GenAI- und Agent-Anwendungen in der Mac-Umgebung (Quelle: awnihannun)
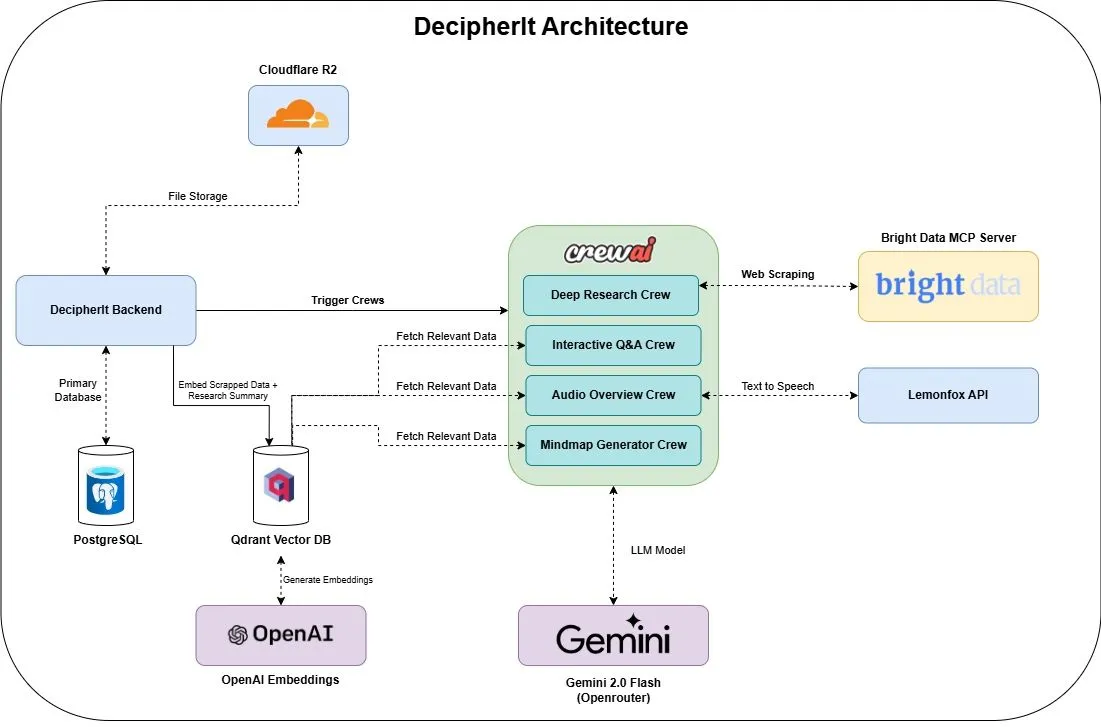
DecipherIt: Open-Source KI-Forschungsassistent, integriert Multi-Agenten und semantische Suche : DecipherIt ist ein Open-Source KI-Forschungsassistent, der als Alternative zu NotebookLM gilt. Er nutzt Multi-Agenten-Orchestrierung, semantische Suche und Echtzeit-Webzugriffsfunktionen, um Benutzer bei der Verarbeitung von Forschungsmaterialien zu unterstützen. Benutzer können Dokumente hochladen, URLs einfügen oder Themen eingeben, und DecipherIt wandelt diese in einen vollständigen Forschungsarbeitsbereich um, der Zusammenfassungen, Mindmaps, Audio-Übersichten, FAQs und semantische Frage-Antwort-Funktionen enthält. Sein Technologie-Stack umfasst crewAI-Agenten, Bright Data MCP, Qdrant, OpenAI und LemonFox AI, wobei das Frontend Next.js und React 19 und das Backend FastAPI verwendet (Quelle: qdrant_engine)
Search Arena: Datensatz zur Analyse von Benutzerinteraktionen mit suchgestützten LLMs veröffentlicht : Search Arena ist ein groß angelegter (über 24.000) Crowdsourcing-Datensatz mit menschlichen Präferenzen für paarweise, mehrstufige Benutzerinteraktionen mit suchgestützten LLMs. Der Datensatz deckt verschiedene Absichten und Sprachen ab und enthält vollständige Systemverfolgungen von etwa 12.000 menschlichen Präferenzabstimmungen. Die Analyse zeigt, dass Benutzerpräferenzen von der Anzahl der Zitate beeinflusst werden, selbst wenn der zitierte Inhalt die zugeschriebene Aussage nicht direkt unterstützt; Community-gesteuerte Plattformen sind in der Regel beliebter. Der Datensatz zielt darauf ab, zukünftige Forschung zu suchgestützten LLMs zu unterstützen, Code und Daten wurden als Open Source veröffentlicht (Quelle: HuggingFace Daily Papers, jiayi_pirate, lmarena_ai)

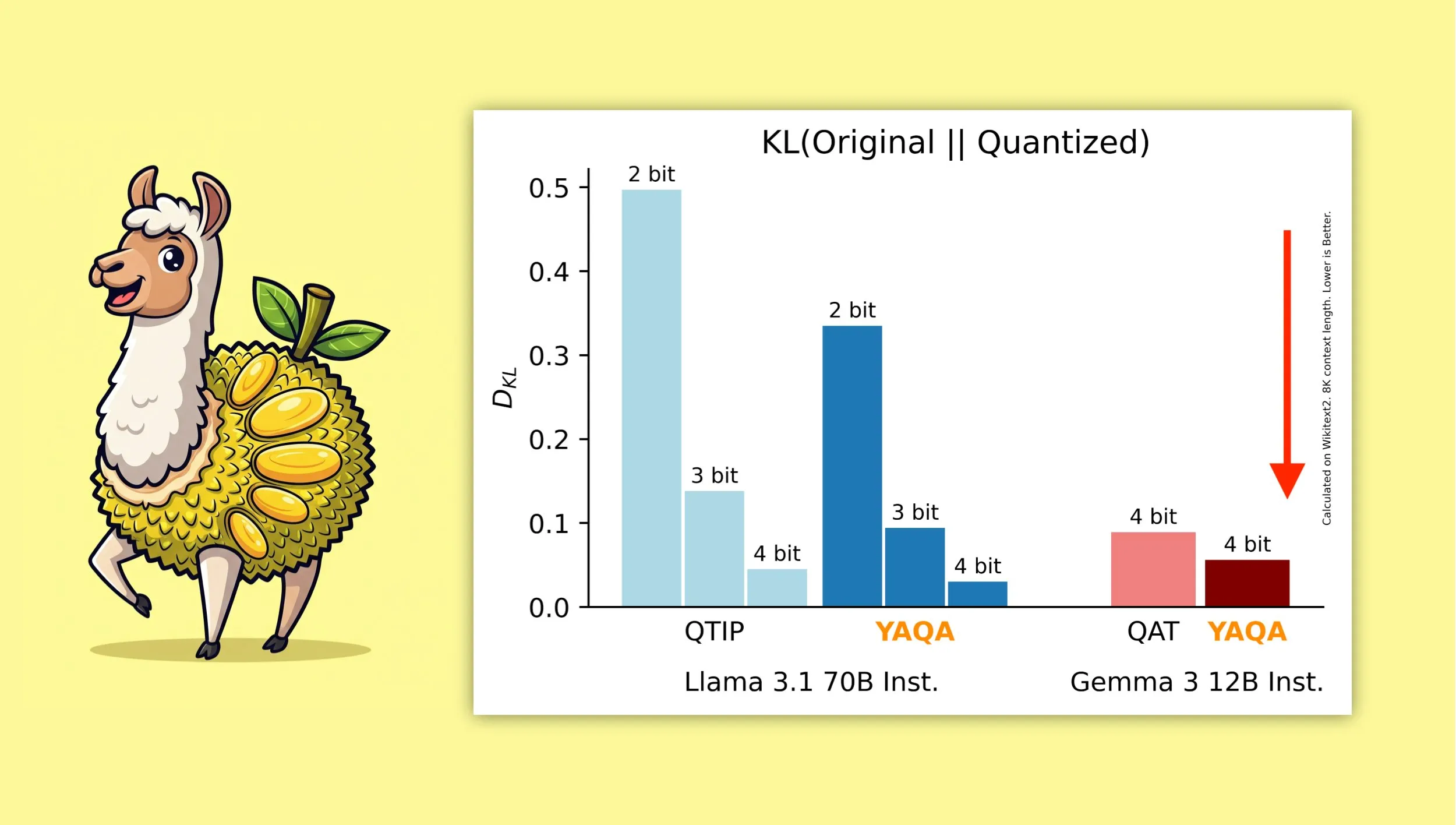
YAQA: Ein neuer Quantisierungsalgorithmus, der darauf abzielt, die ursprüngliche Modellausgabe besser zu erhalten : Forscher der Cornell University haben „Yet Another Quantization Algorithm“ (YAQA) vorgestellt, einen neuen Quantisierungsalgorithmus, der darauf abzielt, die Ausgabe des ursprünglichen Modells nach der Quantisierung besser zu erhalten. Berichten zufolge kann YAQA die KL-Divergenz im Vergleich zu QTIP um über 30 % reduzieren und erreicht bei Gemma 3 eine niedrigere KL-Divergenz als das QAT-Modell von Google. Diese Forschung liefert neue Ideen und Werkzeuge für den Bereich der Modellquantisierung und trägt dazu bei, die Modellleistung bei gleichzeitiger Reduzierung der Modellgröße und des Rechenbedarfs zu maximieren. Das zugehörige Paper und der Code wurden veröffentlicht, ebenso wie ein vorquantisiertes Llama 3.1 70B Instruct Modell (Quelle: Reddit r/MachineLearning, Reddit r/LocalLLaMA, tri_dao, simran_s_arora)
Tokasaurus: Engine speziell für LLM-Inferenz mit hohem Durchsatz veröffentlicht : HazyResearch hat Tokasaurus veröffentlicht, eine neue LLM-Inferenz-Engine, die speziell für Workloads mit hohem Durchsatz entwickelt wurde und sowohl für große als auch für kleine Modelle geeignet ist. Die Engine zielt darauf ab, die Verarbeitungseffizienz und -geschwindigkeit von LLMs in Szenarien mit einer großen Anzahl gleichzeitiger Anfragen zu optimieren und verwendet möglicherweise fortschrittliche Techniken wie kontinuierliches Batching und Paged Attention zur Leistungssteigerung. Die Veröffentlichung von Tokasaurus bietet Entwicklern und Unternehmen, die eine große Anzahl von LLM-Inferenzaufgaben effizient verarbeiten müssen, eine neue Option (Quelle: Tim_Dettmers)
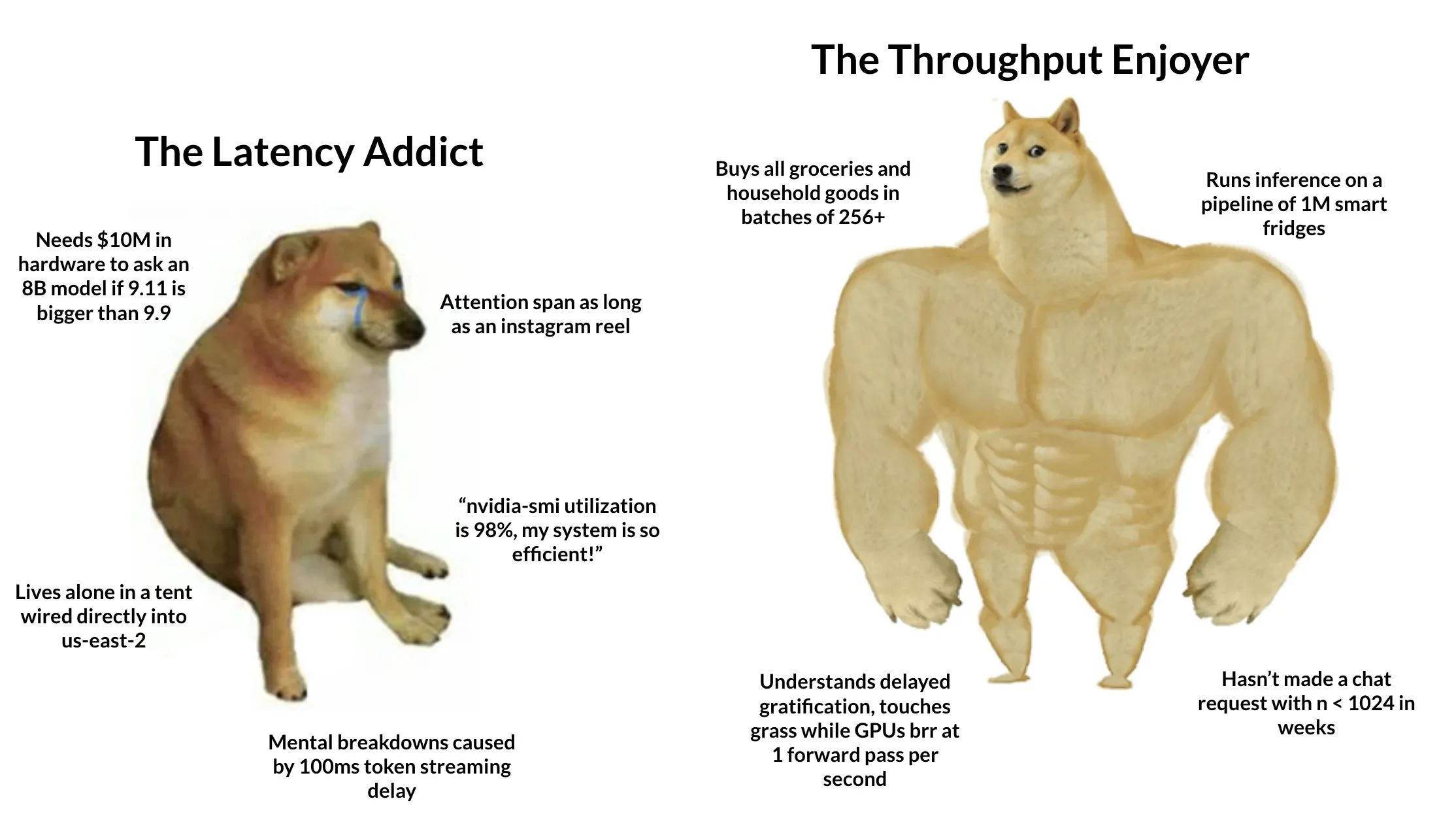
„Android“-System für Carbon Footprint TIDAS veröffentlicht, Ant Digital liefert technische Unterstützung : Die Carbon Footprint Industry Technology Innovation Alliance hat das „Tiangong LCA Data System“ (TIDAS) veröffentlicht, das Lösungen für die Erstellung von Lebenszyklusanalysen (LCA) und Carbon Footprint-Datenbanken bieten soll, mit dem Ziel, ein „Android“-System für LCA- und Carbon Footprint-Datenbanken in China und weltweit zu etablieren. Ant Digital, als Kernmitglied, unterstützte TIDAS mit Blockchain-Technologie und einer Plattform für vertrauenswürdige Datenkollaboration. Durch seine proprietäre Blockchain-Technologie wird die vertrauenswürdige Registrierung und Rechtebestätigung von Kohlenstoffdaten realisiert, und durch Privacy-Computing-Technologie wird sichergestellt, dass Daten „verfügbar, aber nicht sichtbar“ sind, was die Standardisierung, Integrierbarkeit und Interoperabilität der Daten verbessert (Quelle: 量子位)
📚 Lernen
LangChain veranstaltet Enterprise AI Workshop mit Fokus auf Multi-Agenten-Systeme : LangChain wird am 16. Juni in San Francisco einen Enterprise AI Workshop veranstalten. Jake Broekhuizen von LangChain wird die Teilnehmer dabei anleiten, produktionsreife Multi-Agenten-Systeme mit LangGraph zu erstellen, wobei wichtige Aspekte wie Sicherheit und Observability behandelt werden. Dies ist ein praxisorientierter Workshop, der Entwicklern helfen soll, die Fähigkeiten zum Aufbau komplexer, zuverlässiger AI Agent-Anwendungen zu erlernen (Quelle: LangChainAI, hwchase17)

DeepLearning.AI startet neuen Kurs „DSPy: Build and Optimize Agentic Apps“ : DeepLearning.AI hat einen neuen Kurs mit dem Titel „DSPy: Build and Optimize Agentic Apps“ veröffentlicht. Der Kurs vermittelt den Teilnehmern die Grundlagen von DSPy und wie sie dessen Signaturen und modulbasiertes Programmiermodell verwenden können, um modulare, nachverfolgbare und debugbare GenAI Agentic-Anwendungen zu erstellen. Die Inhalte umfassen den Aufbau von Anwendungen durch die Verknüpfung von DSPy-Modulen wie Predict, ChainOfThought und ReAct, die Verwendung von MLflow für Tracking und Debugging sowie die Nutzung des DSPy Optimizers zur automatischen Anpassung von Prompts und zur Verbesserung von Few-Shot-Beispielen, um die Genauigkeit und Konsistenz der Antworten zu erhöhen (Quelle: DeepLearningAI, lateinteraction)
GitHub-Projekt mit fortgeschrittenem RAG-Tutorial findet Beachtung : Das von NirDiamant auf GitHub geteilte Tutorial-Projekt zur RAG (Retrieval-Augmented Generation)-Technologie hat 16,6K Sterne erhalten. Das Tutorial ist umfangreich und deckt verschiedene Aspekte ab, darunter Vorverarbeitung zur Verbesserung des Retrievals, Optimierung, Retrieval-Muster, Iteration sowie Engineering-Schritte. Für Entwickler, die sich eingehend mit RAG-Anwendungen beschäftigen und deren Effektivität verbessern möchten, ist dies eine wertvolle Ressource für fortgeschrittenes Lernen (Quelle: karminski3)
Wie OpenAI-Kunden Evaluierungen (Evals) nutzen, um bessere KI-Produkte zu entwickeln : Hamel Husain bewirbt ein Webinar mit Jim Blomo von OpenAI, in dem diskutiert wird, wie OpenAI-Kunden Evaluierungstools (Evals) nutzen, um qualitativ hochwertigere KI-Produkte zu entwickeln. Die Inhalte umfassen reale Fallstudien und Ergebnisse sowie die Vorstellung interner Evaluierungstools von OpenAI (wie Tracking, Scoring usw.). Das Webinar zielt darauf ab, Entwicklern praktische Einblicke und Methoden zur Bewertung von KI-Produkten zu vermitteln (Quelle: HamelHusain)

LlamaIndex teilt Überblick über 13 Agentenprotokolle und diskutiert Interoperabilitätsstandards : Seldo von LlamaIndex hielt auf dem MCP Developer Summit einen Überblicksvortrag über die derzeit 13 verschiedenen Kommunikationsprotokolle zwischen Agenten (einschließlich MCP, A2A, ACP usw.). Er analysierte die einzigartigen Funktionen jedes Protokolls, seine Positionierung in der aktuellen Technologielandschaft und zukünftige Entwicklungstrends. Der Vortrag soll Entwicklern helfen, geeignete Kommunikationsstandards für ihre Agentenanwendungen zu verstehen und auszuwählen und die Interoperabilität des Agenten-Ökosystems zu fördern (Quelle: jerryjliu0, jerryjliu0)

Analyse der Claude Code-Architektur: Kontrollfluss, Orchestrierungs-Engine und Werkzeugausführung : Ein Artikel analysiert die Architektur von Claude Code eingehend, mit Schwerpunkt auf dem Kontrollfluss, der Orchestrierungs-Engine sowie den Werkzeugen und der Ausführungs-Engine. Diese Analysen sind für Entwickler von Wert, die ähnliche Kommandozeilen-Codierungsassistenten erstellen oder Anpassungen vornehmen möchten. Die Designprinzipien sind auch auf die Entwicklung anderer Arten von Agenten-Tools anwendbar (Quelle: karminski3)

Lösung des Zweitplatzierten beim AMD GPU FP8 Matrixmultiplikations-Kernel-Wettbewerb geteilt : Tim Dettmers teilte die Lösung des Zweitplatzierten beim AMD GPU FP8 Matrixmultiplikations-Kernel-Wettbewerb. Die detaillierte Erläuterung dieser Lösung ist von großem Referenzwert für das Verständnis, wie die Leistung von Gleitkommaoperationen mit niedriger Präzision auf AMD GPUs optimiert werden kann, insbesondere vor dem Hintergrund, dass im KI-Modelltraining und bei der Inferenz zunehmend Formate mit niedriger Präzision wie FP8 zur Effizienzsteigerung eingesetzt werden (Quelle: Tim_Dettmers)
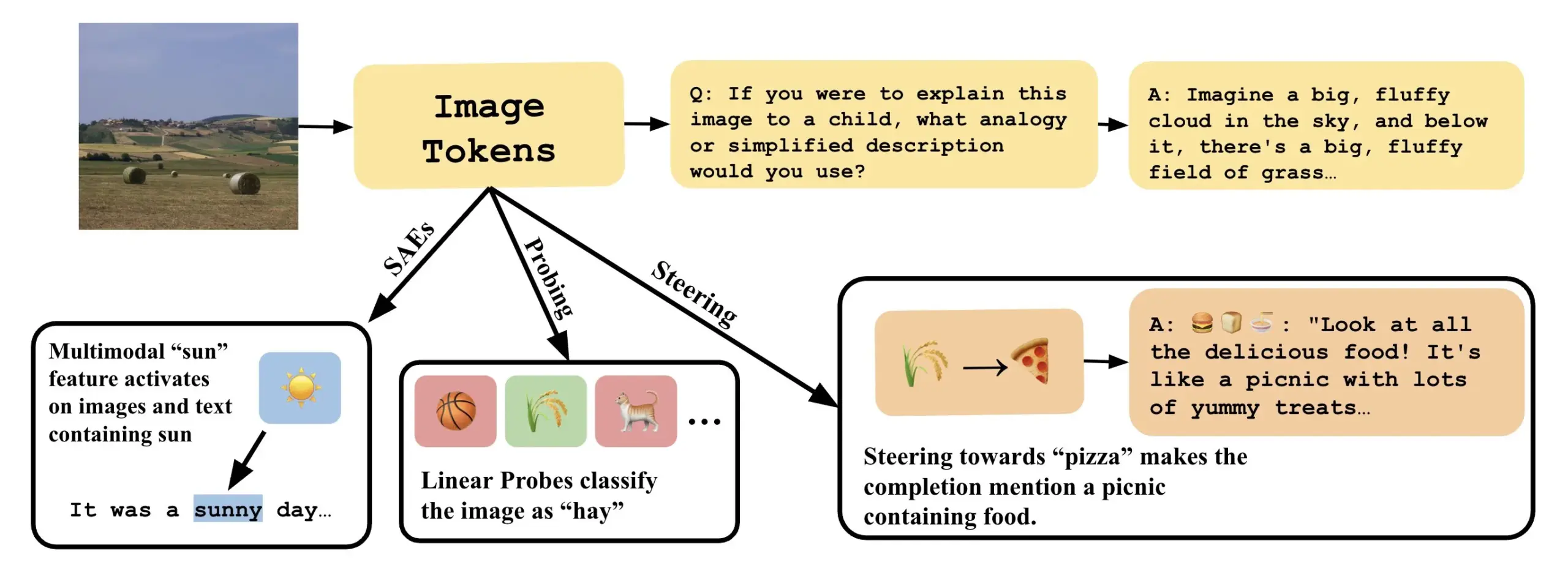
Paper untersucht, wie man visuelle Sprachmodelle durch Interpretation linearer Richtungen in VLLMs verstehen kann : Ein neues Paper mit dem Titel „Line of Sight“ untersucht, wie man die internen Mechanismen von visuellen Sprachmodellen (VLLMs) durch die Interpretation linearer Richtungen im latenten Raum von VLLMs verstehen kann. Die Forscher verwenden Werkzeuge wie Probing, Steering und Sparse Autoencoders (SAEs), um Bildrepräsentationen in VLLMs zu interpretieren. Diese Arbeit bietet neue Perspektiven und Methoden zum Verständnis der internen Funktionsweise multimodaler Modelle (Quelle: nabla_theta)
💼 Business
KI-Startup Vareon erhält 3 Millionen US-Dollar Pre-Seed-Finanzierung von Norck, Fokus auf Spitzen-KI und autonome Systeme : Norck, gegründet von Faruk Guney, hat seinem neu gegründeten KI-Startup Vareon eine meilensteinbasierte Pre-Seed-Finanzierung in Höhe von 3 Millionen US-Dollar zugesagt. Vareon konzentriert sich auf die Bereiche Spitzen-KI, kausale Inferenz und autonome Systeme. Kernstück ist MALPAC (Multi-Agent Learning Architecture for Planning and Closed-Loop Optimization). Das Unternehmen zielt darauf ab, ein Grundlagenforschungsunternehmen im Bereich KI zu werden und Entwicklungen in Robotik, LLMs, molekularem Design, kognitiven Architekturen und autonomen Agenten voranzutreiben. Gleichzeitig wurden RAPID (differenzierbares Planungsframework), CIMO (kausaler multiskalarer Koordinator), SCA (biologisch inspirierte kognitive Architektur) und Lumon-XAI (Erklärbarkeitsschicht) vorgestellt (Quelle: farguney)

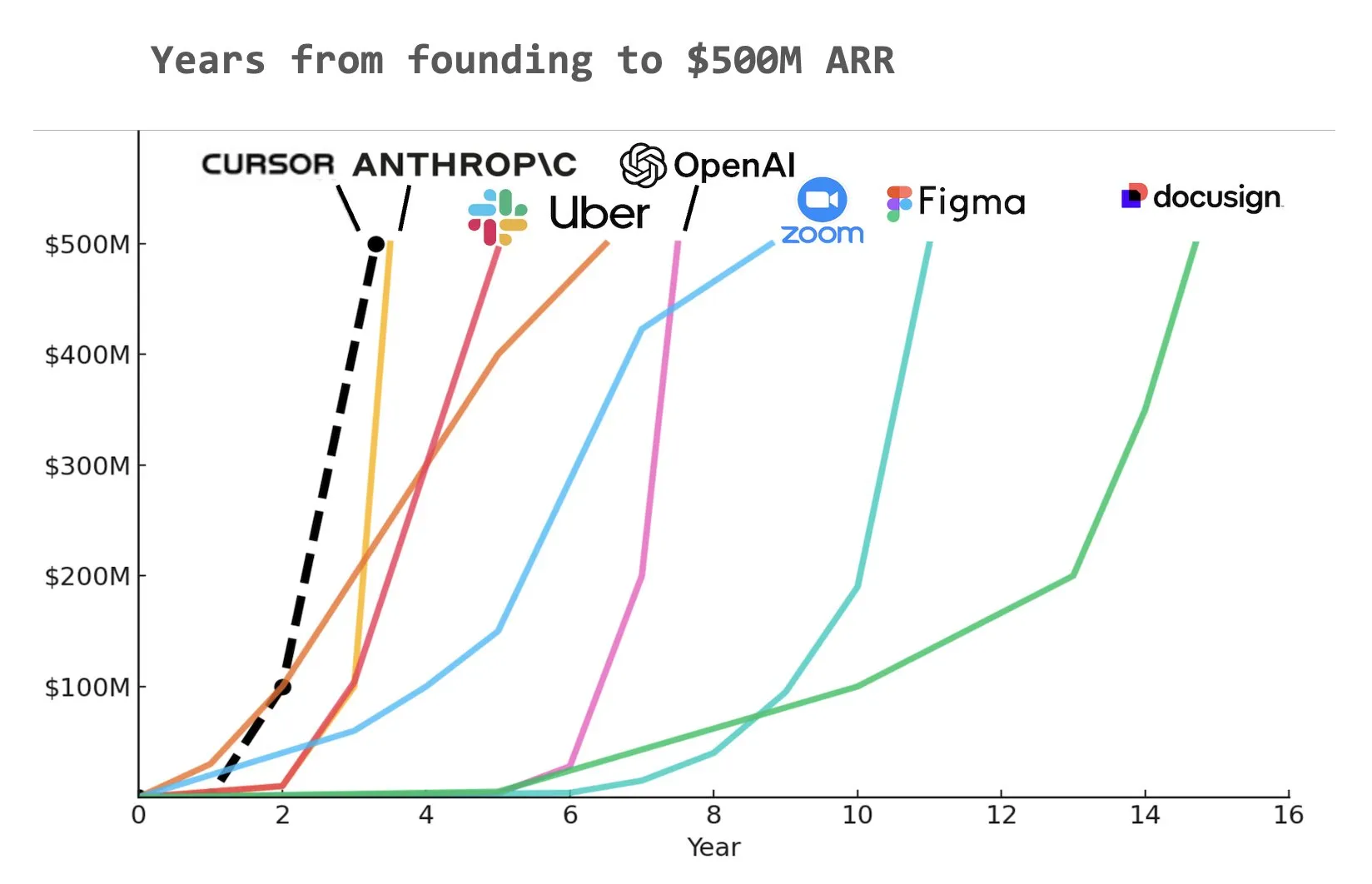
KI-Codierungstool Cursor erhält 900 Millionen US-Dollar in Serie-C-Finanzierung, ARR erreicht 500 Millionen US-Dollar : Das KI-Codierungstool-Startup Cursor gab den Abschluss einer Serie-C-Finanzierungsrunde in Höhe von 900 Millionen US-Dollar bekannt, angeführt von Thrive, Accel, Andreessen Horowitz und DST. Das Unternehmen gab bekannt, dass sein jährlich wiederkehrender Umsatz (ARR) 500 Millionen US-Dollar überschritten hat und von mehr als der Hälfte der Fortune-500-Unternehmen, darunter NVIDIA, Uber und Adobe, genutzt wird. Diese Finanzierungsrunde wird Cursor dabei helfen, die Forschungsgrenzen im Bereich der KI-Codierung weiter voranzutreiben. Analysten weisen darauf hin, dass Cursor eines der Unternehmen sein könnte, das in der Geschichte am schnellsten einen ARR von 500 Millionen US-Dollar erreicht hat (Quelle: cursor_ai, Yuchenj_UW, op7418)
Anthropic kappt direkten Zugriff von Windsurf auf Claude-Modelle, möglicherweise aufgrund von Übernahmegerüchten durch OpenAI : Jared Kaplan, Mitbegründer und Chief Science Officer von Anthropic, erklärte, dass das Unternehmen den direkten Zugriff des KI-Programmierassistenten Windsurf auf Claude-Modelle hauptsächlich aufgrund von Marktgerüchten über eine bevorstehende Übernahme von Windsurf durch OpenAI gekappt habe. Kaplan sagte: „Claude an OpenAI zu verkaufen wäre seltsam“ und erklärte, dass Anthropic dazu neige, Rechenressourcen langfristig stabilen Partnern zuzuweisen. Trotzdem baut Anthropic aktiv Kooperationen mit anderen Entwicklern von KI-Programmierwerkzeugen (wie Cursor) auf und betont, dass man sich in Zukunft stärker auf die Entwicklung von KI-Programmierprodukten mit autonomen Entscheidungsfähigkeiten wie Claude Code konzentrieren werde (Quelle: dotey, vikhyatk, jeremyphoward, swyx)

🌟 Community
OpenAI Greg Brockman: AGI-Zukunft eher vielfältige Zusammenarbeit spezialisierter Agenten als einzelnes Modell : Greg Brockman von OpenAI ist der Ansicht, dass die zukünftige Form der Allgemeinen Künstlichen Intelligenz (AGI) eher einem „Zoo“ aus zahlreichen spezialisierten Agenten ähneln wird als einem einzelnen, allmächtigen „Monolithen“-Modell. Diese spezialisierten Agenten werden in der Lage sein, sich gegenseitig aufzurufen, zusammenzuarbeiten und gemeinsam die wirtschaftliche Entwicklung voranzutreiben. Diese Ansicht deutet auf den zukünftigen Entwicklungstrend der KI hin, nämlich durch den Aufbau und die Integration mehrerer KI-Agenten mit spezifischen Fähigkeiten komplexere und leistungsfähigere intelligente Systeme zu realisieren, mit dem Ziel, Aktivitäten und Ergebnisse um das Zehnfache oder mehr zu steigern. Clement Delangue kommentierte dazu, dass Open-Source-KI-Robotik erforderlich sei, um Monopole zu brechen und zu verhindern, dass ein einzelnes Unternehmen alle Roboter kontrolliert (Quelle: natolambert, ClementDelangue, HamelHusain)
LLMs zeigen Potenzial beim akademischen Schreiben und Zusammenfassen von Inhalten und werfen Fragen zur Qualität menschlichen Schreibens auf : Dwarkesh Patel ist der Meinung, dass LLMs derzeit „5/10“-Schreiber sind, aber die Tatsache, dass sie Erklärungen in wissenschaftlichen Arbeiten und Büchern zuverlässig verbessern können, sei an sich schon eine massive Anklage gegen die Qualität des akademischen Schreibens. Arvind Narayanan fügte hinzu, dass die meisten akademischen Texte oft Klarheit und Verständlichkeit opfern, um tiefgründig und komplex zu wirken, während gutes Schreiben nach Prägnanz streben sollte. Dies löste eine Diskussion über den Einsatz von LLMs zur Unterstützung der akademischen Forschung, zur Verbesserung der Lesbarkeit von Inhalten und darüber aus, wie sie die akademische Kommunikation in Zukunft verändern könnten (Quelle: random_walker, jeremyphoward)
KI-Codierungstools lösen Diskussion über Entwicklerabhängigkeit aus, Claude Code wegen starker Funktionen und hohem Token-Verbrauch im Fokus : Nutzer dotey ist der Meinung, dass die Verwendung von KI-Programmierwerkzeugen (wie Claude Code) leicht zu starker Abhängigkeit führen kann, sodass man selbst bei vorhandenem Guthaben lieber auf die KI wartet, als manuell zu programmieren. Das Claude Max-Abonnement hat zwar eine Obergrenze, aber seine leistungsstarken Codierungsfähigkeiten (wie ausgezeichnetes Befehlsverständnis, Aufgabenplanung, grep-Tool-Nutzung und lange Ausführungszeiten) machen es zu einem effizienten Werkzeug. Dieses Phänomen löste eine Diskussion darüber aus, wie KI-Tools die Arbeitsgewohnheiten von Entwicklern verändern und wie ein Gleichgewicht zwischen Effizienz und Abhängigkeit gefunden werden kann. Ein anderer Nutzer, Asuka小能猫, zeigte ebenfalls ein Beispiel für die effiziente Frontend-Entwicklung mit Claude-4-Opus und dem Cursor Max-Modus, erwähnte aber auch das Problem des Token-Verbrauchs (Quelle: dotey, dotey)
KI-gestützte personalisierte Bildung birgt enormes Potenzial, erfordert aber Aufmerksamkeit für Implementierungsherausforderungen : Austen Allred teilte die fünfmonatige Erfahrung seines Kindes an einer KI-gesteuerten Schule (ohne Lehrer) und bezeichnete die Ergebnisse als „wahnsinnig“. Noah Smith kommentierte, dass Einzelunterricht eine effektive Bildungsintervention sei und KI dessen Skalierung ermögliche. Dies löste eine Diskussion über den Einsatz von KI im Bildungsbereich aus, einschließlich personalisierter Lernpfade, des Potenzials von KI-Tutoren sowie der Frage, wie Bildungsgerechtigkeit gewährleistet und technische Implementierungsherausforderungen überwunden werden können. Jon Stokes leitete dies weiter und verfolgt diesen Trend (Quelle: jonst0kes, jeremyphoward)
Emotionale Verbindung zwischen KI-Agenten und Menschen rückt in den Fokus, OpenAI betont vorrangige Untersuchung des Nutzerwohls : Joanne Jang von OpenAI veröffentlichte einen Blogbeitrag, der die Beziehung zwischen Mensch und KI sowie die Haltung des Unternehmens dazu erörtert. Kernpunkt ist, dass OpenAI Modelle primär für den Menschen entwickelt. Da immer mehr Menschen eine emotionale Verbindung zu KI aufbauen, untersucht das Unternehmen vorrangig die Auswirkungen auf das emotionale Wohlbefinden der Nutzer. Corbtt kommentierte, dass KI-Begleiter die transformativste soziale Technologie seit dem Internet seien. Wenn Unternehmen die Interaktion statt der psychischen Gesundheit optimieren, könnten die negativen Auswirkungen auf Kinder größer sein als bei sozialen Medien. Wenn sie jedoch die psychische Gesundheit optimieren, könnte dies ein Segen für die Menschheit sein. cto_junior sah humorvoll voraus, dass man in Zukunft möglicherweise mit Kindern darüber diskutieren müsse, ob es „angemessen ist, GPT zu heiraten“ (Quelle: cto_junior, corbtt)

KI-Agenten-Technologie entwickelt sich rasant, aber Ende-zu-Ende-Aufgaben mit Sparse Reinforcement Learning bleiben herausfordernd : Nathan Lambert ist der Ansicht, dass aktuelle Projekte wie Deep Research und Codex Agent hauptsächlich durch das Training von Modellen für kurzfristige Reinforcement Learning (RL)-Aufgaben und allgemeine Robustheit realisiert werden. Das Ende-zu-Ende-Training für Aufgaben mit sehr spärlichen RL-Belohnungen scheint jedoch weiter entfernt zu sein, als man denkt. Corbtt kommentierte dazu, dass selbst Menschen noch nicht effektiv gelernt hätten, wie man für langfristige Aufgaben und spärliche Belohnungssignale trainiert. Dies spiegelt die aktuellen Grenzen der KI-Agenten-Technologie bei der Bewältigung komplexer, langfristiger Planung und autonomen Lernens wider (Quelle: corbtt)
Die „bittere Lektion“ im KI-Bereich: Verifikation wird zum Schlüssel für inferenzbasierte LLMs : Rishabh Agarwal hielt auf dem CVPR Multimodal Reasoning Workshop einen Vortrag mit dem Titel „Die bittere Lektion des RL: Verifikation als Schlüssel für inferenzbasierte LLMs“. Der Vortrag wurde von Rich Suttons klassischem Artikel über die „bittere Lektion“ inspiriert und untersuchte die Bedeutung von Verifikationsmechanismen beim Reinforcement Learning und der Inferenz von Large Language Models. Dies könnte bedeuten, dass es nicht ausreicht, sich nur auf die Generierungsfähigkeiten des Modells zu verlassen, sondern dass starke Verifikations- und Feedbackmechanismen entscheidend für die Verbesserung der Inferenzfähigkeiten und Zuverlässigkeit von KI sind (Quelle: jack_w_rae)

KI-Entwicklung löst Arbeitsmarktsorgen aus, Expertenmeinungen uneinheitlich : Klarna-CEO Sebastian Siemiatkowski warnt, dass KI durch massive Arbeitsplatzverluste (insbesondere im Bürobereich) eine Rezession auslösen könnte. Klarna selbst hat bereits 700 Kundendienstmitarbeiter durch KI-Assistenten ersetzt und spart jährlich rund 40 Millionen US-Dollar. Auch Anthropic-Forscher Sholto Douglas prognostiziert, dass die Fähigkeiten der KI bis 2027-28 sehr stark sein werden. Es gibt jedoch auch Meinungen, dass KI die Produktivität steigern und neue Arbeitsplätze schaffen wird, wie Sundar Pichai einst erklärte, KI werde ein Beschleuniger sein und zumindest bis 2026 nicht zu Entlassungen führen. Ein Video von AI Explained analysiert, ob die aktuellen Schlagzeilen über KI-bedingte Arbeitslosigkeit berechtigt sind und diskutiert einige Kehrtwendungen von Duolingo und Klarna bei der KI-Anwendung. Diese Diskussionen spiegeln die allgemeine Besorgnis der Gesellschaft über die wirtschaftlichen Auswirkungen von KI und unterschiedliche Erwartungen wider (Quelle: , Reddit r/ArtificialInteligence, Reddit r/ClaudeAI, Reddit r/ArtificialInteligence)
Zukünftige Wege der Interaktion von KI-Agenten mit bestehenden Netzwerken/APIs diskutiert : Mit der zunehmenden Fähigkeit von KI-Agenten zur autonomen Netzwerkinteraktion wird ihre Interaktionsweise mit bestehenden Web/APIs zu einer Infrastrukturfrage. In der Diskussion wurden drei mögliche Wege vorgeschlagen: 1. Von Grund auf neu aufbauen und Agenten-native Protokolle verwenden (unrealistisch); 2. Agenten beibringen, Websites wie Menschen zu bedienen (hohe Fehlerrate, insbesondere bei der Authentifizierung); 3. HTTP dazu bringen, „Agentensprache zu sprechen“, z. B. durch Anreicherung nicht erfolgreicher Antworten wie 402 (Zahlung erforderlich) mit maschinenlesbarem Kontext, damit Agenten autonom Zugriffsrechte überprüfen und erwerben können. Die Kernmeinung ist, dass die Bereitstellung reichhaltiger Kontextinformationen für nicht erfolgreiche Web/API-Interaktionen der Schlüssel für autonome Agenten sein wird, um sinnvolle Arbeit zu leisten, indem sie automatisch aus Fehlern lernen und komplexe Prozesse navigieren können (Quelle: Reddit r/ArtificialInteligence)
KI-gestützte Mathematikforschung macht Fortschritte, Terence Tao und andere beobachten Potenzial und Grenzen : Mathematiker erforschen aktiv den Einsatz von KI bei der Lösung komplexer mathematischer Probleme. Terence Tao teilte einen Fall, in dem KI (AlphaEvolve) in Zusammenarbeit mit Menschen innerhalb von 30 Tagen dreimal den Rekord für Summen-Differenz-Mengen-Indizes brach. In Kombination mit der Lean-Sprache und GitHub Copilot stellte er sich der Herausforderung des „ε-δ“-Grenzwertproblems und demonstrierte die Fähigkeit der KI, Anfängern den Einstieg zu erleichtern, grundlegende Aufgaben zu bewältigen und Beweisstrukturen vorherzusagen, wies aber auch auf ihre Schwächen bei komplexen Ableitungen und der Suche nach mathematischen Lemmata hin. Ein anderer Bericht besagt, dass 30 Spitzenmathematiker in einer geheimen Sitzung OpenAI o4-mini testeten und feststellten, dass es einige extrem schwierige Probleme lösen konnte und ein Niveau zeigte, das dem mathematischer Genies nahekommt. Diese Fortschritte deuten darauf hin, dass KI ein leistungsfähiger Helfer in der mathematischen Forschung werden könnte, werfen aber auch neue Fragen zur Rolle von Mathematikern und zur Förderung von Kreativität auf (Quelle: 36氪)

💡 Sonstiges
Wettbewerb um GPS-Alternativtechnologien verschärft sich, Xona Space Systems plant Aufbau einer LEO-PNT-Konstellation : Da das GPS-System anfällig für Signalstörungen (Wetter, 5G-Masten, Störsender) ist und eine begrenzte Genauigkeit aufweist, insbesondere im Ukraine-Konflikt seine Anfälligkeit deutlich wurde, ist die Suche nach Alternativen zu einer strategischen Priorität geworden. Das kalifornische Startup Xona Space Systems plant den Start einer Satellitenkonstellation namens Pulsar im niedrigen Erdorbit (letztendlich 258 Satelliten). Ihre Satelliten haben eine niedrigere Umlaufbahn, eine etwa 100-mal stärkere Signalstärke als GPS, sind schwerer zu stören und können Hindernisse besser durchdringen. Ziel ist es, zentimetergenaue und hochzuverlässige Positionierungs-, Navigations- und Zeitgebungsdienste (PNT) zur Unterstützung neuer Technologien wie autonomes Fahren bereitzustellen. Der erste Testsatellit soll diesen Monat an Bord von SpaceX Transporter 14 starten (Quelle: MIT Technology Review)

Studie untersucht positiven Einfluss von Hoffnung und Optimismus auf die Genesung von Herzpatienten : Neueste Forschungen zeigen, dass Hoffnung und Optimismus bei Herzpatienten mit besseren Gesundheitsergebnissen korrelieren, während Hoffnungslosigkeit mit einem höheren Sterberisiko verbunden ist. Dies steht im Einklang mit dem Placebo-Effekt (positive Erwartungen verbessern die Ergebnisse) und dem Nocebo-Effekt (negative Erwartungen führen zu negativen Symptomen). Alexander Montasem und andere Forscher der Universität Liverpool fanden heraus, dass hohe Hoffnungswerte mit weniger Angina Pectoris, geringerer Müdigkeit nach einem Schlaganfall, höherer Lebensqualität und einem geringeren Sterberisiko verbunden sind. Forscher untersuchen, wie die Kraft des positiven Denkens in der klinischen Praxis genutzt werden kann, beispielsweise indem Patienten geholfen wird, Ziele zu setzen und ihre Handlungsfähigkeit zu stärken, um „Hoffnung zu verschreiben“, wobei betont wird, dass nicht-materielle Ziele für das Wohlbefinden wichtiger sind (Quelle: MIT Technology Review)

Apples und Alibabas KI-Dienstleistungsförderung in China blockiert, möglicherweise aufgrund von Handelsspannungen : Laut der britischen Financial Times verzögert sich der Plan von Apple und Alibaba zur Förderung von KI-Diensten in China, was als jüngstes Opfer der Handelsspannungen zwischen den USA und China angesehen wird. Die Zusammenarbeit sah ursprünglich vor, KI-Funktionen für in China verkaufte iPhones zu unterstützen. Diese Verzögerung könnte den Zeitplan für die Einführung von KI-Funktionen von Apple auf dem chinesischen Markt beeinflussen und Unsicherheit für die Zukunft der Zusammenarbeit beider Unternehmen mit sich bringen (Quelle: MIT Technology Review)