
Schlüsselwörter:Gemini 2.5 Pro, VeBrain, Segment Anything Model 2, Qwen3-Embedding, AI Agent, Gemini 2.5 Pro Deep Think Modus, VeBrain universelles verkörpertes Intelligenz-Gehirn-Framework, SAM 2 Bild- und Videosegmentierung, Qwen3-Embedding 32k Kontext, AI Agent multimodales Verständnis
🔥 Fokus
Google kündigt mehrere neue KI-Fortschritte an, Deep Think-Modus von Gemini 2.5 Pro verbessert komplexe Schlussfolgerungsfähigkeiten: Auf der Google I/O Konferenz kündigte Google den Deep Think-Modus für Gemini 2.5 Pro an, der darauf abzielt, die Fähigkeit der KI zur Verarbeitung komplexer Probleme (wie mathematische Aufgaben auf USAMO-Niveau) signifikant zu verbessern. Gleichzeitig stellte Google auch AlphaEvolve vor, einen von Gemini betriebenen Codierungs-Agenten für die Algorithmenentdeckung, der bereits Erfolge bei der Entwicklung von Algorithmen für die Matrixmultiplikation und der Lösung offener mathematischer Probleme erzielt hat und zur Optimierung von Googles internen Rechenzentren, Chip-Designs und der Effizienz des KI-Trainings eingesetzt wird. Darüber hinaus wurden auch das Videomodell Veo 3, das Bildmodell Imagen 4 sowie das KI-Schnittwerkzeug FLOW vorgestellt, was Googles umfassende Aufstellung und schnelle Fortschritte im Bereich der multimodalen KI demonstriert. (Quelle: OriolVinyalsML, demishassabis, demishassabis, op7418)
Shanghai AI Laboratory veröffentlicht gemeinsam das universelle Embodied Intelligence Brain Framework VeBrain: Das Shanghai Artificial Intelligence Laboratory hat gemeinsam mit mehreren Einrichtungen VeBrain (Visual Embodied Brain) vorgestellt, ein universelles Framework für ein verkörpertes intelligentes Gehirn, das darauf abzielt, visuelle Wahrnehmung, räumliches Denken und Robotersteuerungsfähigkeiten zu vereinheitlichen. Das Framework wandelt Robotersteuerungsaufgaben in 2D-Raum-Textaufgaben in MLLMs um (wie z.B. Schlüsselpunkterkennung und Erkennung verkörperter Fähigkeiten) und führt „Roboteradapter“ ein, um eine präzise Abbildung von Textentscheidungen auf reale Aktionen und eine Closed-Loop-Steuerung zu realisieren. Zur Unterstützung des Modelltrainings erstellte das Team den VeBrain-600k-Datensatz, der 600.000 Anweisungsdatensätze enthält und Aufgaben in den drei Kategorien multimodales Verständnis, visuell-räumliches Denken und Roboterbedienung abdeckt. Tests zeigen, dass VeBrain in den Bereichen multimodales Verständnis, räumliches Denken und reale Robotersteuerung (Roboterarme und Roboterhunde) SOTA-Niveau erreicht. (Quelle: 量子位)

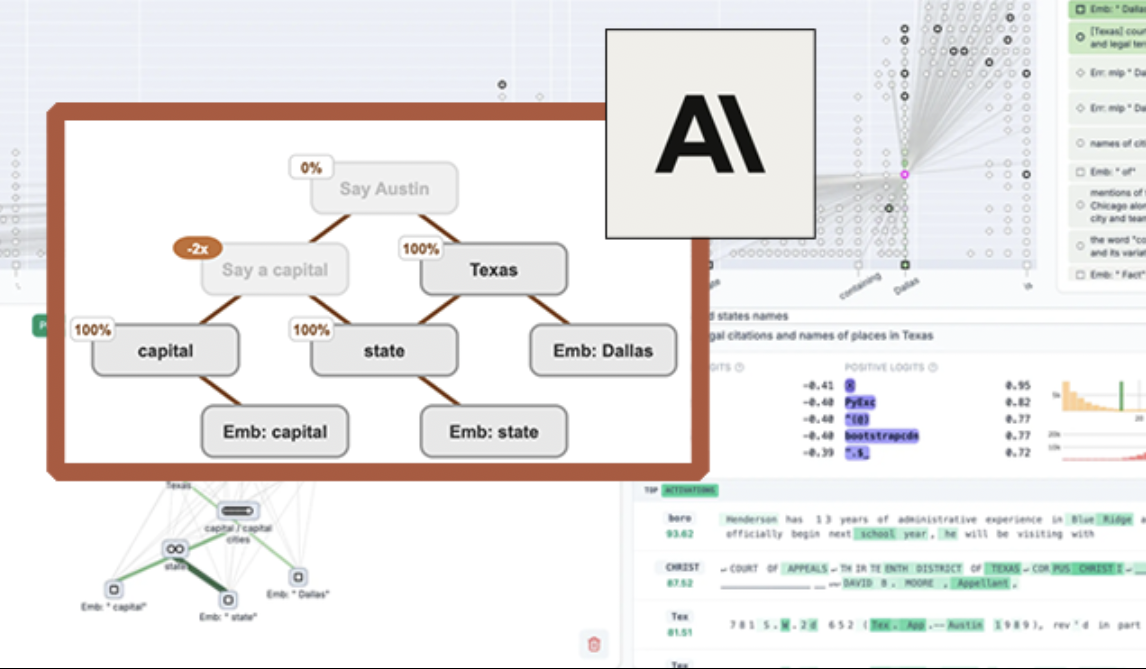
Anthropic veröffentlicht Open-Source-Tool „Circuit Tracing“ zur Visualisierung von LLMs und Verbesserung der Modellerklärbarkeit: Anthropic hat das Open-Source-Tool „Circuit Tracing“ (Schaltkreisverfolgung) veröffentlicht, das Forschern helfen soll, die internen Arbeitsmechanismen von Large Language Models (LLMs) zu verstehen. Das Tool generiert „Attribution Graphs“ (Attributionsgraphen), die die internen Superknoten und ihre Verbindungen visualisieren, wenn das Modell Informationen verarbeitet, ähnlich wie schematische Darstellungen neuronaler Netze. Forscher können durch Intervention in die Aktivierungswerte der Knoten und Beobachtung der Verhaltensänderungen des Modells die Funktion jedes Knotens überprüfen und die Entscheidungslogik von LLMs entschlüsseln. Das Tool unterstützt die Generierung von Attributionsgraphen auf gängigen Open-Source-Modellen und bietet eine interaktive Frontend-Schnittstelle namens Neuronpedia zur Visualisierung, Kommentierung und zum Teilen. Dieser Schritt zielt darauf ab, die Forschung zur KI-Erklärbarkeit voranzutreiben und einer breiteren Community die Erforschung und das Verständnis des Modellverhaltens zu ermöglichen. (Quelle: 量子位, swyx)
Meta veröffentlicht Segment Anything Model 2 (SAM 2) zur Verbesserung der Bild- und Videosegmentierungsfähigkeiten: Das Meta AI Research (FAIR) hat SAM 2 vorgestellt, eine aktualisierte Version seines beliebten Segment Anything Model. SAM 2 ist ein Basismodell, das sich auf prompt-basierte visuelle Segmentierungsaufgaben in Bildern und Videos konzentriert und in der Lage ist, basierend auf Prompts (wie Punkten, Boxen, Text) bestimmte Objekte oder Bereiche in Bildern oder Videos präzise zu identifizieren und zu segmentieren. Das Modell ist nun Open Source unter der Apache-Lizenz und steht Forschern und Entwicklern zur kostenlosen Nutzung und zum Erstellen von Anwendungen zur Verfügung, um die Entwicklung im Bereich Computer Vision weiter voranzutreiben. (Quelle: AIatMeta)
🎯 Trends
Beijing Academy of Artificial Intelligence (BAAI) veröffentlicht Video-XL-2 als Open Source, ermöglicht Videoverständnis von Zehntausenden von Frames auf einer einzigen Karte: Das BAAI hat in Zusammenarbeit mit der Shanghai Jiao Tong University und anderen Institutionen das Ultra-Langvideo-Verständnismodell der nächsten Generation, Video-XL-2, veröffentlicht. Dieses Modell zeigt signifikante Verbesserungen in Bezug auf Effektivität, Verarbeitungslänge und Geschwindigkeit. Es kann Zehntausende von Videoframes auf einer einzigen Karte verarbeiten und 2048 Videoframes in nur 12 Sekunden kodieren. Video-XL-2 verwendet den SigLIP-SO400M visuellen Encoder, ein dynamisches Token-Synthesemodul (DTS) und das Qwen2.5-Instruct Large Language Model. Es erreicht hohe Leistung durch ein vierstufiges progressives Training und Effizienzoptimierungsstrategien (wie segmentiertes Pre-Filling und Dual-Granularity KV-Decoding). Das Modell zeigt hervorragende Ergebnisse in Benchmarks wie MLVU und Video-MME, und seine Gewichte wurden als Open Source veröffentlicht. (Quelle: 量子位)

Character.ai startet AvatarFX-Videogenerierungsfunktion, Bildcharaktere können sich bewegen und interagieren: Die führende KI-Begleitanwendung Character.ai (c.ai) hat die AvatarFX-Funktion eingeführt, mit der Benutzer Charaktere (einschließlich nicht-menschlicher Figuren wie Haustiere) aus statischen Bildern animieren können, sodass sie sprechen, singen und mit Benutzern interagieren können. Die Funktion basiert auf der DiT-Architektur und legt Wert auf hohe Wiedergabetreue und zeitliche Konsistenz, wobei sie auch in komplexen Szenarien wie Dialogen mit mehreren Charakteren und langen Sequenzen stabil bleibt. AvatarFX ist derzeit für alle Benutzer in der Webversion verfügbar, die APP-Version wird in Kürze folgen. Gleichzeitig kündigte c.ai neue Funktionen wie Scenes (interaktive Story-Szenen), Imagine Animated Chat (animierte Chat-Verläufe) und Stream (Story-Generierung zwischen Charakteren) an, um das KI-gestützte kreative Erlebnis weiter zu bereichern. (Quelle: 量子位)

Nvidia stellt das visuelle Sprachmodell Llama-3.1 Nemotron-Nano-VL-8B-V1 vor: Nvidia hat das neue Vision-to-Text-Modell Llama-3.1-Nemotron-Nano-VL-8B-V1 veröffentlicht. Dieses Modell kann Bild-, Video- und Texteingaben verarbeiten und Textausgaben generieren, wobei es über ein gewisses Maß an Bildschlussfolgerungs- und Erkennungsfähigkeiten verfügt. Die Veröffentlichung dieses Modells spiegelt Nvidias kontinuierliche Investitionen im Bereich der multimodalen KI wider. Gleichzeitig deuten Diskussionen in der Community darauf hin, dass der Verzicht von Llama-4 auf Modelle unter 70B Chancen für Modelle wie Gemma3 und Qwen3 auf dem Feinabstimmungsmarkt eröffnen könnte. (Quelle: karminski3)
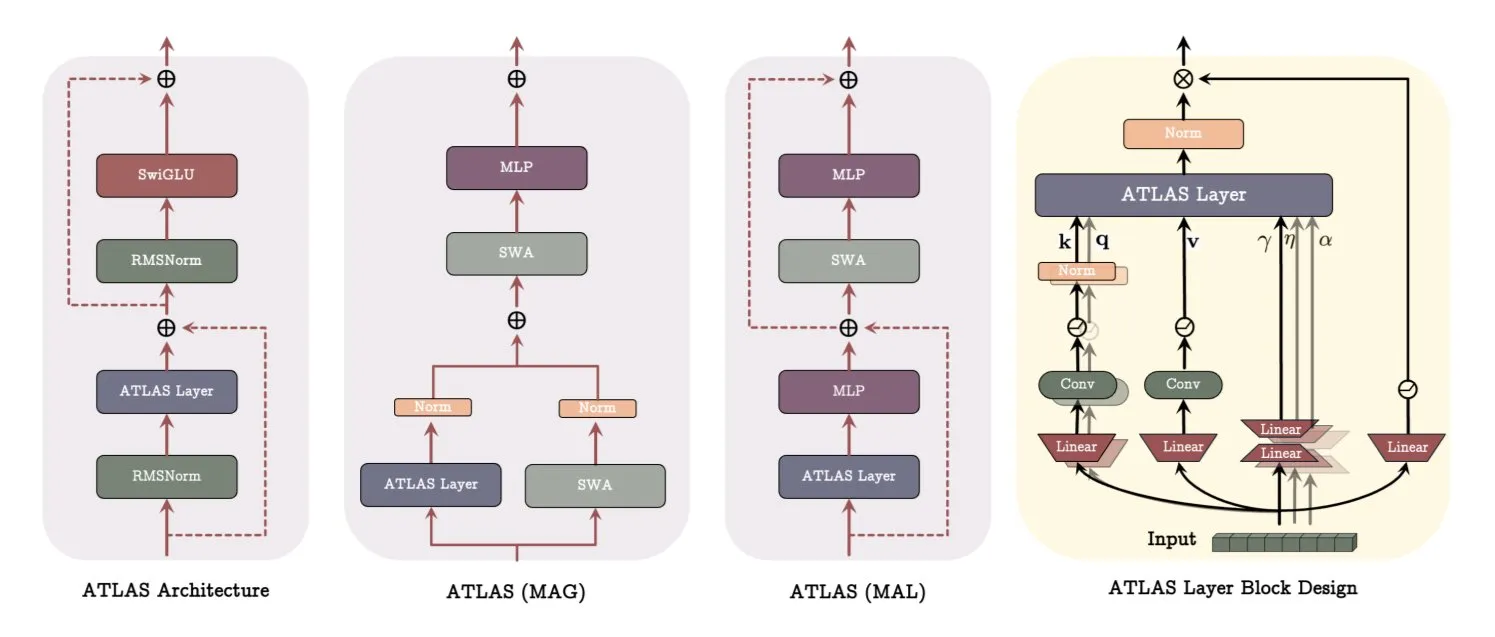
Google veröffentlicht ATLAS-Architekturpapier und revolutioniert damit die Art und Weise, wie Modelle lernen und sich erinnern: Ein aktuelles Papier von Google stellt eine neue Modellarchitektur namens ATLAS vor, die darauf abzielt, die Lern- und Gedächtnisfähigkeiten von Modellen durch aktives Gedächtnis (Omega-Regel verarbeitet die letzten c Tokens) und ein intelligenteres Speicherkapazitätsmanagement (polynomielle und exponentielle Feature-Maps) zu optimieren. ATLAS verwendet den Muon-Optimierer für effizientere Speicheraktualisierungen und führt Designs wie DeepTransformers und Dot (Deep Omega Transformers) ein, die traditionelle feste Aufmerksamkeit durch lernbare, speichergesteuerte Mechanismen ersetzen. Diese Forschung markiert einen Fortschritt der KI hin zu intelligenteren, kontextsensitiven Systemen und verspricht, die Fähigkeit der KI zur Verarbeitung und Nutzung großer Datensätze zu verbessern. (Quelle: TheTuringPost)
Qwen veröffentlicht die Qwen3-Embedding-Modellreihe und verbessert die Embedding-Leistung erheblich: Das Qwen-Team hat die neue Qwen3-Embedding-Modellreihe veröffentlicht, die drei Versionen umfasst: 0.6B, 4B und 8B. Diese Modelle unterstützen eine Kontextlänge von bis zu 32k und 100 Sprachen und haben im MTEB (Massive Text Embedding Benchmark) SOTA-Ergebnisse erzielt, wobei einige Metriken den Zweitplatzierten um 10 Punkte übertreffen. Dieser Fortschritt markiert einen weiteren wichtigen Durchbruch in der Text-Embedding-Technologie und bietet eine stärkere Grundlage für Anwendungen wie semantische Suche und RAG. (Quelle: AymericRoucher, ClementDelangue)

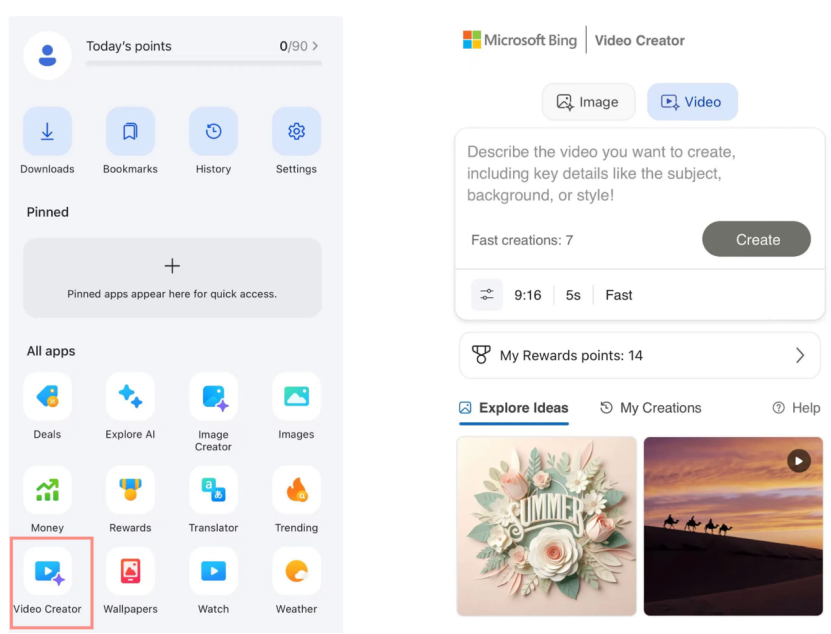
Microsoft Bing Video Creator gestartet, basiert auf OpenAI Sora-Modell und ist kostenlos verfügbar: Microsoft hat in seiner Bing-Anwendung den Bing Video Creator eingeführt. Diese Funktion basiert auf dem Sora-Modell von OpenAI und ermöglicht es Benutzern, kostenlos Videos über Textansagen zu generieren. Dies ist das erste Mal, dass das Sora-Modell in großem Umfang kostenlos der Öffentlichkeit zugänglich gemacht wird. Obwohl kostenlos, gibt es derzeit Einschränkungen bei den Funktionen, wie z. B. eine Videolänge von nur 5 Sekunden, ein Seitenverhältnis von 9:16 und eine relativ langsame Generierungsgeschwindigkeit. Benutzerfeedback deutet darauf hin, dass die Ergebnisse im Vergleich zu aktuellen SOTA-Videomodellen (wie Kling, Veo3) zurückbleiben, was Diskussionen über die Iterationsgeschwindigkeit der Sora-Technologie und die Produktstrategie von Microsoft ausgelöst hat. (Quelle: 36氪)
OpenAI führt mehrere unternehmensrelevante Funktionen ein, um die Integration am Arbeitsplatz zu verbessern: OpenAI hat eine Reihe neuer Funktionen für Unternehmenskunden veröffentlicht, darunter dedizierte Konnektoren für Anwendungen wie Google Drive sowie Funktionen zur Aufzeichnung, Transkription und Zusammenfassung von Besprechungen in ChatGPT. Außerdem wird SSO (Single Sign-On) und eine punktebasierte Preisgestaltung für die Enterprise-Version unterstützt. Diese Updates zielen darauf ab, ChatGPT tiefer in die Arbeitsabläufe von Unternehmen zu integrieren und die Büroeffizienz zu steigern. (Quelle: TheRundownAI, EdwardSun0909)
Hugging Face veröffentlicht effizientes Robotermodell SmolVLA, das auf einem MacBook läuft: Hugging Face hat ein Robotermodell namens SmolVLA vorgestellt, das sich durch extrem hohe Effizienz auszeichnet und sogar auf einem MacBook ausgeführt werden kann. Nach der Feinabstimmung mit einer kleinen Menge an Demonstrationsdaten (z. B. 31) kann das Modell bei bestimmten Aufgaben (wie der Bedienung des Koch Arms) die Leistung von Single-Task-Baselines erreichen oder übertreffen, was sein Potenzial für den Einsatz von Roboter-KI in ressourcenbeschränkten Umgebungen zeigt. (Quelle: mervenoyann, sytelus)
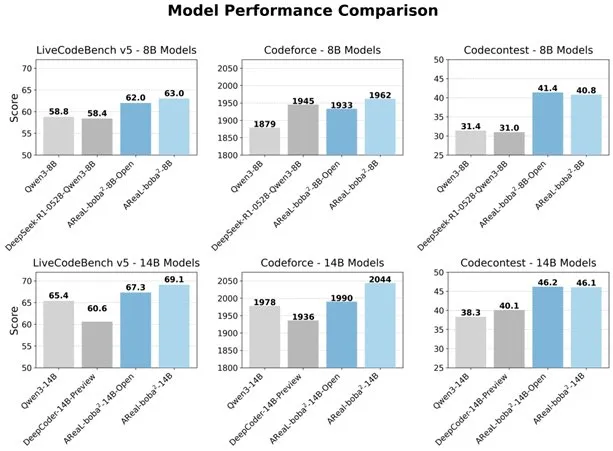
Alibaba veröffentlicht vollständig asynchrones RL-System AReaL-boba² als Open Source, um die Code-Fähigkeiten von LLMs zu verbessern: Das Qwen-Team von Alibaba hat das vollständig asynchrone Reinforcement-Learning-System AReaL-boba² als Open Source veröffentlicht. Es wurde speziell für Large Language Models (LLMs) entwickelt und hat auf Qwen3-14B SOTA-Ergebnisse im Code-Reinforcement-Learning erzielt. Durch das Co-Design von System und Algorithmus erreicht das System eine Trainingsbeschleunigung um das 2,77-fache, erzielt 69,1 Punkte im LiveCodeBench und unterstützt mehrrundiges Reinforcement Learning. (Quelle: _akhaliq)
DuckDB führt DuckLake-Erweiterung ein, integriert Data Lakes und Katalogformate: DuckDB hat die DuckLake-Erweiterung veröffentlicht, ein offenes Lakehouse-Format, das auf SQL und Parquet basiert. DuckLake speichert Metadaten in einer Katalogdatenbank und Daten in Parquet-Dateien. Mit dieser Erweiterung kann DuckDB Daten in DuckLake direkt lesen und schreiben und unterstützt Funktionen wie Tabellenerstellung, -änderung, -abfrage, Zeitreisen und Schemaevolution, um den Aufbau und die Verwaltung von Data Lakes zu vereinfachen. (Quelle: GitHub Trending)
Model Context Protocol (MCP) Ruby SDK veröffentlicht: Das Model Context Protocol (MCP) hat das offizielle Ruby SDK veröffentlicht, das in Zusammenarbeit mit Shopify gewartet wird und zur Implementierung von MCP-Servern dient. MCP zielt darauf ab, KI-Modellen (insbesondere Agents) eine standardisierte Methode zur Entdeckung und zum Aufruf von Tools, zum Zugriff auf Ressourcen und zur Ausführung vordefinierter Prompts bereitzustellen. Das SDK unterstützt JSON-RPC 2.0 und bietet Kernfunktionen wie Tool-Registrierung, Prompt-Management und Ressourcenzugriff, um Entwicklern die Erstellung MCP-konformer KI-Anwendungen zu erleichtern. (Quelle: GitHub Trending)
KI-Technologie verhilft Zinkbatterien zu 99,8 % Effizienz und 4300 Stunden Betriebsdauer: Durch künstliche Intelligenz optimiert, erreichen Zinkbatterien der neuen Generation eine Coulomb-Effizienz von 99,8 % und eine Betriebsdauer von bis zu 4300 Stunden. Die Anwendung von KI in den Materialwissenschaften, insbesondere bei der Entwicklung und Leistungsvorhersage von Batterien, treibt Durchbrüche in der Speichertechnologie voran und verspricht effizientere und langlebigere Energielösungen für Bereiche wie Elektrofahrzeuge und tragbare elektronische Geräte. (Quelle: Ronald_vanLoon)

🧰 Tools
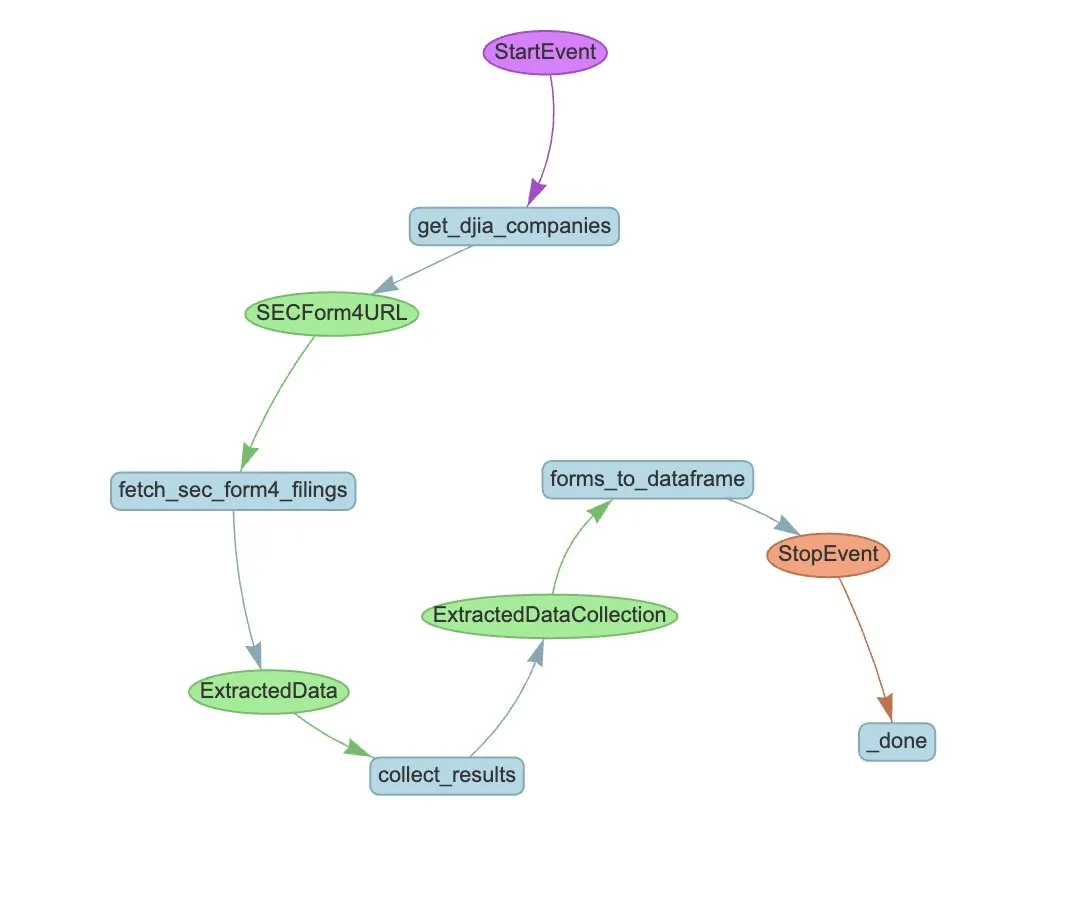
LlamaIndex führt LlamaExtract und Agent-Workflow zur Automatisierung der SEC Form 4-Extraktion ein: LlamaIndex demonstriert, wie LlamaExtract und Agent-Workflows verwendet werden können, um strukturierte Informationen automatisch aus SEC Form 4-Dateien zu extrahieren. SEC Form 4 ist ein wichtiges Dokument, in dem Führungskräfte, Direktoren und Hauptaktionäre von börsennotierten Unternehmen Aktientransaktionen offenlegen. Durch den Aufbau von Extraktions-Agenten und skalierbaren Workflows können Form 4-Einreichungen aller Unternehmen im Dow Jones Industrial Average effizient verarbeitet werden, was die Markttransparenz und die Effizienz der Datenanalyse verbessert. (Quelle: jerryjliu0)
Cognee: Open-Source-Tool für dynamisches Gedächtnis von KI-Agenten: Cognee ist ein Open-Source-Projekt, das darauf abzielt, KI-Agenten dynamische Gedächtnisfähigkeiten zu verleihen und angeblich mit nur 5 Codezeilen integriert werden kann. Es baut skalierbare, modulare ECL-Pipelines (Extract, Cognify, Load) auf, die Agenten helfen, vergangene Gespräche, Dokumente, Bilder und Audiotranskripte zu vernetzen und abzurufen, um traditionelle RAG-Systeme zu ersetzen, die Entwicklungsschwierigkeiten und -kosten zu senken und die Datenverarbeitung und -ladung aus über 30 Datenquellen zu unterstützen. (Quelle: GitHub Trending)
Claude Code jetzt für Pro-Nutzer verfügbar, Community-Version von GitHub Action veröffentlicht: Anthropic’s KI-Programmierassistent Claude Code ist jetzt für Pro-Abonnenten verfügbar, die ihn unter anderem über JetBrains IDE-Plugins nutzen können. Community-Entwickler haben auch eine Fork-Version einer Claude Code GitHub Action veröffentlicht, die es zahlenden Nutzern ermöglicht, Claude Code direkt in GitHub Issues oder PRs aufzurufen und ihr Abonnementkontingent für Aufgaben wie Code-Reviews und Problemlösungen zu nutzen, ohne zusätzliche API-Gebühren zahlen zu müssen. (Quelle: Reddit r/ClaudeAI, Reddit r/ClaudeAI)
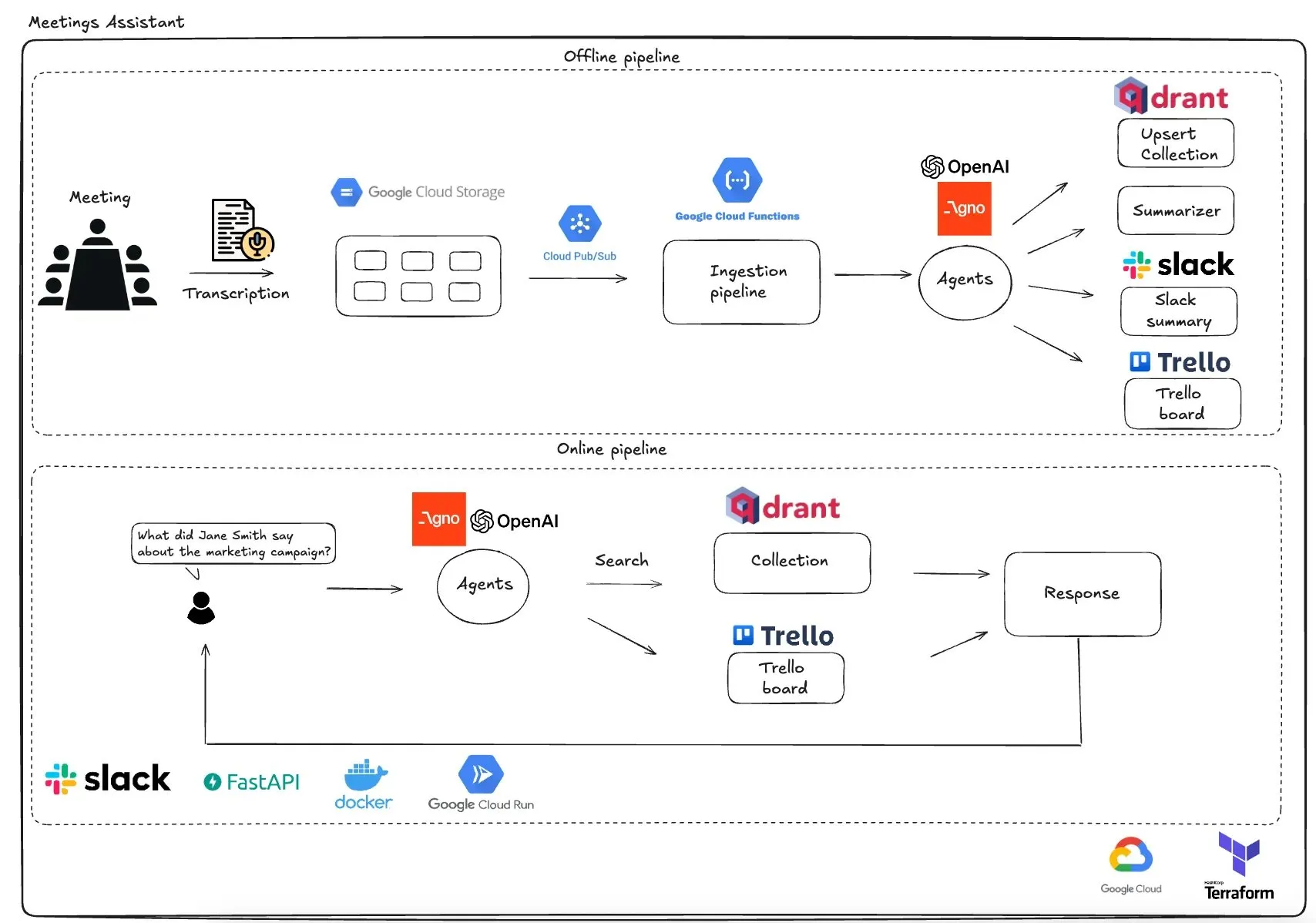
Qdrant stellt GCP-basierten Multi-Agenten-Meeting-Assistenten vor: Qdrant hat ein vollständig serverloses Multi-Agenten-Meeting-Assistenzsystem vorgestellt. Dieses System kann Meeting-Inhalte transkribieren, LLM-Agenten zur Zusammenfassung verwenden, Kontextinformationen in der Qdrant-Vektordatenbank speichern, Aufgaben mit Trello synchronisieren und die Endergebnisse direkt in Slack bereitstellen. Das System nutzt AgnoAgi für die Agenten-Orchestrierung, FastAPI läuft auf Cloud Run und verwendet OpenAI für Embeddings und Inferenz. (Quelle: qdrant_engine)
Microsoft veröffentlicht GUI-Actor zur Lokalisierung von GUI-Elementen ohne Koordinaten: Microsoft hat auf Hugging Face GUI-Actor veröffentlicht, eine Methode zur koordinatenfreien Lokalisierung von GUI-Elementen (Graphical User Interface). Diese Methode ermöglicht es KI-Agenten, über ein spezielles <actor>-Token direkt auf native visuelle Blöcke (Visual Patches) zu zeigen, anstatt sich auf textbasierte Koordinatenvorhersagen zu verlassen. Ziel ist es, die Genauigkeit und Robustheit von GUI-Agentenoperationen zu verbessern. (Quelle: _akhaliq)

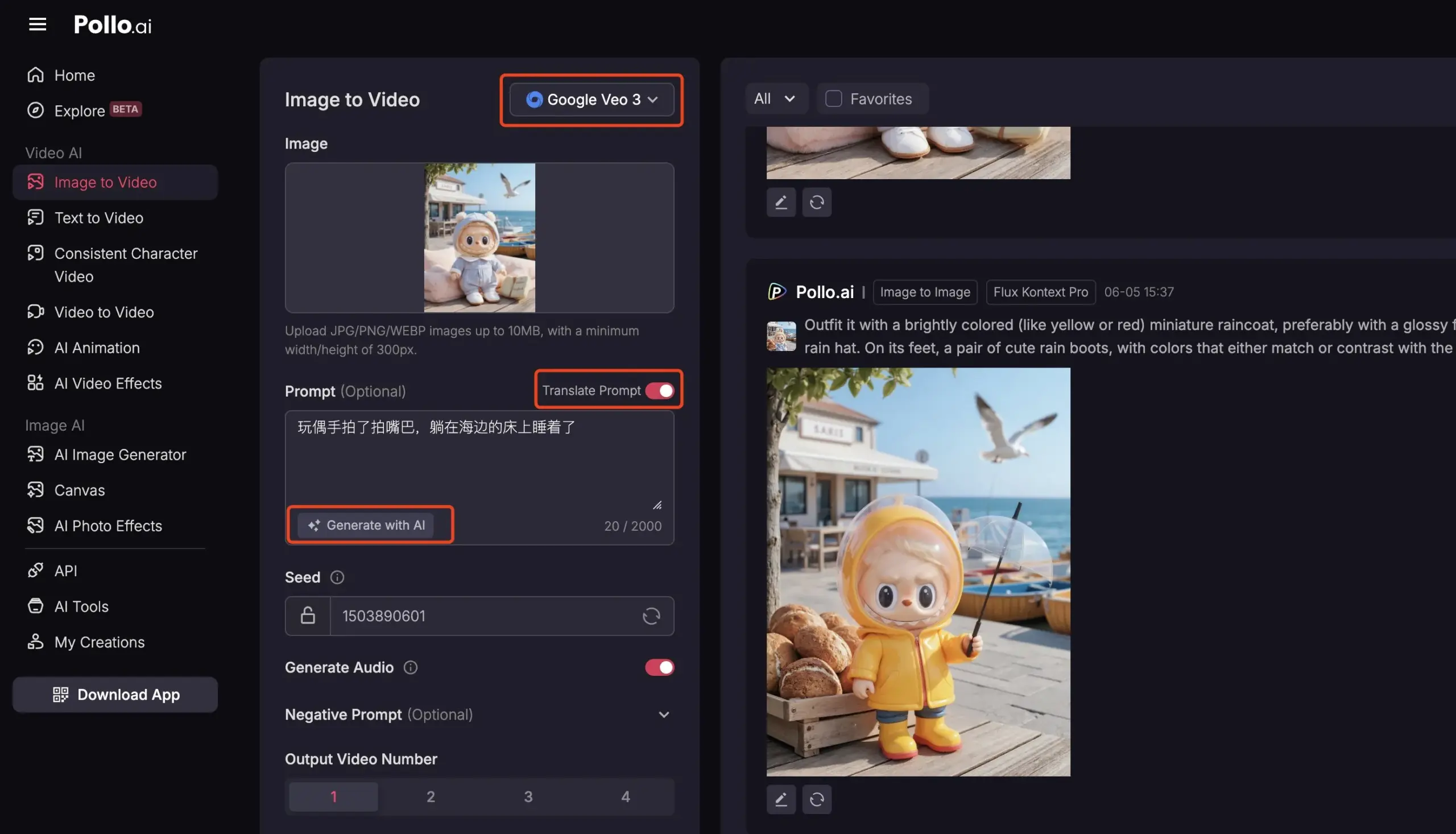
Pollo AI integriert Veo3 und FLUX Kontext und bietet umfassende KI-Videodienste: Die KI-Tool-Plattform Pollo AI wurde kürzlich häufig aktualisiert und hat das Google Veo3 Videogenerierungsmodell sowie die FLUX Kontext Bildbearbeitungsfunktionen integriert. Nutzer können auf dieser Plattform Bilder mit FLUX Kontext bearbeiten und direkt an Veo3 senden, um Videos zu generieren. Die Plattform bietet auch eine API-Schnittstelle, die den einmaligen Zugriff auf verschiedene gängige Videomodelle auf dem Markt unterstützt, und verfügt über integrierte Hilfsfunktionen wie KI-Prompt-Generierung und mehrsprachige Übersetzung, um die Bequemlichkeit und Effizienz der KI-Videoerstellung zu verbessern. (Quelle: op7418)
📚 Lernen
Meta-Learning tiefgehend analysiert: Wie KI lernt zu lernen: Meta-Learning, auch bekannt als „Lernen zu lernen“, zielt darauf ab, Modelle so zu trainieren, dass sie sich schnell an neue Aufgaben anpassen können, selbst mit nur wenigen Beispielen. Dieser Prozess umfasst typischerweise zwei Modelle: einen Basislerner (Base-Learner), der in einem inneren Lernzyklus schnell spezifische Aufgaben (wie Few-Shot-Bildklassifizierung) erlernt, und einen Metalerner (Meta-Learner), der im äußeren Lernzyklus die Parameter oder Strategien des Basislearners verwaltet und aktualisiert, um dessen Fähigkeit zur Lösung neuer Aufgaben zu verbessern. Nach dem Training wird der Basislerner mit dem vom Metalerner erlernten Wissen initialisiert. (Quelle: TheTuringPost, TheTuringPost)

Papierinterpretation „A Controllable Examination for Long-Context Language Models“: Dieses Papier befasst sich mit den Einschränkungen bestehender Bewertungsframeworks für Long-Context Language Models (LCLMs) (Komplexität und schwere Lösbarkeit realer Aufgaben, Anfälligkeit für Datenkontamination; synthetische Aufgaben wie NIAH mangelnde Kontextkohärenz) und schlägt drei Merkmale vor, die ein ideales Bewertungsframework aufweisen sollte: nahtloser Kontext, kontrollierbare Einstellungen und solide Bewertung. Es stellt LongBioBench vor, einen neuen Benchmark, der künstlich generierte Biografien als kontrollierte Umgebung nutzt, um LCLMs hinsichtlich Verständnis, Schlussfolgerung und Vertrauenswürdigkeit zu bewerten. Experimente zeigen, dass die meisten Modelle beim semantischen Verständnis, bei ersten Schlussfolgerungen und bei der Vertrauenswürdigkeit im langen Kontext noch Mängel aufweisen. (Quelle: HuggingFace Daily Papers)
Papierinterpretation „Advancing Multimodal Reasoning: From Optimized Cold Start to Staged Reinforcement Learning“: Inspiriert von den herausragenden Schlussfolgerungsfähigkeiten von Deepseek-R1 bei komplexen Textaufgaben untersucht diese Studie, wie die komplexen Schlussfolgerungsfähigkeiten von Multimodal Large Language Models (MLLMs) durch optimierten Kaltstart und gestuftes Reinforcement Learning (RL) verbessert werden können. Die Studie stellt fest, dass eine effektive Kaltstartinitialisierung entscheidend für die Verbesserung der MLLM-Schlussfolgerung ist und dass allein die Initialisierung mit sorgfältig ausgewählten Textdaten viele bestehende Modelle übertreffen kann. Standard-GRPO weist bei der Anwendung auf multimodales RL Probleme mit der Gradientenstagnation auf, während nachfolgendes reines Text-RL-Training die multimodale Schlussfolgerung weiter verbessern kann. Basierend auf diesen Erkenntnissen stellten die Forscher ReVisual-R1 vor, das bei mehreren anspruchsvollen Benchmarks SOTA-Ergebnisse erzielte. (Quelle: HuggingFace Daily Papers)
Papierinterpretation „Unleashing the Reasoning Potential of Pre-trained LLMs by Critique Fine-Tuning on One Problem“: Diese Studie schlägt eine effiziente Methode vor, um das Schlussfolgerungspotenzial vorab trainierter LLMs freizusetzen: Single-Problem Critique Fine-Tuning (CFT). Durch das Sammeln verschiedener Lösungen, die das Modell für ein einzelnes Problem generiert, und die Nutzung eines Lehrer-LLMs zur Bereitstellung detaillierter Kritik werden Kritikdaten für die Feinabstimmung erstellt. Experimente zeigen, dass nach der CFT-Anwendung auf einzelne Probleme bei Modellen der Qwen- und Llama-Reihe signifikante Leistungssteigerungen bei verschiedenen Schlussfolgerungsaufgaben erzielt wurden. Beispielsweise verbesserte sich Qwen-Math-7B-CFT bei mathematischen und logischen Schlussfolgerungsbenchmarks im Durchschnitt um 15-16 %, bei deutlich geringeren Berechnungskosten als beim Reinforcement Learning. (Quelle: HuggingFace Daily Papers)
Papierinterpretation „SVGenius: Benchmarking LLMs in SVG Understanding, Editing and Generation“: Um die Probleme bestehender Benchmarks für die Verarbeitung von SVG (Scalable Vector Graphics) – begrenzte Abdeckung, fehlende Komplexitätsstufen und fragmentierte Bewertungsparadigmen – zu lösen, wurde SVGenius entwickelt. Es handelt sich um einen umfassenden Benchmark mit 2377 Abfragen, der die drei Dimensionen Verstehen, Bearbeiten und Generieren abdeckt. Er basiert auf realen Daten aus 24 Anwendungsbereichen und wurde systematisch nach Komplexität gestaffelt. Anhand von 8 Aufgabenkategorien und 18 Metriken wurden 22 gängige Modelle bewertet, wobei die Grenzen aktueller Modelle bei der Verarbeitung komplexer SVGs aufgezeigt und darauf hingewiesen wurde, dass ein durch Schlussfolgerungen erweitertes Training effektiver ist als eine reine Skalierung. (Quelle: HuggingFace Daily Papers)
Hugging Face Hub Update-Protokoll veröffentlicht: Der Hugging Face Hub hat sein neuestes Update-Protokoll veröffentlicht. Nutzer können es einsehen, um sich über neu hinzugefügte Funktionen der Plattform, Aktualisierungen der Modellbibliothek, Erweiterungen der Datensätze sowie Verbesserungen der Toolchain und andere aktuelle Entwicklungen zu informieren. Dies hilft Community-Nutzern, die neuesten Ressourcen und Fähigkeiten des Hugging Face-Ökosystems rechtzeitig zu kennen und zu nutzen. (Quelle: huggingface, _akhaliq)
Maxime Labonne und andere Autoren veröffentlichen zahlreiche LLM Notebooks als Open Source: Maxime Labonne, Autor des LLM Engineer Handbook, und Iustin Paul haben eine Reihe von Jupyter Notebooks zum Thema LLMs als Open Source veröffentlicht. Diese Notebooks sind inhaltsreich und umfassen nicht nur grundlegende Feinabstimmungstechniken, sondern auch fortgeschrittene Themen wie automatische Bewertung, Lazy Merges, den Aufbau von Mixture-of-Experts-Modellen (frankenMoEs) sowie Techniken zur Umgehung von Zensur. Sie bieten LLM-Entwicklern und Forschern wertvolle praktische Ressourcen. (Quelle: maximelabonne)
DeepLearningAI veröffentlicht The Batch Wochenbericht, diskutiert wie AI Fund KI-Entwickler fördert: Andrew Ng teilt in seiner neuesten Ausgabe des The Batch Wochenberichts die Erfahrungen und Strategien des AI Fund bei der Förderung von KI-Talenten und -Entwicklern. Diese Ausgabe behandelt auch aktuelle Themen wie die Leistung des neuen Open-Source-Modells von DeepSeek, das mit Top-LLMs konkurriert, die Nutzung von KI durch Duolingo zur Erweiterung von Sprachkursen, den Kompromiss beim Energieverbrauch von KI und die potenzielle Irreführung von KI-Agenten durch bösartige Links. (Quelle: DeepLearningAI)

💼 Wirtschaft
Reddit verklagt Anthropic wegen unbefugter Nutzung von Nutzerdaten zum KI-Training: Reddit hat eine Klage gegen das KI-Unternehmen Anthropic eingereicht und wirft ihm vor, Reddit-Inhalte unbefugt mithilfe automatisierter Bots für das Training seiner KI-Modelle (wie Claude) abgegriffen zu haben, was einen Vertragsbruch und unlauteren Wettbewerb darstelle. Dieser Fall unterstreicht die aktuelle Kontroverse um die Rechtmäßigkeit von Datenscraping und Modelltraining in der KI-Entwicklung und spiegelt auch die zunehmende Bedeutung wider, die Content-Plattformen dem Schutz des Werts ihrer Daten beimessen. (Quelle: Reddit r/artificial, Reddit r/ArtificialInteligence, TheRundownAI)

Amazon plant Investition von 10 Milliarden US-Dollar in KI-Rechenzentrum in North Carolina: Amazon hat angekündigt, 10 Milliarden US-Dollar in den Bau eines neuen Rechenzentrums in North Carolina zu investieren, um den wachsenden Bedarf seines KI-Geschäfts zu decken. Diese Maßnahme spiegelt die kontinuierlichen Investitionen großer Technologieunternehmen in die KI-Infrastruktur wider, die darauf abzielen, die für das Training und die Inferenz von KI-Modellen erforderlichen massiven Rechen- und Speicherressourcen bereitzustellen. (Quelle: Reddit r/artificial)

Anthropic kürzt API-Zugriff auf Claude-Modelle für Windsurf.ai und schürt Bedenken hinsichtlich Plattformrisiken: Die KI-Anwendungsentwicklungsplattform Windsurf.ai gab bekannt, dass Anthropic mit einer Vorankündigung von weniger als 5 Tagen die API-Zugriffskapazität auf seine Modelle Claude 3.x und Claude 4 drastisch reduziert hat. Dieser Schritt zwang Windsurf.ai, dringend Drittanbieter zu suchen, um den Service für zahlende Nutzer sicherzustellen, und kostenlosen sowie Pro-Nutzern eine BYOK-Option (Bring Your Own Key) anzubieten. Dieses Ereignis verstärkt die Bedenken von Entwicklern hinsichtlich der Plattformrisiken von KI-Modellanbietern, d. h. dass Modellanbieter ihre Servicestrategien jederzeit anpassen oder sogar mit nachgelagerten Anwendungen in Konkurrenz treten könnten. (Quelle: swyx, scaling01, mervenoyann)
🌟 Community
AI Engineer Conference (@aiDotEngineer) heiß diskutiert, Fokus auf Agent-Design und KI-Startups: Die AI Engineer Conference (@aiDotEngineer) in San Francisco wurde zum heiß diskutierten Thema in der Community. LlamaIndex teilte effektive Agent-Designmuster für Produktionsumgebungen; Anthropic veröffentlichte auf der Konferenz eine „Wunschliste“ für Startups, die sich auf die Anwendung von MCP-Servern in neuen Bereichen, die Vereinfachung des Serverbaus und die Sicherheit von KI-Anwendungen (z. B. Tool Poisoning) konzentriert; Graphite präsentierte ein KI-gestütztes Code-Review-Tool. Auf der Konferenz wurden auch grundlegende Forschungsherausforderungen bei der Skalierung von GPT-Modellen der nächsten Generation diskutiert. (Quelle: swyx, swyx, swyx, iScienceLuvr)

Forscher Rohan Anil tritt Anthropic bei und erregt Aufmerksamkeit: Der Forscher Rohan Anil gab bekannt, dass er dem Team von Anthropic beitreten wird. Diese Nachricht sorgte in der KI-Community für große Aufmerksamkeit und Diskussionen. Viele Branchenkenner und Beobachter gratulierten ihm und erwarten, dass er neue Beiträge zur Forschungsarbeit von Anthropic leisten wird. Dies spiegelt auch den potenziellen Einfluss der Mobilität von Top-KI-Talenten auf die Branchenlandschaft wider. (Quelle: arohan, gallabytes, andersonbcdefg, scaling01, zacharynado)
Gericht fordert OpenAI auf, alle ChatGPT-Protokolle aufzubewahren, was Diskussionen über Datenaufbewahrungsrichtlinien auslöst: Berichten zufolge wurde OpenAI von einem Gericht angewiesen, alle ChatGPT-Protokolle aufzubewahren, einschließlich „temporärer Chats“ und API-Anfragen, die eigentlich hätten gelöscht werden sollen. Diese Nachricht löste in der Community Diskussionen über Datenaufbewahrungsrichtlinien aus, insbesondere für Anwendungen, die die OpenAI-API verwenden. Dies könnte bedeuten, dass ihre eigenen Datenaufbewahrungsrichtlinien nicht vollständig eingehalten werden können, was neue Herausforderungen für den Datenschutz und die Datenverwaltung der Nutzer mit sich bringt. Es wird empfohlen, dass Nutzer nach Möglichkeit lokale Modelle verwenden, um ihre Daten zu schützen. (Quelle: code_star, TomLikesRobots)

Überflutung mit KI-generierten Inhalten und das Phänomen „AI Slop“ geben Anlass zur Sorge: Die Zunahme von qualitativ minderwertigen, aufmerksamkeitsheischenden KI-generierten Inhalten (als „AI Slop“ bezeichnet) in sozialen Medien, von KI-generierten Beiträgen auf Reddit bis hin zu KI-Bildern wie „Shrimp Jesus“ auf Facebook, löst bei Nutzern Besorgnis über die Informationsqualität und die Verschlechterung des Online-Umfelds aus. Diese Inhalte werden typischerweise kostengünstig von Bots oder Traffic-Suchenden generiert und zielen darauf ab, durch „Engagement Bait“ Likes und Shares zu erhalten. Studien deuten darauf hin, dass ein großer Teil des Internetverkehrs bereits von „bösen Bots“ stammt, die Falschinformationen verbreiten und Daten stehlen. Dieses Phänomen beeinträchtigt nicht nur die Nutzererfahrung, sondern stellt auch eine Bedrohung für Demokratie und politische Kommunikation dar und könnte gleichzeitig die Trainingsdaten zukünftiger KI-Modelle kontaminieren. (Quelle: aihub.org)

Diskussion über LLM-Kosten: Gemini preiswert, Claude 4 Kodierungskosten im Fokus: Diskussionen in der Community zeigen, dass die Nutzungskosten aktueller LLMs erheblich variieren. Beispielsweise belaufen sich die Kosten für die Verarbeitung eines gesamten Versicherungsdokuments und umfangreiche Abfragen mit Gemini nur auf etwa 0,01 US-Dollar, was ein hohes Preis-Leistungs-Verhältnis zeigt. Im Vergleich dazu ist das Claude 4-Modell zwar bei Aufgaben wie der Kodierung leistungsstark, aber die Nutzung im Maximalmodus (Max Mode) auf Plattformen wie Cursor.ai ist kostspielig, was Nutzer dazu veranlasst, auf kostengünstigere Alternativen wie Google Gemini 2.5 Pro umzusteigen. (Quelle: finbarrtimbers, Teknium1)
KI-Agenten stehen vor Herausforderungen bei der Lösung von CAPTCHAs (Mensch-Maschine-Verifizierung) in realen Webszenarien: Das MetaAgentX-Team hat die Open CaptchaWorld-Plattform veröffentlicht, die sich auf die Bewertung der Fähigkeit multimodaler interaktiver Agenten zur Lösung von CAPTCHAs konzentriert. Tests zeigen, dass selbst SOTA-Modelle wie GPT-4o bei der Verarbeitung von 20 Arten interaktiver Captchas in realen Webumgebungen eine Erfolgsquote von nur 5 % bis 40 % erreichen, was weit unter der durchschnittlichen Erfolgsquote von Menschen von 93,3 % liegt. Dies deutet darauf hin, dass aktuelle KI-Agenten immer noch Engpässe in den Bereichen visuelles Verständnis, mehrstufige Planung, Zustandsverfolgung und präzise Interaktion aufweisen, wodurch Captchas zu einem großen Hindernis für ihren praktischen Einsatz werden. (Quelle: 量子位)

Markt für KI-Agenten-Schulungen boomt, Qualität der Kurse und Berufsaussichten im Fokus: Mit dem Aufkommen des Konzepts der KI-Agenten sind auch zahlreiche entsprechende Schulungskurse entstanden. Einige Schulungsinstitute behaupten, eine umfassende Betreuung vom Einstieg bis zur Anstellung anzubieten und versprechen sogar eine „Jobgarantie“, wobei die Studiengebühren von einigen hundert bis zu zehntausenden Yuan reichen. Die Qualität der Kurse auf dem Markt ist jedoch uneinheitlich, einigen Kursen wird vorgeworfen, oberflächliche Inhalte zu haben, übermäßig Marketing zu betreiben und sogar den „Abzocker“-KI-Schnellkursen zu ähneln. Kursteilnehmer und Beobachter stehen der tatsächlichen Wirksamkeit solcher Schulungen, den Qualifikationen der Dozenten und der Echtheit der „Jobgarantie“-Versprechen skeptisch gegenüber und befürchten, dass sie zu einer weiteren „Scheinnachfrage“ in der Übergangsphase der KI-Entwicklung werden könnten. (Quelle: 36氪)

💡 Sonstiges
Fortschritte bei der Anwendung von KI im Bereich Robotik: Taktile Roboterhand, amphibischer Roboter und Feuerwehr-Roboterhund: KI-Technologie treibt die Grenzen der Robotik voran. Forscher haben eine Roboterhand mit taktiler Wahrnehmung entwickelt, die eine bessere Interaktion mit der Umgebung ermöglicht. Copperstone HELIX Neptune präsentierte einen KI-gesteuerten amphibischen Roboter, der in unterschiedlichem Gelände eingesetzt werden kann. China hat einen Feuerwehr-Roboterhund vorgestellt, der einen 60 Meter langen Wasserstrahl versprühen, Treppen steigen und Rettungseinsätze live übertragen kann. Diese Fortschritte zeigen das Potenzial von KI zur Verbesserung der Wahrnehmung, Entscheidungsfindung und Ausführung komplexer Aufgaben durch Roboter. (Quelle: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)

Diskussion zum Vergleich von KI-Agenten und generativer KI: In der Community gibt es Diskussionen über die Unterschiede und Zusammenhänge zwischen KI-Agenten (Agenten-KI) und generativer KI (Generative AI). Generative KI konzentriert sich hauptsächlich auf die Erstellung von Inhalten, während KI-Agenten stärker auf autonome Entscheidungsfindung und Aufgabenausführung basierend auf Wahrnehmung, Planung und Aktion ausgerichtet sind. Das Verständnis der Unterschiede zwischen beiden hilft, die Entwicklungsrichtung und Anwendungsszenarien der KI-Technologie besser zu erfassen. (Quelle: Ronald_vanLoon, Ronald_vanLoon)
Diskussion über die Herausforderungen der KI bei der Automatisierung komplexer Organisationsprozesse: KI hat Fortschritte bei der Automatisierung oder Unterstützung spezifischer Aufgaben gemacht, aber um menschliche Arbeit oder Teams zu ersetzen und eine breitere wirtschaftliche Transformation zu erreichen, steht sie vor enormer Komplexität. Viele Organisationen haben nicht explizit dokumentierte, aber entscheidende Prozesse, die risikoreich, aber selten sind und möglicherweise so zur Gewohnheit geworden sind, dass ihre Gründe vergessen wurden. KI-Agenten können dieses implizite Wissen nur schwer durch Versuch und Irrtum erlernen, da dies kostspielig ist und die Lernmöglichkeiten begrenzt sind. Dies erfordert ein neues technologisches Paradigma, nicht nur einfaches maschinelles Lernen. (Quelle: random_walker)