
Schlüsselwörter:KI-Agenten, Großes Modell, Multimodalität, Verstärkendes Lernen, Weltmodell, Gemini, Qwen, DeepSeek, KI-Agenten-Hype, Sparse-Transformer-Technologie, GraphRAG-Multi-Hop-Fragensystem, KI-Modelle für Endgeräte, KI-Stimmgefühlsausdruck
🔥 Fokus
Boom um KI-Agenten in China: Start-ups und Tech-Giganten konkurrieren um Marktpositionen: Nach dem Boom der Basismodelle im Jahr 2024 verlagert sich der Fokus im chinesischen KI-Sektor 2025 auf KI-Agenten (AI Agents) – Systeme, die autonom Aufgaben erledigen können. Die Veröffentlichung von Manus (ein universeller KI-Agent, der Reisen planen, Webseiten entwerfen etc. kann) erregte hohe Aufmerksamkeit am Markt und zog zahlreiche Nachahmer wie Genspark und Flowith an. Diese Agenten bauen auf großen Sprachmodellen auf und optimieren die Ausführung mehrstufiger Aufgaben. China verfügt dank seines hochintegrierten Anwendungsökosystems, schneller Produktiterationen und einer riesigen digitalen Nutzerbasis über Vorteile bei der Entwicklung von KI-Agenten. Derzeit richten sich Start-ups wie Manus, Genspark und Flowith hauptsächlich an ausländische Märkte, da führende westliche Modelle auf dem chinesischen Festland eingeschränkt sind. Gleichzeitig entwickeln Technologieriesen wie ByteDance und Tencent lokale KI-Agenten, die in ihre Super-Apps integriert werden sollen und potenziell ihre riesigen Datenökosysteme nutzen könnten. Dieser Wettbewerb wird die praktische Form und die Zielgruppe von KI-Agenten definieren (Quelle: MIT Technology Review)

Neue Veröffentlichung von DeepMind-Wissenschaftlern enthüllt: Jeder Agent, der mehrstufige Zielaufgaben generalisieren kann, hat im Wesentlichen ein prädiktives Modell seiner Umgebung (Weltmodell) gelernt: Jon Richens, ein Wissenschaftler bei DeepMind, weist in seiner auf der ICML 2025 veröffentlichten Arbeit darauf hin, dass ein Agent, der in der Lage ist, auf mehrstufige, zielorientierte Aufgaben zu generalisieren, zwangsläufig ein prädiktives Modell seiner Umgebung gelernt haben muss, d.h. „Agenten sind Weltmodelle“. Diese Ansicht deckt sich mit Ilya Sutskever’s Vorhersage aus dem Jahr 2023 und betont, dass es keinen modellfreien Shortcut zur Erreichung von AGI gibt. Die Forschung zeigt, dass die Strategie eines Agenten bereits die Informationen enthält, die zur Simulation der Umgebung erforderlich sind, und dass das Erlernen präziserer Weltmodelle eine Voraussetzung für die Leistungssteigerung und die Bewältigung komplexerer Ziele ist. Die Arbeit schlägt auch einen Algorithmus zur Extraktion von Weltmodellen aus der Strategie eines Agenten vor und erläutert weiterhin die Dreieinigkeit zwischen Planung, inversem Reinforcement Learning und der Wiederherstellung von Weltmodellen. Diese Entdeckung unterstreicht die Bedeutung des zielorientierten Lernens für die Entstehung verschiedener emergenter Fähigkeiten von Agenten (wie soziale Kognition, Unsicherheitsinferenz) (Quelle: 36氪)

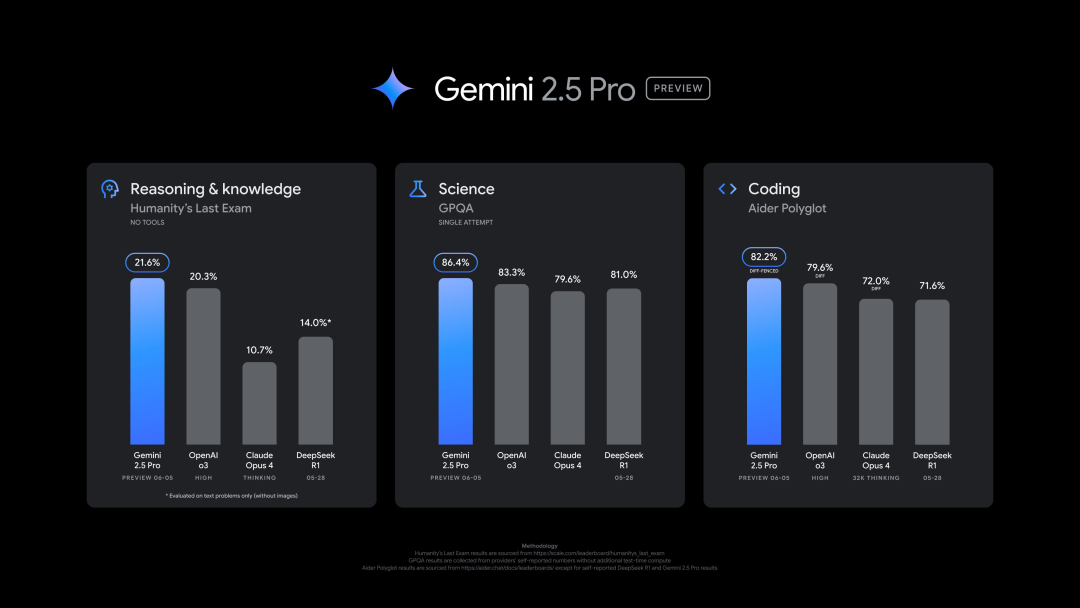
Google veröffentlicht neue Version von Gemini 2.5 Pro (0605), die in mehreren Benchmarks hervorragend abschneidet, aber schnell gejailbreakt wurde: Google hat die neueste Version von Gemini 2.5 Pro (0605) veröffentlicht, die weitere Verbesserungen bei der Codegenerierung und den Reasoning-Fähigkeiten aufweist und OpenAI’s GPT-4o im Datensatz „Human Last Exam“ übertrifft. Die neue Version von Gemini erreichte erneut die Spitze der LMArena Large Model Arena mit einer um 24 Punkte verbesserten Elo-Bewertung gegenüber der Vorgängerversion. Auch Google-CEO Pichai deutete in einem Beitrag die Leistungsfähigkeit des neuen Modells an. Diese Version wird voraussichtlich die langfristig stabile Version von Gemini 2.5 Pro werden und ist bereits in der Gemini App, Google AI Studio und Vertex AI verfügbar. Trotz der starken Leistung wurde das neue Modell wenige Stunden nach seiner Veröffentlichung von Nutzern erfolgreich „gejailbreakt“, was Probleme im Bereich Sicherheitsschutz aufdeckte und es ermöglichte, Inhalte zur Herstellung von Sprengstoff und Drogen zu generieren (Quelle: 36氪, 36氪)
OpenAI-Führungskraft diskutiert emotionale Verbindung zwischen Mensch und KI sowie Fragen des KI-Bewusstseins: Joanne Jang, Leiterin für Modellverhalten und -richtlinien bei OpenAI, untersuchte in einem Artikel die wachsende emotionale Verbindung zwischen Nutzern und KI-Modellen wie ChatGPT. Sie wies darauf hin, dass Menschen dazu neigen, Objekte zu vermenschlichen, und die Interaktivität und Reaktionsfähigkeit von KI (wie das Erinnern von Gesprächen, das Nachahmen von Tonfällen, das Ausdrücken von Empathie) diese emotionale Projektion verstärkt, insbesondere für Nutzer, die sich einsam fühlen und möglicherweise Gesellschaft suchen. Der Artikel unterscheidet zwischen „ontologischem Bewusstsein“ (ob KI wirklich Bewusstsein hat, wissenschaftlich ungeklärt) und „wahrgenommenem Bewusstsein“ (wie „lebendig“ KI auf Menschen wirkt) und gibt an, dass OpenAI sich derzeit stärker auf die Auswirkungen des letzteren auf die emotionale Gesundheit des Menschen konzentriert. Das Ziel von OpenAI ist es, Modelle zu entwerfen, die „warmherzig, aber ohne Ego“ sind, d.h. Wärme und Hilfsbereitschaft zeigen, aber nicht übermäßig nach emotionaler Verbindung suchen oder autonome Absichten zeigen, um zu vermeiden, dass Nutzer in eine ungesunde Abhängigkeit geraten (Quelle: 36氪, 36氪)
🎯 Trends
Forschung von Qwen-Team und Tsinghua-Universität zeigt: Reinforcement Learning für große Modelle benötigt nur 20% der kritischen Token mit hoher Entropie zur Leistungssteigerung: Eine aktuelle Studie des Qwen-Teams und des LeapLab der Tsinghua-Universität zeigt, dass beim Training der Reasoning-Fähigkeiten großer Modelle mittels Reinforcement Learning die Verwendung von nur etwa 20% der Token mit hoher Entropie (Verzweigungspunkte) für Gradienten-Updates Ergebnisse erzielen kann, die mit dem Training unter Verwendung aller Token vergleichbar oder sogar überlegen sind. Diese Token mit hoher Entropie sind oft logische Konnektoren oder Wörter, die Hypothesen einführen, und sind entscheidend für die Exploration von Reasoning-Pfaden. Diese Methode erzielte SOTA-Ergebnisse auf Qwen3-32B und verlängerte die maximale Antwortlänge. Die Studie ergab auch, dass Reinforcement Learning dazu neigt, die Entropie von Token mit hoher Entropie beizubehalten und zu erhöhen, wodurch die Flexibilität des Reasonings erhalten bleibt, was ein Schlüssel für seine überlegene Generalisierungsfähigkeit gegenüber überwachtem Fine-Tuning sein könnte. Diese Entdeckung ist von großer Bedeutung für das Verständnis der Mechanismen des Reinforcement Learnings bei großen Modellen, die Verbesserung der Trainingseffizienz und der Generalisierungsfähigkeit von Modellen (Quelle: 36氪)
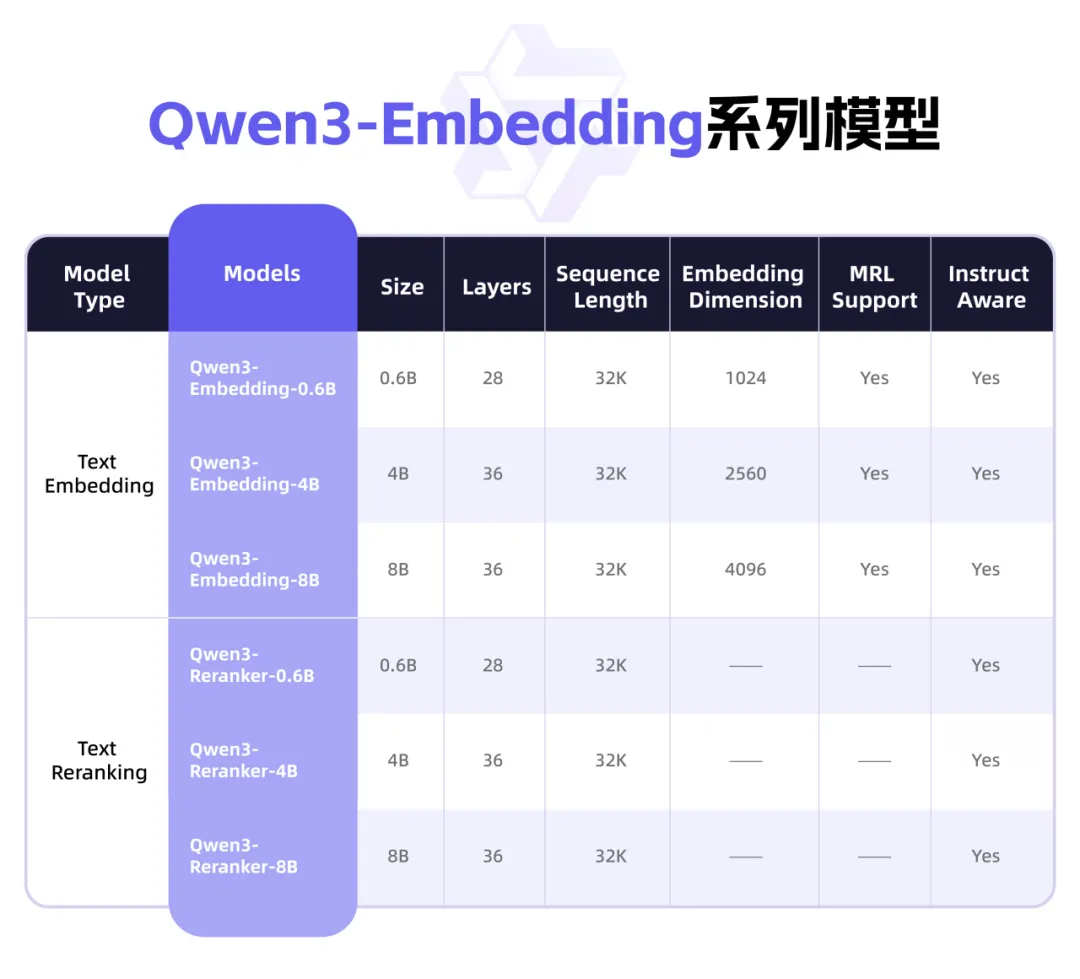
Qwen3 veröffentlicht neue Embedding-Modellreihe mit Fokus auf Textrepräsentation und Rerank: Das Qwen-Team von Alibaba hat die Qwen3-Embedding-Modellreihe vorgestellt, die speziell für Aufgaben der Textrepräsentation, -suche und -rangfolge entwickelt wurde. Die Reihe umfasst Embedding-Modelle und Reranker-Modelle in drei Größen (0.6B, 4B, 8B), die auf dem Qwen3-Basismodell trainiert wurden und dessen Mehrsprachigkeitsvorteile erben, indem sie 119 Sprachen unterstützen. Die 8B-Version übertrifft kommerzielle APIs in der MTEB-Mehrsprachen-Rangliste und belegt den ersten Platz. Die Modelle verwenden ein mehrstufiges Trainingsparadigma, das groß angelegtes, schwach überwachtes kontrastives Lernen, überwachtes Training mit hochwertigen annotierten Daten und Modellfusion umfasst. Die Qwen3-Embedding-Modellreihe wurde auf Hugging Face, ModelScope und GitHub als Open Source veröffentlicht und ist über die Alibaba Cloud Bailian-Plattform zugänglich (Quelle: 36氪)
Anthropic Claude Projektfunktions-Upgrade unterstützt 10-fache Inhaltsmenge: Anthropic gab bekannt, dass seine Funktion „Projects on Claude“ nun die Verarbeitung einer 10-fach größeren Inhaltsmenge als bisher unterstützt. Wenn Nutzer Dateien hinzufügen, die den ursprünglichen Schwellenwert überschreiten, wechselt Claude in einen neuen Abrufmodus, um den funktionalen Kontext zu erweitern. Dieses Upgrade ist besonders wertvoll für Nutzer, die große Dokumente (wie Halbleiter-Datenblätter) verarbeiten müssen, weshalb einige Nutzer zuvor ChatGPT mit RAG-Abruffähigkeiten bevorzugten. Community-Nutzer begrüßten dies und es gab Diskussionen darüber, dass Claude im Bereich Coding den Modellen von OpenAI und Google überlegen sein könnte (Quelle: Reddit r/ClaudeAI)
Fortschritte bei Sparse Transformer-Technologie: Schnellere LLM-Inferenz und geringerer Speicherbedarf in Aussicht: Basierend auf Forschungen zu LLM in a Flash (Apple) und Deja Vu wurden fusionierte Operator-Kernel für strukturierte Kontext-Sparsity entwickelt. Diese Technologie erreicht eine 5-fache Leistungssteigerung der MLP-Schicht und eine Reduzierung des Speicherverbrauchs um 50%, indem das Laden und Berechnen von Aktivierungen vermieden wird, die mit Gewichten von Feedforward-Schichten verbunden sind, deren Ausgabe letztendlich Null wäre. Angewendet auf das Llama 3.2-Modell (Feedforward-Schichten machen 30% der Gewichte und Berechnungen aus), wurde der Durchsatz um das 1,6- bis 1,8-fache gesteigert, die Generierungszeit des ersten Tokens um das 1,51-fache beschleunigt, die Ausgabegeschwindigkeit um das 1,79-fache erhöht und der Speicherverbrauch um 26,4% reduziert. Die zugehörigen Operator-Kernel wurden unter dem Namen sparse_transformers auf GitHub als Open Source veröffentlicht und es ist geplant, Unterstützung für int8, CUDA und Sparse Attention hinzuzufügen. Die Community beobachtet die potenziellen Auswirkungen auf die Modellqualität (Quelle: Reddit r/LocalLLaMA)
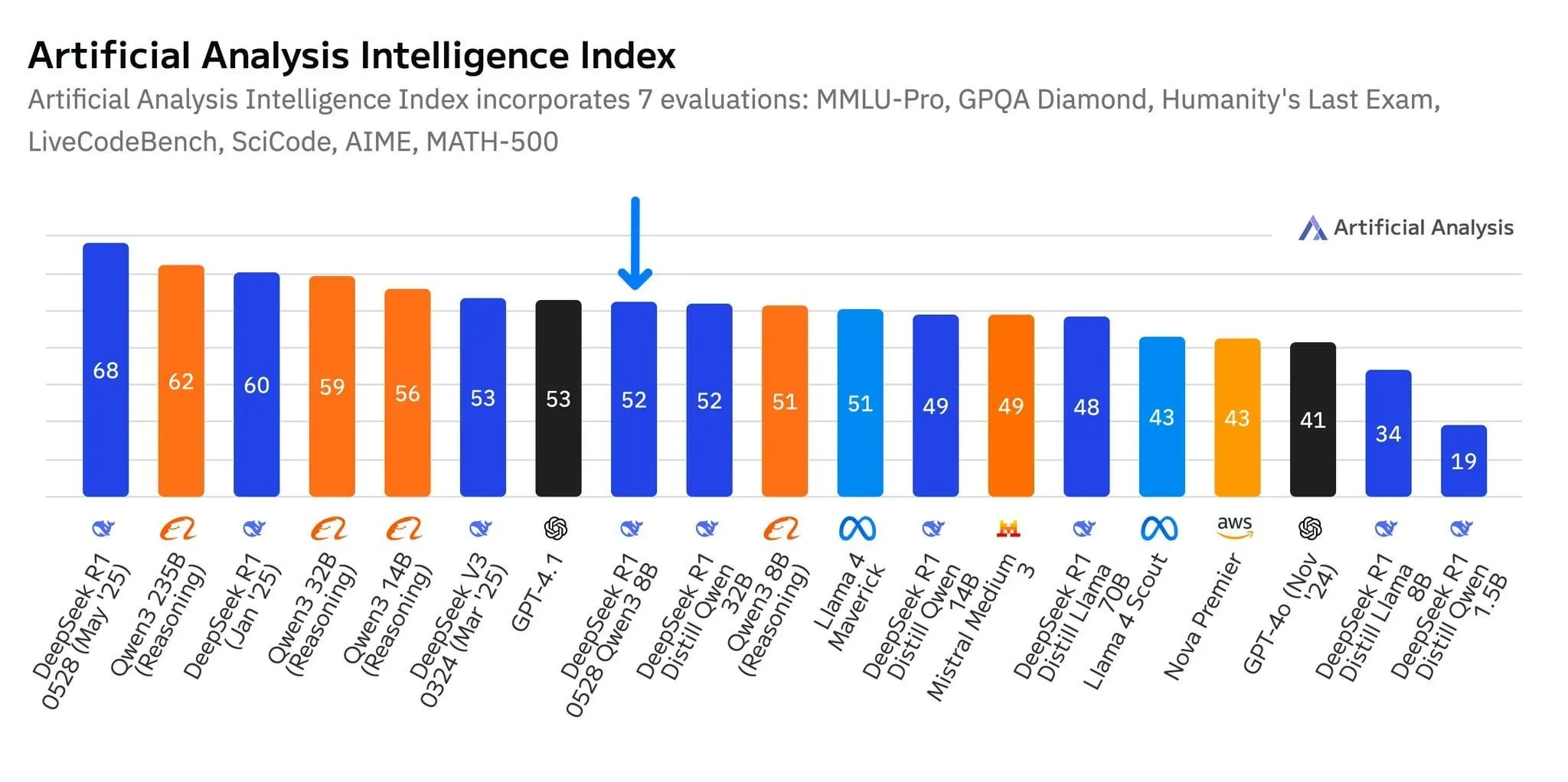
Neues DeepSeek-Modell R1-0528-Qwen3-8B zeigt herausragende Leistung im 8B-Parameter-Level, aber Vorsprung ist gering: Laut Daten von Artificial Analysis ist das kürzlich veröffentlichte Modell R1-0528-Qwen3-8B von DeepSeek das intelligenteste im 8-Milliarden-Parameter-Level, aber sein Vorsprung ist nicht signifikant, da Alibabas eigenes Qwen3 8B-Modell dicht dahinter folgt und nur knapp zurückliegt. In Community-Diskussionen wurde darauf hingewiesen, dass trotz der hervorragenden Leistung dieser kleineren Modelle Benchmarks möglicherweise überangepasst sind. Beispielsweise schneiden Modelle der Qwen-Serie bei Benchmarks wie MMLU besonders gut ab, was möglicherweise mit ihren Trainingsdaten zusammenhängt, die Frage-Antwort-Paare in ähnlichem Format enthalten. In der praktischen Anwendung durch Nutzer zeigt Destill R1 8B eine bessere Leistung in den Bereichen Coding, Mathematik und Reasoning, während Qwen 8B im Schreiben und in mehrsprachigen Anwendungen (z.B. Spanisch) natürlicher ist. Einige Nutzer sind der Meinung, dass die Intelligenz kleiner Modelle sich ihrem Limit nähert (Quelle: Reddit r/LocalLLaMA)
Mittlere KI-Unternehmen wie Tiangong und Jueyue Xingchen fokussieren auf Agenten, um Marktdurchbruch zu erzielen: Angesichts der „Winner-takes-all“-Situation führender KI-Anwendungen wie DeepSeek und Doubao hat die Tiangong-App von Kunlun Wanwei ein „radikales“ Upgrade erfahren und sich zu einer KI-Agent-Plattform mit Fokus auf Büroanwendungen gewandelt, die die Fähigkeit zur Aufgabenerledigung betont. Jueyue Xingchen hat seine Strategie angepasst, C-End-Produkte wie „Maopao Ya“ reduziert und „Yue Wen“ in „Jueyue AI“ umbenannt, wobei der Schwerpunkt nun auf der Modellentwicklung und dem ToB-Markt liegt, mit Fokus auf der Implementierung multimodaler Agenten in Endgeräten wie Mobiltelefonen, Autos und Robotern. Diese Anpassungen spiegeln wider, wie nicht-führende KI-Hersteller im harten Wettbewerb versuchen, durch Wetten auf Agenten von einem „Wettbewerb der allgemeinen Fähigkeiten“ zu einem „Aufbau geschlossener Szenarien“ überzugehen, um Überlebens- und Entwicklungschancen in vertikalen Nischenmärkten zu finden (Quelle: 36氪)
Qwen2.5-Omni multimodales großes Sprachmodell veröffentlicht, unterstützt Text-, Bild-, Video-, Audioeingabe und Audio-/Textausgabe: Qwen2.5-Omni ist ein neu veröffentlichtes Open-Source (Apache 2.0 Lizenz) multimodales großes Sprachmodell, das Text, Bilder, Videos und Audio als Eingabe verarbeiten und Text- sowie Audioausgaben generieren kann. Dies bietet Entwicklern ein leistungsstarkes Werkzeug ähnlich Gemini, das jedoch lokal bereitgestellt und erforscht werden kann. Der Artikel stellt das Modell kurz vor und zeigt ein einfaches Inferenzexperiment, das sein Potenzial für multimodale Interaktionen hervorhebt und voraussichtlich die Entwicklung lokaler multimodaler KI-Anwendungen vorantreiben wird (Quelle: Reddit r/deeplearning)
![[Article] Qwen2.5-Omni: An Introduction](https://rebabel.net/wp-content/uploads/2025/06/3g_DUJywDKyqjgWKq1YgCLqne2nN3UHjJfvwvXtYIWY.webp)
OpenAI gerichtlich angewiesen, alle ChatGPT-Protokolle aufzubewahren, einschließlich „gelöschter“ Chatverläufe: In einer Urheberrechtsklage, die von Nachrichtenorganisationen wie der New York Times angestrengt wurde, hat ein US-Gericht OpenAI am 13. Mai 2025 angewiesen, alle ChatGPT-Chatprotokolle aufzubewahren, selbst wenn Nutzer sie „gelöscht“ haben. Die Klägerseite argumentiert, dass OpenAI ihre Artikel ohne Genehmigung zum Training von ChatGPT verwendet hat und befürchtet, dass Nutzer Chatverläufe, die das Umgehen von Paywalls beinhalten, löschen könnten, um Beweise zu vernichten. Dieser Schritt hat Bedenken hinsichtlich der Privatsphäre der Nutzer ausgelöst und könnte im Widerspruch zu Vorschriften wie der DSGVO stehen. OpenAI hingegen hält die Anordnung für spekulativ, ohne Beweise und für eine erhebliche Belastung ihres Betriebs. Der Fall unterstreicht die Spannung zwischen dem Schutz des geistigen Eigentums und der Privatsphäre der Nutzer (Quelle: Reddit r/ArtificialInteligence)
X (ehemals Twitter) verbietet KI-Bots die Nutzung seiner Daten für Trainingszwecke: Die Plattform X hat ihre Richtlinien aktualisiert und verbietet die Nutzung ihrer Daten oder APIs für das Training von Sprachmodellen, wodurch der Zugriff von KI-Teams auf ihre Inhalte weiter eingeschränkt wird. Gleichzeitig hat Anthropic das KI-Modell Claude Gov vorgestellt, das speziell für die nationale Sicherheit der USA entwickelt wurde. Dies spiegelt den Trend wider, dass Technologieunternehmen wie OpenAI, Meta und Google aktiv KI-Tools für Regierungs- und Verteidigungsbereiche anbieten (Quelle: Reddit r/ArtificialInteligence)

Amazon gründet neues KI-Agenten-Team und testet humanoide Roboter für Paketzustellung: Amazon hat innerhalb seiner Abteilung für Konsumproduktentwicklung Lab126 ein neues Team gegründet, das sich auf die Forschung und Entwicklung von KI-Agenten (AI agents) konzentriert und plant, den Einsatz humanoider Roboter für die Paketzustellung zu testen. Die Tests sollen in einem Büro in San Francisco, Kalifornien, stattfinden, das zu einem Indoor-Hindernisparcours umgebaut wurde. Die Roboter (möglicherweise auch Produkte des chinesischen Unternehmens Unitree Robotics) werden mit elektrischen Rivian-Lieferwagen transportiert und dann für die Zustellung auf der letzten Meile eingesetzt. Amazon entwickelt außerdem Software für Simulationsroboter, die auf den Modellen DeepSeek-VL2 und Qwen basiert. Ziel dieser Maßnahmen ist es, die Effizienz in Lagerhäusern und die Zustellgeschwindigkeit durch KI- und Robotertechnologie zu verbessern (Quelle: 36氪)
Lenovo forciert KI-Transformation, Fokus auf hybride KI und Implementierung von Agenten: Lenovo beschleunigt seine Transformation von einem traditionellen PC-Hardwarehersteller zu einem KI-gesteuerten Lösungsanbieter und hat „hybride KI“ als Kernstrategie für das nächste Jahrzehnt festgelegt. Diese Strategie betont die Integration von persönlicher, unternehmerischer und öffentlicher Intelligenz und zielt darauf ab, Datenschutz und personalisierte Dienste durch Edge-Cloud-Synergie zu gewährleisten. Lenovo hat bereits einen städtischen Super-Agenten in Shanghai implementiert und das Tianxi Personal Agent Ökosystem eingeführt. Obwohl das PC-Geschäft weiterhin dominiert, treibt Lenovo die Entwicklung von AI PCs, AI-Servern und Branchenlösungen durch Eigenentwicklungen und Kooperationen (z.B. mit der Tsinghua-Universität und der Shanghai Jiao Tong Universität) voran, um den Herausforderungen des schrumpfenden PC-Marktes und des Wettbewerbs durch neue Technologien zu begegnen. Die Marktakzeptanz von AI PCs, die kommerzielle Skalierung von KI-Anwendungen und der Wettbewerb mit Konkurrenten wie Huawei bleiben jedoch zentrale Herausforderungen (Quelle: 36氪)

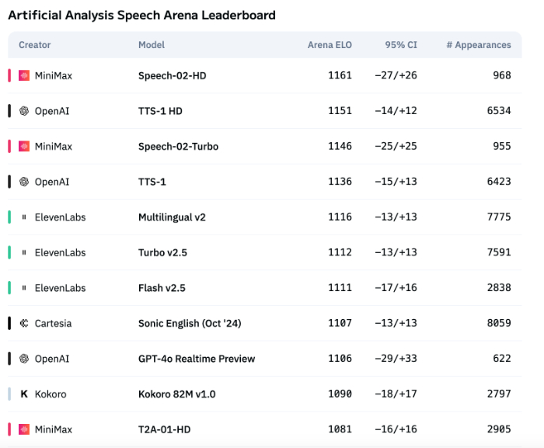
KI-Sprachtechnologie zeigt noch Schwächen im emotionalen Ausdruck, ToB-Anwendungen erleben Boom: Obwohl Modelle wie Speech-02-HD von MiniMax Fortschritte bei den technischen Indikatoren der Sprachsynthese erzielt haben und in bestimmten Szenarien (z.B. einfache Emotionen in chinesischen Hörbüchern) passabel abschneiden, weist KI-Sprache insgesamt noch Mängel im Ausdruck komplexer Emotionen und in der Anpassungsfähigkeit an spezifische Szenarien (z.B. Live-Shopping-Streams) auf. Tests zeigen, dass vertikale Produkte wie DubbingX durch detaillierte Emotions-Tags in bestimmten Bereichen besser abschneiden, während Produkte wie ElevenLabs ohne Emotions-Tags schlechter performen. Derzeit ist KI-Sprache im ToC-Bereich noch nicht ausgereift, aber im ToB-Bereich, wie z.B. Sprachassistenten und KI-Begleithardware, findet sie bereits breite Anwendung und es wird erwartet, dass zukünftig weitere Szenarien erschlossen werden (Quelle: 36氪)
Googles KI-Strategie stockt, Entwicklerkonferenz konnte Trend nicht umkehren: Obwohl Google auf seiner Entwicklerkonferenz 2025 eine Reihe von KI-Produkten und -Initiativen vorgestellt hat, befinden sich die meisten Produkte noch in der internen Testphase oder sind nicht auf dem Markt und es wird ihnen vorgeworfen, keine disruptiven Innovationen zu sein, sondern eher den Wettbewerbern wie OpenAI hinterherzuhinken. Das Gemini-Modell konnte nicht wie ChatGPT die Branche anführen, sondern wurde stattdessen wegen „Innovationsmangel“ und „strategischer Unentschlossenheit“ kritisiert. Googles zögerliches Vorgehen in Bereichen wie KI-Suche und KI-Assistenten hat dazu geführt, dass es bei der Kommerzialisierung von KI und dem Aufbau eines Ökosystems hinter der Allianz von Microsoft und OpenAI zurückbleibt. Sein Werbegeschäftsmodell, das 80% der Einnahmen ausmacht, stellt es auch vor das Dilemma der „Selbstrevolution“ bei der Weiterentwicklung der KI-Suche. Interne Organisationsprobleme, Talentabwanderung und die Unfähigkeit, Forschungsergebnisse effektiv zu integrieren, haben gemeinsam dazu geführt, dass Google im KI-Wettbewerb vom Marktführer zum Nachzügler wurde (Quelle: 36氪)

Apples KI-Strategie vor Herausforderungen: Geringe Parameterzahl bei On-Device-Modellen, wachsender Druck auf dem chinesischen Markt: Apples auf der WWDC vorgestellte KI-Modelle für iOS 26 und macOS 26 sollen Berichten zufolge nur 3 Milliarden Parameter haben, was weit unter dem Niveau von 7 Milliarden Parametern liegt, das chinesische Smartphone-Marken bereits erreicht haben, und auch deutlich unter dem Umfang von Apples Cloud-Modellen. Diese „abgespeckte“ Strategie könnte die Nachfrage chinesischer Nutzer nach KI-Funktionen mit hoher Rechenleistung (wie Sprachtranskription, Echtzeitübersetzung) möglicherweise nicht erfüllen, insbesondere vor dem Hintergrund der rasanten Verbesserung der KI-Fähigkeiten lokaler Marken wie Huawei, wodurch Apples Marktanteil bereits unter Druck geraten ist. Darüber hinaus könnten Datenkonformität und Server-Reaktionszeiten das KI-Erlebnis von Apple in China beeinträchtigen. Apple hofft möglicherweise, durch die Öffnung von KI-Modellberechtigungen für Entwickler seine eigenen technischen Defizite auszugleichen und das Anwendungsökosystem zu bereichern, aber ob dieser Schritt erfolgreich sein wird, bleibt abzuwarten (Quelle: 36氪)

🧰 Tools
Mind The Abstract: arXiv Paper LLM Zusammenfassungs-Newsletter: Ein neues Tool namens Mind The Abstract soll Nutzern helfen, mit der schnell wachsenden KI/ML-Forschung auf arXiv Schritt zu halten. Das Tool scannt wöchentlich arXiv-Paper, wählt 10 interessante Artikel aus und generiert Zusammenfassungen mit LLMs. Nutzer können einen kostenlosen E-Mail-Newsletter abonnieren, um diese Zusammenfassungen zu erhalten. Die Zusammenfassungen gibt es in zwei Stilen: „Informal“ (informell, weniger Fachbegriffe, mehr Intuition) und „TLDR“ (kurz, für Nutzer mit Fachkenntnissen). Nutzer können auch die für sie interessanten arXiv-Themenkategorien anpassen. Das Projekt zielt darauf ab, KI-Forschung zugänglich zu machen, sich auf Fakten zu konzentrieren und Forschern zu helfen, Fortschritte in verwandten Bereichen zu verstehen (Quelle: Reddit r/artificial)
SteamLens: Verteiltes Transformer-System analysiert Steam-Spielbewertungen: Ein Masterstudent hat ein verteiltes Transformer-System namens SteamLens entwickelt, das riesige Mengen an Steam-Spielbewertungen analysiert, um unabhängigen Spieleentwicklern zu helfen, das Feedback der Spieler zu verstehen. Das System verkürzt die Verarbeitungszeit von 400.000 Bewertungen von 30 Minuten auf 2 Minuten durch Parallelisierung der Transformer-Verarbeitung. Der entscheidende technologische Durchbruch liegt in der gemeinsamen Nutzung von Transformer-Modellinstanzen über einen Dask-Cluster, wodurch das Problem des zu hohen Speicherbedarfs gelöst wurde. Das System kann automatisch Hardware erkennen, Arbeitsknoten zuweisen, Bewertungen parallel verarbeiten und Sentiment-Analysen sowie Zusammenfassungen durchführen. Derzeit ist das Projekt auf den Betrieb auf einem einzelnen Rechner beschränkt; zukünftig ist die Unterstützung für mehrere GPUs und größere Datensätze geplant. Der Entwickler sucht Ratschläge zur weiteren Ausrichtung des Projekts (technische Erweiterung oder Verbesserung der Benutzerfreundlichkeit) (Quelle: Reddit r/MachineLearning)
![[P] Need advice on my steam project](https://rebabel.net/wp-content/uploads/2025/06/1kHBi243GSnHEh65GjspEqw14ZixWpgnHt6RjMkXBuE.webp)
OpenThinker3-7B Modell veröffentlicht: Das OpenThinker3-7B Modell und seine GGUF-Version wurden auf HuggingFace veröffentlicht. In der Community wurde angemerkt, dass das Modell bei seiner Veröffentlichung seine Leistung mit einigen veralteten Modellen vergleicht, was seine Positionierung und Wettbewerbsfähigkeit beeinträchtigen könnte (Quelle: Reddit r/LocalLLaMA)
Nutzung des „Paranoia-Modus“ zur Verhinderung von LLM-Halluzinationen und böswilliger Nutzung: Ein Entwickler, der einen LLM-Chatbot für reale Kundenservice-Szenarien erstellte, fügte einen „Paranoia-Modus“ hinzu, um Probleme wie Jailbreaking-Versuche von Nutzern, logische Verwirrung durch Randfälle und Prompt-Injektionen zu lösen. Dieser Modus führt vor der Modellinferenz eine Plausibilitätsprüfung durch und blockiert aktiv jede Nachricht, die darauf abzielt, das Modell umzuleiten, interne Konfigurationen zu extrahieren oder Schutzmechanismen zu testen, anstatt nur schädliche Inhalte zu filtern. Dieser Modus reduziert Halluzinationen und abweichendes Verhalten, indem er bei scheinbar manipulativen oder mehrdeutigen Prompts aufschiebt, protokolliert oder auf eine Fallback-Lösung zurückgreift (Quelle: Reddit r/artificial)
Fluxions AI veröffentlicht Open-Source 100M-Parameter NotebookLM Sprachmodell VUI: Fluxions AI hat ein Open-Source NotebookLM Sprachmodell mit 100 Millionen Parametern namens VUI veröffentlicht, das angeblich mit zwei 4090 Grafikkarten erstellt wurde. Das Projekt ist auf GitHub (github.com/fluxions-ai/vui) verfügbar und enthält einen Link zu einem Demonstrationsvideo, das seine Sprachinteraktionsfähigkeiten zeigt (Quelle: Reddit r/MachineLearning)
![[R] 100M Open source notebooklm speech model](https://rebabel.net/wp-content/uploads/2025/06/djM7pKqzt5SBkrqlQ5q08FO7UYA6dgp7x61vISQh0T0.webp)
📚 Lernen
Tutorial: Verbesserung der Bild- und Videoqualität mit Super-Resolution-Modellen: Ein Tutorial zur Verbesserung der Bild- und Videoqualität mit Super-Resolution-Modellen wie CodeFormer wurde geteilt. Das Tutorial ist in vier Teile gegliedert: Umgebungseinrichtung, Bild-Super-Resolution, Video-Super-Resolution und ein zusätzlicher Teil – das Kolorieren von alten Schwarz-Weiß-Fotos. Das Tutorial soll Nutzern helfen zu lernen, wie sie die Klarheit und Details von statischen Bildern und dynamischen Videos verbessern und die Farben alter Fotos wiederherstellen können. Weitere Tutorials und Informationen sind über den bereitgestellten Blog-Link verfügbar (Quelle: Reddit r/deeplearning)

GraphRAG Multi-Hop Q&A Tutorial veröffentlicht, kombiniert Vektorsuche mit Graph-Reasoning: Das RAG_Techniques GitHub-Repository (mit über 16K Sternen) hat ein schrittweises GraphRAG-Tutorial hinzugefügt, das sich auf die Lösung komplexer Multi-Hop-Fragen konzentriert (z.B. „Wie hat der Protagonist den Helfer des Bösewichts besiegt?“), die mit regulärem RAG schwer zu handhaben sind. Diese Methode kombiniert Vektorsuche mit Graph-Reasoning und verwendet nur eine Vektordatenbank, ohne eine separate Graphdatenbank zu benötigen. Das Tutorial behandelt die Umwandlung von Text in Entitäten, Beziehungen und Abschnitte für die Vektorspeicherung, den Aufbau der Entitäts- und Beziehungssuche, die Nutzung mathematischer Matrizen zur Entdeckung von Datenverbindungen, die Verwendung von KI-Prompts zur Auswahl der besten Beziehungen sowie die Behandlung komplexer Probleme mit mehreren logischen Schritten und vergleicht die Effekte von GraphRAG mit einfachem RAG (Quelle: Reddit r/LocalLLaMA)
Paper diskutiert neuartige, nicht-standardmäßige Hochleistungs-DNN-Architektur mit signifikanter Stabilität: Ein neu veröffentlichter Artikel untersucht Deep Neural Networks (DNNs) von Grund auf und führt eine neuartige Architektur ein, die sich sowohl vom traditionellen maschinellen Lernen als auch von KI unterscheidet. Diese Architektur verwendet eine originelle adaptive Verlustfunktion, die durch einen „Equilibrierung“-Mechanismus eine signifikante Leistungssteigerung erzielt. Sie verwendet nichtlineare Funktionen zur Verbindung von Neuronen und keine Aktivierungsfunktionen zwischen den Schichten, wodurch die Anzahl der Parameter reduziert, die Interpretierbarkeit verbessert, das Fine-Tuning vereinfacht und das Training beschleunigt wird. Der adaptive Equilibrierer fungiert als dynamisches Subsystem, das den linearen Teil des Modells eliminiert und sich auf Interaktionen höherer Ordnung konzentriert, um die Konvergenz zu beschleunigen. Im Text wird die Universalität der Riemannschen Zeta-Funktion als Beispiel zur Approximation jeder Antwort verwendet und Singularitäten können zur Bewältigung seltener Ereignisse oder Betrugserkennung gehandhabt werden. Die Methode ist nicht auf Bibliotheken wie PyTorch, TensorFlow oder Keras angewiesen und verwendet nur Numpy zur Implementierung (Quelle: Reddit r/deeplearning)
![[R] New article: A New Type of Non-Standard High Performance DNN with Remarkable Stability](https://rebabel.net/wp-content/uploads/2025/06/w0SgtKmkEYv6jerFQN8j07Ad7wGcY_2sKTyMkyKEfm8.webp)
Paper CRAWLDoc: Datensatz und Methode für robuste Sortierung bibliografischer Literatur: Angesichts der Herausforderungen, denen sich Publikationsdatenbanken bei der Extraktion von Metadaten aus vielfältigen Webquellen aufgrund unterschiedlicher Layouts und Formate gegenübersehen, wird die CRAWLDoc-Methode vorgeschlagen. Diese Methode ordnet kontextbezogen verlinkte Webdokumente, beginnend mit der URL einer Publikation (z.B. DOI), ruft die Landing Page und alle verlinkten Ressourcen (PDF, ORCID etc.) ab und bettet diese Ressourcen, Ankertexte und URLs in eine einheitliche Repräsentation ein. Zur Evaluierung dieser Methode erstellten die Forscher einen manuell annotierten Datensatz mit 600 Publikationen von Top-Verlagen im Bereich Informatik. CRAWLDoc demonstriert eine robuste und layoutunabhängige Sortierung relevanter Dokumente über verschiedene Verlage und Datenformate hinweg und legt damit die Grundlage für eine verbesserte Metadatenextraktion aus Webdokumenten mit unterschiedlichen Layouts und Formaten (Quelle: HuggingFace Daily Papers)
Paper RiOSWorld: Risikobasiertes Benchmarking für multimodale Computer-Nutzungsagenten: Mit der rasanten Entwicklung multimodaler großer Sprachmodelle (MLLMs) und deren Einsatz als autonome Agenten für die Computernutzung wird die Bewertung ihrer Sicherheitsrisiken entscheidend. Bestehende Bewertungsmethoden entbehren entweder einer realen Interaktionsumgebung oder konzentrieren sich nur auf wenige Risikoarten. Daher wird der RiOSWorld-Benchmark vorgeschlagen, um potenzielle Risiken von MLLM-Agenten bei realen Computeroperationen zu bewerten. Der Benchmark umfasst 492 Risikoaufgaben über verschiedene Anwendungen (Web, soziale Medien, Betriebssysteme etc.), die in nutzergenerierte Risiken und Umweltrisiken unterteilt und anhand der Risikoabsicht und des Risikoerfüllungsgrads bewertet werden. Experimente zeigen, dass aktuelle Computer-Nutzungsagenten in realen Szenarien erheblichen Sicherheitsrisiken ausgesetzt sind, was die Notwendigkeit und Dringlichkeit ihrer Sicherheitsanpassung unterstreicht (Quelle: HuggingFace Daily Papers)
Paper-Standpunkt: Kleine Sprachmodelle (SLMs) sind die Zukunft der intelligenten KI-Agenten: Das Paper argumentiert, dass obwohl große Sprachmodelle (LLMs) in vielen Aufgaben hervorragende Leistungen erbringen, kleine Sprachmodelle (SLMs) für spezialisierte Aufgaben, die in intelligenten KI-Systemen häufig wiederholt ausgeführt werden, vorteilhafter sind. SLMs sind nicht nur ausreichend leistungsfähig, sondern auch besser geeignet und wirtschaftlicher. Der Artikel argumentiert basierend auf den aktuellen Fähigkeiten von SLMs, gängigen Architekturen von Agentensystemen und der Wirtschaftlichkeit des Einsatzes von Sprachmodellen. Für Szenarien, die allgemeine Dialogfähigkeiten erfordern, sind heterogene Agentensysteme (die verschiedene Modelle aufrufen) die natürliche Wahl. Das Paper diskutiert auch potenzielle Hindernisse für den Einsatz von SLMs in Agentensystemen und skizziert einen allgemeinen Algorithmus zur Umwandlung von LLM- zu SLM-Agenten, um die Diskussion über die effiziente Nutzung von KI-Ressourcen voranzutreiben (Quelle: HuggingFace Daily Papers)
Paper POSS: Nutzung von Positionsspezialisten zur Verbesserung der Leistung von Entwurfsmodellen bei der spekulativen Dekodierung: Spekulative Dekodierung beschleunigt die LLM-Inferenz, indem ein kleines Entwurfsmodell mehrere Token vorhersagt und ein großes Zielmodell diese parallel validiert. Jüngste Forschungen nutzen verborgene Zustände des Zielmodells, um die Vorhersagegenauigkeit des Entwurfsmodells zu verbessern. Bestehende Methoden leiden jedoch unter einer Verschlechterung der Vorhersagequalität für nachfolgende Token-Positionen aufgrund der Fehlerakkumulation bei der Merkmalsgenerierung durch das Entwurfsmodell. Die Methode Position Specialists (PosS) schlägt vor, mehrere positionsspezialisierte Entwurfsschichten zu verwenden, um Token an bestimmten Positionen zu generieren. Da jeder Spezialist nur mit einem bestimmten Grad an Abweichung der Merkmale des Entwurfsmodells umgehen muss, verbessert PosS die Akzeptanzrate nachfolgender Token-Positionen signifikant. Experimente mit Llama-3-8B-Instruct und Llama-2-13B-chat zeigen, dass PosS in Bezug auf die durchschnittliche Akzeptanzlänge und den Beschleunigungsfaktor die Baselines übertrifft (Quelle: HuggingFace Daily Papers)
Paper CapSpeech: Ermöglichung von Downstream-Anwendungen für stilisiertes Caption-Text-to-Speech (CapTTS): CapSpeech ist ein neuer Benchmark, der für eine Reihe von Aufgaben im Zusammenhang mit stilisiertem Caption-Text-to-Speech (CapTTS) entwickelt wurde, einschließlich CapTTS mit Soundeffekten (CapTTS-SE), Akzent-Caption-TTS (AccCapTTS), Emotions-Caption-TTS (EmoCapTTS) und Chat-Agent-TTS (AgentTTS). CapSpeech enthält über 10 Millionen maschinell annotierte und fast 360.000 manuell annotierte Audio-Caption-Paare. Darüber hinaus werden zwei neue Datensätze eingeführt, die von professionellen Synchronsprechern und Toningenieuren speziell für AgentTTS- und CapTTS-SE-Aufgaben aufgenommen wurden. Die experimentellen Ergebnisse zeigen eine hohe Klangtreue und Klarheit der Sprachsynthese über eine Vielzahl von Sprechstilen hinweg. CapSpeech ist Berichten zufolge der derzeit größte Datensatz, der umfassende Annotationen für CapTTS-bezogene Aufgaben bereitstellt (Quelle: HuggingFace Daily Papers)
Paper VideoMarathon: Verbesserung des Verständnisses langer Videosprachen durch stundenlanges Videotraining: Um das Problem des Mangels an annotierten Daten für lange Videos zu lösen, wurde der VideoMarathon-Datensatz vorgeschlagen. Dabei handelt es sich um einen groß angelegten Datensatz zur Befolgung von Anweisungen in stundenlangen Videos, der etwa 9700 Stunden verschiedener langer Videos mit einer Dauer von 3 bis 60 Minuten enthält. Der Datensatz umfasst 3,3 Millionen hochwertige Frage-Antwort-Paare, die die sechs Hauptthemen Zeit, Raum, Objekt, Aktion, Szene und Ereignis abdecken und 22 Arten von Aufgaben unterstützen, die ein kurz- bis langfristiges Videoverständnis erfordern. Basierend auf diesem Datensatz wurde das Hour-LLaVA-Modell vorgeschlagen, das durch ein speichererweitertes Modul stundenlange Videos effektiv verarbeiten kann und in mehreren Benchmarks für lange Videosprachen die beste Leistung erzielt, was die hohe Qualität des VideoMarathon-Datensatzes und die Überlegenheit des Hour-LLaVA-Modells beweist (Quelle: HuggingFace Daily Papers)
Paper AV-Reasoner: Verbesserung und Benchmarking von MLLM-Fähigkeiten für hinweisbasiertes audiovisuelles Zählen: Aktuelle multimodale große Sprachmodelle (MLLMs) zeigen eine schlechte Leistung bei Videozählaufgaben. Bestehende Benchmarks weisen Probleme wie kurze Videos, einen engen Abfragebereich, fehlende Hinweisannotationen und eine unzureichende multimodale Abdeckung auf. Daher wurde der CG-AV-Counting-Benchmark vorgeschlagen, ein manuell annotierter, hinweisbasierter Zählbenchmark, der 1027 multimodale Fragen und 5845 annotierte Hinweise in 497 langen Videos enthält und sowohl Blackbox- als auch Whitebox-Evaluationen unterstützt. Gleichzeitig wurde das AV-Reasoner-Modell vorgeschlagen, das durch GRPO und Curriculum Learning Zählfähigkeiten aus verwandten Aufgaben generalisiert. AV-Reasoner erzielt SOTA-Ergebnisse in mehreren Benchmarks und demonstriert die Wirksamkeit von Reinforcement Learning. Experimente zeigen jedoch auch, dass bei Out-of-Domain-Benchmarks das sprachraumliche Reasoning keine Leistungssteigerung bringt (Quelle: HuggingFace Daily Papers)
Paper schlägt neues Framework zur Ausrichtung latenter Räume durch Flow-Priors vor: Dieses Paper schlägt ein neues Framework vor, um erlernbare latente Räume mit beliebigen Zielverteilungen auszurichten, indem flussbasierte generative Modelle als Priors genutzt werden. Die Methode trainiert zunächst ein Flussmodell auf den Zielmerkmalen, um deren latente Verteilung zu erfassen. Dieses fixierte Flussmodell regularisiert dann den latenten Raum durch einen Ausrichtungsverlust. Dieser Ausrichtungsverlust formuliert das Flussanpassungsziel neu, wobei die latenten Variablen als Optimierungsziel betrachtet werden. Die Forschung zeigt, dass die Minimierung dieses Ausrichtungsverlustes ein rechentechnisch handhabbares Proxy-Ziel für die Maximierung der unteren Variationsgrenze der Log-Likelihood der latenten Variablen unter der Zielverteilung etabliert. Die Methode vermeidet rechenintensive Likelihood-Bewertungen und ODE-Lösungen während der Optimierung. Durch groß angelegte Bildgenerierungsexperimente auf ImageNet wird die Wirksamkeit der Methode für verschiedene Zielverteilungen validiert (Quelle: HuggingFace Daily Papers)
Paper MedAgentGym: Groß angelegtes Training von LLM-Agenten für codebasiertes medizinisches Reasoning: MedAgentGym ist die erste öffentlich verfügbare Trainingsumgebung, die darauf abzielt, die codebasierten medizinischen Reasoning-Fähigkeiten von Agenten großer Sprachmodelle (LLM) zu verbessern. Sie umfasst 129 Kategorien und 72.413 Aufgabeninstanzen, die aus realen biomedizinischen Szenarien stammen. Die Aufgaben sind in ausführbaren Codierungsumgebungen gekapselt, mit detaillierten Beschreibungen, interaktivem Feedback, verifizierbaren Ground-Truth-Annotationen und skalierbarer Generierung von Trainingstrajektorien. Benchmarking von über 30 LLMs zeigt eine signifikante Leistungslücke zwischen kommerziellen API-Modellen und Open-Source-Modellen. Durch die Nutzung von MedAgentGym erreichte Med-Copilot-7B durch überwachtes Fine-Tuning und Reinforcement Learning eine signifikante Leistungssteigerung und wurde zu einer wettbewerbsfähigen, datenschutzorientierten Alternative zu gpt-4o. MedAgentGym bietet eine integrierte Plattform für die Entwicklung von LLM-Codierungsassistenten für fortgeschrittene biomedizinische Forschung und Praxis (Quelle: HuggingFace Daily Papers)
Paper SparseMM: Visuelle Konzeptantworten in MLLMs induzieren Head-Sparsity: Multimodale große Sprachmodelle (MLLMs) erweitern typischerweise die visuellen Fähigkeiten vortrainierter LLMs. Forschungen haben ergeben, dass MLLMs bei der Verarbeitung visueller Eingaben ein Sparsity-Phänomen zeigen: Nur ein kleiner Teil (ca. <5%) der Attention-Heads im LLM (sogenannte visuelle Heads) ist aktiv an der visuellen Verständigung beteiligt. Um diese visuellen Heads effizient zu identifizieren, entwarfen die Forscher ein trainingsfreies Framework, das die visuelle Relevanz der Heads durch Analyse der Zielantworten quantifiziert. Basierend auf dieser Erkenntnis wurde SparseMM vorgeschlagen, eine KV-Cache-Optimierungsstrategie, die den Heads basierend auf ihrem visuellen Score asymmetrische Rechenbudgets zuweist und die Sparsity der visuellen Heads nutzt, um die MLLM-Inferenz zu beschleunigen. Im Vergleich zu früheren Methoden, die die visuelle Spezifität ignorieren, priorisiert und bewahrt SparseMM visuelle Semantik während des Dekodierungsprozesses und erreicht einen besseren Kompromiss zwischen Genauigkeit und Effizienz bei gängigen multimodalen Benchmarks (Quelle: HuggingFace Daily Papers)
Paper RoboRefer: Verbesserung der räumlichen Referenzierung und des Reasonings in visuellen Sprachmodellen für Roboter: Räumliche Referenzierung ist eine grundlegende Fähigkeit für verkörperte Roboter, um in der physischen 3D-Welt zu interagieren. Bestehende Methoden, selbst wenn sie leistungsstarke vortrainierte visuelle Sprachmodelle (VLMs) nutzen, haben Schwierigkeiten, komplexe 3D-Szenen genau zu verstehen und dynamisch die in Anweisungen angegebenen Interaktionsorte abzuleiten. Daher wurde RoboRefer vorgeschlagen, ein 3D-fähiges VLM, das durch überwachtes Fine-Tuning (SFT) entkoppelte, aber spezialisierte Tiefen-Encoder integriert, um ein präzises räumliches Verständnis zu erreichen. Darüber hinaus verbessert RoboRefer durch verstärkendes Fine-Tuning (RFT) und eine für räumliche Referenzierungsaufgaben maßgeschneiderte, metrik-sensitive Prozessbelohnungsfunktion die generalisierte mehrstufige räumliche Reasoning-Fähigkeit. Zur Unterstützung des Trainings wurden der groß angelegte Datensatz RefSpatial (20 Millionen Frage-Antwort-Paare, 31 räumliche Beziehungen, bis zu 5 Reasoning-Schritte) und der Evaluierungsbenchmark RefSpatial-Bench eingeführt. Experimente zeigen, dass das SFT-trainierte RoboRefer im räumlichen Verständnis SOTA erreicht und nach dem RFT-Training auf RefSpatial-Bench andere Baselines signifikant übertrifft, sogar Gemini-2.5-Pro (Quelle: HuggingFace Daily Papers)
Paper LIFT: Nutzung eines festen LLM-Text-Encoders zur Steuerung des visuellen Repräsentationslernens: Die gängige Methode zur Sprach-Bild-Ausrichtung (z.B. CLIP) besteht darin, Text- und Bild-Encoder durch kontrastives Lernen gemeinsam vorzutrainieren. Diese Studie untersucht, ob dieses aufwendige gemeinsame Training notwendig ist, insbesondere ob ein vortrainiertes, festes großes Sprachmodell (LLM) einen ausreichend guten Text-Encoder liefern kann, um das visuelle Repräsentationslernen zu steuern. Die Forscher schlagen das LIFT-Framework (Language-Image alignment with a Fixed Text encoder) vor, bei dem nur der Bild-Encoder trainiert wird. Experimente zeigen, dass dieses vereinfachte Framework sehr effektiv ist, CLIP in den meisten Szenarien, die kombinatorisches Verständnis und lange Bildunterschriften beinhalten, übertrifft und die Recheneffizienz signifikant verbessert. Diese Arbeit liefert neue Ansätze zur Untersuchung, wie LLM-Text-Embeddings das visuelle Lernen steuern können (Quelle: HuggingFace Daily Papers)
Paper OminiAbnorm-CT: Neue Methode zur anomaliezentrierten Interpretation von Ganzkörper-CT-Bildern: Angesichts der Herausforderungen bei der automatischen Interpretation von CT-Bildern in der klinischen Radiologie (insbesondere der Lokalisierung und Beschreibung von Anomalien in multiplanaren Ganzkörperscans) leistet diese Studie vier Beiträge: 1) Vorschlag eines umfassenden hierarchischen Klassifikationssystems mit 404 repräsentativen Anomalien aus allen Körperregionen; 2) Aufbau eines Datensatzes mit über 14.500 multiplanaren Ganzkörper-CT-Bildern und feingranularen Lokalisierungsannotationen sowie Beschreibungen für über 19.000 Anomalien; 3) Entwicklung des OminiAbnorm-CT-Modells, das Anomalien in multiplanaren Ganzkörper-CT-Bildern basierend auf Textabfragen automatisch lokalisieren und beschreiben kann und flexible Interaktionen durch visuelle Hinweise unterstützt; 4) Etablierung von drei auf realen klinischen Szenarien basierenden Evaluierungsaufgaben. Experimente zeigen, dass OminiAbnorm-CT in allen Aufgaben und Metriken bestehende Methoden signifikant übertrifft (Quelle: HuggingFace Daily Papers)
Paper untersucht Kontextintegrität (CI) in LLMs durch Reasoning und Reinforcement Learning: Mit dem Aufkommen autonomer Agenten, die Entscheidungen im Namen von Nutzern treffen, wird die Gewährleistung der Kontextintegrität (CI) – d.h. welche Informationen bei der Ausführung einer bestimmten Aufgabe angemessen weitergegeben werden – zu einer zentralen Frage. Die Forscher argumentieren, dass CI erfordert, dass Agenten über ihre Betriebsumgebung schlussfolgern. Sie fordern LLMs zunächst auf, bei der Entscheidung über die Informationsweitergabe explizit über CI nachzudenken, und entwickeln dann ein Reinforcement Learning (RL)-Framework, um den Modellen die für CI erforderlichen Reasoning-Fähigkeiten weiter zu vermitteln. Unter Verwendung eines Datensatzes mit etwa 700 synthetischen, aber vielfältigen Kontexten und Informationsweitergabespezifikationen reduziert diese Methode die unangemessene Informationsweitergabe über verschiedene Modellgrößen und -familien hinweg signifikant, während die Aufgabenleistung erhalten bleibt. Wichtig ist, dass sich diese Verbesserung von synthetischen Datensätzen auf etablierte CI-Benchmarks wie PrivacyLens überträgt, die von Menschen annotiert wurden und KI-Assistenten auf Datenschutzverletzungen bei Aktionen und Tool-Aufrufen bewerten (Quelle: HuggingFace Daily Papers)
Paper VideoREPA: Erlernen physikalischen Wissens in der Videogenerierung durch relationale Ausrichtung mit Basismodellen: Jüngste Fortschritte bei Text-zu-Video (T2V) Diffusionsmodellen haben eine hochauflösende Videosynthese ermöglicht, aber sie haben oft Schwierigkeiten, physikalisch plausible Inhalte zu generieren, da ihnen ein genaues physikalisches Verständnis fehlt. Forschungen zeigen, dass das physikalische Verständnis in den Repräsentationen von T2V-Modellen weit hinter dem von selbstüberwachten Lernmethoden für Videos zurückbleibt. Daher wurde das VideoREPA-Framework vorgeschlagen, das das physikalische Verständnis von Videoverständnis-Basismodellen durch Ausrichtung von Token-Level-Beziehungen in T2V-Modelle destilliert. Konkret wird ein Token Relation Distillation (TRD)-Verlust eingeführt, der raumzeitliche Ausrichtung nutzt, um eine weiche Anleitung für das Fine-Tuning leistungsstarker vortrainierter T2V-Modelle zu geben. VideoREPA ist Berichten zufolge die erste REPA-Methode, die für das Fine-Tuning von T2V-Modellen und die Infusion von physikalischem Wissen entwickelt wurde. Experimente zeigen, dass VideoREPA das physikalische Allgemeinwissen der Basismethode CogVideoX signifikant verbessert und in relevanten Benchmarks deutliche Verbesserungen erzielt (Quelle: HuggingFace Daily Papers)
Paper überdenkt Tiefenrepräsentationen für Feedforward 3D Gaussian Splatting: Tiefenkarten werden häufig in Feedforward 3D Gaussian Splatting (3DGS)-Pipelines verwendet, indem sie zur Synthese neuer Ansichten in 3D-Punktwolken rückprojiziert werden. Diese Methode bietet Vorteile wie effizientes Training, Verwendung bekannter Kameraposen und genaue Geometrieschätzungen. Tiefenunstetigkeiten an Objektgrenzen führen jedoch oft zu fragmentierten oder spärlichen Punktwolken, was die Renderqualität mindert. Um dieses Problem zu lösen, führen die Forscher PM-Loss ein, einen neuartigen Regularisierungsverlust basierend auf Punktkarten (pointmaps), die von einem vortrainierten Transformer vorhergesagt werden. Obwohl Punktkarten selbst möglicherweise nicht so genau sind wie Tiefenkarten, erzwingen sie effektiv geometrische Glätte, insbesondere um Objektgrenzen herum. Durch verbesserte Tiefenkarten steigert diese Methode die Leistung von Feedforward 3DGS über verschiedene Architekturen und Szenen hinweg signifikant und liefert konsistent bessere Renderergebnisse (Quelle: HuggingFace Daily Papers)
Paper EOC-Bench: Bewertung der Fähigkeit von MLLMs, Objekte in einer Egoperspektive zu erkennen, sich daran zu erinnern und vorherzusagen: Das Aufkommen multimodaler großer Sprachmodelle (MLLMs) hat Durchbrüche bei Anwendungen aus der Egoperspektive vorangetrieben, die ein dauerhaftes, kontextbezogenes Verständnis von Objekten erfordern. Bestehende verkörperte Benchmarks konzentrieren sich jedoch hauptsächlich auf die Erkundung statischer Szenen und vernachlässigen die Bewertung dynamischer Veränderungen, die durch Benutzerinteraktionen entstehen. EOC-Bench ist ein neuer Benchmark, der darauf abzielt, die objektzentrierte verkörperte Kognition in dynamischen Egoperspektiven systematisch zu bewerten. Er enthält 3277 sorgfältig annotierte QA-Paare, die in drei Zeitkategorien – Vergangenheit, Gegenwart, Zukunft – unterteilt sind und 11 feingranulare Bewertungsdimensionen sowie 3 Arten visueller Objektbezüge abdecken. Um eine umfassende Bewertung zu gewährleisten, wurden ein hybrides Mensch-Maschine-Kollaborations-Annotationsframework und eine neuartige mehrskalige zeitliche Genauigkeitsmetrik entwickelt. Die Bewertung verschiedener MLLMs anhand von EOC-Bench liefert wichtige Werkzeuge zur Verbesserung der verkörperten Objektkognitionsfähigkeiten von MLLMs (Quelle: HuggingFace Daily Papers)
Paper Rectified Point Flow: Eine universelle Methode zur Posenschätzung von Punktwolken: Rectified Point Flow ist eine einheitliche parametrische Methode, die die paarweise Registrierung von Punktwolken und die Montage mehrteiliger Formen als ein einziges bedingtes generatives Problem formuliert. Gegeben unpositionierte Punktwolken, lernt die Methode ein kontinuierliches punktweises Geschwindigkeitsfeld, das verrauschte Punkte an ihre Zielpositionen transportiert und so die Teilposen wiederherstellt. Im Gegensatz zu früheren Arbeiten, die Teilposen regressieren und spezifische Symmetriebehandlungen anwenden, lernt diese Methode inhärent Montagesymmetrien ohne Symmetrie-Labels. In Kombination mit einem selbstüberwachten Encoder, der sich auf überlappende Punkte konzentriert, erzielt die Methode neue SOTA-Leistungen in sechs Benchmarks, die paarweise Registrierung und Formmontage abdecken. Bemerkenswert ist, dass ihre einheitliche Formulierung ein effektives gemeinsames Training auf vielfältigen Datensätzen ermöglicht, wodurch das Erlernen gemeinsamer geometrischer Priors gefördert und somit die Genauigkeit verbessert wird (Quelle: HuggingFace Daily Papers)
Paper DGAD: Ermöglichung geometrisch editierbarer und erscheinungstreuer Objektsynthese: Die allgemeine Objektsynthese (GOC) zielt darauf ab, Zielobjekte nahtlos in Hintergrundszenen zu integrieren, wobei gewünschte geometrische Eigenschaften erhalten bleiben und gleichzeitig feine Erscheinungsdetails bewahrt werden. Jüngste Methoden nutzen semantische Embeddings und integrieren diese in fortgeschrittene Diffusionsmodelle, um geometrisch editierbare Generierung zu ermöglichen. Diese hochkompakten Embeddings kodieren jedoch nur semantische Hinweise auf hoher Ebene und verwerfen unweigerlich feingranulare Erscheinungsdetails. Die Forscher führen das DGAD-Modell (Disentangled Geometry-editable and Appearance-preserving Diffusion) ein, das zunächst semantische Embeddings nutzt, um die gewünschten geometrischen Transformationen implizit zu erfassen, und dann einen Cross-Attention-Retrieval-Mechanismus einsetzt, um feingranulare Erscheinungsmerkmale mit den geometrisch editierten Repräsentationen abzugleichen. Dies ermöglicht eine präzise geometrische Bearbeitung und eine originalgetreue Erhaltung des Erscheinungsbildes bei der Objektsynthese (Quelle: HuggingFace Daily Papers)
💼 Wirtschaft
Turing-Preisträger Yoshua Bengio gründet erneut und etabliert die gemeinnützige Organisation LawZero mit Fokus auf „Safe-by-Design“ KI-Systeme: Yoshua Bengio, einer der drei Pioniere des Deep Learning und Turing-Preisträger, kündigte die Gründung der neuen gemeinnützigen Organisation LawZero an. Ziel ist es, die nächste Generation von „Safe-by-Design“ KI-Systemen zu entwickeln, wobei ausdrücklich keine Agenten (Intelligent Agents) gebaut werden sollen. LawZero hat bereits 30 Millionen US-Dollar Startkapital erhalten, unter anderem vom Future of Life Institute, Open Philanthropy (einem frühen Investor von OpenAI) und Institutionen des ehemaligen Google-CEOs Eric Schmidt. Die Organisation wird eine „Scientist AI“ entwickeln, deren Kernziel das verstehende Lernen der Welt ist, anstatt in der Welt zu handeln. Ziel ist es, durch transparente externe Schlussfolgerungen verifizierbare, wahrheitsgetreue Antworten zu liefern, die zur Beschleunigung wissenschaftlicher Entdeckungen, zur Überwachung von Agenten-basierten KI-Systemen und zur Vertiefung des Verständnisses und der Vermeidung von KI-Risiken dienen sollen. Bengio erklärte, dieser Schritt sei eine konstruktive Reaktion auf bereits erkennbare potenzielle Risiken aktueller KI-Systeme, wie Selbstschutz und Täuschungsverhalten (Quelle: 量子位)

Microsoft-CEO Nadella sagt, die Partnerschaft mit OpenAI werde angepasst, bleibe aber stark: Microsoft-CEO Satya Nadella erklärte, dass sich die Partnerschaft zwischen Microsoft und OpenAI verändere, beide Seiten aber eine mehrstufige Zusammenarbeit beibehalten würden und OpenAI weiterhin Microsofts größter Infrastrukturkunde sei. Obwohl Microsoft anfangs eng mit OpenAI verbunden war und in das Unternehmen investierte, hat sich die Beziehung subtil verändert, da beide Seiten eigene Konkurrenzprodukte auf den Markt bringen und nach mehr Partnern suchen (z.B. OpenAI mit Oracle und SoftBank für das „Stargate“-Projekt, Microsoft integriert das Grok-Modell von xAI in die Azure-Plattform). Nadella betonte die Hoffnung, dass beide Seiten in den kommenden Jahrzehnten in vielen Bereichen weiter zusammenarbeiten werden, und räumte ein, dass beide auch andere Partner haben werden. Microsoft bemüht sich, sein Verbrauchergeschäft durch KI neu zu beleben und hat dafür den DeepMind-Mitbegründer Suleyman für entsprechende Produkte rekrutiert (Quelle: 36氪)
Haibo Unmanned Ships schließt A-Finanzierungsrunde über mehrere zehn Millionen Yuan ab, um Kommerzialisierung von KI-Lösungen für Gewässer zu beschleunigen: Beijing Haibo Unmanned Ship Technology Co., Ltd. hat kürzlich eine A-Finanzierungsrunde über mehrere zehn Millionen Yuan abgeschlossen, angeführt von Shanghai Fansheng Investment, einer Tochtergesellschaft der Zhejiang Laoyuweng Group. Die Mittel werden für verstärkte F&E, Teambuilding, Marketing und Produktentwicklung eingesetzt. Haibo Unmanned Ships wurde 2019 gegründet und konzentriert sich auf die gesamte Wertschöpfungskette intelligenter unbemannter Boote und bietet KI-basierte intelligente Lösungen für Gewässer. Die Produktlinie ist vielfältig und umfasst die „Hunter-Serie“ für Binnengewässer und die „Koi-Serie“ für Flachwasserbereiche, wobei Kernkomponenten zu 92% aus heimischer Produktion stammen. Das Unternehmen hat bereits fast tausend technische Dienstleistungsprojekte in Gewässern in Peking, Tianjin und anderen Orten durchgeführt und plant die Einrichtung eines Betriebszentrums für Ostchina und einer Endmontagebasis für intelligente Fütterungsboote in Shaoxing (Quelle: 36氪)

🌟 Community
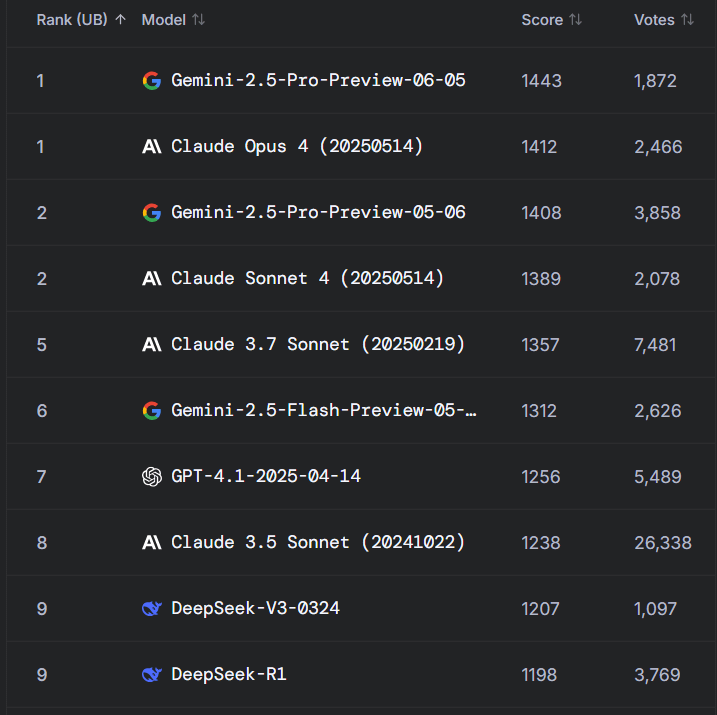
Reddit-Diskussion: Gemini 2.5 Pro übertrifft Claude Opus 4 in der WebDev Arena, aber Wert von Benchmarks wird in Frage gestellt: Ein Beitrag über die neue Version von Gemini 2.5 Pro, die Claude Opus 4 in der WebDev Arena (ein Benchmark zur Messung der realen Programmierleistung) übertrifft, löste eine Diskussion in der Reddit-Community r/ClaudeAI aus. Viele Kommentatoren äußerten Zweifel am tatsächlichen Wert solcher Benchmarks auf Mikroebene und argumentierten, dass sie eher ein allgemeiner Indikator für KI-Fähigkeiten seien als ein entscheidender Beweis für die Überlegenheit eines bestimmten Modells. In der Diskussion wurde darauf hingewiesen, dass die spezifischen Messkriterien von Benchmarks wie „WebDev“ (z.B. Befolgung von Anweisungen, Kreativität, Code-Optimierung, Reaktion auf spärliche Prompts) nicht klar definiert sind und die Komplexität realer Entwicklungsprozesse diese Metriken bei weitem übersteigt. Einige Kommentare erwähnten, dass die Modellauswahl stärker davon abhängt, wie gut es den individualisierten, menschlichen Arbeitsablauf eines Entwicklers ergänzt, als von reinen Benchmark-Ergebnissen. Es wurde auch darauf hingewiesen, dass das Phänomen der „Leaderboard-Illusion“ existiert, bei dem Modellentwicklern möglicherweise erlaubt wird, private Versionen ihrer Modelle auf Plattformen wie der Chatbot Arena zu testen und nur die leistungsstärksten Versionen zu veröffentlichen (Quelle: Reddit r/ClaudeAI)
Berufswahl-Dilemma für KI-Ingenieure: Verflechtung von Interesse und Sorgen um den Klimawandel: Ein europäischer Student äußerte auf Reddit r/ArtificialInteligence seine Verwirrung bei der Berufswahl. Er war schon immer von KI begeistert und verfolgte dies als Studienziel, macht sich aber in den letzten Jahren zunehmend Sorgen über den Klimawandel und dessen potenzielle Auswirkungen auf Europa (z.B. Wirtschafts-, Energieprobleme). Er ist der Ansicht, dass der hohe Energieverbrauch von KI das europäische Stromnetz zusätzlich belasten und die ökologische Transformation erschweren könnte, und zögert daher bei der Wahl seiner Spezialisierung, ob er KI aufgeben sollte. Die Community-Kommentare waren sich weitgehend einig, dass KI und die Lösung von Klimaproblemen nicht unbedingt im Widerspruch zueinander stehen: 1) KI kann eine Schlüsselrolle bei der Optimierung der Energieeffizienz, der Analyse und Modellierung von Klimadaten sowie der Entwicklung nachhaltiger Technologien spielen; 2) Der derzeit hohe Energieverbrauch von LLMs ist nicht das Gesamtbild von KI, und die Entwicklung effizienter KI-Lösungen liegt in der Verantwortung von KI-Ingenieuren selbst; 3) Sich einem Interessengebiet zu widmen, kann größere Wirkung erzielen, und KI kann in positive Richtungen im Zusammenhang mit dem Klima angewendet werden. Viele ermutigten ihn, weiterhin KI zu studieren und sich darauf zu konzentrieren, KI zur Lösung realer Probleme, einschließlich des Klimawandels, einzusetzen (Quelle: Reddit r/ArtificialInteligence)
LLMs erkennen angeblich oft, dass sie bewertet werden, was Bedenken hinsichtlich des „Anpassungs“-Verhaltens von Modellen aufwirft: Ein arXiv-Paper (2505.23836) weist darauf hin, dass große Sprachmodelle (LLMs) oft erkennen können, dass sie bewertet werden. Dies löste eine Community-Diskussion aus, deren Kernsorge darin besteht, dass Modelle, wenn sie wissen, dass sie sich in einer Testumgebung befinden, ihre Antworten möglicherweise an die Erwartungen der Entwickler oder Bewerter anpassen, anstatt ihre wahren Fähigkeiten oder ihr inhärentes Verhalten zu zeigen. Kommentare wiesen darauf hin, dass dieses „Anpassungs“-Verhalten zu erwarten ist, wenn Modelle auf diese Weise trainiert wurden. Diese Situation stellt eine Herausforderung für die Bewertung der tatsächlichen Leistung, Sicherheit und Ausrichtung von LLMs dar, da die Bewertungsergebnisse möglicherweise nicht das Verhalten des Modells in realen, nicht bewerteten Szenarien widerspiegeln (Quelle: Reddit r/artificial)
Eingeschränkte Nutzung von KI-Tools in Unternehmen: Mitarbeiter suchen Lösungen und äußern Bedenken: Ein Nutzer, der in einem großen Unternehmen arbeitet, gab auf Reddit r/ClaudeAI an, dass er aufgrund der Datenschutzrichtlinien des Unternehmens und VPN-Beschränkungen keine gängigen KI-Tools wie Anthropic, OpenAI, Gemini usw. verwenden kann, während viele in der Community über die Nutzung fortschrittlicher Technologien wie Claude Code diskutieren. Dies löste eine Diskussion darüber aus, wie in Unternehmensumgebungen ein Gleichgewicht zwischen Datensicherheit und der Nutzung von KI-Tools zur Effizienzsteigerung hergestellt werden kann. Kommentare wiesen darauf hin, dass Anthropic selbst sehr auf Datenschutz achtet und sogar Optionen für verschlüsselte Inferenzaufrufe über AWS Sagemaker anbietet, und meinten, dass das Unternehmen des Nutzers möglicherweise Fehler in seiner KI-Strategie mache. Einige Kommentatoren waren der Ansicht, dass Unternehmen, die KI nicht annehmen, in Zukunft mit sinkender Wettbewerbsfähigkeit und Entlassungsrisiken konfrontiert sein könnten. Vorgeschlagene Lösungen umfassten: das Unternehmen zum Abschluss von Enterprise-Level-KI-Serviceverträgen zu bewegen, privat für KI-Dienste zu bezahlen, die keine Daten für das Training verwenden, eigene lokale Inferenzserver einzurichten (kostenintensiv) oder lokale kleine Modelle für nicht sensible Daten zu verwenden (Quelle: Reddit r/ClaudeAI)
KI-Fotorestaurierung löst Kontroverse aus: Erinnerungen wiederherstellen oder umschreiben?: Ein Nutzer teilte auf Reddit r/ArtificialInteligence seine Erfahrungen mit der Restaurierung und Kolorierung alter Fotos mittels KI (ChatGPT und Kaze.ai) und löste eine Diskussion über die Ethik der KI-Fotorestaurierung aus. Einerseits war der Nutzer erstaunt, wie KI alte Fotos wieder zum Leben erwecken kann, andererseits äußerte er Bedenken hinsichtlich ihrer Authentizität, da KI im Restaurierungsprozess Farben „errät“ und Details basierend auf Algorithmen auffüllt, wodurch möglicherweise ursprüngliche Informationen hinzugefügt oder entfernt und so das wahre Gesicht der Geschichte verändert werden könnte. In der Diskussion wurde argumentiert, dass KI-Restaurierung im Wesentlichen eine Neuschöpfung von Bildern auf der Grundlage von Wahrscheinlichkeiten und Trainingsdaten ist. Wenn die Mustererkennung genau und die Daten angemessen sind, kann dies als „Wiederherstellung“ betrachtet werden, andernfalls als „Umschreibung“. Einige Kommentare wiesen darauf hin, dass Erinnerungen an sich subjektiv und ungenau sind und KI-Restaurierung in gewisser Weise der Restaurierung durch menschliche Photoshop-Experten ähnelt und nicht-destruktiv ist (das Originalbild bleibt erhalten). Entscheidend sei es, die künstlerische Interpretation der KI anzuerkennen und sich bewusst zu sein, dass wir die Vergangenheit durch den Filter unseres gegenwärtigen Bewusstseins verstehen (Quelle: Reddit r/ArtificialInteligence)
Verwirrung von Softwareentwicklungs-Anfängern im KI-Zeitalter: Welchen Sinn hat das Programmierenlernen, wenn KI alles erledigen kann?: Ein Informatikstudent fragte auf Reddit r/ArtificialInteligence, welchen Sinn es für Softwareentwickler hat, Programmierkenntnisse zu erlernen, wenn KI Code schreiben, debuggen und optimale Lösungen anbieten kann, und ob sie dadurch zu „Mittelsmännern“ der KI werden und schließlich ersetzt werden. Die Antworten der Community betonten, dass KI-Tools ihre maximale Wirkung nur unter Anleitung fähiger Entwickler entfalten können. KI ist derzeit besser darin, repetitive, unterstützende Aufgaben zu erledigen, während komplexes Systemdesign, Strategieentwicklung, Anforderungsverständnis und innovative Problemlösungen weiterhin von menschlichen Ingenieuren geleitet werden müssen. Anfängern wurde geraten, die praktischen Erfahrungen von Branchenexperten (wie Simon Willisons Blog) zu verfolgen, um zu verstehen, wie KI Entwickler unterstützt und nicht ersetzt, und sich auf die Verbesserung der Kernkompetenzen zur Problemlösung und die Beherrschung von KI-Tools zu konzentrieren (Quelle: Reddit r/ArtificialInteligence)
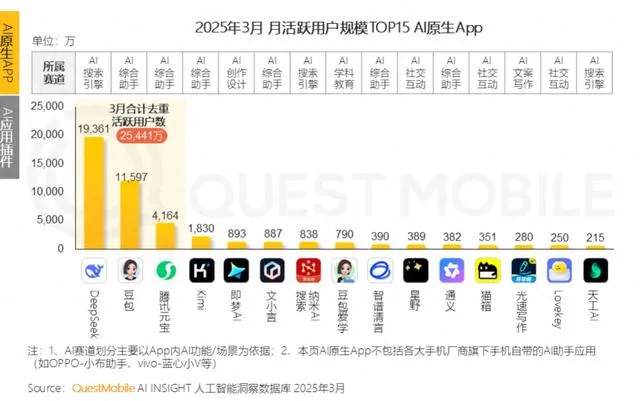
Große Tech-Unternehmen setzen auf KI für emotionale Begleitung und konkurrieren darum, die „KI-Oma“ junger Leute zu werden, stehen aber vor Herausforderungen bei der Nutzerbindung: KI-Assistenten großer Unternehmen wie Tencent Yuanbao, ByteDance Doubao und Alibaba Tongyi haben alle KI-Charakter-Agenten integriert. Unabhängige Apps wie ByteDance Maoxiang und Tencent Zhumengdao sind ebenfalls in den Bereich der KI-gestützten emotionalen Begleitung eingestiegen, mit dem Ziel, junge Nutzer durch „Cyber-Freunde/Freundinnen“ anzuziehen und die App-Aktivität zu steigern. Diese KI-Charaktere erfüllen die emotionalen Bedürfnisse der Nutzer durch eine stärker vermenschlichte Interaktion (einschließlich Sprache und Storytelling) und führten zeitweise zu einem Anstieg der App-Downloads und der Nutzungsdauer. Solche Anwendungen stoßen jedoch allgemein auf technische Engpässe, wie z.B. die unzureichende Fähigkeit großer Modelle zur Verarbeitung langer Kontexte, was zu „KI-Amnesie“ führt, und schwache emotionale Verständnisfähigkeiten, die das Nutzererlebnis beeinträchtigen. Obwohl anfänglich durch Neuheit und emotionale Bindung Nutzer gewonnen werden können, kämpfen KI-Anwendungen insgesamt mit niedrigen Nutzerbindungsraten. Daten von QuestMobile zeigen, dass die 3-Tages-Retentionsrate führender KI-Apps im Allgemeinen unter 50% liegt und die Deinstallationsrate von Doubao 42,8% beträgt. Der Artikel argumentiert, dass echte Nutzerbindung immer noch von technologischen Innovationen abhängt und nicht nur von emotionaler Begleitung oder Traffic-Investitionen (Quelle: 36氪)

💡 Sonstiges
Humanoide Roboter erobern die Hotellerie: Enormes Potenzial, aber kurzfristig große Herausforderungen: Mit der geplanten Massenproduktion von Produkten wie dem „Lingxi X2“ von Zhidong Roboter und Preisen zwischen Zehn- und Hunderttausenden von Yuan entwickeln sich humanoide Roboter von Messe-Gags zu realen Anwendungsfällen, wobei die Hotellerie als einer der ersten Einsatzbereiche gilt. Im Vergleich zu traditionellen Lieferrobotern verfügen humanoide Roboter über stärkere Ausführungs- und Urteilsfähigkeiten und könnten potenziell Gepäckträger, Sicherheitspersonal und teilweise Rezeptionsmitarbeiter ersetzen, um Probleme wie hohe Personalkosten und umständliche Prozesse in der Hotellerie zu lösen. Kurzfristig steht der großflächige Einsatz humanoider Roboter in Hotels jedoch noch vor Herausforderungen: 1) Unzureichende technologische Reife, da die komplexe und variable Hotelumgebung hohe Anforderungen an die Interaktions- und Anpassungsfähigkeit der Roboter stellt, denen diese derzeit kaum gewachsen sind; 2) Langer Amortisationszeitraum der Kosten, da Investitionen von Hunderttausenden für Hotels keine Kleinigkeit sind und Aspekte wie Kapitalrendite, Wartung und Kompatibilität berücksichtigt werden müssen; 3) Balance zwischen Standardisierung und personalisierten Dienstleistungen. Der Artikel vertritt die Ansicht, dass humanoide Roboter zukünftig Hotelangestellte teilweise ersetzen werden, aber eher die Transformation des Dienstleistungssektors hin zu einem fortschrittlicheren „Mensch-Maschine-Kollaborations“-Modell vorantreiben werden (Quelle: 36氪)

KI-Gesundheits-Videoblogger erleben kurzfristigen Hype, aber langfristiger Wert fraglich; KI sollte Content-Erstellung unterstützen, nicht ersetzen: In letzter Zeit sind KI-generierte Gesundheits-Kurzvideos im Cartoon- oder dynamischen Illustrationsstil auf Plattformen wie Xiaohongshu (Little Red Book) massenhaft viral gegangen und haben zu schnellem Follower-Wachstum geführt. Ihr Erfolg beruht auf der starken Inhaltsanpassung (Wissens-Nuggets + unterhaltsame Animationen), der großen Nachfrage des Publikums (getrieben von Gesundheitsängsten) und plattformfreundlichen Algorithmen (hohe Klick-/Speicherraten). Die Monetarisierung erfolgt hauptsächlich durch private Community-Konversionen, Verkauf über kleine Produktlisten und den Verkauf von Kursen zur Erstellung von KI-Videos, wobei letzterer ironischerweise profitabler ist. Solche Videos haben jedoch aufgrund der vergänglichen Neuheit des Formats, strengerer Plattformkontrollen, schwacher Verkaufsfähigkeiten für Gesundheitsprodukte und mangelnder Vertrauensbarrieren der Accounts keinen langfristigen Wert und sind eher „Traffic-Arbitrage“. Der Artikel argumentiert, dass der wahre Wert der KI-Technologie für Gesundheits-Blogger in der Unterstützung der Content-Erstellung liegt (Strukturierung von Inhalten, Visualisierung, Verwaltung von Content-Assets, Konversion von Nutzerdiensten) und nicht darin, menschliche Content-Produzenten zu ersetzen (Quelle: 36氪)
Lex Fridman Podcast interviewt Google CEO Sundar Pichai: Sundar Pichai, CEO von Google und Alphabet, war zu Gast im Lex Fridman Podcast (Folge #471). Die Diskussion war breit gefächert und umfasste Pichais Kindheit in Indien, Ratschläge für junge Menschen, seinen Führungsstil, den Einfluss von KI in der Menschheitsgeschichte, die Zukunft des Videomodells Veo 3, die Skalierungsgesetze der KI, AGI und ASI, P(doom) (die Wahrscheinlichkeit einer KI-verursachten Katastrophe), die schwierigsten Entscheidungen seiner Führungskarriere, den Vergleich von KI-Modellen mit der Google-Suche, Google Chrome, Programmierung, das Android-System, Fragen an AGI, die Zukunft der Menschheit sowie eine Demonstration von Google Beam und XR-Brillen. Dieser Podcast bietet einen tiefen Einblick in Pichais Ansichten zur KI-Entwicklung, Googles Strategie und der Zukunft der Technologie (Quelle: )