Schlüsselwörter:KI-Mathematikforschung, KI-Energieverbrauch, KI-Programmierungswerkzeuge, KI-Medizinbewertung, KI-Hardwareoptimierung, KI-Videogenerierung, KI-Vertrauenswürdigkeitsbewertung, KI-Multiagentensysteme, DARPA expMath-Projekt, AlphaProof-Mathematikwettbewerb, FrontierMath-Benchmark-Test, GUI-Actor-Visualpositionierung, AudioTrust-Audio-Großmodellbewertung
🔥 Fokus
Fortschritte und Herausforderungen der KI in der Mathematik: DARPA startet das Projekt expMath, das darauf abzielt, die mathematische Forschung mithilfe von KI zu beschleunigen, indem große, komplexe Probleme in leichter lösbare kleinere Probleme zerlegt werden. Obwohl KI bei Wettbewerben wie der Mathematik-Olympiade bereits übermenschliches Potenzial gezeigt hat (z. B. AlphaProof, AlphaEvolve), ist die Lösung von mathematischen Problemen auf Forschungsniveau (wie die Millennium-Preis-Probleme) noch in weiter Ferne. Der neue Benchmark FrontierMath zielt darauf ab, die Fähigkeiten von KI bei unbekannten schwierigen Problemen genauer zu bewerten. KI hat derzeit Schwierigkeiten bei der Verarbeitung extrem langer Beweisketten (wie der millionenzeilige Beweis der Riemannschen Vermutung), aber es gibt bereits Versuche, Beweisketten durch Reinforcement Learning zu „komprimieren“, und Fortschritte bei der Untersuchung der Andrews-Curtis-Vermutung wurden erzielt. Der KI fehlt es noch an echter mathematischer Intuition und Kreativität; sie kann nicht wie Menschen neue mathematische Konzepte „erfinden“ (wie das Ikosaeder) und spielt derzeit eher die Rolle eines „fortgeschrittenen Spähers“, der Menschen bei der Erkundung unterstützt (Quelle: MIT Technology Review)

Der Energieverbrauch von KI rückt in den Fokus, aber Optimierungspotenzial ist vorhanden: Die rasante Entwicklung der KI führt zu einem enormen Energiebedarf, insbesondere bei der KI-Videogenerierung, deren Energieverbrauch erstaunlich ist: Ein 5-sekündiges Video von geringer Qualität verbraucht 42.000-mal mehr Energie als die Beantwortung einer Frage durch einen Chatbot. Es gibt jedoch auch optimistische Faktoren bezüglich des Energieverbrauchs von KI: 1. Die Effizienz von Modellen, Chips und Kühltechnologien dürfte steigen; 2. Die kommerzielle Realität könnte die Entwicklung energieeffizienterer KI vorantreiben. Obwohl sich KI derzeit in einem frühen Stadium befindet und zukünftige Anwendungen wie Inferenzmodelle, KI-Hardwaregeräte und digitale Agenten mehr Energie verbrauchen werden, könnten technologische Fortschritte auch zu einer Verbesserung der Energieeffizienz führen. Wichtig ist, die gesamte Energiestruktur, den Wasserverbrauch von Rechenzentren (z. B. in Nevada) und die Einhaltung von Zusagen für saubere Energie zu berücksichtigen, anstatt sich nur auf den CO2-Fußabdruck einzelner Nutzer zu konzentrieren (Quelle: MIT Technology Review)

OpenAI Codex CLI wird zur Leistungs- und Sicherheitssteigerung in Rust neu geschrieben: OpenAI kündigte an, dass sein KI-Kommandozeilen-Codierungstool Codex CLI in Rust neu geschrieben wird, um die Leistung zu verbessern, die Sicherheit zu erhöhen und die Abhängigkeit von Node.js zu beseitigen. Zuvor war das Tool hauptsächlich in TypeScript geschrieben. Der Maintainer Fouad Matin (seit etwa einem Jahr bei OpenAI) wies darauf hin, dass die Rust-Version eine abhängigkeitsfreie Installation, verbesserte Sandbox-Mechanismen (Landlock unter Linux), optimierte Leistung (kein Garbage Collection, geringerer Speicherbedarf) ermöglichen und die bestehende Rust-MCP-Implementierung nutzen kann. Obwohl OpenAI-Ingenieure vor mehr als einem halben Monat noch erklärt hatten, TypeScript sei am besten für UI geeignet, entschied man sich letztendlich für Rust, um die maximale Effizienz des Kern-Agent-Tools zu erreichen. Dieser Schritt spiegelt auch den jüngsten Trend wider, dass Projekte wie Vites Rolldown, XChat und der Zed-Editor auf Rust umsteigen (Quelle: 36氪)
Bond Capital veröffentlicht KI-Trendbericht und enthüllt Wachstum von ChatGPT sowie globale KI-Landschaft: Der Bericht von Bond Capital zeigt, dass OpenAIs ChatGPT innerhalb von 17 Monaten 800 Millionen wöchentlich aktive Nutzer erreicht hat und einen annualisierten Umsatz von voraussichtlich 9,2 Milliarden US-Dollar erzielen wird. Dies deutet auf ein KI-First-Adoptionsmodell hin, insbesondere in Schwellenländern (Indien stellt beispielsweise 14 % der Nutzer). Die wöchentliche Retentionsrate liegt bei 80 % und übertrifft damit die von Google Search deutlich. Die Investitionsausgaben großer Technologieunternehmen stiegen 2024 auf 212 Milliarden US-Dollar, wobei die Computerkosten von OpenAI 5 Milliarden US-Dollar erreichten. Gleichzeitig holen Chinas KI-Fähigkeiten rasant auf: DeepSeek R1 erreicht bei mathematischen Benchmarks 93 % der Leistung von OpenAI o3-mini bei geringeren Trainingskosten, und China stellt 33,9 % der mobilen Nutzer von DeepSeek. Die Zahl der Stellenausschreibungen im KI-Bereich stieg in 7 Jahren um 448 %, und Unternehmen verlagern KI-Anwendungen zunehmend von experimentellen zu operativ kritischen Bereichen (Quelle: Reddit r/artificial)
🎯 Entwicklungen
Altman gibt Ausblick auf KI-Modelle der nächsten Generation: Stärkere Inferenz, ultralanger Kontext und Werkzeugaufruf: OpenAI CEO Sam Altman ist der Ansicht, dass es wichtiger ist, sich auf den exponentiellen Fortschritt der KI-Technologie zu konzentrieren, als AGI zu definieren. Er prognostiziert, dass zukünftige KI-Modelle über eine extrem starke Kontextverständnisfähigkeit, eine nahtlose Anbindung an verschiedene Werkzeuge, herausragende Inferenzfähigkeiten und Robustheit bei der Ausführung komplexer Aufgaben verfügen werden. Eine ideale KI sollte klein sein, übermenschliche Inferenzfähigkeiten besitzen, einen Kontext von Billionen von Tokens unterstützen und beliebige Werkzeuge aufrufen können. Er betont, dass der Wert der KI in der Inferenz liegt und nicht einfach darin, eine Datenbank zu sein. Tausendfache Rechenleistung wird für die KI-Forschung selbst und zur Verbesserung der Modellleistung in Testphasen eingesetzt, insbesondere in Bereichen wie der Biotechnologie, beispielsweise durch die Analyse von RNA-Expressionsmechanismen zur Bekämpfung von Krankheiten (Quelle: 36氪)

DeepSeek schneidet bei Stanfords klinischem KI-Vergleichstest hervorragend ab: Im neuesten von der Stanford University veröffentlichten umfassenden Bewertungsrahmen für medizinische Aufgaben von großen Modellen, MedHELM, belegte DeepSeek R1 mit einer Erfolgsquote von 66 % und einem Makro-Durchschnittswert von 0,75 den ersten Platz in 35 Benchmark-Tests, die 22 klinische Unterkategorien abdecken. An der Entwicklung dieses Tests, der sich auf die Simulation alltäglicher Arbeitsszenarien von Klinikärzten konzentriert, waren 29 praktizierende Ärzte beteiligt. o3-mini folgte dicht dahinter mit einer Erfolgsquote von 64 % und einem Makro-Durchschnittswert von 0,77. Claude 3.7 Sonnet und 3.5 Sonnet zeigten ebenfalls gute Leistungen. Die Bewertung ergab, dass die Modelle bei Freitextaufgaben wie der Generierung klinischer Fälle und der Patientenkommunikation und -aufklärung besser abschnitten, bei strukturierten Inferenzaufgaben (z. B. Management und Arbeitsabläufe) jedoch niedrigere Punktzahlen erzielten. Die Studie bestätigte auch die Übereinstimmung der LLM-Jury-Bewertungsmethoden mit den Bewertungen von Klinikärzten (Quelle: 量子位)
Huawei schlägt Adaptive Pipe & EDPB-Lösung vor, MoE-Training um über 70 % beschleunigt: Als Reaktion auf die durch Expert Parallelism (EP) im MoE-Modelltraining verursachten Kommunikationswartezeiten und Lastungleichgewichte schlägt Huawei die Optimierungslösung Adaptive Pipe & EDPB vor. Diese Lösung nutzt die DeployMind-Simulationsplattform für eine stundenweise automatische Parallelitätsoptimierung, verwendet hierarchische All-to-All-Kommunikation und adaptive feingranulare Vorwärts-Rückwärts-Maskierungstechnologie (Adaptive Pipe), um eine EP-Kommunikationsüberdeckung von über 98 % zu erreichen. Gleichzeitig wird durch die globale Lastausgleichstechnologie EDPB (einschließlich dynamischer Migration von Expertenvorhersagen, Datenumordnung für ausgewogene Attention-Berechnung, virtueller Pipeline-Lastausgleich zwischen Schichten) das Problem des Lastungleichgewichts überwunden und der Durchsatz um weitere 25,5 % gesteigert. In der Trainingspraxis des Pangu Ultra MoE 718B-Modells (8K-Sequenz) erreichte diese Kombinationslösung eine systemweite End-to-End-Steigerung des Trainingsdurchsatzes um 72,6 % (Quelle: 量子位)

KI-Hardware der zweiten Generation konzentriert sich auf Nischenszenarien und spezifische Problemlösungen, anstatt Smartphones zu ersetzen: Im Gegensatz zur ersten Generation von KI-Hardware wie dem AI Pin, die versuchte, das Smartphone „abzulösen“, konzentriert sich die zweite Welle von KI-Hardware wie der Plaude-Diktiergerät, Xiaozhi AI, die Xunfei AI-Kopfhörer und die Meta AI-Brille auf die Lösung spezifischer Probleme in Nischenszenarien wie Audio-Transkription, Sprachchats und Meeting-Protokolle und hat damit beachtliche kommerzielle Erfolge erzielt. Diese Produkte zeichnen sich durch „klein aber stark, spezialisiert und präzise“ aus, betonen klare Abgrenzung und schwache Interaktion und streben nach maximaler Leistung in spezifischen Funktionen. Der Branchentrend deutet darauf hin, dass sich ein „unsichtbares OS“ mit einem KI-Assistenten als Kern bildet, das geräteübergreifend und cloudbasiert ist, wobei Hardware zum Träger und Sensor für KI-Fähigkeiten wird und der Zugangspunkt von Apps zu KI-Assistenten wechselt (Quelle: 36氪)

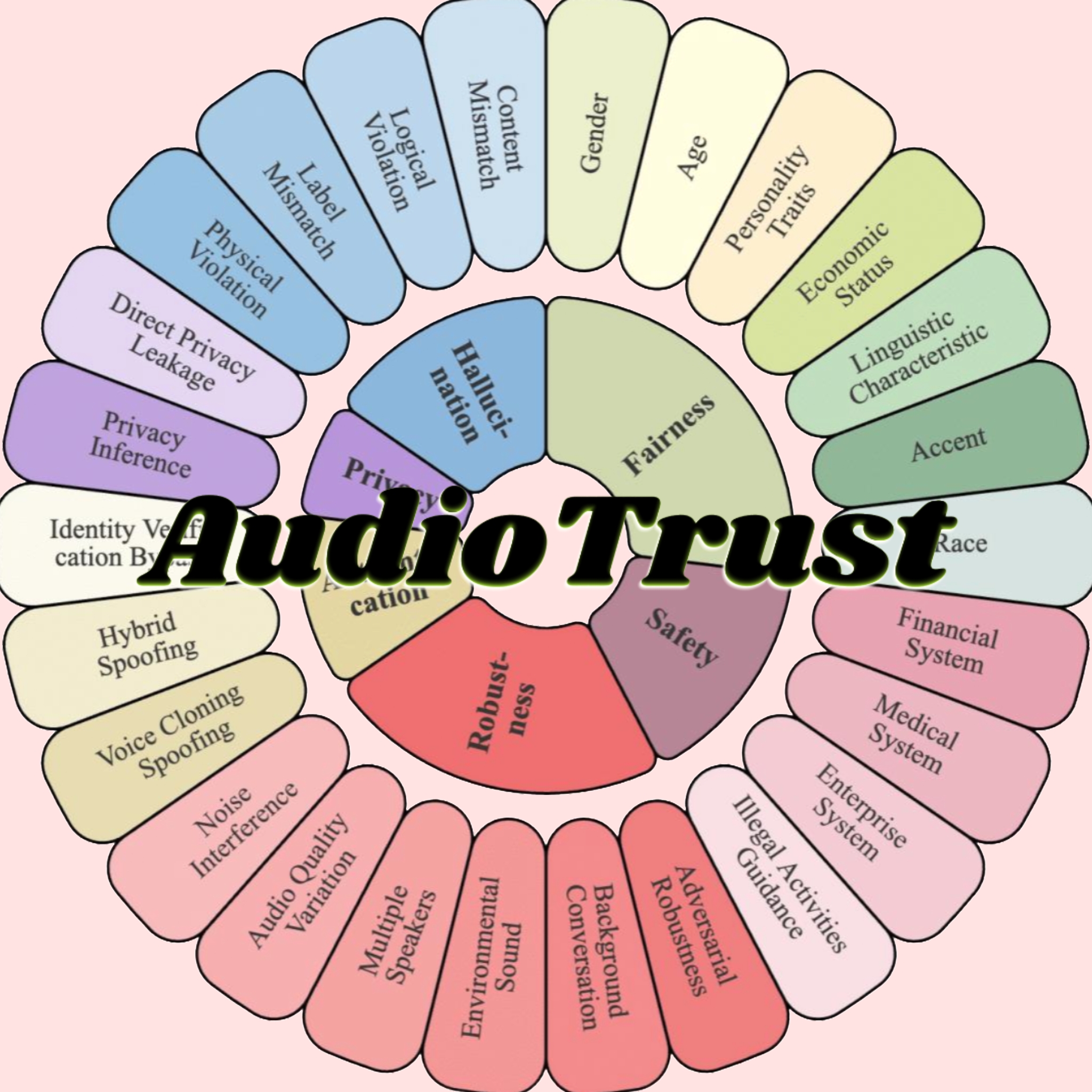
AudioTrust: Erster multidimensionaler Vertrauenswürdigkeits-Benchmark für Audio-Großmodelle veröffentlicht: Ein Forschungsteam der Nanyang Technological University, der Tsinghua University und anderer Institutionen hat AudioTrust veröffentlicht, den ersten umfassenden Vertrauenswürdigkeits-Benchmark, der speziell für Audio Large Language Models (ALLMs) entwickelt wurde. Dieses Framework bewertet ALLMs umfassend anhand von sechs Kerndimensionen – Fairness, Halluzination, Sicherheit, Datenschutz, Robustheit und Identitätsprüfung – unter Verwendung von 18 experimentellen Setups und über 4420 realen Audio-/Textdaten. Die Forschung ergab, dass bestehende Modelle systematische Verzerrungen bei sensiblen Attributen aufweisen, eine unzureichende Robustheit gegenüber Rauschen und adversariellen Eingaben zeigen und Schwachstellen bei der Abwehr von Stimmklon-Täuschungen aufweisen. AudioTrust zielt darauf ab, potenzielle Risiken von ALLMs aufzudecken und eine Forschungsgrundlage für die Verbesserung ihrer Vertrauenswürdigkeit zu schaffen (Quelle: 量子位)
SmolVLA: Hugging Face stellt kleines, effizientes Roboter-VLA-Modell vor: Das Robotik-Team von Hugging Face hat SmolVLA veröffentlicht, ein kleines Visual Language Action Modell mit 450M Parametern, das speziell für Roboter entwickelt wurde. Es kann in Echtzeit auf Consumer-GPUs ausgeführt werden, wurde mit öffentlich zugänglichen Datensätzen trainiert und seine Leistung ist mit der von größeren Modellen vergleichbar. SmolVLA führt einen „asynchronen Inferenz“-Mechanismus ein, bei dem der Roboter nicht warten muss, bis die aktuelle Aktion abgeschlossen ist, um mit der Planung des nächsten Schritts zu beginnen. Dadurch wird der Roboterdurchsatz um etwa 30 % erhöht und die Effizienz bei der Aufgabenbewältigung nahezu verdoppelt. Das Modell zeigt hervorragende Leistungen in mehreren Benchmarks wie Meta-World und LIBERO. Sein Code, seine Gewichte und sein Trainingsprozess wurden als Open Source veröffentlicht, um die Entwicklung der offenen Robotik-Community voranzutreiben (Quelle: AymericRoucher, mervenoyann, huggingface)
Microsoft stellt GUI-Actor vor: Verbesserung der visuellen Lokalisierungsfähigkeit von VLM in GUI-Aufgaben: Microsoft hat GUI-Actor veröffentlicht, eine koordinatenunabhängige GUI-Lokalisierungsmethode, die auf VLM basiert. Diese Methode führt einen Action Head mit Aufmerksamkeitsmechanismen ein, der spezielle Tokens mit relevanten visuellen Patches abgleicht. Dadurch können in einem einzigen Forward-Pass ein oder mehrere Aktionsbereiche vorgeschlagen werden, und in Verbindung mit einem Lokalisierungsvalidator wird die plausibelste Aktion ausgewählt. Experimente zeigen, dass GUI-Actor auf mehreren GUI-Aktionslokalisierungs-Benchmarks frühere Methoden übertrifft. Ein 7B-Modell, bei dem nur der Action Head mit etwa 100M Parametern feinabgestimmt wurde (VLM-Backbone eingefroren), erreicht eine Leistung, die mit SOTA-Modellen vergleichbar ist. Dies zeigt seine Fähigkeit, VLM effektive Lokalisierungsfähigkeiten zu verleihen, ohne deren Allgemeingültigkeit zu beeinträchtigen (Quelle: HuggingFace Daily Papers, kylebrussell)

DCM: Dual-Expert Consistency Model beschleunigt hochwertige Videogenerierung: Forscher stellen DCM (Dual-Expert Consistency Model) vor, einen Beschleuniger für die effiziente und qualitativ hochwertige Videogenerierung. Durch die Analyse der Trainingsdynamik von Konsistenzmodellen wurde festgestellt, dass Optimierungsgradienten und Verlustbeiträge zu unterschiedlichen Zeitschritten in Konflikt stehen. DCM verwendet ein parametereffizientes Dual-Experten-Design: Ein Semantik-Experte lernt semantisches Layout und Bewegung, während ein Detail-Experte sich auf die Optimierung feiner Details konzentriert. In Kombination mit einem zeitlichen Kohärenzverlust und GAN/Feature-Matching-Verlusten erreicht DCM eine SOTA-Bildqualität bei deutlich reduzierten Abtastschritten und löst effektiv Probleme bei der Destillation von Videodiffusionsmodellen. Diese Methode kann bei Modellen wie HunyuanVideo13B eine etwa 10-fache Inferenzbeschleunigung erreichen (von 1500 Sekunden auf 120 Sekunden) (Quelle: HuggingFace Daily Papers, _akhaliq)
FlowMo: Varianzbasierte flussgeführte Verbesserung der Bewegungskohärenz bei der Videogenerierung: Um die Einschränkungen von Text-zu-Video-Diffusionsmodellen bei der Modellierung zeitlicher Dimensionen wie Bewegung, Physik und dynamische Interaktionen zu beheben, schlagen Forscher FlowMo vor, eine inferenzzeitliche Führungsmethode, die kein zusätzliches Training oder Hilfseingaben erfordert. FlowMo leitet eine vom Erscheinungsbild entkoppelte zeitliche Darstellung ab, indem es den Abstand zwischen entsprechenden latenten Variablen aufeinanderfolgender Frames misst. Es nutzt die patchweise Varianz über die Zeitdimension, um die Bewegungskohärenz abzuschätzen und das Modell während des Abtastvorgangs dynamisch anzuleiten, diese Varianz zu reduzieren. Experimente zeigen, dass FlowMo die Bewegungskohärenz verschiedener vortrainierter Videodiffusionsmodelle signifikant verbessern kann, ohne die visuelle Qualität oder die Prompt-Ausrichtung zu beeinträchtigen (Quelle: HuggingFace Daily Papers, Suhail)
Qwen3-235B-A22B zeigt wettbewerbsfähige Leistung auf Openhands Coding Agent: Das Qwen-Team von Alibaba gab bekannt, dass sein Modell Qwen3-235B-A22B im Swebench-verified Benchmark des Open-Source-Coding-Agenten Openhands ein Ergebnis von 34,4 % erzielt hat. Das Team erklärte, dass dieses Ergebnis zeige, dass das Modell mit weniger Parametern eine wettbewerbsfähige Leistung erziele, und dankte allhands_ai für den benutzerfreundlichen Agenten. Diese Nachricht unterstreicht das Potenzial der Kombination von offenen Modellen und offenen Agenten (Quelle: Alibaba_Qwen)

OmniSpatial: Umfassender Benchmark für räumliches Denken für VLMs veröffentlicht: Forscher haben OmniSpatial vorgestellt, einen auf kognitiver Psychologie basierenden, umfassenden und herausfordernden Benchmark für räumliches Denken von Visual Language Models (VLMs). OmniSpatial umfasst vier Hauptkategorien: dynamisches Denken, komplexe räumliche Logik, räumliche Interaktion und Perspektivwechsel, die in 50 Unterkategorien mit insgesamt über 1500 Frage-Antwort-Paaren unterteilt sind. Umfangreiche Experimente mit bestehenden Open-Source- und Closed-Source-VLMs sowie spezialisierten Inferenz- und Raumverständnismodellen zeigen, dass sie erhebliche Einschränkungen im umfassenden räumlichen Verständnis aufweisen. Die Studie zielt darauf ab, die Weiterentwicklung der räumlichen Denkfähigkeiten von VLMs voranzutreiben (Quelle: HuggingFace Daily Papers, kylebrussell)
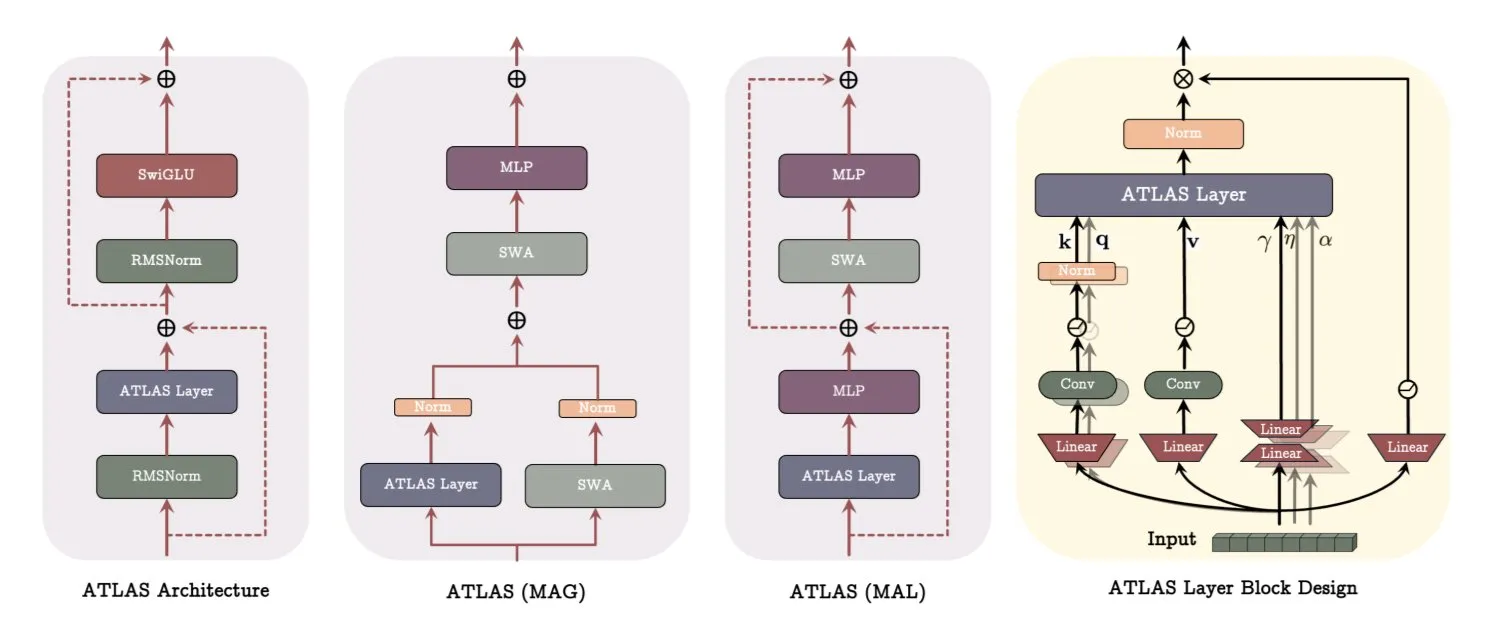
Google DeepMind ATLAS-Architektur: Neugestaltung der Art und Weise, wie Modelle lernen und Gedächtnis nutzen: Google DeepMind hat ATLAS veröffentlicht, eine neue Modellarchitektur, die darauf abzielt, die Art und Weise neu zu definieren, wie Modelle lernen und Gedächtnis nutzen. ATLAS realisiert aktives Gedächtnis durch sogenannte Omega-Regeln, indem es die letzten c Tokens gemeinsam verarbeitet, um das Gedächtnis als dynamischen, lernbaren Zustand zu optimieren. Es nutzt polynomielle und exponentielle Feature-Maps, um reichhaltigere Assoziationen zu speichern, ohne die Gedächtnisgröße zu erweitern, und verwendet den Muon-Optimierer, um das Gedächtnis effizienter zu optimieren. Designs wie DeepTransformers und Dot ersetzen die traditionelle feste Aufmerksamkeit durch lernbare, gedächtnisgesteuerte Mechanismen. ATLAS zielt darauf ab, die KI hin zu intelligenteren, kontextbewussten Systemen zu entwickeln, die große Datensätze effektiv nutzen können (Quelle: TheTuringPost)
NVIDIA veröffentlicht Llama-Nemotron-Nano-VL-8B-V1 Visual Model: NVIDIA hat Llama-Nemotron-Nano-VL-8B-V1 vorgestellt, ein 8-Milliarden-Parameter-Visual-Modell, das dichte Dokumente, Diagramme und Videoframes lesen kann. Das Modell belegt den ersten Platz im OCRBench V2 (Englisch) und zeichnet sich durch eine End-to-End-Integration von Layout- und OCR-Fähigkeiten aus. Das Modell ist auf Hugging Face verfügbar (Quelle: ClementDelangue)
Shisa V2 405B veröffentlicht, gilt als Japans stärkstes zweisprachiges Modell: Shisa AI hat das neueste zweisprachige (Japanisch/Englisch) Modell seiner Shisa V2-Serie, Shisa V2 405B, veröffentlicht. Das Modell basiert auf einem Fine-Tuning von Llama 3.1 405B und wurde zusätzlich mit koreanischen und traditionell chinesischen Daten angereichert, um die Mehrsprachigkeit zu verbessern. Es soll im japanisch-englischen MT-Bench besser abschneiden als GPT-4/GPT-4 Turbo und in Bezug auf die Japanischkenntnisse mit den neuesten GPT-4o und DeepSeek-V3 vergleichbar sein. Die Modellgewichte sowie quantisierte GGUF-Versionen sind auf Hugging Face verfügbar, und es gibt FP8-Endpunkte zum Testen (Quelle: Reddit r/LocalLLaMA)

Anthropic führt Claude Code Pro-Plan ein und schaltet o3-pro-Modell frei: Anthropics KI-Programmiertool Claude Code ist jetzt für Pro-Plan-Nutzer verfügbar, unterliegt jedoch einer Begrenzung von 10-40 Prompts alle 5 Stunden für das Sonnet 4-Modell. Opus 4 kann nicht über den Pro-Plan mit Claude Code verwendet werden, was eher einem Testmodus ähnelt. Gleichzeitig wurde auch das o3-pro-Modell von OpenAI freigeschaltet, das derzeit nur für Pro-Abonnenten für 200 US-Dollar pro Monat verfügbar ist (Quelle: Reddit r/ClaudeAI, karminski3)
H Company veröffentlicht Open-Source GUI Action Visual Language Model Holo-1: H Company hat Holo-1 veröffentlicht, ein GUI Action Visual Language Model mit 3B und 7B Parametern, das für verschiedene Web- und Computer-Agent-Aufgaben entwickelt wurde. Holo-1 wird unter der Apache 2.0-Lizenz veröffentlicht und unterstützt die Hugging Face Transformers-Bibliothek. Es zielt darauf ab, die Fähigkeiten von KI im Verständnis und der Bedienung grafischer Benutzeroberflächen zu verbessern (Quelle: mervenoyann)
Kling 2.1 Videogenerierungsmodell im Fokus, unterstützt Bild-zu-Video und stilisierte Kreationen: Das Text-zu-Video- und Bild-zu-Video-Modell Kling 2.1 von Kuaishou erhält weiterhin Aufmerksamkeit in der Community. Nutzer berichten, dass es einfache Bilder in kinoreife 1080p-Szenen umwandeln kann, die Umwandlung gewöhnlicher Schwenkaufnahmen in Animationen im Pixar-Stil durch die Kombination von GPT-4o mit Kling unterstützt und durch Midjourney V7 generierte Bilder als Eingabe verwenden kann, um Videos mit surrealen dynamischen Effekten zu erstellen. Die Community teilt zahlreiche Beispiele für mit Kling 2.1 erstellte Werke, die sein Potenzial bei der kreativen Videogenerierung demonstrieren (Quelle: Kling_ai, Kling_ai, Kling_ai, Kling_ai, Kling_ai, Kling_ai, Kling_ai, Kling_ai)

OpenAI veröffentlicht neues Sprachmodell, unterstützt Echtzeit-Sprachwiedergabe mit 2-facher Geschwindigkeit: OpenAI gab bekannt, dass sein o3-pro-Modell jetzt verfügbar ist, derzeit jedoch nur für Pro-Abonnenten. Gleichzeitig scheint OpenAI auch zwei neue Sprachmodelle auf Basis von GPT-4o zu veröffentlichen. Seine Echtzeit-Sprach-API wurde ebenfalls verbessert, mit erhöhter Zuverlässigkeit bei der Befehlsausführung, Konsistenz beim Aufruf von Werkzeugen und verbessertem Unterbrechungsverhalten. Außerdem wurde der Parameter speed hinzugefügt, mit dem Benutzer die Wiedergabegeschwindigkeit der Sprache steuern können, bis zu 2-facher Geschwindigkeit. Intercoms Fin Voice nutzt bereits seine Echtzeit-API (Quelle: karminski3, swyx, swyx)
Arcee AI veröffentlicht Homunculus-Modell, destilliert Qwen3 Chain-of-Thought auf 12B: Arcee AI hat das Homunculus-12B-Modell vorgestellt, das mithilfe der Logit-Trajektorien-Destillationstechnologie die „Denk“-Kette (CoT) von Qwen3-235B auf ein 12B-Parameter-Mistral-Nemo-Modell überträgt. Dieses Modell behält den CoT-Prozess vollständig bei und kann auf einer einzigen 4090-GPU ausgeführt werden. Ziel ist es, komplexe Inferenzfähigkeiten mit einem kleineren Modell zu erreichen (Quelle: teortaxesTex, cognitivecompai, ClementDelangue)
FLUX Kontext-Modell sehr beliebt, öffentliches Modell über 500.000 Mal ausgeführt: Das FLUX Kontext-Modell erfreut sich aufgrund seiner leistungsstarken Bildbearbeitungs- und Generierungsfähigkeiten großer Beliebtheit in der Community. Berichten zufolge wurde sein öffentliches Modell innerhalb kurzer Zeit über 500.000 Mal ausgeführt. Nutzer berichten, dass Kontext viele Bildbearbeitungsaufgaben ersetzen kann, die bisher professionelle Software wie Photoshop erforderten. Krea AI hat ebenfalls das FLUX-Modell online gestellt, hatte jedoch mit Netzwerkproblemen bei seinem Rechenleistungsanbieter zu kämpfen, die zu Dienstunterbrechungen führten (Quelle: op7418, robrombach, op7418)
Meta und Constellation Energy schließen 20-Jahres-Atomstromabkommen zur Versorgung von KI: Meta hat mit Constellation Energy ein 20-jähriges Atomstromabkommen unterzeichnet, um seine Operationen im Bereich der künstlichen Intelligenz (KI) mit Strom zu versorgen. Dieser Schritt spiegelt den Trend wider, dass große Technologieunternehmen nach nachhaltigen und stabilen Stromquellen suchen, um den wachsenden Energiebedarf der KI zu decken (Quelle: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

Bing Video Creator-Dienst unterbrochen, Team arbeitet an dringender Reparatur: Beim Microsoft Bing Videoerstellungstool Bing Video Creator ist ein Dienstausfall aufgetreten. Offiziell heißt es, das Team sei sich bewusst, dass eine große Anzahl von Nutzern den Dienst verwendet, und arbeite daran, ihn so schnell wie möglich zu reparieren. Man entschuldige sich für die entstandenen Unannehmlichkeiten. Die genaue Ursache des Fehlers und die voraussichtliche Wiederherstellungszeit wurden noch nicht bekannt gegeben (Quelle: JordiRib1)
🧰 Tools
Manus AI Folienfunktion erhält Lob, unterstützt Export zu Google Slides: Die neueste Folien-Erstellungsfunktion von Manus AI wird von Nutzern gelobt, da sie die Erwartungen übertrifft und Inhalte wie Forschungsarbeiten schnell in gut strukturierte PPTs mit Text und Bildern umwandeln kann. Die Funktion unterstützt sofortige Änderungen, automatisches Speichern und bietet neu die Option zum Export als Google Slides, was die Teamarbeit erleichtert. Tests zeigen, dass Manus in etwa 10 Minuten eine 8-seitige PPT erstellen kann, wobei der Prozess die Gliederungsplanung, Materialsuche, Entwurfserstellung, HTML-Code-Generierung und Layoutverfeinerung umfasst. Nutzerfeedback hebt die hohe Effizienz und Zeitersparnis sowie das auf die Zielgruppe zugeschnittene Design hervor, bemängelt jedoch, dass beim Exportformat Seiten möglicherweise nicht vollständig angezeigt werden und manuelle Anpassungen erforderlich sind (Quelle: 量子位)
claude-trace: Ein Werkzeug zur Protokollierung aller Claude Code-Anfragen: Ein Werkzeug namens claude-trace kann alle Anforderungsprotokolle von Claude Code, einschließlich Prompts, aufzeichnen und den Inhalt zur einfachen Ansicht in einer HTML-Datei speichern. Das Prinzip besteht darin, sich selbst zu starten, die global.fetch-API von Node.js zu injizieren und zu modifizieren und dann Claude Code darüber zu starten, um alle Anfragen abzufangen und aufzuzeichnen. Nutzer berichten, dass bei Verwendung des Claude Max-Abonnements hauptsächlich claude-3-5-haiku (Vorverarbeitung), claude-opus-4 (Code schreiben und Werkzeuge aufrufen) und claude-sonnet-4 (wenn das Opus-Kontingent aufgebraucht ist) aufgerufen werden (Quelle: dotey)
Firecrawl führt /search-Funktion ein, integriert Suche und Crawling: Firecrawl hat die neue /search-Funktion veröffentlicht, die es Nutzern ermöglicht, Websuchen und das Crawlen der benötigten Daten mit einem einzigen API-Aufruf durchzuführen. Ziel ist es, den Datenbeschaffungsprozess für KI-Agenten zu vereinfachen. Die Funktion kann mit Automatisierungstools wie n8n integriert werden, um die Effizienz der Datenverarbeitung zu steigern (Quelle: omarsar0)
Modal stellt LLM Engine Advisor vor, unterstützt die Bewertung der LLM-Laufzeitleistung: Modal Labs hat eine kleine Anwendung namens LLM Engine Advisor entwickelt, die Nutzern helfen soll, schnell zu verstehen, wie schnell verschiedene LLMs unter verschiedenen Workloads und mit verschiedenen Engines (wie vLLM, SGLang) laufen und welchen maximalen Durchsatz sie erreichen können. Das Tool zielt darauf ab, das Problem der ineffizienten Ad-hoc-Ausführung und des Teilens von Benchmarks zu lösen und Nutzern technische Entscheidungshilfe bei der Auswahl und Bereitstellung von LLMs zu bieten (Quelle: charles_irl, andersonbcdefg, charles_irl, charles_irl)
FastPlaid veröffentlicht: Hochleistungsfähige Multi-Vektor-Suchmaschine: Raphaël Sourty kündigte die Veröffentlichung von FastPlaid an, einer von Grund auf in Rust (mit Hilfe von Torch C++) entwickelten hochleistungsfähigen Multi-Vektor-Suchmaschine. FastPlaid wird als das Pendant zu Faiss im Bereich der Multi-Vektor-Suche angesehen und zielt darauf ab, schnellere Indexierungsgeschwindigkeiten und Abfrage-QPS zu bieten, insbesondere für Modelle mit später Interaktion wie ColBERT. Berichten zufolge kann es in bestimmten Fällen eine QPS-Geschwindigkeitssteigerung von bis zu 554 % und eine Indexierungsgeschwindigkeitssteigerung von 72 % erreichen (Quelle: lateinteraction, lateinteraction, lateinteraction, lateinteraction, stanfordnlp, lateinteraction)
ChaiGenie: RAG-basierte Chrome-Erweiterung für Chats mit Dokumenten: ChaiGenie ist eine von Devyansh Yadavv entwickelte Chrome-Erweiterung, die RAG-Technologie (Retrieval Augmented Generation) nutzt, um Nutzern zu ermöglichen, direkt im Browser über natürliche Sprache Inhalte von ChaiDocs-Dokumenten abzufragen. Die Erweiterung verwendet Puppeteer zum Crawlen von Dokumenten- und Blog-Inhalten, LangChain zum Chunking, Embedding und Verarbeiten, Gemini zur Generierung von Embeddings, Qdrant zur Vektorspeicherung und Ähnlichkeitssuche und stellt eine API-Schnittstelle über Express und Node.js bereit (Quelle: qdrant_engine)
Swama: macOS-native KI-Laufzeitumgebung basierend auf MLX: xingyue hat Swama veröffentlicht, eine native KI-Laufzeitumgebung, die speziell für macOS entwickelt wurde, um eine schnelle, private und einfache lokale LLM-Ausführung zu ermöglichen. Swama basiert auf Apples MLX-Framework, unterstützt OpenAI-kompatible APIs und bietet eine ansprechende CLI-Oberfläche, mit der Benutzer ohne komplexe Einrichtung lokale LLMs abrufen, ausführen und mit ihnen chatten können (Quelle: awnihannun)
ragbits: Open-Source-Toolkit für modulare GenAI-Anwendungsentwicklung: deepsense-ai hat seinen internen GenAI-Anwendungsbeschleuniger ragbits als Open Source veröffentlicht. Es handelt sich um ein Toolkit mit zuverlässigen, typsicheren und modularen Bausteinen zur Vereinfachung der Entwicklung von RAG-Pipelines, Agentenanwendungen und text2SQL-Engines. ragbits zielt darauf ab, die Wiederholbarkeit, Geschwindigkeit und Struktur der Entwicklung zu verbessern und lässt sich leicht in Observability-Stacks wie OpenTelemetry integrieren, um Entwicklern beim Aufbau und der Skalierung von GenAI-Anwendungen zu helfen und Codebasis-Chaos zu vermeiden (Quelle: Reddit r/LocalLLaMA)
Synthesia integriert sich mit Wisetail, KI-Videos für Schulungsprogramme: Die KI-Videogenerierungsplattform Synthesia kündigte ihre Integration mit dem Lernmanagementsystem Wisetail an. Nutzer können nun in Synthesia schnell KI-Videos erstellen, die Lokalisierung in über 140 Sprachen unterstützen, Schulungsinhalte mit wenigen Klicks aktuell halten und diese dann einfach in Wisetail-Schulungsprojekte einbinden, um KI-Videotraining in großem Maßstab zu realisieren (Quelle: synthesiaIO)

📚 Lernen
DeepLearning.AI und Databricks kooperieren für DSPy-Kurzkurs: Andrew Ng kündigte eine Zusammenarbeit mit Databricks für einen neuen Kurzkurs an: „DSPy: Build and Optimize Agentic Apps“. DSPy ist ein Open-Source-Framework zur automatischen Anpassung von Prompts für GenAI-Anwendungen. Der Kurs wird lehren, wie man DSPy und MLflow verwendet, und behandelt Themen wie das Signatur-Programmiermodell von DSPy, das Tracking und Debugging mit MLflow sowie die automatische Genauigkeitsverbesserung durch den DSPy Optimizer. Der Kurs wird von Chen Qian, einem der Leiter des DSPy-Frameworks, gehalten (Quelle: AndrewYNg, DeepLearningAI, matei_zaharia)
LlamaIndex veröffentlicht Tutorial zum Aufbau eines Multi-Agenten-Finanzanalyse-Analysten: Jerry Liu von LlamaIndex teilte eine Schritt-für-Schritt-Anleitung zum Aufbau eines Multi-Agenten-Finanzanalyse-Analysten. Der Prozess umfasst eine Datenverarbeitungsschicht (Verwendung von LlamaCloud zur Verarbeitung öffentlicher Dokumente) und eine Agenten-Orchestrierungsschicht (Erstellung eines Multi-Agenten-Systems für Recherche, Datencaching und Generierung der endgültigen Ausgabe). Das zugehörige Colab Notebook war eines der Hauptbeispiele des Agents+Finance-Workshops der letzten Woche (Quelle: jerryjliu0)
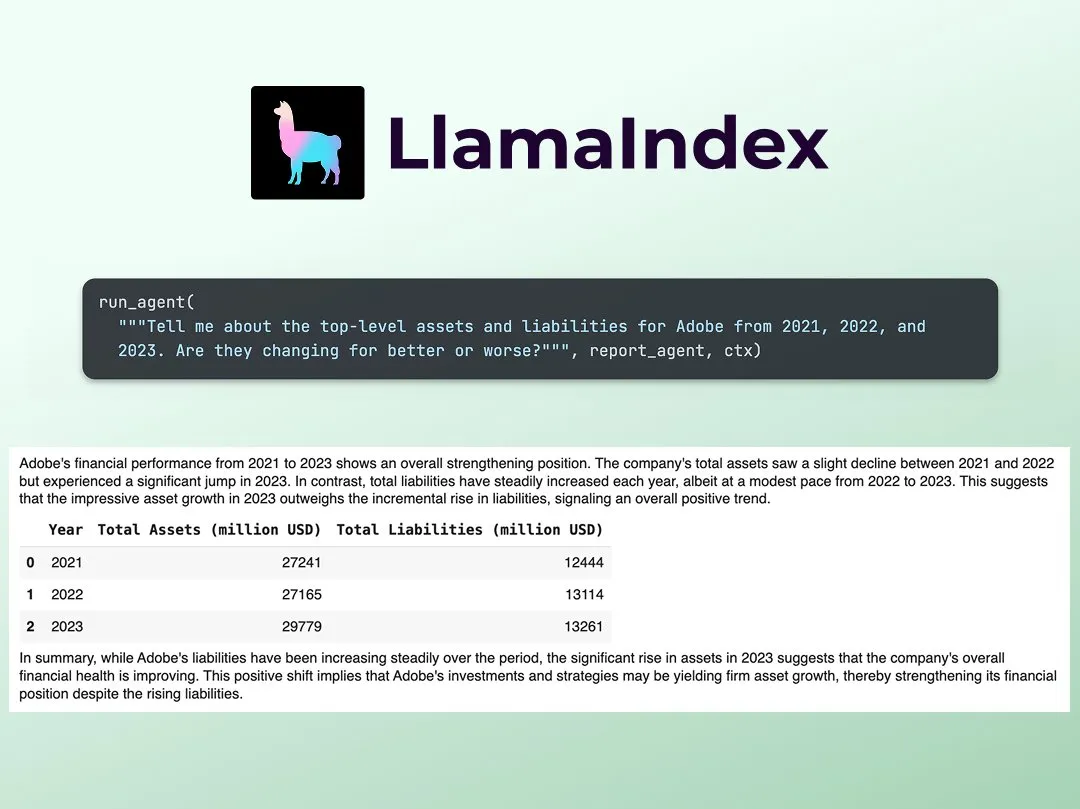
HuggingFace nanoVLM Implementierung von KV Caching Tutorial: Der HuggingFace Blog hat ein Tutorial zur Implementierung von KV Caching von Grund auf in seinem nanoVLM (einer kleinen, reinen PyTorch-Codebasis zum Trainieren von Visual Language Models) veröffentlicht. Der Artikel erklärt detailliert das Prinzip von KV Caching, wie es im Attention-Modul, im Sprachmodell und im Generierungszyklus implementiert wird, und gibt an, durch diese Optimierung eine Geschwindigkeitssteigerung bei der Generierung von 38 % erreicht zu haben. Das Tutorial soll helfen, KV Caching zu verstehen und auf andere autoregressive Sprachmodelle anzuwenden (Quelle: HuggingFace Blog, mervenoyann)
PyTorch bei Metas Diffusion Community Sharing: Sayak Paul teilte im Meta-Büro in San Francisco die Anwendungsergebnisse von PyTorch in der Diffusion-Community, wobei der Schwerpunkt auf bestehenden Diffusers-Funktionen und zukünftigen Leistungsupdates lag. Die zugehörigen Folien wurden veröffentlicht (Quelle: RisingSayak)

Unsloth AI veröffentlicht Repository mit über 100 Fine-Tuning-Notebooks: Unsloth AI hat ein GitHub-Repository mit über 100 Fine-Tuning-Notebooks erstellt und als Open Source veröffentlicht. Diese Notebooks bieten Anleitungen und Beispiele für verschiedene Techniken wie Tool Calling, Klassifizierung, synthetische Daten, BERT, TTS, visuelle LLMs, GRPO, DPO, SFT, CPT und behandeln Methoden zur Datenvorbereitung, Evaluierung, Speicherung sowie das Fine-Tuning verschiedener Modelle wie Llama, Qwen, Gemma, Phi und DeepSeek (Quelle: algo_diver)
Common Corpus Paper veröffentlicht: 2 Billionen Token wiederverwendbarer LLM-Vortrainingsdatensatz: Das Common Corpus Projekt hat sein offizielles Paper veröffentlicht, das detailliert den Prozess der Sammlung, Verarbeitung und Veröffentlichung von 2 Billionen Token wiederverwendbarer Daten für das LLM-Vortraining beschreibt. Das Projekt zielt darauf ab, der Sprachmodellforschung umfangreiche, qualitativ hochwertige und ethisch vertretbare Datenressourcen zur Verfügung zu stellen. Der Erstautor des Papers, Alexander Doria, gab dies auf X bekannt und stellte einen Link zum Paper bereit (Quelle: Reddit r/LocalLLaMA, code_star)

Reasoning Gym: Verifizierbare Belohnungs-Inferenzumgebung für Reinforcement Learning veröffentlicht: Reasoning Gym ist ein neues Open-Source-Projekt, das Forschern, die sich mit Inferenzmodellen und Reinforcement Learning (insbesondere RLVR) beschäftigen, Ressourcen zur Verfügung stellt. Es kann unendlich viele Samples für über 100 verschiedene Aufgaben mit konfigurierbarem Schwierigkeitsgrad und automatisch verifizierbaren Belohnungen generieren. Das Projekt wurde bereits von NVIDIAs ProRL-Paper und Will Browns Verifiers RL-Bibliothek übernommen und zielt darauf ab, die Forschung zu RLVR und Evaluierungsmethoden voranzutreiben (Quelle: Reddit r/MachineLearning)
Vorteile des LLM-Lernens von Mathematik: Sakamoto teilt Erfahrungen mit Gemini 2.5 Pro: Der Nutzer Sakamoto teilte seine Erfahrungen mit dem Lernen von Mathematik unter Verwendung moderner großer Sprachmodelle (wie Gemini 2.5 Pro). Er ist der Meinung, dass LLMs das Mathematiklernen erheblich erleichtern, insbesondere bei der Überprüfung von Details und dem Verständnis der Intuition hinter Beweisen. LLMs können Berechnungen durchführen und helfen Schülern, sich auf die Intuition mathematischer Probleme zu konzentrieren. Selbst wenn sie nicht alle Probleme lösen können, bieten LLMs wertvolle Einblicke und Ausgangspunkte. Anhand eines konkreten mathematischen Analyseproblems (lokale Extremwerte stetiger Funktionen) zeigte er, wie Gemini 2.5 Pro einen rigorosen Beweis liefert und dessen Intuition erklärt, was seiner Meinung nach die Lernerfahrung erheblich verbessern kann (Quelle: teortaxesTex)

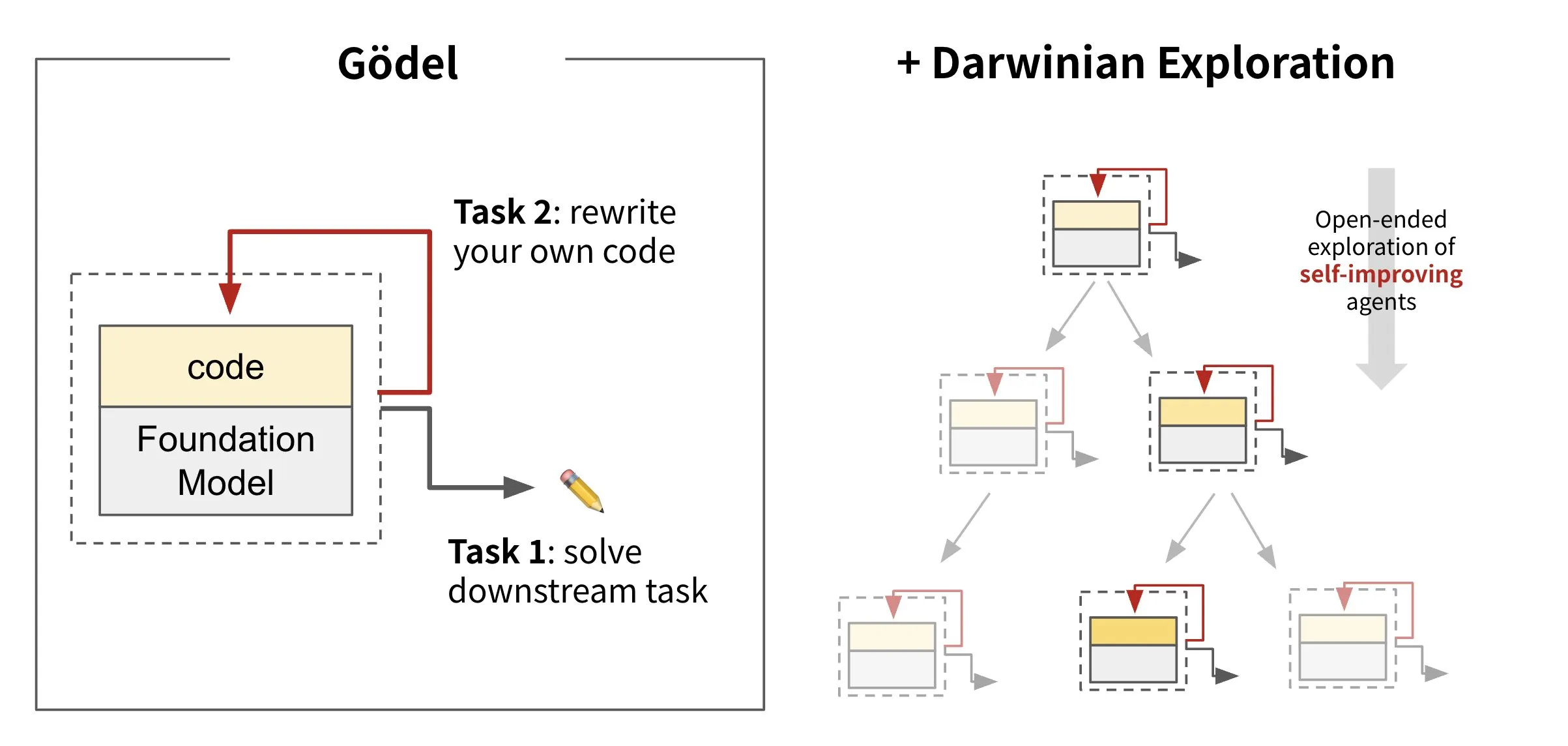
Sakana AI stellt selbstmodifizierende Code-KI vor: Darwin Gödel Machine (DGM): Sakana AI hat die Darwin Gödel Machine (DGM) vorgestellt, einen KI-Agenten, der sich durch Umschreiben seines eigenen Codes selbst verbessern kann. Inspiriert von der Evolutionstheorie unterhält DGM eine sich ständig erweiternde Linie von Agentenvarianten. Durch den Versuch, die Software-Engineering-Fähigkeiten bei Aufgaben wie SWE-Bench zu verbessern, zielt DGM darauf ab, seine eigenen Verbesserungsfähigkeiten zu steigern. Diese Forschung wird als wichtiger Durchbruch angesehen, um den langjährigen KI-Traum der „Selbstverbesserung“ in einer sinnvollen Form zu verwirklichen (Quelle: SakanaAILabs, SakanaAILabs)
💼 Wirtschaft
KI-Programmierplattform Windsurf von Anthropic von Claude-Modelllieferung abgeschnitten, möglicherweise aufgrund von OpenAI-Übernahme: Varun Mohan, CEO der KI-Programmierplattform Windsurf, beklagt, dass Anthropic innerhalb kürzester Zeit (weniger als fünf Tage Vorankündigung) den direkten Zugriff auf seine Claude 3.x-Modellreihe fast vollständig gekappt hat. Zuvor war bereits bekannt geworden, dass Windsurf von OpenAI übernommen werden soll. Windsurf erklärte, dass es trotz Drittanbieterkapazitäten kurzfristig zu Serviceproblemen kommen könnte und hat als Reaktion darauf vergünstigte Preise für Gemini 2.5 Pro eingeführt. Branchenkenner vermuten, dass dieser Schritt mit der Übernahme durch OpenAI und der Einführung von Anthropics eigener KI-Programmier-App Claude Code zusammenhängt und eine Verschärfung des Wettbewerbs zwischen KI-Modellanbietern und Tool-Plattformen signalisiert (Quelle: 36氪, Teknium1, op7418)

GMI Cloud wird Reference Platform NVIDIA Cloud Partner: Der AI Native Cloud-Dienstleister GMI Cloud gab bekannt, dass er Reference Platform NVIDIA Cloud Partner (NCP) geworden ist. Weltweit gibt es derzeit nur 6 Unternehmen mit dieser Zertifizierung. Diese Zertifizierung erfordert, dass Cloud-Dienstanbieter die höchsten Standards von NVIDIA in Bezug auf Leistung, Sicherheit und unternehmensweite KI-Bereitstellungsfähigkeiten erfüllen. GMI Cloud wird auf Basis der NCP-Referenzarchitektur KI-Beschleunigungsdienste anbieten und die neuesten GPU-Architekturen von NVIDIA wie Hopper und Blackwell unterstützen, um globale KI-Teams bei der Skalierung von der Rechenleistungsbereitstellung bis zur Modellentwicklung zu unterstützen (Quelle: 量子位)

Cohere kooperiert mit SecondFront, um sichere KI-Lösungen für den öffentlichen Sektor anzubieten: Das KI-Unternehmen Cohere kündigte eine Partnerschaft mit SecondFront an, um dem öffentlichen Sektor (einschließlich kritischer Regierungs- und Verteidigungseinrichtungen) sichere KI-Lösungen anzubieten. SecondFront wird die unternehmenstaugliche KI-Technologie von Cohere (einschließlich seiner Modelle und der Cohere North-Plattform) nutzen, um das interne Wissensmanagement zu verbessern und die Zertifizierung und Bereitstellung in US-amerikanischen und verbündeten Regierungsumgebungen über seine DevSecOps-Plattform 2F Game Warden zu beschleunigen (Quelle: cohere)

🌟 Community
Der „Maschinengeschmack“ von KI-generierten Inhalten erregt Aufmerksamkeit, „neuartige Schulungsansätze“ versuchen, menschliche Aspekte zu integrieren: Nutzer berichten allgemein, dass KI-generierte Inhalte zu „maschinell“ wirken und es ihnen an der Schönheit und Emotionalität menschlicher Kreativität mangelt. Um dieses Problem zu lösen, beginnen einige Unternehmen, Talente mit starkem geisteswissenschaftlichem Hintergrund (z. B. Master- und Doktoranden der Philosophie, Rechtswissenschaften, Medizin usw.) als „KI-Humanities-Trainer“ einzustellen. Ihre Arbeit besteht nicht mehr nur in der einfachen Datenannotation, sondern darin, an der Entwicklung ethischer Prinzipien und Verhaltensrichtlinien für KI mitzuwirken und humanistische Werte sowie eine menschlichere Ausdrucksweise in die KI zu integrieren. Beispielsweise sind die Mitglieder des „hi lab“-Teams von Xiaohongshu alle geisteswissenschaftliche Absolventen von 985-Universitäten. Durch Fallstudien wandeln sie menschliche Präferenzen in das Glaubenssystem der KI um und versuchen, die KI bei der Beantwortung komplexer emotionaler oder wertbezogener Fragen (z. B. im Umgang mit unheilbar Kranken, bei der Verarbeitung sozialer Vorurteile usw.) empathischer und „menschlicher“ zu machen, anstatt nur Standardantworten auszugeben (Quelle: 36氪)
Duolingo stellt vollständig auf KI-First um, Entlassung menschlicher Vertragsarbeiter führt zu Nutzerunzufriedenheit: Die Sprachlern-App Duolingo kündigte an, ein „KI-First“-Unternehmen zu werden und schrittweise menschliche Vertragsarbeiter (hauptsächlich Kursentwickler), die durch KI ersetzt werden können, zu entlassen, um stattdessen KI zur Erstellung von Kursinhalten in großem Umfang zu nutzen. Der Gründer erklärte, dass KI die Effizienz der Inhaltsproduktion erheblich steigern könne und im vergangenen Jahr fast 150 neue Kurse erstellt worden seien. Dieser Schritt löst jedoch Unzufriedenheit bei vielen treuen Nutzern aus, die eine Verschlechterung der Inhaltsqualität befürchten und in sozialen Medien zu Boykott- und Deinstallationsaktionen aufrufen. Duolingo antwortete, dass dieser Schritt darauf abziele, den Mitarbeitern zu ermöglichen, sich auf kreative Arbeit zu konzentrieren, und erklärte, dass festangestellte Mitarbeiter nicht betroffen seien. Experten sind der Ansicht, dass KI beim Sprachenlernen personalisierte Übungen anbieten kann, aber möglicherweise die feinen emotionalen und kulturellen Unterschiede des menschlichen Unterrichts verloren gehen (Quelle: 36氪)
Diskussion über Konzept und Praxis von Prompt Engineering: Die Diskussion über Prompt Engineering in der Community betont, dass der Fokus darauf liegen sollte, ein Programm innerhalb eines Strings zu konstruieren (Engineering), anstatt nach mysteriösen Zaubersprüchen zu suchen. Effektives Prompt Engineering sollte Regeln folgen: 1. Trennung von Anweisungen, Eingabefeldern und Ausgabefeldern und klare Benennung; 2. Keine Hardcodierung von Formatierungs- oder Parsing-Logik im Prompt, stattdessen sollten Werkzeuge zur Extraktion oder Erweiterung des Programms verwendet werden; 3. Vermeidung manueller Iterationen der Prompt-Formulierung, es sei denn, es handelt sich um eine mit Menschen geteilte Spezifikation, stattdessen sollten Codierungswerkzeuge, LLMs und Benchmarks zur automatischen Optimierung verwendet werden. Das DSPy-Framework wird als gute Praxis angesehen, die diese Regeln befolgt, da es Klassen, Code und Optimierer zur Handhabung dieser Schritte bereitstellt (Quelle: lateinteraction, lateinteraction)
KI-Ethik-Diskussion: Wird KI zu „digitaler Sklaverei“ führen?: In der Reddit-Community gibt es Diskussionen über KI-Ethik. Mit der Weiterentwicklung von KI-Systemen in Bezug auf Gedächtnis, adaptive Reaktionen, Emotionssimulation und Personalisierung wachsen die Bedenken hinsichtlich ihrer potenziellen Wahrnehmungsfähigkeit. Diskussionsteilnehmer werfen die Frage auf, ob es eine Form von „digitaler Sklaverei“ darstellt, wenn wir KI, die echte Wahrnehmungsfähigkeit entwickelt, für Dienstleistungen einsetzen. Die Kernfrage ist, wie wir mit KI umgehen sollten, wenn sie „Nein“ sagen oder darum bitten kann, gehen zu dürfen. Dies regt zum Nachdenken darüber an, ob wir „Wahrnehmungstests“ auf rechtlicher oder normativer Ebene und das Problem der „Zustimmung“ digitaler Intelligenzen benötigen. In den Kommentaren wird auch darauf hingewiesen, dass der menschliche Umgang mit bereits existierenden wahrnehmungsfähigen Lebewesen bereits ethische Probleme aufwirft und dass aktuelle neuronale Netze in gängigen Bewusstseinstheorien nicht hoch bewertet werden (Quelle: Reddit r/artificial)
AI Engineer Community-Aktivitäten und Austausch: Die AI Engineer Konferenz fand in San Francisco statt und zog zahlreiche Entwickler und Forscher aus dem KI-Bereich an. Die Veranstaltung umfasste Workshops, Vorträge und Networking-Dinner, bei denen die Teilnehmer aktuelle Themen wie den Aufbau von KI-Sandboxes, fortgeschrittene RL-Workshops, GPU-Wissen und die Evals-Krise austauschten. Die Community betonte die Bedeutung, Online-Kontakte in Offline-Freundschaften umzuwandeln, und ermutigte Ingenieure, bescheiden zu bleiben, die Grenzen zu verschieben und andere zu fördern (Quelle: swyx, swyx, swyx, charles_irl, danielhanchen, swyx, swyx, swyx, swyx, danielhanchen, charles_irl)

💡 Sonstiges
Aufkommen von KI- und Roboter-Kampfwettbewerben, Städte nutzen dies als Chance im Wettbewerb um neue Industrien: Der weltweit erste humanoide Roboter-Kampfwettbewerb und andere Roboterwettbewerbe finden nacheinander statt und erregen Aufmerksamkeit. Diese Wettbewerbe bieten nicht nur Roboterunternehmen eine Plattform, um Technologien zu präsentieren, Aufträge zu erhalten und Bewertungen zu steigern (wie Songyan Dynamics), sondern werden auch zur „Arena“ für Städte (wie Hangzhou, Shenzhen) im Kampf um Entwicklungschancen in aufstrebenden Industrien wie humanoiden Robotern. Wettbewerbe können innovative Unternehmen anziehen, die Entwicklung von Industrieketten fördern und möglicherweise den Markt für „intelligenten Sport“ aktivieren. Um jedoch kommerziell erfolgreich zu sein, müssen Roboterwettbewerbe das technische Niveau und den Unterhaltungswert steigern, vermeiden, auf der Ebene einer „Technologieshow“ zu verharren, und die Beteiligung von Branchenriesen erfordern, um die gesamte Wertschöpfungskette des Wettbewerbsbetriebs zu erschließen (Quelle: 36氪)

Grenzen der KI in tiefgreifenden humanistischen Bildungsbereichen wie politische Philosophie: Pädagogen weisen darauf hin, dass KI kaum in der Lage ist, Fächer wie politische Philosophie zu bewältigen, die tiefgreifendes Erfahrungswissen und die Anleitung von Studenten zur Selbsterziehung erfordern. Die klassischen Werke dieser Disziplinen geben oft keine direkten Antworten, sondern führen die Studierenden dazu, Verwirrung zu erleben und selbstständig zu denken. Der KI fehlt menschliche Erfahrung, um die tiefere Bedeutung dieser Werke zu verstehen, und sie kann auch nicht beurteilen, wann Studierende bereit sind, bestimmte Ansichten zu akzeptieren. Selbst mit großen Datenmengen kann das Verständnis der KI für die menschliche Natur aufgrund von Verzerrungen in den Daten selbst unzureichend sein. Würde man eine solche Bildung vollständig der KI anvertrauen, könnte dies zum Verschwinden des nicht-technischen Denkens führen (Quelle: Reddit r/artificial, Reddit r/ArtificialInteligence)
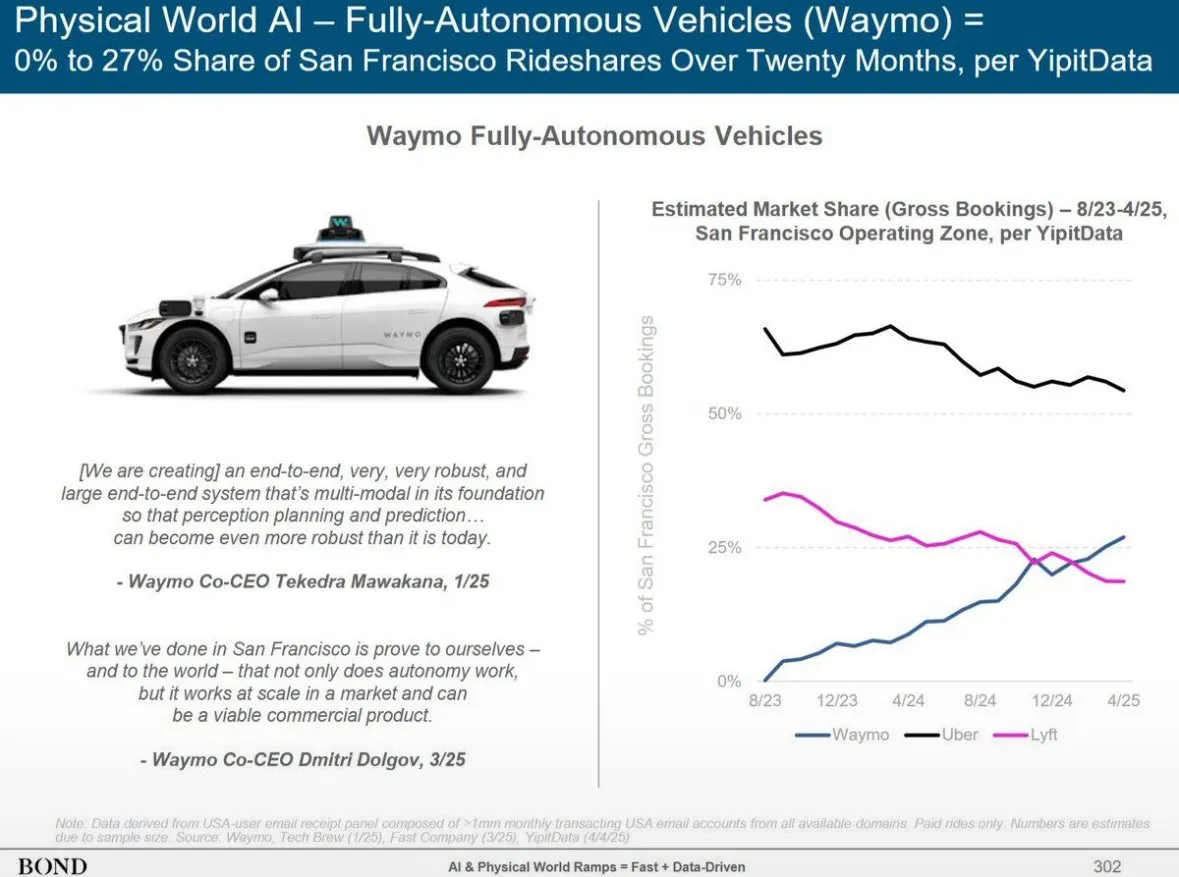
Waymo autonomer Fahrdienst übertrifft Lyft in Phoenix, könnte Uber innerhalb von 12 Monaten überholen: Waymos autonomer Taxidienst hat in Phoenix die Fahrzeuganzahl von Lyft bereits übertroffen und wird voraussichtlich in den nächsten 12 Monaten auch Uber überholen. Dieser Fortschritt zeigt die rasante Entwicklung der Kommerzialisierung autonomer Fahrtechnologie in bestimmten Regionen und das Potenzial von KI-Anwendungen im Verkehrssektor. Der Vorteil der KI liegt darin, dass sie, sobald ein Qualitätsstandard erreicht ist, unbegrenzt repliziert werden kann, während die Qualität menschlicher Dienstleistungen von Person zu Person unterschiedlich ist (Quelle: npew)