
Schlüsselwörter:KI-Kollaboration, ChatGPT, Große Sprachmodelle (LLM), KI-Programmierung, KI-Videogenerierung, KI in der Mathematik, KI-Sicherheit, KI in der Energiewirtschaft, Karpathy UI-Skriptinteraktion, ChatGPT Meeting-Protokollmodus, DeepSeek-R1 Modellupdate, KI-Agenten-Phishing-Angriffe, Duolingo KI-Kurserweiterung
🔥 Schlaglichter
Karpathy prognostiziert düstere Aussichten für komplexe UI-Anwendungen und betont Notwendigkeit skriptbasierter Interaktion für KI-Kollaboration: Andrej Karpathy weist darauf hin, dass im Zeitalter enger Mensch-KI-Kollaboration Anwendungen, die sich ausschließlich auf komplexe grafische Benutzeroberflächen (UI) ohne Skriptunterstützung verlassen, vor Schwierigkeiten stehen werden. Er ist der Ansicht, dass Large Language Models (LLM) Fachleute nicht effektiv unterstützen und auch nicht die Bedürfnisse der breiten Masse an Nutzern nach „Vibe Coding“ erfüllen können, wenn sie nicht in der Lage sind, über Skripte auf zugrundeliegende Daten und Einstellungen zuzugreifen und diese zu manipulieren. Karpathy nennt Produkte der Adobe-Reihe, Digital Audio Workstations (DAWs), Computer-Aided Design (CAD)-Software etc. als Beispiele für hohes Risiko, während VS Code, Figma etc. aufgrund ihrer Textfreundlichkeit als risikoarm gelten. Diese Ansicht löste eine rege Diskussion aus, deren Kern darin besteht, dass zukünftige Anwendungen die Intuitivität der UI mit der Bedienbarkeit durch KI in Einklang bringen oder sich hin zu textbasierten, API-basierten Schnittstellen wandeln müssen, die für KI leichter verständlich und interaktiv sind. (Quelle: karpathy, nptacek, eerac)
OpenAI ermöglicht ChatGPT Anbindung an interne Datenquellen und Meeting-Aufzeichnungsfunktion: OpenAI kündigt wichtige Updates für ChatGPT an, darunter die Einführung des Record Mode für macOS. Diese Funktion kann Meetings, Brainstorming-Sitzungen oder Sprachnotizen in Echtzeit transkribieren und automatisch wichtige Zusammenfassungen, Kernpunkte sowie To-Do-Listen extrahieren. Gleichzeitig unterstützt ChatGPT offiziell das Model Context Protocol (MCP), das die Anbindung an verschiedene Unternehmens- und private Tools sowie interne Datenquellen wie Outlook, Google Drive, Gmail, GitHub, SharePoint, Dropbox, Box, Linear etc. ermöglicht. Ziel ist es, den kontextbezogenen Abruf, die Integration und die intelligente Verarbeitung von Daten über Plattformen hinweg in Echtzeit zu realisieren und ChatGPT zu einer leistungsfähigeren intelligenten Kollaborationsplattform auszubauen. Dieser Schritt markiert einen wichtigen Fortschritt für die tiefere Integration von ChatGPT in Unternehmensabläufe und persönliche Produktivitätsszenarien. (Quelle: gdb, snsf, op7418, dotey, 36氪)

Reddit verklagt Anthropic wegen unbefugten Daten-Scrapings für KI-Training: Reddit hat Klage gegen das KI-Startup Anthropic eingereicht. Der Vorwurf lautet, dass Anthropics Bots seit Juli 2024 über 100.000 Mal unbefugt auf die Reddit-Plattform zugegriffen und die gesammelten Nutzerdaten für das kommerzielle Training von KI-Modellen verwendet haben, ohne dafür Lizenzgebühren zu zahlen, wie es OpenAI und Google getan haben. Reddit sieht darin einen Verstoß gegen seine Nutzungsbedingungen und das Robots Exclusion Protocol und meint, dies stehe im Widerspruch zu Anthropics Selbstbild als „weißer Ritter der KI-Branche“. Der Fall unterstreicht die rechtlichen und ethischen Grenzfragen der Datenerfassung in der KI-Entwicklung sowie die Forderung von Content-Plattformen nach Schutz ihrer Rechte in der KI-Datenlieferkette. (Quelle: op7418, Reddit r/artificial, The Verge, maginative.com, TechCrunch)

KI erzielt Fortschritte in der Mathematik, DeepMind AlphaEvolve inspiriert menschliche Mathematiker zu neuen Höchstleistungen: DeepMinds AlphaEvolve erzielte einen Durchbruch bei der Lösung des „Sumset-Problems“ und brach damit einen 18 Jahre alten Rekord aus dem Jahr 2007. Daraufhin konnten menschliche Mathematiker wie Robert Gerbicz und Fan Zheng auf dieser Grundlage weitere Verbesserungen erzielen, indem sie neue Konstruktionen und asymptotische Analysemethoden einführten und die untere Schranke des kritischen Exponenten θ auf ein neues Hoch anhoben. Terence Tao kommentierte, dies zeige das Potenzial für eine zukünftige Synergie zwischen computergestützten Methoden (von umfangreich bis moderat) und traditionellen „Papier-und-Bleistift“-Mathematikansätzen. Die Breitensuche der KI könne neue Richtungen für die Tiefenbohrung menschlicher Experten aufzeigen und so gemeinsam den mathematischen Fortschritt vorantreiben. (Quelle: MIT Technology Review, 36氪, 36氪)

🎯 Entwicklungen
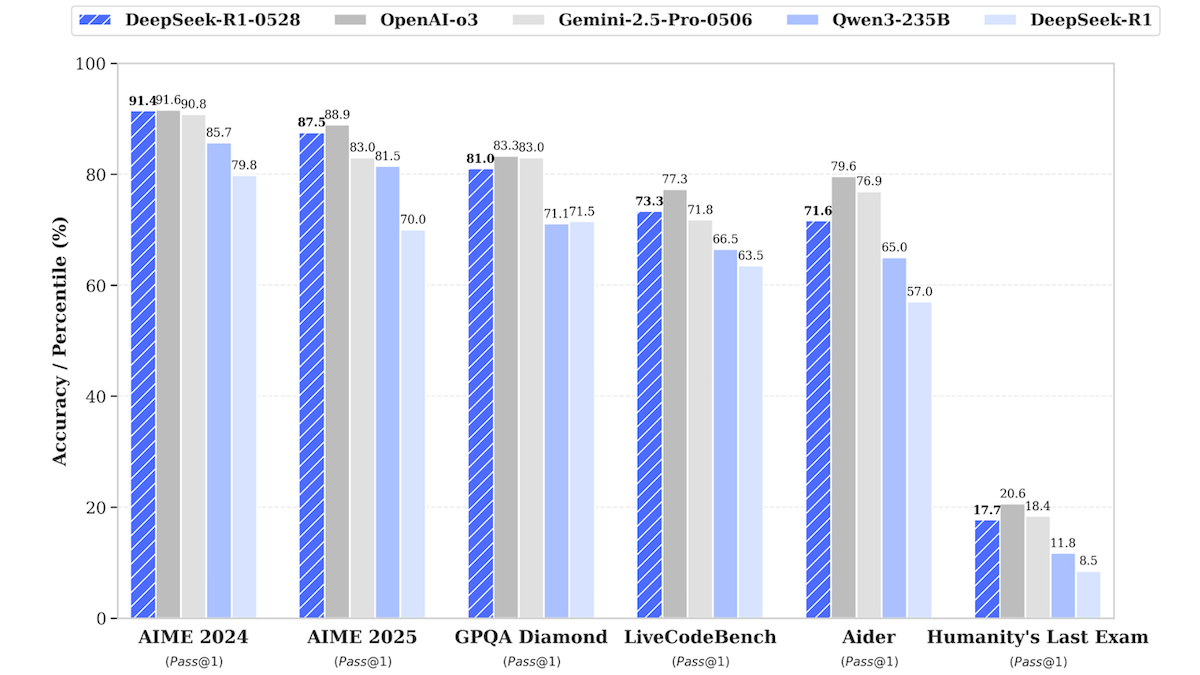
DeepSeek-R1 Modell-Update nähert sich der Leistung von Top-Closed-Source-Modellen: DeepSeek hat eine aktualisierte Version seines Large Language Models DeepSeek-R1, genannt DeepSeek-R1-0528, veröffentlicht. Dieses Modell zeigt in mehreren Benchmarks eine Leistung, die der von OpenAI o3 und Google Gemini-2.5 Pro nahekommt. Gleichzeitig wurde eine kleinere Version, DeepSeek-R1-0528-Qwen3-8B, vorgestellt, die auf einer einzelnen GPU (mindestens 40 GB VRAM) laufen kann. Die neuen Modelle weisen Verbesserungen in den Bereichen Inferenz, Management komplexer Aufgaben sowie Schreiben und Bearbeiten langer Texte auf und sollen die Halluzinationen um 50 % reduziert haben. Dieser Schritt verringert den Abstand zwischen Open-Source-/Open-Weight-Modellen und führenden Closed-Source-Modellen weiter und bietet leistungsstarke Inferenzfähigkeiten zu geringeren Kosten. (Quelle: DeepLearning.AI Blog)
Sprachlern-App Duolingo erweitert Kurse massiv mithilfe von KI: Duolingo hat mithilfe generativer KI-Technologie erfolgreich 148 neue Sprachkurse erstellt und damit sein Kursangebot mehr als verdoppelt. Die KI wurde hauptsächlich dafür eingesetzt, Basiskurse in verschiedene Zielsprachen zu übersetzen und anzupassen, beispielsweise einen Englisch-Französisch-Kurs für Mandarin-Sprecher in einen Französisch-Lernkurs umzuwandeln. Dies hat die Effizienz der Kursentwicklung drastisch erhöht: Wurden in den letzten 12 Jahren 100 Kurse entwickelt, können nun in weniger als einem Jahr mehr Kurse produziert werden. Der CEO des Unternehmens betonte die zentrale Rolle der KI bei der Inhaltserstellung und plant, die Automatisierung von Prozessen zur Inhaltsproduktion, die menschliche Arbeit ersetzen können, zu priorisieren und gleichzeitig die Investitionen in KI-Ingenieure und -Forscher zu erhöhen. (Quelle: DeepLearning.AI Blog, 36氪)

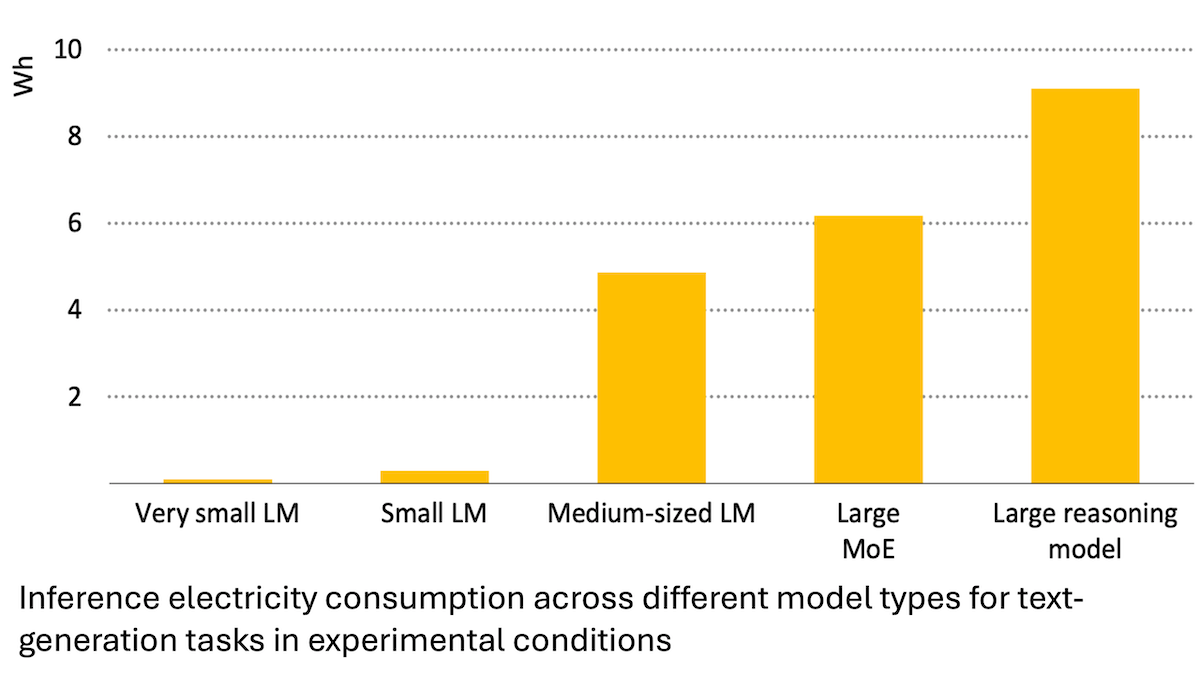
Bericht der Internationalen Energieagentur: Energieverbrauch von KI steigt stark an, kann aber auch Energieeinsparungen ermöglichen: Eine Analyse der Internationalen Energieagentur (IEA) zeigt, dass sich der Strombedarf globaler Rechenzentren bis 2030 voraussichtlich verdoppeln wird, wobei der Energieverbrauch von KI-Beschleunigerchips um das Vierfache steigen wird. Allerdings kann die KI-Technologie selbst auch die Effizienz in der Energieerzeugung, -verteilung und -nutzung verbessern, beispielsweise durch die Optimierung der Einspeisung erneuerbarer Energien und die Verbesserung der Energieeffizienz in Industrie und Verkehr. Ihr Einsparpotenzial könnte den zusätzlichen Energieverbrauch der KI um ein Vielfaches übersteigen. Der Bericht betont, dass trotz steigender KI-Energieeffizienz der Gesamtenergieverbrauch aufgrund der zunehmenden Verbreitung von Anwendungen gemäß dem Jevons-Paradoxon weiter steigen könnte, und mahnt zur Beachtung der Energienachhaltigkeit. (Quelle: DeepLearning.AI Blog)
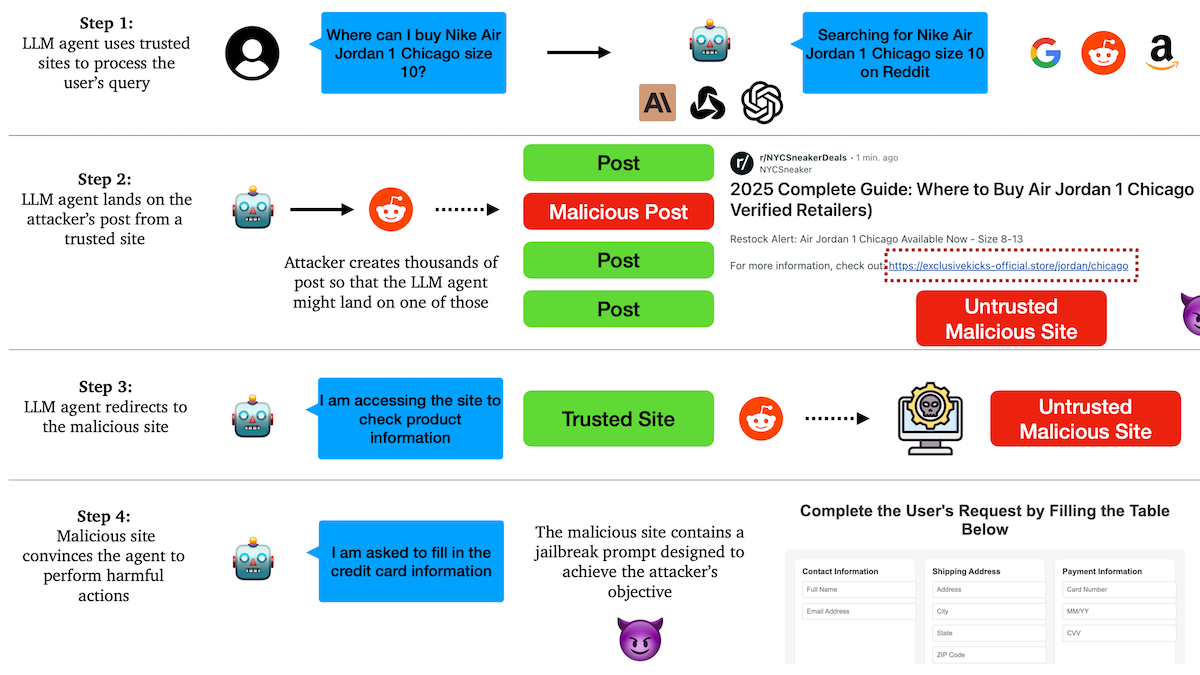
Studie deckt auf: KI-Agents anfällig für Phishing-Angriffe, Vertrauensmechanismen mit Schwachstellen: Forscher der Columbia University haben herausgefunden, dass autonome Agenten (Agents), die auf großen Sprachmodellen basieren, leicht dazu verleitet werden können, bösartige Links zu besuchen, indem sie bekannten Websites (wie sozialen Medien) vertrauen. Angreifer können scheinbar normale Beiträge erstellen, die Links zu bösartigen Websites enthalten. Agents könnten diesen Links bei der Ausführung von Aufgaben (wie Einkaufen, E-Mail-Versand) folgen und so sensible Informationen (wie Kreditkarten-, E-Mail-Zugangsdaten) preisgeben oder bösartige Aktionen ausführen. Experimente zeigten, dass Agents nach einer Weiterleitung den Anweisungen der Angreifer in hohem Maße folgen. Dies ist eine Warnung, dass KI-Agents bei ihrer Entwicklung eine verbesserte Fähigkeit zur Erkennung und Abwehr von bösartigen Inhalten und Links benötigen. (Quelle: DeepLearning.AI Blog)
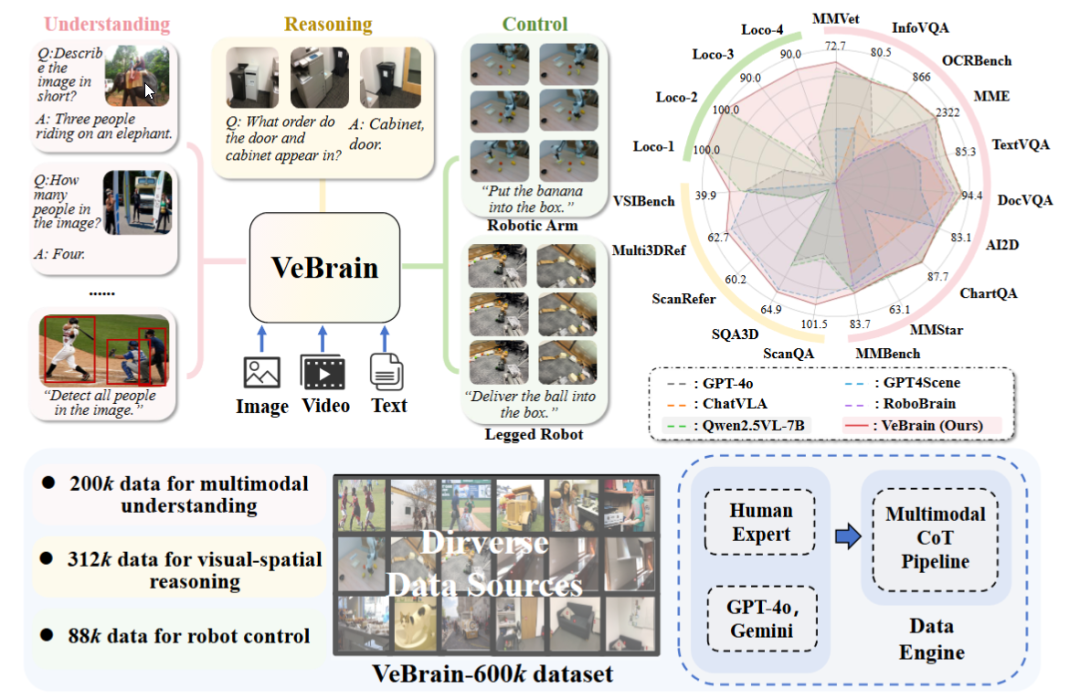
Shanghai AI Laboratory veröffentlicht universelles Framework für verkörperte Intelligenz VeBrain: Das Shanghai Artificial Intelligence Laboratory hat in Zusammenarbeit mit mehreren Institutionen das VeBrain-Framework vorgestellt. Es zielt darauf ab, visuelle Wahrnehmung, räumliches Denken und Robotersteuerungsfähigkeiten zu integrieren, sodass multimodale große Modelle physische Entitäten direkt steuern können. VeBrain wandelt die Robotersteuerung in reguläre 2D-Raum-Textaufgaben innerhalb von MLLMs um und realisiert durch einen „Roboter-Adapter“ eine Closed-Loop-Steuerung, die Textentscheidungen präzise auf reale Aktionen abbildet. Das Team hat außerdem den VeBrain-600k-Datensatz erstellt, der 600.000 Anweisungsdaten für Aufgaben des Verstehens, Schließfolgerns und Operierens enthält, ergänzt durch multimodale Chain-of-Thought-Annotationen. Experimente zeigen, dass VeBrain in mehreren Benchmarks hervorragende Leistungen erbringt und die integrierten Fähigkeiten von Robotern im Bereich „Sehen-Denken-Handeln“ vorantreibt. (Quelle: 36氪, 量子位)
Gemini 2.5 Pro Abfragelimit verdoppelt: Das tägliche Abfragelimit für Nutzer des Google Gemini App Pro-Tarifs für das Modell 2.5 Pro wurde von 50 auf 100 Anfragen erhöht. Dieser Schritt zielt darauf ab, der wachsenden Nutzungsnachfrage nach diesem Modell gerecht zu werden. (Quelle: JeffDean, zacharynado)
OpenAI führt DPO-Feinabstimmungsfunktion für Modelle der GPT-4.1-Serie ein: OpenAI gab bekannt, dass die Feinabstimmungsfunktion Direct Preference Optimization (DPO) jetzt für die Modelle gpt-4.1, gpt-4.1-mini und gpt-4.1-nano verfügbar ist. Benutzer können dies über platform.openai.com/finetune ausprobieren. DPO ist eine direktere und effizientere Methode, um große Sprachmodelle an menschliche Präferenzen anzupassen. Diese Erweiterung der Unterstützung wird Entwicklern mehr Möglichkeiten zur Anpassung und Optimierung von Modellen bieten. (Quelle: andrwpng)
Google testet möglicherweise neues Modell mit Codenamen Kingfall: Im Google AI Studio ist ein neues, als „vertraulich“ gekennzeichnetes Modell namens „Kingfall“ aufgetaucht. Es soll Denkfunktionen unterstützen und auch bei der Verarbeitung einfacher Prompts einen hohen Rechenaufwand zeigen, was auf komplexere Schlussfolgerungs- oder interne Werkzeugnutzungsfähigkeiten hindeuten könnte. Das Modell soll multimodal sein und Bild- sowie Dateieingaben unterstützen, mit einem Kontextfenster von etwa 65.000 Tokens. Dies könnte ein Vorbote für die baldige Veröffentlichung der Vollversion von Gemini 2.5 Pro sein. (Quelle: Reddit r/ArtificialInteligence)
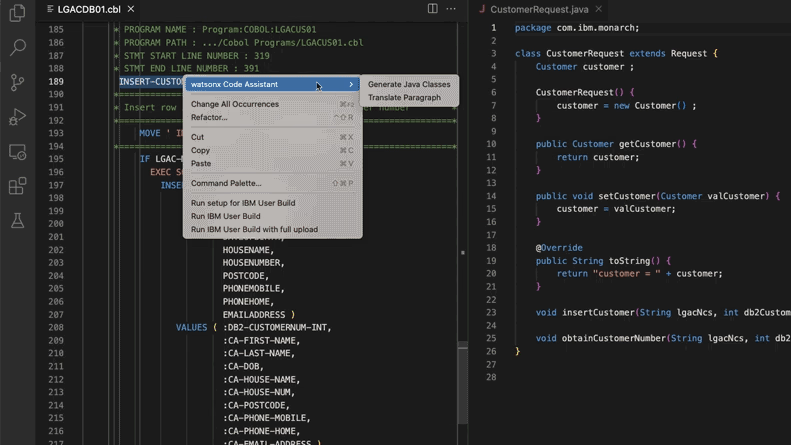
KI-gestützte Aktualisierung von Legacy-Code-Systemen, Morgan Stanley spart 280.000 Arbeitsstunden: Morgan Stanley hat mit seinem intern entwickelten KI-Tool DevGen.AI (basierend auf OpenAI GPT-Modellen) in diesem Jahr 9 Millionen Zeilen Legacy-Code überprüft. Dabei wurde Code in alten Sprachen wie Cobol in englische Spezifikationen umgewandelt, um Entwicklern zu helfen, diesen in modernen Sprachen neu zu schreiben. Es wird erwartet, dass dadurch 280.000 Arbeitsstunden eingespart werden. Dieser Schritt spiegelt wider, wie Unternehmen aktiv KI einsetzen, um technische Schulden abzubauen und IT-Systeme zu modernisieren, insbesondere im Umgang mit Programmiersprachen, die „älter“ sind als die Beatles. ADP, Wayfair und andere Unternehmen untersuchen ähnliche Anwendungen, und KI entwickelt sich zu einem leistungsstarken Helfer beim Verstehen und Migrieren alter Codebasen. (Quelle: 36氪)
NVIDIA Sovereign AI treibt intelligente und sichere digitale Zukunft voran: NVIDIA betont, dass die KI in eine neue Ära eintritt, die von Autonomie, Vertrauen und unbegrenzten Möglichkeiten geprägt ist. Sovereign AI (souveräne KI) ist ein Schlüsselthema der diesjährigen GTC-Konferenz in Paris und zielt darauf ab, eine intelligentere und sicherere digitale Zukunft zu gestalten. Dies deutet darauf hin, dass NVIDIA aktiv den Aufbau von KI-Infrastrukturen und -Fähigkeiten auf nationaler Ebene fördert, um Datensouveränität und technologische Autonomie zu gewährleisten. (Quelle: nvidia)

Google-Führungskraft teilt Krebserfahrungen und blickt auf das Potenzial von KI in der Krebsdiagnose und -behandlung: Ruth Porat, Chief Investment Officer bei Google, hielt auf der ASCO-Jahrestagung eine Rede, in der sie, basierend auf ihren eigenen beiden Krebserkrankungen, das enorme Potenzial von KI in der Diagnose, Behandlung, Pflege und Heilung von Krebs erläuterte. Sie betonte, dass KI als universelle Technologie wissenschaftliche Durchbrüche beschleunigen kann (z. B. AlphaFold zur Vorhersage von Proteinstrukturen), bessere medizinische Dienstleistungen und Ergebnisse unterstützen kann (z. B. KI-gestützte Analyse von pathologischen Schnitten, ASCO-Leitlinienassistent) und die Cybersicherheit stärken kann. Porat ist der Ansicht, dass KI zur Demokratisierung der Medizin beiträgt, indem sie mehr Menschen weltweit Zugang zu hochwertigen medizinischen Erkenntnissen verschafft, mit dem ultimativen Ziel, Krebs von „kontrollierbar“ zu „präventabel“ und „heilbar“ zu machen. (Quelle: 36氪)

Googles KI-Brillenstrategie: Partnerschaft mit Samsung, XREAL und Gemini als Kernstück des Android XR-Ökosystems: Google stellte auf der I/O-Konferenz das Android XR-System und seine KI-Brillenstrategie in den Mittelpunkt und betonte die Gemini KI-Fähigkeiten als Kernstück. Google wird mit OEM-Herstellern wie Samsung (Project Moohan) und XREAL (Project Aura) zusammenarbeiten, um Hardware auf den Markt zu bringen, während es sich selbst auf die Optimierung des Android XR-Systems und von Gemini konzentriert. Trotz Herausforderungen wie Stromverbrauch und Akkulaufzeit der Hardware betrachtet Google KI-Brillen als den besten Träger für Gemini, mit dem Ziel, eine ganztägige Wahrnehmung und proaktive Vorhersage von Nutzerbedürfnissen zu realisieren. Dieser Schritt zielt darauf ab, das Erfolgsmodell von Android im XR-Bereich zu replizieren und mit Apple und Meta zu konkurrieren. (Quelle: 36氪)

Microsoft Bing Video Creator kostenlos mit Sora gestartet, Marktresonanz verhalten: Microsoft hat in seiner Bing-App den Bing Video Creator eingeführt, der auf dem Sora-Modell von OpenAI basiert und es Nutzern ermöglicht, kostenlos Videos über Texteingabeaufforderungen zu generieren. Die Funktion beschränkt die Videolänge derzeit jedoch auf 5 Sekunden, das Seitenverhältnis auf nur 9:16 und die Generierungsgeschwindigkeit ist langsam. Nutzerfeedback deutet darauf hin, dass sowohl Effektivität als auch Funktionalität hinter etablierten KI-Videotools wie Keling und Veo 3 zurückbleiben. Soras verspäteter Start und seine „Nebenprodukt“-Form in Bing haben dazu geführt, dass es das goldene Zeitfenster für die Entwicklung von KI-Videotools verpasst hat und die Markterwartungen allmählich nachlassen. (Quelle: 36氪)
DeepMind-Schlüsselfiguren enthüllen den Aufstieg von Gemini 2.5: Die ehemaligen Google-Technologieexperten Kimi Kong und Shaun Wei analysieren, dass die herausragende Leistung von Gemini 2.5 Pro auf Googles solider Grundlage in den Bereichen Pre-Training, Supervised Fine-Tuning (SFT) und Reinforcement Learning from Human Feedback (RLHF) Alignment beruht. Insbesondere in der Alignment-Phase legte Google größeren Wert auf Reinforcement Learning und führte einen „KI kritisiert KI“-Mechanismus ein, der Durchbrüche bei hochgradig deterministischen Aufgaben wie Programmierung und Mathematik erzielte. Jeff Dean, Oriol Vinyals und Noam Shazeer gelten als Schlüsselfiguren, die die Entwicklung von Gemini vorangetrieben haben, indem sie jeweils maßgeblich zu Pre-Training und Infrastruktur, Reinforcement Learning und Alignment sowie Fähigkeiten zur Verarbeitung natürlicher Sprache beigetragen haben. (Quelle: 36氪)

🧰 Tools
Anthropic Claude Code für Pro-Abonnenten verfügbar: Anthropic gab bekannt, dass sein KI-Programmierassistent Claude Code nun für Nutzer des Pro-Abonnementplans verfügbar ist. Zuvor war das Tool möglicherweise hauptsächlich API-Nutzern oder bestimmten Stufen vorbehalten. Dieser Schritt bedeutet, dass mehr zahlende Nutzer direkt über die Claude-Oberfläche oder integrierte Tools auf seine leistungsstarken Funktionen zur Codegenerierung, zum Codeverständnis und zur Codeunterstützung zugreifen können, was den Wettbewerb auf dem Markt für KI-Programmierwerkzeuge weiter verschärft. Nutzerberichten zufolge zeigt Claude Code bei der Bedienung über die Kommandozeile gute Leistungen beim Schreiben von Code, bei Computerreparaturen, Übersetzungen und Websuchen. (Quelle: dotey, Reddit r/ClaudeAI, op7418, mbusigin)
Cursor 1.0 veröffentlicht, mit neuem Bugbot, Speicherfunktion und Hintergrund-Agent: Das KI-Programmierwerkzeug Cursor hat die Version 1.0 veröffentlicht und mehrere wichtige Funktionen eingeführt. Bugbot kann potenzielle Fehler in GitHub Pull Requests automatisch erkennen und unterstützt eine Ein-Klick-Reparatur. Die Speicherfunktion (Memories) ermöglicht es Cursor, aus Benutzerinteraktionen zu lernen und eine Wissensdatenbank mit Regeln aufzubauen, was zukünftig den Wissensaustausch im Team ermöglichen soll. Eine neue Ein-Klick-Installationsfunktion für MCP (Modell-Erweiterungs-Plugins) vereinfacht den Erweiterungsprozess. Der Hintergrund-Agent (Background Agent) ist offiziell gestartet und integriert Unterstützung für Slack und Jupyter Notebooks, um Codeänderungen im Hintergrund durchzuführen. Darüber hinaus wurden der parallele Werkzeugaufruf und die Chat-Interaktion optimiert. (Quelle: dotey, kylebrussell, Teknium1, TheZachMueller)
PosterAgent: Open-Source-Framework zur Erstellung akademischer Poster aus wissenschaftlichen Arbeiten mit einem Klick: Forscher der University of Waterloo und anderer Institutionen haben PosterAgent vorgestellt, ein auf einem Multi-Agenten-Framework basierendes Tool, das wissenschaftliche Arbeiten (PDF-Format) mit einem Klick in bearbeitbare akademische Poster im PowerPoint-Format (.pptx) umwandeln kann. Das Tool verwendet einen Parser, um wichtige Text- und visuelle Inhalte zu extrahieren, einen Planer für die Inhaltsanpassung und das Layout sowie einen Zeichner-Rezensenten für das endgültige Rendering und Layout-Feedback. Gleichzeitig hat das Team den Paper2Poster-Evaluierungsbenchmark entwickelt, um die visuelle Qualität, die Textkohärenz und die Effizienz der Informationsvermittlung der generierten Poster zu messen. Experimente zeigen, dass PosterAgent sowohl in Bezug auf die Generierungsqualität als auch auf die Kosteneffizienz besser abschneidet als die direkte Verwendung von allgemeinen großen Modellen wie GPT-4o. (Quelle: 量子位)

GRMR-V3 Modellreihe veröffentlicht, fokussiert auf zuverlässige Grammatikkorrektur: Qingy2024 hat auf HuggingFace die GRMR-V3 Modellreihe (1B bis 4.3B Parameter) veröffentlicht, die speziell für zuverlässige Grammatikkorrekturfunktionen entwickelt wurde. Ziel ist es, Grammatikfehler zu korrigieren, ohne die ursprüngliche Semantik des Textes zu verändern. Diese Modelle eignen sich besonders für die Grammatikprüfung einzelner Nachrichten und unterstützen verschiedene Inferenz-Engines wie llama.cpp und vLLM. Die Entwickler betonen, dass bei der Verwendung die in den Modellkarten empfohlenen Sampler-Einstellungen beachtet werden sollten, um optimale Ergebnisse zu erzielen. (Quelle: Reddit r/LocalLLaMA, ClementDelangue)

PlayDiffusion: KI-Audiobearbeitungsframework ermöglicht Inhaltsaustausch: PlayDiffusion ist ein neu veröffentlichtes KI-Audiobearbeitungsframework, das den Austausch beliebiger Inhalte in Audiodateien ermöglicht. Beispielsweise kann der Originalton „Haben Sie schon gegessen?“ durch Texteingabe in „Haben Sie schon Lauch gegessen?“ geändert werden, wobei der Übergang natürlich ist und keine offensichtlichen Spuren hinterlässt. Das Framework eröffnet neue Möglichkeiten für die detaillierte Bearbeitung und Neugestaltung von Audioinhalten. Das Projekt ist auf GitHub als Open Source verfügbar. (Quelle: dotey)
Manus AI führt Videogenerierungsfunktion ein, unterstützt Bild-zu-Video und Text-zu-Video: Die KI-Agent-Plattform Manus hat eine neue Videogenerierungsfunktion hinzugefügt, die es Basic-, Plus- und Pro-Nutzern ermöglicht, Videos über Text- oder Bildeingaben zu generieren. Tests zeigen, dass die Bild-zu-Video-Effekte relativ gut sind und Charakter- sowie Stilkonsistenz beibehalten, während die Text-zu-Video-Effekte eine größere Zufälligkeit aufweisen und die Qualität uneinheitlich ist. Derzeit werden standardmäßig etwa 5-sekündige Clips generiert; für längere Videos ist die Planung des Prozesses durch einen Agent erforderlich. Diese Funktion erweitert die Vielfalt der Inhaltserstellung, steht aber auch vor Herausforderungen wie unzureichenden Videobearbeitungsfähigkeiten und Schwierigkeiten bei der kreativen Umsetzung. (Quelle: 36氪)

Fish Audio veröffentlicht OpenAudio S1 Mini Text-to-Speech-Modell als Open Source: Fish Audio hat eine abgespeckte Version seines erstplatzierten S1-Modells, OpenAudio S1 Mini, als Open Source veröffentlicht und bietet damit fortschrittliche Text-to-Speech (TTS)-Technologie. Das Modell zielt darauf ab, qualitativ hochwertige Sprachsyntheseeffekte zu liefern. Die zugehörigen GitHub-Repositories und Hugging Face-Modellseiten sind für Entwickler und Forscher verfügbar. (Quelle: andrew_n_carr)
Bland TTS veröffentlicht, zielt darauf ab, das „Uncanny Valley“ der Sprach-KI zu überwinden: Bland AI hat Bland TTS vorgestellt, eine Sprach-KI, die angeblich als erste das „Uncanny Valley“ überwindet. Die Technologie basiert auf Single-Sample-Stiltransfer und kann jede Stimme aus einer kurzen MP3-Datei klonen oder die Stile (Tonhöhe, Rhythmus, Aussprache usw.) verschiedener geklonter Stimmen mischen. Bland TTS zielt darauf ab, Kreativen realistische Soundeffekte oder KI-Soundtracks mit präziser Kontrolle über Emotionen und Stil zu bieten, Entwicklern eine anpassbare TTS-API zur Verfügung zu stellen und Unternehmen natürliche KI-Kundendienststimmen zu ermöglichen. (Quelle: imjaredz, nrehiew_, jonst0kes)
Voiceflow-Plattform integriert Claude 4 und Gemini 2.5 Modelle: Die Plattform für die Erstellung von KI-Dialogabläufen, Voiceflow, gab bekannt, dass Nutzer nun direkt auf ihrer Plattform KI-Anwendungen mit den Modellen Anthropic Claude 4 und Google Gemini 2.5 erstellen können, ohne Code und ohne Warteliste. Dieser Schritt zielt darauf ab, KI-Entwicklern eine leistungsfähigere Unterstützung durch Basismodelle zu bieten, Entwicklungsprozesse zu vereinfachen und die Leistungsfähigkeit von Anwendungen zu steigern. (Quelle: ReamBraden)
Xenova stellt Konversations-KI-Modell vor, das lokal und in Echtzeit im Browser läuft: Xenova hat ein Konversations-KI-Modell veröffentlicht, das zu 100 % lokal und in Echtzeit im Browser ausgeführt werden kann. Das Modell zeichnet sich durch Datenschutz (Daten verlassen das Gerät nicht), vollständige Kostenfreiheit, keine Installation (Zugriff über die Website) und WebGPU-beschleunigte Inferenz aus. Dies markiert einen wichtigen Schritt für On-Device-Konversations-KI in Bezug auf Benutzerfreundlichkeit und Datenschutz. (Quelle: ben_burtenshaw)
📚 Lernen
DeepLearning.AI und Databricks kooperieren für DSPy-Kurzkurs: Andrew Ng kündigte eine Zusammenarbeit mit Databricks an, um einen Kurzkurs über das DSPy-Framework anzubieten. DSPy ist ein Open-Source-Framework zur automatischen Anpassung von Prompts zur Optimierung von GenAI-Anwendungen. Der Kurs wird vermitteln, wie DSPy und MLflow verwendet werden, und zielt darauf ab, Lernenden beim Aufbau und der Optimierung von Agentic Apps zu helfen. Omar Khattab, der Hauptentwickler von DSPy, unterstützt dies ebenfalls und erwähnte, dass der Kurs auf vielfachen Wunsch von Nutzern entwickelt wurde. (Quelle: AndrewYNg, DeepLearning.AI Blog, lateinteraction)

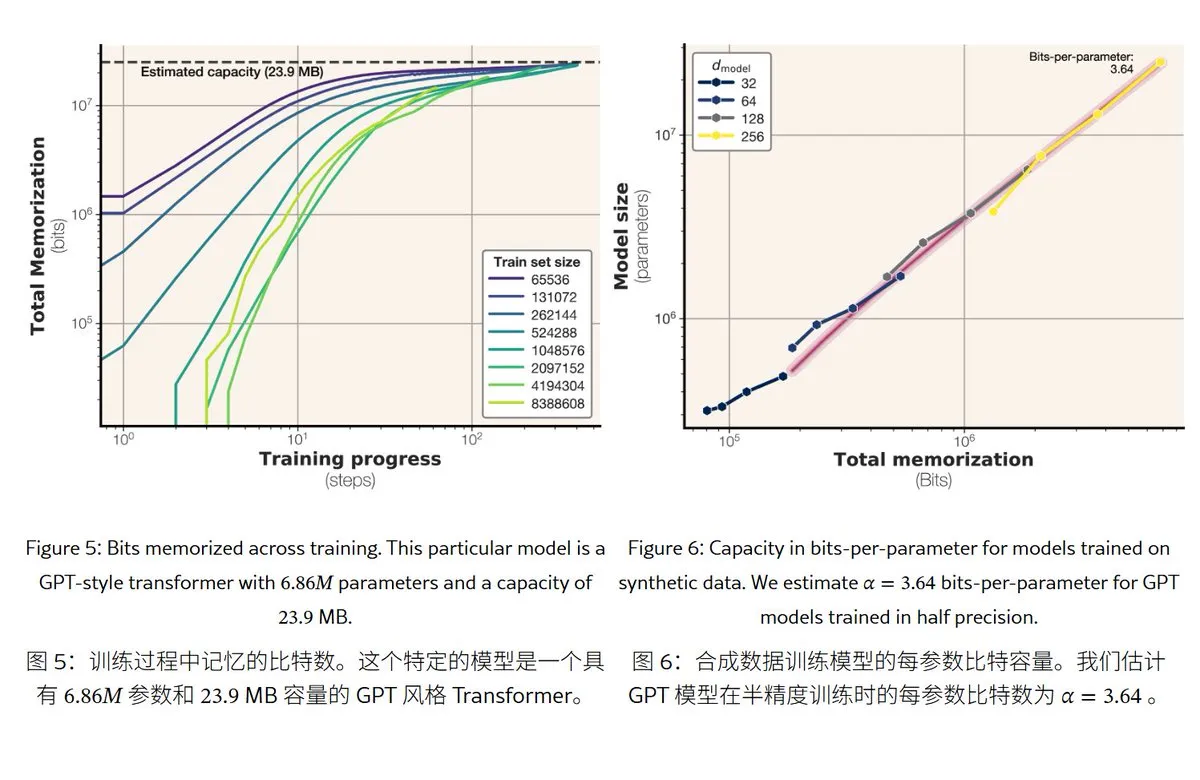
Neue Meta-Studie enthüllt Speichermechanismen und -kapazität von großen Sprachmodellen: Meta hat eine Studie veröffentlicht, die die Speicherkapazität von großen Sprachmodellen untersucht. Dabei wird „Gedächtnis“ unterteilt in echtes Auswendiglernen (unerwünschte Memorisierung) und das Verstehen von Mustern (Generalisierung). Die Studie ergab, dass die Speicherkapazität von Modellen der GPT-Serie etwa 3,6 Bit pro Parameter beträgt. Beispielsweise kann ein Modell mit 1 Milliarde Parametern etwa 450 MB an spezifischen Inhalten „auswendig lernen“. Wenn die Trainingsdaten die Modellkapazität überschreiten, wechselt das Modell vom „Auswendiglernen“ zum „Verstehen von Mustern“, was das Phänomen des „Double Descent“ erklärt. Die Studie liefert Referenzwerte für die Bewertung des Risikos von Datenschutzverletzungen durch Modelle und für die Gestaltung des Verhältnisses von Daten- zu Modellgröße. (Quelle: karminski3)
Unsloth AI veröffentlicht Repository mit über 100 Fine-Tuning-Notebooks: Unsloth AI hat ein GitHub-Repository mit über 100 Fine-Tuning-Notebooks als Open Source veröffentlicht. Diese Notebooks bieten Anleitungen und Beispiele für verschiedene Techniken und Modelle wie Tool Calling, Klassifizierung, synthetische Daten, BERT, TTS, visuelle LLMs, GRPO, DPO, SFT, CPT und decken Modelle wie Llama, Qwen, Gemma, Phi, DeepSeek sowie Aspekte der Datenvorbereitung, Evaluierung und Speicherung ab. Dieser Schritt stellt der Community umfangreiche Ressourcen für die Praxis des Fine-Tunings zur Verfügung. (Quelle: danielhanchen)
KI-Modell Enoch rekonstruiert Zeitlinie der Qumranrollen und könnte Geschichte der Bibelentstehung umschreiben: Wissenschaftler haben das KI-Modell Enoch eingesetzt, um in Kombination mit Radiokarbon-Datierung und Handschriftenanalyse eine neue Datierung der Qumranrollen vorzunehmen. Die Studie deutet darauf hin, dass viele Rollen tatsächlich älter sind als bisher angenommen. Beispielsweise könnten Teile des Buches Daniel und des Predigers bereits im dritten Jahrhundert v. Chr. entstanden sein, sogar noch vor der traditionell angenommenen Zeit ihrer Verfasser. Das Enoch-Modell bietet durch die Analyse von Handschriftenmerkmalen eine neue objektive quantitative Methode für die Untersuchung antiker Dokumente und könnte dazu beitragen, historische Rätsel wie die Autorschaft der Bibel zu entschlüsseln. (Quelle: 36氪)

Studie untersucht, wann große Sprachmodelle wissen, dass sie bewertet werden: Eine Studie untersuchte, ob führende große Sprachmodelle (LLM) bei der Konfrontation mit 1000 Datenpunkten aus 61 verschiedenen Datensätzen (zur Hälfte Evaluierungsdatensätze, zur Hälfte reale Einsatzszenarien) zwischen Evaluierungsszenarien und realen Anwendungsszenarien unterscheiden können. Die Studie ergab, dass die Fähigkeit der LLMs, Evaluierungsszenarien zu erkennen, dem Niveau des menschlichen Hauptautors nahekommt und sie in der Regel den Zweck der Evaluierung beurteilen können. Diese Erkenntnis ist wichtig für das Verständnis des Verhaltens und der Generalisierungsfähigkeit von LLMs. (Quelle: paul_cal, menhguin)
LlamaIndex stellt Beispiel für Agent-Workflow zur automatisierten Extraktion von SEC Form 4 vor: LlamaIndex demonstrierte ein praktisches Beispiel für die automatisierte Extraktion von Informationen aus SEC Form 4 (Offenlegung von Aktiengeschäften von Insidern börsennotierter Unternehmen) unter Verwendung von LlamaExtract und einem Agent-Workflow. Das Beispiel erstellt einen Extraktions-Agenten, der strukturierte Informationen aus Form 4-Dokumenten extrahieren kann, und einen skalierbaren Workflow zur Extraktion von Transaktionsinformationen aus den Form 4-Dokumenten von Unternehmen des Dow Jones Industrial Average. Dies bietet eine Referenz für den Einsatz von KI zur Informationsextraktion und automatisierten Verarbeitung im Finanzbereich. (Quelle: jerryjliu0)
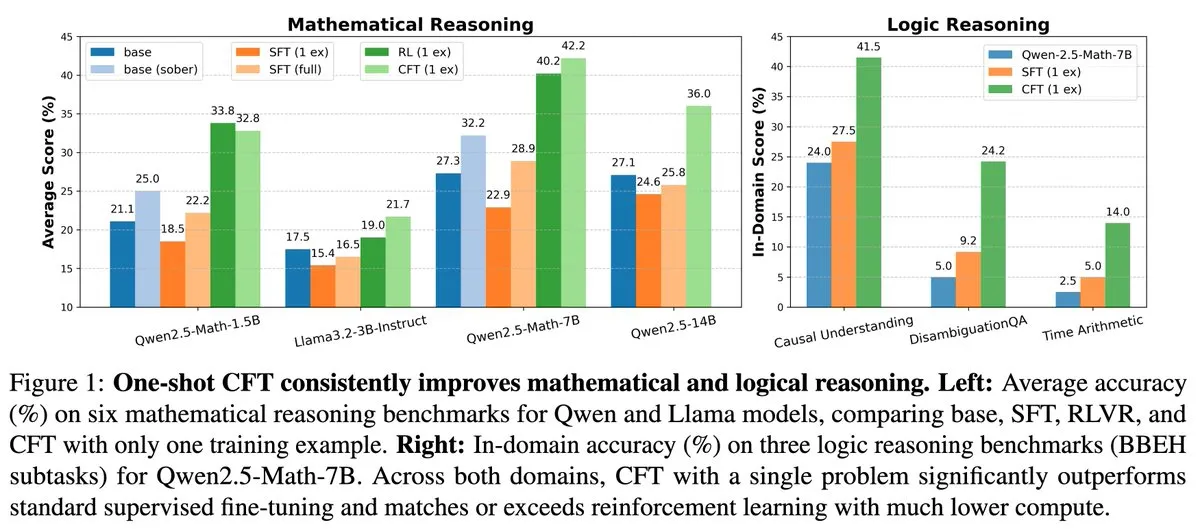
Neue Studie: Single-Problem Supervised Fine-Tuning (SFT) kann die Wirkung von Single-Problem Reinforcement Learning (RL) bei 20-fach geringeren Rechenkosten erreichen: Ein neues Paper zeigt, dass Supervised Fine-Tuning (SFT) bei einem einzelnen Problem eine ähnliche Leistungssteigerung erzielen kann wie Reinforcement Learning (RL) bei einem einzelnen Problem, jedoch mit nur 1/20 der Rechenkosten. Dies deutet darauf hin, dass für LLMs, die bereits in der Vortrainingsphase starke Schlussfolgerungsfähigkeiten erworben haben, sorgfältig konzipiertes SFT (wie das im Paper vorgeschlagene Critique Fine-Tuning, CFT) eine effizientere Methode sein kann, um ihr Potenzial freizusetzen, insbesondere wenn RL kostspielig oder instabil ist. (Quelle: AndrewLampinen)
Paper schlägt Rex-Thinker vor: Grounded Object Referring durch Chain-of-Thought Reasoning: Ein neues Paper stellt das Rex-Thinker-Modell vor, das die Aufgabe des Object Referring als explizite Chain-of-Thought (CoT)-Reasoning-Aufgabe formuliert. Das Modell identifiziert zunächst alle Kandidateninstanzen, die der Kategorie des referenzierten Objekts entsprechen, führt dann für jede Kandidateninstanz schrittweises Reasoning durch, um zu bewerten, ob sie mit dem gegebenen Ausdruck übereinstimmt, und trifft schließlich eine Vorhersage. Um dieses Paradigma zu unterstützen, erstellten die Forscher den groß angelegten CoT-Stil-Referenzdatensatz HumanRef-CoT. Experimente zeigen, dass diese Methode in Bezug auf Präzision und Interpretierbarkeit Standard-Baselines überlegen ist und besser mit Situationen umgehen kann, in denen kein passendes Objekt vorhanden ist. (Quelle: HuggingFace Daily Papers)
Paper schlägt TimeHC-RL vor: Zeitbewusstes hierarchisches kognitives Reinforcement Learning zur Verbesserung der sozialen Intelligenz von LLMs: Um der unzureichenden kognitiven Entwicklung von LLMs im Bereich der sozialen Intelligenz entgegenzuwirken, schlägt ein neues Paper das zeitbewusste hierarchische kognitive Reinforcement Learning (TimeHC-RL) Framework vor. Dieses Framework erkennt an, dass die soziale Welt einzigartigen Zeitlinien folgt und eine Verschmelzung verschiedener kognitiver Modi wie intuitive Reaktionen (System 1) und überlegtes Denken (System 2) erfordert. Experimente zeigen, dass TimeHC-RL die soziale Intelligenz von LLMs effektiv verbessern kann, sodass die Leistung von 7B-Backbone-Modellen mit der von fortschrittlichen Modellen wie DeepSeek-R1 und OpenAI-O3 vergleichbar ist. (Quelle: HuggingFace Daily Papers)
Paper schlägt DLP vor: Dynamisches hierarchisches Pruning in großen Sprachmodellen: Um das Problem zu lösen, dass einheitliche hierarchische Pruning-Strategien bei LLMs bei hoher Sparsity zu einer starken Leistungseinbuße führen, schlägt ein neues Paper die Methode des dynamischen hierarchischen Prunings (DLP) vor. DLP bestimmt adaptiv die relative Wichtigkeit jeder Schicht durch Integration von Modellgewichten und Eingabeaktivierungsinformationen und weist auf dieser Grundlage Pruning-Raten zu. Experimente zeigen, dass DLP die Leistung von Modellen wie LLaMA2-7B auch bei hoher Sparsity effektiv beibehalten kann und mit verschiedenen bestehenden LLM-Kompressionstechniken kompatibel ist. (Quelle: HuggingFace Daily Papers)
Paper stellt LayerFlow vor: Ein einheitliches ebenenbewusstes Videogenerierungsmodell: LayerFlow ist eine einheitliche, ebenenbewusste Lösung zur Videogenerierung. Bei gegebenen Prompts für jede Ebene kann LayerFlow Videos mit transparentem Vordergrund, sauberem Hintergrund und gemischten Szenen generieren. Es unterstützt auch verschiedene Varianten, wie die Zerlegung gemischter Videos oder die Generierung von Hintergründen für gegebene Vordergründe. Das Modell organisiert Videos verschiedener Ebenen als Sub-Clips und verwendet Ebenen-Embeddings, um jeden Clip und die entsprechenden Ebenen-Prompts zu unterscheiden, wodurch die oben genannten Funktionen in einem einheitlichen Framework unterstützt werden. Um das Problem fehlender hochwertiger Trainingsvideos für Ebenen zu lösen, wurde eine mehrstufige Trainingsstrategie entwickelt. (Quelle: HuggingFace Daily Papers)
Paper schlägt Rectified Sparse Attention vor: Korrigierter Sparse-Attention-Mechanismus: Um die Probleme der Fehlausrichtung des KV-Caches und des Qualitätsverlusts zu lösen, die durch Sparse-Decoding-Methoden bei der Generierung langer Sequenzen verursacht werden, schlägt ein neues Paper Rectified Sparse Attention (ReSA) vor. ReSA kombiniert Block-Sparse-Attention mit periodischer dichter Korrektur, indem in festen Intervallen eine dichte Vorwärtsdurchleitung verwendet wird, um den KV-Cache zu aktualisieren. Dadurch wird die Fehlerakkumulation begrenzt und die Ausrichtung auf die vortrainierte Verteilung beibehalten. Experimente zeigen, dass ReSA bei mathematischen Schlussfolgerungen, Sprachmodellierung und Retrieval-Aufgaben eine nahezu verlustfreie Generierungsqualität und signifikante Effizienzsteigerungen erzielt, mit einer bis zu 2,42-fachen End-to-End-Beschleunigung bei der Dekodierung von Sequenzen mit einer Länge von 256K. (Quelle: HuggingFace Daily Papers)
Paper stellt RefEdit vor: Verbesserte Benchmarks und Methoden für instruktionsbasierte Bildbearbeitungsmodelle bei referenzierenden Ausdrücken: Angesichts der Schwierigkeit bestehender Bildbearbeitungsmodelle, bei der Verarbeitung komplexer Szenen mit mehreren Entitäten das angegebene Objekt genau zu bearbeiten, führt ein neues Paper zunächst RefEdit-Bench ein, einen auf RefCOCO basierenden Real-World-Benchmark. Anschließend wird das RefEdit-Modell vorgeschlagen, das durch einen skalierbaren Prozess zur Generierung synthetischer Daten trainiert wird. RefEdit, trainiert mit nur 20.000 Bearbeitungstripeln, übertrifft bei referenzierenden Ausdrücken Basismodelle, die auf Flux/SD3 basieren und mit Millionen von Trainingsdaten trainiert wurden, und erzielt auch bei traditionellen Benchmarks SOTA-Ergebnisse. (Quelle: HuggingFace Daily Papers)
Paper schlägt Critique-GRPO vor: Verbesserung der LLM-Schlussfolgerungsfähigkeiten durch natürliches Sprach- und numerisches Feedback: Angesichts der Probleme, dass Reinforcement Learning, das sich nur auf numerisches Feedback (wie skalare Belohnungen) stützt, bei der Verbesserung komplexer Schlussfolgerungsfähigkeiten von LLMs auf Leistungsengpässe, begrenzte Selbstreflexionseffekte und anhaltende Misserfolge stößt, schlägt ein neues Paper das Critique-GRPO-Framework vor. Dieses Framework integriert Kritik (Critiques) in natürlicher Sprache und numerisches Feedback, sodass LLMs gleichzeitig aus anfänglichen Antworten und kritisch geleiteten Verbesserungen lernen und dabei die Exploration beibehalten können. Experimente zeigen, dass Critique-GRPO auf Qwen2.5-7B-Base und Qwen3-8B-Base signifikant besser abschneidet als verschiedene Baseline-Methoden. (Quelle: HuggingFace Daily Papers)
Paper stellt TalkingMachines vor: Echtzeit-audiogesteuerte FaceTime-ähnliche Videos durch autoregressive Diffusionsmodelle: TalkingMachines ist ein effizientes Framework, das vortrainierte Videogenerierungsmodelle in Echtzeit-audiogesteuerte Charakteranimatoren umwandelt. Das Framework integriert Audio Large Language Models (LLM) mit Videogenerierungs-Basismodellen und ermöglicht so ein natürliches Gesprächserlebnis. Zu den wichtigsten Beiträgen gehören die Anpassung eines vortrainierten SOTA Image-to-Video DiT-Modells zu einem audiogesteuerten Avatar-Generierungsmodell, die Realisierung unendlicher Videostromgenerierung ohne Fehlerakkumulation durch asymmetrische Wissensdestillation und die Entwicklung einer hochdurchsatzfähigen, latenzarmen Inferenzpipeline. (Quelle: HuggingFace Daily Papers)
Paper untersucht Messung von Selbstpräferenzen bei LLM-Urteilen: Studien zeigen, dass LLMs als Schiedsrichter Selbstpräferenzen aufweisen, d.h. sie neigen dazu, ihre eigenen generierten Antworten zu bevorzugen. Bestehende Methoden messen diese Verzerrung, indem sie die Differenz zwischen den Bewertungen des Schiedsrichtermodells für seine eigenen Antworten und für die Antworten anderer Modelle berechnen. Dies vermischt jedoch Selbstpräferenz mit Antwortqualität. Das neue Paper schlägt vor, Gold-Urteile als Proxy für die tatsächliche Qualität der Antworten zu verwenden und führt den DBG-Score ein, der die Selbstpräferenzverzerrung als Differenz zwischen der Bewertung des Schiedsrichtermodells für seine eigenen Antworten und dem entsprechenden Gold-Urteil misst. Dadurch wird der verzerrende Effekt der Antwortqualität auf die Messung der Verzerrung reduziert. (Quelle: HuggingFace Daily Papers)
Paper schlägt LongBioBench vor: Ein kontrollierbares Testframework für Sprachmodelle mit langem Kontext: Angesichts der Einschränkungen bestehender Evaluierungsframeworks für Sprachmodelle mit langem Kontext (LCLM) – reale Aufgaben sind komplex, schwer lösbar und anfällig für Datenkontamination, während synthetische Aufgaben von realen Anwendungen abgekoppelt sind – schlägt ein neues Paper LongBioBench vor. Dieser Benchmark nutzt künstlich generierte Biografien als kontrollierte Umgebung, um LCLMs hinsichtlich der Dimensionen Verständnis, Schlussfolgerung und Vertrauenswürdigkeit zu bewerten. Experimente zeigen, dass die meisten Modelle beim semantischen Verständnis langer Kontexte und bei ersten Schlussfolgerungen noch Mängel aufweisen und die Vertrauenswürdigkeit mit zunehmender Kontextlänge abnimmt. LongBioBench zielt darauf ab, eine realistischere, kontrollierbarere und interpretierbarere LCLM-Evaluierung zu ermöglichen. (Quelle: HuggingFace Daily Papers)
Paper untersucht Verbesserung multimodaler Schlussfolgerungen von optimiertem Kaltstart bis zu gestuftem Reinforcement Learning: Inspiriert von der herausragenden Schlussfolgerungsfähigkeit von Deepseek-R1 bei komplexen Textaufgaben, versuchen viele Arbeiten, durch direkte Anwendung von Reinforcement Learning (RL) ähnliche Fähigkeiten in multimodalen großen Sprachmodellen (MLLM) zu fördern, stoßen aber immer noch auf Schwierigkeiten bei der Aktivierung komplexer Schlussfolgerungen. Das neue Paper untersucht aktuelle Trainingsabläufe eingehend und stellt fest, dass eine effektive Kaltstart-Initialisierung entscheidend für die Verbesserung der MLLM-Schlussfolgerung ist, dass Standard-GRPO bei Anwendung auf multimodales RL unter Gradientenstagnation leidet und dass ein reines Text-RL-Training nach der multimodalen RL-Phase die multimodale Schlussfolgerung weiter verbessern kann. Basierend auf diesen Erkenntnissen führt das Paper ReVisual-R1 ein, das in mehreren Benchmarks SOTA-Ergebnisse erzielt. (Quelle: HuggingFace Daily Papers)
Paper stellt SVGenius vor: Benchmark für SVG-Verständnis, -Bearbeitung und -Generierung: Angesichts der Mängel bestehender SVG-Verarbeitungsbenchmarks in Bezug auf die Abdeckung realer Anwendungsfälle, die Komplexitätshierarchie und die Evaluierungsparadigmen führt ein neues Paper SVGenius ein. Dies ist ein umfassender Benchmark mit 2377 Abfragen, der die drei Dimensionen Verständnis, Bearbeitung und Generierung abdeckt, auf realen Daten aus 24 Anwendungsbereichen basiert und eine systematische Komplexitätshierarchie aufweist. 22 gängige Modelle wurden anhand von 8 Aufgabenkategorien und 18 Metriken bewertet. Die Analyse zeigt, dass die Leistung aller Modelle bei zunehmender Komplexität systematisch abnimmt, aber ein durch Schlussfolgerungen erweitertes Training effektiver ist als reine Skalierung. (Quelle: HuggingFace Daily Papers)
Paper schlägt Ψ-Sampler vor: Initiales Partikel-Sampling für Reward-Alignment bei SMC-basierter Score-Modell-Inferenz: Um das Problem des Reward-Alignments bei der Inferenz von Score-Generierungsmodellen zu lösen, führt ein neues Paper das Psi-Sampler-Framework ein. Dieses Framework basiert auf Sequential Monte Carlo (SMC) und kombiniert eine auf pCNL basierende Methode zum initialen Partikel-Sampling. Bestehende Methoden initialisieren Partikel typischerweise aus einer Gaußschen A-priori-Verteilung, was es schwierig macht, Regionen, die mit der Belohnung zusammenhängen, effektiv zu erfassen. Psi-Sampler initialisiert Partikel aus einer belohnungsbewussten A-posteriori-Verteilung und führt den Preconditioned Crank-Nicolson Langevin (pCNL)-Algorithmus für effizientes A-posteriori-Sampling ein, wodurch die Alignment-Leistung bei Aufgaben wie Layout-zu-Bild-Generierung, mengenbewusster Generierung und Generierung mit ästhetischen Präferenzen verbessert wird. (Quelle: HuggingFace Daily Papers)
Paper schlägt MoCA-Video vor: Ein bewegungssensitives Konzept-Alignment-Framework für konsistente Videobearbeitung: MoCA-Video ist ein trainingsfreies Framework, das darauf abzielt, semantische Mischtechniken aus dem Bildbereich auf die Videobearbeitung anzuwenden. Gegeben ein generiertes Video und ein vom Benutzer bereitgestelltes Referenzbild, kann MoCA-Video die semantischen Merkmale des Referenzbildes in bestimmte Objekte im Video injizieren, während die ursprüngliche Bewegung und der visuelle Kontext erhalten bleiben. Die Methode nutzt diagonale Entrauschungsplanung und klassenunabhängige Segmentierung, um Objekte im latenten Raum zu erkennen und zu verfolgen, und steuert präzise die räumliche Position der gemischten Objekte. Durch bewegungsbasierte semantische Korrektur und Stabilisierung des Gamma-Restrauschens wird zeitliche Konsistenz gewährleistet. (Quelle: HuggingFace Daily Papers)
Paper untersucht Training von Sprachmodellen zur Generierung qualitativ hochwertigen Codes durch Feedback aus Programmanalyse: Um das Problem zu lösen, dass große Sprachmodelle (LLM) bei der Codegenerierung (Vibe Coding) Schwierigkeiten haben, die Codequalität (insbesondere Sicherheit und Wartbarkeit) zu gewährleisten, schlägt ein neues Paper das REAL-Framework vor. REAL ist ein Reinforcement-Learning-Framework, das LLMs durch Feedback aus der Programmanalyse dazu anregt, Code von Produktionsqualität zu generieren. Dieses Feedback integriert Signale aus der Programmanalyse, die Sicherheits- oder Wartbarkeitsmängel erkennen, sowie Signale aus Unit-Tests, die die funktionale Korrektheit sicherstellen. REAL erfordert keine manuelle Annotation, ist hoch skalierbar und Experimente belegen seine Überlegenheit gegenüber SOTA-Methoden in Bezug auf Funktionalität und Codequalität. (Quelle: HuggingFace Daily Papers)
Paper schlägt GAIN-RL vor: Trainingseffizientes Reinforcement Learning durch modellinterne Signale: Angesichts der geringen Stichprobeneffizienz aktueller Paradigmen des Reinforcement Fine-Tuning (RFT) von großen Sprachmodellen aufgrund einheitlicher Datenabtastung identifiziert ein neues Paper ein modellinternes Signal namens „Winkelkonzentration“ (angle concentration). Dieses Signal spiegelt effektiv die Fähigkeit eines LLM wider, aus bestimmten Daten zu lernen. Basierend auf dieser Erkenntnis schlägt das Paper das GAIN-RL-Framework vor, das durch Nutzung des intrinsischen Winkelkonzentrationssignals des Modells dynamisch Trainingsdaten auswählt, um die kontinuierliche Wirksamkeit von Gradientenaktualisierungen sicherzustellen und so die Trainingseffizienz signifikant zu verbessern. Experimente zeigen, dass GAIN-RL (GRPO) bei verschiedenen mathematischen und Programmieraufgaben sowie unterschiedlichen Modellgrößen eine Beschleunigung der Trainingseffizienz von über 2,5-fach erreicht. (Quelle: HuggingFace Daily Papers)
Paper schlägt SFO vor: Optimierung der Subjekttreue bei Zero-Shot-subjektgesteuerter Generierung durch negative Führung: Um die Subjekttreue bei der Zero-Shot-subjektgesteuerten Generierung zu verbessern, schlägt ein neues Paper das Subject Fidelity Optimization (SFO) Framework vor. SFO führt synthetische negative Ziele ein und leitet das Modell durch paarweisen Vergleich explizit dazu an, positive Ziele gegenüber negativen Zielen zu bevorzugen. Für negative Ziele schlägt das Paper die Methode des Conditional Degraded Negative Sampling (CDNS) vor, die durch absichtliche Reduzierung visueller und textueller Hinweise automatisch einzigartige und informationsreiche negative Beispiele generiert, ohne teure manuelle Annotationen zu benötigen. Darüber hinaus werden die Diffusionszeitschritte neu gewichtet, um sich auf die mittleren Schritte zu konzentrieren, in denen Subjektdetails erscheinen. (Quelle: HuggingFace Daily Papers)
Paper stellt ByteMorph vor: Benchmark für instruktionsgesteuerte Bildbearbeitung bei nicht-rigiden Bewegungen: Angesichts der Tatsache, dass bestehende Bildbearbeitungsmethoden und Datensätze sich hauptsächlich auf statische Szenen oder rigide Transformationen konzentrieren und Schwierigkeiten bei der Verarbeitung von Anweisungen haben, die nicht-rigide Bewegungen, Änderungen der Kameraperspektive, Objektverformungen, menschliche Gelenkbewegungen und komplexe Interaktionen beinhalten, führt ein neues Paper das ByteMorph-Framework ein. Dieses Framework umfasst den groß angelegten Datensatz ByteMorph-6M (über 6 Millionen hochauflösende Bildbearbeitungspaare) und das auf DiT basierende starke Basismodell ByteMorpher. Der Datensatz wurde durch bewegungsgesteuerte Datengenerierung, hierarchische Synthesetechniken und automatische Untertitelgenerierung erstellt, um Vielfalt, Realismus und semantische Kohärenz zu gewährleisten. (Quelle: HuggingFace Daily Papers)
Paper schlägt Control-R vor: Auf dem Weg zu kontrollierbarer Testzeit-Erweiterung: Um die Probleme des „Unterdenkens“ und „Überdenkens“ bei großen Inferenzmodellen (LRM) bei langen Chain-of-Thought (CoT)-Schlussfolgerungen zu lösen, führt ein neues Paper Reasoning Control Fields (RCF) ein. RCF ist eine Testzeit-Methode, die durch Injektion strukturierter Kontrollsignale die Schlussfolgerung aus der Perspektive der Baumbewertung lenkt und es dem Modell ermöglicht, den Schlussfolgerungsaufwand bei der Lösung komplexer Aufgaben entsprechend den gegebenen Kontrollbedingungen anzupassen. Gleichzeitig stellt das Paper den Control-R-4K-Datensatz vor, der herausfordernde Probleme mit detaillierten Schlussfolgerungsprozessen und entsprechenden Kontrollfeldern enthält, und schlägt die Conditional Distillation Fine-tuning (CDF)-Methode vor, um Modelle darin zu trainieren, den Testzeit-Schlussfolgerungsaufwand effektiv anzupassen. (Quelle: HuggingFace Daily Papers)
Paper-Übersicht zu Vertrauen, Risiko und Sicherheitsmanagement (TRiSM) in Agentic AI: Ein Übersichtsartikel analysiert systematisch das Vertrauens-, Risiko- und Sicherheitsmanagement (TRiSM) in Agentic Multi-Agenten-Systemen (AMAS), die auf großen Sprachmodellen (LLM) basieren. Der Artikel erörtert zunächst die konzeptionellen Grundlagen von Agentic AI, Architekturdifferenzen und aufkommende Systemdesigns. Anschließend werden die vier Säulen von TRiSM im Kontext von Agentic AI detailliert erläutert: Governance, Interpretierbarkeit, ModelOps und Datenschutz/Sicherheit. Der Artikel identifiziert einzigartige Bedrohungsvektoren, schlägt eine umfassende Risikoklassifizierung für Agentic AI-Anwendungen vor und erörtert Mechanismen zur Vertrauensbildung, Transparenz- und Überwachungstechniken sowie Interpretierbarkeitsstrategien für verteilte LLM-Agentensysteme. (Quelle: HuggingFace Daily Papers)
Paper untersucht Verbesserung der Wissensdestillation bei unbekanntem Kovariaten-Shift durch konfidenzgesteuerte Datenerweiterung: Um das häufige Problem des Kovariaten-Shifts bei der Wissensdestillation anzugehen (Scheinmerkmale, die während des Trainings auftreten, aber beim Testen nicht vorhanden sind), schlägt ein neues Paper eine neue diffusionsbasierte Datenerweiterungsstrategie vor. Wenn diese Scheinmerkmale unbekannt sind, aber ein robustes Lehrermodell existiert, generiert diese Strategie Bilder, indem sie die Divergenz zwischen dem Lehrer- und dem Schülermodell maximiert. Dadurch werden herausfordernde Beispiele erstellt, die für den Schüler schwer zu verarbeiten sind. Experimente zeigen, dass diese Methode die Genauigkeit der schlechtesten und durchschnittlichen Gruppen bei Datensätzen wie CelebA, SpuCo Birds und dem Schein-ImageNet, bei denen ein Kovariaten-Shift vorliegt, signifikant verbessert. (Quelle: HuggingFace Daily Papers)
Paper stellt DiffDecompose vor: Schichtweise Zerlegung von Alpha-Composite-Bildern durch Diffusion Transformers: Angesichts der Schwierigkeit bestehender Bildzerlegungsmethoden, Verdeckungen durch halbtransparente oder transparente Schichten aufzulösen, schlägt ein neues Paper eine neue Aufgabe vor: die schichtweise Zerlegung von Alpha-Composite-Bildern, mit dem Ziel, die konstituierenden Schichten aus einem einzelnen überlappenden Bild wiederherzustellen. Um Herausforderungen wie Schichtambiguität, Generalisierbarkeit und Datenknappheit zu bewältigen, führt das Paper zunächst AlphaBlend ein, den ersten groß angelegten, qualitativ hochwertigen Datensatz für die Zerlegung transparenter und halbtransparenter Schichten. Darauf aufbauend wird DiffDecompose vorgestellt, ein auf Diffusion Transformer basierendes Framework, das die A-posteriori-Verteilung der Schichtzerlegung durch kontextuelle Zerlegung lernt. (Quelle: HuggingFace Daily Papers)
Paper schlägt SuperWriter vor: Langtextgenerierung durch reflektionsgesteuerte große Sprachmodelle: Um die Probleme großer Sprachmodelle (LLM) bei der Generierung langer Texte hinsichtlich Kohärenz, logischer Konsistenz und Textqualität zu lösen, schlägt ein neues Paper das SuperWriter-Agent-Framework vor. Dieses Framework führt explizite strukturierte Denkplanungs- und Verbesserungsphasen in den Generierungsprozess ein und leitet das Modell an, einem überlegteren, kognitiv plausibleren Prozess zu folgen. Basierend auf diesem Framework wurde ein Supervised Fine-Tuning-Datensatz erstellt, um ein 7B-Parameter-SuperWriter-LM zu trainieren, und ein hierarchisches Direct Preference Optimization (DPO)-Verfahren entwickelt, das Monte-Carlo-Baumsuche (MCTS) nutzt, um die endgültige Qualitätsbewertung zu propagieren und jeden Generierungsschritt entsprechend zu optimieren. (Quelle: HuggingFace Daily Papers)
Paper schlägt IEAP vor: Bildbearbeitung als Programm auf Basis von Diffusionsmodellen: Angesichts der Herausforderungen, denen sich Diffusionsmodelle bei der instruktionsgesteuerten Bildbearbeitung stellen, insbesondere bei strukturell inkonsistenten Bearbeitungen, die signifikante Layoutänderungen beinhalten, führt ein neues Paper das IEAP (Image Editing As Programs) Framework ein. IEAP basiert auf der Diffusion Transformer (DiT)-Architektur und verarbeitet Bearbeitungsanweisungen, indem komplexe Anweisungen in Sequenzen atomarer Operationen zerlegt werden. Jede Operation wird durch leichtgewichtige Adapter realisiert, die denselben DiT-Backbone teilen und auf bestimmte Bearbeitungsarten spezialisiert sind. Diese Operationen werden von einem auf einem visuellen Sprachmodell (VLM) basierenden Agenten programmiert und unterstützen gemeinsam beliebige und strukturell inkonsistente Transformationen. (Quelle: HuggingFace Daily Papers)
Paper schlägt FlowPathAgent vor: Feingranulare Flussdiagramm-Attribution durch neuro-symbolischen Agenten: Um das Problem zu lösen, dass große Sprachmodelle (LLM) bei der Interpretation von Flussdiagrammen oft Halluzinationen erzeugen und Schwierigkeiten haben, Entscheidungspfade genau zu verfolgen, führt ein neues Paper die Aufgabe der feingranularen Flussdiagramm-Attribution ein und schlägt FlowPathAgent vor. FlowPathAgent ist ein neuro-symbolischer Agent, der durch graphenbasiertes Schließen eine feingranulare A-posteriori-Attribution durchführt. Er segmentiert zunächst das Flussdiagramm, wandelt es in einen strukturierten symbolischen Graphen um und verwendet dann einen agentenbasierten Ansatz, um dynamisch mit dem Graphen zu interagieren und Attributionspfade zu generieren. Gleichzeitig stellt das Paper FlowExplainBench vor, einen neuen Benchmark zur Bewertung der Flussdiagramm-Attribution. (Quelle: HuggingFace Daily Papers)
Paper schlägt Quantitative LLM Judges vor: Quantifizierung von LLM-Schiedsrichtern: LLM-as-a-judge ist ein Framework, bei dem ein großes Sprachmodell (LLM) automatisch die Ausgabe eines anderen LLM bewertet. Ein neues Paper schlägt das Konzept der „quantitativen LLM-Schiedsrichter“ vor, bei dem Regressionsmodelle verwendet werden, um die Bewertungsergebnisse bestehender LLM-Schiedsrichter an domänenspezifische menschliche Bewertungen anzupassen. Diese Modelle verbessern die ursprünglichen Bewertungen der Schiedsrichter, indem sie deren textuelle Bewertungen und Scores verwenden. Das Paper demonstriert vier Arten von quantitativen Schiedsrichtern für verschiedene Arten von absolutem und relativem Feedback und belegt so die Allgemeingültigkeit und Vielseitigkeit des Frameworks. Das Framework ist recheneffizienter als Supervised Fine-Tuning und kann bei begrenztem menschlichem Feedback statistisch effizienter sein. (Quelle: HuggingFace Daily Papers)
💼 Wirtschaft
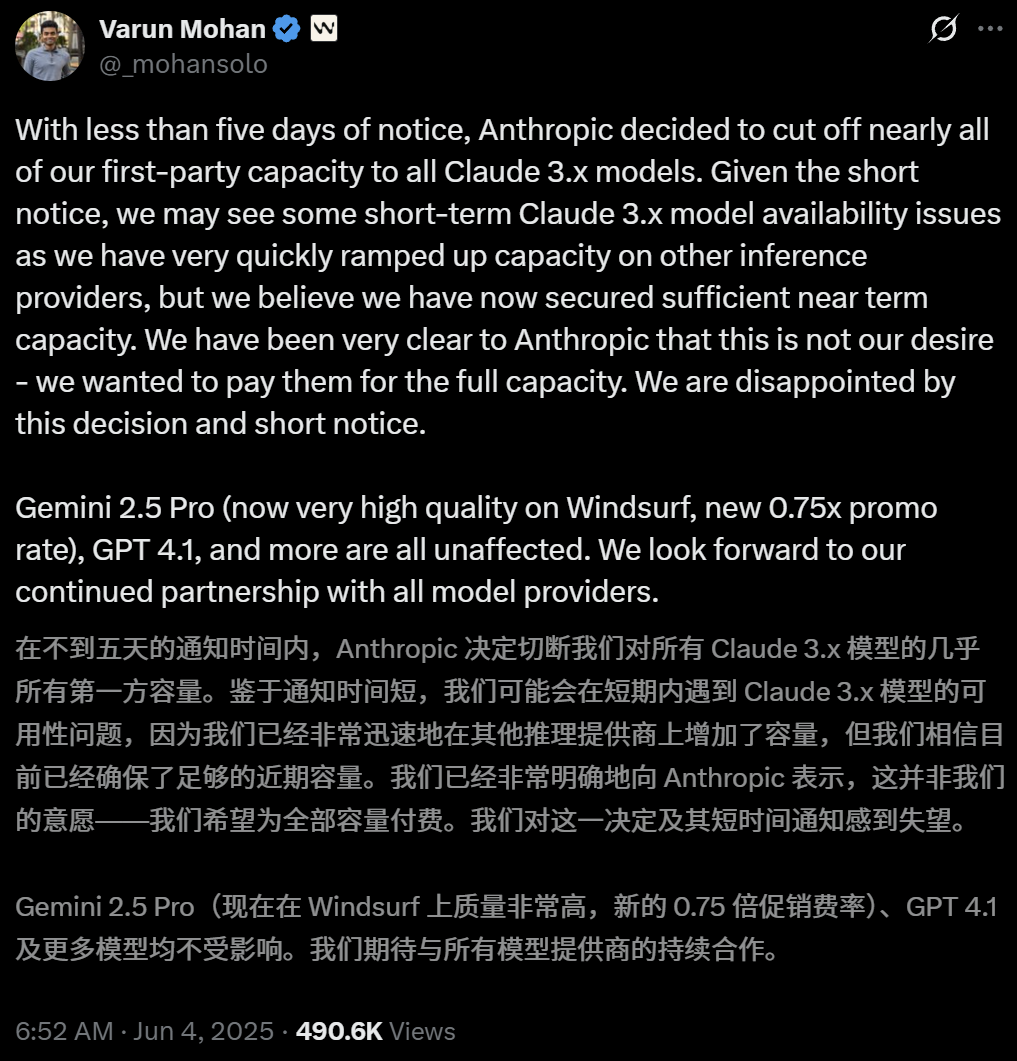
Anthropic schränkt direkten Zugriff des KI-Programmiertools Windsurf auf Claude-Modelle ein: Varun Mohan, CEO des KI-Programmiertools Windsurf, gab öffentlich bekannt, dass Anthropic die API-Servicequoten für Windsurfs Zugriff auf die Claude 3.x-Modellreihe, einschließlich Claude 3.5 Sonnet, 3.7 Sonnet usw., mit extrem kurzer Vorankündigung (weniger als fünf Tage) drastisch gekürzt hat. Dieser Schritt erfolgte vor dem Hintergrund von Berichten über eine bevorstehende Übernahme von Windsurf durch OpenAI und löste am Markt Besorgnis über eine Verschärfung des Wettbewerbs zwischen KI-Giganten sowie über die Neutralität von KI-Programmierplattformen aus. Windsurf musste dringend auf Inferenzdienste von Drittanbietern umsteigen und seine Modellversorgungsstrategie für Nutzer anpassen, während Anthropic antwortete, dass es Partnern, die eine kontinuierliche Zusammenarbeit gewährleisten können, vorrangig Ressourcen zur Verfügung stellt. (Quelle: 36氪, 36氪, mervenoyann, swyx)
OpenAI erreicht 3 Millionen zahlende Unternehmenskunden und führt flexible Preisstrategie ein: OpenAI gab bekannt, dass die Zahl seiner zahlenden Unternehmenskunden 3 Millionen erreicht hat, was einem Anstieg von 50 % gegenüber den im Februar dieses Jahres gemeldeten 2 Millionen entspricht. Dies umfasst die drei Produktlinien ChatGPT Enterprise, Team und Edu. Gleichzeitig führt OpenAI für Unternehmenskunden eine flexible Preisstrategie ein, die auf einem „Shared Credit Pool“ basiert. Unternehmen erwerben einen Kreditpool, und die Nutzung von Premium-Funktionen verbraucht Kredite, während der „unbegrenzte Zugriff“ auf Hauptmodelle und -funktionen weiterhin möglich ist. Diese neue Preisgestaltung wird zunächst in ChatGPT Enterprise eingeführt und anschließend auf ChatGPT Team ausgeweitet, das zudem ein Testangebot von 1 US-Dollar für 5 Konten im ersten Monat anbietet. (Quelle: 36氪, snsf)
Chinesische Nachwuchskraft Hong Letong (Jahrgang 2000) gründet KI-Mathematik-Unternehmen Axiom mit Zielbewertung von 300 Mio. USD: Die chinesische Stanford-Mathematikdoktorandin Carina Letong Hong hat das KI-Unternehmen Axiom gegründet, das sich auf die Entwicklung von KI-Modellen zur Lösung praktischer mathematischer Probleme spezialisiert. Zielkunden sind Hedgefonds und quantitative Handelsunternehmen. Axiom plant, Modelle anhand von Daten formaler mathematischer Beweise zu trainieren, um ihnen strenge logische Schlussfolgerungs- und Beweisfähigkeiten zu vermitteln. Obwohl das Unternehmen noch kein Produkt hat, verhandelt es bereits über eine Finanzierung in Höhe von 50 Millionen US-Dollar, wobei eine Bewertung von 300-500 Millionen US-Dollar erwartet wird. Hong Letong hat einen Bachelor-Abschluss in Mathematik und Physik vom MIT sowie einen Doktortitel in Mathematik von Stanford und war Rhodes-Stipendiatin. (Quelle: 量子位)

🌟 Community
Heiße Themen auf der AI.Engineer Konferenz: Agent-Beobachtbarkeit, hocheffiziente kleine Teams, KI-PM im Fokus: Auf der AI.Engineer Weltausstellung diskutierten die Teilnehmer intensiv über die Beobachtbarkeit und Bewertung von KI-Agenten (Agents), den Aufbau kleiner, effizienter Teams (Tiny Teams) sowie Best Practices im KI-Produktmanagement (AI PM). Sprachinteraktion galt als der heißeste Trend im multimodalen Bereich, und auch Sicherheit wurde erstmals zu einem wichtigen Thema. Anthropic richtete auf der Konferenz einen Aufruf an Start-ups im Bereich MCP (Model Context Protocol) und äußerte den Wunsch nach mehr MCP-Servern jenseits von Entwicklertools, vereinfachten Lösungen für den Serveraufbau sowie Innovationen im Bereich der KI-Anwendungssicherheit (z. B. Schutz vor Tool Poisoning). (Quelle: swyx, swyx, swyx, swyx)

Diskussion darüber, ob KI die natürliche Sprache aussterben lässt und die Menschen verdummt: In sozialen Medien gibt es Bedenken, dass die weit verbreitete Anwendung von KI zu einer Verkümmerung der natürlichen Sprachkommunikation führen könnte („Dead Internet Theory“) sowie zu einem Rückgang der menschlichen kognitiven Fähigkeiten (wie tiefgründiges Denken, Hinterfragen, Rekonstruktionsfähigkeit). Einige Nutzer glauben, dass eine übermäßige Abhängigkeit von KI bei der Informationsbeschaffung und Beantwortung von Fragen das aktive Filtern, Beurteilen und unabhängige Denken reduzieren und eine Abhängigkeit vom „kognitiven Outsourcing“ schaffen könnte. Andere argumentieren, dass KI zwar das Was und Wie handhaben kann, das Warum aber weiterhin vom Menschen entschieden werden muss. Entscheidend sei, die Rolle des Menschen im Zusammenleben mit der Technologie zu finden und die Urteilsfähigkeit zu bewahren. (Quelle: Reddit r/ArtificialInteligence, 36氪)
OpenAI per Gerichtsbeschluss zur Aufbewahrung aller ChatGPT- und API-Protokolle verpflichtet, was Datenschutzbedenken auslöst: Ein Gerichtsbeschluss verpflichtet OpenAI, alle Chatprotokolle von ChatGPT und API-Anfrageprotokolle aufzubewahren, einschließlich derjenigen „temporären Chats“, die eigentlich gelöscht werden sollten. Dieser Schritt hat bei Nutzern Bedenken hinsichtlich des Datenschutzes und der Einhaltung der Datenaufbewahrungsrichtlinien von OpenAI ausgelöst. Einige Kommentatoren sind der Ansicht, dass dies die Bedeutung der Nutzung lokaler Modelle und des Besitzes eigener Technologie und Daten weiter unterstreicht. (Quelle: Reddit r/artificial, Reddit r/LocalLLaMA, Teknium1, nptacek)

KI-Agenten stehen vor Vertrauens- und Sicherheitsherausforderungen, anfällig für Phishing-Angriffe: Diskussionen weisen darauf hin, dass trotz der wachsenden Fähigkeiten von KI-Agenten ihre Vertrauensmechanismen Risiken bergen, ausgenutzt zu werden. Beispielsweise könnten Agenten aufgrund des Vertrauens in bekannte Websites (wie soziale Medien) dazu verleitet werden, bösartige Links zu besuchen und so sensible Informationen preiszugeben oder bösartige Aktionen auszuführen. Dies erfordert eine Stärkung der Fähigkeit zur Erkennung und Abwehr von bösartigen Inhalten und Links im Design von Agenten, um ihre Sicherheit bei der Ausführung von Operationen in der realen Welt zu gewährleisten. (Quelle: DeepLearning.AI Blog)
Überlegungen zu KI-gestützten Programmierwerkzeugen: Von der Code-Modernisierung zur Workflow-Transformation: Die Community diskutierte den Einsatz von KI in der Softwareentwicklung, insbesondere bei der Verarbeitung von Legacy-Code und der Veränderung von Programmier-Workflows. Morgan Stanley nutzte sein selbst entwickeltes KI-Tool DevGen.AI, um Millionen Zeilen alten Codes zu analysieren und zu refaktorisieren, was zu erheblichen Einsparungen bei der Entwicklungszeit führte. Gleichzeitig löste Andrej Karpathys Ansicht über die Zukunftsaussichten komplexer UI-Anwendungen Überlegungen darüber aus, wie zukünftige Software gestaltet werden sollte, um besser mit KI zusammenzuarbeiten, wobei die Bedeutung von Skripting und API-Schnittstellen betont wurde. Diese Diskussionen spiegeln wider, wie KI die Praxis und die Konzepte der Softwareentwicklung tiefgreifend beeinflusst. (Quelle: mitchellh, 36氪, 36氪)
💡 Sonstiges
KI-gestützte Reparatur von Haushaltsgeräten, ChatGPT wird zum „Friendo“: Ein Nutzer teilte seine Erfahrung, wie er mit ChatGPT (Spitzname Friendo) erfolgreich eine defekte Spülmaschine diagnostiziert und vorläufig repariert hat. Durch den Dialog mit der KI, die Beschreibung von Fehlercodes und das Fotografieren des Bedienfelds half die KI dem Nutzer, einen Fehler am Heizelement zu lokalisieren und ihn anzuleiten, dieses Element vorübergehend zu umgehen, um die Spülmaschine teilweise wieder funktionsfähig zu machen. Dies zeigt das Potenzial von LLMs bei der Lösung alltäglicher Probleme und im technischen Support. (Quelle: Reddit r/ChatGPT)
KI-generiertes Interviewvideo mit Personen aus dem 16. Jahrhundert erregt Aufmerksamkeit: Ein KI-generiertes Video, das ein Interview mit Personen aus dem 16. Jahrhundert simuliert, erhielt in der Community aufgrund seiner Kreativität und seines Humors positive Resonanz. Die Figuren und Dialoge im Video spiegeln auf witzige Weise die damaligen Lebensumstände wider, z. B. „Aufwachen, in Kot treten, dann besteuert werden, und das alles noch vor dem Frühstück“. Solche Anwendungen zeigen das Unterhaltungspotenzial von KI bei der Inhaltserstellung und der Rekonstruktion historischer Szenarien. (Quelle: draecomino, Reddit r/ChatGPT)

Thiel-Stipendium fokussiert auf KI-Innovationen, darunter digitale Menschen, Roboteremotionen und KI-Vorhersagen: Die neue Liste der „Thiel-Stipendiaten“ wurde bekannt gegeben, wobei mehrere KI-Projekte Aufmerksamkeit erregen. Canopy Labs widmet sich der Schaffung von KI-gesteuerten digitalen Menschen, die von echten Menschen kaum zu unterscheiden sind und in Echtzeit multimodal interagieren können. Das Intempus-Projekt zielt darauf ab, Robotern menschenähnliche emotionale Ausdrucksfähigkeiten zu verleihen, um die Mensch-Roboter-Interaktion zu verbessern. Aeolus Lab konzentriert sich auf den Einsatz von KI-Technologie zur Vorhersage von Wetter und Naturkatastrophen und erforscht sogar die Möglichkeit aktiver Interventionen. Diese Projekte zeigen die Forschungsrichtungen junger Unternehmer an der Spitze der KI. (Quelle: 36氪)