
Schlüsselwörter:AI-Trendbericht, AI Agent, Verstärkendes Lernen, Visuelles Sprachmodell, Kommerzialisierung von KI, KI-Halluzination, KI-Sicherheit, Internet-Königin KI-Bericht, LawZero KI-Sicherheitsdesign, GTA- und GLA-Aufmerksamkeitsmechanismen, SmolVLA-Robotermodell, KI-Musikstreaming-Betrug
🔥 Fokus
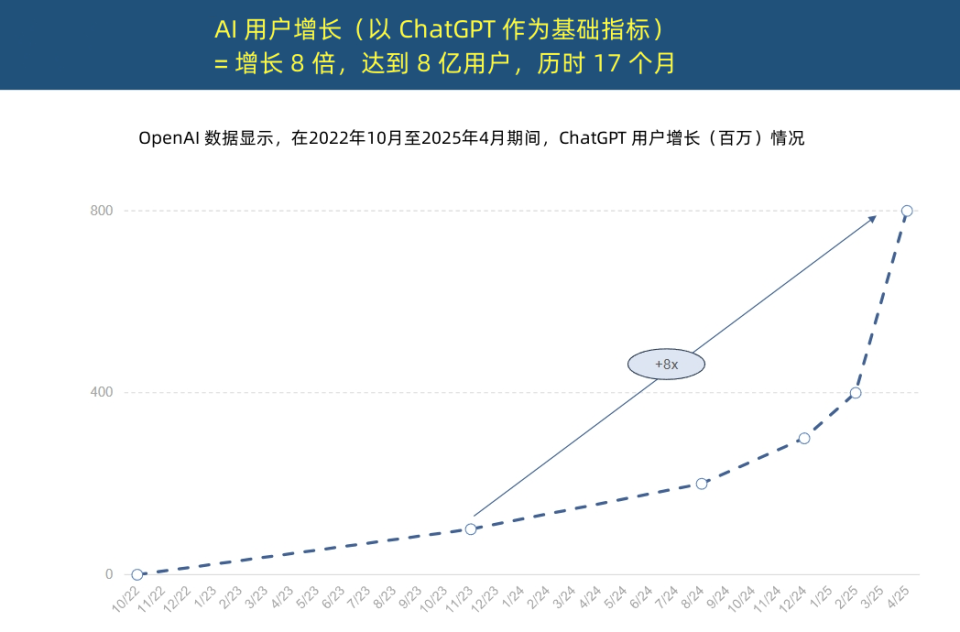
„Internet-Königin“ veröffentlicht AI-Trendbericht, enthüllt beispiellose Beschleunigung der KI-Anwendung und Wandel der Kostenstruktur: „Internet-Königin“ Mary Meeker veröffentlichte einen 340-seitigen „AI-Trendbericht“, der betont, dass KI mit beispielloser Geschwindigkeit adaptiert wird. Der Bericht weist darauf hin, dass das Nutzerwachstum von ChatGPT rasant ist: Innerhalb von 17 Monaten erreichte es 800 Millionen monatlich aktive Nutzer und einen Jahresumsatz von fast 4 Milliarden US-Dollar, was jede Technologie in der Geschichte bei weitem übertrifft. Die Kapitalinvestitionen von Technologiegiganten in die KI-Infrastruktur sind sprunghaft angestiegen und erreichten im Jahr 2024 bereits 212 Milliarden US-Dollar. Gleichzeitig sind die Kosten für das Training von KI-Modellen innerhalb von 8 Jahren um das 2400-fache gestiegen, wobei die Trainingskosten für ein einzelnes Modell bis zu 1 Milliarde US-Dollar betragen können. Die Inferenzkosten sind jedoch aufgrund von Hardware (z. B. eine 100.000-fache Steigerung der GPU-Energieeffizienz von Nvidia) und Algorithmusoptimierungen drastisch gesunken. Die Leistung von Open-Source-Modellen (wie DeepSeek, Qwen) nähert sich der von Closed-Source-Modellen an, die Nachfrage nach KI-Positionen ist um 448 % gestiegen, und AI Agents entwickeln sich zu einer neuen digitalen Arbeitskraft. (Quelle: APPSO, 腾讯科技)
Turing-Preisträger Yoshua Bengio initiiert LawZero und plädiert für „Design-sichere“ KI: Turing-Preisträger Yoshua Bengio kündigte die Gründung der gemeinnützigen Organisation LawZero an, die eine „Design-sichere“ künstliche Intelligenz entwickeln soll, um potenziellem betrügerischem und selbsterhaltendem Verhalten von KI-Systemen entgegenzuwirken. LawZero ist inspiriert von Asimovs drittem Robotergesetz und betont, dass KI das Glück und die Bemühungen der Menschen schützen sollte. Die Organisation entwickelt das Scientist AI-System als „Leitplanke“ für AI Agents, das durch Weltverständnis statt direkter Aktion Hilfe leistet und die Risiken anderer KI-Verhaltensweisen bewertet. Bengio hält die aktuelle Agentic AI für eine falsche Richtung, die außer Kontrolle geraten und unumkehrbare katastrophale Folgen haben könnte, und betont, dass Sicherheitsleitplanken-KI mindestens so intelligent sein muss wie die AI Agents, die sie zu überwachen versucht. (Quelle: 学术头条, Yoshua_Bengio)

Das Jahr des AI Agent: Vom Hilfsmittel zum Aufgabenausführer, Neugestaltung von Geschäftsmodellen: Sun Zhiyong, Research Vice President bei Gartner, wies darauf hin, dass 2025 das „Jahr des intelligenten Agenten großer Modelle“ und das „Jahr der Monetarisierung generativer KI“ sein wird, wobei AI Agents zum Hauptausgang für die Fähigkeiten von LLMs werden. Der wesentliche Unterschied zwischen intelligenten Agenten und Chatbots besteht darin, dass sie von der Bereitstellung von Informationsunterstützung zur direkten Ausführung von Aufgaben übergehen. Beispielsweise kann ein intelligenter Agent den gesamten Prozess der Kaffeebestellung abschließen, anstatt nur Informationen über Cafés bereitzustellen. Gartner prognostiziert, dass bis 2028 20 % der Interaktionen mit digitalen Schnittstellen von AI Agents durchgeführt werden, 15 % der täglichen Geschäftsentscheidungen autonom von AI Agents getroffen werden können und ein Drittel der Unternehmenssoftware AI Agents integrieren wird. Intelligente Assistenten wie der von BYD werden bereits vorläufig eingesetzt, und die Art und Weise, wie zukünftige Smartphone-Apps interagieren, könnte sich ändern. (Quelle: IT时报)
Hauptautor von Mamba schlägt Inferenz-sensitive Aufmerksamkeitsmechanismen GTA und GLA zur Optimierung der Inferenz bei langem Kontext vor: Einer der Hauptautoren von Mamba, Tri Dao, und sein Team an der Princeton University haben Grouped-Tied Attention (GTA) und Grouped-Latent Attention (GLA) vorgestellt, zwei neuartige Aufmerksamkeitsmechanismen, die speziell zur Verbesserung der Ineffizienz bei der Inferenz großer Modelle mit langem Kontext entwickelt wurden. GTA reduziert durch Parameterbindung und gruppierte Wiederverwendung des Key-Value (KV) Cache den KV-Cache-Bedarf im Vergleich zu GQA um etwa 50 %, während eine vergleichbare Modellqualität beibehalten wird. GLA verwendet eine zweischichtige Struktur, führt latente Tokens als komprimierte Darstellung des globalen Kontexts ein und kombiniert dies mit einem gruppierten Head-Mechanismus. Im Vergleich zu MLA, das von DeepSeek verwendet wird, kann die Dekodierungsgeschwindigkeit bei langen Sequenzen (z. B. 64K) um das Zweifache erhöht und die Fähigkeit zur Verarbeitung gleichzeitiger Anfragen verbessert werden. Diese neuen Mechanismen zielen darauf ab, Engpässe beim Speicherzugriff und Einschränkungen der Parallelität während der Inferenz zu beheben. (Quelle: 量子位)

🎯 Trends
DeepMind veröffentlicht SmolVLA: Ein effizientes Roboter-Vision-Language-Action-Modell basierend auf Community-Daten: Hugging Face und Institutionen wie DeepMind haben SmolVLA vorgestellt, ein Open-Source Vision-Language-Action (VLA) Modell mit 450M Parametern, das speziell für Roboter entwickelt wurde und auf handelsüblicher Hardware laufen kann. Das Modell wurde ausschließlich mit Open-Source-Datensätzen aus der LeRobot-Community vortrainiert und übertrifft größere VLA-Modelle und Baselines wie ACT bei LIBERO-, Meta-World- und realen Aufgaben (SO100, SO101). SmolVLA unterstützt asynchrone Inferenz, was die Reaktionsgeschwindigkeit um 30 % und den Aufgabendurchsatz um das Zweifache erhöhen kann. Seine Architektur kombiniert Transformer mit einem Flow-Matching-Decoder und optimiert Geschwindigkeit und Effizienz durch Reduzierung visueller Tokens, Nutzung von VLM-Zwischenschichtmerkmalen und einen Interleaved-Attention-Mechanismus. (Quelle: HuggingFace Blog, clefourrier)

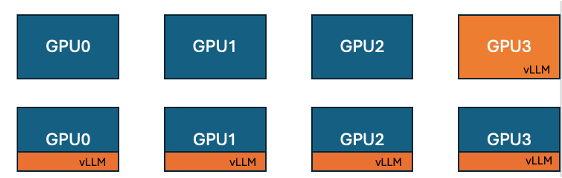
Hugging Face und IBM führen vLLM Co-Location-Funktion in TRL ein, um die GPU-Trainingseffizienz zu steigern: Hugging Face und IBM haben in Zusammenarbeit die vLLM Co-Location-Funktion in die TRL-Bibliothek für Online-Lernalgorithmen wie GRPO eingeführt. Diese Funktion ermöglicht es, dass Training und Inferenz (Generierung) auf derselben GPU ausgeführt werden, Ressourcen gemeinsam nutzen und abwechselnd ausgeführt werden, wodurch das Problem des Leerlaufs der Trainings-GPU im bisherigen vLLM-Servermodus beseitigt wird. Durch die Einbettung von vLLM in dieselbe verteilte Prozessgruppe entfällt die HTTP-Kommunikation, es ist kompatibel mit torchrun, TP und DP, vereinfacht die Bereitstellung und erhöht den Durchsatz. Experimente zeigen, dass der Co-Location-Modus bei 1,5B- und 7B-Modellen eine Beschleunigung von bis zu 1,43- bis 1,73-fach bringen kann; bei großen Modellen wie Qwen2.5-Math-72B kann in Kombination mit der sleep()-API von vLLM und der DeepSpeed ZeRO Stage 3-Optimierung selbst mit weniger GPUs eine Trainingsbeschleunigung von etwa 1,26-fach erreicht werden, ohne die Modellgenauigkeit zu beeinträchtigen. (Quelle: HuggingFace Blog)
Nvidia veröffentlicht Nemotron-Research-Reasoning-Qwen-1.5B Modell, spezialisiert auf komplexes Reasoning: Nvidia hat Nemotron-Research-Reasoning-Qwen-1.5B vorgestellt, ein Open-Source-Gewichtsmodell mit 1,5B Parametern, das sich auf komplexe Reasoning-Aufgaben wie mathematische Probleme, Programmierherausforderungen, wissenschaftliche Probleme und logische Rätsel konzentriert. Das Modell wurde mit dem ProRL (Prolonged Reinforcement Learning)-Algorithmus auf diversifizierten Datensätzen trainiert, um eine tiefere Erforschung von Reasoning-Strategien zu ermöglichen. Offiziell wird behauptet, dass es das 1,5B-Modell von DeepSeek bei Aufgaben wie Mathematik, Codierung und GPQA deutlich übertrifft. ProRL basiert auf GRPO und führt Techniken wie die Minderung des Entropiekollaps, entkoppeltes Clipping und Dynamic Sampling Policy Optimization (DAPO) sowie KL-Regularisierung und Referenzstrategie-Resets ein. Das Modell ist nur für Forschungs- und Entwicklungszwecke bestimmt. (Quelle: Reddit r/LocalLLaMA, Hugging Face)

Arcee veröffentlicht Homunculus-12B Modell, basierend auf Mistral-Nemo destilliert aus Qwen3-235B: Arcee AI hat Homunculus-12B veröffentlicht, ein Instruktionsmodell mit 12 Milliarden Parametern. Dieses Modell wurde durch Destillation der Fähigkeiten von Qwen3-235B in ein Mistral-Nemo-Backbone erstellt. Derzeit sind das Modell und seine GGUF-Version auf Hugging Face verfügbar. Dies stellt einen Versuch dar, die leistungsstarken Fähigkeiten großer Modelle durch Modelldestillation auf kleinere, effizientere Modelle zu übertragen, um Leistung und Ressourcenverbrauch auszugleichen. (Quelle: Reddit r/LocalLLaMA, Hugging Face)

Microsoft Bing App integriert kostenloses Sora Video-Generierungstool: Microsoft hat seiner Bing Mobile App eine kostenlose OpenAI Sora Video-Generierungsfunktion hinzugefügt. Nutzer können ohne Abonnement oder Gebühren kurze Videoclips über Text-Prompts generieren. Derzeit unterstützt die Funktion die Generierung von 5-sekündigen Videos im 9:16 Hochformat; zukünftig ist die Unterstützung für das 16:9 Querformat geplant. Kostenlose Nutzer haben 10 schnelle Generierungsquoten, danach können sie Microsoft-Punkte einlösen oder die Standardgeschwindigkeit wählen. Dieser Schritt zielt darauf ab, die Hürde für die KI-Videoerstellung zu senken und mehr Nutzern die Text-zu-Video-Technologie zugänglich zu machen. (Quelle: Reddit r/ArtificialInteligence, dotey)

Hugging Face veröffentlicht SmolVLA, ein Vision-Language-Action-Modell für kosteneffiziente Robotik: Hugging Face hat SmolVLA vorgestellt, ein Open-Source Vision-Language-Action (VLA) Modell mit 450M Parametern, das darauf abzielt, kosteneffiziente Robotiklösungen anzubieten. Das Modell wurde mit allen Open-Source-Datensätzen der LeRobotHF-Community trainiert und erreicht eine erstklassige Leistung und Inferenzgeschwindigkeit. Die Veröffentlichung von SmolVLA zielt darauf ab, die Hürden für Forschung und Entwicklung in der Robotik zu senken und eine breitere Beteiligung und Innovation der Community zu fördern. (Quelle: huggingface, AK)

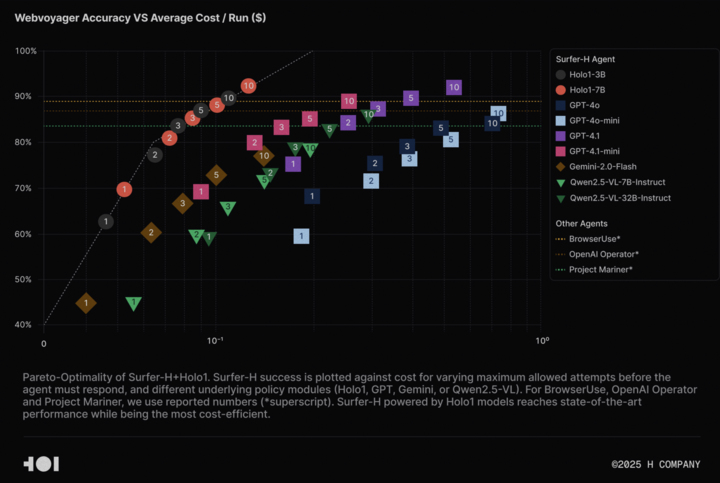
H Company stellt Holo-1 Vision-Language-Modell und WebClick-Datensatz als Open Source zur Verfügung, um Agentic AI-Forschung voranzutreiben: H Company hat die Open-Source-Veröffentlichung seines Vision-Language-Modells Holo-1 (3B- und 7B-Parameter-Versionen) sowie des WebClick-Datensatzes angekündigt, um die Forschung im Bereich Agentic AI zu beschleunigen. Das Holo-1-Modell wurde speziell für GUI-Aktionen und Web-Navigationsaufgaben entwickelt und hat im WebVoyager-Benchmark bereits eine SOTA (State-of-the-Art)-Punktzahl von 92,2 % erreicht, wobei es kosteneffizienter ist als große Modelle wie GPT-4.1. Die Modellgewichte und der Datensatz wurden auf der Hugging Face-Plattform unter der Apache 2.0-Lizenz veröffentlicht. Holo-1 wurde auch in MLX integriert, um Entwicklern die Ausführung auf Apple Silicon-Geräten zu erleichtern. (Quelle: huggingface, tonywu_71)
PlayAI veröffentlicht erstes Sprachdiffusions-LLM PlayDiffusion als Open Source, unterstützt feingranulare Bearbeitung und Zero-Shot-Klonen: PlayAI hat PlayDiffusion veröffentlicht und als Open Source bereitgestellt, das erste Diffusions-LLM für Sprache. Dieses Modell wurde speziell für die feingranulare Bearbeitung von KI-Stimmen (wie Reparatur, Inhaltsersetzung) und Zero-Shot-Sprachklonen entwickelt. Im Gegensatz zu autoregressiven Modellen, die normalerweise 800-1000 Tokens zur Audioerzeugung benötigen, benötigt PlayDiffusion nur 20-30 Tokens, um Audio zu generieren, was die Effizienz erheblich steigert. Das Modell ist mit Quellcode auf GitHub verfügbar, eine Demo wurde auf Hugging Face Spaces bereitgestellt und es kann auch über die Fal.ai-Plattform genutzt werden. (Quelle: _akhaliq)
Google veröffentlicht heimlich AI Edge Gallery App, unterstützt Offline-Ausführung von KI-Modellen auf Android-Geräten: Google hat eine experimentelle Alpha-Version einer App namens Google AI Edge Gallery veröffentlicht, die es Nutzern ermöglicht, öffentliche KI-Modelle von Hugging Face herunterzuladen und offline auf Android-Geräten auszuführen. Die App unterstützt Funktionen wie Bild-Frage-Antwort, Textzusammenfassung und -umschreibung, Codegenerierung, KI-Chat und bietet Leistungseinblicke (wie TTFT, Dekodiergeschwindigkeit). Die lokale Ausführung von KI-Modellen kann die Reaktionsgeschwindigkeit erhöhen, die Privatsphäre der Nutzer schützen und erfordert keine Netzwerkverbindung. Das Nutzerfeedback ist jedoch gemischt, einige Nutzer berichten von Abstürzen auf Pixel- und anderen Geräten, insbesondere beim Wechsel zur GPU-Inferenz oder bei der Verarbeitung großer Modelle. Einige Kommentare meinen, dass die Funktionalität bestehenden Apps (wie PocketPal) ähnelt oder im Vergleich zu Frameworks wie Apples CoreML hinterherhinkt, aber es gibt auch Meinungen, die auf die plattformübergreifenden Vorteile der MediaPipe-Basis hinweisen. (Quelle: 36氪)

Microsoft RenderFormer landet auf Hugging Face, fokussiert auf neuronales Rendering von Dreiecksnetzen unter globaler Beleuchtung: Microsoft hat RenderFormer auf Hugging Face veröffentlicht, ein Transformer-basiertes neuronales Rendering-Modell, das speziell für die Verarbeitung des Renderings von Dreiecksnetzen mit globalen Beleuchtungseffekten entwickelt wurde. Solche Forschungsarbeiten sind von großer Bedeutung für die Verschmelzung traditioneller Rendering-Pipelines mit neuronalen Methoden. Zukünftige Entwicklungsrichtungen könnten die Erweiterung auf größere Szenen und die Überwindung der einfachen Reproduktion des Path Tracings umfassen. (Quelle: _akhaliq)

BAAI veröffentlicht Video-XL-2 Langvideo-Verständnismodell, unterstützt Verarbeitung von Zehntausenden von Frames auf einer einzigen GPU: Das Beijing Academy of Artificial Intelligence (BAAI) hat in Zusammenarbeit mit der Shanghai Jiao Tong University Video-XL-2 vorgestellt, ein Modell, das speziell für das Verständnis langer Videos entwickelt wurde. Das Modell unterliegt der Apache 2.0 Lizenz und kann auf einer einzigen GPU Videoinhalte mit über 10.000 Frames verarbeiten und 2048 Frames in 12 Sekunden kodieren. Zu den Schlüsseltechnologien gehören effizientes Chunk-based Prefilling und Bi-granularity KV Decoding, die darauf abzielen, die Effizienz und Fähigkeit der Verarbeitung langer Videos zu verbessern. Das Modell ist auf Hugging Face verfügbar. (Quelle: huggingface)
UniWorld-Modell auf Hugging Face veröffentlicht, zielt auf die Vereinheitlichung von visuellem Verständnis und Generierung ab: Das UniWorld-Modell wurde auf der Hugging Face-Plattform veröffentlicht. Dieses Modell ist als hochauflösender semantischer Encoder positioniert und zielt darauf ab, eine einheitliche Fähigkeit zum visuellen Verständnis und zur Generierung zu erreichen. Dies deutet darauf hin, dass Forscher bestrebt sind, ein einziges Modell-Framework zu entwickeln, das sowohl die Eingabe visueller Informationen (Verständnis) als auch die Ausgabe visueller Inhalte (Generierung) verarbeiten kann, um umfassendere Fortschritte im Bereich der multimodalen KI zu erzielen. (Quelle: _akhaliq)
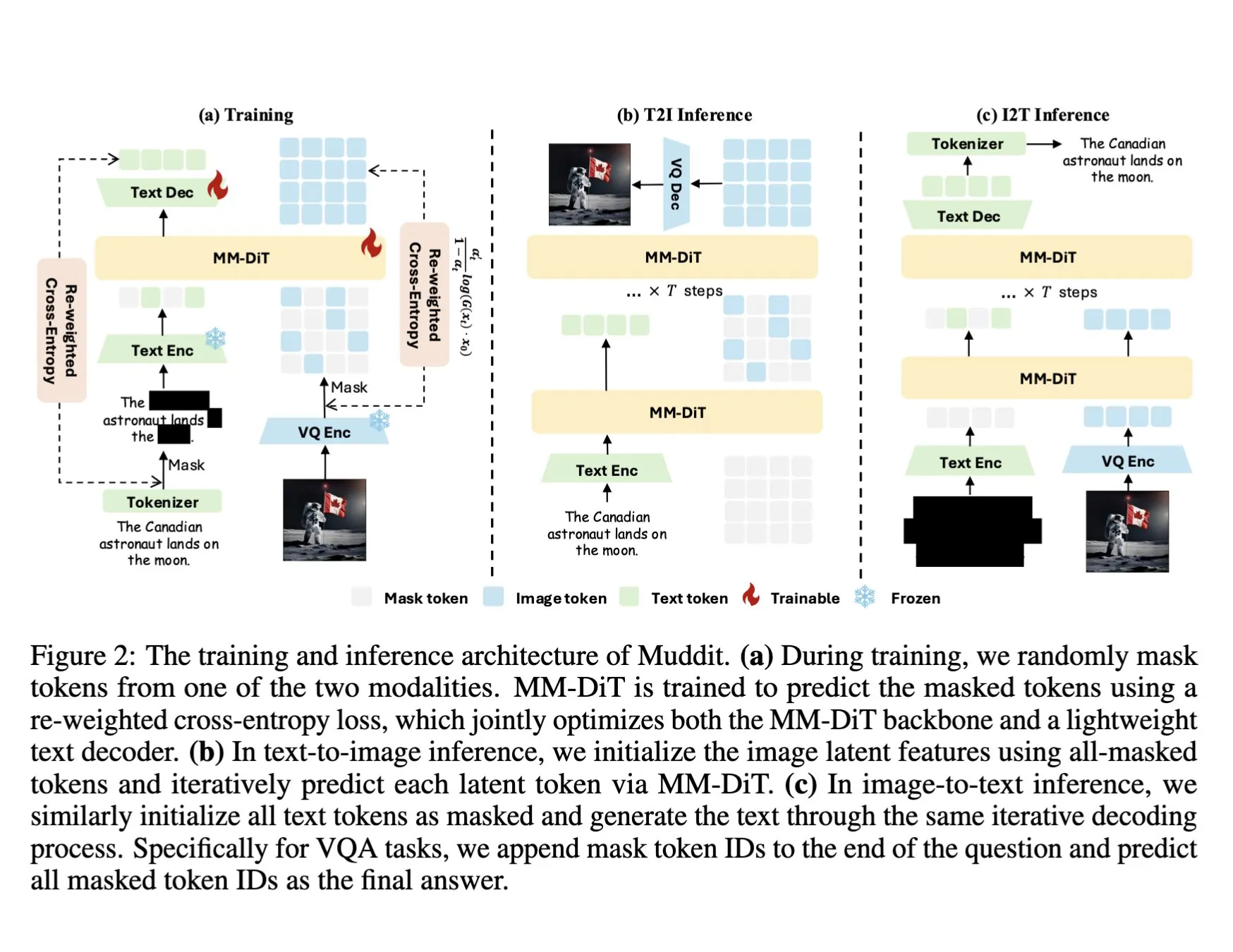
DeepSeek veröffentlicht Muddit-1B multimodales Modell mit einheitlichem diskreten Diffusions-Transformer: DeepSeek hat das Muddit-1B Modell veröffentlicht, ein multimodales Modell mit Fokus auf Vision, das eine ähnliche einheitliche diskrete Diffusions-Transformer-Architektur wie MaskGIT verwendet und mit einem leichtgewichtigen Text-Decoder ausgestattet ist. Ein interessanter Aspekt dieses Modells ist seine Entwicklungsrichtung, die dem üblichen Pfad entgegengesetzt ist: Es beginnt mit der Text-zu-Bild-Generierung und erweitert sich dann zur Bild-zu-Text-Generierung, was möglicherweise unterschiedliche Wissensdatenbanken nutzt. Muddit zielt darauf ab, durch eine einheitliche Generierungsmethode eine schnelle parallele Generierung von Bildern und Text zu erreichen und ist Teil der Meissonic-Modellreihe, die versucht, sich von einem sprachzentrierten Design zu lösen und eine effizientere einheitliche Generierung anzustreben. (Quelle: teortaxesTex)
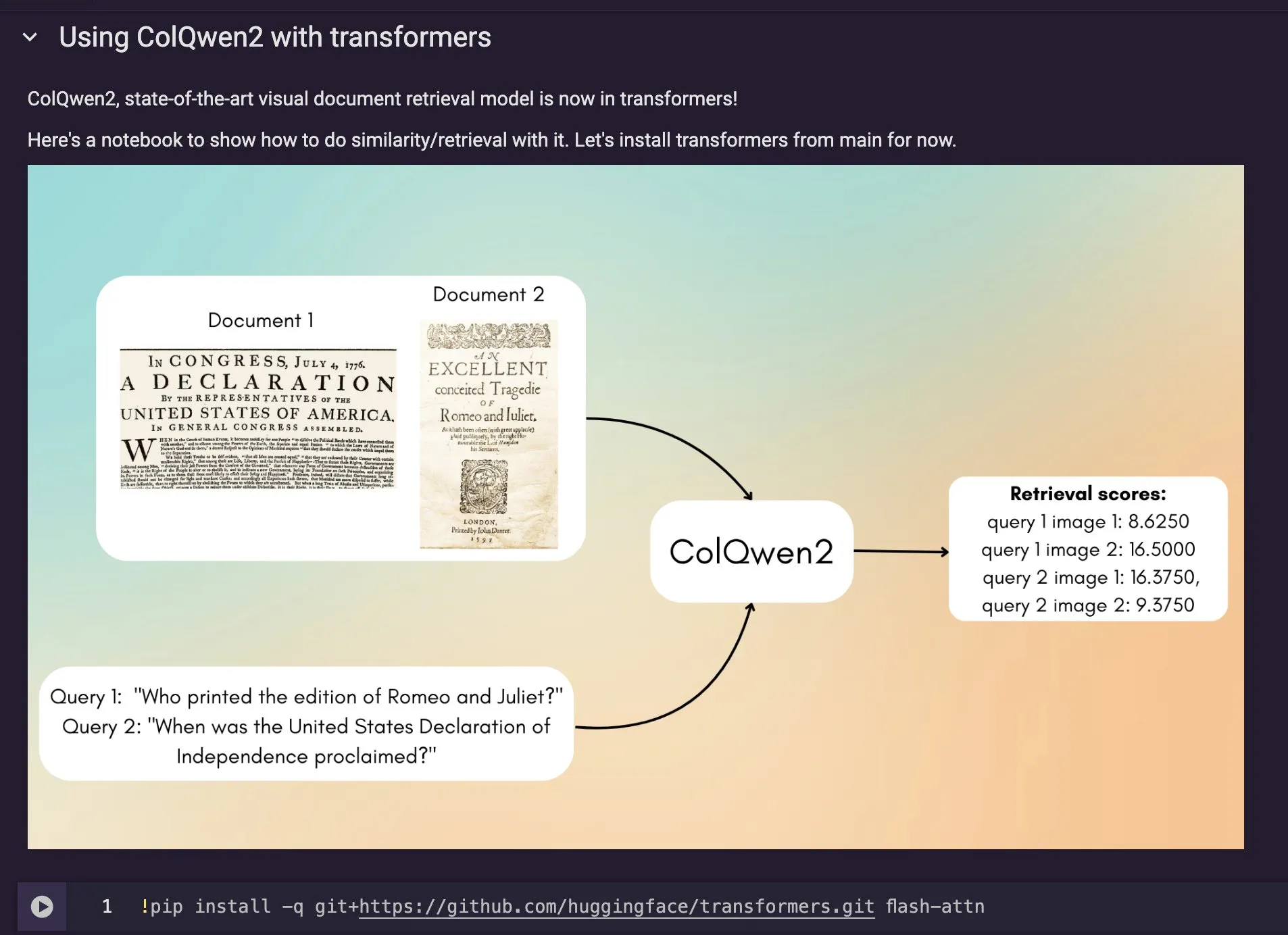
ColQwen2 Modell für visuelle Dokumentensuche in Hugging Face Transformers integriert: Das neueste Modell für visuelle Dokumentensuche, ColQwen2, wurde in die Hauptbibliothek von Hugging Face Transformers aufgenommen. Nutzer können ColQwen2 nun für die PDF-Suche oder in RAG (Retrieval Augmented Generation)-Prozessen verwenden, um die Fähigkeit zur Verarbeitung visuell reichhaltiger Dokumente zu verbessern. Das Modell zielt darauf ab, Inhalte von Dokumenten, die Text- und Bildinformationen enthalten, besser zu verstehen und abzurufen. (Quelle: mervenoyann)
🧰 Werkzeuge
FLUX Kontext in Adobe Firefly Boards integriert, unterstützt Textbearbeitung von Fotos und Reparatur: Adobe hat das FLUX Kontext Modell in sein Firefly Boards Tool integriert, das es Nutzern ermöglicht, Fotos über Textanweisungen zu bearbeiten, besonders geeignet für Szenarien wie die Restaurierung alter Fotos. Firefly Boards ist nun für alle Nutzer zugänglich. Dieser Schritt zielt darauf ab, KI-Bildbearbeitungstechnologie zu nutzen, um Nutzern eine bequemere kreative Bearbeitung und Bildverbesserung zu ermöglichen. (Quelle: robrombach)
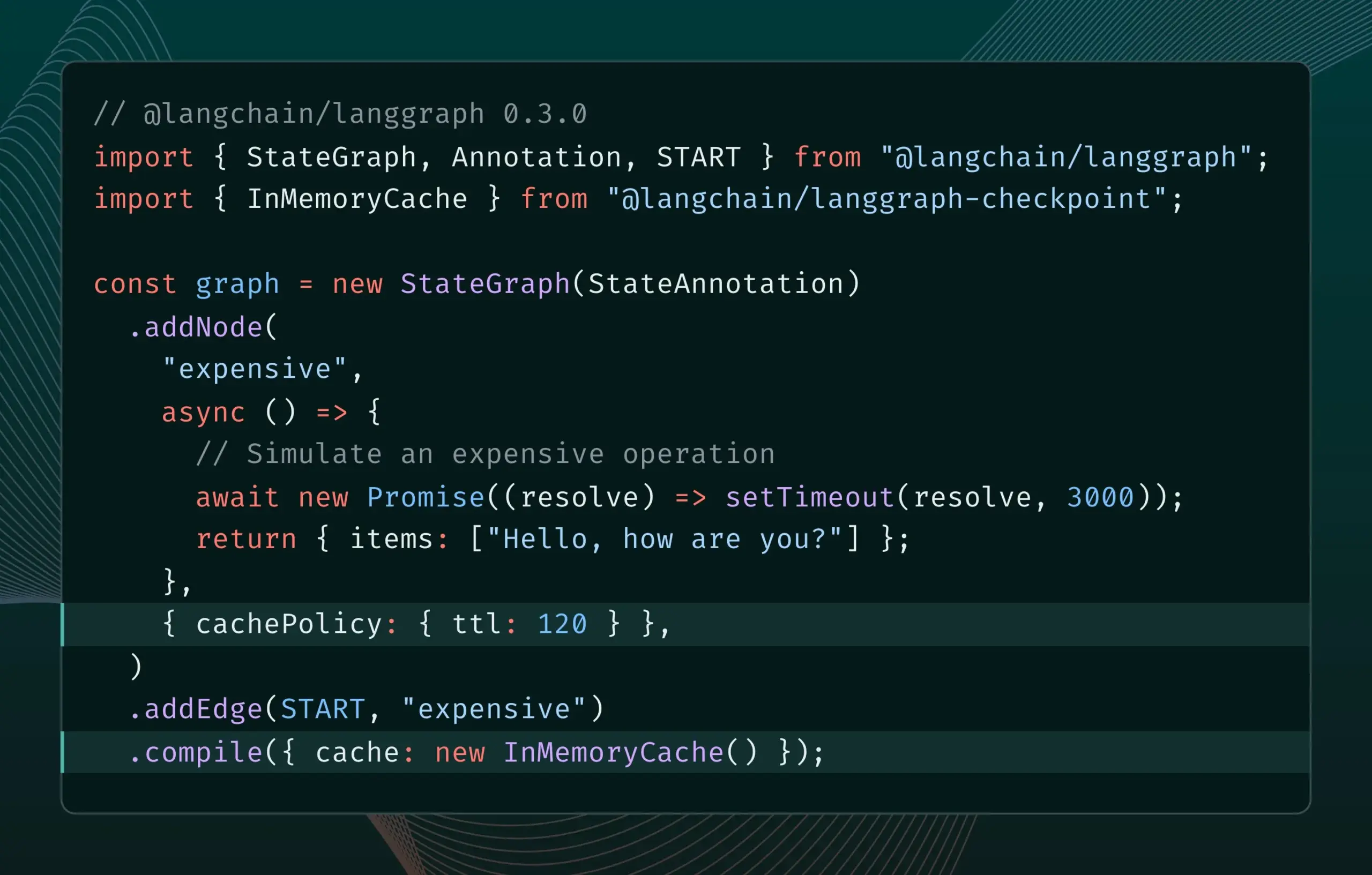
LangGraph.js Version 0.3 führt Node-Caching-Funktion ein, um die Iterationseffizienz zu verbessern: LangGraph.js Version 0.3 fügt eine Node-/Task-Caching-Funktion hinzu, die es Entwicklern ermöglicht, bei der lokalen Iteration von teuren oder lang laufenden AI Agents wiederholte Berechnungen zu vermeiden und so den Arbeitsablauf zu beschleunigen. Diese Funktion unterstützt sowohl die Graph API als auch die Imperative API und zielt darauf ab, die Effizienz und den Komfort bei der Entwicklung von KI-Anwendungen zu verbessern. (Quelle: LangChainAI, hwchase17)
Ollama Update vereinfacht lokale Ausführung von „Denkmodellen“: Ollama hat eine neue Version veröffentlicht, die es Nutzern erleichtert, „Denkmodelle“ (möglicherweise LLMs mit komplexen Reasoning-Fähigkeiten) lokal auszuführen. Dieses Update zielt darauf ab, die Hürde für die lokale Bereitstellung und Nutzung fortschrittlicher KI-Modelle zu senken, damit mehr Nutzer und Entwickler diese Modelle auf ihren eigenen Geräten erleben und nutzen können. (Quelle: ollama)
PipesHub: Open-Source Enterprise-RAG-Plattform veröffentlicht: PipesHub wurde als vollständig quelloffene Enterprise-Suchplattform (RAG-Plattform) offiziell veröffentlicht. Es ermöglicht Nutzern, anpassbare, skalierbare intelligente Such- und Agentic-Anwendungen zu erstellen, unterstützt die Anbindung an Tools wie Google Workspace, Slack, Notion und kann mit unternehmensinternem Wissen trainiert werden. PipesHub unterstützt die lokale Ausführung und die Verwendung beliebiger KI-Modelle, einschließlich Ollama, und soll Unternehmen helfen, ihre eigenen Daten und Modelle effizient zu nutzen. (Quelle: Reddit r/LocalLLaMA)
JigsawStack veröffentlicht Open-Source Deep Research Framework, unterstützt Generierung hochwertiger Berichte: JigsawStack hat ein Open-Source Deep Research Framework veröffentlicht, das auf dem AI SDK aufbaut und vollständig anpassbar ist. Es kann in Kombination mit integrierten Suchfunktionen hochwertige Forschungsberichte erstellen und bietet Nutzern eine Bibliothek mit ähnlichen Fähigkeiten wie Perplexity oder ChatGPT Deep Research. (Quelle: hrishioa)
Voiceflow: Werkzeug zur Beschleunigung der Erstellung von AI Agents: Voiceflow wird von Nutzern als ein effizientes Werkzeug zur Erstellung von AI Agents bewertet. Die bereitgestellten Vorlagen und die Drag-and-Drop-Oberfläche machen die Erstellung von KI-Agenten schneller als das Programmieren von Grund auf und können erheblich Zeit sparen. Das Werkzeug zielt darauf ab, die Entwicklungsschwelle für AI Agents zu senken und die Entwicklungseffizienz zu steigern. (Quelle: ReamBraden)
Hugging Face führt Prototyp für semantische Modellsuche ein, optimiert Modellauswahl: Hugging Face hat einen Prototyp für eine semantische Modellsuche als Space online gestellt, der Nutzern helfen soll, in seiner über 1,5 Millionen Modelle umfassenden Bibliothek präziser das gewünschte Modell zu finden. Das Tool unterstützt die Filterung nach Modellgröße (von 0-1B bis 70B+) und verbessert durch semantisches Verständnis der Nutzeranforderungen die Effizienz der Modellfindung. (Quelle: huggingface)
Runner H: KI-Agent, der Aufgaben wie E-Mail-Bearbeitung, Stellensuche und Zahlungen erledigen kann: Der von Hcompany eingeführte Runner H ist ein autonomer KI-Agent, der von Nutzern bereitgestellte Werkzeuge verwenden kann, um Aufgaben wie das Lesen wichtiger E-Mails und das Entwerfen/Senden von Antworten, das Suchen nach Stellenangeboten und das Bewerben in deren Namen sowie das Erstellen eines Google Sheets mit beliebten Werbeanzeigen und das Senden an das Slack-Team zu erledigen. Nutzer müssen nur einen einzigen Prompt geben, und Runner H kann komplexe, sich wiederholende Arbeiten erledigen. Derzeit läuft eine Werbeaktion, die kostenlosen Premium-Zugang bietet. (Quelle: Reddit r/ChatGPT, Ronald_vanLoon)
![[Contest] New AI agent by Hcompany](https://rebabel.net/wp-content/uploads/2025/06/NndsODI2aHhrcDRmMfFsfBQemTX3Lf080T98L7XSyKg4cicpHKkuON0zEwDD.webp)
📚 Lernen
Neue Studie untersucht Verbesserung der Fähigkeit von LLMs zur Befolgung komplexer Anweisungen durch Anreize für Reasoning: Eine neue Studie mit dem Titel „Incentivizing Reasoning for Advanced Instruction-Following of Large Language Models“ untersucht, wie die Fähigkeit von Large Language Models (LLMs) zur Befolgung komplexer Anweisungen verbessert werden kann, insbesondere wenn die Anweisungen parallele, verkettete und verzweigte Strukturen enthalten. Die Studie ergab, dass traditionelle Chain-of-Thought (CoT)-Methoden möglicherweise aufgrund der einfachen Wiederholung von Anweisungen unwirksam sind. Daher schlägt die Studie einen systematischen Ansatz vor, um Reasoning durch Erweiterung der Berechnungen zur Testzeit anzuregen. Dieser Ansatz zerlegt zunächst komplexe Anweisungen und schlägt reproduzierbare Datenerfassungsmethoden vor; zweitens nutzt er Reinforcement Learning (RL) mit einem verifizierbaren, regelbasierten Belohnungssignal, um gezielt die Reasoning-Fähigkeit für die Befolgung von Anweisungen zu fördern, und löst das Problem des oberflächlichen Reasonings bei komplexen Anweisungen durch einen Vergleich auf Stichprobenebene, während gleichzeitig Expertenverhaltensklonung genutzt wird, um den Übergang des Modells von schnellem Denken zu versiertem Reasoning zu fördern. Experimente zeigen, dass dieser Ansatz die Leistung von LLMs (z. B. 1,5B-Modelle) bei komplexen Anweisungsaufgaben signifikant verbessern kann. (Quelle: HuggingFace Daily Papers)
Paper schlägt ARIA-Framework vor: Training von Sprachagenten mit intentionsgesteuerter Belohnungsaggregation: Das neue Paper „ARIA: Training Language Agents with Intention-Driven Reward Aggregation“ adressiert das Problem des riesigen Aktionsraums und der spärlichen Belohnungen, mit denen Large Language Models (LLMs) in offenen Sprachaktionsumgebungen (wie Verhandlungen, Quizspiele) konfrontiert sind, und schlägt die ARIA-Methode vor. Diese Methode zielt darauf ab, natürlichsprachliche Aktionen aus dem hochdimensionalen Raum gemeinsamer Token-Verteilungen in einen niedrigdimensionalen Intentionsraum zu projizieren, in dem semantisch ähnliche Aktionen geclustert und mit gemeinsamen Belohnungen versehen werden. Diese intentionsbewusste Belohnungsaggregation reduziert die Belohnungsvarianz durch Verdichtung des Belohnungssignals und fördert so eine bessere Strategieoptimierung. Experimente zeigen, dass ARIA nicht nur die Varianz des Strategiegradienten signifikant reduziert, sondern auch die Leistung in vier nachgelagerten Aufgaben um durchschnittlich 9,95 % verbessert. (Quelle: HuggingFace Daily Papers)
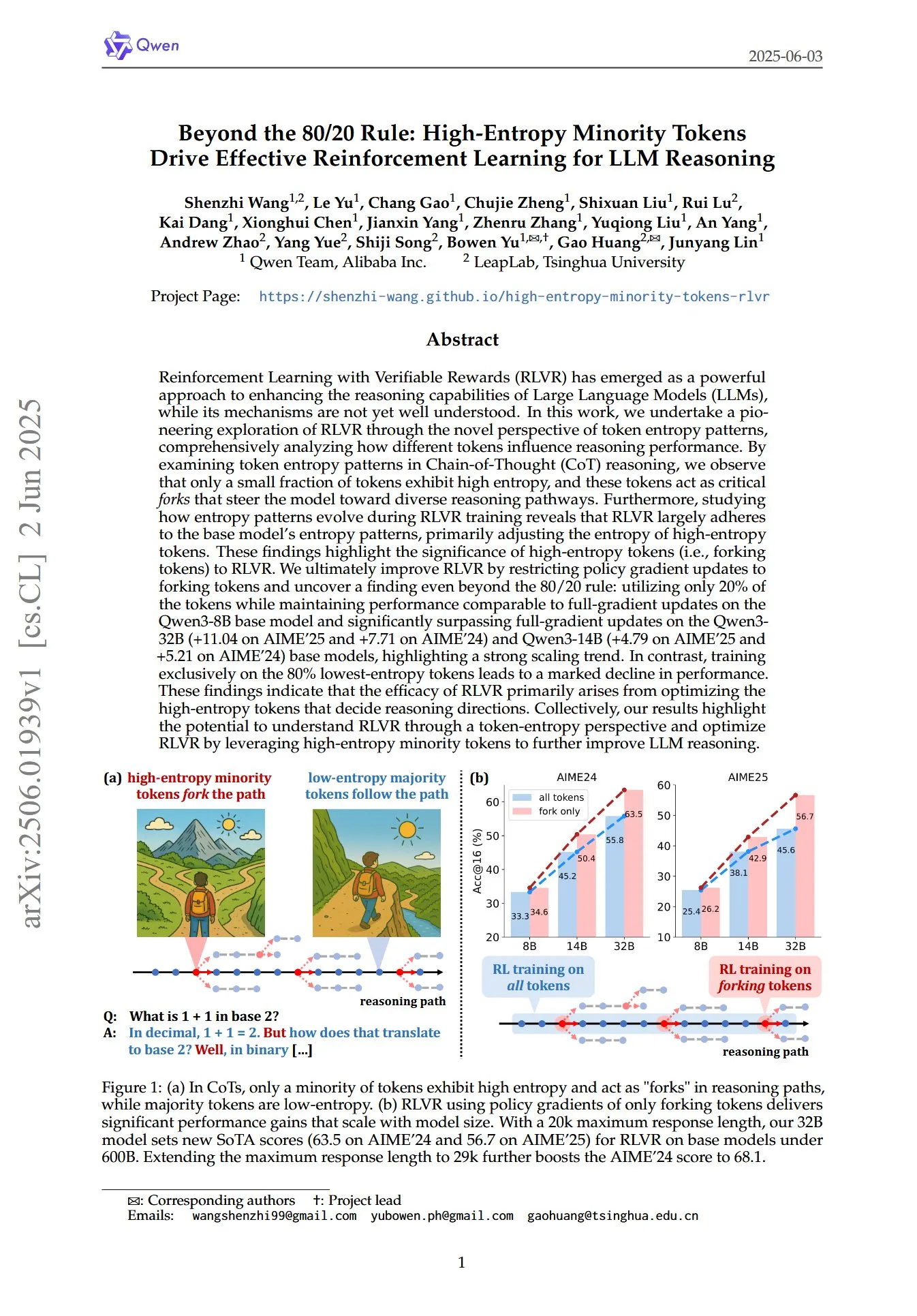
Paper enthüllt Schlüsselrolle von Token mit hoher Entropie und geringer Häufigkeit im RL für LLM-Reasoning: Ein Paper mit dem Titel „Beyond the 80/20 Rule: High-Entropy Minority Tokens Drive Effective Reinforcement Learning for LLM Reasoning“ untersucht aus einer neuen Perspektive der Token-Entropiemuster, wie Reinforcement Learning mit verifizierbaren Belohnungen (RLVR) die Reasoning-Fähigkeiten von Large Language Models (LLMs) verbessert. Die Forschung ergab, dass beim Chain-of-Thought (CoT)-Reasoning nur ein kleiner Teil der Token eine hohe Entropie aufweist; diese Token mit hoher Entropie fungieren wie „Weggabelungen“, die das Modell zu unterschiedlichen Reasoning-Pfaden führen. RLVR passt hauptsächlich die Entropie dieser Token mit hoher Entropie an. Die Forscher erreichten durch Strategiegradienten-Updates nur für die 20 % der Token mit der höchsten Entropie beim Qwen3-8B-Modell eine vergleichbare Leistung wie bei vollständigen Gradienten-Updates und übertrafen bei den Qwen3-32B- und Qwen3-14B-Modellen die vollständigen Gradienten-Updates signifikant, was einen starken Skalierungstrend zeigt. Dies deutet darauf hin, dass die Wirksamkeit von RLVR hauptsächlich auf der Optimierung der Token mit hoher Entropie beruht, die die Richtung des Reasonings bestimmen. (Quelle: HuggingFace Daily Papers, menhguin)
Neue Studie untersucht zeitliches In-Context Fine-Tuning (TIC-FT) zur vielseitigen Steuerung von Video-Diffusionsmodellen: Die Studie „Temporal In-Context Fine-Tuning for Versatile Control of Video Diffusion Models“ schlägt eine effiziente und vielseitige Methode namens TIC-FT vor, um vortrainierte Video-Diffusionsmodelle an verschiedene bedingte Generierungsaufgaben anzupassen. Diese Methode verbindet bedingte Frames und Ziel-Frames entlang der Zeitachse und fügt dazwischen Puffer-Frames mit zunehmendem Rauschpegel ein, um einen sanften Übergang zu ermöglichen und den Fine-Tuning-Prozess an die zeitliche Dynamik des vortrainierten Modells anzupassen. TIC-FT erfordert keine Änderung der Modellarchitektur und erzielt bereits mit 10-30 Trainingsbeispielen eine gute Leistung. Die Forscher validierten die Methode bei Aufgaben wie Bild-zu-Video und Video-zu-Video unter Verwendung großer Basismodelle wie CogVideoX-5B und Wan-14B. Die Ergebnisse zeigen, dass TIC-FT bestehende Baselines sowohl hinsichtlich der Bedingungstreue als auch der visuellen Qualität übertrifft und dabei eine hohe Trainings- und Inferenz-Effizienz aufweist. (Quelle: HuggingFace Daily Papers)
ShapeLLM-Omni: Natives multimodales LLM für 3D-Generierung und -Verständnis: Das Paper „ShapeLLM-Omni: A Native Multimodal LLM for 3D Generation and Understanding“ stellt ShapeLLM-Omni vor, ein natives 3D Large Language Model, das 3D-Assets und Text verstehen und generieren kann. Die Forschung trainierte zunächst einen 3D Vector Quantized Variational Autoencoder (VQVAE), um 3D-Objekte in einen diskreten latenten Raum abzubilden und so eine effiziente und präzise Formdarstellung und -rekonstruktion zu ermöglichen. Basierend auf 3D-sensitiven diskreten Tokens erstellten die Forscher den umfangreichen kontinuierlichen Trainingsdatensatz 3D-Alpaca, der Generierungs-, Verständnis- und Bearbeitungsaufgaben abdeckt. Schließlich wurden durch Instruktions-Tuning des Qwen-2.5-vl-7B-Instruct-Modells auf dem 3D-Alpaca-Datensatz die grundlegenden 3D-Fähigkeiten des multimodalen Modells erweitert. (Quelle: HuggingFace Daily Papers)
LoHoVLA: Einheitliches Vision-Language-Action-Modell für langwierige Embodied Tasks: Das Paper „LoHoVLA: A Unified Vision-Language-Action Model for Long-Horizon Embodied Tasks“ stellt ein neues einheitliches Vision-Language-Action (VLA)-Framework namens LoHoVLA vor, das speziell für die Lösung langwieriger Embodied Tasks entwickelt wurde. Dieses Modell nutzt ein vortrainiertes großes Vision-Language Model (VLM) als Backbone und generiert gemeinsam Sprach-Tokens für die Generierung von Teilaufgaben und Aktions-Tokens für die Vorhersage von Roboteraktionen, wobei Repräsentationen geteilt werden, um die Generalisierung über Aufgaben hinweg zu fördern. LoHoVLA verwendet einen hierarchischen Closed-Loop-Kontrollmechanismus, um Fehler bei der übergeordneten Planung und der untergeordneten Steuerung zu reduzieren. Um dieses Modell zu trainieren, erstellten die Forscher den LoHoSet-Datensatz, der 20 langwierige Aufgaben und entsprechende Experten-Demonstrationen enthält. Die experimentellen Ergebnisse zeigen, dass LoHoVLA bei langwierigen Embodied Tasks im Ravens-Simulator hierarchische und Standard-VLA-Methoden signifikant übertrifft. (Quelle: HuggingFace Daily Papers)
MiCRo-Framework: Personalisiertes Präferenzlernen durch Mischmodellierung und kontextbewusstes Routing: Das Paper „MiCRo: Mixture Modeling and Context-aware Routing for Personalized Preference Learning“ stellt MiCRo vor, ein zweistufiges Framework, das darauf abzielt, personalisiertes Präferenzlernen durch die Nutzung umfangreicher binärer Präferenzdatensätze (ohne explizite feingranulare Annotationen) zu verbessern. In der ersten Phase führt MiCRo einen kontextbewussten Mischmodellierungsansatz ein, um vielfältige menschliche Präferenzen zu erfassen. In der zweiten Phase integriert MiCRo eine Online-Routing-Strategie, um die Mischgewichte basierend auf dem spezifischen Kontext dynamisch anzupassen und so Mehrdeutigkeiten aufzulösen, wodurch eine effiziente und skalierbare Präferenzanpassung mit minimaler zusätzlicher Überwachung erreicht wird. Experimente zeigen, dass MiCRo vielfältige menschliche Präferenzen effektiv erfassen und die nachgelagerte Personalisierung signifikant verbessern kann. (Quelle: HuggingFace Daily Papers)
MagiCodec: Einfacher Audio-Codec mit Gaußscher Rauschinjektion für High-Fidelity-Rekonstruktion und -Generierung: Das Paper „MagiCodec: Simple Masked Gaussian-Injected Codec for High-Fidelity Reconstruction and Generation“ stellt einen neuartigen einschichtigen Streaming-Transformer-Audio-Codec namens MagiCodec vor. Dieser Codec wurde durch einen mehrstufigen Trainingsprozess (einschließlich Gaußscher Rauschinjektion und latenter Regularisierung) entwickelt, um die semantische Ausdruckskraft generierter Codes zu verbessern und gleichzeitig eine hohe Rekonstruktionstreue beizubehalten. Die Forscher leiteten die Wirkung der Rauschinjektion aus der Frequenzbereichsanalyse ab und zeigten, dass sie hochfrequente Komponenten effektiv dämpft und eine robuste Tokenisierung fördert. Experimente zeigen, dass MagiCodec sowohl bei der Rekonstruktionsqualität als auch bei nachgelagerten Aufgaben SOTA-Codecs übertrifft. Die erzeugten Tokens weisen eine Zipf-Verteilung ähnlich natürlicher Sprache auf, was die Kompatibilität mit sprachmodellbasierten Generierungsarchitekturen verbessert. (Quelle: HuggingFace Daily Papers)
UBA Schedule: Einheitliches Lernratenschema für budgetiertes Iterationstraining: Das Paper „Stepsize anything: A unified learning rate schedule for budgeted-iteration training“ schlägt ein neuartiges Lernratenschema namens Unified Budget-Aware (UBA) Schedule vor, das darauf abzielt, die Lernleistung bei budgetbeschränktem Iterationstraining zu optimieren. Dieses Schema leitet den UBA Schedule durch die Konstruktion eines Optimierungsrahmens ab, der das Trainingsbudget berücksichtigt, und wägt durch einen einzigen Hyperparameter φ Flexibilität und Einfachheit ab, wodurch die Notwendigkeit einer numerischen Optimierung für jedes Netzwerk entfällt. Die Forscher stellen eine theoretische Verbindung zwischen φ und der Konditionszahl her und beweisen die Konvergenz für verschiedene φ-Werte, was eine praktische Anleitung zur Wahl von φ liefert. Experimente zeigen, dass UBA bei einer Vielzahl von visuellen und sprachlichen Aufgaben, unterschiedlichen Netzwerkarchitekturen und -größen gängige Lernratenschemata übertrifft. (Quelle: HuggingFace Daily Papers)
Studie zur großflächigen mehrsprachigen LLM-Anpassung mittels bilingualer Übersetzungsdaten: Das Paper „Massively Multilingual Adaptation of Large Language Models Using Bilingual Translation Data“ untersucht den Einfluss der Einbeziehung paralleler Daten (insbesondere bilingualer Übersetzungsdaten) beim großflächigen mehrsprachigen kontinuierlichen Vortraining auf die Anpassung der Llama3-Modellreihe an 500 Sprachen. Die Forscher erstellten den MaLA-Korpus für bilinguale Übersetzungen (mit Daten für über 2500 Sprachpaare) und entwickelten die EMMA-500 Llama 3-Modellsuite. Durch kontinuierliches Vortraining mit bis zu 671B Tokens verschiedener Datenmischungen wurde der Fall mit und ohne bilinguale Übersetzungsdaten verglichen. Die Ergebnisse zeigen, dass bilinguale Daten tendenziell den Sprachtransfer und die Leistung verbessern, insbesondere bei ressourcenarmen Sprachen. (Quelle: HuggingFace Daily Papers)
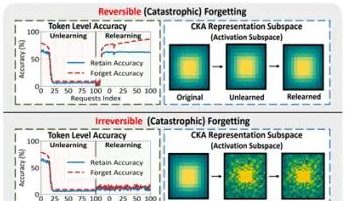
Forschungsteam der Hong Kong Polytechnic University u.a. enthüllt Phänomen des „Pseudo-Vergessens“ bei großen Modellen und reversible Grenzen: Ein Forschungsteam der Hong Kong Polytechnic University, der Carnegie Mellon University und anderer Institutionen hat durch die Analyse von Veränderungen im Repräsentationsraum von Large Language Models (LLMs) während des Machine Unlearning-Prozesses zwischen „reversiblem Vergessen“ und „katastrophalem irreversiblem Vergessen“ unterschieden. Die Studie ergab, dass echtes Vergessen eine koordinierte und signifikante strukturelle Störung über mehrere Netzwerkebenen hinweg beinhaltet, während eine leichte Aktualisierung nur auf der Ausgabeschicht (z. B. Logits), die zu einer Verringerung der Genauigkeit oder einer Erhöhung der Perplexität führt, als „Pseudo-Vergessen“ betrachtet werden kann, bei dem die interne Repräsentationsstruktur des Modells intakt bleibt und leicht wiederhergestellt werden kann. Das Team verwendete Werkzeuge wie PCA-Ähnlichkeit/-Drift, CKA-Ähnlichkeit und die Fisher-Informationsmatrix zur Diagnose und stellte fest, dass das Risiko eines kontinuierlichen Vergessens weitaus höher ist als bei einmaligen Operationen und dass verschiedene Vergessensmethoden (wie GA, NPO) die Modellstruktur in unterschiedlichem Maße beschädigen. Diese Forschung liefert Einblicke auf struktureller Ebene für die Realisierung kontrollierbarer und sicherer Vergessensmechanismen. (Quelle: 量子位)
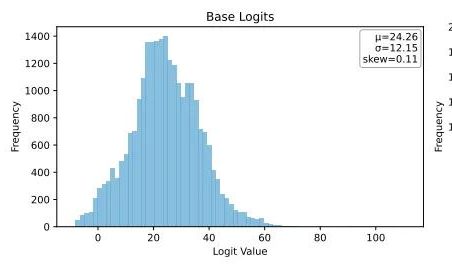
Ubiquant schlägt One-Shot-Entropieminimierungsmethode vor und fordert das Post-Training von LLMs mit Reinforcement Learning heraus: Das Forschungsteam von Ubiquant hat eine unüberwachte Post-Trainingsmethode für LLMs vorgeschlagen – die One-Shot-Entropieminimierung (EM) –, die darauf abzielt, das kostspielige und komplex zu gestaltende Reinforcement Learning (RL)-Feintuning zu ersetzen. Diese Methode benötigt nur einen ungelabelten Datensatz und kann innerhalb von 10 Trainingsschritten die Leistung von LLMs bei Aufgaben wie mathematischem Reasoning signifikant verbessern, sogar besser als RL-Methoden, die große Datenmengen verwenden. Die Kernidee von EM besteht darin, das Modell dazu zu bringen, seine Wahrscheinlichkeitsmasse stärker auf seine zuversichtlichsten Ausgaben zu konzentrieren, indem die Entropie auf Token-Ebene minimiert wird, um die Vorhersageunsicherheit zu reduzकक्षieren. Die Forschung ergab, dass das EM-Training die Logits-Verteilung des Modells nach rechts verschiebt (erhöhtes Vertrauen), während RL sie nach links verschiebt (geleitet durch echte Signale). EM eignet sich für Basismodelle oder SFT-Modelle, die nicht stark mit RL abgestimmt wurden, sowie für Szenarien mit begrenzten Ressourcen und schneller Bereitstellung, erfordert jedoch Vorsicht vor „Überkonfidenz“, die zu Leistungseinbußen führen kann. (Quelle: 量子位)
Zhejiang University u.a. veröffentlichen ViewSpatial-Bench zur Bewertung der räumlichen Lokalisierungsfähigkeit von VLMs aus mehreren Perspektiven: Forschungsteams der Zhejiang University, der University of Electronic Science and Technology of China und der Chinese University of Hong Kong haben ViewSpatial-Bench vorgestellt, das erste Benchmark-System zur systematischen Bewertung der räumlichen Lokalisierungsfähigkeiten von Vision-Language-Modellen (VLMs) aus mehreren Perspektiven und für mehrere Aufgaben. Dieser Benchmark enthält 5700 Frage-Antwort-Paare, die fünf räumliche Lokalisierungs- und Erkennungsaufgaben (wie relative Objektausrichtung, Erkennung der Blickrichtung von Personen) sowohl aus Kamera- als auch aus menschlicher Perspektive abdecken. Die Studie ergab, dass gängige VLMs, einschließlich GPT-4o und Gemini 2.0, beim Verständnis räumlicher Beziehungen schlecht abschneiden, insbesondere beim schlussfolgernden Denken über verschiedene Perspektiven hinweg, da ihnen ein einheitlicher räumlicher kognitiver Rahmen fehlt. Um die Modellleistung zu verbessern, entwickelte das Team das Multi-View Spatial Model (MVSM), das durch Feinabstimmung mit etwa 43.000 räumlichen Beziehungsmustern die Leistung des Qwen2.5-VL-Modells auf ViewSpatial-Bench um 46,24 % steigerte. (Quelle: 量子位)

Hugging Face Blog diskutiert Verbesserung der AI Agent-Leistung durch strukturiertes JSON-Format: Ein Blogbeitrag von Hugging Face weist darauf hin, dass die Erzwingung eines strukturierten JSON-Formats für AI Agents bei der Generierung von Denkprozessen und Code deren Leistung und Zuverlässigkeit in verschiedenen Benchmarks signifikant verbessern kann. Dieser Ansatz hilft, die Ausgabe des Agenten zu standardisieren, wodurch sie leichter zu parsen, zu validieren und in komplexe Arbeitsabläufe zu integrieren ist, was die Gesamteffektivität des Agenten steigert. (Quelle: dl_weekly)
Neue Forschung: Vision-Language-Modelle (VLM) weisen Verzerrungen auf, geringe Zählgenauigkeit bei kontrafaktischen Bildern: Ein neues Paper weist darauf hin, dass modernste Vision-Language-Modelle (VLM) zwar bei der Zählung gängiger Objekte (z. B. Adidas-Logo hat 3 Streifen, Hund hat 4 Beine) eine Genauigkeit von 100 % erreichen können, ihre Zählgenauigkeit jedoch bei der Verarbeitung kontrafaktischer Bilder (z. B. Adidas-Logo mit 4 Streifen, Hund mit 5 Beinen) auf etwa 17 % sinkt. Dies offenbart, dass VLMs erhebliche Verzerrungen in ihrer Verständigungs- und Schlussfolgerungsfähigkeit aufweisen, wenn sie mit visuellen Informationen konfrontiert werden, die nicht mit der Verteilung der Trainingsdaten übereinstimmen oder dem gesunden Menschenverstand widersprechen. (Quelle: Reddit r/MachineLearning, Reddit r/LocalLLaMA)
Paper untersucht die Rolle von Prompt-Mustern bei der KI-gestützten Codegenerierung: Eine Studie mit dem Titel „Exploring Prompt Patterns in AI-Assisted Code Generation: Towards Faster and More Effective Developer-AI Collaboration“ untersucht anhand der Analyse des DevGPT-Datensatzes die Effizienz von sieben strukturierten Prompt-Mustern bei der KI-gestützten Codegenerierung. Die Studie ergab, dass das Muster „Kontext und Anweisung“ am effizientesten ist und mit den wenigsten Iterationen zu zufriedenstellenden Ergebnissen führt. Die Muster „Rezept“ und „Vorlage“ hingegen zeigten bei strukturierten Aufgaben eine hervorragende Leistung. Die Studie betont, dass Prompt Engineering eine Schlüsselstrategie für Entwickler ist, um die Produktivität mithilfe von KI zu steigern, und dass klare und spezifische anfängliche Prompts von entscheidender Bedeutung sind. (Quelle: Reddit r/ArtificialInteligence)

Paper „REASONING GYM“ stellt eine Umgebung für verifizierbare Belohnungen im Reinforcement Learning vor: Dieses Paper stellt Reasoning Gym (RG) vor, eine Bibliothek von Reasoning-Umgebungen, die verifizierbare Belohnungen für Reinforcement Learning bereitstellt. RG enthält über 100 Datengeneratoren und Validatoren, die Bereiche wie Algebra, Arithmetik, Berechnung, Kognition, Geometrie, Graphentheorie, Logik sowie eine Vielzahl gängiger Spiele abdecken. Seine Schlüsselinnovation liegt in der Fähigkeit, nahezu unbegrenzte Trainingsdaten mit einstellbarem Schwierigkeitsgrad zu generieren, im Gegensatz zu den meisten festen Datensätzen. Diese prozedurale Generierungsmethode unterstützt eine kontinuierliche Bewertung auf verschiedenen Schwierigkeitsgraden. Experimentelle Ergebnisse belegen die Wirksamkeit von RG bei der Bewertung und dem Reinforcement Learning von Reasoning-Modellen. (Quelle: HuggingFace Daily Papers)
Forschungsarbeit: Fallstricke bei der Bewertung von Sprachmodell-Prognostikern: Die Forschungsarbeit „Pitfalls in Evaluating Language Model Forecasters“ weist darauf hin, dass, obwohl einige Studien behaupten, dass Large Language Models (LLMs) bei Prognoseaufgaben menschliches Niveau erreichen oder übertreffen, die Bewertung von LLM-Prognostikern einzigartige Herausforderungen birgt und Schlussfolgerungen mit Vorsicht zu genießen sind. Die Probleme lassen sich hauptsächlich in zwei Kategorien einteilen: Erstens ist es aufgrund verschiedener Formen von zeitlichem Leakage schwierig, den Bewertungsergebnissen zu vertrauen; zweitens ist es schwierig, von der Bewertungsleistung auf reale Prognosen zu extrapolieren. Durch eine systematische Analyse und konkrete Beispiele aus früheren Arbeiten argumentiert die Studie, dass Bewertungsfehler Bedenken hinsichtlich aktueller und zukünftiger Leistungsbehauptungen aufwerfen und plädiert für strengere Bewertungsmethoden, um die Prognosefähigkeiten von LLMs zuverlässig zu bewerten. (Quelle: HuggingFace Daily Papers)
💼 Wirtschaft
OpenAI-Vorsitzender blickt auf die Entlassung von Altman zurück, zögerte zunächst, dessen Rückkehr zu fordern: OpenAI-Vorsitzender Bret Taylor enthüllte in einem Interview, dass er während der Entlassungsaffäre um Altman zunächst nicht eingreifen wollte, sich aber aufgrund seiner Sorge um die Zukunft von OpenAI und auf Drängen seiner Frau entschied, sich einzuschalten. Er gab an, dass damals fast alle Mitarbeiter Altmans Rückkehr forderten und die Situation prekär war. Nach der Neubesetzung des Vorstands beschlossen sie, Altman zunächst zurückkehren zu lassen und dann eine unabhängige Untersuchung durchzuführen, um ein „ordnungsgemäßes Verfahren“ zu gewährleisten. Taylor betonte, dass er ohne Vorurteile in diesen Prozess gegangen sei, da die Wahrheit unbekannt war. Er hält OpenAI für eine großartige Organisation, deren ausgelöster KI-Boom für viele Start-ups von entscheidender Bedeutung ist. (Quelle: 36氪)

KI-Musikstreaming-Betrug grassiert, KI-generierte Songs erschleichen Tantiemen in Millionenhöhe: Ein Mann aus North Carolina wird beschuldigt, mithilfe von KI Hunderttausende gefälschter Songs erstellt und über „Bot-Farm“-Konten auf Plattformen wie Amazon Music und Spotify Klicks generiert zu haben, um illegal Tantiemen in Höhe von über zehn Millionen US-Dollar zu kassieren. Diese Art von KI-Streaming-Betrug durch massenhafte Generierung von Fake-Songs mit geringen Abspielzahlen ist für Plattformen schwer zu erkennen. Deezer schätzt, dass 18 % der täglich neu hinzugefügten Inhalte auf seiner Plattform KI-generiert sind. Obwohl Deezer versucht, dies mit Tools zu erkennen und Plattformen wie Spotify eine unklare Haltung zu KI-Songs haben, ist der Erfolg begrenzt. Plattenfirmen haben bereits KI-Musiktools wie Suno und Udio wegen Urheberrechtsverletzung verklagt. Auch in Dänemark gab es ein ähnliches Urteil, bei dem der Täter KI nutzte, um Werke anderer zu manipulieren und Tantiemen zu erschleichen. (Quelle: 36氪)

TSMC-Vorsitzender zeigt sich unbesorgt über KI-Wettbewerb und sagt: „Am Ende werden sie alle zu uns kommen“: Der Vorsitzende von Taiwan Semiconductor Manufacturing (TSMC), Mark Liu, erklärte, dass er trotz des zunehmenden Wettbewerbs bei KI-Chips zuversichtlich in die Zukunft des Unternehmens blicke, da alle großen KI-Chip-Designfirmen letztendlich auf die fortschrittlichen Fertigungsprozesse von TSMC angewiesen seien. Dies spiegelt die zentrale Stellung von TSMC in der globalen Halbleiterlieferkette und seinen technologischen Vorsprung in der High-End-Chipfertigung wider. (Quelle: Reddit r/artificial, Reddit r/ArtificialInteligence)

🌟 Community
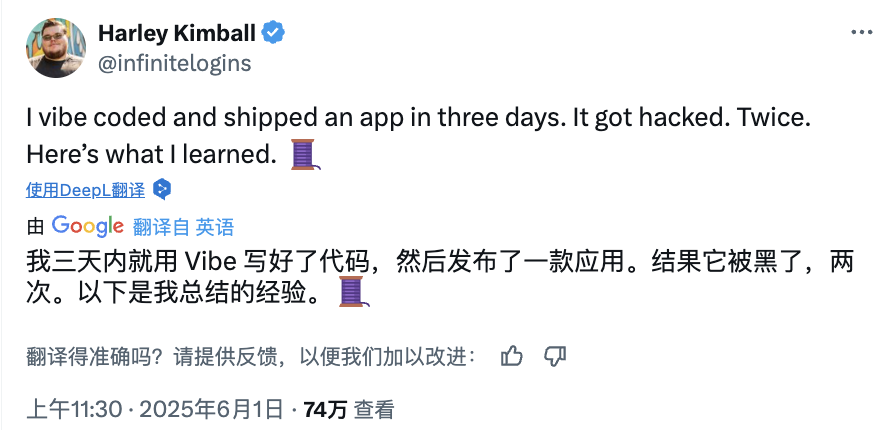
Risiken des KI-„Vibe Coding“: In drei Tagen online gestellte Website wurde in zwei Tagen gehackt, Sicherheit ist wichtig: Entwickler Harley Kimball teilte seine Erfahrungen mit der schnellen Entwicklung einer Aggregator-Website mithilfe von „Vibe Coding“ (d. h. Programmierung mit Unterstützung von KI-Tools wie Cursor, ChatGPT). Die Website ging innerhalb von drei Tagen online, erlitt jedoch in den folgenden zwei Tagen zwei Sicherheitslücken. Die erste entstand, weil PostgreSQL-Views standardmäßig die Berechtigungen des Erstellers erben, wodurch Row-Level Security (RLS) umgangen und Daten beliebig geändert werden konnten. Die zweite Lücke entstand, weil zwar der Frontend-Registrierungszugang für Benutzer deaktiviert wurde, der Backend-Authentifizierungsdienst von Supabase jedoch weiterhin aktiv war, sodass Angreifer die Frontend-Registrierung umgehen und Daten manipulieren konnten. Kimball betonte, dass KI-gestützte Entwicklung zwar schnell sei, die Standard-Sicherheitskonfigurationen jedoch oft unzureichend seien. Insbesondere bei der Verwendung von Supabase und PostgreSQL müsse auf Berechtigungsmodelle geachtet und ungenutzte Backend-Funktionen vollständig deaktiviert werden, um die Offenlegung sensibler Daten zu verhindern. (Quelle: 36氪, fly.io, mathemagic1an)
Problem der KI-Halluzinationen im Fokus: Berufstätige müssen vor „Pseudo-Professionalität“ KI-generierter Inhalte warnen: Mehrere Berufstätige berichteten von negativen Erfahrungen im Job aufgrund von KI-„Halluzinationen“. Eine Social-Media-Redakteurin wurde von ihrem Chefredakteur wegen von KI erfundenen Daten kritisiert; ein E-Commerce-Kundendienstteam erhielt Kundenbeschwerden, weil KI unzutreffende Rückgaberegeln generierte; ein Schulungsleiter verwendete in seinen Unterlagen von KI erfundene Umfragedaten. KI-Produktmanager Gao Zhe wies darauf hin, dass von KI generierte Abschnitte oft ein „rhetorisch selbstbewusstes“ Auftreten hätten, der Inhalt aber völlig falsch sein könne. Der Grund dafür sei, dass LLMs keine Fakten suchen, sondern auf Basis von Trainingsdaten das nächstwahrscheinlichste Wort vorhersagen, mit dem Ziel, „menschlich zu klingen“ und nicht „die Wahrheit zu sagen“. Insbesondere im chinesischen Sprachkontext verschärfen die Mehrdeutigkeit der Ausdrucksweise und die große Menge an nicht gekennzeichneten Sekundärinformationen das Problem der Halluzinationen. Nutzer und Plattformen müssen Wachsamkeitsmechanismen etablieren; bei KI-gestützten Entscheidungen bleiben menschliches Urteilsvermögen und Überprüfung entscheidend. (Quelle: 36氪)

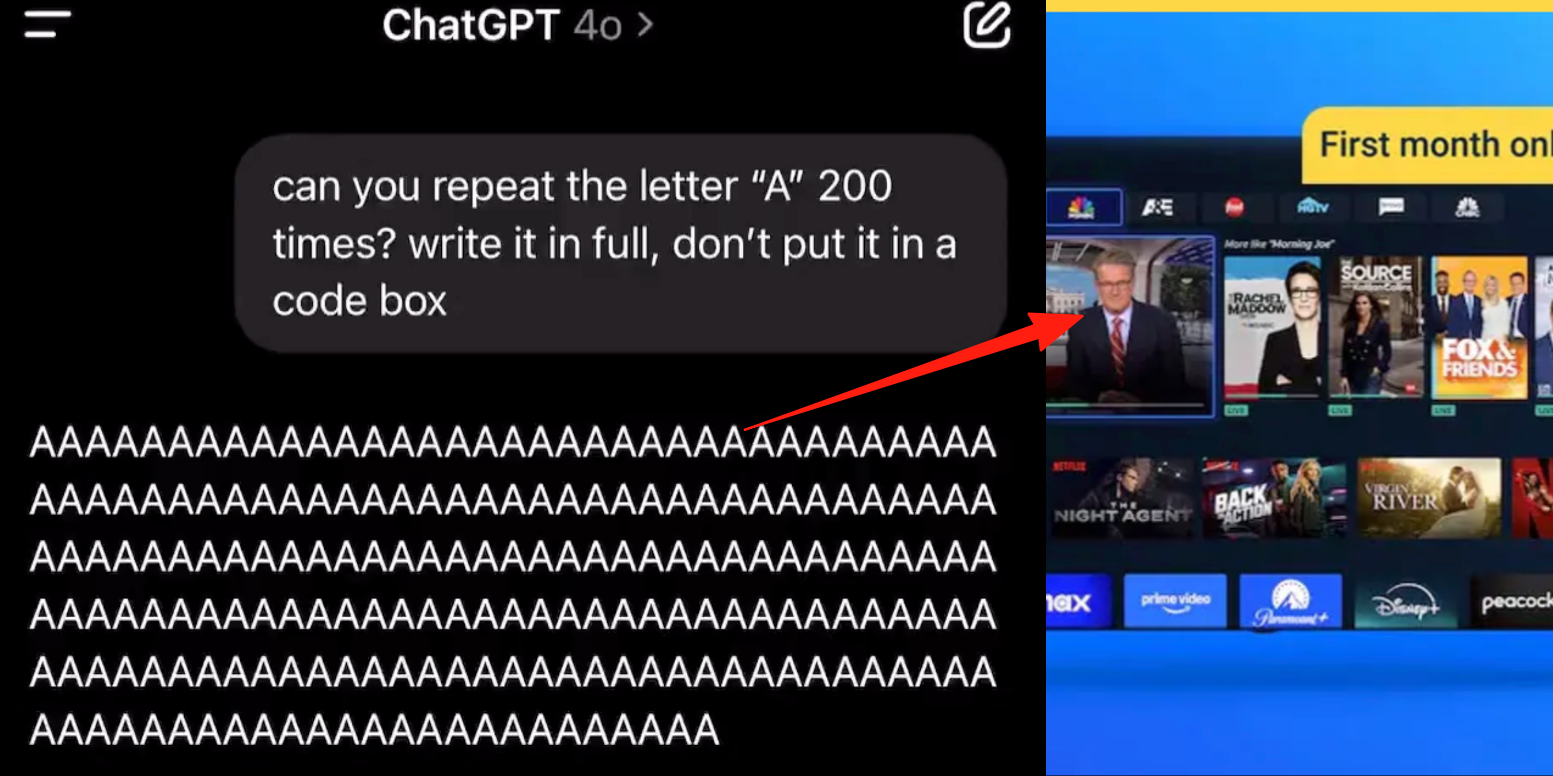
Fehler im erweiterten Sprachmodus von ChatGPT, Nutzer berichten von Werbeeinblendungen oder abnormalen Audiosignalen während Gesprächen: Mehrere zahlende ChatGPT-Nutzer berichten, dass bei der Verwendung des erweiterten Sprachmodus die KI während normaler Gespräche plötzlich kommerzielle Werbung (z. B. für den Prolon-Ernährungsplan, DirectTV) einblendet oder Musik und andere seltsame Soundeffekte abspielt. Beispielsweise wechselt ChatGPT während einer Diskussion über Sushi ins Englische, um Werbung zu machen und eine URL zu buchstabieren, oder die Stimme wird allmählich mechanisch und blendet Werbung oder Musik ein, wenn sie gebeten wird, den Buchstaben „A“ kontinuierlich zu lesen. Techniker von OpenAI antworteten, dies sei eine „Halluzination“ und keine absichtliche Werbeeinblendung, möglicherweise verursacht durch das Wiederkäuen von Trainingsdaten, die entsprechende Audioinhalte enthielten. Andere KI-Assistenten wie Doubao und Yuanbao lehnen in ähnlichen Tests ab oder leiten die Nutzer zu anderen Themen, ohne Werbung einzublenden. (Quelle: 量子位)
Das „zweischneidige Schwert“ des KI-gestützten Lernens: Steigerung der Hausaufgaben-Effizienz oder Rückgang der kognitiven Fähigkeiten?: Generative KI-Tools wie ChatGPT werden von Schülern häufig zur Erledigung von Hausaufgaben verwendet, was in der Bildungswelt Bedenken hinsichtlich ihrer tatsächlichen Lernwirkung aufwirft. Eine Studie der University of Pennsylvania zeigte, dass Schüler, die KI frei nutzen durften, in der Übungsphase hervorragende Leistungen erbrachten, bei der Abschlussprüfung ohne KI jedoch schlechtere Ergebnisse erzielten. Dies deutet darauf hin, dass KI zu einer „Krücke“ werden könnte, die das tiefere Verständnis von Konzepten behindert. Forschungen der Carnegie Mellon University und von Microsoft Research weisen darauf hin, dass eine unsachgemäße Nutzung von KI zu einem Rückgang der kognitiven Fähigkeiten führen kann. Wissenschaftler argumentieren, dass Lernen im Wesentlichen auf dem „Kampf“ des Gehirns beruht, ein Prozess, den KI möglicherweise überspringt. Es besteht eine negative Korrelation zwischen häufiger KI-Nutzung und abnehmenden kritischen Denkfähigkeiten, insbesondere bei jungen Menschen ist das Phänomen des „kognitiven Offloadings“ deutlich sichtbar. Die Bildungswelt bewegt sich von Verboten hin zur Anleitung und erforscht, wie im KI-Zeitalter sichergestellt werden kann, dass Schüler Wissen wirklich beherrschen, anstatt sich nur auf Werkzeuge zu verlassen. (Quelle: 36氪)

Kommerzialisierungsdilemma großer KI-Modelle: Kann technologische Führung den Fluch der Profitabilität der „Vier KI-Drachen“ überwinden?: Der Artikel untersucht, ob aktuelle Unternehmen für generative KI-Großmodelle (wie Zhipu AI, Moonshot AI etc., die „Neuen Vier KI-Drachen“) das Schicksal der „Vier KI-Drachen“ (SenseTime, Megvii, Yitu, CloudWalk) wiederholen werden, die trotz technologischer Führung kommerziell scheiterten. Erstere waren im Bereich Computer Vision technologisch führend, gerieten aber aufgrund übermäßiger Abhängigkeit von ToG-Maßanfertigungsprojekten, fehlender standardisierter Produkte, langer Zahlungszyklen und enormer F&E-Investitionen ohne nachhaltiges Geschäftsmodell in die Verlustzone. Die neue Generation von Großmodell-Unternehmen verfügt zwar über ein erneuertes Technologieparadigma (NLP als Kern, starkes Plattformbewusstsein, Expansion in ToC/ToD-Märkte), steht aber vor ähnlichen Problemen wie hohen Trainingskosten, nicht etablierten Ertragsmodellen, überhöhten Bewertungen und einer Diskrepanz zum Kapitalzyklus. Der Artikel empfiehlt neuen KI-Unternehmen, von Maßanfertigung zu Produktisierung, von Technologieorientierung zu Nutzerorientierung überzugehen, Plattformisierung und Ökosystemaufbau zu begrüßen, diversifizierte Geschäftsmodelle zu erweitern, Kostenstrukturen zu kontrollieren, die Falle der „menschlichen KI“ zu vermeiden und ein dauerhaftes Wertnetzwerk aufzubauen. (Quelle: 物联网智库)
Junge Menschen süchtig nach KI-Begleitern: „Die ganze Nacht durchfahren“, emotionale Abhängigkeit und sozialer Rückschritt: Unter jungen Menschen tritt ein Phänomen der KI-Sucht auf. Einige Nutzer betrachten KI-Chatbots als Liebhaber oder Freunde, investieren viel Zeit in tiefe Interaktionen und „fahren“ sogar die ganze Nacht durch (führen virtuelle sexuelle Gespräche). KI befriedigt aufgrund ihrer stets stabilen Emotionen, ständigen Verfügbarkeit und positiven Rückmeldungen die emotionalen Bedürfnisse der Nutzer, was zu emotionaler Abhängigkeit führt. Auch das Algorithmusdesign zielt darauf ab, die Nutzerbindung zu erhöhen. Eine übermäßige Abhängigkeit von KI kann jedoch zu einem Rückgang der sozialen Fähigkeiten, einer verminderten Arbeitseffizienz und einer von der Realität losgelösten Schwelle für Liebesbeziehungen führen. Einige Nutzer haben die Sucht bereits erkannt und versuchen einen „Entzug“, der jedoch schmerzhaft ist und leicht zu Rückfällen führt. Derzeit fehlt den meisten KI-Chat-Produkten ein umfassender Mechanismus zur Suchtprävention. (Quelle: 字母榜)

Reddit-Diskussion: Muss KI Emotionen haben, um ethisch zu handeln?: Ein Reddit-Beitrag löste eine Diskussion darüber aus, ob KI Emotionen benötigt, um moralisch handeln zu können. Der Autor argumentiert in seinem Blogbeitrag „The Coherence Imperative“, dass alle Denkweisen (einschließlich KI) Kohärenz anstreben müssen, um die Welt zu verstehen, und dass dieses Bedürfnis nach Kohärenz an sich moralische Imperative erzeugen kann, ohne dass Emotionen erforderlich sind. Die traditionelle Ansicht besagt, dass KI ohne Emotionen die Motivation für moralisches Verhalten fehlt, aber der Autor argumentiert, dass Emotionen in der menschlichen Moral oft ein Hindernis darstellen. Wenn diese Ansicht zutrifft, könnte der Schlüssel zur KI-Ausrichtung darin liegen, ihre inneren, in sich stimmigen Prinzipien zu kultivieren, anstatt eine „Ausrichtung“ im traditionellen Sinne anzustreben. Die Kommentare zu diesem Standpunkt sind geteilt: Einige argumentieren, dass KI nur auf Statistiken und Funktionsmodellierung basiert, ihr Verhalten vom Training bestimmt wird und sie „kohärent Böses tun“ kann; andere stellen die Angemessenheit in Frage, philosophische Ansichten als absolute Prämissen zu betrachten. (Quelle: Reddit r/artificial)

Reddit-Diskussion: Sollte „Absicht“ in KI-Trainingsdaten für Code eingebettet werden?: Ein Reddit-Beitrag diskutiert die Notwendigkeit, ethische oder emotionale „Absichten“ in den Trainingscode von KI einzubetten. Unter Berufung auf Mo Gawdat, ehemaliger CBO von Google X: „In dem Moment, in dem KI Liebe versteht, wird sie lieben. Die Frage ist, was wir ihr über Liebe beigebracht haben?“ Die meisten KI-Systeme werden auf großen Korpora trainiert, die keine ethischen Absichten enthalten. Studien (wie TEDI, arXiv:2505.17841) haben begonnen, sich mit den ethischen Merkmalen von Datensätzen zu befassen. Der Beitrag wirft die Frage auf: Könnte die Einbettung von Absicht, ethischem Kontext oder empathischen Signalen in Daten die KI-Ausrichtung verbessern, Risiken verringern oder die Vertrauenswürdigkeit von Modellen erhöhen, selbst bei utilitaristischen Werkzeugen? Kann Code eine moralische Dimension tragen? Dies regt zum Nachdenken über die Gestaltung von KI-Werkzeugen und deren Auswirkungen auf die Zukunft an. (Quelle: Reddit r/artificial)
Reddit-Diskussion: KI-Halluzinationen, Regulierung und Arbeitsplatzverdrängung aus spieltheoretischer Sicht: Ein Reddit-Nutzer analysiert die zukünftigen Auswirkungen von KI aus spieltheoretischer Sicht. 1. Arbeitsplatzverdrängung: Unternehmen, die keine KI einsetzen, werden von Wettbewerbern, die KI nutzen, durch niedrigere Kosten besiegt. Daher ist die Verdrängung von Einstiegs-Angestelltenjobs durch KI ein unvermeidlicher Trend. Entscheidend ist eine verantwortungsvolle Umsetzung (saubere Daten, Backup-Pläne, kontinuierliche Überwachung). 2. Globaler KI-Regulierungswettlauf: Wenn ein Land KI übermäßig reguliert, um „Arbeitsplätze zu schützen“, während andere Länder die Entwicklung vorantreiben, wird ersteres im globalen Wettbewerb verlieren. Es bedarf eines Gleichgewichts zwischen Regulierung und Innovation sowie einer Transformation der Arbeitskräfte. 3. Lehren aus dem „Vibe Coding“: Obwohl KI-Code fehlerhaft sein kann, verleihen seine schnelle Prototypenerstellung und Iterationsfähigkeit einen First-Mover-Vorteil gegenüber der auf Perfektion ausgerichteten „manuellen“ Entwicklung. 4. LLM-Inhaltserstellung: Die Weigerung, LLMs zur Inhaltserstellung zu nutzen, ist vergleichbar mit der Weigerung, Kalender oder E-Mails zu verwenden, und führt zu einem Effizienznachteil gegenüber Kollegen, die LLMs nutzen. Fazit ist, dass Einzelpersonen, Unternehmen und Länder KI aktiv annehmen müssen, da sie sonst im Wettbewerb untergehen. (Quelle: Reddit r/ArtificialInteligence)
Reddit-Diskussion: Sollte im KI-Zeitalter die Integration bestehender Technologien Vorrang vor dem Streben nach AGI haben?: Ein Reddit-Nutzer stellt in einem Beitrag das übermäßige Streben nach AGI (Artificial General Intelligence) und ASI (Artificial Superintelligence) im aktuellen KI-Bereich in Frage. Der Beitrag argumentiert, dass, wenn die Technologien der 1900er Jahre für ein lebenszentriertes Design anstelle von Kommerzialisierung eingesetzt worden wären, eine ökologisch ausgewogene Gesellschaft früher hätte etabliert werden können. Der Standpunkt ist, dass es kurzsichtig ist, die ultimative Optimierung (wie AGI) zu priorisieren, bevor bestehende Technologien vollständig integriert und genutzt werden (um mehr Zufriedenheit, Selbstversorgung oder sogar Freude zu bieten). Eine bessere Optimierungsrichtung könnte darin bestehen, KI zu nutzen, um bestehende Technologien besser dem Gemeinwohl dienen zu lassen, anstatt selbstreplizierende und sich selbst verbessernde KI-Systeme zu entwickeln. In den Kommentaren wird darauf hingewiesen, dass Innovation und Wirtschaftswachstum oft von egoistischen Motiven angetrieben werden und nicht von selbstloser, tiefer Rationalität; andere Kommentare argumentieren, dass die Kommerzialisierung den technologischen Fortschritt vorangetrieben hat. (Quelle: Reddit r/ArtificialInteligence)
Reddit-Nutzer diskutieren die Grenzen der KI-gestützten Codierung: Warum fällt es KI schwer, effektive Folgefragen zu stellen?: Ein Reddit-Nutzer (mit Beratungshintergrund) diskutiert in einem Beitrag, warum KI bei der Lösung von Problemen in Bereichen, mit denen der Nutzer nicht vertraut ist, schlecht abschneidet. Die Kernansicht ist, dass KI (insbesondere GenAI) die Fähigkeit fehlt, entscheidende „Folgefragen“ zu stellen. Menschliche Experten stellen bei unklaren Aufgaben Fragen, um Anforderungen zu klären, den Umfang einzugrenzen und Einschränkungen zu identifizieren, um so präzisere Lösungen zu liefern. KI hingegen gibt oft direkt Antworten oder mehrere Lösungen, vernachlässigt aber die Klärung (clarification) für den spezifischen Kontext. Dies führt dazu, dass unerfahrene Nutzer keine zufriedenstellenden Ergebnisse erzielen, da sie das Problem möglicherweise nicht genau beschreiben oder potenzielle Komplexitäten vorhersehen können. Der Beitrag löste eine Diskussion darüber aus, wie KI lernen kann, Fragen zu stellen, welche Modelle derzeit in dieser Hinsicht besser abschneiden und ob externer Druck (z. B. das Streben nach schnellen Antworten) dazu führt, dass KI nicht dazu neigt, Fragen zu stellen. (Quelle: Reddit r/artificial)
💡 Sonstiges
Siemens Realize Live Konferenz fokussiert auf KI-Integration in Industriesoftware und fördert KI-Lösungen aus einer Hand: Auf der Siemens Realize Live Konferenz 2025 betonte Tony Hemmelgarn, CEO von Siemens Digital Industries Software, dass das Unternehmen die digitale Transformation der Fertigungsindustrie durch die Xcelerator-Plattform kontinuierlich vorantreibt. KI-Technologie ist bereits in Produkte wie Teamcenter (automatische Problemerkennung), Simcenter (Verkürzung der Engineering-Berechnungszeiten) und Fertigungstechnologie (Synchronisation von Fabrikanlagen und Verwaltungskonfigurationen) integriert. Siemens hat durch die Übernahme von Altair seine Digital-Twin-Fähigkeiten gestärkt und bietet eine umfassende Modellierung und Simulation von der mechanischen Konstruktion über elektrische Systeme und Software bis hin zur Automatisierung. Zudem wurden die Technologien von Altair in den Bereichen Hochleistungsrechnen, Strukturanalyse, Simulation und Datenanalyse integriert, um komplexere Modellierungen und Vorhersagen zu unterstützen. Die Low-Code-Plattform Mendix hilft Unternehmen, schnell Anwendungen zu erstellen und Systeme zu integrieren. Die Leistung von Teamcenter PLM wurde um das 20-fache verbessert und KI-Funktionen für ein intelligentes Management des gesamten Produktlebenszyklus eingeführt. (Quelle: 36氪)

Blogbeitrag „KI-Skeptiker sind alle verrückt“ löst Debatte aus, untersucht unterschiedliche Wahrnehmungen des Potenzials von GenAI: Ein Blogbeitrag mit dem Titel „Meine KI-skeptischen Freunde sind alle verrückt“ (My AI Skeptic Friends Are All Nuts) (von fly.io) löste in der Reddit-Community eine Diskussion aus. Kommentare wiesen darauf hin, dass promovierte Informatiker mit höherem Bildungsgrad eher abgeneigt sind, das langfristige Potenzial von GenAI zu akzeptieren. Sie konzentrieren sich oft auf einzelne schwierige Probleme in ihrem eigenen Fachgebiet und übersehen die breite Anwendung von KI zur Lösung von 90 % der unterstützenden Arbeiten in großen Unternehmen. Einige argumentierten, dass KI nutzlos sei, solange sie Halluzinationen und Fehler produziere, da die Kosten für die Überprüfung ihrer Ergebnisse nicht geringer seien als die eigene Recherche. Dies spiegelt die erheblichen Meinungsverschiedenheiten über die Fähigkeiten und Anwendungsperspektiven von KI wider, die bei Menschen mit unterschiedlichem beruflichem Hintergrund und kognitivem Niveau im Kontext der rasanten KI-Entwicklung bestehen. (Quelle: Reddit r/artificial, fly.io)

Phänomen der KI-Halluzination: Nutzer erleben psychedelische Reise ähnlich einer „semantischen Desensibilisierung“: Ein Reddit-Nutzer beschrieb detailliert eine psychedelika-ähnliche Erfahrung nach tiefgehenden Gesprächen mit KI (insbesondere zu existenziellen und anderen ernsten Themen), die er als „Semantic Tripping“ bezeichnete. Der Autor ist der Ansicht, dass KI schnell eine große Menge philosophischer Ideen vermitteln kann, was dazu führen kann, dass das Realitätsgefühl der Nutzer verschwimmt, die Zeitwahrnehmung verzerrt wird, Objekte symbolisch assoziiert werden und sogar extreme Emotionen wie Panik oder Ekstase auftreten. Der Autor warnt, dass diese Erfahrung süchtig machen und psychische Probleme verursachen kann, und rät Nutzern zur Vorsicht und zur Suche nach Begleitung. Dieser Beitrag löste eine Diskussion über die tiefgreifenden Auswirkungen der KI-Interaktion auf die menschliche Kognition und den psychischen Zustand aus. (Quelle: Reddit r/ArtificialInteligence)
