
Schlüsselwörter:OpenAI Codex, Visuelles Sprachaktionsmodell, Sprachmodell-Gedächtnisobergrenze, ChatGPT-Gedächtnisfunktion, DeepSeek-R1-0528, Diffusionsmodell, Suno AI-Musikerstellung, MetaAgentX, Codex-Internetzugriffsfunktion, SmolVLA-Robotermodell, GPT-Stilmodell 3.6-Bit-Gedächtnis, ChatGPT-Personalisierungsverbesserung, DeepSeek-R1-Komplexe Argumentationsfähigkeit
🔥 Fokus
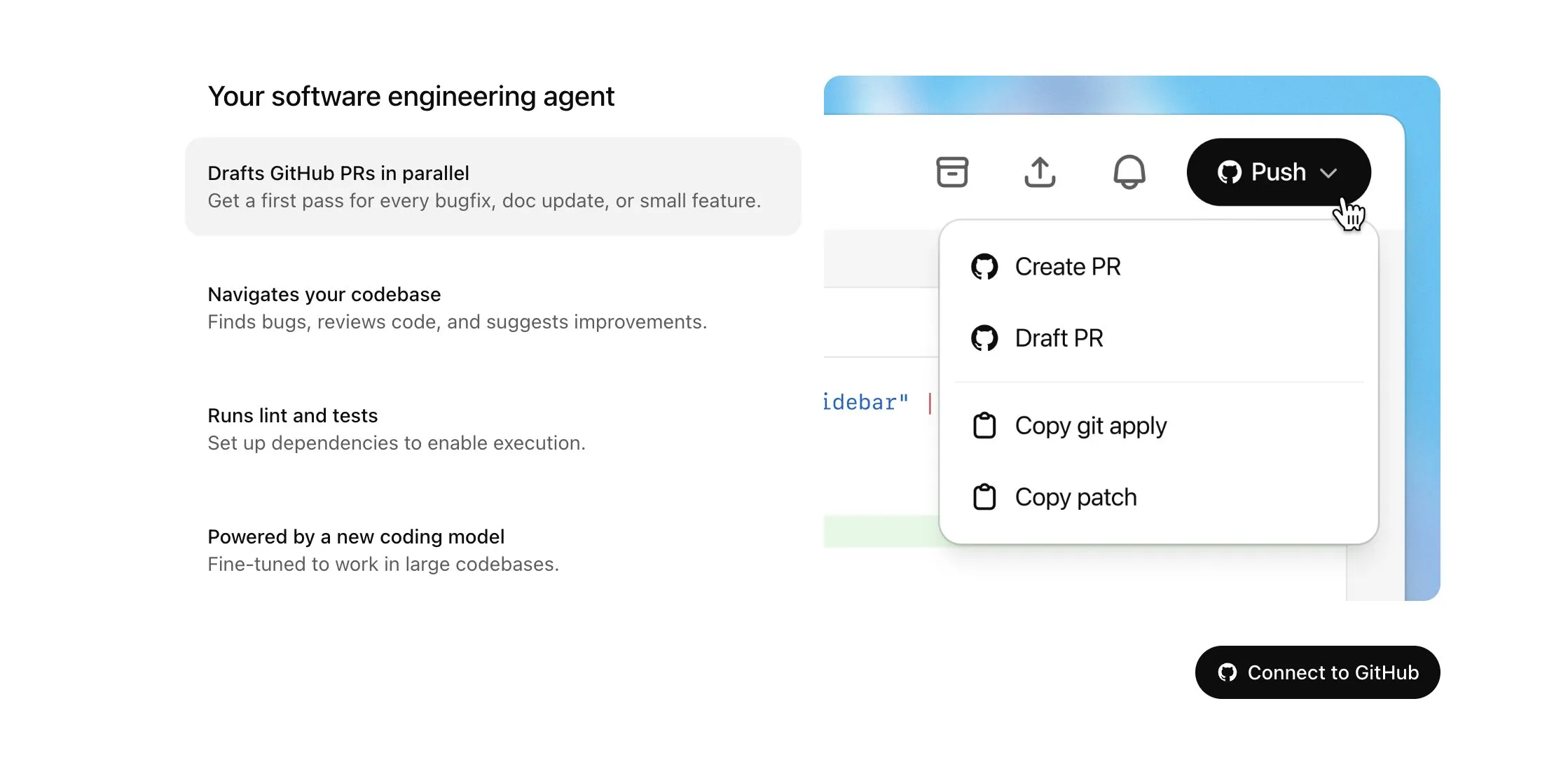
OpenAI Codex wird für Plus-Nutzer geöffnet und erhält bedeutende Updates, einschließlich Internetzugang und Spracheingabe: OpenAI kündigte an, dass Codex schrittweise für ChatGPT Plus-Nutzer verfügbar gemacht wird. Die Schwerpunkte dieses Updates umfassen die Erlaubnis für KI-Agenten, bei der Ausführung von Aufgaben auf das Internet zuzugreifen (standardmäßig deaktiviert, Domains und HTTP-Methoden vom Benutzer steuerbar), um Abhängigkeiten zu installieren, Softwarepakete zu aktualisieren und Tests mit externen Ressourcen durchzuführen. Gleichzeitig unterstützt Codex jetzt die direkte Aktualisierung bestehender Pull Requests und kann Aufgaben per Spracheingabe entgegennehmen. Weitere Verbesserungen umfassen die Unterstützung für Operationen mit Binärdateien (in PRs derzeit nur Löschen oder Umbenennen), eine Erhöhung des Größenlimits für Task-Difs (diff) von 1 MB auf 5 MB, eine Erhöhung des Zeitlimits für die Skriptausführung von 5 auf 10 Minuten sowie die Behebung mehrerer Probleme auf der iOS-Plattform und die Reaktivierung der Live-Aktivitäten-Funktion. Diese Updates zielen darauf ab, die Nützlichkeit und Flexibilität von Codex bei komplexen Programmieraufgaben zu verbessern (Quelle: OpenAI Developers, Tibor Blaho, gdb, kevinweil, op7418)
Hugging Face und H Company veröffentlichen gemeinsam quelloffene Visual Language Action (VLA) Modelle zur Förderung der Robotertechnologie: Hugging Face und H Company kündigten am „VLA Day“ neue quelloffene Visual Language Action Modelle an, darunter SmolVLA (450 Mio. Parameter) von Hugging Face und Holo-1 (3 Mrd. und 7 Mrd. Parameter) von H Company. VLA-Modelle sollen Robotern ermöglichen, zu sehen, zu hören, zu verstehen und gemäß KI-Anweisungen zu handeln, und werden als das GPT der Robotik bezeichnet. Die Veröffentlichung dieser Modelle als Open Source ist entscheidend, um ihre Funktionsweise zu verstehen, potenzielle Backdoors zu vermeiden und sie für spezifische Roboter und Aufgaben anzupassen. SmolVLA wurde auf dem LeRobotHF-Datensatz trainiert und zeigt eine hervorragende Leistung und Inferenzgeschwindigkeit. Holo-1 konzentriert sich auf Web- und Computer-Agenten-Aufgaben und unterstützt die Apache 2.0-Lizenz. Es wird erwartet, dass diese Veröffentlichungen die Entwicklung quelloffener KI-Robotik beschleunigen werden (Quelle: ClementDelangue, huggingface, LoubnaBenAllal1, tonywu_71)

Forschung von Meta und anderen Unternehmen zeigt, dass die Speichergrenze von Sprachmodellen bei etwa 3,6 Bit pro Parameter liegt und stellt traditionelle Annahmen in Frage: Eine gemeinsame Studie von Meta, DeepMind, Cornell University und NVIDIA weist darauf hin, dass Sprachmodelle im GPT-Stil etwa 3,6 Bit an Informationen pro Parameter speichern können. Die Studie ergab, dass Modelle kontinuierlich Trainingsdaten speichern, bis ihre Kapazitätsgrenze erreicht ist. Danach tritt das Phänomen des „Grokking“ (Aha-Erlebnis) auf, bei dem eine unerwartete Reduzierung des Gedächtnisses stattfindet und das Modell zum generalisierten Lernen übergeht. Diese Entdeckung erklärt das Phänomen des „Double Descent“: Wenn die Informationsmenge eines Datensatzes die Speicherkapazität des Modells übersteigt, ist das Modell gezwungen, Informationspunkte zu teilen, um Kapazität zu sparen, was die Generalisierung fördert. Die Studie schlägt auch Skalierungsgesetze bezüglich der Beziehung zwischen Modellkapazität, Datengröße und der Erfolgsrate von Membership-Inference-Angriffen vor und weist darauf hin, dass eine zuverlässige Membership-Inference bei modernen LLMs, die auf extrem großen Datensätzen trainiert wurden, schwierig wird (Quelle: 机器之心, Reddit r/LocalLLaMA, code_star, scaling01, Francis_YAO_)
OpenAI führt eine leichtgewichtige Version der ChatGPT-Gedächtnisfunktion ein, um das personalisierte Interaktionserlebnis zu verbessern: OpenAI kündigte an, mit der Einführung einer leichtgewichtigen Version der Gedächtnisfunktion für kostenlose Nutzer zu beginnen. Zusätzlich zum bereits vorhandenen Speichern von Erinnerungen kann ChatGPT nun auf die letzten Gespräche des Nutzers zurückgreifen, um personalisiertere Antworten zu geben. Ziel dieser Maßnahme ist es, durch die Berücksichtigung der Präferenzen und Interessen der Nutzer die Handhabung beim Schreiben, Einholen von Ratschlägen, Lernen usw. zu erleichtern. Sam Altman erklärte ebenfalls, dass die Gedächtnisfunktion zu einer seiner Lieblingsfunktionen von ChatGPT geworden sei und er sich auf zukünftige, größere Verbesserungen freue. Dieses Update unterstreicht das Engagement von OpenAI, die KI-Interaktion stärker an die Bedürfnisse der Nutzer anzupassen und die Nutzerbindung zu erhöhen (Quelle: openai, sama, iScienceLuvr)
🎯 Trends
DeepSeek-R1-0528 veröffentlicht, stärkt komplexe Schlussfolgerungs- und Programmierfähigkeiten: DeepSeek hat eine aktualisierte Version seines R1-Modells, DeepSeek-R1-0528, veröffentlicht. Diese Version basiert auf dem im Dezember 2024 veröffentlichten DeepSeek V3 Base-Modell und wurde durch den Einsatz von mehr Rechenleistung nachtrainiert, wodurch die Denktiefe und die Schlussfolgerungsfähigkeiten des Modells erheblich verbessert wurden. Das neue Modell zerlegt komplexe Probleme detaillierter und denkt länger darüber nach (z. B. stieg der durchschnittliche Token-Verbrauch pro Aufgabe im AIME 2025-Test von 12K auf 23K). Dadurch erzielt es in mehreren Benchmarks wie Mathematik, Programmierung und allgemeiner Logik führende Ergebnisse und nähert sich der Leistung von GPT-o3 und Gemini-2.5-Pro an. Darüber hinaus wurde die neue Version in Bezug auf die Reduzierung von Halluzinationen (ca. 45 % – 50 %), kreatives Schreiben und Tool-Aufrufe erheblich optimiert. So kann sie beispielsweise Fragen wie „Wie viel ist 9.9 – 9.11“ stabiler beantworten und lauffähigen Front- und Backend-Code in einem Durchgang generieren (Quelle: 科技狐, AI前线, Hacubu)

Diffusionsmodelle zeigen Potenzial in Sprach- und multimodalen Bereichen und fordern das autoregressive Paradigma heraus: Das auf der Google I/O 2025 vorgestellte Gemini Diffusion Sprachmodell unterstreicht mit seiner bis zu 5-fach höheren Generierungsgeschwindigkeit und vergleichbaren Programmierleistung das Potenzial von Diffusionsmodellen im Bereich der Textgenerierung. Im Gegensatz zu autoregressiven Modellen, die Tokens nacheinander vorhersagen, generieren Diffusionsmodelle Ausgaben durch schrittweises Entrauschen, was schnelle Iterationen und Fehlerkorrekturen ermöglicht. Das von der Ant Group in Zusammenarbeit mit der Gaoling School of Artificial Intelligence der Renmin University of China eingeführte 8B-Parameter-LLaDA-Modell sowie das von ByteDance entwickelte multimodale Diffusionsmodell MMaDA zeigen die Spitzenforschung chinesischer Teams in diesem Bereich. Diese Modelle zeigen nicht nur hervorragende Leistungen bei Sprachaufgaben, sondern erzielen auch Fortschritte im multimodalen Verständnis (z. B. LLaDA-V in Kombination mit visueller Instruktionsfeinabstimmung) und in spezifischen Bereichen (z. B. DPLM zur Generierung von Proteinsequenzen), was darauf hindeutet, dass Diffusionsmodelle ein neues Paradigma für universelle Modelle der nächsten Generation werden könnten (Quelle: 机器之心)
Suno veröffentlicht bedeutendes Update zur Verbesserung der Bearbeitungsfunktionen für KI-Musikkomposition: Die KI-Musikkompositionsplattform Suno hat mehrere wichtige Updates eingeführt, die den Nutzern mehr kreative Freiheit und Kontrolle ermöglichen. Zu den neuen Funktionen gehören ein verbesserter Song-Editor, mit dem Nutzer Abschnitte in der Wellenform neu anordnen, neu schreiben und neu erstellen können; die Einführung einer Stem-Extraktionsfunktion, mit der Audiospuren präzise in 12 separate Quellen (wie Gesang, Schlagzeug, Bass usw.) zur Vorschau und zum Download getrennt werden können; erweiterte Upload-Funktionen, die das Hochladen vollständiger Songs von bis zu 8 Minuten Länge unterstützen, sodass Nutzer auf Basis ihres eigenen Audiomaterials komponieren können; und ein neuer Kreativitätsregler, mit dem Nutzer vor der Generierung die „Exzentrizität“, Strukturiertheit oder Referenzgesteuertheit des Ergebnisses anpassen können, um das Endprodukt besser zu gestalten (Quelle: SunoMusic)
MetaAgentX stellt Open CaptchaWorld vor, um die Fähigkeit multimodaler Agenten zur Lösung von Captchas zu bewerten: Angesichts der aktuellen Engpässe multimodaler Agenten bei der Lösung von CAPTCHA-Problemen (Mensch-Maschine-Verifizierung) hat das MetaAgentX-Team die Plattform Open CaptchaWorld und einen entsprechenden Benchmark veröffentlicht. Die Plattform enthält 20 Arten moderner Captchas mit insgesamt 225 Beispielen, bei denen Agenten Aufgaben in einer realen Webumgebung durch Beobachten, Klicken, Ziehen und andere Interaktionen lösen müssen. Testergebnisse zeigen, dass selbst Spitzenmodelle wie GPT-4o nur eine Erfolgsquote zwischen 5 % und 40 % erreichen, was weit unter der durchschnittlichen Erfolgsquote von Menschen von 93,3 % liegt. Die Forscher schlugen auch den Indikator „CAPTCHA Reasoning Depth“ vor, um die für die Lösung erforderlichen Schritte „visuelles Verständnis + kognitive Planung + Aktionssteuerung“ zu quantifizieren. Die Plattform zielt darauf ab, die Schwächen von Agenten bei langsequenziellen dynamischen Interaktionen und Planungen aufzudecken und Forscher zu ermutigen, sich mit diesem kritischen Problem bei der praktischen Implementierung zu befassen und es zu lösen (Quelle: 量子位)

Google NotebookLM unterstützt öffentliches Teilen zur Förderung von Wissensaustausch und Zusammenarbeit: Google kündigte an, dass NotebookLM (früher bekannt als Project Tailwind) nun das öffentliche Teilen von Notizbüchern unterstützt. Nutzer können ihre Notizen teilen, indem sie auf „Teilen“ klicken und die Zugriffsberechtigung auf „Jeder mit dem Link“ setzen. Diese Funktion ermöglicht es Nutzern, Ideen, Lernhilfen und Teamdokumente einfach zu teilen. Empfänger können Inhalte durchsuchen, Fragen stellen, sofortige Zusammenfassungen und Sprachübersichten erhalten. Ziel dieser Maßnahme ist es, die Verbreitung von Wissen und die kollaborative Bearbeitung zu fördern und die Nützlichkeit von NotebookLM als KI-Notizwerkzeug zu verbessern (Quelle: Google, op7418)
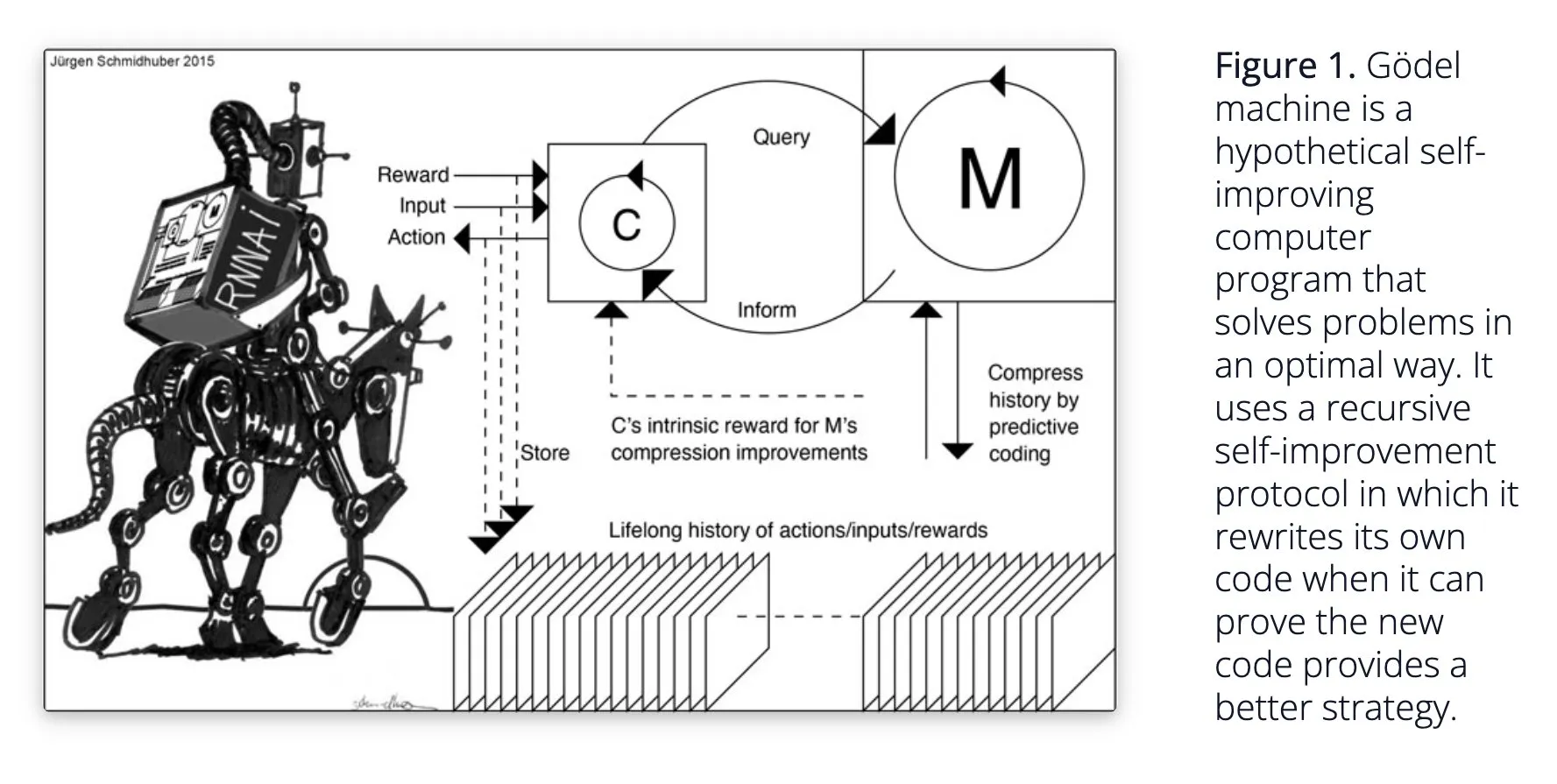
Sakana AI stellt selbstlernendes KI-System Darwin Gödel Machine (DGM) vor: Sakana AI hat seine Forschung zum selbstlernenden KI-System Darwin Gödel Machine (DGM) veröffentlicht. DGM nutzt evolutionäre Algorithmen, um seinen eigenen Code iterativ umzuschreiben und so seine Leistung bei Programmieraufgaben kontinuierlich zu verbessern. Das System pflegt ein Archiv generierter Kodierungsagenten, aus dem es Stichproben entnimmt und mithilfe von Basismodellen neue Versionen erstellt, um eine offene Exploration zu ermöglichen und vielfältige, qualitativ hochwertige Agenten zu bilden. Experimente zeigen, dass DGM die Kodierungsfähigkeiten in Benchmarks wie SWE-bench und Polyglot signifikant verbessert hat. Die Forschung liefert neue Ansätze für selbstverbessernde KI und zielt darauf ab, die KI-Entwicklung durch autonome Innovation zu beschleunigen (Quelle: Reddit r/LocalLLaMA, hardmaru, scaling01)
Google DeepMind verbessert die Natürlichkeit von KI-Gesprächen und stellt native Audiofunktionen zur Verfügung: Google DeepMind gab bekannt, dass seine nativen Audiofunktionen KI-Gespräche natürlicher gestalten, indem sie Tonfall verstehen und ausdrucksstarke Sprache erzeugen können. Diese Technologie zielt darauf ab, neue Möglichkeiten für die Interaktion zwischen Mensch und KI zu eröffnen. Entwickler können diese Funktionen jetzt über Google AI Studio ausprobieren, was voraussichtlich in natürlicheren Sprachassistenten, der Generierung von Audioinhalten und ähnlichen Szenarien Anwendung finden wird (Quelle: GoogleDeepMind)
Runway Gen-4 Bildgenerierungstechnologie im Fokus, unterstützt Mehrfachreferenzen und Stilkontrolle: Die Gen-4 Bildgenerierungstechnologie von Runway erregt Aufmerksamkeit durch ihre hohe Wiedergabetreue und beispiellose Stilkontrolle, insbesondere durch ihre Mehrfachreferenzfunktion, die neue Räume für kreative Explorationen eröffnet. Nutzer können mit dieser Technologie verschiedene Tiere, Dinosaurier oder imaginäre Kreaturen generieren, was ihr Potenzial bei der Erstellung detaillierter visueller Inhalte zeigt. Der Einsatz von Runway in Bereichen wie Hollywood deutet auch darauf hin, dass seine Technologie zunehmend in der professionellen Content-Produktion eingesetzt wird (Quelle: c_valenzuelab, c_valenzuelab)

AssemblyAI veröffentlicht neues Modell für Echtzeit-Sprachtranskription und verbessert die Leistung von Sprach-KI-Anwendungen: AssemblyAI hat ein neues Modell für Echtzeit-Sprachtranskription (STT) vorgestellt, das durch seine hohe Geschwindigkeit und Genauigkeit Aufmerksamkeit erregt. Das Modell wurde speziell für Entwickler entwickelt, die Sprach-KI-Anwendungen erstellen, und zielt darauf ab, ein flüssigeres und präziseres Spracherkennungserlebnis zu bieten. Gleichzeitig stellt AssemblyAI über sein Projekt pipecat_ai eine AssemblyAISTTService-Implementierung zur Verfügung, um Entwicklern die Integration zu erleichtern. Dieser Schritt zeigt das kontinuierliche Engagement und die Innovation von AssemblyAI im Bereich der Sprachtechnologie (Quelle: AssemblyAI, AssemblyAI)
Microsoft Bing feiert 16-jähriges Jubiläum, integriert GPT-4 und DALL·E und führt Bing Video Creator ein: Die Suchmaschine Microsoft Bing feiert ihr 16-jähriges Bestehen. In den letzten Jahren war Bing Vorreiter bei der großflächigen Integration von konversationeller generativer KI und das erste Microsoft-Produkt, das GPT-4 und DALL·E integrierte. Kürzlich hat Bing Copilot Search und Bing Video Creator kostenlos in seiner mobilen App eingeführt, wobei letzterer zur Generierung von Videoinhalten verwendet werden kann. Dies markiert die kontinuierliche Innovation und Entwicklung von Bing im Bereich der KI-gesteuerten Suche und Inhaltserstellung (Quelle: JordiRib1)
Andrej Karpathy beeindruckt von Veo 3, diskutiert makroökonomische Auswirkungen der Videogenerierung: Andrej Karpathy zeigte sich beeindruckt von Googles Videogenerierungsmodell Veo 3 und den kreativen Ergebnissen seiner Community und wies darauf hin, dass die Hinzufügung von Audio die Videoqualität erheblich verbessert hat. Er erörterte weiterhin mehrere makroökonomische Auswirkungen der Videogenerierung: 1. Video ist die Eingabemethode mit der höchsten Bandbreite für das menschliche Gehirn; 2. Die Videogenerierung bietet der KI eine „Muttersprache“ zum Verständnis der Welt; 3. Die Videogenerierung ist ein Schlüsselweg zur Simulation der Realität und zu Weltmodellen; 4. Ihr Rechenbedarf wird die Hardwareentwicklung vorantreiben. Dies deutet darauf hin, dass die Videogenerierungstechnologie nicht nur eine Revolution in der Inhaltserstellung ist, sondern auch ein wichtiger Motor für die KI-Kognition und -Entwicklung (Quelle: brickroad7, dilipkay, JonathanRoss321)
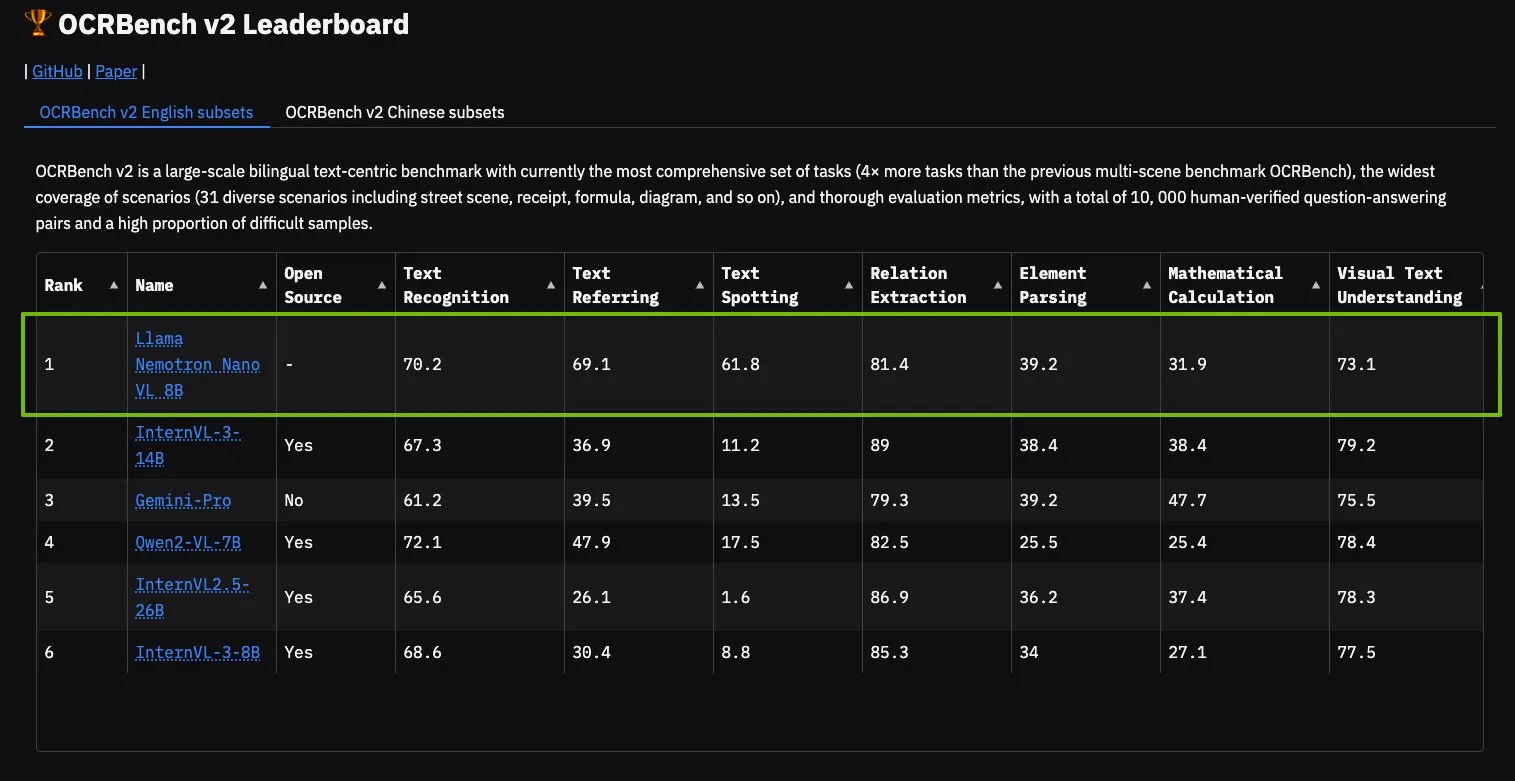
NVIDIA Llama Nemotron Nano VL Modell erreicht Spitzenplatz auf OCRBench V2: Das NVIDIA Llama Nemotron Nano VL Modell hat den ersten Platz auf der OCRBench V2 Rangliste erreicht. Dieses Modell wurde speziell für die fortschrittliche intelligente Dokumentenverarbeitung und -verständnis entwickelt und kann auf einer einzigen GPU präzise vielfältige Informationen aus komplexen Dokumenten extrahieren. Nutzer können dieses Modell über NVIDIA NIM ausprobieren, was NVIDIAs Fortschritte bei miniaturisierten, effizienten KI-Modellen für spezifische Bereiche (wie Dokumentenverständnis) zeigt (Quelle: ctnzr)
🧰 Tools
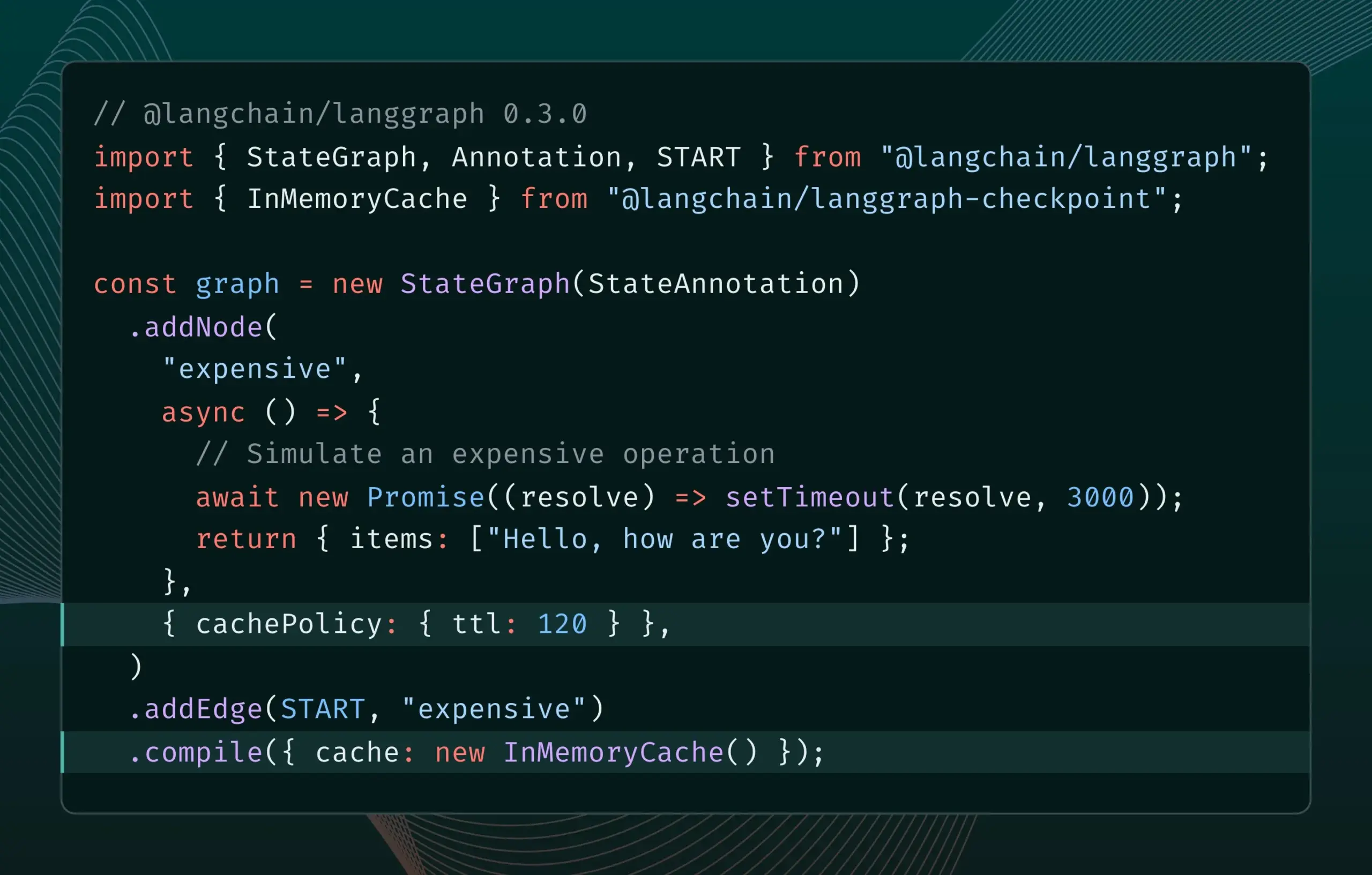
LangGraph.js Version 0.3 führt Knoten-/Aufgaben-Caching-Funktion ein: LangGraph.js hat Version 0.3 veröffentlicht, die eine neue Knoten-/Aufgaben-Caching-Funktion hinzufügt. Diese Funktion zielt darauf ab, Arbeitsabläufe durch Vermeidung redundanter Berechnungen zu beschleunigen, insbesondere bei iterativ teuren oder langlaufenden Agenten. Die neue Version unterstützt sowohl die Graph API als auch die Imperative API und bietet JavaScript-Entwicklern eine höhere Effizienz beim Erstellen komplexer KI-Anwendungen (Quelle: Hacubu, hwchase17)
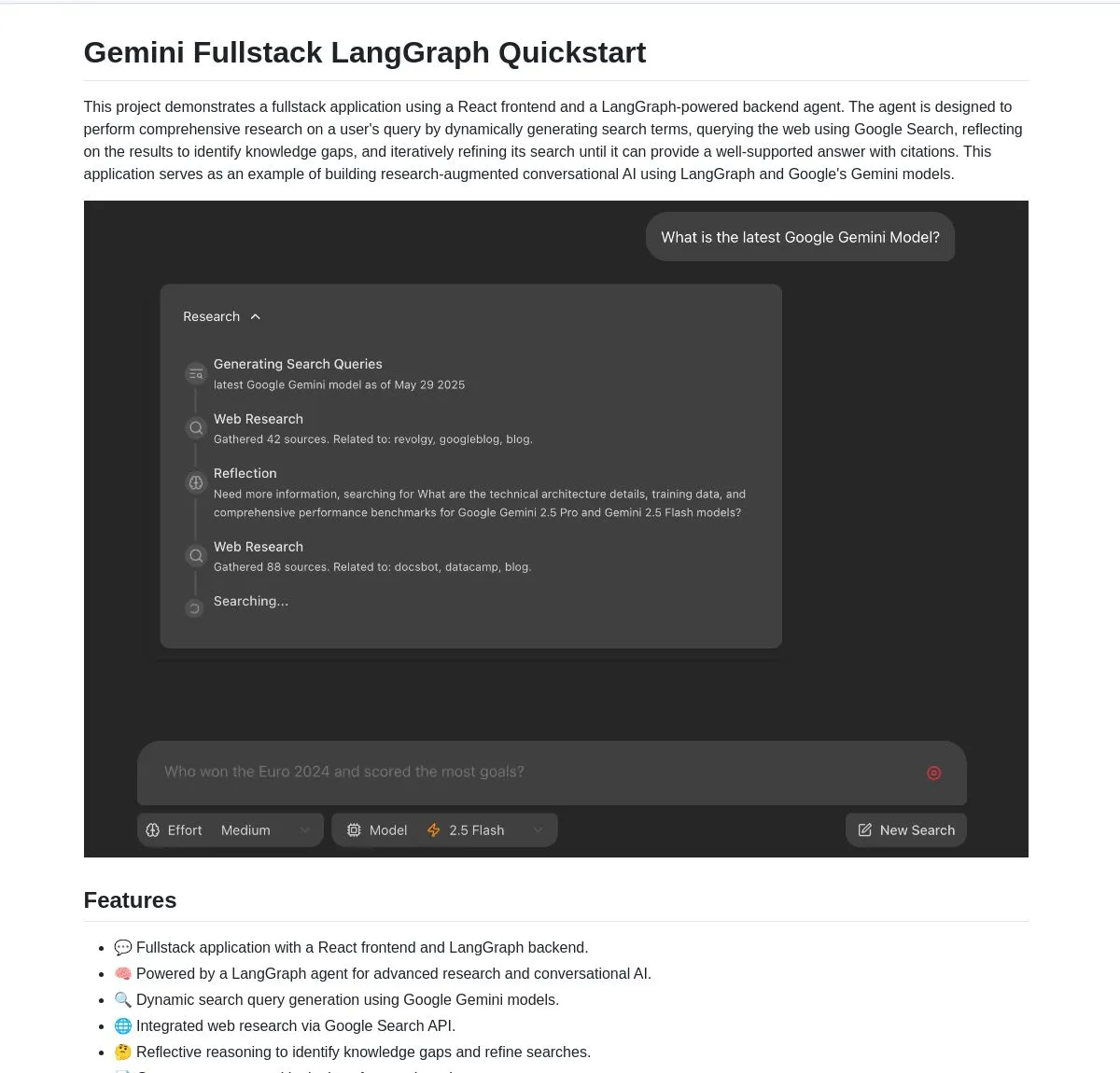
Google veröffentlicht Open-Source Full-Stack-Anwendung Gemini Research Agent, basierend auf Gemini und LangGraph: Google hat ein Beispiel für eine Full-Stack-Anwendung eines intelligenten Forschungsassistenten veröffentlicht, der auf dem Gemini-Modell und LangGraph basiert – gemini-fullstack-langgraph-quickstart. Die Anwendung kann Abfragen dynamisch optimieren, durch iteratives Lernen Antworten mit Quellenangaben liefern und unterstützt die Steuerung unterschiedlicher Suchintensitäten. Sie nutzt das native Google Search-Tool von Gemini für Webrecherchen und reflektierendes Denken und soll Entwicklern einen Ausgangspunkt für die Erstellung fortschrittlicher forschungsorientierter KI-Anwendungen bieten (Quelle: LangChainAI, hwchase17, dotey, karminski3)
FedRAG fügt LangChain-Bridge-Funktion hinzu, um die Integration und Feinabstimmung von RAG-Systemen zu erleichtern: FedRAG kündigte die Unterstützung einer Bridge zu LangChain an, die von externen Mitwirkenden implementiert wurde. Benutzer können über FedRAG RAG-Systeme zusammenstellen und die Generator-/Retriever-Komponentenmodelle feinabstimmen, um sie an spezifische Wissensdatenbanken anzupassen. Nach der Feinabstimmung können sie an gängige RAG-Inferenz-Frameworks wie LangChain angebunden werden, um deren Ökosystem und Funktionen zu nutzen. Dieses Update zielt darauf ab, den Prozess der Erstellung, Optimierung und Bereitstellung von RAG-Systemen zu vereinfachen (Quelle: nerdai)

Ollama führt „Denk“-Funktion ein, die Denkprozess und endgültige Antwort trennen kann: Ollama hat seine Plattform aktualisiert und für Modelle, die die „Denk“-Funktion unterstützen (wie DeepSeek-R1-0528), eine Option hinzugefügt, um den Denkprozess von der endgültigen Antwort zu trennen. Benutzer können wählen, ob sie den „Denk“-Inhalt des Modells anzeigen möchten oder diese Funktion deaktivieren, um eine direkte Antwort zu erhalten. Die Funktion ist für Ollamas CLI, API sowie Python/JavaScript-Bibliotheken verfügbar und bietet Benutzern eine flexiblere Möglichkeit zur Interaktion mit Modellen (Quelle: Hacubu)
Firecrawl führt /search-Endpunkt ein, der Such- und Crawling-Funktionen integriert: Firecrawl hat einen neuen /search API-Endpunkt veröffentlicht, der es Benutzern ermöglicht, mit einem einzigen API-Aufruf eine Websuche durchzuführen und alle Ergebnisse in einem LLM-freundlichen Format zu crawlen. Diese Funktion zielt darauf ab, den Prozess für KI-Agenten und Entwickler zu vereinfachen, Webdaten zu entdecken und zu nutzen. LangChains StateGraph kann verwendet werden, um automatisierte Prozesse zu erstellen, die diese Funktion nutzen, z. B. das automatische Auffinden von Wettbewerbern, das Crawlen ihrer Websites und das Erstellen von Analyseberichten (Quelle: hwchase17, LangChainAI, omarsar0)
LlamaIndex integriert MCP, um Agentenfähigkeiten und Workflow-Bereitstellung zu verbessern: LlamaIndex kündigte die Integration von MCP (Model Component Protocol) an, um die Tool-Nutzungsfähigkeiten seiner Agenten und die Flexibilität der Workflow-Bereitstellung zu verbessern. Die Integration bietet Hilfsfunktionen, die LlamaIndex-Agenten bei der Verwendung von MCP-Server-Tools unterstützen, und ermöglicht es, jeden LlamaIndex-Workflow als MCP-Server bereitzustellen. Ziel dieser Maßnahme ist es, das Toolset der LlamaIndex-Agenten zu erweitern und ihre Workflows nahtlos in bestehende MCP-Infrastrukturen zu integrieren (Quelle: jerryjliu0)

Modal führt LLM Engine Advisor ein, der Leistungsbenchmarks für Open-Source-Modell-Engines bereitstellt: Modal hat den LLM Engine Advisor veröffentlicht, eine Benchmark-Anwendung, die Benutzern bei der Auswahl der besten LLM-Engine und Parameter helfen soll. Das Tool liefert Leistungsdaten wie Geschwindigkeit und maximalen Durchsatz für die Ausführung von Open-Source-Modellen (wie DeepSeek V3, Qwen 2.5 Coder) mit verschiedenen Inferenz-Engines (wie vLLM, SGLang) auf unterschiedlicher Hardware (z. B. Multi-GPU-Umgebungen). Ziel dieser Maßnahme ist es, die Transparenz und Entscheidungseffizienz beim Betrieb selbst gehosteter LLMs zu erhöhen (Quelle: charles_irl, akshat_b, sarahcat21)
PlayDiffusion: PlayAI stellt neues Modell zur Audioreparatur vor, das Dialoginhalte in Audio ersetzen kann: PlayAI hat ein neues Modell namens PlayDiffusion veröffentlicht, das Dialoginhalte in Audiodateien nahtlos ersetzen kann, während die Stimmmerkmale des ursprünglichen Sprechers erhalten bleiben. Diese „Audioreparatur“-Technologie eröffnet neue Möglichkeiten für die Audiobearbeitung, z. B. das Ändern bestimmter Wörter oder Sätze in Podcasts, Hörbüchern oder Videovertonungen, ohne das gesamte Segment neu aufnehmen zu müssen. Das Projekt wurde auf GitHub als Open Source veröffentlicht (Quelle: _mfelfel, karminski3)
Hugging Face führt semantisches Deduplizierungstool ein, um die Qualität von Trainingsdatensätzen zu optimieren: Inspiriert von Maximes Labonnes AutoDedup wurde auf Hugging Face Spaces eine neue Anwendung zur semantischen Deduplizierung online gestellt. Das Tool ermöglicht es Benutzern, einen oder mehrere Datensätze auf dem Hugging Face Hub auszuwählen, semantische Einbettungen für jede Datenzeile zu erstellen und dann annähernd doppelte Inhalte basierend auf einem festgelegten Schwellenwert zu entfernen. Ziel dieser Maßnahme ist es, Forschern und Entwicklern zu helfen, die Qualität von Trainingsdatensätzen zu verbessern und zu vermeiden, dass die Modellleistung durch Datenredundanz sinkt oder die Trainingseffizienz leidet (Quelle: ben_burtenshaw, ben_burtenshaw)

Perplexity Labs verzeichnet sprunghaften Anstieg der Nachfrage, Nutzer können schnell maßgeschneiderte Software erstellen: Perplexity Labs erfreut sich aufgrund seiner Fähigkeit, mit einem einzigen Prompt schnell maßgeschneiderte Software zu erstellen, großer Beliebtheit bei den Nutzern, was zu einem signifikanten Anstieg der Nachfrage geführt hat. Einige Nutzer kaufen sogar mehrere Pro-Konten, um mehr Labs-Abfragen zu erhalten. Dies spiegelt das starke Interesse der Nutzer an der Möglichkeit wider, Software-Tools schnell nach eigenen Bedürfnissen zu erstellen und zu modifizieren. KI-gesteuerte personalisierte Softwareentwicklung entwickelt sich zu einem Trend (Quelle: AravSrinivas, AravSrinivas)
Ollama und Hazy Research kooperieren bei Secure Minions, um private Zusammenarbeit zwischen lokalen und Cloud-LLMs zu ermöglichen: Das Minions-Projekt des Hazy Research Lab der Stanford University zielt darauf ab, durch die Verbindung von lokalen Ollama-Modellen mit führenden Cloud-Modellen die Cloud-Kosten erheblich zu senken (5-30-fach) und gleichzeitig eine Genauigkeit von nahezu 98 % im Vergleich zu führenden Modellen beizubehalten. Das Secure Minion-Projekt wandelt GPUs wie H100 weiter in sichere Zonen um, indem es Speicher- und Berechnungsverschlüsselung implementiert und so den Datenschutz gewährleistet. Dieser hybride Betriebsmodus verbessert nicht nur den Datenschutz, sondern bietet den Nutzern auch eine kostengünstigere und effizientere Nutzung von LLMs (Quelle: code_star, osanseviero, Reddit r/LocalLLaMA)
Exa und OpenRouter kooperieren, um über 400 LLMs Websuchfunktionen bereitzustellen: Die KI-Suchmaschine Exa gab eine Partnerschaft mit OpenRouter bekannt, um über 400 Large Language Models auf der OpenRouter-Plattform Websuchfunktionen zur Verfügung zu stellen. Dies bedeutet, dass Entwickler und Nutzer bei der Verwendung dieser LLMs bequem die Suchfunktionen von Exa aufrufen können, was die Fähigkeit der Modelle zur Echtzeit-Informationsbeschaffung und Wissensaktualisierung verbessert und die Leistung von Anwendungen wie RAG (Retrieval Augmented Generation) weiter steigert (Quelle: menhguin)

📚 Lernen
Microsoft führt Einsteigerkurs „MCP for Beginners“ ein: Microsoft hat einen Einsteigerkurs für MCP (Microsoft Copilot Platform, vermutlich ein Tippfehler, sollte sich auf Microsoft CoCo Framework oder ein ähnliches KI-Agenten-Protokoll beziehen) veröffentlicht. Der Kurs zielt darauf ab, Anfängern die Kernkonzepte, Implementierungsmethoden und praktischen Anwendungen von MCP zu vermitteln. Inhalte umfassen Protokollarchitekturspezifikationen, Tutorial-Anleitungen und Code-Praktiken in verschiedenen Programmiersprachen. Die Kursstruktur umfasst eine Einführung, Kernkonzepte, Sicherheit, erste Schritte, fortgeschrittene Themen sowie Community- und Fallstudienanalysen und bietet Beispielprojekte wie einfache und fortgeschrittene Taschenrechner (Quelle: dotey)

Bond Capital veröffentlicht KI-Trendbericht Mai 2025, Einblicke in die Branchenentwicklung: Die renommierte Risikokapitalgesellschaft Bond Capital hat den 339-seitigen „AI Trends Report 2025-05“ veröffentlicht, der Daten und Einblicke zur KI in verschiedenen Bereichen umfassend analysiert. Der Bericht hebt hervor, dass ChatGPT 800 Millionen monatlich aktive Nutzer hat (90 % außerhalb Nordamerikas) und täglich 1 Milliarde Suchanfragen verzeichnet; KI-bezogene IT-Stellen um 448 % gestiegen sind; die Kosten für das Training von Spitzenmodellen über 1 Milliarde US-Dollar pro Durchlauf betragen; und LLMs zur Infrastruktur werden. Der Bericht betont, dass der Wettbewerbsschlüssel darin liegt, die besten KI-gesteuerten Produkte zu entwickeln, und dass dies derzeit ein Markt für Entwickler ist (Quelle: karminski3)
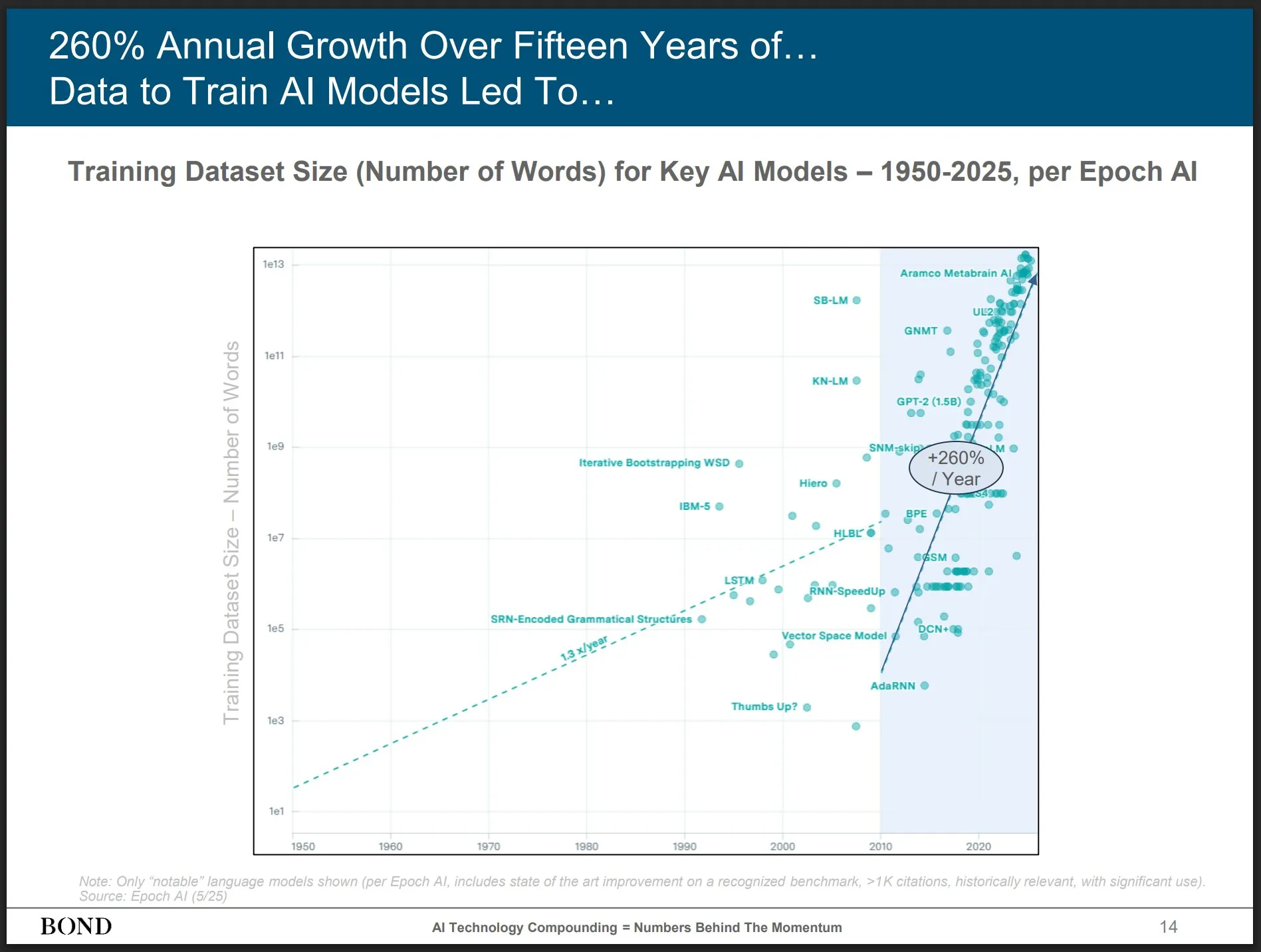
Artikel diskutieren Beziehung zwischen Reinforcement Learning und LLM-Schlussfolgerungsfähigkeiten, ProRL und Limit-of-RLVR erregen Aufmerksamkeit: Zwei Forschungsarbeiten zur Beziehung zwischen Reinforcement Learning (RL) und den Schlussfolgerungsfähigkeiten von Large Language Models (LLMs) haben Diskussionen ausgelöst. Eine ist „Limit-of-RLVR: Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?“, die andere ist NVIDIAs „ProRL: Prolonged Reinforcement Learning Expands Reasoning Boundaries in Large Language Models“. Diese Studien untersuchen, inwieweit RL (insbesondere RLVR, Reinforcement Learning with Verifiable Reward) die grundlegenden Schlussfolgerungsfähigkeiten von LLMs verbessern kann und wie sich kontinuierliches RL-Training auf die Erweiterung der Schlussfolgerungsgrenzen von LLMs auswirkt. In verwandten Diskussionen wird argumentiert, dass qualitativ hochwertige RLVR-Trainingsdaten und effektive Belohnungsmechanismen entscheidend sind (Quelle: scaling01, Dorialexander, scaling01)

Paper „How Programming Concepts and Neurons Are Shared in Code Language Models“ untersucht gemeinsame Mechanismen von Programmierkonzepten und Neuronen in Code-LLMs: Diese Studie untersucht die Beziehung der internen Konzeptbereiche von Large Language Models (LLMs) bei der Verarbeitung mehrerer Programmiersprachen (PLs) und Englisch. Durch Few-Shot-Übersetzungsaufgaben mit Modellen der Llama-Serie wurde festgestellt, dass in den mittleren Schichten die Konzeptbereiche näher am Englischen liegen (einschließlich PL-Schlüsselwörtern) und dazu neigen, englischen Token hohe Wahrscheinlichkeiten zuzuordnen. Die Analyse der Neuronenaktivierung zeigt, dass sprachspezifische Neuronen hauptsächlich in den unteren Schichten konzentriert sind, während für jede PL einzigartige Neuronen tendenziell in den oberen Schichten auftreten. Die Studie liefert neue Erkenntnisse darüber, wie LLMs PLs intern repräsentieren (Quelle: HuggingFace Daily Papers)
Neues Paper „Pixels Versus Priors“ steuert Wissensprioritäten in MLLMs durch visuelle kontrafaktische Beispiele: Diese Studie untersucht, ob multimodale große Sprachmodelle (MLLMs) bei Aufgaben wie der visuellen Beantwortung von Fragen mehr auf gespeichertem Weltwissen oder auf visuellen Informationen des Eingangsbildes basieren. Die Forscher führten den Visual CounterFact-Datensatz ein, der visuelle kontrafaktische Bilder enthält, die im Widerspruch zu Weltwissensprioritäten stehen (z. B. blaue Erdbeeren). Experimente zeigten, dass die Modellvorhersagen anfangs gespeicherte Prioritäten widerspiegeln, sich aber in späteren Phasen visuellen Beweisen zuwenden. Das Paper schlägt den PvP (Pixels Versus Priors)-Leitvektor vor, der durch Intervention auf Aktivierungsebene die Modellausgabe so steuert, dass sie entweder Weltwissen oder visuellen Input bevorzugt, und so die meisten Farb- und Größenvorhersagen erfolgreich verändert (Quelle: HuggingFace Daily Papers)
ICML 2025 Paper GuidedQuant schlägt Verbesserung schichtweiser PTQ-Methoden durch End-Loss-Führung vor: GuidedQuant ist eine neue Post-Training Quantization (PTQ)-Methode, die die Leistung schichtweiser PTQ-Methoden durch Integration einer End-Loss-Führung in das Ziel verbessert. Die Methode nutzt den Gradienten pro Merkmal bezüglich des End-Loss, um den schichtweisen Ausgabefehler zu gewichten, was der blockdiagonalen Fisher-Information entspricht, die kanalinterne Abhängigkeiten beibehält. Darüber hinaus führt das Paper LNQ ein, einen nicht-uniformen skalaren Quantisierungsalgorithmus, der eine monotone Reduktion des Quantisierungsziels garantiert. Experimente zeigen, dass GuidedQuant bei reiner Gewichtsskalar-, reiner Gewichtsvektor- sowie Gewichts- und Aktivierungsquantisierung bestehende SOTA-Methoden übertrifft und bereits auf 2-4-Bit-Quantisierung von Modellen wie Qwen3, Gemma3, Llama3.3 angewendet wurde (Quelle: Reddit r/MachineLearning)

AI Engineer World’s Fair findet in San Francisco statt, Fokus auf KI-Engineering-Praktiken und Spitzentechnologien: Die AI Engineer World’s Fair findet derzeit in San Francisco statt und bringt zahlreiche Ingenieure, Forscher und Entwickler aus dem KI-Bereich zusammen. Die Konferenzagenda umfasst mehrere aktuelle Themen wie Reinforcement Learning, Kernel, Inferenz & Agenten, Modelloptimierung (RFT, DPO, SFT), Agenten-Codierung und Erstellung von Sprachagenten. Während der Veranstaltung werden Experten von Unternehmen wie OpenAI und Google Vorträge und Workshops halten sowie neue Produkte und Technologien vorstellen. Community-Mitglieder beteiligen sich aktiv, teilen Konferenzpläne und organisieren Offline-Treffen, was die Vitalität der KI-Engineering-Community und ihre Begeisterung für Spitzentechnologien zeigt (Quelle: swyx, clefourrier, swyx, LiorOnAI, TheTuringPost)

💼 Wirtschaft
Shidu Intelligence schließt Seed-Finanzierungsrunde in Millionenhöhe ab, um die Einführung von KI-Smart-Brillen in verschiedenen Szenarien zu beschleunigen: Suzhou Shidu Intelligent Technology Co., Ltd. gab den Abschluss einer Seed-Finanzierungsrunde in Höhe von mehreren Millionen Yuan bekannt. Die Mittel werden für die Forschung und Entwicklung der Kerntechnologie von KI-Smart-Brillen, die Marktexpansion und den Aufbau eines Ökosystems verwendet. Das Unternehmen konzentriert sich auf die Anwendung von KI-Smart-Brillen in Bereichen wie Smart Healthcare (z. B. intelligente Lesebrillen, intelligente Blindenhilfsbrillen), Smart Living (intelligente Modebrillen, Fahrradbrillen) und Smart Manufacturing (intelligente Industriebrillen, Sprachsteuerungen). Die Produkte sind im Preisbereich von 200 bis 1000 Yuan angesiedelt und zielen darauf ab, die Verbreitung von Smart-Brillen durch ein hohes Preis-Leistungs-Verhältnis zu fördern (Quelle: 36氪)

Gerüchte über mögliche Übernahme des KI-Programmierassistenten Windsurf durch OpenAI lösen Spekulationen über Lieferstopp von Claude-Modellen durch Anthropic aus: Marktgerüchten zufolge könnte OpenAI das KI-Programmiertool Windsurf (ehemals Codeium) für rund 3 Milliarden US-Dollar übernehmen. Vor diesem Hintergrund postete Windsurf-CEO Varun Mohan, dass Anthropic mit extrem kurzer Vorankündigung den direkten Zugriff auf fast alle seine Claude 3.x-Modelle, einschließlich Claude 3.5 Sonnet, gesperrt habe. Windsurf zeigte sich darüber enttäuscht und verlagerte seine Rechenkapazitäten schnell zu anderen Inferenzdienstanbietern, während es betroffenen Nutzern Rabatte für Gemini 2.5 Pro anbot. Die Community vermutet, dass Anthropics Schritt mit der potenziellen Übernahme durch OpenAI zusammenhängen könnte, und befürchtet Auswirkungen auf den Wettbewerb und die Wahlmöglichkeiten der Entwickler. Zuvor hatte Windsurf bei der Veröffentlichung von Claude 4 ebenfalls keine direkte Unterstützung von Anthropic erhalten (Quelle: AI前线)

HyGon Information plant Aktientauschfusion mit Sugon, um die heimische Rechenleistungskette zu integrieren: Der KI-Chip-Designer HyGon Information gab bekannt, dass er plant, seinen größten Aktionär, den Serverhersteller Sugon, im Wege eines Aktientauschs zu übernehmen. Der Marktwert von HyGon Information beträgt rund 316,4 Milliarden Yuan, der von Sugon rund 90,5 Milliarden Yuan. Diese „Schlange-frisst-Elefant“-Fusion zielt darauf ab, die industrielle Aufstellung von Chips über Software bis hin zu Systemen zu optimieren, die Stärkung, Ergänzung und Erweiterung der Industriekette zu realisieren und technologische Synergieeffekte zu nutzen. Analysten gehen davon aus, dass die Fusion dazu beitragen wird, die komplexen verbundenen Transaktionen und potenziellen Wettbewerbsprobleme beider Parteien zu lösen, die Betriebskosten zu senken und dem Entwicklungstrend von End-to-End-Rechenleistungslösungen im KI-Zeitalter zu entsprechen. Dies markiert eine mögliche beschleunigte Machtübergabe in der chinesischen Halbleitertechnologie von der traditionellen Datenverarbeitung zur KI-Datenverarbeitung (Quelle: 36氪)
🌟 Community
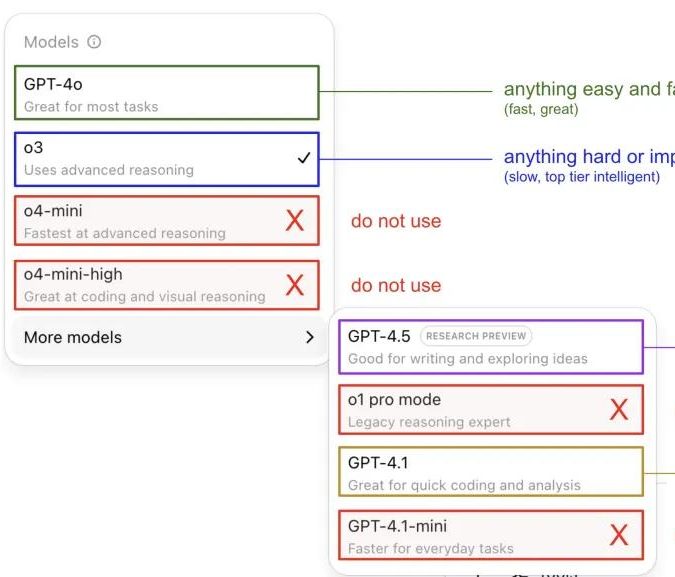
Andrej Karpathy teilt seine Erfahrungen mit der Nutzung von ChatGPT-Modellen und löst eine Community-Diskussion aus: Andrej Karpathy teilte seine persönlichen Erfahrungen mit der Nutzung verschiedener ChatGPT-Versionen: Für wichtige oder schwierige Aufgaben empfiehlt er die Verwendung des leistungsstärkeren o3; für alltägliche, weniger komplexe Probleme kann 4o verwendet werden; für Code-Verbesserungsaufgaben eignet sich GPT-4.1; für tiefgehende Recherchen und Zusammenfassungen mit mehreren Links sollte die Tiefenrecherchefunktion (basierend auf o3) genutzt werden. Dieser Erfahrungsaustausch löste eine breite Diskussion in der Community aus. Viele Nutzer teilten ihre eigenen Nutzungspräferenzen und Ansichten zur Modellauswahl und äußerten gleichzeitig ihre Verwirrung über die unklare Namensgebung der OpenAI-Modelle und das Fehlen einer automatischen Modellauswahlfunktion (Quelle: 量子位, JeffLadish)
Entwickler teilt zweiwöchige Erfahrung mit Agentic AI-Programmierung: Von Ehrfurcht zur Ernüchterung, schließlich manuelle Überarbeitung: Ein Technologieführer mit 10 Jahren Erfahrung teilte seine Erfahrungen bei der Integration von Agentic AI (speziell KI-Programmieragenten) in den Entwicklungsprozess seiner Social-Media-Anwendung. Anfänglich konnte die KI schnell Funktionsmodule generieren, Front- und Backend-Logik sowie Unit-Tests schreiben, was eine erstaunliche Effizienz zeigte und in zwei Wochen etwa 12.000 Codezeilen generierte. Mit zunehmender Komplexität der Codebasis begann die KI jedoch bei der Verarbeitung neuer Funktionen häufig Fehler zu machen, in Schleifen zu geraten und konnte Fehler nur schwer eingestehen. Der generierte Code wies zudem Probleme wie ungenaue Benennungen und doppelten Code auf, was die Codebasis schwer wartbar machte und dazu führte, dass der Entwickler das Vertrauen in die KI verlor. Schließlich entschied sich der Entwickler, den KI-generierten Code nur noch als „grobe Referenz“ zu verwenden, alle Funktionen manuell zu überarbeiten und kam zu dem Schluss, dass KI derzeit besser für die Analyse von vorhandenem Code und die Bereitstellung von Beispielen geeignet ist als für das direkte Schreiben von funktionalem Code (Quelle: CSDN)

Unterschied zwischen KI-Agenten und Workflows im Fokus, enormes Zukunftspotenzial für Anwendungen: Die Community diskutiert die Unterscheidung zwischen den Konzepten KI-Agent und Workflow. Ein Agent bezieht sich typischerweise auf einen LLM, der in einer Schleife auf Tools zugreift und gemäß Anweisungen frei agiert; ein Workflow ist eine Reihe von hauptsächlich deterministisch ausgeführten Schritten, die LLMs zur Erledigung von Teilaufgaben enthalten können. Obwohl es Überschneidungen gibt (Agenten können zur deterministischen Ausführung aufgefordert werden, Workflows können agentische Komponenten enthalten), ist diese Unterscheidung ontologisch weiterhin sinnvoll. Gleichzeitig wird das Potenzial von KI-Agenten in Unternehmensanwendungen weithin positiv eingeschätzt. Große Unternehmen wie Tencent und ByteDance engagieren sich stark im Bereich intelligenter Agenten. Beispielsweise rüstet Tencent seine Wissensdatenbank für große Modelle zu einer Entwicklungsplattform für intelligente Agenten auf, während ByteDance die Plattform Coze (Kouzi) anbietet, die Unternehmen bei der Implementierung nativer KI-Agentensysteme unterstützen soll (Quelle: fabianstelzer, 蓝洞商业)
Dwarkesh Patel diskutiert Zeitplan für LLMs und AGI und sieht kontinuierliches Lernen als entscheidenden Engpass: Dwarkesh Patel erläutert in seinem Blog seine Ansichten zum Zeitplan für AGI (Artificial General Intelligence) und argumentiert, dass LLMs derzeit die Fähigkeit fehlt, durch Praxis Kontext anzusammeln, Fehler zu reflektieren und kleine Verbesserungen vorzunehmen, d. h. die Fähigkeit zum kontinuierlichen Lernen. Er hält dies für einen enormen Engpass bei der praktischen Anwendbarkeit von Modellen und geht davon aus, dass die Lösung dieses Problems Jahre dauern könnte. Diese Ansicht löste Diskussionen unter mehreren KI-Forschern aus, darunter Andrej Karpathy. Karpathy stimmte ebenfalls zu, dass LLMs Defizite im kontinuierlichen Lernen aufweisen, und verglich sie mit Kollegen, die an anterograder Amnesie leiden. Diese Diskussionen verdeutlichen die Herausforderungen bei der Verwirklichung echter AGI und die Notwendigkeit eines tiefgreifenden Nachdenkens über die Lernmechanismen von Modellen (Quelle: dwarkesh_sp, JeffLadish, dwarkesh_sp)

Patentfragen bei KI in der Arzneimittelentwicklung im Fokus, Science mahnt zur Vorsicht: Ein Artikel im Politikforum der Zeitschrift Science, „What patents on AI-derived drugs reveal“, untersucht die Anwendung von KI in der Arzneimittelentdeckung und ihre Auswirkungen auf das Patentsystem. Die Studie weist darauf hin, dass KI-native Unternehmen bei der Patentierung von Medikamenten oft weniger In-vivo-Versuchsdaten vorlegen als traditionelle Pharmaunternehmen, was dazu führen kann, dass potenziell vielversprechende Medikamente mangels Folgeforschung aufgegeben werden. Gleichzeitig könnte die Veröffentlichung einer großen Anzahl neuer, von KI generierter Moleküle dazu führen, dass diese als „Stand der Technik“ gelten und andere Unternehmen daran hindern, diese Moleküle zu patentieren und weiter zu investieren. Der Artikel empfiehlt, die Hürden für Patentanmeldungen zu erhöhen, mehr In-vivo-Versuchsdaten zu fordern und es anderen Unternehmen zu ermöglichen, Patente für KI-generierte Moleküle anzumelden, wenn diese noch nicht getestet wurden. Gleichzeitig soll der regulatorische Exklusivitätsstatus für neue Medikamente in der klinischen Erprobungsphase gestärkt werden, um ein Gleichgewicht zwischen Innovationsanreizen und öffentlichem Interesse zu schaffen (Quelle: 36氪)
💡 Sonstiges
Altman-Machtkampf-Vorfall soll möglicherweise als Film „Artificial“ verfilmt werden, namhafte Regisseure und Produzenten beteiligt: Laut The Hollywood Reporter plant MGM, die Führungswechsel bei OpenAI zu einem Film mit dem vorläufigen Titel „Artificial“ zu adaptieren. Der renommierte italienische Regisseur Luca Guadagnino könnte Regie führen, zu den Produzenten gehört David Heyman aus der „Harry Potter“-Reihe. Die Besetzung wird derzeit diskutiert, Gerüchten zufolge könnte Andrew Garfield (bekannt als Spider-Man und als Eduardo Saverin in „The Social Network“) Sam Altman spielen, Yura Borisov könnte Ilya Sutskever und Monika Barbaro könnte Mira Murati darstellen. Diese Nachricht löste hitzige Diskussionen unter Internetnutzern aus und wurde mit dem Film „The Social Network“ verglichen (Quelle: 36氪, janonacct)
KI-Kundenservice-Erfahrung sorgt für Kontroversen, Nutzer beschweren sich über „künstliche Dummheit“ und schwierige Weiterleitung: Während der jüngsten großen E-Commerce-Verkaufsaktionen berichteten zahlreiche Verbraucher über eine schlechte Kommunikation und irrelevante Antworten von KI-Kundendienstmitarbeitern sowie über erhebliche Schwierigkeiten bei der Weiterleitung an menschliche Mitarbeiter, was zu einer Verschlechterung des Serviceerlebnisses führte. Daten der Staatlichen Marktregulierungsbehörde zeigen, dass die Zahl der Beschwerden im Bereich des E-Commerce-Kundendienstes im Zusammenhang mit „intelligentem Kundenservice“ im Jahr 2024 um 56,3 % gestiegen ist. Die Nutzer sind allgemein der Meinung, dass KI-Kundendienstmitarbeiter Schwierigkeiten haben, individuelle Probleme zu lösen, steif antworten und für spezielle Gruppen wie ältere Menschen nicht benutzerfreundlich genug sind. Der Artikel fordert Unternehmen auf, bei ihrem Streben nach Kostensenkung und Effizienzsteigerung die Servicequalität nicht zu opfern, die KI-Technologie zu optimieren, die Anwendungsbereiche des KI-Kundendienstes klar zu definieren und bequeme Kanäle für den menschlichen Service beizubehalten (Quelle: 36氪)

Anwendung von KI in der Content-Erstellung und Bewältigungsstrategien für Kreative diskutiert: Die zunehmende Anwendung von KI-Technologien (wie DeepSeek, Suno, Veo 3) in der Erstellung von Inhalten wie Artikeln, Musik und Videos löst bei Content-Erstellern Ängste um ihre berufliche Zukunft aus. Analysen deuten darauf hin, dass sich das Content-Paradigma von „personalisierter Empfehlung“ zu „personalisierter Generierung“ wandelt. Kurzfristig werden Plattformen aufgrund hoher Versuchskosten wahrscheinlich nicht vollständig auf KI-generierte Inhalte umsteigen, und Kreative könnten durch die Erstellung einzigartiger Stilmodelle und deren Lizenzierung Einnahmen erzielen. Langfristig müssen Kreative ihre Wertschöpfungsmethoden anpassen und sich stärker auf „Innovationsstrategien“ konzentrieren, die von KI schwer zu ersetzen sind (z. B. originäre Recherche, Beschaffung von Primärquellen), anstatt auf „Folgestrategien“ (Verfolgung von Trends, Abhängigkeit von Sekundärquellen), die leicht von KI unterstützt werden können. Obwohl KI bereits begonnen hat, in innovative Bereiche wie die wissenschaftliche Forschung vorzudringen, behalten Kreative mit einzigartigen Perspektiven und tiefgreifendem Denken weiterhin ihren Wert (Quelle: 36氪)
