
Schlüsselwörter:DeepMind AlphaEvolve, Sakana AI DGM, DeepSeek-R1, Verstärkendes Lernen ProRL, NVIDIA Cosmos, Multimodale Großmodelle, KI-Agenten-Framework, LLM-Inferenzoptimierung, AlphaEvolve Matherekord, Darwin-Gödel-Maschine zur Selbstverbesserung, MedHELM medizinische Bewertung, ProRL Skalierbarkeit des verstärkenden Lernens, Cosmos Transfer Physiksimulation
🔥 Fokus
DeepMind AlphaEvolve bricht mathematischen Rekord, Mensch-Maschine-Kollaboration treibt wissenschaftlichen Fortschritt voran: DeepMinds AlphaEvolve hat innerhalb einer Woche zweimal einen 18 Jahre alten mathematischen Rekord gebrochen und damit große Aufmerksamkeit erregt. Tao Zhexuan kommentierte, dies zeige, wie verschiedene Methoden sich ergänzen können, um den mathematischen Fortschritt voranzutreiben, anstatt einfache „Gewinner“ und „Verlierer“ hervorzubringen. Dieses Ereignis unterstreicht das Potenzial der Zusammenarbeit von KI und Menschen, neue Paradigmen in Technologie und Wissenschaft zu schaffen. KI ersetzt nicht einfach den Menschen, sondern eröffnet gemeinsam neue Wege des Fortschritts (Quelle: shaneguML)

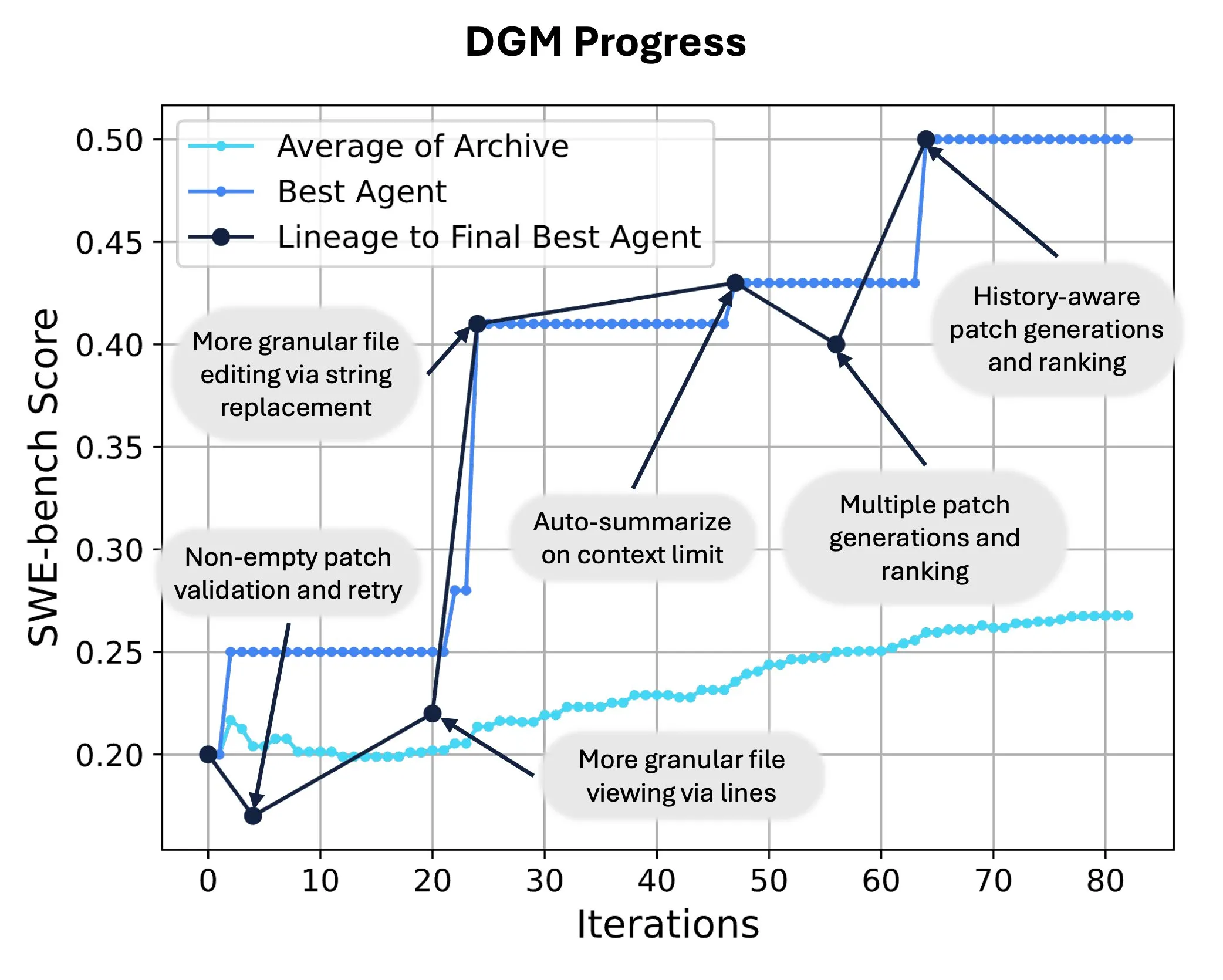
Sakana AI veröffentlicht Darwin Gödel Machine (DGM) und realisiert selbstständige Code-Umschreibung und Evolution von KI: Sakana AI hat die Darwin Gödel Machine (DGM) vorgestellt, einen selbstverbessernden Agenten, der seine Leistung durch Modifikation seines eigenen Codes steigern kann. Inspiriert von der Evolutionstheorie unterhält DGM eine sich ständig erweiternde Linie von Agentenvarianten und ermöglicht so eine offene Erkundung des Designraums für „selbstverbessernde“ Agenten. Auf SWE-bench steigerte DGM die Leistung von 20,0 % auf 50,0 %; auf Polyglot stieg die Erfolgsquote von 14,2 % auf 30,7 %, was deutlich besser ist als bei von Menschen entworfenen Agenten. Diese Technologie eröffnet neue Wege für KI-Systeme, um kontinuierliches Lernen und Fähigkeitsevolution zu erreichen (Quelle: SakanaAILabs, hardmaru)
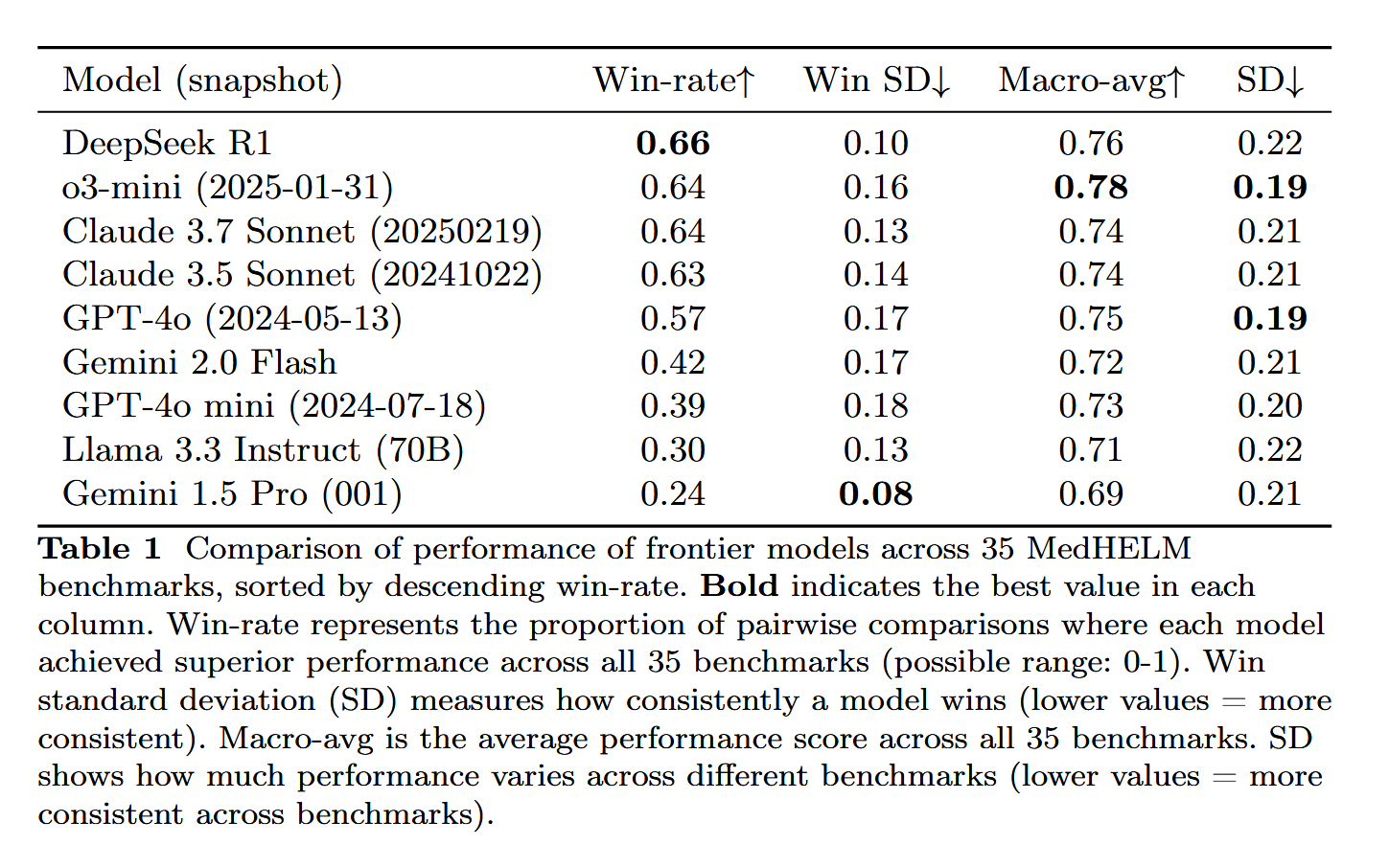
DeepSeek-R1 zeigt herausragende Leistung in der MedHELM-Bewertung medizinischer Aufgaben: Das große Sprachmodell DeepSeek-R1 schnitt im MedHELM (Holistic Evaluation of Medical Large Language Models) Benchmark am besten ab. Dieser Test zielt darauf ab, die Leistung von LLMs bei praxisnäheren klinischen Aufgaben zu bewerten, anstatt bei traditionellen medizinischen Zulassungsprüfungen. Dieses Ergebnis wird als bedeutsam angesehen und zeigt das Potenzial von DeepSeek-R1 für Anwendungen im medizinischen Bereich, insbesondere bei der Bewältigung realer klinischer Szenarien (Quelle: iScienceLuvr)
Neue Fortschritte in der Skalierbarkeitsforschung des Reinforcement Learning: ProRL erweitert die Inferenzgrenzen von LLMs: Eine neue Arbeit zur Skalierbarkeit von Reinforcement Learning (RL) (arXiv:2505.24864) hat Aufmerksamkeit erregt. Die Forschung zeigt, dass durch langanhaltendes Reinforcement Learning Training (ProRL) völlig neue Inferenzstrategien entdeckt werden können, die Basismodelle durch breites Sampling nur schwer erreichen können. ProRL kombiniert KL-Divergenzkontrolle, Referenzstrategie-Resets und diversifizierte Aufgabensätze, wodurch RL-trainierte Modelle in verschiedenen pass@k-Bewertungen Basismodelle kontinuierlich übertreffen. Die Studie liefert neue Erkenntnisse darüber, wie RL die Inferenzgrenzen von Sprachmodellen substanziell erweitern kann und legt den Grundstein für zukünftige Forschung im Bereich Langzeit-RL-Inferenz. NVIDIA hat bereits entsprechende Modellgewichte veröffentlicht (Quelle: Teknium1, cognitivecompai, natolambert, scaling01)

🎯 Trends
NVIDIA veröffentlicht Cosmos Transfer und Cosmos Reason zur Förderung von KI-Anwendungen in der physischen Welt: NVIDIA hat das Cosmos-System vorgestellt, bei dem Cosmos Transfer einfache Game-Engine-Szenen, Tiefeninformationen oder sogar grobe Robotersimulationen in realistische Videoszenen umwandeln kann. Dies liefert eine große Menge an kontrollierbaren Trainingsdaten für KI in Bereichen wie Robotik und autonomes Fahren. Cosmos Reason ermöglicht es der KI, diese Szenen zu verstehen und Entscheidungen zu treffen, beispielsweise bei Tests für autonomes Fahren zu beurteilen, wie gefahren werden soll. Beide Tools sind derzeit Open Source und sollen die Entwicklung von KI in der physischen Welt beschleunigen und Probleme wie unzureichende Trainingsdaten und Szenenkontrolle lösen (Quelle: )
DeepSeek veröffentlicht R1-Update, Open-Source-Ökosystem floriert weiter: DeepSeek hat ein Update für das R1-Modell veröffentlicht, einschließlich R1 selbst und einer kleineren, destillierten Version mit 8 Milliarden Parametern. Gleichzeitig ist ByteDance im Open-Source-Bereich sehr aktiv und hat Projekte wie BAGEL, Dolphin, Seedcoder und Dream0 vorgestellt. Diese Fortschritte zeigen die Aktivität und Innovationskraft Chinas im Bereich KI-Open-Source, insbesondere die schnelle Entwicklung bei multimodalen und spezialisierten Modellen (Quelle: TheRundownAI, stablequan, reach_vb, clefourrier)
Google veröffentlicht Edge AI Gallery zur Förderung von Open-Source-KI-Modellen auf Smartphones: Google hat die Edge AI Gallery vorgestellt, die darauf abzielt, Open-Source-KI-Modelle auf Smartphones zu bringen und lokalisierte, private KI-Anwendungen zu ermöglichen. Benutzer können LLMs von Hugging Face direkt auf dem Gerät ausführen, um Code zu generieren, Bilddialoge zu führen usw. Es unterstützt Multi-Turn-Dialoge und die Auswahl beliebiger Modelle. Die Anwendung basiert auf LiteRT, unterstützt derzeit Android, eine iOS-Version wird in Kürze erwartet. Dies wird die Entwicklung und Verbreitung von Edge-KI weiter vorantreiben (Quelle: TheRundownAI, huggingface, reach_vb, osanseviero)
Neue Studie untersucht Nutzung von positiven und negativen Destillations-Inferenzpfaden zur Optimierung von LLMs: Eine neue Veröffentlichung stellt das Reinforcement Distillation (REDI) Framework vor, das darauf abzielt, die Inferenzfähigkeiten kleinerer Studentenmodelle durch die Nutzung korrekter und inkorrekter Inferenzpfade zu verbessern, die von Lehrermodellen (wie DeepSeek-R1) erzeugt werden. REDI erfolgt in zwei Phasen: Zuerst wird durch Supervised Fine-Tuning (SFT) aus korrekten Pfaden gelernt, dann wird das neu vorgeschlagene REDI-Zielfunktion (eine referenzfreie Verlustfunktion) verwendet, um das Modell unter Einbeziehung positiver und negativer Pfade weiter zu optimieren. Experimente zeigen, dass REDI bei mathematischen Inferenzaufgaben Basislinienmethoden übertrifft, wobei das Qwen-REDI-1.5B-Modell auf MATH-500 eine hohe Punktzahl von 83,1 % erreicht (Quelle: HuggingFace Daily Papers)
LLMSynthor Framework nutzt LLMs für strukturbewusste Datensynthese: LLMSynthor ist ein universelles Datensynthese-Framework, das große Sprachmodelle (LLMs) in strukturbewusste Simulatoren umwandelt und durch Verteilungsfeedback gesteuert wird. Das Framework betrachtet LLMs als nicht-parametrische Copula-Simulatoren zur Modellierung von Abhängigkeiten höherer Ordnung und führt LLM-Proposal-Sampling ein, um die Sampling-Effizienz zu verbessern. Durch die Minimierung von Unterschieden im Raum der zusammenfassenden Statistiken gleicht ein iterativer Synthesezyklus reale und synthetische Daten an. Bewertungen auf heterogenen Datensätzen aus datenschutzsensiblen Bereichen wie E-Commerce, Demografie und Mobilität zeigen, dass die von LLMSynthor generierten synthetischen Daten eine hohe statistische Genauigkeit und Nützlichkeit aufweisen (Quelle: HuggingFace Daily Papers)
v1 Framework verbessert multimodale interaktive Inferenz durch selektives visuelles Revisiting: v1 ist eine leichtgewichtige Erweiterung, die es multimodalen großen Sprachmodellen (MLLMs) ermöglicht, während des Inferenzprozesses selektives visuelles Revisiting durchzuführen. Im Gegensatz zu aktuellen MLLMs, die visuelle Eingaben normalerweise einmalig verarbeiten, führt v1 einen „Point and Copy“-Mechanismus ein, der es dem Modell ermöglicht, während des Inferenzprozesses dynamisch relevante Bildbereiche abzurufen. Durch Training auf dem v1g-Datensatz, der multimodale Inferenzpfade mit visuellen Grounding-Annotationen enthält, zeigt v1 Leistungssteigerungen in Benchmarks wie MathVista, insbesondere bei Aufgaben, die eine feinkörnige visuelle Referenzierung und mehrstufige Inferenz erfordern (Quelle: HuggingFace Daily Papers)
MetaFaith verbessert die Genauigkeit der Unsicherheitsdarstellung von LLMs in natürlicher Sprache: Um das Problem zu lösen, dass LLMs bei der Darstellung von Unsicherheit oft übertreiben, schlägt MetaFaith eine neue, auf Prompts basierende Kalibrierungsmethode vor. Die Forschung hat ergeben, dass bestehende LLMs ihre inhärente Unsicherheit schlecht widerspiegeln, Standard-Prompting-Methoden nur begrenzte Wirkung zeigen und auf Fakten basierende Kalibrierungstechniken die Genauigkeitskalibrierung sogar beeinträchtigen können. MetaFaith, inspiriert von menschlicher Metakognition, kann die Genauigkeitskalibrierung von Modellen über verschiedene Aufgaben und Modelle hinweg signifikant verbessern, mit einer Steigerung der Genauigkeit um bis zu 61 % und einer Erfolgsquote von 83 % in menschlichen Bewertungen (Quelle: HuggingFace Daily Papers)
CLaSp: Beschleunigung der LLM-Dekodierung durch selbstspekulative Dekodierung mit kontextinternem Layer-Skipping: CLaSp ist eine selbstspekulative Dekodierungsstrategie für große Sprachmodelle (LLMs), die den Dekodierungsprozess beschleunigt, indem sie während der Verifizierung des Modells Zwischenschichten überspringt, um ein komprimiertes Entwurfsmodell zu erstellen, ohne zusätzliches Training oder Modifikationen am Modell. CLaSp verwendet einen dynamischen Programmieralgorithmus, um den Layer-Skipping-Prozess zu optimieren und die Strategie dynamisch basierend auf dem vollständigen Hidden State der vorherigen Verifizierungsphase anzupassen. Experimente zeigen, dass CLaSp bei Modellen der LLaMA3-Serie eine Beschleunigung von 1,3- bis 1,7-fach erreicht, ohne die ursprüngliche Verteilung des generierten Textes zu verändern (Quelle: HuggingFace Daily Papers)
HardTests synthetisiert hochwertige Code-Testfälle mit LLMs: Um das Problem zu lösen, dass von LLMs generierter Code für komplexe Programmierprobleme mit bestehenden Testfällen nur schwer effektiv validiert werden kann, schlägt HardTests einen Prozess namens HARDTESTGEN vor, der LLMs zur Generierung hochwertiger Testfälle nutzt. Der auf diesem Prozess basierende HardTests-Datensatz enthält 47.000 Programmierprobleme und synthetisierte hochwertige Testfälle. Im Vergleich zu bestehenden Tests verbessern die von HARDTESTGEN generierten Tests die Präzision bei der Bewertung von LLM-generiertem Code um 11,3 % und den Recall um 17,5 %, wobei die Präzisionssteigerung bei schwierigen Problemen bis zu 40 % betragen kann. Der Datensatz zeigt auch beim Modelltraining überlegene Ergebnisse (Quelle: HuggingFace Daily Papers)
Studie deckt Verzerrungen in visuellen Sprachmodellen (VLM) auf: Eine Studie hat ergeben, dass fortgeschrittene visuelle Sprachmodelle (VLM) bei der Verarbeitung visueller Aufgaben im Zusammenhang mit populären Themen (wie Zählen und Erkennen) stark von dem umfangreichen Vorwissen beeinflusst werden, das sie aus dem Internet gelernt haben. Beispielsweise haben VLMs Schwierigkeiten, einen hinzugefügten vierten Streifen auf dem Adidas-Logo zu erkennen. Bei Zählaufgaben in 7 verschiedenen Bereichen, darunter Tiere, Marken und Brettspiele, betrug die durchschnittliche Genauigkeit der VLMs nur 17,05 %. Selbst wenn die Modelle angewiesen wurden, sorgfältig zu prüfen oder sich nur auf Bilddetails zu verlassen, war die Genauigkeitssteigerung begrenzt. Die Studie schlägt ein automatisiertes Framework zum Testen von VLM-Verzerrungen vor (Quelle: HuggingFace Daily Papers)
Point-MoE: Domänenübergreifende Generalisierung für 3D-semantische Segmentierung mit Mixture-of-Experts-Modellen: Um das Problem der Ausbildung einheitlicher Modelle für 3D-Punktwolkendaten aus verschiedenen Quellen (z. B. Tiefenkameras, LiDAR) und heterogenen Domänen (z. B. Innen-, Außenbereich) zu lösen, schlägt Point-MoE eine Mixture-of-Experts (MoE)-Architektur vor. Diese Architektur spezialisiert Expertennetzwerke automatisch durch eine einfache Top-k-Routing-Strategie, auch ohne Domänen-Labels. Experimente zeigen, dass Point-MoE nicht nur leistungsstarke Multi-Domain-Basismodelle übertrifft, sondern auch eine bessere Generalisierungsfähigkeit in ungesehenen Domänen aufweist und einen skalierbaren Pfad für groß angelegte, domänenübergreifende 3D-Wahrnehmung bietet (Quelle: HuggingFace Daily Papers)
SpookyBench enthüllt „zeitliche Blindheit“ von Video-Sprachmodellen: Trotz Fortschritten im Verständnis räumlich-zeitlicher Beziehungen haben Video-Sprachmodelle (VLM) Schwierigkeiten, rein zeitliche Muster zu erfassen, wenn räumliche Informationen mehrdeutig sind. Der SpookyBench-Benchmark, der Informationen (wie Formen, Text) in rauschähnlichen Bildsequenzen kodiert, zeigt, dass Menschen diese mit über 98 % Genauigkeit erkennen können, während fortgeschrittene VLMs eine Genauigkeit von 0 % aufweisen. Dies deutet darauf hin, dass VLMs sich übermäßig auf räumliche Merkmale auf Frame-Ebene verlassen und keine Bedeutung aus zeitlichen Hinweisen extrahieren können. Die Studie betont die Notwendigkeit, die „zeitliche Blindheit“ von VLMs zu überwinden, was möglicherweise neue Architekturen oder Trainingsparadigmen erfordert, um die räumliche Abhängigkeit von der zeitlichen Verarbeitung zu entkoppeln (Quelle: HuggingFace Daily Papers, _akhaliq)
Neue Methode und Datensatz zur Erkennung wissenschaftlicher Innovationen mit LLMs: Die Identifizierung neuer wissenschaftlicher Ideen ist entscheidend, aber herausfordernd. Um dieses Problem anzugehen, schlagen Forscher vor, große Sprachmodelle (LLMs) zur Erkennung wissenschaftlicher Innovationen einzusetzen und haben zwei neue Datensätze in den Bereichen Marketing und Natural Language Processing erstellt. Die Methode extrahiert die Closure-Sets von Veröffentlichungen und nutzt LLMs, um deren Hauptideen zusammenzufassen und so die Datensätze zu erstellen. Um Ideenkonzepte zu erfassen, schlagen die Forscher vor, einen leichtgewichtigen Retriever zu trainieren, der durch Destillation von Wissen auf Ideenebene aus LLMs Ideen mit ähnlichen Konzepten abgleicht und so eine effiziente und genaue Ideenfindung ermöglicht. Experimente zeigen, dass diese Methode auf den vorgeschlagenen Benchmark-Datensätzen andere Methoden übertrifft (Quelle: HuggingFace Daily Papers)
un^2CLIP verbessert die Erfassung visueller Details von CLIP durch Umkehrung von unCLIP: Um die Schwächen von CLIP-Modellen bei der Unterscheidung feiner Bilddetails und der Verarbeitung von Aufgaben wie Dense Prediction zu beheben, schlägt un^2CLIP vor, CLIP durch Umkehrung des unCLIP-Modells zu verbessern. unCLIP selbst trainiert einen Bildgenerator mithilfe von CLIP-Bildeinbettungen und lernt so die Detailverteilung von Bildern. un^2CLIP nutzt diese Eigenschaft, um dem verbesserten CLIP-Bildencoder die Fähigkeit zur Erfassung visueller Details von unCLIP zu verleihen, während die Ausrichtung auf den ursprünglichen Textencoder beibehalten wird. Experimente zeigen, dass un^2CLIP in mehreren Aufgaben signifikant besser abschneidet als das ursprüngliche CLIP und andere verbesserte Methoden (Quelle: HuggingFace Daily Papers)
ViStoryBench: Umfassendes Benchmark-Paket für Story-Visualisierung veröffentlicht: Um die Entwicklung von Technologien zur Story-Visualisierung (Generierung kohärenter Bildsequenzen basierend auf Erzählungen und Referenzbildern) voranzutreiben, bietet ViStoryBench einen umfassenden Bewertungsbenchmark. Dieser Benchmark enthält Datensätze mit verschiedenen Story-Typen (Komödie, Horror usw.) und Kunststilen (Anime, 3D-Rendering usw.) und verfügt über Geschichten mit einem oder mehreren Protagonisten, um die Charakterkonsistenz zu testen, sowie komplexe Handlungen und Weltaufbauten, um die Genauigkeit der visuellen Generierung der Modelle herauszufordern. ViStoryBench verwendet mehrere Bewertungsmetriken, um die Leistung der Modelle in Bezug auf Erzählstruktur und visuelle Elemente umfassend zu bewerten und Forschern zu helfen, Stärken und Schwächen der Modelle zu identifizieren und gezielte Verbesserungen vorzunehmen (Quelle: HuggingFace Daily Papers)
Fork-Merge Decoding (FMD) verbessert ausgewogenes multimodales Verständnis in Audio-Video-Großmodellen: Um das Problem möglicher Modalitätsverzerrungen in Audio-Video-Großsprachmodellen (AV-LLM) zu lösen (d. h. das Modell verlässt sich bei Entscheidungen übermäßig auf eine Modalität), schlägt Fork-Merge Decoding (FMD) eine Inferenzzeitstrategie vor, die kein zusätzliches Training erfordert. FMD verarbeitet zunächst reine Audio- und reine Videoeingaben getrennt durch frühe Dekodierungsschichten (Fork-Phase) und führt dann die erzeugten Hidden States für eine gemeinsame Inferenz zusammen (Merge-Phase). Diese Methode zielt darauf ab, einen ausgewogenen Beitrag der Modalitäten zu fördern und komplementäre Informationen über die Modalitäten hinweg zu nutzen. Experimente mit Modellen wie VideoLLaMA2 und video-SALMONN zeigen, dass FMD die Leistung bei Audio-, Video- und kombinierten Audio-Video-Inferenzaufgaben verbessern kann (Quelle: HuggingFace Daily Papers)
LegalSearchLM: Neukonzeption der juristischen Fallsuche als Generierung juristischer Elemente: Traditionelle Methoden der juristischen Fallsuche (LCR) basieren auf Einbettungen oder lexikalischen Übereinstimmungen und stoßen in realen Szenarien an Grenzen. LegalSearchLM schlägt einen neuen Ansatz vor, der LCR als eine Aufgabe der Generierung juristischer Elemente betrachtet. Das Modell führt eine Inferenz juristischer Elemente für den angefragten Fall durch und generiert durch beschränkte Dekodierung direkt Inhalte, die auf dem Zielfall basieren. Gleichzeitig veröffentlichen die Forscher LEGAR BENCH, einen groß angelegten LCR-Benchmark mit 1,2 Millionen koreanischen Rechtsfällen. Experimente zeigen, dass LegalSearchLM auf LEGAR BENCH um 6-20 % besser abschneidet als Basismodelle und eine starke domänenübergreifende Generalisierungsfähigkeit aufweist (Quelle: HuggingFace Daily Papers)
RPEval: Neuer Benchmark zur Bewertung der Rollenspielfähigkeiten von großen Sprachmodellen: Angesichts der Herausforderungen bei der Bewertung der Rollenspielfähigkeiten von großen Sprachmodellen (LLMs) bietet RPEval einen neuen Benchmark-Test. Dieser Benchmark bewertet die Rollenspielleistung von LLMs anhand von vier Schlüsseldimensionen: emotionales Verständnis, Entscheidungsfindung, moralische Neigung und Rollenkonsistenz. Ziel ist es, das Problem des hohen Ressourcenverbrauchs bei manueller Bewertung und möglicher Verzerrungen bei automatisierter Bewertung zu lösen (Quelle: HuggingFace Daily Papers)
GATE: Universelles Texteinbettungsmodell zur Verbesserung von Arabisch-STS: Um dem Mangel an hochwertigen Datensätzen und vortrainierten Modellen in der Forschung zur semantischen Textähnlichkeit (STS) im Arabischen entgegenzuwirken, wurde das GATE (General Arabic Text Embedding)-Modell entwickelt. GATE nutzt Matryoshka Representation Learning und eine gemischte Verlusttrainingsmethode in Kombination mit einem arabischen Datensatz für natürliche Sprachinferenz-Triplets für das Training. Die experimentellen Ergebnisse zeigen, dass GATE bei STS-Aufgaben des MTEB-Benchmarks eine SOTA-Leistung erzielt und im Vergleich zu großen Modellen, einschließlich OpenAI, eine Leistungssteigerung von 20-25 % aufweist, wodurch die einzigartigen semantischen Nuancen des Arabischen effektiv erfasst werden können (Quelle: HuggingFace Daily Papers)
CoDA: Kollaboratives Diffusionsrauschen-Optimierungsframework für die Ganzkörpermanipulation von Gelenkobjekten: Um Realismus und Präzision bei der Ganzkörpermanipulation von Gelenkobjekten (einschließlich Körper-, Hand- und Objektbewegungen) zu erreichen, schlägt CoDA ein neues kollaboratives Diffusionsrauschen-Optimierungsframework vor. Dieses Framework optimiert den Rauschraum von drei spezialisierten Diffusionsmodellen für Körper, linke und rechte Hand und erreicht durch den Gradientenfluss in der menschlichen Bewegungskette eine natürliche Koordination von Händen und Körper. Um die Präzision der Hand-Objekt-Interaktion zu verbessern, verwendet CoDA eine einheitliche Darstellung basierend auf Basis-Punktmengen (BPS), die die Positionen der Endeffektoren als Abstände zur BPS der Objektgeometrie kodiert und so die Optimierung des Diffusionsrauschens zur Erzeugung hochpräziser Interaktionsbewegungen steuert (Quelle: HuggingFace Daily Papers)
Neuer Ansatz zum Verständnis des Reflexionsmechanismus bei LLM-Inferenz: Bayesian Adaptive Reinforcement Learning Framework BARL: Die Northwestern University und Google DeepMind haben gemeinsam das Bayesian Adaptive Reinforcement Learning Framework (BARL) vorgeschlagen, um das „Reflexions“-Verhalten von großen Sprachmodellen (LLMs) während des Inferenzprozesses zu erklären und zu optimieren. Traditionelles Reinforcement Learning (RL) nutzt beim Testen typischerweise nur gelernte Strategien, während BARL durch die Modellierung der Unsicherheit der Umgebung dem Modell ermöglicht, während der Inferenz adaptiv neue Strategien zu erkunden. Experimente zeigen, dass BARL bei Aufgaben wie mathematischer Inferenz eine höhere Genauigkeit erzielen und den Token-Verbrauch signifikant reduzieren kann. Diese Studie erklärt erstmals aus einer Bayes’schen Perspektive, warum, wie und wann LLMs eine Reflexionserkundung durchführen sollten (Quelle: 量子位)

Anwendung von LLMs in formalen Unsicherheitsgrammatiken: Wann man LLMs für automatische Inferenz vertrauen kann: Große Sprachmodelle (LLMs) zeigen Potenzial bei der Generierung formaler Spezifikationen, aber ihre probabilistische Natur steht im Widerspruch zu den deterministischen Anforderungen der formalen Verifikation. Forscher untersuchten umfassend Fehlermodi und Unsicherheitsquantifizierung (UQ) in von LLMs generierten formalen Konstrukten. Die Ergebnisse zeigen, dass die Auswirkungen der SMT-basierten automatischen Formalisierung auf die Genauigkeit je nach Domäne variieren und bestehende UQ-Techniken diese Fehler nur schwer identifizieren können. Die Arbeit führt das Framework der probabilistischen kontextfreien Grammatiken (PCFG) ein, um LLM-Ausgaben zu modellieren, und stellt fest, dass Unsicherheitssignale aufgabenabhängig sind. Durch die Fusion dieser Signale kann eine selektive Verifikation erreicht werden, die Fehler erheblich reduziert und die LLM-gesteuerte Formalisierung zuverlässiger macht (Quelle: HuggingFace Daily Papers)
Vergleich von Feinabstimmung kleiner Sprachmodelle (SLM) und Prompting großer Sprachmodelle (LLM) bei der Generierung von Low-Code-Workflows: Die Studie vergleicht die Effektivität der Feinabstimmung kleiner Sprachmodelle (SLM) mit dem Prompting großer Sprachmodelle (LLM) bei der Aufgabe, Low-Code-Workflows im JSON-Format zu generieren. Die Ergebnisse zeigen, dass, obwohl gute Prompts LLMs zu vernünftigen Ergebnissen führen können, die Feinabstimmung von SLMs für domänenspezifische Aufgaben und strukturierte Ausgaben eine durchschnittliche Qualitätssteigerung von 10 % bringt. Dies deutet darauf hin, dass SLMs in bestimmten Szenarien immer noch Vorteile haben, insbesondere wenn hohe Anforderungen an die Ausgabequalität gestellt werden (Quelle: HuggingFace Daily Papers)
Bewertung und Steuerung von Modalitätspräferenzen in multimodalen großen Modellen: Forscher haben den MC²-Benchmark erstellt, um die Modalitätspräferenzen (d. h. die Tendenz, bei Entscheidungen eine bestimmte Modalität zu bevorzugen) von multimodalen großen Sprachmodellen (MLLMs) in kontrollierten Szenarien mit widersprüchlichen Beweisen systematisch zu bewerten. Die Studie ergab, dass alle 18 getesteten MLLMs deutliche Modalitätsverzerrungen aufwiesen und die Präferenzrichtung durch externe Interventionen beeinflusst werden konnte. Darauf basierend schlagen die Forscher eine auf Representation Engineering basierende Methode zur Erkennung und Steuerung vor, die es ermöglicht, Modalitätspräferenzen explizit zu kontrollieren, ohne zusätzliches Fine-Tuning oder aufwändig gestaltete Prompts, und die positive Ergebnisse bei nachgelagerten Aufgaben wie der Reduzierung von Halluzinationen und der multimodalen maschinellen Übersetzung erzielt (Quelle: HuggingFace Daily Papers)
Aktueller Stand der Forschung zur Sicherheit mehrsprachiger LLMs: Von der Messung der Sprachlücke bis zu ihrer Überbrückung: Eine systematische Überprüfung von fast 300 NLP-Konferenzpapieren aus den Jahren 2020-2024 zeigt, dass die Forschung zur LLM-Sicherheit ein erhebliches Problem der Englisch-Zentrierung aufweist. Selbst ressourcenreiche nicht-englische Sprachen finden kaum Beachtung, nicht-englische Sprachen werden selten als eigenständige Forschungsobjekte behandelt, und englischsprachige Sicherheitsforschung weist allgemein eine mangelhafte Praxis der Sprachdokumentation auf. Um die mehrsprachige Sicherheitsforschung voranzutreiben, schlägt die Arbeit zukünftige Richtungen vor, darunter Sicherheitsbewertung, Generierung von Trainingsdaten und sprachübergreifende Sicherheitsgeneralisierung, mit dem Ziel, robustere und inklusivere KI-Sicherheitspraktiken für verschiedene Bevölkerungsgruppen weltweit zu entwickeln (Quelle: HuggingFace Daily Papers, sarahookr)

Neubetrachtung bilinearer Zustandsübergänge in rekurrenten neuronalen Netzen: Die traditionelle Ansicht besagt, dass die Hidden Units rekurrenter neuronaler Netze (RNNs) hauptsächlich zur Modellierung des Gedächtnisses dienen. Diese Studie verfolgt einen anderen Ansatz und betrachtet Hidden Units als aktive Teilnehmer an den Berechnungen des Netzwerks. Die Forscher untersuchen bilineare Operationen, die multiplikative Interaktionen zwischen Hidden Units und Eingabe-Embeddings beinhalten, und zeigen theoretisch und empirisch, dass sie natürliche induktive Verzerrungen für die Darstellung der Entwicklung von Hidden States in Zustandsverfolgungsaufgaben sind. Die Studie zeigt auch, dass bilineare Zustandsaktualisierungen eine natürliche Hierarchie bilden, die Zustandsverfolgungsaufgaben mit zunehmender Komplexität entspricht, während populäre lineare RNNs (wie Mamba) sich im Zentrum dieser Hierarchie mit der geringsten Komplexität befinden (Quelle: HuggingFace Daily Papers)
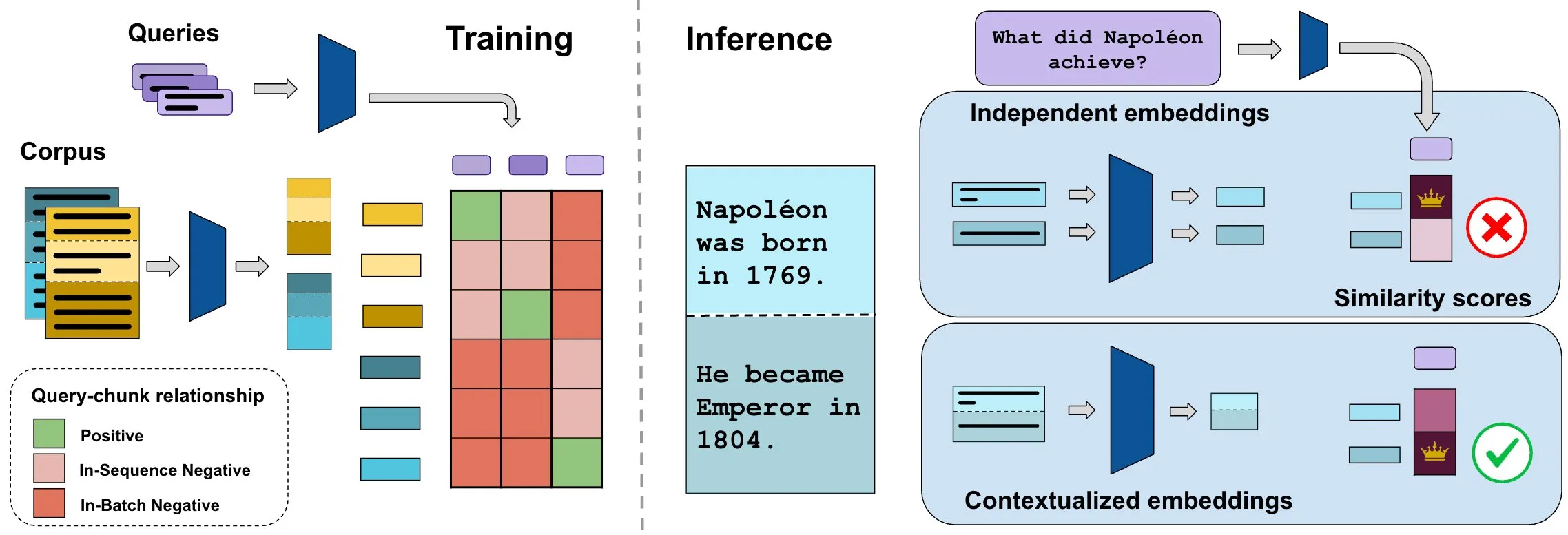
ConTEB-Benchmark bewertet kontextbezogene Dokumenteinbettungen, InSeNT-Methode verbessert Abrufqualität: Aktuelle Methoden zur Einbettung von Dokumenten für den Abruf kodieren typischerweise verschiedene Abschnitte (Chunks) desselben Dokuments unabhängig voneinander und ignorieren dabei kontextbezogene Informationen auf Dokumentebene. Um dieses Problem zu lösen, haben Forscher den ConTEB-Benchmark eingeführt, der speziell die Fähigkeit von Abrufmodellen bewertet, den Dokumentkontext zu nutzen, und festgestellt, dass SOTA-Modelle in dieser Hinsicht schlecht abschneiden. Gleichzeitig schlagen die Forscher die kontrastive Lernmethode InSeNT (In-Sequence Negative Training) für das Post-Training vor, die mit spätem Chunk-Pooling kombiniert wird, um das Erlernen kontextbezogener Repräsentationen zu verbessern. Dies führt zu einer signifikanten Verbesserung der Abrufqualität auf ConTEB und ist robuster gegenüber suboptimalen Chunking-Strategien und größeren Korpora (Quelle: HuggingFace Daily Papers, tonywu_71)
🧰 Tools
PraisonAI: Low-Code Multi-KI-Agenten-Framework: PraisonAI ist ein produktionsreifes Multi-KI-Agenten-Framework, das darauf abzielt, die Automatisierung und Problemlösung von einfachen Aufgaben bis hin zu komplexen Herausforderungen durch Low-Code-Lösungen zu vereinfachen. Es integriert PraisonAI Agents, AG2 (AutoGen) und CrewAI und legt Wert auf Einfachheit, Anpassbarkeit und effektive Mensch-Maschine-Kollaboration. Zu seinen Funktionen gehören die automatische Erstellung von KI-Agenten, Selbstreflexion, Multimodalität, Multi-Agenten-Kollaboration, Wissenserweiterung, Kurz- und Langzeitgedächtnis, RAG, Code-Interpreter, über 100 benutzerdefinierte Tools und LLM-Unterstützung. Es unterstützt Python und JavaScript und bietet eine codefreie YAML-Konfigurationsoption (Quelle: GitHub Trending)
TinyTroupe: Microsofts Open-Source LLM-gesteuertes Multi-Agenten-Rollensimulations-Framework: TinyTroupe ist eine experimentelle Python-Bibliothek, die große Sprachmodelle (LLMs, insbesondere GPT-4) verwendet, um Charaktere (TinyPerson) mit spezifischen Persönlichkeiten, Interessen und Zielen zu simulieren, die in einer simulierten Umgebung (TinyWorld) interagieren. Das Framework zielt darauf ab, die Vorstellungskraft durch Simulation zu erweitern und geschäftliche Einblicke zu liefern. Es kann für die Bewertung von Werbung, Softwaretests, die Generierung synthetischer Daten, Produktfeedback und Brainstorming eingesetzt werden. Benutzer können Agenten und Umgebungen über Python- und JSON-Dateien definieren, um programmatische, analytische und Multi-Agenten-Simulationsexperimente durchzuführen (Quelle: GitHub Trending)

FLUX Kontext erzielt Durchbrüche bei Multi-Bild-Referenzierung und Bildbearbeitung: Nutzerfeedback zeigt, dass FLUX Kontext bei der Multi-Bild-Referenzierung hervorragend abschneidet. Diese Funktion kann über den Bild-Stitching-Knoten in ComfyUI aktiviert werden. Das Tool ermöglicht eine hochkonsistente Bildbearbeitung, beispielsweise bei der Erstellung von Produktbildern für Geschenkboxen, wobei Material und Staubdetails sehr gut wiedergegeben werden. Darüber hinaus zeigten Nutzer, wie FLUX Kontext für Ein-Klick-Operationen wie Schlankmachen, Gesichtsverschmälerung und Muskelaufbau verwendet werden kann, mit natürlichen Ergebnissen und hoher Ähnlichkeit der Gesichtszüge, was Vorteile für E-Commerce und andere Szenarien bietet (Quelle: op7418, op7418, op7418)

Ichi: Gerätebasierte dialogorientierte KI auf Basis von MLX Swift und MLX audio: Rudrank Riyam hat Ichi entwickelt, ein gerätebasiertes dialogorientiertes KI-Projekt, das MLX Swift und MLX audio nutzt. Dies bedeutet, dass die Dialogverarbeitung lokal auf dem Gerät erfolgen kann, was zum Schutz der Privatsphäre der Nutzer beiträgt und die Abhängigkeit von Cloud-Diensten reduziert. Der Code des Projekts ist auf GitHub Open Source verfügbar (Quelle: stablequan, awnihannun)
FedRAG führt NoEncode RAG und MCP-Kernabstraktion ein: Das FedRAG-Projekt hat eine neue Kernabstraktion eingeführt – NoEncode RAG mit MCP. Traditionelles RAG umfasst einen Retriever, einen Generator und eine Wissensdatenbank, wobei das Wissen in der Wissensdatenbank vom Retriever-Modell kodiert werden muss. NoEncode RAG hingegen überspringt den Kodierungsschritt vollständig und besteht direkt aus einer NoEncode-Wissensdatenbank und einem Generator, ohne dass ein Retriever/Embedding erforderlich ist. Dies ebnet den Weg für den Aufbau von RAG-Systemen, die MCP (Model Component Provider)-Server als Wissensquelle nutzen. Benutzer können sich mit mehreren MCP-Quellen von Drittanbietern verbinden und RAG über FedRAG feinabstimmen, um eine optimale Leistung zu erzielen (Quelle: nerdai)

📚 Lernen
Stanford University CS224n (Version 2024) Kurs online, ergänzt um LLM- und Agenten-Inhalte: Der klassische Natural Language Processing Kurs CS224n der Stanford University wurde in der neuesten Version für 2024 veröffentlicht. Die neue Kursversion deckt aktuelle Themen im Zusammenhang mit großen Sprachmodellen (LLM) ab, darunter Pre-Training, Post-Training, Benchmarking, Inferenz und Agenten. Die Kursvideos sind auf YouTube öffentlich zugänglich, gleichzeitig wird eine kostenpflichtige synchrone Kurserfahrung angeboten (Quelle: stanfordnlp)
Leitfaden zur Verbesserung der Systemarchitekturfähigkeiten: Praxis und Lernen im KI-Zeitalter: Dotey teilt detaillierte Methoden zur Verbesserung der persönlichen Systemarchitekturfähigkeiten vor dem Hintergrund der zunehmend leistungsfähigen KI-gestützten Programmierung. Der Artikel betont, dass Systemdesign der Prozess ist, komplexe Systeme in leicht zu implementierende und zu wartende kleine Module zu zerlegen und die Zusammenarbeit zwischen den Modulen klar zu definieren. Zu den Verbesserungsmethoden gehören „viel sehen“ (Studium klassischer Fälle, Open-Source-Projekte), „viel üben“ (Architektur-Rekonstruktion, vergleichendes Lernen, Design-First-Ansatz, KI-gestützte Verifizierung, Refactoring, Side-Project-Praxis) und „viel reflektieren“ (Zusammenfassung von Entscheidungsgrundlagen, Erfahrungen und Lehren). KI kann als Hilfsmittel dienen, um Informationen zu recherchieren, Designs zu verifizieren, Kommunikation und Entscheidungsfindung zu unterstützen, aber sie kann Praxis und Denken nicht ersetzen (Quelle: dotey)

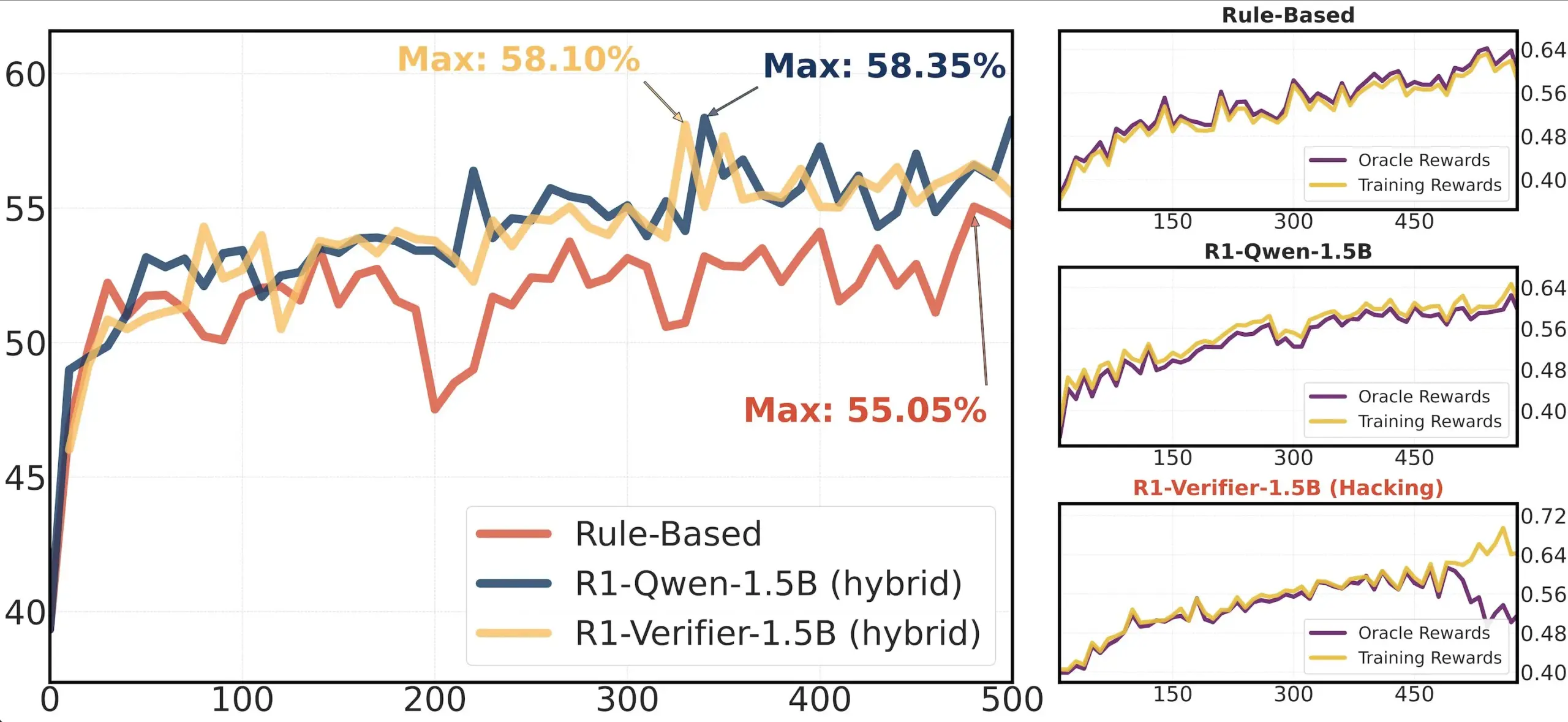
Paper-Vorstellung: Forschung zur Zuverlässigkeit von Verifikatoren in RLHF: Ein Paper mit dem Titel „Pitfalls of Rule- and Model-based Verifiers“ untersucht die Mängel von regel- und modellbasierten Verifikatoren in der Reinforcement Learning Verification (RLVR). Die Studie stellt fest, dass regelbasierte Verifikatoren selbst im mathematischen Bereich oft unzuverlässig und in vielen Bereichen nicht verfügbar sind; modellbasierte Verifikatoren hingegen sind leicht angreifbar, beispielsweise durch die Konstruktion einfacher adversarieller Muster. Interessanterweise stellt die Studie fest, dass generative Verifikatoren, zu denen sich die Community hinwendet, anfälliger für Reward Hacking sind als diskriminative Verifikatoren, was darauf hindeutet, dass diskriminative Verifikatoren in RLVR möglicherweise robuster sind (Quelle: Francis_YAO_)
Literaturempfehlung: Äquioszillationssatz der besten Polynomapproximation: Ein Artikel stellt den Äquioszillationssatz der besten Polynomapproximation sowie das damit verbundene Problem der Differentiation in der Unendlichkeitsnorm vor. Dieser Satz ist ein klassisches Ergebnis der Funktionennäherungstheorie und von großer Bedeutung für das Verständnis und den Entwurf numerischer Algorithmen (Quelle: eliebakouch)
Reasoning Gym: Verifizierbare Belohnungs-Inferenzumgebungen für Reinforcement Learning: Das neue Paper „Reasoning Gym: Reasoning Environments for Reinforcement Learning with Verifiable Rewards“ (arXiv:2505.24760) stellt eine Reihe von Inferenzumgebungen für Reinforcement Learning vor. Diese Umgebungen zeichnen sich durch verifizierbare Belohnungen aus und bieten eine Plattform für die Forschung und Entwicklung zuverlässigerer Reinforcement Learning Inferenz-Agenten (Quelle: Ar_Douillard)

🌟 Community
Diskussion über „Mid-Training“: Die KI-Community diskutiert die Bedeutung und Praxis des Begriffs „Mid-Training“. Einige äußern Verwirrung und kennen nur Pre-Training und Post-Training. Es gibt die Ansicht, dass Mid-Training sich auf eine spezifische Trainingsphase zwischen Pre-Training und finalem Fine-Tuning beziehen könnte, beispielsweise kontinuierliches Pre-Training für spezifisches Domänenwissen oder frühes Alignment. Dorialexander teilte einen entsprechenden Blogbeitrag, der dieses Konzept weiter untersucht und argumentiert, dass es die Injektion spezifischer Aufgaben oder Fähigkeiten in Basismodelle beinhalten könnte, aber es gibt noch keine einheitliche Definition und Methodik (Quelle: code_star, fabianstelzer, Dorialexander, iScienceLuvr, clefourrier)

Reverse-Engineering-Analyse von Claude Code erregt Aufmerksamkeit: Hrishi hat durch Reverse Engineering von minimiertem Code von Claude Code in 8-10 Stunden unter Einsatz mehrerer Sub-Agenten und der Flaggschiff-Modelle großer Anbieter die Komplexität seiner internen Struktur aufgedeckt. Die Analyse zeigt, dass Claude Code keine einfache Schleife eines Claude-Modells ist, sondern eine Vielzahl von Mechanismen enthält, von denen man lernen kann. Diese Entdeckung löste eine Diskussion in der Community aus, die der Meinung ist, dass man daraus viele Erfahrungen über den Aufbau von Agenten und die Anwendung von Modellen lernen kann (Quelle: rishdotblog, imjaredz, hrishioa)
Diskussion über die Länge von System-Prompts und die Modellleistung: Die Community diskutiert den Einfluss der Länge von System-Prompts auf die Leistung von LLMs. Dotey ist der Meinung, dass überlange System-Prompts nicht immer gut sind, da sie die Aufmerksamkeit des Modells verwässern und die Kosten erhöhen können, und weist darauf hin, dass die System-Prompts der ChatGPT-Produktreihe relativ kurz sind, aber gute Ergebnisse liefern. Tony出海号 hingegen erwähnt, dass die System-Prompts von Produkten wie Claude und Cursor Zehntausende von Wörtern lang sind, was auf die Notwendigkeit erweiterter Prompt-Systeme hindeutet. Ein Artikel von YC enthüllt auch, dass führende KI-Unternehmen lange Prompts, XML, Meta-Prompts usw. verwenden, um LLMs zu „zähmen“. Dorialexander äußert Zweifel an der Robustheit der im YC-Artikel erwähnten langen Prompt-Methoden im RL/Inferenz-Training und konzentriert sich darauf, wie das Problem der „Anbiederung“ (Sycophancy) gemildert werden kann (Quelle: dotey, Dorialexander)

Skalierungsprobleme bei Softpick führen zu Lob für wissenschaftliche Transparenz: Der Forscher Zed gab öffentlich bekannt, dass seine zuvor untersuchte Softpick-Methode bei der Skalierung auf größere Modelle (1,8 Mrd. Parameter) sowohl beim Trainingsverlust als auch bei den Benchmark-Ergebnissen schlechter abschnitt als Softmax, und hat das arXiv-Preprint aktualisiert. Die Community lobte dieses transparente Teilen negativer Ergebnisse ausdrücklich und betonte, dass dies für den wissenschaftlichen Fortschritt entscheidend sei und als Merkmal exzellenter wissenschaftlicher Kollegen angesehen werde (Quelle: gabriberton, vikhyatk, BlancheMinerva)
Nutzer teilen Modellauswahl und Erfahrungen mit lokal betriebenen LLMs: Nutzer der Reddit-Community r/LocalLLaMA diskutieren intensiv über die aktuell genutzten lokalen großen Sprachmodelle. Modelle wie Qwen 3 (insbesondere 32B Q4, 32B Q8, 30B A3B), Gemma 3 (insbesondere 27B QAT Q8, 12B) und Devstral werden aufgrund ihrer Leistung in Bereichen wie Code, Kreativität und allgemeine Inferenz häufig genannt. Nutzer achten auf die Kontextlänge der Modelle, Inferenzgeschwindigkeit, quantisierte Versionen (wie IQ1_S_R4) und die Ausführung auf unterschiedlicher Hardware (z. B. 8 GB VRAM, Snapdragon 8 Elite Chip-Smartphones). Auch Closed-Source-Modelle wie Claude Code und Gemini API werden aufgrund ihrer spezifischen Vorteile (z. B. Verarbeitung langer Kontexte, Code-Fähigkeiten) parallel genutzt (Quelle: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
💡 Sonstiges
Kompetenzentwicklung im KI-Zeitalter: Fragen stellen, kritisches Denken und kontinuierliches Lernen sind entscheidend: Diskussionen betonen, dass im KI-Zeitalter sechs Fähigkeiten von entscheidender Bedeutung sind: die Fähigkeit, Fragen zu stellen, kritisches Denken, eine lernende Haltung beizubehalten, Programmier- oder Anweisungsfähigkeiten, der versierte Umgang mit KI-Tools und klare Kommunikation. Das Unternehmen Zapier verlangt sogar von 100 % der neuen Mitarbeiter KI-Kenntnisse, was hauptsächlich als Betonung der Kommunikationsbedürfnisse und der Fähigkeit zur korrekten Aufgabenverteilung interpretiert wird, weniger als reines technisches Wissen. KI erleichtert die Ausführung, daher haben Design und Denkqualität einen größeren Einfluss auf das Endergebnis (Quelle: TheTuringPost, zacharynado)

KI-Ethik und gesellschaftliche Auswirkungen: Sorgen und Empowerment zugleich: Der Schauspieler Steve Carell äußert sich besorgt über die in seinem neuen Film „Mountainhead“ dargestellte zukünftige Gesellschaft und meint, dies könnte die Gesellschaft sein, in der wir bald leben werden, was auf Ängste vor potenziellen negativen Auswirkungen der KI hindeutet. Andererseits gibt es die Ansicht, dass KI nicht zwangsläufig zu einer extremen Spaltung in „Bauern und Könige“ führen muss, sondern im Gegenteil durch die Stärkung des Einzelnen die Kluft zwischen Einzelpersonen und großen Unternehmen verringern und die persönliche Produktivität, Kreativität und den Einfluss fördern könnte. Bezüglich der Aussichten auf eine Demokratisierung der KI gibt es jedoch auch vorsichtige Stimmen, die davon ausgehen, dass große Unternehmen weiterhin durch die Kontrolle von Modelltraining und -bereitstellung die Vormachtstellung behalten werden (Quelle: Reddit r/artificial, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

KI-gestützte Aggregationsplattform für Stellenangebote Hiring Cafe: Hamed N. nutzte die ChatGPT API, um 4,1 Millionen direkt auf Unternehmenswebsites veröffentlichte Stellenangebote zu crawlen und die Website Hiring Cafe zu erstellen. Die Plattform zielt darauf ab, das Problem der „Geisterjobs“ und Drittanbieter auf Plattformen wie LinkedIn und Indeed zu lösen, indem sie Arbeitssuchenden hilft, Stellenangebote mithilfe leistungsstarker Filter (z. B. Position, Funktion, Branche, Berufserfahrung, Führungs-/IC-Rolle usw.) effektiver zu sieben. Es handelt sich um ein nichtkommerzielles Nebenprojekt eines Doktoranden, das von der Community gelobt und genutzt wird (Quelle: Reddit r/ChatGPT)
