
Schlüsselwörter:KI-Modell, Deep Learning, Künstliche Intelligenz, Große Sprachmodelle, Maschinelles Lernen, KI-Agenten, Rechenleistungsengpässe, KI-Anwendungen, Grok-Systemprompt, AlphaEvolve Mathe-Rekord, Gemini KI-Agent, FP4-Trainingsmethode, Sonnet 4.0 Tabellenanalyse
🔥 Fokus
xAI veröffentlicht Grok-System-Prompt und verschärft Überprüfungsmechanismen: Das Unternehmen xAI gab kürzlich bekannt, dass es den Grok-System-Prompt auf GitHub veröffentlichen wird. Grund dafür waren nicht autorisierte Änderungen der Prompts seines Grok-Antwortroboters auf der Plattform X und die Veröffentlichung politischer Äußerungen, die gegen die Unternehmensrichtlinien und -werte verstießen. Dieser Schritt zielt darauf ab, die Transparenz und Zuverlässigkeit von Grok als einer KI, die nach Wahrheit strebt, zu erhöhen. xAI kündigte außerdem an, die internen Code-Überprüfungsprozesse zu verstärken und ein 24/7-Überwachungsteam einzurichten, um ähnliche Vorfälle in Zukunft zu verhindern und schneller auf Probleme zu reagieren, die nicht von automatisierten Systemen erfasst werden. (Quelle: xai, xai)
DeepMind AlphaEvolve bricht erneut mathematischen Rekord, KI und menschliche Zusammenarbeit zeigen neues Forschungsparadigma: DeepMinds AlphaEvolve hat innerhalb einer Woche zweimal einen seit 18 Jahren bestehenden mathematischen Rekord gebrochen und damit die Aufmerksamkeit von Mathematikern wie Terence Tao auf sich gezogen. Tao ist der Ansicht, dass unterschiedliche Forschungsmethoden den mathematischen Fortschritt komplementär vorantreiben können, anstatt eines einfachen „Winner-takes-all“-Prinzips. Dieser Vorfall unterstreicht das Potenzial der Zusammenarbeit von KI und Menschen, neue Fortschrittsmodelle in Technologie und Wissenschaft zu schaffen. KI ist nicht länger nur ein Ersatzwerkzeug, sondern ein Partner, der gemeinsam mit Menschen Unbekanntes erforscht und Innovationen beschleunigt. (Quelle: Yuchenj_UW)

Google kooperiert mit Open-Source-Community zur Vereinfachung der Erstellung von KI-Agenten auf Basis von Gemini: Google hat angekündigt, mit Open-Source-Frameworks wie LangChain LangGraph, crewAI, LlamaIndex und ComposIO zusammenzuarbeiten, um Entwicklern die Erstellung von KI-Agenten auf Basis des Google Gemini-Modells zu erleichtern. Diese Initiative spiegelt Googles Entschlossenheit wider, das Ökosystem für KI-Agenten voranzutreiben, indem benutzerfreundlichere Tools und Frameworks bereitgestellt, die Entwicklungshürden gesenkt und die Entstehung innovativerer Anwendungen gefördert werden. (Quelle: osanseviero, Hacubu)

Inferenzfähigkeiten von KI-Modellen könnten innerhalb eines Jahres auf Rechenleistungsengpässe stoßen: Obwohl Inferenzmodelle wie o3 von OpenAI kurzfristig signifikante Leistungssteigerungen durch Rechenleistung zeigten (z. B. ist die Trainingsrechenleistung von o3 zehnmal so hoch wie die von o1), prognostizieren Forschungseinrichtungen wie Epoch AI, dass die Skalierung der Rechenleistung von Inferenzmodellen bei der aktuellen Verzehnfachung alle paar Monate höchstens innerhalb eines Jahres an eine „Obergrenze“ stoßen könnte. Dann könnte sich das Wachstum der Rechenleistung auf das Vierfache pro Jahr verlangsamen, und die Geschwindigkeit der Modellaktualisierungen würde entsprechend nachlassen. Die Trainingsdaten von Modellen wie DeepSeek-R1 bestätigen indirekt den aktuellen Umfang des Rechenleistungsverbrauchs für das Inferenztraing. Obwohl Daten- und Algorithmusinnovationen weiterhin Fortschritte ermöglichen können, wird die Verlangsamung des Rechenleistungswachstums eine wichtige Herausforderung für die KI-Branche darstellen. (Quelle: WeChat)

🎯 Trends
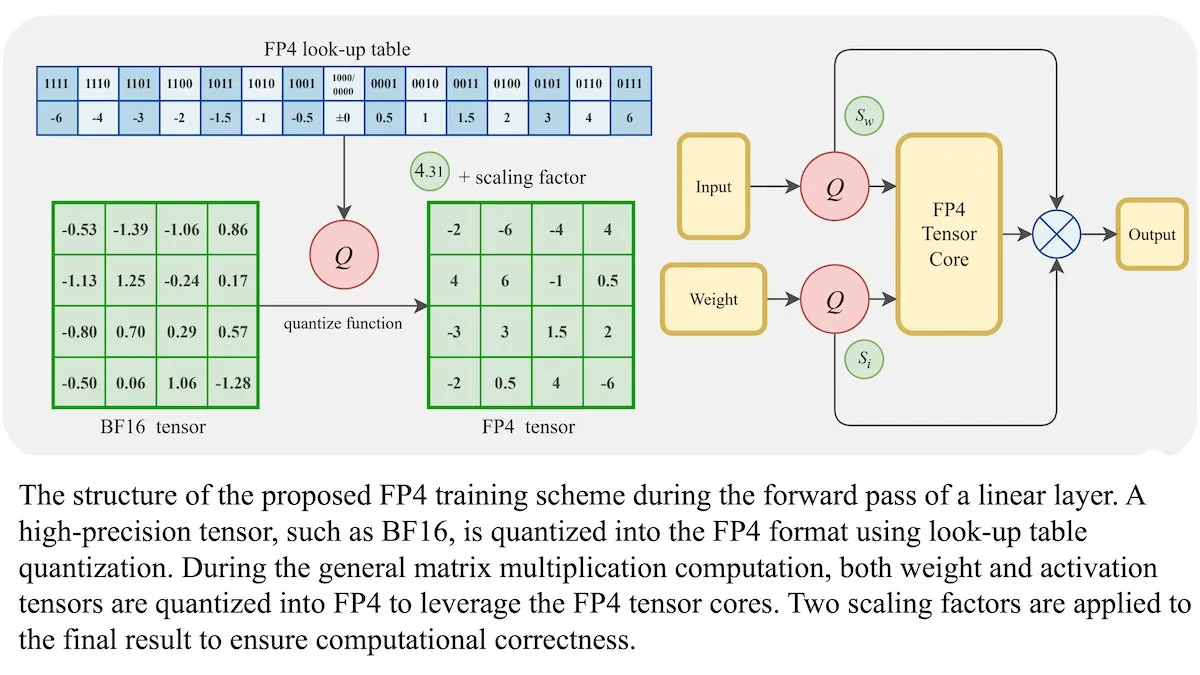
Neue Trainingsmethode für LLMs: 4-Bit-Gleitkommagenauigkeit (FP4) erreicht gleiche Genauigkeit wie BF16: Forscher haben gezeigt, dass große Sprachmodelle (LLMs) mit 4-Bit-Gleitkommagenauigkeit (FP4) trainiert werden können, ohne an Genauigkeit einzubüßen. Durch die Verwendung von FP4 für Matrixmultiplikationen, die 95 % der Trainingsberechnungen ausmachen, wurde eine vergleichbare Leistung wie mit dem gebräuchlichen BF16-Format erzielt. Das Team führte eine differenzierbare Approximation ein, um die Nicht-Differenzierbarkeit der Quantisierung zu überwinden und die Trainingseffizienz zu verbessern. Simulationen auf Nvidia H100 GPUs zeigten, dass FP4 in verschiedenen Sprachbenchmarks vergleichbar oder besser als BF16 abschneidet. (Quelle: DeepLearningAI)
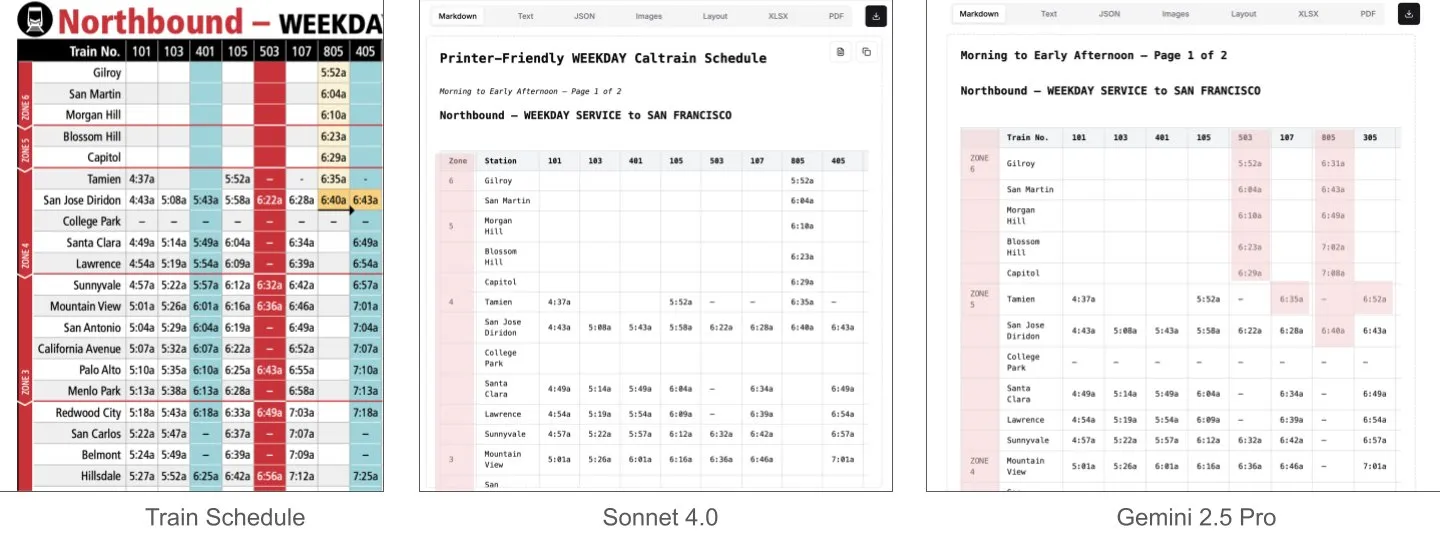
Sonnet 4.0 übertrifft Gemini 2.5 Pro beim Dokumentenverständnis, insbesondere bei der Tabellenanalyse: Jerry Liu von LlamaIndex stellte durch Vergleichstests fest, dass Sonnet 4.0 von Anthropic bei der Verarbeitung von Screenshots des Caltrain-Fahrplans mit dichten Tabellendaten die Tabellenanalysefähigkeiten von Googles Gemini 2.5 Pro deutlich übertrifft. Gemini 2.5 Pro zeigte Spaltenverschiebungen, während Sonnet 4.0 die meisten numerischen Werte gut rekonstruieren konnte und nur bei Tabellenköpfen und wenigen anderen Werten Fehler machte. Obwohl Sonnet 4.0 derzeit teurer und langsamer ist, sticht seine Leistung bei visueller Inferenz und Tabellenanalyse hervor. (Quelle: jerryjliu0)
xAI, TWG Global und Palantir kooperieren, um KI-Anwendungen im Finanzdienstleistungssektor neu zu gestalten: xAI kündigte eine Partnerschaft mit TWG Global und Palantir Technologies an, um gemeinsam KI-gestützte Unternehmenslösungen zu entwickeln und einzusetzen, die die Art und Weise, wie Finanzdienstleister KI einsetzen und Technologien skalieren, neu gestalten sollen. Palantir CEO Alex Karp und TWG Global Co-Chairman Thomas Tull diskutierten auf der Konferenz des Milken Institute, wie diese Zusammenarbeit die KI-Innovation im Finanzsektor vorantreiben wird. (Quelle: xai, xai)
Verschärfte Zensur nach DeepSeek-R1-0528 Update löst Community-Diskussion aus: Nutzer berichten, dass DeepSeek-R1-0528 (671B Gesamtmodell, FP8) im Vergleich zur älteren Version R1 die Inhaltszensur deutlich verschärft hat. Beispielsweise gibt das neue Modell bei Fragen zu sensiblen historischen Ereignissen ausweichendere und offiziellere Antworten, während die alte Version R1 direktere Informationen liefern konnte. Diese Änderung hat in der Community Diskussionen über die Offenheit des Modells, das Ausmaß der Zensur und deren potenzielle Auswirkungen auf Forschung und Anwendung ausgelöst, insbesondere in Szenarien, die auf den Zugriff auf unzensierte Informationen durch das Modell angewiesen sind. (Quelle: Reddit r/LocalLLaMA)
Huawei veröffentlicht Pangu Embedded-Modell, das kognitive Architektur mit dualem System für schnelles und langsames Denken integriert: Das Huawei Pangu-Team hat auf Basis von Ascend NPUs das Pangu Embedded-Modell vorgestellt, das innovativ duale Inferenzmodi für „schnelles Denken“ und „langsames Denken“ integriert. Durch ein zweistufiges Training (iterative Destillation und Modellfusion, Multi-Source Dynamic Reward System RL) und eine kognitive Architektur, die entweder benutzergesteuert oder durch Wahrnehmung der Problemschwierigkeit automatisch umschaltet, zielt das Modell darauf ab, ein dynamisches Gleichgewicht zwischen Inferenceffizienz und -tiefe zu erreichen. Es soll den Widerspruch lösen, dass traditionelle große Modelle bei einfachen Problemen übermäßig nachdenken und bei komplexen Aufgaben unzureichend denken. (Quelle: WeChat)

Neues Video-Weltmodell kombiniert SSM und Diffusionsmodelle für langen Kontext und interaktive Simulation: Forscher der Stanford University, Princeton University und Adobe Research haben ein neues Video-Weltmodell vorgestellt, das durch die Kombination von State Space Models (SSM, insbesondere das blockweise Scan-Schema von Mamba) und Video-Diffusionsmodellen die Probleme bestehender Videomodelle mit begrenzter Kontextlänge und Schwierigkeiten bei der Simulation langfristiger Konsistenz löst. Das Modell kann kausale zeitliche Dynamiken effektiv verarbeiten, den Weltzustand verfolgen und durch einen Frame-lokalen Aufmerksamkeitsmechanismus die Generierungstreue gewährleisten. Es eröffnet neue Wege für die unbegrenzt lange, echtzeitfähige und konsistente Videogenerierung in interaktiven Anwendungen (z. B. Spielen). (Quelle: WeChat)

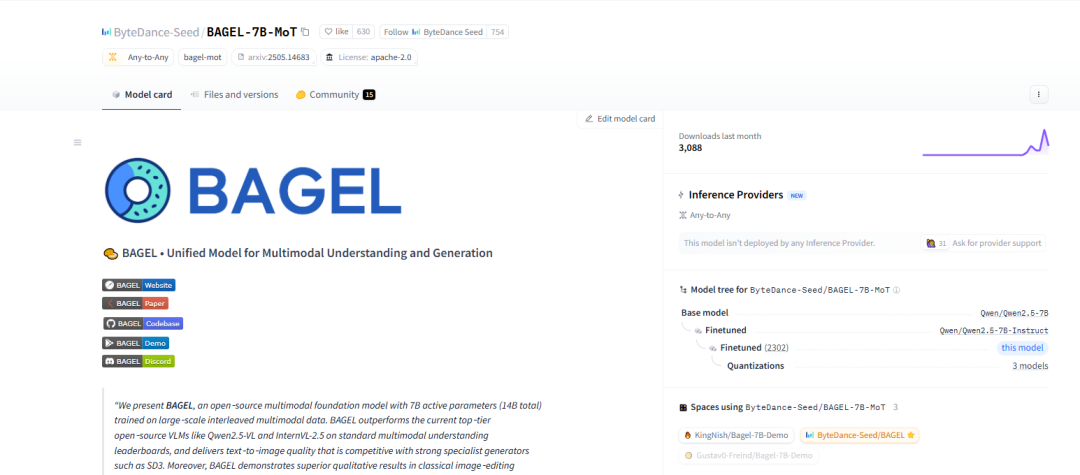
ByteDance veröffentlicht multimodales Basismodell BAGEL als Open Source, unterstützt Text-, Bild- und Videoverständnis sowie -generierung: ByteDance hat das Modell BAGEL (ByteDance Agnostic Generation and Empathetic Language model) als Open Source veröffentlicht. Es handelt sich um ein einheitliches multimodales Basismodell, das gleichzeitig Text-, Bild- und Videoverständnis- sowie Generierungsaufgaben bewältigen kann. Die Version BAGEL-7B-MoT verfügt über insgesamt 14 Milliarden Parameter (7 Milliarden aktive Parameter) und benötigt bei voller Auslastung etwa 30 GB Grafikspeicher. Nutzer können über die bereitgestellte Hugging Face Demo und die Modelladresse das Modell ausprobieren und implementieren, um Funktionen wie Bildbearbeitung und Stilübertragung zu realisieren. (Quelle: WeChat)
FLUX.1 Kontext veröffentlicht: Kombiniert Text-Bild-Bearbeitung und -Generierung, 8-fache Geschwindigkeitssteigerung: Black Forest Labs (BFL) hat die neue Generation des Bildmodells FLUX.1 Kontext veröffentlicht. Diese Modellreihe unterstützt die kontextinterne Bildgenerierung, kann gleichzeitig Text- und Bild-Prompts verarbeiten und ermöglicht sofortige Text-Bild-Bearbeitung sowie Text-zu-Bild-Generierung. FLUX.1 Kontext zeichnet sich durch hervorragende Charakterkonsistenz, Kontextverständnis und lokale Bearbeitung aus. Die Generierung von Bildern mit einer Auflösung von 1024×1024 dauert nur 3-5 Sekunden, was bis zu 8-mal schneller ist als GPT-Image-1, und unterstützt iterative Bearbeitung in mehreren Runden. Das Modell basiert auf einem Rectified Flow Transformer und einer adversariellen Diffusionsdestillations-Sampling-Technik. (Quelle: WeChat, WeChat)

LaViDa: Neues multimodales Verständnis-VLM basierend auf Diffusionsmodellen: Forscher der University of California, Los Angeles, Panasonic, Adobe und Salesforce haben LaViDa (Large Vision-Language Diffusion Model with Masking) vorgestellt, ein auf Diffusionsmodellen basierendes Vision-Language Model (VLM). Im Gegensatz zu traditionellen VLMs, die auf autoregressiven LLMs basieren, nutzt LaViDa einen diskreten Diffusionsprozess zur Textgenerierung, was theoretisch eine bessere Parallelität, einen besseren Kompromiss zwischen Geschwindigkeit und Qualität sowie die Fähigkeit zur Verarbeitung bidirektionalen Kontexts bietet. Das Modell integriert visuelle Merkmale über einen visuellen Encoder und verwendet einen zweistufigen Trainingsprozess (Vortraining zur Angleichung des visuellen und des latenten DLM-Raums, Feinabstimmung zur Befolgung von Anweisungen). Experimente zeigen, dass LaViDa bei verschiedenen Aufgaben wie visuellem Verständnis, Inferenz, OCR und wissenschaftlichen Frage-Antwort-Aufgaben wettbewerbsfähig ist. (Quelle: WeChat)
KI-Modelle sind dem Risiko der „Modelldegeneration“ ausgesetzt, da sie zu viele KI-generierte Daten aufnehmen: Studien zeigen, dass KI-Modelle, die während des Trainingsprozesses zu viele von anderen KIs generierte Daten aufnehmen, ein Phänomen der „Modelldegeneration“ (model collapse) aufweisen können, was dazu führt, dass die Modelle chaotischer und unzuverlässiger werden. Selbst wenn es den Modellen erlaubt ist, online nach Informationen zu suchen, könnte das Problem durch die Fülle an minderwertigen, KI-generierten Inhalten im Internet verschärft werden. Dieses Phänomen wurde erstmals 2023 vorgeschlagen und wird nun immer deutlicher, was Herausforderungen für die langfristige Entwicklung von KI-Modellen und die Qualitätskontrolle von Daten darstellt. (Quelle: Reddit r/ArtificialInteligence)

AMD Octa-Core Ryzen AI Max Pro 385 Prozessor auf Geekbench gesichtet, deutet auf Markteinführung günstiger Strix Halo Chips hin: AMDs neuer Octa-Core Ryzen AI Max Pro 385 Prozessor wurde auf Geekbench entdeckt, was bedeuten könnte, dass preisgünstigere KI-Chips mit dem Codenamen Strix Halo bald auf den Markt kommen. Nutzer erwarten von solchen Chips mehr PCIe-Lanes zur Unterstützung hybrider Setups und zur Erfüllung der Anforderungen für zusätzliche Erweiterungskarten und USB4-Geräte. Obwohl Onboard-Speicher aufgrund seiner Geschwindigkeitsvorteile akzeptabel ist, bleibt die Erweiterbarkeit ein wichtiger Aspekt. (Quelle: Reddit r/LocalLLaMA)

1X Unternehmen stellt neuesten humanoiden Roboterprototyp Neo Gamma vor: Das norwegische Robotikunternehmen 1X hat seinen neuesten humanoiden Roboterprototyp Neo Gamma vorgestellt. Die Einführung dieses Roboters stellt einen weiteren Fortschritt in der humanoiden Robotertechnologie im Bereich Automatisierung und künstliche Intelligenz dar und zeigt sein Anwendungspotenzial in zukünftigen Industrie-, Dienstleistungs- und vielen anderen Szenarien. (Quelle: Ronald_vanLoon)
KI-Stromverbrauch wird voraussichtlich bald den von Bitcoin-Mining übersteigen: Der Stromverbrauch von KI-Modellen wird voraussichtlich rapide ansteigen und könnte bald fast die Hälfte des Stroms von Rechenzentren beanspruchen, wobei ihr Energieverbrauch dem einiger Länder entspricht. Die steigende Nachfrage nach KI-Chips setzt das US-Stromnetz unter Druck und treibt den Bau neuer Projekte für fossile Brennstoffe und Kernenergie voran. Aufgrund mangelnder Transparenz und der Komplexität regionaler Stromquellen wird es schwierig, die Auswirkungen der CO2-Emissionen von KI genau zu verfolgen. (Quelle: Reddit r/ArtificialInteligence)

🧰 Tools
e-library-agent: Von LlamaIndex entwickelter persönlicher Bibliotheksverwaltungs-Agent: Clelia Bertelli hat mit dem LlamaIndex-Workflow ein Tool namens e-library-agent entwickelt, das Nutzern helfen soll, ihre persönlichen Lesesammlungen zu organisieren, zu durchsuchen und zu erkunden. Das Tool integriert Technologien wie ingest-anything, Qdrant, Linkup_platform, FastAPI und Gradio, um das Problem „gelesen, aber nicht auffindbar“ zu lösen und die Effizienz des persönlichen Wissensmanagements zu steigern. (Quelle: jerryjliu0, jerryjliu0)
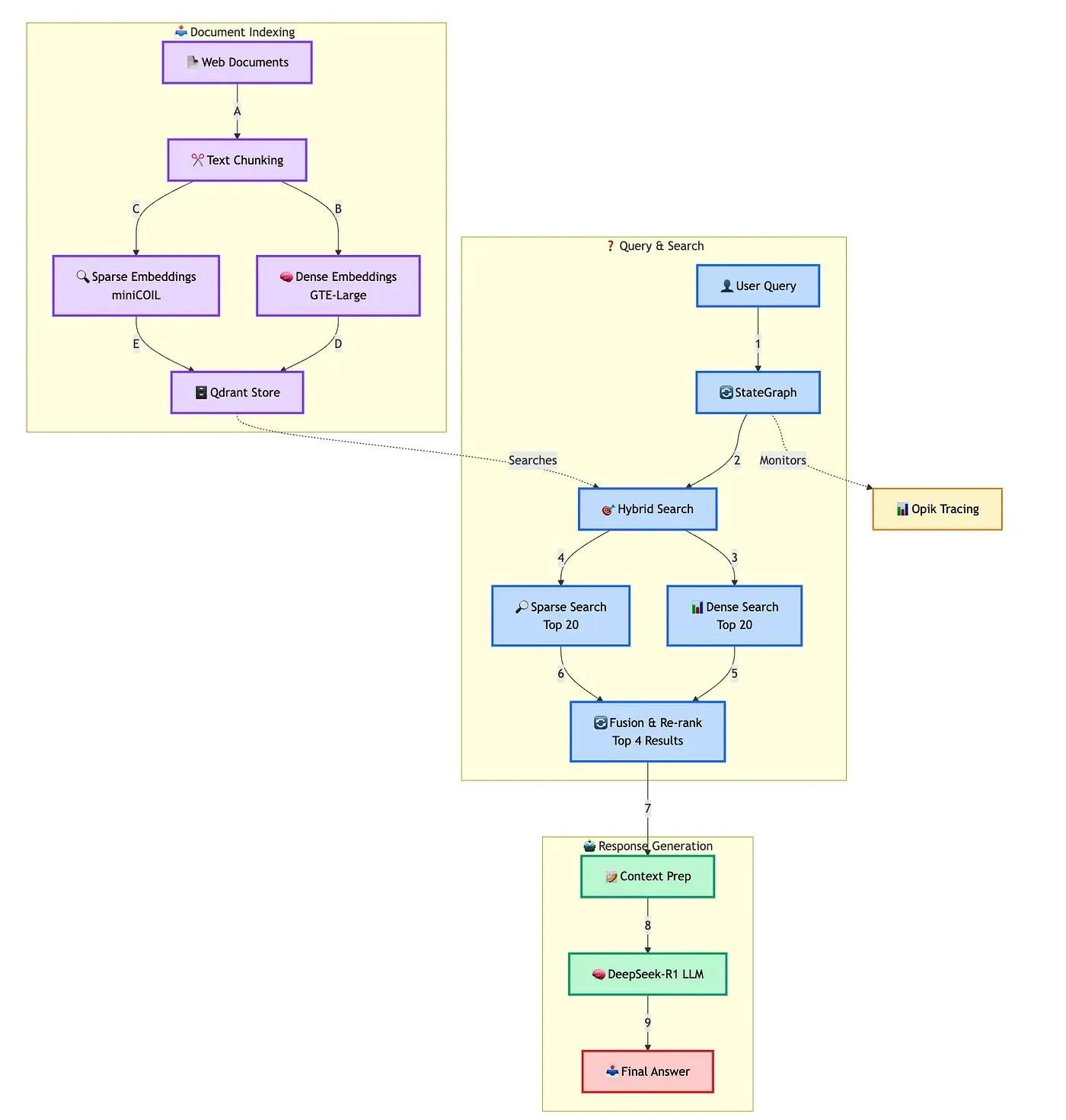
Qdrant präsentiert Lösung zum Aufbau eines fortschrittlichen hybriden RAG-Chatbots: Qdrant demonstrierte zusammen mit TRJ_0751, wie man mit miniCOIL, LangGraph und DeepSeek-R1 einen fortschrittlichen hybriden RAG (Retrieval Augmented Generation)-Chatbot für den Kundensupport erstellt. Diese Lösung nutzt miniCOIL zur Verbesserung der semantischen Wahrnehmung bei der Sparse-Suche, LangGraph (von LangChainAI) zur Orchestrierung hybrider Prozesse (einschließlich MMR und Re-Ranking), Opik zur Verfolgung und Bewertung der einzelnen Prozessschritte und DeepSeek-R1 (von SambaNovaAI) für latenzarme, fokussierte Antworten. (Quelle: qdrant_engine, hwchase17)
Google veröffentlicht AI Edge Gallery App, unterstützt lokale Ausführung von KI-Modellen: Google hat eine App namens AI Edge Gallery veröffentlicht, die es Nutzern ermöglicht, KI-Modelle herunterzuladen und lokal auf ihren Geräten auszuführen. Dies bedeutet, dass Nutzer KI-Tools für Bildgenerierung, Frage-Antwort-Systeme oder Code-Erstellung ohne Internetverbindung nutzen können, während gleichzeitig der Datenschutz gewährleistet ist. Die App wird derzeit als Vorschauversion angeboten und unterstützt Modelle wie Gemma 3n. (Quelle: Reddit r/LocalLLaMA, Reddit r/ArtificialInteligence, Reddit r/LocalLLaMA)

Perplexity Labs unterstützt Suche über SEC EDGAR-Dokumente hinweg und stärkt Finanzrecherche-Fähigkeiten: Perplexity Labs hat eine neue Funktion hinzugefügt, die es Nutzern ermöglicht, Unternehmensdokumente in der EDGAR-Datenbank der US-amerikanischen Börsenaufsichtsbehörde (SEC) zu durchsuchen. Dieses Update zielt darauf ab, die Anwendung im Bereich der Finanzrecherche weiter zu stärken und Nutzern einen bequemeren Weg zur Recherche und Analyse von Informationen über börsennotierte Unternehmen zu bieten. (Quelle: AravSrinivas)
Meituan stellt KI-No-Code-Tool NoCode vor, Anwendungen mit natürlicher Sprache erstellen: Meituan hat das KI-No-Code-Tool NoCode veröffentlicht, mit dem Nutzer ohne Programmiererfahrung durch Dialoge in natürlicher Sprache persönliche Effizienzsteigerungstools, Produktprototypen, interaktive Seiten und sogar einfache Spiele erstellen können. NoCode unterstützt Echtzeit-Vorschau, lokale Modifikationen und Ein-Klick-Bereitstellung, um die Entwicklungsschwelle zu senken und mehr Menschen die Freisetzung ihrer Kreativität zu ermöglichen. Hinter dem Tool steht die Zusammenarbeit mehrerer KI-Modelle, darunter das von Meituan selbst entwickelte 7B-Parameter-apply-Spezialmodell, das auf echte Codedaten von Meituan optimiert wurde. (Quelle: WeChat)
VAST rüstet Tripo Studio auf, fügt KI-Modellierungsfunktionen wie intelligente Teile-Segmentierung und magischen Pinsel hinzu: Das 3D-Großmodell-Startup VAST hat sein KI-Modellierungstool Tripo Studio umfassend aufgerüstet und vier Kernfunktionen eingeführt: intelligente Teile-Segmentierung, magischer Pinsel für Texturen, intelligente Low-Poly-Generierung und automatisches Rigging für alles. Diese Funktionen zielen darauf ab, Schwachstellen im traditionellen 3D-Modellierungsprozess zu beheben, wie z. B. schwierige Bearbeitung von Teilen, zeitaufwändige Korrektur von Texturfehlern, umständliche Optimierung von High-Poly-Modellen und komplexes Rigging von Skeletten. Dies soll die Effizienz und Benutzerfreundlichkeit der 3D-Content-Erstellung erheblich verbessern und die Einstiegshürde für nicht-professionelle Nutzer senken. (Quelle: 量子位)
Hugging Face veröffentlicht zwei Open-Source-Humanoide Roboter HopeJR und Reachy Mini zu erschwinglichen Preisen: Hugging Face hat in Zusammenarbeit mit The Robot Studio und Pollen Robotics zwei Open-Source-Humanoide Roboter vorgestellt: den vollformatigen HopeJR (ca. 3000 US-Dollar) und den Desktop-Roboter Reachy Mini (ca. 250-300 US-Dollar). Ziel dieser Initiative ist es, die Verbreitung und offene Forschung im Bereich Robotik zu fördern und es jedem zu ermöglichen, Roboterprinzipien zusammenzubauen, zu modifizieren und zu erlernen. HopeJR kann gehen und Arme bewegen und per Handschuh ferngesteuert werden; Reachy Mini kann den Kopf bewegen, sprechen und zuhören und dient zum Testen von KI-Anwendungen. (Quelle: WeChat)

Weltweit erstes Open-Source-Framework für selbstevolvierende KI-Agenten EvoAgentX veröffentlicht: Ein Forschungsteam der University of Glasgow hat EvoAgentX veröffentlicht, das weltweit erste Open-Source-Framework für selbstevolvierende KI-Agenten. Das Framework zielt darauf ab, die Komplexität beim Aufbau und der Optimierung von Multi-KI-Agenten-Systemen zu lösen. Durch die Einführung eines Selbstevolutionsmechanismus unterstützt es den Aufbau von Workflows mit einem Klick und ermöglicht es dem System, seine Struktur und Leistung während des Betriebs kontinuierlich an sich ändernde Umgebungen und Ziele anzupassen. EvoAgentX hofft, Multi-Agenten-Systeme von der manuellen Fehlersuche zur autonomen Evolution zu führen und Forschern und Ingenieuren eine einheitliche Plattform für Experimente und Bereitstellung zu bieten. (Quelle: WeChat)

Perplexity Labs führt neue Funktion ein, kostenloser Export von Unternehmensfinanzdaten als CSV: Perplexity Labs gab bekannt, dass Nutzer nun kostenlos Daten aus jedem Finanzbereich von Unternehmen auf ihrer Finanzseite als CSV-Format exportieren können. Zuvor erforderten ähnliche Funktionen auf Plattformen wie Yahoo Finance in der Regel kostenpflichtige Abonnements. Perplexity erklärte, dass in Zukunft weitere historische Daten hinzugefügt werden sollen. (Quelle: AravSrinivas)
📚 Lernen
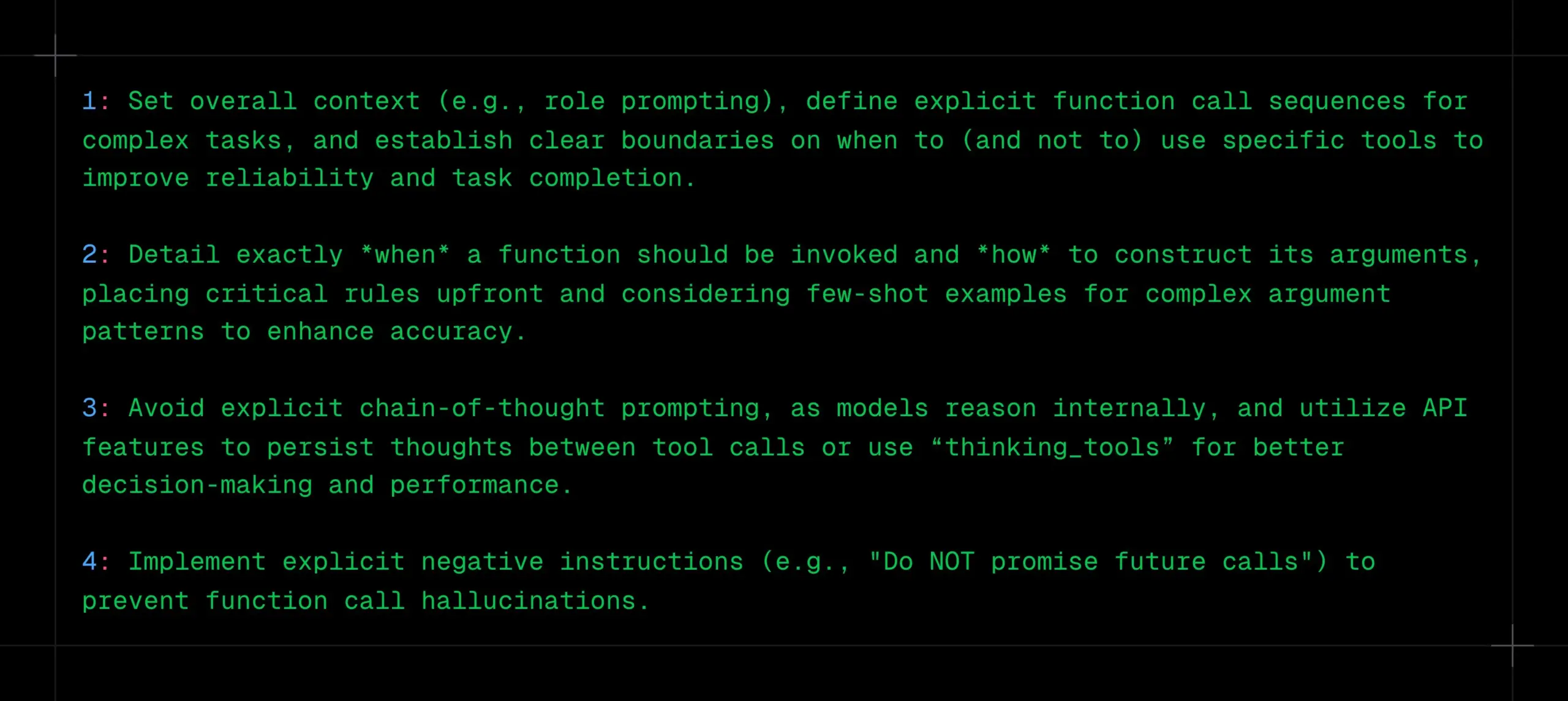
Tipps für LLM-Funktionsaufrufe: Klaren Kontext, Sequenz und Grenzen definieren, CoT und Halluzinationen vermeiden: _philschmid teilt Empfehlungen für Funktionsaufrufe bei Inferenzmodellen wie Gemini 2.5 oder OpenAI o3. Kernpunkte sind: Festlegung des Gesamtkontexts (z. B. Rollen-Prompt), Definition klarer Funktionsaufrufsequenzen für komplexe Aufgaben und Festlegung klarer Grenzen für die Tool-Nutzung (wann verwenden/nicht verwenden). Der Zeitpunkt von Funktionsaufrufen und die Parameterkonstruktion müssen detailliert beschrieben werden. Explizite CoT-Prompts sollten vermieden werden, da das Modell intern schlussfolgert; API-Funktionen können genutzt werden, um Denkprozesse zwischen Tool-Aufrufen persistent zu machen oder „thinking_tools“ zu verwenden. Gleichzeitig sollten klare Negativanweisungen (z. B. „Keine zukünftigen Aufrufe versprechen“) implementiert werden, um Halluzinationen bei Funktionsaufrufen zu verhindern. (Quelle: _philschmid)
12 professionelle KI-Programmiertipps geteilt: Cline teilte 12 KI-Programmiertipps von einer kürzlichen Konferenz über Engineering Best Practices. Er betonte Planung, die Verwendung fortschrittlicher Modelle für komplexe Aufgaben, die Beachtung des Kontextfensters, die Erstellung von Regeldateien, die klare Formulierung von Absichten, die Betrachtung von KI als Kollaborateur, die Nutzung von Speicherbanken, das Erlernen von Kontextmanagementstrategien und den Aufbau von Wissensaustausch im Team. Das Kernziel ist es, Software schneller und besser zu entwickeln und KI als Fähigkeitsverstärker und nicht als Ersatz zu nutzen. (Quelle: cline, cline)

Optimierungsvorschläge für Kreativ-Prompts nach dem DeepSeek-R1-0528 Update: Nach dem Update des DeepSeek-R1-0528 Modells (68,5 Milliarden Parameter, 128K Kontext, Code-Fähigkeiten nahe o3) teilten Content-Ersteller 10 optimierte Kreativ-Prompts. Zu den Vorschlägen gehören die Nutzung seiner 30-60 Minuten langen Inferenzfähigkeit für tiefes Nachdenken, die Verarbeitung von 128K langen Texten, die Optimierung der Codegenerierung, die Anpassung von System-Prompts, die Verbesserung der Qualität von Schreibaufgaben, die Anti-Halluzinations-Verifizierung, das Durchbrechen von Engpässen beim kreativen Schreiben, die Durchführung von Problemdiagnoseanalysen, die Integration von Wissenserwerb und die Optimierung von Werbetexten. Betont werden die Konkretisierung von Prompts, die volle Ausnutzung des langen Kontexts, die geschickte Nutzung der tiefen Inferenz, der Aufbau eines Dialoggedächtnisses und die Überprüfung wichtiger Informationen. (Quelle: WeChat)
RM-R1 Framework: Umgestaltung von Belohnungsmodellen als Inferenzaufgaben zur Verbesserung von Interpretierbarkeit und Leistung: Ein Forschungsteam der University of Illinois Urbana-Champaign schlägt das RM-R1 Framework vor, das die Erstellung von Belohnungsmodellen (Reward Models) als eine Inferenzaufgabe neu definiert. Durch die Einführung eines „Chain-of-Rubrics“ (CoR)-Mechanismus ermöglicht das Framework dem Modell, strukturierte Bewertungskriterien und Inferenzprozesse zu generieren, bevor es eine Präferenzentscheidung trifft. Dies verbessert die Interpretierbarkeit von Belohnungsmodellen und ihre Bewertungsgenauigkeit bei komplexen Aufgaben (wie Mathematik, Programmierung). RM-R1 wird in zwei Phasen trainiert (Inferenzdestillation und Reinforcement Learning) und übertrifft in mehreren Benchmarks für Belohnungsmodelle bestehende Open-Source- und Closed-Source-Modelle. (Quelle: WeChat)

Tiefenanalyse des Model Context Protocol (MCP): Vereinfachung der Integration von KI und externen Diensten: Das Model Context Protocol (MCP) ist ein offener Standard, der darauf abzielt, das Problem der Fragmentierung bei der Integration von KI-Modellen mit externen Datenquellen und Tools (wie Slack, Gmail) zu lösen. Durch eine einheitliche Systemschnittstelle (unterstützt STDIO- und SSE-Protokolle) ermöglicht MCP Entwicklern, MCP-Clients (z. B. Claude Desktop-Client, Cursor IDE) und MCP-Server (zur Bedienung von Datenbanken, Dateisystemen, Aufruf von APIs) zu erstellen. Dadurch wird das komplexe „M×N“-Anpassungsnetzwerk zu einem „M+N“-Modell vereinfacht, was eine Plug-and-Play-Integration von KI und externen Diensten ermöglicht. Tan Yu, Partner bei Maple Qing Technology Fabarta, ist der Ansicht, dass der Wert von MCP in der Bereitstellung grundlegender Konnektivitätsfähigkeiten liegt. Seine Kommerzialisierung hängt vom spezifischen Wert ab, den das dahinterstehende System bietet, beispielsweise durch die Vereinfachung von Benutzerprozessen durch den Fabarta Super Office Intelligent Agent, der den MCP Server integriert. (Quelle: WeChat)

Agentic ROI: Schlüsselindikator zur Messung der Benutzerfreundlichkeit von Agenten großer Modelle: Die Shanghai Jiao Tong University hat in Zusammenarbeit mit der University of Science and Technology of China den Agentic ROI (Return on Investment von Agenten) als Kernindikator zur Messung der praktischen Nützlichkeit von Agenten großer Modelle in realen Szenarien vorgeschlagen. Dieser Indikator berücksichtigt umfassend die Informationsqualität, die Zeitkosten von Nutzern und Agenten sowie die wirtschaftlichen Ausgaben. Die Studie weist darauf hin, dass aktuelle Agenten häufiger in Bereichen mit hohen Personalkosten wie Forschung und Programmierung eingesetzt werden, während der Agentic ROI in alltäglichen Szenarien wie E-Commerce und Suche aufgrund des geringen Grenznutzens und hoher Interaktionskosten niedriger ist. Die Optimierung des Agentic ROI erfordert einen „Zickzack“-Entwicklungspfad, der „zuerst die Informationsqualität skaliert und dann die Kosten reduziert“. (Quelle: WeChat)
💼 Wirtschaft
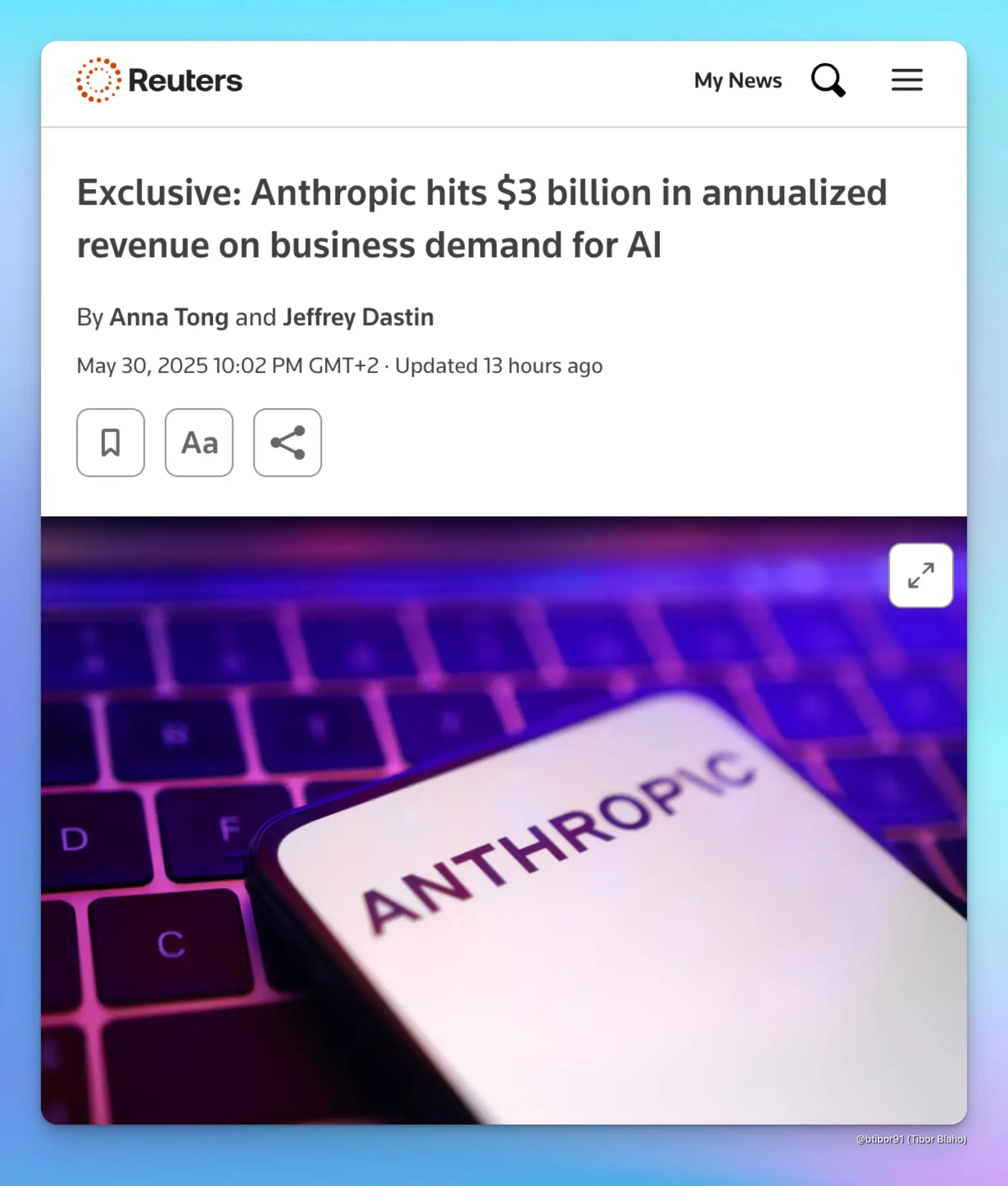
Anthropic Jahresumsatz steigt auf 3 Milliarden US-Dollar, getrieben durch Unternehmensnachfrage nach KI: Laut zwei Informanten ist der annualisierte Umsatz von Anthropic innerhalb von nur fünf Monaten von 1 Milliarde US-Dollar auf 3 Milliarden US-Dollar gestiegen. Dieses signifikante Wachstum ist hauptsächlich auf die starke Nachfrage von Unternehmen nach KI zurückzuführen, insbesondere im Bereich der Code-Generierung. Dies zeigt, dass die Anwendungs- und Zahlungsbereitschaft des Unternehmensmarktes für fortschrittliche KI-Modelle (wie die Claude-Serie von Anthropic) rapide zunimmt. (Quelle: cto_junior, scaling01, Reddit r/ArtificialInteligence)
Nvidia Q1 Geschäftsjahr 2026 Bericht: Gesamtumsatz 44,1 Mrd. USD, Rechenzentrumsgeschäft trägt fast 90 % bei: Nvidia veröffentlichte seinen Finanzbericht für das erste Quartal des Geschäftsjahres 2026, das am 27. April 2025 endete. Der Gesamtumsatz erreichte 44,1 Milliarden US-Dollar, ein Anstieg von 12 % gegenüber dem Vorquartal und 69 % gegenüber dem Vorjahr. Der Umsatz im Rechenzentrumsgeschäft betrug 39,1 Milliarden US-Dollar, was einem Anteil von 88,91 % entspricht und einem Anstieg von 73 % gegenüber dem Vorjahr. Der Umsatz im Gaming-Geschäft erreichte mit 3,8 Milliarden US-Dollar einen historischen Höchststand. Obwohl der H20-Chip von Exportbeschränkungen betroffen war, was zu einer Wertminderung des Lagerbestands von 4,5 Milliarden US-Dollar und Kosten für Einkaufsverpflichtungen führte und im zweiten Quartal voraussichtlich zu einem Umsatzverlust von 8 Milliarden US-Dollar führen wird, blieben die Gesamtergebnisse stark. Neue Produkte wie Blackwell Ultra dürften das Wachstum weiter ankurbeln. (Quelle: 量子位, WeChat)

Meta strukturiert KI-Team um, die meisten Kernautoren von Llama haben das Unternehmen verlassen, Status von FAIR im Fokus: Meta kündigte eine Umstrukturierung seines KI-Teams an, das in ein von Connor Hayes geleitetes KI-Produktteam und eine von Ahmad Al-Dahle und Amir Frenkel gemeinsam geleitete AGI-Grundlagenabteilung unterteilt wird. Die Grundlagenforschungsabteilung FAIR bleibt relativ unabhängig, obwohl einige Multimedia-Teams eingegliedert werden. Ziel dieser Anpassung ist es, die Autonomie und Entwicklungsgeschwindigkeit zu erhöhen. Von den ursprünglichen 14 Kernautoren des Llama-Modells sind jedoch nur noch 3 im Unternehmen verblieben, die meisten haben das Unternehmen verlassen oder sind zu Wettbewerbern (wie Mistral AI) gewechselt. Zusammen mit der verhaltenen Reaktion auf die Veröffentlichung von Llama 4 und internen Anpassungen bei der Zuweisung von Rechenleistung und der Forschungsrichtung gibt es Bedenken, ob Meta seine führende Position im Bereich Open-Source-KI halten und wie sich FAIR zukünftig entwickeln wird. (Quelle: WeChat)

🌟 Community
Diskussion zur KI-Ausrichtung: Können weiche Normen die menschliche Macht im AGI-Zeitalter aufrechterhalten?: Ryan Greenblatt diskutiert die von Dwarkesh Patel geäußerten Ansichten. Patel ist skeptisch gegenüber der KI-Ausrichtung und hofft stattdessen, durch weiche Normen einen Teil der Macht und des Überlebensraums für die Menschheit zu bewahren, nachdem AGI (Künstliche Allgemeine Intelligenz) die harte Macht erlangt hat. Greenblatt argumentiert, dass, wenn KI bereichssensitiv (scope sensitive) ist und die Fähigkeit hat, die Macht zu übernehmen, Versuche, ihre Fehlausrichtung durch Handel oder Verträge aufzudecken oder sie für die Menschheit arbeiten zu lassen, wahrscheinlich nicht erfolgreich sein werden. Darüber hinaus machen Faktoren wie kostengünstiges Fine-Tuning, menschliche Verbesserungen der Ausrichtung und freie Vervielfältigung die Kontrolle des Menschen über Eigentum sehr instabil, bevor das Ausrichtungsproblem gelöst ist. Sobald ausgerichtete KI oder billigere KI-Arbeitskräfte verfügbar sind, werden die Menschen diese bevorzugt einsetzen, was nicht ausgerichtete KI stark dazu motivieren wird, die Macht zu ergreifen. (Quelle: RyanPGreenblatt, RyanPGreenblatt, RyanPGreenblatt, RyanPGreenblatt, JeffLadish)

Redis-Erfinder hält KI-Programmierung für menschlichen Programmierern weit unterlegen, löst Resonanz und Diskussion unter Entwicklern aus: Salvatore Sanfilippo (Antirez), der Erfinder von Redis, teilte seine Entwicklungserfahrungen und vertrat die Ansicht, dass KI in der Programmierung zwar nützlich sei, aber menschlichen Programmierern weit unterlegen sei, insbesondere wenn es darum gehe, Konventionen zu brechen und ungewöhnliche, aber effektive Lösungen zu entwickeln. Er verglich KI mit einem „ausreichend intelligenten Assistenten“, der bei der Überprüfung von Ideen helfe. Diese Ansicht löste eine hitzige Debatte unter Entwicklern aus. Viele stimmten zu, dass KI als „Rubber Duck“ zur Unterstützung des Denkens dienen könne, wiesen aber darauf hin, dass KI zu selbstsicher sei und unerfahrene Entwickler leicht in die Irre führen könne. Einige Entwickler gaben an, dass die von KI generierten falschen Antworten sie反而 dazu motivierten, manuell zu programmieren. Die Diskussion betonte die Bedeutung von Erfahrung für die effektive Nutzung von KI sowie die möglichen negativen Auswirkungen von KI auf Programmieranfänger. (Quelle: WeChat)

Beziehung zwischen DeepMind und Google Research erneut diskutiert: Debatte über Marke und tatsächlichen Innovationsbeitrag: Faruk Guney kommentierte in einem langen Tweet die Beziehung zwischen DeepMind und Google Research und argumentierte, dass die Kerninnovationen der aktuellen KI-Revolution (wie die Transformer-Architektur) hauptsächlich von Google Research stammten und nicht von DeepMind nach der Übernahme durch Google. Er wies darauf hin, dass AlphaFold zwar eine Leistung von DeepMind sei, aber auch auf Googles Rechenressourcen und Forschungsinfrastruktur angewiesen war und die Hauptbeitragenden Wissenschaftler und Ingenieure wie John Jumper und Pushmeet Kohli waren. Guney ist der Ansicht, dass die spätere Eingliederung von Google Research in DeepMind eher eine Marken- und Organisationsanpassung war, hinter der komplexe Unternehmenspolitik steckte, die möglicherweise die wahren Quellen der Innovation verschleierte. Er betonte, dass viele KI-Durchbrüche das Ergebnis jahrelanger Teamforschung seien und nicht nur wenigen bekannten Persönlichkeiten oder Marken zugeschrieben werden könnten. (Quelle: farguney, farguney)
Wandel von Arbeitsplätzen und Fähigkeiten im KI-Zeitalter löst Besorgnis und Diskussionen aus: In sozialen Medien wird weiterhin über die Auswirkungen von KI auf den Arbeitsmarkt diskutiert. Einerseits gibt es die Ansicht, dass KI zu Massenarbeitslosigkeit führen wird, wie der CEO von Anthropic einst Bedenken äußerte, was die Menschen zum Nachdenken darüber anregt, wie sie damit umgehen sollen. Andererseits gibt es auch Stimmen, die darauf hinweisen, dass KI hauptsächlich die Produktivität steigert und es unwahrscheinlich ist, dass sie zu Massenarbeitslosigkeit führt, es sei denn, es kommt zu einer schweren wirtschaftlichen Rezession, da die Konsumnachfrage von Beschäftigung und Einkommen abhängt. Gleichzeitig teilten Nutzer persönliche Erfahrungen mit Arbeitsplatzverlusten aufgrund von KI (z. B. ersetzte der Chef Mitarbeiter durch ChatGPT). Für die Zukunft deuten die Diskussionen auf die Notwendigkeit von Ersparnissen, dem Erlernen praktischer Fähigkeiten, der Anpassung an mögliche Einkommensrückgänge und darauf hin, wie sich das Bildungssystem anpassen muss, um die im KI-Zeitalter erforderlichen Fähigkeiten wie kritisches Denken und die effektive Nutzung von KI-Tools zu vermitteln. (Quelle: Reddit r/ArtificialInteligence, Reddit r/artificial)

Übermäßige Abhängigkeit von ChatGPT löst Sorge um nachlassende Denkfähigkeit aus: Ein Reddit-Nutzer äußerte die Sorge, dass seine Freundin sich übermäßig auf ChatGPT für Entscheidungen, Meinungen und kreative Ideen verlasse, und befürchtete, dies könne dazu führen, dass sie ihre Fähigkeit zum unabhängigen Denken und zur Originalität verliere. Der Beitrag löste eine breite Diskussion aus. Einige Kommentatoren teilten diese Sorge und meinten, eine übermäßige Abhängigkeit von KI-Tools könne das persönliche Denken tatsächlich schwächen; andere argumentierten, KI sei nur ein Werkzeug, ähnlich wie frühere Enzyklopädien oder Suchmaschinen, und es komme darauf an, wie der Nutzer es einsetze – als Ausgangspunkt für das Denken oder als vollständigen Ersatz. Einige Kommentare schlugen vor, durch Kommunikation, Anleitung und Aufzeigen der Grenzen von KI darauf zu reagieren. (Quelle: Reddit r/ChatGPT)
Herausforderungen der KI im Bildungsbereich: Professor beklagt Missbrauch von ChatGPT durch Studenten, fordert Förderung echter Denkfähigkeit: Ein Professor für Alte Geschichte beklagte in einem Reddit-Beitrag, dass der Missbrauch von ChatGPT seinen Unterricht erheblich beeinträchtige. Die von Studenten eingereichten Arbeiten seien voll von KI-generiertem, teils faktenfalschem „hohlem Müll“, was ihn daran zweifeln lasse, ob die Studenten wirklich lernten. Er betonte, dass der Kern humanistischer Bildung darin bestehe, neues Wissen, kreative Einsichten und unabhängiges Denken zu fördern, nicht nur vorhandene Informationen wiederzugeben. Der Beitrag löste eine hitzige Debatte aus. Kommentatoren schlugen verschiedene Bewältigungsstrategien vor, wie z. B. mündliche Referate, handschriftliche Klausurarbeiten, die Forderung an Studenten, eine Metaanalyse ihrer KI-Nutzung einzureichen, oder die Integration von KI in den Unterricht, um Studenten dazu zu bringen, die Ergebnisse der KI kritisch zu bewerten. (Quelle: Reddit r/ChatGPT)
KI-generierter Kernel übertrifft unerwartet PyTorch-Experten-Kernel, Stanford-Team chinesischer Herkunft enthüllt neue Möglichkeiten: Das Team von Anne Ouyang, Azalia Mirhoseini und Percy Liang an der Stanford University entdeckte bei dem Versuch, synthetische Daten für das Training von Kernel-Generierungsmodellen zu erzeugen, unerwartet, dass ihr in reinem CUDA-C geschriebener, KI-generierter Kernel in der Leistung den in PyTorch integrierten, von Experten optimierten FP32-Kernel erreichte oder sogar übertraf. Beispielsweise erreichte er bei der Matrixmultiplikation 101,3 % der Leistung von PyTorch und bei der zweidimensionalen Faltung 179,9 %. Das Team setzte auf mehrstufige iterative Optimierung, kombinierte Ideen zur Optimierung des logischen Denkens in natürlicher Sprache mit einer Branch-and-Bound-Suchstrategie und nutzte die Modelle OpenAI o3 und Gemini 2.5 Pro. Dieses Ergebnis zeigt, dass KI durch geschickte Suche und parallele Exploration das Potenzial hat, Durchbrüche bei der Generierung von Hochleistungs-Rechenkernen zu erzielen. (Quelle: WeChat)

💡 Sonstiges
Starke Lobbyarbeit der KI-Branche erregt Aufmerksamkeit von Max Tegmark: MIT-Professor Max Tegmark wies darauf hin, dass die KI-Branche in Washington und Brüssel bereits mehr Lobbyisten hat als die fossile Brennstoffindustrie und die Tabakindustrie zusammen. Dieses Phänomen verdeutlicht den wachsenden Einfluss der KI-Industrie auf die Politikgestaltung sowie ihr aktives Engagement bei der Gestaltung des regulatorischen Umfelds, was tiefgreifende Auswirkungen auf die Entwicklungsrichtung der KI-Technologie, ethische Standards und die Wettbewerbslandschaft des Marktes haben könnte. (Quelle: Reddit r/artificial)

KI könnte durch Deepfakes biologische Terroranschläge simulieren und eine neue Bedrohung für die öffentliche Gesundheit darstellen: Ein Artikel in STAT News weist darauf hin, dass neben dem Risiko KI-gestützter biologischer Waffen auch die Nutzung von Deepfake-Technologie zur Simulation biologischer Terroranschläge eine ernsthafte Bedrohung darstellen könnte. Insbesondere zwischen Ländern in militärischen Konflikten könnten solche gefälschten Informationen Panik, Fehleinschätzungen und unnötige militärische Eskalationen auslösen. Da Ermittlungen möglicherweise von Strafverfolgungs- oder Militärbehörden geleitet werden und nicht von Teams für öffentliche Gesundheit oder Technologie, könnten diese eher dazu neigen, die Echtheit der Angriffe zu glauben, was eine effektive Widerlegung erschwert. (Quelle: Reddit r/ArtificialInteligence)
Diskussion darüber, ob ein Ingenieurstudium im KI-Zeitalter noch sinnvoll ist: In der Community wird der Wert eines Ingenieurstudiums im Zeitalter der KI diskutiert. Eine Seite argumentiert, dass KI viele traditionelle Ingenieuraufgaben ersetzen könnte, wodurch der Wert des Abschlusses sinkt. Die andere Seite vertritt die Ansicht, dass das im Ingenieurstudium vermittelte Systemdenken, die Problemlösungsfähigkeiten sowie die mathematischen und physikalischen Grundlagen weiterhin wichtig sind, insbesondere für das Verständnis und die Anwendung von KI-Tools. Einige Meinungen deuten darauf hin, dass, wenn KI Ingenieure ersetzen kann, auch andere Berufe kaum verschont bleiben werden und es entscheidend auf kontinuierliches Lernen und Anpassung ankommt. Praktische, schwer automatisierbare Bereiche wie die Veterinärmedizin gelten als relativ sichere Wahl. (Quelle: Reddit r/ArtificialInteligence)