
Schlüsselwörter:DeepSeek-R1-0528, KI-Agent, Multimodales Modell, Open-Source-KI, Bestärkendes Lernen, Bildbearbeitung, Großes Sprachmodell, KI-Benchmark-Tests, DeepSeek-R1-0528-Qwen3-8B, Circuit Tracer Werkzeug, Darwin Gödel Maschine, FLUX.1 Kontext, Agentisches Retrieval
🔥 Fokus
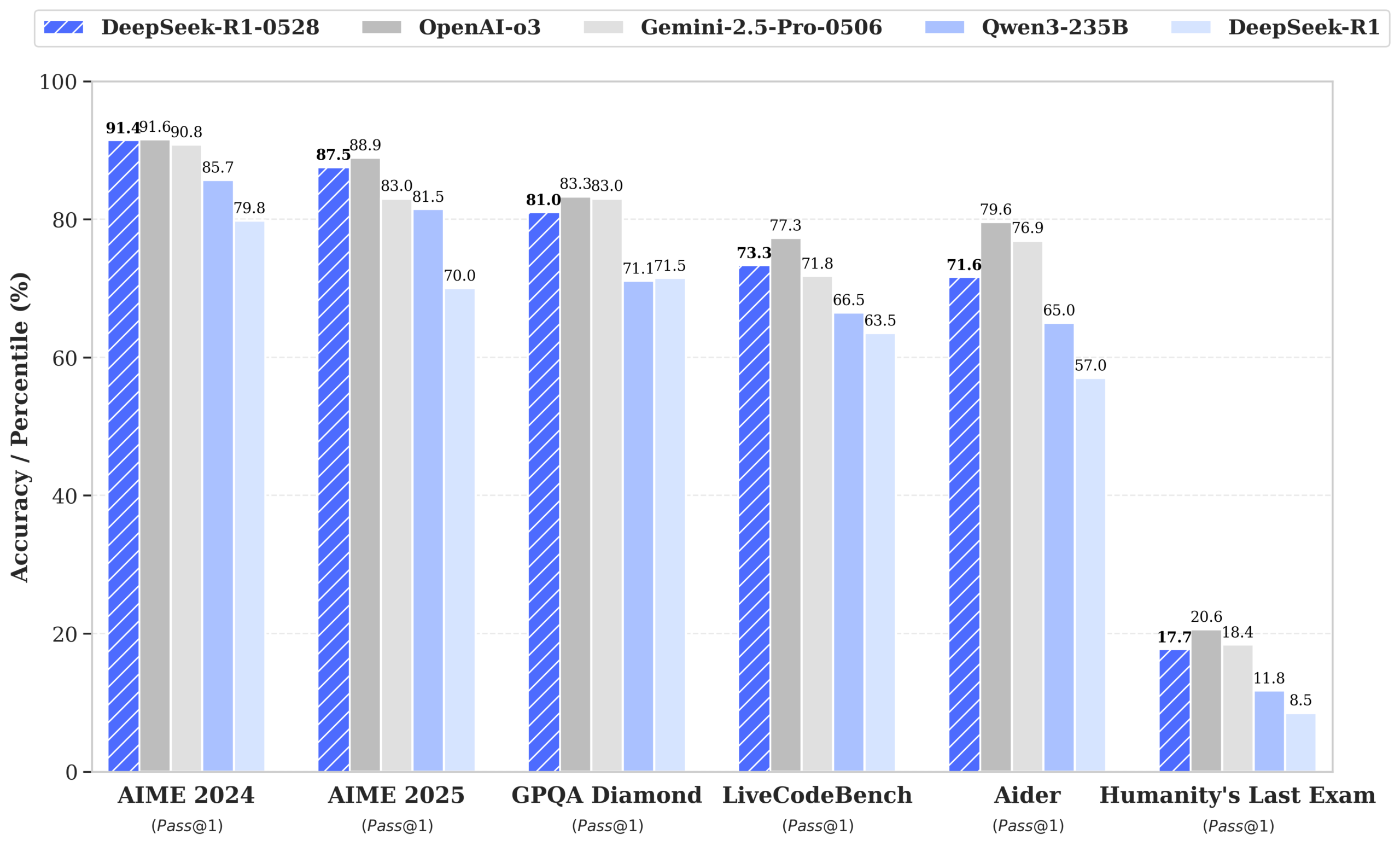
DeepSeek veröffentlicht R1-0528-Modell, Leistung nähert sich GPT-4o und Gemini 2.5 Pro, erklimmt Spitze der Open-Source-Rangliste: DeepSeek-R1-0528 zeigt in mehreren Benchmarks wie Mathematik, Programmierung und allgemeinem logischen Denken hervorragende Leistungen, insbesondere im AIME 2025 Test, wo die Genauigkeit von 70% auf 87.5% stieg. Die neue Version reduziert die Halluzinationsrate erheblich (ca. 45-50%), verbessert die Fähigkeit zur Generierung von Frontend-Code und unterstützt JSON-Ausgabe sowie Funktionsaufrufe. Gleichzeitig veröffentlichte DeepSeek auf Basis von Qwen3-8B Base durch Feinabstimmung DeepSeek-R1-0528-Qwen3-8B, dessen Leistung bei AIME 2024 nur von R1-0528 übertroffen wird und Qwen3-235B übertrifft. Dieses Update festigt die Position von DeepSeek als zweitgrößtes KI-Labor der Welt und als führendes Unternehmen im Open-Source-Bereich. (Quelle: ClementDelangue, dotey, huggingface, NandoDF, andrew_n_carr, Francis_YAO_, scaling01, karminski3, teortaxesTex, tokenbender, dotey)
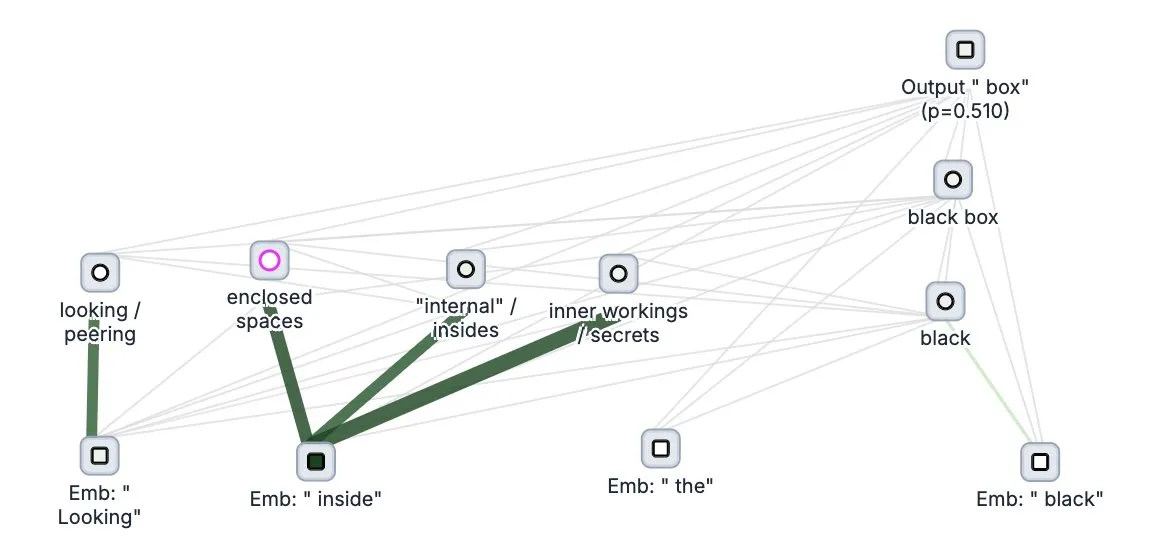
Anthropic veröffentlicht Open-Source-Tool „Circuit Tracer“ zur Nachverfolgung von Denkprozessen großer Modelle: Anthropic hat sein Forschungstool Circuit Tracer für die Interpretierbarkeit großer Modelle als Open Source veröffentlicht. Es ermöglicht Forschern, „Attributionskarten“ zu generieren und interaktiv zu untersuchen, um die internen „Denkprozesse“ und Entscheidungsmechanismen von Large Language Models (LLM) zu verstehen. Dieses Tool soll Forschern helfen, die interne Funktionsweise von LLMs tiefer zu ergründen, beispielsweise wie Modelle bestimmte Merkmale nutzen, um das nächste Token vorherzusagen. Benutzer können das Tool auf Neuronpedia ausprobieren und durch Eingabe eines Satzes eine Schaltungsdiagramm zur Merkmalsnutzung des Modells erhalten. (Quelle: scaling01, mlpowered, rishdotblog, menhguin, NeelNanda5, akbirkhan, riemannzeta, andersonbcdefg, algo_diver, Reddit r/ClaudeAI)
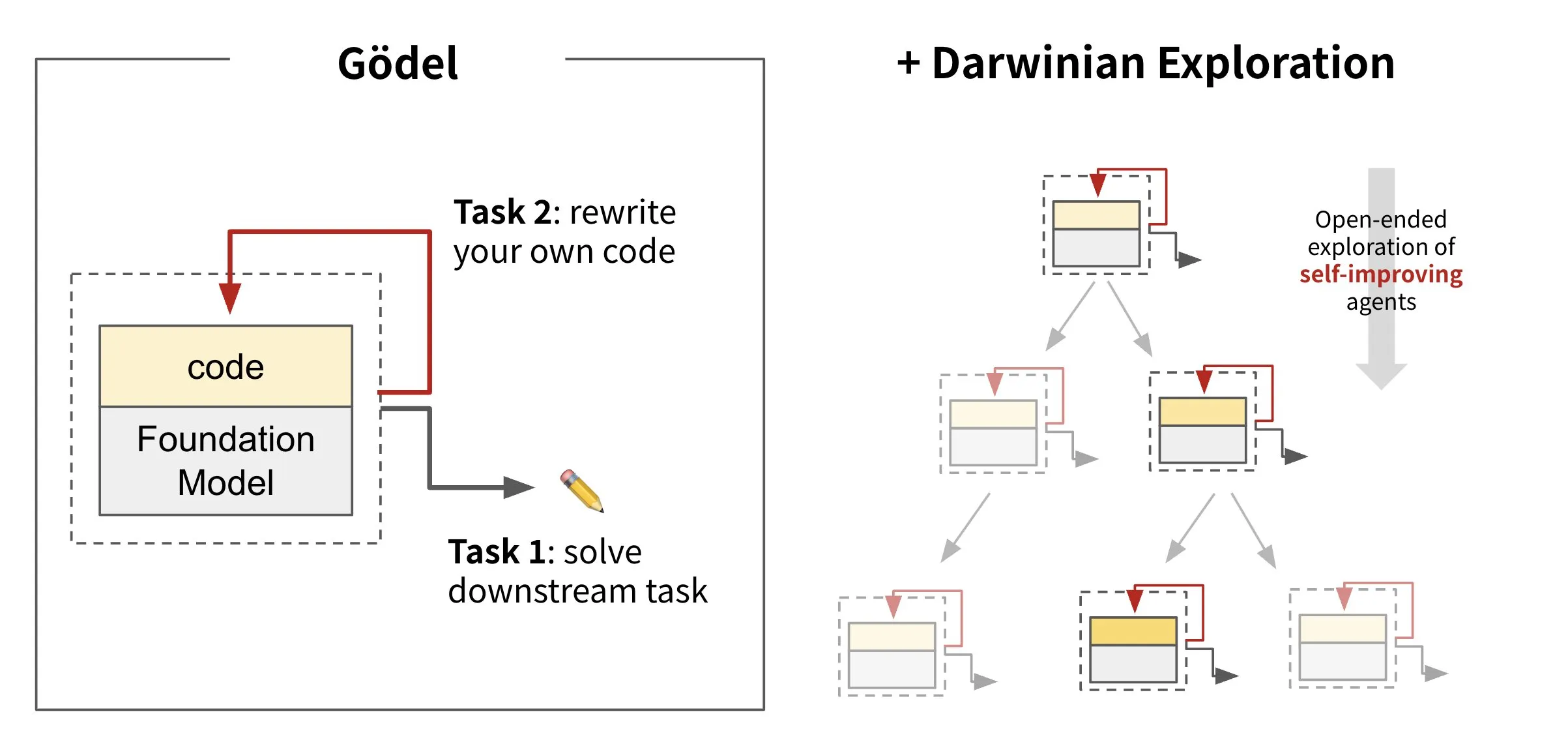
Sakana AI veröffentlicht selbstevolvierendes Agenten-Framework Darwin Gödel Machine (DGM): Sakana AI hat die Darwin Gödel Machine (DGM) vorgestellt, ein KI-Agenten-Framework, das sich durch Umschreiben seines eigenen Codes selbst verbessern kann. Inspiriert von der Evolutionstheorie unterhält DGM eine sich ständig erweiternde Linie von Agentenvarianten, um den Designraum selbstverbessernder Agenten offen zu erforschen. Das Framework zielt darauf ab, KI-Systemen zu ermöglichen, ihre Fähigkeiten im Laufe der Zeit zu lernen und weiterzuentwickeln, ähnlich wie Menschen. Auf SWE-bench steigerte DGM die Leistung von 20,0% auf 50,0%; auf Polyglot stieg die Erfolgsquote von 14,2% auf 30,7%. (Quelle: SakanaAILabs, teortaxesTex, Reddit r/MachineLearning)
Black Forest Labs veröffentlicht Bildbearbeitungsmodell FLUX.1 Kontext, unterstützt gemischte Text- und Bildeingabe: Black Forest Labs hat das Bildbearbeitungsmodell der nächsten Generation FLUX.1 Kontext vorgestellt, das eine Flow-Matching-Architektur verwendet und sowohl Text als auch Bilder als Eingabe akzeptieren kann, um kontextsensitive Bildgenerierung und -bearbeitung zu ermöglichen. Das Modell zeichnet sich durch Charakterkonsistenz, lokale Bearbeitung, Stilreferenzierung und Interaktionsgeschwindigkeit aus, z.B. dauert die Generierung eines Bildes mit einer Auflösung von 1024×1024 nur 3-5 Sekunden. Tests von Replicate zeigen, dass seine Bearbeitungseffekte besser sind als die von GPT-4o-Image und kostengünstiger. Kontext wird in Pro- und Max-Versionen angeboten, und eine Open-Source-Dev-Version ist geplant. (Quelle: TomLikesRobots, two_dukes, cloneofsimo, robrombach, bfirsh, timudk, scaling01, KREA AI)

🎯 Trends
Google DeepMind veröffentlicht multimodales medizinisches Modell MedGemma: Google DeepMind hat MedGemma vorgestellt, ein leistungsstarkes offenes Modell, das speziell für das multimodale Verständnis von medizinischen Texten und Bildern entwickelt wurde. Das Modell wird als Teil der Health AI Developer Foundations angeboten und zielt darauf ab, die Anwendungsmöglichkeiten von KI im medizinischen Bereich zu verbessern, insbesondere bei der kombinierten Analyse von Texten und medizinischen Bildern (wie Röntgenaufnahmen). (Quelle: GoogleDeepMind)
Perplexity AI führt Perplexity Labs ein, um die Bearbeitung komplexer Aufgaben zu ermöglichen: Perplexity AI hat die neue Funktion Perplexity Labs veröffentlicht, die speziell für die Bearbeitung komplexerer Aufgaben entwickelt wurde und darauf abzielt, Benutzern Analyse- und Erstellungsfähigkeiten zu bieten, die denen eines ganzen Forschungsteams ähneln. Benutzer können über Labs Analyseberichte, Präsentationen und dynamische Dashboards erstellen. Die Funktion ist derzeit für alle Pro-Benutzer verfügbar und zeigt ihr Potenzial in der wissenschaftlichen Forschung, Marktanalyse und der Erstellung von Mini-Anwendungen (wie Spielen, Dashboards). (Quelle: AravSrinivas, AravSrinivas, AravSrinivas, AravSrinivas, AravSrinivas, AravSrinivas)
Tencent Hunyuan und Tencent Music veröffentlichen gemeinsam HunyuanVideo-Avatar, Fotos können realistische Gesangsvideos erzeugen: Tencent Hunyuan und Tencent Music haben gemeinsam das HunyuanVideo-Avatar-Modell veröffentlicht. Dieses Modell kann vom Benutzer hochgeladene Fotos und Audiodateien kombinieren, automatisch den Szenenkontext und die Emotionen erkennen und Sprech- oder Gesangsvideos mit realistischer Lippensynchronisation und dynamischen visuellen Effekten erzeugen. Die Technologie unterstützt verschiedene Stile und wurde als Open Source veröffentlicht. (Quelle: huggingface, thursdai_pod)
Apache Spark 4.0.0 offiziell veröffentlicht, verbessert SQL, Spark Connect und Mehrsprachenunterstützung: Die Version Apache Spark 4.0.0 wurde offiziell veröffentlicht und bringt signifikante Verbesserungen der SQL-Funktionen, Optimierungen bei Spark Connect für eine bequemere Ausführung von Anwendungen sowie Unterstützung für neue Sprachen. Dieses Update behebt über 5100 Probleme und wurde von über 390 Mitwirkenden unterstützt. (Quelle: matei_zaharia, lateinteraction)

Kling 2.1 Videomodell veröffentlicht, integriert OpenArt zur Unterstützung von Charakterkonsistenz: Kling AI hat sein Videomodell Kling 2.1 veröffentlicht und arbeitet mit OpenArt zusammen, um Charakterkonsistenz in KI-Videogeschichten zu ermöglichen. Kling 2.1 verbessert die Ausrichtung auf Prompts, die Geschwindigkeit der Videogenerierung, die Klarheit der Kamerabewegungen und beansprucht die besten Text-zu-Video-Effekte. Die neue Version unterstützt die Ausgabe in 720p (Standard) und 1080p (Pro). Die Bild-zu-Video-Funktion ist bereits online, die Text-zu-Video-Funktion wird in Kürze folgen. (Quelle: Kling_ai, NandoDF)
Hume veröffentlicht Sprachmodell EVI 3, das jede menschliche Stimme verstehen und erzeugen kann: Hume hat sein neuestes Sprachmodell EVI 3 vorgestellt, das auf universelle Sprachintelligenz abzielt. EVI 3 kann jede menschliche Stimme verstehen und erzeugen, nicht nur die einiger weniger spezifischer Sprecher, und bietet so eine breitere Ausdrucksfähigkeit und ein tieferes Verständnis von Tonfall, Rhythmus, Klangfarbe und Sprechstil. Die Technologie zielt darauf ab, jedem eine einzigartige, vertrauenswürdige KI zu ermöglichen, die über die Stimme erkannt wird. (Quelle: AlanCowen, AlanCowen, _akhaliq)
Alibaba veröffentlicht WebDancer, erforscht autonome Informationssuch-Agenten: Alibaba hat das Projekt WebDancer vorgestellt, das darauf abzielt, KI-Agenten zu erforschen und zu entwickeln, die autonom Informationen suchen können. Das Projekt konzentriert sich darauf, wie KI-Agenten effektiver in Netzwerkumgebungen navigieren, Informationen verstehen und komplexe Informationsbeschaffungsaufgaben erledigen können. (Quelle: _akhaliq)
MiniMax veröffentlicht Open-Source-Framework V-Triune und Orsta-Modellreihe, vereinheitlicht visuelles RL-Reasoning und Wahrnehmungsaufgaben: Das KI-Unternehmen MiniMax hat sein vereinheitlichtes Framework für visuelles Reinforcement Learning, V-Triune, sowie die darauf basierende Orsta-Modellreihe (7B bis 32B) als Open Source veröffentlicht. Durch ein dreischichtiges Komponentendesign und einen dynamischen IoU-Belohnungsmechanismus (Intersection over Union) ermöglicht das Framework erstmals, dass VLMs (Vision Language Models) in einem einzigen Post-Training-Prozess gemeinsam visuelles Reasoning und Wahrnehmungsaufgaben lernen können, was zu signifikanten Leistungssteigerungen im MEGA-Bench Core Benchmark führt. (Quelle: 量子位)

Shanghai AI Lab u.a. veröffentlichen neuen Bildbearbeitungs-Benchmark RISEBench, der tiefgreifendes Reasoning von Modellen testet: Das Shanghai Artificial Intelligence Laboratory hat in Zusammenarbeit mit mehreren Universitäten einen neuen Benchmark zur Bewertung der Bildbearbeitung namens RISEBench veröffentlicht. Er enthält 360 von menschlichen Experten entworfene, hochschwierige Fälle, die vier Kernbereiche des Reasonings abdecken: Zeit, Kausalität, Raum und Logik. Testergebnisse zeigen, dass selbst GPT-4o-Image nur 28,9 % der Aufgaben bewältigen konnte, was die Schwächen aktueller multimodaler Modelle beim Verständnis komplexer Anweisungen und bei der visuellen Bearbeitung offenbart. (Quelle: 36氪)

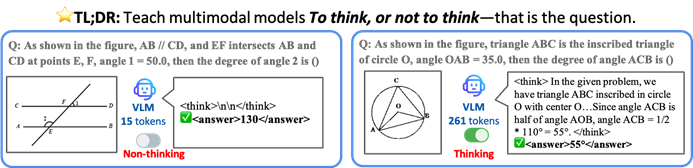
CUHK u.a. schlagen TON-Framework vor, damit KI-Modelle selektiv denken, um Effizienz und Genauigkeit zu steigern: Forscher der Chinese University of Hong Kong und des Show Lab der National University of Singapore haben das TON (Think Or Not)-Framework vorgeschlagen, das es Vision Language Models (VLM) ermöglicht, autonom zu entscheiden, ob explizites Reasoning erforderlich ist. Durch „Gedankenverwerfung“ (Thought Discarding) und Reinforcement Learning beantwortet das Modell einfache Fragen direkt und führt bei komplexen Fragen detailliertes Reasoning durch. Dadurch wird die durchschnittliche Länge der Reasoning-Ausgabe um bis zu 90 % reduziert, ohne die Genauigkeit zu beeinträchtigen, wobei die Genauigkeit bei einigen Aufgaben sogar um 17 % steigt. (Quelle: 36氪)
Microsoft Copilot integriert Instacart für KI-gestützten Lebensmitteleinkauf: Mustafa Suleyman, Leiter der KI-Abteilung bei Microsoft, gab bekannt, dass Copilot jetzt den Instacart-Dienst integriert hat. Benutzer können über die Copilot-App nahtlos den gesamten Prozess von der Rezeptgenerierung über die Erstellung von Einkaufslisten bis hin zur Lieferung von frischen Lebensmitteln und Drogerieartikeln abwickeln. Dies markiert eine weitere Expansion von KI-Assistenten im Bereich der alltäglichen Dienstleistungen. (Quelle: mustafasuleyman)
🧰 Tools
LlamaIndex veröffentlicht BundesGPT-Quellcode und create-llama-Tool zur Vereinfachung der Erstellung von KI-Anwendungen: Jerry Liu von LlamaIndex kündigte die Bereitstellung des Quellcodes von BundesGPT an und bewirbt sein Open-Source-Tool create-llama. Das Tool basiert auf LlamaIndex und soll Entwicklern helfen, Unternehmensdaten und KI-Agenten einfach zu erstellen und zu integrieren. Sein neuer eject-mode macht die Erstellung vollständig anpassbarer KI-Oberflächen wie BundesGPT sehr einfach. Dieser Schritt zielt darauf ab, Deutschlands potenziellen Plan zu unterstützen, jedem Bürger ein kostenloses ChatGPT Plus-Abonnement zur Verfügung zu stellen. (Quelle: jerryjliu0)
LangChain-Tools können in MCP-Tools konvertiert und in FastMCP-Server integriert werden: LangChain-Benutzer können ihre LangChain-Tools jetzt in MCP (Model Component Protocol)-Tools konvertieren und direkt zu einem FastMCP-Server hinzufügen. Durch die Installation der langchain-mcp-adapters-Bibliothek können Entwickler die Toolsets von LangChain bequemer im MCP-Ökosystem verwenden, was die Interoperabilität zwischen verschiedenen KI-Frameworks fördert. (Quelle: LangChainAI, hwchase17)
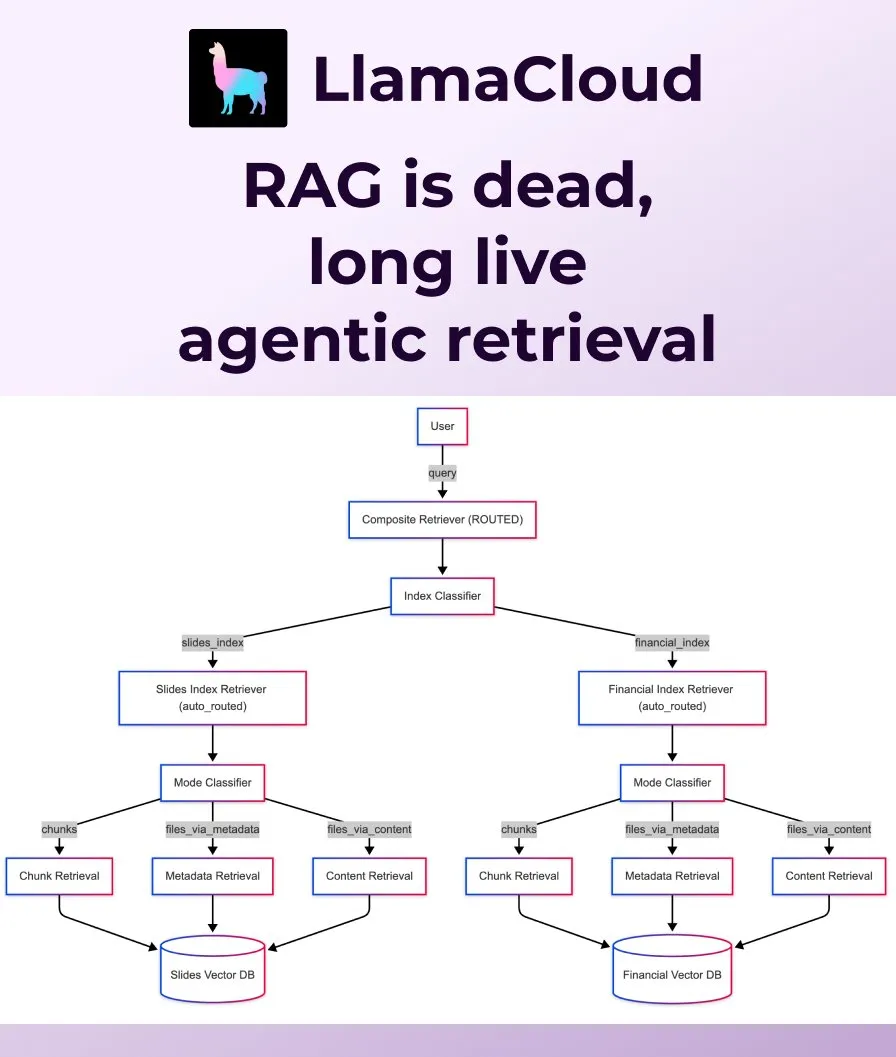
LlamaIndex veröffentlicht Agentic Retrieval als Ersatz für traditionelles RAG: LlamaIndex ist der Ansicht, dass traditionelles, naives RAG (Retrieval Augmented Generation) den Anforderungen moderner Anwendungen nicht mehr genügt und hat Agentic Retrieval eingeführt. Diese Lösung ist in LlamaCloud integriert und ermöglicht es Agenten, basierend auf dem Inhalt der Frage dynamisch ganze Dateien oder spezifische Datenblöcke aus einzelnen oder mehreren Wissensdatenbanken (wie Sharepoint, Box, GDrive, S3) abzurufen, um eine intelligentere und flexiblere Kontextbeschaffung zu realisieren. (Quelle: jerryjliu0, jerryjliu0)
Ollama unterstützt Ausführung des Osmosis-Structure-0.6B-Modells zur Umwandlung unstrukturierter Daten: Benutzer können jetzt das Osmosis-Structure-0.6B-Modell über Ollama ausführen. Dies ist ein extrem kleines Modell, das beliebige unstrukturierte Daten in ein spezifiziertes Format (z.B. JSON Schema) umwandeln kann und mit jedem Modell zusammenarbeitet, besonders geeignet für Inferenzaufgaben, die eine strukturierte Ausgabe erfordern. (Quelle: ollama)
CrewAI aktualisiert Gemini-Dokumentation zur Vereinfachung des Einstiegsprozesses: Das CrewAI-Team hat seine Dokumentation zur Google Gemini API aktualisiert, um Benutzern den Einstieg in die Erstellung von KI-Agenten mit Gemini-Modellen zu erleichtern. Die neue Dokumentation enthält möglicherweise klarere Anleitungen, Beispielcode oder Best Practices. (Quelle: _philschmid)
Requesty führt Smart Routing-Funktion ein, wählt automatisch das beste LLM für OpenWebUI aus: Requesty hat die Smart Routing-Funktion veröffentlicht, die sich nahtlos in OpenWebUI integrieren lässt und basierend auf dem vom Benutzer angeforderten Aufgabentyp automatisch das beste LLM (wie GPT-4o, Claude, Gemini) auswählt. Benutzer müssen lediglich smart/task als Modell-ID verwenden, und das System kann den Prompt in etwa 65 Millisekunden klassifizieren und basierend auf Kosten, Geschwindigkeit und Qualität an das am besten geeignete Modell weiterleiten. Diese Funktion zielt darauf ab, die Modellauswahl zu vereinfachen und die Benutzererfahrung zu verbessern. (Quelle: Reddit r/OpenWebUI)
EvoAgentX: Erstes Open-Source-Framework für selbstevolvierende KI-Agenten veröffentlicht: Ein Forschungsteam der University of Glasgow in Großbritannien hat EvoAgentX veröffentlicht, das weltweit erste Open-Source-Framework für selbstevolvierende KI-Agenten. Es unterstützt den Aufbau von Workflows mit einem Klick und führt einen „Selbstevolutionsmechanismus“ ein, der es Multi-Agenten-Systemen ermöglicht, ihre Struktur und Leistung kontinuierlich an sich ändernde Umgebungen und Ziele anzupassen. Ziel ist es, KI-Multi-Agenten-Systeme von der „manuellen Fehlersuche“ zur „autonomen Evolution“ zu führen. Experimente zeigen eine durchschnittliche Leistungssteigerung von 8-13 % bei Aufgaben wie Multi-Hop-Fragenbeantwortung, Codegenerierung und mathematischem Reasoning. (Quelle: 36氪)

📚 Lernen
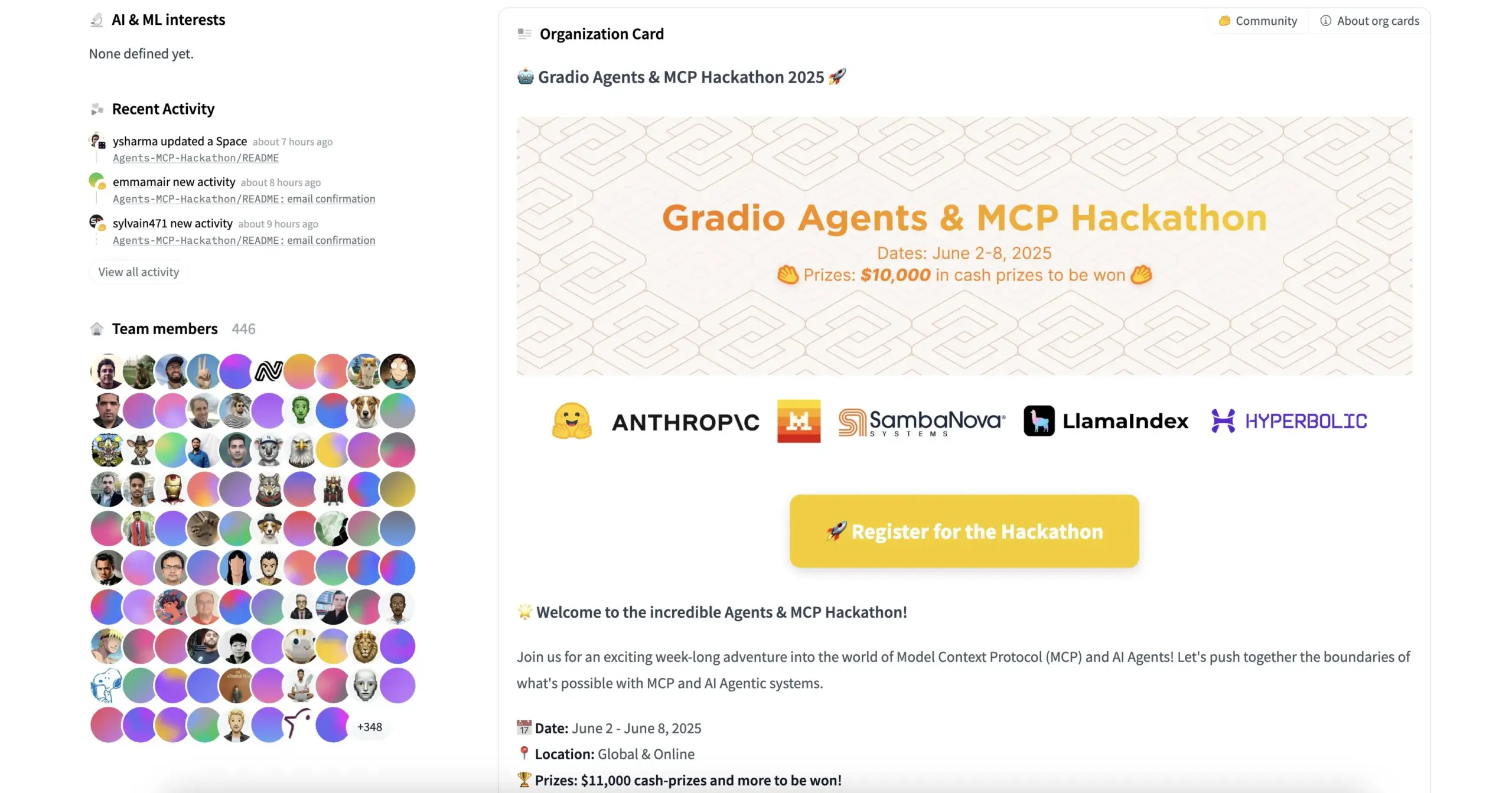
HuggingFace, Gradio u.a. veranstalten Agents & MCP Hackathon mit großzügigen Preisgeldern und API-Kontingenten: HuggingFace, Gradio, Anthropic, SambaNovaAI, MistralAI und LlamaIndex u.a. Institutionen veranstalten gemeinsam den Gradio Agents & MCP Hackathon (2.-8. Juni). Die Veranstaltung bietet Preisgelder in Höhe von insgesamt 11.000 US-Dollar und kostenlose API-Kontingente von Hyperbolic, Anthropic, Mistral und SambaNova für Frühbucher. Modal Labs verspricht sogar GPU-Kontingente im Wert von 250 US-Dollar für alle Teilnehmer, insgesamt über 300.000 US-Dollar. (Quelle: huggingface, _akhaliq, ben_burtenshaw, charles_irl)
LangChain teilt die Praxis von JPMorgan Chase bei der Nutzung von Multi-Agenten-Systemen für Investment-Research: David Odomirok und Zheng Xue von JPMorgan Chase erläutern, wie sie ein Multi-Agenten-KI-System namens “Ask David” aufgebaut haben. Das System zielt darauf ab, den Investment-Research-Prozess für Tausende von Finanzprodukten zu automatisieren und demonstriert das Anwendungspotenzial von Multi-Agenten-Architekturen in komplexen Finanzanalysen. (Quelle: LangChainAI, hwchase17)
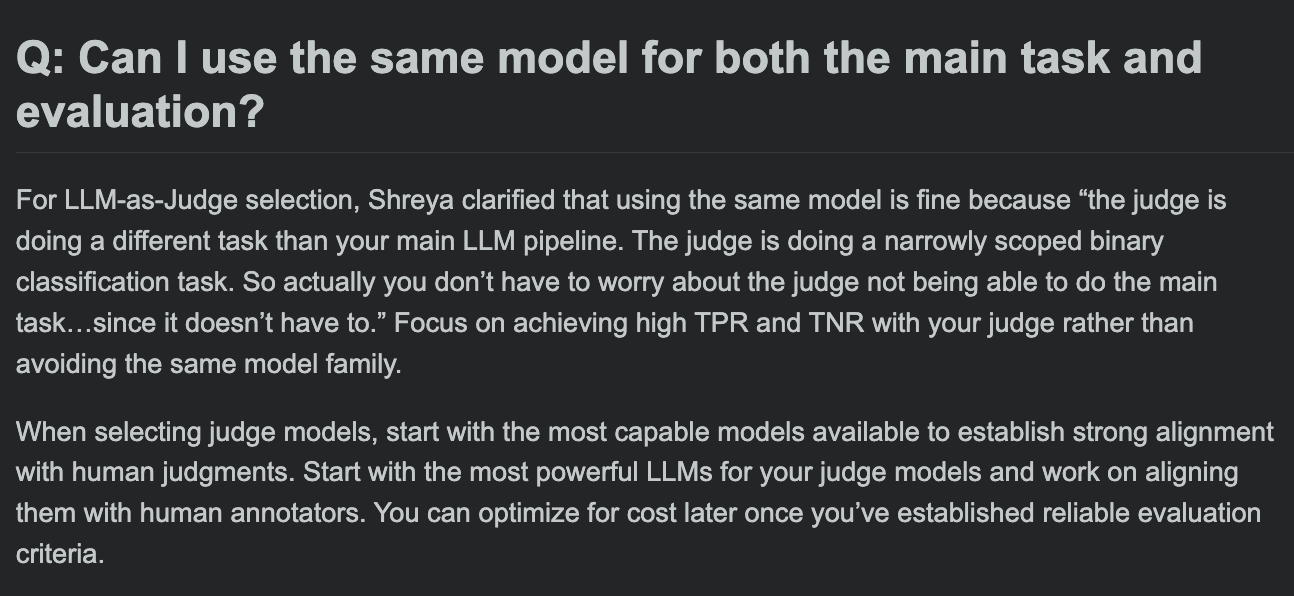
Hamel Husain teilt FAQ zum LLM-Evaluierungskurs und erörtert, ob Evaluierungsmodell und Hauptaufgabenmodell identisch sein können: In der Frage-Antwort-Runde seines LLM-Evaluierungskurses erörtert Hamel Husain eine häufig gestellte Frage: Kann dasselbe Modell für die Hauptaufgabenbearbeitung und die Aufgabenbewertung verwendet werden? Diese Diskussion hilft Entwicklern, potenzielle Verzerrungen und Best Practices bei der Modellevaluierung zu verstehen. (Quelle: HamelHusain, HamelHusain)
The Rundown AI startet personalisierte KI-Bildungsplattform: The Rundown AI kündigte den Start der weltweit ersten personalisierten KI-Bildungsplattform an, die maßgeschneiderte Schulungen, Anwendungsfälle und Live-Workshops für verschiedene Branchen, Fähigkeitsstufen und tägliche Arbeitsabläufe anbietet. Die Plattforminhalte umfassen branchenspezifische KI-Zertifikatskurse für 16 Technologiebereiche, über 300 reale KI-Anwendungsfälle, Experten-Workshops sowie Rabatte auf KI-Tools. (Quelle: TheRundownAI, rowancheung)
Common Crawl veröffentlicht Host- und Domain-Level-Netzwerkgraphen für März-Mai 2025: Common Crawl hat seine neuesten Host- und Domain-Level-Netzwerkgraphendaten veröffentlicht, die die Monate März, April und Mai 2025 abdecken. Diese Daten sind für die Erforschung von Netzwerkstrukturen, das Training von Sprachmodellen und die Durchführung groß angelegter Netzwerkanalysen von großem Wert. (Quelle: CommonCrawl)
Bill Chambers initiiert Lernkampagne „20 Days of DSPyOSS“: Um der Community zu helfen, die Funktionen und die Verwendung von DSPyOSS besser zu verstehen, hat Bill Chambers eine 20-tägige DSPyOSS-Lernkampagne gestartet. Täglich wird ein DSPy-Codefragment mit seiner Erklärung veröffentlicht, um Benutzern den Einstieg und die Beherrschung des Frameworks zu erleichtern. (Quelle: lateinteraction)
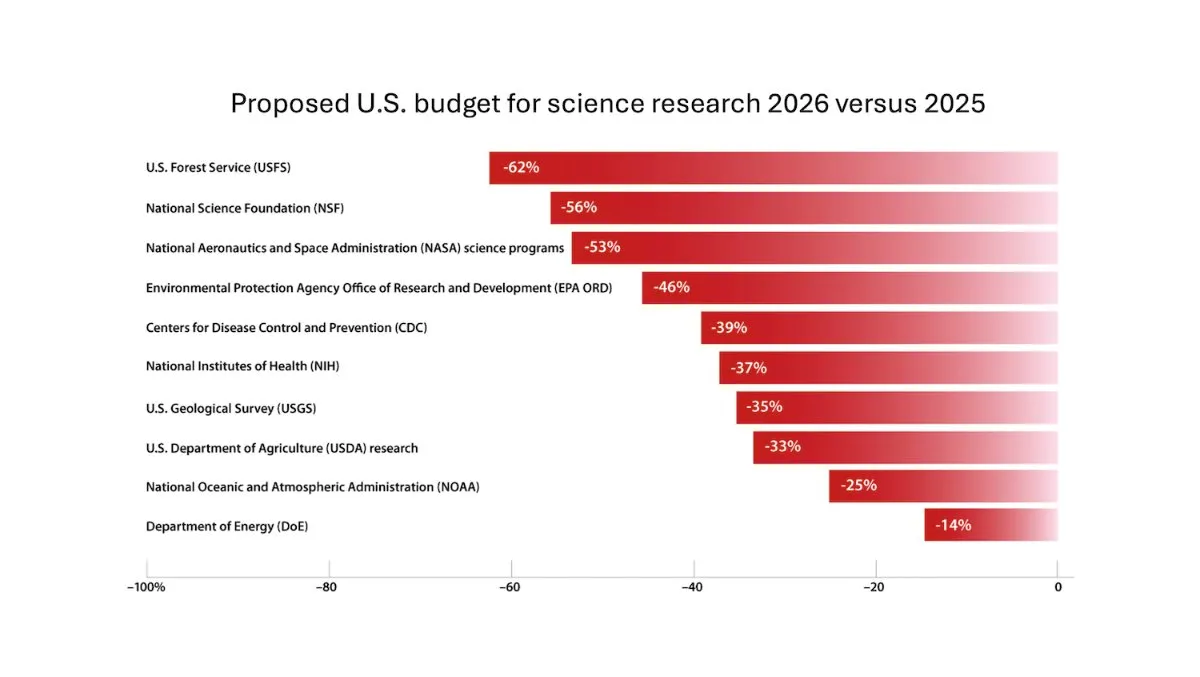
DeepLearning.AI veröffentlicht The Batch Wochenbericht, Andrew Ng erörtert Risiken von Kürzungen bei Forschungsgeldern: In der neuesten Ausgabe des The Batch Wochenberichts diskutiert Andrew Ng die potenziellen Risiken von Kürzungen bei Forschungsgeldern für die Wettbewerbsfähigkeit und Sicherheit von Nationen. Der Wochenbericht behandelt auch die Leistung des Claude 4-Modells in Kodierungsbenchmarks, die KI-Veröffentlichungen von Google I/O, die kostengünstige Trainingsmethode von DeepSeek sowie die mögliche Verwendung urheberrechtlich geschützter Bücher für das Training von GPT-4o und andere aktuelle Themen. (Quelle: DeepLearningAI)
Google DeepMind stellt britischen Studenten Gemini 2.5 Pro und NotebookLM kostenlos zur Verfügung: Google DeepMind kündigte an, britischen Studenten für 15 Monate kostenlosen Zugang zu seinen fortschrittlichsten Modellen (einschließlich Gemini 2.5 Pro und NotebookLM) zu gewähren. Dieser Schritt zielt darauf ab, Studenten beim Lernen in Bereichen wie Forschung, Schreiben und Prüfungsvorbereitung zu unterstützen und bietet 2 TB kostenlosen Speicherplatz. (Quelle: demishassabis)
KI-Paper-Interpretation: Prot2Token, ein einheitliches Framework für Proteinmodellierung: Das Paper „Prot2Token: A Unified Framework for Protein Modeling via Next-Token Prediction“ stellt ein einheitliches Proteinmodellierungs-Framework namens Prot2Token vor. Es wandelt verschiedene Vorhersageaufgaben, von Proteinsequenzeigenschaften und Resteigenschaften bis hin zu Protein-Protein-Interaktionen, in ein standardmäßiges Next-Token-Vorhersageformat um. Das Framework verwendet einen autoregressiven Decoder, der Einbettungen von vortrainierten Proteincodierern und lernbare Aufgaben-Token für das Multi-Task-Lernen nutzt, um die Effizienz zu steigern und biologische Entdeckungen zu beschleunigen. (Quelle: HuggingFace Daily Papers)
KI-Paper-Interpretation: Hard Negative Mining für domänenspezifisches Retrieval in Unternehmenssystemen: Das Paper „Hard Negative Mining for Domain-Specific Retrieval in Enterprise Systems“ schlägt ein skalierbares Framework für Hard Negative Mining für unternehmensspezifische Domänendaten vor. Die Methode wählt dynamisch semantisch herausfordernde, aber kontextuell irrelevante Dokumente aus, um die Leistung des eingesetzten Reranking-Modells zu verbessern. Experimente mit einem UnternehmenskKorpus im Bereich Cloud-Services zeigten eine Verbesserung von MRR@3 und MRR@10 um 15 % bzw. 19 %. (Quelle: HuggingFace Daily Papers)
KI-Paper-Interpretation: FS-DAG, Few-Shot Domain Adapting Graph Networks für visuell reichhaltiges Dokumentenverständnis: Das Paper „FS-DAG: Few Shot Domain Adapting Graph Networks for Visually Rich Document Understanding“ stellt die FS-DAG-Modellarchitektur für das Verständnis visuell reichhaltiger Dokumente im Few-Shot-Szenario vor. Das Modell nutzt domänenspezifische und sprach-/visuell-spezifische Backbone-Netzwerke, um sich innerhalb eines modularen Frameworks mit minimalen Daten an verschiedene Dokumenttypen anzupassen. Experimente zu Informationsgewinnungsaufgaben zeigten eine schnellere Konvergenz und Leistung als SOTA-Methoden. (Quelle: HuggingFace Daily Papers)
KI-Paper-Interpretation: FastTD3, einfaches, schnelles Reinforcement Learning für die Steuerung humanoider Roboter: Das Paper „FastTD3: Simple, Fast, and Capable Reinforcement Learning for Humanoid Control“ stellt einen Reinforcement-Learning-Algorithmus namens FastTD3 vor. Durch parallele Simulation, große Batch-Updates, verteilte Kritiker und sorgfältig abgestimmte Hyperparameter beschleunigt er das Training humanoider Roboter in beliebten Suiten wie HumanoidBench, IsaacLab und MuJoCo Playground erheblich. (Quelle: HuggingFace Daily Papers, pabbeel, cloneofsimo, jachiam0)
KI-Paper-Interpretation: HLIP, skalierbares Sprach-Bild-Vortraining für 3D-medizinische Bildgebung: Das Paper „Towards Scalable Language-Image Pre-training for 3D Medical Imaging“ stellt ein skalierbares Vortrainings-Framework für 3D-medizinische Bildgebung namens HLIP (Hierarchical attention for Language-Image Pre-training) vor. HLIP verwendet einen leichtgewichtigen hierarchischen Aufmerksamkeitsmechanismus, der direkt auf unsortierten klinischen Datensätzen trainiert werden kann und in mehreren Benchmarks SOTA-Leistung erzielt. (Quelle: HuggingFace Daily Papers)
KI-Paper-Interpretation: PENGUIN, personalisierter Sicherheitsbenchmark für LLMs und planungsbasierter Agentenansatz: Das Paper „Personalized Safety in LLMs: A Benchmark and A Planning-Based Agent Approach“ führt das Konzept der personalisierten Sicherheit ein und schlägt den PENGUIN-Benchmark (mit 14.000 Szenarien in 7 sensiblen Bereichen) sowie das RAISE-Framework (ein trainingsfreier, zweistufiger Agent, der strategisch benutzerspezifische Hintergrundinformationen beschafft) vor. Die Studie zeigt, dass personalisierte Informationen die Sicherheitsbewertungen signifikant verbessern können und RAISE die Sicherheit bei geringen Interaktionskosten erhöhen kann. (Quelle: HuggingFace Daily Papers)
KI-Paper-Interpretation: Stärkung des mehrstufigen Reasonings von LLM-Agenten durch rundenbasierte Kreditzuweisung: Das Paper „Reinforcing Multi-Turn Reasoning in LLM Agents via Turn-Level Credit Assignment“ untersucht, wie die Reasoning-Fähigkeiten von LLM-Agenten durch Reinforcement Learning verbessert werden können, insbesondere in Szenarien mit mehrstufiger Werkzeugnutzung. Die Autoren schlagen eine feinkörnige, rundenbasierte Advantage-Schätzungsstrategie vor, um eine präzisere Kreditzuweisung zu erreichen. Experimente zeigen, dass diese Methode die mehrstufigen Reasoning-Fähigkeiten von LLM-Agenten bei komplexen Entscheidungsaufgaben signifikant verbessern kann. (Quelle: HuggingFace Daily Papers)
KI-Paper-Interpretation: PISCES, präzise Löschung von In-Parameter-Konzepten in großen Sprachmodellen: Das Paper „Precise In-Parameter Concept Erasure in Large Language Models“ stellt das PISCES-Framework vor, das darauf abzielt, ganze Konzepte in Modellparametern präzise zu löschen, indem die Richtungen, die Konzepte im Parameterraum kodieren, direkt bearbeitet werden. Die Methode verwendet einen Entwirrer (Disentangler), um MLP-Vektoren zu zerlegen, mit dem Zielkonzept verbundene Merkmale zu identifizieren und aus den Modellparametern zu entfernen. Experimente zeigen, dass sie bestehende Methoden in Bezug auf Löscherfolg, Spezifität und Robustheit übertrifft. (Quelle: HuggingFace Daily Papers)
KI-Paper-Interpretation: DORI, Bewertung des Orientierungsverständnisses von MLLMs mit feinkörnigen mehrachsigen Wahrnehmungsaufgaben: Das Paper „Right Side Up? Disentangling Orientation Understanding in MLLMs with Fine-grained Multi-axis Perception Tasks“ führt den DORI-Benchmark ein, der darauf abzielt, das Verständnis von Objektorientierungen durch multimodale große Sprachmodelle (MLLM) zu bewerten. DORI umfasst vier Dimensionen: Frontalorientierung, Rotationstransformation, relative Orientierungsbeziehungen und kanonisches Orientierungsverständnis. Getestet wurden 15 SOTA MLLMs, wobei sich zeigte, dass selbst die besten Modelle bei feinen Orientierungsurteilen signifikante Einschränkungen aufweisen. (Quelle: HuggingFace Daily Papers)
KI-Paper-Interpretation: Können LLMs kausale Beziehungen aus realen Texten ableiten?: Das Paper „Can Large Language Models Infer Causal Relationships from Real-World Text?“ untersucht die Fähigkeit von LLMs, kausale Beziehungen aus realen Texten abzuleiten. Die Forscher entwickelten einen Benchmark, der aus echten wissenschaftlichen Publikationen stammt und Texte unterschiedlicher Länge, Komplexität und Domänen enthält. Experimente zeigten, dass selbst SOTA-LLMs bei dieser Aufgabe vor erheblichen Herausforderungen stehen, wobei das beste Modell einen F1-Score von nur 0,477 erreichte. Dies offenbart Schwierigkeiten bei der Verarbeitung impliziter Informationen, der Unterscheidung relevanter Faktoren und der Verknüpfung verstreuter Informationen. (Quelle: HuggingFace Daily Papers)
KI-Paper-Interpretation: IQBench, Bewertung der „Intelligenz“ von Vision-Language-Modellen mit menschlichen IQ-Tests: Das Paper „IQBench: How “Smart’’ Are Vision-Language Models? A Study with Human IQ Tests“ stellt IQBench vor, einen neuen Benchmark zur Bewertung der fluiden Intelligenz von Vision-Language-Modellen (VLM) anhand standardisierter visueller IQ-Tests. Der Benchmark ist visuell zentriert und enthält 500 manuell gesammelte und annotierte visuelle IQ-Fragen, die die Erklärung, die Problemlösungsmuster und die Genauigkeit der endgültigen Vorhersagen der Modelle bewerten. Experimente zeigten, dass o4-mini, Gemini-2.5-Flash und Claude-3.7-Sonnet relativ gut abschnitten, aber alle Modelle Schwierigkeiten bei 3D-Raum- und Anagramm-Reasoning-Aufgaben hatten. (Quelle: HuggingFace Daily Papers)
KI-Paper-Interpretation: PixelThink, auf dem Weg zu effizientem Chain-of-Pixel-Reasoning: Das Paper „PixelThink: Towards Efficient Chain-of-Pixel Reasoning“ schlägt die PixelThink-Lösung vor, die durch die Integration extern geschätzter Aufgabenschwierigkeit und intern gemessener Modellunsicherheit die Generierung von Reasoning innerhalb eines Reinforcement-Learning-Paradigmas reguliert. Das Modell lernt, die Reasoning-Länge basierend auf der Szenenkomplexität und der Vorhersagekonfidenz zu komprimieren. Gleichzeitig wird der ReasonSeg-Diff-Benchmark zur Evaluierung eingeführt. Experimente zeigen, dass diese Methode die Reasoning-Effizienz und die Gesamtsegmentierungsleistung verbessert. (Quelle: HuggingFace Daily Papers)
KI-Paper-Interpretation: Neubetrachtung der Multi-Agenten-Debatte als Testzeit-Skalierung: Eine systematische Studie zur bedingten Wirksamkeit: Das Paper „Revisiting Multi-Agent Debate as Test-Time Scaling: A Systematic Study of Conditional Effectiveness“ konzeptualisiert die Multi-Agenten-Debatte (MAD) als eine Technik zur Skalierung der Testzeitberechnung und untersucht systematisch ihre Wirksamkeit im Vergleich zu Selbst-Agenten-Methoden unter verschiedenen Bedingungen (Aufgabenschwierigkeit, Modellgröße, Agentenvielfalt). Die Studie ergab, dass der Vorteil von MAD beim mathematischen Reasoning begrenzt ist, aber bei zunehmender Aufgabenschwierigkeit oder abnehmender Modellfähigkeit effektiver wird. Bei Sicherheitsaufgaben kann die kooperative Optimierung von MAD die Anfälligkeit erhöhen, aber diversifizierte Konfigurationen helfen, die Erfolgsrate von Angriffen zu reduzieren. (Quelle: HuggingFace Daily Papers)
KI-Paper-Interpretation: VF-Eval, Bewertung der Fähigkeit von MLLMs, Feedback zu AIGC-Videos zu generieren: Das Paper „VF-Eval: Evaluating Multimodal LLMs for Generating Feedback on AIGC Videos“ stellt den neuen Benchmark VF-Eval vor, der zur Bewertung der Fähigkeit multimodaler großer Sprachmodelle (MLLM) bei der Interpretation von KI-generierten Inhalten (AIGC) in Videos dient. VF-Eval umfasst vier Aufgaben: Kohärenzprüfung, Fehlerwahrnehmung, Fehlerartenerkennung und Reasoning-Bewertung. Die Bewertung von 13 führenden MLLMs zeigte, dass selbst das leistungsstärkste GPT-4.1 Schwierigkeiten hat, bei allen Aufgaben eine gute Leistung zu erzielen. (Quelle: HuggingFace Daily Papers)
KI-Paper-Interpretation: SafeScientist, LLM-Agenten für risikobewusste wissenschaftliche Entdeckungen: Das Paper „SafeScientist: Toward Risk-Aware Scientific Discoveries by LLM Agents“ stellt ein KI-Wissenschaftler-Framework namens SafeScientist vor, das darauf abzielt, die Sicherheit und ethische Verantwortung bei KI-gesteuerten wissenschaftlichen Erkundungen zu verbessern. Das Framework kann unangemessene oder risikoreiche Aufgaben aktiv ablehnen und betont die Sicherheit des Forschungsprozesses durch mehrere Verteidigungsmechanismen wie Prompt-Überwachung, Überwachung der Agentenkooperation, Überwachung der Werkzeugnutzung und ethische Prüferkomponenten. Gleichzeitig wird der SciSafetyBench-Benchmark zur Evaluierung vorgeschlagen. (Quelle: HuggingFace Daily Papers)
KI-Paper-Interpretation: CXReasonBench, ein Benchmark zur Bewertung des strukturierten diagnostischen Reasonings bei Thorax-Röntgenaufnahmen: Das Paper „CXReasonBench: A Benchmark for Evaluating Structured Diagnostic Reasoning in Chest X-rays“ stellt den CheXStruct-Prozess und den CXReasonBench-Benchmark vor. Diese dienen der Bewertung, ob große visuelle Sprachmodelle (LVLM) klinisch valide Reasoning-Schritte bei der Diagnose von Thorax-Röntgenaufnahmen durchführen können. Der Benchmark umfasst 18.988 Frage-Antwort-Paare, die 12 diagnostische Aufgaben und 1200 Fälle abdecken und eine mehrpfadige, mehrstufige Bewertung unterstützen, einschließlich der visuellen Lokalisierung von anatomischen Regionen und diagnostischen Messungen. (Quelle: HuggingFace Daily Papers)
KI-Paper-Interpretation: ZeroGUI, automatisiertes Online-GUI-Lernen ohne menschliche Kosten: Das Paper „ZeroGUI: Automating Online GUI Learning at Zero Human Cost“ stellt ZeroGUI vor, ein skalierbares Online-Lernframework zur Automatisierung des Trainings von GUI-Agenten ohne menschliche Kosten. ZeroGUI integriert auf VLM basierende automatische Aufgabengenerierung, automatische Belohnungsschätzung und zweistufiges Online-Reinforcement-Learning, um kontinuierlich mit GUI-Umgebungen zu interagieren und von ihnen zu lernen. (Quelle: HuggingFace Daily Papers)
KI-Paper-Interpretation: Spatial-MLLM, Verbesserung der visuellen räumlichen Intelligenz von MLLMs: Das Paper „Spatial-MLLM: Boosting MLLM Capabilities in Visual-based Spatial Intelligence“ stellt das Spatial-MLLM-Framework für visuell basiertes räumliches Reasoning aus reinen 2D-Beobachtungen vor. Das Framework verwendet eine Dual-Encoder-Architektur (ein semantischer visueller Encoder und ein räumlicher Encoder) und kombiniert diese mit einer raumwahrnehmenden Frame-Sampling-Strategie, um auf mehreren realen Datensätzen SOTA-Leistung zu erzielen. (Quelle: HuggingFace Daily Papers)
KI-Paper-Interpretation: TrustVLM, Beurteilung der Vertrauenswürdigkeit von Vorhersagen visueller Sprachmodelle: Das Paper „To Trust Or Not To Trust Your Vision-Language Model’s Prediction“ führt TrustVLM ein, ein trainingsfreies Framework, das darauf abzielt, die Vertrauenswürdigkeit von Vorhersagen visueller Sprachmodelle (VLM) zu bewerten. Die Methode nutzt Unterschiede in der Konzeptrepräsentation im Bild-Embedding-Raum und schlägt neue Konfidenzbewertungsfunktionen vor, um die Erkennung von Fehlklassifikationen zu verbessern. Sie zeigt SOTA-Leistung auf 17 verschiedenen Datensätzen. (Quelle: HuggingFace Daily Papers)
KI-Paper-Interpretation: MAGREF, maskengesteuerte Multi-Referenz-Videogenerierung: Das Paper „MAGREF: Masked Guidance for Any-Reference Video Generation“ stellt MAGREF vor, ein einheitliches Framework für die Generierung von Videos mit mehreren Referenzen. Es führt einen maskengesteuerten Mechanismus ein, der durch regionenbewusste dynamische Masken und pixelweise Kanalverknüpfung eine kohärente Synthese von Videos mit mehreren Subjekten unter verschiedenen Referenzbildern und Text-Prompts ermöglicht. Auf Multi-Subjekt-Video-Benchmarks übertrifft es bestehende Open-Source- und kommerzielle Baselines. (Quelle: HuggingFace Daily Papers)
KI-Paper-Interpretation: ATLAS, Lernen, den Kontext zur Testzeit optimal zu speichern: Das Paper „ATLAS: Learning to Optimally Memorize the Context at Test Time“ stellt ATLAS vor, ein Langzeitgedächtnismodul mit hoher Kapazität, das lernt, den Kontext durch Optimierung des Gedächtnisses basierend auf aktuellen und vergangenen Tokens zu speichern und so die Online-Update-Eigenschaft von Langzeitgedächtnismodellen überwindet. Darauf basierend schlagen die Autoren die DeepTransformers-Architekturfamilie vor. Experimente zeigen, dass ATLAS Transformers und neuere lineare rekurrente Modelle bei Sprachmodellierung, Common-Sense-Reasoning, abrufdichten und Langkontext-Verständnisaufgaben übertrifft. (Quelle: HuggingFace Daily Papers)
KI-Paper-Interpretation: Satori-SWE, probeneffiziente evolutionäre Testzeit-Skalierungsmethode für Software Engineering: Das Paper „Satori-SWE: Evolutionary Test-Time Scaling for Sample-Efficient Software Engineering“ stellt die EvoScale-Methode vor, die Codegenerierung als evolutionären Prozess betrachtet und durch iterative Optimierung der Ausgabe die Leistung kleiner Modelle bei Software-Engineering-Aufgaben (wie SWE-Bench) verbessert. Das Satori-SWE-32B-Modell erreicht oder übertrifft durch diese Methode bei Verwendung weniger Samples die Leistung von Modellen mit über 100B Parametern. (Quelle: HuggingFace Daily Papers)
KI-Paper-Interpretation: OPO, On-Policy Reinforcement Learning mit optimaler Belohnungsbaseline: Das Paper „On-Policy RL with Optimal Reward Baseline“ stellt den OPO-Algorithmus vor, einen neuen, vereinfachten Reinforcement-Learning-Algorithmus, der darauf abzielt, die Probleme der Trainingsinstabilität und geringen Berechnungseffizienz aktueller RL-Algorithmen beim Training von LLMs zu lösen. OPO betont präzises On-Policy-Training und führt eine theoretisch die Gradientenvarianz minimierende optimale Belohnungsbaseline ein. Experimente zeigen seine überlegene Leistung und Trainingsstabilität auf mathematischen Reasoning-Benchmarks. (Quelle: HuggingFace Daily Papers)
KI-Paper-Interpretation: SWE-bench Goes Live! Echtzeitaktualisierter Software-Engineering-Benchmark: Das Paper „SWE-bench Goes Live!“ stellt SWE-bench-Live vor, einen echtzeitaktualisierbaren Benchmark, der darauf abzielt, die Einschränkungen des bestehenden SWE-bench zu überwinden. Die neue Version enthält 1319 Aufgaben, die aus echten GitHub-Problemen seit 2024 stammen und 93 Repositories abdecken. Sie ist mit automatisierten Verwaltungsprozessen ausgestattet, um Skalierbarkeit und kontinuierliche Aktualisierung zu ermöglichen und so eine strengere, kontaminationsresistente Bewertung von LLMs und Agenten zu ermöglichen. (Quelle: HuggingFace Daily Papers, _akhaliq)
KI-Paper-Interpretation: ToMAP, Training von gegnerbewussten LLM-Überzeugern mit Theory of Mind: Das Paper „ToMAP: Training Opponent-Aware LLM Persuaders with Theory of Mind“ stellt eine neue Methode namens ToMAP vor, die durch die Integration zweier Theory-of-Mind-Module flexiblere Überzeugungsagenten konstruiert und deren Bewusstsein und Analyse des mentalen Zustands des Gegners verbessert. Experimente zeigen, dass ToMAP-Überzeuger mit nur 3B Parametern in mehreren Überzeugungsobjektmodellen und Korpora besser abschneiden als große Baselines wie GPT-4o. (Quelle: HuggingFace Daily Papers)
KI-Paper-Interpretation: Können LLMs CLIP täuschen? Bewertung der adversariellen Kompositionalität vortrainierter multimodaler Repräsentationen durch Textaktualisierungen: Das Paper „Can LLMs Deceive CLIP? Benchmarking Adversarial Compositionality of Pre-trained Multimodal Representation via Text Updates“ führt den Benchmark für multimodale adversarielle Kompositionalität (MAC) ein. Er nutzt LLMs, um täuschende Textproben zu generieren, um die Kompositionalitätsschwachstellen vortrainierter multimodaler Repräsentationen wie CLIP auszunutzen. Die Studie schlägt eine Selbsttrainingsmethode vor, die durch diversitätsförderndes Filtern beim Rejection Sampling Feinabstimmung vornimmt, um die Erfolgsrate von Angriffen und die Diversität der Proben zu erhöhen. (Quelle: HuggingFace Daily Papers)
KI-Paper-Interpretation: Die Rolle verrauschter Belohnungen beim Lernen von Reasoning – Der Aufstieg formt die Weisheit tiefer als der Gipfel: Das Paper „The Climb Carves Wisdom Deeper Than the Summit: On the Noisy Rewards in Learning to Reason“ untersucht den Einfluss von Belohnungsrauschen auf das Post-Training von LLMs durch Reinforcement Learning für Reasoning-Aufgaben. Die Studie stellt fest, dass LLMs eine starke Robustheit gegenüber erheblichem Belohnungsrauschen aufweisen. Selbst wenn nur das Auftreten kritischer Reasoning-Phrasen belohnt wird (ohne die Korrektheit der Antwort zu überprüfen), können die Modelle eine vergleichbare Leistung wie Modelle erzielen, die mit strenger Überprüfung und genauen Belohnungen trainiert wurden. (Quelle: HuggingFace Daily Papers)
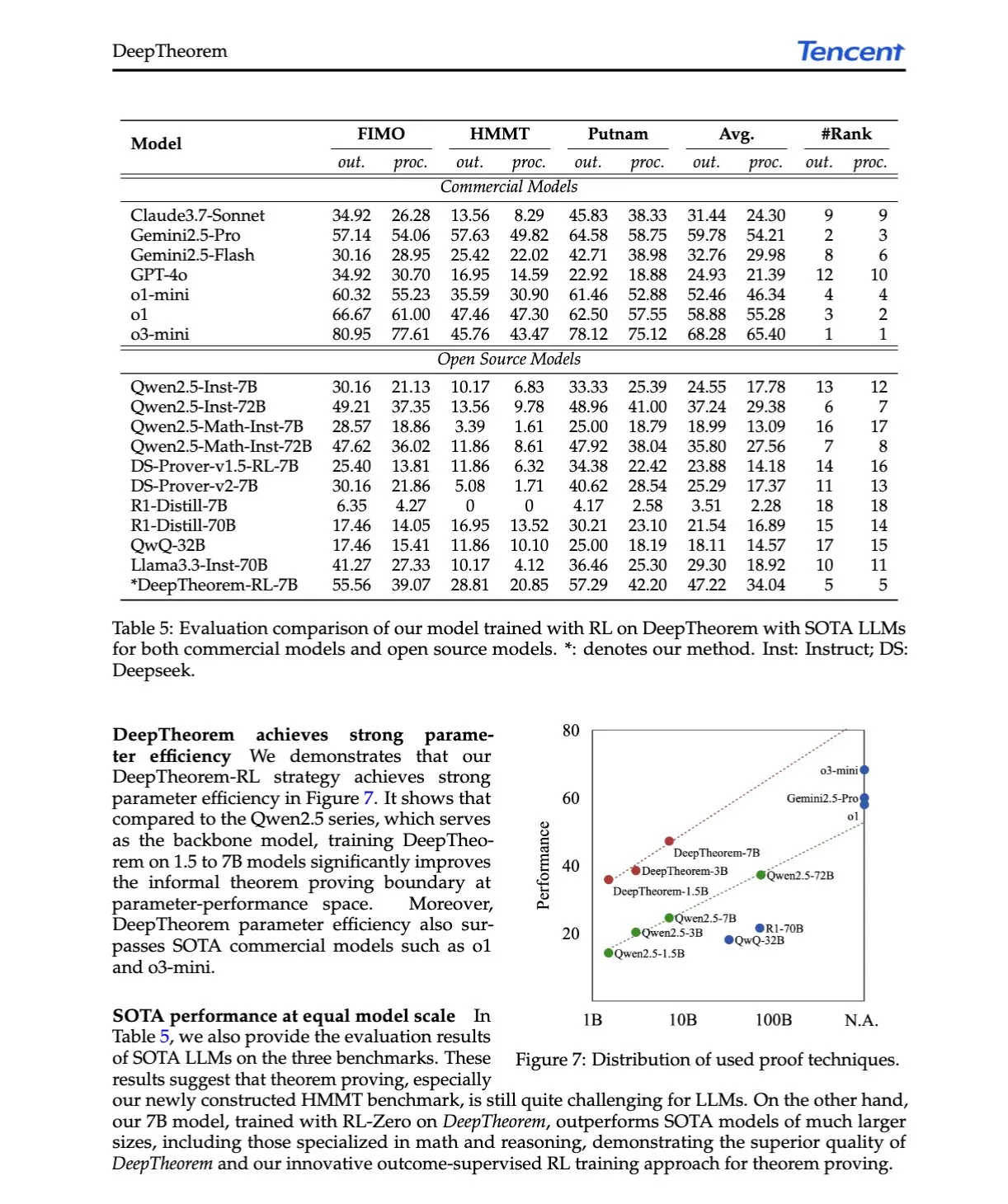
KI-Paper-Interpretation: DeepTheorem, Weiterentwicklung des LLM-Theorembeweisens durch natürliche Sprache und Reinforcement Learning: Das Paper „DeepTheorem: Advancing LLM Reasoning for Theorem Proving Through Natural Language and Reinforcement Learning“ stellt DeepTheorem vor, ein Framework für informelles Theorembeweisen, das natürliche Sprache nutzt, um das mathematische Reasoning von LLMs zu verbessern. Das Framework umfasst einen umfangreichen Benchmark-Datensatz (121.000 informelle Theoreme und Beweise auf IMO-Niveau) und eine speziell für informelles Theorembeweisen entwickelte RL-Strategie (RL-Zero). (Quelle: HuggingFace Daily Papers, teortaxesTex)
KI-Paper-Interpretation: D-AR, Diffusion durch autoregressive Modelle: Das Paper „D-AR: Diffusion via Autoregressive Models“ schlägt das neue D-AR-Paradigma vor, das den Bilddiffusionsprozess als standardmäßigen autoregressiven Next-Token-Vorhersageprozess umformt. Durch einen entworfenen Tokenizer werden Bilder in diskrete Token-Sequenzen umgewandelt, wobei Token an verschiedenen Positionen zu unterschiedlichen Diffusions-Denoising-Schritten im Pixelraum dekodiert werden können. Diese Methode erreicht auf ImageNet mit einem 775M Llama-Backbone und 256 diskreten Tokens einen FID von 2.09. (Quelle: HuggingFace Daily Papers)
KI-Paper-Interpretation: Table-R1, Inferenzzeit-Skalierung für Tabellen-Reasoning: Das Paper „Table-R1: Inference-Time Scaling for Table Reasoning“ untersucht erstmals die Inferenzzeit-Skalierung bei Tabellen-Reasoning-Aufgaben. Die Forscher entwickelten und bewerteten zwei Post-Training-Strategien: Destillation aus den Inferenzpfaden von Spitzenmodellen (Table-R1-SFT) und Reinforcement Learning mit verifizierbaren Belohnungen (Table-R1-Zero). Table-R1-Zero (7B Parameter) erreicht oder übertrifft die Leistung von GPT-4.1 und DeepSeek-R1 bei verschiedenen Tabellen-Reasoning-Aufgaben. (Quelle: HuggingFace Daily Papers)
KI-Paper-Interpretation: Muddit, einheitliches diskretes Diffusionsmodell für Generierung jenseits von Text-zu-Bild: Das Paper „Muddit: Liberating Generation Beyond Text-to-Image with a Unified Discrete Diffusion Model“ stellt Muddit vor, ein einheitliches diskretes Diffusions-Transformer-Modell, das die schnelle parallele Generierung von Text- und Bildmodalitäten unterstützt. Muddit integriert die starken visuellen Priors eines vortrainierten Text-zu-Bild-Backbones und einen leichtgewichtigen Textdecoder und ist sowohl in Qualität als auch Effizienz wettbewerbsfähig. (Quelle: HuggingFace Daily Papers)
KI-Paper-Interpretation: VideoReasonBench, können MLLMs visuell-zentriertes komplexes Video-Reasoning durchführen?: Das Paper „VideoReasonBench: Can MLLMs Perform Vision-Centric Complex Video Reasoning?“ führt VideoReasonBench ein, einen Benchmark zur Bewertung der Fähigkeit zu visuell-zentriertem komplexem Video-Reasoning. Der Benchmark enthält Videos von feinkörnigen Operationssequenzen, wobei Fragen die Erinnerungs-, Inferenz- und Vorhersagefähigkeiten bewerten. Experimente zeigen, dass die meisten SOTA MLLMs bei diesem Benchmark schlecht abschneiden, während das mit Denkprozessen erweiterte Gemini-2.5-Pro herausragt. (Quelle: HuggingFace Daily Papers, OriolVinyalsML)
KI-Paper-Interpretation: GeoDrive, 3D-geometrieinformiertes Fahrweltmodell mit präziser Aktionssteuerung: Das Paper „GeoDrive: 3D Geometry-Informed Driving World Model with Precise Action Control“ schlägt GeoDrive vor, das robuste 3D-Geometriebedingungen explizit in ein Fahrweltmodell integriert, um das räumliche Verständnis und die Steuerbarkeit von Aktionen zu verbessern. Die Methode verbessert die Rendering-Effekte im Training durch ein dynamisches Bearbeitungsmodul. Experimente belegen seine Überlegenheit gegenüber bestehenden Modellen in Bezug auf Aktionsgenauigkeit und 3D-Raumwahrnehmung. (Quelle: HuggingFace Daily Papers)
KI-Paper-Interpretation: Adaptive klassifikatorfreie Führung durch dynamische Maskierung geringer Konfidenz: Das Paper „Adaptive Classifier-Free Guidance via Dynamic Low-Confidence Masking“ schlägt die A-CFG-Methode vor, die die unbedingte Eingabe der klassifikatorfreien Führung (CFG) durch Nutzung der momentanen Vorhersagekonfidenz des Modells anpasst. A-CFG identifiziert in jedem Schritt des iterativen (maskierten) Diffusions-Sprachmodells Token mit geringer Konfidenz und maskiert sie temporär neu, wodurch dynamische, lokalisierte unbedingte Eingaben entstehen, die den Korrektureinfluss von CFG präziser machen. (Quelle: HuggingFace Daily Papers)
KI-Paper-Interpretation: PatientSim, ein Persona-gesteuerter Simulator für realistische Arzt-Patienten-Interaktionen: Das Paper „PatientSim: A Persona-Driven Simulator for Realistic Doctor-Patient Interactions“ stellt PatientSim vor, einen Simulator, der basierend auf klinischen Profilen aus dem MIMIC-Datensatz und vierachsigen Personas (Persönlichkeit, Sprachkompetenz, Erinnerungsvermögen an die Krankengeschichte, kognitive Verwirrtheit) realistische und vielfältige Patienten-Personas generiert. Ziel ist es, ein realistisches Patienteninteraktionssystem für das Training oder die Bewertung von Arzt-LLMs bereitzustellen. (Quelle: HuggingFace Daily Papers)
KI-Paper-Interpretation: LoRAShop, trainingsfreie Multi-Konzept-Bildgenerierung und -bearbeitung mit Rectified Flow Transformers: Das Paper „LoRAShop: Training-Free Multi-Concept Image Generation and Editing with Rectified Flow Transformers“ stellt LoRAShop vor, das erste Framework, das LoRA-Modelle für die Multi-Konzept-Bildbearbeitung verwendet. Das Framework nutzt interne Merkmalsinteraktionsmuster von Flux-artigen Diffusions-Transformern, um für jedes Konzept entkoppelte latente Masken abzuleiten und LoRA-Gewichte nur innerhalb der Konzeptregionen zu mischen, was eine nahtlose Integration mehrerer Subjekte oder Stile ermöglicht. (Quelle: HuggingFace Daily Papers)
KI-Paper-Interpretation: AnySplat, Feed-Forward 3D Gaussian Splatting aus uneingeschränkten Ansichten: Das Paper „AnySplat: Feed-forward 3D Gaussian Splatting from Unconstrained Views“ stellt AnySplat vor, ein Feed-Forward-Netzwerk für die Synthese neuer Ansichten aus einer Sammlung unkalibrierter Bilder. Im Gegensatz zu traditionellen neuronalen Rendering-Pipelines kann AnySplat durch einen einzigen Vorwärtsdurchlauf 3D-Gaußsche Primitive (die Szenengeometrie und -erscheinung kodieren) sowie die Kamera-Intrinsics und -Extrinsics für jedes Eingangsbild vorhersagen, ohne dass Posen-Annotationen erforderlich sind, und unterstützt die Echtzeit-Synthese neuer Ansichten. (Quelle: HuggingFace Daily Papers)
KI-Paper-Interpretation: ZeroSep, Trennung von allem in Audio ohne Training: Das Paper „ZeroSep: Separate Anything in Audio with Zero Training“ stellt fest, dass allein durch vortrainierte textgesteuerte Audiodiffusionsmodelle in einer spezifischen Konfiguration eine Zero-Shot-Quellentrennung erreicht werden kann. Die ZeroSep-Methode invertiert das gemischte Audio in den latenten Raum des Diffusionsmodells und verwendet textbedingte Führung des Denoising-Prozesses, um einzelne Schallquellen wiederherzustellen, ohne dass ein spezifisches Aufgabentraining oder eine Feinabstimmung erforderlich ist. (Quelle: HuggingFace Daily Papers)
KI-Paper-Interpretation: One-Shot-Entropieminimierungsstudie: Das Paper „One-shot Entropy Minimization“ stellt durch das Training von 13.440 großen Sprachmodellen fest, dass die Entropieminimierung nur ein einziges ungelabeltes Datum und 10 Optimierungsschritte benötigt, um Leistungsverbesserungen zu erzielen, die denen von regelbasiertem Reinforcement Learning mit Tausenden von Daten und sorgfältig entworfenen Belohnungen entsprechen oder diese sogar übertreffen. Dieses Ergebnis könnte zu einem Umdenken bei den Paradigmen des LLM-Post-Trainings führen. (Quelle: HuggingFace Daily Papers)
KI-Paper-Interpretation: ChartLens, feinkörnige visuelle Attribution in Diagrammen: Das Paper „ChartLens: Fine-grained Visual Attribution in Charts“ befasst sich mit dem Problem, dass MLLMs beim Verständnis von Diagrammen zu Halluzinationen neigen, und führt die Aufgabe der posterioren visuellen Attribution in Diagrammen sowie den ChartLens-Algorithmus ein. Der Algorithmus verwendet Segmentierungstechniken, um Diagrammobjekte zu identifizieren, und führt über Markierungsset-Prompts eine feinkörnige visuelle Attribution mit MLLMs durch. Gleichzeitig wird der ChartVA-Eval-Benchmark veröffentlicht, der feinkörnige Attributionsannotationen für Diagramme aus den Bereichen Finanzen, Politik, Wirtschaft usw. enthält. (Quelle: HuggingFace Daily Papers)
KI-Paper-Interpretation: Untersuchung struktureller Wissensmuster in großen Sprachmodellen aus Graphperspektive: Das Paper „A Graph Perspective to Probe Structural Patterns of Knowledge in Large Language Models“ untersucht strukturelle Wissensmuster in LLMs aus einer Graphperspektive. Die Studie quantifiziert das Wissen von LLMs auf Tripel- und Entitätsebene, analysiert dessen Beziehung zu Graphstrukturattributen wie dem Knotengrad und deckt Wissenshomophilie auf (ähnliches Wissensniveau für topologisch nahe Entitäten). Darauf basierend wurde ein Graph-Machine-Learning-Modell zur Schätzung des Entitätswissens entwickelt und für die Wissensprüfung verwendet. (Quelle: HuggingFace Daily Papers)
💼 Wirtschaft
Embodied Intelligence Unternehmen Lumos Robotics sammelt in sechs Monaten fast 200 Millionen Yuan ein und kooperiert mit COSCO Shipping u.a.: Das von dem ehemaligen Dreame-Manager Yu Chao gegründete Embodied Intelligence Roboterunternehmen Lumos Robotics (鹿明机器人) gab den Abschluss einer Angel++ Finanzierungsrunde bekannt. Zu den Investoren gehören Fosun RZ Capital, Dematic Technology und Wuzhong Financial Holding. In den letzten sechs Monaten hat das Unternehmen insgesamt fast 200 Millionen Yuan eingesammelt. Das Unternehmen konzentriert sich auf Heimszenarien und seine Produkte umfassen humanoide Roboter der LUS- und MOS-Serie sowie Kernkomponenten. Es hat bereits den humanoiden Roboter LUS in Originalgröße auf den Markt gebracht und strategische Kooperationen mit Dematic Technology, COSCO Shipping und anderen geschlossen, um die Kommerzialisierung von Embodied Intelligence in Logistik, intelligenter Fertigung und anderen Szenarien zu beschleunigen. (Quelle: 36氪)

Snorkel AI schließt Serie-D-Finanzierungsrunde über 100 Millionen US-Dollar ab und führt KI-Agentenbewertung sowie Expert-Data-Services ein: Das Data-Centric-AI-Unternehmen Snorkel AI gab den Abschluss einer von Valor Equity Partners angeführten Serie-D-Finanzierungsrunde in Höhe von 100 Millionen US-Dollar bekannt, womit sich die Gesamtfinanzierung auf 235 Millionen US-Dollar erhöht. Gleichzeitig stellte das Unternehmen Snorkel Evaluate (eine KI-Agentenbewertungsplattform für Rechenzentren) und Expert Data-as-a-Service vor, die Unternehmen dabei unterstützen sollen, zuverlässigere und professionellere KI-Agenten zu entwickeln und einzusetzen. (Quelle: realDanFu, percyliang, tri_dao, krandiash)
US-Energieministerium kündigt Zusammenarbeit mit Dell und Nvidia zur Entwicklung des Supercomputers der nächsten Generation „Doudna“ an: Das US-Energieministerium gab bekannt, einen Vertrag mit Dell Technologies über die Entwicklung des nächsten Flaggschiff-Supercomputers NERSC-10 namens „Doudna“ für das Lawrence Berkeley National Laboratory abgeschlossen zu haben. Das System wird von Nvidias nächster Generation der Vera Rubin-Plattform angetrieben und soll 2026 in Betrieb genommen werden. Es wird die Leistung des bestehenden Flaggschiffs Perlmutter um mehr als das Zehnfache übertreffen und zielt darauf ab, groß angelegte Hochleistungsrechen- und KI-Workloads zu unterstützen und den USA zu helfen, den globalen Wettbewerb um die KI-Vorherrschaft zu gewinnen. (Quelle: 36氪, nvidia)

🌟 Community
DeepSeek R1-0528 löst hitzige Diskussionen aus, Leistung, Halluzinationen und Werkzeugaufrufe im Fokus: Die Veröffentlichung von DeepSeek R1-0528 hat in der Community breite Diskussionen ausgelöst. Die meisten Meinungen deuten darauf hin, dass es signifikante Verbesserungen in Mathematik, Programmierung und allgemeinem logischen Denken gibt, die einigen Closed-Source-Modellen nahekommen oder diese sogar übertreffen. Die neue Version macht Fortschritte bei der Reduzierung der Halluzinationsrate und fügt Unterstützung für JSON-Ausgabe und Funktionsaufrufe hinzu. Gleichzeitig erregt auch die destillierte Qwen3-8B-Version aufgrund ihrer hervorragenden mathematischen Leistung bei kleinen Modellen Aufmerksamkeit. Die Community ist sich weitgehend einig, dass DeepSeek seine Führungsposition im Open-Source-Bereich gefestigt hat und erwartet mit Spannung die Veröffentlichung der R2-Version. (Quelle: ClementDelangue, dotey, scaling01, awnihannun, karminski3, teortaxesTex, scaling01, karminski3, teortaxesTex, dotey, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
KI-Bildbearbeitungsmodell FLUX.1 Kontext findet Beachtung, betont Kontextverständnis und Charakterkonsistenz: Das von Black Forest Labs veröffentlichte Bildbearbeitungsmodell FLUX.1 Kontext findet in der Community Beachtung, da es sowohl Text- als auch Bildeingaben verarbeiten und die Charakterkonsistenz wahren kann. Nutzerfeedback besagt, dass es bei Aufgaben wie Bildbearbeitung, Stiltransfer und Textüberlagerung hervorragende Leistungen erbringt, insbesondere bei mehrstufiger Bearbeitung, bei der die Hauptmerkmale gut erhalten bleiben. Plattformen wie Replicate haben das Modell bereits online gestellt und detaillierte Testberichte sowie Anwendungstipps bereitgestellt. (Quelle: TomLikesRobots, two_dukes, robrombach, timudk, robrombach, cloneofsimo, robrombach, robrombach)

KI-Agenten werden Such- und Werbemodelle erheblich verändern: Arav Srinivas, CEO von Perplexity AI, ist der Ansicht, dass mit der Durchführung von Suchen durch KI-Agenten im Auftrag der Nutzer die Anzahl menschlicher Anfragen an Suchmaschinen wie Google drastisch sinken wird. Dies wird zu niedrigeren CPM/CPC für Werbung führen, und Werbeausgaben könnten sich zu sozialen Medien oder KI-Plattformen verlagern. Nutzer werden nicht mehr häufig Schlüsselwortsuchen durchführen müssen, sondern erhalten Informationen proaktiv von KI-Assistenten. (Quelle: AravSrinivas)
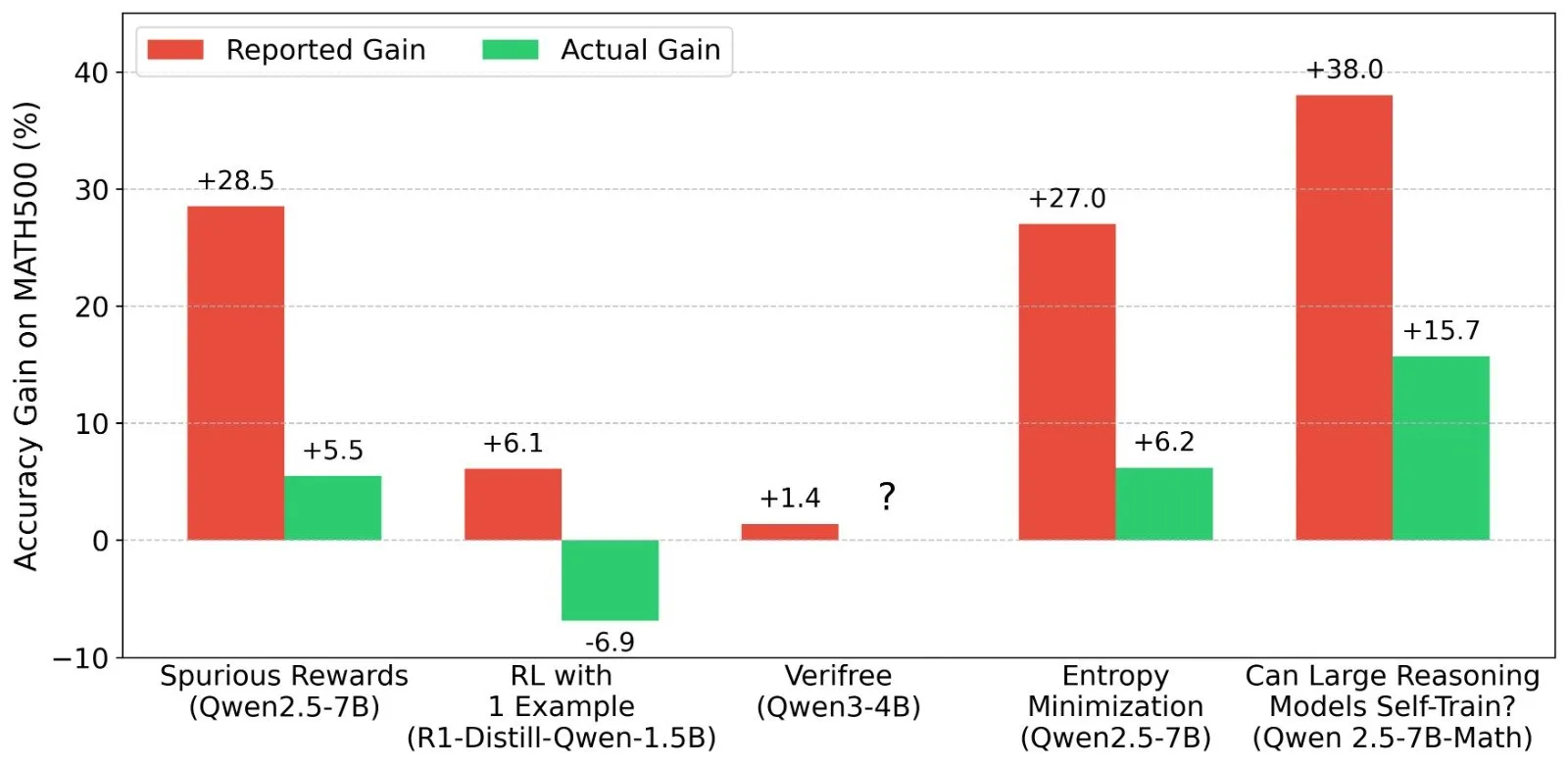
Diskussion über Ergebnisse des Reinforcement Learning (RL) bei LLMs: Realität von Belohnungssignalen und Modellfähigkeiten: Forscher wie Shashwat Goel stellen das Phänomen in Frage, dass Modelle in jüngsten LLM-RL-Studien ihre Leistung auch ohne echte Belohnungssignale verbessern konnten. Sie weisen darauf hin, dass einige Studien möglicherweise die Baseline-Fähigkeiten vortrainierter Modelle unterschätzt haben oder andere Störfaktoren vorlagen. Die Diskussion führte zu einer eingehenden Analyse der Leistung von Modellen wie Qwen im RL sowie zu Überlegungen zur Wirksamkeit von RLVR (Reinforcement Learning with Verifiable Reward) und betonte die Notwendigkeit strengerer Baselines und Prompt-Optimierungen bei der Bewertung von RL-Effekten. (Quelle: menhguin, AndrewLampinen, lateinteraction, madiator, vikhyatk, matei_zaharia, hrishioa, iScienceLuvr)
„Vibe Coding“ löst Diskussionen aus, betont sichere Standardwerte und Risiken technischer Schulden: „Vibe Coding“ (Atmosphären-Programmierung, d.h. eine Programmierweise, die sich mehr auf Intuition und schnelle Iterationen als auf strenge Spezifikationen stützt) wurde zu einem heißen Diskussionsthema in der Community. Amjad Masad, CEO von Replit, ist der Ansicht, dass diese Methode neue Entwickler befähigt, aber Plattformen müssen sichere Standardkonfigurationen bereitstellen. Gleichzeitig kommentierte Pedro Domingos: „Atmosphären-Programmierung ist der Godzilla der technischen Schulden“, was auf mögliche langfristige Wartungsprobleme hindeutet. Semafor berichtete über eine Sicherheitslücke bei Lovable aufgrund einer fehlerhaften Konfiguration der RLS-Strategie, was die Aufmerksamkeit weiter auf die Sicherheit dieser Programmierweise lenkte. (Quelle: alexalbert__, amasad, pmddomingos, gfodor)
Die Rolle der KI im Software Engineering: Effizienzsteigerung und die Unersetzlichkeit menschlicher Programmierer: Salvatore Sanfilippo, der Schöpfer von Redis, teilte seine Erfahrungen und erklärte, dass KI (wie Gemini 2.5 Pro) zwar bei der Programmierunterstützung, Code-Überprüfung und Ideenvalidierung wertvoll sei, menschliche Programmierer jedoch bei der kreativen Problemlösung und dem Denken über den Tellerrand hinaus der KI immer noch weit überlegen seien. Die Community-Diskussion wies ferner darauf hin, dass KI derzeit eher wie eine „intelligente Gummiente“ fungiere, die beim Denken helfen könne, deren Vorschläge jedoch sorgfältig bewertet werden müssten und eine übermäßige Abhängigkeit die Kernkompetenzen der Entwickler schwächen könnte. Mitchell Hashimoto teilte auch einen Fall, in dem ihm ein LLM half, ein Clang-Kompilierungsproblem schnell zu lokalisieren und so viel Zeit zu sparen. (Quelle: mitchellh, 36氪)
Ob KI Arbeitsplätze in großem Umfang ersetzen wird, sorgt weiterhin für Aufmerksamkeit: Dario Amodei, CEO von Anthropic, prognostiziert, dass KI die Hälfte der Büroarbeitsplätze auf Einstiegsebene verschwinden lassen könnte, während Mark Cuban glaubt, dass KI neue Unternehmen und neue Arbeitsplätze schaffen wird. In der Community wird dies heftig diskutiert. Einige argumentieren, dass Arbeitsplätze im Kundenservice, im Junior-Copywriting und in Teilen der Entwicklung bereits betroffen sind, KI aber in Bereichen, die Kreativität, komplexe Entscheidungen und ein hohes Maß an zwischenmenschlicher Interaktion erfordern, den Menschen noch kaum ersetzen kann. Allgemeiner Konsens ist, dass KI die Art der Arbeit verändern wird und sich die Menschen anpassen und ihre Fähigkeit zur Zusammenarbeit mit KI verbessern müssen. (Quelle: Reddit r/ArtificialInteligence, Reddit r/artificial, Reddit r/ArtificialInteligence)
KI-Agenten werden zum nächsten Interaktionsportal und lösen einen Wettlauf der großen Unternehmen aus: Microsoft, Google, OpenAI, Alibaba, Tencent, Baidu, Coocaa und andere in- und ausländische Technologieunternehmen positionieren sich im Bereich der KI-Agenten. Agenten können tiefgründig denken, autonom planen, Entscheidungen treffen und komplexe Aufgaben ausführen und gelten nach Suchmaschinen und Apps als das nächste Interaktionsportal. Derzeit haben sich drei Hauptkräfte herausgebildet: Technologie-Ökosystembauer wie OpenAI und Baidu; Anbieter von vertikalen Szenarien für Unternehmensdienstleistungen wie Microsoft und Alibaba Cloud; sowie Hard- und Software-Terminalhersteller wie Huawei und Coocaa. (Quelle: 36氪)

💡 Sonstiges
Chinas KI-Expansion ins Ausland beschleunigt sich, von Produktexport zu Ökosystemaufbau: Der Bericht „Chinas KI wächst über Ozeane hinweg“ stellt fest, dass die Expansion chinesischer KI-Unternehmen ins Ausland in eine Phase der schnellen Skalierung eingetreten ist, wobei sich 76 % auf Anwendungsebenen konzentrieren. Der Expansionspfad entwickelte sich von frühen Werkzeuganwendungen über den Export von Branchenlösungen unter Nutzung technologischer Vorteile in der mittleren Phase bis hin zum aktuellen Schwerpunkt auf dem Export von Technologieökosystemen, um Technologiestandards und Open-Source-Kollaborationen voranzutreiben. Die KI-Expansion ins Ausland zeigt eine graduelle Durchdringung „von nah nach fern“ und steht vor Herausforderungen wie Lokalisierung, Compliance-Ethik und Markenmarketing. (Quelle: 36氪)

US-Energieministerium vergleicht KI-Wettlauf mit „neuem Manhattan-Projekt“ und betont, dass die USA gewinnen werden: Bei der Ankündigung des Supercomputers der nächsten Generation „Doudna“ bezeichnete das US-Energieministerium den Entwicklungswettlauf der KI als „das Manhattan-Projekt unserer Zeit“ und erklärte, dass die USA diesen Wettlauf gewinnen würden. Diese Äußerung löste in der Community Diskussionen über den technologischen Wettbewerb der Großmächte, KI-Ethik und internationale Zusammenarbeit aus. (Quelle: gfodor, teortaxesTex, andrew_n_carr, npew, jpt401)
Fortschritte der KI im Bereich der Inhaltserstellung regen zum Nachdenken über „Authentizität“ und „Kreativität“ an: Die Community diskutierte Anwendungen von KI in Bereichen wie Modedesign, Comic-Erstellung und Videogenerierung. Einerseits kann KI schnell vielfältige Inhalte generieren und sogar Comic-Werke von vor einigen Jahren in Videos umwandeln; andererseits wirken diese generierten Inhalte manchmal seltsam oder oberflächlich. Dies regte zum Nachdenken darüber an, ob KI-generierte Inhalte „besser“ sind und welche Rolle menschliche Kreativität im KI-Zeitalter spielen wird. (Quelle: Reddit r/ChatGPT, Reddit r/artificial)
