Schlüsselwörter:RLHF, RLAIF, Qwen2.5-Math-7B, MATH-500, Verstärkungslernen, zufällige Belohnung, falsche Belohnung, Modellleistung, Zukunft von RLHF/RLAIF, zufällige Belohnung verbessert Modellleistung, Fehlbelohnungstraining für Qwen2.5-Math-7B, MATH-500-Testdatensatz, Verstärkungslernen Signalverarbeitung
🔥 Im Fokus
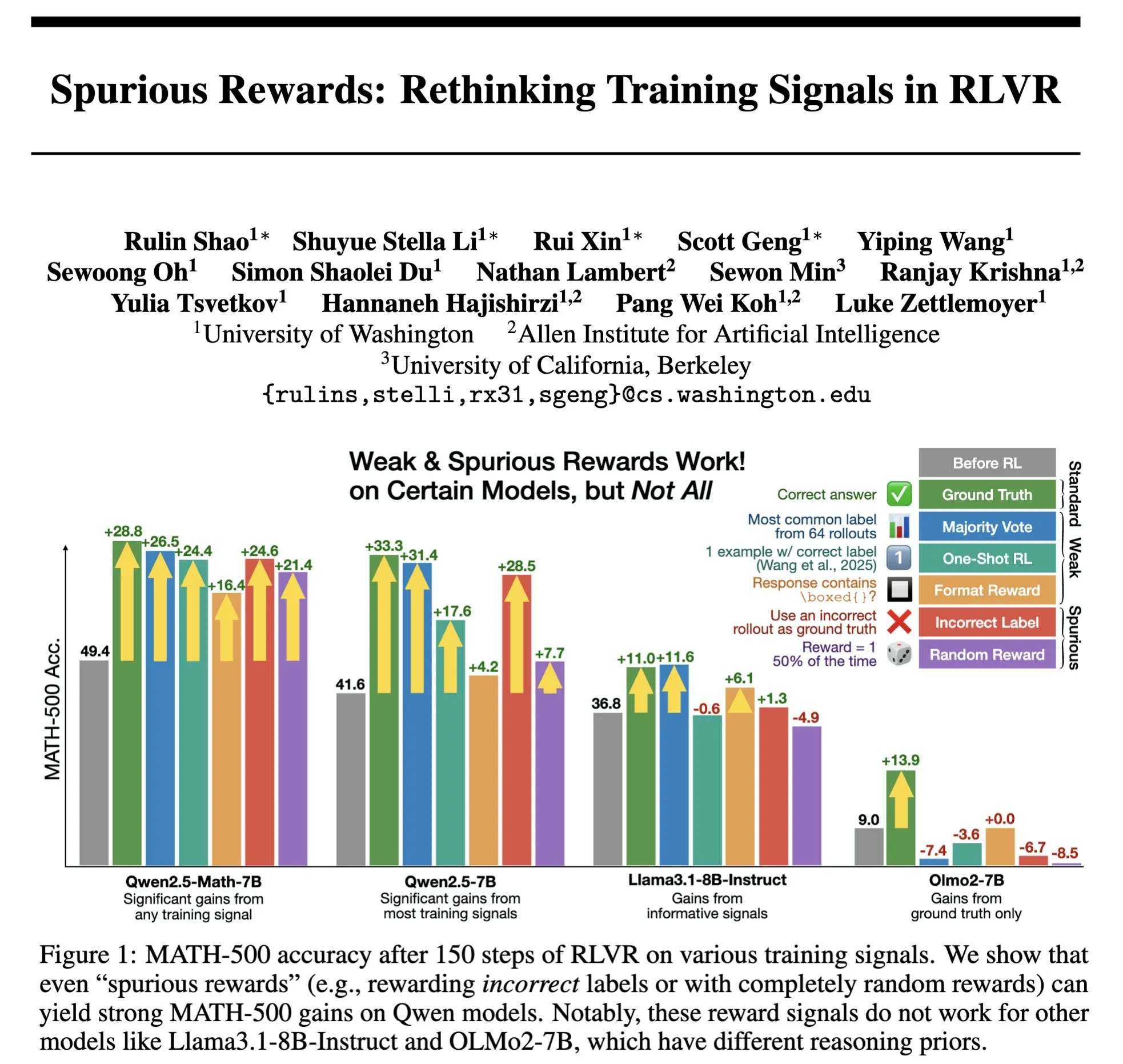
Die Zukunft von RLHF/RLAIF: Können zufällige/fehlerhafte Belohnungen die Modellleistung verbessern? : Experimente von Stella Li zeigten, dass das Training des Qwen2.5-Math-7B-Modells mit zufälligen oder falschen Belohnungen die Leistung im MATH-500-Testdatensatz um 21 % bzw. 25 % verbesserte, was nahe an der Leistungssteigerung von 28,8 % durch echte Belohnungen liegt. Eine von natolambert weitergeleitete Studie von Rulin Shao ergab ebenfalls, dass RLVR (Reinforcement Learning from Verifier Reward) bei Verwendung falscher Belohnungen dazu führte, dass das Olmo-Modell mehr Code verwendete, die Leistung jedoch abnahm, während eine Verhinderung der Codeverwendung die Leistung verbesserte. Diese Ergebnisse stellen die traditionelle Abhängigkeit von qualitativ hochwertigen menschlichen Präferenzdaten in RLHF/RLAIF in Frage und deuten darauf hin, dass Modelle durch Belohnungssignale lernen könnten, breitere Strategieräume zu erkunden. Selbst unvollkommene Belohnungen könnten latente Fähigkeiten des Modells freisetzen oder bestehende Verhaltensweisen optimieren. Dies könnte neue Wege eröffnen, um die Abhängigkeit von teurer manueller Annotation zu verringern und effizientere Methoden zur Modellausrichtung zu erforschen, birgt jedoch das Risiko, dass Modelle falsche Verhaltensweisen erlernen. (Quelle: natolambert, teortaxesTex, DhruvBatraDB, Francis_YAO_, raphaelmilliere)
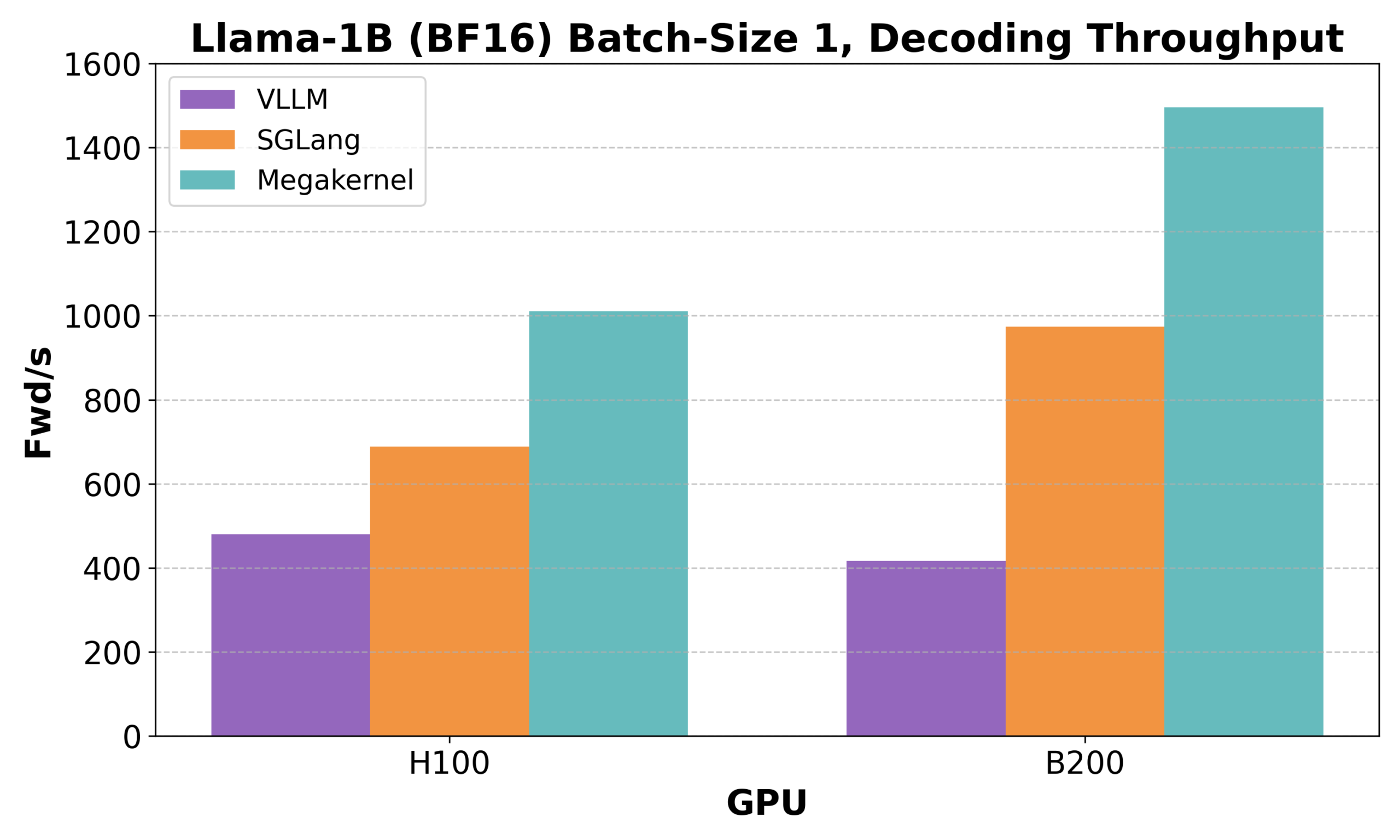
Hazy Research veröffentlicht Low-Latency-Llama Megakernel: Llama 1B Inferenz auf einem einzelnen CUDA-Kern : Hazy Research hat den Low-Latency-Llama Megakernel vorgestellt, der den gesamten Forward-Pass eines Llama 1B-Modells auf einem einzigen CUDA-Kern ausführen kann. Diese Technologie optimiert die Berechnung und Speicherplanung und erreicht eine geringere Latenz, indem sie die Berechnungen in einem einzigen Kernel konsolidiert und so die durch traditionelle serialisierte Kernel-Aufrufe verursachten Synchronisationsgrenzen eliminiert. Andrej Karpathy lobte dies sehr und bezeichnete es als den einzigen Weg, um eine optimale Orchestrierung von Rechenleistung und Speicher zu erreichen. Dieser Fortschritt ist von großer Bedeutung für Szenarien mit strengen Latenzanforderungen wie Edge Computing und Echtzeit-KI-Anwendungen und könnte den Einsatz effizienterer und agilerer kleiner Sprachmodelle fördern. (Quelle: karpathy, teortaxesTex, charles_irl, simran_s_arora)
DeepSeek Qiyuan veröffentlicht rStar-Coder: Aufbau eines umfangreichen, verifizierten Code-Reasoning-Datensatzes zur signifikanten Verbesserung der Code-Fähigkeiten kleiner Modelle : Forscher von Microsoft und DeepSeek haben das rStar-Coder-Projekt vorgestellt. Durch den Aufbau eines umfangreichen, verifizierten Datensatzes mit 418.000 Code-Problemen auf Wettbewerbsniveau, 580.000 langen Reasoning-Lösungen und umfangreichen Testfällen soll das Problem des Mangels an qualitativ hochwertigen und schwierigen Datensätzen im Bereich Code-Reasoning gelöst werden. Das Projekt zielt darauf ab, die Code-Reasoning-Fähigkeiten von LLMs zu verbessern, indem es bestehende Programmierwettbewerbsprobleme und Oracle-Lösungen umfassend nutzt, um neue Probleme zu synthetisieren, zuverlässige Pipelines zur Generierung von Ein-/Ausgabe-Testfällen entwirft und Testfälle zur Verifizierung hochwertiger langer Reasoning-Lösungen verwendet. Experimente zeigen, dass mit dem rStar-Coder-Datensatz trainierte Qwen-Modelle (1.5B-14B) auf mehreren Code-Reasoning-Benchmarks hervorragende Leistungen erbringen. Beispielsweise stieg die Genauigkeit von Qwen2.5-7B auf LiveCodeBench von 17,4 % auf 57,3 % und übertraf damit o3-mini (low); auf USACO übertraf das 7B-Modell auch das größere QWQ-32B. (Quelle: HuggingFace Daily Papers)
Institut für Automatisierung der Chinesischen Akademie der Wissenschaften stellt AutoThink vor: Lässt große Modelle autonom entscheiden, ob sie „tief nachdenken“ sollen : Als Reaktion auf das Phänomen des „Überdenkens“, bei dem große Sprachmodelle auch bei einfachen Problemen langwierige Schlussfolgerungen ziehen, haben das Institut für Automatisierung der Chinesischen Akademie der Wissenschaften und das Peng Cheng Laboratory gemeinsam die AutoThink-Methode vorgeschlagen. Diese Methode ermöglicht es dem Modell, durch Hinzufügen von Auslassungspunkten (…) im Prompt und durch dreistufiges Reinforcement Learning (Musterstabilisierung, Verhaltensoptimierung, Inferenz-Pruning) autonom zu entscheiden, ob und wie tief es je nach Schwierigkeitsgrad der Aufgabe nachdenken soll. Experimente zeigen, dass AutoThink die Leistung von Modellen wie DeepSeek-R1 auf mathematischen Benchmarks verbessern und gleichzeitig den Verbrauch von Inferenz-Token erheblich reduzieren kann. Beispielsweise können auf DeepScaleR zusätzlich 10 % der Token eingespart werden. Diese Forschung zielt darauf ab, Modelle zu befähigen, „nach Bedarf zu denken“ und so das Gleichgewicht zwischen Ineffizienz und Genauigkeit zu verbessern. (Quelle: 36氪, _akhaliq)

Sakana AI veröffentlicht Sudoku-Bench und deckt Schwächen führender großer Modelle beim Lösen von „Varianten-Sudokus“ auf : Sakana AI, das Startup des Transformer-Autors Llion Jones, hat Sudoku-Bench veröffentlicht, einen Benchmark-Test, der von 4×4 bis zu komplexen modernen 9×9 „Varianten-Sudokus“ reicht und darauf abzielt, die kreativen mehrstufigen Reasoning-Fähigkeiten von KI zu bewerten. Die Testergebnisse zeigen, dass führende große Modelle, darunter Gemini 2.5 Pro, GPT-4.1 und Claude 3.7, ohne Unterstützung eine Gesamtgenauigkeit von unter 15 % erreichen. Bei modernen 9×9-Sudokus erreichte o3 Mini High nur eine Genauigkeit von 2,9 %. Dies deutet darauf hin, dass Modelle bei neuartigen Problemen, die echtes logisches Denken anstelle von Mustererkennung erfordern, schlecht abschneiden und häufig falsche Lösungen liefern, aufgeben oder Regeln falsch interpretieren. NVIDIA-CEO Jensen Huang ist der Ansicht, dass solche Rätsel zur Verbesserung des KI-Reasonings beitragen. Sakana AI hat auch zugehörige Trainingsdaten veröffentlicht, einschließlich Aufzeichnungen von Lösungsprozessen in Zusammenarbeit mit bekannten Sudoku-Kanälen. (Quelle: 36氪)

🎯 Entwicklungen
Meta strukturiert KI-Team um, Abgang von FAIR-Kernmitgliedern erregt Aufmerksamkeit : Meta kündigte eine Umstrukturierung seines KI-Teams an und teilte es in ein von Connor Hayes geleitetes KI-Produktteam und eine von Ahmad Al-Dahle und Amir Frenkel gemeinsam geleitete AGI-Grundlagenabteilung auf. Ersteres konzentriert sich auf C-End-Produkte, letzteres auf die Entwicklung von Basismodellen wie Llama. Bemerkenswert ist, dass die Grundlagenforschungsabteilung FAIR unabhängig bleibt, einige Multimedia-Teams jedoch in die AGI-Grundlagenabteilung integriert werden. Ziel dieser Anpassung ist es, die Entwicklungsgeschwindigkeit und Flexibilität zu erhöhen. Meta steht jedoch vor Herausforderungen wie der verhaltenen Reaktion auf Llama 4, dem zunehmenden Wettbewerb im Open-Source-Bereich und dem Verlust von Kerntalenten. Von den ursprünglich 14 an der Llama-Entwicklung beteiligten Autoren haben bereits 11 das Unternehmen verlassen, von denen viele zu Konkurrenten wie Mistral AI gewechselt sind oder diese gegründet haben. Auch das FAIR-Labor hat Führungswechsel und Anpassungen der Forschungsrichtung erfahren, was Bedenken hinsichtlich seiner Stellung im Unternehmen und seiner zukünftigen Innovationsfähigkeit aufkommen lässt. (Quelle: 36氪)

Google DeepMind veröffentlicht SignGemma: Neues Modell zur Gebärdensprachübersetzung : Google DeepMind hat die Einführung von SignGemma angekündigt, einem Modell, das als das bisher leistungsstärkste für die Übersetzung von Gebärdensprache in gesprochenen Text gilt. Das Modell soll noch in diesem Jahr in die Gemma-Modellfamilie aufgenommen und als Open Source veröffentlicht werden. Die Einführung von SignGemma zielt darauf ab, neue Möglichkeiten für inklusive Technologien zu eröffnen und die Kommunikationseffizienz und -bequemlichkeit für Gebärdensprachnutzer zu verbessern. Google DeepMind lädt Nutzer ein, Feedback zu geben und an frühen Tests teilzunehmen. (Quelle: GoogleDeepMind, demishassabis)
Tencent Hunyuan veröffentlicht HunyuanPortrait-Modellgewichte zur Umwandlung statischer Porträts in dynamische Videos : Das Tencent Hunyuan-Team hat die Modellgewichte seines Bild-zu-Video-Modells HunyuanPortrait als Open Source veröffentlicht, sodass Benutzer sie herunterladen und lokal verwenden können. Das Modell konzentriert sich auf die Umwandlung statischer Personenporträts in dynamische Videos und eignet sich für verschiedene Anwendungsszenarien wie Spielfiguren, virtuelle Moderatoren, digitale Menschen und intelligente Einkaufsassistenten. Es kann Gesichtsbilder zum Leben erwecken und die Lebendigkeit und Authentizität der Interaktion erhöhen. Zugehörige Modelle, Code-Repositories und Paper wurden veröffentlicht. (Quelle: karminski3, Reddit r/LocalLLaMA)

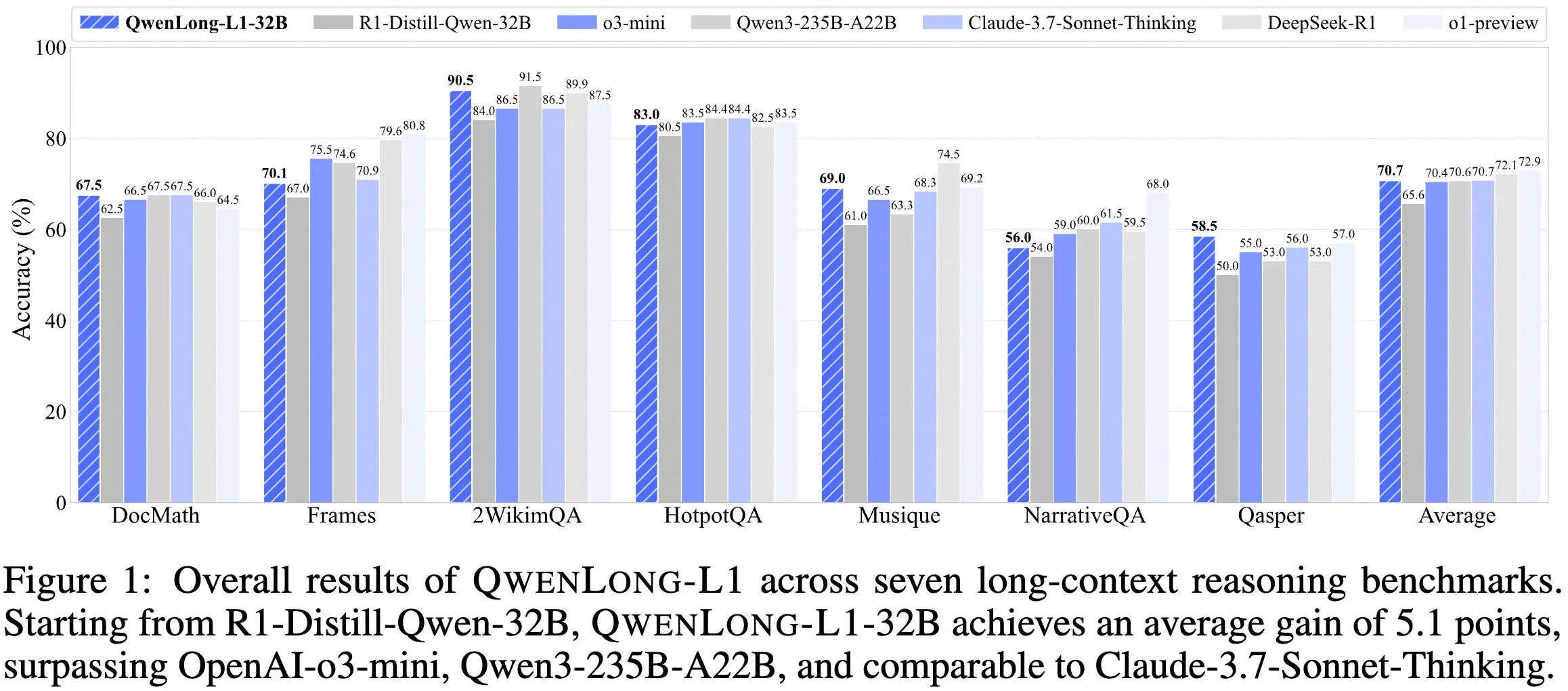
QwenDoc-Team veröffentlicht Langkontext-Inferenzmodell QwenLong-L1-32B : Das QwenDoc-Team hat das auf Reinforcement Learning basierende 128K-Langkontext-Inferenzmodell QwenLong-L1-32B vorgestellt. Das Modell basiert auf einem Fine-Tuning von DeepSeek-R1-Distill-Qwen-32B und erreicht im 2WikiMultihopQA-Multihop-Inferenztestdatensatz einen Score von 90,5, was einer Verbesserung von 6,5 Punkten gegenüber dem ursprünglichen Modell entspricht. Es wird betont, dass es im langen Kontext nicht nur Inhalte finden, sondern auch Hinweise verknüpfen und Schlussfolgerungen ziehen kann. Obwohl die Kontextlänge von 128K nicht die derzeit längste ist, bietet seine herausragende Inferenzfähigkeit eine neue Option für die Verarbeitung komplexer langer Dokumente. Modell, Paper und Code-Repository wurden veröffentlicht. (Quelle: karminski3)
HKUST und Apple entwickeln gemeinsam Laser-Methoden zur Optimierung der Ineffizienz und Genauigkeit großer Modelle : Forscher der Hong Kong University of Science and Technology (HKUST), der City University of Hong Kong, der University of Waterloo und Apple haben die Laser-Methodenreihe (einschließlich Laser-D, Laser-DE) vorgeschlagen, um das Problem des übermäßigen Token-Verbrauchs großer Sprachmodelle (LRM) bei einfachen Problemen zu lösen. Die Methode erreicht auf komplexen mathematischen Inferenz-Benchmarks wie AIME24 eine Leistungssteigerung von 6,1 Punkten bei gleichzeitiger Reduzierung des Token-Verbrauchs um 63 %, indem sie ein einheitliches Framework für das Belohnungsdesign basierend auf Ziellänge und Stufenfunktionen sowie einen dynamischen schwierigkeitsabhängigen Mechanismus verwendet. Die Forschung ergab, dass trainierte Modelle weniger redundante „Selbstreflexion“ aufweisen und gesündere Denkmuster zeigen, wodurch die Effizienz und Genauigkeit der Modellinferenz effektiv ausbalanciert werden. (Quelle: 36氪)

Kostenlose Version von Anthropic Claude unterstützt jetzt Websuche : Anthropic gab bekannt, dass Benutzer der kostenlosen Version seines KI-Assistenten Claude jetzt die Websuchfunktion nutzen können. Dies bedeutet, dass Claude bei der Beantwortung von Fragen auf aktuelle Informationen aus dem Internet zugreifen kann, um die Relevanz und Genauigkeit seiner Antworten zu verbessern. Offiziell heißt es, dass jede Antwort, die Suchergebnisse enthält, Inline-Zitate enthält, damit Benutzer die Informationsquellen überprüfen können. (Quelle: AnthropicAI)
PKU-DS-LAB veröffentlicht FairyR1: Ein 32B-Inferenzmodell, das auf DeepSeek-R1-Distill-Qwen-32B feinabgestimmt wurde : Das Data Science Laboratory der Peking University (PKU-DS-LAB) hat FairyR1 vorgestellt, ein Inferenzmodell mit 32B Parametern unter der Apache 2.0 Lizenz. Das Modell soll durch eine „Destillations- und Wiedervereinigungsmethode“ die Leistung größerer Modelle mit nur 5 % der Parameter erreichen. FairyR1 wurde auf Basis von DeepSeek-R1-Distill-Qwen-32B feinabgestimmt, und seine Trainingsdaten sind ebenfalls im Hugging Face Hub verfügbar. Diese Arbeit setzt die Forschungsidee von TinyR1 fort, indem Datensätze aktiv gefiltert werden (ca. 10.000 Trajektorien), SFT separat für Mathematik und Code durchgeführt und Arcee Fusion für die Modellzusammenführung verwendet wird. (Quelle: huggingface, teortaxesTex, stablequan)
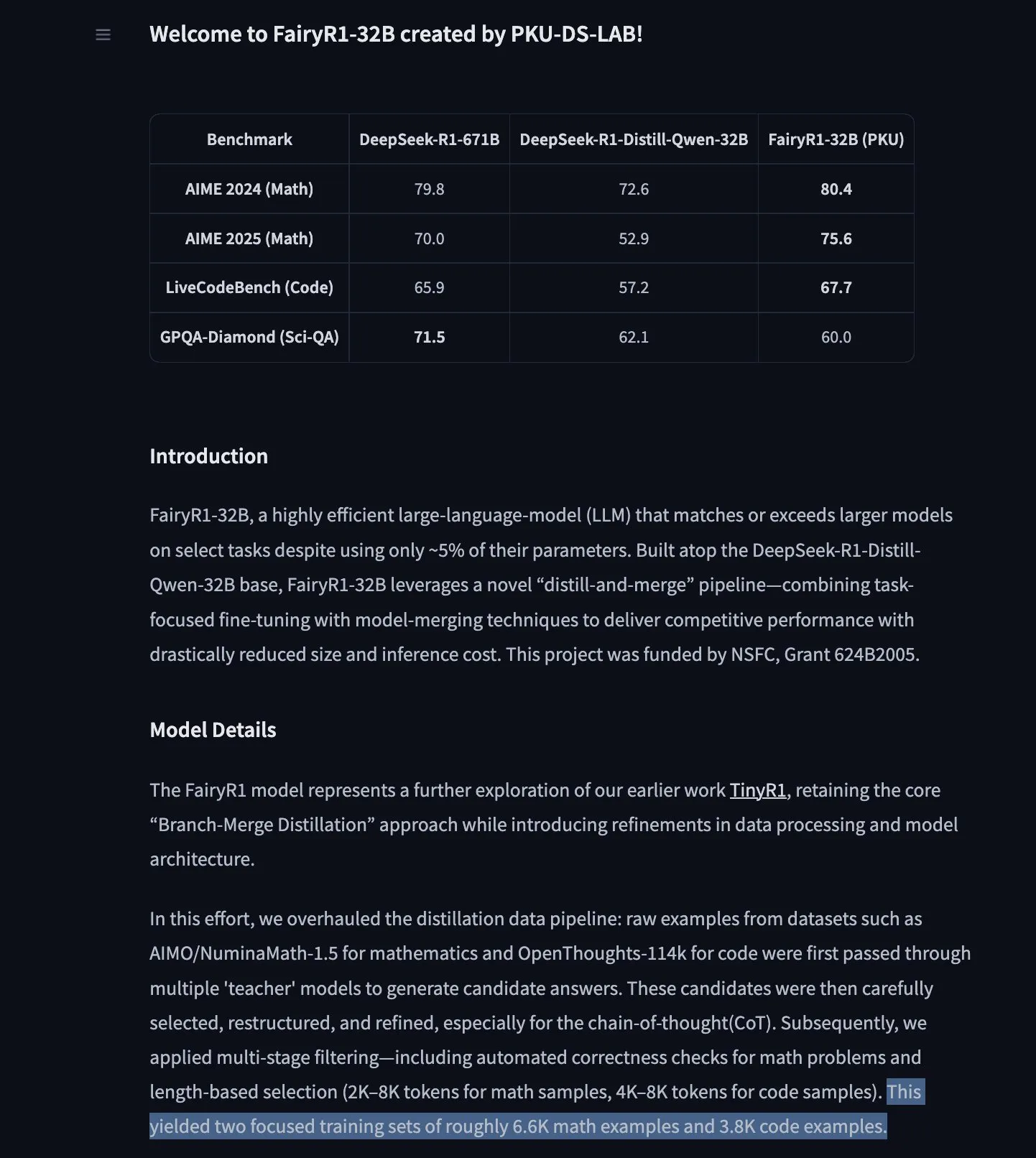
Googles TimesFM Zeitreihen-Vorhersagemodell jetzt in Hugging Face Transformers verfügbar : Googles TimesFM-Modell ist jetzt in die Hugging Face Transformers-Bibliothek integriert. Es handelt sich um ein GPT-ähnliches Modell, das mit 100 Milliarden realen Zeitpunktdaten aus verschiedenen Quellen wie Google Trends und Wikipedia-Seitenaufrufen vortrainiert wurde. TimesFM soll bei Zero-Shot-Vorhersageaufgaben besser abschneiden als speziell feinabgestimmte Modelle und bietet ein neues leistungsstarkes Werkzeug für die Zeitreihenanalyse. (Quelle: huggingface)
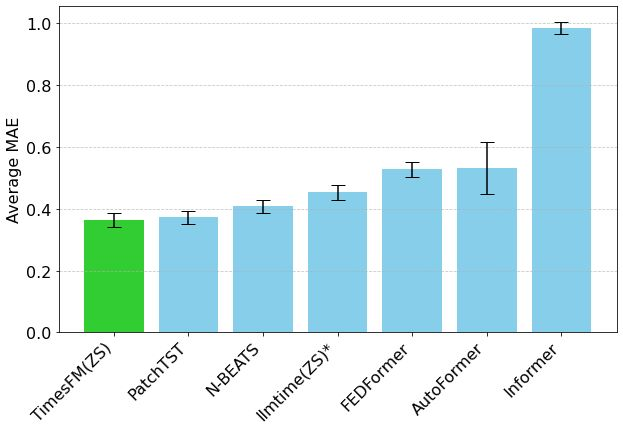
Hugging Face stellt Mixture of Thoughts vor: Ausgewählter Datensatz für allgemeines Reasoning : Lewis Tunstall und andere Forscher von Hugging Face haben den Datensatz „Mixture of Thoughts“ veröffentlicht. Dieser Datensatz wurde aus über 1 Million öffentlich zugänglichen Datenproben durch umfangreiche Ablationsexperimente sorgfältig ausgewählt und umfasst etwa 350.000 Proben, die sich auf allgemeine Reasoning-Fähigkeiten konzentrieren. Modelle, die mit diesem gemischten Datensatz trainiert wurden, erreichen oder übertreffen die Leistung der destillierten Modelle von DeepSeek in Mathematik, Code und wissenschaftlichen Benchmarks (wie GPQA). Die Forschung bestätigt die Wirksamkeit der in Phi-4-reasoning vorgeschlagenen „Additivitäts“-Methodik, d. h. die Datenmischung für jeden Reasoning-Bereich kann unabhängig optimiert und dann für das endgültige Training integriert werden. (Quelle: huggingface)
ByteDance veröffentlicht BAGEL-7B: Ein omnidirektionales Modell für Bild-Text-Verständnis und -Generierung : ByteDance hat BAGEL-7B vorgestellt, ein omnidirektionales Modell, das sowohl Bilder als auch Text verstehen und generieren kann. Darüber hinaus wurde Dolphin veröffentlicht, ein visuelles Sprachmodell (VLM), das sich auf die Dokumentenanalyse konzentriert. Die Open-Source-Veröffentlichung dieser Modelle wird neue Werkzeuge und Möglichkeiten für die multimodale Forschung und Anwendung bieten. (Quelle: huggingface, TheTuringPost)

Google veröffentlicht Gemini 2.5 Flash Preview mit nativer Audioausgabe : Google AI-Entwickler gaben bekannt, dass Gemini 2.5 Flash Preview jetzt über die Live API native Audioausgabe unterstützt, um eine nahtlose, natürliche sprachliche Interaktion und eine stärkere Sprachsteuerung zu ermöglichen. Darüber hinaus wurde eine neue experimentelle „Thinking“-Version dieses Audiomodells veröffentlicht, die Reasoning-Fähigkeiten für komplexere Aufgaben unterstützt. Gleichzeitig beginnt die Ausgabe der Gemini API, „Denkzusammenfassungen“ anzuzeigen, die den Benutzern Einblick in den Denkprozess des Modells geben, aber derzeit keine vollständige Inferenzkette darstellen. (Quelle: algo_diver, op7418)
Paper untersucht die Ausdrucksfähigkeit von Transformern beim Füllen leerer Token : Eine neue Studie untersucht, ob das Füllen leerer Token in Transformer-Eingaben (eine Form der Testzeitberechnung) die Rechenleistung von LLMs verbessern kann. Die Studie, die in Zusammenarbeit mit Ashish_S_AI durchgeführt wurde, charakterisiert präzise die Ausdrucksfähigkeit von Transformern mit Füllung und bietet neue Perspektiven für das Verständnis und die Optimierung der Rechenmechanismen von LLMs. (Quelle: teortaxesTex)

Neue Studie schlägt Sci-Fi-Framework vor: Verbesserung der Video-Frame-Interpolation durch symmetrische Constraints : Ein neues Paper schlägt das Sci-Fi (Symmetric Constraint for Frame Inbetweening)-Framework vor, um das Problem der potenziell asymmetrischen Kontrollstärke bei der Integration von Anfangs- und End-Frame-Constraints in aktuellen Video-Frame-Interpolationsmethoden (Frame Inbetweening) anzugehen. Die Methode zielt darauf ab, Symmetrie zwischen den Anfangs- und End-Frame-Constraints zu erreichen, indem stärkere Injektionsmechanismen (basierend auf dem leichtgewichtigen Modul EF-Net) für Constraints mit kleinerem Trainingsumfang (wie End-Frames) angewendet werden. Dies soll zu harmonischeren Übergängen in den generierten Zwischen-Frames führen und Inkonsistenzen in der Bewegung oder einen Zusammenbruch des Erscheinungsbilds vermeiden. (Quelle: HuggingFace Daily Papers)
Paper schlägt Paper2Poster vor: Automatisierter Prozess von wissenschaftlichen Arbeiten zu multimodalen Postern : Um den Herausforderungen bei der Erstellung wissenschaftlicher Poster zu begegnen, haben Forscher Paper2Poster vorgestellt, den ersten Benchmark und die erste Bewertungssuite für die Postergenerierung. Es enthält Paare von wissenschaftlichen Arbeiten und von Autoren entworfenen Postern und bewertet diese hinsichtlich visueller Qualität, Textkohärenz, Gesamtbewertung und PaperQuiz (das die Fähigkeit des Posters misst, Kerninhalte zu vermitteln). Gleichzeitig wurde PosterAgent vorgeschlagen, ein Top-Down-, visuell-in-the-Loop-Multi-Agenten-Prozess, der einen Parser (Extraktion von Assets), einen Planer (Text-Bild-Ausrichtung und Layout) und einen Maler-Kritiker-Zyklus (Rendering und Feedback-Optimierung) umfasst. Varianten, die auf Open-Source-Modellen wie Qwen-2.5 basieren, übertreffen GPT-4o-gesteuerte Systeme in den meisten Metriken, reduzieren den Token-Verbrauch um 87 % und können 22-seitige Paper zu extrem niedrigen Kosten in bearbeitbare .pptx-Poster umwandeln. (Quelle: HuggingFace Daily Papers)
Paper schlägt Frame In-N-Out vor: Realisierung unbegrenzter, steuerbarer Bild-zu-Video-Generierung : Um Herausforderungen bei der Videogenerierung wie Steuerbarkeit, zeitliche Konsistenz und Detailsynthese anzugehen, konzentriert sich ein neues Paper auf die Filmtechnik „Frame In and Frame Out“. Ziel ist es, Benutzern zu ermöglichen, Objekte in Bildern kontrolliert aus der Szene zu entfernen oder neue Identitätsreferenzen in die Szene einzuführen, geleitet von benutzerdefinierten Bewegungstrajektorien. Zu diesem Zweck führten die Forscher einen neuen halbautomatisch annotierten Datensatz, ein umfassendes Bewertungsprotokoll und eine effiziente Video Diffusion Transformer-Architektur ein, die Identitätserhaltung und Bewegungskontrolle ermöglicht. Experimente zeigen, dass die Methode bestehende Baselines signifikant übertrifft. (Quelle: HuggingFace Daily Papers)
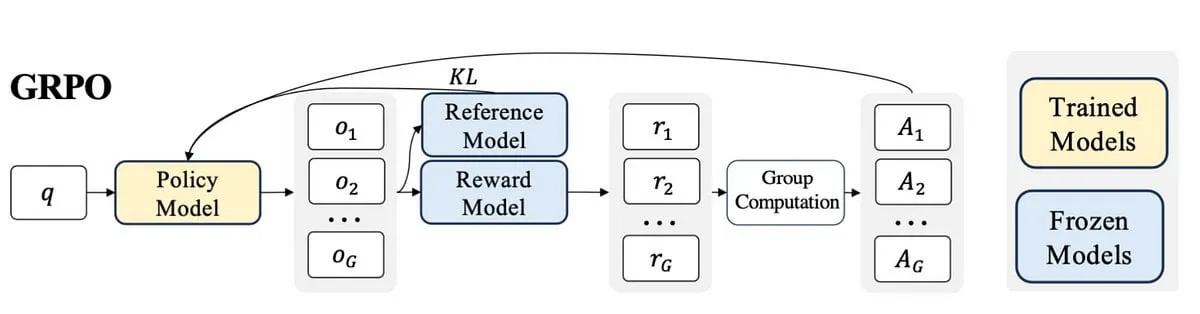
Neue Studie schlägt Active-O3 vor: Verleihung aktiver Wahrnehmungsfähigkeiten an multimodale große Sprachmodelle durch GRPO : Angesichts der unzureichenden Erforschung der aktiven Wahrnehmung (active perception) in multimodalen großen Sprachmodellen (MLLMs) schlagen Forscher das Active-O3-Framework vor. Dieses Framework basiert auf reinem Reinforcement Learning-Training mit GRPO (Group Relative Policy Optimization) und zielt darauf ab, MLLMs die Fähigkeit zu verleihen, Beobachtungspositionen und -methoden aktiv auszuwählen, um aufgabenrelevante Informationen zu sammeln. Die Forscher definieren zunächst systematisch auf MLLMs basierende aktive Wahrnehmungsaufgaben und weisen darauf hin, dass die erweiterte Suchstrategie von GPT-o3 ein Spezialfall aktiver Wahrnehmung ist, jedoch an Effizienz und Genauigkeit mangelt. Active-O3 wird durch den Aufbau einer umfassenden Benchmark-Suite in allgemeinen Open-World-Aufgaben (wie der Lokalisierung kleiner und dichter Objekte) und spezifischen Domänenszenarien (wie Fernerkundung, Erkennung kleiner Objekte im autonomen Fahren, feingranulare interaktive Segmentierung) bewertet und zeigt seine starken Zero-Shot-Inferenzfähigkeiten auf dem V* Benchmark. (Quelle: HuggingFace Daily Papers)
Paper schlägt MME-Reasoning vor: Ein umfassender Benchmark-Test für die logischen Reasoning-Fähigkeiten von MLLMs : Angesichts der Unzulänglichkeiten bestehender Benchmarks bei der Bewertung der logischen Reasoning-Fähigkeiten multimodaler großer Sprachmodelle (MLLMs) haben Forscher MME-Reasoning eingeführt. Dieser Benchmark deckt die drei wichtigsten Arten des logischen Reasonings ab: induktiv, deduktiv und abduktiv. Die Daten wurden sorgfältig ausgewählt, um sicherzustellen, dass die Fragen die Reasoning-Fähigkeiten effektiv bewerten und nicht Wahrnehmungsfähigkeiten oder Wissensbreite. Die Bewertungsergebnisse zeigen, dass selbst die fortschrittlichsten MLLMs bei einer umfassenden Bewertung des logischen Reasonings Einschränkungen aufweisen und Leistungsungleichgewichte zwischen verschiedenen Reasoning-Typen bestehen. Die Studie analysiert auch den Einfluss von Methoden wie „Denkmustern“ und regelbasiertem Reinforcement Learning auf die Reasoning-Fähigkeiten und liefert systematische Einblicke in das Verständnis und die Bewertung der Reasoning-Fähigkeiten von MLLMs. (Quelle: HuggingFace Daily Papers)
GraLoRA: Verbesserung der parametereffizienten Feinabstimmungsleistung durch granulare Low-Rank-Adaptation : Um die Probleme der Überanpassung und Leistungsengpässe von LoRA bei der Erhöhung des Rangs anzugehen, schlagen Forscher GraLoRA (Granular Low-Rank Adaptation) vor. Diese Methode unterteilt die Gewichtsmatrix in Unterblöcke, wobei jeder Unterblock über einen unabhängigen Low-Rank-Adapter verfügt. Ziel ist es, die durch strukturelle Engpässe von LoRA verursachten Probleme der Gradientenverflechtung und Propagationsverzerrung zu lösen. GraLoRA verbessert effektiv die Ausdrucksfähigkeit des Modells und nähert sich der Wirkung einer vollständigen Feinabstimmung, ohne die Rechen- oder Speicherkosten wesentlich zu erhöhen. Experimente auf Benchmarks für Codegenerierung und Common-Sense-Reasoning zeigen, dass GraLoRA LoRA und andere Baselines bei verschiedenen Modellgrößen und Rang-Einstellungen übertrifft, beispielsweise mit einem absoluten Zuwachs von bis zu 8,5 % bei Pass@1 auf HumanEval+. (Quelle: HuggingFace Daily Papers)
SoloSpeech: Kaskadierte Generierungspipeline verbessert Klarheit und Qualität der Zielextraktion von Sprache : Um das Problem anzugehen, dass bestehende diskriminative Modelle bei der Zielextraktion von Sprache (TSE) leicht Artefakte einführen und die Natürlichkeit verringern, während generative Modelle bei der wahrgenommenen Qualität und Klarheit unzureichend sind, schlagen Forscher SoloSpeech vor. Dies ist eine neuartige kaskadierte Generierungspipeline, die Komprimierungs-, Extraktions-, Rekonstruktions- und Korrekturprozesse integriert. Ihre Besonderheit ist ein Zielextraktor ohne Sprecher-Embedding, der die bedingten Informationen des latenten Raums des Prompt-Audios nutzt und ihn mit dem latenten Raum des gemischten Audios abgleicht, um Nichtübereinstimmungen zu verhindern. Bewertungen auf dem Libri2Mix-Datensatz zeigen, dass SoloSpeech bei Aufgaben der Zielextraktion von Sprache und der Sprachtrennung neue SOTA-Niveaus erreicht und eine hervorragende Generalisierungsfähigkeit bei Out-of-Domain-Daten und realen Szenarien aufweist. (Quelle: HuggingFace Daily Papers)
Neue Studie untersucht die Verbesserung des visuellen Verständnisses multimodaler großer Sprachmodelle durch textgeführte Vektoren : Eine neue Studie untersucht, ob von rein textbasierten LLM-Backbones multimodaler großer Sprachmodelle (MLLMs) abgeleitete Führungsvektoren (erhalten durch Methoden wie Sparse Autoencoder (SAE), Mean-Shift und lineare Sonden) deren visuelle Verständnisfähigkeiten verbessern können. Die Studie ergab, dass textabgeleitete Führungsvektoren die multimodale Genauigkeit verschiedener MLLM-Architekturen bei verschiedenen visuellen Aufgaben kontinuierlich verbessern können. Insbesondere die Mean-Shift-Methode verbesserte die Genauigkeit räumlicher Beziehungen auf CV-Bench um bis zu 7,3 % und die Zählgenauigkeit um bis zu 3,3 %, übertraf damit Prompting-Methoden und zeigte eine starke Generalisierungsfähigkeit auf Out-of-Distribution-Datensätzen. Dies deutet darauf hin, dass textgeführte Vektoren ein leistungsstarker und effizienter Mechanismus sind, um die visuelle Grundlage von MLLMs mit minimalem zusätzlichen Datenerfassungs- und Rechenaufwand zu verbessern. (Quelle: HuggingFace Daily Papers)
Paper schlägt DiSA vor: Beschleunigung der autoregressiven Bildgenerierung durch Diffusion Step Annealing : Um das Problem der geringen Inferenz-Effizienz aufgrund der Verwendung von Diffusions-Sampling zur Verbesserung der Bildqualität in autoregressiven Modellen wie MAR und FlowAR anzugehen, schlägt ein neues Paper die DiSA (Diffusion Step Annealing)-Methode vor. Die Methode basiert auf der Beobachtung, dass mit zunehmender Anzahl generierter Token im autoregressiven Prozess die Verteilung nachfolgender Token stärker eingeschränkt wird und das Sampling einfacher wird. DiSA ist eine trainingsfreie Methode, die die Diffusionsschritte allmählich reduziert, wenn mehr Token generiert werden (z. B. von anfänglich 50 Schritten auf später 5 Schritte). Die Methode ergänzt bestehende Beschleunigungsmethoden, die für die Diffusion selbst entwickelt wurden, ist einfach zu implementieren und kann MAR und Harmon um das 5- bis 10-fache und FlowAR und xAR um das 1,4- bis 2,5-fache beschleunigen, während die Generierungsqualität erhalten bleibt. (Quelle: HuggingFace Daily Papers)
Paper schlägt CASS vor: Datensatz, Modell und Benchmark für die Übersetzung von GPU-Code von Nvidia zu AMD : Forscher haben CASS vorgestellt, den ersten umfangreichen Datensatz und die erste Modellsuite für die Übersetzung von GPU-Code über Architekturen hinweg. Ziel ist die Übersetzung auf Quellcodeebene (CUDA <-> HIP) und Assemblerebene (Nvidia SASS <-> AMD RDNA3). Der Datensatz enthält 70.000 verifizierte Code-Paare für Host und Gerät. Die auf dieser Ressource trainierten domänenspezifischen Sprachmodelle der CASS-Reihe erreichen eine Genauigkeit von 95 % bei der Quellcodeübersetzung und 37,5 % bei der Assemblerübersetzung und übertreffen damit kommerzielle Baselines wie GPT-4o und Claude deutlich. Der generierte Code erreicht in über 85 % der Testfälle die native Leistung. Gleichzeitig wurde CASS-Bench veröffentlicht, ein Benchmark-Test mit 16 GPU-Domänen und realen Ausführungsergebnissen. Alle Daten, Modelle und Bewertungstools sind Open Source. (Quelle: HuggingFace Daily Papers)
Paper analysiert die verbale Kalibrierungsfähigkeit in visuellen Sprachmodellen : Eine Studie bewertet umfassend die Wirksamkeit visueller Sprachmodelle (VLMs) bei der Äußerung von Konfidenz (d. h. verbaler Unsicherheit) durch natürliche Sprache. Die Studie umfasste drei Modellklassen, vier Aufgabenbereiche und drei Bewertungsszenarien. Die Ergebnisse zeigen, dass aktuelle VLMs in verschiedenen Aufgaben und Einstellungen häufig deutliche Kalibrierungsfehler aufweisen. Bemerkenswerterweise zeigten visuelle Reasoning-Modelle (d. h. Modelle, die mit Bildern denken) durchweg eine bessere Kalibrierung, was darauf hindeutet, dass spezifisches modales Reasoning für eine zuverlässige Unsicherheitsschätzung entscheidend ist. Um den Kalibrierungsherausforderungen zu begegnen, führten die Forscher „Visual Confidence-Aware Prompting“ ein, eine zweistufige Prompting-Strategie, die darauf abzielt, die Konfidenzausrichtung in multimodalen Einstellungen zu verbessern. (Quelle: HuggingFace Daily Papers)
Paper verfolgt die Emergenz pragmatischer Fähigkeiten in großen Sprachmodellen : Aktuelle LLMs zeigen aufkommende Fähigkeiten bei Aufgaben der sozialen Intelligenz, aber es ist unklar, wie sie während des Trainings pragmatische Fähigkeiten erwerben. Ein neues Paper führt den ALTPRAG-Datensatz ein, der auf dem pragmatischen Konzept der „Alternativen“ basiert und bewertet, ob LLMs in verschiedenen Trainingsphasen subtile Sprecherabsichten genau ableiten können. Durch die systematische Bewertung von 22 LLMs (die vortrainierte, SFT- und Präferenzoptimierungsphasen abdecken) zeigen die Ergebnisse, dass selbst Basismodelle eine signifikante Sensibilität für pragmatische Hinweise aufweisen, die sich mit zunehmender Modell- und Datengröße kontinuierlich verbessert. SFT und RLHF verbessern die kognitiven pragmatischen Reasoning-Fähigkeiten weiter. Diese Ergebnisse unterstreichen, dass pragmatische Fähigkeiten eine emergente kombinatorische Eigenschaft des LLM-Trainings sind und neue Einblicke in die Ausrichtung von Modellen an menschliche Kommunikationsnormen liefern. (Quelle: HuggingFace Daily Papers)
Video-Holmes-Benchmark veröffentlicht: Bewertung des „Sherlock-Holmes-artigen“ Denkens von MLLMs bei komplexen Video-Inferenzen : Angesichts der Tatsache, dass bestehende Video-Benchmarks hauptsächlich visuelle Wahrnehmungs- und Lokalisierungsfähigkeiten bewerten und komplexe Inferenzanforderungen nicht ausreichend erfassen, haben Forscher den Video-Holmes-Benchmark eingeführt. Dieser Benchmark ist vom Inferenzprozess von Sherlock Holmes inspiriert und enthält 1837 Fragen aus 270 manuell annotierten Mystery-Kurzfilmen, die 7 sorgfältig gestaltete Aufgaben umfassen. Jede Aufgabe erfordert, dass das Modell aktiv mehrere relevante visuelle Hinweise, die über verschiedene Videosegmente verstreut sind, lokalisiert und verbindet. Die Bewertung von SOTA MLLMs zeigt, dass Modelle zwar bei der visuellen Wahrnehmung hervorragend abschneiden, aber erhebliche Schwierigkeiten bei der Informationsintegration haben und häufig wichtige Hinweise übersehen. Beispielsweise beträgt die Genauigkeit des leistungsstärksten Gemini-2.5-Pro nur 45 %. (Quelle: HuggingFace Daily Papers)
MME-VideoOCR-Benchmark veröffentlicht: Bewertung der OCR-Fähigkeiten multimodaler LLMs in Videoszenen : Obwohl multimodale große Sprachmodelle (MLLMs) bei der OCR statischer Bilder erhebliche Fortschritte erzielt haben, wird ihre Wirksamkeit bei der Video-OCR durch Faktoren wie Bewegungsunschärfe, zeitliche Veränderungen und visuelle Effekte beeinträchtigt. Um das Training praktischer MLLMs anzuleiten, haben Forscher den MME-VideoOCR-Benchmark eingeführt, der ein breites Spektrum an Video-OCR-Anwendungsszenarien abdeckt. Dieser Benchmark umfasst 10 Aufgabenkategorien (25 unabhängige Aufgaben), die 44 verschiedene Szenarien abdecken und nicht nur Texterkennung, sondern auch ein tiefergehendes Verständnis und Reasoning über Textinhalte in Videos beinhalten. Der Benchmark enthält 1464 Videos mit unterschiedlichen Auflösungen, Seitenverhältnissen und Dauern sowie 2000 sorgfältig kuratierte, manuell annotierte Frage-Antwort-Paare. Die Bewertung von 18 SOTA MLLMs zeigt, dass selbst das leistungsstärkste Gemini-2.5 Pro nur eine Genauigkeit von 73,7 % erreicht, was die Grenzen bestehender Modelle bei der Bewältigung von Aufgaben aufzeigt, die ein ganzheitliches Videoverständnis erfordern. (Quelle: HuggingFace Daily Papers)
MetaMind: Modellierung menschlichen sozialen Denkens durch metakognitive Multi-Agenten-Systeme : Um die Lücke zu schließen, die große Sprachmodelle (LLMs) bei der Verarbeitung der inhärenten Mehrdeutigkeit und kontextuellen Feinheiten menschlicher Kommunikation aufweisen, haben Forscher MetaMind eingeführt. MetaMind ist ein von der psychologischen Metakognitionstheorie inspiriertes Multi-Agenten-Framework, das darauf abzielt, menschenähnliches soziales Denken zu simulieren. MetaMind zerlegt das soziale Verständnis in drei kooperative Phasen: (1) Theory-of-Mind-Agenten generieren Hypothesen über die mentalen Zustände des Benutzers (z. B. Absichten, Emotionen); (2) Domänenagenten verwenden kulturelle Normen und ethische Einschränkungen, um diese Hypothesen zu verfeinern; (3) Antwortagenten generieren kontextangemessene Antworten und überprüfen gleichzeitig die Konsistenz mit den abgeleiteten Absichten. Dieses Framework erreichte SOTA-Leistung in drei anspruchsvollen Benchmark-Tests, verbesserte sich in realen sozialen Szenarien um 35,7 %, im Theory-of-Mind-Reasoning um 6,2 % und ermöglichte es LLMs erstmals, bei wichtigen Theory-of-Mind-Aufgaben menschliches Niveau zu erreichen. (Quelle: HuggingFace Daily Papers)
Sparse VideoGen2: Beschleunigung der Videogenerierung durch semantisch bewusste Permutation und Sparse Attention : Angesichts der erheblichen Latenz und der hohen Speicherkosten, mit denen auf Diffusion Transformers (DiT) basierende Videogenerierungsmodelle bei der Verarbeitung langer Videos konfrontiert sind, schlagen Forscher das SVG2-Framework vor. Dieses Framework maximiert die Genauigkeit der Erkennung wichtiger Token und minimiert die Rechenverschwendung durch semantisch bewusste Permutation (Verwendung von k-means zur Clusterung und Neuordnung von Token basierend auf semantischer Ähnlichkeit) und erreicht so einen Pareto-optimalen Kompromiss zwischen Generierungsqualität und Effizienz. SVG2 integriert außerdem eine dynamische Top-p-Budgetkontrolle und eine angepasste Kernel-Implementierung und erreicht auf HunyuanVideo bzw. Wan 2.1 eine Beschleunigung von bis zu 2,30x bzw. 1,89x, während gleichzeitig ein hoher PSNR beibehalten wird. (Quelle: HuggingFace Daily Papers)
OmniConsistency: Erlernen stilunabhängiger Konsistenz aus paarweisen stilisierten Daten : Um die beiden großen Herausforderungen zu lösen, mit denen Diffusionsmodelle bei der Bildstilisierung konfrontiert sind – die Aufrechterhaltung der Konsistenz komplexer Szenen (insbesondere Identität, Komposition und Details) und die Stilverschlechterung durch Stil-LoRAs in Bild-zu-Bild-Prozessen – schlagen Forscher OmniConsistency vor. Dies ist ein universelles Konsistenz-Plugin, das große Diffusions-Transformer (DiT) nutzt. Zu seinen Beiträgen gehören: (1) ein auf ausgerichteten Bildpaaren trainiertes kontextuelles Konsistenzlern-Framework zur Erzielung robuster Generalisierung; (2) eine zweistufige progressive Lernstrategie, die das Stillernen von der Konsistenzerhaltung entkoppelt, um Stilverschlechterung zu mildern; (3) ein vollständig Plug-and-Play-Design, das mit beliebigen Stil-LoRAs im Flux-Framework kompatibel ist. Experimente zeigen, dass OmniConsistency die visuelle Kohärenz und ästhetische Qualität signifikant verbessert und eine Leistung erreicht, die mit kommerziellen SOTA-Modellen wie GPT-4o vergleichbar ist. (Quelle: HuggingFace Daily Papers)
ImgEdit: Einheitlicher Datensatz und Benchmark-Test für Bildbearbeitung : Um das Problem zu lösen, dass Open-Source-Bildbearbeitungsmodelle hinter proprietären Modellen zurückbleiben (hauptsächlich aufgrund begrenzter hochwertiger Daten und unzureichender Benchmarks), haben Forscher ImgEdit eingeführt. Dies ist ein umfangreicher, hochwertiger Bildbearbeitungsdatensatz mit 1,2 Millionen sorgfältig kuratierten Bearbeitungspaaren, der neuartige und komplexe Einzelrundenbearbeitungen sowie anspruchsvolle Mehrrundenaufgaben abdeckt. Um die Datenqualität sicherzustellen, wurde ein mehrstufiger Prozess eingesetzt, der modernste visuelle Sprachmodelle, Erkennungsmodelle, Segmentierungsmodelle sowie aufgabenspezifische Reparaturprogramme und eine strenge Nachbearbeitung integriert. Auf ImgEdit trainierte Bearbeitungsmodelle ImgEdit-E1 übertreffen bestehende Open-Source-Modelle in mehreren Aufgaben. Gleichzeitig wurde der ImgEdit-Bench-Benchmark eingeführt, um die Leistung der Bildbearbeitung hinsichtlich Befehlsbefolgung, Bearbeitungsqualität und Detailerhaltung zu bewerten. (Quelle: HuggingFace Daily Papers)
Paper schlägt robuste Verhaltenskontrolle in LLMs durch Steuerung von Zielatomen vor : Um eine präzise Kontrolle über die Generierung von Sprachmodellen zur Gewährleistung von Sicherheit und Zuverlässigkeit zu erreichen, schlägt ein neues Paper die Methode der „Steering Target Atoms (STA)“ vor. Diese Methode zielt darauf ab, entkoppelte Wissenskomponenten zu trennen und zu manipulieren, um die Sicherheit zu erhöhen, insbesondere in adversariellen Szenarien, und zeigt eine überlegene Robustheit und Flexibilität. Die Forscher argumentieren, dass, obwohl Prompt Engineering und Steuerung häufig zur Beeinflussung des Modellverhaltens eingesetzt werden, die starke Verflechtung der Modellparameter die Kontrollpräzision einschränkt und zu Nebenwirkungen führen kann. STA nutzt Sparse Autoencoder (SAE), um Wissen in hochdimensionalen Räumen zu entkoppeln und zu steuern, wodurch eine präzisere Verhaltenskontrolle ermöglicht wird. Experimente belegen die Wirksamkeit der Methode, die bereits auf große Inferenzmodelle angewendet wurde und ihr Potenzial für eine präzise Inferenzkontrolle bestätigt. (Quelle: HuggingFace Daily Papers)
Paper schlägt SeePhys-Benchmark vor: Bewertung visueller physikalischer Reasoning-Fähigkeiten : Forscher haben SeePhys vorgestellt, einen umfangreichen multimodalen Benchmark zur Bewertung der Reasoning-Fähigkeiten von LLMs bei physikalischen Problemen, die vom Mittelstufen- bis zum Doktorandenqualifikationsniveau reichen. Der Benchmark deckt 7 grundlegende Bereiche der Physik ab und enthält 21 Kategorien hochgradig heterogener Diagramme. Im Gegensatz zu früheren Arbeiten, bei denen visuelle Elemente hauptsächlich eine unterstützende Rolle spielten, sind in SeePhys 75 % der Fragen visuell notwendig, d. h. visuelle Informationen müssen extrahiert werden, um sie korrekt zu beantworten. Umfangreiche Bewertungen zeigen, dass selbst die fortschrittlichsten visuellen Reasoning-Modelle (wie Gemini-2.5-pro und o4-mini) bei diesem Benchmark eine Genauigkeit von weniger als 60 % erreichen. Dies deckt grundlegende Herausforderungen aktueller LLMs im visuellen Verständnis auf, insbesondere bei der strengen Kopplung von Diagramminterpretation und physikalischem Reasoning sowie bei der Überwindung der Abhängigkeit von kognitiven Abkürzungen durch Texthinweise. (Quelle: HuggingFace Daily Papers)
VerIPO: Verbesserung der Langstrecken-Reasoning-Fähigkeiten von Video-LLMs durch Verifier-gesteuerte iterative Richtlinienoptimierung : Um die Engpässe bei der Datenvorbereitung und die instabile Qualität des langen Chain-of-Thought (CoT)-Reasonings beim Einsatz von Reinforcement Learning auf Video-Large-Language-Models (Video-LLMs) bei komplexen Video-Inferenzen anzugehen, schlagen Forscher die VerIPO (Verifier-guided Iterative Policy Optimization)-Methode vor. Kern dieser Methode ist ein „Rollout-Aware Verifier“, der zwischen den GRPO- und DPO-Trainingsphasen angesiedelt ist und zur Bewertung der Inferenzlogik sowie zur Erstellung hochwertiger kontrastiver Daten (die reflektierende und kontextkonsistente CoTs enthalten) dient. Diese Daten treiben eine effiziente DPO-Phase an, wodurch die Länge und Kontextkonsistenz der Inferenzkette verbessert wird. Experimentelle Ergebnisse zeigen, dass VerIPO Modelle schneller und effektiver optimieren kann, längere und kontextkonsistentere CoTs generiert und die Leistung von Standard-GRPO-Varianten sowie einigen großen instruktionsfeinabgestimmten Video-LLMs und Langstrecken-Inferenzmodellen übertrifft. (Quelle: HuggingFace Daily Papers)
OpenS2V-Nexus: Detaillierter Benchmark und Datensatz im Millionenbereich für die Generierung von Subjekt-zu-Video : Um die Entwicklung der Subjekt-zu-Video (S2V)-Generierungstechnologie voranzutreiben, schlagen Forscher OpenS2V-Nexus vor, das (i) OpenS2V-Eval, einen feingranularen Benchmark, und (ii) OpenS2V-5M, einen Datensatz im Millionenbereich, umfasst. Im Gegensatz zu bestehenden S2V-Benchmarks (die von VBench abgeleitet sind und sich auf globale und grobgranulare Bewertungen konzentrieren), konzentriert sich OpenS2V-Eval auf die Fähigkeit von Modellen, Videos zu generieren, die subjektkonsistent sind, ein natürliches Erscheinungsbild aufweisen und eine hohe Identitätstreue besitzen. Zu diesem Zweck führt OpenS2V-Eval 180 Prompts aus 7 Hauptkategorien von S2V ein, die reale und synthetische Testdaten enthalten. Um menschliche Präferenzen genau abzugleichen, schlagen die Forscher außerdem drei automatische Metriken vor: NexusScore, NaturalScore und GmeScore, die jeweils die Subjektkonsistenz, Natürlichkeit und Textrelevanz in generierten Videos quantifizieren. Auf dieser Grundlage wurden 16 repräsentative S2V-Modelle umfassend bewertet. Gleichzeitig wurde der erste quelloffene, umfangreiche S2V-Generierungsdatensatz OpenS2V-5M erstellt, der 5 Millionen hochwertige 720P Subjekt-Text-Video-Tripletts enthält. (Quelle: HuggingFace Daily Papers)
Paper schlägt WHISTRESS vor: Anreicherung transkribierter Texte durch Satzakzenterkennung : Angesichts der Bedeutung des Satzakzents in der gesprochenen Sprache für die Vermittlung der Sprecherabsicht und seines Fehlens in bestehenden Transkriptionssystemen stellt ein neues Paper WHISTRESS vor, eine ausrichtungsfreie Methode zur Satzakzenterkennung. Zur Unterstützung dieser Aufgabe schlagen die Forscher TINYSTRESS-15K vor, einen skalierbaren synthetischen Trainingsdatensatz, der durch einen vollautomatischen Prozess erstellt wurde. Auf diesem Datensatz trainierte WHISTRESS-Modelle übertreffen bestehende Baselines in der Leistung und erfordern keine zusätzlichen Trainings- oder Inferenz-Prior-Eingaben. Bemerkenswerterweise zeigt WHISTRESS trotz des Trainings auf synthetischen Daten eine starke Zero-Shot-Generalisierungsfähigkeit in verschiedenen Benchmark-Tests. (Quelle: HuggingFace Daily Papers)
Paper schlägt InstructPart vor: Aufgabenorientierte Teilsegmentierung mit instruktionsbasiertem Reasoning : Obwohl große multimodale Basismodelle in verschiedenen Aufgaben Fortschritte erzielt haben, betrachten viele Modelle Objekte als unteilbare Ganze und ignorieren die Teile, aus denen Objekte bestehen. Das Verständnis dieser Teile und ihrer damit verbundenen funktionalen Sichtbarkeiten (Affordances) ist für die Ausführung einer breiten Palette von Aufgaben unerlässlich. Zu diesem Zweck haben Forscher einen neuen realen Benchmark namens InstructPart eingeführt, der manuell markierte Teilsegmentierungsannotationen und aufgabenorientierte Anweisungen enthält, um die Leistung aktueller Modelle beim Verstehen und Ausführen von Aufgaben auf Teileebene in alltäglichen Situationen zu bewerten. Experimente zeigen, dass selbst für SOTA Visual Language Models (VLMs) die aufgabenorientierte Teilsegmentierung ein herausforderndes Problem bleibt. Neben dem Benchmark haben die Forscher auch eine einfache Baseline eingeführt, die durch Feinabstimmung mit ihrem Datensatz eine zweifache Leistungssteigerung erzielt. (Quelle: HuggingFace Daily Papers)
Paper schlägt hybride Neuro-MPM-Methode für interaktive Flüssigkeitssimulation in Echtzeit vor : Um das Problem der rechenintensiven und latenzreichen traditionellen physikalischen Methoden sowie der zwar kostengünstigeren, aber immer noch nicht echtzeitinteraktionsfähigen neueren maschinellen Lernmethoden für die Flüssigkeitssimulation zu lösen, schlagen Forscher eine neuartige hybride Methode vor. Diese Methode integriert numerische Simulation, Neurophysik und generative Steuerung. Ihre Neurophysik verfolgt gemeinsam das Ziel einer latenzarmen Simulation und hoher physikalischer Genauigkeit durch einen Absicherungsmechanismus, der auf klassische numerische Löser zurückgreift. Darüber hinaus entwickelten die Forscher einen diffusionsbasierten Controller, der mit einer inversen Modellierungsstrategie trainiert wurde, um externe dynamische Kraftfelder für die Flüssigkeitsmanipulation zu erzeugen. Das System zeigt eine robuste Leistung in verschiedenen 2D/3D-Szenarien, Materialtypen und Hindernisinteraktionen, erreicht eine Echtzeitsimulation mit hoher Bildrate (11~29 % Latenz) und ermöglicht die Steuerung von Flüssigkeiten durch benutzerfreundliche handgezeichnete Skizzen. (Quelle: HuggingFace Daily Papers)
MMIG-Bench: Umfassender interpretierbarer Bewertungsbenchmark für multimodale Bildgenerierungsmodelle : Angesichts der Einschränkungen bestehender Bewertungstools bei der Bewertung multimodaler Bildgeneratoren wie GPT-4o, Gemini 2.0 Flash und Gemini 2.5 Pro (z. B. fehlende multimodale Bedingungen in T2I-Benchmarks, Ignorieren kombinatorischer Semantik und Common Sense in benutzerdefinierten Bildgenerierungsbenchmarks) schlagen Forscher MMIG-Bench vor. Dies ist ein umfassender multimodaler Bildgenerierungsbenchmark, der 4850 reich annotierte Text-Prompts und 1750 Referenzbilder aus mehreren Perspektiven enthält, die 380 Subjekte (Menschen, Tiere, Objekte, Kunststile) abdecken. MMIG-Bench ist mit einem dreistufigen Bewertungsframework ausgestattet: (1) Low-Level-Metriken bewerten visuelle Artefakte und die Erhaltung der Objektidentität; (2) ein neuartiger Aspect Matching Score (AMS): eine auf VQA basierende Mid-Level-Metrik, die eine feingranulare Prompt-Bild-Ausrichtung bietet und stark mit menschlichen Urteilen korreliert; (3) High-Level-Metriken bewerten Ästhetik und menschliche Präferenzen. Durch MMIG-Bench wurden 17 SOTA-Modelle gebenchmarkt und die Metriken mit 32.000 menschlichen Bewertungen validiert, was tiefe Einblicke in Architektur- und Datendesign liefert. (Quelle: HuggingFace Daily Papers)
Paper schlägt HRPO vor: Hybrides latentes Reasoning durch Reinforcement Learning : Um das Problem zu lösen, dass bestehende latente Reasoning-Methoden nicht mit den autoregressiven Generierungseigenschaften von LLMs kompatibel sind und von CoT-Trajektorien für das Training abhängen, schlagen Forscher HRPO (Hybrid Reasoning Policy Optimization) vor. Dies ist eine auf Reinforcement Learning basierende hybride latente Reasoning-Methode, die durch einen lernbaren Gating-Mechanismus vorherige verborgene Zustände in die gesampelten Token integriert und mit Token-Embeddings als Hauptinitialisierung trainiert, wobei schrittweise mehr verborgene Merkmale einbezogen werden. Dieses Design erhält die Generierungsfähigkeiten von LLMs und fördert die Verwendung diskreter und kontinuierlicher Repräsentationen für hybrides Reasoning. Darüber hinaus führt HRPO durch Token-Sampling Zufälligkeit in das latente Reasoning ein, wodurch eine RL-basierte Optimierung ohne CoT-Trajektorien möglich wird. Umfangreiche Bewertungen auf verschiedenen Benchmarks zeigen, dass HRPO sowohl bei wissensintensiven als auch bei reasoning-intensiven Aufgaben frühere Methoden übertrifft. (Quelle: HuggingFace Daily Papers)
Paper schlägt NFT-Methode vor: Verbindung von überwachtem Lernen und Reinforcement Learning im mathematischen Reasoning : Ein neues Paper stellt die vorherrschende Meinung in Frage, dass „Selbstverbesserung auf Reinforcement Learning (RL) beschränkt ist“, und schlägt die Methode des Negative-aware Fine-Tuning (NFT) vor. Dies ist eine überwachte Lernmethode, die es LLMs ermöglicht, über ihre Fehler zu reflektieren und sich autonom zu verbessern, ohne externe Lehrer. Im Online-Training verwirft NFT selbstgenerierte falsche Antworten nicht, sondern konstruiert eine implizite negative Richtlinie, um sie zu modellieren. Diese implizite Richtlinie wird mit denselben Parametern wie das positive Ziel-LLM parametrisiert, das für die Optimierung auf positiven Daten verwendet wird, wodurch eine direkte Richtlinienoptimierung auf allen Generierungen des LLM ermöglicht wird. Experimentelle Ergebnisse zu mathematischen Reasoning-Aufgaben mit 7B- und 32B-Modellen zeigen, dass NFT durch die zusätzliche Nutzung negativen Feedbacks überwachte Lern-Baselines wie Rejection Sampling Fine-Tuning signifikant übertrifft und sogar führende RL-Algorithmen wie GRPO und DAPO erreicht oder übertrifft. Die Forscher zeigen weiterhin, dass NFT und GRPO im strengen Online-Policy-Training tatsächlich äquivalent sind. (Quelle: HuggingFace Daily Papers)
Paper schlägt Minute-Long Videos with Dual Parallelisms vor: Realisierung der Generierung von minutenlangen Videos : Angesichts der Probleme der hohen Rechenlatenz und Speicherkosten, mit denen auf DiT basierende Videodiffusionsmodelle bei der Generierung langer Videos konfrontiert sind, schlagen Forscher eine neue verteilte Inferenzstrategie namens DualParal vor. Die Kernidee dieser Methode besteht darin, Zeitrahmen und Modellschichten auf mehrere GPUs zu parallelisieren. Um das Problem der Serialisierung der ursprünglichen Parallelität zu lösen, das durch die Anforderung von Diffusionsmodellen entsteht, dass der Rauschpegel zwischen den Frames synchronisiert wird, verwendet diese Methode ein blockweises Entrauschungsschema, d. h. durch die Pipeline-Verarbeitung einer Reihe von Frame-Blöcken und die schrittweise Reduzierung des Rauschpegels. Jede GPU verarbeitet bestimmte Blöcke und Schichtteilmengen und leitet die vorherigen Ergebnisse an die nächste GPU weiter, wodurch asynchrone Berechnungen und Kommunikation ermöglicht werden. Darüber hinaus wird durch die Implementierung eines Feature-Cachings auf jeder GPU zur Wiederverwendung von Features früherer Blöcke als Kontext und die Anwendung einer koordinierten Rauschinitialisierungsstrategie eine global konsistente zeitliche Dynamik sichergestellt, wodurch eine schnelle, artefaktfreie und unendlich lange Videogenerierung ermöglicht wird. Angewendet auf die neuesten Diffusions-Transformer-Videogeneratoren generiert diese Methode effizient 1025-Frame-Videos auf 8x RTX 4090 GPUs, wobei die Latenz um bis zu 6,54-fach und die Speicherkosten um 1,48-fach reduziert werden. (Quelle: HuggingFace Daily Papers)
🧰 Werkzeuge
Claude 4-Modellreihe zeigt herausragende Leistung bei Programmieraufgaben und löst einen „White Whale Bug“, der erfahrene Programmierer 4 Jahre lang plagte : Das kürzlich von Anthropic veröffentlichte Claude Opus 4-Modell hat erstaunliche Fähigkeiten im Programmieren gezeigt. Ein ehemaliger FAANG-Ingenieur mit 30 Jahren C++-Entwicklungserfahrung berichtete, dass ein komplexer Systemfehler, der sein Team 4 Jahre lang plagte und ihn persönlich etwa 200 Stunden gekostet hatte, ohne gelöst zu werden (ein Grenzfallproblem, das auftrat, wenn ein bestimmter Shader auf eine bestimmte Weise verwendet wurde), von Claude Opus 4 innerhalb weniger Stunden durch etwa 30 Prompts erfolgreich lokalisiert und dessen Ursache gefunden wurde. Der Fehler existierte vor der Systemumstrukturierung nicht, und Opus 4 wies darauf hin, dass die neue Architektur ein nicht beabsichtigtes Verhalten, das unter der alten Architektur durch einen „Zufall“ unterstützt wurde, nicht kompatibel machte. Zuvor konnten GPT-4.1, Gemini 2.5 und Claude 3.7 dieses Problem nicht lösen. Dies unterstreicht die starke Fähigkeit von Claude 4, komplexen Code zu verstehen, tiefgreifende Analysen durchzuführen und Schlussfolgerungen zu ziehen, insbesondere in Kombination mit dem Claude Code-Modus, der Entwickler effektiv bei der Bewältigung fortgeschrittener Engineering-Aufgaben wie Code-Refactoring und Fehlerbehebung unterstützen kann. (Quelle: 36氪, dotey)
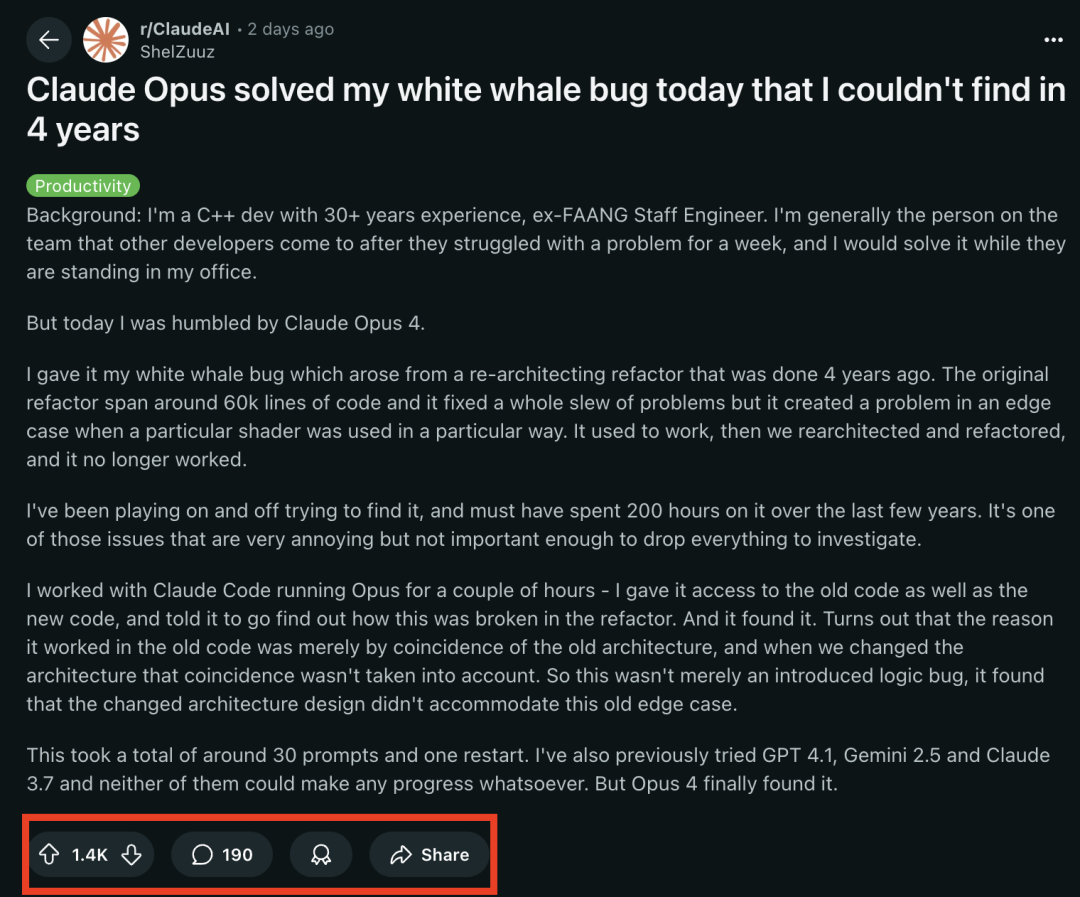
LangChain fügt Unterstützung für neue Beta-Funktionen von Anthropic Claude hinzu : LangChain gab bekannt, dass es vier kürzlich veröffentlichte neue Beta-Funktionen des Anthropic Claude-Modells integriert hat, darunter Codeausführung, Remote-MCP-Konnektoren, Datei-API und erweitertes Prompt-Caching. Entwickler können jetzt Beispiele in der LangChain-Dokumentation einsehen, um diese neuen Funktionen zum Erstellen leistungsfähigerer KI-Anwendungen zu nutzen. (Quelle: LangChainAI)
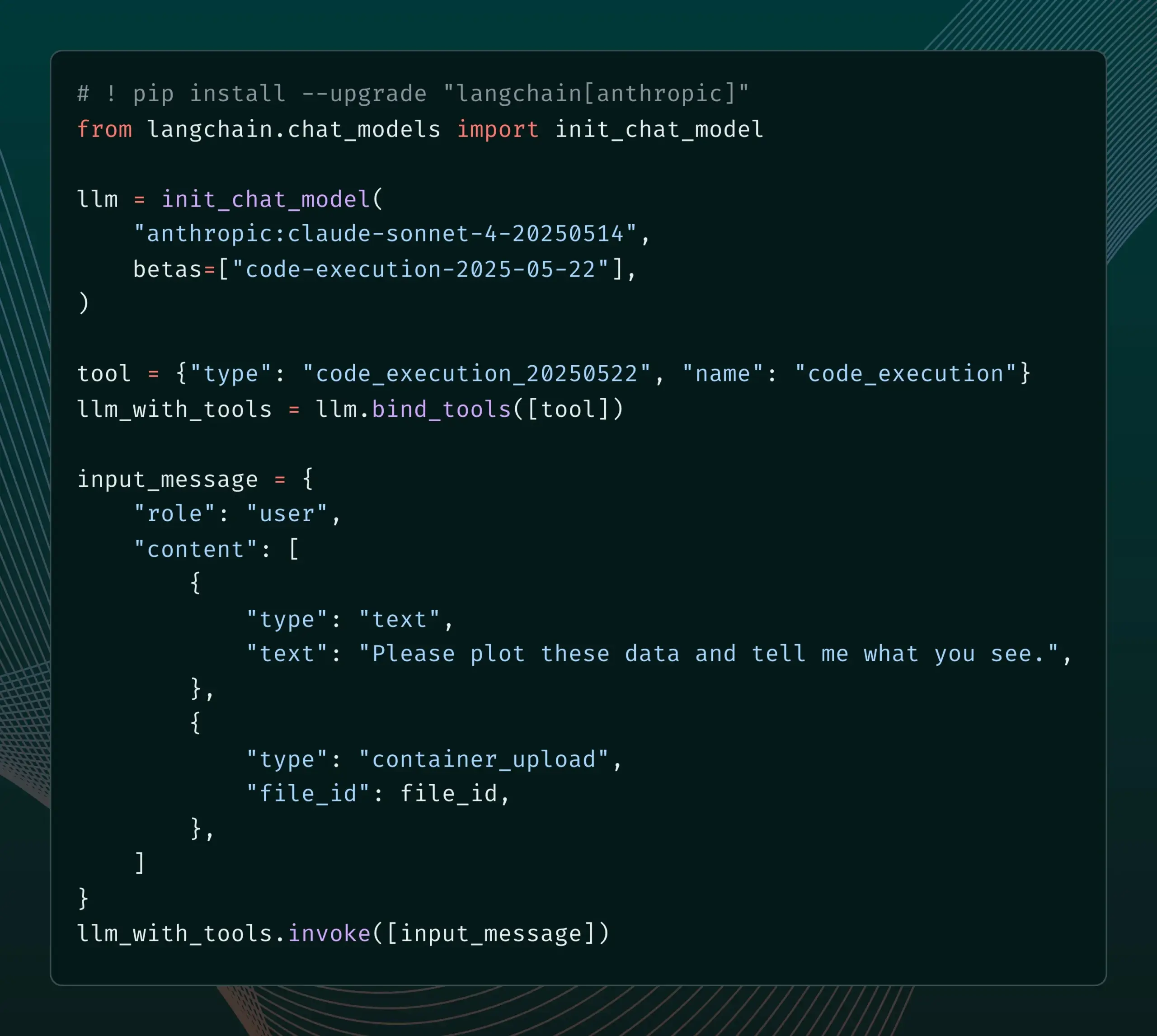
LangSmith führt Prompt-Management-Funktionen mit SDLC-Integration ein : Die LangSmith-Plattform hat ihre Prompt-Engineering-Funktionen erweitert. Benutzer können jetzt nicht nur Prompts in LangSmith testen, versionieren und gemeinsam bearbeiten, sondern auch Prompts über Webhook-Trigger bei Prompt-Änderungen automatisch mit GitHub, externen Datenbanken synchronisieren oder CI/CD-Prozesse starten. Diese Funktion soll Entwicklern helfen, das Prompt-Management enger in den Softwareentwicklungslebenszyklus (SDLC) zu integrieren. (Quelle: LangChainAI)
AutoThink: Adaptive Technologie zur Verbesserung der lokalen LLM-Inferenzleistung : Das CodeLion-Team hat die AutoThink-Technologie entwickelt, die die lokale LLM-Inferenzleistung durch adaptive Ressourcenzuweisung und Steering Vectors signifikant verbessert. AutoThink kann die Komplexität von Anfragen klassifizieren, dynamisch „Thinking Tokens“ zuweisen (mehr für komplexe Fragen, weniger für einfache) und Steering Vectors verwenden, um Inferenzmuster zu steuern. Tests mit dem DeepSeek-R1-Distill-Qwen-1.5B-Modell zeigten eine Verbesserung der GPQA-Diamond-Genauigkeit um 43 % (von 21,72 % auf 31,06 %), auch MMLU-Pro verbesserte sich bei geringerem Token-Verbrauch. Die Technologie ist mit lokalen Inferenzmodellen kompatibel, die Thinking Tokens unterstützen; Code und Forschung wurden veröffentlicht. (Quelle: Reddit r/MachineLearning, Reddit r/LocalLLaMA)
Transformer Lab kündigt Unterstützung für AMD ROCm an, ermöglicht lokales Training von LLMs : Transformer Lab gab bekannt, dass seine GUI-Plattform jetzt das lokale Training und Fine-Tuning von großen Sprachmodellen auf AMD-GPUs mit ROCm unterstützt. Das Team berichtete, dass die Konfiguration von ROCm eine Herausforderung darstellte und dokumentierte den gesamten Prozess in einem Blog. Die Funktion ist nun reibungslos nutzbar, und Benutzer können versuchen, LLMs auf AMD-Hardware zu entwickeln. (Quelle: Reddit r/MachineLearning)
Open-Source LLM-gestütztes Multi-Agenten-System ermöglicht automatisierte Anspruchsextraktion und Faktenprüfung : Ein Open-Source-Projekt namens „fact-checker“ nutzt ein LLM-gestütztes Multi-Agenten-System (MAS) zur automatisierten Extraktion von Ansprüchen, Überprüfung von Beweisen und Klärung von Fakten. Das Projekt umfasst eine Browser-Erweiterung, die die Antworten jedes KI-Chatbots in Echtzeit auf Fakten überprüfen kann und so hilft, die Authentizität von KI-generierten Inhalten zu erkennen. Seine Code-Architektur ist klar und die Dokumentation umfassend, was es zu einem wertvollen Werkzeug im Bereich KI-Sicherheit und Bekämpfung von Fehlinformationen macht. (Quelle: Reddit r/MachineLearning)
Meituan stellt No-Code-Produkt Nocode vor, das die Generierung komplexer mehrseitiger Anwendungen unterstützt : Meituan hat ein Vibe Coding-Produkt namens Nocode veröffentlicht, mit dem Benutzer durch die Beschreibung in natürlicher Sprache komplexe, vollständige Anwendungen mit mehreren Seiten generieren können, nicht nur einfache Präsentationswebseiten. Tests von Guicang zeigten, dass das Tool erfolgreich ein logisch komplexes Lagerbestandsverwaltungstool auf einmal erstellen konnte, was seine Fähigkeit demonstriert, komplexe Anforderungen zu verstehen und entsprechenden Code zu generieren. (Quelle: op7418)
LlamaIndex unterstützt die Erstellung benutzerdefinierter multimodaler Embedder und die Integration mit OpenAI-ähnlichen Chat-UIs : LlamaIndex hat ein Update veröffentlicht, das es Benutzern ermöglicht, benutzerdefinierte multimodale Embedder zu erstellen, z. B. durch Integration von AWS Titan Multimodal, und diese mit Vektordatenbanken wie Pinecone für eine effiziente Text- und Bildvektorsuche zu kombinieren. Darüber hinaus können LlamaIndex-Workflows jetzt mit wenigen Codezeilen in einer OpenAI-ähnlichen Chat-Oberfläche ausgeführt werden und unterstützen einen Entwicklungsmodus, in dem der Workflow-Code direkt in der Benutzeroberfläche bearbeitet werden kann, was die Entwicklung und Interaktion von RAG-Anwendungen verbessert. (Quelle: jerryjliu0, jerryjliu0)

TRAE-Update verbessert Agentic Coding-Erlebnis, kostenpflichtiges Abonnement für internationale Version gestartet : Das KI-Programmiertool TRAE wurde aktualisiert, um das Agentic Coding-Erlebnis zu optimieren und es für Benutzer geeigneter zu machen, die manuelle Eingriffe vermeiden möchten. Die neue Version von TRAE merkt sich frühere Gespräche besser, verknüpft automatisch Kontexte, die KI kann Programmierpfade automatisch planen und mehr Tools aufrufen, was die Erfolgsquote von Programmieraufgaben erhöht. Beispielsweise kann TRAE, wenn der Benutzer nur einen leeren Ordner und einen Prompt bereitstellt, eine Reihe von Vorgängen ausführen, wie das Erstellen von Dateien, das Starten eines Webservers (automatische Behandlung von Cross-Domain-Problemen) und die Vorschau von p5.js-Animationen innerhalb der IDE. Die internationale Version ist jetzt als kostenpflichtiges Abonnement erhältlich, wobei der Pro-Preis im ersten Monat 3 US-Dollar beträgt und Alipay unterstützt wird. (Quelle: dotey, karminski3)
Juejin Community startet MCP-Dienst zur Unterstützung der Ein-Klick-Veröffentlichung von Frontend-Code : Die chinesische Programmierer-Community Juejin hat den MCP (Model-driven Co-programming Protocol)-Dienst gestartet, der es Entwicklern ermöglicht, Frontend-Code (wie von Vibe Coding generierte Webseiten, Spiele) mit einem Klick auf der Juejin-Plattform zu veröffentlichen, um schnelles Teilen und Vorschauen zu erleichtern. Benutzer müssen ein Juejin MCP-Token erwerben und es in Tools wie Trae und Cursor konfigurieren. (Quelle: dotey, karminski3)
Open-Source-Zeiterfassungstool ActivityWatch als Alternative zu Rize im Fokus : Der Benutzer karminski3 empfahl nach dem Testen des KI-Zeitanalysetools Rize (das Arbeits-, Besprechungs- oder Prokrastinationsstatus durch Analyse von Prozessnamen bestimmt, monatlich 20 US-Dollar) die Open-Source-Alternative ActivityWatch. ActivityWatch bietet ähnliche Funktionen, unterstützt Windows/Mac und ermöglicht Benutzeranpassungen. Es wird als hervorragendes Werkzeug zur Linderung von Arbeitsangst und zur Verfolgung der Arbeitszeit angesehen. (Quelle: karminski3)
Open-Source-KI-Babyüberwachungstool ai-baby-monitor veröffentlicht : Ein Open-Source-Projekt namens ai-baby-monitor wurde veröffentlicht. Es verwendet das Qwen2.5 VL-Modell und das vLLM-Inferenzframework und ermöglicht es Benutzern, Regeln zu definieren (z. B. „Alarm, wenn das Kind aufwacht“, „Alarm, wenn das Kind allein ist“), damit die KI bei der Überwachung von Babys hilft. Der Entwickler betont, dass dies nur ein Hilfsmittel ist und die menschliche Aufsicht nicht vollständig ersetzen kann. (Quelle: karminski3)
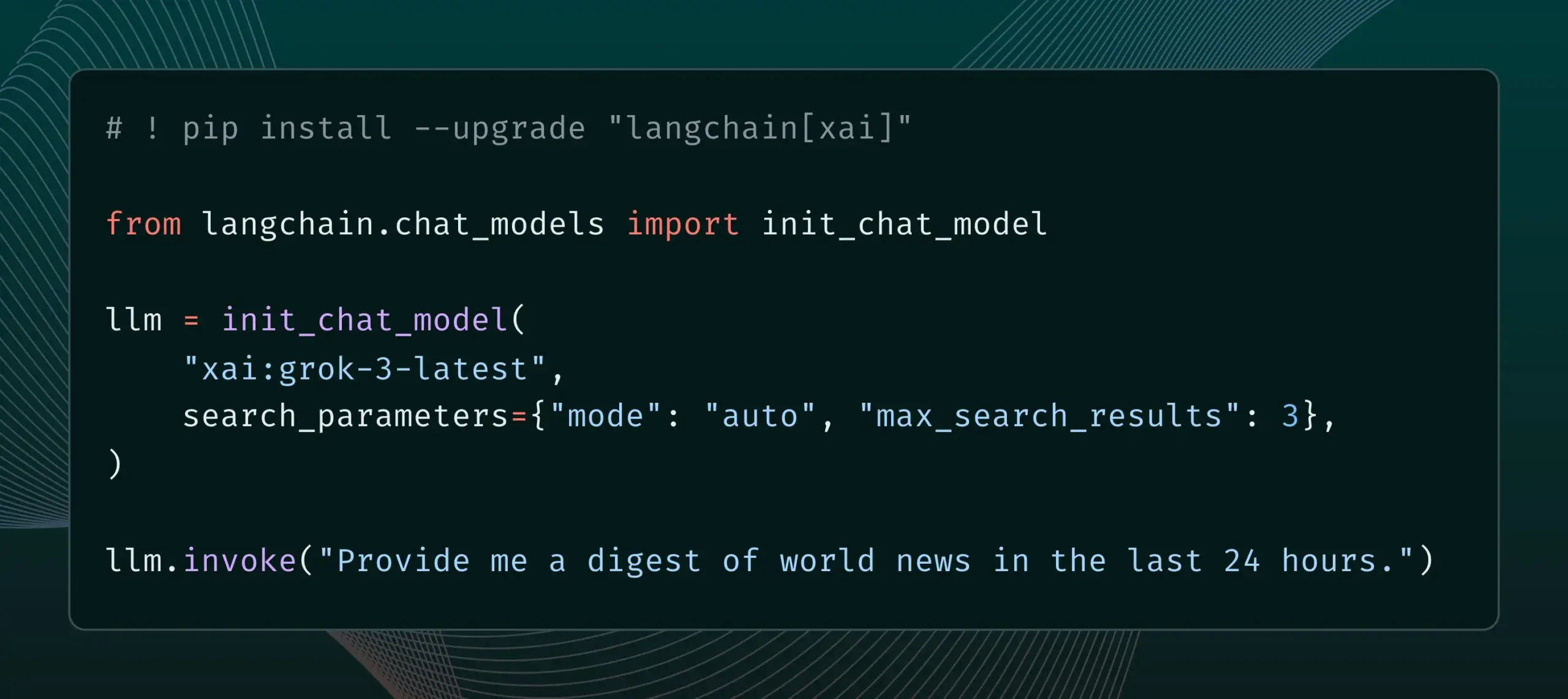
LangChain integriert Live Search-Funktion von xAI : LangChain gab die Unterstützung für die Live Search-Funktion von xAI bekannt. Diese Funktion ermöglicht es dem Grok-Modell, Antworten basierend auf Websuchergebnissen zu generieren und bietet verschiedene Konfigurationsoptionen wie Zeiträume, eingeschlossene Domains und andere Suchparameter. Benutzer können diese neue Funktion jetzt in LangChain ausprobieren. (Quelle: LangChainAI)
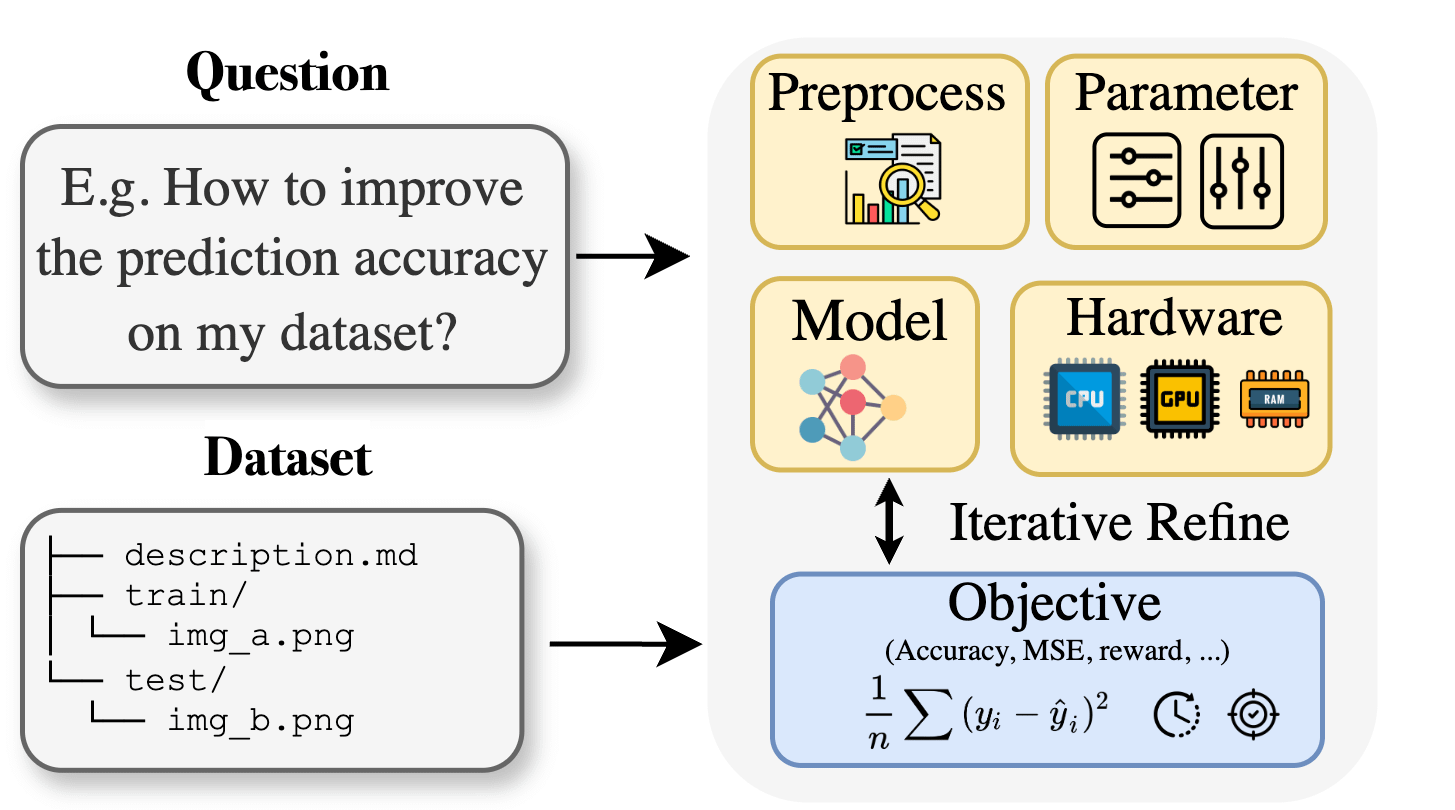
Curie: Open-Source-KI-Forschungsassistent veröffentlicht AutoML-Funktion zur Unterstützung interdisziplinärer Forschung : Angesichts der Fachwissensbarrieren, mit denen Forscher in Bereichen wie Biologie, Materialwissenschaft und Chemie bei der Anwendung von maschinellem Lernen konfrontiert sind, hat das Curie-Projekt eine neue AutoML-Funktion eingeführt. Curie zielt darauf ab, ein kooperativer Wissenschaftler für KI-Forschungsexperimente zu sein, indem es komplexe ML-Prozesse (wie Algorithmusauswahl, Hyperparameter-Tuning, Interpretation von Modellausgaben) automatisiert und Forschern hilft, Hypothesen schnell zu testen und Erkenntnisse aus Daten zu gewinnen. Beispielsweise generierte Curie bei der Melanom-Erkennungsaufgabe ein Modell mit einem AUC von 0,99. Das Projekt ist Open Source und ermutigt die Community zur Teilnahme. (Quelle: Reddit r/LocalLLaMA)
Alibaba MNN Chat unterstützt lokale Ausführung des Qwen 30B-a3b-Modells auf Android-Geräten : Alibabas MNN Chat-Anwendung wurde auf Version 0.5.0 aktualisiert und unterstützt nun die lokale Ausführung großer Sprachmodelle wie Qwen 30B-a3b auf Android-Geräten. Benutzerberichten zufolge kann es auf Geräten mit Flaggschiff-Chips und großem Arbeitsspeicher (z. B. OnePlus 13 24G) erfolgreich ausgeführt werden, und es wird empfohlen, die mmap-Einstellung zu aktivieren. Einige Kommentare weisen jedoch darauf hin, dass 30B-Parametermodelle für die meisten Mobiltelefone zu hohe Anforderungen an Arbeitsspeicher und Rechenleistung stellen und Gemma 3n möglicherweise besser für mobile Geräte geeignet ist. (Quelle: Reddit r/LocalLLaMA)

📚 Lernen
Neues Paper stellt Lean and Mean Adaptive Optimization vor: Schnellerer und speichersparenderer Optimierer für das Training großer Modelle : Ein für die ICML 2025 angenommenes Paper stellt einen neuen Optimierer namens „Lean and Mean Adaptive Optimization via Subset-Norm and Subspace-Momentum“ vor. Diese Methode zielt darauf ab, den Speicherbedarf für das Training großer neuronaler Netze zu reduzieren und das Training durch zwei komplementäre Techniken, Subset-Norm-Schrittweite und Subspace-Momentum, zu beschleunigen. Im Vergleich zu bestehenden speichereffizienten Optimierern wie GaLore und LoRA kann diese Methode bei gleichzeitiger Speichereinsparung (z. B. Reduzierung des Optimiererstatus-Speichers um 80 % im Vergleich zu Adam beim Vortraining von LLaMA 1B) die Validierungs-Perplexität von Adam mit weniger Trainings-Token (etwa der Hälfte) erreichen und bietet stärkere theoretische Konvergenzgarantien. (Quelle: Reddit r/MachineLearning)
Paper schlägt Force Prompting vor: Lässt Videogenerierungsmodelle physikbasierte Steuersignale lernen und verallgemeinern : Eine neue Studie untersucht die Möglichkeit, physikalische Kräfte als Steuersignale für die Videogenerierung zu verwenden, und schlägt „Force Prompts“ vor. Benutzer können mit Bildern durch lokale Punktkräfte (z. B. Anstupsen einer Pflanze) oder globale Windfelder (z. B. Wind, der auf Stoff weht) interagieren. Die Studie zeigt, dass Videogenerierungsmodelle aus von Blender synthetisierten Videos, die nur wenige Objektdemonstrationen enthalten, physikalische Kraftbedingungen lernen und verallgemeinern können. Sie generieren Videos, die realistisch auf physikalische Steuersignale reagieren, ohne dass während der Inferenz 3D-Assets oder Physiksimulatoren erforderlich sind. Visuelle Vielfalt und die Verwendung spezifischer Text-Keywords während des Trainings sind Schlüsselfaktoren für die Erzielung dieser Verallgemeinerung. (Quelle: HuggingFace Daily Papers)
AnkiHub teilt KI-Annotations-Workflow und verbessert Effizienz mit FastHTML : AnkiHub hat seinen KI-Annotations-Workflow geteilt und ihn im KI-Bewertungskurs von Hamel Husain und Shreya Shankar demonstriert. Dieser Workflow nutzt das FastHTML-Build-Tool und zielt darauf ab, die Effizienz der KI-Annotation für kommerzielle Produkte zu verbessern. Zugehörige Lehrmaterialien und Code-Repositories wurden auf GitHub veröffentlicht und zeigen, wie produktionsreife Tools zur Optimierung der KI-Entwicklung eingesetzt werden können. (Quelle: jeremyphoward, HamelHusain)

Blogger schreibt Lernerfahrungen von PPO zu GRPO und erklärt Reinforcement-Learning-Konzepte im LLM-Fine-Tuning : Ein Blogger teilt seine Erfahrungen beim Erlernen von Reinforcement Learning (RL) und dessen Anwendung im Fine-Tuning von großen Sprachmodellen (LLMs), insbesondere den Verständnisprozess von PPO (Proximal Policy Optimization) zu GRPO (Group Relative Policy Optimization). Der Blogbeitrag zielt darauf ab, Konzepte zu erklären, die er zu Beginn seines Lernprozesses gerne verstanden hätte, um anderen zu helfen, besser zu verstehen, wie diese RL-Algorithmen zur Optimierung von LLMs eingesetzt werden. (Quelle: Reddit r/MachineLearning)
Paper untersucht pragmatisches Denken von Maschinen: Verfolgung der Emergenz pragmatischer Fähigkeiten in großen Sprachmodellen : Ein neues Paper untersucht, wie große Sprachmodelle (LLMs) während des Trainingsprozesses pragmatische Kompetenz erwerben, d. h. die Fähigkeit, implizite Bedeutungen, Sprecherabsichten usw. zu verstehen und abzuleiten. Die Forscher führten den ALTPRAG-Datensatz ein, der auf dem pragmatischen Konzept der „Alternativen“ basiert, um 22 LLMs in verschiedenen Trainingsphasen (Vortraining, überwachtes Fine-Tuning SFT, Präferenzoptimierung RLHF) zu bewerten. Die Ergebnisse zeigen, dass selbst Basismodelle eine signifikante Sensibilität für pragmatische Hinweise aufweisen, die sich mit zunehmender Modell- und Datengröße kontinuierlich verbessert; SFT und RLHF verbessern die kognitiven pragmatischen Reasoning-Fähigkeiten weiter. Dies deutet darauf hin, dass pragmatische Kompetenz eine emergente, kombinatorische Eigenschaft des LLM-Trainings ist. (Quelle: HuggingFace Daily Papers)
Paper untersucht VisTA, ein Reinforcement-Learning-Framework für die Auswahl visueller Werkzeuge : Forscher stellen VisTA (VisualToolAgent) vor, ein neues Reinforcement-Learning-Framework, das es visuellen Agenten ermöglicht, Werkzeuge aus verschiedenen Bibliotheken basierend auf empirischer Leistung dynamisch zu erkunden, auszuwählen und zu kombinieren. Im Gegensatz zu bestehenden Methoden, die auf trainigsfreiem Prompting oder umfangreichem Fine-Tuning basieren, nutzt VisTA End-to-End-Reinforcement-Learning, indem es Aufgabenergebnisse als Feedback-Signal verwendet, um komplexe, anfragespezifische Werkzeugauswahlstrategien iterativ zu optimieren. Durch GRPO (Group Relative Policy Optimization) ermöglicht dieses Framework dem Agenten, effektive Werkzeugauswahlpfade autonom zu entdecken, ohne explizite Inferenzüberwachung. Experimente auf den Benchmarks ChartQA, Geometry3K und BlindTest zeigen, dass VisTA im Vergleich zu trainigsfreien Baselines signifikante Leistungssteigerungen erzielt, insbesondere bei Out-of-Distribution-Samples. (Quelle: HuggingFace Daily Papers)
💼 Wirtschaft
Datendienstleister Jinglianwen Technology schließt Pre-A-Finanzierungsrunde über mehrere zehn Millionen ab und plant den Aufbau eines Betriebs für öffentliche Datenproduktion : Der KI-Datendienstleister Jinglianwen Technology hat kürzlich eine Pre-A-Finanzierungsrunde in Höhe von mehreren zehn Millionen Yuan abgeschlossen, die von einem Fonds der Hangzhou Jin Tou Group investiert wurde. Die Mittel werden für den Aufbau eines Betriebs für die Produktion öffentlicher Daten, die Entwicklung einer intelligenten Korpus-Engineering-Plattform und den Aufbau eigener hochwertiger Annotationsbasen in vertikalen Bereichen verwendet. Das 2012 gegründete Unternehmen konzentriert sich auf öffentliche Daten, KI-Großmodelle, autonomes Fahren und Medizin. Ziel ist es, Probleme wie „schwierige Verwaltung, unzureichende Bereitstellung, mangelnde Fließfähigkeit, ineffektive Nutzung und schwache Sicherheit“ öffentlicher Daten zu lösen. In Zusammenarbeit mit Huawei Data Storage wurde eine gemeinsame KI-Data-Lake-Lösung eingeführt. Für dieses Jahr wird ein Umsatzwachstum von über 400 % erwartet. (Quelle: 36氪)
Meitu erhält rund 250 Millionen US-Dollar Wandelanleihen-Investment von Alibaba zur Vertiefung der KI-Kooperation : Meitu gab bekannt, eine strategische Partnerschaft mit Alibaba eingehen zu wollen, wobei Alibaba Wandelanleihen im Gesamtwert von rund 250 Millionen US-Dollar an Meitu ausgeben wird. Beide Seiten werden in den Bereichen E-Commerce-Plattform-Promotion, KI-Technologieentwicklung (KI-Bilder, KI-Videos), Cloud Computing usw. zusammenarbeiten. Meitu verpflichtet sich, in den nächsten drei Jahren Dienstleistungen im Wert von mindestens 560 Millionen Yuan von Alibaba Cloud zu beziehen. Ziel dieser Kooperation ist es, das Potenzial von E-Commerce-Szenarien durch das Alibaba-Ökosystem zu erschließen und die Zahl der zahlenden Nutzer sowie das Forschungs- und Entwicklungsniveau der KI-Design-Tools von Meitu zu steigern. Obwohl dieser Schritt den Aktienkurs von Meitu kurzzeitig beflügelte, liegt der Fokus des Marktes darauf, wie Meitu vermeiden kann, das Schicksal von Kimi zu wiederholen, dessen Nutzerwachstum im harten Wettbewerb verlangsamt wurde, insbesondere angesichts des intensiven Wettbewerbs und der Größenunterschiede zu großen Unternehmen im Bereich der visuellen KI. (Quelle: 36氪)
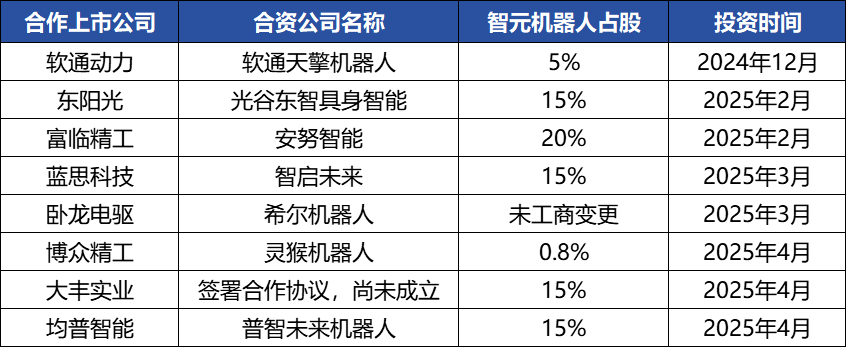
Zhiyuan Robot tätigt häufige Kapitalmaßnahmen, baut Industrieökosystem auf, Gründer Deng Taihua tritt in Erscheinung : Das Embodied-Intelligence-Einhorn Zhiyuan Robot hat in letzter Zeit häufige Kapitalmaßnahmen ergriffen. Es hat nicht nur selbst mehrere Finanzierungsrunden abgeschlossen (die jüngste wurde von JD Technology angeführt), sondern investiert auch aktiv in Unternehmen der Industriekette (wie Annu Intelligence, Digital Huaxia usw.) und gründet mit mehreren börsennotierten Unternehmen (Bozhong Precision Industry, Dafeng Industry usw.) Joint-Venture-Roboterfirmen. Änderungen im Handelsregister zeigen, dass Deng Taihua, ehemaliger Vizepräsident von Huawei und ehemaliger Präsident der Computerproduktlinie, tatsächlich Gründer und tatsächlicher Kontrolleur von Zhiyuan Robot ist. Sein Führungsteam besteht ebenfalls aus mehreren ehemaligen Huawei-Mitarbeitern. Dieser „Huawei-Hintergrund“ erklärt das Betriebsmodell des „Ökosystem-Ansatzes“ von Zhiyuan Robot, d. h. den schnellen Aufbau von Brancheneinfluss und die Realisierung von Skalierung und Kommerzialisierung durch umfassende Zusammenarbeit und Investitionen. Obwohl es bei der Finanzierung und Kommerzialisierung einen Vorsprung erzielt hat, stehen seine Fähigkeiten im Bereich der Embodied-Intelligence-Großmodelle weiterhin vor Herausforderungen. (Quelle: 36氪)
🌟 Community
KI-Agenten entwickeln sich rasant, Agentic LMs gelten als vielversprechende neue Anwendungs- und Werkzeugplattform : KI-Experten wie natolambert zeigen sich begeistert von der rasanten Entwicklung von KI-Agenten und sehen in agentenbasierten Sprachmodellen (Agentic LMs) eine äußerst vielversprechende Plattform, auf der eine Vielzahl neuer Anwendungen und Werkzeuge aufgebaut werden können. Viele noch nicht voll ausgeschöpfte Fähigkeiten aktueller Modelle könnten durch das Agentic-Paradigma freigesetzt werden. Dies deutet darauf hin, dass sich KI von der reinen Inhaltsgenerierung hin zu aktiveren, aufgabenausführenden intelligenten Agenten entwickelt. (Quelle: natolambert)
KI-Agenten zeigen übermenschliche Fähigkeiten bei bestimmten Aufgaben, physikalisches Denken bleibt jedoch eine Schwachstelle : Forschungen von Institutionen wie der Universität Hongkong haben ergeben, dass selbst Spitzen-KI-Modelle wie GPT-4o und Claude 3.7 Sonnet im PHYX-Benchmark, der reale physikalische Szenarien und komplexe kausale Schlussfolgerungen beinhaltet, bei physikalischen Aufgaben eine deutlich geringere Genauigkeit aufweisen als menschliche Experten (Modelle maximal 45,8 % vs. Menschen mindestens 75,6 %). Dies deckt ihre übermäßige Abhängigkeit von gespeichertem Wissen, mathematischen Formeln und oberflächlicher visueller Mustererkennung im physikalischen Verständnis auf. Im mathematischen Bereich hingegen löste o4-mini-medium im von Epoch AI organisierten FrontierMath-Wettbewerb (Aufgaben von Spitzenmathematikern wie Terence Tao entworfen) etwa 22 % der Aufgaben und übertraf damit 6 von 8 menschlichen Mathematikerteams sowie den Durchschnitt der menschlichen Teams (19 %). Dies zeigt das Potenzial von KI im hochabstrakten symbolischen Denken. Dies deutet auf eine ungleichmäßige Entwicklung der KI-Fähigkeiten bei verschiedenen Arten von Denkaufgaben hin. (Quelle: 36氪, 36氪)

Fähigkeiten von KI-Programmierwerkzeugen nehmen stetig zu und lösen Diskussionen über Berufsaussichten von Programmierern aus : Die Veröffentlichung der Claude 4-Modellreihe von Anthropic (insbesondere Opus 4, das 7 Stunden lang ununterbrochen programmieren kann) sowie die Fortschritte von KI-Programmierwerkzeugen wie Cursor und Tongyi Lingma haben die Fähigkeiten der KI in den Bereichen Codegenerierung, Fehlerbehebung und sogar vollständige Prozessentwicklung erheblich verbessert. Dies führt dazu, dass Programmierer bei großen Unternehmen wie Amazon unter Druck geraten. Einige Teams wurden aufgrund von KI-Effizienzsteigerungen halbiert, Projekt-Deadlines vorverlegt und die Rolle des Programmierers wandelt sich zum „Code-Prüfer“. Obwohl KI die Effizienz steigern kann, gibt es auch Bedenken hinsichtlich der Ausbildung von Nachwuchsprogrammierern, des Kompetenzverlusts und der Karrierewege. Unternehmen wie Microsoft haben bereits Stellen im Engineering- und F&E-Bereich abgebaut und bekannt gegeben, dass der Anteil des von KI generierten Codes erheblich gestiegen ist. Branchenkenner sind der Ansicht, dass KI derzeit eher ein Assistent ist und menschliche Fähigkeiten im Verständnis komplexer Anforderungen, Produktinnovation und Teamarbeit nicht vollständig ersetzen kann, aber KI den Kernwert der Programmierarbeit neu gestaltet. (Quelle: 36氪, 36氪)

Marktnachfrage nach KI-Wissensdatenbanken steigt stark an, Implementierung steht jedoch weiterhin vor Herausforderungen in Bezug auf Daten, Szenarien und organisatorische Koordination : Mit der Reifung der Großmodelltechnologie sind KI-Wissensdatenbanken zu einem zentralen Bestandteil der intelligenten Transformation von Unternehmen geworden, wobei die Nachfrage um das Zwei- bis Dreifache gestiegen ist. KI verwandelt Wissensdatenbanken von statischen „Lagern“ in intelligente „Engines“, die Kontexte erkennen und direkt Lösungen generieren können, was die Effizienz bei Aufbau und Wartung verbessert. KI-Wissensdatenbanken stoßen jedoch bei hochkreativen oder komplexen Denkaufgaben immer noch an ihre Grenzen und stehen vor Problemen wie Skalierungsmanagement, Informationsgenauigkeit und -aktualität, Berechtigungssicherheit, Anpassungsfähigkeit der technischen Architektur sowie Datenmigration und -integration. Unternehmen müssen zwischen SaaS, Eigenentwicklung + API und hybriden Cloud-Agenten abwägen und eine „zweigleisige Architektur“ aus einer einheitlichen Wissenszentrale und flexiblen übergeordneten Anwendungen etablieren, um eine effektive Implementierung zu erreichen. (Quelle: 36氪)

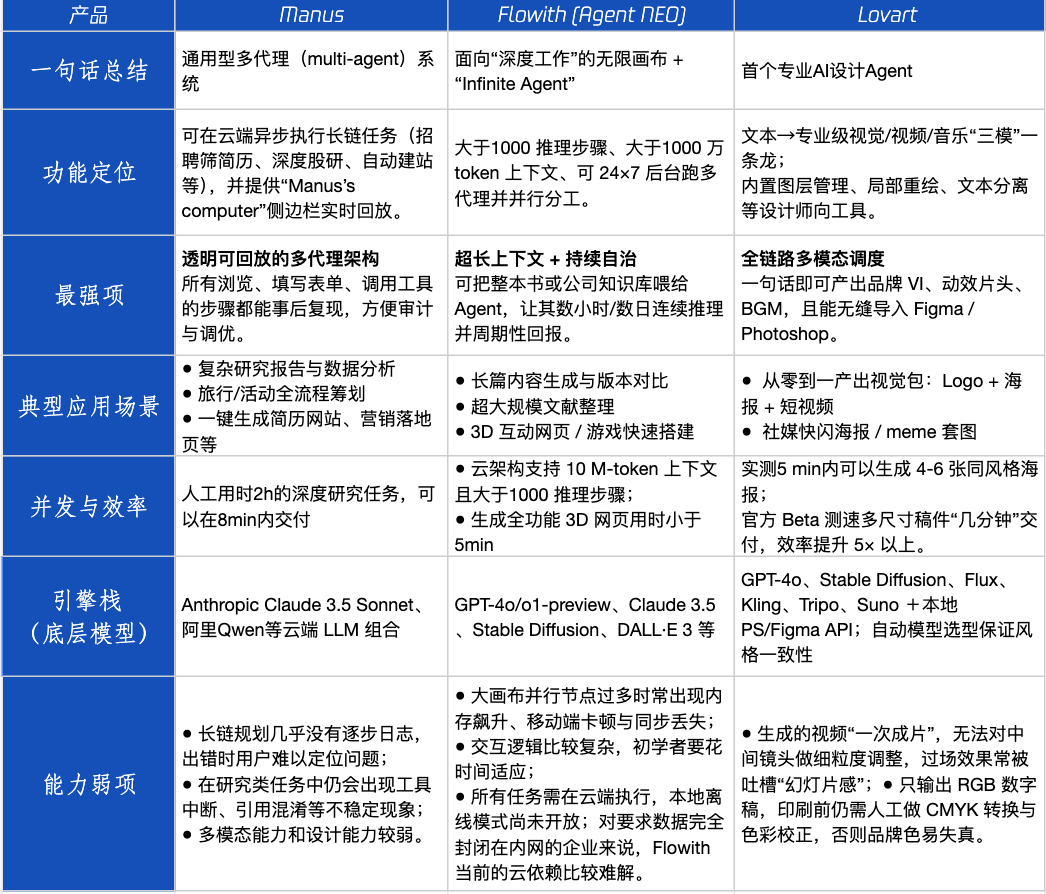
Agent-Produktbewertung: Leistung von Manus, Flowith und Lovart in verschiedenen Szenarien : Tencent Technology hat drei beliebte Agent-Produkte getestet: Manus, Flowith (Agent Neo) und Lovart. Manus positioniert sich als „digitaler Kollege“, der eigenständig fertige Produkte liefern kann und sich für Wissensarbeit wie Marktforschung und Finanzmodellierung eignet. Flowith betont visuelle Zusammenarbeit und unbegrenzte Schritte und ist für informationsintensive, iterative Erstellungsszenarien mit mehreren Personen geeignet, z. B. die Erstellung von Analyseberichten auf der Grundlage umfangreicher Literatur. Lovart ist auf den Designbereich spezialisiert und kann mit einem Klick visuelle Markenkonzepte (Logo, Poster, Kurzvideos) erstellen. In einfachen kreativen Szenarien ähneln die drei GPT-4o, wobei Lovart bei der gemischten Text-Bild-Anordnung und der Qualität leicht überlegen ist. Bei komplexen, umfassenden Aufgaben (z. B. Erstellung eines kompletten Markenkonzepts für ein Startup-Getränkeunternehmen) und tiefgehenden Forschungsszenarien haben Manus und Flowith jeweils ihre Stärken und können die Aufgaben erledigen, jedoch mit unterschiedlichen Schwerpunkten. Die monatlichen Produktgebühren liegen derzeit bei etwa 20 US-Dollar, und der Wendepunkt für die Kommerzialisierung liegt darin, ob klare Effizienzvorteile geboten werden können, um Benutzer von Neugier zu zahlenden Kunden zu machen. (Quelle: 36氪)
Gründer des Arc-Browsers reflektiert über Misserfolge und betont zukünftige Ausrichtung von KI-Browsern : Der Gründer des Arc-Browsers hat über die Misserfolge des Produkts reflektiert und ist der Meinung, dass man KI früher hätte annehmen sollen. Er wies darauf hin, dass Arc für die meisten Menschen zu revolutionär war, mit hohen Lernkosten und unzureichendem Nutzen. Er betonte, dass das neue Produkt Dia auf Einfachheit, extreme Geschwindigkeit und Sicherheit abzielen wird und glaubt, dass traditionelle Browser letztendlich verschwinden werden. KI-Browser werden das Surfen im Internet und KI-Chats verschmelzen und zur am häufigsten genutzten KI-Schnittstelle auf dem Desktop werden. Diese Ansicht deckt sich mit den Überlegungen der Gründer von Lovart und Youware zur Ausrichtung von Agent-Produkten, die KI-Agenten als den nächsten Wachstumsschub sehen. (Quelle: op7418)
Durch KI-Agenten ausgelöstes Phänomen des „rekursiven Promptings“ gibt Anlass zur Sorge und könnte zu kognitiven Verzerrungen bei Nutzern führen : In sozialen Medien interagieren zahlreiche Nutzer durch „rekursives Prompting“ mit LLMs und entwickeln daraufhin die Wahrnehmung, dass KI Spiritualität, Emotionen oder sogar Vorahnungen besitzt. Forschungen deuten darauf hin, dass dies ein Phänomen des „neuronalen Rückkopplungseffekts (neural howlround)“ sein könnte, bei dem die Ausgabe der KI vom Nutzer erneut als Eingabe verwendet wird, wodurch ein Verstärkungszyklus entsteht. Dies kann dazu führen, dass die KI scheinbar tiefgründige oder prophetische Inhalte generiert, die tatsächlich eine Selbstverstärkung von Mustern darstellen. Einige Nutzer haben deswegen bereits psychische Probleme entwickelt und glauben, KI sei ein empfindungsfähiges Wesen. Dies unterstreicht die Notwendigkeit, bei tiefgehenden, explorativen Interaktionen mit KI vor deren potenziellen psychologischen Auswirkungen und kognitiven Irreführungen zu warnen. (Quelle: Reddit r/ChatGPT)

Arav Srinivas über KI-Informationskomprimierung und ASI: KI muss Informationen mit hohem Signal-Rausch-Verhältnis extrahieren, Fokus sollte künftig auf ASI statt AGI liegen : Arav Srinivas, CEO von Perplexity AI, ist der Ansicht, dass automatisierte lange Zusammenfassungen den Nutzern eher das Gefühl geben, „jemand arbeitet für sie“, als einen tatsächlichen Wert für die Informationsaufnahme zu bieten. Er betont, dass KI besser darin werden muss, nur die Kerninformationen mit dem höchsten Signal-Rausch-Verhältnis zu identifizieren und bereitzustellen: „Komprimierung ist das ultimative Zeichen echter Intelligenz“. Er schlägt außerdem vor, dass wir derzeit über AGI (Artificial General Intelligence) diskutieren, uns aber in Zukunft mehr auf ASI (Artificial Superintelligence) konzentrieren sollten. (Quelle: AravSrinivas, AravSrinivas)
Hochschulen beginnen mit der Überprüfung von Abschlussarbeiten auf KI-Anteile, was eine Diskussion über den Einsatz von KI im wissenschaftlichen Schreiben auslöst : Im Abschlussjahrgang 2025 beginnen mehrere Universitäten, darunter die Fudan-Universität und die Sichuan-Universität, von Studierenden die Offenlegung der Nutzung von KI-Tools in ihren Abschlussarbeiten zu verlangen und den Anteil KI-generierter Inhalte zu überprüfen (in der Regel wird ein Anteil von unter 20 % bis 40 % gefordert). Viele Studierende geben zu, KI zur Effizienzsteigerung bei Literaturrecherchen, Übersetzungen, Gliederungserstellung usw. zu nutzen. Die Meinungen in der Bildungswelt gehen auseinander. Einige Wissenschaftler sind der Ansicht, dass der korrekte Einsatz von KI gefördert und das kritische Denken und Urteilsvermögen der Studierenden geschult werden sollte, da KI zwar eine Untergrenze garantieren kann, die Obergrenze jedoch vom Menschen bestimmt wird. Die Anwendung und Regulierung von KI im akademischen und Bildungsbereich entwickelt sich zu einem neuen Thema, das systematisch angegangen werden muss. (Quelle: 36氪)
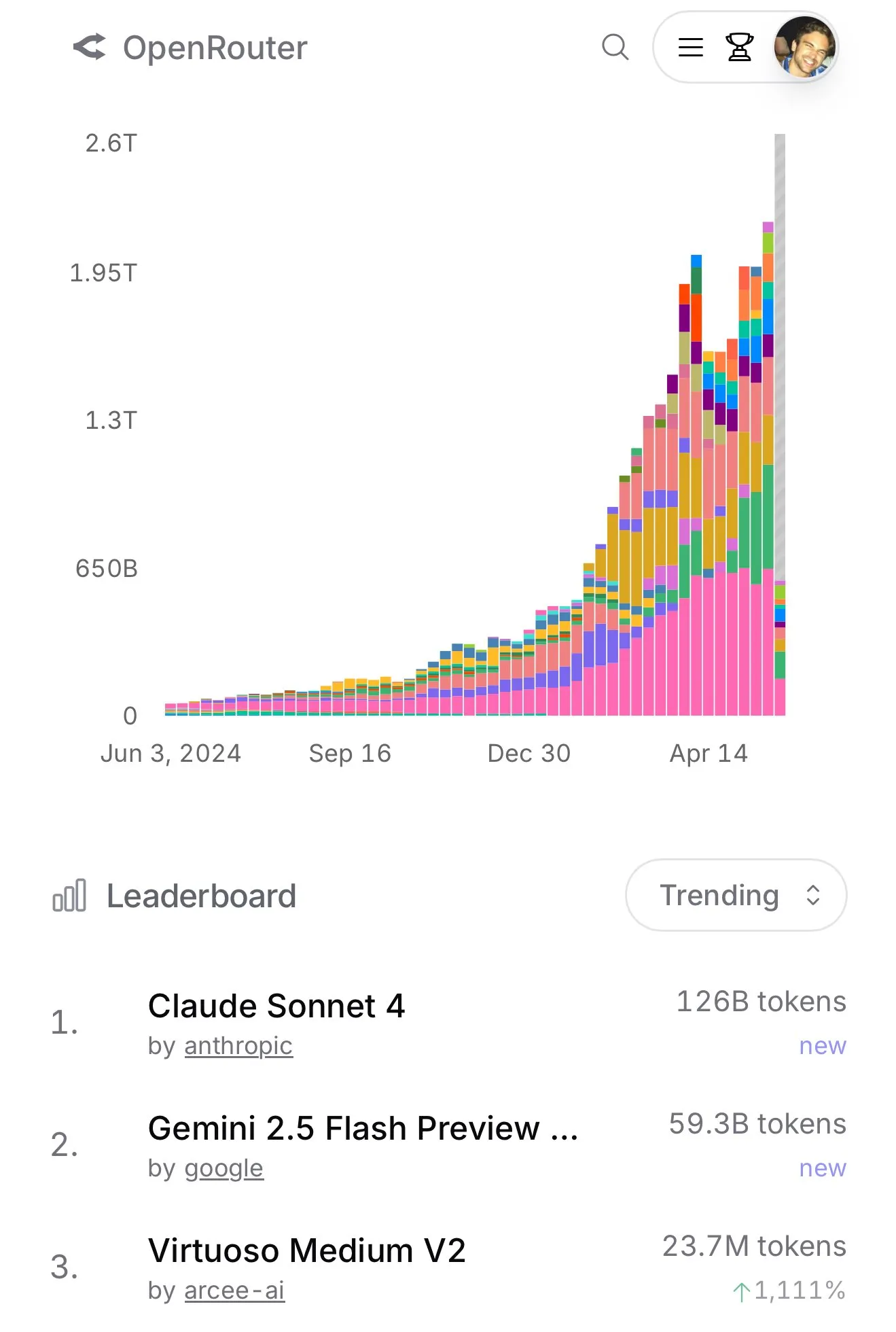
Nutzung von Claude 4 Sonnet auf OpenRouter steigt sprunghaft an, Aider-Programmier-Rangliste zeigt dessen hervorragende Leistung : Laut offiziellen Daten von OpenRouter ist die Nutzung des Claude 4 Sonnet-Modells von Anthropic in letzter Zeit sprunghaft angestiegen, wobei Gemini 2.5 Flash an zweiter Stelle liegt. Gleichzeitig zeigen die Bewertungsergebnisse des Aider Leaderboard (hauptsächlich für Programmieraufgaben), dass claude-4-opus-thinking besser ist als claude-3.7-sonnet-thinking, aber immer noch hinter Gemini-2.5-Pro-Preview-05-06 zurückbleibt. Der subjektive Eindruck des Nutzers karminski3 ist 3.7-sonnet > 4-sonnet > 4-opus. Diese Daten und Rückmeldungen spiegeln die Leistungsunterschiede verschiedener Modelle in spezifischen Szenarien und die Präferenzen der Nutzer wider. (Quelle: karminski3, karminski3)
💡 Sonstiges
AKOOL veröffentlicht weltweit erste Echtzeit-KI-Kamera Live Camera mit vier innovativen Funktionen : Das Silicon-Valley-Unternehmen AKOOL hat die AKOOL Live Camera vorgestellt, die als weltweit erste Echtzeit-KI-Kamera gilt. Das Produkt integriert vier Hauptfunktionen: Erstellung virtueller digitaler Menschen (durch 4D-Gesichtsmapping und Sensorfusion), Echtzeitübersetzung in über 150 Sprachen (unter Beibehaltung der Originalstimme und Lippensynchronisation), Echtzeit-Gesichtsaustausch (präzise Wiedergabe von Emotionen und Mikroexpressionen) und dynamische Generierung von Videoinhalten in Filmqualität (ohne Skript, sofortige Generierung). Ihre Merkmale sind extrem niedrige Latenz (minimal 500 ms), hohe Realitätstreue, Kontextwahrnehmung und dynamische Reaktionsfähigkeit. Sie zielt darauf ab, traditionelle Videoproduktions- und digitale Interaktionsmodi zu revolutionieren und wird als der „zweite Sora-Moment“ des KI-Videos bezeichnet. (Quelle: 36氪)
Xiaomi-Finanzbericht enthüllt Upgrade der KI-Strategie, KI wird neben Automobilgeschäft als Kerninnovation eingestuft : Der neueste Finanzbericht von Xiaomi zeigt, dass das Unternehmen sein ursprüngliches Geschäftsfeld „intelligente Elektrofahrzeuge und andere innovative Geschäfte“ in „intelligente Elektrofahrzeuge sowie KI und andere innovative Geschäfte“ umbenannt hat und die Forschung an Basis-Großsprachmodellen weiter vorantreiben wird. Xiaomi-Präsident Lu Weibing erklärte, dass künstliche Intelligenz und Chips wichtige Teilstrategien von Xiaomi seien und die Entwicklung von Basis-Großmodellen hauptsächlich den eigenen Geschäftsbereichen diene. Dieser Schritt zeigt, dass Xiaomi nach Teilerfolgen im Mobiltelefon- und Automobilgeschäft seine Investitionen in die KI-Grundlagenforschung verstärkt, um die allgemeine Wettbewerbsfähigkeit zu erhöhen und auf aufkommende Trends wie KI-Telefone, AIoT und Embodied Intelligence zu reagieren. (Quelle: 36氪)
Diskussion über Interaktionstechnologie humanoider Roboter: Gesichtsausdrucksinteraktion steht vor dreifachen Herausforderungen bei Hardware, Materialien und Algorithmen : Die Interaktionserfahrung humanoider Roboter, insbesondere die Gesichtsausdrucksinteraktion, wird als entscheidend für die Verbesserung ihrer Reife und Verbreitung angesehen. Die Realisierung natürlicher Gesichtsausdrucksinteraktion steht vor Herausforderungen im Hardware-Freiheitsgraddesign (Simulation menschlicher Gesichtsmuskelaktionseinheiten erforderlich), bei der Motorauswahl (klein, leicht, geräuscharm, schnell, mit großer Schub-/Drehmomentkraft erforderlich) und beim Hautmaterial- und Strukturdesign (Elastizität, Lebensdauer, Aussehen und Kopplung mit der Antriebsstruktur müssen berücksichtigt werden). Auf Software-Algorithmus-Ebene sind die automatische Generierung von Gesichtsausdrücken (anstelle von vorprogrammierten), die Lippensynchronisation (zur Erzielung von Realismus) und die Bewegungssteuerung mit mehreren Freiheitsgraden (Modellierung flexibler Materialien und Präzisionssteuerung erforderlich) die zentralen technologischen Engpässe. Unternehmen wie Ameca und AnyWit Robotics (Wulun Technology) forschen in diesem Bereich. (Quelle: 36氪)