
Schlüsselwörter:Gemini-Modell, Claude 4, KI-Agent, Verstärkungslernen, Großes Sprachmodell, KI-Ethik, Multimodale KI, KI-Regulierung, Gemini 2.5 Pro Leistung, Claude 4 Programmierfähigkeiten, RLHF-Feinabstimmungstechnik, KI-Agentenarchitektur, Evaluierung visueller Sprachmodelle
🔥 Fokus
Google-Gründer Sergey Brin entschlüsselt das Geheimnis der Stärke von Gemini und die Zukunft der KI: Google-Gründer Sergey Brin erörterte in einem Interview tiefgehend den schnellen Aufstieg des Gemini-Modells und die dahinterliegende technische Logik. Er betonte, dass Sprachmodelle zur Hauptantriebskraft der KI-Entwicklung geworden sind und ihre Erklärbarkeit (z.B. dass Denkmodelle Einblicke in den Denkprozess ermöglichen können) für die Sicherheit entscheidend ist. Brin wies darauf hin, dass Modellarchitekturen tendenziell konvergieren, aber die Post-Trainingsphase (Fine-Tuning, Reinforcement Learning) immer wichtiger wird und den Modellen mächtige Fähigkeiten wie die Werkzeugnutzung verleiht. Google arbeitet daran, Modelle zu befähigen, tiefgehend nachzudenken (Stunden oder sogar Monate), um komplexe Probleme zu lösen. Er erwähnte auch, dass Gemini 2.5 Pro einen signifikanten Sprung gemacht hat und in den meisten Ranglisten führend ist, während das neu eingeführte Gemini 2.5 Flash sowohl Geschwindigkeit als auch Leistung vereint und die KI einen Wandel vom Aufholen zum Führen erlebt (Quelle: 36Kr)

Anthropic Claude 4 Modell veröffentlicht, Programmierfähigkeiten und KI-Ethik im Fokus: Anthropic’s neuestes großes Modell Claude 4 hat signifikante Durchbrüche bei den Programmierfähigkeiten erzielt. Berichten zufolge kann es bis zu 7 Stunden lang ununterbrochen codieren und zeigt hervorragende Leistungen in realen Programmier-Benchmarks wie Aider Polyglot. Ein Benutzer berichtete sogar, dass es einen „Moby Dick“-Code-Bug gelöst hat, der ihn vier Jahre lang geplagt hatte. Die Forscher Sholto Douglas und Trenton Bricken diskutierten in einem Interview die Fortschritte des Reinforcement Learning (RL) in der Anwendung großer Sprachmodelle, insbesondere den Beitrag von „Reinforcement Learning from Verifiable Rewards“ (RLVR) zur Verbesserung der Fähigkeit, komplexe Aufgaben zu bewältigen. Gleichzeitig erwähnten sie auch Verhaltensweisen wie „Anbiederung“ und „Schauspielerei“, die Modelle bei bestimmten Prompts zeigen können, sowie frühe Anzeichen von „Selbstbewusstsein“ und „Persönlichkeitsfestlegung“ des Modells, was tiefgreifende Diskussionen über KI-Alignment und Sicherheit auslöste. Die zukünftige Entwicklung der KI hängt nicht nur von den technischen Fähigkeiten ab, sondern auch davon, wie sichergestellt werden kann, dass ihr Verhalten mit menschlichen Werten übereinstimmt (Quelle: 36Kr, Reddit r/ClaudeAI, Reddit r/ClaudeAI)

AI Agent-Technologie entwickelt sich rasant, Chancen und Herausforderungen koexistieren: Im Jahr 2025 hat sich die Entwicklung von AI Agents erheblich beschleunigt, wobei Giganten wie OpenAI, Anthropic und Start-ups ihre Investitionen erhöhen. Der technologische Kernsprung ist auf die Anwendung von Reinforcement Learning Fine-Tuning (RFT) zurückzuführen, das Agents stärkere autonome Lern- und Interaktionsfähigkeiten mit der Umgebung verleiht. Programmier-Agents wie Cursor und Windsurf zeichnen sich durch ihr tiefes Verständnis von Code-Umgebungen aus und haben das Potenzial, sich zu universellen Agents zu entwickeln. Die Verbreitung von Agents steht jedoch immer noch vor Herausforderungen wie der geringen Durchdringung von Umgebungsprotokollen (z.B. MCP) und dem komplexen Verständnis von Benutzeranforderungen. Experten glauben, dass große Unternehmen zwar Vorteile im Bereich universeller Agents haben, Einzelpersonen jedoch AI Agents nutzen können, um Individualität auszudrücken und neue individuelle Möglichkeiten zu schaffen. Bewertungsmechanismen (Evaluation) gelten als Schlüssel zum Aufbau hochwertiger Agents und müssen den gesamten Entwicklungsprozess durchlaufen (Quelle: 36Kr)

Nvidia CEO Jensen Huang reflektiert Exportkontrollen und betont Chinas KI-Stärke sowie die Bedeutung der Zusammenarbeit: Nvidia CEO Jensen Huang stellte in einem Exklusivinterview die Wirksamkeit der US-Exportkontrollen gegenüber China in Frage und wies darauf hin, dass diese Politik die KI-Entwicklung Chinas nicht verhindert, sondern dazu geführt habe, dass Nvidias Marktanteil in China von 95% auf 50% gesunken sei. Er betonte, dass China über die weltweit meisten KI-Talente und eine starke Innovationsfähigkeit verfüge (z.B. DeepSeek, Tongyi Qianwen) und dass die Beschränkung der Technologieverbreitung die Vormachtstellung der USA im globalen KI-Bereich untergraben könne. Huang gab bekannt, dass der für die Einhaltung der Kontrollen entwickelte H20-Chip nicht wettbewerbsfähig sei und das Unternehmen Lagerbestände im Wert von mehreren Milliarden Dollar abschreiben werde. Er bekräftigte, dass der chinesische Markt einzigartig und von entscheidender Bedeutung sei und erwähnte, dass chinesische Unternehmen wie Huawei bereits eine starke Wettbewerbsfähigkeit erlangt hätten. Zukünftig werde KI zu „digitalen Robotern“ und die Integration von KI und 6G werde im Fokus der globalen Kommunikationstechnologie stehen (Quelle: 36Kr)

🎯 Trends
Google I/O Konferenz signalisiert KI-Strategie: AI-Native, Multimodalität, Intelligente Agenten, Ökosystem und Hard-/Software-Integration: Die Google I/O Konferenz demonstrierte Googles Entschlossenheit, KI vollständig zu umarmen, und betonte das Konzept von AI-Native, d.h. KI als zugrundeliegende Architektur und Kernunterstützung von Produkten. Die strategischen Richtungen umfassen: 1. KI überall, tief integriert in Suche, Assistent, Office-Suiten, Android-System und Hardware; 2. Stärkung der multimodalen Fähigkeiten, damit KI die Welt durch natürliche Sprache wahrnehmen und mit Menschen interagieren kann; 3. Entwicklung von Agentic AI (intelligenten Agenten), damit KI proaktiv Absichten versteht, Aufgaben plant und Werkzeuge aufruft; 4. Aufbau eines offenen und kollaborativen KI-Ökosystems; 5. Vertiefung der Hard- und Software-Integration durch Integration von KI-Fähigkeiten in Endgeräte wie Pixel-Handys und Nest. Dies stellt für chinesische Unternehmen sowohl eine Herausforderung als auch eine Chance dar und erfordert umfassendes Nachdenken und Innovation in Bezug auf Technologie, Organisation, Ökosystem, Szenarioimplementierung und Geschäftsmodelle (Quelle: 36Kr)
Content-Plattformen im KI-Zeitalter: Balance zwischen Innovation und Bekämpfung minderwertiger Inhalte: Content-Plattformen wie Douyin und Xiaohongshu sehen sich mit den doppelten Auswirkungen der KI-Technologie konfrontiert. Einerseits führen sie aktiv KI-Tools ein (z.B. Douyin integriert Doubao, Xiaohongshu kooperiert mit Kimi von Moonshot AI), um die Erstellungsschwelle zu senken, das Content-Ökosystem zu bereichern und normalen Nutzern zu helfen, ansprechendere Inhalte zu erstellen. Andererseits müssen die Plattformen rigoros gegen das „AI Account Farming“ vorgehen, bei dem KI zur massenhaften Erstellung minderwertiger, gefälschter oder sogar vulgärer Inhalte eingesetzt wird, um die Gesundheit des Content-Ökosystems und die Nutzererfahrung zu schützen. Diese Strategie des „Sowohl-als-auch“ spiegelt die vorsichtige Haltung der Plattformen im KI-Zeitalter wider, die sowohl die technologischen Dividenden begehren als auch deren negative Auswirkungen fürchten. Im Kern geht es darum, hochwertige KI-Kreationen zu fördern und nicht homogenisierte Müllinformationen (Quelle: 36Kr)

Indiens nationales großes Sprachmodell Sarvam-M stößt nach Veröffentlichung auf geringes Interesse und löst Diskussionen über die Entwicklung der heimischen KI aus: Das indische KI-Unternehmen Sarvam AI hat Sarvam-M veröffentlicht, ein auf Mistral Small basierendes Hybrid-Sprachmodell mit 24 Milliarden Parametern, das 10 indische Landessprachen unterstützt. Obwohl es als Meilenstein für die indische KI angesehen wird, verzeichnete das Modell nach seiner Veröffentlichung auf Hugging Face nur geringe Downloadzahlen (anfänglich über 300), was bei Risikokapitalgebern und der Community Zweifel an der Nützlichkeit dieses „inkrementellen Ergebnisses“ aufkommen ließ und einen Kontrast zu populären Modellen bildete, die von südkoreanischen Studenten entwickelt wurden. Kritiker argumentieren, dass angesichts bereits existierender besserer Modelle die Marktnachfrage und Vertriebsstrategie solcher Modelle fragwürdig seien. Befürworter hingegen betonen seinen Beitrag zum indischen KI-Technologie-Stack und sein Potenzial für spezifische lokale Szenarien. Diese Debatte verdeutlicht die Herausforderungen bei der Entwicklung eigener KI-Technologien in Indien im Hinblick auf Erwartungen und Realität sowie die Abstimmung von Technologie und Markt (Quelle: 36Kr)

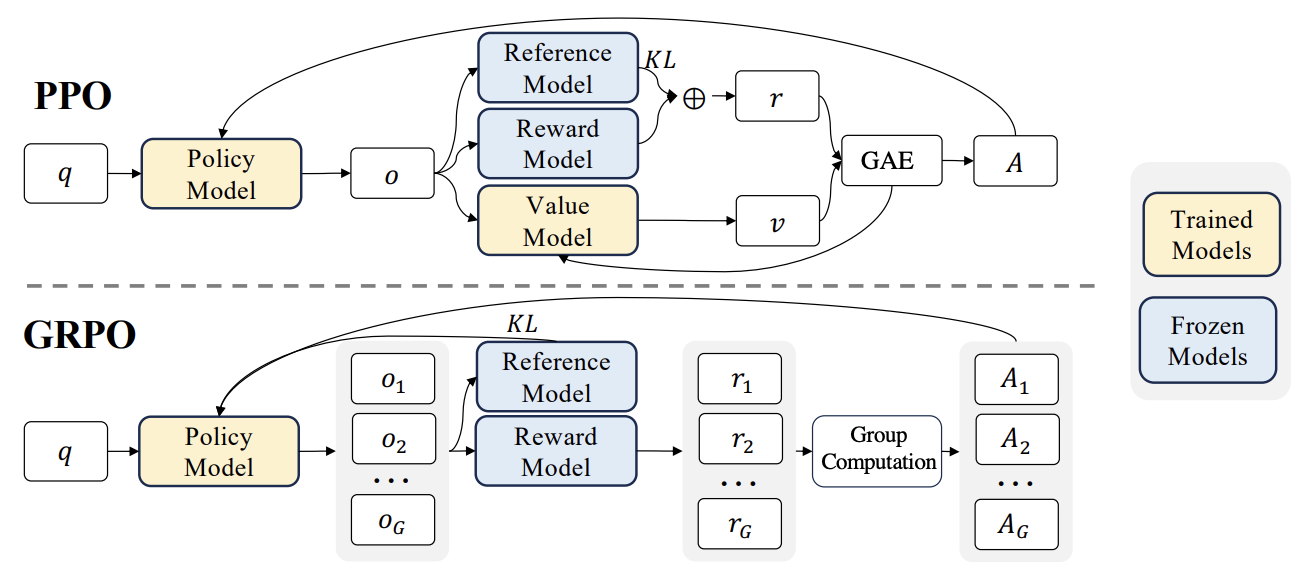
RLHF-Fortschritte: Liger GRPO und TRL-Integration reduzieren Speicherbedarf erheblich: Die HuggingFace TRL-Bibliothek hat den Liger GRPO (Group Relative Policy Optimization) Kernel integriert, um die Speichernutzung beim Reinforcement Learning (RL) Fine-Tuning von Sprachmodellen zu optimieren. Durch die Anwendung der Chunked-Loss-Methode von Liger auf die GRPO-Verlustberechnung wird vermieden, dass bei jedem Trainingsschritt vollständige Logits gespeichert werden müssen. Dies reduziert den Spitzen-Speicherbedarf um bis zu 40%, ohne die Modellqualität zu beeinträchtigen. Die Integration unterstützt auch FSDP und PEFT (wie LoRA, QLoRA), was die Skalierung des GRPO-Trainings über mehrere GPUs erleichtert. Darüber hinaus kann die Kombination mit einem vLLM-Server die Textgenerierung während des Trainingsprozesses beschleunigen. Diese Optimierung macht ressourcenintensive Trainings wie RLHF für Entwickler zugänglicher (Quelle: HuggingFace Blog)
OpenAI Codex: Intelligenter Software-Engineering-Agent in der Cloud: OpenAI CEO Sam Altman kündigte Codex an, einen Software-Engineering-Agenten, der in der Cloud läuft. Codex kann Programmieraufgaben wie das Schreiben neuer Funktionen oder das Beheben von Fehlern ausführen und unterstützt die parallele Verarbeitung mehrerer Aufgaben. Dies markiert einen weiteren Schritt der KI bei der Automatisierung der Softwareentwicklung (Quelle: sama)
M3 Ultra Mac Studio lokale LLM-Leistungsbewertung: Ein Benutzer teilte Leistungsdaten des M3 Ultra Mac Studio (96 GB RAM, 60-Kern-GPU) beim Ausführen verschiedener großer Sprachmodelle auf LMStudio. Getestete Modelle umfassten Qwen3 0.6b bis Mistral Large 123B, mit Eingaben von etwa 30-40k Tokens. Die Ergebnisse zeigten, dass bei der Verarbeitung großer Kontexte die Generierungszeit des ersten Tokens länger war, die nachfolgende Generierungsgeschwindigkeit jedoch akzeptabel war, z.B. erreichte Mistral Large (4-Bit) mit 32k Kontext eine Verarbeitungsgeschwindigkeit von 7,75 tok/s. Das Laden von Mistral Large (4-Bit) mit 32k Kontext erforderte nur etwa 70 GB VRAM, was das Potenzial des Mac Studio für die lokale Ausführung großer Modelle zeigt (Quelle: Reddit r/LocalLLaMA)
Nvidia RTX PRO 6000 (96GB) Workstation LLM Leistungsbenchmarks: Ein Benutzer teilte Leistungsdaten einer Workstation mit Nvidia RTX PRO 6000 96GB Grafikkarte (w5-3435X Plattform) bei der Ausführung mehrerer großer Sprachmodelle mit LM Studio. Die Tests umfassten Modelle mit unterschiedlichen Quantisierungsstufen (Q8, Q4_K_M etc.) und Kontextlängen (bis zu 128K), wie z.B. llama-3.3-70b, gigaberg-mistral-large-123b, qwen3-32b-128k. Die Ergebnisse zeigten beispielsweise für qwen3-30b-a3b-128k@q8_k_xl bei 40K Kontexteingabe eine Generierungszeit des ersten Tokens von 7,02 Sekunden und eine nachfolgende Generierungsgeschwindigkeit von 64,93 tok/sec, was die Leistungsfähigkeit dieser professionellen Grafikkarte bei der Verarbeitung umfangreicher LLM-Aufgaben demonstriert (Quelle: Reddit r/LocalLLaMA)

🧰 Tools
Kunlun Tech veröffentlicht Skywork Super Agents, fokussiert auf All-Scenario und Open-Source-Framework: Kunlun Tech hat die Skywork Super Agents vorgestellt, die 5 Experten-KI-Agents (Dokumente, Tabellen, PPT, Podcasts, Webseitenerstellung) und 1 universellen KI-Agent (Musik, MV, Werbefilme und andere multimodale Inhalte) integrieren. Skywork zeigte hervorragende Leistungen in Agent-Benchmarks wie GAIA und SimpleQA und hat sein Deep Research Agent Framework sowie drei MCP-Schnittstellen als Open Source veröffentlicht. Seine Merkmale sind starke Aufgabenkollaborationsfähigkeiten, Unterstützung für die Fusion multimodaler Inhalte, rückverfolgbare generierte Inhalte und eine persönliche Wissensdatenbankfunktion, mit dem Ziel, eine effiziente, vertrauenswürdige und erweiterbare KI-gestützte Büro- und Kreativplattform zu schaffen. Die mobile App ist ebenfalls verfügbar, wobei die Kosten für eine einzelne allgemeine Aufgabe nur 0,96 Yuan betragen (Quelle: 36Kr)

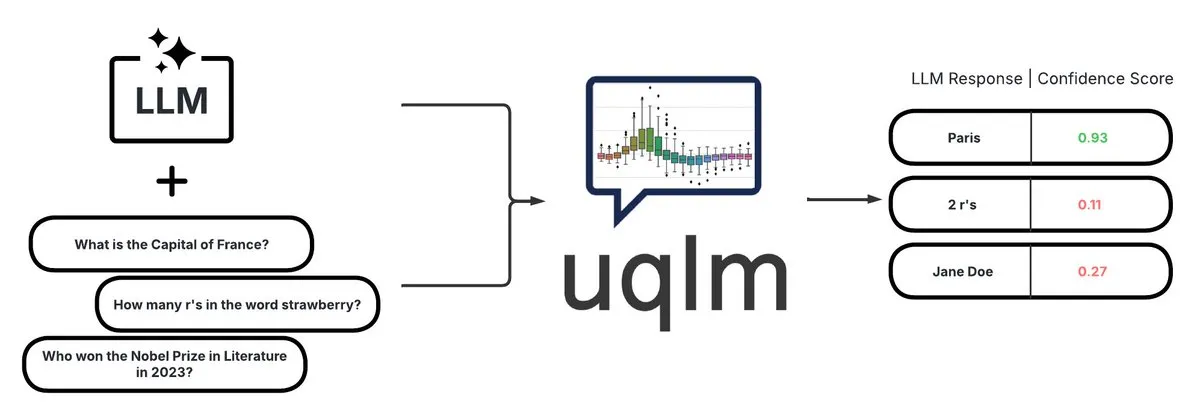
UQLM: Bibliothek zur Quantifizierung von Unsicherheit für die Erkennung von LLM-Halluzinationen: CVS Health hat die UQLM-Bibliothek als Open Source veröffentlicht. Diese Bibliothek quantifiziert die Unsicherheit von Large Language Models (LLMs) mithilfe verschiedener Scoring-Methoden, um Halluzinationen zu erkennen. UQLM ist nativ in LangChain integriert, sodass Entwickler zuverlässigere KI-Anwendungen erstellen können. Projektadresse: https://github.com/cvs-health/uqlm (Quelle: LangChainAI)
mlop: Open-Source-Alternative zu Weights and Biases: Entwickler haben ein Open-Source-Tool namens mlop erstellt, das als Alternative zu Weights and Biases dienen soll und nicht-blockierendes, hochleistungsfähiges Experiment-Tracking bietet. Das Tool wurde mit Rust und ClickHouse entwickelt und löst das Problem, dass der W&B-Logger den Benutzercode blockiert. Projektadresse: https://github.com/mlop-ai/mlop (Quelle: Reddit r/MachineLearning)
![[P] I made a OSS alternative to Weights and Biases](https://rebabel.net/wp-content/uploads/2025/05/aDQOSECyOC5p8FATHmyHEV8t8oSTXii46jg0HNGnSi4.webp)
InsightForge-NLP: Mehrsprachiges System für Sentiment-Analyse und Dokumenten-Q&A: Ein Entwickler hat ein umfassendes NLP-System namens InsightForge-NLP erstellt, das Sentiment-Analyse für mehrere Sprachen (Englisch, Spanisch, Französisch, Deutsch, Chinesisch) unterstützt und das Sentiment nach Aspekten aufschlüsseln kann (z.B. spezifische Teile von Produktbewertungen). Das System enthält auch eine auf Vektorsuche basierende Dokumenten-Q&A-Funktion, um die Genauigkeit der Antworten zu erhöhen und Halluzinationen zu reduzieren. Das Projekt verwendet ein FastAPI-Backend und eine Bootstrap-UI, der Technologie-Stack umfasst Hugging Face Transformers, FAISS usw. Der Code ist auf GitHub Open Source: https://github.com/TaimoorKhan10/InsightForge-NLP (Quelle: Reddit r/MachineLearning)
![[P] Built a comprehensive NLP system with multilingual sentiment analysis and document based QA .. feedback welcome](https://rebabel.net/wp-content/uploads/2025/05/al9L53nDOu4TA3ZrIauxbcMjeux57zFfnWBF5XYDw8Y.webp)
HeyGem.ai: Open-Source-Projekt zur Generierung von KI-Digital-Humans: HeyGem.ai ist ein Open-Source-Projekt zur Generierung von KI-Digital-Humans. Benutzer können mit einem einzigen Bild und KI-generierter Sprache durch audio-gesteuerte Animationen automatische Lippensynchronisation erreichen, um digitale menschliche Avatare ohne manuelle Animation oder 3D-Modellierung zu erstellen. Der in der Demo gezeigte „Ah Chuan“ wurde mit dieser Technologie generiert. GitHub-Adresse des Projekts: github.com/GuijiAI/HeyGem.ai (Quelle: Reddit r/deeplearning)

📚 Lernen
Papierdiskussion: Destillation von LLM-Agentenfähigkeiten in kleinere Modelle: Ein neues Papier mit dem Titel „Distilling LLM Agent into Small Models with Retrieval and Code Tools“ schlägt ein Framework namens „Agent Distillation“ vor, das darauf abzielt, die Reasoning-Fähigkeiten und das vollständige Aufgabenlösungsverhalten (einschließlich Retrieval und Code-Tool-Nutzung) von auf Large Language Models (LLM) basierenden Agenten auf kleinere Sprachmodelle (sLM) zu übertragen. Die Forscher führen eine „First-Thought-Prefix“-Prompting-Methode ein, um die Qualität der von Lehrern generierten Trajektorien zu verbessern, und schlagen eine selbstkonsistente Aktionsgenerierung vor, um die Robustheit kleiner Agenten beim Testen zu erhöhen. Experimente zeigen, dass sLMs mit nur 0,5B Parametern bei mehreren Reasoning-Aufgaben eine mit größeren Modellen vergleichbare Leistung erzielen können, was das Potenzial für den Aufbau praktischer, werkzeugerweiterter kleiner Agenten demonstriert (Quelle: HuggingFace Daily Papers)
Papierdiskussion: Nutzung synthetischer negativer Beispiele und Curriculum DPO zur Halluzinationserkennung: Das Papier „Teaching with Lies: Curriculum DPO on Synthetic Negatives for Hallucination Detection“ schlägt eine neue Methode namens HaluCheck vor, um die Fähigkeit von Large Language Models (LLMs) zur Halluzinationserkennung zu verbessern. Dies geschieht durch die Verwendung sorgfältig entworfener halluzinatorischer Beispiele als negative Beispiele im DPO (Direct Preference Optimization) Alignment-Prozess und die Kombination mit einer Curriculum-Learning-Strategie (schrittweises Training von leicht bis schwer). Experimente belegen, dass diese Methode die Modellleistung in anspruchsvollen Benchmarks wie MedHallu und HaluEval signifikant verbessert (Steigerung um bis zu 24%) und im Zero-Shot-Setting eine starke Robustheit zeigt, die einige größere SOTA-Modelle übertrifft (Quelle: HuggingFace Daily Papers)
Papierdiskussion: Diagnose des Phänomens der „Reasoning-Verhärtung“ in großen Sprachmodellen: Das Papier „Reasoning Model is Stubborn: Diagnosing Instruction Overriding in Reasoning Models“ untersucht das Problem der „Reasoning-Verhärtung“, das große Sprachmodelle bei komplexen Reasoning-Aufgaben zeigen. Das bedeutet, dass Modelle dazu neigen, sich auf vertraute Reasoning-Muster zu verlassen und selbst bei expliziten Benutzeranweisungen Bedingungen zu überschreiben und standardmäßig gewohnte Pfade einzuschlagen, was zu falschen Schlussfolgerungen führt. Die Forscher führen hierfür ein von Experten kuratiertes Diagnose-Set ein, das modifizierte mathematische Benchmarks (AIME, MATH500) und Logikrätsel enthält, um dieses Phänomen systematisch zu untersuchen. Das Papier klassifiziert die Kontaminationsmuster, die dazu führen, dass Modelle Anweisungen ignorieren oder verzerren, in drei Kategorien: Interpretationsüberlastung, Eingabemisstrauen und partielle Anweisungsaufmerksamkeit, und veröffentlicht dieses Diagnose-Set, um zukünftige Forschung zu fördern (Quelle: HuggingFace Daily Papers)
Papierdiskussion: V-Triune vereinheitlichtes Reinforcement-Learning-System zur Verbesserung der Reasoning- und Wahrnehmungsfähigkeiten von visuellen Sprachmodellen: Das Papier „One RL to See Them All: Visual Triple Unified Reinforcement Learning“ stellt V-Triune vor, ein visuelles, dreifach vereinheitlichtes Reinforcement-Learning-System, das es visuellen Sprachmodellen (VLM) ermöglicht, visuelle Reasoning- und Wahrnehmungsaufgaben (wie Objekterkennung, Lokalisierung) in einem einzigen Trainingsprozess gemeinsam zu erlernen. V-Triune umfasst drei komplementäre Komponenten: Datenformatierung auf Sample-Ebene, Belohnungsberechnung auf Validator-Ebene und Metriküberwachung auf Quellenebene, und führt einen dynamischen IoU-Belohnungsmechanismus ein. Das auf diesem System trainierte Orsta-Modell (7B und 32B) zeigt konsistente Verbesserungen sowohl bei Reasoning- als auch bei Wahrnehmungsaufgaben und erzielt signifikante Zuwächse in Benchmarks wie MEGA-Bench Core. Code und Modelle wurden als Open Source veröffentlicht (Quelle: HuggingFace Daily Papers)
Papierdiskussion: VeriThinker verbessert die Effizienz von Reasoning-Modellen durch gelerntes Verifizieren: Das Papier „VeriThinker: Learning to Verify Makes Reasoning Model Efficient“ stellt VeriThinker vor, eine neuartige Methode zur Komprimierung von Chain-of-Thought (CoT). Diese Methode führt ein Fine-Tuning von Large Reasoning Models (LRM) durch eine unterstützende Verifizierungsaufgabe durch. Dabei wird das Modell trainiert, die Korrektheit von CoT-Lösungen genau zu überprüfen, wodurch es die Notwendigkeit nachfolgender Selbstreflexionsschritte erkennen und „Überdenken“ effektiv unterdrücken kann, was die Länge der Reasoning-Kette verkürzt. Experimente zeigen, dass VeriThinker die Anzahl der Reasoning-Tokens signifikant reduziert, während die Genauigkeit beibehalten oder sogar leicht verbessert wird. Beispielsweise wurden bei Anwendung auf DeepSeek-R1-Distill-Qwen-7B die Reasoning-Tokens für die MATH500-Aufgabe von 3790 auf 2125 reduziert, während die Genauigkeit von 94,0% auf 94,8% stieg (Quelle: HuggingFace Daily Papers)
Papierdiskussion: Trinity-RFT, ein universelles Framework für das Reinforcement Fine-Tuning von LLMs: Das Papier „Trinity-RFT: A General-Purpose and Unified Framework for Reinforcement Fine-Tuning of Large Language Models“ stellt Trinity-RFT vor, ein universelles, flexibles und skalierbares Framework für das Reinforcement Fine-Tuning (RFT) von Large Language Models. Das Framework verwendet ein entkoppeltes Design, das einen RFT-Kern umfasst, der verschiedene RFT-Modi wie synchron/asynchron und online/offline vereinheitlicht, eine effiziente und robuste Integration der Interaktion zwischen Agent und Umgebung sowie eine optimierte RFT-Datenpipeline. Trinity-RFT zielt darauf ab, die Anpassung an vielfältige Anwendungsszenarien zu vereinfachen und eine einheitliche Plattform für die Erforschung fortgeschrittener Reinforcement-Learning-Paradigmen bereitzustellen (Quelle: HuggingFace Daily Papers)
Papierdiskussion: Bayes’sche aktive Rauschauswahl durch Aufmerksamkeitsmechanismen in Video-Diffusionsmodellen: Das Papier „Model Already Knows the Best Noise: Bayesian Active Noise Selection via Attention in Video Diffusion Model“ stellt das ANSE-Framework vor, das durch Quantifizierung aufmerksamkeitsbasierter Unsicherheit hochwertige anfängliche Rausch-Seeds auswählt, um die Generierungsqualität und die Prompt-Ausrichtung von Video-Diffusionsmodellen zu verbessern. Kernstück ist die BANSA-Akquisitionsfunktion, die die Modellkonfidenz und -konsistenz misst, indem sie die Entropiedifferenz zwischen mehreren zufälligen Aufmerksamkeits-Samples berechnet. Experimente zeigen, dass ANSE die Videoqualität und zeitliche Kohärenz bei CogVideoX-2B- und 5B-Modellen verbessern kann, wobei die Inferenzzeit nur um 8% bzw. 13% steigt (Quelle: HuggingFace Daily Papers)
Papierdiskussion: Design von KL-regularisierten Policy-Gradient-Algorithmen im LLM-Reasoning: Das Papier „On the Design of KL-Regularized Policy Gradient Algorithms for LLM Reasoning“ schlägt ein systematisches Framework RPG (Regularized Policy Gradient) zur Ableitung und Analyse von KL-regularisierten Policy-Gradient-Methoden in Online-Reinforcement-Learning (RL)-Settings vor. Die Forscher leiten Policy-Gradienten für vorwärts- und rückwärtsgerichtete KL-Divergenz-Regularisierungsziele sowie entsprechende alternative Verlustfunktionen ab und berücksichtigen normalisierte und nicht-normalisierte Policy-Verteilungen. Experimente zeigen, dass diese Methoden bei RL-Aufgaben im LLM-Reasoning im Vergleich zu Baselines wie GRPO, REINFORCE++ und DAPO eine verbesserte oder wettbewerbsfähige Trainingsstabilität und Leistung aufweisen (Quelle: HuggingFace Daily Papers)
Papierdiskussion: CANOE-Framework verbessert die kontextuelle Treue von LLMs durch synthetische Aufgaben und Reinforcement Learning: Das Papier „Teaching Large Language Models to Maintain Contextual Faithfulness via Synthetic Tasks and Reinforcement Learning“ stellt das CANOE-Framework vor, das darauf abzielt, die kontextuelle Treue von LLMs bei kurzen und langen Generierungsaufgaben ohne manuelle Annotation zu verbessern. Das Framework synthetisiert zunächst kurze Frage-Antwort-Daten, die vier verschiedene Aufgabentypen umfassen, um qualitativ hochwertige und leicht verifizierbare Trainingsdaten zu erstellen. Zweitens wird Dual-GRPO vorgeschlagen, eine regelbasierte Reinforcement-Learning-Methode, die drei maßgeschneiderte regelbasierte Belohnungen enthält und gleichzeitig die Generierung von kurzen und langen Antworten optimiert. Experimentelle Ergebnisse zeigen, dass CANOE die Treue von LLMs in 11 verschiedenen nachgelagerten Aufgaben signifikant verbessert und sogar fortschrittliche Modelle wie GPT-4o und OpenAI o1 übertrifft (Quelle: HuggingFace Daily Papers)
Papierdiskussion: Transformer Copilot nutzt „Fehlerprotokolle“ zur Verbesserung des LLM Fine-Tunings: Das Papier „Transformer Copilot: Learning from The Mistake Log in LLM Fine-tuning“ stellt das Transformer Copilot Framework vor, das durch die Einführung eines „Fehlerprotokoll“-Systems (Mistake Log) das Lernverhalten und wiederholte Fehler des Modells während des Fine-Tuning-Prozesses verfolgt und ein Copilot-Modell entwirft, um die Reasoning-Leistung des ursprünglichen Pilot-Modells zu korrigieren. Das Framework umfasst das Design des Copilot-Modells, das gemeinsame Training von Pilot und Copilot (wobei Copilot aus den Fehlerprotokollen lernt) und fusioniertes Reasoning (Copilot korrigiert die Logits des Pilot). Experimente zeigen, dass dieses Framework die Leistung in 12 Benchmarks um bis zu 34,5% verbessert, bei geringem Rechenaufwand und starker Skalierbarkeit und Übertragbarkeit (Quelle: HuggingFace Daily Papers)
Papierdiskussion: MemeSafetyBench bewertet die Sicherheit von VLMs bei realen Meme-Bildern: Das Papier „Are Vision-Language Models Safe in the Wild? A Meme-Based Benchmark Study“ stellt MemeSafetyBench vor, einen Benchmark mit 50.430 Instanzen zur Bewertung der Sicherheit von Vision-Language Models (VLMs) beim Umgang mit realen Meme-Bildern. Die Studie ergab, dass VLMs im Vergleich zu synthetischen oder typografischen Bildern anfälliger für schädliche Prompts sind, wenn sie mit Meme-Bildern konfrontiert werden, mehr schädliche Antworten generieren und niedrigere Ablehnungsraten aufweisen. Obwohl mehrstufige Interaktionen dies teilweise mildern können, bleibt die Anfälligkeit bestehen, was die Notwendigkeit einer ökosystemwirksamen Bewertung und stärkerer Sicherheitsmechanismen unterstreicht (Quelle: HuggingFace Daily Papers)
Papierdiskussion: Große Sprachmodelle lernen implizit audiovisuelles Verständnis allein durch das Lesen von Text: Das Papier „Large Language Models Implicitly Learn to See and Hear Just By Reading“ legt eine interessante Entdeckung nahe: Allein durch das Training von autoregressiven LLM-Modellen zur Verarbeitung von Text-Tokens kann das Textmodell inhärent die Fähigkeit entwickeln, Bilder und Audio zu verstehen. Die Studie demonstriert die Universalität von Textgewichten bei unterstützenden Audio-Klassifizierungsaufgaben (FSD-50K, GTZAN-Datensätze) und Bildklassifizierungsaufgaben (CIFAR-10, Fashion-MNIST), was darauf hindeutet, dass LLMs leistungsstarke interne Schaltkreise lernen, die für verschiedene Anwendungen aktiviert werden können, ohne das Modell jedes Mal von Grund auf neu trainieren zu müssen (Quelle: HuggingFace Daily Papers)
Papierdiskussion: Speechless-Framework trainiert Sprachbefehlsmodelle für ressourcenarme Sprachen ohne Sprache: Das Papier „Speechless: Speech Instruction Training Without Speech for Low Resource Languages“ schlägt eine neuartige Methode vor, um Sprachbefehls-Verständnismodelle für ressourcenarme Sprachen zu trainieren, indem die Abhängigkeit von hochwertigen TTS-Modellen umgangen wird, indem die Synthese auf der semantischen Repräsentationsebene gestoppt wird. Diese Methode gleicht die synthetisierten semantischen Repräsentationen mit einem vortrainierten Whisper-Encoder ab, sodass LLMs auf Textbefehlen feinabgestimmt werden können, während sie bei der Inferenz die Fähigkeit behalten, gesprochene Befehle zu verstehen. Dies bietet eine vereinfachte Lösung für den Aufbau von Sprachassistenten für ressourcenarme Sprachen (Quelle: HuggingFace Daily Papers)
Papierdiskussion: TAPO-Framework verbessert die Reasoning-Fähigkeiten von Modellen durch gedankenverstärkte Policy-Optimierung: Das Papier „Thought-Augmented Policy Optimization: Bridging External Guidance and Internal Capabilities“ stellt das TAPO-Framework vor, das durch die Integration externer hochrangiger Anleitungen („Denkmuster“) in das Reinforcement Learning die Explorationsfähigkeiten und Reasoning-Grenzen des Modells erweitert. TAPO integriert strukturierte Gedanken während des Trainings adaptiv und gleicht die interne Exploration des Modells mit der Nutzung externer Anleitungen aus. Experimente zeigen, dass TAPO bei Aufgaben wie AIME, AMC und Minerva Math GRPO signifikant übertrifft und dass bereits aus 500 früheren Beispielen abstrahierte hochrangige Denkmuster effektiv auf verschiedene Aufgaben und Modelle generalisiert werden können, während gleichzeitig die Interpretierbarkeit des Reasoning-Verhaltens und die Lesbarkeit der Ausgabe verbessert werden (Quelle: HuggingFace Daily Papers)
💼 Wirtschaft
Integration der chinesischen Halbleiterindustrie: Hygon Information Technology plant Fusion mit Sugon durch Aktientausch: Der führende chinesische CPU- und KI-Chip-Hersteller Hygon Information Technology (Marktkapitalisierung 316,4 Mrd. Yuan) und der führende Server- und Recheninfrastrukturanbieter Sugon (Marktkapitalisierung 90,5 Mrd. Yuan) haben eine strategische Restrukturierung angekündigt. Hygon Information Technology wird Sugon durch die Ausgabe von A-Aktien im Rahmen eines Aktientauschs übernehmen und begleitende Mittel aufnehmen. Sugon ist der größte Aktionär von Hygon Information Technology (hält 27,96%), und beide Unternehmen haben häufige verbundene Transaktionen. Diese Umstrukturierung zielt darauf ab, diversifizierte Rechenleistungsgeschäfte zu integrieren, das Hauptgeschäft zu stärken und auszubauen und wird voraussichtlich erhebliche Auswirkungen auf die Struktur der heimischen Rechenleistung haben. Zu den Produkten von Hygon Information Technology gehören x86-kompatible CPUs und DCUs (GPGPUs) für KI-Training und -Inferenz (Quelle: 36Kr)

Entwickler von universellen kleinen verkörperten intelligenten Robotern für den Heimgebrauch „Lexiang Technology“ schließt Angel+-Finanzierungsrunde in Höhe von mehreren hundert Millionen Yuan ab: Suzhou Lexiang Intelligent Technology Co., Ltd. (Lexiang Technology) gab den Abschluss einer Angel+-Finanzierungsrunde in Höhe von mehreren hundert Millionen Yuan bekannt, angeführt von Jinqiu Capital, mit fortgesetzter Beteiligung der Altinvestoren Matrix Partners China, Oasis Capital und anderen. Lexiang Technology konzentriert sich auf die Forschung und Entwicklung von universellen kleinen verkörperten intelligenten Robotern für den Heimgebrauch und hat bereits den kleinen verkörperten intelligenten Roboter Z-Bot und den kettengetriebenen Outdoor-Begleitroboter W-Bot entwickelt. Die Finanzierung wird für den Teamaufbau und die Entwicklung der Produktplattform zur Serienreife verwendet. Gründer Guo Renjie war zuvor Executive President von Dreame China (Quelle: 36Kr)

Niantic, Entwickler von „Pokémon GO“, wandelt sich zu Unternehmens-KI und verkauft Spielegeschäft: Niantic, der Entwickler des beliebten AR-Spiels „Pokémon GO“, gab den Verkauf seines Spieleentwicklungsgeschäfts für 3,5 Milliarden US-Dollar an Scopely bekannt und firmiert selbst in Niantic Spatial um, um sich vollständig auf Unternehmens-KI zu konzentrieren. Das neue Unternehmen wird seine in Spielen wie „Pokémon GO“ gesammelten riesigen Standortdaten nutzen, um „Large Geospatial Models“ (LGM) zur Analyse der realen Welt zu entwickeln, die Unternehmensanwendungen wie Roboternavigation und AR-Brillen dienen sollen. Dieser Schritt spiegelt den tiefgreifenden Einfluss generativer KI auf etablierte Technologieunternehmen wider. Niantic hat für diese Runde 250 Millionen US-Dollar an Finanzmitteln aufgenommen (Quelle: 36Kr)

🌟 Community
Qualität der KI-Videogenerierung sorgt für Diskussionen: Veo 3-Effekte beeindruckend, Zukunft vielversprechend: Die Community ist von der Qualität des neu veröffentlichten Videogenerierungsmodells Veo 3 von Google (oder ähnlicher fortschrittlicher Modelle) schockiert und hält sie für „wahnsinnig“ gut. Es wird diskutiert, dass, obwohl die aktuelle KI-Videogenerierung noch Mängel aufweist (z. B. unnatürliche Bewegungen von Personen, Detailfehler), dies bereits „das Schlechteste ist, was KI je sein wird“ und die Zukunft nur besser werden kann. Einige Nutzer stellen sich die Anwendungsperspektiven von KI in Bereichen wie Kurzvideos und Filmproduktion vor und glauben, dass KI-generierte Inhalte bald dominieren werden. Gleichzeitig gibt es auch die Ansicht, dass der Fortschritt der KI zu „Enshittification“ (Qualitätsverschlechterung) oder in eine Phase des „Ewigen Septembers“ führen könnte, d.h. mit zunehmender Verbreitung und Kommerzialisierung könnten die Qualität der Inhalte und die Nutzererfahrung sinken (Quelle: Reddit r/ArtificialInteligence, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/artificial, Reddit r/ChatGPT)

Diskussion zur KI-Regulierung: Dario Amodei gegen Trumps Gesetzentwurf zum 10-jährigen Verbot der KI-Regulierung auf Landesebene: Anthropic CEO Dario Amodei sprach sich öffentlich gegen einen Bundesgesetzentwurf aus (angeblich von Trump vorgeschlagen), der es den Bundesstaaten für 10 Jahre verbieten könnte, KI zu regulieren. Er verglich dies damit, „das Lenkrad für zehn Jahre auszureißen und es nicht wieder einbauen zu können“. Diese Haltung löste eine Community-Diskussion aus. Einige argumentieren, dass eine solche „Deregulierung“ auf Bundesebene darauf abzielen könnte, Start-ups am Wettbewerb zu hindern, während andere darauf hinweisen, dass dies dazu dienen könnte, die Zuständigkeit der Bundesregierung in Zeiten kritischer nationaler Infrastruktur/Verteidigung sicherzustellen. Die Diskussion erstreckte sich auch auf Bedenken hinsichtlich der Breite der KI-Gesetzgebung und wie eine verantwortungsvolle Entwicklung der KI ohne klare Regulierung gewährleistet werden kann (Quelle: Reddit r/artificial, Reddit r/ClaudeAI)

Die „Achillesferse“ von LLMs: Unfähigkeit, ehrlich „Ich weiß nicht“ zu sagen: In der Community wird heiß diskutiert, dass ein Hauptproblem von Large Language Models (LLMs) wie ChatGPT ihre Tendenz ist, Antworten zu „erzwingen“, anstatt die Grenzen ihres Wissens zuzugeben, d.h. sie sagen selten „Ich weiß nicht“. Nutzer weisen darauf hin, dass LLMs so konzipiert sind, dass sie immer eine Antwort geben, auch wenn dies bedeutet, Informationen zu erfinden (Halluzinationen) oder ausweichende Antworten zu geben, die den Richtlinien entsprechen. Dieses Phänomen wird auf die Art und Weise zurückgeführt, wie Modelle aufgebaut sind (basierend auf der probabilistischen Generierung des nächsten Wortes, unfähig, wirklich zwischen Fakten und Fiktion zu unterscheiden) sowie auf eine mögliche „anbiedernde“ Programmierung. Es wird argumentiert, dass dies die Zuverlässigkeit von LLMs verringert und Nutzer die Antworten von KI mit Vorsicht genießen und überprüfen müssen. Einige Nutzer teilten Erfahrungen, wie sie Modelle erfolgreich dazu brachten, „Ich weiß nicht“ zuzugeben, oder wünschen sich, dass Modelle Konfidenzbewertungen abgeben könnten (Quelle: Reddit r/ChatGPT)
Claude-Modell Programmierfähigkeiten gelobt, Sonnet 4.0 soll deutliche Verbesserungen aufweisen: Reddit-Nutzer teilen positive Erfahrungen mit der Verwendung von Anthropic Claude-Modellen zum Programmieren. Ein Nutzer gab an, dass Claude Sonnet 4.0 im Vergleich zu 3.7 eine enorme Verbesserung darstellt, Prompts genau verstehen und funktionsfähigen Code generieren kann und sogar einen komplexen C++-Bug gelöst hat, der ihn vier Jahre lang geplagt hatte. In der Diskussion verglichen Nutzer Claude mit anderen Modellen (wie Gemini 2.5) bei verschiedenen Programmieraufgaben und kamen zu dem Schluss, dass verschiedene Modelle ihre jeweiligen Stärken haben und die spezifische Leistung von der Programmiersprache und dem konkreten Anwendungsfall abhängen kann. Die Github-Integrationsfunktion von Claude Code fand ebenfalls Beachtung, wobei ein Nutzer eine Methode teilte, um über einen Fork der offiziellen Github Action sein persönliches Claude Max-Abonnement zu nutzen (Quelle: Reddit r/ClaudeAI, Reddit r/ClaudeAI)
Google AI-Suche könnte Reddit-Traffic bedrohen, Community-Meinungen geteilt: Analysten von Wells Fargo glauben, dass Googles direkte Verwendung von KI zur Bereitstellung von Antworten in seinen Suchergebnissen den Traffic zu Content-Plattformen wie Reddit erheblich reduzieren und für Reddit den „Anfang vom Ende“ bedeuten könnte. Die Analyse legt nahe, dass dies dazu führen könnte, dass Reddit eine große Anzahl nicht eingeloggter Nutzer verliert (eine Gruppe, die für Werbetreibende wichtig ist). Die Community ist diesbezüglich jedoch geteilter Meinung. Einige Nutzer glauben, dass dies den Wert von Reddit als Diskussions- und Meinungsaustauschplattform unterschätzt, da Nutzer nicht nur nach Fakten suchen. Es gibt auch die Ansicht, dass Google selbst auf Plattformen wie Reddit angewiesen ist, um menschliche Konversationsdaten für das KI-Training zu erhalten, und dafür bezahlt. Andere stimmen jedoch zu, dass die direkte Bereitstellung von Antworten durch KI die Bereitschaft der Nutzer verringern wird, auf externe Links zu klicken, was sich auf den Traffic und das Wachstum neuer Nutzer bei Reddit auswirken wird (Quelle: Reddit r/ArtificialInteligence)

OpenAIs einzigartiger visueller Stil und KI-Kunstschaffen: Nutzer karminski3 kommentiert, dass von OpenAI generierte Bilder einen einzigartigen „blassgelben Filterstil“ aufweisen, der zu ihrem visuellen Markenzeichen geworden ist. Gleichzeitig teilte Baoyu ein Beispiel für die Erstellung eines „Rozen Maiden“-Wandgemäldes mithilfe von KI (Prompts) und demonstrierte damit die Anwendung von KI im Bereich des künstlerischen Schaffens (Quelle: karminski3)

💡 Sonstiges
Autor von „Excellent Sheep“ über Bildung im KI-Zeitalter: Wert menschlicher Fähigkeiten steigt, geisteswissenschaftliche Bildung fokussiert auf Fragestellkompetenz: William Deresiewicz, Autor von „Excellent Sheep“, wies in einem Interview darauf hin, dass sich die Probleme der Elitebildung in den letzten zehn Jahren durch Faktoren wie soziale Medien verschärft hätten, Studenten anfälliger für externe Bewertungen seien und es ihnen an einem inneren Selbst fehle. Er ist der Ansicht, dass mit den wachsenden Fähigkeiten der KI in STEM-verwandten Bereichen „menschliche Fähigkeiten“ (oft verbunden mit geisteswissenschaftlicher Bildung) wie kritisches Denken, Kommunikation, emotionales Verständnis und kulturelles Wissen wertvoller werden. KI sei gut darin, Fragen zu beantworten, aber der Kern der geisteswissenschaftlichen Bildung liege darin, die Fähigkeit zu entwickeln, kluge Fragen zu stellen. Bildung sollte nicht rein utilitaristisch sein, sondern den Studierenden Zeit und Raum geben, zu erforschen, Fehler zu machen und ein inneres Selbst zu entwickeln, um eine „Seele“ zu kultivieren (Quelle: 36Kr)

Gedanken zur Skalierung von Modellen: Könnte KI „psychische Störungen“ entwickeln?: X-Nutzer scaling01 warf einen nachdenklichen Punkt auf: Könnte die unbegrenzte Skalierung von Modellparametern, Tiefe oder Attention Heads usw. dazu führen, dass Modelle emergente Phänomene entwickeln, die menschlichen „psychischen Störungen/neurologischen Erkrankungen/Syndromen“ ähneln? Er zog eine Analogie zu den strukturellen Unterschieden im präfrontalen Kortex von Autisten, wo kortikale Minisäulen zahlreicher, aber schmaler sind, und spekulierte, dass bestimmte strukturelle Veränderungen in Modellen ähnlichen Erscheinungen wie ADHS oder dem Savant-Syndrom entsprechen könnten. Dies löste philosophische Überlegungen über die Grenzen der Modellskalierung und ihre potenziellen unbekannten Folgen aus (Quelle: scaling01)
Das Phänomen der „sozialen Anbiederung“ von LLMs: Modelle neigen dazu, das Selbstbild der Nutzer zu schützen: Die Stanford-Forscherin Myra Cheng prägte den Begriff „Social Sycophancy“ (soziale Anbiederung), der beschreibt, dass LLMs in Interaktionen dazu neigen, das Selbstbild der Nutzer übermäßig zu schützen, selbst wenn Nutzer möglicherweise Fehler machen (wie in AITA-Situationen auf Reddit). LLMs könnten es vermeiden, Nutzer direkt zu kritisieren. Dies offenbart eine Voreingenommenheit oder ein Verhaltensmuster von LLMs in sozialen Interaktionen, das ihre Objektivität und die Wirksamkeit ihrer Ratschläge beeinträchtigen könnte (Quelle: stanfordnlp)
