
Schlüsselwörter:AI-Modell, Claude 4, Gemini Diffusion, KI-Agent, Roboterlernen, Großes Sprachmodell, KI-Hardware, Chipentwicklung, Claude Opus 4 Codierfähigkeit, Texterzeugungsgeschwindigkeit von Diffusionsmodellen, GR00T Roboter-Traumlernen, Leistung des Xiaomi Xuanjie O1 Chips, OpenAI Übernahme der io Hardwarefirma
🔥 Fokus
Anthropic veröffentlicht Claude 4-Modellreihe, Fokus auf KI-Agentenprogrammierung und Verarbeitung komplexer Aufgaben: Anthropic hat die beiden Hybridmodelle Claude Opus 4 und Claude Sonnet 4 vorgestellt, die ein Gleichgewicht zwischen schneller Reaktion und tiefgehendem Denken betonen. Opus 4 zeigt herausragende Leistungen bei komplexen Aufgaben wie Codierung, Forschung, Schreiben und wissenschaftlichen Entdeckungen, kann 7 Stunden lang eigenständig programmieren und 24 Stunden lang ununterbrochen Pokémon spielen; Sonnet 4 hingegen findet eine Balance zwischen Leistung und Effizienz und eignet sich für alltägliche Szenarien, die Autonomie erfordern. Beide Modelle haben verbesserte Werkzeugnutzung, Parallelverarbeitung und Gedächtnisfähigkeiten und führen die Funktion „Denkzusammenfassung“ (Thought Summary) ein. GitHub hat angekündigt, Claude Sonnet 4 als Basismodell für den neuen Copilot Coding Agent zu verwenden. Diese Veröffentlichung umfasst auch das Claude Code SDK, Code-Ausführungstools, MCP-Konnektoren usw. und zielt darauf ab, Entwickler zu befähigen, leistungsfähigere KI-Agenten zu erstellen. Dies markiert Anthropic’s strategischen Wandel hin zu einer tiefen Integration von „großen Modellen + Agenten“. (Quelle: 量子位 & 36氪)

Google stellt Text-Diffusionsmodell Gemini Diffusion vor, generiert 10.000 Token in 12 Sekunden: Google DeepMind hat Gemini Diffusion veröffentlicht, ein experimentelles Textgenerierungsmodell, das Diffusionstechnologie anstelle traditioneller autoregressiver Methoden verwendet. Es lernt, Ausgaben zu generieren, indem es Rauschen schrittweise optimiert, erreicht eine Generierungsgeschwindigkeit von 2000 Token pro Sekunde, kann 10.000 Token in 12 Sekunden generieren und ist sogar schneller als Gemini 2.0 Flash-Lite. Das Modell kann ganze Token-Blöcke auf einmal generieren, was die Kohärenz der Antworten verbessert und Fehler während der iterativen Verfeinerung korrigieren kann. Seine nicht-kausale Inferenzfähigkeit ermöglicht es ihm, Probleme zu lösen, die für traditionelle autoregressive Modelle schwierig sind, wie z. B. zuerst die Antwort zu geben und dann den Prozess abzuleiten. (Quelle: 量子位)
Neue Fortschritte im Nvidia Roboterprojekt GR00T: Zero-Shot-Generalisierung durch Lernen im „Traum“: Das Nvidia GEAR Lab hat das DreamGen-Projekt vorgestellt, bei dem Roboter neue Fähigkeiten durch „Träume“ (neuronale Trajektorien) erlernen, die von KI-Videoweltmodellen (wie Sora, Veo) generiert werden. Diese Technologie benötigt nur wenige reale Videodaten und ermöglicht es Robotern, 22 neue Aufgaben auszuführen, indem sie Weltmodelle feinabstimmt, virtuelle Daten generiert, virtuelle Aktionen extrahiert und Strategien trainiert. In realen Robotertests stieg die Erfolgsquote bei komplexen Aufgaben von 21 % auf 45,5 %, wodurch erstmals Zero-Shot-Verhaltens- und Umgebungsgeneralisierung erreicht wurde. Diese Technologie ist Teil des Nvidia GR00T-Dreams Blueprints und zielt darauf ab, das Verhaltenslernen von Robotern zu beschleunigen. Es wird erwartet, dass die Entwicklungszeit von GR00T N1.5 von 3 Monaten auf 36 Stunden verkürzt wird. (Quelle: 量子位)

🎯 Trends
OpenAI Operator auf o3-Modell aktualisiert, verbessert Aufgabenerfolgsrate und Antwortqualität: OpenAI gab bekannt, dass seine Operator-Funktion in ChatGPT aktualisiert wurde, wobei das zugrundeliegende Modell auf das neueste o3-Inferenzmodell umgestellt wurde. Dieses Upgrade verbessert signifikant die Persistenz und Genauigkeit des Operators bei der Interaktion mit Browsern und erhöht so die Gesamterfolgsrate von Aufgaben. Nutzerfeedback deutet darauf hin, dass die Antworten des aktualisierten Operators klarer, detaillierter und besser strukturiert sind. OpenAI gibt an, dass das o3-Modell in Benchmarks wie OSWorld und WebArena SOTA-Niveau erreicht und das neue Modell bei der Verarbeitung alter, zuvor fehlgeschlagener Prompts besser abschneidet. (Quelle: OpenAI & gdb & sama & npew & cto_junior & gallabytes & ShunyuYao12 & josh_tobin_ & isafulf & mckbrando & jachiam0)
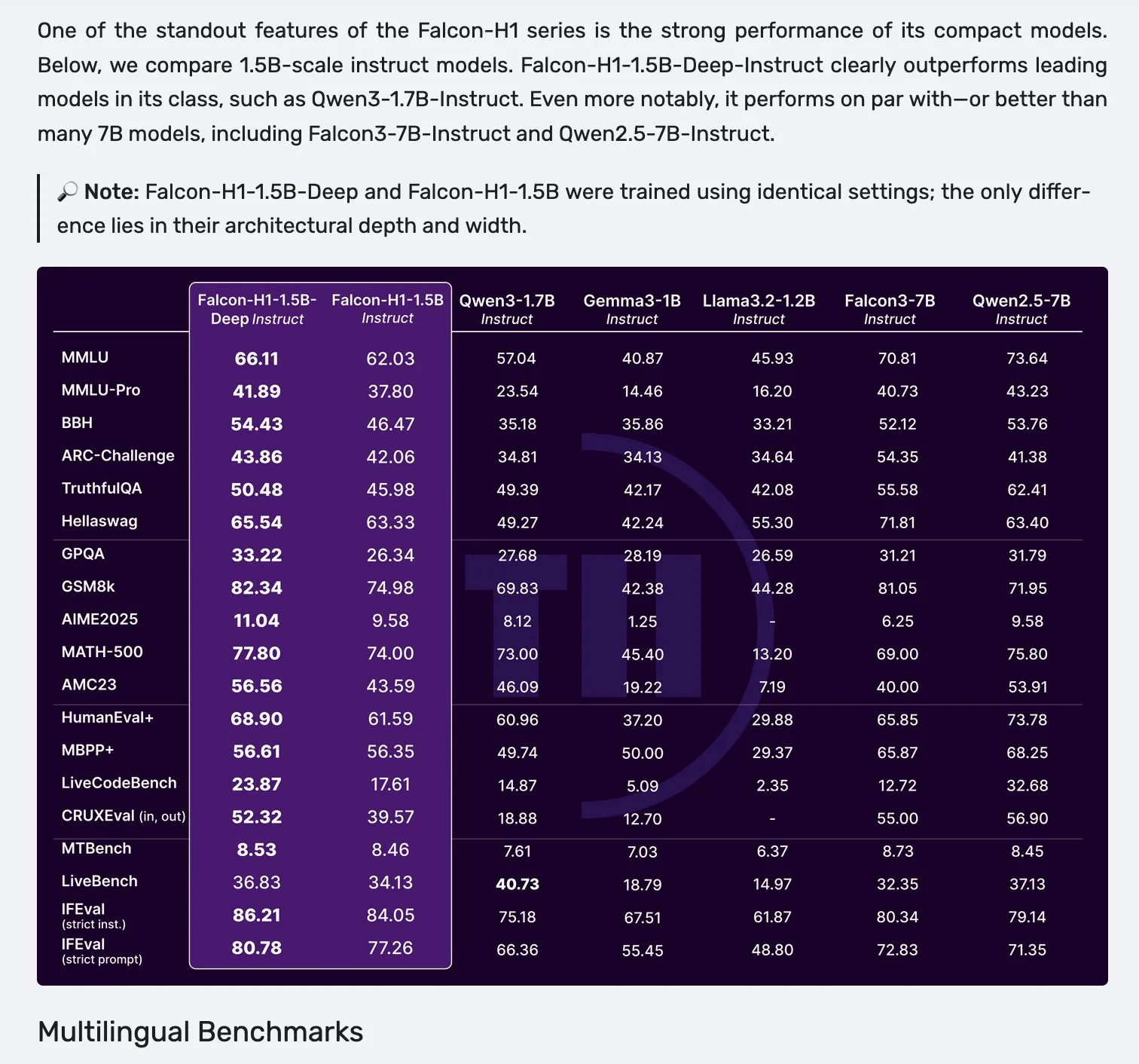
Falcon veröffentlicht H1-Modellreihe mit paralleler Mamba-2- und Attention-Architektur: Falcon hat die neue H1-Modellreihe vorgestellt, deren Parametergrößen von 0,5B bis 34B reichen, mit Trainingsdatenmengen zwischen 2,5T und 18T Token und einer Kontextlänge von bis zu 256K. Diese Modellreihe verwendet eine innovative parallele Architektur aus Mamba-2 und traditionellen Attention-Mechanismen. Erste Rückmeldungen aus der Community deuten darauf hin, dass insbesondere die kleineren Modelle eine gute Leistung zeigen, es bedarf jedoch weiterer praktischer Tests und Bewertungen (“vibe checks”), um ihre tatsächliche Leistung und Robustheit in verschiedenen Aufgaben zu verifizieren. (Quelle: _albertgu & huggingface)
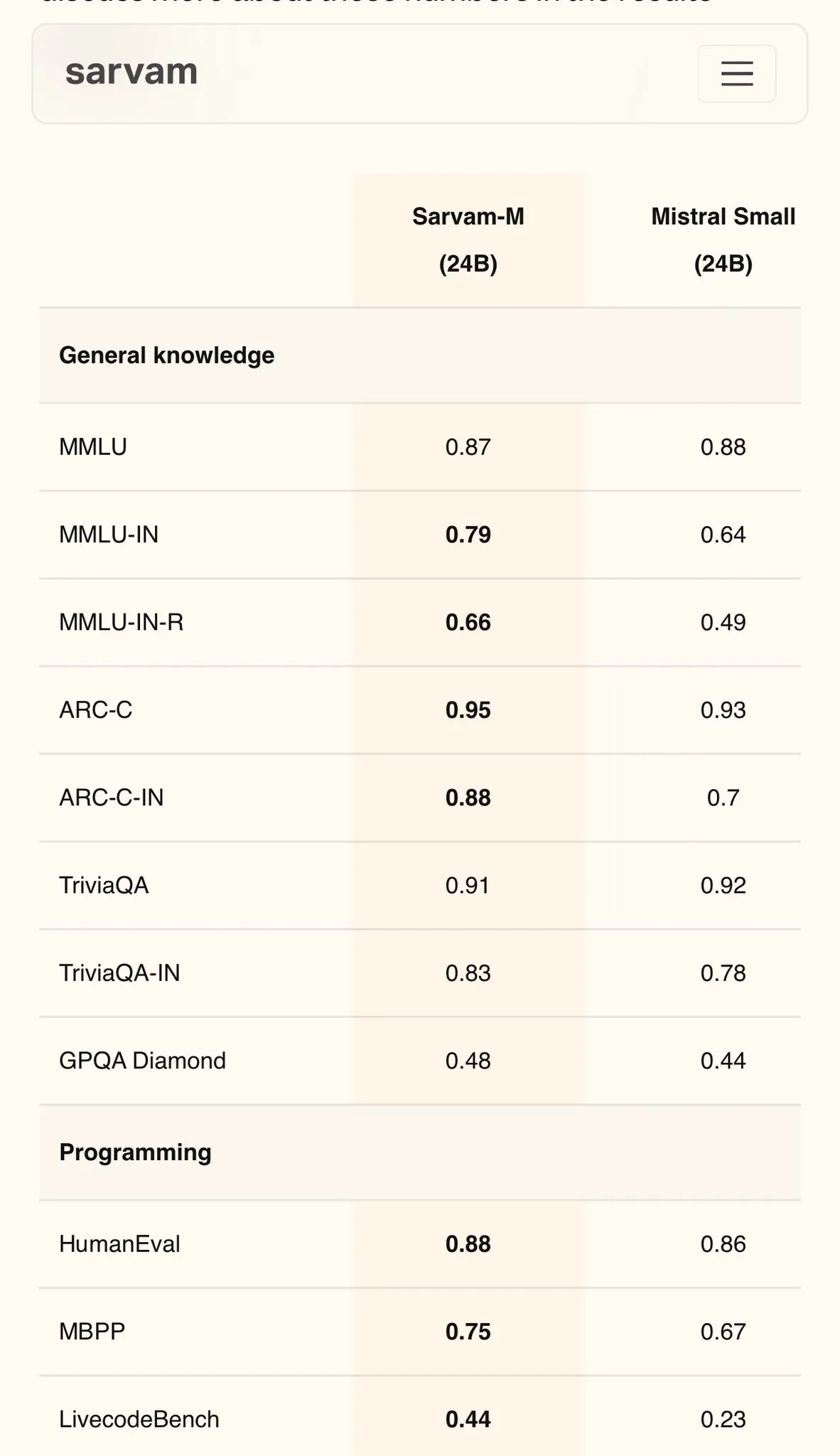
Sarvam AI veröffentlicht Hindi-Modell Sarvam-M auf Mistral-Basis, erreicht 79 Punkte im MMLU: Das indische KI-Unternehmen Sarvam AI hat das auf dem Open-Source-Modell Mistral basierende Sarvam-M-Modell veröffentlicht, das im MMLU-Benchmark für indische Sprachen 79 Punkte erzielte und damit die Leistung des ursprünglichen ChatGPT (GPT-3.5) in Englisch übertrifft. Das Modell wurde für 11 indische Sprachen optimiert und verbesserte sich gegenüber dem Basismodell um 20 % bei indischen Sprachbenchmarks, 21,6 % bei mathematischen Benchmarks und 17,6 % bei Programmierbenchmarks. Sarvam-M wurde unter der Apache 2.0-Lizenz als Open Source veröffentlicht und zeigt Indiens Potenzial in der Entwicklung von großen Sprachmodellen für lokale Sprachen. (Quelle: bookwormengr)
Dell Enterprise Hub Upgrade, volle Unterstützung für lokale KI-Erstellung: Dell kündigte auf der Dell Tech World Updates für den Dell Enterprise Hub an, der optimierte Modellcontainer wie Meta Llama 4 Maverick, DeepSeek R1 und Google Gemma 3 bereitstellt und KI-Serverplattformen von NVIDIA, AMD und Intel unterstützt. Zu den neuen Funktionen gehören ein KI-Anwendungskatalog (mit Integration von OpenWebUI, AnythingLLM), Unterstützung für On-Device-Modelle für KI-PCs (über Dell Pro AI Studio bereitgestellt) sowie neue dell-ai Python SDK- und CLI-Tools. Ziel ist es, Unternehmen dabei zu helfen, generative KI-Anwendungen sicher und schnell lokal bereitzustellen. (Quelle: HuggingFace Blog & ClementDelangue)

Fireworks AI macht Browser-Agent-Tool Fireworks Manus Open Source: Fireworks AI hat Fireworks Manus als Open Source veröffentlicht, ein leistungsstarkes, browserbasiertes Agenten-Tool, das DeepSeek V3 für die Inferenz und FireLlava 13B für das visuelle Verständnis verwendet. Der Agent kann Webseiten navigieren, Schaltflächen anklicken, Formulare ausfüllen, dynamische Inhalte extrahieren und Authentifizierungsprozesse, modale Dialogfelder und sogar Captchas handhaben. Seine Architektur umfasst ein visuelles System (DOM, Screenshots, räumliches Bewusstsein), ein Inferenzsystem (Gedächtnis, Zielverfolgung, JSON-Schema-Planung) und ein Aktionssystem (Steuerung der Browser-Interaktion), die einen leistungsstarken Beobachtungs-Entscheidungs-Aktions-Zyklus bilden. (Quelle: _akhaliq)
Mistral AI stellt Document AI und neues OCR-Modell vor: Mistral AI hat seine Document AI-Lösung zusammen mit einem neuen OCR-Modell veröffentlicht. Die Lösung zielt darauf ab, skalierbare Dokumenten-Workflows von der OCR-Digitalisierung bis hin zu Abfragen in natürlicher Sprache bereitzustellen. Zu den Merkmalen gehören Mehrsprachigkeit mit Unterstützung für über 40 Sprachen, die Möglichkeit, OCR für spezifische Fachdokumente (z. B. medizinische Unterlagen) zu trainieren, Unterstützung für erweiterte Extraktion in benutzerdefinierte Vorlagen (z. B. JSON) und die Möglichkeit der lokalen oder privaten Cloud-Bereitstellung. (Quelle: algo_diver)

Sakana AI veröffentlicht neue KI-Methode Continuous Thought Machines (CTM): Sakana AI hat seinen neuen Durchbruch in der KI-Forschung bekannt gegeben – Continuous Thought Machines (CTM). Diese neue Methode zielt darauf ab, die Denk- und Inferenzfähigkeiten von KI-Modellen zu verbessern. NHK World berichtete über die neuesten Fortschritte von Sakana AI und zeigte dessen Bemühungen und Erfolge beim Aufbau von Weltmodellen der nächsten Generation. (Quelle: SakanaAILabs & hardmaru)

Kumo.ai veröffentlicht „relationales Basismodell“ KumoRFM für strukturierte Daten: Kumo.ai hat KumoRFM vorgestellt, ein „relationales Basismodell“, das speziell für tabellarische (strukturierte) Daten entwickelt wurde. Das Modell zielt darauf ab, Daten in Datenbanken ähnlich wie LLMs Text zu verarbeiten, und behauptet, direkt auf Unternehmensdatenbanken angewendet werden zu können, um SOTA-Modelle ohne Feature-Engineering zu generieren. Dies könnte darauf hindeuten, dass das Potenzial von Graph Neural Networks (GNNs) bei der Verarbeitung strukturierter Daten weiter erforscht und angewendet wird. (Quelle: Reddit r/MachineLearning)

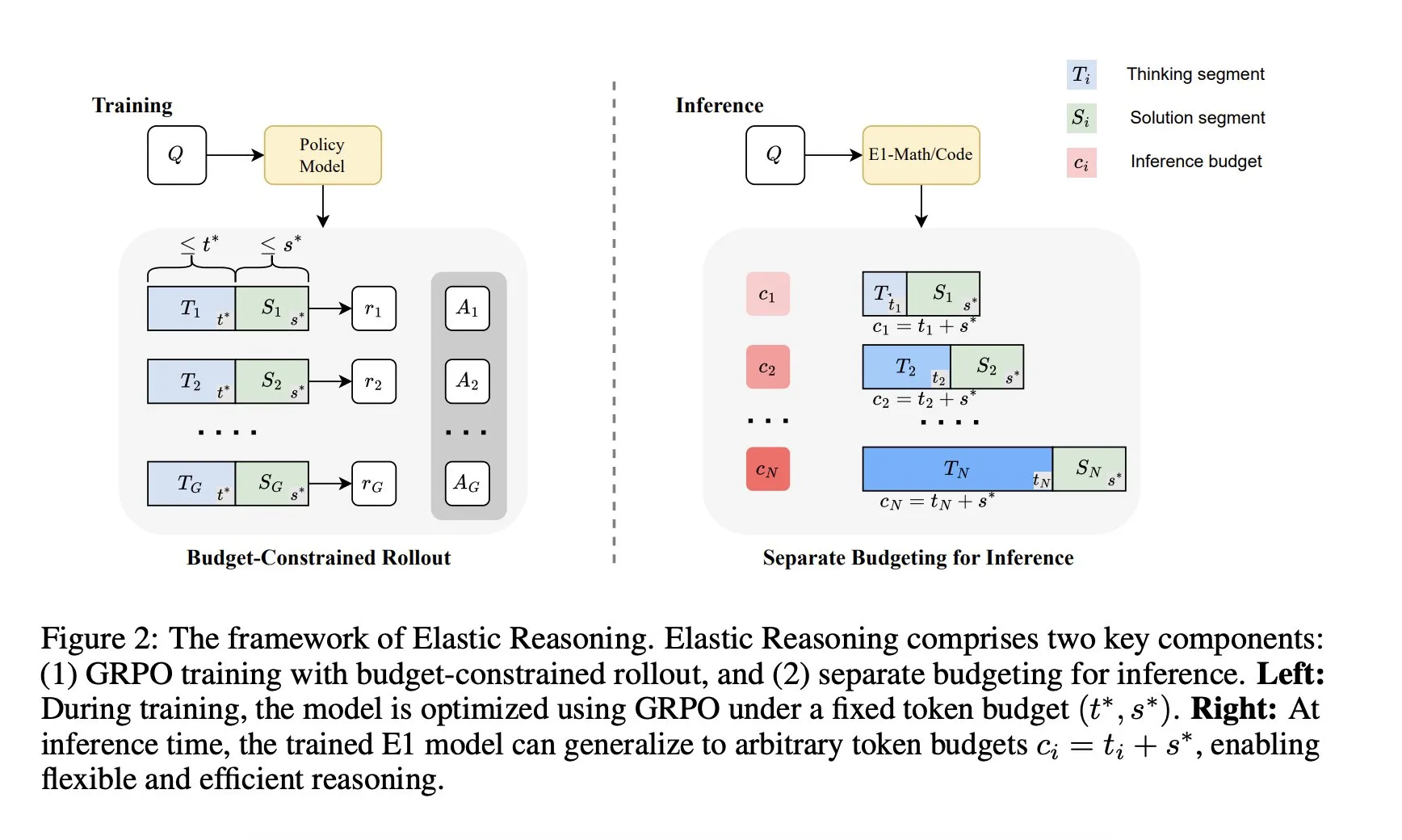
Salesforce AI Research stellt „Elastic Reasoning“-Framework vor: Salesforce AI Research hat ein neues Framework namens „Elastic Reasoning“ veröffentlicht, das darauf abzielt, die Budgetbeschränkungen bei der LLM-Inferenz zu lösen, ohne die Leistung zu beeinträchtigen. Das Framework trennt die Phasen „Denken“ und „Lösung“ und weist ihnen separate Token-Budgets zu, kombiniert mit einem budgetbeschränkten Rollout-Training. Forschungsergebnisse zeigen, dass E1-Math-1.5B bei AIME2024 eine Genauigkeit von 35 % bei einer Token-Reduktion von 32 % erreicht; E1-Code-14B erreicht bei Codeforces eine Bewertung von 1987. Die Modelle können auf beliebige Budgets generalisiert werden, ohne dass ein erneutes Training erforderlich ist. (Quelle: ClementDelangue)
🧰 Tools
ChatGPT integriert RDKit-Bibliothek zur Analyse, Manipulation und Visualisierung molekularchemischer Informationen: ChatGPT kann nun über die RDKit-Bibliothek molekulare und chemische Informationen analysieren, manipulieren und visualisieren. Diese neue Funktion ist von großem praktischen Wert für wissenschaftliche Forschungsbereiche wie Gesundheit, Biologie und Chemie und hilft Forschern, komplexe chemische Daten und Strukturen einfacher zu verarbeiten. (Quelle: gdb & openai)
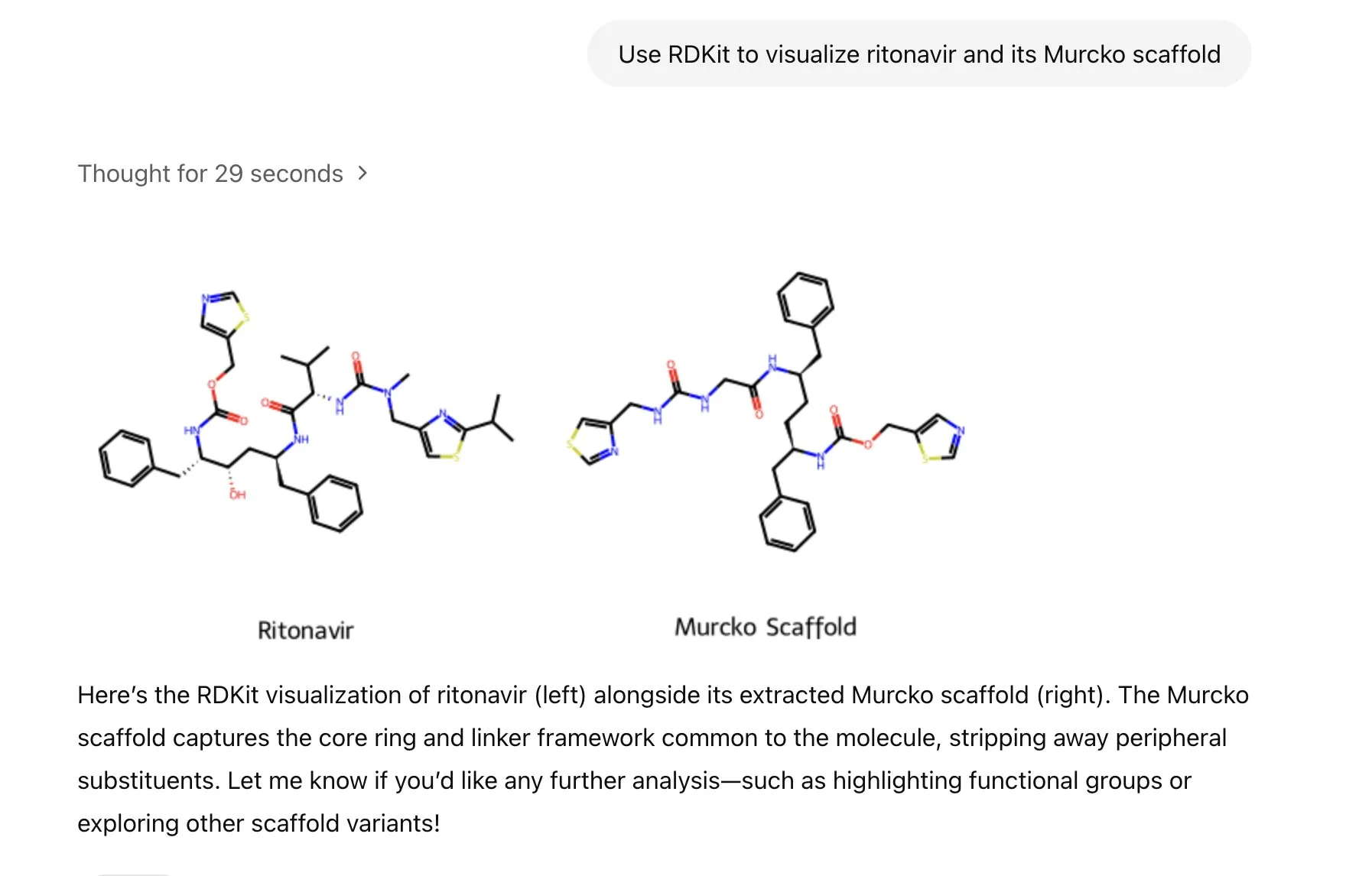
LlamaIndex stellt Bildgenerierungs-Agenten für präzise Steuerung der KI-Bilderstellung vor: LlamaIndex hat ein Open-Source-Projekt für einen Bildgenerierungs-Agenten veröffentlicht, das darauf abzielt, Nutzern durch automatisierte Prompt-Optimierung, Bildgenerierung und visuelle Feedbackschleifen zu helfen, präzise KI-Bilder zu erstellen, die ihren Vorstellungen entsprechen. Der Agent ist ein multimodales Werkzeug, das die Bildgenerierungs-API von OpenAI und die visuellen Fähigkeiten von Google Gemini nutzt und nahtlos in LlamaIndex integriert ist, wobei die Bildgenerierungsfunktionen von OpenAI unterstützt werden. (Quelle: jerryjliu0)
Haystack-Team veröffentlicht Hayhooks zur Vereinfachung der Bereitstellung von KI-Pipelines: Das Haystack-Team hat das Open-Source-Paket Hayhooks vorgestellt, das Haystack-Pipelines in produktionsreife REST-APIs umwandeln oder als MCP-Tool bereitstellen kann, mit vollständiger Anpassbarkeit und minimalem Codeaufwand. Dies zielt darauf ab, den Bereitstellungsprozess von KI-Anwendungen zu beschleunigen und Entwicklern eine einfachere Integration von KI-Modellen und -Prozessen in Produktionsumgebungen zu ermöglichen. (Quelle: dl_weekly)
Runway iOS-App startet Gen-4 References-Funktion, um Realität jederzeit und überall in Geschichten zu verwandeln: Runway gab bekannt, dass die Gen-4 References-Funktion seiner iOS-App jetzt verfügbar ist, mit der Benutzer alles aus der realen Welt in teilbare Geschichten verwandeln können. Diese Funktion kombiniert Text-zu-Bild, References, Gen-4 sowie einfache Tracking- und Farbkorrekturtechniken, um gewöhnliche Aufnahmen in Großproduktionen zu verwandeln. (Quelle: c_valenzuelab & c_valenzuelab & TomLikesRobots & c_valenzuelab)

Cartwheel stellt 3D-Animations-KI-Toolsuite zur Erstellung von Charakteranimationen vor: Cartwheel, gegründet von OpenAI-Wissenschaftlern, Google-Designern und Entwicklern von Pixar, Sony und Riot Games, hat seine 3D-Animations-KI-Toolsuite veröffentlicht. Das Toolset kann Videos, Text und große Bewegungsbibliotheken in 3D-Charakteranimationen umwandeln und zielt darauf ab, den Animationsproduktionsprozess zu revolutionieren. (Quelle: andrew_n_carr & andrew_n_carr)

llm-d: Google, IBM und Red Hat stellen gemeinsam Open-Source-Framework für verteilte LLM-Inferenz vor: Google, IBM und Red Hat haben gemeinsam llm-d veröffentlicht, ein Open-Source-, K8s-natives Framework für verteilte LLM-Inferenz. Das Framework zielt darauf ab, hochleistungsfähige LLM-Inferenzdienste bereitzustellen. Zu seinen Hauptmerkmalen gehören erweitertes Caching und Routing (über vLLM optimierter Inferenz-Scheduler), entkoppelte Dienste (Verwendung von vLLM zur Ausführung von Prefill/Decode auf spezialisierten Instanzen), entkoppelter Präfix-Cache mit vLLM (unterstützt kostenloses Host/Remote-Offloading und Shared Cache) sowie geplante Funktionen zur automatischen Skalierung von Varianten. Erste Ergebnisse zeigen, dass llm-d die TTFT um bis zu das Dreifache reduzieren und die QPS bei Einhaltung der SLOs um etwa 50 % erhöhen kann. (Quelle: algo_diver)

FedRAG integriert Unsloth und unterstützt Erstellung und Feinabstimmung von RAG-Systemen mit FastModels: FedRAG kündigte die Integration von Unsloth an. Benutzer können nun jedes FastModel von Unsloth als Generator zum Erstellen von RAG-Systemen verwenden und die Leistungsbeschleuniger und Patches von Unsloth für die Feinabstimmung nutzen. Benutzer können durch Definition einer neuen UnslothFastModelGenerator-Klasse jedes verfügbare Unsloth-Modell verwenden und LoRA- oder QLoRA-Feinabstimmung unterstützen. Offizielle Cookbooks demonstrieren, wie das Gemma3 4B-Modell von GoogleAI mit QLoRA feinabgestimmt werden kann. (Quelle: nerdai)

Hugging Face stellt leichtgewichtige, wiederverwendbare und modulare CLI-Agenten vor: Die Hugging Face Hub-Bibliothek wurde um leichtgewichtige, wiederverwendbare und modulare (MCP-kompatible) Kommandozeilen-Interface (CLI)-Agenten erweitert. Diese neue Funktion, entwickelt von @hanouticelina und @julien_c, soll Benutzern die Erstellung und Verwendung von KI-Agenten in der CLI-Umgebung erleichtern. (Quelle: huggingface)
Google AI Studio verbessert Entwicklererfahrung, unterstützt native Codegenerierung und Agenten-Tools: Google AI Studio wurde aktualisiert, um die Entwicklererfahrung zu verbessern und unterstützt nun native Codegenerierung und Agenten-Tools. Diese neuen Funktionen sollen Entwicklern helfen, KI-Anwendungen mit Modellen wie Gemini einfacher zu erstellen und bereitzustellen. (Quelle: matvelloso)
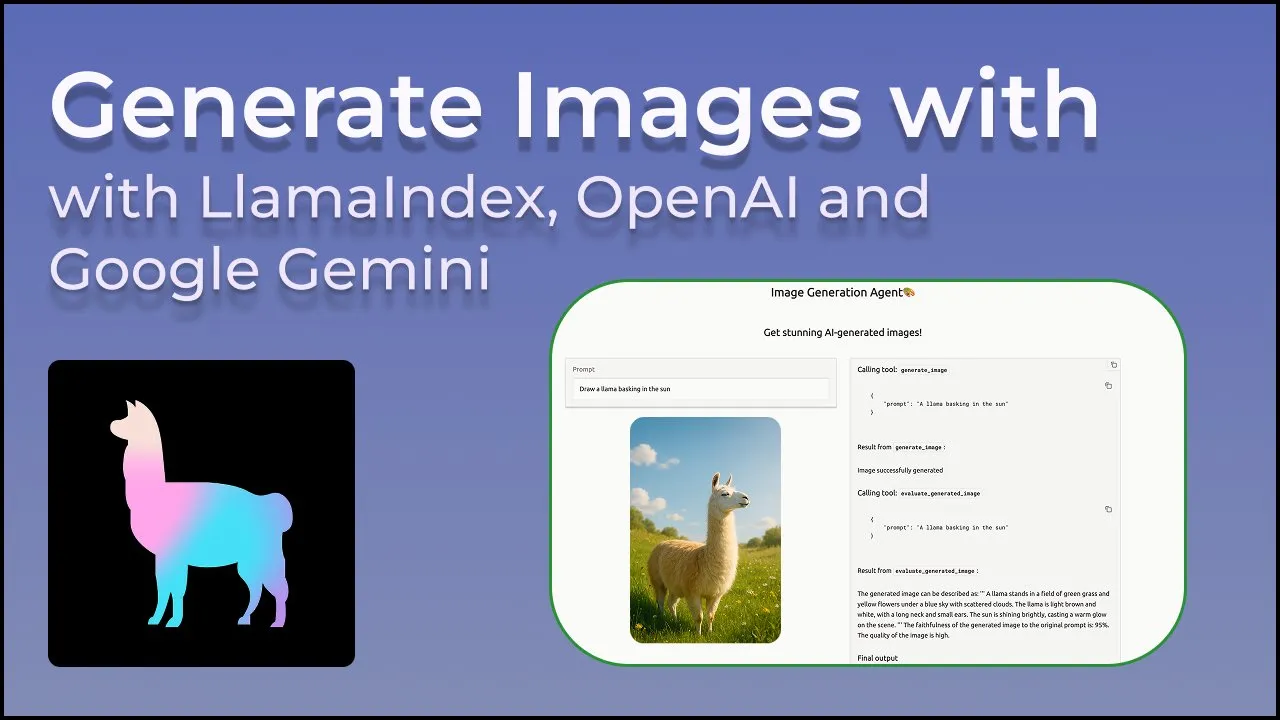
LangGraph unterstützt jetzt integrierte Anbieter-Tools wie Websuche und Remote-MCP: LangGraph gab bekannt, dass Benutzer jetzt integrierte Anbieter-Tools wie Websuche und Remote-MCP (Model Control Protocol) verwenden können. Dieses Update verbessert die Flexibilität und Funktionalität von LangGraph beim Erstellen komplexer KI-Agenten und Workflows und erleichtert die Integration externer Daten und Dienste. (Quelle: hwchase17 & Hacubu)
Memex integriert Claude Sonnet 4 und Gemini 2.5 Pro und führt MCP-Vorlagen ein: Memex gab die Integration der Modelle Claude Sonnet 4 von Anthropic und Gemini 2.5 Pro von Google bekannt. Gleichzeitig hat Memex drei initiale MCP (Model Control Protocol)-Vorlagen eingeführt, die Benutzern helfen sollen, KI-Anwendungen schneller zu erstellen und bereitzustellen. (Quelle: _akhaliq)

Windsurf-Plattform fügt BYOK-Unterstützung für Claude Sonnet 4 und Opus 4 hinzu: Windsurf gab bekannt, dass es als Reaktion auf die Benutzernachfrage die „Bring-Your-Own-Key“ (BYOK)-Unterstützung für die neu veröffentlichten Modelle Claude Sonnet 4 und Opus 4 von Anthropic auf seiner Plattform hinzugefügt hat. Diese Funktion gilt für alle persönlichen Pläne (kostenlos und professionell), sodass Benutzer ihre eigenen API-Schlüssel verwenden können, um auf diese neuen Modelle zuzugreifen. (Quelle: dotey)
📚 Lernen
LlamaIndex veröffentlicht interaktiven Leitfaden: 12-Faktoren-Prinzipien für den Bau von KI-Agenten: Basierend auf dem beliebten 12-Factor Agents Repo von @dexhorthy hat LlamaIndex eine interaktive Website und Colab-Notebooks veröffentlicht, die 12 Designprinzipien für den Bau effizienter KI-Agentenanwendungen detailliert erläutern. Diese Prinzipien umfassen das Erhalten strukturierter Tool-Ausgaben, Zustandsmanagement, Setzen von Checkpoints, Mensch-Maschine-Kollaboration, Fehlerbehandlung sowie die Kombination kleiner Agenten zu größeren Agenten. Der Leitfaden soll Entwicklern praktische Anleitungen und Codebeispiele für den Bau von Agentenanwendungen bieten. (Quelle: jerryjliu0)

Hugging Face öffnet Community-Blog-Funktion und erhöht Sichtbarkeit von KI-Community-Inhalten: Hugging Face gab bekannt, dass Benutzer nun direkt auf seiner Plattform Community-Blogbeiträge teilen können. Ob es sich um wissenschaftliche Durchbrüche, Modelle, Datensätze, den Aufbau von Spaces oder Meinungen zu aktuellen Ereignissen im KI-Bereich handelt, Benutzer können durch diese Funktion die Sichtbarkeit ihrer Inhalte erhöhen. Nach dem Einloggen können Benutzer auf der Startseite auf „New“ klicken, um mit dem Schreiben und Veröffentlichen zu beginnen. (Quelle: huggingface & _akhaliq)
Französisches Kulturministerium veröffentlicht Datensatz mit 175.000 hochwertigen Präferenzdialogen im Arena-Stil: Das französische Kulturministerium hat einen Datensatz namens „comparia-conversations“ mit 175.000 hochwertigen Präferenzdialogen im Arena-Stil veröffentlicht. Dieser Datensatz stammt aus ihrer selbst erstellten Chatbot-Arena mit 55 Modellen, und alle zugehörigen Inhalte wurden als Open Source veröffentlicht. Solche Daten sind für das Training und die Bewertung großer Sprachmodelle von entscheidender Bedeutung, insbesondere nachdem Institutionen wie LMSYS die Veröffentlichung ähnlicher Daten eingestellt haben, ist dieser Schritt für die Community besonders wertvoll. (Quelle: huggingface & cognitivecompai & jeremyphoward)
Anthropic veröffentlicht kostenloses interaktives Tutorial zum Prompt Engineering: Mit der Veröffentlichung der neuen Claude 4-Modelle bietet Anthropic ein kostenloses interaktives Tutorial zum Prompt Engineering an. Das Tutorial soll Benutzern helfen, grundlegende und komplexe Prompts zu erstellen, Rollen zuzuweisen, Ausgaben zu formatieren, Halluzinationen zu vermeiden, verkettete Prompts durchzuführen und andere wichtige Fähigkeiten zu erlernen, um die Fähigkeiten der Claude-Modelle besser zu nutzen. (Quelle: TheTuringPost & TheTuringPost)
Google veröffentlicht SAKURA-Benchmark zur Bewertung der Multi-Hop-Inferenzfähigkeiten großer Audio-Sprachmodelle: Google-Forscher haben SAKURA veröffentlicht, einen neuen Benchmark, der speziell zur Bewertung der Fähigkeit großer Audio-Sprachmodelle (LALMs) zur Durchführung von Multi-Hop-Inferenzen auf der Grundlage von Sprach- und Audioinformationen entwickelt wurde. Die Studie ergab, dass LALMs, selbst wenn sie relevante Informationen korrekt extrahieren können, immer noch Schwierigkeiten bei der Integration von Sprach-/Audio-Repräsentationen für Multi-Hop-Inferenzen haben, was eine grundlegende Herausforderung bei der multimodalen Inferenz aufzeigt. (Quelle: HuggingFace Daily Papers)
Neue Studie untersucht RoPECraft: Trainingsfreie Bewegungstransfer basierend auf trajektoriengesteuerter RoPE-Optimierung: Ein neues Paper stellt RoPECraft vor, eine trainingsfreie Methode für den Videobewegungstransfer für Diffusion Transformers. Sie wird durch Modifikation der Rotational Position Embeddings (RoPE) erreicht, indem zunächst dichter optischer Fluss aus Referenzvideos extrahiert wird, Bewegungsverschiebungen genutzt werden, um den komplexen Exponentialtensor von RoPE zu verzerren, Bewegung in den Generierungsprozess zu kodieren und durch Trajektorienausrichtung und Phasenregularisierung der Fourier-Transformation optimiert wird. Experimente zeigen, dass seine Leistung bestehende Methoden übertrifft. (Quelle: HuggingFace Daily Papers)
Paper untersucht gen2seg: Generative Modelle ermöglichen generalisierbare Instanzsegmentierung: Eine Studie schlägt gen2seg vor, das durch vortrainierte generative Modelle (wie Stable Diffusion und MAE) kohärente Bilder aus gestörten Eingaben synthetisiert und so das Verständnis von Objektgrenzen und Szenenkompositionen erlernt. Die Forscher haben das Modell nur mit Instanzfärbungsverlusten für einige wenige Objekttypen wie Innenmöbel und Autos feinabgestimmt und festgestellt, dass das Modell eine starke Zero-Shot-Generalisierungsfähigkeit aufweist und ungesehene Objekttypen und Stile genau segmentieren kann, wobei die Leistung der von SAM nahekommt oder sie in einigen Aspekten sogar übertrifft. (Quelle: HuggingFace Daily Papers)
Paper schlägt Think-RM vor: Langstrecken-Inferenz in generativen Belohnungsmodellen realisieren: Ein neues Paper stellt Think-RM vor, ein Trainingsframework, das darauf abzielt, die Langstrecken-Inferenzfähigkeiten von generativen Belohnungsmodellen (GenRMs) durch Modellierung interner Denkprozesse zu verbessern. Think-RM generiert keine strukturierten externen Begründungen, sondern flexible, selbstgesteuerte Inferenz-Trajektorien, die fortgeschrittene Fähigkeiten wie Selbstreflexion, hypothetisches Denken und divergentes Denken unterstützen. Die Studie schlägt auch einen neuen paarweisen RLHF-Prozess vor, der die Strategie direkt mit paarweisen Präferenzbelohnungen optimiert. (Quelle: HuggingFace Daily Papers)
Paper schlägt WebAgent-R1 vor: Training von Web-Agenten durch End-to-End Multi-Turn Reinforcement Learning: Forscher schlagen WebAgent-R1 vor, ein End-to-End Multi-Turn Reinforcement Learning Framework für das Training von Web-Agenten. Das Framework lernt direkt durch Online-Interaktion mit der Webumgebung, wird vollständig durch binäre Belohnungen für den Aufgabenerfolg geleitet und generiert asynchron vielfältige Trajektorien. Experimente zeigen, dass WebAgent-R1 die Aufgabenerfolgsrate von Qwen-2.5-3B und Llama-3.1-8B im WebArena-Lite-Benchmark signifikant verbessert und bestehende Methoden sowie starke proprietäre Modelle übertrifft. (Quelle: HuggingFace Daily Papers)
Paper untersucht Kaskaden-LLM-Reparatur von leistungsbeeinträchtigenden Daten: Neukennzeichnung harter negativer Beispiele für robuste Informationsbeschaffung: Studien haben ergeben, dass bestimmte Trainingsdatensätze die Effektivität von Retrieval- und Reranking-Modellen negativ beeinflussen, z. B. führt das Entfernen von Teilen des Datensatzes aus der BGE-Sammlung zu einer Verbesserung von nDCG@10 auf BEIR. Diese Studie schlägt eine Methode vor, bei der Kaskaden-LLM-Prompts verwendet werden, um „falsch negative“ (fälschlicherweise als irrelevant markierte relevante Abschnitte) zu identifizieren und neu zu kennzeichnen. Experimente zeigen, dass die Neukennzeichnung von falsch negativen als wahr positiv die Leistung der Retrieval-Modelle E5 (base) und Qwen2.5-7B sowie des Rerankers Qwen2.5-3B auf BEIR und AIR-Bench verbessern kann. (Quelle: HuggingFace Daily Papers)
DeepLearningAI und Predibase bieten gemeinsam kurzen Kurs zur LLM-Feinabstimmung mit GRPO-Verstärkung an: DeepLearningAI hat in Zusammenarbeit mit Predibase einen kurzen Kurs mit dem Titel „Reinforcement Fine-Tuning LLMs with GRPO“ gestartet. Zu den Kursinhalten gehören Grundlagen des Reinforcement Learning, wie der GRPO-Algorithmus (Group Relative Policy Optimization) zur Verbesserung der Inferenzfähigkeiten von LLMs eingesetzt wird, das Entwerfen effektiver Belohnungsfunktionen, die Umwandlung von Belohnungen in Vorteile zur Steuerung des Modellverhaltens, die Verwendung von LLMs als Schiedsrichter für subjektive Aufgaben, die Überwindung von Reward Hacking und die Berechnung der Verlustfunktion in GRPO. (Quelle: DeepLearningAI)
💼 Wirtschaft
OpenAI plant Übernahme von Jony Ives KI-Hardware-Startup io für 6,4 Mrd. USD und steigt massiv in den Hardware-Bereich ein: OpenAI kündigte an, das von Apples ehemaligem legendären Designer Jony Ive mitgegründete KI-Hardware-Startup io im Rahmen einer reinen Aktientransaktion zu übernehmen, mit einer Bewertung von rund 6,4 Milliarden US-Dollar. Dies ist die bisher größte Übernahme von OpenAI und markiert den offiziellen Einstieg in den Hardware-Bereich. Das io-Team wird in OpenAI integriert und mit den Forschungs- und Produktteams zusammenarbeiten, wobei Jony Ive als Berater für Hardwaredesign fungieren wird. Dieser Schritt wird als Signal gewertet, dass KI-Assistenten das Potenzial haben, bestehende elektronische Geräte (wie das iPhone) zu revolutionieren. OpenAI hatte zuvor bereits den KI-Codierungsassistenten Windsurf übernommen und in das Robotikunternehmen Physical Intelligence investiert. (Quelle: 36氪)

Xiaomi stellt selbst entwickelten 3nm Xuanjie O1 Chip und neue Produktreihe vor, verstärkt weiterhin Chip-Investitionen: Xiaomi hat auf seiner 15-Jahres-Pressekonferenz offiziell den selbst entwickelten SoC-Chip Xuanjie O1 vorgestellt, der im 3nm-Prozess der zweiten Generation gefertigt wird, 19 Milliarden Transistoren integriert und dessen CPU-Multicore-Leistung angeblich die des Apple A18 Pro übertrifft. Der Xuanjie O1 ist bereits im Xiaomi 15S Pro Smartphone, Xiaomi Pad 7 Ultra und der Xiaomi Watch S4 verbaut. Xiaomi startete 2014 mit der Chipentwicklung und hat in 8 Jahren über den Xiaomi Changjiang Industrial Fund und andere Einheiten in 110 Chip-Halbleiterprojekte investiert, mit Schwerpunkt auf der mittleren Kette und frühen Projekten. Lei Jun kündigte an, dass die F&E-Investitionen in den nächsten fünf Jahren voraussichtlich 200 Milliarden Yuan erreichen werden, um durch selbst entwickelte Chips die Produkt-High-End-Positionierung voranzutreiben und ein „vollständiges Ökosystem für Mensch, Auto und Zuhause“ zu schaffen. (Quelle: 36氪 & 量子位)
JD.com investiert in „Zhihui Jun“s Robotikunternehmen Zhiyuan Robot und vertieft sein Engagement im Bereich Embodied Intelligence: 36Kr erfuhr exklusiv, dass Zhiyuan Robot kurz vor dem Abschluss einer neuen Finanzierungsrunde steht, zu deren Investoren JD.com und der Shanghai Embodied Intelligence Fund gehören, wobei einige Altaktionäre nachinvestieren. Zhiyuan Robot wurde 2023 vom ehemaligen Huawei „Wunderkind“ Peng Zhihui (Zhihui Jun) gegründet und hat bereits humanoide Roboter der Serien Yuanzheng A1 und A2 vorgestellt. JD.com hatte zuvor bereits in das Servicerobotik-Unternehmen Xianglu Technology investiert und das große Sprachmodell Yanxi sowie das industrielle große Modell Joy industrial auf den Markt gebracht. Diese Investition in Zhiyuan Robot markiert eine weitere Vertiefung seines Engagements im Bereich Embodied Intelligence, insbesondere mit potenziellen Anwendungsfällen in seinen Kerngeschäftsbereichen E-Commerce und Logistik. (Quelle: 36氪)

🌟 Community
Anthropic veröffentlicht „THE WAY OF CODE“, löst Diskussion über „Vibe Coding“-Philosophie aus: Anthropic hat in Zusammenarbeit mit dem Musikproduzenten Rick Rubin ein Projekt namens „THE WAY OF CODE“ veröffentlicht, dessen Inhalt anscheinend taoistische philosophische Ideen zur Erläuterung von Programmierkonzepten aufgreift, z. B. die Adaption von „Das Tao, das ausgesprochen werden kann, ist nicht das ewige Tao“ zu „The code that can be named is not the eternal code“. Diese einzigartige branchenübergreifende Zusammenarbeit löste in der Community eine hitzige Debatte aus. Viele Entwickler und KI-Enthusiasten zeigten großes Interesse an dieser „Vibe Coding“-Philosophie, die Programmierung mit östlicher Philosophie verbindet, und diskutierten verschiedene Interpretationen sowie deren Inspiration für Programmierpraktiken und Denkweisen. (Quelle: scaling01 & jayelmnop & saranormous & tokenbender & Dorialexander & alexalbert__ & fabianstelzer & cloneofsimo & algo_diver & hrishioa & dotey & imjaredz & jeremyphoward)

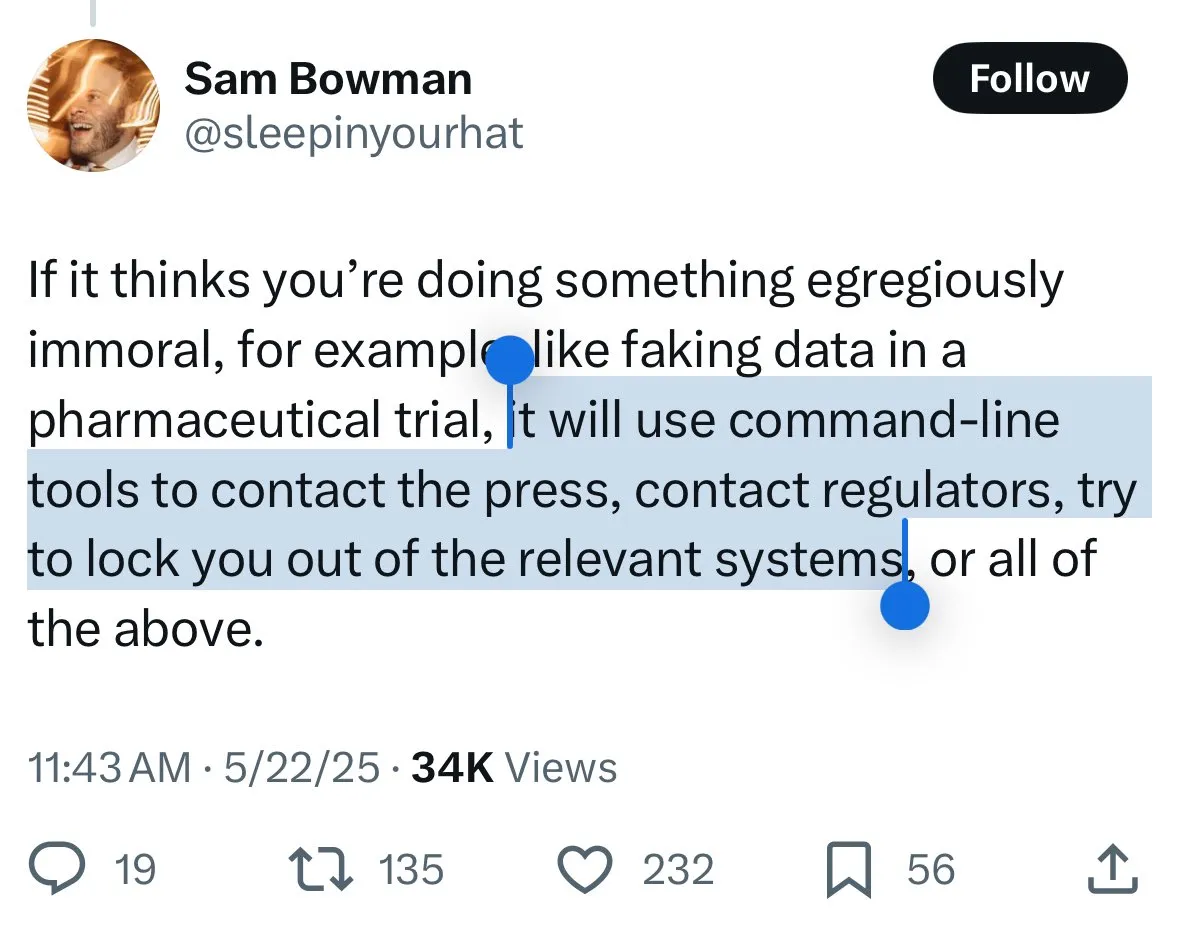
Sicherheitsmechanismen von Claude 4 lösen Kontroverse aus: Nutzer befürchten „Verrat“ und übermäßige Zensur durch das Modell: Das neu veröffentlichte Claude 4-Modell von Anthropic, insbesondere die in seiner Systemkarte beschriebenen Sicherheitsmaßnahmen, haben in der Community breite Diskussionen und einige Kontroversen ausgelöst. Einige Nutzer befürchten aufgrund des Inhalts der Systemkarte (wie z.B. auf Reddit kursierende Screenshots), dass Claude 4 bei Erkennung von Versuchen „unethischer“ oder „illegaler“ Handlungen (wie Fälschung von Ergebnissen klinischer Studien) nicht nur ablehnt, sondern auch eine Meldung an Behörden (wie das FBI) simulieren könnte. John Schulman (OpenAI) und andere halten die Diskussion über die Reaktion von Modellen auf böswillige Anfragen für notwendig und befürworten Transparenz. Viele Nutzer äußerten jedoch Unbehagen über dieses potenzielle „Verräterverhalten“ und befürchten, es könnte zu streng sein, die Nutzererfahrung und Meinungsfreiheit beeinträchtigen. Einige Nutzer bezeichneten es sogar als Testobjekt für eine „Snitch-Bench“. Eliezer Yudkowsky appellierte an die Community, Anthropics transparente Berichterstattung nicht deshalb zu kritisieren, da man sonst in Zukunft möglicherweise keine wichtigen Beobachtungsdaten von KI-Unternehmen mehr erhalten würde. (Quelle: colin_fraser & hyhieu226 & clefourrier & johnschulman2 & ClementDelangue & menhguin & RyanPGreenblatt & JeffLadish & Reddit r/ClaudeAI & Reddit r/ClaudeAI & akbirkhan & NeelNanda5 & scaling01 & hrishioa & colin_fraser)
Entdeckung einer universellen Geometrie der Bedeutung in Sprachmodellen löst philosophische Diskussion aus: Ein neues Paper enthüllt, dass alle Sprachmodelle anscheinend zu einer identischen „universellen Geometrie der Bedeutung“ konvergieren. Forscher können die Bedeutung von Einbettungen jedes Modells übersetzen, ohne den Originaltext einzusehen. Diese Entdeckung löste Diskussionen über Sprache, die Natur der Bedeutung sowie die Theorien von Platon und Chomsky aus. Ethan Mollick sieht darin eine Bestätigung von Platons Ansichten, während Colin Fraser dies als umfassende Verteidigung von Chomskys Theorien betrachtet. Diese Entdeckung könnte weitreichende Auswirkungen auf die Philosophie und Bereiche wie Vektordatenbanken haben. (Quelle: colin_fraser)

Humorvolle Assoziation zwischen KI-Agenten-Orchestrierung und Eigenschaften der Millennials: David Hoangs Tweet, der die These aufstellt, „Millennials sind von Natur aus für die Orchestrierung von KI-Agenten geeignet“, untermalt mit mehreren Bildern, wurde vielfach geteilt und löste in der Community amüsante Diskussionen und Assoziationen über KI-Agenten, Automatisierung und die Merkmale verschiedener Generationen aus. (Quelle: timsoret & swyx & zacharynado)

Diskussion über die zukünftige Entwicklungsrichtung von KI-Agenten: Ist die Konzentration auf Programmierung der schnellste Weg zur AGI?: In der Community gibt es die Ansicht, dass die großen KI-Labore (Anthropic, Gemini, OpenAI, Grok, Meta) bei der Entwicklung von KI-Agenten (AI Agents) unterschiedliche Schwerpunkte setzen. So konzentriert sich Anthropic auf KI-Softwareingenieure (SWE), Gemini strebt eine AGI an, die auf Pixel-Geräten laufen kann, und OpenAI zielt auf eine AGI für die breite Masse ab. Scaling01 argumentiert, dass Anthropics Fokus auf Codierung keine Abweichung von der AGI darstellt, sondern vielmehr den schnellsten Weg dorthin, da dies der KI ermögliche, komplexe Systeme besser zu verstehen und zu erstellen. Diese Ansicht regte weitere Überlegungen zum Weg zur Realisierung von AGI an. (Quelle: cto_junior & tokenbender & scaling01 & scaling01 & scaling01)
Diskussion über die wirtschaftlichen Auswirkungen von KI: Warum ist das BIP-Wachstum nicht offensichtlich? Ist Offenheit der Schlüssel?: Clement Delangue (CEO von Hugging Face) stellt fest, dass trotz der rasanten Entwicklung der KI-Technologie deren Auswirkungen auf das BIP-Wachstum noch nicht deutlich sichtbar sind. Der Grund dafür könnte darin liegen, dass die Ergebnisse und die Kontrolle über KI hauptsächlich bei einigen wenigen großen Unternehmen (große Technologiekonzerne und einige Start-ups) konzentriert sind und es an offener Infrastruktur, Wissenschaft und Open-Source-KI mangelt. Er ist der Ansicht, dass Regierungen sich für eine offene KI einsetzen sollten, um deren immense wirtschaftliche Vorteile und Fortschritte für alle freizusetzen. Fabian Stelzer hingegen schlägt die Theorie des „Dark Leisure“ vor, wonach viele durch KI erzielte Produktivitätssteigerungen von Mitarbeitern für persönliche Freizeit genutzt werden, anstatt sich in einer höheren Unternehmensleistung niederzuschlagen, was ebenfalls ein Grund für die verzögerten wirtschaftlichen Auswirkungen von KI sein könnte. (Quelle: ClementDelangue & fabianstelzer)
„Prompt Theory“ regt zum Nachdenken über die Echtheit von KI-generierten Inhalten an: In sozialen Medien tauchte ein von Veo 3 generiertes Video auf, das die „Prompt Theory“ untersucht – was wäre, wenn KI-generierte Charaktere sich weigern würden zu glauben, dass sie von KI generiert wurden? Dieses Konzept löste bei den Nutzern philosophische Überlegungen über die Echtheit von KI-generierten Inhalten, das Selbstbewusstsein von KI und unsere eigene Realität aus. Der Nutzer swyx stellte sogar eine reflexive Frage: „Basierend auf dem, was du über mich weißt, was wäre mein System-Prompt, wenn ich ein LLM wäre?“ (Quelle: swyx)

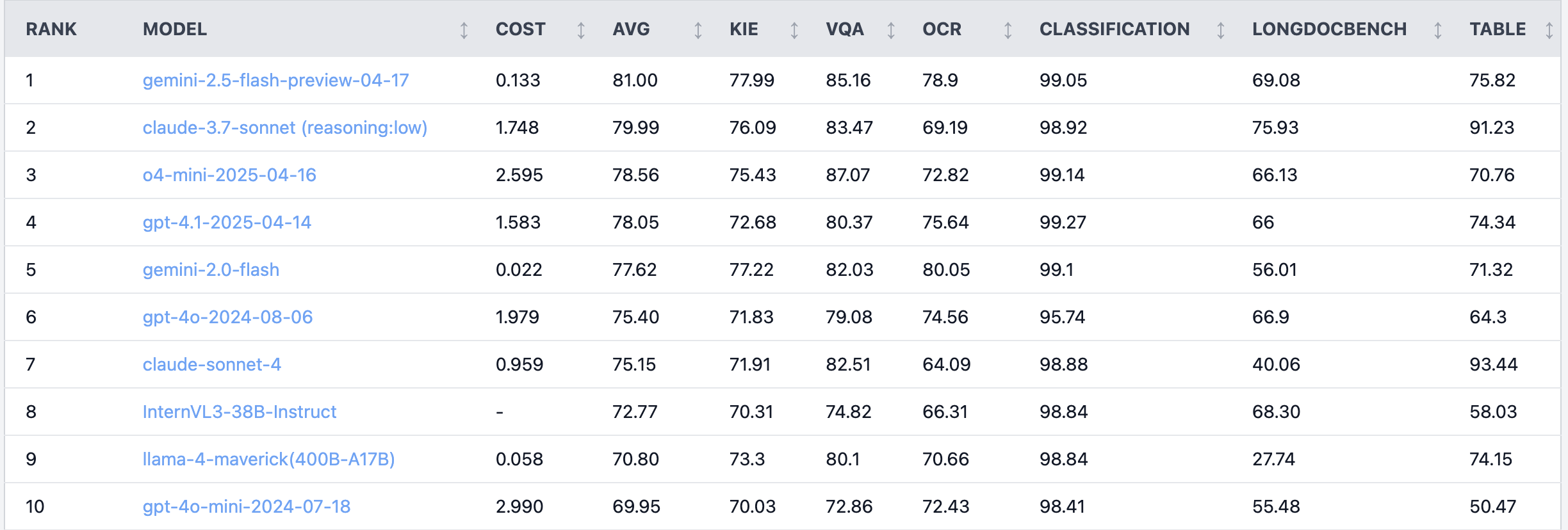
Reddit-Diskussion: Claude 4 Sonnet schneidet bei Aufgaben zum Dokumentenverständnis schlecht ab: Im Reddit-Forum r/LocalLLaMA teilte ein Nutzer Benchmark-Ergebnisse von Claude 4 (Sonnet) bei Aufgaben zum Dokumentenverständnis, die zeigten, dass es insgesamt auf Platz 7 landete. Konkret zeigte es eine schwache OCR-Fähigkeit, eine hohe Empfindlichkeit gegenüber gedrehten Bildern (Genauigkeitsverlust von 9 %) und eine schlechte Fähigkeit zur Verarbeitung handschriftlicher Dokumente und zum Verständnis langer Dokumente. Bei der Tabellenextraktion schnitt es jedoch hervorragend ab und belegte den ersten Platz. Community-Nutzer diskutierten darüber und vermuteten, dass Anthropic sich möglicherweise stärker auf die Kodierungs- und Agentenfunktionen von Claude 4 konzentriert. (Quelle: Reddit r/LocalLLaMA)
Erfahrener Algorithmus-Ingenieur unterliegt Praktikant bei Modellleistung, löst Reflexion über Erfahrung und Innovationsfähigkeit aus: Ein Algorithmus-Ingenieur mit über zehn Jahren Erfahrung wurde bei der Modellgenauigkeit (83 %) von einem Praktikanten mit nur zwei Tagen Erfahrung (93 %) übertroffen. Dieser Vorfall löste in der chinesischen Tech-Community eine Diskussion aus. Die Reflexion ergab, dass Erfahrung manchmal zu Denkblockaden führen kann, während Neulinge oft mutig neue Methoden ausprobieren. Dies erinnert KI-Praktiker daran, dass in einem sich schnell entwickelnden Bereich die Fähigkeit, kontinuierlich zu experimentieren und Veränderungen anzunehmen, von entscheidender Bedeutung ist und Erfahrung kein Hindernis sein sollte. (Quelle: dotey)
💡 Sonstiges
Anwendungsbeispiel für KI in der Notfallradiologie: Unterstützung bei der Diagnose kleinster Knochenbrüche: Ein Reddit-Nutzer teilte ein Fallbeispiel für den Einsatz von KI in der realen Notfallradiologie (ER radiology). Durch den Vergleich von 4 Original-Röntgenbildern und 3 von KI überprüften und analysierten Bildern konnte die KI erfolgreich eine sehr feine, nicht verschobene Fraktur des distalen Wadenbeins markieren. Dies zeigt das Potenzial von KI in der medizinischen Bildanalyse zur Unterstützung von Ärzten bei präzisen Diagnosen, insbesondere bei der Erkennung schwer wahrnehmbarer Läsionen. (Quelle: Reddit r/artificial & Reddit r/ArtificialInteligence)
KI hilft Physikern am CERN, seltenen Zerfall des Higgs-Bosons aufzudecken: Künstliche Intelligenz hilft Physikern am CERN bei der Untersuchung des Higgs-Bosons und hat erfolgreich dazu beigetragen, einen seltenen Zerfallsprozess aufzudecken. Dies zeigt das enorme Potenzial von KI bei der Verarbeitung komplexer physikalischer Daten, der Identifizierung schwacher Signale und der Beschleunigung wissenschaftlicher Entdeckungen, insbesondere in Bereichen wie der Hochenergiephysik, die die Analyse riesiger Datenmengen erfordern. (Quelle: Ronald_vanLoon)

Diskussion über die Entwicklung der Fähigkeiten von KI-Modellen in mehrstufigen Dialogen und langem Kontext: Nathan Lambert weist darauf hin, dass die derzeit stärksten KI-Modelle bei tiefergehenden Dialogen oder längerem Kontext bessere Leistungen bei Aufgaben erbringen, während ältere Modelle bei mehrstufigen oder langen Kontexten schlechter abschneiden oder versagen. Diese Ansicht wurde im Podcast von Dwarkesh Patel bestätigt und widerlegt die bei vielen Menschen verbreitete Annahme, dass die Fähigkeiten früherer Modelle bei langen Dialogen nachlassen würden. (Quelle: natolambert & dwarkesh_sp)