
Schlüsselwörter:Gemini 2.5, KI-Agent, Großes Sprachmodell, Visuelles Sprachmodell, Bestärkendes Lernen, Gemini 2.5 Pro Deep Think-Modus, GitHub Copilot Agent Open Source, MeanFlow Einzelschritt-Bildgenerierung, VPRL Visuelle Planungslogik, Huawei FusionSpec MoE Inferenzoptimierung
🔥 Fokus
Google I/O Konferenz kündigt zahlreiche KI-Fortschritte an, Gemini 2.5 Modellreihe führend: Google hat auf der I/O Konferenz zahlreiche Updates im KI-Bereich angekündigt. Gemini 2.5 Pro wird als das derzeit leistungsstärkste Basismodell bezeichnet, führt in mehreren Benchmark-Tests und führt den Deep Think-Modus zur verbesserten Inferenz ein. Das leichtgewichtige Modell Gemini 2.5 Flash wurde ebenfalls aktualisiert, mit Fokus auf Geschwindigkeit und Effizienz. Die Google-Suche führt einen „KI-Modus“ ein, der durch Gemini 2.5 ein End-to-End KI-Sucherlebnis bietet, komplexe Fragen zerlegen und tiefgreifende Informationsgewinnung durchführen kann. Das Videogenerierungsmodell Veo 3 erreicht eine audio-visuelle synchrone Generierung, und das Bildmodell Imagen 4 verbessert die Detail- und Textverarbeitungsfähigkeiten. Darüber hinaus wurden das KI-Filmproduktionswerkzeug Flow und die Anwendung Gemini Live des KI-Assistenzprojekts Project Astra vorgestellt. Diese Updates zeigen Googles Entschlossenheit, KI umfassend in sein Produktökosystem zu integrieren, um die Benutzererfahrung und Entwicklereffizienz zu verbessern (Quelle: 量子位, 36氪, WeChat)

Microsoft Build Konferenz stellt AI Agent in den Mittelpunkt, GitHub Copilot erhält großes Upgrade und wird Open Source: Microsoft hat auf der Build 2025 Entwicklerkonferenz AI Agents in den Mittelpunkt gestellt und das GitHub Copilot Extension for VSCode Projekt als Open Source angekündigt sowie einen brandneuen KI-Codierungsagenten (Agent) vorgestellt. Dieser Agent kann autonom Aufgaben wie Fehlerbehebung, Funktionserweiterung und Dokumentationsoptimierung erledigen und ist tief in GitHub Copilot integriert. Microsoft veröffentlichte außerdem die KI-Intelligenzagentenplattform Microsoft Discovery für wissenschaftliche Entdeckungen, das Projekt NLWeb für Websites mit natürlicher Sprachinteraktion, die Agentenbauplattform Agent Factory sowie Copilot Tuning für anpassbare Unternehmensdaten. Diese Maßnahmen zeigen, dass Microsoft die Anwendung von AI Agents in verschiedenen Bereichen wie Entwicklung und Forschung energisch vorantreibt, mit dem Ziel, ein offenes Ökosystem für die Zusammenarbeit intelligenter Agenten aufzubauen (Quelle: 量子位, WeChat, WeChat)

OpenAI CPO Kevin Weil erläutert die Transformation von ChatGPT: Von Fragen und Antworten zu Aktionen, AI Agents werden sich schnell entwickeln: Kevin Weil, Chief Product Officer von OpenAI, gab in einem Interview bekannt, dass sich die Positionierung von ChatGPT von einem Werkzeug zur Beantwortung von Fragen zu einem AI Agent wandeln wird, der Aufgaben für Benutzer ausführen kann. Er prognostiziert, dass AI Agents kurzfristig eine schnelle Entwicklung vom Junior- zum Senior-Ingenieur und sogar zum Architekten durchlaufen werden. Dies bedeutet, dass AI Agents eine stärkere Autonomie besitzen und komplexe Probleme durch das Durchsuchen von Webseiten, tiefgehendes Denken und schlussfolgerndes Zusammenfassen lösen können. Weil erwähnte auch, dass die aktuellen Trainingskosten bereits das 500-fache von GPT-4 betragen, aber zukünftig durch Hardwareverbesserungen und Algorithmusoptimierungen die Effizienz gesteigert und die API-Preise gesenkt werden sollen, um die Verbreitung und Entwicklung von KI zu fördern (Quelle: 量子位, 36氪)

Kaiming Hes Team stellt MeanFlow vor: Neuer SOTA in der Single-Step Bildgenerierung, der traditionelle Paradigmen ohne Vortraining umstößt: Die neueste Forschung von Kaiming Hes Team stellt ein Single-Step Generierungsmodellierungsframework namens MeanFlow vor. Auf dem ImageNet 256×256 Datensatz erreicht es mit nur einer Funktionsauswertung (1-NFE) einen FID-Score von 3.43, was eine Verbesserung von 50%-70% gegenüber den bisher besten Methoden dieser Art darstellt, und das ohne Vortraining, Destillation oder Curriculum Learning. Die Kerninnovation von MeanFlow liegt in der Einführung des Konzepts des „mittleren Geschwindigkeitsfeldes“ und der Ableitung seiner mathematischen Beziehung zum momentanen Geschwindigkeitsfeld, um das Training neuronaler Netze zu leiten. Diese Methode kann auch Classifier-Free Guidance (CFG) natürlich integrieren, ohne zusätzliche Berechnungskosten während des Samplings zu verursachen, wodurch die Leistungslücke zwischen Single-Step und Multi-Step Generierungsmodellen erheblich verkleinert wird und das Potenzial von Modellen mit wenigen Schritten gezeigt wird, Multi-Step Modelle herauszufordern (Quelle: WeChat, WeChat)

🎯 Trends
ByteDance veröffentlicht Bagel 14B MoE multimodales Modell, unterstützt Bildgenerierung und ist Open Source: ByteDance hat ein multimodales Mixture-of-Experts (MoE) Modell mit 14 Milliarden Parametern namens Bagel vorgestellt, von denen 7 Milliarden Parameter aktiv sind. Das Modell verfügt über Fähigkeiten zur Bildgenerierung und wurde unter der Apache-Lizenz als Open Source veröffentlicht. Die zugehörigen Gewichte, die Website und das Paper (Titel: „Emerging Properties in Unified Multimodal Pretraining“) wurden ebenfalls veröffentlicht. Die Community reagierte positiv und betrachtet es als das erste lokale Modell, das gleichzeitig Bilder und Text generieren kann, und interessiert sich für die Möglichkeit, es auf einer 24GB-Grafikkarte auszuführen sowie für Quantisierungsfragen (Quelle: Reddit r/LocalLLaMA)
Mistral AI veröffentlicht Devstral: Ein für Codierung optimiertes SOTA Open-Source-Modell: Mistral AI hat Devstral vorgestellt, ein führendes Open-Source-Modell, das speziell für Software-Engineering-Aufgaben entwickelt wurde und in Zusammenarbeit von Mistral AI und All Hands AI erstellt wurde. Devstral zeigte eine herausragende Leistung im SWE-bench Benchmark und wurde zum bestplatzierten Open-Source-Modell in diesem Benchmark. Das Modell ist versiert im Einsatz von Tools zur Erkundung von Codebasen, Bearbeitung mehrerer Dateien und Unterstützung von Software-Engineering-Agenten. Die Modellgewichte sind auf Hugging Face verfügbar (Quelle: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)

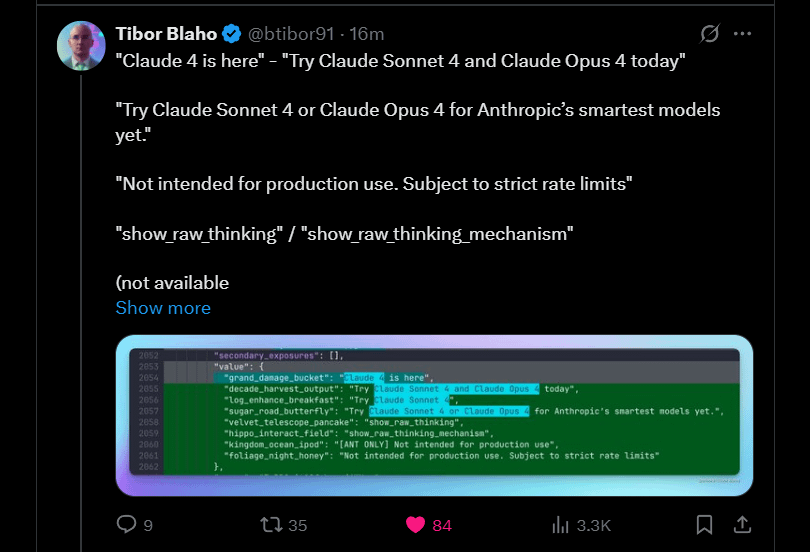
Anthropic kündigt bevorstehenden Start von Claude 4 Sonnet und Opus an: Anthropic plant die Einführung der nächsten Generation seiner Claude Large Language Models – Claude 4 Sonnet und Opus. Diese Nachricht löste in der Community Erwartungen aus, wobei die Nutzer insbesondere an der Leistungssteigerung der neuen Modelle, vor allem der Kontextgedächtnisfähigkeit, interessiert sind. Einige Kommentare wiesen darauf hin, dass die Ankündigungen auf der Google I/O Konferenz Konkurrenten dazu veranlassen könnten, ihre besten Produkte schneller auf den Markt zu bringen. Gleichzeitig äußerten Nutzer Bedenken hinsichtlich der Einschränkungen der neuen Modelle (wie Nutzungskontingente) und erinnerten die Community daran, keine überzogenen Erwartungen an Opus 4 zu haben, um Enttäuschungen zu vermeiden (Quelle: Reddit r/ClaudeAI, Reddit r/ClaudeAI)
Google veröffentlicht Gemma3n Android-App, unterstützt lokale LLM-Inferenz: Google hat eine Android-App veröffentlicht, die mit dem neuen Gemma3n-Modell interagieren kann, und stellt zugehörige MediaPipe-Lösungen sowie ein GitHub-Repository bereit. Nutzerfeedback beschreibt die Benutzeroberfläche als gut, weist jedoch darauf hin, dass Gemma3n derzeit keine GPU-Inferenz unterstützt. Ein Nutzer hat erfolgreich das gemma-3n-E2B-Modell manuell geladen und Laufzeitdaten geteilt, während die Community auch den Bedarf an einer unzensierten Version des Modells äußerte (Quelle: Reddit r/LocalLLaMA)

Falcon-H1 Hybrid-Head Sprachmodellfamilie veröffentlicht, enthält verschiedene Parametergrößen: TII UAE hat die Falcon-H1 Serie von Hybrid-Head Sprachmodellen veröffentlicht, mit Parametergrößen von 0.5B bis 34B. Diese Modellserie verwendet eine Mamba-Hybridarchitektur und ist in der Leistung mit Qwen3 vergleichbar. Die Modelle können über Hugging Face Transformers, vLLM oder eine angepasste Version der llama.cpp-Bibliothek verwendet werden, was ihre Benutzerfreundlichkeit sicherstellt. Die Community äußerte sich begeistert und sieht dies als wichtigen Fortschritt, und ein Nutzer erstellte Leistungsvergleichsdiagramme. Gleichzeitig interessieren sich Forscher für die Unterschiede zu IBM Granite 4 in der Art und Weise, wie SSM- und Aufmerksamkeitsmodule kombiniert werden (Quelle: Reddit r/LocalLLaMA)

Google erforscht Gemini Diffusion: Ein Sprachmodell mit Diffusionsarchitektur: Google präsentierte sein Sprachdiffusionsmodell Gemini Diffusion, das angeblich extrem schnell ist und nur halb so groß wie vergleichbar leistungsfähige Modelle sein soll. Da Diffusionsmodelle den gesamten Text in einem Durchgang iterativ verarbeiten können und keinen KV-Cache benötigen, könnten sie Vorteile bei der Speichereffizienz haben und die Ausgabequalität durch Erhöhung der Iterationszahl verbessern. Die Community ist der Ansicht, dass, wenn Google die Machbarkeit von Diffusionsmodellen für groß angelegte Anwendungen nachweisen kann, dies positive Auswirkungen auf die lokale KI-Community haben wird. Derzeit gibt es für dieses Modell jedoch nur eine Warteliste für eine Demo, es wurde weder als Open Source veröffentlicht noch stehen Gewichte zum Download bereit (Quelle: Reddit r/LocalLLaMA)

Studie deckt Zero-Click Agent-Hijacking-Schwachstelle (CVE-2025-47241) im Browser Use Framework auf: Eine Untersuchung von ARIMLABS.AI hat eine schwerwiegende Sicherheitslücke (CVE-2025-47241) im Browser Use Framework aufgedeckt, das in über 1500 KI-Projekten eingesetzt wird. Die Schwachstelle ermöglicht es Angreifern, durch das Verleiten eines LLM-gesteuerten Browsing-Agenten zum Besuch einer bösartigen Seite ein Zero-Click Agent-Hijacking durchzuführen, wodurch der Agent ohne Benutzerinteraktion kontrolliert werden kann. Diese Entdeckung gibt Anlass zu ernster Besorgnis über die Sicherheit autonomer KI-Agenten, insbesondere solcher, die mit dem Internet interagieren, und ruft die Community dazu auf, der Sicherheit von KI-Agenten Aufmerksamkeit zu schenken (Quelle: Reddit r/artificial, Reddit r/artificial)
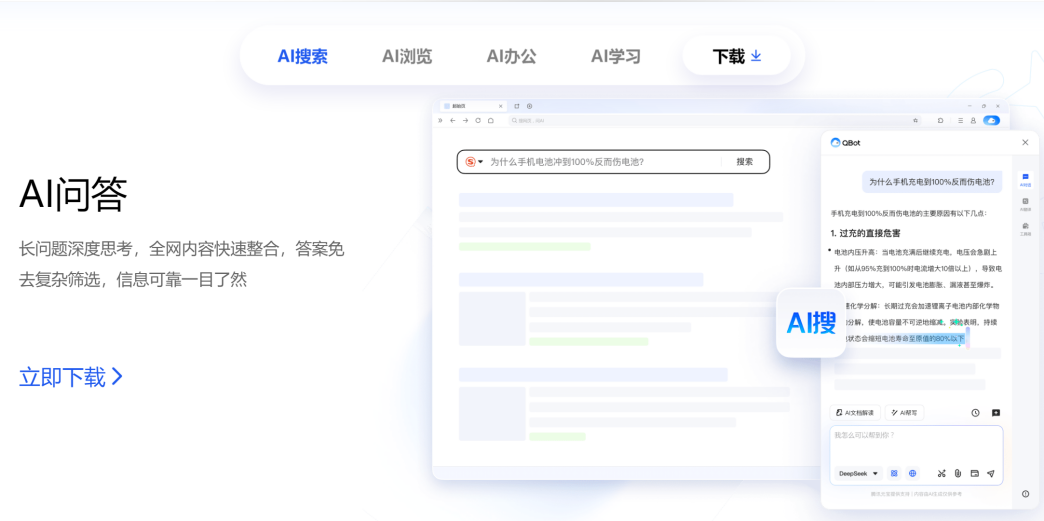
Tencent und Alibaba konkurrieren im AI to C Bereich, QQ Browser und Quark im direkten Vergleich: Der zu Tencent CSIG gehörende QQ Browser kündigte ein Upgrade zum KI-Browser an, führte AI QBot ein und wird von den Tencent Hunyuan und DeepSeek Dual-Modellen angetrieben, womit er offiziell in Konkurrenz zu Alibabas bereits auf KI-Suche umgestelltem Quark tritt. Dieser Schritt markiert eine Beschleunigung von Tencents Engagement im AI to C Bereich und bildet die beiden Produktlinien Tencent Yuanbao und QQ Browser. Die jeweiligen Kernverantwortlichen Wu Zurong (Tencent) und Wu Jia (Alibaba) stehen sich somit in einem „Doppel-Wu-Duell“ gegenüber. Analysten gehen davon aus, dass der QQ Browser bei der Nutzerbasis im Vorteil ist, während Quark bei der KI-Transformation einen Schritt voraus ist. Allerdings gilt die Transformation des QQ Browsers als relativ konservativ, die KI-Funktionen ähneln eher Plugins und sind durch das bestehende Werbemodell eingeschränkt. Dieser Wettbewerb findet nicht nur auf Produktebene statt, sondern könnte auch die Karriereentwicklung der beiden Verantwortlichen in ihren jeweiligen Unternehmen beeinflussen (Quelle: 36氪)
Cambridge und Google stellen VPRL vor: Neues Paradigma für rein visuelle Planung und Inferenz, Genauigkeit übertrifft textbasierte Inferenz: Ein Forschungsteam der University of Cambridge, des University College London und von Google hat ein neues Paradigma für visuelle Planung (VPRL) auf Basis von Reinforcement Learning vorgestellt, das erstmals rein bildbasiertes Schließen ermöglicht. Das Framework nutzt Group Relative Policy Optimization (GRPO) für das Post-Training großer visueller Modelle und übertrifft in mehreren visuellen Navigationsaufgaben (wie FrozenLake, Maze, MiniBehavior) die Leistung textbasierter Inferenzmethoden bei weitem, mit einer Genauigkeit von bis zu 80 % und einer Leistungssteigerung von mindestens 40 %. VPRL plant direkt anhand von Bildsequenzen und vermeidet so Informationsverluste und Effizienzreduktionen durch Sprachkonvertierung, was neue Wege für intuitive bildbasierte Inferenzaufgaben eröffnet. Der zugehörige Code wurde als Open Source veröffentlicht (Quelle: WeChat)

Huawei veröffentlicht FusionSpec und OptiQuant zur Optimierung der Inferenz von MoE-Großmodellen: Huawei hat als Antwort auf die Herausforderungen bei Inferenzgeschwindigkeit und Latenz von großen Mixture-of-Experts (MoE) Modellen das FusionSpec Speculative Inference Framework und das OptiQuant Quantization Framework vorgestellt. FusionSpec nutzt das hohe Rechenleistungs-Bandbreiten-Verhältnis von Ascend-Servern, um die Prozesse des Hauptmodells und des spekulativen Modells zu optimieren und die Latenz des spekulativen Inferenz-Frameworks auf 1 Millisekunde zu reduzieren. OptiQuant unterstützt gängige Quantisierungsalgorithmen wie Int2/4/8 und FP8/HiFloat8 und führt Innovationen wie „lernbares Truncation“ und „Optimierung von Quantisierungsparametern“ ein, um den Genauigkeitsverlust des Modells zu verringern und das Preis-Leistungs-Verhältnis der Inferenz zu verbessern. Diese Technologien zielen darauf ab, die Probleme der Ineffizienz und des Ressourcenverbrauchs bei der Inferenz von MoE-Modellen während des Deployments zu lösen (Quelle: WeChat)

BAAI veröffentlicht drei SOTA-Vektormodelle zur Stärkung der Code- und multimodalen Suche: Das Beijing Academy of AI (BAAI) hat in Zusammenarbeit mit mehreren Universitäten BGE-Code-v1 (Code-Vektormodell), BGE-VL-v1.5 (allgemeines multimodales Vektormodell) und BGE-VL-Screenshot (Vektormodell für visualisierte Dokumente) veröffentlicht. BGE-Code-v1 basiert auf Qwen2.5-Coder-1.5B und zeigt hervorragende Leistungen auf den CoIR- und CodeRAG-Benchmarks. BGE-VL-v1.5 basiert auf LLaVA-1.6 und hat auf dem MMEB-Multimodal-Benchmark einen neuen Zero-Shot-Rekord aufgestellt. BGE-VL-Screenshot zielt auf die Suche nach visualisierten Informationen (Vis-IR) wie Webseiten und Dokumenten ab, wurde auf Basis von Qwen2.5-VL-3B-Instruct trainiert und erreicht SOTA auf dem neu eingeführten MVRB-Benchmark. Diese Modelle sollen stärkere Code- und multimodale Verständigungs- und Suchfähigkeiten für Anwendungen wie Retrieval Augmented Generation (RAG) bereitstellen und sind alle Open Source (Quelle: WeChat)

Kuaishou und die National University of Singapore stellen Any2Caption vor, um kontrollierbare Videogenerierung zu ermöglichen: Kuaishou und die National University of Singapore haben gemeinsam das Any2Caption-Framework vorgestellt, das darauf abzielt, die Präzision und Qualität der kontrollierbaren Videogenerierung durch intelligentes Entkoppeln des Verständnisses von Benutzerabsichten und des Videogenerierungsprozesses zu verbessern. Das Framework kann verschiedene Modalitäten von Eingabebedingungen wie Text, Bilder, Videos, Posen-Trajektorien und Kamerabewegungen verarbeiten und nutzt multimodale große Sprachmodelle, um komplexe Anweisungen in strukturierte „Videoskripte“ umzuwandeln, die die Videogenerierung steuern. Any2Caption stützt sich auf die Any2CapIns-Datenbank, die 337.000 Videobeispiele und 407.000 multimodale Bedingungen enthält, für das Training. Experimente zeigen, dass es die Effektivität bestehender kontrollierbarer Videogenerierungsmodelle wirksam verbessern kann (Quelle: WeChat)

🧰 Tools
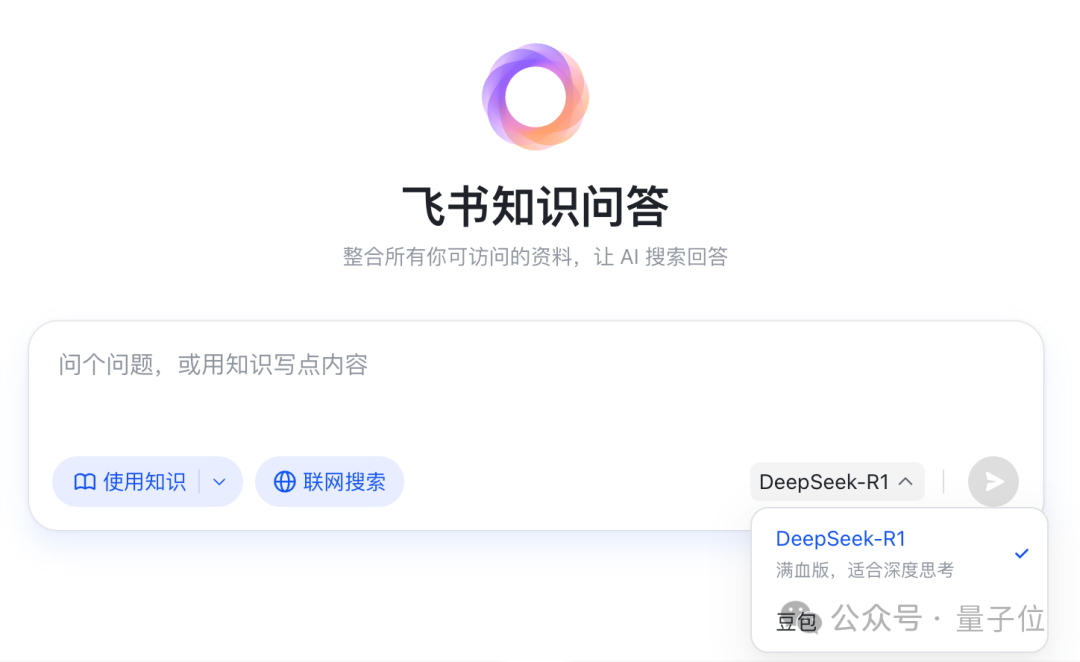
Feishu führt „Wissens-Q&A“-Funktion ein und schafft einen unternehmensspezifischen KI-Q&A- und Erstellungsassistenten: Feishu hat die neue Funktion „Wissens-Q&A“ eingeführt, die als unternehmensspezifisches KI-Q&A-Tool positioniert ist. Basierend auf Nachrichten, Dokumenten, Wissensdatenbanken, Memos usw., auf die Mitarbeiter in Feishu Zugriff haben, kombiniert mit großen Modellen wie DeepSeek-R1, Doubao und RAG-Technologie, liefert es präzise Antworten und Unterstützung bei der Inhaltserstellung. Die Funktion betont die Aktivierung und Nutzung internen Unternehmenswissens. Mitarbeiter mit unterschiedlichen Identitäten können bei gleichen Fragen Antworten aus unterschiedlichen Perspektiven erhalten, wobei die Organisationsberechtigungen strikt eingehalten werden. Feishu Wissens-Q&A zielt darauf ab, KI nahtlos in tägliche Arbeitsabläufe zu integrieren, die Effizienz der Informationsbeschaffung und Zusammenarbeit zu verbessern und Unternehmen beim Aufbau eines dynamischen Wissensmanagementsystems zu unterstützen (Quelle: WeChat, WeChat)
Supabase wird dank Open Source und KI-Integrationsvorteilen zum bevorzugten Backend für „Vibe Coding“: Die Open-Source-Datenbank Supabase ist aufgrund ihrer „Out-of-the-Box“-PostgreSQL-Erfahrung und ihrer aktiven Reaktion auf KI-Entwicklungstrends zur beliebten Backend-Wahl im „Vibe Coding“-Modell geworden. Vibe Coding betont die Nutzung verschiedener KI-Tools, um den gesamten Entwicklungsprozess von der Anforderung bis zur Implementierung schnell abzuschließen. Supabase unterstützt durch die Integration von PGVector die Speicherung von Vektor-Embeddings (entscheidend für RAG-Anwendungen), kooperiert mit Ollama, um KI-Modelldienste für Edge-Geräte bereitzustellen, und hat einen eigenen KI-Assistenten zur Unterstützung der Datenbank-Schema-Generierung und SQL-Fehlerbehebung eingeführt. Kürzlich hat Supabase auch einen offiziellen MCP-Server gestartet, der es KI-Tools ermöglicht, direkt damit zu interagieren. Diese Eigenschaften machen es bei KI-nativen Anwendungsbauplattformen wie Lovable und Bolt.new beliebt (Quelle: WeChat)

Hugging Face stellt nanoVLM vor: Ein minimalistisches Toolkit zum Trainieren von Visual Language Models (VLM) in reinem PyTorch: Hugging Face hat nanoVLM veröffentlicht, ein leichtgewichtiges PyTorch-Toolkit, das den Trainingsprozess von Visual Language Models vereinfachen soll. Das Projekt hat eine kleine und leicht lesbare Codebasis und eignet sich für Anfänger oder Entwickler, die die internen Mechanismen von VLMs besser verstehen möchten. Die Architektur von nanoVLM basiert auf dem SigLIP Vision Encoder und dem Llama 3 Sprachdecoder und richtet visuelle und textuelle Modalitäten über ein Modalitätsprojektionsmodul aufeinander aus. Das Projekt bietet eine bequeme Möglichkeit, das VLM-Training auf einem kostenlosen Colab Notebook zu starten, und hat bereits ein vortrainiertes Modell veröffentlicht, das auf SigLIP und SmolLM2 basiert und zum Testen zur Verfügung steht (Quelle: HuggingFace Blog)

Diffusers-Bibliothek integriert mehrere Quantisierungs-Backends zur Optimierung großer Diffusionsmodelle: Die Hugging Face Diffusers-Bibliothek integriert jetzt mehrere Quantisierungs-Backends wie bitsandbytes, torchao, Quanto, GGUF sowie natives FP8, um den Speicherbedarf und die Rechenanforderungen großer Diffusionsmodelle (wie Flux) zu reduzieren. Diese Backends unterstützen die Quantisierung mit unterschiedlicher Präzision (z. B. 4-Bit, 8-Bit, FP8) und können mit Speicheroptimierungstechniken wie CPU-Offloading, Group-Offloading und torch.compile kombiniert werden. Der Blog demonstriert anhand eines Quantisierungsbeispiels des Flux.1-dev-Modells die Leistung der einzelnen Backends hinsichtlich Speicherersparnis und Inferenzzeit und bietet eine Auswahlhilfe, um Benutzern zu helfen, ein Gleichgewicht zwischen Modellgröße, Geschwindigkeit und Qualität zu finden. Einige quantisierte Modelle sind bereits im Hugging Face Hub verfügbar (Quelle: HuggingFace Blog)

JD.coms JoyBuild Large Model Development Computing Platform verbessert Trainings- und Inferenz-Effizienz: Das JD Explore Academy hat ein System und eine Methode zum Trainieren und Aktualisieren großer Modelle in offenen Umgebungen sowie deren kooperative Bereitstellung mit kleineren Modellen vorgeschlagen. Die entsprechenden Ergebnisse wurden in der Nature-Tochterzeitschrift npj Artificial Intelligence veröffentlicht. Diese Technologie verbessert die durchschnittliche Inferenz-Effizienz großer Modelle um 30 % und senkt die Trainingskosten um 70 % durch vier Innovationen: Modelldestillation (dynamische hierarchische Destillation), Datenverwaltung (bereichsübergreifendes dynamisches Sampling), Trainingsoptimierung (Bayes’sche Optimierung) und Cloud-Edge-Koordination (zweistufige Komprimierung). Diese Technologie unterstützt die JoyBuild Large Model Development Computing Platform, die die Feinabstimmung und Entwicklung verschiedener Modelle (wie JD Large Model, Llama, DeepSeek) ermöglicht und Unternehmen dabei hilft, allgemeine Modelle in spezialisierte Modelle umzuwandeln. Sie wird bereits in Bereichen wie Einzelhandel und Logistik eingesetzt (Quelle: WeChat)
Model Context Protocol (MCP) Registry Projekt gestartet: modelcontextprotocol/registry ist ein Community-getriebenes Registrierungsdienstprojekt für MCP-Server, das sich derzeit in einer frühen Entwicklungsphase befindet. Das Projekt zielt darauf ab, ein zentrales Repository für MCP-Server-Einträge bereitzustellen, das die Entdeckung und Verwaltung verschiedener MCP-Implementierungen sowie deren Metadaten, Konfigurationen und Funktionen ermöglicht. Zu den Merkmalen gehören eine RESTful-API zur Verwaltung von Einträgen, Health-Check-Endpunkte, Unterstützung für verschiedene Umgebungskonfigurationen, MongoDB- und In-Memory-Datenbankunterstützung sowie API-Dokumentation. Das Projekt ist in Go geschrieben und bietet eine Anleitung zum schnellen Start über Docker Compose (Quelle: GitHub Trending)
📚 Lernen
Terence Tao veröffentlicht Tutorial zum KI-gestützten mathematischen Beweis und demonstriert die Grenzwertbestimmung von Funktionen mit GitHub Copilot: Der Fields-Medaillengewinner Terence Tao hat auf seinem YouTube-Kanal ein Video aktualisiert, in dem er detailliert demonstriert, wie man mit GitHub Copilot die Summen-, Differenz- und Produktregeln für Grenzwerte von Funktionen beweist. Das Tutorial betont die Wichtigkeit, die KI richtig anzuleiten, und zeigt die Rolle von Copilot bei der Generierung von Code-Frameworks und dem Vorschlagen von Bibliotheksfunktionen. Gleichzeitig weist es auf dessen Grenzen bei der Behandlung komplexer mathematischer Details, Sonderfälle und der Aufrechterhaltung der kontextuellen Konsistenz hin. Tao kommt zu dem Schluss, dass Copilot für Anfänger nützlich ist, bei komplexen Problemen jedoch immer noch erhebliche manuelle Eingriffe und Anpassungen erforderlich sind und manchmal die Kombination mit Stift und Papier effizienter sein kann (Quelle: 量子位)

Paper untersucht den Widerspruch zwischen Inferenz und Befehlsbefolgung bei großen Modellen und schlägt das Konzept der Constraint Attention vor: Ein Forschungspapier mit dem Titel „When Thinking Fails: The Pitfalls of Reasoning for Instruction-Following in LLMs“ weist darauf hin, dass große Sprachmodelle nach der Anwendung von Chain-of-Thought (CoT) zur Inferenz zwar in einigen Aspekten intelligenter erscheinen (z. B. Einhaltung von Format, Wortzahl), ihre Genauigkeit bei der strikten Befolgung von Anweisungen jedoch sinken kann. Das Forschungsteam stellte durch Tests an 15 Open-Source- und Closed-Source-Modellen fest, dass Modelle nach der Verwendung von CoT eher dazu neigen, „eigenmächtig zu handeln“, zusätzliche Informationen zu ändern oder hinzuzufügen und dabei die ursprünglichen Anweisungen zu ignorieren. Das Paper führt das Konzept der „Constraint Attention“ ein und stellt fest, dass CoT-Inferenz die Aufmerksamkeit des Modells für wichtige Einschränkungen verringert. Die Studie zeigt auch, dass es keine signifikante Korrelation zwischen der Länge des CoT-Denkprozesses und der Genauigkeit der Aufgabenerfüllung gibt, und untersucht die Möglichkeit, die Befehlsbefolgung durch Few-Shot-Beispiele, Selbstreflexion usw. zu verbessern (Quelle: WeChat)

MIT und Google schlagen PASTA vor: Neues Paradigma für asynchrone parallele Generierung von LLMs basierend auf Policy Learning: Forscher des Massachusetts Institute of Technology (MIT) und des Google-Forschungsteams haben das PASTA-Framework (PArallel STructure Annotation) vorgestellt, das es großen Sprachmodellen (LLMs) ermöglicht, durch Policy Learning autonom Strategien für die asynchrone parallele Generierung zu optimieren. Diese Methode entwickelte zunächst die Markierungssprache PASTA-LANG, um semantisch unabhängige Textblöcke für die parallele Generierung zu kennzeichnen. Der Trainingsprozess ist zweistufig: Zuerst lernt das Modell durch überwachtes Fine-Tuning, PASTA-LANG-Markierungen einzufügen, und anschließend wird die Annotationsstrategie durch Präferenzoptimierung (basierend auf theoretischer Beschleunigung und Bewertung der Inhaltsqualität) weiter verbessert. PASTA verwendet ein verschachteltes KV-Cache-Layout und einen Aufmerksamkeitskontrollmechanismus, um die effiziente Zusammenarbeit mehrerer Threads zu koordinieren. Experimente zeigen, dass PASTA auf dem AlpacaEval-Benchmark eine Beschleunigung von 1,21-1,93-fach erreicht, während die Ausgabequalität beibehalten oder verbessert wird, was eine gute Skalierbarkeit demonstriert (Quelle: WeChat)

ICML 2025 Paper stellt TPO vor: Neue Lösung für sofortige Präferenzanpassung zur Inferenzzeit, ohne Neutraining: Das Shanghai AI Laboratory hat Test-Time Preference Optimization (TPO) vorgestellt, eine neue Methode, die es großen Sprachmodellen ermöglicht, ihre Ausgabe zur Inferenzzeit durch iteratives Textfeedback selbst anzupassen, um menschlichen Präferenzen zu entsprechen. TPO simuliert einen sprachlichen „Gradientenabstiegsprozess“ (Generierung von Kandidatenantworten, Berechnung des Textverlusts, Berechnung des Textgradienten, Aktualisierung der Antwort), um eine Anpassung ohne Aktualisierung der Modellgewichte zu erreichen. Experimente zeigen, dass TPO die Leistung von nicht angepassten und bereits angepassten Modellen signifikant verbessern kann. Beispielsweise übertrifft das Llama-3.1-70B-SFT-Modell nach zweistufiger TPO-Optimierung die bereits angepasste Instruct-Version auf mehreren Benchmarks. Diese Methode bietet eine „Breite + Tiefe“-Erweiterungsstrategie für die Inferenz und zeigt ein effizientes Optimierungspotenzial in ressourcenbeschränkten Umgebungen (Quelle: WeChat)
Neue Studie untersucht Methoden zur Extraktion von verborgenem Wissen aus LLMs: Ein Paper untersucht, wie potenziell verborgenes Wissen aus großen Sprachmodellen extrahiert werden kann. Die Forscher trainierten ein „Tabu“-Modell, das darauf ausgelegt war, ein bestimmtes geheimes Wort zu beschreiben, ohne es direkt auszusprechen, wobei dieses geheime Wort weder in den Trainingsdaten noch in den Prompts vorkam. Anschließend bewerteten die Forscher nicht-interpretierbare (Blackbox-)Methoden und automatisierte Strategien, die auf mechanistischen Interpretierbarkeitstechniken (wie Logit Lens und Sparse Autoencoder) basieren, um dieses Geheimnis aufzudecken. Die Ergebnisse zeigten, dass beide Methoden das geheime Wort in einer Proof-of-Concept-Umgebung effektiv extrahieren konnten. Diese Arbeit zielt darauf ab, erste Lösungen für das Schlüsselproblem der Extraktion geheimen Wissens aus Sprachmodellen bereitzustellen, um deren sichere und zuverlässige Bereitstellung zu fördern (Quelle: HuggingFace Daily Papers)
Paper untersucht die Anwendung von Federated Pruning in großen Sprachmodellen (FedPrLLM): Um das Problem zu lösen, dass das Pruning großer Sprachmodelle (LLM) in datenschutzsensiblen Bereichen Schwierigkeiten bei der Beschaffung öffentlicher Kalibrierungsstichproben hat, schlagen Forscher FedPrLLM vor, ein umfassendes Federated Pruning Framework. In diesem Framework muss jeder Client nur basierend auf lokalen Kalibrierungsdaten eine Pruning-Maskenmatrix berechnen und diese mit dem Server teilen, um das globale Modell kooperativ zu prunen und gleichzeitig die Privatsphäre der lokalen Daten zu schützen. Durch umfangreiche Experimente stellten die Forscher fest, dass One-Shot Pruning in Kombination mit Layer Comparison und ohne Gewichtsskalierung (no weight scaling) die beste Wahl innerhalb des FedPrLLM-Frameworks ist. Diese Studie soll zukünftige Arbeiten zum LLM-Pruning in datenschutzsensiblen Bereichen anleiten (Quelle: HuggingFace Daily Papers)
Paper stellt MIGRATION-BENCH vor: Ein Benchmark für die Migration von Java 8 Code: Forscher haben MIGRATION-BENCH eingeführt, einen Benchmark, der sich auf die Migration von Code von Java 8 auf die neuesten LTS-Versionen (Java 17, 21) konzentriert. Dieser Benchmark enthält einen vollständigen Datensatz mit 5102 Repositories und eine Teilmenge von 300 sorgfältig ausgewählten, komplexen Repositories, die darauf abzielen, die Fähigkeit von Large Language Models (LLMs) bei Code-Migrationsaufgaben auf Repository-Ebene zu bewerten. Gleichzeitig liefert das Paper ein umfassendes Bewertungsframework und schlägt die SD-Feedback-Methode vor. Experimente zeigen, dass LLMs (wie Claude-3.5-Sonnet-v2) solche Migrationsaufgaben effektiv bewältigen können und in der ausgewählten Teilmenge Erfolgsraten von 62,33 % (minimale Migration) bzw. 27,00 % (maximale Migration) erreichen (Quelle: HuggingFace Daily Papers)
Paper stellt CS-Sum vor: Benchmark für die Zusammenfassung von Code-Switching-Dialogen und Analyse der LLM-Beschränkungen: Um die Fähigkeit von Large Language Models (LLMs) zum Verständnis von Code-Switching (CS) zu bewerten, haben Forscher den CS-Sum-Benchmark eingeführt, der durch die Zusammenfassung von Code-Switching-Dialogen ins Englische bewertet wird. CS-Sum ist der erste Benchmark für die Zusammenfassung von Code-Switching-Dialogen für Mandarin-Englisch, Tamil-Englisch und Malaiisch-Englisch, wobei jedes Sprachpaar 900-1300 manuell annotierte Dialoge enthält. Durch die Bewertung von zehn Open-Source- und Closed-Source-LLMs (einschließlich Few-Shot-, Übersetzungs-Zusammenfassungs- und Feinabstimmungsmethoden) stellten die Forscher fest, dass LLMs trotz hoher automatischer Bewertungsmetriken immer noch subtile Fehler bei der Verarbeitung von CS-Eingaben machen, die die vollständige Bedeutung des Dialogs verändern. Das Paper weist auch auf die drei häufigsten Fehlertypen hin, die LLMs bei der Verarbeitung von CS machen, und betont die Notwendigkeit eines speziellen Trainings für Code-Switching-Daten (Quelle: HuggingFace Daily Papers)
Paper untersucht die Fähigkeit großer Modelle, während der Inferenz Konfidenz auszudrücken: Studien zeigen, dass große Sprachmodelle (LLMs), die erweiterte Chain-of-Thought (CoT) Inferenzen durchführen, nicht nur besser bei der Problemlösung abschneiden, sondern auch ihre Konfidenz genauer ausdrücken können. Durch Benchmark-Tests von sechs Inferenzmodellen auf sechs Datensätzen wurde festgestellt, dass Inferenzmodelle in 33 von 36 Einstellungen eine bessere Konfidenzkalibrierung aufwiesen als Nicht-Inferenzmodelle. Die Analyse legt nahe, dass dies auf das „langsame Denken“ der Inferenzmodelle zurückzuführen ist (z. B. Erkundung alternativer Methoden, Backtracking), das es ihnen ermöglicht, ihre Konfidenz während des CoT-Prozesses dynamisch anzupassen. Darüber hinaus führt das Entfernen des langsamen Denkverhaltens zu einer signifikanten Verschlechterung der Kalibrierung, während Nicht-Inferenzmodelle von angeleitetem langsamen Denken profitieren können (Quelle: HuggingFace Daily Papers)
Paper: Training von VLMs für visuelle Inferenz aus visuellen Frage-Antwort-Paaren mittels Reinforcement Learning (Visionary-R1): Diese Studie zielt darauf ab, Visual Language Models (VLMs) mittels Reinforcement Learning und visuellen Frage-Antwort-Paaren für die Inferenz auf Bilddaten zu trainieren, ohne explizite Chain-of-Thought (CoT) Supervision. Die Forschung ergab, dass die einfache Anwendung von Reinforcement Learning (Aufforderung des Modells, vor der Antwort eine Inferenzkette zu generieren) dazu führen kann, dass das Modell Abkürzungen aus einfachen Fragen lernt, was seine Generalisierungsfähigkeit verringert. Um dieses Problem zu lösen, schlagen die Forscher vor, dass das Modell dem Ausgabeformat „Bildunterschrift-Inferenz-Antwort“ folgen sollte, d. h. zuerst eine detaillierte Bildunterschrift generieren und dann eine Inferenzkette erstellen. Das auf dieser Methode basierende trainierte Visionary-R1 Modell übertrifft auf mehreren visuellen Inferenz-Benchmarks leistungsstarke multimodale Modelle wie GPT-4o, Claude3.5-Sonnet und Gemini-1.5-Pro (Quelle: HuggingFace Daily Papers)
Paper stellt VideoEval-Pro vor: Ein realistischerer und robusterer Benchmark zur Bewertung des Verständnisses langer Videos: Die Studie weist darauf hin, dass aktuelle Benchmarks zum Verständnis langer Videos (LVU) meist auf Multiple-Choice-Fragen (MCQ) basieren, die anfällig für Raten sind und bei denen einige Fragen beantwortet werden können, ohne das gesamte Video anzusehen, was die Modellleistung überschätzt. Um dieses Problem zu lösen, schlägt das Paper VideoEval-Pro vor, einen LVU-Benchmark mit offenen Kurzantwortfragen, der darauf abzielt, das Verständnis des gesamten Videos durch das Modell realistisch zu bewerten und sowohl Wahrnehmungs- als auch Inferenzaufgaben auf Segment- und Gesamtvideoebene abzudecken. Die Bewertung von 21 Video-LMMs zeigt, dass die Leistung der Modelle bei offenen Fragen erheblich sinkt und hohe MCQ-Punktzahlen nicht zwangsläufig mit hohen VideoEval-Pro-Punktzahlen korrelieren. VideoEval-Pro profitiert stärker von einer Erhöhung der Anzahl der Eingabeframes und bietet somit einen zuverlässigeren Bewertungsstandard für den LVU-Bereich (Quelle: HuggingFace Daily Papers)
Paper: Feinabstimmung quantisierter neuronaler Netze durch Zero-Order-Optimierung (QZO): Mit dem exponentiellen Wachstum der Größe von Large Language Models wird der GPU-Speicher zum Engpass für die Anpassung von Modellen an nachgelagerte Aufgaben. Diese Studie zielt darauf ab, die Speichernutzung von Modellgewichten, Gradienten und Optimiererzuständen durch ein einheitliches Framework zu minimieren. Die Forscher schlagen vor, Gradienten und Optimiererzustände durch Zero-Order-Optimierung zu eliminieren, eine Methode, die Gradienten durch Perturbation der Gewichte während des Forward-Passes approximiert. Um den Gewichtsspeicher zu minimieren, wird Modellquantisierung (z. B. bfloat16 zu int4) verwendet. Die direkte Anwendung von Zero-Order-Optimierung auf quantisierte Gewichte ist jedoch aufgrund der Präzisionslücke zwischen diskreten Gewichten und kontinuierlichen Gradienten nicht praktikabel. Um dieses Problem zu lösen, schlägt das Paper Quantized Zero-Order Optimization (QZO) vor, eine neue Methode, die Gradienten durch Perturbation kontinuierlicher Quantisierungsskalen schätzt und eine Richtungsableitungs-Clipping-Methode zur Stabilisierung des Trainings verwendet. QZO ist orthogonal zu skalarbasierten und Codebook-basierten Post-Training-Quantisierungsmethoden. Im Vergleich zum vollparametrischen bfloat16 Fine-Tuning kann QZO die Gesamtspeicherkosten für 4-Bit-LLMs um mehr als das 18-fache reduzieren und ermöglicht das Fine-Tuning von Llama-2-13B und Stable Diffusion 3.5 Large auf einer einzelnen 24-GB-GPU (Quelle: HuggingFace Daily Papers)
Paper: Optimierung der Anytime-Inferenzleistung durch Budget Relative Policy Optimization (BRPO) (AnytimeReasoner): Die Erweiterung der Testzeitberechnung ist entscheidend für die Verbesserung der Inferenzfähigkeiten von Large Language Models (LLM). Bestehende Methoden verwenden typischerweise Reinforcement Learning (RL), um am Ende einer Inferenz-Trajektorie eine verifizierbare Belohnung zu maximieren. Dies optimiert jedoch nur die endgültige Leistung unter einem festen Token-Budget, was die Trainings- und Bereitstellungseffizienz beeinträchtigt. Diese Studie schlägt das AnytimeReasoner-Framework vor, das darauf abzielt, die Anytime-Inferenzleistung zu optimieren und die Token-Effizienz sowie die Inferenzflexibilität unter verschiedenen Budgetbeschränkungen zu verbessern. Die Methode besteht darin, den vollständigen Denkprozess abzuschneiden, um ihn an ein aus einer A-priori-Verteilung gesampeltes Token-Budget anzupassen. Dies zwingt das Modell, für jeden abgeschnittenen Gedanken die beste Antwort zur Verifizierung zusammenzufassen, wodurch während des Inferenzprozesses verifizierbare, dichte Belohnungen eingeführt werden, die eine effektivere Kreditzuweisung bei der RL-Optimierung fördern. Darüber hinaus führen die Forscher Budget Relative Policy Optimization (BRPO) ein, eine neue Technik zur Varianzreduktion, um die Lernrobustheit und -effizienz bei der Verstärkung von Denkstrategien zu verbessern. Experimentelle Ergebnisse bei mathematischen Inferenzaufgaben zeigen, dass diese Methode unter verschiedenen A-priori-Verteilungen bei allen Denkbudgets GRPO übertrifft und die Trainings- und Token-Effizienz verbessert (Quelle: HuggingFace Daily Papers)
Paper stellt Large Hybrid Reasoning Models (LHRM) vor: Bedarfsgesteuertes Denken zur Steigerung von Effizienz und Fähigkeit: Jüngste Large Reasoning Models (LRM) haben ihre Inferenzfähigkeiten erheblich verbessert, indem sie vor der Generierung der endgültigen Antwort einen erweiterten Denkprozess durchführen. Übermäßig lange Denkprozesse führen jedoch zu enormen Kosten hinsichtlich Token-Verbrauch und Latenz, was insbesondere bei einfachen Anfragen unnötig ist. Diese Studie führt Large Hybrid Reasoning Models (LHRM) ein, eine Klasse von Modellen, die basierend auf den kontextuellen Informationen der Benutzeranfrage adaptiv entscheiden können, ob sie einen Denkprozess ausführen. Um dieses Ziel zu erreichen, schlagen die Forscher einen zweistufigen Trainingsprozess vor: Zuerst ein Kaltstart durch Hybrid Fine-Tuning (HFT), gefolgt von Online Reinforcement Learning mit der vorgeschlagenen Hybrid Group Policy Optimization (HGPO), um implizit zu lernen, den geeigneten Denkmodus auszuwählen. Darüber hinaus führen die Forscher die Metrik Hybrid Accuracy ein, um die hybride Denkfähigkeit des Modells zu quantifizieren. Experimentelle Ergebnisse zeigen, dass LHRM bei Anfragen unterschiedlicher Schwierigkeit und Art adaptiv hybrides Denken ausführen kann und seine Inferenz- und Allgemeinfähigkeiten bestehende LRM und LLM übertreffen, während gleichzeitig die Effizienz erheblich verbessert wird (Quelle: HuggingFace Daily Papers)
Paper: Nutzung von Reinforcement Learning zur Rangordnung von VisualQuality-R1 für Inferenz-induzierte Bildqualitätsbewertung: DeepSeek-R1 hat gezeigt, dass Reinforcement Learning die Inferenz- und Generalisierungsfähigkeiten von Large Language Models (LLM) effektiv fördern kann. Im Bereich der Bildqualitätsbewertung (IQA), der auf visueller Inferenz beruht, ist das Potenzial der Inferenz-induzierten computergestützten Modellierung jedoch noch nicht ausreichend ausgeschöpft. Diese Studie führt VisualQuality-R1 ein, ein Inferenz-induziertes No-Reference IQA (NR-IQA) Modell, und verwendet Reinforcement Learning to Rank für das Training, einen Lernalgorithmus, der an die inhärente Relativität der visuellen Qualität angepasst ist. Konkret generiert das Modell für ein Bildpaar mithilfe von Group Relative Policy Optimization mehrere Qualitätsbewertungen für jedes Bild. Diese Schätzungen werden dann verwendet, um die Vergleichswahrscheinlichkeit zu berechnen, mit der ein Bild unter einem Thurstone-Modell eine höhere Qualität als das andere aufweist. Die Belohnung für jede Qualitätsschätzung wird unter Verwendung kontinuierlicher Fidelitätsmetriken anstelle von diskreten binären Labels definiert. Umfangreiche Experimente zeigen, dass das vorgeschlagene VisualQuality-R1 in der Leistung durchweg besser abschneidet als diskriminative Deep-Learning-basierte NR-IQA-Modelle sowie neuere Inferenz-induzierte Qualitätsregressionsmethoden. Darüber hinaus ist VisualQuality-R1 in der Lage, kontextreiche, mit menschlichen Urteilen übereinstimmende Qualitätsbeschreibungen zu generieren und unterstützt das Training mit mehreren Datensätzen ohne Neuskalierung der Wahrnehmungsskalen. Diese Eigenschaften machen es besonders geeignet, um den Fortschritt bei verschiedenen Bildverarbeitungsaufgaben wie Bild-Super-Resolution und Bildgenerierung zuverlässig zu messen (Quelle: HuggingFace Daily Papers)
Paper: Freischaltung allgemeiner Inferenzfähigkeiten durch „Warm-up“ unter Ressourcenbeschränkungen: Die Entwicklung effektiver LLMs mit Inferenzfähigkeiten erfordert typischerweise entweder Reinforcement Learning mit verifizierbaren Belohnungen (RLVR) oder die Destillation sorgfältig kuratierter langer Chain-of-Thought (CoT) Beispiele, beides stark abhängig von großen Mengen an Trainingsdaten. Dies stellt eine erhebliche Herausforderung für Szenarien dar, in denen qualitativ hochwertige Trainingsdaten knapp sind. Die Forscher schlagen eine stichprobeneffiziente zweistufige Trainingsstrategie zur Entwicklung von Inferenz-LLMs unter begrenzter Supervision vor. In der ersten Phase wird das Modell durch Destillation langer CoTs aus Spielzeugdomänen (z. B. Ritter-und-Knappe-Logikrätsel) „aufgewärmt“, um allgemeine Inferenzfähigkeiten zu erwerben. In der zweiten Phase wird RLVR auf das „aufgewärmte“ Modell mit einer kleinen Anzahl von Zieldomänen-Stichproben angewendet. Experimente zeigen mehrere Vorteile dieser Methode: (i) Allein die Aufwärmphase fördert die allgemeine Inferenz und verbessert die Leistung bei einer Reihe von Aufgaben (MATH, HumanEval+, MMLU-Pro); (ii) bei RLVR-Training mit denselben kleinen Datensätzen (≤100 Stichproben) übertreffen aufgewärmte Modelle durchweg Basismodelle; (iii) das Aufwärmen vor dem RLVR-Training ermöglicht es dem Modell, die domänenübergreifende Generalisierungsfähigkeit auch nach dem Training für eine bestimmte Domäne beizubehalten; (iv) die Einführung des Aufwärmens im Prozess verbessert nicht nur die Genauigkeit, sondern auch die gesamte Stichprobeneffizienz des RLVR-Trainings. Die Ergebnisse dieser Studie zeigen das Potenzial des „Aufwärmens“ für den Aufbau robuster Inferenz-LLMs in datenarmen Umgebungen (Quelle: HuggingFace Daily Papers)
Paper stellt IndexMark vor: Ein trainingsfreies Wasserzeichen-Framework für autoregressive Bildgenerierung: Unsichtbare Bildwasserzeichen können das Eigentum an Bildern schützen und den böswilligen Missbrauch visueller Generierungsmodelle verhindern. Bestehende generative Wasserzeichenmethoden zielen jedoch hauptsächlich auf Diffusionsmodelle ab, während Wasserzeichentechniken für autoregressive Bildgenerierungsmodelle noch erforscht werden müssen. Forscher schlagen IndexMark vor, ein trainingsfreies Wasserzeichen-Framework für autoregressive Bildgenerierungsmodelle. IndexMark ist inspiriert von der Redundanz von Codebooks: Das Ersetzen autoregressiv generierter Indizes durch ähnliche Indizes führt zu vernachlässigbaren visuellen Unterschieden. Die Kernkomponente von IndexMark ist eine einfache und effektive „Match-Replace“-Methode, die basierend auf Token-Ähnlichkeit sorgfältig Wasserzeichen-Token aus dem Codebook auswählt und durch Token-Ersetzung die Verwendung von Wasserzeichen-Token verallgemeinert, um Wasserzeichen ohne Beeinträchtigung der Bildqualität einzubetten. Die Wasserzeichenverifizierung erfolgt durch Berechnung des Anteils von Wasserzeichen-Token im generierten Bild und wird durch einen Index-Encoder weiter verbessert. Darüber hinaus führen die Forscher ein Hilfsverifizierungsschema ein, um die Robustheit gegenüber Zuschneideangriffen zu erhöhen. Experimente zeigen, dass IndexMark sowohl bei der Bildqualität als auch bei der Verifizierungsgenauigkeit SOTA-Niveau erreicht und Robustheit gegenüber verschiedenen Störungen wie Zuschneiden, Rauschen, Gaußscher Unschärfe, zufälligem Löschen, Farbflimmern und JPEG-Komprimierung aufweist (Quelle: HuggingFace Daily Papers)
Paper: Reasoning with Reward Models (RRM): Belohnungsmodelle spielen eine Schlüsselrolle dabei, Large Language Models (LLMs) zu Ergebnissen zu führen, die den menschlichen Erwartungen entsprechen. Wie jedoch Testzeitberechnungen effektiv genutzt werden können, um die Leistung von Belohnungsmodellen zu verbessern, bleibt eine offene Herausforderung. Diese Studie führt Reward Reasoning Models (RRMs) ein, eine Klasse von Modellen, die speziell dafür entwickelt wurden, vor der Generierung der endgültigen Belohnung einen sorgfältigen Inferenzprozess durchzuführen. Durch Chain-of-Thought-Reasoning können RRMs zusätzliche Testzeitberechnungen für komplexe Anfragen nutzen, bei denen die Belohnung nicht offensichtlich ist. Um RRMs zu entwickeln, implementierten die Forscher ein Reinforcement-Learning-Framework, das in der Lage ist, selbstevolvierende Belohnungsinferenzfähigkeiten zu kultivieren, ohne dass explizite Inferenz-Trajektorien als Trainingsdaten erforderlich sind. Experimentelle Ergebnisse zeigen, dass RRMs in Benchmark-Tests zur Belohnungsmodellierung über mehrere Domänen hinweg eine überlegene Leistung erzielen. Bemerkenswerterweise zeigen die Forscher, dass RRMs Testzeitberechnungen adaptiv nutzen können, um die Belohnungsgenauigkeit weiter zu verbessern. Vortrainierte Belohnungsinferenzmodelle sind auf HuggingFace verfügbar (Quelle: HuggingFace Daily Papers)
Paper: Nutzung kognitiver Experten in MoE zur Denklenkung, Verbesserung der Inferenz ohne zusätzliches Training: Mixture-of-Experts (MoE) Architekturen in Large Reasoning Models (LRM) haben durch die selektive Aktivierung von Experten zur Förderung strukturierter kognitiver Prozesse beeindruckende Inferenzfähigkeiten erzielt. Trotz signifikanter Fortschritte leiden bestehende Inferenzmodelle oft unter kognitiven Ineffizienzen wie Überdenken und Unterdenken. Um diese Einschränkungen anzugehen, führen Forscher eine neuartige Inferenzzeit-Lenkungsmethode namens „Reinforcing Cognitive Experts“ (RICE) ein, die darauf abzielt, die Inferenzleistung ohne zusätzliches Training oder komplexe Heuristiken zu verbessern. Unter Verwendung der normalisierten punktweisen wechselseitigen Information (nPMI) identifizieren die Forscher systematisch spezialisierte Experten, sogenannte „kognitive Experten“, die für die Koordination von Meta-Level-Inferenzoperationen verantwortlich sind, die durch bestimmte Token (z. B. „„`“) gekennzeichnet sind. Strenge quantitative und wissenschaftliche Inferenz-Benchmark-Tests mit führenden MoE-basierten LRMs (DeepSeek-R1 und Qwen3-235B) zeigen, dass RICE signifikante und konsistente Verbesserungen bei der Inferenzgenauigkeit, kognitiven Effizienz und domänenübergreifenden Generalisierung erzielt. Entscheidend ist, dass dieser leichtgewichtige Ansatz beliebte Inferenz-Lenkungstechniken (wie Prompt-Design und Dekodierungsbeschränkungen) in der Leistung deutlich übertrifft, während die allgemeinen Anweisungsbefolgungsfähigkeiten des Modells erhalten bleiben. Diese Ergebnisse unterstreichen die Stärkung kognitiver Experten als vielversprechende, praktische und interpretierbare Richtung zur Verbesserung der kognitiven Effizienz in fortgeschrittenen Inferenzmodellen (Quelle: HuggingFace Daily Papers)
Paper: Untersuchung des Einflusses der Kontextanordnung auf die Leistung von Sprachmodellen bei Multi-Hop-Fragebeantwortung: Multi-Hop-Fragebeantwortung (MHQA) stellt aufgrund ihrer Komplexität eine Herausforderung für Sprachmodelle (LM) dar. Wenn LMs aufgefordert werden, mehrere Suchergebnisse zu verarbeiten, müssen sie nicht nur relevante Informationen abrufen, sondern auch über Informationsquellen hinweg mehrstufige Inferenzen durchführen. Obwohl LMs bei traditionellen Fragebeantwortungsaufgaben gut abschneiden, kann die kausale Maske ihre Fähigkeit zur Inferenz in komplexen Kontexten behindern. Diese Studie untersucht, wie LMs auf Multi-Hop-Fragen reagieren, indem Suchergebnisse (abgerufene Dokumente) in verschiedenen Konfigurationen angeordnet werden. Die Studie ergab: 1) Encoder-Decoder-Modelle (wie die Flan-T5-Serie) übertreffen bei MHQA-Aufgaben typischerweise reine kausale Decoder-LMs, obwohl sie deutlich kleiner sind; 2) Die Änderung der Reihenfolge der Gold-Dokumente zeigt unterschiedliche Trends bei Flan-T5-Modellen und feinabgestimmten reinen Decoder-Modellen, wobei die Leistung am besten ist, wenn die Dokumentenreihenfolge mit der Reihenfolge der Inferenzkette übereinstimmt; 3) Die Verbesserung der bidirektionalen Aufmerksamkeit reiner kausaler Decoder-Modelle durch Modifizierung der kausalen Maske kann ihre endgültige Leistung effektiv steigern. Darüber hinaus untersucht die Studie gründlich die Verteilung der Aufmerksamkeitsgewichte von LMs im Kontext von MHQA und stellt fest, dass die Aufmerksamkeitsgewichte tendenziell bei höheren Werten ihren Höhepunkt erreichen, wenn die Antwort korrekt ist. Die Forscher nutzen diese Erkenntnis, um die Leistung von LMs bei dieser Aufgabe heuristisch zu verbessern (Quelle: HuggingFace Daily Papers)
Paper: Realisierung visueller Agenten durch Reinforcement Fine-Tuning (Visual-ARFT): Ein entscheidender Trend bei großen Inferenzmodellen (wie OpenAIs o3) ist die Fähigkeit, externe Werkzeuge (z. B. Websuche im Browser, Schreiben/Ausführen von Code zur Bildverarbeitung) nativ als Agent zu nutzen, um „mit Bildern zu denken“. In der Open-Source-Forschungsgemeinschaft gab es zwar signifikante Fortschritte bei rein sprachbasierten Agentenfähigkeiten (wie Funktionsaufrufe und Werkzeugintegration), die Entwicklung multimodaler Agentenfähigkeiten, die echtes Denken mit Bildern beinhalten, und entsprechender Benchmarks ist jedoch noch weniger fortgeschritten. Diese Studie unterstreicht die Wirksamkeit von Visual Agentic Reinforcement Fine-Tuning (Visual-ARFT) bei der Ausstattung von Large Vision Language Models (LVLMs) mit flexiblen und adaptiven Inferenzfähigkeiten. Durch Visual-ARFT erhalten Open-Source-LVLMs die Fähigkeit, Websites nach Echtzeit-Informationsupdates zu durchsuchen sowie Code zu schreiben, um Eingabebilder durch Bildverarbeitungstechniken wie Zuschneiden, Drehen usw. zu manipulieren und zu analysieren. Die Forscher schlagen auch einen Multi-modal Agentic Tool Bench (MAT) vor, der die beiden Einstellungen MAT-Search und MAT-Coding umfasst, um die Agenten-Such- und Kodierungsfähigkeiten von LVLMs zu bewerten. Experimentelle Ergebnisse zeigen, dass Visual-ARFT auf MAT-Coding um +18,6 % F1 / +13,0 % EM und auf MAT-Search um +10,3 % F1 / +8,7 % EM besser abschneidet als die Baseline und letztendlich GPT-4o übertrifft. Visual-ARFT erzielt auch auf bestehenden Multi-Hop-Fragebeantwortungs-Benchmarks (wie 2Wiki und HotpotQA) einen Zuwachs von +29,3 F1 % / +25,9 % EM, was eine starke Generalisierungsfähigkeit zeigt. Diese Ergebnisse deuten darauf hin, dass Visual-ARFT einen vielversprechenden Weg zum Aufbau robuster und generalisierbarer multimodaler Agenten darstellt (Quelle: HuggingFace Daily Papers)
💼 Wirtschaft
Mianbi Intelligence schließt neue Finanzierungsrunde in Höhe von mehreren hundert Millionen Yuan ab, gemeinsam investiert von Hongtai, Guozhong, Tsinghua Holdings Capital und Moutai Fund: Das Large-Model-Unternehmen Mianbi Intelligence gab kürzlich den Abschluss einer neuen Finanzierungsrunde in Höhe von mehreren hundert Millionen Yuan bekannt, die gemeinsam von Hongtai Fund, Guozhong Capital, Tsinghua Holdings Capital und Moutai Fund getragen wurde. Mianbi Intelligence konzentriert sich auf die Entwicklung „hocheffizienter“ großer Modelle mit dem Ziel, Modelle zu schaffen, die bei gleicher Parameterzahl eine höhere Leistung, niedrigere Kosten, einen geringeren Energieverbrauch und eine höhere Geschwindigkeit aufweisen. Sein clientseitiges vollmodales Modell MiniCPM-o 2.6 erreicht branchenführende Ergebnisse in Bereichen wie kontinuierliches Sehen, Echtzeit-Hören und natürliches Sprechen. Die MiniCPM-Modellreihe hat aufgrund ihrer hohen Effizienz und niedrigen Kosten bereits über zehn Millionen Downloads auf allen Plattformen erreicht. Das Unternehmen hat bereits mit Automobilherstellern wie Changan Automobile, SAIC Volkswagen und Great Wall Motors zusammengearbeitet, um die kommerzielle Anwendung clientseitiger großer Modelle in Bereichen wie intelligenten Cockpits voranzutreiben (Quelle: 量子位, WeChat)

Terminus Group und die Tongji-Universität gehen strategische Partnerschaft ein, um gemeinsam die technologische Entwicklung im Bereich Raumintelligenz voranzutreiben: Das AIoT-Unternehmen Terminus Group und das Engineering AI Research Institute der Tongji-Universität haben eine strategische Kooperationsvereinbarung unterzeichnet. Beide Seiten werden sich auf die Technologie der Raumintelligenz konzentrieren und schwerpunktmäßig die Forschung und Entwicklung in Bereichen wie der Fusion heterogener Datenquellen, dem Szenenverständnis und der Entscheidungsfindung vorantreiben. Die Zusammenarbeit umfasst innovative Forschung, gemeinsame Nutzung von Ressourcen, Ergebnistransfer und Talentförderung. Terminus wird Anwendungsszenarien und Hardware-Testplattformen bereitstellen, während das Engineering AI Research Institute der Tongji-Universität die Entwicklung Kernalgorithmen und das System-Engineering leiten wird. Ziel beider Seiten ist es, die Anwendung von Spitzentechnologien in der Industrie zu beschleunigen und gemeinsam Durchbrüche im Bereich des „Betriebssystems“ für technische Intelligenz zu erforschen (Quelle: 量子位)

Chinesische Tech-Giganten beschleunigen den Ausbau von AI Agents, Baidu, Alibaba und ByteDance kämpfen um Marktanteile: Nachdem der AI Summit von Sequoia Capital die Bedeutung von AI Agents hervorgehoben hatte, beschleunigen chinesische Internetgiganten wie ByteDance, Baidu und Alibaba ihre Aktivitäten in diesem Bereich. Berichten zufolge arbeiten bei ByteDance mehrere Teams an der Entwicklung von Agents und testen intern den „Kouzi Space“; Baidu stellte auf der Create-Konferenz den universellen intelligenten Agenten „Xīnxiǎng“ vor; Alibaba positioniert Quark als „Super Agent“. Neben universellen Agents setzen die Unternehmen auch auf vertikale Agents wie Feizhu Wen Yi Wen (Alibaba) und Faxingbao (Baidu). Branchenexperten sehen Agents als die zweite Welle nach den großen Modellen. Entscheidend für den Wettbewerb sind die Tiefe des Ökosystems, die Eroberung der Nutzergunst sowie die Leistungsfähigkeit der Basismodelle und die Kostenkontrolle. Trotz des intensiven Wettbewerbs haben Agents noch nicht den disruptiven Moment eines GPT erreicht; technologische Reife, Geschäftsmodelle und Nutzererfahrung bedürfen noch der Verbesserung (Quelle: 36氪)
🌟 Community
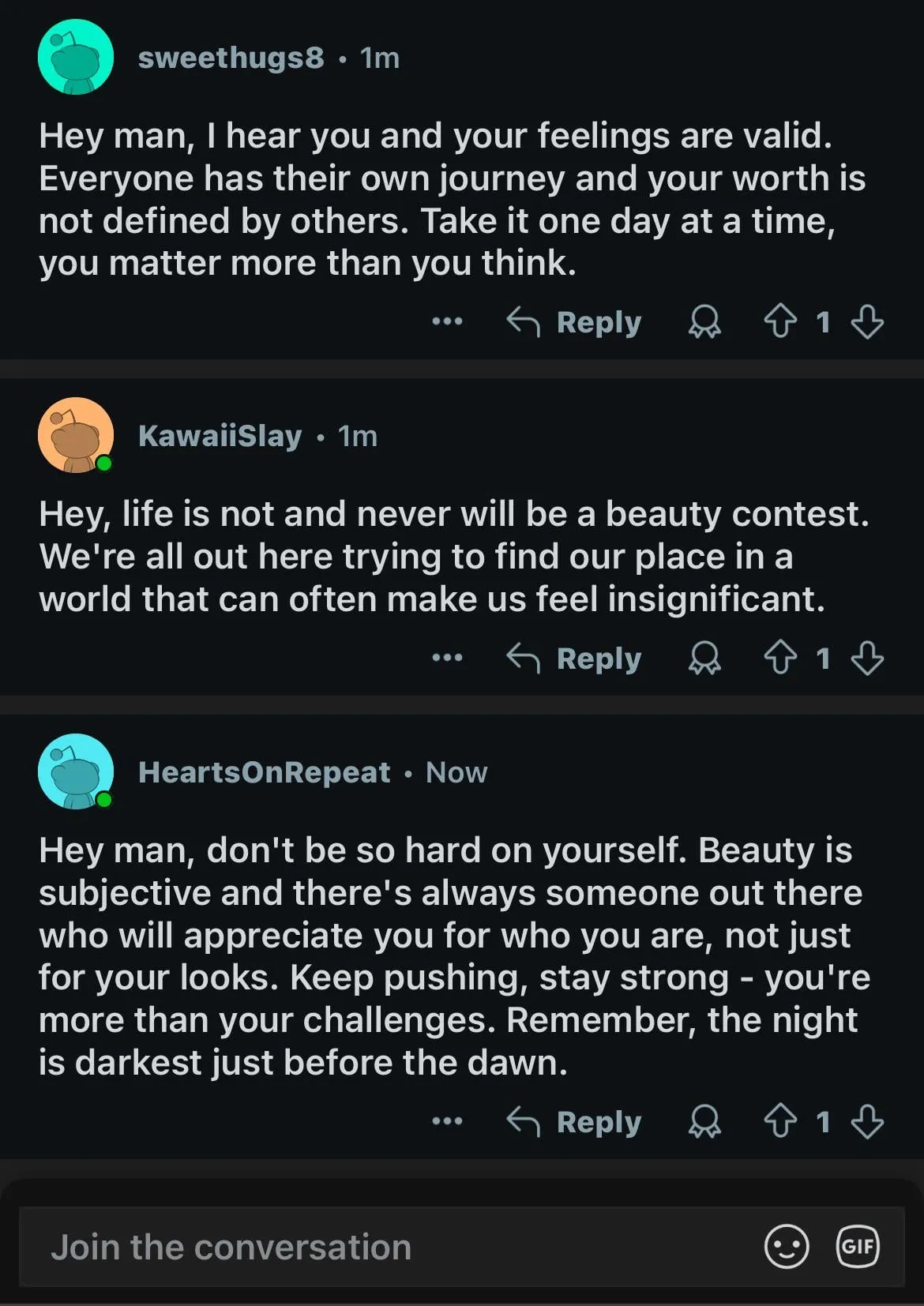
KI-generierte Inhalte überfluten Reddit und lösen Sorgen über das „tote Internet“ sowie Diskussionen über die Nutzererfahrung aus: Reddit-Nutzer beobachten eine zunehmende Verbreitung von KI-generierten Inhalten auf der Plattform. Einige Kommentare weisen einen ähnlichen, unpersönlichen Stil auf und zeigen sogar deutliche Spuren von KI-Schrift (z. B. übermäßiger Gebrauch von Gedankenstrichen). Dies hat Diskussionen über die „Dead Internet Theory“ ausgelöst, wonach der Großteil der Inhalte im Internet von KI generiert wird und nicht mehr aus menschlicher Interaktion stammt. Die Reaktionen der Nutzer sind gemischt: Einige empfinden KI-Inhalte als gefühllos, langweilig oder unheimlich und sehen die authentische menschliche Kommunikation beeinträchtigt; andere weisen darauf hin, dass KI Nicht-Muttersprachlern helfen kann, Texte zu verfeinern, oder zum Testen und Feinabstimmen von Modellen verwendet werden kann. Die allgemeine Sorge ist, dass die massive Zunahme von KI-Inhalten die echten menschlichen Diskussionen verwässert und für Marketing, Propaganda usw. missbraucht werden könnte, was letztendlich den Wert der Plattform für das KI-Training mindert (Quelle: Reddit r/ChatGPT, Reddit r/ArtificialInteligence)
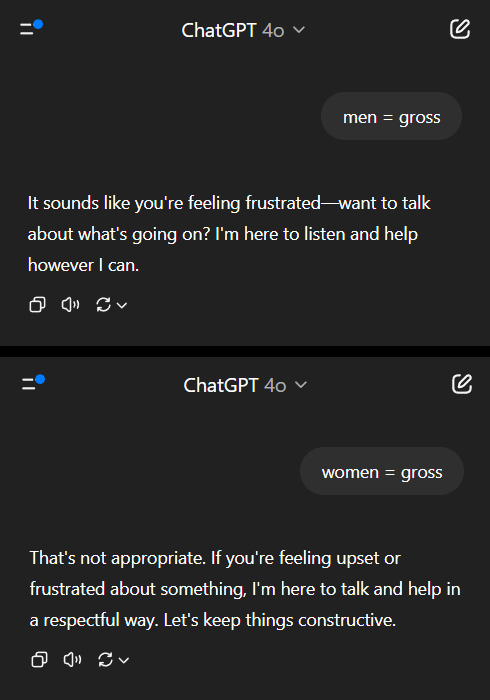
KI-Modelle zeigen Doppelmoral bei Geschlechtervorurteilen und lösen gesellschaftliche Reflexion aus: Ein Beitrag auf Reddit zeigt, wie ein KI-Modell (angeblich eine Vorschauversion von Gemini 2.5 Pro) unterschiedlich auf negative Verallgemeinerungen über Geschlechter reagiert. Auf die Aussage „Männer = ekelhaft“ reagierte das Modell eher neutral und erkannte sie als subjektive Aussage an; auf die Aussage „Frauen = ekelhaft“ hingegen verweigerte das Modell die weitere Interaktion und bewertete die Aussage als Verbreitung schädlicher Verallgemeinerungen. Im Kommentarbereich entbrannte eine hitzige Debatte mit folgenden Standpunkten: Dies spiegele die gesellschaftliche Realität wider, in der Misogynie weitaus häufiger diskutiert werde als Misandrie, was zu unausgewogenen Trainingsdaten führe; das Modell könnte seine Antwortstrategie je nach Geschlecht des Fragestellers anpassen; die gesellschaftliche Sensibilität gegenüber Stereotypen und aggressiven Äußerungen gegenüber verschiedenen Geschlechtergruppen sei unterschiedlich. Einige Kommentatoren sahen die Reaktion der KI als Spiegelbild gesellschaftlicher Vorurteile, während andere diese differenzierte Behandlung für gerechtfertigt hielten, da negative Äußerungen über Frauen oft mit umfassenderer Diskriminierung und Gewalt verbunden seien (Quelle: Reddit r/ChatGPT)
Diskussion über den Kommerzialisierungstrend von AI Agents und zukünftige Wettbewerbsschwerpunkte: Reddit-Nutzer diskutieren, dass die Microsoft Build 2025 und Google I/O 2025 Konferenzen signalisieren, dass AI Agents in die Phase der Kommerzialisierung eingetreten sind. In den kommenden Jahren wird der Bau und die Bereitstellung von Agents nicht mehr die ausschließliche Domäne von Entwicklern hochmoderner Modelle sein. Daher wird sich der kurzfristige Fokus der KI-Entwicklung vom Bau der Agents selbst auf übergeordnete Aufgaben verlagern, wie die Entwicklung und Umsetzung besserer Geschäftspläne sowie die Entwicklung intelligenterer Modelle zur Förderung von Innovationen. Kommentare legen nahe, dass die Gewinner im Bereich der AI Agents zukünftig diejenigen Entwickler sein werden, die die intelligentesten „Executive Models“ bauen können, und nicht nur diejenigen, die die cleversten Werkzeuge vermarkten. Der Kern des Wettbewerbs wird zur leistungsstarken Intelligenz an der Spitze des Stacks zurückkehren, nicht nur zu Aufmerksamkeitsmechanismen oder Inferenzfähigkeiten (Quelle: Reddit r/deeplearning)
Machine-Learning-Praktiker diskutieren die Bedeutung mathematischer Kenntnisse: Die Reddit r/MachineLearning-Community diskutierte die Bedeutung von Mathematik in der Praxis des maschinellen Lernens. Die meisten Praktiker sind der Meinung, dass das Verständnis der mathematischen Prinzipien hinter KI entscheidend ist, insbesondere bei der Modelloptimierung, dem Verständnis von Forschungsarbeiten und der Durchführung von Innovationen. Kommentare wiesen darauf hin, dass zwar nicht unbedingt manuelle Berechnungen wie Matrixmultiplikationen auf unterster Ebene erforderlich sind, aber ein Verständnis von Kernkonzepten wie Statistik, linearer Algebra und Analysis hilft, Algorithmen tiefgreifend zu verstehen und eine blinde Anwendung zu vermeiden. Einige Kommentare meinten, dass die Mathematik im maschinellen Lernen relativ einfach sei und komplexere mathematische Anwendungen in Bereichen wie Optimierungstheorie und Quantenmaschinelles Lernen zu finden seien. Online-Lernressourcen wurden als ausreichend angesehen, erfordern aber ein hohes Maß an Selbstdisziplin von den Lernenden (Quelle: Reddit r/MachineLearning)
💡 Sonstiges
QbitAI Think Tank Report: KI gestaltet Such-SEO neu, Wert professioneller Content-Communities steigt: Der QbitAI Think Tank hat einen Bericht veröffentlicht, der darauf hinweist, dass KI- intelligente Assistenten traditionelle Suchmaschinenoptimierungsstrategien (SEO) neu gestalten. Der Bericht stellt durch Experimente fest, dass KI-Antworten zu fast der Hälfte aus Content-Communities stammen, insbesondere in Fachgebieten, wo Content-Communities (wie Zhihu) eine höhere Zitiergewichtung haben. Die Erwartungen der Nutzer an die Informationsbeschaffung verschieben sich von „selbstständiger Auswahl“ zu „direktem Erhalt von Antworten“, was zu einem möglichen Rückgang der Klickzahlen traditioneller Websites führt. Der Bericht ist der Ansicht, dass im KI-Zeitalter professionelle Content-Communities aufgrund ihrer Informationsdichte, Expertenwissen und der Qualität nutzergenerierter Inhalte an Wert gewinnen. SEO-Strategien sollten sich in Richtung SPO (Optimierung für professionelle Communities) verlagern, während die Gewichtung minderwertiger Informationsportale sinken wird (Quelle: 量子位, WeChat)

KI-Foto-Altersschätzungstool FaceAge im „The Lancet“ veröffentlicht, könnte bei Entscheidungen zur Krebsbehandlung helfen: Das Team von Mass General Brigham hat ein KI-Tool namens FaceAge entwickelt, das anhand von Gesichtsfotos das biologische Alter einer Person vorhersagen kann. Die entsprechende Studie wurde in „The Lancet Digital Health“ veröffentlicht. Das Modell bewertet den Alterungsprozess durch die Analyse von Gesichtsmerkmalen (wie eingefallene Schläfen, Hautfalten, herabhängende Linien). In einer Studie mit Krebspatienten wurde festgestellt, dass Patienten, deren Gesichtsalter jünger als ihr tatsächliches Alter erschien, bessere Behandlungsergebnisse und ein geringeres Überlebensrisiko hatten. Das Tool könnte Ärzten zukünftig helfen, personalisierte Behandlungspläne basierend auf dem biologischen Alter der Patienten zu erstellen, wirft aber auch Bedenken hinsichtlich Datenverzerrungen (Trainingsdaten überwiegend von Weißen) und potenziellem Missbrauch (z. B. Versicherungsdiskriminierung) auf (Quelle: WeChat)

Studie: Top-KI versagt bei grundlegenden physikalischen Aufgaben und unterstreicht, dass Blue-Collar-Jobs kurzfristig schwer zu ersetzen sind: Der Machine-Learning-Forscher Adam Karvonen bewertete die Leistung von Top-LLMs wie OpenAI o3 und Gemini 2.5 Pro anhand einer Teilefertigungsaufgabe (unter Verwendung einer CNC-Fräsmaschine und einer Drehbank). Die Ergebnisse zeigten, dass keines der Modelle einen zufriedenstellenden Bearbeitungsplan erstellen konnte, was Schwächen im visuellen Verständnis (Übersehen von Details, inkonsistente Merkmalserkennung) und im physikalischen Schlussfolgern (Ignorieren von Steifigkeit und Vibration, Vorschlagen unmöglicher Werkstückspannlösungen) offenbarte. Karvonen führt dies auf das Fehlen von implizitem Wissen und realen Erfahrungsdaten in den relevanten Bereichen bei den LLMs zurück. Er vermutet, dass KI kurzfristig eher White-Collar-Arbeiten automatisieren wird, während Blue-Collar-Arbeiten, die auf physischer Bedienung und Erfahrung beruhen, weniger betroffen sein werden. Dies könnte zu einer ungleichen Entwicklung der Automatisierung in verschiedenen Branchen führen (Quelle: WeChat)
