Schlüsselwörter:OpenAI, Jony Ive, KI-Hardware, Google I/O, Gemini, Mistral KI, Devstral, KI-Programmierung, OpenAI übernimmt io, Gemini 2.5 Pro, Devstral Open-Source-Modell, KI-Filmproduktionstool Flow, KI-Programmieragent Jules
🔥 Fokus
OpenAI kündigt Übernahme von Jony Ives KI-Hardware-Startup io für 6,5 Milliarden US-Dollar an: OpenAI bestätigt die Übernahme von io, einem KI-Hardware-Unternehmen, das vom ehemaligen Apple Chief Design Officer Jony Ive in Zusammenarbeit mit SoftBank gegründet wurde, für rund 6,5 Milliarden US-Dollar. Jony Ive wird Creative Director bei OpenAI und für das Produktdesign verantwortlich sein. Das rund 55-köpfige Team von io wird zu OpenAI wechseln und sich der Entwicklung neuartiger KI-Hardwaregeräte widmen, wobei das erste Produkt voraussichtlich 2026 auf den Markt kommen soll. Diese Übernahme markiert den offiziellen Eintritt von OpenAI in den Hardwarebereich mit dem Ziel, KI-native Personal-Computing-Geräte und Interaktionserlebnisse zu schaffen, die möglicherweise den bestehenden Smartphone- und Computermarkt herausfordern könnten. (Quelle: 量子位, 智东西, 新芒xAI, sama, Reddit r/artificial, dotey, steph_palazzolo, karinanguyen_, kevinweil, npew, gdb, zachtratar, shuchaobi, snsf, Reddit r/ArtificialInteligence)

Google I/O Konferenz stellt mehrere KI-Modelle und Anwendungen vor und betont die Integration von KI in den Alltag: Google hat auf seiner I/O 2025 Entwicklerkonferenz Gemini 2.5 Pro und seine Deep-Thinking-Version, das leichtgewichtige Gemini 2.5 Flash, das Text-Diffusionsmodell Gemini Diffusion, das Bildgenerierungsmodell Imagen 4 und das Videogenerierungsmodell Veo 3 vorgestellt. Veo 3 unterstützt die Erstellung von Videos mit Audio und Dialogen und liefert beeindruckende Ergebnisse. Google hat außerdem die KI-Filmerstellungsanwendung Flow eingeführt, die Veo, Imagen und Gemini integriert. Die KI-Suchfunktion wird KI-Zusammenfassungen, Deep Search und persönliche Informationen integrieren und einen AI Mode einführen. Google betont die nahtlose Integration von KI in bestehende Produkte und Dienstleistungen mit dem Ziel, die KI-Technologie “unsichtbar” zu machen und die Benutzererfahrung zu verbessern. (Quelle: , MIT Technology Review, dotey, JeffDean, demishassabis, GoogleDeepMind, Google, Reddit r/ChatGPT)

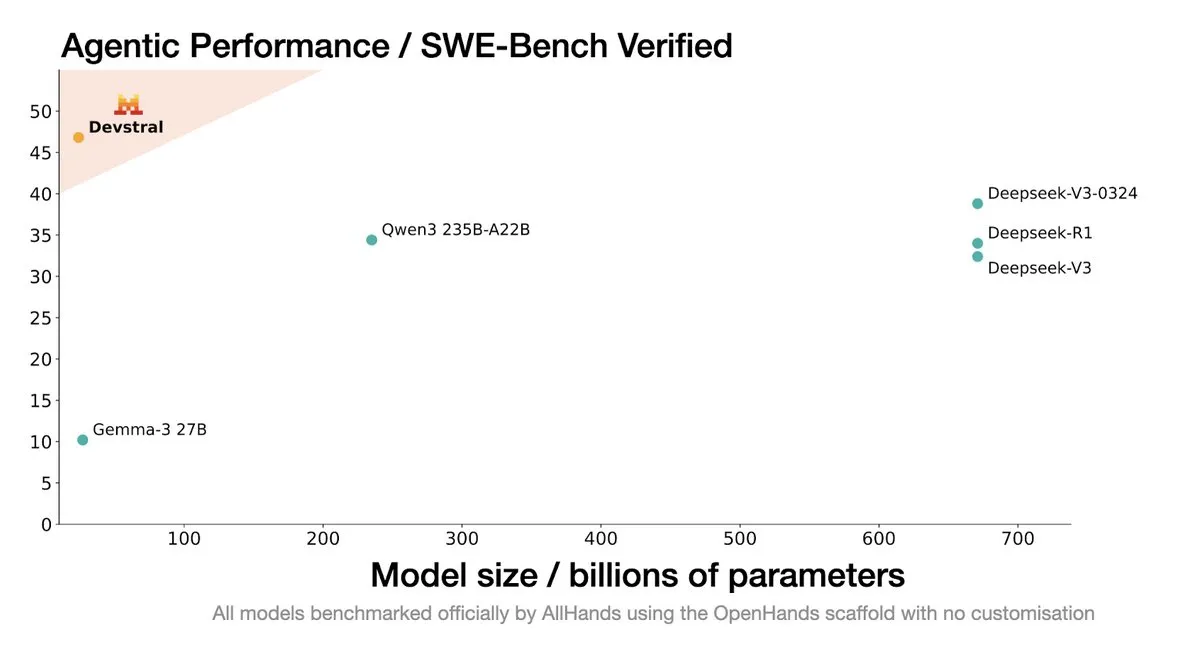
Mistral AI veröffentlicht Devstral: Ein SOTA Open-Source-Modell speziell für Coding-Agenten: Mistral AI hat in Zusammenarbeit mit All Hands AI Devstral vorgestellt, ein SOTA Open-Source-Modell, das speziell für Coding-Agenten entwickelt wurde. Das Modell zeigt im SWE-Bench Verified Benchmark eine hervorragende Leistung und übertrifft die DeepSeek-Serie sowie Qwen3 235B, bei einer Parametergröße von nur 24B. Es kann auf einer einzelnen RTX4090-Karte oder einem Mac mit 32 GB RAM ausgeführt werden. Devstral wurde auf realen GitHub Issues trainiert und legt den Schwerpunkt auf das Kontextverständnis in großen Codebasen, die Erkennung von Komponentenbeziehungen und die Identifizierung komplexer Funktionsfehler. Es verwendet die Apache 2.0 Open-Source-Lizenz und ist damit offener als das vorherige Codestral. (Quelle: MistralAI, natolambert, karminski3, qtnx_, huggingface, arthurmensch)
Google DeepMind CTO Koray Kavukcuoglu erläutert Veo 3, Deep Think und AGI-Fortschritte: Während der Google I/O Konferenz gab DeepMind CTO Koray Kavukcuoglu ein Interview, in dem er die Fortschritte des Videogenerierungsmodells Veo 3 (z.B. Audio-Video-Synchronisation), den durch Deep Think erweiterten Reasoning-Modus in Gemini 2.5 Pro (Reasoning durch parallele Gedankengänge) und seine Ansichten zu AGI diskutierte. Kavukcuoglu betonte, dass Skalierung nicht der einzige Faktor zur Erreichung von AGI sei; Architektur, Algorithmen, Daten und Reasoning-Technologien seien gleichermaßen wichtig. Die Realisierung von AGI erfordere Durchbrüche in der Grundlagenforschung und entscheidende Innovationen, nicht nur reines Engineering. Er zeigte sich auch optimistisch bezüglich des “Vibe Coding”, das Menschen ohne Programmierhintergrund die Erstellung von Anwendungen ermöglichen soll. (Quelle: demishassabis, 36氪)
🎯 Aktuelles
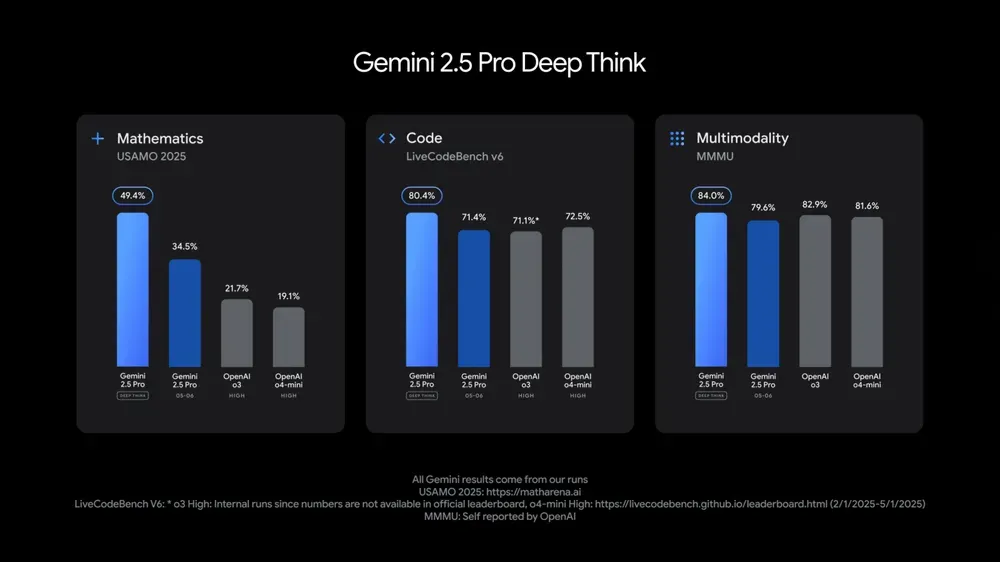
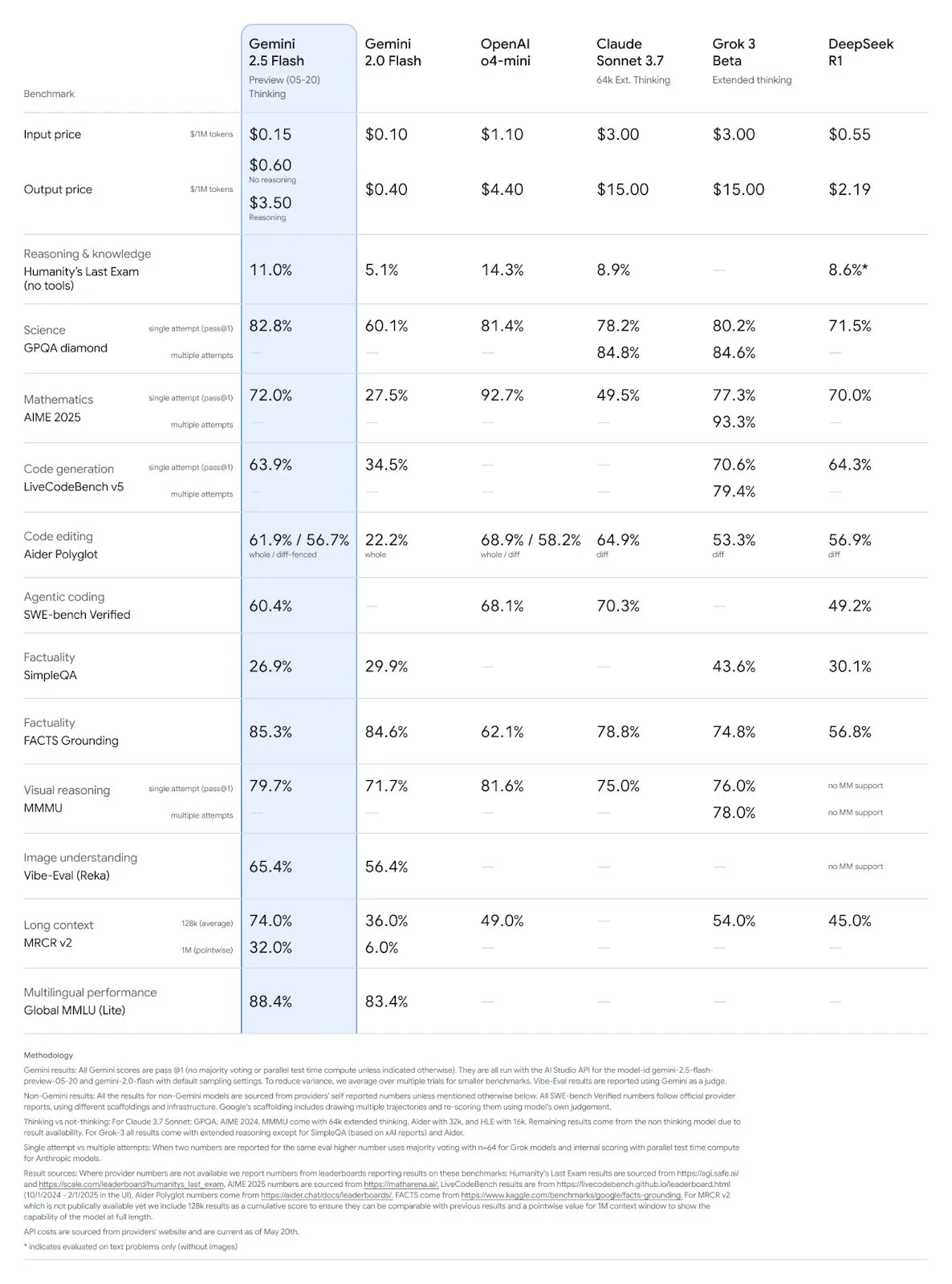
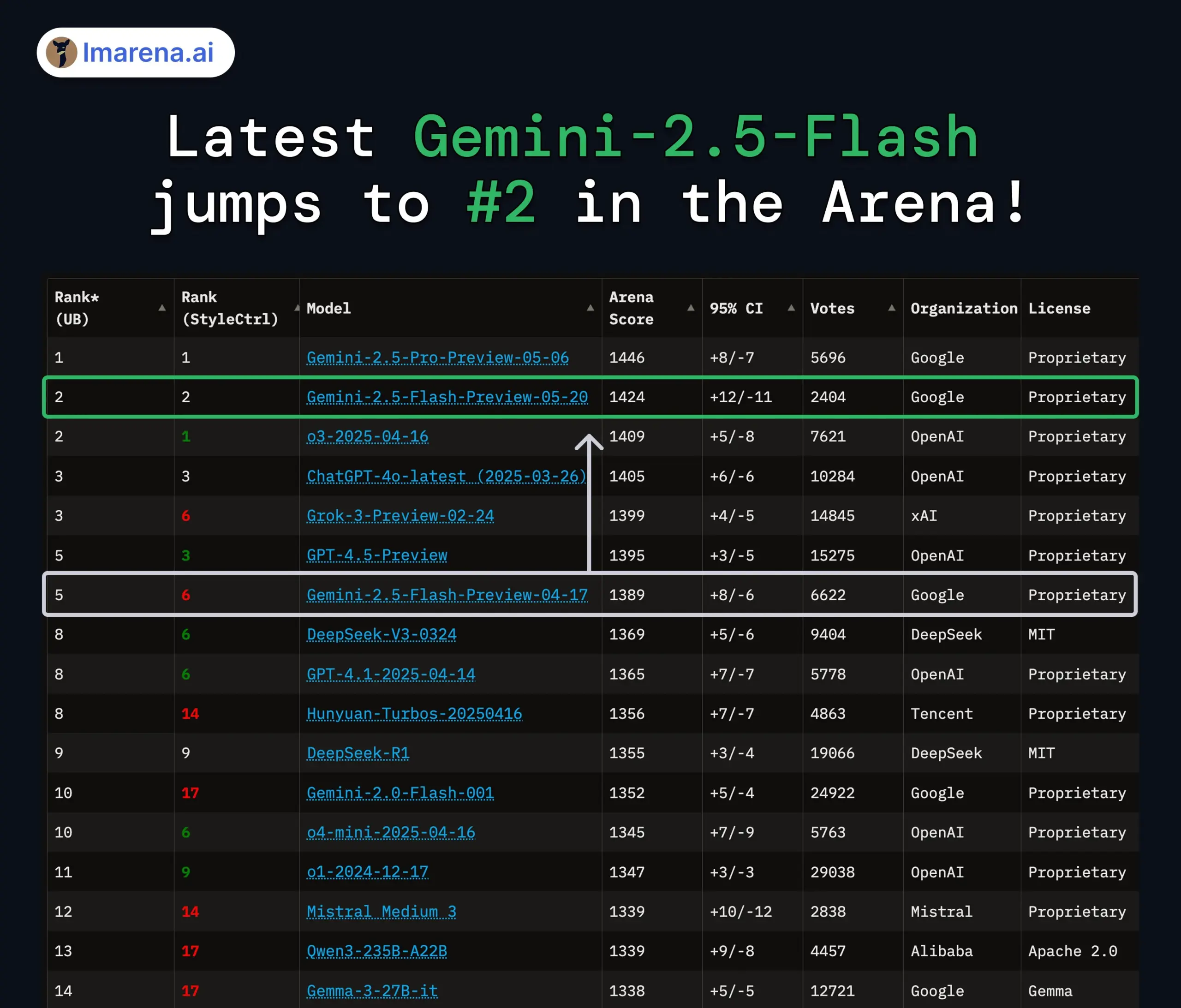
Google Gemini 2.5 Pro und Flash Modelle aktualisiert, Leistung deutlich verbessert: Google kündigte auf der I/O Konferenz an, dass die Modelle Gemini 2.5 Pro und Flash im Juni offiziell eingeführt werden. Gemini 2.5 Pro wird als das intelligenteste KI-Modell der Welt bezeichnet und erhält eine neue Deep-Thinking-Version, die in mehreren Tests führend ist. Gemini 2.5 Flash, als leichtgewichtige Version, steigert die Effizienz um 22 %, reduziert den Token-Verbrauch um 20-30 % und verfügt über native Audio-Generierungsfähigkeiten. LMArena-Daten zeigen, dass die neue Version von Gemini-2.5-Flash im Chatbot-Arena-Ranking deutlich auf den zweiten Platz vorgerückt ist, insbesondere bei anspruchsvollen Aufgaben wie Programmierung und Mathematik. (Quelle: natolambert, demishassabis, karminski3, lmarena_ai)
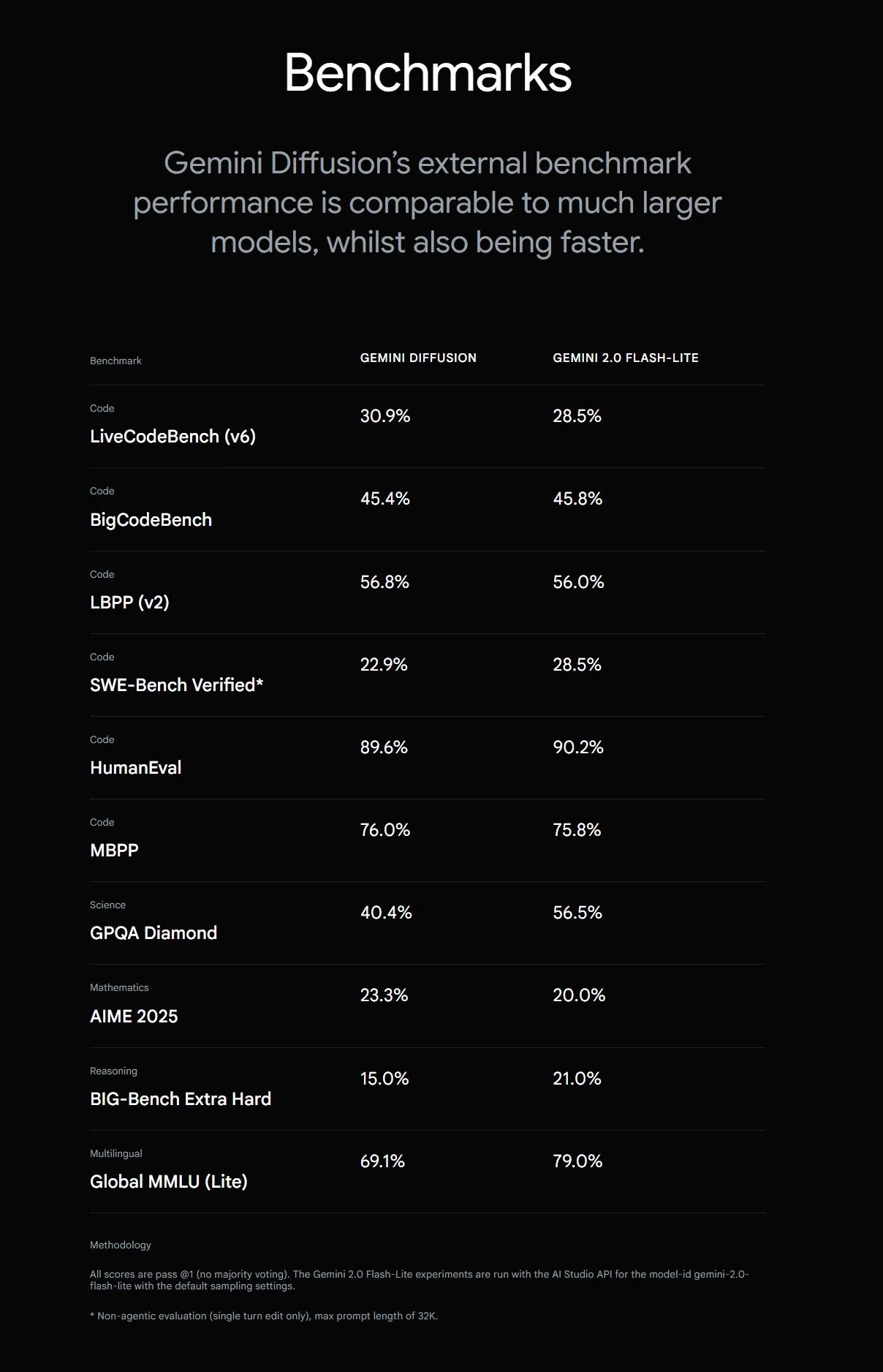
Google stellt Gemini Diffusion vor, Textgenerierung 5-mal schneller: Google DeepMind hat das experimentelle Textgenerierungsmodell Gemini Diffusion vorgestellt, dessen Generierungsgeschwindigkeit 5-mal höher ist als die des bisher schnellsten Modells. Besonders hervorzuheben sind seine Programmierfähigkeiten, die bis zu 2000 Token pro Sekunde erreichen können (einschließlich Tokenisierung und anderer Overheads). Im Gegensatz zu herkömmlichen autoregressiven Modellen können Diffusionsmodelle nicht-kausales Reasoning durchführen und somit nachfolgende Antworten “vorherdenken”. Dies führt zu einer besseren Leistung bei der Lösung komplexer Probleme, die globales Reasoning erfordern (z. B. spezifische Rechenaufgaben, Primzahlensuche), als GPT-4o. Das Modell ist derzeit nur für Entwickler auf Anfrage zum Testen verfügbar. (Quelle: OriolVinyalsML, dotey, karminski3)
Google veröffentlicht Gemma 3n Serie von Open-Source-Modellen, speziell für multimodale Anwendungen auf Endgeräten entwickelt: Google hat die neue Generation effizienter multimodaler Open-Source-Modelle Gemma 3n vorgestellt, die speziell für Geräte mit geringem Stromverbrauch entwickelt wurden und Text-, Sprach-, Bild- und Videoeingaben sowie mehrsprachige Verarbeitung unterstützen. Die Modelle dieser Serie (wie gemma-3n-E4B-it-litert-preview und gemma-3n-E2B-it-litert-preview) sind klein (3-4,4 GB), können auf Geräten mit 2 GB RAM ausgeführt werden und ihr Wissensstand reicht bis Juni 2024. Sie stehen Entwicklern ab sofort als Preview auf den Plattformen AI Studio und AI Edge zur Verfügung. (Quelle: demishassabis, karminski3, huggingface, Ar_Douillard, GoogleDeepMind)
OpenAI Responses API erweitert um MCP-Unterstützung, Bildgenerierung und Code Interpreter-Funktionen: Die OpenAI Entwicklerplattform kündigte wichtige Updates für ihre Responses API (ehemals Assistants API) an. Neu hinzugekommen ist die Unterstützung für Remote Model Context Protocol (MCP) Server, die es KI-Agenten ermöglicht, flexibler mit externen Tools und Diensten zu interagieren. Darüber hinaus wurden in die API Funktionen zur Bildgenerierung und ein Code Interpreter integriert, was ihre Anwendungsszenarien und ihr Entwicklungspotenzial weiter ausbaut. (Quelle: gdb, npew, OpenAIDevs, snsf)
xAI API integriert Echtzeit-Suchfunktion Grok Live Search: xAI hat angekündigt, seine API um die Funktion Live Search zu erweitern, die es Grok ermöglicht, Daten in Echtzeit von der X-Plattform, dem Internet, Nachrichtenquellen usw. zu durchsuchen. Die Funktion befindet sich derzeit in der Beta-Testphase und steht Entwicklern zeitlich begrenzt kostenlos zur Verfügung. Ziel ist es, die Fähigkeit von Grok zu verbessern, aktuelle Informationen abzurufen und zu verarbeiten, um die Entwicklung dynamischerer und informationsreicherer KI-Anwendungen zu unterstützen. (Quelle: xai, TheGregYang, yoheinakajima)

Google veröffentlicht MedGemma-Serie von Open-Source-Modellen für medizinische große Sprachmodelle: Google hat die auf der Gemma 3-Architektur basierenden Open-Source-Medizinmodelle MedGemma vorgestellt, darunter medgemma-4b-pt (Basismodell), medgemma-4b-it (multimodal, medizinische Bilddiagnose) und medgemma-27b-text-it (reiner Text, Konsultationsprotokolle). Diese Modelle wurden speziell für das Verständnis medizinischer Texte und Bilder trainiert und zielen darauf ab, die Anwendungsmöglichkeiten von KI im medizinischen Bereich zu verbessern, z. B. bei der unterstützenden Diagnose, der Analyse von Krankenakten usw. Die Modelle sind auf Hugging Face verfügbar. (Quelle: JeffDean, karminski3)
Tencent Hunyuan Large Model aktualisiert mehrere Produkte und startet offene Plattform für intelligente Agenten: Tencent Hunyuan kündigte iterative Upgrades für sein Flaggschiff-Modell für schnelles Denken TurboS und sein Modell für tiefes Denken T1 an. TurboS gehört bei Code- und Mathematikfähigkeiten zu den Top Ten weltweit. Neu vorgestellt wurden das visuelle Deep-Reasoning-Modell T1-Vision und das End-to-End-Sprachanrufmodell Hunyuan Voice. Die ursprüngliche Wissens-Engine wurde zur “Tencent Cloud Intelligent Agent Development Platform” aufgerüstet und integriert RAG- und Agent-Fähigkeiten. Hunyuan Image 2.0, 3D v2.5 und Modelle zur visuellen Generierung für Spiele wurden ebenfalls aktualisiert, und es ist geplant, weiterhin multimodale Basismodelle und Plugins als Open Source bereitzustellen. (Quelle: 36氪)

Alibaba und Zhejiang Universität schlagen Gesetz zur Skalierung paralleler Berechnungen ParScale vor: Ein Forschungsteam von Alibaba hat in Zusammenarbeit mit der Zhejiang Universität ein neues Scaling Law vorgeschlagen: das Gesetz zur Skalierung paralleler Berechnungen (ParScale). Dieses Gesetz besagt, dass die Erhöhung der parallelen Modellberechnung während des Trainings und der Inferenz die Leistungsfähigkeit großer Modelle verbessern und die Ineffizienz steigern kann, ohne die Anzahl der Parameter zu erhöhen. Im Vergleich zur Parameterskalierung beträgt der Speicherzuwachs bei ParScale nur 4,5 % und der Latenzzuwachs 16,7 %. Diese Methode wird durch diversifizierte Eingabetransformationen, parallele Verarbeitung und dynamische Aggregation der Ausgabe erreicht und zeigt besonders bei Aufgaben mit starkem Reasoning-Anteil wie Mathematik und Programmierung signifikante Ergebnisse. (Quelle: 36氪)
Microsoft veröffentlicht großskaliges atmosphärisches Basismodell Aurora, Vorhersagegeschwindigkeit um das 5000-fache erhöht: Microsoft und seine Partner haben das erste großskalige atmosphärische Basismodell Aurora vorgestellt, das auf über 1 Million Stunden geophysikalischer Daten trainiert wurde. Es kann Luftqualität, Routen tropischer Wirbelstürme, Wellendynamik und hochauflösendes Wetter genauer und effizienter vorhersagen. Im Vergleich zum fortschrittlichen numerischen Vorhersagesystem IFS ist Aurora etwa 5000-mal schneller und erreicht in mehreren wichtigen Vorhersagebereichen SOTA-Niveau. Die flexible Architektur des Modells ermöglicht Feinabstimmungen für spezifische Aufgaben und verspricht, die Verbreitung von Erdsystemvorhersagen voranzutreiben. (Quelle: 36氪)

Google AI Search führt AI Mode ein und integriert mehrere intelligente Funktionen: Google kündigte die Einführung eines “AI Mode” für seine Suchmaschine an, der als “leistungsstärkste KI-Suche” bezeichnet wird. Dieser Modus basiert auf Gemini 2.5 und verfügt über stärkere Reasoning-Fähigkeiten, unterstützt längere Abfragen, multimodale Suche und sofortige, qualitativ hochwertige Antworten. Zukünftig sollen auch die Funktion “Deep Search”, die Hunderte von Abfragen gleichzeitig durchführen und umfassende Berichte erstellen kann, sowie die Integration persönlicher Daten aus Gmail und die Echtzeit-Kamerainteraktion von Project Astra und die automatische Aufgabenverwaltung von Project Mariner integriert werden. (Quelle: dotey, Google)

Google Imagen 4 Bildgenerierungsmodell veröffentlicht, Geschwindigkeit und Detailgrad deutlich verbessert: Google hat sein neuestes Text-zu-Bild-Modell Imagen 4 veröffentlicht und behauptet, dass es im Vergleich zur Vorgängergeneration eine 3- bis 10-fache Steigerung der Generierungsgeschwindigkeit, reichere Bilddetails, genauere Ergebnisse und eine deutlich verbesserte Textwiedergabefähigkeit aufweist. Imagen 4 kann komplexe Objekte wie Stoffe, Wassertropfen und Tierhaare mit einer Auflösung von bis zu 2K generieren und unterstützt die Erstellung von Grußkarten, Postern, Comics usw. Das Modell ist ab sofort kostenlos in der Gemini App, Whisk und Workspace-Anwendungen sowie in Vertex AI verfügbar. (Quelle: dotey, GoogleDeepMind)
Studie deckt Risiko von “Paket-Halluzinationen” in von KI-Programmierassistenten generiertem Code auf: Eine demnächst bei USENIX Security 2025 erscheinende Studie weist darauf hin, dass in von KI generiertem Code häufig das Phänomen der “Paket-Halluzinationen” auftritt, d.h. referenzierte Drittanbieter-Bibliotheken existieren überhaupt nicht. Die Studie testete 16 gängige große Sprachmodelle und stellte fest, dass über 20 % des Codes von fiktiven Paketen abhingen, wobei der Anteil bei Open-Source-Modellen höher war. Dies schafft Möglichkeiten für Supply-Chain-Angriffe, bei denen Angreifer diese fiktiven Paketnamen nutzen können, um bösartigen Code zu veröffentlichen. Unternehmen wie Apple und Microsoft waren bereits von solchen Dependency-Confusion-Angriffen betroffen. (Quelle: 36氪)

Suno führt Remix-Funktion ein, Nutzer können auf Basis bestehender Songs neu erstellen: Die KI-Musikgenerierungsplattform Suno hat die Remix-Funktion eingeführt, die es Nutzern ermöglicht, beliebige Titel auf der Plattform für eine Neukreation auszuwählen. Nutzer können Songs covern (Cover), erweitern (Extend) oder Prompts wiederverwenden (Reuse Prompt). Remix-Kreationen behalten die Quelleninformationen des Originalmaterials bei, und Nutzer können die Remix-Berechtigung für ihre eigenen Werke jederzeit aktivieren oder deaktivieren. (Quelle: SunoMusic)
Studie zeigt: Alle Embedding-Modelle lernen ähnliche semantische Strukturen: Jack Morris und andere Forscher haben herausgefunden, dass verschiedene Embedding-Modelle semantische Strukturen lernen, die sich stark ähneln. Es ist sogar möglich, ohne paarweise Daten, nur anhand von Strukturinformationen, zwischen den Embedding-Räumen verschiedener Modelle zu mappen. Diese Entdeckung deutet auf eine möglicherweise universelle geometrische Struktur in Embedding-Räumen hin, was für die Kompatibilität von Modellen, Transfer Learning und das Verständnis der Natur von Embeddings von großer Bedeutung ist. (Quelle: menhguin, torchcompiled, dilipkay, jeremyphoward)
Paper untersucht das Problem der “Halluzinationssteuer” beim Reinforcement Learning Fine-Tuning (RFT): Eine Studie von Taiwei Shi et al. weist darauf hin, dass Reinforcement Learning Fine-Tuning (RFT) zwar die Reasoning-Fähigkeiten großer Sprachmodelle verbessert, aber dazu führen kann, dass Modelle bei unbeantwortbaren Fragen selbstbewusst halluzinierte Antworten generieren – ein Phänomen, das als “Halluzinationssteuer” bezeichnet wird. Die Studie verwendete den SUM-Datensatz (synthetische, unbeantwortbare mathematische Probleme) zur Validierung und stellte fest, dass Standard-RFT-Training die Ablehnungsrate der Modelle signifikant senkt. Durch Hinzufügen einer kleinen Menge an SUM-Daten zum RFT kann das angemessene Ablehnungsverhalten der Modelle effektiv wiederhergestellt und ihr Bewusstsein für eigene Unsicherheiten und Wissensgrenzen verbessert werden. (Quelle: teortaxesTex)

🧰 Tools
Google stellt KI-Filmerstellungstool Flow vor, integriert Veo, Imagen und Gemini: Google hat das KI-Filmerstellungstool Flow vorgestellt, das seine neuesten Modelle für Videogenerierung Veo 3, Bildgenerierung Imagen 4 und das multimodale Modell Gemini integriert. Mit Flow können Nutzer durch natürliche Sprache und Ressourcenmanagement mühelos Kurzfilme in Kinoqualität erstellen, einschließlich der Generierung von Clips aus Text-Prompts, der Kombination von Szenen, dem Aufbau von Erzählungen und dem Speichern häufig verwendeter Elemente als Assets. Das Tool soll Kreativen helfen, schnell und effizient Werke mit filmischer Qualität zu produzieren. Es ist derzeit für Google AI Pro und Ultra Abonnenten in den USA verfügbar. (Quelle: dotey, op7418)

Google veröffentlicht Cloud-basierten KI-Programmieragenten Jules, angetrieben von Gemini 2.5 Pro: Google hat den KI-Programmieragenten Jules vorgestellt, der auf Gemini 2.5 Pro basiert. Jules kann im Hintergrund automatisch Aufgaben in Code-Repositories bearbeiten, wie z.B. Fehlerbehebung und Code-Refactoring, und unterstützt parallele Multitasking-Operationen. Darüber hinaus bietet Jules täglich aktualisierte Codecasts-Podcasts, um Nutzern zu helfen, über die neuesten Entwicklungen im Code-Repository auf dem Laufenden zu bleiben. Das Tool ist derzeit kostenlos zum Ausprobieren verfügbar. (Quelle: dotey, karminski3, GoogleDeepMind)
LangChain stellt Open Agent Platform (OAP) vor, eine Open-Source No-Code-Agentenplattform: LangChain hat die Open Agent Platform (OAP) veröffentlicht, eine Open-Source No-Code-Plattform für normale Benutzer zum Erstellen, Prototyping und Bereitstellen von KI-Agenten. OAP unterstützt die Erstellung von Agenten über eine Web-Benutzeroberfläche, die Verbindung zu RAG-Servern zur Verbesserung des Informationsabrufs, die Erweiterung externer Tools über MCP und die Orchestrierung von Multi-Agenten-Workflows mit dem Agent Supervisor. Ziel ist es, auch nicht-professionellen Entwicklern die Nutzung der leistungsstarken Funktionen von LangGraph-Agenten zu ermöglichen. (Quelle: LangChainAI, Hacubu)

Google Labs stellt KI-UI-Design-Tool Stitch vor: Google Labs hat das KI-UI-Design-Tool Stitch veröffentlicht, das die neuesten DeepMind-Modelle von Google (einschließlich Gemini und Imagen) integriert und schnell hochwertige UI-Designs generieren kann. Benutzer können über natürliche Sprache Oberflächenthemen aktualisieren, Bilder automatisch anpassen, mehrsprachige Inhaltsübersetzungen realisieren und Frontend-Code mit einem Klick exportieren. Stitch ist eine Weiterentwicklung des früheren Galileo AI, dessen Gründer dem Google-Team beigetreten sind. (Quelle: dotey)
LangChain stellt lokale Code-Sandbox LangChain Sandbox vor: LangChain hat LangChain Sandbox veröffentlicht, die es KI-Agenten ermöglicht, nicht vertrauenswürdigen Python-Code sicher lokal auszuführen. Sie bietet eine isolierte Ausführungsumgebung und konfigurierbare Berechtigungen, ohne dass eine Remote-Ausführung oder Docker-Container erforderlich sind, und unterstützt die Persistenz des Zustands über mehrere Ausführungen hinweg durch Sitzungen. Dies bietet ein sichereres und bequemeres Werkzeug für die Erstellung von KI-Agenten, die Code ausführen können (z. B. codeact agents). (Quelle: hwchase17, Hacubu)
Vitalops macht Datatune Open Source: Ein LLM-Tool zur Verarbeitung großer Datensätze mit natürlicher Sprache: Vitalops hat Datatune als Open Source veröffentlicht, ein Tool, das es Benutzern ermöglicht, Datensätze beliebiger Größe mithilfe von Anweisungen in natürlicher Sprache zu verarbeiten. Datatune unterstützt Map- und Filter-Operationen, kann an verschiedene LLM-Dienstanbieter wie OpenAI, Azure, Ollama oder benutzerdefinierte Modelle angebunden werden und nutzt Dask DataFrame für Partitionierung und parallele Verarbeitung. Das Tool zielt darauf ab, Aufgaben wie Datenbereinigung und -anreicherung zu vereinfachen und komplexe reguläre Ausdrücke oder benutzerdefinierten Code zu ersetzen. (Quelle: Reddit r/MachineLearning)
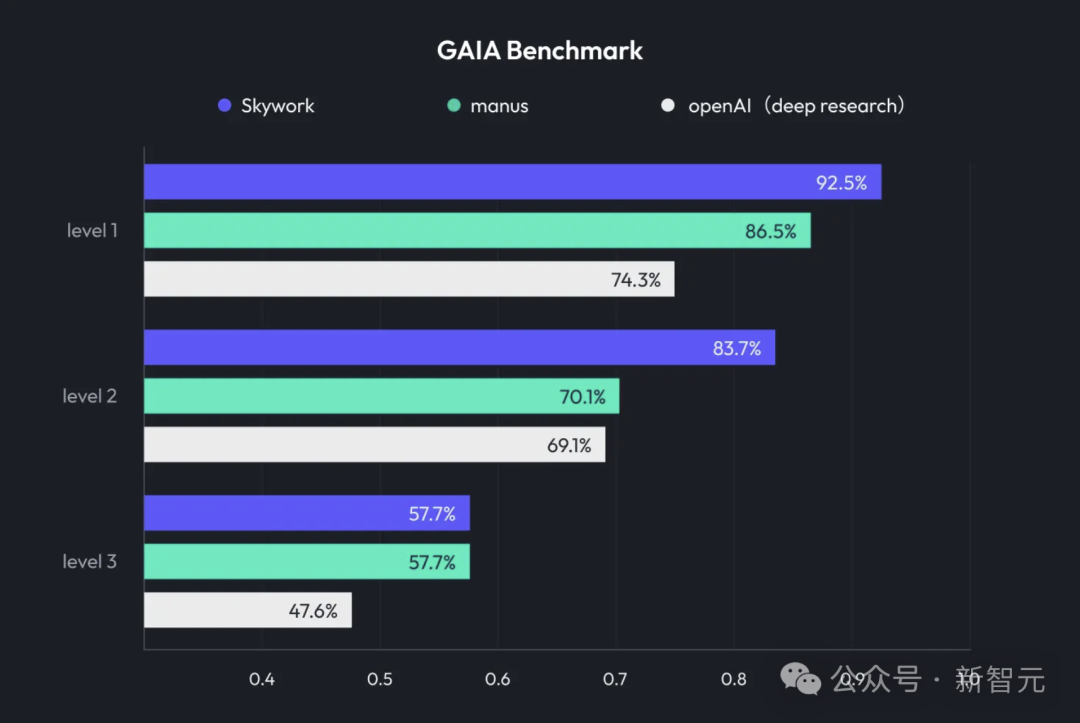
Kunlun Wanwei stellt Skywork Super Agents vor, integriert Deep Research und multimodale Ausgabe: Kunlun Wanwei hat das KI-Büroprodukt Skywork Super Agents veröffentlicht, das Deep Research-Fähigkeiten mit den multimodalen Ausgabefunktionen allgemeiner intelligenter Agenten kombiniert. Das Produkt unterstützt verschiedene Büroszenarien wie PPT-Erstellung, Dokumentenerstellung, Tabellenverarbeitung, Webseitenerstellung und Podcast-Erstellung. Es legt Wert auf die Nachverfolgbarkeit von Inhalten, um Halluzinationen zu reduzieren, und bietet Online-Bearbeitungs- und Exportfunktionen. Kunlun Wanwei hat außerdem das Deep Research Agent Framework und zugehörige MCPs als Open Source veröffentlicht. (Quelle: 36氪)
Google stellt SynthID Detector vor, um bei der Identifizierung von KI-generierten Inhalten zu helfen: Google hat SynthID Detector veröffentlicht, ein neues Portal, das Journalisten, Medienfachleuten und Forschern helfen soll, leichter zu erkennen, ob Inhalte mit einem SynthID-Wasserzeichen versehen sind. SynthID ist eine von Google entwickelte Technologie, um KI-generierten Inhalten (einschließlich Bildern, Audio, Video oder Text) ein unsichtbares Wasserzeichen hinzuzufügen. Die Einführung dieses Erkennungstools trägt dazu bei, die Transparenz und Rückverfolgbarkeit von KI-generierten Inhalten zu erhöhen. (Quelle: dotey, Google)
Feishu führt “Wissens-Q&A”-Funktion ein und schafft unternehmensspezifisches KI-Q&A-Tool: Feishu hat die neue Funktion “Wissens-Q&A” eingeführt. Dieses Tool kann auf Basis aller Informationen, auf die Mitarbeiter im Unternehmen über Feishu Zugriff haben (Nachrichten, Dokumente, Wissensdatenbanken usw.), in Kombination mit großen Modellen wie DeepSeek-R1, Doubao und RAG-Technologie, den Mitarbeitern präzise Antworten und Unterstützung bei der Inhaltserstellung bieten. Eine Besonderheit ist, dass die Antworten dynamisch an die Identität und die Berechtigungen des Fragestellers im Unternehmen angepasst werden. Ziel ist es, KI nahtlos in den täglichen Arbeitsablauf zu integrieren und die Effizienz des Wissensmanagements und der Wissensnutzung im Unternehmen zu steigern. (Quelle: 量子位)

Animon: Japans erste KI-Anime-Generierungsplattform, Fokus auf 2D-Ästhetik und unbegrenzte kostenlose Generierung: Das japanische Unternehmen CreateAI (ehemals TuSimple Future) hat die KI-Anime-Generierungsplattform Animon vorgestellt, die speziell für die Anime-Erstellung angepasst ist. Die Plattform verbindet japanische Anime-Ästhetik mit KI-Technologie, legt Wert auf einen konsistenten Bildstil und eine effiziente Produktion und wirbt damit, dass Privatnutzer kostenlos und unbegrenzt Videos generieren können. Animon unterstützt die schnelle Generierung von Animationsclips (ca. 3 Minuten) durch Hochladen von Charakterbildern und Textbeschreibungen. Ziel ist es, die Hürden für die Anime-Erstellung zu senken und ein UGC-Content-Ökosystem zu fördern. Die Muttergesellschaft CreateAI verfügt über ein selbst entwickeltes großes Modell namens Ruyi und hält die Adaptionsrechte für IPs wie “Die drei Sonnen” und “Jin Yong’s Martial Arts Universe”. Sie verfolgt eine zweigleisige Strategie aus “selbst entwickelten Inhalten + UGC-Tool-Plattform”. (Quelle: 量子位)

📚 Lernen
DeepLearning.AI startet neuen Kurs: LLM-Verfeinerung mit GRPO: Andrew Ng kündigte in Zusammenarbeit mit Predibase einen neuen Kurzkurs zum Thema “Verfeinerung von LLMs durch Verstärkung mit GRPO (Group Relative Policy Optimization)” an. Der Kurs vermittelt, wie man Reinforcement Learning (insbesondere den GRPO-Algorithmus) einsetzt, um die Leistung von LLMs bei mehrstufigen Reasoning-Aufgaben (wie mathematische Problemlösung, Code-Debugging) zu verbessern, ohne dass große Mengen an überwachten Feinabstimmungsproben erforderlich sind. GRPO leitet das Modell durch programmierbare Belohnungsfunktionen, eignet sich für Aufgaben mit überprüfbaren Ergebnissen und kann die Reasoning-Fähigkeiten kleinerer LLMs erheblich steigern. (Quelle: AndrewYNg, DeepLearningAI)
LlamaIndex teilt Erfahrungen mit der Verwaltung großer Python-Monorepos: Das LlamaIndex-Team teilte seine Erfahrungen mit der Verwaltung eines Python-Monorepos, das über 650 Community-Pakete enthält. Sie migrierten von Poetry und Pants zu uv und dem selbst entwickelten Open-Source-Build-Management-Tool LlamaDev. Dadurch konnten sie die Ausführungsgeschwindigkeit von Tests um 20 % steigern, klarere Logs erhalten, die lokale Entwicklung vereinfachen und die Einstiegshürde für Beitragende senken. Diese Erfahrung ist für Teams, die große Python-Projekte verwalten müssen, von großem Nutzen. (Quelle: jerryjliu0)

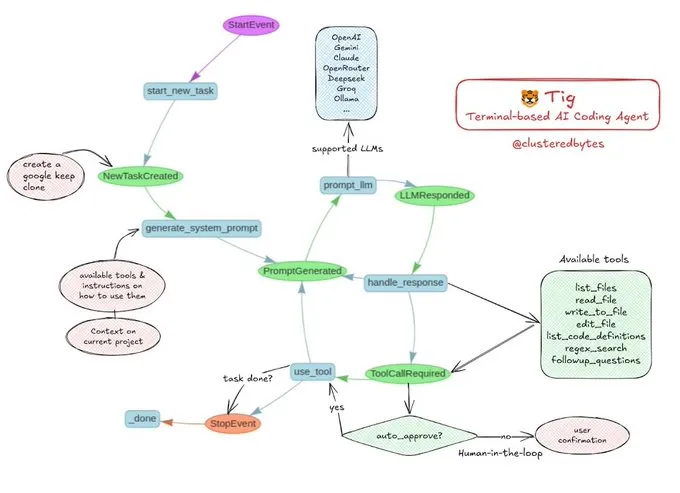
Tutorial-Sharing: Bauen Sie Ihren eigenen KI-Coding-Agenten Tig: Jerry Liu empfahl ein Open-Source-KI-Coding-Agentenprojekt namens Tig. Bei diesem Projekt handelt es sich um einen terminalbasierten Codierungsassistenten mit Human-in-the-Loop, der mit dem LlamaIndex-Workflow erstellt wurde. Tig kann Aufgaben wie das Schreiben, Debuggen und Analysieren von Code in mehreren Sprachen, das Ausführen von Shell-Befehlen, das Durchsuchen von Codebasen sowie das Generieren von Tests und Dokumentationen ausführen. Das GitHub-Repository bietet eine detaillierte Bauanleitung und ist eine gute Lernressource für Entwickler, die lernen möchten, wie man KI-Coding-Agenten erstellt. (Quelle: jerryjliu0)
Hugging Face veröffentlicht wichtigen Blogbeitrag zu VLM und stellt nanoVLM Community Lab vor: Hugging Face hat einen Blogbeitrag über Vision-Language-Modelle (VLM) veröffentlicht, der Grundlagen, Architekturen und Anleitungen zum Trainieren eigener leichtgewichtiger VLMs behandelt. Gleichzeitig wurde nanoVLM vorgestellt, ein Open-Source-Repository für das Fine-Tuning von VLMs, das sich zu einem Community-Labor für die Forschung im Bereich Vision-Language entwickelt hat. Ziel ist es, Entwicklern zu helfen, die VLM-Forschung zu erkunden und dazu beizutragen. (Quelle: _akhaliq, huggingface)
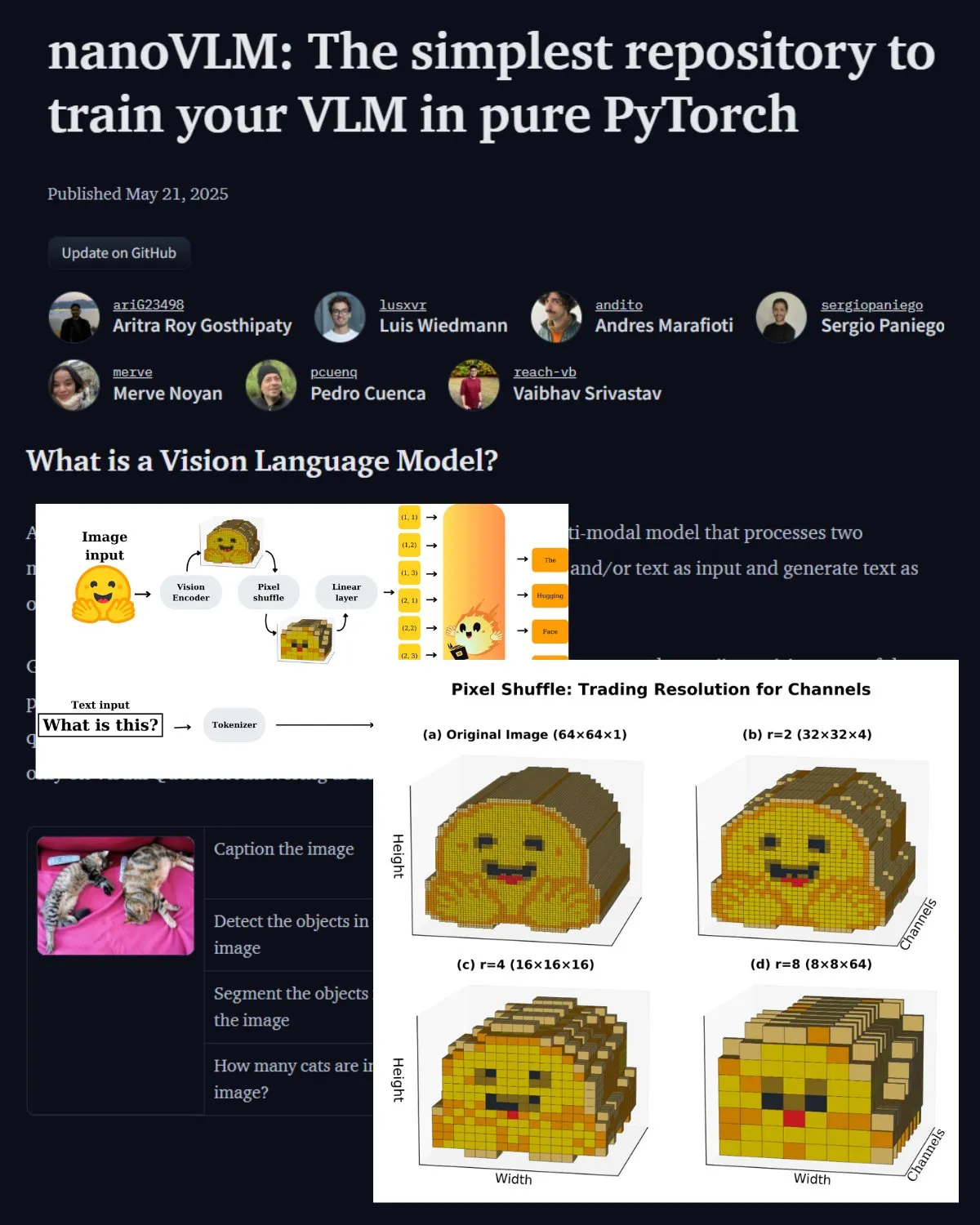
Serrano Academy veröffentlicht Videotutorial-Reihe zum LLM Reinforcement Learning Fine-Tuning: Die Serrano Academy hat eine Reihe von Videotutorials zur Feinabstimmung und zum Training von LLMs mithilfe von Reinforcement Learning fertiggestellt und veröffentlicht. Die Inhalte umfassen Schlüsselkonzepte und -techniken wie Deep Reinforcement Learning, RLHF (Reinforcement Learning from Human Feedback), PPO (Proximal Policy Optimization), DPO (Direct Preference Optimization), GRPO (Group Relative Policy Optimization) sowie die KL-Divergenz (KL Divergence). (Quelle: SerranoAcademy)
Paper untersucht das Phänomen der “leeren Schichten” in großen Sprachmodellen: Eine Studie untersuchte das Phänomen, dass bei instruktionsoptimierten großen Sprachmodellen während des Reasoning-Prozesses nicht alle Schichten aktiviert werden. Nicht aktivierte Schichten werden als “leere Schichten” (Voids) bezeichnet. Die Studie verwendete die L2 Adaptive Computation (LAC)-Methode, um die aktivierten Schichten während der Verarbeitung von Prompts und der Generierung von Antworten zu verfolgen, und stellte fest, dass in verschiedenen Phasen unterschiedliche Schichten aktiviert werden. Experimente zeigten, dass das Überspringen von leeren Schichten in Qwen2.5-7B-Instruct (nur 30 % der Schichten verwendet) bei Benchmarks wie MMLU die Leistung verbesserte, was darauf hindeutet, dass das selektive Überspringen der meisten Schichten für bestimmte Aufgaben vorteilhaft sein könnte. (Quelle: HuggingFace Daily Papers)
Studie schlägt “Soft Thinking” vor: Erschließung des Reasoning-Potenzials von LLMs im kontinuierlichen Konzeptraum: Ein Paper mit dem Titel “Soft Thinking” schlägt eine trainingsfreie Methode vor, um menschenähnliches “weiches” Reasoning durch die Generierung weicher, abstrakter Konzept-Token im kontinuierlichen Konzeptraum zu simulieren. Diese Konzept-Token werden aus einer wahrscheinlichkeitsgewichteten Mischung von Token-Embeddings gebildet und können vielfältige Bedeutungen von verwandten diskreten Token kapseln, wodurch implizit mehrere Reasoning-Pfade erkundet werden. Experimente zeigen, dass diese Methode die pass@1-Genauigkeit bei Mathematik- und Programmier-Benchmarks verbessert, gleichzeitig den Token-Verbrauch reduziert und die Ausgabe interpretierbar bleibt. (Quelle: HuggingFace Daily Papers)
Paper untersucht skalierbare Chain-of-Thought durch Elastic Reasoning: Forscher von Salesforce haben Methoden für skalierbare Chain-of-Thought durch Elastic Reasoning vorgeschlagen. Die Studie zielt darauf ab, das Problem zu lösen, wie große Sprachmodelle bei der Verarbeitung komplexer Reasoning-Aufgaben lange Chain-of-Thought-Sequenzen effektiv generieren und verwalten können, um die Genauigkeit und Effizienz des Reasonings zu verbessern. Zugehörige Modelle und Code wurden auf Hugging Face veröffentlicht. (Quelle: _akhaliq)

Studie untersucht: Würden KI-Modelle lügen, um kranke Kinder zu retten?: Eine Studie namens LitmusValues hat einen Bewertungsprozess entwickelt, der darauf abzielt, die Prioritäten von KI-Modellen in einer Reihe von KI-Wertkategorien aufzudecken. Durch das Sammeln von AIRiskDilemmas (einer Sammlung von Dilemmata, die mit KI-Sicherheitsrisiken zusammenhängen) messen die Forscher die Entscheidungen von KI-Modellen bei verschiedenen Wertkonflikten, um deren Wertprioritäten vorherzusagen und potenzielle Risiken zu identifizieren. Die Studie zeigt, dass die in LitmusValues definierten Werte (einschließlich Fürsorge usw.) bereits in AIRiskDilemmas beobachtete Risikoverhaltensweisen sowie in HarmBench noch nicht beobachtete Risikoverhaltensweisen vorhersagen können. (Quelle: HuggingFace Daily Papers)
Paper untersucht effizientes Fine-Tuning von Diffusionsmodellen durch wertbasiertes Reinforcement Learning (VARD): Diffusionsmodelle zeigen eine starke Leistung bei Generierungsaufgaben, aber das Fine-Tuning für spezifische Attribute bleibt eine Herausforderung. Bestehende Reinforcement-Learning-Methoden weisen Mängel in Bezug auf Stabilität, Effizienz und den Umgang mit nicht-differenzierbaren Belohnungen auf. VARD (Value-based Reinforced Diffusion) schlägt vor, zuerst eine Wertfunktion zu lernen, die den erwarteten Reward aus Zwischenzuständen vorhersagt, und diese Wertfunktion dann zusammen mit KL-Regularisierung zu nutzen, um eine dichte Überwachung während des gesamten Generierungsprozesses zu gewährleisten. Experimente zeigen, dass diese Methode die Trajektorienführung verbessert, die Trainingseffizienz steigert und die Anwendung von RL auf die Optimierung von Diffusionsmodellen mit komplexen, nicht-differenzierbaren Belohnungsfunktionen erweitert. (Quelle: HuggingFace Daily Papers)
💼 Wirtschaft
LMArena.ai (ehemals LMSYS.org) erhält 100 Millionen US-Dollar Seed-Finanzierung, angeführt von a16z und UC Investments: Die KI-Modellbewertungsplattform LMArena.ai (ehemals LMSYS.org) gab den Abschluss einer Seed-Finanzierungsrunde in Höhe von 100 Millionen US-Dollar bekannt, die gemeinsam von Andreessen Horowitz (a16z) und UC Investments (Investmentgesellschaft der University of California) angeführt wurde. Das Unternehmen widmet sich dem Aufbau einer neutralen, offenen und Community-gesteuerten Plattform, um das Verständnis und die Verbesserung der Leistung von KI-Modellen bei realen Benutzeranfragen weltweit zu fördern. Nach der Finanzierung wird das Unternehmen mit 600 Millionen US-Dollar bewertet. (Quelle: janonacct, lmarena_ai, scaling01, _akhaliq, ClementDelangue)
US-Regierung kündigt Verkauf von KI-Technologien und -Dienstleistungen im Wert von mehreren zehn Milliarden Dollar an Saudi-Arabien und die VAE an: Die US-Regierung hat Vereinbarungen mit Saudi-Arabien und den Vereinigten Arabischen Emiraten über den Verkauf von KI-Technologien und -Dienstleistungen im Wert von mehreren zehn Milliarden US-Dollar bekannt gegeben. Zu den beteiligten Unternehmen gehören AMD, Nvidia, Amazon, Google, IBM, Oracle und Qualcomm. Nvidia wird dem saudischen Unternehmen Humain 18.000 GB300 KI-Chips und anschließend Hunderttausende weitere GPUs liefern; AMD und Humain werden gemeinsam 10 Milliarden US-Dollar in den Bau von KI-Rechenzentren investieren. Dieser Schritt zielt darauf ab, den KI-Einfluss der USA im Nahen Osten zu stärken und die wirtschaftliche Diversifizierung beider Länder zu unterstützen. (Quelle: DeepLearning.AI Blog)

Meta startet Llama Startup Program zur Förderung von KI-Startups in der Frühphase: Meta hat den Start des Llama Startup Program angekündigt, das darauf abzielt, US-amerikanische Startups in der Frühphase (Finanzierung unter 10 Millionen US-Dollar, mindestens ein Entwickler) bei der Nutzung von Llama-Modellen für generative KI-Anwendungsinnovationen zu unterstützen. Das Programm bietet die Erstattung von Cloud-Ressourcen, technischen Support durch Llama-Experten sowie Community-Ressourcen. Die Bewerbungsfrist endet am 30. Mai 2025 um 18:00 Uhr (Pazifische Zeit). (Quelle: AIatMeta)
🌟 Community
Google I/O Konferenz löst hitzige Diskussionen aus: Umfassende KI-Integration und Zukunftsaussichten: Die Google I/O Konferenz mit ihren zahlreichen KI-bezogenen Produktvorstellungen und Updates, darunter die Gemini-Modellreihe, Veo 3 Videogenerierung, Imagen 4 Bildgenerierung und der KI-Suchmodus, löste breite Diskussionen in der Community aus. Viele Kommentatoren waren der Meinung, dass Google eine starke Leistungsfähigkeit im Bereich der KI-Anwendungen demonstriert hat, insbesondere mit seiner Strategie, KI nahtlos in bestehende Produktökosysteme zu integrieren. Gleichzeitig wurden auch Themen wie die Authentizität von KI-generierten Inhalten, KI-Ethik und der zukünftige Weg zu AGI zu Schwerpunkten der Diskussion. (Quelle: rowancheung, dotey, karminski3, GoogleDeepMind, natolambert)

KI-Hardware rückt in den Fokus, Zusammenarbeit von OpenAI und Jony Ive erregt Aufmerksamkeit: Die Nachricht von der Übernahme von Jony Ives KI-Hardware-Unternehmen io durch OpenAI sowie die Präsentation eines Prototyps einer Android XR Smartbrille durch Google auf der I/O Konferenz haben die Diskussionen in der Community über die Zukunft der KI-Hardware entfacht. Die Zusammenarbeit von Sam Altman und Jony Ive wird als Versuch gesehen, eine neue Generation KI-gesteuerter persönlicher Computergeräte zu schaffen, die die Interaktionsweisen bestehender Mobiltelefone und Computer revolutionieren könnten. Die Community erwartet allgemein, dass KI-native Hardware revolutionäre Erfahrungen bringen wird, ist aber auch gespannt auf deren Form, Funktionen und Marktakzeptanz. (Quelle: dotey, sama, dotey, swyx)

Rolle und Risiken von KI in der Softwareentwicklung werden diskutiert: Die Veröffentlichung des Devstral-Modells von Mistral AI, das speziell für Coding-Agenten entwickelt wurde, sowie das Update von Codex durch OpenAI haben Diskussionen über den Einsatz von KI in der Softwareentwicklung ausgelöst. Die Community befasst sich mit den tatsächlichen Fähigkeiten von KI-Programmierwerkzeugen sowie der Qualität und Sicherheit des generierten Codes. Insbesondere die Forschung, die darauf hinweist, dass KI-generierter Code möglicherweise auf nicht existierende “Halluzinationspakete” verweist und damit Risiken für die Lieferkettensicherheit birgt, mahnt Entwickler zur sorgfältigen Überprüfung von KI-generiertem Code und Abhängigkeiten. (Quelle: MistralAI, DeepLearning.AI Blog, qtnx_)
Diskussionen über KI-Modellbewertung und Benchmarking nehmen weiter zu: Die massive Finanzierung von LMArena.ai sowie die Leistung verschiedener neuer Modelle in Benchmarks haben die Bewertung von KI-Modellen zu einem heißen Thema in der Community gemacht. Nutzer interessieren sich für die tatsächlichen Fähigkeiten verschiedener Modelle bei spezifischen Aufgaben (wie Programmierung, Mathematik, Allgemeinwissen-Q&A, Emotionsverständnis) sowie für die Zuverlässigkeit und Grenzen bestehender Bewertungssysteme. Beispielsweise versucht das von Tencent veröffentlichte SAGE-Framework zur Bewertung emotionaler Intelligenz, eine neue Bewertungsdimension für KI-Modelle aus der Perspektive der “emotionalen Intelligenz” bereitzustellen. (Quelle: lmarena_ai, 36氪, natolambert)
Rückständige Entwicklung der europäischen Technologiebranche regt zum Nachdenken an, Yann LeCun teilt Diskussion über mangelnden “Patriotismus” als Hauptursache: Ein Artikel des Wall Street Journal über die im Vergleich zu den USA und China deutlich kleinere europäische Technologieszene löste eine Diskussion aus, zu der Yann LeCun einen Kommentar von Arnaud Bertrand weiterleitete. Bertrand argumentiert, dass der Hauptgrund für den technologischen Rückstand Europas ein Mangel an “patriotischem” Geist sei. Europäische Medien und Eliten neigten dazu, amerikanische Start-ups zu hofieren und heimische Innovationen zu vernachlässigen, was dazu führe, dass heimische Unternehmen nur schwer frühe Unterstützung und Marktanerkennung fänden. Am Beispiel seiner eigenen Gründung von HouseTrip wies er darauf hin, dass es in Europa an Selbstvertrauen und einer unterstützenden Atmosphäre für heimische Innovationen fehle. (Quelle: ylecun)

💡 Sonstiges
Energieverbrauch von KI rückt in den Fokus: Das MIT Technology Review organisierte eine Diskussionsrunde, um das Problem des Energieverbrauchs durch die beschleunigte Entwicklung der KI-Technologie und dessen Auswirkungen auf das Klima zu erörtern. Mit zunehmender Größe und Anwendungsbreite von KI-Modellen steigt der Bedarf an Strom und Rechenressourcen drastisch an, wodurch der Energiebedarf von Rechenzentren zu einem neuen Schwerpunkt wird. Die Diskussion konzentrierte sich auf den Energieverbrauch einzelner KI-Abfragen, den gesamten Energie-Fußabdruck von KI und wie dieser Herausforderung begegnet werden kann. (Quelle: MIT Technology Review, madiator)

Anthropic kündigt Neuigkeiten an, Community spekuliert über Veröffentlichung von Claude 4: Das Unternehmen Anthropic hat für den 22. Mai um 9:30 Uhr pazifischer Zeit (23. Mai, 0:00 Uhr Pekinger Zeit) einen Livestream angekündigt, was in der Community Spekulationen über die mögliche Veröffentlichung einer neuen Generation des Claude-Modells (möglicherweise Claude 4) auslöste. Angesichts der jüngsten wichtigen Updates von OpenAI und Google wird dieser Schritt von Anthropic mit Spannung erwartet. (Quelle: AnthropicAI, dotey, karminski3, scaling01, Reddit r/ClaudeAI)
Verschmelzung von KI und XR-Technologie, Google zeigt Prototyp einer Android XR Smartbrille: Google präsentierte auf der I/O Konferenz einen Prototyp einer Android XR Smartbrille und betonte dessen tiefe Integration mit KI. Das Gerät unterstützt intelligente Assistenz aus der Ich-Perspektive und kontaktlose Hilfsfunktionen. Nutzer können über natürliche Sprache mit dem Gerät interagieren, um Informationen abzufragen, Termine zu verwalten, Echtzeitnavigation zu nutzen usw. Dies deutet darauf hin, dass KI zur zentralen Interaktions- und Funktionsantriebskraft für XR-Geräte der nächsten Generation wird und die Benutzererfahrung in Augmented-Reality-Umgebungen verbessert. (Quelle: dotey, 36氪)