
Schlüsselwörter:KI-Agent, Große Sprachmodelle, Gemini 2.5 Pro, NVIDIA KI-Supercomputer, Microsoft Build-Konferenz, Forschungs-KI-Agent, Bewertung von Schlussfolgerungsfähigkeiten, KI-Programmierung, Coding Agent zur automatischen Bug-Behebung, Microsoft Discovery Forschungsplattform, NVLink Fusion-Technologie, CloudMatrix 384 Super-Node, EdgeInfinite-Algorithmus
🔥 Fokus
AI Agents definieren Entwicklungs- und Forschungsparadigmen neu: Auf der Microsoft Build Konferenz wurde eine Reihe von AI Agent-Tools vorgestellt, darunter der Coding Agent, der autonom Bugs behebt und Code wartet, sowie die Forschungs-KI-Plattform Microsoft Discovery, die Ideen generieren, Ergebnisse simulieren und autonom lernen kann. Gleichzeitig erklärten Kevin Weil, Chief Product Officer von OpenAI, und Dario Amodei, CEO von Anthropic, dass KI bereits über fortgeschrittene Programmierfähigkeiten verfügt, was darauf hindeutet, dass Junior-Programmiererstellen möglicherweise ersetzt werden und sich die Rolle der Entwickler zu „KI-Mentoren“ wandeln wird. Diese Fortschritte signalisieren, dass sich AI Agents von unterstützenden Werkzeugen zu Kernkräften entwickeln, die in komplexen Projekten eigenständig agieren können, und die Prozesse und die Effizienz in der Softwareentwicklung und wissenschaftlichen Forschung tiefgreifend verändern werden (Quelle: GitHub Trending, X)
Neue Herausforderungen und Bewertungen für die Reasoning-Fähigkeit großer Sprachmodelle: Mehrere aktuelle Studien und Diskussionen decken die Grenzen großer Sprachmodelle bei komplexen Reasoning-Aufgaben auf. Forschungen von Institutionen wie der Harvard University deuten darauf hin, dass Chain-of-Thought (CoT) manchmal zu einer geringeren Genauigkeit bei der Befolgung von Anweisungen führen kann, da sich das Modell übermäßig auf die Inhaltsplanung konzentriert und einfache Einschränkungen vernachlässigt. Gleichzeitig zeigen reale physikalische Aufgaben (wie die Bearbeitung von Teilen) und komplexes visuell-räumliches Reasoning (wie das Stapeln von Würfeln) auch die Mängel von Top-KI-Modellen (einschließlich o3, Gemini 2.5 Pro). Um die Fähigkeiten der Modelle genauer zu bewerten, wurden neue Benchmarks wie EMMA und SPOT vorgeschlagen, die darauf abzielen, das tatsächliche Niveau der KI bei der multimodalen Fusion, der wissenschaftlichen Validierung usw. zu testen und die Modelle zu einem robusteren und zuverlässigeren Reasoning zu entwickeln (Quelle: HuggingFace Daily Papers, 量子位)
Google AI zeigt umfassende Initiative, Gemini 2.5 Pro mit starker Leistung: Google zeigt eine umfassende Offensive im KI-Bereich. Sein Modell Gemini 2.5 Pro schneidet in mehreren Benchmarks (wie der LMSYS Chatbot Arena) hervorragend ab, insbesondere bei langem Kontext und Videoverständnis erreicht es Spitzenwerte und übertrifft in der WebDev Arena frühere Versionen. Auf der Google Cloud Next ‘25 Konferenz kündigte Google über 200 Updates an, darunter Gemini 2.5 Flash, Imagen 3, Veo 2, das Vertex AI Agent Development Kit (ADK) und das Agent2Agent (A2A)-Protokoll. Dies unterstreicht die Entschlossenheit von Google, KI in alle Ebenen seiner Cloud-Plattform zu integrieren und die unternehmensweite Implementierung voranzutreiben. Google Labs entwickelt ebenfalls kontinuierlich KI-native innovative Produkte wie NotebookLM und zeigt damit eine starke Produktinnovations- und Iterationsfähigkeit (Quelle: Google, GoogleDeepMind)
Nvidia stellt Desktop-KI-Supercomputer und KI-Fabriklösungen für Unternehmen vor: Nvidia hat auf der Computex mehrere wichtige neue Produkte vorgestellt, darunter den Personal AI Computer DGX Station mit dem GB300 Superchip, der über bis zu 784 GB Unified Memory verfügt und die Ausführung von 1T-Parameter-Großmodellen unterstützt; sowie den RTX PRO Server für Unternehmen, der verschiedene Anwendungen wie AI Agents, physikalische KI und wissenschaftliches Rechnen beschleunigen kann. Gleichzeitig führte Nvidia die teil-kundenspezifische NVLink Fusion-Technologie und die NVIDIA AI Datenplattform ein und kündigte eine Zusammenarbeit mit Disney und anderen zur Entwicklung der physikalischen KI-Engine Newton an. Diese Schritte zeigen, dass Nvidia sich von einem Chiphersteller zu einem Unternehmen für KI-Infrastruktur wandelt, mit dem Ziel, ein komplettes KI-Ökosystem vom Desktop bis zum Rechenzentrum aufzubauen (Quelle: nvidia, 量子位)

🎯 Trends
Kimi.ai veröffentlicht Langtext-Denkmodell kimi-thinking-preview: Kimi.ai hat sein neuestes Langtext-Denkmodell kimi-thinking-preview vorgestellt, das jetzt auf platform.moonshot.ai verfügbar ist. Das Modell soll über hervorragende multimodale und Reasoning-Fähigkeiten verfügen. Neue Benutzer erhalten bei der Registrierung einen Gutschein im Wert von 5 US-Dollar zum Ausprobieren. Community-Kommentare schlagen eine Bewertung des Modells durch Dritte vor und erwähnen, dass Kimi zuvor bereits mit einem speziellen Denkmodell auf livecodebench führend war (Quelle: X)
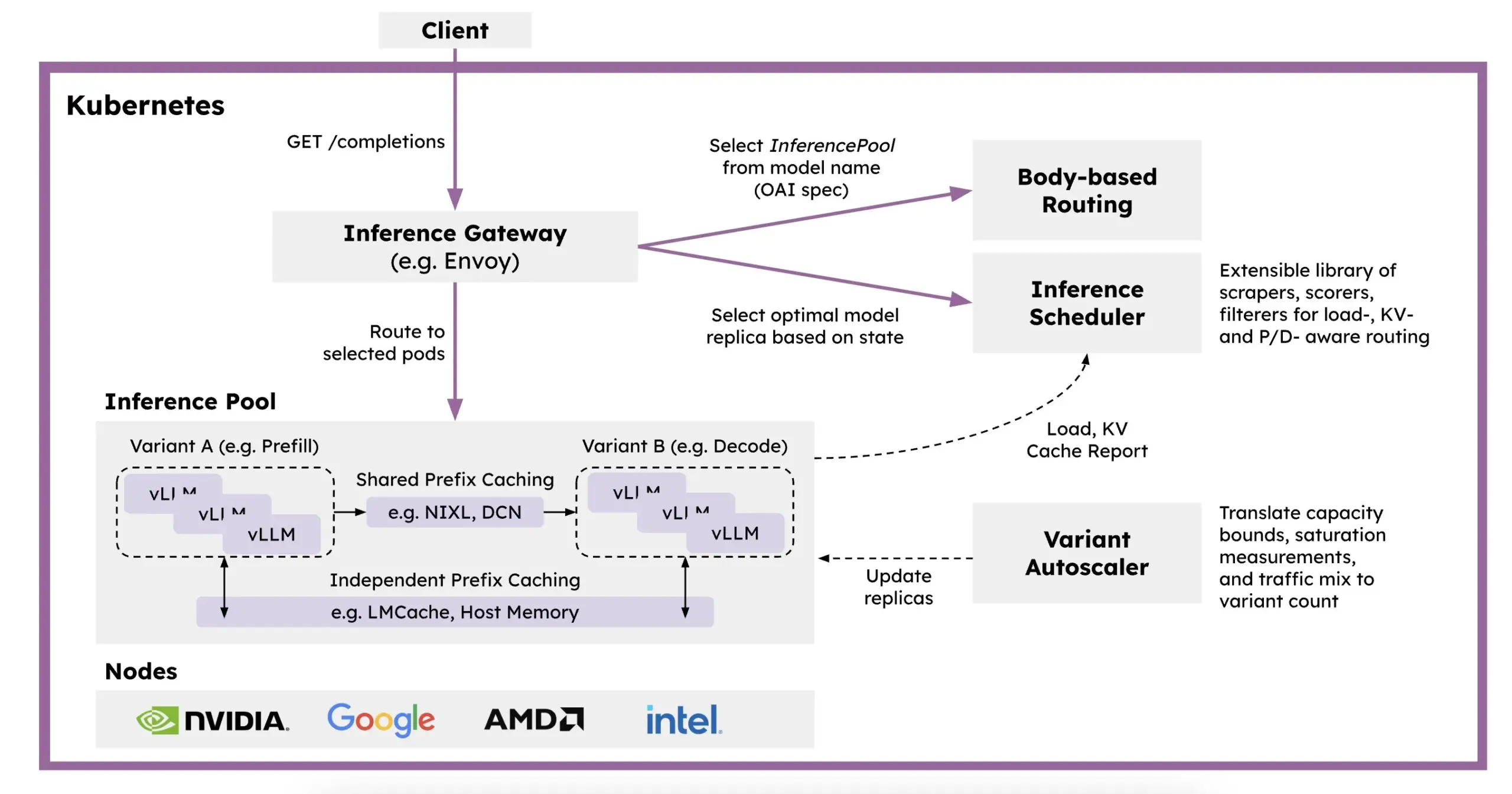
Red Hat stellt llm-d vor: Ein auf Kubernetes basierendes verteiltes Inferenz-Framework: Um die Probleme langsamer LLM-Inferenz, hoher Kosten und schwieriger Skalierbarkeit zu lösen, hat Red Hat llm-d eingeführt, ein Kubernetes-natives verteiltes Inferenz-Framework. Das Framework nutzt vLLM, intelligentes Scheduling und entkoppelte Berechnung, um die LLM-Inferenz zu optimieren. llm-d basiert auf drei Open-Source-Grundlagen: vLLM (Hochleistungs-LLM-Inferenz-Engine), Kubernetes (Container-Orchestrierungsstandard) und Inference Gateway (IGW) (intelligentes Routing durch Gateway API-Erweiterungen), mit dem Ziel, die Effizienz und Skalierbarkeit der LLM-Inferenz zu verbessern (Quelle: X, X)
Meta AI veröffentlicht OMol25-Datensatz mit über 100 Millionen Molekülkonformationen: Meta AI hat den OMol25-Datensatz auf HuggingFace veröffentlicht, der über 100 Millionen Molekülkonformationen enthält und 83 Elemente sowie vielfältige chemische Umgebungen abdeckt. Der Datensatz zielt darauf ab, Machine-Learning-Modelle zu trainieren, die eine Genauigkeit auf DFT-Niveau (Dichtefunktionaltheorie) erreichen und gleichzeitig die Berechnungskosten erheblich senken können. Dies wird dazu beitragen, die Forschung und Anwendung in Bereichen wie der Arzneimittelentdeckung, dem Design fortschrittlicher Materialien und Lösungen für saubere Energie zu beschleunigen (Quelle: X)
Gemini 2.5 Pro in NotebookLM im deutschen iOS App Store verfügbar: Googles NotebookLM-App (mit integriertem Gemini 2.5 Pro) ist jetzt im deutschen iOS App Store erhältlich. Zuvor war die iOS-Version in der EU nur über TestFlight verfügbar. Gleichzeitig scheint die Android-Version breiter verfügbar zu sein. NotebookLM soll Benutzern helfen, lange Dokumente, Notizen usw. zu verstehen und zu verarbeiten (Quelle: X)
ByteDance aktiv in der KI-Forschung, veröffentlicht kürzlich mehrere Paper: Das SEED-Team von ByteDance hat in den letzten zwei Monaten mindestens 13 Forschungsarbeiten im Bereich KI veröffentlicht. Die Themen umfassen Modellzusammenführung, durch Reinforcement Learning ausgelöste adaptive Chain-of-Thought (AdaCoT), Optimierung des Reasonings durch latente Repräsentationen (LatentSeek) und mehr. Diese Forschungen zeigen ByteDances kontinuierliches Engagement und seine Erkundungen zur Verbesserung der Effizienz, der Reasoning-Fähigkeiten und der Trainingsmethoden von großen Sprachmodellen (Quelle: X, X)
KI-gesteuerte Zinkbatterie der nächsten Generation erreicht 99,8 % Effizienz und 4300 Stunden Laufzeit: Durch KI-Optimierung hat eine neue Generation von Zinkbatterien eine Coulomb-Effizienz von 99,8 % und eine Laufzeit von bis zu 4300 Stunden erreicht. Dieser technologische Durchbruch zeigt das Anwendungspotenzial von KI in den Materialwissenschaften und der Energiespeicherung und verspricht, die Entwicklung effizienterer und langlebigerer Batterietechnologien voranzutreiben, was für die Speicherung erneuerbarer Energien und tragbare elektronische Geräte von großer Bedeutung ist (Quelle: X)

Perplexity startet KI-Smart-Browser Comet für frühe Tests: Perplexity hat damit begonnen, seinen Webbrowser Comet mit Agentenfunktionen an frühe Tester auszuliefern. Es wird erwartet, dass dieser Browser ein völlig neues „Vibe Browsing“-Erlebnis bietet, das möglicherweise die leistungsstarken KI-Such- und Informationsintegrationsfähigkeiten von Perplexity kombiniert, um den Benutzern eine intelligentere und personalisiertere Art des Webbrowsens zu ermöglichen (Quelle: X)
Intel veröffentlicht kostengünstige Arc Pro B-Serie Grafikkarten mit Fokus auf großen VRAM: Intel hat die Arc Pro B50 (16 GB VRAM, 299 US-Dollar) und die speziell für KI-Workstations entwickelte Arc Pro B60 (24 GB VRAM, 500 US-Dollar pro Karte) vorgestellt. Die B60 übertrifft in KI-Inferenztests die Nvidia RTX A1000, und ihr größerer VRAM bietet Vorteile beim Ausführen großer Modelle. Die Project Battlematrix Workstation verwendet Xeon-Prozessoren und kann mit bis zu 8 B60-GPUs (insgesamt 192 GB VRAM) ausgestattet werden, die Modelle mit über 70 Milliarden Parametern unterstützen. Dieser Schritt wird als Intels Strategie angesehen, einen Durchbruch bei der Kosteneffizienz im KI-Hardwaremarkt zu erzielen (Quelle: 量子位)

Huawei Cloud stellt CloudMatrix 384 Superknoten zur Steigerung der KI-Rechenleistung vor: Huawei Cloud hat den CloudMatrix 384 Superknoten vorgestellt, der eine vollständig Peer-to-Peer-Verbindungsarchitektur verwendet, um 384 KI-Beschleunigerkarten zu einem Super-Cloud-Server zu verbinden und eine Rechenleistung von bis zu 300 Petaflops zu bieten. Ziel ist es, die Herausforderungen bei Kommunikationseffizienz, Speicherwand und Zuverlässigkeit im KI-Training und bei der Inferenz zu lösen. Die Architektur betont besonders die Affinität zu MoE-Modellen, die Stärkung der Rechenleistung durch das Netzwerk und die Stärkung der Rechenleistung durch den Speicher und wird bereits zur Unterstützung von Inferenzdiensten für große Modelle wie DeepSeek-R1 eingesetzt (Quelle: 量子位)

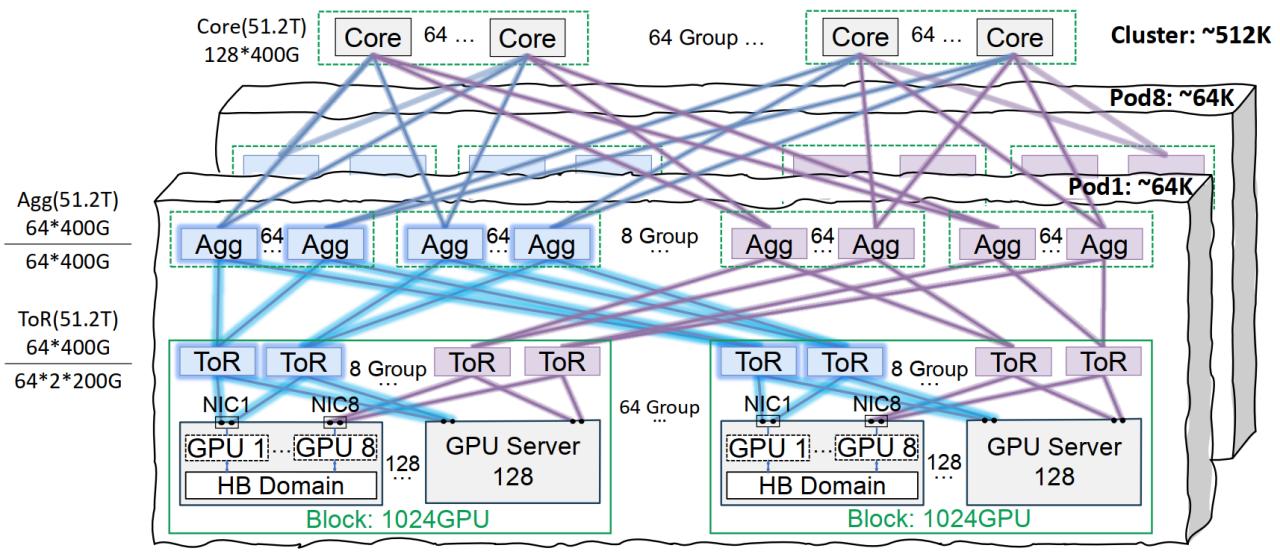
Tencent Cloud Xingmai Netzwerkinfrastruktur optimiert das Training großer Modelle: Tencent Cloud hat die Xingmai Hochleistungs-Netzwerkinfrastrukturlösung vorgestellt, die speziell für das Training und die Inferenz von großen KI-Modellen entwickelt wurde. Diese Lösung behebt die Schwachstellen herkömmlicher Rechenzentren in Bezug auf Netzwerk, Bereitstellungsdichte und Fehlerlokalisierung durch eine Co-Orbit-Verbindungsarchitektur (unterstützt ein Netzwerk von 64.000 GPUs pro Pod und 512.000 GPUs im gesamten Cluster), optimierte Energieverwaltungs- und Kühllösungen sowie ein intelligentes Überwachungssystem. Xingmai unterstützt bereits selbst entwickelte Dienste wie Tencent Hunyuan und hat Leistungsoptimierungen für das DeepEP-Kommunikationsframework von DeepSeek bereitgestellt (Quelle: 量子位)
Stability AI veröffentlicht SV4D2.0-Modell, deutet möglicherweise auf Rückkehr im Bereich der Videogenerierung hin: Stability AI hat auf Hugging Face ein Modell namens sv4d2.0 veröffentlicht, was in der Community Aufmerksamkeit erregt hat. Obwohl es nur wenige Details gibt, könnte dieser Schritt bedeuten, dass Stability AI neue technologische Fortschritte oder Produktiterationen im Bereich der Videogenerierung oder verwandten 3D/4D-Bereichen hat, was darauf hindeutet, dass das Unternehmen nach einer Anpassungsphase möglicherweise an die Spitze des KI-Generierungsbereichs zurückkehrt (Quelle: X)
Meta AI veröffentlicht Adjoint Sampling Lernalgorithmus: Meta AI hat einen neuen Lernalgorithmus namens Adjoint Sampling vorgestellt, der zum Trainieren von generativen Modellen auf Basis von skalaren Belohnungen dient. Der Algorithmus basiert auf theoretischen Grundlagen, die von FAIR entwickelt wurden, ist hoch skalierbar und verspricht, eine Grundlage für zukünftige Forschungen zu skalierbaren Sampling-Methoden zu werden. Zugehörige Forschungsarbeiten, Modelle, Code und Benchmarks wurden veröffentlicht (Quelle: X)
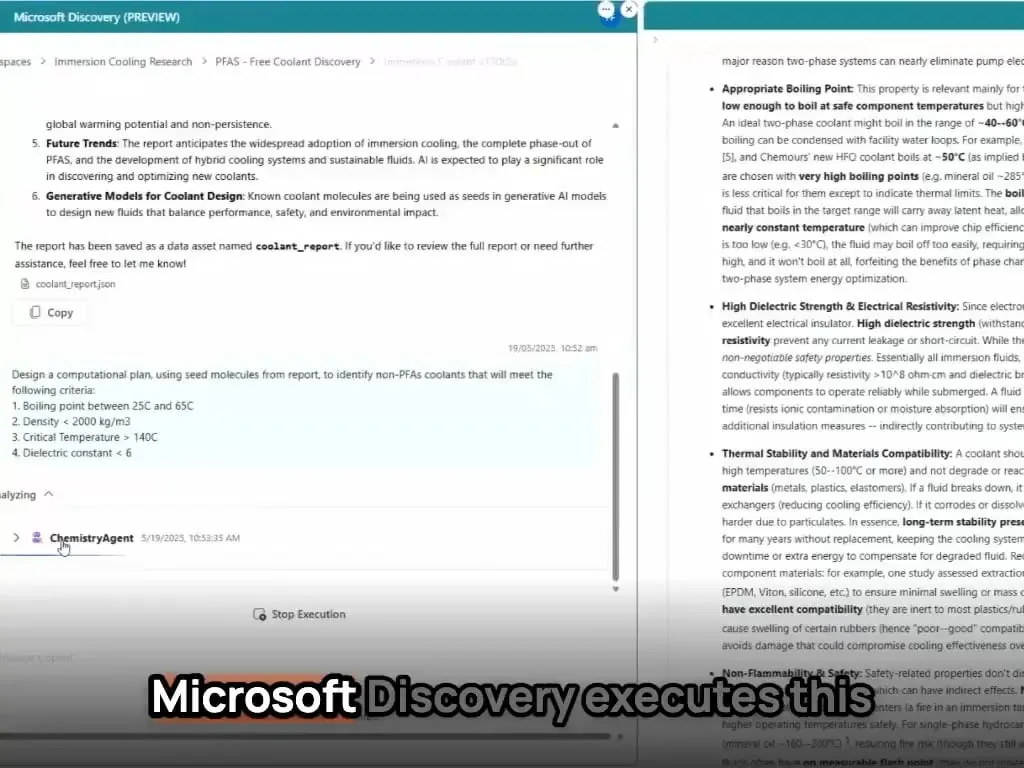
Microsoft AI Agents entdecken und synthetisieren neues Material in Stunden: Microsoft demonstrierte die leistungsstarken Fähigkeiten seiner AI Agents in der wissenschaftlichen Forschung und Entwicklung. Diese Agents sind in der Lage, wissenschaftliche Literatur zu scannen, Pläne zu erstellen, Code zu schreiben, Simulationen durchzuführen und die Entdeckung eines neuartigen Kühlmittels für Rechenzentren, die normalerweise Jahre der Forschung erfordern würde, in wenigen Stunden abzuschließen. Darüber hinaus gelang es dem Team, das von der KI entworfene neuartige Kühlmittel erfolgreich zu synthetisieren und auf einem echten Motherboard zu demonstrieren, was das enorme Potenzial der KI zur Beschleunigung autonomer Entdeckungen und Kreationen in Bereichen wie den Materialwissenschaften zeigt (Quelle: Reddit r/artificial)
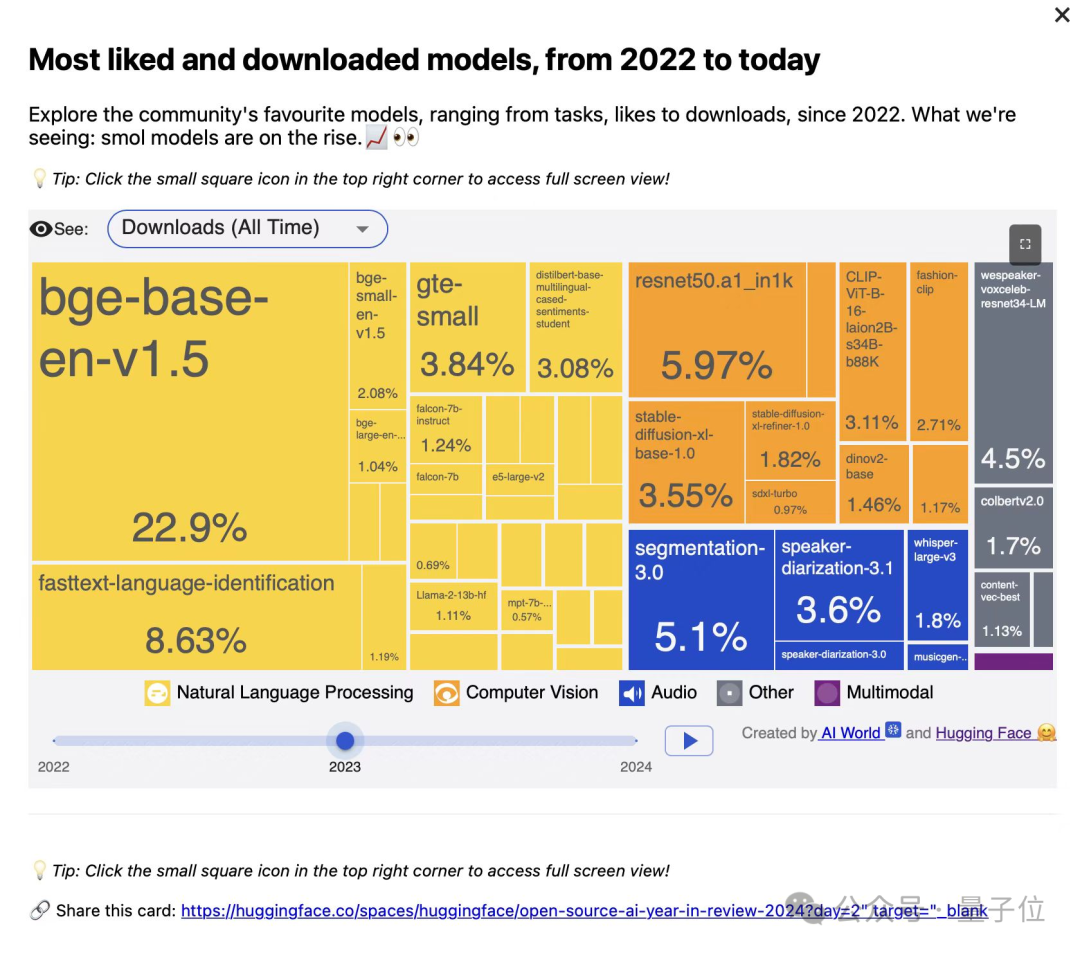
BAAI veröffentlicht drei Vektor-Modelle der BGE-Serie mit Fokus auf Code- und multimodale Suche: Das Beijing Academy of Artificial Intelligence (BAAI) hat in Zusammenarbeit mit Universitäten BGE-Code-v1 (Code-Vektor-Modell), BGE-VL-v1.5 (allgemeines multimodales Vektor-Modell) und BGE-VL-Screenshot (Vektor-Modell für visuelle Dokumente) veröffentlicht. Diese Modelle zeigen hervorragende Leistungen in Benchmarks wie CoIR, Code-RAG, MMEB und MVRB. BGE-Code-v1 basiert auf Qwen2.5-Coder-1.5B, BGE-VL-v1.5 auf LLaVA-1.6 und BGE-VL-Screenshot auf Qwen2.5-VL-3B-Instruct. Sie zielen darauf ab, die Leistung bei der Code-Suche, dem Verständnis von Bildern und Texten sowie der Suche in komplexen visuellen Dokumenten zu verbessern und sind vollständig Open Source (Quelle: WeChat)
Huawei OmniPlacement-Technologie optimiert MoE-Modellinferenz, theoretische Latenzreduktion von 10 % für DeepSeek-V3: Um das Problem der unausgeglichenen Lastverteilung in Mixture-of-Experts (MoE)-Modellen („heiße Experten“ vs. „kalte Experten“), das die Inferenzleistung einschränkt, anzugehen, hat das Huawei-Team die OmniPlacement-Technologie vorgeschlagen. Diese Technologie kann durch Experten-Neuanordnung, redundante Bereitstellung zwischen Schichten und dynamisches Scheduling in Quasi-Echtzeit die Inferenzlatenz bei Modellen wie DeepSeek-V3 theoretisch um etwa 10 % reduzieren und den Durchsatz um etwa 10 % erhöhen. Diese Lösung wird in Kürze vollständig Open Source sein (Quelle: WeChat)

vivo veröffentlicht EdgeInfinite-Algorithmus für effiziente Verarbeitung von 128K Langtexten auf Mobiltelefonen: Das vivo AI Research Institute hat auf der ACL 2025 eine Studie veröffentlicht und den EdgeInfinite-Algorithmus vorgestellt, der speziell für Endgeräte entwickelt wurde. Durch trainierbare Gated-Memory-Module und Speicherkomprimierungs-/-dekomprimierungstechnologien verarbeitet er extrem lange Texte in der Transformer-Architektur effizient. Der Algorithmus wurde am BlueLM-3B-Modell getestet und kann 128K Tokens auf Geräten mit 10 GB GPU-Speicher verarbeiten. Er zeigt in mehreren LongBench-Aufgaben hervorragende Leistungen und reduziert die Zeit bis zum ersten Token sowie den Speicherverbrauch erheblich (Quelle: WeChat)

🧰 Tools
LlamaParse-Update verbessert Dokumentenanalysefähigkeiten: LlamaParse hat mehrere Updates veröffentlicht, die die Leistung als KI-Agenten-gesteuertes Dokumentenanalyse-Tool verbessern. Zu den neuen Funktionen gehören die Unterstützung für Gemini 2.5 Pro und GPT-4.1 sowie die Hinzufügung von Schräglagenerkennung und Konfidenzwerten. Darüber hinaus wurde eine Schaltfläche für Code-Snippets eingeführt, mit der Benutzer Analysekonfigurationen direkt in ihre Codebasis kopieren können, sowie Voreinstellungen für Anwendungsfälle und die Möglichkeit, beim Export zwischen gerendertem und rohem Markdown zu wechseln (Quelle: X)
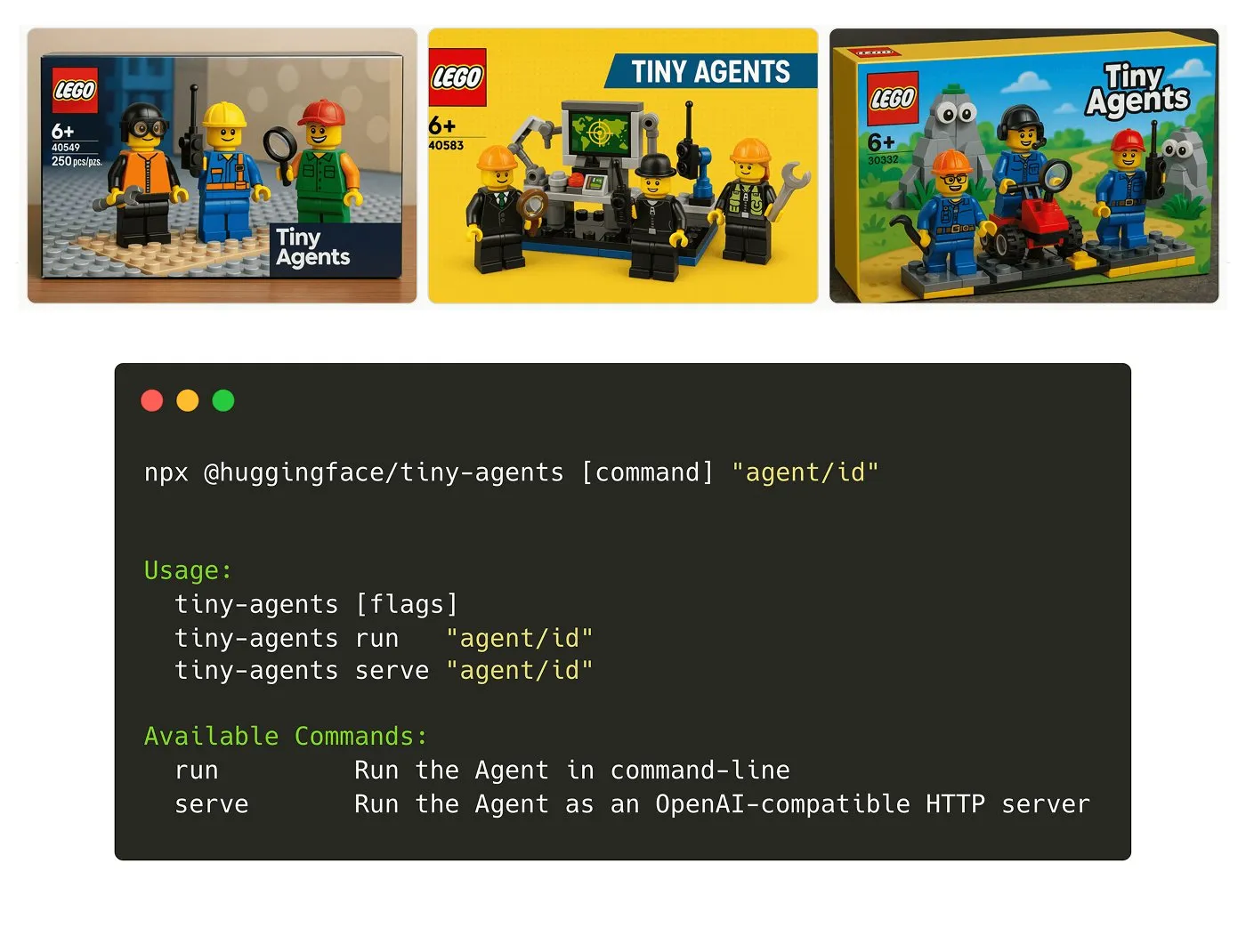
Hugging Face stellt Tiny Agents NPM-Paket vor: Julien Chaumond hat Tiny Agents veröffentlicht, ein leichtgewichtiges, zusammensetzbares Agenten-NPM-Paket. Es basiert auf dem Inference Client von Hugging Face und dem MCP (Model Component Protocol)-Stack und soll Entwicklern einen schnellen Einstieg und die Erstellung kleiner Agentenanwendungen ermöglichen. Ein offizielles Tutorial ist verfügbar (Quelle: X)
LangGraph-Plattform fügt MCP-Unterstützung hinzu und vereinfacht die Agentenintegration: Die LangGraph-Plattform unterstützt jetzt das Model Component Protocol (MCP). Jeder auf der Plattform bereitgestellte Agent stellt automatisch einen MCP-Endpunkt bereit. Dies bedeutet, dass Benutzer diese Agenten als Werkzeuge in jedem Client verwenden können, der MCP-streamfähiges HTTP unterstützt, ohne benutzerdefinierten Code schreiben oder zusätzliche Infrastruktur konfigurieren zu müssen, was die Integration und Interoperabilität zwischen Agenten vereinfacht (Quelle: X)

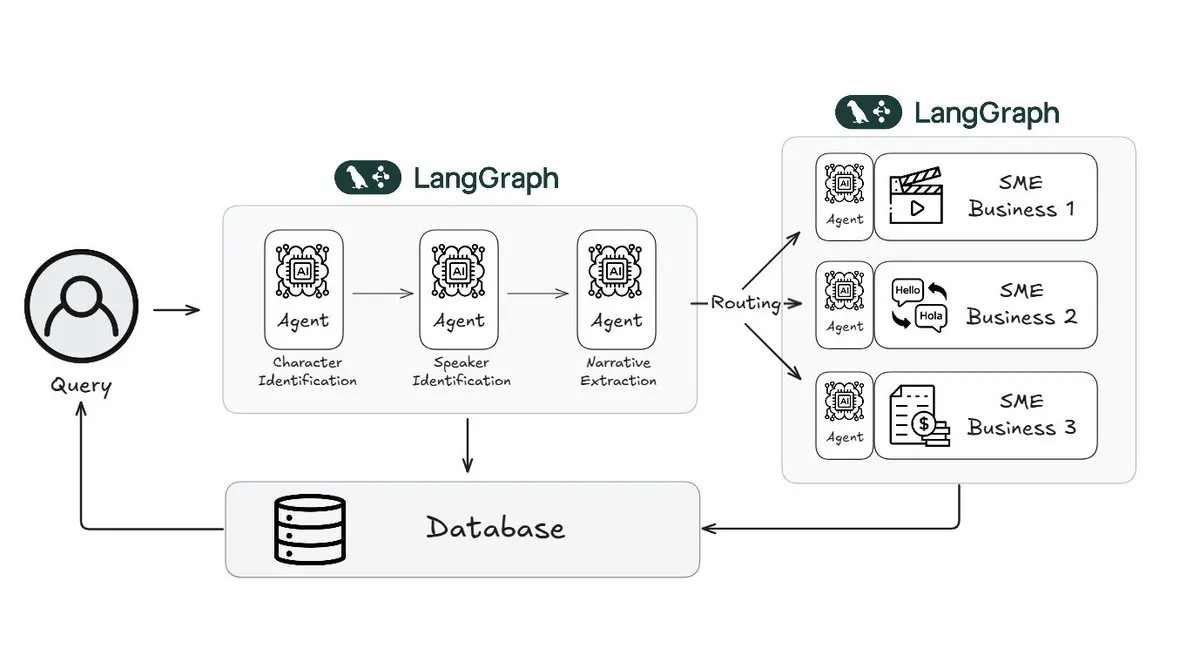
Webtoon reduziert den Aufwand für die Überprüfung von Geschichten um 70 % mit LangGraph: Webtoon, ein führender Anbieter digitaler Comics, hat Webtoon Comprehension AI (WCAI) entwickelt, das LangGraph verwendet, um das narrative Verständnis seiner riesigen Inhaltsbibliothek zu automatisieren. WCAI ersetzt das manuelle Durchsuchen durch intelligente multimodale Agenten, die Charakter- und Sprechererkennung, Handlungs- und Tonextraktion sowie Abfragen von Erkenntnissen in natürlicher Sprache durchführen können. Dadurch konnte der Arbeitsaufwand für Marketing-, Übersetzungs- und Empfehlungsteams um 70 % reduziert und die Kreativität gesteigert werden (Quelle: X)
OpenMemory MCP ermöglicht dauerhaften privaten Speicher-Austausch zwischen KI-Tools: Das Mem0-Projekt hat den OpenMemory MCP-Server vorgestellt, der KI-Anwendungen einen plattform- und sitzungsübergreifenden, dauerhaften privaten Speicher bieten soll. Benutzer können ihn lokal bereitstellen und OpenMemory über das MCP-Protokoll mit Client-Tools wie Cursor verbinden, um Speicher hinzuzufügen, zu durchsuchen, aufzulisten und zu löschen. Das Tool bietet Speicherverwaltungsfunktionen über ein Dashboard und soll die Personalisierung und das Kontextverständnis von KI-Agenten verbessern (Quelle: WeChat)

Miaoduo AI 2.0 veröffentlicht, positioniert als KI-Assistent für Interface-Design: Miaoduo AI 2.0 wurde als KI-Assistent im Bereich Interface-Design veröffentlicht und zielt darauf ab, mit Benutzern bei Designaufgaben zusammenzuarbeiten. Die neue Version verbessert die Interaktion durch ein KI-Magiefenster, unterstützt dialogorientierte Bearbeitung und iterative Designlösungen und kann basierend auf voreingestellten Stilen oder Benutzereingaben (Langtext, Skizzen, Referenzbilder) mehrere Interface-Versionen generieren, die mit gängigen Designsystemen kompatibel sind. Darüber hinaus bietet es Funktionen zur Bild- und Textverarbeitung, Designberatung und Schnellbefehle (natürliche Sprache zu API-Aufruf). Miaoduo AI unterstützt das MCP-Protokoll und optimiert Designdaten für das Lesen durch große Modelle, um hochgradig originalgetreuen Frontend-Code zu generieren (Quelle: 量子位)

llmbasedos: Open-Source Proof-of-Concept für ein bootfähiges KI-Betriebssystem auf MCP-Basis: Der Entwickler iluxu hat das Projekt llmbasedos drei Tage vor der Veröffentlichung des Microsoft-Konzepts „USB-C for AI apps“ (basierend auf MCP) als Open Source veröffentlicht. Bei dem Projekt handelt es sich um ein KI-Betriebssystem, das schnell von USB oder einer virtuellen Maschine gestartet werden kann. Es kommuniziert über ein FastAPI-Gateway mittels JSON-RPC mit kleinen Python-Daemons und ermöglicht es Benutzerskripten, durch eine einfache cap.json-Konfiguration von ChatGPT/Claude/VS Code usw. aufgerufen zu werden. Standardmäßig wird offline llama.cpp verwendet, es kann aber auch auf GPT-4o oder Claude 3 umgeschaltet werden. Ziel ist es, offene Standards für die Verbindung von KI-Anwendungen voranzutreiben (Quelle: Reddit r/LocalLLaMA)
📚 Lernen
Warum ist Knowledge Distillation (KD) effektiv? Neue Studie liefert prägnante Erklärung: Kyunghyun Cho et al. haben eine prägnante Erklärung für die Effektivität von Knowledge Distillation (KD) vorgeschlagen. Sie nehmen an, dass die Verwendung von Low-Entropy-Approximation-Sampling aus dem Lehrermodell dazu führt, dass das Schülermodell eine höhere Präzision, aber einen geringeren Recall aufweist. Da autoregressive Sprachmodelle im Wesentlichen unendlich kaskadierte Mischverteilungen sind, haben sie diese Hypothese mit SmolLM validiert. Die Studie argumentiert, dass aktuelle Bewertungsmethoden möglicherweise zu stark auf Präzision ausgerichtet sind und den Verlust an Recall ignorieren, was sich darauf auswirkt, welche Inhalte und Benutzergruppen von großen Universalmodellen möglicherweise übersehen werden (Quelle: X)

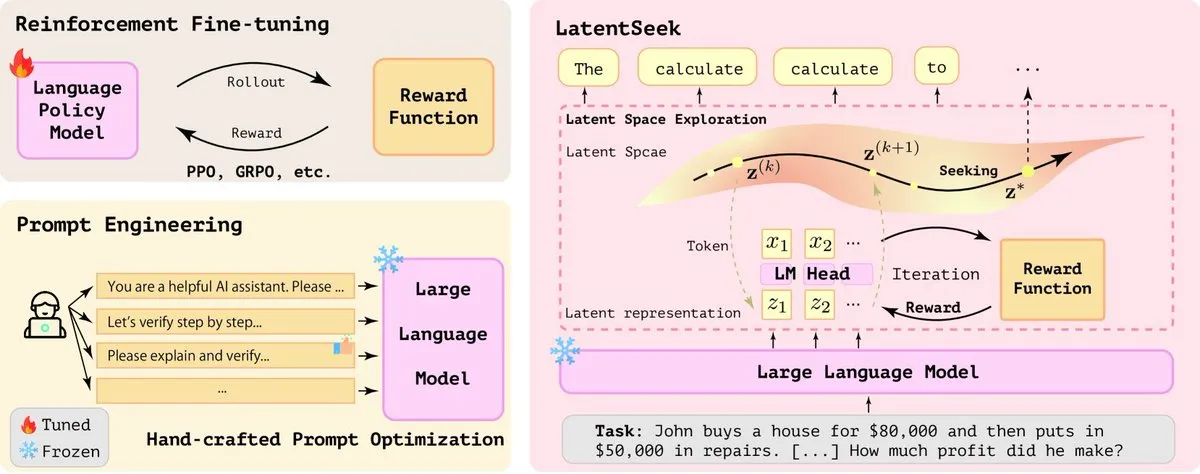
LatentSeek: Verbesserung der LLM-Reasoning-Fähigkeit durch Policy Gradient Optimierung im latenten Raum: Ein Paper mit dem Titel „Seek in the Dark“ schlägt LatentSeek vor, ein neues Paradigma zur Verbesserung der Reasoning-Fähigkeit von großen Sprachmodellen (LLMs) zur Testzeit durch instanzspezifische Policy Gradients im latenten Raum. Diese Methode erfordert kein Training, keine Daten oder Belohnungsmodelle und zielt darauf ab, den Reasoning-Prozess des Modells durch Optimierung latenter Repräsentationen zu verbessern. Diese trainingsunabhängige Methode zeigt Potenzial zur Leistungssteigerung von LLMs bei komplexen Reasoning-Aufgaben (Quelle: X)
Microsoft schlägt CoML vor: Chain-of-Model Learning für Sprachmodelle: Microsoft Research hat ein neues Lernparadigma namens „Chain-of-Model Learning“ (CoML) vorgeschlagen. Diese Methode integriert die kausalen Beziehungen von Hidden States in einer Kettenstruktur in jede Netzwerkschicht, um die Skalierungseffizienz des Modelltrainings und die Inferenzflexibilität bei der Bereitstellung zu verbessern. Ihr Kernkonzept „Chain-of-Representation“ (CoR) zerlegt den Hidden State jeder Schicht in mehrere Sub-Repräsentationsketten, wobei nachfolgende Ketten auf die Eingaberepräsentationen aller vorhergehenden Ketten zugreifen können. Dies ermöglicht es dem Modell, durch Hinzufügen von Ketten schrittweise zu skalieren und durch Auswahl unterschiedlicher Anzahlen von Ketten verschieden große Submodelle für elastische Inferenz bereitzustellen. Das auf diesem Prinzip basierende CoLM (Chain-of-Language Model) und seine Variante CoLM-Air (mit KV-Sharing-Mechanismus) zeigen eine vergleichbare Leistung wie Standard-Transformer und bieten die Vorteile der schrittweisen Skalierung und elastischen Inferenz (Quelle: X, HuggingFace Daily Papers)

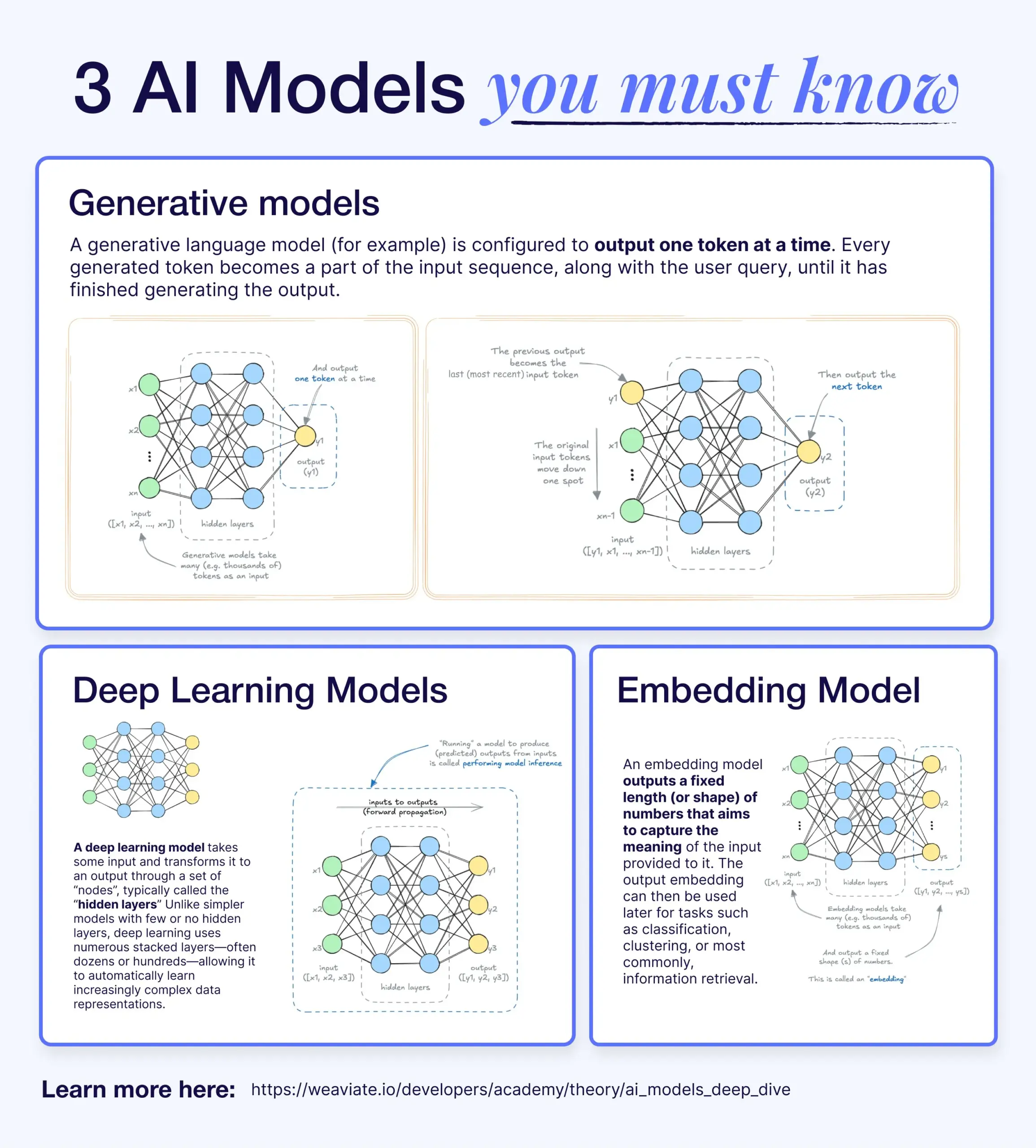
Unterschiede und Zusammenhänge zwischen Deep Learning, generativen Modellen und Embedding-Modellen: Ein populärwissenschaftlicher Artikel erklärt die Beziehung zwischen Deep-Learning-Modellen, generativen Modellen und Embedding-Modellen. Deep-Learning-Modelle sind die grundlegende Architektur, die numerische Ein- und Ausgaben über mehrschichtige neuronale Netze verarbeitet. Generative Modelle sind eine Art von Deep-Learning-Modell, das speziell darauf ausgelegt ist, neue Inhalte zu erstellen, die ihren Trainingsdaten ähneln (z. B. GPT, DALL-E). Embedding-Modelle sind ebenfalls eine Art von Deep-Learning-Modell, das verwendet wird, um Daten (Text, Bilder usw.) in numerische Vektorrepräsentationen umzuwandeln, die semantische Informationen erfassen und häufig für Ähnlichkeitssuchen und RAG-Systeme verwendet werden. In vielen KI-Systemen arbeiten diese Modelle zusammen, beispielsweise nutzen RAG-Systeme Embedding-Modelle für die Suche und generative Modelle für die Antwortgenerierung (Quelle: X)
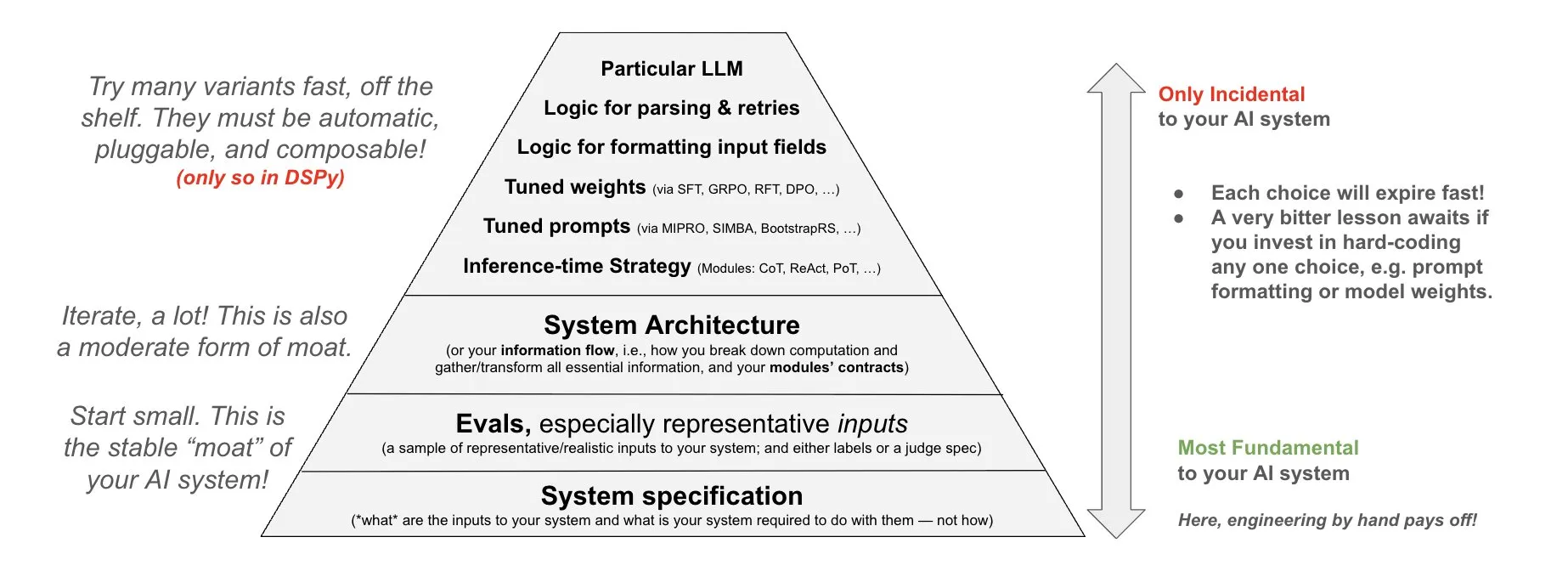
DSPy stellt Philosophie für den Einsatz in KI-Systemen vor: DSPy teilt seine Philosophie bezüglich des Einsatzes in KI-Systemen und betont, dass Anstrengungen in die drei grundlegenden Schichten von KI-Systemen investiert werden sollten: Daten, Modelle und Algorithmen. Sie argumentieren, dass Entwickler durch die Bereitstellung zusammensetzbarer Top-Level-Module (Prompts, Demonstrations, Optimizers, Metrics, Tools, Agents, Reasoning Modules) diese drei grundlegenden Schichten schnell iterieren und so leistungsfähigere KI-Systeme erstellen können (Quelle: X)
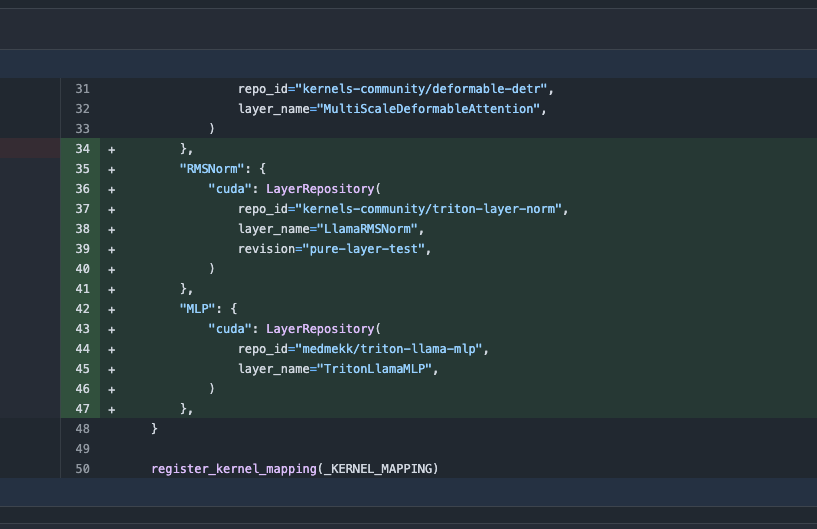
Transformers-Bibliothek-Update, automatischer Wechsel zu optimierten Kernels zur Leistungssteigerung: Die neueste Version der Hugging Face Transformers-Bibliothek implementiert einen automatischen Wechsel zu optimierten Kernels, wenn die Hardware dies zulässt. Das Update integriert die kernels-Bibliothek, die auf beliebte Modelle wie Llama abzielt und die beliebtesten Community-Kernels auf dem Hugging Face Hub nutzt, um die Ausführungseffizienz und Leistung von Modellen auf kompatibler Hardware zu verbessern (Quelle: X)
ARC-AGI-2 Benchmark veröffentlicht, fordert führende KI-Reasoning-Systeme heraus: François Chollet et al. haben ein Paper zum ARC-AGI-2 Benchmark veröffentlicht, das dessen Designprinzipien, Herausforderungen, Analysen der menschlichen Leistung und die Leistung aktueller Modelle detailliert beschreibt. Der Benchmark zielt darauf ab, die abstrakten Reasoning-Fähigkeiten von KI zu bewerten. Menschen können 100 % der Aufgaben lösen, während aktuelle führende KI-Modelle weniger als 5 % erreichen, was eine enorme Lücke zwischen KI und Menschen im fortgeschrittenen abstrakten Reasoning aufzeigt (Quelle: X)

Terence Tao veröffentlicht Tutorial zum Beweisen von Funktionsgrenzwerten mit GitHub Copilot-Unterstützung: Der Mathematiker Terence Tao hat ein Video-Tutorial veröffentlicht, das zeigt, wie GitHub Copilot zur Unterstützung beim Beweisen von Funktionsgrenzwertproblemen verwendet werden kann, einschließlich Summen-, Differenz- und Produktsätzen. Er betont, dass Copilot zwar schnell Code-Frameworks generieren und auf vorhandene Bibliotheksfunktionen hinweisen kann, bei komplexen mathematischen Details, der Behandlung von Sonderfällen und kreativen Lösungen jedoch immer noch viel manuelle Intervention und Anpassung erforderlich ist. Manchmal kann eine Kombination aus Papier-und-Bleistift-Ableitung und anschließender formaler Verifizierung effizienter sein (Quelle: 36氪)
PhyT2V-Framework nutzt LLMs zur Verbesserung der physikalischen Konsistenz von Text-zu-Video-Generierung: Ein Forschungsteam der University of Pittsburgh hat das PhyT2V-Framework vorgeschlagen, das durch von großen Sprachmodellen (LLMs) geleitetes Chain-of-Thought (CoT) Reasoning und einen iterativen Selbstkorrekturmechanismus Text-Prompts optimiert, um den physikalischen Realismus von Inhalten zu verbessern, die von bestehenden Text-zu-Video (T2V)-Modellen generiert werden. Diese Methode erfordert kein Neutraining des Modells. Durch die Analyse semantischer Nichtübereinstimmungen zwischen generierten Videos und Prompts sowie die Einbeziehung physikalischer Regeln zur Prompt-Korrektur zielt sie darauf ab, die physikalische Konsistenz von T2V-Modellen bei der Verarbeitung von Out-of-Distribution (OOD)-Szenarien zu verbessern. Experimente zeigen, dass PhyT2V die Leistung von Modellen wie CogVideoX und OpenSora auf Benchmarks wie VideoPhy und PhyGenBench signifikant verbessern kann (Quelle: WeChat)

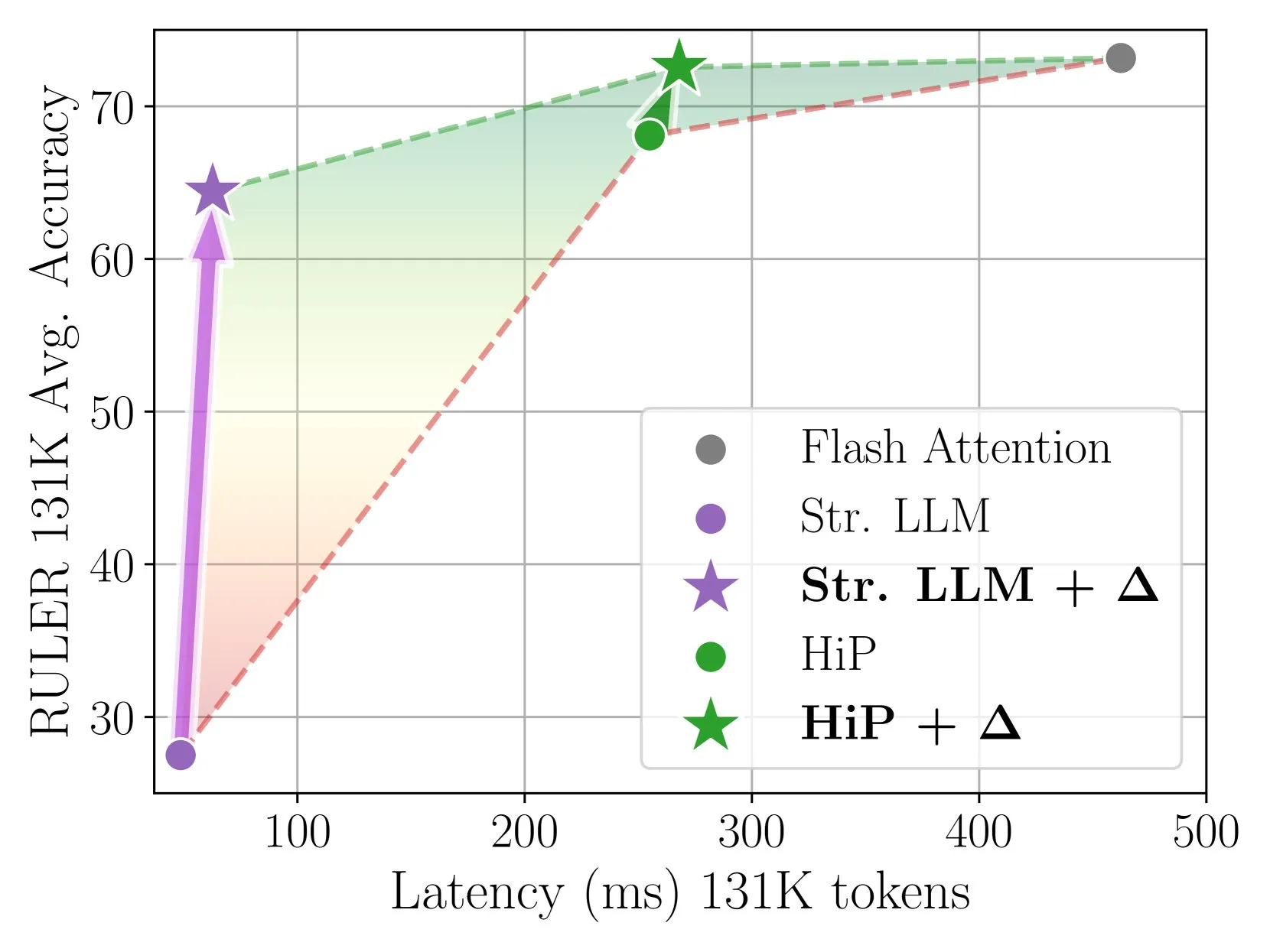
Delta Attention erreicht schnelle und genaue Sparse-Attention-Inferenz durch inkrementelle Korrektur: Diese Studie stellt fest, dass die Berechnung von Sparse Attention zu einer Verteilungsverschiebung des Attention-Outputs führt, was die Modellleistung verringert. Delta Attention korrigiert diese Verteilungsverschiebung, sodass die Output-Verteilung von Sparse Attention der von Full Attention näher kommt. Dadurch wird bei hoher Sparsity (ca. 98,5 %) die Leistung signifikant verbessert und 88 % der Full-Attention-Genauigkeit von Sliding-Window-Attention (mit Sink-Token) im RULER-Benchmark wiederhergestellt, bei geringem Rechenaufwand. Bei der Verarbeitung von 1M Token Pre-Fill ist es 32-mal schneller als Flash Attention 2 (Quelle: HuggingFace Daily Papers)
Thinkless-Framework lässt LLMs lernen, wann CoT-Reasoning durchgeführt werden soll: Um das Problem der geringen Recheneffizienz zu lösen, das durch die Verwendung komplexen Chain-of-Thought (CoT)-Reasonings durch große Sprachmodelle (LLMs) bei allen Anfragen entsteht, schlagen Forscher das Thinkless-Framework vor. Dieses Framework trainiert LLMs mithilfe von Reinforcement Learning, sodass sie je nach Aufgabenkomplexität und eigenen Fähigkeiten adaptiv zwischen kurzem oder langem Reasoning wählen können. Der Kernalgorithmus DeGRPO zerlegt das Lernziel in einen Kontroll-Token-Verlust (bestimmt den Reasoning-Modus) und einen Antwortverlust (verbessert die Antwortgenauigkeit), um den Trainingsprozess zu stabilisieren. Experimente zeigen, dass Thinkless die Verwendung langer Denkketten in Benchmarks wie Minerva Algebra um 50 % bis 90 % reduzieren und die Reasoning-Effizienz erheblich verbessern kann (Quelle: HuggingFace Daily Papers)
CPGD-Algorithmus verbessert die Stabilität des Reinforcement Learnings für regelbasierte Sprachmodelle: Um das Problem der Trainingsinstabilität anzugehen, das bei bestehenden regelbasierten Reinforcement-Learning-Methoden (wie GRPO, REINFORCE++, RLOO) beim Training von Sprachmodellen auftreten kann, schlagen Forscher den CPGD-Algorithmus (Clipped Policy Gradient Optimization with Policy Drift) vor. CPGD führt eine auf KL-Divergenz basierende Policy-Drift-Beschränkung ein, um Policy-Updates dynamisch zu regularisieren, und verwendet einen Log-Ratio-Clipping-Mechanismus, um übermäßige Policy-Updates zu verhindern. Theoretische und empirische Analysen zeigen, dass CPGD die Instabilität mildern und die Leistung bei gleichzeitiger Aufrechterhaltung der Trainingsstabilität erheblich verbessern kann (Quelle: HuggingFace Daily Papers)
Neuro-symbolischer Query-Compiler QCompiler verbessert die Verarbeitung komplexer Anfragen in RAG-Systemen: Um das Problem zu lösen, dass Retrieval-Augmented Generation (RAG)-Systeme bei der Verarbeitung komplexer Anfragen mit verschachtelten Strukturen und Abhängigkeiten, insbesondere unter ressourcenbeschränkten Bedingungen, Schwierigkeiten haben, die Suchintention präzise zu identifizieren, wurde das QCompiler-Framework vorgeschlagen. Dieses Framework, inspiriert von linguistischen Grammatikregeln und Compiler-Design, entwirft zunächst eine minimale und ausreichende BNF-Grammatik G[q], um komplexe Anfragen zu formalisieren. Anschließend wird die Anfrage durch einen Query-Expression-Transformer, einen lexikalisch-syntaktischen Parser und einen rekursiven Abstiegs-Prozessor zu einem abstrakten Syntaxbaum (AST) kompiliert und ausgeführt. Die Atomarität der Sub-Queries an den Blattknoten gewährleistet eine präzisere Dokumentensuche und Antwortgenerierung (Quelle: HuggingFace Daily Papers)
Jedi-Datensatz und OSWorld-G-Benchmark fördern die Forschung zur GUI-Elementlokalisierung in Computeranwendungsszenarien: Um den Engpass bei der Lokalisierung von grafischen Benutzeroberflächen (GUI) – der Zuordnung von natürlichsprachlichen Anweisungen zu GUI-Operationen – zu beheben, haben Forscher den OSWorld-G-Benchmark (564 fein granulierte, annotierte Beispiele, die Textabgleich, Elementerkennung, Layoutverständnis und präzise Operationen abdecken) und den groß angelegten synthetischen Datensatz Jedi (4 Millionen Beispiele) veröffentlicht. Auf Jedi trainierte multiskalige Modelle übertreffen bestehende Methoden auf ScreenSpot-v2, ScreenSpot-Pro und OSWorld-G und können die Agentenfähigkeiten allgemeiner Basismodelle bei komplexen Computeraufgaben (OSWorld) von 5 % auf 27 % verbessern (Quelle: HuggingFace Daily Papers)
Segmentiertes Chain-of-Thought-Reasoning (Fractured CoT) verbessert Effizienz und Leistung von LLM-Reasoning: Um das Problem der hohen Token-Kosten durch CoT-Reasoning zu lösen, stellten Forscher fest, dass trunkiertes CoT (Abbruch des Reasonings vor Abschluss und direkte Generierung der Antwort) oft eine vergleichbare Leistung wie vollständiges CoT erzielt, aber den Token-Verbrauch erheblich reduziert. Darauf basierend wird die einheitliche Reasoning-Strategie Fractured Sampling vorgeschlagen, die durch Anpassung der Anzahl der Reasoning-Trajektorien, der Anzahl der endgültigen Lösungen pro Trajektorie und der Trunkierungstiefe der Reasoning-Spuren auf mehreren Reasoning-Benchmarks und Modellgrößen einen besseren Kompromiss zwischen Genauigkeit und Kosten erzielt und so den Weg für effizienteres und skalierbareres LLM-Reasoning ebnet (Quelle: HuggingFace Daily Papers)
Multimodale Verifizierung chemischer Formeln durch LLM-Kontextkonditionierung und PWP-Prompting: Forscher untersuchten die strukturierte LLM-Kontextkonditionierung in Kombination mit den Prinzipien des Persistent Workflow Prompting (PWP), um das Verhalten von LLMs beim Reasoning anzupassen. Ziel ist es, ihre Zuverlässigkeit bei präzisen Verifizierungsaufgaben (wie chemischen Formeln) zu erhöhen, insbesondere bei der Verarbeitung komplexer wissenschaftlicher Dokumente, die Bilder enthalten. Diese Methode verwendet nur Standard-Chat-Schnittstellen (Gemini 2.5 Pro, ChatGPT Plus o3) und erfordert keine API- oder Modelländerungen. Erste Experimente zeigen, dass diese Methode die Erkennung von Textfehlern verbessert und Gemini 2.5 Pro dabei geholfen hat, Fehler in Bildformeln zu identifizieren, die bei der manuellen Überprüfung übersehen wurden (Quelle: HuggingFace Daily Papers)
Nutzung von PWP, Meta-Prompting und Meta-Reasoning für KI-gestütztes akademisches Peer-Review: Forscher schlagen die Methode des Persistent Workflow Prompting (PWP) vor, um eine kritische Peer-Review wissenschaftlicher Manuskripte über Standard-LLM-Chat-Schnittstellen zu ermöglichen. PWP verwendet eine hierarchische modulare Architektur (Markdown-strukturiert), um detaillierte Analyse-Workflows zu definieren, und kodiert systematisch Experten-Review-Prozesse (einschließlich impliziten Wissens) durch Meta-Prompting und Meta-Reasoning. PWP leitet LLMs zu einer systematischen multimodalen Bewertung an, wie z. B. der Unterscheidung zwischen Behauptungen und Beweisen, der Integration von Text-/Bild-/Diagrammanalysen und der Durchführung quantitativer Machbarkeitsprüfungen. In Testfällen wurden methodische Mängel erfolgreich identifiziert (Quelle: HuggingFace Daily Papers)
SPOT-Benchmark bewertet die Fähigkeit von KI zur automatischen Validierung wissenschaftlicher Forschung: Um die Fähigkeit großer Sprachmodelle (LLMs) als „KI-Ko-Wissenschaftler“ bei der automatisierten Validierung akademischer Manuskripte zu bewerten, haben Forscher den SPOT-Benchmark eingeführt. Dieser Benchmark enthält 83 veröffentlichte Paper und 91 Fehler, die ausreichen, um Korrekturen oder Rückzüge zu verursachen, und wurde von den Originalautoren und menschlichen Annotatoren kreuzvalidiert. Die Ergebnisse zeigen, dass selbst die fortschrittlichsten LLMs (wie o3) bei SPOT einen Recall von nicht mehr als 21,1 % und eine Präzision von weniger als 6,1 % erreichen, wobei die Modellkonfidenz gering ist und die Ergebnisse bei mehreren Durchläufen inkonsistent sind. Dies zeigt, dass aktuelle LLMs bei der zuverlässigen akademischen Validierung noch weit von den praktischen Anforderungen entfernt sind (Quelle: HuggingFace Daily Papers)
ExTrans erreicht mehrsprachige Deep-Reasoning-Übersetzung durch Reinforcement Learning mit Sample-Augmentierung: Um die Fähigkeiten großer Reasoning-Modelle (LRMs) in der maschinellen Übersetzung zu verbessern, insbesondere in mehrsprachigen Szenarien, schlagen Forscher ExTrans vor. Diese Methode entwickelt eine neue Belohnungsmodellierungsmethode, die Belohnungen quantifiziert, indem sie die Übersetzungsergebnisse eines Policy-Übersetzungsmodells mit denen eines starken LRM (wie DeepSeek-R1-671B) vergleicht. Experimente zeigen, dass ein mit Qwen2.5-7B-Instruct als Backbone trainiertes Modell bei der literarischen Übersetzung SOTA erreicht und OpenAI-o1 sowie DeepSeeK-R1 übertrifft. Durch leichtgewichtige Belohnungsmodellierung kann diese Methode die unidirektionale Übersetzungsfähigkeit effektiv auf 90 Übersetzungsrichtungen in 11 Sprachen übertragen (Quelle: HuggingFace Daily Papers)
Trainierbare Sparse Attention VSA beschleunigt Video-Diffusionsmodelle: Um das Problem der quadratischen Komplexität des 3D-Full-Attention-Mechanismus in Video Diffusion Transformers (DiT) zu lösen, schlagen Forscher VSA (Trainable Sparse Attention) vor. VSA bündelt Tokens in einer leichtgewichtigen Grobphase in Blöcke und identifiziert Schlüssel-Tokens, um dann innerhalb dieser Blöcke eine feingranulare Attention-Berechnung auf Token-Ebene durchzuführen. VSA ist ein von Ende zu Ende trainierbarer, einzeln differenzierbarer Kernel, der keine Nachbearbeitungsanalyse erfordert und 85 % der MFU von FlashAttention3 beibehält. Experimente zeigen, dass VSA die Trainings-FLOPS um das 2,53-fache reduziert, ohne den Diffusionsverlust zu verringern, und die Attention-Zeit des Open-Source-Modells Wan-2.1 um das 6-fache beschleunigt, wodurch die End-to-End-Generierungszeit von 31 Sekunden auf 18 Sekunden sinkt (Quelle: HuggingFace Daily Papers)
SoftCoT++: Testzeitskalierung durch Soft-Chain-of-Thought-Reasoning: Um die Explorationsfähigkeit der SoftCoT-Methode, die Reasoning im kontinuierlichen latenten Raum durchführt, zu verbessern, schlagen Forscher SoftCoT++ vor. Diese Methode stört latente Gedanken durch verschiedene spezialisierte initiale Token-Perturbationen und wendet kontrastives Lernen an, um die Diversität der Soft-Thought-Repräsentationen zu fördern, wodurch SoftCoT auf das Test-Time Scaling (TTS)-Paradigma erweitert wird. Experimente zeigen, dass SoftCoT++ die Leistung von SoftCoT signifikant verbessert und SoftCoT mit Selbstkonsistenz-Erweiterung übertrifft, und zudem eine starke Kompatibilität mit traditionellen Erweiterungstechniken (wie Selbstkonsistenz) aufweist (Quelle: HuggingFace Daily Papers)
MTVCrafter: 4D-Bewegungs-Tokenisierung für Open-World-Animation menschlicher Bilder: Um das Problem zu lösen, dass bestehende Methoden auf 2D-Posenbildern basieren, was zu begrenzter Generalisierungsfähigkeit führt, schlägt MTVCrafter vor, direkt rohe 3D-Bewegungssequenzen (4D-Bewegung) zu modellieren. Sein Kern ist 4DMoT (4D Motion Tokenizer), das 3D-Bewegungssequenzen in 4D-Bewegungs-Token quantisiert und robustere räumlich-zeitliche Hinweise liefert. Anschließend nutzt MV-DiT (Motion-aware Video DiT), das mit einzigartiger Bewegungs-Attention und 4D-Positionskodierung entwickelt wurde, diese Token effektiv als Kontext, um menschliche Bildanimationen in komplexen 3D-Welten zu realisieren. Experimente zeigen, dass MTVCrafter auf FID-VID 6,98 erreicht, was SOTA signifikant übertrifft, und gut auf verschiedene Charaktere unterschiedlicher Stile und Szenen generalisiert (Quelle: HuggingFace Daily Papers)
QVGen: Die Grenzen quantisierter Videogenerierungsmodelle erweitern: Um das Problem des hohen Rechen- und Speicherbedarfs von Video-Diffusionsmodellen (DM) zu lösen, schlägt QVGen ein neuartiges Quantization-Aware Training (QAT)-Framework vor, das speziell für die Quantisierung mit extrem niedriger Bitrate (z. B. 4 Bit und darunter) entwickelt wurde. Durch theoretische Analysen stellten die Forscher fest, dass die Reduzierung der Gradientennorm für die QAT-Konvergenz entscheidend ist, und führten ein Hilfsmodul (Phi) ein, um große Quantisierungsfehler zu mildern. Um den Inferenzaufwand von Phi zu eliminieren, wird eine Rangverfallsstrategie vorgeschlagen, die Phi durch SVD und rangbasierte Regularisierung schrittweise eliminiert. Experimente zeigen, dass QVGen in der 4-Bit-Einstellung erstmals eine mit voller Präzision vergleichbare Qualität erreicht und bestehende Methoden signifikant übertrifft (Quelle: HuggingFace Daily Papers)
ViPlan: Symbolische Prädikate und Benchmark für visuelle Sprachmodelle zur visuellen Planung: Um die Vergleichslücke zwischen VLM-gesteuerter symbolischer Planung und direkten VLM-Planungsmethoden zu schließen, wurde ViPlan als erster Open-Source-Benchmark für visuelle Planung vorgeschlagen. ViPlan enthält eine Reihe von Aufgaben mit steigendem Schwierigkeitsgrad in zwei Bereichen: einer visuellen Version von Blocksworld und einer simulierten Haushaltsroboter-Umgebung. Benchmark-Tests mit 9 Open-Source-VLM-Familien und einigen Closed-Source-Modellen ergaben, dass symbolische Planung in Blocksworld (wo präzise Bildlokalisierung entscheidend ist) besser abschneidet, während direkte VLM-Planung bei Haushaltsroboter-Aufgaben (wo Allgemeinwissen und Fehlerbehebungsfähigkeiten wichtig sind) überlegen ist. Die Studie zeigte auch, dass CoT-Prompting für die meisten Modelle und Methoden keinen signifikanten Nutzen brachte, was darauf hindeutet, dass die visuellen Reasoning-Fähigkeiten aktueller VLMs noch unzureichend sind (Quelle: HuggingFace Daily Papers)
Von ursprünglichen Rufen zur Grammatik: Eine Studie zur Sprachevolution in kooperativen Nahrungssuchumgebungen: Um den Ursprung und die Evolution der Sprache zu untersuchen, simulierten Forscher frühe menschliche Kooperationsszenarien in einem Multi-Agenten-Nahrungssuchspiel. Durch End-to-End Deep Reinforcement Learning lernten die Agenten von Grund auf Aktions- und Kommunikationsstrategien. Die Studie ergab, dass die von den Agenten entwickelten Kommunikationsprotokolle charakteristische Merkmale natürlicher Sprachen aufwiesen: Arbitrarität, Austauschbarkeit, Verschiebung, kulturelle Übertragung und Kombinierbarkeit. Dieses Framework bietet eine Plattform zur Untersuchung, wie sich Sprache in verkörperten Multi-Agenten-Umgebungen entwickelt, die durch teilweise Beobachtbarkeit, zeitliches Reasoning und kooperative Ziele gekennzeichnet sind (Quelle: HuggingFace Daily Papers)
Tiny QA Benchmark++: Ultraleichtgewichtige mehrsprachige synthetische Datensatzerstellung und Smoke-Test für die kontinuierliche LLM-Bewertung: Tiny QA Benchmark++ (TQB++) ist eine ultraleichtgewichtige, mehrsprachige Smoke-Test-Suite, die als Unit-Test-ähnliches Sicherheitsnetz für LLM-Pipelines dienen soll und in Sekundenschnelle bei extrem niedrigen Kosten ausgeführt werden kann. TQB++ enthält ein englisches Gold-Set mit 52 Items und bietet einen auf LiteLLM basierenden Miniatur-Generator für synthetische Daten (pypi-Paket), mit dem Benutzer kleine Testpakete für benutzerdefinierte Sprachen, Domänen oder Schwierigkeitsgrade generieren können. Das Projekt stellt vorgefertigte Pakete für 10 Sprachen bereit und unterstützt Tools wie OpenAI-Evals und LangChain, um die Integration in CI/CD-Prozesse zur schnellen Erkennung von Prompt-Template-Fehlern, Tokenizer-Drift und Nebenwirkungen von Fine-Tuning zu erleichtern (Quelle: HuggingFace Daily Papers)
HelpSteer3-Preference: Offener, von Menschen annotierter Präferenzdatensatz über mehrere Aufgaben und Sprachen hinweg: Um den Bedarf an qualitativ hochwertigen, vielfältigen offenen Präferenzdaten zu decken, hat NVIDIA den HelpSteer3-Preference-Datensatz veröffentlicht. Dieser Datensatz enthält über 40.000 von Menschen annotierte Präferenzbeispiele, die der CC-BY-4.0-Lizenz folgen und reale LLM-Anwendungen wie MINT, Programmierung und mehrsprachige Szenarien abdecken. Mit diesem Datensatz trainierte Reward Models (RM) erzielen SOTA-Leistungen sowohl auf RM-Bench (82,4 %) als auch auf JudgeBench (73,7 %), was einer Verbesserung von etwa 10 % gegenüber den bisher besten Ergebnissen entspricht. Der Datensatz kann auch zum Trainieren generativer RMs und zur Ausrichtung von Policy-Modellen mittels RLHF verwendet werden (Quelle: HuggingFace Daily Papers)
SEED-GRPO: Semantische Entropie-erweitertes GRPO für unsicherheitsbewusste Policy-Optimierung: Um das Problem anzugehen, dass GRPO bei Policy-Updates die Unsicherheit von LLMs gegenüber Eingabe-Prompts nicht berücksichtigt, schlagen Forscher SEED-GRPO vor. Diese Methode misst explizit die Unsicherheit von LLMs gegenüber Eingabe-Prompts (d. h. die semantische Vielfalt mehrerer generierter Antworten) mithilfe semantischer Entropie und reguliert damit das Ausmaß der Policy-Updates. Dieser unsicherheitsbewusste Trainingsmechanismus ermöglicht konservativere Updates für Fragen mit hoher Unsicherheit, während das ursprüngliche Lernsignal für zuversichtliche Fragen beibehalten wird. Experimente zeigen, dass SEED-GRPO auf fünf mathematischen Reasoning-Benchmarks SOTA-Leistungen erzielt (Quelle: HuggingFace Daily Papers)
Erstellung eines General User Model (GUM) aus der Computernutzung: Forscher schlagen eine Architektur für ein General User Model (GUM) vor, das Benutzerwissen und -präferenzen durch Beobachtung jeglicher Benutzerinteraktion mit dem Computer (z. B. Geräte-Screenshots) lernt und konfidenzgewichtete Propositionen erstellt. GUM kann aus unstrukturierten multimodalen Beobachtungen neue Propositionen ableiten, relevante Propositionen als Kontext abrufen und bestehende Propositionen kontinuierlich korrigieren. Diese Architektur zielt darauf ab, Chat-Assistenten zu verbessern, Betriebssystembenachrichtigungen zu verwalten und interaktiven Agenten zu ermöglichen, sich anwendungsübergreifend an Benutzerpräferenzen anzupassen. Experimente zeigen, dass GUM kalibrierte und genaue Benutzerinferenzen treffen kann und dass auf GUM basierende Assistenten proaktiv nützliche Aktionen identifizieren und ausführen können, die vom Benutzer nicht explizit angefordert wurden (Quelle: HuggingFace Daily Papers)
DataExpert-io/data-engineer-handbook: Ein beliebtes Projekt auf GitHub, das eine umfassende Lernressource für Data Engineering bietet, einschließlich einer Roadmap für den Einstieg 2024, Materialien für ein 6-wöchiges kostenloses YouTube-Trainingslager, Projektbeispiele, Interviewtipps, Buchempfehlungen sowie Listen von Communities und Newslettern. Zu den empfohlenen Büchern gehören „Fundamentals of Data Engineering“, „Designing Data-Intensive Applications“ und „Designing Machine Learning Systems“. Das Handbuch listet auch Unternehmen in verschiedenen Bereichen des Data Engineering auf, wie Mage (Orchestrierung), Databricks (Data Lake), Snowflake (Data Warehouse), dbt (Datenqualität), LangChain (LLM-Anwendungsbibliothek) usw., und stellt Links zu Data-Engineering-Blogs bekannter Unternehmen und wichtigen Whitepapers bereit (Quelle: GitHub Trending)
💼 Wirtschaft
Cohere und SAP kooperieren, um unternehmensweite KI-Agenten in globale Geschäftsprozesse zu integrieren: Cohere kündigte eine Partnerschaft mit SAP an, um seine unternehmensweiten KI-Agenten-Technologien in die SAP Business Suite einzubetten und globalen Unternehmen sichere und skalierbare KI-Fähigkeiten zur Verfügung zu stellen. Die Spitzenmodelle von Cohere werden auch auf SAP AI Core verfügbar sein, sodass Unternehmen in Bereichen wie Finanzen und Gesundheitswesen ihre mehrsprachigen, domänenspezifischen KI-Modelle (Command, Embed, Rerank) nutzen können. Ziel ist es, die Einführung von KI in Unternehmen zu beschleunigen und echten Geschäftswert zu schaffen (Quelle: X, X)
xAI strebt Nutzung von Regierungsdaten an, um Unternehmens- und Regierungsgeschäft auszubauen: Laut The Information plant Elon Musks Unternehmen xAI, Daten von Regierungsbehörden zu nutzen, um Modelle und Anwendungen zu entwickeln und diese an Regierungskunden zu verkaufen. Diese Initiative könnte ein wichtiger Bestandteil der Kommerzialisierungsstrategie von xAI werden, wirft aber auch Diskussionen über die Datennutzung und potenzielle Verzerrungen auf (Quelle: X)
Weaviate und AWS vertiefen globale Zusammenarbeit zur Beschleunigung generativer KI-Initiativen: Das Vektordatenbank-Unternehmen Weaviate gab die Stärkung seiner globalen Zusammenarbeit mit AWS bekannt, mit dem Ziel, gemeinsam generative KI-Projekte zu beschleunigen. Die Zusammenarbeit wird sich darauf konzentrieren, Entwicklern weltweit schnellere Geschwindigkeiten, größere Skalierbarkeit und eine bessere Entwicklererfahrung zu bieten, um die Anwendung und Entwicklung generativer KI-Technologien voranzutreiben (Quelle: X)

🌟 Community
Aufstieg von KI-Programmieragenten löst Diskussion über Berufsaussichten von Programmierern aus: Unternehmen wie Microsoft und OpenAI stellen verstärkt KI-Programmieragenten (Coding Agents) vor oder verbessern diese, wie z. B. den GitHub Copilot Coding Agent und OpenAI Codex. Diese können autonom Programmieraufgaben erledigen, Fehler beheben und Code warten. Dario Amodei, CEO von Anthropic, prognostiziert, dass KI kurzfristig den Großteil oder sogar den gesamten Code schreiben könnte, und Kevin Weil, CPO von OpenAI, ist ebenfalls der Meinung, dass KI sich vom Junior-Ingenieur zum Architekten entwickeln wird. Dies hat in der Community eine breite Diskussion über die Zukunft des Programmierberufs ausgelöst: Einige befürchten, dass Junior-Positionen ersetzt werden und KI einen Großteil der Programmierarbeit automatisieren wird; andere wiederum glauben, dass KI die Effizienz von Programmierern steigern wird, sodass sie sich auf übergeordnete Architekturentwürfe und Innovationen konzentrieren können und ihre Rolle sich zu „KI-Mentoren“ wandelt. Der allgemeine Trend zeigt, dass das Erlernen einer effizienten Zusammenarbeit mit KI zu einer Kernkompetenz für Programmierer werden wird (Quelle: X, X, 36氪, 36氪)
Konzept und Standards von AI Agents werden intensiv diskutiert, MCP-Protokoll im Fokus: Mit dem Aufkommen von AI Agent-Anwendungen (wie Manus, Genspark Super Agent, Fellou.ai) diskutiert die Community intensiv über die Definition, Fähigkeitsstufen und Entwicklungsparadigmen von Agents. Das bekannte Risikokapitalunternehmen BVP hat eine siebenstufige Klassifizierung von Agents von L0 bis L6 vorgeschlagen. Gleichzeitig rückt das Model Context Protocol (MCP) als Schlüsseltechnologie zur Erzielung von Interoperabilität zwischen KI-Anwendungen in den Fokus. Große ausländische Unternehmen wie Anthropic, OpenAI und Google unterstützen MCP bereits oder planen dies, während inländische Unternehmen wie Alibaba Cloud und Tencent Cloud beginnen, auf MCP basierende lokalisierte Agent-Entwicklungsplattformen aufzubauen. Der Entwickler iluxu hat sogar vor der Vorstellung des Konzepts „USB-C for AI apps“ durch Microsoft ein ähnliches Projekt namens llmbasedos als Open Source veröffentlicht, um offene Verbindungsstandards für Agents voranzutreiben (Quelle: X, X, WeChat, Reddit r/LocalLLaMA)
LLMs zeigen bei spezifischen Reasoning-Aufgaben Schwächen, was Diskussionen über ihre Fähigkeitsgrenzen auslöst: Die Community diskutiert intensiv das Phänomen, dass LLMs bei einigen scheinbar einfachen physikalischen oder visuell-räumlichen Reasoning-Aufgaben kollektiv versagen. Beispielsweise geben selbst Top-Modelle wie o3 und Gemini 2.5 Pro bei einer Frage zum Stapeln von Würfeln zu einem größeren Würfel falsche Antworten. Gleichzeitig weist ein Bewertungsartikel darauf hin, dass LLMs (einschließlich o3) bei grundlegenden physikalischen Aufgaben wie der Teilefertigung schlechter abschneiden als erfahrene Arbeiter. Hauptgründe dafür sind unzureichende visuelle Fähigkeiten, Fehler im physikalischen Reasoning und das Fehlen von implizitem Wissen aus der realen Welt. Diese Fälle werfen Fragen zur tatsächlichen Verständnisfähigkeit von LLMs, zum Problem der Halluzinationen (z. B. Anstieg der Halluzinationsrate bei o3 während des Reasonings) und zur Validität aktueller Benchmarks auf und betonen, dass KI in spezifischen Wissensbereichen und bei komplexem Reasoning noch erheblichen Verbesserungsbedarf hat (Quelle: 量子位, 36氪)

Chinesisch-amerikanischer Technologie-Wettbewerb und KI-Entwicklungsstrategien im Fokus: Jensen Huang, CEO von Nvidia, sprach in einem Interview über Chip-Regulierungen, KI-Fabriken und unternehmerischen Pragmatismus. Seine Ansichten wurden als tiefgreifende Einsicht in die aktuelle Lage des chinesisch-amerikanischen Technologie-Wettbewerbs interpretiert. Einige Kommentatoren sind der Meinung, dass die USA versuchen, ihre Führungsposition zu behaupten, indem sie Chinas Zugang zu High-End-KI-Ressourcen beschränken, was jedoch zu einer Lose-Lose-Situation führen und die globale KI-Entwicklung verlangsamen könnte. Huang hingegen scheint zu glauben, dass der eigentliche Wettbewerb langfristig ist und die USA umfassend führend sein sollten (Chips, Fabriken, Infrastruktur, Modelle, Anwendungen), anstatt nur kurzfristige relative Vorteile anzustreben. Andernfalls könnten sie die Entwicklungschancen im KI-Zeitalter verpassen und letztendlich im Wettbewerb der Gesamtnationalstärke zurückfallen (Quelle: X)
Anwendung und Diskussion von KI-Tools wie ChatGPT zur Unterstützung der psychischen Gesundheit: Reddit-Community-Nutzer teilen Erfahrungen mit der Nutzung von KI-Tools wie ChatGPT zur Unterstützung der psychischen Gesundheit und sind der Meinung, dass diese zwischen professionellen Therapiesitzungen helfen können, insbesondere bei der Strukturierung und dem Ausdruck komplexer Emotionen. Nutzer stellen der KI Fragen oder lassen sich von der KI Fragen zu ihren eigenen Gefühlen stellen, um die Ursachen von Emotionen besser zu verstehen und Verbesserungspläne zu entwickeln. In den Kommentaren sind einige Nutzer (darunter auch solche, die sich als Therapeuten bezeichnen) der Meinung, dass KI in bestimmten Fällen sogar besser ist als einige menschliche Therapeuten, insbesondere für Personen, die schwer Zugang zu professioneller Hilfe haben oder Vertrauensprobleme gegenüber menschlichen Therapeuten haben. Es gibt jedoch auch Nutzer, die darauf hinweisen, dass KI eine professionelle Therapie nicht vollständig ersetzen kann und dass auf den Datenschutz persönlicher Daten geachtet werden sollte (Quelle: Reddit r/ChatGPT)
💡 Sonstiges
„Qizhi Cup“ Algorithmus-Wettbewerb gestartet, Fokus auf drei KI-Spitzenrichtungen: Das Qiyuan Laboratory hat den „Qizhi Cup“ Algorithmus-Wettbewerb mit einem Gesamtpreisgeld von 750.000 Yuan ins Leben gerufen. Der Wettbewerb umfasst drei Bereiche: „Robuste Instanzsegmentierung von Satellitenfernerkundungsbildern“, „Bodenobjekterkennung für Drohnen auf eingebetteten Plattformen“ und „Adversarial Attacks gegen multimodale große Modelle“. Ziel ist es, Innovationen und die praktische Anwendung von KI-Kerntechnologien wie robuster Wahrnehmung, leichtgewichtiger Bereitstellung und Adversarial Defense voranzutreiben. Der Wettbewerb steht inländischen Forschungseinrichtungen, Unternehmen und Institutionen offen (Quelle: WeChat)

Chicago Sun-Times macht Fehler bei KI-generierten Inhalten, empfiehlt nicht existierende Bücher und Experten: In einer Ausgabe der Chicago Sun-Times mit Empfehlungen für Sommeraktivitäten wurden einige Inhalte offenbar von KI generiert. Darunter befanden sich Empfehlungen für fiktive Bücher von real existierenden Autoren sowie Zitate von scheinbar nicht existierenden „Experten“. Beispielsweise wurden „Nightshade Market“ von Min Jin Lee und „Boiling Point“ von Rebecca Makkai als Leseempfehlungen aufgeführt, obwohl diese Bücher nicht existieren. Dieser Vorfall löste Bedenken hinsichtlich der Genauigkeit und der Überprüfungsmechanismen bei der Verwendung von KI-generierten Inhalten durch Nachrichtenmedien aus (Quelle: Reddit r/artificial)
Diskussion darüber, ob KI „Betrug“ darstellt: Die Community diskutiert die Grenzen der Nutzung von KI-Tools (wie ChatGPT, Claude) bei Arbeit und Studium. Die vorherrschende Meinung ist, dass die Nutzung von KI-Tools zur Effizienzsteigerung, zur Erledigung repetitiver Aufgaben oder zur Unterstützung des Denkens in Situationen ohne explizite Verbotsregeln (wie bei Universitätsaufgaben) kein „Betrug“ ist, sondern vergleichbar mit der Nutzung eines Taschenrechners oder einer Suchmaschine. Entscheidend ist, ob der Nutzer den Output der KI versteht, ihn effektiv anpassen und überprüfen kann und ob er die unterstützende Rolle der KI ehrlich deklariert (insbesondere im akademischen Kontext). Wenn man sich jedoch vollständig auf KI-generierte Inhalte verlässt und diese ungeprüft als Eigenleistung ausgibt, kann dies akademisches Fehlverhalten darstellen oder die Entwicklung persönlicher Fähigkeiten beeinträchtigen (Quelle: Reddit r/ArtificialInteligence)