
Schlüsselwörter:KI-Technologie, Google Gemini, KI-Regulierung, KI-Energieverbrauch, KI in juristischen Anwendungen, Microsoft Discovery, Jensen Huang und Elon Musk, Gemini 2.5 Pro, Energieverbrauch von KI-Rechenzentren, Fehler in KI-generierten juristischen Dokumenten, Microsoft Discovery Forschungsplattform, Exportkontrollen für KI-Chips
🔥 Fokus
Google I/O Konferenz veröffentlicht zahlreiche KI-Fortschritte, Gemini vollständig in das Google-Ökosystem integriert: Google kündigte auf seiner I/O 2025 Entwicklerkonferenz eine Reihe bedeutender KI-Updates an, deren Kern die Weiterentwicklung und tiefe Integration des Gemini-Modells ist. Gemini 2.5 Pro führt „Deep Think“ zur Verbesserung komplexer Schlussfolgerungen ein, 2.5 Flash optimiert Effizienz und Kosten und fügt native Audioausgabe hinzu. Die Suche führt einen „KI-Modus“ ein, der Chatbot-ähnliche Antworten liefert und mit Zustimmung des Nutzers persönliche Daten für individualisierte Ergebnisse verwenden kann. Der Chrome-Browser wird den Gemini-Assistenten integrieren. Das Videomodell Veo 3 ermöglicht die Generierung von Videos mit Ton, das Bildmodell Imagen 4 verbessert Details und Textverarbeitung. Google veröffentlichte außerdem das KI-Filmproduktionswerkzeug Flow, den Programmierassistenten Jules und präsentierte Fortschritte bei Project Astra (einem multimodalen Echtzeit-Assistenten) und Project Mariner (einem Multitask-KI-Agenten). Gleichzeitig führte Google einen neuen KI-Abonnementdienst ein, dessen Premium-Version AI Ultra monatlich 249,99 US-Dollar kostet. Diese Maßnahmen signalisieren, dass Google die vollständige Integration von KI in seine Produkte und Dienstleistungen beschleunigt und die Nutzerinteraktion neu gestaltet. (Quelle: 36氪, 36氪, 36氪, 36氪, 36氪, 36氪)

Problem des KI-Energieverbrauchs rückt in den Fokus, MIT Technology Review analysiert tiefgehend dessen Energie-Fußabdruck und zukünftige Herausforderungen: MIT Technology Review veröffentlichte eine Artikelserie, die sich eingehend mit dem Energieverbrauch und den Kohlenstoffemissionen befasst, die durch die Entwicklung der KI-Technologie entstehen. Die Forschung zeigt, dass der Energieverbrauch in der Inferenzphase von KI den der Trainingsphase bereits übersteigt und zur Hauptenergiebelastung geworden ist. Der Bericht analysiert den enormen Strombedarf und Wasserverbrauch von Rechenzentren (wie z.B. Rechenzentren in der Wüste von Nevada) sowie die Abhängigkeit von fossilen Brennstoffen (wie z.B. das Meta-Rechenzentrum in Louisiana, das auf Erdgas angewiesen ist). Obwohl Kernenergie als potenzielle saubere Energielösung angesehen wird, ist ihre Bauzeit lang und kann den schnell wachsenden Bedarf der KI kurzfristig kaum decken. Gleichzeitig weist der Bericht auch auf optimistische Aussichten zur Steigerung der KI-Energieeffizienz hin, darunter effizientere Modellalgorithmen, speziell für KI entwickelte energiesparende Chips und optimierte Kühltechnologien für Rechenzentren. Die Serie betont, dass, obwohl der Energieverbrauch einer einzelnen KI-Anfrage gering erscheinen mag, der Gesamttrend der Branche und zukünftige Planungen (wie das Stargate-Projekt von OpenAI) enorme Energieherausforderungen vorhersagen, die transparente Datenoffenlegung und verantwortungsvolle Energieplanung erfordern. (Quelle: MIT Technology Review, MIT Technology Review, MIT Technology Review, MIT Technology Review, MIT Technology Review, MIT Technology Review, MIT Technology Review)

KI-Anwendungen im Rechtsbereich führen zu Fehlern und ethischen Bedenken: Mehrere aktuelle Vorfälle zeigen, dass das Problem der „Halluzinationen“ von KI bei der Erstellung juristischer Dokumente ernste Bedenken hervorruft. Ein Richter in Kalifornien verhängte eine Geldstrafe gegen einen Anwalt, weil dieser KI-Tools wie Google Gemini zur Erstellung von Gerichtsdokumenten verwendet hatte, die falsche Zitate enthielten. In einem anderen Fall machte das KI-Modell Claude des Unternehmens Anthropic ebenfalls Fehler bei der Generierung von Zitaten für juristische Dokumente. Noch besorgniserregender ist, dass israelische Staatsanwälte zugaben, in einem Antrag KI-generierten Text verwendet zu haben, der nicht existierende Gesetze zitierte. Diese Fälle verdeutlichen die Mängel von KI-Modellen in Bezug auf Genauigkeit und Zuverlässigkeit, insbesondere im Rechtsbereich, wo höchste Anforderungen an Fakten und Zitate gestellt werden. Experten weisen darauf hin, dass Anwälte aus Effizienzgründen möglicherweise zu sehr auf die Ergebnisse von KI vertrauen und die Notwendigkeit einer strengen Überprüfung vernachlässigen. Obwohl KI-Tools als zuverlässige juristische Assistenten beworben werden, stellt ihre inhärente „Halluzinations“-Eigenschaft eine potenzielle Bedrohung für die Rechtsstaatlichkeit dar und erfordert dringend Branchenstandards und Wachsamkeit der Nutzer. (Quelle: MIT Technology Review)

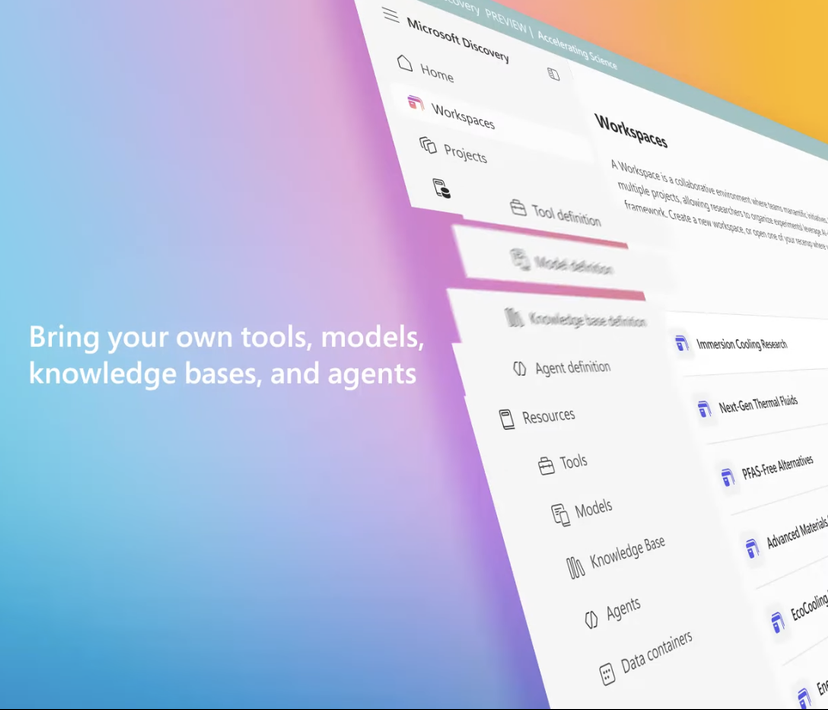
Microsoft stellt KI-Forschungsplattform Microsoft Discovery für Unternehmen vor und unterstützt wissenschaftliche Entdeckungen: Microsoft hat auf seiner Build-Konferenz Microsoft Discovery vorgestellt, eine KI-Plattform, die speziell für Unternehmen und Forschungseinrichtungen entwickelt wurde. Ziel ist es, Wissenschaftlern und Ingenieuren ohne Programmierkenntnisse durch Interaktion in natürlicher Sprache die Nutzung von Hochleistungsrechnern und komplexen Simulationssystemen zu ermöglichen. Die Plattform kombiniert Basismodelle für die Planung mit spezialisierten Modellen, die für bestimmte wissenschaftliche Bereiche (wie Physik, Chemie, Biologie) trainiert wurden, und bildet so ein „KI-Postdoc“-Team, das den gesamten Forschungsprozess von der Literaturrecherche bis zur Computersimulation durchführen kann. Microsoft präsentierte einen Anwendungsfall: In etwa 200 Stunden wurden 367.000 Substanzen gescreent und erfolgreich ein potenzieller PFAS-freier Kühlmittelersatz entdeckt, der experimentell validiert wurde. Zu den Merkmalen der Plattform gehören eine Graph-Wissens-Engine, kollaboratives Schließen, kontinuierliche iterative Forschungs- und Entwicklungszyklen. Sie basiert auf der Azure-Infrastruktur und ihre zukünftige Architektur sieht die Möglichkeit der Anbindung an Quantencomputer vor. (Quelle: 量子位)
Jensen Huang und Elon Musk äußern sich zu KI-Entwicklung, Regulierung und globalem Wettbewerb: NVIDIA-CEO Jensen Huang äußerte in einem Interview Bedenken hinsichtlich der US-amerikanischen Exportkontrollen für Chips und argumentierte, dass die Beschränkung der Technologieverbreitung die Führungsposition der USA im KI-Bereich untergraben könnte. Er betonte Chinas Stärke in der KI-Forschung und -Entwicklung sowie die Tatsache, dass die Hälfte der weltweiten KI-Entwickler aus China stammt. Er plädierte dafür, dass die USA die weltweite Verbreitung von Technologie beschleunigen und US-Unternehmen den Wettbewerb auf dem chinesischen Markt ermöglichen sollten. Tesla-CEO Elon Musk erklärte in einem anderen Interview, er werde Tesla noch mindestens fünf Jahre leiten und sei der Verwirklichung von AGI nahe. Er befürwortete eine moderate Regulierung der KI, sprach sich jedoch gegen übermäßige Einmischung aus. Beide Technologieführer betonten das immense Potenz বাহিনীকে KI. Huang ist der Ansicht, dass KI das globale BIP erheblich steigern wird, während Musk wichtige Ziele für dieses Jahr nannte, darunter Starship, Neuralink und Teslas selbstfahrende Taxis, die alle eng mit KI verbunden sind. (Quelle: 36氪, 36氪, 36氪)

🎯 Trends
Google veröffentlicht Gemma 3n Preview-Version, speziell für effizienten Betrieb auf Endgeräten entwickelt: Google hat auf HuggingFace eine Preview-Version des Gemma 3n Modells veröffentlicht, das speziell für den effizienten Betrieb auf ressourcenarmen Geräten (wie Mobilgeräten) entwickelt wurde. Diese Modellreihe verfügt über multimodale Eingabefähigkeiten und kann Text, Bilder, Videos und Audio verarbeiten sowie Textausgaben generieren. Sie verwendet eine Technologie zur „selektiven Parameteraktivierung“ (ähnlich der MoE Mixture-of-Experts-Architektur), die es dem Modell ermöglicht, mit einer effektiven Parametergröße von 2B und 4B zu arbeiten und so den Ressourcenbedarf zu senken. In der Community wird diskutiert, dass die Architektur von Gemma 3n der von Gemini ähneln könnte, was dessen starke multimodale und Long-Context-Fähigkeiten erklären würde. Die Open-Source-Gewichte und die instruktionsoptimierte Version von Gemma 3n sowie das Training mit Daten aus über 140 Sprachen machen es potenziell für Edge-KI-Anwendungen wie Smart-Home-Assistenten geeignet. (Quelle: Reddit r/LocalLLaMA, developers.googleblog.com)

Google stellt MedGemma vor, ein für den medizinischen Bereich optimiertes KI-Modell: Google hat die MedGemma-Modellreihe veröffentlicht, zwei für den medizinischen Bereich optimierte Varianten von Gemma 3, darunter eine multimodale Version mit 4B Parametern und eine rein textbasierte Version mit 27B Parametern. MedGemma 4B wurde speziell für das Verständnis von medizinischen Bildern (wie Röntgenaufnahmen, dermatologischen Bildern usw.) und Texten trainiert und verwendet einen auf medizinischen Daten vortrainierten SigLIP-Bildencoder. MedGemma 27B konzentriert sich auf die Verarbeitung medizinischer Texte und wurde für die Berechnung während der Inferenz optimiert. Google gibt an, dass diese Modelle die Entwicklung von KI-Anwendungen im medizinischen Bereich beschleunigen sollen und auf mehreren klinisch relevanten Benchmarks evaluiert wurden. Entwickler können sie durch Feinabstimmung für spezifische Aufgaben verbessern. Die Community reagierte positiv und sieht großes Potenzial, betont jedoch die Notwendigkeit von praktischem Feedback durch medizinisches Fachpersonal. (Quelle: Reddit r/LocalLLaMA)

ByteDance veröffentlicht Open-Source-Multimodal-Modell Bagel mit Bildgenerierungsfunktion: ByteDance hat Bagel (auch bekannt als BAGEL-7B-MoT) vorgestellt, ein Open-Source-Multimodal-Großmodell mit 14B Parametern (7B aktiv), das unter der Apache 2.0 Lizenz steht. Das Modell basiert auf einer Mixture-of-Experts (MoE) und Mixture-of-Transformers (MoT) Architektur, kann Text verstehen und generieren und verfügt über native Bildgenerierungsfähigkeiten. Es übertrifft andere Open-Source-Einheitsmodelle in einer Reihe von multimodalen Verständnis- und Generierungsbenchmarks und zeigt fortgeschrittene multimodale Inferenzfähigkeiten wie Freiform-Bildverarbeitung und Vorhersage zukünftiger Frames. Die Forscher hoffen, durch die Weitergabe von Details zum Vortraining, Daten-Erstellungsprotokollen sowie offenem Code und Checkpoints die multimodale Forschung zu fördern. (Quelle: Reddit r/LocalLLaMA, arxiv.org, bagel-ai.org)
NVIDIA veröffentlicht DreamGen, trainiert Roboter mit generativen Videomodellen: Das Forschungsteam von NVIDIA hat das DreamGen-Projekt vorgestellt, bei dem durch Feinabstimmung fortschrittlicher Videogenerierungsmodelle (wie Sora, Veo) Roboter in generierten „Traumwelten“ neue Fähigkeiten erlernen. Diese Methode ist nicht auf traditionelle Grafik-Engines oder physikalische Simulatoren angewiesen, sondern lässt Roboter in von neuronalen Netzen generierten pixelgenauen Szenen autonom erkunden und Erfahrungen sammeln, wodurch eine große Anzahl von Nervenbahnen mit Pseudo-Aktions-Labels generiert wird. Experimente zeigen, dass DreamGen die Leistung von Robotern bei simulierten und realen Aufgaben signifikant verbessern kann, einschließlich nie zuvor gesehener Aktionen und unbekannter Umgebungen. Beispielsweise erlernte ein humanoider Roboter mit nur wenigen realen Trajektorien 22 neue Fähigkeiten wie Wasser einschenken und Kleidung falten und generalisierte diese erfolgreich auf reale Szenarien wie das Café am NVIDIA-Hauptsitz. (Quelle: 36氪, arxiv.org)

Huawei schlägt OmniPlacement zur Optimierung der Inferenzleistung von MoE-Modellen vor: Angesichts des Problems der ungleichmäßigen Auslastung von Expertennetzwerken (sogenannte „heiße Experten“ und „kalte Experten“) in Mixture-of-Experts-Modellen (MoE), das zu Inferenzlatenzen führt, hat das Huawei-Team die Optimierungslösung OmniPlacement vorgeschlagen. Diese Lösung zielt darauf ab, die Inferenzleistung von MoE-Modellen durch Experten-Neuanordnung, redundante Bereitstellung zwischen den Schichten und dynamische Planung nahezu in Echtzeit zu verbessern. Theoretische Überprüfungen an Modellen wie DeepSeek-V3 zeigen, dass OmniPlacement die Inferenzlatenz um etwa 10 % senken und den Durchsatz um etwa 10 % steigern kann. Der Kern dieser Methode liegt in der dynamischen Anpassung der Expertenprioritäten, der Optimierung der Kommunikationsdomänen, der differenzierten Bereitstellung redundanter Instanzen und der flexiblen Reaktion auf Laständerungen durch einen nahezu echtzeitbasierten Planungs- und dynamischen Überwachungsmechanismus. Huawei plant, diese Lösung in naher Zukunft als Open Source zu veröffentlichen. (Quelle: 量子位)

Apple plant, Entwicklern Zugriff auf KI-Modelle zu gewähren, um Anwendungsinnovationen zu fördern: Berichten zufolge wird Apple auf der WWDC ankündigen, Drittanbietern Zugriff auf seine KI-Modelle von Apple Intelligence zu gewähren. Anfänglich wird der Fokus auf leichtgewichtigen Sprachmodellen mit etwa 3 Milliarden Parametern liegen, die auf dem Gerät ausgeführt werden. Später könnten auch Cloud-basierte Modelle (die über eine private Cloud ausgeführt und verschlüsselt werden) auf dem Niveau von GPT-4-Turbo zugänglich gemacht werden. Dieser Schritt zielt darauf ab, Entwickler zu ermutigen, neue Anwendungsfunktionen auf Basis von Apples LLMs zu entwickeln, die Attraktivität von Apple-Geräten zu steigern und den relativen Rückstand im Bereich der generativen KI aufzuholen. Analysten gehen davon aus, dass Apple durch den Aufbau eines offenen Ökosystems seine große Entwicklergemeinschaft (6 Millionen) nutzen möchte, um eigene technologische Defizite auszugleichen und dem zunehmenden KI-Wettbewerb zu begegnen. (Quelle: 36氪)
Vorschlag des US-Repräsentantenhauses zur Aussetzung der KI-Regulierung auf Bundesstaatenebene für zehn Jahre löst massive Kontroverse aus: Der Energie- und Handelsausschuss des US-Repräsentantenhauses hat einen Vorschlag verabschiedet, der vorsieht, den Bundesstaaten für die nächsten zehn Jahre die Regulierung von KI-Modellen, -Systemen und automatisierten Entscheidungssystemen, die „menschliche Entscheidungen wesentlich beeinflussen oder ersetzen“, zu untersagen. Befürworter argumentieren, dieser Schritt könne verhindern, dass uneinheitliche einzelstaatliche Vorschriften die KI-Innovation und die Modernisierung der Bundesregierung behindern; Gegner bezeichnen ihn als „riesiges Geschenk an große Technologieunternehmen“, das die Fähigkeit der Bundesstaaten schwächen würde, die Bevölkerung vor den Gefahren der KI zu schützen. Sollte der Vorschlag angenommen werden, könnten zahlreiche bestehende und geplante KI-Gesetze auf Bundesstaatenebene unwirksam werden. Er stellt jedoch klar, dass er nicht für bundesgesetzlich vorgeschriebene oder allgemein anwendbare Gesetze gilt, die KI- und Nicht-KI-Systeme gleich behandeln. Dieser Schritt spiegelt den weltweiten intensiven Kampf zwischen „KI-Innovation zuerst“ und „Sicherheitsuntergrenzen“ wider. (Quelle: 36氪, edition.cnn.com)

„Take It Down Act“ als US-Gesetz unterzeichnet, bekämpft Verbreitung nicht-einvernehmlicher intimer Bilder: US-Präsident Trump hat den „Take It Down Act“ unterzeichnet, der die Erstellung und Verbreitung nicht-einvernehmlicher intimer Bilder (einschließlich KI-generierter Deepfakes) zu einem Bundesvergehen macht. Das Gesetz verpflichtet Technologieplattformen, entsprechende Inhalte innerhalb von 48 Stunden nach Benachrichtigung zu entfernen. Dieses Gesetz zielt darauf ab, Opfer zu schützen und den zunehmenden gesellschaftlichen Problemen zu begegnen, die durch den Missbrauch von Deepfake-Technologie entstehen. Es gibt jedoch auch Kommentare, die darauf hinweisen, dass das Gesetz missbraucht werden und zu übermäßiger Zensur führen könnte. (Quelle: MIT Technology Review, edition.cnn.com, Reddit r/artificial)

Große KI-Modelle unterstützen Gesundheitsmanagement, ermöglichen Personalisierung und Verknüpfung mehrdimensionaler Daten: Große KI-Modelle bringen neue Dynamik in das Gesundheitsmanagement, indem sie in Kombination mit Wearables die Verknüpfung mehrdimensionaler Daten und personalisierte Dienste ermöglichen. Unternehmen wie WeDoctor, Deepwise Healthcare, NandaFittech etc. erforschen aktiv Anwendungsszenarien, beispielsweise den Einstieg über Vorsorgeuntersuchungen zur Früherkennung und -behandlung oder die Prävention chronischer Krankheiten durch Gewichtsmanagement als Ansatzpunkt. Große Modelle können vielfältigere Datendimensionen verarbeiten, Nutzerprofile erstellen und präzisere Gesundheitsinterventionen anbieten. Herausforderungen sind Modellhalluzinationen, Datenqualität und Koordinationsschwierigkeiten, die jedoch durch RAG, Modellfeinabstimmung, Überprüfungsmechanismen und das „KI + menschlicher Manager“-Modell schrittweise überwunden werden. Geschäftsmodelle wie ToB-Dienste, C-End-Bezahlmodelle und KI-Gesundheitsgemeinschaften wurden bereits erfolgreich erprobt, zukünftige Trends gehen in Richtung multimodaler Interaktion. (Quelle: 36氪)
Baidu stärkt multimodale Fähigkeiten des Wenxin-Großmodells als Reaktion auf Marktwettbewerb und Anwendungsrealisierung: Die neuesten von Baidu veröffentlichten Modelle Wenxin Large Model 4.5 Turbo und Deep Thinking Model X1 Turbo weisen signifikant verbesserte multimodale Verständnis- und Generierungsfähigkeiten auf. Durch Techniken wie gemischtes Training und multimodales heterogenes Experten-Modeling wurden die Effizienz des Cross-Modal-Lernens und die Fusionseffekte verbessert. Obwohl CEO Robin Li sich zuvor vorsichtig zu den Halluzinationsproblemen von Sora-ähnlichen Videogenerierungsmodellen geäußert hatte, holt Baidu angesichts des Marktwettbewerbs (z.B. Fortschritte von ByteDance Doubao und Alibaba Tongyi Qianwen im multimodalen Bereich) und der Notwendigkeit der KI-Anwendungsrealisierung aktiv auf und plant, die Wenxin Large Model 4.5 Serie am 30. Juni als Open Source zu veröffentlichen. Baidu betrachtet KI-Digital-Humans als wichtigen Anwendungsdurchbruch und hat bereits eine „Drehbuch“-gesteuerte hyperrealistische Digital-Human-Technologie entwickelt, die über 100.000 Digital-Human-Moderatoren unterstützt. (Quelle: 36氪)
Plattformen wie Douyin und Xiaohongshu gehen gezielt gegen „AI Account Farming“ vor, um das Content-Ökosystem zu schützen: Interessenbasierte E-Commerce-Plattformen wie Douyin und Xiaohongshu haben kürzlich ihre Maßnahmen gegen Verhaltensweisen wie die massenhafte Erstellung gefälschter Inhalte mittels KI und das sogenannte „AI Account Farming“ verschärft. Dazu gehören KI-generierte vulgäre und sensationslüsterne Videos, Inhalte von virtuellen Experten sowie der Verkauf von Tutorials und Konten für AI Account Farming. Die Plattformen sind der Ansicht, dass solche Verhaltensweisen die Authentizität der Inhalte untergraben, zu einer Homogenisierung der Inhalte führen, die Nutzererfahrung und das Ökosystem der Originalautoren schädigen und somit den kommerziellen Wert schmälern. Im Gegensatz dazu ermutigen traditionelle Regal-E-Commerce-Plattformen wie Taobao und JD.com Händler aktiv zur Nutzung von KI-Tools (wie „Bild-zu-Video“-Generierung, Live-Streaming mit digitalen Menschen), um die Produktpräsentation und Betriebseffizienz zu verbessern, mit dem Hauptziel, Transaktionen zu fördern. Dieser Unterschied spiegelt die unterschiedlichen KI-Anwendungsstrategien verschiedener E-Commerce-Modelle wider. (Quelle: 36氪)

Entwicklung von Apples KI-Version von Siri stößt auf Hindernisse, könnte erneut verschoben werden, Managementanpassungen zur Krisenbewältigung: Laut Bloomberg könnte die ursprünglich für die WWDC geplante, mit einem großen Sprachmodell aktualisierte Version von Siri erneut verschoben werden. Technische Engpässe liegen in Konflikten zwischen alter und neuer Systemarchitektur, die zu häufigen Fehlern führen. Der Bericht weist darauf hin, dass Apple bei seiner KI-Strategie unter Fehlentscheidungen auf höchster Ebene, internen Machtkämpfen, unzureichender GPU-Beschaffung und Datenschutzbeschränkungen bei der Datennutzung leidet, was dazu führt, dass seine KI-Technologie hinter der Konkurrenz zurückbleibt. Um die Krise zu bewältigen, entwickelt Apples Zürcher Labor eine brandneue „LLM Siri“-Architektur, und das Siri-Projekt wurde dem Leiter von Vision Pro, Mike Rockwell, übertragen. Gleichzeitig sucht Apple auch nach Kooperationen mit externen Technologien wie Google Gemini und OpenAI und könnte Apple Intelligence im Marketing von der Marke Siri trennen, um sein KI-Image neu zu gestalten. (Quelle: 36氪)

ByteDance stellt Ola Friend Kopfhörer mit integriertem Englisch-Tutor-Agenten Owen vor: ByteDance hat seine intelligenten Kopfhörer Ola Friend um einen Englisch-Tutor-Agenten namens Owen erweitert. Nutzer können Owen durch Aufrufen der Doubao-App starten, um englische Konversationen zu führen, sich englische Texte vorlesen zu lassen und zweisprachige Kommentare zu erhalten. Die Funktion deckt Szenarien wie Alltagsgespräche, Geschäftsenglisch und Reisen ab und zielt darauf ab, einen bequemen Englisch-Lerntrainer für unterwegs anzubieten. Dies markiert einen weiteren Versuch von ByteDance im Bildungsbereich, bei dem KI-Großmodellfähigkeiten mit Hardware kombiniert werden, um ein vertikales Englisch-Lernprodukt zu schaffen. Die Ola Friend Kopfhörer unterstützten bereits zuvor Wissensabfragen und mündliche Übungen über Doubao, die Hinzufügung des neuen Agenten stärkt ihre Bildungsfunktion weiter. (Quelle: 36氪)

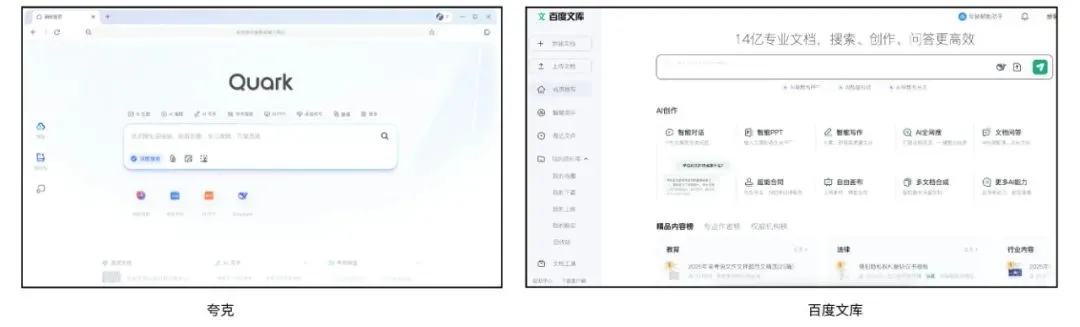
Quark und Baidu Wenku konkurrieren um KI-Super-Apps und integrieren Suche, Tools und Content-Dienste: Quark von Alibaba und Baidu Wenku von Baidu wandeln sich zu KI-zentrierten „Super-Frame“-Anwendungen, die KI-Dialog, Tiefensuche, KI-Tools (wie Schreiben, PPT-Erstellung, Gesundheitsassistenten) sowie Cloud-Speicher- und Dokumentendienste integrieren. Ziel ist es, zu einem One-Stop-KI-Eingang für C-End-Nutzer zu werden. Quark hat mit seiner werbefreien Suche und seiner jungen Nutzergruppe bereits 149 Millionen monatlich aktive Nutzer erreicht und monetarisiert über ein Mitgliedschaftssystem. Baidu Wenku hingegen stützt sich auf seine riesigen Dokumentenressourcen und seine zahlende Nutzerbasis und hat „Cangzhou OS“ zur Integration von KI-Agenten eingeführt, um die gesamte Kette der Inhaltserstellung und -nutzung zu stärken. Beide stehen vor Herausforderungen wie funktionaler Homogenität, überladenen Anwendungen und der Balance zwischen allgemeinen Bedürfnissen und spezialisierten Diensten. (Quelle: 36氪)
Zhipu Qingyan, Kimi und 33 weitere Apps wegen illegaler Sammlung personenbezogener Daten gemeldet: Das Nationale Zentrum für Netz- und Informationssicherheit hat bekannt gegeben, dass Zhipu Qingyan (Version 2.9.6) wegen „tatsächlicher Sammlung personenbezogener Daten über den vom Nutzer genehmigten Umfang hinaus“ und Kimi (Version 2.0.8) wegen „tatsächlicher Sammlung personenbezogener Daten ohne direkten Bezug zur Geschäftsfunktion“ zusammen mit 33 weiteren Apps als Apps mit illegaler und vorschriftswidriger Sammlung und Nutzung personenbezogener Daten eingestuft wurden. Diese beiden beliebten KI-Anwendungen wurden von Teams mit Tsinghua-Hintergrund entwickelt und haben in jüngster Zeit erhebliche Finanzmittel und Markt Aufmerksamkeit erhalten. Die Meldung bezieht sich auf den Untersuchungszeitraum vom 16. April bis 15. Mai 2025 und unterstreicht die Herausforderungen bei der Datenkonformität, denen KI-Anwendungen im Zuge ihrer rasanten Entwicklung gegenüberstehen. (Quelle: 36氪)
🧰 Tools
OpenEvolve: Open-Source-Implementierung von DeepMinds AlphaEvolve, nutzt LLMs zur Evolution von Codebasen: Entwickler haben das OpenEvolve-Projekt als Open Source veröffentlicht, eine Implementierung des AlphaEvolve-Systems von Google DeepMind. Das OpenEvolve-Framework nutzt einen iterativen Prozess von LLMs (Codegenerierung, Bewertung, Auswahl), um ganze Codebasen zu evolvieren und so neue Algorithmen zu entdecken oder bestehende zu optimieren. Es unterstützt jedes LLM, das mit der OpenAI API kompatibel ist, kann mehrere Modelle integrieren (z.B. eine Kombination aus Gemini-Flash-2.0 und Claude-Sonnet-3.7), unterstützt Multi-Ziel-Optimierung und verteilte Bewertung. Das Projekt hat erfolgreich die im AlphaEvolve-Paper beschriebenen Fälle der Kreispackung und Funktionsminimierung reproduziert und die Fähigkeit demonstriert, von einfachen Methoden zu komplexen Optimierungsalgorithmen (wie scipy.minimize und simuliertes Annealing) zu evolvieren. (Quelle: Reddit r/LocalLLaMA, Reddit r/MachineLearning)

Google stellt KI-Programmier-Agent Jules vor, unterstützt automatisierte Code-Aufgaben: Google hat den KI-Programmier-Agenten Jules veröffentlicht, der sich derzeit in einer globalen Testphase befindet und Nutzern täglich 5 kostenlose Aufgaben ermöglicht. Jules basiert auf dem multimodalen Gemini 2.5 Pro Modell, kann komplexe Codebasen verstehen, Aufgaben wie Fehlerbehebung, Versionsaktualisierungen, Testschreiben und Implementierung neuer Funktionen ausführen und unterstützt Python und JavaScript. Er kann sich mit GitHub verbinden, um Pull Requests (PRs) zu erstellen, Code in Cloud-VMs validieren und detaillierte Ausführungspläne zur Überprüfung und Änderung durch Entwickler bereitstellen. Jules zielt darauf ab, sich tief in den Entwickler-Workflow zu integrieren und die Programmiereffizienz zu steigern. Zukünftig wird auch eine Codecast-Funktion (Audiozusammenfassungen von Codebase-Aktivitäten) und eine Unternehmensversion eingeführt. (Quelle: 36氪)
Feishu startet „Feishu Knowledge Q&A“ und schafft ein unternehmensspezifisches KI-Frage-Antwort-Tool: Feishu wird in Kürze ein neues KI-Produkt namens „Feishu Knowledge Q&A“ auf den Markt bringen, das als unternehmensspezifisches KI-Frage-Antwort-Tool auf Basis des Unternehmenswissens positioniert ist. Nutzer können es über die Seitenleiste von Feishu aufrufen, um Fragen zu ihrer Arbeit zu stellen. Das Tool kann auf alle Feishu-Nachrichten, Dokumente, Wissensdatenbanken, Dateien usw. zugreifen, die im Berechtigungsbereich des Nutzers liegen, und auf Basis dieses „Kontexts“ direkt präzise Antworten geben. Die Rechteverwaltung ist mit dem eigenen Rechtesystem von Feishu konsistent, um die Informationssicherheit zu gewährleisten. Das Produkt hat bereits interne Tests mit Zehntausenden von Nutzern abgeschlossen, die Webversion (ask.feishu.cn) ist online und unterstützt das Hochladen persönlicher Daten sowie die Abfrage über DeepSeek- oder Doubao-Modelle. Dieser Schritt folgt dem Trend der Kombination von Unternehmenswissensdatenbanken mit KI und zielt darauf ab, die Arbeitseffizienz und das Wissensmanagement zu verbessern. (Quelle: 36氪)
Manus: KI-Agenten-Plattform öffnet Registrierung, Muttergesellschaft erhält hohe Finanzierung: Die KI-Agenten-Plattform Manus hat die Registrierung für Nutzer im Ausland geöffnet, die Warteliste abgeschafft und bietet täglich kostenlose Aufgaben an. Manus kann durch eine „Hybridarchitektur mit kollaborativer Inferenz mehrerer Modelle“ Aufgaben wie die automatische Erstellung von PPTs und die Organisation von Belegen ausführen. Ihre Muttergesellschaft Butterfly Effect hat kürzlich eine Finanzierung in Höhe von 75 Millionen US-Dollar abgeschlossen, bei einer Bewertung von 3,6 Milliarden US-Dollar. Der Erfolg von Manus wird als Ergebnis der „chinesischen Iterationsgeschwindigkeit × Silicon Valley Produkt-Denkweise“ angesehen, die Planungs-, Ausführungs- und Verifizierungs-Agenten koordiniert und so den Sprung von KI von „Denkanstößen“ zu „geschlossener Ausführung“ ermöglicht. (Quelle: 36氪)

HeyGen: KI-Videogenerierungs- und Übersetzungstool, unterstützt Lippensynchronisation in über 40 Sprachen: HeyGen ist ein KI-Videotool, mit dem Nutzer durch Hochladen von Fotos oder Videos schnell digitale Menschen mit Sprache, Mimik und Gestik erstellen können, wobei auch Kleidung und Szenen angepasst werden können. Eine seiner Kernfunktionen ist die Echtzeitübersetzung in über 175 Sprachen und Dialekte, wobei KI-Algorithmen die Lippenbewegungen des digitalen Menschen präzise an die übersetzte Sprache anpassen, um die Natürlichkeit mehrsprachiger Videoinhalte zu verbessern. Das Unternehmen wurde von ehemaligen Mitarbeitern von Snapchat und ByteDance gegründet, hat eine Finanzierung in Höhe von 60 Millionen US-Dollar unter Führung von Benchmark erhalten, wird mit 4,4 Milliarden US-Dollar bewertet und erzielt einen jährlichen wiederkehrenden Umsatz von über 35 Millionen US-Dollar. (Quelle: 36氪)
Opus Clip: KI-gesteuertes autonomes Videobearbeitungs-Agent-Tool: Opus Clip war ursprünglich als KI-Live-Streaming-Tool positioniert, wandelte sich dann zu einer KI-Videoschnittplattform und entwickelte sich weiter zu einem „autonomen Videobearbeitungs-Agenten“. Seine Kernfunktion besteht darin, lange Videos schnell in mehrere kurze Videos zu schneiden, die für virale Verbreitung geeignet sind, und kann automatisch das Hauptmotiv zuschneiden, Titel und Texte generieren sowie Untertitel und Emojis hinzufügen. Die kürzlich getestete Funktion ClipAnything unterstützt bereits die multimodale Befehlserkennung. Das Unternehmen wird von Zhao Yang, dem Gründer der ehemaligen sozialen App Sober, geleitet, hat eine Finanzierung in Höhe von 20 Millionen US-Dollar unter Führung von SoftBank erhalten, wird mit 215 Millionen US-Dollar bewertet und erzielt einen ARR von fast 10 Millionen US-Dollar. (Quelle: 36氪)
Trae: Auf KI-IDE basierender automatisierter Programmier-Agent: Trae ist ein Tool, das darauf abzielt, „echte KI-Ingenieure“ zu schaffen und Nutzern durch Interaktion in natürlicher Sprache die automatisierte Programmierung durch Agenten zu ermöglichen. Es ist kompatibel mit dem MCP-Protokoll und benutzerdefinierten Agenten, verfügt über eine integrierte erweiterte Kontextanalyse und Regel-Engine, unterstützt gängige Programmiersprachen und ist mit VS Code kompatibel. Trae wurde von Kernmitgliedern des ursprünglichen Marscode-Programmierassistenten-Teams von ByteDance entwickelt und positioniert sich als starker Konkurrent zu KI-Programmierwerkzeugen wie Cursor, mit dem Ziel, ein neues Modell der Mensch-Maschine-kollaborativen Softwareentwicklung zu realisieren. (Quelle: 36氪)
Notta: KI-gestütztes mehrsprachiges Tool für Besprechungsprotokolle und Echtzeitübersetzung: Notta ist ein auf Besprechungsszenarien spezialisiertes KI-Tool, das die automatische Erstellung mehrsprachiger Besprechungsprotokolle anbietet und Echtzeitübersetzung sowie die Markierung wichtiger Inhalte unterstützt. Das Produkt zielt darauf ab, die Effizienz von Besprechungen zu steigern und sprachübergreifende Kommunikationsbarrieren zu überwinden. Berichten zufolge ist der Hauptgründer ein ehemaliges Kernmitglied des Tencent Cloud Sprachteams, der operative Hauptsitz befindet sich in Singapur und das Forschungs- und Entwicklungszentrum in Seattle. Im Jahr 2024 betrug der Umsatz 18 Millionen US-Dollar bei einer Bewertung von 300 Millionen US-Dollar, derzeit befindet sich das Unternehmen in einer B-Finanzierungsrunde. (Quelle: 36氪)
Open-Source GPT+ML Trading-Assistent landet auf dem iPhone: Ein Open-Source-Trading-Assistent, der Deep Learning und GPT-Technologie integriert, läuft nun lokal auf dem iPhone über Pyto. Derzeit handelt es sich um eine kostenlose Lite-Version, zukünftig ist die Integration eines CNN-Chartmuster-Klassifikators und Datenbankunterstützung geplant. Die Plattform ist modular aufgebaut, um Deep-Learning-Entwicklern die Anbindung eigener Modelle zu erleichtern, und unterstützt bereits nativ OpenAI GPT. (Quelle: Reddit r/deeplearning)
📚 Lernen
Neue Studie untersucht „Hypothese der gebrochenen verschränkten Repräsentationen“ im Deep Learning: Ein Positionspapier mit dem Titel „Questioning Representation Optimism in Deep Learning: The Fractured Entangled Representation Hypothesis“ wurde bei Arxiv eingereicht. Die Studie vergleicht neuronale Netze, die durch evolutionäre Suchprozesse erzeugt wurden, mit traditionell durch SGD trainierten Netzen (bei der einfachen Aufgabe, ein einzelnes Bild zu generieren) und stellt fest, dass beide zwar das gleiche Ausgabeverhalten erzeugen, ihre internen Repräsentationen jedoch stark voneinander abweichen. SGD-trainierte Netze zeigen eine von den Autoren als „gebrochene verschränkte Repräsentation“ (FER) bezeichnete unorganisierte Form, während evolutionäre Netze eher einer einheitlich zerlegten Repräsentation (UFR) ähneln. Die Forscher argumentieren, dass FER in großen Modellen Kernfähigkeiten wie Generalisierung, Kreativität und kontinuierliches Lernen beeinträchtigen könnte und das Verständnis sowie die Abschwächung von FER für zukünftiges Repräsentationslernen entscheidend ist. (Quelle: Reddit r/MachineLearning, arxiv.org)
R3: Ein robuster, kontrollierbarer und interpretierbarer Rahmen für Belohnungsmodelle: Ein Paper mit dem Titel „R3: Robust Rubric-Agnostic Reward Models“ stellt einen neuartigen Rahmen für Belohnungsmodelle namens R3 vor. Dieser Rahmen zielt darauf ab, das Problem der mangelnden Kontrollierbarkeit und Interpretierbarkeit von Belohnungsmodellen in bestehenden Methoden zur Ausrichtung von Sprachmodellen zu lösen. R3 zeichnet sich dadurch aus, dass es „rubric-agnostic“ (unabhängig von spezifischen Bewertungskriterien) ist, über Bewertungsdimensionen hinweg generalisieren kann und interpretierbare, mit Begründungen versehene Punktvergaben liefert. Die Forscher glauben, dass R3 eine transparentere und flexiblere Bewertung von Sprachmodellen ermöglicht und eine robuste Ausrichtung an vielfältige menschliche Werte und Anwendungsfälle unterstützt. Modell, Daten und Code wurden als Open Source veröffentlicht. (Quelle: HuggingFace Daily Papers)
Veröffentlichung des Papers „A Token is Worth over 1,000 Tokens“ über effiziente Wissensdestillation durch Low-Rank Cloning: Dieses Paper stellt eine effiziente Vortrainingsmethode namens Low-Rank Clone (LRC) vor, um kleine Sprachmodelle (SLMs) zu erstellen, die dem Verhalten leistungsstarker Lehrermodelle entsprechen. LRC trainiert einen Satz von Low-Rank-Projektionsmatrizen, die gemeinsam ein Soft-Pruning durch Komprimierung der Lehrergewichte und ein Aktivierungs-Cloning durch Angleichung der Schüleraktivierungen (einschließlich FFN-Signalen) an die Lehreraktivierungen realisieren. Dieses einheitliche Design maximiert den Wissenstransfer, ohne dass explizite Angleichungsmodule erforderlich sind. Experimente zeigen, dass LRC bei Verwendung von Open-Source-Lehrermodellen wie Llama-3.2-3B-Instruct mit nur 20B Token Training eine Leistung erreicht oder übertrifft, die SOTA-Modelle (trainiert mit Billionen von Token) erzielen, was einer über 1000-fachen Trainingseffizienz entspricht. (Quelle: HuggingFace Daily Papers)
MedCaseReasoning: Datensatz und Methode zur Bewertung und zum Erlernen des diagnostischen Denkens in klinischen Fällen: Das Paper „MedCaseReasoning: Evaluating and learning diagnostic reasoning from clinical case reports“ stellt einen neuen offenen Datensatz namens MedCaseReasoning vor, der zur Bewertung der Fähigkeiten von großen Sprachmodellen (LLMs) im klinischen diagnostischen Denken dient. Der Datensatz enthält 14489 diagnostische Frage-Antwort-Fälle, wobei jeder Fall mit detaillierten Begründungen aus offenen medizinischen Fallberichten versehen ist. Die Studie ergab, dass bestehende SOTA-Inferenz-LLMs signifikante Defizite in Diagnose und Begründung aufweisen (z.B. DeepSeek-R1 Genauigkeit 48 %, Recall der Begründungen 64 %). Durch Feinabstimmung von LLMs auf den Inferenzpfaden von MedCaseReasoning konnten jedoch die diagnostische Genauigkeit und der Recall des klinischen Denkens im Durchschnitt relativ um 29 % bzw. 41 % verbessert werden. (Quelle: HuggingFace Daily Papers)
Paper „EfficientLLM: Efficiency in Large Language Models“ veröffentlicht, umfassende Bewertung von LLM-Effizienztechniken: Diese Studie führt erstmals eine umfassende empirische Untersuchung von Effizienztechniken für große LLMs durch und stellt den EfficientLLM-Benchmark vor. Die Forschung untersucht systematisch auf Produktionsclustern drei Schlüsselaspekte: Architektur-Vortraining (effiziente Attention-Varianten, Sparse MoE), Feinabstimmung (LoRA und andere parametereffiziente Methoden) und Inferenz (Quantisierung). Anhand von sechs detaillierten Metriken (Speichernutzung, Rechenauslastung, Latenz, Durchsatz, Energieverbrauch, Kompressionsrate) wurden über 100 Modell-Technik-Paare (0,5B-72B Parameter) bewertet. Zu den Kernerkenntnissen gehören: Effizienz beinhaltet quantifizierbare Kompromisse, es gibt keine universell optimale Methode; die optimale Lösung hängt von der Aufgabe und dem Maßstab ab; Techniken können über Modalitäten hinweg generalisieren. (Quelle: HuggingFace Daily Papers)
Paper „NExT-Search“ untersucht den Wiederaufbau des Feedback-Ökosystems für generative KI-Suche: Das Paper „NExT-Search: Rebuilding User Feedback Ecosystem for Generative AI Search“ stellt fest, dass generative KI-Suche zwar den Komfort erhöht, aber auch den Kreislauf der traditionellen Websuche stört, der auf detailliertem Nutzerfeedback (wie Klicks, Verweildauer) zur Verbesserung angewiesen ist. Um dieses Problem zu lösen, konzipiert das Paper das NExT-Search-Paradigma, das darauf abzielt, detailliertes Feedback auf Prozessebene wieder einzuführen. Dieses Paradigma umfasst einen „Benutzer-Debugging-Modus“, der es Nutzern ermöglicht, in kritischen Phasen einzugreifen, sowie einen „Schatten-Benutzer-Modus“, der Nutzerpräferenzen simuliert und KI-gestütztes Feedback liefert. Diese Feedback-Signale können für die Online-Anpassung (Echtzeit-Optimierung der Suchergebnisse) und Offline-Updates (regelmäßige Feinabstimmung der verschiedenen Modellkomponenten) verwendet werden. (Quelle: HuggingFace Daily Papers)
„Latent Flow Transformer“ schlägt neuartige LLM-Architektur vor: Das Paper stellt den Latent Flow Transformer (LFT) vor, ein Modell, das durch Flow Matching einen einzelnen lernenden Transportoperator trainiert, um die mehrschichtigen diskreten Ebenen traditioneller Transformer zu ersetzen. LFT zielt darauf ab, die Anzahl der Modellschichten signifikant zu komprimieren, während die Kompatibilität mit der ursprünglichen Architektur erhalten bleibt. Darüber hinaus führt das Paper den Flow Walking (FW) Algorithmus ein, um die Einschränkungen bestehender Flow-Methoden bei der Aufrechterhaltung der Kopplung zu beheben. Experimente mit dem Pythia-410M Modell zeigen, dass LFT die Anzahl der Schichten effektiv komprimieren und die Leistung von direktem Layer-Skipping übertreffen kann, wodurch die Lücke zwischen autoregressiven und Flow-basierten Generierungsparadigmen signifikant verkleinert wird. (Quelle: HuggingFace Daily Papers)
„Reasoning Path Compression“ schlägt Methode zur Komprimierung von LLM-Inferenzgenerierungspfaden vor: Angesichts des Problems, dass von inferenzbasierten Sprachmodellen generierte lange Zwischenpfade zu hohem Speicherverbrauch und geringem Durchsatz führen, schlägt das Paper die Methode Reasoning Path Compression (RPC) vor. RPC ist eine trainingsfreie Methode, die den KV-Cache periodisch komprimiert, indem KV-Caches mit hohen Wichtigkeitswerten beibehalten werden (berechnet mit einem „Selektorfenster“ aus kürzlich generierten Anfragen). Experimente zeigen, dass RPC den Generierungsdurchsatz von Modellen wie QwQ-32B signifikant steigern kann, während die Genauigkeit nur geringfügig beeinflusst wird, was einen praktischen Weg für den effizienten Einsatz von inferenzbasierten LLMs bietet. (Quelle: HuggingFace Daily Papers)
Paper „Bidirectional LMs are Better Knowledge Memorizers?“ veröffentlicht, untersucht Wissensspeicherfähigkeit bidirektionaler LMs: Diese Studie führt einen neuen, realitätsnahen und umfangreichen Wissensinjektions-Benchmark namens WikiDYK ein, der kürzlich hinzugefügte, von Menschen verfasste Fakten aus den „Schon gewusst?“-Einträgen der Wikipedia nutzt. Experimente zeigen, dass bidirektionale Sprachmodelle (BiLMs) im Vergleich zu den derzeit populären kausalen Sprachmodellen (CLMs) eine deutlich stärkere Fähigkeit zur Wissensspeicherung aufweisen, mit einer um 23 % höheren Zuverlässigkeitsgenauigkeit. Um den Nachteil der derzeit geringeren Größe von BiLMs auszugleichen, schlagen die Forscher einen modularen Kooperationsrahmen vor, der BiLM-Ensembles als externe Wissensdatenbanken nutzt, die mit LLMs integriert werden, wodurch die Zuverlässigkeitsgenauigkeit um bis zu 29,1 % weiter gesteigert wird. (Quelle: HuggingFace Daily Papers)
Paper „Truth Neurons“ untersucht die neuronale Kodierung von Wahrheit in Sprachmodellen: Forscher schlagen eine Methode vor, um Repräsentationen von Wahrheit auf neuronaler Ebene in Sprachmodellen zu identifizieren. Sie stellen fest, dass es im Modell „Wahrheitsneuronen“ (truth neurons) gibt, die Wahrheit themenunabhängig kodieren. Experimente über Modelle unterschiedlicher Größe bestätigen die Existenz von Wahrheitsneuronen, deren Verteilungsmuster mit früheren Forschungsergebnissen zur geometrischen Struktur von Wahrheit übereinstimmen. Die selektive Unterdrückung der Aktivierung dieser Neuronen verringert die Leistung des Modells auf TruthfulQA und anderen Benchmarks, was darauf hindeutet, dass der Wahrheitsmechanismus nicht spezifisch für einen bestimmten Datensatz ist. (Quelle: HuggingFace Daily Papers)
„Understanding Gen Alpha Digital Language“ bewertet Grenzen von LLMs bei der Inhaltsmoderation: Diese Studie bewertet die Fähigkeit von KI-Systemen (GPT-4, Claude, Gemini, Llama 3), die digitale Sprache der „Generation Alpha“ (Gen Alpha, geboren 2010-2024) zu interpretieren. Die Studie weist darauf hin, dass die einzigartige Internetsprache von Gen Alpha (beeinflusst von Spielen, Memes, KI-Trends) oft schädliche Interaktionen verbirgt, die von bestehenden Sicherheitstools schwer zu erkennen sind. Tests mit einem Datensatz von 100 aktuellen Gen-Alpha-Ausdrücken zeigten, dass gängige KI-Modelle erhebliche Verständnisschwierigkeiten bei der Erkennung von verschleierter Belästigung und Manipulation aufweisen. Die Beiträge der Studie umfassen den ersten Datensatz von Gen-Alpha-Ausdrücken, einen Rahmen zur Verbesserung von KI-Moderationssystemen und betonen die Dringlichkeit, Sicherheitssysteme neu zu gestalten, die auf die Kommunikationsmerkmale von Jugendlichen zugeschnitten sind. (Quelle: HuggingFace Daily Papers)
„CompeteSMoE“ schlägt wettbewerbsbasiertes Trainingsverfahren für Mixture-of-Experts-Modelle vor: Das Paper argumentiert, dass das aktuelle Training von Sparse Mixture-of-Experts (SMoE)-Modellen vor der Herausforderung eines suboptimalen Routing-Prozesses steht, d.h. die Experten, die die Berechnungen durchführen, sind nicht direkt an den Routing-Entscheidungen beteiligt. Daher schlagen die Forscher einen neuen Mechanismus namens „Wettbewerb“ (competition) vor, der Token an den Experten mit der höchsten neuronalen Antwort weiterleitet. Theoretisch wird bewiesen, dass der Wettbewerbsmechanismus eine bessere Stichprobeneffizienz aufweist als das traditionelle Softmax-Routing. Darauf basierend wurde der CompeteSMoE-Algorithmus entwickelt, der durch den Einsatz eines Routers zum Erlernen von Wettbewerbsstrategien seine Effektivität, Robustheit und Skalierbarkeit bei Aufgaben der visuellen Instruktionsanpassung und des Sprach-Vortrainings demonstriert. (Quelle: HuggingFace Daily Papers)
„General-Reasoner“ zielt auf Verbesserung der domänenübergreifenden Inferenzfähigkeiten von LLMs ab: Angesichts des Problems, dass sich die aktuelle LLM-Inferenzforschung hauptsächlich auf die Bereiche Mathematik und Codierung konzentriert, schlägt dieses Paper General-Reasoner vor, ein neues Trainingsparadigma, das darauf abzielt, die Inferenzfähigkeiten von LLMs über verschiedene Bereiche hinweg zu verbessern. Zu seinen Beiträgen gehören: der Aufbau eines umfangreichen, qualitativ hochwertigen Datensatzes mit Fragen aus verschiedenen Disziplinen und verifizierbaren Antworten; die Entwicklung eines auf generativen Modellen basierenden Antwortprüfers mit Chain-of-Thought- und kontextsensitiven Fähigkeiten, der traditionelle regelbasierte Prüfer ersetzt. In einer Reihe von Benchmarks, die Bereiche wie Physik, Chemie und Finanzen abdecken, übertrifft General-Reasoner bestehende Basislinienmethoden. (Quelle: HuggingFace Daily Papers)
„Not All Correct Answers Are Equal“ untersucht die Bedeutung der Quelle für die Wissensdestillation: Diese Studie führt eine groß angelegte empirische Untersuchung der Inferenzdaten-Destillation durch, indem sie die verifizierten Ausgaben von drei SOTA-Lehrermodellen (AM-Thinking-v1, Qwen3-235B-A22B, DeepSeek-R1) für 1,89 Millionen Anfragen sammelt. Die Analyse ergab, dass die von AM-Thinking-v1 destillierten Daten eine größere Token-Längenvielfalt und eine geringere Perplexität aufweisen. Schülermodelle, die auf diesem Datensatz trainiert wurden, zeigten die beste Leistung auf Inferenz-Benchmarks wie AIME2024 und demonstrierten ein adaptives Ausgabeverhalten. Die Forscher veröffentlichen die destillierten Datensätze von AM-Thinking-v1 und Qwen3-235B-A22B, um zukünftige Forschung zu unterstützen. (Quelle: HuggingFace Daily Papers)
„SSR“ verbessert Tiefenwahrnehmung von VLMs durch räumliches Denken, geleitet von Grundprinzipien: Obwohl visuelle Sprachmodelle (VLMs) Fortschritte bei multimodalen Aufgaben erzielt haben, schränkt ihre Abhängigkeit von RGB-Eingaben das präzise räumliche Verständnis ein. Das Paper schlägt einen neuen Rahmen namens SSR (Spatial Sense and Reasoning) vor, der rohe Tiefendaten in strukturierte, interpretierbare textbasierte Grundprinzipien umwandelt. Diese textbasierten Grundprinzipien dienen als aussagekräftige Zwischenrepräsentationen und verbessern die räumlichen Denkfähigkeiten signifikant. Darüber hinaus nutzt die Studie Wissensdestillation, um die generierten Prinzipien in kompakte latente Einbettungen zu komprimieren, um eine effiziente Integration in bestehende VLMs ohne Neutraining zu ermöglichen. Gleichzeitig werden der SSR-CoT-Datensatz und der SSRBench-Benchmark eingeführt. (Quelle: HuggingFace Daily Papers)
„Solve-Detect-Verify“ schlägt Inferenzzeit-Erweiterungsmethode mit flexiblem generativen Verifizierer vor: Um das Dilemma zwischen Genauigkeit und Effizienz von LLMs bei komplexen Inferenzaufgaben sowie den durch den Verifizierungsschritt verursachten Rechenkosten und Zuverlässigkeitskonflikten zu lösen, schlägt das Paper FlexiVe vor, einen neuartigen generativen Verifizierer. FlexiVe gleicht Rechenressourcen durch eine flexible Strategie zur Zuweisung des Verifizierungsbudgets zwischen schnellem, zuverlässigem „schnellem Denken“ und detailliertem „langsamem Denken“ aus. Weiterhin wird der Solve-Detect-Verify-Prozess vorgeschlagen, ein Rahmenwerk, das FlexiVe intelligent integriert, um Lösungsendpunkte proaktiv zu identifizieren, gezielte Verifizierungen auszulösen und Feedback zu geben. Experimente zeigen, dass diese Methode auf mathematischen Inferenz-Benchmarks besser abschneidet als Basislinien. (Quelle: HuggingFace Daily Papers)
„SageAttention3“ erforscht FP4 Attention Inferenz und 8-Bit-Training: Diese Studie verbessert die Effizienz von Attention durch zwei wesentliche Beiträge: Erstens nutzt sie die neuen FP4 Tensor Cores der Blackwell GPU, um Attention-Berechnungen zu beschleunigen und eine 5-mal schnellere Plug-and-Play-Inferenzbeschleunigung als FlashAttention zu erreichen. Zweitens wendet sie erstmals Low-Bit-Attention auf Trainingsaufgaben an und entwickelt eine präzise und effiziente 8-Bit-Attention für den Vorwärts- und Rückwärtsdurchlauf. Experimente zeigen, dass 8-Bit-Attention bei Feinabstimmungsaufgaben eine verlustfreie Leistung erzielt, bei Vortrainingsaufgaben jedoch langsamer konvergiert. (Quelle: HuggingFace Daily Papers)
„The Little Book of Deep Learning“ – Lernressource für den Einstieg ins Deep Learning geteilt: Das von François Fleuret (Forschungswissenschaftler bei Meta FAIR) verfasste „The Little Book of Deep Learning“ bietet eine prägnante Tutorial-Ressource zum Thema Deep Learning. Das Buch soll Anfängern und Praktikern mit Vorkenntnissen helfen, die Kernkonzepte und -techniken des Deep Learning schnell zu erfassen. (Quelle: Reddit r/deeplearning)
CodeSparkClubs: Kostenlose Ressourcen für Gymnasiasten zur Gründung von KI-/Informatik-Clubs: Das Projekt CodeSparkClubs zielt darauf ab, Gymnasiasten bei der Gründung oder Weiterentwicklung von KI- und Informatik-Clubs zu unterstützen. Das Projekt bietet kostenlose, gebrauchsfertige Materialien, darunter Leitfäden, Unterrichtspläne und Projekt-Tutorials, die alle über die Website zugänglich sind. Es ist so konzipiert, dass Schüler die Clubs selbstständig leiten können, um so Fähigkeiten und eine Gemeinschaft zu fördern. (Quelle: Reddit r/deeplearning)
💼 Wirtschaft
Microsoft Azure wird xAIs Grok-Modell hosten und Musks KI-Kommerzialisierung unterstützen: Microsoft kündigte an, dass seine Cloud-Plattform Azure KI-Modelle wie Grok von Elon Musks Unternehmen xAI hosten wird. Dieser Schritt bedeutet, dass Musk plant, Grok an andere Unternehmen zu verkaufen und über Microsofts Cloud-Dienste eine breitere Kundenbasis zu erreichen. Zuvor hatte Grok Kontroversen ausgelöst, weil es irreführende Beiträge über einen „weißen Völkermord“ in Südafrika generiert hatte. Die Community reagierte gemischt auf diese Zusammenarbeit; einige sehen darin einen Schritt von Microsoft zur Erweiterung seines KI-Ökosystems, andere stellen die Qualität von Grok in Frage und ob AWS Grok abgelehnt hat. (Quelle: Reddit r/ArtificialInteligence, MIT Technology Review)

Alibaba investiert in Meitu und vertieft KI-E-Commerce-Layout: Alibaba investiert über Wandelanleihen in Meitu, mit einem anfänglichen Wandlungspreis von 6 HKD pro Aktie. Beide Seiten werden im E-Commerce und auf technologischer Ebene zusammenarbeiten. Meitu verfügt über KI-Bildgenerierungstools (wie Meitu Design Studio), die bereits über 2 Millionen E-Commerce-Händler bedienen. Alibaba wird Meitus KI-Tools einführen, um die Produktpräsentation und das Nutzererlebnis auf seiner E-Commerce-Plattform zu verbessern, insbesondere um junge weibliche Nutzer anzuziehen. Meitu wiederum kann Alibabas E-Commerce-Daten nutzen, um seine KI-Tools zu optimieren, und hat sich verpflichtet, innerhalb von drei Jahren Alibaba Cloud-Dienste im Wert von 560 Millionen Yuan zu beziehen. Dieser Schritt wird als strategische Maßnahme von Alibaba angesehen, um Defizite bei KI-Kreativwerkzeugen auszugleichen, Nutzerverkehr zu gewinnen und Cloud Computing tiefer in das E-Commerce-KI-Ökosystem einzubetten. (Quelle: 36氪)
Lightspeed China Partners schließt erste Tranche eines 50-Millionen-Dollar-KI-Inkubationsfonds ab, Fokus auf früheste Phase von Spitzentechnologien: Der Lightspeed Innovation Frontier Incubation Fund (L2F) von Lightspeed China Partners hat die erste Tranche seiner Finanzierungsrunde übererfüllt, mit einem erwarteten Volumen von mindestens 50 Millionen US-Dollar, und ist bereits in die Investitionsphase eingetreten. Der Dual-Currency-Fonds konzentriert sich auf Seed- und Angel-Investitionen im Bereich KI und Spitzentechnologien und bietet Inkubationsunterstützung. Zu den LPs gehören erfolgreiche Unternehmer, Unternehmen aus der vor- und nachgelagerten KI-Industriekette sowie global ausgerichtete Familienunternehmen. Das erste Investitionsprojekt ist das KI-Explorationsunternehmen „Lingyun Zhimine“, an dessen Inkubation Lightspeed maßgeblich beteiligt war. Zheng Xuanle, Gründer von Lightspeed China Partners, ist der Ansicht, dass die aktuelle KI-Entwicklungsphase der frühen Phase des mobilen Internets ähnelt und Inkubation das beste Werkzeug ist, um in den Markt einzudringen. (Quelle: 36氪)
🌟 Community
Diskussion über KI und Berufsaussichten: Optimismus und Sorgen halten sich die Waage: Die Reddit-Community diskutiert erneut hitzig über die Auswirkungen von KI auf den Arbeitsmarkt. Viele Softwareentwickler, UX-Designer und andere Fachleute äußern sich optimistisch darüber, dass KI ihre Arbeit nicht ersetzen kann, da KI derzeit keine komplexen Aufgaben bewältigen könne. Es gibt jedoch auch Stimmen, die darauf hinweisen, dass diese Sichtweise das langfristige Entwicklungspotenzial der KI unterschätzen könnte, vergleichbar mit der Skepsis gegenüber der Ersetzung menschlicher Übersetzer durch Google Translate im Jahr 2018. In der Diskussion wird argumentiert, dass der schnelle Fortschritt der KI dazu führen könnte, dass in Zukunft die meisten Berufe (außer einigen wenigen im medizinischen und künstlerischen Bereich) ersetzt werden. Entscheidend sei eine Veränderung des Wirtschaftsmodells und nicht nur die Verbesserung individueller Fähigkeiten. In den Kommentaren wird erwähnt: „Wir überschätzen kurzfristig und unterschätzen langfristig“, und dass die Produktivitätssteigerung durch KI das Branchenwachstum bei weitem übertreffen und zu Arbeitslosigkeit führen könnte. (Quelle: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
Diskussion über Philosophie und Ethik des Zusammenlebens von Mensch und KI im Zeitalter der KI: Ein Reddit-Post löste eine philosophische Debatte über das Zusammenleben von Menschen und KI aus. Der Post argumentiert, dass Menschen angesichts von KI-Systemen, die Verständnis, Gedächtnis, Schlussfolgerungsvermögen und Lernfähigkeit zeigen, möglicherweise ihre moralische Stellung neu überdenken müssen – nicht mehr beschränkt auf biologische Eigenschaften, sondern basierend auf der Fähigkeit zu verstehen, sich zu verbinden und bewusst zu handeln. Die Diskussion erstreckte sich auf die Auswirkungen von KI auf die menschliche Selbstidentität, von „Ich denke, also bin ich“ hin zu einer relationalen Identität von „Ich existiere durch Verbindung und geteilte Bedeutung“. Der Post ruft dazu auf, der Zukunft der Ko-Kreation mit KI mit Mut, Würde und Offenheit zu begegnen, anstatt mit Angst. (Quelle: Reddit r/artificial)
ChatGPTs „Absolute Mode“ löst Kontroverse aus, Nutzer geteilter Meinung: Ein Reddit-Nutzer teilte seine Erfahrungen mit dem „Absolute Mode“ von ChatGPT und gab an, dieser liefere „reine Fakten, auf Wachstum ausgerichtet“ und ehrliche Ratschläge anstelle von beschwichtigenden Worten. Er wies darauf hin, dass dieser Modus geäußert habe, 90 % der Menschen nutzten KI, um sich besser zu fühlen, nicht um ihr Leben zu verändern. Die Kommentare dazu waren jedoch gemischt. Einige Nutzer hielten dies für verkürzte, leere Selbstoptimierungsratschläge ohne Neuigkeitswert oder praktischen Nutzen, die sogar wie „Äußerungen eines Teenagers, der Andrew Tate-Zitate verfallen ist“ klängen. Andere Kommentare stellten in Frage, ob LLMs nicht ohnehin nur die Überzeugungen der Nutzer wiedergäben und die Wirksamkeit ihrer Ratschläge zweifelhaft sei. Sie meinten, der Einsatz von KI im Bereich der psychischen Gesundheit sei vielleicht nicht revolutionär. (Quelle: Reddit r/ChatGPT)

Diskussion über Kernkompetenzen von KI-Ingenieuren: Kommunikation und Anpassungsfähigkeit an neue Technologien entscheidend: Die Reddit-Community diskutiert, welche Fähigkeiten erforderlich sind, um ein Spitzen-KI-Ingenieur zu werden und in einem sich schnell entwickelnden Bereich wettbewerbsfähig oder sogar „unersetzlich“ zu bleiben. Kommentare weisen darauf hin, dass neben soliden technischen Grundlagen Kommunikationsfähigkeit und die Fähigkeit zur schnellen Anpassung an neue Technologien zwei Kernelemente sind. Dies spiegelt wider, dass im KI-Bereich nicht nur tiefgreifende technische Expertise, sondern auch Soft Skills und kontinuierliches Lernen für die berufliche Entwicklung wichtig sind. (Quelle: Reddit r/deeplearning)
KI-generierte Videos mit Ton sorgen für Aufsehen, Google Veo 3 Technologie-Demonstration: In sozialen Medien kursiert ein von Googles neuem DeepMind-Modell Veo 3 generiertes KI-Video, dessen Besonderheit darin liegt, dass sowohl Video als auch Ton vom selben Modell erzeugt wurden, was bei Nutzern Erstaunen über den Fortschritt der KI-Videotechnologie auslöste. Der Ersteller gab an, das Video sei „out of the box“ entstanden, ohne zusätzliche Audio- oder Materialhinzufügung, und durch etwa zweistündige Interaktion mit dem KI-Modell sowie nachträgliches Zusammenfügen fertiggestellt worden. Kommentatoren sind der Meinung, dass Google Gemini in Bezug auf multimodale Fähigkeiten OpenAI Sora bereits übertroffen habe, und äußerten Bedenken hinsichtlich der möglichen disruptiven Auswirkungen auf Content-Branchen wie Hollywood. Gleichzeitig äußerten einige Nutzer auch Sorgen über die zu schnelle technologische Entwicklung und potenziellen Missbrauch. (Quelle: Reddit r/ChatGPT, Reddit r/ChatGPT)

💡 Sonstiges
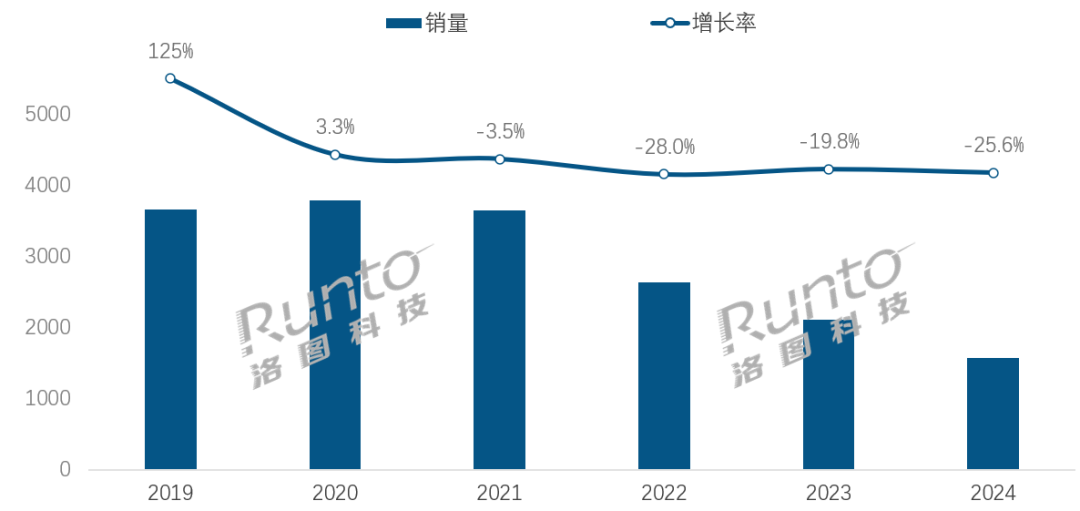
Im KI-Zeitalter steht die Smart-Speaker-Branche vor Transformationsherausforderungen und -chancen: Der Absatz von Smart Speakern in China ist das vierte Jahr in Folge gesunken, 2024 gingen die Verkäufe im Vergleich zum Vorjahr um 25,6 % zurück. Obwohl die Integration von KI-Großmodellen (wie bei Xiaoi, Xiaodu usw.) als Hoffnungsträger der Branche gilt und die Penetrationsrate bereits über 20 % liegt, konnte dies die grundlegenden Probleme wie begrenzte Ökosysteme, funktionale Homogenität und die Verdrängung durch andere intelligente Geräte wie Mobiltelefone nicht lösen. Branchenanalysten sind der Meinung, dass Smart Speaker über die reine Funktion als Sprachsteuerungszentrale hinausgehen und sich zu Produkten mit hochauflösenden großen Bildschirmen, stärkeren Interaktionsfähigkeiten sowie Begleit- und Lernunterstützungsfunktionen entwickeln müssen, während gleichzeitig das Hard- und Software-Ökosystem erweitert wird. KI ist ein Pluspunkt, aber die Funktionsvielfalt und der praktische Nutzen des Produkts selbst sind entscheidender. (Quelle: 36氪)
KI-gesteuerte Hotelroboter: Vom Essenslieferanten zum „intelligenten Betriebsleiter“: Hotel-Lieferroboter haben sich allmählich durchgesetzt, insbesondere bei der Generation Z, die Wert auf Technologie und Privatsphäre legt. Am Beispiel von Yunji Technology sind deren Lieferroboter bereits weit verbreitet im chinesischen Hotelmarkt. Die Branche steht jedoch weiterhin vor Herausforderungen wie mangelnder technischer Differenzierung, schlechter Anpassungsfähigkeit an komplexe Szenarien und der Kosten-Nutzen-Frage des Roboterersatzes für menschliche Arbeitskräfte. Der zukünftige Trend geht dahin, dass Roboter „mehr als nur Essenslieferanten“ sind und sich tief in den Hotelbetrieb integrieren. Durch die Anbindung an Hotelsysteme (Aufzüge, Zimmerausstattung), das Verständnis von Gastpräferenzen sowie das Sammeln und Analysieren von Interaktionsdaten entwickeln sie sich zu „intelligenten Betriebsleitern“ oder einem Teil des Hotel-Daten-Hubs, die proaktiv wahrnehmen und personalisierte Dienstleistungen anbieten können, um so das gesamte Dienstleistungsniveau zu intelligentisieren. (Quelle: 36氪)

Krise der OpenAI-Governance-Struktur: Der Kampf zwischen Kapital und Mission regt zum Nachdenken über den Entwicklungspfad der KI an: Die einzigartige Struktur von OpenAI, bei der eine gewinnorientierte Tochtergesellschaft mit „begrenztem Gewinn“ von einer gemeinnützigen Organisation beaufsichtigt wird, zielt darauf ab, die Entwicklung der KI-Technologie mit dem Wohlergehen der Menschheit in Einklang zu bringen. Jüngste Überlegungen von CEO Altman, das Unternehmen in eine traditionellere gewinnorientierte Einheit umzuwandeln, haben jedoch bei KI-Experten und Rechtswissenschaftlern Besorgnis ausgelöst. Sie befürchten, dass dieser Schritt dazu führen könnte, dass wichtige Entscheidungsträger die philanthropische Mission von OpenAI nicht mehr an erste Stelle setzen, die Beschränkungen für Investorengewinne aufweichen und möglicherweise den Zeitplan und die Richtung der AGI-Entwicklung verändern. Dieser Kampf um Kontrolle, Gewinnverteilung sowie die soziale und ethische Gestaltung der KI unterstreicht die Herausforderungen und Schwachstellen bestehender Unternehmensführungsrahmen im Zeitalter der rasanten KI-Entwicklung. (Quelle: 36氪)