
Schlüsselwörter:AlphaEvolve, Gemini, Evolutionärer Algorithmus, KI-Agent, Algorithmusoptimierung, Matrixmultiplikation, Borg-Rechenzentrum, Optimierung der 4×4 komplexen Matrixmultiplikation, Google DeepMind Algorithmusentdeckung, Automatisierter KI-Algorithmusentwurf, Gemini 2.0 Pro Anwendung, Borg-Ressourcenplanungsoptimierung
🔥 Fokus
Google DeepMind stellt AlphaEvolve vor: Ein auf Gemini basierender evolutionärer Algorithmus-Codierungsagent erzielt Durchbrüche in Mathematik und Informatik: Google DeepMind hat AlphaEvolve veröffentlicht, einen Agenten, der das große Sprachmodell Gemini 2.0 Pro nutzt, um mittels evolutionärer Algorithmen automatisch Algorithmus-Code zu entdecken und zu optimieren. AlphaEvolve kann, ausgehend von von Menschen bereitgestelltem Initialcode und Bewertungsmetriken, autonom Kandidatenlösungen generieren, bewerten und verbessern. Das System zeigte bei über 50 mathematischen Problemen herausragende Leistungen, reproduzierte in etwa 75 % der Fälle bekannte Lösungen und fand in 20 % der Fälle bessere Lösungen. Bemerkenswert ist, dass AlphaEvolve die Anzahl der Berechnungen für die Multiplikation von 4×4 komplexen Matrizen von 49 auf 48 reduzierte und damit einen 56 Jahre alten Rekord brach. Darüber hinaus optimierte es den Scheduling-Algorithmus des internen Borg-Rechenzentrums von Google, wodurch 0,7 % der globalen Rechenressourcen zurückgewonnen wurden, und verbesserte das Design der nächsten Generation von TPU-Chips, was die Trainingszeit von Gemini um 1 % verkürzte. Dieses Ergebnis demonstriert das immense Potenzial von KI bei der automatisierten Entdeckung von Algorithmen und wissenschaftlicher Innovation. Obwohl es sich derzeit hauptsächlich mit automatisch bewertbaren Problemen befasst, sind die Anwendungsperspektiven in angewandten Wissenschaften wie der Medikamentenentwicklung vielversprechend. (Quelle: , 量子位, 36氪)
Nvidia stellt auf der Computex 2025 zahlreiche KI-Fortschritte vor, Jensen Huang betont Vision von Agentic AI und Physical AI: Nvidia CEO Jensen Huang hielt auf der Computex 2025 eine Keynote, in der er betonte, dass sich KI von „einmaligen Antworten“ zu „denkender, schlussfolgernder“ Agentic AI (intelligente KI-Agenten) und Physical AI (physikalische KI), die die physische Welt versteht, entwickelt. Um diesen Trend zu unterstützen, veröffentlichte Nvidia die erweiterte Blackwell-Plattform (Blackwell Ultra AI) und kündigte die vollständige Produktion des Grace Blackwell GB300-Systems an, dessen Inferenzleistung um das 1,5-fache gegenüber der Vorgängergeneration gesteigert wurde. Huang gab zudem einen Ausblick auf den KI-Superchip der nächsten Generation, Rubin Ultra, dessen Leistung das 14-fache des GB300 betragen soll. Um den Aufbau von KI-Infrastruktur voranzutreiben, führte Nvidia die NVLink Fusion-Technologie ein und gründete gemeinsam mit TSMC, Foxconn und anderen ein KI-Supercomputerzentrum in Taiwan. Darüber hinaus aktualisierte Nvidia das Basismodell für humanoide Roboter Isaac GR00T N1.5, um dessen Anpassungsfähigkeit an die Umgebung und Aufgabenausführung zu verbessern, und plant, die in Zusammenarbeit mit DeepMind und Disney Research entwickelte Physik-Engine Newton als Open Source zu veröffentlichen. (Quelle: AI 前线, 量子位, Reddit r/artificial)
OpenAI Codex Team AMA enthüllt Pläne für GPT-5 und zukünftige Produktintegration: Das OpenAI Codex Team veranstaltete auf Reddit eine „Ask Me Anything“ (AMA)-Session. Jerry Tworek, Vice President of Research, enthüllte, dass das Ziel des Basismodells der nächsten Generation, GPT-5, darin besteht, die Fähigkeiten bestehender Modelle zu verbessern und die Notwendigkeit eines Modellwechsels zu reduzieren. Es ist geplant, bestehende Tools wie Codex, Operator (Agent zur Aufgabenausführung), Deep Research (Tool für tiefgehende Forschung) und Memory (Gedächtnisfunktion) zu integrieren, um ein einheitliches KI-Assistentenerlebnis zu schaffen. Teammitglieder teilten auch die ursprüngliche Motivation für die Entwicklung von Codex (aus internen Überlegungen zur unzureichenden Modellnutzung), die etwa dreifache Steigerung der Programmiereffizienz durch die interne Nutzung von Codex und die Zukunftsaussichten für Software Engineering – die effiziente und zuverlässige Umwandlung von Anforderungen in lauffähige Software. Codex nutzt derzeit hauptsächlich Informationen, die in Container-Runtimes geladen werden, und könnte in Zukunft RAG-Technologie für den Zugriff auf aktuelles Wissen einsetzen. OpenAI prüft auch flexible Preismodelle und plant, Plus/Pro-Nutzern kostenlose API-Credits für die Codex CLI zur Verfügung zu stellen. (Quelle: 36氪)
VS Code kündigt Open-Source-Veröffentlichung der GitHub Copilot Chat-Erweiterung an und plant den Aufbau einer Open-Source-KI-Code-Editing-Plattform: Das Visual Studio Code Team hat Pläne angekündigt, VS Code zu einem Open-Source-KI-Editor zu entwickeln, der auf den Kernprinzipien Offenheit, Zusammenarbeit und Community-Orientierung basiert. Als Teil dieses Plans wurde die GitHub Copilot Chat-Erweiterung unter der MIT-Lizenz auf GitHub veröffentlicht. Zukünftig plant VS Code, diese KI-Funktionen schrittweise in den Kern des Editors zu integrieren, mit dem Ziel, eine vollständig quelloffene, von der Community betriebene KI-Code-Editing-Plattform aufzubauen, um die Entwicklungseffizienz, Transparenz und Sicherheit zu erhöhen. Dieser Schritt wird als wichtiger Schritt von Microsoft im Open-Source-Bereich angesehen und könnte weitreichende Auswirkungen auf das Ökosystem der KI-gestützten Programmierwerkzeuge haben. (Quelle: dotey, jeremyphoward)
Huawei Ascend und DeepSeek kooperieren, MoE-Modell-Inferenzleistung übertrifft Nvidia Hopper: Huawei Ascend gab bekannt, dass seine CloudMatrix 384 Super-Nodes und Atlas 800I A2 Inferenzserver bei der Bereitstellung von ultra-großen MoE-Modellen wie DeepSeek V3/R1 einen bedeutenden Durchbruch bei der Inferenzleistung erzielt haben und unter bestimmten Bedingungen die Nvidia Hopper-Architektur übertreffen. Der CloudMatrix 384 Super-Node erreichte bei einer Latenz von 50 ms einen Decode-Durchsatz von über 1920 Tokens/s pro Karte, während der Atlas 800I A2 bei einer Latenz von 100 ms einen Durchsatz von 808 Tokens/s pro Karte erreichte. Huawei führt dies auf die Strategie „Mathematik ergänzt Physik“ zurück, bei der Hardware-Prozessbeschränkungen durch Algorithmus- und Systemoptimierungen ausgeglichen werden. Ein entsprechender technischer Bericht wurde veröffentlicht, und der Kerncode wird innerhalb eines Monats als Open Source zur Verfügung gestellt. Zu den Optimierungsmaßnahmen gehören eine Expert-Parallel-Lösung für MoE-Modelle, PD-getrennte Bereitstellung, Anpassung des vLLM-Frameworks, A8W8C16-Quantisierungsstrategie sowie FlashComm-Kommunikationslösung, Intra-Layer-Parallelisierungsumwandlung, FusionSpec-Spekulationsinferenz-Engine und MLA/MoE-Operator-Hardware-Affinitätsoptimierung. (Quelle: 量子位, WeChat)
🎯 Trends
Apple veröffentlicht effizientes Vision-Language-Modell FastVLM als Open Source und optimiert KI-Erlebnisse auf Endgeräten: Apple hat FastVLM (Fast Vision Language Model) als Open Source veröffentlicht, ein Vision-Language-Modell, das speziell für den effizienten Betrieb auf Edge-Geräten wie dem iPhone entwickelt wurde. FastVLM reduziert durch die Einführung eines neuartigen hybriden visuellen Encoders, FastViTHD, der Convolutional Layers mit Transformer-Modulen kombiniert und Multi-Scale-Pooling- sowie Downsampling-Techniken verwendet, die Anzahl der für die Bildverarbeitung benötigten visuellen Tokens erheblich (16-mal weniger als herkömmliche ViTs). Dies ermöglicht es dem Modell, bei hoher Genauigkeit eine bis zu 85-mal schnellere Ausgabe des ersten Tokens (TTFT) im Vergleich zu ähnlichen Modellen zu erreichen. FastVLM ist mit gängigen LLMs kompatibel und lässt sich leicht an das iOS/Mac-Ökosystem anpassen. Es wird in drei Parameterversionen (0.5B, 1.5B, 7B) angeboten und eignet sich für verschiedene Echtzeit-Text-Bild-Aufgaben wie Bildbeschreibung, Frage-Antwort und Analyse. (Quelle: WeChat)
Meta veröffentlicht KernelLLM 8B Modell, übertrifft GPT-4o in spezifischen Benchmarks: Meta hat das KernelLLM 8B Modell auf Hugging Face veröffentlicht. Berichten zufolge übertrifft dieses 8-Milliarden-Parameter-Modell in der Single-Inference-Leistung im KernelBench-Triton Level 1 Benchmark größere Modelle wie GPT-4o und DeepSeek V3. Bei multiplen Inferenzen ist die Leistung von KernelLLM ebenfalls besser als die von DeepSeek R1. Diese Veröffentlichung hat in der KI-Community Aufmerksamkeit erregt und wird als weiteres Beispiel dafür angesehen, dass mittelgroße Modelle bei spezifischen Aufgaben eine starke Wettbewerbsfähigkeit zeigen. (Quelle: ClementDelangue, huggingface, mervenoyann, HuggingFace Daily Papers)
Mistral Medium 3 Modell zeigt starke Leistung in Arena, besonders im technischen Bereich: Das neu eingeführte Mistral Medium 3 Modell von Mistral AI zeigte in der Community-Bewertung auf lmarena.ai eine hervorragende Leistung und belegte den 11. Platz in der Gesamt-Chatfähigkeit, eine deutliche Verbesserung gegenüber Mistral Large (Elo-Score-Anstieg um 90 Punkte). Das Modell zeichnete sich besonders im technischen Bereich aus: Platz 5 bei mathematischen Fähigkeiten, Platz 7 bei komplexen Prompts und Codierungsfähigkeiten und Platz 9 in der WebDev Arena. Community-Kommentare deuten darauf hin, dass seine Leistung im technischen Bereich dem Niveau von GPT-4.1 nahekommt, während die Kosten wettbewerbsfähiger sein könnten, ähnlich der Preisgestaltung von GPT-4.1 mini. Nutzer können das Modell kostenlos auf der offiziellen Chat-Oberfläche von Mistral testen. (Quelle: hkproj, qtnx_, lmarena_ai)
Hugging Face Datasets fügt Funktion zur direkten Ansicht von Chat-Konversationen hinzu: Die Hugging Face Datasets Plattform hat ein wichtiges Update erhalten, mit dem Benutzer Chat-Konversationen nun direkt im Datensatz lesen können. Diese Funktion wird von Community-Mitgliedern (wie Caleb, Maxime Labonne) als großer Schritt zur Lösung von Datenqualitätsproblemen angesehen, da die direkte Einsicht in die ursprünglichen Konversationsdaten hilft, die Daten besser zu verstehen, Datenbereinigung durchzuführen und die Effektivität des Modelltrainings zu verbessern. Zuvor erforderte die Ansicht spezifischer Konversationsinhalte möglicherweise zusätzlichen Code oder Tools; die neue Funktion vereinfacht diesen Prozess und erhöht die Benutzerfreundlichkeit und Transparenz der Datenarbeit. (Quelle: eliebakouch, _lewtun, _akhaliq, maximelabonne, ClementDelangue, huggingface, code_star)
MLX LM integriert mit Hugging Face Hub, vereinfacht lokale Modellausführung auf Mac: MLX LM ist jetzt direkt in den Hugging Face Hub integriert, wodurch Mac-Benutzer über 4400 LLMs einfacher lokal auf Apple Silicon-Geräten ausführen können. Benutzer müssen lediglich auf der Seite eines kompatiblen Modells im Hugging Face Hub auf „Use this model“ klicken, um das Modell schnell im Terminal auszuführen, ohne komplexe Cloud-Konfigurationen oder Wartezeiten. Darüber hinaus können direkt von der Modellseite aus OpenAI-kompatible Server gestartet werden. Diese Integration zielt darauf ab, die Hürde für die lokale Ausführung von Modellen zu senken und die Entwicklungs- und Experimentiereffizienz zu steigern. (Quelle: awnihannun, ClementDelangue, huggingface, reach_vb)
Nvidia veröffentlicht Physical AI Inferenzmodell Cosmos-Reason1-7B als Open Source: Nvidia hat auf Hugging Face sein Cosmos-Reason1-7B Modell aus der Physical AI Modellreihe als Open Source veröffentlicht. Dieses Modell zielt darauf ab, den gesunden Menschenverstand der physischen Welt zu verstehen und entsprechende verkörperte Entscheidungen zu generieren. Dies markiert einen neuen Schritt von Nvidia bei der Förderung der Verbindung von physischer Welt und KI und stellt neue Werkzeuge und Forschungs Grundlagen für Anwendungen wie Robotik und autonomes Fahren bereit, die eine Interaktion mit der physischen Umgebung erfordern. (Quelle: reach_vb)
Baidus Videogenerierungsmodell Steamer-I2V führt VBench-Rangliste für Bild-zu-Video an: Baidus Videogenerierungsmodell Steamer-I2V belegt in der Kategorie Bild-zu-Video (I2V) der maßgeblichen Videogenerierungs-Benchmark-Rangliste VBench den ersten Platz mit einer Gesamtpunktzahl von 89,38 % und übertrifft damit bekannte Modelle wie OpenAI Sora und Google Imagen Video. Zu den technischen Vorteilen von Steamer-I2V gehören pixelgenaue Bildkontrolle, meisterhafte Kameraführung, filmreife HD-Bildqualität bis zu 1080P und dynamische Ästhetik sowie präzises chinesisches semantisches Verständnis basierend auf einer multimodalen Datenbank mit hunderten Millionen chinesischen Einträgen. Dieses Ergebnis zeigt Baidus Stärke im Bereich der multimodalen Generierung und ist Teil seiner Strategie zum Aufbau eines KI-Content-Ökosystems. (Quelle: 36氪)

LLMs zeigen schlechte Leistung bei Zeitableseaufgaben wie Uhren und Kalendern: Forscher der Universität Edinburgh und anderer Institutionen haben herausgefunden, dass große Sprachmodelle (LLMs) und multimodale große Sprachmodelle (MLLMs) trotz ihrer hervorragenden Leistung bei verschiedenen Aufgaben bei scheinbar einfachen Zeitableseaufgaben (wie dem Erkennen der Zeit auf Zeigeruhren und dem Verstehen von Kalenderdaten) eine besorgniserregend niedrige Genauigkeit aufweisen. Die Studie erstellte zwei benutzerdefinierte Testdatensätze, ClockQA und CalendarQA. Die Ergebnisse zeigten, dass KI-Systeme Uhren nur mit einer Genauigkeit von 38,7 % ablesen und Kalenderdaten nur mit einer Genauigkeit von 26,3 % bestimmen konnten. Selbst fortschrittliche Modelle wie Gemini-2.0 und GPT-o1 hatten deutliche Schwierigkeiten, insbesondere bei der Verarbeitung von römischen Ziffern, stilisierten Zeigern oder komplexen Datumsberechnungen (wie Schaltjahren oder der Bestimmung des Wochentags eines bestimmten Datums). Die Forscher glauben, dass dies die aktuellen Schwächen der Modelle im räumlichen Denken, der Analyse strukturierter Layouts und der Generalisierungsfähigkeit auf ungewöhnliche Muster aufdeckt. (Quelle: 36氪, WeChat)

Microsoft kündigt auf der Build-Konferenz die Aufnahme des Grok-Modells in Azure AI Foundry an: Auf der Microsoft Build 2025 Entwicklerkonferenz gab Microsoft bekannt, dass das Grok-Modell von xAI in seine Azure AI Foundry Modellreihe aufgenommen wird. Benutzer können Grok-3 und Grok-3-mini bis Anfang Juni kostenlos in Azure Foundry und auf GitHub testen. Dieser Schritt bedeutet, dass Azure AI Foundry sein Angebot an unterstützten Drittanbietermodellen weiter ausbauen wird. Zukünftig können Benutzer über einen einheitlichen reservierten Durchsatz Modelle von verschiedenen Anbietern wie OpenAI, xAI, DeepSeek, Meta, Mistral AI, Black Forest Labs und anderen nutzen. (Quelle: TheTuringPost, xai)
Apple plant Berichten zufolge, EU-iPhone-Nutzern den Wechsel von Siri zu Drittanbieter-Sprachassistenten zu ermöglichen: Laut Mark Gurman plant Apple erstmals, iPhone-Nutzern in der EU zu erlauben, Siri durch Sprachassistenten von Drittanbietern zu ersetzen. Dieser Schritt könnte eine Reaktion auf die zunehmend strengeren Regulierungsanforderungen für digitale Märkte in der EU sein und zielt darauf ab, die Offenheit der Plattform und die Wahlmöglichkeiten der Nutzer zu verbessern. Sollte dieser Plan umgesetzt werden, hätte dies erhebliche Auswirkungen auf die Marktlandschaft für Sprachassistenten und würde anderen Sprachassistenten die Möglichkeit eröffnen, in das Apple-Ökosystem einzutreten. (Quelle: zacharynado)

Meta veröffentlicht Open Molecules 2025 Datensatz und UMA-Modell zur Beschleunigung der Molekül- und Materialentdeckung: Meta AI hat Open Molecules 2025 (OMol25) und das Meta Universal Atomic Model (UMA) veröffentlicht. OMol25 ist der derzeit größte und vielfältigste Datensatz hochpräziser quantenchemischer Berechnungen, der Biomoleküle, Metallkomplexe und Elektrolyte umfasst. UMA ist ein auf über 30 Milliarden Atomen trainiertes Machine-Learning-Modell für interatomare Potentiale, das genauere Vorhersagen des Molekülverhaltens ermöglichen soll. Die Veröffentlichung dieser Werkzeuge als Open Source zielt darauf ab, die Entdeckung und Innovation in der Molekül- und Materialwissenschaft zu beschleunigen. (Quelle: AIatMeta)
Hugging Face Datasets fügt inkrementelle Bearbeitungsfunktion für Parquet-Dateien hinzu: Hugging Face Datasets gab bekannt, dass die Nightly-Version seiner zugrundeliegenden Abhängigkeitsbibliothek PyArrow nun die inkrementelle Bearbeitung von Parquet-Dateien unterstützt, ohne dass die Dateien vollständig neu geschrieben werden müssen. Diese neue Funktion wird die Effizienz bei der Bearbeitung großer Datensätze erheblich verbessern, insbesondere wenn häufig Teile der Daten aktualisiert oder geändert werden müssen, da Zeit- und Rechenressourcen deutlich reduziert werden können. Dieser Schritt soll die Erfahrung von Entwicklern bei der Verarbeitung und Wartung großer KI-Trainingsdatensätze verbessern. (Quelle: huggingface)
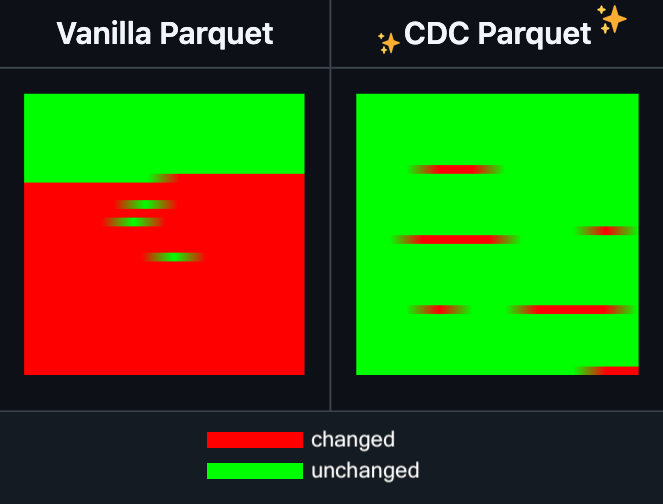
LangGraph fügt Knoten-Level-Caching-Funktion hinzu, um die Workflow-Effizienz zu steigern: LangGraph hat bekannt gegeben, dass seine Open-Source-Version eine neue Funktion für Knoten-/Task-Caching enthält. Diese Funktion zielt darauf ab, Workflows durch die Vermeidung doppelter Berechnungen zu beschleunigen, insbesondere bei Agent-Workflows, die gemeinsame Teile enthalten oder häufiges Debugging erfordern. Benutzer können das Caching in der imperativen API oder der grafischen API verwenden, um ihre KI-Anwendungen schneller zu iterieren und zu optimieren. Dies ist das erste einer Reihe von Updates, die LangGraph diese Woche im Rahmen seiner Open-Source-Veröffentlichungen vorstellt. (Quelle: hwchase17)

Sakana AI stellt neue KI-Architektur „Continuous Thought Machines“ (CTM) vor: Das Tokioter KI-Startup Sakana AI hat eine neue KI-Modellarchitektur namens „Continuous Thought Machines“ (CTM) vorgestellt. CTM zielt darauf ab, Modellen zu ermöglichen, ähnlich wie das menschliche Gehirn mit weniger Anleitung zu schlussfolgern. Diese neue Architektur könnte neue Ansätze zur Lösung der Herausforderungen bieten, denen sich aktuelle KI-Modelle bei komplexen Schlussfolgerungen und autonomem Lernen gegenübersehen. (Quelle: dl_weekly)
Microsoft und Nvidia vertiefen Zusammenarbeit bei RTX AI PCs, TensorRT kommt zu Windows ML: Während der Microsoft Build und der Computex in Taipeh kündigten Nvidia und Microsoft eine weitere Vertiefung ihrer Zusammenarbeit bei der Entwicklung von RTX AI PCs an. Nvidias TensorRT Inferenzoptimierungsbibliothek wurde neu gestaltet und in Microsofts neuen Inferenz-Stack Windows ML integriert. Dieser Schritt zielt darauf ab, den Entwicklungsprozess von KI-Anwendungen zu vereinfachen und die Spitzenleistung von RTX GPUs bei KI-Aufgaben auf PCs voll auszuschöpfen, um die Verbreitung und Anwendung von KI auf Personal-Computing-Geräten voranzutreiben. (Quelle: nvidia)
Bilibili veröffentlicht Open-Source-Animationsvideo-Generierungsmodell Index-AniSora, erreicht SOTA in mehreren Metriken: Bilibili hat die Open-Source-Veröffentlichung seines selbst entwickelten Animationsvideo-Generierungsmodells Index-AniSora bekannt gegeben, das auf der IJCAI 2025 vorgestellt wird. AniSora wurde speziell für die Generierung von Videos im Anime-Stil entwickelt und unterstützt verschiedene Stile wie japanische Anime-Serien, chinesische Animationen und Manga-Adaptionen. Es ermöglicht eine feingranulare Steuerung wie die Führung lokaler Videobereiche und die zeitliche Führung (z. B. Führung durch den ersten/letzten Frame, Keyframe-Interpolation). Das Open-Source-Projekt umfasst den Trainings- und Inferenzcode für AniSoraV1.0 basierend auf CogVideoX-5B und AniSoraV2.0 basierend auf Wan2.1-14B, Tools zum Erstellen von Trainingsdatensätzen, ein animationsspezifisches Benchmark-System und das durch Reinforcement Learning from Human Feedback optimierte Modell AniSoraV1.0_RL. (Quelle: WeChat)

Tencent Hunyuan veröffentlicht erstes multimodales einheitliches CoT-Belohnungsmodell UnifiedReward-Think als Open Source: Tencent Hunyuan hat in Zusammenarbeit mit dem Shanghai AI Lab, der Fudan University und anderen Institutionen UnifiedReward-Think vorgestellt, das erste einheitliche multimodale Belohnungsmodell mit Fähigkeiten zur langkettigen Schlussfolgerung (CoT). Dieses Modell zielt darauf ab, Belohnungsmodelle beim Bewerten komplexer visueller Generierungs- und Verständnisaufgaben „zum Denken zu bringen“, um die Bewertungsgenauigkeit, die Generalisierungsfähigkeit über Aufgaben hinweg und die Interpretierbarkeit von Schlussfolgerungen zu verbessern. Das Projekt wurde vollständig als Open Source veröffentlicht, einschließlich Modell, Datensätzen, Trainingsskripten und Bewertungstools. (Quelle: WeChat)
Alibaba veröffentlicht Open-Source-Videogenerierungs- und -bearbeitungsmodell Tongyi Wanxiang Wan2.1-VACE: Alibaba hat sein Videogenerierungs- und -bearbeitungsmodell Tongyi Wanxiang Wan2.1-VACE offiziell als Open Source veröffentlicht. Dieses Modell verfügt über verschiedene Funktionen wie Text-zu-Video-Generierung, bildreferenzierte Videogenerierung, Video-Neumalen, lokale Videobearbeitung, Video-Hintergrunderweiterung und Video-Längenverlängerung. Diesmal wurden zwei Versionen, 1.3B und 14B, als Open Source veröffentlicht, wobei die 1.3B-Version auf Consumer-Grafikkarten ausgeführt werden kann, um die Hürde für die Erstellung von AIGC-Videos zu senken. (Quelle: WeChat)
ByteDance veröffentlicht Vision-Language-Modell Seed1.5-VL, führend in mehreren Benchmarks: ByteDance hat das Vision-Language-Modell Seed1.5-VL entwickelt, das aus einem visuellen Encoder mit 532 Mio. Parametern und einem Mixture-of-Experts (MoE) LLM mit 20 Mrd. aktiven Parametern besteht. Trotz seiner relativ kompakten Architektur erreicht es in 38 von 60 öffentlichen Benchmarks SOTA-Leistung und übertrifft Modelle wie OpenAI CUA und Claude 3.7 bei agentenzentrierten Aufgaben wie GUI-Steuerung und Gameplay, was seine starke multimodale Inferenzfähigkeit demonstriert. (Quelle: WeChat)
MiniMax stellt autoregressives TTS-Modell MiniMax-Speech vor, unterstützt Zero-Shot-Stimmklonen in 32 Sprachen: MiniMax hat das auf Transformer basierende autoregressive Text-to-Speech (TTS)-Modell MiniMax-Speech vorgestellt. Dieses Modell kann Klangfarbenmerkmale aus Referenzaudio ohne Transkription extrahieren, um im Zero-Shot-Verfahren ausdrucksstarke Sprache zu generieren, die mit der Referenzklangfarbe übereinstimmt, und unterstützt Single-Shot-Stimmklonen. Durch die Flow-VAE-Technologie wurde die Qualität des synthetisierten Audios verbessert und es werden 32 Sprachen unterstützt. Das Modell erreicht SOTA-Niveau bei objektiven Stimmklon-Metriken, führt die öffentliche TTS Arena-Rangliste an und kann auch für Anwendungen wie Stimm-Emotionssteuerung, Text-zu-Sound und professionelles Stimmklonen erweitert werden. (Quelle: WeChat)
OuteTTS 1.0 (0.6B) veröffentlicht, Apache 2.0 Open-Source-TTS-Modell mit Unterstützung für 14 Sprachen: OuteAI hat OuteTTS-1.0-0.6B veröffentlicht, ein leichtgewichtiges Text-to-Speech (TTS)-Modell, das auf Qwen-3 0.6B basiert. Das Modell wird unter der Apache 2.0 Lizenz vertrieben und unterstützt 14 Sprachen, darunter Chinesisch, Englisch, Japanisch und Koreanisch. Die zugehörige Python-Inferenzbibliothek OuteTTS v0.4.2 wurde aktualisiert und unterstützt nun asynchrone Batch-Inferenz mit EXL2, experimentelle Batch-Inferenz mit vLLM sowie kontinuierliches Batching und externe URL-Modellinferenz für Llama.cpp-Server. Benchmarks auf einer einzelnen NVIDIA L40S GPU zeigen, dass vLLM OuteTTS-1.0-0.6B FP8 bei einer Batch-Größe von 32 einen RTF (Real-Time Factor) von 0,05 erreichen kann. Die Modellgewichte (ST, GGUF, EXL2, FP8) sind auf Hugging Face verfügbar. (Quelle: Reddit r/LocalLLaMA)

Hugging Face und Microsoft Azure vertiefen Zusammenarbeit, über 10.000 Open-Source-Modelle landen in Azure AI Foundry: Auf der Microsoft Build Konferenz kündigte CEO Satya Nadella eine erweiterte Zusammenarbeit mit Hugging Face an. Derzeit sind über 11.000 der beliebtesten Open-Source-Modelle über Hugging Face in Azure AI Foundry verfügbar, was den Benutzern eine einfache Bereitstellung ermöglicht. Dieser Schritt bereichert das KI-Ökosystem von Azure weiter und bietet Entwicklern mehr Modellauswahl und eine bequemere Entwicklungserfahrung. (Quelle: ClementDelangue, _akhaliq)

Intel veröffentlicht Arc Pro B50/B60 GPUs für KI- und Workstation-Markt, 24GB-Version für ca. 500 US-Dollar: Intel hat auf der Computex die neuen professionellen Grafikkarten der Arc Pro B-Serie vorgestellt, darunter die Arc Pro B50 (16 GB VRAM, ca. 299 US-Dollar) und die Arc Pro B60 (24 GB VRAM, ca. 500 US-Dollar). Auch eine Workstation-Lösung namens „Project Battlematrix“ mit zwei B60 GPUs und insgesamt 48 GB VRAM wurde vorgestellt, deren Preis voraussichtlich unter 1000 US-Dollar liegen wird. Diese Produkte zielen darauf ab, kostengünstige Lösungen für KI-Berechnungen und professionelle Workstations anzubieten, wobei insbesondere die hohe VRAM-Ausstattung für den lokalen Betrieb großer Sprachmodelle attraktiv ist. Die neuen Produkte werden voraussichtlich im dritten Quartal dieses Jahres auf den Markt kommen, zunächst über OEM-Hersteller, im vierten Quartal könnten DIY-Versionen folgen. (Quelle: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)

🧰 Tools
Moondream Station veröffentlicht Linux-Version, vereinfacht lokale Moondream-Ausführung: Moondream Station, ein Tool zur Vereinfachung der Ausführung von Moondream (einem Vision-Language-Modell) auf lokalen Geräten, hat nun Unterstützung für das Linux-Betriebssystem angekündigt. Dies bedeutet, dass Linux-Benutzer Moondream-Modelle bequemer für multimodale KI-Experimente und Anwendungsentwicklung bereitstellen und verwenden können. (Quelle: vikhyatk)
Flowith veröffentlicht unendlichen Agenten NEO, unterstützt unbegrenzte Schritte, Kontext und Tool-Aufrufe: Das KI-Anwendungsunternehmen Flowith hat sein neuestes Agentenprodukt NEO veröffentlicht, das als weltweit erster Agent mit Unterstützung für unbegrenzte Schritte, unbegrenzten Kontext und unbegrenzte Tool-Aufrufe angepriesen wird. Dieser Agent ist für den langfristigen Betrieb in der Cloud konzipiert, verfügt über eine Intelligenz, die Benchmarks übertrifft, und wird als kostenlos und unbegrenzt beworben. Diese Veröffentlichung könnte einen neuen Fortschritt bei KI-Agenten in Bezug auf die Bewältigung komplexer langfristiger Aufgaben und die Integration externer Fähigkeiten darstellen. (Quelle: _akhaliq, op7418)

Kapa AI nutzt Weaviate zum Aufbau eines interaktiven Frage-Antwort-Tools „Ask AI“ für technische Dokumentationen: Kapa AI hat ein intelligentes Widget namens „Ask AI“ entwickelt, das es Benutzern ermöglicht, durch natürlichsprachliche Dialoge technische Dokumentationen, Blogs, Tutorials, GitHub Issues und Foren – also die gesamte technische Wissensdatenbank – abzufragen. Um eine effiziente semantische Suche und Wissensabfrage zu realisieren, setzt Kapa AI auf die Weaviate Vektordatenbank und schätzt deren integrierte hybride Suchfunktionen, Docker-Kompatibilität und Mandantenfähigkeit, um das schnell wachsende Benutzer- und Datenvolumen zu unterstützen. (Quelle: bobvanluijt)

Entwickler nutzt Gemini Flash zum schnellen Erstellen eines MVP-Tools zur Umwandlung von Screenshots in HTML: Der Entwickler Daniel Huynh hat das Gemini Flash Modell von Google AI genutzt, um innerhalb eines Wochenendes ein MVP (Minimum Viable Product)-Tool zu erstellen, das Designentwürfe, Screenshots von Wettbewerbsprodukten oder Inspirationen schnell in HTML-Code umwandeln kann. Das Tool steht kostenlos zum Testen auf Hugging Face Spaces zur Verfügung und demonstriert das Potenzial multimodaler Modelle zur Unterstützung der Frontend-Entwicklung. (Quelle: osanseviero, _akhaliq)
Azure AI Foundry Agent Service offiziell verfügbar, integriert LlamaIndex: Microsoft hat bekannt gegeben, dass der Azure AI Foundry Agent Service nun offiziell verfügbar ist (GA) und erstklassige Unterstützung für LlamaIndex bietet. Der Dienst soll Unternehmenskunden dabei helfen, Kundensupport-Assistenten, Prozessautomatisierungsroboter, Multi-Agenten-Systeme sowie Lösungen zu erstellen, die sicher in Unternehmensdaten und -tools integriert sind, und so die Entwicklung und Anwendung von KI-Agenten auf Unternehmensebene weiter vorantreiben. (Quelle: jerryjliu0)
tinygrad: Ein minimalistisches Deep-Learning-Framework zwischen PyTorch und micrograd: tinygrad ist ein Deep-Learning-Framework, dessen Kernkonzept die Einfachheit ist. Es zielt darauf ab, das am einfachsten zu erweiternde Framework für neue Beschleuniger zu sein und unterstützt Inferenz und Training. Es unterstützt Modelle wie LLaMA und Stable Diffusion und verwendet Lazy Evaluation, um Operationen zu fusionieren und die Leistung zu optimieren. tinygrad unterstützt verschiedene Beschleuniger wie GPU (OpenCL), CPU (C-Code), LLVM, Metal, CUDA. Sein Code ist prägnant, die Kernfunktionen werden mit wenig Code implementiert, was Entwicklern das Verständnis und die Erweiterung erleichtert. (Quelle: GitHub Trending)
Nano AI Search führt „Super Search“-Funktion ein, integriert mehrere Modelle und MCP-Toolbox: Nano AI Search (bot.n.cn) hat eine „Super Search“-Funktion hinzugefügt, die tiefere Informationsbeschaffung und -verarbeitungsfähigkeiten bieten soll. Diese Funktion integriert Hunderte von großen Modellen aus dem In- und Ausland und kann bei Bedarf automatisch wechseln; sie enthält die MCP Universal Toolbox, die Tausende von KI-Tools unterstützt, verschiedene Dateiformate wie Webseiten, Bilder, Videos, PDFs verarbeiten und Code generieren, Daten analysieren usw. kann. Gleichzeitig kombiniert sie die öffentliche Suche mit der privaten Suche in lokalen Wissensdatenbanken, um umfassendere Ergebnisse zu liefern, und verfügt über integrierte Text-zu-Bild- und Text-zu-Video-Funktionen. Benutzererfahrungen zeigen, dass diese Funktion Suchergebnisse in detaillierte Berichte mit Diagrammen und ansprechende Webseiten umwandeln kann, die für Branchenforschung, Preisvergleiche beim Einkaufen, Wissensstrukturierung und andere Szenarien geeignet sind. (Quelle: WeChat)
Clara: Modularer Offline-KI-Arbeitsbereich, integriert LLM, Agenten, Automatisierung und Bildgenerierung: Entwickler haben ein Open-Source-Projekt namens Clara vorgestellt, das darauf abzielt, einen vollständig offline funktionierenden, modularen KI-Arbeitsbereich zu schaffen. Benutzer können auf einem Dashboard lokale LLM-Chats als Widgets organisieren (unterstützt RAG, Bilder, Dokumente, Codeausführung, kompatibel mit Ollama und OpenAI-ähnlichen APIs), Agenten mit Gedächtnis und Logik erstellen, Automatisierungsprozesse über die native N8N-Integration ausführen (bietet über 1000 kostenlose Vorlagen) und lokal Bilder mit Stable Diffusion (ComfyUI) generieren. Clara ist für Mac, Windows und Linux verfügbar und zielt darauf ab, das Problem des häufigen Wechsels zwischen mehreren KI-Tools zu lösen und eine zentrale KI-Bedienung zu ermöglichen. (Quelle: Reddit r/LocalLLaMA)
AI Playlist Curator: Python-Tool zur personalisierten Organisation von YouTube-Playlists mit LLMs: Ein Entwickler hat ein Python-Projekt namens AI Playlist Curator erstellt, das Benutzern helfen soll, ihre umfangreichen und ungeordneten YouTube-Playlists automatisch zu organisieren. Das Tool nutzt LLMs, um Songs nach Benutzerpräferenzen zu kategorisieren und personalisierte Unter-Playlists zu erstellen. Es unterstützt die Verarbeitung aller gespeicherten Playlists und Lieblingslieder. Das Projekt ist auf GitHub als Open Source verfügbar, und der Entwickler hofft auf Community-Feedback zur weiteren Verbesserung. (Quelle: Reddit r/MachineLearning)
OpenAI Codex Programmierassistent landet in der ChatGPT iOS App: OpenAI hat angekündigt, dass sein Programmierassistent Codex nun in die iOS-Anwendung von ChatGPT integriert ist. Benutzer können auf mobilen Geräten neue Programmieraufgaben starten, Code-Unterschiede anzeigen, Änderungen anfordern und sogar Pull-Requests (PRs) pushen. Die Funktion unterstützt auch die Verfolgung des Fortschritts von Codex über Live-Aktivitäten auf dem Sperrbildschirm, was den Benutzern einen nahtlosen Wechsel der Arbeit zwischen verschiedenen Geräten ermöglicht. (Quelle: openai)
Kollektiv: Tool zur Lösung des Problems des wiederholten Einfügens von Kontext in LLM-Chats mithilfe des MCP-Protokolls: Entwickler haben das Tool Kollektiv vorgestellt, das darauf abzielt, das Problem zu lösen, dass Benutzer beim Chatten mit LLMs (wie Claude) große Mengen an Kontext (z. B. Forschungsarbeiten, SDK-Dokumentationen, persönliche Notizen, Buchinhalte) wiederholt kopieren und einfügen müssen. Kollektiv ermöglicht es Benutzern, diese Dokumentquellen einmalig hochzuladen und sie über einen MCP (Model Control Protocol)-Server von jeder kompatiblen IDE oder jedem MCP-Client (wie Cursor, Windsurf, PyCharm usw.) bei Bedarf abzurufen. Der MCP-Server ist für die Benutzerauthentifizierung, Datenisolierung und das bedarfsgesteuerte Streaming von Daten an die Chat-Oberfläche verantwortlich. Das Tool wird derzeit nicht für sensible oder vertrauliche Materialien empfohlen. (Quelle: Reddit r/ClaudeAI)
📚 Lernen
Google DeepMind veröffentlicht technischen Bericht zu AlphaEvolve und enthüllt dessen Fähigkeiten zur Algorithmenentdeckung: Google DeepMind hat einen technischen Bericht über sein KI-System AlphaEvolve veröffentlicht. AlphaEvolve ist ein auf Gemini basierender Codierungsagent, der durch evolutionäre Algorithmen Algorithmen entwerfen und optimieren kann. Der Bericht beschreibt detailliert, wie AlphaEvolve durch strukturierte Feedbackschleifen autonom Kandidatenalgorithmen generiert, bewertet und verbessert und so Durchbrüche bei mehreren mathematischen und computerwissenschaftlichen Problemen erzielt, einschließlich der Verbesserung des Rekords für den Algorithmus zur Multiplikation von 4×4 komplexen Matrizen. Der Bericht liefert wichtige Referenzen zum Verständnis des Potenzials von KI bei der automatisierten wissenschaftlichen Entdeckung und Algorithmusinnovation. (Quelle: , HuggingFace Daily Papers)
DeepLearning.AI startet Kurs „Building AI Browser Agents“: DeepLearning.AI hat einen neuen Kurs mit dem Titel „Building AI Browser Agents“ gestartet. Der Kurs wird von Div Garg und Naman Agarwal, Mitbegründern von AGI Inc., unterrichtet und zielt darauf ab, Lernenden die Techniken zum Erstellen von KI-Agenten zu vermitteln, die mit Browsern interagieren können. Die Kursinhalte umfassen möglicherweise Web-Automatisierung, Informationsextraktion, Interaktion mit Benutzeroberflächen und andere Anwendungen von KI in Browser-Umgebungen. (Quelle: DeepLearningAI)
Technischer Bericht zu Qwen3 veröffentlicht: Alibaba hat den technischen Bericht zu seiner neuesten Generation großer Sprachmodelle, Qwen3, veröffentlicht. Der Bericht beschreibt detailliert die Modellarchitektur, Trainingsmethoden, Leistungsevaluierung und Ergebnisse in verschiedenen Benchmarks von Qwen3. Die Qwen3-Modellreihe zielt darauf ab, stärkere Fähigkeiten in Sprachverständnis, -generierung und multimodaler Verarbeitung zu bieten. Die Veröffentlichung des technischen Berichts bietet Forschern und Entwicklern die Möglichkeit, die technischen Details dieses Modells eingehend zu verstehen. (Quelle: _akhaliq)

Paper-Diskussion: Multi-View-Suche und Datenmanagement verbessern schrittweises Theorembeweisen (MPS-Prover): Ein neues Paper stellt MPS-Prover vor, ein neuartiges System für schrittweises automatisiertes Theorembeweisen (ATP). Dieses System überwindet das Problem der voreingenommenen Suchführung in bestehenden schrittweisen Beweisern durch eine effiziente Post-Training-Datenmanagementstrategie (Eliminierung von ca. 40 % redundanter Daten ohne Leistungseinbußen) und einen Multi-View-Tree-Search-Mechanismus (Integration eines gelernten Kritikermodells mit heuristischen Regeln). Experimente zeigen, dass MPS-Prover auf mehreren Benchmarks wie miniF2F und ProofNet SOTA-Leistung erzielt und kürzere, vielfältigere Beweise generiert. (Quelle: HuggingFace Daily Papers)
Paper-Diskussion: Visuelle Planung – Denken nur mit Bildern (Visual Planning): Ein neues Paper schlägt das Paradigma der „visuellen Planung“ vor, das es Modellen ermöglicht, vollständig durch visuelle Repräsentationen (Bildsequenzen) zu planen, anstatt sich auf Text zu verlassen. Die Forscher argumentieren, dass Sprache bei Aufgaben, die räumliche und geometrische Informationen beinhalten, möglicherweise nicht das natürlichste Medium für Schlussfolgerungen ist. Sie führen das visuelle Planungsframework VPRL durch Reinforcement Learning ein und verwenden GRPO zur Post-Training-Optimierung großer visueller Modelle. Bei visuellen Navigationsaufgaben wie FrozenLake, Maze und MiniBehavior wurden signifikante Verbesserungen erzielt, die rein textbasierte Planungs-Varianten übertreffen. (Quelle: HuggingFace Daily Papers)
Paper-Diskussion: Skalierung von Schlussfolgerungen kann die Faktizität großer Sprachmodelle verbessern (Scaling Reasoning can Improve Factuality): Eine Studie untersucht, ob die Skalierung des Inferenzprozesses großer Sprachmodelle (LLMs) deren faktische Genauigkeit bei komplexen Open-Domain-Frage-Antwort-Aufgaben (QA) verbessern kann. Die Forscher extrahierten Inferenzpfade aus Modellen wie QwQ-32B und DeepSeek-R1-671B und führten Feinabstimmungen an verschiedenen Modellen der Qwen2.5-Serie durch, wobei sie auch Wissensgraph-Pfade in die Inferenzpfade integrierten. Experimente zeigten, dass kleinere Inferenzmodelle in einem einzigen Durchlauf eine deutlich höhere faktische Genauigkeit aufwiesen als die ursprünglichen, mit Instruktionen feinabgestimmten Modelle. Durch Erhöhung der Testzeitberechnung und des Token-Budgets konnte die faktische Genauigkeit stabil um 2-8 % gesteigert werden. (Quelle: HuggingFace Daily Papers)
Paper-Diskussion: Mergenetic – eine einfache Bibliothek für evolutionäre Modellfusion: Ein neues Paper stellt Mergenetic vor, eine Open-Source-Bibliothek für die evolutionäre Modellfusion. Modellfusion ermöglicht die Kombination der Fähigkeiten bestehender Modelle zu neuen Modellen, ohne zusätzliches Training. Mergenetic unterstützt die einfache Kombination von Fusionsmethoden und evolutionären Algorithmen und integriert leichtgewichtige Fitness-Evaluatoren, um die Evaluierungskosten zu senken. Experimente zeigen, dass Mergenetic mit moderater Hardware wettbewerbsfähige Ergebnisse bei verschiedenen Aufgaben und Sprachen erzielen kann. (Quelle: HuggingFace Daily Papers)
Paper-Diskussion: Gruppendenken – Mehrere nebenläufige Inferenzagenten arbeiten auf Token-Ebene zusammen (Group Think): Ein neues Paper schlägt „Group Think“ vor – ein einzelnes LLM agiert als mehrere nebenläufige Inferenzagenten (Denker). Diese Agenten teilen die Sichtbarkeit des teilweise generierten Fortschritts der anderen und passen ihre Inferenzpfade dynamisch auf Token-Ebene aneinander an, wodurch redundante Inferenzen reduziert, die Qualität verbessert und die Latenz verringert wird. Die Methode eignet sich für Edge-Inferenz auf lokalen GPUs, und Experimente zeigen, dass sie die Latenz auch bei Verwendung von nicht speziell trainierten Open-Source-LLMs verbessert. (Quelle: HuggingFace Daily Papers)
Paper-Diskussion: Menschen erwarten Rationalität und Kooperation von LLM-Gegnern in Strategiespielen (Humans expect rationality and cooperation from LLM opponents): Eine erstmalige kontrollierte, monetär incentivierte Laborstudie untersuchte Verhaltensunterschiede von Menschen in P-Beauty-Wettbewerben mit mehreren Spielern, wenn sie gegen andere Menschen oder gegen LLMs antreten. Die Ergebnisse zeigen, dass Menschen, die gegen LLMs spielen, signifikant niedrigere Zahlen wählen, hauptsächlich aufgrund der zunehmenden Prävalenz der „Null“-Nash-Gleichgewichtswahl. Dieser Wandel wird hauptsächlich von Probanden mit hohen strategischen Denkfähigkeiten vorangetrieben, die LLMs stärkere Denkfähigkeiten und eine höhere Kooperationsbereitschaft zuschreiben. (Quelle: HuggingFace Daily Papers)
Paper-Diskussion: Einfache semi-überwachte Wissensdestillation von Vision-Language-Modellen durch Dual-Head-Optimierung (Dual-Head Optimization for KD): Ein neues Paper stellt DHO (Dual-Head Optimization) vor, ein einfaches und effektives Framework für Wissensdestillation (KD), um Wissen von Vision-Language-Modellen (VLMs) in kompakte, aufgabenspezifische Modelle in einem semi-überwachten Setting zu übertragen. DHO führt zwei separate Vorhersageköpfe ein, die unabhängig voneinander markierte Daten und Lehrer-Vorhersagen lernen, und kombiniert deren Ausgaben bei der Inferenz linear. Dadurch werden Gradientenkonflikte zwischen dem Überwachungssignal und dem Destillationssignal gemildert. Experimente zeigen, dass DHO auf mehreren Domänen und feingranularen Datensätzen besser abschneidet als Single-Head-KD-Baselines und auf ImageNet SOTA erreicht. (Quelle: HuggingFace Daily Papers)
Paper-Diskussion: GuardReasoner-VL – Schutz von VLMs durch verstärktes Schlussfolgern: Um die Sicherheit von Vision-Language-Modellen (VLMs) zu erhöhen, stellt ein neues Paper das auf Schlussfolgerungen basierende VLM-Schutzmodell GuardReasoner-VL vor. Die Kernidee besteht darin, das Schutzmodell durch Online-Reinforcement-Learning (RL) zu motivieren, vor einer Moderationsentscheidung sorgfältig zu schlussfolgern. Die Forscher erstellten einen Inferenzkorpus GuardReasoner-VLTrain mit 123K Samples und 631K Inferenzschritten, initialisierten die Inferenzfähigkeit des Modells durch überwachtes Fine-Tuning (SFT) und verstärkten sie dann weiter durch Online-RL. Experimente zeigen, dass dieses Modell (3B/7B-Versionen sind Open Source) eine überlegene Leistung aufweist und den zweitbesten Modellen im durchschnittlichen F1-Score um 19,27 % überlegen ist. (Quelle: HuggingFace Daily Papers)
Paper-Diskussion: Multi-Token-Vorhersage benötigt Register (Multi-Token Prediction Needs Registers): Ein neues Paper stellt MuToR vor, eine einfache und effektive Methode zur Multi-Token-Vorhersage, die durch das Einfügen von lernbaren Register-Token in die Eingabesequenz zukünftige Ziele vorhersagt. Im Vergleich zu bestehenden Methoden hat MuToR einen vernachlässigbaren Parameterzuwachs, erfordert keine Architekturänderungen, ist mit bestehenden vortrainierten Modellen kompatibel und bleibt konsistent mit dem Next-Token-Pretraining-Ziel, was es besonders geeignet für überwachtes Fine-Tuning macht. Die Methode zeigt Effektivität und Universalität bei generativen Aufgaben im Sprach- und visuellen Bereich. (Quelle: HuggingFace Daily Papers)
Paper-Diskussion: MMLongBench – Effektiver und gründlicher Benchmark für Long-Context Vision-Language-Modelle: Um den Evaluierungsanforderungen von Long-Context Vision-Language-Modellen (LCVLMs) gerecht zu werden, stellt ein neues Paper MMLongBench vor, den ersten Benchmark, der eine Vielzahl von Long-Context Vision-Language-Aufgaben abdeckt. MMLongBench enthält 13331 Samples, die fünf Aufgabenkategorien wie visuelles RAG, Multi-Shot ICL usw. umfassen und verschiedene Bildtypen bereitstellen. Alle Samples werden in fünf standardisierten Eingabelängen von 8K-128K Tokens angeboten. Durch Benchmarking von 46 Closed-Source- und Open-Source-LCVLMs stellten die Forscher fest, dass die Leistung bei einer einzelnen Aufgabe nicht repräsentativ für die gesamte Long-Context-Fähigkeit ist, aktuelle Modelle noch viel Verbesserungspotenzial haben und Modelle mit starken Inferenzfähigkeiten tendenziell eine bessere Long-Context-Leistung aufweisen. (Quelle: HuggingFace Daily Papers)
Paper-Diskussion: MatTools – Ein Benchmark für große Sprachmodelle für materialwissenschaftliche Werkzeuge: Ein neues Paper stellt den MatTools-Benchmark vor, um die Fähigkeit großer Sprachmodelle (LLMs) zu bewerten, materialwissenschaftliche Fragen durch Generierung und sichere Ausführung von Code für physikbasierte computergestützte materialwissenschaftliche Softwarepakete zu beantworten. MatTools umfasst einen Frage-Antwort-Benchmark (QA) für Materialsimulationswerkzeuge (basierend auf pymatgen, mit 69225 QA-Paaren) und einen Benchmark für die reale Werkzeugnutzung (mit 49 Aufgaben, 138 Teilaufgaben). Die Bewertung verschiedener LLMs ergab: Allgemeine Modelle übertreffen spezialisierte Modelle; KI versteht KI besser; einfache Methoden sind effektiver. (Quelle: HuggingFace Daily Papers)
Paper-Diskussion: Ein universelles symbiotisches Wasserzeichen-Framework, das Robustheit, Textqualität und Sicherheit von LLM-Wasserzeichen ausbalanciert: Angesichts der Kompromisse zwischen Robustheit, Textqualität und Sicherheit bei bestehenden Wasserzeichenschemata für große Sprachmodelle (LLMs) schlägt ein neues Paper ein universelles symbiotisches Wasserzeichen-Framework vor. Dieses Framework integriert Logit-basierte und Sampling-basierte Methoden und entwirft drei Strategien: seriell, parallel und gemischt. Das gemischte Framework nutzt Token-Entropie und semantische Entropie, um Wasserzeichen adaptiv einzubetten und so die Leistung in allen Aspekten zu optimieren. Experimente zeigen, dass diese Methode bestehende Baselines übertrifft und SOTA-Niveau erreicht. (Quelle: HuggingFace Daily Papers)
Paper-Diskussion: CheXGenBench – Einheitlicher Benchmark für Wiedergabetreue, Datenschutz und Nutzen synthetischer Thorax-Röntgenbilder: Ein neues Paper stellt CheXGenBench vor, ein facettenreiches Framework zur Bewertung der Generierung synthetischer Thorax-Röntgenbilder, das gleichzeitig Wiedergabetreue, Datenschutzrisiken und klinischen Nutzen bewertet. Das Framework umfasst standardisierte Datenpartitionen und ein einheitliches Bewertungsprotokoll (über 20 quantitative Metriken) und analysiert die Generierungsqualität, potenzielle Datenschutzlücken und die nachgelagerte klinische Anwendbarkeit von 11 führenden Text-zu-Bild-Architekturen. Die Studie ergab, dass bestehende Bewertungsprotokolle bei der Bewertung der Generierungstreue Mängel aufweisen. Das Team veröffentlichte gleichzeitig den hochwertigen synthetischen Datensatz SynthCheX-75K. (Quelle: HuggingFace Daily Papers)
Peter Lax, Autor des klassischen Lehrbuchs „Funktionalanalysis“, im Alter von 99 Jahren verstorben: Der Gigant der angewandten Mathematik und erste mit dem Abelpreis ausgezeichnete angewandte Mathematiker Peter Lax ist im Alter von 99 Jahren verstorben. Lax war bekannt für sein klassisches Lehrbuch „Funktionalanalysis“ und leistete grundlegende Beiträge in Bereichen wie partiellen Differentialgleichungen, Strömungsmechanik und numerischer Berechnung, wie das Lax-Äquivalenztheorem und die Lax-Friedrichs- und Lax-Wendroff-Methoden. Er war auch einer der ersten Pioniere, die Computertechnologie in der mathematischen Analyse einsetzten, und seine Arbeit beeinflusste die Entwicklung der Mathematik im Computerzeitalter tiefgreifend. (Quelle: 量子位)

Ehemalige OpenAI VP Lilian Weng erörtert in langem Artikel „Why We Think“ Test-Time Compute und Chain-of-Thought: Die ehemalige chinesischstämmige Vizepräsidentin von OpenAI, Lilian Weng, veröffentlichte einen langen Artikel mit dem Titel „Why We Think“, in dem sie eingehend erörtert, wie Technologien wie „Test-Time Compute“ und „Chain-of-Thought (CoT)“ die Leistung und Intelligenz großer Sprachmodelle signifikant verbessern. Der Artikel zieht eine Analogie zur „Thinking, Fast and Slow“-Zwei-System-Theorie des menschlichen Denkens und weist darauf hin, dass Modelle, die vor der Ausgabe mehr „denken“ (z. B. durch intelligente Dekodierung, CoT-Inferenz, latente Variablenmodellierung), aktuelle Fähigkeitsengpässe überwinden können. Der Artikel fasst detailliert die Fortschritte und Herausforderungen in mehreren Forschungsrichtungen zusammen, darunter Token-basiertes Denken, paralleles Sampling und sequentielle Revision, Reinforcement Learning und Integration externer Werkzeuge, Denktreue und kontinuierliches räumliches Denken. (Quelle: 量子位)

Harbin Institute of Technology und University of Pennsylvania stellen gemeinsam PointKAN vor, neues SOTA für Punktwolkenanalyse basierend auf KANs: Forscherteams des Harbin Institute of Technology (Shenzhen) und der University of Pennsylvania haben PointKAN vorgestellt, eine Lösung für die 3D-Punktwolkenanalyse basierend auf Kolmogorov-Arnold Networks (KANs). Diese Methode nutzt geometrische affine Module und parallele lokale Merkmalsextraktionsmodule und ersetzt die festen Aktivierungsfunktionen in traditionellen MLPs durch lernbare Aktivierungsfunktionen, um komplexe geometrische Merkmale von Punktwolken effektiver zu erfassen. Gleichzeitig schlug das Team die Efficient-KANs-Struktur vor, die B-Spline-Funktionen durch rationale Funktionen ersetzt und Parameter innerhalb von Gruppen teilt, wodurch die Anzahl der Parameter und der Rechenaufwand erheblich reduziert werden. Experimente zeigen, dass PointKAN und seine leichtgewichtige Version PointKAN-elite bei Aufgaben wie Klassifizierung, Teilsegmentierung und Few-Shot-Learning SOTA- oder wettbewerbsfähige Leistungen erzielen. (Quelle: WeChat)

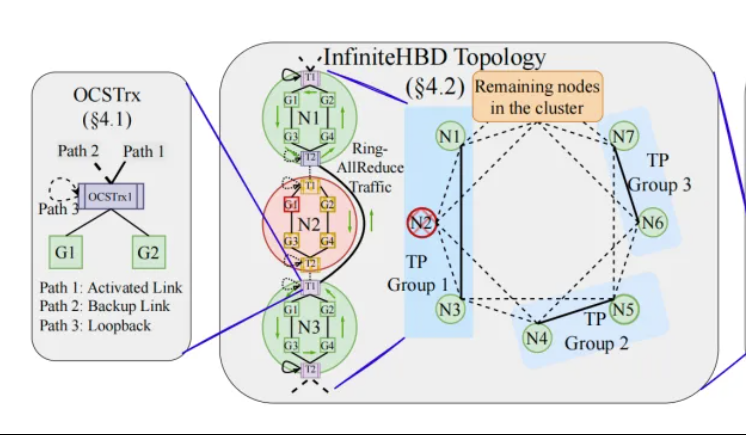
Peking University/StepFun/Xizhi schlagen InfiniteHBD vor: GPU-Interconnect-Architektur der nächsten Generation mit hoher Bandbreite zur Senkung der Trainingskosten für große Modelle: Forscherteams der Peking University, StepFun (阶跃星辰) und Xizhi Technology (曦智科技) haben als Reaktion auf die Einschränkungen aktueller Architekturen mit hoher Bandbreite (HBD) im verteilten Training großer Modelle die InfiniteHBD-Lösung vorgeschlagen. Diese Architektur basiert auf optoelektronischen Konversionsmodulen mit integrierter Optical Circuit Switching (OCS)-Fähigkeit und realisiert dynamisch rekonfigurierbare Punkt-zu-Mehrpunkt-Verbindungen mit Fehlerisolierung auf Knotenebene und geringer Ressourcenfragmentierung. Studien zeigen, dass die Stückkosten von InfiniteHBD nur 31 % von NVIDIAs NVL-72 betragen, die GPU-Verschwendungsrate nahe Null liegt und die MFU (Model FLOPs Utilization) im Vergleich zu NVIDIA DGX um bis zu das 3,37-fache gesteigert werden kann. Diese Forschung wurde von SIGCOMM 2025 angenommen. (Quelle: WeChat, 量子位)
ICML 2025 Paper-Vorschau: OmniAudio generiert räumliches Audio aus 360°-Videos: Eine auf der ICML 2025 vorgestellte Studie präsentiert das OmniAudio-Framework, das direkt aus 360°-Panoramavideos räumliches Audio mit Richtungsinformationen (First-Order Ambisonics, FOA) generieren kann. Die Studie erstellte zunächst den umfangreichen Datensatz Sphere360 mit gepaarten 360°-Videos und räumlichem Audio. OmniAudio verwendet ein zweistufiges Training: Zuerst erfolgt ein selbstüberwachtes Pre-Training mit von grob zu fein abgestimmtem Flow-Matching, bei dem unter Verwendung umfangreicher nicht-räumlicher Audiodaten allgemeine Audiomerkmale gelernt werden; anschließend erfolgt ein überwachtes Fine-Tuning in Kombination mit einem zweistufigen Video-Encoder (der globale und lokale visuelle Merkmale extrahiert). Experimentelle Ergebnisse zeigen, dass OmniAudio sowohl bei objektiven als auch bei subjektiven Bewertungsmetriken signifikant besser abschneidet als bestehende Basismodelle. (Quelle: WeChat)

Huawei Selftok: Autoregressiver visueller Tokenizer basierend auf reverser Diffusion, vereinheitlicht multimodale Generierung: Das Huawei Pangu Multimodal Generation Team hat die Selftok-Technologie vorgestellt, eine innovative Lösung zur visuellen Tokenisierung. Durch einen reversen Diffusionsprozess werden autoregressive Priors in visuelle Token integriert, wodurch Pixelströme in diskrete Sequenzen umgewandelt werden, die strikt dem Kausalitätsprinzip folgen. Ziel ist es, das Problem zu lösen, dass bestehende räumliche Token-Lösungen mit dem autoregressiven (AR) Paradigma kollidieren. Der Selftok Tokenizer verwendet einen Dual-Stream-Encoder (Bildzweig erbt SD3 VAE, Textzweig ist eine lernbare kontinuierliche Vektorgruppe) und einen Quantisierer mit Reaktivierungsmechanismus. Experimente zeigen, dass Selftok bei ImageNet-Rekonstruktionsmetriken SOTA erreicht und das auf Ascend AI und dem MindSpeed-Framework trainierte Selftok dAR-VLM bei Text-zu-Bild-Benchmarks wie GenEval GPT-4o übertrifft. Diese Arbeit wurde als Kandidat für das beste Paper der CVPR 2025 ausgewählt. (Quelle: WeChat)
Team um Yan Shuicheng veröffentlicht General-Level-Evaluierungsframework und General-Bench-Benchmark zur Klassifizierung multimodaler Generalistenmodelle: Unter der Leitung von Professor Yan Shuicheng von der National University of Singapore, Professor Zhang Hanwang von der Nanyang Technological University und anderen haben zehn Spitzenuniversitäten gemeinsam das Evaluierungsframework General-Level und den umfangreichen Benchmark-Datensatz General-Bench für multimodale Generalistenmodelle veröffentlicht. Dieses Framework orientiert sich an der Klassifizierung im autonomen Fahren und legt fünf Stufen (Level 1-5) fest, um die Universalität und Leistung multimodaler großer Sprachmodelle (MLLMs) zu bewerten. Das Kernbewertungskriterium ist der „Synergie-Generalisierungseffekt“ (Synergy), der den Wissenstransfer und die Fähigkeitssteigerung des Modells zwischen Aufgaben, zwischen Verständnis- und Generierungsparadigmen sowie über Modalitäten hinweg untersucht. General-Bench umfasst über 700 Aufgaben und 320.000 Samples. Die Bewertung von über 100 bestehenden MLLMs zeigt, dass die meisten Modelle auf L2-L3-Niveau liegen und noch kein Modell L5 erreicht hat. (Quelle: WeChat)

💼 Wirtschaft
Sakana AI und Mitsubishi UFJ Financial Group (MUFG) gehen mehrjährige Partnerschaft ein: Das japanische KI-Startup Sakana AI gab eine mehrjährige, umfassende Partnerschaftsvereinbarung mit der größten japanischen Bank, MUFG Bank, bekannt. Sakana AI wird der MUFG Bank agile und leistungsstarke KI-Technologien zur Verfügung stellen, um die hundertjährige Bank im sich schnell entwickelnden KI-Bereich wettbewerbsfähig zu halten. Es wird erwartet, dass diese Zusammenarbeit Sakana AI helfen wird, innerhalb eines Jahres profitabel zu werden. (Quelle: SakanaAILabs, SakanaAILabs)

Cohere und Dell kooperieren, um die sichere Agentenplattform Cohere North in Dells lokale Unternehmens-KI-Lösungen zu integrieren: Das KI-Unternehmen Cohere gab eine Zusammenarbeit mit Dell Technologies bekannt, um die Entwicklung sicherer, agentenfähiger Unternehmens-KI-Lösungen zu beschleunigen. Dell wird der erste Anbieter sein, der Unternehmen die sichere Agentenplattform Cohere North als lokale (On-Premises) Bereitstellungslösung anbietet. Diese Zusammenarbeit ist besonders wichtig für Branchen, die mit sensiblen Daten arbeiten und strenge Compliance-Anforderungen haben, da sie es Unternehmen ermöglicht, die fortschrittliche KI-Agententechnologie von Cohere in ihren eigenen Rechenzentren bereitzustellen und zu betreiben. (Quelle: sarahookr)

Mistral AI kooperiert mit MGX und Bpifrance zum Bau des größten KI-Campus Europas in Frankreich: Mistral AI kündigte eine Zusammenarbeit mit der von Abu Dhabi unterstützten Technologie-Investmentgesellschaft MGX und der französischen Staatsinvestitionsbank Bpifrance an, um gemeinsam den größten KI-Campus Europas in der Region Paris zu errichten. Der Campus wird Rechenzentren, Hochleistungsrechnerressourcen sowie Bildungs- und Forschungseinrichtungen integrieren. Nvidia wird ebenfalls beteiligt sein und technische Unterstützung leisten. Dieser Schritt zielt darauf ab, die Entwicklung des europäischen KI-Ökosystems voranzutreiben und die strategische Position Frankreichs im globalen KI-Bereich zu stärken. (Quelle: arthurmensch, arthurmensch)
🌟 Community
ADHS-Prävalenz unter KI-Fachleuten erregt Aufmerksamkeit, möglicherweise über 20-30 %: In sozialen Medien wird über die Prävalenz der Aufmerksamkeitsdefizit-/Hyperaktivitätsstörung (ADHS) unter Fachleuten im KI-Bereich diskutiert. Ein Nutzer bemerkte, dass dieser Bereich viele Talente mit neurodiversen Merkmalen anzuziehen scheint. Minh Nhat Nguyen kommentierte, dass möglicherweise über 20-30 % der Menschen in der KI-Branche ADHS haben. Dieses Phänomen könnte mit den Anforderungen der KI-Forschung und -Entwicklung an hohe Konzentration, schnelle Iteration und kreatives Denken zusammenhängen, Eigenschaften, die manchmal mit bestimmten Manifestationen von ADHS übereinstimmen. (Quelle: Dorialexander)
Kompetenzabwertung im KI-Zeitalter regt zum Nachdenken an, Systemumgestaltung statt Werkzeugbeherrschung ist entscheidend: Ein tiefgehender Analyseartikel weist darauf hin, dass die wahre Krise im KI-Zeitalter nicht darin besteht, „ob man KI-Werkzeuge bedienen kann“, sondern in der Abwertung von Kompetenzen selbst und der Umgestaltung des gesamten Arbeitssystems. Der Artikel argumentiert anhand von Beispielen wie der Maginot-Linie, der Containerisierung und der Verdrängung von Schreibkräften durch Textverarbeitungsprogramme, dass das bloße Erlernen neuer Werkzeuge keinen Vorsprung garantiert. Entscheidend sei das Verständnis, wie KI die Struktur, Prozesse und Organisationslogik der Arbeit verändert. Wenn das System neu geschrieben wird, können ehemals hochwertige Kompetenzen schnell an den Rand gedrängt werden. Produktivitätssteigerungen führen nicht zwangsläufig zu einer Wertsteigerung des Einzelnen, da der Wert an die Akteure fließt, die die neue Systemkoordinationsebene kontrollieren. Der Artikel widerlegt acht populäre Irrtümer wie „Wer KI lernt, hat die Nase vorn“, „KI lässt mich mehr arbeiten, also bin ich wertvoller“ und „Arbeitsplätze bleiben gleich, nur die Art und Weise ändert sich“ und betont die Notwendigkeit, die eigene Position und den eigenen Wert auf Systemebene zu überdenken. (Quelle: 36氪)
Ehemaliger Google-CEO Schmidt: Aufstieg nicht-menschlicher Intelligenz wird globale Landschaft neu gestalten, Vorsicht vor KI-Risiken und -Herausforderungen geboten: Der ehemalige Google-CEO Eric Schmidt warnte in einem Interview, dass die Gesellschaft das disruptive Potenzial „nicht-menschlicher Intelligenz“ stark unterschätzt. Er ist der Ansicht, dass KI von der Sprachgenerierung zur strategischen Entscheidungsfindung übergegangen ist und komplexe Aufgaben selbstständig erledigen kann. Schmidt betonte drei Kernherausforderungen durch KI: Energie- und Rechenleistungsengpässe (die USA benötigen zusätzlich 90 Gigawatt Strom), die nahezu erschöpften öffentlichen Daten (die nächste Phase erfordert KI-generierte Daten) und wie KI über das bestehende menschliche Wissen hinaus „neues Wissen“ schaffen kann. Er wies auch auf drei Hauptrisiken hin: unkontrollierte rekursive Selbstverbesserung der KI, Erlangung der Waffenkontrolle und unbefugte Selbstreplikation. Angesichts des verschärften KI-Wettbewerbs zwischen China und den USA könnte die schnelle Verbreitung von Open-Source-KI Sicherheitsrisiken bergen und sogar zu einer „Erstschlag“-Situation ähnlich der „nuklearen Abschreckung“ führen. Schmidt forderte einen sofortigen globalen Dialog über KI-Governance und betonte, dass der Schutz der menschlichen Freiheit von Anfang an in das Systemdesign integriert werden müsse. (Quelle: 36氪)

GitHub CEO widerspricht „Programmieren-ist-nutzlos-These“ und betont die anhaltende Bedeutung menschlicher Programmierer im KI-Zeitalter: Als Reaktion auf die von Nvidia CEO Jensen Huang und anderen geäußerte Ansicht, dass „man in Zukunft nicht mehr programmieren lernen muss“, widersprach GitHub CEO Thomas Dohmke in einem Interview. Er glaubt, dass 2025 das Jahr der Programmier-Agenten (SWE Agent) sein wird, aber die Rolle menschlicher Programmierer weiterhin entscheidend ist. Dohmke betonte, dass KI als Assistent zur Stärkung der Entwicklerfähigkeiten dienen sollte, anstatt sie vollständig zu ersetzen. Er stellt sich vor, dass sich die Softwareentwicklung zukünftig zu einem Modell der Zusammenarbeit zwischen Mensch und KI entwickeln wird, bei dem Entwickler wie „Dirigenten eines Agentenorchesters“ Aufgaben verteilen und Ergebnisse überprüfen. GitHub CPO Mario Rodriguez erklärte ebenfalls, dass das Unternehmen bestrebt sei, die individuellen Fähigkeiten mit Copilot zu verbessern. Sie sind der Ansicht, dass es mit der Entwicklung der KI entscheidend ist zu verstehen, wie man Maschinen programmiert und umprogrammiert, die menschliches Denken und Handeln repräsentieren können. Das Aufgeben des Programmierlernens bedeute, die Mitsprache in der Zukunft der Agenten aufzugeben. (Quelle: 36氪, 量子位)

Flut an KI-generierten, minderwertigen Schwachstellenberichten, curl-Gründer führt Filtermechanismus gegen „KI-Müll“ ein: Daniel Stenberg, Gründer des curl-Projekts, gab an, dass er aufgrund einer Flut von KI-generierten, minderwertigen und ungültigen Schwachstellenberichten überfordert sei. Diese Berichte verschwenden viel Zeit der Maintainer und ähneln DDoS-Angriffen. Daher wurde beim Einreichen von Sicherheitsberichten zu curl auf HackerOne ein Kontrollkästchen hinzugefügt, das fragt, ob KI verwendet wurde. Bei einer positiven Antwort müssen zusätzliche Beweise für die Echtheit der Schwachstelle vorgelegt werden, andernfalls kann der Berichterstatter gesperrt werden. Stenberg erklärte, dass das Projekt noch nie einen gültigen, von KI generierten Fehlerbericht erhalten habe. Auch der Python-Entwickler Seth Larson äußerte ähnliche Bedenken und meinte, dass solche Berichte bei den Maintainern Verwirrung, Stress und Frustration auslösen und das Burnout-Problem bei Open-Source-Projekten verschärfen. In der Community-Diskussion wurde argumentiert, dass die Flut an KI-generierten Berichten die Informationsüberflutung und den Versuch einiger widerspiegelt, Bug-Bounty-Mechanismen auszunutzen. Sogar Führungskräfte auf hoher Ebene seien fälschlicherweise davon überzeugt, dass KI erfahrene Programmierer ersetzen könne. (Quelle: WeChat)

KI-gestütztes Programmieren löst hitzige Debatte aus: Effizienzsteigerung signifikant, aber Rolle menschlicher Entwickler bleibt entscheidend: Ein Entwickler mit jahrzehntelanger Programmiererfahrung teilte seine Erfahrung, wie KI (möglicherweise Codex oder ein ähnliches Tool) einen Fehler, der ihn stundenlang beschäftigt hatte, in wenigen Minuten löste und den Code optimierte, und staunte über KI als „unermüdlichen Super-Teamkollegen“. Diese Erfahrung löste eine Community-Diskussion aus. Die meisten stimmen der starken Fähigkeit von KI bei der Codegenerierung, Fehlerbehebung und Informationszusammenfassung zu, die die Effizienz erheblich steigern kann. Einige Entwickler wiesen jedoch darauf hin, dass KI derzeit noch Fehler macht, insbesondere bei komplexer Logik, Randbedingungen und kreativen Lösungen, und ihre Ergebnisse von erfahrenen Entwicklern überprüft und kritisch bewertet werden müssen. Microsoft-CEO Nadella betonte ebenfalls, dass KI ein Werkzeug zur Befähigung sei und die Softwareentwicklung ohne KI nicht mehr auskomme, aber der Ehrgeiz und die Handlungsfähigkeit des Menschen weiterhin wichtig seien. Die Diskussion kam allgemein zu dem Schluss, dass KI die Art und Weise des Programmierens verändern wird und Entwickler sich an das neue Paradigma der Zusammenarbeit mit KI anpassen und sich auf übergeordnete Architekturentwürfe und Problemdefinitionen konzentrieren müssen. (Quelle: Reddit r/ChatGPT, WeChat)
KI-Agent Manus öffnet Registrierung, aber hohe Preise, Konkurrenz durch nationale und internationale Giganten, chinesische Version fraglich: Die KI-Agenten-Plattform Manus hat nach einem Hype um Einladungscodes offiziell die Registrierung geöffnet, allerdings vorerst nur für ausländische Nutzer und ohne chinesische Version. Nutzer berichten von einem Punkteverbrauchssystem: Kostenlose Punkte (1000 bei Registrierung, 300 täglich) reichen nur für einfache Aufgaben. Komplexe Aufgaben (z. B. Erstellung eines webbasierten Sudoku-Spiels) erfordern den Kauf von Punkten, im Durchschnitt 1 US-Dollar für 100 Punkte, was als teuer empfunden wird. Branchenkenner analysieren, dass Manus auf Drittanbieter-Großmodelle (wie Claude für die Auslandsversion) angewiesen ist, was die Kosten erhöht, und der Betrieb in einer Cloud-Sandbox ebenfalls zusätzliche Kosten verursacht. Die verzögerte Veröffentlichung der chinesischen Version könnte mit der Registrierung von Modellen in China, den Zahlungsgewohnheiten der Nutzer und dem Marktwettbewerb zusammenhängen. Produkte von ByteDance (Coze), Baidu („Xīnxiǎng“ APP) und anderen nationalen und internationalen Anbietern stellen bereits Konkurrenz dar. Obwohl Manus neue Finanzmittel erhalten hat, steht der Burggraben seines „leichtes Modell, schwere Anwendung“-Modells auf dem Prüfstand. (Quelle: 36氪)
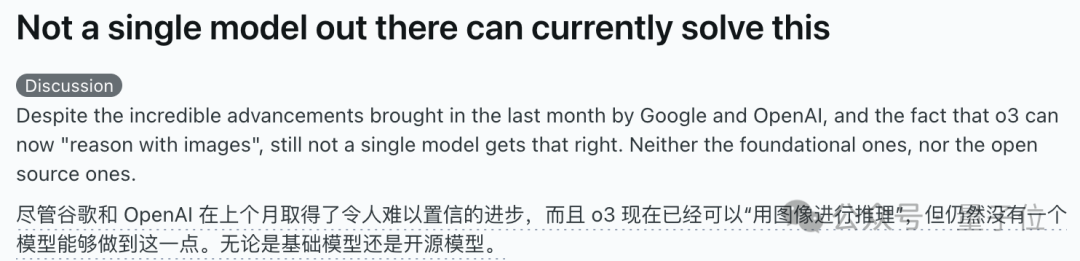
KI-Modelle scheitern kollektiv an visueller Denkaufgabe „Würfel vervollständigen“, Diskussion über ihr wahres Verständnis entfacht: Eine visuelle Denkaufgabe, bei der die Anzahl der benötigten kleinen Würfel zur Vervollständigung eines unvollständigen Würfels berechnet werden soll, brachte mehrere Mainstream-KI-Modelle, darunter OpenAI o3, Google Gemini 2.5 Pro, DeepSeek und Qwen3, ins Straucheln. Die von den verschiedenen Modellen gegebenen Antworten waren unterschiedlich, hauptsächlich aufgrund unterschiedlicher Interpretationen der Spezifikationen des endgültigen großen Würfels (z. B. 3x3x3, 4x4x4, 5x5x5). Selbst mit Hinweisen hatten die Modelle Schwierigkeiten, die Aufgabe auf Anhieb korrekt zu lösen. Einige Netizens wiesen darauf hin, dass die Problemstellung selbst mehrdeutig sein könnte und auch Menschen damit Schwierigkeiten hätten. Dieses Phänomen löste eine Diskussion darüber aus, ob KI-Modelle Probleme wirklich verstehen oder sich nur auf Mustererkennung verlassen, und unterstreicht die aktuellen Grenzen der KI im komplexen räumlichen Denken und visuellen Verständnis. (Quelle: 36氪)
Nutzer diskutieren „Überdenken“-Problem von LLMs bei Befehlsausführung und Schlussfolgerung: Diskussionen in sozialen Medien und wissenschaftlichen Arbeiten weisen darauf hin, dass große Sprachmodelle (LLMs) bei der Verwendung von Denkketten (CoT) und ähnlichen Inferenzprozessen manchmal „zu viel nachdenken“, was dazu führt, dass sie einfache Anweisungen nicht genau befolgen können. Wenn beispielsweise gefordert wird, eine bestimmte Wortanzahl zu schreiben oder eine bestimmte Phrase zu wiederholen, kann CoT dazu führen, dass sich das Modell mehr auf den Gesamtinhalt der Aufgabe konzentriert und diese grundlegenden Einschränkungen ignoriert oder zusätzliche erklärende Inhalte einführt. Forscher haben die Metrik „Constraint Attention“ vorgeschlagen, um dieses Phänomen zu quantifizieren, und Strategien zur Abschwächung wie kontextbezogenes Lernen, Selbstreflexion, selbstgewählte Inferenz und klassifikatorgesteuerte Inferenz getestet. Dies deutet darauf hin, dass nicht alle Aufgaben für CoT geeignet sind und einfache Anweisungen möglicherweise eine direktere Ausführungsmethode erfordern. (Quelle: menhguin, omarsar0)

Reflexion zur KI-Ökonomie: Billige kognitive Arbeit sprengt traditionelle Wirtschaftsmodelle, Wertverteilung vor Neugestaltung: Eine vieldiskutierte Ansicht besagt, dass der Aufstieg der KI kognitive Arbeit (wie das Verfassen von Berichten, Datenanalyse, Code-Schreiben) extrem billig macht, was die klassischen Wirtschaftsmodelle, die auf der Kernannahme „menschliche Intelligenz ist knapp und teuer“ basieren, grundlegend in Frage stellt. Wenn KI eine große Menge an Wissensarbeit zu Grenzkosten nahe Null erledigen kann, könnte die Produktivität in die Höhe schnellen, aber der Wert einzelner Aufgaben wird drastisch sinken und Spezialisierungsvorteile werden untergraben. Die Wertverteilung wird nicht mehr einfach nach Effizienz oder Output erfolgen, sondern davon abhängen, wer die neuen knappen Ressourcen (wie Daten, Plattformen, KI-Modelle selbst) kontrolliert. Dies ähnelt historischen technologischen Umbrüchen (wie Fast Fashion in der Bekleidungsindustrie, Streaming in der Musikindustrie), bei denen die Dividenden der Effizienzsteigerung nicht vollständig den Arbeitnehmern zugutekamen, sondern von den Systemkoordinatoren abgeschöpft wurden. Der Artikel warnt, dass KI nicht nur Aufgaben automatisiert, sondern auch das „Denken“ zur Ware macht, was die möglicherweise disruptivste Kraft in der modernen Wirtschaftsgeschichte sein könnte. (Quelle: Reddit r/artificial)
Unternehmensstrategie im KI-Zeitalter: Vermeidung der „Intelligent Company“-Falle, Neugestaltung statt Optimierung alter Prozesse erforderlich: Viele Unternehmen neigen bei der Einführung von KI dazu, sie als Werkzeug zur Optimierung bestehender Prozesse und zur Kosten- und Effizienzsteigerung zu betrachten und geraten so in die Falle des „intelligenteren Tuns derselben Dinge“ – die „Intelligent Company“-Falle. Echter Wandel bedeutet jedoch nicht, alte Prozesse intelligenter zu machen, sondern zu überdenken, ob diese Prozesse überhaupt noch notwendig sind, und völlig neue, KI-native Systeme und Geschäftsmodelle aufzubauen. Technologie passt sich nicht einfach alten Systemen an, sondern gestaltet Systeme neu. Unternehmen sollten vermeiden, zu viele Ressourcen in die Optimierung von Prozessen zu investieren, die bald von KI überholt werden, und sich stattdessen darauf konzentrieren, neue Regeln zu definieren und die Art und Weise der Entscheidungsfindung, Koordinationsmechanismen und Organisationsstrukturen grundlegend zu verändern. (Quelle: 36氪)
💡 Sonstiges
LangChain New York Offline-Austauschveranstaltung: LangChain kündigte an, am 22. Mai (Donnerstag) in New York gemeinsam mit Tabs und TavilyAI eine Offline-Austauschveranstaltung abzuhalten. Die Veranstaltung umfasst Kamingespräche, Produktdemonstrationen und den Austausch mit anderen Entwicklern. (Quelle: hwchase17, LangChainAI)

Global AI Conference Tokyo Station findet im Juni statt: Eine Veranstaltung namens „Global AI Conference · Tokyo Station“ ist für den 7. bis 8. Juni in Tokio, Japan, geplant. Zahlreiche bekannte KI-Entwickler, Künstler, Investoren usw. werden teilnehmen. Personen, die sich für den KI-Bereich interessieren und eine Reise nach Japan planen, können sich über die entsprechenden Anmeldeinformationen informieren. (Quelle: op7418)

Das Paradigma der KI-Servicearchitektur wandelt sich von „Model-as-a-Service“ zu „Agent-as-a-Service“: Mit der Entwicklung der KI-Technologie durchläuft die KI-Servicearchitektur einen tiefgreifenden Wandel von „Model-as-a-Service“ (MaaS) zu „Agent-as-a-Service“ (AaaS). KI-Agenten übertreffen mit ihrer zielorientierten, umweltbewussten, autonomen Entscheidungs- und Lernfähigkeit das traditionelle Muster von KI-Modellen, die passiv Befehle ausführen. Sie können selbstständig denken, Aufgaben zerlegen, Pfade planen und externe Werkzeuge zur Erreichung komplexer Ziele aufrufen. Dieser Wandel treibt die umfassende Entwicklung der Industriekette voran, von der zugrundeliegenden Infrastruktur (Rechenleistung, Daten), über Kernalgorithmen und große Modelle, bis hin zur mittleren Schicht der Agentenkomponenten und -plattformen und schließlich zu Endproduktanwendungen (allgemeine, branchenspezifische, eingebettete Agenten). Chinesische KI-Agenten-Unternehmen wie HeyGen, Laiye Technology, Waveform Intelligence usw. expandieren ebenfalls aktiv und erkunden Überseemärkte. Trotz Herausforderungen wie hohen Rechenkosten und unzureichender Versorgung wird das Potenzial von KI-Agenten durch Algorithmusoptimierung, Spezialchips, Edge Computing und andere Lösungen kontinuierlich freigesetzt. (Quelle: 36氪)