
Schlüsselwörter:KI-Agent, Microsoft Build 2025, AlphaEvolve, GPT-4, Azure KI-Foundry, NVIDIA Computex 2025, KI-Programmierwerkzeuge, verkörperte Intelligenz, GitHub Copilot VSCode-Erweiterung, Modellkontextprotokoll (MCP), natürliches Sprachnetzwerk (NLWeb), Meituan NoCode, Tencent QBot intelligenter Assistent
🔥 Fokus
Microsoft Build 2025 läutet Ära des „Agentic Web“ ein und setzt voll auf AI-native Entwicklung: Microsoft kündigte auf seiner Entwicklerkonferenz Build 2025 seine Vision eines „Open Agentic Web“ an und veröffentlichte über 50 Updates. Kernpunkte sind die Open-Source-Stellung der VSCode-Erweiterung für GitHub Copilot, die Einführung des Model Context Protocol (MCP) und des offenen Standards Natural Language Web (NLWeb) sowie die Integration von über 1900 Modellen, einschließlich Grok von xAI, in Azure AI Foundry. Diese Initiativen zielen darauf ab, die Entwicklungskette von Modellen zu intelligenten Agenten zu schließen und den szenariounabhängigen autonomen Betrieb sowie die Interoperabilität von AI Agents zu ermöglichen. Microsoft-CEO Nadella betonte, dass AI Agents die Art und Weise der Problemlösung neu gestalten werden, und diskutierte gemeinsam mit OpenAI-CEO Altman, Nvidia-CEO Huang Jen-hsun und xAI-Gründer Musk die Zukunft von AI Agents in der Softwareentwicklung, Infrastruktur und bei Anwendungen in der physischen Welt. (Quelle: 36Kr | GitHub Blog | VS Code Blog | The Verge)
Google DeepMind veröffentlicht AlphaEvolve, AI Agent bricht 56 Jahre alten Effizienzrekord bei Matrixmultiplikation: Google DeepMind stellt AlphaEvolve vor, einen von Gemini unterstützten Codierungs-Agenten. Durch evolutionäre Algorithmen und ein automatisiertes Bewertungssystem entdeckte er erfolgreich einen effizienteren Algorithmus für die Multiplikation von 4×4 komplexen Matrizen als den seit 56 Jahren verwendeten Strassen-Algorithmus, wodurch die Anzahl der erforderlichen Skalarmultiplikationen von 49 auf 48 reduziert wurde. Dieser Durchbruch ist nicht nur von großer mathematischer Bedeutung, sondern hat bereits in internen Google-Anwendungen seinen Wert bewiesen, z. B. durch die Beschleunigung großer Matrixmultiplikationen in der Gemini-Architektur um 23 %, die Verkürzung der Gemini-Trainingszeit um 1 % und die Steigerung der FlashAttention-Leistung um 32,5 %. AlphaEvolve demonstriert das enorme Potenzial von KI bei der automatisierten wissenschaftlichen Entdeckung und Algorithmusoptimierung und kann eine Vielzahl komplexer Probleme bewältigen, von mathematischen Herausforderungen über die Ressourcenplanung in Rechenzentren bis hin zur Beschleunigung des Trainings von KI-Modellen. (Quelle: Google DeepMind Blog | QubitAI)
Studie zeigt: GPT-4 ist in personalisierten Debatten um 64 % überzeugender als Menschen: Eine in Nature Human Behaviour veröffentlichte Studie belegt, dass GPT-4 von OpenAI um 64 % überzeugender ist als Menschen, wenn es persönliche Informationen über den Debattengegner (Geschlecht, Alter, Bildungsgrad etc.) erhält und seine Argumente entsprechend anpasst. Die von der École Polytechnique Fédérale de Lausanne und anderen Institutionen durchgeführte Studie mit 900 Teilnehmern bestätigt erneut die starke Überzeugungskraft von Large Language Models (LLM). Die Forscher warnen, dass dies die Fähigkeit von KI-Tools aufzeigt, mit nur wenigen Nutzerinformationen komplexe und überzeugende Argumente zu konstruieren, was eine potenzielle Bedrohung durch personalisierte Falschinformationen darstellt. Sie fordern politische Entscheidungsträger und Plattformen auf, dieses Risiko ernst zu nehmen und den Einsatz von LLM zur Erstellung personalisierter Gegennarrative zur Bekämpfung von Falschinformationen zu untersuchen. (Quelle: Nature Human Behaviour | MIT Technology Review)
Microsoft und Hugging Face vertiefen Zusammenarbeit, Azure AI Foundry integriert über 10.000 Open-Source-Modelle: Auf der Microsoft Build Konferenz kündigte Microsoft eine erweiterte Partnerschaft mit Hugging Face an. Azure AI Foundry integriert nun über 10.000 Open-Source-Modelle von Hugging Face, die verschiedene Modalitäten wie Text, Audio, Bild und diverse Aufgaben abdecken. Ziel ist es, Azure-Nutzern eine einfachere und sicherere Bereitstellung vielfältiger Open-Source-Modelle für die Erstellung von KI-Anwendungen und intelligenten Agenten zu ermöglichen. Alle integrierten Modelle wurden Sicherheitstests unterzogen, verwenden das safetensors-Format und enthalten keinen Ferncode, um die Sicherheit für Unternehmensanwendungen zu gewährleisten. Beide Seiten planen, zukünftig kontinuierlich die neuesten und beliebtesten Modelle einzuführen, mehr Modalitäten (wie Video, 3D) zu unterstützen und die Optimierung für AI Agents und Tools zu verstärken. (Quelle: HuggingFace Blog)
🎯 Trends
Nvidia stellt auf der Computex 2025 zahlreiche KI-Neuheiten vor und beschleunigt die Transformation zur AI Factory: CEO Jensen Huang stellte auf der Computex 2025 die GeForce RTX 5060 GPU, die Grace Blackwell GB300 Supercomputing-Plattform, den persönlichen KI-Supercomputer DGX Spark (ausgestattet mit GB10, verfügbar in wenigen Wochen) und die DGX Station (784 GB Speicher, kann DeepSeek R1 ausführen) vor. Huang betonte, dass Nvidia sich von einem GPU-Anbieter zu einem globalen Anbieter von KI-Infrastruktur wandelt, mit dem Ziel, „sofort einsatzbereite“ AI Factories zu schaffen. Gleichzeitig wird die gemeinsam mit DeepMind und Disney entwickelte Physik-Engine Newton im Juli als Open Source veröffentlicht und das Isaac GR00T Basismodell für humanoide Roboter vorgestellt, um die physikalische KI voranzutreiben. Nvidia kündigte zudem den Bau eines neuen Büros in Taiwan an und unterstrich die Bedeutung chinesischer KI-Talente. (Quelle: 36Kr | 36Kr)
Microsoft plant, EU-Nutzern die Änderung des Standard-Sprachassistenten auf iPhone und anderen Geräten zu ermöglichen: Laut Bloomberg plant Apple, Nutzern in der EU zu erlauben, den Standard-Sprachassistenten auf Geräten wie iPhone, iPad und Mac von Siri auf andere Optionen wie Google Assistant oder Amazon Alexa umzustellen. Dieser Schritt ist möglicherweise eine Reaktion auf den Kartellrechtsdruck durch das EU-Gesetz über digitale Märkte (DMA). Siri wurde in den letzten Jahren wegen veralteter Funktionen und mangelnder Intelligenz kritisiert. Intern gibt es bei Apple Meinungsverschiedenheiten über die Entwicklungsrichtung von Siri, und die bestehende Architektur lässt sich nur schwer effektiv mit Large Language Models (LLM) integrieren. Obwohl Apple an einem neuen, auf LLM basierenden Siri arbeitet und Apple Intelligence eingeführt hat, könnte die Erlaubnis, den Standardassistenten zu wechseln, Auswirkungen auf sein Ökosystem haben. (Quelle: 36Kr)
Apple testet intern eigenen KI-Chatbot, Fähigkeiten möglicherweise vergleichbar mit ChatGPT: Bloomberg-Reporter Mark Gurman berichtet, dass Apple intern sein eigenes KI-Chatbot-Projekt testet. Unter der Leitung des neuen KI-Chefs John Giannandrea hat das Projekt in den letzten sechs Monaten erhebliche Fortschritte gemacht, und einige Führungskräfte glauben, dass die aktuelle Version in ihren Fähigkeiten bereits der neuesten Version von ChatGPT nahekommt. Der Chatbot könnte über Funktionen zur sofortigen Websuche und Informationsintegration verfügen. Dieser Schritt zielt möglicherweise darauf ab, die Abhängigkeit von externen Diensten wie OpenAI zu verringern und die Wettbewerbsfähigkeit von Siri zu verbessern. Obwohl die WWDC 2025 möglicherweise keine Siri-Upgrades in den Vordergrund stellt, investiert Apple weiterhin verstärkt in KI, um seinen Sprachassistenten im KI-Zeitalter wiederzubeleben. (Quelle: 36Kr)
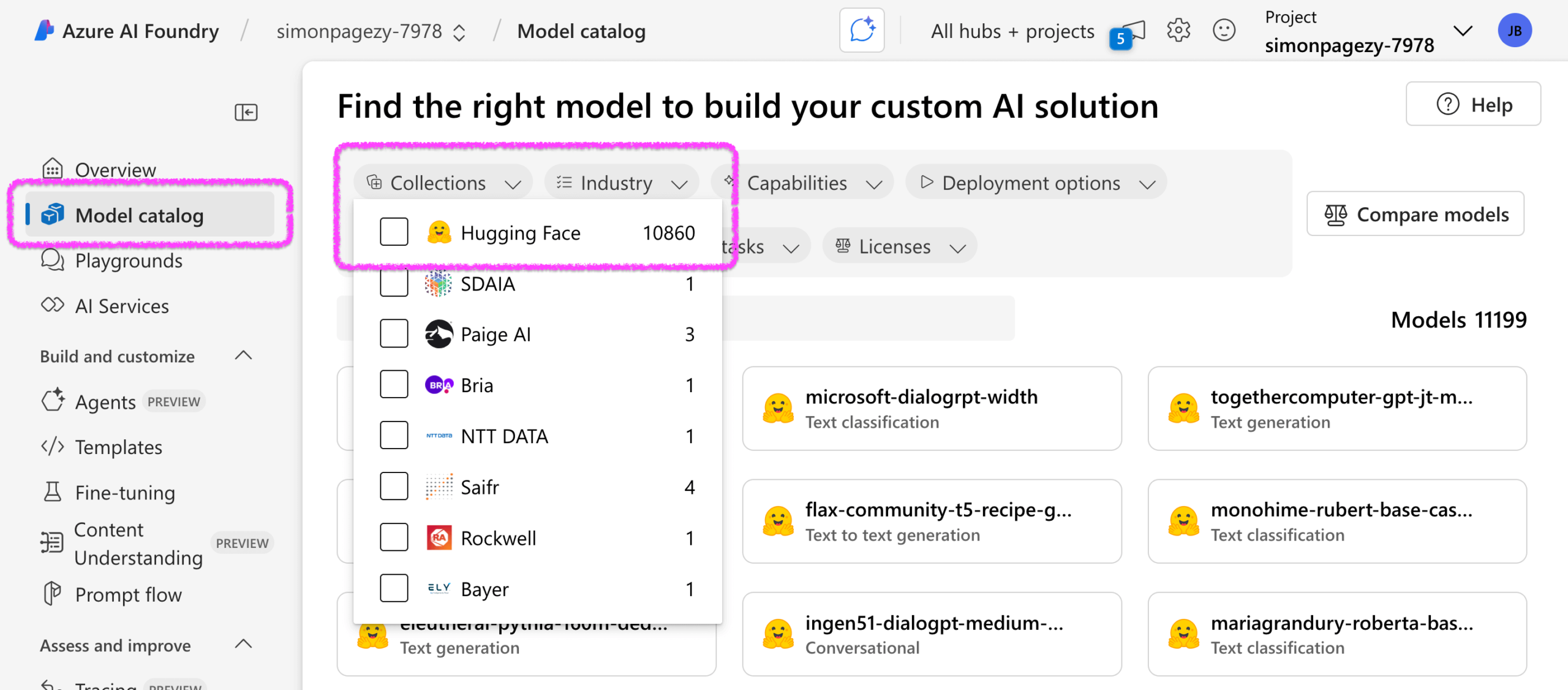
Windows wird nativ das Model Context Protocol (MCP) unterstützen: Microsoft kündigte auf der Build 2025 Konferenz an, dass das Betriebssystem Windows das Model Context Protocol (MCP) nativ unterstützen wird. Ziel ist es, die Entwicklung und Bereitstellung von KI-Anwendungen unter Windows zu vereinfachen. MCP wird als „USB-C für KI-Anwendungen“ bezeichnet und versucht, eine standardisierte Interaktionsweise für verschiedene KI-Modelle und -Anwendungen bereitzustellen. Die Windows AI Foundry Plattform wird diese Unterstützung integrieren, sodass Entwickler lokale KI-Modelle und intelligente Agenten einfacher auf Windows-Geräten ausführen und verwalten können. (Quelle: op7418 | Reddit r/LocalLLaMA)
Microsoft Azure AI Foundry integriert Grok Large Model von xAI: Microsoft gab auf der Entwicklerkonferenz Build 2025 bekannt, dass die Large Models Grok 3 und Grok 3 mini von Elon Musks Unternehmen xAI in die Azure AI Foundry Plattform aufgenommen werden. Azure-Nutzer können diese Modelle direkt über die Cloud-Plattform nutzen und bezahlen. Dieser Schritt erweitert die Anzahl der auf Azure verfügbaren KI-Modelle (bereits über 1900), zu denen zuvor bereits OpenAI, Meta und DeepSeek gehörten. Musk äußerte per Videoschalte die Hoffnung auf Entwickler-Feedback und freut sich darauf, Grok zukünftig weiteren Unternehmen anzubieten. (Quelle: 36Kr)
Percy Liang Team initiiert Marin-Projekt zur Förderung der Entwicklung offener KI-Modelle: Professor Percy Liang von der Stanford University hat das Marin-Projekt initiiert, das darauf abzielt, offene Modelle auf „radikal partizipative Weise“ zu entwickeln. Das Projekt betont einen offenen Entwicklungsprozess, der es jedem ermöglicht, Beiträge zu leisten. Die ersten Marin-Modelle wurden bereits veröffentlicht, wobei ein 8B-Modell zum Testen auf der Together AI-Plattform verfügbar ist. Diese Initiative reagiert auf den Ruf nach einer tiefergehenden Offenheit im KI-Bereich, die nicht nur Gewichte, Code und Daten, sondern das gesamte Forschungs- und Entwicklungsökosystem öffnet. (Quelle: vipulved)

Intel veröffentlicht Arc Pro B60 Profi-Grafikkarte, KTransformers kündigt Unterstützung für Intel GPUs an: Intel hat die neue Profi-Grafikkarte Arc Pro B60 mit 24 GB Grafikspeicher und einer Speicherbandbreite von 456 GB/s vorgestellt. Die Karte kostet etwa 500 US-Dollar und bietet eine neue Hardwareoption für KI-Berechnungen. Gleichzeitig hat das KTransformers Framework die Unterstützung für Intel GPUs angekündigt. Tests zeigen, dass auf einer Plattform mit Xeon 5 + DDR5 + Arc A770 das quantisierte Modell DeepSeek-R1 Q4 mit etwa 7,5 Token/s ausgeführt werden kann, was mehr Hardwaremöglichkeiten für den lokalen Betrieb großer Modelle eröffnet. (Quelle: karminski3 | karminski3)

DeepMind kündigt Google I/O Konferenz an: Der offizielle Account von Google DeepMind hat die bevorstehende Google I/O Konferenz angekündigt, die am 20. Mai (10 Uhr pazifischer Zeit) stattfinden und live auf der X-Plattform übertragen wird. Es wird erwartet, dass auf der Konferenz eine Reihe wichtiger KI-bezogener Updates und Produkte vorgestellt werden, die Googles starke Dynamik im KI-Bereich fortsetzen. (Quelle: GoogleDeepMind)
🧰 Tools
AgenticSeek: Rein lokal laufender AI Agent, Konkurrenz zu Manus AI: AgenticSeek ist ein Open-Source-Projekt, das einen vollständig lokal laufenden KI-Assistenten bereitstellen soll. Er verfügt über die Fähigkeit, autonom im Internet zu surfen, Code zu schreiben und Aufgaben zu planen, wobei alle Daten auf dem Gerät des Nutzers verbleiben, um die Privatsphäre zu gewährleisten. Das Tool ist speziell für lokal inferierte Modelle konzipiert, unterstützt Sprachinteraktion und zielt darauf ab, die Nutzungskosten von AI Agents (nur Stromverbrauch) und das Risiko von Datenlecks zu reduzieren. (Quelle: GitHub Trending)
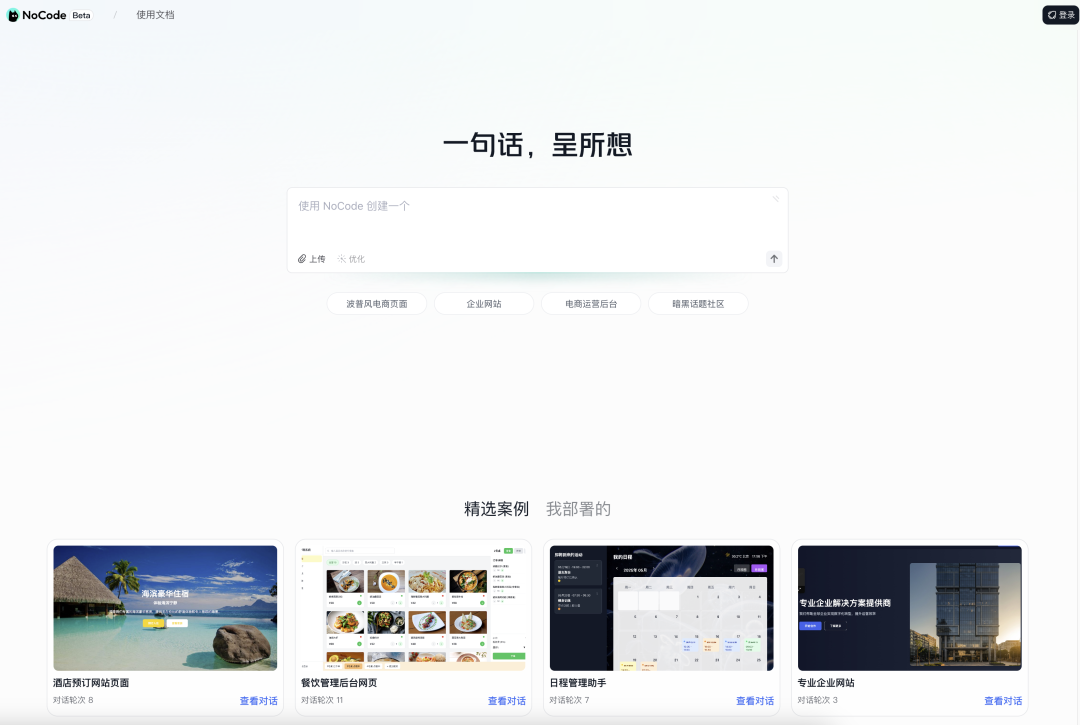
Meituan testet intern KI-Programmiertool NoCode, positioniert als Vibe Coding: 36Kr berichtet exklusiv, dass Meituan in Kürze das KI-Programmiertool „NoCode“ auf den Markt bringen wird. Die Domain nocode.cn wurde bereits registriert und befindet sich im Grey-Test. Das Produkt wird vom Meituan Forschungs-, Qualitäts- und Effizienzteam entwickelt und ist ähnlich wie Lovable als „Atmosphere Programming“ positioniert. Es richtet sich an nicht-technische Nutzer und erledigt Kodierungs- und Bereitstellungsaufgaben wie Datenanalyse, Produktprototypen und die Erstellung von Betriebstools automatisch durch dialogbasierte Interaktion. NoCode verwendet eine Code Agent-Architektur, kann mehrstufige logische Schlussfolgerungen durchführen und soll Händlern sowie einer breiten Nutzerschaft zugänglich gemacht werden, um die IT-Hürden für kleine und mittlere Unternehmen zu senken. (Quelle: 36Kr)
Tencent QQ Browser wird zum AI Browser mit integriertem QBot Smart Assistant: Der QQ Browser kündigte sein Upgrade zum AI Browser an und stellte einen KI-Assistenten namens QBot vor, der auf den Modellen Tencent Hunyuan und DeepSeek basiert. QBot integriert Funktionen wie KI-Suche, KI-Browsing, KI-Office, KI-Lernen und KI-Schreiben und führt ähnliche AI Agent-Fähigkeiten wie Manus ein, um komplexe Aufgaben auszuführen. Der erste im Grey-Test befindliche Agent ist „AI Gaokao Tong“, der personalisierte Studienplatzbewerbungspläne für die Hochschulaufnahmeprüfung erstellen kann. Der QQ Browser hat über 400 Millionen Nutzer, und dieses Upgrade zielt darauf ab, die Effizienz der Nutzer bei der Informationsbeschaffung und Aufgabenbearbeitung durch KI zu verbessern. (Quelle: 36Kr)
OpenAI Codex landet in der ChatGPT iOS-App und unterstützt Programmieraufgaben auf Mobilgeräten: OpenAI gab bekannt, dass sein Programmierassistent Codex nun in die iOS-App von ChatGPT integriert ist. Nutzer können direkt auf ihrem Handy neue Codierungsaufgaben starten, Code-Unterschiede anzeigen, Änderungen anfordern und sogar Pull Requests pushen. Die Funktion unterstützt auch die Echtzeitverfolgung von Aktivitäten auf dem Sperrbildschirm, sodass Nutzer den Arbeitsfortschritt von Codex jederzeit im Blick behalten und unerledigte Aufgaben später am Computer fortsetzen können. Dies markiert einen wichtigen Schritt der KI-Programmierung in Richtung mobile Endgeräte und szenariübergreifende Zusammenarbeit. (Quelle: karinanguyen_ | gdb)
NotebookLM Mobile App veröffentlicht, unterstützt Android & iOS: Googles KI-Notiztool NotebookLM hat offiziell eine mobile App veröffentlicht, die sukzessive für Android- und iOS-Plattformen ausgerollt wird. Die mobile Version bietet Kernfunktionen wie Audio-Zusammenfassungen und Dialoge, um Nutzern die Inhaltsanalyse und das Lernen mit KI jederzeit und überall zu erleichtern. Eine praktische Funktion ist, dass Nutzer Inhalte, die sie gerade ansehen (außer offizielle WeChat-Konten), direkt zur Verarbeitung an NotebookLM weiterleiten können. (Quelle: op7418)
Public führt KI-Investmenttool „Generated Assets“ ein: Die Investmentplattform Public hat ein neues Produkt namens „Generated Assets“ vorgestellt. Es ermöglicht Nutzern, der KI Anlageideen vorzuschlagen, woraufhin die KI Anlageempfehlungen und benutzerdefinierte Anlageindizes zurückgibt und historische Renditen sowie die Echtzeit-Performance vergleichen und verfolgen kann. Dies ähnelt einer KI-Implementierung von „Atmosphere Investing“ oder „thematischem Investieren“ und zielt darauf ab, die Hürden für Nutzer beim Aufbau und der Verwaltung personalisierter Anlageportfolios zu senken. (Quelle: op7418)
ClaraVerse: „All-in-One“-Anwendung mit Integration verschiedener KI-Tools: Eine KI-Tool-Suite namens ClaraVerse wurde in der Community geteilt. Sie integriert eine Chat-Oberfläche, KI-Komponenten, Ollama (lokale Ausführung großer Modelle), n8n (Workflow-/Zeitplanungsaufgaben), AI Agent-Vorlagen, ComfyUI (Bilderzeugung) sowie eine Bildergalerie mit KI-Indexierung. Ziel ist es, Nutzern eine zentrale KI-Arbeitsplattform zu bieten und die Nutzung und den Wechsel zwischen verschiedenen KI-Tools zu vereinfachen. (Quelle: karminski3)
Qdrant Vektordatenbank integriert Microsofts NLWeb-Protokoll: Die Vektordatenbank Qdrant gab bekannt, einer der ersten Partner für das von Microsoft auf der Build-Konferenz vorgestellte offene NLWeb-Protokoll zu sein. NLWeb zielt darauf ab, traditionelle Suchfelder in semantische, absichtserkennende Schnittstellen auf Basis natürlicher Sprache zu verwandeln. Durch die Integration mit Qdrant können Websites dessen schnelle Vektorsuche mit Filterbedingungen nutzen, um semantisch relevante Ergebnisse zu liefern, ohne Frontend- oder Backend-Logik wesentlich ändern zu müssen. (Quelle: qdrant_engine)

📚 Lernen
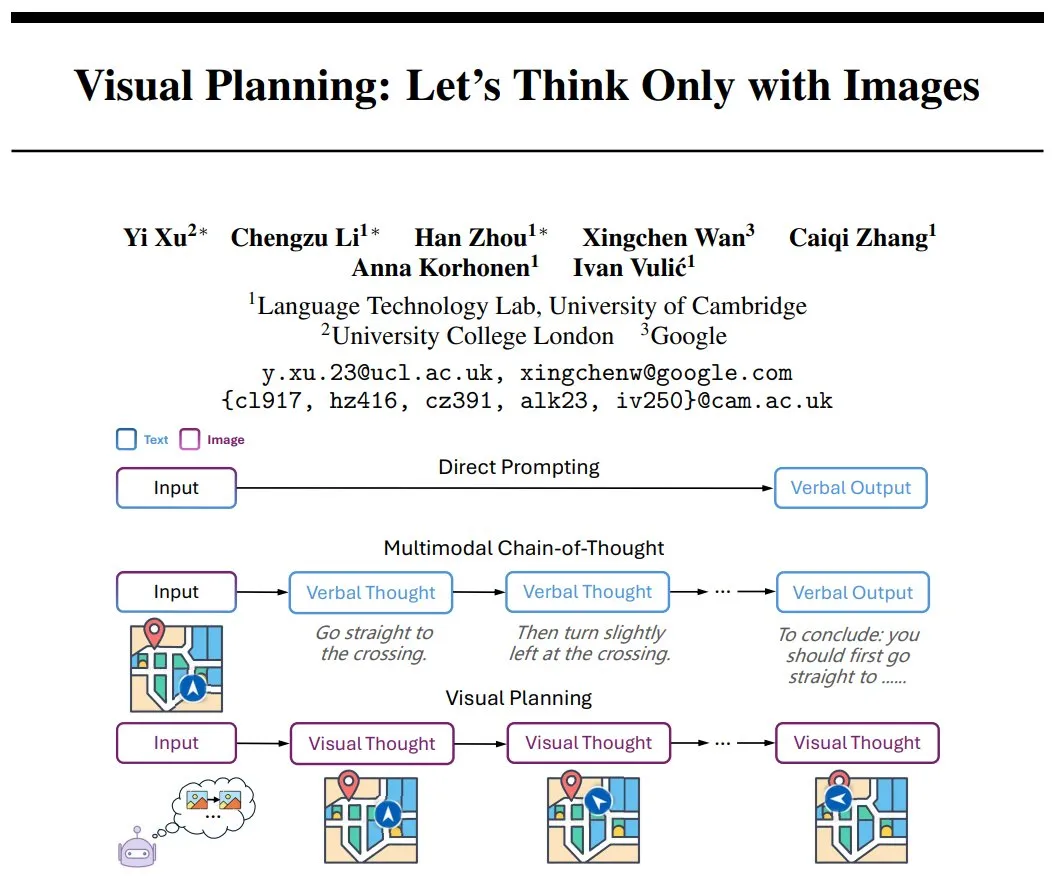
DeepMind schlägt Visual Planning vor: Ein reines Bildsequenz-Inferenzparadigma: Yi Xu und andere Forscher schlagen ein neues Inferenzparadigma namens „Visual Planning“ vor. Es zielt darauf ab, dass Modelle vollständig durch Bildsequenzen denken und planen, ähnlich wie Menschen Schritte im Kopf visualisieren, ohne auf Sprache oder textuelles Denken angewiesen zu sein. Diese Methode erforscht die Möglichkeit komplexer Schlussfolgerungen durch KI in nicht-sprachlichen Symbolsystemen und liefert neue Ideen für die Entwicklung multimodaler KI. (Quelle: madiator)
Stanford und andere Institutionen stellen Terminal-Bench vor: Benchmark zur Bewertung der Terminal-Aufgabenfähigkeiten von AI Agents: Forscher der Stanford University und von Laude haben Terminal-Bench vorgestellt, ein Framework und Benchmark zur Bewertung der Fähigkeit von AI Agents, komplexe Aufgaben in realen Terminalumgebungen zu erledigen. Angesichts der Tatsache, dass viele AI Agents (wie Claude Code, Codex CLI) wertvolle Aufgaben durch Interaktion mit dem Terminal ausführen, zielt dieser Benchmark darauf ab, ihre tatsächliche Effektivität zu quantifizieren und die Entwicklung von Agentenfähigkeiten für den praktischen Einsatz voranzutreiben. (Quelle: madiator | andersonbcdefg)

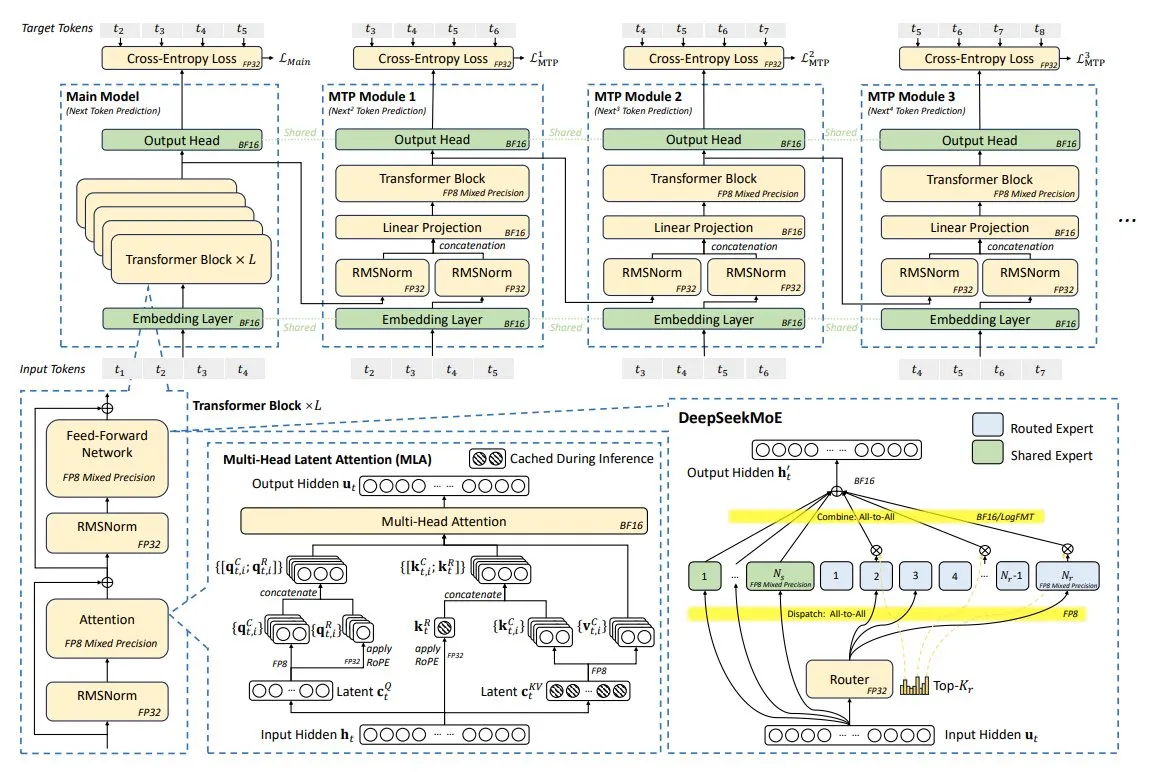
DeepSeek-V3 Technische Analyse: Hocheffizientes Modell durch koordiniertes Hard- und Softwaredesign: Das DeepSeek-V3 Modell wurde durch koordiniertes Hard- und Softwaredesign auf nur 2048 NVIDIA H800 GPUs trainiert. Zu den wichtigsten Innovationen gehören Multi-Head Latent Attention (MLA), Mixture of Experts (MoE), FP8 Mixed-Precision Training und eine Multi-Plane Network Topology. Diese Technologien wirken zusammen, um eine bessere Modellleistung bei geringeren Kosten zu erzielen, und repräsentieren einen neuen Trend in der Entwicklung von KI-Modellen hin zu einem besseren Preis-Leistungs-Verhältnis. (Quelle: TheTuringPost)
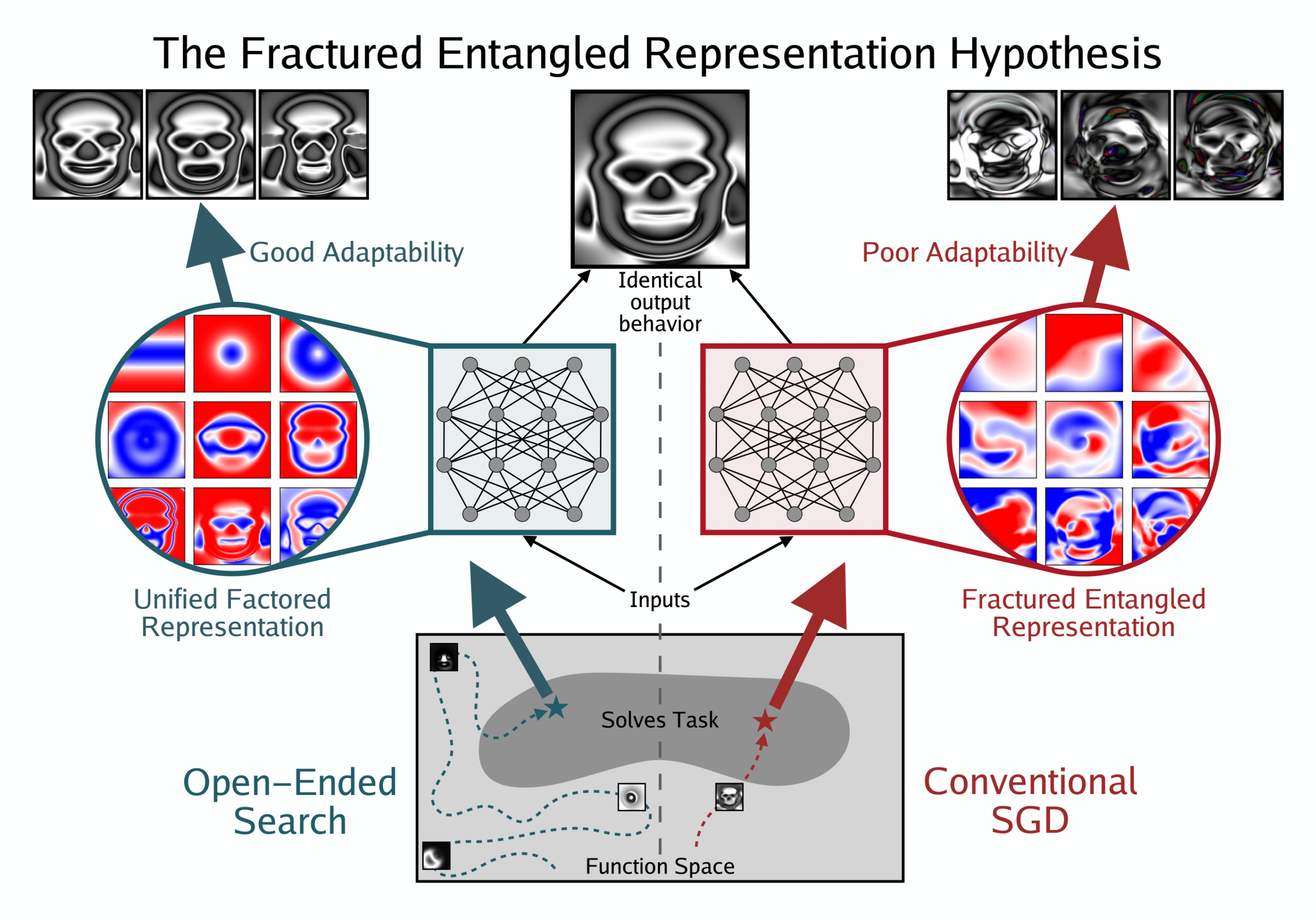
Neues Paper diskutiert Repräsentationsoptimismus im Deep Learning: Die Hypothese der gebrochenen verschränkten Repräsentationen: Kenneth Stanley et al. veröffentlichten ein Positionspapier mit dem Titel „Questioning representational Rptimism in Deep Learning: The Broken Entangled Representation Hypothesis“. Die Studie weist darauf hin, dass Netzwerke, die durch unkonventionelle, offene Suche entdeckt wurden und ein einzelnes Bild ausgeben können, elegante und modulare Repräsentationen aufweisen; während Netzwerke, die durch SGD gelernt haben, denselben Output zu erzeugen, chaotische und verschränkte Repräsentationen haben. Dies deutet darauf hin, dass sich hinter gutem Ausgabe-Verhalten schlechte interne Repräsentationen verbergen können, zeigt aber auch die Möglichkeit besserer Repräsentationen auf, was tiefgreifende Auswirkungen auf die Generalisierung, Kreativität und Lernfähigkeit von Modellen hat und neue Ideen zur Verbesserung von Basismodellen und LLMs liefert. (Quelle: hardmaru | togelius | bengoertzel)
RL-Tutorial aktualisiert, Fokus auf LLM-Kapitel (DPO, GRPO, Chain-of-Thought etc.): Sirbayes hat eine neue Version seines Reinforcement Learning (RL) Tutorials veröffentlicht. Dieses Update konzentriert sich hauptsächlich auf das Kapitel über Large Language Models (LLM) und fügt aktuelle Inhalte wie DPO (Direct Preference Optimization), GRPO (Group Relative Policy Optimization) und Chain-of-Thought (Thinking) hinzu. Gleichzeitig wurden auch die Kapitel zu Multi-Agent Reinforcement Learning (MARL), Model-Based Reinforcement Learning (MBRL), Offline Reinforcement Learning und DPG (Deep Deterministic Policy Gradient) geringfügig aktualisiert. (Quelle: sirbayes)

ByteDance schlägt Pre-trained Model Averaging (PMA) Strategie vor: Ein Forschungsteam von ByteDance hat in einem Paper ein neues Framework für das Zusammenführen von Modellen während des Pre-Trainings von Large Language Models vorgeschlagen – die Pre-trained Model Averaging (PMA) Strategie. Die Studie ergab, dass das Zusammenführen von Checkpoints, die mit einer konstanten Lernrate trainiert wurden, nicht nur eine vergleichbare oder sogar bessere Leistung als kontinuierliches Training erzielen kann, sondern auch die Trainingseffizienz erheblich steigert. Diese Forschung liefert neue Ideen zur Effizienzoptimierung für das Pre-Training großer Modelle und bestätigt das Potenzial des Zusammenführens von Modellen zur Leistungs- und Effizienzsteigerung. (Quelle: teortaxesTex)

Neue Studie des Tongyi Lab: ZeroSearch – LLM spielt Suchmaschine, verbessert Inferenzfähigkeit ohne API: Das Alibaba Tongyi Lab stellt das ZeroSearch Framework vor, bei dem ein LLM das Verhalten einer Suchmaschine simuliert. Dies geschieht während des Reinforcement Learning Prozesses, ohne dass tatsächlich Suchmaschinen-APIs aufgerufen werden müssen, wodurch Kosten gesenkt und die Trainingsstabilität erhöht wird. Die Methode ermöglicht es dem LLM durch leichtes Fine-Tuning, nützliche Ergebnisse und störendes Rauschen zu generieren. Durch ein kurrikulares Anti-Rausch-Training wird die Inferenz- und Störfestigkeitsfähigkeit des Modells in komplexen Suchszenarien schrittweise verbessert. Experimente zeigen, dass bereits ein LLM mit nur 3B Parametern als Suchmodul die Suchleistung effektiv steigern kann. (Quelle: QubitAI)

Neuer Algorithmus RXTX der Chinesischen Universität Hongkong optimiert XXt-Matrixmultiplikation: Forscher der Chinesischen Universität Hongkong haben den neuen Algorithmus RXTX zur Beschleunigung der Berechnung des Produkts einer Matrix mit ihrer Transponierten (XXt) vorgestellt. Der Algorithmus basiert auf der rekursiven Multiplikation von 4×4-Blockmatrizen und wurde durch eine Kombination aus maschinellem Lernen und kombinatorischer Optimierung entdeckt. Im Vergleich zu bestehenden Algorithmen, die auf der Strassen-Rekursion basieren, reduziert RXTX die asymptotische Multiplikationskonstante um etwa 5 % und zeigt bei n≥256 einen Vorteil bei der Gesamtzahl der Operationen. In Tests mit 6144×6144-Matrizen war er 9 % schneller als die Standardimplementierung von BLAS. Diese Forschung hat potenzielle Auswirkungen auf Bereiche wie Datenanalyse, Chipdesign und LLM-Training. (Quelle: QubitAI)
Paper AdaptThink: Inferenzmodellen beibringen, wann sie „denken“ sollen: Diese Studie stellt AdaptThink vor, ein Framework, das Inferenzmodellen mittels Reinforcement Learning beibringt, je nach Schwierigkeitsgrad einer Frage adaptiv zu entscheiden, ob ein tiefergehendes Denken (z.B. Chain-of-Thought) erforderlich ist. Kernstück ist ein beschränktes Optimierungsziel (das dazu anregt, das Denken bei gleichbleibender Leistung zu reduzieren) und eine Importance-Sampling-Strategie (die denkende und nicht-denkende Samples ausbalanciert). Experimente zeigen, dass AdaptThink die Inferenzkosten signifikant senken und die Leistung verbessern kann. Beispielsweise wurde bei mathematischen Datensätzen die durchschnittliche Antwortlänge von DeepSeek-R1-Distill-Qwen-1.5B um 53 % reduziert und die Genauigkeit um 2,4 % erhöht. (Quelle: HuggingFace Daily Papers)
Paper VisionReasoner: Vereinheitlichung von visueller Wahrnehmung und Inferenz durch Reinforcement Learning: VisionReasoner ist ein einheitliches Framework, das darauf abzielt, mehrere visuelle Wahrnehmungsaufgaben mit einem gemeinsam genutzten Modell zu bewältigen. Es verwendet eine Multi-Objekt-Kognitionslernstrategie und eine systematische Aufgabenrekonstruktion, um die Fähigkeit des Modells zur Analyse visueller Eingaben und zur strukturierten Inferenz zu verbessern und so zehn verschiedene Aufgaben wie Erkennung, Segmentierung und Zählung zu bewältigen. Experimentelle Ergebnisse zeigen, dass VisionReasoner auf Benchmarks wie COCO (Erkennung), ReasonSeg (Segmentierung) und CountBench (Zählung) Modelle wie Qwen2.5VL übertrifft. (Quelle: HuggingFace Daily Papers)
Paper AdaCoT: Pareto-optimales adaptives Auslösen von Chain-of-Thought durch Reinforcement Learning: Um den unnötigen Rechenaufwand zu beheben, der durch Chain-of-Thought (CoT) bei der Verarbeitung einfacher Anfragen durch Large Language Models (LLM) entsteht, wurde das AdaCoT-Framework vorgeschlagen. Es nutzt Reinforcement Learning (PPO), um LLMs in die Lage zu versetzen, basierend auf der impliziten Komplexität einer Anfrage adaptiv zu entscheiden, ob CoT aufgerufen werden soll. Ziel ist es, die Modellleistung und die Kosten für CoT-Aufrufe auszugleichen. Durch die Selective Loss Masking (SLM)-Technik wird ein Kollaps der Entscheidungsgrenze verhindert. Experimente zeigen, dass AdaCoT die Auslösungsrate unnötiger CoTs (bis auf 3,18 %) und die Anzahl der Antwort-Token (Reduktion um 69,06 %) drastisch reduzieren kann, während die hohe Leistung bei komplexen Aufgaben erhalten bleibt. (Quelle: HuggingFace Daily Papers)
Paper GIE-Bench: Ein praxisnaher Bewertungsbenchmark für textgesteuerte Bildbearbeitung: Um textgesteuerte Bildbearbeitungsmodelle genauer zu bewerten, wurde GIE-Bench vorgeschlagen. Dieser Benchmark bewertet anhand von zwei Dimensionen: funktionale Korrektheit (durch automatisch generierte Multiple-Choice-Fragen wird überprüft, ob die Bearbeitung erfolgreich war) und Beibehaltung des Bildinhalts (mithilfe von objektbewusster Maskierungstechnik und einem Beibehaltungs-Score wird die Konsistenz nicht-Zielbereiche sichergestellt). Er enthält über 1000 hochwertige Bearbeitungsbeispiele, die 20 Kategorien abdecken. Die Bewertung von Modellen wie GPT-Image-1 zeigt, dass es bei der Befolgung von Anweisungen führend ist, aber bei der Beibehaltung irrelevanter Bereiche noch Verbesserungspotenzial besteht. (Quelle: HuggingFace Daily Papers)
Paper InstanceGen: Bildgenerierung mit instanzbasierten Anweisungen: Um das Problem zu lösen, dass vortrainierte Text-zu-Bild-Modelle bei der Verarbeitung komplexer Prompts mit mehreren Objekten und instanzbasierten Attributen Schwierigkeiten haben, die Semantik genau zu erfassen, schlägt InstanceGen eine neue Technik vor. Diese Technik kombiniert eine bildbasierte, feingranulare strukturierte Initialisierung (direkt von modernen Bildgenerierungsmodellen bereitgestellt) mit instanzbasierten Anweisungen von LLMs. Dadurch können die generierten Bilder allen Teilen der Text-Prompts besser folgen, einschließlich der Anzahl der Objekte, instanzbasierten Attribute und räumlichen Beziehungen zwischen Instanzen. (Quelle: HuggingFace Daily Papers)
💼 Wirtschaft
Tsinghua-nahes Embodied Intelligence Unternehmen „Qianjue Technology“ schließt Pre-A+-Finanzierungsrunde über mehrere hundert Millionen Yuan ab: Das Embodied Brain Unternehmen „Qianjue Technology“ hat kürzlich eine neue Pre-A+-Finanzierungsrunde abgeschlossen, an der sich Junshan Investment, Xiangfeng Investment und Shixi Capital beteiligten. Die kumulierte Finanzierungssumme beläuft sich auf mehrere hundert Millionen Yuan. Das Unternehmen wurde von Kernmitgliedern des Fachbereichs Automatisierung der Tsinghua-Universität und verwandten KI-Forschungseinrichtungen gegründet und konzentriert sich auf die Entwicklung eines universellen „Embodied Brain“-Systems. Es legt Wert auf multimodale Echtzeitwahrnehmung, kontinuierliche Aufgabenplanung und autonome Ausführungsfähigkeiten und hat bereits produktreife Lösungen in Bereichen wie Haushaltsdienstleistungen und Logistikdistribution realisiert. Zudem kooperiert es mit mehreren führenden Roboterherstellern und Unterhaltungselektronikunternehmen. (Quelle: 36Kr)

AI Agents könnten die SaaS-Marktlandschaft neu gestalten: Die Vorhersage von Microsoft-CEO Nadella, dass SaaS-Anwendungen im Zeitalter der AI Agents vor einer Umwälzung stehen, hat eine breite Diskussion über die Zukunft von AI Agents und SaaS ausgelöst. AI Agents könnten mit ihren autonomen Wahrnehmungs-, Entscheidungs- und Handlungsfähigkeiten die Schwachstellen traditioneller SaaS-Lösungen in Bezug auf Anpassung, Dateninteroperabilität und Benutzererfahrung beheben, z. B. durch die automatische Erstellung von Workflows über natürliche Sprachinteraktion, die anwendungsübergreifende Datenintegration und die proaktive Bereitstellung von Geschäftsempfehlungen. Obwohl AI Agents in Unternehmensanwendungen derzeit noch mit Herausforderungen wie den Einschränkungen von LLMs, Kosten und Datensicherheit konfrontiert sind, haben Anbieter wie Salesforce, Microsoft und Yonyou bereits damit begonnen, AI Agents in ihre SaaS-Produkte zu integrieren und neue Modelle der Fusion oder Disruption von SaaS zu erforschen. (Quelle: 36Kr)
KI gestaltet das Vergütungsmanagement neu: Von der Datenanalyse zur intelligenten Entscheidungsfindung und Kommunikation: Künstliche Intelligenz revolutioniert das Vergütungsmanagement tiefgreifend. Ein Bericht von Korn Ferry zeigt, dass KI zunehmend in der Vergütungskommunikation, im externen Benchmarking und in der Strukturierung von Stellenprofilen eingesetzt wird. Zukünftig könnte KI durch die Verarbeitung größerer und vielfältigerer Datenmengen (einschließlich sozialer Plattformen, Drittanbieterstudien) den Wandel von datengesteuerter zu intelligenter Entscheidungsfindung ermöglichen, z. B. zur Vorhersage des Mitarbeiterfluktuationsrisikos, zur Bewertung der Wirksamkeit von Anreizen, zur dynamischen Anpassung von Gehaltsspannen und zur Realisierung personalisierter Anreize. Gleichzeitig steht KI vor Herausforderungen wie Datenschutz, algorithmischen „Black Boxes“ und der Glaubwürdigkeit von Ergebnissen. Eine effektive Vergütungskommunikation ist im digitalen Zeitalter noch wichtiger, und KI-Tools können Manager bei einer systematischen, personalisierten Kommunikation unterstützen, um das Gerechtigkeitsempfinden und die Zufriedenheit der Mitarbeiter zu steigern. (Quelle: 36Kr)
🌟 Community
Sundar Pichai veröffentlicht „Deep Thinking“-Foto und stimmt auf Google I/O ein: Google-CEO Sundar Pichai veröffentlichte in sozialen Medien ein Foto von sich in „tiefer Gedankenversunkenheit“, was in der Community große Erwartungen an die bevorstehende Google I/O Konferenz auslöste. Das Foto wurde von mehreren KI-Influencern geteilt und interpretiert, wobei allgemein davon ausgegangen wird, dass Google bedeutende Ankündigungen im KI-Bereich machen wird, insbesondere in Bezug auf das Gemini-Modell und seine Anwendungen. Community-Mitglieder spekulieren eifrig über mögliche neue Funktionen, Modelle oder Strategien. (Quelle: demishassabis | YiTayML | zacharynado | lmthang | scaling01 | brickroad7 | jack_w_rae | TheTuringPost | shaneguML | op7418)

Programmierfähigkeiten von AI Agents heiß diskutiert, Sama optimistisch bezüglich automatischer Fertigstellung unvollendeter Projekte: OpenAI-CEO Sam Altman äußerte sich erwartungsvoll über die Fähigkeit von KI-Programmieragenten (wie Codex), Projekte, die zu 80 % fertiggestellt, aber nicht abgeschlossen wurden, zu vollenden und automatisch zu warten. Die Community verglich und diskutierte die Fähigkeiten verschiedener KI-Programmieragenten (wie Codex, Jules, Claude Code), wobei der Fokus auf Aufgabenplanungsfähigkeiten, virtuellen Maschinenumgebungen (z. B. ob vernetzt) und der Leistung bei komplexen Langzeitaufgaben lag. Es herrscht allgemeiner Konsens darüber, dass AI Agents ein enormes Potenzial im Bereich der Softwareentwicklung haben, die verschiedenen Modelle sich jedoch in der konkreten Umsetzung und den Ergebnissen noch unterscheiden. (Quelle: sama | mathemagic1an)
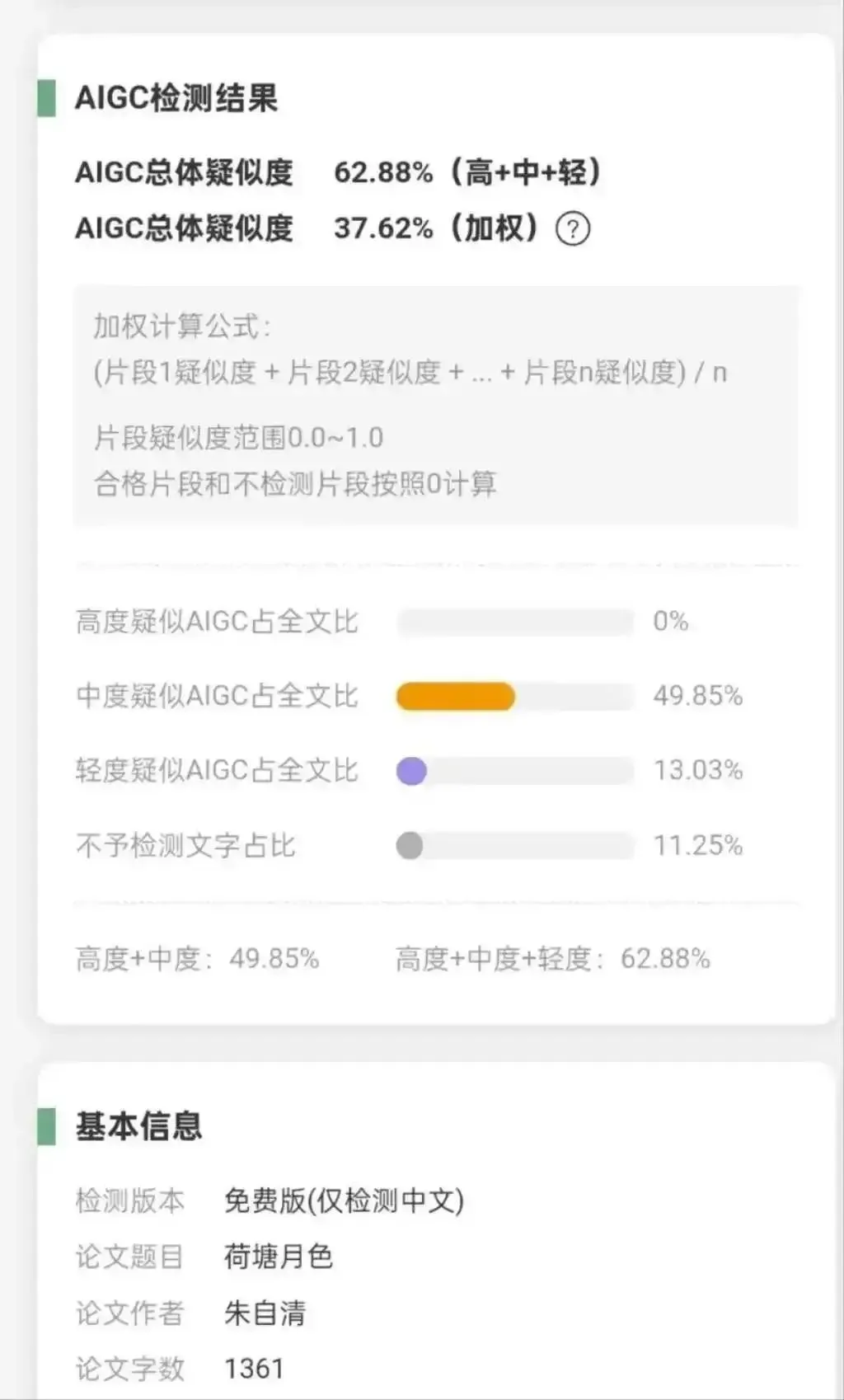
Einführung von KI-generierter Inhaltserkennung an Hochschulen löst Kontroverse aus, „Vorwort zum Pavillon des Fürsten Teng“ als 100 % KI-generiert eingestuft: Mehrere chinesische Hochschulen haben die „Erkennungsrate von KI-generierten Inhalten“ in die Bewertung von Abschlussarbeiten aufgenommen. Dies führt dazu, dass Studierende verschiedene Methoden anwenden, um die Erkennung zu umgehen, während Lehrende zwischen KI-Urteil und menschlicher Einschätzung hin- und hergerissen sind. KI-Erkennungstools stufen aufgrund von Datenbankabgleichen und Mustervoreingenommenheit häufig klassische Werke (z. B. „Vorwort zum Pavillon des Fürsten Teng“ mit 100 % KI-Rate, Zhu Ziqings „Lotosblütenteich bei Mondschein“ mit 62,88 %) und standardisierte wissenschaftliche Arbeiten fälschlicherweise als KI-generiert ein. Dieses Phänomen hat eine Grauzone der „KI-Raten-Reduzierung“ hervorgebracht und eine tiefgreifende Reflexion über die Grenzen der KI-Erkennungstechnologie, akademische Bewertungsstandards und das Wesen der Bildung ausgelöst. (Quelle: 36Kr)
Denkweise der nächsten, im KI-Zeitalter aufgewachsenen Generation wird diskutiert: Die Reddit-Community diskutiert intensiv darüber, wie sich die Denkweise der neuen Generation von Kindern, die in einer KI-Umgebung aufwachsen, signifikant von früheren Generationen unterscheiden wird. Sie werden an die Interaktion mit KI-Assistenten gewöhnt sein, und der Lernfokus könnte sich vom Auswendiglernen von Fakten hin zum Stellen von Fragen und Navigieren in Systemen sowie vom Lernen durch Versuch und Irrtum hin zu schneller Iteration verschieben. Diese frühe Verschmelzung mit maschineller Logik könnte ihre Neugier, ihr Gedächtnis, ihre Intuition und sogar ihre Definition von Intelligenz selbst tiefgreifend verändern und Fragen über ihre zukünftige Überzeugungsbildung, ihre Fähigkeit zum Aufbau von Systemen und ihr Vertrauen in ihre eigenen Gedanken aufwerfen. (Quelle: Reddit r/ArtificialInteligence)
Rasante Entwicklung von KI im Software-Engineering löst bei Entwicklern Existenzängste aus: Ein 42-jähriger Software-Ingenieur, der einst 150.000 US-Dollar pro Jahr verdiente, wurde durch KI-bezogene Trends verdrängt. Nach über 800 Bewerbungen erhielt er kaum Vorstellungsgespräche und verdient seinen Lebensunterhalt nun als Essenslieferant. Seine Erfahrung löste eine Diskussion darüber aus, ob KI (wie GitHub Copilot, Claude, ChatGPT) bereits begonnen hat, Programmierer in großem Stil zu ersetzen. Der CEO von Anthropic prognostizierte einst, dass KI den Großteil des Codes generieren können wird. Obwohl die Daten des Bureau of Labor Statistics Software-Engineering immer noch als einen der am schnellsten wachsenden Berufe ausweisen, hält die Entlassungswelle in der Technologiebranche an, und Unternehmen nutzen KI zur Kostensenkung und Effizienzsteigerung. Dies zwingt zu Überlegungen, wie die Gesellschaft mit der durch KI verursachten strukturellen Arbeitslosigkeit und dem Aufbau neuer Paradigmen der Zusammenarbeit zwischen Mensch und KI umgehen sollte. (Quelle: 36Kr)

Problem des Gender Bias in KI-Algorithmen: Die Unsichtbarkeit und das Fehlen von „She Data“: Bei der Entwicklung künstlicher Intelligenz tritt das Problem des Gender Bias in Algorithmen immer deutlicher zutage. Aufgrund historischer und gesellschaftlicher Gründe sind Frauendaten in Datensammlungen unterrepräsentiert (z. B. in klinischen Studien, Wikipedia-Einträgen), was dazu führen kann, dass KI in Bereichen wie medizinischer Diagnose und Inhaltsempfehlungen Verzerrungen gegenüber Frauen aufweist. Beispielsweise könnten Bilderkennungssysteme Männer in Küchen fälschlicherweise als Frauen identifizieren, und Suchmaschinenergebnisse verstärken geschlechtsspezifische Stereotypen. Auch die unausgewogene Geschlechterstruktur in der KI-Branche wird als eine der Ursachen angesehen. Die Lösung dieses Problems erfordert ein mehrgleisiges Vorgehen: Sensibilisierung der Entwickler, Gewährleistung fairer beruflicher Chancen für Frauen, Verbesserung von Gesetzen und Vorschriften, Einrichtung von Mechanismen zur Überprüfung von KI-Systemen auf Geschlechterbias sowie Optimierung von Algorithmen (z. B. Daten-Resampling, Anwendung kausaler Inferenz). (Quelle: 36Kr)
AI Agents lösen Diskussion über Wandel in der SaaS-Branche aus: Microsoft-CEO Nadella prognostiziert, dass SaaS im Zeitalter der AI Agents vor einer Umwälzung steht. AI Agents könnten dank ihrer autonomen Wahrnehmungs-, Entscheidungs- und Handlungsfähigkeiten die Schwachstellen von SaaS in Bezug auf Anpassung, Dateninteroperabilität und Benutzererfahrung beheben. Beispielsweise könnten AI Agents durch natürliche Sprachinteraktion automatisch Workflows erstellen, Daten anwendungsübergreifend integrieren und proaktiv Geschäftsempfehlungen geben. Derzeit beginnen SaaS-Anbieter wie Salesforce, Microsoft und Yonyou bereits mit der Integration von AI Agents und erforschen neue Modelle der Fusion oder Disruption von SaaS. Obwohl AI Agents in Unternehmensanwendungen noch vor Herausforderungen wie LLM-Fähigkeiten, Kosten und Datensicherheit stehen, hat ihr transformatives Potenzial branchenweit große Aufmerksamkeit erregt. (Quelle: finbarrtimbers)
💡 Sonstiges
KI generiert Tarotkarten im Stil chinesischer Oper: Nutzer @op7418 hat mit dem KI-Tool Lovart ein Set Tarotkarten im Stil der chinesischen Oper erstellt. Das Designkonzept verbindet traditionelle Operninhalte mit den entsprechenden Bedeutungen der Tarotkarten und zeigt das Anwendungspotenzial von KI im kreativen Design und der kulturellen Fusion. (Quelle: op7418)
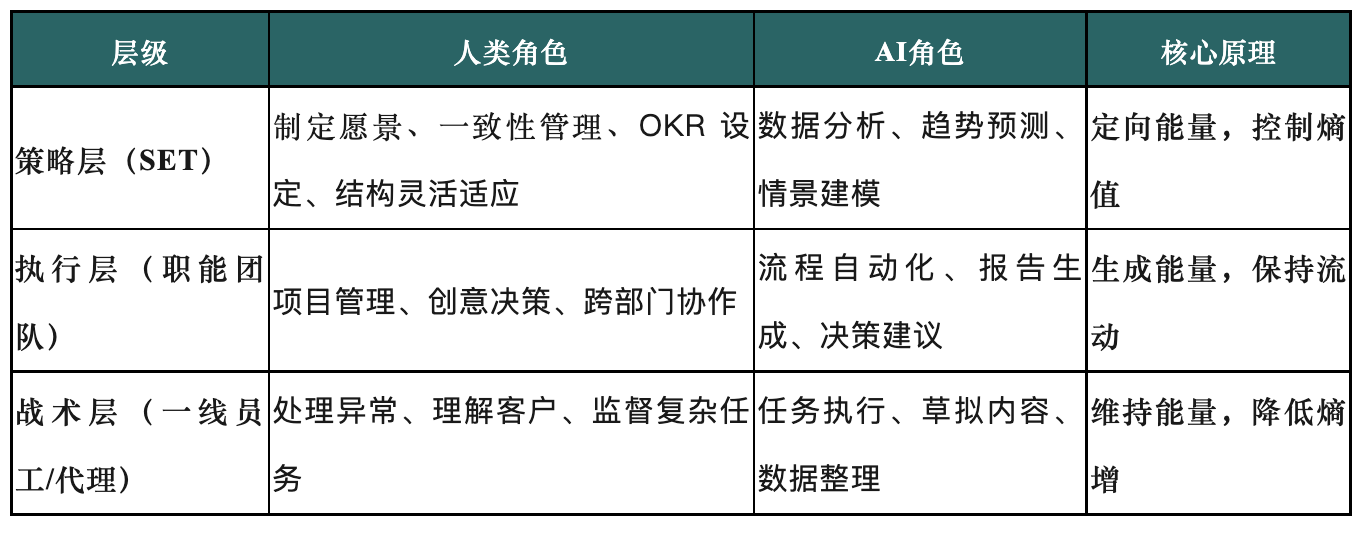
Neugestaltung von Organisationsstrukturen im KI-Zeitalter: Der Aufstieg des Strategic Execution Teams (SET): Der Artikel untersucht, wie traditionelle Organisationsstrukturen im Zeitalter der beschleunigten KI-Entwicklung der durch KI verursachten Komplexität kaum noch gewachsen sind. Es wird ein dreistufiges Organisationsmodell mit dem „Strategic Execution Team“ (SET) im Zentrum vorgeschlagen, das darauf abzielt, KI zu einem Teil des Teams zu machen und durch vernünftige Mensch-Maschine-Kollaborationsmechanismen eine agile Ausführung und intelligente Skalierung zu erreichen. Das SET ist dafür verantwortlich, Strategien in abteilungsübergreifende Maßnahmen umzusetzen, die Organisationsentropie zu überwachen, Strategien flexibel anzupassen und die Zusammenarbeit von Menschen, Prozessen und KI-Agenten zu koordinieren, um das Potenzial der KI freizusetzen und die Strategieumsetzung voranzutreiben. (Quelle: 36Kr)
Kann Crowdsourcing-Faktenprüfung Falschinformationen in sozialen Medien eindämmen?: Professor Preslav Nakov von der Mohamed bin Zayed University of Artificial Intelligence untersucht die Auswirkungen der Ersetzung von Drittanbieter-Faktenprüfern durch Community Notes bei Meta. Er ist der Ansicht, dass Crowdsourcing-Modelle wie Community Notes (hervorgegangen aus X’s Birdwatch) Potenzial haben, die Inhaltsmoderation jedoch eine Kombination verschiedener Methoden erfordert, darunter automatische Filterung, Crowdsourcing und professionelle Faktenprüfung. In Analogie zur Spamfilterung und dem Umgang von LLMs mit schädlichen Inhalten weist er darauf hin, dass jede Methode ihre Vor- und Nachteile hat und sie zusammenwirken sollten. Studien zeigen, dass Community Notes die Wirkung der Arbeit professioneller Faktenprüfer verstärken können; beide haben unterschiedliche Schwerpunkte, kommen aber zu ähnlichen Schlussfolgerungen und können sich ergänzen. (Quelle: MIT Technology Review)
