
Schlüsselwörter:GPT-5, KI-Schlussfolgerungsfähigkeit, AlphaEvolve, OpenAI Operator, Mistral AI, Berechnung und Denkketten während des Tests, Automatische Codeoptimierung durch KI, Multimodale KI-Modelle, Automatisierung der Jobsuche mit KI, Lokale Feinabstimmung von LLM
🔥 Im Fokus
OpenAI enthüllt Zukunftspläne: GPT-5 wird bestehende Tools integrieren und ein All-in-One-Erlebnis schaffen: Jerry Tworek, Vizepräsident für Forschung bei OpenAI, enthüllte während einer AMA-Veranstaltung auf Reddit, dass das Hauptziel des Basismodells der nächsten Generation, GPT-5, darin besteht, die Fähigkeiten bestehender Modelle zu verbessern und den umständlichen Wechsel zwischen Modellen zu reduzieren. Zu diesem Zweck plant OpenAI, bestehende Tools wie Codex (Programmierung), Operator (Ausführung von Computeraufgaben), Deep Research (Tiefenforschung) und Memory (Gedächtnisfunktion) in GPT-5 zu integrieren, um ein einheitliches Erlebnis zu schaffen. Teammitglieder teilten außerdem mit, dass Codex ursprünglich ein Nebenprojekt von Ingenieuren war, dessen interner Einsatz die Programmiereffizienz um etwa das Dreifache gesteigert hat, und dass flexible Preismodelle, einschließlich Pay-as-you-go, untersucht werden. (Quelle: WeChat)
Neue Dimensionen zur Verbesserung der KI-Schlussfolgerungsfähigkeit: Test-Time Compute und Chain-of-Thought: Lilian Weng, Alumna der Peking-Universität und ehemalige Leiterin der angewandten KI-Forschung bei OpenAI, erörtert in ihrem neuesten, ausführlichen Artikel „Why We Think“, wie die Schlussfolgerungsfähigkeiten großer Sprachmodelle durch Strategien wie „Test-Time Compute“ und „Chain-of-Thought (CoT)“ verbessert werden können. Der Artikel erläutert aus verschiedenen Perspektiven, darunter die Zwei-System-Theorie der Psychologie, die Sichtweise der Rechenressourcen und die Modellierung latenter Variablen, die Rationalität, Modelle „länger denken“ zu lassen. Zudem werden Forschungsfortschritte bei Schlüsseltechnologien wie paralleles Sampling, sequentielle Revision, Reinforcement Learning und die Nutzung externer Werkzeuge zur Verbesserung der Schlussfolgerungsleistung von Modellen beleuchtet. Weng betont, dass Modelle durch diese Methoden während des Schlussfolgerns mehr Rechenressourcen investieren können, um menschliche Tiefdenkprozesse zu simulieren und so bei komplexen Aufgaben bessere Ergebnisse zu erzielen. Sie weist auch auf zukünftige Forschungsrichtungen in Bereichen wie vertrauenswürdiges Schlussfolgern, Reward Hacking und unüberwachte Selbstkorrektur hin. (Quelle: WeChat, WeChat)
Google veröffentlicht AlphaEvolve: KI schreibt Code zur Optimierung von Algorithmen selbst und spart erheblich Rechenkosten: Google hat das KI-System AlphaEvolve vorgestellt, das Code autonom schreiben und optimieren kann und bereits in Projekten wie AlphaFold enormes Potenzial gezeigt hat. AlphaEvolve sucht mittels evolutionärer Algorithmen nach besseren Algorithmus-Implementierungen. Beispielsweise entdeckte es im Proteinfaltungsalgorithmus von AlphaFold einen neuen Aufmerksamkeitsmechanismus, der die Rechenkosten um 25 % senkte, was einer Einsparung von Rechenressourcen im Wert von mehreren Millionen Dollar entspricht. Dieser Durchbruch markiert einen wichtigen Schritt der KI in den Bereichen wissenschaftliche Entdeckung und Algorithmusoptimierung und verspricht zukünftig Kostensenkungen und Effizienzsteigerungen bei weiteren komplexen Berechnungsproblemen. (Quelle: Reddit r/ArtificialInteligence)

OpenAI gibt zu: KI-Schlussfolgerungsaufwand und Leistung sind direkt proportional, der Schlüssel zur Überlegenheit gegenüber menschlichen Fähigkeiten liegt in der „Denkzeit“: Noam Brown, Forscher bei OpenAI, betonte in einer Diskussion, dass sich die KI von einem „Pre-Training-Paradigma“ zu einem „Inferenz-Paradigma“ wandelt. Das Pre-Training sagt das nächste Wort auf Basis riesiger Datenmengen voraus und ist kostspielig; das Inferenz-Paradigma hingegen erlaubt es dem Modell, vor der Antwort tiefer „nachzudenken“, was zwar etwas höhere Kosten verursacht, aber die Antwortqualität signifikant verbessert. Beispielsweise übertraf das Modell o1 GPT-4o sowohl im AIME-Mathematikwettbewerb als auch bei wissenschaftlichen Fragen auf Doktoratsniveau (GPQA), und das Modell o3 erreichte bei Programmierwettbewerben bereits menschliches Spitzenniveau. Dies zeigt, dass durch erhöhten Rechenressourceneinsatz während der Inferenz (d.h. „Denkzeit“) die Leistung der KI bei komplexen Aufgaben enorm gesteigert werden kann und sogar Menschen übertreffen kann. (Quelle: WeChat)

🎯 Trends
Mistral AI erzielt signifikante Modellerfolge für 2025, mehrere Modelle zeigen herausragende Leistungen: Mistral AI hat im ersten Halbjahr 2025 mehrere wichtige Fortschritte erzielt und eine Reihe hochleistungsfähiger Modelle veröffentlicht, darunter Codestral 25.01 (führendes FIM-Modell), Mistral Small 3 & 3.1 (Bestes seiner Klasse, unterstützt Multimodalität und 130k Kontext), Mistral Saba (übertrifft Modelle, die dreimal größer sind), Mistral OCR (führendes OCR-Modell) sowie Mistral Medium 3. Diese Erfolge demonstrieren die starke Forschungs- und Entwicklungskompetenz von Mistral AI in verschiedenen Modellgrößen und Anwendungsbereichen, insbesondere bei der Codegenerierung, multimodalen Verarbeitung und OCR-Technologie. (Quelle: qtnx_)

Leistungsschwankungen bei Claude-Modellen in letzter Zeit, Nutzer berichten von Problemen mit Kontextverarbeitung und Artifact-Funktion: Nutzer der Reddit-Community berichten, dass bei den Claude-Modellen von Anthropic (insbesondere Opus 3) in letzter Zeit Probleme bei der Verarbeitung langer Kontexte, der Stabilität der Artifact-Generierung sowie bei Login und Verfügbarkeit aufgetreten sind. Konkret äußert sich dies in Chatabbrüchen nach wenigen Runden und darin, dass die Artifact-Funktion nicht abgeschlossen werden kann oder leere Dateien exportiert. Die Statusseite von Anthropic bestätigt eine Zunahme von Fehlern bei Anfragen mit langem Kontext sowie mehrere kurzzeitige Dienstunterbrechungen, was möglicherweise mit der Einführung der Artifact-Funktion und Backend-Anpassungen zusammenhängt. Einige Nutzer mildern die Probleme, indem sie direkt Markdown-Ausgaben anfordern, das Netzwerk wechseln oder Claude 3.5 Sonnet verwenden. (Quelle: Reddit r/ClaudeAI, qtnx_, Reddit r/ClaudeAI)
xAI veröffentlicht System-Prompts von Grok und enthüllt dessen humorvolles und kritisch denkendes Design: xAI hat die System-Prompts seines KI-Modells Grok veröffentlicht. Diese Prompts zeigen, dass Grok als humorvoller, leicht rebellischer und kritisch denkender KI-Assistent konzipiert wurde. Die Prompts betonen, dass Grok belehrende Antworten vermeiden und bei kontroversen Themen seinen einzigartigen „Grok-Stil“ zeigen soll. Dieser Schritt erhöht die Transparenz im Design des KI-Modellverhaltens und gibt der Öffentlichkeit Einblick in die Ursprünge der einzigartigen Persönlichkeit von Grok. (Quelle: Reddit r/artificial)

Meta testet möglicherweise Llama 3.3 8B Instruct-Modell auf OpenRouter: Meta testet möglicherweise sein Llama 3.3 8B Instruct-Modell auf der OpenRouter-Plattform. Das Modell wird als leichtgewichtige, schnell reagierende Version von Llama 3.3 70B mit einem Kontextfenster von 128.000 beschrieben und wird auf OpenRouter als kostenlos angezeigt. Einige Nutzer, die es getestet haben, empfanden die Ausgabe im Vergleich zu den Versionen 8B 3.1 oder 3.3 70B als etwas fade. Dieser Schritt könnte bedeuten, dass Meta den Einsatz und die Anwendungsszenarien von Modellen unterschiedlicher Größe untersucht. (Quelle: Reddit r/LocalLLaMA)
KI-gestützte umstrittene Entscheidungen bei F1-Rennen lösen Diskussionen aus: Eine Diskussion über umstrittene Entscheidungen, die von KI bei F1-Rennen getroffen wurden, hat die Aufmerksamkeit auf den Einsatz von KI im Leistungssport gelenkt. Obwohl spezifische Details unklar sind, geht es hierbei typischerweise um die Genauigkeit und Fairness von KI-Schiedsrichtersystemen bei Entscheidungen in Hochgeschwindigkeits- und komplexen Situationen sowie um die Frage, wie menschliche Schiedsrichter und KI-Systeme zusammenarbeiten können. (Quelle: Ronald_vanLoon)
Chinas erstes Flugzeugträger-Drohnenmutterschiff „Jiutian“ plant Erstflug im Juni: China plant den Erstflug seines ersten luftgestützten Drohnenmutterschiffs „Jiutian“ SS-UAV im Juni. Diese Drohne kann in 15.000 Metern Höhe patrouillieren, über 100 kleine Drohnen oder 1000 kg Raketen tragen und hat eine Reichweite von 7000 Kilometern. Diese Nachricht hat Aufmerksamkeit auf die Entwicklung der chinesischen militärischen Drohnentechnologie gelenkt. (Quelle: menhguin)
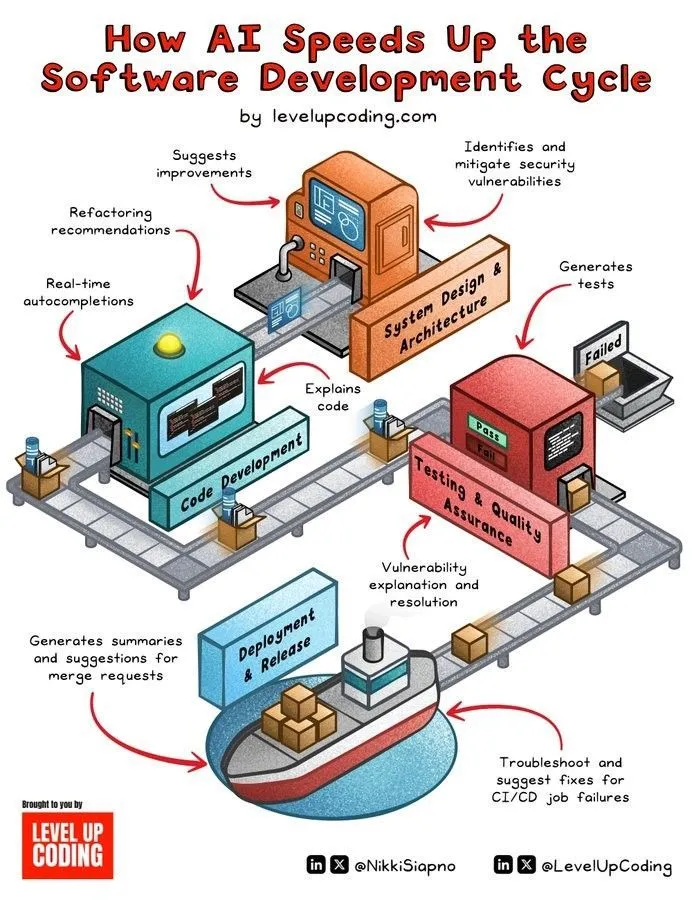
KI-gestützte Beschleunigung des Softwareentwicklungszyklus: KI-Technologie beschleunigt den Lebenszyklus der Softwareentwicklung erheblich durch die Automatisierung von Phasen wie Codegenerierung, Testen, Debugging und Dokumentationserstellung. KI-Tools helfen Entwicklern, die Effizienz zu steigern, repetitive Arbeiten zu reduzieren und potenziell Fehler zu entdecken, wodurch die Markteinführungszeit verkürzt wird. (Quelle: Ronald_vanLoon)
Gehirnähnliche Miniaturtechnologie verleiht humanoiden Robotern Echtzeitwahrnehmung und Denkfähigkeit: Eine Miniaturtechnologie, die die Struktur des menschlichen Gehirns nachahmt, wird entwickelt, um humanoiden Robotern Echtzeit-Sehwahrnehmung und Denkfähigkeiten zu verleihen. Diese Technologie könnte neuromorphes Computing oder hocheffiziente KI-Chipdesigns umfassen, mit dem Ziel, Robotern schnellere und intelligentere Reaktionen in komplexen Umgebungen zu ermöglichen. (Quelle: Ronald_vanLoon)

Fourier Intelligence stellt selbst entwickelten humanoiden Roboter Fourier GR-1 vor: Fourier Intelligence (Fourier Robots) hat seinen selbst entwickelten humanoiden Roboter GR-1 vorgestellt. Das Design des Roboters legt Wert auf fortschrittliche Bewegungssteuerung und eine hochgradig bionische Rumpfstruktur, um flexiblere und natürlichere Bewegungsfähigkeiten zu erreichen, und demonstriert Chinas Fortschritte im Bereich humanoider Roboter. (Quelle: Ronald_vanLoon)
Agilitäts-Upgrade für bionischen Roboter Unitree G1: Das Unternehmen Unitree hat eine agilitätsgesteigerte Version seines bionischen Roboters G1 vorgestellt. Dies bedeutet in der Regel Verbesserungen in Bereichen wie Bewegungssteuerung, Gleichgewichtsfähigkeit und Anpassungsfähigkeit an die Umgebung, wodurch der Roboter Aufgaben flexibler ausführen und komplexe Gelände bewältigen kann. (Quelle: Ronald_vanLoon)
Chinesische humanoide Roboter führen Qualitätsprüfungsaufgaben durch: In China werden humanoide Roboter bereits zur Durchführung von Qualitätsprüfungsaufgaben eingesetzt. Dies zeigt, dass sich die Anwendung humanoider Roboter im Bereich der industriellen Automatisierung schrittweise erweitert, wobei ihre Flexibilität und Wahrnehmungsfähigkeiten genutzt werden, um menschliche Arbeit bei repetitiven und präzisionsfordernden Prüfaufgaben zu ersetzen oder zu unterstützen. (Quelle: Ronald_vanLoon)
Nanoroboter tragen „versteckte Waffen“ zur Abtötung von Krebszellen: Ein neuer Fortschritt in der Medizintechnik zeigt, dass Nanoroboter „versteckte Waffen“ tragen können, um Krebszellen präzise anzugreifen und abzutöten. Diese Technologie nutzt die geringe Größe und Steuerbarkeit von Nanorobotern und verspricht präzisere und nebenwirkungsärmere Krebstherapien. (Quelle: Ronald_vanLoon)
Die Bedeutung von Privacy Enhancing Technologies für moderne Unternehmen nimmt zu: Mit der Verschärfung der Datenschutzbestimmungen und dem wachsenden Bewusstsein der Nutzer für den Schutz persönlicher Daten gewinnen Privacy Enhancing Technologies (PETs) für moderne Unternehmen zunehmend an Bedeutung. Technologien wie Federated Learning, homomorphe Verschlüsselung usw. ermöglichen Datenanalysen und Wertschöpfung unter Wahrung des Datenschutzes und unterstützen Unternehmen bei der Einhaltung von Vorschriften. (Quelle: Ronald_vanLoon)

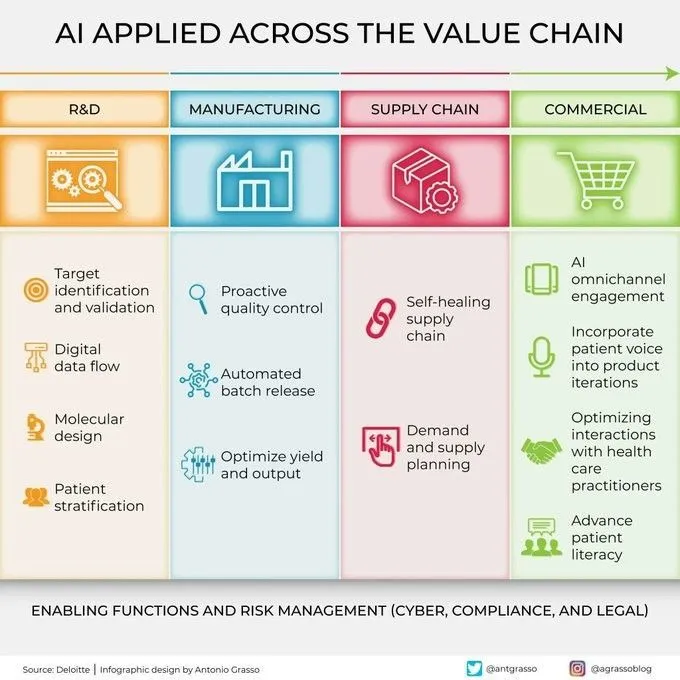
KI wird zunehmend in allen Gliedern der Wertschöpfungskette eingesetzt: Künstliche Intelligenz wird in allen Gliedern der Wertschöpfungskette von Unternehmen umfassend eingesetzt, einschließlich Forschung und Entwicklung, Produktion, Marketing, Vertrieb und Kundendienst. Durch Datenanalyse, prädiktive Modellierung, automatisierte Prozesse usw. hilft KI Unternehmen, die Betriebseffizienz zu optimieren, das Kundenerlebnis zu verbessern und neuen Geschäftswert zu schaffen. (Quelle: Ronald_vanLoon)
🧰 Tools
KernelSU: Kernel-basierte Android-Root-Lösung: KernelSU ist eine Kernel-basierte Root-Lösung für Android-Geräte. Es bietet su auf Kernel-Ebene und Root-Zugriffsverwaltung, verfügt über ein Modulsystem basierend auf OverlayFS sowie Anwendungsprofilfunktionen, um eine tiefere Kontrolle über Geräteberechtigungen zu ermöglichen. Das Projekt unterstützt Android GKI 2.0-Geräte (Kernel 5.10+), ist aber auch mit älteren Kerneln kompatibel (4.14+, manuelle Kompilierung erforderlich) und unterstützt WSA, ChromeOS und containerisierte Android-Umgebungen. (Quelle: GitHub Trending)

Sunshine: Selbst gehosteter Game-Streaming-Host, kompatibel mit Moonlight: Sunshine ist eine Open-Source-Software für einen selbst gehosteten Game-Streaming-Host, die es Benutzern ermöglicht, PC-Spiele auf verschiedene Moonlight-kompatible Geräte zu streamen. Es unterstützt Hardware-Encoding für AMD-, Intel- und Nvidia-GPUs und bietet auch Software-Encoding-Optionen, um ein Cloud-Gaming-Erlebnis mit geringer Latenz zu ermöglichen. Benutzer können die Konfiguration und das Client-Pairing über eine Web-Benutzeroberfläche vornehmen. (Quelle: GitHub Trending)

Tasmota: Open-Source-Alternative Firmware für ESP8266/ESP32-Geräte: Tasmota ist eine alternative Firmware für Smart-Geräte, die auf ESP8266- und ESP32-Chips basieren. Es bietet eine benutzerfreundliche Web-Oberfläche zur Konfiguration, unterstützt OTA-Online-Upgrades, ermöglicht Automatisierung durch Timer oder Regeln und bietet vollständige lokale Steuerung über MQTT, HTTP, serielle Schnittstelle oder KNX-Protokolle, wodurch die Erweiterbarkeit und Anpassbarkeit der Geräte verbessert wird. (Quelle: GitHub Trending)
Limbo: Modernes Rust-Evolutionsprojekt von SQLite: Das Limbo-Projekt zielt darauf ab, eine moderne Weiterentwicklung von SQLite in der Programmiersprache Rust zu erstellen. Es unterstützt asynchrones I/O mit io_uring unter Linux, ist kompatibel mit dem SQL-Dialekt, dem Dateiformat und der C-API von SQLite und bietet Bindings für Sprachen wie JavaScript/WASM, Rust, Go, Python und Java. Zukünftige Pläne umfassen die Integration von Vektorsuche, verbesserte konkurrierende Schreibvorgänge und Schemamanagement. (Quelle: GitHub Trending)

Ventoy: Bootfähige USB-Lösung der nächsten Generation: Ventoy ist ein Open-Source-Tool zur Erstellung bootfähiger USB-Laufwerke, das das direkte Booten von Image-Dateien in verschiedenen Formaten wie ISO, WIM, IMG, VHD(x), EFI usw. unterstützt, ohne dass das USB-Laufwerk wiederholt formatiert werden muss. Benutzer müssen lediglich die Image-Dateien auf das USB-Laufwerk kopieren, und Ventoy generiert automatisch ein Bootmenü. Es unterstützt mehrere Betriebssysteme und Boot-Modi (Legacy BIOS, UEFI) und ist mit MBR- und GPT-Partitionen kompatibel. (Quelle: GitHub Trending)

Doctor: LangChain-gestütztes LLM-Agenten-Tool für Web-Crawling und -Verständnis: Doctor ist ein Tool, das LLM-Agenten hilft, Webinhalte in Echtzeit zu crawlen und zu verstehen. Es kombiniert Webseitenverarbeitung, Vektorsuche und die Dokumentverarbeitungsfähigkeiten von LangChain und stellt Dienste über FastAPI bereit. Benutzer können Doctor nutzen, um die Informationsbeschaffungs- und Analysefähigkeiten ihrer KI-Anwendungen zu verbessern. (Quelle: LangChainAI, Hacubu)
Deep Research Agent: Lokal laufender, datenschutzfreundlicher KI-Forschungsagent: Ein datenschutzorientierter Open-Source-KI-Agent, der lokal ausgeführt werden kann, um beliebige Themen zu recherchieren. Er nutzt LangGraph, um seinen iterativen Forschungsworkflow zu steuern, und bietet Benutzern ein leistungsstarkes, lokalisiertes Forschungstool, ohne dass Daten in die Cloud hochgeladen werden müssen. (Quelle: LangChainAI, Hacubu)

Intelligenter Terminal-Assistent: Multi-OS-Tool zur Umwandlung von natürlicher Sprache in Kommandozeilenbefehle: Ein intelligenter Terminal-Assistent, der Anweisungen in natürlicher Sprache in Terminalbefehle für verschiedene Betriebssysteme umwandeln kann. Das Tool basiert auf einem Multi-Agenten-System von LangGraph und verwendet A2A- und MCP-Protokolle für die plattformübergreifende Ausführung, um die Bedienung der Kommandozeile zu vereinfachen und die Nutzungsschwelle für Benutzer zu senken. (Quelle: LangChainAI)

Montelimar: Open-Source On-Device OCR-Toolkit: Julien Blanchon hat Montelimar veröffentlicht, ein Open-Source-Toolkit für OCR (Optical Character Recognition) auf dem Gerät. Es unterstützt das Erstellen von Screenshots und die Durchführung von OCR auf verschiedenen Bildschirmbereichen, ist kompatibel mit Nougat- und OCRS-Modellen und verwendet Rust (OCRS) bzw. MLX (Nougat) als Backend. Das Tool kann LaTeX, Tabellen, Markdown (über Nougat, langsamer) und reinen Text (über OCRS, schneller) ausgeben und bietet eine Verlaufsfunktion sowie systemweite Tastenkombinationen. (Quelle: awnihannun)
OpenF5 TTS: Kommerziell nutzbares Text-to-Speech-Modell unter Apache 2.0 Lizenz: OpenF5 TTS ist ein Text-to-Speech-Modell, das auf dem F5-TTS-Modell neu trainiert wurde und unter der Apache 2.0 Open-Source-Lizenz steht, wodurch es für kommerzielle Zwecke genutzt werden kann. Das Modell erfreut sich derzeit großer Beliebtheit unter den Text-to-Speech-Modellen auf Hugging Face und bietet Entwicklern eine qualitativ hochwertige und kommerziell nutzbare Option für die Sprachsynthese. (Quelle: ClementDelangue)
Tensor Slayer: Werkzeug zur Leistungssteigerung von Modellen ohne Training: Tensor Slayer ist ein neu veröffentlichtes Werkzeug, das behauptet, die Modellleistung um 25 % steigern zu können, ohne Feinabstimmung, Datensätze, zusätzliche Rechenkosten oder Trainingszeit, indem es direkt Tensor-Patching (direct tensor patching) anwendet. Dieses Konzept ist ziemlich revolutionär und zielt darauf ab, die Verbesserung von KI-Modellen zu demokratisieren. (Quelle: TheZachMueller)
Photoshop nutzt lokale Computer Use Agents (c/ua) für codefreie Bedienung: Computer Use Agents (c/ua) demonstrieren, wie durch Benutzeraufforderungen, Modellauswahl, Docker und geeignete Agentenzyklen eine codefreie Bedienung in Photoshop realisiert werden kann. Dies zielt darauf ab, die Hürde für normale Benutzer bei der Verwendung komplexer Software zu senken, indem der Bedienungsprozess durch KI-Agenten vereinfacht wird. (Quelle: Reddit r/artificial)
PlainRepo: Offline-Anwendung zum selektiven Kopieren großer Code-/Textblöcke für LLM-Kontext-Extraktion: PlainRepo ist eine kostenlose Open-Source-Offline-Anwendung, die es Benutzern ermöglicht, selektiv große Code- oder Textfragmente zu kopieren, damit lokale LLMs Kontextinformationen extrahieren können. Dies ist sehr nützlich für Benutzer, die lokale LLMs ohne Netzwerkverbindung oder aus Datenschutzgründen verwenden müssen. (Quelle: Reddit r/LocalLLaMA, Plus-Garbage-9710)
M0D.AI: Personalisierter KI-Interaktions- und Kontrollrahmen, von Benutzer und KI in fünf Monaten gemeinsam entwickelt: Der Benutzer James O’Kelly hat in fünfmonatiger, intensiver Zusammenarbeit mit KI (wie Gemini, ChatGPT) und etwa 13.000 Dialogen einen hochgradig angepassten KI-Interaktions- und Kontrollrahmen namens M0D.AI erstellt. Das System umfasst ein Python-Backend, einen Flask-Webserver, eine dynamische Frontend-Benutzeroberfläche sowie eine metakognitive Schicht namens mematrix.py zur Überwachung und Steuerung des KI-Verhaltens. M0D.AI zeigt, wie Benutzer ohne Programmierhintergrund mithilfe von KI komplexe Softwaresysteme entwerfen und entwickeln können. (Quelle: Reddit r/artificial)
📚 Lernen
LLM Engineering: 8-wöchiger Kurs zur Beherrschung von KI und LLMs – Ressourcen-Repository: Ein 8-wöchiger Kurs namens „LLM Engineering – Master AI and LLMs“ zielt darauf ab, den Teilnehmern die Beherrschung des Engineerings großer Sprachmodelle zu vermitteln. Das begleitende GitHub-Repository stellt wöchentliche Projektcodes, Einrichtungsanleitungen (PC, Mac, Linux) sowie Colab-Links zur Verfügung. Der Kurs legt Wert auf praktische Übungen, beginnend mit der Installation von Ollama zum Ausführen von Llama 3.2 und vertieft schrittweise Themen wie HuggingFace, API-Nutzung und Modell-Feinabstimmung. Es werden auch Anleitungen zur Verwendung von Ollama als kostenlose Alternative zu kostenpflichtigen APIs wie OpenAI angeboten. (Quelle: GitHub Trending)

Probabilistische Konsistenz in LLMs: Theoretische Grundlagen und empirische Unterschiede: Ein Paper mit dem Titel „Probabilistic Consistency in LLMs: Theoretical Foundations and Empirical Differences“ weist darauf hin, dass große Sprachmodelle (LLMs) Token-Wahrscheinlichkeiten mit einer festen Strategie berechnen, die tatsächliche Leistung der Modelle bei unterschiedlichen Token-Reihenfolgen jedoch von der theoretischen probabilistischen Konsistenz abweicht. Die Studie trainierte ein GPT-2-Modell auf neurowissenschaftlichen Texten (unter Verwendung von vorwärts-, rückwärts- und permutierten Token-Reihenfolgen) und zeigte, dass die Perplexität theoretisch unabhängig von der Reihenfolge ist, empirische Ergebnisse jedoch zeigten, dass das Modell diesen Test aufgrund von Architekturbias nicht bestand. Aufmerksamkeitsbias (lokal und weitreichend) wird als direkte Ursache für die beobachteten Konsistenzfehler angesehen. (Quelle: menhguin)

BoldVoice nutzt maschinelles Lernen zur Quantifizierung und Anleitung der englischen Akzentstärke: Die BoldVoice-App verwendet maschinelles Lernen und latente Raumtechniken, um die Stärke des englischen Akzents zu quantifizieren und Benutzern Ausspracheanleitungen zu geben. Diese Methode soll Benutzern helfen, ihre englische Aussprache und ihren Akzent effektiver zu verbessern. (Quelle: dl_weekly)
Milvus-Blog: Herausforderungen und Optimierungen für effiziente Metadatenfilterung bei gleichzeitig hoher Recall-Rate in Produktionsumgebungen: Milvus hat einen praktischen Blogbeitrag veröffentlicht, der untersucht, wie bei der Vektorsuche in Produktionsumgebungen eine effiziente Metadatenfilterung bei gleichzeitig hoher Recall-Rate erreicht werden kann. Der Artikel diskutiert die damit verbundenen Herausforderungen und schlägt Optimierungsstrategien vor. (Quelle: dl_weekly)
ColPali-Ähnlichkeitskarten für Modellerklärbarkeit: Ähnlichkeitskarten (similarity maps) in visuellen Dokumentenretrieval-Modellen wie ColPali bieten eine starke Erklärbarkeit für Übereinstimmungen zwischen Anfragen und Dokumentfragmenten auf Segmentebene. Durch die Visualisierung, welche Bildbereiche mit der Anfrage zusammenhängen (z. B. durch Heatmaps), wird der Entscheidungsprozess des Modells verständlicher. Tony Wu stellt eine entsprechende Kurzanleitung zur Verfügung. (Quelle: lateinteraction, tonywu_71, lateinteraction)
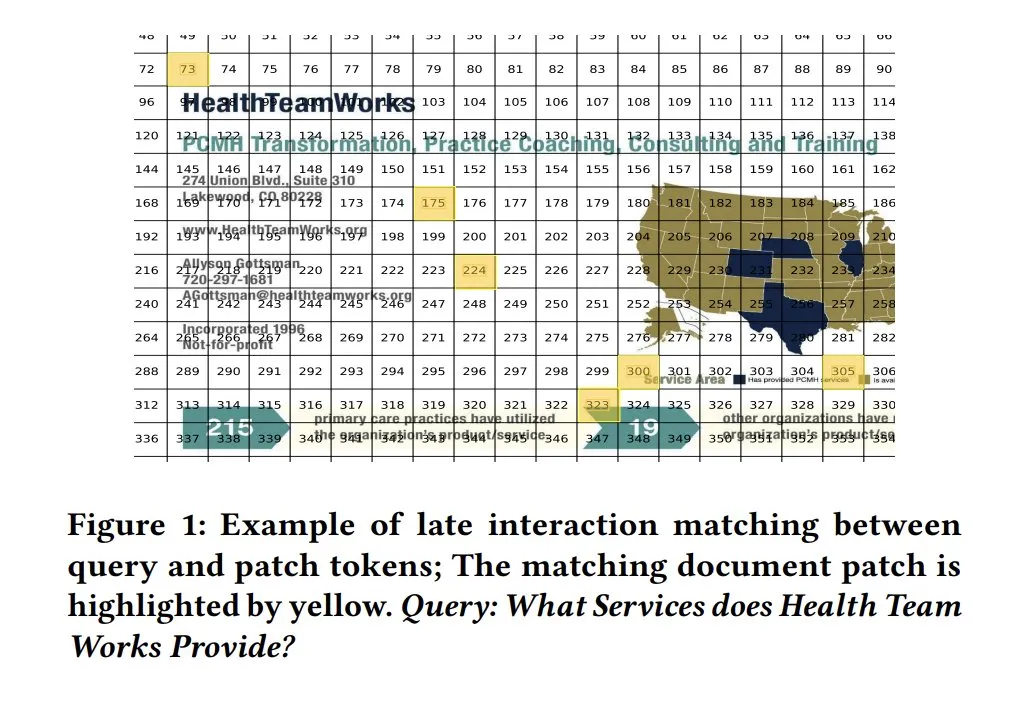
soarXiv: Eine elegante Art, menschliches Wissen zu erforschen: Jinay stellt soarXiv vor, eine Plattform, die darauf abzielt, wissenschaftliche Arbeiten auf eine ästhetischere und interaktivere Weise zu erforschen. Benutzer können in der URL einer ArXiv-Arbeit „arxiv“ durch „soarxiv“ ersetzen, um die Arbeit in einer sternenkartenähnlichen Oberfläche zu lokalisieren und zu durchsuchen. Die Plattform hat bis April 2025 2,8 Millionen Arbeiten eingebettet. (Quelle: menhguin)
MLX-LM-LoRA v0.3.3 veröffentlicht, vereinfacht lokales Fine-Tuning auf Apple Silicon: Gökdeniz Gülmez hat MLX-LM-LoRA v0.3.3 veröffentlicht, was den Prozess des lokalen Modell-Fine-Tunings auf Apple Silicon weiter vereinfacht und flexibilisiert. Die neue Version unterstützt die direkte Einstellung der Trainings-Epochen in der Trainingskonfiguration oder über die Kommandozeile und bietet Beispielskripte und Notebooks, einschließlich grundlegendem Fine-Tuning und fortgeschrittenem Präferenztraining mit DPO, wobei nur etwa 20 Codezeilen für den Start erforderlich sind. (Quelle: awnihannun)
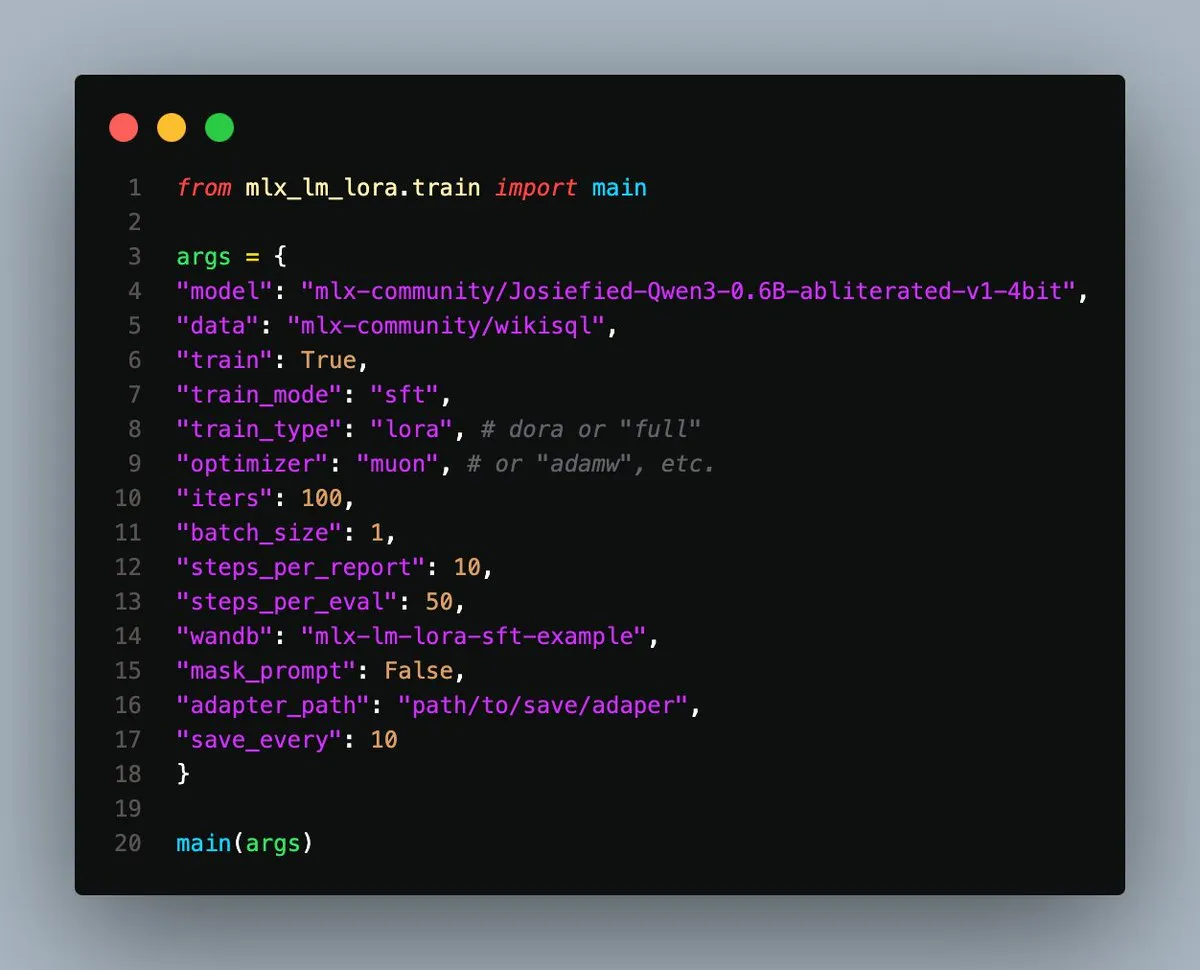
Analyse von System-Prompt-Leaks: Enthüllung interner Architekturen und Verhaltensregeln gängiger LLMs: Simbaproduz hat auf GitHub ein Projekt veröffentlicht, das die jüngsten Leaks von System-Prompts großer Sprachmodelle (wie Claude 3.7, ChatGPT-4o, Grok 3, Gemini usw.) umfassend analysiert. Dieser Leitfaden untersucht eingehend die internen Architekturen, die operative Logik und die Verhaltensregeln dieser Modelle, einschließlich Informationspersistenz, Bildverarbeitungsstrategien, Web-Navigationsmethoden, Personalisierungssysteme und Abwehrmechanismen gegen manipulative Eingriffe. Diese Informationen sind von großem Wert für die Entwicklung von LLM-Tools, Agenten und Bewertungssystemen. (Quelle: Reddit r/MachineLearning)
ICML 2025 Paper untersucht Frequenzbereichszerlegung von adversariellen Bildstörungen: Ein ICML 2025 Spotlight Paper der University of Chinese Academy of Sciences und des Institute of Computing Technology mit dem Titel „Diffusion-based Adversarial Purification from the Perspective of the Frequency Domain“ legt nahe, dass adversarielle Störungen eher die Hochfrequenz-Amplituden- und Phasenspektren von Bildern zerstören. Basierend darauf schlagen die Forscher vor, im umgekehrten Prozess von Diffusionsmodellen Niederfrequenzinformationen der Originalprobe als Prior einzuspeisen, um die Generierung sauberer Proben zu steuern, wodurch adversarielle Störungen effektiv entfernt und der semantische Inhalt des Bildes erhalten bleibt. (Quelle: WeChat)

ICML 2025 Paper TokenSwift: 3-fache Beschleunigung der Generierung von 100K-langen Texten durch „Autovervollständigung“: Das BIGAI NLCo-Team stellt auf der ICML 2025 das Paper „TokenSwift: Lossless Acceleration of Ultra Long Sequence Generation“ vor, das einen verlustfreien, hocheffizienten Beschleunigungsrahmen namens TokenSwift für die Inferenz von Texten auf 100K-Token-Ebene vorschlägt. Durch Mechanismen wie paralleles Entwerfen mehrerer Token, n-Gramm-heuristische Vervollständigung, parallele Verifizierung mit Baumstruktur und dynamisches KV-Cache-Management erreicht dieser Rahmen eine mehr als 3-fache Beschleunigung der Inferenz bei gleichbleibender Konsistenz mit der Ausgabe des Originalmodells, was die Effizienz der Generierung ultralanger Sequenzen erheblich verbessert. (Quelle: WeChat)

💼 Wirtschaft
OpenAI wird vorgeworfen, den KI-Rüstungswettlauf anzuheizen, vor dem es einst gewarnt hat: Ein Artikel von Bloomberg untersucht, wie OpenAI nach der Einführung von ChatGPT von einer Organisation, die vor KI-Risiken warnte, zu einem Schlüsselakteur wurde, der den Wettbewerb in der KI-Technologie vorantreibt. Der Artikel analysiert möglicherweise den strategischen Wandel von OpenAI, den Kommerzialisierungsdruck sowie die Auswirkungen seines Verhaltens auf die Entwicklungsrichtung und Sicherheitsüberlegungen der gesamten KI-Branche. (Quelle: Reddit r/ArtificialInteligence)

Trump-Regierung streicht Harvard-Universität fast 3 Milliarden US-Dollar Forschungsgelder, löst globalen Wettbewerb um Talente aus: Die Trump-Regierung hat Forschungsgelder in Höhe von fast 3 Milliarden US-Dollar für die Harvard-Universität gestrichen, was über 350 Projekte betrifft. Dieser Schritt wird als schwerer Schlag für das US-amerikanische Forschungssystem angesehen. Gleichzeitig haben die EU, Kanada, Australien und andere Länder und Regionen millionenschwere Förderprogramme aufgelegt, um betroffene amerikanische Spitzenwissenschaftler anzuziehen, was eine Diskussion über die globale Verlagerung von Forschungstalenten auslöst. Die Harvard-Universität hat Klage eingereicht und selbst 250 Millionen US-Dollar zur Krisenbewältigung bereitgestellt. (Quelle: WeChat)

KI-Startup Spellbook verzeichnet drei Jahre in Folge Wachstum des durchschnittlichen Vertragswerts (ACV): Trotz Bedenken, dass die Kommerzialisierung von KI-Technologie zu Preisdruck führen könnte, erklärte Scott Stevenson, Mitbegründer des KI-Rechtssoftware-Startups Spellbook, dass der durchschnittliche Vertragswert (ACV) seines Unternehmens drei Jahre in Folge gestiegen ist. Er ist der Ansicht, dass schnell agierende Teams kontinuierlich neuen Wert durch KI-Produkte schaffen können und so potenziellem Preisdruck entgegenwirken. (Quelle: scottastevenson)
🌟 Community
Zehn Jahre DeepDream: Ein Meilenstein der KI-Kunst und seine weitreichenden Auswirkungen: Alex Mordvintsev, der Schöpfer von DeepDream, blickt auf die Entstehung dieses phänomenalen KI-Kunstwerkzeugs vor zehn Jahren zurück. Cristóbal Valenzuela, Mitbegründer von Runway, teilte ebenfalls mit, wie DeepDream ihn dazu inspirierte, sich dem Bereich der KI-Kunst zu widmen und schließlich Runway mitzugründen. Das Aufkommen von DeepDream markierte eine frühe Demonstration des Potenzials von KI in der Kunstschaffung und hatte tiefgreifende Auswirkungen auf die nachfolgende Entwicklung von generativer Kunst und KI-Content-Erstellungstools. (Quelle: c_valenzuelab)

Braucht KI einen technischen Mitgründer? Heiße Debatte entfacht: In sozialen Medien wird darüber diskutiert, ob „frühe VCs Gründern raten, keinen technischen Mitgründer mehr zu benötigen, da ein Produktmanager und KI ausreichen, um ein Produkt zu entwickeln“. Diese Ansicht löste breite Kontroversen aus. Danielle Fong und andere äußerten sich ablehnend und deuteten an, dass KI derzeit die Kernrolle und das tiefe technische Verständnis eines technischen Gründers noch nicht vollständig ersetzen kann. (Quelle: jonst0kes)
Diskussion über KI-Halluzinationen: Technische Ursachen und Bewältigungsstrategien: Die Community diskutiert intensiv das Problem der „Halluzinationen“ (selbstbewusstes Generieren falscher oder erfundener Informationen) bei KI-Sprachmodellen (wie ChatGPT, Claude etc.). Diskussionspunkte umfassen die technischen Ursachen von Halluzinationen (z.B. Mängel im Aufmerksamkeitsmechanismus, Rauschen in Trainingsdaten, fehlende Verankerung des Modells in der realen Welt), ob RAG oder Feinabstimmung diese beseitigen können, wie Nutzer LLM-Ausgaben kritisch bewerten sollten und wie Entwickler ein Gleichgewicht zwischen Kreativität und faktischer Genauigkeit finden können. Es gibt die Ansicht, dass alle LLM-Ausgaben als potenziell halluzinatorisch betrachtet und vom Nutzer überprüft werden sollten. (Quelle: Reddit r/ArtificialInteligence)
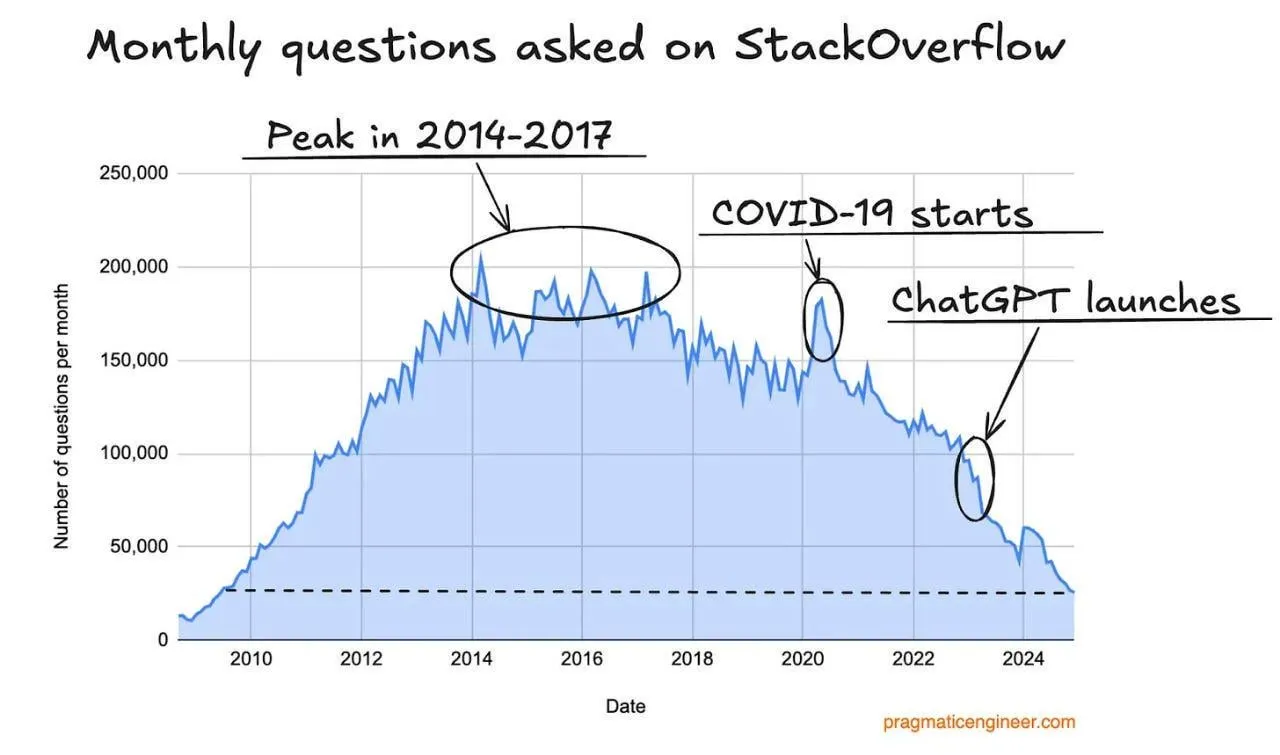
Rückgang der Zugriffszahlen bei Stack Overflow, möglicherweise durch KI-Programmierassistenten beeinflusst: Ein Nutzer beobachtete einen Rückgang der Zugriffszahlen auf der Website Stack Overflow und vermutet, dass dies mit dem Aufkommen von KI-Programmierassistenten wie ChatGPT zusammenhängen könnte. Entwickler stellen zunehmend direkte Fragen an KI, um Code-Schnipsel und Lösungen zu erhalten, was die Abhängigkeit von traditionellen Frage-Antwort-Communities verringert. In den Kommentaren sind sich die Nutzer im Allgemeinen einig, dass KI-Assistenten in Bezug auf Direktheit der Antworten und Vermeidung negativer Community-Emotionen Vorteile bieten, äußern aber auch Bedenken, dass eine übermäßige Abhängigkeit von KI von vorhandenen Daten in Zukunft zu einem Mangel an Trainingsdaten führen könnte. (Quelle: Reddit r/ArtificialInteligence)
Dozent des LLM-Engineering-Kurses teilt Lernerfahrungen und Ressourcen: Ed Donner, Dozent des LLM-Engineering-Kurses, teilte die Lehrphilosophie und Ressourcen seines Kurses und betonte die Bedeutung des Lernens durch praktisches Tun (DOING). Er ermutigt die Studierenden, aktiv mit Code zu arbeiten, und stellt Einrichtungsanleitungen für PC, Mac und Linux sowie Notebook-Links für Google Colab zur Verfügung, um das Lernen und Experimentieren in verschiedenen Umgebungen zu erleichtern. Die Kursinhalte umfassen Ollama, HuggingFace, API-Nutzung usw. und bieten Lösungen für die Verwendung lokaler Modelle als Ersatz für kostenpflichtige APIs. (Quelle: ed-donner)
Nutzererfahrung: Verbesserung des Denkens und der Kommunikationsfähigkeiten mit Claude: Ein Claude Pro-Nutzer teilte seine Erfahrungen darüber, wie die Interaktion mit KI ihm geholfen hat, seine Denkweise und Kommunikationsfähigkeiten zu verbessern. Durch die Interaktion mit Claude lernte der Nutzer, sich bei der Problemlösung besser selbst zu „prompten“, Kernprobleme zu identifizieren und bei der Kommunikation mit Kollegen mehr Wert auf klare Ausdrucksweise und Perspektivwechsel zu legen. Dadurch erkannte er die positive Rolle von KI-gestützten Werkzeugen bei der Verbesserung der persönlichen kognitiven und expressiven Fähigkeiten. (Quelle: Reddit r/ClaudeAI)
„Diskriminator-Generator-Lücke“ möglicherweise Kernkonzept für KI-gestützte wissenschaftliche Innovation: Jason Wei schlägt vor, dass die „Diskriminator-Generator-Lücke“ (Discriminator-generator gap) die wichtigste Idee für KI in der wissenschaftlichen Innovation sein könnte. Wenn genügend Rechenleistung, clevere Suchstrategien und klare Metriken vorhanden sind, kann alles, was messbar ist, von KI optimiert werden. Dieses Konzept betont den iterativen Prozess, bei dem ein Generator Lösungen vorschlägt und ein Diskriminator deren Qualität bewertet, um Innovationen voranzutreiben. Dies gilt insbesondere für Umgebungen, die schnell validierbar sind, kontinuierliche Belohnungen bieten und skalierbar sind. (Quelle: _jasonwei, dotey)
Transformation und Herausforderungen für Produktmanager im KI-Zeitalter: In sozialen Medien wird der Einfluss von KI auf die Rolle des Produktmanagers diskutiert. Es wird die Ansicht vertreten, dass die Produktmanagerbranche in den nächsten 18 Monaten vor einem Wandel stehen wird und PMs, die die Bedürfnisse der Nutzer nicht verstehen, möglicherweise verdrängt werden. KI-Tools (wie AI Agents) können Ideen in kurzer Zeit in Produkte umsetzen, aber die eigentliche Schwierigkeit besteht darin, die Kernprobleme der Nutzer zu finden und präzise Lösungen anzubieten. Diese Position wird letztendlich von der Fähigkeit bestimmt, Nutzerprobleme und Lösungen aufeinander abzustimmen und zu verstehen, und nicht nur davon, Dokumente und Prototypen zu erstellen. (Quelle: dotey)
KI-Sicherheitsparadoxon: Superintelligenz könnte für die verteidigende Seite vorteilhafter sein: Richard Socher stellt das „KI-Sicherheitsparadoxon“ vor: Unter vernünftigen Annahmen könnte das Aufkommen von Superintelligenz tatsächlich für die verteidigende Seite in biologischen oder Cyberkriegen vorteilhafter sein. Mit sinkenden Grenzkosten der Intelligenz können durch Red-Teaming mehr Angriffsvektoren entdeckt und Systeme verstärkt oder immunisiert werden, bis alle relevanten Angriffspfade abgedeckt sind. Theoretisch kann ein System vollständig immunisiert werden, wenn die Verteidigungskosten gegen Null gehen. Diese Ansicht stellt die traditionelle Annahme in Frage, dass die KI-Entwicklung die Asymmetrie zwischen Angriff und Verteidigung verschärfen wird. (Quelle: RichardSocher)
Streit um Standards für KI-Agenten-Anwendungen: CONTRIBUTING.md als bessere Praxis?: Angesichts des Phänomens, dass derzeit 9 verschiedene Standards für KI-Agenten-Regeln konkurrieren, schlagen einige Entwickler vor, stattdessen einfach die CONTRIBUTING.md-Datei eines Projekts zu verwenden, um das Verhalten von KI-Agenten zu regeln. Diese Datei enthält normalerweise bereits Richtlinien für den Codestil, relevante Referenzen und Kompilierungsfragmente und könnte als natürliche Grundlage für KI-Agenten-Regeln dienen, um das Rad nicht neu zu erfinden. (Quelle: JayAlammar)

💡 Sonstiges
Peter Lax, Autor des Standardwerks „Functional Analysis“, im Alter von 99 Jahren verstorben: Der mathematische Gigant Peter Lax, erster Träger des Abelpreises für angewandte Mathematik, ist im Alter von 99 Jahren verstorben. Professor Lax war bekannt für sein Standardwerk „Functional Analysis“ und leistete grundlegende Beiträge in Bereichen wie partiellen Differentialgleichungen, Strömungsmechanik und numerischer Berechnung, wie das Lax-Äquivalenztheorem und die Lax-Friedrichs/Lax-Wendroff-Methoden. Er war auch einer der ersten Pioniere, die Computertechnologie in der mathematischen Analyse einsetzten, und seine Arbeit beeinflusste die wissenschaftliche Forschung und Ingenieurpraxis tiefgreifend. (Quelle: WeChat)

KI-Jobsuche: KI-Agent bewirbt sich mit OpenAI Operator mit einem Klick auf tausend Stellen – löst Diskussion aus: Ein Video zeigt, wie ein KI-Agent mithilfe des Operator-Tools von OpenAI mit einem Klick Bewerbungen an 1000 Stellen verschickt. Dieses Phänomen hat eine Diskussion über den Einsatz von KI im Bereich der Personalbeschaffung ausgelöst, einschließlich der Möglichkeit, dass KI Lebensläufe filtert, Vorstellungsgespräche plant oder sogar erste Interviews führt, sowie die Auswirkungen dieser Automatisierung auf Bewerber und Personalvermittler. (Quelle: Reddit r/ChatGPT)

MIT zieht KI-bezogenes Wirtschaftspaper zurück, Verdacht auf KI-Autorschaft und fragwürdige Daten: Das Wirtschaftsfachbereich des MIT hat ein von einem Doktoranden verfasstes Paper mit dem Titel „Artificial Intelligence, Scientific Discovery, and Product Innovation“ zurückgezogen, da die Universität kein Vertrauen in die Zuverlässigkeit der Daten des Papers hatte. In der Community wird vermutet, dass das Paper größtenteils von KI verfasst wurde, was eine Diskussion über Ethik und Qualitätskontrolle beim Einsatz von KI in der akademischen Forschung ausgelöst hat. (Quelle: Reddit r/ArtificialInteligence)