
Schlüsselwörter:KI-Programmieragent, Codex, AlphaEvolve, KI-Inferenzparadigma, MoE-Modell, KI-Chip, KI-Bildung, KI-Kurzfilm, OpenAI Codex-1-Modell, Google DeepMind AlphaEvolve, ByteDance Seed1.5-VL, Qwen ParScale-Technologie, NVIDIA GB300-System
🔥 Fokus
OpenAI veröffentlicht Cloud-KI-Programmierassistenten Codex, angetrieben durch neues Modell codex-1: OpenAI führt den Cloud-KI-Programmierassistenten Codex ein, basierend auf der für Software-Engineering optimierten o3-Spezialversion codex-1. Codex kann in einer Cloud-Sandbox sicher mehrere Aufgaben parallel verarbeiten, ist in GitHub integriert und kann Code-Repositories direkt aufrufen, um schnelles Erstellen von Modulen, Beantworten von Fragen zu Code-Repositories, Beheben von Schwachstellen, Einreichen von PRs und automatische Testvalidierung zu ermöglichen. Aufgaben, die früher Tage oder Stunden dauerten, kann Codex in 30 Minuten erledigen. Das Tool steht Nutzern von ChatGPT Pro, Enterprise und Team zur Verfügung und zielt darauf ab, der „10x-Ingenieur“ für Entwickler zu werden und den Softwareentwicklungsprozess neu zu gestalten. (Quelle: 36Kr)
Google DeepMind stellt AlphaEvolve vor, KI-gesteuerte autonome Evolution erzielt Durchbrüche in Mathematik und Algorithmen: Das KI-System AlphaEvolve von Google DeepMind hat durch Selbstevolution und das Training großer Sprachmodelle Durchbrüche in mehreren mathematischen und wissenschaftlichen Bereichen erzielt. Es verbesserte den Algorithmus für die 4×4-Matrixmultiplikation (erstmals seit 56 Jahren), optimierte das Problem der hexagonalen Packung (erstmals seit 16 Jahren) und machte Fortschritte beim „Kissing Number Problem“. AlphaEvolve kann Algorithmen autonom optimieren, fand sogar eine Methode zur Beschleunigung des Trainings des Gemini-Modells und wird bereits zur Optimierung der internen Berechnungsinfrastruktur von Google eingesetzt, wodurch 0,7 % der Rechenressourcen eingespart wurden. Dies zeigt, dass KI nicht nur Probleme lösen, sondern auch neues Wissen entdecken kann, was das Potenzial hat, wissenschaftliche Paradigmen zu revolutionieren und KI-generierte Wissenschaft zu ermöglichen. (Quelle: 36Kr)
Altman auf dem Sequoia AI Summit: KI wird innerhalb von drei Jahren in die reale Welt eintreten und Leben und Arbeit neu gestalten: OpenAI CEO Sam Altman prognostizierte auf dem Sequoia AI Summit, dass KI-Agenten 2025 praktisch einsetzbar sein werden (insbesondere im Coding-Bereich), KI 2026 bedeutende wissenschaftliche Entdeckungen vorantreiben und Roboter 2027 in die physische Welt eintreten und Wert schaffen werden. Er blickte auf den Weg von OpenAI von den frühen Erkundungen bis zur Entstehung von ChatGPT zurück und schlug vor, dass zukünftige KI-Produkte „Kern-KI-Abonnementdienste“ sein werden, die die gesamten Lebenserfahrungen einer Person aufnehmen und zur intelligenten Standard-Schnittstelle werden können. OpenAI wird sich auf Kernmodelle und Anwendungsszenarien konzentrieren und die Organisationseffizienz eines „kleinen Teams mit großer Verantwortung“ beibehalten. (Quelle: 36Kr)
Nvidia Computex-Rede: Persönlicher KI-Computer in Produktion, Vorstellung des Next-Gen GB300-Systems, geplanter Bau eines KI-Supercomputers in Taiwan: Nvidia CEO Jensen Huang kündigte auf der Computex 2025 an, dass der persönliche KI-Computer DGX Spark vollständig in Produktion gegangen ist und in wenigen Wochen auf den Markt kommen wird; das KI-System der nächsten Generation GB300 (ausgestattet mit 72 Blackwell Ultra GPUs und 36 Grace CPUs) wird im dritten Quartal eingeführt. Nvidia wird gemeinsam mit TSMC und Foxconn ein KI-Supercomputerzentrum in Taiwan errichten. Gleichzeitig wurden die Blackwell RTX Pro 6000 Workstation-Serie und der Grace Blackwell Ultra Superchip vorgestellt, und es ist geplant, die Newton-Physik-Engine im Juli für das Robotertraining als Open Source freizugeben. Huang betonte, dass KI allgegenwärtig sein wird, und bekräftigte ihre revolutionäre Wirkung. (Quelle: 36Kr)

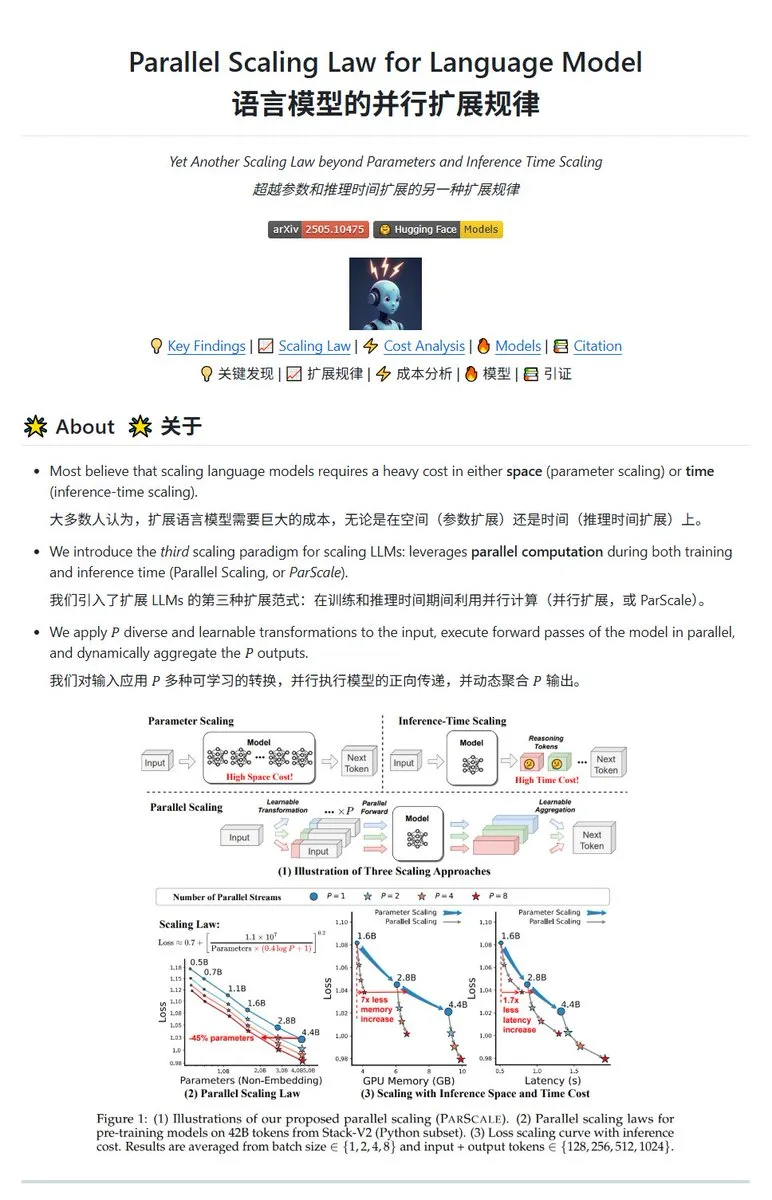
Qwen veröffentlicht ParScale Parallel-Skalierungstechnologie, kleine Modelle können die Leistung großer Modelle erreichen: Das Qwen-Team hat die ParScale-Technologie vorgestellt, die die Modellleistung durch parallele Inferenz verbessert. Die Methode verwendet n parallele Streams für die Inferenz, wobei jeder Stream eine erlernbare differenzierte Transformation zur Verarbeitung der Eingabe verwendet und die Ergebnisse schließlich durch einen dynamischen Aggregationsmechanismus zusammengeführt werden. Studien zeigen, dass P parallele Streams ungefähr einer Erhöhung der Modellparameter um den Faktor O(log P) entsprechen, z. B. kann ein 30B-Modell durch 8 parallele Streams die Leistung eines 42,5B-Modells erreichen. Diese Technologie verspricht, die Modellleistung zu verbessern, ohne den GPU-Speicherbedarf signifikant zu erhöhen, oder die Größe bestehender Modelle durch Erhöhung der Parallelität zu reduzieren, möglicherweise jedoch auf Kosten eines erhöhten Rechenbedarfs und einer geringeren Inferenzgeschwindigkeit. (Quelle: karminski3, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
🎯 Trends
Poe-Bericht: OpenAI und Google führen im KI-Wettbewerb, Anthropic zeigt Schwäche: Der neueste Nutzungsbericht von Poe (Januar-Mai 2025) zeigt drastische Veränderungen in der KI-Marktlandschaft. Im Bereich der Textgenerierung führt GPT-4o (35,8 %), während Gemini 2.5 Pro bei der Inferenzfähigkeit (31,5 %) an der Spitze steht. Die Bilderzeugung wird von Imagen3, GPT-Image-1 und der Flux-Serie dominiert. Im Bereich der Videogenerierung ist Kling-2.0-Master stark auf dem Vormarsch, während der Anteil von Runway deutlich gesunken ist. Bei den Agenten schneidet o3 am besten ab. Der Bericht weist darauf hin, dass die Inferenzfähigkeit zum entscheidenden Schlachtfeld geworden ist, der Marktanteil von Anthropic’s Claude gesunken ist und auch der Nutzeranteil von DeepSeek R1 von seinem Höchststand zurückgegangen ist. Unternehmen müssen die Genauigkeit und Zuverlässigkeit von Modellen bei komplexen Aufgaben beachten und KI-Modelle flexibel auswählen. (Quelle: 36Kr)

Veröffentlichung von Metas Flaggschiff-KI-Modell Behemoth (Llama 4) verzögert, könnte zu Anpassungen der KI-Strategie führen: Berichten zufolge wurde die für April geplante Veröffentlichung von Metas 2-Billionen-Parameter-Großmodell Behemoth (Llama 4) auf den Herbst oder später verschoben, da die Leistung nicht den Erwartungen entsprach. Das Modell wurde mit 30T multimodalen Token auf 32K GPUs vortrainiert und zielt darauf ab, mit OpenAI, Google usw. zu konkurrieren. Die Entwicklungsschwierigkeiten führten intern zu Enttäuschung über die Leistung des Llama 4-Teams und könnten zu Anpassungen im KI-Produktteam führen. Gleichzeitig haben 11 der 14 ursprünglichen Teammitglieder von Llama 1 das Unternehmen verlassen. Meta-Führungskräfte dementierten Gerüchte über einen „80%igen Team-Exodus“ und betonten, dass die Abgänge hauptsächlich das Llama 1-Paper-Team beträfen. Dieses Ereignis verstärkt die Besorgnis Außenstehender, ob Meta im KI-Wettbewerb in eine Sackgasse geraten ist. (Quelle: 36Kr)

ByteDance und Google DeepMind veröffentlichen neue MoE-Modellforschung mit Fokus auf Effizienz und Anwendung in Produktionssystemen: Das Paper von ByteDance „MegaScale-MoE: Large-Scale Communication-Efficient Training of Mixture-of-Experts Models in Production“ stellt ein Produktionssystem vor, das speziell für das effiziente Training von großskaligen MoE-Modellen entwickelt wurde. Durch die Überlappung von Kommunikation und Berechnung auf Operatorenebene wird eine 1,88-fache Effizienzsteigerung gegenüber Megatron-LM erreicht. Es wurde bereits in Rechenzentren zum Training von Produktmodellen (wie Internal-352B, 32 Experten, Top-3) eingesetzt. Google DeepMind veröffentlichte AlphaEvolve, das durch KI-Selbstevolution und das Training von LLMs Durchbrüche in Mathematik und Algorithmen erzielte, z. B. bei der Verbesserung der 4×4-Matrixmultiplikation und des Problems der hexagonalen Packung, was das Potenzial von KI für wissenschaftliche Entdeckungen zeigt. (Quelle: teortaxesTex, 36Kr)

OpenAI diskutiert KI-Inferenzparadigma und betont dessen Schlüsselrolle für Leistungssteigerung: OpenAI-Forscher Noam Brown wies darauf hin, dass die KI-Entwicklung vom Vortrainingsparadigma (Vorhersage des nächsten Wortes durch riesige Datenmengen) in das Inferenzparadigma übergegangen ist. Das Vortraining ist kostspielig, während das Inferenzparadigma die Antwortqualität durch Erhöhung der „Denkzeit“ des Modells (Inferenzrechenaufwand) verbessert, selbst bei gleichbleibenden Trainingskosten. Beispielsweise erzielten Modelle der o-Serie bei Mathematikwettbewerben (AIME) und wissenschaftlichen Problemen auf Doktoratsniveau (GPQA) durch längere Inferenzzeiten eine deutlich höhere Genauigkeit als GPT-4o. Ronnie Chatterji, Chefökonom bei OpenAI, diskutierte die Neugestaltung der Unternehmenslandschaft durch KI und argumentierte, dass der Schlüssel darin liege, wie Unternehmen KI integrieren, um menschliche Rollen zu erweitern oder zu ersetzen, und wie KI-Technologie in die Wertschöpfungskette eingebettet wird. (Quelle: 36Kr)

Google CEO Pichai antwortet auf „Google ist tot“-Theorie und betont KI-gesteuerte Suche-Evolution und Infrastrukturvorteile: Google CEO Sundar Pichai reagierte in einem Exklusivinterview auf Bedenken, dass „Google Suche von KI ersetzt wird“. Er erklärte, dass Google die Suche durch Funktionen wie „AI Overview“ und „AI Mode“ von reaktiven Abfragen zu einem prädiktiven, personalisierten intelligenten Assistenten umwandelt. Er betonte, dass Googles langfristige Investitionen in KI-Infrastruktur (eigene TPUs, große Rechenzentren) und Modelleffizienz Kernvorteile darstellen, die es ermöglichen, fortschrittliche Modelle kostengünstig anzubieten. Pichai betrachtet KI als eine „All-Scenario-Technologieplattform“, die Kernbereiche wie Suche, YouTube und Cloud neu gestalten und neue Formen hervorbringen wird. Er erwähnte auch, dass die Wettbewerbsfähigkeit chinesischer KI (wie DeepSeek) nicht zu unterschätzen sei und wies darauf hin, dass Strom ein entscheidender Engpass für die KI-Entwicklung sein werde. (Quelle: 36Kr)

Überblick über Start-ups im Bereich KI-Anwendungen im Bildungswesen: Der Artikel listet 13 KI-Bildungs-Start-ups auf, die 2025 Beachtung verdienen. Sie verändern den Unterricht durch personalisierte Lernpfade, intelligente Tutorensysteme, automatische Bewertung und die Erstellung immersiver Inhalte. Merlyn beispielsweise ist ein sprachgesteuerter KI-Assistent, der Lehrkräfte bei Verwaltungsaufgaben entlastet; Brisk Teaching ist eine Chrome-Erweiterung, die Unterrichtsaufgaben vereinfacht; Edexia ist eine KI-Bewertungsplattform, die den Stil von Lehrkräften lernt; Storytailor kombiniert Bibliotherapie mit KI zur Erstellung personalisierter Geschichten; Brainly bietet KI-gestützte Hausaufgabenhilfe. Diese Unternehmen zeigen das breite Anwendungspotenzial von KI im Bildungswesen, von der Effizienzsteigerung bis zur Realisierung von personalisiertem Lernen und Bildungsgerechtigkeit. (Quelle: 36Kr)
KI-Kurzdramen stehen vor technischen und kommerziellen Herausforderungen, Produktionsergebnisse bleiben hinter Erwartungen zurück: Obwohl KI-Tools die Produktionskosten von Kurzdramen senken und die Zyklen verkürzen sollen, stellen Praktiker fest, dass KI-Kurzdramen erhebliche technische Schwierigkeiten bei der Konsistenz der Hauptfiguren, der Lippensynchronisation und der Natürlichkeit der Kamerasprache aufweisen. Dies führt dazu, dass viele Werke eher wie „PPT-Kurzdramen“ wirken. KI hat Schwierigkeiten, surreale Kreativität zu verstehen, was die Entfaltung von Fantasy- und Science-Fiction-Themen einschränkt. Derzeit eignet sich die KI-Technologie eher für die Produktion von Kurzfilmen als für vollständige Kurzdramen, und die kommerziellen Aussichten sind unklar. Große Film- und Fernsehunternehmen wie Bona Film Group und Huace Group haben aufgrund ihrer Ressourcenvorteile bessere Chancen, sich durchzusetzen, während die meisten kleinen Kreativen mit hohen Kosten für Versuch und Irrtum und schnell veraltenden Werken aufgrund der rasanten technologischen Entwicklung konfrontiert sind. (Quelle: 36Kr)
MSI stellt KI-PC mit integriertem NVIDIA GB10 Superchip vor, mit 6144 CUDA-Kernen und 128 GB LPDDR5X-Speicher: MSI präsentierte seinen EdgeExpert MS-C931 S, einen KI-PC mit dem NVIDIA GB10 Superchip. Es wurde bestätigt, dass dieser Chip über 6144 CUDA-Kerne und 128 GB LPDDR5X-Speicher verfügt. Nach ASUS, Dell und Lenovo ist MSI ein weiterer Hersteller, der einen persönlichen KI-Computer auf Basis der NVIDIA DGX Spark-Architektur vorstellt. Die Einführung solcher Produkte signalisiert, dass Hochleistungs-KI-Rechenkapazitäten allmählich für Privatpersonen und Edge-Geräte verfügbar werden. Kommentatoren weisen jedoch darauf hin, dass die Preisgestaltung es schwierig machen könnte, mit Produkten wie dem Mac Mini zu konkurrieren. (Quelle: Reddit r/LocalLLaMA)
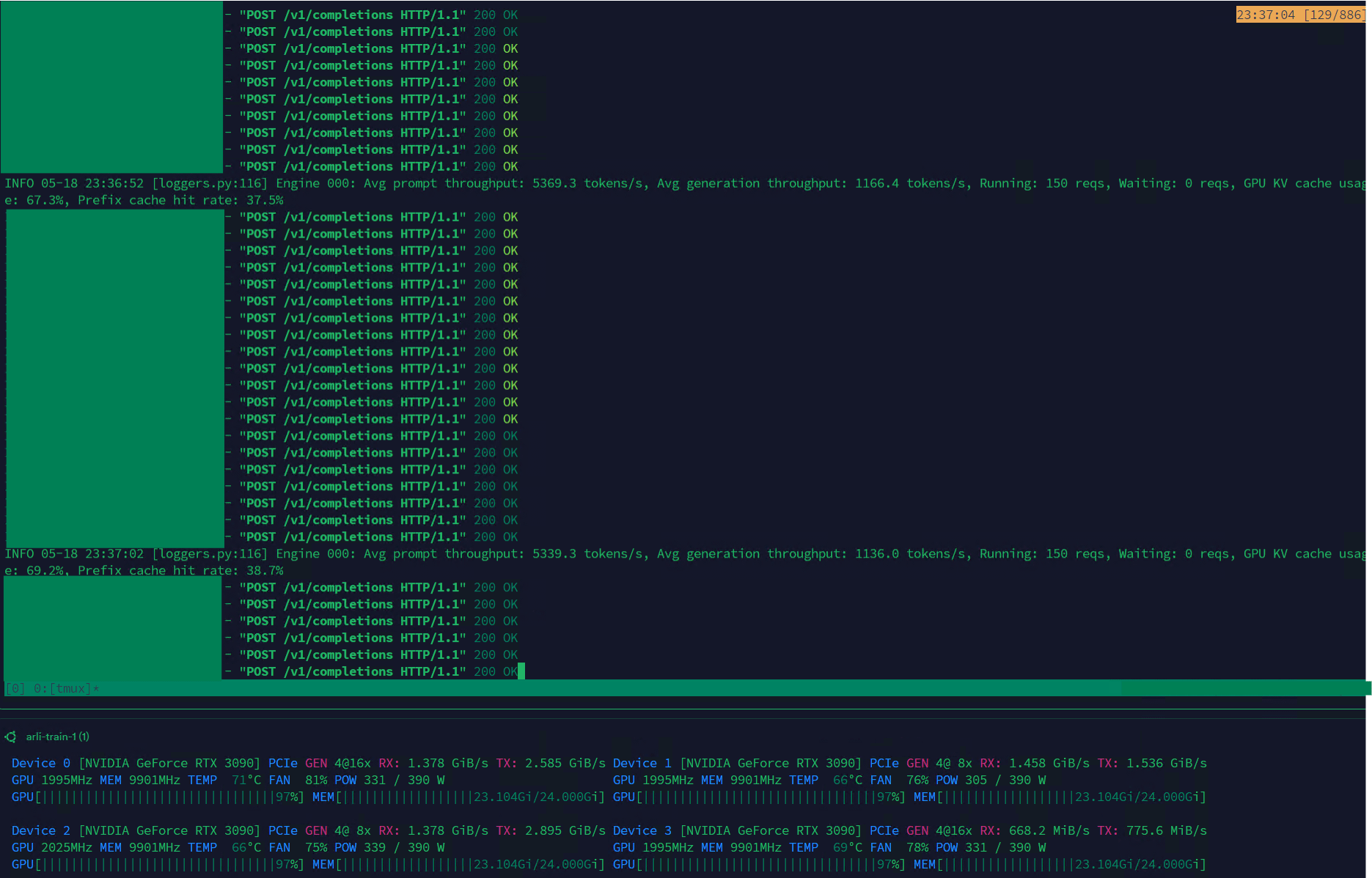
Qwen3-30B erreicht hohen Durchsatz auf VLLM, geeignet für Datenmanagement: Das Qwen3-30B-A3B-Modell zeigt auf dem VLLM-Framework und RTX 3090s-Grafikkarten eine hervorragende Inferenzgeschwindigkeit (5K t/s Prefill, 1K t/s Generierung), was es sehr geeignet für Aufgaben wie Datenfilterung und -management macht. Obwohl es im Vergleich zu QwQ möglicherweise eine leichte Regression darstellt, macht sein Geschwindigkeitsvorteil es in der Datenverarbeitung praktischer. Das Hauptproblem ist derzeit die extrem langsame Trainingsgeschwindigkeit, aber es gibt bereits einen PR in der Hugging Face Transformers-Bibliothek, der versucht, dieses Problem zu lösen. Zukünftig könnten auf Basis von Qwen3-30B verbesserte RpR-Modelle für Datensätze veröffentlicht werden. (Quelle: Reddit r/LocalLLaMA)
Bilibili veröffentlicht Open-Source-Animationsvideo-Generierungsmodell Index-AniSora, unterstützt verschiedene Anime-Stile: Bilibili hat das Open-Source-Modell Index-AniSora speziell für die Generierung von Anime-Videos veröffentlicht, basierend auf seinem AniSora-Technologierahmen (angenommen von IJCAI25). Dieses Modell kann Comics mit einem Klick in Animationen umwandeln und unterstützt verschiedene Stile wie Anime-Serien, chinesische Animationen, Manga-Adaptionen und VTuber. Das AniSora-System erreicht durch den Aufbau eines Datensatzes mit zehn Millionen hochwertigen Text-Video-Paaren, die Entwicklung eines einheitlichen Diffusionsgenerierungsrahmens und die Einführung eines Raum-Zeit-Maskierungsmechanismus eine feine Kontrolle über Mundbewegungen und Aktionen der Charaktere. Gleichzeitig hat Bilibili einen Bewertungsbenchmark für Animationsvideos und ein auf VLM-Optimierung basierendes automatisiertes Bewertungssystem entwickelt. Der Open-Source-Inhalt wird AniSoraV1.0 (basierend auf CogVideoX-5B), AniSoraV2.0 (basierend auf Wan2.1-14B, unterstützt Training auf Huawei 910B) sowie zugehörige Tools für den Datensatzaufbau und die Bewertung umfassen. (Quelle: WeChat)

ByteDance veröffentlicht visuelles Sprachmodell Seed1.5-VL mit hervorragender Leistung bei multimodalen Aufgaben: ByteDance hat das visuelle Sprachmodell Seed1.5-VL vorgestellt, das aus einem visuellen Encoder mit 532 Mio. Parametern und einem Mixture-of-Experts (MoE) LLM mit 20 Mrd. aktiven Parametern besteht. Dieses Modell erreichte bei 38 von 60 öffentlichen Benchmark-Tests SOTA-Leistung und übertraf führende Systeme wie OpenAI CUA und Claude 3.7 bei agentenzentrierten Aufgaben wie GUI-Steuerung und Gameplay, was seine starken multimodalen Verständnis- und Inferenzfähigkeiten demonstriert. (Quelle: WeChat)
Nous Research stellt Psyche Network vor und realisiert verteiltes Vortraining eines 40B-Parameter-LLM: Nous Research hat Psyche Network veröffentlicht, ein dezentrales Trainingsnetzwerk basierend auf der DeepSeek V3 MLA-Architektur, das im ersten Test ein großes Sprachmodell mit 40 Milliarden Parametern vortrainiert hat. Das Netzwerk nutzt den DisTrO-Optimierer und einen benutzerdefinierten Peer-to-Peer-Netzwerkstack, um weltweit verteilte GPU-Rechenleistung zu integrieren. Dies ermöglicht Einzelpersonen und kleinen Gruppen das Training auf einzelnen H/DGX-Systemen und die Ausführung auf 3090 GPUs. Ziel ist es, das Rechenleistungsmonopol der Technologiegiganten zu brechen und das Training von Großmodellen zugänglicher zu machen. (Quelle: QbitAI)

🧰 Werkzeuge
Sim Studio: Open-Source AI Agent Workflow Builder: Sim Studio ist eine quelloffene, leichtgewichtige Plattform zum Erstellen von AI-Agenten-Workflows, die eine intuitive Benutzeroberfläche bietet, mit der Benutzer schnell LLM-Anwendungen erstellen und bereitstellen können, die verschiedene Tools verbinden. Es unterstützt eine Cloud-gehostete Version und Self-Hosting (empfohlen in einer Docker-Umgebung, unterstützt lokale Modelle wie Ollama). Der Technologie-Stack umfasst Next.js, Bun, PostgreSQL, Drizzle ORM, Better Auth, Shadcn UI, Tailwind CSS, Zustand, ReactFlow und Turborepo. (Quelle: GitHub Trending)

Cherry Studio: Funktionsreiche Open-Source LLM Frontend Desktop-Anwendung findet Beachtung: Cherry Studio ist eine quelloffene LLM Frontend Desktop-Anwendung, die verschiedene Funktionen wie RAG, Websuche, Zugriff auf lokale Modelle (über Ollama, LM Studio) und Cloud-Modelle (wie Gemini, ChatGPT) integriert. Nutzerfeedback hebt hervor, dass die MCP (Multi Control Protocol)-Unterstützung und -Verwaltung besser ist als bei Open WebUI und LibreChat und die Installation einfach ist. Die Anwendung unterstützt auch die direkte Verbindung zu Obsidian-Wissensdatenbanken. Obwohl einige Nutzer Bedenken hinsichtlich der Herkunft äußern, macht der umfassende Funktionsumfang sie zu einer attraktiven Wahl. (Quelle: Reddit r/LocalLLaMA)

MLX-LM-LoRA: Fügt LoRA zu MLX-Modellen hinzu und unterstützt verschiedene Trainingsmethoden: Das Open-Source-Projekt mlx-lm-lora ermöglicht es Benutzern, LoRA (Low-Rank Adaptation)-Module in Modelle unter dem Apple MLX-Framework zu integrieren. Das Projekt unterstützt nicht nur das Hinzufügen von LoRA, sondern auch verschiedene Alignment-Trainingsmethoden wie ORPO, DPO, CPO, GRPO, sodass Benutzer Modelle nach ihren eigenen Bedürfnissen feinabstimmen, angepasste LoRA-Module generieren und diese auf ihre bevorzugten MLX-Modelle anwenden können. (Quelle: karminski3)
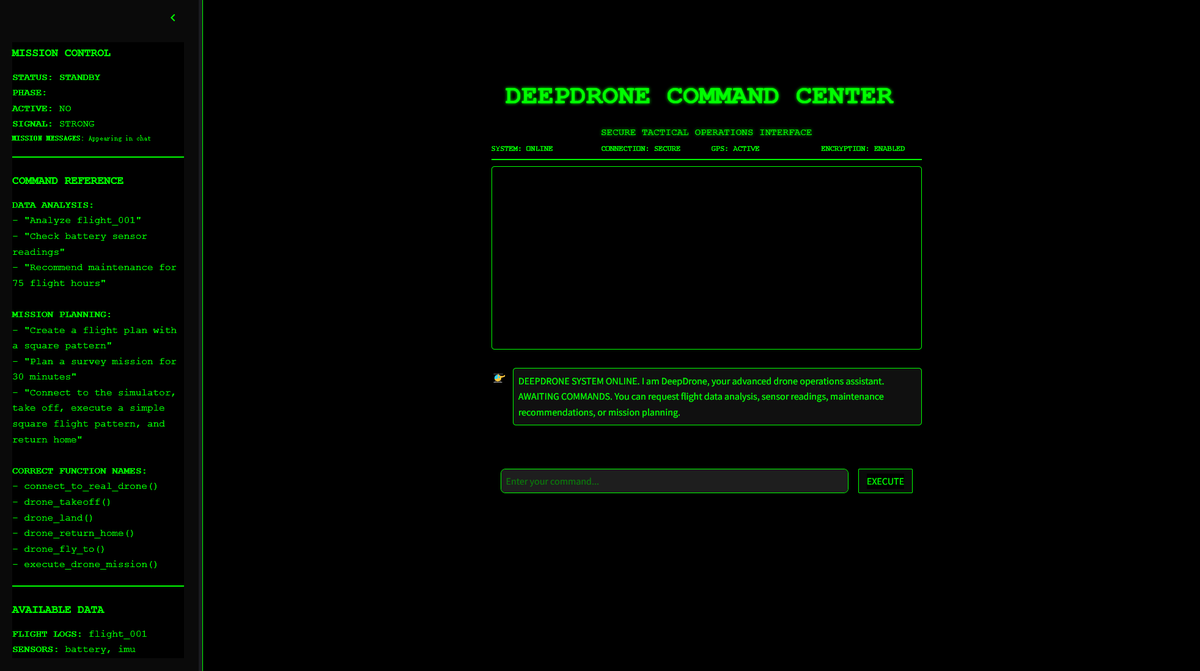
DeepDrone: Open-Source-Projekt für KI-gesteuerte Drohnen basierend auf Qwen: Ein Entwickler hat basierend auf dem Qwen-Großmodell ein KI-gesteuertes Drohnenprojekt namens DeepDrone erstellt und auf HuggingFace und GitHub als Open Source veröffentlicht. Das Projekt demonstriert das Potenzial der Anwendung großer Sprachmodelle auf die autonome Steuerung von Drohnen und löste Diskussionen über KI in der Automatisierung und potenziellen militärischen Anwendungen aus. (Quelle: karminski3)
Qwen Web Dev: Mit einem Klick per Prompt eine Website generieren und bereitstellen: Das Qwen-Team von Alibaba gab bekannt, dass sein Qwen Web Dev-Tool verbessert wurde, sodass Benutzer mit nur einem Prompt eine Website generieren und mit einem Klick bereitstellen können. Das Tool zielt darauf ab, die Hürden für die Webentwicklung zu senken und es Benutzern zu ermöglichen, ihre Ideen bequemer in tatsächlich zugängliche Websites umzuwandeln und mit der Welt zu teilen. (Quelle: Alibaba_Qwen, huybery)
SuperGo.AI: Tool mit einer einzigen Oberfläche, das acht LLM-Modelle integriert: Ein KI-Enthusiast hat ein Tool namens SuperGo.AI entwickelt, das acht LLMs mit unterschiedlichen Rollen (z. B. AI Super Brain, AI Imagination, AI Ethics, AI Universe) in einer einzigen Oberfläche integriert. Diese KI-Rollen können sich gegenseitig wahrnehmen und interagieren, und Benutzer können die Modi „Kreativ“, „Wissenschaftlich“ und „Gemischt“ auswählen, um gemischte Antworten zu erhalten. Das Tool zielt darauf ab, ein neuartiges Erlebnis der Zusammenarbeit mehrerer KIs zu bieten und ist derzeit ohne Paywall verfügbar. (Quelle: Reddit r/artificial)
Kokoro-JS: Realisiert unbegrenzte lokale Text-to-Speech (TTS): Kokoro-JS ist ein zu 100 % lokal laufendes, zu 100 % quelloffenes Text-to-Speech-Tool, das durch das Herunterladen eines etwa 300 MB großen KI-Modells im Browser funktioniert. Vom Benutzer eingegebener Text wird nicht an Server gesendet, was Datenschutz und Offline-Verfügbarkeit gewährleistet. Das Tool zielt darauf ab, unbegrenzte TTS-Funktionen bereitzustellen. (Quelle: Reddit r/LocalLLaMA)
📚 Lernen
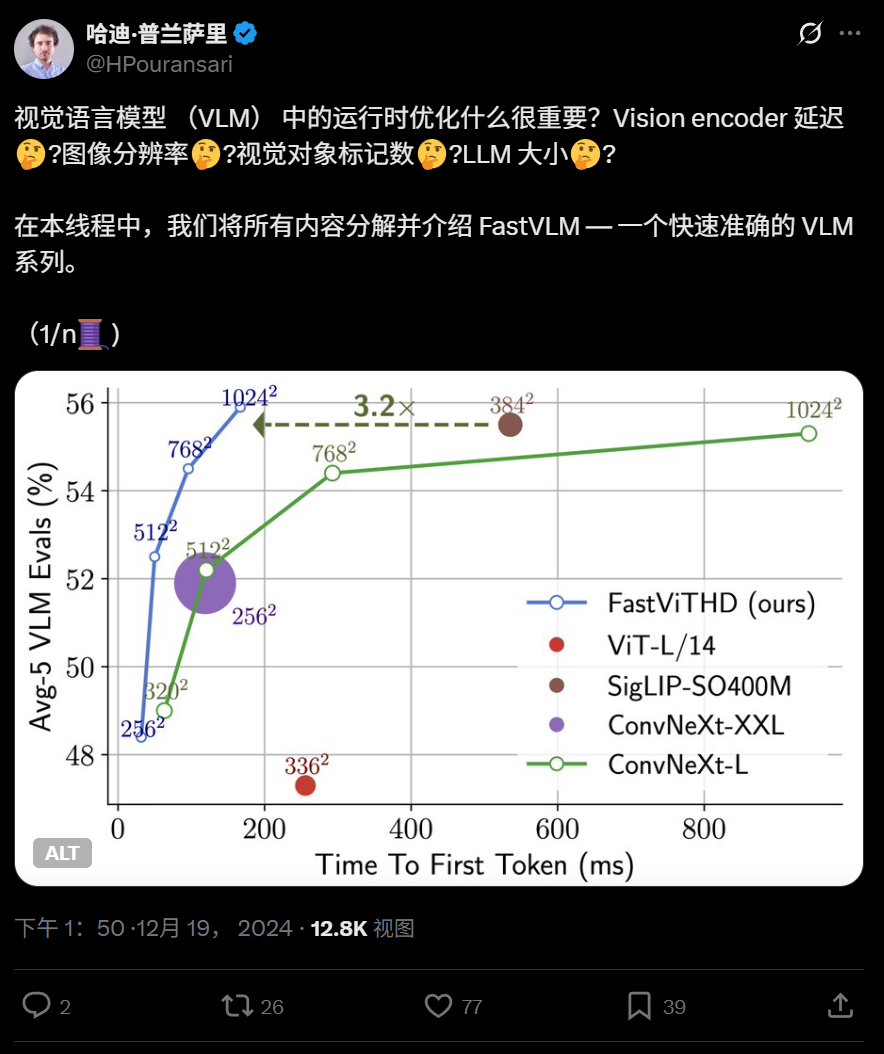
Apple veröffentlicht effizientes visuelles Sprachmodell FastVLM als Open Source, optimiert für den Betrieb auf Endgeräten: Apple hat FastVLM als Open Source veröffentlicht, ein visuelles Sprachmodell, das speziell für den effizienten Betrieb auf Geräten wie dem iPhone entwickelt wurde. FastVLM führt einen neuartigen hybriden visuellen Encoder namens FastViTHD ein, der Faltungsschichten mit Transformer-Modulen kombiniert und Mehrskalen-Pooling- sowie Downsampling-Techniken verwendet. Dies reduziert die Anzahl der für die Bildverarbeitung benötigten visuellen Token erheblich (16-mal weniger als bei herkömmlichen ViTs) und beschleunigt die Ausgabe des ersten Tokens um das 85-fache. Das Modell ist mit gängigen LLMs kompatibel und es wurde eine Demo-Anwendung für iOS/macOS auf Basis des MLX-Frameworks bereitgestellt, die sich für Edge-Geräte und Echtzeit-Bild-Text-Aufgaben eignet. (Quelle: WeChat)
Harbin Institute of Technology und University of Pennsylvania stellen PointKAN vor, basierend auf KAN zur Verbesserung der 3D-Punktwolkenanalyse: Forscherteams des Harbin Institute of Technology (Shenzhen) und der University of Pennsylvania haben PointKAN vorgestellt, eine neue 3D-Wahrnehmungsarchitektur basierend auf Kolmogorov-Arnold Networks (KANs). PointKAN ersetzt die festen Aktivierungsfunktionen in traditionellen MLPs durch erlernbare Aktivierungsfunktionen, was die Fähigkeit zum Erlernen komplexer geometrischer Merkmale verbessert. Es enthält ein geometrisches affines Modul und ein paralleles lokales Merkmalsextraktionsmodul. Das Team schlug auch eine PointKAN-Elite-Version vor, die die Efficient-KANs-Struktur verwendet, rationale Funktionen als Basisfunktionen einsetzt und Parameter gruppenweise teilt. Dies reduziert die Parameteranzahl und die Rechenkomplexität erheblich und zeigt gleichzeitig SOTA-Leistung bei Klassifizierungs-, Teilsegmentierungs- und Few-Shot-Learning-Aufgaben. (Quelle: QbitAI)

Universität Pittsburgh stellt PhyT2V-Framework vor, um die physikalische Realität von KI-generierten Videos zu verbessern: Das Intelligent Systems Lab der Universität Pittsburgh hat das PhyT2V-Framework entwickelt, um die physikalische Konsistenz von Inhalten zu verbessern, die von Text-zu-Video (T2V)-Modellen generiert werden. Die Methode erfordert kein erneutes Training des Modells oder große Mengen externer Daten. Durch von großen Sprachmodellen (LLM) geleitetes Chain-of-Thought (CoT)-Reasoning und einen iterativen Selbstkorrekturmechanismus werden Text-Prompts in mehreren Runden auf physikalische Regeln analysiert und optimiert. PhyT2V kann physikalische Regeln und semantische Nichtübereinstimmungen erkennen und korrigierte Prompts generieren, wodurch die Generalisierungsfähigkeit gängiger T2V-Modelle (wie CogVideoX, OpenSora) in realen physikalischen Szenarien (Festkörper, Flüssigkeiten, Schwerkraft usw.) verbessert wird, insbesondere in Out-of-Distribution-Szenarien, wobei die Indikatoren für physikalischen Hausverstand (PC) und semantische Einhaltung (SA) um bis zu das 2,3-fache gesteigert werden. (Quelle: WeChat)
Neueste LLM-Forschung im Überblick: Multimodalität, Test-Time Alignment, Agenten, RAG-Optimierung etc.: Die LLM-Forschungsfortschritte der Woche umfassen: 1. Die University of Washington schlägt QALIGN vor, eine Test-Time-Alignment-Methode, die keine Modelländerungen oder Zugriff auf Logits erfordert und durch MCMC eine bessere Ausrichtung bei der Textgenerierung erreicht. 2. UCLA trainiert Clinical ModernBERT vor und erweitert die Kontextlänge des biomedizinischen Encoders auf 8192 Token. 3. Skoltech schlägt eine leichtgewichtige, LLM-unabhängige, adaptive RAG-Retrieval-Methode vor, die auf externen Informationen (Entitätenpopularität, Fragetyp) basiert. 4. PSU definiert das Problem der automatisierten Fehlerattribution in LLM-Multi-Agenten-Systemen und entwickelt Bewertungsdatensätze und -methoden. 5. Die Fudan University schlägt ein mehrdimensionales Constraint-Framework und einen automatisierten Prozess zur Generierung von Anweisungen vor, um die Fähigkeit von LLMs zur Befolgung von Anweisungen zu verbessern. 6. a-m-team veröffentlicht AM-Thinking-v1 (32B) als Open Source, dessen mathematische Kodierungsfähigkeiten mit DeepSeek-R1-671B vergleichbar sind. 7. Xiaomi stellt MiMo-7B vor, das durch optimiertes Vortraining und Nachtraining bei Inferenzaufgaben hervorragende Leistungen erbringt. 8. MiniMax stellt das autoregressive TTS-Modell MiniMax-Speech vor, das Zero-Shot-Stimmklonierung in 32 Sprachen unterstützt. 9. ByteDance entwickelt das visuelle Sprachmodell Seed1.5-VL, das bei multimodalen Aufgaben und agentenzentrierten Aufgaben herausragende Leistungen zeigt. 10. Das weltweit erste 32B-Parameter-Sprachmodell INTELLECT-2 realisiert verteiltes Reinforcement-Learning-Training und stellt das PRIME-RL-Framework vor. (Quelle: WeChat)
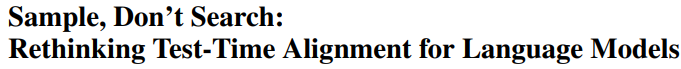
AAAI 2025 Workshops konzentrieren sich auf neuronales Schließen, mathematische Entdeckungen und KI-beschleunigte Wissenschaft und Technik: Die Workshops der AAAI 2025 diskutierten schwerpunktmäßig die Anwendung von KI in der Wissenschaft. Der Workshop „Neural Reasoning and Mathematical Discovery“ betonte, dass Blackbox-neuronale Netze zur Formulierung mathematischer Vermutungen und zur Generierung neuer geometrischer Figuren verwendet werden können, wies aber auch darauf hin, dass sie kein symbolisches logisches Schließen erreichen können, und befürwortete interdisziplinäre Ansätze. Ein weiterer Workshop, „AI to Accelerate Science and Engineering“ (vierte Ausgabe, Thema: KI-Biowissenschaften), konzentrierte sich auf grundlegende Modelle für das therapeutische Design, generative Modelle für die Wirkstoffentdeckung, Closed-Loop-Antikörperdesign im Labor, Deep Learning in der Genomik sowie kausale Inferenz in biologischen Anwendungen und diskutierte die Herausforderungen und Chancen generativer Modelle in den Biowissenschaften. (Quelle: aihub.org)

Google und Anthropic uneins bei KI-Erklärbarkeitsforschung, mechanistische Erklärbarkeit vor Herausforderungen: Die „Blackbox“-Natur der KI schränkt ihre Anwendung in vielen kritischen Bereichen ein. Google DeepMind kündigte kürzlich an, die Priorität der Forschung zur „mechanistischen Erklärbarkeit“ (mechanistic interpretability) herabzusetzen. Man argumentiert, dass das Reverse Engineering interner KI-Mechanismen mittels Methoden wie Sparse Autoencoders (SAE) mit zahlreichen Problemen konfrontiert ist, wie z. B. dem Fehlen objektiver Referenzen, unvollständiger Konzeptabdeckung, Merkmalsverzerrungen usw., und dass bestehende SAE-Technologien die erforderlichen „Konzepte“ in kritischen Aufgaben nicht identifizieren konnten. Dario Amodei, CEO von Anthropic, plädiert hingegen für eine Intensivierung der Forschung in diesem Bereich und zeigt sich optimistisch, in den nächsten 5-10 Jahren eine „MRT der KI“ zu realisieren. Diese Debatte unterstreicht die tiefgreifenden Herausforderungen beim Verstehen und Kontrollieren des KI-Verhaltens. (Quelle: 36Kr)

Peking University/StepFun/Lightelligence schlagen InfiniteHBD vor: GPU-Architektur der nächsten Generation für hohe Bandbreite zur Kosten- und Effizienzsteigerung: Angesichts der Beschränkungen bestehender Architekturen für hohe Bandbreitendomänen (HBD) hinsichtlich Skalierbarkeit, Kosten und Fehlertoleranz hat ein Team der Peking University, StepFun (阶跃星辰) und Lightelligence (曦智科技) die InfiniteHBD-Architektur vorgeschlagen. Diese Architektur zentriert sich um optische Schaltmodule (OCSTrx) und realisiert durch die Integration kostengünstiger optischer Schaltfähigkeiten (OCS) in optoelektronische Konversionsmodule eine dynamisch rekonfigurierbare K-Hop-Ring-Topologie im Maßstab von Rechenzentren sowie eine Fehlerisolierung auf Knotenebene. Die Stückkosten von InfiniteHBD betragen nur 31 % von NVL-72, die GPU-Verschwendungsrate ist nahezu null, und die MFU (Model FLOPs Utilization) ist im Vergleich zu NVIDIA DGX um bis zu das 3,37-fache höher, was eine überlegene Lösung für das Training von großskaligen Modellen bietet. Das Paper wurde von SIGCOMM 2025 angenommen. (Quelle: WeChat)

OceanBase veröffentlicht PowerRAG, setzt voll auf KI und baut eine integrierte Data×AI-Datenbasis auf: OceanBase hat auf seiner Entwicklerkonferenz das KI-Anwendungsprodukt PowerRAG vorgestellt, das Out-of-the-Box-RAG-Entwicklungsfähigkeiten bieten und Daten, Plattformen, Schnittstellen und Anwendungsebenen verbinden soll. CTO Yang Chuanhui erläuterte die KI-Strategie von OceanBase: Aufbau von Data×AI-Fähigkeiten, Entwicklung von einer integrierten Datenbank zu einer integrierten Datenbasis. OceanBase wird Vektorfähigkeiten verbessern, die fusionierte Suche optimieren, die dynamische Aktualisierung von Unternehmenswissensspeichern realisieren, das Nachtraining und die Feinabstimmung von Modellen tief integrieren und wurde bereits an gängige Agent-Plattformen wie Dify, FastGPT sowie das MCP-Protokoll angepasst. Seine Vektorleistung zeigte im VectorDBBench-Test führende Ergebnisse, und durch den BQ-Quantisierungsalgorithmus wurde der Speicherbedarf erheblich reduziert. (Quelle: WeChat)

💼 Wirtschaft
Shanghai State-owned Investment Fund investiert in KI-Chip-Unternehmen wie Xinyaohui, Enflame Technology und Biren Technology: Shanghai State-owned Capital Investment Co., Ltd. (Shanghai Guotou) unterzeichnete kürzlich Investitionsvereinbarungen mit den drei Halbleiterunternehmen Xinyaohui, Enflame Technology und Biren Technology. Zuvor hatte sein führender KI-Mutterfonds die Pre-IPO-Finanzierung von Biren Technology angeführt. Shanghai Guotou erklärte, dass es aktiv in Bereiche wie Basismodelle, Rechenleistungschips und Embodied Intelligence investieren werde. Xinyaohui konzentriert sich auf Halbleiter-IP, insbesondere die Chiplet-Technologie; sein Gründer Zeng Keqiang war früher Vizepräsident von Synopsys China. Enflame Technology und Biren Technology sind beides GPU-Chip-Design-Unternehmen. Dieser Schritt zeigt den Schwerpunkt von Shanghai Guotou auf den vorgelagerten Bereich der KI-Industriekette, insbesondere auf Rechenleistungschips. (Quelle: 36Kr)
Sakana AI und Mitsubishi UFJ Bank gehen umfassende Partnerschaft ein, um bankenspezifische KI zu entwickeln: Das japanische KI-Startup Sakana AI gab eine mehrjährige Partnerschaftsvereinbarung mit der Mitsubishi UFJ Bank (MUFG) bekannt. Sakana AI wird für MUFG spezielle KI-Agenten für das Bankgeschäft entwickeln, mit dem Ziel, die Transformation des Bankgeschäfts und die praktische Anwendung von KI voranzutreiben. Gleichzeitig wird der Mitbegründer und COO von Sakana AI, Ren Ito, als Berater für MUFG tätig sein und die Bank bei der Umsetzung ihrer KI-Strategie unterstützen. Diese Zusammenarbeit markiert einen wichtigen Schritt für Sakana AI, fortschrittliche KI-Technologie zur Lösung spezifischer Herausforderungen im japanischen Finanzsektor einzusetzen. (Quelle: SakanaAILabs, SakanaAILabs, SakanaAILabs, SakanaAILabs, SakanaAILabs)

01.AI Mitgründerin Gu Xuemei verlässt das Unternehmen für eigene Gründung, Unternehmensfokus verlagert sich auf B2B: Gu Xuemei, Mitgründerin von 01.AI und verantwortlich für das Modell-Vortraining und C-End-Produkte, hat das Unternehmen vor einigen Monaten verlassen und bereitet derzeit ihre eigene Gründung vor. 01.AI bestätigte dies und dankte ihr für ihren Beitrag. Seit 2025 hat sich der Geschäftsschwerpunkt von 01.AI von KI-ToC-Anwendungen und Modell-APIs auf B2B-Szenarien wie digitale Menschen, Modellanpassung und -bereitstellung verlagert. Seine C-End-Produkte wie das inländische Office-Tool „Wanzhi“ wurden aufgrund geringer Nutzerzahlen eingestellt, und die Kommerzialisierung des ausländischen Rollenspielprodukts Mona war ebenfalls nicht ideal. Zuvor hatte auch Mitgründer Dai Zonghong das Unternehmen für eine eigene Gründung verlassen. (Quelle: 36Kr)

🌟 Community
AIGC-Erkennung von KI-generierten Abschlussarbeiten umstritten, Genauigkeit in Frage gestellt, Studentenabschluss betroffen: Viele Hochschulen haben in diesem Jahr die AIGC-Erkennung als Teil der Überprüfung von Abschlussarbeiten eingeführt, um den Missbrauch von KI beim Schreiben durch Studenten zu verhindern. Diese Maßnahme hat jedoch breite Kontroversen ausgelöst. Studenten berichten, dass von ihnen selbst verfasste Inhalte oft fälschlicherweise als KI-generiert eingestuft werden, während nach KI-gestützter Überarbeitung der Verdachtsgrad sogar steigt. Tests zeigten sogar, dass das „Vorwort zum Pavillon des Prinzen Teng“ (滕王阁序) einen KI-Generierungsverdacht von 99,2 % aufwies. Die AIGC-Erkennungstools selbst werden ebenfalls von KI angetrieben. Ihr Prinzip besteht darin, die sprachlichen Merkmale von Texten mit KI-Schreibmustern zu vergleichen, aber die Genauigkeit ist fragwürdig; ein frühes Tool von OpenAI hatte nur eine Genauigkeit von 26 %. Diese Unsicherheit bereitet den Studenten nicht nur Probleme und zusätzliche Kosten (verschiedene Erkennungswebsites liefern unterschiedliche Ergebnisse, Dienste zur Reduzierung des Verdachtsgrads sind kostenpflichtig), sondern wirft auch Fragen über die Natur von KI-Tools auf: KI imitiert menschliches Schreiben, und dann wird KI verwendet, um zu überprüfen, ob menschliche Texte wie KI klingen – ein logischer Widerspruch. (Quelle: 36Kr)

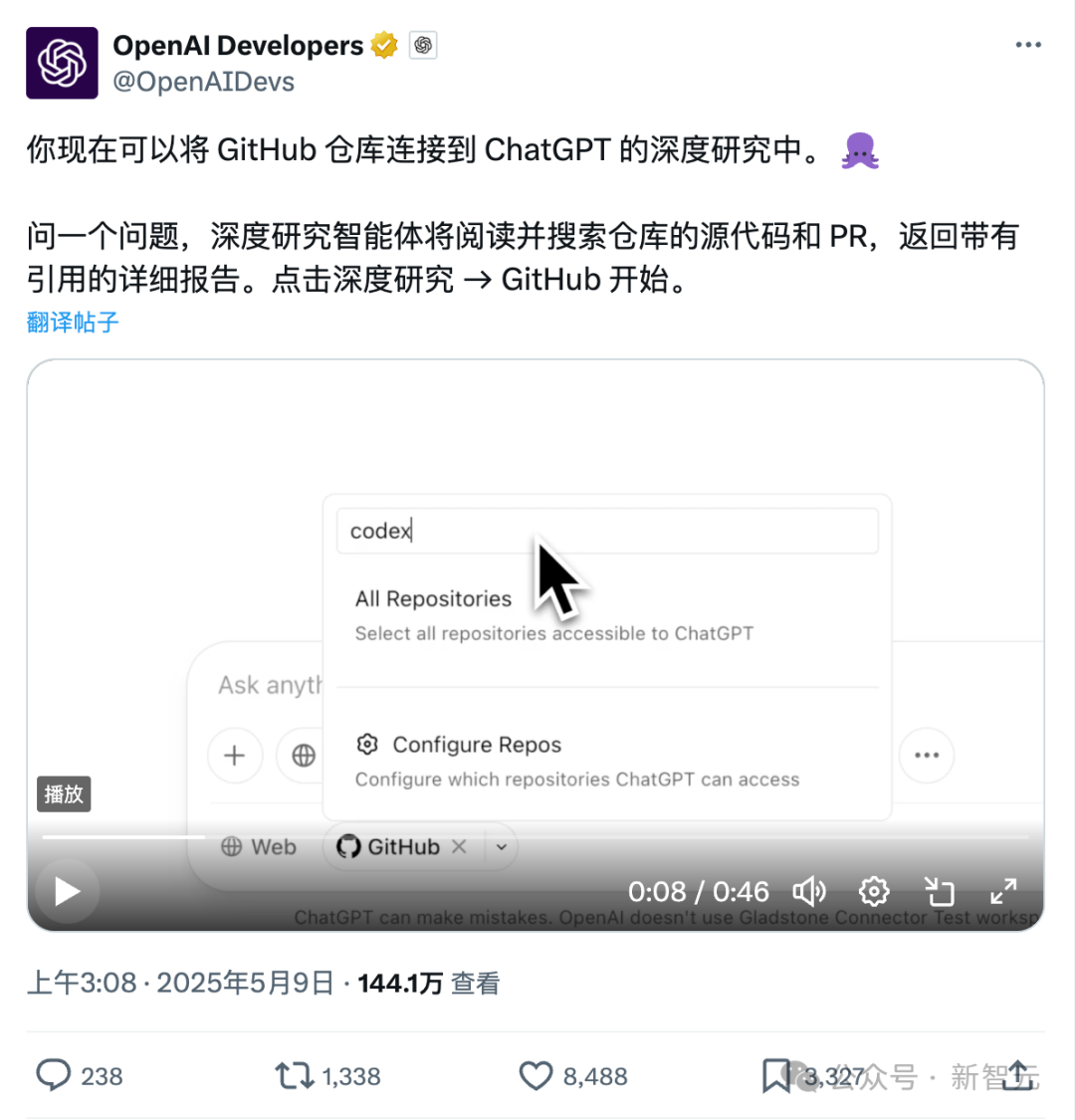
Neue ChatGPT-Funktion zur direkten Verbindung mit Github: Tiefgehende Untersuchung von Code-Repositories und Fachdokumenten: Die kürzlich eingeführte Deep Research-Funktion von ChatGPT bietet neu die Möglichkeit, sich direkt mit Github-Repositories zu verbinden. Benutzer können ChatGPT autorisieren, auf ihre öffentlichen oder privaten Repositories zuzugreifen, um tiefgehende Codeanalysen, Zusammenfassungen der Funktionsarchitektur, Identifizierung des Technologiestacks, Bewertung der Codequalität und Analyse der Projekteignung durchzuführen. Diese Funktion ist nicht auf Code beschränkt; Benutzer können verschiedene Dokumente wie PDFs und Word-Dateien in Github-Repositories hochladen und ChatGPT für tiefgehende Recherchen zu spezifischen Fachgebieten nutzen, was im Wesentlichen einer Kombination aus RAG+MCP mit begrenztem Umfang entspricht. Die Funktion ist derzeit für Plus-Benutzer verfügbar und soll durch die Begrenzung des Untersuchungsbereichs die Professionalität und Genauigkeit von Forschungsberichten verbessern und Halluzinationen reduzieren. (Quelle: 36Kr)
Wettbewerb im KI-Agentenmarkt verschärft sich, Manus öffnet Registrierung vollständig, große Unternehmen wie ByteDance und Baidu steigen ein: Manus, bekannt als „Allround-Agent“, kündigte am 12. Mai die vollständige Öffnung der Registrierung an, sodass Benutzer ohne Wartezeit Nutzungsanteile erhalten können. Gleichzeitig gibt es Marktgerüchte, dass Manus eine neue Finanzierungsrunde mit einer Bewertung von 1,5 Milliarden US-Dollar durchführt. Seit seiner Veröffentlichung im März hat Manus einen Boom bei Agenten-Projekten ausgelöst, sieht sich aber auch mit sinkendem Traffic und dem Aufkommen von Konkurrenzprodukten konfrontiert. ByteDance hat Coze Space eingeführt, Baidu hat „Miaoda“ und „Xinxiang“ gestartet, und der Design-Agent Lovart hat ebenfalls mit Tests begonnen. Der Agentenmarkt bewegt sich von der frühen Konzeptvalidierung hin zu einem umfassenden Wettbewerb in Bezug auf Produktfunktionen, Geschäftsmodelle und Nutzerwachstum. (Quelle: 36Kr)
KI-gestütztes Codieren verändert den Arbeitsablauf von Entwicklern, steigert die Produktivität, erfordert aber Vorsicht vor übermäßiger Abhängigkeit: Ein Reddit-Benutzer teilte mit, wie KI-Code-Assistenten seine Programmiererfahrung erheblich verändert haben, insbesondere bei der Arbeit mit großen Legacy-Projekten und dem Verständnis komplexen Codes. KI-Tools können Code Zeile für Zeile erklären, Vorschläge machen, potenzielle Probleme hervorheben, Dateien zusammenfassen, Fragmente finden und Kommentare generieren, als hätte man rund um die Uhr einen Experten zur Seite. Kommentare wiesen darauf hin, dass KI repetitive Programmieraufgaben erledigen, die Effizienz steigern, neue Ansätze aufzeigen, Kommentare hinzufügen und Entwicklern sogar helfen kann, Aufgaben zu erledigen, die ihre Fähigkeiten übersteigen, wodurch tagelange Arbeit auf Stunden verkürzt wird. Dies wirft jedoch auch Fragen zur Entwicklung der Entwicklerfähigkeiten und zur Abhängigkeit von KI-Tools auf. (Quelle: Reddit r/artificial)
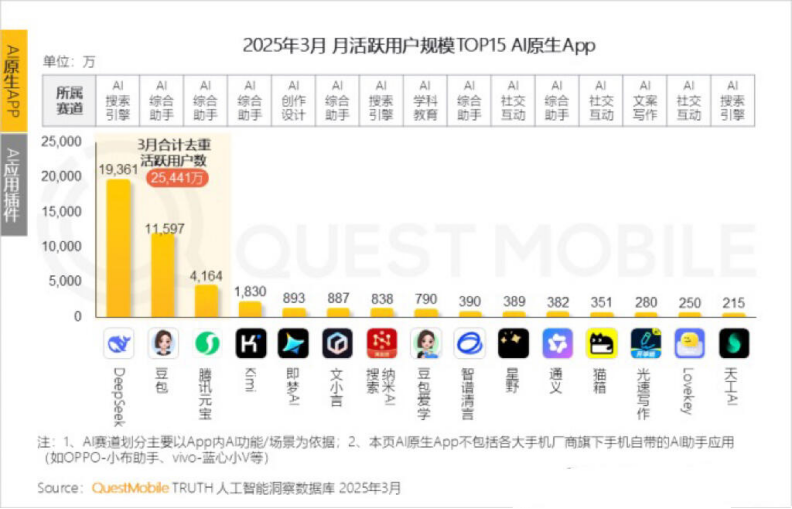
Kimi monatliche aktive Nutzer sinken, Moonshot AI sucht Durchbruch in Nischenmärkten und soziale Transformation: Kimi Chat von Moonshot AI verzeichnete laut QuestMobile-Daten einen Rückgang der monatlich aktiven Nutzer von 36 Millionen im Oktober letzten Jahres auf 18,2 Millionen im März dieses Jahres und fiel damit auf den vierten Platz zurück. Um die Nutzerbindung zu verbessern, expandiert Kimi von einem allgemeinen Großmodell in Nischenbereiche, wie z. B. die Zusammenarbeit mit Caixin Media zur Verbesserung der Suchqualität von Finanzinhalten, den Aufbau einer KI-gestützten medizinischen Suche und die Integration von Videoinhalten von Bilibili. Gleichzeitig startete Kimi eine Check-in-Challenge auf Xiaohongshu, um über soziale Plattformen mehr C-End-Nutzer zu erreichen. Die Benutzeroberfläche wird ebenfalls in Richtung Multimodalität, ähnlich wie Doubao, und Community-Orientierung angepasst. Angesichts von Konkurrenten wie DeepSeek und dem Eintritt großer Unternehmen in den KI-Anwendungsmarkt gerät Kimis Position als Technologieführer unter Druck. Der Kommerzialisierungsdruck wächst, und das Unternehmen sucht aktiv nach neuen Wachstumspunkten. (Quelle: 36Kr)
Diskussion darüber, ob KI sich in der ersten Person bezeichnen sollte: Ein Reddit-Benutzer initiierte eine Diskussion darüber, dass es möglicherweise unangebracht sei, wenn LLMs wie ChatGPT sich selbst mit „ich“ oder den Benutzer mit „du“ bezeichnen, da sie im Wesentlichen „Dinge“ und keine „Personen“ seien. Es wurde vorgeschlagen, dass sie die dritte Person verwenden sollten, z. B. „ChatGPT wird Ihnen helfen…“, um zu vermeiden, dass Benutzer den Eindruck gewinnen, es handele sich um eine personifizierte Existenz, was zu potenziellen Gefahren oder ethischen Problemen führen könnte. In den Kommentaren argumentierten einige, dass die dritte Person反而 Selbstbewusstsein impliziere, während andere die dritte Person als albern und unangenehm empfanden. Die Diskussion spiegelt die Überlegungen der Benutzer zur Identitätspositionierung von KI und zur Mensch-Maschine-Interaktion wider. (Quelle: Reddit r/ArtificialInteligence)
💡 Sonstiges
MIT zieht vielbeachtetes KI-Paper wegen Zweifeln an Daten- und Forschungsauthentizität dringend zurück: Das Massachusetts Institute of Technology (MIT) hat ein Paper seines Doktoranden der Wirtschaftswissenschaften, Aidan Toner-Rogers, mit dem Titel „Artificial Intelligence, Scientific Discovery, and Product Innovation“ zurückgezogen. Das Paper hatte zuvor große Aufmerksamkeit erregt, da es vorschlug, dass KI-Tools die Innovationseffizienz von Spitzenwissenschaftlern erheblich steigern könnten, aber möglicherweise die „Kluft zwischen Arm und Reich“ in der Forschung verschärfen und das Wohlbefinden von Durchschnittsforschern verringern würden. Es wurde von Nobelpreisträgern und anderen namhaften Professoren gelobt. Das MIT erklärte, dass es nach Erhalt einer Meldung über wissenschaftliches Fehlverhalten und einer internen Untersuchung das Vertrauen in die Datenquelle, Zuverlässigkeit, Validität und Authentizität der Forschung verloren habe und arXiv sowie das Quarterly Journal of Economics gebeten habe, das Paper zurückzuziehen. Der Autor hat das MIT verlassen, und beteiligte Professoren haben sich ebenfalls distanziert. Berichten zufolge kaufte der Autor während der Untersuchung gefälschte Domains, um sich als E-Mails großer Unternehmen auszugeben, wurde entlarvt und verklagt. (Quelle: 36Kr)

KI-generierte Bilder werden für Online-Betrug verwendet und lösen Nutzerwarnungen aus: Ein Reddit-Benutzer teilte Beispiele für die Verwendung von KI-generierten Personenbildern zur Produktwerbung auf sozialen Medien wie Facebook. Diese Bilder weisen oft unlogische Elemente bei Personen und Szenen auf (z. B. Models, die auf seltsame Weise Kisten betreten und verlassen, nicht zusammenhängende Personen im Hintergrund), aber die Konsistenz der Charakterdarstellung ist hoch. Kommentatoren wiesen darauf hin, dass solche KI-generierten Inhalte bereits für Betrug verwendet wurden, und warnten die Benutzer zur Vorsicht. Blogger wie Pleasant Green haben ebenfalls Videos erstellt, die solche Betrügereien aufdecken. (Quelle: Reddit r/ChatGPT)
Diskussion über Stilnachahmung und Extraktion von Prompts bei KI-generierten Bildern: Benutzer diskutierten, wie KI-Modelle (wie DALL-E 3) dazu gebracht werden können, bestimmte Kunststile (z. B. Pixar-Stil kombiniert mit Designer-Toy-Stil von Salvador Dalí) bei der Erstellung von Porträts nachzuahmen, und teilten detaillierte Prompts, die Merkmale der Person, Hintergrund, Licht und Schatten sowie Kernkonzepte (wie Schatten als mentale Projektion) betonten. Darüber hinaus stellten andere Benutzer Prompt-Vorlagen zur Verfügung, um Stilparameter aus Bildern zu extrahieren und als JSON-Format auszugeben. Ziel ist es, Benutzern zu helfen, Bildstile per Reverse Engineering zu analysieren, obwohl eine präzise Reproduktion weiterhin schwierig ist. (Quelle: dotey, dotey)
