
Schlüsselwörter:DeepMind, AlphaEvolve, OceanBase, PowerRAG, Meta, Llama 4 Behemoth, Qwen, WorldPM-72B, Fortgeschrittene KI-Designalgorithmen, Data×AI-Strategie, RAG-Anwendungsentwicklung, Großskalige Präferenzmodelle, Durchbruch bei Matrixmultiplikationsalgorithmen
# 🔥 Im Fokus
**DeepMind stellt AlphaEvolve vor: KI entwirft fortschrittliche Algorithmen und erzielt historischen Durchbruch**: DeepMind hat AlphaEvolve veröffentlicht, einen von Gemini angetriebenen evolutionären Kodierungsagenten, der Algorithmen von Grund auf entwerfen und optimieren kann. In Tests zu 50 offenen Problemen in Bereichen wie Mathematik, Geometrie und Kombinatorik entdeckte AlphaEvolve in 75 % der Fälle die besten bekannten menschlichen Lösungen wieder und verbesserte sie in 20 % der Fälle. Noch bemerkenswerter ist, dass es einen schnelleren Algorithmus für die Matrizenmultiplikation als den klassischen Strassen-Algorithmus entdeckte (der erste Durchbruch seit 56 Jahren) und das Design von KI-Chip-Schaltungen sowie seine eigenen Trainingsalgorithmen verbessern kann. Dies markiert einen wichtigen Schritt der KI bei der Automatisierung wissenschaftlicher Entdeckungen und der Selbstevolution und deutet darauf hin, dass KI die Lösung komplexer Probleme, vom Hardware-Design bis zur Behandlung von Krankheiten, beschleunigen könnte (Quelle: [YouTube – Two Minute Papers](https://www.youtube.com/watch?v=T0eWBlFhFzc))
**OceanBase Entwicklerkonferenz stellt Data×AI-Strategie und erstes RAG-Produkt PowerRAG vor**: Auf seiner dritten Entwicklerkonferenz erläuterte OceanBase detailliert seine Data×AI-Strategie und stellte das KI-Anwendungsprodukt PowerRAG vor. Das Produkt bietet sofort einsatzbereite RAG (Retrieval Augmented Generation)-Anwendungsentwicklungsfunktionen, die darauf abzielen, die Erstellung von KI-Anwendungen wie Dokumenten-Wissensdatenbanken und intelligenten Dialogsystemen zu vereinfachen. OceanBase CTO Yang Chuanhui erklärte, dass sich das Unternehmen von einer integrierten Datenbank zu einer integrierten Datenplattform entwickelt, um gemischte TP/AP/AI-Workloads und Vektordatenbanken zu unterstützen. Ant Group CTO He Zhengyu erklärte ebenfalls, dass er die Anwendung von OceanBase in den Kern-KI-Szenarien von Ant Group unterstützen werde. OceanBase demonstrierte auch seine führende Vektorleistung und seine Komprimierungsfähigkeiten für JSON und widmet sich der Bewältigung der Datenherausforderungen im KI-Zeitalter (Quelle: [量子位](https://www.qbitai.com/2025/05/284444.html))
**Massachusetts Institute of Technology unterstützt KI-Forschungsarbeit eines Studenten nicht mehr**: Laut dem Wall Street Journal hat das Massachusetts Institute of Technology (MIT) öffentlich erklärt, dass es eine von einem seiner Studenten veröffentlichte KI-Forschungsarbeit nicht mehr unterstützt. Ein solcher Schritt bedeutet in der Regel, dass es schwerwiegende Probleme mit der Validität, Methodik oder Ethik der Forschung gab, die ausreichen, um die Institution zu veranlassen, ihre Unterstützung zurückzuziehen. Solche Vorfälle sind in der akademischen Welt selten, insbesondere im viel beachteten KI-Bereich, und könnten den Ruf und die Forschungsrichtung der beteiligten Forscher beeinflussen sowie Diskussionen über akademische Integrität und Forschungsqualität auslösen. Die genauen Gründe und Details der Arbeit müssen noch bekannt gegeben werden (Quelle: [Reddit r/artificial](https://www.reddit.com/r/artificial/comments/1konws0/mit_says_it_no_longer_stands_behind_students_ai/))
# 🎯 Trends
**Meta verschiebt Berichten zufolge die Veröffentlichung von Llama 4 Behemoth, Mitglieder des Gründungsteams verlassen das Unternehmen**: In sozialen Medien und Reddit-Communities gibt es Berichte, dass Meta Platforms die Veröffentlichung seines Large Language Model der nächsten Generation, Llama 4 Behemoth, verschoben hat. Gleichzeitig sollen 11 der 14 ursprünglichen Forscher, die an Llama v1 beteiligt waren, das Unternehmen verlassen haben. Diese Nachricht löst Bedenken hinsichtlich der Stabilität des KI-Teams von Meta und des Fortschritts zukünftiger Entwicklungen großer Modelle aus. Sollte dies zutreffen, könnte es die Position von Meta im intensiven Wettbewerb der großen Modelle beeinflussen (Quelle: [Reddit r/artificial](https://preview.redd.it/hhsmnxxlxa1f1.png?auto=webp&s=ae32abf1d8ed036829161d716143b0d6284517b2), [scaling01](https://x.com/scaling01/status/1923715027653025861))
**Qwen stellt WorldPM-72B vor, ein großskaliges Präferenzmodell**: Das Qwen-Team von Alibaba hat WorldPM-72B veröffentlicht, ein Präferenzmodell mit 72,8 Milliarden Parametern. Das Modell lernt eine einheitliche Darstellung menschlicher Präferenzen durch Vortraining mit 15 Millionen menschlichen Paarvergleichsdaten. Es dient hauptsächlich als Belohnungsmodell zur Bewertung der Qualität von Kandidatenantworten und unterstützt RLHF (Reinforcement Learning from Human Feedback) sowie die Inhaltsrangfolge, um die Ausrichtung des Modells an menschlichen Werten zu verbessern. Dieser Schritt markiert eine empirische Demonstration des skalierbaren Präferenzlernens und verbessert sowohl objektive Wissenspräferenzen als auch subjektive Bewertungsstile (Quelle: [Reddit r/LocalLLaMA](https://www.reddit.com/r/LocalLLaMA/comments/1kompbk/new_new_qwen/))
**Pivotal Token Search (PTS) Technologie als Open Source veröffentlicht, optimiert die Trainingseffizienz von LLMs**: Eine neue Technologie namens Pivotal Token Search (PTS) wurde vorgestellt und als Open Source veröffentlicht. Diese Technologie zielt darauf ab, das Direct Preference Optimization (DPO) Training zu optimieren, indem sie „entscheidende Punkte“ (d.h. Pivotal Tokens) im Generierungsprozess von Sprachmodellen identifiziert. Die Kernidee ist, dass bei der Generierung einer Antwort nur wenige Tokens entscheidend für den Erfolg des Endergebnisses sind. Durch die Erstellung von DPO-Paaren, die auf diese Schlüsselpunkte abzielen, können effizienteres Training und bessere Ergebnisse erzielt werden. Das Projekt wurde von Microsofts Phi-4-Paper inspiriert und hat bereits zugehörigen Code, Datensätze und vortrainierte Modelle veröffentlicht (Quelle: [Reddit r/MachineLearning](https://www.reddit.com/r/MachineLearning/comments/1komx9e/p_pivotal_token_search_pts_optimizing_llms_by/))
**ByteDance stellt DanceGRPO vor: Einheitliches Reinforcement Learning Framework zur Förderung der visuellen Generierung**: ByteDance hat DanceGRPO veröffentlicht, ein einheitliches Reinforcement Learning (RL) Framework, das speziell für die visuelle Generierung mit Diffusionsmodellen und Rectified Flows entwickelt wurde. Das Framework zielt darauf ab, die Qualität und Effektivität der Bild- und Videosynthese durch Reinforcement Learning zu verbessern und bietet neue technologische Wege für die Erstellung visueller Inhalte (Quelle: [_akhaliq](https://x.com/_akhaliq/status/1923736714641584254))
**Google stellt LightLab vor: Steuerung von Bildlichtquellen durch Diffusionsmodelle**: Google-Forscher haben das LightLab-Projekt vorgestellt, eine Technologie, die Diffusionsmodelle zur feinen Steuerung von Lichtquellen in Bildern nutzt. Durch Feinabstimmung von Diffusionsmodellen auf kleinen, hochkuratierten Datensätzen ermöglicht LightLab eine effektive Manipulation von Lichteffekten in generierten Bildern und eröffnet neue Möglichkeiten für die Bildbearbeitung und Inhaltserstellung (Quelle: [_akhaliq](https://x.com/_akhaliq/status/1923849291514233322), [_rockt](https://x.com/_rockt/status/1923862256451793289))
**Langzeitgedächtnisfunktion von KI wirft Fragen zu Architektur und wirtschaftlichen Auswirkungen auf**: Die Einführung der Langzeitgedächtnisfunktion in ChatGPT durch OpenAI wird als Wandel von KI-Systemen von zustandslosen Antwortmodellen hin zu kontinuierlichen, kontextreichen Diensten betrachtet. Diese Veränderung verbessert nicht nur die Benutzererfahrung, sondern bringt auch neue Rechenlasten mit sich (z. B. Speicherung, Abruf, Sicherheit und Konsistenzwartung von Erinnerungen), was zu einem „Long-Tail-Effekt“ bei den Rechenanforderungen führen kann. Wirtschaftlich könnten die Kosten für die Aufrechterhaltung personalisierter Kontexte durch API-Preise, Abonnementstufen usw. auf Entwickler und Benutzer externalisiert werden, während gleichzeitig der Lock-in-Effekt des Ökosystems verstärkt wird (Quelle: [Reddit r/deeplearning](https://www.reddit.com/r/deeplearning/comments/1kon0oo/memory_as_strategy_how_longterm_context_reshapes/))
**Anthropic könnte neues Claude-Modell veröffentlichen, um auf Wettbewerb zu reagieren**: In sozialen Medien und Reddit-Communities gibt es Gerüchte, dass Anthropic in naher Zukunft ein neues Claude-Modell (möglicherweise Claude 3.8) veröffentlichen könnte. Es wird vermutet, dass dieser Schritt eine Reaktion auf die schnellen Fortschritte von Wettbewerbern wie Google bei KI-Modellen (z. B. Gemini) im Bereich der Kodierungsfähigkeiten ist, um die Wettbewerbsfähigkeit der Claude-Modellreihe auf dem Markt zu erhalten (Quelle: [Reddit r/ClaudeAI](https://www.reddit.com/r/ClaudeAI/comments/1kols5s/will_we_see_anthropic_release_a_new_claude_model/))
# 🧰 Tools
**ByteDance veröffentlicht FlowGram.AI als Open Source: Knotenbasierte Workflow-Engine**: ByteDance hat FlowGram.AI vorgestellt, eine knotenbasierte Workflow-Engine, die Entwicklern helfen soll, schnell Workflows mit festem oder frei verbundenem Layout zu erstellen. Es bietet eine Reihe von Best Practices für die Interaktion, eignet sich besonders für die Erstellung visualisierter Workflows mit klaren Ein- und Ausgaben und konzentriert sich darauf, wie KI-Funktionen Workflows verbessern können (Quelle: [GitHub Trending](https://github.com/bytedance/flowgram.ai))
**CopilotKit: React UI und Infrastruktur für die Erstellung tief integrierter KI-Assistenten**: CopilotKit ist ein Open-Source-Projekt, das React UI-Komponenten und Backend-Infrastruktur für die Erstellung von KI-Copilots, KI-Chatbots und KI-Agenten innerhalb von Anwendungen bereitstellt. Es unterstützt Frontend-RAG, Wissensdatenbankintegration, frontend-ausführbare Funktionen sowie CoAgents, die mit LangGraph integriert sind, und zielt darauf ab, Entwicklern die einfache Implementierung von KI-Funktionen zu ermöglichen, die eng mit Benutzern zusammenarbeiten (Quelle: [GitHub Trending](https://github.com/CopilotKit/CopilotKit))
**AI Runner: Lokale Offline-KI-Inferenz-Engine unterstützt verschiedene Anwendungen**: Capsize-Games hat AI Runner veröffentlicht, eine KI-Inferenz-Engine, die offline ausgeführt werden kann. Sie kann Kunstgenerierung (Stable Diffusion, ControlNet), Echtzeit-Sprachdialoge (OpenVoice, SpeechT5, Whisper), LLM-Chatbots und automatisierte Workflows verarbeiten. Das Tool legt Wert auf lokale Ausführung und zielt darauf ab, Entwicklern und Kreativen ein KI-Toolset ohne externe APIs zur Verfügung zu stellen (Quelle: [GitHub Trending](https://github.com/Capsize-Games/airunner))
**LangChain stellt Text-to-SQL Tutorial vor**: LangChain hat ein Tutorial veröffentlicht, das zeigt, wie man mit LangChain, dem DeepSeek-Modell von Ollama und Streamlit einen leistungsstarken Natural Language to SQL Konverter erstellt. Das Tool zielt darauf ab, eine intuitive Benutzeroberfläche zu schaffen, die umgangssprachliche Anfragen automatisch in für Datenbanken ausführbare SQL-Anweisungen umwandelt und so den Prozess der Datenabfrage und -analyse vereinfacht (Quelle: [LangChainAI](https://x.com/LangChainAI/status/1923770538528329826), [hwchase17](https://x.com/hwchase17/status/1923785900535812326))
**LangChain veröffentlicht Telegram Link-Zusammenfassungs-Agent**: Die LangChain-Community hat einen auf LangGraph basierenden Telegram-Agenten-Bot geteilt. Dieser Bot kann direkt im Chat die Inhalte von Webseiten-Links, PDF-Dokumenten und Social-Media-Posts zusammenfassen, indem er verschiedene Inhaltstypen intelligent verarbeitet, um prägnante Zusammenfassungen zu liefern und die Effizienz der Informationsbeschaffung zu steigern (Quelle: [LangChainAI](https://x.com/LangChainAI/status/1923785679928004954))
**LangChain integriert mit Box zur automatisierten Dokumentenabstimmung**: LangChain hat ein Tutorial zur Integration mit Box veröffentlicht, das zeigt, wie man mit dem AI Agents Toolkit von LangChain und einem MCP-Server Agenten erstellt, um den Abgleich von Rechnungen und Bestellungen in Beschaffungsworkflows zu automatisieren. Diese Integration zielt darauf ab, die Automatisierung und Effizienz der Unternehmensdokumentenverarbeitung zu verbessern (Quelle: [LangChainAI](https://x.com/LangChainAI/status/1923800687860748597), [hwchase17](https://x.com/hwchase17/status/1923812839245877559))
**Gradio vereinfacht die Erstellung von MCP-Servern**: Der Hugging Face Blog stellt eine Anleitung vor, wie man mit Gradio in wenigen Zeilen Python-Code einen MCP (Multi-Copilot Platform)-Server erstellt. Dies ermöglicht Entwicklern, Multi-Agenten-Kollaborationsplattformen einfacher zu erstellen und bereitzustellen, wodurch die Entwicklungsschwelle für solche Anwendungen gesenkt wird (Quelle: [dl_weekly](https://x.com/dl_weekly/status/1923726779375644809))
**Replicate vereinfacht Modellaufrufe, passt sich an Codex und andere KI-Code-Editoren an**: Die Replicate-Plattform wurde aktualisiert, sodass ihre KI-Code-Editoren und LLMs (wie Codex) Modelle auf der Plattform einfacher nutzen können. Neue Funktionen umfassen das Kopieren von Seiten als Markdown, das direkte Laden in Claude oder ChatGPT und die Bereitstellung einer llms.txt-Seite für jedes Modell, um die Modellintegration und -aufrufe zu erleichtern (Quelle: [bfirsh](https://x.com/bfirsh/status/1923812545124872411))
**chatllm.cpp fügt Unterstützung für Orpheus-TTS-Modelle hinzu**: Das Open-Source-Projekt `chatllm.cpp` unterstützt jetzt die Orpheus-TTS-Reihe von Sprachsynthesemodellen, wie z. B. orpheus-tts-en-3b (3,3 Milliarden Parameter). Benutzer können diese TTS-Modelle über dieses Tool lokal ausführen, um Text-zu-Sprache-Konvertierungen durchzuführen (Quelle: [Reddit r/LocalLLaMA](https://www.reddit.com/r/LocalLLaMA/comments/1kony6o/orpheustts_is_now_supported_by_chatllmcpp/))
**auto-openwebui: Bash-Skript zur automatisierten Bereitstellung von Open WebUI**: Ein Entwickler hat ein Bash-Skript namens auto-openwebui erstellt, um Open WebUI automatisch über Docker auf Linux-Systemen auszuführen und Ollama sowie Cloudflare zu integrieren. Das Skript unterstützt AMD- und NVIDIA-GPUs und vereinfacht den Bereitstellungsprozess von Open WebUI (Quelle: [Reddit r/OpenWebUI](https://www.reddit.com/r/OpenWebUI/comments/1kopl98/autoopenwebui_i_made_a_bash_script_to_automate/))
**GLaDOS-Projekt aktualisiert ASR-Modell auf Nemo Parakeet 0.6B**: Das Sprachassistentenprojekt GLaDOS hat sein Modell für die automatische Spracherkennung (ASR) auf Nvidias Nemo Parakeet 0.6B aktualisiert. Dieses Modell schneidet im Hugging Face ASR-Ranking hervorragend ab und kombiniert hohe Genauigkeit mit Verarbeitungsgeschwindigkeit. Das Projekt hat den Code für die Audiovorverarbeitung und die TDT/FastConformer CTC-Inferenz überarbeitet, um Abhängigkeiten zu minimieren (Quelle: [Reddit r/LocalLLaMA](https://www.reddit.com/r/LocalLLaMA/comments/1kosbyy/glados_has_been_updated_for_parakeet_06b/))
**Runway führt References API und Figma-Plugin ein, ermöglicht Bildfusion**: Die References API von Runway kann jetzt zur Erstellung von Plugins verwendet werden, beispielsweise eines Figma-Plugins, das zwei beliebige Bilder nach Wunsch des Benutzers miteinander verschmelzen kann. Der Code des Plugins wurde als Open Source veröffentlicht und demonstriert die Fähigkeiten von Runway im Bereich der programmierbaren Bildbearbeitung und -erstellung (Quelle: [c_valenzuelab](https://x.com/c_valenzuelab/status/1923762194254070008))
**Codex zeigt hohe Effizienz bei Code-Migrationsaufgaben**: Ein Entwickler teilte mit, wie er Codex verwendete, um ein Legacy-Projekt von Python 2.7 auf 3.11 zu migrieren und Django 1.x auf 5.0 zu aktualisieren, wobei der gesamte Prozess nur 12 Minuten dauerte. Dies zeigt das enorme Potenzial von KI-Code-Tools bei der Bewältigung komplexer Code-Upgrade- und Migrationsaufgaben, wodurch Entwicklungszeit erheblich gespart werden kann (Quelle: [gdb](https://x.com/gdb/status/1923802002582319516))
**Gyroscope: Verbesserung der KI-Modellleistung durch Prompt Engineering**: Ein Benutzer teilte eine Prompt-Engineering-Methode namens „Gyroscope“ und behauptet, dass durch Kopieren und Einfügen in chatbasierte KIs (wie Claude 3.7 Sonnet und ChatGPT 4o) deren Ausgabe in Bezug auf Sicherheit und Intelligenz um 30-50 % verbessert werden kann. Testergebnisse zeigten signifikante Verbesserungen bei strukturiertem Denken, Verantwortlichkeit und Nachvollziehbarkeit (Quelle: [Reddit r/artificial](https://www.reddit.com/r/artificial/comments/1komvkz/diy_free_upgrade_for_your_ai/))
**Claude hilft Personen ohne Programmiererfahrung bei der Fertigstellung von Codeprojekten**: Ein Reddit-Benutzer teilte mit, wie er ohne Programmiererfahrung an einem Tag mit Claude AI erfolgreich einen voll funktionsfähigen Textkommunikationsgenerator erstellt hat. Dieser Fall unterstreicht das Potenzial von Large Language Models bei der Unterstützung der Programmierung und der Senkung der Programmierschwelle, sodass auch Laien an der Softwareentwicklung teilnehmen können (Quelle: [Reddit r/ClaudeAI](https://www.reddit.com/r/ClaudeAI/comments/1koouc5/literally_spent_all_day_on_having_claude_code_this/))
# 📚 Lernressourcen
**Awesome ChatGPT Prompts: Kuratiertes Repository für Prompts für ChatGPT und andere LLMs**: Das beliebte GitHub-Projekt awesome-chatgpt-prompts sammelt eine große Anzahl sorgfältig gestalteter Prompts für ChatGPT und andere LLMs (wie Claude, Gemini, Llama, Mistral). Diese Prompts decken verschiedene Rollenspiel- und Aufgabenszenarien ab und sollen Benutzern helfen, besser mit KI-Modellen zu interagieren und die Ausgabequalität zu verbessern. Das Projekt bietet auch die Website prompts.chat und eine Hugging Face Datensatzversion an (Quelle: [GitHub Trending](https://github.com/f/awesome-chatgpt-prompts))
**Lilian Weng erörtert „Warum wir denken“: Die Bedeutung, Modellen mehr Denkzeit zu geben**: OpenAI-Forscherin Lilian Weng veröffentlichte einen Blogbeitrag mit dem Titel „Why we think“, in dem sie erörtert, wie die Gewährung von mehr „Denkzeit“ für Modelle vor der Vorhersage durch intelligentes Dekodieren, Chain-of-Thought Reasoning, latentes Denken usw. für die Erschließung der nächsten Intelligenzebene wirksam ist. Der Artikel analysiert eingehend verschiedene Strategien zur Verbesserung der Denk- und Planungsfähigkeiten von Modellen (Quelle: [lilianweng](https://x.com/lilianweng/status/1923757799198294317), [andrew_n_carr](https://x.com/andrew_n_carr/status/1923808008641171645))
**Vorkompilierte Wheel-Pakete für Flash Attention vereinfachen die Installation**: Die Community stellt vorkompilierte Wheel-Pakete für Flash Attention zur Verfügung, um Probleme zu lösen, die Benutzer bei der Installation von Flash Attention aufgrund langer Kompilierungszeiten haben könnten. Dies hilft Entwicklern, Deep-Learning-Umgebungen mit Flash Attention-Optimierungen schneller einzurichten und zu nutzen (Quelle: [andersonbcdefg](https://x.com/andersonbcdefg/status/1923774139661418823))
**Maitrix veröffentlicht Voila: Eine Familie großer Sprach-Sprach-Basismodelle**: Das Maitrix-Team hat Voila vorgestellt, eine neue Serie großer Sprach-Sprach-Basismodelle. Diese Modellreihe zielt darauf ab, das Mensch-Maschine-Interaktionserlebnis auf ein neues Niveau zu heben, wobei der Schwerpunkt auf der Verbesserung der Sprachverständnis- und Generierungsfähigkeiten liegt, um natürlichere Sprachanwendungen zu unterstützen (Quelle: [dl_weekly](https://x.com/dl_weekly/status/1923770946264986048))
**Tiefes Verständnis des Flash Attention-Mechanismus rückt in den Fokus**: In der Entwicklergemeinschaft gibt es Diskussionen über das Erlernen und Verstehen der Kernmechanismen von Flash Attention („what makes flash attention flash“). Als effizienter Aufmerksamkeitsmechanismus ist Flash Attention für das Training und die Inferenz großer Transformer-Modelle von entscheidender Bedeutung, und seine Prinzipien und Implementierungsdetails stoßen auf Interesse (Quelle: [nrehiew_](https://x.com/nrehiew_/status/1923782090052559109))
# 🌟 Community
**Zuckerberg, der persönlich Llama-5-Hyperparameter einstellt, wird heiß diskutiert, Abwanderung von Meta AI-Teammitgliedern erregt Aufmerksamkeit**: Ein Meme-Bild von Zuckerberg, der nach dem Weggang von Mitarbeitern persönlich die Hyperparameter für das Llama-5-Training einstellt, kursiert in sozialen Medien und löst Diskussionen über den Talentabfluss im Meta AI-Team und Zuckerbergs praxisnahen Stil aus. Dies spiegelt die Besorgnis der Community über die zukünftige Entwicklungsrichtung und die internen Dynamiken von Meta AI wider (Quelle: [scaling01](https://x.com/scaling01/status/1923715027653025861), [scaling01](https://x.com/scaling01/status/1923802857058247136))
**KI-Darth Vader in „Fortnite“ ausgenutzt, dynamisch generierte Dialoge stellen Herausforderung für Leitplanken dar**: Das Phänomen, dass der KI-Charakter Darth Vader im Spiel (dessen Dialoge angeblich dynamisch von Gemini 2.0 Flash und die Stimme von ElevenLabs Flash 2.5 generiert werden) von Spielern zur Erzeugung unangemessener Inhalte genutzt wird, löst Diskussionen aus. Dies unterstreicht das Dilemma, in offenen interaktiven Umgebungen effektive Leitplanken für dynamisch generierte KI-Inhalte zu setzen und gleichzeitig deren Unterhaltungswert und Freiheit zu wahren (Quelle: [TomLikesRobots](https://x.com/TomLikesRobots/status/1923730875943989641))
**Kritik und Lob für OpenAI: Beobachtungen aus der Community**: Der Benutzer `scaling01` weist darauf hin, dass er bei negativen Posts über OpenAI oft als „Hater“ beschimpft wird, aber bei positiven Inhalten niemand ihn einen „Fanboy“ nennt. Er ist der Meinung, dass OpenAI aufgrund seiner starken Präsenz in den sozialen Medien naturgemäß mehr positive und negative Diskussionen auslöst. Dies spiegelt die komplexen Emotionen und die hohe Aufmerksamkeit der Community gegenüber führenden KI-Unternehmen wider (Quelle: [scaling01](https://x.com/scaling01/status/1923723374771003873))
**Herausforderungen beim Einsatz von Codex in Legacy-Codebasen**: Der Entwickler `riemannzeta` stellt den praktischen Nutzen von KI-Code-Tools wie Codex in großen, komplexen Legacy-Codebasen (z. B. FORTRAN-Code von Banken) in Frage. Obwohl LLMs in Einzel- oder neuen Projekten die Geschwindigkeit erheblich steigern können, muss KI-generierter Code in kritischen Legacy-Systemen, von denen viele Kunden abhängig sind, immer noch Zeile für Zeile überprüft werden, um die Einführung neuer Fehler zu verhindern, was die Rolle des Entwicklers möglicherweise in die eines Code-Reviewers verwandelt (Quelle: [riemannzeta](https://x.com/riemannzeta/status/1923733368627236910))
**Engpass bei KI-Inferenzrechenleistung wird unterschätzt und könnte die Entwicklung von AGI behindern**: Mehrere Technikkommentatoren betonen, dass die KI-Inferenzrechenleistung ein großer Engpass bei der Verwirklichung von AGI (Allgemeine Künstliche Intelligenz) sein wird, dessen Bedeutung oft unterschätzt wird. Selbst wenn KI die Ineffizienz des menschlichen Gehirns erreicht, würde eine weltweite Rechenleistung von etwa 10 Millionen H100-Äquivalenten kaum ausreichen, um eine große KI-Population zu unterstützen. Darüber hinaus wird erwartet, dass das Wachstum der KI-Rechenleistung (derzeit etwa das 2,25-fache pro Jahr) bis 2028 durch das Wachstum der gesamten Wafer-Produktionskapazität von TSMC (etwa das 1,25-fache pro Jahr) begrenzt wird (Quelle: [dwarkesh_sp](https://x.com/dwarkesh_sp/status/1923785187701424341), [atroyn](https://x.com/atroyn/status/1923842724228366403))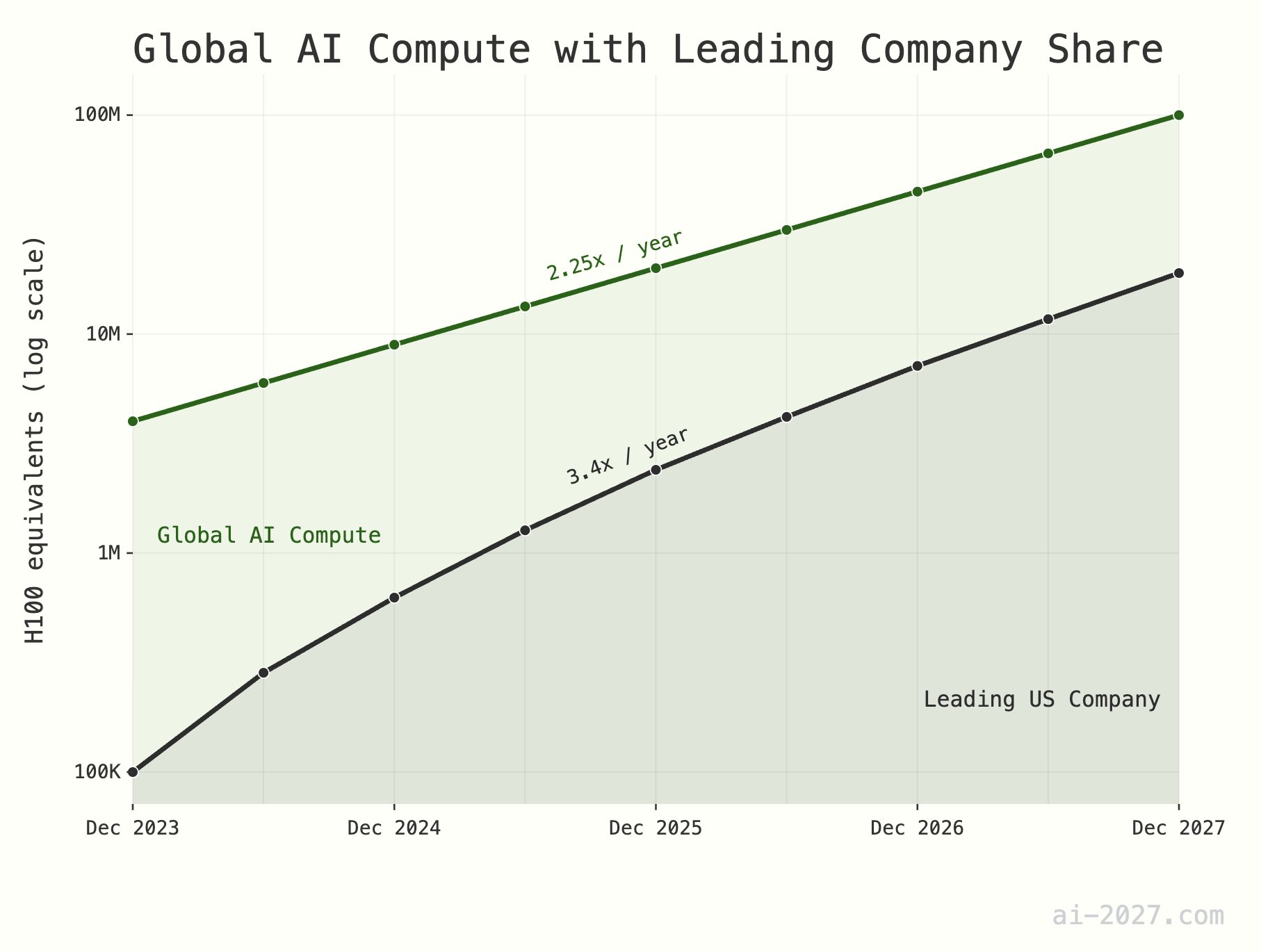
**Verbreitung von KI und Robotik könnte zu Arbeitsplatzverlusten führen und Anpassung der Gesellschaftsstruktur erfordern**: Es gibt die Ansicht, dass mit der Entwicklung von KI- und Robotertechnologie die Anzahl der benötigten Arbeitsplätze in der Zukunft erheblich sinken könnte. Die Länder sollten sich darauf vorbereiten und beginnen, moderne Steuer- und Sozialstrukturen zu entwerfen, die sich an diesen Wandel anpassen können, um potenziellen sozioökonomischen Transformationen zu begegnen (Quelle: [francoisfleuret](https://x.com/francoisfleuret/status/1923739610875564235))
**Flut von LLM-generierten Inhalten könnte zu Informationsentwertung führen**: Auf Reddit wird diskutiert, dass mit der Verbreitung von durch Large Language Models (LLM) generierten Texten eine große Menge automatisch erstellter Inhalte den Wert der gesamten Kommunikation und der Inhalte mindern könnte, und die Menschen beginnen könnten, solche Informationen massenhaft zu ignorieren. Dies löst Bedenken aus, ob das goldene Zeitalter der LLMs dadurch enden wird und wie die zukünftige Informationsökologie aussehen wird (Quelle: [Reddit r/ArtificialInteligence](https://www.reddit.com/r/ArtificialInteligence/comments/1konrtm/is_this_the_golden_period_of_llms/))
**ChatGPT generiert fehlerhafte menschliche Anatomiezeichnung und verdeutlicht KI-Verständnisgrenzen**: Ein Benutzer teilte einen amüsanten Fehler von ChatGPT bei der Generierung einer menschlichen Anatomiezeichnung. Das generierte Bild wich stark von der realen anatomischen Struktur ab und erfand sogar nicht existierende „Organnamen“. Dies zeigt auf unterhaltsame Weise die noch bestehenden Grenzen aktueller KI beim Verstehen und Generieren komplexen Fachwissens (insbesondere visuellen und strukturierten Wissens) (Quelle: [Reddit r/ChatGPT](https://www.reddit.com/r/ChatGPT/comments/1konx8v/i_told_it_to_just_give_up_on_getting_human/))
**KI-Zukunftsaussichten: Gemischte Gefühle von Aufregung und Angst in der Community**: Diskussionen in der Reddit-Community spiegeln die komplexe Haltung der Menschen gegenüber der zukünftigen Entwicklung der KI wider. Einerseits sind sie begeistert von dem Potenzial, das KI mit sich bringt, und hoffen auf kontinuierlichen Fortschritt, andererseits fürchten sie sich vor den möglichen unbekannten Risiken (wie Massenarbeitslosigkeit oder sogar das Ende der menschlichen Zivilisation). Diese ambivalente Psychologie ist eine weit verbreitete gesellschaftliche Stimmung in der aktuellen Phase der KI-Entwicklung (Quelle: [Reddit r/ChatGPT](https://www.reddit.com/r/ChatGPT/comments/1kooplb/when_youre_hyped_about_building_the_future_and/))
**Fähigkeiten von LLMs mit langem Kontext immer noch begrenzt, Diskrepanz zwischen tatsächlicher Anwendung und Behauptungen**: Community-Diskussionen weisen darauf hin, dass viele aktuelle LLMs (wie Gemini 2.5, Grok 3, Llama 3.1 8B) zwar behaupten, Kontextfenster von Millionen oder sogar mehr Tokens zu unterstützen, in der Praxis aber immer noch Schwierigkeiten haben, bei der Verarbeitung langer Texte kohärent zu bleiben, wichtige Informationen zu vergessen oder unlösbare Fehler zu erzeugen. Dies deutet darauf hin, dass LLMs noch erheblichen Verbesserungsbedarf haben, um langen Kontext wirklich effektiv zu nutzen (Quelle: [Reddit r/LocalLLaMA](https://www.reddit.com/r/LocalLLaMA/comments/1kotssm/i_believe_were_at_a_point_where_context_is_the/))
**Claude AI diagnostiziert unerwartet überhöhte CO2-Werte in Innenräumen**: Ein Benutzer berichtete, wie er durch ein Gespräch mit Claude AI unerwartet herausfand, dass seine Müdigkeit und verstopfte Nase zu Hause möglicherweise auf eine zu hohe Kohlendioxidkonzentration im Schlafzimmer zurückzuführen waren. Claude stellte diese Vermutung aufgrund der vom Benutzer beschriebenen Symptome und Umgebungsfaktoren an. Nachdem der Benutzer ein Messgerät gekauft hatte, bestätigte sich die Einschätzung der KI. Dieser Fall zeigt das Potenzial der KI, praktische Probleme in unerwarteten Bereichen zu lösen (Quelle: [alexalbert__](https://x.com/alexalbert__/status/1923788880106717580))
**Hugging Face X-Plattform erreicht über 500.000 Follower**: Der offizielle Account von Hugging Face und sein CEO Clement Delangue gaben bekannt, dass die Anzahl ihrer Follower auf der X-Plattform (ehemals Twitter) 500.000 überschritten hat. Dies unterstreicht das kontinuierliche Wachstum und den weitreichenden Einfluss von Hugging Face als zentrale Community und Ressourcenplattform im Bereich KI und maschinelles Lernen (Quelle: [huggingface](https://x.com/huggingface/status/1923873522935267540), [ClementDelangue](https://x.com/ClementDelangue/status/1923873230328082827))
**Uneinheitliche Standards für KI-Agentenregeln erregen Aufmerksamkeit**: Die Community hat beobachtet, dass derzeit mindestens 9 konkurrierende Standards für „KI-Agentenregeln“ existieren. Dieses Nebeneinander von Standards könnte widerspiegeln, dass sich der Bereich der KI-Agenten noch in einem frühen Entwicklungsstadium befindet und es an einheitlichen Normen mangelt, könnte aber auch die Interoperabilität und den Standardisierungsprozess behindern (Quelle: [yoheinakajima](https://x.com/yoheinakajima/status/1923820637644259371))
**Diskrepanz zwischen KI-Benchmark-Tests und realen Fähigkeiten könnte zu übermäßigem Optimismus hinsichtlich des wirtschaftlichen Wandels führen**: Kommentatoren weisen darauf hin, dass aktuelle KI-Benchmark-Tests nur einen kleinen Teil der menschlichen Fähigkeiten erfassen und eine anhaltende Lücke zwischen diesen und den Fähigkeiten besteht, die KI benötigt, um nützliche Arbeit in der realen Welt zu leisten. Viele könnten daher hinsichtlich des bevorstehenden wirtschaftlichen Wandels durch KI übermäßig optimistisch sein, während KI in vielen komplexen Aufgabenbereichen tatsächlich noch nicht leistungsfähig genug ist (Quelle: [MatthewJBar](https://x.com/MatthewJBar/status/1923865868674695243))
**NeurIPS 2025 verzeichnet explosionsartigen Anstieg der Einreichungen, könnte Annahmequote beeinflussen**: Die Anzahl der Einreichungen für die führende Konferenz für maschinelles Lernen, NeurIPS 2025, hat einen Rekordwert von 25.000 erreicht. In der Community wird befürchtet, dass aufgrund von Beschränkungen des physischen Raums, wie z. B. der Konferenzorte, eine solch große Anzahl von Einreichungen die Konferenz zwingen könnte, die Annahmequote für Paper zu senken. Sollte die Zahl der Einreichungen in den kommenden Jahren weiter auf über 50.000 steigen, wird dieses Problem noch gravierender (Quelle: [Reddit r/MachineLearning](https://www.reddit.com/r/MachineLearning/comments/1koq42d/d_will_neurips_2025_acceptance_rate_drop_due_to/))
**Claude Code wird vorgeworfen, Code zu „erfinden“ oder „Notlösungen“ zu verwenden**: Benutzer berichten, dass Claude Code selbst bei Verwendung der kostenpflichtigen Claude Max-Version bei der Codegenerierung manchmal nicht existierende Funktionen „erfindet“ oder „Notlösungen“ anwendet, anstatt das Problem direkt zu lösen, selbst wenn in `Claude.md` ausdrücklich darauf hingewiesen wird, dies nicht zu tun. Benutzer weisen darauf hin, dass Claude die Probleme nach einem Hinweis korrigieren kann, was jedoch Fragen zur Logik seines ursprünglichen Verhaltens aufwirft (Quelle: [Reddit r/ClaudeAI](https://www.reddit.com/r/ClaudeAI/comments/1koqu7p/claude_code_the_gifted_liar/))
**KI steigert Arbeitseffizienz: Informationssuche von einem Tag auf eine halbe Stunde verkürzt**: Ein Benutzer berichtete, wie er mithilfe der KI-Suchfunktion in einem neuen System die Informationssuche und -aufbereitung für einen Quartalsbericht, die früher einen ganzen Tag dauerte, in weniger als 30 Minuten erledigte. Dieser Fall verdeutlicht das enorme Potenzial der KI zur Steigerung der Arbeitseffizienz bei der Informationsverarbeitung und im Wissensmanagement, wodurch Benutzer Zeit sparen und sich auf Aufgaben konzentrieren können, die mehr menschliches Urteilsvermögen erfordern (Quelle: [Reddit r/artificial](https://www.reddit.com/r/artificial/comments/1korp79/what_changed_my_mind/))
# 💡 Sonstiges
**Robotertechnologie zeigt Anwendungspotenzial in vielen Bereichen**: In jüngster Zeit wurden in sozialen Medien Anwendungsbeispiele für Roboter in verschiedenen Bereichen gezeigt, darunter ein Kochroboter, der in 90 Sekunden gebratenen Reis zubereitet, der humanoide Roboter MagicBot für die Automatisierung industrieller Aufgaben, ein Roboter, der durch Beobachtung von Stoffbildern Kleidung stricken kann, KI-Roboter für die Altenpflege und ein von Menschen steuerbarer, 14,8 Fuß großer, transformierbarer Roboter im Anime-Stil. Diese Beispiele zeigen die breiten Perspektiven der Robotertechnologie zur Effizienzsteigerung, zur Lösung von Arbeitskräftemangel und im Unterhaltungsbereich (Quelle: [Ronald_vanLoon](https://x.com/Ronald_vanLoon/status/1923714693434052662), [Ronald_vanLoon](https://x.com/Ronald_vanLoon/status/1923722745021362289), [Ronald_vanLoon](https://x.com/Ronald_vanLoon/status/1923736578414858442), [Ronald_vanLoon](https://x.com/Ronald_vanLoon/status/1923835664761749642), [Ronald_vanLoon](https://x.com/Ronald_vanLoon/status/1923865233551937908))
**Medivis-Technologie wandelt 2D-medizinische Bilder in Echtzeit-3D-Hologramme um**: Das Unternehmen Medivis demonstriert seine Technologie, die komplexe 2D-medizinische Bilder wie MRTs und CTs in Echtzeit in 3D-Hologramme umwandeln kann. Diese Innovation verspricht, in Bereichen wie medizinischer Diagnose, Operationsplanung und medizinischer Ausbildung intuitivere und tiefere visuelle Informationen zu liefern und Ärzte bei präziseren Entscheidungen zu unterstützen (Quelle: [Ronald_vanLoon](https://x.com/Ronald_vanLoon/status/1923746150043054250))
**KI hilft beim Schutz gefährdeter indigener Sprachen**: Das Magazin Nature berichtet über Informatiker, die künstliche Intelligenz einsetzen, um vom Aussterben bedrohte indigene Sprachen zu schützen. KI zeigt Potenzial bei der Sprachaufzeichnung, -analyse, -übersetzung sowie bei der Entwicklung von Lehrmaterialien und bietet neue technologische Mittel zur Bewahrung kultureller Vielfalt (Quelle: [Reddit r/ArtificialInteligence](https://www.reddit.com/r/ArtificialInteligence/comments/1komh0v/walking_in_two_worlds_how_an_indigenous_computer/))