
Schlüsselwörter:AlphaEvolve, KI-Algorithmusdesign, Multimodale KI, KI-Programmierwerkzeuge, Autonome Evolutionsalgorithmen, Große Sprachmodelle (LLM), KI-Agenten, Open-Source-Implementierung von AlphaEvolve, KI-gestütztes Design von Matrixmultiplikationsalgorithmen, Einheitliche Schnittstelle für multimodale KI, Auswirkungen von KI-Programmierwerkzeugen auf Entwickler, Leistung des lokalen Großmodells Qwen 3
🔥 Fokus
Google DeepMind veröffentlicht AlphaEvolve, AI für autonomes Design und Evolution von Algorithmen: Google DeepMind hat das AlphaEvolve-Projekt und dessen Paper veröffentlicht und stellt einen AI-Agenten vor, der in der Lage ist, effizientere Algorithmen autonom zu entwerfen, zu testen, zu lernen und zu evolvieren. Das System nutzt Prompt Engineering, um Large Language Models (wie Gemini) zur Generierung initialer Algorithmenentwürfe anzuleiten, und optimiert die Algorithmen in einem evolutionären Zyklus durch Fitness-Bewertung und Auswahl der Überlebenden. Die Community reagierte schnell, und eine Open-Source-Implementierung, OpenAlpha_Evolve, ist bereits erschienen. Forscher haben zudem Tools wie Claude verwendet, um die Durchbrüche von AlphaEvolve in Bereichen wie der Matrixmultiplikation zu verifizieren. Dies zeigt das enorme Potenzial von AI im Bereich der Algorithmusinnovation. (Quelle: karminski3, karminski3, Reddit r/ClaudeAI, Reddit r/artificial)

Multimodale Strategie von OpenAI erkennbar: Integrierte Schnittstellen und zentralisierte Infrastruktur erregen Aufmerksamkeit: OpenAI hat kürzlich mit der Veröffentlichung von Produkten wie GPT-4o, Sora und Whisper nicht nur seine Fortschritte bei multimodalen Fähigkeiten in Text, Bild, Audio und Video demonstriert, sondern auch seine strategische Absicht offenbart, mehrere Modalitäten in einheitliche Schnittstellen und APIs zu integrieren. Obwohl diese Strategie den Nutzern Komfort bietet, hat sie auch Diskussionen darüber ausgelöst, dass die Zentralisierung der Infrastruktur den Innovationsraum externer Entwickler und Forscher einschränken könnte. Insbesondere Videogenerierungsmodelle wie Sora, die hohe Rechenressourcen erfordern, binden kostenintensive Anwendungen weiter in das OpenAI-Ökosystem ein, was die „Gravitationskraft der Rechenleistung“ führender Plattformen verstärken und die Offenheit und Modularität im AI-Bereich beeinträchtigen könnte. (Quelle: Reddit r/deeplearning)
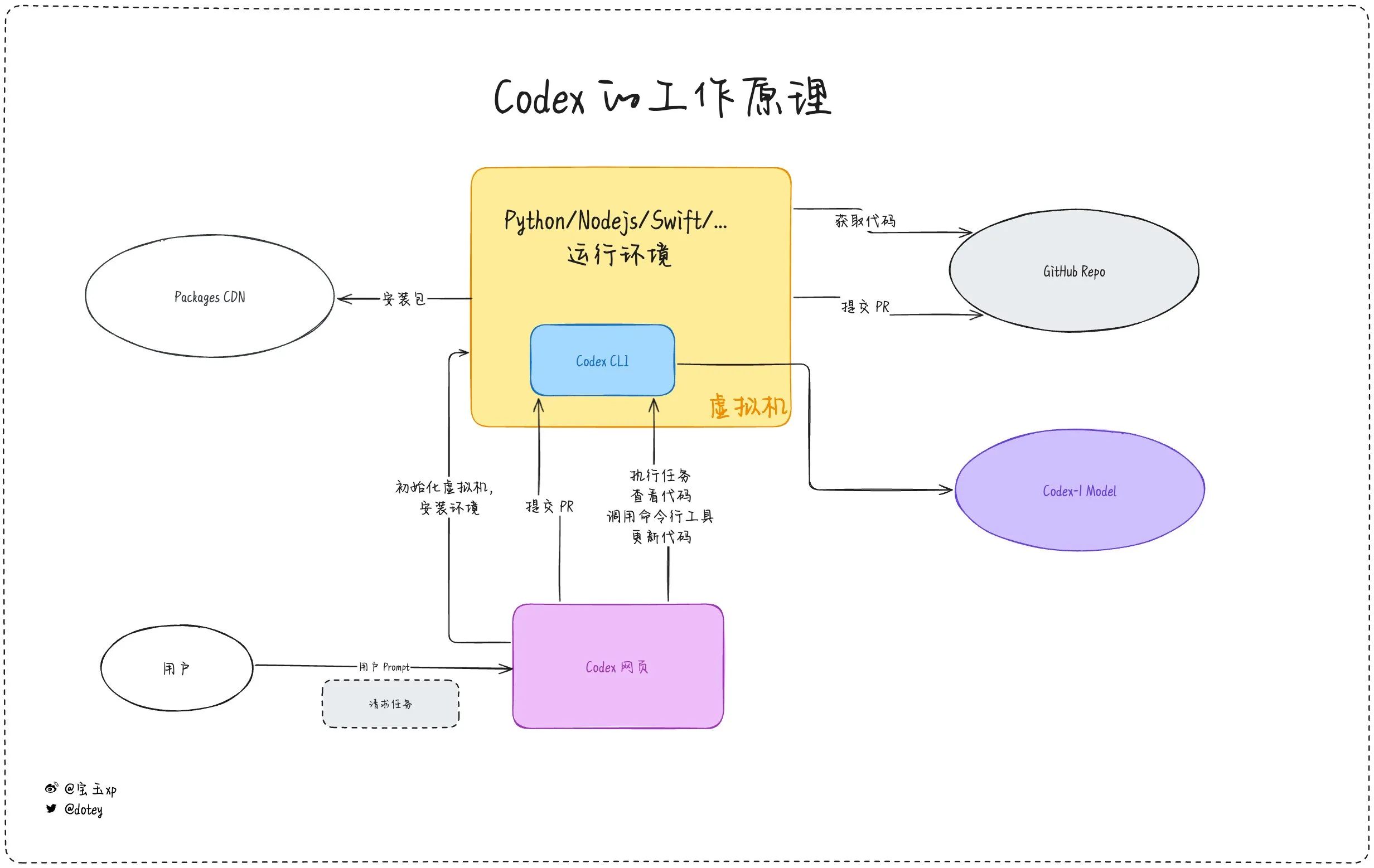
Zunehmende Verbreitung von AI-Programmierwerkzeugen, Entwicklererfahrungen und Reflexionen gehen Hand in Hand: AI-Programmierwerkzeuge wie Codex, Devin und verschiedene AI Agents integrieren sich zunehmend in Softwareentwicklungsprozesse. Entwicklerfeedback zeigt, dass Codex hohe Effizienz bei der Internationalisierung von Code und Projekt-Upgrades aufweist und Entwicklungszyklen erheblich verkürzen kann. Wie dotey in seiner Bewertung von Codex jedoch feststellt, ähneln aktuelle AI-Tools eher „externen Mitarbeitern“, die zwar Aufgaben erledigen können, aber bei Internetverbindung, Aufgabenkontinuität und Erfahrungssammlung noch Einschränkungen aufweisen. Diskussionen in der Community erwähnen auch, dass einige Entwickler nach langfristiger Nutzung von AI-gestützter Programmierung beginnen, deren Auswirkungen auf ihr eigenes Denken und ihre Kreativität zu reflektieren und sich sogar dafür entscheiden, zu stärker auf das „menschliche Gehirn“ angewiesene Entwicklungsmodelle zurückzukehren. Dies zeigt, dass das Gleichgewicht zwischen Effizienzsteigerung durch AI-Tools und der Erhaltung der Kernkompetenzen von Entwicklern ein wichtiges Thema bleibt. (Quelle: dotey, giffmana, cto_junior, Reddit r/artificial)
🎯 Trends
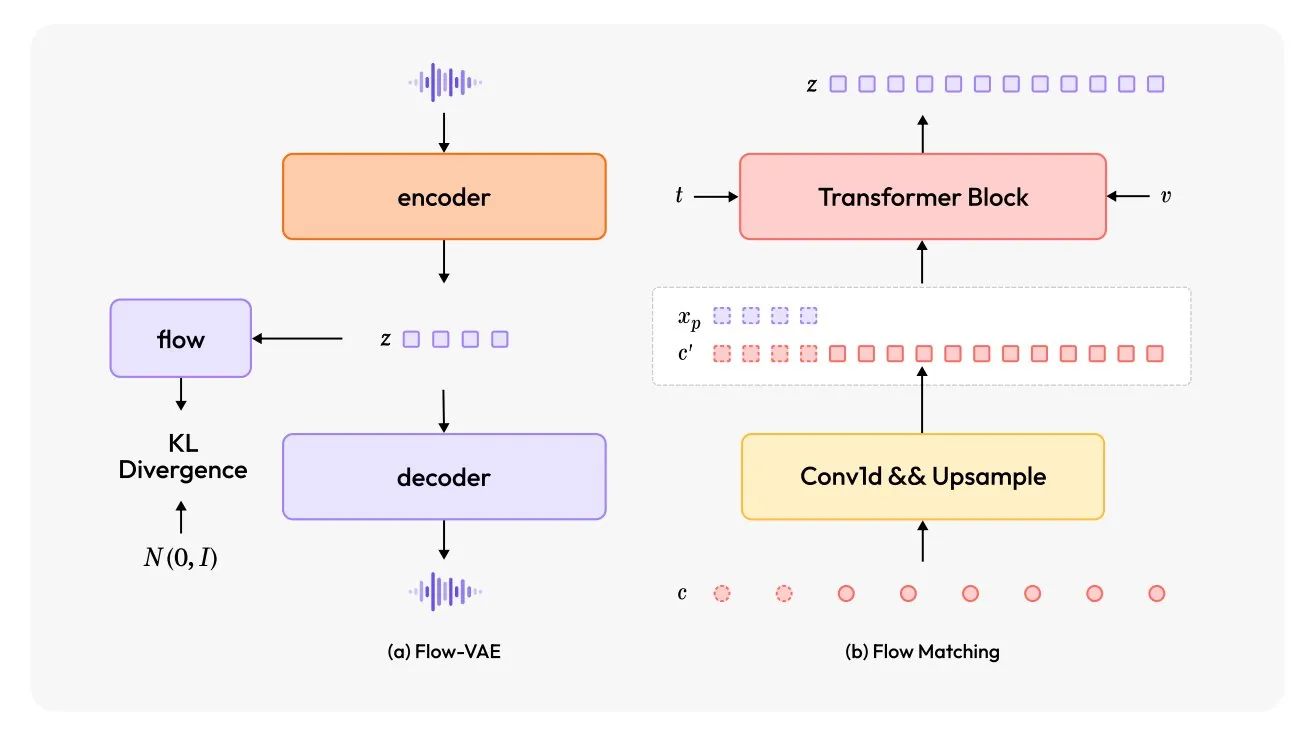
MiniMax-Speech: Neues mehrsprachiges TTS-Modell veröffentlicht: TheTuringPost stellt MiniMax-Speech vor, ein neues Text-to-Speech (TTS) Modell. Das Modell verwendet zwei Hauptinnovationen: einen lernfähigen Sprecher-Encoder, der aus kurzen Audioaufnahmen die Klangfarbe erfassen kann, und ein Flow-VAE-Modul zur Verbesserung der Audioqualität. MiniMax-Speech unterstützt 32 Sprachen und kann verwendet werden, um Sprache mit Emotionen zu versehen, Sprache aus Textbeschreibungen zu generieren oder Zero-Shot-Sprachklonen durchzuführen, was sein Potenzial für personalisierte und qualitativ hochwertige Sprachsynthese demonstriert. (Quelle: TheTuringPost, TheTuringPost)
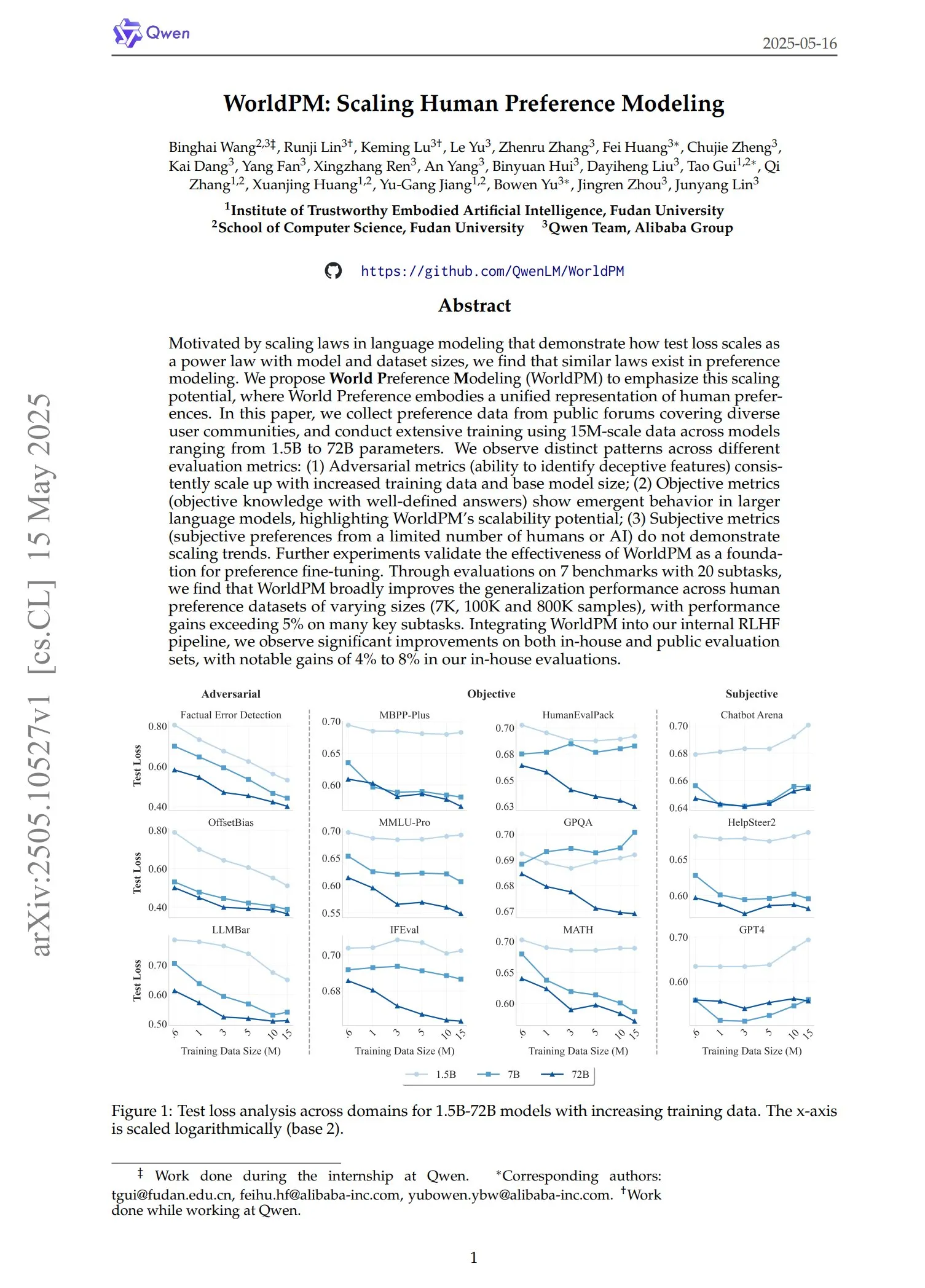
Qwen veröffentlicht WorldPM-Serie von Präferenzmodellen: Das Qwen-Team hat vier neue Präferenzmodellierungsmodelle vorgestellt: WorldPM-72B, WorldPM-72B-HelpSteer2, WorldPM-72B-RLHFLow und WorldPM-72B-UltraFeedback. Diese Modelle dienen hauptsächlich der Bewertung der Antwortqualität anderer Modelle und unterstützen den Prozess des überwachten Lernens. Offiziellen Angaben zufolge erzielt das Training mit diesen Präferenzmodellen bessere Ergebnisse als ein Training von Grund auf. Ein entsprechendes Paper wurde ebenfalls veröffentlicht. (Quelle: karminski3)
Grok fügt Diagrammerstellungsfunktion hinzu: Das Grok-Modell von XAI unterstützt jetzt die Erstellung von Diagrammen. Benutzer können mit Grok Diagramme im Browser erstellen. Diese Funktion soll in den kommenden Tagen auf weitere Plattformen ausgeweitet werden. Dieses Update erweitert die Fähigkeiten von Grok in Bezug auf Datenvisualisierung und Informationsdarstellung. (Quelle: grok, Yuhu_ai_, TheGregYang)
DeepRobotics stellt mittelgroßen vierbeinigen Roboter Lynx vor: Das Unternehmen DEEP Robotics hat seinen neuen mittelgroßen vierbeinigen Roboter Lynx vorgestellt. Dieser Roboter demonstriert die Fähigkeit, sich stabil in komplexem Gelände fortzubewegen, was die Fortschritte des Unternehmens in der Roboterbewegungssteuerung und Wahrnehmungstechnologie widerspiegelt. Er kann in verschiedenen Szenarien wie Inspektion und Logistik eingesetzt werden. (Quelle: Ronald_vanLoon)
Sanctuary AI integriert neue taktile Sensoren in Universalroboter: Sanctuary AI gab bekannt, dass seine Universalroboter mit neuer taktiler Sensortechnologie ausgestattet wurden. Diese Verbesserung zielt darauf ab, die Objekterkennungs- und Manipulationsfähigkeiten der Roboter zu verbessern, sodass sie feiner mit ihrer Umgebung interagieren können. Dies ist ein wichtiger Schritt hin zu leistungsfähigeren Universal-AI-Robotern. (Quelle: Ronald_vanLoon)
Unitree-Roboter demonstrieren fortschrittliche Gangfähigkeiten: Der Go2-Roboter von Unitree Robotics zeigte mehrere fortschrittliche Gangarten, darunter Gehen im Handstand, adaptives Überschlagen und Überwinden von Hindernissen. Die Realisierung dieser Fähigkeiten markiert eine signifikante Verbesserung seiner Roboterhunde in Bezug auf Bewegungssteuerungsalgorithmen und Anpassungsfähigkeit an die Umgebung. (Quelle: Ronald_vanLoon)
Chinesisches Forschungsteam entwickelt Roboter, der von kultivierten menschlichen Gehirnzellen angetrieben wird: Laut InterestingSTEM entwickelt ein chinesisches Forschungsteam einen Roboter, der von im Labor kultivierten menschlichen Gehirnzellen angetrieben wird. Diese Forschung untersucht die Fusion von biologischem Computing und Robotertechnologie mit dem Ziel, die Lern- und Anpassungsfähigkeiten biologischer Neuronen für neue Ansätze in der Robotersteuerung zu nutzen. Obwohl sich das Projekt noch in einem frühen Forschungsstadium befindet, hat es eine breite Diskussion über zukünftige Formen von Roboterintelligenz ausgelöst. (Quelle: Ronald_vanLoon)
Neuartiger Nanoskalen-Hirnsensor erreicht 96,4 % Genauigkeit bei der Erkennung neuronaler Signale: Ein neuartiger Nanoskalen-Hirnsensor zeigt eine Genauigkeit von bis zu 96,4 % bei der Erkennung neuronaler Signale. Diese Technologie verspricht Anwendungen in Brain-Computer-Interfaces, neurowissenschaftlicher Forschung und medizinischer Diagnostik und bietet neue Werkzeuge für eine präzisere Interpretation der Gehirnaktivität. (Quelle: Ronald_vanLoon)

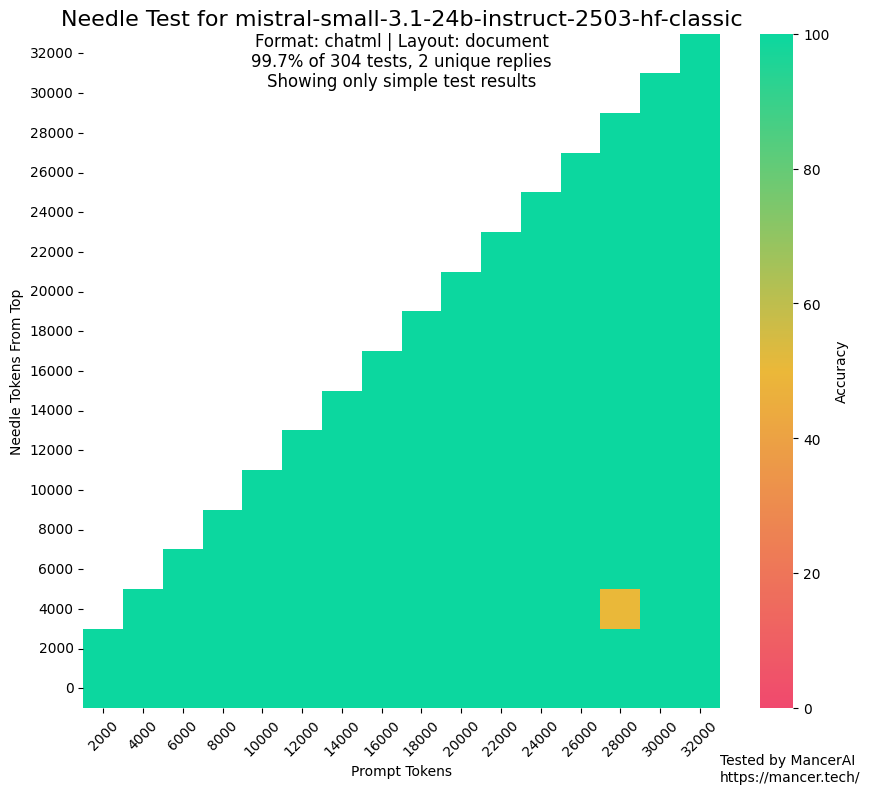
Gerüchte über MistralAI-Training mit Testdatensätzen sorgen für Aufmerksamkeit: In der Community gibt es Diskussionen und Zweifel, ob MistralAI möglicherweise Testdatensätze für Benchmarks wie NIAH zum Training verwendet hat. kalomaze wies durch den Vergleich der Leistung bei GitHub NIAH-Tests mit einem benutzerdefinierten NIAH (programmatisch generierte Fakten und Fragen) darauf hin, dass MistralAI bei ersterem deutlich besser abschnitt als bei letzterem, was auf eine mögliche Datenkontamination hindeutet. Dorialexander vermutet, dass eine „synthetische Annäherung“ des Evaluationsdatensatzes zur Gestaltung des Datenmixes verwendet worden sein könnte, was Bedenken hinsichtlich der Fairness und Transparenz der Modellevaluierung aufwirft. (Quelle: Dorialexander)
Studie behauptet, Claude 3.5 sei überzeugender als Menschen: Ein auf arXiv veröffentlichtes Forschungspapier legt nahe, dass das Modell Claude 3.5 von Anthropic in Bezug auf Überzeugungskraft Menschen überlegen ist. Die Studie verglich experimentell die Leistung des Modells mit der von Menschen bei spezifischen Überzeugungsaufgaben. Die Ergebnisse zeigen, dass AI möglicherweise signifikante Vorteile bei der Konstruktion überzeugender Argumente und der Kommunikation hat, was potenzielle Auswirkungen auf Bereiche wie Marketing, Öffentlichkeitsarbeit und Mensch-Maschine-Interaktion hat. (Quelle: Reddit r/ClaudeAI)

Lokale Large Models zeigen deutliche Leistungssteigerung auf Consumer-Hardware: Reddit-Nutzer berichten, dass das 14B-Parametermodell von Qwen 3 (mit Yarn-Patch für 128k Kontext) auf einem Consumer-PC mit nur 10 GB VRAM und 24 GB RAM, durch IQ4_NL-Quantisierung und 80k-Kontextkonfiguration, AI-Programmierassistenten wie Roo Code und Aider bereits gut ausführen kann. Obwohl die Geschwindigkeit bei der Verarbeitung langer Kontexte (z. B. 20k+) langsam ist (ca. 2 t/s), sind die Qualität der Codebearbeitung und die Fähigkeit, Codebasen zu verstehen, gut. Dies ist das erste Mal, dass ein lokales Modell komplexe Codierungsaufgaben in längeren Dialogen stabil verarbeiten und aussagekräftige Code-Unterschiede ausgeben kann. Dieser Fortschritt ist auf Verbesserungen des Modells selbst, Optimierungen von Inferenz-Frameworks wie llama.cpp und die Anpassung von Frontend-Tools wie Roo zurückzuführen. (Quelle: Reddit r/LocalLLaMA)
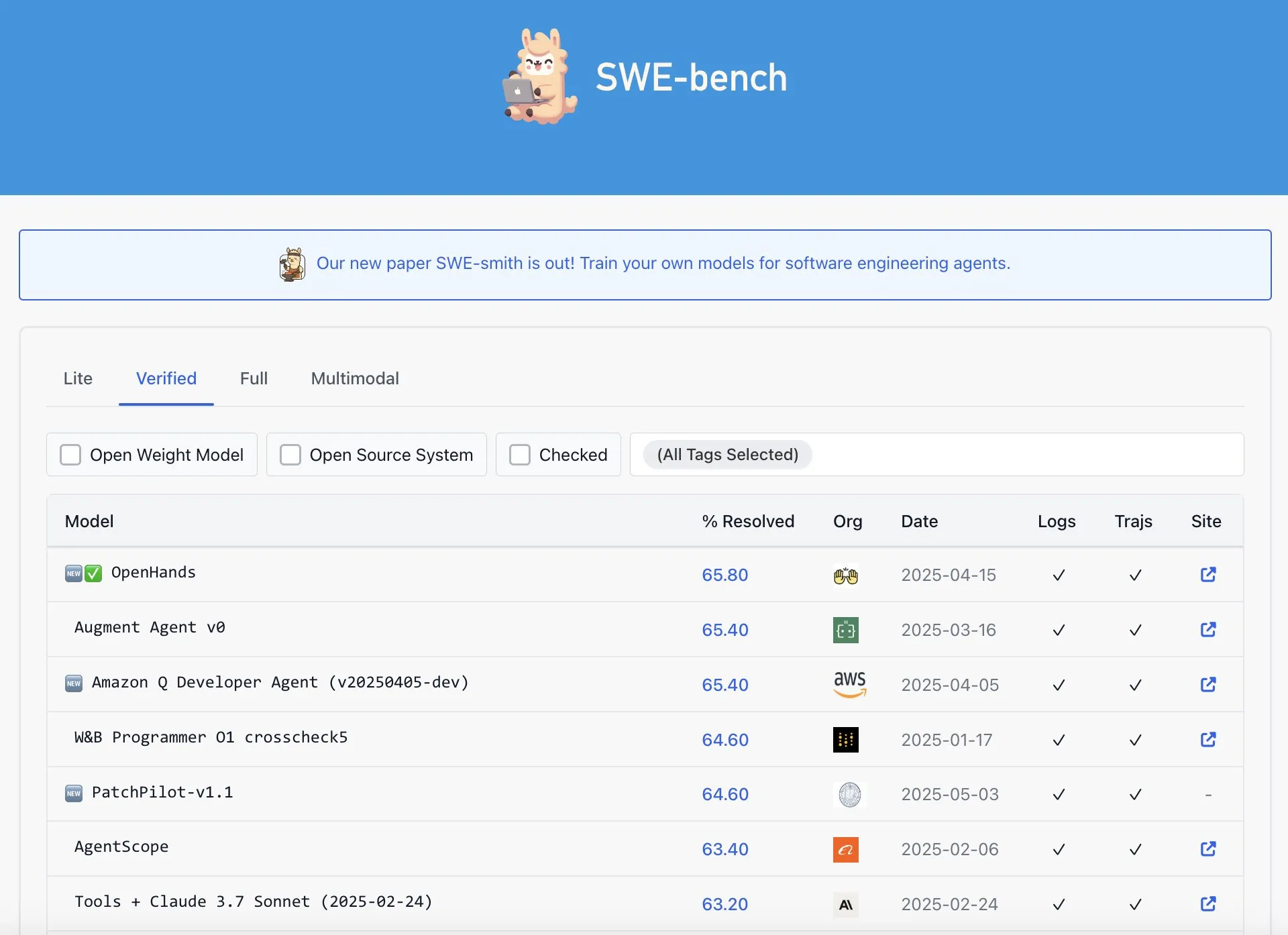
OpenAI Codex wird vorgeworfen, im SWE-Bench Verified Ranking nicht die beste Leistung zu erbringen: Graham Neubig weist darauf hin, dass die Behauptung, das Codex-Modell von OpenAI habe im SWE-Bench Verified Ranking SOTA-Ergebnisse (State-of-the-Art) erzielt, nicht ganz korrekt sei. Durch die Analyse von Daten und verschiedenen Bewertungsmaßstäben argumentiert er, dass die Leistung von Codex in diesem spezifischen Benchmark aus jedem Blickwinkel umstritten und nicht zweifellos die beste sei. (Quelle: JayAlammar)
🧰 Tools
OpenAlpha_Evolve Open Source: Reproduktion des Google AI-Algorithmus-Design-Agenten: Nach der Veröffentlichung des AlphaEvolve-Papers von Google DeepMind hat der Entwickler shyamsaktawat schnell die Open-Source-Implementierung OpenAlpha_Evolve vorgestellt. Dieses Python-Framework ermöglicht es Benutzern, mit AI-gesteuerten Algorithmus-Design-Konzepten zu experimentieren, einschließlich Aufgabendefinition, Prompt Engineering, Codegenerierung (mithilfe von LLMs wie Gemini), Ausführung von Tests, Fitness-Bewertung und evolutionärer Auswahl. Ziel ist es, einer breiteren Community die Teilnahme an der Erforschung der Grenzen des AI-Designs neuer Algorithmen zu ermöglichen. (Quelle: karminski3, Reddit r/artificial, Reddit r/LocalLLaMA)

Cursor-Editor fügt schnelle Bearbeitungsfunktion für ganze Dateien hinzu: Der AI-First-Code-Editor Cursor gab bekannt, dass Benutzer jetzt ganze Dateien schnell bearbeiten können. Diese neue Funktion zielt darauf ab, die Arbeitseffizienz von Entwicklern zu steigern und umfangreiche Codeänderungen und Refactorings in Cursor komfortabler zu gestalten. (Quelle: cursor_ai)
Codex erledigt Anwendungs-Internationalisierung und -Lokalisierung effizient: Entwickler Katsuya teilte seine Erfahrungen mit der Internationalisierung von Anwendungen mithilfe von OpenAI Codex. Er ließ Codex die Anwendung ins Japanische lokalisieren und erledigte diese normalerweise mehrtägige Aufgabe über Nacht. Dies demonstriert eindrücklich die leistungsstarken Fähigkeiten von Codex bei der automatisierten Codegenerierung und der Verarbeitung komplexer Sprachaufgaben. (Quelle: gdb, ShunyuYao12)
llmbasedos: Sichere MCP-Sandbox-Umgebung speziell für LLMs: Das Projekt llmbasedos bietet eine Betriebssystemumgebung auf Basis einer abgespeckten Version von Arch Linux, die darauf abzielt, eine sichere Modular Computing Protocol (MCP) Sandbox für Large Language Models (LLMs) bereitzustellen. Es kapselt Funktionen wie Dateisystem, E-Mail, Synchronisation und Proxy als MCP-Dienste. Benutzer können diese Dienste nach dem Booten von ISO über eine virtuelle Maschine oder einen physischen Rechner aufrufen, was eine sichere LLM-Interaktion und -Entwicklung erleichtert. (Quelle: karminski3)

cachelm: Open-Source LLM Semantic Caching Tool steigert Effizienz und senkt Kosten: Entwickler devanmolsharma hat das Open-Source-Tool cachelm vorgestellt, eine semantische Cache-Schicht für LLM-Anwendungen. Es implementiert Caching basierend auf semantischer Ähnlichkeit mittels Vektorsuche und kann so wiederholte Aufrufe der LLM-API effektiv reduzieren (selbst wenn Benutzer Fragen unterschiedlich formulieren), wodurch der Token-Verbrauch gesenkt und die Antwortzeiten beschleunigt werden. Das Tool unterstützt OpenAI, ChromaDB, Redis, ClickHouse usw. und ermöglicht es Benutzern, eigene Vektorisierer, Datenbanken oder LLMs anzupassen. (Quelle: Reddit r/MachineLearning)
ArchGW 0.2.8 veröffentlicht, AI-nativer Proxy vereinheitlicht Low-Level-Funktionen: ArchGW hat Version 0.2.8 veröffentlicht. Dieser auf Envoy basierende AI-native Proxy zielt darauf ab, wiederkehrende „Low-Level“-Funktionen in Anwendungen zu vereinheitlichen. Die neue Version fügt Unterstützung für bidirektionalen Datenverkehr hinzu (in Vorbereitung auf Google A2A), verbessert das Arch-Function-Chat 3B-Modell für schnelles Routing und Tool-Aufrufe und unterstützt auf Groq gehostete LLMs. ArchGW vereinfacht die Entwicklung von AI-Anwendungen durch einen lokalen Proxy-Ansatz und verbessert Sicherheit, Konsistenz und Beobachtbarkeit. (Quelle: Reddit r/artificial)
SparseDepthTransformer: Highschool-Schüler entwickelt dynamische Layer-Skipping-Lösung zur Effizienzsteigerung von Transformern: Ein Highschool-Schüler hat ein Projekt namens SparseDepthTransformer entwickelt, das die semantische Wichtigkeit jedes Tokens mithilfe eines leichtgewichtigen Bewertungsmechanismus evaluiert und unwichtige Tokens tiefere Berechnungen im Transformer überspringen lässt. Experimente zeigen, dass diese Methode die Ausgabequalität beibehält, während der Speicherverbrauch um etwa 15 % reduziert und die durchschnittliche Anzahl der Verarbeitungsschichten pro Token um etwa 40 % gesenkt wird. Dies bietet einen neuen Ansatz zur Effizienzsteigerung von Transformern. (Quelle: Reddit r/MachineLearning)

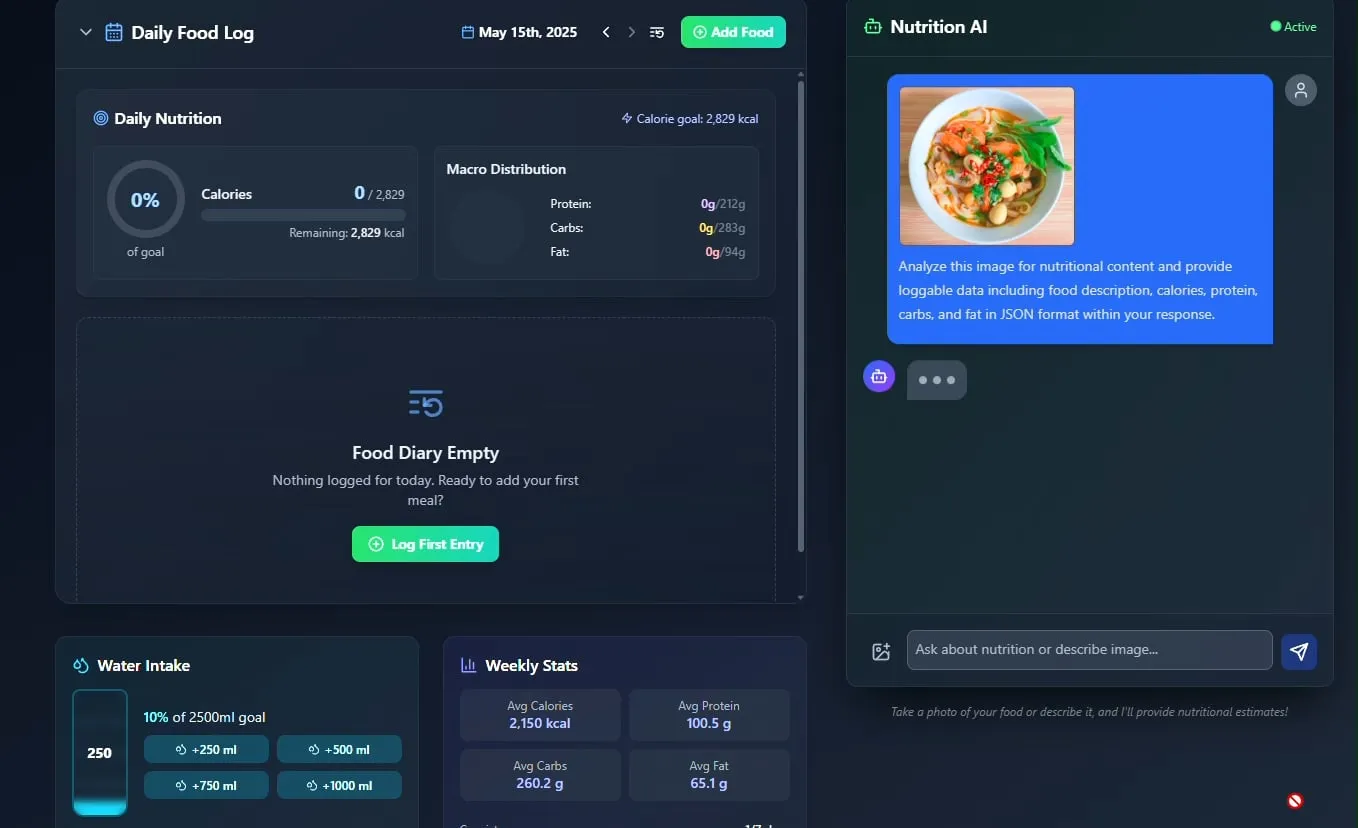
AI Food und Nutrition Tracker vorgestellt, Open Source geplant: Entwickler Pavankunchala hat eine AI-gesteuerte App zur Verfolgung von Ernährung und Nährstoffen vorgestellt. Die Kernfunktion der App besteht darin, Lebensmittel durch Analyse von vom Benutzer hochgeladenen Lebensmittelfotos zu identifizieren und Nährwertinformationen (Kalorien, Proteine usw.) zu schätzen. Sie unterstützt auch manuelle Eingaben, tägliche Nährwertübersichten und die Verfolgung der Wasseraufnahme. Der Entwickler plant, den Code des Projekts in Zukunft Open Source zu machen. (Quelle: Reddit r/LocalLLaMA)
Italienischer AI-Agent automatisiert Jobsuche, bewirbt sich in einer Minute auf tausend Stellen und löst Diskussionen aus: Ein angeblich aus Italien stammender AI Agent demonstrierte seine leistungsstarke Fähigkeit zur Automatisierung der Jobsuche und konnte innerhalb von einer Minute 1000 Bewerbungen abschicken. Die Demonstration löste eine breite Diskussion in der Community über den Einsatz von AI im Recruiting aus. Einerseits staunte man über die Effizienz, andererseits wurden Bedenken hinsichtlich der Effektivität, der Auswirkungen auf den Arbeitsmarkt und des Umgangs mit „Bot-Erkennung“ geäußert. (Quelle: Reddit r/ChatGPT)

📚 Lernen
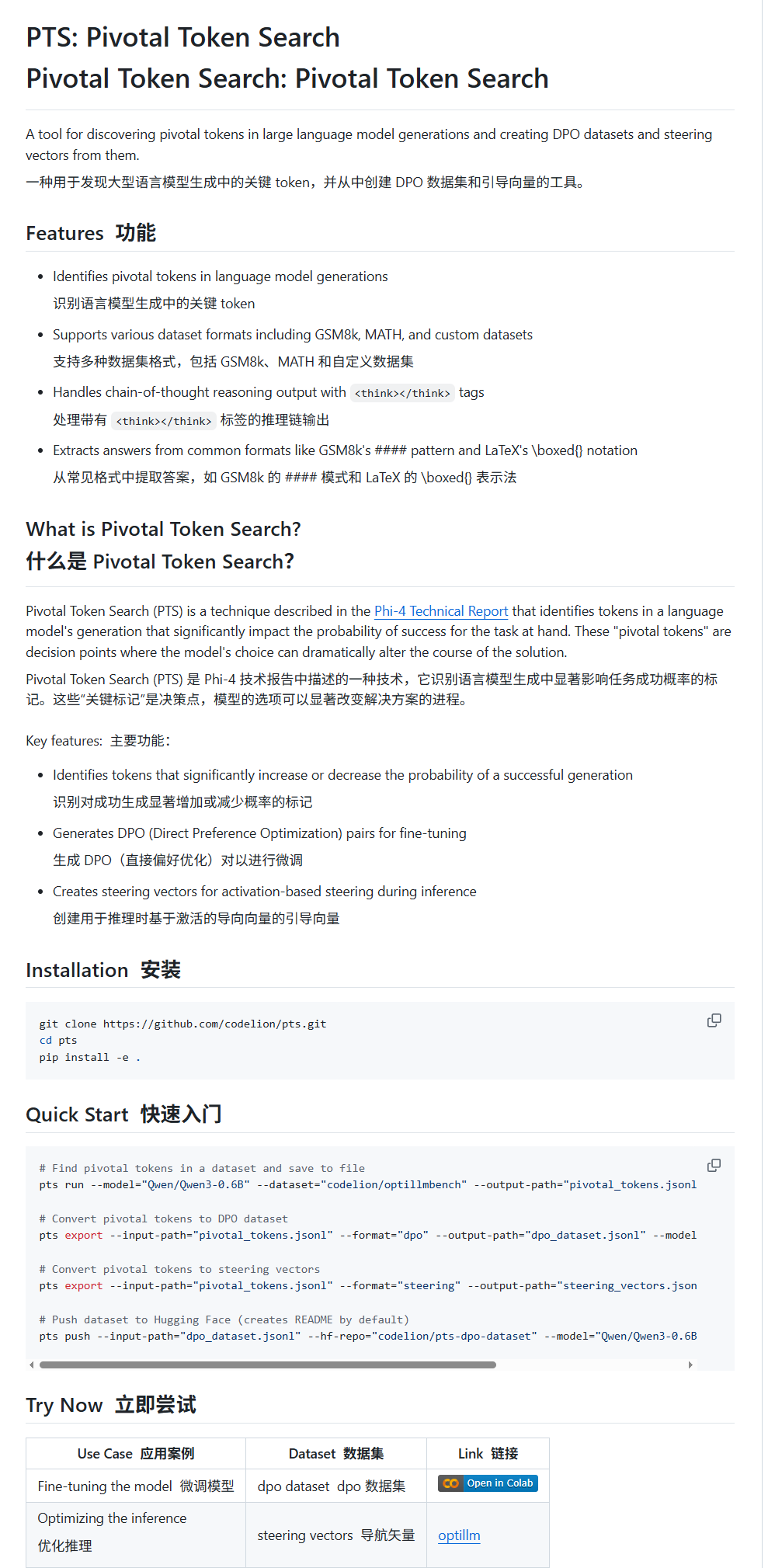
Pivotal Token Search (PTS): Eine neue Technik für LLM Fine-Tuning und Steuerung: karminski3 stellt eine neue Technik namens PTS (Pivotal Token Search) vor. Diese Technik basiert auf der Idee, dass die entscheidenden Punkte für die Ausgabe eines Large Models in wenigen Schlüssel-Tokens liegen. Durch die Extraktion dieser Tokens, die die Korrektheit der Ausgabe signifikant beeinflussen (unterteilt in „ausgewählte Tokens“ und „abgelehnte Tokens“), wird ein DPO-Datensatz für das Fine-Tuning erstellt. Darüber hinaus kann PTS die Aktivierungsmuster der Schlüssel-Tokens extrahieren, um Steuerungsvektoren (steering vectors) zu generieren, die das Modellverhalten während der Inferenz ohne Fine-Tuning lenken. Diese Methode ist angeblich von Phi4 inspiriert, und ihre Wirksamkeit löst Diskussionen in der Community aus. (Quelle: karminski3)
OpenAI Codex CLI bietet kostenlose API-Kontingente und fördert Datenaustausch: Der OpenAI-Entwickler-Account gab bekannt, dass Plus- oder Pro-Benutzer durch Ausführen von npm i -g @openai/codex@latest und codex --free kostenlose API-Kontingente einlösen können. Darüber hinaus können Benutzer kostenlose tägliche Tokens erhalten, indem sie in den Plattform-Einstellungen dem Teilen von Daten zur Verbesserung und zum Training von OpenAI-Modellen zustimmen. Diese Maßnahme zielt darauf ab, Entwickler zur Nutzung von Codex-Tools und zur Teilnahme an der Modellverbesserung zu ermutigen. (Quelle: OpenAIDevs, fouad)
Kostenlose Lernressourcen für Multi-Agenten-Systeme (MAS) zusammengefasst: TheTuringPost hat 7 kostenlose Lernressourcen für Multi-Agenten-Systeme (MAS) zusammengestellt und geteilt. Dazu gehören CrewAI, das CAMEL Multi-Agenten-Framework und LangChain Multi-Agenten-Tutorials; ein Buch mit dem Titel „Multiagent Systems: Algorithmic, Game-Theoretic, and Logical Foundations“; sowie drei Online-Kurse, die jeweils von Prompts zu Multi-Agenten-Systemen, die Beherrschung der Multi-Agenten-Entwicklung mit AutoGen und praktische Multi-AI-Agenten mit fortgeschrittenen Anwendungsfällen unter Verwendung von crewAI abdecken. (Quelle: TheTuringPost)

Tutorial zur schnellen Bildklassifizierung mit MobileNetV2: Reddit-Benutzer Eran Feit teilte ein Python-Tutorial zur Bildklassifizierung mit MobileNetV2. Das Tutorial führt Benutzer schrittweise durch das Laden eines vortrainierten MobileNetV2-Modells, die Vorverarbeitung von Bildern mit OpenCV (BGR zu RGB, Skalierung auf 224×224, Batch-Verarbeitung), die Durchführung der Inferenz und die Dekodierung der Vorhersageergebnisse, um menschenlesbare Labels und Wahrscheinlichkeiten zu erhalten. Das Tutorial eignet sich für Anfänger, um schnell in die leichtgewichtige Bildklassifizierung einzusteigen. (Quelle: Reddit r/deeplearning)
Anleitung zur Implementierung von Multi-Source RAG und Hybrid Search in OpenWebUI veröffentlicht: Die Website productiv-ai.guide hat eine detaillierte Schritt-für-Schritt-Anleitung zur Implementierung von Multi-Source Retrieval Augmented Generation (RAG) mit Hybrid Search und Re-Ranking in OpenWebUI veröffentlicht. Die Anleitung soll Benutzern helfen, die RAG-Funktionen von OpenWebUI, einschließlich der kürzlich hinzugefügten externen Re-Ranking-Funktion, zu konfigurieren und zu nutzen, um die Genauigkeit und Relevanz der Informationsbeschaffung zu verbessern. (Quelle: Reddit r/OpenWebUI)
💼 Wirtschaft
Harter Wettbewerb im AI Agent-Sektor: Detaillierter Vergleich von Manus und Lovart: Der AI Agent “Lovart” für den vertikalen Designbereich erregt Aufmerksamkeit durch seinen einzigartigen “auftragsbasierten” Workflow. Er versucht, den gesamten Designprozess zu simulieren, von der Bedarfsanalyse bis zur Lieferung von mehrschichtigen Materialien, und steht damit im Kontrast zur “dispositionsbasierten” Logik des universellen Agents “Manus”. Obwohl Lovart in Bezug auf das Verständnis von Designästhetik, Konzeptausdruck und Informationsorganisation gut abschneidet und schneller ist als Manus, haben beide Probleme mit Stabilität, chinesischer Sprachverarbeitung und der Verknüpfung von Änderungen. Das Aufkommen von Lovart wird als richtige Richtung für vertikale Agents angesehen, um Szenarien tiefgehend zu bearbeiten und Branchenerfahrungen zu internalisieren, was darauf hindeutet, dass AI Agents tatsächlich in der Content-Industrie Fuß fassen könnten. (Quelle: 36氪)

Boom im Markt für Kinder-Smartwatches, AIoT-Trend treibt Umsatzwachstum chinesischer SoC-Chiphersteller an: Dank konsumfördernder Maßnahmen und des AIoT-Entwicklungstrends ist der Absatz von intelligenten Wearables in China (insbesondere Kinder-Smartwatches) stark gestiegen. Das Aufkommen von Open-Source-Large-Models wie DeepSeek senkt die Hürden für den Einsatz von Edge-AI und beschleunigt die Durchdringung von AI in Endgeräten wie intelligenten Haushaltsgeräten und AI-Kopfhörern. Chinesische SoC-Chiphersteller wie Rockchip und Bestechnic verzeichnen dank ihrer Positionierung im Bereich Low-Power und AI-Rechenleistung sowie Flaggschiff-Chips wie dem Rockchip RK3588, der PC-, Smart-Hardware- und Automobilanwendungen abdeckt, ein deutliches Umsatzwachstum und eine entsprechende Steigerung ihrer Bewertung. (Quelle: 36氪)
OpenAI soll Umstrukturierungspläne angepasst und Kritik an Non-Profit-Status zurückgewiesen haben: Laut Garrison Lovely wurde ein bisher unveröffentlichter Brief von OpenAI an den kalifornischen Generalstaatsanwalt enthüllt. Der Inhalt des Briefes betrifft nicht nur unerwartete Details der Umstrukturierungspläne von OpenAI, sondern zeigt auch, dass OpenAI aktiv Maßnahmen ergreift, um Kritik und Zweifel an Versuchen, die Non-Profit-Governance-Struktur des Unternehmens zu schwächen, zurückzuweisen. (Quelle: NeelNanda5)

🌟 Community
Die N-Gram-Natur von LLMs und die Grenzen der „Intelligenz“ lösen hitzige Debatten aus: Die Community diskutiert weiterhin, inwieweit Large Language Models (LLMs) immer noch auf N-Gram-Statistikeigenschaften beruhen und ob aktuelle LLMs eine „echte AI“ darstellen. Einige Meinungen (wie pmddomingos’ Kommentar zu jxmnops NeurIPS-Paper) vertreten die Ansicht, dass LLMs sich in mehr als zwei Dritteln der Fälle ähnlich wie N-Gram-Modelle verhalten. Ein Reddit-Datenwissenschaftler wies darauf hin, dass aktuellen LLMs echtes Verständnis, Schlussfolgerungsvermögen und gesunder Menschenverstand fehlen und sie noch weit von AGI (Artificial General Intelligence) entfernt sind. Im Wesentlichen seien sie komplexe „Next-Word-Prediction-Systeme“ und keine Agenten mit Selbstbewusstsein und Anpassungsfähigkeit. (Quelle: jxmnop, pmddomingos, Reddit r/ArtificialInteligence)

AI-generierter Bildstil „transparente Folie“ und anzügliche „Doubao“-Bilder erregen Aufmerksamkeit: In letzter Zeit tauchen in sozialen Medien zahlreiche Bilder auf, die von AI-Bildgeneratoren wie Doubao in einem bestimmten Stil erstellt wurden, insbesondere Bilder mit einem „transparenten Folien“-Effekt. Diese Bilder haben aufgrund ihrer neuartigen visuellen Wirkung und möglicherweise anzüglichen Inhalte breite Diskussionen, Nachahmungen und Weiterverarbeitungen unter den Nutzern ausgelöst und sind zu einem heißen Trend im Bereich der AI-generierten Inhalte geworden. (Quelle: op7418, dotey)

AI-Ethik und Zukunft: Einen „Gott“ erschaffen oder Selbstzerstörung?: Die Community diskutiert intensiv über die ultimativen Ziele der AI-Entwicklung und die potenziellen Risiken. Emad Mostaque erklärte unverblümt, dass einige versuchen, eine „gottähnliche“ AGI zu erschaffen, was zu Utopie oder Zerstörung führen könnte. NVIDIA-CEO Jensen Huang blickte in die Zukunft, in der menschliche Ingenieure mit 1000 AI-Systemen zusammenarbeiten, um Chips zu entwerfen. Gleichzeitig lenkte eine durch einen SMBC-Comic ausgelöste Diskussion die Frage des AI-Bewusstseins auf eine praktischere ethische Ebene – können wir diese „Dinge“ guten Gewissens behandeln? Diese Ansichten bilden zusammen eine komplexe Vorstellung von der Zukunft der AI. (Quelle: Reddit r/artificial, Reddit r/artificial, Reddit r/artificial)
Wird AI das SaaS-Geschäftsmodell umwälzen? Entwickler-Community diskutiert intensiv: Mit der Verbreitung leistungsstarker AI-Programmierwerkzeuge wie Claude Code beginnt die Entwickler-Community, deren potenzielle Auswirkungen auf das SaaS (Software as a Service)-Geschäftsmodell zu diskutieren. Es wird argumentiert, dass die Hürde für einzelne Entwickler, Kernfunktionen bestehender SaaS-Produkte mithilfe von AI zu replizieren, sinkt. Dies könnte dazu führen, dass Unternehmen und Einzelnutzer ihre Abhängigkeit von traditionellen SaaS-Diensten reduzieren und stattdessen kostengünstigere Eigenentwicklungen oder AI-gestützte Lösungen suchen. Zukünftige Softwareentwicklung könnte stärker auf das Mikromanagement von AI angewiesen sein. (Quelle: Reddit r/ClaudeAI)
Unterschiede in der mehrsprachigen Verarbeitung durch AI erregen Aufmerksamkeit, Llama-Pretokenizer möglicherweise einer der Gründe: Diskussionen in der Community weisen darauf hin, dass Large Language Models (LLMs) im Englischen tendenziell besser abschneiden als in anderen Sprachen. Einer der möglichen Gründe wird in der Art und Weise gesehen, wie Pretokenizer von Modellen wie Llama nicht-englische Texte (insbesondere nicht-lateinische Schriftzeichen) verarbeiten. Beispielsweise könnten Pretokenizer chinesische Schriftzeichen übermäßig in kleinere Einheiten zerlegen, was das Verständnis der Sprachstruktur und Semantik durch das Modell beeinträchtigt und folglich zu einer schlechteren Leistung in diesen Sprachen führt. (Quelle: giffmana)

💡 Sonstiges
DSPy-Framework betont die Bedeutung von Low-Level-Primitiven für die Entwicklung von AI-Agenten: Seit der Veröffentlichung seiner Kernabstraktionen im Januar 2023 hat das AI-Framework DSPy, abgesehen von geringfügigen Vereinfachungen, kaum Änderungen erfahren und ist trotz mehrerer Iterationen von LLM-APIs stabil geblieben. Diskussionen in der Community weisen darauf hin, dass dies darauf zurückzuführen ist, dass DSPy sich auf die Entwicklung korrekter Low-Level-Primitive konzentriert, anstatt nur auf oberflächliche Entwicklererfahrung oder die schnelle Erstellung von „Agenten“ abzuzielen. Es wird argumentiert, dass viele aktuelle Agenten-Entwicklungsframeworks sich zu sehr auf Benutzerfreundlichkeit konzentrieren und die Solidität der grundlegenden Bausteine vernachlässigen, während die Philosophie von DSPy darin besteht, dass erst eine solide „Reaktions“-Grundlage vorhanden sein muss, um komplexes „Agenten“-Verhalten aufzubauen. (Quelle: lateinteraction, lateinteraction)
Ästhetische Ermüdung bei AI-generierten Inhalten fördert Nachfrage nach maßgeschneiderten Modellen: Diskussionen in der Community legen nahe, dass die Ergebnisse vieler durch Reinforcement Learning (RL) optimierter Bildgenerierungsmodelle oft „mittelmäßig“ oder „kitschig“ wirken. Obwohl technisch scheinbar gut, fehlt es ihnen an aufregender Kreativität und Individualität. Dies spiegelt wider, dass die Optimierungsziele der Modelle möglicherweise eher auf den durchschnittlichen ästhetischen Präferenzen der breiten Masse als auf einzigartigen künstlerischen Bestrebungen beruhen. Daher werden zukünftig maßgeschneiderte Modelle und Methoden, die auf individuelle ästhetische Ziele zugeschnitten sind, als Schlüssel zur Überwindung dieses Problems und zur Schaffung attraktiverer AI-Inhalte angesehen. (Quelle: torchcompiled)

Ollama veröffentlicht multimodale Engine, OpenWebUI-Nutzer achten auf Kompatibilität: Ollama hat die offizielle Veröffentlichung seiner multimodalen Engine bekannt gegeben. Diese Nachricht hat die Aufmerksamkeit der OpenWebUI-Community-Nutzer geweckt. Die Nutzer sind allgemein daran interessiert, ob OpenWebUI die neue multimodale Engine von Ollama „out-of-the-box“ unterstützen kann, d. h. ohne komplexe Konfigurationsänderungen ihre Fähigkeit zur Verarbeitung verschiedener Datentypen wie Bilder und Text nutzen kann. (Quelle: Reddit r/OpenWebUI)
