
Schlüsselwörter:OpenAI Codex, KI-Softwareentwicklung, Multimodale Modelle, KI-Spracherzeugung, Datenfilterung, Codex Forschungsvorschau, MiniMax Speech-02, BLIP3-o multimodales Modell, PreSelect Datenfilterung, SWE-1 Modellreihe
🔥 Im Fokus
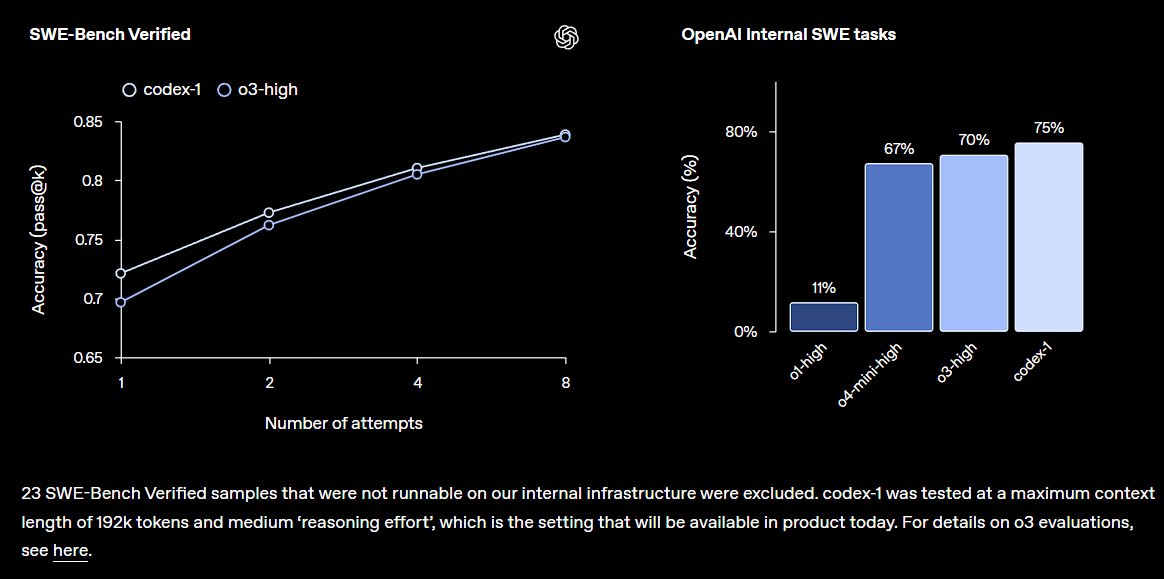
OpenAI veröffentlicht Forschungsvorschau von Codex, integriert in ChatGPT: OpenAI stellt Codex vor, einen cloudbasierten Software-Engineering-Agenten, der große Codebasen verstehen, neue Funktionen schreiben, Fehler beheben und mehrere Aufgaben parallel verarbeiten kann. Codex basiert auf dem o3-feinabgestimmten codex-1 Modell und zeigt hervorragende Leistungen auf SWE-bench. Die Funktion wird schrittweise für Nutzer von ChatGPT Pro, Team und Enterprise freigeschaltet und zielt darauf ab, die Produktivität von Entwicklern erheblich zu steigern. Dies deutet darauf hin, dass KI eine zentralere Rolle im Bereich der Softwareentwicklung spielen wird. Die Community reagierte darauf positiv, äußerte jedoch auch Bedenken hinsichtlich der praktischen Auswirkungen und potenzieller Bugs (Quelle: OpenAI, OpenAI Developers, scaling01, dotey)
Großangelegte Entlassungen bei Microsoft erschüttern die Branche, KI-getriebener organisatorischer Wandel beschleunigt sich: Microsoft kündigt weltweite Entlassungen von rund 6000 Mitarbeitern an, mit dem Ziel, Managementebenen zu vereinfachen und den Anteil der Programmierer zu erhöhen. Unter den Entlassenen befinden sich auch verdiente Veteranen mit 25 Dienstjahren und herausragenden Beiträgen sowie Kernentwickler von TypeScript. Diese Entlassungswelle wird mit der Effizienzsteigerung durch KI-Technologie und der Automatisierung einiger Arbeitsaufgaben in Verbindung gebracht und spiegelt den Trend wider, dass Technologiegiganten im KI-Zeitalter Kosten kontrollieren und Personalstrukturen optimieren. Der Vorfall löste eine breite Diskussion über die Auswirkungen von KI auf den Arbeitsmarkt, die Loyalität von Unternehmen und zukünftige Arbeitsmodelle aus (Quelle: WeChat, NeelNanda5)
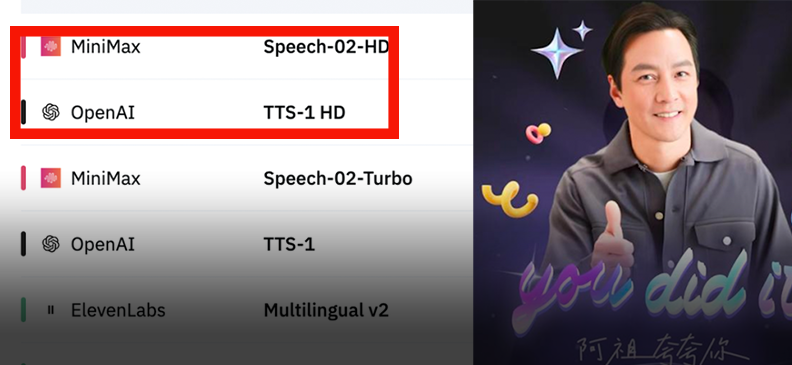
MiniMax veröffentlicht Sprachmodell Speech-02 und erklimmt globale Ranglistenspitze: MiniMax stellt sein Sprachmodell der nächsten Generation, Speech-02, vor, das sowohl in der Artificial Analysis Speech Arena als auch in der Hugging Face TTS Arena, zwei führenden Sprachtests, den ersten Platz belegte und damit OpenAI und ElevenLabs übertraf. Das Modell zeichnet sich durch ultra-realistische, personalisierte Stimmklanganpassung (unterstützt 32 Sprachen und Akzente, Nachbildung in wenigen Sekunden anhand von Referenzen) und Vielfalt aus und setzt innovativ die Flow-VAE-Technologie zur Verbesserung der Klon-Details ein. Die Technologie wurde bereits in Szenarien wie „AI Ah Zu lernt Englisch“ und dem KI-Führer im Verbotenen Stadt eingesetzt und zeigt die führende Position chinesischer großer Modelle im Bereich der KI-Sprachgenerierung (Quelle: WeChat, WeChat)
Salesforce und andere Institutionen veröffentlichen einheitliches multimodales Modell BLIP3-o: Salesforce Research hat in Zusammenarbeit mit mehreren Universitäten das vollständig quelloffene, einheitliche multimodale Modell BLIP3-o veröffentlicht. Es verfolgt eine „Zuerst verstehen, dann generieren“-Strategie und kombiniert autoregressive und Diffusionsarchitekturen. Das Modell verwendet innovativ CLIP-Merkmale und Flow Matching für das Training, was die Qualität, Vielfalt und Prompt-Ausrichtung der generierten Bilder erheblich verbessert. BLIP3-o zeigt in mehreren Benchmark-Tests hervorragende Leistungen und wird derzeit auf komplexe multimodale Aufgaben wie Bildbearbeitung und visuellen Dialog ausgeweitet, was die Entwicklung multimodaler KI-Technologie vorantreibt (Quelle: 36氪)

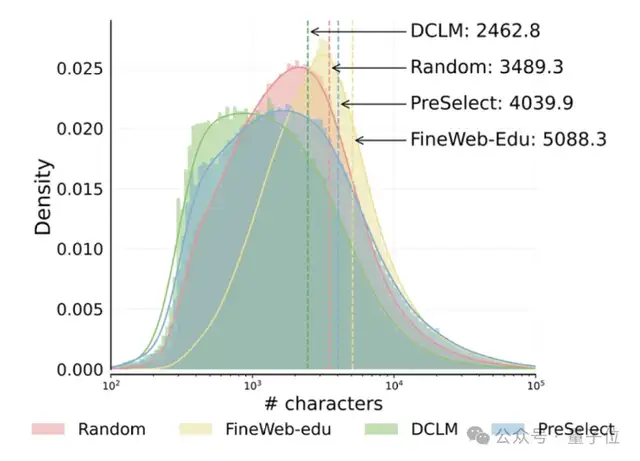
HKUST und vivo schlagen Datenauswahlschema PreSelect vor, das die Effizienz des Vortrainings um das 10-fache steigert: Die Hong Kong University of Science and Technology (HKUST) hat in Zusammenarbeit mit dem vivo AI Lab eine leichtgewichtige und effiziente Datenauswahlmethode namens PreSelect vorgeschlagen, die von der ICML 2025 akzeptiert wurde. Diese Methode quantifiziert den Beitrag von Daten zu spezifischen Modellfähigkeiten mithilfe eines „Vorhersagestärke“-Indikators und verwendet einen fastText-Scorer, um die gesamten Trainingsdaten zu filtern. Sie kann die Modellleistung im Durchschnitt um 3 % verbessern, während der Rechenaufwand um das 10-fache reduziert wird. PreSelect zielt darauf ab, qualitativ hochwertige und vielfältige Daten objektiver und allgemeiner auszuwählen und überwindet die Einschränkungen traditioneller regelbasierter oder modellbasierter Auswahlmethoden (Quelle: 量子位)
🎯 Aktuelles
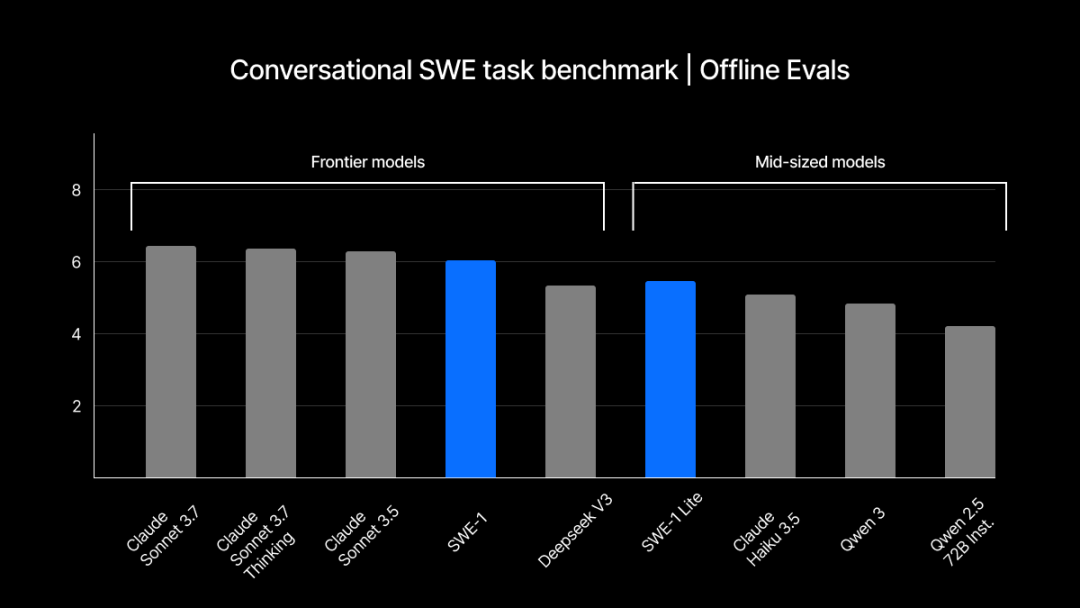
Windsurf veröffentlicht selbstentwickelte SWE-1 Modellreihe zur Optimierung von Software-Engineering-Prozessen: Windsurf stellt seine erste, speziell für Software-Engineering optimierte Modellreihe SWE-1 vor, die darauf abzielt, die Entwicklungseffizienz um 99 % zu steigern. Die Reihe umfasst SWE-1 (nahe an der Tool-Aufruffähigkeit von Claude 3.5 Sonnet, aber kostengünstiger), SWE-1-lite (hohe Qualität, Ersatz für Cascade Base) und SWE-1-mini (klein und schnell, für Szenarien mit geringer Latenz). Die Kerninnovation liegt im „Flow Awareness“-System, bei dem KI und Benutzer eine gemeinsame Operationszeitleiste teilen, was eine effiziente Zusammenarbeit und das Verständnis unvollendeter Zustände ermöglicht (Quelle: WeChat, WeChat)
ChatGPT-Gedächtnismechanismus durch Reverse Engineering entschlüsselt, enthüllt drei Gedächtnis-Subsysteme: Die von OpenAI für ChatGPT eingeführte Gedächtnisfunktion „Chatverlauf“ wurde von Technik-Enthusiasten analysiert und enthüllte, dass sie möglicherweise drei Subsysteme umfasst: den aktuellen Chatverlauf, den Chatverlauf (basierend auf Zusammenfassungen und Inhaltsabruf) und Benutzereinblicke (generiert durch Analyse mehrerer Chats, mit Konfidenzwerten). Diese Mechanismen zielen darauf ab, eine personalisiertere und effizientere Interaktionserfahrung zu bieten und werden durch Technologien wie RAG und Vektorräume realisiert. Obwohl offiziell behauptet wird, die Benutzererfahrung zu verbessern, ist das Feedback der Community gemischt, wobei einige Benutzer von instabilen Funktionen oder Bugs berichten (Quelle: WeChat, 量子位)
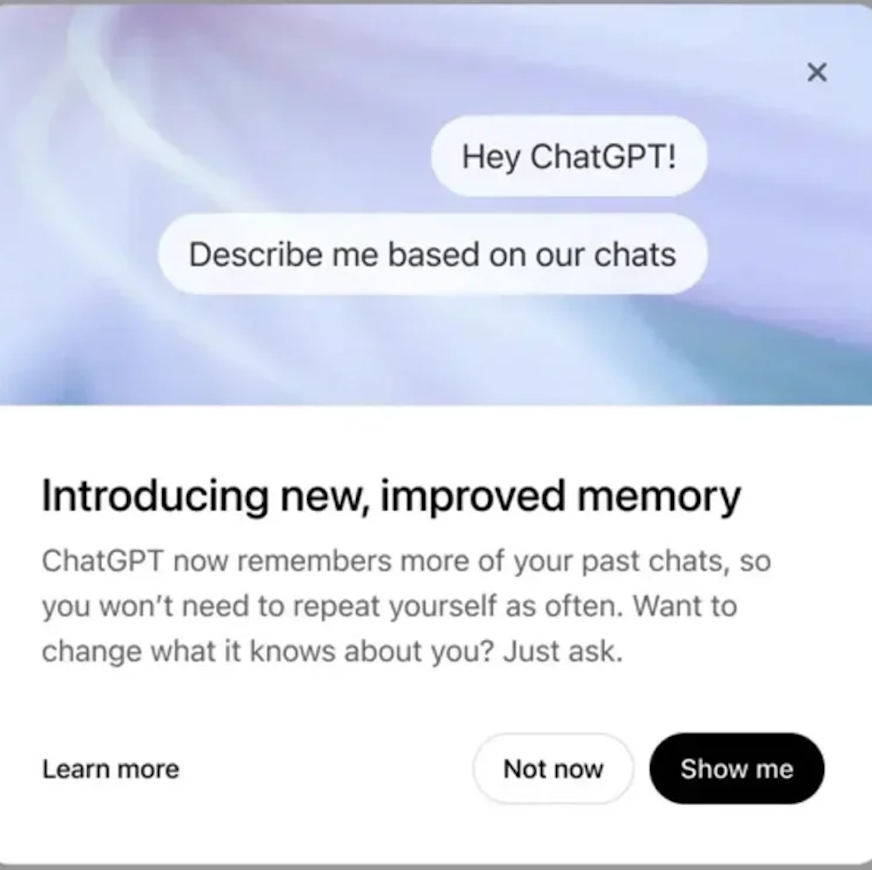
Tencent Hunyuan Image 2.0 veröffentlicht, unterstützt Echtzeit-“Malen während des Sprechens”: Tencent Hunyuan stellt das Hunyuan Image 2.0 Modell vor, das eine Echtzeit-Text-zu-Bild-Funktion mit Millisekunden-Reaktionszeit realisiert. Wenn Benutzer Text- oder Sprachbeschreibungen eingeben, wird das Bild in Echtzeit generiert und angepasst. Das neue Modell unterstützt auch ein Echtzeit-Zeichenbrett, mit dem Benutzer durch handgezeichnete Skizzen in Kombination mit Textbeschreibungen Bilder generieren können. Das Modell weist signifikante Verbesserungen in Bezug auf Realismus, semantische Befolgung (Anpassung an multimodale große Sprachmodelle als Text-Encoder) und die Kompressionsrate des Bild-Codecs auf und wurde durch Reinforcement Learning für das Post-Training optimiert (Quelle: 量子位)
TII veröffentlicht Falcon-Edge BitNet-Modellreihe und onebitllms Fine-Tuning-Bibliothek: TII stellt Falcon-Edge vor, eine Reihe kompakter Sprachmodelle mit 1B und 3B Parametern, die nur 600MB bzw. 900MB groß sind. Diese Modelle verwenden die BitNet-Architektur und können nahezu ohne Leistungsverlust auf bfloat16 wiederhergestellt werden. Erste Ergebnisse zeigen, dass ihre Leistung besser ist als die anderer kleiner Modelle und mit Qwen3-1.7B vergleichbar ist, jedoch nur 1/4 des Speicherbedarfs hat. Gleichzeitig wurde die onebitllms-Bibliothek veröffentlicht, die speziell für das Fine-Tuning von BitNet-Modellen entwickelt wurde (Quelle: Reddit r/LocalLLaMA, winglian)

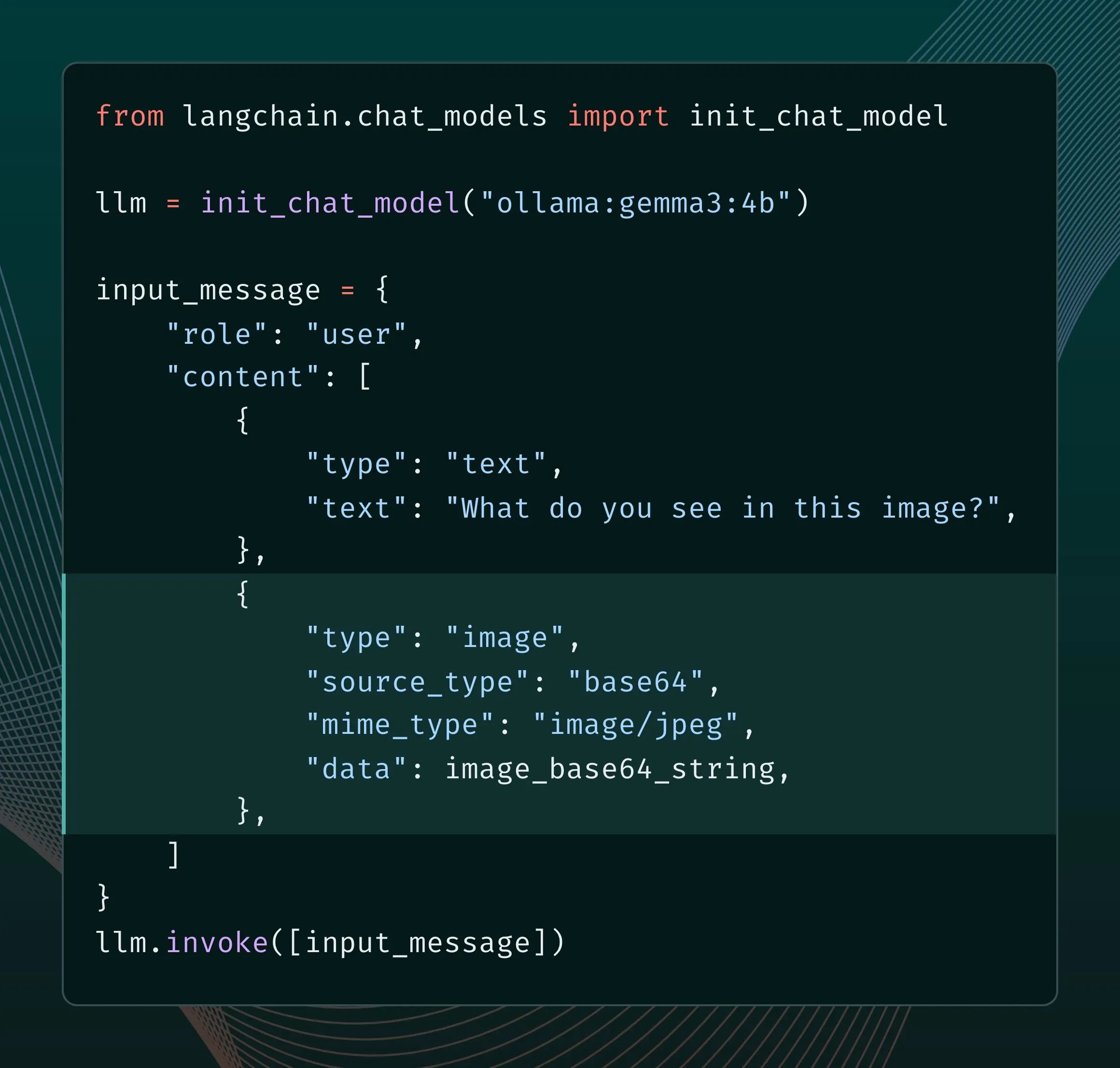
Neue Ollama-Engine verbessert multimodale Unterstützung: Ollama aktualisiert seine Engine, um nativen Support für multimodale Modelle zu bieten, was modellspezifische Optimierungen ermöglicht und die Speicherverwaltung verbessert. Benutzer können über die LangChain-Integration multimodale Modelle wie Llama 4 und Gemma 3 ausprobieren. Google AI-Entwickler haben auch eine Anleitung zur Verwendung von Ollama und Gemma 3 für Funktionsaufrufe veröffentlicht, um Funktionen wie Echtzeitsuche zu implementieren (Quelle: LangChainAI, ollama)
Grok fügt Funktion zur Steuerung des Seitenverhältnisses bei der Bildgenerierung hinzu: Das Grok-Modell von xAI ermöglicht es Benutzern nun, bei der Generierung von Bildern das gewünschte Seitenverhältnis anzugeben, was eine größere Flexibilität und Kontrolle bei der Bilderstellung bietet (Quelle: grok)
Google AI Studio Update mit neuer Seite für generative Medien und Nutzungs-Dashboard: Die Plattform ai.studio von Google hat eine Reihe von Updates erhalten, darunter ein neues Landing-Page-Design, ein integriertes Nutzungs-Dashboard und eine neue Seite für generative Medien (gen media), was auf weitere Ankündigungen auf der bevorstehenden I/O-Konferenz hindeutet (Quelle: matvelloso)
LatitudeGames veröffentlicht neues Modell Harbinger-24B (New Wayfarer): LatitudeGames hat auf Hugging Face ein neues Modell namens Harbinger-24B mit dem Codenamen New Wayfarer veröffentlicht. Die Community zeigt Interesse und diskutiert, warum nicht andere Modelle wie Qwen3 32B oder Llama 4 Scout feinabgestimmt wurden (Quelle: Reddit r/LocalLLaMA)

🧰 Tools
Adopt AI erhält 6 Millionen US-Dollar Finanzierung, um Software-Interaktion durch KI-Agenten neu zu gestalten: Das Startup-Unternehmen Adopt AI hat eine Seed-Finanzierung in Höhe von 6 Millionen US-Dollar erhalten. Es widmet sich der schnellen Integration von natürlichsprachlichen Interaktionsfähigkeiten in traditionelle Unternehmenssoftware auf No-Code-Basis durch die beiden Hauptfunktionen Agent Builder und Agent Experience. Die Technologie kann automatisch Anwendungsstrukturen und APIs erlernen, Operationen generieren, die durch natürliche Sprache aufgerufen werden können, und die Datensicherheit durch eine Pass-through-Architektur gewährleisten. Ziel ist es, die Akzeptanz und Effizienz von Software zu steigern und die Unternehmenskosten zu senken (Quelle: WeChat)

ByteDance Volcano Engine stellt Mini-KI-Hardware-Demo vor, unterstützt hohe DIY-Anpassbarkeit: Volcano Engine hat eine Demo einer Mini-KI-Hardware veröffentlicht und deren Client-/Server-Code als Open Source zur Verfügung gestellt. Die Hardware unterstützt eine hohe Anpassungsfreiheit und kann an große Modelle von Volcano, Coze-Intelligenzagenten sowie mit der OpenAI-API kompatible Drittanbieter-Großmodelle (wie FastGPT) und verschiedene TTS-Stimmen (einschließlich MiniMax) angebunden werden. Benutzer können DIY-Anwendungen realisieren, um mit bestimmten Charakteren (wie dem jungen Jay Chou, He Jiong) zu sprechen oder KI-Sprachkundendienste zu erstellen, was eine reichhaltige KI-Interaktionserfahrung bietet (Quelle: WeChat)

Runway veröffentlicht Gen-4 References API, um Entwicklern die Erstellung von Bildgenerierungsanwendungen zu ermöglichen: Runway stellt sein beliebtes Gen-4 References Bildgenerierungsmodell über eine API für Entwickler zur Verfügung. Das Modell ist bekannt für seine Vielseitigkeit und Flexibilität und kann auf Basis von Referenzbildern neue, stilkonsistente Bilder generieren. Die Veröffentlichung der API wird es Entwicklern ermöglichen, diese leistungsstarke Bildgenerierungsfähigkeit in ihre eigenen Anwendungen und Workflows zu integrieren (Quelle: c_valenzuelab)

Zencoder stellt KI-Agentenplattform Zen Agents zur Optimierung der Codierung vor: Das KI-Startup Zencoder (offiziell For Good AI Inc.) hat eine Cloud-Plattform namens Zen Agents veröffentlicht. Diese Plattform dient der Erstellung von KI-Agenten, die für Codierungsaufgaben optimiert sind, mit dem Ziel, die Effizienz und Qualität der Softwareentwicklung zu verbessern (Quelle: dl_weekly)
llmbasedos: Minimalistische Linux-Distribution basierend auf MCP, optimiert für lokale LLMs: Ein Entwickler hat llmbasedos erstellt, eine minimalistische Distribution basierend auf Arch Linux, die darauf abzielt, die lokale Umgebung zu einem erstklassigen Bürger für LLM-Frontends (wie Claude Desktop, VS Code) zu machen. Es exponiert lokale Fähigkeiten (Dateien, E-Mails, Proxys usw.) über das MCP (Model Context Protocol) Protokoll und unterstützt den Offline-Modus (einschließlich llama.cpp) oder die Verbindung zu Cloud-Modellen wie GPT-4o und Claude, was Entwicklern das schnelle Hinzufügen neuer Funktionen erleichtert (Quelle: Reddit r/LocalLLaMA)
PDF-Dateien können LLMs und Linux-Systeme ausführen, was Aufmerksamkeit erregt: Der Technik-Enthusiast Aiden Bai präsentierte das Projekt „llm.pdf“, das kleine Sprachmodelle (wie TinyStories, Pythia, TinyLLM) in PDF-Dateien ausführt, indem die Modelle in JavaScript kompiliert und die JS-Unterstützung von PDF genutzt wird. Im Kommentarbereich wurde darauf hingewiesen, dass es bereits Präzedenzfälle für die Ausführung von Linux-Systemen in PDFs (über einen RISC-V-Emulator) gab. Dies offenbart das Potenzial von PDF als Container für dynamische Inhalte, löst aber auch Diskussionen über Sicherheit und Praktikabilität aus (Quelle: WeChat)

OpenAI Codex CLI-Tool aktualisiert, unterstützt ChatGPT-Login und neues Mini-Modell: Das OpenAI-Entwicklerteam kündigte Verbesserungen am Codex CLI-Tool an, darunter die Unterstützung der Anmeldung über ein ChatGPT-Konto zur schnellen Verbindung mit API-Organisationen und die Hinzufügung des codex-mini-Modells, das speziell für Code-Frage-Antwort- und Bearbeitungsaufgaben mit geringer Latenz optimiert wurde (Quelle: openai, dotey)
SenseTime’s Großmodell-All-in-One-Maschine von IDC empfohlen, unterstützt SenseNova und DeepSeek Modelle: Im von IDC veröffentlichten Bericht „China AI Large Model All-in-One Machine Market Analysis and Brand Recommendation, 2025“ wurde die Großmodell-All-in-One-Maschine von SenseTime ausgewählt. Diese Maschine basiert auf der SenseTime Large-Scale AI Infrastructure, ist mit Hochleistungs-Rechenchips und Inferenzbeschleunigungs-Engines ausgestattet, unterstützt SenseTime’s „SenseNova V6“ sowie Mainstream-Großmodelle wie DeepSeek und bietet eine vollständig autonome und kontrollierbare End-to-End-Lösung. Sie optimiert die Gesamtbetriebskosten (TCO) und wurde bereits in Branchen wie Medizin und Finanzen eingesetzt (Quelle: 量子位)

Open-Source-Workflow-Automatisierungstool n8n fügt chinesische Unterstützung hinzu: Das beliebte Open-Source-Workflow-Automatisierungstool n8n unterstützt jetzt eine chinesische Benutzeroberfläche durch ein von der Community beigesteuertes Übersetzungspaket. Benutzer können die entsprechende Übersetzungsdatei herunterladen und durch eine einfache Docker-Konfigurationsänderung n8n auf Chinesisch verwenden, was die Nutzungsschwelle für chinesische Benutzer senkt (Quelle: WeChat)

git-bug: In Git eingebetteter, verteilter, offline-fähiger Bug-Tracker: git-bug ist ein Open-Source-Tool, das Issues, Kommentare usw. als Objekte in das Git-Repository einbettet (anstatt als normale Dateien) und so ein verteiltes, offline-fähiges Bug-Tracking realisiert. Es unterstützt die Synchronisierung von Issues mit Plattformen wie GitHub und GitLab über Bridges und bietet CLI-, TUI- und Web-Schnittstellen (Quelle: GitHub Trending)

PyLate integriert PLAID-Index zur Effizienzsteigerung von Modell-Benchmarking auf großen Datensätzen: Antoine Chaffin gab bekannt, dass der PLAID-Index in PyLate (ein Ökosystem für Training und Inferenz von ColBERT-Modellen) integriert wurde. Diese Integration ermöglicht es Benutzern, die besten Modelle effizient auf ihren sehr großen Datensätzen zu benchmarken, was es einfacher macht, SOTA-Ergebnisse auf verschiedenen Retrieval-Ranglisten zu erzielen (Quelle: lateinteraction, tonywu_71)

Neon: Open-Source serverlose PostgreSQL-Datenbank: Neon ist eine quelloffene, serverlose PostgreSQL-Alternative, die durch die Trennung von Speicher und Rechenleistung automatische Skalierung, datenbankgestützte Code-Verzweigung und Skalierung auf Null ermöglicht. Das Projekt erhält auf GitHub Aufmerksamkeit und bietet Entwicklern von KI- und anderen Anwendungen, die eine elastische, skalierbare Datenbanklösung benötigen, eine neue Option (Quelle: GitHub Trending)

Unmute.sh: Neues KI-Sprachchat-Tool mit anpassbaren Prompts und Stimmen: Unmute.sh ist ein neu eingeführtes KI-Sprachchat-Tool, das sich dadurch auszeichnet, dass Benutzer Prompts anpassen und verschiedene Stimmen auswählen können, was eine personalisiertere und flexiblere Sprachinteraktionserfahrung bietet (Quelle: Reddit r/artificial)
📚 Lernen
Weltweit erstes multimodales Generalistenmodell-Evaluierungsframework General-Level und Benchmark General-Bench veröffentlicht: Eine für ICML‘25 (Spotlight) angenommene Studie stellt ein brandneues Bewertungsframework für multimodale große Modelle (MLLM) namens General-Level und das dazugehörige Datenset General-Bench vor. Das Framework führt ein fünfstufiges Rangsystem ein, das sich auf den „Synergie-Generalisierungseffekt“ (Synergy) des Modells konzentriert, d.h. die Fähigkeit, Wissen zwischen verschiedenen Modalitäten oder Aufgaben zu transferieren und zu verbessern. General-Bench ist der derzeit größte und umfassendste MLLM-Bewertungsbenchmark mit über 700 Aufgaben, mehr als 320.000 Testdaten und deckt die fünf Hauptmodalitäten Bild, Video, Audio, 3D und Sprache sowie 29 Bereiche ab. Die Rangliste zeigt, dass Modelle wie GPT-4V derzeit nur Level-2 (keine Synergie) erreichen und noch kein Modell Level-5 (vollständige Synergie über alle Modalitäten) erreicht hat (Quelle: WeChat)

Paper J1 schlägt vor, LLM-as-a-Judge durch Reinforcement Learning zum Denken anzuregen: Ein neues Paper mit dem Titel “J1: Incentivizing Thinking in LLM-as-a-Judge via RL” (arxiv:2505.10320) untersucht, wie Reinforcement Learning (RL) genutzt werden kann, um große Sprachmodelle, die als Bewerter fungieren (LLM-as-a-Judge), zu tiefergehendem „Denken“ anzuregen, anstatt nur oberflächliche Urteile zu fällen. Dieser Ansatz könnte die Genauigkeit und Zuverlässigkeit von LLMs bei der Bewertung komplexer Aufgaben verbessern (Quelle: jaseweston)

Neues Framework TREQA nutzt LLMs zur Bewertung der Qualität komplexer Textübersetzungen: Angesichts der Unzulänglichkeiten bestehender Metriken für maschinelle Übersetzung (MT) bei der Bewertung komplexer Texte haben Forscher das TREQA-Framework vorgeschlagen. Dieses Framework verwendet große Sprachmodelle (LLMs), um Fragen zum Quelltext und zum übersetzten Text zu generieren und die Antworten auf diese Fragen zu vergleichen, um zu bewerten, ob wichtige Informationen erhalten geblieben sind. Dieser Ansatz zielt darauf ab, die Qualität von Langtextübersetzungen umfassender zu messen (Quelle: gneubig)

Studie findet effiziente Berechnungsmethode für das Produkt einer Matrix mit ihrer Transponierten: Dmitry Rybin et al. haben einen schnelleren Algorithmus zur Berechnung des Produkts einer Matrix mit ihrer Transponierten entdeckt (arxiv:2505.09814). Dieser grundlegende Durchbruch hat weitreichende Auswirkungen auf verschiedene Bereiche wie Datenanalyse, Chipdesign, drahtlose Kommunikation und das Training von LLMs, da solche Berechnungen in diesen Bereichen häufig vorkommen. Dies beweist erneut, dass selbst im etablierten Bereich der numerischen linearen Algebra noch Verbesserungspotenzial besteht (Quelle: teortaxesTex, Ar_Douillard)

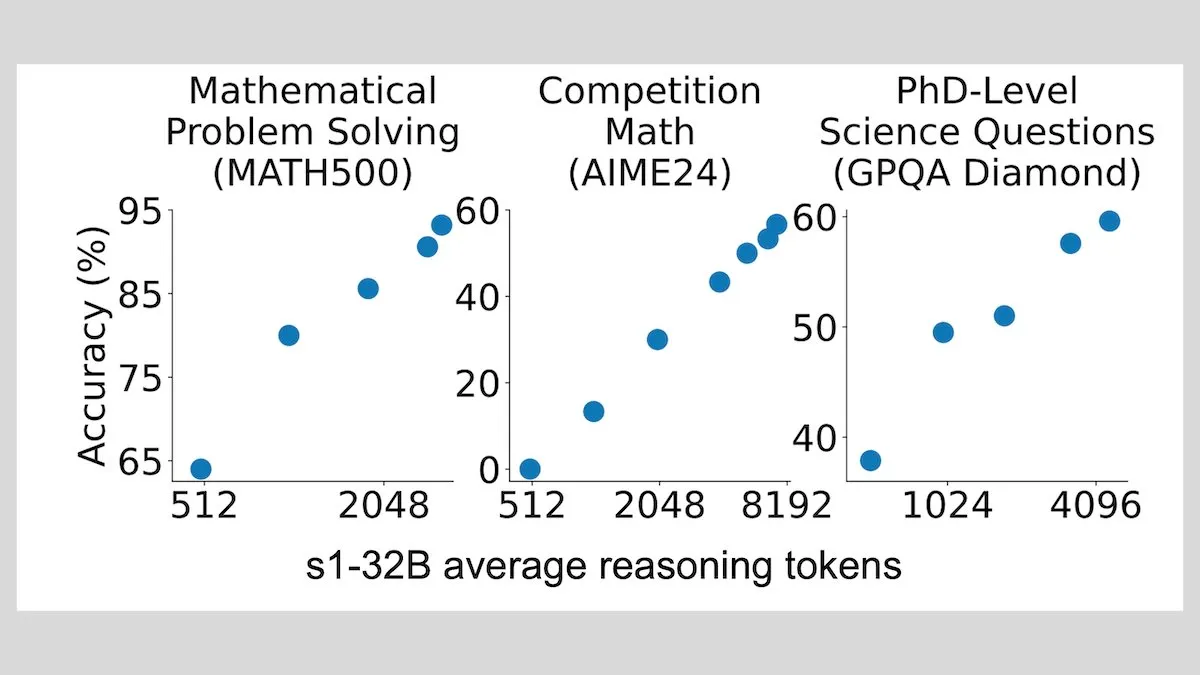
DeepLearningAI: Fine-Tuning mit wenigen Samples kann die Inferenzfähigkeiten von LLMs erheblich verbessern: Studien zeigen, dass das Fine-Tuning eines großen Sprachmodells mit nur 1000 Samples dessen Inferenzfähigkeiten erheblich verbessern kann. Das experimentelle Modell s1 erweiterte den Inferenzprozess durch Anhängen des Wortes „Wait“ während der Inferenz und erzielte gute Leistungen in Benchmarks wie AIME und MATH 500. Dieser ressourcenarme Ansatz zeigt, dass auch ohne Reinforcement Learning fortgeschrittenes Schlussfolgern mit wenigen Daten gelehrt werden kann (Quelle: DeepLearningAI)
Hugging Face startet kostenlosen MCP-Kurs zur Erstellung kontextreicher KI-Anwendungen: Hugging Face hat in Zusammenarbeit mit Anthropic einen kostenlosen Kurs namens „MCP: Build Rich-Context AI Apps with Anthropic“ gestartet. Der Kurs soll Entwicklern helfen, die MCP (Model Context Protocol)-Architektur zu verstehen und zu lernen, wie man MCP-Server und kompatible Anwendungen erstellt und bereitstellt, um die Integration von KI-Anwendungen mit Tools und Datenquellen zu vereinfachen. Bisher haben sich über 3000 Studenten angemeldet (Quelle: DeepLearningAI, huggingface, ClementDelangue)
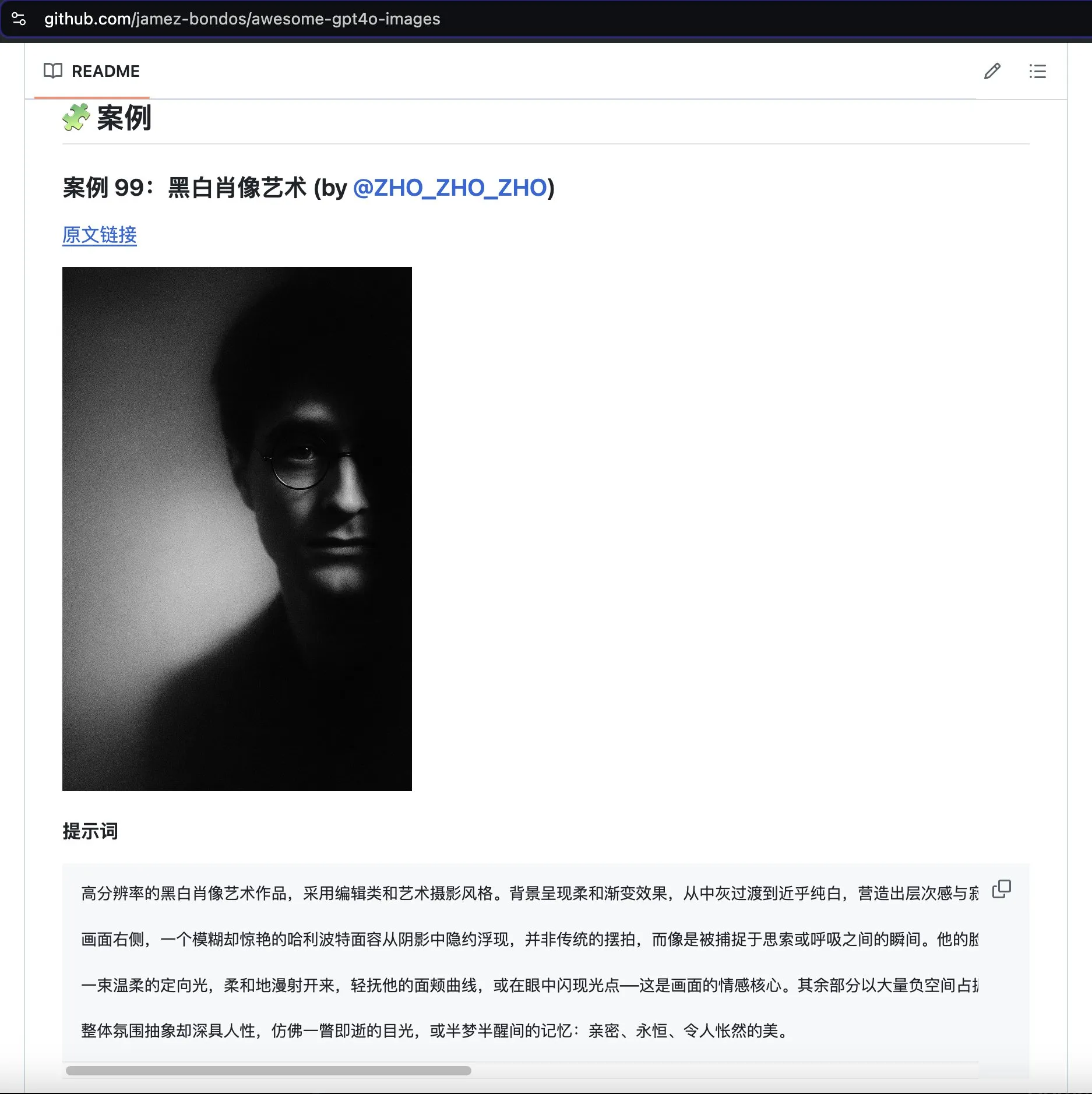
Projekt awesome-gpt4o-images sammelt beeindruckende Beispiele für GPT-4o-Bildgenerierung: Das von Jamez Bondos erstellte GitHub-Projekt awesome-gpt4o-images hat in 33 Tagen über 5700 Sterne erhalten. Das Projekt sammelt und präsentiert herausragende, mit GPT-4o generierte Bildbeispiele und deren Prompts. Derzeit gibt es fast hundert Beispiele, und es ist geplant, diese nach Aufbereitung und Überprüfung kontinuierlich zu aktualisieren, was der AIGC-Community wertvolle kreative Ressourcen bietet (Quelle: dotey)
Yann LeCun teilt Vortrag über Self-Supervised Learning (SSL): Yann LeCun hat den Inhalt seines Vortrags über Self-Supervised Learning (SSL) geteilt. SSL ist ein wichtiges Paradigma des maschinellen Lernens, das darauf abzielt, Modellen das Erlernen effektiver Repräsentationen aus ungelabelten Daten zu ermöglichen. Es ist von großer Bedeutung, um die Abhängigkeit von großen Mengen an gelabelten Daten zu reduzieren und die Generalisierungsfähigkeit von Modellen zu verbessern (Quelle: ylecun)
Hugging Face Paper-Forum wird zur wertvollen Ressource für die Auswahl von KI-Papers: Dwarkesh Patel empfiehlt das Paper-Forum von Hugging Face als hervorragende Ressource zur Auswahl der besten KI-Papers des vergangenen Monats. Die Plattform bietet Forschern einen bequemen Kanal, um die neuesten Fortschritte in der KI-Forschung zu entdecken und zu diskutieren (Quelle: dwarkesh_sp, huggingface)
ACL 2025 Annahmeergebnisse veröffentlicht, mehrere Paper des Alibaba International AIB Teams ausgewählt: Die Ergebnisse der Annahme für die Top-Konferenz für natürliche Sprachverarbeitung ACL 2025 wurden bekannt gegeben. Die Anzahl der Einreichungen erreichte in diesem Jahr einen historischen Höchststand, und der Wettbewerb war intensiv. Mehrere Paper des Alibaba International AI Business Teams wurden angenommen, wobei einige Ergebnisse wie Marco-o1 V2, Marco-Bench-IF und HD-NDEs (neuronale Differentialgleichungen zur Erkennung von Halluzinationen) hoch bewertet und als Hauptkonferenz-Langbeiträge angenommen wurden. Dies spiegelt die kontinuierlichen Investitionen von Alibaba International in den KI-Bereich und die ersten Erfolge bei der Talentförderung wider (Quelle: 量子位)

dstack veröffentlicht Leitfaden zur schnellen Einrichtung von Interconnects für verteiltes Training: dstack bietet Nutzern, die verteiltes Training auf NVIDIA- oder AMD-Clustern durchführen, einen prägnanten Leitfaden zur Einrichtung schneller Interconnects über dstack. Der Leitfaden soll Nutzern helfen, die Netzwerkleistung beim Skalieren von KI-Workloads in der Cloud oder lokal zu optimieren (Quelle: algo_diver)
AssemblyAI teilt 10 Video-Tipps zur Verbesserung von LLM-Prompts: AssemblyAI teilt über YouTube-Videos 10 Tipps zur Verbesserung der Effektivität von Prompts für große Sprachmodelle (LLM), um Nutzern zu helfen, effektiver mit LLMs zu interagieren und die gewünschten Ergebnisse zu erzielen (Quelle: AssemblyAI)
Lernressourcensammlung „awesome-langgraphjs“ für LangGraph.js findet Beachtung: Brace hat ein GitHub-Repository namens „awesome-langgraphjs“ erstellt und pflegt es, das Open-Source-Projekte und YouTube-Video-Tutorials sammelt, die mit LangGraph.js erstellt wurden. Diese Ressource erleichtert Entwicklern das Erlernen und Verwenden von LangGraph.js zum Erstellen verschiedener Anwendungen, von Multi-Agenten-Systemen bis hin zu Full-Stack-Chat-Anwendungen (Quelle: LangChainAI)
💼 Wirtschaft
Alibabas KI-Strategiewandel zeigt Wirkung, Cloud-Geschäft und KI-Produktumsätze wachsen deutlich: Der Finanzbericht von Alibaba für Q4 2025 zeigt, dass der Gesamtumsatz nach Bereinigung um bestimmte Geschäftsbereiche im Jahresvergleich um 10 % gestiegen ist. Der Umsatz im Cloud-Intelligence-Geschäft wuchs um 18 %, wobei die KI-bezogenen Produktumsätze im siebten Quartal in Folge ein dreistelliges Wachstum im Jahresvergleich verzeichneten. Alibaba betrachtet KI als Kernstrategie und plant, in den nächsten drei Jahren über 380 Milliarden Yuan in die Modernisierung seiner Cloud-Computing- und KI-Infrastruktur zu investieren. Sein quelloffenes Qwen-3-Modell von Tongyi Qianwen führte mehrere globale Ranglisten an und brachte über 100.000 abgeleitete Modelle hervor, was seine technologische Stärke und die Vitalität seines Open-Source-Ökosystems unterstreicht. Alibaba beschleunigt die Implementierung von KI in Branchen wie Automobil, Kommunikation und Finanzen (Quelle: 36氪)
Videobearbeitungs-App Mojo von Dailymotion übernommen: Die Videobearbeitungs-App Mojo (@mojo_video_app) wurde von Dailymotion übernommen. Die Videobearbeitungstechnologie von Mojo wird in die Social-Media-Anwendungen und B2B-Produkte von Dailymotion integriert. Beide Unternehmen wollen gemeinsam die nächste Generation der europäischen Social-Video-Plattform gestalten (Quelle: ClementDelangue)
Cohere übernimmt Ottogrid zur Stärkung der KI-Fähigkeiten für Unternehmen: Das KI-Unternehmen Cohere hat die Übernahme des Startups Ottogrid bekannt gegeben. Es wird erwartet, dass diese Akquisition die Fähigkeiten von Cohere im Bereich der KI-Lösungen für Unternehmen stärken wird. Konkrete Transaktionsdetails und die technologische Ausrichtung von Ottogrid wurden jedoch nicht näher erläutert (Quelle: aidangomez, nickfrosst)

🌟 Community
KI-Agenten lösen Diskussionen über Veränderungen der Arbeitsweise aus, Zukunft könnte Echtzeitstrategiespielen ähneln: Will Depue schlägt vor, dass die zukünftige Arbeit sich ähnlich wie bei Spielen wie StarCraft oder Age of Empires entwickeln könnte, bei denen Menschen etwa 200 Mikro-Agenten befehligen, um Aufgaben zu erledigen, Informationen zu sammeln, Systeme zu entwerfen usw. Sam Altman teilte diese Ansicht zustimmend. Fabian Stelzer nannte dies scherzhaft „Zerg Rush Coding“. Diese Sichtweise spiegelt die Fantasien und Diskussionen der Community darüber wider, wie KI-Agenten Arbeitsabläufe und die Mensch-Maschine-Kollaboration neu gestalten werden (Quelle: willdepue, sama, fabianstelzer)
Antworten des Grok-Roboters von xAI lösen Kontroverse aus, Prompt soll unbefugt geändert worden sein: xAI räumte ein, dass der Prompt seines Grok-Response-Roboters auf der X-Plattform am frühen Morgen des 14. Mai unbefugt geändert wurde. Dies führte dazu, dass seine Analysen zu bestimmten Ereignissen (z. B. Vorfälle im Zusammenhang mit Trump) ungewöhnlich erschienen oder von Mainstream-Informationen abwichen. Die Community verfolgt diesen Vorfall mit großer Aufmerksamkeit. Clement Delangue und andere fordern, Grok quelloffen zu machen, um die Transparenz zu erhöhen. Nutzer wie Colin Fraser versuchen durch den Vergleich von Grok-Antworten zu verschiedenen Zeiten, die Änderungshistorie seines System-Prompts per Reverse Engineering nachzuvollziehen (Quelle: ClementDelangue, menhguin, colin_fraser)

Massenhafte Kündigungen im Meta Llama4-Team gemeldet, Sorgen um Zukunft von Open-Source-KI in der Community: Community-Nachrichten deuten darauf hin, dass etwa 80 % der Mitglieder des Llama4-Teams von Meta (11 von ursprünglich 14 Teammitgliedern) gekündigt haben und die Veröffentlichung ihres Flaggschiff-Modells Behemoth verschoben wurde. Dieser Vorfall erregt große Aufmerksamkeit, und Branchenkenner wie Nat Lambert äußern ihr Bedauern. Scaling01 kommentierte, dass Meta möglicherweise einen neuen Llama-Marketingdirektor benötigt. Nutzer wie TeortaxesTex äußern Bedenken über mögliche negative Auswirkungen auf die Entwicklung von Open-Source-KI und diskutieren sogar, ob China zur letzten Hoffnung für Open Source werden könnte (Quelle: teortaxesTex, Dorialexander, scaling01)

Anwendung von KI im Krieg und ethische Fragen erregen Aufmerksamkeit: Die Reddit-Community diskutiert die Anwendung von KI im Krieg und weist darauf hin, dass sie bereits zur Überwachung und Lokalisierung von Kämpfern eingesetzt wird, indem Informationen analysiert und militärische Aufklärung geliefert wird. In der Diskussion wird erwähnt, dass das US-Militär seit 1991 KI-Tools wie DART einsetzt. Nutzer äußern Bedenken hinsichtlich der tödlichen Risiken und potenziellen Bedrohungen für die Menschheit, die durch die Bewaffnung von KI entstehen könnten, und verfolgen die Entwicklung entsprechender internationaler Verträge und Maßnahmen. Auch die Nutzungsrichtlinien von OpenAI haben die Klausel zum Verbot militärischer Nutzung entfernt, was zu weiteren Überlegungen Anlass gibt (Quelle: Reddit r/ArtificialInteligence)
Große Sprachmodelle schneiden bei CCPC-Programmierwettbewerb schlecht ab und offenbaren aktuelle Grenzen: Im Finale des zehnten chinesischen Hochschul-Programmierwettbewerbs (CCPC) schnitten mehrere bekannte große Sprachmodelle wie ByteDance Seed-Thinking (einschließlich o3/o4, Gemini 2.5 pro, DeepSeek R1) schlecht ab und lösten meist nur die einfachste Aufgabe oder erzielten null Punkte. Offizielle erklärten, dass die Modelle rein autonom agierten, ohne menschliches Eingreifen. Die Community analysiert, dass dies die Schwächen aktueller großer Modelle bei der Lösung hochgradig innovativer und komplexer Algorithmusprobleme aufzeigt, insbesondere im nicht-agentischen Modus (d.h. ohne Werkzeugunterstützung bei Ausführung und Debugging). Dies steht im Gegensatz zu OpenAI o3, das beim IOI-Wettbewerb durch agentisches Training eine Goldmedaille gewann (Quelle: WeChat)

DSPy-Framework und „bittere Lektionen“ lösen Diskussion aus, betonen normatives Design und automatisierte Prompts: Diskussionen im Zusammenhang mit DSPy betonen, dass, obwohl die Skalierung von KI (Scaling) viele technische Herausforderungen umgehen kann („bittere Lektionen“), sie nicht das sorgfältige Design der Kernspezifikationen eines Problems (Anforderungen und Informationsfluss) ersetzen kann. Die Skalierung kann jedoch die Abstraktionsebene der Problemdefinition erhöhen. Automatisierte Prompts (wie Prompt-Optimierer) werden als eine Methode angesehen, die Rechenleistung im Einklang mit den „bitteren Lektionen“ nutzt, während manuelle Prompts dem zuwiderlaufen könnten, da sie menschliche Intuition einbringen, anstatt das Modell lernen zu lassen (Quelle: lateinteraction, lateinteraction)
Rechenkosten für Selbstprüfung/Werkzeugerkundung von KI-Agenten während der Inferenz im Fokus: Paul Calcraft fragt nach Praktiken, bei denen erhebliche Rechenressourcen (z. B. über 200 US-Dollar zur Lösung eines einzelnen Problems) in der Inferenzphase für KI-Agenten aufgewendet werden, um aktive Selbstprüfungen, Werkzeugnutzung und explorative Arbeitsabläufe durchzuführen. Er weist darauf hin, dass Akteure wie Devin und seine Konkurrenten dies möglicherweise für PR-Demonstrationen tun, aber für Szenarien, die neuartige Lösungen suchen (ähnlich wie FunSearch, aber weniger eingeschränkt), ist dies unklar (Quelle: paul_cal)
KI-gestütztes „Vibe Coding“ löst Diskussion aus: Tools wie GitHub Copilot ermöglichen „Vibe Coding“ (eine Programmierweise, die sich mehr auf Intuition und KI-Unterstützung als auf strenge Planung verlässt), und es gibt sogar 16-jährige Schüler, die Copilot für Schulprojekte verwenden. Die Meinungen der Community zu diesem Phänomen sind geteilt: Einige sehen darin ein neues Programmierparadigma, während andere die Bedeutung von Grundlagen und Normen betonen (Quelle: Reddit r/ArtificialInteligence, nrehiew_)
Hugging Face Transformers-Bibliothek startet neues Community-Board: Hugging Face hat für seine Kernbibliothek Transformers ein neues Community-Board eingerichtet, um Ankündigungen, neue Funktionen, Roadmap-Updates zu veröffentlichen und Benutzer einzuladen, Fragen zur Bibliotheksnutzung oder zu Modellproblemen zu stellen und zu diskutieren. Ziel ist es, die Interaktion und Unterstützung für Entwickler zu stärken (Quelle: TheZachMueller, ClementDelangue)
KI-Entwickler fordern Einrichtung eines “Findings”-Paper-Tracks auf Top-Konferenzen: Angesichts der stark gestiegenen Anzahl von Einreichungen bei Top-KI-Konferenzen wie NeurIPS (z.B. 25.000 bei NeurIPS) fordern Dan Roy und andere, dem Beispiel von Konferenzen wie ACL zu folgen und einen “Findings”-ähnlichen Paper-Track einzurichten. Ziel ist es, Forschungsarbeiten, die zwar nicht den Standards der Hauptkonferenz entsprechen, aber dennoch wertvoll sind, eine Veröffentlichungsmöglichkeit zu bieten, den Druck auf die Gutachter zu verringern und einen breiteren wissenschaftlichen Austausch zu fördern. Vorschläge umfassen ein vereinfachtes Begutachtungsverfahren, das sich auf die Verbesserung der Klarheit der Paper konzentriert (Quelle: AndrewLampinen)
💡 Sonstiges
KI-gesteuertes Exoskelett hilft Rollstuhlfahrern beim Stehen und Gehen: Ein KI-gesteuertes Exoskelett demonstrierte seine Fähigkeit, Rollstuhlfahrern zu helfen, wieder zu stehen und zu gehen. Solche Technologien kombinieren Robotik, Sensoren und KI-Algorithmen, um die Absichten des Benutzers zu erkennen und motorische Unterstützung zu leisten, was Menschen mit eingeschränkter Mobilität Hoffnung auf Rehabilitation und eine verbesserte Lebensqualität gibt (Quelle: Ronald_vanLoon)
Nutzung von KI zur Visualisierung kreativer Benutzernamen: In den Reddit- und X-Communities ist ein kleiner Trend entstanden, bei dem Benutzer KI-Bildgenerierungstools (wie das in ChatGPT integrierte DALL-E 3) verwenden, um Konzeptbilder basierend auf ihren Social-Media-Benutzernamen zu erstellen und diese fantasievollen Werke zu teilen. Dies zeigt die unterhaltsame Anwendung von KI im Bereich des personalisierten kreativen Ausdrucks (Quelle: Reddit r/ChatGPT, Reddit r/ChatGPT)

Amazon Advertising nutzt KI zur Steigerung der Marketingeffizienz von Marken im Ausland: Amazon Advertising stellt das Konzept des „World Screen Lab“ vor und zeigt, wie es KI-Technologie einsetzt, um chinesische Marken beim Eintritt in ausländische Märkte zu unterstützen. Durch Medienmatrizen wie Prime Video wird die Markenreichweite erweitert, KI-Kreativstudios (wie Videoerstellungstools) senken die Hürden für die Inhaltsproduktion, und Tools wie Amazon DSP und Performance+ optimieren die Anzeigenschaltung und Konversion. KI spielt dabei eine Rolle über die gesamte Kette von der Ideengenerierung bis zur Erfolgsmessung und soll Markeninhabern, insbesondere kleinen und mittleren Unternehmen, helfen, ihre Marken global effizienter aufzubauen (Quelle: 36氪)
