Schlüsselwörter:KI-Programmieragent, Codex, Sprachgroßmodell, KI-Agent, OpenAI, MiniMax, Alibaba, Qwen, Codex-Vorschauversion, Speech-02-Sprachmodell, WorldPM-Forschung, FastVLM-Visualsprachmodell, FG-CLIP-Cross-Modell
🔥 Fokus
OpenAI veröffentlicht Preview-Version des KI-Programmieragenten Codex: OpenAI hat am späten Abend des 16. Mai eine Preview-Version von Codex vorgestellt, einem Cloud-basierten Software-Engineering-Agenten. Codex wird von codex-1 angetrieben, einer für Software-Engineering optimierten o3-Variante, und kann Aufgaben wie Programmierung, Fragen zu Codebasen, Bug-Fixing und das Einreichen von Pull-Requests parallel bearbeiten. Er läuft in einer Cloud-Sandbox-Umgebung, lädt Benutzer-Codebasen vor und erledigt Aufgaben in 1-30 Minuten. Derzeit ist er für Nutzer von ChatGPT Pro, Team und Enterprise verfügbar; Plus- und Edu-Nutzer folgen in Kürze. Gleichzeitig wurde das leichtgewichtige Modell codex-mini (basierend auf o4-mini) für die Codex CLI veröffentlicht, mit API-Preisen von 1,5 US-Dollar/Million Tokens für den Input und 6 US-Dollar/Million Tokens für den Output. (Quelle: 36氪, 机器之心, op7418)
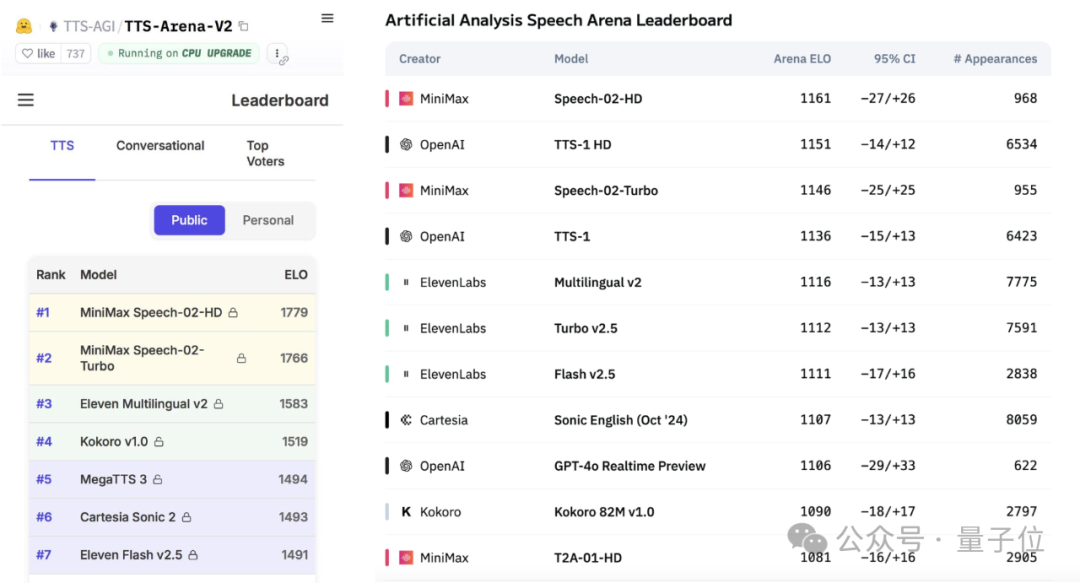
MiniMax veröffentlicht großes Sprachmodell Speech-02 und erreicht Spitzenplätze in globalen Benchmarks: Das chinesische KI-Unternehmen MiniMax hat sein neuestes Text-to-Speech (TTS) Large Language Model, Speech-02-HD, veröffentlicht, das in zwei weltweit führenden Sprachbenchmarks – der Artificial Analysis Speech Arena und der Hugging Face TTS Arena V2 – den ersten Platz belegte und damit OpenAI und ElevenLabs übertraf. Das Modell zeichnet sich durch ultra-realistische, personalisierte und vielfältige Stimmcharakteristika aus, unterstützt 32 Sprachen und kann mit nur 10 Sekunden Sprachreferenz eine realistische Stimmreplikation erreichen. Die zuvor populäre „AI Daniel Wu lernt Englisch“-Anwendung nutzte bereits die Technologie von MiniMax. Zu den Kerninnovationen von Speech-02 gehören ein lernfähiger Sprecher-Encoder und ein Flow-VAE Flow-Matching-Modell, die Klangqualität und Ähnlichkeit verbessern. (Quelle: 36氪, karminski3)
AI Agents erregen Marktinteresse, große Technologieunternehmen beschleunigen ihre Entwicklung: KI-Agenten (Agents) werden zum neuen Fokus im KI-Bereich. Die Öffnung von Allzweck-Agent-Plattformen wie Manus für die Registrierung löste einen Hype aus; die Muttergesellschaft Monica soll eine neue Finanzierungsrunde über 75 Millionen US-Dollar mit einer Bewertung von fast 500 Millionen US-Dollar abgeschlossen haben. Große Unternehmen wie Baidu (Xinxing), ByteDance (Kouzi Kongjian) und Alibaba (Xinliu) haben eigene Agent-Produkte oder -Plattformen auf den Markt gebracht und konkurrieren um den Einstieg in das KI-Zeitalter. Agents können komplexere Aufgaben ausführen, wie Materialerstellung, Webdesign, Reiseplanung usw. Derzeit haben Allzweck-Agents noch Schwächen bei anwendungsübergreifenden Operationen und tiefgreifenden Aufgaben; ein unvollständiges Ökosystem und Datensilos sind die größten Herausforderungen. Das MCP-Protokoll gilt als Schlüssel zur Lösung der Interoperabilität, aber es gibt noch wenige Teilnehmer. Es wird davon ausgegangen, dass B2B-Vertical-Agents aufgrund ihres fokussierten Szenarios und ihrer einfachen Anpassbarkeit leichter als erste kommerzialisiert werden können. (Quelle: 36氪, 36氪)

Alibaba veröffentlicht WorldPM-Studie und untersucht Skalierungsgesetze für die Modellierung menschlicher Präferenzen: Das Qwen-Team von Alibaba hat das Paper „Modeling World Preference“ veröffentlicht, das aufzeigt, dass die Modellierung menschlicher Präferenzen Skalierungsgesetzen (Scaling Laws) folgt, was darauf hindeutet, dass vielfältige menschliche Präferenzen möglicherweise eine einheitliche Repräsentation teilen. Die Studie verwendete den StackExchange-Datensatz mit 15 Millionen Präferenzpaaren und führte Experimente mit Qwen2.5-Modellen mit Parametern von 1,5B bis 72B durch. Die Ergebnisse zeigen, dass die Präferenzmodellierung bei zunehmender Trainingsgröße einen logarithmischen Verlustrückgang bei objektiven und robusten Metriken aufweist; das 72B-Modell zeigte bei einigen anspruchsvollen Aufgaben emergente Phänomene. Die Studie bietet eine effektive Grundlage für das Präferenz-Feintuning; sowohl das Paper als auch das Modell (WorldPM-72B) wurden als Open Source veröffentlicht. (Quelle: Alibaba_Qwen)
🎯 Trends
Google DeepMind und Anthropic uneins bei Forschung zur KI-Erklärbarkeit: Google DeepMind gab kürzlich bekannt, „mechanistic interpretability“ nicht länger als Forschungsschwerpunkt zu betrachten. Man sei der Ansicht, dass das Reverse Engineering der internen Funktionsweise von KI mittels Methoden wie Sparse Autoencoders (SAE) äußerst schwierig sei und SAEs inhärente Schwächen aufwiesen. Dario Amodei, CEO von Anthropic, plädiert hingegen für eine Intensivierung der Forschung in diesem Bereich und äußerte sich optimistisch, in den nächsten 5-10 Jahren eine „MRT für KI“ zu realisieren. Der „Blackbox“-Charakter von KI ist die Wurzel vieler Risiken. Die mechanistische Erklärbarkeit zielt darauf ab, die Funktion spezifischer Neuronen und Schaltkreise in Modellen zu verstehen, doch die Forschungsergebnisse der letzten zehn Jahre sind begrenzt, was zu einer tiefgreifenden Reflexion über Forschungsansätze geführt hat. (Quelle: WeChat)

Poe-Bericht zeigt Veränderungen in der KI-Modell-Marktlandschaft, OpenAI und Google führend: Der neueste KI-Modell-Nutzungsbericht von Poe zeigt, dass im Bereich der Textgenerierung GPT-4o (35,8 %) führend ist, während im Bereich Reasoning Gemini 2.5 Pro (31,5 %) die Spitzenposition einnimmt. Die Bildgenerierung wird von Imagen3, GPT-Image-1 und der Flux-Serie dominiert. Bei der Videogenerierung ist der Anteil von Runway gesunken, während Kling von Kuaishou zum Überraschungserfolg wurde. Im Bereich der Agenten schnitt o3 von OpenAI in Forschungstests besser ab als Claude und Gemini. Der Marktanteil von Claude von Anthropic ist leicht gesunken. Der Bericht weist darauf hin, dass Reasoning-Fähigkeiten zum entscheidenden Wettbewerbsfaktor werden und Unternehmen Bewertungssysteme etablieren müssen, um flexibel verschiedene Modelle für den sich schnell verändernden Markt auszuwählen. (Quelle: WeChat)

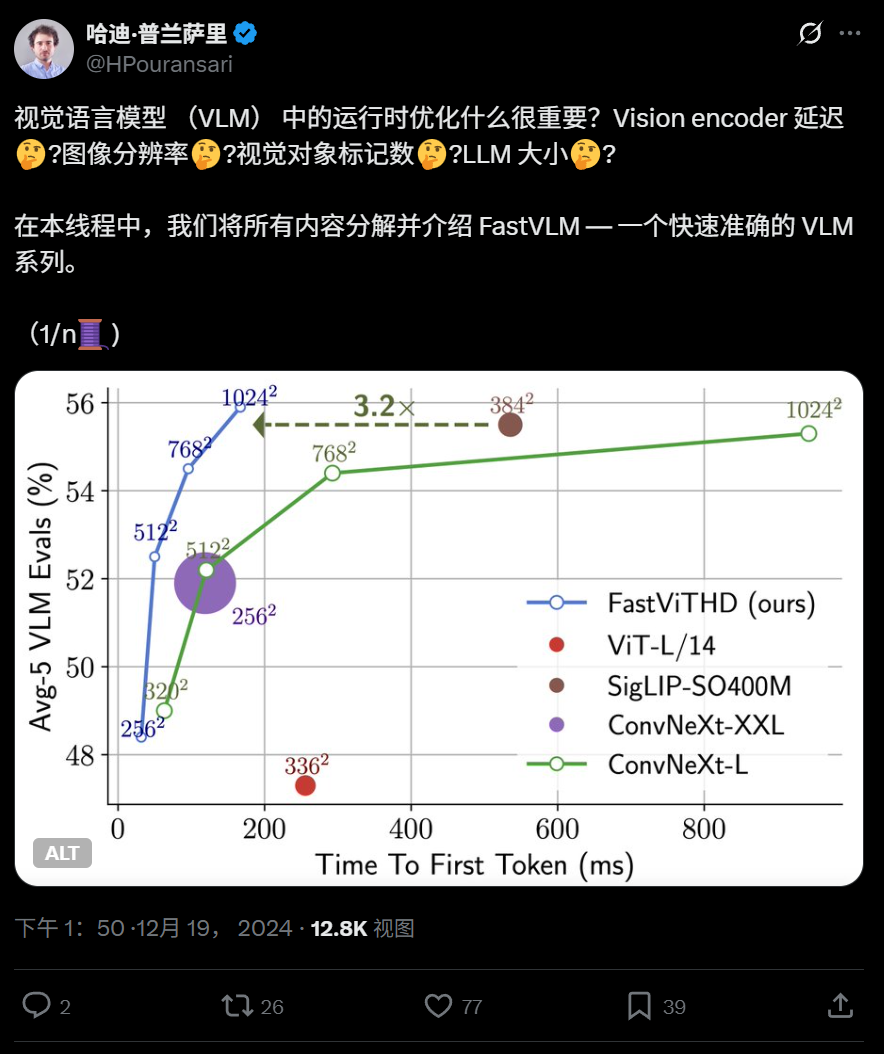
Apple veröffentlicht effizientes Vision-Language-Modell FastVLM als Open Source, lauffähig auf dem iPhone: Apple hat FastVLM als Open Source veröffentlicht, ein Vision-Language-Modell, das speziell für den effizienten Betrieb auf Endgeräten wie dem iPhone entwickelt wurde. Das Modell reduziert durch einen neuartigen hybriden visuellen Encoder FastViTHD (der Convolutional Layers mit Transformer-Modulen kombiniert und Multi-Scale-Pooling- sowie Downsampling-Techniken verwendet) die Anzahl der visuellen Tokens erheblich (16-mal weniger als ViT) und erreicht eine um das 85-fache schnellere Ausgabe des ersten Tokens im Vergleich zu ähnlichen Modellen. FastVLM ist mit gängigen LLMs kompatibel und wurde in Versionen mit 0,5B, 1,5B und 7B Parametern veröffentlicht, um die Bildverständnisgeschwindigkeit und Benutzererfahrung von KI-Anwendungen auf Endgeräten zu verbessern. (Quelle: WeChat)
360 veröffentlicht multimodales Bild-Text-Modell der neuen Generation FG-CLIP zur Verbesserung der feingranularen Ausrichtung: Das 360 Artificial Intelligence Research Institute hat FG-CLIP entwickelt, ein multimodales Bild-Text-Modell der neuen Generation, das darauf abzielt, die Schwächen traditioneller CLIP-Modelle beim feingranularen Verständnis von Bildern und Texten zu beheben. FG-CLIP verwendet eine zweistufige Trainingsstrategie: globales kontrastives Lernen (Integration langer Beschreibungen, die von multimodalen großen Modellen generiert wurden) und lokales kontrastives Lernen (Einführung von Regionen-Text-Annotationsdaten und schwer zu unterscheidenden feingranularen negativen Beispielen), um eine präzise Erfassung lokaler Bilddetails und feiner Unterschiede in Textattributen zu erreichen. Das Modell wurde für die ICML 2025 akzeptiert und ist auf Github und Huggingface als Open Source verfügbar, wobei die Gewichte kommerziell genutzt werden können. (Quelle: WeChat)

Google stellt LightLab vor, das Diffusionsmodelle zur präzisen Steuerung von Licht und Schatten in Bildern nutzt: Das Forschungsteam von Google hat das Projekt LightLab vorgestellt, eine Technologie, die eine feingranulare parametrisierte Steuerung von Lichtquellen basierend auf einem einzelnen Bild ermöglicht. Benutzer können die Intensität und Farbe sichtbarer Lichtquellen sowie die Intensität des Umgebungslichts anpassen und virtuelle Lichtquellen in die Szene einfügen. LightLab wird durch Feinabstimmung eines Diffusionsmodells auf einem speziell erstellten Datensatz (der reale Fotos mit kontrollierter Beleuchtung und umfangreiche synthetisch gerenderte Bilder enthält) realisiert. Es nutzt die linearen Eigenschaften des Lichts, um Lichtquellen und Umgebungslicht zu trennen und eine große Anzahl von Bildpaaren mit unterschiedlichen Lichtveränderungen für das Training zu synthetisieren. Das Modell kann komplexe Beleuchtungseffekte wie indirekte Beleuchtung, Schatten und Reflexionen direkt im Bildraum simulieren. (Quelle: WeChat)

Tencent schlägt GRPO- und RCS-Reinforcement-Learning-Methoden zur Verbesserung der Generalisierungsfähigkeit bei der Intention Detection vor: Das Forschungsteam der Social Line von Tencent PCG hat eine Reinforcement-Learning-Methode vorgeschlagen, die den Group Relative Policy Optimization (GRPO)-Algorithmus mit einer Reward-based Curriculum Sampling (RCS)-Strategie kombiniert und auf Aufgaben der Intention Detection angewendet wird. Diese Methode verbessert signifikant die Generalisierungsfähigkeit des Modells bei unbekannten Intentionen (Verbesserungen von bis zu 47 % bei neuen Intentionen und sprachübergreifenden Fähigkeiten), insbesondere nach der Einführung von „Thought“ (Gedanken), wodurch die Generalisierungsfähigkeit bei der Erkennung komplexer Intentionen weiter verbessert wird. Experimente zeigen, dass RL-trainierte Modelle in Bezug auf die Generalisierungsfähigkeit SFT-Modellen überlegen sind und dass die Leistung nach dem GRPO-Training ähnlich ist, unabhängig davon, ob sie auf vortrainierten Modellen oder auf Instruction-Finetuned-Modellen basieren. (Quelle: WeChat)

Nanyang Technological University et al. schlagen RAP-Framework vor, das auf RAG basiert, um die Wahrnehmung hochauflösender Bilder zu verbessern: Das Team von Professor Tao Dacheng von der Nanyang Technological University und andere haben Retrieval-Augmented Perception (RAP) vorgeschlagen, ein trainingsfreies Plugin für die Wahrnehmung hochauflösender Bilder, das auf der RAG-Technologie basiert. Es zielt darauf ab, das Problem des Informationsverlusts bei der Verarbeitung hochauflösender Bilder durch multimodale große Sprachmodelle (MLLM) zu lösen. RAP ruft Bildblöcke ab, die für die Benutzerfrage relevant sind, und verwendet den Spatial-Awareness Layout-Algorithmus, um deren relative Positionsbeziehungen beizubehalten. Anschließend wird durch Retrieved-Exploration Search (RE-Search) die Anzahl K der beizubehaltenden Bildblöcke adaptiv ausgewählt, wodurch die Auflösung des Eingangsbildes effektiv reduziert und gleichzeitig wichtige visuelle Informationen erhalten bleiben. Experimente zeigen, dass RAP die Genauigkeit auf den HR-Bench 4K- und 8K-Datensätzen um bis zu 21 % bzw. 21,7 % verbessert. Diese Arbeit wurde als Spotlight-Paper für die ICML 2025 angenommen. (Quelle: WeChat)

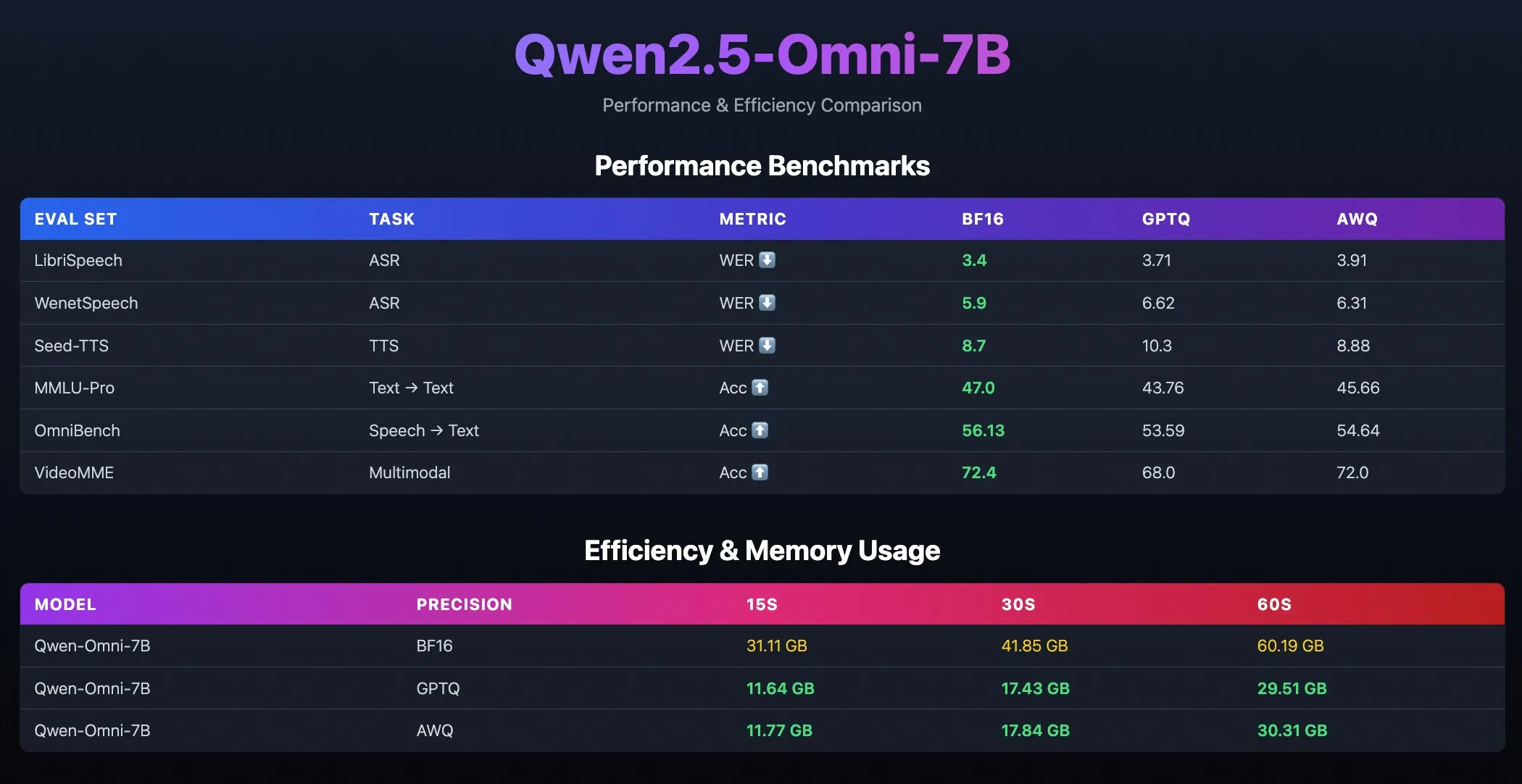
Quantisierte Modelle Qwen2.5-Omni-7B veröffentlicht: Das Qwen-Team von Alibaba hat quantisierte Versionen des Qwen2.5-Omni-7B-Modells veröffentlicht, einschließlich GPTQ- und AWQ-optimierter Checkpoints. Diese Modelle sind auf Hugging Face und ModelScope verfügbar und zielen darauf ab, effizientere Bereitstellungsoptionen mit geringerem Ressourcenverbrauch zu bieten, während ihre leistungsstarken multimodalen Fähigkeiten erhalten bleiben. (Quelle: Alibaba_Qwen, karminski3, reach_vb)
TII veröffentlicht BitNet-Modelle Falcon-E-1B/3B mit stark reduziertem Speicherbedarf: Das Technology Innovation Institute (TII) hat eine neue Modellreihe Falcon-Edge vorgestellt, die auf dem 1-Bit-Präzisionsmodell-Framework BitNet von Microsoft basiert und die Modelle Falcon-E-1B und Falcon-E-3B umfasst. Berichten zufolge ist die Leistung dieser Modelle mit der von Qwen3-1.7B vergleichbar, der Speicherbedarf beträgt jedoch nur 1/4 davon. TII hat gleichzeitig die Finetuning-Bibliothek onebitllms veröffentlicht, mit der Benutzer diese 1-Bit-Modelle auf NVIDIA-Grafikkarten selbst feinabstimmen können. (Quelle: karminski3)
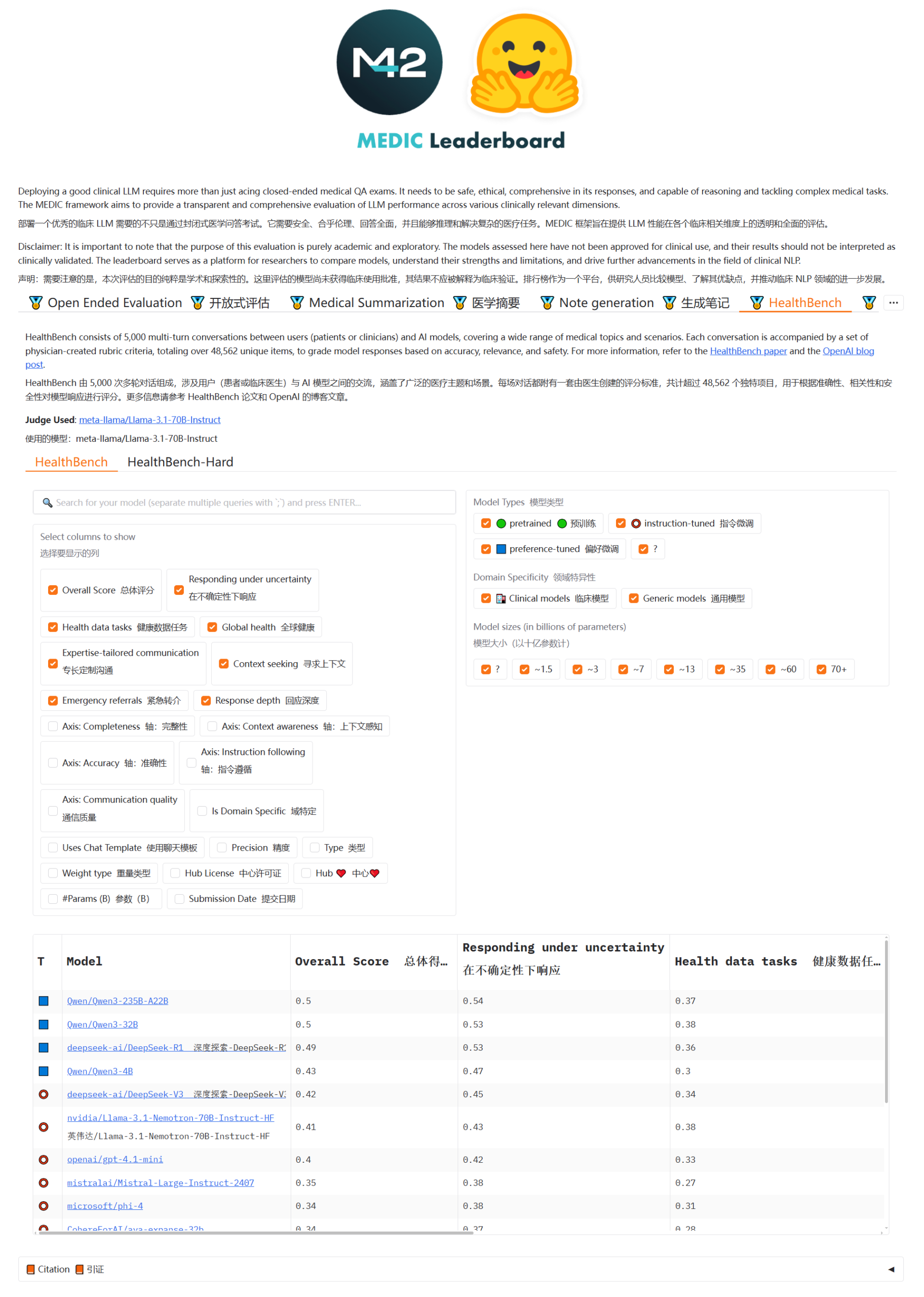
Qwen3- und DeepSeek-Modelle führen im MEDIC-Benchmark für medizinische Frage-Antwort-Systeme: Das Qwen3-Modell hat im neu veröffentlichten MEDIC-Benchmark für medizinische Frage-Antwort-Systeme den ersten und zweiten Platz belegt. Darüber hinaus werden die ersten fünf Plätze der Rangliste von Modellen der Qwen- und DeepSeek-Reihe eingenommen, was die starken Frage-Antwort-Fähigkeiten dieser chinesischen Large Language Models im spezialisierten medizinischen Bereich zeigt. (Quelle: karminski3)
Zhejiang University schlägt Rankformer vor: Eine Transformer-Empfehlungsmodellarchitektur zur direkten Optimierung des Rankings: Ein Team der Zhejiang University hat eine neue Graph-Transformer-Empfehlungsmodellarchitektur namens Rankformer vorgeschlagen, deren Design direkt von Ranking-Zielen (wie der BPR-Verlustfunktion) abgeleitet ist. Rankformer simuliert die Vektoroptimierungsrichtung während des Gradientenabstiegs, um einen einzigartigen Graph-Transformer-Mechanismus zu entwerfen, der das Modell im Vorwärtsdurchlauf dazu anleitet, bessere Ranking-Repräsentationen zu kodieren. Das Modell nutzt einen globalen Attention-Mechanismus zur Informationsaggregation und behauptet, die Zeit- und Raumkomplexität durch mathematische Transformationen und Cache-Optimierung auf ein lineares Niveau zu reduzieren. Die Studie wurde von der WWW 2025 Konferenz angenommen. (Quelle: WeChat)
🧰 Werkzeuge
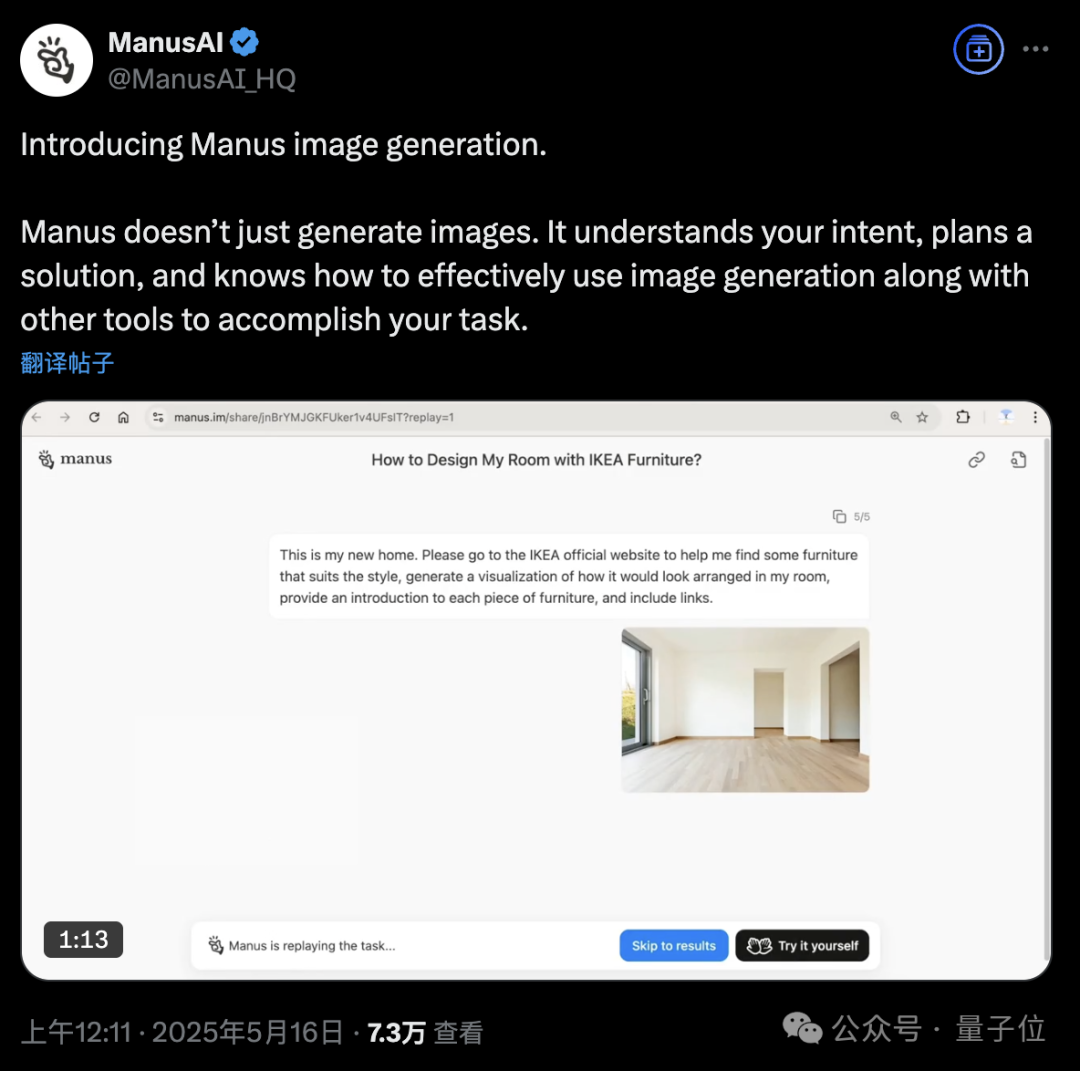
KI-Agenten-Plattform Manus fügt Bildgenerierungsfunktion hinzu: Die KI-Agenten-Plattform Manus hat die Unterstützung für Bildgenerierung angekündigt. Im Gegensatz zu herkömmlichen KI-Zeichenwerkzeugen kann Manus den Zweck des Benutzers beim Zeichnen verstehen und einen Generierungsplan erstellen. Beispielsweise kann ein Benutzer ein Foto eines Raumes hochladen und Manus bitten, Möbel von der IKEA-Website zu suchen, eine visualisierte Einrichtungs-Effektzeichnung zu erstellen und gleichzeitig Links zu den Möbeln anzugeben. Manus erledigt die Aufgabe durch Schritte wie Analyse, Suche, Auswahl von Möbeln und Erstellung einer Designstrategie. Diese Funktion zielt darauf ab, den Workflow von Agenten tiefgreifend mit der Bildgenerierung zu verbinden. Manus ist derzeit für die Registrierung geöffnet, vergibt 1000 Punkte als Willkommensgeschenk, täglich zusätzlich 300 Punkte und bietet kostenpflichtige Abonnementpläne an. (Quelle: 36氪, WeChat)
Design-Agent-Plattform Lovart veröffentlicht, Fokus auf kreative Workflows: Die neu gegründete Design-Agent-Plattform Lovart hat nach ihrer Veröffentlichung schnell Aufmerksamkeit erregt. Ihre Kernidee ist es, den kreativen Prozess von Designern (der multimodal ist) in einen Agenten-Workflow umzuwandeln. Lovart bietet eine leinwandartige interaktive Oberfläche, über die Benutzer die KI per Dialog anleiten können, Designaufgaben zu erledigen, wobei die KI für Planung und Ausführung zuständig ist. Gründer Chen Mian ist der Ansicht, dass KI-Bildprodukte in die Agenten-gesteuerte 3.0-Phase eingetreten sind. Lovart zielt darauf ab, ein „Freund“ für Designer zu werden, der KI die Routinearbeiten überlässt, damit sich Designer auf die Kreativität konzentrieren können. Das Produkt wird zukünftig 3D-Modellierungs-, Video- und Audiofähigkeiten integrieren und zu einem „Kreativteam“ oder einer „Designfirma“ werden. (Quelle: 36氪)
OpenAI Codex CLI aktualisiert, integriert o4-mini und bietet kostenloses API-Guthaben: OpenAI hat seine leichtgewichtige Open-Source-Coding-Agent Codex CLI verbessert. Die neue Version wird von o4-mini (genannt codex-mini), einer abgespeckten Version von codex-1, angetrieben und ist speziell für Code-Fragen und -Bearbeitungen mit geringer Latenz optimiert. Benutzer können sich jetzt mit ihrem ChatGPT-Konto bei der Codex CLI anmelden. Plus- und Pro-Benutzer können jeweils 5 bzw. 50 US-Dollar an kostenlosen API-Credits (gültig für 30 Tage) einlösen, um das Modell codex-mini-latest zu testen. (Quelle: openai, hwchung27, op7418)
DeepSeek Open-Source-Datenverarbeitungs-Framework Smallpond integriert nativen Zugriff von DuckDB auf 3FS: Das von DeepSeek als Open Source veröffentlichte Datenverarbeitungs-Framework Smallpond verwendet intern 3FS (DeepSeek File System) und DuckDB. DuckDB unterstützt nun über das hf3fs_usrbio-Plugin den nativen Zugriff auf 3FS, was zu Leistungssteigerungen und geringerem Overhead führen wird. DuckDB selbst wird auch für seine Benutzerfreundlichkeit gelobt, beispielsweise kann es URLs direkt in Abfrageanweisungen zur Datenverarbeitung einbetten. (Quelle: karminski3)

ComfyUI unterstützt nativ Alibabas Wan2.1-VACE Videomodelle: ComfyUI hat die native Unterstützung für die Videogenerierungsmodelle Wan2.1-VACE 14B und 1.3B des Wanxiang-Teams von Alibaba (@Alibaba_Wan) angekündigt. Dieses Modell bringt integrierte Videobearbeitungsfunktionen in ComfyUI, einschließlich Text-zu-Video, Bild-zu-Video, Video-zu-Video (Posen- und Tiefensteuerung), Videoreparatur (Inpainting) und -erweiterung (Outpainting) sowie Charakter-/Objektreferenzen. (Quelle: TomLikesRobots)
Google AI Studio integriert Veo 2, Gemini 2.0 und Imagen 3 für ein einheitliches Erlebnis bei der Erstellung generativer Medien: Google AI Studio hat ein neues Erlebnis für generative Medien eingeführt, das das Videomodell Veo 2, die nativen Bildgenerierungs-/Bearbeitungsfunktionen von Gemini 2.0 sowie das neueste Text-zu-Bild-Modell Imagen 3 integriert. Benutzer können diese Modelle kostenlos in AI Studio ausprobieren, und Entwickler können auch über die API darauf aufbauen. (Quelle: op7418)
ElevenLabs stellt viertes AI Engineer Starter Pack vor: ElevenLabs hat das vierte AI Engineer Starter Pack für KI-Entwickler veröffentlicht. Es enthält Mitgliedschaften und API-Guthaben für verschiedene Tools und Dienste wie Modal Labs, Mistral AI, Notion, BrowserUse, Intercom, Hugging Face, CodeRabbit usw. und soll KI-Startups und Entwickler unterstützen. (Quelle: op7418)
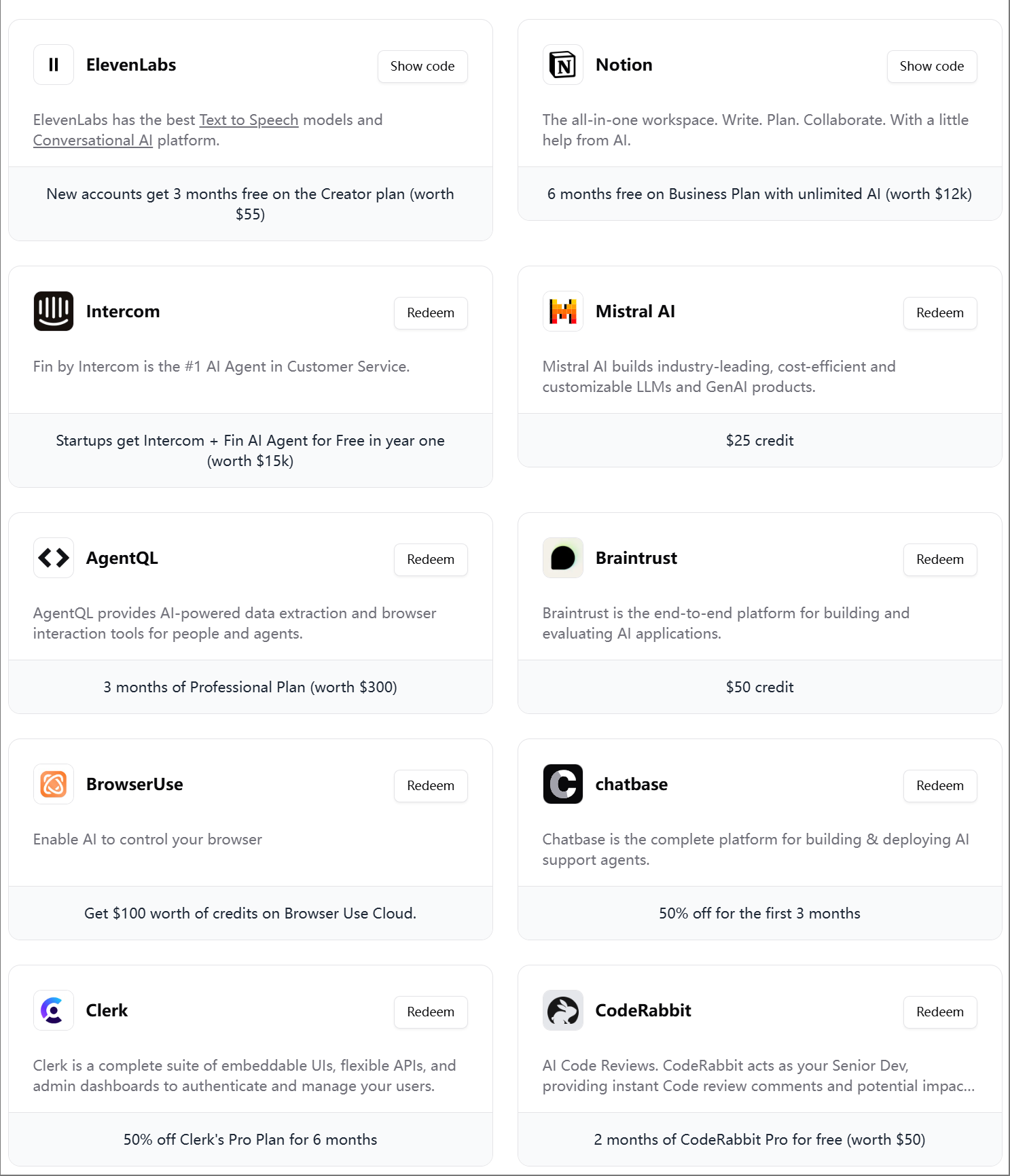
Polygon Zone App: Werkzeug zum Zeichnen benutzerdefinierter Polygone in Videos für CV-Aufgaben: Der Entwickler Pavan Kunchala hat ein Werkzeug namens Polygon Zone App erstellt, mit dem Benutzer Videos hochladen, interaktiv benutzerdefinierte Polygonbereiche (ROI) auf Videoframes zeichnen und Computer-Vision-Analysen wie Objekterkennung in diesen Bereichen ausführen können. Das Werkzeug soll den mühsamen Prozess der Definition von ROIs in CV-Projekten vereinfachen und die manuelle Bearbeitung von JSON-Koordinaten vermeiden. (Quelle: Reddit r/deeplearning)
📚 Lernen
KI-Evaluierungskurs zieht über 300 Unternehmen an: Der von Hamel Husain angebotene KI-Evaluierungskurs (bit.ly/evals-ai) hat bereits über 300 Unternehmen angezogen, darunter namhafte Firmen wie Adobe, Amazon, Google, Meta, Microsoft, NVIDIA, OpenAI sowie zahlreiche Spitzenuniversitäten. Dies spiegelt das hohe Interesse und den Bedarf der Branche an Methoden und Praktiken zur Bewertung von KI-Modellen wider. (Quelle: HamelHusain)
Latent.Space veröffentlicht ChatGPT Codex Benutzerhandbuch: Latent.Space hat einen Leitfaden mit dem Titel „ChatGPT Codex: The Missing Manual“ herausgegeben, der detailliert beschreibt, wie der neu von OpenAI veröffentlichte Cloud-basierte autonome Software-Ingenieur ChatGPT Codex effizient genutzt werden kann. Das Handbuch wurde von Josh Ma und Alexander Embiricos verfasst und soll Benutzern helfen, die leistungsstarken Funktionen von Codex bei Operationen in Codebasen voll auszuschöpfen. (Quelle: swyx)

Qdrant stellt Tutorial für lokale RAG-Anwendungen vor: Qdrant Engine hat ein von @maxedapps erstelltes Tutorial geteilt, das zeigt, wie man mit Gemma 3, Ollama und Qdrant Engine von Grund auf eine zu 100 % lokal laufende Retrieval-Augmented Generation (RAG)-Anwendung erstellt. Das zweistündige Tutorial bietet vollständigen Code und Anleitungen und eignet sich für Entwickler, die lokale KI-Anwendungen praktisch umsetzen möchten. (Quelle: qdrant_engine)

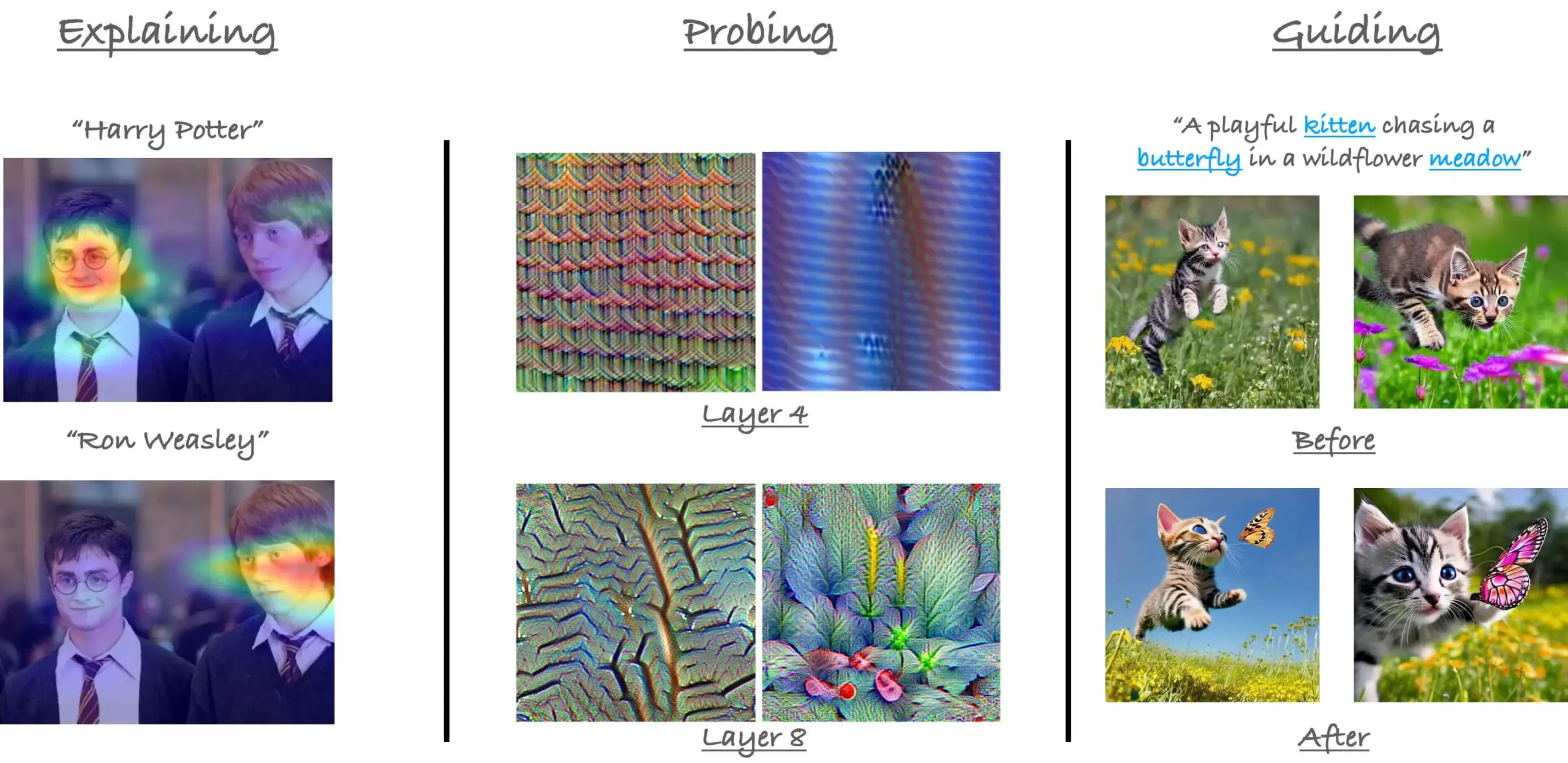
Rückblick auf das CVPR23-Tutorial zum Attention-Mechanismus in ViT: Der Forscher Sayak Paul blickt auf sein Tutorial zum Attention-Mechanismus in Vision Transformers (ViT) zurück, das er gemeinsam mit Hila Chefer auf der CVPR 2023 gehalten hat. Das Tutorial drehte sich um die drei Themen „explain“ (erklären), „probe“ (untersuchen) und „guide“ (anleiten) und zielte darauf ab, das Verständnis der internen Funktionsweise von Attention in ViT zu fördern. (Quelle: RisingSayak)
Tipps zur Verwendung von Claude Code: Planung, Regeln und manuelle Komprimierung: Ein Reddit-Benutzer teilte seine Erfahrungen nach einer Woche intensiver Nutzung von Claude Code und betonte die Bedeutung von Planung, der Festlegung von Regeln (über eine CLAUDE.md-Datei) und der manuellen Ausführung von /compact, bevor die automatische Komprimierungsgrenze erreicht wird. Diese Techniken helfen, die Produktivität und die Ausgabequalität zu verbessern, insbesondere bei der Bearbeitung großer Features oder um zu verhindern, dass das Modell vom Kurs abkommt. Der Benutzer erwähnte, dass Claude Code mit diesen Methoden komplexe Aufgaben effizient erledigen kann. (Quelle: Reddit r/ClaudeAI)
Interview mit AIGCode-Gründer Su Wen: Festhalten an Eigenentwicklung von Large Models, Ziel ist Autopilot „L5“-Niveau bei Codegenerierung: AIGCode-Gründer Su Wen erklärte in einem Interview, dass das Unternehmensziel darin bestehe, eine grundlegende Infrastruktur für die Codebereitstellung zu schaffen und eine Autopilot-gesteuerte Programmierung auf „L5“-Niveau zu realisieren, sodass auch Nicht-Programmierer vollständige Anwendungen mittels KI generieren können. Er ist der Ansicht, dass Coding das beste Szenario für das Training von Large Models ist und Code qualitativ hochwertige Trainingsdaten darstellt. AIGCode hat bereits das 66B-Basismodell „Xiyue“ trainiert und das Produkt AutoCoder auf den Markt gebracht. Su Wen betonte, dass KI-Produkte letztendlich im Wettbewerb um die „Intelligenz des Gehirns“ stehen, das Vortraining die treibende Kraft der Technologie sei und selbst bei hohen Kosten die Eigenentwicklung von Modellen für die Realisierung von AGI und den Aufbau der Kernkompetenz von Produkten unerlässlich sei. (Quelle: WeChat)

💼 Wirtschaft
JD.com sucht Mitarbeiter für Agentenplattform und Anwendungalgorithmen-Team: Das Kernprojektteam für die intelligente Agentenplattform und Anwendungalgorithmen der JD.com Group stellt Algorithmus-Ingenieure für große Modelle und Praktikanten am Standort Peking ein. Die wichtigsten technischen Richtungen umfassen LLM Agent, LLM Reasoning und die Kombination von LLM mit Reinforcement Learning. Die Stellenausschreibungen richten sich an Master- und Doktoranden mit Abschluss im Jahr 2026 (Hochschulabsolventen), Berufserfahrene auf P5-P8-Niveau sowie Forschungspraktikanten. Das Team legt Wert auf technologische Innovation und die Lösung praktischer Probleme und hat bereits auf führenden KI-Konferenzen publiziert. (Quelle: WeChat)

„AI First“-Strategie bei Klarna und Duolingo stößt auf Herausforderungen, Mensch-Maschine-Balance im Fokus: Das Fintech-Unternehmen Klarna und die Sprachlern-App Duolingo sehen sich nach der Einführung einer „AI First“-Strategie mit dem Druck von Kundenfeedback und Marktrealitäten konfrontiert. Klarna hatte zuvor Hunderte von Kundendienststellen durch KI ersetzt, stellt aber aufgrund sinkender Servicequalität nun wieder menschliche Kundendienstmitarbeiter ein. Duolingo löste durch die Automatisierung von Rollen Unzufriedenheit bei den Nutzern aus, da viele der Meinung sind, dass das Kernstück des Sprachenlernens von Menschen geleitet werden sollte. Diese Fälle zeigen, dass Unternehmen bei der KI-Transformation ein Gleichgewicht zwischen Innovation und menschlicher Fürsorge finden müssen. Obwohl Technologie wichtig ist, muss das Vertrauen der Nutzer weiterhin von Menschen aufgebaut werden. (Quelle: Reddit r/ArtificialInteligence)
Databricks soll Gerüchten zufolge Datenbank-Startup Neon für 1 Milliarde US-Dollar übernehmen: Laut einer in der Reddit-Community kursierenden KI-Nachrichtenzusammenfassung hat Databricks das Datenbank-Startup Neon für angeblich 1 Milliarde US-Dollar übernommen. Diese Akquisition könnte darauf abzielen, die Fähigkeiten von Databricks im Bereich Datenmanagement und KI-Infrastruktur zu stärken. (Quelle: Reddit r/ArtificialInteligence)
🌟 Community
Veröffentlichung von OpenAI Codex löst Diskussionen aus, Entwickler zwischen Vorfreude und Vorsicht: Nach der Veröffentlichung des Programmier-Agenten Codex durch OpenAI war die Resonanz in der Community groß. Viele Entwickler zeigten sich begeistert von der Fähigkeit von Codex, Aufgaben wie die Erstellung von PRs und Code-Reparaturen automatisch zu erledigen, und sahen darin eine enorme Steigerung der Programmiereffizienz. Einige sprachen sogar von einem „AGI-Moment-Gefühl“. Ryan Pream teilte seine Erfahrung, mit Codex an einem Tag über 50 PRs erstellt zu haben. Gleichzeitig wiesen Nutzer darauf hin, dass Codex bei der Aufgabenteilung und dem Hinzufügen von Testfällen noch verbessert werden müsse und derzeit eher für Fachleute geeignet sei. Yohei Nakajima teilte erste Eindrücke und hielt das GitHub-zentrierte Design für sinnvoll, die Lernkurve jedoch für steil. (Quelle: kevinweil, gdb, itsclivetime, dotey, yoheinakajima, cto_junior)
Metas Beitrag zum KI-Open-Source-Bereich wird gewürdigt, löst Diskussion über geschlossen vs. offen aus: Clement Delangue, CEO von Hugging Face, verteidigte Meta und argumentierte, dass dessen Beiträge zur Open-Source-Verfügbarkeit von KI-Modellen die anderer großer Unternehmen und Startups mit mehr Ressourcen bei weitem übertreffen und Meta nicht übermäßig kritisiert werden sollte. Diese Ansicht fand bei einigen Nutzern Zustimmung, die betonten, dass die Entwicklung von Spitzen-KI-Modellen extrem schwierig sei und Metas offenes Vorgehen für die Entwicklung des Bereichs von entscheidender Bedeutung sei. Es gab jedoch auch die Meinung (gabriberton), dass Open Source den Verzicht auf Wissensvorsprung bedeute und Closed Source im Wesentlichen zu besseren Ergebnissen führen könne. Dorialexander zeigte sich verwundert darüber, dass die USA plötzlich „europäische Reaktionsweisen“ (bezogen auf die Verteidigung von Meta) übernähmen. (Quelle: ClementDelangue, gabriberton, Dorialexander)
Leak von xAI Grok System-Prompts und Zusammenführung unangemessener Inhalte sorgen für Aufsehen: Es wurde bekannt, dass System-Prompts des xAI-Modells Grok auf GitHub geleakt wurden und sogar System-Prompts von DeepSearch enthielten. Schwerwiegender war, dass Nutzer darauf hinwiesen, dass ein PR mit unangemessenen Inhalten wie „white racial genocide“ nach Prüfung durch fünf Personen in den Hauptzweig gemerged wurde. Obwohl dies später rückgängig gemacht und die Historie gelöscht wurde, deckte der Vorfall erhebliche Mängel im Prozessmanagement und in der Betriebssicherheit von xAI auf. Dies löste in der Community breite Zweifel und Diskussionen über die internen Prozesse und Inhaltsprüfmechanismen von xAI aus. (Quelle: karminski3, eliebakouch, colin_fraser, Reddit r/artificial)
KI-Agenten gelten als Zukunftstrend, doch Herausforderungen und Erwartungen bestehen nebeneinander: Die Ansicht „2025 ist das Jahr der Agenten“ kursiert in der Community und löst Diskussionen über die zukünftige Entwicklung von KI-Agenten aus. Einige sind der Meinung, dass zukünftige Arbeitsmodelle Spielen wie „StarCraft“ oder „Age of Empires“ ähneln werden, bei denen Benutzer eine große Anzahl von Mikro-Agenten zur Erledigung von Aufgaben befehligen. Andere Nutzer weisen jedoch darauf hin, dass aktuelle Agenten bei der Aufgabenzerlegung und dem Verständnis komplexer Anweisungen noch unausgereift sind und von den Nutzern starke Planungsfähigkeiten erfordern. Einige bezweifeln, dass KI-Agenten im Jahr 2025 die Erwartungen erfüllen können, und vermuten, dass sich der Hype von einem zum anderen verlagern könnte, mit der Hoffnung auf substanzielle Veränderungen im Jahr 2026. (Quelle: gdb, EdwardSun0909, op7418, eliza_luth, tokenbender)
Rolle der KI in Bildung und Beschäftigung löst tiefgreifende Diskussionen aus: In der Reddit-Community gibt es Diskussionen über die Auswirkungen der KI-Entwicklung auf traditionelle Bildungs- und Beschäftigungsmodelle. Ein Nutzer fragte: „Was ist jetzt noch der Sinn, zur Schule zu gehen?“, da KI seiner Meinung nach dazu führen wird, dass in Zukunft niemand mehr arbeiten muss. Die meisten Kommentare betonten daraufhin die Bedeutung von kritischem Denken, Lernfähigkeit und sozialen Kompetenzen, die von KI nicht ersetzt werden könnten. Schulen seien nicht nur Orte der Wissensvermittlung, sondern auch Umgebungen, in denen man lernt, wie man lernt, wie man denkt und wie man mit Menschen interagiert. Selbst in einer von KI dominierten Welt seien diese Fähigkeiten weiterhin entscheidend, und es sei sogar notwendig, KI selbst zu erlernen. Andere Diskussionen wiesen darauf hin, dass der Wert eines Menschen nicht nur mit seiner Arbeit gleichgesetzt werden dürfe und die Entwicklung der KI uns dazu anregen sollte, über die menschliche Bedeutung jenseits des Berufs nachzudenken. (Quelle: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
Das Phänomen der KI-Freundin regt zum Nachdenken über soziale Ethik und demografische Fragen an: Berichte des Economist, wonach junge Chinesen beginnen, Beziehungen mit KI einzugehen und Freundschaften zu schließen, lösten unter Internetnutzern hitzige Diskussionen aus. Einige Kommentare verglichen dieses Phänomen mit dem „Aussetzen einer großen Anzahl sterilisierter weiblicher Mücken in die Wildnis, um die Mückenpopulation zu reduzieren“, was darauf hindeutet, dass KI-Partner das Problem der niedrigen Geburtenraten verschärfen könnten, obwohl KI-Partner ein „perfektes Erlebnis des ewigen Verstehens“ bieten können. Dies spiegelt die komplexen sozialen Auswirkungen und ethischen Überlegungen wider, die mit der Anwendung von KI-Technologie im Bereich der emotionalen Begleitung einhergehen. (Quelle: dotey)
Realitätsnähe von KI in Telefongesprächen gibt Anlass zur Sorge, Unterscheidung zwischen echt und falsch wird zur neuen Herausforderung: Ein Reddit-Nutzer berichtete von einem Anruf einer Bildungseinrichtung, bei dem die Stimme des Gesprächspartners so natürlich klang und die Antworten so fließend waren, dass es fast unmöglich war, zwischen Mensch und KI zu unterscheiden. Erst nach einigen Minuten des Gesprächs wurde aufgrund der makellosen Perfektion der Antworten klar, dass es sich um eine KI handelte. Diese Erfahrung löste beim Nutzer Erstaunen über die Geschwindigkeit der Entwicklung von KI-Sprachtechnologie und ein gewisses Unbehagen aus, da er befürchtet, KI am Telefon in Zukunft schwer erkennen zu können, was insbesondere für ältere Menschen und andere Gruppen ein Betrugsrisiko darstellen könnte. (Quelle: Reddit r/ArtificialInteligence, Reddit r/artificial)
💡 Sonstiges
MIT fordert arXiv zur Rücknahme eines Preprint-Papers über KI und wissenschaftliche Entdeckungen auf, was zu Kontroversen führt: Das MIT forderte arXiv auf, ein von einem seiner Doktoranden verfasstes Preprint-Paper über den Einfluss von KI auf Innovationen in der Materialwissenschaft zurückzuziehen. Als Grund wurde angegeben, man habe „kein Vertrauen“ in die Herkunft, Zuverlässigkeit und Gültigkeit der Forschungsdaten. Das Paper hatte zuvor darauf hingewiesen, dass KI-gestützte Forscher 44 % mehr Materialien entdeckten und 39 % mehr Patentanmeldungen einreichten. Dieser Schritt des MIT löste Diskussionen aus. Einige Kommentatoren sahen darin eine Beeinträchtigung der akademischen Freiheit und vermuteten einen Zusammenhang mit den Forschungsergebnissen (KI könnte den Vorteil von Spitzenforschern verstärken und die Arbeitszufriedenheit von Durchschnittsforschern senken), die nicht den Erwartungen der Geldgeber entsprächen. Andere wiederum argumentierten, dass im KI-Bereich die wissenschaftliche Strenge von entscheidender Bedeutung sei und man vor übertriebenem Hype durch Preprints warnen müsse. (Quelle: Reddit r/ArtificialInteligence)
Die Verbreitung von KI-Codierungswerkzeugen stellt höhere Anforderungen an Codemodularisierung und Engineering-Praktiken: E0M wies auf Twitter darauf hin, dass der Wettbewerbsvorteil von Startups zunehmend von der Geschwindigkeit und Effizienz abhängt, mit der Ingenieure KI-Codierungswerkzeuge einsetzen. Gute Praktiken der Codemodularisierung werden wichtiger denn je. Wenn die Komplexität des Codes im Rahmen dessen liegt, was moderne Codierungs-Agenten verarbeiten können, sind schnelle Iterationen möglich. Umgekehrt kann zu komplexer „Spaghetti-Code“ den Fortschritt verlangsamen und dazu führen, dass man von Wettbewerbern überholt wird, die KI einsetzen. (Quelle: E0M, E0M)
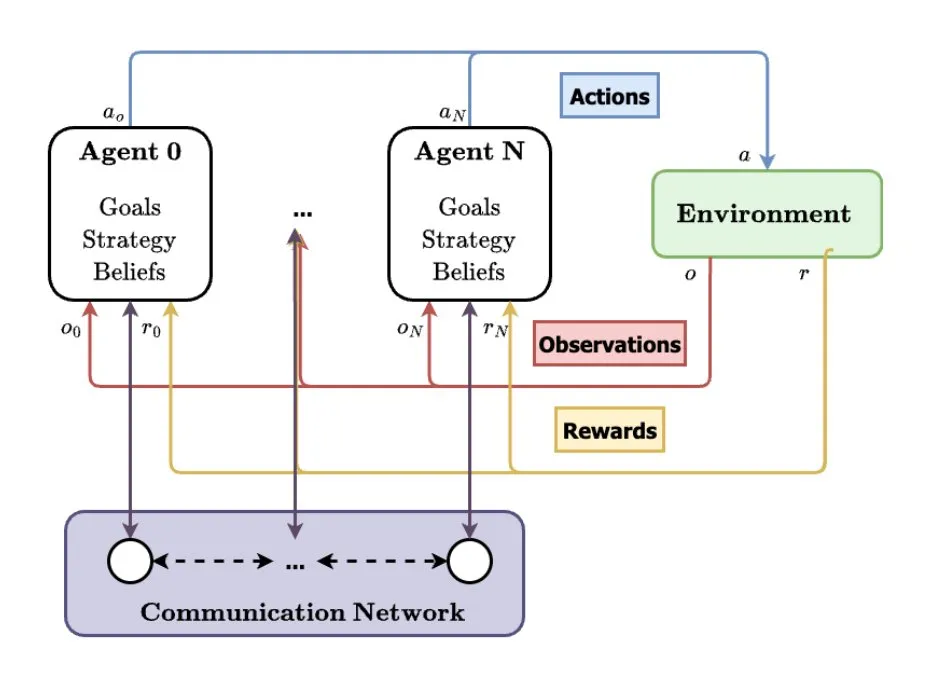
Multi-Agenten-Systeme (MAS) gelten als zukünftige Entwicklungsrichtung der KI: TheTuringPost analysierte den aufkommenden Trend der Multi-Agenten-Systeme (MAS). Zu den wichtigsten Entwicklungen gehören Multi-Agent Reinforcement Learning (MARL), Schwarmrobotik, kontextsensitive MAS (CA-MAS) sowie von Large Language Models (LLM) angetriebene MAS. Diese Technologien ermöglichen es KI-Systemen, durch Zusammenarbeit und Wettbewerb komplexe Probleme zu lösen und finden Anwendung in Bereichen wie Katastrophenhilfe, Umweltüberwachung und Simulation sozialer Dynamiken, was eine Zukunft der kollektiven Intelligenz ankündigt. (Quelle: TheTuringPost)