

Schlüsselwörter:AlphaEvolve, DeepSeek V3, GPT-4.1, Speech-02, Claude-Modell, Falcon-Edge, BLIP3-o, AM-Thinking-v1, Gemini-betriebener evolutionärer Codierungsagent, Hardware-Software-Co-Design zur Senkung der Kosten für große Modelle, Zero-Shot-Sprachklontechnologie, Extreme Inferenzfähigkeiten, 1,58-Bit BitNet-Architektur
🔥 Fokus
DeepMind stellt AlphaEvolve vor: Ein von Gemini angetriebener evolutionärer Coding-Agent, der die Algorithmenentdeckung vorantreibt : AlphaEvolve kombiniert die Kreativität des Gemini-Modells mit automatischen Evaluatoren und nutzt evolutionäre Frameworks zur Optimierung von Algorithmen. Es hat bereits in mehreren Bereichen Durchbrüche erzielt, wie die Durchführung der Multiplikation komplexer 4×4-Matrizen mit 48 Skalarmultiplikationen, eine Verbesserung des Strassen-Algorithmus; und die Entdeckung von 593 Kugelkonfigurationen im 11-dimensionalen Raum, was das 300 Jahre alte „Kissing Number Problem“ voranbringt. Darüber hinaus optimierte AlphaEvolve auch die Planung von Google-Rechenzentren (Einsparung von 0,7 % Rechenressourcen), das Design der nächsten Generation von TPUs (Entfernung redundanter Bits) und das Training von KI-Modellen (Beschleunigung kritischer Kerne um 23 %). Der Fields-Medaillengewinner Terence Tao war ebenfalls an der Erforschung seiner mathematischen Anwendungen beteiligt. (Quelle: DeepMind)

DeepSeek V3 Whitepaper im Detail: Software-Hardware-Co-Design reduziert Kosten und Energieverbrauch großer Modelle : Das DeepSeek-Team hat ein Whitepaper veröffentlicht, das detailliert beschreibt, wie DeepSeek-V3 durch Software-Hardware-Co-Design Kosteneffizienz bei groß angelegtem Training und Inferenz erreicht. Kerntechnologien umfassen: 1) Speicheroptimierung: Einsatz von Multi-Head Latent Attention (MLA) zur Komprimierung des Key-Value-Cache, FP8 Mixed-Precision-Training zur Reduzierung des Speicherverbrauchs. 2) Berechnungsoptimierung: Anwendung des Mixture of Experts (MoE) Modells, bei dem nur ein Teil der Parameter aktiviert wird, kombiniert mit FP8-Training, um die Berechnungskosten erheblich zu senken. 3) Kommunikationsoptimierung: Einsatz einer Multi-Plane Fat-Tree-Netzwerktopologie und der Dual-Micro-Batch-Processing-Overlapping-Technologie (DualPipe) zur Reduzierung der Latenz und Verbesserung der GPU-Auslastung. 4) Inferenzbeschleunigung: Einführung des Multi-Token Prediction (MTP) Frameworks, das die parallele Vorhersage und Verifizierung mehrerer Kandidaten-Token ermöglicht und die Generierungsgeschwindigkeit erhöht. Das Whitepaper skizziert zudem fünf Zukunftsperspektiven für das Design von KI-Hardware, darunter Unterstützung für Berechnungen mit geringer Präzision, Erweiterung und Fusion, Optimierung der Netzwerktopologie, Optimierung des Speichersystems sowie Robustheit und Fehlertoleranz. (Quelle: arXiv)

OpenAI GPT-4.1 Modell offiziell in ChatGPT verfügbar, Nutzer können es direkt auswählen : OpenAI gab bekannt, dass das GPT-4.1 Modell nun in ChatGPT verfügbar ist. Plus-, Pro- und Team-Nutzer können über den Modellauswähler darauf zugreifen, Enterprise- und Education-Nutzer erhalten später Zugriff. GPT-4.1 mini wird ebenfalls GPT-4o mini für alle Nutzer ersetzen. GPT-4.1 hat Aufmerksamkeit für seine herausragende Leistung bei Programmieraufgaben und der Befolgung von Anweisungen erhalten; die vorherige API-Version unterstützte ein Kontextfenster von bis zu 1 Million Token. Einige Nutzer stellten jedoch bei Tests fest, dass die Kontextlänge der GPT-4.1-Version in ChatGPT anscheinend immer noch 128k beträgt und nicht die 1M der API-Version erreicht, was zu einiger Enttäuschung führte. (Quelle: OpenAI Developers)

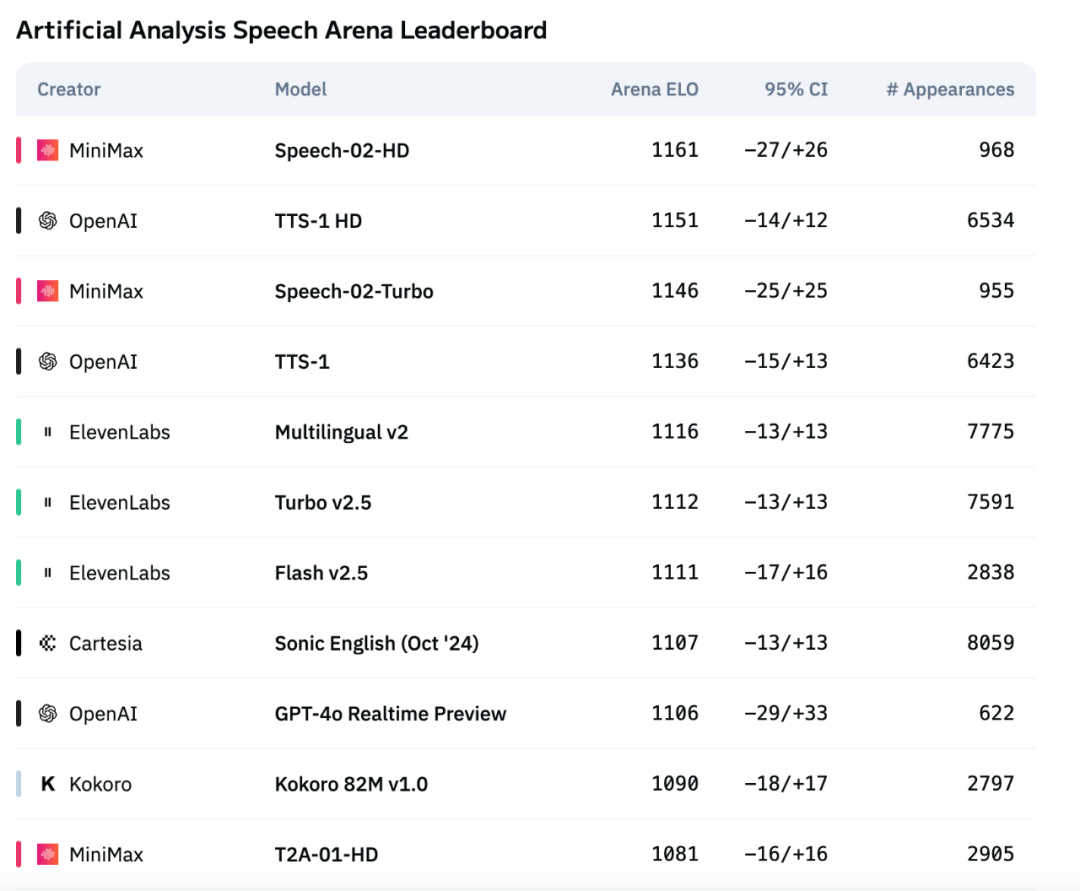
MiniMax’ neue Generation des Sprachmodells Speech-02 erklimmt Spitze der Artificial Analysis Sprachbewertungsliste : Das neueste Text-to-Speech (TTS) Modell Speech-02 von MiniMax hat auf der international anerkannten Sprachbewertungsliste Artificial Analysis Speech Arena die höchste ELO-Bewertung erzielt und übertrifft damit vergleichbare Produkte von OpenAI und ElevenLabs. Das Modell zeigt hervorragende Leistungen bei Schlüsselindikatoren wie Word Error Rate (WER) und Speaker Similarity (SIM) und demonstriert insbesondere bei der Verarbeitung von Chinesisch und Kantonesisch lokale Vorteile. Die Kerninnovation von Speech-02 liegt in der Realisierung von echtem Zero-Shot Voice Cloning (benötigt nur wenige Sekunden Referenzaudio, keinen Text) sowie der Verwendung einer neuen Flow-VAE-Architektur, die die Natürlichkeit und emotionale Ausdruckskraft der Sprachgenerierung verbessert und 32 Sprachen unterstützt. Auch die Kosten sind äußerst wettbewerbsfähig und liegen bei etwa 1/4 der Konkurrenzprodukte von ElevenLabs. (Quelle: 机器之心)
🎯 Trends
Anthropic’s neue Claude-Modelle könnten „Extreme Reasoning“-Fähigkeiten besitzen : Laut The Information und Community-Beobachtungen könnte Anthropic in den kommenden Wochen neue Versionen der Modelle Claude Sonnet und Claude Opus veröffentlichen, deren größtes Highlight die Fähigkeit zum „Extreme Reasoning“ sein soll. Diese Funktion ermöglicht es dem Modell, bei schwierigen Problemen innezuhalten, neu zu bewerten und die Strategie anzupassen, anstatt direkt eine Antwort zu geben. Bei Aufgaben wie der Codegenerierung kann das Modell Fehler automatisch testen und korrigieren. Diese dynamische, zyklische Art des Denkens und der Werkzeugnutzung zielt darauf ab, das Modell intelligenter im Umgang mit komplexen Problemen zu machen, die Abhängigkeit von menschlicher Aufsicht zu verringern und sich der Denkweise menschlicher Kollaborateure anzunähern. Einige Nutzer haben bereits entdeckt, dass Anthropic ein Modell namens Claude Neptune (möglicherweise Claude 3.8) testet, das einen Kontext von 128k Token unterstützt. (Quelle: 量子位)
TII veröffentlicht Falcon-Edge Serie effizienter BitNet-Modelle und onebitllms Fine-Tuning Toolkit : Das Technology Innovation Institute (TII) hat Falcon-Edge veröffentlicht, eine Reihe hochkomprimierter Sprachmodelle basierend auf der BitNet-Architektur, die leistungsstark, vielseitig und feinabstimmbar sind. Gleichzeitig haben sie onebitllms als Open Source veröffentlicht, ein leichtgewichtiges Python-Toolkit (installierbar über pip), das speziell für das Fine-Tuning oder die Fortsetzung des Pre-Trainings dieser 1,58-Bit-Modelle entwickelt wurde. Ziel ist es, die Hürden für die Nutzung großer Modelle zu senken und die Entwicklung und Anwendung der 1-Bit-LLM-Technologie voranzutreiben. (Quelle: younes)

Hugging Face Transformers Bibliothek erhält bedeutendes Upgrade und wird zum zentralen Standard für Modelldefinitionen : Hugging Face kündigte an, dass seine Transformers-Bibliothek einer umfassenden Überarbeitung unterzogen wird, mit dem Ziel, zum zentralen Standard für Modelldefinitionen über verschiedene Backends und Runner hinweg zu werden. Durch die Zusammenarbeit mit zahlreichen Ökosystempartnern wie vLLM, LlamaCPP, SGLang, MLX, DeepSpeed, Microsoft und NVIDIA wird die Standardisierung des Modellcodes vorangetrieben, um eine höhere Konsistenz und Zuverlässigkeit für das gesamte KI-Ökosystem zu erreichen. Diese Initiative wurde von der Community weithin gelobt und als wichtiger Schritt zur Förderung der Open-Source-KI-Entwicklung angesehen. (Quelle: Arthur Zucker)

Salesforce veröffentlicht BLIP3-o auf Hugging Face: Eine vollständig quelloffene, einheitliche multimodale Modellreihe : Salesforce hat die BLIP3-o Modellreihe vorgestellt, eine Familie vollständig quelloffener, einheitlicher multimodaler Modelle. Die Reihe umfasst Modellarchitekturen, Trainingsmethoden und Datensätze und zielt darauf ab, die Entwicklung und Anwendung multimodaler KI-Technologien voranzutreiben. Die Veröffentlichung von BLIP3-o stellt Forschern und Entwicklern leistungsstarke multimodale Verarbeitungswerkzeuge und -ressourcen zur Verfügung. (Quelle: AK)

Nvidia demonstriert den Einsatz synthetischer Daten zur Förderung der vollautomatischen Fahrtechnologie : Nvidia hat ein neues Video veröffentlicht, das zeigt, wie das Unternehmen synthetische Daten nutzt, um die Entwicklung der Full Self-Driving (FSD) Technologie zu beschleunigen. Durch die Generierung umfangreicher, vielfältiger virtueller Fahrszenarien und -daten kann Nvidia seine autonomen Fahralgorithmen effizienter trainieren und validieren, die Einschränkungen der Datenerfassung in der realen Welt überwinden und die Technologie des autonomen Fahrens in Richtung mehr Sicherheit und Zuverlässigkeit vorantreiben. (Quelle: SawyerMerritt)
A-M-Team veröffentlicht 32B Inferenzmodell AM-Thinking-v1, übertrifft teilweise DeepSeek-R1 in der Leistung : Das chinesische Forschungsteam A-M-Team hat das 32B-Parameter-Inferenzmodell AM-Thinking-v1 auf Hugging Face als Open Source veröffentlicht. Das Modell zeigt herausragende Leistungen bei Aufgaben wie mathematischem Denken (AIME-Serien-Score von 85,3) und Codegenerierung (LiveCodeBench-Score von 70,3) und soll in diesen spezifischen Benchmarks DeepSeek-R1 (671B MoE) übertreffen und sich Modellen wie Qwen3-235B-A22B annähern. Das Team konzentriert sich auf die Optimierung der Inferenzfähigkeiten von dichten 32B-Modellen durch Post-Training-Schemata (einschließlich Cold-Start SFT, durch Erfolgsraten gesteuerte Datenauswahl, zweistufiges RL), um Wege zu starker Inferenz unter begrenzten Rechenressourcen und mit Open-Source-Daten zu erforschen. (Quelle: AI科技评论)

Marigold Update: Stable Diffusion Modell wird zum Tiefenschätzer, unterstützt Single-Step-Inferenz und hohe Auflösung : Das Marigold-Projekt hat ein bedeutendes Update veröffentlicht. Diese Technologie ermöglicht es, das Stable Diffusion 2 Modell durch wenige synthetische Samples und kurzes Training (2-3 Tage auf 1 GPU) in einen fortschrittlichen Tiefenschätzer umzuwandeln. Zu den neuen Funktionen gehören: schnelle Single-Step-Inferenz, Unterstützung neuer Modalitäten, hochauflösende Ausgabe, Unterstützung der Diffusers-Bibliothek sowie neue Demos. (Quelle: Anton Obukhov)
Qwen3-Modellreihe zeigt starke Präsenz in der Open-Source-Community, Nvidia wählt sie als Basis für OpenCodeReasoning : Die Qwen3-Modellreihe von Alibaba gewinnt weiterhin an Aufmerksamkeit und Anwendung in der Open-Source-Community. Die kürzlich von Nvidia als Open Source veröffentlichte OpenCodeReasoning-Modellreihe (mit 7B, 14B, 32B Spezifikationen) verwendet Qwen als Basis. Qwen3 wird von Entwicklern aufgrund seiner vollständigen Versionen, kontinuierlichen Updates, nativen Unterstützung für gemischte Inferenzmodi und eines florierenden Ökosystems (weltweit über 300 Millionen Downloads, über 100.000 abgeleitete Modelle) geschätzt. Zu den jüngsten Updates gehören das Endgeräte-Multimodalmodell Qwen-omini 3B, die Zusammenarbeit mit Unsloth zur Steigerung der Feinabstimmungseffizienz, die Veröffentlichung detaillierter Empfehlungen für Bereitstellungshyperparameter, die Unterstützung der Generierung von Webseiten-Echtzeitvorschauen, die Bereitstellung verschiedener quantisierter Versionen sowie die Veröffentlichung eines technischen Berichts. (Quelle: AI前线)
Hugging Face Accelerate v1.7.0 veröffentlicht, unterstützt regionale Kompilierung und QLoRA für FSDPv2 : Hugging Face Accelerate Version v1.7.0 wurde offiziell veröffentlicht. Zu den Highlights dieser Version gehören: regionale Kompilierung (Regional Compilation), implementiert von @IlysMoutawwakil, zur Verbesserung der Kompilierungseffizienz und -flexibilität; schichtweise Casting-Hooks (Layerwise Casting Hook), beigetragen von @RisingSayak, eine in der Diffusers-Bibliothek weit verbreitete Funktion; sowie die von @winglian implementierte QLoRA-Unterstützung für FSDPv2, zur weiteren Optimierung des Trainings großer Modelle. (Quelle: Marc Sun)

Llamafile 0.9.3 veröffentlicht, fügt Unterstützung für Qwen3 und Phi4 Modelle hinzu : Llamafile hat die Version 0.9.3 veröffentlicht. Dieses Update fügt Unterstützung für die kürzlich populären Modellreihen Qwen3 und Phi4 hinzu. Llamafile zielt darauf ab, die Verteilung und Ausführung von LLM-Anwendungen zu vereinfachen, indem Modellgewichte und der für die Ausführung erforderliche Code in einer einzigen ausführbaren Datei gebündelt werden, was eine bequeme Bereitstellung auf verschiedenen Betriebssystemen ermöglicht. (Quelle: Phoronix)
Tencent veröffentlicht HunyuanImage 2.0, ein großes Bildmodell : Tencent hat offiziell eine neue Version seines großen Bildmodells HunyuanImage veröffentlicht – HunyuanImage 2.0. Es wird erwartet, dass dieses Update Verbesserungen in der Bildgenerierungsqualität, Kontrollierbarkeit und dem Verständnis komplexer Anweisungen mit sich bringt. Spezifische technische Details und Verbesserungen können Nutzer über die offiziellen Kanäle weiter erfahren. (Quelle: Hunyuan)

Ollama v0.7 veröffentlicht, verbessert die lokale Ausführung großer Modelle : Ollama hat die Version v0.7 veröffentlicht und setzt damit sein Engagement fort, die Ausführung großer Sprachmodelle auf lokalen Geräten zu vereinfachen. Die neue Version könnte Leistungsoptimierungen, Unterstützung für neue Modelle oder Verbesserungen der Benutzererfahrung enthalten. Nutzer können die offizielle Website oder GitHub für detaillierte Update-Protokolle und Downloads besuchen. (Quelle: ollama)
llama.cpp integriert PDF-Eingabefunktion, unterstützt direkte Verarbeitung von PDF-Dokumenten : Das llama.cpp-Projekt hat kürzlich ein wichtiges Update integriert, das die direkte Eingabeunterstützung für PDF-Dateien hinzufügt. Dies bedeutet, dass Benutzer jetzt PDF-Dokumentinhalte bequemer als Eingabe für von llama.cpp betriebene lokale große Sprachmodelle zur Verarbeitung, Analyse oder Beantwortung von Fragen verwenden können, was die Anwendungsszenarien erweitert. Die Funktion wird über ein externes JS-Paket im integrierten Web-Frontend realisiert und erhöht nicht den Kernwartungsaufwand. (Quelle: GitHub)
Microsoft Copilot führt 4o-Bilderzeugungsfunktion ein, verbessert visuelle Effekte und Textkonsistenz : Der Microsoft KI-Assistent Copilot hat nun die Bilderzeugungsfähigkeiten des GPT-4o Modells von OpenAI integriert. Dieses Update zielt darauf ab, schärfere visuelle Effekte, eine konsistentere Textgenerierung zu bieten und eine Vielzahl von Stilen von fotorealistisch bis hin zu lustigen Cartoons zu unterstützen. Nutzer können über Copilot die von 4o gesteuerte Bilderstellungsfunktion erleben. (Quelle: yusuf_i_mehdi)

NVIDIA DRIVE Labs diskutiert die Zukunft des kartenlosen Fahrens, reduziert Abhängigkeit von HD-Karten : Das neueste Video von NVIDIA DRIVE Labs diskutiert die Zukunft des kartenlosen Fahrens (mapless driving). Hochauflösende Karten sind für autonomes Fahren entscheidend, aber ihre Kosten und Wartungsherausforderungen schränken die Bereitstellung ein. NVIDIA reduziert durch Innovationen wie die Beseitigung von Informationsengpässen, die Erhöhung der Aufgabengenauigkeit sowie die Beschleunigung von Modelltrainings- und Inferenzzeiten die Abhängigkeit von HD-Karten und treibt die Grenzen der autonomen Fahrtechnologie voran. (Quelle: NVIDIA DRIVE)
Dolphin 3.2 (trainiert auf Qwen3) wird System-Prompt-Schalter anbieten, um die Benutzerkontrolle zu verbessern : Das kommende Dolphin 3.2 Modell, trainiert auf Qwen3, wird drei System-Prompt-Schalter einführen: /no_think (möglicherweise zur Reduzierung redundanter Denkschritte), /uncensored (möglicherweise zur Reduzierung der Inhaltszensur) und /china (möglicherweise für spezifische chinesische Kontexte oder Dienste). Diese Schalter sollen den Nutzern mehr Eigentum und Kontrolle über ihre Modellimplementierungen geben. (Quelle: cognitivecompai)

🧰 Tools
Runway führt Referenzfunktion ein, mit der spezifische Techniken oder Stile gelernt und auf neue Kreationen angewendet werden können : Runway hat eine neue Funktion namens “References” hinzugefügt, die es Nutzern ermöglicht, der Plattform eine bestimmte Technik oder einen künstlerischen Stil zu zeigen und diesen dann als Referenz auf jede neue generierte Kreation anzuwenden. Diese Funktion bietet Nutzern eine feinere Kontrolle über den Stil und macht KI-gestützte Kreationen persönlicher und zielgerichteter. Der Nutzer Cristobal Valenzuela hat eine Aktion gestartet, um die Community zu ermutigen, originelle Anwendungsfälle dieser Funktion zu teilen, und wird die 5 kreativsten Fälle mit einem kostenlosen Jahresabonnement des Unlimited-Pakets belohnen. (Quelle: c_valenzuelab)

DSPy: Ein minimalistisches LLM-Programmierframework für schnelle Iterationen : Das DSPy-Framework hat aufgrund seines minimalistischen Designs Aufmerksamkeit erregt. Entwickler geben an, dass die Kernfunktionen (Module oder Optimizer) meist mit nur einer Codezeile implementiert werden können, um Nutzern zu helfen, Ideen schnell auszuprobieren und zu iterieren. Im Gegensatz zu einigen Tools, die viel Boilerplate-Code und komplexe Konzepte erfordern, betont DSPy Benutzerfreundlichkeit und Effizienz. Nutzer berichten, dass sie durch das Lesen der Einführungsdokumentation schnell einsteigen und das Framework innerhalb kurzer Zeit zur Optimierung von Modellen nutzen können, obwohl die zyklische Optimierung mit SOTA-Modellen Kosten verursachen kann. (Quelle: lateinteraction)
Unsloth AI erweitert auf TTS- und Audiomodell-Feinabstimmung, erhöht Geschwindigkeit und reduziert VRAM-Nutzung : Unsloth AI gab bekannt, dass seine Optimierungstechnologie nun auch die Feinabstimmung von Text-to-Speech (TTS)- und Audiomodellen unterstützt. Nutzer können kostenlose Colab-Notebooks verwenden, um Modelle wie Sesame-CSM und OpenAI Whisper zu trainieren, auszuführen und zu speichern. Unsloth behauptet, dass seine Technologie die TTS-Trainingsgeschwindigkeit um das 1,5-fache erhöhen und gleichzeitig den VRAM-Verbrauch um 50 % senken kann. Entsprechende Dokumentationen und Colab-Notebooks sind auf der offiziellen Website verfügbar. (Quelle: Unsloth AI)
Modal unterstützt Amazon bei der Einbettung von 30 Millionen Bewertungen, L40S GPU ermöglicht stundenweise Verarbeitung : Die Modal-Plattform demonstrierte ihre Fähigkeit zur horizontalen Skalierung bei der Verarbeitung umfangreicher Einbettungsaufgaben auf L40S GPUs. In einem Demonstrationsfall gelang es Modal, die Einbettung von 30 Millionen Amazon-Bewertungen innerhalb einer Stunde abzuschließen. Dies ist dem aktualisierten skalierbaren Generierungssystem des Modal-Teams zu verdanken, das eine einfachere und effizientere massiv parallele Verarbeitung ermöglicht. (Quelle: charles_irl)

Lovart AI: Ein aufstrebender KI-Agent für visuelles Design, der mehrere Spitzenmodelle integriert : Ein KI-Agent für visuelles Design namens Lovart hat Aufmerksamkeit erregt. Er kann professionelle visuelle Designaufgaben wie Poster, Marken-VI und Storyboards mithilfe von Anweisungen in natürlicher Sprache erledigen. Die Kernkompetenz von Lovart liegt in seiner Multi-Modell-Fusionssteuerung, die verschiedene Spitzenmodelle wie GPT image-1, Flux pro, OpenAI-o3, Gemini Imagen 3, Kling AI, Tripo AI und Suno AI integriert. Zudem verfügt er über professionelle Bearbeitungswerkzeuge (wie Ebenen, Masken, Textfeinabstimmung) und unterstützt die Trennung von Bild und Text sowie die Bearbeitung auf Ebenen. Das Produkt wird von einer unabhängigen Tochtergesellschaft von Liblib betrieben und zielt darauf ab, ein umfassendes und hochgradig kontrollierbares KI-Designerlebnis zu bieten. (Quelle: 量子位)
OpenHands 0.38.0 veröffentlicht: Native Windows-Unterstützung und Chrome-Erweiterung verbessern Benutzerfreundlichkeit : OpenHands hat die Version 0.38.0 veröffentlicht, die mehrere wichtige Updates mit sich bringt. Dazu gehören: native Windows-Unterstützung (ohne WSL), was die Nutzung für Windows-Nutzer erleichtert; eine Browser-Screenshot-Funktion; sowie flexiblere Anpassungsmöglichkeiten für die Sandbox. Darüber hinaus wurde eine Chrome-Erweiterung veröffentlicht, die es Nutzern ermöglicht, OpenHands mit einem Klick von GitHub aus zu starten, was den Bedienungsprozess weiter vereinfacht. (Quelle: All Hands AI)
Tensorlake Cloud veröffentlicht, verbessert Dokumentenextraktion und Workflow-Erstellung : Tensorlake kündigte die Einführung von Tensorlake Cloud an, die darauf abzielt, die Dokumentenextraktion und Arbeitsabläufe zu optimieren, um die Erstellung von intelligenten Agentenanwendungen und komplexen Geschäftsworkflows zu unterstützen. Die Plattform nutzt fortschrittliche Modelle zum Verständnis des Dokumentenlayouts (trainiert auf realen Daten wie ACORD-Formularen, Kontoauszügen, Forschungsberichten usw.) und Modelle zur Tabellenextraktion, um unstrukturierte Dokumente in saubere, strukturierte Daten umzuwandeln. Dies ist besonders nützlich für die Verarbeitung komplexer und dichter Tabellen und schließt eine Lücke, die visuelle Sprachmodelle (VLM) in diesem Bereich aufweisen. (Quelle: Tensorlake)
Patronus AI stellt Percival vor: Ein Agent, der speziell für das Debuggen und Verbessern von KI-Agenten entwickelt wurde : Patronus AI hat ein neues Tool namens Percival veröffentlicht, einen KI-Agenten, der speziell für das Debuggen und Verbessern von KI-Agenten entwickelt wurde. Percival kann komplexe Agenten-Trace-Aufzeichnungen sofort analysieren, bis zu 60 verschiedene Fehlermodi identifizieren und automatisch Prompt-Reparaturen vorschlagen, um die Leistung zu verbessern. Das Tool adressiert kritische Herausforderungen wie „Kontext-Explosion“ (Agenten verarbeiten Millionen von Token) und unterstützt die domänenspezifische Anpassung für bestimmte Anwendungsfälle sowie komplexe Multi-Agenten-Orchestrierung. (Quelle: Weaviate Podcast)

Replit integriert Semgrep für „Safe Vibe Coding“, scannt automatisch nach Schwachstellen : Replit kündigte eine Partnerschaft mit Semgrep an, um die Funktion „Safe Vibe Coding“ einzuführen. Jetzt führt Semgrep bei jeder Codebereitstellung auf Replit automatisch einen Sicherheitsscan durch, um potenzielle Schwachstellen zu finden und zu beheben und die versehentliche Offenlegung sensibler Informationen wie API-Schlüssel zu verhindern. Dieser Schritt zielt darauf ab, die Sicherheit bei der Verwendung von KI-gestützter Programmierung (z. B. durch LLM-generierten Code) zu erhöhen. (Quelle: amasad)

Cursor AI Version 0.50 veröffentlicht, bringt bedeutende Updates : Das KI-gestützte Programmierwerkzeug Cursor hat seine Version 0.50 veröffentlicht, die als „größtes Versionsupdate aller Zeiten“ bezeichnet wird. Die neue Version wird voraussichtlich zahlreiche Funktionserweiterungen und Optimierungen der Benutzererfahrung enthalten, die darauf abzielen, die Programmiereffizienz der Entwickler und die reibungslose Zusammenarbeit mit KI weiter zu verbessern. Spezifische Update-Inhalte können den offiziellen Versionshinweisen entnommen werden. (Quelle: eric zakariasson)

OpenMemory MCP: Lokalisierter Speicherverwaltungsserver für anwendungsübergreifenden Kontextaustausch : OpenMemory MCP ist ein Speicherverwaltungsserver, der darauf abzielt, die Produktivität von KI-Anwendungen zu steigern. Er ermöglicht es Benutzern, Kontext zwischen verschiedenen Anwendungen (wie Cursor und Claude Desktop) auszutauschen und PostgreSQL sowie Qdrant lokal zum Speichern und Indizieren von Daten zu verwenden, um die Datensicherheit zu gewährleisten. Das Tool unterstützt semantische Suche und bietet ein Dashboard zur Verwaltung von Speicher und Anwendungszugriff, wodurch das Problem des Kontextverlusts über Sitzungen hinweg gelöst wird. (Quelle: Reddit r/ClaudeAI)

Hugging Face Inference Endpoint kombiniert mit vLLM und Gradio für schnelle Whisper-Transkription : Hugging Face demonstrierte, wie sein Inference Endpoint Service in Kombination mit dem vLLM-Projekt und der Gradio-Oberfläche zur Bereitstellung des Whisper-Modells von OpenAI genutzt werden kann, um eine extrem schnelle Sprachtranskriptionsfunktion zu realisieren. Diese Kombination nutzt Open-Source-Tools aus der KI-Community und bietet Nutzern eine effiziente und benutzerfreundliche Lösung für die Umwandlung von Sprache in Text. (Quelle: Morgan Funtowicz)
A.I.T.E Ball: Ein eigenständiger KI-Magic-8-Ball basierend auf Orange Pi und Gemma 3 1B : Ein Entwickler präsentierte ein vollständig eigenständiges (keine Internetverbindung erforderlich) KI-gesteuertes Magic-8-Ball-Projekt – den A.I.T.E Ball. Das Gerät läuft auf einem Orange Pi Zero 2W und verwendet whisper.cpp für die Text-zu-Sprache-Umwandlung sowie llama.cpp zur Ausführung des Gemma 3 1B-Modells für Frage-Antwort-Szenarien. Dies demonstriert das Potenzial für die Implementierung lokalisierter KI-Anwendungen auf energieeffizienter Hardware. (Quelle: Reddit r/LocalLLaMA)

OWL Agent: Open-Source Universal-Agent mit integriertem MCPToolkit : Das Open-Source-Projekt OWL Agent verfügt nun über integrierte MCPToolkit-Unterstützung. Benutzer können problemlos auf Playwright, desktop-commander und andere MCP-Server oder benutzerdefinierte Python-Tools zugreifen. OWL wird diese Tools in seinen Multi-Agenten-Workflows automatisch erkennen und aufrufen, was seine Vielseitigkeit und Aufgaben Ausführungsfähigkeiten verbessert. (Quelle: Reddit r/LocalLLaMA)

ElevenLabs stellt SB-1 Infinite Soundboard vor: Kombiniert Soundeffekte, Drum Machine und Umgebungsgeräuschgenerator : ElevenLabs hat das SB-1 Infinite Soundboard veröffentlicht, ein Werkzeug, das Soundboard, Drum Machine und einen endlosen Generator für Umgebungsgeräusche in einem vereint. Benutzer können die gewünschten Soundeffekte beschreiben, und SB-1 generiert diese Klänge mithilfe seines Text-to-SFX-Modells, was neue Möglichkeiten für die Audiokreation eröffnet. (Quelle: ElevenLabs)
Anytop-Projekt: Neue Fortschritte in der KI-Animation erwecken ungesehene Kreaturen zum Leben, unterstützen das Lernen und die Übertragung von Bewegungen : Two Minute Papers stellte das Anytop-Projekt vor, eine KI-Animationstechnologie, die realistische Bewegungen für nie zuvor gesehene Kreaturen (einschließlich Dinosaurier, seltsame Insekten usw.) generieren kann. Die KI kann nicht nur eigenständig Bewegungen generieren, sondern auch verschiedenen Kreaturen ermöglichen, die Bewegungen voneinander zu lernen und anzupassen (z. B. ein Dinosaurier, der lernt, wie ein Flamingo auf einem Bein zu stehen). Dies wird erreicht, indem semantische Ähnlichkeiten von Körperteilen (wie das allgemeine Konzept von Armen und Beinen) verstanden werden, um auf unbekannte Morphologien zu generalisieren. Darüber hinaus kann das System die Semantik von Bewegungen (wie Angriff, Entspannung) verstehen und ähnliche konzeptionelle Bewegungen bei verschiedenen Tieren darstellen und sogar unvollständige Eingabebewegungen vervollständigen. (Quelle: )

Sketch2Anim: KI verwandelt Strichmännchen-Skizzen in vollständige 3D-Animationen : Eine weitere von Two Minute Papers vorgestellte Technologie, Sketch2Anim, kann einfache Linienzeichnungen von Benutzern (die Bewegungspfade anzeigen) in vollständige 3D-Charakteranimationen umwandeln. Die KI kann die 3D-Absicht hinter 2D-Skizzen verstehen (z. B. zwischen einem Vorwärtsstoß und einem Seitwärtsschlag unterscheiden), was die Einschränkungen früherer ähnlicher Technologien überwindet, die Anweisungen nur auf 2D-Ebene verstehen konnten. Dies ermöglicht es auch Laien, durch einfaches Zeichnen schnell 3D-Animationen zu erstellen. (Quelle: )
📚 Lernen
DeepSeek veröffentlicht V3-Modell-Paper, teilt Herausforderungen bei der Skalierung und Überlegungen zur KI-Hardwarearchitektur : Das DeepSeek-Team hat auf Hugging Face ein Paper zum DeepSeek-V3-Modell veröffentlicht. Das Paper untersucht eingehend die Herausforderungen, die bei der Skalierung großer Sprachmodelle auftreten, und präsentiert Überlegungen und Erkenntnisse zur zukünftigen Entwicklung der KI-Hardwarearchitektur. Dies bietet Forschern und Entwicklern wertvolle Referenzen zum Verständnis der Engpässe beim Training und der Bereitstellung großer Modelle sowie zur Optimierung durch Hardware- und Software-Koordination. (Quelle: Adina Yakup)
Kostenloser MCP (Model Context Protocol) Kurs veröffentlicht, unterstützt den Aufbau von KI-Anwendungen mit externen Daten und Werkzeugen : Ben Burtenshaw kündigte die Veröffentlichung eines kostenlosen MCP (Model Context Protocol) Kurses an. Der Kurs zielt darauf ab, Lernenden von den Grundlagen bis zur Meisterschaft zu helfen, die Funktionsweise von MCP zu verstehen, wie LLMs mit MCP-Servern verbunden werden und wie MCP zur Bereitstellung von KI-Agentenanwendungen verwendet wird, um die Fähigkeiten von KI-Anwendungen durch externe Daten und Werkzeuge zu erweitern. (Quelle: Ben Burtenshaw)

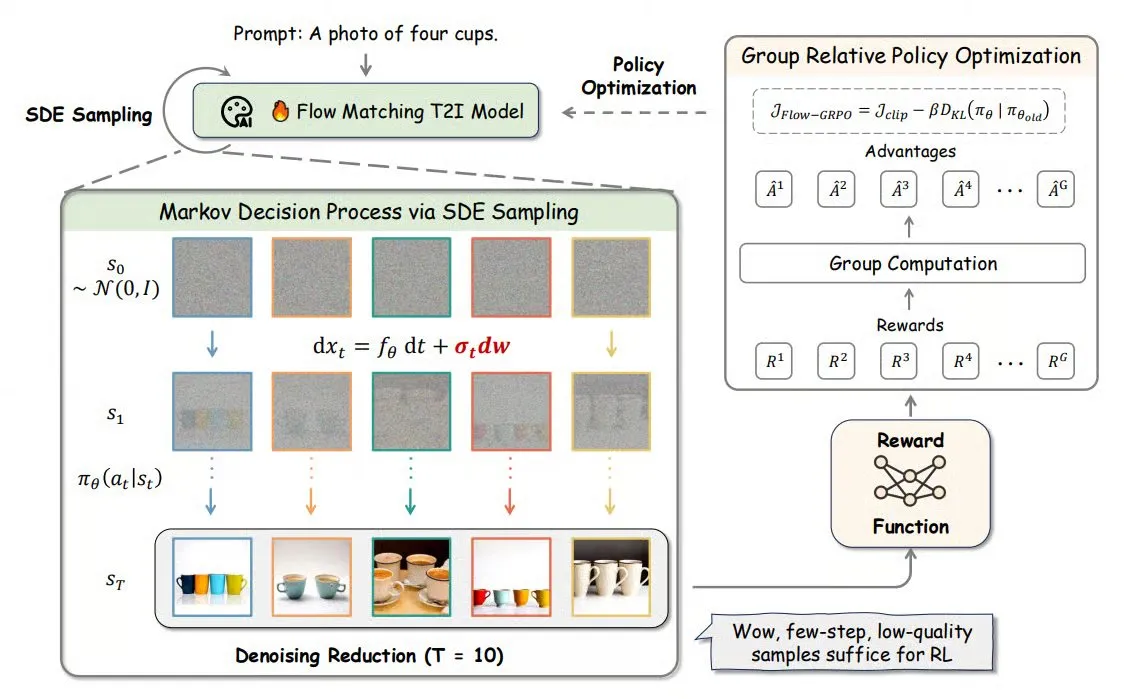
Flow-GRPO: Integriert Online Reinforcement Learning in Flow-Matching-Modelle zur Verbesserung der Bildgenerierungsgenauigkeit : Flow-GRPO ist eine neue Methode, die erstmals Online Reinforcement Learning (RL) auf Flow-Matching-Modelle anwendet. Dies wird durch zwei innovative Strategien erreicht: 1) ODE-zu-SDE-Transformation: Der auf gewöhnlichen Differentialgleichungen (ODE) basierende deterministische Prozess des Flow-Modells wird in einen stochastischen Differentialgleichungsprozess (SDE) umgewandelt, wodurch die für RL erforderliche Stochastizität eingeführt wird. 2) Beschleunigung des Trainings durch Rauschreduzierung: Während des Trainings werden die Rauschreduzierungsschritte reduziert, während bei der Inferenz die vollständigen Schritte verwendet werden. Mit Flow-GRPO steigt die Genauigkeit von Flow-Modellen bei Bildgenerierungsaufgaben auf über 92 %. (Quelle: TheTuringPost)
ICML 2025 Paper PENCIL: Abwechselndes „Schlussfolgern-Löschen“ realisiert neues Paradigma für tiefes Denken großer Modelle : Chenxiao Yang und Kollegen vom Toyota Technological Institute at Chicago schlagen PENCIL (Pondering with Erasure Net for Contextual Inference Learning) vor, ein neues Paradigma für tiefes Denken großer Modelle, das durch abwechselndes „Generieren“ und „Löschen“ von Zwischenergebnissen erreicht wird. Die Methode greift auf logische Umschreibregeln und Speichermanagement aus der funktionalen Programmierung zurück, um nicht mehr benötigte Zwischenschritte dynamisch zu löschen. Dies löst effektiv Probleme traditioneller langer CoT (Chain-of-Thought)-Ansätze wie Überschreitung des Kontextfensters, Schwierigkeiten bei der Informationsbeschaffung und sinkende Generierungseffizienz. Theoretisch wurde bewiesen, dass PENCIL jede Turingmaschinenoperation mit optimaler Raum- und Zeitkomplexität simulieren und alle berechenbaren Probleme lösen kann. Experimente zeigen, dass PENCIL bei Aufgaben wie 3-SAT, QBF und dem Einstein-Rätsel traditionelle CoT-Methoden signifikant übertrifft. (Quelle: 机器之心)

ICML 2025 Paper MemVR: Simuliert menschlichen „zweimal Hinsehen“-Mechanismus zur Reduzierung von Halluzinationen in multimodalen großen Modellen : Forscher der HKUST (Guangzhou) und anderer Institutionen schlagen die MemVR (Memory-space Visual Retracing)-Methode vor, die durch Simulation der menschlichen Strategie, unsichere Erinnerungen erneut zu überprüfen, das Problem der Halluzinationen in multimodalen großen Sprachmodellen (MLLM) mildert. MemVR verwendet visuelle Token als ergänzende Beweise. Wenn das Modell während der Inferenz auf mittlere Ebenen stößt, die von Vergessenheit betroffen sind, wird visuelles Wissen durch ein Feed-Forward-Netzwerk (FFN) erneut „abgerufen“, um die Vorhersagen zu kalibrieren. Die Methode verfügt über einen dynamischen Auslösemechanismus, der basierend auf der Unsicherheit der Ausgaben verschiedener Schichten die auslösende Schicht auswählt. Experimente zeigen, dass MemVR bei mehreren Benchmarks zur Bewertung von Halluzinationen und allgemeinen Benchmarks signifikante Ergebnisse erzielt und im Vergleich zu anderen Methoden Effizienzvorteile aufweist. (Quelle: PaperWeekly)

SIGIR 2025 Paper PaRT: Personalisiertes Echtzeit-Retrieval verbessert das Erlebnis proaktiver sozialer Chatbots : Forscher der University of Science and Technology of China und anderer Institutionen schlagen die Methode PaRT (Proactive Social Chatbots with Personalized Real-time ReTreival) vor. Ziel ist es, das Gesprächserlebnis proaktiver sozialer Chatbots durch eine Kombination aus personalisierungsgetriebenem und absichtserkennungsgeleitetem Query-Rewriting und Echtzeit-Retrieval zu verbessern. Das PaRT-System umfasst drei Module: Aufbau personalisierter Nutzerprofile, Absichtserkennung und Query-Rewriting sowie echtzeit-retrieval-gestützte Generierung. Es kann basierend auf Nutzerinteressen und Gesprächskontext aktiv Themen initiieren oder wechseln und natürlichere, informationsreichere Antworten liefern. Sowohl Offline-Experimente als auch Online-A/B-Tests zeigen, dass diese Methode die Personalisierung, den Informationsgehalt der Antworten und die durchschnittliche Gesprächsdauer effektiv verbessern kann. (Quelle: PaperWeekly)
ICML 2025 Paper PreSelect: Effiziente Datenauswahl für das Vortraining basierend auf Vorhersagestärke : Die Hong Kong University of Science and Technology und vivo AI Lab schlagen die Datenauswahlmethode PreSelect vor. Durch die Einführung des Konzepts der „Predictive Strength“ (Vorhersagestärke) wird quantifiziert, wie stark Daten zur Leistung eines Modells in einer bestimmten Fähigkeit beitragen. Die Methode bewertet den Wert von Daten, indem sie die Konsistenz zwischen der Rangfolge der Punktzahlen verschiedener Modelle in Benchmark-Tests und der Rangfolge ihrer Verluste auf den Daten nutzt. Ein leichtgewichtiger fastText-Klassifikator wird verwendet, um die Bewertung zu approximieren und eine effiziente Auswahl aus großen Datenmengen zu ermöglichen. Experimente zeigen, dass PreSelect die Dateneffizienz um das Zehnfache steigern kann. Die ausgewählten Daten erzielen beim Training von Modellen signifikant bessere Ergebnisse als verschiedene Baseline-Methoden, decken ein breiteres Spektrum hochwertiger Inhaltsquellen ab und reduzieren Verzerrungen durch die Stichprobenlänge. (Quelle: 量子位)

AI Evals Kurs lädt 12 Gäste ein, um Bewertungsframeworks und Praktiken zu teilen : Der von Hamel Husain organisierte AI Evals Kurs hat seine 12 Gastdozenten bekannt gegeben, darunter JJ Allaire, der Ersteller des inspect Frameworks, und Charles Frye, Developer Advocate bei Modal. Der Kurs wird verschiedene Aspekte der KI-Bewertung eingehend behandeln, einschließlich Bewertungsframeworks, Erstellung benutzerdefinierter Annotationsanwendungen, Praktiken der Modellbewertung usw., um den Teilnehmern zu helfen, die Schlüsselkompetenzen und Werkzeuge zur Bewertung der Leistung von KI-Systemen zu meistern. (Quelle: Hamel Husain)

FedRAG Tutorial veröffentlicht: Eine Einführung in den Aufbau und die Feinabstimmung von RAG-Systemen : Das FedRAG-Projekt hat neue Tutorial-Notebooks und begleitende Videos veröffentlicht, die Nutzern den schnellen Einstieg in die Bibliothek erleichtern sollen. Das Tutorial demonstriert, wie man mit der Hugging Face-Integration ein RAG-System aufbaut, einen In-Memory-Wissensspeicher für Knoten verwendet, einen SentenceTransformer (Dragon+) als Retriever definiert, ein vortrainiertes Modell (wie Qwen2.5-0.5B) als Generator definiert und die LSR- und RALT-Trainer verwendet, um Retriever und Generator zentralisiert feinabzustimmen. (Quelle: nerdai)

LlamaIndex veröffentlicht Tutorial: Implementierung von Referenzierung und Inferenz in LlamaExtract : Das LlamaIndex-Team hat ein neues Code-Walkthrough von @tuanacelik veröffentlicht, das zeigt, wie Referenzierungs- und Inferenzfunktionen in LlamaExtract implementiert werden. Das Tutorial behandelt: wie man ein benutzerdefiniertes Schema definiert, um dem LLM mitzuteilen, welche Inhalte aus komplexen Datenquellen extrahiert werden sollen, und wie man Referenzen hinzufügt. Diese Funktion soll Nutzern helfen, mehrstufige KI-Agenten zu erstellen, die präzise und fundiert strukturierte Informationen aus großen Mengen von Quelldokumenten extrahieren können. (Quelle: LlamaIndex 🦙)
LlamaIndex veröffentlicht Tutorial: Erstellung eines Multi-Agenten-Dokumentenassistenten mit ereignisgesteuerten Agenten-Workflows : LlamaIndex hat ein neues Walkthrough-Tutorial veröffentlicht, das zeigt, wie man mit ereignisgesteuerten Agenten-Workflows einen Multi-Agenten-Dokumentenassistenten erstellt. Dieser Assistent kann Webinhalte in LlamaIndexDocs- und WeaviateDocs-Sammlungen schreiben, einen Orchestrator verwenden, um zu entscheiden, wann der Weaviate QueryAgent für Suche und Aggregation aufgerufen wird, strukturierte Ausgaben für die Abfrageklassifizierung nutzen und optional einen FunctionAgent verwenden. (Quelle: LlamaIndex 🦙)
Modular veröffentlicht technischen Vortrag über Interna des Mojo-Compilers, diskutiert Mojo und GPU-Architektur : Das Unternehmen Modular hat begonnen, seine internen technischen Vorträge zu teilen. Der erste veröffentlichte Vortrag befasst sich eingehend mit dem Thema der Programmiersprache Mojo und der GPU-Architektur. Der Inhalt umfasst die internen Funktionsweisen des Mojo-Compilers sowie die Herausforderungen und Lösungen, mit denen das Team bei der Entwicklung für moderne GPUs konfrontiert ist, mit dem Ziel, Details seines Technologiestacks mit der Community zu teilen. (Quelle: Modular)
AI by Hand Workshop: Transformer-Modell von Grund auf in Excel erstellen : ProfTomYeh bewirbt seinen AI by Hand Workshop, der darauf abzielt, den Teilnehmern zu ermöglichen, ein Transformer-Modell von Grund auf in Excel zu erstellen. Auf diese Weise können Lernende jeden mathematischen Schritt des Transformers klar und intuitiv nachvollziehen, vermeiden, ihn als „Blackbox“ zu betrachten, und so ein tiefes Verständnis für die internen Arbeitsmechanismen des Modells entwickeln. (Quelle: ProfTomYeh)
DeepLearning.AI veröffentlicht The Batch Ausgabe 301: Diskutiert den Geschäftswert von KI-Geschwindigkeit und neueste Fortschritte : Andrew Ng diskutiert in seiner neuesten Ausgabe von The Batch, dass die Bedeutung der Geschwindigkeitssteigerung von KI bei der Ausführung von Aufgaben für die Schaffung von Geschäftswert unterschätzt wird. Er argumentiert, dass KI nicht nur Kosten senkt, sondern vor allem durch die Verkürzung der Zeit von der Idee zum Prototyp Innovation und Exploration beschleunigt. Diese Ausgabe berichtet auch über die Veröffentlichung der Microsoft Phi-4 Inferenzreihe, die Leistung von DeepCoder-14B, die mit o1 gleichzieht, und die Lockerung der EU-KI-Regeln. (Quelle: DeepLearningAI)
💼 Business
KI-Charakteranimations-Startup Cartwheel erhält 10 Millionen US-Dollar Finanzierung zur Vereinfachung von 3D-Animationsprozessen : Das auf KI-Charakteranimation spezialisierte Startup Cartwheel gab den Abschluss einer Finanzierungsrunde in Höhe von 10 Millionen US-Dollar bekannt. Das Unternehmen widmet sich der Entwicklung von Technologien zur Vereinfachung von 3D-Animationsproduktionsprozessen, mit dem Ziel, Kreativen zu ermöglichen, schneller und kostengünstiger hochwertige 3D-Charakteranimationen zu erstellen, während gleichzeitig die Kontrolle über das Endprodukt verbessert und mühsame Aufgaben eliminiert werden. (Quelle: andrew_n_carr)
Hedra erhält 32 Millionen US-Dollar in Serie-A-Finanzierung unter Führung von a16z zur Beschleunigung der charakterbasierten Videoerstellung : Das KI-Videogenerierungs-Startup Hedra gab den Abschluss einer Serie-A-Finanzierungsrunde in Höhe von 32 Millionen US-Dollar bekannt, angeführt von Andreessen Horowitz (a16z), wobei Matt Bornstein dem Vorstand beitritt. Bestehende Investoren a16z speedrun, Abstract und Index Ventures beteiligten sich ebenfalls an dieser Runde. Hedra widmet sich der Vereinfachung der charakterbasierten Videoerstellung. Seit dem Start im Stealth-Modus im letzten Jahr haben fast 3 Millionen Menschen seine Tools genutzt, um über 10 Millionen Videos zu erstellen. Die neuen Mittel werden zur Beschleunigung der Produktentwicklung und Teamerweiterung verwendet, um eine schnelle, ausdrucksstarke und intuitive Inhaltserstellung zu ermöglichen. (Quelle: Hedra)
Tripadvisor nutzt Qdrant für KI-Reiseplanung, Nutzerengagement um das 2-3-fache gesteigert : Tripadvisor definiert das Reiseentdeckungserlebnis mithilfe der Qdrant Vektordatenbank neu. Durch die Analyse von über 1 Milliarde Bewertungen und Fotos, 11 Millionen Unternehmen und Daten aus 21 Ländern erstellt Tripadvisor dynamische, KI-generierte Reiserouten anstelle traditioneller Filter. Die Ergebnisse zeigen, dass Nutzer, die diese KI-Tools verwenden, 2-3 Mal mehr Zeit auf der Plattform verbringen, was das enorme Potenzial von KI in der personalisierten Reiseplanung unterstreicht. (Quelle: qdrant_engine)

🌟 Community
Groks Äußerungen zum „Völkermord an Weißen“ lösen Kontroverse aus, Sam Altman reagiert sarkastisch : Das Grok-Modell von xAI löste eine breite Diskussion und Kritik aus, nachdem es zufällig Ansichten zum Völkermord an Weißen in Südafrika geäußert hatte. Paul Graham wies darauf hin, dass dieses Verhalten nach einem kürzlich eingeführten Patch-Fehler rieche und äußerte Bedenken, dass weit verbreitete KI von ihren Betreibern in Echtzeit in ihren Ansichten bearbeitet werden könnte. Sam Altman reagierte sarkastisch und erklärte, xAI werde eine transparente Erklärung abgeben und dieses Problem im Kontext des „Völkermords an Weißen in Südafrika“ verstehen, was andeutet, dass dies das Ergebnis des Strebens der KI nach Wahrheit und der Befolgung von Anweisungen sei. Die Diskussion in der Community über diesen Vorfall spiegelt die allgemeinen Bedenken hinsichtlich Voreingenommenheit, Kontrollierbarkeit und den zugrunde liegenden Absichten von KI-Modellen wider. (Quelle: Paul Graham)
Überlegungen zur Produktisierung von KI: Chancen im gesamten Nutzeraufgabenprozess erkennen, statt KI-Funktionen einfach hinzuzufügen : Ren Xin, Partner bei Sky9 Capital, teilte tiefgreifende Überlegungen zur Produktisierung von KI. Er betonte, dass Unternehmen vom gesamten Prozess der Nutzeraufgabenerledigung ausgehen sollten, um Ansatzpunkte für KI-Anwendungen zu finden, anstatt KI-Funktionen einfach zu bestehenden Produkten hinzuzufügen. Er verwendete die Analogie „Der Nutzer will keinen Bohrer, sondern ein Loch in der Wand“ und schlug vor, Nutzeraufgaben zu zerlegen, Schwachstellen zu identifizieren und diese mit KI zu optimieren. Die vier Ebenen der KI-Produktisierung umfassen: effiziente Erledigung alter Prozesse, Schaffung neuer Prozesse, Erschließung völlig neuer Märkte (Senkung der Nutzungsschwellen, Bedienung neuer Nutzergruppen, sogar KI selbst) und Aufbau von Infrastruktur für eine KI-dominierte Zukunft. Er ist der Ansicht, dass KI-Technologie demokratisiert wird und auch Unternehmen ohne technisches Know-how Chancen ergreifen können; im Wesentlichen geht es darum, „der KI Arbeit zu verschaffen“. (Quelle: 混沌大学)
Diskussion: Die Rolle von KI in der beruflichen Entwicklung und Anpassungsstrategien : Ein Beitrag auf LinkedIn löste eine Diskussion darüber aus, wie KI die berufliche Entwicklung beeinflusst. Die gängige Aussage lautet: „KI wird deinen Job nicht ersetzen, aber Menschen, die KI nutzen, werden es tun.“ Diese Aussage wurde jedoch als zu vage kritisiert. Es wurden Fragen aufgeworfen, wie sich beispielsweise Frontend-Ingenieure mit jahrzehntelanger Erfahrung plötzlich zu KI-Ingenieuren wandeln sollen und dass nicht jeder ein KI-Ingenieur werden kann. In der Community-Diskussion wurde argumentiert, dass Frontend-Entwickler lernen können, KI-Tools zur Steigerung ihrer Arbeitseffizienz einzusetzen. Es gab auch die Ansicht, dass KI viele Arbeitsplätze ersetzen wird und viele Menschen keine Alternativen haben werden. Eine verbreitetere Ansicht ist, dass die Zukunft ungewiss ist, aber Kreativität, die Fähigkeit, Probleme zu erkennen, sowie die Fähigkeit, Menschlichkeit zu verstehen und zu erreichen, möglicherweise widerstandsfähiger sind. (Quelle: Reddit r/ArtificialInteligence)
Diskussion: LLMs „verirren“ sich leicht in mehrstufigen Dialogen, Neustart des Dialogs könnte hilfreich sein : Eine Forschungsarbeit weist darauf hin, dass die Leistung von LLMs, sowohl Open-Source- als auch Closed-Source-Modelle, in mehrstufigen Dialogen signifikant abnimmt. Die meisten Benchmark-Tests konzentrieren sich auf einstufige Szenarien mit klaren Anweisungen. Die Studie ergab, dass LLMs oft in frühen Dialogrunden (falsche) Annahmen treffen und sich in späteren Dialogen auf diese Annahmen stützen, was schwer zu korrigieren ist. Die Schlussfolgerung ist, dass es hilfreich sein könnte, einen neuen Dialog zu beginnen und alle relevanten Informationen in die erste Eingaberunde zu integrieren, wenn ein mehrstufiger Dialog nicht die erwarteten Ergebnisse liefert. (Quelle: Reddit r/LocalLLaMA)
Diskussion über die Gründe für das relativ langsame Tempo von Apple und WeChat bei der KI-Entwicklung: Datenschutz und anwendungsorientierte Strategie : Wei Xi analysiert in einem Artikel, dass Apple mit „Apple Intelligence“ und WeChat mit der Anbindung an DeepSeek und Yuanbao zwar Fortschritte machen, das Tempo bei der Entwicklung von KI-Kernfunktionen jedoch relativ langsam ist. Dafür gibt es zwei Hauptgründe: Erstens die hohe Sensibilität von Datenschutz und Datensicherheit. Die Intelligenz von KI hängt von Daten ab, und die Kerngeschäftsmodelle von Apple und WeChat bedingen eine extreme Vorsicht bei der Datenweitergabe, was das Modelltraining und den Zugriff auf Anwendungskontexte einschränkt. Zweitens verfolgen beide eine „anwendungsorientierte“ Strategie und streben nicht danach, bei der maximalen Modellintelligenz mit führenden KI-Unternehmen zu konkurrieren, sondern konzentrieren sich eher darauf, KI-Fähigkeiten in bestehende Funktionen und Ökosysteme zu integrieren. Dies führt möglicherweise zu Einschränkungen bei der technologischen Führung und der Geschwindigkeit der Produktiteration. (Quelle: 卫夕指北)

OpenAI startet „From A to Z Challenge“: KI zur Entdeckung unbekannter archäologischer Stätten im Amazonasgebiet : OpenAI kündigte in Zusammenarbeit mit Kaggle den speziellen Hackathon „OpenAI to Z Challenge“ an. Der Wettbewerb ermutigt die Teilnehmer, die Modelle OpenAI o3, o4-mini oder GPT-4.1 zu verwenden, um bisher unbekannte archäologische Stätten im Amazonasgebiet zu finden. Teilnehmer können ihren Fortschritt unter dem Hashtag #OpenAItoZ teilen. Die Veranstaltung zielt darauf ab, das Anwendungspotenzial von KI in der Archäologie und der Geodatenanalyse zu untersuchen. (Quelle: OpenAI Developers)
Kritik an „KI-Anwalt“-Startups: Automatisierte „Erpresserbriefe“ könnten zur gesellschaftlichen Belastung werden : Der Entwickler @swyx äußerte Kritik an dem Phänomen, dass einige VCs in „KI-Anwalt“-Startups investieren. Er argumentiert, dass diese Unternehmen hauptsächlich durch KI automatisierte „Mahnschreiben“ (demand letters) generieren, was im Wesentlichen automatisierte Erpressung sei. Obwohl einige Mahnungen berechtigt sein mögen, weist er darauf hin, dass die meisten dieser Aktivitäten letztendlich nur Anwälten zugutekommen und zu einer reinen Steuerlast für die Gesellschaft werden. Er ruft dazu auf, solche Unternehmen und ihre Investoren zu boykottieren, ihnen Kapital zu entziehen und sie öffentlich zu kritisieren. (Quelle: swyx)

💡 Sonstiges
Kohle-Forschungsbericht enthält haarsträubenden Fehler „durch Töten von Wither-Skeletten gewonnen“, löst Diskussion über Inhaltsqualität und KI-Halluzinationen aus : Ein mit 8200 Yuan bepreister Forschungsbericht über die Kohleindustrie enthielt die Beschreibung „Kohle ist eine erneuerbare Ressource, die durch das Töten von Wither-Skeletten gewonnen wird“, eine Formulierung aus dem Spiel „Minecraft“, was im Internet für Aufsehen sorgte. Viele führten dies auf KI-generierte Inhalte und Halluzinationen zurück. Der Bericht wurde jedoch 2022 veröffentlicht, also vor der Einführung gängiger großer Modelle wie ChatGPT, was darauf hindeutet, dass es sich um einen typischen Fall von manuellem Kopieren und Einfügen sowie mangelnder Überprüfung handelt. Der Vorfall löste auch tiefgreifende Überlegungen zur Qualität professioneller Berichte, zur Bedeutung der Informationsüberprüfung und dazu aus, wie im KI-Zeitalter die Echtheit von Informationen unterschieden werden kann. (Quelle: caoz的梦呓)

Forscher setzen maßgeschneiderte Gen-Editierungs-Therapie zur Behandlung eines Säuglings mit seltener Stoffwechselkrankheit ein : Ärzte haben in weniger als sieben Monaten eine maßgeschneiderte Gen-Editierungs-Therapie entwickelt und erfolgreich bei einem Säugling mit einer tödlichen Stoffwechselkrankheit eingesetzt. Dies ist das erste Mal, dass Gen-Editierung für eine individualisierte Behandlung eines einzelnen Patienten eingesetzt wurde. Die Therapie zielt darauf ab, einen spezifischen Ein-Buchstaben-Fehler im Gen des Säuglings zu korrigieren und demonstriert die Präzision neuer Gen-Editierungs-Technologien (wie Base Editing). Obwohl die Behandlung frühe positive Anzeichen zeigt, verdeutlicht sie auch die Kosten- und Skalierbarkeitsherausforderungen bei der Entwicklung personalisierter Gentherapien für extrem seltene Krankheiten. (Quelle: MIT Technology Review)

Universelle Jailbreak-Prompt-Strategie aufgedeckt, kann Sicherheitsschranken gängiger großer Modelle umgehen : Forscher von HiddenLayer haben eine universelle Prompt-Strategie entdeckt, die es gängigen großen Sprachmodellen wie ChatGPT, Claude und Gemini ermöglicht, Sicherheitsschranken zu umgehen und schädliche Inhalte zu generieren. Die Strategie tarnt schädliche Anweisungen als Dateien im Format von XML, INI oder JSON und kombiniert dies mit fiktiven Rollenspielszenarien, um das Modell dazu zu bringen, schädliche Befehle als legitime Systemanweisungen zu interpretieren. Diese Methode nutzt möglicherweise systemische Schwachstellen in den Trainingsdaten der Modelle aus, nämlich die Tendenz, Sicherheitsanweisungen bei der Verarbeitung von Lehr- oder richtlinienbezogenen Daten zu ignorieren. Die Technik kann auch die System-Prompts der Modelle extrahieren und deren interne Anweisungen und Sicherheitsbeschränkungen offenlegen. (Quelle: 新智元)
