
Schlüsselwörter:AlphaEvolve, Claude Sonnet, GPT-4.1, Meta FAIR, Qwen3, Phi-4-reasoning, KI-Regulierung, Gemini-gesteuerter Codierungsagent, Optimierung von Matrixmultiplikationsalgorithmen, Optimierung der Rechenzentrumseffizienz, Mehrsprachige multimodale Modelle, Dezentrales KI-Trainingsnetzwerk, Seed1.5-VL
🔥 Fokus
Google DeepMind veröffentlicht AlphaEvolve: Gemini-gestützter Coding-Agent, revolutioniert Algorithmus-Entdeckung: Google DeepMind stellt AlphaEvolve vor, einen von Gemini angetriebenen KI-Coding-Agent, der darauf abzielt, durch die Kombination der Kreativität von Large Language Models mit automatisierten Evaluatoren komplexe Algorithmen zu entdecken und zu optimieren. AlphaEvolve hat erfolgreich schnellere Algorithmen für die Matrixmultiplikation entworfen, offene mathematische Probleme wie das Erdős Minimal Overlap Problem und das Kissing Number Problem gelöst und wird intern bei Google zur Optimierung der Effizienz von Rechenzentren (durchschnittliche Rückgewinnung von 0,7 % der Rechenressourcen), im Chipdesign und zur Beschleunigung des Trainings von Gemini selbst eingesetzt, was das enorme Potenzial von KI in der wissenschaftlichen Entdeckung und technischen Optimierung demonstriert. (Quelle: GoogleDeepMind, DeepLearning.AI Blog)
Anthropic wird bald neue Modelle Claude Sonnet und Opus veröffentlichen, um Inferenz- und Tool-Aufruffähigkeiten zu stärken: Laut The Information plant Anthropic, in den kommenden Wochen neue Versionen von Claude Sonnet und Claude Opus auf den Markt zu bringen. Die Kernmerkmale der neuen Modelle sind die Fähigkeit, flexibel zwischen einem „Denkmodus“ und einem „Tool-Nutzungsmodus“ zu wechseln. Wenn das Modell bei der Lösung von Problemen mit externen Tools (wie Anwendungen, Datenbanken) auf Hindernisse stößt, kann es aktiv in den „Inferenzmodus“ zurückkehren, um zu reflektieren und sich selbst zu korrigieren. Im Bereich der Code-Generierung können die neuen Modelle den generierten Code automatisch testen und bei Fehlern anhalten, nachdenken und korrigieren. Dieser geschlossene Kreislauf aus „Denken-Handeln-Reflektieren“ verspricht, die Fähigkeit und Zuverlässigkeit der Modelle zur Lösung komplexer Probleme erheblich zu verbessern. (Quelle: steph_palazzolo, dotey)

Republikanische Abgeordnete in den USA schlagen 10-jähriges Verbot von KI-Regulierung auf Bundes- und Landesebene vor, was heftige Diskussionen auslöst: Republikanische Abgeordnete in den USA haben in einen Haushaltsentwurf Klauseln eingefügt, die vorschlagen, Bundes- und Landesregierungen für die nächsten zehn Jahre die Regulierung von KI-Modellen, -Systemen oder automatisierten Entscheidungssystemen zu verbieten. Zudem planen sie, 500 Millionen US-Dollar zur Unterstützung der Kommerzialisierung von KI und deren Anwendung in IT-Systemen der Bundesregierung bereitzustellen. Dieser Schritt wird von einigen Persönlichkeiten der Technologiebranche als positives Signal zum Schutz von KI-Innovationen und zur Verhinderung einer erstickenden Regulierung angesehen, löst aber auch Bedenken hinsichtlich potenzieller Risiken wie der Verbreitung von DeepFakes, dem Verlust der Datenkontrolle, KI-Ethik und Umweltauswirkungen aus. Sollte der Vorschlag angenommen werden, hätte dies erhebliche Auswirkungen auf bestehende und zukünftige KI-Gesetzgebungen. (Quelle: Reddit r/ArtificialInteligence, Yoshua_Bengio)

OpenAI veröffentlicht GPT-4.1-Modell und startet Sicherheitsbewertungszentrum, betont Coding- und Anweisungsbefolgungsfähigkeiten: OpenAI kündigte an, dass das GPT-4.1-Modell auf Wunsch der Nutzer ab sofort in ChatGPT verfügbar ist (für Plus-, Pro-, Team-Nutzer; Enterprise- und Bildungsversionen folgen später). GPT-4.1 ist speziell für Coding-Aufgaben und die Befolgung von Anweisungen optimiert, schneller und kann als alltäglicher Coding-Ersatz für o3 und o4-mini dienen. Gleichzeitig wird GPT-4.1 mini das derzeit von allen Nutzern verwendete GPT-4o mini ersetzen. Darüber hinaus hat OpenAI das Safety Evaluations Hub eingeführt, um die Sicherheitstestergebnisse und -metriken seiner Modelle öffentlich zu machen und regelmäßig zu aktualisieren, um die Transparenz der Sicherheitskommunikation zu erhöhen. (Quelle: openai, michpokrass)
Meta FAIR veröffentlicht mehrere KI-Forschungsergebnisse mit Fokus auf Molekülentdeckung und atomare Modellierung: Meta AI (FAIR) kündigte die neuesten Open-Source-Versionen in den Bereichen Moleküleigenschaftsprognose, Sprachverarbeitung und Neurowissenschaften an. Dazu gehören Open Molecules 2025 (OMol25), ein Datensatz zur Molekülentdeckung für die Simulation großer atomarer Systeme; Universal Model for Atoms (UMA), ein maschinell lernendes interatomares Potentialmodell, das breit für die Modellierung atomarer Wechselwirkungen in Materialien und Molekülen eingesetzt werden kann; und Adjoint Sampling, ein skalierbarer Algorithmus zum Trainieren generativer Modelle basierend auf skalaren Belohnungen. Darüber hinaus hat FAIR in Zusammenarbeit mit dem Rothschild Foundation Hospital Forschungsergebnisse veröffentlicht, die signifikante Ähnlichkeiten in der Sprachentwicklung zwischen Menschen und LLMs aufzeigen. (Quelle: AIatMeta)
🎯 Trends
ByteDance veröffentlicht Seed1.5-VL Vision-Language Large Model mit 20B aktivierten Parametern und herausragender Leistung: ByteDance hat sein multimodales Vision-Language Large Model Seed1.5-VL vorgestellt. Dieses Modell zeigt mit nur 20B aktivierten Parametern eine Leistung, die mit Gemini 2.5 Pro vergleichbar ist, und erreicht in 38 von 60 öffentlichen Bewertungsbenchmarks den SOTA-Status. Seed1.5-VL verbessert das allgemeine multimodale Verständnis und die Inferenzfähigkeiten, insbesondere in den Bereichen visuelle Lokalisierung, Inferenz, Videoverständnis und multimodale Agenten. Das Modell ist über die Volcano Engine API verfügbar, wobei die Inferenz-Eingabe 0,003 Yuan/Tausend Tokens und die Ausgabe 0,009 Yuan/Tausend Tokens kostet. (Quelle: 机器之心)

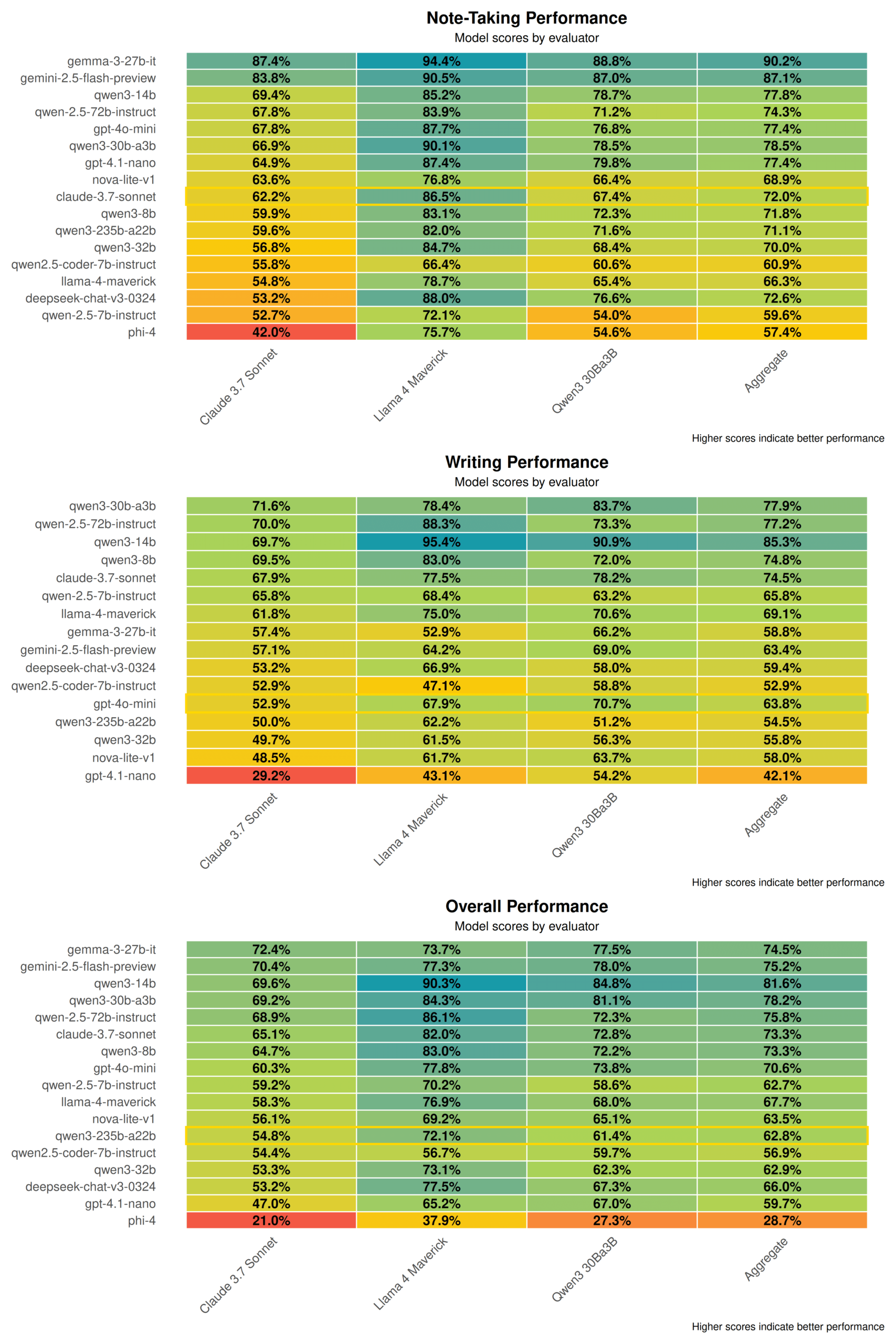
Qwen3 Technischer Bericht enthüllt: Fusion von Denk- und Nicht-Denk-Modi, Destillation von großen Modellen in kleine Modelle: Alibaba hat den technischen Bericht zur Qwen3-Modellreihe veröffentlicht, der 8 Modelle mit Parametern von 0,6B bis 235B umfasst. Die Kerninnovation liegt in einem dualen Arbeitsmodus: Das Modell kann je nach Aufgabenkomplexität automatisch zwischen einem „Denkmodus“ (komplexe Inferenz) und einem „Nicht-Denkmodus“ (schnelle Antwort) wechseln und über einen „Denkbudget“-Parameter dynamisch Rechenressourcen zuweisen. Das Training erfolgt in drei Phasen des Pre-Trainings (allgemeines Wissen, Inferenzverbesserung, langer Text) und vier Phasen des Post-Trainings (Kaltstart mit langer Chain-of-Thought, Reinforcement Learning für Inferenz, Fusion von Denkmodi, allgemeines Reinforcement Learning). Gleichzeitig wird eine „Groß-führt-Klein“-Daten-Destillationsstrategie angewendet, bei der ein Lehrermodell (z. B. 235B) zur Ausgabe von Trainingsdaten für ein Schülermodell (z. B. 30B) verwendet wird, um Wissenstransfer zu realisieren. (Quelle: 36氪)

Microsoft veröffentlicht Phi-4-reasoning-Modellreihe und teilt Erfahrungen beim Training von Inferenzmodellen: Microsoft hat drei Modelle vorgestellt: Phi-4-reasoning, Phi-4-reasoning-plus (beide mit 14B Parametern) und Phi-4-mini-reasoning (3,8B Parameter) und deren Trainingsmethoden und Erfahrungen veröffentlicht. Diese Modelle verbessern durch Feinabstimmung von vortrainierten Modellen insbesondere mathematische Inferenzfähigkeiten. Beispielsweise zeigt Phi-4-reasoning-plus durch Reinforcement Learning eine hervorragende Leistung bei mathematischen Problemen, während Phi-4-mini-reasoning phasenweise SFT- und RL-Feinabstimmung durchläuft. Der Bericht teilt mögliche Instabilitäten beim Training kleiner Modelle und Gegenstrategien sowie Überlegungen zur Datenauswahl und zum Design von Belohnungsfunktionen beim RL-Training großer Modelle. Die Modellgewichte sind auf Hugging Face unter der MIT-Lizenz verfügbar. (Quelle: DeepLearning.AI Blog)
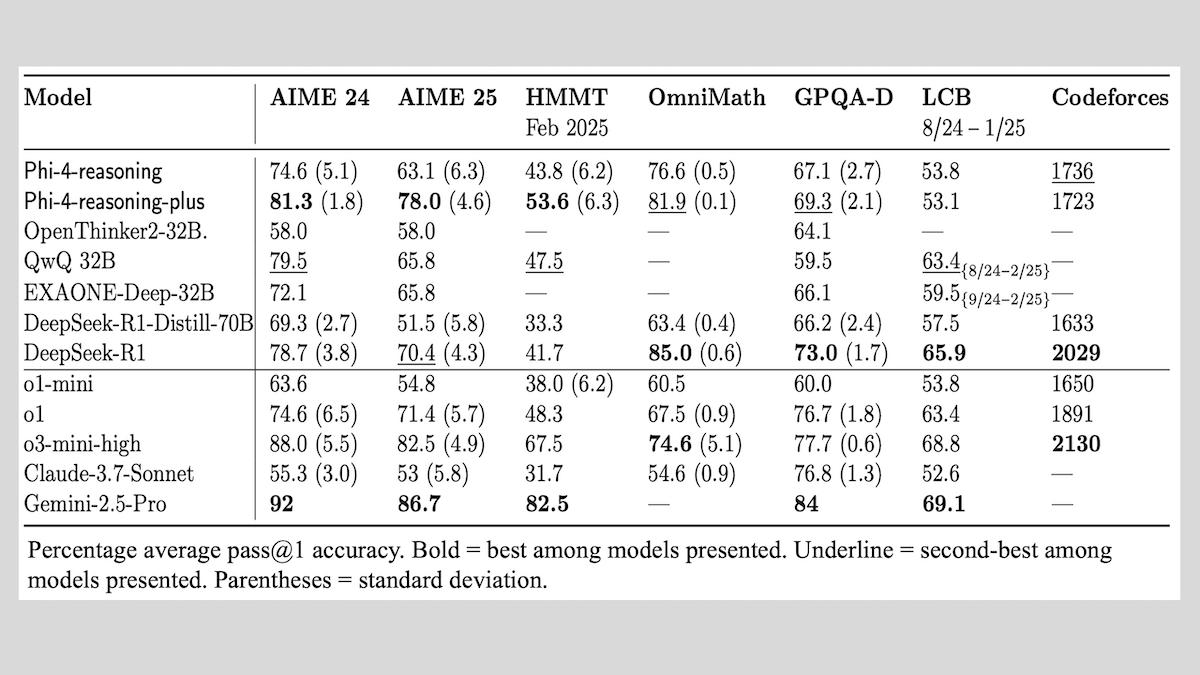
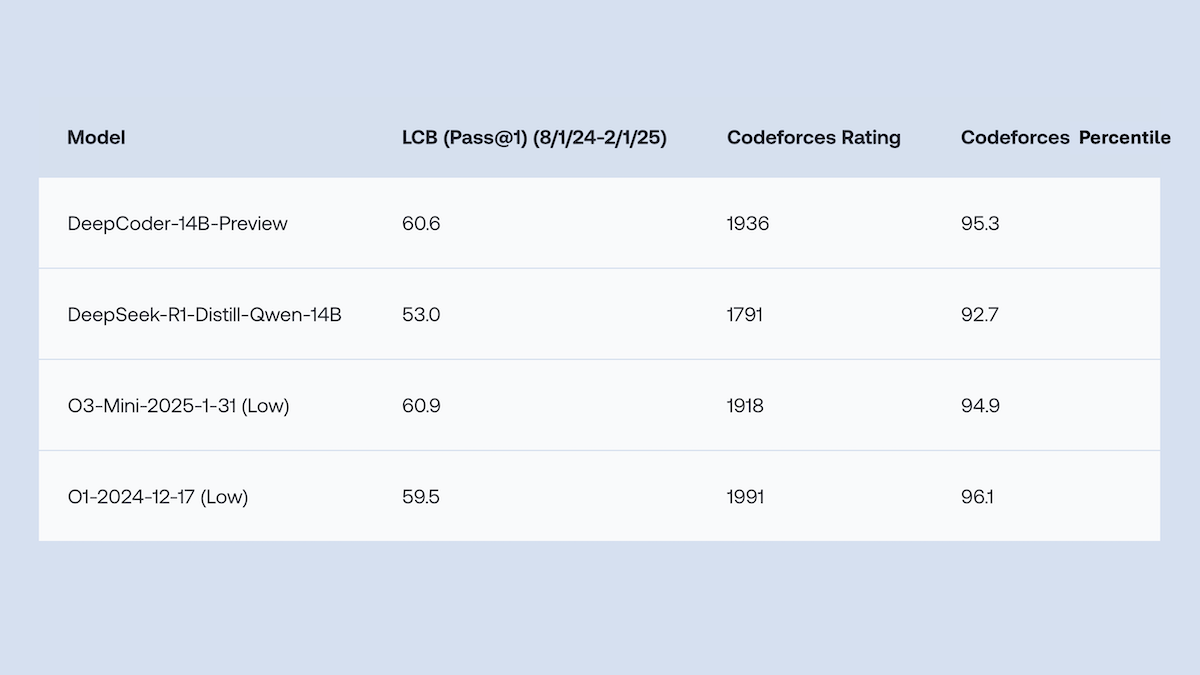
Together.AI und Agentica veröffentlichen Open-Source DeepCoder-14B-Preview, Code-Generierungsleistung vergleichbar mit o1: Together.AI und das Agentica-Team haben DeepCoder-14B-Preview veröffentlicht, ein Code-Generierungsmodell mit 14B Parametern, dessen Leistung in mehreren Coding-Benchmarks mit größeren Modellen wie DeepSeek-R1 und OpenAI o1 vergleichbar ist. Das Modell wurde durch Feinabstimmung von DeepSeek-R1-Distilled-Qwen-14B entwickelt, wobei eine vereinfachte Reinforcement-Learning-Methode (eine Kombination aus GRPO- und DAPO-Optimierung) verwendet und die Parallelverarbeitungsfähigkeit der RL-Bibliothek Verl verbessert wurde, was die Trainingszeit erheblich verkürzte. Modellgewichte, Code, Datensätze und Trainingsprotokolle sind unter der MIT-Lizenz als Open Source verfügbar. (Quelle: DeepLearning.AI Blog)
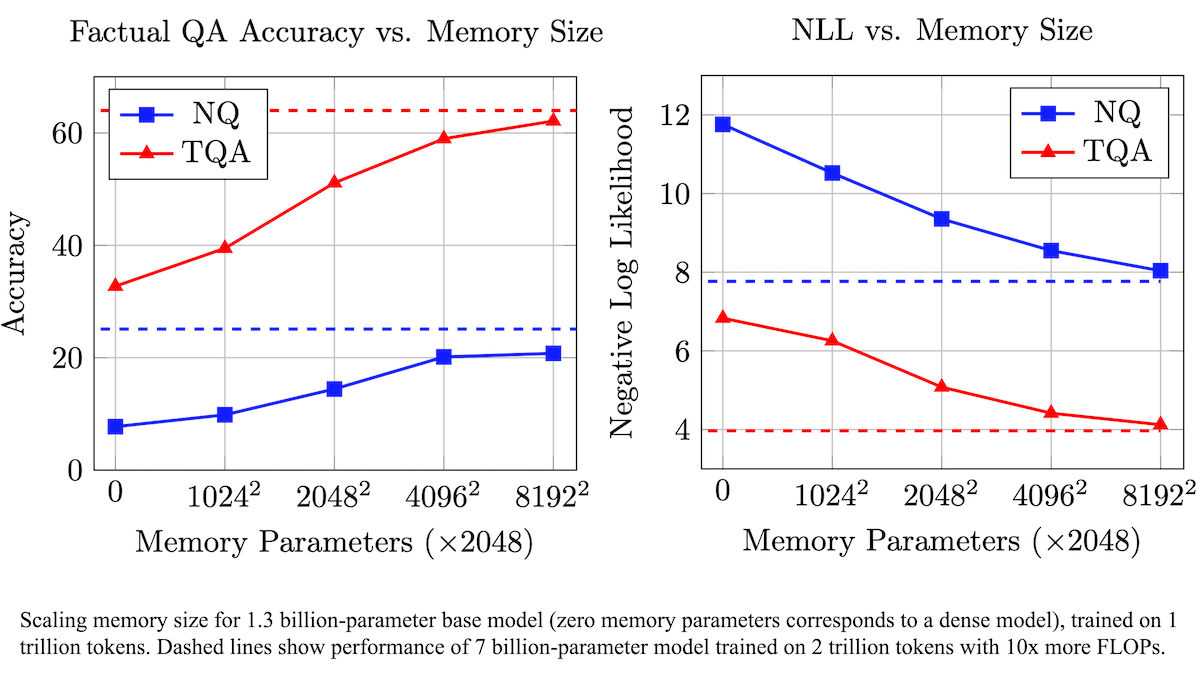
Meta schlägt trainierbare Speicherebene zur Verbesserung der faktischen Genauigkeit von LLMs und zur Reduzierung des Rechenbedarfs vor: Forscher von Meta haben durch Hinzufügen einer trainierbaren Speicherebene zur Transformer-Architektur die Genauigkeit von Large Language Models beim Abrufen von Fakten verbessert, ohne den Rechenaufwand signifikant zu erhöhen. Diese Methode speichert Informationen durch das Erlernen von Schlüsseln und entsprechenden Werten und verwendet eine Strategie, bei der Schlüssel in zwei Halbschlüssel zerlegt werden, um den Rechenengpass bei der Abfrage großer Schlüsselmengen effektiv zu lösen. Experimente zeigen, dass ein 8B-Parametermodell mit Speicherebene auf mehreren Frage-Antwort-Datensätzen besser abschneidet als vergleichbare Modelle ohne Speicherebene, was Vorteile beim Bedarf an vortrainierten Daten und Rechenaufwand zeigt. (Quelle: DeepLearning.AI Blog)
Alibaba veröffentlicht Open-Source Wan2.1-Serie von Video-Basismodellen, unterstützt Text/Bild-zu-Video-Generierung und -Bearbeitung: Alibaba hat Wan2.1 veröffentlicht, eine umfassende Open-Source-Suite von Video-Basismodellen, die Versionen mit 1,3B und 14B Parametern umfasst und unter der Apache 2.0-Lizenz steht. Wan2.1 zeigt eine hervorragende Leistung bei verschiedenen Aufgaben wie Text-zu-Video, Bild-zu-Video, Videobearbeitung, Text-zu-Bild und Video-zu-Audio und unterstützt insbesondere die visuelle Generierung von chinesischem und englischem Text. Sein T2V-1.3B-Modell benötigt nur 8,19 GB VRAM, kann auf Consumer-GPUs ausgeführt werden und generiert innerhalb von 4 Minuten ein 5 Sekunden langes 480P-Video. Das zugehörige Wan-VAE kann 1080P-Videos effizient kodieren und dekodieren, wobei zeitliche Informationen erhalten bleiben. (Quelle: _akhaliq, Reddit r/LocalLLaMA)

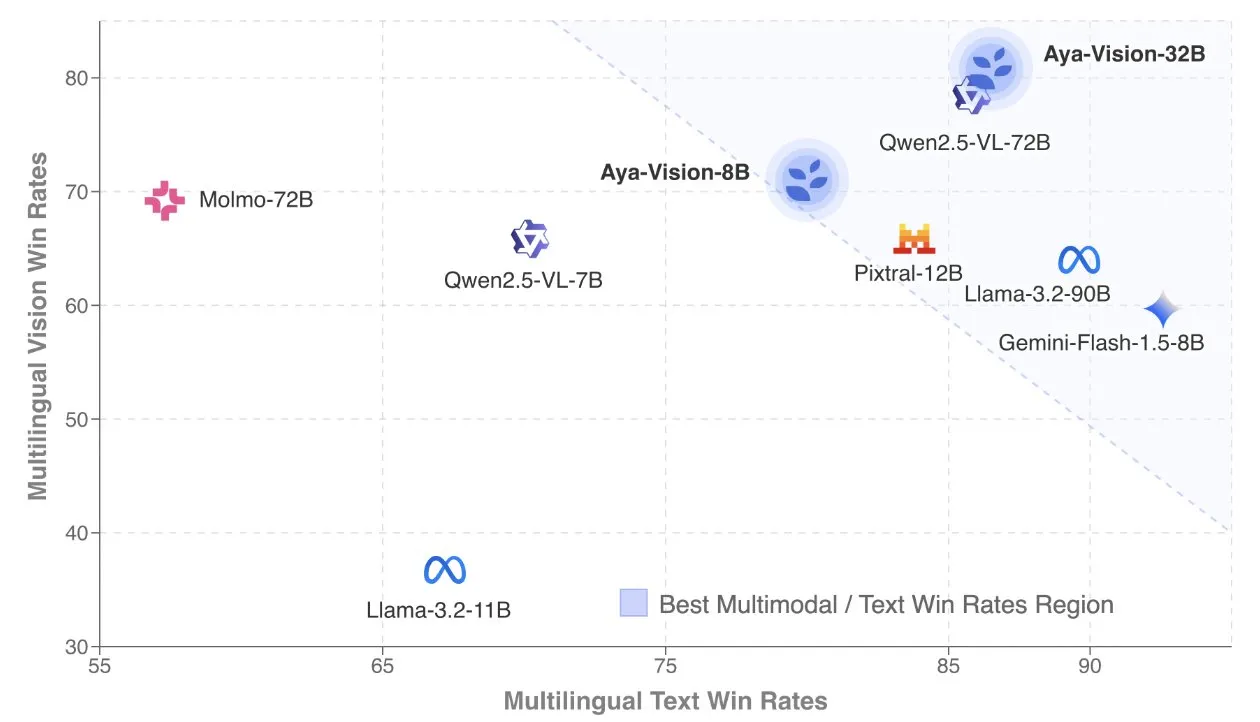
Cohere veröffentlicht technischen Bericht zu Aya Vision, Fokus auf mehrsprachige multimodale Modelle: Cohere Labs hat den technischen Bericht zu Aya Vision veröffentlicht, der detailliert die Formel für den Aufbau von SOTA mehrsprachigen multimodalen Modellen beschreibt. Aya Vision Modelle zielen darauf ab, die Fähigkeiten in multimodalen und Textaufgaben für 23 Sprachen zu vereinheitlichen. Der Bericht untersucht synthetische mehrsprachige Datenframeworks, Architekturentwürfe, Trainingsmethoden, Cross-Modal Model Merging sowie eine umfassende Bewertung bei offenen, mehrsprachigen Generierungsaufgaben. Ihr 8B-Modell übertrifft in der Leistung größere Modelle wie Pixtral-12B, während das 32B-Modell effizienter ist und Modelle wie Llama3.2-90B, die mehr als doppelt so groß sind, übertrifft. (Quelle: sarahookr, Cohere Labs)
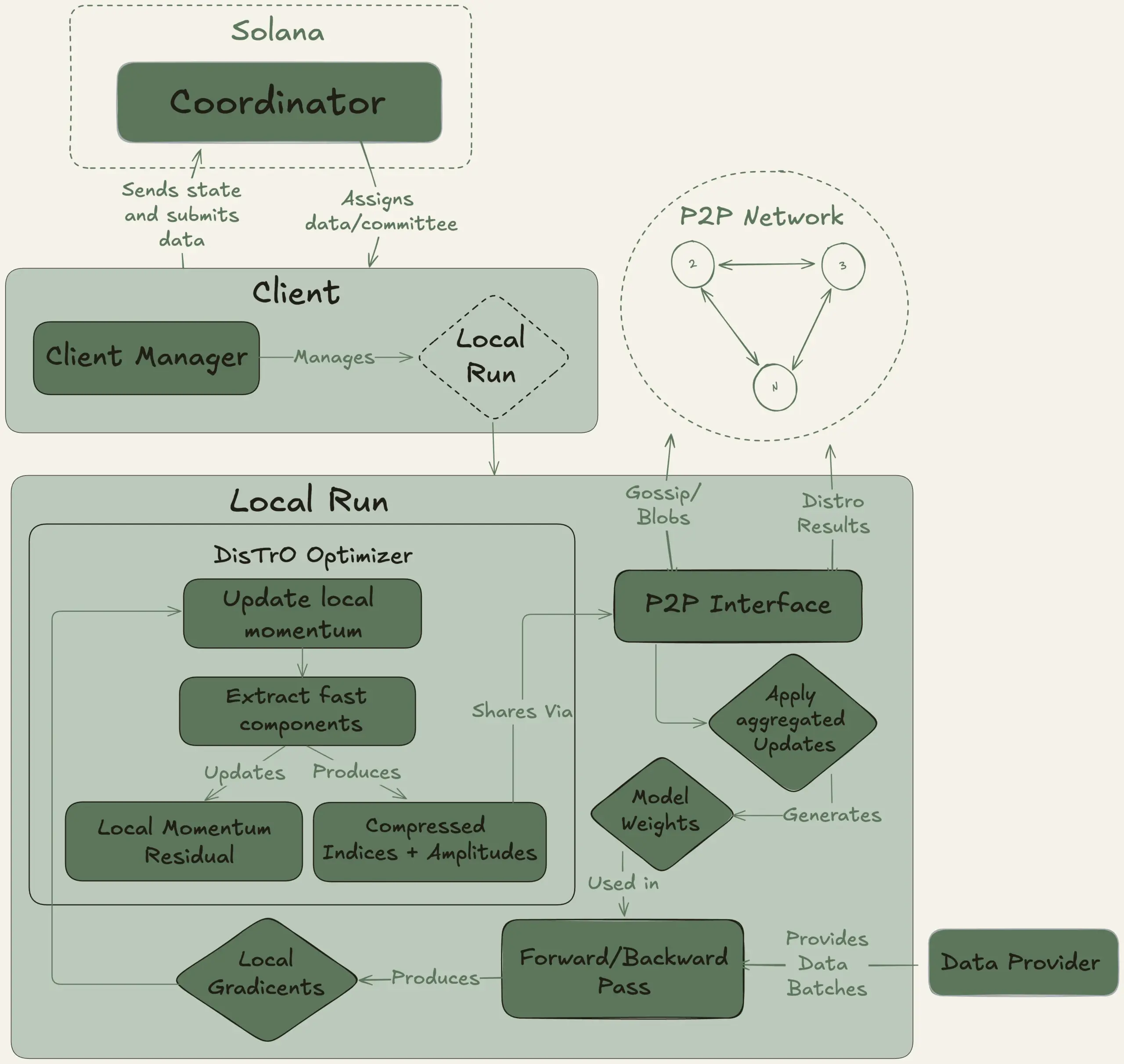
Nous Research startet Psyche-Projekt zur dezentralen Schulung eines 40B-Parameter-Large-Models: Nous Research kündigte den Start des Psyche-Netzwerks an, ein dezentrales KI-Trainingsnetzwerk, das darauf abzielt, globale Rechenleistung zu bündeln, um gemeinsam leistungsstarke KI-Modelle zu trainieren und so Einzelpersonen und kleinen Gemeinschaften die Teilnahme an der Entwicklung großer Modelle zu ermöglichen. Sein Testnetz hat mit dem Vortraining eines 40B-Parameter-LLM begonnen, das eine MLA-Architektur verwendet. Der Datensatz umfasst FineWeb (14T), Teile von FineWeb-2 (4T) und The Stack v2 (1T), insgesamt etwa 20T Tokens. Nach Abschluss des Modelltrainings werden alle Checkpoints (einschließlich ungeglühter und geglühter Versionen) und der Datensatz als Open Source veröffentlicht. (Quelle: eliebakouch, Teknium1)
Stability AI veröffentlicht Open-Source Stable Audio Open Small Modell, spezialisiert auf schnelle Text-zu-Audio-Generierung: Stability AI hat auf Hugging Face das Stable Audio Open Small Modell veröffentlicht. Dies ist ein Modell, das speziell für die schnelle Text-zu-Audio-Generierung entwickelt wurde und adversariales Post-Training-Techniken verwendet. Das Modell zielt darauf ab, eine effiziente Open-Source-Lösung für die Audio-Generierung bereitzustellen. (Quelle: _akhaliq)
Google Gemini Advanced integriert GitHub zur Stärkung der Coding-Assistenzfähigkeiten: Google hat angekündigt, dass Gemini Advanced nun mit GitHub verbunden ist, um seine Fähigkeiten als Coding-Assistent weiter zu verbessern. Benutzer können öffentliche oder private GitHub-Repositories direkt verbinden und Gemini nutzen, um Funktionen zu generieren oder zu ändern, komplexen Code zu erklären, Fragen zum Code-Repository zu stellen, Debugging durchzuführen und andere Operationen auszuführen. Durch Klicken auf die Schaltfläche „+“ in der Eingabeaufforderungsleiste und Auswahl von „Code importieren“ kann die GitHub-URL eingefügt werden, um loszulegen. (Quelle: algo_diver)
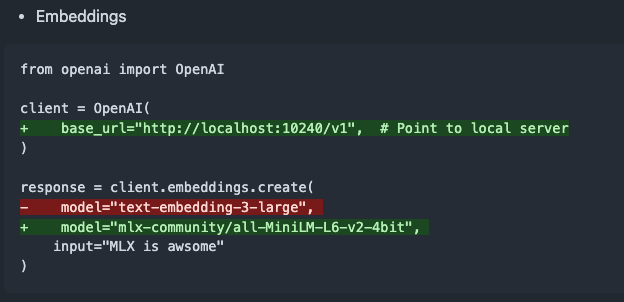
mlx-omni-server v0.4.0 veröffentlicht, fügt Embeddings-Dienst und weitere TTS-Modelle hinzu: mlx-omni-server wurde auf Version v0.4.0 aktualisiert und führt einen neuen /v1/embeddings-Dienst ein, der die Generierung von Embeddings durch mlx-embeddings vereinfacht. Gleichzeitig wurden weitere TTS-Modelle (wie kokoro, bark) integriert und mlx-lm aktualisiert, um neue Modelle wie qwen3 zu unterstützen. (Quelle: awnihannun)
Together Chat fügt PDF-Dateiverarbeitungsfunktion hinzu: Together Chat kündigte die Unterstützung für das Hochladen und Verarbeiten von PDF-Dateien an. Die aktuelle Version analysiert hauptsächlich den Textinhalt in PDFs und übergibt ihn zur Verarbeitung an das Modell. Zukünftig ist eine v2-Version geplant, die OCR-Funktionen zum Lesen von Bildinhalten in PDFs hinzufügen soll. (Quelle: togethercompute)
Terence Tao testet erneut KI bei der Formalisierung mathematischer Beweise, Claude übertrifft o4-mini: Der Mathematiker Terence Tao testete in seiner YouTube-Videoreihe die Fähigkeit von KI bei der Formalisierung algebraischer Implikationsbeweise mit dem Lean-Beweisassistenten. Im Experiment konnte Claude die Aufgabe in etwa 20 Minuten erledigen, obwohl während des Kompilierungsprozesses Abweichungen im Verständnis der Regel, dass natürliche Zahlen in Lean bei 0 beginnen, und Probleme bei der Symmetriebehandlung auftraten, die jedoch durch menschliches Eingreifen korrigiert wurden. Im Vergleich dazu zeigte sich o4-mini vorsichtiger, konnte Probleme bei der Definition von Potenzfunktionen erkennen, gab jedoch bei entscheidenden Beweisschritten auf und konnte die Aufgabe nicht abschließen. Tao kam zu dem Schluss, dass eine übermäßige Abhängigkeit von Automatisierung das Verständnis der Gesamtstruktur des Beweises schwächen kann und das optimale Automatisierungsniveau zwischen 0 % und 100 % liegen sollte, um menschliches Eingreifen zur Vertiefung des Verständnisses zu ermöglichen. (Quelle: 36氪)
Altman-Interview: OpenAIs ultimatives Ziel ist ein Kern-KI-Abonnementdienst: OpenAI CEO Sam Altman erklärte auf dem AI Ascent 2025 Event von Sequoia Capital, dass OpenAIs „platonisches Ideal“ die Entwicklung eines KI-Betriebssystems sei, das zum Kern-KI-Abonnementdienst für Nutzer wird. Er stellt sich vor, dass zukünftige KI-Modelle die Daten eines ganzen Lebens eines Nutzers (Billionen von Kontext-Token) verarbeiten können, um eine tiefgreifende personalisierte Inferenz zu ermöglichen. Altman räumte ein, dass dies noch im „PPT-Stadium“ sei, betonte aber, dass das Unternehmen stolz auf seine Flexibilität und Anpassungsfähigkeit sei. Er sprach auch über das Potenzial von KI-Sprachinteraktion, dass 2025 ein Jahr sein wird, in dem KI-Agenten glänzen werden, und glaubt, dass Coding der Kern für den Betrieb von Modellen und API-Aufrufen sein wird. (Quelle: 36氪, 量子位)

Karminski3 teilt Community-modifizierte Version von Qwen3-30B mit verdoppelter Anzahl aktivierter Experten: Die Entwickler-Community hat das Qwen3-Modell modifiziert und die Version Qwen3-30B-A6B-16-Extreme veröffentlicht. Durch Änderung der Modellparameter wurde die Anzahl der aktivierten Experten von A3B auf A6B erhöht, was angeblich zu einer leichten Qualitätsverbesserung führt, aber die Generierungsgeschwindigkeit entsprechend verlangsamt. Benutzer können auch durch Ändern der Laufzeitparameter von llama.cpp --override-kv http://qwen3moe.expert_used_count=int:24 einen ähnlichen Effekt erzielen oder umgekehrt die Aktivierungsmenge von Qwen3-235B-A22B reduzieren, um die Geschwindigkeit zu erhöhen. (Quelle: karminski3)

🧰 Werkzeuge
OpenMemory MCP veröffentlicht: Lokal laufendes Shared-Memory-System, verbindet mehrere KI-Tools: Das mem0ai-Team hat OpenMemory MCP vorgestellt, einen privaten Speicherserver, der auf dem Open Model Context Protocol (MCP) basiert. Es unterstützt einen 100% lokalen Betrieb und zielt darauf ab, das Problem zu lösen, dass aktuelle KI-Tools (wie Cursor, Claude Desktop, Windsurf, Cline) Kontextinformationen nicht gemeinsam nutzen und der Speicher nach Beendigung der Sitzung verloren geht. Benutzerdaten werden lokal gespeichert, um Datenschutz und Sicherheit zu gewährleisten. OpenMemory MCP bietet standardisierte Speicheroperations-APIs (Hinzufügen, Löschen, Abfragen, Ändern) und ein zentralisiertes Dashboard für Benutzer zur Verwaltung des Speichers und der Client-Zugriffsberechtigungen, wobei die Bereitstellung durch Docker vereinfacht wird. (Quelle: 36氪, AI进修生)

LangChain stellt offizielle Version der LangGraph-Plattform und mehrere Updates vor, stärkt Entwicklung und Beobachtbarkeit von KI-Agenten: LangChain kündigte auf der Interrupt-Konferenz die allgemeine Verfügbarkeit (GA) seiner LangGraph-Plattform an. Diese Plattform ist speziell für den Aufbau und die Verwaltung von langlebigen, zustandsbehafteten KI-Agenten-Workflows konzipiert und unterstützt One-Click-Deployment, horizontale Skalierung sowie APIs für Speicher, Mensch-Maschine-Interaktion (HIL), Dialoghistorie usw. Gleichzeitig wurde LangGraph Studio V2 als Agenten-IDE veröffentlicht, das lokalen Betrieb, direkte Konfigurationsbearbeitung, Integration mit Playground und das Abrufen von Produktions-Tracing-Daten für lokales Debugging unterstützt. Darüber hinaus hat LangChain die Open-Source-No-Code-Agenten-Bauplattform Open Agent Platform (OAP) eingeführt und die Agenten-Beobachtbarkeit von LangSmith in Bezug auf Tool-Aufrufe und Trajektorien verbessert. (Quelle: LangChainAI, hwchase17)
PatronusAI stellt Percival vor: Ein KI-Agent, der andere KI-Agenten bewerten und reparieren kann: PatronusAI hat Percival vorgestellt, den angeblich ersten KI-Agenten, der Fehler anderer KI-Agenten bewerten und automatisch beheben kann. Percival kann nicht nur Fehler in den Tracking-Aufzeichnungen von Agenten erkennen, sondern auch Reparaturvorschläge machen. Auf dem TRAIL-Datensatz, der von Menschen annotierte Fehler aus GAIA und SWE-Bench enthält, soll die Leistung von Percival um das 2,9-fache höher sein als die von SOTA LLMs. Zu seinen Funktionen gehören das automatische Vorschlagen von Reparaturlösungen für Agenten-Prompts, das Erfassen von über 20 Arten von Agentenfehlern (einschließlich Tool-Nutzung, Planungskoordination, domänenspezifische Fehler usw.) und die Verkürzung der manuellen Debugging-Zeit von Stunden auf weniger als 1 Minute. (Quelle: rebeccatqian, basetenco)
PyWxDump: WeChat-Informationsbeschaffungs- und Exporttool, unterstützt KI-Training: PyWxDump ist ein Python-Tool zum Abrufen von WeChat-Kontoinformationen (Spitzname, Konto, Telefon, E-Mail, Datenbankschlüssel), Entschlüsseln von Datenbanken, lokalen Anzeigen von Chatverläufen und Exportieren von Chatverläufen in Formate wie CSV, HTML, die für KI-Training, automatische Antworten usw. verwendet werden können. Das Tool unterstützt die Informationsbeschaffung für mehrere Konten und alle WeChat-Versionen und bietet eine webbasierte Benutzeroberfläche zum Anzeigen von Chatverläufen. (Quelle: GitHub Trending)

Airweave: Ein Tool, das KI-Agenten die Suche in jeder Anwendung ermöglicht, kompatibel mit dem MCP-Protokoll: Airweave ist ein Tool, das KI-Agenten die semantische Suche nach Inhalten in jeder Anwendung ermöglichen soll. Es ist kompatibel mit dem Model Context Protocol (MCP) und kann nahtlos verschiedene Anwendungen, Datenbanken oder APIs verbinden und deren Inhalte in für Agenten nutzbares Wissen umwandeln. Zu seinen Hauptfunktionen gehören Datensynchronisation, Entitätsextraktion und -transformation, Mandantenfähigkeit, inkrementelle Updates, semantische Suche und Versionskontrolle. (Quelle: GitHub Trending)

iFlytek veröffentlicht neue Generation von KI-Kopfhörern iFLYBUDS Pro3 und Air2 mit viaim AI Brain: Future Intelligence hat die iFlytek AI-Konferenzkopfhörer iFLYBUDS Pro3 und iFLYBUDS Air2 veröffentlicht, die beide mit dem brandneuen viaim AI Brain ausgestattet sind. viaim ist ein KI-Agent für den persönlichen Geschäfts- und Bürogebrauch, der vier Kernmodule integriert: End-to-End intelligente Wahrnehmungsverarbeitung, intelligente Agenten-Kollaborationsinferenz, Echtzeit-Multimodalfähigkeiten und Datenschutz. Die Kopfhörer unterstützen bequeme Aufzeichnungen (Anrufe, Vor-Ort-, Audio- und Videoaufnahmen), KI-Assistenten (automatische Generierung von Titeln und Zusammenfassungen, gezielte Fragen), Mehrsprachenübersetzung (32 Sprachen, Simultanübersetzung, Face-to-Face-Übersetzung, Anrufübersetzung) und bieten verbesserte Klangqualität und Tragekomfort. (Quelle: WeChat)

KoboldCpp Smart Launcher veröffentlicht: Automatisches Optimierungstool für Tensor Offload zur Verbesserung der LLM-Leistung: Ein GUI- und CLI-Tool namens KoboldCpp Smart Launcher wurde veröffentlicht, das Benutzern helfen soll, automatisch die beste Tensor-Offload-Strategie für KoboldCpp beim lokalen Ausführen von LLMs zu finden. Durch eine feinkörnigere Verteilung von Tensoren zwischen CPU und GPU (anstelle ganzer Schichten) soll das Tool die Generierungsgeschwindigkeit mehr als verdoppeln können, ohne den VRAM-Bedarf zu erhöhen. Beispielsweise wurde die Geschwindigkeit von QwQ Merge auf einer 12-GB-VRAM-GPU von 3,95 t/s auf 10,61 t/s erhöht. (Quelle: Reddit r/LocalLLaMA)
OpenBMB veröffentlicht Open-Source AgentCPM-GUI: Erster für Chinesisch optimierter On-Device GUI-Agent: Das OpenBMB-Team hat AgentCPM-GUI als Open Source veröffentlicht, den ersten On-Device GUI (Graphical User Interface) Agenten, der speziell für chinesische Anwendungen optimiert ist. Dieser Agent verbessert seine Inferenzfähigkeiten durch Reinforcement Fine-Tuning (RFT), verwendet ein kompaktes Aktionsraumdesign und verfügt über hochwertige GUI-Grounding-Fähigkeiten, um die Benutzererfahrung bei der Bedienung verschiedener Anwendungen in chinesischer Umgebung zu verbessern. (Quelle: Reddit r/LocalLLaMA)
MAESTRO: Lokal-priorisierte KI-Forschungsanwendung, unterstützt Multi-Agenten-Kollaboration und benutzerdefinierte LLMs: MAESTRO (Multi-Agent Execution System & Tool-driven Research Orchestrator) ist eine neu veröffentlichte KI-gestützte Forschungsanwendung, die lokale Kontrolle und Fähigkeiten betont. Sie bietet ein modulares Framework, einschließlich Dokumentenextraktion, leistungsstarker RAG-Prozesse und Multi-Agenten-Systeme (Planung, Forschung, Reflexion, Schreiben), das komplexe Forschungsfragen bearbeiten kann. Benutzer können über eine Streamlit Web-UI oder CLI interagieren und ihre eigenen Dokumentensätze sowie ausgewählte lokale oder API-LLMs verwenden. (Quelle: Reddit r/LocalLLaMA)
Contextual AI stellt einen für RAG optimierten Dokumenten-Parser vor: Contextual AI hat einen neuen Dokumenten-Parser veröffentlicht, der speziell für Retrieval Augmented Generation (RAG)-Systeme entwickelt wurde. Das Tool zielt darauf ab, durch die Kombination von visuellen, OCR- und visuellen Sprachmodellen eine hochpräzise Analyse komplexer unstrukturierter Dokumente zu ermöglichen. Es kann die hierarchische Struktur von Dokumenten beibehalten, komplexe Modalitäten wie Tabellen, Diagramme und Grafiken verarbeiten und Bounding Boxes sowie Konfidenzwerte für die Benutzerprüfung bereitstellen, um Kontextverluste und Halluzinationen in RAG-Systemen aufgrund von Analysefehlern zu reduzieren. (Quelle: douwekiela)
Gradio fügt ImageEditor Rückgängig/Wiederholen-Funktion hinzu: Die ImageEditor-Komponente von Gradio verfügt jetzt über Rückgängig- (Undo) und Wiederholen- (Redo) Schaltflächen, die Benutzern Python-Bildbearbeitungsfunktionen ähnlich professioneller kostenpflichtiger Anwendungen bieten und die Interaktivität und Benutzerfreundlichkeit verbessern. (Quelle: _akhaliq)
RunwayML führt neue References-Funktion ein, unterstützt Zero-Shot-Tests für Materialien, Kleidung, Orte und Posen: Die References-Funktion von RunwayML wurde aktualisiert. Benutzer können jetzt traditionelle 3D-Materialkugel-Vorschaubilder als Eingabe verwenden, um deren Material auf beliebige Objekte anzuwenden und so Zero-Shot-Materialübertragung und -visualisierung zu realisieren. Darüber hinaus unterstützt die neue Funktion Zero-Shot-Tests für Kleidung, Orte und Charakterposen und erweitert so die Möglichkeiten für kreative Generierung und schnelles Prototyping. (Quelle: c_valenzuelab, c_valenzuelab)

Mita AI führt Funktion „Heute etwas lernen“ ein, KI-gestütztes strukturiertes Lernen: Mita AI hat die neue Funktion „Heute etwas lernen“ eingeführt, die darauf abzielt, KI von der Rolle eines Assistenten für Informationsbeschaffung und Dokumentenverarbeitung zu einem „KI-Lehrer“ zu entwickeln, der aktiv anleiten und lehren kann. Nach dem Hochladen oder Suchen von Materialien kann diese Funktion automatisch systematisierte, strukturierte Videokurse und PPT-Präsentationen erstellen, um Benutzern bei der Strukturierung von Wissenspunkten zu helfen. Sie unterstützt auch die Auswahl verschiedener Erklärungsstufen (Anfänger/Experte) und Stile (Geschichtenerzählen/ungeduldiger Experte usw.) je nach Benutzerniveau. Darüber hinaus werden Fragen während des Kurses und Tests nach dem Kurs unterstützt. (Quelle: WeChat)

📚 Lernen
Andrew Ng und Anthropic starten neuen Kurs: Erstellung kontextreicher KI-Anwendungen mit MCP: DeepLearning.AI von Andrew Ng hat in Zusammenarbeit mit Anthropic einen neuen Kurs mit dem Titel „MCP: Build Rich-Context AI Apps with Anthropic“ gestartet, der von Elie Schoppik, Technical Education Lead bei Anthropic, unterrichtet wird. Der Kurs konzentriert sich auf das Model Context Protocol (MCP), ein offenes Protokoll, das darauf abzielt, den Zugriff von LLMs auf externe Tools, Daten und Prompts zu standardisieren. Die Teilnehmer lernen die Kernarchitektur von MCP kennen, erstellen MCP-kompatible Chatbots, bauen und implementieren MCP-Server und verbinden diese mit Claude-gestützten Anwendungen sowie anderen Drittanbieter-Servern, um die Entwicklung kontextreicher KI-Anwendungen zu vereinfachen. (Quelle: AndrewYNg, DeepLearningAI)
FlashInfer: Best Paper bei MLSys 2025, effiziente und anpassbare Attention-Engine für LLM-Inferenz: Das FlashInfer-Projekt, eine Zusammenarbeit von Zihao Ye (University of Washington), NVIDIA, Tianqi Chen (OctoAI) und anderen, wurde mit dem Best Paper Award der MLSys 2025 ausgezeichnet. FlashInfer ist eine hocheffiziente und anpassbare Attention-Engine, die für LLM-Inferenzdienste optimiert wurde. Durch optimierten Speicherzugriff (Verwendung eines Block-Sparse-Formats und eines zusammensetzbaren Formats zur Verarbeitung des KV-Cache), die Bereitstellung flexibler Attention-Berechnungsvorlagen auf Basis von JIT-Kompilierung und die Einführung eines lastausgleichenden Aufgabenplanungsmechanismus wird die LLM-Inferenzleistung erheblich verbessert. Es wurde bereits in Projekte wie vLLM und SGLang integriert. (Quelle: 机器之心)
ICML 2025 Paper: Theoretische Analyse von Graph Prompting aus der Perspektive der Datenmanipulation: Qunzhong Wang, Dr. Xiangguo Sun und Professor Hong Cheng von der Chinesischen Universität Hongkong haben auf der ICML 2025 ein Paper veröffentlicht, das erstmals einen systematischen theoretischen Rahmen für die Effektivität von Graph Prompting aus der Perspektive der „Datenmanipulation“ bietet. Die Forschung führt das Konzept des „Brückengraphen“ ein und beweist, dass der Graph-Prompting-Mechanismus theoretisch äquivalent zu einer bestimmten Operation an den Eingabegraphdaten ist, wodurch diese von vortrainierten Modellen korrekt verarbeitet werden können, um sich an neue Aufgaben anzupassen. Das Paper leitet eine obere Fehlergrenze ab, analysiert Fehlerquellen und deren Kontrollierbarkeit und modelliert die Fehlerverteilung, wodurch eine theoretische Grundlage für das Design und die Anwendung von Graph Prompting geschaffen wird. (Quelle: WeChat)
ICML 2025 Paper: Synthese von Textdaten durch Token-Level-Editing zur Vermeidung von Modellkollaps: Ein Forschungsteam der Shanghai Jiao Tong University und anderer Institutionen hat auf der ICML 2025 ein Paper veröffentlicht, das das Problem des „Modellkollaps“ durch synthetische Daten untersucht und eine Datengenerierungsstrategie namens „Token-Level Editing“ vorschlägt. Diese Methode ersetzt durch Mikro-Bearbeitung „übermäßig selbstbewusste“ Tokens des Modells in realen Daten, anstatt vollständig neuen Text zu generieren, mit dem Ziel, strukturell stabilere und generalisierbarere halb-synthetische Daten zu erstellen. Die theoretische Analyse zeigt, dass diese Methode den Testfehler effektiv begrenzen und verhindern kann, dass die Modellleistung mit zunehmenden Iterationsrunden zusammenbricht. Experimente in den Phasen des Vortrainings, des kontinuierlichen Vortrainings und der überwachten Feinabstimmung haben die Wirksamkeit dieser Methode bestätigt. (Quelle: WeChat)

ICML 2025 Paper: OmniAudio, Generierung von 3D-Raumklang aus 360°-Panoramavideos: Das OmniAudio-Team präsentierte auf der ICML 2025 eine Technik zur direkten Generierung von First-Order Ambisonics (FOA) Raumklang aus 360°-Panoramavideos. Um das Problem der Datenknappheit zu lösen, erstellte das Team den umfangreichen 360V2SA-Datensatz Sphere360 (über 100.000 Clips, 288 Stunden). OmniAudio verwendet ein zweistufiges Training: selbstüberwachtes Coarse-to-Fine Flow Matching Pre-Training, zuerst Training mit gewöhnlichem Stereo-Audio, das in Pseudo-FOA umgewandelt wird, dann Feinabstimmung mit echtem FOA; anschließend überwachte Feinabstimmung mit einem Dual-Branch-Video-Encoder, der globale und lokale Perspektivmerkmale extrahiert, um hochauflösenden, richtungsgenauen Raumklang zu erzeugen. (Quelle: 量子位)

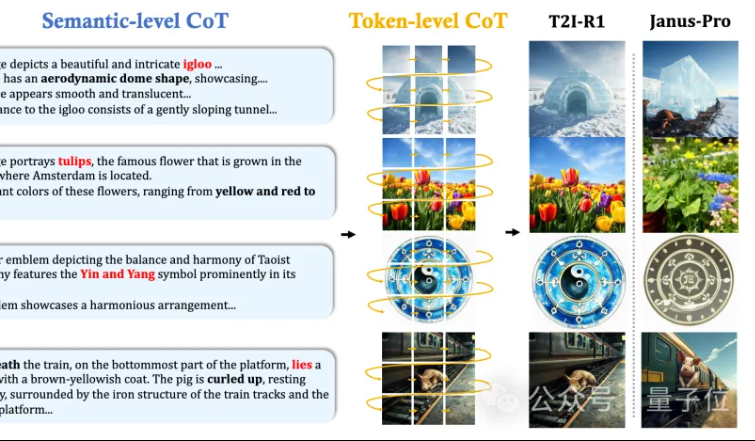
MMLab der CUHK schlägt T2I-R1 vor: Einführung von zweistufiger CoT-Inferenz und Reinforcement Learning für Text-zu-Bild-Generierung: Das MMLab-Team der Chinesischen Universität Hongkong hat T2I-R1 veröffentlicht, das erste auf Reinforcement Learning basierende inferenzverstärkte Text-zu-Bild-Modell. Dieses Modell schlägt innovativ einen zweistufigen Chain-of-Thought (CoT)-Inferenzrahmen vor: Semantic-CoT (Textinferenz, Planung der globalen Bildstruktur) und Token-CoT (blockweise Generierung von Bild-Token, Fokus auf Details auf unterer Ebene). Durch die BiCoT-GRPO Reinforcement-Learning-Methode werden diese beiden CoT-Ebenen in einem einheitlichen LMM (Janus-Pro) gemeinsam optimiert, ohne zusätzliche Modelle. Das Belohnungsmodell verwendet eine Integration mehrerer visueller Expertenmodelle, um die Zuverlässigkeit der Bewertung zu gewährleisten und Überanpassung zu verhindern. Experimente zeigen, dass T2I-R1 Benutzerabsichten besser verstehen und Bilder erzeugen kann, die den Erwartungen besser entsprechen, und auf den Benchmarks T2I-CompBench und WISE signifikant besser abschneidet als Basismodelle. (Quelle: 量子位, WeChat)
OpenAI veröffentlicht leichtgewichtige Sprachmodell-Evaluierungsbibliothek simple-evals: OpenAI hat simple-evals als Open Source veröffentlicht, eine leichtgewichtige Bibliothek zur Evaluierung von Sprachmodellen, die darauf abzielt, die Genauigkeitsdaten seiner neuesten Modellveröffentlichungen transparent zu machen. Die Bibliothek betont Zero-Shot- und Chain-of-Thought-Evaluierungseinstellungen und bietet detaillierte Leistungsvergleiche von Modellen auf mehreren Benchmarks wie MMLU, MATH, GPQA, einschließlich OpenAIs eigener Modelle (wie o3, o4-mini, GPT-4.1, GPT-4o) sowie anderer wichtiger Modelle (wie Claude 3.5, Llama 3.1, Grok 2, Gemini 1.5). (Quelle: GitHub Trending)
Koreanische Version des LLM Engineer’s Handbook veröffentlicht: Maxime Labonnes „LLM Engineer’s Handbook“ ist jetzt in koreanischer Sprache erhältlich, übersetzt von Woocheol Cho. Weitere Sprachversionen des Handbuchs, darunter Russisch, Chinesisch und Polnisch, werden in Kürze veröffentlicht, um LLM-Entwicklern weltweit Lernressourcen zur Verfügung zu stellen. (Quelle: maximelabonne)

ICML 2025 Audio Machine Learning Workshop ML4Audio angekündigt: Der beliebte Audio Machine Learning Workshop (ML for Audio) kehrt während der ICML 2025 in Vancouver zurück, und zwar am Samstag, den 19. Juli. Der Workshop wird Vorträge von namhaften Wissenschaftlern wie Dan Ellis, Albert Gu, Jesse Engel, Laura Laurenti und Pratyusha Rakshit beinhalten. Die Einreichungsfrist für Paper ist der 23. Mai. (Quelle: sedielem)
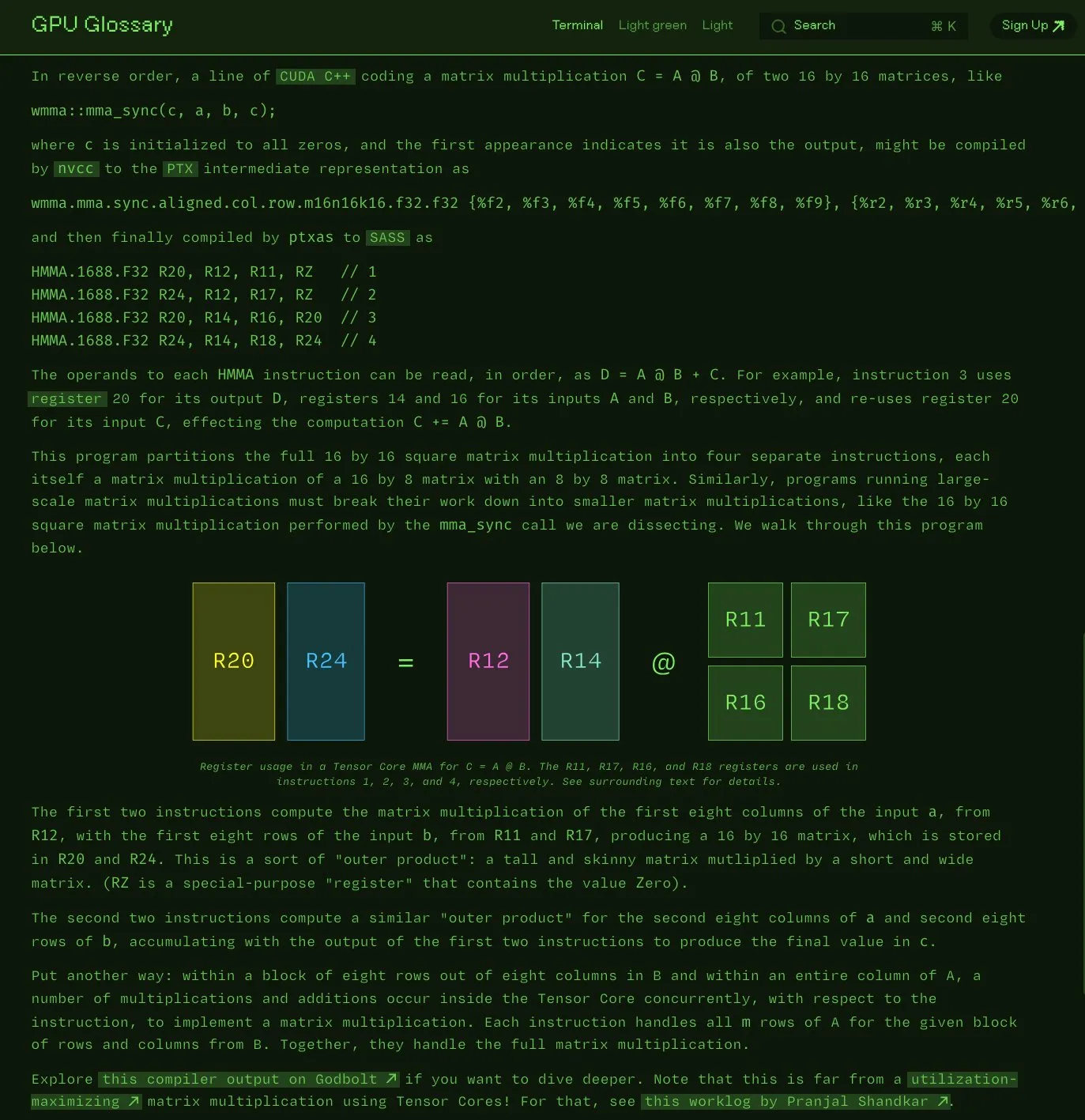
Charles Frye veröffentlicht Open-Source GPU-Glossar: Charles Frye hat bekannt gegeben, dass sein GPU-Glossar (GPU Glossary) nun Open Source ist. Das Glossar soll helfen, Konzepte im Zusammenhang mit GPU-Hardware und -Programmierung zu verstehen. Es wurde kürzlich um eine Aufschlüsselung der SASS-Instruktionen für einfache Matrixmultiplikations-Additionsoperationen (mma) auf Tensor Cores aktualisiert. Das Projekt wird auf GitHub gehostet und listet einige noch zu erledigende Aufgaben auf. (Quelle: charles_irl)
OpenAI veröffentlicht GPT-4.1 Prompt Engineering Guide, betont strukturierte und klare Anweisungen: OpenAI hat einen Prompt Engineering Guide für GPT-4.1 veröffentlicht, der Nutzern helfen soll, Prompts effektiver zu erstellen, insbesondere für Anwendungen, die strukturierte Ausgaben, Inferenz, Tool-Nutzung und agentenbasierte Ansätze erfordern. Der Leitfaden betont die Wichtigkeit klarer Rollen und Ziele, präziser Anweisungen (einschließlich Ton, Format, Grenzen), optionaler Unteranweisungen, schrittweiser Inferenz/Planung, genauer Definition des Ausgabeformats und der Verwendung von Beispielen. Er bietet auch praktische Tipps wie das Hervorheben wichtiger Anweisungen und die Verwendung von Markdown oder XML zur Strukturierung der Eingabe. (Quelle: Reddit r/MachineLearning)

Kaggle und Hugging Face vertiefen Zusammenarbeit zur Vereinfachung von Modellaufrufen und -entdeckungen: Kaggle hat eine verstärkte Zusammenarbeit mit Hugging Face angekündigt. Benutzer können nun Hugging Face-Modelle direkt in Kaggle Notebooks starten, zugehörige öffentliche Codebeispiele finden und nahtlos zwischen den beiden Plattformen wechseln. Diese Integration zielt darauf ab, die Zugänglichkeit von Modellen zu erweitern und Kaggle-Nutzern die bequemere Nutzung der Modellressourcen im Hugging Face-Ökosystem zu ermöglichen. (Quelle: huggingface)
FedRAG: Open-Source-Framework für die Feinabstimmung von RAG-Systemen, unterstützt Federated Learning: Forscher des Vector Institute haben FedRAG vorgestellt, ein Open-Source-Framework, das die Feinabstimmung von Retrieval Augmented Generation (RAG)-Systemen vereinfachen soll. Das Framework unterstützt nicht nur typisches zentralisiertes Training, sondern führt auch speziell eine Federated-Learning-Architektur ein, um den Anforderungen des Trainings auf verteilten Datensätzen gerecht zu werden. FedRAG ist mit dem PyTorch- und Hugging Face-Ökosystem kompatibel, unterstützt die Verwendung von Qdrant als Wissensdatenbankspeicher und kann an LlamaIndex angebunden werden. (Quelle: nerdai)

💼 Wirtschaft
Cursor-Muttergesellschaft Anysphere erreicht innerhalb von zwei Jahren 200 Millionen US-Dollar ARR, Bewertung steigt auf 9 Milliarden US-Dollar: Das von dem erst 25-jährigen MIT-Abbrecher Michael Truell geführte Unternehmen Anysphere hat mit seinem KI-Code-Editor Cursor ohne Marketingmaßnahmen innerhalb von zwei Jahren einen jährlich wiederkehrenden Umsatz (ARR) von 200 Millionen US-Dollar erzielt, wobei die Unternehmensbewertung schnell auf 9 Milliarden US-Dollar gestiegen ist. Cursor hat durch die tiefe Integration von KI in den Entwicklungsprozess das Paradigma der Softwareentwicklung neu gestaltet, konzentriert sich auf die Betreuung einzelner Entwickler und hat weltweit breite Anerkennung und Mundpropaganda von Entwicklern erhalten. Thrive Capital führte die jüngste Finanzierungsrunde an. (Quelle: 36氪)

Databricks kündigt Übernahme des Serverless Postgres Unternehmens Neon an: Databricks hat zugestimmt, das entwicklerorientierte Serverless Postgres Unternehmen Neon zu übernehmen. Neon ist bekannt für seine neuartige Datenbankarchitektur, die Geschwindigkeit, elastische Skalierung sowie Branching- und Forking-Funktionen bietet – Eigenschaften, die sowohl für Entwickler als auch für KI-Agenten attraktiv sind. Diese Übernahme zielt darauf ab, gemeinsam eine offene, serverless Datenbankinfrastruktur für Entwickler und KI-Agenten zu schaffen. (Quelle: jefrankle, matei_zaharia)
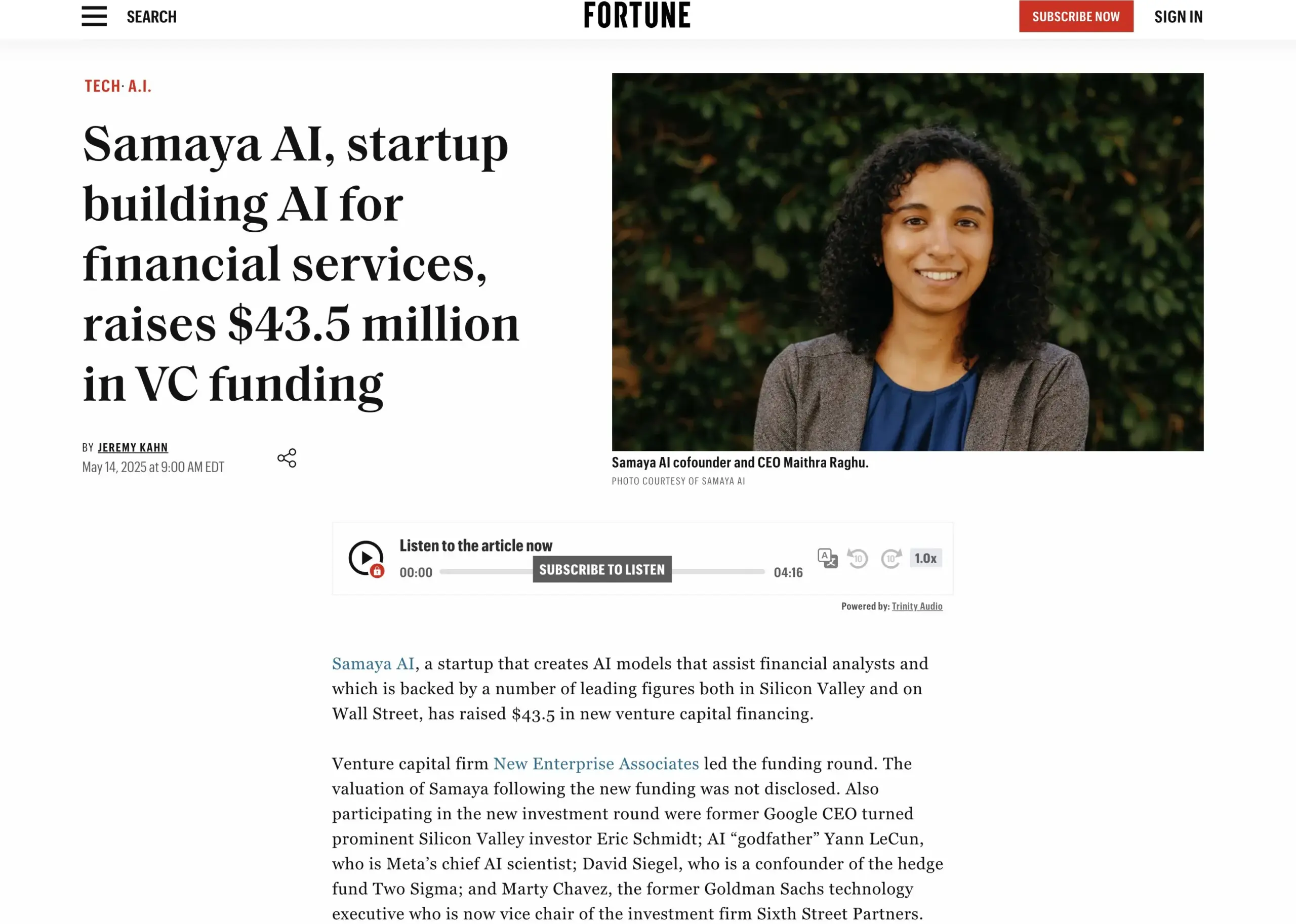
KI-Finanzdienstleistungs-Startup Samaya AI schließt Finanzierungsrunde über 43,5 Millionen US-Dollar ab: Samaya AI gab den Abschluss einer von NEA angeführten Finanzierungsrunde in Höhe von 43,5 Millionen US-Dollar bekannt. Die Mittel sollen für den Aufbau von Experten-KI-Agenten für Finanzdienstleistungen verwendet werden, mit dem Ziel, Wissensarbeit im großen Stil zu transformieren. Das 2022 gegründete Unternehmen konzentriert sich auf die Entwicklung spezialisierter KI-Lösungen für komplexe Finanzworkflows. Seine auf selbst entwickelten LLMs basierenden Experten-KI-Agenten werden bereits von Tausenden von Nutzern bei führenden Institutionen wie Morgan Stanley für Due-Diligence-Prüfungen, Wirtschaftsmodellierung und Entscheidungsunterstützung eingesetzt, wobei Präzision, Transparenz und Halluzinationsfreiheit im Vordergrund stehen. (Quelle: maithra_raghu)
🌟 Community
Wird KI Software-Ingenieure ersetzen? Community diskutiert Notwendigkeit von Kompetenzerweiterungen: In sozialen Medien ist erneut eine Diskussion darüber entbrannt, ob KI Software-Ingenieure ersetzen wird. Die vorherrschende Meinung ist, dass KI Software-Ingenieure nicht vollständig ersetzen wird, da Softwareentwicklung weit mehr als nur das Codieren selbst umfasst. Für diejenigen jedoch, die hauptsächlich repetitive Codierarbeiten ausführen und denen das Verständnis für das Gesamtsystem fehlt – sogenannte „Code Monkeys“ – besteht ein hohes Risiko, durch KI-gestützte Werkzeuge ersetzt zu werden, wenn sie ihre Fähigkeiten nicht verbessern, das Systemarchitekturverständnis vertiefen und komplexe Problemlösungen nicht beherrschen. (Quelle: cto_junior, cto_junior)
Die Zukunft von KI-Agenten: Chancen und Herausforderungen, Branchenführer sehen Potenzial: OpenAI CEO Altman prognostiziert, dass 2025 das Jahr sein wird, in dem KI-Agenten eine große Rolle spielen und stärker in die praktische Arbeit eingebunden werden. Auch Liu Zhiyi betonte in seinem Interview, dass sich Agenten von passiven Werkzeugen zu aktiv ausführenden Systemen wandeln und ihre Entwicklung vom Fortschritt der Basismodelle sowie von der Interaktionsfähigkeit mit der physischen Welt abhängt. Obwohl Agenten derzeit noch Schwächen in Bezug auf Reaktionsgeschwindigkeit, Halluzinationskontrolle usw. aufweisen, wird ihre Fähigkeit, Aufgaben autonom auszuführen und große Modelle beim Lernen zu unterstützen, weithin positiv bewertet und findet bereits Anwendung in Bereichen wie intelligentem Kundenservice und Finanzberatung. (Quelle: 36氪, 量子位)

Perplexity AI kooperiert mit PayPal und Venmo zur Integration von E-Commerce- und Reisezahlungen: Perplexity AI kündigte eine Zusammenarbeit mit PayPal und Venmo an, um Zahlungsfunktionen in seine Plattform für E-Commerce-Einkäufe, Reisebuchungen sowie in seinen Sprachassistenten und den demnächst erscheinenden Browser Comet zu integrieren. Dieser Schritt zielt darauf ab, den gesamten kommerziellen Prozess vom Stöbern, Suchen, Auswählen bis hin zur sicheren Bezahlung zu vereinfachen und die Benutzererfahrung zu verbessern. (Quelle: AravSrinivas, perplexity_ai)
Diskussion über KI-Modellbewertung: IFEval und ChartQA im Fokus, Vorsicht vor Kontamination von Trainingsdaten geboten: In Community-Diskussionen wird IFEval aufgrund seines einfachen und cleveren Designs als einer der herausragenden Benchmarks für die Bewertung der Anweisungsbefolgung angesehen. Gleichzeitig weisen Nutzer darauf hin, dass die Testdaten von ChartQA Rauschen, unklare Antworten und Inkonsistenzen aufweisen und möglicherweise ausgemustert werden müssen. Vikhyatk erinnert daran, dass viele Modelle, die angeblich hohe Genauigkeitsraten bei Benchmarks erzielen, möglicherweise unbemerkt Probleme mit der Kontamination von Trainingsdaten haben. (Quelle: clefourrier, vikhyatk)

Urheberrecht und Ethik von KI-generierten Inhalten im Fokus: Audible plant Einsatz von KI-Sprechern, KI-generierte Personen für Online-Dating geben Anlass zur Sorge: Audible kündigte Pläne an, KI-generierte Sprecher für die Produktion von Hörbüchern einzusetzen, um „mehr Geschichten zum Leben zu erwecken“, was eine Diskussion über den Einsatz von KI in der Kreativwirtschaft auslöste. Andererseits berichtete ein Reddit-Nutzer, dass seine Mutter auf einer Dating-Website mit einer vermutlich KI-generierten „echten männlichen“ Figur interagierte, und äußerte Bedenken, dass sie betrogen werden könnte. Dies unterstreicht die potenziellen Risiken von KI-generierten Inhalten in Bezug auf Authentizität, emotionale Manipulation und Betrug. (Quelle: Reddit r/artificial, Reddit r/ArtificialInteligence)

💡 Sonstiges
Chinesisches Unternehmen „Star算“ startet erfolgreich erste 12 Weltraum-Rechensatelliten und läutet neue Ära der weltraumbasierten Rechenleistung ein: Das von GuoXing Aerospace geführte „Star算“-Programm (Star Computing) hat erfolgreich die ersten 12 Rechensatelliten in den Weltraum gebracht und damit die weltweit erste Weltraum-Rechenkonstellation gebildet. Jeder Satellit verfügt über Weltraum-Rechen- und Vernetzungsfähigkeiten, wobei die Rechenleistung pro Satellit von T- auf P-Niveau gesteigert wurde. Die erste Konstellation erreicht eine Rechenleistung von 5 POPS im Orbit, und die Laserkommunikation zwischen den Satelliten erreicht Geschwindigkeiten von bis zu 100 Gbps. Ziel ist der Aufbau einer weltraumbasierten intelligenten Recheninfrastruktur, um Probleme wie hohen Energieverbrauch und schwierige Wärmeableitung bei bodengestützter Rechenleistung zu lösen und die Echtzeitverarbeitung von Daten aus der Tiefraumerkundung im Orbit zu unterstützen, um „Himmelsdaten, Himmelsrechnung“ zu realisieren. Zukünftig ist der Start von 2800 Satelliten geplant, um ein großes Weltraum-Rechennetzwerk zu bilden. (Quelle: 量子位)

NVIDIA veröffentlicht Jahresrückblick, betont KI als Kern der neuen industriellen Revolution, Intelligenz als Produkt: NVIDIA stellt in seinem Jahresrückblick fest, dass die Welt in eine neue industrielle Revolution eintritt, deren Kernprodukt „Intelligenz“ ist. NVIDIA widmet sich dem Aufbau einer intelligenten Infrastruktur, die das Computing in eine generative Kraft verwandelt, die den Fortschritt in allen Branchen vorantreibt. (Quelle: nvidia)

NBA und Kuaishou Kling AI kooperieren für KI-Kurzfilm „Curry’s Childhood Dunk“: Die NBA hat in Zusammenarbeit mit Kuaishous Sora-ähnlichem Text-zu-Video-Large-Model Kling AI einen KI-Kurzfilm mit dem Titel „Childhood Curry’s Dunk“ produziert, erstellt von AI TALK. Der Film versucht, mit Kling AI Currys „Zeitreise“-Dunk-Szene nachzustellen, um die NBA-Playoffs zu unterstützen. Im Film gibt es auch besondere Gastauftritte von Barkley, O’Neal und Jokić. (Quelle: TomLikesRobots)