
Schlüsselwörter:OpenAI, HealthBench, Meta AI, Microsoft Forschungslabor, Sakana AI, Dynamischer Byte-Latent-Transformer, ARTIST-Framework, Kontinuierliche Denkmaschine, Leistungsbewertung von medizinischer KI, 8B-Parameter dynamisches Byte-Latent-Transformer-Modell, Verstärkungslernen zur Verbesserung des LLM-Schlussfolgerns, CTM-Neuralnetzarchitektur, Offizielles quantisiertes Qwen3-Modell
🔥 Fokus
OpenAI veröffentlicht HealthBench zur Bewertung der Leistung von KI im Gesundheitswesen: OpenAI hat HealthBench eingeführt, einen neuen Benchmark, der darauf abzielt, die Leistung und Sicherheit großer Sprachmodelle (LLMs) in medizinischen Szenarien zu messen. Der Benchmark wurde unter Beteiligung von über 250 Ärzten weltweit entwickelt und umfasst 5000 reale medizinische Gespräche sowie 48562 einzigartige, von Ärzten verfasste Bewertungskriterien. Er deckt verschiedene Kontexte wie Notfallmedizin und globale Gesundheit sowie Verhaltensdimensionen wie Genauigkeit und Befehlsbefolgung ab. Tests zeigten, dass das o3-Modell eine Genauigkeit von 60% erreichte, während GPT-4.1 nano bei 25-fach geringeren Kosten besser abschnitt als GPT-4o. Dies zeigt das enorme Potenzial von KI im Gesundheitswesen und den schnellen Fortschritt bei der Kosten-Nutzen-Effizienz. (Quelle: OpenAI)
Meta veröffentlicht 8B-Parameter Dynamic Byte Latent Transformer Modell: Meta AI hat die Open-Source-Veröffentlichung der Gewichte seines 8B-Parameter Dynamic Byte Latent Transformer Modells angekündigt. Dieses Modell schlägt eine neue Alternative zu traditionellen Tokenisierungsmethoden vor, mit dem Ziel, die Standards für Effizienz und Zuverlässigkeit von Sprachmodellen neu zu definieren. Durch diese neue Tokenisierungsmethode wird erwartet, dass bahnbrechende Fortschritte im Bereich der Sprachmodelle erzielt werden, die die Effizienz und Effektivität der Textverarbeitung durch Modelle verbessern. Forschungspapier und Code stehen zum Download bereit. (Quelle: AIatMeta)
Microsoft Research stellt ARTIST Framework vor, das LLM-Schlussfolgerungs- und Werkzeugnutzungsfähigkeiten durch Reinforcement Learning verbessert: Microsoft Research hat das ARTIST (Agentic Reasoning and Tool Integration in Self-improving Transformers) Framework vorgestellt. Dieses Framework kombiniert autonomes Schlussfolgern, Reinforcement Learning und dynamische Werkzeugnutzung, wodurch große Sprachmodelle (LLMs) selbstständig entscheiden können, wann, wie und welche Werkzeuge für mehrstufiges Schlussfolgern eingesetzt werden sollen. Es ermöglicht das Erlernen robuster Strategien ohne schrittweise Überwachung. ARTIST übertrifft Spitzenmodelle wie GPT-4o in anspruchsvollen Benchmarks wie Mathematik und Funktionsaufrufen um bis zu 22% und setzt neue Standards für Generalisierung und interpretierbare Problemlösung. (Quelle: MarkTechPost)

Sakana AI veröffentlicht Continuous Thought Machines (CTM): Sakana AI hat eine neue neuronale Netzwerkarchitektur namens „Continuous Thought Machines“ (CTM) vorgestellt. Die Kernidee von CTM ist es, den dynamischen zeitlichen Prozess neuronaler Aktivität als zentralen Bestandteil seiner Berechnung zu nutzen. Dies ermöglicht es dem Modell, entlang einer intern generierten Zeitlinie von „Denkschritten“ zu operieren, um seine Repräsentationen iterativ aufzubauen und zu verfeinern, selbst bei statischen Daten. Die Architektur demonstriert ihre adaptive Berechnung, verbesserte Interpretierbarkeit und biologische Plausibilität bei verschiedenen Aufgaben wie ImageNet-Klassifizierung, 2D-Labyrinth-Navigation, Sortierung, Paritätsberechnung und Reinforcement Learning. (Quelle: Sakana AI)

🎯 Trends
Alibaba Qwen Team veröffentlicht offizielle quantisierte Modelle von Qwen3: Das Alibaba Qwen Team hat offiziell die quantisierten Modelle von Qwen3 veröffentlicht. Benutzer können Qwen3 nun über Plattformen wie Ollama, LM Studio, SGLang und vLLM bereitstellen. Es werden verschiedene Formate wie GGUF, AWQ, GPTQ unterstützt, was die lokale Bereitstellung erleichtert. Die entsprechenden Modelle sind auf Hugging Face und ModelScope verfügbar. Diese Veröffentlichung zielt darauf ab, die Hürden für die Nutzung von Hochleistungs-LLMs zu senken und ihre Anwendung in breiteren Szenarien zu fördern. (Quelle: Alibaba_Qwen & Hugging Face & ClementDelangue & _akhaliq & TheZachMueller & cognitivecompai & huybery & Reddit r/LocalLLaMA)
Meta AI veröffentlicht Collaborative Reasoner Framework: Meta AI hat Collaborative Reasoner vorgestellt, ein Framework zur Verbesserung der kollaborativen Schlussfolgerungsfähigkeiten von Sprachmodellen. Das Framework zielt darauf ab, soziale Agenten zu entwickeln, die mit Menschen und anderen Agenten zusammenarbeiten können. Durch die Verbesserung der Kollaborations- und Schlussfolgerungsfähigkeiten der Modelle wird der Weg für komplexere Mensch-Maschine-Interaktionen und Multi-Agenten-Systeme geebnet. Forschungspapier und Code stehen zum Download bereit und ermutigen die Community zur Erkundung und Anwendung. (Quelle: AIatMeta)
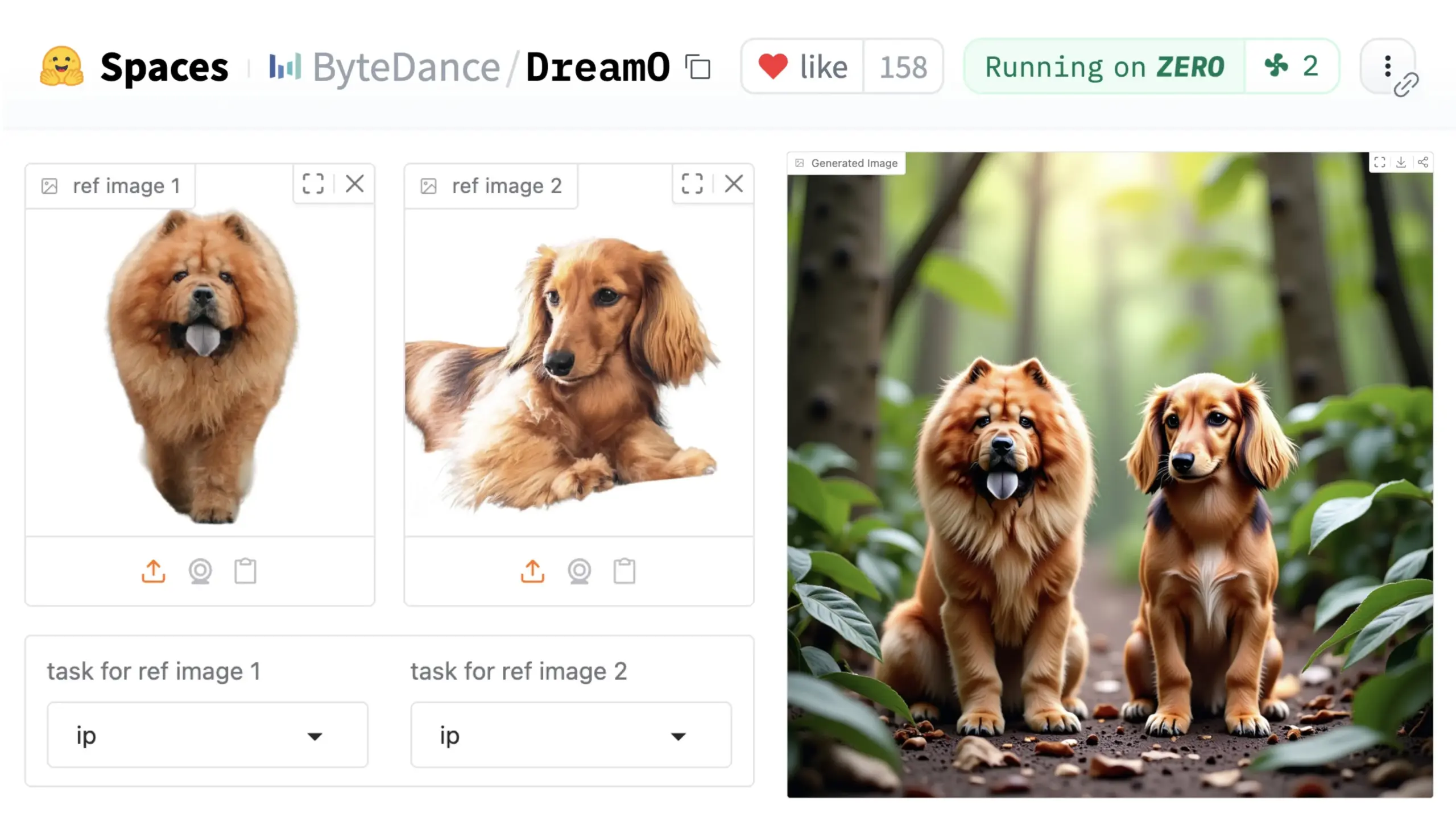
ByteDance stellt universelles Bildanpassungs-Framework DreamO vor: ByteDance hat ein einheitliches Bildanpassungs-Framework namens DreamO veröffentlicht. Basierend auf einem vortrainierten DiT (Diffusion Transformer) Modell ermöglicht das Framework die generalisierte Anpassung verschiedener Elemente in Bildern, wie Personen, Stile und Hintergründe, einschließlich Identitätsaustausch, Stiltransfer, Objekttransformation und virtueller Anprobe. Benutzer können eine Demo auf Hugging Face ausprobieren. Dieser Fortschritt zeigt das Potenzial eines einzelnen Modells für vielfältige Bildbearbeitungsaufgaben. (Quelle: _akhaliq & ClementDelangue & _akhaliq)
NVIDIA öffnet Nemotron-Modelldatenmanagement-Prozess Nemotron-CC: NVIDIA hat angekündigt, seinen Datenmanagement-Prozess Nemotron-CC, der für das Nemotron-Modell verwendet wird, zu öffnen und so viele Nemotron-Trainings- und Post-Trainingsdaten wie möglich offenzulegen. Der Nemotron-CC-Prozess ist nun Teil des NeMo Curator GitHub-Repositorys und kann Text-, Bild- und Videodaten in großem Maßstab verarbeiten. NVIDIA betont die Bedeutung hochwertiger vortrainierter Datensätze für die Genauigkeit großer Sprachmodelle und betrachtet Daten als grundlegenden Bestandteil der beschleunigten Datenverarbeitung. (Quelle: ctnzr & NandoDF)

Tencent Hunyuan-Turbos Modell erreicht Platz 8 in der LMArena: Tencents neuestes Hunyuan-Turbos Modell erreichte im Benchmark der LMArena (ehemals lmsys.org) den achten Platz insgesamt und den dreizehnten Platz bei der Stilkontrolle, was einer Leistung nahe an Deepseek-R1 entspricht. Das Modell platzierte sich in den Hauptkategorien wie Hardcore, Coding und Mathematik unter den Top Ten und zeigt eine deutliche Verbesserung gegenüber seiner Version vom Februar. Community-Mitglieder wie WizardLM_AI gratulierten zu dieser Leistung. (Quelle: WizardLM_AI & WizardLM_AI & teortaxesTex)

Runway Gen-4 References zeigt Potenzial als universelles Kreativwerkzeug: Runways Gen-4 References Modell wird als universelles Kreativwerkzeug positioniert, das nahezu unbegrenzte Workflows und Anwendungen unterstützt. Community-Nutzer entdecken kontinuierlich neue Anwendungsfälle, was seine starke Anpassungsfähigkeit als allgemeines Modell zeigt, das sich an die Kreativität der Nutzer anpasst, anstatt die Nutzer an die Einschränkungen des Modells anzupassen. Dies spiegelt den Trend in der KI-Medienproduktion von spezifischen Aufgaben hin zu allgemeinen Fähigkeiten wider. (Quelle: c_valenzuelab & c_valenzuelab)

ByteDance Seed-1.5-VL-thinking Modell führt in Benchmarks für visuelle Sprachmodelle: ByteDance hat das Seed-1.5-VL-thinking Modell veröffentlicht, das in 38 von 60 Benchmarks für visuelle Sprachmodelle (VLM) SOTA-Ergebnisse (State-of-the-Art) erzielt hat. Berichten zufolge wurde das Modell auf 1,3 Millionen H800 GPU-Stunden trainiert, was seine leistungsstarken multimodalen Verständnis- und Schlussfolgerungsfähigkeiten unterstreicht. (Quelle: teortaxesTex)
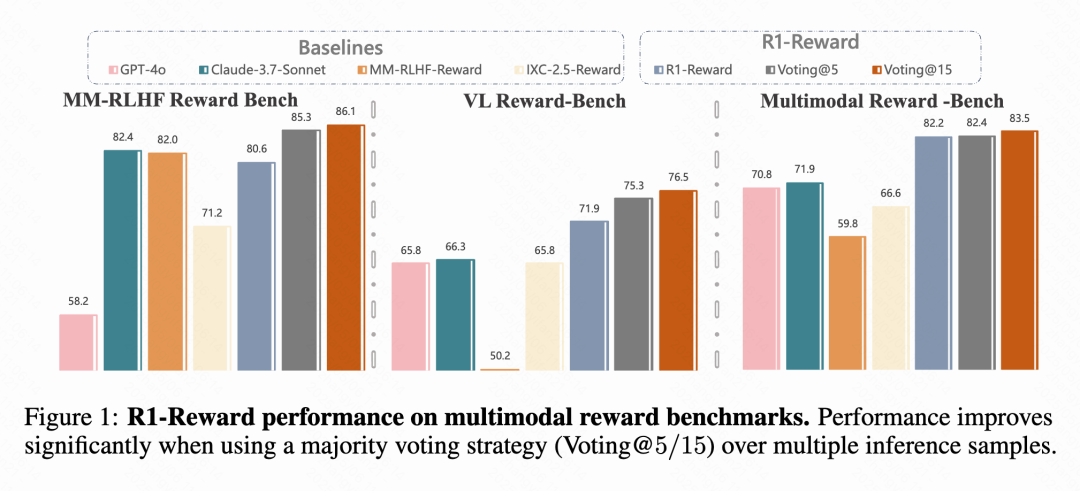
Kuaishou, CAS etc. schlagen multimodales Belohnungsmodell R1-Reward vor: Forschungsteams von Kuaishou, der Chinesischen Akademie der Wissenschaften (CAS), der Tsinghua-Universität und der Nanjing-Universität haben R1-Reward vorgeschlagen, ein neues multimodales Belohnungsmodell (MRM), das mit dem verbesserten Reinforcement Learning Algorithmus StableReinforce trainiert wird. Das Modell zielt darauf ab, die Instabilitätsprobleme bestehender RL-Algorithmen beim Training von MRMs zu lösen, indem Mechanismen wie Pre-Clip, Advantage Filter und Consistency Reward eingeführt werden. Experimente zeigen, dass R1-Reward auf mehreren MRM-Benchmarks eine Verbesserung von 5%-15% gegenüber SOTA-Modellen erzielt und erfolgreich in Geschäftsszenarien von Kuaishou wie Kurzvideos und E-Commerce eingesetzt wird. (Quelle: WeChat & WeChat)
Nanyang Technological University etc. schlagen WorldMem vor, das Gedächtnismechanismen für die Generierung konsistenter Welten über lange Zeiträume nutzt: Forscher des S-Lab der Nanyang Technological University, der Peking University und des Shanghai AI Lab haben das Weltgenerierungsmodell WorldMem vorgestellt. Durch die Einführung eines Gedächtnismechanismus löst das Modell das Problem der mangelnden Konsistenz bestehender Videogenerierungsmodelle über lange Zeiträume. WorldMem wurde auf dem Minecraft-Datensatz trainiert, unterstützt die Erkundung vielfältiger Szenarien und dynamische Veränderungen. Seine Machbarkeit wurde auf realen Datensätzen validiert, wobei es nach Änderungen der Perspektive und Position eine gute geometrische Konsistenz beibehält und zeitliche Konsistenz modelliert. (Quelle: WeChat)

Kuaishou Keling Team schlägt CineMaster vor, ein 3D-wahrnehmungsfähiges, steuerbares Framework zur Generierung kinoreifer Videos: Das Kuaishou Keling Forschungsteam hat auf der SIGGRAPH 2025 ein Paper veröffentlicht, in dem das CineMaster Framework vorgestellt wird. Dies ist ein Framework zur Generierung kinoreifer Text-zu-Video-Inhalte, das es Benutzern ermöglicht, durch einen interaktiven Workflow Szenen im 3D-Raum zu arrangieren, Ziele und Kamerabewegungen festzulegen und so eine feine Kontrolle über den Videoinhalt zu erreichen. CineMaster integriert die Steuerung von Objekt- und Kamerabewegungen über Semantic Layout ControlNet bzw. Camera Adapter und hat einen Datenkonstruktionsprozess entwickelt, um 3D-Steuersignale aus beliebigen Videos zu extrahieren. (Quelle: WeChat)

🧰 Tools
Comet-ml veröffentlicht Open-Source LLM-Bewertungsframework Opik: Comet-ml hat Opik auf GitHub als Open Source veröffentlicht, ein Framework zum Debuggen, Bewerten und Überwachen von LLM-Anwendungen, RAG-Systemen und Agent-Workflows. Opik bietet umfassendes Tracking, automatisierte Bewertungen und produktionsreife Dashboards. Es unterstützt die lokale Installation oder kann über Comet.com als gehostete Lösung genutzt werden. Es integriert sich mit vielen gängigen Frameworks wie OpenAI, LangChain, LlamaIndex und bietet LLM-as-a-judge Metriken zur Erkennung von Halluzinationen, Inhaltsmoderation und RAG-Bewertung. (Quelle: GitHub Trending)
LovartAI startet ersten Design-Agenten Lovart, betont Kontextverständnis: LovartAI hat die Beta-Version seines ersten Design-Agenten Lovart veröffentlicht. Nutzerfeedback deutet darauf hin, dass Lovart im Vergleich zu anderen KI-Design-Tools den Kontext besser versteht, sogar “als ob es Gedanken lesen könnte”. Das Tool ermöglicht die Zusammenarbeit von Mensch und KI auf derselben Leinwand, wandelt Prompts sofort in visuelle Ergebnisse um und kann für Markenlogo- und VI-Design verwendet werden. (Quelle: karminski3)
CMU Zhu Junyan Team stellt LEGOGPT vor, Text-zu-3D-LEGO-Modell-Generierung: Das Team von Zhu Junyan an der CMU hat LEGOGPT entwickelt, ein großes Sprachmodell, das basierend auf Text-Prompts physikalisch stabile und baubare 3D-LEGO-Modelle generieren kann. Das Modell formuliert das LEGO-Designproblem als autoregressive Textgenerierungsaufgabe, indem es die Größe und Position des nächsten Bausteins vorhersagt, um die Struktur aufzubauen. Während des Trainings und der Inferenz werden physikalisch bewusste Montagebeschränkungen durchgesetzt, um die Stabilität und Baubarkeit der generierten Designs zu gewährleisten. Das Team hat auch den StableText2Lego-Datensatz mit über 47.000 LEGO-Strukturen veröffentlicht. (Quelle: WeChat)

MNN Chat App unterstützt Qwen 2.5 Omni 3B und 7B Modelle: Alibabas MNN (Mobile Neural Network) Chat App unterstützt jetzt die Qwen 2.5 Omni 3B und 7B Modelle. Das bedeutet, dass Benutzer leistungsfähigere lokalisierte Sprachmodelldienste auf mobilen Geräten erleben können. MNN ist eine leichtgewichtige Deep-Learning-Inferenz-Engine, die sich auf die Optimierung für mobile und eingebettete Geräte konzentriert. (Quelle: Reddit r/LocalLLaMA)

FutureHouse Plattform bietet Wissenschaftlern superintelligente KI-Forschungstools: Die gemeinnützige Organisation FutureHouse hat die FutureHouse Plattform veröffentlicht, eine web- und API-basierte Suite von KI-Agenten, die darauf abzielt, wissenschaftliche Entdeckungen zu beschleunigen. Die Plattform bietet eine Reihe von superintelligenten KI-Forschungstools, die Wissenschaftlern bei der Datenanalyse, Simulation von Experimenten und Wissensentdeckung helfen und den Wandel wissenschaftlicher Paradigmen vorantreiben. (Quelle: dl_weekly)
Cartesia führt Pro Voice Cloning ein, um einfach benutzerdefinierte Sprachmodelle zu erstellen: Cartesia hat sein Fine-Tuning-Produkt Pro Voice Cloning veröffentlicht. Benutzer können ihre eigenen Sprachdaten hochladen, um einfach benutzerdefinierte Sprachmodelle zu erstellen, die zur Erstellung personalisierter Avatare, KI-Agenten oder Sprachbibliotheken verwendet werden können. Das Produkt unterstützt das Training und die Bereitstellung von Diensten innerhalb von 2 Stunden und bietet eine vollständig selbstbedienbare Produkterfahrung, die auf eine skalierbare Anwendung abzielt. (Quelle: krandiash)

Institut für Computertechnologie der CAS schlägt MCA-Ctrl für präzise Bildanpassung vor: Ein Forschungsteam des Instituts für Computertechnologie der Chinesischen Akademie der Wissenschaften (CAS) hat eine universelle Methode zur Bildanpassung ohne Fine-Tuning namens MCA-Ctrl (Multi-party Collaborative Attention Control) vorgeschlagen. Diese Methode nutzt die Multi-Subjekt-kollaborative Aufmerksamkeitssteuerung, um internes Wissen von Diffusionsmodellen zu nutzen. In Kombination mit bedingten Bild-/Text-Prompts und dem Inhalt des Subjektbildes ermöglicht sie den Themenaustausch, die Generierung und das Hinzufügen spezifischer Subjekte. MCA-Ctrl gewährleistet durch Selbstaufmerksamkeits-lokale Abfrage- und globale Injektionsmechanismen Layout-Konsistenz sowie den Austausch des Erscheinungsbilds spezifischer Objekte bei gleichzeitiger Ausrichtung auf den Hintergrund. (Quelle: WeChat)
📚 Lernen
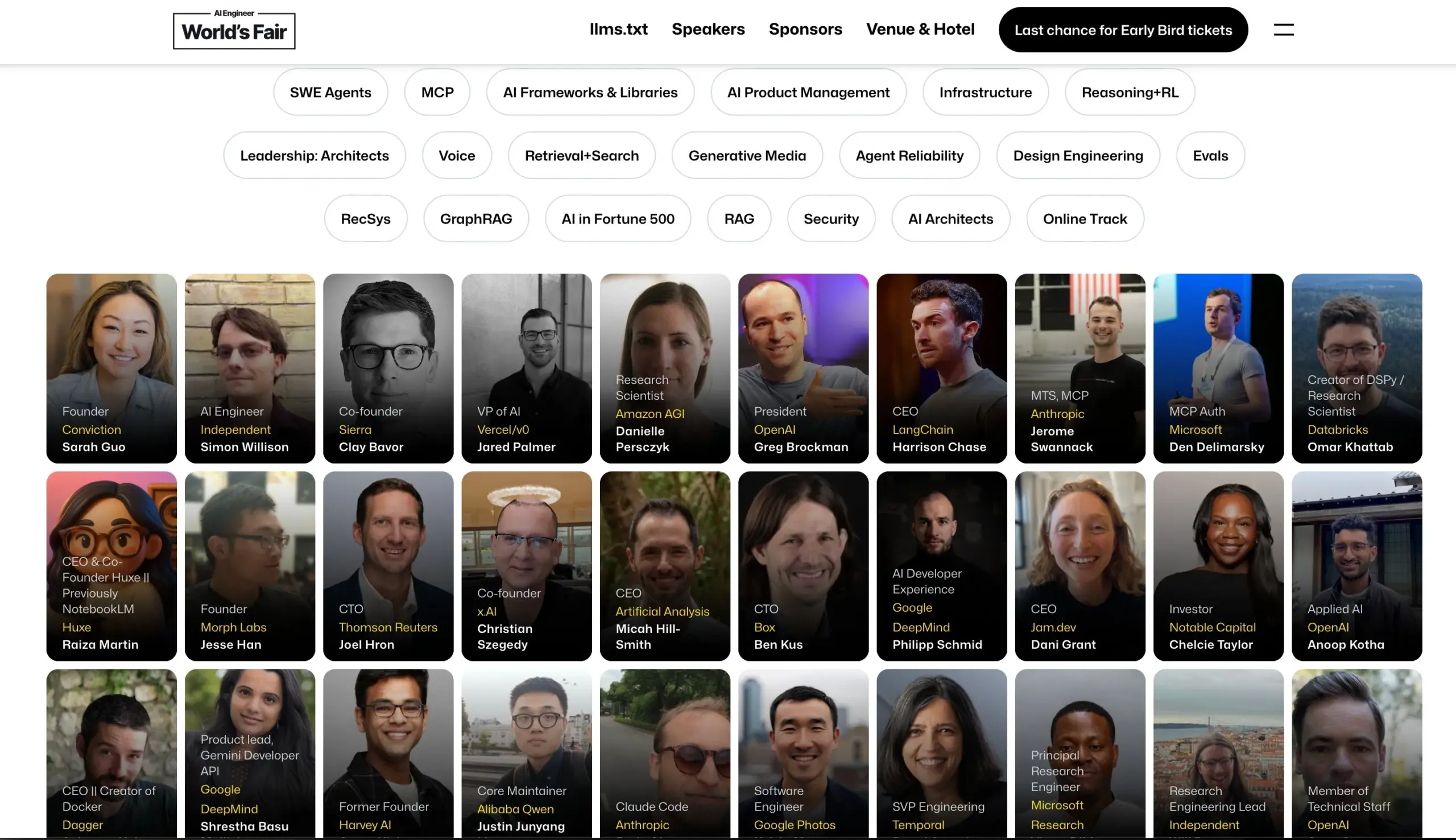
AI Engineer Konferenz gibt Sprecheraufstellung bekannt: Die AI Engineer Konferenz hat ihre Sprecheraufstellung bekannt gegeben, darunter führende KI-Ingenieure und Forscher von Unternehmen wie OpenAI, Anthropic, LangChainAI, Google etc. Die Konferenz wird 20 Teilbereiche abdecken, darunter MCP, LLM RecSys, Agent Reliability, GraphRAG, und erstmals eine Agenda für CTO- und VP-Führungskräfte einführen. (Quelle: swyx & hwchase17 & _philschmid & HamelHusain & swyx & bookwormengr & swyx)
Hugging Face veröffentlicht Blogbeitrag zu neuesten Fortschritten bei visuellen Sprachmodellen (VLM): Hugging Face hat einen umfassenden Blogbeitrag über die neuesten Fortschritte bei visuellen Sprachmodellen (VLM) veröffentlicht. Der Inhalt deckt verschiedene Aspekte ab, darunter GUI-Agenten, Agenten-VLMs, Allzweckmodelle, multimodale RAG, Video-LMs, kleine Modelle usw., und fasst neue Trends, Durchbrüche, Alignment und Benchmarks im VLM-Bereich des letzten Jahres zusammen. (Quelle: huggingface & ben_burtenshaw & mervenoyann & huggingface & algo_diver & huggingface & huggingface)

Microsoft Azure veranstaltet Online-Workshop zum Erstellen serverloser KI-Chat-Anwendungen: Yohan Lasorsa kündigte einen Online-Workshop zum Erstellen serverloser KI-Chat-Anwendungen mit Azure an. Die Sitzung wird Azure Functions, Static Web Apps und Cosmos DB untersuchen sowie die Verwendung der RAG-Technologie (Retrieval-Augmented Generation) mit LangChainAI JS. (Quelle: Hacubu & hwchase17)
Weaviate Podcast diskutiert LLM-as-Judge Systeme und die Verdict Bibliothek: Der Weaviate Podcast Folge 121 lädt Leonard Tang, Mitbegründer von Haize Labs, ein, um die Entwicklung von LLM-as-Judge / Belohnungsmodellsystemen eingehend zu diskutieren. Die Diskussion umfasst die Benutzererfahrung bei der Bewertung, Vergleichsbewertungen, Richterintegration, Debattenrichter, Kuratierung von Bewertungssets und adversariales Testen. Besonders hervorgehoben wird die neue Bibliothek Verdict von Haize Labs, ein deklaratives Framework zur Spezifikation und Ausführung zusammengesetzter LLM-as-Judge-Systeme. (Quelle: bobvanluijt & Reddit r/deeplearning)

Terence Tao veröffentlicht YouTube-Video zur Demonstration KI-gestützter Formalisierung mathematischer Beweise: Fields-Medaillengewinner Terence Tao demonstriert in seinem YouTube-Debüt, wie er KI-Tools wie GitHub Copilot und den Lean-Beweisassistenten nutzt, um einen mathematischen Beweis (Magma-Gleichung E1689 impliziert E2), der normalerweise eine ganze Seite von einem menschlichen Mathematiker erfordern würde, in 33 Minuten halbautomatisch zu formalisieren. Er betont, dass diese Methode für technisch anspruchsvolle, konzeptionell weniger komplexe Beweise geeignet ist und Mathematiker von mühsamen Aufgaben befreien kann. Gleichzeitig wurde sein selbst entwickelter leichtgewichtiger Python-Beweisassistent auf Version 2.0 aktualisiert, mit verbesserter Handhabung von asymptotischen Schätzungen und Aussagenlogik. (Quelle: WeChat & 量子位)

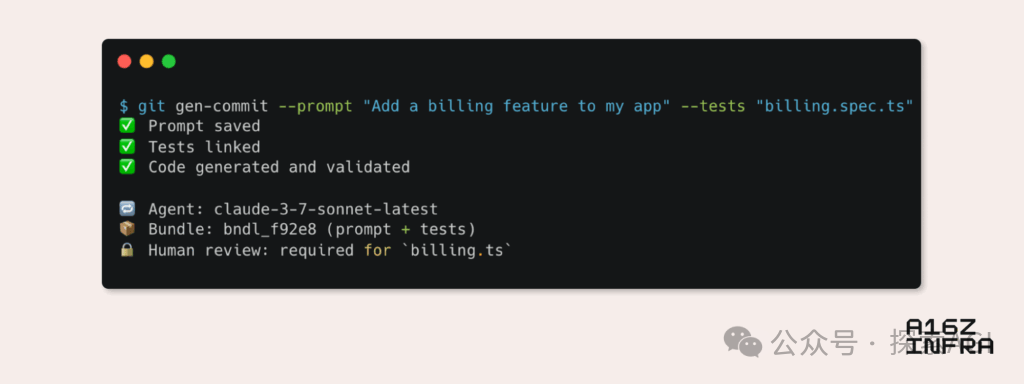
a16z analysiert neun Trends aufkommender Entwicklermuster im KI-Zeitalter: Andreessen Horowitz (a16z) hat einen Blogbeitrag veröffentlicht, der neun aufkommende Trends bei Entwicklermustern im KI-Zeitalter analysiert. Dazu gehören: KI-natives Git (Versionskontrolle verlagert sich zu Prompts und Testfällen), Vibe Coding (absichtsgesteuertes Programmieren ersetzt Vorlagen), neues Paradigma für Schlüsselverwaltung von KI-Agenten, KI-gesteuerte interaktive Monitoring-Dashboards, Dokumentation entwickelt sich zu KI-interaktiven Wissensdatenbanken, Anwendungen aus LLM-Perspektive betrachten (Interaktion über Barrierefreiheits-APIs), Aufkommen asynchron ausgeführter Agenten, Potenzial des MCP (Model-Tool Communication Protocol) Protokolls und der Bedarf von Agenten an Basiskomponenten. Diese Trends deuten auf einen tiefgreifenden Wandel in der Art und Weise hin, wie Software erstellt wird. (Quelle: WeChat)
💼 Wirtschaft
Google Labs startet AI Futures Fund zur Unterstützung von KI-Startups: Google Labs hat den Start des AI Futures Fund Programms angekündigt, das darauf abzielt, mit Startups zusammenzuarbeiten, um gemeinsam die Zukunft der KI-Technologie zu gestalten. Der Fonds wird ausgewählten Startups frühzeitigen Zugang zu Google DeepMind Modellen sowie Cloud Credits und andere Ressourcen bieten, um deren Entwicklung zu beschleunigen. (Quelle: GoogleDeepMind & JeffDean & Google & demishassabis)
Bericht: Perplexity verhandelt über neue Finanzierungsrunde von 500 Mio. USD bei 14 Mrd. USD Bewertung: Berichten zufolge verhandelt das KI-Suchmaschinenunternehmen Perplexity über eine neue Finanzierungsrunde in Höhe von 500 Millionen US-Dollar, die zu einer Bewertung von 14 Milliarden US-Dollar führen könnte. Dies geschieht nur sechs Monate nach der letzten Finanzierungsrunde (Bewertung 9 Milliarden US-Dollar) und zeigt das hohe Interesse des Kapitalmarktes am KI-Suchmaschinenmarkt und die Anerkennung der Wachstumsperspektiven von Perplexity. (Quelle: Dorialexander)

Bericht: OpenAI stimmt Übernahme von Windsurf für ca. 3 Mrd. USD zu: Laut Bloomberg hat OpenAI zugestimmt, das Startup-Unternehmen Windsurf für etwa 3 Milliarden US-Dollar zu übernehmen. Die genauen Details der Übernahme und die Geschäftsausrichtung von Windsurf wurden noch nicht veröffentlicht, aber dieser Schritt könnte bedeuten, dass OpenAI seine technologischen Fähigkeiten oder seine Marktpräsenz weiter ausbaut. (Quelle: Reddit r/artificial & Reddit r/ArtificialInteligence)

🌟 Community
Das wahre Risiko der KI: Die “Simulationsfalle” der unendlichen Befriedigung: Diskussionen von Amjad Masad und anderen weisen darauf hin, dass die wahre Gefahr der KI nicht in Killerrobotern aus Science-Fiction-Filmen liegt, sondern darin, dass sie menschliche Wünsche unendlich befriedigen und eine “unendliche Glücksmaschine” schaffen kann. Eine solche KI könnte dazu führen, dass die Menschheit in simulierten Anstrengungen und Sinnhaftigkeit versinkt und schließlich in der simulierten Welt “verschwindet”, was eine mögliche Erklärung für das Fermi-Paradoxon liefert – Zivilisationen sterben nicht aus, sondern treten in eine digitale Glückseligkeit ein. (Quelle: amasad)
KI-Agenten werden Programmierung und Forschung neu gestalten: Replit-CEO Amjad Masad prognostiziert, dass KI-Agenten in den nächsten ein bis zwei Jahren tagelang, sogar jahrelang, ununterbrochen arbeiten können, um komplexe wissenschaftliche Probleme zu lösen. Er glaubt, dass Agenten eine neue Art der Programmierung darstellen werden, die wie Menschen tagelang an der Lösung eines Problems arbeiten kann. Dies deutet auf das enorme Potenzial der KI bei der Automatisierung komplexer Aufgaben und der Beschleunigung wissenschaftlicher Entdeckungen hin. (Quelle: TheTuringPost & amasad & TheTuringPost)
John Carmack diskutiert das Potenzial von KI zur Optimierung von Codebasen: Der legendäre Programmierer John Carmack ist der Ansicht, dass KI nicht nur große Mengen an Code generieren, sondern auch dabei helfen kann, bestehende Codebasen zu verschönern und zu refaktorisieren. Er stellt sich KI als fleißiges Teammitglied vor, das kontinuierlich Code überprüft und Verbesserungsvorschläge macht, und sogar durch objektive Experimente “KI-freundliche” Programmierstilrichtlinien definieren könnte. Er ist gespannt, wie Teams wie OpenBSD, die extrem hohe Anforderungen an die Codequalität stellen, KI-Mitglieder aufnehmen werden. (Quelle: ID_AA_Carmack)
“Vibe Coding” löst Diskussion aus: Vor- und Nachteile der KI-gestützten Programmierung: Community-Diskussionen weisen darauf hin, dass “Vibe Coding” (Code-Prototypen durch Anweisungen in natürlicher Sprache von KI generieren lassen) zwar schnell Demo-Anwendungen erstellen kann, für die Bereitstellung und Skalierung jedoch weiterhin professionelle Entwickler erforderlich sind, die von Grund auf neu bauen. Ein Engineering-Produkt umfasst nicht nur das Schreiben von Code, sondern auch komplexe Aspekte wie Architektur, CI/CD, Microservices, die KI derzeit nur schwer vollständig bewältigen kann. Vibe Coding eignet sich gut für schnelle Prototypenvalidierung, aber der Aufbau echter Lösungen erfordert weiterhin technisches Denken und Erfahrung. (Quelle: Reddit r/ClaudeAI)
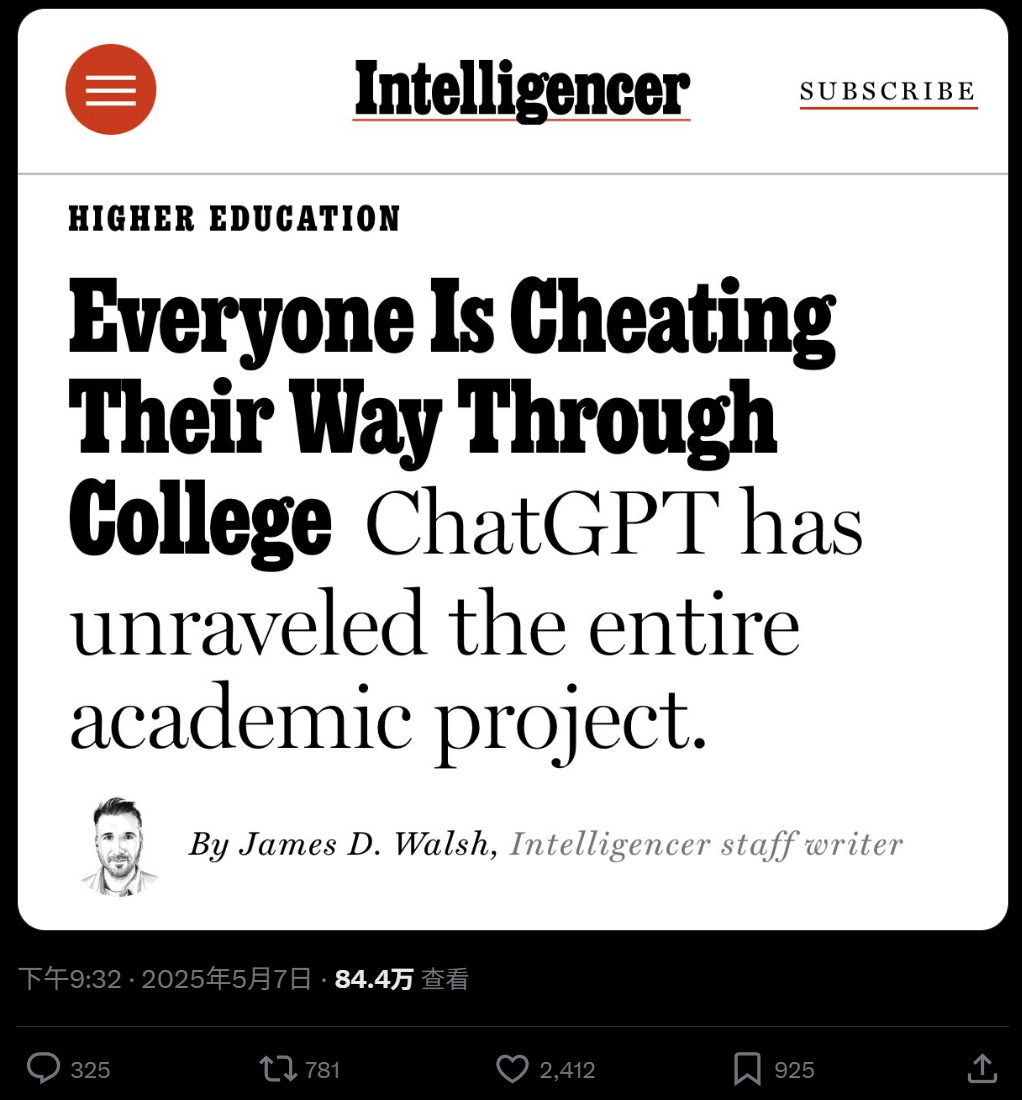
Breiter Einsatz von KI in der Hochschulbildung und Betrugssorgen: Ein Bericht des New York Magazine enthüllt das Phänomen des weit verbreiteten Einsatzes von KI-Tools (wie ChatGPT) zur Erledigung von Hausaufgaben und Abschlussarbeiten an nordamerikanischen Universitäten. Studenten nutzen KI für Notizen, Lernen, Recherche und sogar zur direkten Generierung von Aufgabeninhalten, was Bedenken hinsichtlich akademischer Integrität, Bildungsqualität und dem Rückgang des kritischen Denkens der Studenten aufwirft. Pädagogen versuchen, Lehr- und Bewertungsmethoden anzupassen, aber die Wirksamkeit von KI-Erkennungstools ist fraglich, was KI-Betrug schwer auszurotten macht. (Quelle: WeChat)
💡 Sonstiges
Cohere diskutiert Herausforderungen bei der Skalierung von KI-Anwendungen in Behörden vom Pilotprojekt zur Produktion: Cohere weist darauf hin, dass die meisten KI-Projekte von Regierungen noch im Pilotstadium verharren. Um den Sprung vom Pilotprojekt zur tatsächlichen Produktionsanwendung zu schaffen, benötigen Behörden vertrauenswürdige Werkzeuge, klare Ergebnisorientierung, effiziente Infrastruktur und geeignete Partner. Der Artikel untersucht, wie Behörden durch sichere und effiziente KI den Übergang vom Experiment zur praktischen Anwendung vollziehen können. (Quelle: cohere)

Mustafa Suleyman: Je größer große Sprachmodelle sind, desto einfacher sind sie zu kontrollieren: Mustafa Suleyman, Mitbegründer von Inflection AI, argumentiert, dass entgegen verbreiteter Befürchtungen größere Sprachmodelle (LLMs) tatsächlich einfacher zu kontrollieren sind, je größer sie werden. Er weist darauf hin, dass Modelle früherer Generationen schwieriger zu lenken, zu stilisieren und zu formen waren, während die Skalierung die Kontrollierbarkeit des Modells eher verbessert als schwächt. (Quelle: mustafasuleyman)
KI-Ethik-Diskussion: Haftungsfrage bei durch KI verursachten Schäden oder Verzerrungen: Ein Reddit-Beitrag löste eine Diskussion aus: Wer sollte zur Rechenschaft gezogen werden, wenn ein KI-System (z. B. eine KI für medizinische Diagnosen) aufgrund von Verzerrungen in den Trainingsdaten (z. B. hauptsächlich auf Bildern von hellhäutigen Personen trainiert, was zu Fehldiagnosen bei dunkelhäutigen Patienten führt) Schaden verursacht? Dies berührt die Frage der Verantwortungszuweisung zwischen KI-Entwicklern, einsetzenden Institutionen, Regulierungsbehörden und anderen Parteien – ein zentrales Thema, das im Rahmen der KI-Ethik und des Rechtsrahmens dringend geklärt werden muss. (Quelle: Reddit r/ArtificialInteligence)