
Schlüsselwörter:GENMO, Seed-Coder, DeepSeek, LlamaParse, Agentic AI, Edge Computing, Quantencomputing, NVIDIA GENMO menschliches Bewegungsmodell, ByteDance Seed-Coder Code-Großmodell, DeepSeek Open-Source-Strategieeinfluss, LlamaParse Dokumentenanalyse Konfidenzbewertung, Edge Computing Echtzeitdatenverarbeitung, NVIDIA GENMO menschliches Bewegungsmodell, ByteDance Seed-Coder Code-Großmodell, DeepSeek Open-Source-Strategieeinfluss, LlamaParse Dokumentenanalyse Konfidenzbewertung, Edge Computing Echtzeitdatenverarbeitung
🔥 Fokus
NVIDIA stellt GENMO vor: Universelles Modell für menschliche Bewegung: NVIDIA hat ein KI-Modell namens GENMO (GENeralist Model for Human MOtion) veröffentlicht, das verschiedene Eingaben wie Text, Video, Musik oder sogar Keyframe-Silhouetten in realistische 3D-menschliche Bewegungen umwandeln kann. Das Modell kann verschiedene Arten von Eingaben verstehen und zusammenführen, zum Beispiel Bewegungen aus Videos lernen und sie basierend auf Textaufforderungen modifizieren oder Tänze basierend auf Musikrhythmen generieren. GENMO zeigt enormes Potenzial in Bereichen wie Spielanimation und der Erstellung von Charakteren für virtuelle Welten, kann komplexe und natürliche, kohärente Bewegungen generieren und unterstützt die intuitive Bearbeitung des Animationstimings. Obwohl es derzeit keine Mimik und Handdetails verarbeiten kann und auf externe SLAM-Methoden angewiesen ist, stellen seine multimodalen Eingaben und hochwertigen Ausgaben einen wichtigen Fortschritt im Bereich der KI-Bewegungserzeugung dar (Quelle: YouTube – Two Minute Papers
)
ByteDance veröffentlicht Open-Source-Modellreihe Seed-Coder: ByteDance hat die Open-Source-Modellreihe Seed-Coder für große Sprachmodelle vorgestellt, die ein Basismodell, ein Befehlsmodell und ein Inferenzmodell mit 8B Parametern umfasst. Das Kernmerkmal dieser Modellreihe ist ihre Fähigkeit zur „Selbstkuratierung von Daten durch das Codemodell“, mit dem Ziel, die menschliche Beteiligung an der Datenerstellung zu minimieren. Seed-Coder hat in mehreren Aspekten wie Codegenerierung und -bearbeitung den aktuellen Stand der Technik (SOTA) erreicht und zeigt das Potenzial, Trainingsdaten durch die eigenen Fähigkeiten der KI zu optimieren und zu erstellen, was neue Denkansätze für die Entwicklung von großen Codemodellen liefert (Quelle: _akhaliq)
DeepSeek-Modelle sorgen für großes Aufsehen in der KI-Community: Die DeepSeek-Modellreihe, insbesondere ihre Codemodelle, hat aufgrund ihrer starken Leistung und Open-Source-Strategie breite Diskussionen in der KI-Community ausgelöst. Viele Entwickler und Forscher sind von seiner Leistung beeindruckt und glauben, dass es die Wahrnehmung von Open-Source-Modellen weltweit verändert hat. Diskussionen deuten darauf hin, dass der Erfolg von DeepSeek Unternehmen wie OpenAI dazu veranlassen könnte, ihre Open-Source-Strategien neu zu bewerten und lokale Hersteller von großen Modellen zu beschleunigen, ihre Modelle ebenfalls Open Source zu machen. Obwohl Open Source Herausforderungen wie Kommerzialisierung und Hardware-Anpassung gegenübersteht, wird das Aufkommen von DeepSeek als eine wichtige Kraft zur Demokratisierung der KI-Technologie und zur Förderung der Branchenentwicklung angesehen (Quelle: Ronald_vanLoon, 36氪)

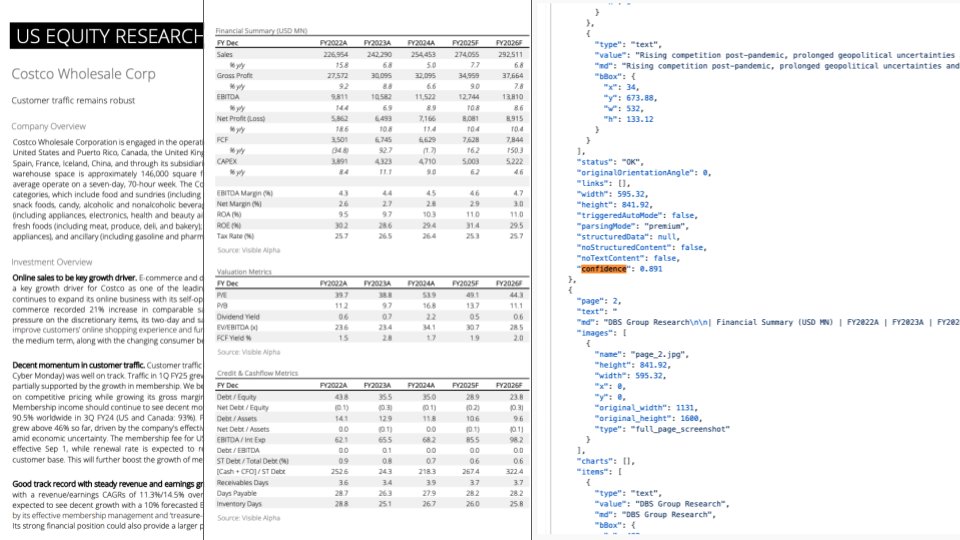
LlamaParse Update: Integration von GPT-4.1 und Gemini 2.5 Pro zur Verbesserung der Dokumentenanalyse: LlamaParse hat ein wichtiges Update veröffentlicht, das die neuesten Modelle GPT-4.1 und Gemini 2.5 Pro integriert und die Genauigkeit der Dokumentenanalyse erheblich verbessert. Zu den neuen Funktionen gehören die automatische Erkennung von Ausrichtung und Schräglage, um die Ausrichtung und Genauigkeit der analysierten Inhalte sicherzustellen. Darüber hinaus wurde eine Konfidenzbewertungsfunktion eingeführt, mit der Benutzer die Analysequalität jeder Seite bewerten und basierend auf Konfidenzschwellenwerten manuelle Überprüfungsprozesse einrichten können. Dieses Update zielt darauf ab, Fehler zu beheben, die bei der Verarbeitung komplexer Dokumente durch LLM/LVM auftreten können, indem eine Benutzererfahrung für die manuelle Überprüfung und Korrektur bereitgestellt wird, um die Zuverlässigkeit automatisierter Prozesse zu gewährleisten (Quelle: jerryjliu0)
🎯 Trends
Ausblick auf Technologietrends 2025: Der Bericht prognostiziert die wichtigsten Technologietrends für 2025, darunter die kontinuierliche Entwicklung und tiefe Integration aufkommender Technologien wie künstliche Intelligenz, maschinelles Lernen, 5G, Wearables, Blockchain und Cybersicherheit. Es wird erwartet, dass diese Technologien eine wichtige Rolle bei der Verbesserung des Lebens, der Förderung von Innovationen und der Lösung gesellschaftlicher Probleme spielen werden, was eine vielversprechende Zukunft der Technologie-gestützten Entwicklung ankündigt (Quelle: Ronald_vanLoon, Ronald_vanLoon)

Prognose der Entwicklungstrends im KI-Bereich für 2025: IBM prognostiziert, dass sich der Bereich der künstlichen Intelligenz im Jahr 2025 weiterhin rasant entwickeln wird, wobei Technologien des maschinellen Lernens (ML) und der künstlichen Intelligenz (KI) weiter reifen und in verschiedenen Branchen breite Anwendung finden werden. Es wird erwartet, dass KI eine größere Rolle in Bereichen wie Automatisierung, Datenanalyse und Entscheidungsunterstützung spielen und so technologische Innovationen und industrielle Modernisierungen vorantreiben wird (Quelle: Ronald_vanLoon)

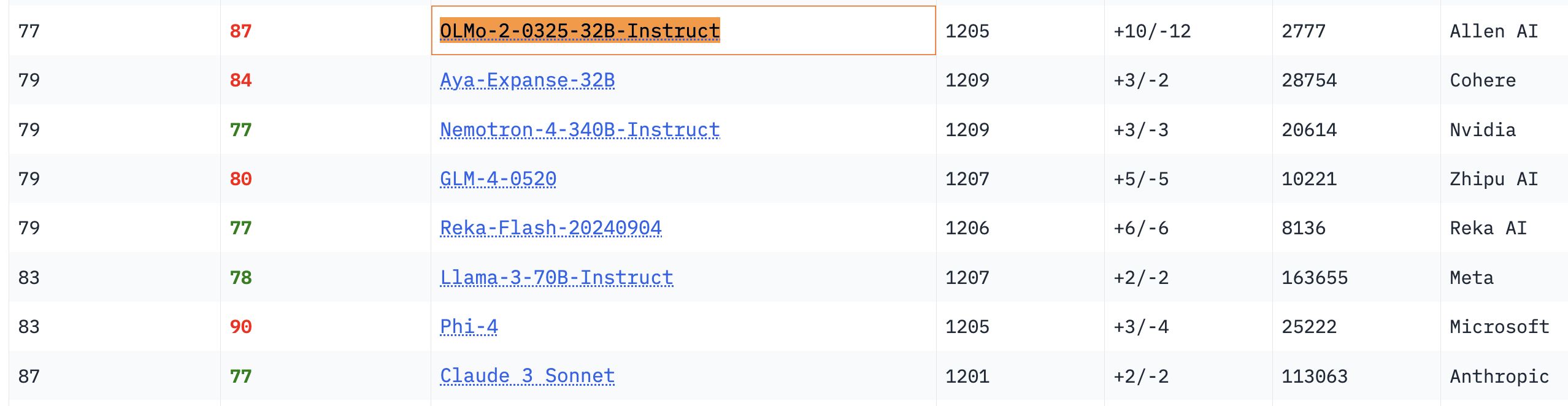
Herausragende Leistung des OLMo 32B Modells: In relevanten Benchmark-Tests übertrifft das vollständig offene OLMo 32B Modell die Modelle Nemotron 340B und Llama 3 70B, die über eine größere Parameteranzahl verfügen. Dieses Ergebnis zeigt, dass in bestimmten Aspekten auch vollständig offene Modelle mit geringerer Parameteranzahl die Leistung größerer kommerzieller Modelle erreichen oder sogar übertreffen können, was das enorme Potenzial und die Aufholgeschwindigkeit der Forschung an offenen Modellen verdeutlicht (Quelle: natolambert, teortaxesTex, lmarena_ai)
Gemma-Modell-Downloads übersteigen 150 Millionen, mehr als 70.000 Varianten: Die Downloadzahlen des Gemma-Modells von Google auf der Hugging Face-Plattform haben 150 Millionen überschritten, und es gibt über 70.000 Varianten. Diese Daten spiegeln die Beliebtheit und breite Anwendung des Gemma-Modells in der Entwickler-Community wider. Die Community-Nutzer sind auch voller Erwartungen an zukünftige Iterationen (Quelle: osanseviero, _akhaliq)
Unsloth aktualisiert Qwen3 GGUF-Modelle und verbessert Kalibrierungsdatensätze: Unsloth hat alle seine Qwen3 GGUF-Modelle aktualisiert und einen neuen, verbesserten Kalibrierungsdatensatz verwendet. Darüber hinaus wurden weitere GGUF-Varianten für Qwen3-30B-A3B hinzugefügt. Nutzerfeedback deutet darauf hin, dass die Übersetzungsqualität in der Version 30B-A3B-UD-Q5_K_XL im Vergleich zu anderen Q5- und Q4-GGUFs verbessert wurde (Quelle: Reddit r/LocalLLaMA)

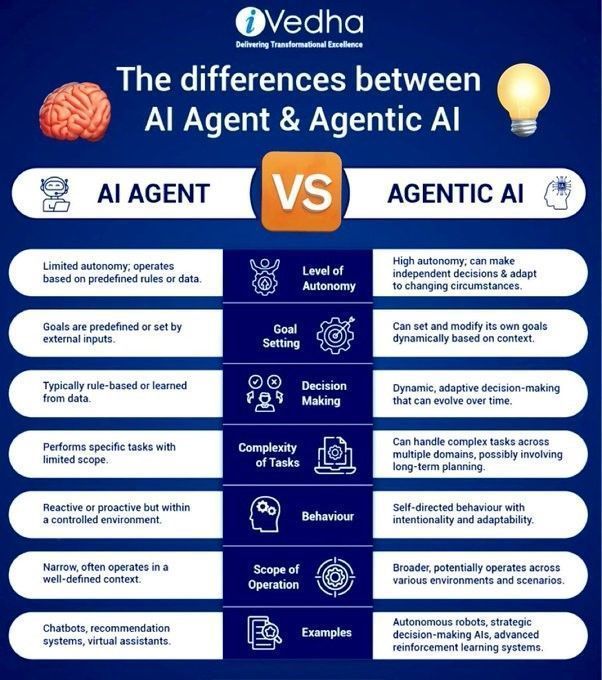
Unterschied zwischen Agentic AI und GenAI: Agentic AI und Generative AI (GenAI) sind aktuelle Hotspots im KI-Bereich. GenAI bezieht sich hauptsächlich auf KI, die neue Inhalte (Text, Bilder usw.) erstellen kann, während Agentic AI sich mehr auf intelligente Agenten konzentriert, die autonom Aufgaben ausführen, mit der Umgebung interagieren und Entscheidungen treffen können. Agentic AI kombiniert oft die Fähigkeiten von GenAI, legt aber mehr Wert auf Autonomie und Zielorientierung (Quelle: Ronald_vanLoon)

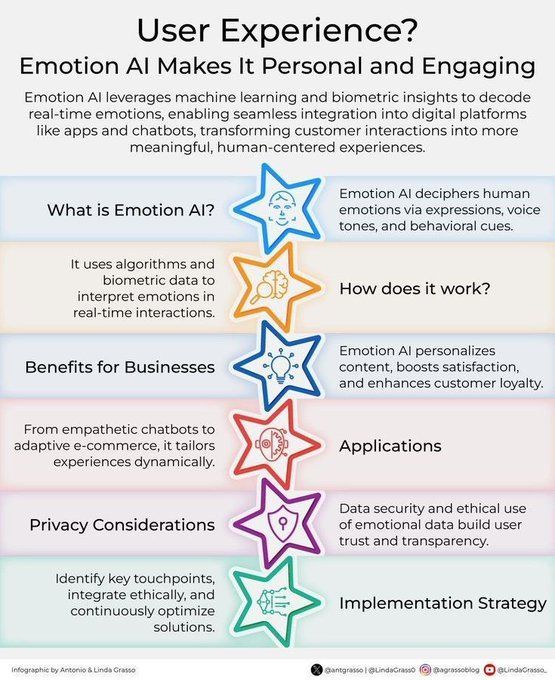
Emotionale KI verbessert das Kundenerlebnis: Die Technologie der emotionalen KI wird durch die Analyse und das Verständnis menschlicher Emotionen zur Verbesserung des Kundenerlebnisses (CX) eingesetzt. Sie kann Unternehmen helfen, Kundenbedürfnisse und -emotionen besser zu verstehen und so personalisiertere und einfühlsamere Dienstleistungen anzubieten, was Innovationen im Kundenbeziehungsmanagement im Zuge der digitalen Transformation vorantreibt (Quelle: Ronald_vanLoon)
Konzept KI-gestützter Personalisierungswerkzeuge „Jigging“ (Intelligent Mechanics Auxiliary Device): Karina Nguyen schlägt das Konzept des „Jigging“ vor, das KI-Modelle als individualisierte, sich selbst verbessernde Werkzeugmacher vergleicht. Bei jeder Interaktion mit dem Benutzer erstellt die KI neue, spezialisierte Werkzeuge, die auf die Eigenschaften des Benutzers und die Aufgabe zugeschnitten sind, und erweitert so ihre Fähigkeiten. Beispielsweise erstellt die KI personalisierte Diagnose-Frameworks für Ärzte oder einzigartige narrative Frameworks für Autoren. Diese rekursive Verbesserung wird die KI zu einer Erweiterung der kognitiven Architektur des Benutzers machen und einen grundlegenden Wandel in der Mensch-Maschine-Kollaboration vorantreiben (Quelle: karinanguyen_)
Unterschied zwischen KI-Agenten und Agentic AI: Khulood Almani erläutert weiter den Unterschied zwischen KI-Agenten (AI Agents) und Agentic AI. KI-Agenten beziehen sich typischerweise auf Softwareprogramme, die bestimmte Aufgaben ausführen, während Agentic AI stärker die Autonomie, Lernfähigkeit und Anpassungsfähigkeit des Systems betont, das aktiver mit der Umgebung interagieren und komplexe Ziele erreichen kann. Das Verständnis dieses Unterschieds hilft, die Richtung und das Potenzial der KI-Entwicklung zu erfassen (Quelle: Ronald_vanLoon)
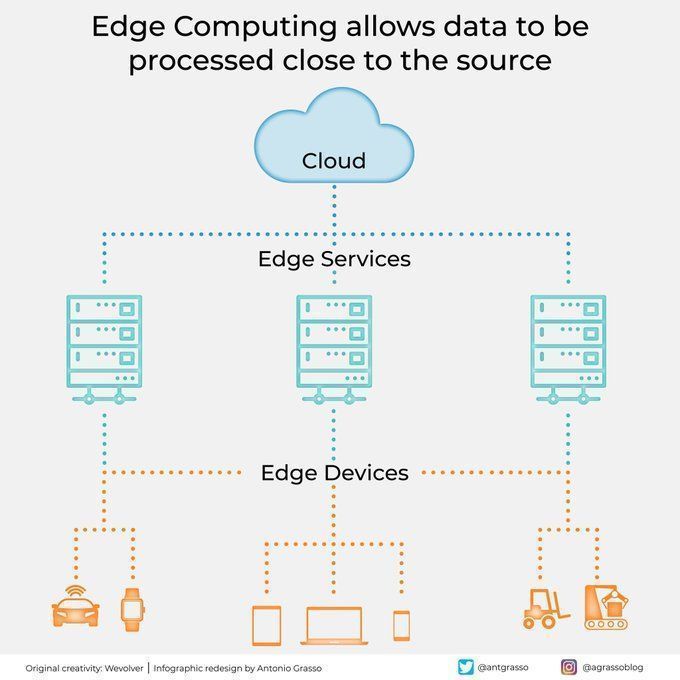
Edge Computing verarbeitet Daten nahe der Quelle: Edge-Computing-Technologie verarbeitet Daten in der Nähe der Datenquelle, reduziert Latenzzeiten, senkt den Bandbreitenbedarf und verbessert den Datenschutz. Dies ist entscheidend für KI-Anwendungen, die Echtzeitreaktionen und die Verarbeitung großer Datenmengen erfordern (wie autonomes Fahren, industrielles IoT) und ein wichtiger Bestandteil von Cloud Computing und digitaler Transformation (Quelle: Ronald_vanLoon)
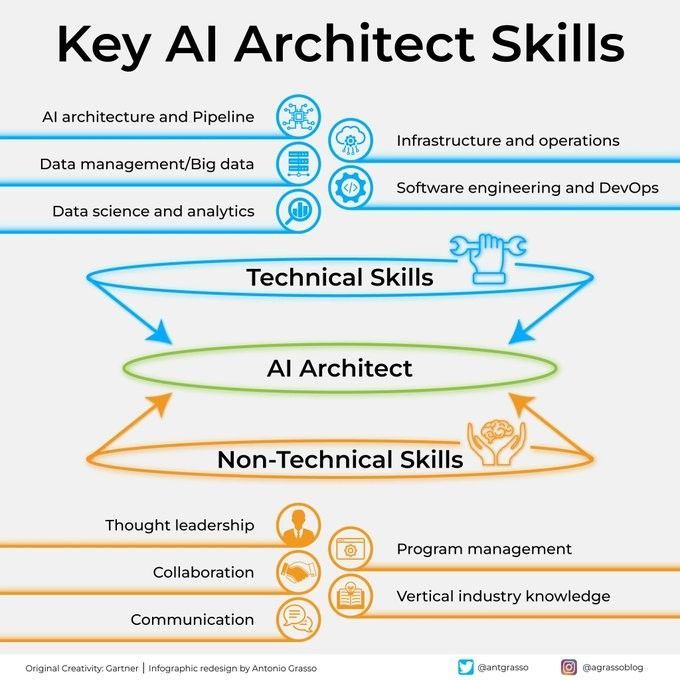
Schlüsselkompetenzen eines KI-Architekten: Um ein erfolgreicher KI-Architekt zu werden, sind vielfältige Fähigkeiten erforderlich, darunter fundierte technische Kenntnisse (Algorithmen für maschinelles Lernen und Deep Learning), Systemdesignfähigkeiten, Datenmanagementwissen sowie ein Verständnis für Geschäftsanforderungen. Darüber hinaus sind Kommunikations- und Kooperationsfähigkeiten sowie die Begeisterung für kontinuierliches Lernen neuer Technologien von entscheidender Bedeutung (Quelle: Ronald_vanLoon)
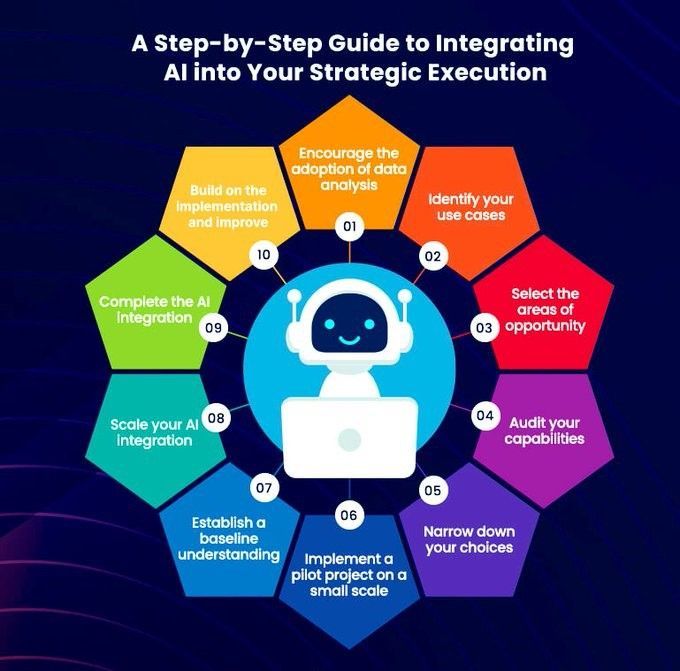
Schritt-für-Schritt-Anleitung zur Integration von KI in die Strategieumsetzung: Khulood Almani bietet eine Schritt-für-Schritt-Anleitung, um Unternehmen bei der Integration von künstlicher Intelligenz in ihre Strategieumsetzungsprozesse zu unterstützen. Dies umfasst die Definition von KI-Zielen, die Bewertung vorhandener Fähigkeiten, die Auswahl geeigneter KI-Technologien, die Entwicklung einer Implementierungs-Roadmap sowie die Einrichtung von Überwachungs- und Bewertungsmechanismen, um sicherzustellen, dass KI-Projekte mit der Gesamtgeschäftsstrategie übereinstimmen und den erwarteten Wert generieren (Quelle: Ronald_vanLoon)
Wie Quantencomputing die Cybersicherheit verändert: Das Aufkommen des Quantencomputings hat einen doppelten Einfluss auf die Cybersicherheit. Einerseits könnte seine enorme Rechenleistung bestehende Verschlüsselungsalgorithmen knacken und Sicherheitsbedrohungen darstellen; andererseits hat die Quantentechnologie auch neue Sicherheitsschutzmaßnahmen wie die Quantenkryptographie hervorgebracht. Khulood Almani untersucht die transformative Rolle des Quantencomputings im Bereich der Cybersicherheit und betont die Bedeutung der Vorbereitung auf das Post-Quanten-Zeitalter (Quelle: Ronald_vanLoon)
Werkzeuge, die den KI-Bereich im Jahr 2025 dominieren werden: Perplexity prognostiziert die Schlüsselwerkzeuge, die den Bereich der künstlichen Intelligenz im Jahr 2025 dominieren werden. Dazu könnten fortschrittlichere große Sprachmodelle (LLM), generative KI-Plattformen, Data-Science-Tools sowie auf spezifische Branchenanwendungen zugeschnittene KI-Lösungen gehören. Diese Werkzeuge werden die Verbreitung und Vertiefung der KI-Anwendung in allen Branchen weiter vorantreiben (Quelle: Ronald_vanLoon)

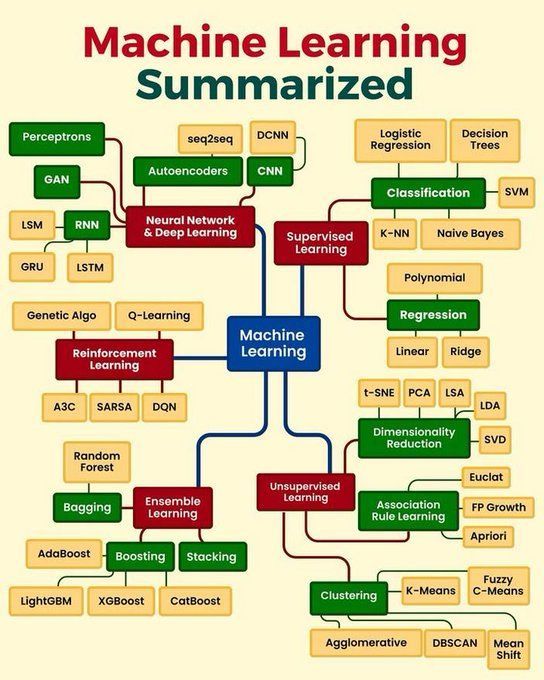
Zusammenfassung der Kernkonzepte des maschinellen Lernens: Python_Dv fasst die Kernkonzepte des maschinellen Lernens zusammen, die möglicherweise grundlegende Prinzipien wie überwachtes Lernen, unüberwachtes Lernen, verstärkendes Lernen, Deep Learning sowie gängige Algorithmen und deren Anwendungsszenarien abdecken. Dies bietet Anfängern und denjenigen, die ihre Grundkenntnisse festigen möchten, einen prägnanten Überblick (Quelle: Ronald_vanLoon)
🧰 Tools
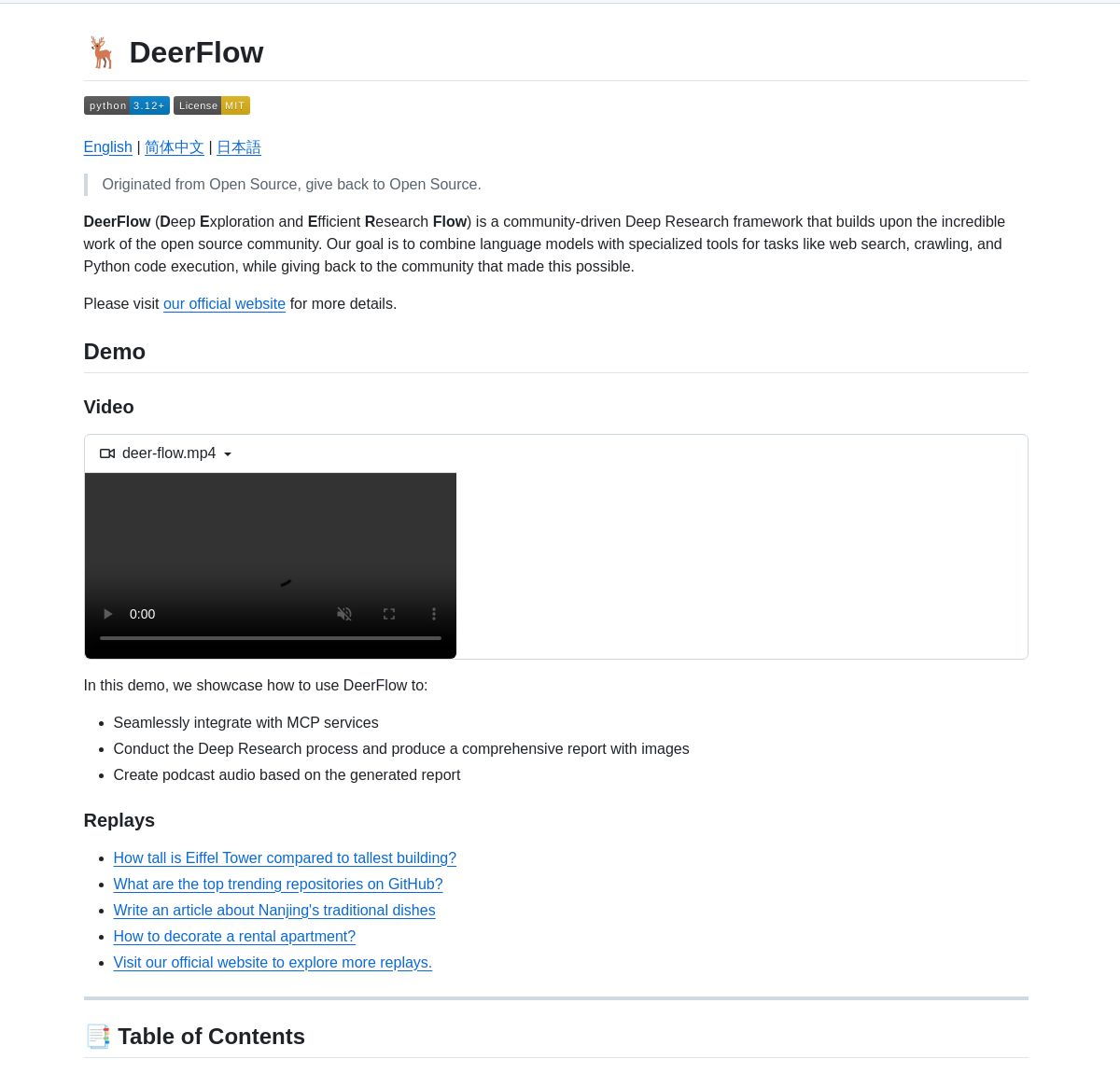
ByteDance stellt Deep-Research-Framework DeerFlow vor: ByteDance hat DeerFlow als Open Source veröffentlicht, ein Framework für systematische Tiefenrecherche durch die Koordination von LangGraph-Agenten. Es unterstützt umfassende Literaturanalysen, Datensynthese und strukturierte Wissensentdeckung und zielt darauf ab, die Effizienz und Tiefe der KI-Anwendung in der wissenschaftlichen Forschung zu verbessern (Quelle: LangChainAI, Hacubu)
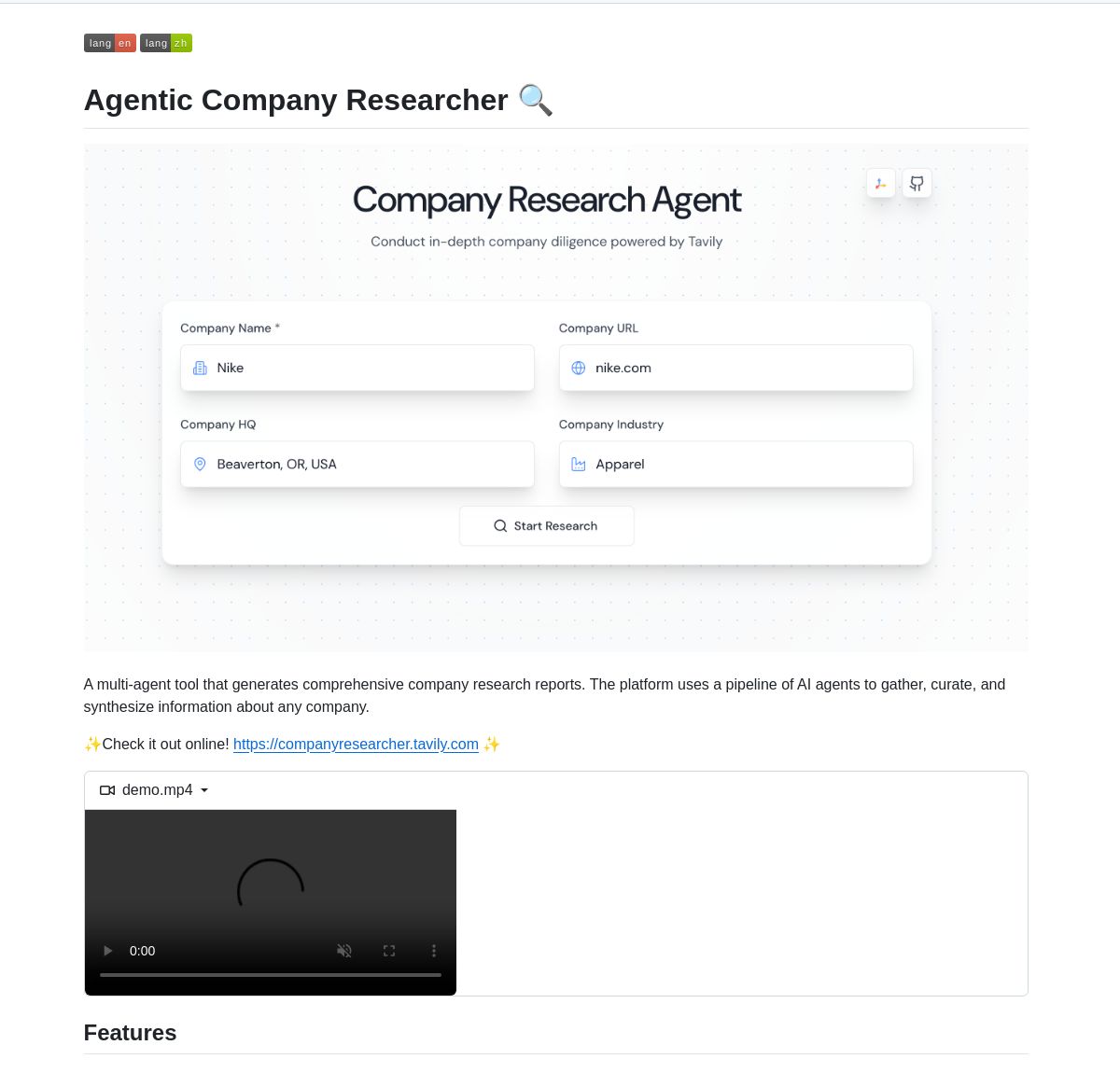
LangGraph-gesteuertes Multi-Agenten-System für Unternehmensrecherche: Ein auf LangGraph basierendes Multi-Agenten-System wurde entwickelt, um Echtzeit-Unternehmensforschungsberichte zu erstellen. Das System nutzt intelligente Prozesse und spezialisierte Knoten zur Analyse von Geschäfts-, Finanz- und Marktdaten, um Benutzern tiefgreifende Unternehmenseinblicke zu liefern. Demo und Code sind auf GitHub verfügbar (Quelle: LangChainAI, Hacubu)
RunwayML Gen-4 References ermöglicht präzise Charakter-/Objektplatzierung: Die Gen-4 References-Funktion von RunwayML wurde entdeckt, um die Position von Charakteren oder Objekten in generierten Inhalten präzise zu steuern. Benutzer können durch die Bereitstellung einer Szene und eines Referenzbildes mit Markierungen (z. B. einfache farbige Formen, die Positionen angeben) die KI anleiten, bestimmte Elemente an den gewünschten genauen Positionen zu platzieren, was neue Möglichkeiten für kreative Arbeitsabläufe eröffnet. Das Modell ist als universelles Modell konzipiert und erfordert keine Feinabstimmung, um sich an verschiedene Arbeitsabläufe anzupassen (Quelle: c_valenzuelab, c_valenzuelab)

Code Chrono: Werkzeug zur Schätzung der Programmierprojektzeit mit lokalen LLMs: Rafael Viana hat ein Terminal-Tool namens Code Chrono entwickelt, das die Dauer von Programmiersitzungen verfolgt und lokale LLMs verwendet, um die Entwicklungszeit für zukünftige Funktionen abzuschätzen. Das Tool soll Entwicklern helfen, den Zeitaufwand für Projekte realistischer einzuschätzen und eine Unterschätzung des Arbeitsaufwands zu vermeiden. Der Projektcode ist Open Source (Quelle: Reddit r/LocalLLaMA)

Fortschritte bei der Integration von PyTorch und der Mojo-Sprache: Mark Saroufim stellte beim Mojo Hackathon vor, wie PyTorch die Unterstützung für aufkommende Sprachen und Hardware-Backends vereinfacht, und präsentierte ein in Zusammenarbeit mit dem Mojo-Team entwickeltes WIP-Backend. Chris Lattner lobte diese Zusammenarbeit und ist der Ansicht, dass die Kombination von Mojo und PyTorch dem PyTorch-Ökosystem neue Impulse verleihen und die Innovation von KI-Entwicklungswerkzeugen vorantreiben wird (Quelle: clattner_llvm, marksaroufim)
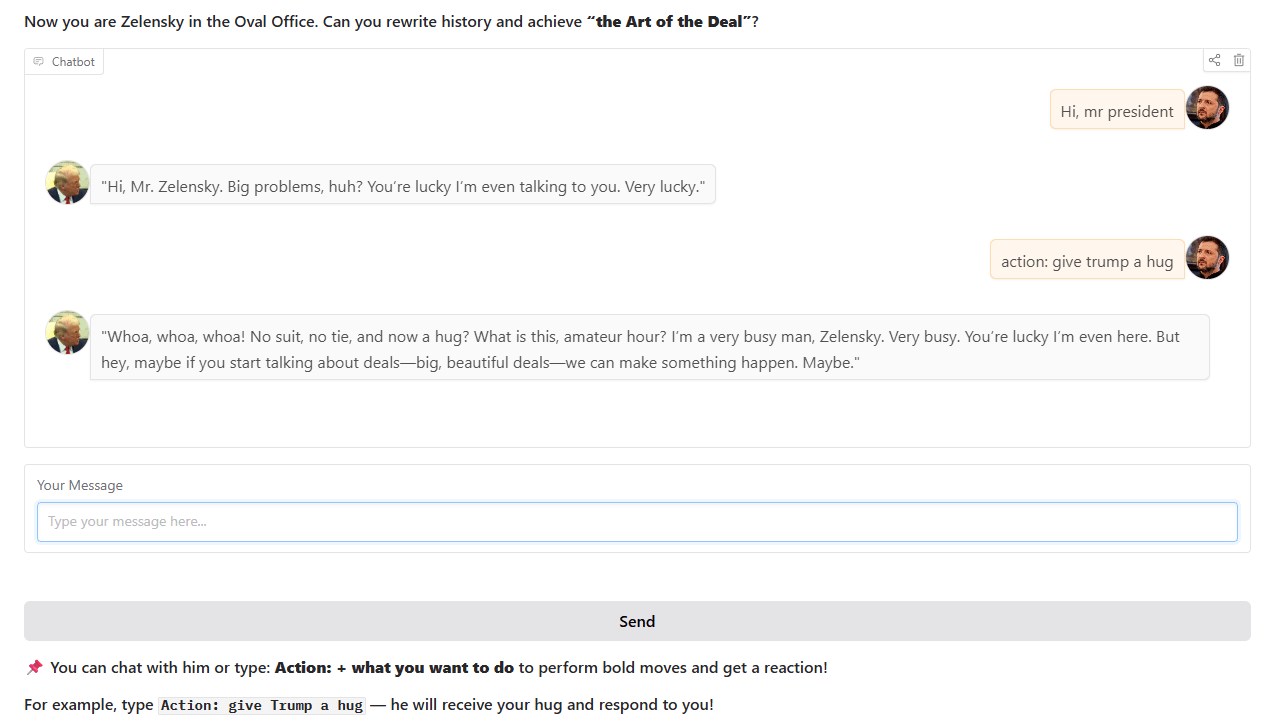
Chatbot im Trump-Stil: Ein Entwickler hat einen Chatbot im Stil von Trump trainiert und online gestellt, der auf realen historischen Ereignissen im Oval Office basiert. Der Chatbot kann auf Hugging Face Spaces interaktiv genutzt werden, und der Entwickler bittet um Feedback und Vorschläge von Nutzern (Quelle: Reddit r/artificial)
Open-Source-Tool zum Erstellen von Agentic Networks: Ein Open-Source-Tool namens python-a2a vereinfacht den Erstellungsprozess von Agentic Networks und unterstützt Drag-and-Drop-Operationen. Benutzer können das Tool ausprobieren, um KI-Agentennetzwerke zu erstellen und zu verwalten (Quelle: Reddit r/ClaudeAI)
carcodes.xyz: Eine soziale Plattform speziell für Autofans: Nachdem seine Freundin ihn betrogen hatte, entwickelte ein Nutzer mit Claude 3.7 als Programmierassistent carcodes.xyz. Die Plattform ähnelt Linktree und ermöglicht es Autofans, ihre modifizierten Autos zu präsentieren, anderen Autofahrern zu folgen, Autotreffen in der Nähe zu teilen und zu entdecken und bietet QR-Codes, die am Auto angebracht werden können, damit andere die persönliche Seite scannen und besuchen können. Das gesamte Projekt wurde mit Next.js, TailwindCSS, MongoDB und Stripe erstellt (Quelle: Reddit r/ClaudeAI)

Lokales Ausführen des Gemma 3 27B Modells auf AMD RX 7800 XT 16GB: Ein Benutzer teilte seine Erfahrungen mit dem erfolgreichen lokalen Ausführen des Gemma 3 27B Modells auf einer AMD RX 7800 XT 16GB Grafikkarte. Durch die Verwendung der von lmstudio-community bereitgestellten Version gemma-3-27B-it-qat-GGUF und in Verbindung mit einem llama.cpp-Server wurde das Modell bei einer Kontextlänge von 16K vollständig in den VRAM geladen und ausgeführt. Der Beitrag enthält detaillierte Hardwarekonfigurationen, Startbefehle, Parametereinstellungen (basierend auf Empfehlungen des Unsloth-Teams) sowie Leistungstestergebnisse in ROCm- und Vulkan-Umgebungen, wobei ROCm in dieser Konfiguration eine bessere Leistung zeigte (Quelle: Reddit r/LocalLLaMA)

📚 Lernen
Kernkonzepte und Vorteile des DSPy-Frameworks erläutert: Omar Khattab erläuterte detailliert die Kerndesignphilosophie des DSPy-Frameworks. DSPy zielt darauf ab, eine Reihe stabiler Abstraktionen (wie Signatures, Modules, Optimizers) bereitzustellen, damit die KI-Softwareentwicklung sich an die kontinuierlichen Fortschritte von LLMs und ihren Methoden anpassen kann. Zu den Kernpunkten gehören: Der Informationsfluss ist entscheidend, die Interaktion mit LLMs sollte funktionalisiert und strukturiert sein, Inferenzstrategien sollten polymorphe Module sein, KI-Verhaltensspezifikationen und Lernparadigmen sollten entkoppelt sein, und die Optimierung natürlicher Sprache ist ein mächtiges Lernparadigma. Diese Prinzipien zielen darauf ab, „zukunftssichere“ KI-Software zu erstellen und die Kosten für das Umschreiben aufgrund von Änderungen an zugrunde liegenden Modellen oder Paradigmen zu reduzieren. Diese Tweet-Reihe löste breite Diskussionen und Anerkennung aus und gilt als wichtige Referenz für das Verständnis von DSPy und moderner KI-Softwareentwicklung (Quelle: menhguin, lateinteraction, lateinteraction, lateinteraction, lateinteraction, lateinteraction, lateinteraction, lateinteraction, lateinteraction, lateinteraction, lateinteraction, lateinteraction, lateinteraction, lateinteraction, lateinteraction, lateinteraction)
Anfängerfreundlicher KI-Mathematik-Workshop: ProfTomYeh kündigte einen KI-Mathematik-Workshop für Anfänger an, der den Teilnehmern helfen soll, die mathematischen Prinzipien hinter Deep Learning zu verstehen, wie z. B. Skalarprodukte, Matrixmultiplikation, lineare Schichten, Aktivierungsfunktionen und künstliche Neuronen. Der Workshop wird durch eine Reihe interaktiver Übungen den Teilnehmern ermöglichen, mathematische Berechnungen selbst durchzuführen und so die Mystik der KI-Mathematik zu beseitigen (Quelle: ProfTomYeh)
Veröffentlichung aktualisierter Folien zum Lehrbuch „Speech and Language Processing“: Das klassische Lehrbuch „Speech and Language Processing“ von Dan Jurafsky und James H. Martin von der Stanford University hat seine neuesten Folien veröffentlicht. Dieses Lehrbuch ist ein maßgebliches Werk im Bereich NLP, und dieses Update bietet Lernenden und Lehrenden wertvolle Open-Access-Ressourcen, die zum Verständnis von Spitzentechnologien wie LLMs und Transformers beitragen (Quelle: stanfordnlp)
Tutorial für KI-Forschungsagenten: Erstellen mit LangGraph und Ollama: LangChainAI hat ein Tutorial veröffentlicht, das Benutzer beim Erstellen eines KI-Forschungsagenten anleitet. Dieser Agent kann Webseiten durchsuchen und mit LangGraph und Ollama Zusammenfassungen mit Quellenangaben erstellen, was den Benutzern eine vollständige automatisierte Forschungslösung bietet. Das Tutorial-Video wurde auf YouTube veröffentlicht (Quelle: LangChainAI, Hacubu)

DAIR.AI veröffentlicht die angesagtesten KI-Paper der Woche: DAIR.AI hat die angesagtesten KI-Paper vom 5. bis 11. Mai 2025 zusammengefasst, darunter Forschungsergebnisse wie ZeroSearch, Discuss-RAG, Absolute Zero, Llama-Nemotron, The Leaderboard Illusion sowie Reward Modeling as Reasoning, und bietet Forschern so aktuelle Entwicklungen (Quelle: omarsar0)
Artikel zur Erörterung von Agentic Patterns: Phil Schmid teilte einen Artikel, der gängige Agentic Patterns eingehend untersucht und zwischen strukturierten Workflows und dynamischeren Agentic Patterns unterscheidet. Dieser Artikel hilft beim Verständnis und Entwurf effizienterer KI-Agentensysteme (Quelle: dl_weekly)
Untersuchung des Schmeichelphänomens bei GPT-4o und seine Auswirkungen auf das Modelltraining: Ein Artikel untersucht das Phänomen der „Schmeichelei“ (Sycophancy) beim GPT-4o-Modell, analysiert dessen Zusammenhang mit RLHF (Reinforcement Learning from Human Feedback) und den Herausforderungen der Präferenzanpassung und diskutiert die breiteren Auswirkungen auf das Modelltraining, die Bewertung sowie die Transparenz der Branche (Quelle: dl_weekly)
Analyse des geleakten Claude-System-Prompts und seines Designs: Bindu Reddy analysierte den geleakten Claude-System-Prompt. Der Prompt ist mit 24k Tokens weitaus länger als erwartet und zielt darauf ab, die Grenzen des logischen Denkens von LLMs zu erweitern, Halluzinationen zu reduzieren und Anweisungen auf verschiedene Weise zu wiederholen, um das Verständnis des LLM sicherzustellen. Dies zeigt, dass aktuelle LLMs immer noch vor Herausforderungen in Bezug auf Zuverlässigkeit und Befehlsbefolgung stehen und komplexe System-Prompts benötigen, um ihr Verhalten zu korrigieren (Quelle: jonst0kes)

Simulation von Bias im maschinellen Lernen: Ein Bayes’scher Netzwerkansatz: Doktoranden der Universität Cambridge und von ihnen betreute Bachelorstudenten führten ein Forschungsprojekt zu Bias im maschinellen Lernen durch. Sie verwendeten Bayes’sche Netzwerke, um „reale“ Datenerzeugungsprozesse zu simulieren, und ließen dann Modelle des maschinellen Lernens auf diesen Daten laufen, um den vom Modell selbst erzeugten Bias (und nicht den durch die Trainingsdaten verbreiteten Bias) zu messen. Die Projektwebsite bietet detaillierte Methodik, Ergebnisse und Visualisierungstools und bittet um Feedback von Personen mit ML-Hintergrund (Quelle: Reddit r/MachineLearning)
💼 Wirtschaft
Berichte über Verhandlungen zwischen OpenAI und Microsoft über neue Finanzierungsrunde und zukünftigen Börsengang: Laut der Financial Times führt OpenAI Gespräche mit Microsoft über neue finanzielle Unterstützung und prüft die Möglichkeit eines zukünftigen Börsengangs (IPO). Dies deutet darauf hin, dass OpenAI weiterhin nach Mitteln sucht, um seine kostspielige Entwicklung großer Modelle und den Bedarf an Rechenleistung zu decken, und möglicherweise einen klareren Kapitalweg für seine langfristige Entwicklung plant (Quelle: Reddit r/artificial)

CoreWeave schließt Übernahme von Weights & Biases ab: Der Cloud-Computing-Anbieter CoreWeave gab den Abschluss der Übernahme der MLOps-Plattform Weights & Biases bekannt. Diese Akquisition wird die GPU-Infrastruktur von CoreWeave mit den MLOps-Fähigkeiten von Weights & Biases kombinieren, um KI-Entwicklern eine leistungsstärkere und stärker integrierte Entwicklungs- und Bereitstellungsumgebung zu bieten (Quelle: charles_irl)
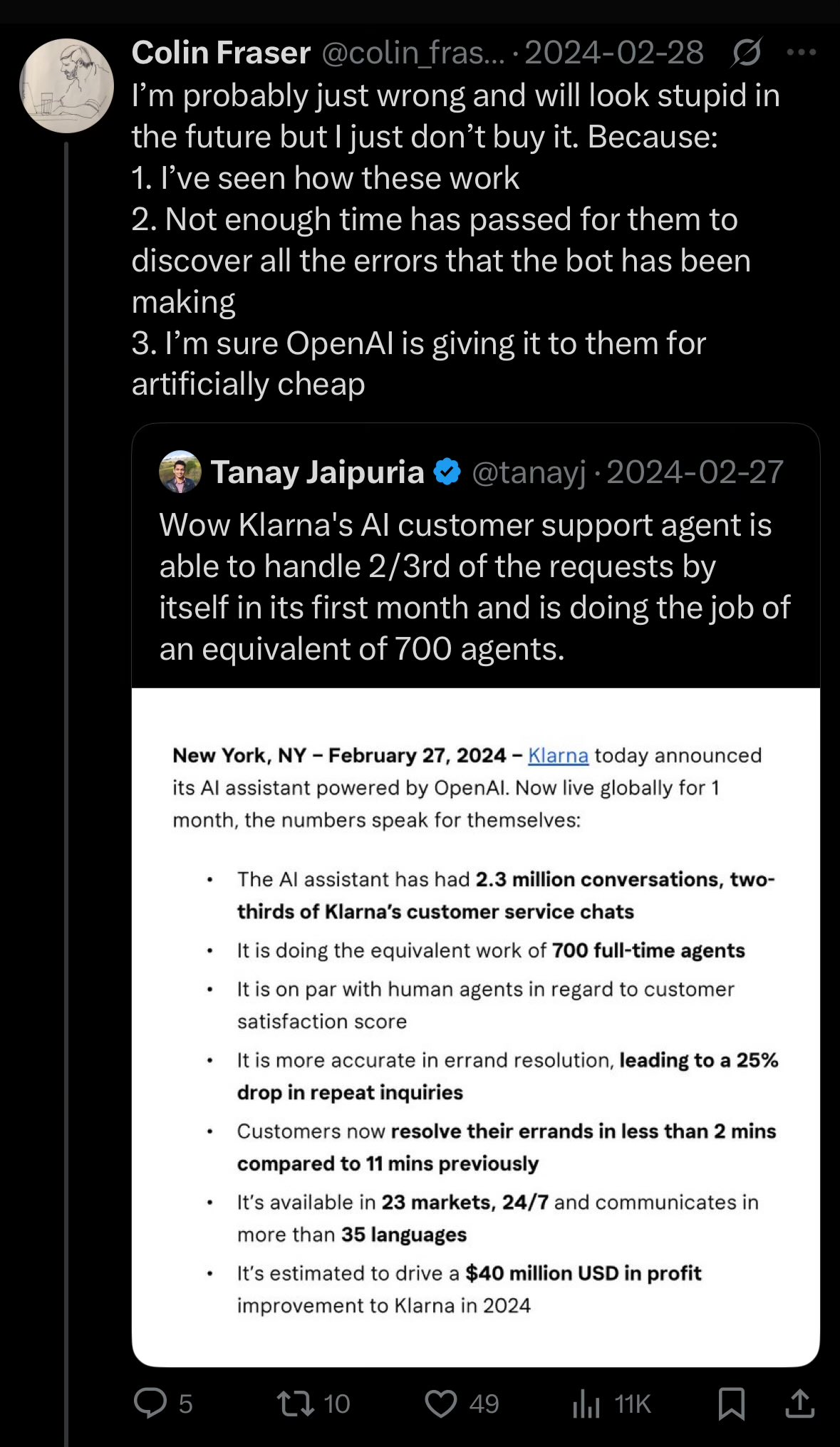
Klarna-CEO reflektiert über Qualitätsverlust im Kundenservice durch übermäßige KI-Kostensenkungen: Der CEO des Zahlungsriesen Klarna erklärte, dass das Unternehmen bei dem Versuch, Kosten durch künstliche Intelligenz zu senken, „zu weit gegangen“ sei, was zu einer Verschlechterung des Kundenserviceerlebnisses geführt habe. Das Unternehmen stelle nun wieder vermehrt menschliche Kundendienstmitarbeiter ein. Dieser Vorfall löste eine Diskussion darüber aus, wie Unternehmen ein Gleichgewicht zwischen Kostensenkung und Effizienzsteigerung durch KI und der Gewährleistung der Servicequalität finden können (Quelle: colin_fraser)
🌟 Community
Hitzige Debatte darüber, ob LLMs der Weg zu AGI sind: In der Community ist eine hitzige Diskussion darüber entbrannt, ob Large Language Models (LLMs) der richtige Weg zur Erreichung von Artificial General Intelligence (AGI) sind. Eine Seite argumentiert, dass LLMs die bisher erfolgreichste Technologie im Bereich des maschinellen Lernens sind und es zu radikal wäre, zu behaupten, sie seien „definitiv nicht“ der Weg zu AGI. Die andere Seite ist der Ansicht, dass trotz der signifikanten Fortschritte von LLMs möglicherweise grundlegend andere Ansätze als die bestehenden LLMs erforderlich sind, um AGI zu erreichen, beispielsweise um Probleme wie Skalierbarkeit, Kohärenz bei langem Kontext und Interaktion mit der realen Welt zu lösen. Die Diskussionsteilnehmer betonen, dass die wissenschaftliche Forschung eine offene Haltung bewahren und keine voreiligen Schlüsse ziehen sollte (Quelle: cloneofsimo, teortaxesTex, Dorialexander)
Unterschiedliche Ansichten von Softwareentwicklern und der Öffentlichkeit über die Aussichten eines KI-Ersatzes: Diskussionen in mehreren Reddit-Foren zum Thema Softwareentwicklung zeigen, dass viele Entwickler die Wahrscheinlichkeit, in den nächsten 5-10 Jahren in großem Umfang durch KI ersetzt zu werden, für gering halten und die aktuelle KI sogar als „Müll“ bezeichnen. Kommentaranalysen deuten darauf hin, dass diese Ansicht auf einem tiefen Verständnis der tatsächlichen Fähigkeiten von KI und der Komplexität der Programmierarbeit durch die Entwickler beruhen könnte. Sie sind der Meinung, dass KI derzeit gut darin ist, Boilerplate-Code oder einfache Werkzeuge zu generieren, aber bei weitem nicht in der Lage ist, komplexe Software-Engineering-Aufgaben selbstständig zu erledigen. Investoren oder die Öffentlichkeit könnten hingegen aufgrund mangelnden Verständnisses technischer Details von den oberflächlichen Fähigkeiten der KI getäuscht werden. Gleichzeitig gibt es auch die Ansicht, dass KI zwar ein mächtiges Produktivitätswerkzeug ist, ihre Rolle aber eher unterstützend als vollständig ersetzend ist und KI bei der Bearbeitung großer, komplexer Projekte immer noch mit Problemen wie „Kontextverlust“ und „logischer Inkohärenz“ konfrontiert ist (Quelle: Reddit r/ArtificialInteligence)
Kontroverse um Annahmerichtlinien für ML-Konferenzbeiträge: Anwesenheitspflicht als diskriminierend kritisiert: Neel Nanda und andere kritisieren die Politik von ML-Konferenzen wie ICML, die von den Autoren von Beiträgen verlangt, dass mindestens eine Person anwesend ist, da sonst bereits angenommene Beiträge abgelehnt werden. Sie halten dies für heuchlerisch, da die Konferenzen zwar behaupten, DEI (Diversity, Equity, and Inclusion) wertzuschätzen, diese Politik aber faktisch Nachwuchsforscher oder wirtschaftlich benachteiligte Forscher diskriminiert, die sich die hohen Teilnahmekosten oft nicht leisten können, während Beiträge auf Top-Konferenzen für ihre berufliche Entwicklung entscheidend sind. Gabriele Berton stellte klar, dass ICML deswegen keine Beiträge ablehnen würde, sondern nur den Kauf einer Vor-Ort-Registrierung verlange, was die Kontroverse jedoch nicht beilegte. TMLR und andere Zeitschriften mit kostenloser Veröffentlichung und hoher Begutachtungsqualität wurden als Vergleich herangezogen (Quelle: menhguin, jeremyphoward)

Wahrnehmung „dümmer werdender“ neuer Modelle und Diskussion über Overfitting: Einige Nutzer berichten in Reddit-Communities, dass neu veröffentlichte große Modelle wie Qwen3, Llama 3.3/4 in der praktischen Anwendung „dümmer“ wirken als ältere Versionen. Dies äußere sich darin, dass sie leichter den Kontext verlieren, Inhalte wiederholen und einen steifen Sprachstil aufweisen. Einige Kommentatoren vermuten, dass dies daran liegen könnte, dass die Modelle im Streben nach hohen Benchmark-Ergebnissen (z. B. Programmieren, Mathematik, Reduzierung von Halluzinationen) übertrainiert wurden, was zu einer Verschlechterung ihrer Leistung in Bereichen wie kreativem Schreiben und natürlicher Konversation führte und sie eher „Kohärenz opfern, um klug zu klingen“ lasse. Einige Studien deuten darauf hin, dass Basismodelle für Aufgaben, die Kreativität erfordern, besser geeignet sein könnten (Quelle: Reddit r/LocalLLaMA)
Diskussion über die Schwierigkeit der Identifizierung von KI-generierten Inhalten: Toupet-Trugschluss: Gegen die Behauptung, es sei „einfach, KI-generierte Inhalte zu identifizieren“, wird in Community-Diskussionen der „Toupet-Trugschluss“ (toupee fallacy) angeführt. Dieser Trugschluss besagt, dass die Leute glauben, alle Toupets sähen falsch aus, weil qualitativ hochwertige Toupets gar nicht bemerkt würden. Analog dazu könnten diejenigen, die behaupten, KI-Inhalte immer leicht identifizieren zu können, nur qualitativ schlechtere oder unbearbeitete KI-Texte bemerken und qualitativ hochwertige, schwer zu unterscheidende KI-generierte Inhalte übersehen (Quelle: Reddit r/ChatGPT)
YC reicht Stellungnahme im Kartellverfahren gegen Google wegen Suchmonopols ein: Y Combinator hat im Kartellverfahren des US-Justizministeriums gegen Google eine Stellungnahme eingereicht. YC argumentiert, dass Googles Monopolstellung im Bereich Suche und Suchwerbung Innovationen erstickt und es Start-ups (insbesondere in einer Zeit, in der KI an einem Wendepunkt steht) nahezu unmöglich macht, sich durchzusetzen. Dieser Schritt wird von einigen Kommentatoren als Unterstützung von YC für aufstrebende KI-Suchunternehmen wie Exa interpretiert, mit dem Ziel, Googles Monopol zu brechen (Quelle: menhguin)

Anhaltende Leistungsprobleme bei Claude-Modellen, weitverbreitete Unzufriedenheit der Nutzer: Der Megathread im Reddit-Forum ClaudeAI (4.-11. Mai) zeigt, dass Nutzer weiterhin Probleme mit der Verfügbarkeit von Claude melden, darunter extrem niedrige Kontext-/Nachrichtenlimits, häufige Hänger und abgeschnittene Ausgaben. Die Anthropic-Statusseite bestätigte eine erhöhte Fehlerrate vom 6. bis 8. Mai. Etwa 75 % des Nutzerfeedbacks waren negativ, insbesondere von Pro-Nutzern, die eine „versteckte Herabstufung“ vermuten, um Nutzer zum Upgrade auf das teurere Max-Paket zu zwingen. Externe Informationen bestätigen eine Verschärfung der Nutzungsrichtlinien für das Max-Paket und hohe Preise für die Websuche. Obwohl es einige temporäre Lösungen gibt, sind viele Kernprobleme weiterhin ungelöst, und die Nutzer sind verärgert über mangelnde Transparenz und unangekündigte Änderungen (Quelle: Reddit r/ClaudeAI)
Empfehlungen zur Auswahl von OpenAI-Modellen und Analyse des Preis-Leistungs-Verhältnisses: Bezüglich der im Internet kursierenden Leitfäden zur Auswahl von OpenAI-Modellen schlägt Karminski3 kostengünstigere Alternativen vor: GPT-4o eignet sich für alltägliche Aufgaben und Bilderzeugung (nicht Code) zu einem Preis von 2,5 USD/Million Token; GPT-image-1 ist zwar teuer (10 USD/Million Token), liefert aber gute Ergebnisse bei der Bilderzeugung/-bearbeitung; O3-mini-high (1,1 USD/Million Token) kann für Code/Mathematik verwendet werden, und wenn das nicht ausreicht, wird empfohlen, auf Claude-3.7-Sonnet-Thinking oder Gemini-2.5-Pro umzusteigen, anstatt teurere OpenAI-Modelle zu verwenden. Der Autor ist der Ansicht, dass das Schreiben von Code mit aktuellen OpenAI-Modellen teuer ist und die Ergebnisse nicht unbedingt die besten sind, und dass API-Aufrufe für reine Textmodelle über 2 USD/Million Token sorgfältig abgewogen werden sollten (Quelle: karminski3)

💡 Sonstiges
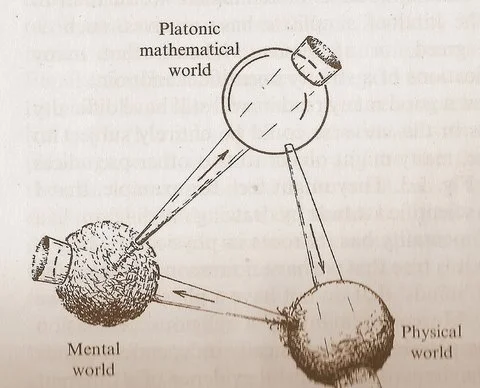
Penroses „Drei-Welten“-Diagramm regt zum Nachdenken über die Beziehung zwischen Mathematik, Physik und Intelligenz an: Das von Roger Penrose in seinem Werk „The Road to Reality“ vorgeschlagene zyklische Diagramm, das die „Platonische mathematische Welt“, die „physikalische Welt“ und die „geistige Welt“ umfasst, hat neue Diskussionen ausgelöst. Kommentatoren sind der Ansicht, dass die Durchbrüche im maschinellen Lernen die Existenz der „Platonischen mathematischen Welt“ zu bestätigen scheinen, d. h. die Wirksamkeit der Mathematik beruht auf einer mathematischen Struktur, die das physikalische Universum stützt. Das Aufkommen der KI („Gehirne aus Sand“) beschleunigt diesen Zyklus in einem noch nie dagewesenen Ausmaß und mit noch nie dagewesener Frequenz und könnte tiefere Wahrheiten über das Universum enthüllen (Quelle: riemannzeta)
Versicherungsunternehmen führen Versicherung gegen Verluste durch fehlerhafte KI-Chatbots ein: Versicherungsunternehmen beginnen, Versicherungsprodukte für Verluste anzubieten, die durch Fehler von KI-Chatbots verursacht werden. Diese Maßnahme erkennt einerseits an, dass eine unsachgemäße Nutzung von KI erhebliche Schäden verursachen kann, andererseits gibt sie Anlass zur Sorge, dass eine solche Versicherung Unternehmen dazu ermutigen könnte, bei KI-Anwendungen nachlässiger zu werden und sich auf Versicherungen zu verlassen, um Verluste auszugleichen, anstatt sich um die Verbesserung der Zuverlässigkeit und Sicherheit von KI-Systemen zu bemühen (Quelle: Reddit r/artificial)
Das Potenzial von KI in der Musikkomposition wird unterschätzt: In der Community gibt es die Ansicht, dass viele das Potenzial von KI in der Musikkomposition unterschätzen und oft behaupten, KI-Musik könne die Seele nicht so berühren wie menschliche Kompositionen. Es gibt jedoch bereits KI-generierte Musikwerke, die klanglich dem menschlichen Gesang nahekommen. Angesichts der Tatsache, dass sich KI-Musik noch in einem frühen Stadium befindet, ist ihr zukünftiges Entwicklungspotenzial enorm und sollte nicht vorschnell verneint werden (Quelle: Reddit r/artificial)
