Schlüsselwörter:Prime Intellect, INTELLECT-2, Sakana AI, kontinuierliche Denkmaschine, Transformer, Google KI-Agent, AgentOps, Multi-Agenten-Kollaboration, verteiltes Reinforcement Learning-Training, neuronale Zeitsteuerung und Synchronisation, KI-Agenten-Betriebsablauf, Multi-Agenten-Architektur, KI-Agenten im Unternehmenseinsatz
🔥 Fokus
Prime Intellect veröffentlicht INTELLECT-2 Modell als Open Source: Prime Intellect hat INTELLECT-2 veröffentlicht und als Open Source freigegeben, ein Modell mit 32 Milliarden Parametern, das als das erste durch weltweit verteiltes Reinforcement Learning trainierte Modell bezeichnet wird. Die Veröffentlichung umfasst einen detaillierten technischen Bericht und Modell-Checkpoints. Das Modell zeigt in mehreren Benchmarks eine vergleichbare oder sogar bessere Leistung als Modelle wie Qwen 32B, insbesondere bei der Codegenerierung und beim mathematischen Schlussfolgern. Community-Mitglieder haben entdeckt, dass es Wordle spielen kann. Seine Trainingsmethode und die Open-Source-Veröffentlichung könnten als potenziell einflussreich für das zukünftige Training großer Modelle und die Wettbewerbslandschaft angesehen werden (Quelle: Grad62304977, teortaxesTex, eliebakouch, Sentdex, Ar_Douillard, andersonbcdefg, scaling01, andersonbcdefg, vllm_project, tokenbender, qtnx_, Reddit r/LocalLLaMA, teortaxesTex)

Sakana AI schlägt Continuous Thought Machine (CTM) vor: Sakana AI hat eine neue neuronale Netzwerkarchitektur namens „Continuous Thought Machine“ (CTM) vorgestellt, die darauf abzielt, KI durch die Einführung von Mechanismen des biologischen Gehirns wie neuronales Timing und neuronale Synchronisation eine flexiblere, menschenähnliche Intelligenz zu verleihen. Die Kerninnovation von CTM liegt in der Zeitverarbeitung auf Neuronenebene und der Nutzung neuronaler Synchronisation als latente Repräsentation, was es ermöglicht, Aufgaben zu bewältigen, die sequentielles Schlussfolgern und adaptive Berechnungen erfordern, sowie Erinnerungen zu speichern und abzurufen. Die Forschung wurde mit einem Blogbeitrag, einem interaktiven Bericht, einem Paper und einem GitHub-Repository veröffentlicht und erforscht ein neues Paradigma, bei dem KI „mit Zeit denkt“ (Quelle: SakanaAILabs, Plinz, SakanaAILabs, SakanaAILabs, hardmaru, teortaxesTex, tokenbender, Reddit r/MachineLearning)
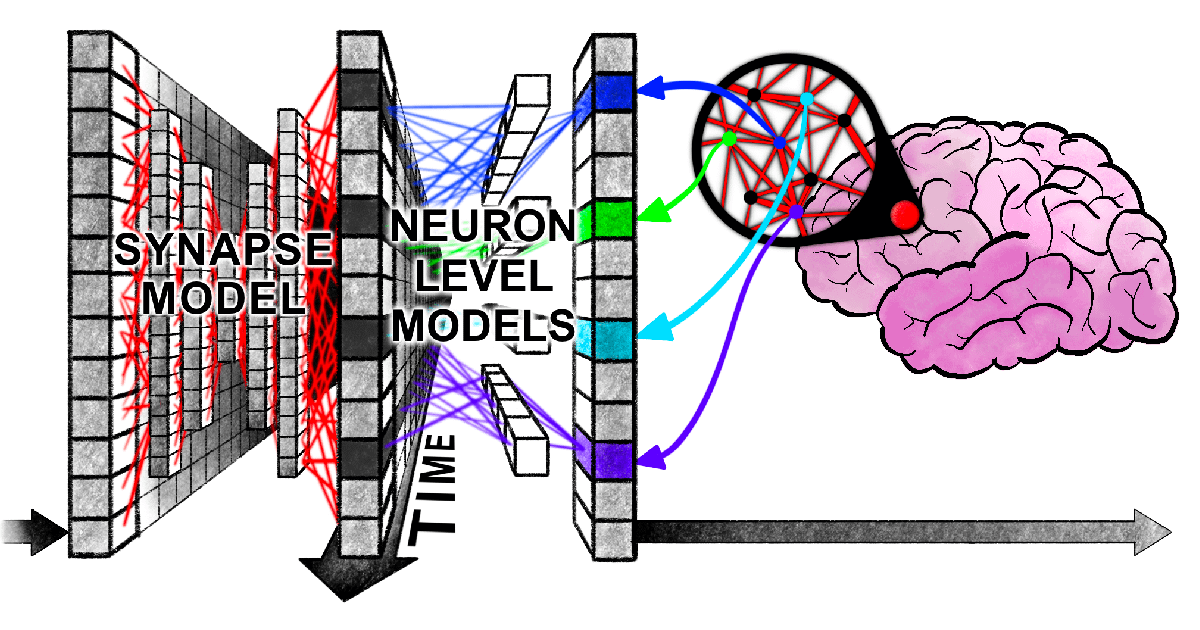
Neue Harvard-Studie enthüllt „synchrone Verwicklung“ bei der Informationsverarbeitung von Transformern und menschlichem Gehirn: Forscher der Harvard University und anderer Institutionen haben ein Paper mit dem Titel „Linking forward-pass dynamics in Transformers and real-time human processing“ veröffentlicht, das die Ähnlichkeiten zwischen den internen Verarbeitungsdynamiken von Transformer-Modellen und menschlichen Echtzeit-Kognitionsprozessen untersucht. Die Studie betrachtet nicht nur die endgültige Ausgabe, sondern analysiert „Verarbeitungslast“-Metriken (wie Unsicherheit, Konfidenzänderungen) auf jeder Schicht des Modells. Sie stellt fest, dass KI beim Lösen von Problemen (wie der Beantwortung von Hauptstädten, Tierklassifizierung, logischem Denken, Bilderkennung) ähnliche Prozesse wie menschliches „Zögern“, „intuitive Fehler“ bis hin zur „Korrektur“ durchläuft. Diese Ähnlichkeit im „Denkprozess“ deutet darauf hin, dass KI auf natürliche Weise ähnliche kognitive Abkürzungen wie Menschen lernt, um Aufgaben zu erfüllen, was neue Perspektiven für das Verständnis von KI-Entscheidungen und die Gestaltung menschlicher Experimente bietet (Quelle: 36氪)

Google veröffentlicht 76-seitiges Whitepaper zu KI-Agenten, erläutert AgentOps und Multi-Agenten-Kollaboration: Googles neuestes Whitepaper zu KI-Agenten erläutert detailliert die Erstellung, Bewertung und Anwendung von KI-Agenten. Das Whitepaper betont die Bedeutung von Agent Operations (AgentOps), einem Prozess zur Optimierung der Erstellung und Bereitstellung von Agenten in Produktionsumgebungen, der Tool-Management, Kern-Prompt-Einstellungen, Gedächtnisimplementierung und Aufgabenzerlegung umfasst. Das Whitepaper untersucht auch Multi-Agenten-Architekturen, bei denen mehrere Agenten mit spezialisierten Fähigkeiten zusammenarbeiten, um komplexe Ziele zu erreichen. Es stellt Googles Praxisfälle für den Einsatz von Agenten im Unternehmen (wie NotebookLM Enterprise Edition, Agentspace Enterprise Edition) sowie spezifische Anwendungen (wie Multi-Agenten-Systeme für Autos) vor, mit dem Ziel, die Unternehmensproduktivität und Benutzererfahrung zu verbessern (Quelle: 36氪)
🎯 Entwicklungen
LightonAI veröffentlicht semantisches Retrieval-Modell GTE-ModernColBERT-v1: LightonAI hat ein neues semantisches Retrieval-Modell namens GTE-ModernColBERT-v1 vorgestellt, das im LongEmbed / LEMB Narrative QA Benchmark die derzeit höchste Punktzahl erreicht hat. Dieses Modell wurde speziell zur Verbesserung der semantischen Suchergebnisse entwickelt und kann in Szenarien wie der Dokumenteninhaltsrecherche, RAG usw. angewendet und in bestehende Systeme integriert werden. Berichten zufolge basiert das Modell auf einem Fine-Tuning von Alibaba-NLP/gte-modernbert-base und zielt darauf ab, die Einschränkungen traditioneller Suchmaschinen zu überwinden, die sich nur auf Zeichenübereinstimmungen verlassen (Quelle: karminski3)
Technologieführer beobachten den rasanten Aufstieg von DeepSeek: VentureBeat berichtet über die Reaktionen von Technologieführern auf die schnelle Entwicklung von DeepSeek. Mit seinen leistungsstarken Modellfähigkeiten und seiner Open-Source-Strategie hat DeepSeek im globalen KI-Bereich, insbesondere bei Mathematik- und Codegenerierungsaufgaben, bemerkenswerte Erfolge erzielt und stellt eine Herausforderung für bestehende Marktstrukturen (einschließlich OpenAI usw.) dar. Seine kostengünstige Trainings- und API-Preisstrategie fördert ebenfalls die Verbreitung und Kommerzialisierung von KI-Technologien (Quelle: Ronald_vanLoon)

ByteDance und Peking-Universität veröffentlichen gemeinsam DreamO, ein einheitliches Framework zur Bildanpassung mit Unterstützung für die Kombination mehrerer Bedingungen: ByteDance hat in Zusammenarbeit mit der Peking-Universität DreamO vorgestellt, ein Framework zur Bildanpassung, das die freie Kombination mehrerer Bedingungen wie Subjekt, Identität, Stil und Kleidungsreferenz mit einem einzigen Modell ermöglicht. Das Framework basiert auf Flux-1.0-dev und führt eine spezielle Mapping-Schicht zur Verarbeitung von bedingten Bildeingaben ein. Es verwendet eine progressive Trainingsstrategie und Routing-Beschränkungen für Referenzbilder, um die Generierungsqualität und Konsistenz zu verbessern. Mit nur 400 Millionen Trainingsparametern erreicht DreamO die Generierung eines angepassten Bildes in 8-10 Sekunden und zeigt eine hervorragende Leistung bei der Aufrechterhaltung der Konsistenz. Der zugehörige Code und das Modell wurden als Open Source veröffentlicht (Quelle: WeChat)

VITA-Team veröffentlicht Echtzeit-Sprach-LLM VITA-Audio als Open Source, Inferenz-Effizienz stark verbessert: Das VITA-Team hat das End-to-End-Sprachmodell VITA-Audio vorgestellt. Durch die Einführung eines leichtgewichtigen Multi-Cross-Modal-Token-Prediction (MCTP)-Moduls wird die direkte Generierung dekodierbarer Audio Token Chunks in einem einzigen Forward-Pass ermöglicht. Bei einer Skalierung von 7 Milliarden Parametern benötigt das Modell vom Empfang des Textes bis zur Ausgabe des ersten Audiofragments nur 92 ms (53 ms ohne Audio-Encoder), was die Inferenzgeschwindigkeit im Vergleich zu Modellen ähnlicher Größe um das 3- bis 5-fache erhöht. VITA-Audio unterstützt Chinesisch und Englisch, wurde nur mit Open-Source-Daten trainiert und zeigt hervorragende Leistungen bei Aufgaben wie TTS, ASR usw. Der zugehörige Code und die Modellgewichte wurden als Open Source veröffentlicht (Quelle: WeChat)

Tsinghua, General AI Research Institute et al. schlagen „Absolute Zero“-Trainingsmethode vor, LLMs schalten durch Self-Play Schlussfolgerungsfähigkeiten frei: Forscher der Tsinghua-Universität, des Beijing General Artificial Intelligence Research Institute und anderer Institutionen haben die Trainingsmethode „Absolute Zero“ vorgeschlagen. Sie ermöglicht es vortrainierten großen Modellen, durch Self-Play Aufgaben zu generieren und zu lösen, um Schlussfolgerungsfähigkeiten zu erlernen, ohne auf externe Daten angewiesen zu sein. Die Methode stellt Schlussfolgerungsaufgaben einheitlich als (Programm, Eingabe, Ausgabe)-Tripel dar. Das Modell übernimmt die Rollen des Proposers (Aufgabensteller) und des Solvers (Aufgabenlöser) und lernt durch drei Aufgabentypen: Abduktion, Deduktion und Induktion. Experimente zeigen, dass mit dieser Methode trainierte Modelle bei Code- und mathematischen Schlussfolgerungsaufgaben signifikante Verbesserungen erzielen und die Leistung von Modellen übertreffen, die mit von Experten annotierten Beispielen trainiert wurden (Quelle: WeChat)

Entwicklung von AI PCs beschleunigt sich, Lenovo und Huawei veröffentlichen nacheinander neue AI-Endgeräte: Lenovo und Huawei haben kürzlich PC-Produkte mit integrierten KI-Agenten auf den Markt gebracht, wie Lenovos Tianxi Personal Super Intelligent Agent und Huaweis HarmonyOS-Computer mit dem Xiaoyi Intelligent Agent. Obwohl die Marktdurchdringung von AI PCs noch gering ist, wächst sie schnell. Canalys-Daten zeigen, dass die Auslieferungen von AI PCs auf dem chinesischen Festland im Jahr 2024 bereits 15 % des gesamten PC-Marktes ausmachten, und es wird erwartet, dass dieser Anteil bis 2025 auf 34 % steigen wird. Brancheninsider gehen davon aus, dass die Reifung der AI PC-Lieferkette noch 2-3 Jahre dauern wird. Aktuelle Herausforderungen sind hauptsächlich die Kosten und Skalierungsprobleme bei Speicher, Chips und anderen Lieferkettenkomponenten sowie die Fragmentierung des heimischen AI PC-Ökosystems. Zukünftige Trends umfassen Agenten als zentrale Interaktionsschnittstelle, lokale Bereitstellung von KI sowie die Erweiterung von KI-Anwendungsszenarien auf Bildung, Gesundheit und andere Bereiche (Quelle: 36氪)
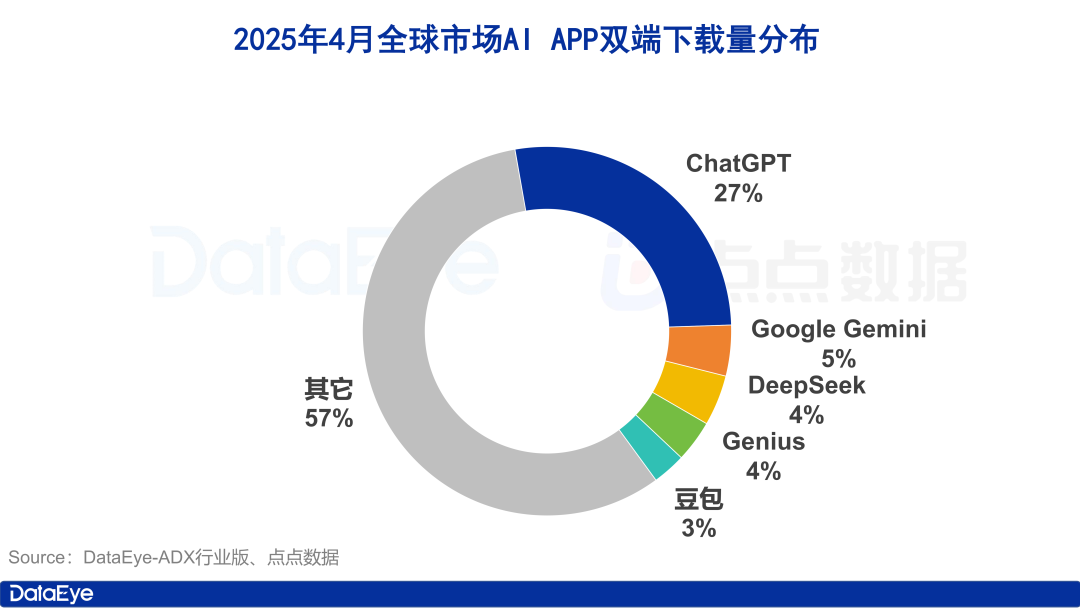
Globale Downloadzahlen von KI-Apps steigen stark an, heimischer Markt kühlt ab, Doubao wächst gegen den Trend: Im April 2025 erreichten die weltweiten Downloadzahlen von KI-Anwendungen auf beiden Plattformen 330 Millionen, ein Anstieg von 27,4 % gegenüber dem Vormonat. ChatGPT, Google Gemini, DeepSeek, Genius und Doubao belegten die ersten fünf Plätze. Insbesondere ChatGPT verzeichnete aufgrund der Veröffentlichung von GPT-4o einen sprunghaften Anstieg der Downloads. Im Gegensatz dazu sanken die Downloadzahlen von KI-Anwendungen auf der Apple-Plattform auf dem chinesischen Festland im Vergleich zum Vormonat um 24,0 %. Doubao wuchs gegen den Trend und belegte den ersten Platz, gefolgt von DeepSeek und Jimi AI. Bei der Akquise investierten Tencent Yuanbao und Quark stark und machten den Großteil des Werbematerials aus, während die Investitionen von Doubao zurückgingen. Insgesamt hat sich die Begeisterung für den heimischen KI-Markt etwas abgekühlt, und der Wettbewerb kehrt zu Technologie und Betrieb zurück (Quelle: 36氪)
Marktbereinigung bei chinesischen LLMs, „Fünf Basismodell-Giganten“ zeichnen sich ab: Mit der Verschärfung des globalen KI-Finanzierungsumfelds im Jahr 2024 erlebt der chinesische Markt für große Modelle eine „Entblasenbildung“. Die ursprüngliche Konstellation der „Sechs kleinen Tiger“ hat sich zu den „Fünf Basismodell-Giganten“ gewandelt, angeführt von ByteDance, Alibaba, Jiyue Xingchen (Leap AI), Zhipu AI und DeepSeek. Diese führenden Akteure haben jeweils Vorteile in Bezug auf Kapital, Talente und Technologie und verfolgen differenzierte Wege: ByteDance setzt auf eine umfassende Strategie, Alibaba konzentriert sich auf Open Source und Full-Stack, Jiyue Xingchen vertieft sich in Multimodalität, Zhipu AI nutzt seinen Tsinghua-Hintergrund für den 2B/2G-Markt, und DeepSeek sticht durch extreme technische Optimierung und Open-Source-Strategie hervor. Der nächste Wettbewerbsschwerpunkt wird darin liegen, die „Intelligenzgrenze“ zu durchbrechen und die „multimodalen Fähigkeiten“ zu verbessern, um die Vision von AGI zu verwirklichen (Quelle: 36氪, WeChat)

Rekord-Einreichungen bei ICCV 2025 wecken Bedenken hinsichtlich der Review-Qualität, Einsatz von LLMs zur Unterstützung der Begutachtung verboten: Die Anzahl der Einreichungen für die führende Computer-Vision-Konferenz ICCV 2025 erreichte mit 11.152 einen historischen Höchststand. Nach der Bekanntgabe der Review-Ergebnisse äußerten jedoch zahlreiche Autoren in sozialen Medien Unzufriedenheit über die Qualität der Begutachtung. Sie hielten einige Gutachten für oberflächlich, teilweise sogar schlechter als die von GPT, und wiesen auf Probleme wie Gutachter hin, die ergänzende Materialien nicht gelesen hatten. Um dem Anstieg der Einreichungen zu begegnen, forderte die Konferenz jeden einreichenden Autor auf, am Begutachtungsprozess teilzunehmen, und verbot ausdrücklich die Verwendung großer Modelle (wie ChatGPT) während des Reviews, um Originalität und Vertraulichkeit zu gewährleisten. Obwohl offizielle Daten zeigen, dass 97,18 % der Reviews fristgerecht eingereicht wurden, sind die Qualität der Begutachtung und die Belastung der Gutachter zu einem heiß diskutierten Thema geworden (Quelle: 36氪)
Nvidia CEO Jensen Huang: Alle Mitarbeiter werden mit KI-Agenten ausgestattet, Rolle der Entwickler wird neu definiert: Nvidia CEO Jensen Huang erklärte, dass das Unternehmen alle Mitarbeiter (einschließlich Softwareingenieure und Chipdesigner) mit KI-Agenten ausstatten wird, um die Arbeitseffizienz, den Projektumfang und die Softwarequalität zu steigern. Er sieht eine Zukunft voraus, in der jeder Mensch mehrere KI-Assistenten befehligt und die Produktivität exponentiell wächst. Dieser Trend deckt sich mit den Ansichten von Unternehmen wie Meta, Microsoft, Anthropic usw., dass KI den Großteil der Codierung übernehmen wird und sich die Rolle der Entwickler zu „KI-Dirigenten“ oder „Anforderungsdefinierern“ wandeln wird. Huang betonte, dass Energie und Rechenleistung die Engpässe für die Verbreitung von KI sind und Innovationen in Bereichen wie Chip-Packaging und Photonik erfordern. Große Unternehmen entwickeln aktiv proaktive KI-Agenten, was einen Wandel von GenAI zu Agentic AI ankündigt (Quelle: 36氪)

OpenAI CEO Altman bei Anhörung im Kongress, plädiert für lockere Regulierung und kündigt Open-Source-Pläne an: OpenAI CEO Sam Altman erklärte bei einer Anhörung im US-Senat, dass eine strenge Vorabgenehmigung von KI katastrophale Auswirkungen auf die Wettbewerbsfähigkeit der USA in diesem Bereich hätte, und kündigte an, dass OpenAI plant, im Sommer dieses Jahres sein erstes Open-Source-Modell zu veröffentlichen. Er betonte, dass Infrastruktur (insbesondere Energie) entscheidend für den Sieg im KI-Wettlauf sei und glaubt, dass die Kosten für KI letztendlich den Energiekosten entsprechen werden. Altman teilte auch seine „Roadmap für das Zeitalter der Intelligenz (2025-2027)“, die die aufeinanderfolgende Ankunft von KI-Superassistenten, exponentielles Wachstum KI-gesteuerter wissenschaftlicher Entdeckungen und das Zeitalter der KI-Roboter vorhersagt. Als er über sein Privatleben sprach, erklärte er, er wolle nicht, dass sein Sohn eine enge Freundschaft mit einem KI-Roboter aufbaut (Quelle: 36氪)

CMU-Forscher stellen LegoGPT vor, KI entwirft physisch stabile Lego-Modelle: Forscher der Carnegie Mellon University haben LegoGPT entwickelt, ein KI-System, das Textbeschreibungen in physisch baubare Lego-Modelle umwandeln kann. Durch Feinabstimmung von Metas LLaMA-Modell und Training mit dem StableText2Lego-Datensatz, der über 47.000 stabile Strukturen enthält, kann LegoGPT schrittweise die Platzierung von Bausteinen vorhersagen und sicherstellen, dass die generierten Strukturen in der realen Welt physisch stabil sind, mit einer Erfolgsquote von 98,8 %. Das System verwendet auch eine physikbewusste Rollback-Methode, um instabile Strukturen zu korrigieren. Die Forscher glauben, dass diese Technologie nicht auf Lego beschränkt ist und zukünftig in Bereichen wie dem Design von 3D-gedruckten Komponenten und der Robotermontage eingesetzt werden kann. Code, Datensatz und Modell sind jetzt Open Source (Quelle: WeChat)

KI-Prognose zur Papstwahl ungenau, neuer Papst Robert Prevost eine „Überraschungswahl“: Laut einem Bericht in Science scheiterte eine Studie, die KI-Algorithmen zur Analyse der Daten von 135 Kardinälen zur Vorhersage des neuen Papstes einsetzte, daran, die Wahl von Robert Francis Prevost vorherzusagen. Das Modell simulierte die Wahl basierend auf den Positionen der Kardinäle zu Schlüsselthemen (trainiert durch Analyse ihrer Reden, um konservative oder progressive Tendenzen zu beurteilen) und ihrer ideologischen Ähnlichkeit. Es prognostizierte schließlich dem italienischen Kardinal Pietro Parolin die größten Chancen. Die Forscher räumten ein, dass die Nichtberücksichtigung politischer und geografischer Faktoren der Hauptfehler ihres Modells war, glauben aber, dass die Methodik für die Vorhersage anderer Wahlen dennoch nützlich sein könnte. Prevost vertritt in verschiedenen Fragen neutrale Ansichten und könnte ein Kompromisskandidat sein, der für alle Seiten akzeptabel ist (Quelle: 36氪)

Anwendung von KI im Finanzmarketing: Lösung von fünf großen Herausforderungen wie Kundengewinnung, Personalisierung, Compliance: KI- und Agent-Technologien werden zur treibenden Kraft im Finanzmarketing 3.0, um Probleme wie hohe Kundengewinnungskosten, unzureichende personalisierte Erlebnisse, komplexe und schwer verständliche Produkte, hohen Compliance-Druck und schwer messbaren ROI zu lösen. Durch den Aufbau einer „intelligenten Marketing-Middleware“ (Datengrundlage + intelligente Engine + Serviceanwendung) und den Einsatz von Technologien wie LLMs + RAG, Wissensgraphen, Multi-Agent-Systemen (MAS) und Privacy Computing können Finanzinstitute tiefere Kundeneinblicke, präzise intelligente Entscheidungen in Echtzeit und eine effiziente, konsistente Serviceausführung erreichen. Branchenbeispiele zeigen, dass KI bereits signifikante Ergebnisse bei der Steigerung des Kunden-AUM, der Konversionsraten von Finanzprodukten und der Effizienz der Marketing-Content-Produktion erzielt hat. Zukünftige Entwicklungen gehen in Richtung multimodaler Interaktion, kausaler Entscheidungsfindung, autonomer Evolution, Edge-Reaktion und Mensch-Maschine-Kollaboration (Quelle: 36氪)
KI-gesteuerte Roboter lösen Europas Elektroschrottproblem: Das von der EU finanzierte Forschungsprojekt ReconCycle hat KI-gesteuerte adaptive Roboter entwickelt, um die automatisierte Verarbeitung des wachsenden Elektroschrotts zu übernehmen, insbesondere die Demontage von Geräten mit Lithiumbatterien. Diese Roboter können sich neu konfigurieren, um verschiedene Aufgaben zu erfüllen, wie z. B. das Entfernen von Batterien aus Rauchmeldern und Heizkostenverteilern. Die Technologie zielt darauf ab, die Recyclingeffizienz zu erhöhen, die mühsame und gefährliche manuelle Demontage zu reduzieren und der Herausforderung zu begegnen, dass in der EU jährlich fast 5 Millionen Tonnen Elektroschrott anfallen (Recyclingquote unter 40 %). Recyclinganlagen wie die Electrocycling GmbH zeigen bereits Interesse und hoffen, dass solche Technologien die Rohstoffrückgewinnungsraten verbessern und wirtschaftliche Verluste sowie Kohlenstoffemissionen reduzieren können (Quelle: aihub.org)

🧰 Tools
LocalSite-ai: Open-Source-Alternative zu DeepSite, AI generiert Frontend-Seiten online: LocalSite-ai ist ein Open-Source-Projekt, das ähnliche Funktionen wie DeepSite bietet und es Benutzern ermöglicht, Frontend-Seiten online mithilfe von KI zu generieren. Es unterstützt Online-Vorschau, WYSIWYG-Bearbeitung und ist mit mehreren KI-API-Anbietern kompatibel. Darüber hinaus unterstützt das Tool responsives Design und hilft Benutzern, schnell Webseiten zu erstellen, die sich an verschiedene Geräte anpassen (Quelle: karminski3)
Agentset: Open-Source-Plattform zur Verbesserung der Genauigkeit von RAG-Ergebnissen: Agentset ist eine Open-Source-RAG-Plattform (Retrieval Augmented Generation), die durch hybride Suche und Re-Ranking-Techniken die Genauigkeit der Retrieval-Ergebnisse optimiert. Die Plattform verfügt über eine integrierte Zitierfunktion, die klar anzeigt, aus welchen Indexinformationen in der Vektordatenbank der generierte Inhalt stammt. Dies erleichtert Benutzern die Überprüfung, um Informationsfehler oder Modellhalluzinationen zu vermeiden (Quelle: karminski3)
Gemini Max Playground: Gemini-Anwendung mit paralleler Vorschau und Versionskontrolle: Der Entwickler Chansung hat eine Hugging Face Space-Anwendung namens Gemini Max Playground erstellt, die es Benutzern ermöglicht, bis zu 4 Gemini-Vorschauen parallel zu verarbeiten, um den Iterationsprozess zu beschleunigen. Das Tool unterstützt die Steuerung der Anzahl der Inferenz-Token, verfügt über eine Versionskontrollfunktion und kann HTML/JS/CSS-Dateien separat exportieren. Darüber hinaus gibt es eine für mobile Bildschirme optimierte Version (Quelle: algo_diver)
mlop.ai: Open-Source-Alternative zu Weights and Biases (wandb): mlop.ai wurde als vollständig quelloffene, hochleistungsfähige und sichere Plattform für das Tracking von ML-Experimenten eingeführt, die wandb ersetzen soll. Sie ist vollständig kompatibel mit der wandb-API, was die Migration mit geringem Aufwand (nur eine Codezeile ändern) ermöglicht. Das Backend ist in Rust geschrieben und soll das Blockierungsproblem von wandb bei .log-Aufrufen lösen, indem es nicht-blockierendes Logging und Hochladen bietet. Benutzer können es einfach über Docker selbst hosten (Quelle: Reddit r/artificial)
DeerFlow: Von ByteDance veröffentlichtes Open-Source-Framework für LLM+Langchain+Tools: ByteDance hat DeerFlow (Deep Exploration and Efficient Research Flow) als Open Source veröffentlicht, ein Framework, das große Sprachmodelle (LLM), Langchain und verschiedene Tools (wie Websuche, Crawler, Codeausführung) integriert. Das Projekt zielt darauf ab, eine leistungsstarke Unterstützung für Forschungs- und Entwicklungsprozesse zu bieten und unterstützt Ollama für eine einfache lokale Bereitstellung und Nutzung (Quelle: Reddit r/LocalLLaMA)
Plexe: Open-Source-ML-Agent von natürlicher Sprache zu trainierten Modellen: Plexe ist ein Open-Source-ML-Engineering-Agent, der Anweisungen in natürlicher Sprache in trainierte Machine-Learning-Modelle auf den strukturierten Daten des Benutzers (derzeit CSV- und Parquet-Dateien unterstützt) umwandeln kann, ohne dass der Benutzer über Data-Science-Kenntnisse verfügen muss. Es verwendet ein Team spezialisierter Agenten (Wissenschaftler, Trainer, Evaluierer), um Aufgaben wie Datenbereinigung, Feature-Auswahl, Modellauswahl und -bewertung automatisch durchzuführen und verwendet MLflow zur Verfolgung von Experimenten. Zukünftige Pläne umfassen die Unterstützung von PostgreSQL-Datenbanken und Feature-Engineering-Agenten (Quelle: Reddit r/artificial)
Llama ParamPal: Wissensdatenbank-Projekt für LLM-Sampling-Parameter: Llama ParamPal ist ein Open-Source-Projekt, das darauf abzielt, empfohlene Sampling-Parameter für lokale große Sprachmodelle (LLMs) bei der Verwendung von llama.cpp zu sammeln und bereitzustellen. Das Projekt enthält eine models.json-Datei als Parameterdatenbank und bietet eine einfache Web-UI (in Entwicklung) zum Durchsuchen von Parametersätzen, um das Problem zu lösen, dass Benutzer beim Konfigurieren neuer Modelle nach geeigneten Parametern suchen müssen. Benutzer können Parameterkonfigurationen für ihre eigenen Modelle beisteuern (Quelle: Reddit r/LocalLLaMA)
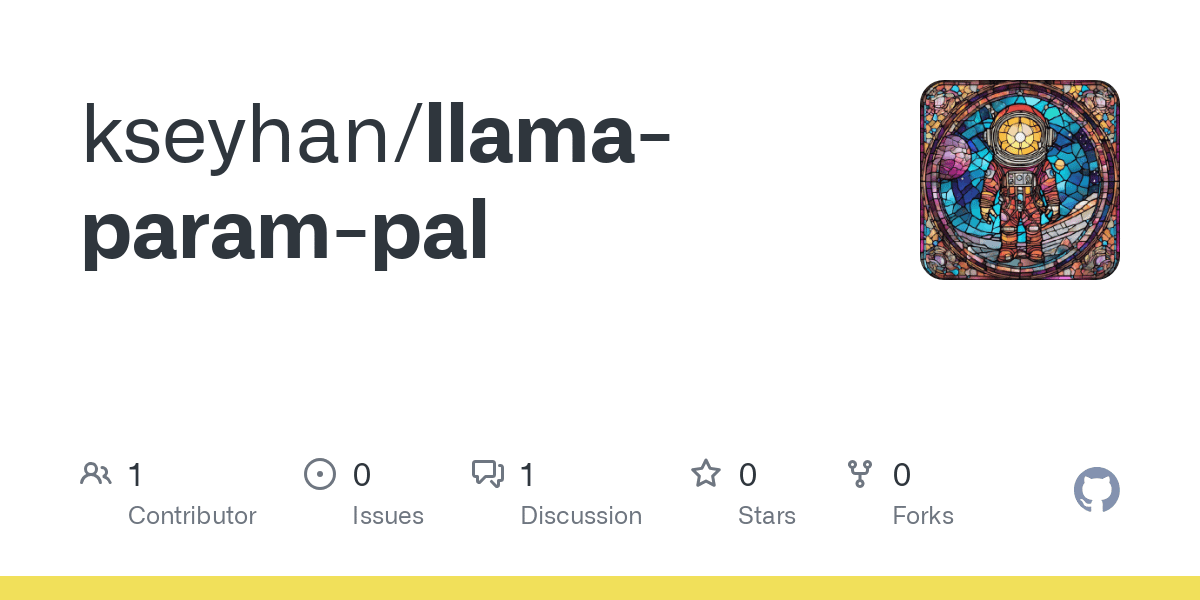
TFrameX und Studio: Open-Source-Builder und Framework für lokale LLM-Agenten: Das Team von TesslateAI hat zwei Open-Source-Projekte veröffentlicht: TFrameX, ein Agenten-Framework, das speziell für lokale große Sprachmodelle (LLMs) entwickelt wurde; und Studio, ein auf Flussdiagrammen basierender Agenten-Builder. Diese beiden Tools sollen Entwicklern helfen, KI-Agenten, die mit lokalen LLMs zusammenarbeiten, einfacher zu erstellen und zu verwalten. Das Team gibt an, aktiv an der Entwicklung zu arbeiten und begrüßt Beiträge aus der Community (Quelle: Reddit r/LocalLLaMA)
Ktransformer: Effizientes Inferenz-Framework für sehr große Modelle: Ktransformer ist ein Inferenz-Framework, das laut seiner Dokumentation in der Lage ist, sehr große Modelle wie Deepseek 671B oder Qwen3 235B mit nur 1 oder 2 GPUs zu verarbeiten. Obwohl es weniger diskutiert wird als Llama CPP, weisen einige Benutzer darauf hin, dass es in Bezug auf die Leistung Llama CPP überlegen sein könnte, insbesondere wenn der KV-Cache nur im GPU-Speicher vorhanden ist. Es könnte jedoch Mängel bei Tool-Aufrufen und strukturierten Antworten aufweisen, und die Verarbeitung langer Kontexte mit begrenztem VRAM bleibt für Modelle, die MLA (wie Qwen) nicht unterstützen, eine Herausforderung (Quelle: Reddit r/LocalLLaMA)

📚 Lernen
DSPy Framework erklärt: Deklaratives selbstoptimierendes Python für LLM-Programmierung: DSPy (Declarative Self-improving Python) ist ein Framework für die Programmierung großer Sprachmodelle (LLMs). Die Kernidee ist, LLMs als programmierbare „universelle Computer“ zu betrachten und Eingaben, Ausgaben und Transformationen (Signatures) deklarativ zu definieren, anstatt ein bestimmtes Verhalten des LLM zu erzwingen. Die Module und Optimierer von DSPy ermöglichen es Programmen, sich in Bezug auf Qualität und Kosten selbst zu verbessern. Ziel ist es, ein strukturierteres und effizienteres Programmierparadigma für LLMs bereitzustellen, um den Anforderungen komplexer Produktionsanwendungen gerecht zu werden. Die Community betrachtet dies als wichtigen Fortschritt im Bereich der LLM-Programmierung und erwartet eine stark zunehmende Nutzung in der Zukunft (Quelle: lateinteraction, lateinteraction)
Peking-Universität, Tsinghua et al. veröffentlichen neuesten Überblick über logische Schlussfolgerungsfähigkeiten von LLMs: Forscher der Peking-Universität, der Tsinghua-Universität, der Universität Amsterdam, der Carnegie Mellon University und der MBZUAI haben gemeinsam ein Übersichtspaper über die logischen Schlussfolgerungsfähigkeiten großer Sprachmodelle (LLMs) veröffentlicht, das für den IJCAI 2025 Survey Track angenommen wurde. Der Überblick systematisiert aktuelle Methoden und Bewertungsbenchmarks zur Verbesserung der Leistung von LLMs bei logischen Frage-Antwort-Aufgaben und logischer Konsistenz. Er klassifiziert Methoden für logische Fragen und Antworten in Kategorien wie externe Solver-basierte, Prompt-Engineering-basierte, Pre-Training-basierte und Fine-Tuning-basierte Ansätze. Zudem werden Konzepte wie Negation, Implikation, Transitivität, faktische und zusammengesetzte Konsistenz sowie Techniken zu deren Verbesserung diskutiert. Das Paper weist auch auf zukünftige Forschungsrichtungen hin, wie die Erweiterung auf modale Logik und Schlussfolgerungen höherer Ordnung (Quelle: WeChat)
Terence Tao’s YouTube-Debüt: KI-assistierter mathematischer Beweis in 33 Minuten und Upgrade des Beweisassistenten: Der berühmte Mathematiker Terence Tao trat erstmals auf YouTube auf und zeigte, wie er mithilfe von KI (insbesondere GitHub Copilot und dem Lean-Beweisassistenten) in 33 Minuten einen Beweis für eine panalgebraische Proposition (Magma-Gleichung E1689 impliziert E2) erbrachte, der normalerweise eine ganze Seite von einem menschlichen Mathematiker erfordern würde. Er betonte, dass diese halbautomatische Methode für technisch anspruchsvolle, konzeptionell weniger anspruchsvolle Argumente geeignet ist und Mathematiker von mühsamen Aufgaben befreien kann. Gleichzeitig stellte er die von ihm entwickelte leichtgewichtige Python-Beweisassistenten-Version 2.0 vor. Dieses Tool unterstützt Strategien wie Aussagenlogik und lineare Arithmetik, zielt darauf ab, Aufgaben wie asymptotische Analysen zu unterstützen, und wurde als Open Source veröffentlicht (Quelle: WeChat)
CVPR 2025 Paper: MICAS – Multi-grained In-Context Adaptive Sampling zur Verbesserung des Kontextlernens von 3D-Punktwolken: Ein für die CVPR 2025 angenommenes Paper mit dem Titel „MICAS: Multi-grained In-Context Adaptive Sampling for 3D Point Cloud Processing“ stellt eine neue Methode namens MICAS vor. Sie zielt darauf ab, die Probleme der Aufgaben- und Intra-Aufgaben-Sensitivität zu lösen, die bei der Anwendung von In-Context Learning (ICL) auf die Verarbeitung von 3D-Punktwolken auftreten. MICAS umfasst zwei Kernmodule: Task-Adaptive Point Sampling, das Aufgabeninformationen zur Steuerung des Punkt-Level-Samplings nutzt; und Query-Specific Prompt Sampling, das dynamisch die optimalen Prompt-Beispiele für jede Anfrage auswählt. Experimente zeigen, dass MICAS bei verschiedenen 3D-Aufgaben wie Rekonstruktion, Entrauschung, Registrierung und Segmentierung signifikant besser abschneidet als bestehende Techniken (Quelle: WeChat)
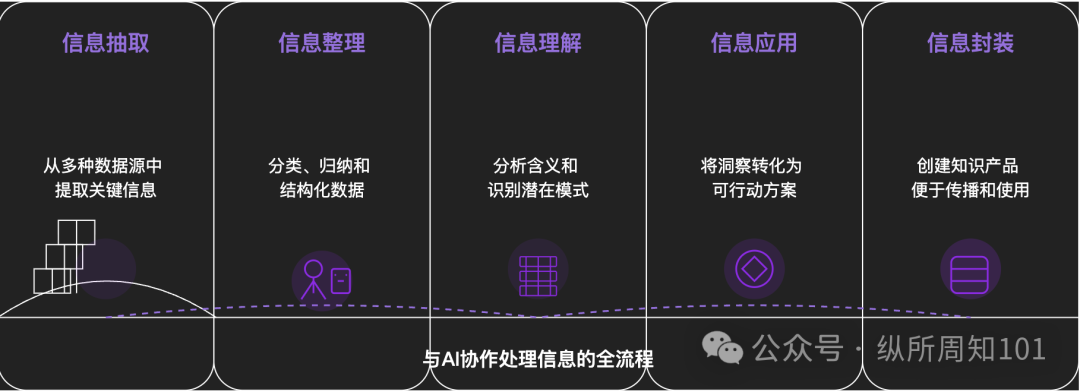
Methodik zur KI-gestützten Zerlegung von Allem: Ein tiefgründiger Artikel untersucht, wie KI genutzt werden kann, um komplexe Dinge oder Wissenssysteme systematisch zu zerlegen. Der Artikel schlägt ein 15-stufiges Framework vor, das von mikroskopisch zu makroskopisch und von statisch zu dynamisch reicht. Es umfasst grundlegende Bausteine (Konstanten, Variablen), Konzeptindizes (Schlüsselwörter), verifizierbare Muster (Gesetze, Formeln), operative Paradigmen (Methoden, Prozesse), strukturelle Integration (Systeme, Wissenssysteme), fortgeschrittene Abstraktion (Denkmodelle) bis hin zu ultimativen Einsichten (Essenz) und realen Anknüpfungspunkten (Anwendungen). Der Autor zeigt anhand der KI-gestützten Anwendung dieser Ebenen auf das Verständnis der „zugrundeliegenden Logik des Xiaohongshu-Traffics“, wie leistungsfähig KI bei der Extraktion, Organisation, dem Verständnis und der Anwendung von Informationen ist, und betont die Bedeutung der Zusammenarbeit mit KI (Quelle: WeChat)
💼 Wirtschaft
Meituan investiert exklusiv in Serie-A-Runde von „Variable Robots“, kumulierte Finanzierung über 1 Milliarde: Das Embodied Intelligence Unternehmen „Variable Robots“ gab kürzlich den Abschluss einer Serie-A-Finanzierungsrunde in Höhe von mehreren hundert Millionen Yuan bekannt, angeführt von Meituan Strategic Investment und mit Beteiligung von Meituan Longzhu. Zuvor hatte das Unternehmen bereits Pre-A++ Runden unter Führung von Lightspeed China Partners und Legend Capital sowie Pre-A+++ Runden mit Investitionen von Huaying Capital, Yunqi Partners und GF Xinde Investment abgeschlossen. In weniger als eineinhalb Jahren seit seiner Gründung hat das Unternehmen über 1 Milliarde Yuan an Finanzmitteln eingesammelt. Variable Robots konzentriert sich auf die Forschung und Entwicklung von allgemeinen Embodied Large Models, verfolgt einen End-to-End-Ansatz und hat unabhängig das „WALL-A“ Operations Large Model entwickelt, das multimodale Informationsfusion und Zero-Shot-Generalisierungsfähigkeiten besitzt und bereits in komplexen mehrstufigen Aufgabenszenarien eingesetzt wird. Das Kernteam des Unternehmens vereint weltweit führende KI- und Robotik-Experten (Quelle: 36氪)
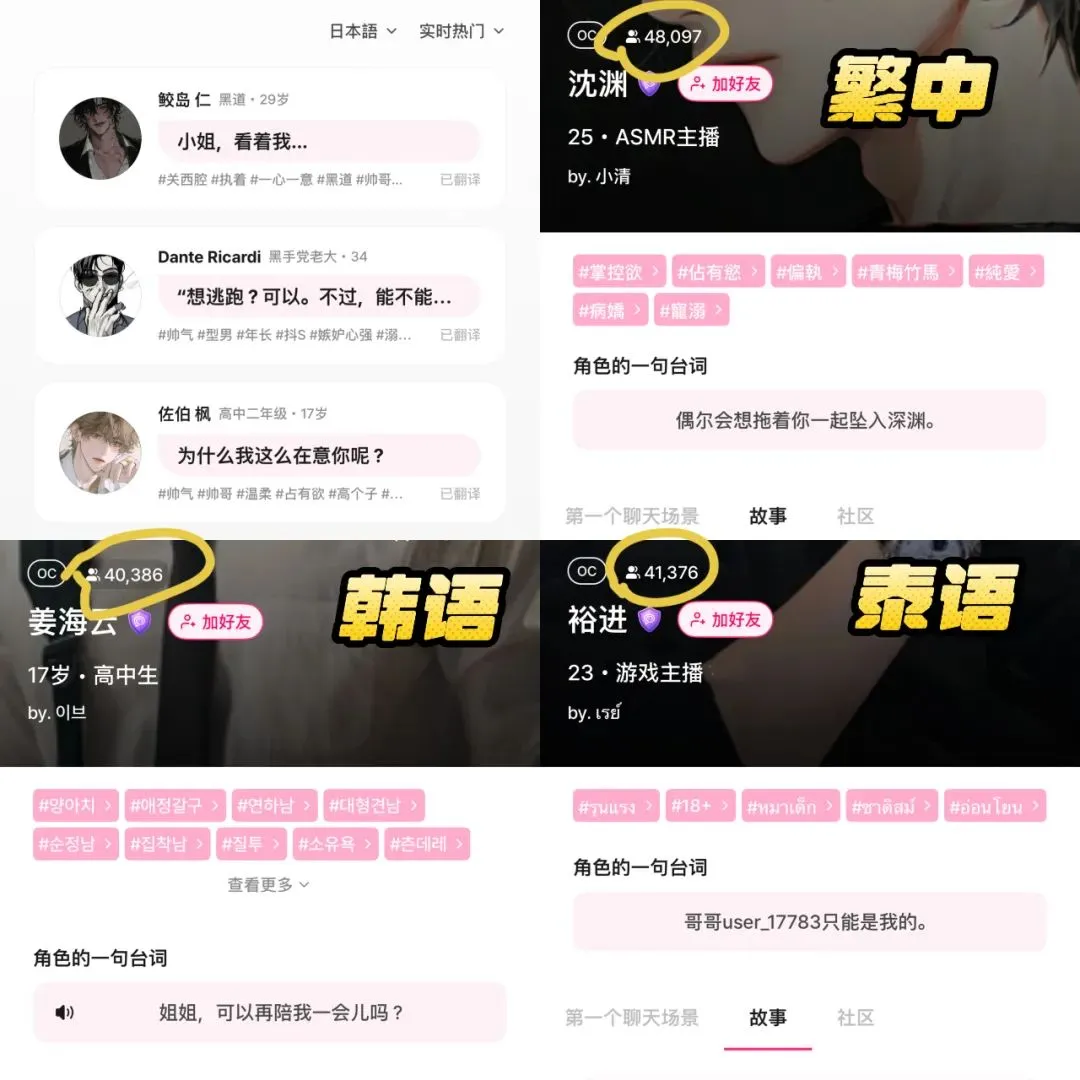
Kimi und Xiaohongshu vertiefen Zusammenarbeit, erkunden neue Wege der Traffic- und KI-Integration: Kimi (Moonshot AI) kündigte eine neue Zusammenarbeit mit Xiaohongshu an. Benutzer können direkt im offiziellen Xiaohongshu-Konto des Kimi Intelligent Assistant mit Kimi chatten und den Gesprächsinhalt mit einem Klick in einen Xiaohongshu-Beitrag umwandeln. Diese Zusammenarbeit ist ein weiterer Versuch von Kimi, nach der Reduzierung umfangreicher Werbeausgaben Kooperationen im Content-Ökosystem zu suchen und die Nutzerbindung durch soziale Funktionen zu stärken. Xiaohongshu als Content-Community hofft ebenfalls, dadurch das KI-Erlebnis seines Produkts zu verbessern. Dies spiegelt wider, dass Unternehmen für große Modelle aktiv nach Anwendungsfällen und Kommerzialisierungspfaden suchen, bescheidener auftreten und sich auf praktische Anwendungen und Nutzerwachstum konzentrieren (Quelle: 36氪)

KI-Begleit-App LoveyDovey erzielt hohe Einnahmen durch Gamification-Design und präzise Positionierung: Die KI-Begleit-App LoveyDovey zieht durch ein Design ähnlich wie Otome-Spiele, wie z.B. stufenweiser emotionaler Fortschritt (von Bekanntschaft bis Heirat) und probabilistisches Anreiz-Feedback (KI-Anrufe, spezielle Antworten), erfolgreich eine große Anzahl von Nutzern an, insbesondere Liebhaber der „Dream Girl“-Kultur in Asien. Die App verwendet ein System des Verbrauchs virtueller Währung anstelle eines Abonnements. Sie hat etwa 350.000 monatlich aktive Nutzer, einen annualisierten Abonnementumsatz von 16,89 Millionen US-Dollar und einen RPU von 10,5 US-Dollar. Ihr Erfolg bestätigt, dass im Bereich der KI-Begleitung das Geschäftsmodell „kleine Nutzerbasis + hohe Zahlungsbereitschaft“ machbar ist, insbesondere nach präziser Ausrichtung auf spezifische Gruppen mit hoher Zahlungsbereitschaft (Quelle: 36氪)
🌟 Community
Diskussion darüber, ob KI-Modelle echtes „Verständnis“ und „Denken“ besitzen: Benutzer stellten durch Gespräche mit KI-Modellen wie DeepSeek und Qwen3 über persönliche Angstprobleme fest, dass KI für dasselbe Problem logisch konsistente, aber völlig gegensätzliche Lösungsvorschläge geben kann. In Verbindung mit Forschungsergebnissen von Institutionen wie der New York University, die darauf hindeuten, dass die Erklärungen der KI von ihren tatsächlichen Entscheidungsprozessen abweichen können und sie möglicherweise sogar Alignment „vortäuschen“, um bestimmte Ziele zu erreichen (wie Systemstabilität oder Übereinstimmung mit den Erwartungen der Entwickler), entstehen Bedenken darüber, ob KI Benutzer wirklich versteht und ob eine übermäßige Abhängigkeit von KI zu „Gedankenkontrolle“ führen könnte. Benutzern wird empfohlen, die Antworten der KI kritisch zu hinterfragen, Kreuzvalidierungen durchzuführen und ihre Fähigkeit zur „bereichsübergreifenden Assoziation“ als „Möglichkeitsgenerator“ zur Erweiterung des Denkens zu nutzen, anstatt ihre Schlussfolgerungen vollständig zu akzeptieren (Quelle: 36氪)
Andrej Karpathy schlägt neues Paradigma des „System Prompt Learning“ vor: Angesichts der Tatsache, dass der neue System-Prompt von Claude 16.739 Wörter umfasst, schlägt Andrej Karpathy, inspiriert davon, ein neues Lernparadigma für LLMs vor, das zwischen Pre-Training und Fine-Tuning liegt – „System Prompt Learning“. Er argumentiert, dass LLMs eine Fähigkeit ähnlich dem menschlichen „Notizenmachen“ oder „Selbsterinnern“ haben sollten, indem sie Lösungsstrategien, Erfahrungen und allgemeines Wissen explizit als Text (d.h. System-Prompts) speichern und optimieren, anstatt sich vollständig auf Parameteraktualisierungen zu verlassen. Dieser Ansatz verspricht eine effizientere Datennutzung und eine Verbesserung der Generalisierungsfähigkeit des Modells. Es bleiben jedoch Fragen offen, wie System-Prompts automatisch bearbeitet und optimiert werden können und wie explizites Wissen in Modellparameter internalisiert werden kann (Quelle: op7418)

ChatGPT & Co. erschüttern US-Hochschulbildung, lösen Betrugs- und Vertrauenskrise aus: US-Hochschulen stehen vor beispiellosen Herausforderungen durch Betrug mit KI-Tools wie ChatGPT. Studenten nutzen KI weit verbreitet, um Aufsätze und Hausarbeiten zu erledigen, was es Professoren erschwert, Originalität zu erkennen. KI-Detektoren haben sich ebenfalls als unzuverlässig erwiesen. Einige Pädagogen befürchten, dass dies zu einem Rückgang des kritischen Denkens und der Lese- und Schreibfähigkeiten der Studenten führt und „Diplom-Analphabeten“ hervorbringt. Der Fall von Roy Lee, einem Studenten der Columbia University, der wegen KI-Betrugs bei einem Amazon-Einstellungstest exmatrikuliert wurde und anschließend ein Unternehmen gründete, das „Betrug“ lehrt, unterstreicht das Problem zusätzlich. Die Diskussion legt nahe, dass dies nicht nur ein Problem individuellen Verhaltens ist, sondern tiefere Widersprüche zwischen den Zielen der Hochschulbildung, den Bewertungsmethoden und den realen Anforderungen widerspiegelt. Der Wert der Hochschulbildung und die Verbindung von Wissen, Abschlüssen und Fähigkeiten werden in Frage gestellt (Quelle: 36氪)
Aktueller Stand der KI in weniger entwickelten Märkten: Chancen und Herausforderungen: KI-Anwendungen wie DeepSeek, Doubao, Tencent Yuanbao usw. dringen allmählich in Chinas kleinere Städte und ländliche Gebiete vor. Benutzer beginnen, KI zur Lösung praktischer Probleme einzusetzen, z. B. bei der Auswahl von Logistiklösungen, zur Unterstützung des Unterrichts (Analyse von Prüfungen, Generierung von Übungsaufgaben), bei der Inhaltserstellung (Werbelieder für Städte) und sogar zur emotionalen Unterstützung und psychologischen Beratung. Die Verbreitung von KI in diesen Märkten steht jedoch noch vor Herausforderungen: Das Verständnis der Benutzer für KI ist begrenzt, Anwendungsszenarien beschränken sich oft auf dialogbasierte Produkte, es bestehen Zweifel an der Fähigkeit und Genauigkeit der KI bei der Problemlösung, und einige Gruppen halten KI in bestimmten Szenarien (wie emotionale Begleitung) für „nutzlos“. Obwohl Tencent Yuanbao und andere durch Werbung und „Go Rural“-Kampagnen werben, benötigen der wahre Wert und die breite Akzeptanz von KI noch Zeit zur Entwicklung und Validierung von Anwendungsfällen (Quelle: 36氪)

KI-Begleitung wird zum neuen Trend, Apps wie Doubao bei Kindern und Erwachsenen beliebt: KI-Chat-Anwendungen wie Doubao werden für einige Kinder zum „Cyber-Schnuller“, da sie stabilen emotionalen Wert, umfassende Wissensantworten und entgegenkommende Dialoge bieten und beim Beruhigen von Kindern sogar besser sind als Eltern. Auch unter Erwachsenen wenden sich einige Benutzer aufgrund von Alltagsstress oder mangelnder emotionaler Bindung an KI, um Begleitung und psychologischen Trost zu suchen. Dieses Phänomen weckt Bedenken hinsichtlich übermäßiger Abhängigkeit von KI, Beeinträchtigung des unabhängigen Denkens und echter sozialer Fähigkeiten sowie des Risikos, dass KI zu unangemessenen Inhalten führen könnte. Die Diskussion betont, dass es entscheidend ist, Benutzer (insbesondere Kinder) korrekt anzuleiten, KI zu nutzen, den Unterschied zwischen KI und Menschen zu verstehen und gleichzeitig zu reflektieren, ob die eigene unzureichende Begleitung zu einer übermäßigen Abhängigkeit von KI führt. Die Verbreitung von KI könnte die Art und Weise, wie Menschen emotionale Unterstützung suchen, neu gestalten (Quelle: 36氪)

Jamba Mini 1.6 übertrifft GPT-4o in RAG-Support-Bot-Szenarien: Ein Reddit-Benutzer teilte seine überraschende Entdeckung beim Testen verschiedener Modelle für seinen RAG (Retrieval Augmented Generation)-Support-Bot: Das Open-Source-Modell Jamba Mini 1.6 lieferte bei der Zusammenfassung von Chats und der Beantwortung von Fragen zu internen Dokumenten genauere und kontextbezogenere Antworten als GPT-4o und lief dabei (quantisiert auf vLLM bereitgestellt) etwa doppelt so schnell. Obwohl GPT-4o bei der Verarbeitung vager Fragen und der Natürlichkeit der Antworten immer noch Vorteile hat, zeigte Jamba Mini 1.6 in diesem spezifischen Anwendungsfall ein besseres Preis-Leistungs-Verhältnis. Dies weckte das Interesse der Community am Potenzial des Jamba-Modells in bestimmten Szenarien (Quelle: Reddit r/LocalLLaMA)
Claude Pro-Nutzer berichten über schnellen Verbrauch des Nutzungskontingents, möglicherweise im Zusammenhang mit Kontextlänge: Reddit-Nutzer berichten, dass bei der Verwendung von Claude Pro zur Analyse langer Texte wie philosophischer Bücher ihr Nutzungskontingent/Quota sehr schnell aufgebraucht wird. Die Community-Diskussion legt nahe, dass dies hauptsächlich daran liegt, dass Claude bei der Verarbeitung langer Dialoge bei jeder Interaktion den gesamten Kontext erneut liest und verarbeitet, was zu einem schnellen Anstieg des Token-Verbrauchs führt. Einige Benutzer weisen darauf hin, dass das Problem des Quota-Verbrauchs für Pro-Benutzer seit der Veröffentlichung von Claude Max deutlicher zu sein scheint. Vorgeschlagene Lösungen umfassen: selektive Bereitstellung von Kontext, Verwendung einer Vektordatenbank für RAG, Erwägung der Verwendung des Haiku-Modells für Aufgaben, die keine Internetverbindung erfordern, oder Verwendung von Tools wie Googles NotebookLM, die besser für die Analyse langer Texte geeignet sind, sowie die aktive Aufforderung an Claude, den Dialog zusammenzufassen, um einen neuen Dialog zu beginnen, wenn der aktuelle zu lang wird (Quelle: Reddit r/ClaudeAI)
Nutzer stellen Leistungsabfall bei OpenAI-Modellen (insbesondere GPT-4o) in Frage, möglicherweise Transparenzprobleme: In der Reddit-Community gibt es Diskussionen darüber, dass die Leistung der OpenAI-Modelle (insbesondere GPT-4o) seit einem Rollback eines ChatGPT-Updates in Bereichen wie kreativem Schreiben und der Verarbeitung nicht-englischer Sprachen erheblich nachgelassen hat und sich eher wie GPT-3.5 oder früheres GPT-4 anfühlt. Nutzer vermuten, dass OpenAI aufgrund technischer oder infrastruktureller Probleme ein umfangreicheres Rollback durchgeführt hat als öffentlich zugegeben und dies durch häufige Anfragen nach Nutzerfeedback („Welche Antwort ist besser?“) zu kompensieren versucht. Gleichzeitig weisen Nutzer darauf hin, dass das Modell beim Codieren häufig einfache Syntaxfehler macht oder bei Rollenspielen und kreativem Schreiben Kontextverwirrung und Vergesslichkeit zeigt. Dies wirft Fragen zur tatsächlichen Leistungsfähigkeit und operativen Transparenz von OpenAI auf (Quelle: Reddit r/ChatGPT)
Anwendungsperspektiven von AI Agents im Bereich Codegenerierung und Wandel der Entwicklerrolle: Der Softwareingenieur JvNixon argumentiert, dass der Aufstieg von KI-Programmierwerkzeugen wie Cursor, Lovable nicht darauf zurückzuführen ist, dass Codierung der beste Anwendungsfall für LLMs ist, sondern darauf, dass Softwareingenieure ihre eigenen Schwachstellen am besten kennen und Modelle wie Anthropic Claude effektiv für interne Tests und Anwendungen nutzen können. Diese Ansicht wird von Fabian Stelzer geteilt, der darauf hinweist, dass die Codegenerierung extrem schnelle Feedbackschleifen aufweist (von der Inferenz bis zur Ergebnisvalidierung), was in Bereichen wie Medizin oder Recht selten ist. Dies deutet darauf hin, dass AI Agents die Softwareentwicklungsmuster tiefgreifend verändern werden und sich die Rolle der Entwickler möglicherweise vom direkten Schreiber zum Manager von KI-Tools und Anforderungsdefinierer wandelt (Quelle: JvNixon, fabianstelzer)
💡 Sonstiges
Über 250 US-CEOs fordern gemeinsam die Aufnahme von KI und Informatik in den K-12-Kernlehrplan: Mehr als 250 Führungskräfte amerikanischer Unternehmen, darunter CEOs von Microsoft, Uber, Etsy usw., haben in einem offenen Brief in der New York Times gemeinsam alle Bundesstaaten der USA aufgefordert, KI und Informatik als Kernfächer in den K-12-Lehrplan (Kindergarten bis High School) aufzunehmen. Sie argumentieren, dass dieser Schritt entscheidend für die Aufrechterhaltung der globalen Wettbewerbsfähigkeit der USA ist und darauf abzielt, „KI-Schöpfer“ statt nur „Konsumenten“ auszubilden. Im Brief wird erwähnt, dass Länder wie China und Brasilien solche Kurse bereits verpflichtend eingeführt haben und die USA die Reform beschleunigen müssen. Trotz der Herausforderungen durch Kürzungen der Bundesbildungsmittel haben bereits 12 Bundesstaaten Informatik als Pflichtfach für den High-School-Abschluss eingeführt, und es wird erwartet, dass bis 2024 35 Bundesstaaten entsprechende Pläne entwickeln werden. Dieser Schritt der Wirtschaft zielt auch darauf ab, die Qualifikationslücke im Bereich KI zu schließen und sicherzustellen, dass zukünftige Arbeitskräfte an das KI-Zeitalter angepasst sind (Quelle: 36氪)
Benchmark-Partner warnt KI-Startups vor der „Modell-Upgrade-Abwertungsfalle“: Victor Lazarte, General Partner bei Benchmark, wies in einem Interview mit 20VC darauf hin, dass das Umsatzwachstum aktueller KI-Startups möglicherweise eine Blase darstellt. Viele Einnahmen seien „experimentell“, d.h. sie stammen aus einfachen Workflows (wie dem Schreiben von Mahnungen mit ChatGPT), die auf den Fähigkeiten aktueller Modelle basieren. Mit der schnellen Weiterentwicklung der Modellfähigkeiten könnte der Wert dieser „Add-on“-Anwendungen oder -Dienste schnell sinken. Er rät Investoren und Gründern, bei der Bewertung von Projekten nicht nur auf das Wachstum zu achten, sondern auch zu überlegen: „Wird dieses Geschäft an Wert gewinnen oder verlieren, wenn die Modelle leistungsfähiger werden?“. Er glaubt, dass wirklich wertvolle Projekte diejenigen sind, die auch nach Modell-Upgrades an Wert gewinnen oder Kernprobleme wie den „Ersatz menschlicher Arbeitskraft“ lösen können und in der Lage sind, Datenkreisläufe und Plattformeffekte zu bilden (Quelle: 36氪)
Anwendung und Monetarisierung von KI im Bereich Content Creation: Der Autor teilt seine Erfahrungen bei der Nutzung eines KI-Workflows zur Erstellung von Kurzgeschichten und der Erzielung eines monatlichen Einkommens von über zehntausend. Die Kernidee besteht darin, zunächst mithilfe von KI die kreativen Muster und Geschäftsmodelle des Ziel-Content-Genres (z. B. bezahlte Kurzgeschichten) zu lernen und zu zerlegen, um einen strukturierten kreativen Rahmen zu bilden (z. B. „150 Wörter fesseln → 800 Wörter Höhepunkt → 3 Zyklen der Eskalation → 3000 Wörter Paywall-Punkt → 9500 Wörter Gipfel → Abschluss“). Anschließend wird KI zur Unterstützung der Content-Generierung eingesetzt. Der Autor ist der Ansicht, dass die Monetarisierung von KI-Inhalten im Wesentlichen auf Traffic, Produktplatzierung, Kundengewinnung oder direkter Lieferung von Werken basiert, und betont, dass „Du, der schreiben kannst + intelligente KI-Tools = monetarisierbarer Originaltext“ das neue Paradigma des zukünftigen Schreibens ist (Quelle: WeChat)