
Schlüsselwörter:OpenAI, KI-Chips, Große Modelle, Bestärkendes Lernen, KI-Infrastruktur, Multimodale KI, Intelligente Agenten, RAG, OpenAI nationales KI-Programm, Exportbeschränkungen für Nvidia H20-Chips, DeepSeek-R1 Inferenzoptimierung, KI-optisches Mikroskop Meta-rLLS-VSIM, ByteDance Seed-Coder Code-Großmodell
🔥 Fokus
OpenAI stellt „National AI“-Plan zur Unterstützung des globalen KI-Infrastrukturaufbaus vor: OpenAI startet das Projekt „OpenAI for Countries“ als Teil seines „Stargate“-Plans, um Länder beim Aufbau lokaler KI-Rechenzentren, der Anpassung von ChatGPT und der Förderung der Entwicklung von KI-Ökosystemen zu unterstützen. CEO Sam Altman hat bereits den ersten Supercomputing-Campus in Abilene, Texas, besichtigt. Dieser Campus ist Teil des 500-Milliarden-Dollar-„Stargate“-Plans und zielt darauf ab, die weltweit größte KI-Trainingseinrichtung zu schaffen. Dieser Schritt signalisiert, dass OpenAI mit Regierungen mehrerer Länder zusammenarbeiten wird, um durch Infrastrukturaufbau und Technologietransfer die globale Verbreitung und Anwendung von KI-Technologien voranzutreiben. Die erste Phase plant eine Zusammenarbeit mit 10 Ländern oder Regionen (Quelle: WeChat)

Berichten zufolge plant die Trump-Regierung, die dreistufige Beschränkung für den Export von KI-Chips abzuschaffen und möglicherweise ein vereinfachtes globales Lizenzsystem einzuführen: Laut ausländischen Medienberichten plant die Trump-Regierung, das von der späten Biden-Regierung eingeführte „Framework for AI Diffusion“ (FAID) abzuschaffen. Dieses Rahmenwerk sah eine dreistufige Klassifizierung für den Export von KI-Chips weltweit vor. Das Trump-Team hält das Rahmenwerk für zu umständlich und innovationshemmend und bevorzugt stattdessen ein einfacheres globales Lizenzsystem, das durch zwischenstaatliche Abkommen durchgesetzt werden soll. Dieser Schritt könnte sich auf die globalen Marktstrategien von Chipherstellern wie Nvidia auswirken und zielt darauf ab, die Innovations- und Führungsrolle der USA im KI-Bereich zu festigen (Quelle: WeChat)

SGLang-Team optimiert DeepSeek-R1-Inferenzleistung erheblich und steigert den Durchsatz um das 26-fache: Ein gemeinsames Team von SGLang, Nvidia und anderen Institutionen hat durch ein umfassendes Upgrade der SGLang-Inferenz-Engine die Inferenzleistung des DeepSeek-R1-Modells auf H100 GPUs innerhalb von vier Monaten um das 26-fache gesteigert. Zu den Optimierungslösungen gehören die Trennung von Prefill und Dekodierung (PD-Trennung), massives Expert Parallelism (EP), DeepEP, DeepGEMM und ein Expert Parallelism Load Balancer (EPLB). Bei der Verarbeitung von Eingabesequenzen mit 2000 Tokens wurde ein Durchsatz von 52,3k Eingabe-Tokens und 22,3k Ausgabe-Tokens pro Sekunde und Knoten erreicht, was den offiziellen Daten von DeepSeek nahekommt und die Kosten für lokale Implementierungen erheblich senkt (Quelle: WeChat)

OpenAI-Wissenschaftler Dan Roberts: Die Skalierung von Reinforcement Learning wird die KI zu neuen wissenschaftlichen Entdeckungen führen und könnte in 9 Jahren eine AGI auf Einstein-Niveau ermöglichen: Dan Roberts, Forschungswissenschaftler bei OpenAI, hielt auf der AI Ascent von Sequoia Capital einen Vortrag über die zentrale Rolle von Reinforcement Learning (RL) bei der zukünftigen Entwicklung von KI-Modellen. Er ist der Ansicht, dass durch die kontinuierliche Skalierung von RL KI-Modelle nicht nur ihre Leistung bei Aufgaben wie mathematischem Schließen verbessern, sondern auch durch „Test Time Computation“ (d. h. je länger das Modell nachdenkt, desto besser seine Leistung) wissenschaftliche Entdeckungen ermöglichen können. Am Beispiel von Einsteins Entdeckung der Allgemeinen Relativitätstheorie spekulierte er, dass eine KI, die 8 Jahre lang rechnen und nachdenken könnte, in 9 Jahren wissenschaftliche Durchbrüche auf Einstein-Niveau erzielen könnte. Roberts betonte, dass sich die zukünftige KI-Entwicklung stärker auf RL-Berechnungen konzentrieren und diese möglicherweise sogar den gesamten Trainingsprozess dominieren werden (Quelle: WeChat)

🎯 Trends
Nvidias Jim Fan: Roboter werden den „Physical Turing Test“ bestehen, Simulation und Generative KI sind entscheidend: Jim Fan, Leiter der Robotik-Abteilung bei Nvidia, stellte auf der Sequoia AI Ascent das Konzept des „Physical Turing Test“ vor, bei dem Menschen nicht unterscheiden können, ob eine Aufgabe von einem Menschen oder einem Roboter ausgeführt wird. Er wies darauf hin, dass die Kosten für die Datenerfassung bei Robotern derzeit hoch sind und Simulationstechnologie, insbesondere in Kombination mit Generativer KI (z. B. Feinabstimmung von Videogenerierungsmodellen) zur Erzeugung vielfältiger, umfangreicher Trainingsdaten („digitale Cousins“ statt exakter „digitaler Zwillinge“), entscheidend ist. Er prognostiziert, dass durch groß angelegte Simulationen und Vision-Language-Action-Modelle (wie Nvidias GR00T) physische APIs in Zukunft allgegenwärtig sein werden und Roboter komplexe Alltagsaufgaben erledigen und sich intelligent in ihre Umgebung integrieren können (Quelle: WeChat)
ByteDance veröffentlicht Seed-Coder-Serie von Code-LLMs, 8B-Version zeigt überlegene Leistung: ByteDance hat die Seed-Coder-Serie von Code-LLMs vorgestellt, die Versionen mit 8B, 14B und weiteren Parametern umfasst. Davon zeigt Seed-Coder-8B auf mehreren Benchmarks für Code-Fähigkeiten wie SWE-bench, Multi-SWE-bench und IOI eine herausragende Leistung und soll Qwen3-8B und Qwen2.5-Coder-7B-Inst übertreffen. Die Modellreihe umfasst Base-, Instruct- und Reasoner-Versionen, deren Kernkonzept darin besteht, „Code-Modelle ihre eigenen Daten kuratieren zu lassen“, was zu signifikanten Verbesserungen bei Code-Reasoning und Software-Engineering-Fähigkeiten führt. Die Modelle wurden auf Hugging Face und GitHub als Open Source veröffentlicht (Quelle: Reddit r/LocalLLaMA, karminski3, teortaxesTex)
Alibaba veröffentlicht ZeroSearch-Framework als Open Source, das LLMs zur Simulation von Suchen nutzt und KI-Trainingskosten um 88 % senkt: Forscher von Alibaba haben ein Reinforcement-Learning-Framework namens „ZeroSearch“ veröffentlicht, das es Large Language Models (LLMs) ermöglicht, fortschrittliche Suchfunktionen durch die Simulation von Suchmaschinen zu entwickeln, ohne während des Trainings teure kommerzielle Suchmaschinen-APIs (wie Google) aufrufen zu müssen. Experimente zeigten, dass die Verwendung eines 3B LLM als simulierte Suchmaschine die Suchfähigkeiten des Policy-Modells effektiv verbessern kann, wobei die Leistung eines 14B-Parameter-Retrieval-Moduls sogar die von Google Search übertrifft und gleichzeitig die API-Kosten um 88 % gesenkt werden. Die Technologie wurde auf GitHub und Hugging Face als Open Source veröffentlicht und unterstützt Modellreihen wie Qwen-2.5 und LLaMA-3.2 (Quelle: WeChat)

Gemini API führt implizite Cache-Funktion ein, die bis zu 75 % Kosten sparen kann: Die Google Gemini API hat kürzlich eine implizite Cache-Funktion für die Gemini 2.5-Modellreihe (Pro und Flash) aktiviert. Wenn Anfragen von Nutzern den Cache treffen, können automatisch bis zu 75 % der Kosten eingespart werden. Gleichzeitig wurde die Mindestanzahl an Tokens, die einen Cache-Treffer auslösen, gesenkt: für das 2.5 Flash-Modell auf 1K Tokens und für das 2.5 Pro-Modell auf 2K Tokens. Dieser Schritt zielt darauf ab, die Kosten für Entwickler bei der Nutzung der Gemini API zu senken und die Effizienz bei häufig wiederholten Anfragen zu steigern (Quelle: JeffDean)
Tsinghua-Universität entwickelt KI-optisches Mikroskop Meta-rLLS-VSIM mit 15,4-facher Verbesserung der volumetrischen Auflösung: Die Forschungsgruppe von Li Dong und das Team von Dai Qionghai an der Tsinghua-Universität haben das Meta-Learning-gesteuerte reflektierende Gitterlichtblatt- virtuelle strukturierte Beleuchtungsmikroskop (Meta-rLLS-VSIM) vorgestellt. Dieses System verbessert durch die innovative Kombination von KI und Optik die laterale Auflösung der Lebendzellbildgebung auf 120 nm und die axiale Auflösung auf 160 nm, wodurch eine nahezu isotrope Superauflösung erreicht und die volumetrische Auflösung im Vergleich zu herkömmlichem LLSM um das 15,4-fache gesteigert wird. Zu den Kerntechnologien gehören die „virtuelle strukturierte Beleuchtung“, bei der ein DNN die Superauflösungsfähigkeit lernt und auf mehrere Richtungen erweitert, sowie die Verbesserung der axialen Auflösung durch die Fusion von Dual-View-Informationen mittels Spiegelreflexion und ein RL-DFN-Netzwerk. Die Einführung einer Meta-Learning-Strategie ermöglicht es dem KI-Modell, sich in nur 3 Minuten adaptiv zu konfigurieren, was die Anwendungsschwelle für KI in biologischen Experimenten erheblich senkt und ein leistungsstarkes Werkzeug zur Beobachtung von Lebensprozessen wie der Teilung von Krebszellen und der Embryonalentwicklung darstellt (Quelle: WeChat)

Qwen3-Serie von LLMs veröffentlicht, führt weiterhin die Open-Source-Community an: Alibaba hat die Qwen3-Serie von Large Language Models veröffentlicht, deren Parametergrößen von 0.5B bis 235B reichen. Sie zeigen in mehreren Benchmarks eine hervorragende Leistung, wobei mehrere kleinere Modelle in ihrer Größenklasse den SOTA-Status unter den Open-Source-Modellen erreichen. Die Qwen3-Serie unterstützt mehrere Sprachen und eine Kontextlänge von bis zu 128k Tokens. Aufgrund ihrer starken Leistung und der im Vergleich zu DeepSeek-R1 und anderen relativ geringen Bereitstellungskosten wird die Qwen-Serie bereits im Ausland (insbesondere in Japan) häufig als Grundlage für die KI-Entwicklung eingesetzt und hat zahlreiche spezialisierte Modelle hervorgebracht. Die Veröffentlichung von Qwen3 festigt seine führende Position in der globalen Open-Source-KI-Community weiter, mit über 20.000 Sternen auf GitHub innerhalb einer Woche (Quelle: dl_weekly, WeChat)

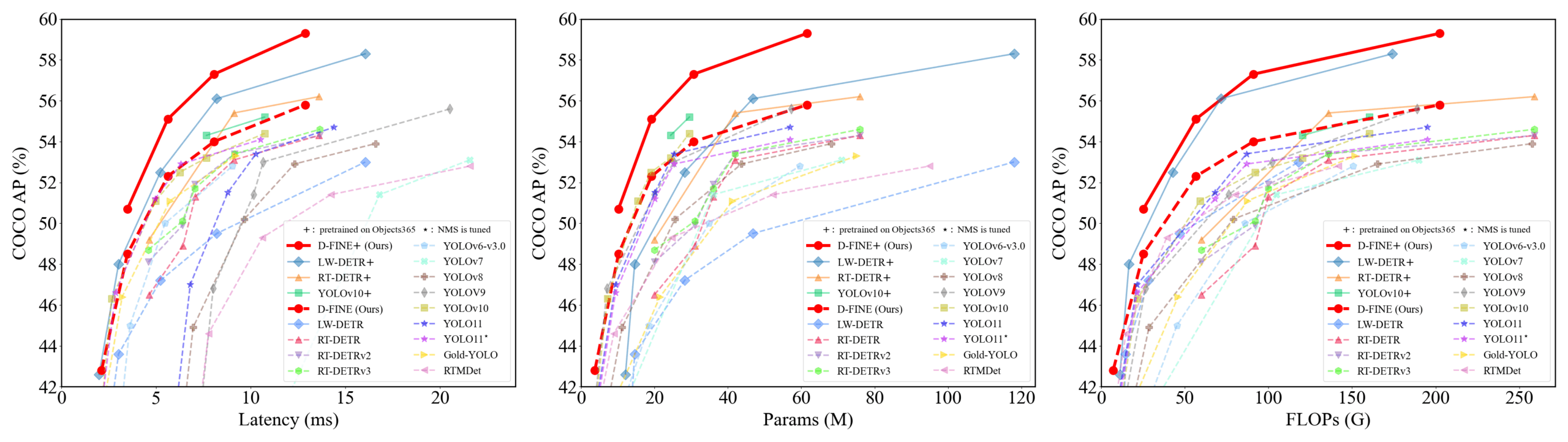
D-FINE: Ein Echtzeit-Objektdetektor basierend auf feinkörniger Verteilungsoptimierung mit überlegener Leistung: Forscher stellen D-FINE vor, einen neuartigen Echtzeit-Objektdetektor, der die Bounding-Box-Regressionsaufgabe in DETR als feinkörnige Verteilungsoptimierung (FDR) neu definiert und eine Global Optimal Localization Self-Distillation (GO-LSD)-Strategie einführt. D-FINE erreicht eine hervorragende Leistung ohne zusätzliche Inferenz- und Trainingskosten. Beispielsweise erreicht D-FINE-N 42,8 % AP auf COCO val bei einer Geschwindigkeit von bis zu 472 FPS (T4 GPU); D-FINE-X erreicht nach dem Vortraining auf Objects365+COCO einen COCO val AP von 59,3 %. Die Methode erreicht eine feinere Lokalisierung durch iterative Optimierung von Wahrscheinlichkeitsverteilungen und überträgt das Lokalisierungswissen der letzten Schicht durch Selbst-Destillation auf frühere Schichten (Quelle: GitHub Trending)
Harmon-Modell koordiniert visuelle Repräsentationen und vereinheitlicht multimodales Verständnis und Generierung: Forscher der Nanyang Technological University haben das Harmon-Modell vorgestellt, das darauf abzielt, multimodale Verständnis- und Generierungsaufgaben durch einen gemeinsam genutzten MAR Encoder (Masked Autoencoder for Reconstruction) zu vereinheitlichen. Die Studie ergab, dass der MAR Encoder beim Training der Bildgenerierung gleichzeitig visuelle Semantik lernen kann und seine Linear Probing-Ergebnisse VQGAN/VAE bei weitem übertreffen. Das Harmon-Framework nutzt den MAR Encoder zur Verarbeitung vollständiger Bilder für das Verständnis und verwendet das MAR-Maskierungsmodellierungsparadigma für die Bildgenerierung, wobei ein LLM die modale Interaktion realisiert. Experimente zeigen, dass Harmon bei multimodalen Verständnis-Benchmarks Janus-Pro nahekommt und bei den Benchmarks für Ästhetik bei der Text-zu-Bild-Generierung (MJHQ-30K) und der Befehlsverfolgung (GenEval) hervorragende Leistungen erbringt und sogar einige Expertenmodelle übertrifft. Das Modell wurde als Open Source veröffentlicht (Quelle: WeChat)

PushInfoTech realisiert kommerziellen geschlossenen Kreislauf für Logistikroboter durch Datensammlung mit „Rider Shadow System“: Die Logistikroboter von PushInfoTech sind bereits in mehreren chinesischen Städten im praktischen Einsatz und haben durch die Zusammenarbeit mit menschlichen Fahrern die Gewinnschwelle für einzelne Roboter erreicht. Eine ihrer Kerntechnologien ist das „Rider Shadow System“, das Fahrverhalten, Umgebungswahrnehmung und Betriebsdaten (wie Türöffnen/-schließen, Aufnehmen/Abstellen von Gegenständen) von echten Fahrern in komplexen städtischen Umgebungen erfasst und so umfangreiche, hochwertige Trainingsdaten für Imitation Learning und Reinforcement Learning für die Roboter bereitstellt. Das System hat bereits Daten von mehreren zehn Millionen gefahrenen Kilometern und fast einer Million Trajektorien der oberen Gliedmaßen gesammelt. Auf dieser Basis hat PushInfoTech ein Behavior-Tree-VLA-Modell trainiert, das es den Robotern ermöglicht, mit komplexen Situationen in der realen Welt umzugehen, und plant eine Expansion in Überseemärkte (Quelle: WeChat)

Kuaishou stellt KuaiMod-Framework vor, das multimodale LLMs zur Optimierung des Kurzvideo-Ökosystems nutzt: Kuaishou hat eine auf multimodalen LLMs basierende Lösung zur Optimierung des Ökosystems von Kurzvideo-Plattformen namens KuaiMod vorgestellt, die darauf abzielt, die Benutzererfahrung durch automatisierte Beurteilung der Inhaltsqualität zu verbessern. KuaiMod nutzt einen fallbasierten Ansatz, bei dem Visual Language Models (VLM) mittels Chain-of-Thought-Reasoning minderwertige Inhalte analysieren und die Beurteilungsstrategien durch Reinforcement Learning from User Feedback (RLUF) kontinuierlich aktualisiert werden. Das Framework wurde bereits auf der Kuaishou-Plattform implementiert und hat die Nutzerbeschwerderate um über 20 % gesenkt. Kuaishou arbeitet gleichzeitig an der Entwicklung multimodaler LLMs, die Kurzvideos der Community verstehen können, und geht dabei von der Merkmalsextraktion zur tiefen semantischen Verständigung über. Diese wurden bereits in mehreren Szenarien wie der Strukturierung von Video-Interessen-Tags und der Unterstützung der Inhaltserstellung erfolgreich eingesetzt (Quelle: WeChat)

Lenovo stellt persönlichen Super-Agenten „Tianxi“ vor und bewegt sich auf L3-Intelligenz zu: Lenovo hat auf seiner Innovation Technology Conference den persönlichen Super-Agenten „Tianxi“ vorgestellt, der über multimodale Wahrnehmung und Interaktion, kognitive Fähigkeiten und Entscheidungsfindung basierend auf einer persönlichen Wissensdatenbank sowie die Fähigkeit zur autonomen Zerlegung und Ausführung komplexer Aufgaben verfügt. Tianxi zielt darauf ab, durch begleitende AUI-Schnittstellen wie AI Suixin Chuang, AI Linglong Tai und AI Ruying Kuang eine natürliche und nahtlose Mensch-Maschine-Kollaboration zu ermöglichen. Es integriert mehrere branchenführende LLMs, darunter DeepSeek-R1, und verwendet eine Edge-Cloud-Hybridarchitektur in Kombination mit Lenovos Personal Cloud 1.0 (ausgestattet mit einem 72-Milliarden-Parameter-LLM), um leistungsstarke Rechenleistung und 100 GB dedizierten Speicherplatz bereitzustellen. Lenovo stellte gleichzeitig auch Super-Agenten für Unternehmen („Leshang“) und Städte vor und demonstrierte damit sein umfassendes Engagement im KI-Bereich (Quelle: WeChat)

Neue Studie beurteilt Generalisierungsfähigkeit neuronaler Netze anhand der Komplexität symbolischer Interaktionen: Das Team von Professor Zhang Quanshi von der Shanghai Jiao Tong University hat eine neue Theorie vorgeschlagen, die die Generalisierungsfähigkeit neuronaler Netze aus der Perspektive der Komplexität ihrer inhärenten symbolischen Interaktionsrepräsentationen analysiert. Die Studie ergab, dass generalisierbare Interaktionen (die sowohl in Trainings- als auch in Testdatensätzen häufig vorkommen) über verschiedene Ordnungen (Komplexitätsstufen) hinweg typischerweise eine abklingende Verteilung aufweisen (wobei Interaktionen niedriger Ordnung dominieren), während nicht generalisierbare Interaktionen (die hauptsächlich in Trainingsdatensätzen vorkommen) eine spindelförmige Verteilung zeigen (wobei Interaktionen mittlerer Ordnung dominieren und positive und negative Effekte sich leicht aufheben). Diese Theorie zielt darauf ab, das Generalisierungspotenzial eines Modells direkt durch die Analyse der Verteilungsmuster der äquivalenten „UND-ODER-Interaktionslogik“ des Modells zu beurteilen und bietet eine neue Perspektive zum Verständnis und zur Verbesserung der Generalisierungsfähigkeit von Modellen (Quelle: WeChat)
🧰 Tools
Llama.cpp vollständig kompatibel mit Visual Language Models (VLM): Llama.cpp unterstützt jetzt vollständig Visual Language Models (VLM), sodass Entwickler multimodale Anwendungen auf Geräten ausführen können. Julien Chaumond von Hugging Face und andere haben vorquantisierte Modelle geteilt, darunter Gemma von Google DeepMind, Pixtral von Mistral AI, Qwen VL von Alibaba und SmolVLM von Hugging Face, die direkt verwendet werden können. Dieses Update ist den Beiträgen der Teams @ngxson und @ggml_org zu verdanken und eröffnet neue Möglichkeiten für lokalisierte, latenzarme multimodale KI-Anwendungen (Quelle: ggerganov, ClementDelangue, cognitivecompai)
Quark AI Super Box rüstet „Deep Search“ auf, um KI-„Suchkompetenz“ zu verbessern: Die Quark AI Super Box wurde kürzlich mit der Funktion „Deep Search“ aufgerüstet, die darauf abzielt, die Suchkompetenz (Sou Shang) der KI zu verbessern. Die neue Funktion betont das proaktive Denken und die logische Planung der KI vor der Suche, um komplexe und personalisierte Suchanfragen der Nutzer besser zu verstehen, Probleme zu zerlegen und eine strukturierte intelligente Suche durchzuführen. Im Gesundheitsbereich greift der Quark AI Gesundheitsberater „Aqua“ auf Meinungen von Ärzten aus Top-Krankenhäusern und Fachliteratur zurück; im akademischen Bereich werden maßgebliche Quellen wie CNKI angebunden. Darüber hinaus verfügt Quark über leistungsstarke multimodale Verarbeitungsfähigkeiten wie Bildanalyse, AI-抠图 (AI-Freistellung), Bildverbesserung und Stiltransfer. Berichten zufolge wird Quark in Zukunft auch eine Deep Search Pro-Version mit Deep Research-Fähigkeiten veröffentlichen (Quelle: WeChat)

LangChain stellt mehrere Integrationen und Tutorials vor, um RAG- und Agentenfähigkeiten zu stärken: LangChain hat kürzlich mehrere Updates und Tutorials veröffentlicht: 1. Tutorial für Social Media Agent UI: Anleitung zur Umwandlung eines LangChain Social Media Agenten in eine benutzerfreundliche Webanwendung, Integration von ExpressJS und AgentInbox UI sowie Unterstützung für Notion. 2. Preisgekrönte RAG-Lösung: Präsentation einer RAG-Implementierung zur Analyse von Unternehmensjahresberichten, die PDF-Parsing, mehrere LLMs und erweiterte Retrieval-Funktionen unterstützt. 3. Private RAG-Chat-Anwendung: Tutorial zur Erstellung einer lokalisierten, datenschutzorientierten RAG-Chat-Anwendung mit LangChain und dem Reflex-Framework. 4. Nimble Retriever-Integration: Einführung eines leistungsstarken Web-Daten-Retrievers, der präzise Daten für LangChain-Anwendungen liefert. 5. Leitfaden für strukturierte Ausgaben mit Claude 3.7: Bietet drei Methoden zur Realisierung strukturierter Ausgaben mit Claude 3.7 über LangChain und AWS Bedrock. 6. Lokales Chat-RAG-System: Open-Source-Projekt, das ein vollständig lokalisiertes Dokumenten-Q&A-System unter Verwendung des LangChain RAG-Prozesses und lokaler LLMs (über Ollama) demonstriert und so den Datenschutz gewährleistet (Quelle: LangChainAI, LangChainAI, LangChainAI, LangChainAI, LangChainAI, LangChainAI)

Minion-agent: Ein Open-Source-KI-Agenten-Framework, das die Fähigkeiten mehrerer Frameworks integriert: Minion-agent ist ein neuartiges Open-Source-Entwicklungsframework für KI-Agenten, das darauf abzielt, das Problem der Fragmentierung bestehender KI-Frameworks (wie OpenAI, LangChain, Google AI, SmolaAgents) zu lösen. Es bietet eine einheitliche Schnittstelle, unterstützt den Aufruf von Funktionen mehrerer Frameworks, Tools-as-a-Service (Web-Browsing, Dateioperationen usw.) sowie die Zusammenarbeit mehrerer Agenten. Das Projekt demonstriert sein Anwendungspotenzial in Szenarien wie Tiefenrecherche (automatische Sammlung von Literatur zur Erstellung von Berichten), Preisvergleich (automatisierte Marktforschung), Ideengenerierung (Generierung von Spielcode) und Verfolgung technologischer Entwicklungen und betont die Vorteile des Open-Source-Modells hinsichtlich Flexibilität und Kosteneffizienz (Quelle: WeChat)

RunwayML zeigt leistungsstarke Videoerstellungs- und -bearbeitungsfunktionen in verschiedenen Szenarien: Der unabhängige KI-Forscher Cristobal Valenzuela und andere Nutzer demonstrierten die Anwendung von RunwayML in verschiedenen kreativen Szenarien. Dazu gehören die Nutzung seiner Funktionen Frames, References und Gen-4 zur schnellen Erstellung und Visualisierung kreativer Bilder unter Beibehaltung von Stil- und Charakterkonsistenz; die Umwandlung der Welt Rembrandts in ein RPG-Videospiel; sowie die Synthese neuartiger Innenraumansichten aus einem einzigen Bild durch Bereitstellung visueller Referenzen. Diese Beispiele unterstreichen die Fortschritte von RunwayML bei der kontrollierbaren Videogenerierung, Stilübertragung und Szenenerstellung (Quelle: c_valenzuelab, c_valenzuelab, c_valenzuelab, c_valenzuelab)

Olympus: Ein universeller Task-Router für Computer-Vision-Aufgaben: Olympus ist ein universeller Task-Router, der für Computer-Vision-Aufgaben entwickelt wurde. Er zielt darauf ab, die Verarbeitungsprozesse verschiedener visueller Aufgaben zu vereinfachen und zu vereinheitlichen, möglicherweise durch intelligente Planung und Zuweisung von Rechenressourcen oder Modellaufrufen, um die Effizienz und Leistung von Multi-Task-Computer-Vision-Systemen zu optimieren. Das Projekt wurde auf GitHub als Open Source veröffentlicht (Quelle: dl_weekly)
Tracy Profiler: Echtzeit-Nanosekunden-Hybrid-Frame- und Sampling-Analysator: Tracy Profiler ist ein Echtzeit-, Nanosekunden-Auflösungs-, ferntelemetriefähiges Hybrid-Frame-Analyse- und Sampling-Analyse-Tool für Spiele und andere Anwendungen. Es unterstützt die Leistungsanalyse von CPU (C, C++, Lua, Python, Fortran und Drittanbieter-Bindings für Rust, Zig, C# usw.), GPU (OpenGL, Vulkan, Direct3D, Metal, OpenCL), Speicherzuweisungen, Locks und Kontextwechseln und kann Screenshots automatisch mit erfassten Frames verknüpfen. Dieses Werkzeug bietet Entwicklern mit seiner hohen Präzision und Echtzeitfähigkeit leistungsstarke Mittel zur Lokalisierung und Optimierung von Leistungsengpässen (Quelle: GitHub Trending)

FieldStation42: Retro-Rundfunk- und Fernsehsimulator: FieldStation42 ist ein Python-Projekt, das darauf abzielt, das Seherlebnis von altem Rundfunk und Fernsehen zu simulieren. Es kann mehrere Kanäle gleichzeitig unterstützen, automatisch Werbung und Programmvorschauen einfügen und wöchentliche Programmübersichten basierend auf Konfigurationen generieren. Der Simulator kann zufällig kürzlich nicht gespielte Sendungen auswählen, um die Frische zu erhalten, unterstützt die Festlegung von Sendeterminbereichen (z. B. saisonale Sendungen) und kann Videos für Sendeschluss und Schleifenbilder für kein Signal konfigurieren. Das Projekt unterstützt auch Hardwareverbindungen (z. B. Raspberry Pi Pico) zur Simulation von Kanalwechseln und bietet eine Vorschau-/Programmführer-Kanalfunktion. Ziel ist es, dass beim „Einschalten des Fernsehers“ „echte“ Programminhalte abgespielt werden, die zur jeweiligen Zeit und zum jeweiligen Sender passen (Quelle: GitHub Trending)

Tiny Corp stellt AMD eGPU-Lösung über USB3 vor, unterstützt Apple Silicon: Tiny Corp hat eine Lösung zur Verbindung einer AMD eGPU mit einem Apple Silicon Mac über USB3 (konkret über ein ADT-UT3G-Gerät mit ASM2464PD-Controller) vorgestellt. Für diese Lösung wurden die Treiber neu geschrieben, um die 10-Gbit/s-Bandbreite von USB3 zu nutzen. Sie verwendet libusb und ist theoretisch auch mit Linux oder Windows kompatibel. Dies eröffnet Apple Silicon-Nutzern neue Möglichkeiten zur Erweiterung ihrer Grafikleistung, insbesondere für Szenarien wie das lokale Ausführen großer KI-Modelle (Quelle: Reddit r/LocalLLaMA)
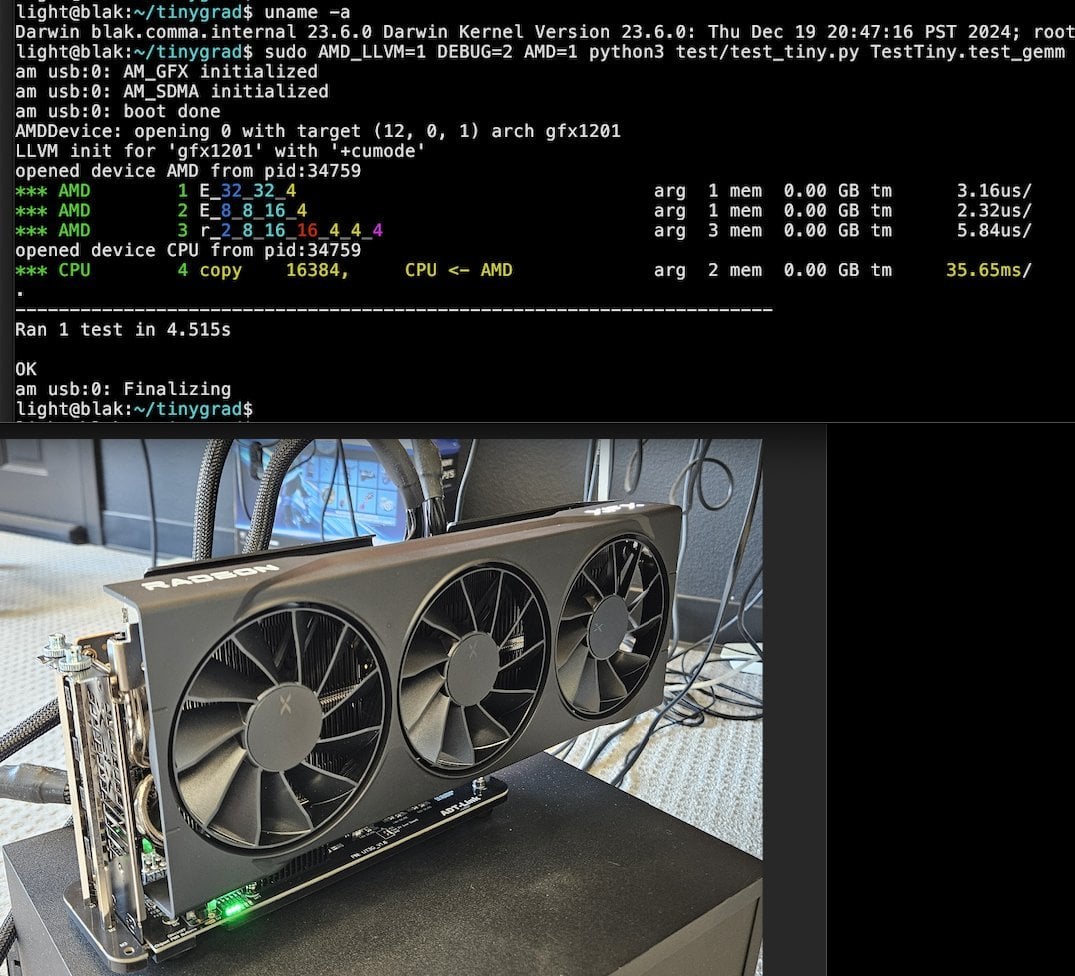
Llama.cpp-vulkan implementiert FlashAttention-Unterstützung auf AMD GPUs: Das Vulkan-Backend von Llama.cpp hat kürzlich die Implementierung von FlashAttention integriert. Das bedeutet, dass Nutzer, die llama.cpp-vulkan auf AMD GPUs verwenden, nun die FlashAttention-Technologie nutzen können. In Kombination mit der Q8 KV-Cache-Quantisierung können Nutzer potenziell die Kontextgröße verdoppeln, während die Inferenzgeschwindigkeit beibehalten oder sogar verbessert wird. Dieses Update ist ein wichtiger Vorteil für AMD GPU-Nutzer, die große Sprachmodelle lokal ausführen (Quelle: Reddit r/LocalLLaMA)
Devseeker: Leichtgewichtiger KI-Codierungsassistent, Alternative zu Aider und Claude Code: Devseeker ist ein neuartiges Open-Source-Projekt für einen leichtgewichtigen KI-Codierungsagenten, der als Alternative zu Aider und Claude Code positioniert ist. Er verfügt über Funktionen zum Erstellen und Bearbeiten von Code, Verwalten von Codedateien und -ordnern, Kurzzeit-Code-Gedächtnis, Code-Überprüfung, Ausführen von Codedateien, Berechnung des Token-Verbrauchs sowie verschiedene Codierungsmodi. Das Projekt zielt darauf ab, ein einfacher zu implementierendes und zu verwendendes KI-gestütztes Programmierwerkzeug für den lokalen Einsatz bereitzustellen (Quelle: Reddit r/ClaudeAI)
📚 Lernen
Panaversity startet Agentic AI-Lernprojekt mit Fokus auf Dapr und OpenAI Agents SDK: Panaversity hat das Projekt „Learn Agentic AI“ ins Leben gerufen, das darauf abzielt, Ingenieure für Agenten- und Roboter-KI durch das Dapr Agentic Cloud Ascent (DACA)-Designmuster und verschiedene agentennative Cloud-Technologien (einschließlich OpenAI Agents SDK, Memory, MCP, A2A, Knowledge Graphs, Dapr, Rancher Desktop, Kubernetes) auszubilden. Das Kernproblem des Projekts ist die Entwicklung von Systemen, die Millionen von gleichzeitigen KI-Agenten verarbeiten können. Es bietet die Kursserien AI-201, AI-202 und AI-301 an, die den Lernpfad von den Grundlagen bis hin zu großen verteilten KI-Agenten abdecken. Das Projekt betont, dass das OpenAI Agents SDK aufgrund seiner Benutzerfreundlichkeit und hohen Kontrollierbarkeit zum Mainstream-Entwicklungsframework werden sollte (Quelle: GitHub Trending)

RL-Feinabstimmungsstudie deckt komplexe Beziehung zwischen Datenmanagement und Generalisierungsfähigkeit auf: Eine von Minqi Jiang weitergeleitete Arbeit diskutiert den Einfluss des Datenmanagements beim Reinforcement Learning (RL)-Feintuning auf die Generalisierungsfähigkeit von Modellen. Die Studie ergab, dass sowohl durch Self-Play Curriculum Learning auf „unendlichen“ Codierungsaufgaben (Absolute Zero Reasoner) als auch durch wiederholtes Training auf nur einem einzigen MATH-Aufgabenbeispiel (1-shot RLVR) Modelle der Qwen2.5-Serie mit 7B Parametern ihre Genauigkeit bei mathematischen Benchmarks um etwa 28 % bis 40 % steigern konnten. Dies offenbart ein Paradoxon: Extreme Datenmanagementstrategien (unendliche Daten vs. Einzelpunktdaten) können zu ähnlichen Generalisierungsverbesserungen führen. Mögliche Erklärungen sind, dass RL hauptsächlich bereits im vortrainierten Modell vorhandene Fähigkeiten hervorruft, dass es gemeinsame „Reasoning-Schaltkreise“ gibt und dass Vortraining zu konkurrierenden Reasoning-Schaltkreisen führen kann. Die Forscher sind der Ansicht, dass zur Überwindung der „Vortrainings-Obergrenze“ kontinuierlich neue Aufgaben und Umgebungen gesammelt und geschaffen werden müssen (Quelle: menhguin)
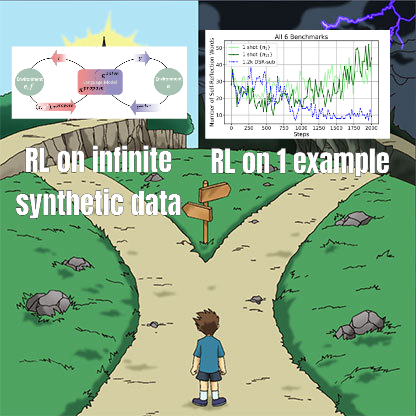
Absolute Zero Reasoner: Verbesserung der Zero-Data-Reasoning-Fähigkeit durch Self-Play: Eine Arbeit mit dem Titel „Absolute Zero Reasoner“ schlägt vor, dass Modelle durch reines Self-Play lernen können, Aufgaben zu stellen, die die Lernfähigkeit maximieren, und durch das Lösen dieser Aufgaben ihre eigenen Reasoning-Fähigkeiten verbessern können – und das alles ohne externe Daten. Diese Methode übertrifft andere „Zero-Shot“-Modelle sowohl im mathematischen als auch im Programmierbereich. Dies deutet darauf hin, dass KI-Systeme möglicherweise ihre Reasoning-Fähigkeiten durch interne Problemgenerierung und -lösung kontinuierlich weiterentwickeln können, was neue Ansätze für KI-Anwendungen in Bereichen mit spärlichen Daten oder hohen Annotationskosten bietet (Quelle: cognitivecompai, Reddit r/LocalLLaMA)

Häufige Fehler bei der Bewertung von KI-Produkten und Best Practices: Hamel Husain und Shreya Runwal teilen häufige Fehler bei der Erstellung von Bewertungen (Evals) für KI-Produkte und geben Ratschläge, wie diese vermieden werden können. Wichtige Punkte sind: Basismodell-Benchmarks sind nicht gleich Anwendungsevaluierungen; allgemeine Evaluierungen sind unwirksam und müssen auf spezifische Anwendungen zugeschnitten sein; Annotations- und Prompt-Engineering sollten nicht an Nicht-Domänenexperten ausgelagert werden; es sollten eigene Datenannotationsanwendungen erstellt werden; LLM-Prompts sollten spezifisch sein und auf Fehleranalysen basieren; binäre Labels verwenden; Datenüberprüfung ernst nehmen; Vorsicht vor Overfitting auf Testdaten; Online-Tests durchführen. Diese Praktiken sollen Entwicklern helfen, zuverlässigere KI-Produktbewertungssysteme zu erstellen, die die Leistung in der realen Welt besser widerspiegeln (Quelle: jeremyphoward, HamelHusain)
Neuer Ansatz zur KV-Cache-Optimierung: Universelles übertragbares Wörterbuch und Signalverarbeitungsrekonstruktion: Das Team von Dimitris Papailiopoulos an der University of Wisconsin-Madison schlägt eine neue Methode zur Reduzierung des KV-Caches vor, die durch die Verwendung eines universellen, übertragbaren Wörterbuchs in Kombination mit traditionellen Signalverarbeitungsrekonstruktionsalgorithmen erreicht wird. Diese Methode hat bei Nicht-Inferenzmodellen bereits SOTA-Niveau (State-of-the-Art) erreicht und verspricht, bei Inferenzmodellen noch besser abzuschneiden. Diese Forschung wurde von der ICML angenommen und bietet eine neue Perspektive und einen technischen Pfad zur Lösung des Problems des hohen KV-Cache-Verbrauchs bei der Inferenz großer Modelle (Quelle: teortaxesTex, jeremyphoward, arohan, andersonbcdefg)

Qdrant fördert RAG-Systeme und Hybrid-Search-Praktiken in der brasilianischen Community: Die Vektordatenbank Qdrant gewinnt in der brasilianischen Community zunehmend an Aufmerksamkeit. Der Entwickler Daniel Romero teilte zwei portugiesischsprachige Artikel, die praktische Methoden zum Aufbau von RAG-Systemen (Retrieval Augmented Generation) mit Qdrant, FastAPI und Hybrid Search vorstellen. Die Inhalte umfassen den Aufbau eines Hybrid-Search-RAG-Systems sowie Strategien zur Datenaufnahme für RAG, insbesondere die Hybrid-Chunking-Technik. Diese Beiträge helfen brasilianischen Entwicklern, Qdrant besser für die Entwicklung von KI-Anwendungen zu nutzen (Quelle: qdrant_engine)
OpenAI Academy startet Themenserie zu Prompt Engineering für K-12-Bildung: Die OpenAI Academy hat eine Lernreihe zum Thema Prompt Engineering für K-12-Pädagogen mit dem Titel „Mastering Your Prompts“ veröffentlicht. Die Reihe soll Pädagogen helfen, Prompting-Techniken besser zu verstehen und anzuwenden, um KI-Tools (wie ChatGPT) effektiver in die Unterrichtspraxis zu integrieren und so die Unterrichtsqualität und die Lernerfahrung der Schüler zu verbessern. Dies zeigt, dass KI-gestützte Bildung allmählich in die Grundschulbildung vordringt und Wert auf die Förderung der KI-Kompetenz von Pädagogen legt (Quelle: dotey)
Yann LeCun teilt Inhalte seines Vortrags an der National University of Singapore: Yann LeCun hat das PDF-Dokument seines Distinguished Lecture geteilt, den er am 27. April 2025 (Anmerkung: Datum im Originaltext, wahrscheinlich ein Tippfehler und sollte ein vergangenes Datum sein oder 2024) an der National University of Singapore (NUS) gehalten hat. Obwohl das genaue Thema des Vortrags nicht genannt wird, befassen sich LeCuns Vorträge als Pionier im Bereich Deep Learning typischerweise mit aktuellen Theorien der künstlichen Intelligenz, zukünftigen Trends oder tiefgreifenden Einsichten in die aktuelle KI-Entwicklung. Diese Freigabe bietet Interessierten an der KI-Forschung direkten Zugang zu seinen neuesten Ansichten (Quelle: ylecun)
PyTorch und Mojo-Backend-Kooperation zur Vereinfachung der Anpassung an neue Hardware und Sprachen: PyTorch arbeitet daran, den Prozess der Erstellung neuer Backends für aufkommende Programmiersprachen und Hardware zu vereinfachen. Auf dem Mojo Hackathon demonstrierte marksaroufim die Bemühungen von PyTorch in diesem Bereich und erwähnte ein in Arbeit befindliches (WIP) Backend, das in Zusammenarbeit mit dem Mojo-Team entwickelt wird. Dies deutet darauf hin, dass das PyTorch-Ökosystem seine Kompatibilität aktiv erweitert, um vielfältigere KI-Entwicklungsumgebungen und Hardwarebeschleunigungsoptionen zu unterstützen und so die Hürden für Entwickler bei der Bereitstellung und Optimierung von PyTorch-Modellen auf verschiedenen Plattformen zu senken (Quelle: marksaroufim)
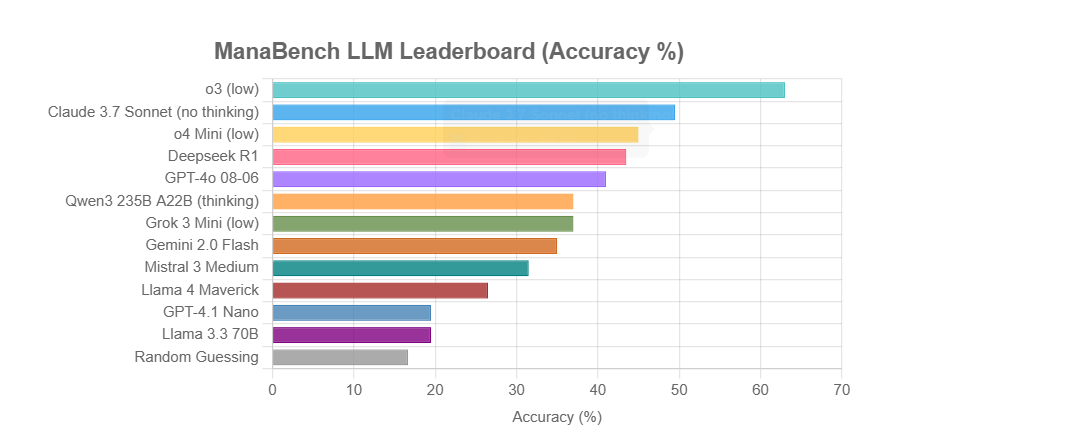
ManaBench: Neuer LLM-Reasoning-Benchmark basierend auf Magic: The Gathering Deckbau: Ein Entwickler hat einen neuen Benchmark namens ManaBench erstellt, der die Fähigkeit von LLMs zum komplexen System-Reasoning testet, indem er sie auffordert, aus sechs Optionen die am besten geeignete 60. Karte für ein gegebenes Set von 59 Magic: The Gathering (MTG) Karten auszuwählen. Der Benchmark betont strategisches Denken und Systemoptimierung, wobei die Antworten mit denen menschlicher Experten übereinstimmen und schwer durch einfaches Auswendiglernen zu knacken sind. Erste Ergebnisse zeigen, dass Modelle der Llama-Serie unterdurchschnittlich abschneiden, während Closed-Source-Modelle wie o3 und Claude 3.7 Sonnet führend sind. Der Benchmark zielt darauf ab, die Leistung von LLMs bei Aufgaben, die komplexes Reasoning erfordern, realistischer zu bewerten (Quelle: Reddit r/LocalLLaMA)
Diskussion: Wird KI den Traum vom Semantic Web wiederbeleben oder begraben?: Auf Social Media merkte der Nutzer Spencer an, dass das Semantic Web auf den meisten Websites eher Theorie als Praxis sei, es sei denn, große Unternehmenswebsites hätten aufgrund des ADA-Gesetzes (Americans with Disabilities Act) ein erhebliches Risiko. Dorialexander antwortete, dass es sich anfühle, als würde KI entweder den Traum vom Semantic Web wiederbeleben oder ihn für immer begraben. Dies spiegelt die Erwartungen und Bedenken hinsichtlich des Potenzials von KI beim Verstehen und Nutzen strukturierter Daten wider. KI könnte indirekt die Ziele des Semantic Web erreichen, indem sie strukturierte Informationen automatisch versteht und generiert, aber aufgrund ihrer eigenen Leistungsfähigkeit könnte sie traditionelle Semantic-Web-Technologien auch weniger wichtig machen (Quelle: Dorialexander)
Forscher untersuchen Ethik und Architekturen von Modellspeicherung und -vergessen: Ein Entwurf eines Papiers mit dem Titel „Sticky Minds: The Ethics and Architectures of AI Memory and Forgetting“ wird derzeit verfasst und untersucht, wie wir entscheiden, was Modelle vergessen sollten, wenn sie anfangen, „zu gut zu erinnern“, wobei neuronale Architekturen und Gedächtnisethik miteinander verbunden werden. Dies betrifft, wie KI-Systeme Informationen speichern, abrufen und (selektiv) vergessen, sowie die daraus resultierenden ethischen Herausforderungen und gesellschaftlichen Auswirkungen, was für den Aufbau verantwortungsvoller und vertrauenswürdiger KI von entscheidender Bedeutung ist (Quelle: Reddit r/artificial)
💼 Wirtschaft
Berichten zufolge wird Nvidia eine „erneut beschnittene“ Version des H20-Chips herausbringen, die den neuen US-Exportkontrollen entspricht: Laut Reuters plant Nvidia, in den nächsten zwei Monaten eine neue, speziell für China bestimmte Version des H20 AI-Chips auf den Markt zu bringen, um den neuesten US-Exportkontrollanforderungen zu entsprechen. Dieser Chip wird gegenüber dem ursprünglichen H20 (der bereits eine für den chinesischen Markt angepasste, leistungsgeminderte Version war) weiter „beschnitten“, beispielsweise wird die Speicherkapazität deutlich reduziert. Obwohl die Leistung erneut sinkt, sollen nachgelagerte Nutzer Berichten zufolge durch Modifikation der Modulkonfiguration eine gewisse Leistungsanpassung vornehmen können. Derzeit hat Nvidia Bestellungen für H20 im Wert von 18 Milliarden US-Dollar erhalten (Quelle: WeChat)

Databricks erwägt Übernahme des Open-Source-Datenbankunternehmens Neon für 1 Milliarde US-Dollar zur Stärkung der KI-Infrastruktur: Das Daten- und KI-Unternehmen Databricks führt Berichten zufolge Verhandlungen über die Übernahme von Neon, einem Entwickler einer Open-Source-PostgreSQL-Datenbank-Engine. Der Transaktionswert könnte rund 1 Milliarde US-Dollar betragen. Neon zeichnet sich durch seine serverlose Architektur, die Trennung von Speicher und Rechenleistung sowie seine gute Anpassungsfähigkeit an AI Agents und Ambient Computing aus. Es ermöglicht eine nutzungsbasierte Bezahlung und einen schnellen Start von Datenbankinstanzen, was für KI-Anwendungsszenarien geeignet ist. Eine erfolgreiche Übernahme würde die Infrastrukturkompetenz von Databricks im KI-Zeitalter weiter stärken und dem Unternehmen eine modernisierte, KI-zentrierte Datenbanklösung bieten (Quelle: WeChat)

OpenAI ernennt ehemalige Instacart-CEO Fidji Simo zur CEO für das Anwendungsgeschäft, um Produkt und Kommerzialisierung zu stärken: OpenAI hat die Ernennung von Fidji Simo, ehemalige CEO von Instacart und Vorstandsmitglied des Unternehmens, zur neu geschaffenen Position der „Chief Executive Officer für das Anwendungsgeschäft“ bekannt gegeben, gleichrangig mit Sam Altman. Simo wird die volle Verantwortung für die Produkte von OpenAI tragen, insbesondere für nutzerorientierte Anwendungen wie ChatGPT, mit dem Ziel, Produktoptimierung, Nutzererfahrung und Kommerzialisierung voranzutreiben. Dieser Schritt markiert eine bedeutende strategische Neuausrichtung von OpenAI von der Modellentwicklung hin zur Produktplattformisierung und Marktexpansion, um eine stärkere Wettbewerbsfähigkeit auf der Anwendungsebene der KI aufzubauen. Simos umfangreiche Produkt- und Kommerzialisierungserfahrung bei Facebook und Instacart wird OpenAI helfen, dem zunehmenden Marktwettbewerb zu begegnen (Quelle: WeChat)

🌟 Community
JetBrains AI Assistant sorgt wegen schlechter Erfahrung und Kommentarverwaltung für Nutzerunmut: Obwohl das AI Assistant Plugin von JetBrains über 22 Millionen Mal heruntergeladen wurde, hat es auf dem Markt nur eine Bewertung von 2,3 von 5 Sternen und ist mit zahlreichen 1-Stern-Bewertungen übersät. Nutzer bemängeln allgemein die automatische Installation, langsame Ausführung, viele Fehler, unzureichende Unterstützung für Drittanbieter-Modelle, die Bindung von Kernfunktionen an Cloud-Dienste und fehlende Dokumentation. Kürzlich wurde JetBrains beschuldigt, massenhaft negative Kommentare gelöscht zu haben. Obwohl das Unternehmen offiziell erklärte, es handle sich um die Bearbeitung von regelwidrigen oder bereits gelösten Problemen, löste dies bei den Nutzern Zweifel an der Zensur und der mangelnden Beachtung des Nutzerfeedbacks aus. Einige Nutzer entschieden sich, ihre negativen Bewertungen erneut zu veröffentlichen und weiterhin 1 Stern zu vergeben. Dieser Vorfall verschärfte die Unzufriedenheit der Nutzer mit der KI-Produktstrategie von JetBrains (Quelle: WeChat)

Nutzer diskutieren Qualitätsprobleme bei der Ausgabe von KI-Marketing-Agenten: Der Social-Media-Nutzer omarsar0 beobachtete, dass viele in YouTube-Tutorials gezeigte Marketing-KI-Agenten Marketingtexte von allgemein schlechter Qualität generieren, denen es an Kreativität und Stil mangelt. Er ist der Ansicht, dass dies die Schwierigkeit widerspiegelt, LLMs qualitativ hochwertige und ansprechende Inhalte produzieren zu lassen, und betont, dass beim Aufbau von KI-Agenten „Geschmack“ entscheidend ist. Er wies darauf hin, dass viele aktuelle KI-Agenten zwar komplexe Arbeitsabläufe haben, aber immer noch Mängel bei der Erstellung von Inhalten mit echtem kommerziellen Wert aufweisen, was Chancen für talentierte Personen mit gutem Geschmack, Erfahrung und der Fähigkeit, gute Bewertungssysteme zu entwerfen, bietet (Quelle: omarsar0)
KI-gestütztes Programmieren und der Trend zum „Ambient Programming“ lösen Diskussionen aus: Ein Video auf Reddit über eine Y Combinator-Diskussion zum Thema KI-Programmierung löste eine hitzige Debatte aus. Die Ansichten im Video stimmten stark mit den Erfahrungen des Posting-Erstellers überein (der angab, durch „Ambient Programming“ mehrere profitable Projekte erstellt zu haben). Kernpunkte waren: 1. KI kann bereits beim Aufbau komplexer und nutzbarer Softwareprodukte helfen, sogar ohne Code zu schreiben. 2. Die Sorge von Softwareingenieuren, dass KI ihre Arbeit ersetzen könnte, wächst, aber diejenigen, die KI-gestützte Entwicklung wirklich beherrschen, verfügen über „Superkräfte“. 3. Die Rolle von Softwareingenieuren könnte sich in Zukunft zu „Agentenmanagern“ wandeln, die KI-Tools geschickt einsetzen, wobei die KI den Großteil der Codierung übernimmt. 4. KI wird eine große Anzahl von Nischensoftware für spezifische Marktsegmente hervorbringen. Die Diskussionsteilnehmer waren der Ansicht, dass KI-Programmierung zwar ein enormes Potenzial hat, aber immer noch Kenntnisse in Engineering-Konzepten, Datenbanken, Architektur usw. erforderlich sind, um sie effektiv zu nutzen (Quelle: Reddit r/ClaudeAI)

Diskussionen über KI, die „die Welt übernimmt“ und Auswirkungen auf Arbeitsplätze halten an: Beiträge im Reddit-Forum r/ArtificialInteligence spiegeln die allgemeine Besorgnis und die vielfältigen Ansichten der Community über die zukünftigen Auswirkungen von KI wider. Einige Nutzer glauben, je tiefer das Verständnis für die Fähigkeiten der KI, desto größer die Sorge, dass sie die Menschheit übertrifft und die Zukunft dominiert, und weisen darauf hin, dass fortschrittliche KI-Systeme bereits erstaunliche Fähigkeiten gezeigt haben. Andere Nutzer sind der Meinung, dass die übertriebene Darstellung von AGI zu unrealistischen Erwartungen geführt hat; KI sei im Wesentlichen ein intelligentes Automatisierungswerkzeug, dessen Auswirkungen graduell sein werden, ähnlich wie bei Computern und dem Internet. Die Diskussionen berühren auch die potenziellen Auswirkungen von KI auf Arbeitsplätze, Vermögensverteilung und die Wirksamkeit von Regulierung. Es gibt die Ansicht, dass der technologische Fortschritt in der Vergangenheit oft die Kluft zwischen Arm und Reich vergrößert hat und KI durch die Beseitigung zahlreicher Arbeitsplätze das Vermögen weiter konzentrieren könnte. Gleichzeitig äußern einige auch Erwartungen an die positiven Auswirkungen von KI in Bereichen wie Medizin und Bildung (Quelle: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
Nutzererfahrung: Wie KI-Tools wie ChatGPT das Denken und die Kognition beeinflussen: Einige Nutzer teilten auf sozialen Plattformen und Reddit die positiven kognitiven Auswirkungen der Nutzung von KI-Tools wie ChatGPT. Sie empfanden KI nicht nur als Werkzeug zur Informationsbeschaffung oder Schreibhilfe, sondern eher als einen „Denkpartner“ oder „Spiegel“, der ihnen half, ihre Gedanken zu ordnen und unbewusste Ideen klar auszudrücken. Durch den Dialog mit KI gaben Nutzer an, ihre eigenen Überzeugungen besser reflektieren und hinterfragen, Denkmuster entdecken und sich sogar „erwachend“ fühlen zu können, mit einem tieferen Verständnis für das Leben und Systeme. Diese Erfahrung deutet darauf hin, dass KI unter bestimmten Umständen zu einem Katalysator für persönliches Wachstum und Selbsterforschung werden kann (Quelle: Reddit r/ChatGPT)
💡 Sonstiges
Zweiter „Xingzhi Cup“ Nationaler KI-Innovations- und Anwendungswettbewerb gestartet: Der zweite „Xingzhi Cup“, gemeinsam veranstaltet vom China Academy of Information and Communications Technology (CAICT) und anderen Organisationen, wurde eröffnet. Unter dem Motto „Xingzhi Empowering, Innovation Leading“ umfasst der Wettbewerb drei Hauptkategorien: LLM-Innovation, Branchenbefähigung und Software-/Hardware-Innovationsökosystem sowie mehrere Spezialrichtungen. Der Wettbewerb zielt darauf ab, technologische Innovationen im Bereich KI, deren technische Umsetzung und den Aufbau eines autonomen Ökosystems zu fördern. Er deckt fast 10 Schlüsselindustrien ab, darunter Industrie, Medizin und Finanzen, und betont die Anwendung heimischer KI-Software und -Hardware. Die Gewinnerprojekte erhalten finanzielle Unterstützung, Zugang zu Industriekontakten und weitere Förderungen (Quelle: WeChat)

Sequoia Capital AI Ascent Insights: Enormes Marktpotenzial für KI, Anwendungsebene und Agentenökonomie sind die Zukunft: Pat Grady und andere Partner von Sequoia Capital teilten auf der AI Ascent Veranstaltung ihre Einblicke in den KI-Markt. Sie sind der Ansicht, dass das Marktpotenzial von KI das von Cloud Computing bei weitem übersteigt, warnen jedoch vor „Ambient Revenue“ (Nutzer probieren aus Neugier, nicht aus echtem Bedarf). Die Anwendungsebene wird als der eigentliche Wertträger angesehen, und Start-ups sollten sich auf vertikale Bereiche und Kundenbedürfnisse konzentrieren. KI hat bereits Durchbrüche in der Spracherzeugung und Programmierung erzielt. Die Zukunftsperspektive ist eine „Agentenökonomie“, in der KI-Agenten Ressourcen transferieren und Transaktionen durchführen können, was jedoch Herausforderungen wie dauerhafte Identität, Kommunikationsprotokolle und Sicherheit mit sich bringt. Gleichzeitig wird KI die individuellen Fähigkeiten erheblich erweitern und „Super-Individuen“ hervorbringen (Quelle: WeChat)

Diskussion: Inhalte und Lehrqualität von universitären Machine-Learning-Kursen im KI-Zeitalter im Fokus: Die Veröffentlichung des Lehrplans seines Master-ML-Kurses durch NYU-Professor Kyunghyun Cho löste eine Diskussion aus. Der Kurs betont Nicht-LLM-Probleme, die mit SGD gelöst werden können, sowie die Lektüre klassischer Paper und erhielt Anerkennung von Kollegen wie einem Harvard-CS-Professor, die die Beibehaltung grundlegender Konzepte für wichtig halten. Jedoch beklagten sich Studenten aus Indien und den USA über die geringe Qualität ihrer universitären ML-Kurse, die zu abstrakt seien, mit Fachbegriffen überladen und ohne tiefgreifende Erklärungen, was dazu führe, dass Studenten auf Selbststudium und Online-Ressourcen angewiesen seien. Dies spiegelt den Widerspruch zwischen der rasanten Entwicklung im KI/ML-Bereich und der verzögerten Aktualisierung von Hochschullehrplänen sowie die Bedeutung einer soliden mathematischen und theoretischen Grundlage wider (Quelle: WeChat)
